From f289505d896ae17e188d87632c45db3605bd8012 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Fri, 19 May 2023 11:33:03 +0800
Subject: [PATCH 1/8] [doc] update gradient clipping document
---
docs/sidebars.json | 1 +
docs/source/en/features/gradient_clipping.md | 2 +-
.../gradient_clipping_with_booster.md | 144 ++++++++++++++++++
.../zh-Hans/features/gradient_clipping.md | 2 +-
.../gradient_clipping_with_booster.md | 144 ++++++++++++++++++
5 files changed, 291 insertions(+), 2 deletions(-)
create mode 100644 docs/source/en/features/gradient_clipping_with_booster.md
create mode 100644 docs/source/zh-Hans/features/gradient_clipping_with_booster.md
diff --git a/docs/sidebars.json b/docs/sidebars.json
index 44287c17eadf..a9d3a7d384e8 100644
--- a/docs/sidebars.json
+++ b/docs/sidebars.json
@@ -45,6 +45,7 @@
"features/gradient_clipping",
"features/gradient_handler",
"features/zero_with_chunk",
+ "features/gradient_clipping_with_booster",
{
"type": "category",
"label": "Tensor Parallel",
diff --git a/docs/source/en/features/gradient_clipping.md b/docs/source/en/features/gradient_clipping.md
index f606dde6c393..a6dde70a2228 100644
--- a/docs/source/en/features/gradient_clipping.md
+++ b/docs/source/en/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# Gradient Clipping
+# Gradient Clipping (outdated)
Author: Boxiang Wang, Haichen Huang, Yongbin Li
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
new file mode 100644
index 000000000000..14fe612e954d
--- /dev/null
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -0,0 +1,144 @@
+# Gradient Clipping (latest)
+
+Author: Boxiang Wang, Haichen Huang, Yongbin Li
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+**Related Paper**
+- [On the difficulty of training Recurrent Neural Networks](https://arxiv.org/abs/1211.5063)
+
+## Introduction
+
+In order to speed up training process and seek global optimum for better performance, more and more learning rate schedulers have been proposed. People turn to control learning rate to adjust descent pace during training, which makes gradient vector better to be uniformed in every step. In that case, the descent pace can be controlled as expected. As a result, gradient clipping, a technique which can normalize the gradient vector to circumscribe it in a uniformed length, becomes indispensable for those who desire their better performance of their models.
+
+You do not have to worry about implementing gradient clipping when using Colossal-AI, we support gradient clipping in a powerful and convenient way. All you need is just an additional command in your configuration file.
+
+## Why you should use gradient clipping provided by Colossal-AI
+
+The reason of why we do not recommend users to write gradient clipping by themselves is that naive gradient clipping may fail when applying tensor parallelism, pipeline parallelism or MoE.
+
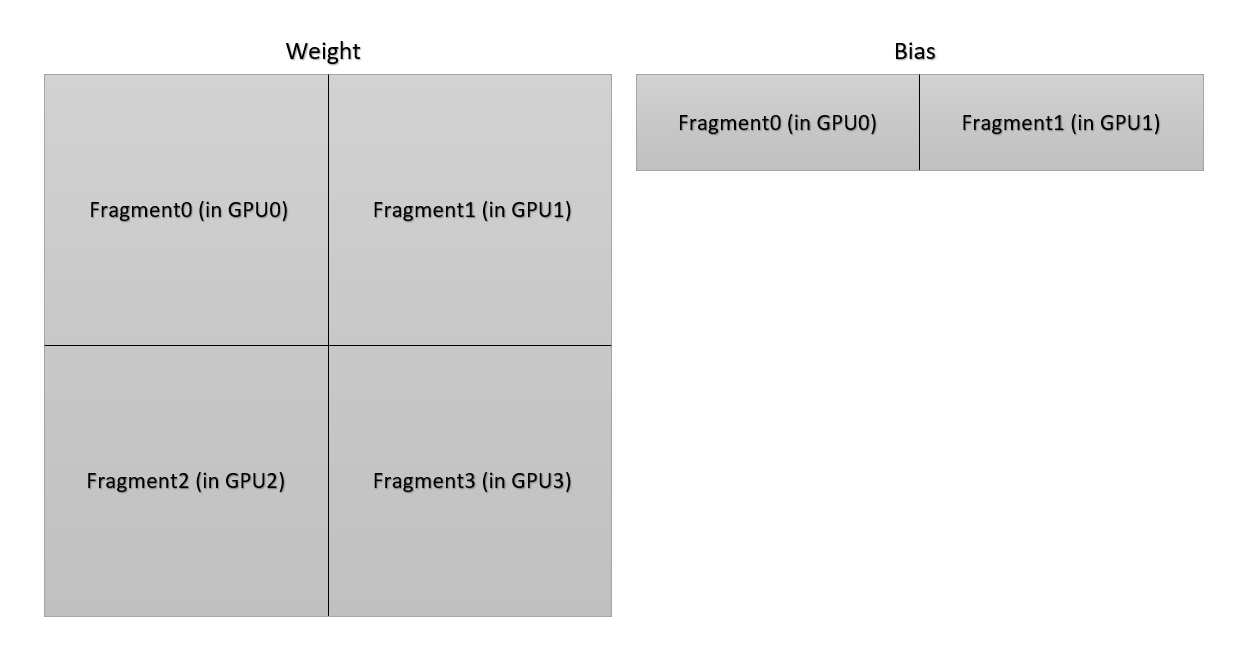
+According to the illustration below, each GPU only owns a portion of parameters of the weight in a linear layer. To get correct norm of gradient vector of the weight of the linear layer, the norm of every gradient vector in each GPU should be summed together. More complicated thing is that the distribution of bias is different from the distribution of the weight. The communication group is different in the sum operation.
+
+(PS: This situation is an old version of 2D parallelism, the implementation in the code is not the same. But it is a good example about the difficulty to unify all communication in gradient clipping.)
+
+
+ +Layout of parameters
+
+
+Do not worry about it, since Colossal-AI have handled it for you.
