diff --git a/.github/PULL_REQUEST_TEMPLATE.md b/.github/PULL_REQUEST_TEMPLATE.md
index d450f442c..dfc217a75 100644
--- a/.github/PULL_REQUEST_TEMPLATE.md
+++ b/.github/PULL_REQUEST_TEMPLATE.md
@@ -16,7 +16,9 @@ Before a pull request can be merged, the following items must be checked:
* [ ] Tests have been added for any new functionality or bug fixes.
* [ ] All linting and tests pass.
+
diff --git a/.github/workflows/docs.yml b/.github/workflows/docs.yml
index a2f4394ad..095e039fe 100644
--- a/.github/workflows/docs.yml
+++ b/.github/workflows/docs.yml
@@ -18,8 +18,6 @@ jobs:
steps:
- uses: actions/checkout@v4
- with:
- ref: ${{ github.event.workflow_run.head_branch }}
- name: Install pandoc
run: sudo apt-get install pandoc
@@ -48,6 +46,12 @@ jobs:
rm docs/tutorials/*.h5*
rm docs/tutorials/*.traj*
+ - name: Generate package treemap
+ run: |
+ uv pip install --system . --config-settings editable-mode=compat
+ uv pip install --system git+https://github.com/janosh/pymatviz
+ python docs/_static/draw_pkg_treemap.py
+
- name: Build
run: sphinx-build docs docs_build
diff --git a/.gitignore b/.gitignore
index 1338587b6..29646ebf1 100644
--- a/.gitignore
+++ b/.gitignore
@@ -31,3 +31,6 @@ docs/reference/torch_sim.*
# coverage
coverage.xml
.coverage
+
+# env
+uv.lock
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index ac331b822..c821e502d 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -34,10 +34,14 @@ repos:
hooks:
- id: codespell
stages: [pre-commit, commit-msg]
- args: [--ignore-words-list, "statics,crate,annote,atomate,nd,te,titel,coo,slite,fro"]
+ args: [--ignore-words-list, "statics,atomate,nd,te,titel,coo,slite,fro"]
- repo: https://github.com/igorshubovych/markdownlint-cli
rev: v0.44.0
hooks:
- id: markdownlint
- exclude: \.md$
+ # MD013: line length
+ # MD033: no inline HTML
+ # MD041: first line in a file should be a top-level heading
+ # MD034: bare URL used
+ args: [--disable, MD013, MD033, MD041, MD034, "--"]
diff --git a/CHANGELOG.md b/CHANGELOG.md
index aea2ef386..63423bbc8 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -1,12 +1,14 @@
## v0.2.0
### Bug Fixes 🐛
+
* Fix integrate reporting kwarg to arg error, https://github.com/Radical-AI/torch-sim/issues/113 (raised by @hn-yu)
* Allow runners to take large initial batches, https://github.com/Radical-AI/torch-sim/issues/128 (raised by @YutackPark)
* Add Fairchem model support for PBC, https://github.com/Radical-AI/torch-sim/issues/111 (raised by @ryanliu30)
### Enhancements 🛠
-* **[breaking]** Rename `HotSwappingAutobatcher` to `InFlightAutobatcher` and `ChunkingAutoBatcher` to `BinningAutoBatcher`, https://github.com/Radical-AI/torch-sim/pull/143 @orionarcher
+
+* **breaking** Rename `HotSwappingAutobatcher` to `InFlightAutobatcher` and `ChunkingAutoBatcher` to `BinningAutoBatcher`, https://github.com/Radical-AI/torch-sim/pull/143 @orionarcher
* Support for Orbv3, https://github.com/Radical-AI/torch-sim/pull/140, @AdeeshKolluru
* Support metatensor models, https://github.com/Radical-AI/torch-sim/pull/141, @frostedoyter @Luthaf
* Support for graph-pes models, https://github.com/Radical-AI/torch-sim/pull/118 @jla-gardner
@@ -18,10 +20,12 @@
* New correlation function module, https://github.com/Radical-AI/torch-sim/pull/115 @stefanbringuier
### Documentation 📖
+
* Imoved model documentation, https://github.com/Radical-AI/torch-sim/pull/121 @orionarcher
* Plot of TorchSim module graph in docs, https://github.com/Radical-AI/torch-sim/pull/132 @janosh
### House-Keeping 🧹
+
* Only install HF for fairchem tests, https://github.com/Radical-AI/torch-sim/pull/134 @CompRhys
* Don't download MBD in CI, https://github.com/Radical-AI/torch-sim/pull/135 @orionarcher
* Tighten graph-pes test bounds, https://github.com/Radical-AI/torch-sim/pull/143 @orionarcher
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 67551fe66..5163c72b3 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -13,6 +13,7 @@ Our CLA-bot will automatically verify your signature on pull requests. For quest
## Code Reviews
All submissions require review by project maintainers before merging:
+
- Submit changes via GitHub pull requests
- Maintainers' submissions also require review by other maintainers
- Address any feedback or requested changes promptly
diff --git a/README.md b/README.md
index 3182bb1d9..80ab3f4b4 100644
--- a/README.md
+++ b/README.md
@@ -123,7 +123,9 @@ To understand how TorchSim works, start with the [comprehensive tutorials](https
## Core Modules
-TorchSim's structure is summarized in the [API reference](https://radical-ai.github.io/torch-sim/reference/index.html) documentation.
+TorchSim's package structure is summarized in the [API reference](https://radical-ai.github.io/torch-sim/reference/index.html) documentation and drawn as a treemap below.
+
+
## License
diff --git a/docs/_static/draw_pkg_treemap.py b/docs/_static/draw_pkg_treemap.py
new file mode 100644
index 000000000..3e2775a3d
--- /dev/null
+++ b/docs/_static/draw_pkg_treemap.py
@@ -0,0 +1,25 @@
+"""Draw a treemap of the torch_sim package structure.
+
+Run with `uv run docs/_static/draw_pkg_treemap.py`
+"""
+
+# /// script
+# dependencies = [
+# "pymatviz @ git+https://github.com/janosh/pymatviz",
+# ]
+# ///
+
+import os
+
+import pymatviz as pmv
+
+
+module_dir = os.path.dirname(__file__)
+pmv.set_plotly_template("plotly_white")
+
+pkg_name = "torch-sim"
+fig = pmv.py_pkg_treemap(pkg_name.replace("-", "_"))
+fig.layout.title.update(text=f"{pkg_name} Package Structure", font_size=20, x=0.5, y=0.98)
+fig.show()
+# pmv.io.save_and_compress_svg(fig, f"{module_dir}/{pkg_name}-pkg-treemap.svg")
+fig.write_html(f"{module_dir}/{pkg_name}-pkg-treemap.html", include_plotlyjs="cdn")
diff --git a/docs/_static/torch-sim-module-graph.dot b/docs/_static/torch-sim-module-graph.dot
deleted file mode 100644
index 2925c67a8..000000000
--- a/docs/_static/torch-sim-module-graph.dot
+++ /dev/null
@@ -1,142 +0,0 @@
-digraph G {
- layout=dot;
- concentrate = true;
- ratio = 0.8;
- nodesep = 0.08;
- ranksep = 0.1;
- rankdir = LR;
- overlap = false;
- node [style=filled,fillcolor="#ffffff",fontcolor="#000000",fontname=Helvetica,fontsize=10,margin="0.08,0.02",height=0.5];
-
- // Color legend by node connectedness
- // #2d35e5 = 0-1 connections
- // #2daee5 = 2-3 connections
- // #2de5a3 = 4-5 connections
- // #31e52d = 6-7 connections
- // #aae52d = 8-10 connections
- // #e5a72d = 11-15 connections
- // #e52d2d = 16+ connections
-
- torch_sim_autobatching [fillcolor="#2daee5",fontcolor="white",label="autobatching\n(821 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/autobatching.py",tooltip="View source on GitHub"];
- torch_sim_elastic [fillcolor="#2daee5",fontcolor="white",label="elastic\n(887 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/elastic.py",tooltip="View source on GitHub"];
- torch_sim_integrators [fillcolor="#2daee5",fontcolor="white",label="integrators\n(953 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/integrators.py",tooltip="View source on GitHub"];
- torch_sim_io [fillcolor="#2daee5",fontcolor="white",label="io\n(307 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/io.py",tooltip="View source on GitHub"];
- torch_sim_math [fillcolor="#2daee5",fontcolor="white",label="math\n(732 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/math.py",tooltip="View source on GitHub"];
- torch_sim_models_fairchem [fillcolor="#2daee5",fontcolor="white",label="models.fairchem\n(315 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/models/fairchem.py",tooltip="View source on GitHub"];
- torch_sim_models_graphpes [fillcolor="#2daee5",fontcolor="white",label="models.graphpes\n(144 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/models/graphpes.py",tooltip="View source on GitHub"];
- torch_sim_models_interface [fillcolor="#e52d2d",fontcolor="white",label="models.interface\n(250 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/models/interface.py",tooltip="View source on GitHub"];
- torch_sim_models_lennard_jones [fillcolor="#2de5a3",fontcolor="white",label="models.lennard_jones\n(251 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/models/lennard_jones.py",tooltip="View source on GitHub"];
- torch_sim_models_mace [fillcolor="#2de5a3",fontcolor="white",label="models.mace\n(277 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/models/mace.py",tooltip="View source on GitHub"];
- torch_sim_models_mattersim [fillcolor="#2daee5",fontcolor="white",label="models.mattersim\n(114 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/models/mattersim.py",tooltip="View source on GitHub"];
- torch_sim_models_morse [fillcolor="#2de5a3",fontcolor="white",label="models.morse\n(258 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/models/morse.py",tooltip="View source on GitHub"];
- torch_sim_models_orb [fillcolor="#2daee5",fontcolor="white",label="models.orb\n(341 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/models/orb.py",tooltip="View source on GitHub"];
- torch_sim_models_sevennet [fillcolor="#2de5a3",fontcolor="white",label="models.sevennet\n(191 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/models/sevennet.py",tooltip="View source on GitHub"];
- torch_sim_models_soft_sphere [fillcolor="#2de5a3",fontcolor="white",label="models.soft_sphere\n(616 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/models/soft_sphere.py",tooltip="View source on GitHub"];
- torch_sim_monte_carlo [fillcolor="#2d35e5",fontcolor="white",label="monte_carlo\n(208 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/monte_carlo.py",tooltip="View source on GitHub"];
- torch_sim_neighbors [fillcolor="#e5a72d",fontcolor="white",label="neighbors\n(621 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/neighbors.py",tooltip="View source on GitHub"];
- torch_sim_optimizers [fillcolor="#2daee5",fontcolor="white",label="optimizers\n(961 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/optimizers.py",tooltip="View source on GitHub"];
- torch_sim_properties_correlations [fillcolor="#2d35e5",fontcolor="white",label="properties.correlations\n(349 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/properties/correlations.py",tooltip="View source on GitHub"];
- torch_sim_quantities [fillcolor="#2de5a3",fontcolor="white",label="quantities\n(114 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/quantities.py",tooltip="View source on GitHub"];
- torch_sim_runners [fillcolor="#31e52d",fontcolor="white",label="runners\n(368 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/runners.py",tooltip="View source on GitHub"];
- torch_sim_state [fillcolor="#e52d2d",fontcolor="white",label="state\n(687 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/state.py",tooltip="View source on GitHub"];
- torch_sim_trajectory [fillcolor="#2daee5",fontcolor="white",label="trajectory\n(762 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/trajectory.py",tooltip="View source on GitHub"];
- torch_sim_transforms [fillcolor="#e5a72d",fontcolor="white",label="transforms\n(891 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/transforms.py",tooltip="View source on GitHub"];
- torch_sim_unbatched_models_lennard_jones [fillcolor="#2de5a3",fontcolor="white",label="unbatched.models.lennard_jones\n(188 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/unbatched/models/lennard_jones.py",tooltip="View source on GitHub"];
- torch_sim_unbatched_models_mace [fillcolor="#2de5a3",fontcolor="white",label="unbatched.models.mace\n(199 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/unbatched/models/mace.py",tooltip="View source on GitHub"];
- torch_sim_unbatched_models_morse [fillcolor="#2de5a3",fontcolor="white",label="unbatched.models.morse\n(190 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/unbatched/models/morse.py",tooltip="View source on GitHub"];
- torch_sim_unbatched_models_particle_life [fillcolor="#2de5a3",fontcolor="white",label="unbatched.models.particle_life\n(151 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/unbatched/models/particle_life.py",tooltip="View source on GitHub"];
- torch_sim_unbatched_models_soft_sphere [fillcolor="#31e52d",fontcolor="white",label="unbatched.models.soft_sphere\n(373 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/unbatched/models/soft_sphere.py",tooltip="View source on GitHub"];
- torch_sim_unbatched_unbatched_integrators [fillcolor="#2de5a3",fontcolor="white",label="unbatched.unbatched_integrators\n(1723 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/unbatched/unbatched_integrators.py",tooltip="View source on GitHub"];
- torch_sim_unbatched_unbatched_optimizers [fillcolor="#2de5a3",fontcolor="white",label="unbatched.unbatched_optimizers\n(854 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/unbatched/unbatched_optimizers.py",tooltip="View source on GitHub"];
- torch_sim_units [fillcolor="#2daee5",fontcolor="white",label="units\n(98 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/units.py",tooltip="View source on GitHub"];
- torch_sim_workflows_a2c [fillcolor="#2de5a3",fontcolor="white",label="workflows.a2c\n(703 lines)",shape="box",URL="https://github.com/radical-ai/torch-sim/blob/main/torch_sim/workflows/a2c.py",tooltip="View source on GitHub"];
-
- torch_sim_autobatching -> torch_sim_models_interface;
- torch_sim_autobatching -> torch_sim_state;
- torch_sim_elastic -> torch_sim_state;
- torch_sim_integrators -> torch_sim_state;
- torch_sim_integrators -> torch_sim_transforms;
- torch_sim_io -> torch_sim_state;
- torch_sim_models_fairchem -> torch_sim_models_interface;
- torch_sim_models_fairchem -> torch_sim_state;
- torch_sim_models_graphpes -> torch_sim_models_interface;
- torch_sim_models_graphpes -> torch_sim_neighbors;
- torch_sim_models_graphpes -> torch_sim_state;
- torch_sim_models_interface -> torch_sim_io;
- torch_sim_models_interface -> torch_sim_state;
- torch_sim_models_lennard_jones -> torch_sim_models_interface;
- torch_sim_models_lennard_jones -> torch_sim_neighbors;
- torch_sim_models_lennard_jones -> torch_sim_state;
- torch_sim_models_lennard_jones -> torch_sim_transforms;
- torch_sim_models_lennard_jones -> torch_sim_unbatched_models_lennard_jones;
- torch_sim_models_mace -> torch_sim_models_interface;
- torch_sim_models_mace -> torch_sim_neighbors;
- torch_sim_models_mace -> torch_sim_state;
- torch_sim_models_mattersim -> torch_sim_models_interface;
- torch_sim_models_mattersim -> torch_sim_state;
- torch_sim_models_mattersim -> torch_sim_units;
- torch_sim_models_morse -> torch_sim_models_interface;
- torch_sim_models_morse -> torch_sim_neighbors;
- torch_sim_models_morse -> torch_sim_state;
- torch_sim_models_morse -> torch_sim_transforms;
- torch_sim_models_morse -> torch_sim_unbatched_models_morse;
- torch_sim_models_orb -> torch_sim_elastic;
- torch_sim_models_orb -> torch_sim_models_interface;
- torch_sim_models_orb -> torch_sim_state;
- torch_sim_models_sevennet -> torch_sim_elastic;
- torch_sim_models_sevennet -> torch_sim_models_interface;
- torch_sim_models_sevennet -> torch_sim_neighbors;
- torch_sim_models_sevennet -> torch_sim_state;
- torch_sim_models_soft_sphere -> torch_sim_models_interface;
- torch_sim_models_soft_sphere -> torch_sim_neighbors;
- torch_sim_models_soft_sphere -> torch_sim_state;
- torch_sim_models_soft_sphere -> torch_sim_transforms;
- torch_sim_models_soft_sphere -> torch_sim_unbatched_models_soft_sphere;
- torch_sim_monte_carlo -> torch_sim_state;
- torch_sim_neighbors -> torch_sim_math;
- torch_sim_neighbors -> torch_sim_transforms;
- torch_sim_optimizers -> torch_sim_math;
- torch_sim_optimizers -> torch_sim_state;
- torch_sim_properties_correlations -> torch_sim_state;
- torch_sim_quantities -> torch_sim_state;
- torch_sim_quantities -> torch_sim_units;
- torch_sim_runners -> torch_sim_autobatching;
- torch_sim_runners -> torch_sim_models_interface;
- torch_sim_runners -> torch_sim_quantities;
- torch_sim_runners -> torch_sim_state;
- torch_sim_runners -> torch_sim_trajectory;
- torch_sim_runners -> torch_sim_units;
- torch_sim_state -> torch_sim_io;
- torch_sim_trajectory -> torch_sim_state;
- torch_sim_unbatched_models_lennard_jones -> torch_sim_models_interface;
- torch_sim_unbatched_models_lennard_jones -> torch_sim_neighbors;
- torch_sim_unbatched_models_lennard_jones -> torch_sim_transforms;
- torch_sim_unbatched_models_lennard_jones -> torch_sim_unbatched_unbatched_integrators;
- torch_sim_unbatched_models_mace -> torch_sim_models_interface;
- torch_sim_unbatched_models_mace -> torch_sim_models_mace;
- torch_sim_unbatched_models_mace -> torch_sim_neighbors;
- torch_sim_unbatched_models_mace -> torch_sim_state;
- torch_sim_unbatched_models_morse -> torch_sim_models_interface;
- torch_sim_unbatched_models_morse -> torch_sim_neighbors;
- torch_sim_unbatched_models_morse -> torch_sim_state;
- torch_sim_unbatched_models_morse -> torch_sim_transforms;
- torch_sim_unbatched_models_particle_life -> torch_sim_models_interface;
- torch_sim_unbatched_models_particle_life -> torch_sim_neighbors;
- torch_sim_unbatched_models_particle_life -> torch_sim_state;
- torch_sim_unbatched_models_particle_life -> torch_sim_transforms;
- torch_sim_unbatched_models_soft_sphere -> torch_sim_models_interface;
- torch_sim_unbatched_models_soft_sphere -> torch_sim_neighbors;
- torch_sim_unbatched_models_soft_sphere -> torch_sim_state;
- torch_sim_unbatched_models_soft_sphere -> torch_sim_transforms;
- torch_sim_unbatched_unbatched_integrators -> torch_sim_quantities;
- torch_sim_unbatched_unbatched_integrators -> torch_sim_state;
- torch_sim_unbatched_unbatched_integrators -> torch_sim_transforms;
- torch_sim_unbatched_unbatched_optimizers -> torch_sim_math;
- torch_sim_unbatched_unbatched_optimizers -> torch_sim_state;
- torch_sim_unbatched_unbatched_optimizers -> torch_sim_unbatched_unbatched_integrators;
- torch_sim_workflows_a2c -> torch_sim_optimizers;
- torch_sim_workflows_a2c -> torch_sim_state;
- torch_sim_workflows_a2c -> torch_sim_transforms;
- torch_sim_workflows_a2c -> torch_sim_unbatched_models_soft_sphere;
- torch_sim_workflows_a2c -> torch_sim_unbatched_unbatched_optimizers;
-}
diff --git a/docs/_static/torch-sim-module-graph.svg b/docs/_static/torch-sim-module-graph.svg
deleted file mode 100644
index 1369f7961..000000000
--- a/docs/_static/torch-sim-module-graph.svg
+++ /dev/null
@@ -1 +0,0 @@
-
diff --git a/docs/dev/add_model.md b/docs/dev/add_model.md
index 11773f2d7..6967f979f 100644
--- a/docs/dev/add_model.md
+++ b/docs/dev/add_model.md
@@ -8,29 +8,29 @@ of MLIP developers and users.
