diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index aa2d907da4bd..a2bb870dc6df 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -28,8 +28,8 @@
title: Load community pipelines
- local: using-diffusers/using_safetensors
title: Load safetensors
- - local: using-diffusers/kerascv
- title: Load KerasCV Stable Diffusion checkpoints
+ - local: using-diffusers/other-formats
+ title: Load different Stable Diffusion formats
title: Loading & Hub
- sections:
- local: using-diffusers/pipeline_overview
diff --git a/docs/source/en/using-diffusers/kerascv.mdx b/docs/source/en/using-diffusers/kerascv.mdx
deleted file mode 100644
index 06981cc8fdd1..000000000000
--- a/docs/source/en/using-diffusers/kerascv.mdx
+++ /dev/null
@@ -1,179 +0,0 @@
-
-
-# Using KerasCV Stable Diffusion Checkpoints in Diffusers
-
-
-
-This is an experimental feature.
-
-
-
-[KerasCV](https://github.com/keras-team/keras-cv/) provides APIs for implementing various computer vision workflows. It
-also provides the Stable Diffusion [v1 and v2](https://github.com/keras-team/keras-cv/blob/master/keras_cv/models/stable_diffusion)
-models. Many practitioners find it easy to fine-tune the Stable Diffusion models shipped by KerasCV. However, as of this writing, KerasCV offers limited support to experiment with Stable Diffusion models for inference and deployment. On the other hand,
-Diffusers provides tooling dedicated to this purpose (and more), such as different [noise schedulers](https://huggingface.co/docs/diffusers/using-diffusers/schedulers), [flash attention](https://huggingface.co/docs/diffusers/optimization/xformers), and [other
-optimization techniques](https://huggingface.co/docs/diffusers/optimization/fp16).
-
-How about fine-tuning Stable Diffusion models in KerasCV and exporting them such that they become compatible with Diffusers to combine the
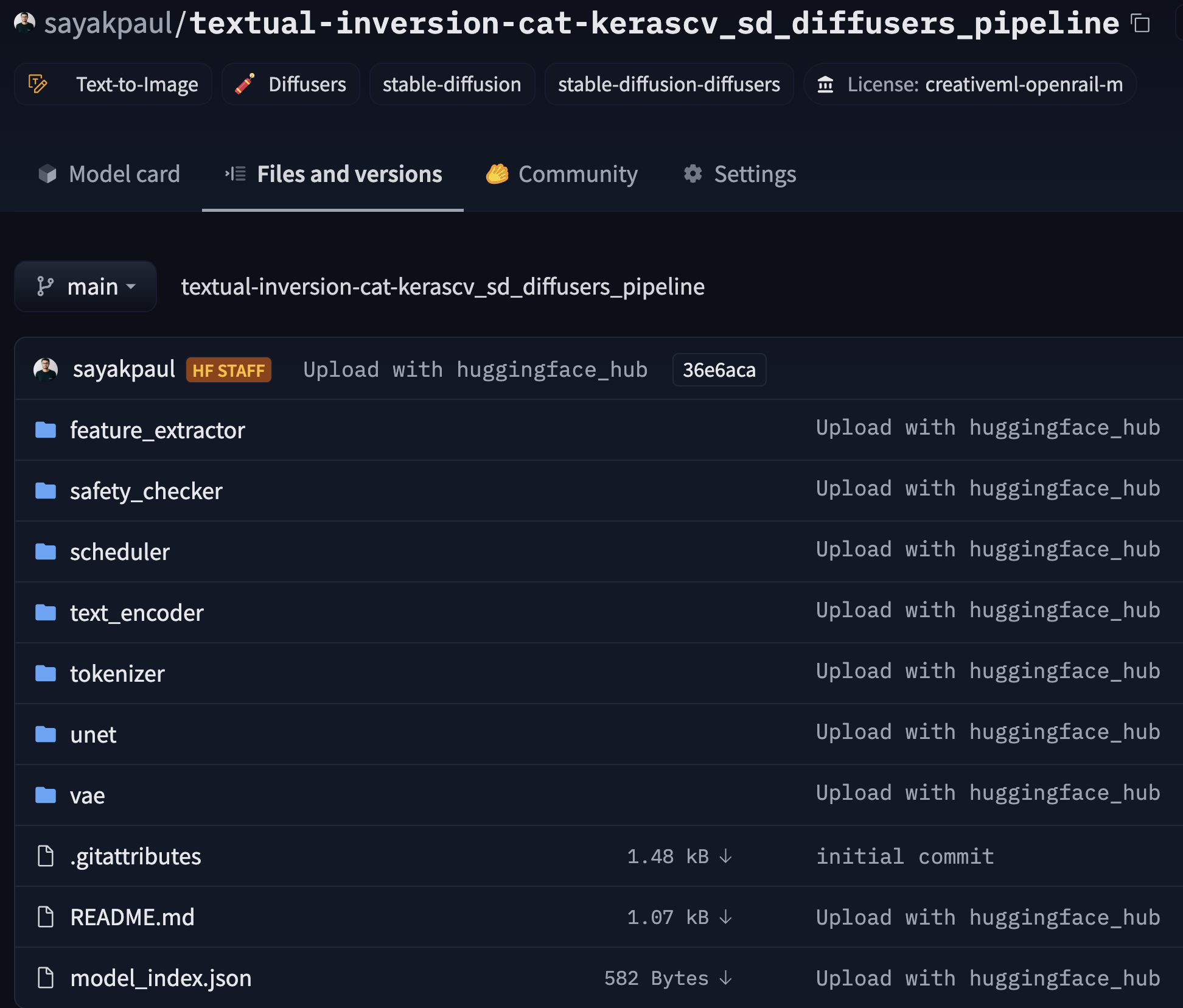
-best of both worlds? We have created a [tool](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers) that
-lets you do just that! It takes KerasCV Stable Diffusion checkpoints and exports them to Diffusers-compatible checkpoints.