+
+## Usage
+To use gradient clipping, you can just add the following code to your configuration file, and call `clip_grad_by_norm` or `clip_grad_by_value` method of optimizer which after boost if it support clip gradients.
+
+## Hands-On Practice
+
+We now demonstrate gradient clipping. In this example, we set the gradient clipping vector norm to be 1.0.
+
+### step 1. Import libraries in train.py
+Create a `train_with_engine.py` and import the necessary dependencies.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet34
+from tqdm import tqdm
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import CosineAnnealingLR
+```
+
+### Step 2. Initialize Distributed Environment
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md)
+for other initialization methods.
+
+```python
+ colossalai.launch_from_torch(config=dict())
+ logger = get_dist_logger()
+```
+
+
+### Step 3. Create training components
+
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is
+obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])`
+to a path on your machine. Data will be automatically downloaded to the root path.
+```python
+ # define training hyperparameters
+ NUM_EPOCHS = 200
+ BATCH_SIZE = 128
+ GRADIENT_CLIPPING = 0.1
+ # build resnet
+ model = resnet34(num_classes=10)
+ # build dataloaders
+ train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+ # build criterion
+ criterion = torch.nn.CrossEntropyLoss()
+
+ # optimizer
+ optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+ # lr_scheduler
+ lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+
+```
+### Step 4. Inject Gradient Clipping Feature
+
+create a `TorchDDPPlugin` object and instantiate `Booster` with it, then boost all training components.
+```python
+ plugin = TorchDDPPlugin()
+ booster = Booster(mixed_precision='fp16', plugin=plugin)
+ train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+ model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+
+```
+
+### Step 5. Train with Booster
+Use booster in a normal training loops.
+```python
+ # verify gradient clipping
+ model.train()
+ for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
+```
+
+### Step 6. Invoke Training Scripts
+You can run the script using this command:
+
+```shell
+colossalai run --nproc_per_node 1 train.py --config config/config.py
+```
+
+
diff --git a/docs/source/zh-Hans/features/gradient_clipping.md b/docs/source/zh-Hans/features/gradient_clipping.md
index 203f66a3fea2..e186dff858f2 100644
--- a/docs/source/zh-Hans/features/gradient_clipping.md
+++ b/docs/source/zh-Hans/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# 梯度裁剪
+# 梯度裁剪 (旧版本)
作者: Boxiang Wang, Haichen Huang, Yongbin Li
diff --git a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
new file mode 100644
index 000000000000..ee1fe7738bb0
--- /dev/null
+++ b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
@@ -0,0 +1,144 @@
+# 梯度裁剪 (新版本)
+
+作者: Boxiang Wang, Haichen Huang, Yongbin Li
+
+**前置教程**
+- [定义配置文件](../basics/define_your_config.md)
+- [booster使用](../basics/booster_api.md)
+
+**相关论文**
+- [On the difficulty of training Recurrent Neural Networks](https://arxiv.org/abs/1211.5063)
+
+## 引言
+
+为了加快训练过程和寻求全局最优以获得更好的性能,越来越多的学习率调度器被提出。人们通过控制学习率来调整训练中的下降速度。这使得梯度向量在每一步都能更好地统一。在这种情况下,下降速度可以按预期被控制。
+因此,梯度裁剪,一种可以将梯度向量归一化,以将其限制在统一长度的技术,对于那些希望模型性能更好的人来说是不可或缺的。
+
+在使用 Colossal-AI 时,你不必担心实现梯度剪裁,我们以一种有效而方便的方式支持梯度剪裁。你所需要的只是在你的配置文件中增加一个命令。
+
+## 为什么应该使用 Colossal-AI 中的梯度裁剪
+
+我们不建议用户自己编写梯度剪裁,因为朴素的梯度剪裁在应用张量并行、流水线并行、MoE 等功能时可能会失败。
+
+根据下图,每个 GPU 只拥有线性层中权重的一部分参数。为了得到线性层权重的梯度向量的正确范数,每个 GPU 中的每个梯度向量的范数应该相加。更复杂的是,偏置的分布不同于权重的分布。通信组在求和运算中有所不同。
+
+(注: 这种情况是旧版本的 2D 并行,在代码中的实现是不一样的。但这是一个很好的例子,能够说明在梯度剪裁中统一所有通信的困难。)
+
+
+
+参数分布
+
+
+不用担心它,因为 Colossal-AI 已经为你处理好。
+
+### 使用
+要使用梯度裁剪,只需booster之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。config.py中可配置max_norm。
+
+
+
+
+### 实例
+
+下面我们将介绍如何使用梯度裁剪,在本例中,我们将梯度裁剪范数设置为1.0。
+
+### 步骤 1. 在训练中导入相关库
+创建`train.py`并导入相关库。
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet34
+from tqdm import tqdm
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import CosineAnnealingLR
+```
+
+### 步骤 2. 初始化分布式环境
+我们需要初始化分布式环境. 为了快速演示,我们使用`launch_from_torch`. 您可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)
+
+```python
+ colossalai.launch_from_torch(config=dict())
+ logger = get_dist_logger()
+```
+
+
+### 步骤 3. 创建训练组件
+
+构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`在你的机器上设置路径。数据将会被自动下载到该路径。
+```python
+ # define training hyperparameters
+ NUM_EPOCHS = 200
+ BATCH_SIZE = 128
+ GRADIENT_CLIPPING = 0.1
+ # build resnet
+ model = resnet34(num_classes=10)
+ # build dataloaders
+ train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+ # build criterion
+ criterion = torch.nn.CrossEntropyLoss()
+
+ # optimizer
+ optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+ # lr_scheduler
+ lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+
+```
+### 步骤 4. 注入梯度裁剪特性
+
+创建`TorchDDPPlugin`对象并初始化`Booster`, 使用booster注入相关特性。
+```python
+ plugin = TorchDDPPlugin()
+ booster = Booster(plugin=plugin)
+ train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+ model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+
+```
+
+### 步骤 5. 使用booster训练
+使用booster进行训练。
+```python
+ # verify gradient clipping
+ model.train()
+ for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
+```
+
+### 步骤 6. 启动训练脚本
+你可以使用以下命令运行脚本:
+
+```shell
+colossalai run --nproc_per_node 1 train.py --config config/config.py
+```
+
From e2e4ee6974ad7b676b9a645327ccfee92498c390 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Fri, 19 May 2023 11:48:15 +0800
Subject: [PATCH 2/8] [doc] update gradient clipping document
---
docs/source/en/features/gradient_clipping.md | 2 +-
.../en/features/gradient_clipping_with_booster.md | 14 ++++++--------
.../features/gradient_clipping_with_booster.md | 7 ++-----
3 files changed, 9 insertions(+), 14 deletions(-)
diff --git a/docs/source/en/features/gradient_clipping.md b/docs/source/en/features/gradient_clipping.md
index a6dde70a2228..52ea04a8b16c 100644
--- a/docs/source/en/features/gradient_clipping.md
+++ b/docs/source/en/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# Gradient Clipping (outdated)
+# Gradient Clipping (outdated)
Author: Boxiang Wang, Haichen Huang, Yongbin Li
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
index 14fe612e954d..c88e1b9e5726 100644
--- a/docs/source/en/features/gradient_clipping_with_booster.md
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -1,6 +1,6 @@
# Gradient Clipping (latest)
-Author: Boxiang Wang, Haichen Huang, Yongbin Li
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
**Prerequisite**
- [Define Your Configuration](../basics/define_your_config.md)
@@ -31,14 +31,14 @@ According to the illustration below, each GPU only owns a portion of parameters
Do not worry about it, since Colossal-AI have handled it for you.
