From ea34c3b2c85c903554b437950187b063f882db4a Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Wed, 5 Jul 2023 13:57:40 +0800
Subject: [PATCH 1/5] [shardformer] opt support flash attention
---
colossalai/shardformer/README.md | 43 +++++++++-
..._benchmark.py => convergence_benchmark.py} | 0
..._benchmark.sh => convergence_benchmark.sh} | 2 +-
.../examples/performance_benchmark.py | 86 +++++++++++++++++++
4 files changed, 129 insertions(+), 2 deletions(-)
rename colossalai/shardformer/examples/{shardformer_benchmark.py => convergence_benchmark.py} (100%)
rename colossalai/shardformer/examples/{shardformer_benchmark.sh => convergence_benchmark.sh} (76%)
create mode 100644 colossalai/shardformer/examples/performance_benchmark.py
diff --git a/colossalai/shardformer/README.md b/colossalai/shardformer/README.md
index fca401562be6..f2ae806258f2 100644
--- a/colossalai/shardformer/README.md
+++ b/colossalai/shardformer/README.md
@@ -381,7 +381,7 @@ To be added.
### Convergence
-To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/shardformer_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
+To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/convergence_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
| accuracy | f1 | loss | GPU number | model shard |
| :------: | :-----: | :-----: | :--------: | :---------: |
@@ -390,3 +390,44 @@ To validate that training the model using shardformers does not impact its conve
| 0.81855 | 0.87124 | 0.10357 | 1 | False |
Overall, the results demonstrate that using shardformers during model training does not affect the convergence.
+
+### performance
+
+We also conducted [benchmark tests](./examples/performance_benchmark.py) to evaluate the performance improvement of Shardformer. We compared the training time between the original model and the shard model.
+
+We set the batch size to 4, the number of attention heads to 8, and the head dimension to 64. 'N_CTX' refers to the sequence length.
+
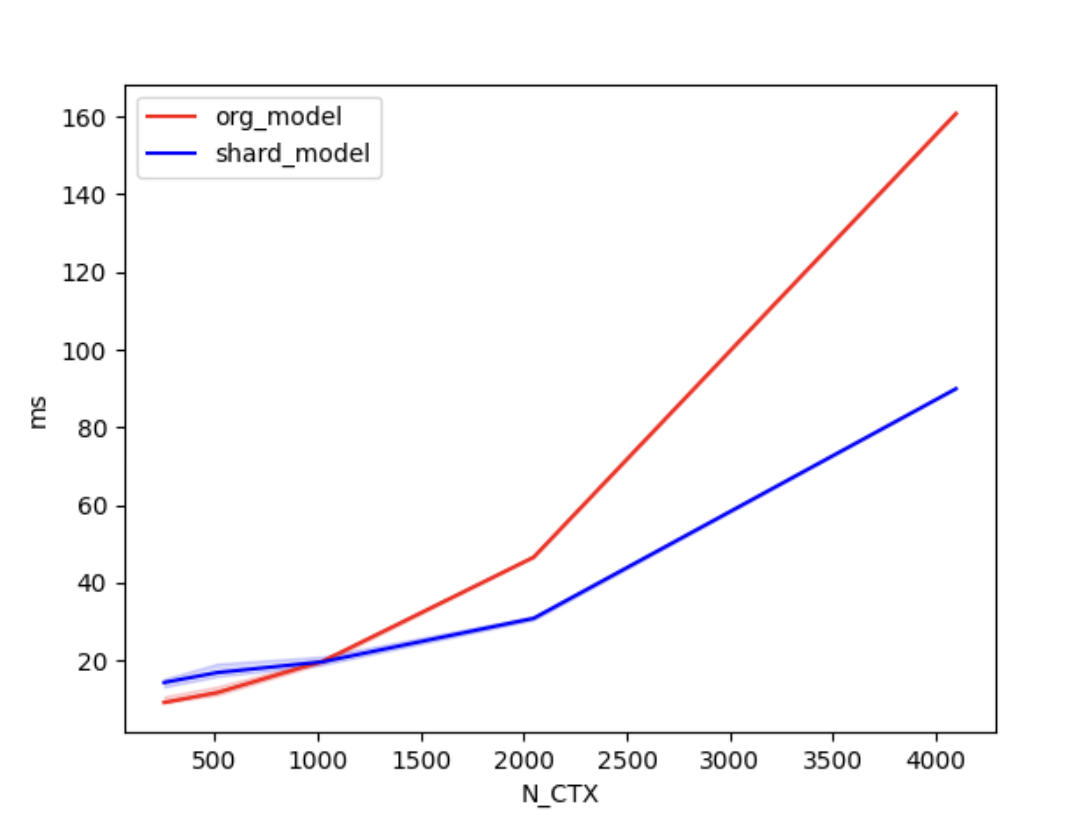
+In the case of using 2 GPUs, the training times are as follows.