-More specifically, it first converts the checkpoints to PyTorch and then wraps them into a
-[`StableDiffusionPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview) which is ready
-for inference. Finally, it pushes the converted checkpoints to a repository on the Hugging Face Hub.
-
-We welcome you to try out the tool [here](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers)
-and share feedback via [discussions](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers/discussions/new).
-
-## Getting Started
-
-First, you need to obtain the fine-tuned KerasCV Stable Diffusion checkpoints. We provide an
-overview of the different ways Stable Diffusion models can be fine-tuned [using `diffusers`](https://huggingface.co/docs/diffusers/training/overview). For the Keras implementation of some of these methods, you can check out these resources:
-
-* [Teach StableDiffusion new concepts via Textual Inversion](https://keras.io/examples/generative/fine_tune_via_textual_inversion/)
-* [Fine-tuning Stable Diffusion](https://keras.io/examples/generative/finetune_stable_diffusion/)
-* [DreamBooth](https://keras.io/examples/generative/dreambooth/)
-* [Prompt-to-Prompt editing](https://github.com/miguelCalado/prompt-to-prompt-tensorflow)
-
-Stable Diffusion is comprised of the following models:
-
-* Text encoder
-* UNet
-* VAE
-
-Depending on the fine-tuning task, we may fine-tune one or more of these components (the VAE is almost always left untouched). Here are some common combinations:
-
-* DreamBooth: UNet and text encoder
-* Classical text to image fine-tuning: UNet
-* Textual Inversion: Just the newly initialized embeddings in the text encoder
-
-### Performing the Conversion
-
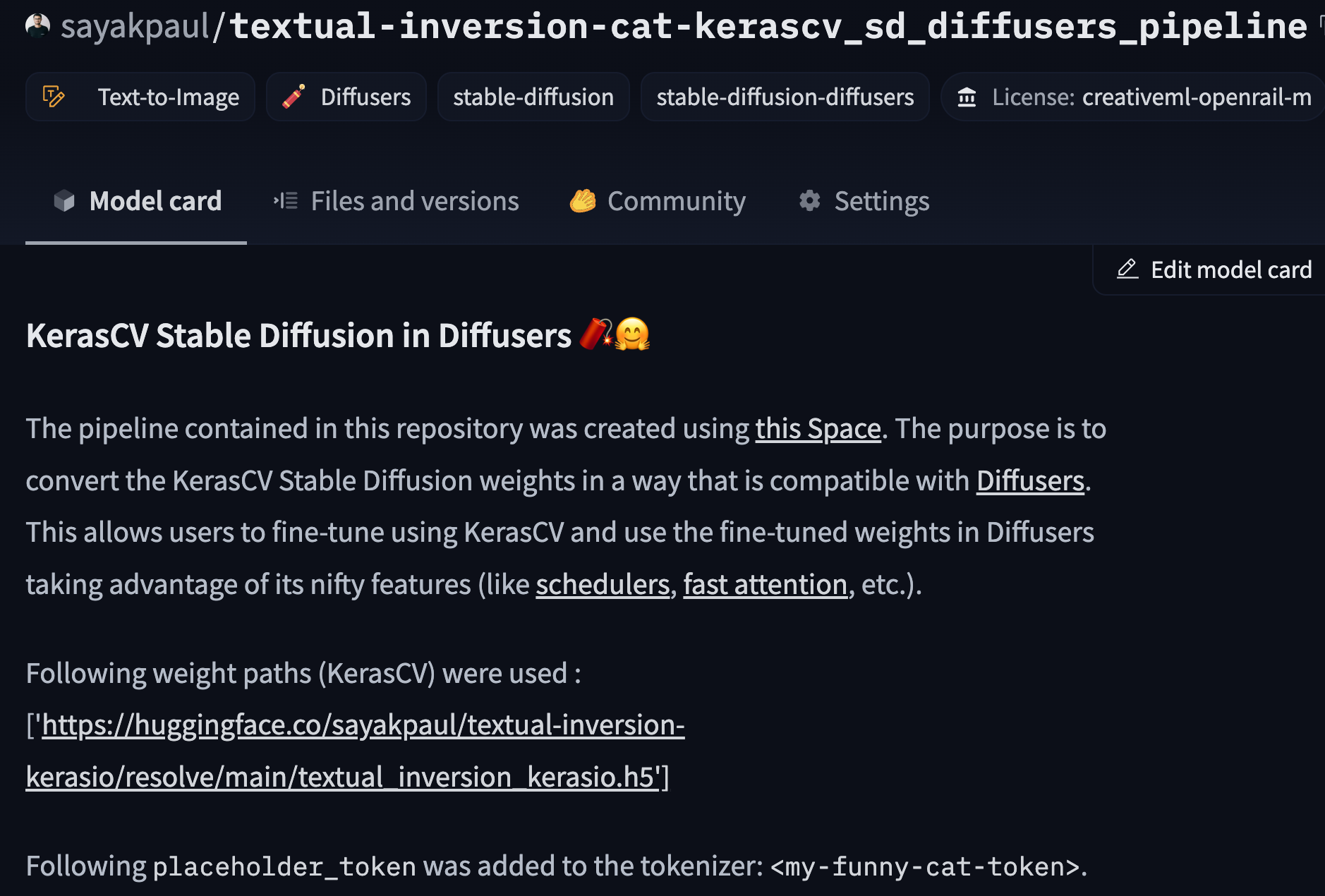
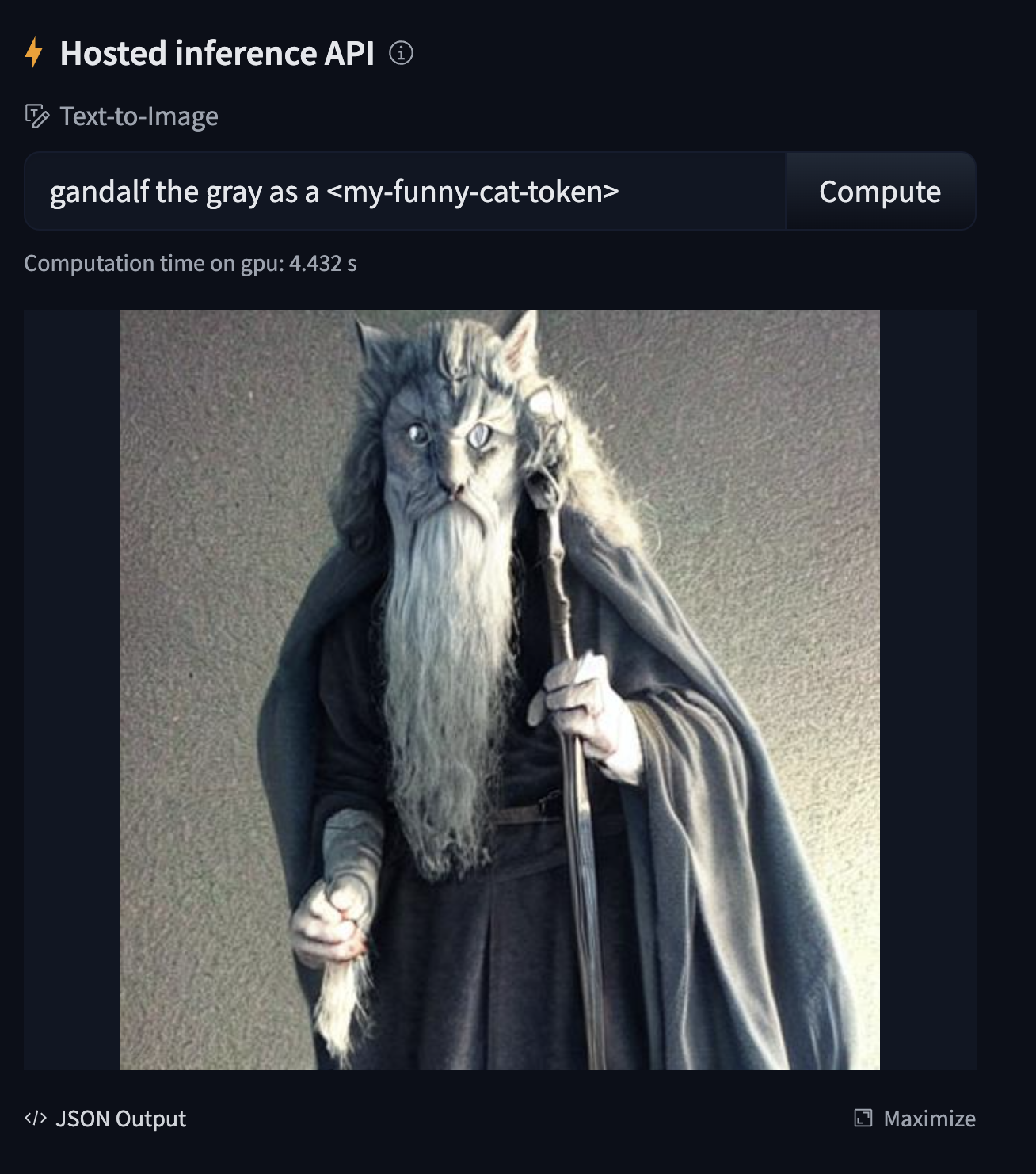
-Let's use [this checkpoint](https://huggingface.co/sayakpaul/textual-inversion-kerasio/resolve/main/textual_inversion_kerasio.h5) which was generated
-by conducting Textual Inversion with the following "placeholder token": ``.
