@@ -162,20 +184,20 @@ Model performance in [Anthropics paper](https://arxiv.org/abs/2204.05862):
We also train the reward model based on LLaMA-7B, which reaches the ACC of 72.06% after 1 epoch, performing almost the same as Anthropic's best RM.
### Arg List
-- --strategy: the strategy using for training, choices=['ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
-- --model: model type, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
-- --pretrain: pretrain model, type=str, default=None
-- --model_path: the path of rm model(if continue to train), type=str, default=None
-- --save_path: path to save the model, type=str, default='output'
-- --need_optim_ckpt: whether to save optim ckpt, type=bool, default=False
-- --max_epochs: max epochs for training, type=int, default=3
-- --dataset: dataset name, type=str, choices=['Anthropic/hh-rlhf', 'Dahoas/rm-static']
-- --subset: subset of the dataset, type=str, default=None
-- --batch_size: batch size while training, type=int, default=4
-- --lora_rank: low-rank adaptation matrices rank, type=int, default=0
-- --loss_func: which kind of loss function, choices=['log_sig', 'log_exp']
-- --max_len: max sentence length for generation, type=int, default=512
-- --test: whether is only testing, if it's true, the dataset will be small
+
+- `--strategy`: the strategy using for training, choices=['ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
+- `--model`: model type, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
+- `--pretrain`: pretrain model, type=str, default=None
+- `--model_path`: the path of rm model(if continue to train), type=str, default=None
+- `--save_path`: path to save the model, type=str, default='output'
+- `--need_optim_ckpt`: whether to save optim ckpt, type=bool, default=False
+- `--max_epochs`: max epochs for training, type=int, default=3
+- `--dataset`: dataset name, type=str, choices=['Anthropic/hh-rlhf', 'Dahoas/rm-static']
+- `--subset`: subset of the dataset, type=str, default=None
+- `--batch_size`: batch size while training, type=int, default=4
+- `--lora_rank`: low-rank adaptation matrices rank, type=int, default=0
+- `--loss_func`: which kind of loss function, choices=['log_sig', 'log_exp']
+- `--max_len`: max sentence length for generation, type=int, default=512
## Stage3 - Training model using prompts with RL
@@ -186,53 +208,89 @@ Stage3 uses reinforcement learning algorithm, which is the most complex part of
You can run the `examples/train_prompts.sh` to start PPO training.
+
You can also use the cmd following to start PPO training.
[[Stage3 tutorial video]](https://www.youtube.com/watch?v=Z8wwSHxPL9g)
-```
+```bash
torchrun --standalone --nproc_per_node=4 train_prompts.py \
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --prompt_dataset /path/to/your/prompt_dataset \
- --pretrain_dataset /path/to/your/pretrain_dataset \
- --rm_pretrain /your/pretrain/rm/definition \
- --rm_path /your/rm/model/path
+ --pretrain "/path/to/LLaMa-7B/" \
+ --model 'llama' \
+ --strategy colossalai_zero2 \
+ --prompt_dataset /path/to/your/prompt_dataset \
+ --pretrain_dataset /path/to/your/pretrain_dataset \
+ --rm_pretrain /your/pretrain/rm/definition \
+ --rm_path /your/rm/model/path
```
Prompt dataset: the instruction dataset mentioned in the above figure which includes the instructions, e.g. you can use the [script](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/generate_prompt_dataset.py) which samples `instinwild_en.json` or `instinwild_ch.json` in [InstructionWild](https://github.com/XueFuzhao/InstructionWild/tree/main/data#instructwild-data) to generate the prompt dataset.
Pretrain dataset: the pretrain dataset including the instruction and corresponding response, e.g. you can use the [InstructWild Data](https://github.com/XueFuzhao/InstructionWild/tree/main/data) in stage 1 supervised instructs tuning.
+**Note**: the required datasets follow the following format,
+
+- `pretrain dataset`
+
+ ```json
+ [
+ {
+ "instruction": "Provide a list of the top 10 most popular mobile games in Asia",
+ "input": "",
+ "output": "The top 10 most popular mobile games in Asia are:\n1) PUBG Mobile\n2) Pokemon Go\n3) Candy Crush Saga\n4) Free Fire\n5) Clash of Clans\n6) Mario Kart Tour\n7) Arena of Valor\n8) Fantasy Westward Journey\n9) Subway Surfers\n10) ARK Survival Evolved",
+ "id": 0
+ },
+ ...
+ ]
+ ```
+
+- `prompt dataset`
+
+ ```json
+ [
+ {
+ "instruction": "Edit this paragraph to make it more concise: \"Yesterday, I went to the store and bought some things. Then, I came home and put them away. After that, I went for a walk and met some friends.\"",
+ "id": 0
+ },
+ {
+ "instruction": "Write a descriptive paragraph about a memorable vacation you went on",
+ "id": 1
+ },
+ ...
+ ]
+ ```
+
### Arg List
-- --strategy: the strategy using for training, choices=['ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
-- --model: model type of actor, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
-- --pretrain: pretrain model, type=str, default=None
-- --rm_model: reward model type, type=str, choices=['gpt2', 'bloom', 'opt', 'llama'], default=None
-- --rm_pretrain: pretrain model for reward model, type=str, default=None
-- --rm_path: the path of rm model, type=str, default=None
-- --save_path: path to save the model, type=str, default='output'
-- --prompt_dataset: path of the prompt dataset, type=str, default=None
-- --pretrain_dataset: path of the ptx dataset, type=str, default=None
-- --need_optim_ckpt: whether to save optim ckpt, type=bool, default=False
-- --num_episodes: num of episodes for training, type=int, default=10
-- --num_update_steps: number of steps to update policy per episode, type=int
-- --num_collect_steps: number of steps to collect experience per episode, type=int
-- --train_batch_size: batch size while training, type=int, default=8
-- --ptx_batch_size: batch size to compute ptx loss, type=int, default=1
-- --experience_batch_size: batch size to make experience, type=int, default=8
-- --lora_rank: low-rank adaptation matrices rank, type=int, default=0
-- --kl_coef: kl_coef using for computing reward, type=float, default=0.1
-- --ptx_coef: ptx_coef using for computing policy loss, type=float, default=0.9
+
+- `--strategy`: the strategy using for training, choices=['ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
+- `--model`: model type of actor, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
+- `--pretrain`: pretrain model, type=str, default=None
+- `--rm_model`: reward model type, type=str, choices=['gpt2', 'bloom', 'opt', 'llama'], default=None
+- `--rm_pretrain`: pretrain model for reward model, type=str, default=None
+- `--rm_path`: the path of rm model, type=str, default=None
+- `--save_path`: path to save the model, type=str, default='output'
+- `--prompt_dataset`: path of the prompt dataset, type=str, default=None
+- `--pretrain_dataset`: path of the ptx dataset, type=str, default=None
+- `--need_optim_ckpt`: whether to save optim ckpt, type=bool, default=False
+- `--num_episodes`: num of episodes for training, type=int, default=10
+- `--num_update_steps`: number of steps to update policy per episode, type=int
+- `--num_collect_steps`: number of steps to collect experience per episode, type=int
+- `--train_batch_size`: batch size while training, type=int, default=8
+- `--ptx_batch_size`: batch size to compute ptx loss, type=int, default=1
+- `--experience_batch_size`: batch size to make experience, type=int, default=8
+- `--lora_rank`: low-rank adaptation matrices rank, type=int, default=0
+- `--kl_coef`: kl_coef using for computing reward, type=float, default=0.1
+- `--ptx_coef`: ptx_coef using for computing policy loss, type=float, default=0.9
## Inference example - After Stage3
+
We support different inference options, including int8 and int4 quantization.
For details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
-
## Attention
+
The examples are demos for the whole training process.You need to change the hyper-parameters to reach great performance.
#### data
+
- [x] [rm-static](https://huggingface.co/datasets/Dahoas/rm-static)
- [x] [hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)
- [ ] [openai/summarize_from_feedback](https://huggingface.co/datasets/openai/summarize_from_feedback)
@@ -242,14 +300,16 @@ The examples are demos for the whole training process.You need to change the hyp
## Support Model
### GPT
-- [x] GPT2-S (s)
-- [x] GPT2-M (m)
-- [x] GPT2-L (l)
-- [x] GPT2-XL (xl)
-- [x] GPT2-4B (4b)
-- [ ] GPT2-6B (6b)
+
+- [x] GPT2-S (s)
+- [x] GPT2-M (m)
+- [x] GPT2-L (l)
+- [x] GPT2-XL (xl)
+- [x] GPT2-4B (4b)
+- [ ] GPT2-6B (6b)
### BLOOM
+
- [x] [BLOOM-560m](https://huggingface.co/bigscience/bloom-560m)
- [x] [BLOOM-1b1](https://huggingface.co/bigscience/bloom-1b1)
- [x] [BLOOM-3b](https://huggingface.co/bigscience/bloom-3b)
@@ -257,6 +317,7 @@ The examples are demos for the whole training process.You need to change the hyp
- [ ] [BLOOM-175b](https://huggingface.co/bigscience/bloom)
### OPT
+
- [x] [OPT-125M](https://huggingface.co/facebook/opt-125m)
- [x] [OPT-350M](https://huggingface.co/facebook/opt-350m)
- [x] [OPT-1.3B](https://huggingface.co/facebook/opt-1.3b)
@@ -266,10 +327,11 @@ The examples are demos for the whole training process.You need to change the hyp
- [ ] [OPT-30B](https://huggingface.co/facebook/opt-30b)
### [LLaMA](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md)
-- [x] LLaMA-7B
-- [x] LLaMA-13B
-- [ ] LLaMA-33B
-- [ ] LLaMA-65B
+
+- [x] LLaMA-7B
+- [x] LLaMA-13B
+- [ ] LLaMA-33B
+- [ ] LLaMA-65B
## Add your own models
@@ -282,12 +344,12 @@ if it is supported in huggingface [transformers](https://github.com/huggingface/
r you can build your own model by yourself.
### Actor model
-```
+
+```python
from ..base import Actor
from transformers.models.coati import CoatiModel
class CoatiActor(Actor):
-
def __init__(self,
pretrained: Optional[str] = None,
checkpoint: bool = False,
@@ -302,7 +364,8 @@ class CoatiActor(Actor):
```
### Reward model
-```
+
+```python
from ..base import RewardModel
from transformers.models.coati import CoatiModel
@@ -325,12 +388,11 @@ class CoatiRM(RewardModel):
### Critic model
-```
+```python
from ..base import Critic
from transformers.models.coati import CoatiModel
class CoatiCritic(Critic):
-
def __init__(self,
pretrained: Optional[str] = None,
checkpoint: bool = False,
diff --git a/applications/Chat/examples/community/README.md b/applications/Chat/examples/community/README.md
index cd7b9d99bf06..e14ac1767fc1 100644
--- a/applications/Chat/examples/community/README.md
+++ b/applications/Chat/examples/community/README.md
@@ -1,5 +1,9 @@
+:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
+
# Community Examples
+
---
+
We are thrilled to announce the latest updates to ColossalChat, an open-source solution for cloning ChatGPT with a complete RLHF (Reinforcement Learning with Human Feedback) pipeline.
As Colossal-AI undergoes major updates, we are actively maintaining ColossalChat to stay aligned with the project's progress. With the introduction of Community-driven example, we aim to create a collaborative platform for developers to contribute exotic features built on top of ColossalChat.
@@ -14,11 +18,12 @@ For more information about community pipelines, please have a look at this [issu
Community examples consist of both inference and training examples that have been added by the community. Please have a look at the following table to get an overview of all community examples. Click on the Code Example to get a copy-and-paste ready code example that you can try out. If a community doesn't work as expected, please open an issue and ping the author on it.
-| Example | Description | Code Example | Colab | Author |
-|:---------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------:|
-| Peft | Adding Peft support for SFT and Prompts model training | [Huggingface Peft](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/peft) | - | [YY Lin](https://github.com/yynil) |
-| Train prompts on Ray | A Ray based implementation of Train prompts example | [Training On Ray](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/ray) | - | [MisterLin1995](https://github.com/MisterLin1995) |
-|...|...|...|...|...|
+| Example | Description | Code Example | Colab | Author |
+| :------------------- | :----------------------------------------------------- | :-------------------------------------------------------------------------------------------------------------- | :---- | ------------------------------------------------: |
+| Peft | Adding Peft support for SFT and Prompts model training | [Huggingface Peft](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/peft) | - | [YY Lin](https://github.com/yynil) |
+| Train prompts on Ray | A Ray based implementation of Train prompts example | [Training On Ray](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/ray) | - | [MisterLin1995](https://github.com/MisterLin1995) |
+| ... | ... | ... | ... | ... |
### How to get involved
+
To join our community-driven initiative, please visit the [ColossalChat GitHub repository](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples), review the provided information, and explore the codebase. To contribute, create a new issue outlining your proposed feature or enhancement, and our team will review and provide feedback. We look forward to collaborating with you on this exciting project!
diff --git a/applications/Chat/examples/community/peft/README.md b/applications/Chat/examples/community/peft/README.md
index 844bfd3d22c3..8b2edc48cd99 100644
--- a/applications/Chat/examples/community/peft/README.md
+++ b/applications/Chat/examples/community/peft/README.md
@@ -1,3 +1,5 @@
+:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
+
# Add Peft support for SFT and Prompts model training
The original implementation just adopts the loralib and merges the layers into the final model. The huggingface peft is a better lora model implementation and can be easily training and distributed.
@@ -5,7 +7,9 @@ The original implementation just adopts the loralib and merges the layers into t
Since reward model is relative small, I just keep it as original one. I suggest train full model to get the proper reward/critic model.
# Preliminary installation
+
Since the current pypi peft package(0.2) has some bugs, please install the peft package using source.
+
```
git clone https://github.com/huggingface/peft
cd peft
@@ -13,6 +17,7 @@ pip install .
```
# Usage
+
For SFT training, just call train_peft_sft.py
Its arguments are almost identical to train_sft.py instead adding a new eval_dataset if you have a eval_dataset file. The data file is just a plain datafile, please check the format in the easy_dataset.py.
@@ -21,4 +26,5 @@ For stage-3 rlhf training, call train_peft_prompts.py.
Its arguments are almost identical to train_prompts.py. The only difference is that I use text files to indicate the prompt and pretrained data file. The models are included in easy_models.py. Currently only bloom models are tested, but technically gpt2/opt/llama should be supported.
# Dataformat
+
Please refer the formats in test_sft.txt, test_prompts.txt, test_pretrained.txt.
diff --git a/applications/Chat/examples/community/ray/README.md b/applications/Chat/examples/community/ray/README.md
index 64360bd73ddc..a679a58336a7 100644
--- a/applications/Chat/examples/community/ray/README.md
+++ b/applications/Chat/examples/community/ray/README.md
@@ -1,17 +1,31 @@
+:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
+
# ColossalAI on Ray
+
## Abstract
+
This is an experimental effort to run ColossalAI Chat training on Ray
+
## How to use?
+
### 1. Setup Ray clusters
+
Please follow the official [Ray cluster setup instructions](https://docs.ray.io/en/latest/cluster/getting-started.html) to setup an cluster with GPU support. Record the cluster's api server endpoint, it should be something similar to http://your.head.node.addrees:8265
+
### 2. Clone repo
+
Clone this project:
+
```shell
git clone https://github.com/hpcaitech/ColossalAI.git
```
+
### 3. Submit the ray job
+
```shell
python applications/Chat/examples/community/ray/ray_job_script.py http://your.head.node.addrees:8265
```
+
### 4. View your job on the Ray Dashboard
+
Open your ray cluster dashboard http://your.head.node.addrees:8265 to view your submitted training job.
diff --git a/applications/Chat/inference/README.md b/applications/Chat/inference/README.md
index 4848817e0fd1..eea4ef5b86ca 100644
--- a/applications/Chat/inference/README.md
+++ b/applications/Chat/inference/README.md
@@ -20,21 +20,21 @@ Tha data is from [LLaMA Int8 4bit ChatBot Guide v2](https://rentry.org/llama-tar
### 8-bit
-| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
-| :---: | :---: | :---: | :---: | :---: |
-| LLaMA-7B | 9.2GB | 10GB | 24GB | 3060 12GB, RTX 3080 10GB, RTX 3090 |
-| LLaMA-13B | 16.3GB | 20GB | 32GB | RTX 3090 Ti, RTX 4090 |
-| LLaMA-30B | 36GB | 40GB | 64GB | A6000 48GB, A100 40GB |
-| LLaMA-65B | 74GB | 80GB | 128GB | A100 80GB |
+| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
+| :-------: | :---------: | :-----------------: | :----------: | :--------------------------------: |
+| LLaMA-7B | 9.2GB | 10GB | 24GB | 3060 12GB, RTX 3080 10GB, RTX 3090 |
+| LLaMA-13B | 16.3GB | 20GB | 32GB | RTX 3090 Ti, RTX 4090 |
+| LLaMA-30B | 36GB | 40GB | 64GB | A6000 48GB, A100 40GB |
+| LLaMA-65B | 74GB | 80GB | 128GB | A100 80GB |
### 4-bit
-| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
-| :---: | :---: | :---: | :---: | :---: |
-| LLaMA-7B | 3.5GB | 6GB | 16GB | RTX 1660, 2060, AMD 5700xt, RTX 3050, 3060 |
-| LLaMA-13B | 6.5GB | 10GB | 32GB | AMD 6900xt, RTX 2060 12GB, 3060 12GB, 3080, A2000 |
-| LLaMA-30B | 15.8GB | 20GB | 64GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 |
-| LLaMA-65B | 31.2GB | 40GB | 128GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000, Titan Ada |
+| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
+| :-------: | :---------: | :-----------------: | :----------: | :--------------------------------------------------------: |
+| LLaMA-7B | 3.5GB | 6GB | 16GB | RTX 1660, 2060, AMD 5700xt, RTX 3050, 3060 |
+| LLaMA-13B | 6.5GB | 10GB | 32GB | AMD 6900xt, RTX 2060 12GB, 3060 12GB, 3080, A2000 |
+| LLaMA-30B | 15.8GB | 20GB | 64GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 |
+| LLaMA-65B | 31.2GB | 40GB | 128GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000, Titan Ada |
## General setup
diff --git a/colossalai/amp/naive_amp/mixed_precision_optimizer.py b/colossalai/amp/naive_amp/mixed_precision_optimizer.py
new file mode 100644
index 000000000000..626a00c96d04
--- /dev/null
+++ b/colossalai/amp/naive_amp/mixed_precision_optimizer.py
@@ -0,0 +1,149 @@
+from typing import Dict, List
+
+import torch
+from torch import Tensor
+from torch.nn import Parameter
+from torch.optim import Optimizer
+
+from colossalai.interface import OptimizerWrapper
+
+from .mixed_precision_mixin import BF16MixedPrecisionMixin, FP16MixedPrecisionMixin
+
+
+class NaiveFP16MixedPrecisionMixin(FP16MixedPrecisionMixin):
+
+ def __init__(self,
+ working_params: List[Parameter],
+ initial_scale: float = 2**16,
+ min_scale: float = 1,
+ growth_factor: float = 2,
+ backoff_factor: float = 0.5,
+ growth_interval: int = 1000,
+ hysteresis: int = 2,
+ max_scale: float = 2**32) -> None:
+ super().__init__(initial_scale, min_scale, growth_factor, backoff_factor, growth_interval, hysteresis,
+ max_scale)
+ self.params = working_params
+
+ def check_local_overflow(self) -> bool:
+ for p in self.params:
+ if p.grad is not None and not torch.isfinite(p.grad).all():
+ return True
+ return False
+
+
+class MixedPrecisionOptimizer(OptimizerWrapper):
+
+ def __init__(self,
+ optim: Optimizer,
+ precision: str = 'fp16',
+ initial_scale: float = 2**16,
+ min_scale: float = 1,
+ growth_factor: float = 2,
+ backoff_factor: float = 0.5,
+ growth_interval: int = 1000,
+ hysteresis: int = 2,
+ max_scale: float = 2**32,
+ max_norm: float = 0.0):
+ super().__init__(optim)
+ if precision == 'fp16':
+ working_params = []
+ for group in self.optim.param_groups:
+ for p in group['params']:
+ working_params.append(p)
+ self.mixed_precision = NaiveFP16MixedPrecisionMixin(working_params,
+ initial_scale=initial_scale,
+ min_scale=min_scale,
+ growth_factor=growth_factor,
+ backoff_factor=backoff_factor,
+ growth_interval=growth_interval,
+ hysteresis=hysteresis,
+ max_scale=max_scale)
+ elif precision == 'bf16':
+ self.mixed_precision = BF16MixedPrecisionMixin()
+ else:
+ raise ValueError(f'Unsupported precision: {precision}')
+ if max_norm > 0.0:
+ raise NotImplementedError('max_norm is not supported yet.')