## Usage
-To use gradient clipping, you can just add the following code to your configuration file, and call `clip_grad_by_norm` or `clip_grad_by_value` method of optimizer which after boost if it support clip gradients.
+To use gradient clipping, you can just add the following code to your configuration file, and after boosted, you can call `clip_grad_by_norm` or `clip_grad_by_value` method of optimizer, if it support clip gradients.
## Hands-On Practice
-We now demonstrate gradient clipping. In this example, we set the gradient clipping vector norm to be 1.0.
+We now demonstrate how to use gradient clipping. In this example, we set the gradient clipping vector norm to be 1.0.
### step 1. Import libraries in train.py
-Create a `train_with_engine.py` and import the necessary dependencies.
+Create a `train.py` and import the necessary dependencies.
```python
import os
@@ -69,9 +69,7 @@ for other initialization methods.
### Step 3. Create training components
-Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is
-obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])`
-to a path on your machine. Data will be automatically downloaded to the root path.
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])` to a path on your machine. Data will be automatically downloaded to the root path.
```python
# define training hyperparameters
NUM_EPOCHS = 200
@@ -100,7 +98,7 @@ to a path on your machine. Data will be automatically downloaded to the root pat
```
### Step 4. Inject Gradient Clipping Feature
-create a `TorchDDPPlugin` object and instantiate `Booster` with it, then boost all training components.
+Create a `TorchDDPPlugin` object and instantiate `Booster` with it, and get a data loader from plugin, then boost all training components.
```python
plugin = TorchDDPPlugin()
booster = Booster(mixed_precision='fp16', plugin=plugin)
diff --git a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
index ee1fe7738bb0..778d74c3913c 100644
--- a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
+++ b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
@@ -1,6 +1,6 @@
# 梯度裁剪 (新版本)
-作者: Boxiang Wang, Haichen Huang, Yongbin Li
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
**前置教程**
- [定义配置文件](../basics/define_your_config.md)
@@ -32,10 +32,7 @@
不用担心它,因为 Colossal-AI 已经为你处理好。
### 使用
-要使用梯度裁剪,只需booster之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。config.py中可配置max_norm。
-
-
-
+要使用梯度裁剪,只需booster之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。
### 实例
From 0dbe98726cafbf486df193a6bb6a54542ab42de9 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Fri, 19 May 2023 11:49:56 +0800
Subject: [PATCH 3/8] [doc] update gradient clipping document
---
docs/source/zh-Hans/features/gradient_clipping_with_booster.md | 3 +--
1 file changed, 1 insertion(+), 2 deletions(-)
diff --git a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
index 778d74c3913c..11296ac1b4d8 100644
--- a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
+++ b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
@@ -32,7 +32,7 @@
不用担心它,因为 Colossal-AI 已经为你处理好。
### 使用
-要使用梯度裁剪,只需booster之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。
+要使用梯度裁剪,只需在使用booster注入特性之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。
### 实例
@@ -66,7 +66,6 @@ from colossalai.nn.lr_scheduler import CosineAnnealingLR
logger = get_dist_logger()
```
-
### 步骤 3. 创建训练组件
构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`在你的机器上设置路径。数据将会被自动下载到该路径。
From e09767dd0f153451c4dcc73b4097984c29366c52 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Fri, 19 May 2023 11:59:03 +0800
Subject: [PATCH 4/8] [doc] update gradient clipping document
---
docs/source/en/features/gradient_clipping_with_booster.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
index c88e1b9e5726..f28a4c10eee0 100644
--- a/docs/source/en/features/gradient_clipping_with_booster.md
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -98,7 +98,7 @@ Build your model, optimizer, loss function, lr scheduler and dataloaders. Note t
```
### Step 4. Inject Gradient Clipping Feature
-Create a `TorchDDPPlugin` object and instantiate `Booster` with it, and get a data loader from plugin, then boost all training components.
+Create a `TorchDDPPlugin` object and `Booster` object, get a data loader from plugin, then boost all training components.