See https://github.com/Radical-AI/torch-sim/discussions/120 for
our current posture on adding models to TorchSim.
-0. Open a PR or an issue to get feedback. We are happy to take a look,
+1. Open a PR or an issue to get feedback. We are happy to take a look,
even if you haven't finished your implementation yet.
1. Create a new model file in `torch_sim/models`. It should inherit
from `torch_sim.models.interface.ModelInterface` and `torch.nn.module`.
-2. Add `torch_sim.models.tests.make_validate_model_outputs_test` and
+1. Add `torch_sim.models.tests.make_validate_model_outputs_test` and
`torch_sim.models.tests.make_model_calculator_consistency_test` as
models tests. See any of the other model tests for examples.
-3. Update `test.yml` to include proper installation and
+1. Update `test.yml` to include proper installation and
testing of the relevant model.
-4. Pull the model import up to `torch_sim.models` by adding import to
+1. Pull the model import up to `torch_sim.models` by adding import to
`torch_sim.models.__init__.py` in try except clause.
-5. Update `docs/conf.py` to include model in `autodoc_mock_imports = [...]`
+1. Update `docs/conf.py` to include model in `autodoc_mock_imports = [...]`
## Optional
-6. Write a tutorial or example showing off your model.
+1. Write a tutorial or example showing off your model.
-7. Update the `.github/workflows/docs.yml` to ensure your model
+1. Update the `.github/workflows/docs.yml` to ensure your model
is being correctly included in the documentation.
We are also happy for developers to implement model interfaces in their
diff --git a/docs/reference/index.rst b/docs/reference/index.rst
index f74ba5677..a21d7418b 100644
--- a/docs/reference/index.rst
+++ b/docs/reference/index.rst
@@ -29,12 +29,11 @@ Overview of the TorchSim API.
units
-TorchSim module graph. Each node represents a Python module. Arrows indicate
+TorchSim module treemap. Each node represents a Python module. Arrows indicate
imports between modules. Node color indicates connectedness: blue nodes have fewer
dependents, red nodes have more (up to 16). The number in parentheses is the number of
lines of code in the module. Click on nodes to navigate to the file.
-.. image:: /_static/torch-sim-module-graph.svg
- :alt: torch-sim Module Graph
- :width: 100%
- :align: center
+.. raw:: html
+
+
diff --git a/docs/user/overview.md b/docs/user/overview.md
index 0b252a1c4..a7c0655d9 100644
--- a/docs/user/overview.md
+++ b/docs/user/overview.md
@@ -25,7 +25,6 @@ Efficiently tracking trajectory information is a core feature of simulation engi
Learn more in [Understanding Reporting](../tutorials/reporting_tutorial.ipynb)
-
## High-level vs Low-Level
Under the hood, TorchSim takes a modular functional approach to atomistic simulation. Each integrator or optimizer function, such as `nvt_langevin,` takes in a model and parameters and returns `init` and `update` functions that act on a unique `State.` The state inherits from `SimState` and tracks the fixed and fluctuating parameters of the simulation, such as the `momenta` for NVT or the timestep for FIRE. The runner functions take this basic structure and wrap it in a convenient interface with autobatching and reporting.
diff --git a/examples/scripts/1_Introduction/1.1_Lennard_Jones.py b/examples/scripts/1_Introduction/1.1_Lennard_Jones.py
index 860834c63..262c96b08 100644
--- a/examples/scripts/1_Introduction/1.1_Lennard_Jones.py
+++ b/examples/scripts/1_Introduction/1.1_Lennard_Jones.py
@@ -88,7 +88,7 @@
results = model(state)
# Print the results
-print(f"Energy: {results['energy']}")
+print(f"Energy: {float(results['energy']):.4f}")
print(f"Forces: {results['forces']}")
print(f"Stress: {results['stress']}")
print(f"Energies: {results['energies']}")
diff --git a/examples/scripts/1_Introduction/1.2_MACE.py b/examples/scripts/1_Introduction/1.2_MACE.py
index 13d84fafb..2d6d2749d 100644
--- a/examples/scripts/1_Introduction/1.2_MACE.py
+++ b/examples/scripts/1_Introduction/1.2_MACE.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -19,7 +19,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
@@ -51,6 +51,6 @@
results = model(state)
# Print results
-print(f"Energy: {results['energy']}")
+print(f"Energy: {float(results['energy']):.4f}")
print(f"Forces: {results['forces']}")
print(f"Stress: {results['stress']}")
diff --git a/examples/scripts/1_Introduction/1.3_Batched_MACE.py b/examples/scripts/1_Introduction/1.3_Batched_MACE.py
index 59b543160..89885b57f 100644
--- a/examples/scripts/1_Introduction/1.3_Batched_MACE.py
+++ b/examples/scripts/1_Introduction/1.3_Batched_MACE.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -19,7 +19,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/2_Structural_optimization/2.10_Batched_MACE_FrechetCellFilter_FIRE.py b/examples/scripts/2_Structural_optimization/2.10_Batched_MACE_FrechetCellFilter_FIRE.py
index e34c3b3f4..3165083d5 100644
--- a/examples/scripts/2_Structural_optimization/2.10_Batched_MACE_FrechetCellFilter_FIRE.py
+++ b/examples/scripts/2_Structural_optimization/2.10_Batched_MACE_FrechetCellFilter_FIRE.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -22,7 +22,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/2_Structural_optimization/2.3_MACE_FIRE.py b/examples/scripts/2_Structural_optimization/2.3_MACE_FIRE.py
index ffc6af08e..2f20fead4 100644
--- a/examples/scripts/2_Structural_optimization/2.3_MACE_FIRE.py
+++ b/examples/scripts/2_Structural_optimization/2.3_MACE_FIRE.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -23,7 +23,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/2_Structural_optimization/2.4_MACE_UnitCellFilter_FIRE.py b/examples/scripts/2_Structural_optimization/2.4_MACE_UnitCellFilter_FIRE.py
index c24b402f6..5cd5a01ba 100644
--- a/examples/scripts/2_Structural_optimization/2.4_MACE_UnitCellFilter_FIRE.py
+++ b/examples/scripts/2_Structural_optimization/2.4_MACE_UnitCellFilter_FIRE.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -24,7 +24,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/2_Structural_optimization/2.5_MACE_FrechetCellFilter_FIRE.py b/examples/scripts/2_Structural_optimization/2.5_MACE_FrechetCellFilter_FIRE.py
index edcd3d996..0613ea172 100644
--- a/examples/scripts/2_Structural_optimization/2.5_MACE_FrechetCellFilter_FIRE.py
+++ b/examples/scripts/2_Structural_optimization/2.5_MACE_FrechetCellFilter_FIRE.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -24,7 +24,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/2_Structural_optimization/2.6_Batched_MACE_Gradient_Descent.py b/examples/scripts/2_Structural_optimization/2.6_Batched_MACE_Gradient_Descent.py
index e5d513fcc..0bc7d7300 100644
--- a/examples/scripts/2_Structural_optimization/2.6_Batched_MACE_Gradient_Descent.py
+++ b/examples/scripts/2_Structural_optimization/2.6_Batched_MACE_Gradient_Descent.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -23,7 +23,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/2_Structural_optimization/2.7_Batched_MACE_FIRE.py b/examples/scripts/2_Structural_optimization/2.7_Batched_MACE_FIRE.py
index d216d5aff..8e2295cbc 100644
--- a/examples/scripts/2_Structural_optimization/2.7_Batched_MACE_FIRE.py
+++ b/examples/scripts/2_Structural_optimization/2.7_Batched_MACE_FIRE.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
diff --git a/examples/scripts/2_Structural_optimization/2.8_Batched_MACE_UnitCellFilter_Gradient_Descent.py b/examples/scripts/2_Structural_optimization/2.8_Batched_MACE_UnitCellFilter_Gradient_Descent.py
index 07f3d0652..0ad9f53d9 100644
--- a/examples/scripts/2_Structural_optimization/2.8_Batched_MACE_UnitCellFilter_Gradient_Descent.py
+++ b/examples/scripts/2_Structural_optimization/2.8_Batched_MACE_UnitCellFilter_Gradient_Descent.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -23,7 +23,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/2_Structural_optimization/2.9_Batched_MACE_UnitCellFilter_FIRE.py b/examples/scripts/2_Structural_optimization/2.9_Batched_MACE_UnitCellFilter_FIRE.py
index f1ea2cf7b..c6eaa0386 100644
--- a/examples/scripts/2_Structural_optimization/2.9_Batched_MACE_UnitCellFilter_FIRE.py
+++ b/examples/scripts/2_Structural_optimization/2.9_Batched_MACE_UnitCellFilter_FIRE.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -23,7 +23,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/3_Dynamics/3.10_Hybrid_swap_mc.py b/examples/scripts/3_Dynamics/3.10_Hybrid_swap_mc.py
index eea142db7..fba17e162 100644
--- a/examples/scripts/3_Dynamics/3.10_Hybrid_swap_mc.py
+++ b/examples/scripts/3_Dynamics/3.10_Hybrid_swap_mc.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# "pymatgen>=2025.2.18",
# ]
# ///
@@ -26,7 +26,7 @@
kT = 1000 * MetalUnits.temperature
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/3_Dynamics/3.12_MACE_NPT_Langevin.py b/examples/scripts/3_Dynamics/3.12_MACE_NPT_Langevin.py
index a157e13a2..6bc05ffa0 100644
--- a/examples/scripts/3_Dynamics/3.12_MACE_NPT_Langevin.py
+++ b/examples/scripts/3_Dynamics/3.12_MACE_NPT_Langevin.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -28,7 +28,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/3_Dynamics/3.13_MACE_NVE_non_pbc.py b/examples/scripts/3_Dynamics/3.13_MACE_NVE_non_pbc.py
index 8c3dedf24..91dac7b3b 100644
--- a/examples/scripts/3_Dynamics/3.13_MACE_NVE_non_pbc.py
+++ b/examples/scripts/3_Dynamics/3.13_MACE_NVE_non_pbc.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
diff --git a/examples/scripts/3_Dynamics/3.2_MACE_NVE.py b/examples/scripts/3_Dynamics/3.2_MACE_NVE.py
index 54841754e..f5370d339 100644
--- a/examples/scripts/3_Dynamics/3.2_MACE_NVE.py
+++ b/examples/scripts/3_Dynamics/3.2_MACE_NVE.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -25,7 +25,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/3_Dynamics/3.3_MACE_NVE_cueq.py b/examples/scripts/3_Dynamics/3.3_MACE_NVE_cueq.py
index c165d4cd3..223becc52 100644
--- a/examples/scripts/3_Dynamics/3.3_MACE_NVE_cueq.py
+++ b/examples/scripts/3_Dynamics/3.3_MACE_NVE_cueq.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -25,7 +25,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/3_Dynamics/3.4_MACE_NVT_Langevin.py b/examples/scripts/3_Dynamics/3.4_MACE_NVT_Langevin.py
index 13332c2fe..58dac6318 100644
--- a/examples/scripts/3_Dynamics/3.4_MACE_NVT_Langevin.py
+++ b/examples/scripts/3_Dynamics/3.4_MACE_NVT_Langevin.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -24,7 +24,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/3_Dynamics/3.5_MACE_NVT_Nose_Hoover.py b/examples/scripts/3_Dynamics/3.5_MACE_NVT_Nose_Hoover.py
index 523ec3088..9f2177023 100644
--- a/examples/scripts/3_Dynamics/3.5_MACE_NVT_Nose_Hoover.py
+++ b/examples/scripts/3_Dynamics/3.5_MACE_NVT_Nose_Hoover.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -27,7 +27,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/3_Dynamics/3.6_MACE_NVT_Nose_Hoover_temp_profile.py b/examples/scripts/3_Dynamics/3.6_MACE_NVT_Nose_Hoover_temp_profile.py
index 252c47733..27b90447a 100644
--- a/examples/scripts/3_Dynamics/3.6_MACE_NVT_Nose_Hoover_temp_profile.py
+++ b/examples/scripts/3_Dynamics/3.6_MACE_NVT_Nose_Hoover_temp_profile.py
@@ -4,7 +4,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# "plotly>=6",
# "kaleido",
# ]
@@ -81,7 +81,7 @@ def get_kT(
# Model configuration
# Option 1: Load from URL (uncomment to use)
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/3_Dynamics/3.8_MACE_NPT_Nose_Hoover.py b/examples/scripts/3_Dynamics/3.8_MACE_NPT_Nose_Hoover.py
index 4e196cff9..73b30e65e 100644
--- a/examples/scripts/3_Dynamics/3.8_MACE_NPT_Nose_Hoover.py
+++ b/examples/scripts/3_Dynamics/3.8_MACE_NPT_Nose_Hoover.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -29,7 +29,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/3_Dynamics/3.9_MACE_NVT_staggered_stress.py b/examples/scripts/3_Dynamics/3.9_MACE_NVT_staggered_stress.py
index 9f921246b..b9bde402c 100644
--- a/examples/scripts/3_Dynamics/3.9_MACE_NVT_staggered_stress.py
+++ b/examples/scripts/3_Dynamics/3.9_MACE_NVT_staggered_stress.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -27,7 +27,7 @@
dtype = torch.float32
# Option 1: Load the raw model from the downloaded model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/4_High_level_api/4.1_high_level_api.py b/examples/scripts/4_High_level_api/4.1_high_level_api.py
index d5197e2fa..397996fd3 100644
--- a/examples/scripts/4_High_level_api/4.1_high_level_api.py
+++ b/examples/scripts/4_High_level_api/4.1_high_level_api.py
@@ -4,7 +4,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# "pymatgen>=2025.2.18",
# ]
# ///
diff --git a/examples/scripts/4_High_level_api/4.2_auto_batching_api.py b/examples/scripts/4_High_level_api/4.2_auto_batching_api.py
index 50bc4ab90..1610fbdb1 100644
--- a/examples/scripts/4_High_level_api/4.2_auto_batching_api.py
+++ b/examples/scripts/4_High_level_api/4.2_auto_batching_api.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
diff --git a/examples/scripts/5_Workflow/5.1_a2c_silicon.py b/examples/scripts/5_Workflow/5.1_a2c_silicon.py
index 69af3ecb5..b32878c71 100644
--- a/examples/scripts/5_Workflow/5.1_a2c_silicon.py
+++ b/examples/scripts/5_Workflow/5.1_a2c_silicon.py
@@ -4,7 +4,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# "moyopy>=0.4.1",
# "pymatgen>=2025.2.18",
# ]
@@ -55,7 +55,7 @@
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float32
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
raw_model = mace_mp(model=mace_checkpoint_url, return_raw_model=True)
# Define system and model
diff --git a/examples/scripts/5_Workflow/5.2_a2c_silicon_batched.py b/examples/scripts/5_Workflow/5.2_a2c_silicon_batched.py
index 2af8a6326..055d86a9f 100644
--- a/examples/scripts/5_Workflow/5.2_a2c_silicon_batched.py
+++ b/examples/scripts/5_Workflow/5.2_a2c_silicon_batched.py
@@ -55,7 +55,7 @@
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float32
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
raw_model = mace_mp(model=mace_checkpoint_url, return_raw_model=True)
# Define system and model
diff --git a/examples/scripts/5_Workflow/5.3_In_Flight_WBM.py b/examples/scripts/5_Workflow/5.3_In_Flight_WBM.py
index 9ac1dd11a..9617d5bb3 100644
--- a/examples/scripts/5_Workflow/5.3_In_Flight_WBM.py
+++ b/examples/scripts/5_Workflow/5.3_In_Flight_WBM.py
@@ -25,7 +25,7 @@
# --- Model Initialization ---
print("Loading MACE model...")
