diff --git a/docs/source/en/model_doc/videomae.md b/docs/source/en/model_doc/videomae.md
index e0ebbaa42885..7455a9a3db39 100644
--- a/docs/source/en/model_doc/videomae.md
+++ b/docs/source/en/model_doc/videomae.md
@@ -15,30 +15,102 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2022-03-23 and added to Hugging Face Transformers on 2022-08-04.*
+
+
# VideoMAE
-
+[VideoMAE](https://huggingface.co/papers/2203.12602) is a self-supervised video representation learning model that extends [Masked Autoencoders(MAE)](vit_mae) to video inputs. It learns by randomly masking a large portion of video patches (typically 90%–95%) and reconstructing the missing parts, making it highly data-efficient. Without using any external data, VideoMAE achieves competitive performance across popular video classification benchmarks. Its simple design, strong results, and ability to work with limited labeled data make it a practical choice for video understanding tasks.
+
+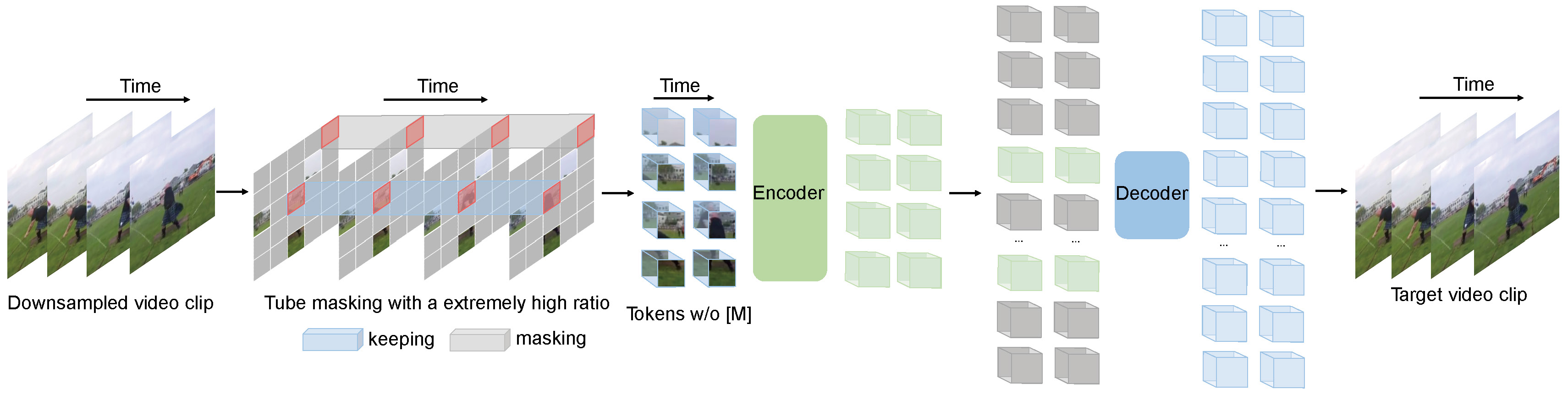 -## Overview
+You can find all the original VideoMAE checkpoints under the [MCG-NJU](https://huggingface.co/MCG-NJU/models) organization.
-The VideoMAE model was proposed in [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://huggingface.co/papers/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
-VideoMAE extends masked auto encoders ([MAE](vit_mae)) to video, claiming state-of-the-art performance on several video classification benchmarks.
+> [!TIP]
+> This model was contributed by [nielsr](https://huggingface.co/nielsr).
+>
+> Click on the VideoMAE models in the right sidebar for more examples of how to apply VideoMAE to vision tasks.
-The abstract from the paper is the following:
+The example below demonstrates how to perform video classification with [`pipeline`] or the [`AutoModel`] class.
