 -Whichever way you choose to contribute, please be mindful to respect our
-[code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md).
+Whichever way you choose to contribute, we strive to be part of an open, welcoming, and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions. We also recommend you become familiar with the [ethical guidelines](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines) that guide our project and ask you to adhere to the same principles of transparency and responsibility.
-## You can contribute in so many ways!
+We enormously value feedback from the community, so please do not be afraid to speak up if you believe you have valuable feedback that can help improve the library - every message, comment, issue, and pull request (PR) is read and considered.
-There are 4 ways you can contribute to diffusers:
-* Fixing outstanding issues with the existing code;
-* Implementing [new diffusion pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines#contribution), [new schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) or [new models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models)
-* [Contributing to the examples](https://github.com/huggingface/diffusers/tree/main/examples) or to the documentation;
-* Submitting issues related to bugs or desired new features.
+## Overview
-In particular there is a special [Good First Issue](https://github.com/huggingface/diffusers/contribute) listing.
-It will give you a list of open Issues that are open to anybody to work on. Just comment in the issue that you'd like to work on it.
-In that same listing you will also find some Issues with `Good Second Issue` label. These are
-typically slightly more complicated than the Issues with just `Good First Issue` label. But if you
-feel you know what you're doing, go for it.
+You can contribute in many ways ranging from answering questions on issues to adding new diffusion models to
+the core library.
-*All are equally valuable to the community.*
+In the following, we give an overview of different ways to contribute, ranked by difficulty in ascending order. All of them are valuable to the community.
-## Submitting a new issue or feature request
+* 1. Asking and answering questions on [the Diffusers discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers) or on [Discord](https://discord.gg/G7tWnz98XR).
+* 2. Opening new issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues/new/choose)
+* 3. Answering issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues)
+* 4. Fix a simple issue, marked by the "Good first issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
+* 5. Contribute to the [documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
+* 6. Contribute a [Community Pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3Acommunity-examples)
+* 7. Contribute to the [examples](https://github.com/huggingface/diffusers/tree/main/examples).
+* 8. Fix a more difficult issue, marked by the "Good second issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22).
+* 9. Add a new pipeline, model, or scheduler, see ["New Pipeline/Model"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) and ["New scheduler"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) issues. For this contribution, please have a look at [Design Philosophy](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md).
-Do your best to follow these guidelines when submitting an issue or a feature
-request. It will make it easier for us to come back to you quickly and with good
-feedback.
+As said before, **all contributions are valuable to the community**.
+In the following, we will explain each contribution a bit more in detail.
-### Did you find a bug?
+For all contributions 4.-9. you will need to open a PR. It is explained in detail how to do so in [Opening a pull requst](#how-to-open-a-pr)
+
+### 1. Asking and answering questions on the Diffusers discussion forum or on the Diffusers Discord
+
+Any question or comment related to the Diffusers library can be asked on the [discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/) or on [Discord](https://discord.gg/G7tWnz98XR). Such questions and comments include (but are not limited to):
+- Reports of training or inference experiments in an attempt to share knowledge
+- Presentation of personal projects
+- Questions to non-official training examples
+- Project proposals
+- General feedback
+- Paper summaries
+- Asking for help on personal projects that build on top of the Diffusers library
+- General questions
+- Ethical questions regarding diffusion models
+- ...
+
+Every question that is asked on the forum or on Discord actively encourages the community to publicly
+share knowledge and might very well help a beginner in the future that has the same question you're
+having. Please do pose any questions you might have.
+In the same spirit, you are of immense help to the community by answering such questions because this way you are publicly documenting knowledge for everybody to learn from.
+
+**Please** keep in mind that the more effort you put into asking or answering a question, the higher
+the quality of the publicly documented knowledge. In the same way, well-posed and well-answered questions create a high-quality knowledge database accessible to everybody, while badly posed questions or answers reduce the overall quality of the public knowledge database.
+In short, a high quality question or answer is *precise*, *concise*, *relevant*, *easy-to-understand*, *accesible*, and *well-formated/well-posed*. For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
+
+**NOTE about channels**:
+[*The forum*](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) is much better indexed by search engines, such as Google. Posts are ranked by popularity rather than chronologically. Hence, it's easier to look up questions and answers that we posted some time ago.
+In addition, questions and answers posted in the forum can easily be linked to.
+In contrast, *Discord* has a chat-like format that invites fast back-and-forth communication.
+While it will most likely take less time for you to get an answer to your question on Discord, your
+question won't be visible anymore over time. Also, it's much harder to find information that was posted a while back on Discord. We therefore strongly recommend using the forum for high-quality questions and answers in an attempt to create long-lasting knowledge for the community. If discussions on Discord lead to very interesting answers and conclusions, we recommend posting the results on the forum to make the information more available for future readers.
+
+### 2. Opening new issues on the GitHub issues tab
The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
the problems they encounter. So thank you for reporting an issue.
-First, we would really appreciate it if you could **make sure the bug was not
-already reported** (use the search bar on Github under Issues).
+Remember, GitHub issues are reserved for technical questions directly related to the Diffusers library, bug reports, feature requests, or feedback on the library design.
-### Do you want to implement a new diffusion pipeline / diffusion model?
+In a nutshell, this means that everything that is **not** related to the **code of the Diffusers library** (including the documentation) should **not** be asked on GitHub, but rather on either the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
-Awesome! Please provide the following information:
+**Please consider the following guidelines when opening a new issue**:
+- Make sure you have searched whether your issue has already been asked before (use the search bar on GitHub under Issues).
+- Please never report a new issue on another (related) issue. If another issue is highly related, please
+open a new issue nevertheless and link to the related issue.
+- Make sure your issue is written in English. Please use one of the great, free online translation services, such as [DeepL](https://www.deepl.com/translator) to translate from your native language to English if you are not comfortable in English.
+- Check whether your issue might be solved by updating to the newest Diffusers version. Before posting your issue, please make sure that `python -c "import diffusers; print(diffusers.__version__)"` is higher or matches the latest Diffusers version.
+- Remember that the more effort you put into opening a new issue, the higher the quality of your answer will be and the better the overall quality of the Diffusers issues.
-* Short description of the diffusion pipeline and link to the paper;
-* Link to the implementation if it is open-source;
-* Link to the model weights if they are available.
+New issues usually include the following.
+
+#### 2.1. Reproducible, minimal bug reports.
+
+A bug report should always have a reproducible code snippet and be as minimal and concise as possible.
+This means in more detail:
+- Narrow the bug down as much as you can, **do not just dump your whole code file**
+- Format your code
+- Do not include any external libraries except for Diffusers depending on them.
+- **Always** provide all necessary information about your environment; for this, you can run: `diffusers-cli env` in your shell and copy-paste the displayed information to the issue.
+- Explain the issue. If the reader doesn't know what the issue is and why it is an issue, she cannot solve it.
+- **Always** make sure the reader can reproduce your issue with as little effort as possible. If your code snippet cannot be run because of missing libraries or undefined variables, the reader cannot help you. Make sure your reproducible code snippet is as minimal as possible and can be copy-pasted into a simple Python shell.
+- If in order to reproduce your issue a model and/or dataset is required, make sure the reader has access to that model or dataset. You can always upload your model or dataset to the [Hub](https://huggingface.co) to make it easily downloadable. Try to keep your model and dataset as small as possible, to make the reproduction of your issue as effortless as possible.
+
+For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
-If you are willing to contribute the model yourself, let us know so we can best
-guide you.
+You can open a bug report [here](https://github.com/huggingface/diffusers/issues/new/choose).
-### Do you want a new feature (that is not a model)?
+#### 2.2. Feature requests.
A world-class feature request addresses the following points:
1. Motivation first:
- * Is it related to a problem/frustration with the library? If so, please explain
- why. Providing a code snippet that demonstrates the problem is best.
- * Is it related to something you would need for a project? We'd love to hear
- about it!
- * Is it something you worked on and think could benefit the community?
- Awesome! Tell us what problem it solved for you.
+* Is it related to a problem/frustration with the library? If so, please explain
+why. Providing a code snippet that demonstrates the problem is best.
+* Is it related to something you would need for a project? We'd love to hear
+about it!
+* Is it something you worked on and think could benefit the community?
+Awesome! Tell us what problem it solved for you.
2. Write a *full paragraph* describing the feature;
3. Provide a **code snippet** that demonstrates its future use;
4. In case this is related to a paper, please attach a link;
5. Attach any additional information (drawings, screenshots, etc.) you think may help.
-If your issue is well written we're already 80% of the way there by the time you
-post it.
+You can open a feature request [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=).
+
+#### 2.3 Feedback.
+
+Feedback about the library design and why it is good or not good helps the core maintainers immensely to build a user-friendly library. To understand the philosophy behind the current design philosophy, please have a look [here](https://huggingface.co/docs/diffusers/conceptual/philosophy). If you feel like a certain design choice does not fit with the current design philosophy, please explain why and how it should be changed. If a certain design choice follows the design philosophy too much, hence restricting use cases, explain why and how it should be changed.
+If a certain design choice is very useful for you, please also leave a note as this is great feedback for future design decisions.
+
+You can open an issue about feedback [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
+
+#### 2.4 Technical questions.
+
+Technical questions are mainly about why certain code of the library was written in a certain way, or what a certain part of the code does. Please make sure to link to the code in question and please provide detail on
+why this part of the code is difficult to understand.
+
+You can open an issue about a technical question [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&template=bug-report.yml).
+
+#### 2.5 Proposal to add a new model, scheduler, or pipeline.
+
+If the diffusion model community released a new model, pipeline, or scheduler that you would like to see in the Diffusers library, please provide the following information:
+
+* Short description of the diffusion pipeline, model, or scheduler and link to the paper or public release.
+* Link to any of its open-source implementation.
+* Link to the model weights if they are available.
+
+If you are willing to contribute to the model yourself, let us know so we can best guide you. Also, don't forget
+to tag the original author of the component (model, scheduler, pipeline, etc.) by GitHub handle if you can find it.
+
+You can open a request for a model/pipeline/scheduler [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=New+model%2Fpipeline%2Fscheduler&template=new-model-addition.yml).
+
+### 3. Answering issues on the GitHub issues tab
+
+Answering issues on GitHub might require some technical knowledge of Diffusers, but we encourage everybody to give it a try even if you are not 100% certain that your answer is correct.
+Some tips to give a high-quality answer to an issue:
+- Be as concise and minimal as possible
+- Stay on topic. An answer to the issue should concern the issue and only the issue.
+- Provide links to code, papers, or other sources that prove or encourage your point.
+- Answer in code. If a simple code snippet is the answer to the issue or shows how the issue can be solved, please provide a fully reproducible code snippet.
+
+Also, many issues tend to be simply off-topic, duplicates of other issues, or irrelevant. It is of great
+help to the maintainers if you can answer such issues, encouraging the author of the issue to be
+more precise, provide the link to a duplicated issue or redirect them to [the forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR)
+
+If you have verified that the issued bug report is correct and requires a correction in the source code,
+please have a look at the next sections.
+
+For all of the following contributions, you will need to open a PR. It is explained in detail how to do so in the [Opening a pull requst](#how-to-open-a-pr) section.
+
+### 4. Fixing a "Good first issue"
+
+*Good first issues* are marked by the [Good first issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) label. Usually, the issue already
+explains how a potential solution should look so that it is easier to fix.
+If the issue hasn't been closed and you would like to try to fix this issue, you can just leave a message "I would like to try this issue.". There are usually three scenarios:
+- a.) The issue description already proposes a fix. In this case and if the solution makes sense to you, you can open a PR or draft PR to fix it.
+- b.) The issue description does not propose a fix. In this case, you can ask what a proposed fix could look like and someone from the Diffusers team should answer shortly. If you have a good idea of how to fix it, feel free to directly open a PR.
+- c.) There is already an open PR to fix the issue, but the issue hasn't been closed yet. If the PR has gone stale, you can simply open a new PR and link to the stale PR. PRs often go stale if the original contributor who wanted to fix the issue suddenly cannot find the time anymore to proceed. This often happens in open-source and is very normal. In this case, the community will be very happy if you give it a new try and leverage the knowledge of the existing PR. If there is already a PR and it is active, you can help the author by giving suggestions, reviewing the PR or even asking whether you can contribute to the PR.
+
+
+### 5. Contribute to the documentation
+
+A good library **always** has good documentation! The official documentation is often one of the first points of contact for new users of the library, and therefore contributing to the documentation is a **highly
+valuable contribution**.
+
+Contributing to the library can have many forms:
+
+- Correcting spelling or grammatical errors.
+- Correct incorrect formatting of the docstring. If you see that the official documentation is weirdly displayed or a link is broken, we are very happy if you take some time to correct it.
+- Correct the shape or dimensions of a docstring input or output tensor.
+- Clarify documentation that is hard to understand or incorrect.
+- Update outdated code examples.
+- Translating the documentation to another language.
+
+Anything displayed on [the official Diffusers doc page](https://huggingface.co/docs/diffusers/index) is part of the official documentation and can be corrected, adjusted in the respective [documentation source](https://github.com/huggingface/diffusers/tree/main/docs/source).
+
+Please have a look at [this page](https://github.com/huggingface/diffusers/tree/main/docs) on how to verify changes made to the documentation locally.
+
+
+### 6. Contribute a community pipeline
-## Start contributing! (Pull Requests)
+[Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) are usually the first point of contact between the Diffusers library and the user.
