diff --git a/colossalai/booster/plugin/hybrid_parallel_plugin.py b/colossalai/booster/plugin/hybrid_parallel_plugin.py
index 35a88d1e8980..42942aaeb89d 100644
--- a/colossalai/booster/plugin/hybrid_parallel_plugin.py
+++ b/colossalai/booster/plugin/hybrid_parallel_plugin.py
@@ -37,7 +37,8 @@ def __init__(self, module: Module, precision: str, shard_config: ShardConfig, dp
self.shared_param_process_groups = []
for shared_param in self.shared_params:
if len(shared_param) > 0:
- self.stage_manager.init_process_group_by_stages(list(shared_param.keys()))
+ self.shared_param_process_groups.append(
+ self.stage_manager.init_process_group_by_stages(list(shared_param.keys())))
if precision == 'fp16':
module = module.half().cuda()
elif precision == 'bf16':
@@ -49,8 +50,10 @@ def __init__(self, module: Module, precision: str, shard_config: ShardConfig, dp
def sync_shared_params(self):
for shared_param, group in zip(self.shared_params, self.shared_param_process_groups):
- param = shared_param[self.stage_manager.stage]
- dist.all_reduce(param.grad, group=group)
+ if self.stage_manager.stage in shared_param:
+ param = shared_param[self.stage_manager.stage]
+ dist.all_reduce(param.grad, group=group)
+ dist.barrier()
def no_sync(self) -> Iterator[None]:
# no sync grads across data parallel
diff --git a/colossalai/kernel/cuda_native/flash_attention.py b/colossalai/kernel/cuda_native/flash_attention.py
index 3db7374509a0..91bef0908dbb 100644
--- a/colossalai/kernel/cuda_native/flash_attention.py
+++ b/colossalai/kernel/cuda_native/flash_attention.py
@@ -6,6 +6,7 @@
import math
import os
import subprocess
+import warnings
import torch
@@ -14,7 +15,7 @@
HAS_MEM_EFF_ATTN = True
except ImportError:
HAS_MEM_EFF_ATTN = False
- print('please install xformers from https://github.com/facebookresearch/xformers')
+ warnings.warn(f'please install xformers from https://github.com/facebookresearch/xformers')
if HAS_MEM_EFF_ATTN:
@@ -22,7 +23,12 @@
from einops import rearrange
from xformers.ops.fmha import MemoryEfficientAttentionCutlassOp
- from xformers.ops.fmha.attn_bias import BlockDiagonalMask, LowerTriangularMask, LowerTriangularMaskWithTensorBias
+ from xformers.ops.fmha.attn_bias import (
+ BlockDiagonalCausalMask,
+ BlockDiagonalMask,
+ LowerTriangularMask,
+ LowerTriangularMaskWithTensorBias,
+ )
from .scaled_softmax import AttnMaskType
@@ -86,11 +92,14 @@ def backward(ctx, grad_output):
class ColoAttention(torch.nn.Module):
- def __init__(self, embed_dim: int, num_heads: int, dropout: float = 0.0):
+ def __init__(self, embed_dim: int, num_heads: int, dropout: float = 0.0, scale=None):
super().__init__()
assert embed_dim % num_heads == 0, \
f"the embed dim ({embed_dim}) is not divisible by the number of attention heads ({num_heads})."
- self.scale = 1 / math.sqrt(embed_dim // num_heads)
+ if scale is not None:
+ self.scale = scale
+ else:
+ self.scale = 1 / math.sqrt(embed_dim // num_heads)
self.dropout = dropout
@staticmethod
@@ -116,7 +125,7 @@ def forward(self,
bias: Optional[torch.Tensor] = None):
batch_size, tgt_len, src_len = query.shape[0], query.shape[1], key.shape[1]
attn_bias = None
- if attn_mask_type == AttnMaskType.padding: # bert style
+ if attn_mask_type and attn_mask_type.value % 2 == 1: # bert style
assert attn_mask is not None, \
f"attention mask {attn_mask} is not valid for attention mask type {attn_mask_type}."
assert attn_mask.dim() == 2, \
@@ -134,7 +143,10 @@ def forward(self,
if batch_size > 1:
query = rearrange(query, "b s ... -> c (b s) ...", c=1)
key, value = self.unpad(torch.stack([query, key, value], dim=2), kv_indices).unbind(dim=2)
- attn_bias = BlockDiagonalMask.from_seqlens(q_seqlen, kv_seqlen)
+ if attn_mask_type == AttnMaskType.padding:
+ attn_bias = BlockDiagonalMask.from_seqlens(q_seqlen, kv_seqlen)
+ elif attn_mask_type == AttnMaskType.paddedcausal:
+ attn_bias = BlockDiagonalCausalMask.from_seqlens(q_seqlen, kv_seqlen)
elif attn_mask_type == AttnMaskType.causal: # gpt style
attn_bias = LowerTriangularMask()
@@ -146,7 +158,7 @@ def forward(self,
out = memory_efficient_attention(query, key, value, attn_bias=attn_bias, p=self.dropout, scale=self.scale)
- if attn_mask_type == AttnMaskType.padding and batch_size > 1:
+ if attn_mask_type and attn_mask_type.value % 2 == 1 and batch_size > 1:
out = self.repad(out, q_indices, batch_size, tgt_len)
out = rearrange(out, 'b s h d -> b s (h d)')
diff --git a/colossalai/kernel/cuda_native/scaled_softmax.py b/colossalai/kernel/cuda_native/scaled_softmax.py
index 24e458bb3ea5..41cd4b20faa1 100644
--- a/colossalai/kernel/cuda_native/scaled_softmax.py
+++ b/colossalai/kernel/cuda_native/scaled_softmax.py
@@ -19,6 +19,7 @@
class AttnMaskType(enum.Enum):
padding = 1
causal = 2
+ paddedcausal = 3
class ScaledUpperTriangMaskedSoftmax(torch.autograd.Function):
@@ -139,7 +140,7 @@ def is_kernel_available(self, mask, b, np, sq, sk):
if 0 <= sk <= 2048:
batch_per_block = self.get_batch_per_block(sq, sk, b, np)
- if self.attn_mask_type == AttnMaskType.causal:
+ if self.attn_mask_type.value > 1:
if attn_batches % batch_per_block == 0:
return True
else:
@@ -151,7 +152,7 @@ def forward_fused_softmax(self, input, mask):
b, np, sq, sk = input.size()
scale = self.scale if self.scale is not None else 1.0
- if self.attn_mask_type == AttnMaskType.causal:
+ if self.attn_mask_type.value > 1:
assert sq == sk, "causal mask is only for self attention"
# input is 3D tensor (attn_batches, sq, sk)
diff --git a/colossalai/pipeline/p2p.py b/colossalai/pipeline/p2p.py
index f741b8363f13..af7a00b5c720 100644
--- a/colossalai/pipeline/p2p.py
+++ b/colossalai/pipeline/p2p.py
@@ -3,6 +3,7 @@
import io
import pickle
+import re
from typing import Any, List, Optional, Union
import torch
@@ -31,7 +32,10 @@ def _cuda_safe_tensor_to_object(tensor: torch.Tensor, tensor_size: torch.Size) -
if b'cuda' in buf:
buf_array = bytearray(buf)
device_index = torch.cuda.current_device()
- buf_array[buf_array.find(b'cuda') + 5] = 48 + device_index
+ # There might be more than one output tensors during forward
+ for cuda_str in re.finditer(b'cuda', buf_array):
+ pos = cuda_str.start()
+ buf_array[pos + 5] = 48 + device_index
buf = bytes(buf_array)
io_bytes = io.BytesIO(buf)
diff --git a/colossalai/pipeline/policy/__init__.py b/colossalai/pipeline/policy/__init__.py
new file mode 100644
index 000000000000..fd9e6e04588e
--- /dev/null
+++ b/colossalai/pipeline/policy/__init__.py
@@ -0,0 +1,22 @@
+from typing import Any, Dict, List, Optional, Tuple, Type
+
+from torch import Tensor
+from torch.nn import Module, Parameter
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+from .base import Policy
+from .bert import BertModel, BertModelPolicy
+
+POLICY_MAP: Dict[Type[Module], Type[Policy]] = {
+ BertModel: BertModelPolicy,
+}
+
+
+def pipeline_parallelize(
+ model: Module,
+ stage_manager: PipelineStageManager) -> Tuple[Dict[str, Parameter], Dict[str, Tensor], List[Dict[int, Tensor]]]:
+ if type(model) not in POLICY_MAP:
+ raise NotImplementedError(f"Policy for {type(model)} not implemented")
+ policy = POLICY_MAP[type(model)](stage_manager)
+ return policy.parallelize_model(model)
diff --git a/colossalai/pipeline/policy/base.py b/colossalai/pipeline/policy/base.py
new file mode 100644
index 000000000000..9736f1004fe4
--- /dev/null
+++ b/colossalai/pipeline/policy/base.py
@@ -0,0 +1,141 @@
+from typing import Any, Dict, List, Optional, Tuple
+
+import numpy as np
+from torch import Tensor
+from torch.nn import Module, Parameter
+
+from colossalai.lazy import LazyTensor
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+
+class Policy:
+
+ def __init__(self, stage_manager: PipelineStageManager) -> None:
+ self.stage_manager = stage_manager
+
+ def setup_model(self, module: Module) -> Tuple[Dict[str, Parameter], Dict[str, Tensor]]:
+ """Setup model for pipeline parallel
+
+ Args:
+ module (Module): Module to be setup
+
+ Returns:
+ Tuple[Dict[str, Parameter], Dict[str, Tensor]]: Hold parameters and buffers
+ """
+ hold_params = set()
+ hold_buffers = set()
+
+ def init_layer(layer: Module):
+ for p in layer.parameters():
+ if isinstance(p, LazyTensor):
+ p.materialize()
+ p.data = p.cuda()
+ hold_params.add(p)
+ for b in layer.buffers():
+ if isinstance(b, LazyTensor):
+ b.materialize()
+ b.data = b.cuda()
+ hold_buffers.add(b)
+
+ hold_layers = self.get_hold_layers(module)
+
+ for layer in hold_layers:
+ init_layer(layer)
+
+ hold_params_dict = {}
+ hold_buffers_dict = {}
+
+ # release other tensors
+ for n, p in module.named_parameters():
+ if p in hold_params:
+ hold_params_dict[n] = p
+ else:
+ if isinstance(p, LazyTensor):
+ p.materialize()
+ p.data = p.cuda()
+ p.storage().resize_(0)
+ for n, b in module.named_buffers():
+ if b in hold_buffers:
+ hold_buffers_dict[n] = b
+ else:
+ if isinstance(b, LazyTensor):
+ b.materialize()
+ b.data = b.cuda()
+ # FIXME(ver217): use meta tensor may be better
+ b.storage().resize_(0)
+ return hold_params_dict, hold_buffers_dict
+
+ def replace_forward(self, module: Module) -> None:
+ """Replace module forward in place. This method should be implemented by subclass. The output of internal layers must be a dict
+
+ Args:
+ module (Module): _description_
+ """
+ raise NotImplementedError
+
+ def get_hold_layers(self, module: Module) -> List[Module]:
+ """Get layers that should be hold in current stage. This method should be implemented by subclass.
+
+ Args:
+ module (Module): Module to be setup
+
+ Returns:
+ List[Module]: List of layers that should be hold in current stage
+ """
+ raise NotImplementedError
+
+ def get_shared_params(self, module: Module) -> List[Dict[int, Tensor]]:
+ """Get parameters that should be shared across stages. This method should be implemented by subclass.
+
+ Args:
+ module (Module): Module to be setup
+
+ Returns:
+ List[Module]: List of parameters that should be shared across stages. E.g. [{0: module.model.embed_tokens.weight, 3: module.lm_head.weight}]
+ """
+ raise NotImplementedError
+
+ def parallelize_model(self,
+ module: Module) -> Tuple[Dict[str, Parameter], Dict[str, Tensor], List[Dict[int, Tensor]]]:
+ """Parallelize model for pipeline parallel
+
+ Args:
+ module (Module): Module to be setup
+
+ Returns:
+ Tuple[Dict[str, Parameter], Dict[str, Tensor], List[Dict[int, Tensor]]]: Hold parameters, buffers and shared parameters
+ """
+ hold_params, hold_buffers = self.setup_model(module)
+ self.replace_forward(module)
+ shared_params = self.get_shared_params(module)
+ return hold_params, hold_buffers, shared_params
+
+ @staticmethod
+ def distribute_layers(num_layers: int, num_stages: int) -> List[int]:
+ """
+ divide layers into stages
+ """
+ quotient = num_layers // num_stages
+ remainder = num_layers % num_stages
+
+ # calculate the num_layers per stage
+ layers_per_stage = [quotient] * num_stages
+
+ # deal with the rest layers
+ if remainder > 0:
+ start_position = num_layers // 2 - remainder // 2
+ for i in range(start_position, start_position + remainder):
+ layers_per_stage[i] += 1
+ return layers_per_stage
+
+ @staticmethod
+ def get_stage_index(layers_per_stage: List[int], stage: int) -> List[int]:
+ """
+ get the start index and end index of layers for each stage.
+ """
+ num_layers_per_stage_accumulated = np.insert(np.cumsum(layers_per_stage), 0, 0)
+
+ start_idx = num_layers_per_stage_accumulated[stage]
+ end_idx = num_layers_per_stage_accumulated[stage + 1]
+
+ return [start_idx, end_idx]
diff --git a/colossalai/pipeline/policy/bert.py b/colossalai/pipeline/policy/bert.py
new file mode 100644
index 000000000000..abce504e9d61
--- /dev/null
+++ b/colossalai/pipeline/policy/bert.py
@@ -0,0 +1,523 @@
+from functools import partial
+from types import MethodType
+from typing import Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+from torch import Tensor
+from torch.nn import CrossEntropyLoss, Module
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPast,
+ BaseModelOutputWithPastAndCrossAttentions,
+ BaseModelOutputWithPoolingAndCrossAttentions,
+ CausalLMOutputWithCrossAttentions,
+)
+from transformers.models.bert.modeling_bert import (
+ BertForPreTraining,
+ BertForPreTrainingOutput,
+ BertLMHeadModel,
+ BertModel,
+)
+from transformers.utils import ModelOutput, logging
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+from .base import Policy
+
+logger = logging.get_logger(__name__)
+
+
+def bert_model_forward(
+ self: BertModel,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ # labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None, # this is from the previous stage
+):
+ # TODO: add explaination of the output here.
+ r"""
+ encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ """
+ # debugging
+ # preprocess:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if self.config.is_decoder:
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ else:
+ use_cache = False
+
+ if stage_manager.is_first_stage():
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ input_shape = input_ids.size()
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+ batch_size, seq_length = input_shape
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ else:
+ input_shape = hidden_states.size()[:-1]
+ batch_size, seq_length = input_shape
+ device = hidden_states.device
+
+ # TODO: left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once('use_cache=True is not supported for pipeline models at the moment.')
+ use_cache = False
+
+ # past_key_values_length
+ past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
+
+ if attention_mask is None:
+ attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device)
+
+ if token_type_ids is None:
+ if hasattr(self.embeddings, "token_type_ids"):
+ buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
+
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
+ attention_mask = extended_attention_mask
+ # If a 2D or 3D attention mask is provided for the cross-attention
+ # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if self.config.is_decoder and encoder_hidden_states is not None:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
+ encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
+ if encoder_attention_mask is None:
+ encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
+ encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+ hidden_states = hidden_states if hidden_states is not None else None
+
+ if stage_manager.is_first_stage():
+ hidden_states = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ inputs_embeds=inputs_embeds,
+ past_key_values_length=past_key_values_length,
+ )
+
+ # inherit from bert_layer,this should be changed when we add the feature to record hidden_states
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
+
+ if self.encoder.gradient_checkpointing and self.encoder.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+ next_decoder_cache = () if use_cache else None
+
+ # calculate the num_layers
+ num_layers_per_stage = len(self.encoder.layer) // stage_manager.num_stages
+ start_layer = stage_manager.stage * num_layers_per_stage
+ end_layer = (stage_manager.stage + 1) * num_layers_per_stage
+
+ # layer_outputs
+ layer_outputs = hidden_states if hidden_states is not None else None
+ for idx, encoder_layer in enumerate(self.encoder.layer[start_layer:end_layer], start=start_layer):
+ if stage_manager.is_first_stage() and idx == 0:
+ encoder_attention_mask = encoder_extended_attention_mask
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[idx] if head_mask is not None else None
+ past_key_value = past_key_values[idx] if past_key_values is not None else None
+
+ if self.encoder.gradient_checkpointing and self.encoder.training:
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ return module(*inputs, past_key_value, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(encoder_layer),
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+ else:
+ layer_outputs = encoder_layer(
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ hidden_states = layer_outputs[0]
+ if use_cache:
+ next_decoder_cache += (layer_outputs[-1],)
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+ if self.config.add_cross_attention:
+ all_cross_attentions = all_cross_attentions + \
+ (layer_outputs[2],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ # end of a stage loop
+ sequence_output = layer_outputs[0] if layer_outputs is not None else None
+
+ if stage_manager.is_last_stage():
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+ if not return_dict:
+ return (sequence_output, pooled_output) + layer_outputs[1:]
+ # return dict is not supported at this moment
+ else:
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+ # output of non-first and non-last stages: must be a dict
+ else:
+ # intermediate stage always return dict
+ return {
+ 'hidden_states': hidden_states,
+ }
+
+
+# The layer partition policy for bertmodel
+class BertModelPolicy(Policy):
+
+ def __init__(
+ self,
+ stage_manager: PipelineStageManager,
+ num_layers: int,
+ ):
+ super().__init__(stage_manager=stage_manager)
+ self.stage_manager = stage_manager
+ self.layers_per_stage = self.distribute_layers(num_layers, stage_manager.num_stages)
+
+ def get_hold_layers(self, module: BertModel) -> List[Module]:
+ """
+ get pipeline layers for current stage
+ """
+ hold_layers = []
+ if self.stage_manager.is_first_stage():
+ hold_layers.append(module.embeddings)
+ start_idx, end_idx = self.get_stage_index(self.layers_per_stage, self.stage_manager.stage)
+ hold_layers.extend(module.encoder.layer[start_idx:end_idx])
+ if self.stage_manager.is_last_stage():
+ hold_layers.append(module.pooler)
+
+ return hold_layers
+
+ def get_shared_params(self, module: BertModel) -> List[Dict[int, Tensor]]:
+ '''no shared params in bertmodel'''
+ return []
+
+ def replace_forward(self, module: Module) -> None:
+ module.forward = MethodType(partial(bert_model_forward, stage_manager=self.stage_manager), module)
+
+
+def bert_for_pretraining_forward(
+ self: BertForPreTraining,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ next_sentence_label: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+):
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ # TODO: left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if return_dict:
+ logger.warning_once('return_dict is not supported for pipeline models at the moment')
+ return_dict = False
+
+ outputs = bert_model_forward(self.bert,
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states if hidden_states is not None else None)
+ past_key_values = None
+ all_hidden_states = None
+ all_self_attentions = None
+ all_cross_attentions = None
+ if stage_manager.is_last_stage():
+ sequence_output, pooled_output = outputs[:2]
+ prediction_scores, seq_relationship_score = self.cls(sequence_output, pooled_output)
+ # the last stage for pretraining model
+ total_loss = None
+ if labels is not None and next_sentence_label is not None:
+ loss_fct = CrossEntropyLoss()
+ masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
+ next_sentence_loss = loss_fct(seq_relationship_score.view(-1, 2), next_sentence_label.view(-1))
+ total_loss = masked_lm_loss + next_sentence_loss
+
+ if not return_dict:
+ output = (prediction_scores, seq_relationship_score) + outputs[2:]
+ return ((total_loss,) + output) if total_loss is not None else output
+
+ return BertForPreTrainingOutput(
+ loss=total_loss,
+ prediction_logits=prediction_scores,
+ seq_relationship_logits=seq_relationship_score,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+
+ # intermediate stage always return dict
+ return {
+ 'hidden_states': hidden_states,
+ }
+
+
+class BertForPreTrainingPolicy(Policy):
+
+ def __init__(self, stage_manager: PipelineStageManager, num_layers: int):
+ super().__init__(stage_manager=stage_manager)
+ self.stage_manager = stage_manager
+ self.layers_per_stage = self.distribute_layers(num_layers, stage_manager.num_stages)
+
+ def get_hold_layers(self, module: BertForPreTraining) -> List[Module]:
+ """
+ get pipeline layers for current stage
+ """
+ hold_layers = []
+ if self.stage_manager.is_first_stage():
+ hold_layers.append(module.bert.embeddings)
+
+ start_idx, end_idx = self.get_stage_index(self.layers_per_stage, self.stage_manager.stage)
+ hold_layers.extend(module.bert.encoder.layer[start_idx:end_idx])
+
+ if self.stage_manager.is_last_stage():
+ hold_layers.append(module.bert.pooler)
+ hold_layers.append(module.cls)
+
+ return hold_layers
+
+ def get_shared_params(self, module: BertForPreTraining) -> List[Dict[int, Tensor]]:
+ '''no shared params in bertmodel'''
+ return []
+
+ def replace_forward(self, module: Module) -> None:
+ module.forward = MethodType(partial(bert_for_pretraining_forward, stage_manager=self.stage_manager),
+ module.forward)
+
+
+def bert_lmhead_forward(self: BertLMHeadModel,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.Tensor]] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_manager: Optional[PipelineStageManager] = None):
+ r"""
+ encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
+ `[-100, 0, ..., config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are
+ ignored (masked), the loss is only computed for the tokens with labels n `[0, ..., config.vocab_size]`
+ past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if labels is not None:
+ use_cache = False
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if return_dict:
+ logger.warning_once('return_dict is not supported for pipeline models at the moment')
+ return_dict = False
+
+ outputs = bert_model_forward(self.bert,
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states if hidden_states is not None else None)
+ past_key_values = None
+ all_hidden_states = None
+ all_self_attentions = None
+ all_cross_attentions = None
+
+ if stage_manager.is_last_stage():
+ sequence_output = outputs[0]
+ prediction_scores = self.cls(sequence_output)
+
+ lm_loss = None
+ if labels is not None:
+ # we are doing next-token prediction; shift prediction scores and input ids by one
+ shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
+ labels = labels[:, 1:].contiguous()
+ loss_fct = CrossEntropyLoss()
+ lm_loss = loss_fct(shifted_prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
+
+ if not return_dict:
+ output = (prediction_scores,) + outputs[2:]
+ return ((lm_loss,) + output) if lm_loss is not None else output
+
+ return CausalLMOutputWithCrossAttentions(
+ loss=lm_loss,
+ logits=prediction_scores,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ cross_attentions=outputs.cross_attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+ # intermediate stage always return dict
+ return {'hidden_states': hidden_states}
+
+
+class BertLMHeadModelPolicy(Policy):
+
+ def __init__(self, stage_manager: PipelineStageManager, num_layers: int):
+ super().__init__(stage_manager=stage_manager)
+ self.stage_manager = stage_manager
+ self.layers_per_stage = self.distribute_layers(num_layers, stage_manager.num_stages)
+
+ def get_hold_layers(self, module: BertLMHeadModel) -> List[Module]:
+ """
+ get pipeline layers for current stage
+ """
+ hold_layers = []
+ if self.stage_manager.is_first_stage():
+ hold_layers.append(module.bert.embeddings)
+ start_idx, end_idx = self.get_stage_index(self.layers_per_stage, self.stage_manager.stage)
+ hold_layers.extend(module.bert.encoder.layer[start_idx:end_idx])
+ if self.stage_manager.is_last_stage():
+ hold_layers.append(module.bert.pooler)
+ hold_layers.append(module.cls)
+
+ return hold_layers
+
+ def get_shared_params(self, module: BertLMHeadModel) -> List[Dict[int, Tensor]]:
+ '''no shared params in bertmodel'''
+ return []
+
+ def replace_forward(self, module: Module) -> None:
+ module.forward = MethodType(partial(bert_lmhead_forward, stage_manager=self.stage_manager), module)
diff --git a/colossalai/pipeline/policy/bloom.py b/colossalai/pipeline/policy/bloom.py
new file mode 100644
index 000000000000..cf5592ea2f4e
--- /dev/null
+++ b/colossalai/pipeline/policy/bloom.py
@@ -0,0 +1,220 @@
+import warnings
+from functools import partial
+from types import MethodType
+from typing import Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+from torch import Tensor
+from torch.nn import CrossEntropyLoss, Module
+from transformers.modeling_outputs import BaseModelOutputWithPastAndCrossAttentions
+from transformers.models.bloom.modeling_bloom import BloomModel
+from transformers.utils import logging
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+from .base import Policy
+
+logger = logging.get_logger(__name__)
+
+
+def bloom_model_forward(
+ self: BloomModel,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ **deprecated_arguments,
+) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+ if len(deprecated_arguments) > 0:
+ raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # add warnings here
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once('use_cache=True is not supported for pipeline models at the moment.')
+ use_cache = False
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape batch_size x num_heads x N x N
+
+ # head_mask has shape n_layer x batch x num_heads x N x N
+ head_mask = self.get_head_mask(head_mask, self.config.n_layer)
+
+ # case: First stage of training
+ if stage_manager.is_first_stage():
+ # check input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+
+ hidden_states = self.word_embeddings_layernorm(inputs_embeds)
+ # initialize in the first stage and then pass to the next stage
+ else:
+ input_shape = hidden_states.shape[:-1]
+ batch_size, seq_length = input_shape
+
+ # extra recording tensor should be generated in the first stage
+ presents = () if use_cache else None
+ all_self_attentions = () if output_attentions else None
+ all_hidden_states = () if output_hidden_states else None
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+
+ if past_key_values is None:
+ past_key_values = tuple([None] * len(self.h))
+ # Compute alibi tensor: check build_alibi_tensor documentation,build for every stage
+ seq_length_with_past = seq_length
+ past_key_values_length = 0
+ if past_key_values[0] is not None:
+ past_key_values_length = past_key_values[0][0].shape[2] # source_len
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, seq_length_with_past), device=hidden_states.device)
+ else:
+ attention_mask = attention_mask.to(hidden_states.device)
+
+ alibi = self.build_alibi_tensor(attention_mask, self.num_heads, dtype=hidden_states.dtype)
+
+ # causal_mask is constructed every stage and its input is passed through different stages
+ causal_mask = self._prepare_attn_mask(
+ attention_mask,
+ input_shape=(batch_size, seq_length),
+ past_key_values_length=past_key_values_length,
+ )
+
+ # calculate the num_layers
+ num_layers_per_stage = len(self.h) // stage_manager.num_stages
+ start_layer = stage_manager.stage * num_layers_per_stage
+ end_layer = (stage_manager.stage + 1) * num_layers_per_stage
+
+ for i, (block, layer_past) in enumerate(zip(self.h[start_layer:end_layer], past_key_values[start_layer:end_layer])):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ # None for past_key_value
+ return module(*inputs, use_cache=use_cache, output_attentions=output_attentions)
+
+ return custom_forward
+
+ outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(block),
+ hidden_states,
+ alibi,
+ causal_mask,
+ layer_past,
+ head_mask[i],
+ )
+ else:
+ outputs = block(
+ hidden_states,
+ layer_past=layer_past,
+ attention_mask=causal_mask,
+ head_mask=head_mask[i],
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ alibi=alibi,
+ )
+
+ hidden_states = outputs[0]
+
+ if use_cache is True:
+ presents = presents + (outputs[1],)
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + \
+ (outputs[2 if use_cache else 1],)
+
+ if stage_manager.is_last_stage():
+ # Add last hidden state
+ hidden_states = self.ln_f(hidden_states)
+
+ # TODO: deal with all_hidden_states, all_self_attentions, presents
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
+
+ # attention_mask is not returned ; presents = past_key_values
+
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=presents,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class BloomModelPolicy(Policy):
+
+ def __init__(self, stage_manager: PipelineStageManager, num_layers: int, num_stages: int):
+ super().__init__(stage_manager=stage_manager)
+ self.stage_manager = stage_manager
+ self.layers_per_stage = self.distribute_layers(num_layers, num_stages)
+
+ def get_hold_layers(self, module: BloomModel) -> List[Module]:
+ """
+ get pipeline layers for current stage
+ """
+ hold_layers = []
+ if self.stage_manager.is_first_stage():
+ hold_layers.append(module.word_embeddings)
+ hold_layers.append(module.word_embeddings_layernorm)
+
+ start_idx, end_idx = self.get_stage_index(self.layers_per_stage, self.stage_manager.stage)
+ hold_layers.extend(module.h[start_idx:end_idx])
+
+ if self.stage_manager.is_last_stage():
+ hold_layers.append(module.ln_f)
+
+ return hold_layers
+
+ def get_shared_params(self, module: BloomModel) -> List[Dict[int, Tensor]]:
+ '''no shared params in bloommodel'''
+ pass
+
+ def replace_forward(self, module: Module) -> None:
+ module.forward = MethodType(partial(bloom_model_forward, stage_manager=self.stage_manager), module.model)
diff --git a/colossalai/pipeline/schedule/_utils.py b/colossalai/pipeline/schedule/_utils.py
index 045c86e40e63..3ed9239272f1 100644
--- a/colossalai/pipeline/schedule/_utils.py
+++ b/colossalai/pipeline/schedule/_utils.py
@@ -86,7 +86,7 @@ def retain_grad(x: Any) -> None:
Args:
x (Any): Object to be called.