+ self.max_norm = max_norm
+ self.working_to_master_map: Dict[Parameter, Tensor] = {}
+ self.master_to_working_map: Dict[Tensor, Parameter] = {}
+
+ # create master weights
+ for group in self.optim.param_groups:
+ master_params = []
+ for p in group['params']:
+ if p.requires_grad:
+ master_p = p
+ if p.dtype != torch.float:
+ master_p = p.detach().float()
+ self.working_to_master_map[p] = master_p
+ self.master_to_working_map[master_p] = p
+ master_params.append(master_p)
+ group['params'] = master_params
+
+ def backward(self, loss: Tensor, *args, **kwargs):
+ loss = self.mixed_precision.pre_backward(loss)
+ loss.backward(*args, **kwargs)
+
+ def backward_by_grad(self, tensor: Tensor, grad: Tensor):
+ grad = self.mixed_precision.pre_backward_by_grad(tensor, grad)
+ tensor.backward(grad)
+
+ def zero_grad(self, *args, **kwargs):
+ for p in self.working_to_master_map.keys():
+ p.grad = None
+ self.mixed_precision.pre_zero_grad()
+ return super().zero_grad(*args, **kwargs)
+
+ def _unscale_and_clip_grads(self, total_norm: float) -> None:
+ div_scale = 1.0
+ if self.mixed_precision is not None:
+ div_scale = self.mixed_precision.get_grad_div_scale()
+
+ if self.max_norm > 0.:
+ # norm is in fact norm*scale
+ clip = ((total_norm / div_scale) + 1e-6) / self.max_norm
+ if clip > 1:
+ div_scale = clip * div_scale
+
+ for group in self.param_groups:
+ for p in group['params']:
+ if p.grad is None:
+ continue
+ p.grad.data.mul_(1. / div_scale)
+
+ def _compute_grad_norm(self) -> float:
+ if self.max_norm <= 0.:
+ return 0.
+ grads = [p.grad for group in self.param_groups for p in group['params'] if p.grad is not None]
+ if len(grads) == 0:
+ return 0.
+ device = grads[0].device
+ # TODO(ver217): support tp
+ total_norm = torch.norm(torch.stack([torch.norm(g.detach(), 2).to(device) for g in grads]), 2)
+ return total_norm.item()
+
+ def step(self, *args, **kwargs):
+ if self.mixed_precision.should_skip_step():
+ self.zero_grad()
+ return
+ # prepare grads
+ for group in self.optim.param_groups:
+ for p in group['params']:
+ working_param = self.master_to_working_map[p]
+ if p is working_param:
+ continue
+ if working_param.grad is not None:
+ p.grad = working_param.grad.data.float()
+ working_param.grad = None
+ total_norm = self._compute_grad_norm()
+ self._unscale_and_clip_grads(total_norm)
+ self.optim.step(*args, **kwargs)
+ # update working params
+ for group in self.optim.param_groups:
+ for p in group['params']:
+ working_param = self.master_to_working_map[p]
+ if p is working_param:
+ continue
+ working_param.data.copy_(p.data)
diff --git a/colossalai/booster/booster.py b/colossalai/booster/booster.py
index ec3dc7fc143f..adb8f62a5084 100644
--- a/colossalai/booster/booster.py
+++ b/colossalai/booster/booster.py
@@ -1,6 +1,6 @@
import warnings
from contextlib import contextmanager
-from typing import Callable, Iterator, List, Optional, Tuple, Union
+from typing import Any, Callable, Iterator, List, Optional, Union
import torch
import torch.nn as nn
@@ -14,6 +14,7 @@
from .accelerator import Accelerator
from .mixed_precision import MixedPrecision, mixed_precision_factory
from .plugin import Plugin
+from .plugin.pp_plugin_base import PipelinePluginBase
__all__ = ['Booster']
@@ -138,20 +139,21 @@ def backward(self, loss: torch.Tensor, optimizer: Optimizer) -> None:
loss (torch.Tensor): The loss to be backpropagated.
optimizer (Optimizer): The optimizer to be updated.
"""
- # TODO: implement this method with plugin
+ # TODO(frank lee): implement this method with plugin
optimizer.backward(loss)
def execute_pipeline(self,
data_iter: Iterator,
model: nn.Module,
- criterion: Callable[[torch.Tensor], torch.Tensor],
+ criterion: Callable[[Any, Any], torch.Tensor],
optimizer: Optimizer,
return_loss: bool = True,
- return_outputs: bool = False) -> Tuple[Optional[torch.Tensor], ...]:
- # TODO: implement this method
+ return_outputs: bool = False) -> dict:
# run pipeline forward backward pass
# return loss or outputs if needed
- pass
+ assert isinstance(self.plugin,
+ PipelinePluginBase), f'The plugin {self.plugin.__class__.__name__} does not support pipeline.'
+ return self.plugin.execute_pipeline(data_iter, model, criterion, optimizer, return_loss, return_outputs)
def no_sync(self, model: nn.Module = None, optimizer: OptimizerWrapper = None) -> contextmanager:
"""Context manager to disable gradient synchronization across DP process groups.
diff --git a/colossalai/booster/plugin/__init__.py b/colossalai/booster/plugin/__init__.py
index a3b87b5f11d3..f48bf38bd724 100644
--- a/colossalai/booster/plugin/__init__.py
+++ b/colossalai/booster/plugin/__init__.py
@@ -1,9 +1,10 @@
from .gemini_plugin import GeminiPlugin
+from .hybrid_parallel_plugin import HybridParallelPlugin
from .low_level_zero_plugin import LowLevelZeroPlugin
from .plugin_base import Plugin
from .torch_ddp_plugin import TorchDDPPlugin
-__all__ = ['Plugin', 'TorchDDPPlugin', 'GeminiPlugin', 'LowLevelZeroPlugin']
+__all__ = ['Plugin', 'TorchDDPPlugin', 'GeminiPlugin', 'LowLevelZeroPlugin', 'HybridParallelPlugin']
import torch
from packaging import version
diff --git a/colossalai/booster/plugin/hybrid_parallel_plugin.py b/colossalai/booster/plugin/hybrid_parallel_plugin.py
new file mode 100644
index 000000000000..28a19af0ce91
--- /dev/null
+++ b/colossalai/booster/plugin/hybrid_parallel_plugin.py
@@ -0,0 +1,345 @@
+import random
+from contextlib import nullcontext
+from typing import Any, Callable, Iterator, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.distributed as dist
+from torch.distributed import ProcessGroup
+from torch.nn import Module
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
+from torch.utils.data import DataLoader
+from torch.utils.data.distributed import DistributedSampler
+
+from colossalai.amp.naive_amp.mixed_precision_optimizer import MixedPrecisionOptimizer
+from colossalai.checkpoint_io import CheckpointIO
+from colossalai.cluster import ProcessGroupMesh
+from colossalai.interface import ModelWrapper, OptimizerWrapper
+from colossalai.pipeline.schedule import OneForwardOneBackwardSchedule
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer import ShardConfig, ShardFormer
+from colossalai.zero.low_level import LowLevelZeroOptimizer
+
+from .pp_plugin_base import PipelinePluginBase
+
+DP_AXIS, PP_AXIS, TP_AXIS = 0, 1, 2
+
+
+class HybridParallelModule(ModelWrapper):
+
+ def __init__(self, module: Module, precision: str, shard_config: ShardConfig, dp_group: ProcessGroup) -> None:
+ self.stage_manager = shard_config.pipeline_stage_manager
+ self.dp_group = dp_group
+ shardformer = ShardFormer(shard_config)
+ module, self.shared_params = shardformer.optimize(module)
+ # TODO(ver217): add input type cast
+ self.shared_param_process_groups = []
+ for shared_param in self.shared_params:
+ if len(shared_param) > 0:
+ self.shared_param_process_groups.append(
+ self.stage_manager.init_process_group_by_stages(list(shared_param.keys())))
+ if precision == 'fp16':
+ module = module.half().cuda()
+ elif precision == 'bf16':
+ module = module.to(dtype=torch.bfloat16).cuda()
+ else:
+ module = module.cuda() # train without AMP
+ # TODO(ver217): support TP+DP
+ super().__init__(module)
+
+ def sync_shared_params(self):
+ for shared_param, group in zip(self.shared_params, self.shared_param_process_groups):
+ if self.stage_manager.stage in shared_param:
+ param = shared_param[self.stage_manager.stage]
+ dist.all_reduce(param.grad, group=group)
+ dist.barrier()
+
+ def no_sync(self) -> Iterator[None]:
+ # no sync grads across data parallel
+ return nullcontext()
+
+ def sync_grads(self):
+ # sync grad across data parallel
+ if self.dp_group.size() == 1:
+ return
+ for p in self.module.parameters():
+ if p.grad is not None:
+ dist.all_reduce(p.grad, group=self.dp_group)
+ p.grad.div_(self.dp_group.size())
+
+
+def init_pipeline_optimizer(optim: Optimizer, model: Module):
+ params = set(model.parameters())
+ new_param_groups = []
+ for group in optim.param_groups:
+ params = [p for p in group['params'] if p in params]
+ new_param_groups.append({**group, 'params': params})
+ optim.__setstate__({'param_groups': new_param_groups})
+
+
+class HybridParallelNaiveOptimizer(OptimizerWrapper):
+
+ def __init__(self, optim: Optimizer, model: Module, use_pipeline: bool):
+ if use_pipeline:
+ init_pipeline_optimizer(optim, model)
+ super().__init__(optim)
+
+
+class HybridParallelAMPOptimizer(MixedPrecisionOptimizer):
+
+ def __init__(self,
+ optim: Optimizer,
+ model: Module,
+ use_pipeline: bool,
+ precision: str = 'fp16',
+ initial_scale: float = 2**16,
+ min_scale: float = 1,
+ growth_factor: float = 2,
+ backoff_factor: float = 0.5,
+ growth_interval: int = 1000,
+ hysteresis: int = 2,
+ max_scale: float = 2**32,
+ max_norm: float = 0):
+ if use_pipeline:
+ init_pipeline_optimizer(optim, model)
+ super().__init__(optim, precision, initial_scale, min_scale, growth_factor, backoff_factor, growth_interval,
+ hysteresis, max_scale, max_norm)
+
+
+class HybridParallelZeroOptimizer(LowLevelZeroOptimizer):
+
+ def __init__(
+ self,
+ optimizer: Optimizer,
+ model: Module,
+ use_pipeline: bool,
+ initial_scale: int = 2**16, # grad scaler config
+ min_scale: int = 1,
+ growth_factor: float = 2.,
+ backoff_factor: float = .5,
+ growth_interval: int = 2000,
+ hysteresis: int = 2,
+ max_scale: int = 2**24,
+ clip_grad_norm: float = 0.0, # grad clipping
+ verbose: bool = False,
+ reduce_bucket_size: int = 1024 * 1024, # communication
+ communication_dtype: Optional[torch.dtype] = None,
+ overlap_communication: bool = True,
+ partition_grad: bool = False, # stage 2 flag
+ cpu_offload: bool = False, # cpu offload
+ dp_process_group: Optional[ProcessGroup] = None, # the dp pg for comm
+ tp_process_group: Optional[ProcessGroup] = None, # if using tp
+ forced_dtype: Optional[torch.dtype] = None):
+ if use_pipeline:
+ init_pipeline_optimizer(optimizer, model)
+ super().__init__(optimizer, initial_scale, min_scale, growth_factor, backoff_factor, growth_interval,
+ hysteresis, max_scale, clip_grad_norm, verbose, reduce_bucket_size, communication_dtype,
+ overlap_communication, partition_grad, cpu_offload, dp_process_group, tp_process_group,
+ forced_dtype)
+
+
+class HybridParallelPlugin(PipelinePluginBase):
+
+ def __init__(
+ self,
+ tp_size: int,
+ pp_size: int,
+ precision: str = 'fp16',
+ zero_stage: int = 0,
+ cpu_offload: bool = False,
+ enable_all_optimization: bool = False,
+ enable_fused_normalization: bool = False,
+ enable_flash_attention: bool = False,
+ enable_jit_fused: bool = False,
+ num_microbatches: Optional[int] = None,
+ initial_scale: float = 2**16,
+ min_scale: float = 1,
+ growth_factor: float = 2,
+ backoff_factor: float = 0.5,
+ growth_interval: int = 1000,
+ hysteresis: int = 2,
+ max_scale: float = 2**32,
+ max_norm: float = 0,
+ ) -> None:
+ super().__init__()
+ assert dist.get_world_size() % (
+ tp_size * pp_size
+ ) == 0, f'world size {dist.get_world_size()} is not divisible by tp_size {tp_size} * pp_size {pp_size}'
+ # TODO(ver217): support zero
+ assert zero_stage == 0, 'zero is not support yet'
+ self.tp_size = tp_size
+ self.pp_size = pp_size
+ self.dp_size = dist.get_world_size() // (tp_size * pp_size)
+ self.precision = precision
+ self.zero_stage = zero_stage
+ self.cpu_offload = cpu_offload
+ self.enable_all_optimization = enable_all_optimization
+ self.enable_fused_normalization = enable_fused_normalization
+ self.enable_flash_attention = enable_flash_attention
+ self.enable_jit_fused = enable_jit_fused
+ self.pg_mesh = ProcessGroupMesh(self.dp_size, self.pp_size, self.tp_size)
+ self.stage_manager = None
+ self.schedule = None
+ assert zero_stage in (0, 1, 2)
+ if self.pp_size > 1:
+ assert num_microbatches is not None, 'num_microbatches must be specified when using pipeline parallelism'
+ assert self.zero_stage <= 1, 'zero stage must be 0 or 1 when using pipeline parallelism'
+ self.stage_manager = PipelineStageManager(self.pg_mesh, PP_AXIS)
+ self.schedule = OneForwardOneBackwardSchedule(num_microbatches, self.stage_manager)
+ self.tp_group = self.pg_mesh.get_group_along_axis(TP_AXIS)
+ self.dp_group = self.pg_mesh.get_group_along_axis(DP_AXIS)
+ self.shard_config = ShardConfig(tensor_parallel_process_group=self.tp_group,
+ pipeline_stage_manager=self.stage_manager,
+ enable_tensor_parallelism=self.tp_size > 1,
+ enable_all_optimization=self.enable_all_optimization,
+ enable_fused_normalization=self.enable_fused_normalization,
+ enable_flash_attention=self.enable_flash_attention,
+ enable_jit_fused=self.enable_jit_fused)
+ self.amp_config = dict(
+ initial_scale=initial_scale,
+ growth_factor=growth_factor,
+ backoff_factor=backoff_factor,
+ growth_interval=growth_interval,
+ hysteresis=hysteresis,
+ min_scale=min_scale,
+ max_scale=max_scale,
+ )
+ self.max_norm = max_norm
+
+ @property
+ def enable_pipeline_parallelism(self) -> bool:
+ return self.pp_size > 1
+
+ def supported_devices(self) -> List[str]:
+ return ['cuda']
+
+ def supported_precisions(self) -> List[str]:
+ return ['fp16', 'bf16', 'fp32']
+
+ def control_device(self) -> bool:
+ return True
+
+ def control_precision(self) -> bool:
+ return True
+
+ def support_no_sync(self) -> bool:
+ return False
+
+ def control_checkpoint_io(self) -> bool:
+ return True
+
+ def configure(
+ self,
+ model: Module,
+ optimizer: Optional[Optimizer] = None,
+ criterion: Optional[Callable] = None,
+ dataloader: Optional[DataLoader] = None,
+ lr_scheduler: Optional[LRScheduler] = None,
+ ) -> Tuple[Module, OptimizerWrapper, Callable, DataLoader, LRScheduler]:
+ if not isinstance(model, ModelWrapper):
+ model = HybridParallelModule(model, self.precision, self.shard_config, self.dp_group)
+ if optimizer is not None and not isinstance(optimizer, OptimizerWrapper):
+ if self.zero_stage == 0:
+ if self.precision in ['fp16', 'bf16']:
+ optimizer = HybridParallelAMPOptimizer(optimizer,
+ model,
+ use_pipeline=self.enable_pipeline_parallelism,
+ precision=self.precision,
+ max_norm=self.max_norm,
+ **self.amp_config)
+ else:
+ optimizer = HybridParallelNaiveOptimizer(optimizer,
+ model,
+ use_pipeline=self.enable_pipeline_parallelism)
+ else:
+ optimizer = HybridParallelZeroOptimizer(optimizer,
+ model,
+ use_pipeline=self.enable_pipeline_parallelism,
+ partition_grad=(self.zero_stage == 2),
+ cpu_offload=self.cpu_offload,
+ dp_process_group=self.dp_group,
+ tp_process_group=self.tp_group,
+ verbose=True,
+ clip_grad_norm=self.max_norm,
+ **self.amp_config)
+ return model, optimizer, criterion, dataloader, lr_scheduler
+
+ def execute_pipeline(self,
+ data_iter: Iterator,
+ model: HybridParallelModule,
+ criterion: Callable[[Any, Any], torch.Tensor],
+ optimizer: Union[HybridParallelNaiveOptimizer, HybridParallelAMPOptimizer,
+ HybridParallelZeroOptimizer],
+ return_loss: bool = True,
+ return_outputs: bool = False) -> dict:
+ assert self.enable_pipeline_parallelism, 'pipeline parallelism is not enabled'
+ # return loss or outputs if needed
+ ctx = optimizer.no_sync() if isinstance(optimizer, HybridParallelZeroOptimizer) else model.no_sync()
+ with ctx:
+ outputs = self.schedule.forward_backward_step(model, optimizer, data_iter, criterion, return_loss,
+ return_outputs)
+ model.sync_shared_params()
+ if isinstance(optimizer, HybridParallelZeroOptimizer):
+ optimizer.sync_grad()
+ else:
+ model.sync_grads()
+ return outputs
+
+ def prepare_dataloader(self,
+ dataset,
+ batch_size,
+ shuffle=False,
+ seed=1024,
+ drop_last=False,
+ pin_memory=False,
+ num_workers=0,
+ **kwargs):
+ r"""
+ Prepare a dataloader for distributed training. The dataloader will be wrapped by
+ `torch.utils.data.DataLoader` and `torch.utils.data.DistributedSampler`.
+
+
+ Args:
+ dataset (`torch.utils.data.Dataset`): The dataset to be loaded.
+ shuffle (bool, optional): Whether to shuffle the dataset. Defaults to False.
+ seed (int, optional): Random worker seed for sampling, defaults to 1024.
+ add_sampler: Whether to add ``DistributedDataParallelSampler`` to the dataset. Defaults to True.
+ drop_last (bool, optional): Set to True to drop the last incomplete batch, if the dataset size
+ is not divisible by the batch size. If False and the size of dataset is not divisible by
+ the batch size, then the last batch will be smaller, defaults to False.
+ pin_memory (bool, optional): Whether to pin memory address in CPU memory. Defaults to False.
+ num_workers (int, optional): Number of worker threads for this dataloader. Defaults to 0.
+ kwargs (dict): optional parameters for ``torch.utils.data.DataLoader``, more details could be found in
+ `DataLoader
`_.
+
+ Returns:
+ :class:`torch.utils.data.DataLoader`: A DataLoader used for training or testing.