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
mace = mace_mp(model=mace_checkpoint_url, return_raw_model=True)
mace_model = ts.models.MaceModel(
model=mace,
diff --git a/examples/scripts/5_Workflow/5.4_Elastic.py b/examples/scripts/5_Workflow/5.4_Elastic.py
index 686b32588..9a6f8e3b6 100644
--- a/examples/scripts/5_Workflow/5.4_Elastic.py
+++ b/examples/scripts/5_Workflow/5.4_Elastic.py
@@ -3,7 +3,7 @@
# /// script
# dependencies = [
# "ase>=3.24",
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
@@ -19,7 +19,7 @@
unit_conv = ts.units.UnitConversion
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float64
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
enable_cueq=False,
diff --git a/examples/scripts/6_Phonons/6.1_Phonons_MACE.py b/examples/scripts/6_Phonons/6.1_Phonons_MACE.py
index af93d817b..abc738ff9 100644
--- a/examples/scripts/6_Phonons/6.1_Phonons_MACE.py
+++ b/examples/scripts/6_Phonons/6.1_Phonons_MACE.py
@@ -2,7 +2,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# "phonopy>=2.35",
# "pymatviz[export-figs]>=0.15.1",
# "seekpath",
@@ -89,7 +89,7 @@ def get_labels_qpts(ph: Phonopy, n_points: int = 101) -> tuple[list[str], list[b
dtype = torch.float32
# Load the raw model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
@@ -158,8 +158,8 @@ def get_labels_qpts(ph: Phonopy, n_points: int = 101) -> tuple[list[str], list[b
cell=atoms.cell,
pbc=True,
)
-qpts, connections = get_qpts_and_connections(ase_atoms)
-ph.run_band_structure(qpts, connections)
+q_pts, connections = get_qpts_and_connections(ase_atoms)
+ph.run_band_structure(q_pts, connections)
# Define axis style for plots
axis_style = dict(
diff --git a/examples/scripts/6_Phonons/6.2_QuasiHarmonic_MACE.py b/examples/scripts/6_Phonons/6.2_QuasiHarmonic_MACE.py
index 7c4ba9d24..04080ea8a 100644
--- a/examples/scripts/6_Phonons/6.2_QuasiHarmonic_MACE.py
+++ b/examples/scripts/6_Phonons/6.2_QuasiHarmonic_MACE.py
@@ -4,7 +4,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# "phonopy>=2.35",
# "pymatviz[export-figs]>=0.15.1",
# ]
@@ -212,7 +212,7 @@ def get_qha_phonons(
autobatcher = False
# Load the raw model
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/scripts/6_Phonons/6.3_Conductivity_MACE.py b/examples/scripts/6_Phonons/6.3_Conductivity_MACE.py
index 439984032..b8c80bc39 100644
--- a/examples/scripts/6_Phonons/6.3_Conductivity_MACE.py
+++ b/examples/scripts/6_Phonons/6.3_Conductivity_MACE.py
@@ -4,7 +4,7 @@
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# "phono3py>=3.12",
# "pymatgen>=2025.2.18",
# ]
@@ -50,7 +50,7 @@ def print_relax_info(trajectory_file: str, device: torch.device) -> None:
dtype = torch.float64
# Load the raw model from URL
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url, return_raw_model=True, default_dtype=dtype, device=device
)
@@ -66,11 +66,8 @@ def print_relax_info(trajectory_file: str, device: torch.device) -> None:
# Structure and input parameters
struct = bulk("Si", "diamond", a=5.431, cubic=True) # ASE structure
mesh = [8, 8, 8] # Phonon mesh
-supercell_matrix = [
- 1,
- 1,
- 1,
-] # supercell matrix for phonon calculation (use larger supercell for better accuracy)
+# supercell matrix for phonon calculation (use larger cell for better accuracy)
+supercell_matrix = [1, 1, 1]
supercell_matrix_fc2 = [2, 2, 2] # supercell matrix for FC2 calculation
Nrelax = 300 # number of relaxation steps
fmax = 1e-3 # force convergence
diff --git a/examples/scripts/7_Others/7.5_Batched_MACE_NEB.py b/examples/scripts/7_Others/7.5_Batched_MACE_NEB.py
new file mode 100644
index 000000000..14091d469
--- /dev/null
+++ b/examples/scripts/7_Others/7.5_Batched_MACE_NEB.py
@@ -0,0 +1,96 @@
+import torch
+import torch_sim as ts
+import matplotlib.pyplot as plt
+import numpy as np
+from ase.io import read
+from torch_sim.models.mace import MaceModel
+from torch_sim.workflows.neb import NEB
+
+# Configure logging to DEBUG level first
+import logging
+import sys
+logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(message)s', stream=sys.stdout)
+logging.getLogger('torch_sim.workflows.neb').setLevel(logging.DEBUG)
+
+
+torch_sim_device = 'cuda' if torch.cuda.is_available() else 'cpu'
+torch_sim_dtype = torch.float32 # because I wanna go fast
+
+# Load the actual MACE model
+mace_potential = torch.load("../../../../forge/scratch/potentials/mace_gen_7_ensemble/job_gen_7-2025-04-14_model_0_pr_stagetwo.model", map_location=torch_sim_device)
+
+# Create the torch_sim wrapper
+ts_mace_model = MaceModel(
+ model=mace_potential,
+ device=torch_sim_device,
+ dtype=torch_sim_dtype,
+ compute_forces=True, # Default, but good to be explicit
+ compute_stress=True, # Needed by interface if we want stress later
+)
+
+initial_trajectory = read('../../../../forge/scratch/data/neb_workflow_data/Cr7Ti8V104W8Zr_Cr_to_V_site102_to_69_initial.xyz', index=':')
+
+print(len(initial_trajectory))
+
+initial_system = ts.io.atoms_to_state(initial_trajectory[0], device=torch_sim_device, dtype=torch_sim_dtype)
+final_system = ts.io.atoms_to_state(initial_trajectory[-1], device=torch_sim_device, dtype=torch_sim_dtype)
+
+neb_workflow = NEB(
+ model=ts_mace_model,
+ device=torch_sim_device,
+ dtype=torch_sim_dtype,
+ spring_constant=0.1,
+ n_images=5,
+ use_climbing_image=True, # Turn climbing off for initial GD test
+ optimizer_type="gd", # Select Gradient Descent
+ optimizer_params={"lr": 0.01},
+ trajectory_filename="neb_path_gd_5im.hdf5"
+)
+
+final_path_gd = neb_workflow.run(
+ initial_system=initial_system,
+ final_system=final_system,
+ max_steps=600, # Allow enough steps for potentially slow GD
+ fmax=0.05
+)
+
+# Check if it converged and plot results
+results = ts_mace_model(
+ dict(
+ positions=final_path_gd.positions,
+ cell=final_path_gd.cell,
+ atomic_numbers=final_path_gd.atomic_numbers,
+ batch=final_path_gd.batch,
+ pbc=True,
+ )
+)
+
+energies = results['energy'].tolist()
+
+# Including the energies from the ASE NEB calculation for comparison
+ase_energies = [0.0, 0.154541015625, 0.6151123046875, 0.8592529296875, 0.8148193359375, 0.5965576171875, 0.47705078125]
+
+scaled_energies = [e - energies[0] for e in energies]
+
+print(scaled_energies)
+torch_sim_barrier = max(scaled_energies) - scaled_energies[0]
+ase_barrier = max(ase_energies) - ase_energies[0]
+
+# Create normalized reaction coordinates (0 to 1) for both datasets
+torch_sim_coords = np.linspace(0, 1, len(scaled_energies))
+ase_coords = np.linspace(0, 1, len(ase_energies))
+
+# Create a common x-axis with 100 points for smoother plotting
+common_coords = np.linspace(0, 1, 100)
+
+# Interpolate both energy profiles to the common coordinate system
+torch_sim_interp = np.interp(common_coords, torch_sim_coords, scaled_energies)
+ase_interp = np.interp(common_coords, ase_coords, ase_energies)
+
+plt.plot(common_coords, torch_sim_interp, label='torch-sim')
+plt.plot(common_coords, ase_interp, label='ASE')
+plt.xlabel('Reaction Coordinate')
+plt.ylabel('Energy (eV)')
+plt.title(f'ASE Barrier = {ase_barrier:.4f} eV, torch-sim Barrier = {torch_sim_barrier:.4f} eV, Difference = {torch_sim_barrier - ase_barrier:.4f} eV')
+plt.legend()
+plt.show()
\ No newline at end of file
diff --git a/examples/scripts/readme.md b/examples/scripts/readme.md
index f3e2a87ac..2d74ca5a2 100644
--- a/examples/scripts/readme.md
+++ b/examples/scripts/readme.md
@@ -60,7 +60,7 @@ This folder contains a series of examples demonstrating the use of TorchSim, a l
1. **Workflow** - [`examples/5_Workflow/5.1_a2c_silicon.py`](5_Workflow/5.1_a2c_silicon.py): Run the a2c workflow with the MACE model.
- 1. **Workflow** - [`examples/5_Workflow/5.4_Elastic.py`](5_Workflow/5.4_Elastic.py): Calculate elastic tensor, bulk modulus and shear modulus with MACE.
+ 1. **Workflow** - [`examples/5_Workflow/5.4_Elastic.py`](5_Workflow/5.4_Elastic.py): Calculate elastic tensor, bulk modulus and shear modulus with MACE.
1. **Phonons**
diff --git a/examples/tutorials/autobatching_tutorial.py b/examples/tutorials/autobatching_tutorial.py
index 833d6193b..e3288fc59 100644
--- a/examples/tutorials/autobatching_tutorial.py
+++ b/examples/tutorials/autobatching_tutorial.py
@@ -3,7 +3,7 @@
# Dependencies
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
#
diff --git a/examples/tutorials/high_level_tutorial.py b/examples/tutorials/high_level_tutorial.py
index d615aae36..9d6c4ab4d 100644
--- a/examples/tutorials/high_level_tutorial.py
+++ b/examples/tutorials/high_level_tutorial.py
@@ -3,7 +3,7 @@
# Dependencies
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# "pymatgen>=2025.2.18",
# "ase>=3.23.1",
# ]
diff --git a/examples/tutorials/hybrid_swap_tutorial.py b/examples/tutorials/hybrid_swap_tutorial.py
index 83bf4b60b..28c73fc08 100644
--- a/examples/tutorials/hybrid_swap_tutorial.py
+++ b/examples/tutorials/hybrid_swap_tutorial.py
@@ -3,7 +3,7 @@
# Dependencies
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# "pymatgen>=2025.2.18",
# ]
# ///
diff --git a/examples/tutorials/low_level_tutorial.py b/examples/tutorials/low_level_tutorial.py
index 16f91f857..e3cf06de6 100644
--- a/examples/tutorials/low_level_tutorial.py
+++ b/examples/tutorials/low_level_tutorial.py
@@ -3,7 +3,7 @@
# Dependencies
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# ]
# ///
#
@@ -68,7 +68,7 @@
from torch_sim.models import MaceModel
# load mace_mp using the mace package
-mace_checkpoint_url = "https://github.com/ACEsuit/mace-mp/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
+mace_checkpoint_url = "https://github.com/ACEsuit/mace-foundations/releases/download/mace_mpa_0/mace-mpa-0-medium.model"
loaded_model = mace_mp(
model=mace_checkpoint_url,
return_raw_model=True,
diff --git a/examples/tutorials/reporting_tutorial.py b/examples/tutorials/reporting_tutorial.py
index ccb803605..c387c74d6 100644
--- a/examples/tutorials/reporting_tutorial.py
+++ b/examples/tutorials/reporting_tutorial.py
@@ -3,7 +3,7 @@
# Dependencies
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# "pymatgen>=2025.2.18",
# "ase>=3.23.1",
# ]
diff --git a/examples/tutorials/state_tutorial.py b/examples/tutorials/state_tutorial.py
index 3c94ef360..1abf5d285 100644
--- a/examples/tutorials/state_tutorial.py
+++ b/examples/tutorials/state_tutorial.py
@@ -3,7 +3,7 @@
# Dependencies
# /// script
# dependencies = [
-# "mace-torch>=0.3.11",
+# "mace-torch>=0.3.12",
# "pymatgen>=2024.11.3",
# "ase>=3.24",
# "phonopy>=2.37.0",
diff --git a/pyproject.toml b/pyproject.toml
index aa8211be8..f621f23a8 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -45,12 +45,12 @@ test = [
"pytest-cov>=6",
"pytest>=8",
]
-mace = ["mace-torch>=0.3.11"]
+mace = ["mace-torch>=0.3.12"]
mattersim = ["mattersim>=0.1.2"]
metatensor = ["metatensor-torch>=0.7,<0.8", "metatrain[pet]>=2025.4"]
orb = ["orb-models>=0.5.2"]
sevenn = ["sevenn>=0.11.0"]
-graphpes = ["graph-pes>=0.0.34", "mace-torch>=0.3.11"]
+graphpes = ["graph-pes>=0.0.34", "mace-torch>=0.3.12"]
docs = [
"autodoc_pydantic==2.2.0",
"furo==2024.8.6",
diff --git a/tests/models/conftest.py b/tests/models/conftest.py
index 2b1934c06..251b7ef35 100644
--- a/tests/models/conftest.py
+++ b/tests/models/conftest.py
@@ -14,7 +14,7 @@
from torch_sim.state import SimState
-consistency_test_simstate_fixtures: Final[list[str]] = [
+consistency_test_simstate_fixtures: Final[tuple[str, ...]] = (
"cu_sim_state",
"mg_sim_state",
"sb_sim_state",
@@ -28,14 +28,14 @@
"ar_supercell_sim_state",
"fe_supercell_sim_state",
"benzene_sim_state",
-]
+)
def make_model_calculator_consistency_test(
test_name: str,
model_fixture_name: str,
calculator_fixture_name: str,
- sim_state_names: list[str],
+ sim_state_names: tuple[str, ...],
rtol: float = 1e-5,
atol: float = 1e-5,
):
@@ -45,7 +45,7 @@ def make_model_calculator_consistency_test(
test_name: Name of the test (used in the function name and messages)
model_fixture_name: Name of the model fixture
calculator_fixture_name: Name of the calculator fixture
- sim_state_names: List of sim_state fixture names to test
+ sim_state_names: sim_state fixture names to test
rtol: Relative tolerance for numerical comparisons
atol: Absolute tolerance for numerical comparisons
"""
diff --git a/tests/models/test_mace.py b/tests/models/test_mace.py
index 8c5750e05..ecd3a2395 100644
--- a/tests/models/test_mace.py
+++ b/tests/models/test_mace.py
@@ -15,7 +15,7 @@
from mace.calculators.foundations_models import mace_mp, mace_off
from torch_sim.models.mace import MaceModel
-except ImportError:
+except (ImportError, ValueError):
pytest.skip("MACE not installed", allow_module_level=True)
diff --git a/tests/test_autobatching.py b/tests/test_autobatching.py
index 52ce95a02..77ad33312 100644
--- a/tests/test_autobatching.py
+++ b/tests/test_autobatching.py
@@ -163,6 +163,53 @@ def test_binning_auto_batcher(
assert torch.all(restored_states[1].atomic_numbers == states[1].atomic_numbers)
+def test_binning_auto_batcher_auto_metric(
+ si_sim_state: SimState,
+ fe_supercell_sim_state: SimState,
+ lj_model: LennardJonesModel,
+ monkeypatch: Any,
+) -> None:
+ """Test BinningAutoBatcher with different states."""
+ # monkeypath determine max memory scaler
+ monkeypatch.setattr(
+ "torch_sim.autobatching.determine_max_batch_size",
+ lambda *args, **kwargs: 50, # noqa: ARG005
+ )
+
+ # Create a list of states with different sizes
+ states = [si_sim_state, fe_supercell_sim_state]
+
+ # Initialize the batcher with a fixed max_metric to avoid GPU memory testing
+ batcher = BinningAutoBatcher(
+ model=lj_model,
+ memory_scales_with="n_atoms",
+ )
+ batcher.load_states(states)
+
+ # Check that the batcher correctly identified the metrics
+ assert len(batcher.memory_scalers) == 2
+ assert batcher.memory_scalers[0] == si_sim_state.n_atoms
+ assert batcher.memory_scalers[1] == fe_supercell_sim_state.n_atoms
+
+ # Get batches until None is returned
+ batches = list(batcher)
+
+ # Check we got the expected number of batches
+ assert len(batches) == len(batcher.batched_states)
+
+ # Test restore_original_order
+ restored_states = batcher.restore_original_order(batches)
+ assert len(restored_states) == len(states)
+
+ # Check that the restored states match the original states in order
+ assert restored_states[0].n_atoms == states[0].n_atoms
+ assert restored_states[1].n_atoms == states[1].n_atoms
+
+ # Check atomic numbers to verify the correct order
+ assert torch.all(restored_states[0].atomic_numbers == states[0].atomic_numbers)
+ assert torch.all(restored_states[1].atomic_numbers == states[1].atomic_numbers)
+
+
def test_binning_auto_batcher_with_indices(
si_sim_state: SimState, fe_supercell_sim_state: SimState, lj_model: LennardJonesModel
) -> None:
diff --git a/tests/test_elastic.py b/tests/test_elastic.py
index 7d4748bd2..d94a503de 100644
--- a/tests/test_elastic.py
+++ b/tests/test_elastic.py
@@ -2,13 +2,13 @@
import torch
from torch_sim.elastic import (
- BravaisType,
calculate_elastic_moduli,
calculate_elastic_tensor,
get_bravais_type,
)
from torch_sim.optimizers import frechet_cell_fire
from torch_sim.state import SimState
+from torch_sim.typing import BravaisType
from torch_sim.units import UnitConversion
diff --git a/tests/test_io.py b/tests/test_io.py
index b0b27db15..350f6a55b 100644
--- a/tests/test_io.py
+++ b/tests/test_io.py
@@ -252,5 +252,7 @@ def test_state_round_trip(
assert sim_state.pbc == round_trip_state.pbc
if isinstance(intermediate_format[0], Atoms):
- # TODO: the round trip for pmg and phonopy masses is not exact.
+ # TODO: masses round trip for pmg and phonopy masses is not exact
+ # since both use their own isotope masses based on species,
+ # not the ones in the state
assert torch.allclose(sim_state.masses, round_trip_state.masses)
diff --git a/tests/test_neighbors.py b/tests/test_neighbors.py
index 4c9531eda..7de4d681c 100644
--- a/tests/test_neighbors.py
+++ b/tests/test_neighbors.py
@@ -33,7 +33,7 @@ def ase_to_torch_batch(
Defaults to torch.float32.
Returns:
- Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
+ tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
A tuple containing:
- pos: Tensor of atomic positions.
- cell: Tensor of unit cell vectors.
diff --git a/tests/test_runners.py b/tests/test_runners.py
index 2c5e7d4fb..0b440c884 100644
--- a/tests/test_runners.py
+++ b/tests/test_runners.py
@@ -515,11 +515,9 @@ def test_optimize_with_default_autobatcher(
"""Test optimize with autobatcher."""
def mock_estimate(*args, **kwargs) -> float: # noqa: ARG001
- return 10_000.0
+ return 200
- monkeypatch.setattr(
- "torch_sim.autobatching.estimate_max_memory_scaler", mock_estimate
- )
+ monkeypatch.setattr("torch_sim.autobatching.determine_max_batch_size", mock_estimate)
states = [ar_supercell_sim_state, fe_supercell_sim_state, ar_supercell_sim_state]
triple_state = initialize_state(
diff --git a/tests/unbatched/conftest.py b/tests/unbatched/conftest.py
index 317a18b7a..2f9cb5e1f 100644
--- a/tests/unbatched/conftest.py
+++ b/tests/unbatched/conftest.py
@@ -13,7 +13,7 @@
from torch_sim.state import SimState
-consistency_test_simstate_fixtures = [
+consistency_test_simstate_fixtures = (
"cu_sim_state",
"mg_sim_state",
"sb_sim_state",
@@ -26,14 +26,14 @@
"ar_supercell_sim_state",
"fe_supercell_sim_state",
"benzene_sim_state",
-]
+)
def make_unbatched_model_calculator_consistency_test(
test_name: str,
model_fixture_name: str,
calculator_fixture_name: str,
- sim_state_names: list[str],
+ sim_state_names: tuple[str, ...],
rtol: float = 1e-5,
atol: float = 1e-5,
):
@@ -43,7 +43,7 @@ def make_unbatched_model_calculator_consistency_test(
test_name: Name of the test (used in the function name and messages)
model_fixture_name: Name of the model fixture
calculator_fixture_name: Name of the calculator fixture
- sim_state_names: List of sim_state fixture names to test
+ sim_state_names: sim_state fixture names to test
rtol: Relative tolerance for numerical comparisons
atol: Absolute tolerance for numerical comparisons
"""
diff --git a/torch_sim/__init__.py b/torch_sim/__init__.py
index 0920e5c0b..ae161ed7f 100644
--- a/torch_sim/__init__.py
+++ b/torch_sim/__init__.py
@@ -54,7 +54,4 @@
PKG_DIR = os.path.dirname(__file__)
ROOT = os.path.dirname(PKG_DIR)
-
SCRIPTS_DIR = f"{ROOT}/examples"
-
-today = f"{datetime.now().astimezone():%Y-%m-%d}"
diff --git a/torch_sim/autobatching.py b/torch_sim/autobatching.py
index 0db427a36..3b87d4898 100644
--- a/torch_sim/autobatching.py
+++ b/torch_sim/autobatching.py
@@ -23,12 +23,13 @@
import logging
from collections.abc import Callable, Iterator
from itertools import chain
-from typing import Any, Literal
+from typing import Any, get_args
import torch
from torch_sim.models.interface import ModelInterface
from torch_sim.state import SimState, concatenate_states
+from torch_sim.typing import MemoryScaling
def to_constant_volume_bins( # noqa: C901, PLR0915
@@ -262,7 +263,7 @@ def determine_max_batch_size(
error or reaches the specified maximum atom count.
