2025.08.20 - #46 - Context as Memory, GameFactory, ReMEmbR, Anything 시리즈 리뷰, ECoT #48
Description
Interesting papers
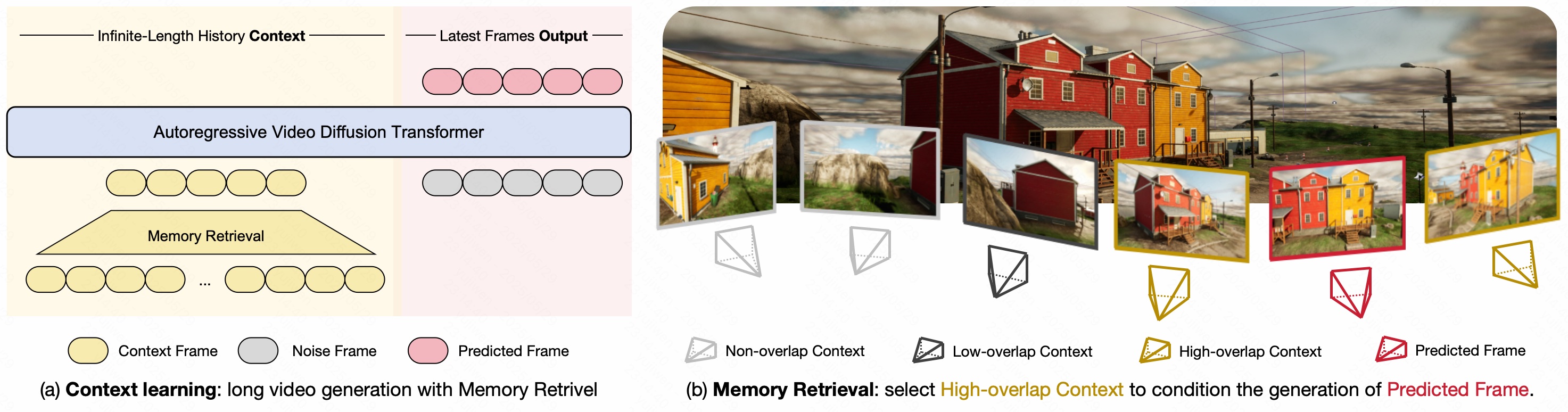
Context as Memory: Scene-Consistent Interactive Long Video Generation with Memory Retrieval
- https://context-as-memory.github.io
- https://arxiv.org/pdf/2506.03141
- Genie3와 같은 Video generation 모델들이 3D consistent하게 geometry 생성을 어떻게 하는가?
- 바로 Keyframe을 만들어서, context로서 집어넣는 것... 오호 마치 SLAM 같구나


GameFactory - Creating New Games with Generative Interactive Videos
- https://yujiwen.github.io/gamefactory/
- Genie3와 굉장히 유사함