"""
- if isinstance(x, torch.Tensor):
+ if isinstance(x, torch.Tensor) and x.requires_grad:
x.retain_grad()
diff --git a/colossalai/pipeline/schedule/one_f_one_b.py b/colossalai/pipeline/schedule/one_f_one_b.py
index d907d53edcde..ade3cf456fe3 100644
--- a/colossalai/pipeline/schedule/one_f_one_b.py
+++ b/colossalai/pipeline/schedule/one_f_one_b.py
@@ -107,8 +107,15 @@ def backward_step(self, optimizer: OptimizerWrapper, input_obj: Optional[dict],
if output_obj_grad is None:
optimizer.backward(output_obj)
else:
- for k, grad in output_obj_grad.items():
- optimizer.backward_by_grad(output_obj[k], grad)
+ if "backward_tensor_keys" not in output_obj:
+ for k, grad in output_obj_grad.items():
+ optimizer.backward_by_grad(output_obj[k], grad)
+ else:
+ for k, grad in output_obj_grad.items():
+ output_obj[k].grad = grad
+ for k in output_obj["backward_tensor_keys"]:
+ tensor_to_backward = output_obj[k]
+ optimizer.backward_by_grad(tensor_to_backward, tensor_to_backward.grad)
# Collect the grad of the input_obj.
input_obj_grad = None
diff --git a/colossalai/shardformer/README.md b/colossalai/shardformer/README.md
index 357e8ac3397e..1c11b4b85444 100644
--- a/colossalai/shardformer/README.md
+++ b/colossalai/shardformer/README.md
@@ -31,7 +31,7 @@
### Quick Start
-The sample API usage is given below:
+The sample API usage is given below(If you enable the use of flash attention, please install xformers.):
``` python
from colossalai.shardformer import ShardConfig, Shard
@@ -106,6 +106,20 @@ We will follow this roadmap to develop Shardformer:
- [ ] Multi-modal
- [x] SAM
- [x] BLIP-2
+- [ ] Flash Attention Support
+ - [ ] NLP
+ - [x] BERT
+ - [x] T5
+ - [x] LlaMa
+ - [x] GPT2
+ - [x] OPT
+ - [x] BLOOM
+ - [ ] GLM
+ - [ ] RoBERTa
+ - [ ] ALBERT
+ - [ ] ERNIE
+ - [ ] GPT Neo
+ - [ ] GPT-J
## 💡 API Design
@@ -378,11 +392,49 @@ pytest tests/test_shardformer
### System Performance
-To be added.
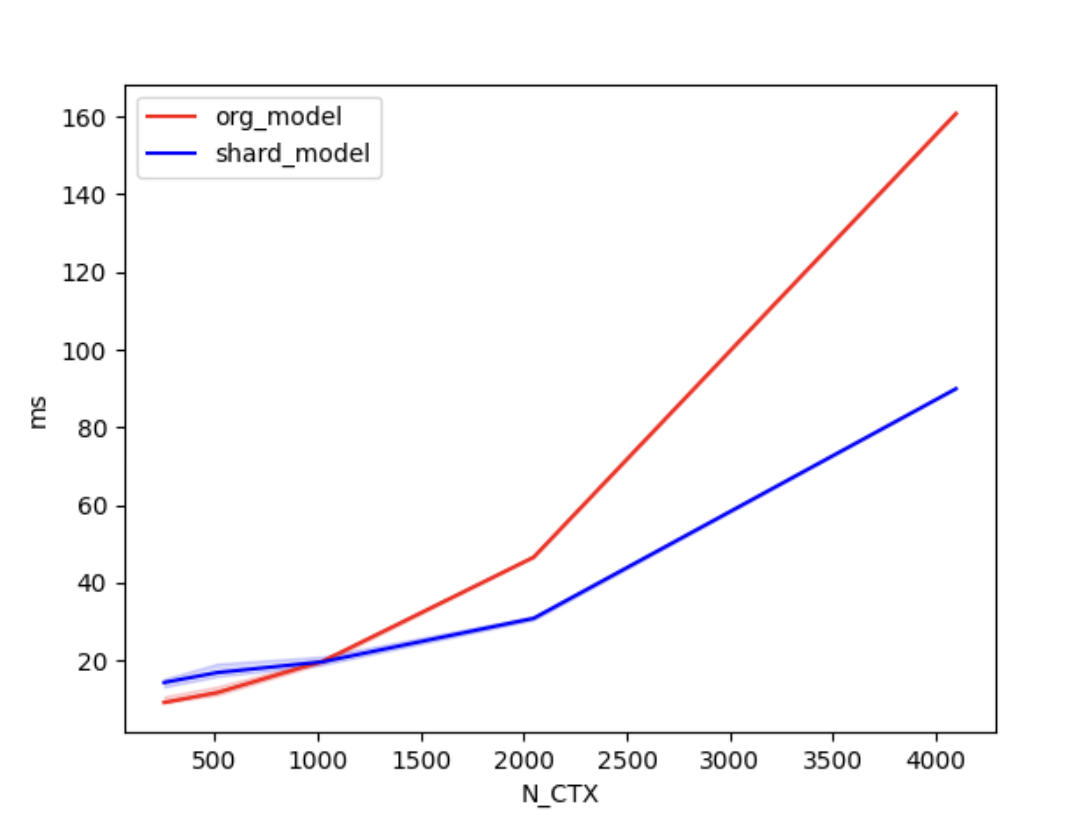
+We conducted [benchmark tests](./examples/performance_benchmark.py) to evaluate the performance improvement of Shardformer. We compared the training time between the original model and the shard model.
+
+We set the batch size to 4, the number of attention heads to 8, and the head dimension to 64. 'N_CTX' refers to the sequence length.
+
+In the case of using 2 GPUs, the training times are as follows.
+| N_CTX | org_model | shard_model |
+| :------: | :-----: | :-----: |
+| 256 | 11.2ms | 17.2ms |
+| 512 | 9.8ms | 19.5ms |
+| 1024 | 19.6ms | 18.9ms |
+| 2048 | 46.6ms | 30.8ms |
+| 4096 | 160.5ms | 90.4ms |
+
+
+
+  +
+
+
+
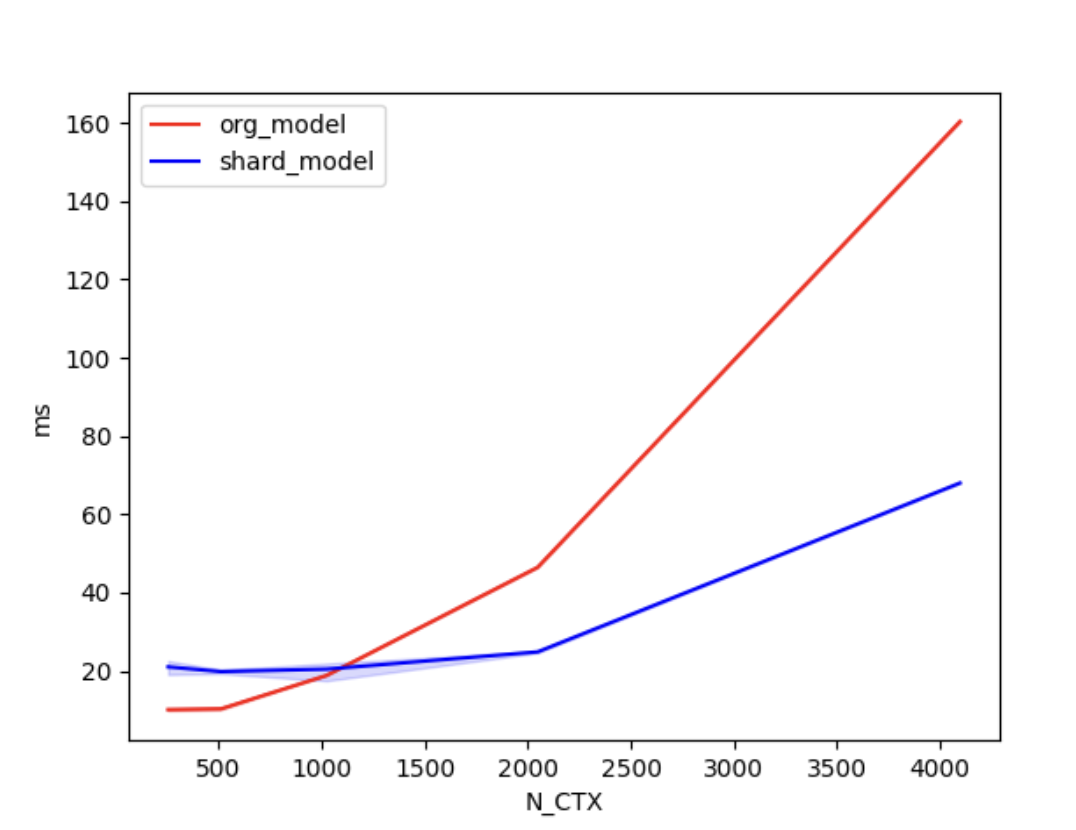
+In the case of using 4 GPUs, the training times are as follows.
+
+| N_CTX | org_model | shard_model |
+| :------: | :-----: | :-----: |
+| 256 | 10.0ms | 21.1ms |
+| 512 | 11.5ms | 20.2ms |
+| 1024 | 22.1ms | 20.6ms |
+| 2048 | 46.9ms | 24.8ms |
+| 4096 | 160.4ms | 68.0ms |
+
+
+
+
+  +
+
+
+
+
+As shown in the figures above, when the sequence length is around 1000 or greater, the parallel optimization of Shardformer for long sequences starts to become evident.
### Convergence
-To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/shardformer_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
+
+To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/convergence_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
| accuracy | f1 | loss | GPU number | model shard |
| :------: | :-----: | :-----: | :--------: | :---------: |
diff --git a/colossalai/shardformer/examples/shardformer_benchmark.py b/colossalai/shardformer/examples/convergence_benchmark.py
similarity index 100%
rename from colossalai/shardformer/examples/shardformer_benchmark.py
rename to colossalai/shardformer/examples/convergence_benchmark.py
diff --git a/colossalai/shardformer/examples/shardformer_benchmark.sh b/colossalai/shardformer/examples/convergence_benchmark.sh
similarity index 76%
rename from colossalai/shardformer/examples/shardformer_benchmark.sh
rename to colossalai/shardformer/examples/convergence_benchmark.sh
index f42b19a32d35..1c281abcda6d 100644
--- a/colossalai/shardformer/examples/shardformer_benchmark.sh
+++ b/colossalai/shardformer/examples/convergence_benchmark.sh
@@ -1,4 +1,4 @@
-torchrun --standalone --nproc_per_node=4 shardformer_benchmark.py \
+torchrun --standalone --nproc_per_node=4 convergence_benchmark.py \
--model "bert" \
--pretrain "bert-base-uncased" \
--max_epochs 1 \
diff --git a/colossalai/shardformer/examples/performance_benchmark.py b/colossalai/shardformer/examples/performance_benchmark.py
new file mode 100644
index 000000000000..9c7b76bcf0a6
--- /dev/null
+++ b/colossalai/shardformer/examples/performance_benchmark.py
@@ -0,0 +1,86 @@
+"""
+Shardformer Benchmark
+"""
+import torch
+import torch.distributed as dist
+import transformers
+import triton
+
+import colossalai
+from colossalai.shardformer import ShardConfig, ShardFormer
+
+
+def data_gen(batch_size, seq_length):
+ input_ids = torch.randint(0, seq_length, (batch_size, seq_length), dtype=torch.long)
+ attention_mask = torch.ones((batch_size, seq_length), dtype=torch.long)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def data_gen_for_sequence_classification(batch_size, seq_length):
+ # LM data gen
+ # the `labels` of LM is the token of the output, cause no padding, use `input_ids` as `labels`
+ data = data_gen(batch_size, seq_length)
+ data['labels'] = torch.ones((batch_size), dtype=torch.long)
+ return data
+
+
+MODEL_CONFIG = transformers.LlamaConfig(num_hidden_layers=4,
+ hidden_size=128,
+ intermediate_size=256,
+ num_attention_heads=4,
+ max_position_embeddings=128,
+ num_labels=16)
+BATCH, N_HEADS, N_CTX, D_HEAD = 4, 8, 4096, 64
+model_func = lambda: transformers.LlamaForSequenceClassification(MODEL_CONFIG)
+
+# vary seq length for fixed head and batch=4
+configs = [
+ triton.testing.Benchmark(x_names=['N_CTX'],
+ x_vals=[2**i for i in range(8, 13)],
+ line_arg='provider',
+ line_vals=['org_model', 'shard_model'],
+ line_names=['org_model', 'shard_model'],
+ styles=[('red', '-'), ('blue', '-')],
+ ylabel='ms',
+ plot_name=f'lama_for_sequence_classification-batch-{BATCH}',
+ args={
+ 'BATCH': BATCH,
+ 'dtype': torch.float16,
+ 'model_func': model_func
+ })
+]
+
+
+def train(model, data):
+ output = model(**data)
+ loss = output.logits.mean()
+ loss.backward()
+
+
+@triton.testing.perf_report(configs)
+def bench_shardformer(BATCH, N_CTX, provider, model_func, dtype=torch.float32, device="cuda"):
+ warmup = 10
+ rep = 100
+ # prepare data
+ data = data_gen_for_sequence_classification(BATCH, N_CTX)
+ data = {k: v.cuda() for k, v in data.items()}
+ model = model_func().to(device)
+ model.train()
+ if provider == "org_model":
+ fn = lambda: train(model, data)
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+ return ms
+ if provider == "shard_model":
+ shard_config = ShardConfig(enable_fused_normalization=True, enable_tensor_parallelism=True)
+ shard_former = ShardFormer(shard_config=shard_config)
+ sharded_model = shard_former.optimize(model).cuda()
+ fn = lambda: train(sharded_model, data)
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+ return ms
+
+
+# start benchmark, command:
+# torchrun --standalone --nproc_per_node=2 performance_benchmark.py
+if __name__ == "__main__":
+ colossalai.launch_from_torch({})
+ bench_shardformer.run(save_path='.', print_data=dist.get_rank() == 0)
diff --git a/colossalai/shardformer/layer/utils.py b/colossalai/shardformer/layer/utils.py
index f2ac6563c46f..09cb7bfe1407 100644
--- a/colossalai/shardformer/layer/utils.py
+++ b/colossalai/shardformer/layer/utils.py
@@ -122,6 +122,13 @@ def increment_index():
"""
Randomizer._INDEX += 1
+ @staticmethod
+ def reset_index():
+ """
+ Reset the index to zero.
+ """
+ Randomizer._INDEX = 0
+
@staticmethod
def is_randomizer_index_synchronized(process_group: ProcessGroup = None):
"""
diff --git a/colossalai/shardformer/modeling/bert.py b/colossalai/shardformer/modeling/bert.py
index 1b3c14d9d1c9..b9d4b5fda7af 100644
--- a/colossalai/shardformer/modeling/bert.py
+++ b/colossalai/shardformer/modeling/bert.py
@@ -1,5 +1,6 @@
+import math
import warnings
-from typing import Any, Dict, List, Optional, Tuple
+from typing import Dict, List, Optional, Tuple
import torch
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
@@ -962,3 +963,138 @@ def bert_for_question_answering_forward(
else:
hidden_states = outputs.get('hidden_states')
return {'hidden_states': hidden_states}
+
+
+def get_bert_flash_attention_forward():
+
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+ from transformers.models.bert.modeling_bert import BertAttention
+
+ def forward(
+ self: BertAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ mixed_query_layer = self.query(hidden_states)
+
+ # If this is instantiated as a cross-attention module, the keys
+ # and values come from an encoder; the attention mask needs to be
+ # such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ if is_cross_attention and past_key_value is not None:
+ # reuse k,v, cross_attentions
+ key_layer = past_key_value[0]
+ value_layer = past_key_value[1]
+ attention_mask = encoder_attention_mask
+ elif is_cross_attention:
+ key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
+ value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
+ attention_mask = encoder_attention_mask
+ elif past_key_value is not None:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+ else:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ use_cache = past_key_value is not None
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_layer, value_layer)
+
+ final_attention_mask = None
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ query_length, key_length = query_layer.shape[2], key_layer.shape[2]
+ if use_cache:
+ position_ids_l = torch.tensor(key_length - 1, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ else:
+ position_ids_l = torch.arange(query_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(key_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+
+ positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == "relative_key":
+ relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ final_attention_mask = relative_position_scores
+ elif self.position_embedding_type == "relative_key_query":
+ relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
+ final_attention_mask = relative_position_scores_query + relative_position_scores_key
+
+ scale = 1 / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ if final_attention_mask != None:
+ final_attention_mask = final_attention_mask * scale + attention_mask
+ else:
+ final_attention_mask = attention_mask
+ batch_size, src_len = query_layer.size()[0], query_layer.size()[2]
+ tgt_len = key_layer.size()[2]
+ final_attention_mask = final_attention_mask.expand(batch_size, self.num_attention_heads, src_len, tgt_len)
+
+ query_layer = query_layer.permute(0, 2, 1, 3).contiguous()
+ key_layer = key_layer.permute(0, 2, 1, 3).contiguous()
+ value_layer = value_layer.permute(0, 2, 1, 3).contiguous()
+
+ context_layer = me_attention(query_layer,
+ key_layer,
+ value_layer,
+ attn_bias=final_attention_mask,
+ p=self.dropout.p,
+ scale=scale)
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, None)
+
+ if self.is_decoder:
+ outputs = outputs + (past_key_value,)
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_bert_self_output_forward():
+
+ from transformers.models.bert.modeling_bert import BertSelfOutput
+
+ def forward(self: BertSelfOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+ return forward
+
+
+def get_jit_fused_bert_output_forward():
+
+ from transformers.models.bert.modeling_bert import BertOutput
+
+ def forward(self: BertOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/modeling/blip2.py b/colossalai/shardformer/modeling/blip2.py
index b7945423ae83..c5c6b14ba993 100644
--- a/colossalai/shardformer/modeling/blip2.py
+++ b/colossalai/shardformer/modeling/blip2.py
@@ -1,3 +1,4 @@
+import math
from typing import Optional, Tuple, Union
import torch
@@ -58,3 +59,62 @@ def forward(
return outputs
return forward
+
+
+def get_blip2_flash_attention_forward():
+
+ from transformers.models.blip_2.modeling_blip_2 import Blip2Attention
+
+ from colossalai.kernel.cuda_native.flash_attention import AttnMaskType, ColoAttention
+
+ def forward(
+ self: Blip2Attention,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ bsz, tgt_len, embed_dim = hidden_states.size()
+ mixed_qkv = self.qkv(hidden_states)
+ mixed_qkv = mixed_qkv.reshape(bsz, tgt_len, 3, self.num_heads, -1).permute(2, 0, 1, 3, 4)
+ query_states, key_states, value_states = mixed_qkv[0], mixed_qkv[1], mixed_qkv[2]
+
+ attention = ColoAttention(embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ dropout=self.dropout.p,
+ scale=self.scale)
+ context_layer = attention(query_states, key_states, value_states)
+
+ output = self.projection(context_layer)
+ outputs = (output, None)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_blip2_QFormer_self_output_forward():
+
+ from transformers.models.blip_2.modeling_blip_2 import Blip2QFormerSelfOutput
+
+ def forward(self: Blip2QFormerSelfOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+ return forward
+
+
+def get_jit_fused_blip2_QFormer_output_forward():
+
+ from transformers.models.blip_2.modeling_blip_2 import Blip2QFormerOutput
+
+ def forward(self: Blip2QFormerOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/modeling/bloom.py b/colossalai/shardformer/modeling/bloom.py
index 76948fc70439..57c45bc6adfa 100644
--- a/colossalai/shardformer/modeling/bloom.py
+++ b/colossalai/shardformer/modeling/bloom.py
@@ -5,6 +5,7 @@
import torch.distributed as dist
from torch.distributed import ProcessGroup
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from torch.nn import functional as F
from transformers.modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
CausalLMOutputWithCrossAttentions,
@@ -675,3 +676,223 @@ def bloom_for_question_answering_forward(
else:
hidden_states = outputs.get('hidden_states')
return {'hidden_states': hidden_states}
+
+
+def get_bloom_flash_attention_forward(enabel_jit_fused=False):
+
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+ from transformers.models.bloom.modeling_bloom import BloomAttention
+
+ def forward(
+ self: BloomAttention,
+ hidden_states: torch.Tensor,
+ residual: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ ):
+
+ fused_qkv = self.query_key_value(hidden_states)
+ (query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
+ batch_size, tgt_len, _ = hidden_states.size()
+ assert tgt_len % 4 == 0, "Flash Attention Error: The sequence length should be a multiple of 4."