Args:
- state (SimState): SimState to replicate for testing.
+ state (SimState): State to replicate for testing.
model (ModelInterface): Model to test with.
max_atoms (int): Upper limit on number of atoms to try (for safety).
Defaults to 500,000.
@@ -309,7 +310,7 @@ def determine_max_batch_size(
def calculate_memory_scaler(
state: SimState,
- memory_scales_with: Literal["n_atoms_x_density", "n_atoms"] = "n_atoms_x_density",
+ memory_scales_with: MemoryScaling = "n_atoms_x_density",
) -> float:
"""Calculate a metric that estimates memory requirements for a state.
@@ -322,7 +323,7 @@ def calculate_memory_scaler(
Args:
state (SimState): State to calculate metric for, with shape information
specific to the SimState instance.
- memory_scales_with ("n_atoms_x_density" |s "n_atoms"): Type of metric
+ memory_scales_with ("n_atoms_x_density" | "n_atoms"): Type of metric
to use. "n_atoms" uses only atom count and is suitable for models that
have a fixed number of neighbors. "n_atoms_x_density" uses atom count
multiplied by number density and is better for models with radial cutoffs
@@ -351,7 +352,9 @@ def calculate_memory_scaler(
volume = torch.abs(torch.linalg.det(state.cell[0])) / 1000
number_density = state.n_atoms / volume.item()
return state.n_atoms * number_density
- raise ValueError(f"Invalid metric: {memory_scales_with}")
+ raise ValueError(
+ f"Invalid metric: {memory_scales_with}, must be one of {get_args(MemoryScaling)}"
+ )
def estimate_max_memory_scaler(
@@ -458,11 +461,12 @@ def __init__(
self,
model: ModelInterface,
*,
- memory_scales_with: Literal["n_atoms", "n_atoms_x_density"] = "n_atoms_x_density",
+ memory_scales_with: MemoryScaling = "n_atoms_x_density",
max_memory_scaler: float | None = None,
return_indices: bool = False,
max_atoms_to_try: int = 500_000,
memory_scaling_factor: float = 1.6,
+ max_memory_padding: float = 1.0,
) -> None:
"""Initialize the binning auto-batcher.
@@ -484,6 +488,8 @@ def __init__(
iteration. Larger values will get a batch size more quickly, smaller
values will get a more accurate limit. Must be greater than 1. Defaults
to 1.6.
+ max_memory_padding (float): Multiply the autodetermined max_memory_scaler
+ by this value to account for fluctuations in max memory. Defaults to 1.0.
"""
self.max_memory_scaler = max_memory_scaler
self.max_atoms_to_try = max_atoms_to_try
@@ -491,6 +497,7 @@ def __init__(
self.return_indices = return_indices
self.model = model
self.memory_scaling_factor = memory_scaling_factor
+ self.max_memory_padding = max_memory_padding
def load_states(
self,
@@ -540,8 +547,7 @@ def load_states(
max_atoms=self.max_atoms_to_try,
scale_factor=self.memory_scaling_factor,
)
- else:
- self.max_memory_scaler = self.max_memory_scaler
+ self.max_memory_scaler = self.max_memory_scaler * self.max_memory_padding
# verify that no systems are too large
max_metric_value = max(self.memory_scalers)
@@ -705,7 +711,8 @@ class InFlightAutoBatcher:
To avoid a slow memory estimation step, set the `max_memory_scaler` to a
known value.
- 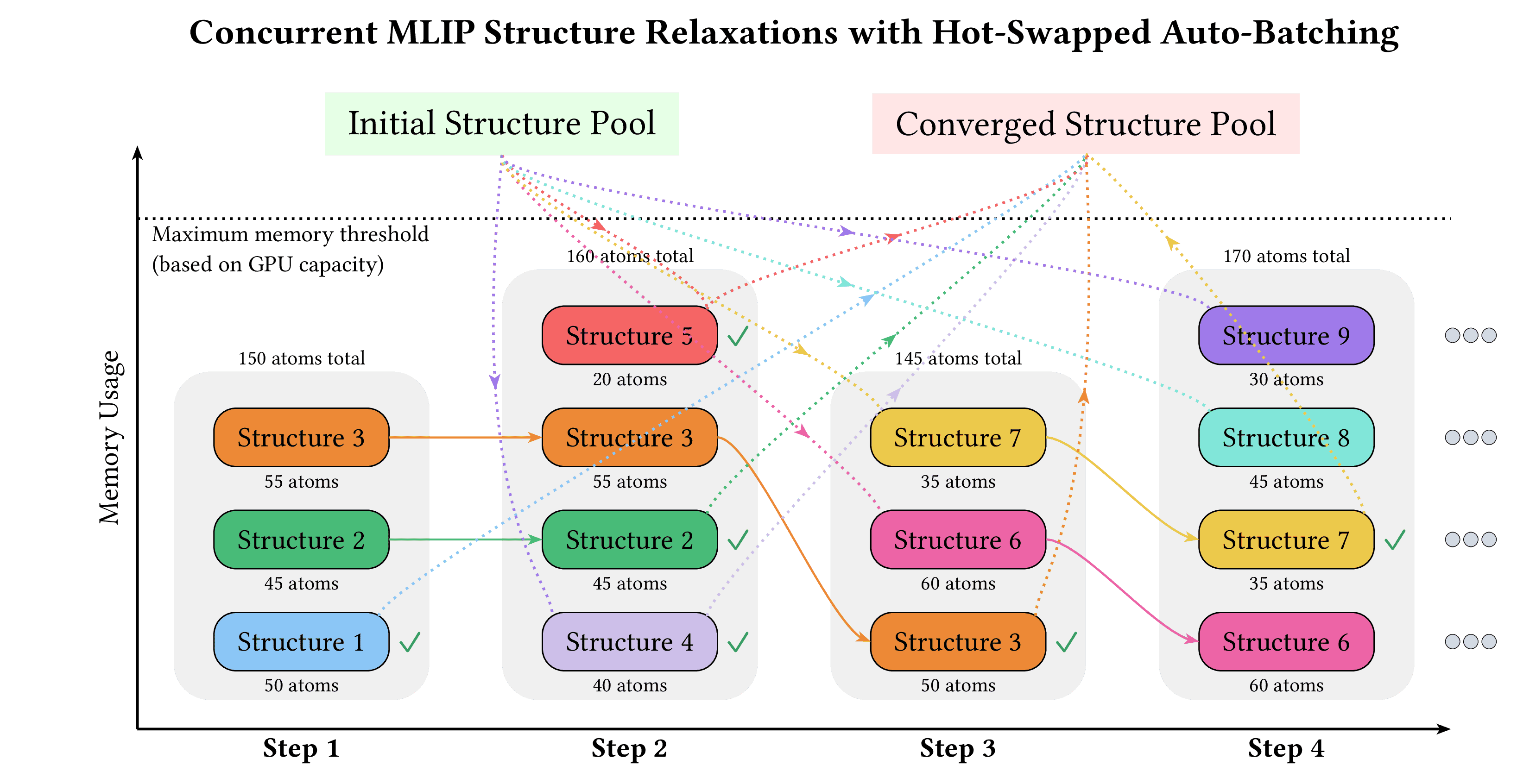
+ .. image:: https://github.com/janosh/diagrams/raw/main/assets/in-flight-auto-batcher/in-flight-auto-batcher.svg
+ :alt: In-flight auto-batcher diagram
Attributes:
model (ModelInterface): Model used for memory estimation and processing.
@@ -752,12 +759,13 @@ def __init__(
self,
model: ModelInterface,
*,
- memory_scales_with: Literal["n_atoms", "n_atoms_x_density"] = "n_atoms_x_density",
+ memory_scales_with: MemoryScaling = "n_atoms_x_density",
max_memory_scaler: float | None = None,
max_atoms_to_try: int = 500_000,
memory_scaling_factor: float = 1.6,
return_indices: bool = False,
max_iterations: int | None = None,
+ max_memory_padding: float = 1.0,
) -> None:
"""Initialize the hot-swapping auto-batcher.
@@ -782,6 +790,8 @@ def __init__(
max_iterations (int | None): Maximum number of iterations to process a state
before considering it complete, regardless of convergence. Used to prevent
infinite loops. Defaults to None (no limit).
+ max_memory_padding (float): Multiply the autodetermined max_memory_scaler
+ by this value to account for fluctuations in max memory. Defaults to 1.0.
"""
self.model = model
self.memory_scales_with = memory_scales_with
@@ -790,6 +800,7 @@ def __init__(
self.memory_scaling_factor = memory_scaling_factor
self.return_indices = return_indices
self.max_attempts = max_iterations # TODO: change to max_iterations
+ self.max_memory_padding = max_memory_padding
def load_states(
self,
@@ -843,6 +854,7 @@ def load_states(
self.first_batch_returned = False
self._first_batch = self._get_first_batch()
+ return self.max_memory_scaler
def _get_next_states(self) -> list[SimState]:
"""Add states from the iterator until max_memory_scaler is reached.
@@ -918,19 +930,17 @@ def _get_first_batch(self) -> SimState:
self.current_idx += [0]
self.swap_attempts.append(0) # Initialize attempt counter for first state
self.iterator_idx += 1
- # self.total_metric += first_metric
# if max_metric is not set, estimate it
has_max_metric = bool(self.max_memory_scaler)
if not has_max_metric:
- self.max_memory_scaler = estimate_max_memory_scaler(
+ n_batches = determine_max_batch_size(
+ first_state,
self.model,
- [first_state],
- [first_metric],
max_atoms=self.max_atoms_to_try,
scale_factor=self.memory_scaling_factor,
)
- self.max_memory_scaler = self.max_memory_scaler * 0.8
+ self.max_memory_scaler = n_batches * first_metric * 0.8
states = self._get_next_states()
@@ -942,7 +952,7 @@ def _get_first_batch(self) -> SimState:
max_atoms=self.max_atoms_to_try,
scale_factor=self.memory_scaling_factor,
)
- print(f"Max metric calculated: {self.max_memory_scaler}")
+ self.max_memory_scaler = self.max_memory_scaler * self.max_memory_padding
return concatenate_states([first_state, *states])
def next_batch(
diff --git a/torch_sim/elastic.py b/torch_sim/elastic.py
index ff7367726..b407955fa 100644
--- a/torch_sim/elastic.py
+++ b/torch_sim/elastic.py
@@ -21,11 +21,11 @@
from collections.abc import Callable
from dataclasses import dataclass
-from enum import Enum
import torch
from torch_sim.state import SimState
+from torch_sim.typing import BravaisType
@dataclass
@@ -47,26 +47,6 @@ class DeformationRule:
symmetry_handler: Callable
-class BravaisType(Enum):
- """Enumeration of the seven Bravais lattice types in 3D crystals.
-
- These lattice types represent the distinct crystal systems classified
- by their symmetry properties, from highest symmetry (cubic) to lowest
- symmetry (triclinic).
-
- Each type has specific constraints on lattice parameters and angles,
- which determine the number of independent elastic constants.
- """
-
- CUBIC = "cubic"
- HEXAGONAL = "hexagonal"
- TRIGONAL = "trigonal"
- TETRAGONAL = "tetragonal"
- ORTHORHOMBIC = "orthorhombic"
- MONOCLINIC = "monoclinic"
- TRICLINIC = "triclinic"
-
-
def get_bravais_type( # noqa: PLR0911
state: SimState, length_tol: float = 1e-3, angle_tol: float = 0.1
) -> BravaisType:
@@ -931,9 +911,9 @@ def get_elastic_coeffs(
bravais_type: Crystal system (BravaisType enum)
Returns:
- Tuple containing:
+ tuple containing:
- torch.Tensor: Cij elastic constants
- - Tuple containing:
+ - tuple containing:
- torch.Tensor: Bij Birch coefficients
- torch.Tensor: Residuals from least squares fit
- int: Rank of solution
diff --git a/torch_sim/integrators.py b/torch_sim/integrators.py
index 8bca00aa2..e7924663c 100644
--- a/torch_sim/integrators.py
+++ b/torch_sim/integrators.py
@@ -24,8 +24,9 @@
import torch
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
from torch_sim.transforms import pbc_wrap_batched
+from torch_sim.typing import StateDict
@dataclass
@@ -348,8 +349,7 @@ def nvt_langevin(
- Weak coupling (small gamma) preserves dynamics but with slower thermalization
- Strong coupling (large gamma) faster thermalization but may distort dynamics
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
gamma = gamma or 1 / (100 * dt)
@@ -603,7 +603,7 @@ def _compute_cell_force(
# Calculate virials from stress and external pressure
# Internal stress is negative of virial tensor divided by volume
- virial = -volumes * state.stress + pressure_tensor * volumes
+ virial = -volumes * (state.stress + pressure_tensor)
# Add kinetic contribution (kT * Identity)
batch_kT = kT
@@ -669,8 +669,7 @@ def npt_langevin( # noqa: C901, PLR0915
Notes:
- The model must provide stress tensor calculations for proper pressure coupling
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
# Set default values if not provided
if alpha is None:
diff --git a/torch_sim/models/fairchem.py b/torch_sim/models/fairchem.py
index 0130e8191..49361213b 100644
--- a/torch_sim/models/fairchem.py
+++ b/torch_sim/models/fairchem.py
@@ -19,11 +19,12 @@
import copy
import typing
from types import MappingProxyType
+from typing import Any
import torch
from torch_sim.models.interface import ModelInterface
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
try:
@@ -46,7 +47,7 @@ class FairChemModel(torch.nn.Module, ModelInterface):
It raises an ImportError if FairChem is not installed.
"""
- def __init__(self, *_args: typing.Any, **_kwargs: typing.Any) -> None:
+ def __init__(self, *_args: Any, **_kwargs: Any) -> None:
"""Dummy init for type checking."""
raise ImportError("FairChem must be installed to use this model.")
@@ -55,6 +56,8 @@ def __init__(self, *_args: typing.Any, **_kwargs: typing.Any) -> None:
from collections.abc import Callable
from pathlib import Path
+ from torch_sim.typing import StateDict
+
_DTYPE_DICT = {
torch.float16: "float16",
torch.float32: "float32",
diff --git a/torch_sim/models/graphpes.py b/torch_sim/models/graphpes.py
index 41d55df34..80fead9b4 100644
--- a/torch_sim/models/graphpes.py
+++ b/torch_sim/models/graphpes.py
@@ -20,7 +20,8 @@
from torch_sim.models.interface import ModelInterface
from torch_sim.neighbors import vesin_nl_ts
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
+from torch_sim.typing import StateDict
try:
diff --git a/torch_sim/models/interface.py b/torch_sim/models/interface.py
index 2bf7c6191..514ea1143 100644
--- a/torch_sim/models/interface.py
+++ b/torch_sim/models/interface.py
@@ -28,12 +28,13 @@ def forward(self, positions, cell, batch, atomic_numbers=None, **kwargs):
from abc import ABC, abstractmethod
from pathlib import Path
-from typing import Literal, Self
+from typing import Self
import torch
import torch_sim as ts
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
+from torch_sim.typing import MemoryScaling, StateDict
class ModelInterface(ABC):
@@ -49,7 +50,7 @@ class ModelInterface(ABC):
dtype (torch.dtype): Data type used for tensor calculations.
compute_stress (bool): Whether the model calculates stress tensors.
compute_forces (bool): Whether the model calculates atomic forces.
- memory_scales_with (Literal["n_atoms", "n_atoms_x_density"]): The metric
+ memory_scales_with (MemoryScaling): The metric
that the model scales with. "n_atoms" uses only atom count and is suitable
for models that have a fixed number of neighbors. "n_atoms_x_density" uses
atom count multiplied by number density and is better for models with
@@ -151,7 +152,7 @@ def compute_forces(self, compute_forces: bool) -> None:
)
@property
- def memory_scales_with(self) -> Literal["n_atoms", "n_atoms_x_density"]:
+ def memory_scales_with(self) -> MemoryScaling:
"""The metric that the model scales with.
Models with radial neighbor cutoffs scale with "n_atoms_x_density",
diff --git a/torch_sim/models/lennard_jones.py b/torch_sim/models/lennard_jones.py
index 4910bea47..d611d3f96 100644
--- a/torch_sim/models/lennard_jones.py
+++ b/torch_sim/models/lennard_jones.py
@@ -28,8 +28,9 @@
from torch_sim.models.interface import ModelInterface
from torch_sim.neighbors import vesin_nl_ts
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
from torch_sim.transforms import get_pair_displacements
+from torch_sim.typing import StateDict
from torch_sim.unbatched.models.lennard_jones import (
lennard_jones_pair,
lennard_jones_pair_force,
diff --git a/torch_sim/models/mace.py b/torch_sim/models/mace.py
index 3e02f9f0f..e28318f3d 100644
--- a/torch_sim/models/mace.py
+++ b/torch_sim/models/mace.py
@@ -25,7 +25,8 @@
from torch_sim.models.interface import ModelInterface
from torch_sim.neighbors import vesin_nl_ts
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
+from torch_sim.typing import StateDict
try:
diff --git a/torch_sim/models/mattersim.py b/torch_sim/models/mattersim.py
index 0a303765f..dd7157180 100644
--- a/torch_sim/models/mattersim.py
+++ b/torch_sim/models/mattersim.py
@@ -8,7 +8,7 @@
import torch_sim as ts
from torch_sim.models.interface import ModelInterface
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
from torch_sim.units import MetalUnits
@@ -34,6 +34,8 @@ def __init__(self, *args, **kwargs) -> None: # noqa: ARG002
if TYPE_CHECKING:
from mattersim.forcefield import Potential
+ from torch_sim.typing import StateDict
+
class MatterSimModel(torch.nn.Module, ModelInterface):
"""Computes atomistic energies, forces and stresses using an MatterSim model.