+Pipelines are examples of how to use Diffusers [models](https://huggingface.co/docs/diffusers/api/models) and [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview).
+We support two types of pipelines:
+
+- Official Pipelines
+- Community Pipelines
+
+Both official and community pipelines follow the same design and consist of the same type of components.
+
+Official pipelines are tested and maintained by the core maintainers of Diffusers. Their code
+resides in [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
+In contrast, community pipelines are contributed and maintained purely by the **community** and are **not** tested.
+They reside in [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and while they can be accessed via the [PyPI diffusers package](https://pypi.org/project/diffusers/), their code is not part of the PyPI distribution.
+
+The reason for the distinction is that the core maintainers of the Diffusers library cannot maintain and test all
+possible ways diffusion models can be used for inference, but some of them may be of interest to the community.
+Officially released diffusion pipelines,
+such as Stable Diffusion are added to the core src/diffusers/pipelines package which ensures
+high quality of maintenance, no backward-breaking code changes, and testing.
+More bleeding edge pipelines should be added as community pipelines. If usage for a community pipeline is high, the pipeline can be moved to the official pipelines upon request from the community. This is one of the ways we strive to be a community-driven library.
+
+To add a community pipeline, one should add a
-Whichever way you choose to contribute, please be mindful to respect our
-[code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md).
+Whichever way you choose to contribute, we strive to be part of an open, welcoming, and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions. We also recommend you become familiar with the [ethical guidelines](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines) that guide our project and ask you to adhere to the same principles of transparency and responsibility.
-## You can contribute in so many ways!
+We enormously value feedback from the community, so please do not be afraid to speak up if you believe you have valuable feedback that can help improve the library - every message, comment, issue, and pull request (PR) is read and considered.
-There are 4 ways you can contribute to diffusers:
-* Fixing outstanding issues with the existing code;
-* Implementing [new diffusion pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines#contribution), [new schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) or [new models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models)
-* [Contributing to the examples](https://github.com/huggingface/diffusers/tree/main/examples) or to the documentation;
-* Submitting issues related to bugs or desired new features.
+## Overview
-In particular there is a special [Good First Issue](https://github.com/huggingface/diffusers/contribute) listing.
-It will give you a list of open Issues that are open to anybody to work on. Just comment in the issue that you'd like to work on it.
-In that same listing you will also find some Issues with `Good Second Issue` label. These are
-typically slightly more complicated than the Issues with just `Good First Issue` label. But if you
-feel you know what you're doing, go for it.
+You can contribute in many ways ranging from answering questions on issues to adding new diffusion models to
+the core library.
-*All are equally valuable to the community.*
+In the following, we give an overview of different ways to contribute, ranked by difficulty in ascending order. All of them are valuable to the community.
-## Submitting a new issue or feature request
+* 1. Asking and answering questions on [the Diffusers discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers) or on [Discord](https://discord.gg/G7tWnz98XR).
+* 2. Opening new issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues/new/choose)
+* 3. Answering issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues)
+* 4. Fix a simple issue, marked by the "Good first issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
+* 5. Contribute to the [documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
+* 6. Contribute a [Community Pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3Acommunity-examples)
+* 7. Contribute to the [examples](https://github.com/huggingface/diffusers/tree/main/examples).
+* 8. Fix a more difficult issue, marked by the "Good second issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22).
+* 9. Add a new pipeline, model, or scheduler, see ["New Pipeline/Model"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) and ["New scheduler"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) issues. For this contribution, please have a look at [Design Philosophy](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md).
-Do your best to follow these guidelines when submitting an issue or a feature
-request. It will make it easier for us to come back to you quickly and with good
-feedback.
+As said before, **all contributions are valuable to the community**.
+In the following, we will explain each contribution a bit more in detail.
-### Did you find a bug?
+For all contributions 4.-9. you will need to open a PR. It is explained in detail how to do so in [Opening a pull requst](#how-to-open-a-pr)
+
+### 1. Asking and answering questions on the Diffusers discussion forum or on the Diffusers Discord
+
+Any question or comment related to the Diffusers library can be asked on the [discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/) or on [Discord](https://discord.gg/G7tWnz98XR). Such questions and comments include (but are not limited to):
+- Reports of training or inference experiments in an attempt to share knowledge
+- Presentation of personal projects
+- Questions to non-official training examples
+- Project proposals
+- General feedback
+- Paper summaries
+- Asking for help on personal projects that build on top of the Diffusers library
+- General questions
+- Ethical questions regarding diffusion models
+- ...
+
+Every question that is asked on the forum or on Discord actively encourages the community to publicly
+share knowledge and might very well help a beginner in the future that has the same question you're
+having. Please do pose any questions you might have.
+In the same spirit, you are of immense help to the community by answering such questions because this way you are publicly documenting knowledge for everybody to learn from.
+
+**Please** keep in mind that the more effort you put into asking or answering a question, the higher
+the quality of the publicly documented knowledge. In the same way, well-posed and well-answered questions create a high-quality knowledge database accessible to everybody, while badly posed questions or answers reduce the overall quality of the public knowledge database.
+In short, a high quality question or answer is *precise*, *concise*, *relevant*, *easy-to-understand*, *accesible*, and *well-formated/well-posed*. For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
+
+**NOTE about channels**:
+[*The forum*](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) is much better indexed by search engines, such as Google. Posts are ranked by popularity rather than chronologically. Hence, it's easier to look up questions and answers that we posted some time ago.
+In addition, questions and answers posted in the forum can easily be linked to.
+In contrast, *Discord* has a chat-like format that invites fast back-and-forth communication.
+While it will most likely take less time for you to get an answer to your question on Discord, your
+question won't be visible anymore over time. Also, it's much harder to find information that was posted a while back on Discord. We therefore strongly recommend using the forum for high-quality questions and answers in an attempt to create long-lasting knowledge for the community. If discussions on Discord lead to very interesting answers and conclusions, we recommend posting the results on the forum to make the information more available for future readers.
+
+### 2. Opening new issues on the GitHub issues tab
The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
the problems they encounter. So thank you for reporting an issue.
-First, we would really appreciate it if you could **make sure the bug was not
-already reported** (use the search bar on Github under Issues).
+Remember, GitHub issues are reserved for technical questions directly related to the Diffusers library, bug reports, feature requests, or feedback on the library design.
-### Do you want to implement a new diffusion pipeline / diffusion model?
+In a nutshell, this means that everything that is **not** related to the **code of the Diffusers library** (including the documentation) should **not** be asked on GitHub, but rather on either the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
-Awesome! Please provide the following information:
+**Please consider the following guidelines when opening a new issue**:
+- Make sure you have searched whether your issue has already been asked before (use the search bar on GitHub under Issues).
+- Please never report a new issue on another (related) issue. If another issue is highly related, please
+open a new issue nevertheless and link to the related issue.
+- Make sure your issue is written in English. Please use one of the great, free online translation services, such as [DeepL](https://www.deepl.com/translator) to translate from your native language to English if you are not comfortable in English.
+- Check whether your issue might be solved by updating to the newest Diffusers version. Before posting your issue, please make sure that `python -c "import diffusers; print(diffusers.__version__)"` is higher or matches the latest Diffusers version.
+- Remember that the more effort you put into opening a new issue, the higher the quality of your answer will be and the better the overall quality of the Diffusers issues.
-* Short description of the diffusion pipeline and link to the paper;
-* Link to the implementation if it is open-source;
-* Link to the model weights if they are available.
+New issues usually include the following.
+
+#### 2.1. Reproducible, minimal bug reports.
+
+A bug report should always have a reproducible code snippet and be as minimal and concise as possible.
+This means in more detail:
+- Narrow the bug down as much as you can, **do not just dump your whole code file**
+- Format your code
+- Do not include any external libraries except for Diffusers depending on them.
+- **Always** provide all necessary information about your environment; for this, you can run: `diffusers-cli env` in your shell and copy-paste the displayed information to the issue.
+- Explain the issue. If the reader doesn't know what the issue is and why it is an issue, she cannot solve it.
+- **Always** make sure the reader can reproduce your issue with as little effort as possible. If your code snippet cannot be run because of missing libraries or undefined variables, the reader cannot help you. Make sure your reproducible code snippet is as minimal as possible and can be copy-pasted into a simple Python shell.
+- If in order to reproduce your issue a model and/or dataset is required, make sure the reader has access to that model or dataset. You can always upload your model or dataset to the [Hub](https://huggingface.co) to make it easily downloadable. Try to keep your model and dataset as small as possible, to make the reproduction of your issue as effortless as possible.
+
+For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
-If you are willing to contribute the model yourself, let us know so we can best
-guide you.
+You can open a bug report [here](https://github.com/huggingface/diffusers/issues/new/choose).
-### Do you want a new feature (that is not a model)?
+#### 2.2. Feature requests.
A world-class feature request addresses the following points:
1. Motivation first:
- * Is it related to a problem/frustration with the library? If so, please explain
- why. Providing a code snippet that demonstrates the problem is best.
- * Is it related to something you would need for a project? We'd love to hear
- about it!
- * Is it something you worked on and think could benefit the community?
- Awesome! Tell us what problem it solved for you.
+* Is it related to a problem/frustration with the library? If so, please explain
+why. Providing a code snippet that demonstrates the problem is best.
+* Is it related to something you would need for a project? We'd love to hear
+about it!
+* Is it something you worked on and think could benefit the community?
+Awesome! Tell us what problem it solved for you.
2. Write a *full paragraph* describing the feature;
3. Provide a **code snippet** that demonstrates its future use;
4. In case this is related to a paper, please attach a link;
5. Attach any additional information (drawings, screenshots, etc.) you think may help.
-If your issue is well written we're already 80% of the way there by the time you
-post it.
+You can open a feature request [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=).
+
+#### 2.3 Feedback.
+
+Feedback about the library design and why it is good or not good helps the core maintainers immensely to build a user-friendly library. To understand the philosophy behind the current design philosophy, please have a look [here](https://huggingface.co/docs/diffusers/conceptual/philosophy). If you feel like a certain design choice does not fit with the current design philosophy, please explain why and how it should be changed. If a certain design choice follows the design philosophy too much, hence restricting use cases, explain why and how it should be changed.
+If a certain design choice is very useful for you, please also leave a note as this is great feedback for future design decisions.
+
+You can open an issue about feedback [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
+
+#### 2.4 Technical questions.
+
+Technical questions are mainly about why certain code of the library was written in a certain way, or what a certain part of the code does. Please make sure to link to the code in question and please provide detail on
+why this part of the code is difficult to understand.
+
+You can open an issue about a technical question [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&template=bug-report.yml).
+
+#### 2.5 Proposal to add a new model, scheduler, or pipeline.
+
+If the diffusion model community released a new model, pipeline, or scheduler that you would like to see in the Diffusers library, please provide the following information:
+
+* Short description of the diffusion pipeline, model, or scheduler and link to the paper or public release.
+* Link to any of its open-source implementation.
+* Link to the model weights if they are available.
+
+If you are willing to contribute to the model yourself, let us know so we can best guide you. Also, don't forget
+to tag the original author of the component (model, scheduler, pipeline, etc.) by GitHub handle if you can find it.
+
+You can open a request for a model/pipeline/scheduler [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=New+model%2Fpipeline%2Fscheduler&template=new-model-addition.yml).
+
+### 3. Answering issues on the GitHub issues tab
+
+Answering issues on GitHub might require some technical knowledge of Diffusers, but we encourage everybody to give it a try even if you are not 100% certain that your answer is correct.
+Some tips to give a high-quality answer to an issue:
+- Be as concise and minimal as possible
+- Stay on topic. An answer to the issue should concern the issue and only the issue.
+- Provide links to code, papers, or other sources that prove or encourage your point.
+- Answer in code. If a simple code snippet is the answer to the issue or shows how the issue can be solved, please provide a fully reproducible code snippet.
+
+Also, many issues tend to be simply off-topic, duplicates of other issues, or irrelevant. It is of great
+help to the maintainers if you can answer such issues, encouraging the author of the issue to be
+more precise, provide the link to a duplicated issue or redirect them to [the forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR)
+
+If you have verified that the issued bug report is correct and requires a correction in the source code,
+please have a look at the next sections.
+
+For all of the following contributions, you will need to open a PR. It is explained in detail how to do so in the [Opening a pull requst](#how-to-open-a-pr) section.
+
+### 4. Fixing a "Good first issue"
+
+*Good first issues* are marked by the [Good first issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) label. Usually, the issue already
+explains how a potential solution should look so that it is easier to fix.
+If the issue hasn't been closed and you would like to try to fix this issue, you can just leave a message "I would like to try this issue.". There are usually three scenarios:
+- a.) The issue description already proposes a fix. In this case and if the solution makes sense to you, you can open a PR or draft PR to fix it.
+- b.) The issue description does not propose a fix. In this case, you can ask what a proposed fix could look like and someone from the Diffusers team should answer shortly. If you have a good idea of how to fix it, feel free to directly open a PR.
+- c.) There is already an open PR to fix the issue, but the issue hasn't been closed yet. If the PR has gone stale, you can simply open a new PR and link to the stale PR. PRs often go stale if the original contributor who wanted to fix the issue suddenly cannot find the time anymore to proceed. This often happens in open-source and is very normal. In this case, the community will be very happy if you give it a new try and leverage the knowledge of the existing PR. If there is already a PR and it is active, you can help the author by giving suggestions, reviewing the PR or even asking whether you can contribute to the PR.