+| N_CTX | org_model | shard_model |
+| :------: | :-----: | :-----: |
+| 256 | 11.2ms | 17.2ms |
+| 512 | 9.8ms | 19.5ms |
+| 1024 | 19.6ms | 18.9ms |
+| 2048 | 46.6ms | 30.8ms |
+| 4096 | 160.5ms | 90.4ms |
+
+
+
+  +
+
+
+
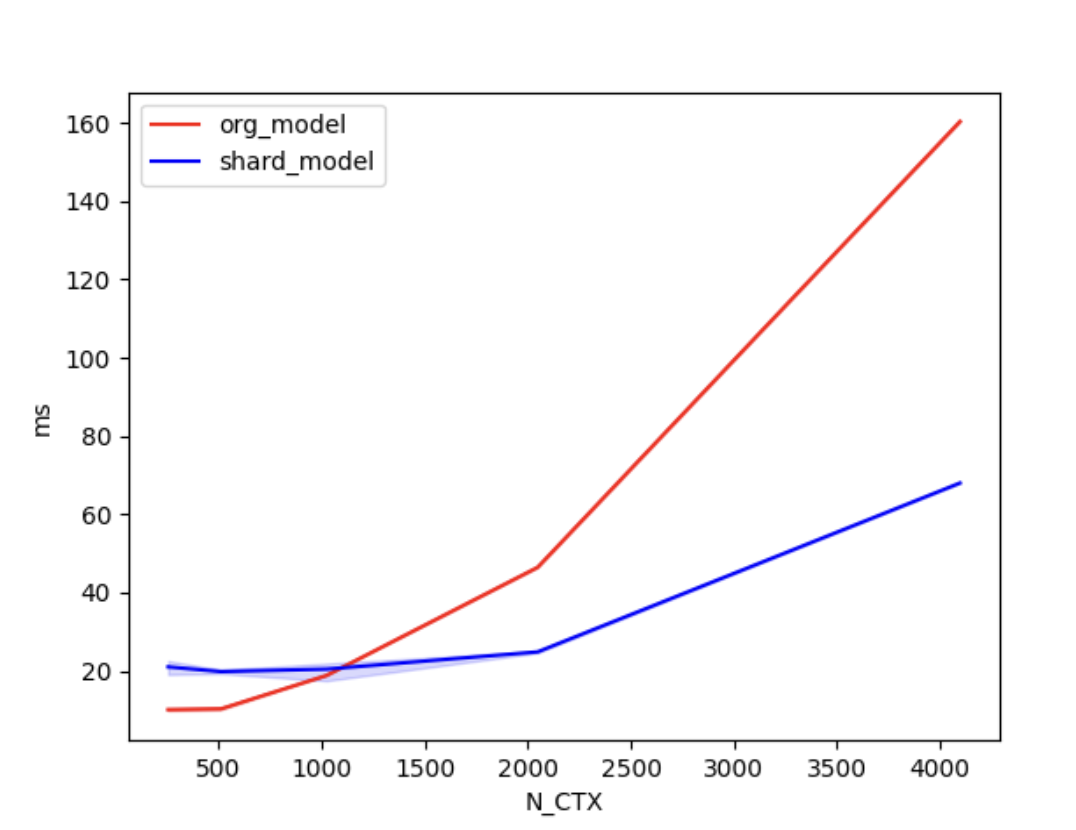
+In the case of using 4 GPUs, the training times are as follows.
+
+| N_CTX | org_model | shard_model |
+| :------: | :-----: | :-----: |
+| 256 | 10.0ms | 21.1ms |
+| 512 | 11.5ms | 20.2ms |
+| 1024 | 22.1ms | 20.6ms |
+| 2048 | 46.9ms | 24.8ms |
+| 4096 | 160.4ms | 68.0ms |
+
+
+
+
+  +
+
+
+
+
+As shown in the figures above, when the sequence length is around 1000 or greater, the parallel optimization of Shardformer for long sequences starts to become evident.
