-
+
- LLaMA
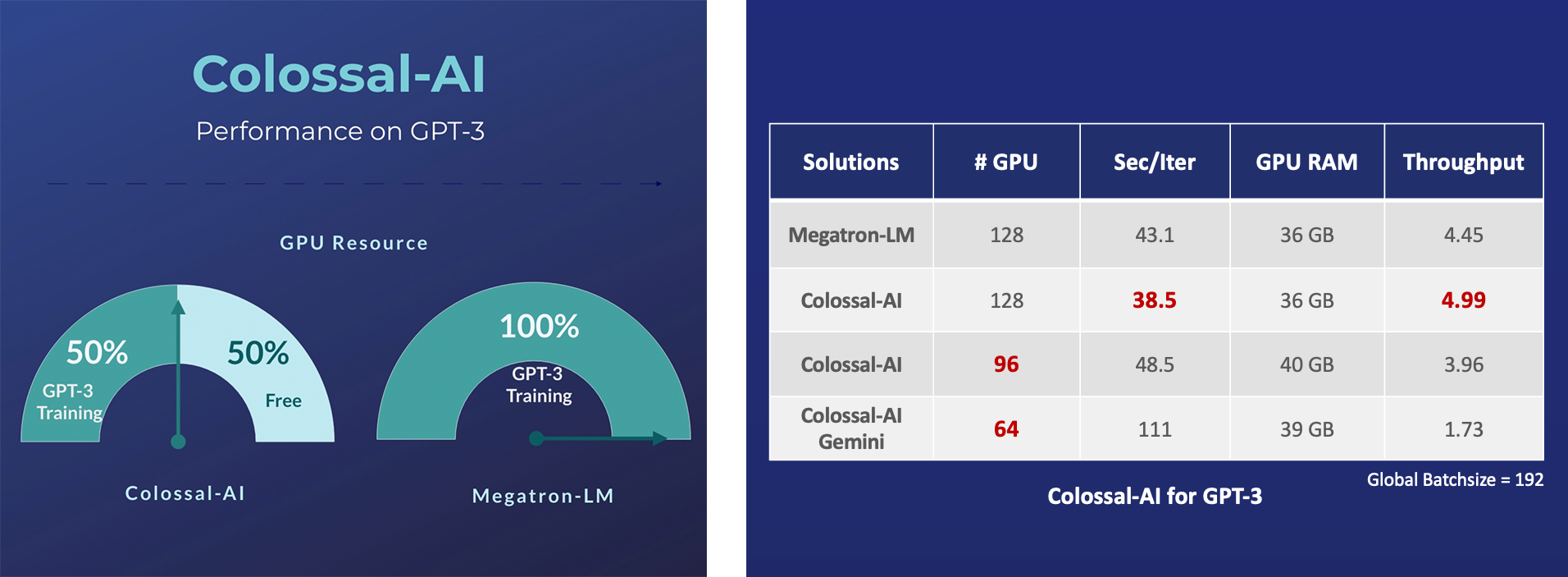
- GPT-3
- GPT-2
- BERT @@ -216,6 +218,15 @@ Acceleration of [AlphaFold Protein Structure](https://alphafold.ebi.ac.uk/) ## Parallel Training Demo +### LLaMA +
-
并行训练样例展示
-
+
- LLaMA
- GPT-3
- GPT-2
- BERT @@ -209,6 +211,14 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
(返回顶端)
## 并行训练样例展示 +### LLaMA ++
+ +- 650亿参数大模型预训练加速38% +[[代码]](https://github.com/hpcaitech/ColossalAI/tree/example/llama/examples/language/llama) +[[博客]](https://www.hpc-ai.tech/blog/large-model-pretraining) ### GPT-3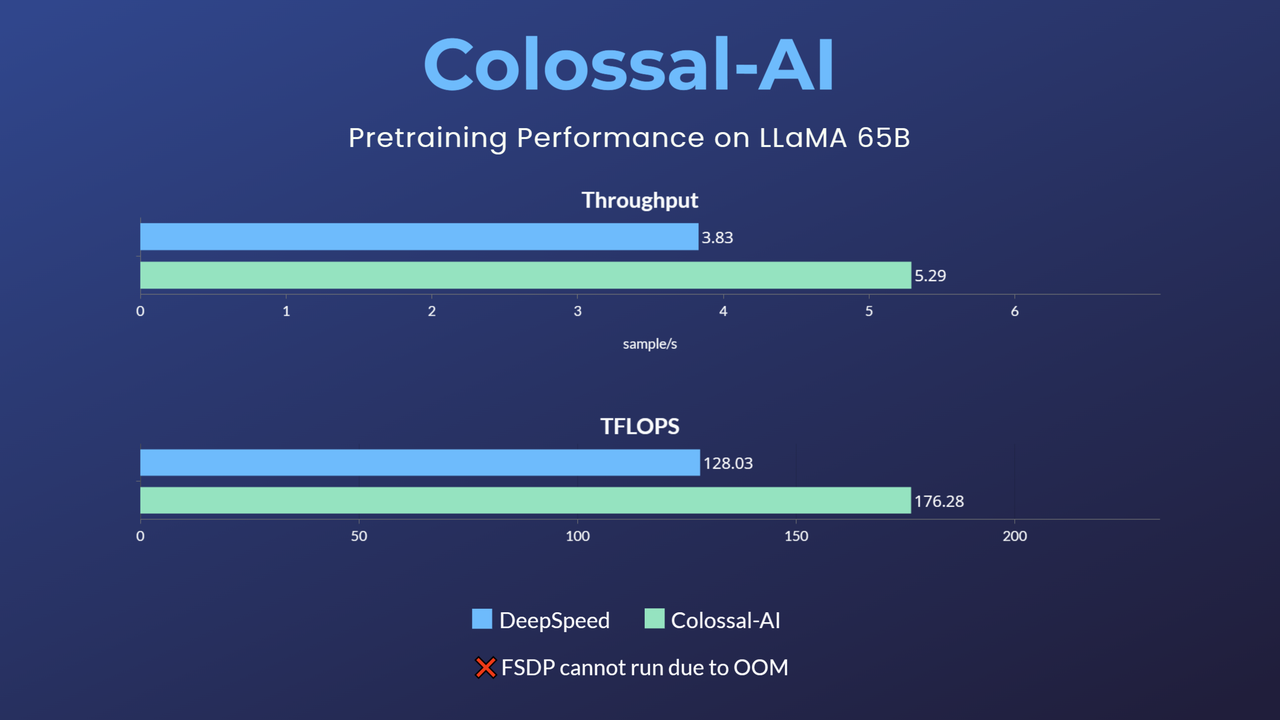 +
+diff --git a/examples/language/llama/README.md b/examples/language/llama/README.md new file mode 100644 index 000000000000..871804f2ca86 --- /dev/null +++ b/examples/language/llama/README.md @@ -0,0 +1,11 @@ +# Pretraining LLaMA: best practices for building LLaMA-like base models + +
+
+ +- 65-billion-parameter large model pretraining accelerated by 38% +[[code]](https://github.com/hpcaitech/ColossalAI/tree/example/llama/examples/language/llama) +[[blog]](https://www.hpc-ai.tech/blog/large-model-pretraining) + +> Since the main branch is being updated, in order to maintain the stability of the code, this example is temporarily kept as an [independent branch](https://github.com/hpcaitech/ColossalAI/tree/example/llama/examples/language/llama). From e3da89accf62e612d7855f470fc7fef0e3300be0 Mon Sep 17 00:00:00 2001 From: Qianran Ma
+
+
+
 diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md