+
+
+### 5. Contribute to the documentation
+
+A good library **always** has good documentation! The official documentation is often one of the first points of contact for new users of the library, and therefore contributing to the documentation is a **highly
+valuable contribution**.
+
+Contributing to the library can have many forms:
+
+- Correcting spelling or grammatical errors.
+- Correct incorrect formatting of the docstring. If you see that the official documentation is weirdly displayed or a link is broken, we are very happy if you take some time to correct it.
+- Correct the shape or dimensions of a docstring input or output tensor.
+- Clarify documentation that is hard to understand or incorrect.
+- Update outdated code examples.
+- Translating the documentation to another language.
+
+Anything displayed on [the official Diffusers doc page](https://huggingface.co/docs/diffusers/index) is part of the official documentation and can be corrected, adjusted in the respective [documentation source](https://github.com/huggingface/diffusers/tree/main/docs/source).
+
+Please have a look at [this page](https://github.com/huggingface/diffusers/tree/main/docs) on how to verify changes made to the documentation locally.
+
+
+### 6. Contribute a community pipeline
-## Start contributing! (Pull Requests)
+[Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) are usually the first point of contact between the Diffusers library and the user.
+Pipelines are examples of how to use Diffusers [models](https://huggingface.co/docs/diffusers/api/models) and [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview).
+We support two types of pipelines:
+
+- Official Pipelines
+- Community Pipelines
+
+Both official and community pipelines follow the same design and consist of the same type of components.
+
+Official pipelines are tested and maintained by the core maintainers of Diffusers. Their code
+resides in [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
+In contrast, community pipelines are contributed and maintained purely by the **community** and are **not** tested.
+They reside in [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and while they can be accessed via the [PyPI diffusers package](https://pypi.org/project/diffusers/), their code is not part of the PyPI distribution.
+
+The reason for the distinction is that the core maintainers of the Diffusers library cannot maintain and test all
+possible ways diffusion models can be used for inference, but some of them may be of interest to the community.
+Officially released diffusion pipelines,
+such as Stable Diffusion are added to the core src/diffusers/pipelines package which ensures
+high quality of maintenance, no backward-breaking code changes, and testing.
+More bleeding edge pipelines should be added as community pipelines. If usage for a community pipeline is high, the pipeline can be moved to the official pipelines upon request from the community. This is one of the ways we strive to be a community-driven library.
+
+To add a community pipeline, one should add a  . We discuss the hottest trends about diffusion models, help each other with contributions, personal projects or
+just hang out ☕.
+
## Credits
This library concretizes previous work by many different authors and would not have been possible without their great research and implementations. We'd like to thank, in particular, the following implementations which have helped us in our development and without which the API could not have been as polished today:
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 09012a5c693d..1a0d8f5cd6c8 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -4,7 +4,7 @@
- local: quicktour
title: Quicktour
- local: stable_diffusion
- title: Stable Diffusion
+ title: Effective and efficient diffusion
- local: installation
title: Installation
title: Get started
@@ -33,19 +33,19 @@
- local: using-diffusers/pipeline_overview
title: Overview
- local: using-diffusers/unconditional_image_generation
- title: Unconditional Image Generation
+ title: Unconditional image generation
- local: using-diffusers/conditional_image_generation
- title: Text-to-Image Generation
+ title: Text-to-image generation
- local: using-diffusers/img2img
- title: Text-Guided Image-to-Image
+ title: Text-guided image-to-image
- local: using-diffusers/inpaint
- title: Text-Guided Image-Inpainting
+ title: Text-guided image-inpainting
- local: using-diffusers/depth2img
- title: Text-Guided Depth-to-Image
+ title: Text-guided depth-to-image
- local: using-diffusers/reusing_seeds
- title: Reusing seeds for deterministic generation
+ title: Improve image quality with deterministic generation
- local: using-diffusers/reproducibility
- title: Reproducibility
+ title: Create reproducible pipelines
- local: using-diffusers/custom_pipeline_examples
title: Community Pipelines
- local: using-diffusers/contribute_pipeline
@@ -68,6 +68,10 @@
title: Text-to-image
- local: training/lora
title: Low-Rank Adaptation of Large Language Models (LoRA)
+ - local: training/controlnet
+ title: ControlNet
+ - local: training/instructpix2pix
+ title: InstructPix2Pix Training
title: Training
- sections:
- local: using-diffusers/rl
@@ -130,6 +134,8 @@
title: AltDiffusion
- local: api/pipelines/audio_diffusion
title: Audio Diffusion
+ - local: api/pipelines/audioldm
+ title: AudioLDM
- local: api/pipelines/cycle_diffusion
title: Cycle Diffusion
- local: api/pipelines/dance_diffusion
@@ -154,6 +160,8 @@
title: Score SDE VE
- local: api/pipelines/semantic_stable_diffusion
title: Semantic Guidance
+ - local: api/pipelines/spectrogram_diffusion
+ title: "Spectrogram Diffusion"
- sections:
- local: api/pipelines/stable_diffusion/overview
title: Overview
@@ -183,6 +191,8 @@
title: MultiDiffusion Panorama
- local: api/pipelines/stable_diffusion/controlnet
title: Text-to-Image Generation with ControlNet Conditioning
+ - local: api/pipelines/stable_diffusion/model_editing
+ title: Text-to-Image Model Editing
title: Stable Diffusion
- local: api/pipelines/stable_diffusion_2
title: Stable Diffusion 2
@@ -190,6 +200,8 @@
title: Stable unCLIP
- local: api/pipelines/stochastic_karras_ve
title: Stochastic Karras VE
+ - local: api/pipelines/text_to_video
+ title: Text-to-Video
- local: api/pipelines/unclip
title: UnCLIP
- local: api/pipelines/latent_diffusion_uncond
diff --git a/docs/source/en/api/models.mdx b/docs/source/en/api/models.mdx
index dc425e98628c..2361fd4f6597 100644
--- a/docs/source/en/api/models.mdx
+++ b/docs/source/en/api/models.mdx
@@ -37,6 +37,12 @@ The models are built on the base class ['ModelMixin'] that is a `torch.nn.module
## UNet2DConditionModel
[[autodoc]] UNet2DConditionModel
+## UNet3DConditionOutput
+[[autodoc]] models.unet_3d_condition.UNet3DConditionOutput
+
+## UNet3DConditionModel
+[[autodoc]] UNet3DConditionModel
+
## DecoderOutput
[[autodoc]] models.vae.DecoderOutput
@@ -58,6 +64,12 @@ The models are built on the base class ['ModelMixin'] that is a `torch.nn.module
## Transformer2DModelOutput
[[autodoc]] models.transformer_2d.Transformer2DModelOutput
+## TransformerTemporalModel
+[[autodoc]] models.transformer_temporal.TransformerTemporalModel
+
+## Transformer2DModelOutput
+[[autodoc]] models.transformer_temporal.TransformerTemporalModelOutput
+
## PriorTransformer
[[autodoc]] models.prior_transformer.PriorTransformer
@@ -87,3 +99,9 @@ The models are built on the base class ['ModelMixin'] that is a `torch.nn.module
## FlaxAutoencoderKL
[[autodoc]] FlaxAutoencoderKL
+
+## FlaxControlNetOutput
+[[autodoc]] models.controlnet_flax.FlaxControlNetOutput
+
+## FlaxControlNetModel
+[[autodoc]] FlaxControlNetModel
diff --git a/docs/source/en/api/pipelines/alt_diffusion.mdx b/docs/source/en/api/pipelines/alt_diffusion.mdx
index cb86208ddbe1..dbe3b079a201 100644
--- a/docs/source/en/api/pipelines/alt_diffusion.mdx
+++ b/docs/source/en/api/pipelines/alt_diffusion.mdx
@@ -12,7 +12,7 @@ specific language governing permissions and limitations under the License.
# AltDiffusion
-AltDiffusion was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu
+AltDiffusion was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu.
The abstract of the paper is the following:
@@ -28,7 +28,7 @@ The abstract of the paper is the following:
## Tips
-- AltDiffusion is conceptually exaclty the same as [Stable Diffusion](./api/pipelines/stable_diffusion/overview).
+- AltDiffusion is conceptually exactly the same as [Stable Diffusion](./api/pipelines/stable_diffusion/overview).
- *Run AltDiffusion*
diff --git a/docs/source/en/api/pipelines/audioldm.mdx b/docs/source/en/api/pipelines/audioldm.mdx
new file mode 100644
index 000000000000..f3987d2263ac
--- /dev/null
+++ b/docs/source/en/api/pipelines/audioldm.mdx
@@ -0,0 +1,82 @@
+
+
+# AudioLDM
+
+## Overview
+
+AudioLDM was proposed in [AudioLDM: Text-to-Audio Generation with Latent Diffusion Models](https://arxiv.org/abs/2301.12503) by Haohe Liu et al.
+
+Inspired by [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview), AudioLDM
+is a text-to-audio _latent diffusion model (LDM)_ that learns continuous audio representations from [CLAP](https://huggingface.co/docs/transformers/main/model_doc/clap)
+latents. AudioLDM takes a text prompt as input and predicts the corresponding audio. It can generate text-conditional
+sound effects, human speech and music.
+
+This pipeline was contributed by [sanchit-gandhi](https://huggingface.co/sanchit-gandhi). The original codebase can be found [here](https://github.com/haoheliu/AudioLDM).
+
+## Text-to-Audio
+
+The [`AudioLDMPipeline`] can be used to load pre-trained weights from [cvssp/audioldm](https://huggingface.co/cvssp/audioldm) and generate text-conditional audio outputs:
+
+```python
+from diffusers import AudioLDMPipeline
+import torch
+import scipy
+
+repo_id = "cvssp/audioldm"
+pipe = AudioLDMPipeline.from_pretrained(repo_id, torch_dtype=torch.float16)
+pipe = pipe.to("cuda")
+
+prompt = "Techno music with a strong, upbeat tempo and high melodic riffs"
+audio = pipe(prompt, num_inference_steps=10, audio_length_in_s=5.0).audios[0]
+
+# save the audio sample as a .wav file
+scipy.io.wavfile.write("techno.wav", rate=16000, data=audio)
+```
+
+### Tips
+
+Prompts:
+* Descriptive prompt inputs work best: you can use adjectives to describe the sound (e.g. "high quality" or "clear") and make the prompt context specific (e.g., "water stream in a forest" instead of "stream").
+* It's best to use general terms like 'cat' or 'dog' instead of specific names or abstract objects that the model may not be familiar with.
+
+Inference:
+* The _quality_ of the predicted audio sample can be controlled by the `num_inference_steps` argument: higher steps give higher quality audio at the expense of slower inference.
+* The _length_ of the predicted audio sample can be controlled by varying the `audio_length_in_s` argument.
+
+### How to load and use different schedulers
+
+The AudioLDM pipeline uses [`DDIMScheduler`] scheduler by default. But `diffusers` provides many other schedulers
+that can be used with the AudioLDM pipeline such as [`PNDMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`],
+[`EulerAncestralDiscreteScheduler`] etc. We recommend using the [`DPMSolverMultistepScheduler`] as it's currently the fastest
+scheduler there is.
+
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`]
+method, or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the
+[`DPMSolverMultistepScheduler`], you can do the following:
+
+```python
+>>> from diffusers import AudioLDMPipeline, DPMSolverMultistepScheduler
+>>> import torch
+
+>>> pipeline = AudioLDMPipeline.from_pretrained("cvssp/audioldm", torch_dtype=torch.float16)
+>>> pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> dpm_scheduler = DPMSolverMultistepScheduler.from_pretrained("cvssp/audioldm", subfolder="scheduler")
+>>> pipeline = AudioLDMPipeline.from_pretrained("cvssp/audioldm", scheduler=dpm_scheduler, torch_dtype=torch.float16)
+```
+
+## AudioLDMPipeline
+[[autodoc]] AudioLDMPipeline
+ - all
+ - __call__
diff --git a/docs/source/en/api/pipelines/overview.mdx b/docs/source/en/api/pipelines/overview.mdx
index 6d0a9a1159b2..3b0e7c66152f 100644
--- a/docs/source/en/api/pipelines/overview.mdx
+++ b/docs/source/en/api/pipelines/overview.mdx
@@ -19,9 +19,9 @@ components - all of which are needed to have a functioning end-to-end diffusion
As an example, [Stable Diffusion](https://huggingface.co/blog/stable_diffusion) has three independently trained models:
- [Autoencoder](./api/models#vae)
- [Conditional Unet](./api/models#UNet2DConditionModel)
-- [CLIP text encoder](https://huggingface.co/docs/transformers/v4.21.2/en/model_doc/clip#transformers.CLIPTextModel)
+- [CLIP text encoder](https://huggingface.co/docs/transformers/v4.27.1/en/model_doc/clip#transformers.CLIPTextModel)
- a scheduler component, [scheduler](./api/scheduler#pndm),
-- a [CLIPFeatureExtractor](https://huggingface.co/docs/transformers/v4.21.2/en/model_doc/clip#transformers.CLIPFeatureExtractor),
+- a [CLIPImageProcessor](https://huggingface.co/docs/transformers/v4.27.1/en/model_doc/clip#transformers.CLIPImageProcessor),
- as well as a [safety checker](./stable_diffusion#safety_checker).
All of these components are necessary to run stable diffusion in inference even though they were trained
or created independently from each other.