-*Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (VideoMAE) are data-efficient learners for self-supervised video pre-training (SSVP). We are inspired by the recent ImageMAE and propose customized video tube masking and reconstruction. These simple designs turn out to be effective for overcoming information leakage caused by the temporal correlation during video reconstruction. We obtain three important findings on SSVP: (1) An extremely high proportion of masking ratio (i.e., 90% to 95%) still yields favorable performance of VideoMAE. The temporally redundant video content enables higher masking ratio than that of images. (2) VideoMAE achieves impressive results on very small datasets (i.e., around 3k-4k videos) without using any extra data. This is partially ascribed to the challenging task of video reconstruction to enforce high-level structure learning. (3) VideoMAE shows that data quality is more important than data quantity for SSVP. Domain shift between pre-training and target datasets are important issues in SSVP. Notably, our VideoMAE with the vanilla ViT backbone can achieve 83.9% on Kinects-400, 75.3% on Something-Something V2, 90.8% on UCF101, and 61.1% on HMDB51 without using any extra data.*
+
+
-
+```python
+from transformers import pipeline
+from huggingface_hub import list_repo_files, hf_hub_download
+
+pipeline = pipeline(
+ task="video-classification",
+ model="MCG-NJU/videomae-base-finetuned-kinetics"
+)
+
+files = list_repo_files("nateraw/kinetics-mini", repo_type="dataset")
+videos = [f for f in files if f.endswith(".mp4")]
+video_path = hf_hub_download("nateraw/kinetics-mini", repo_type="dataset", filename=videos[0])
+
+preds = pipeline(video_path)
+print(preds)
+```
+
+
+
+
+```python
+import torch
+from huggingface_hub import list_repo_files, hf_hub_download
+from torchvision.io import read_video
+from torchvision.transforms.functional import to_pil_image
+from transformers import AutoProcessor, AutoModelForVideoClassification
+
+files = list_repo_files("nateraw/kinetics-mini", repo_type="dataset")
+videos = [f for f in files if f.endswith(".mp4")]
+video_path = hf_hub_download("nateraw/kinetics-mini", repo_type="dataset", filename=videos[0])
- VideoMAE pre-training. Taken from the original paper.
+video, _, _ = read_video(video_path, pts_unit="sec")
+T = video.shape[0]
+indices = torch.linspace(0, T - 1, steps=16).long().tolist()
+frames = [to_pil_image(video[i].permute(2, 0, 1)) for i in indices]
-This model was contributed by [nielsr](https://huggingface.co/nielsr).
-The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
+processor = AutoProcessor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
+model = AutoModelForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics").eval()
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+inputs = processor(frames, return_tensors="pt").to(device)
+model.to(device)
+
+with torch.no_grad():
+ logits = model(**inputs).logits
+
+probs = logits.softmax(-1)[0]
+topk = probs.topk(5)
+
+id2label = model.config.id2label
+print([{ "label": id2label[i.item()], "score": probs[i].item() } for i in topk.indices])
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [BitsAndBytes](https://huggingface.co/docs/transformers/main/en/quantization/bitsandbytes) to quantize the weights to 8-bit precision:
+
+```python
+from transformers import AutoModelForVideoClassification
+
+model = AutoModelForVideoClassification.from_pretrained(
+ "MCG-NJU/videomae-base-finetuned-kinetics",
+ load_in_8bit=True,
+ device_map="auto"
+).eval()
+```
## Using Scaled Dot Product Attention (SDPA)
@@ -68,6 +140,24 @@ On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32`
| 4 | 43 | 32 | 1.34 |
| 8 | 84 | 60 | 1.4 |
+## Notes
+
+- Pre-training uses heavy masking (90–95%) on video patches.
+- Fine-tuning checkpoints are available for datasets like Kinetics-400, UCF101, and Something-Something-V2.
+- For custom datasets, you can follow the [Video classification](../tasks/video_classification) task guide.
+
+ ```py
+ # Example: feature extraction + forward pass
+ from transformers import VideoMAEFeatureExtractor, VideoMAEModel
+
+ feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base")
+ model = VideoMAEModel.from_pretrained("MCG-NJU/videomae-base")
+
+ video = ... # load frames
+ inputs = feature_extractor(list(video), return_tensors="pt")
+ outputs = model(**inputs)
+ ```
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with VideoMAE. If
-## Overview
+You can find all the original VideoMAE checkpoints under the [MCG-NJU](https://huggingface.co/MCG-NJU/models) organization.
-The VideoMAE model was proposed in [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://huggingface.co/papers/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
-VideoMAE extends masked auto encoders ([MAE](vit_mae)) to video, claiming state-of-the-art performance on several video classification benchmarks.
+> [!TIP]
+> This model was contributed by [nielsr](https://huggingface.co/nielsr).
+>
+> Click on the VideoMAE models in the right sidebar for more examples of how to apply VideoMAE to vision tasks.
-The abstract from the paper is the following:
+The example below demonstrates how to perform video classification with [`pipeline`] or the [`AutoModel`] class.