+
+ _, kv_length, _, _ = key_layer.size()
+
+ proj_shape = (batch_size, tgt_len, self.num_heads, self.head_dim)
+ query_layer = query_layer.contiguous().view(*proj_shape)
+ key_layer = key_layer.contiguous().view(*proj_shape)
+ value_layer = value_layer.contiguous().view(*proj_shape)
+
+ if layer_past is not None:
+ past_key, past_value = layer_past
+ # concatenate along seq_length dimension:
+ # - key: [batch_size * self.num_heads, head_dim, kv_length]
+ # - value: [batch_size * self.num_heads, kv_length, head_dim]
+ key_layer = torch.cat((past_key, key_layer), dim=1)
+ value_layer = torch.cat((past_value, value_layer), dim=1)
+
+ if use_cache is True:
+ present = (key_layer, value_layer)
+ else:
+ present = None
+
+ tgt_len = key_layer.size()[1]
+
+ attention_numerical_mask = torch.zeros((batch_size, self.num_heads, tgt_len, kv_length),
+ dtype=torch.float32,
+ device=query_layer.device,
+ requires_grad=True)
+ attention_numerical_mask = attention_numerical_mask + alibi.view(batch_size, self.num_heads, 1,
+ kv_length) * self.beta
+ attention_numerical_mask = torch.masked_fill(attention_numerical_mask, attention_mask,
+ torch.finfo(torch.float32).min)
+
+ context_layer = me_attention(query_layer,
+ key_layer,
+ value_layer,
+ attn_bias=attention_numerical_mask,
+ scale=self.inv_norm_factor,
+ p=self.attention_dropout.p)
+ context_layer = context_layer.reshape(-1, kv_length, self.hidden_size)
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ slices = self.hidden_size / self.pretraining_tp
+ output_tensor = torch.zeros_like(context_layer)
+ for i in range(self.pretraining_tp):
+ output_tensor = output_tensor + F.linear(
+ context_layer[:, :, int(i * slices):int((i + 1) * slices)],
+ self.dense.weight[:, int(i * slices):int((i + 1) * slices)],
+ )
+ else:
+ output_tensor = self.dense(context_layer)
+
+ # TODO to replace with the bias_dropout_add function in jit
+ output_tensor = self.dropout_add(output_tensor, residual, self.hidden_dropout, self.training)
+ outputs = (output_tensor, present, None)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_bloom_attention_forward():
+
+ from transformers.models.bloom.modeling_bloom import BloomAttention
+
+ def forward(
+ self: BloomAttention,
+ hidden_states: torch.Tensor,
+ residual: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ ):
+ fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
+
+ # 3 x [batch_size, seq_length, num_heads, head_dim]
+ (query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
+
+ batch_size, q_length, _, _ = query_layer.shape
+
+ query_layer = query_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
+ key_layer = key_layer.permute(0, 2, 3, 1).reshape(batch_size * self.num_heads, self.head_dim, q_length)
+ value_layer = value_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
+ if layer_past is not None:
+ past_key, past_value = layer_past
+ # concatenate along seq_length dimension:
+ # - key: [batch_size * self.num_heads, head_dim, kv_length]
+ # - value: [batch_size * self.num_heads, kv_length, head_dim]
+ key_layer = torch.cat((past_key, key_layer), dim=2)
+ value_layer = torch.cat((past_value, value_layer), dim=1)
+
+ _, _, kv_length = key_layer.shape
+
+ if use_cache is True:
+ present = (key_layer, value_layer)
+ else:
+ present = None
+
+ # [batch_size * num_heads, q_length, kv_length]
+ # we use `torch.Tensor.baddbmm` instead of `torch.baddbmm` as the latter isn't supported by TorchScript v1.11
+ matmul_result = alibi.baddbmm(
+ batch1=query_layer,
+ batch2=key_layer,
+ beta=self.beta,
+ alpha=self.inv_norm_factor,
+ )
+
+ # change view to [batch_size, num_heads, q_length, kv_length]
+ attention_scores = matmul_result.view(batch_size, self.num_heads, q_length, kv_length)
+
+ # cast attention scores to fp32, compute scaled softmax and cast back to initial dtype - [batch_size, num_heads, q_length, kv_length]
+ input_dtype = attention_scores.dtype
+ # `float16` has a minimum value of -65504.0, whereas `bfloat16` and `float32` have a minimum value of `-3.4e+38`
+ if input_dtype == torch.float16:
+ attention_scores = attention_scores.to(torch.float)
+ attn_weights = torch.masked_fill(attention_scores, attention_mask, torch.finfo(attention_scores.dtype).min)
+ attention_probs = F.softmax(attn_weights, dim=-1, dtype=torch.float32).to(input_dtype)
+
+ # [batch_size, num_heads, q_length, kv_length]
+ attention_probs = self.attention_dropout(attention_probs)
+
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ # change view [batch_size x num_heads, q_length, kv_length]
+ attention_probs_reshaped = attention_probs.view(batch_size * self.num_heads, q_length, kv_length)
+
+ # matmul: [batch_size * num_heads, q_length, head_dim]
+ context_layer = torch.bmm(attention_probs_reshaped, value_layer)
+
+ # change view [batch_size, num_heads, q_length, head_dim]
+ context_layer = self._merge_heads(context_layer)
+
+ # aggregate results across tp ranks. See here: https://github.com/pytorch/pytorch/issues/76232
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ slices = self.hidden_size / self.pretraining_tp
+ output_tensor = torch.zeros_like(context_layer)
+ for i in range(self.pretraining_tp):
+ output_tensor = output_tensor + F.linear(
+ context_layer[:, :, int(i * slices):int((i + 1) * slices)],
+ self.dense.weight[:, int(i * slices):int((i + 1) * slices)],
+ )
+ else:
+ output_tensor = self.dense(context_layer)
+
+ output_tensor = self.dropout_add(output_tensor, residual, self.hidden_dropout, self.training)
+
+ outputs = (output_tensor, present)
+ if output_attentions:
+ outputs += (attention_probs,)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_bloom_mlp_forward():
+
+ from transformers.models.bloom.modeling_bloom import BloomMLP
+
+ def forward(self: BloomMLP, hidden_states: torch.Tensor, residual: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.gelu_impl(self.dense_h_to_4h(hidden_states))
+
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ intermediate_output = torch.zeros_like(residual)
+ slices = self.dense_4h_to_h.weight.shape[-1] / self.pretraining_tp
+ for i in range(self.pretraining_tp):
+ intermediate_output = intermediate_output + F.linear(
+ hidden_states[:, :, int(i * slices):int((i + 1) * slices)],
+ self.dense_4h_to_h.weight[:, int(i * slices):int((i + 1) * slices)],
+ )
+ else:
+ intermediate_output = self.dense_4h_to_h(hidden_states)
+ output = self.dropout_add(intermediate_output, residual, self.hidden_dropout, self.training)
+ return output
+
+ return forward
+
+
+def get_jit_fused_bloom_gelu_forward():
+
+ from transformers.models.bloom.modeling_bloom import BloomGelu
+
+ from colossalai.kernel.jit.bias_gelu import GeLUFunction as JitGeLUFunction
+
+ def forward(self: BloomGelu, x: torch.Tensor) -> torch.Tensor:
+ bias = torch.zeros_like(x)
+ if self.training:
+ return JitGeLUFunction.apply(x, bias)
+ else:
+ return self.bloom_gelu_forward(x, bias)
+
+ return forward
diff --git a/colossalai/shardformer/modeling/chatglm.py b/colossalai/shardformer/modeling/chatglm.py
new file mode 100644
index 000000000000..3d453c3bd6db
--- /dev/null
+++ b/colossalai/shardformer/modeling/chatglm.py
@@ -0,0 +1,299 @@
+""" PyTorch ChatGLM model. """
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from torch.nn import CrossEntropyLoss, LayerNorm
+from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
+from transformers.utils import logging
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer.modeling.chatglm2_6b.configuration_chatglm import ChatGLMConfig
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
+ ChatGLMForConditionalGeneration,
+ ChatGLMModel,
+ GLMBlock,
+)
+
+
+def get_flash_core_attention_forward():
+
+ from colossalai.kernel.cuda_native.flash_attention import AttnMaskType, ColoAttention
+
+ from .chatglm2_6b.modeling_chatglm import CoreAttention
+
+ def forward(self: CoreAttention, query_layer, key_layer, value_layer, attention_mask):
+ pytorch_major_version = int(torch.__version__.split(".")[0])
+ if pytorch_major_version >= 2:
+ query_layer, key_layer, value_layer = [k.permute(1, 2, 0, 3) for k in [query_layer, key_layer, value_layer]]
+ if attention_mask is None and query_layer.shape[2] == key_layer.shape[2]:
+ context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer,
+ key_layer,
+ value_layer,
+ is_causal=True)
+ else:
+ if attention_mask is not None:
+ attention_mask = ~attention_mask
+ context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
+ attention_mask)
+ context_layer = context_layer.permute(2, 0, 1, 3)
+ new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
+ context_layer = context_layer.reshape(*new_context_layer_shape)
+ else:
+ # Raw attention scores
+ query_layer = query_layer.permute(1, 0, 2, 3).contiguous()
+ key_layer = key_layer.permute(1, 0, 2, 3).contiguous()
+ value_layer = value_layer.permute(1, 0, 2, 3).contiguous()
+
+ scale = 1.0 / self.norm_factor
+ if self.coeff is not None:
+ scale = scale * self.coeff
+
+ flash_attention_mask = None
+ attn_mask_type = None
+ if attention_mask is None:
+ attn_mask_type = AttnMaskType.causal
+ else:
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool)).contiguous()
+ attn_mask_type = AttnMaskType.paddedcausal
+
+ attention = ColoAttention(embed_dim=self.hidden_size_per_partition,
+ num_heads=self.num_attention_heads_per_partition,
+ dropout=self.attention_dropout.p,
+ scale=scale)
+ context_layer = attention(query_layer,
+ key_layer,
+ value_layer,
+ attn_mask=flash_attention_mask,
+ attn_mask_type=attn_mask_type)
+
+ context_layer = context_layer.permute(1, 0, -1).contiguous()
+
+ return context_layer
+
+ return forward
+
+
+def get_jit_fused_glm_block_forward():
+
+ from .chatglm2_6b.modeling_chatglm import GLMBlock
+
+ def forward(
+ self: GLMBlock,
+ hidden_states,
+ attention_mask,
+ rotary_pos_emb,
+ kv_cache=None,
+ use_cache=True,
+ ):
+ # hidden_states: [s, b, h]
+ # Layer norm at the beginning of the transformer layer.
+ layernorm_output = self.input_layernorm(hidden_states)
+ # Self attention.
+ attention_output, kv_cache = self.self_attention(
+ layernorm_output,
+ attention_mask,
+ rotary_pos_emb,
+ kv_cache=kv_cache,
+ use_cache=use_cache,
+ )
+
+ # Residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = hidden_states
+
+ layernorm_input = self.dropout_add(attention_output, residual, self.hidden_dropout, self.training)
+
+ # Layer norm post the self attention.
+ layernorm_output = self.post_attention_layernorm(layernorm_input)
+
+ # MLP.
+ mlp_output = self.mlp(layernorm_output)
+
+ # Second residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = layernorm_input
+
+ output = self.dropout_add(mlp_output, residual, self.hidden_dropout, self.training)
+
+ return output, kv_cache
+
+ return forward
+
+
+
+class ChatGLMPipelineForwards:
+ '''
+ This class serves as a micro library for ChatGLM model forwards under pipeline parallelism.
+ '''
+
+ @staticmethod
+ def chatglm_model_forward(
+ self: ChatGLMModel,
+ input_ids,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.BoolTensor] = None,
+ full_attention_mask: Optional[torch.BoolTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ logger = logging.get_logger(__name__)
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ # TODO: left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if past_key_values:
+ logger.warning_once('Non-empty past_key_values is not supported for pipeline models at the moment.')
+ past_key_values = None
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once('use_cache=True is not supported for pipeline models at the moment.')
+ use_cache = False
+ if stage_manager.is_first_stage():
+ batch_size, seq_length = input_ids.shape
+ if inputs_embeds is None:
+ inputs_embeds = self.embedding(input_ids)
+ hidden_states = inputs_embeds
+ else:
+ seq_length, batch_size = hidden_states.shape[:2]
+ if self.pre_seq_len is not None:
+ if past_key_values is None:
+ past_key_values = self.get_prompt(batch_size=batch_size,
+ device=input_ids.device,
+ dtype=inputs_embeds.dtype)
+ if attention_mask is not None:
+ attention_mask = torch.cat([attention_mask.new_ones((batch_size, self.pre_seq_len)), attention_mask],
+ dim=-1)
+ if full_attention_mask is None:
+ if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
+ full_attention_mask = self.get_masks(input_ids, past_key_values, padding_mask=attention_mask)
+ # Rotary positional embeddings
+ rotary_pos_emb = self.rotary_pos_emb(self.seq_length)
+ if position_ids is not None:
+ rotary_pos_emb = rotary_pos_emb[position_ids]
+ else:
+ rotary_pos_emb = rotary_pos_emb[None, :seq_length]
+ rotary_pos_emb = rotary_pos_emb.transpose(0, 1).contiguous()
+ if not past_key_values:
+ past_key_values = [None for _ in range(self.num_layers)]
+ presents = () if use_cache else None
+ if self.encoder.gradient_checkpointing and self.encoder.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+ all_self_attentions = None
+ all_hidden_states = () if output_hidden_states else None
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ for idx in range(start_idx, end_idx):
+ layer = self.encoder._get_layer(idx)
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+ if self.encoder.gradient_checkpointing and self.encoder.training:
+ layer_ret = torch.utils.checkpoint.checkpoint(layer, hidden_states, attention_mask, rotary_pos_emb,
+ past_key_values[idx], use_cache)
+ else:
+ layer_ret = layer(hidden_states,
+ full_attention_mask,
+ rotary_pos_emb,
+ kv_cache=past_key_values[idx],
+ use_cache=use_cache)
+ hidden_states, kv_cache = layer_ret
+ if use_cache:
+ presents = presents + (kv_cache,)
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+ if stage_manager.is_last_stage():
+ # final layer_norm
+ if self.encoder.post_layer_norm:
+ hidden_states = self.encoder.final_layernorm(hidden_states)
+ if not return_dict:
+ return tuple(
+ v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=presents,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+ else:
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def chatglm_for_conditional_generation_forward(
+ self: ChatGLMForConditionalGeneration,
+ input_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ return_last_logit: Optional[bool] = False,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ logger = logging.get_logger(__name__)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = (return_dict if return_dict is not None else self.config.use_return_dict)
+ transformer_outputs = ChatGLMPipelineForwards.chatglm_model_forward(
+ self.transformer,
+ input_ids=input_ids,
+ position_ids=position_ids,
+ attention_mask=attention_mask,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ )
+ if stage_manager.is_last_stage():
+ hidden_states = transformer_outputs[0]
+ if return_last_logit:
+ hidden_states = hidden_states[-1:]
+ lm_logits = self.transformer.output_layer(hidden_states)
+ lm_logits = lm_logits.transpose(0, 1).contiguous()
+ loss = None
+ if labels is not None:
+ lm_logits = lm_logits.to(torch.float32)
+ # Shift so that tokens < n predict n
+ shift_logits = lm_logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss(ignore_index=-100)
+ loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
+ lm_logits = lm_logits.to(hidden_states.dtype)
+ loss = loss.to(hidden_states.dtype)
+ if not return_dict:
+ output = (lm_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=lm_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
+ else:
+ return transformer_outputs
diff --git a/tests/kit/model_zoo/transformers/chatglm2_6b/configuration_chatglm.py b/colossalai/shardformer/modeling/chatglm2_6b/configuration_chatglm.py
similarity index 100%
rename from tests/kit/model_zoo/transformers/chatglm2_6b/configuration_chatglm.py
rename to colossalai/shardformer/modeling/chatglm2_6b/configuration_chatglm.py
diff --git a/tests/kit/model_zoo/transformers/chatglm2_6b/modeling_chatglm.py b/colossalai/shardformer/modeling/chatglm2_6b/modeling_chatglm.py
similarity index 99%
rename from tests/kit/model_zoo/transformers/chatglm2_6b/modeling_chatglm.py
rename to colossalai/shardformer/modeling/chatglm2_6b/modeling_chatglm.py
index bae6d425878d..a21ee0231422 100644
--- a/tests/kit/model_zoo/transformers/chatglm2_6b/modeling_chatglm.py
+++ b/colossalai/shardformer/modeling/chatglm2_6b/modeling_chatglm.py
@@ -223,14 +223,15 @@ class RMSNorm(torch.nn.Module):
def __init__(self, normalized_shape, eps=1e-5, device=None, dtype=None, **kwargs):
super().__init__()
- self.weight = torch.nn.Parameter(torch.empty(normalized_shape, device=device, dtype=dtype))
+ self.elementwise_affine = True
+ self.normalized_shape = normalized_shape
+ self.weight = torch.nn.Parameter(torch.ones(normalized_shape, device=device, dtype=dtype))
self.eps = eps
def forward(self, hidden_states: torch.Tensor):
input_dtype = hidden_states.dtype
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.eps)
-
return (self.weight * hidden_states).to(input_dtype)
diff --git a/colossalai/shardformer/modeling/gpt2.py b/colossalai/shardformer/modeling/gpt2.py
index dc5a81dc912b..e02581fbaa9b 100644
--- a/colossalai/shardformer/modeling/gpt2.py
+++ b/colossalai/shardformer/modeling/gpt2.py
@@ -668,3 +668,88 @@ def gpt2_for_sequence_classification_forward(
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
+
+
+def get_gpt2_flash_attention_forward():
+
+ from transformers.models.gpt2.modeling_gpt2 import GPT2Attention
+
+ from colossalai.kernel.cuda_native.flash_attention import AttnMaskType, ColoAttention
+
+ def split_heads(tensor, num_heads, attn_head_size):
+ """
+ Splits hidden_size dim into attn_head_size and num_heads
+ """
+ new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
+ tensor = tensor.view(new_shape)
+ return tensor
+
+ def forward(
+ self: GPT2Attention,
+ hidden_states: Optional[Tuple[torch.FloatTensor]],
+ layer_past: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = False,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:
+ _, tgt_len, _ = hidden_states.size()
+ assert tgt_len % 4 == 0, "Flash Attention Error: The sequence length should be a multiple of 4."
+
+ if encoder_hidden_states is not None:
+ if not hasattr(self, "q_attn"):
+ raise ValueError(
+ "If class is used as cross attention, the weights `q_attn` have to be defined. "
+ "Please make sure to instantiate class with `GPT2Attention(..., is_cross_attention=True)`.")
+
+ query = self.q_attn(hidden_states)
+ key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
+ attention_mask = encoder_attention_mask
+ else:
+ query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
+
+ query = split_heads(query, self.num_heads, self.head_dim)
+ key = split_heads(key, self.num_heads, self.head_dim)
+ value = split_heads(value, self.num_heads, self.head_dim)
+
+ if layer_past is not None:
+ past_key, past_value = layer_past
+ key = torch.cat((past_key, key), dim=1)
+ value = torch.cat((past_value, value), dim=1)
+
+ if use_cache is True:
+ present = (key, value)
+ else:
+ present = None
+
+ if not self.is_cross_attention:
+ attn_mask_type = AttnMaskType.causal
+ flash_attention_mask = None
+ if attention_mask != None:
+ if attn_mask_type == AttnMaskType.causal:
+ attn_mask_type == AttnMaskType.paddedcausal
+ else:
+ attn_mask_type = AttnMaskType.padding
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool)).contiguous()
+
+ scale = value.size(-1)**-0.5
+ if self.scale_attn_by_inverse_layer_idx:
+ scale = scale * (1 / float(self.layer_idx + 1))
+
+ # use coloattention
+ attention = ColoAttention(embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ dropout=self.attn_dropout.p,
+ scale=scale)
+
+ attn_output = attention(query, key, value, attn_mask=flash_attention_mask, attn_mask_type=attn_mask_type)
+
+ attn_output = self.c_proj(attn_output)
+ attn_output = self.resid_dropout(attn_output)
+ outputs = (attn_output, present, None)
+
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/modeling/jit.py b/colossalai/shardformer/modeling/jit.py
new file mode 100644
index 000000000000..6434348ef823
--- /dev/null
+++ b/colossalai/shardformer/modeling/jit.py
@@ -0,0 +1,34 @@
+import torch
+
+
+def get_dropout_add_func():
+
+ from transformers.models.bloom.modeling_bloom import dropout_add
+
+ def self_dropout_add(self, x: torch.Tensor, residual: torch.Tensor, prob: float, training: bool) -> torch.Tensor:
+ return dropout_add(x, residual, prob, training)
+
+ return self_dropout_add
+
+
+def get_jit_fused_dropout_add_func():
+
+ from colossalai.kernel.jit import bias_dropout_add_fused_inference, bias_dropout_add_fused_train
+
+ def self_dropout_add(self, x: torch.Tensor, residual: torch.Tensor, prob: float, training: bool) -> torch.Tensor:
+ bias = torch.zeros_like(x)
+ if training:
+ return bias_dropout_add_fused_train(x, bias, residual, prob)
+ return bias_dropout_add_fused_inference(x, bias, residual, prob)
+
+ return self_dropout_add
+
+
+def get_jit_fused_gelu_forward_func():
+
+ from colossalai.kernel.jit.bias_gelu import bias_gelu
+
+ def bloom_gelu_forward(x: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:
+ return bias_gelu(bias, x)
+
+ return bloom_gelu_forward
diff --git a/colossalai/shardformer/modeling/llama.py b/colossalai/shardformer/modeling/llama.py
index e1ed5f64665c..9d6335503b36 100644
--- a/colossalai/shardformer/modeling/llama.py
+++ b/colossalai/shardformer/modeling/llama.py
@@ -1,4 +1,4 @@
-from typing import Callable, List, Optional
+from typing import Callable, List, Optional, Tuple
import torch
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
@@ -386,3 +386,67 @@ def llama_for_sequence_classification_forward(
else:
hidden_states = transformer_outputs.get('hidden_states')
return {'hidden_states': hidden_states}
+
+
+def get_llama_flash_attention_forward():
+
+ from transformers.models.llama.modeling_llama import LlamaAttention, apply_rotary_pos_emb
+
+ from colossalai.kernel.cuda_native.flash_attention import AttnMaskType, ColoAttention
+
+ def forward(
+ self: LlamaAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+ assert q_len % 4 == 0, "Flash Attention Error: The sequence length should be a multiple of 4."
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ me_input_shape = (bsz, q_len, self.num_heads, self.head_dim)
+ query_states = query_states.transpose(1, 2).contiguous().view(*me_input_shape)
+ key_states = key_states.transpose(1, 2).contiguous().view(*me_input_shape)
+ value_states = value_states.transpose(1, 2).contiguous().view(*me_input_shape)
+
+ flash_attention_mask = None
+ attn_mask_type = AttnMaskType.causal
+ if attention_mask != None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}")
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool)).contiguous()
+ attn_mask_type = AttnMaskType.paddedcausal
+
+ attention = ColoAttention(embed_dim=self.hidden_size, num_heads=self.num_heads)
+ attn_output = attention(query_states,
+ key_states,
+ value_states,
+ attn_mask=flash_attention_mask,
+ attn_mask_type=attn_mask_type)
+
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+ return forward
diff --git a/colossalai/shardformer/modeling/opt.py b/colossalai/shardformer/modeling/opt.py
new file mode 100644
index 000000000000..299dfb5562f3
--- /dev/null
+++ b/colossalai/shardformer/modeling/opt.py
@@ -0,0 +1,174 @@
+from typing import Optional, Tuple
+
+import torch
+from torch import nn
+
+
+def get_opt_flash_attention_forward():
+
+ from transformers.models.opt.modeling_opt import OPTAttention
+
+ from colossalai.kernel.cuda_native.flash_attention import AttnMaskType, ColoAttention
+
+ def forward(
+ self: OPTAttention,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+ bsz, tgt_len, _ = hidden_states.size()
+ assert tgt_len % 4 == 0, "Flash Attention Error: The sequence length should be a multiple of 4."
+
+ attention_input_shape = (bsz, -1, self.num_heads, self.head_dim)
+ # get query proj
+ query_states = self.q_proj(hidden_states).view(*attention_input_shape)
+ # get key, value proj
+ if is_cross_attention and past_key_value is not None:
+ # reuse k, v, cross_attentions
+ key_states = past_key_value[0].transpose(1, 2).contiguous().view(*attention_input_shape)
+ value_states = past_key_value[1].transpose(1, 2).contiguous().view(*attention_input_shape)
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self.k_proj(key_value_states).view(*attention_input_shape)
+ value_states = self.v_proj(key_value_states).view(*attention_input_shape)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self.k_proj(hidden_states).view(*attention_input_shape)
+ value_states = self.v_proj(hidden_states).view(*attention_input_shape)
+ key_states = torch.cat([past_key_value[0], key_states], dim=1)
+ value_states = torch.cat([past_key_value[1], value_states], dim=1)
+ else:
+ # self_attention
+ key_states = self.k_proj(hidden_states).view(*attention_input_shape)
+ value_states = self.v_proj(hidden_states).view(*attention_input_shape)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ src_len = key_states.size(1)
+ if layer_head_mask != None:
+ if layer_head_mask.size() != (self.num_heads,):
+ raise ValueError(f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
+ f" {layer_head_mask.size()}")
+
+ flash_attention_mask = None
+ attn_mask_type = AttnMaskType.causal
+ if attention_mask != None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}")
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool)).contiguous()
+ attn_mask_type = AttnMaskType.paddedcausal
+
+ attention = ColoAttention(embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ dropout=self.dropout,
+ scale=self.scaling)
+ attn_output = attention(query_states,
+ key_states,
+ value_states,
+ attn_mask=flash_attention_mask,
+ attn_mask_type=attn_mask_type)
+
+ attn_output = self.out_proj(attn_output)
+ return attn_output, None, past_key_value
+
+ return forward
+
+
+def get_jit_fused_opt_decoder_layer_forward():
+
+ from transformers.models.opt.modeling_opt import OPTDecoderLayer
+
+ def forward(
+ self: OPTDecoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`, *optional*): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+
+ residual = hidden_states
+
+ # 125m, 1.7B, ..., 175B applies layer norm BEFORE attention
+ if self.do_layer_norm_before:
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ past_key_value=past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ # 350m applies layer norm AFTER attention
+ if not self.do_layer_norm_before:
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Fully Connected
+ hidden_states_shape = hidden_states.shape
+ hidden_states = hidden_states.reshape(-1, hidden_states.size(-1))
+ residual = hidden_states
+
+ # 125m, 1.7B, ..., 175B applies layer norm BEFORE attention
+ if self.do_layer_norm_before:
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ hidden_states = self.fc1(hidden_states)
+ hidden_states = self.activation_fn(hidden_states)
+
+ hidden_states = self.fc2(hidden_states)
+
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training).view(hidden_states_shape)
+
+ # 350m applies layer norm AFTER attention
+ if not self.do_layer_norm_before:
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/modeling/sam.py b/colossalai/shardformer/modeling/sam.py
index 63ebfe89d5fa..c40c02ec411a 100644
--- a/colossalai/shardformer/modeling/sam.py
+++ b/colossalai/shardformer/modeling/sam.py
@@ -1,4 +1,9 @@
+import math
+from typing import Tuple
+
import torch
+import torch.nn.functional as F
+from torch import Tensor
def forward_fn():
@@ -37,3 +42,162 @@ def forward(self, hidden_states: torch.Tensor, output_attentions=False) -> torch
return outputs
return forward
+
+
+def get_sam_flash_attention_forward():
+
+ from transformers.models.sam.modeling_sam import SamAttention
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+
+ def _separate_heads(hidden_states: Tensor, num_attention_heads: int) -> Tensor:
+ batch, point_batch_size, n_tokens, channel = hidden_states.shape
+ c_per_head = channel // num_attention_heads
+ hidden_states = hidden_states.reshape(batch * point_batch_size, n_tokens, num_attention_heads, c_per_head)
+ return hidden_states
+
+ def _recombine_heads(hidden_states: Tensor, point_batch_size: int) -> Tensor:
+ batch, n_tokens, n_heads, c_per_head = hidden_states.shape
+ return hidden_states.reshape(batch // point_batch_size, point_batch_size, n_tokens, n_heads * c_per_head)
+
+ def forward(self: SamAttention,
+ query: Tensor,
+ key: Tensor,
+ value: Tensor,
+ attention_similarity: Tensor = None) -> Tensor:
+ # Input projections
+ query = self.q_proj(query)
+ key = self.k_proj(key)
+ value = self.v_proj(value)
+
+ point_batch_size = query.shape[1]
+ # Separate into heads
+ query = _separate_heads(query, self.num_attention_heads)
+ key = _separate_heads(key, self.num_attention_heads)
+ value = _separate_heads(value, self.num_attention_heads)
+
+ # SamAttention
+ _, _, _, c_per_head = query.shape
+ bias = None
+ if attention_similarity is not None:
+ bias = attention_similarity
+
+ scale = 1.0 / math.sqrt(c_per_head)
+ out = me_attention(query, key, value, attn_bias=bias, scale=scale)
+
+ out = _recombine_heads(out, point_batch_size)
+ out = self.out_proj(out)
+
+ return out
+
+ return forward
+
+
+def get_sam_vision_flash_attention_forward():
+
+ from transformers.models.sam.modeling_sam import SamVisionAttention
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+
+ def add_decomposed_rel_pos(
+ query: torch.Tensor,
+ rel_pos_h: torch.Tensor,
+ rel_pos_w: torch.Tensor,
+ q_size: Tuple[int, int],
+ k_size: Tuple[int, int],
+ ) -> torch.Tensor:
+ """
+ Calculate decomposed Relative Positional Embeddings from :paper:`mvitv2`.
+ https://github.com/facebookresearch/mvit/blob/19786631e330df9f3622e5402b4a419a263a2c80/mvit/models/attention.py
+
+ Args:
+ attn (`torch.Tensor`):
+ attention map.
+ query (`torch.Tensor`):
+ query q in the attention layer with shape (batch_size, query_height * query_width, channel).
+ rel_pos_h (`torch.Tensor`):
+ relative position embeddings (Lh, channel) for height axis.
+ rel_pos_w (`torch.Tensor`):
+ relative position embeddings (Lw, channel) for width axis.
+ q_size (tuple):
+ spatial sequence size of query q with (query_height, query_width).
+ k_size (tuple):
+ spatial sequence size of key k with (key_height, key_width).
+
+ Returns:
+ attn (`torch.Tensor`):
+ attention map with added relative positional embeddings.
+ """
+
+ query_height, query_width = q_size
+ key_height, key_width = k_size
+ relative_position_height = get_rel_pos(query_height, key_height, rel_pos_h)
+ relative_position_width = get_rel_pos(query_width, key_width, rel_pos_w)
+
+ batch_size, _, nHead, dim = query.shape
+ reshaped_query = query.transpose(1, 2).reshape(batch_size * nHead, query_height, query_width, dim)
+ rel_h = torch.einsum("bhwc,hkc->bhwk", reshaped_query, relative_position_height)
+ rel_w = torch.einsum("bhwc,wkc->bhwk", reshaped_query, relative_position_width)
+ rel_pos = rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :]
+ rel_pos = rel_pos.reshape(batch_size, nHead, query_height * query_width, key_height * key_width)
+ return rel_pos
+
+ def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torch.Tensor:
+ """
+ Get relative positional embeddings according to the relative positions of
+ query and key sizes.
+
+ Args:
+ q_size (int):
+ size of the query.
+ k_size (int):
+ size of key k.
+ rel_pos (`torch.Tensor`):
+ relative position embeddings (L, channel).
+
+ Returns:
+ Extracted positional embeddings according to relative positions.
+ """
+ max_rel_dist = int(2 * max(q_size, k_size) - 1)
+ # Interpolate rel pos.
+ rel_pos_resized = F.interpolate(
+ rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1),
+ size=max_rel_dist,
+ mode="linear",
+ )
+ rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0)
+
+ # Scale the coords with short length if shapes for q and k are different.
