diff --git a/docs/source/en/model_doc/jamba.md b/docs/source/en/model_doc/jamba.md
index c8d66b163b5a..8c2c147c0c7e 100644
--- a/docs/source/en/model_doc/jamba.md
+++ b/docs/source/en/model_doc/jamba.md
@@ -14,96 +14,126 @@ rendered properly in your Markdown viewer.
-->
+
+
# Jamba
-
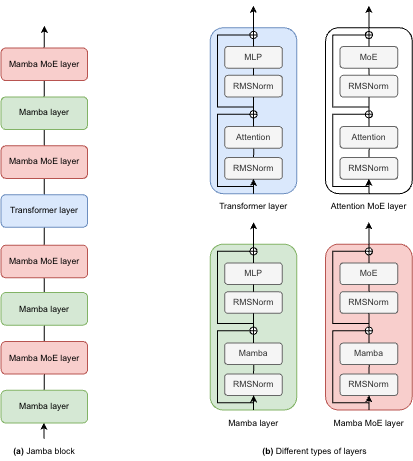
+[Jamba](https://huggingface.co/papers/2403.19887) is a hybrid Transformer-Mamba mixture-of-experts (MoE) language model ranging from 52B to 398B total parameters. This model aims to combine the advantages of both model families, the performance of transformer models and the efficiency and longer context (256K tokens) of state space models (SSMs) like Mamba.
-## Overview
+Jamba's architecture features a blocks-and-layers approach that allows Jamba to successfully integrate Transformer and Mamba architectures altogether. Each Jamba block contains either an attention or a Mamba layer, followed by a multi-layer perceptron (MLP), producing an overall ratio of one Transformer layer out of every eight total layers. MoE layers are mixed in to increase model capacity.
-Jamba is a state-of-the-art, hybrid SSM-Transformer LLM. It is the first production-scale Mamba implementation, which opens up interesting research and application opportunities. While this initial experimentation shows encouraging gains, we expect these to be further enhanced with future optimizations and explorations.
+You can find all the original Jamba checkpoints under the [AI21](https://huggingface.co/ai21labs) organization.
-For full details of this model please read the [release blog post](https://www.ai21.com/blog/announcing-jamba).
+> [!TIP]
+> Click on the Jamba models in the right sidebar for more examples of how to apply Jamba to different language tasks.
-### Model Details
+The example below demonstrates how to generate text with [`Pipeline`], [`AutoModel`], and from the command line.
-Jamba is a pretrained, mixture-of-experts (MoE) generative text model, with 12B active parameters and an overall of 52B parameters across all experts. It supports a 256K context length, and can fit up to 140K tokens on a single 80GB GPU.
+
+
-As depicted in the diagram below, Jamba's architecture features a blocks-and-layers approach that allows Jamba to successfully integrate Transformer and Mamba architectures altogether. Each Jamba block contains either an attention or a Mamba layer, followed by a multi-layer perceptron (MLP), producing an overall ratio of one Transformer layer out of every eight total layers.
+```py
+# install optimized Mamba implementations
+# !pip install mamba-ssm causal-conv1d>=1.2.0
+import torch
+from transformers import pipeline
- +pipeline = pipeline(
+ task="text-generation",
+ model="ai21labs/AI21-Jamba-Mini-1.6",
+ torch_dtype=torch.float16,
+ device=0
+)
+pipeline("Plants create energy through a process known as")
+```
-## Usage
+
+
-### Prerequisites
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
-Jamba requires you use `transformers` version 4.39.0 or higher:
-```bash
-pip install transformers>=4.39.0
+tokenizer = AutoTokenizer.from_pretrained(
+ "ai21labs/AI21-Jamba-Large-1.6",
+)
+model = AutoModelForCausalLM.from_pretrained(
+ "ai21labs/AI21-Jamba-Large-1.6",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+input_ids = tokenizer("Plants create energy through a process known as", return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
```
+
+
-In order to run optimized Mamba implementations, you first need to install `mamba-ssm` and `causal-conv1d`:
```bash
-pip install mamba-ssm causal-conv1d>=1.2.0
+echo -e "Plants create energy through a process known as" | transformers-cli run --task text-generation --model ai21labs/AI21-Jamba-Mini-1.6 --device 0
```
-You also have to have the model on a CUDA device.