diff --git a/torch_sim/models/metatensor.py b/torch_sim/models/metatensor.py
index 63d468a21..dbda41931 100644
--- a/torch_sim/models/metatensor.py
+++ b/torch_sim/models/metatensor.py
@@ -17,7 +17,8 @@
import vesin.torch.metatensor
from torch_sim.models.interface import ModelInterface
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
+from torch_sim.typing import StateDict
try:
diff --git a/torch_sim/models/morse.py b/torch_sim/models/morse.py
index 357ab86f5..4b3dbbcd4 100644
--- a/torch_sim/models/morse.py
+++ b/torch_sim/models/morse.py
@@ -29,8 +29,9 @@
from torch_sim.models.interface import ModelInterface
from torch_sim.neighbors import vesin_nl_ts
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
from torch_sim.transforms import get_pair_displacements
+from torch_sim.typing import StateDict
from torch_sim.unbatched.models.morse import morse_pair, morse_pair_force
diff --git a/torch_sim/models/orb.py b/torch_sim/models/orb.py
index 6a1b3066a..3b763aeb0 100644
--- a/torch_sim/models/orb.py
+++ b/torch_sim/models/orb.py
@@ -22,7 +22,7 @@
from torch_sim.elastic import voigt_6_to_full_3x3_stress
from torch_sim.models.interface import ModelInterface
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
try:
@@ -60,6 +60,8 @@ def __init__(self, *args, **kwargs) -> None: # noqa: ARG002
from orb_models.forcefield.featurization_utilities import EdgeCreationMethod
from orb_models.forcefield.graph_regressor import GraphRegressor
+ from torch_sim.typing import StateDict
+
def state_to_atom_graphs( # noqa: PLR0915
state: SimState,
@@ -102,10 +104,7 @@ def state_to_atom_graphs( # noqa: PLR0915
system_config = SystemConfig(radius=6.0, max_num_neighbors=20)
# Handle batch information if present
- if state.batch is not None:
- n_node = torch.bincount(state.batch)
- else:
- n_node = torch.tensor([len(state.positions)])
+ n_node = torch.bincount(state.batch)
# Set default dtype if not provided
output_dtype = torch.get_default_dtype() if output_dtype is None else output_dtype
@@ -146,45 +145,46 @@ def state_to_atom_graphs( # noqa: PLR0915
if wrap and (torch.any(row_vector_cell != 0) and torch.any(pbc)):
positions = feat_util.batch_map_to_pbc_cell(positions, row_vector_cell, n_node)
- # Compute edges of the graph
- edge_index, edge_vectors, unit_shifts, batch_num_edges = (
- feat_util.batch_compute_pbc_radius_graph(
- positions=positions,
- cells=row_vector_cell,
- pbc=pbc.unsqueeze(0).repeat(len(n_node), 1),
- radius=system_config.radius,
- n_node=n_node,
- max_number_neighbors=torch.tensor([max_num_neighbors] * len(n_node)),
- edge_method=edge_method,
- half_supercell=half_supercell,
- device=device,
- )
- )
- senders, receivers = edge_index[0], edge_index[1]
-
n_systems = state.batch.max().item() + 1
+
+ # Prepare lists to collect data from each system
+ all_edges = []
+ all_vectors = []
+ all_unit_shifts = []
+ num_edges = []
node_feats_list = []
edge_feats_list = []
graph_feats_list = []
- system_edges = torch.repeat_interleave(
- torch.arange(n_systems, device=state.device), batch_num_edges
- )
+
+ # Process each system in a single loop
+ offset = 0
for i in range(n_systems):
batch_mask = state.batch == i
- system_edge_mask = system_edges == i
- try:
- positions_per_system = positions[batch_mask]
- atomic_numbers_per_system = atomic_numbers[batch_mask]
- atomic_numbers_embedding_per_system = atomic_numbers_embedding[batch_mask]
- edge_vectors_per_system = edge_vectors[system_edge_mask]
- unit_shifts_per_system = unit_shifts[system_edge_mask]
- except Exception: # noqa: BLE001
- import pdb # noqa: T100
-
- pdb.set_trace() # noqa: T100
-
+ positions_per_system = positions[batch_mask]
+ atomic_numbers_per_system = atomic_numbers[batch_mask]
+ atomic_numbers_embedding_per_system = atomic_numbers_embedding[batch_mask]
cell_per_system = row_vector_cell[i]
pbc_per_system = pbc
+
+ # Compute edges directly for this system
+ edges, vectors, unit_shifts = feat_util.compute_pbc_radius_graph(
+ positions=positions_per_system,
+ cell=cell_per_system,
+ pbc=pbc_per_system,
+ radius=system_config.radius,
+ max_number_neighbors=max_num_neighbors,
+ edge_method=edge_method,
+ half_supercell=half_supercell,
+ device=device,
+ )
+
+ # Adjust indices for the global batch
+ all_edges.append(edges + offset)
+ all_vectors.append(vectors)
+ all_unit_shifts.append(unit_shifts)
+ num_edges.append(len(edges[0]))
+
+ # Calculate lattice parameters
lattice_per_system = torch.from_numpy(
cell_to_cellpar(cell_per_system.squeeze(0).cpu().numpy())
)
@@ -200,8 +200,8 @@ def state_to_atom_graphs( # noqa: PLR0915
}
edge_feats = {
- "vectors": edge_vectors_per_system,
- "unit_shifts": unit_shifts_per_system,
+ "vectors": vectors,
+ "unit_shifts": unit_shifts,
}
graph_feats = {
@@ -219,6 +219,16 @@ def state_to_atom_graphs( # noqa: PLR0915
edge_feats_list.append(edge_feats)
graph_feats_list.append(graph_feats)
+ # Update offset for next system
+ offset += len(positions_per_system)
+
+ # Concatenate all the edge data
+ edge_index = torch.cat(all_edges, dim=1)
+ unit_shifts = torch.cat(all_unit_shifts, dim=0)
+ batch_num_edges = torch.tensor(num_edges, dtype=torch.int64, device=device)
+
+ senders, receivers = edge_index[0], edge_index[1]
+
# Create and return AtomGraphs object
return AtomGraphs(
senders=senders,
diff --git a/torch_sim/models/sevennet.py b/torch_sim/models/sevennet.py
index 3a0c96d03..d21449d48 100644
--- a/torch_sim/models/sevennet.py
+++ b/torch_sim/models/sevennet.py
@@ -10,7 +10,7 @@
from torch_sim.elastic import voigt_6_to_full_3x3_stress
from torch_sim.models.interface import ModelInterface
from torch_sim.neighbors import vesin_nl_ts
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
if TYPE_CHECKING:
@@ -18,6 +18,8 @@
from sevenn.nn.sequential import AtomGraphSequential
+ from torch_sim.typing import StateDict
+
try:
import sevenn._keys as key
diff --git a/torch_sim/models/soft_sphere.py b/torch_sim/models/soft_sphere.py
index c7a97db19..2f6ea813d 100644
--- a/torch_sim/models/soft_sphere.py
+++ b/torch_sim/models/soft_sphere.py
@@ -46,8 +46,9 @@
from torch_sim.models.interface import ModelInterface
from torch_sim.neighbors import vesin_nl_ts
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
from torch_sim.transforms import get_pair_displacements
+from torch_sim.typing import StateDict
from torch_sim.unbatched.models.soft_sphere import (
soft_sphere_pair,
soft_sphere_pair_force,
diff --git a/torch_sim/neighbors.py b/torch_sim/neighbors.py
index a2ff0cb51..722ff6517 100644
--- a/torch_sim/neighbors.py
+++ b/torch_sim/neighbors.py
@@ -738,7 +738,7 @@ def torch_nl_n2(
Default is False.
Returns:
- Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
mapping (torch.Tensor [2, n_neighbors]):
A tensor containing the indices of the neighbor list for the given
positions array. `mapping[0]` corresponds to the central atom indices,
@@ -793,7 +793,7 @@ def torch_nl_linked_cell(
Default is False.
Returns:
- Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
A tuple containing:
- mapping (torch.Tensor [2, n_neighbors]):
A tensor containing the indices of the neighbor list for the given
diff --git a/torch_sim/optimizers.py b/torch_sim/optimizers.py
index b503e7b5b..e8eb0b3b7 100644
--- a/torch_sim/optimizers.py
+++ b/torch_sim/optimizers.py
@@ -21,7 +21,8 @@
import torch
import torch_sim.math as tsm
-from torch_sim.state import DeformGradMixin, SimState, StateDict
+from torch_sim.state import DeformGradMixin, SimState
+from torch_sim.typing import StateDict
@dataclass
@@ -76,8 +77,7 @@ def gradient_descent(
The learning rate controls the step size during optimization. Larger values can
speed up convergence but may cause instability in the optimization process.
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
def gd_init(
state: SimState | StateDict,
@@ -242,8 +242,7 @@ def unit_cell_gradient_descent( # noqa: PLR0915, C901
- Larger values for positions_lr and cell_lr can speed up convergence but
may cause instability in the optimization process
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
def gd_init(
state: SimState,
@@ -315,7 +314,7 @@ def gd_init(
# Calculate virial
volumes = torch.linalg.det(state.cell).view(-1, 1, 1)
- virial = -volumes * stress + pressure
+ virial = -volumes * (stress + pressure)
if hydrostatic_strain:
diag_mean = torch.diagonal(virial, dim1=1, dim2=2).mean(dim=1, keepdim=True)
@@ -329,12 +328,6 @@ def gd_init(
3, device=device
).unsqueeze(0).expand(state.n_batches, -1, -1)
- # Scale virial by cell_factor
- virial = virial / cell_factor
-
- # Reshape virial for cell forces
- cell_forces = virial # shape: (n_batches, 3, 3)
-
return UnitCellGDState(
positions=state.positions,
forces=forces,
@@ -351,7 +344,7 @@ def gd_init(
atomic_numbers=state.atomic_numbers,
batch=state.batch,
cell_positions=cell_positions,
- cell_forces=cell_forces,
+ cell_forces=virial / cell_factor,
cell_masses=cell_masses,
)
@@ -420,7 +413,7 @@ def gd_step(
# Calculate virial for cell forces
volumes = torch.linalg.det(new_row_vector_cell).view(-1, 1, 1)
- virial = -volumes * state.stress + state.pressure
+ virial = -volumes * (state.stress + state.pressure)
if state.hydrostatic_strain:
diag_mean = torch.diagonal(virial, dim1=1, dim2=2).mean(dim=1, keepdim=True)
virial = diag_mean.unsqueeze(-1) * torch.eye(3, device=device).unsqueeze(
@@ -432,12 +425,9 @@ def gd_step(
3, device=device
).unsqueeze(0).expand(n_batches, -1, -1)
- # Scale virial by cell_factor
- virial = virial / state.cell_factor
-
# Update cell forces
state.cell_positions = cell_positions_new
- state.cell_forces = virial
+ state.cell_forces = virial / state.cell_factor
return state
@@ -499,6 +489,7 @@ def fire(
f_dec: float = 0.5,
alpha_start: float = 0.1,
f_alpha: float = 0.99,
+ maxstep: float = 0.2,
) -> tuple[
FireState,
Callable[[FireState], FireState],
@@ -517,6 +508,7 @@ def fire(
f_dec (float): Factor for timestep decrease when power is negative
alpha_start (float): Initial velocity mixing parameter
f_alpha (float): Factor for mixing parameter decrease
+ maxstep (float): Maximum distance an atom can move per step.
Returns:
tuple: A pair of functions:
@@ -529,20 +521,14 @@ def fire(
- The algorithm adaptively adjusts step sizes and mixing parameters based
on the dot product of forces and velocities
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
eps = 1e-8 if dtype == torch.float32 else 1e-16
# Setup parameters
- params = [dt_max, dt_start, alpha_start, f_inc, f_dec, f_alpha, n_min]
- dt_max, dt_start, alpha_start, f_inc, f_dec, f_alpha, n_min = [
- (
- p
- if isinstance(p, torch.Tensor)
- else torch.tensor(p, device=device, dtype=dtype)
- )
- for p in params
+ params = [dt_max, dt_start, alpha_start, f_inc, f_dec, f_alpha, n_min, maxstep]
+ dt_max, dt_start, alpha_start, f_inc, f_dec, f_alpha, n_min, maxstep = [
+ torch.as_tensor(p, device=device, dtype=dtype) for p in params
]
def fire_init(
@@ -601,49 +587,31 @@ def fire_step(
state: FireState,
alpha_start: float = alpha_start,
dt_start: float = dt_start,
+ maxstep: float = maxstep,
) -> FireState:
"""Perform one FIRE optimization step for batched atomic systems.
Implements one step of the Fast Inertial Relaxation Engine (FIRE) algorithm for
- optimizing atomic positions in a batched setting. Uses velocity Verlet
- integration with adaptive velocity mixing.
+ optimizing atomic positions in a batched setting. Logic adapted to follow
+ ASE FIRE implementation more closely.
Args:
state: Current optimization state containing atomic parameters
- alpha_start: Initial mixing parameter for velocity update
- dt_start: Initial timestep for velocity Verlet integration
+ alpha_start: Initial mixing parameter for velocity update (used on reset)
+ dt_start: Initial timestep (unused in step function)
+ maxstep: Maximum allowed atom displacement per step.
Returns:
Updated state after performing one FIRE step
"""
n_batches = state.n_batches
- # Setup parameters
- dt_start = torch.full((n_batches,), dt_start, device=device, dtype=dtype)
- alpha_start = torch.full((n_batches,), alpha_start, device=device, dtype=dtype)
-
- # Velocity Verlet first half step (v += 0.5*a*dt)
- atom_wise_dt = state.dt[state.batch].unsqueeze(-1)
- state.velocities += 0.5 * atom_wise_dt * state.forces / state.masses.unsqueeze(-1)
-
- # Split positions and forces into atomic and cell components
- atomic_positions = state.positions # shape: (n_atoms, 3)
-
- # Update atomic positions
- atomic_positions_new = atomic_positions + atom_wise_dt * state.velocities
-
- # Update state with new positions and cell
- state.positions = atomic_positions_new
+ # Ensure parameters are tensors
+ alpha_start_t = torch.full((n_batches,), alpha_start, device=device, dtype=dtype)
+ maxstep_t = torch.as_tensor(maxstep, device=device, dtype=dtype)
- # Get new forces, energy, and stress
- results = model(state)
- state.energy = results["energy"]
- state.forces = results["forces"]
-
- # Velocity Verlet first half step (v += 0.5*a*dt)
- state.velocities += 0.5 * atom_wise_dt * state.forces / state.masses.unsqueeze(-1)
-
- # Calculate power (F·V) for atoms
+ # 1. Calculate Power P = F · V (using current forces and velocities)
+ # Note: ASE calculates this *before* the VV step
atomic_power = (state.forces * state.velocities).sum(dim=1) # [n_atoms]
atomic_power_per_batch = torch.zeros(
n_batches, device=device, dtype=atomic_power.dtype
@@ -651,39 +619,81 @@ def fire_step(
atomic_power_per_batch.scatter_add_(
dim=0, index=state.batch, src=atomic_power
) # [n_batches]
-
- # Calculate power for cell DOFs
batch_power = atomic_power_per_batch
- for batch_idx in range(n_batches):
- # FIRE specific updates
- if batch_power[batch_idx] > 0: # Power is positive
- state.n_pos[batch_idx] += 1
- if state.n_pos[batch_idx] > n_min:
- state.dt[batch_idx] = min(state.dt[batch_idx] * f_inc, dt_max)
- state.alpha[batch_idx] = state.alpha[batch_idx] * f_alpha
- else: # Power is negative
- state.n_pos[batch_idx] = 0
- state.dt[batch_idx] = state.dt[batch_idx] * f_dec
- state.alpha[batch_idx] = alpha_start[batch_idx]
- # Reset velocities for both atoms and cell
- state.velocities[state.batch == batch_idx] = 0
+ # 2. Determine which batches are moving downhill (P > 0)
+ # Create masks for convenience
+ downhill_mask_batch = batch_power > 0
+ uphill_mask_batch = ~downhill_mask_batch
- # Mix velocity and force direction using FIRE for atoms
- v_norm = torch.norm(state.velocities, dim=1, keepdim=True)
- f_norm = torch.norm(state.forces, dim=1, keepdim=True)
- # Avoid division by zero
- # mask = f_norm > 1e-10
- # state.velocity = torch.where(
- # mask,
- # (1.0 - state.alpha) * state.velocity
- # + state.alpha * state.forces * v_norm / f_norm,
- # state.velocity,
- # )
- batch_wise_alpha = state.alpha[state.batch].unsqueeze(-1)
- state.velocities = (
- 1.0 - batch_wise_alpha
- ) * state.velocities + batch_wise_alpha * state.forces * v_norm / (f_norm + eps)
+ # Get atom-wise masks
+ downhill_mask_atoms = downhill_mask_batch[state.batch]
+ uphill_mask_atoms = uphill_mask_batch[state.batch]
+
+ # 3. Adapt dt and alpha based on Power (per batch)
+ # Increase dt/decrease alpha for downhill batches after Nmin steps
+ increase_dt_mask = downhill_mask_batch & (state.n_pos > n_min)
+ state.dt[increase_dt_mask] = torch.minimum(
+ state.dt[increase_dt_mask] * f_inc, dt_max
+ )
+ state.alpha[increase_dt_mask] *= f_alpha
+ state.n_pos[downhill_mask_batch] += 1 # Increment steps for all downhill batches
+
+ # Decrease dt and reset alpha/n_pos for uphill batches
+ state.dt[uphill_mask_batch] *= f_dec
+ state.alpha[uphill_mask_batch] = alpha_start_t[uphill_mask_batch]
+ state.n_pos[uphill_mask_batch] = 0
+
+ # 4. Update velocities step 1: Apply mixing only if P > 0, Reset if P <= 0
+ # Mix velocity and force direction using FIRE for downhill atoms
+ v_current = state.velocities
+ f_current = state.forces
+ v_norm = torch.norm(v_current, dim=1, keepdim=True)
+ f_norm = torch.norm(f_current, dim=1, keepdim=True)
+ atom_wise_alpha = state.alpha[state.batch].unsqueeze(-1)
+
+ # Calculate mixed velocity component (only used if downhill)
+ v_mixed = (1.0 - atom_wise_alpha) * v_current + \
+ atom_wise_alpha * f_current * v_norm / (f_norm + eps)
+
+ # Apply mixing only for downhill atoms, reset velocity for uphill atoms
+ state.velocities = torch.where(downhill_mask_atoms.unsqueeze(-1), v_mixed, 0.0)
+
+ # 5. Update velocities step 2: Add force contribution (like v += F*dt)
+ # This is slightly different from ASE's v += dt*f before mixing,
+ # but closer to the original FIRE paper's spirit within VV.
+ # Effectively v_new = v_mixed_or_zero + F*dt (where F is current force)
+ atom_wise_dt = state.dt[state.batch].unsqueeze(-1)
+ state.velocities += atom_wise_dt * f_current # Using f_current consistent with P calc
+
+ # 6. Calculate displacement dr and apply maxstep constraint (per atom)
+ dr = atom_wise_dt * state.velocities # Proposed displacement
+ # norm_dr = torch.norm(dr, dim=1) # Norm for each atom -- OLD per-atom
+
+ # Calculate global norm across all atoms
+ global_norm_dr = torch.norm(dr)
+
+ # Scale dr if norm > maxstep
+ # scale = torch.minimum(maxstep_t / (norm_dr + eps), torch.tensor(1.0, device=device, dtype=dtype)) # OLD per-atom scale
+ # dr_scaled = dr * scale.unsqueeze(-1) # OLD per-atom scaling
+
+ # Calculate global scaling factor
+ global_scale = torch.minimum(maxstep_t / (global_norm_dr + eps), torch.tensor(1.0, device=device, dtype=dtype))
+
+ # Apply global scaling to all displacements
+ dr_scaled = dr * global_scale
+
+ # 7. Update positions
+ state.positions += dr_scaled
+
+ # 8. Get new forces and energy for the *next* step
+ # (This part remains the same - model uses the updated positions)
+ results = model(state)
+ state.energy = results["energy"]
+ state.forces = results["forces"]
+
+ # NOTE: We removed the Verlet half-step logic as ASE FIRE doesn't use it explicitly.