+ """
+ _kwargs = kwargs.copy()
+ sampler = DistributedSampler(dataset,
+ num_replicas=self.pg_mesh.size(DP_AXIS),
+ rank=self.pg_mesh.coordinate(DP_AXIS),
+ shuffle=shuffle)
+
+ # Deterministic dataloader
+ def seed_worker(worker_id):
+ worker_seed = seed
+ np.random.seed(worker_seed)
+ torch.manual_seed(worker_seed)
+ random.seed(worker_seed)
+
+ return DataLoader(dataset,
+ batch_size=batch_size,
+ sampler=sampler,
+ worker_init_fn=seed_worker,
+ drop_last=drop_last,
+ pin_memory=pin_memory,
+ num_workers=num_workers,
+ **_kwargs)
+
+ def get_checkpoint_io(self) -> CheckpointIO:
+ return None
+
+ def no_sync(self, model: Module) -> Iterator[None]:
+ raise NotImplementedError
diff --git a/colossalai/booster/plugin/pp_plugin_base.py b/colossalai/booster/plugin/pp_plugin_base.py
new file mode 100644
index 000000000000..67ade9330f5b
--- /dev/null
+++ b/colossalai/booster/plugin/pp_plugin_base.py
@@ -0,0 +1,21 @@
+from abc import abstractmethod
+from typing import Any, Callable, Iterator
+
+import torch
+
+from colossalai.interface import ModelWrapper, OptimizerWrapper
+
+from .plugin_base import Plugin
+
+
+class PipelinePluginBase(Plugin):
+
+ @abstractmethod
+ def execute_pipeline(self,
+ data_iter: Iterator,
+ model: ModelWrapper,
+ criterion: Callable[[Any, Any], torch.Tensor],
+ optimizer: OptimizerWrapper,
+ return_loss: bool = True,
+ return_outputs: bool = False) -> dict:
+ pass
diff --git a/colossalai/cluster/__init__.py b/colossalai/cluster/__init__.py
index 2fbdfd3cc999..44f571ca2501 100644
--- a/colossalai/cluster/__init__.py
+++ b/colossalai/cluster/__init__.py
@@ -1,5 +1,6 @@
from .device_mesh_manager import DeviceMeshManager
from .dist_coordinator import DistCoordinator
from .process_group_manager import ProcessGroupManager
+from .process_group_mesh import ProcessGroupMesh
-__all__ = ['DistCoordinator', 'ProcessGroupManager', 'DeviceMeshManager']
+__all__ = ['DistCoordinator', 'ProcessGroupManager', 'DeviceMeshManager', 'ProcessGroupMesh']
diff --git a/colossalai/cluster/process_group_mesh.py b/colossalai/cluster/process_group_mesh.py
new file mode 100644
index 000000000000..1dfd261d5d01
--- /dev/null
+++ b/colossalai/cluster/process_group_mesh.py
@@ -0,0 +1,203 @@
+import itertools
+from functools import reduce
+from operator import mul
+from typing import Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import torch.distributed as dist
+from torch.distributed import ProcessGroup
+
+
+def prod(nums: List[int]) -> int:
+ """Product of a list of numbers.
+
+ Args:
+ nums (List[int]): A list of numbers.
+
+ Returns:
+ int: The product of the numbers.
+ """
+ return reduce(mul, nums)
+
+
+class ProcessGroupMesh:
+ """A helper class to manage the process group mesh. It only describes how to organize process groups, and it's decoupled with parallel method.
+ It just initialize process groups and cache them. The parallel method should manage them and use them to do the parallel computation.
+
+ We use a ND-tuple to represent the process group mesh. And a ND-coordinate is to represent each process.
+ For example, ``(0, 1, 0)`` represents the process whose rank is 2 in a 3D process group mesh with size ``(2, 2, 2)``.
+
+ Args:
+ *size (int): The size of each dimension of the process group mesh. The product of the size must be equal to the world size.
+
+ Attributes:
+ shape (Tuple[int, ...]): The shape of the process group mesh.
+ rank (int): The rank of the current process.
+ """
+
+ def __init__(self, *size: int) -> None:
+ assert dist.is_initialized(), "Please initialize torch.distributed first."
+ assert prod(size) == dist.get_world_size(), "The product of the size must be equal to the world size."
+ self._shape = size
+ self._rank = dist.get_rank()
+ self._coord = ProcessGroupMesh.unravel(self._rank, self._shape)
+ self._ranks_to_group: Dict[Tuple[int, ...], ProcessGroup] = {}
+ self._group_to_ranks: Dict[ProcessGroup, Tuple[int, ...]] = {}
+
+ @property
+ def shape(self) -> Tuple[int, ...]:
+ return self._shape
+
+ @property
+ def rank(self) -> int:
+ return self._rank
+
+ def size(self, dim: Optional[int] = None) -> Union[int, Tuple[int, ...]]:
+ """Get the size of the process group mesh.
+
+ Args:
+ dim (Optional[int], optional): Dimension of the process group mesh. `None` means all dimensions. Defaults to None.
+
+ Returns:
+ Union[int, Tuple[int, ...]]: Size of the target dimension or the whole process group mesh.
+ """
+ if dim is None:
+ return self._shape
+ else:
+ return self._shape[dim]
+
+ def coordinate(self, dim: Optional[int] = None) -> Union[int, Tuple[int, ...]]:
+ """Get the coordinate of the process group mesh.
+
+ Args:
+ dim (Optional[int], optional): Dimension of the process group mesh. `None` means all dimensions. Defaults to None.
+
+ Returns:
+ Union[int, Tuple[int, ...]]: Coordinate of the target dimension or the whole process group mesh.
+ """
+ if dim is None:
+ return self._coord
+ else:
+ return self._coord[dim]
+
+ @staticmethod
+ def unravel(rank: int, shape: Tuple[int, ...]) -> Tuple[int, ...]:
+ """Convert a rank to a coordinate.
+
+ Args:
+ rank (int): Rank to be converted.
+ shape (Tuple[int, ...]): Shape of the process group mesh.
+
+ Returns:
+ Tuple[int, ...]: Coordinate of the rank.
+ """
+ return np.unravel_index(rank, shape)
+
+ @staticmethod
+ def ravel(coord: Tuple[int, ...], shape: Tuple[int, ...]) -> int:
+ """Convert a coordinate to a rank.
+
+ Args:
+ coords (Tuple[int, ...]): Coordinate to be converted.
+ shape (Tuple[int, ...]): Shape of the process group mesh.
+
+ Returns:
+ int: Rank of the coordinate.
+ """
+ return np.ravel_multi_index(coord, shape)
+
+ def get_group(self, ranks_in_group: List[int], backend: Optional[str] = None) -> ProcessGroup:
+ """Get the process group with the given ranks. It the process group doesn't exist, it will be created.
+
+ Args:
+ ranks_in_group (List[int]): Ranks in the process group.
+ backend (Optional[str], optional): Backend of the process group. Defaults to None.
+
+ Returns:
+ ProcessGroup: The process group with the given ranks.
+ """
+ ranks_in_group = sorted(ranks_in_group)
+ if tuple(ranks_in_group) not in self._group_to_ranks:
+ group = dist.new_group(ranks_in_group, backend=backend)
+ self._ranks_to_group[tuple(ranks_in_group)] = group
+ self._group_to_ranks[group] = tuple(ranks_in_group)
+ return self._ranks_to_group[tuple(ranks_in_group)]
+
+ def get_ranks_in_group(self, group: ProcessGroup) -> List[int]:
+ """Get the ranks in the given process group. The process group must be created by this class.
+
+ Args:
+ group (ProcessGroup): The process group.
+
+ Returns:
+ List[int]: Ranks in the process group.
+ """
+ return list(self._group_to_ranks[group])
+
+ @staticmethod
+ def get_coords_along_axis(base_coord: Tuple[int, ...], axis: int,
+ indices_at_axis: List[int]) -> List[Tuple[int, ...]]:
+ """Get coordinates along the given axis.
+
+ Args:
+ base_coord (Tuple[int, ...]): Base coordinate which the coordinates along the axis are based on.
+ axis (int): Axis along which the coordinates are generated.
+ indices_at_axis (List[int]): Indices at the axis.
+
+ Returns:
+ List[Tuple[int, ...]]: Coordinates along the axis.
+ """
+ coords_in_group = []
+ for idx in indices_at_axis:
+ coords_in_group.append(base_coord[:axis] + (idx,) + base_coord[axis + 1:])
+ return coords_in_group
+
+ def create_group_along_axis(self,
+ axis: int,
+ indices_at_axis: Optional[List[int]] = None,
+ backend: Optional[str] = None) -> ProcessGroup:
+ """Create all process groups along the given axis, and return the one which the current process belongs to.
+
+ Args:
+ axis (int): Axis along which the process groups are created.
+ indices_at_axis (Optional[List[int]], optional): Indices at the axis. Defaults to None.
+ backend (Optional[str], optional): Backend of the process group. Defaults to None.
+
+ Returns:
+ ProcessGroup: The process group along the given axis which the current process belongs to.
+ """
+ indices_at_axis = indices_at_axis or list(range(self._shape[axis]))
+ reduced_shape = list(self._shape)
+ # the choices on the axis are reduced to 1, since it's determined by `indices_at_axis`
+ reduced_shape[axis] = 1
+ target_group = None
+ # use Cartesian product to generate all combinations of coordinates
+ for base_coord in itertools.product(*[range(s) for s in reduced_shape]):
+ coords_in_group = ProcessGroupMesh.get_coords_along_axis(base_coord, axis, indices_at_axis)
+ ranks_in_group = tuple([ProcessGroupMesh.ravel(coord, self._shape) for coord in coords_in_group])
+ group = self.get_group(ranks_in_group, backend=backend)
+ if self._rank in ranks_in_group:
+ target_group = group
+ return target_group
+
+ def get_group_along_axis(self,
+ axis: int,
+ indices_at_axis: Optional[List[int]] = None,
+ backend: Optional[str] = None) -> ProcessGroup:
+ """Get the process group along the given axis which the current process belongs to. If the process group doesn't exist, it will be created.
+
+ Args:
+ axis (int): Axis along which the process groups are created.
+ indices_at_axis (Optional[List[int]], optional): Indices at the axis. Defaults to None.
+ backend (Optional[str], optional): Backend of the process group. Defaults to None.
+
+ Returns:
+ ProcessGroup: The process group along the given axis which the current process belongs to.
+ """
+ indices_at_axis = indices_at_axis or list(range(self._shape[axis]))
+ coords_in_group = ProcessGroupMesh.get_coords_along_axis(self._coord, axis, indices_at_axis)
+ ranks_in_group = tuple([ProcessGroupMesh.ravel(coord, self._shape) for coord in coords_in_group])
+ if ranks_in_group not in self._ranks_to_group:
+ # no need to cache it explicitly, since it will be cached in `create_group_along_axis`
+ return self.create_group_along_axis(axis, indices_at_axis, backend=backend)
+ return self._ranks_to_group[ranks_in_group]
diff --git a/colossalai/interface/optimizer.py b/colossalai/interface/optimizer.py
index 0eaf2e1ef8ba..bc270b1d9c89 100644
--- a/colossalai/interface/optimizer.py
+++ b/colossalai/interface/optimizer.py
@@ -1,5 +1,6 @@
from typing import Union
+import torch
import torch.nn as nn
from torch import Tensor
from torch.optim import Optimizer
@@ -53,6 +54,9 @@ def backward(self, loss: Tensor, *args, **kwargs):
"""
loss.backward(*args, **kwargs)
+ def backward_by_grad(self, tensor: Tensor, grad: Tensor):
+ torch.autograd.backward(tensor, grad)
+
def state_dict(self):
"""
Returns the optimizer state.
diff --git a/colossalai/kernel/cuda_native/__init__.py b/colossalai/kernel/cuda_native/__init__.py
index 4910717b5723..e0136d86e561 100644
--- a/colossalai/kernel/cuda_native/__init__.py
+++ b/colossalai/kernel/cuda_native/__init__.py
@@ -1,8 +1,9 @@
from .layer_norm import MixedFusedLayerNorm as LayerNorm
from .mha.mha import ColoAttention
from .multihead_attention import MultiHeadAttention
-from .scaled_softmax import FusedScaleMaskSoftmax, ScaledUpperTriangMaskedSoftmax
+from .scaled_softmax import AttnMaskType, FusedScaleMaskSoftmax, ScaledUpperTriangMaskedSoftmax
__all__ = [
- 'LayerNorm', 'MultiHeadAttention', 'FusedScaleMaskSoftmax', 'ScaledUpperTriangMaskedSoftmax', 'ColoAttention'
+ 'LayerNorm', 'MultiHeadAttention', 'FusedScaleMaskSoftmax', 'ScaledUpperTriangMaskedSoftmax', 'ColoAttention',
+ 'AttnMaskType'
]
diff --git a/colossalai/lazy/lazy_init.py b/colossalai/lazy/lazy_init.py
index 1f5345015bf2..e071563c045a 100644
--- a/colossalai/lazy/lazy_init.py
+++ b/colossalai/lazy/lazy_init.py
@@ -6,6 +6,7 @@
import torch.distributed as dist
import torch.nn as nn
from torch import Tensor
+from torch.nn import Parameter
from torch.utils._pytree import tree_map
from colossalai._analyzer._subclasses import MetaTensor
@@ -99,8 +100,11 @@ def _convert_cls(tensor: 'LazyTensor', target: torch.Tensor) -> torch.Tensor:
Returns:
torch.Tensor: the converted tensor
"""
- cls_to_become = nn.Parameter if isinstance(tensor, nn.Parameter) else torch.Tensor
+ cls_to_become = Parameter if isinstance(tensor, Parameter) else torch.Tensor
tensor.__class__ = cls_to_become
+ if cls_to_become is Parameter:
+ # to fit UninitializedParameter
+ delattr(tensor, '_is_param')
tensor.data = target
tensor.requires_grad = target.requires_grad
# subclass of torch.Tensor does not have tolist() method
@@ -198,10 +202,10 @@ def distribute(self, device_mesh: DeviceMesh, sharding_spec: ShardingSpec) -> to
def clean(self) -> None:
"""Clean all stored operations, meta data and materialized data, which prevents memory leaking. This should be called after all tensors are materialized.
"""
- self._factory_method = None
- self._op_buffer = None
- self._materialized_data = None
- self._meta_data = None
+ delattr(self, '_factory_method')
+ delattr(self, '_op_buffer')
+ delattr(self, '_materialized_data')
+ delattr(self, '_meta_data')
@staticmethod
def _replace_with_materialized(x):
@@ -350,20 +354,19 @@ def __deepcopy__(self, memo):
def factory_fn():
# if self is materialized, return self
new_tensor = self.materialize() if type(self) is LazyTensor else self
- copied = new_tensor.detach().clone()
- if new_tensor.requires_grad:
- copied.requires_grad_()
- return copied
+ return _copy_tensor(new_tensor, new_tensor.requires_grad)
if self._materialized_data is not None:
# self is early materialized
- copied = self._materialized_data.detach().clone()
- if self.requires_grad:
- copied.requires_grad_()
+ copied = _copy_tensor(self._materialized_data, self.requires_grad)
target = LazyTensor(lambda: None, concrete_data=copied)
else:
target = LazyTensor(factory_fn, meta_data=self._meta_data)
+ if isinstance(self, Parameter):
+ # hack isinstance check of parameter
+ target._is_param = True
+
memo[id(self)] = target
return target
@@ -408,6 +411,10 @@ def tolist(self) -> list:
def __hash__(self):
return id(self)
+ def __rpow__(self, other):
+ dtype = torch.result_type(self, other)
+ return torch.tensor(other, dtype=dtype, device=self.device)**self
+
class LazyInitContext:
"""Context manager for lazy initialization. Enables initializing the model without allocating real memory.
@@ -536,7 +543,7 @@ def __exit__(self, exc_type, exc_val, exc_tb):
@staticmethod
def materialize(module: nn.Module, verbose: bool = False) -> nn.Module:
- """Initialize all ``nn.Parameter`` from ``LazyTensor``. This function will modify the module in-place.
+ """Initialize all ``Parameter`` from ``LazyTensor``. This function will modify the module in-place.
Args:
module (nn.Module): Target ``nn.Module``
@@ -553,7 +560,7 @@ def distribute(module: nn.Module,
device_mesh: DeviceMesh,
sharding_spec_dict: Dict[str, ShardingSpec],
verbose: bool = False) -> nn.Module:
- """Distribute all ``nn.Parameter`` from ``LazyTensor``. This function will modify the module in-place.
+ """Distribute all ``Parameter`` from ``LazyTensor``. This function will modify the module in-place.
Args:
module (nn.Module): Target ``nn.Module``
@@ -625,3 +632,9 @@ def _is_int_tuple(args) -> bool:
if not isinstance(x, int):
return False
return True
+
+
+def _copy_tensor(tensor: Tensor, requires_grad: bool) -> Tensor:
+ copied = tensor.data.clone()
+ copied.requires_grad = requires_grad
+ return copied
diff --git a/colossalai/pipeline/p2p.py b/colossalai/pipeline/p2p.py
new file mode 100644
index 000000000000..af7a00b5c720
--- /dev/null
+++ b/colossalai/pipeline/p2p.py
@@ -0,0 +1,233 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import io
+import pickle
+import re
+from typing import Any, List, Optional, Union
+
+import torch
+import torch.distributed as dist
+from packaging.version import Version
+from torch.distributed import ProcessGroup
+from torch.distributed import distributed_c10d as c10d
+
+from .stage_manager import PipelineStageManager
+
+_unpickler = pickle.Unpickler
+
+
+def _cuda_safe_tensor_to_object(tensor: torch.Tensor, tensor_size: torch.Size) -> object:
+ """transform tensor to object with unpickle.
+ Info of the device in bytes stream will be modified into current device before unpickling
+
+ Args:
+ tensor (:class:`torch.tensor`): tensor to be unpickled
+ tensor_size (:class:`torch.Size`): Size of the real info in bytes
+
+ Returns:
+ Any: object after unpickled
+ """
+ buf = tensor.numpy().tobytes()[:tensor_size]
+ if b'cuda' in buf:
+ buf_array = bytearray(buf)
+ device_index = torch.cuda.current_device()
+ # There might be more than one output tensors during forward
+ for cuda_str in re.finditer(b'cuda', buf_array):
+ pos = cuda_str.start()
+ buf_array[pos + 5] = 48 + device_index
+ buf = bytes(buf_array)
+
+ io_bytes = io.BytesIO(buf)
+ byte_pickler = _unpickler(io_bytes)
+ unpickle = byte_pickler.load()
+
+ return unpickle
+
+
+def _broadcast_object_list(object_list: List[Any],
+ src: int,
+ group: ProcessGroup,
+ device: Optional[Union[torch.device, str, int]] = None):
+ """This is a modified version of the broadcast_object_list in torch.distribution
+ The only difference is that object will be move to correct device after unpickled.
+ If local_rank = src, then object list will be sent to rank src. Otherwise, object list will
+ be updated with data sent from rank src.
+
+ Args:
+ object_list (List[Any]): list of object to broadcast
+ src (int): source rank to broadcast
+ dst (int): dst rank to broadcast
+ device (:class:`torch.device`): device to do broadcast. current device in default
+
+ """
+
+ if c10d._rank_not_in_group(group):
+ c10d._warn_not_in_group("broadcast_object_list")
+ return
+
+ is_nccl_backend = c10d._check_for_nccl_backend(group)
+ current_device = None
+
+ if device is not None:
+ if is_nccl_backend and device.type != "cuda":
+ raise ValueError("device type must be cuda for nccl backend")
+ current_device = device
+ else:
+ current_device = torch.device("cpu")
+ if is_nccl_backend:
+ current_device = torch.device("cuda", torch.cuda.current_device())
+
+ my_rank = dist.get_rank()
+ # Serialize object_list elements to tensors on src rank.
+ if my_rank == src:
+ if Version(torch.__version__) >= Version("1.13.0"):
+ tensor_list, size_list = zip(*[c10d._object_to_tensor(obj, device=current_device) for obj in object_list])
+ else:
+ tensor_list, size_list = zip(*[c10d._object_to_tensor(obj) for obj in object_list])
+ object_sizes_tensor = torch.cat(size_list)
+ else:
+ object_sizes_tensor = torch.empty(len(object_list), dtype=torch.long)
+
+ if is_nccl_backend:
+ object_sizes_tensor = object_sizes_tensor.to(current_device)
+
+ # Broadcast object sizes
+ c10d.broadcast(object_sizes_tensor, src=src, group=group, async_op=False)
+
+ # Concatenate and broadcast serialized object tensors
+ if my_rank == src:
+ object_tensor = torch.cat(tensor_list)
+ else:
+ object_tensor = torch.empty( # type: ignore[call-overload]
+ torch.sum(object_sizes_tensor).item(), # type: ignore[arg-type]
+ dtype=torch.uint8,
+ )
+
+ if is_nccl_backend:
+ object_tensor = object_tensor.to(current_device)
+
+ c10d.broadcast(object_tensor, src=src, group=group, async_op=False)
+
+ # Deserialize objects using their stored sizes.