-You can run the model not using the optimized Mamba kernels, but it is **not** recommended as it will result in significantly lower latencies. In order to do that, you'll need to specify `use_mamba_kernels=False` when loading the model.
+
+
-### Run the model
-```python
-from transformers import AutoModelForCausalLM, AutoTokenizer
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes) to only quantize the weights to 8-bits.
-model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1")
-tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
-input_ids = tokenizer("In the recent Super Bowl LVIII,", return_tensors='pt').to(model.device)["input_ids"]
+quantization_config = BitsAndBytesConfig(load_in_8bit=True,
+ llm_int8_skip_modules=["mamba"])
-outputs = model.generate(input_ids, max_new_tokens=216)
+# a device map to distribute the model evenly across 8 GPUs
+device_map = {'model.embed_tokens': 0, 'model.layers.0': 0, 'model.layers.1': 0, 'model.layers.2': 0, 'model.layers.3': 0, 'model.layers.4': 0, 'model.layers.5': 0, 'model.layers.6': 0, 'model.layers.7': 0, 'model.layers.8': 0, 'model.layers.9': 1, 'model.layers.10': 1, 'model.layers.11': 1, 'model.layers.12': 1, 'model.layers.13': 1, 'model.layers.14': 1, 'model.layers.15': 1, 'model.layers.16': 1, 'model.layers.17': 1, 'model.layers.18': 2, 'model.layers.19': 2, 'model.layers.20': 2, 'model.layers.21': 2, 'model.layers.22': 2, 'model.layers.23': 2, 'model.layers.24': 2, 'model.layers.25': 2, 'model.layers.26': 2, 'model.layers.27': 3, 'model.layers.28': 3, 'model.layers.29': 3, 'model.layers.30': 3, 'model.layers.31': 3, 'model.layers.32': 3, 'model.layers.33': 3, 'model.layers.34': 3, 'model.layers.35': 3, 'model.layers.36': 4, 'model.layers.37': 4, 'model.layers.38': 4, 'model.layers.39': 4, 'model.layers.40': 4, 'model.layers.41': 4, 'model.layers.42': 4, 'model.layers.43': 4, 'model.layers.44': 4, 'model.layers.45': 5, 'model.layers.46': 5, 'model.layers.47': 5, 'model.layers.48': 5, 'model.layers.49': 5, 'model.layers.50': 5, 'model.layers.51': 5, 'model.layers.52': 5, 'model.layers.53': 5, 'model.layers.54': 6, 'model.layers.55': 6, 'model.layers.56': 6, 'model.layers.57': 6, 'model.layers.58': 6, 'model.layers.59': 6, 'model.layers.60': 6, 'model.layers.61': 6, 'model.layers.62': 6, 'model.layers.63': 7, 'model.layers.64': 7, 'model.layers.65': 7, 'model.layers.66': 7, 'model.layers.67': 7, 'model.layers.68': 7, 'model.layers.69': 7, 'model.layers.70': 7, 'model.layers.71': 7, 'model.final_layernorm': 7, 'lm_head': 7}
+model = AutoModelForCausalLM.from_pretrained("ai21labs/AI21-Jamba-Large-1.6",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+ quantization_config=quantization_config,
+ device_map=device_map)
-print(tokenizer.batch_decode(outputs))
-# ["<|startoftext|>In the recent Super Bowl LVIII, the Kansas City Chiefs emerged victorious, defeating the San Francisco 49ers in a thrilling overtime showdown. The game was a nail-biter, with both teams showcasing their skills and determination.\n\nThe Chiefs, led by their star quarterback Patrick Mahomes, displayed their offensive prowess, while the 49ers, led by their strong defense, put up a tough fight. The game went into overtime, with the Chiefs ultimately securing the win with a touchdown.\n\nThe victory marked the Chiefs' second Super Bowl win in four years, solidifying their status as one of the top teams in the NFL. The game was a testament to the skill and talent of both teams, and a thrilling end to the NFL season.\n\nThe Super Bowl is not just about the game itself, but also about the halftime show and the commercials. This year's halftime show featured a star-studded lineup, including Usher, Alicia Keys, and Lil Jon. The show was a spectacle of music and dance, with the performers delivering an energetic and entertaining performance.\n"]
-```
+tokenizer = AutoTokenizer.from_pretrained("ai21labs/AI21-Jamba-Large-1.6")