```python
plugin = TorchDDPPlugin()
booster = Booster(mixed_precision='fp16', plugin=plugin)
From e126faf2cd2c63c9e2466be8f7a30c976dada591 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Fri, 19 May 2023 13:03:40 +0800
Subject: [PATCH 5/8] [doc] update gradient clipping document
---
docs/source/en/features/gradient_clipping.md | 2 +-
docs/source/en/features/gradient_clipping_with_booster.md | 2 +-
docs/source/zh-Hans/features/gradient_clipping.md | 2 +-
3 files changed, 3 insertions(+), 3 deletions(-)
diff --git a/docs/source/en/features/gradient_clipping.md b/docs/source/en/features/gradient_clipping.md
index 52ea04a8b16c..c23e589f5c7a 100644
--- a/docs/source/en/features/gradient_clipping.md
+++ b/docs/source/en/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# Gradient Clipping (outdated)
+# Gradient Clipping (Outdated)
Author: Boxiang Wang, Haichen Huang, Yongbin Li
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
index f28a4c10eee0..fa88f0e7481e 100644
--- a/docs/source/en/features/gradient_clipping_with_booster.md
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -1,4 +1,4 @@
-# Gradient Clipping (latest)
+# Gradient Clipping (Latest)
Author: [Mingyan Jiang](https://github.com/jiangmingyan)
diff --git a/docs/source/zh-Hans/features/gradient_clipping.md b/docs/source/zh-Hans/features/gradient_clipping.md
index e186dff858f2..caef2b526a24 100644
--- a/docs/source/zh-Hans/features/gradient_clipping.md
+++ b/docs/source/zh-Hans/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# 梯度裁剪 (旧版本)
+# 梯度裁剪(旧版本)
作者: Boxiang Wang, Haichen Huang, Yongbin Li
From 6b083efc83c87f52acb20b967336e6ec73d69f1f Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Mon, 22 May 2023 12:04:39 +0800
Subject: [PATCH 6/8] [doc] update gradient clipping document
---
.../gradient_clipping_with_booster.md | 98 +++++++++----------
.../gradient_clipping_with_booster.md | 98 +++++++++----------
2 files changed, 98 insertions(+), 98 deletions(-)
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
index fa88f0e7481e..b9c7bb20631c 100644
--- a/docs/source/en/features/gradient_clipping_with_booster.md
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -62,8 +62,8 @@ We then need to initialize distributed environment. For demo purpose, we uses `l
for other initialization methods.
```python
- colossalai.launch_from_torch(config=dict())
- logger = get_dist_logger()
+colossalai.launch_from_torch(config=dict())
+logger = get_dist_logger()
```
@@ -71,65 +71,65 @@ for other initialization methods.
Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])` to a path on your machine. Data will be automatically downloaded to the root path.
```python
- # define training hyperparameters
- NUM_EPOCHS = 200
- BATCH_SIZE = 128
- GRADIENT_CLIPPING = 0.1
- # build resnet
- model = resnet34(num_classes=10)
- # build dataloaders
- train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
- download=True,
- transform=transforms.Compose([
- transforms.RandomCrop(size=32, padding=4),
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
- ]))
- # build criterion
- criterion = torch.nn.CrossEntropyLoss()
-
- # optimizer
- optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
-
- # lr_scheduler
- lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+# define training hyperparameters
+NUM_EPOCHS = 200
+BATCH_SIZE = 128
+GRADIENT_CLIPPING = 0.1
+# build resnetå
+model = resnet34(num_classes=10)
+# build dataloaders
+train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+# lr_scheduler
+lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
```
### Step 4. Inject Gradient Clipping Feature
Create a `TorchDDPPlugin` object and `Booster` object, get a data loader from plugin, then boost all training components.
```python
- plugin = TorchDDPPlugin()
- booster = Booster(mixed_precision='fp16', plugin=plugin)
- train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
- model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+plugin = TorchDDPPlugin()
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
```
### Step 5. Train with Booster
Use booster in a normal training loops.
```python
- # verify gradient clipping
- model.train()
- for idx, (img, label) in enumerate(train_dataloader):
- img = img.cuda()
- label = label.cuda()
-
- model.zero_grad()
- output = model(img)
- train_loss = criterion(output, label)
- booster.backward(train_loss, optimizer)
- optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
- optimizer.step()
- lr_scheduler.step()
-
- ele_1st = next(model.parameters()).flatten()[0]
- logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
-
- # only run for 4 iterations
- if idx == 3:
- break
+# verify gradient clipping
+model.train()
+for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
```
### Step 6. Invoke Training Scripts
diff --git a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
index 11296ac1b4d8..2f023cefe35e 100644
--- a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
+++ b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
@@ -62,73 +62,73 @@ from colossalai.nn.lr_scheduler import CosineAnnealingLR
我们需要初始化分布式环境. 为了快速演示,我们使用`launch_from_torch`. 您可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)
```python
- colossalai.launch_from_torch(config=dict())
- logger = get_dist_logger()
+colossalai.launch_from_torch(config=dict())
+logger = get_dist_logger()
```
### 步骤 3. 创建训练组件
构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`在你的机器上设置路径。数据将会被自动下载到该路径。
```python
- # define training hyperparameters
- NUM_EPOCHS = 200
- BATCH_SIZE = 128
- GRADIENT_CLIPPING = 0.1
- # build resnet
- model = resnet34(num_classes=10)
- # build dataloaders
- train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
- download=True,
- transform=transforms.Compose([
- transforms.RandomCrop(size=32, padding=4),