+ offset = 0
+
+ if my_rank != src:
+ for i, obj_size in enumerate(object_sizes_tensor):
+ obj_view = object_tensor[offset:offset + obj_size]
+ obj_view = obj_view.type(torch.uint8)
+ if obj_view.device != torch.device("cpu"):
+ obj_view = obj_view.cpu()
+ offset += obj_size
+ # unpickle
+ unpickle_object = _cuda_safe_tensor_to_object(obj_view, obj_size)
+
+ # unconsistence in device
+ if isinstance(unpickle_object,
+ torch.Tensor) and unpickle_object.device.index != torch.cuda.current_device():
+ unpickle_object = unpickle_object.cuda()
+
+ object_list[i] = unpickle_object
+
+
+def _send_object(object: Any, src: int, dst: int, group: ProcessGroup) -> None:
+ """send anything to dst rank
+
+ Args:
+ object (Any): object needed to be sent
+ dst (int): rank of the destination
+
+ Returns:
+ None
+ """
+ # then broadcast safely
+ _broadcast_object_list([object], src, group)
+
+
+def _recv_object(src: int, dst: int, group: ProcessGroup) -> Any:
+ """recv anything from src
+
+ Args:
+ src (int): source rank of data. local rank will receive data from src rank.
+
+ Returns:
+ Any: Object received from src.
+ """
+ object_list = [None]
+ _broadcast_object_list(object_list, src, group)
+
+ return object_list[0]
+
+
+class PipelineP2PCommunication:
+
+ def __init__(self, stage_manager: PipelineStageManager) -> None:
+ self.stage_manager = stage_manager
+
+ def recv_forward(self, prev_rank: int = None) -> Any:
+ """Copy the forward output from the previous stage in pipeline as the input tensor of this stage.
+
+ Args:
+ prev_rank (int, optional): The rank of the source of the tensor.
+
+ Returns:
+ Any: The input tensor or input tensor list.
+ """
+ if self.stage_manager.is_first_stage():
+ input_tensor = None
+ else:
+ if prev_rank is None:
+ prev_rank = self.stage_manager.get_prev_rank()
+ cur_rank = self.stage_manager.get_rank()
+ input_tensor = _recv_object(prev_rank, cur_rank,
+ self.stage_manager.get_p2p_process_group(prev_rank, cur_rank))
+
+ return input_tensor
+
+ def recv_backward(self, next_rank: int = None) -> Any:
+ """Copy the gradient tensor from the next stage in pipeline as the input gradient of this stage.
+
+ Args:
+ next_rank (int, optional): The rank of the source of the tensor.
+
+ Returns:
+ Any: The input gradient tensor or gradient tensor list.
+ """
+ if self.stage_manager.is_last_stage():
+ output_tensor_grad = None
+ else:
+ if next_rank is None:
+ next_rank = self.stage_manager.get_next_rank()
+ cur_rank = self.stage_manager.get_rank()
+ output_tensor_grad = _recv_object(next_rank, cur_rank,
+ self.stage_manager.get_p2p_process_group(next_rank, cur_rank))
+
+ return output_tensor_grad
+
+ def send_forward(self, output_object: Any, next_rank: int = None) -> None:
+ """Sends the input tensor to the next stage in pipeline.
+
+ Args:
+ output_object (Any): Object to be sent.
+ next_rank (int, optional): The rank of the recipient of the tensor.
+ """
+ if not self.stage_manager.is_last_stage():
+ if next_rank is None:
+ next_rank = self.stage_manager.get_next_rank()
+ cur_rank = self.stage_manager.get_rank()
+ _send_object(output_object, cur_rank, next_rank,
+ self.stage_manager.get_p2p_process_group(cur_rank, next_rank))
+
+ def send_backward(self, input_object: Any, prev_rank: int = None) -> None:
+ """Sends the gradient tensor to the previous stage in pipeline.
+
+ Args:
+ input_object (Any): Object to be sent.
+ prev_rank (int, optional): The rank of the recipient of the tensor
+ """
+ if not self.stage_manager.is_first_stage():
+ if prev_rank is None:
+ prev_rank = self.stage_manager.get_prev_rank()
+ cur_rank = self.stage_manager.get_rank()
+ _send_object(input_object, cur_rank, prev_rank,
+ self.stage_manager.get_p2p_process_group(cur_rank, prev_rank))
diff --git a/colossalai/pipeline/schedule/__init__.py b/colossalai/pipeline/schedule/__init__.py
new file mode 100644
index 000000000000..8b13413b1a31
--- /dev/null
+++ b/colossalai/pipeline/schedule/__init__.py
@@ -0,0 +1,7 @@
+from .base import PipelineSchedule
+from .one_f_one_b import OneForwardOneBackwardSchedule
+
+__all__ = [
+ 'PipelineSchedule',
+ 'OneForwardOneBackwardSchedule',
+]
diff --git a/colossalai/pipeline/schedule/_utils.py b/colossalai/pipeline/schedule/_utils.py
new file mode 100644
index 000000000000..3ed9239272f1
--- /dev/null
+++ b/colossalai/pipeline/schedule/_utils.py
@@ -0,0 +1,129 @@
+from typing import Any, List, Optional
+
+import torch
+import torch.cuda
+from torch.nn import Module
+from torch.utils._pytree import tree_flatten, tree_map, tree_unflatten
+
+
+def to_device(x: Any, device: Optional[torch.device] = None) -> Any:
+ """Move object to device if it is a tensor.
+
+ Args:
+ x (Any): Object to be moved.
+ device (Optional[torch.device], optional): Target device. Defaults to None.
+
+ Returns:
+ Any: Moved object.
+ """
+ if isinstance(x, torch.Tensor):
+ return x.to(device)
+ return x
+
+
+def get_batch_size(batch: Any) -> int:
+ """Get the batch size (size of dimension-0) of the first tensor in the batch.
+
+ Args:
+ batch (Any): Batch to be inspected.
+
+ Raises:
+ RuntimeError: If no tensor is found in the batch.
+
+ Returns:
+ int: Batch size.
+ """
+ data_list, _ = tree_flatten(batch)
+ for data in data_list:
+ if isinstance(data, torch.Tensor):
+ return data.size(0)
+ raise RuntimeError('No tensor found in the batch')
+
+
+def get_micro_batch(batch: Any, start: int, micro_batch_size: int) -> Any:
+ """Get a micro batch of the original batch.
+
+ Args:
+ batch (Any): Batch to be sliced.
+ start (int): Start index of the micro batch.
+ micro_batch_size (int): Size of the micro batch.
+
+ Returns:
+ Any: Target micro batch.
+ """
+
+ def _get_tensor_slice(x: Any):
+ if isinstance(x, torch.Tensor):
+ return x[start:start + micro_batch_size]
+ return x
+
+ return tree_map(_get_tensor_slice, batch)
+
+
+def model_forward(model: Module, data: Any, internal_inputs: Optional[dict]) -> Any:
+ """Call model forward function with data and internal inputs.
+
+ Args:
+ model (Module): Model to be called.
+ data (Any): Data loaded from data iterator.
+ internal_inputs (Optional[dict]): Data from previous stage. It must be a dict or None if it's the first stage.
+
+ Returns:
+ Any: Outputs of the model.
+ """
+ if internal_inputs is None:
+ internal_inputs = {}
+ if isinstance(data, (list, tuple)):
+ return model(*data, **internal_inputs)
+ elif isinstance(data, dict):
+ return model(**data, **internal_inputs)
+ return model(data, **internal_inputs)
+
+
+def retain_grad(x: Any) -> None:
+ """Call retain_grad() on a tensor.
+
+ Args:
+ x (Any): Object to be called.
+ """
+ if isinstance(x, torch.Tensor) and x.requires_grad:
+ x.retain_grad()
+
+
+def detach(x: Any) -> Any:
+ """Call detach() on a tensor.
+
+ Args:
+ x (Any): Object to be called.
+
+ Returns:
+ Any: The detached object.
+ """
+ if isinstance(x, torch.Tensor):
+ return x.detach()
+ return x
+
+
+def merge_batch(data: List[Any]) -> Any:
+ """Merge micro batches into a batch.
+
+ Args:
+ data (List[Any]): A list of micro batches.
+
+ Returns:
+ Any: Merge batch.
+ """
+ if len(data) == 0:
+ return
+ flattened_data = []
+ tree_spec = None
+ for d in data:
+ elems, tree_spec = tree_flatten(d)
+ flattened_data.append(elems)
+ merged_data = []
+ for elem_batch in zip(*flattened_data):
+ if isinstance(elem_batch[0], torch.Tensor):
+ merged_data.append(torch.cat(elem_batch, dim=0))
+ else:
+ merged_data.append(list(elem_batch))
+ return tree_unflatten(merged_data, tree_spec)
diff --git a/colossalai/pipeline/schedule/base.py b/colossalai/pipeline/schedule/base.py
new file mode 100644
index 000000000000..9cd9beded65a
--- /dev/null
+++ b/colossalai/pipeline/schedule/base.py
@@ -0,0 +1,35 @@
+from typing import Any, Callable, Iterable
+
+from torch import Tensor
+from torch.nn import Module
+
+from colossalai.interface import OptimizerWrapper
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+
+class PipelineSchedule:
+
+ def __init__(self, stage_manager: PipelineStageManager) -> None:
+ self.stage_manager = stage_manager
+
+ def forward_backward_step(self,
+ model: Module,
+ optimizer: OptimizerWrapper,
+ data_iter: Iterable,
+ criterion: Callable[[Any, Any], Tensor],
+ return_loss: bool = False,
+ return_outputs: bool = False) -> dict:
+ """Forward and backward step for pipeline training.
+
+ Args:
+ model (Module): Model to be trained.
+ optimizer (OptimizerWrapper): Optimizer to be used.
+ data_iter (Iterable): Data iterator.
+ criterion (Callable[[Any, Any], Tensor]): Criterion to be used. It should take two arguments: model outputs and inputs, and returns loss tensor.
+ return_loss (bool, optional): Whether to return loss. Defaults to False. Whether to return loss.
+ return_outputs (bool, optional): Whether to return model outputs. Defaults to False. Whether to return model outputs.
+
+ Returns:
+ dict: A dict with keys: 'loss' and 'outputs'.
+ """
+ raise NotImplementedError
diff --git a/colossalai/pipeline/schedule/one_f_one_b.py b/colossalai/pipeline/schedule/one_f_one_b.py
new file mode 100644
index 000000000000..ade3cf456fe3
--- /dev/null
+++ b/colossalai/pipeline/schedule/one_f_one_b.py
@@ -0,0 +1,234 @@
+from functools import partial
+from typing import Any, Callable, Iterable, List, Optional, Union
+
+import torch
+import torch.cuda
+from torch.nn import Module
+from torch.utils._pytree import tree_map
+
+from colossalai.interface import OptimizerWrapper
+from colossalai.pipeline.p2p import PipelineP2PCommunication
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.utils.cuda import get_current_device
+
+from ._utils import detach, get_batch_size, get_micro_batch, merge_batch, model_forward, retain_grad, to_device
+from .base import PipelineSchedule
+
+
+class OneForwardOneBackwardSchedule(PipelineSchedule):
+
+ def __init__(self, num_microbatches: int, stage_manager: PipelineStageManager) -> None:
+ super().__init__(stage_manager)
+ self.comm = PipelineP2PCommunication(stage_manager)
+ self.num_microbatches = num_microbatches
+ self.batch: Optional[Any] = None
+ self.batch_size: Optional[int] = None
+ self.microbatch_offset: Optional[int] = None
+ self.microbatch_size: Optional[int] = None
+
+ def load_batch(self, data_iter: Iterable, device: Optional[torch.device] = None) -> None:
+ """Load a batch from data iterator.
+
+ Args:
+ data_iter (Iterable): Data iterator.
+ device (Optional[torch.device], optional): Target device. Defaults to None.
+ """
+ batch = next(data_iter)
+ if device is not None:
+ batch = tree_map(partial(to_device, device=device), batch)
+ self.batch = batch
+ self.batch_size = get_batch_size(batch)
+ self.microbatch_offset = 0
+ assert self.batch_size % self.num_microbatches == 0, \
+ "Batch size should divided by the number of microbatches"
+ self.microbatch_size = self.batch_size // self.num_microbatches
+
+ def load_micro_batch(self) -> Any:
+ """Load a micro batch from the current batch.
+
+ Returns:
+ Any: Micro batch.
+ """
+ micro_batch = get_micro_batch(self.batch, self.microbatch_offset, self.microbatch_size)
+ self.microbatch_offset += self.microbatch_size
+ return tree_map(partial(to_device, device=get_current_device()), micro_batch)
+
+ def forward_step(self,
+ model: Module,
+ input_obj: Optional[dict],
+ criterion: Callable,
+ accum_loss: Optional[torch.Tensor] = None,
+ outputs: Optional[List[Any]] = None) -> Union[torch.Tensor, dict]:
+ """Forward one step of the pipeline
+
+ Args:
+ model (Module): Model to be run
+ input_obj (Optional[dict]): The output from the previous stage. If it is the first stage, the `input_obj` is None.
+ criterion (Callable): Criterion to calculate loss.
+ accum_loss (Optional[torch.Tensor], optional): Accumulated loss. Defaults to None.
+ outputs (Optional[List[Any]], optional): List to store the output of the last stage (final output). Defaults to None.
+
+ Returns:
+ Union[torch.Tensor, dict]: The intermediate output (dict) of the current stage. If it is the last stage, the output is the loss (Tensor).
+ """
+ micro_batch = self.load_micro_batch()
+
+ # for the first stage, input_obj is None
+ # for the non-first stage, input_obj is the output of the previous stage and it's must be a dict
+ output_obj = model_forward(model, micro_batch, input_obj)
+ if self.stage_manager.is_last_stage():
+ loss = criterion(output_obj, micro_batch) / self.num_microbatches
+ if accum_loss is not None:
+ accum_loss.add_(loss.detach())
+ if outputs is not None:
+ outputs.append(tree_map(detach, output_obj))
+ return loss
+ else:
+ return output_obj
+
+ def backward_step(self, optimizer: OptimizerWrapper, input_obj: Optional[dict],
+ output_obj: Union[dict, torch.Tensor], output_obj_grad: Optional[dict]) -> Optional[dict]:
+ """Backward one step of the pipeline
+
+ Args:
+ optimizer (OptimizerWrapper): Optimizer to update the model
+ input_obj (Optional[dict]): Output of the previous stage. If it is the first stage, the `input_obj` is None.
+ output_obj (Union[dict, torch.Tensor]): Output of the current stage. If it is the last stage, the output is the loss (Tensor).
+ output_obj_grad (dict): Gradient of the `output_obj`. If it is the last stage, the `output_obj_grad` is None.
+
+ Returns:
+ Optional[dict]: Gradient of the `input_obj`. If it is the first stage, the `input_obj_grad` is None.
+ """
+
+ # Retain the grad on the input_obj.
+ tree_map(retain_grad, input_obj)
+
+ # Backward pass.
+ if output_obj_grad is None:
+ optimizer.backward(output_obj)
+ else:
+ if "backward_tensor_keys" not in output_obj:
+ for k, grad in output_obj_grad.items():
+ optimizer.backward_by_grad(output_obj[k], grad)
+ else:
+ for k, grad in output_obj_grad.items():
+ output_obj[k].grad = grad
+ for k in output_obj["backward_tensor_keys"]:
+ tensor_to_backward = output_obj[k]
+ optimizer.backward_by_grad(tensor_to_backward, tensor_to_backward.grad)
+
+ # Collect the grad of the input_obj.
+ input_obj_grad = None
+ if input_obj is not None:
+ input_obj_grad = {}
+ for k, v in input_obj.items():
+ if isinstance(v, torch.Tensor) and v.grad is not None:
+ input_obj_grad[k] = v.grad
+ return input_obj_grad
+
+ def forward_backward_step(self,
+ model: Module,
+ optimizer: OptimizerWrapper,
+ data_iter: Iterable,
+ criterion: Callable[..., Any],
+ return_loss: bool = False,
+ return_outputs: bool = False) -> dict:
+ """Runs non-interleaved 1F1B schedule, with communication between pipeline stages.
+
+ Args:
+ model (Module): Model to be trained.
+ optimizer (OptimizerWrapper): Optimizer to be used.
+ data_iter (Iterable): Data iterator.
+ criterion (Callable[[Any, Any], Tensor]): Criterion to be used. It should take two arguments: model outputs and inputs, and returns loss tensor.
+ return_loss (bool, optional): Whether to return loss. Defaults to False. Whether to return loss.
+ return_outputs (bool, optional): Whether to return model outputs. Defaults to False. Whether to return model outputs.
+
+ Returns:
+ dict: A dict with keys: 'loss' and 'outputs'.
+ """
+ forward_only = not torch.is_grad_enabled()
+
+ self.load_batch(data_iter)
+
+ # num_warmup_microbatches is the step when not all the processes are working
+ num_warmup_microbatches = self.stage_manager.num_stages - self.stage_manager.stage - 1
+ num_warmup_microbatches = min(num_warmup_microbatches, self.num_microbatches)
+ num_microbatches_remaining = self.num_microbatches - num_warmup_microbatches
+
+ # Input, output tensors only need to be saved when doing backward passes
+ input_objs = None
+ output_objs = None
+
+ if not forward_only:
+ input_objs = []
+ output_objs = []
+
+ outputs = [] if return_outputs and self.stage_manager.is_last_stage() else None
+ if return_loss and self.stage_manager.is_last_stage():
+ accum_loss = torch.zeros(1, device=get_current_device())
+ else:
+ accum_loss = None
+
+ # Run warmup forward passes.
+ for i in range(num_warmup_microbatches):
+ input_obj = self.comm.recv_forward()
+
+ output_obj = self.forward_step(model, input_obj, criterion, accum_loss, outputs)
+
+ self.comm.send_forward(output_obj)
+
+ if not forward_only:
+ input_objs.append(input_obj)
+ output_objs.append(output_obj)
+
+ # Before running 1F1B, need to receive first forward tensor.
+ # If all microbatches are run in warmup / cooldown phase, then no need to
+ # receive this tensor here.
+ if num_microbatches_remaining > 0:
+ input_obj = self.comm.recv_forward()
+
+ # Run 1F1B in steady state.
+ for i in range(num_microbatches_remaining):
+ last_iteration = (i == (num_microbatches_remaining - 1))
+
+ output_obj = self.forward_step(model, input_obj, criterion, accum_loss, outputs)
+ if forward_only:
+ self.comm.send_forward(output_obj)
+
+ if not last_iteration:
+ input_obj = self.comm.recv_forward()
+
+ else:
+ # TODO adjust here
+ self.comm.send_forward(output_obj)
+ output_obj_grad = self.comm.recv_backward()
+
+ # Add input_obj and output_obj to end of list.
+ input_objs.append(input_obj)
+ output_objs.append(output_obj)
+
+ # Pop output_obj and output_obj from the start of the list for
+ # the backward pass.
+ input_obj = input_objs.pop(0)
+ output_obj = output_objs.pop(0)
+ input_obj_grad = self.backward_step(optimizer, input_obj, output_obj, output_obj_grad)
+
+ if last_iteration:
+ input_obj = None
+ else:
+ input_obj = self.comm.recv_forward()
+ self.comm.send_backward(input_obj_grad)
+
+ # Run cooldown backward passes.
+ if not forward_only:
+ for i in range(num_warmup_microbatches):
+ input_obj = input_objs.pop(0)
+ output_obj = output_objs.pop(0)
+
+ output_obj_grad = self.comm.recv_backward()
+ input_obj_grad = self.backward_step(optimizer, input_obj, output_obj, output_obj_grad)
+ self.comm.send_backward(input_obj_grad)
+
+ if outputs is not None:
+ outputs = merge_batch(outputs)
+ return {'loss': accum_loss, 'outputs': outputs}
diff --git a/colossalai/pipeline/stage_manager.py b/colossalai/pipeline/stage_manager.py
new file mode 100644
index 000000000000..fe228e2270dd
--- /dev/null
+++ b/colossalai/pipeline/stage_manager.py
@@ -0,0 +1,176 @@
+from contextlib import contextmanager
+from typing import Dict, List, Optional, Tuple
+
+import torch.distributed as dist
+from torch.distributed import ProcessGroup
+
+from colossalai.cluster import ProcessGroupMesh
+
+
+class PipelineStageManager:
+ """PipelineStageManager is a helper class to manage pipeline stages.
+
+ Args:
+ pg_mesh (ProcessGroupMesh): Process group mesh.