@@ -77,6 +77,7 @@ available a colab notebook to directly try them out.
| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Text-to-Image Generation |
| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Image-to-Image Text-Guided Generation |
| [stochastic_karras_ve](./stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
+| [text_to_video_sd](./api/pipelines/text_to_video) | [Modelscope's Text-to-video-synthesis Model in Open Domain](https://modelscope.cn/models/damo/text-to-video-synthesis/summary) | Text-to-Video Generation |
| [unclip](./unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) | Text-to-Image Generation |
| [versatile_diffusion](./versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
| [versatile_diffusion](./versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
@@ -107,7 +108,7 @@ from the local path.
each pipeline, one should look directly into the respective pipeline.
**Note**: All pipelines have PyTorch's autograd disabled by decorating the `__call__` method with a [`torch.no_grad`](https://pytorch.org/docs/stable/generated/torch.no_grad.html) decorator because pipelines should
-not be used for training. If you want to store the gradients during the forward pass, we recommend writing your own pipeline, see also our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community)
+not be used for training. If you want to store the gradients during the forward pass, we recommend writing your own pipeline, see also our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community).
## Contribution
@@ -172,7 +173,7 @@ You can also run this example on colab [ shows how to do it step by step. You can also run it in Google Colab [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb).
+You can generate your own latents to reproduce results, or tweak your prompt on a specific result you liked. [This notebook](https://github.com/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb) shows how to do it step by step. You can also run it in Google Colab [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
### In-painting using Stable Diffusion
diff --git a/docs/source/en/api/pipelines/paint_by_example.mdx b/docs/source/en/api/pipelines/paint_by_example.mdx
index 04390a14b758..5abb3406db44 100644
--- a/docs/source/en/api/pipelines/paint_by_example.mdx
+++ b/docs/source/en/api/pipelines/paint_by_example.mdx
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
## Overview
-[Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://arxiv.org/abs/2211.13227) by Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, Fang Wen
+[Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://arxiv.org/abs/2211.13227) by Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, Fang Wen.
The abstract of the paper is the following:
diff --git a/docs/source/en/api/pipelines/spectrogram_diffusion.mdx b/docs/source/en/api/pipelines/spectrogram_diffusion.mdx
new file mode 100644
index 000000000000..c98300fe791f
--- /dev/null
+++ b/docs/source/en/api/pipelines/spectrogram_diffusion.mdx
@@ -0,0 +1,54 @@
+
+
+# Multi-instrument Music Synthesis with Spectrogram Diffusion
+
+## Overview
+
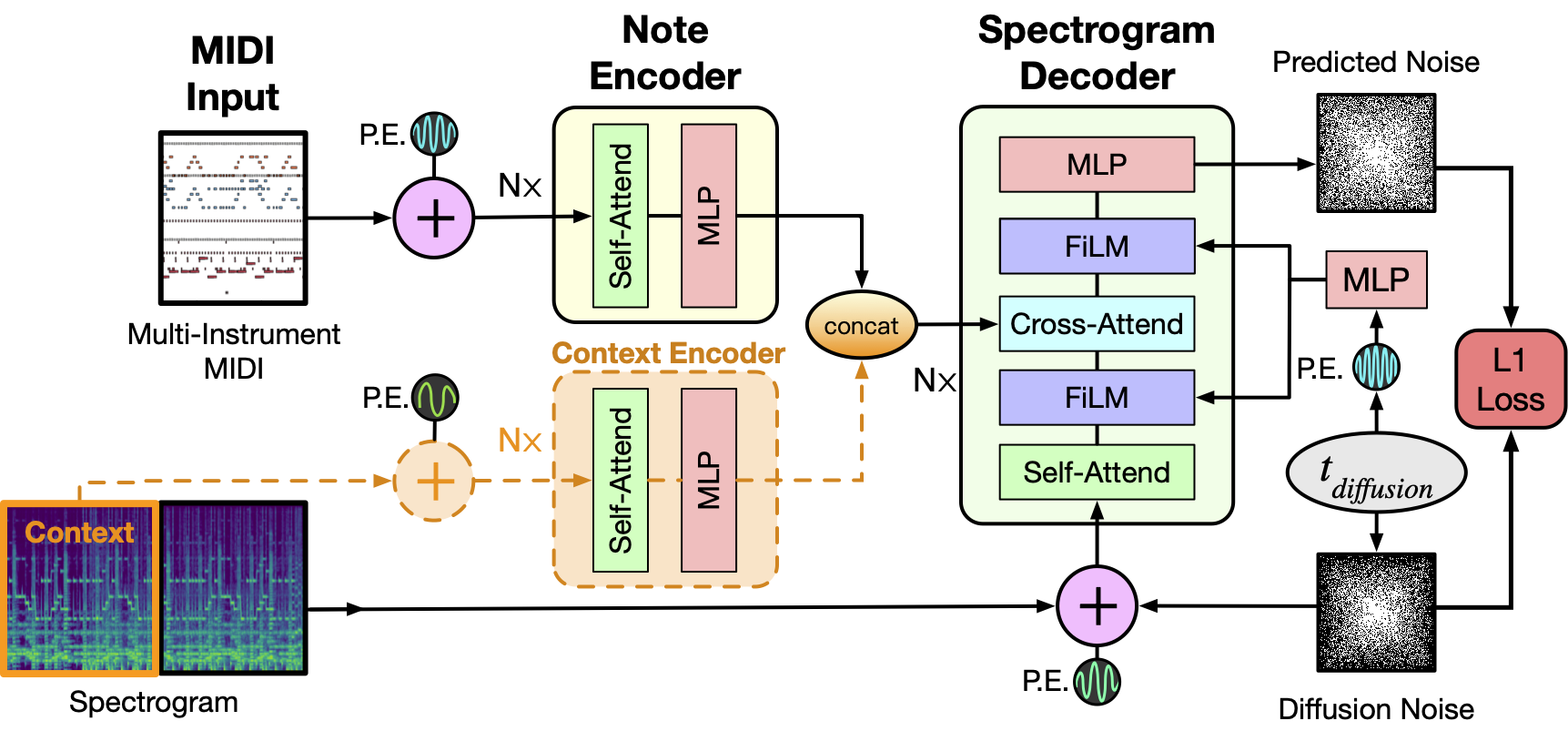
+[Spectrogram Diffusion](https://arxiv.org/abs/2206.05408) by Curtis Hawthorne, Ian Simon, Adam Roberts, Neil Zeghidour, Josh Gardner, Ethan Manilow, and Jesse Engel.
+
+An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on any music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fréchet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.
+
+The original codebase of this implementation can be found at [magenta/music-spectrogram-diffusion](https://github.com/magenta/music-spectrogram-diffusion).
+
+## Model
+
+
+
+As depicted above the model takes as input a MIDI file and tokenizes it into a sequence of 5 second intervals. Each tokenized interval then together with positional encodings is passed through the Note Encoder and its representation is concatenated with the previous window's generated spectrogram representation obtained via the Context Encoder. For the initial 5 second window this is set to zero. The resulting context is then used as conditioning to sample the denoised Spectrogram from the MIDI window and we concatenate this spectrogram to the final output as well as use it for the context of the next MIDI window. The process repeats till we have gone over all the MIDI inputs. Finally a MelGAN decoder converts the potentially long spectrogram to audio which is the final result of this pipeline.
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_spectrogram_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion) | *Unconditional Audio Generation* | - |
+
+
+## Example usage
+
+```python
+from diffusers import SpectrogramDiffusionPipeline, MidiProcessor
+
+pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
+pipe = pipe.to("cuda")
+processor = MidiProcessor()
+
+# Download MIDI from: wget http://www.piano-midi.de/midis/beethoven/beethoven_hammerklavier_2.mid
+output = pipe(processor("beethoven_hammerklavier_2.mid"))
+
+audio = output.audios[0]
+```
+
+## SpectrogramDiffusionPipeline
+[[autodoc]] SpectrogramDiffusionPipeline
+ - all
+ - __call__
diff --git a/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx b/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
index b5fa350e5f04..4c93bbf23f83 100644
--- a/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
+++ b/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
@@ -135,6 +135,113 @@ This should take only around 3-4 seconds on GPU (depending on hardware). The out
+## Combining multiple conditionings
+
+Multiple ControlNet conditionings can be combined for a single image generation. Pass a list of ControlNets to the pipeline's constructor and a corresponding list of conditionings to `__call__`.
+
+When combining conditionings, it is helpful to mask conditionings such that they do not overlap. In the example, we mask the middle of the canny map where the pose conditioning is located.
+
+It can also be helpful to vary the `controlnet_conditioning_scales` to emphasize one conditioning over the other.
+
+### Canny conditioning
+
+The original image:
+
+
. We discuss the hottest trends about diffusion models, help each other with contributions, personal projects or
+just hang out ☕.
+
## Credits
This library concretizes previous work by many different authors and would not have been possible without their great research and implementations. We'd like to thank, in particular, the following implementations which have helped us in our development and without which the API could not have been as polished today:
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 09012a5c693d..1a0d8f5cd6c8 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -4,7 +4,7 @@
- local: quicktour
title: Quicktour
- local: stable_diffusion
- title: Stable Diffusion
+ title: Effective and efficient diffusion
- local: installation
title: Installation
title: Get started
@@ -33,19 +33,19 @@
- local: using-diffusers/pipeline_overview
title: Overview
- local: using-diffusers/unconditional_image_generation
- title: Unconditional Image Generation
+ title: Unconditional image generation
- local: using-diffusers/conditional_image_generation
- title: Text-to-Image Generation
+ title: Text-to-image generation
- local: using-diffusers/img2img
- title: Text-Guided Image-to-Image
+ title: Text-guided image-to-image
- local: using-diffusers/inpaint
- title: Text-Guided Image-Inpainting
+ title: Text-guided image-inpainting
- local: using-diffusers/depth2img
- title: Text-Guided Depth-to-Image
+ title: Text-guided depth-to-image
- local: using-diffusers/reusing_seeds
- title: Reusing seeds for deterministic generation
+ title: Improve image quality with deterministic generation
- local: using-diffusers/reproducibility
- title: Reproducibility
+ title: Create reproducible pipelines
- local: using-diffusers/custom_pipeline_examples
title: Community Pipelines
- local: using-diffusers/contribute_pipeline
@@ -68,6 +68,10 @@
title: Text-to-image
- local: training/lora
title: Low-Rank Adaptation of Large Language Models (LoRA)
+ - local: training/controlnet
+ title: ControlNet
+ - local: training/instructpix2pix
+ title: InstructPix2Pix Training
title: Training
- sections:
- local: using-diffusers/rl
@@ -130,6 +134,8 @@
title: AltDiffusion
- local: api/pipelines/audio_diffusion
title: Audio Diffusion
+ - local: api/pipelines/audioldm
+ title: AudioLDM
- local: api/pipelines/cycle_diffusion
title: Cycle Diffusion
- local: api/pipelines/dance_diffusion
@@ -154,6 +160,8 @@
title: Score SDE VE
- local: api/pipelines/semantic_stable_diffusion
title: Semantic Guidance
+ - local: api/pipelines/spectrogram_diffusion
+ title: "Spectrogram Diffusion"
- sections:
- local: api/pipelines/stable_diffusion/overview
title: Overview
@@ -183,6 +191,8 @@
title: MultiDiffusion Panorama
- local: api/pipelines/stable_diffusion/controlnet
title: Text-to-Image Generation with ControlNet Conditioning
+ - local: api/pipelines/stable_diffusion/model_editing
+ title: Text-to-Image Model Editing
title: Stable Diffusion
- local: api/pipelines/stable_diffusion_2
title: Stable Diffusion 2
@@ -190,6 +200,8 @@
title: Stable unCLIP
- local: api/pipelines/stochastic_karras_ve
title: Stochastic Karras VE
+ - local: api/pipelines/text_to_video
+ title: Text-to-Video
- local: api/pipelines/unclip
title: UnCLIP
- local: api/pipelines/latent_diffusion_uncond
diff --git a/docs/source/en/api/models.mdx b/docs/source/en/api/models.mdx
index dc425e98628c..2361fd4f6597 100644
--- a/docs/source/en/api/models.mdx
+++ b/docs/source/en/api/models.mdx
@@ -37,6 +37,12 @@ The models are built on the base class ['ModelMixin'] that is a `torch.nn.module
## UNet2DConditionModel
[[autodoc]] UNet2DConditionModel
+## UNet3DConditionOutput
+[[autodoc]] models.unet_3d_condition.UNet3DConditionOutput
+
+## UNet3DConditionModel
+[[autodoc]] UNet3DConditionModel
+
## DecoderOutput
[[autodoc]] models.vae.DecoderOutput
@@ -58,6 +64,12 @@ The models are built on the base class ['ModelMixin'] that is a `torch.nn.module
## Transformer2DModelOutput
[[autodoc]] models.transformer_2d.Transformer2DModelOutput
+## TransformerTemporalModel
+[[autodoc]] models.transformer_temporal.TransformerTemporalModel
+
+## Transformer2DModelOutput
+[[autodoc]] models.transformer_temporal.TransformerTemporalModelOutput
+
## PriorTransformer
[[autodoc]] models.prior_transformer.PriorTransformer
@@ -87,3 +99,9 @@ The models are built on the base class ['ModelMixin'] that is a `torch.nn.module
## FlaxAutoencoderKL
[[autodoc]] FlaxAutoencoderKL
+
+## FlaxControlNetOutput
+[[autodoc]] models.controlnet_flax.FlaxControlNetOutput
+
+## FlaxControlNetModel
+[[autodoc]] FlaxControlNetModel
diff --git a/docs/source/en/api/pipelines/alt_diffusion.mdx b/docs/source/en/api/pipelines/alt_diffusion.mdx
index cb86208ddbe1..dbe3b079a201 100644
--- a/docs/source/en/api/pipelines/alt_diffusion.mdx
+++ b/docs/source/en/api/pipelines/alt_diffusion.mdx
@@ -12,7 +12,7 @@ specific language governing permissions and limitations under the License.