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
- ]))
- # build criterion
- criterion = torch.nn.CrossEntropyLoss()
-
- # optimizer
- optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
-
- # lr_scheduler
- lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+# define training hyperparameters
+NUM_EPOCHS = 200
+BATCH_SIZE = 128
+GRADIENT_CLIPPING = 0.1
+# build resnet
+model = resnet34(num_classes=10)
+# build dataloaders
+train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+# lr_scheduler
+lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
```
### 步骤 4. 注入梯度裁剪特性
创建`TorchDDPPlugin`对象并初始化`Booster`, 使用booster注入相关特性。
```python
- plugin = TorchDDPPlugin()
- booster = Booster(plugin=plugin)
- train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
- model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+plugin = TorchDDPPlugin()
+booster = Booster(plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
```
### 步骤 5. 使用booster训练
使用booster进行训练。
```python
- # verify gradient clipping
- model.train()
- for idx, (img, label) in enumerate(train_dataloader):
- img = img.cuda()
- label = label.cuda()
-
- model.zero_grad()
- output = model(img)
- train_loss = criterion(output, label)
- booster.backward(train_loss, optimizer)
- optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
- optimizer.step()
- lr_scheduler.step()
-
- ele_1st = next(model.parameters()).flatten()[0]
- logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
-
- # only run for 4 iterations
- if idx == 3:
- break
+# verify gradient clipping
+model.train()
+for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
```
### 步骤 6. 启动训练脚本
From c8573a40ac575195877824ad55533aa5348d02c0 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Mon, 22 May 2023 12:11:15 +0800
Subject: [PATCH 7/8] [doc] update gradient clipping doc, fix sidebars.json
---
docs/sidebars.json | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/sidebars.json b/docs/sidebars.json
index a9d3a7d384e8..d67a6dc46f91 100644
--- a/docs/sidebars.json
+++ b/docs/sidebars.json
@@ -42,10 +42,10 @@
"items": [
"features/mixed_precision_training",
"features/gradient_accumulation",
+ "features/gradient_clipping_with_booster",
"features/gradient_clipping",
"features/gradient_handler",
"features/zero_with_chunk",
- "features/gradient_clipping_with_booster",
{
"type": "category",
"label": "Tensor Parallel",
From c34fe4b7094842b552f1a0334d45f1823caf0c5d Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Mon, 22 May 2023 12:20:03 +0800
Subject: [PATCH 8/8] [doc] update gradient clipping doc, fix doc test
---
docs/source/en/features/gradient_clipping.md | 2 ++
docs/source/zh-Hans/features/gradient_clipping.md | 2 ++
2 files changed, 4 insertions(+)
diff --git a/docs/source/en/features/gradient_clipping.md b/docs/source/en/features/gradient_clipping.md
index c23e589f5c7a..5a23c68e3e27 100644
--- a/docs/source/en/features/gradient_clipping.md
+++ b/docs/source/en/features/gradient_clipping.md
@@ -60,3 +60,5 @@ to demonstrate gradient clipping. In this example, we set the gradient clipping
```shell
python -m torch.distributed.launch --nproc_per_node 1 --master_addr localhost --master_port 29500 train_with_engine.py
```
+
+
diff --git a/docs/source/zh-Hans/features/gradient_clipping.md b/docs/source/zh-Hans/features/gradient_clipping.md
index caef2b526a24..2f62c31766a6 100644
--- a/docs/source/zh-Hans/features/gradient_clipping.md
+++ b/docs/source/zh-Hans/features/gradient_clipping.md
@@ -49,3 +49,5 @@ clip_grad_norm = 1.0
```shell
python -m torch.distributed.launch --nproc_per_node 1 --master_addr localhost --master_port 29500 train_with_engine.py
```
+
+
+Layout of parameters
+
+
+Do not worry about it, since Colossal-AI have handled it for you.
+
+## Usage
+To use gradient clipping, you can just add the following code to your configuration file, and call `clip_grad_by_norm` or `clip_grad_by_value` method of optimizer which after boost if it support clip gradients.
+
+## Hands-On Practice
+
+We now demonstrate gradient clipping. In this example, we set the gradient clipping vector norm to be 1.0.
+
+### step 1. Import libraries in train.py
+Create a `train_with_engine.py` and import the necessary dependencies.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet34
+from tqdm import tqdm
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import CosineAnnealingLR
+```
+
+### Step 2. Initialize Distributed Environment
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md)
+for other initialization methods.
+
+```python
+ colossalai.launch_from_torch(config=dict())
+ logger = get_dist_logger()
+```
+
+
+### Step 3. Create training components
+
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is
+obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])`
+to a path on your machine. Data will be automatically downloaded to the root path.
+```python
+ # define training hyperparameters
+ NUM_EPOCHS = 200
+ BATCH_SIZE = 128
+ GRADIENT_CLIPPING = 0.1
+ # build resnet
+ model = resnet34(num_classes=10)
+ # build dataloaders
+ train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+ # build criterion
+ criterion = torch.nn.CrossEntropyLoss()
+
+ # optimizer
+ optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+ # lr_scheduler
+ lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+
+```
+### Step 4. Inject Gradient Clipping Feature
+
+create a `TorchDDPPlugin` object and instantiate `Booster` with it, then boost all training components.
+```python
+ plugin = TorchDDPPlugin()
+ booster = Booster(mixed_precision='fp16', plugin=plugin)
+ train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+ model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+
+```
+
+### Step 5. Train with Booster
+Use booster in a normal training loops.
