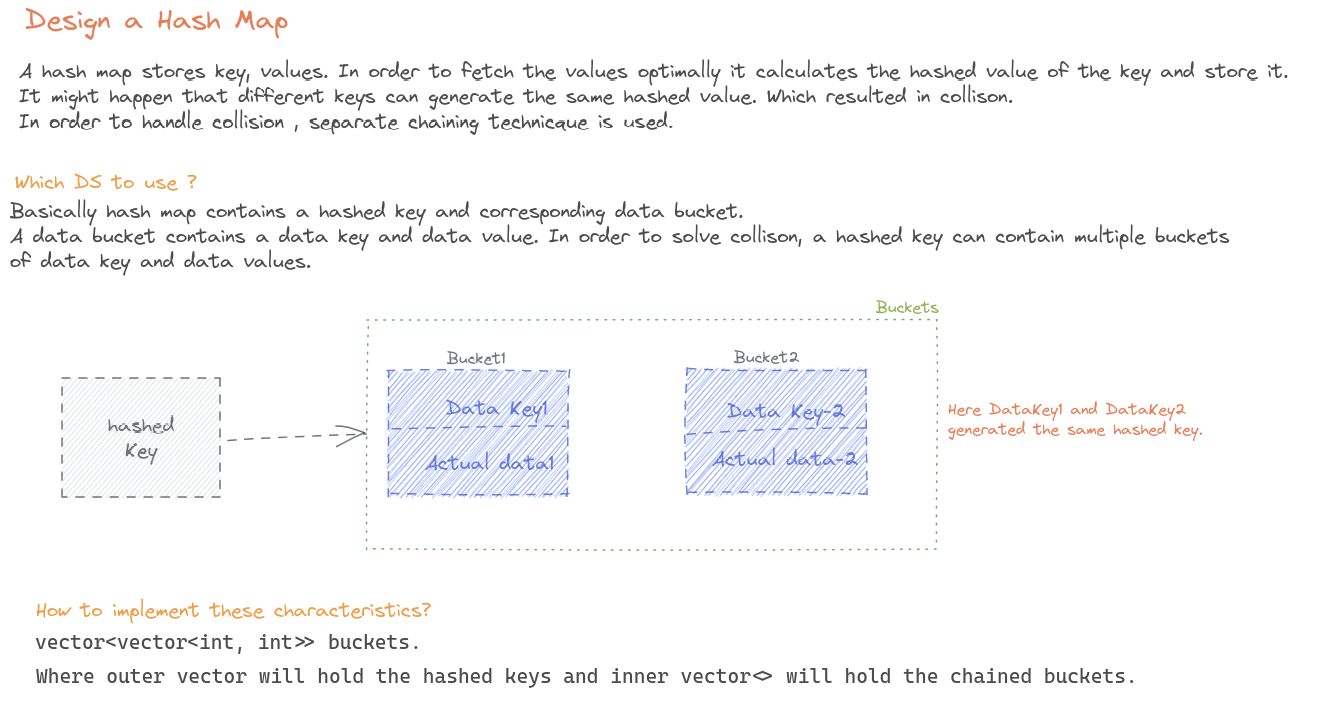
Design a HashMap without using any built-in hash table libraries.
Implement the MyHashMap class:
MyHashMap() initializes the object with an empty map.
void put(int key, int value) inserts a (key, value) pair into the HashMap.
If the key already exists in the map, update the corresponding value.
int get(int key) returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key.