+ # The core is: Calculate P -> Adapt dt/alpha -> Mix/Reset v -> Update v+=f*dt -> Apply maxstep -> Update x
return state
@@ -821,20 +831,14 @@ def unit_cell_fire( # noqa: C901, PLR0915
- The cell_factor parameter controls the relative scale of atomic vs cell
optimization
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
eps = 1e-8 if dtype == torch.float32 else 1e-16
# Setup parameters
params = [dt_max, dt_start, alpha_start, f_inc, f_dec, f_alpha, n_min]
dt_max, dt_start, alpha_start, f_inc, f_dec, f_alpha, n_min = [
- (
- p
- if isinstance(p, torch.Tensor)
- else torch.tensor(p, device=device, dtype=dtype)
- )
- for p in params
+ torch.as_tensor(p, device=device, dtype=dtype) for p in params
]
def fire_init(
@@ -890,7 +894,7 @@ def fire_init(
stress = model_output["stress"] # [n_batches, 3, 3]
volumes = torch.linalg.det(state.cell).view(-1, 1, 1)
- virial = -volumes * stress + pressure
+ virial = -volumes * (stress + pressure) # P is P_ext * I
if hydrostatic_strain:
diag_mean = torch.diagonal(virial, dim1=1, dim2=2).mean(dim=1, keepdim=True)
@@ -904,8 +908,7 @@ def fire_init(
3, device=device
).unsqueeze(0).expand(n_batches, -1, -1)
- virial = virial / cell_factor
- cell_forces = virial
+ cell_forces = virial / cell_factor
# Sum masses per batch using segment_reduce
# TODO (AG): check this
@@ -1015,14 +1018,17 @@ def fire_step( # noqa: PLR0915
# Get new forces, energy, and stress
results = model(state)
state.energy = results["energy"]
+
+ # Combine new atomic forces and cell forces
forces = results["forces"]
stress = results["stress"]
state.forces = forces
state.stress = stress
+
# Calculate virial
- volumes = torch.linalg.det(new_cell).view(-1, 1, 1)
- virial = -volumes * stress + state.pressure
+ volumes = torch.linalg.det(state.cell).view(-1, 1, 1)
+ virial = -volumes * (stress + state.pressure)
if state.hydrostatic_strain:
diag_mean = torch.diagonal(virial, dim1=1, dim2=2).mean(dim=1, keepdim=True)
virial = diag_mean.unsqueeze(-1) * torch.eye(3, device=device).unsqueeze(
@@ -1034,10 +1040,40 @@ def fire_step( # noqa: PLR0915
3, device=device
).unsqueeze(0).expand(n_batches, -1, -1)
- virial = virial / state.cell_factor
- state.cell_forces = virial
+ # Perform batched matrix multiplication
+ ucf_cell_grad = torch.bmm(
+ virial, torch.linalg.inv(torch.transpose(cur_deform_grad, 1, 2))
+ )
- # Velocity Verlet first half step (v += 0.5*a*dt)
+ # Pre-compute all 9 direction matrices
+ directions = torch.zeros((9, 3, 3), device=device, dtype=dtype)
+ for idx, (mu, nu) in enumerate([(i, j) for i in range(3) for j in range(3)]):
+ directions[idx, mu, nu] = 1.0
+
+ # Calculate cell forces batch by batch
+ cell_forces = torch.zeros_like(ucf_cell_grad)
+ for b in range(n_batches):
+ # Calculate all 9 Frechet derivatives at once
+ expm_derivs = torch.stack(
+ [
+ tsm.expm_frechet(
+ cur_deform_grad[b], direction, compute_expm=False
+ )
+ for direction in directions
+ ]
+ )
+
+ # Calculate all 9 cell forces components
+ forces_flat = torch.sum(
+ expm_derivs * ucf_cell_grad[b].unsqueeze(0), dim=(1, 2)
+ )
+ cell_forces[b] = forces_flat.reshape(3, 3)
+
+ # Scale by cell_factor
+ cell_forces = cell_forces / state.cell_factor
+ state.cell_forces = cell_forces
+
+ # Velocity Verlet second half step (v += 0.5*a*dt)
state.velocities += 0.5 * atom_wise_dt * state.forces / state.masses.unsqueeze(-1)
state.cell_velocities += (
0.5 * cell_wise_dt * state.cell_forces / state.cell_masses.unsqueeze(-1)
@@ -1058,14 +1094,17 @@ def fire_step( # noqa: PLR0915
) # [n_batches]
batch_power = atomic_power_per_batch + cell_power
+ # FIRE updates for each batch
for batch_idx in range(n_batches):
# FIRE specific updates
- if batch_power[batch_idx] > 0: # Power is positive
+ if batch_power[batch_idx] > 0:
+ # Power is positive
state.n_pos[batch_idx] += 1
if state.n_pos[batch_idx] > n_min:
state.dt[batch_idx] = min(state.dt[batch_idx] * f_inc, dt_max)
state.alpha[batch_idx] = state.alpha[batch_idx] * f_alpha
- else: # Power is negative
+ else:
+ # Power is negative
state.n_pos[batch_idx] = 0
state.dt[batch_idx] = state.dt[batch_idx] * f_dec
state.alpha[batch_idx] = alpha_start[batch_idx]
@@ -1076,14 +1115,6 @@ def fire_step( # noqa: PLR0915
# Mix velocity and force direction using FIRE for atoms
v_norm = torch.norm(state.velocities, dim=1, keepdim=True)
f_norm = torch.norm(state.forces, dim=1, keepdim=True)
- # Avoid division by zero
- # mask = f_norm > 1e-10
- # state.velocity = torch.where(
- # mask,
- # (1.0 - state.alpha) * state.velocity
- # + state.alpha * state.forces * v_norm / f_norm,
- # state.velocity,
- # )
batch_wise_alpha = state.alpha[state.batch].unsqueeze(-1)
state.velocities = (
1.0 - batch_wise_alpha
@@ -1237,20 +1268,14 @@ def frechet_cell_fire( # noqa: C901, PLR0915
- To fix the cell and only optimize atomic positions, set both
constant_volume=True and hydrostatic_strain=True
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
eps = 1e-8 if dtype == torch.float32 else 1e-16
# Setup parameters
params = [dt_max, dt_start, alpha_start, f_inc, f_dec, f_alpha, n_min]
dt_max, dt_start, alpha_start, f_inc, f_dec, f_alpha, n_min = [
- (
- p
- if isinstance(p, torch.Tensor)
- else torch.tensor(p, device=device, dtype=dtype)
- )
- for p in params
+ torch.as_tensor(p, device=device, dtype=dtype) for p in params
]
def fire_init(
@@ -1318,7 +1343,7 @@ def fire_init(
# Calculate virial for cell forces
volumes = torch.linalg.det(state.cell).view(-1, 1, 1)
- virial = -volumes * stress + pressure
+ virial = -volumes * (stress + pressure) # P is P_ext * I
if hydrostatic_strain:
diag_mean = torch.diagonal(virial, dim1=1, dim2=2).mean(dim=1, keepdim=True)
@@ -1466,7 +1491,7 @@ def fire_step( # noqa: PLR0915
# Calculate virial
volumes = torch.linalg.det(state.cell).view(-1, 1, 1)
- virial = -volumes * stress + state.pressure
+ virial = -volumes * (stress + state.pressure)
if state.hydrostatic_strain:
diag_mean = torch.diagonal(virial, dim1=1, dim2=2).mean(dim=1, keepdim=True)
virial = diag_mean.unsqueeze(-1) * torch.eye(3, device=device).unsqueeze(
diff --git a/torch_sim/quantities.py b/torch_sim/quantities.py
index 594ebe5b0..5a1baa644 100644
--- a/torch_sim/quantities.py
+++ b/torch_sim/quantities.py
@@ -26,8 +26,7 @@ def calc_kT( # noqa: N802
velocities: torch.Tensor | None = None,
batch: torch.Tensor | None = None,
) -> torch.Tensor:
- """Calculate temperature from momenta/velocities and masses.
- Temperature returned in energy units.
+ """Calculate temperature in energy units from momenta/velocities and masses.
Args:
momenta (torch.Tensor): Particle momenta, shape (n_particles, n_dim)
@@ -37,7 +36,7 @@ def calc_kT( # noqa: N802
each particle
Returns:
- Scalar temperature value
+ torch.Tensor: Scalar temperature value
"""
if momenta is not None and velocities is not None:
raise ValueError("Must pass either momenta or velocities, not both")
@@ -45,12 +44,12 @@ def calc_kT( # noqa: N802
if momenta is None and velocities is None:
raise ValueError("Must pass either momenta or velocities")
- if momenta is not None:
- # If momentum provided, calculate v^2 = p^2/m^2
- squared_term = (momenta**2) / masses.unsqueeze(-1)
- else:
+ if momenta is None:
# If velocity provided, calculate mv^2
squared_term = (velocities**2) * masses.unsqueeze(-1)
+ else:
+ # If momentum provided, calculate v^2 = p^2/m^2
+ squared_term = (momenta**2) / masses.unsqueeze(-1)
if batch is None:
# Count total degrees of freedom
@@ -88,7 +87,7 @@ def calc_temperature(
units (object): Units to return the temperature in
Returns:
- Temperature value in specified units
+ torch.Tensor: Temperature value in specified units
"""
return calc_kT(momenta, masses, velocities, batch) / units
@@ -137,18 +136,15 @@ def batchwise_max_force(state: SimState) -> torch.Tensor:
"""Compute the maximum force per batch.
Args:
- state (SimState): SimState to compute the maximum force per batch for
+ state (SimState): State to compute the maximum force per batch for.
Returns:
- Tensor of maximum forces per batch
+ torch.Tensor: Maximum forces per batch
"""
batch_wise_max_force = torch.zeros(
state.n_batches, device=state.device, dtype=state.dtype
)
max_forces = state.forces.norm(dim=1)
return batch_wise_max_force.scatter_reduce(
- dim=0,
- index=state.batch,
- src=max_forces,
- reduce="amax",
+ dim=0, index=state.batch, src=max_forces, reduce="amax"
)
diff --git a/torch_sim/runners.py b/torch_sim/runners.py
index 75f4bce8c..ae2eb498d 100644
--- a/torch_sim/runners.py
+++ b/torch_sim/runners.py
@@ -15,8 +15,9 @@
from torch_sim.autobatching import BinningAutoBatcher, InFlightAutoBatcher
from torch_sim.models.interface import ModelInterface
from torch_sim.quantities import batchwise_max_force, calc_kinetic_energy, calc_kT
-from torch_sim.state import SimState, StateLike, concatenate_states, initialize_state
+from torch_sim.state import SimState, concatenate_states, initialize_state
from torch_sim.trajectory import TrajectoryReporter
+from torch_sim.typing import StateLike
from torch_sim.units import UnitSystem
@@ -77,6 +78,7 @@ def _configure_batches_iterator(
autobatcher = BinningAutoBatcher(
model=model,
return_indices=True,
+ max_memory_padding=0.9,
)
autobatcher.load_states(state)
batches = autobatcher
@@ -87,7 +89,7 @@ def _configure_batches_iterator(
elif autobatcher is False:
batches = [(state, [])]
else:
- raise ValueError(
+ raise TypeError(
f"Invalid autobatcher type: {type(autobatcher).__name__}, "
"must be bool or BinningAutoBatcher."
)
@@ -130,9 +132,7 @@ def integrate(
# create a list of temperatures
temps = temperature if hasattr(temperature, "__iter__") else [temperature] * n_steps
if len(temps) != n_steps:
- raise ValueError(
- f"len(temperature) = {len(temps)}. It must equal n_steps = {n_steps}"
- )
+ raise ValueError(f"{len(temps)=:,}. It must equal n_steps = {n_steps=:,}")
# initialize the state
state: SimState = initialize_state(system, model.device, model.dtype)
@@ -206,7 +206,7 @@ def _configure_in_flight_autobatcher(
if isinstance(autobatcher, InFlightAutoBatcher):
autobatcher.return_indices = True
autobatcher.max_attempts = max_attempts
- else:
+ elif isinstance(autobatcher, bool):
if autobatcher:
memory_scales_with = model.memory_scales_with
max_memory_scaler = None
@@ -219,7 +219,12 @@ def _configure_in_flight_autobatcher(
max_memory_scaler=max_memory_scaler,
memory_scales_with=memory_scales_with,
max_iterations=max_attempts,
+ max_memory_padding=0.9,
)
+ else:
+ autobatcher_type = type(autobatcher).__name__
+ cls_name = InFlightAutoBatcher.__name__
+ raise TypeError(f"Invalid {autobatcher_type=}, must be bool or {cls_name}.")
return autobatcher
diff --git a/torch_sim/state.py b/torch_sim/state.py
index 12fa22e72..e5997cf4f 100644
--- a/torch_sim/state.py
+++ b/torch_sim/state.py
@@ -6,40 +6,22 @@
import copy
import importlib
-import typing
import warnings
from dataclasses import dataclass, field
-from typing import Literal, Self, TypeVar, Union
+from typing import TYPE_CHECKING, Literal, Self
import torch
import torch_sim as ts
+from torch_sim.typing import StateLike
-if typing.TYPE_CHECKING:
+if TYPE_CHECKING:
from ase import Atoms
from phonopy.structure.atoms import PhonopyAtoms
from pymatgen.core import Structure
-_T = TypeVar("_T", bound="SimState")
-StateLike = Union[
- "Atoms",
- "Structure",
- "PhonopyAtoms",
- list["Atoms"],
- list["Structure"],
- list["PhonopyAtoms"],
- _T,
- list[_T],
-]
-
-StateDict = dict[
- Literal["positions", "masses", "cell", "pbc", "atomic_numbers", "batch"],
- torch.Tensor,
-]
-
-
@dataclass
class SimState:
"""State representation for atomistic systems with batched operations support.
@@ -622,7 +604,9 @@ def _split_state(
Args:
state (SimState): The SimState to split
ambiguous_handling ("error" | "globalize"): How to handle ambiguous
- properties
+ properties. If "error", an error is raised if a property has ambiguous
+ scope. If "globalize", properties with ambiguous scope are treated as
+ global.
Returns:
list[SimState]: A list of SimState objects, each containing a single
@@ -674,7 +658,9 @@ def _pop_states(
state (SimState): The SimState to modify
pop_indices (list[int] | torch.Tensor): The batch indices to extract and remove
ambiguous_handling ("error" | "globalize"): How to handle ambiguous
- properties
+ properties. If "error", an error is raised if a property has ambiguous
+ scope. If "globalize", properties with ambiguous scope are treated as
+ global.
Returns:
tuple[SimState, list[SimState]]: A tuple containing:
diff --git a/torch_sim/trajectory.py b/torch_sim/trajectory.py
index d709f631a..22195fc0f 100644
--- a/torch_sim/trajectory.py
+++ b/torch_sim/trajectory.py
@@ -798,7 +798,7 @@ def _get_state_arrays(self, frame: int) -> dict[str, torch.Tensor]:
frame = n_frames + frame
if frame > n_frames:
- raise ValueError(f"{frame=} is out of range. Total frames: {n_frames}")
+ raise ValueError(f"{frame=} is out of range. Total frames: {n_frames:,}")
arrays["positions"] = self.get_array("positions", start=frame, stop=frame + 1)[0]
diff --git a/torch_sim/transforms.py b/torch_sim/transforms.py
index da6fea5d7..660540a2e 100644
--- a/torch_sim/transforms.py
+++ b/torch_sim/transforms.py
@@ -258,7 +258,7 @@ def get_pair_displacements(
shifts (Optional[torch.Tensor]): Shift vectors for periodic images [n_pairs, 3].
Returns:
- Tuple[torch.Tensor, torch.Tensor]:
+ tuple[torch.Tensor, torch.Tensor]:
- Displacement vectors [n_pairs, 3].
- Distances [n_pairs].
"""
@@ -580,7 +580,7 @@ def get_fully_connected_mapping(
self-interactions in the mapping.
Returns:
- Tuple[torch.Tensor, torch.Tensor]: A tuple containing:
+ tuple[torch.Tensor, torch.Tensor]: A tuple containing:
- mapping (torch.Tensor): A tensor of shape (n_pairs, 2)
representing the pairs of indices for which distances
will be computed.
@@ -637,7 +637,7 @@ def build_naive_neighborhood(
self-interactions.
Returns:
- Tuple[torch.Tensor, torch.Tensor, torch.Tensor]: A tuple containing:
+ tuple[torch.Tensor, torch.Tensor, torch.Tensor]: A tuple containing:
- mapping (torch.Tensor): A tensor of shape (n_pairs, 2)
representing the pairs of indices for neighboring atoms.
- batch_mapping (torch.Tensor): A tensor of shape (n_pairs,)
@@ -823,7 +823,7 @@ def linked_cell( # noqa: PLR0915
atoms will be included as their own neighbors. Default is False.
Returns:
- Tuple[torch.Tensor, torch.Tensor]:
+ tuple[torch.Tensor, torch.Tensor]:
- neigh_atom (torch.Tensor): A tensor containing pairs of indices
where neigh_atom[0] represents the original atom indices
and neigh_atom[1] represents their corresponding neighbor
@@ -989,7 +989,7 @@ def build_linked_cell_neighborhood(
their own neighbors. Default is False.
Returns:
- Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
- mapping (torch.Tensor): A tensor containing pairs of indices where
mapping[0] represents the central atom indices and mapping[1]
represents their corresponding neighbor indices.
diff --git a/torch_sim/typing.py b/torch_sim/typing.py
new file mode 100644
index 000000000..13f0db94e
--- /dev/null
+++ b/torch_sim/typing.py
@@ -0,0 +1,52 @@
+"""Types used across torch-sim."""
+
+from enum import Enum
+from typing import TYPE_CHECKING, Literal, TypeVar, Union
+
+import torch
+
+
+if TYPE_CHECKING:
+ from ase import Atoms
+ from phonopy.structure.atoms import PhonopyAtoms
+ from pymatgen.core import Structure
+
+ from torch_sim.state import SimState
+
+
+MemoryScaling = Literal["n_atoms_x_density", "n_atoms"]
+StateKey = Literal["positions", "masses", "cell", "pbc", "atomic_numbers", "batch"]
+StateDict = dict[StateKey, torch.Tensor]
+SimStateVar = TypeVar("SimStateVar", bound="SimState")
+
+
+class BravaisType(Enum):
+ """Enumeration of the seven Bravais lattice types in 3D crystals.
+
+ These lattice types represent the distinct crystal systems classified
+ by their symmetry properties, from highest symmetry (cubic) to lowest
+ symmetry (triclinic).
+
+ Each type has specific constraints on lattice parameters and angles,
+ which determine the number of independent elastic constants.