+```python
+ # verify gradient clipping
+ model.train()
+ for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
+```
+
+### Step 6. Invoke Training Scripts
+You can run the script using this command:
+
+```shell
+colossalai run --nproc_per_node 1 train.py --config config/config.py
+```
+
+
diff --git a/docs/source/zh-Hans/features/gradient_clipping.md b/docs/source/zh-Hans/features/gradient_clipping.md
index 203f66a3fea2..e186dff858f2 100644
--- a/docs/source/zh-Hans/features/gradient_clipping.md
+++ b/docs/source/zh-Hans/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# 梯度裁剪
+# 梯度裁剪 (旧版本)
作者: Boxiang Wang, Haichen Huang, Yongbin Li
diff --git a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
new file mode 100644
index 000000000000..ee1fe7738bb0
--- /dev/null
+++ b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
@@ -0,0 +1,144 @@
+# 梯度裁剪 (新版本)
+
+作者: Boxiang Wang, Haichen Huang, Yongbin Li
+
+**前置教程**
+- [定义配置文件](../basics/define_your_config.md)
+- [booster使用](../basics/booster_api.md)
+
+**相关论文**
+- [On the difficulty of training Recurrent Neural Networks](https://arxiv.org/abs/1211.5063)
+
+## 引言
+
+为了加快训练过程和寻求全局最优以获得更好的性能,越来越多的学习率调度器被提出。人们通过控制学习率来调整训练中的下降速度。这使得梯度向量在每一步都能更好地统一。在这种情况下,下降速度可以按预期被控制。
+因此,梯度裁剪,一种可以将梯度向量归一化,以将其限制在统一长度的技术,对于那些希望模型性能更好的人来说是不可或缺的。
+
+在使用 Colossal-AI 时,你不必担心实现梯度剪裁,我们以一种有效而方便的方式支持梯度剪裁。你所需要的只是在你的配置文件中增加一个命令。
+
+## 为什么应该使用 Colossal-AI 中的梯度裁剪
+
+我们不建议用户自己编写梯度剪裁,因为朴素的梯度剪裁在应用张量并行、流水线并行、MoE 等功能时可能会失败。
+
+根据下图,每个 GPU 只拥有线性层中权重的一部分参数。为了得到线性层权重的梯度向量的正确范数,每个 GPU 中的每个梯度向量的范数应该相加。更复杂的是,偏置的分布不同于权重的分布。通信组在求和运算中有所不同。
+
+(注: 这种情况是旧版本的 2D 并行,在代码中的实现是不一样的。但这是一个很好的例子,能够说明在梯度剪裁中统一所有通信的困难。)
+
+
+
+参数分布
+
+
+不用担心它,因为 Colossal-AI 已经为你处理好。
+
+### 使用
+要使用梯度裁剪,只需booster之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。config.py中可配置max_norm。
+
+
+
+
+### 实例
+
+下面我们将介绍如何使用梯度裁剪,在本例中,我们将梯度裁剪范数设置为1.0。
+
+### 步骤 1. 在训练中导入相关库
+创建`train.py`并导入相关库。
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet34
+from tqdm import tqdm
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import CosineAnnealingLR
+```
+
+### 步骤 2. 初始化分布式环境
+我们需要初始化分布式环境. 为了快速演示,我们使用`launch_from_torch`. 您可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)
+
+```python
+ colossalai.launch_from_torch(config=dict())
+ logger = get_dist_logger()
+```
+
+
+### 步骤 3. 创建训练组件
+
+构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`在你的机器上设置路径。数据将会被自动下载到该路径。
+```python
+ # define training hyperparameters
+ NUM_EPOCHS = 200
+ BATCH_SIZE = 128
+ GRADIENT_CLIPPING = 0.1
+ # build resnet
+ model = resnet34(num_classes=10)
+ # build dataloaders
+ train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+ # build criterion
+ criterion = torch.nn.CrossEntropyLoss()
+
+ # optimizer
+ optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+ # lr_scheduler
+ lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+
+```
+### 步骤 4. 注入梯度裁剪特性
+
+创建`TorchDDPPlugin`对象并初始化`Booster`, 使用booster注入相关特性。
+```python
+ plugin = TorchDDPPlugin()
+ booster = Booster(plugin=plugin)
+ train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+ model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+
+```
+
+### 步骤 5. 使用booster训练
+使用booster进行训练。
+```python
+ # verify gradient clipping
+ model.train()
+ for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
+```
+
+### 步骤 6. 启动训练脚本
+你可以使用以下命令运行脚本:
+
+```shell
+colossalai run --nproc_per_node 1 train.py --config config/config.py
+```
+
From e2e4ee6974ad7b676b9a645327ccfee92498c390 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Fri, 19 May 2023 11:48:15 +0800
Subject: [PATCH 2/8] [doc] update gradient clipping document
---
docs/source/en/features/gradient_clipping.md | 2 +-
.../en/features/gradient_clipping_with_booster.md | 14 ++++++--------
.../features/gradient_clipping_with_booster.md | 7 ++-----
3 files changed, 9 insertions(+), 14 deletions(-)
diff --git a/docs/source/en/features/gradient_clipping.md b/docs/source/en/features/gradient_clipping.md
index a6dde70a2228..52ea04a8b16c 100644
--- a/docs/source/en/features/gradient_clipping.md
+++ b/docs/source/en/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# Gradient Clipping (outdated)
+# Gradient Clipping (outdated)
Author: Boxiang Wang, Haichen Huang, Yongbin Li
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
index 14fe612e954d..c88e1b9e5726 100644
--- a/docs/source/en/features/gradient_clipping_with_booster.md
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -1,6 +1,6 @@
# Gradient Clipping (latest)
-Author: Boxiang Wang, Haichen Huang, Yongbin Li
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
**Prerequisite**
- [Define Your Configuration](../basics/define_your_config.md)
@@ -31,14 +31,14 @@ According to the illustration below, each GPU only owns a portion of parameters
Do not worry about it, since Colossal-AI have handled it for you.
## Usage
-To use gradient clipping, you can just add the following code to your configuration file, and call `clip_grad_by_norm` or `clip_grad_by_value` method of optimizer which after boost if it support clip gradients.
+To use gradient clipping, you can just add the following code to your configuration file, and after boosted, you can call `clip_grad_by_norm` or `clip_grad_by_value` method of optimizer, if it support clip gradients.
## Hands-On Practice
-We now demonstrate gradient clipping. In this example, we set the gradient clipping vector norm to be 1.0.
+We now demonstrate how to use gradient clipping. In this example, we set the gradient clipping vector norm to be 1.0.
### step 1. Import libraries in train.py
-Create a `train_with_engine.py` and import the necessary dependencies.
+Create a `train.py` and import the necessary dependencies.
```python
import os
@@ -69,9 +69,7 @@ for other initialization methods.
### Step 3. Create training components
-Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is
-obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])`
-to a path on your machine. Data will be automatically downloaded to the root path.
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])` to a path on your machine. Data will be automatically downloaded to the root path.
```python
# define training hyperparameters
NUM_EPOCHS = 200
@@ -100,7 +98,7 @@ to a path on your machine. Data will be automatically downloaded to the root pat
```
### Step 4. Inject Gradient Clipping Feature
-create a `TorchDDPPlugin` object and instantiate `Booster` with it, then boost all training components.