-
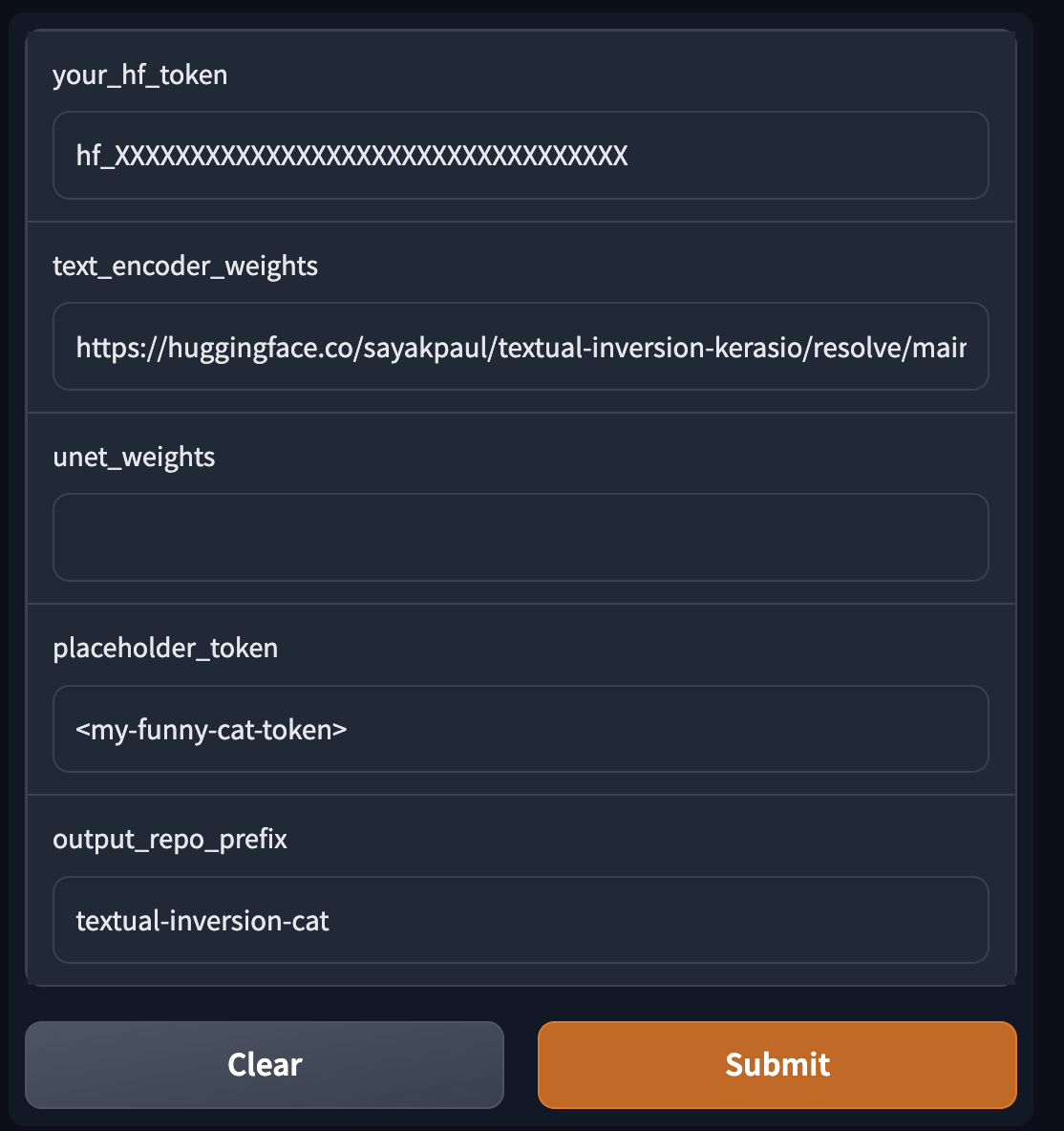
-On the tool, we supply the following things:
-
-* Path(s) to download the fine-tuned checkpoint(s) (KerasCV)
-* An HF token
-* Placeholder token (only applicable for Textual Inversion)
-
-
-
-
-

-
-
-
-
-
-
-
-

-
-

-