+ """
+
+ CUBIC = "cubic"
+ HEXAGONAL = "hexagonal"
+ TRIGONAL = "trigonal"
+ TETRAGONAL = "tetragonal"
+ ORTHORHOMBIC = "orthorhombic"
+ MONOCLINIC = "monoclinic"
+ TRICLINIC = "triclinic"
+
+
+StateLike = Union[
+ "Atoms",
+ "Structure",
+ "PhonopyAtoms",
+ list["Atoms"],
+ list["Structure"],
+ list["PhonopyAtoms"],
+ SimStateVar,
+ list[SimStateVar],
+]
diff --git a/torch_sim/unbatched/models/mace.py b/torch_sim/unbatched/models/mace.py
index 2b87f8579..9bd491241 100644
--- a/torch_sim/unbatched/models/mace.py
+++ b/torch_sim/unbatched/models/mace.py
@@ -12,7 +12,8 @@
from torch_sim.models.interface import ModelInterface
from torch_sim.neighbors import vesin_nl_ts
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
+from torch_sim.typing import StateDict
try:
diff --git a/torch_sim/unbatched/models/morse.py b/torch_sim/unbatched/models/morse.py
index 2038d6221..354a3fade 100644
--- a/torch_sim/unbatched/models/morse.py
+++ b/torch_sim/unbatched/models/morse.py
@@ -4,8 +4,9 @@
from torch_sim.models.interface import ModelInterface
from torch_sim.neighbors import vesin_nl_ts
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
from torch_sim.transforms import get_pair_displacements
+from torch_sim.typing import StateDict
# Default parameter values defined at module level
diff --git a/torch_sim/unbatched/models/soft_sphere.py b/torch_sim/unbatched/models/soft_sphere.py
index 4ad3b6655..166f844f3 100644
--- a/torch_sim/unbatched/models/soft_sphere.py
+++ b/torch_sim/unbatched/models/soft_sphere.py
@@ -4,8 +4,9 @@
from torch_sim.models.interface import ModelInterface
from torch_sim.neighbors import vesin_nl_ts
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
from torch_sim.transforms import get_pair_displacements, safe_mask
+from torch_sim.typing import StateDict
# Default parameter values defined at module level
diff --git a/torch_sim/unbatched/unbatched_integrators.py b/torch_sim/unbatched/unbatched_integrators.py
index 33520152c..fd285b76a 100644
--- a/torch_sim/unbatched/unbatched_integrators.py
+++ b/torch_sim/unbatched/unbatched_integrators.py
@@ -7,8 +7,9 @@
import torch
from torch_sim.quantities import calc_kinetic_energy, count_dof
-from torch_sim.state import SimState, StateDict
+from torch_sim.state import SimState
from torch_sim.transforms import pbc_wrap_general
+from torch_sim.typing import StateDict
@dataclass
@@ -228,8 +229,7 @@ def nve(
- Initial velocities sampled from Maxwell-Boltzmann distribution
- Model must return dict with 'energy' and 'forces' keys
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
def nve_init(
state: SimState | StateDict,
@@ -348,8 +348,7 @@ def nvt_langevin(
- Preserves detailed balance for correct NVT sampling
- Handles periodic boundary conditions if enabled in state
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
gamma = gamma or 1 / (100 * dt)
if isinstance(gamma, float):
@@ -565,8 +564,7 @@ def npt_langevin( # noqa: C901, PLR0915
- Callable[[MDState, torch.Tensor], MDState]: Update function that evolves
system by one timestep
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
# Set default values for coupling parameters if not provided
alpha = alpha or 1 / (100 * dt)
@@ -1372,7 +1370,7 @@ def nvt_nose_hoover(
sy_steps: Number of Suzuki-Yoshida steps - must be 1, 3, 5, or 7 (default: 3)
Returns:
- Tuple containing:
+ tuple containing:
- Initialization function that takes a state and returns NVTNoseHooverState
- Update function that performs one complete integration step
@@ -1396,8 +1394,7 @@ def nvt_nose_hoover(
4. Update chain kinetic energy
5. Second half-step of chain evolution
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
def nvt_nose_hoover_init(
state: SimState | StateDict,
@@ -1696,8 +1693,7 @@ def npt_nose_hoover( # noqa: C901, PLR0915
- Cell dynamics use logarithmic coordinates for volume updates
- Conserves extended system Hamiltonian
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
def _npt_cell_info(
state: NPTNoseHooverState,
diff --git a/torch_sim/unbatched/unbatched_optimizers.py b/torch_sim/unbatched/unbatched_optimizers.py
index 5648fbfda..c8497c875 100644
--- a/torch_sim/unbatched/unbatched_optimizers.py
+++ b/torch_sim/unbatched/unbatched_optimizers.py
@@ -6,7 +6,8 @@
import torch
import torch_sim.math as tsm
-from torch_sim.state import DeformGradMixin, SimState, StateDict
+from torch_sim.state import DeformGradMixin, SimState
+from torch_sim.typing import StateDict
from torch_sim.unbatched.unbatched_integrators import velocity_verlet
@@ -47,19 +48,18 @@ def gradient_descent(
energy surfaces.
Args:
- model: Neural network model that computes energies and forces
- lr: Step size for position updates (default: 0.01)
+ model (torch.nn.Module): Neural network model that computes energies and forces
+ lr (float): Step size for position updates (default: 0.01)
Returns:
- Tuple containing:
+ tuple containing:
- Initialization function that creates the initial GDState
- Update function that performs one gradient descent step
Notes:
- Best suited for systems close to their minimum energy configuration
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
# Convert learning rate to tensor
if not isinstance(lr, torch.Tensor):
@@ -194,14 +194,12 @@ def fire(
References:
- Bitzek et al., PRL 97, 170201 (2006) - Original FIRE paper
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
# Convert parameters to tensors
params = [dt_max, n_min, f_inc, f_dec, f_alpha, dt_start, alpha_start]
dt_max, n_min, f_inc, f_dec, f_alpha, dt_start, alpha_start = [
- p if isinstance(p, torch.Tensor) else torch.tensor(p, device=device, dtype=dtype)
- for p in params
+ torch.as_tensor(p, device=device, dtype=dtype) for p in params
]
def fire_init(state: SimState | StateDict, **kwargs) -> FIREState:
@@ -358,7 +356,7 @@ def fire_ase( # noqa: PLR0915
downhill_check: Whether to verify energy decreases each step (default: False)
Returns:
- Tuple containing:
+ tuple containing:
- Initial FIREState with system state and optimization parameters
- Update function that performs one FIRE step
Notes:
@@ -376,16 +374,14 @@ def fire_ase( # noqa: PLR0915
- Bitzek et al., PRL 97, 170201 (2006) - Original FIRE paper
- ASE implementation: https://wiki.fysik.dtu.dk/ase/ase/optimize.html
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
eps = 1e-8 if dtype == torch.float32 else 1e-16
# Convert scalar parameters to tensors
params = [dt, dt_max, max_step, f_inc, f_dec, f_alpha, alpha_start]
dt, dt_max, max_step, f_inc, f_dec, f_alpha, alpha_start = [
- p if isinstance(p, torch.Tensor) else torch.tensor(p, device=device, dtype=dtype)
- for p in params
+ torch.as_tensor(p, device=device, dtype=dtype) for p in params
]
def fire_init(state: SimState | StateDict, **kwargs) -> FIREState:
@@ -581,20 +577,18 @@ def unit_cell_fire( # noqa: PLR0915, C901
cell_factor: Scaling factor for cell optimization (default: number of atoms)
Returns:
- Tuple containing:
+ tuple containing:
- Initialization function that creates a UnitCellFIREState
- Update function that performs one FIRE step
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
eps = 1e-8 if dtype == torch.float32 else 1e-16
# Setup parameters
params = [dt_max, dt_start, alpha_start, f_inc, f_dec, f_alpha, n_min]
dt_max, dt_start, alpha_start, f_inc, f_dec, f_alpha, n_min = [
- p if isinstance(p, torch.Tensor) else torch.tensor(p, device=device, dtype=dtype)
- for p in params
+ torch.as_tensor(p, device=device, dtype=dtype) for p in params
]
def fire_init(
@@ -648,7 +642,7 @@ def fire_init(
# Calculate virial
volume = torch.linalg.det(state.cell).view(1, 1)
- virial = -volume * stress + pressure
+ virial = -volume * (stress + pressure)
if hydrostatic_strain:
diag_mean = torch.diagonal(virial).mean().view(1, 1)
@@ -658,9 +652,6 @@ def fire_init(
diag_mean = torch.diagonal(virial).mean().view(1, 1)
virial = virial - diag_mean * torch.eye(3, device=device)
- virial = virial / cell_factor
- cell_forces = virial
-
# Create cell masses
cell_masses = torch.full((3,), state.masses.sum(), device=device, dtype=dtype)
@@ -684,7 +675,7 @@ def fire_init(
atomic_numbers=atomic_numbers,
cell_positions=cell_positions,
cell_velocities=torch.zeros_like(cell_positions),
- cell_forces=cell_forces,
+ cell_forces=virial / cell_factor,
cell_masses=cell_masses,
)
@@ -742,7 +733,7 @@ def fire_step( # noqa: PLR0915
# Calculate virial for cell forces
volume = torch.linalg.det(new_row_vector_cell).view(1, 1)
- virial = -volume * stress + state.pressure
+ virial = -volume * (stress + state.pressure)
if state.hydrostatic_strain:
diag_mean = torch.diagonal(virial).mean().view(1, 1)
@@ -752,8 +743,7 @@ def fire_step( # noqa: PLR0915
diag_mean = torch.diagonal(virial).mean().view(1, 1)
virial = virial - diag_mean * torch.eye(3, device=device)
- virial = virial / state.cell_factor
- state.cell_forces = virial
+ state.cell_forces = virial / state.cell_factor
# Velocity Verlet second half step
state.velocities += 0.5 * state.dt * state.forces / state.masses.unsqueeze(-1)
@@ -892,7 +882,7 @@ def frechet_cell_fire( # noqa: PLR0915, C901
cell_factor: Scaling factor for cell optimization (default: number of atoms)
Returns:
- Tuple containing:
+ tuple containing:
- Initialization function that creates a FrechetCellFIREState
- Update function that performs one FIRE step with Frechet derivatives
@@ -900,16 +890,14 @@ def frechet_cell_fire( # noqa: PLR0915, C901
- https://github.com/lan496/lan496.github.io/blob/main/notes/cell_grad.pdf
- https://github.com/JuliaMolSim/JuLIP.jl/blob/master/src/expcell.jl
"""
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
eps = 1e-8 if dtype == torch.float32 else 1e-16
# Setup parameters
params = [dt_max, dt_start, alpha_start, f_inc, f_dec, f_alpha]
dt_max, dt_start, alpha_start, f_inc, f_dec, f_alpha = [
- p if isinstance(p, torch.Tensor) else torch.tensor(p, device=device, dtype=dtype)
- for p in params
+ torch.as_tensor(p, device=device, dtype=dtype) for p in params
]
def fire_init(
@@ -964,7 +952,7 @@ def fire_init(
# Calculate virial
volume = torch.linalg.det(state.cell).view(1, 1)
- virial = -volume * stress + pressure
+ virial = -volume * (stress + pressure)
if hydrostatic_strain:
diag_mean = torch.diagonal(virial).mean().view(1, 1)
@@ -1060,7 +1048,7 @@ def fire_step( # noqa: PLR0915
# Calculate virial for cell forces
volume = torch.linalg.det(state.cell).view(1, 1)
- virial = -volume * stress + state.pressure
+ virial = -volume * (stress + state.pressure)
if state.hydrostatic_strain:
diag_mean = torch.diagonal(virial).mean().view(1, 1)
diff --git a/torch_sim/workflows/a2c.py b/torch_sim/workflows/a2c.py
index 68c99e8ac..19420c369 100644
--- a/torch_sim/workflows/a2c.py
+++ b/torch_sim/workflows/a2c.py
@@ -738,8 +738,7 @@ def get_unit_cell_relaxed_structure(
- float: Final pressure in eV/ų
"""
# Get device and dtype from model
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
logger = {
"energy": torch.zeros((max_iter, 1), device=device, dtype=dtype),
@@ -811,8 +810,7 @@ def get_unit_cell_relaxed_structure_batched(
- float: Final pressure in eV/ų
"""
# Get device and dtype from model
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
logger = {
"energy": torch.zeros((max_iter, state.n_batches), device=device, dtype=dtype),
@@ -885,8 +883,7 @@ def get_relaxed_structure(
- float: Final pressure in eV/ų
"""
# Get device and dtype from model
- device = model.device
- dtype = model.dtype
+ device, dtype = model.device, model.dtype
logger = {"energy": torch.zeros((max_iter, 1), device=device, dtype=dtype)}
diff --git a/torch_sim/workflows/neb.py b/torch_sim/workflows/neb.py
new file mode 100644
index 000000000..bd06044eb
--- /dev/null
+++ b/torch_sim/workflows/neb.py
@@ -0,0 +1,572 @@
+"""Nudged Elastic Band (NEB) workflow.
+
+This module implements the Nudged Elastic Band method for finding minimum energy
+paths between two given atomic configurations.
+"""
+
+import logging
+from contextlib import nullcontext
+from dataclasses import dataclass, field
+from typing import Any, Literal
+
+import torch
+
+from torch_sim.models.interface import ModelInterface
+from torch_sim.optimizers import (
+ FireState,
+ FrechetCellFIREState,
+ GDState,
+ fire,
+ frechet_cell_fire,
+ gradient_descent,
+)
+from torch_sim.state import SimState, concatenate_states, initialize_state
+from torch_sim.trajectory import TorchSimTrajectory
+from torch_sim.transforms import minimum_image_displacement
+from torch_sim.typing import StateLike
+
+
+logger = logging.getLogger(__name__)
+
+# Add epsilon for numerical stability
+_EPS = torch.finfo(torch.float64).eps
+
+
+@dataclass
+class NEB:
+ """Nudged Elastic Band (NEB) optimizer.
+
+ Finds the minimum energy path (MEP) between an initial and final state using
+ the NEB algorithm.
+
+ Attributes:
+ model: The energy/force model (e.g., MACE) wrapped in a ModelInterface.
+ n_images: Number of intermediate images between initial and final states.
+ spring_constant: Spring constant connecting adjacent images (eV/Ang^2).
+ use_climbing_image: Whether to use a climbing image.
+ optimizer_type: Type of optimizer to use.
+ optimizer_params: Parameters for the chosen optimizer.
+ trajectory_filename: Optional filename for saving the NEB trajectory.
+ device: Computation device (e.g., 'cpu', 'cuda'). If None, uses model device.
+ dtype: Computation data type (e.g., torch.float32). If None, uses model dtype.
+ """
+
+ model: ModelInterface
+ n_images: int
+ spring_constant: float = 0.1 # eV/Ang^2, typical ASE default
+ use_climbing_image: bool = False
+ optimizer_type: Literal["fire", "gd", "frechet_cell_fire"] = "fire"
+ optimizer_params: dict[str, Any] = field(default_factory=dict)
+ trajectory_filename: str | None = None
+ device: torch.device | None = None
+ dtype: torch.dtype | None = None
+
+ def __post_init__(self) -> None:
+ """Initializes device, dtype, and optimizer functions after dataclass creation."""
+ if self.device is None:
+ self.device = self.model.device
+ if self.dtype is None:
+ self.dtype = self.model.dtype
+
+ # Initialize FIRE optimizer functions
+ # self._fire_init, self._fire_step = fire(self.model, **self.fire_params)
+
+ # Conditionally initialize optimizer functions and state type
+ if self.optimizer_type == "fire":
+ # TODO: Reinstate fire_params if needed, maybe via optimizer_params dict
+ self._init_fn, self._step_fn = fire(self.model, **self.optimizer_params)
+ self._OptimizerStateType = FireState
+ elif self.optimizer_type == "frechet_cell_fire":
+ # Initialize Frechet Cell FIRE, passing params.
+ # Ensure constant_volume=True is set by user.
+ self._init_fn, self._step_fn = frechet_cell_fire(
+ self.model, **self.optimizer_params
+ )
+ self._OptimizerStateType = FrechetCellFIREState
+ elif self.optimizer_type == "gd":
+ # Use .get() for lr with a default, in case user doesn't pass it
+ self._init_fn, self._step_fn = gradient_descent(
+ self.model, lr=self.optimizer_params.get("lr", 0.01)
+ )
+ self._OptimizerStateType = GDState
+ else:
+ raise ValueError(f"Unsupported optimizer_type: {self.optimizer_type}")
+
+ def _interpolate_path(self, initial_state: SimState, final_state: SimState) -> SimState:
+ """Linearly interpolate the initial path between states using MIC.
+
+ Generates `n_images` intermediate states between the initial and final states
+ by linear interpolation of atomic positions, respecting periodic boundary
+ conditions via the Minimum Image Convention (MIC).
+
+ Args:
+ initial_state (SimState): The starting SimState (must be single-batch).
+ final_state (SimState): The ending SimState (must be single-batch).
+
+ Returns:
+ SimState: A single SimState containing all interpolated intermediate
+ images, batched together. The batch index corresponds to the image
+ index (0 to n_images-1).
+
+ Raises:
+ ValueError: If initial and final states are incompatible (e.g., different
+ number of atoms, atom types, PBC settings, or if they are not
+ single-batch states).
+ """
+ # --- Input Validation ---
+ if initial_state.n_batches != 1 or final_state.n_batches != 1:
+ raise ValueError("Initial and final states must be single-batch SimStates.")
+ if initial_state.n_atoms != final_state.n_atoms:
+ raise ValueError(
+ f"Initial ({initial_state.n_atoms}) and final ({final_state.n_atoms}) "
+ "states must have the same number of atoms."
+ )
+ if not torch.equal(initial_state.atomic_numbers, final_state.atomic_numbers):
+ # Comparing floats might be tricky, but atomic numbers should be exact
+ raise ValueError("Initial and final states must have the same atom types.")
+ if initial_state.pbc != final_state.pbc:
+ # TODO: Could potentially support different PBCs, but complex for NEB.
+ raise ValueError("Initial and final states must have the same PBC setting.")
+ # For fixed-cell NEB, cells should ideally be identical. Warn if not?
+ # if not torch.allclose(initial_state.cell, final_state.cell):
+
+ n_atoms_per_image = initial_state.n_atoms
+
+ # --- Interpolation ---
+ initial_pos = initial_state.positions
+ final_pos = final_state.positions
+
+ # Calculate displacement using Minimum Image Convention
+ displacement = minimum_image_displacement(
+ dr=final_pos - initial_pos,
+ cell=initial_state.cell[0], # Use cell from initial state
+ pbc=initial_state.pbc
+ )
+ # Ensure shape is correct [n_atoms, 3]
+ displacement = displacement.reshape(n_atoms_per_image, 3)
+
+ # Generate interpolation factors (e.g., for n_images=3: 0.25, 0.5, 0.75)
+ factors = torch.linspace(
+ 0.0, 1.0, steps=self.n_images + 2, device=self.device, dtype=self.dtype
+ )[1:-1] # Exclude 0.0 and 1.0
+ factors = factors.view(-1, 1, 1) # Shape: [n_images, 1, 1]
+
+ # Calculate interpolated positions: initial + factor * displacement
+ # Broadcasting: [N_atoms, 3] + [N_images, 1, 1] * [N_atoms, 3] -> [N_images, N_atoms, 3]
+ interpolated_pos = initial_pos.unsqueeze(0) + factors * displacement.unsqueeze(0)
+
+ # Reshape to [n_images * n_atoms_per_image, 3]
+ all_positions = interpolated_pos.reshape(-1, 3)
+
+ # --- Create Batched State ---
+ # Repeat other attributes for each image
+ all_atomic_numbers = initial_state.atomic_numbers.repeat(self.n_images)
+ all_masses = initial_state.masses.repeat(self.n_images)
+ # Use initial state's cell, repeated for each image
+ all_cells = initial_state.cell.repeat(self.n_images, 1, 1) # Shape: [n_images, 3, 3]
+
+ # Create batch tensor: [0, 0, ..., 1, 1, ..., n_images-1, ...]
