+  +
+  +
+  +
+
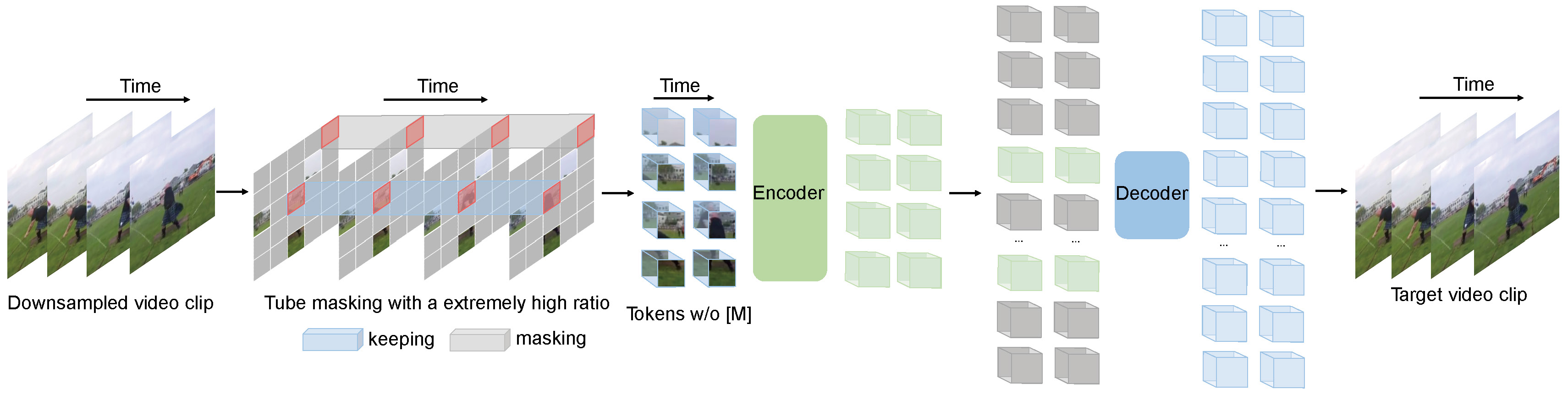 - VideoMAE pre-training. Taken from the original paper.
+You can find all the original VideoMAE checkpoints under the [MCG-NJU](https://huggingface.co/MCG-NJU/models) organization.
-This model was contributed by [nielsr](https://huggingface.co/nielsr).
-The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
+> [!TIP]
+> Click on the VideoMAE models in the right sidebar for more examples of how to apply VideoMAE to vision tasks.
## Using Scaled Dot Product Attention (SDPA)
From 3ee65ac9ddbf2b8d1627c020a572da78dd62867a Mon Sep 17 00:00:00 2001
From: Jiwook Han <33192762+mreraser@users.noreply.github.com>
Date: Sun, 31 Aug 2025 18:59:59 +0900
Subject: [PATCH 2/4] Finalize and clean up videomae.md model card
---
docs/source/en/model_doc/videomae.md | 97 +++++++++++++++++++++++++++-
1 file changed, 95 insertions(+), 2 deletions(-)
diff --git a/docs/source/en/model_doc/videomae.md b/docs/source/en/model_doc/videomae.md
index 019750a7d1af..082422339fb6 100644
--- a/docs/source/en/model_doc/videomae.md
+++ b/docs/source/en/model_doc/videomae.md
@@ -25,8 +25,6 @@ rendered properly in your Markdown viewer.
# VideoMAE
-## Overview
-
[VideoMAE](https://huggingface.co/papers/2203.12602) is a self-supervised video representation learning model that extends [Masked Autoencoders(MAE)](vit_mae) to video inputs. It learns by randomly masking a large portion of video patches (typically 90%–95%) and reconstructing the missing parts, making it highly data-efficient. Without using any external data, VideoMAE achieves competitive performance across popular video classification benchmarks. Its simple design, strong results, and ability to work with limited labeled data make it a practical choice for video understanding tasks.
You can find all the original VideoMAE checkpoints under the [MCG-NJU](https://huggingface.co/MCG-NJU/models) organization.
> [!TIP]
+> This model was contributed by [nielsr](https://huggingface.co/nielsr).
+>
> Click on the VideoMAE models in the right sidebar for more examples of how to apply VideoMAE to vision tasks.
+The example below demonstrates how to perform video classification with [`pipeline`] or the [`AutoModel`] class.
+
+
- VideoMAE pre-training. Taken from the original paper.
+You can find all the original VideoMAE checkpoints under the [MCG-NJU](https://huggingface.co/MCG-NJU/models) organization.
-This model was contributed by [nielsr](https://huggingface.co/nielsr).
-The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
+> [!TIP]
+> Click on the VideoMAE models in the right sidebar for more examples of how to apply VideoMAE to vision tasks.
## Using Scaled Dot Product Attention (SDPA)
From 3ee65ac9ddbf2b8d1627c020a572da78dd62867a Mon Sep 17 00:00:00 2001
From: Jiwook Han <33192762+mreraser@users.noreply.github.com>
Date: Sun, 31 Aug 2025 18:59:59 +0900
Subject: [PATCH 2/4] Finalize and clean up videomae.md model card
---
docs/source/en/model_doc/videomae.md | 97 +++++++++++++++++++++++++++-
1 file changed, 95 insertions(+), 2 deletions(-)
diff --git a/docs/source/en/model_doc/videomae.md b/docs/source/en/model_doc/videomae.md
index 019750a7d1af..082422339fb6 100644
--- a/docs/source/en/model_doc/videomae.md
+++ b/docs/source/en/model_doc/videomae.md
@@ -25,8 +25,6 @@ rendered properly in your Markdown viewer.
# VideoMAE
-## Overview
-
[VideoMAE](https://huggingface.co/papers/2203.12602) is a self-supervised video representation learning model that extends [Masked Autoencoders(MAE)](vit_mae) to video inputs. It learns by randomly masking a large portion of video patches (typically 90%–95%) and reconstructing the missing parts, making it highly data-efficient. Without using any external data, VideoMAE achieves competitive performance across popular video classification benchmarks. Its simple design, strong results, and ability to work with limited labeled data make it a practical choice for video understanding tasks.
You can find all the original VideoMAE checkpoints under the [MCG-NJU](https://huggingface.co/MCG-NJU/models) organization.
> [!TIP]
+> This model was contributed by [nielsr](https://huggingface.co/nielsr).
+>
> Click on the VideoMAE models in the right sidebar for more examples of how to apply VideoMAE to vision tasks.
+The example below demonstrates how to perform video classification with [`pipeline`] or the [`AutoModel`] class.
+
+