+ q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0)
+ k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0)
+ relative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0)
+
+ return rel_pos_resized[relative_coords.long()]
+
+ def forward(self: SamVisionAttention, hidden_states: torch.Tensor, output_attentions=False) -> torch.Tensor:
+ batch_size, height, width, _ = hidden_states.shape
+ # qkv with shape (3, batch_size, nHead, height * width, channel)
+ qkv = (self.qkv(hidden_states).reshape(batch_size, height * width, 3, self.num_attention_heads,
+ -1).permute(2, 0, 1, 3, 4))
+
+ query, key, value = qkv.reshape(3, batch_size, height * width, self.num_attention_heads, -1).unbind(0)
+
+ rel_pos = None
+ if self.use_rel_pos:
+ rel_pos = add_decomposed_rel_pos(query, self.rel_pos_h, self.rel_pos_w, (height, width), (height, width))
+
+ attn_output = me_attention(query, key, value, attn_bias=rel_pos, p=self.dropout, scale=self.scale)
+
+ attn_output = attn_output.reshape(batch_size, height, width, -1)
+
+ attn_output = self.proj(attn_output)
+
+ outputs = (attn_output, None)
+
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/modeling/t5.py b/colossalai/shardformer/modeling/t5.py
index 7eb4d17928d6..d622da452366 100644
--- a/colossalai/shardformer/modeling/t5.py
+++ b/colossalai/shardformer/modeling/t5.py
@@ -238,7 +238,8 @@ def custom_forward(*inputs):
return {
'hidden_states': hidden_states,
'position_bias': position_bias,
- 'encoder_decoder_position_bias': encoder_decoder_position_bias
+ 'encoder_decoder_position_bias': encoder_decoder_position_bias,
+ 'backward_tensor_keys': ['hidden_states']
}
@staticmethod
@@ -261,8 +262,10 @@ def t5_model_forward(
return_dict: Optional[bool] = None,
stage_manager: Optional[PipelineStageManager] = None,
hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
position_bias: Optional[torch.Tensor] = None,
encoder_decoder_position_bias: Optional[torch.Tensor] = None,
+ backward_tensor_keys: Optional[List[str]] = None,
stage_index: Optional[List[int]] = None,
decoder_starting_stage: Optional[int] = None,
) -> Union[Tuple[torch.FloatTensor], Seq2SeqModelOutput]:
@@ -303,7 +306,6 @@ def t5_model_forward(
decoder_head_mask = head_mask
in_decoder = stage_manager.stage >= decoder_starting_stage
-
# Stage is in encoder, directly return the output of t5_stack_forward
if not in_decoder:
encoder_outputs = T5PipelineForwards.t5_stack_forward(
@@ -323,25 +325,18 @@ def t5_model_forward(
decoder_starting_stage=decoder_starting_stage)
if stage_manager.stage == decoder_starting_stage - 1:
# last stage of encoder
- return {'encoder_outputs': encoder_outputs}
+ return {'encoder_hidden_states': encoder_outputs[0]}
else:
return encoder_outputs
at_last_decoder_stage = stage_manager.is_last_stage()
at_first_decoder_stage = stage_manager.stage == decoder_starting_stage
- if encoder_outputs is None:
- raise ValueError("Non-empty encoder_outputs should be passed in at decoder stages.")
-
- encoder_hidden_states = encoder_outputs[0]
- if return_dict and not isinstance(encoder_outputs, BaseModelOutput):
- encoder_outputs = BaseModelOutput(
- last_hidden_state=encoder_outputs[0],
- hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
- attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
- )
+ if encoder_outputs is not None:
+ encoder_hidden_states = encoder_outputs[0]
+ elif encoder_hidden_states is None:
+ raise ValueError("Non-empty encoder_hidden_states should be passed in at decoder stages.")
- # Stage is in decoder, we assume that the outputs of last stage of encoder will be passed in.
if not at_first_decoder_stage and hidden_states is None:
raise ValueError("If not at the first layer of decoder, non-empty hidden_states must be provided.")
@@ -360,6 +355,7 @@ def t5_model_forward(
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
+ stage_manager=stage_manager,
hidden_states=hidden_states,
position_bias=position_bias,
encoder_decoder_position_bias=encoder_decoder_position_bias,
@@ -368,22 +364,19 @@ def t5_model_forward(
# Directly return outputs of overloaded T5Stack forward if not at last stage.
if not at_last_decoder_stage:
- decoder_outputs['encoder_outputs'] = encoder_outputs # encoder_outputs should be passed to the next stage
+ # encoder_hidden_states should be passed to the next stage
+ decoder_outputs['encoder_hidden_states'] = encoder_hidden_states
return decoder_outputs
if not return_dict:
- return decoder_outputs + encoder_outputs
-
- return Seq2SeqModelOutput(
- last_hidden_state=decoder_outputs.last_hidden_state,
- past_key_values=decoder_outputs.past_key_values,
- decoder_hidden_states=decoder_outputs.hidden_states,
- decoder_attentions=decoder_outputs.attentions,
- cross_attentions=decoder_outputs.cross_attentions,
- encoder_last_hidden_state=encoder_outputs.last_hidden_state,
- encoder_hidden_states=encoder_outputs.hidden_states,
- encoder_attentions=encoder_outputs.attentions,
- )
+ return decoder_outputs + encoder_hidden_states
+ else:
+ return Seq2SeqModelOutput(last_hidden_state=decoder_outputs.last_hidden_state,
+ past_key_values=decoder_outputs.past_key_values,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
+ encoder_last_hidden_state=encoder_hidden_states)
@staticmethod
def t5_for_conditional_generation_forward(
@@ -406,8 +399,10 @@ def t5_for_conditional_generation_forward(
return_dict: Optional[bool] = None,
stage_manager: Optional[PipelineStageManager] = None,
hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
position_bias: Optional[torch.Tensor] = None,
encoder_decoder_position_bias: Optional[torch.Tensor] = None,
+ backward_tensor_keys: Optional[List[str]] = None,
stage_index: Optional[List[int]] = None,
decoder_starting_stage: Optional[int] = None,
) -> Union[Tuple[torch.FloatTensor], Seq2SeqLMOutput]:
@@ -468,28 +463,25 @@ def t5_for_conditional_generation_forward(
decoder_starting_stage=decoder_starting_stage)
if stage_manager.stage == decoder_starting_stage - 1:
# last stage of encoder
- return {'encoder_outputs': encoder_outputs}
+ return {'encoder_hidden_states': encoder_outputs[0]}
else:
return encoder_outputs
at_last_decoder_stage = stage_manager.is_last_stage()
at_first_decoder_stage = stage_manager.stage == decoder_starting_stage
- if encoder_outputs is None:
- raise ValueError("Non-empty encoder_outputs should be passed in at decoder stages.")
-
- encoder_hidden_states = encoder_outputs[0]
- if return_dict and not isinstance(encoder_outputs, BaseModelOutput):
- encoder_outputs = BaseModelOutput(
- last_hidden_state=encoder_outputs[0],
- hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
- attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
- )
+ if encoder_outputs is not None:
+ encoder_hidden_states = encoder_outputs[0]
+ elif encoder_hidden_states is None:
+ raise ValueError("Non-empty encoder_hidden_states should be passed in at decoder stages.")
- # Stage is in decoder, we assume that the outputs of last stage of encoder will be passed in.
if not at_first_decoder_stage and hidden_states is None:
raise ValueError("If not at the first layer of decoder, non-empty hidden_states must be provided.")
+ if labels is not None and decoder_input_ids is None and decoder_inputs_embeds is None:
+ # get decoder inputs from shifting lm labels to the right
+ decoder_input_ids = self._shift_right(labels)
+
# Decode
decoder_outputs = T5PipelineForwards.t5_stack_forward(
self.decoder,
@@ -505,6 +497,7 @@ def t5_for_conditional_generation_forward(
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
+ stage_manager=stage_manager,
hidden_states=hidden_states,
position_bias=position_bias,
encoder_decoder_position_bias=encoder_decoder_position_bias,
@@ -513,7 +506,8 @@ def t5_for_conditional_generation_forward(
# Directly return outputs of overloaded T5Stack forward if not at last stage.
if not at_last_decoder_stage:
- decoder_outputs['encoder_outputs'] = encoder_outputs # encoder_outputs should be passed to the next stage
+ # encoder_hidden_states should be passed to the next stage
+ decoder_outputs['encoder_hidden_states'] = encoder_hidden_states
return decoder_outputs
sequence_output = decoder_outputs[0]
@@ -533,20 +527,16 @@ def t5_for_conditional_generation_forward(
loss = loss_fct(lm_logits.view(-1, lm_logits.size(-1)), labels.view(-1))
if not return_dict:
- output = (lm_logits,) + decoder_outputs[1:] + encoder_outputs
+ output = (lm_logits,) + decoder_outputs[1:] + encoder_hidden_states
return ((loss,) + output) if loss is not None else output
- return Seq2SeqLMOutput(
- loss=loss,
- logits=lm_logits,
- past_key_values=decoder_outputs.past_key_values,
- decoder_hidden_states=decoder_outputs.hidden_states,
- decoder_attentions=decoder_outputs.attentions,
- cross_attentions=decoder_outputs.cross_attentions,
- encoder_last_hidden_state=encoder_outputs.last_hidden_state,
- encoder_hidden_states=encoder_outputs.hidden_states,
- encoder_attentions=encoder_outputs.attentions,
- )
+ return Seq2SeqLMOutput(loss=loss,
+ logits=lm_logits,
+ past_key_values=decoder_outputs.past_key_values,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
+ encoder_last_hidden_state=encoder_hidden_states)
@staticmethod
def t5_encoder_model_forward(
@@ -562,6 +552,7 @@ def t5_encoder_model_forward(
hidden_states: Optional[torch.FloatTensor] = None,
position_bias: Optional[torch.Tensor] = None,
encoder_decoder_position_bias: Optional[torch.Tensor] = None,
+ backward_tensor_keys: Optional[List[str]] = None,
stage_index: Optional[List[int]] = None,
decoder_starting_stage: Optional[int] = None,
) -> Union[Tuple[torch.FloatTensor], BaseModelOutput]:
@@ -587,3 +578,209 @@ def t5_encoder_model_forward(
decoder_starting_stage=decoder_starting_stage)
return outputs
+
+
+def get_t5_flash_attention_forward():
+
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+ from transformers.models.t5.modeling_t5 import T5Attention
+
+ def forward(
+ self: T5Attention,
+ hidden_states: torch.Tensor,
+ mask: Optional[torch.Tensor] = None,
+ key_value_states: Optional[torch.Tensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ query_length: Optional[int] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]:
+ """
+ Self-attention (if key_value_states is None) or attention over source sentence (provided by key_value_states).
+ """
+ # Input is (batch_size, seq_length, dim)
+ # Mask is (batch_size, key_length) (non-causal) or (batch_size, key_length, key_length)
+ # past_key_value[0] is (batch_size, n_heads, q_len - 1, dim_per_head)
+ batch_size, seq_length = hidden_states.shape[:2]
+
+ real_seq_length = seq_length
+
+ if past_key_value is not None:
+ if len(past_key_value) != 2:
+ raise ValueError(
+ f"past_key_value should have 2 past states: keys and values. Got { len(past_key_value)} past states"
+ )
+ real_seq_length += past_key_value[0].shape[2] if query_length is None else query_length
+
+ key_length = real_seq_length if key_value_states is None else key_value_states.shape[1]
+
+ def shape(states):
+ """projection"""
+ return states.view(batch_size, -1, self.n_heads, self.key_value_proj_dim)
+
+ def unshape(states):
+ """reshape"""
+ return states.view(batch_size, -1, self.inner_dim)
+
+ def project(hidden_states, proj_layer, key_value_states, past_key_value):
+ """projects hidden states correctly to key/query states"""
+ if key_value_states is None:
+ # self-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(hidden_states))
+ elif past_key_value is None:
+ # cross-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(key_value_states))
+
+ if past_key_value is not None:
+ if key_value_states is None:
+ # self-attn
+ # (batch_size, n_heads, key_length, dim_per_head)
+ hidden_states = torch.cat([past_key_value, hidden_states], dim=1)
+ elif past_key_value.shape[1] != key_value_states.shape[1]:
+ # checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ # cross-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(key_value_states))
+ else:
+ # cross-attn
+ hidden_states = past_key_value
+ return hidden_states
+
+ # get query states
+ query_states = shape(self.q(hidden_states)) # (batch_size, n_heads, seq_length, dim_per_head)
+
+ # get key/value states
+ key_states = project(hidden_states, self.k, key_value_states,
+ past_key_value[0] if past_key_value is not None else None)
+ value_states = project(hidden_states, self.v, key_value_states,
+ past_key_value[1] if past_key_value is not None else None)
+
+ if position_bias is None:
+ if not self.has_relative_attention_bias:
+ position_bias = torch.zeros((1, self.n_heads, real_seq_length, key_length),
+ device=query_states.device,
+ dtype=query_states.dtype)
+ if self.gradient_checkpointing and self.training:
+ position_bias.requires_grad = True
+ else:
+ position_bias = self.compute_bias(real_seq_length, key_length, device=query_states.device)
+
+ # if key and values are already calculated
+ # we want only the last query position bias
+ if past_key_value is not None:
+ position_bias = position_bias[:, :, -hidden_states.size(1):, :]
+
+ if mask is not None:
+ position_bias = position_bias + mask # (batch_size, n_heads, seq_length, key_length)
+
+ if self.pruned_heads:
+ mask = torch.ones(position_bias.shape[1])
+ mask[list(self.pruned_heads)] = 0
+ position_bias_masked = position_bias[:, mask.bool()]
+ else:
+ position_bias_masked = position_bias
+
+ position_bias_masked = position_bias_masked.contiguous()
+ attn_output = me_attention(query_states,
+ key_states,
+ value_states,
+ attn_bias=position_bias_masked,
+ p=self.dropout,
+ scale=1.0)
+ attn_output = unshape(attn_output)
+ attn_output = self.o(attn_output)
+
+ present_key_value_state = (key_states, value_states) if (self.is_decoder and use_cache) else None
+
+ outputs = (attn_output,) + (present_key_value_state,) + (position_bias,)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_T5_layer_ff_forward():
+
+ from transformers.models.t5.modeling_t5 import T5LayerFF
+
+ def forward(self: T5LayerFF, hidden_states: torch.Tensor) -> torch.Tensor:
+ forwarded_states = self.layer_norm(hidden_states)
+ forwarded_states = self.DenseReluDense(forwarded_states)
+ hidden_states = self.dropout_add(forwarded_states, hidden_states, self.dropout.p, self.dropout.training)
+ return hidden_states
+
+ return forward
+
+
+def get_T5_layer_self_attention_forward():
+
+ from transformers.models.t5.modeling_t5 import T5LayerSelfAttention
+
+ def forward(
+ self: T5LayerSelfAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]:
+ normed_hidden_states = self.layer_norm(hidden_states)
+ attention_output = self.SelfAttention(
+ normed_hidden_states,
+ mask=attention_mask,
+ position_bias=position_bias,
+ layer_head_mask=layer_head_mask,
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.dropout_add(attention_output[0], hidden_states, self.dropout.p, self.dropout.training)
+ outputs = (hidden_states,) + attention_output[1:] # add attentions if we output them
+ return outputs
+
+ return forward
+
+
+def get_T5_layer_cross_attention_forward():
+
+ from transformers.models.t5.modeling_t5 import T5LayerCrossAttention
+
+ def forward(
+ self: T5LayerCrossAttention,
+ hidden_states: torch.Tensor,
+ key_value_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ use_cache: bool = False,
+ query_length: Optional[int] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]:
+ normed_hidden_states = self.layer_norm(hidden_states)
+ attention_output = self.EncDecAttention(
+ normed_hidden_states,
+ mask=attention_mask,
+ key_value_states=key_value_states,
+ position_bias=position_bias,
+ layer_head_mask=layer_head_mask,
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ query_length=query_length,
+ output_attentions=output_attentions,
+ )
+ layer_output = self.dropout_add(attention_output[0], hidden_states, self.dropout.p, self.dropout.training)
+ outputs = (layer_output,) + attention_output[1:] # add attentions if we output them
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/modeling/vit.py b/colossalai/shardformer/modeling/vit.py
index f28c13ad0aa2..22c4dd998cac 100644
--- a/colossalai/shardformer/modeling/vit.py
+++ b/colossalai/shardformer/modeling/vit.py
@@ -1,4 +1,5 @@
import logging
+import math
from typing import Dict, List, Optional, Set, Tuple, Union
import torch
@@ -335,3 +336,51 @@ def pp_forward(
)
return pp_forward
+
+
+def get_vit_flash_self_attention_forward():
+
+ from transformers.models.vit.modeling_vit import ViTSelfAttention
+
+ from colossalai.kernel.cuda_native.flash_attention import ColoAttention
+
+ def transpose_for_scores(x: torch.Tensor, num_attention_heads, attention_head_size) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (num_attention_heads, attention_head_size)
+ x = x.view(new_x_shape)
+ return x
+
+ def forward(self: ViTSelfAttention,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = transpose_for_scores(self.key(hidden_states), self.num_attention_heads, self.attention_head_size)
+ value_layer = transpose_for_scores(self.value(hidden_states), self.num_attention_heads,
+ self.attention_head_size)
+ query_layer = transpose_for_scores(mixed_query_layer, self.num_attention_heads, self.attention_head_size)
+
+ scale = 1.0 / math.sqrt(self.attention_head_size)
+ attention = ColoAttention(embed_dim=self.all_head_size,
+ num_heads=self.num_attention_heads,
+ dropout=self.dropout.p,
+ scale=scale)
+ context_layer = attention(query_layer, key_layer, value_layer)
+
+ outputs = (context_layer,)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_vit_output_forward():
+
+ from transformers.models.vit.modeling_vit import ViTOutput
+
+ def forward(self: ViTOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/modeling/whisper.py b/colossalai/shardformer/modeling/whisper.py
new file mode 100644
index 000000000000..6bc387ac8974
--- /dev/null
+++ b/colossalai/shardformer/modeling/whisper.py
@@ -0,0 +1,249 @@
+from typing import Optional, Tuple
+
+import torch
+from torch import nn
+
+
+def get_whisper_flash_attention_forward():
+
+ from transformers.models.whisper.modeling_whisper import WhisperAttention
+
+ from colossalai.kernel.cuda_native.flash_attention import AttnMaskType, ColoAttention
+
+ def shape(tensor: torch.Tensor, seq_len: int, bsz: int, num_heads: int, head_dim: int):
+ return tensor.view(bsz, seq_len, num_heads, head_dim).contiguous()
+
+ def forward(
+ self: WhisperAttention,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ # get key, value proj
+ # `past_key_value[0].shape[2] == key_value_states.shape[1]`
+ # is checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ if (is_cross_attention and past_key_value is not None
+ and past_key_value[0].shape[1] == key_value_states.shape[1]):
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0]
+ value_states = past_key_value[1]
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = shape(self.k_proj(key_value_states), -1, bsz, self.num_heads, self.head_dim)
+ value_states = shape(self.v_proj(key_value_states), -1, bsz, self.num_heads, self.head_dim)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = shape(self.k_proj(hidden_states), -1, bsz, self.num_heads, self.head_dim)
+ value_states = shape(self.v_proj(hidden_states), -1, bsz, self.num_heads, self.head_dim)
+ key_states = torch.cat([past_key_value[0], key_states], dim=1)
+ value_states = torch.cat([past_key_value[1], value_states], dim=1)
+ else:
+ # self_attention
+ key_states = shape(self.k_proj(hidden_states), -1, bsz, self.num_heads, self.head_dim)
+ value_states = shape(self.v_proj(hidden_states), -1, bsz, self.num_heads, self.head_dim)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ # get query proj
+ query_states = shape(self.q_proj(hidden_states), tgt_len, bsz, self.num_heads, self.head_dim)
+
+ src_len = key_states.size(1)
+ if layer_head_mask is not None:
+ if layer_head_mask.size() != (self.num_heads,):
+ raise ValueError(f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
+ f" {layer_head_mask.size()}")
+
+ attn_type = None
+ flash_attention_mask = None
+
+ if self.is_decoder:
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
+ )
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool).contiguous())
+ attn_type = AttnMaskType.paddedcausal
+
+ attention = ColoAttention(embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ dropout=self.dropout,
+ scale=self.scaling)
+ attn_output = attention(query_states,
+ key_states,
+ value_states,
+ attn_mask=flash_attention_mask,
+ attn_mask_type=attn_type)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+ return forward
+
+
+def get_jit_fused_whisper_encoder_layer_forward():
+
+ from transformers.models.whisper.modeling_whisper import WhisperEncoderLayer
+
+ def forward(
+ self: WhisperEncoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_head_mask: torch.Tensor,
+ output_attentions: bool = False,
+ ) -> torch.Tensor:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+ hidden_states, attn_weights, _ = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ residual = hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ if hidden_states.dtype == torch.float16 and (torch.isinf(hidden_states).any()
+ or torch.isnan(hidden_states).any()):
+ clamp_value = torch.finfo(hidden_states.dtype).max - 1000
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_whisper_decoder_layer_forward():
+
+ from transformers.models.whisper.modeling_whisper import WhisperDecoderLayer
+
+ def forward(
+ self: WhisperDecoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ cross_attn_layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = True,
+ ) -> torch.Tensor:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ encoder_hidden_states (`torch.FloatTensor`):
+ cross attention input to the layer of shape `(batch, seq_len, embed_dim)`
+ encoder_attention_mask (`torch.FloatTensor`): encoder attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ cross_attn_layer_head_mask (`torch.FloatTensor`): mask for cross-attention heads in a given layer of
+ size `(decoder_attention_heads,)`.
+ past_key_value (`Tuple(torch.FloatTensor)`): cached past key and value projection states
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Self Attention
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
+ # add present self-attn cache to positions 1,2 of present_key_value tuple
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ past_key_value=self_attn_past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ # Cross-Attention Block
+ cross_attn_present_key_value = None
+ cross_attn_weights = None
+ if encoder_hidden_states is not None:
+ residual = hidden_states
+ hidden_states = self.encoder_attn_layer_norm(hidden_states)
+
+ # cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
+ cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
+ hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
+ hidden_states=hidden_states,
+ key_value_states=encoder_hidden_states,
+ attention_mask=encoder_attention_mask,
+ layer_head_mask=cross_attn_layer_head_mask,
+ past_key_value=cross_attn_past_key_value,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ # add cross-attn to positions 3,4 of present_key_value tuple
+ present_key_value = present_key_value + cross_attn_present_key_value
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights, cross_attn_weights)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/policies/bert.py b/colossalai/shardformer/policies/bert.py
index 6f86de232fad..ace9ada3904f 100644
--- a/colossalai/shardformer/policies/bert.py
+++ b/colossalai/shardformer/policies/bert.py
@@ -7,7 +7,14 @@
import colossalai.shardformer.layer as col_nn
-from ..modeling.bert import BertPipelineForwards
+from .._utils import getattr_, setattr_
+from ..modeling.bert import (
+ BertPipelineForwards,
+ get_bert_flash_attention_forward,
+ get_jit_fused_bert_output_forward,
+ get_jit_fused_bert_self_output_forward,
+)
+from ..modeling.jit import get_jit_fused_dropout_add_func
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = [
@@ -37,7 +44,13 @@ def preprocess(self):
return self.model
def module_policy(self):
- from transformers.models.bert.modeling_bert import BertEmbeddings, BertLayer
+ from transformers.models.bert.modeling_bert import (
+ BertEmbeddings,
+ BertLayer,
+ BertOutput,
+ BertSelfAttention,
+ BertSelfOutput,
+ )
policy = {}
@@ -126,6 +139,23 @@ def module_policy(self):
policy=policy,
target_key=BertEmbeddings)
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[BertSelfAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_bert_flash_attention_forward(),
+ })
+
+ # use jit operator
+ if self.shard_config.enable_jit_fused:
+ policy[BertSelfOutput] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bert_self_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[BertOutput] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bert_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
return policy
def add_lm_head_policy(self, base_policy):
diff --git a/colossalai/shardformer/policies/blip2.py b/colossalai/shardformer/policies/blip2.py
index a244d70b56f5..50356302e93e 100644
--- a/colossalai/shardformer/policies/blip2.py
+++ b/colossalai/shardformer/policies/blip2.py
@@ -3,7 +3,13 @@
import colossalai.shardformer.layer as col_nn
from .._utils import getattr_, setattr_
-from ..modeling.blip2 import forward_fn
+from ..modeling.blip2 import (
+ forward_fn,
+ get_blip2_flash_attention_forward,
+ get_jit_fused_blip2_QFormer_output_forward,
+ get_jit_fused_blip2_QFormer_self_output_forward,
+)
+from ..modeling.jit import get_jit_fused_dropout_add_func
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ['BlipPolicy', 'BlipModelPolicy']
@@ -33,6 +39,8 @@ def module_policy(self):
Blip2EncoderLayer,
Blip2QFormerLayer,
Blip2QFormerModel,
+ Blip2QFormerOutput,
+ Blip2QFormerSelfOutput,
Blip2VisionModel,
)
from transformers.models.opt.modeling_opt import OPTDecoderLayer, OPTForCausalLM
@@ -275,6 +283,24 @@ def module_policy(self):
policy=policy,
target_key=OPTDecoderLayer)
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[Blip2Attention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_blip2_flash_attention_forward(),
+ })
+
+ # use jit operator
+ if self.shard_config.enable_jit_fused:
+ policy[Blip2QFormerSelfOutput] = ModulePolicyDescription(
+ method_replacement={
+ 'forward': get_jit_fused_blip2_QFormer_self_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[Blip2QFormerOutput] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_blip2_QFormer_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
return policy
def postprocess(self):
diff --git a/colossalai/shardformer/policies/bloom.py b/colossalai/shardformer/policies/bloom.py
index 15bae2f4a959..b35764db3870 100644
--- a/colossalai/shardformer/policies/bloom.py
+++ b/colossalai/shardformer/policies/bloom.py
@@ -7,7 +7,16 @@
import colossalai.shardformer.layer as col_nn
-from ..modeling.bloom import BloomPipelineForwards, build_bloom_alibi_tensor_fn
+from .._utils import getattr_, setattr_
+from ..modeling.bloom import (
+ BloomPipelineForwards,
+ build_bloom_alibi_tensor_fn,
+ get_bloom_flash_attention_forward,
+ get_jit_fused_bloom_attention_forward,
+ get_jit_fused_bloom_gelu_forward,
+ get_jit_fused_bloom_mlp_forward,
+)
+from ..modeling.jit import get_dropout_add_func, get_jit_fused_dropout_add_func, get_jit_fused_gelu_forward_func
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
@@ -30,7 +39,7 @@ def preprocess(self):
return self.model
def module_policy(self):
- from transformers.models.bloom.modeling_bloom import BloomBlock, BloomModel
+ from transformers.models.bloom.modeling_bloom import BloomAttention, BloomBlock, BloomGelu, BloomMLP, BloomModel
policy = {}
@@ -107,6 +116,27 @@ def module_policy(self):
policy=policy,
target_key=BloomBlock)
+ if self.shard_config.enable_flash_attention:
+ policy[BloomAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_bloom_flash_attention_forward(),
+ 'dropout_add': get_dropout_add_func()
+ })
+
+ # enable jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[BloomAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bloom_attention_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[BloomMLP] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bloom_mlp_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[BloomGelu] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bloom_gelu_forward(),
+ 'bloom_gelu_forward': get_jit_fused_gelu_forward_func(),
+ })
+
return policy
def postprocess(self):
diff --git a/colossalai/shardformer/policies/chatglm.py b/colossalai/shardformer/policies/chatglm.py
index 732a817b0655..e6b458936637 100644
--- a/colossalai/shardformer/policies/chatglm.py
+++ b/colossalai/shardformer/policies/chatglm.py
@@ -1,32 +1,47 @@
-from typing import Dict, Union
+from functools import partial
+from typing import Callable, Dict, List, Optional, Tuple, Union
import torch.nn as nn
+from torch import Tensor
+from transformers.modeling_outputs import BaseModelOutputWithPast
import colossalai.shardformer.layer as col_nn
-
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer.modeling.chatglm import ChatGLMPipelineForwards
+from colossalai.shardformer.modeling.chatglm2_6b.configuration_chatglm import ChatGLMConfig
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
+ ChatGLMForConditionalGeneration,
+ ChatGLMModel,
+ GLMBlock,
+)
+
+from ..modeling.chatglm import get_flash_core_attention_forward, get_jit_fused_glm_block_forward
+from ..modeling.jit import get_jit_fused_dropout_add_func
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
-__all__ = ['ChatGLMModelPolicy', 'ChatGLMForConditionalGenerationPolicy']
+__all__ = ['ChatGLMPolicy', 'ChatGLMModelPolicy', 'ChatGLMForConditionalGenerationPolicy']
-class ChatGLMModelPolicy(Policy):
+class ChatGLMPolicy(Policy):
def config_sanity_check(self):
pass
def preprocess(self):
# Resize embedding
- vocab_size = self.model.config.padded_vocab_size
- world_size = self.shard_config.tensor_parallel_size
+ if self.shard_config.enable_tensor_parallelism:
+ vocab_size = self.model.config.padded_vocab_size
+ world_size = self.shard_config.tensor_parallel_size
- if vocab_size % world_size != 0:
- new_vocab_size = vocab_size + world_size - vocab_size % world_size
- self.model.resize_token_embeddings(new_vocab_size)
+ if vocab_size % world_size != 0:
+ new_vocab_size = vocab_size + world_size - vocab_size % world_size
+ self.model.resize_token_embeddings(new_vocab_size)
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
- from tests.kit.model_zoo.transformers.chatglm2_6b.modeling_chatglm import ChatGLMModel, GLMBlock
+
+ from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import ChatGLMModel, CoreAttention, GLMBlock
policy = {}
@@ -107,14 +122,107 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
policy=policy,
target_key=ChatGLMModel)
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[CoreAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_flash_core_attention_forward(),
+ })
+
+ # use jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[GLMBlock] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_glm_block_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
return policy
def postprocess(self):
return self.model
+ def get_held_layers(self) -> List[nn.Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == 'ChatGLMModel':
+ module = self.model
+ else:
+ module = self.model.transformer
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(module.num_layers, stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embedding)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.encoder.layers[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ if module.encoder.post_layer_norm:
+ held_layers.append(module.encoder.final_layernorm)
+
+ # rotary_pos_emb is needed for all stages
+ held_layers.append(module.rotary_pos_emb)
+
+ return held_layers
+
+ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
+ """If under pipeline parallel setting, replacing the original forward method of huggingface
+ to customized forward method, and add this changing to policy."""