+Create a `TorchDDPPlugin` object and instantiate `Booster` with it, and get a data loader from plugin, then boost all training components.
```python
plugin = TorchDDPPlugin()
booster = Booster(mixed_precision='fp16', plugin=plugin)
diff --git a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
index ee1fe7738bb0..778d74c3913c 100644
--- a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
+++ b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
@@ -1,6 +1,6 @@
# 梯度裁剪 (新版本)
-作者: Boxiang Wang, Haichen Huang, Yongbin Li
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
**前置教程**
- [定义配置文件](../basics/define_your_config.md)
@@ -32,10 +32,7 @@
不用担心它,因为 Colossal-AI 已经为你处理好。
### 使用
-要使用梯度裁剪,只需booster之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。config.py中可配置max_norm。
-
-
-
+要使用梯度裁剪,只需booster之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。
### 实例
From 0dbe98726cafbf486df193a6bb6a54542ab42de9 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Fri, 19 May 2023 11:49:56 +0800
Subject: [PATCH 3/8] [doc] update gradient clipping document
---
docs/source/zh-Hans/features/gradient_clipping_with_booster.md | 3 +--
1 file changed, 1 insertion(+), 2 deletions(-)
diff --git a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
index 778d74c3913c..11296ac1b4d8 100644
--- a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
+++ b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
@@ -32,7 +32,7 @@
不用担心它,因为 Colossal-AI 已经为你处理好。
### 使用
-要使用梯度裁剪,只需booster之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。
+要使用梯度裁剪,只需在使用booster注入特性之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。
### 实例
@@ -66,7 +66,6 @@ from colossalai.nn.lr_scheduler import CosineAnnealingLR
logger = get_dist_logger()
```
-
### 步骤 3. 创建训练组件
构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`在你的机器上设置路径。数据将会被自动下载到该路径。
From e09767dd0f153451c4dcc73b4097984c29366c52 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Fri, 19 May 2023 11:59:03 +0800
Subject: [PATCH 4/8] [doc] update gradient clipping document
---
docs/source/en/features/gradient_clipping_with_booster.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
index c88e1b9e5726..f28a4c10eee0 100644
--- a/docs/source/en/features/gradient_clipping_with_booster.md
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -98,7 +98,7 @@ Build your model, optimizer, loss function, lr scheduler and dataloaders. Note t
```
### Step 4. Inject Gradient Clipping Feature
-Create a `TorchDDPPlugin` object and instantiate `Booster` with it, and get a data loader from plugin, then boost all training components.
+Create a `TorchDDPPlugin` object and `Booster` object, get a data loader from plugin, then boost all training components.
```python
plugin = TorchDDPPlugin()
booster = Booster(mixed_precision='fp16', plugin=plugin)
From e126faf2cd2c63c9e2466be8f7a30c976dada591 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Fri, 19 May 2023 13:03:40 +0800
Subject: [PATCH 5/8] [doc] update gradient clipping document
---
docs/source/en/features/gradient_clipping.md | 2 +-
docs/source/en/features/gradient_clipping_with_booster.md | 2 +-
docs/source/zh-Hans/features/gradient_clipping.md | 2 +-
3 files changed, 3 insertions(+), 3 deletions(-)
diff --git a/docs/source/en/features/gradient_clipping.md b/docs/source/en/features/gradient_clipping.md
index 52ea04a8b16c..c23e589f5c7a 100644
--- a/docs/source/en/features/gradient_clipping.md
+++ b/docs/source/en/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# Gradient Clipping (outdated)
+# Gradient Clipping (Outdated)
Author: Boxiang Wang, Haichen Huang, Yongbin Li
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
index f28a4c10eee0..fa88f0e7481e 100644
--- a/docs/source/en/features/gradient_clipping_with_booster.md
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -1,4 +1,4 @@
-# Gradient Clipping (latest)
+# Gradient Clipping (Latest)
Author: [Mingyan Jiang](https://github.com/jiangmingyan)
diff --git a/docs/source/zh-Hans/features/gradient_clipping.md b/docs/source/zh-Hans/features/gradient_clipping.md
index e186dff858f2..caef2b526a24 100644
--- a/docs/source/zh-Hans/features/gradient_clipping.md
+++ b/docs/source/zh-Hans/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# 梯度裁剪 (旧版本)
+# 梯度裁剪(旧版本)
作者: Boxiang Wang, Haichen Huang, Yongbin Li
From 6b083efc83c87f52acb20b967336e6ec73d69f1f Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Mon, 22 May 2023 12:04:39 +0800
Subject: [PATCH 6/8] [doc] update gradient clipping document
---
.../gradient_clipping_with_booster.md | 98 +++++++++----------
.../gradient_clipping_with_booster.md | 98 +++++++++----------
2 files changed, 98 insertions(+), 98 deletions(-)
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
index fa88f0e7481e..b9c7bb20631c 100644
--- a/docs/source/en/features/gradient_clipping_with_booster.md
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -62,8 +62,8 @@ We then need to initialize distributed environment. For demo purpose, we uses `l
for other initialization methods.
```python
- colossalai.launch_from_torch(config=dict())
- logger = get_dist_logger()
+colossalai.launch_from_torch(config=dict())
+logger = get_dist_logger()
```
@@ -71,65 +71,65 @@ for other initialization methods.
Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])` to a path on your machine. Data will be automatically downloaded to the root path.
```python
- # define training hyperparameters
- NUM_EPOCHS = 200
- BATCH_SIZE = 128
- GRADIENT_CLIPPING = 0.1
- # build resnet
- model = resnet34(num_classes=10)
- # build dataloaders
- train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
- download=True,
- transform=transforms.Compose([
- transforms.RandomCrop(size=32, padding=4),
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
- ]))
- # build criterion
- criterion = torch.nn.CrossEntropyLoss()
-
- # optimizer
- optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
-
- # lr_scheduler
- lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+# define training hyperparameters
+NUM_EPOCHS = 200
+BATCH_SIZE = 128
+GRADIENT_CLIPPING = 0.1
+# build resnetå
+model = resnet34(num_classes=10)
+# build dataloaders
+train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+# lr_scheduler
+lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
```
### Step 4. Inject Gradient Clipping Feature
Create a `TorchDDPPlugin` object and `Booster` object, get a data loader from plugin, then boost all training components.