diff --git a/colossalai/shardformer/examples/shardformer_benchmark.py b/colossalai/shardformer/examples/convergence_benchmark.py
similarity index 100%
rename from colossalai/shardformer/examples/shardformer_benchmark.py
rename to colossalai/shardformer/examples/convergence_benchmark.py
diff --git a/colossalai/shardformer/examples/shardformer_benchmark.sh b/colossalai/shardformer/examples/convergence_benchmark.sh
similarity index 76%
rename from colossalai/shardformer/examples/shardformer_benchmark.sh
rename to colossalai/shardformer/examples/convergence_benchmark.sh
index f42b19a32d35..1c281abcda6d 100644
--- a/colossalai/shardformer/examples/shardformer_benchmark.sh
+++ b/colossalai/shardformer/examples/convergence_benchmark.sh
@@ -1,4 +1,4 @@
-torchrun --standalone --nproc_per_node=4 shardformer_benchmark.py \
+torchrun --standalone --nproc_per_node=4 convergence_benchmark.py \
--model "bert" \
--pretrain "bert-base-uncased" \
--max_epochs 1 \
diff --git a/colossalai/shardformer/examples/performance_benchmark.py b/colossalai/shardformer/examples/performance_benchmark.py
new file mode 100644
index 000000000000..9c7b76bcf0a6
--- /dev/null
+++ b/colossalai/shardformer/examples/performance_benchmark.py
@@ -0,0 +1,86 @@
+"""
+Shardformer Benchmark
+"""
+import torch
+import torch.distributed as dist
+import transformers
+import triton
+
+import colossalai
+from colossalai.shardformer import ShardConfig, ShardFormer
+
+
+def data_gen(batch_size, seq_length):
+ input_ids = torch.randint(0, seq_length, (batch_size, seq_length), dtype=torch.long)
+ attention_mask = torch.ones((batch_size, seq_length), dtype=torch.long)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def data_gen_for_sequence_classification(batch_size, seq_length):
+ # LM data gen
+ # the `labels` of LM is the token of the output, cause no padding, use `input_ids` as `labels`
+ data = data_gen(batch_size, seq_length)
+ data['labels'] = torch.ones((batch_size), dtype=torch.long)
+ return data
+
+
+MODEL_CONFIG = transformers.LlamaConfig(num_hidden_layers=4,
+ hidden_size=128,
+ intermediate_size=256,
+ num_attention_heads=4,
+ max_position_embeddings=128,
+ num_labels=16)
+BATCH, N_HEADS, N_CTX, D_HEAD = 4, 8, 4096, 64
+model_func = lambda: transformers.LlamaForSequenceClassification(MODEL_CONFIG)
+
+# vary seq length for fixed head and batch=4
+configs = [
+ triton.testing.Benchmark(x_names=['N_CTX'],
+ x_vals=[2**i for i in range(8, 13)],
+ line_arg='provider',
+ line_vals=['org_model', 'shard_model'],
+ line_names=['org_model', 'shard_model'],
+ styles=[('red', '-'), ('blue', '-')],
+ ylabel='ms',
+ plot_name=f'lama_for_sequence_classification-batch-{BATCH}',
+ args={
+ 'BATCH': BATCH,
+ 'dtype': torch.float16,
+ 'model_func': model_func
+ })
+]
+
+
+def train(model, data):
+ output = model(**data)
+ loss = output.logits.mean()
+ loss.backward()
+
+
+@triton.testing.perf_report(configs)
+def bench_shardformer(BATCH, N_CTX, provider, model_func, dtype=torch.float32, device="cuda"):
+ warmup = 10
+ rep = 100
+ # prepare data
+ data = data_gen_for_sequence_classification(BATCH, N_CTX)
+ data = {k: v.cuda() for k, v in data.items()}
+ model = model_func().to(device)
+ model.train()
+ if provider == "org_model":
+ fn = lambda: train(model, data)
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+ return ms
+ if provider == "shard_model":
+ shard_config = ShardConfig(enable_fused_normalization=True, enable_tensor_parallelism=True)
+ shard_former = ShardFormer(shard_config=shard_config)
+ sharded_model = shard_former.optimize(model).cuda()
+ fn = lambda: train(sharded_model, data)
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+ return ms
+
+
+# start benchmark, command:
+# torchrun --standalone --nproc_per_node=2 performance_benchmark.py
+if __name__ == "__main__":
+ colossalai.launch_from_torch({})
+ bench_shardformer.run(save_path='.', print_data=dist.get_rank() == 0)
From 55d7ad08c4b48a77bdf68c8322ba23c07f44a40d Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Wed, 5 Jul 2023 14:16:33 +0800
Subject: [PATCH 2/5] [shardformer] opt support flash attention
---
colossalai/shardformer/README.md | 1 +
1 file changed, 1 insertion(+)
diff --git a/colossalai/shardformer/README.md b/colossalai/shardformer/README.md
index f2ae806258f2..0d2bf36ce9fd 100644
--- a/colossalai/shardformer/README.md
+++ b/colossalai/shardformer/README.md
@@ -381,6 +381,7 @@ To be added.