+ if not self.pipeline_stage_manager:
+ raise ValueError("set_pipeline_forward method can only be called when pipeline parallel is enabled.")
+ stage_manager = self.pipeline_stage_manager
+ if self.model.__class__.__name__ == 'ChatGLMModel':
+ module = self.model
+ else:
+ module = self.model.transformer
+
+ layers_per_stage = Policy.distribute_layers(module.num_layers, stage_manager.num_stages)
+ stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
+ method_replacement = {'forward': partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=model_cls)
+
+
+class ChatGLMModelPolicy(ChatGLMPolicy):
+
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ from transformers.models.gpt2.modeling_gpt2 import GPT2Model
+
+ policy = super().module_policy()
+
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=ChatGLMModel,
+ new_forward=ChatGLMPipelineForwards.chatglm_model_forward,
+ policy=policy)
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ return super().get_held_layers()
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in ChatGLMModel."""
+ return []
+
class ChatGLMForConditionalGenerationPolicy(ChatGLMModelPolicy):
def module_policy(self):
policy = super().module_policy()
+
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=ChatGLMForConditionalGeneration,
+ new_forward=ChatGLMPipelineForwards.chatglm_for_conditional_generation_forward,
+ policy=policy)
return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ if self.pipeline_stage_manager.is_last_stage():
+ held_layers.append(self.model.transformer.output_layer)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in ChatGLMForConditionalGenerationModel."""
+ return []
diff --git a/colossalai/shardformer/policies/gpt2.py b/colossalai/shardformer/policies/gpt2.py
index 6d734b063036..20e5fa372c8f 100644
--- a/colossalai/shardformer/policies/gpt2.py
+++ b/colossalai/shardformer/policies/gpt2.py
@@ -5,7 +5,8 @@
import colossalai.shardformer.layer as col_nn
-from ..modeling.gpt2 import GPT2PipelineForwards
+from .._utils import getattr_, setattr_
+from ..modeling.gpt2 import GPT2PipelineForwards, get_gpt2_flash_attention_forward
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = [
@@ -33,7 +34,7 @@ def preprocess(self):
return self.model
def module_policy(self):
- from transformers.models.gpt2.modeling_gpt2 import GPT2Block, GPT2Model
+ from transformers.models.gpt2.modeling_gpt2 import GPT2Attention, GPT2Block, GPT2Model
policy = {}
@@ -53,42 +54,42 @@ def module_policy(self):
"attn.split_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
"attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
},
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="attn.c_attn",
- target_module=col_nn.GPT2FusedLinearConv1D_Col,
- kwargs={
- "n_fused": 3,
- },
- ),
- SubModuleReplacementDescription(
- suffix="attn.c_proj",
- target_module=col_nn.GPT2FusedLinearConv1D_Row,
- ),
- SubModuleReplacementDescription(
- suffix="mlp.c_fc",
- target_module=col_nn.GPT2FusedLinearConv1D_Col,
- kwargs={
- "n_fused": 1,
- },
- ),
- SubModuleReplacementDescription(
- suffix="mlp.c_proj",
- target_module=col_nn.GPT2FusedLinearConv1D_Row,
- ),
- SubModuleReplacementDescription(
- suffix="attn.attn_dropout",
- target_module=col_nn.DropoutForParallelInput,
- ),
- SubModuleReplacementDescription(
- suffix="attn.resid_dropout",
- target_module=col_nn.DropoutForParallelInput,
- ),
- SubModuleReplacementDescription(
- suffix="mlp.dropout",
- target_module=col_nn.DropoutForParallelInput,
- ),
- ])
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="attn.c_attn",
+ target_module=col_nn.GPT2FusedLinearConv1D_Col,
+ kwargs={
+ "n_fused": 3,
+ },
+ ),
+ SubModuleReplacementDescription(
+ suffix="attn.c_proj",
+ target_module=col_nn.GPT2FusedLinearConv1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.c_fc",
+ target_module=col_nn.GPT2FusedLinearConv1D_Col,
+ kwargs={
+ "n_fused": 1,
+ },
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.c_proj",
+ target_module=col_nn.GPT2FusedLinearConv1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attn.attn_dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attn.resid_dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ ])
# optimization configuration
if self.shard_config.enable_fused_normalization:
@@ -96,8 +97,8 @@ def module_policy(self):
suffix="ln_f",
target_module=col_nn.FusedLayerNorm,
),
- policy=policy,
- target_key=GPT2Model)
+ policy=policy,
+ target_key=GPT2Model)
self.append_or_create_submodule_replacement(description=[
SubModuleReplacementDescription(
@@ -112,8 +113,13 @@ def module_policy(self):
target_module=col_nn.FusedLayerNorm,
ignore_if_not_exist=True)
],
- policy=policy,
- target_key=GPT2Block)
+ policy=policy,
+ target_key=GPT2Block)
+
+ if self.shard_config.enable_flash_attention:
+ policy[GPT2Attention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_gpt2_flash_attention_forward(),
+ })
return policy
def postprocess(self):
diff --git a/colossalai/shardformer/policies/llama.py b/colossalai/shardformer/policies/llama.py
index 5988366ed57b..5ee95f3be8fa 100644
--- a/colossalai/shardformer/policies/llama.py
+++ b/colossalai/shardformer/policies/llama.py
@@ -7,7 +7,7 @@
from colossalai.shardformer.layer import FusedRMSNorm, Linear1D_Col, Linear1D_Row, VocabParallelEmbedding1D
-from ..modeling.llama import LlamaPipelineForwards
+from ..modeling.llama import LlamaPipelineForwards, get_llama_flash_attention_forward
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ['LlamaPolicy', 'LlamaForCausalLMPolicy', 'LlamaForSequenceClassificationPolicy']
@@ -31,7 +31,7 @@ def preprocess(self):
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
- from transformers.models.llama.modeling_llama import LlamaDecoderLayer, LlamaModel
+ from transformers.models.llama.modeling_llama import LlamaAttention, LlamaDecoderLayer, LlamaModel
policy = {}
@@ -104,6 +104,11 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
policy=policy,
target_key=LlamaModel)
+ if self.shard_config.enable_flash_attention:
+ policy[LlamaAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_llama_flash_attention_forward(),
+ })
+
return policy
def postprocess(self):
diff --git a/colossalai/shardformer/policies/opt.py b/colossalai/shardformer/policies/opt.py
index 6fc3a2d31f4d..88ecd8565091 100644
--- a/colossalai/shardformer/policies/opt.py
+++ b/colossalai/shardformer/policies/opt.py
@@ -25,6 +25,8 @@
from colossalai.shardformer.layer import FusedLayerNorm, Linear1D_Col, Linear1D_Row, VocabParallelEmbedding1D
from .._utils import getattr_, setattr_
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from ..modeling.opt import get_jit_fused_opt_decoder_layer_forward, get_opt_flash_attention_forward
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = [
@@ -114,6 +116,19 @@ def module_policy(self):
policy=policy,
target_key=OPTDecoderLayer)
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[OPTAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_opt_flash_attention_forward(),
+ })
+
+ # use jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[OPTDecoderLayer] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_opt_decoder_layer_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
return policy
def postprocess(self):
@@ -189,13 +204,11 @@ def module_policy(self):
from transformers.models.opt.modeling_opt import OPTForCausalLM
policy = super().module_policy()
-
if self.shard_config.enable_tensor_parallelism:
self.append_or_create_submodule_replacement(description=SubModuleReplacementDescription(
suffix="lm_head", target_module=Linear1D_Col, kwargs=dict(gather_output=True)),
policy=policy,
target_key=OPTForCausalLM)
-
if self.pipeline_stage_manager:
self.set_pipeline_forward(model_cls=OPTForCausalLM,
new_forward=OPTPipelineForwards.opt_for_causal_lm_forward,
diff --git a/colossalai/shardformer/policies/sam.py b/colossalai/shardformer/policies/sam.py
index ca20fff715f2..b1eba0432b49 100644
--- a/colossalai/shardformer/policies/sam.py
+++ b/colossalai/shardformer/policies/sam.py
@@ -3,7 +3,7 @@
import colossalai.shardformer.layer as col_nn
from .._utils import getattr_, setattr_
-from ..modeling.sam import forward_fn
+from ..modeling.sam import forward_fn, get_sam_flash_attention_forward, get_sam_vision_flash_attention_forward
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ['SamPolicy', 'SamModelPolicy']
@@ -19,6 +19,7 @@ def preprocess(self):
def module_policy(self):
from transformers.models.sam.modeling_sam import (
+ SamAttention,
SamFeedForward,
SamTwoWayAttentionBlock,
SamTwoWayTransformer,
@@ -196,6 +197,15 @@ def module_policy(self):
policy=policy,
target_key=SamTwoWayTransformer)
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[SamAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_sam_flash_attention_forward(),
+ })
+ policy[SamVisionAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_sam_vision_flash_attention_forward(),
+ })
+
return policy
def postprocess(self):
diff --git a/colossalai/shardformer/policies/t5.py b/colossalai/shardformer/policies/t5.py
index 0ee18d6c4940..2ef52c214c6b 100644
--- a/colossalai/shardformer/policies/t5.py
+++ b/colossalai/shardformer/policies/t5.py
@@ -14,7 +14,14 @@
from colossalai.shardformer.policies.base_policy import ModulePolicyDescription
from .._utils import getattr_, setattr_
-from ..modeling.t5 import T5PipelineForwards
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from ..modeling.t5 import (
+ T5PipelineForwards,
+ get_jit_fused_T5_layer_ff_forward,
+ get_t5_flash_attention_forward,
+ get_T5_layer_cross_attention_forward,
+ get_T5_layer_self_attention_forward,
+)
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ["distribute_t5_layers", "T5ModelPolicy", "T5ForConditionalGenerationPolicy", "T5EncoderPolicy"]
@@ -168,6 +175,27 @@ def module_policy(self):
suffix="final_layer_norm", target_module=FusedRMSNorm),
policy=policy,
target_key=T5Stack)
+
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[T5Attention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_t5_flash_attention_forward(),
+ })
+
+ # use jit operator
+ if self.shard_config.enable_jit_fused:
+ policy[T5LayerFF] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_T5_layer_ff_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[T5LayerSelfAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_T5_layer_self_attention_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[T5LayerCrossAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_T5_layer_cross_attention_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
return policy
def postprocess(self):
@@ -232,7 +260,7 @@ def get_held_layers(self) -> List[nn.Module]:
model = self.model
encoder = self.model.encoder
- decoder = self.model.__dict__.get('decoder', None)
+ decoder = getattr(self.model, 'decoder', None)
num_encoder_layers = len(encoder.block)
num_decoder_layers = len(decoder.block) if decoder else 0
@@ -272,7 +300,7 @@ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, poli
stage_manager = self.pipeline_stage_manager
encoder = self.model.encoder
- decoder = self.model.__dict__.get('decoder', None)
+ decoder = getattr(self.model, 'decoder', None)
num_encoder_layers = len(encoder.block)
num_decoder_layers = len(decoder.block) if decoder else 0
@@ -327,15 +355,6 @@ def get_shared_params(self) -> List[Dict[int, Tensor]]:
return [{0: module.shared.weight, decoder_starting_stage: module.decoder.embed_tokens.weight}]
return []
- def postprocess(self):
- if self.shard_config.enable_tensor_parallelism and self.pipeline_stage_manager is None:
- binding_map = {"shared.weight": ["encoder.embed_tokens.weight", "decoder.embed_tokens.weight"]}
- for k, v in binding_map.items():
- src = getattr_(self.model, k)
- for dst in v:
- setattr_(self.model, dst, src)
- return self.model
-
class T5ForConditionalGenerationPolicy(T5BasePolicy):
@@ -381,28 +400,21 @@ def get_shared_params(self) -> List[Dict[int, Tensor]]:
stage_manager.num_stages)
shared_params = []
+ shared_embedding = {}
if id(module.decoder.embed_tokens.weight) == id(module.shared.weight):
- shared_params.append({
- 0: module.shared.weight,
- decoder_starting_stage: module.decoder.embed_tokens.weight
- })
+ shared_embedding[0] = module.shared.weight
+ shared_embedding[decoder_starting_stage] = module.decoder.embed_tokens.weight
+
if id(module.lm_head.weight) == id(module.shared.weight):
- shared_params.append({0: module.shared.weight, stage_manager.num_stages - 1: module.lm_head.weight})
- return shared_params
- return []
+ shared_embedding[0] = module.shared.weight
+ shared_embedding[stage_manager.num_stages - 1] = module.lm_head.weight
- def postprocess(self):
- super().postprocess()
- if self.shard_config.enable_tensor_parallelism and self.pipeline_stage_manager is None:
- binding_map = {
- "shared.weight": ["encoder.embed_tokens.weight", "decoder.embed_tokens.weight", "lm_head.weight"]
- }
- for k, v in binding_map.items():
- src = getattr_(self.model, k)
- for dst in v:
- setattr_(self.model, dst, src)
+ if len(shared_embedding) > 0:
+ shared_params.append(shared_embedding)
- return self.model
+ return shared_params
+
+ return []
class T5EncoderPolicy(T5BasePolicy):
@@ -434,12 +446,3 @@ def get_held_layers(self) -> List[nn.Module]:
def get_shared_params(self) -> List[Dict[int, Tensor]]:
return []
-
- def postprocess(self):
- if self.shard_config.enable_tensor_parallelism and self.pipeline_stage_manager is None:
- binding_map = {"shared.weight": ["encoder.embed_tokens.weight"]}
- for k, v in binding_map.items():
- src = getattr_(self.model, k)
- for dst in v:
- setattr_(self.model, dst, src)
- return self.model
diff --git a/colossalai/shardformer/policies/vit.py b/colossalai/shardformer/policies/vit.py
index 47f2c58fc436..07b1a9a2e7c7 100644
--- a/colossalai/shardformer/policies/vit.py
+++ b/colossalai/shardformer/policies/vit.py
@@ -3,12 +3,21 @@
import torch.nn as nn
-import colossalai.shardformer.layer as col_nn
+from colossalai.shardformer.layer import (
+ DropoutForParallelInput,
+ DropoutForReplicatedInput,
+ FusedLayerNorm,
+ Linear1D_Col,
+ Linear1D_Row,
+)
+from ..modeling.jit import get_jit_fused_dropout_add_func
from ..modeling.vit import (
ViTForImageClassification_pipeline_forward,
ViTForMaskedImageModeling_pipeline_forward,
ViTModel_pipeline_forward,
+ get_jit_fused_vit_output_forward,
+ get_vit_flash_self_attention_forward,
)
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
@@ -24,7 +33,8 @@ def preprocess(self):
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
- from transformers.models.vit.modeling_vit import ViTEmbeddings, ViTLayer
+
+ from transformers.models.vit.modeling_vit import ViTEmbeddings, ViTLayer, ViTModel, ViTOutput, ViTSelfAttention
policy = {}
@@ -34,7 +44,7 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
sub_module_replacement=[
SubModuleReplacementDescription(
suffix="dropout",
- target_module=col_nn.DropoutForReplicatedInput,
+ target_module=DropoutForReplicatedInput,
)
])
@@ -48,42 +58,54 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
sub_module_replacement=[
SubModuleReplacementDescription(
suffix="attention.attention.query",
- target_module=col_nn.Linear1D_Col,
+ target_module=Linear1D_Col,
),
SubModuleReplacementDescription(
suffix="attention.attention.key",
- target_module=col_nn.Linear1D_Col,
+ target_module=Linear1D_Col,
),
SubModuleReplacementDescription(
suffix="attention.attention.value",
- target_module=col_nn.Linear1D_Col,
+ target_module=Linear1D_Col,
),
SubModuleReplacementDescription(
suffix="attention.attention.dropout",
- target_module=col_nn.DropoutForParallelInput,
+ target_module=DropoutForParallelInput,
),
SubModuleReplacementDescription(
suffix="attention.output.dense",
- target_module=col_nn.Linear1D_Row,
+ target_module=Linear1D_Row,
),
SubModuleReplacementDescription(
suffix="attention.output.dropout",
- target_module=col_nn.DropoutForReplicatedInput,
+ target_module=DropoutForReplicatedInput,
),
SubModuleReplacementDescription(
suffix="intermediate.dense",
- target_module=col_nn.Linear1D_Col,
+ target_module=Linear1D_Col,
),
SubModuleReplacementDescription(
suffix="output.dense",
- target_module=col_nn.Linear1D_Row,
+ target_module=Linear1D_Row,
),
SubModuleReplacementDescription(
suffix="output.dropout",
- target_module=col_nn.DropoutForReplicatedInput,
+ target_module=DropoutForReplicatedInput,
),
])
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[ViTSelfAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_vit_flash_self_attention_forward(),
+ })
+
+ # use jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[ViTOutput] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_vit_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
return policy
def new_model_class(self):
@@ -166,7 +188,7 @@ def module_policy(self):
ViTForImageClassification:
ModulePolicyDescription(sub_module_replacement=[
SubModuleReplacementDescription(
- suffix="classifier", target_module=col_nn.Linear1D_Col, kwargs=dict(gather_output=True))
+ suffix="classifier", target_module=Linear1D_Col, kwargs=dict(gather_output=True))
])
}
policy.update(new_item)
diff --git a/colossalai/shardformer/policies/whisper.py b/colossalai/shardformer/policies/whisper.py
index 2f3565bdaa96..2ac7a49fd27b 100644
--- a/colossalai/shardformer/policies/whisper.py
+++ b/colossalai/shardformer/policies/whisper.py
@@ -3,6 +3,12 @@
import colossalai.shardformer.layer as col_nn
from .._utils import getattr_, setattr_
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from ..modeling.whisper import (
+ get_jit_fused_whisper_decoder_layer_forward,
+ get_jit_fused_whisper_encoder_layer_forward,
+ get_whisper_flash_attention_forward,
+)
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = [
@@ -30,6 +36,7 @@ def preprocess(self):
def module_policy(self):
from transformers.models.whisper.modeling_whisper import (
+ WhisperAttention,
WhisperDecoder,
WhisperDecoderLayer,
WhisperEncoder,
@@ -181,6 +188,24 @@ def module_policy(self):
],
policy=policy,
target_key=WhisperDecoder)
+
+ # enable flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[WhisperAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_whisper_flash_attention_forward(),
+ })
+
+ # use jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[WhisperEncoderLayer] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_whisper_encoder_layer_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[WhisperDecoderLayer] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_whisper_decoder_layer_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
return policy
def add_lm_head_policy(self, base_policy):
diff --git a/colossalai/shardformer/shard/shard_config.py b/colossalai/shardformer/shard/shard_config.py
index 75fad4eb7431..ec6e0cd0d4be 100644
--- a/colossalai/shardformer/shard/shard_config.py
+++ b/colossalai/shardformer/shard/shard_config.py
@@ -26,6 +26,8 @@ class ShardConfig:
enable_tensor_parallelism: bool = True
enable_fused_normalization: bool = False
enable_all_optimization: bool = False
+ enable_flash_attention: bool = False
+ enable_jit_fused: bool = False
# TODO: add support for tensor parallel
# pipeline_parallel_size: int
@@ -44,7 +46,6 @@ def __post_init__(self):
else:
# get the parallel size
self._tensor_parallel_size = dist.get_world_size(self.tensor_parallel_process_group)
-
# turn on all optimization if all_optimization is set to True
if self.enable_all_optimization:
self._turn_on_all_optimization()
@@ -55,3 +56,5 @@ def _turn_on_all_optimization(self):
"""
# you can add all the optimization flag here
self.enable_fused_normalization = True
+ self.enable_flash_attention = True
+ self.enable_jit_fused = True
diff --git a/colossalai/shardformer/shard/sharder.py b/colossalai/shardformer/shard/sharder.py
index ae8cd8c6e553..0ed745a1fc4a 100644
--- a/colossalai/shardformer/shard/sharder.py
+++ b/colossalai/shardformer/shard/sharder.py
@@ -198,6 +198,20 @@ def _replace_sub_module(
setattr_(org_layer, suffix, replace_layer)
+ def _get_recursive_held_layers(self, held_layers: Optional[List[nn.Module]]) -> Optional[List[nn.Module]]:
+
+ def collect_sub_modules(module: nn.Module):
+ if module is None:
+ return
+ recursive_held_layers.append(module)
+ for name, child in module.named_children():
+ collect_sub_modules(child)
+
+ recursive_held_layers = []
+ for module in held_layers:
+ collect_sub_modules(module)
+ return recursive_held_layers
+
def _release_unheld_layers(self) -> Optional[Set[nn.Module]]:
r"""
Release the unheld layers in the model
@@ -205,7 +219,7 @@ def _release_unheld_layers(self) -> Optional[Set[nn.Module]]:
if self.shard_config and self.shard_config.pipeline_stage_manager:
held_layers = self.policy.get_held_layers()
set_tensors_to_none(self.model, exclude=set(held_layers))
- return set(held_layers)
+ return set(self._get_recursive_held_layers(held_layers))
return None
def _materialize(self) -> None:
diff --git a/pytest.ini b/pytest.ini
index 01e5cd217c5d..e8a60c85336b 100644
--- a/pytest.ini
+++ b/pytest.ini
@@ -4,3 +4,4 @@ markers =
gpu: tests which requires a single GPU
dist: tests which are run in a multi-GPU or multi-machine environment
experiment: tests for experimental features
+addopts = --ignore=tests/test_analyzer --ignore=tests/test_auto_parallel --ignore=tests/test_autochunk --ignore=tests/test_moe
diff --git a/requirements/requirements-test.txt b/requirements/requirements-test.txt
index 6f8a72e3962f..fa797f26a4ca 100644
--- a/requirements/requirements-test.txt
+++ b/requirements/requirements-test.txt
@@ -13,7 +13,9 @@ torchrec==0.2.0
contexttimer
einops
triton==2.0.0.dev20221202
-git+https://github.com/HazyResearch/flash-attention.git@c422fee3776eb3ea24e011ef641fd5fbeb212623#egg=flash_attn
+# git+https://github.com/HazyResearch/flash-attention.git@c422fee3776eb3ea24e011ef641fd5fbeb212623#egg=flash_attn
requests==2.27.1 # downgrade to avoid huggingface error https://github.com/huggingface/transformers/issues/17611
SentencePiece
datasets
+ninja
+flash-attn
diff --git a/requirements/requirements.txt b/requirements/requirements.txt
index b34dc2e223ae..3ee1567db7fa 100644
--- a/requirements/requirements.txt
+++ b/requirements/requirements.txt
@@ -10,3 +10,4 @@ contexttimer
ninja
torch>=1.11
safetensors
+flash-attn
diff --git a/tests/kit/model_zoo/torchrec/__init__.py b/tests/kit/model_zoo/torchrec/__init__.py
index 43952e6998cf..4a19f2449602 100644
--- a/tests/kit/model_zoo/torchrec/__init__.py
+++ b/tests/kit/model_zoo/torchrec/__init__.py
@@ -1 +1 @@
-from .torchrec import *
+#from .torchrec import *
diff --git a/tests/kit/model_zoo/transformers/bert.py b/tests/kit/model_zoo/transformers/bert.py
index 1993af51ad63..52158596bcf8 100644
--- a/tests/kit/model_zoo/transformers/bert.py
+++ b/tests/kit/model_zoo/transformers/bert.py
@@ -20,7 +20,7 @@ def data_gen():
# token_type_ids = tokenized_input['token_type_ids']
input_ids = torch.tensor([[101, 7592, 1010, 2026, 3899, 2003, 10140, 102]], dtype=torch.int64)
token_type_ids = torch.tensor([[0, 0, 0, 0, 0, 0, 0, 0]], dtype=torch.int64)
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 0]], dtype=torch.int64)
return dict(input_ids=input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
@@ -69,19 +69,21 @@ def data_gen_for_mcq():
# data['labels'] = torch.tensor([0], dtype=torch.int64)
input_ids = torch.tensor([[[
101, 1999, 3304, 1010, 10733, 2366, 1999, 5337, 10906, 1010, 2107, 2004, 2012, 1037, 4825, 1010, 2003, 3591,
- 4895, 14540, 6610, 2094, 1012, 102, 2009, 2003, 8828, 2007, 1037, 9292, 1998, 1037, 5442, 1012, 102
+ 4895, 14540, 6610, 2094, 1012, 102, 2009, 2003, 8828, 2007, 1037, 9292, 1998, 1037, 5442, 1012, 102, 102
],
[
101, 1999, 3304, 1010, 10733, 2366, 1999, 5337, 10906, 1010, 2107, 2004, 2012, 1037,
4825, 1010, 2003, 3591, 4895, 14540, 6610, 2094, 1012, 102, 2009, 2003, 8828, 2096,
- 2218, 1999, 1996, 2192, 1012, 102, 0
+ 2218, 1999, 1996, 2192, 1012, 102, 0, 0
]]])
token_type_ids = torch.tensor(
- [[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
- [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]]])
+ [[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0,
+ 0]]])
attention_mask = torch.tensor(
- [[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]]])
+ [[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0,
+ 0]]])
labels = torch.tensor([0], dtype=torch.int64)
return dict(input_ids=input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask, labels=labels)
@@ -102,7 +104,8 @@ def data_gen_for_qa():
output_transform_fn = lambda x: x
# define loss funciton
-loss_fn_for_bert_model = lambda x: x.pooler_output.mean()
+loss_fn_for_bert_model = lambda x: torch.nn.functional.mse_loss(x.last_hidden_state, torch.ones_like(x.last_hidden_state
+ ))
loss_fn = lambda x: x.loss
config = transformers.BertConfig(hidden_size=128,
diff --git a/tests/kit/model_zoo/transformers/blip2.py b/tests/kit/model_zoo/transformers/blip2.py
index 7338f740be7f..984a6ffa920d 100644
--- a/tests/kit/model_zoo/transformers/blip2.py
+++ b/tests/kit/model_zoo/transformers/blip2.py
@@ -38,6 +38,7 @@ def data_gen():
loss_fn_blip2_model = lambda x: x.loss
config = transformers.Blip2Config()
+config.vision_config.patch_size = 14
config.text_config.num_hidden_layers = 1
config.qformer_config.num_hidden_layers = 1
config.vision_config.num_hidden_layers = 1
diff --git a/tests/kit/model_zoo/transformers/bloom.py b/tests/kit/model_zoo/transformers/bloom.py
index 71146c0b9819..177edbef8935 100644
--- a/tests/kit/model_zoo/transformers/bloom.py
+++ b/tests/kit/model_zoo/transformers/bloom.py
@@ -16,8 +16,8 @@ def data_gen():