-*Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (VideoMAE) are data-efficient learners for self-supervised video pre-training (SSVP). We are inspired by the recent ImageMAE and propose customized video tube masking and reconstruction. These simple designs turn out to be effective for overcoming information leakage caused by the temporal correlation during video reconstruction. We obtain three important findings on SSVP: (1) An extremely high proportion of masking ratio (i.e., 90% to 95%) still yields favorable performance of VideoMAE. The temporally redundant video content enables higher masking ratio than that of images. (2) VideoMAE achieves impressive results on very small datasets (i.e., around 3k-4k videos) without using any extra data. This is partially ascribed to the challenging task of video reconstruction to enforce high-level structure learning. (3) VideoMAE shows that data quality is more important than data quantity for SSVP. Domain shift between pre-training and target datasets are important issues in SSVP. Notably, our VideoMAE with the vanilla ViT backbone can achieve 83.9% on Kinects-400, 75.3% on Something-Something V2, 90.8% on UCF101, and 61.1% on HMDB51 without using any extra data.*
+
+
-
+```python
+from transformers import pipeline
+from huggingface_hub import list_repo_files, hf_hub_download
+
+pipeline = pipeline(
+ task="video-classification",
+ model="MCG-NJU/videomae-base-finetuned-kinetics"
+)
+
+files = list_repo_files("nateraw/kinetics-mini", repo_type="dataset")
+videos = [f for f in files if f.endswith(".mp4")]
+video_path = hf_hub_download("nateraw/kinetics-mini", repo_type="dataset", filename=videos[0])
+
+preds = pipeline(video_path)
+print(preds)
+```
+
+
+
+
+```python
+import torch
+from huggingface_hub import list_repo_files, hf_hub_download
+from torchvision.io import read_video
+from torchvision.transforms.functional import to_pil_image
+from transformers import AutoProcessor, AutoModelForVideoClassification
+
+files = list_repo_files("nateraw/kinetics-mini", repo_type="dataset")
+videos = [f for f in files if f.endswith(".mp4")]
+video_path = hf_hub_download("nateraw/kinetics-mini", repo_type="dataset", filename=videos[0])
- VideoMAE pre-training. Taken from the original paper.
+video, _, _ = read_video(video_path, pts_unit="sec")
+T = video.shape[0]
+indices = torch.linspace(0, T - 1, steps=16).long().tolist()
+frames = [to_pil_image(video[i].permute(2, 0, 1)) for i in indices]
-This model was contributed by [nielsr](https://huggingface.co/nielsr).
-The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
+processor = AutoProcessor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
+model = AutoModelForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics").eval()
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+inputs = processor(frames, return_tensors="pt").to(device)
+model.to(device)
+
+with torch.no_grad():
+ logits = model(**inputs).logits
+
+probs = logits.softmax(-1)[0]
+topk = probs.topk(5)
+
+id2label = model.config.id2label
+print([{ "label": id2label[i.item()], "score": probs[i].item() } for i in topk.indices])
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [BitsAndBytes](https://huggingface.co/docs/transformers/main/en/quantization/bitsandbytes) to quantize the weights to 8-bit precision:
+
+```python
+from transformers import AutoModelForVideoClassification
+
+model = AutoModelForVideoClassification.from_pretrained(
+ "MCG-NJU/videomae-base-finetuned-kinetics",
+ load_in_8bit=True,
+ device_map="auto"
+).eval()
+```
## Using Scaled Dot Product Attention (SDPA)
@@ -68,6 +140,24 @@ On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32`
| 4 | 43 | 32 | 1.34 |
| 8 | 84 | 60 | 1.4 |
+## Notes
+
+- Pre-training uses heavy masking (90–95%) on video patches.
+- Fine-tuning checkpoints are available for datasets like Kinetics-400, UCF101, and Something-Something-V2.
+- For custom datasets, you can follow the [Video classification](../tasks/video_classification) task guide.
+
+ ```py
+ # Example: feature extraction + forward pass
+ from transformers import VideoMAEFeatureExtractor, VideoMAEModel
+
+ feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base")
+ model = VideoMAEModel.from_pretrained("MCG-NJU/videomae-base")
+
+ video = ... # load frames
+ inputs = feature_extractor(list(video), return_tensors="pt")
+ outputs = model(**inputs)
+ ```
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with VideoMAE. If
 +
+  +
+  +
+