void remove(key) removes the key and its corresponding value if the map contains the mapping for the key.# Capacity for internal array
INITIAL_CAPACITY = 50
# Node data structure - essentially a LinkedList node
class Node:
def __init__(self, key, value):
self.key = key
self.value = value
self.next = None
def __str__(self):
return "<Node: (%s, %s), next: %s>" % (self.key, self.value, self.next != None)
def __repr__(self):
return str(self)
# Hash table with separate chaining
class HashTable:
# Initialize hash table
def __init__(self):
self.capacity = INITIAL_CAPACITY
self.size = 0
self.buckets = [None]*self.capacity
# Generate a hash for a given key
# Input: key - string
# Output: Index from 0 to self.capacity
def hash(self, key):
hashsum = 0
# For each character in the key
for idx, c in enumerate(key):
# Add (index + length of key) ^ (current char code)
hashsum += (idx + len(key)) ** ord(c)
# Perform modulus to keep hashsum in range [0, self.capacity - 1]
hashsum = hashsum % self.capacity
return hashsum
# Insert a key,value pair to the hashtable
# Input: key - string
# value - anything
# Output: void
def insert(self, key, value):
# 1. Increment size
self.size += 1
# 2. Compute index of key
index = self.hash(key)
# Go to the node corresponding to the hash
node = self.buckets[index]
# 3. If bucket is empty:
if node is None:
# Create node, add it, return
self.buckets[index] = Node(key, value)
return
# 4. Iterate to the end of the linked list at provided index
prev = node
while node is not None:
prev = node
node = node.next
# Add a new node at the end of the list with provided key/value
prev.next = Node(key, value)
# Find a data value based on key
# Input: key - string
# Output: value stored under "key" or None if not found
def find(self, key):
# 1. Compute hash
index = self.hash(key)
# 2. Go to first node in list at bucket
node = self.buckets[index]
# 3. Traverse the linked list at this node
while node is not None and node.key != key:
node = node.next
# 4. Now, node is the requested key/value pair or None
if node is None:
# Not found
return None
else:
# Found - return the data value
return node.value
# Remove node stored at key
# Input: key - string
# Output: removed data value or None if not found
def remove(self, key):
# 1. Compute hash
index = self.hash(key)
node = self.buckets[index]
prev = None
# 2. Iterate to the requested node
while node is not None and node.key != key:
prev = node
node = node.next
# Now, node is either the requested node or none
if node is None:
# 3. Key not found
return None
else:
# 4. The key was found.
self.size -= 1
result = node.value
# Delete this element in linked list
if prev is None:
self.buckets[index] = node.next # May be None, or the next match
else:
prev.next = prev.next.next # LinkedList delete by skipping over
# Return the deleted result
return resultQuestion1: How the above solves the collisons?
Whenever two keys have the same hash value, it is considered a collision. What should our hash table do? If it just wrote the data into the location anyway, we would be losing the object that is already stored under a different key. With separate chaining, we create a Linked List at each index of our buckets array, containing all keys for a given index. When we need to look up one of those items, we iterate the list until we find the Node matching the requested key.
class Node:
def __init__(self, key, value):
self.key = key
self.value = value
self.next = NoneEach bucket will actually contain a LinkedList of nodes containing the objects stored at that index. This is one method of collision resolution.
Question2: How to handle uneven distribution of keys ?
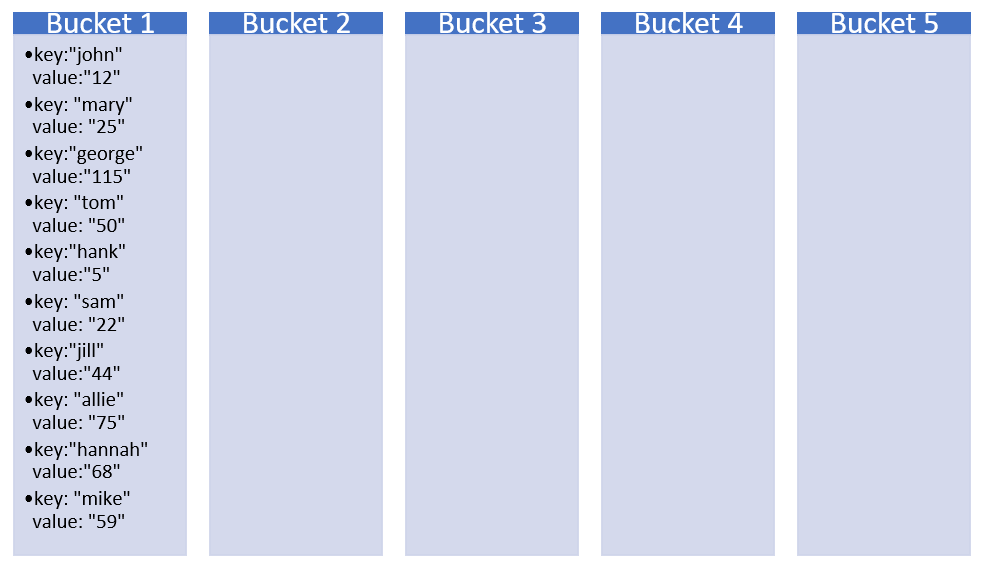
The above is called as uneven distribution , as most of the keys are mapped to bucket 1. Because our hash function must be h(x) = 1. In order to maintain a proper distribution across the buckets , our hash function is like below:
def hash(self, key):
hashsum = 0
# For each character in the key
for idx, c in enumerate(key):
# Add (index + length of key) ^ (current char code)
hashsum += (idx + len(key)) ** ord(c)
# Perform modulus to keep hashsum in range [0, self.capacity - 1]
hashsum = hashsum % self.capacity
return hashsum