index 1dde7a816676..e229c65d890c 100644
--- a/docs/README-zh-Hans.md
+++ b/docs/README-zh-Hans.md
@@ -24,6 +24,7 @@
## 新闻
+* [2023/07] [65B Model Pretraining Accelerated by 38%, Best Practices for Building LLaMA-Like Base Models Open-Source](https://www.hpc-ai.tech/blog/large-model-pretraining)
* [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
* [2023/03] [Intel and Colossal-AI Partner to Deliver Cost-Efficient Open-Source Solution for Protein Folding Structure Prediction](https://www.hpc-ai.tech/blog/intel-habana)
* [2023/03] [AWS and Google Fund Colossal-AI with Startup Cloud Programs](https://www.hpc-ai.tech/blog/aws-and-google-fund-colossal-ai-with-startup-cloud-programs)
@@ -49,6 +50,7 @@
diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md
index 1dde7a816676..e229c65d890c 100644
--- a/docs/README-zh-Hans.md
+++ b/docs/README-zh-Hans.md
@@ -24,6 +24,7 @@
## 新闻
+* [2023/07] [65B Model Pretraining Accelerated by 38%, Best Practices for Building LLaMA-Like Base Models Open-Source](https://www.hpc-ai.tech/blog/large-model-pretraining)
* [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
* [2023/03] [Intel and Colossal-AI Partner to Deliver Cost-Efficient Open-Source Solution for Protein Folding Structure Prediction](https://www.hpc-ai.tech/blog/intel-habana)
* [2023/03] [AWS and Google Fund Colossal-AI with Startup Cloud Programs](https://www.hpc-ai.tech/blog/aws-and-google-fund-colossal-ai-with-startup-cloud-programs)
@@ -49,6 +50,7 @@