# tokenized_input = tokenizer(input, return_tensors='pt')
# input_ids = tokenized_input['input_ids']
# attention_mask = tokenized_input['attention_mask']
- input_ids = torch.tensor([[59414, 15, 2670, 35433, 632, 207595]], dtype=torch.int64)
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ input_ids = torch.tensor([[59414, 15, 2670, 35433, 632, 207595, 632, 207595]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
return dict(input_ids=input_ids, attention_mask=attention_mask)
@@ -33,7 +33,7 @@ def data_gen_for_token_classification():
# token classification data gen
# `labels` is the type not the token id for token classification, 0 or 1
data = data_gen()
- data['labels'] = torch.tensor([[0, 0, 0, 0, 0, 0]], dtype=torch.int64)
+ data['labels'] = torch.tensor([[0, 0, 0, 0, 0, 0, 0, 0]], dtype=torch.int64)
return data
@@ -53,19 +53,25 @@ def data_gen_for_question_answering():
# inputs = tokenizer(question, text, return_tensors="pt")
input_ids = torch.tensor(
- [[57647, 1620, 23967, 620, 107373, 34, 91514, 620, 107373, 1620, 267, 35378, 48946, 18161]], dtype=torch.int64)
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
- return dict(input_ids=input_ids, attention_mask=attention_mask)
+ [[57647, 1620, 23967, 620, 107373, 34, 91514, 620, 107373, 1620, 267, 35378, 48946, 18161, 48946, 18161]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ start_positions = torch.tensor([1], dtype=torch.int64)
+ end_positions = torch.tensor([10], dtype=torch.int64)
+ return dict(input_ids=input_ids,
+ attention_mask=attention_mask,
+ start_positions=start_positions,
+ end_positions=end_positions)
# define output transform function
output_transform_fn = lambda x: x
# define loss function
-loss_fn_for_bloom_model = lambda x: x.last_hidden_state.mean()
+loss_fn_for_bloom_model = lambda x: torch.nn.functional.mse_loss(x.last_hidden_state,
+ torch.ones_like(x.last_hidden_state))
loss_fn_for_causal_lm = lambda x: x.loss
-loss_fn_for_classification = lambda x: x.logits.mean()
-loss_fn_for_question_answering = lambda x: x.end_logits.mean()
+loss_fn_for_classification = lambda x: x.loss
+loss_fn_for_question_answering = lambda x: x.loss
config = transformers.BloomConfig(n_layer=1,
n_head=4,
diff --git a/tests/kit/model_zoo/transformers/chatglm.py b/tests/kit/model_zoo/transformers/chatglm.py
index 04e73a832abe..90bb70bc7f79 100644
--- a/tests/kit/model_zoo/transformers/chatglm.py
+++ b/tests/kit/model_zoo/transformers/chatglm.py
@@ -1,9 +1,10 @@
import torch
import transformers
+from colossalai.shardformer.modeling.chatglm2_6b.configuration_chatglm import ChatGLMConfig
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import ChatGLMForConditionalGeneration, ChatGLMModel
+
from ..registry import ModelAttribute, model_zoo
-from .chatglm2_6b.configuration_chatglm import ChatGLMConfig
-from .chatglm2_6b.modeling_chatglm import ChatGLMForConditionalGeneration, ChatGLMModel
# ================================
# Register single-sentence ChatGLM
@@ -20,15 +21,18 @@ def data_gen():
output_transform_fn = lambda x: x
# define loss function
-loss_fn_for_chatglm_model = lambda x: x.last_hidden_state.mean()
-loss_fn = lambda x: x.logits.mean()
+loss_fn_for_chatglm_model = lambda x: x.last_hidden_state.sum()
+loss_fn = lambda x: x.logits.sum()
+
config = ChatGLMConfig(num_layers=1,
padded_vocab_size=65024,
hidden_size=64,
num_attention_heads=8,
- rmsnorm=False,
+ rmsnorm=True,
original_rope=True,
- use_cache=True)
+ use_cache=True,
+ torch_dtype=torch.float32)
+
model_zoo.register(name='transformers_chatglm',
model_fn=lambda: ChatGLMModel(config, empty_init=False),
diff --git a/tests/kit/model_zoo/transformers/gpt.py b/tests/kit/model_zoo/transformers/gpt.py
index fcde75abdedc..5c3eb4438bc8 100644
--- a/tests/kit/model_zoo/transformers/gpt.py
+++ b/tests/kit/model_zoo/transformers/gpt.py
@@ -1,3 +1,5 @@
+import copy
+
import torch
import transformers
@@ -16,8 +18,8 @@ def data_gen():
# tokenized_input = tokenizer(input, return_tensors='pt')
# input_ids = tokenized_input['input_ids']
# attention_mask = tokenized_input['attention_mask']
- input_ids = torch.tensor([[15496, 11, 616, 3290, 318, 13779]], dtype=torch.int64)
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ input_ids = torch.tensor([[15496, 11, 616, 3290, 318, 13779, 318, 13779]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
return dict(input_ids=input_ids, attention_mask=attention_mask)
@@ -44,14 +46,14 @@ def data_gen_for_token_classification():
# token classification data gen
# `labels` is the type not the token id for token classification, 0 or 1
data = data_gen()
- data['labels'] = torch.tensor([[0, 0, 0, 0, 0, 0]], dtype=torch.int64)
+ data['labels'] = torch.tensor([[0, 0, 0, 0, 0, 0, 0, 1]], dtype=torch.int64)
return data
def data_gen_for_sequence_classification():
# sequence classification data gen
data = data_gen()
- data['labels'] = torch.tensor([0], dtype=torch.int64)
+ data['labels'] = torch.tensor([1], dtype=torch.int64)
return data
@@ -59,7 +61,8 @@ def data_gen_for_sequence_classification():
output_transform_fn = lambda x: x
# define loss function
-loss_fn_for_gpt2_model = lambda x: x.last_hidden_state.mean()
+loss_fn_for_gpt2_model = lambda x: torch.nn.functional.mse_loss(x.last_hidden_state, torch.ones_like(x.last_hidden_state
+ ))
loss_fn = lambda x: x.loss
config = transformers.GPT2Config(n_layer=2,
@@ -73,6 +76,9 @@ def data_gen_for_sequence_classification():
problem_type="single_label_classification",
pad_token_id=50256)
+config_for_token_classification = copy.deepcopy(config)
+config_for_token_classification.num_labels = 2
+
# register the following models
model_zoo.register(name='transformers_gpt',
model_fn=lambda: transformers.GPT2Model(config),
@@ -99,13 +105,13 @@ def data_gen_for_sequence_classification():
loss_fn=loss_fn,
model_attribute=ModelAttribute(has_control_flow=True))
model_zoo.register(name='transformers_gpt_for_token_classification',
- model_fn=lambda: transformers.GPT2ForTokenClassification(config),
+ model_fn=lambda: transformers.GPT2ForTokenClassification(config_for_token_classification),
data_gen_fn=data_gen_for_token_classification,
output_transform_fn=output_transform_fn,
loss_fn=loss_fn,
model_attribute=ModelAttribute(has_control_flow=True))
model_zoo.register(name='transformers_gpt_for_sequence_classification',
- model_fn=lambda: transformers.GPT2ForSequenceClassification(config),
+ model_fn=lambda: transformers.GPT2ForSequenceClassification(config_for_token_classification),
data_gen_fn=data_gen_for_sequence_classification,
output_transform_fn=output_transform_fn,
loss_fn=loss_fn,
diff --git a/tests/kit/model_zoo/transformers/opt.py b/tests/kit/model_zoo/transformers/opt.py
index 4463ae12b901..29430afc0661 100644
--- a/tests/kit/model_zoo/transformers/opt.py
+++ b/tests/kit/model_zoo/transformers/opt.py
@@ -44,7 +44,8 @@ def data_gen_for_question_answering():
output_transform_fn = lambda x: x
-loss_fn_for_opt_model = lambda x: x.last_hidden_state.mean()
+loss_fn_for_opt_model = lambda x: torch.nn.functional.mse_loss(x.last_hidden_state, torch.ones_like(x.last_hidden_state)
+ )
loss_fn_for_lm = lambda x: x.loss
config = transformers.OPTConfig(
hidden_size=128,
diff --git a/tests/kit/model_zoo/transformers/t5.py b/tests/kit/model_zoo/transformers/t5.py
index 689db2c40abb..435cb6f46937 100644
--- a/tests/kit/model_zoo/transformers/t5.py
+++ b/tests/kit/model_zoo/transformers/t5.py
@@ -16,8 +16,9 @@ def data_gen_for_encoder_only():
# config = T5Config(decoder_start_token_id=0)
# tokenizer = T5Tokenizer.from_pretrained("t5-small")
# input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
- input_ids = torch.Tensor([[13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5, 1]]).long()
- return dict(input_ids=input_ids)
+ input_ids = torch.Tensor([[13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5, 1, 12]]).long()
+ attention_mask = torch.Tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]]).long()
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
def data_gen_for_conditional_generation():
@@ -25,17 +26,16 @@ def data_gen_for_conditional_generation():
#
# labels = tokenizer("Das Haus ist wunderbar.", return_tensors="pt").input_ids
data = data_gen_for_encoder_only()
- labels = torch.Tensor([[644, 4598, 229, 19250, 5, 1]]).long()
+ labels = torch.Tensor([[644, 4598, 229, 19250, 5, 1, 644, 4598, 229, 19250, 5, 1]]).long()
data['labels'] = labels
return data
def data_gen_for_t5_model():
# decoder_inputs_ids is obtained with the following code
- #
# decoder_input_ids = model._shift_right(input_ids)
data = data_gen_for_encoder_only()
- decoder_input_ids = torch.Tensor([[0, 13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5]]).long()
+ decoder_input_ids = torch.Tensor([[0, 13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5, 5]]).long()
data['decoder_input_ids'] = decoder_input_ids
return data
diff --git a/tests/kit/model_zoo/transformers/whisper.py b/tests/kit/model_zoo/transformers/whisper.py
index b58716217cb5..f7cdc052aaf0 100644
--- a/tests/kit/model_zoo/transformers/whisper.py
+++ b/tests/kit/model_zoo/transformers/whisper.py
@@ -22,7 +22,7 @@ def data_gen():
# input_features = inputs.input_features
# decoder_input_ids = torch.tensor([[1, 1]]) * model.config.decoder_start_token_id
- input_features = torch.randn(1, 80, 3000)
+ input_features = torch.rand(1, 80, 3000)
decoder_input_ids = torch.tensor([[1, 1]]) * 50258
return dict(input_features=input_features, decoder_input_ids=decoder_input_ids)
@@ -53,7 +53,7 @@ def data_gen_for_audio_classification():
output_transform_fn = lambda x: x
# define loss funciton
-loss_fn = lambda x: x.last_hidden_state.mean()
+loss_fn = lambda x: torch.nn.functional.mse_loss(x.last_hidden_state, torch.ones_like(x.last_hidden_state))
loss_fn_attr = lambda x: x.loss
config = transformers.WhisperConfig(
@@ -76,14 +76,14 @@ def data_gen_for_audio_classification():
loss_fn=loss_fn,
model_attribute=ModelAttribute(has_control_flow=True))
-model_zoo.register(name='transformers_whisperForConditionalGeneration',
+model_zoo.register(name='transformers_whisper_for_conditional_generation',
model_fn=lambda: transformers.WhisperForConditionalGeneration(config),
data_gen_fn=data_gen_for_conditional_generation,
output_transform_fn=output_transform_fn,
loss_fn=loss_fn_attr,
model_attribute=ModelAttribute(has_control_flow=True))
-model_zoo.register(name='transformers_whisperWhisperForAudioClassification',
+model_zoo.register(name='transformers_whisper_for_audio_classification',
model_fn=lambda: transformers.WhisperForAudioClassification(config),
data_gen_fn=data_gen_for_audio_classification,
output_transform_fn=output_transform_fn,
diff --git a/tests/test_booster/test_plugin/test_gemini_plugin.py b/tests/test_booster/test_plugin/test_gemini_plugin.py
index a06b2c963bfe..fee153baf1ac 100644
--- a/tests/test_booster/test_plugin/test_gemini_plugin.py
+++ b/tests/test_booster/test_plugin/test_gemini_plugin.py
@@ -93,7 +93,7 @@ def check_gemini_plugin(init_method: str = 'none', early_stop: bool = True):
'transformers_vit_for_image_classification', 'transformers_chatglm',
'transformers_chatglm_for_conditional_generation', 'transformers_blip2',
'transformers_blip2_conditional_gerneration', 'transformers_sam', 'transformers_whisper',
- 'transformers_whisperForConditionalGeneration', 'transformers_whisperWhisperForAudioClassification'
+ 'transformers_whisper_for_conditional_generation', 'transformers_whisper_for_audio_classification'
]:
continue
diff --git a/tests/test_booster/test_plugin/test_low_level_zero_plugin.py b/tests/test_booster/test_plugin/test_low_level_zero_plugin.py
index 7181e6c2b31b..97ee22730ea8 100644
--- a/tests/test_booster/test_plugin/test_low_level_zero_plugin.py
+++ b/tests/test_booster/test_plugin/test_low_level_zero_plugin.py
@@ -21,6 +21,7 @@
_STUCK_MODELS = [
'diffusers_vq_model', 'transformers_albert', 'transformers_albert_for_pretraining', 'transformers_bert',
'transformers_bert_for_pretraining', 'transformers_gpt_double_heads', 'transformers_vit',
+ 'transformers_bert_lm_head_model', 'transformers_bert_for_masked_lm',
'transformers_vit_for_masked_image_modeling', 'transformers_vit_for_image_classification', 'transformers_sam',
'transformers_chatglm', 'transformers_chatglm_for_conditional_generation'
]
diff --git a/tests/test_pipeline/test_policy/test_t5_pipeline_utils.py b/tests/test_pipeline/test_policy/test_t5_pipeline_utils.py
deleted file mode 100644
index 0cbb852b97a0..000000000000
--- a/tests/test_pipeline/test_policy/test_t5_pipeline_utils.py
+++ /dev/null
@@ -1,39 +0,0 @@
-from colossalai.shardformer.policies.t5 import T5BasePolicy
-
-
-def test_t5_pipeline_distribution():
- num_test_cases = 8
- test_dict = {
- 'num_encoder_layers': [2, 1, 3, 2, 3, 2, 10, 5],
- 'num_decoder_layers': [2, 8, 0, 2, 1, 5, 6, 22],
- 'num_stages': [2, 2, 2, 4, 4, 4, 8, 8],
- 'decoder_starting_stage': [1, 1, 2, 2, 3, 1, 5, 2]
- }
-
- for i in range(num_test_cases):
- _, decoder_starting_stage = T5BasePolicy.distribute_t5_layers(test_dict['num_encoder_layers'][i],
- test_dict['num_decoder_layers'][i],
- test_dict['num_stages'][i])
- assert test_dict['decoder_starting_stage'][i] == decoder_starting_stage
-
-
-def test_t5_pipeline_layers():
- num_test_cases = 4
- test_dict = {
- 'num_encoder_layers': [2, 3, 2, 4],
- 'num_decoder_layers': [2, 0, 2, 8],
- 'num_stages': [2, 2, 4, 4],
- 'layers_per_stage': [[[0, 2], [0, 2]], [[0, 1], [1, 3]], [[0, 1], [1, 2], [0, 1], [1, 2]],
- [[0, 4], [0, 3], [3, 6], [6, 8]]]
- }
-
- for i in range(num_test_cases):
- layers_per_stage, decoder_starting_stage = T5BasePolicy.distribute_t5_layers(
- test_dict['num_encoder_layers'][i], test_dict['num_decoder_layers'][i], test_dict['num_stages'][i])
-
- for stage in range(test_dict['num_stages'][i]):
- start_idx, end_idx = test_dict['layers_per_stage'][i][stage]
- predicted_start, predicted_end = T5BasePolicy.get_t5_stage_index(layers_per_stage, stage,
- decoder_starting_stage)
- assert start_idx == predicted_start
- assert end_idx == predicted_end
diff --git a/tests/test_shardformer/test_model/_utils.py b/tests/test_shardformer/test_model/_utils.py
index 2320c725d444..f75fbc9f9920 100644
--- a/tests/test_shardformer/test_model/_utils.py
+++ b/tests/test_shardformer/test_model/_utils.py
@@ -1,14 +1,32 @@
import copy
from contextlib import nullcontext
+from typing import Any, Callable, Dict, List, Optional
import torch
+import torch.distributed as dist
+from torch import Tensor
+from torch import distributed as dist
+from torch.distributed import ProcessGroup
from torch.nn import Module
+from torch.optim import Adam, Optimizer
+from colossalai.booster import Booster
+from colossalai.booster.plugin import HybridParallelPlugin
from colossalai.lazy import LazyInitContext
+from colossalai.pipeline.stage_manager import PipelineStageManager
from colossalai.shardformer import ShardConfig, ShardFormer
+from colossalai.shardformer._utils import getattr_
+from colossalai.shardformer.policies.auto_policy import Policy
+from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
-def build_model(model_fn, enable_fused_normalization=True, enable_tensor_parallelism=True, use_lazy_init: bool = False):
+def build_model(model_fn,
+ enable_fused_normalization=True,
+ enable_tensor_parallelism=True,
+ enable_flash_attention=False,
+ enable_jit_fused=False,
+ use_lazy_init: bool = False):
+ # create new model
ctx = LazyInitContext() if use_lazy_init else nullcontext()
with ctx:
# create new model
@@ -18,7 +36,10 @@ def build_model(model_fn, enable_fused_normalization=True, enable_tensor_paralle
ctx.materialize(org_model)
# shard model
shard_config = ShardConfig(enable_fused_normalization=enable_fused_normalization,
- enable_tensor_parallelism=enable_tensor_parallelism)
+ enable_tensor_parallelism=enable_tensor_parallelism,
+ enable_flash_attention=enable_flash_attention,
+ enable_jit_fused=enable_jit_fused)
+ model_copy = copy.deepcopy(org_model)
shard_former = ShardFormer(shard_config=shard_config)
sharded_model, shared_params = shard_former.optimize(model_copy)
return org_model.cuda(), sharded_model.cuda()
@@ -28,7 +49,8 @@ def build_pipeline_model(model_fn,
stage_manager=None,
enable_fused_normalization=False,
enable_tensor_parallelism=False,
- use_lazy_init: bool = False):
+ use_lazy_init: bool = False,
+ policy: Optional[Policy] = None):
ctx = LazyInitContext() if use_lazy_init else nullcontext()
with ctx:
# create new model
@@ -43,7 +65,7 @@ def build_pipeline_model(model_fn,
pipeline_stage_manager=stage_manager)
shard_former = ShardFormer(shard_config=shard_config)
- sharded_model, shared_params = shard_former.optimize(model_copy)
+ sharded_model, shared_params = shard_former.optimize(model_copy, policy=policy)
return org_model.cuda(), sharded_model.cuda()
@@ -74,3 +96,159 @@ def check_state_dict(org_model: Module, sharded_model: Module, name: str = ''):
assert v.shape == shard_v.shape, f'{name} {k} shape mismatch, {v.shape} vs {shard_v.shape}'
assert v.dtype == shard_v.dtype, f'{name} {k} dtype mismatch, {v.dtype} vs {shard_v.dtype}'
assert torch.equal(v, shard_v), f'{name} {k} value mismatch'
+
+
+def build_model_from_hybrid_plugin(model_fn: Callable, loss_fn: Callable, test_config: Dict[str, Any]):
+
+ use_lazy_init = False
+ if 'use_lazy_init' in test_config:
+ use_lazy_init = test_config.pop('use_lazy_init')
+
+ if use_lazy_init:
+ ctx = LazyInitContext()
+ else:
+ ctx = nullcontext()
+
+ plugin = HybridParallelPlugin(**test_config)
+ booster = Booster(plugin=plugin)
+
+ with ctx:
+ org_model = model_fn().cuda()
+ sharded_model = copy.deepcopy(org_model)
+
+ if use_lazy_init:
+ org_model = ctx.materialize(org_model)
+
+ org_optimizer = Adam(org_model.parameters(), lr=1e-3)
+ sharded_optimizer = Adam(sharded_model.parameters(), lr=1e-3)
+ criterion = loss_fn
+
+ sharded_model, sharded_optimizer, criterion, _, _ = booster.boost(sharded_model, sharded_optimizer, criterion)
+
+ return org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster
+
+
+def run_forward_backward_with_hybrid_plugin(org_model: Module, sharded_model: Module, sharded_optimizer: Optimizer,
+ data_gen_fn: Callable, output_transform_fn: Callable, criterion: Callable,
+ booster: Booster):
+ org_model.cuda()
+ sharded_model.cuda()
+
+ def _criterion(outputs, inputs):
+ outputs = output_transform_fn(outputs)
+ loss = criterion(outputs)
+ return loss
+
+ data = data_gen_fn()
+ sharded_model.train()
+ if booster.plugin.stage_manager is not None:
+ if org_model.__class__.__name__ == 'BertForMultipleChoice':
+ for k, v in data.items():
+ repeat_size = [1] * v.dim()
+ repeat_size[0] = 4
+ data[k] = v.repeat(*repeat_size).to('cuda')
+ else:
+ data = {
+ k: v.to('cuda').repeat(4, 1) if torch.is_tensor(v) or 'Tensor' in v.__class__.__name__ else v
+ for k, v in data.items()
+ }
+ data_iter = iter([data])
+ sharded_output = booster.execute_pipeline(data_iter,
+ sharded_model,
+ _criterion,
+ sharded_optimizer,
+ return_loss=True,
+ return_outputs=True)
+ sharded_loss = sharded_output['loss']
+ else:
+ data = {k: v.cuda() for k, v in data.items()}
+ sharded_output = sharded_model(**data)
+ sharded_loss = criterion(sharded_output)
+ sharded_loss.backward()
+
+ org_model.train()
+ org_output = org_model(**data)
+ org_loss = criterion(org_output)
+ org_loss.backward()
+
+ return org_loss, org_output, sharded_loss, sharded_output
+
+
+def check_output_hidden_state(org_output: Tensor,
+ sharded_output: Tensor,
+ stage_manager: Optional[PipelineStageManager] = None,
+ atol: float = 1e-5,
+ rtol: float = 1e-3):
+
+ org_hidden_state = org_output.last_hidden_state
+
+ if stage_manager is None:
+ sharded_hidden_state = sharded_output.last_hidden_state
+
+ if stage_manager and stage_manager.is_last_stage():
+ sharded_hidden_state = torch.cat([output.last_hidden_state for output in sharded_output['outputs']], dim=0)
+
+ assert torch.allclose(org_hidden_state, sharded_hidden_state, atol=atol, rtol=rtol), \
+ f"shard model's output hidden state is not equal to origin model's last hidden state\n{org_hidden_state}\n{sharded_hidden_state}"
+
+
+def check_loss(org_loss: Tensor, sharded_loss: Tensor, atol: float = 1e-5, rtol: float = 1e-3):
+ assert torch.allclose(org_loss, sharded_loss, atol=atol, rtol=rtol), \
+ f"shard model loss is not equal to origin model loss\n{org_loss}\n{sharded_loss}"
+
+
+def check_weight(org_model: Module,
+ sharded_model: Module,
+ layer_suffix: List[str],
+ tp_group: Optional[ProcessGroup] = None,
+ dim: int = 0,
+ atol: float = 1e-5,
+ rtol: float = 1e-3,
+ verbose: bool = False):
+
+ for suffix in layer_suffix:
+ org_weight = getattr_(org_model, suffix).weight
+ sharded_weight = getattr_(sharded_model, suffix).weight
+
+ if is_distributed_tensor(sharded_weight) or is_customized_distributed_tensor(sharded_weight):
+ sharded_weight_list = [
+ torch.zeros([*sharded_weight.shape]).to('cuda') for _ in range(dist.get_world_size(tp_group))
+ ]
+ dist.all_gather(sharded_weight_list, sharded_weight, tp_group)
+ sharded_weight = torch.cat(sharded_weight_list, dim=dim)
+
+ if verbose and dist.get_rank() == 0:
+ print(f"'{suffix}' weight: {org_weight}, {sharded_weight}")
+
+ assert torch.allclose(org_weight, sharded_weight, atol=atol, rtol=rtol), \
+ f"shard model weight is not equal to origin model weight\n{org_weight}\n{sharded_weight}"
+
+
+def check_grad(org_model: Module,
+ sharded_model: Module,
+ layer_suffix: List[str],
+ tp_group: ProcessGroup = None,
+ dim: int = 0,
+ atol: float = 1e-5,
+ rtol: float = 1e-3,
+ verbose: bool = False):
+ for suffix in layer_suffix:
+ org_grad = getattr_(org_model, suffix).weight.grad
+ shard_grad = getattr_(sharded_model, suffix).weight.grad
+ shard_weight = getattr_(sharded_model, suffix).weight
+
+ if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
+ shard_grad_list = [
+ torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(dist.get_world_size(tp_group))
+ ]
+ dist.all_gather(shard_grad_list, shard_grad, tp_group)
+ shard_grad = torch.cat(shard_grad_list, dim=dim)
+
+ # embedding may be resized when using tensor parallel
+ if shard_grad.shape[0] > org_grad.shape[0]:
+ shard_grad = shard_grad[:org_grad.shape[0], :]
+ if verbose and dist.get_rank() == 0:
+ print(f"'{suffix}' grad: {org_grad}, {shard_grad}")
+ assert torch.allclose(
+ org_grad, shard_grad, rtol=rtol, atol=atol
+ ), f"error attribute '{suffix}', orgin model grad is not equal to shard model grad\n{org_grad}\n{shard_grad}"
diff --git a/tests/test_shardformer/test_model/test_shard_bert.py b/tests/test_shardformer/test_model/test_shard_bert.py
index 6d0d3c798c4e..fdbcd014e1b8 100644
--- a/tests/test_shardformer/test_model/test_shard_bert.py
+++ b/tests/test_shardformer/test_model/test_shard_bert.py
@@ -1,86 +1,98 @@
import pytest
import torch
+from torch import distributed as dist
import colossalai
-from colossalai.cluster import ProcessGroupMesh
from colossalai.logging import disable_existing_loggers
-from colossalai.pipeline.stage_manager import PipelineStageManager
-from colossalai.shardformer.policies.auto_policy import get_autopolicy
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
-from colossalai.testing import (
- assert_hf_output_close,
- clear_cache_before_run,
- parameterize,
- rerun_if_address_is_in_use,
- spawn,
-)
+from colossalai.shardformer.layer.utils import Randomizer
+from colossalai.tensor.d_tensor.api import clear_layout_converter
+from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, check_state_dict, run_forward
-
-
-def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
- # check forward
- org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
- output_transform_fn, loss_fn)
- assert_hf_output_close(org_output, shard_output)
-
- # do backward
- org_loss.backward()
- shard_loss.backward()
-
- assert torch.allclose(org_loss, shard_loss,
- atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
+from tests.test_shardformer.test_model._utils import (
+ build_model_from_hybrid_plugin,
+ check_grad,
+ check_loss,
+ check_output_hidden_state,
+ check_weight,
+ run_forward_backward_with_hybrid_plugin,
+)
- # check grad
+def check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config):
+
+ org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster = \
+ build_model_from_hybrid_plugin(model_fn, loss_fn, test_config)
+
+ org_loss, org_output, sharded_loss, sharded_output = \
+ run_forward_backward_with_hybrid_plugin(
+ org_model,
+ sharded_model,
+ sharded_optimizer,
+ data_gen_fn,
+ output_transform_fn,
+ criterion,
+ booster)
+ stage_manager = booster.plugin.stage_manager
+ tp_group = booster.plugin.tp_group
+ # check last hidden state & loss
+ if stage_manager is None or stage_manager.is_last_stage():
+ if org_model.__class__.__name__ == 'BertModel':
+ check_output_hidden_state(org_output, sharded_output, stage_manager, atol=1e-5, rtol=1e-3)
+
+ check_loss(org_loss, sharded_loss, atol=1e-5, rtol=1e-3)
+ # unwrap model
if org_model.__class__.__name__ == 'BertModel':
bert = org_model
- sharded_bert = sharded_model
+ sharded_bert = sharded_model.unwrap()
else:
bert = org_model.bert
- sharded_bert = sharded_model.bert
+ sharded_bert = sharded_model.unwrap().bert
- # compare self attention grad
- org_grad = bert.encoder.layer[0].attention.self.query.weight.grad
- shard_grad = sharded_bert.encoder.layer[0].attention.self.query.weight.grad
- shard_weight = sharded_bert.encoder.layer[0].attention.self.query.weight
+ col_layer_for_check = ['encoder.layer[0].output.dense']
+ row_layer_for_check = ['embeddings.word_embeddings', 'encoder.layer[0].intermediate.dense']