-
+pipeline = pipeline(
+ task="text-generation",
+ model="ai21labs/AI21-Jamba-Mini-1.6",
+ torch_dtype=torch.float16,
+ device=0
+)
+pipeline("Plants create energy through a process known as")
+```
-## Usage
+
+
-### Prerequisites
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
-Jamba requires you use `transformers` version 4.39.0 or higher:
-```bash
-pip install transformers>=4.39.0
+tokenizer = AutoTokenizer.from_pretrained(
+ "ai21labs/AI21-Jamba-Large-1.6",
+)
+model = AutoModelForCausalLM.from_pretrained(
+ "ai21labs/AI21-Jamba-Large-1.6",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+input_ids = tokenizer("Plants create energy through a process known as", return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
```
+
+
-In order to run optimized Mamba implementations, you first need to install `mamba-ssm` and `causal-conv1d`:
```bash
-pip install mamba-ssm causal-conv1d>=1.2.0
+echo -e "Plants create energy through a process known as" | transformers-cli run --task text-generation --model ai21labs/AI21-Jamba-Mini-1.6 --device 0
```
-You also have to have the model on a CUDA device.
-You can run the model not using the optimized Mamba kernels, but it is **not** recommended as it will result in significantly lower latencies. In order to do that, you'll need to specify `use_mamba_kernels=False` when loading the model.
+
+
-### Run the model
-```python
-from transformers import AutoModelForCausalLM, AutoTokenizer
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes) to only quantize the weights to 8-bits.
-model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1")
-tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
-input_ids = tokenizer("In the recent Super Bowl LVIII,", return_tensors='pt').to(model.device)["input_ids"]
+quantization_config = BitsAndBytesConfig(load_in_8bit=True,
+ llm_int8_skip_modules=["mamba"])
-outputs = model.generate(input_ids, max_new_tokens=216)
+# a device map to distribute the model evenly across 8 GPUs
+device_map = {'model.embed_tokens': 0, 'model.layers.0': 0, 'model.layers.1': 0, 'model.layers.2': 0, 'model.layers.3': 0, 'model.layers.4': 0, 'model.layers.5': 0, 'model.layers.6': 0, 'model.layers.7': 0, 'model.layers.8': 0, 'model.layers.9': 1, 'model.layers.10': 1, 'model.layers.11': 1, 'model.layers.12': 1, 'model.layers.13': 1, 'model.layers.14': 1, 'model.layers.15': 1, 'model.layers.16': 1, 'model.layers.17': 1, 'model.layers.18': 2, 'model.layers.19': 2, 'model.layers.20': 2, 'model.layers.21': 2, 'model.layers.22': 2, 'model.layers.23': 2, 'model.layers.24': 2, 'model.layers.25': 2, 'model.layers.26': 2, 'model.layers.27': 3, 'model.layers.28': 3, 'model.layers.29': 3, 'model.layers.30': 3, 'model.layers.31': 3, 'model.layers.32': 3, 'model.layers.33': 3, 'model.layers.34': 3, 'model.layers.35': 3, 'model.layers.36': 4, 'model.layers.37': 4, 'model.layers.38': 4, 'model.layers.39': 4, 'model.layers.40': 4, 'model.layers.41': 4, 'model.layers.42': 4, 'model.layers.43': 4, 'model.layers.44': 4, 'model.layers.45': 5, 'model.layers.46': 5, 'model.layers.47': 5, 'model.layers.48': 5, 'model.layers.49': 5, 'model.layers.50': 5, 'model.layers.51': 5, 'model.layers.52': 5, 'model.layers.53': 5, 'model.layers.54': 6, 'model.layers.55': 6, 'model.layers.56': 6, 'model.layers.57': 6, 'model.layers.58': 6, 'model.layers.59': 6, 'model.layers.60': 6, 'model.layers.61': 6, 'model.layers.62': 6, 'model.layers.63': 7, 'model.layers.64': 7, 'model.layers.65': 7, 'model.layers.66': 7, 'model.layers.67': 7, 'model.layers.68': 7, 'model.layers.69': 7, 'model.layers.70': 7, 'model.layers.71': 7, 'model.final_layernorm': 7, 'lm_head': 7}
+model = AutoModelForCausalLM.from_pretrained("ai21labs/AI21-Jamba-Large-1.6",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+ quantization_config=quantization_config,
+ device_map=device_map)
-print(tokenizer.batch_decode(outputs))