+ batch_indices = torch.arange(
+ self.n_images, device=self.device, dtype=torch.int64
+ )
+ all_batch = torch.repeat_interleave(batch_indices, repeats=n_atoms_per_image)
+
+ return SimState(
+ positions=all_positions,
+ atomic_numbers=all_atomic_numbers,
+ masses=all_masses,
+ cell=all_cells,
+ pbc=initial_state.pbc,
+ batch=all_batch,
+ )
+
+ def _compute_tangents( # noqa: C901
+ self,
+ all_pos: torch.Tensor, # Shape: [n_total_images, n_atoms, 3]
+ all_energies: torch.Tensor, # Shape: [n_total_images]
+ cell: torch.Tensor, # Shape: [3, 3]
+ *, # Make pbc keyword-only
+ pbc: bool,
+ ) -> torch.Tensor:
+ """Compute normalized tangent vectors for intermediate NEB images.
+
+ Implements the improved tangent estimate of Henkelman and Jónsson (2000)
+ to determine the local tangent direction at each intermediate image based
+ on the positions and energies of its neighbors.
+
+ Args:
+ all_pos (torch.Tensor): Atomic configurations for all images in the path
+ (initial + intermediate + final), shape [n_total_images, n_atoms, 3].
+ all_energies (torch.Tensor): Potential energy of each image, shape
+ [n_total_images].
+ cell (torch.Tensor): Unit cell vectors (shape [3, 3]), assumed constant
+ for the path.
+ pbc (bool): Flag indicating if periodic boundary conditions are active.
+
+ Returns:
+ torch.Tensor: Normalized local tangent vectors for the intermediate
+ images only, shape [n_images, n_atoms, 3]. Tangents are zero for
+ numerically identical adjacent images.
+ """
+ n_total_images, n_atoms_per_image, _ = all_pos.shape
+ n_intermediate_images = n_total_images - 2
+ device = all_pos.device
+ dtype = all_pos.dtype
+
+ # Initialize tangents for intermediate images only
+ tangents = torch.zeros(
+ (n_intermediate_images, n_atoms_per_image, 3), device=device, dtype=dtype
+ )
+
+ # Calculate displacements between adjacent images using MIC
+ # dR_forward[i] = R_{i+1} - R_i
+ displacements = minimum_image_displacement(
+ dr=all_pos[1:] - all_pos[:-1], cell=cell, pbc=pbc
+ )
+ # Ensure shape is correct after MIC if needed
+ displacements = displacements.reshape(n_total_images - 1, n_atoms_per_image, 3)
+
+ # Energy differences V_{i+1} - V_i
+ dE_forward = all_energies[1:] - all_energies[:-1] # Shape: [n_total_images - 1]
+
+ # Compute tangents for intermediate images (indices 1 to N in all_pos)
+ for i in range(n_intermediate_images):
+ img_idx = i + 1 # Index in all_pos, all_energies
+
+ # Displacements adjacent to image `img_idx`
+ # Note: displacements[k] is R_{k+1} - R_k
+ dR_plus = displacements[img_idx] # R_{i+1} - R_i (where i = img_idx)
+ dR_minus = displacements[img_idx - 1] # R_i - R_{i-1} (where i = img_idx)
+
+ # Energy differences adjacent to image `img_idx`
+ dE_plus = dE_forward[img_idx] # V_{i+1} - V_i
+ dE_minus = dE_forward[img_idx - 1] # V_i - V_{i-1}
+
+ # Select tangent based on energy profile (Henkelman & Jónsson criteria)
+ tangent_i = torch.zeros_like(dR_plus)
+
+ # Ascending segment (minimum)
+ if dE_plus > 0 and dE_minus > 0:
+ # Use ternary operator for simple assignment
+ tangent_i = dR_plus if dE_plus > dE_minus else dR_minus
+ # Descending segment (maximum)
+ elif dE_plus < 0 and dE_minus < 0:
+ # Weight by energy difference magnitude (originally absolute value based in ref code)
+ # Simplified version: use lower energy difference direction
+ # Let's use the reference code's logic more closely:
+ # if abs(dE_plus) < abs(dE_minus): # Towards lower energy drop
+ # tangent_i = dR_plus
+ # else:
+ # tangent_i = dR_minus
+ # Alternative based on reference code logic:
+ # Weight lower-energy direction
+ # This implementation seems slightly different from reference, let's try that:
+ abs_dE_plus = abs(dE_plus)
+ abs_dE_minus = abs(dE_minus)
+ if torch.isclose(abs_dE_plus, abs_dE_minus, rtol=1e-6):
+ # Symmetric max: bisect angle (normalize sum of unit vectors)
+ norm_plus = torch.linalg.norm(dR_plus)
+ norm_minus = torch.linalg.norm(dR_minus)
+ if norm_plus > _EPS and norm_minus > _EPS:
+ tangent_i = (dR_plus / norm_plus) + (dR_minus / norm_minus)
+ # Handle cases where one norm is zero (e.g., duplicate image)
+ elif norm_plus > _EPS:
+ tangent_i = dR_plus / norm_plus
+ elif norm_minus > _EPS:
+ tangent_i = dR_minus / norm_minus
+ # else: tangent_i remains zero if both norms are zero
+ elif abs_dE_plus < abs_dE_minus:
+ tangent_i = dR_plus
+ else:
+ tangent_i = dR_minus
+
+ # Uphill slope
+ elif dE_plus > 0 and dE_minus <= 0: # Modified condition slightly for plateaus
+ tangent_i = dR_plus
+ # Downhill slope
+ elif dE_plus <= 0 and dE_minus > 0: # Modified condition slightly for plateaus
+ tangent_i = dR_minus
+ # Plateau or unexpected case (should ideally not happen in smooth path)
+ # Fallback based on magnitude (consistent with reference code fallback)
+ elif abs(dE_plus) > abs(dE_minus):
+ tangent_i = dR_plus
+ else:
+ tangent_i = dR_minus
+
+
+ # Normalize the tangent vector for the image
+ # Sum over atoms and dims: [1]
+ # Use torch.linalg.norm for clarity and potential stability
+ norm_i = torch.linalg.norm(tangent_i)
+ if norm_i > _EPS:
+ tangents[i] = tangent_i / norm_i
+ # else: tangent remains zero if norm is too small
+
+ return tangents
+
+ def _calculate_neb_forces(
+ self,
+ path_state: SimState,
+ true_forces: torch.Tensor,
+ true_energies: torch.Tensor,
+ initial_energy: torch.Tensor,
+ final_energy: torch.Tensor,
+ step: int,
+ ) -> torch.Tensor:
+ """Calculate the NEB forces for intermediate images.
+
+ The NEB force is composed of the true force perpendicular to the path tangent
+ and the spring force parallel to the path tangent. Handles climbing image
+ force modification if enabled.
+
+ Args:
+ path_state (SimState): SimState containing the full path (initial +
+ intermediate + final images). Batches are assumed to be ordered.
+ true_forces (torch.Tensor): Forces from the potential energy model for
+ the *intermediate* images only, shape [n_movable_atoms, 3].
+ true_energies (torch.Tensor): Potential energies for the *intermediate*
+ images only, shape [n_images].
+ initial_energy (torch.Tensor): Potential energy of the initial state
+ (scalar tensor).
+ final_energy (torch.Tensor): Potential energy of the final state
+ (scalar tensor).
+ step (int): Current optimization step number (used for climbing image delay).
+
+ Returns:
+ torch.Tensor: Calculated NEB forces for the intermediate images, ready to
+ be passed to the optimizer, shape [n_movable_atoms, 3].
+ """
+ n_total_images = path_state.n_batches
+ n_intermediate_images = n_total_images - 2
+ assert n_intermediate_images == self.n_images
+ n_atoms_per_image = path_state.n_atoms // n_total_images
+
+ # --- Reshape inputs ---
+ # Positions for all images: [n_total_images, n_atoms, 3]
+ all_pos = path_state.positions.reshape(n_total_images, n_atoms_per_image, 3)
+ # True forces for intermediate images: [n_images, n_atoms, 3]
+ true_forces_reshaped = true_forces.reshape(
+ n_intermediate_images, n_atoms_per_image, 3
+ )
+ # Cell vectors (assuming fixed cell for now, take from first batch)
+ cell = path_state.cell[0] # Shape [3, 3]
+ pbc = path_state.pbc
+
+ # --- Get Energies for Tangent Calculation ---
+ all_energies = torch.cat(
+ [
+ initial_energy.unsqueeze(0),
+ true_energies,
+ final_energy.unsqueeze(0),
+ ]
+ )
+
+ # --- Calculate Tangents (tau) using the improved method ---
+ # tangents shape: [n_images, n_atoms, 3]
+ tangents = self._compute_tangents(all_pos, all_energies, cell, pbc=pbc)
+
+ # --- Calculate Displacements for Spring Force ---
+ # Recalculate here or reuse from _compute_tangents if efficient
+ # For clarity, recalculate:
+ displacements = minimum_image_displacement(
+ dr=all_pos[1:] - all_pos[:-1], cell=cell, pbc=pbc
+ )
+ displacements = displacements.reshape(n_total_images - 1, n_atoms_per_image, 3)
+
+
+ # --- Calculate NEB Force Components ---
+
+ # 1. Perpendicular component of true force
+ # F_perp = F_true - (F_true . tau) * tau
+ # Dot product (sum over atoms and dims): [n_images]
+ F_true_dot_tau = (true_forces_reshaped * tangents).sum(
+ dim=(-1, -2), keepdim=True
+ )
+ F_perp = true_forces_reshaped - F_true_dot_tau * tangents
+
+ # 2. Parallel component of spring force
+ # F_spring_par = k * (|R_{i+1}-R_i| - |R_i-R_{i-1}|) * tau_i
+ # Segment lengths (scalar magnitude per segment): [n_images+1]
+ # segment_lengths = torch.sqrt((displacements**2).sum(dim=(-1, -2))) # Old way
+ segment_lengths = torch.linalg.norm(
+ displacements, dim=(-1, -2)
+ ) # Cleaner way [n_total_images-1]
+ # Spring force magnitude (scalar per intermediate image): [n_images]
+ F_spring_mag = self.spring_constant * (
+ segment_lengths[1:] - segment_lengths[:-1]
+ )
+ # Project onto tangent: [n_images, 1, 1] -> [n_images, n_atoms, 3]
+ F_spring_par = F_spring_mag.view(-1, 1, 1) * tangents
+
+ # --- Combine Components for NEB Force ---
+ # Initial NEB force = F_perp + F_spring_par
+ neb_forces = F_perp + F_spring_par
+
+ # --- Handle Climbing Image ---
+ climbing_delay_steps = 10 # Example value
+ if self.use_climbing_image and n_intermediate_images > 0 and step >= climbing_delay_steps: # Check step number
+ # Find index of highest energy image among intermediates
+ climbing_image_idx = torch.argmax(true_energies).item() # Index from 0 to n_images-1
+ # Calculate the climbing force: F_climb = F_true - 2 * (F_true . tau) * tau
+ # This effectively inverts the component of the true force parallel to the tangent
+ F_climb = true_forces_reshaped[climbing_image_idx] - (
+ 2
+ * F_true_dot_tau[climbing_image_idx]
+ * tangents[climbing_image_idx]
+ )
+ # Replace the NEB force for the climbing image with F_climb
+ # This overwrites the spring force component for this image, as required.
+ neb_forces[climbing_image_idx] = F_climb
+
+ # --- Logging (Optional) ---
+ logger.debug(
+ " Max True Force Mag: "
+ f"{torch.linalg.norm(true_forces_reshaped, dim=(-1,-2)).max().item():.4f}"
+ )
+ logger.debug(
+ " Max F_perp Mag: "
+ f"{torch.linalg.norm(F_perp, dim=(-1,-2)).max().item():.4f}"
+ )
+ logger.debug(
+ " Max F_spring_par Mag: "
+ f"{torch.linalg.norm(F_spring_par, dim=(-1,-2)).max().item():.4f}"
+ )
+ logger.debug(
+ " Max NEB Force Mag: "
+ f"{torch.linalg.norm(neb_forces, dim=(-1,-2)).max().item():.4f}"
+ )
+
+
+ # --- Reshape output ---
+ return neb_forces.reshape(-1, 3) # [n_movable_atoms, 3]
+
+ def run(
+ self,
+ initial_system: StateLike,
+ final_system: StateLike,
+ max_steps: int = 100,
+ fmax: float = 0.05,
+ # TODO: add convergence criteria, batching options, output frequency etc.
+ ) -> SimState: # Or maybe return trajectory?
+ """Run the Nudged Elastic Band optimization.
+
+ Optimizes the path between the initial and final systems to find the
+ Minimum Energy Path (MEP).
+
+ Args:
+ initial_system (StateLike): The starting configuration (can be ASE Atoms,
+ SimState, or other compatible format recognized by initialize_state).
+ final_system (StateLike): The ending configuration.
+ max_steps (int): Maximum number of optimization steps allowed.
+ fmax (float): Convergence criterion based on the maximum NEB force component
+ acting on any single atom across all intermediate images (in eV/Ang).
+
+ Returns:
+ SimState: The final optimized NEB path, including the initial,
+ intermediate, and final images, concatenated into a single SimState.
+ """
+ logger.info("Starting NEB optimization")
+
+ # 1. Initialize initial and final states
+ initial_state = initialize_state(initial_system, self.device, self.dtype)
+ final_state = initialize_state(final_system, self.device, self.dtype)
+ # TODO: Add checks (e.g., same number of atoms, atom types)
+
+ # 1b. Calculate endpoint energies/forces (needed for tangent calculation)
+ # Note: Forces aren't strictly needed here but model usually returns both
+ logger.info("Calculating endpoint energies...")
+ endpoint_states = concatenate_states([initial_state, final_state])
+ endpoint_output = self.model(endpoint_states)
+ initial_energy = endpoint_output["energy"][0]
+ final_energy = endpoint_output["energy"][1]
+ logger.info(
+ f"Initial Energy: {initial_energy:.4f}, Final Energy: {final_energy:.4f}"
+ )
+
+ # 2. Create initial interpolated path (movable images only)
+ interpolated_images = self._interpolate_path(initial_state, final_state)
+
+ # 3. Initialize FIRE optimizer state for the movable images
+ # Use the generic initializer and state type
+ opt_state: self._OptimizerStateType = self._init_fn(interpolated_images)
+
+ # 4. Optimization loop
+ logger.info(f"Running NEB for max {max_steps} steps or fmax < {fmax} eV/Ang.")
+
+ # Context manager for trajectory writing
+ traj_context = (
+ TorchSimTrajectory(self.trajectory_filename, mode="w")
+ if self.trajectory_filename
+ else nullcontext() # Use a dummy context if no filename
+ )
+
+ with traj_context as traj:
+ for step in range(max_steps):
+ # a. Get current true forces and energies
+ true_forces = opt_state.forces
+ true_energies = opt_state.energy
+
+ # b. Calculate NEB forces
+ full_path_state_calc = concatenate_states(
+ [initial_state, opt_state, final_state]
+ )
+ neb_forces = self._calculate_neb_forces(
+ full_path_state_calc,
+ true_forces,
+ true_energies,
+ initial_energy,
+ final_energy,
+ step=step,
+ )
+
+ # c. Update the forces in the FIRE state object with NEB forces
+ opt_state.forces = neb_forces
+
+ # d. Perform FIRE optimization step
+ # Use the generic step function
+ opt_state = self._step_fn(opt_state)
+ logger.debug(
+ " Max True Force Mag (after step): "
+ f"{torch.sqrt((opt_state.forces**2).sum(dim=-1)).max().item():.4f}"
+ )
+
+ # e. Write to trajectory (if enabled)
+ if self.trajectory_filename is not None: # Use explicit check
+ # Create the full path state for writing (including endpoints)
+ current_full_path = concatenate_states(
+ [initial_state, opt_state, final_state]
+ )
+ # Write arrays directly using traj.write_arrays
+ data_to_write = {
+ "positions": current_full_path.positions
+ }
+ if step == 0: # Write static data only on the first step
+ # Assuming fixed cell NEB, cell is static
+ data_to_write["cell"] = current_full_path.cell
+ # These should also be static for the whole band
+ data_to_write["atomic_numbers"] = current_full_path.atomic_numbers
+ data_to_write["masses"] = current_full_path.masses
+ # Convert bool to tensor for saving
+ data_to_write["pbc"] = torch.tensor(current_full_path.pbc)
+ # Save the batch tensor to map atoms to images
+ data_to_write["image_indices"] = current_full_path.batch
+
+ traj.write_arrays(data_to_write, steps=step)
+
+ # f. Check convergence
+ max_force_magnitude = torch.sqrt((neb_forces**2).sum(dim=-1)).max()
+ max_intermediate_energy = opt_state.energy.max()
+ logger.info(
+ f"Step {step+1:4d}: Max Force = {max_force_magnitude:.4f} Max Energy = {max_intermediate_energy:.4f}"
+ # f"Energy = {fire_state.energy.mean():.4f} eV (mean per image), " # Removed mean energy for brevity
+ )
+ if max_force_magnitude < fmax:
+ logger.info("NEB optimization converged.")
+ break
+ else: # Loop finished without break
+ logger.warning("NEB optimization did not converge within max_steps.")
+
+ # 5. Return the final path (including endpoints)
+ return concatenate_states(
+ [initial_state, opt_state, final_state]
+ )
diff --git a/torch_sim/workflows/readme.md b/torch_sim/workflows/readme.md
index 41dfeabb5..559f540f3 100755
--- a/torch_sim/workflows/readme.md
+++ b/torch_sim/workflows/readme.md
@@ -2,7 +2,6 @@
TorchSim enables a lot of cool research! We wanted a place where the community to show off their work in an accessible and reproducible way so we created the workflows folder. Currently, this contains a reimplementation of the A2C method by [Aykol et al.](https://arxiv.org/abs/2310.01117) but we intend to expand it to include workflows for phonons, elastic properties, and more.
-
## Implemented Workflows
As a start, we implemented the A2C method created by [Aykol et al.](https://arxiv.org/abs/2310.01117) and originally [implemented in jax-md](https://github.com/jax-md/jax-md/blob/main/jax_md/a2c/a2c_workflow.py). The [a2c.py](/torch_sim/workflows/a2c.py) file contains many of the core operations in the paper, which are then linked together in the [a2c_silicon.py](/examples/scripts/5_Workflow/5.2_a2c_silicon_batched.py) file.