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
-
- # compare embedding grad
- org_grad = bert.embeddings.word_embeddings.weight.grad
- shard_grad = sharded_bert.embeddings.word_embeddings.weight.grad
- shard_weight = sharded_bert.embeddings.word_embeddings.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
+ if stage_manager is None or stage_manager.is_first_stage():
+ #check_weight(bert.embeddings.word_embeddings, sharded_bert.embeddings.word_embeddings, tp_group, atol=1e-5, rtol=1e-3)
+ #check_weight(bert.encoder.layer[0].attention.self.query, sharded_bert.encoder.layer[0].attention.self.query, tp_group, atol=5e-3, rtol=1e-3)
+ check_grad(bert, sharded_bert, col_layer_for_check, tp_group, atol=1e-4, rtol=1e-3, dim=1, verbose=False)
+ check_grad(bert, sharded_bert, row_layer_for_check, tp_group, atol=1e-4, rtol=1e-3, dim=0, verbose=False)
+
+ # check weights after optimizer.step()
+ org_optimizer.step()
+ sharded_optimizer.step()
+ if stage_manager is None or stage_manager.is_first_stage():
+ check_weight(bert, sharded_bert, col_layer_for_check, tp_group, atol=5e-3, rtol=1e-3, dim=1, verbose=False)
+
+ torch.cuda.empty_cache()
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+@parameterize('test_config', [{
+ 'tp_size': 1,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'use_lazy_init': True
+}, {
+ 'tp_size': 2,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'enable_fused_normalization': False,
+ 'use_lazy_init': False
+}, {
+ 'tp_size': 4,
+ 'pp_size': 1,
+ 'enable_fused_normalization': True,
+ 'use_lazy_init': False
+}])
+def run_bert_test(test_config):
-@parameterize('enable_fused_normalization', [False, True])
-@parameterize('enable_tensor_parallelism', [False, True])
-@parameterize('use_lazy_init', [False, True])
-def run_bert_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
sub_model_zoo = model_zoo.get_sub_registry('transformers_bert')
+ test_config['precision'] = 'float'
+
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
- use_lazy_init)
- check_state_dict(org_model, sharded_model, name=name)
- check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
+ check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config)
+ clear_layout_converter()
+ Randomizer.reset_index()
torch.cuda.empty_cache()
@@ -94,7 +106,7 @@ def check_bert(rank, world_size, port):
@rerun_if_address_is_in_use()
@clear_cache_before_run()
def test_bert():
- spawn(check_bert, 2)
+ spawn(check_bert, 4)
if __name__ == "__main__":
diff --git a/tests/test_shardformer/test_model/test_shard_bert_pipeline.py b/tests/test_shardformer/test_model/test_shard_bert_pipeline.py
deleted file mode 100644
index 3170b58a1175..000000000000
--- a/tests/test_shardformer/test_model/test_shard_bert_pipeline.py
+++ /dev/null
@@ -1,107 +0,0 @@
-import pytest
-import torch
-
-import colossalai
-from colossalai.cluster import ProcessGroupMesh
-from colossalai.logging import disable_existing_loggers
-from colossalai.pipeline.stage_manager import PipelineStageManager
-from colossalai.shardformer.policies.auto_policy import get_autopolicy
-from colossalai.shardformer.shard import ShardConfig
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
-from colossalai.testing import (
- assert_hf_output_close,
- clear_cache_before_run,
- parameterize,
- rerun_if_address_is_in_use,
- spawn,
-)
-from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, build_pipeline_model, run_forward
-
-
-def check_bert_model_policy(name, model: torch.nn.Module, stage_manager: PipelineStageManager):
- stage_manager = stage_manager
- policy = get_autopolicy(model)
- policy.set_model(model)
- model_config = ShardConfig(pipeline_stage_manager=stage_manager, enable_tensor_parallelism=False)
- policy.set_shard_config(model_config)
- layers = policy.get_held_layers()
- if stage_manager.is_first_stage():
- assert len(layers) == 1 + 1
- else:
- if name == "transformers_bert":
- assert len(layers) == 1 + 1
- elif name in [
- "transformers_bert_for_sequence_classification", "transformers_bert_for_token_classification",
- "transformers_bert_for_mcq"
- ]:
- assert len(layers) == 1 + 3
- else:
- assert len(layers) == 1 + 2
-
-
-def check_bert_model_pipeline_forward(name, sharded_model, stage_manager: PipelineStageManager):
- if name == 'transformers_bert_for_mcq':
- x = torch.randint(0, 1000, (2, 3, 3)).cuda()
- attention_mask = torch.ones_like(x).cuda()
- if stage_manager.stage == 0:
- output = sharded_model(input_ids=x, attention_mask=attention_mask, stage_manager=stage_manager)
- assert output['hidden_states'].shape == (6, 3, 128)
- else:
- hidden_states = torch.randint(0, 1000, (6, 3, 128)).to(torch.float32).cuda()
- output = sharded_model(input_ids=x,
- hidden_states=hidden_states,
- attention_mask=attention_mask,
- stage_manager=stage_manager)
- assert output[0].shape == (2, 3)
- else:
- x = torch.randint(0, 1000, (2, 3)).cuda()
- # one batch, 2 single sentences, each sentence has 3 tokens
- hidden_states = torch.randint(0, 1000, (2, 3, 128)).to(torch.float32).cuda()
- if stage_manager.stage == 0:
- attention_mask = torch.ones_like(x).cuda()
- output = sharded_model(input_ids=x, attention_mask=attention_mask, stage_manager=stage_manager)
- assert output['hidden_states'].shape == (2, 3, 128)
- else:
- attention_mask = torch.ones((2, 3)).cuda()
- output = sharded_model(hidden_states=hidden_states,
- attention_mask=attention_mask,
- stage_manager=stage_manager)
- assert output[0].shape[0] == 2
-
-
-@parameterize('enable_fused_normalization', [False])
-@parameterize('enable_tensor_parallelism', [False])
-@parameterize('use_lazy_init', [False])
-#TODO: merge this into test_shard_bert
-def run_bert_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
- PP_DIM = 0
- PP_SIZE = 2
- pg_mesh = ProcessGroupMesh(PP_SIZE)
- stage_manager = PipelineStageManager(pg_mesh, PP_DIM)
-
- sub_model_zoo = model_zoo.get_sub_registry('transformers_bert')
- for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_pipeline_model(model_fn, stage_manager, enable_fused_normalization,
- enable_tensor_parallelism, use_lazy_init)
- check_bert_model_policy(name, org_model, stage_manager)
- check_bert_model_pipeline_forward(name, sharded_model, stage_manager)
-
- torch.cuda.empty_cache()
-
-
-def check_bert(rank, world_size, port):
- disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
- run_bert_test()
-
-
-@pytest.mark.dist
-@rerun_if_address_is_in_use()
-@clear_cache_before_run()
-def test_bert():
- spawn(check_bert, 2)
-
-
-if __name__ == "__main__":
- test_bert()
diff --git a/tests/test_shardformer/test_model/test_shard_blip2.py b/tests/test_shardformer/test_model/test_shard_blip2.py
index f96299e55a49..cd034d0c139a 100644
--- a/tests/test_shardformer/test_model/test_shard_blip2.py
+++ b/tests/test_shardformer/test_model/test_shard_blip2.py
@@ -3,7 +3,6 @@
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
from colossalai.testing import (
assert_hf_output_close,
clear_cache_before_run,
@@ -12,7 +11,7 @@
spawn,
)
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, run_forward
+from tests.test_shardformer.test_model._utils import build_model, check_grad, run_forward
def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
@@ -33,58 +32,28 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
blip2 = org_model
sharded_blip2 = sharded_model
- # compare vision_model grad
-
- org_grad = blip2.vision_model.encoder.layers[0].self_attn.qkv.weight.grad
- shard_grad = sharded_blip2.vision_model.encoder.layers[0].self_attn.qkv.weight.grad
- shard_weight = sharded_blip2.vision_model.encoder.layers[0].self_attn.qkv.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
-
- # compare qformer grad
- org_grad = blip2.qformer.encoder.layer[0].attention.attention.query.weight.grad
- shard_grad = sharded_blip2.qformer.encoder.layer[0].attention.attention.query.weight.grad
- shard_weight = sharded_blip2.qformer.encoder.layer[0].attention.attention.query.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
-
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
-
- # compare language_model grad
- org_grad = blip2.language_model.model.decoder.layers[0].self_attn.k_proj.weight.grad
- shard_grad = sharded_blip2.language_model.model.decoder.layers[0].self_attn.k_proj.weight.grad
- shard_weight = sharded_blip2.language_model.model.decoder.layers[0].self_attn.k_proj.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
-
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+ # check grad
+ col_layer_for_check = [
+ 'vision_model.encoder.layers[0].self_attn.qkv', 'qformer.encoder.layer[0].attention.attention.query',
+ 'language_model.model.decoder.layers[0].self_attn.k_proj'
+ ]
+ row_layer_for_check = [
+ 'vision_model.encoder.layers[0].self_attn.projection', 'qformer.encoder.layer[0].attention.output.dense',
+ 'language_model.model.decoder.layers[0].self_attn.out_proj'
+ ]
+ check_grad(blip2, sharded_blip2, col_layer_for_check, atol=1e-6, rtol=1e-5, dim=0, verbose=False)
+ check_grad(blip2, sharded_blip2, row_layer_for_check, atol=1e-6, rtol=1e-5, dim=1, verbose=False)
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
-def run_blip2_test(enable_fused_normalization, enable_tensor_parallelism):
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_blip2_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused):
sub_model_zoo = model_zoo.get_sub_registry('transformers_blip2')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism)
+ org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
+ enable_flash_attention, enable_jit_fused)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_shardformer/test_model/test_shard_bloom.py b/tests/test_shardformer/test_model/test_shard_bloom.py
index fe4686aeb979..e11bcf92ea3c 100644
--- a/tests/test_shardformer/test_model/test_shard_bloom.py
+++ b/tests/test_shardformer/test_model/test_shard_bloom.py
@@ -3,7 +3,6 @@
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
from colossalai.testing import (
assert_hf_output_close,
clear_cache_before_run,
@@ -12,7 +11,7 @@
spawn,
)
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, check_state_dict, run_forward
+from tests.test_shardformer.test_model._utils import build_model, check_grad, check_state_dict, run_forward
def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
@@ -26,7 +25,7 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
shard_loss.backward()
assert torch.allclose(org_loss, shard_loss,
- atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
+ atol=1e-6), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
# unwrap model
if org_model.__class__.__name__ == 'BloomModel':
@@ -36,46 +35,24 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
bloom = org_model.transformer
sharded_bloom = sharded_model.transformer
- # check attention grad
- org_grad = bloom.h[0].self_attention.query_key_value.weight.grad
- shard_grad = sharded_bloom.h[0].self_attention.query_key_value.weight.grad
- shard_weight = sharded_bloom.h[0].self_attention.query_key_value.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
-
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
-
- # check embedding weights
- org_grad = bloom.word_embeddings.weight.grad
- shard_grad = sharded_bloom.word_embeddings.weight.grad
- shard_weight = sharded_bloom.word_embeddings.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
-
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+ # check grad
+ col_layer_for_check = ['h[0].self_attention.query_key_value']
+ row_layer_for_check = ['h[0].self_attention.dense']
+ check_grad(bloom, sharded_bloom, col_layer_for_check, atol=1e-6, rtol=1e-5, dim=0, verbose=False)
+ check_grad(bloom, sharded_bloom, row_layer_for_check, atol=1e-6, rtol=1e-5, dim=1, verbose=False)
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
@parameterize('use_lazy_init', [False, True])
-def run_bloom_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
+def run_bloom_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused,
+ use_lazy_init):
sub_model_zoo = model_zoo.get_sub_registry('transformers_bloom')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
- use_lazy_init)
- check_state_dict(org_model, sharded_model, name=name)
+ enable_flash_attention, enable_jit_fused, use_lazy_init)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_shardformer/test_model/test_shard_chatglm.py b/tests/test_shardformer/test_model/test_shard_chatglm.py
index 36f240a0ffc0..c455a99d26ce 100644
--- a/tests/test_shardformer/test_model/test_shard_chatglm.py
+++ b/tests/test_shardformer/test_model/test_shard_chatglm.py
@@ -60,7 +60,7 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
shard_weight = shard_chatglm_model.embedding.word_embeddings.weight
if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
+ shard_grad_list = [torch.zeros_like(shard_grad) for _ in range(2)]
torch.distributed.all_gather(shard_grad_list, shard_grad)
all_shard_grad = torch.cat(shard_grad_list, dim=0)
else:
@@ -72,7 +72,9 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
-def run_chatglm_test(enable_fused_normalization, enable_tensor_parallelism):
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_chatglm_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused):
sub_model_zoo = model_zoo.get_sub_registry('transformers_chatglm')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
# create new model
@@ -80,7 +82,9 @@ def run_chatglm_test(enable_fused_normalization, enable_tensor_parallelism):
# shard model
shard_config = ShardConfig(enable_fused_normalization=enable_fused_normalization,
- enable_tensor_parallelism=enable_tensor_parallelism)
+ enable_tensor_parallelism=enable_tensor_parallelism,
+ enable_flash_attention=enable_flash_attention,
+ enable_jit_fused=enable_jit_fused)
model_copy = copy.deepcopy(org_model)
shard_former = ShardFormer(shard_config=shard_config)
if name == "transformers_chatglm":
diff --git a/tests/test_shardformer/test_model/test_shard_chatglm_pipeline.py b/tests/test_shardformer/test_model/test_shard_chatglm_pipeline.py
new file mode 100644
index 000000000000..ee474ac7be3b
--- /dev/null
+++ b/tests/test_shardformer/test_model/test_shard_chatglm_pipeline.py
@@ -0,0 +1,86 @@
+import copy
+import os
+
+import pytest
+import torch
+
+import colossalai
+from colossalai.cluster import ProcessGroupMesh
+from colossalai.logging import disable_existing_loggers
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer.policies.chatglm import ChatGLMForConditionalGenerationPolicy, ChatGLMModelPolicy
+from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
+from colossalai.testing import (
+ assert_hf_output_close,
+ clear_cache_before_run,
+ parameterize,
+ rerun_if_address_is_in_use,
+ spawn,
+)
+from tests.kit.model_zoo import model_zoo
+from tests.test_shardformer.test_model._utils import build_model, build_pipeline_model, run_forward
+
+
+@parameterize('enable_fused_normalization', [False])
+@parameterize('enable_tensor_parallelism', [False])
+@parameterize('use_lazy_init', [False])
+def run_chatglm_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
+ DP_DIM, PP_DIM = 0, 1
+ DP_SIZE, PP_SIZE = 2, 2
+ pg_mesh = ProcessGroupMesh(DP_SIZE, PP_SIZE)
+ stage_manager = PipelineStageManager(pg_mesh, PP_DIM)
+ sub_model_zoo = model_zoo.get_sub_registry('transformers_chatglm')
+ for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
+ # create new model for test
+ inputs = data_gen_fn()
+ inputs = {k: v.cuda() for k, v in inputs.items()}
+ input_ids = inputs['input_ids']
+ hidden_size = 64
+ batch_size, seq_len = input_ids.shape
+ hidden_state_shape = (seq_len, batch_size, hidden_size)
+ if name == "transformers_chatglm":
+ _, sharded_model = build_pipeline_model(model_fn, stage_manager, enable_fused_normalization,
+ enable_tensor_parallelism, use_lazy_init, ChatGLMModelPolicy())
+ if stage_manager.is_last_stage():
+ hidden_states = torch.randn(*hidden_state_shape).cuda()
+ inputs['input_ids'] = None
+ inputs['hidden_states'] = hidden_states
+ outputs = sharded_model(**inputs)
+ if stage_manager.is_last_stage():
+ assert outputs[0].shape == hidden_state_shape
+
+ else:
+ assert outputs['hidden_states'].shape == hidden_state_shape
+
+ if name == "transformers_chatglm_for_conditional_generation":
+ _, sharded_model = build_pipeline_model(model_fn, stage_manager, enable_fused_normalization,
+ enable_tensor_parallelism, use_lazy_init,
+ ChatGLMForConditionalGenerationPolicy())
+ if stage_manager.is_last_stage():
+ hidden_states = torch.randn(*hidden_state_shape).cuda()
+ inputs['input_ids'] = None
+ inputs['hidden_states'] = hidden_states
+ outputs = sharded_model(**inputs)
+ if stage_manager.is_last_stage():
+ assert outputs[0].shape == (batch_size, seq_len, 65024)
+ else:
+ assert outputs['hidden_states'].shape == hidden_state_shape
+
+ torch.cuda.empty_cache()
+
+
+def check_chatglm(rank, world_size, port):
+ disable_existing_loggers()
+ colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ run_chatglm_test()
+
+
+@pytest.mark.dist
+@rerun_if_address_is_in_use()
+@clear_cache_before_run()
+def test_chatglm():
+ spawn(check_chatglm, 4)
+
+
+if __name__ == "__main__":
+ test_chatglm()
diff --git a/tests/test_shardformer/test_model/test_shard_gpt2.py b/tests/test_shardformer/test_model/test_shard_gpt2.py
index eae4f2ffb799..1882bf7822cc 100644
--- a/tests/test_shardformer/test_model/test_shard_gpt2.py
+++ b/tests/test_shardformer/test_model/test_shard_gpt2.py
@@ -1,160 +1,84 @@
-import copy
-from contextlib import nullcontext
-
import pytest
import torch
from torch import distributed as dist
-from torch.optim import Adam
import colossalai
-from colossalai.booster import Booster
-from colossalai.booster.plugin import HybridParallelPlugin
-from colossalai.lazy.lazy_init import LazyInitContext
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import (
- clear_layout_converter,
- is_customized_distributed_tensor,
- is_distributed_tensor,
-)
+from colossalai.tensor.d_tensor.api import clear_layout_converter
from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, check_state_dict, run_forward
+from tests.test_shardformer.test_model._utils import (
+ build_model_from_hybrid_plugin,
+ check_grad,
+ check_loss,
+ check_output_hidden_state,
+ check_weight,
+ run_forward_backward_with_hybrid_plugin,
+)
def check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config):
- use_lazy_init = False
- if 'use_lazy_init' in test_config:
- use_lazy_init = test_config.pop('use_lazy_init')
+ org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster = \
+ build_model_from_hybrid_plugin(model_fn, loss_fn, test_config)
- if use_lazy_init:
- ctx = LazyInitContext()
- else:
- ctx = nullcontext()
-
- # prepare booster
- plugin = HybridParallelPlugin(**test_config)
- booster = Booster(plugin=plugin)
- stage_manager = plugin.stage_manager
-
- # prepare models and optimizers
- with ctx:
- org_model = model_fn().cuda()
- sharded_model = copy.deepcopy(org_model)
-
- if use_lazy_init:
- org_model = ctx.materialize(org_model)
-
- org_optimizer = Adam(org_model.parameters(), lr=1e-3)
- sharded_optimizer = Adam(sharded_model.parameters(), lr=1e-3)
- criterion = loss_fn
-
- sharded_model, sharded_optimizer, criterion, _, _ = booster.boost(sharded_model, sharded_optimizer, criterion)
-
- def _criterion(outputs, inputs):
- outputs = output_transform_fn(outputs)
- loss = criterion(outputs)
- return loss
-
- # do forward and backward
- data = data_gen_fn()
- sharded_model.train()
- if stage_manager:
- data = {
- k: v.to('cuda').repeat(4, 1) if torch.is_tensor(v) or 'Tensor' in v.__class__.__name__ else v
- for k, v in data.items()
- }
- data_iter = iter([data])
- sharded_output = booster.execute_pipeline(data_iter,
- sharded_model,
- _criterion,
- sharded_optimizer,
- return_loss=True,
- return_outputs=True)
- sharded_loss = sharded_output['loss']
- else:
- data = {k: v.cuda() for k, v in data.items()}
- sharded_output = sharded_model(**data)
- sharded_loss = criterion(sharded_output)
- sharded_loss.backward()
- org_model.train()
- org_output = org_model(**data)
- org_loss = criterion(org_output)
- org_loss.backward()
+ org_loss, org_output, sharded_loss, sharded_output = \
+ run_forward_backward_with_hybrid_plugin(
+ org_model,
+ sharded_model,
+ sharded_optimizer,
+ data_gen_fn,
+ output_transform_fn,
+ criterion,
+ booster)
+
+ stage_manager = booster.plugin.stage_manager
+ tp_group = booster.plugin.tp_group
+ # check last hidden state & loss
if stage_manager is None or stage_manager.is_last_stage():
- # check last hidden state
if org_model.__class__.__name__ == 'GPT2Model':
- org_hidden_state = org_output.last_hidden_state
+ check_output_hidden_state(org_output, sharded_output, stage_manager, atol=1e-5, rtol=1e-3)
- if stage_manager is None:
- sharded_hidden_state = sharded_output.last_hidden_state
-
- if stage_manager and stage_manager.is_last_stage():
- sharded_hidden_state = torch.cat([output.last_hidden_state for output in sharded_output['outputs']],
- dim=0)
-
- assert torch.allclose(org_hidden_state, sharded_hidden_state, atol=1e-5, rtol=1e-3), \
- f"shard model's output hidden state is not equal to origin model's last hidden state\n{org_hidden_state}\n{sharded_hidden_state}"
-
- # check loss
- assert torch.allclose(org_loss, sharded_loss, atol=1e-5, rtol=1e-3), \
- f"shard model loss is not equal to origin model loss\n{org_loss}\n{sharded_loss}"
+ check_loss(org_loss, sharded_loss, atol=1e-5, rtol=1e-3)
# unwrap model
if org_model.__class__.__name__ == 'GPT2Model':
- org_model = org_model
- sharded_model = sharded_model.unwrap()
+ gpt2 = org_model
+ sharded_gpt2 = sharded_model.unwrap()
else:
- org_model = org_model.transformer
- sharded_model = sharded_model.unwrap().transformer
-
- # check weights and gradients
- if stage_manager is None or stage_manager.is_first_stage():
+ gpt2 = org_model.transformer
+ sharded_gpt2 = sharded_model.unwrap().transformer
- shard_weight = sharded_model.h[0].mlp.c_fc.weight
- org_grad = org_model.h[0].mlp.c_fc.weight.grad
- shard_grad = sharded_model.h[0].mlp.c_fc.weight.grad
+ col_layer_for_check = ['h[0].mlp.c_fc']
+ row_layer_for_check = ['wte', 'h[0].mlp.c_proj']
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(plugin.tp_size)]
- dist.all_gather(shard_grad_list, shard_grad, plugin.tp_group)
- shard_grad = torch.cat(shard_grad_list, dim=1)
-
- assert torch.allclose(org_grad, shard_grad, atol=1e-5, rtol=1e-3), \
- f"shard model grad is not equal to origin model grad\n{org_grad}\n{shard_grad}"
+ # check grad
+ if stage_manager is None or stage_manager.is_first_stage():
+ check_grad(gpt2, sharded_gpt2, col_layer_for_check, tp_group, atol=1e-4, rtol=1e-3, dim=1, verbose=False)
+ check_grad(gpt2, sharded_gpt2, row_layer_for_check, tp_group, atol=1e-4, rtol=1e-3, dim=0, verbose=False)
# check weights after optimizer.step()
org_optimizer.step()
sharded_optimizer.step()
if stage_manager is None or stage_manager.is_first_stage():
-
- org_weight = org_model.h[0].mlp.c_fc.weight
- shard_weight = sharded_model.h[0].mlp.c_fc.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_weight_list = [torch.zeros([*shard_weight.shape]).to('cuda') for _ in range(plugin.tp_size)]
- dist.all_gather(shard_weight_list, shard_weight, plugin.tp_group)
- shard_weight = torch.cat(shard_weight_list, dim=1)
-
- assert torch.allclose(org_weight, shard_weight, atol=5e-3, rtol=1e-3), \
- f"shard model weight is not equal to origin model weight\n{org_weight}\n{shard_weight}"
+ check_weight(gpt2, sharded_gpt2, col_layer_for_check, tp_group, atol=5e-3, rtol=1e-3, dim=1, verbose=False)
torch.cuda.empty_cache()
@parameterize('test_config', [{
- 'tp_size': 1,
+ 'tp_size': 2,
'pp_size': 2,
'num_microbatches': 4,
+ 'enable_fused_normalization': True,
'use_lazy_init': True
}, {
- 'tp_size': 2,
+ 'tp_size': 1,
'pp_size': 2,
'num_microbatches': 4,
- 'enable_fused_normalization': False,
'use_lazy_init': False
}, {
'tp_size': 4,
@@ -165,9 +89,11 @@ def _criterion(outputs, inputs):
@clear_cache_before_run()
def run_gpt2_test(test_config):
- # TODO: add plugin_config for TP+DP after supporting & debugging it
+ # TODO: add test_config for TP+DP after supporting & debugging it
# {'tp_size': 2, 'pp_size': 1, 'enable_fused_normalization': True}
+ # TODO: add test_config for flash attention & jit operator after supporting
+
sub_model_zoo = model_zoo.get_sub_registry('transformers_gpt')
test_config['precision'] = 'float' # Do not use fp16/bf16 in testing
diff --git a/tests/test_shardformer/test_model/test_shard_llama.py b/tests/test_shardformer/test_model/test_shard_llama.py
index aaeef13ef873..ead14ab111e6 100644
--- a/tests/test_shardformer/test_model/test_shard_llama.py
+++ b/tests/test_shardformer/test_model/test_shard_llama.py
@@ -5,7 +5,6 @@
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
from colossalai.testing import (
assert_hf_output_close,
clear_cache_before_run,
@@ -14,7 +13,7 @@
spawn,
)
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, check_state_dict, run_forward
+from tests.test_shardformer.test_model._utils import build_model, check_grad, check_state_dict, run_forward
os.environ['TRANSFORMERS_NO_ADVISORY_WARNINGS'] = 'true'
@@ -24,7 +23,7 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
output_transform_fn, loss_fn)
# forward check
- assert_hf_output_close(org_output, shard_output, ignore_keys=['past_key_values'], rtol=1e-4)
+ assert_hf_output_close(org_output, shard_output, ignore_keys=['past_key_values'], rtol=1e-5)
# run backward
org_loss.backward()
@@ -41,43 +40,22 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