- 얘는 깊게 얘기하지 않을겁니다. CaM이 잘 적용된 예시를 보여주기 위함임
- 관심있으신 분들께서는 아래 논문도 보세요
- Position: Interactive Generative Video as Next-Generation Game Engine (https://arxiv.org/abs/2503.17359)
- A Survey of Interactive Generative Video (https://arxiv.org/abs/2504.21853)

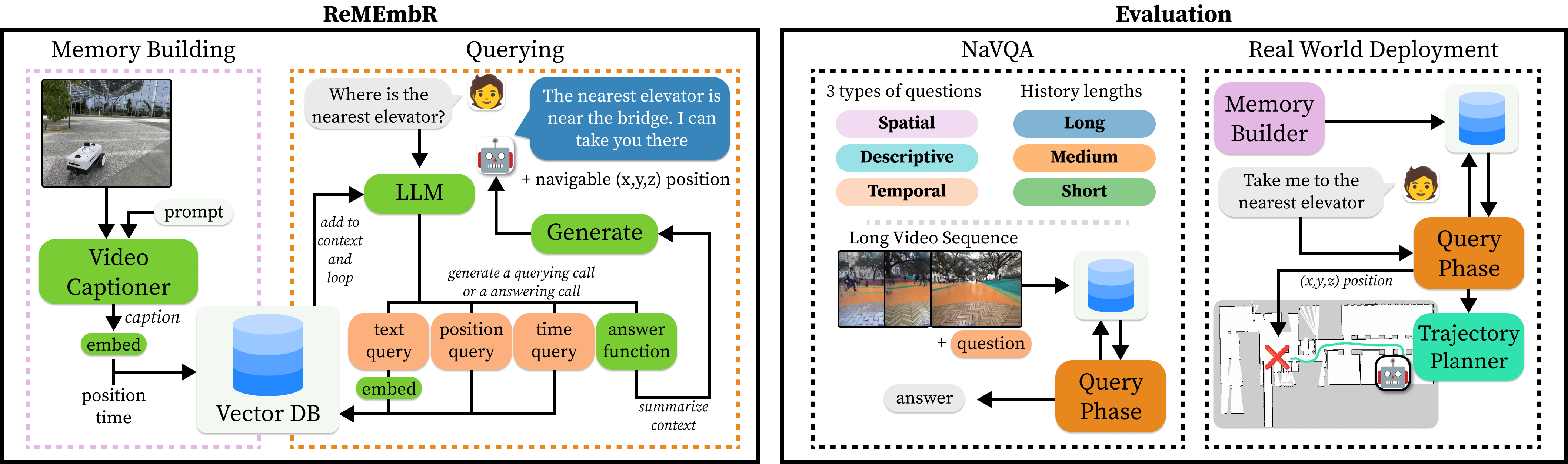
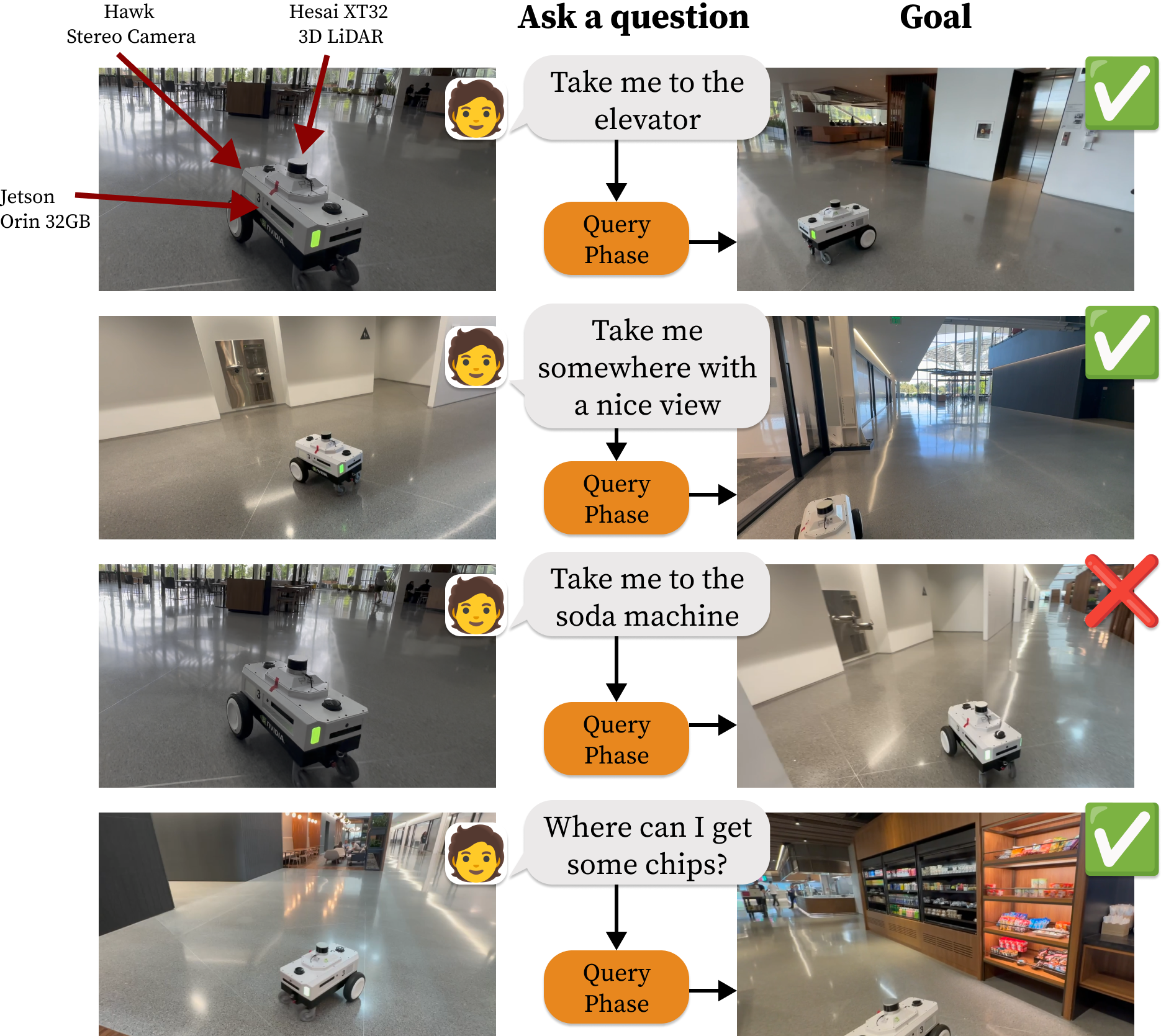
ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
- https://nvidia-ai-iot.github.io/remembr/
- Visual-language embedding을 사용해서 RAG DB를 구축한 후, LLM을 이용해서 query를 해 navigation을 하는 방식
Metadata
Metadata
Assignees
Labels
No labels