# AltDiffusion
-AltDiffusion was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu
+AltDiffusion was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu.
The abstract of the paper is the following:
@@ -28,7 +28,7 @@ The abstract of the paper is the following:
## Tips
-- AltDiffusion is conceptually exaclty the same as [Stable Diffusion](./api/pipelines/stable_diffusion/overview).
+- AltDiffusion is conceptually exactly the same as [Stable Diffusion](./api/pipelines/stable_diffusion/overview).
- *Run AltDiffusion*
diff --git a/docs/source/en/api/pipelines/audioldm.mdx b/docs/source/en/api/pipelines/audioldm.mdx
new file mode 100644
index 000000000000..f3987d2263ac
--- /dev/null
+++ b/docs/source/en/api/pipelines/audioldm.mdx
@@ -0,0 +1,82 @@
+
+
+# AudioLDM
+
+## Overview
+
+AudioLDM was proposed in [AudioLDM: Text-to-Audio Generation with Latent Diffusion Models](https://arxiv.org/abs/2301.12503) by Haohe Liu et al.
+
+Inspired by [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview), AudioLDM
+is a text-to-audio _latent diffusion model (LDM)_ that learns continuous audio representations from [CLAP](https://huggingface.co/docs/transformers/main/model_doc/clap)
+latents. AudioLDM takes a text prompt as input and predicts the corresponding audio. It can generate text-conditional
+sound effects, human speech and music.
+
+This pipeline was contributed by [sanchit-gandhi](https://huggingface.co/sanchit-gandhi). The original codebase can be found [here](https://github.com/haoheliu/AudioLDM).
+
+## Text-to-Audio
+
+The [`AudioLDMPipeline`] can be used to load pre-trained weights from [cvssp/audioldm](https://huggingface.co/cvssp/audioldm) and generate text-conditional audio outputs:
+
+```python
+from diffusers import AudioLDMPipeline
+import torch
+import scipy
+
+repo_id = "cvssp/audioldm"
+pipe = AudioLDMPipeline.from_pretrained(repo_id, torch_dtype=torch.float16)
+pipe = pipe.to("cuda")
+
+prompt = "Techno music with a strong, upbeat tempo and high melodic riffs"
+audio = pipe(prompt, num_inference_steps=10, audio_length_in_s=5.0).audios[0]
+
+# save the audio sample as a .wav file
+scipy.io.wavfile.write("techno.wav", rate=16000, data=audio)
+```
+
+### Tips
+
+Prompts:
+* Descriptive prompt inputs work best: you can use adjectives to describe the sound (e.g. "high quality" or "clear") and make the prompt context specific (e.g., "water stream in a forest" instead of "stream").
+* It's best to use general terms like 'cat' or 'dog' instead of specific names or abstract objects that the model may not be familiar with.
+
+Inference:
+* The _quality_ of the predicted audio sample can be controlled by the `num_inference_steps` argument: higher steps give higher quality audio at the expense of slower inference.
+* The _length_ of the predicted audio sample can be controlled by varying the `audio_length_in_s` argument.
+
+### How to load and use different schedulers
+
+The AudioLDM pipeline uses [`DDIMScheduler`] scheduler by default. But `diffusers` provides many other schedulers
+that can be used with the AudioLDM pipeline such as [`PNDMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`],
+[`EulerAncestralDiscreteScheduler`] etc. We recommend using the [`DPMSolverMultistepScheduler`] as it's currently the fastest
+scheduler there is.
+
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`]
+method, or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the
+[`DPMSolverMultistepScheduler`], you can do the following:
+
+```python
+>>> from diffusers import AudioLDMPipeline, DPMSolverMultistepScheduler
+>>> import torch
+
+>>> pipeline = AudioLDMPipeline.from_pretrained("cvssp/audioldm", torch_dtype=torch.float16)
+>>> pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> dpm_scheduler = DPMSolverMultistepScheduler.from_pretrained("cvssp/audioldm", subfolder="scheduler")
+>>> pipeline = AudioLDMPipeline.from_pretrained("cvssp/audioldm", scheduler=dpm_scheduler, torch_dtype=torch.float16)
+```
+
+## AudioLDMPipeline
+[[autodoc]] AudioLDMPipeline
+ - all
+ - __call__
diff --git a/docs/source/en/api/pipelines/overview.mdx b/docs/source/en/api/pipelines/overview.mdx
index 6d0a9a1159b2..3b0e7c66152f 100644
--- a/docs/source/en/api/pipelines/overview.mdx
+++ b/docs/source/en/api/pipelines/overview.mdx
@@ -19,9 +19,9 @@ components - all of which are needed to have a functioning end-to-end diffusion
As an example, [Stable Diffusion](https://huggingface.co/blog/stable_diffusion) has three independently trained models:
- [Autoencoder](./api/models#vae)
- [Conditional Unet](./api/models#UNet2DConditionModel)
-- [CLIP text encoder](https://huggingface.co/docs/transformers/v4.21.2/en/model_doc/clip#transformers.CLIPTextModel)
+- [CLIP text encoder](https://huggingface.co/docs/transformers/v4.27.1/en/model_doc/clip#transformers.CLIPTextModel)
- a scheduler component, [scheduler](./api/scheduler#pndm),
-- a [CLIPFeatureExtractor](https://huggingface.co/docs/transformers/v4.21.2/en/model_doc/clip#transformers.CLIPFeatureExtractor),
+- a [CLIPImageProcessor](https://huggingface.co/docs/transformers/v4.27.1/en/model_doc/clip#transformers.CLIPImageProcessor),
- as well as a [safety checker](./stable_diffusion#safety_checker).
All of these components are necessary to run stable diffusion in inference even though they were trained
or created independently from each other.
@@ -77,6 +77,7 @@ available a colab notebook to directly try them out.
| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Text-to-Image Generation |
| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Image-to-Image Text-Guided Generation |
| [stochastic_karras_ve](./stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
+| [text_to_video_sd](./api/pipelines/text_to_video) | [Modelscope's Text-to-video-synthesis Model in Open Domain](https://modelscope.cn/models/damo/text-to-video-synthesis/summary) | Text-to-Video Generation |
| [unclip](./unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) | Text-to-Image Generation |
| [versatile_diffusion](./versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
| [versatile_diffusion](./versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
@@ -107,7 +108,7 @@ from the local path.
each pipeline, one should look directly into the respective pipeline.
**Note**: All pipelines have PyTorch's autograd disabled by decorating the `__call__` method with a [`torch.no_grad`](https://pytorch.org/docs/stable/generated/torch.no_grad.html) decorator because pipelines should
-not be used for training. If you want to store the gradients during the forward pass, we recommend writing your own pipeline, see also our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community)
+not be used for training. If you want to store the gradients during the forward pass, we recommend writing your own pipeline, see also our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community).
## Contribution
@@ -172,7 +173,7 @@ You can also run this example on colab [ shows how to do it step by step. You can also run it in Google Colab [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb).
+You can generate your own latents to reproduce results, or tweak your prompt on a specific result you liked. [This notebook](https://github.com/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb) shows how to do it step by step. You can also run it in Google Colab [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
### In-painting using Stable Diffusion
diff --git a/docs/source/en/api/pipelines/paint_by_example.mdx b/docs/source/en/api/pipelines/paint_by_example.mdx
index 04390a14b758..5abb3406db44 100644
--- a/docs/source/en/api/pipelines/paint_by_example.mdx
+++ b/docs/source/en/api/pipelines/paint_by_example.mdx
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
## Overview
-[Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://arxiv.org/abs/2211.13227) by Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, Fang Wen
+[Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://arxiv.org/abs/2211.13227) by Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, Fang Wen.
The abstract of the paper is the following:
diff --git a/docs/source/en/api/pipelines/spectrogram_diffusion.mdx b/docs/source/en/api/pipelines/spectrogram_diffusion.mdx
new file mode 100644
index 000000000000..c98300fe791f
--- /dev/null
+++ b/docs/source/en/api/pipelines/spectrogram_diffusion.mdx
@@ -0,0 +1,54 @@
+
+
+# Multi-instrument Music Synthesis with Spectrogram Diffusion
+
+## Overview
+
+[Spectrogram Diffusion](https://arxiv.org/abs/2206.05408) by Curtis Hawthorne, Ian Simon, Adam Roberts, Neil Zeghidour, Josh Gardner, Ethan Manilow, and Jesse Engel.
+
+An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on any music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fréchet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.
+
+The original codebase of this implementation can be found at [magenta/music-spectrogram-diffusion](https://github.com/magenta/music-spectrogram-diffusion).
+
+## Model
+
+
+
+As depicted above the model takes as input a MIDI file and tokenizes it into a sequence of 5 second intervals. Each tokenized interval then together with positional encodings is passed through the Note Encoder and its representation is concatenated with the previous window's generated spectrogram representation obtained via the Context Encoder. For the initial 5 second window this is set to zero. The resulting context is then used as conditioning to sample the denoised Spectrogram from the MIDI window and we concatenate this spectrogram to the final output as well as use it for the context of the next MIDI window. The process repeats till we have gone over all the MIDI inputs. Finally a MelGAN decoder converts the potentially long spectrogram to audio which is the final result of this pipeline.
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_spectrogram_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion) | *Unconditional Audio Generation* | - |
+
+
+## Example usage
+
+```python
+from diffusers import SpectrogramDiffusionPipeline, MidiProcessor
+
+pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
+pipe = pipe.to("cuda")
+processor = MidiProcessor()
+
+# Download MIDI from: wget http://www.piano-midi.de/midis/beethoven/beethoven_hammerklavier_2.mid
+output = pipe(processor("beethoven_hammerklavier_2.mid"))
+
+audio = output.audios[0]
+```
+
+## SpectrogramDiffusionPipeline
+[[autodoc]] SpectrogramDiffusionPipeline
+ - all
+ - __call__
diff --git a/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx b/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
index b5fa350e5f04..4c93bbf23f83 100644
--- a/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
+++ b/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
@@ -135,6 +135,113 @@ This should take only around 3-4 seconds on GPU (depending on hardware). The out
+## Combining multiple conditionings
+
+Multiple ControlNet conditionings can be combined for a single image generation. Pass a list of ControlNets to the pipeline's constructor and a corresponding list of conditionings to `__call__`.
+
+When combining conditionings, it is helpful to mask conditionings such that they do not overlap. In the example, we mask the middle of the canny map where the pose conditioning is located.
+
+It can also be helpful to vary the `controlnet_conditioning_scales` to emphasize one conditioning over the other.
+
+### Canny conditioning
+
+The original image:
+
+ +
+Prepare the conditioning:
+
+```python
+from diffusers.utils import load_image
+from PIL import Image
+import cv2
+import numpy as np
+from diffusers.utils import load_image
+
+canny_image = load_image(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
+)
+canny_image = np.array(canny_image)
+
+low_threshold = 100
+high_threshold = 200
+
+canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
+
+# zero out middle columns of image where pose will be overlayed
+zero_start = canny_image.shape[1] // 4
+zero_end = zero_start + canny_image.shape[1] // 2
+canny_image[:, zero_start:zero_end] = 0
+
+canny_image = canny_image[:, :, None]
+canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
+canny_image = Image.fromarray(canny_image)
+```
+
+
+
+Prepare the conditioning:
+
+```python
+from diffusers.utils import load_image
+from PIL import Image
+import cv2
+import numpy as np
+from diffusers.utils import load_image
+
+canny_image = load_image(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
+)
+canny_image = np.array(canny_image)
+
+low_threshold = 100
+high_threshold = 200
+
+canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
+
+# zero out middle columns of image where pose will be overlayed
+zero_start = canny_image.shape[1] // 4
+zero_end = zero_start + canny_image.shape[1] // 2
+canny_image[:, zero_start:zero_end] = 0
+
+canny_image = canny_image[:, :, None]
+canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
+canny_image = Image.fromarray(canny_image)
+```
+
+ +
+### Openpose conditioning
+
+The original image:
+
+
+
+### Openpose conditioning
+
+The original image:
+
+ +
+Prepare the conditioning:
+
+```python
+from controlnet_aux import OpenposeDetector
+from diffusers.utils import load_image
+
+openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
+
+openpose_image = load_image(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
+)
+openpose_image = openpose(openpose_image)
+```
+
+
+
+Prepare the conditioning:
+
+```python
+from controlnet_aux import OpenposeDetector
+from diffusers.utils import load_image
+
+openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
+
+openpose_image = load_image(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
+)
+openpose_image = openpose(openpose_image)
+```
+
+ +
+### Running ControlNet with multiple conditionings
+
+```python
+from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
+import torch
+
+controlnet = [
+ ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
+ ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
+]
+
+pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+)
+pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+
+pipe.enable_xformers_memory_efficient_attention()
+pipe.enable_model_cpu_offload()
+
+prompt = "a giant standing in a fantasy landscape, best quality"
+negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
+
+generator = torch.Generator(device="cpu").manual_seed(1)
+
+images = [openpose_image, canny_image]
+
+image = pipe(
+ prompt,
+ images,
+ num_inference_steps=20,
+ generator=generator,
+ negative_prompt=negative_prompt,
+ controlnet_conditioning_scale=[1.0, 0.8],
+).images[0]
+
+image.save("./multi_controlnet_output.png")
+```
+
+
+
+### Running ControlNet with multiple conditionings
+
+```python
+from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
+import torch
+
+controlnet = [
+ ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
+ ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
+]
+
+pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+)
+pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+
+pipe.enable_xformers_memory_efficient_attention()
+pipe.enable_model_cpu_offload()
+
+prompt = "a giant standing in a fantasy landscape, best quality"
+negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
+
+generator = torch.Generator(device="cpu").manual_seed(1)
+
+images = [openpose_image, canny_image]
+
+image = pipe(
+ prompt,
+ images,
+ num_inference_steps=20,
+ generator=generator,
+ negative_prompt=negative_prompt,
+ controlnet_conditioning_scale=[1.0, 0.8],
+).images[0]
+
+image.save("./multi_controlnet_output.png")
+```
+
+ +
## Available checkpoints
ControlNet requires a *control image* in addition to the text-to-image *prompt*.