+ pipeline_axis (int): The axis along which the pipeline is constructed.
+
+ Attributes:
+ num_stages (int): Number of stages in the pipeline.
+ stage (int): The current stage.
+ num_virtual_stages (int): Number of virtual stages in the pipeline.
+ virtual_stage (int): The current virtual stage.
+ """
+
+ def __init__(self, pg_mesh: ProcessGroupMesh, pipeline_axis: int) -> None:
+ self.pg_mesh = pg_mesh
+ self.pipeline_axis = pipeline_axis
+ self.num_virtual_stages: Optional[int] = None
+ self.virtual_stage: Optional[int] = None
+ self.prev_rank: Optional[Tuple[int, ...]] = None
+ self.next_rank: Optional[Tuple[int, ...]] = None
+ self.p2p_groups: Dict[Tuple[int, int], ProcessGroup] = {}
+ # init prev and next coord
+ coord = self.pg_mesh.coordinate()
+ if self.stage > 0:
+ prev_coord = coord[: self.pipeline_axis] + \
+ (coord[self.pipeline_axis] - 1,) + coord[self.pipeline_axis + 1:]
+ self.prev_rank = self.pg_mesh.ravel(prev_coord, self.pg_mesh.shape)
+ if self.stage < self.num_stages - 1:
+ next_coord = coord[: self.pipeline_axis] + \
+ (coord[self.pipeline_axis] + 1,) + coord[self.pipeline_axis + 1:]
+ self.next_rank = self.pg_mesh.ravel(next_coord, self.pg_mesh.shape)
+
+ # init p2p process groups
+ stages = list(range(self.num_stages))
+ for prev, cur in zip(stages[:-1], stages[1:]):
+ group = self.pg_mesh.get_group_along_axis(self.pipeline_axis, [prev, cur])
+ if self.stage in [prev, cur]:
+ ranks_in_group = self.pg_mesh.get_ranks_in_group(group)
+ self.p2p_groups[tuple(ranks_in_group)] = group
+
+ def is_first_stage(self, virtual: bool = False) -> bool:
+ """Is the current stage the first stage.
+
+ Args:
+ virtual (bool, optional): Whether to consider virtual stages. Defaults to False.
+
+ Returns:
+ bool: Whether the current stage is the first stage.
+ """
+ if virtual:
+ assert self.num_virtual_stages is not None
+ return self.virtual_stage == 0
+ return self.stage == 0
+
+ def is_last_stage(self, virtual: bool = False) -> bool:
+ """Is the current stage the last stage.
+
+ Args:
+ virtual (bool, optional): Whether to consider virtual stages. Defaults to False.
+
+ Returns:
+ bool: Whether the current stage is the last stage.
+ """
+ if virtual:
+ assert self.num_virtual_stages is not None
+ return self.virtual_stage == self.num_virtual_stages - 1
+ return self.stage == self.num_stages - 1
+
+ @property
+ def num_stages(self) -> int:
+ """Number of stages in the pipeline.
+
+ Returns:
+ int: Number of stages in the pipeline.
+ """
+ return self.pg_mesh.size(self.pipeline_axis)
+
+ @property
+ def stage(self) -> int:
+ """Current stage.
+
+ Returns:
+ int: Current stage.
+ """
+ return self.pg_mesh.coordinate(self.pipeline_axis)
+
+ def get_rank(self) -> int:
+ """Get the rank of the current process.
+
+ Returns:
+ int: Rank of the current process.
+ """
+ return dist.get_rank()
+
+ def get_prev_rank(self) -> int:
+ """Get the rank of the previous stage.
+
+ Returns:
+ int: Rank of the previous stage.
+ """
+ assert not self.is_first_stage(), "Cannot get previous rank in the first stage."
+ return self.prev_rank
+
+ def get_next_rank(self) -> int:
+ """Get the rank of the next stage.
+
+ Returns:
+ int: Rank of the next stage.
+ """
+ assert not self.is_last_stage(), "Cannot get next rank in the last stage."
+ return self.next_rank
+
+ def set_num_virtual_stages(self, num_virtual_stages: int) -> None:
+ """Set the number of virtual stages.
+
+ Args:
+ num_virtual_stages (int): Number of virtual stages.
+ """
+ self.num_virtual_stages = num_virtual_stages
+
+ def set_virtual_stage(self, virtual_stage: int) -> None:
+ """Set the virtual stage.
+
+ Args:
+ virtual_stage (int): Virtual stage.
+ """
+ self.virtual_stage = virtual_stage
+
+ @contextmanager
+ def switch_virtual_stage(self, virtual_stage: int) -> None:
+ """A context manager to switch virtual stage.
+
+ Args:
+ virtual_stage (int): Target virtual stage.
+ """
+ old_stage = self.virtual_stage
+ try:
+ self.set_virtual_stage(virtual_stage)
+ yield
+ finally:
+ self.set_virtual_stage(old_stage)
+
+ def get_p2p_process_group(self, first_rank: int, second_rank: int) -> ProcessGroup:
+ """Get the p2p process group between two ranks. The order of the two ranks does not matter.
+
+ Args:
+ first_rank (int): The first rank.
+ second_rank (int): The second rank.
+
+ Returns:
+ ProcessGroup: P2P process group between the two ranks.
+ """
+ if first_rank > second_rank:
+ first_rank, second_rank = second_rank, first_rank
+ return self.p2p_groups[(first_rank, second_rank)]
+
+ def init_process_group_by_stages(self, stages: List[int]) -> ProcessGroup:
+ """Get the process group of the given stages.
+
+ Args:
+ stages (List[int]): List of stages.
+
+ Returns:
+ ProcessGroup: Process group of the given stages.
+ """
+ return self.pg_mesh.get_group_along_axis(self.pipeline_axis, stages)
diff --git a/colossalai/shardformer/README.md b/colossalai/shardformer/README.md
index bf4215c52980..7dc15f0a0635 100644
--- a/colossalai/shardformer/README.md
+++ b/colossalai/shardformer/README.md
@@ -30,7 +30,7 @@
### Quick Start
-The sample API usage is given below:
+The sample API usage is given below(If you enable the use of flash attention, please install `flash_attn`. In addition, xformers's `cutlass_op` provide a supplementary optimization, It requires that the sequence length be a multiple of 8.):
```python
from colossalai.shardformer import ShardConfig, Shard
@@ -102,9 +102,24 @@ We will follow this roadmap to develop Shardformer:
- [ ] SwinTransformer
- [ ] SwinTransformer V2
- [ ] Audio
- - [ ] Whisper
+ - [x] Whisper
- [ ] Multi-modal
- - [ ] To be added
+ - [x] SAM
+ - [x] BLIP-2
+- [ ] Flash Attention Support
+ - [ ] NLP
+ - [x] BERT
+ - [x] T5
+ - [x] LlaMa
+ - [x] GPT2
+ - [x] OPT
+ - [x] BLOOM
+ - [ ] GLM
+ - [ ] RoBERTa
+ - [ ] ALBERT
+ - [ ] ERNIE
+ - [ ] GPT Neo
+ - [ ] GPT-J
## 💡 API Design
@@ -372,11 +387,49 @@ pytest tests/test_shardformer
### System Performance
-To be added.
+We conducted [benchmark tests](./examples/performance_benchmark.py) to evaluate the performance improvement of Shardformer. We compared the training time between the original model and the shard model.
+
+We set the batch size to 4, the number of attention heads to 8, and the head dimension to 64. 'N_CTX' refers to the sequence length.
+
+In the case of using 2 GPUs, the training times are as follows.
+| N_CTX | org_model | shard_model |
+| :------: | :-----: | :-----: |
+| 256 | 11.2ms | 17.2ms |
+| 512 | 9.8ms | 19.5ms |
+| 1024 | 19.6ms | 18.9ms |
+| 2048 | 46.6ms | 30.8ms |
+| 4096 | 160.5ms | 90.4ms |
+
+
+
+ 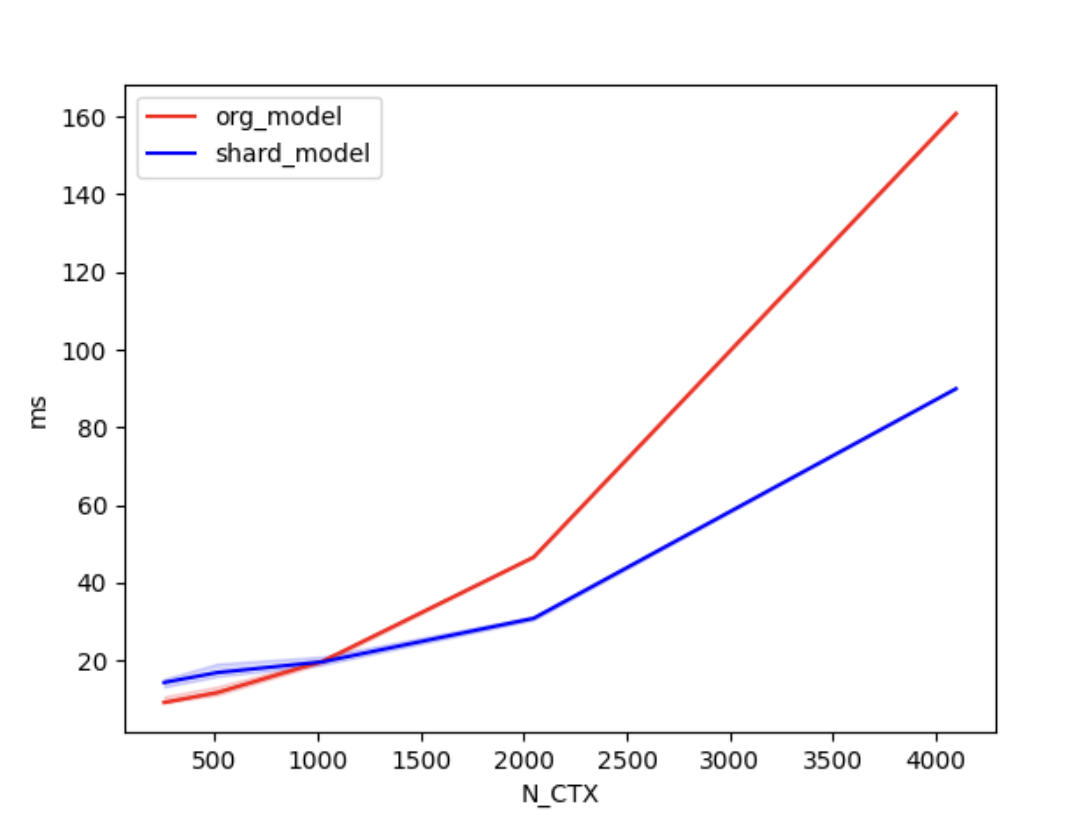 +
+
+
+
+In the case of using 4 GPUs, the training times are as follows.
+
+| N_CTX | org_model | shard_model |
+| :------: | :-----: | :-----: |
+| 256 | 10.0ms | 21.1ms |
+| 512 | 11.5ms | 20.2ms |
+| 1024 | 22.1ms | 20.6ms |
+| 2048 | 46.9ms | 24.8ms |
+| 4096 | 160.4ms | 68.0ms |
+
+
+
+
+ 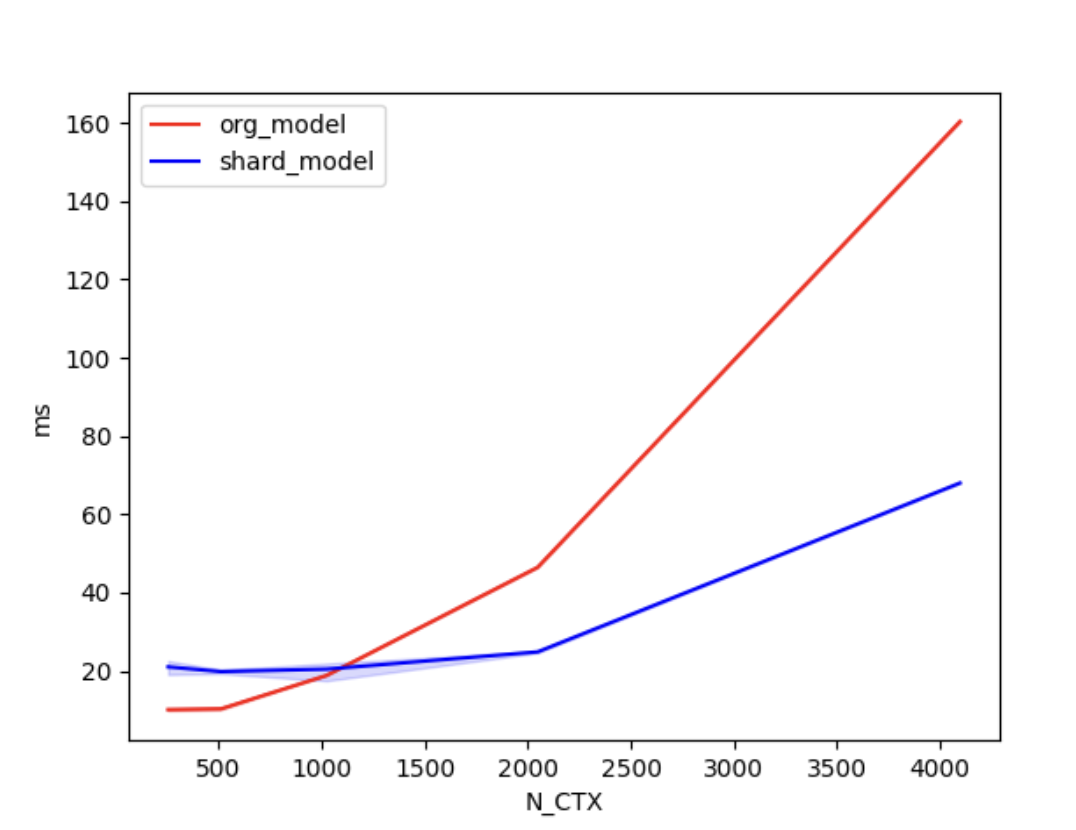 +
+
+
+
+
+As shown in the figures above, when the sequence length is around 1000 or greater, the parallel optimization of Shardformer for long sequences starts to become evident.
### Convergence
-To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/shardformer_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
+
+To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/convergence_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
| accuracy | f1 | loss | GPU number | model shard |
| :------: | :-----: | :-----: | :--------: | :---------: |
diff --git a/colossalai/shardformer/_utils.py b/colossalai/shardformer/_utils.py
index 4ad877e72357..c553080de0a0 100644
--- a/colossalai/shardformer/_utils.py
+++ b/colossalai/shardformer/_utils.py
@@ -1,25 +1,57 @@
import re
-def get_obj_list_element(obj, a):
+def get_obj_list_element(obj, attr: str):
r"""
Get the element of the list in the object
+
+ If the attr is a normal attribute, return the attribute of the object.
+ If the attr is a index type, return the element of the index in the list, like `layers[0]`.
+
+ Args:
+ obj (Object): The object to get
+ attr (str): The suffix of the attribute to get
+
"""
re_pattern = r'\[\d+\]'
prog = re.compile(re_pattern)
- result = prog.search(a)
+ result = prog.search(attr)
if result:
matched_brackets = result.group()
matched_index = matched_brackets.replace('[', '')
matched_index = matched_index.replace(']', '')
- a_ = a.replace(matched_brackets, '')
- container_obj = getattr(obj, a_)
+ attr_ = attr.replace(matched_brackets, '')
+ container_obj = getattr(obj, attr_)
obj = container_obj[int(matched_index)]
else:
- obj = getattr(obj, a)
+ obj = getattr(obj, attr)
return obj
+def set_obj_list_element(obj, attr: str, value):
+ r"""
+ Set the element to value of a list object
+
+ It used like set_obj_list_element(obj, 'lyaers[0]', new_layer), it will set obj.layers[0] to value
+
+ Args:
+ obj (object): The object to set
+ attr (str): the string including a list index like `layers[0]`
+ """
+ re_pattern = r'\[\d+\]'
+ prog = re.compile(re_pattern)
+ result = prog.search(attr)
+ if result:
+ matched_brackets = result.group()
+ matched_index = matched_brackets.replace('[', '')
+ matched_index = matched_index.replace(']', '')
+ attr_ = attr.replace(matched_brackets, '')
+ container_obj = getattr(obj, attr_)
+ container_obj[int(matched_index)] = value
+ else:
+ setattr(obj, attr, value)
+
+
def hasattr_(obj, attr: str):
r"""
Check whether the object has the multi sublevel attr
@@ -56,7 +88,7 @@ def setattr_(obj, attr: str, value, ignore: bool = False):
if ignore:
return
raise AttributeError(f"Object {obj.__class__.__name__} has no attribute {attr}")
- setattr(obj, attrs[-1], value)
+ set_obj_list_element(obj, attrs[-1], value)
def getattr_(obj, attr: str, ignore: bool = False):
diff --git a/colossalai/shardformer/examples/shardformer_benchmark.py b/colossalai/shardformer/examples/convergence_benchmark.py
similarity index 100%
rename from colossalai/shardformer/examples/shardformer_benchmark.py
rename to colossalai/shardformer/examples/convergence_benchmark.py
diff --git a/colossalai/shardformer/examples/shardformer_benchmark.sh b/colossalai/shardformer/examples/convergence_benchmark.sh
similarity index 76%
rename from colossalai/shardformer/examples/shardformer_benchmark.sh
rename to colossalai/shardformer/examples/convergence_benchmark.sh
index f42b19a32d35..1c281abcda6d 100644
--- a/colossalai/shardformer/examples/shardformer_benchmark.sh
+++ b/colossalai/shardformer/examples/convergence_benchmark.sh
@@ -1,4 +1,4 @@
-torchrun --standalone --nproc_per_node=4 shardformer_benchmark.py \
+torchrun --standalone --nproc_per_node=4 convergence_benchmark.py \
--model "bert" \
--pretrain "bert-base-uncased" \
--max_epochs 1 \
diff --git a/colossalai/shardformer/examples/performance_benchmark.py b/colossalai/shardformer/examples/performance_benchmark.py
new file mode 100644
index 000000000000..9c7b76bcf0a6
--- /dev/null
+++ b/colossalai/shardformer/examples/performance_benchmark.py
@@ -0,0 +1,86 @@
+"""
+Shardformer Benchmark
+"""
+import torch
+import torch.distributed as dist
+import transformers
+import triton
+
+import colossalai
+from colossalai.shardformer import ShardConfig, ShardFormer
+
+
+def data_gen(batch_size, seq_length):
+ input_ids = torch.randint(0, seq_length, (batch_size, seq_length), dtype=torch.long)
+ attention_mask = torch.ones((batch_size, seq_length), dtype=torch.long)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def data_gen_for_sequence_classification(batch_size, seq_length):
+ # LM data gen
+ # the `labels` of LM is the token of the output, cause no padding, use `input_ids` as `labels`
+ data = data_gen(batch_size, seq_length)
+ data['labels'] = torch.ones((batch_size), dtype=torch.long)
+ return data
+
+
+MODEL_CONFIG = transformers.LlamaConfig(num_hidden_layers=4,
+ hidden_size=128,
+ intermediate_size=256,
+ num_attention_heads=4,
+ max_position_embeddings=128,
+ num_labels=16)
+BATCH, N_HEADS, N_CTX, D_HEAD = 4, 8, 4096, 64
+model_func = lambda: transformers.LlamaForSequenceClassification(MODEL_CONFIG)
+
+# vary seq length for fixed head and batch=4
+configs = [
+ triton.testing.Benchmark(x_names=['N_CTX'],
+ x_vals=[2**i for i in range(8, 13)],
+ line_arg='provider',
+ line_vals=['org_model', 'shard_model'],
+ line_names=['org_model', 'shard_model'],
+ styles=[('red', '-'), ('blue', '-')],
+ ylabel='ms',
+ plot_name=f'lama_for_sequence_classification-batch-{BATCH}',
+ args={
+ 'BATCH': BATCH,
+ 'dtype': torch.float16,
+ 'model_func': model_func
+ })
+]
+
+
+def train(model, data):
+ output = model(**data)
+ loss = output.logits.mean()
+ loss.backward()
+
+
+@triton.testing.perf_report(configs)
+def bench_shardformer(BATCH, N_CTX, provider, model_func, dtype=torch.float32, device="cuda"):
+ warmup = 10
+ rep = 100
+ # prepare data
+ data = data_gen_for_sequence_classification(BATCH, N_CTX)
+ data = {k: v.cuda() for k, v in data.items()}
+ model = model_func().to(device)
+ model.train()
+ if provider == "org_model":
+ fn = lambda: train(model, data)
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+ return ms
+ if provider == "shard_model":
+ shard_config = ShardConfig(enable_fused_normalization=True, enable_tensor_parallelism=True)
+ shard_former = ShardFormer(shard_config=shard_config)
+ sharded_model = shard_former.optimize(model).cuda()
+ fn = lambda: train(sharded_model, data)
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+ return ms
+
+
+# start benchmark, command:
+# torchrun --standalone --nproc_per_node=2 performance_benchmark.py
+if __name__ == "__main__":
+ colossalai.launch_from_torch({})
+ bench_shardformer.run(save_path='.', print_data=dist.get_rank() == 0)
diff --git a/colossalai/shardformer/layer/__init__.py b/colossalai/shardformer/layer/__init__.py
index 7fad4948dfd0..c4586d18b90c 100644
--- a/colossalai/shardformer/layer/__init__.py
+++ b/colossalai/shardformer/layer/__init__.py
@@ -3,10 +3,11 @@
from .linear import Linear1D_Col, Linear1D_Row
from .loss import cross_entropy_1d
from .normalization import FusedLayerNorm, FusedRMSNorm
-from .qkv_fused_linear import GPT2FusedLinearConv1D_Col, GPT2FusedLinearConv1D_Row
+from .parallel_module import ParallelModule
+from .qkv_fused_linear import FusedLinear1D_Col, GPT2FusedLinearConv1D_Col, GPT2FusedLinearConv1D_Row
__all__ = [
"Embedding1D", "VocabParallelEmbedding1D", "Linear1D_Col", "Linear1D_Row", 'GPT2FusedLinearConv1D_Col',
'GPT2FusedLinearConv1D_Row', 'DropoutForParallelInput', 'DropoutForReplicatedInput', "cross_entropy_1d",
- 'FusedLayerNorm', 'FusedRMSNorm'
+ 'FusedLayerNorm', 'FusedRMSNorm', 'FusedLinear1D_Col', 'ParallelModule'
]
diff --git a/colossalai/shardformer/layer/embedding.py b/colossalai/shardformer/layer/embedding.py
index db39a457b7fd..847ca175ad57 100644
--- a/colossalai/shardformer/layer/embedding.py
+++ b/colossalai/shardformer/layer/embedding.py
@@ -1,7 +1,7 @@
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
-from typing import Callable, List, Union
+from typing import Callable, List, Optional, Union
import torch
import torch.distributed as dist
@@ -9,11 +9,16 @@
import torch.nn.functional as F
from torch import Tensor
from torch.distributed import ProcessGroup
-from torch.nn.parameter import Parameter
+from colossalai.lazy import LazyInitContext
from colossalai.nn import init as init
from colossalai.nn.layer.utils import divide
-from colossalai.tensor.d_tensor.api import shard_colwise, shard_rowwise, sharded_tensor_to_param
+from colossalai.tensor.d_tensor.api import (
+ is_distributed_tensor,
+ shard_colwise,
+ shard_rowwise,
+ sharded_tensor_to_existing_param,
+)
from ._operation import gather_forward_split_backward, reduce_forward
from .parallel_module import ParallelModule
@@ -60,6 +65,7 @@ def __init__(self,
device: torch.device = None,
process_group: ProcessGroup = None,
gather_output: bool = True,
+ weight: Optional[nn.Parameter] = None,
weight_initializer: Callable = init.normal_(),
*args,
**kwargs):
@@ -74,18 +80,24 @@ def __init__(self,
self.embed_kwargs = kwargs
self.gather_output = gather_output
- # Parameters.