```python
- plugin = TorchDDPPlugin()
- booster = Booster(mixed_precision='fp16', plugin=plugin)
- train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
- model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+plugin = TorchDDPPlugin()
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
```
### Step 5. Train with Booster
Use booster in a normal training loops.
```python
- # verify gradient clipping
- model.train()
- for idx, (img, label) in enumerate(train_dataloader):
- img = img.cuda()
- label = label.cuda()
-
- model.zero_grad()
- output = model(img)
- train_loss = criterion(output, label)
- booster.backward(train_loss, optimizer)
- optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
- optimizer.step()
- lr_scheduler.step()
-
- ele_1st = next(model.parameters()).flatten()[0]
- logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
-
- # only run for 4 iterations
- if idx == 3:
- break
+# verify gradient clipping
+model.train()
+for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
```
### Step 6. Invoke Training Scripts
diff --git a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
index 11296ac1b4d8..2f023cefe35e 100644
--- a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
+++ b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
@@ -62,73 +62,73 @@ from colossalai.nn.lr_scheduler import CosineAnnealingLR
我们需要初始化分布式环境. 为了快速演示,我们使用`launch_from_torch`. 您可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)
```python
- colossalai.launch_from_torch(config=dict())
- logger = get_dist_logger()
+colossalai.launch_from_torch(config=dict())
+logger = get_dist_logger()
```
### 步骤 3. 创建训练组件
构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`在你的机器上设置路径。数据将会被自动下载到该路径。
```python
- # define training hyperparameters
- NUM_EPOCHS = 200
- BATCH_SIZE = 128
- GRADIENT_CLIPPING = 0.1
- # build resnet
- model = resnet34(num_classes=10)
- # build dataloaders
- train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
- download=True,
- transform=transforms.Compose([
- transforms.RandomCrop(size=32, padding=4),
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
- ]))
- # build criterion
- criterion = torch.nn.CrossEntropyLoss()
-
- # optimizer
- optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
-
- # lr_scheduler
- lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+# define training hyperparameters
+NUM_EPOCHS = 200
+BATCH_SIZE = 128
+GRADIENT_CLIPPING = 0.1
+# build resnet
+model = resnet34(num_classes=10)
+# build dataloaders
+train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+# lr_scheduler
+lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
```
### 步骤 4. 注入梯度裁剪特性
创建`TorchDDPPlugin`对象并初始化`Booster`, 使用booster注入相关特性。
```python
- plugin = TorchDDPPlugin()
- booster = Booster(plugin=plugin)
- train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
- model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+plugin = TorchDDPPlugin()
+booster = Booster(plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
```
### 步骤 5. 使用booster训练
使用booster进行训练。
```python
- # verify gradient clipping
- model.train()
- for idx, (img, label) in enumerate(train_dataloader):
- img = img.cuda()
- label = label.cuda()
-
- model.zero_grad()
- output = model(img)
- train_loss = criterion(output, label)
- booster.backward(train_loss, optimizer)
- optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
- optimizer.step()
- lr_scheduler.step()
-
- ele_1st = next(model.parameters()).flatten()[0]
- logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
-
- # only run for 4 iterations
- if idx == 3:
- break
+# verify gradient clipping
+model.train()
+for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
```
### 步骤 6. 启动训练脚本
From c8573a40ac575195877824ad55533aa5348d02c0 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Mon, 22 May 2023 12:11:15 +0800
Subject: [PATCH 7/8] [doc] update gradient clipping doc, fix sidebars.json
---
docs/sidebars.json | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/sidebars.json b/docs/sidebars.json
index a9d3a7d384e8..d67a6dc46f91 100644
--- a/docs/sidebars.json
+++ b/docs/sidebars.json
@@ -42,10 +42,10 @@
"items": [
"features/mixed_precision_training",
"features/gradient_accumulation",
+ "features/gradient_clipping_with_booster",
"features/gradient_clipping",
"features/gradient_handler",
"features/zero_with_chunk",
- "features/gradient_clipping_with_booster",
{
"type": "category",
"label": "Tensor Parallel",
From c34fe4b7094842b552f1a0334d45f1823caf0c5d Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Mon, 22 May 2023 12:20:03 +0800
Subject: [PATCH 8/8] [doc] update gradient clipping doc, fix doc test
---
docs/source/en/features/gradient_clipping.md | 2 ++
docs/source/zh-Hans/features/gradient_clipping.md | 2 ++
2 files changed, 4 insertions(+)
diff --git a/docs/source/en/features/gradient_clipping.md b/docs/source/en/features/gradient_clipping.md
index c23e589f5c7a..5a23c68e3e27 100644
--- a/docs/source/en/features/gradient_clipping.md
+++ b/docs/source/en/features/gradient_clipping.md
@@ -60,3 +60,5 @@ to demonstrate gradient clipping. In this example, we set the gradient clipping
```shell
python -m torch.distributed.launch --nproc_per_node 1 --master_addr localhost --master_port 29500 train_with_engine.py
```
+
+
diff --git a/docs/source/zh-Hans/features/gradient_clipping.md b/docs/source/zh-Hans/features/gradient_clipping.md
index caef2b526a24..2f62c31766a6 100644
--- a/docs/source/zh-Hans/features/gradient_clipping.md
+++ b/docs/source/zh-Hans/features/gradient_clipping.md
@@ -49,3 +49,5 @@ clip_grad_norm = 1.0
```shell
python -m torch.distributed.launch --nproc_per_node 1 --master_addr localhost --master_port 29500 train_with_engine.py
```
+
+