@@ -165,3 +272,9 @@ All checkpoints can be found under the authors' namespace [lllyasviel](https://h
- disable_vae_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
+
+## FlaxStableDiffusionControlNetPipeline
+[[autodoc]] FlaxStableDiffusionControlNetPipeline
+ - all
+ - __call__
+
diff --git a/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx b/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx
new file mode 100644
index 000000000000..7aae35ba2a91
--- /dev/null
+++ b/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx
@@ -0,0 +1,61 @@
+
+
+# Editing Implicit Assumptions in Text-to-Image Diffusion Models
+
+## Overview
+
+[Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://arxiv.org/abs/2303.08084) by Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov.
+
+The abstract of the paper is the following:
+
+*Text-to-image diffusion models often make implicit assumptions about the world when generating images. While some assumptions are useful (e.g., the sky is blue), they can also be outdated, incorrect, or reflective of social biases present in the training data. Thus, there is a need to control these assumptions without requiring explicit user input or costly re-training. In this work, we aim to edit a given implicit assumption in a pre-trained diffusion model. Our Text-to-Image Model Editing method, TIME for short, receives a pair of inputs: a "source" under-specified prompt for which the model makes an implicit assumption (e.g., "a pack of roses"), and a "destination" prompt that describes the same setting, but with a specified desired attribute (e.g., "a pack of blue roses"). TIME then updates the model's cross-attention layers, as these layers assign visual meaning to textual tokens. We edit the projection matrices in these layers such that the source prompt is projected close to the destination prompt. Our method is highly efficient, as it modifies a mere 2.2% of the model's parameters in under one second. To evaluate model editing approaches, we introduce TIMED (TIME Dataset), containing 147 source and destination prompt pairs from various domains. Our experiments (using Stable Diffusion) show that TIME is successful in model editing, generalizes well for related prompts unseen during editing, and imposes minimal effect on unrelated generations.*
+
+Resources:
+
+* [Project Page](https://time-diffusion.github.io/).
+* [Paper](https://arxiv.org/abs/2303.08084).
+* [Original Code](https://github.com/bahjat-kawar/time-diffusion).
+* [Demo](https://huggingface.co/spaces/bahjat-kawar/time-diffusion).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionModelEditingPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_model_editing.py) | *Text-to-Image Model Editing* | [🤗 Space](https://huggingface.co/spaces/bahjat-kawar/time-diffusion)) |
+
+This pipeline enables editing the diffusion model weights, such that its assumptions on a given concept are changed. The resulting change is expected to take effect in all prompt generations pertaining to the edited concept.
+
+## Usage example
+
+```python
+import torch
+from diffusers import StableDiffusionModelEditingPipeline
+
+model_ckpt = "CompVis/stable-diffusion-v1-4"
+pipe = StableDiffusionModelEditingPipeline.from_pretrained(model_ckpt)
+
+pipe = pipe.to("cuda")
+
+source_prompt = "A pack of roses"
+destination_prompt = "A pack of blue roses"
+pipe.edit_model(source_prompt, destination_prompt)
+
+prompt = "A field of roses"
+image = pipe(prompt).images[0]
+image.save("field_of_roses.png")
+```
+
+## StableDiffusionModelEditingPipeline
+[[autodoc]] StableDiffusionModelEditingPipeline
+ - __call__
+ - all
diff --git a/docs/source/en/api/pipelines/stable_diffusion/overview.mdx b/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
index 160fa0d2ebce..70731fd294b9 100644
--- a/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
+++ b/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
@@ -35,6 +35,7 @@ For more details about how Stable Diffusion works and how it differs from the ba
| [StableDiffusionInstructPix2PixPipeline](./pix2pix) | **Experimental** – *Text-Based Image Editing * | | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://huggingface.co/spaces/timbrooks/instruct-pix2pix)
| [StableDiffusionAttendAndExcitePipeline](./attend_and_excite) | **Experimental** – *Text-to-Image Generation * | | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://huggingface.co/spaces/AttendAndExcite/Attend-and-Excite)
| [StableDiffusionPix2PixZeroPipeline](./pix2pix_zero) | **Experimental** – *Text-Based Image Editing * | | [Zero-shot Image-to-Image Translation](https://arxiv.org/abs/2302.03027)
+| [StableDiffusionModelEditingPipeline](./model_editing) | **Experimental** – *Text-to-Image Model Editing * | | [Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://arxiv.org/abs/2303.08084)
diff --git a/docs/source/en/api/pipelines/stable_diffusion_safe.mdx b/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
index 900f22badf6f..688eb5013c6a 100644
--- a/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
+++ b/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
@@ -36,7 +36,7 @@ Safe Stable Diffusion can be tested very easily with the [`StableDiffusionPipeli
### Interacting with the Safety Concept
-To check and edit the currently used safety concept, use the `safety_concept` property of [`StableDiffusionPipelineSafe`]
+To check and edit the currently used safety concept, use the `safety_concept` property of [`StableDiffusionPipelineSafe`]:
```python
>>> from diffusers import StableDiffusionPipelineSafe
@@ -60,7 +60,7 @@ You may use the 4 configurations defined in the [Safe Latent Diffusion paper](ht
The following configurations are available: `SafetyConfig.WEAK`, `SafetyConfig.MEDIUM`, `SafetyConfig.STRONG`, and `SafetyConfig.MAX`.
-### How to load and use different schedulers.
+### How to load and use different schedulers
The safe stable diffusion pipeline uses [`PNDMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`DDIMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
diff --git a/docs/source/en/api/pipelines/stable_unclip.mdx b/docs/source/en/api/pipelines/stable_unclip.mdx
index 40bc3e27af77..372242ae2dff 100644
--- a/docs/source/en/api/pipelines/stable_unclip.mdx
+++ b/docs/source/en/api/pipelines/stable_unclip.mdx
@@ -16,6 +16,10 @@ Stable unCLIP checkpoints are finetuned from [stable diffusion 2.1](./stable_dif
Stable unCLIP also still conditions on text embeddings. Given the two separate conditionings, stable unCLIP can be used
for text guided image variation. When combined with an unCLIP prior, it can also be used for full text to image generation.
+To know more about the unCLIP process, check out the following paper:
+
+[Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) by Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen.
+
## Tips
Stable unCLIP takes a `noise_level` as input during inference. `noise_level` determines how much noise is added
@@ -24,50 +28,86 @@ we do not add any additional noise to the image embeddings i.e. `noise_level = 0
### Available checkpoints:
-TODO
+* Image variation
+ * [stabilityai/stable-diffusion-2-1-unclip](https://hf.co/stabilityai/stable-diffusion-2-1-unclip)
+ * [stabilityai/stable-diffusion-2-1-unclip-small](https://hf.co/stabilityai/stable-diffusion-2-1-unclip-small)
+* Text-to-image
+ * Coming soon!
### Text-to-Image Generation
+Coming soon!
+
+
+### Text guided Image-to-Image Variation
+
```python
+from diffusers import StableUnCLIPImg2ImgPipeline
+from diffusers.utils import load_image
import torch
-from diffusers import StableUnCLIPPipeline
-pipe = StableUnCLIPPipeline.from_pretrained(
- "fusing/stable-unclip-2-1-l", torch_dtype=torch.float16
-) # TODO update model path
+pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
+)
pipe = pipe.to("cuda")
-prompt = "a photo of an astronaut riding a horse on mars"
-images = pipe(prompt).images
-images[0].save("astronaut_horse.png")
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
+init_image = load_image(url)
+
+images = pipe(init_image).images
+images[0].save("variation_image.png")
```
+Optionally, you can also pass a prompt to `pipe` such as:
-### Text guided Image-to-Image Variation
+```python
+prompt = "A fantasy landscape, trending on artstation"
-```python
-import requests
-import torch
-from PIL import Image
-from io import BytesIO
+images = pipe(init_image, prompt=prompt).images
+images[0].save("variation_image_two.png")
+```
+
+### Memory optimization
+If you are short on GPU memory, you can enable smart CPU offloading so that models that are not needed
+immediately for a computation can be offloaded to CPU:
+
+```python
from diffusers import StableUnCLIPImg2ImgPipeline
+from diffusers.utils import load_image
+import torch
pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
- "fusing/stable-unclip-2-1-l-img2img", torch_dtype=torch.float16
-) # TODO update model path
-pipe = pipe.to("cuda")
+ "stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
+)
+# Offload to CPU.
+pipe.enable_model_cpu_offload()
-url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
+init_image = load_image(url)
-response = requests.get(url)
-init_image = Image.open(BytesIO(response.content)).convert("RGB")
-init_image = init_image.resize((768, 512))
+images = pipe(init_image).images
+images[0]
+```
-prompt = "A fantasy landscape, trending on artstation"
+Further memory optimizations are possible by enabling VAE slicing on the pipeline:
+
+```python
+from diffusers import StableUnCLIPImg2ImgPipeline
+from diffusers.utils import load_image
+import torch
+
+pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
+)
+pipe.enable_model_cpu_offload()
+pipe.enable_vae_slicing()
+
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
+init_image = load_image(url)
-images = pipe(prompt, init_image).images
-images[0].save("fantasy_landscape.png")
+images = pipe(init_image).images
+images[0]
```
### StableUnCLIPPipeline
diff --git a/docs/source/en/api/pipelines/text_to_video.mdx b/docs/source/en/api/pipelines/text_to_video.mdx
new file mode 100644
index 000000000000..82b2f19ce1b2
--- /dev/null
+++ b/docs/source/en/api/pipelines/text_to_video.mdx
@@ -0,0 +1,130 @@
+
+
+
+
## Available checkpoints
ControlNet requires a *control image* in addition to the text-to-image *prompt*.
@@ -165,3 +272,9 @@ All checkpoints can be found under the authors' namespace [lllyasviel](https://h
- disable_vae_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
+
+## FlaxStableDiffusionControlNetPipeline
+[[autodoc]] FlaxStableDiffusionControlNetPipeline
+ - all
+ - __call__
+
diff --git a/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx b/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx
new file mode 100644
index 000000000000..7aae35ba2a91
--- /dev/null
+++ b/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx
@@ -0,0 +1,61 @@
+
+
+# Editing Implicit Assumptions in Text-to-Image Diffusion Models
+
+## Overview
+
+[Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://arxiv.org/abs/2303.08084) by Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov.
+
+The abstract of the paper is the following:
+
+*Text-to-image diffusion models often make implicit assumptions about the world when generating images. While some assumptions are useful (e.g., the sky is blue), they can also be outdated, incorrect, or reflective of social biases present in the training data. Thus, there is a need to control these assumptions without requiring explicit user input or costly re-training. In this work, we aim to edit a given implicit assumption in a pre-trained diffusion model. Our Text-to-Image Model Editing method, TIME for short, receives a pair of inputs: a "source" under-specified prompt for which the model makes an implicit assumption (e.g., "a pack of roses"), and a "destination" prompt that describes the same setting, but with a specified desired attribute (e.g., "a pack of blue roses"). TIME then updates the model's cross-attention layers, as these layers assign visual meaning to textual tokens. We edit the projection matrices in these layers such that the source prompt is projected close to the destination prompt. Our method is highly efficient, as it modifies a mere 2.2% of the model's parameters in under one second. To evaluate model editing approaches, we introduce TIMED (TIME Dataset), containing 147 source and destination prompt pairs from various domains. Our experiments (using Stable Diffusion) show that TIME is successful in model editing, generalizes well for related prompts unseen during editing, and imposes minimal effect on unrelated generations.*
+
+Resources:
+
+* [Project Page](https://time-diffusion.github.io/).
+* [Paper](https://arxiv.org/abs/2303.08084).
+* [Original Code](https://github.com/bahjat-kawar/time-diffusion).
+* [Demo](https://huggingface.co/spaces/bahjat-kawar/time-diffusion).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionModelEditingPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_model_editing.py) | *Text-to-Image Model Editing* | [🤗 Space](https://huggingface.co/spaces/bahjat-kawar/time-diffusion)) |
+
+This pipeline enables editing the diffusion model weights, such that its assumptions on a given concept are changed. The resulting change is expected to take effect in all prompt generations pertaining to the edited concept.