- factory_kwargs = {'device': device, 'dtype': dtype}
- weight = torch.empty((num_embeddings, self.embedding_dim), **factory_kwargs)
- sharded_weight = shard_colwise(weight, process_group)
- self.weight = sharded_tensor_to_param(sharded_weight)
-
# offset the seed with randomizer index and rank
seed = torch.random.initial_seed()
self.randomizer = create_randomizer_with_offset(seed, process_group=self.process_group)
- with self.randomizer.fork_rng(enable_cpu=True):
- self.reset_parameters(weight_initializer)
+ # Parameters.
+ if weight is None:
+ factory_kwargs = {'device': device, 'dtype': dtype}
+ self.weight = nn.Parameter(torch.empty((num_embeddings, self.embedding_dim), **factory_kwargs))
+ else:
+ weight.data = weight.data.to(device=device, dtype=dtype)
+ self.weight = weight
+ if not is_distributed_tensor(self.weight):
+ sharded_weight = shard_colwise(self.weight.data, process_group)
+ sharded_tensor_to_existing_param(sharded_weight, self.weight)
+
+ if weight is None:
+ with self.randomizer.fork_rng(enable_cpu=True):
+ self.reset_parameters(weight_initializer)
@staticmethod
def from_native_module(module: nn.Embedding,
@@ -95,6 +107,7 @@ def from_native_module(module: nn.Embedding,
r"""
Build a 1D parallelized Embedding from a native nn.Embedding module.
"""
+ LazyInitContext.materialize(module)
# get the attributes
num_embedding = module.num_embeddings
embedding_dim = module.embedding_dim
@@ -120,14 +133,10 @@ def from_native_module(module: nn.Embedding,
norm_type=norm_type,
scale_grad_by_freq=scale_grad_by_freq,
sparse=sparse,
+ weight=module.weight,
*args,
**kwargs)
- # copy the weight
- with torch.no_grad():
- sharded_weight = shard_colwise(module.weight.data, process_group)
- embedding.weight.copy_(sharded_weight)
-
return embedding
def reset_parameters(self, weight_initializer) -> None:
@@ -142,7 +151,6 @@ def _fill_padding_idx_with_zero(self) -> None:
def forward(self, input_: Tensor) -> Tensor:
output_parallel = F.embedding(input_, self.weight, self.padding_idx, *self.embed_args, **self.embed_kwargs)
-
if self.gather_output:
output = gather_forward_split_backward(output_parallel, dim=-1, process_group=self.process_group)
return output
@@ -187,13 +195,13 @@ def __init__(self,
dtype: torch.dtype = None,
device: torch.device = None,
process_group: ProcessGroup = None,
+ weight: Optional[nn.Parameter] = None,
weight_initializer: Callable = init.normal_(),
*args,
**kwargs):
super().__init__()
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
- self.padding_idx = padding_idx
self.embed_args = args
self.embed_kwargs = kwargs
self.process_group = process_group
@@ -206,16 +214,26 @@ def __init__(self,
self.vocab_start_index = tensor_parallel_rank * self.num_embeddings_per_partition
self.vocab_end_index = self.vocab_start_index + self.num_embeddings_per_partition
- # parameter
- factory_kwargs = {'device': device, 'dtype': dtype}
- weight = torch.empty((num_embeddings, self.embedding_dim), **factory_kwargs)
- sharded_weight = shard_rowwise(weight, process_group)
- self.weight = sharded_tensor_to_param(sharded_weight)
+ # padding index
+ self.padding_idx = self._select_padding_idx(padding_idx)
# offset the seed with randomizer index and rank
seed = torch.random.initial_seed()
self.randomizer = create_randomizer_with_offset(seed, process_group=self.process_group)
- self.reset_parameters(weight_initializer)
+
+ # parameter
+ if weight is None:
+ factory_kwargs = {'device': device, 'dtype': dtype}
+ self.weight = nn.Parameter(torch.empty((num_embeddings, self.embedding_dim), **factory_kwargs))
+ else:
+ weight.data = weight.data.to(device=device, dtype=dtype)
+ self.weight = weight
+ if not is_distributed_tensor(self.weight):
+ sharded_weight = shard_rowwise(self.weight.data, process_group)
+ sharded_tensor_to_existing_param(sharded_weight, self.weight)
+
+ if weight is None:
+ self.reset_parameters(weight_initializer)
@staticmethod
def from_native_module(module: nn.Embedding, process_group: Union[ProcessGroup, List[ProcessGroup]], *args,
@@ -223,6 +241,7 @@ def from_native_module(module: nn.Embedding, process_group: Union[ProcessGroup,
r"""
Convert a native pytorch embedding module to a parallel module.
"""
+ LazyInitContext.materialize(module)
# get the origin attributes
num_embeddings = module.num_embeddings
embedding_dim = module.embedding_dim
@@ -241,13 +260,9 @@ def from_native_module(module: nn.Embedding, process_group: Union[ProcessGroup,
padding_idx=padding_idx,
device=device,
process_group=process_group,
+ weight=module.weight,
*args,
**kwargs)
- with torch.no_grad():
- # shard and slice the weight along the vocabulary(num_embeddings) dimension
- # the shape of the weight is (num_embeddings, embedding_dim)
- shard_weight = shard_rowwise(module.weight.data, process_group)
- vocab_embedding_1d.weight.data.copy_(shard_weight)
return vocab_embedding_1d
@@ -263,6 +278,15 @@ def _fill_padding_idx_with_zero(self) -> None:
with torch.no_grad():
self.weight[self.padding_idx - self.vocab_start_index].fill_(0)
+ def _select_padding_idx(self, padding_idx: int):
+ # select padding index according to the rank
+ if padding_idx is None:
+ return None
+ elif padding_idx < self.vocab_end_index and padding_idx >= self.vocab_start_index:
+ return padding_idx - self.vocab_start_index
+ else:
+ return None
+
def forward(self, input_: Tensor) -> Tensor:
# Build the mask.
input_mask = (input_ < self.vocab_start_index) | (input_ >= self.vocab_end_index)
diff --git a/colossalai/shardformer/layer/linear.py b/colossalai/shardformer/layer/linear.py
index 26ba5883c64f..d59b68ce4480 100644
--- a/colossalai/shardformer/layer/linear.py
+++ b/colossalai/shardformer/layer/linear.py
@@ -2,7 +2,7 @@
# -*- encoding: utf-8 -*-
import math
-from typing import Callable, List, Tuple, Union
+from typing import Callable, List, Optional, Tuple, Union
import torch
import torch.distributed as dist
@@ -12,9 +12,15 @@
from torch.distributed import ProcessGroup
from torch.nn.parameter import Parameter
+from colossalai.lazy import LazyInitContext
from colossalai.nn import init as init
from colossalai.nn.layer.utils import divide
-from colossalai.tensor.d_tensor import shard_colwise, shard_rowwise, sharded_tensor_to_param
+from colossalai.tensor.d_tensor.api import (
+ is_distributed_tensor,
+ shard_colwise,
+ shard_rowwise,
+ sharded_tensor_to_existing_param,
+)
from ._operation import (
gather_forward_split_backward,
@@ -64,6 +70,8 @@ def __init__(self,
process_group: ProcessGroup = None,
gather_output: bool = False,
skip_bias_add: bool = False,
+ weight: Optional[Parameter] = None,
+ bias_: Optional[Parameter] = None,
weight_initializer: Callable = init.kaiming_uniform_(a=math.sqrt(5)),
bias_initializer: Callable = init.xavier_uniform_(a=1, scale=1)):
super().__init__()
@@ -79,26 +87,42 @@ def __init__(self,
if skip_bias_add and not bias:
raise ValueError('cannot skip bias addition if bias is None')
- # Parameters.
- factory_kwargs = {'device': device, 'dtype': dtype}
+ # offset the seed with randomizer index and rank
+ seed = torch.random.initial_seed()
+ self.randomizer = create_randomizer_with_offset(seed, process_group=self.process_group)
- weight = torch.empty(self.out_features, self.in_features, **factory_kwargs)
- sharded_weight = shard_rowwise(weight, self.process_group)
- self.weight = sharded_tensor_to_param(sharded_weight)
+ # sanity check
+ if weight is not None:
+ assert not bias or bias_ is not None, 'bias_ must be provided if bias is True when weight is not None'
+ else:
+ assert bias_ is None, 'bias_ must be None if weight is None'
+
+ # Parameters.
+ if weight is None:
+ factory_kwargs = {'device': device, 'dtype': dtype}
+ self.weight = Parameter(torch.empty(self.out_features, self.in_features, **factory_kwargs))
+ else:
+ weight.data = weight.data.to(device=device, dtype=dtype)
+ self.weight = weight
+ if not is_distributed_tensor(self.weight):
+ sharded_weight = shard_rowwise(self.weight.data, self.process_group)
+ sharded_tensor_to_existing_param(sharded_weight, self.weight)
if bias:
- bias = torch.empty(self.out_features, **factory_kwargs)
- sharded_bias = shard_colwise(bias, self.process_group)
- self.bias = sharded_tensor_to_param(sharded_bias)
+ if bias_ is None:
+ self.bias = Parameter(torch.empty(self.out_features, **factory_kwargs))
+ else:
+ bias_.data = bias_.data.to(device=device, dtype=dtype)
+ self.bias = bias_
+ if not is_distributed_tensor(self.bias):
+ sharded_bias = shard_colwise(self.bias.data, self.process_group)
+ sharded_tensor_to_existing_param(sharded_bias, self.bias)
else:
self.bias = None
- # offset the seed with randomizer index and rank
- seed = torch.random.initial_seed()
- self.randomizer = create_randomizer_with_offset(seed, process_group=self.process_group)
-
- # init weights
- self.reset_parameters(weight_initializer, bias_initializer)
+ if weight is None:
+ # init weights
+ self.reset_parameters(weight_initializer, bias_initializer)
@staticmethod
def from_native_module(module: nn.Linear, process_group: Union[ProcessGroup, List[ProcessGroup]], *args,
@@ -106,6 +130,7 @@ def from_native_module(module: nn.Linear, process_group: Union[ProcessGroup, Lis
r"""
Convert a native PyTorch linear layer to a parallelized linear layer.
"""
+ LazyInitContext.materialize(module)
# get the attributes
in_features = module.in_features
out_features = module.out_features
@@ -118,22 +143,24 @@ def from_native_module(module: nn.Linear, process_group: Union[ProcessGroup, Lis
f'Expected only one process group, got {len(process_group)}.'
process_group = process_group[0]
+ tp_size = dist.get_world_size(process_group)
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!")
+
linear_1d = Linear1D_Col(in_features=in_features,
out_features=out_features,
bias=bias,
device=device,
process_group=process_group,
+ weight=module.weight,
+ bias_=module.bias,
*args,
**kwargs)
- with torch.no_grad():
- # the weigh to the linear layer is a transpose
- # thus shard on row is equal to shard on column
- sharded_weight = shard_rowwise(module.weight.data, process_group)
- linear_1d.weight.data.copy_(sharded_weight)
- if bias:
- sharded_bias = shard_colwise(module.bias.data, process_group)
- linear_1d.bias.copy_(sharded_bias)
return linear_1d
def reset_parameters(self, weight_initializer, bias_initializer) -> None:
@@ -196,6 +223,8 @@ def __init__(self,
process_group: ProcessGroup = None,
parallel_input: bool = True,
skip_bias_add: bool = False,
+ weight: Optional[Parameter] = None,
+ bias_: Optional[Parameter] = None,
weight_initializer: Callable = init.kaiming_uniform_(a=math.sqrt(5)),
bias_initializer: Callable = init.xavier_uniform_(a=1, scale=1),
stream_chunk_num: int = 1):
@@ -214,27 +243,44 @@ def __init__(self,
if skip_bias_add and not bias:
raise ValueError('cannot skip bias addition if bias is None')
+ # offset the seed with randomizer index and rank
+ seed = torch.random.initial_seed()
+ self.randomizer = create_randomizer_with_offset(seed, process_group=self.process_group)
+
+ # sanity check
+ if weight is not None:
+ assert not bias or bias_ is not None, 'bias_ must be provided if bias is True when weight is not None'
+ else:
+ assert bias_ is None, 'bias_ must be None if weight is None'
+
# Parameters.
- # Initialize weight.
- factory_kwargs = {'device': device, 'dtype': dtype}
- weight = torch.empty(self.out_features, self.in_features, **factory_kwargs)
- sharded_weight = shard_colwise(weight, self.process_group)
- self.weight = sharded_tensor_to_param(sharded_weight)
+ if weight is None:
+ # Initialize weight.
+ factory_kwargs = {'device': device, 'dtype': dtype}
+ self.weight = Parameter(torch.empty(self.out_features, self.in_features, **factory_kwargs))
+ else:
+ weight.data = weight.data.to(device=device, dtype=dtype)
+ self.weight = weight
+ if not is_distributed_tensor(self.weight):
+ sharded_weight = shard_colwise(self.weight.data, self.process_group)
+ sharded_tensor_to_existing_param(sharded_weight, self.weight)
if self.stream_chunk_num > 1:
# TODO() work for inference only
self.chunk_weight()
+
if bias:
- self.bias = Parameter(torch.empty(self.out_features, **factory_kwargs))
+ if bias_ is None:
+ self.bias = Parameter(torch.empty(self.out_features, **factory_kwargs))
+ else:
+ bias_.data = bias_.data.to(device=device, dtype=dtype)
+ self.bias = bias_
else:
self.bias = None
- # offset the seed with randomizer index and rank
- seed = torch.random.initial_seed()
- self.randomizer = create_randomizer_with_offset(seed, process_group=self.process_group)
-
- with self.randomizer.fork_rng(enable_cpu=True):
- self.reset_parameters(weight_initializer, bias_initializer)
+ if weight is None:
+ with self.randomizer.fork_rng(enable_cpu=True):
+ self.reset_parameters(weight_initializer, bias_initializer)
@staticmethod
def from_native_module(module: nn.Linear, process_group: Union[ProcessGroup, List[ProcessGroup]], *args,
@@ -242,6 +288,7 @@ def from_native_module(module: nn.Linear, process_group: Union[ProcessGroup, Lis
r"""
Convert a native PyTorch linear layer to a parallelized linear layer.
"""
+ LazyInitContext.materialize(module)
# get the attributes
in_features = module.in_features
out_features = module.out_features
@@ -254,24 +301,24 @@ def from_native_module(module: nn.Linear, process_group: Union[ProcessGroup, Lis
f'Expected only one process group, got {len(process_group)}.'
process_group = process_group[0]
+ tp_size = dist.get_world_size(process_group)
+ if in_features < tp_size:
+ return module
+
+ if in_features % tp_size != 0:
+ raise ValueError(
+ f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!")