llama_model = org_model
shard_llama_model = sharded_model
- # check attention grad
- org_grad = llama_model.layers[0].self_attn.q_proj.weight.grad
- shard_grad = shard_llama_model.layers[0].self_attn.q_proj.weight.grad
- shard_weight = shard_llama_model.layers[0].self_attn.q_proj.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(4)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{shard_grad}"
-
- # check embedding grad
- org_grad = llama_model.embed_tokens.weight.grad
- shard_grad = shard_llama_model.embed_tokens.weight.grad
- shard_weight = shard_llama_model.embed_tokens.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(4)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{shard_grad}"
+ # check grad
+ col_layer_for_check = ['layers[0].self_attn.q_proj', 'embed_tokens']
+ row_layer_for_check = ['layers[0].self_attn.o_proj']
+ check_grad(llama_model, shard_llama_model, col_layer_for_check, atol=1e-6, rtol=1e-4, dim=0, verbose=False)
+ check_grad(llama_model, shard_llama_model, row_layer_for_check, atol=1e-6, rtol=1e-4, dim=1, verbose=False)
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
+@parameterize('enable_flash_attention', [True, False])
@parameterize('use_lazy_init', [False, True])
-def run_gpt2_llama(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
+def run_gpt2_llama(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, use_lazy_init):
sub_model_zoo = model_zoo.get_sub_registry('transformers_llama')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
- use_lazy_init)
+ enable_flash_attention, use_lazy_init)
check_state_dict(org_model, sharded_model, name=name)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_shardformer/test_model/test_shard_opt.py b/tests/test_shardformer/test_model/test_shard_opt.py
index 297affceb68a..99a278d4303a 100644
--- a/tests/test_shardformer/test_model/test_shard_opt.py
+++ b/tests/test_shardformer/test_model/test_shard_opt.py
@@ -6,7 +6,6 @@
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
from colossalai.testing import (
assert_hf_output_close,
clear_cache_before_run,
@@ -15,7 +14,7 @@
spawn,
)
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, check_state_dict, run_forward
+from tests.test_shardformer.test_model._utils import build_model, check_grad, check_state_dict, run_forward
os.environ['TRANSFORMERS_NO_ADVISORY_WARNINGS'] = 'true'
@@ -23,7 +22,7 @@
def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
output_transform_fn, loss_fn)
- assert_hf_output_close(org_output, shard_output, ignore_keys=['past_key_values'], rtol=1e-4)
+ assert_hf_output_close(org_output, shard_output, ignore_keys=['past_key_values'], rtol=1e-5)
# run backward
org_loss.backward()
@@ -40,43 +39,24 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
opt_model = org_model
shard_opt_model = sharded_model
- # check attention grad
- org_grad = opt_model.decoder.layers[0].self_attn.q_proj.weight.grad
- shard_grad = shard_opt_model.decoder.layers[0].self_attn.q_proj.weight.grad
- shard_weight = shard_opt_model.decoder.layers[0].self_attn.q_proj.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(4)]
- torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
-
- # check embedding grad
- org_grad = opt_model.decoder.embed_tokens.weight.grad
- shard_grad = shard_opt_model.decoder.embed_tokens.weight.grad
- shard_weight = shard_opt_model.decoder.embed_tokens.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(4)]
- torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+ # check grad
+ col_layer_for_check = ['decoder.layers[0].self_attn.q_proj', 'decoder.embed_tokens']
+ row_layer_for_check = ['decoder.layers[0].self_attn.out_proj']
+ check_grad(opt_model, shard_opt_model, col_layer_for_check, atol=1e-6, rtol=1e-3, dim=0, verbose=False)
+ check_grad(opt_model, shard_opt_model, row_layer_for_check, atol=1e-6, rtol=1e-3, dim=1, verbose=False)
+@parameterize('use_lazy_init', [False, True])
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
-@parameterize('use_lazy_init', [False, True])
-def run_t5_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_opt_test(use_lazy_init, enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention,
+ enable_jit_fused):
sub_model_zoo = model_zoo.get_sub_registry('transformers_opt')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
- use_lazy_init)
+ enable_flash_attention, enable_jit_fused, use_lazy_init)
check_state_dict(org_model, sharded_model, name=name)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
@@ -85,7 +65,7 @@ def run_t5_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_
def check_OPTModel(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
- run_t5_test()
+ run_opt_test()
@pytest.mark.dist
diff --git a/tests/test_shardformer/test_model/test_shard_sam.py b/tests/test_shardformer/test_model/test_shard_sam.py
index 1d047d8e0c42..616104cd7828 100644
--- a/tests/test_shardformer/test_model/test_shard_sam.py
+++ b/tests/test_shardformer/test_model/test_shard_sam.py
@@ -3,7 +3,6 @@
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
from colossalai.testing import (
assert_hf_output_close,
clear_cache_before_run,
@@ -12,7 +11,7 @@
spawn,
)
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, run_forward
+from tests.test_shardformer.test_model._utils import build_model, check_grad, run_forward
def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
@@ -33,43 +32,21 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
sam = org_model
sharded_sam = sharded_model
- # compare mask decoder grad
-
- org_grad = sam.mask_decoder.transformer.layers[0].self_attn.q_proj.weight.grad
- shard_grad = sharded_sam.mask_decoder.transformer.layers[0].self_attn.q_proj.weight.grad
- shard_weight = sharded_sam.mask_decoder.transformer.layers[0].self_attn.q_proj.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
-
- # compare vision_encoder grad
- org_grad = sam.vision_encoder.layers[0].mlp.lin1.weight.grad
- shard_grad = sharded_sam.vision_encoder.layers[0].mlp.lin1.weight.grad
- shard_weight = sharded_sam.vision_encoder.layers[0].mlp.lin1.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
-
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+ # check grad
+ col_layer_for_check = ['mask_decoder.transformer.layers[0].self_attn.q_proj', 'vision_encoder.layers[0].mlp.lin1']
+ row_layer_for_check = ['mask_decoder.transformer.layers[0].self_attn.out_proj', 'vision_encoder.layers[0].mlp.lin2']
+ check_grad(sam, sharded_sam, col_layer_for_check, atol=1e-5, rtol=1e-3, dim=0, verbose=False)
+ check_grad(sam, sharded_sam, row_layer_for_check, atol=1e-3, rtol=1e-3, dim=1, verbose=False)
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
-def run_sam_test(enable_fused_normalization, enable_tensor_parallelism):
+@parameterize('enable_flash_attention', [True, False])
+def run_sam_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention):
sub_model_zoo = model_zoo.get_sub_registry('transformers_sam')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism)
+ org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
+ enable_flash_attention)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_shardformer/test_model/test_shard_t5.py b/tests/test_shardformer/test_model/test_shard_t5.py
index 96dfdeb73827..d807ffa06296 100644
--- a/tests/test_shardformer/test_model/test_shard_t5.py
+++ b/tests/test_shardformer/test_model/test_shard_t5.py
@@ -1,95 +1,110 @@
-import os
-
import pytest
import torch
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
-from colossalai.testing import (
- assert_hf_output_close,
- clear_cache_before_run,
- parameterize,
- rerun_if_address_is_in_use,
- spawn,
-)
+from colossalai.shardformer.layer.utils import Randomizer
+from colossalai.tensor.d_tensor.api import clear_layout_converter
+from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, check_state_dict, run_forward
-
-
-def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
- # check forward
- # the value "past_key_values" is sharded, so we ignore
- org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
- output_transform_fn, loss_fn)
- assert_hf_output_close(org_output, shard_output, ignore_keys=['past_key_values'])
-
- # do backward
- org_loss.backward()
- shard_loss.backward()
-
- assert torch.allclose(org_loss, shard_loss,
- atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
-
- # check attention grad
- org_grad = org_model.encoder.block[0].layer[0].SelfAttention.q.weight.grad
- shard_grad = sharded_model.encoder.block[0].layer[0].SelfAttention.q.weight.grad
- shard_weight = sharded_model.encoder.block[0].layer[0].SelfAttention.q.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{shard_grad}"
-
- # check self attention embed
- org_grad = org_model.encoder.block[0].layer[0].SelfAttention.relative_attention_bias.weight.grad
- shard_grad = sharded_model.encoder.block[0].layer[0].SelfAttention.relative_attention_bias.weight.grad
- shard_weight = sharded_model.encoder.block[0].layer[0].SelfAttention.relative_attention_bias.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=1)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
-
- # check token embedding grad
- org_grad = org_model.shared.weight.grad
-
- # check weights are tied
- if hasattr(org_model, 'lm_head'):
- assert org_model.shared.weight.data.data_ptr() == org_model.lm_head.weight.data.data_ptr()
- assert sharded_model.shared.weight.data.data_ptr() == sharded_model.lm_head.weight.data.data_ptr()
-
- shard_grad = sharded_model.shared.weight.grad
- shard_weight = sharded_model.shared.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
-
-
-@parameterize('enable_fused_normalization', [True, False])
-@parameterize('enable_tensor_parallelism', [True, False])
-@parameterize('use_lazy_init', [False, True])
-def run_t5_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
+from tests.test_shardformer.test_model._utils import (
+ build_model_from_hybrid_plugin,
+ check_grad,
+ check_loss,
+ check_output_hidden_state,
+ check_weight,
+ run_forward_backward_with_hybrid_plugin,
+)
+
+
+def check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config):
+
+ org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster = \
+ build_model_from_hybrid_plugin(model_fn, loss_fn, test_config)
+
+ org_loss, org_output, sharded_loss, sharded_output = \
+ run_forward_backward_with_hybrid_plugin(
+ org_model,
+ sharded_model,
+ sharded_optimizer,
+ data_gen_fn,
+ output_transform_fn,
+ criterion,
+ booster)
+
+ stage_manager = booster.plugin.stage_manager
+ tp_group = booster.plugin.tp_group
+
+ # check last hidden state & loss
+ if stage_manager is None or stage_manager.is_last_stage():
+
+ if org_model.__class__.__name__ != 'T5ForConditionalGeneration':
+ check_output_hidden_state(org_output, sharded_output, stage_manager, atol=1e-5, rtol=1e-3)
+
+ check_loss(org_loss, sharded_loss, atol=1e-5, rtol=1e-3)
+
+ # unwrap model
+ t5 = org_model
+ sharded_t5 = sharded_model.unwrap()
+
+ row_layer_for_check = ['shared', 'encoder.block[0].layer[0].SelfAttention.q']
+
+ # check weights and gradients
+ if stage_manager is None or stage_manager.is_first_stage():
+ check_grad(t5, sharded_t5, row_layer_for_check, tp_group, atol=1e-5, rtol=1e-3, dim=0)
+
+ # check weights after optimizer.step()
+ org_optimizer.step()
+ sharded_optimizer.step()
+ if stage_manager is None or stage_manager.is_first_stage():
+ check_weight(t5, sharded_t5, row_layer_for_check, tp_group, atol=1e-4, rtol=1e-3, dim=0, verbose=False)
+
+ torch.cuda.empty_cache()
+
+
+@parameterize('test_config', [{
+ 'tp_size': 2,
+ 'pp_size': 2,
+ 'num_microbatches': 2,
+ 'enable_fused_normalization': True,
+ 'use_lazy_init': True
+}, {
+ 'tp_size': 1,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'use_lazy_init': False
+}, {
+ 'tp_size': 4,
+ 'pp_size': 1,
+ 'enable_fused_normalization': True,
+ 'use_lazy_init': False
+}, {
+ 'tp_size': 1,
+ 'pp_size': 4,
+ 'num_microbatches': 4,
+ 'use_lazy_init': False
+}])
+@clear_cache_before_run()
+def run_t5_test(test_config):
+
+ # TODO: add plugin_config for TP+DP after supporting & debugging it
+ # {'tp_size': 2, 'pp_size': 1, 'enable_fused_normalization': True}
+
+ # TODO: add test_config for flash attention & jit operator after supporting
+
sub_model_zoo = model_zoo.get_sub_registry('transformers_t5')
+ test_config['precision'] = 'float' # Do not use fp16/bf16 in testing
+
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
- use_lazy_init)
- check_state_dict(org_model, sharded_model, name=name)
- check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
+
+ # skip 4-stage pp test for t5_encoder
+ if test_config['pp_size'] > 2 and name == 'transformers_t5_encoder_model':
+ continue
+
+ check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config)
+
+ clear_layout_converter()
+ Randomizer.reset_index()
torch.cuda.empty_cache()
@@ -103,7 +118,7 @@ def check_t5(rank, world_size, port):
@rerun_if_address_is_in_use()
@clear_cache_before_run()
def test_t5():
- spawn(check_t5, 2)
+ spawn(check_t5, 4)
if __name__ == "__main__":
diff --git a/tests/test_shardformer/test_model/test_shard_t5_pipeline.py b/tests/test_shardformer/test_model/test_shard_t5_pipeline.py
deleted file mode 100644
index 7f3a5f2ea40b..000000000000
--- a/tests/test_shardformer/test_model/test_shard_t5_pipeline.py
+++ /dev/null
@@ -1,101 +0,0 @@
-import pytest
-import torch
-
-import colossalai
-from colossalai.cluster import ProcessGroupMesh
-from colossalai.logging import disable_existing_loggers
-from colossalai.pipeline.stage_manager import PipelineStageManager
-from colossalai.shardformer.policies.t5 import T5BasePolicy
-from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
-from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_pipeline_model
-
-
-def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
- # TODO: add tests for forward/backward later
- pass
-
-
-@parameterize('enable_tensor_parallelism', [False])
-@parameterize('enable_fused_normalization', [False])
-@parameterize('use_lazy_init', [False])
-#TODO: merge this into test_shard_t5.py
-def run_t5_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
- DP_DIM, PP_DIM = 0, 1
- DP_SIZE, PP_SIZE = 2, 2
- pg_mesh = ProcessGroupMesh(DP_SIZE, PP_SIZE)
- stage_manager = PipelineStageManager(pg_mesh, PP_DIM)
-
- sub_model_zoo = model_zoo.get_sub_registry('transformers_t5')
- for name, (model_fn, data_gen_fn, _, _, _) in sub_model_zoo.items():
-
- inputs = data_gen_fn()
- inputs = {k: v.cuda() for k, v in inputs.items()}
- input_ids = inputs['input_ids']
-
- _, sharded_model = build_pipeline_model(model_fn, stage_manager, enable_fused_normalization,
- enable_tensor_parallelism, use_lazy_init)
-
- batch_size, seq_len = input_ids.shape
- hidden_size = sharded_model.config.d_model
- num_heads = sharded_model.config.num_heads
- hidden_state_shape = (batch_size, seq_len, hidden_size)
- position_bias_shape = (batch_size, num_heads, seq_len, seq_len)
-
- num_encoder_layers = len(sharded_model.encoder.block)
- decoder = sharded_model.__dict__.get('decoder', None)
- num_decoder_layers = len(decoder.block) if decoder else 0
-
- _, decoder_starting_stage = T5BasePolicy.distribute_t5_layers(num_encoder_layers, num_decoder_layers, PP_SIZE)
- stage = stage_manager.stage
- at_first_stage = (stage == 0) or (stage == decoder_starting_stage)
- at_last_stage = (stage == decoder_starting_stage - 1) or (stage == stage_manager.num_stages - 1)
- in_decoder = stage >= decoder_starting_stage
-
- if not at_first_stage:
- # change inputs if not the first stage
- hidden_states = torch.zeros(*hidden_state_shape).cuda()
- position_bias = torch.zeros(*position_bias_shape).cuda()
- encoder_decoder_position_bias = torch.zeros(*position_bias_shape).cuda()
- inputs['input_ids'] = None
- inputs['hidden_states'] = hidden_states
- inputs['position_bias'] = position_bias
- inputs['encoder_decoder_position_bias'] = encoder_decoder_position_bias
- if in_decoder:
- encoder_output_states = torch.zeros(*hidden_state_shape).cuda()
- inputs['encoder_outputs'] = (encoder_output_states,)
-
- sharded_model.train()
- output = sharded_model(**inputs)
- if at_last_stage:
- if name == 'transformers_t5_for_conditional_generation' and in_decoder:
- assert output.loss is not None
- else:
- if name != 'transformers_t5_encoder_model' and not in_decoder:
- output = output['encoder_outputs']
- assert output[0].shape == hidden_state_shape
- else:
- assert output['hidden_states'].shape == hidden_state_shape
- # position_bias information should be passed in T5
- assert output['position_bias'].shape == position_bias_shape
- if in_decoder:
- assert output['encoder_decoder_position_bias'].shape == position_bias_shape
-
- torch.cuda.empty_cache()
-
-
-def check_t5(rank, world_size, port):
- disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
- run_t5_test()
-
-
-@pytest.mark.dist
-@rerun_if_address_is_in_use()
-@clear_cache_before_run()
-def test_t5():
- spawn(check_t5, 4)
-
-
-if __name__ == "__main__":
- test_t5()
diff --git a/tests/test_shardformer/test_model/test_shard_vit.py b/tests/test_shardformer/test_model/test_shard_vit.py
index 2b02c83e0d27..d179c8a8ee32 100644
--- a/tests/test_shardformer/test_model/test_shard_vit.py
+++ b/tests/test_shardformer/test_model/test_shard_vit.py
@@ -5,7 +5,6 @@
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
from colossalai.testing import (
assert_hf_output_close,
clear_cache_before_run,
@@ -14,14 +13,16 @@
spawn,
)
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, run_forward
+from tests.test_shardformer.test_model._utils import build_model, check_grad, run_forward
def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
# check forward
org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
output_transform_fn, loss_fn)
+
assert_hf_output_close(org_output, shard_output, atol=1e-3, rtol=1e-3)
+
# do backward
org_loss.backward()
shard_loss.backward()
@@ -37,27 +38,22 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
vit_model = org_model.vit
shard_vit_model = sharded_model.vit
- # check attention grad
- org_grad = vit_model.encoder.layer[0].attention.attention.query.weight.grad
- shard_grad = shard_vit_model.encoder.layer[0].attention.attention.query.weight.grad
- shard_weight = shard_vit_model.encoder.layer[0].attention.attention.query.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{shard_grad}"
+ # check grad
+ col_layer_for_check = ['encoder.layer[0].attention.attention.query']
+ row_layer_for_check = ['encoder.layer[0].attention.output.dense']
+ check_grad(vit_model, shard_vit_model, col_layer_for_check, atol=1e-5, rtol=1e-3, dim=0, verbose=False)
+ check_grad(vit_model, shard_vit_model, row_layer_for_check, atol=1e-5, rtol=1e-3, dim=1, verbose=False)
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
-def run_vit_test(enable_fused_normalization, enable_tensor_parallelism):
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_vit_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused):
sub_model_zoo = model_zoo.get_sub_registry('transformers_vit')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism)
+ org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
+ enable_flash_attention, enable_jit_fused)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_shardformer/test_model/test_shard_whisper.py b/tests/test_shardformer/test_model/test_shard_whisper.py
index 8932a4ab902c..9b38ae07b1d6 100644
--- a/tests/test_shardformer/test_model/test_shard_whisper.py
+++ b/tests/test_shardformer/test_model/test_shard_whisper.py
@@ -3,7 +3,6 @@
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
from colossalai.testing import (
assert_hf_output_close,
clear_cache_before_run,
@@ -12,14 +11,14 @@
spawn,
)
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, run_forward
+from tests.test_shardformer.test_model._utils import build_model, check_grad, run_forward
def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
# check forward
org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
output_transform_fn, loss_fn)
- assert_hf_output_close(org_output, shard_output, ignore_keys='past_key_values')
+ assert_hf_output_close(org_output, shard_output, ignore_keys='past_key_values', atol=1e-5)
# do backward
org_loss.backward()
@@ -28,8 +27,7 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
assert torch.allclose(org_loss, shard_loss,
atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
- # check grad
-
+ # unwarp the model
if org_model.__class__.__name__ == 'WhisperForConditionalGeneration':
whisper = org_model.model
sharded_whisper = sharded_model.model
@@ -37,48 +35,29 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
whisper = org_model
sharded_whisper = sharded_model
- # compare self attention grad
- org_grad = whisper.encoder.layers[0].self_attn.q_proj.weight.grad
- shard_grad = sharded_whisper.encoder.layers[0].self_attn.q_proj.weight.grad
- shard_weight = sharded_whisper.encoder.layers[0].self_attn.q_proj.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
-
- # WhisperForAudioClassification does not have decoder and embedding layer
+ # check grad
if org_model.__class__.__name__ == 'WhisperForAudioClassification':
- return
-
- # compare embedding grad
- org_grad = whisper.decoder.embed_tokens.weight.grad
- shard_grad = sharded_whisper.decoder.embed_tokens.weight.grad
- shard_weight = sharded_whisper.decoder.embed_tokens.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
+ col_layer_for_check = ['encoder.layers[0].self_attn.q_proj']
+ row_layer_for_check = ['encoder.layers[0].self_attn.out_proj']
else:
- all_shard_grad = shard_grad
-
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+ col_layer_for_check = ['encoder.layers[0].self_attn.q_proj', 'decoder.layers[0].self_attn.q_proj']
+ row_layer_for_check = ['encoder.layers[0].self_attn.out_proj', 'decoder.layers[0].self_attn.out_proj']
+ check_grad(whisper, sharded_whisper, col_layer_for_check, atol=1e-6, rtol=1e-5, dim=0, verbose=False)
+ check_grad(whisper, sharded_whisper, row_layer_for_check, atol=1e-6, rtol=1e-5, dim=1, verbose=False)
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
-def run_whisper_test(enable_fused_normalization, enable_tensor_parallelism):
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_whisper_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused):
sub_model_zoo = model_zoo.get_sub_registry('transformers_whisper')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
org_model, sharded_model = build_model(model_fn,
enable_fused_normalization=enable_fused_normalization,
- enable_tensor_parallelism=enable_tensor_parallelism)
+ enable_tensor_parallelism=enable_tensor_parallelism,
+ enable_flash_attention=enable_flash_attention,
+ enable_jit_fused=enable_jit_fused)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_utils/test_flash_attention.py b/tests/test_utils/test_flash_attention.py
index 7a28b0157384..938f85b410e1 100644
--- a/tests/test_utils/test_flash_attention.py
+++ b/tests/test_utils/test_flash_attention.py
@@ -24,8 +24,9 @@ def baseline_attention(Z, N_CTX, H, q, k, v, sm_scale):
@pytest.mark.skipif(HAS_MEM_EFF_ATTN == False, reason="xformers is not available")
@clear_cache_before_run()
-@parameterize('B, S, H, D_HEAD', [(6, 8, 4, 16)])
-def test_attention_gpt(B, S, H, D_HEAD, dtype=torch.float16):
+@parameterize('proj_shape', [(1, 128, 4, 16)])
+def test_attention_gpt(proj_shape, dtype=torch.float16):
+ (B, S, H, D_HEAD) = proj_shape
D = H * D_HEAD
c_attn = torch.nn.Linear(D, 3 * D, dtype=dtype, device="cuda")
@@ -35,7 +36,11 @@ def test_attention_gpt(B, S, H, D_HEAD, dtype=torch.float16):
qkv = c_attn(x)
q, k, v = rearrange(qkv, 'b s (n h d) -> n b s h d', n=3, h=H)
- y = attn(q, k, v, attn_mask_type=AttnMaskType.causal)
+
+ mask = [torch.ones(S - i, dtype=dtype, device="cuda") for i in range(B)]
+ mask = torch.nn.utils.rnn.pad_sequence(mask, batch_first=True)
+
+ y = attn(q, k, v, attn_mask=mask, attn_mask_type=AttnMaskType.paddedcausal)
assert list(y.shape) == [B, S, D]
@@ -45,8 +50,9 @@ def test_attention_gpt(B, S, H, D_HEAD, dtype=torch.float16):
@pytest.mark.skipif(HAS_MEM_EFF_ATTN == False, reason="xformers is not available")
@clear_cache_before_run()
-@parameterize('B, S, H, D_HEAD', [(6, 8, 4, 16)])
-def test_attention_bert(B, S, H, D_HEAD, dtype=torch.float16):
+@parameterize('proj_shape', [(1, 128, 4, 16)])
+def test_attention_bert(proj_shape, dtype=torch.float16):
+ (B, S, H, D_HEAD) = proj_shape
D = H * D_HEAD
c_attn = torch.nn.Linear(D, 3 * D, dtype=dtype, device="cuda")
@@ -69,8 +75,9 @@ def test_attention_bert(B, S, H, D_HEAD, dtype=torch.float16):
@pytest.mark.skipif(HAS_MEM_EFF_ATTN == False, reason="xformers is not available")
@clear_cache_before_run()
-@parameterize('B, S, H, D_HEAD', [(6, 8, 4, 16)])
-def test_attention_no_mask(B, S, H, D_HEAD, dtype=torch.float16):
+@parameterize('proj_shape', [(6, 128, 4, 16)])
+def test_attention_no_mask(proj_shape, dtype=torch.float16):
+ (B, S, H, D_HEAD) = proj_shape
D = H * D_HEAD
c_attn = torch.nn.Linear(D, 3 * D, dtype=dtype, device="cuda")
@@ -89,8 +96,9 @@ def test_attention_no_mask(B, S, H, D_HEAD, dtype=torch.float16):
@pytest.mark.skipif(HAS_MEM_EFF_ATTN == False, reason="xformers is not available")
@clear_cache_before_run()
-@parameterize('B, S, T, H, D_HEAD', [(6, 24, 8, 4, 16)])
-def test_cross_attention(B, S, T, H, D_HEAD, dtype=torch.float16):
+@parameterize('proj_shape', [(6, 128, 256, 4, 16)])
+def test_cross_attention(proj_shape, dtype=torch.float16):
+ (B, S, T, H, D_HEAD) = proj_shape
D = H * D_HEAD
q_attn = torch.nn.Linear(D, D, dtype=dtype, device="cuda")