+
+## Usage example
+
+```python
+import torch
+from diffusers import StableDiffusionModelEditingPipeline
+
+model_ckpt = "CompVis/stable-diffusion-v1-4"
+pipe = StableDiffusionModelEditingPipeline.from_pretrained(model_ckpt)
+
+pipe = pipe.to("cuda")
+
+source_prompt = "A pack of roses"
+destination_prompt = "A pack of blue roses"
+pipe.edit_model(source_prompt, destination_prompt)
+
+prompt = "A field of roses"
+image = pipe(prompt).images[0]
+image.save("field_of_roses.png")
+```
+
+## StableDiffusionModelEditingPipeline
+[[autodoc]] StableDiffusionModelEditingPipeline
+ - __call__
+ - all
diff --git a/docs/source/en/api/pipelines/stable_diffusion/overview.mdx b/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
index 160fa0d2ebce..70731fd294b9 100644
--- a/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
+++ b/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
@@ -35,6 +35,7 @@ For more details about how Stable Diffusion works and how it differs from the ba
| [StableDiffusionInstructPix2PixPipeline](./pix2pix) | **Experimental** – *Text-Based Image Editing * | | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://huggingface.co/spaces/timbrooks/instruct-pix2pix)
| [StableDiffusionAttendAndExcitePipeline](./attend_and_excite) | **Experimental** – *Text-to-Image Generation * | | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://huggingface.co/spaces/AttendAndExcite/Attend-and-Excite)
| [StableDiffusionPix2PixZeroPipeline](./pix2pix_zero) | **Experimental** – *Text-Based Image Editing * | | [Zero-shot Image-to-Image Translation](https://arxiv.org/abs/2302.03027)
+| [StableDiffusionModelEditingPipeline](./model_editing) | **Experimental** – *Text-to-Image Model Editing * | | [Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://arxiv.org/abs/2303.08084)
diff --git a/docs/source/en/api/pipelines/stable_diffusion_safe.mdx b/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
index 900f22badf6f..688eb5013c6a 100644
--- a/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
+++ b/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
@@ -36,7 +36,7 @@ Safe Stable Diffusion can be tested very easily with the [`StableDiffusionPipeli
### Interacting with the Safety Concept
-To check and edit the currently used safety concept, use the `safety_concept` property of [`StableDiffusionPipelineSafe`]
+To check and edit the currently used safety concept, use the `safety_concept` property of [`StableDiffusionPipelineSafe`]:
```python
>>> from diffusers import StableDiffusionPipelineSafe
@@ -60,7 +60,7 @@ You may use the 4 configurations defined in the [Safe Latent Diffusion paper](ht
The following configurations are available: `SafetyConfig.WEAK`, `SafetyConfig.MEDIUM`, `SafetyConfig.STRONG`, and `SafetyConfig.MAX`.
-### How to load and use different schedulers.
+### How to load and use different schedulers
The safe stable diffusion pipeline uses [`PNDMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`DDIMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
diff --git a/docs/source/en/api/pipelines/stable_unclip.mdx b/docs/source/en/api/pipelines/stable_unclip.mdx
index 40bc3e27af77..372242ae2dff 100644
--- a/docs/source/en/api/pipelines/stable_unclip.mdx
+++ b/docs/source/en/api/pipelines/stable_unclip.mdx
@@ -16,6 +16,10 @@ Stable unCLIP checkpoints are finetuned from [stable diffusion 2.1](./stable_dif
Stable unCLIP also still conditions on text embeddings. Given the two separate conditionings, stable unCLIP can be used
for text guided image variation. When combined with an unCLIP prior, it can also be used for full text to image generation.
+To know more about the unCLIP process, check out the following paper:
+
+[Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) by Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen.
+
## Tips
Stable unCLIP takes a `noise_level` as input during inference. `noise_level` determines how much noise is added
@@ -24,50 +28,86 @@ we do not add any additional noise to the image embeddings i.e. `noise_level = 0
### Available checkpoints:
-TODO
+* Image variation
+ * [stabilityai/stable-diffusion-2-1-unclip](https://hf.co/stabilityai/stable-diffusion-2-1-unclip)
+ * [stabilityai/stable-diffusion-2-1-unclip-small](https://hf.co/stabilityai/stable-diffusion-2-1-unclip-small)
+* Text-to-image
+ * Coming soon!
### Text-to-Image Generation
+Coming soon!
+
+
+### Text guided Image-to-Image Variation
+
```python
+from diffusers import StableUnCLIPImg2ImgPipeline
+from diffusers.utils import load_image
import torch
-from diffusers import StableUnCLIPPipeline
-pipe = StableUnCLIPPipeline.from_pretrained(
- "fusing/stable-unclip-2-1-l", torch_dtype=torch.float16
-) # TODO update model path
+pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
+)
pipe = pipe.to("cuda")
-prompt = "a photo of an astronaut riding a horse on mars"
-images = pipe(prompt).images
-images[0].save("astronaut_horse.png")
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
+init_image = load_image(url)
+
+images = pipe(init_image).images
+images[0].save("variation_image.png")
```
+Optionally, you can also pass a prompt to `pipe` such as:
-### Text guided Image-to-Image Variation
+```python
+prompt = "A fantasy landscape, trending on artstation"
-```python
-import requests
-import torch
-from PIL import Image
-from io import BytesIO
+images = pipe(init_image, prompt=prompt).images
+images[0].save("variation_image_two.png")
+```
+
+### Memory optimization
+If you are short on GPU memory, you can enable smart CPU offloading so that models that are not needed
+immediately for a computation can be offloaded to CPU:
+
+```python
from diffusers import StableUnCLIPImg2ImgPipeline
+from diffusers.utils import load_image
+import torch
pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
- "fusing/stable-unclip-2-1-l-img2img", torch_dtype=torch.float16
-) # TODO update model path
-pipe = pipe.to("cuda")
+ "stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
+)
+# Offload to CPU.
+pipe.enable_model_cpu_offload()
-url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
+init_image = load_image(url)
-response = requests.get(url)
-init_image = Image.open(BytesIO(response.content)).convert("RGB")
-init_image = init_image.resize((768, 512))
+images = pipe(init_image).images
+images[0]
+```
-prompt = "A fantasy landscape, trending on artstation"
+Further memory optimizations are possible by enabling VAE slicing on the pipeline:
+
+```python
+from diffusers import StableUnCLIPImg2ImgPipeline
+from diffusers.utils import load_image
+import torch
+
+pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
+)
+pipe.enable_model_cpu_offload()
+pipe.enable_vae_slicing()
+
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
+init_image = load_image(url)
-images = pipe(prompt, init_image).images
-images[0].save("fantasy_landscape.png")
+images = pipe(init_image).images
+images[0]
```
### StableUnCLIPPipeline
diff --git a/docs/source/en/api/pipelines/text_to_video.mdx b/docs/source/en/api/pipelines/text_to_video.mdx
new file mode 100644
index 000000000000..82b2f19ce1b2
--- /dev/null
+++ b/docs/source/en/api/pipelines/text_to_video.mdx
@@ -0,0 +1,130 @@
+
+
++  +
+ |
+ +  +
+ |
+
-We encourage everyone to start by saying 👋 in our public Discord channel. We discuss the hottest trends about diffusion models, ask questions, show-off personal projects, help each other with contributions, or just hang out ☕.
-
-Whichever way you choose to contribute, we strive to be part of an open, welcoming and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions.
+Whichever way you choose to contribute, we strive to be part of an open, welcoming, and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions. We also recommend you become familiar with the [ethical guidelines](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines) that guide our project and ask you to adhere to the same principles of transparency and responsibility.
+We enormously value feedback from the community, so please do not be afraid to speak up if you believe you have valuable feedback that can help improve the library - every message, comment, issue, and pull request (PR) is read and considered.
## Overview
-You can contribute in so many ways! Just to name a few:
+You can contribute in many ways ranging from answering questions on issues to adding new diffusion models to
+the core library.
+
+In the following, we give an overview of different ways to contribute, ranked by difficulty in ascending order. All of them are valuable to the community.
+
+* 1. Asking and answering questions on [the Diffusers discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers) or on [Discord](https://discord.gg/G7tWnz98XR).
+* 2. Opening new issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues/new/choose)
+* 3. Answering issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues)
+* 4. Fix a simple issue, marked by the "Good first issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
+* 5. Contribute to the [documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
+* 6. Contribute a [Community Pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3Acommunity-examples)
+* 7. Contribute to the [examples](https://github.com/huggingface/diffusers/tree/main/examples).
+* 8. Fix a more difficult issue, marked by the "Good second issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22).
+* 9. Add a new pipeline, model, or scheduler, see ["New Pipeline/Model"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) and ["New scheduler"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) issues. For this contribution, please have a look at [Design Philosophy](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md).
+
+As said before, **all contributions are valuable to the community**.
+In the following, we will explain each contribution a bit more in detail.
+
+For all contributions 4.-9. you will need to open a PR. It is explained in detail how to do so in [Opening a pull requst](#how-to-open-a-pr)
+
+### 1. Asking and answering questions on the Diffusers discussion forum or on the Diffusers Discord
+
+Any question or comment related to the Diffusers library can be asked on the [discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/) or on [Discord](https://discord.gg/G7tWnz98XR). Such questions and comments include (but are not limited to):
+- Reports of training or inference experiments in an attempt to share knowledge
+- Presentation of personal projects
+- Questions to non-official training examples
+- Project proposals
+- General feedback
+- Paper summaries
+- Asking for help on personal projects that build on top of the Diffusers library
+- General questions
+- Ethical questions regarding diffusion models
+- ...
+
+Every question that is asked on the forum or on Discord actively encourages the community to publicly
+share knowledge and might very well help a beginner in the future that has the same question you're
+having. Please do pose any questions you might have.
+In the same spirit, you are of immense help to the community by answering such questions because this way you are publicly documenting knowledge for everybody to learn from.
+
+**Please** keep in mind that the more effort you put into asking or answering a question, the higher
+the quality of the publicly documented knowledge. In the same way, well-posed and well-answered questions create a high-quality knowledge database accessible to everybody, while badly posed questions or answers reduce the overall quality of the public knowledge database.
+In short, a high quality question or answer is *precise*, *concise*, *relevant*, *easy-to-understand*, *accesible*, and *well-formated/well-posed*. For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
+
+**NOTE about channels**:
+[*The forum*](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) is much better indexed by search engines, such as Google. Posts are ranked by popularity rather than chronologically. Hence, it's easier to look up questions and answers that we posted some time ago.
+In addition, questions and answers posted in the forum can easily be linked to.
+In contrast, *Discord* has a chat-like format that invites fast back-and-forth communication.
+While it will most likely take less time for you to get an answer to your question on Discord, your
+question won't be visible anymore over time. Also, it's much harder to find information that was posted a while back on Discord. We therefore strongly recommend using the forum for high-quality questions and answers in an attempt to create long-lasting knowledge for the community. If discussions on Discord lead to very interesting answers and conclusions, we recommend posting the results on the forum to make the information more available for future readers.
+
+### 2. Opening new issues on the GitHub issues tab
-* Fixing outstanding issues with the existing code.
-* Implementing [new diffusion pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines#contribution), [new schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) or [new models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models).
-* [Contributing to the examples](https://github.com/huggingface/diffusers/tree/main/examples).
-* [Contributing to the documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
-* Submitting issues related to bugs or desired new features.
+The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
+the problems they encounter. So thank you for reporting an issue.
-*All are equally valuable to the community.*
+Remember, GitHub issues are reserved for technical questions directly related to the Diffusers library, bug reports, feature requests, or feedback on the library design.
-### Browse GitHub issues for suggestions
+In a nutshell, this means that everything that is **not** related to the **code of the Diffusers library** (including the documentation) should **not** be asked on GitHub, but rather on either the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
-If you need inspiration, you can look out for [issues](https://github.com/huggingface/diffusers/issues) you'd like to tackle to contribute to the library. There are a few filters that can be helpful:
+**Please consider the following guidelines when opening a new issue**:
+- Make sure you have searched whether your issue has already been asked before (use the search bar on GitHub under Issues).
+- Please never report a new issue on another (related) issue. If another issue is highly related, please
+open a new issue nevertheless and link to the related issue.
+- Make sure your issue is written in English. Please use one of the great, free online translation services, such as [DeepL](https://www.deepl.com/translator) to translate from your native language to English if you are not comfortable in English.
+- Check whether your issue might be solved by updating to the newest Diffusers version. Before posting your issue, please make sure that `python -c "import diffusers; print(diffusers.__version__)"` is higher or matches the latest Diffusers version.
+- Remember that the more effort you put into opening a new issue, the higher the quality of your answer will be and the better the overall quality of the Diffusers issues.
-- See [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) for general opportunities to contribute and getting started with the codebase.
-- See [New pipeline/model](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) to contribute exciting new diffusion models or diffusion pipelines.
-- See [New scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) to work on new samplers and schedulers.
+New issues usually include the following.
+#### 2.1. Reproducible, minimal bug reports.
-## Submitting a new issue or feature request
+A bug report should always have a reproducible code snippet and be as minimal and concise as possible.
+This means in more detail:
+- Narrow the bug down as much as you can, **do not just dump your whole code file**
+- Format your code
+- Do not include any external libraries except for Diffusers depending on them.
+- **Always** provide all necessary information about your environment; for this, you can run: `diffusers-cli env` in your shell and copy-paste the displayed information to the issue.