+
linear_1d = Linear1D_Row(in_features=in_features,
out_features=out_features,
bias=bias,
device=device,
process_group=process_group,
+ weight=module.weight,
+ bias_=module.bias,
*args,
**kwargs)
- # TODO: copy the sharded weights
- with torch.no_grad():
- # the weigh to the linear layer is a transpose
- # thus shard on col is equal to shard on row
- sharded_weight = shard_colwise(module.weight.data, process_group)
- linear_1d.weight.data.copy_(sharded_weight)
-
- if bias:
- linear_1d.bias.copy_(module.bias.data)
-
return linear_1d
def chunk_weight(self):
diff --git a/colossalai/shardformer/layer/normalization.py b/colossalai/shardformer/layer/normalization.py
index b27307154a76..0aea295664a7 100644
--- a/colossalai/shardformer/layer/normalization.py
+++ b/colossalai/shardformer/layer/normalization.py
@@ -4,6 +4,8 @@
import torch
import torch.nn as nn
+from colossalai.lazy import LazyInitContext
+
__all__ = ['FusedLayerNorm', 'FusedRMSNorm']
FAST_LAYERNORM_SUPPORTED_SIZE = [
@@ -35,6 +37,7 @@ def from_native_module(module: nn.LayerNorm, *args, **kwargs) -> nn.Module:
raise ImportError(
'Please install apex from source (https://github.com/NVIDIA/apex) to use the fused layernorm kernel')
+ LazyInitContext.materialize(module)
# get the attributes of the module
normalized_shape = module.normalized_shape
eps = module.eps
@@ -57,10 +60,8 @@ def from_native_module(module: nn.LayerNorm, *args, **kwargs) -> nn.Module:
layernorm = ApexFusedLayerNorm(normalized_shape, eps=eps,
elementwise_affine=elementwise_affine).to(dtype).to(device)
- with torch.no_grad():
- # copy weight and bias
- layernorm.weight.copy_(module.weight)
- layernorm.bias.copy_(module.bias)
+ layernorm.weight = module.weight
+ layernorm.bias = module.bias
return layernorm
@@ -84,6 +85,7 @@ def from_native_module(module: nn.Module, *args, **kwargs) -> nn.Module:
'Please install apex from source (https://github.com/NVIDIA/apex) to use the fused RMS normalization kernel'
)
+ LazyInitContext.materialize(module)
# to check if it is huggingface LlamaRMSNorm
if module.__class__.__name__ == "LlamaRMSNorm":
normalized_shape = module.weight.shape[0]
@@ -97,8 +99,6 @@ def from_native_module(module: nn.Module, *args, **kwargs) -> nn.Module:
rmsnorm = ApexFusedRMSNorm(normalized_shape=normalized_shape, eps=eps, elementwise_affine=elementwise_affine)
- with torch.no_grad():
- # copy weight and bias
- rmsnorm.weight.copy_(module.weight)
+ rmsnorm.weight = module.weight
return rmsnorm
diff --git a/colossalai/shardformer/layer/qkv_fused_linear.py b/colossalai/shardformer/layer/qkv_fused_linear.py
index 9d51670c65dd..df942d43ee2d 100644
--- a/colossalai/shardformer/layer/qkv_fused_linear.py
+++ b/colossalai/shardformer/layer/qkv_fused_linear.py
@@ -2,27 +2,30 @@
# -*- encoding: utf-8 -*-
import math
-from typing import Callable, List, Tuple, Union
+from typing import Callable, List, Optional, Tuple, Union
import torch
import torch.distributed as dist
import torch.nn as nn
-import torch.nn.functional as F
from torch import Tensor
from torch.distributed import ProcessGroup
from torch.nn.parameter import Parameter
+from colossalai.lazy import LazyInitContext
from colossalai.nn import init as init
from colossalai.nn.layer.utils import divide
from colossalai.tensor.d_tensor.api import (
- customized_distributed_tensor_to_param,
+ customized_distributed_tensor_to_existing_param,
distribute_tensor_with_customization,
+ is_customized_distributed_tensor,
+ is_distributed_tensor,
shard_rowwise,
- sharded_tensor_to_param,
+ sharded_tensor_to_existing_param,
)
from ._operation import (
gather_forward_split_backward,
+ linear_with_async_comm,
matmul_with_async_comm,
reduce_backward,
reduce_forward,
@@ -31,7 +34,7 @@
from .parallel_module import ParallelModule
from .utils import create_randomizer_with_offset
-__all__ = ['FusedLinear1D_Col', 'FusedLinear1D_Row']
+__all__ = ['FusedLinear1D_Col', 'FusedLinear1D_Row', 'GPT2FusedLinearConv1D_Col', 'GPT2FusedLinearConv1D_Row']
# ====================================
# For GPT Only
@@ -172,6 +175,8 @@ def __init__(self,
gather_output: bool = False,
skip_bias_add: bool = False,
n_fused: int = 3,
+ weight: Optional[Parameter] = None,
+ bias_: Optional[Parameter] = None,
weight_initializer: Callable = init.kaiming_uniform_(a=math.sqrt(5)),
bias_initializer: Callable = init.xavier_uniform_(a=1, scale=1)):
super().__init__()
@@ -189,40 +194,56 @@ def __init__(self,
if skip_bias_add and not bias:
raise ValueError('cannot skip bias addition if bias is None')
+ # offset the seed with randomizer index and rank
+ seed = torch.random.initial_seed()
+ self.randomizer = create_randomizer_with_offset(seed, process_group=self.process_group)
+
+ # sanity check
+ if weight is not None:
+ assert not bias or bias_ is not None, 'bias_ must be provided if bias is True when weight is not None'
+ else:
+ assert bias_ is None, 'bias_ must be None if weight is None'
+
# Parameters.
- # Initialize weight.
- factory_kwargs = {'device': device, 'dtype': dtype}
- weight = torch.empty(self.in_features, self.out_features, **factory_kwargs)
+ if weight is None:
+ # Initialize weight.
+ factory_kwargs = {'device': device, 'dtype': dtype}
+ self.weight = Parameter(torch.empty(self.in_features, self.out_features, **factory_kwargs))
+ else:
+ weight.data = weight.data.to(device=device, dtype=dtype)
+ self.weight = weight
def shard_fn(tensor):
return split_fused_qkv_in_gpt2_style(tensor, self.n_fused, self.process_group, True)
def gather_fn(tensor):
- return gather_fused_qkv_in_gpt2_style(tensor, 3, self.process_group, True)
+ return gather_fused_qkv_in_gpt2_style(tensor, self.n_fused, self.process_group, True)
- with torch.no_grad():
- sharded_weight = distribute_tensor_with_customization(weight, shard_fn, gather_fn)
- self.weight = customized_distributed_tensor_to_param(sharded_weight)
+ if not is_customized_distributed_tensor(self.weight):
+ with torch.no_grad():
+ sharded_weight = distribute_tensor_with_customization(self.weight.data, shard_fn, gather_fn)
+ customized_distributed_tensor_to_existing_param(sharded_weight, self.weight)
if bias:
- bias = torch.empty(self.out_features, **factory_kwargs)
-
- with torch.no_grad():
- sharded_bias = distribute_tensor_with_customization(bias, shard_fn, gather_fn)
- self.bias = customized_distributed_tensor_to_param(sharded_bias)
+ if bias_ is None:
+ self.bias = Parameter(torch.empty(self.out_features, **factory_kwargs))
+ else:
+ bias_.data = bias_.data.to(device=device, dtype=dtype)
+ self.bias = bias_
+ if not is_customized_distributed_tensor(self.bias):
+ with torch.no_grad():
+ sharded_bias = distribute_tensor_with_customization(self.bias.data, shard_fn, gather_fn)
+ customized_distributed_tensor_to_existing_param(sharded_bias, self.bias)
else:
self.bias = None
- # offset the seed with randomizer index and rank
- seed = torch.random.initial_seed()
- self.randomizer = create_randomizer_with_offset(seed, process_group=self.process_group)
-
- # init weights
- self.reset_parameters(weight_initializer, bias_initializer)
+ if weight is None:
+ # init weights
+ self.reset_parameters(weight_initializer, bias_initializer)
@staticmethod
- def from_native_module(module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], n_fused: int,
- *args, **kwargs) -> ParallelModule:
+ def from_native_module(module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args,
+ **kwargs) -> ParallelModule:
r"""
Convert a huggingface layer `Conv1D` in gpt2 to a parallelized linear layer.
@@ -231,6 +252,7 @@ def from_native_module(module: nn.Module, process_group: Union[ProcessGroup, Lis
process_group (`Union[ProcessGroup, List[ProcessGroup]]`): The process group to be used for weight sharding and communication.
n_fused (int): The number of layers to be fused. In GPT2, Q,K,V are fused in one weight.
"""
+ LazyInitContext.materialize(module)
# get the attributes
in_features = module.weight.shape[0]
out_features = module.weight.shape[1]
@@ -243,29 +265,24 @@ def from_native_module(module: nn.Module, process_group: Union[ProcessGroup, Lis
f'Expected only one process group, got {len(process_group)}.'
process_group = process_group[0]
+ tp_size = dist.get_world_size(process_group)
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!")
+
linear_1d = GPT2FusedLinearConv1D_Col(in_features=in_features,
out_features=out_features,
bias=bias,
device=device,
process_group=process_group,
+ weight=module.weight,
+ bias_=module.bias,
*args,
**kwargs)
- # TODO: copy the sharded weights
- with torch.no_grad():
- sharded_weight = split_fused_qkv_in_gpt2_style(module.weight.data,
- n_fused=n_fused,
- process_group=process_group,
- is_transposed=True)
- linear_1d.weight.data.copy_(sharded_weight.data)
-
- if bias:
- sharded_bias = split_fused_qkv_in_gpt2_style(module.bias.data,
- n_fused=n_fused,
- process_group=process_group,
- is_transposed=True)
- linear_1d.bias.data.copy_(sharded_bias.data)
-
return linear_1d
def reset_parameters(self, weight_initializer, bias_initializer) -> None:
@@ -331,6 +348,8 @@ def __init__(self,
process_group: ProcessGroup = None,
parallel_input: bool = True,
skip_bias_add: bool = False,
+ weight: Optional[Parameter] = None,
+ bias_: Optional[Parameter] = None,
weight_initializer: Callable = init.kaiming_uniform_(a=math.sqrt(5)),
bias_initializer: Callable = init.xavier_uniform_(a=1, scale=1),
stream_chunk_num: int = 1):
@@ -349,30 +368,46 @@ def __init__(self,
if skip_bias_add and not bias:
raise ValueError('cannot skip bias addition if bias is None')
+ # offset the seed with randomizer index and rank
+ seed = torch.random.initial_seed()
+ self.randomizer = create_randomizer_with_offset(seed, process_group=self.process_group)
+
# Divide the weight matrix along the last dimension.
self.input_size_per_partition = divide(in_features, self.num_partitions)
+ # sanity check
+ if weight is not None:
+ assert not bias or bias_ is not None, 'bias_ must be provided if bias is True when weight is not None'
+ else:
+ assert bias_ is None, 'bias_ must be None if weight is None'
+
# Parameters.
- # Initialize weight.
- factory_kwargs = {'device': device, 'dtype': dtype}
- weight = torch.empty(self.in_features, self.out_features, **factory_kwargs)
- sharded_weight = shard_rowwise(weight, self.process_group)
- self.weight = sharded_tensor_to_param(sharded_weight)
+ if weight is None:
+ # Initialize weight.
+ factory_kwargs = {'device': device, 'dtype': dtype}
+ self.weight = Parameter(torch.empty(self.in_features, self.out_features, **factory_kwargs))
+ else:
+ weight.data = weight.data.to(device=device, dtype=dtype)
+ self.weight = weight
+ if not is_distributed_tensor(self.weight):
+ sharded_weight = shard_rowwise(self.weight.data, self.process_group)
+ sharded_tensor_to_existing_param(sharded_weight, self.weight)
if self.stream_chunk_num > 1:
# TODO() work for inference only
self.chunk_weight()
if bias:
- self.bias = Parameter(torch.empty(self.out_features, **factory_kwargs))
+ if bias_ is None:
+ self.bias = Parameter(torch.empty(self.out_features, **factory_kwargs))
+ else:
+ bias_.data = bias_.data.to(device=device, dtype=dtype)
+ self.bias = bias_
else:
self.bias = None
- # offset the seed with randomizer index and rank
- seed = torch.random.initial_seed()
- self.randomizer = create_randomizer_with_offset(seed, process_group=self.process_group)
-
- # init weights
- self.reset_parameters(weight_initializer, bias_initializer)
+ if weight is None:
+ # init weights
+ self.reset_parameters(weight_initializer, bias_initializer)
@staticmethod
def from_native_module(module: nn.Linear, process_group: Union[ProcessGroup, List[ProcessGroup]], *args,
@@ -380,6 +415,7 @@ def from_native_module(module: nn.Linear, process_group: Union[ProcessGroup, Lis
r"""
Convert a native PyTorch linear layer to a parallelized linear layer.
"""
+ LazyInitContext.materialize(module)
# get the attributes
in_features = module.weight.shape[0]
out_features = module.weight.shape[1]
@@ -392,24 +428,24 @@ def from_native_module(module: nn.Linear, process_group: Union[ProcessGroup, Lis
f'Expected only one process group, got {len(process_group)}.'
process_group = process_group[0]
+ tp_size = dist.get_world_size(process_group)
+ if in_features < tp_size:
+ return module
+
+ if in_features % tp_size != 0:
+ raise ValueError(
+ f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!")
+
linear_1d = GPT2FusedLinearConv1D_Row(in_features=in_features,
out_features=out_features,
bias=bias,
device=device,
process_group=process_group,
+ weight=module.weight,
+ bias_=module.bias,
*args,
**kwargs)
- # TODO: copy the sharded weights
- with torch.no_grad():
- # the weigh to the linear layer is a transpose
- # thus shard on col is equal to shard on row
- sharded_weight = shard_rowwise(module.weight.data, process_group)
- linear_1d.weight.data.copy_(sharded_weight.data)
-
- if bias:
- linear_1d.bias.copy_(module.bias.data)
-
return linear_1d
def chunk_weight(self):
@@ -428,21 +464,21 @@ def reset_parameters(self, weight_initializer, bias_initializer) -> None:
src_rank = dist.distributed_c10d._get_global_rank(self.process_group, 0)
origin_device = self.bias.device
- self.bias = self.bias.cuda()
+ self.bias.data = self.bias.cuda()
dist.broadcast(self.bias, src=src_rank, group=self.process_group)
- self.bias = self.bias.to(origin_device)
+ self.bias.data = self.bias.to(origin_device)
def forward(self, input_: Tensor) -> Tensor:
# Set up backprop all-reduce.
if self.parallel_input:
assert input_.shape[-1] == self.weight.shape[0], \
'Invalid shapes in Linear1D_Row forward: input={}, weight={}. Expected last dim of input {}.'.format(
- input_.shape, self.weight.shape, self.weight.shape[-1])
+ input_.shape, self.weight.shape, self.weight.shape[0])
input_ = input_
else:
assert divide(input_.shape[-1], self.num_partitions) == self.weight.shape[0], \
'Invalid shapes in Linear1D_Row forward: input={}, weight={}. Expected last dim of input {}.'.format(
- input_.shape, self.weight.shape, self.weight.shape[-1] * self.num_partitions)
+ input_.shape, self.weight.shape, self.weight.shape[0] * self.num_partitions)
input_ = split_forward_gather_backward(input_, dim=-1, process_group=self.process_group)
if self.stream_chunk_num > 1:
@@ -471,3 +507,194 @@ def forward(self, input_: Tensor) -> Tensor:
return output
else:
return output, self.bias
+
+
+# ====================================
+# For Fused torch.nn.Linear
+# ====================================
+
+
+class FusedLinear1D_Col(ParallelModule):
+ r"""Fused Linear layer with column parallelism.
+
+ The linear layer is defined as :math:`Y = XA + b`. A is parallelized along
+ its second dimension as :math:`A = [A_1, ..., A_p]`. This layer is used to fit `torch.nn.Linear` layer (Fused QKV) in normal torch layer of huggingface, like SAM.
+
+ Args:
+ in_features (int): size of each input sample.
+ out_features (int): size of each output sample.
+ bias (bool, optional): If set to ``False``, the layer will not learn an additive bias, defaults to ``True``.
+ dtype (`torch.dtype`): The dtype of parameters, defaults to None.
+ device (`torch.device`): The device of parameters, defaults to None.
+ n_fused (int): The number items fused, defaults to 3 (QKV).
+ process_group (`torch.distributed.ProcessGroup`): The process group to be used for weight sharding and communication, defaults to None.
+ gather_output (bool, optional): If true, call all-gather on output and make Y available
+ to all GPUs, otherwise, every GPU will have its output
+ which is :math:`Y_i = XA_i`, defaults to False
+ skip_bias_add (bool): If set to ``True``, it will skip bias add for linear layer,
+ which is preserved for kernel fusion, defaults to False
+ weight_initializer (`typing.Callable`):
+ The initializer of weight, defaults to kaiming uniform initializer.
+ bias_initializer (`typing.Callable`):
+ The initializer of bias, defaults to xavier uniform initializer.
+
+ More details about ``initializer`` please refer to
+ `init `_.
+ """
+
+ def __init__(self,
+ in_features: int,
+ out_features: int,
+ bias: bool = True,
+ dtype: torch.dtype = None,
+ device: torch.device = None,
+ process_group: ProcessGroup = None,
+ async_communication: bool = False,
+ gather_output: bool = False,
+ skip_bias_add: bool = False,
+ n_fused: int = 3,
+ weight: Optional[Parameter] = None,
+ bias_: Optional[Parameter] = None,
+ weight_initializer: Callable = init.kaiming_uniform_(a=math.sqrt(5)),
+ bias_initializer: Callable = init.xavier_uniform_(a=1, scale=1)):
+ super().__init__()
+ # Keep input parameters
+ self.in_features = in_features
+ self.out_features = out_features
+ self.gather_output = gather_output
+ self.skip_bias_add = skip_bias_add
+ self.device = device
+ self.n_fused = n_fused
+ self.process_group = process_group
+ self.async_communication = async_communication
+
+ if skip_bias_add and not bias:
+ raise ValueError('cannot skip bias addition if bias is None')
+
+ # offset the seed with randomizer index and rank
+ seed = torch.random.initial_seed()
+ self.randomizer = create_randomizer_with_offset(seed, process_group=self.process_group)
+
+ # sanity check
+ if weight is not None:
+ assert not bias or bias_ is not None, 'bias_ must be provided if bias is True when weight is not None'
+ else:
+ assert bias_ is None, 'bias_ must be None if weight is None'
+
+ # Parameters.
+ if weight is None:
+ # Initialize weight.
+ factory_kwargs = {'device': device, 'dtype': dtype}
+ self.weight = Parameter(torch.empty(self.out_features, self.in_features, **factory_kwargs))
+ else:
+ weight.data = weight.data.to(device=device, dtype=dtype)
+ self.weight = weight
+
+ def shard_fn(tensor):
+ return split_fused_qkv_in_gpt2_style(tensor, self.n_fused, self.process_group, False)
+
+ def gather_fn(tensor):
+ return gather_fused_qkv_in_gpt2_style(tensor, self.n_fused, self.process_group, False)
+
+ if not is_customized_distributed_tensor(self.weight):
+ with torch.no_grad():
+ sharded_weight = distribute_tensor_with_customization(self.weight.data, shard_fn, gather_fn)
+ customized_distributed_tensor_to_existing_param(sharded_weight, self.weight)
+
+ if bias:
+ if bias_ is None:
+ self.bias = Parameter(torch.empty(self.out_features, **factory_kwargs))
+ else:
+ bias_.data = bias_.data.to(device=device, dtype=dtype)
+ self.bias = bias_
+ if not is_customized_distributed_tensor(self.bias):
+ with torch.no_grad():
+ sharded_bias = distribute_tensor_with_customization(self.bias.data, shard_fn, gather_fn)
+ customized_distributed_tensor_to_existing_param(sharded_bias, self.bias)
+ else:
+ self.bias = None
+
+ if weight is None:
+ # init weights
+ self.reset_parameters(weight_initializer, bias_initializer)
+
+ @staticmethod
+ def from_native_module(module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], n_fused: int,
+ *args, **kwargs) -> ParallelModule:
+ r"""
+ Convert a fused `torch.nn.linear` layer to a parallelized linear layer.
+
+ Args:
+ module (`nn.Linear`): The module to be converted.
+ process_group (`Union[ProcessGroup, List[ProcessGroup]]`): The process group to be used for weight sharding and communication.
+ n_fused (int): The number of layers to be fused. In common, Q,K,V are fused in one weight.
+ """
+ # get the attributes
+ in_features = module.in_features
+ out_features = module.out_features
+ bias = module.bias is not None
+ device = module.weight.device
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, \
+ f'Expected only one process group, got {len(process_group)}.'
+ process_group = process_group[0]
+
+ linear_1d = FusedLinear1D_Col(in_features=in_features,
+ out_features=out_features,
+ bias=bias,
+ device=device,
+ process_group=process_group,
+ weight=module.weight,
+ bias_=module.bias,
+ *args,
+ **kwargs)
+
+ # # TODO: copy the sharded weights
+ # with torch.no_grad():
+ # sharded_weight = split_fused_qkv_in_gpt2_style(module.weight.data,
+ # n_fused=n_fused,
+ # process_group=process_group,
+ # is_transposed=False)
+ # linear_1d.weight.data.copy_(sharded_weight.data)
+
+ # if bias:
+ # sharded_bias = split_fused_qkv_in_gpt2_style(module.bias.data,
+ # n_fused=n_fused,
+ # process_group=process_group,
+ # is_transposed=False)
+ # linear_1d.bias.data.copy_(sharded_bias.data)
+ print(linear_1d.weight.shape)
+ return linear_1d
+
+ def reset_parameters(self, weight_initializer, bias_initializer) -> None:
+ with self.randomizer.fork_rng(enable_cpu=True):
+ fan_in, fan_out = self.in_features, self.out_features
+ weight_initializer(self.weight, fan_in=fan_in, fan_out=fan_out)
+ if self.bias is not None:
+ bias_initializer(self.bias, fan_in=fan_in)
+
+ def forward(self, input_: Tensor) -> Tuple[Tensor, Tensor]:
+ assert input_.shape[-1] == self.weight.shape[-1], \
+ 'Invalid shapes in Linear1D_Col forward: input={}, weight={}. Expected last dim of input {}.'.format(
+ input_.shape, self.weight.shape, self.weight.shape[-1])
+ # Set up backprop all-reduce.