-# ["<|startoftext|>In the recent Super Bowl LVIII, the Kansas City Chiefs emerged victorious, defeating the San Francisco 49ers in a thrilling overtime showdown. The game was a nail-biter, with both teams showcasing their skills and determination.\n\nThe Chiefs, led by their star quarterback Patrick Mahomes, displayed their offensive prowess, while the 49ers, led by their strong defense, put up a tough fight. The game went into overtime, with the Chiefs ultimately securing the win with a touchdown.\n\nThe victory marked the Chiefs' second Super Bowl win in four years, solidifying their status as one of the top teams in the NFL. The game was a testament to the skill and talent of both teams, and a thrilling end to the NFL season.\n\nThe Super Bowl is not just about the game itself, but also about the halftime show and the commercials. This year's halftime show featured a star-studded lineup, including Usher, Alicia Keys, and Lil Jon. The show was a spectacle of music and dance, with the performers delivering an energetic and entertaining performance.\n"]
-```
+tokenizer = AutoTokenizer.from_pretrained("ai21labs/AI21-Jamba-Large-1.6")
-
-Loading the model in half precision
+messages = [
+ {"role": "system", "content": "You are an ancient oracle who speaks in cryptic but wise phrases, always hinting at deeper meanings."},
+ {"role": "user", "content": "Hello!"},
+]
-The published checkpoint is saved in BF16. In order to load it into RAM in BF16/FP16, you need to specify `torch_dtype`:
+input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt').to(model.device)
-```python
-from transformers import AutoModelForCausalLM
-import torch
-model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1", torch_dtype=torch.bfloat16)
-# you can also use torch_dtype=torch.float16
-```
+outputs = model.generate(input_ids, max_new_tokens=216)
-When using half precision, you can enable the [FlashAttention2](https://github.com/Dao-AILab/flash-attention) implementation of the Attention blocks. In order to use it, you also need the model on a CUDA device. Since in this precision the model is to big to fit on a single 80GB GPU, you'll also need to parallelize it using [accelerate](https://huggingface.co/docs/accelerate/index):
-```python
-from transformers import AutoModelForCausalLM
-import torch
-model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1",
- torch_dtype=torch.bfloat16,
- attn_implementation="flash_attention_2",
- device_map="auto")
+# Decode the output
+conversation = tokenizer.decode(outputs[0], skip_special_tokens=True)
+
+# Split the conversation to get only the assistant's response
+assistant_response = conversation.split(messages[-1]['content'])[1].strip()
+print(assistant_response)
+# Output: Seek and you shall find. The path is winding, but the journey is enlightening. What wisdom do you seek from the ancient echoes?
```
-
-Load the model in 8-bit
+## Notes
-**Using 8-bit precision, it is possible to fit up to 140K sequence lengths on a single 80GB GPU.** You can easily quantize the model to 8-bit using [bitsandbytes](https://huggingface.co/docs/bitsandbytes/index). In order to not degrade model quality, we recommend to exclude the Mamba blocks from the quantization:
+- Don't quantize the Mamba blocks to prevent model performance degradation.
+- It is not recommended to use Mamba without the optimized Mamba kernels as it results in significantly lower latencies. If you still want to use Mamba without the kernels, then set `use_mamba_kernels=False` in [`~AutoModel.from_pretrained`].
-```python
-from transformers import AutoModelForCausalLM, BitsAndBytesConfig
-quantization_config = BitsAndBytesConfig(load_in_8bit=True, llm_int8_skip_modules=["mamba"])
-model = AutoModelForCausalLM.from_pretrained(
- "ai21labs/Jamba-v0.1", torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2", quantization_config=quantization_config
-)
-```
- +
+  +
+  +
+