+- Explain the issue. If the reader doesn't know what the issue is and why it is an issue, she cannot solve it.
+- **Always** make sure the reader can reproduce your issue with as little effort as possible. If your code snippet cannot be run because of missing libraries or undefined variables, the reader cannot help you. Make sure your reproducible code snippet is as minimal as possible and can be copy-pasted into a simple Python shell.
+- If in order to reproduce your issue a model and/or dataset is required, make sure the reader has access to that model or dataset. You can always upload your model or dataset to the [Hub](https://huggingface.co) to make it easily downloadable. Try to keep your model and dataset as small as possible, to make the reproduction of your issue as effortless as possible.
-Do your best to follow these guidelines when submitting an issue or a feature
-request. It will make it easier for us to come back to you quickly and with good
-feedback.
+For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
-### Did you find a bug?
+You can open a bug report [here](https://github.com/huggingface/diffusers/issues/new/choose).
-The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
-the problems they encounter. So thank you for reporting an issue.
+#### 2.2. Feature requests.
+
+A world-class feature request addresses the following points:
+
+1. Motivation first:
+* Is it related to a problem/frustration with the library? If so, please explain
+why. Providing a code snippet that demonstrates the problem is best.
+* Is it related to something you would need for a project? We'd love to hear
+about it!
+* Is it something you worked on and think could benefit the community?
+Awesome! Tell us what problem it solved for you.
+2. Write a *full paragraph* describing the feature;
+3. Provide a **code snippet** that demonstrates its future use;
+4. In case this is related to a paper, please attach a link;
+5. Attach any additional information (drawings, screenshots, etc.) you think may help.
+
+You can open a feature request [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=).
+
+#### 2.3 Feedback.
+
+Feedback about the library design and why it is good or not good helps the core maintainers immensely to build a user-friendly library. To understand the philosophy behind the current design philosophy, please have a look [here](https://huggingface.co/docs/diffusers/conceptual/philosophy). If you feel like a certain design choice does not fit with the current design philosophy, please explain why and how it should be changed. If a certain design choice follows the design philosophy too much, hence restricting use cases, explain why and how it should be changed.
+If a certain design choice is very useful for you, please also leave a note as this is great feedback for future design decisions.
+
+You can open an issue about feedback [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
-First, we would really appreciate it if you could **make sure the bug was not
-already reported** (use the search bar on GitHub under Issues).
+#### 2.4 Technical questions.
-### Do you want to implement a new diffusion pipeline / diffusion model?
+Technical questions are mainly about why certain code of the library was written in a certain way, or what a certain part of the code does. Please make sure to link to the code in question and please provide detail on
+why this part of the code is difficult to understand.
-Awesome! Please provide the following information:
+You can open an issue about a technical question [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&template=bug-report.yml).
-* Short description of the diffusion pipeline and link to the paper;
-* Link to the implementation if it is open-source;
+#### 2.5 Proposal to add a new model, scheduler, or pipeline.
+
+If the diffusion model community released a new model, pipeline, or scheduler that you would like to see in the Diffusers library, please provide the following information:
+
+* Short description of the diffusion pipeline, model, or scheduler and link to the paper or public release.
+* Link to any of its open-source implementation.
* Link to the model weights if they are available.
-If you are willing to contribute the model yourself, let us know so we can best
-guide you.
+If you are willing to contribute to the model yourself, let us know so we can best guide you. Also, don't forget
+to tag the original author of the component (model, scheduler, pipeline, etc.) by GitHub handle if you can find it.
-### Do you want a new feature (that is not a model)?
+You can open a request for a model/pipeline/scheduler [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=New+model%2Fpipeline%2Fscheduler&template=new-model-addition.yml).
-A world-class feature request addresses the following points:
+### 3. Answering issues on the GitHub issues tab
-1. Motivation first:
- * Is it related to a problem/frustration with the library? If so, please explain
- why. Providing a code snippet that demonstrates the problem is best.
- * Is it related to something you would need for a project? We'd love to hear
- about it!
- * Is it something you worked on and think could benefit the community?
- Awesome! Tell us what problem it solved for you.
-2. Write a *full paragraph* describing the feature;
-3. Provide a **code snippet** that demonstrates its future use;
-4. In case this is related to a paper, please attach a link;
-5. Attach any additional information (drawings, screenshots, etc.) you think may help.
+Answering issues on GitHub might require some technical knowledge of Diffusers, but we encourage everybody to give it a try even if you are not 100% certain that your answer is correct.
+Some tips to give a high-quality answer to an issue:
+- Be as concise and minimal as possible
+- Stay on topic. An answer to the issue should concern the issue and only the issue.
+- Provide links to code, papers, or other sources that prove or encourage your point.
+- Answer in code. If a simple code snippet is the answer to the issue or shows how the issue can be solved, please provide a fully reproducible code snippet.
+
+Also, many issues tend to be simply off-topic, duplicates of other issues, or irrelevant. It is of great
+help to the maintainers if you can answer such issues, encouraging the author of the issue to be
+more precise, provide the link to a duplicated issue or redirect them to [the forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR)
+
+If you have verified that the issued bug report is correct and requires a correction in the source code,
+please have a look at the next sections.
+
+For all of the following contributions, you will need to open a PR. It is explained in detail how to do so in the [Opening a pull requst](#how-to-open-a-pr) section.
+
+### 4. Fixing a "Good first issue"
+
+*Good first issues* are marked by the [Good first issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) label. Usually, the issue already
+explains how a potential solution should look so that it is easier to fix.
+If the issue hasn't been closed and you would like to try to fix this issue, you can just leave a message "I would like to try this issue.". There are usually three scenarios:
+- a.) The issue description already proposes a fix. In this case and if the solution makes sense to you, you can open a PR or draft PR to fix it.
+- b.) The issue description does not propose a fix. In this case, you can ask what a proposed fix could look like and someone from the Diffusers team should answer shortly. If you have a good idea of how to fix it, feel free to directly open a PR.
+- c.) There is already an open PR to fix the issue, but the issue hasn't been closed yet. If the PR has gone stale, you can simply open a new PR and link to the stale PR. PRs often go stale if the original contributor who wanted to fix the issue suddenly cannot find the time anymore to proceed. This often happens in open-source and is very normal. In this case, the community will be very happy if you give it a new try and leverage the knowledge of the existing PR. If there is already a PR and it is active, you can help the author by giving suggestions, reviewing the PR or even asking whether you can contribute to the PR.
+
+
+### 5. Contribute to the documentation
+
+A good library **always** has good documentation! The official documentation is often one of the first points of contact for new users of the library, and therefore contributing to the documentation is a **highly
+valuable contribution**.
+
+Contributing to the library can have many forms:
-If your issue is well written we're already 80% of the way there by the time you
-post it.
+- Correcting spelling or grammatical errors.
+- Correct incorrect formatting of the docstring. If you see that the official documentation is weirdly displayed or a link is broken, we are very happy if you take some time to correct it.
+- Correct the shape or dimensions of a docstring input or output tensor.
+- Clarify documentation that is hard to understand or incorrect.
+- Update outdated code examples.
+- Translating the documentation to another language.
-## Start contributing! (Pull Requests)
+Anything displayed on [the official Diffusers doc page](https://huggingface.co/docs/diffusers/index) is part of the official documentation and can be corrected, adjusted in the respective [documentation source](https://github.com/huggingface/diffusers/tree/main/docs/source).
+
+Please have a look at [this page](https://github.com/huggingface/diffusers/tree/main/docs) on how to verify changes made to the documentation locally.
+
+
+### 6. Contribute a community pipeline
+
+[Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) are usually the first point of contact between the Diffusers library and the user.
+Pipelines are examples of how to use Diffusers [models](https://huggingface.co/docs/diffusers/api/models) and [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview).
+We support two types of pipelines:
+
+- Official Pipelines
+- Community Pipelines
+
+Both official and community pipelines follow the same design and consist of the same type of components.
+
+Official pipelines are tested and maintained by the core maintainers of Diffusers. Their code
+resides in [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
+In contrast, community pipelines are contributed and maintained purely by the **community** and are **not** tested.
+They reside in [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and while they can be accessed via the [PyPI diffusers package](https://pypi.org/project/diffusers/), their code is not part of the PyPI distribution.
+
+The reason for the distinction is that the core maintainers of the Diffusers library cannot maintain and test all
+possible ways diffusion models can be used for inference, but some of them may be of interest to the community.
+Officially released diffusion pipelines,
+such as Stable Diffusion are added to the core src/diffusers/pipelines package which ensures
+high quality of maintenance, no backward-breaking code changes, and testing.
+More bleeding edge pipelines should be added as community pipelines. If usage for a community pipeline is high, the pipeline can be moved to the official pipelines upon request from the community. This is one of the ways we strive to be a community-driven library.
+
+To add a community pipeline, one should add a  +
+ +
+ +
+ +
+ +
+ +
+ +
+
+  +
+
+  +
+
 |
|  |
+
+Play around with the Spaces below and see if you notice a difference between generated images with and without a depth map!
+
+
diff --git a/docs/source/en/using-diffusers/img2img.mdx b/docs/source/en/using-diffusers/img2img.mdx
index 6ebe1f0633f0..71540fbf5dd9 100644
--- a/docs/source/en/using-diffusers/img2img.mdx
+++ b/docs/source/en/using-diffusers/img2img.mdx
@@ -10,11 +10,11 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
specific language governing permissions and limitations under the License.
-->
-# Text-Guided Image-to-Image Generation
+# Text-guided image-to-image generation
[[open-in-colab]]
-The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images. This tutorial shows how to use it for text-guided image-to-image generation with Stable Diffusion model.
+The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images.
Before you begin, make sure you have all the necessary libraries installed:
@@ -22,27 +22,22 @@ Before you begin, make sure you have all the necessary libraries installed:
!pip install diffusers transformers ftfy accelerate
```
-Get started by creating a [`StableDiffusionImg2ImgPipeline`] with a pretrained Stable Diffusion model.
+Get started by creating a [`StableDiffusionImg2ImgPipeline`] with a pretrained Stable Diffusion model like [`nitrosocke/Ghibli-Diffusion`](https://huggingface.co/nitrosocke/Ghibli-Diffusion).
```python
import torch
import requests
from PIL import Image
from io import BytesIO
-
from diffusers import StableDiffusionImg2ImgPipeline
-```
-Load the pipeline:
-
-```python
device = "cuda"
-pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to(
+pipe = StableDiffusionImg2ImgPipeline.from_pretrained("nitrosocke/Ghibli-Diffusion", torch_dtype=torch.float16).to(
device
)
```
-Download an initial image and preprocess it so we can pass it to the pipeline:
+Download and preprocess an initial image so you can pass it to the pipeline:
```python
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
@@ -53,61 +48,52 @@ init_image.thumbnail((768, 768))
init_image
```
-
-
-Define the prompt and run the pipeline:
-
-```python
-prompt = "A fantasy landscape, trending on artstation"
-```
+
|
+
+Play around with the Spaces below and see if you notice a difference between generated images with and without a depth map!
+
+
diff --git a/docs/source/en/using-diffusers/img2img.mdx b/docs/source/en/using-diffusers/img2img.mdx
index 6ebe1f0633f0..71540fbf5dd9 100644
--- a/docs/source/en/using-diffusers/img2img.mdx
+++ b/docs/source/en/using-diffusers/img2img.mdx
@@ -10,11 +10,11 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
specific language governing permissions and limitations under the License.
-->
-# Text-Guided Image-to-Image Generation
+# Text-guided image-to-image generation
[[open-in-colab]]
-The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images. This tutorial shows how to use it for text-guided image-to-image generation with Stable Diffusion model.
+The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images.
Before you begin, make sure you have all the necessary libraries installed:
@@ -22,27 +22,22 @@ Before you begin, make sure you have all the necessary libraries installed:
!pip install diffusers transformers ftfy accelerate
```
-Get started by creating a [`StableDiffusionImg2ImgPipeline`] with a pretrained Stable Diffusion model.
+Get started by creating a [`StableDiffusionImg2ImgPipeline`] with a pretrained Stable Diffusion model like [`nitrosocke/Ghibli-Diffusion`](https://huggingface.co/nitrosocke/Ghibli-Diffusion).
```python
import torch
import requests
from PIL import Image
from io import BytesIO
-
from diffusers import StableDiffusionImg2ImgPipeline
-```
-Load the pipeline:
-
-```python
device = "cuda"
-pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to(
+pipe = StableDiffusionImg2ImgPipeline.from_pretrained("nitrosocke/Ghibli-Diffusion", torch_dtype=torch.float16).to(
device
)
```
-Download an initial image and preprocess it so we can pass it to the pipeline:
+Download and preprocess an initial image so you can pass it to the pipeline:
```python
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
@@ -53,61 +48,52 @@ init_image.thumbnail((768, 768))
init_image
```
-
-
-Define the prompt and run the pipeline:
-
-```python
-prompt = "A fantasy landscape, trending on artstation"
-```
+ +
+ +
+ +
+ |
|  | ***Face of a yellow cat, high resolution, sitting on a park bench*** |
| ***Face of a yellow cat, high resolution, sitting on a park bench*** |  |
-
+ | | ***Face of a yellow cat, high resolution, sitting on a park bench*** |
|
-
+ | | ***Face of a yellow cat, high resolution, sitting on a park bench*** |  |
-You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
|
-You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
+
+
+
+