### Convergence
+
To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/convergence_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
| accuracy | f1 | loss | GPU number | model shard |
From eb6f149717d7e703b4b8d9d522ed940701a78252 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Wed, 5 Jul 2023 14:20:00 +0800
Subject: [PATCH 3/5] [shardformer] opt support flash attention
---
colossalai/shardformer/README.md | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/colossalai/shardformer/README.md b/colossalai/shardformer/README.md
index 0d2bf36ce9fd..8e0e9c7e4168 100644
--- a/colossalai/shardformer/README.md
+++ b/colossalai/shardformer/README.md
@@ -392,7 +392,8 @@ To validate that training the model using shardformers does not impact its conve
Overall, the results demonstrate that using shardformers during model training does not affect the convergence.
-### performance
+### Performance
+
We also conducted [benchmark tests](./examples/performance_benchmark.py) to evaluate the performance improvement of Shardformer. We compared the training time between the original model and the shard model.
From d82a7b618932caadc019c9859e0373e7a0e243d9 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Wed, 5 Jul 2023 15:28:55 +0800
Subject: [PATCH 4/5] [shardformer] benchmark fix
---
colossalai/shardformer/README.md | 33 ++++++++++++++------------------
1 file changed, 14 insertions(+), 19 deletions(-)
diff --git a/colossalai/shardformer/README.md b/colossalai/shardformer/README.md
index 8e0e9c7e4168..6e9f05542899 100644
--- a/colossalai/shardformer/README.md
+++ b/colossalai/shardformer/README.md
@@ -377,25 +377,7 @@ pytest tests/test_shardformer
### System Performance
-To be added.
-
-### Convergence
-
-
-To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/convergence_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
-
-| accuracy | f1 | loss | GPU number | model shard |
-| :------: | :-----: | :-----: | :--------: | :---------: |
-| 0.82594 | 0.87441 | 0.09913 | 4 | True |
-| 0.81884 | 0.87299 | 0.10120 | 2 | True |
-| 0.81855 | 0.87124 | 0.10357 | 1 | False |
-
-Overall, the results demonstrate that using shardformers during model training does not affect the convergence.
-
-### Performance
-
-
-We also conducted [benchmark tests](./examples/performance_benchmark.py) to evaluate the performance improvement of Shardformer. We compared the training time between the original model and the shard model.
+We conducted [benchmark tests](./examples/performance_benchmark.py) to evaluate the performance improvement of Shardformer. We compared the training time between the original model and the shard model.
We set the batch size to 4, the number of attention heads to 8, and the head dimension to 64. 'N_CTX' refers to the sequence length.
@@ -433,3 +415,16 @@ In the case of using 4 GPUs, the training times are as follows.
As shown in the figures above, when the sequence length is around 1000 or greater, the parallel optimization of Shardformer for long sequences starts to become evident.
+
+### Convergence
+
+
+To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/convergence_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
+
+| accuracy | f1 | loss | GPU number | model shard |
+| :------: | :-----: | :-----: | :--------: | :---------: |
+| 0.82594 | 0.87441 | 0.09913 | 4 | True |
+| 0.81884 | 0.87299 | 0.10120 | 2 | True |
+| 0.81855 | 0.87124 | 0.10357 | 1 | False |
+
+Overall, the results demonstrate that using shardformers during model training does not affect the convergence.
From 6a7279429fc4eee936fee764f0b99ba6f8faccb1 Mon Sep 17 00:00:00 2001
From: Mingyan Jiang <1829166702@qq.com>
Date: Thu, 6 Jul 2023 12:03:20 +0800
Subject: [PATCH 5/5] [shardformer] benchmark fix
---
colossalai/shardformer/README.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/colossalai/shardformer/README.md b/colossalai/shardformer/README.md
index 6e9f05542899..c9650ce4f712 100644
--- a/colossalai/shardformer/README.md
+++ b/colossalai/shardformer/README.md
@@ -396,7 +396,7 @@ In the case of using 2 GPUs, the training times are as follows.
-In the case of using 4 GPUs, the training times are as follows.
+In the case of using 4 GPUs, the training times are as follows.
| N_CTX | org_model | shard_model |
| :------: | :-----: | :-----: |
@@ -419,7 +419,7 @@ As shown in the figures above, when the sequence length is around 1000 or greate
### Convergence
-To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/convergence_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
+To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/convergence_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
| accuracy | f1 | loss | GPU number | model shard |
| :------: | :-----: | :-----: | :--------: | :---------: |