+ # input_parallel = reduce_backward(input_, self.process_group)
+ input_parallel = input_
+
+ # Matrix multiply.
+ bias = self.bias if not self.skip_bias_add else None
+
+ output_parallel = linear_with_async_comm(input_parallel, self.weight, bias, self.process_group, True)
+
+ if self.gather_output:
+ # All-gather across the partitions.
+ output = gather_forward_split_backward(output_parallel, dim=-1, process_group=self.process_group)
+ else:
+ output = output_parallel
+
+ if self.skip_bias_add:
+ return output, self.bias
+ else:
+ return output
diff --git a/colossalai/shardformer/layer/utils.py b/colossalai/shardformer/layer/utils.py
index f2ac6563c46f..577bef076a7e 100644
--- a/colossalai/shardformer/layer/utils.py
+++ b/colossalai/shardformer/layer/utils.py
@@ -29,8 +29,6 @@ class Randomizer:
_INDEX = 0
def __init__(self, seed: int):
- # TODO: remove colossalai.context.random
-
self.seed = seed
# Handle CUDA rng state
@@ -122,6 +120,13 @@ def increment_index():
"""
Randomizer._INDEX += 1
+ @staticmethod
+ def reset_index():
+ """
+ Reset the index to zero.
+ """
+ Randomizer._INDEX = 0
+
@staticmethod
def is_randomizer_index_synchronized(process_group: ProcessGroup = None):
"""
diff --git a/colossalai/shardformer/modeling/bert.py b/colossalai/shardformer/modeling/bert.py
new file mode 100644
index 000000000000..5bd1c531cc68
--- /dev/null
+++ b/colossalai/shardformer/modeling/bert.py
@@ -0,0 +1,1103 @@
+import math
+import warnings
+from typing import Dict, List, Optional, Tuple
+
+import torch
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPoolingAndCrossAttentions,
+ CausalLMOutputWithCrossAttentions,
+ MaskedLMOutput,
+ MultipleChoiceModelOutput,
+ NextSentencePredictorOutput,
+ QuestionAnsweringModelOutput,
+ SequenceClassifierOutput,
+ TokenClassifierOutput,
+)
+from transformers.models.bert.modeling_bert import (
+ BertForMaskedLM,
+ BertForMultipleChoice,
+ BertForNextSentencePrediction,
+ BertForPreTraining,
+ BertForPreTrainingOutput,
+ BertForQuestionAnswering,
+ BertForSequenceClassification,
+ BertForTokenClassification,
+ BertLMHeadModel,
+ BertModel,
+)
+from transformers.utils import logging
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+
+class BertPipelineForwards:
+ '''
+ This class serves as a micro library for forward function substitution of Bert models
+ under pipeline setting.
+ '''
+
+ @staticmethod
+ def bert_model_forward(
+ self: BertModel,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None, # this is from the previous stage
+ stage_index: Optional[List[int]] = None,
+ ):
+ # TODO(jianghai): add explaination of the output here.
+ r"""
+ encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ """
+ logger = logging.get_logger(__name__)
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if self.config.is_decoder:
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ else:
+ use_cache = False
+
+ if stage_manager.is_first_stage():
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ input_shape = input_ids.size()
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+ batch_size, seq_length = input_shape
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ if token_type_ids is None:
+ if hasattr(self.embeddings, "token_type_ids"):
+ buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
+ else:
+ input_shape = hidden_states.size()[:-1]
+ batch_size, seq_length = input_shape
+ device = hidden_states.device
+
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once('use_cache=True is not supported for pipeline models at the moment.')
+ use_cache = False
+
+ # past_key_values_length
+ past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
+
+ if attention_mask is None:
+ attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device)
+
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
+ attention_mask = extended_attention_mask
+ # If a 2D or 3D attention mask is provided for the cross-attention
+ # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if self.config.is_decoder and encoder_hidden_states is not None:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
+ encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
+ if encoder_attention_mask is None:
+ encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
+ encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+ hidden_states = hidden_states if hidden_states is not None else None
+
+ if stage_manager.is_first_stage():
+ hidden_states = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ inputs_embeds=inputs_embeds,
+ past_key_values_length=past_key_values_length,
+ )
+
+ # inherit from bert_layer,this should be changed when we add the feature to record hidden_states
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
+
+ if self.encoder.gradient_checkpointing and self.encoder.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+ next_decoder_cache = () if use_cache else None
+
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ # layer_outputs
+ layer_outputs = hidden_states if hidden_states is not None else None
+ for idx, encoder_layer in enumerate(self.encoder.layer[start_idx:end_idx], start=start_idx):
+ if stage_manager.is_first_stage() and idx == 0:
+ encoder_attention_mask = encoder_extended_attention_mask
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[idx] if head_mask is not None else None
+ past_key_value = past_key_values[idx] if past_key_values is not None else None
+
+ if self.encoder.gradient_checkpointing and self.encoder.training:
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ return module(*inputs, past_key_value, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(encoder_layer),
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+ else:
+ layer_outputs = encoder_layer(
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ hidden_states = layer_outputs[0]
+ if use_cache:
+ next_decoder_cache += (layer_outputs[-1],)
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+ if self.config.add_cross_attention:
+ all_cross_attentions = all_cross_attentions + \
+ (layer_outputs[2],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ # end of a stage loop
+ sequence_output = layer_outputs[0] if layer_outputs is not None else None
+
+ if stage_manager.is_last_stage():
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+ if not return_dict:
+ return (sequence_output, pooled_output) + layer_outputs[1:]
+ # return dict is not supported at this moment
+ else:
+ return BaseModelOutputWithPoolingAndCrossAttentions(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+ # output of non-first and non-last stages: must be a dict
+ else:
+ # intermediate stage always return dict
+ return {
+ 'hidden_states': hidden_states,
+ }
+
+ @staticmethod
+ def bert_for_pretraining_forward(
+ self: BertForPreTraining,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ next_sentence_label: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ # TODO(jianghai) left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ outputs = BertPipelineForwards.bert_model_forward(
+ self.bert,
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states if hidden_states is not None else None,
+ stage_index=stage_index,
+ )
+ past_key_values = None
+ all_hidden_states = None
+ all_self_attentions = None
+ all_cross_attentions = None
+
+ if stage_manager.is_last_stage():
+ sequence_output, pooled_output = outputs[:2]
+ prediction_scores, seq_relationship_score = self.cls(sequence_output, pooled_output)
+ # the last stage for pretraining model
+ total_loss = None
+ if labels is not None and next_sentence_label is not None:
+ loss_fct = CrossEntropyLoss()
+ masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
+ next_sentence_loss = loss_fct(seq_relationship_score.view(-1, 2), next_sentence_label.view(-1))
+ total_loss = masked_lm_loss + next_sentence_loss
+
+ if not return_dict:
+ output = (prediction_scores, seq_relationship_score) + outputs[2:]
+ return ((total_loss,) + output) if total_loss is not None else output
+
+ return BertForPreTrainingOutput(
+ loss=total_loss,
+ prediction_logits=prediction_scores,
+ seq_relationship_logits=seq_relationship_score,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+
+ # intermediate stage always return dict
+ return {
+ 'hidden_states': hidden_states,
+ }
+
+ @staticmethod
+ def bert_lm_head_model_forward(
+ self: BertLMHeadModel,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.Tensor]] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ r"""
+ encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
+ `[-100, 0, ..., config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are
+ ignored (masked), the loss is only computed for the tokens with labels n `[0, ..., config.vocab_size]`
+ past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ """
+ logger = logging.get_logger(__name__)
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if labels is not None:
+ use_cache = False
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ outputs = BertPipelineForwards.bert_model_forward(
+ self.bert,
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states if hidden_states is not None else None,
+ stage_index=stage_index)
+ past_key_values = None
+ all_hidden_states = None
+ all_self_attentions = None
+ all_cross_attentions = None
+
+ if stage_manager.is_last_stage():
+ sequence_output = outputs[0]
+ prediction_scores = self.cls(sequence_output)
+
+ lm_loss = None
+ if labels is not None:
+ # we are doing next-token prediction; shift prediction scores and input ids by one
+ shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
+ labels = labels[:, 1:].contiguous()
+ loss_fct = CrossEntropyLoss()
+ lm_loss = loss_fct(shifted_prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
+
+ if not return_dict:
+ output = (prediction_scores,) + outputs[2:]
+ return ((lm_loss,) + output) if lm_loss is not None else output
+
+ return CausalLMOutputWithCrossAttentions(
+ loss=lm_loss,
+ logits=prediction_scores,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ cross_attentions=outputs.cross_attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+ # intermediate stage always return dict
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def bert_for_masked_lm_forward(
+ self: BertForMaskedLM,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.Tensor] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
+ config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
+ loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
+ """
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ outputs = BertPipelineForwards.bert_model_forward(
+ self.bert,
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ hidden_states=hidden_states,
+ stage_manager=stage_manager,
+ stage_index=stage_index,
+ )
+
+ if stage_manager.is_last_stage():
+ sequence_output = outputs[0]
+ prediction_scores = self.cls(sequence_output)
+
+ masked_lm_loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss() # -100 index = padding token
+ masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
+
+ if not return_dict:
+ output = (prediction_scores,) + outputs[2:]
+ return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
+
+ return MaskedLMOutput(
+ loss=masked_lm_loss,
+ logits=prediction_scores,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def bert_for_next_sentence_prediction_forward(
+ self: BertForNextSentencePrediction,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.Tensor] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ stage_index: Optional[List[int]] = None,
+ **kwargs,
+ ):
+ # -> Union[Tuple[torch.Tensor], NextSentencePredictorOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the next sequence prediction (classification) loss. Input should be a sequence pair
+ (see `input_ids` docstring). Indices should be in `[0, 1]`:
+
+ - 0 indicates sequence B is a continuation of sequence A,
+ - 1 indicates sequence B is a random sequence.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, BertForNextSentencePrediction
+ >>> import torch
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+ >>> model = BertForNextSentencePrediction.from_pretrained("bert-base-uncased")
+
+ >>> prompt = "In Italy, pizza served in formal settings, such as at a restaurant, is presented unsliced."
+ >>> next_sentence = "The sky is blue due to the shorter wavelength of blue light."
+ >>> encoding = tokenizer(prompt, next_sentence, return_tensors="pt")
+
+ >>> outputs = model(**encoding, labels=torch.LongTensor([1]))
+ >>> logits = outputs.logits
+ >>> assert logits[0, 0] < logits[0, 1] # next sentence was random
+ ```
+ """
+ logger = logging.get_logger(__name__)
+
+ if "next_sentence_label" in kwargs:
+ warnings.warn(
+ "The `next_sentence_label` argument is deprecated and will be removed in a future version, use"
+ " `labels` instead.",
+ FutureWarning,
+ )
+ labels = kwargs.pop("next_sentence_label")
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ outputs = BertPipelineForwards.bert_model_forward(self.bert,
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ hidden_states=hidden_states,
+ stage_manager=stage_manager,
+ stage_index=stage_index)
+
+ if stage_manager.is_last_stage():
+ pooled_output = outputs[1]
+ seq_relationship_scores = self.cls(pooled_output)
+
+ next_sentence_loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ next_sentence_loss = loss_fct(seq_relationship_scores.view(-1, 2), labels.view(-1))
+
+ if not return_dict:
+ output = (seq_relationship_scores,) + outputs[2:]
+ return ((next_sentence_loss,) + output) if next_sentence_loss is not None else output
+
+ return NextSentencePredictorOutput(
+ loss=next_sentence_loss,
+ logits=seq_relationship_scores,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+ # intermediate stage always return dict
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def bert_for_sequence_classification_forward(
+ self: BertForSequenceClassification,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.Tensor] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ outputs = BertPipelineForwards.bert_model_forward(self.bert,
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ hidden_states=hidden_states,
+ stage_manager=stage_manager,
+ stage_index=stage_index)
+
+ if stage_manager.is_last_stage():
+ pooled_output = outputs[1]
+
+ pooled_output = self.dropout(pooled_output)
+ logits = self.classifier(pooled_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def bert_for_token_classification_forward(
+ self: BertForTokenClassification,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.Tensor] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
+ """
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ outputs = BertPipelineForwards.bert_model_forward(
+ self.bert,
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ hidden_states=hidden_states,
+ stage_manager=stage_manager,
+ stage_index=stage_index,
+ )
+
+ if stage_manager.is_last_stage():
+ sequence_output = outputs[0]
+
+ sequence_output = self.dropout(sequence_output)
+ logits = self.classifier(sequence_output)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return TokenClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def bert_for_multiple_choice_forward(
+ self: BertForMultipleChoice,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.Tensor] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the multiple choice classification loss. Indices should be in `[0, ...,
+ num_choices-1]` where `num_choices` is the size of the second dimension of the input tensors. (See
+ `input_ids` above)
+ """
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ # in our pipeline design,input ids are copied for every stage and shouldn't be none
+ # the input_ids for multiple choice model is [batch_size, num_choices, sequence_length]
+ if stage_manager.is_last_stage():
+ num_choices = input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
+
+ input_ids = input_ids.view(-1, input_ids.size(-1)) if input_ids is not None else None
+ attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
+ token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
+ position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
+ inputs_embeds = (inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
+ if inputs_embeds is not None else None)
+
+ outputs = BertPipelineForwards.bert_model_forward(
+ self.bert,
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ hidden_states=hidden_states,
+ stage_manager=stage_manager,
+ stage_index=stage_index,
+ )
+ if stage_manager.is_last_stage():
+ pooled_output = outputs[1]
+ pooled_output = self.dropout(pooled_output)
+ logits = self.classifier(pooled_output)
+ reshaped_logits = logits.view(-1, num_choices)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(reshaped_logits, labels)
+
+ if not return_dict:
+ output = (reshaped_logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return MultipleChoiceModelOutput(
+ loss=loss,
+ logits=reshaped_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def bert_for_question_answering_forward(
+ self: BertForQuestionAnswering,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ start_positions: Optional[torch.Tensor] = None,
+ end_positions: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.Tensor] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ # NOTE: the arg start_position and end_position are used only for the last stage
+ r"""
+ start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the start of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+ end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the end of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+ """
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ outputs = BertPipelineForwards.bert_model_forward(
+ self.bert,
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ hidden_states=hidden_states,
+ stage_manager=stage_manager,
+ stage_index=stage_index,
+ )
+ if stage_manager.is_last_stage():
+ sequence_output = outputs[0]
+
+ logits = self.qa_outputs(sequence_output)
+ start_logits, end_logits = logits.split(1, dim=-1)
+ start_logits = start_logits.squeeze(-1).contiguous()
+ end_logits = end_logits.squeeze(-1).contiguous()
+
+ total_loss = None
+ if start_positions is not None and end_positions is not None:
+ # If we are on multi-GPU, split add a dimension
+ if len(start_positions.size()) > 1:
+ start_positions = start_positions.squeeze(-1)
+ if len(end_positions.size()) > 1:
+ end_positions = end_positions.squeeze(-1)
+ # sometimes the start/end positions are outside our model inputs, we ignore these terms
+ ignored_index = start_logits.size(1)
+ start_positions = start_positions.clamp(0, ignored_index)
+ end_positions = end_positions.clamp(0, ignored_index)
+
+ loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
+ start_loss = loss_fct(start_logits, start_positions)
+ end_loss = loss_fct(end_logits, end_positions)
+ total_loss = (start_loss + end_loss) / 2
+
+ if not return_dict:
+ output = (start_logits, end_logits) + outputs[2:]
+ return ((total_loss,) + output) if total_loss is not None else output
+
+ return QuestionAnsweringModelOutput(
+ loss=total_loss,
+ start_logits=start_logits,
+ end_logits=end_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+
+def get_bert_flash_attention_forward():
+
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+ from transformers.models.bert.modeling_bert import BertAttention
+
+ def forward(
+ self: BertAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ mixed_query_layer = self.query(hidden_states)
+
+ # If this is instantiated as a cross-attention module, the keys
+ # and values come from an encoder; the attention mask needs to be
+ # such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ if is_cross_attention and past_key_value is not None:
+ # reuse k,v, cross_attentions
+ key_layer = past_key_value[0]
+ value_layer = past_key_value[1]
+ attention_mask = encoder_attention_mask
+ elif is_cross_attention:
+ key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
+ value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
+ attention_mask = encoder_attention_mask
+ elif past_key_value is not None:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+ else:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ use_cache = past_key_value is not None
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_layer, value_layer)
+
+ final_attention_mask = None
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ query_length, key_length = query_layer.shape[2], key_layer.shape[2]
+ if use_cache:
+ position_ids_l = torch.tensor(key_length - 1, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ else:
+ position_ids_l = torch.arange(query_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(key_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+
+ positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == "relative_key":
+ relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ final_attention_mask = relative_position_scores
+ elif self.position_embedding_type == "relative_key_query":
+ relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
+ final_attention_mask = relative_position_scores_query + relative_position_scores_key
+
+ scale = 1 / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ if final_attention_mask != None:
+ final_attention_mask = final_attention_mask * scale + attention_mask
+ else:
+ final_attention_mask = attention_mask
+
+ if final_attention_mask is not None:
+ batch_size, src_len = query_layer.size()[0], query_layer.size()[2]
+ tgt_len = key_layer.size()[2]
+ final_attention_mask = final_attention_mask.expand(batch_size, self.num_attention_heads, src_len,
+ tgt_len).contiguous()
+
+ query_layer = query_layer.permute(0, 2, 1, 3).contiguous()
+ key_layer = key_layer.permute(0, 2, 1, 3).contiguous()
+ value_layer = value_layer.permute(0, 2, 1, 3).contiguous()
+
+ context_layer = me_attention(query_layer,
+ key_layer,
+ value_layer,
+ attn_bias=final_attention_mask,
+ p=self.dropout.p,
+ scale=scale)
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, None)
+
+ if self.is_decoder:
+ outputs = outputs + (past_key_value,)
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_bert_self_output_forward():
+
+ from transformers.models.bert.modeling_bert import BertSelfOutput
+
+ def forward(self: BertSelfOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+ return forward
+
+
+def get_jit_fused_bert_output_forward():
+
+ from transformers.models.bert.modeling_bert import BertOutput
+
+ def forward(self: BertOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/modeling/blip2.py b/colossalai/shardformer/modeling/blip2.py
new file mode 100644
index 000000000000..69730fd3d254
--- /dev/null
+++ b/colossalai/shardformer/modeling/blip2.py
@@ -0,0 +1,120 @@
+import math
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+
+
+def forward_fn():
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ bsz, tgt_len, embed_dim = hidden_states.size()
+
+ mixed_qkv = self.qkv(hidden_states)
+
+ # modified from original code, which is:
+ # mixed_qkv = mixed_qkv.reshape(bsz, tgt_len, 3, self.num_heads, embed_dim // self.num_heads).permute(
+ # 2, 0, 3, 1, 4
+ # )
+ # to:
+ mixed_qkv = mixed_qkv.reshape(bsz, tgt_len, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
+ query_states, key_states, value_states = (
+ mixed_qkv[0],
+ mixed_qkv[1],
+ mixed_qkv[2],
+ )
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_states, key_states.transpose(-1, -2))
+
+ attention_scores = attention_scores * self.scale
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_states).permute(0, 2, 1, 3)
+
+ new_context_layer_shape = context_layer.size()[:-2] + (self.embed_dim,)
+ context_layer = context_layer.reshape(new_context_layer_shape)
+
+ output = self.projection(context_layer)
+
+ outputs = (output, attention_probs) if output_attentions else (output, None)
+
+ return outputs
+
+ return forward
+
+
+def get_blip2_flash_attention_forward():
+
+ from transformers.models.blip_2.modeling_blip_2 import Blip2Attention
+
+ from colossalai.kernel.cuda_native import ColoAttention
+
+ def forward(
+ self: Blip2Attention,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ bsz, tgt_len, embed_dim = hidden_states.size()
+ mixed_qkv = self.qkv(hidden_states)
+ mixed_qkv = mixed_qkv.reshape(bsz, tgt_len, 3, self.num_heads, -1).permute(2, 0, 1, 3, 4)
+ query_states, key_states, value_states = mixed_qkv[0], mixed_qkv[1], mixed_qkv[2]
+
+ attention = ColoAttention(embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ dropout=self.dropout.p,
+ scale=self.scale)
+ context_layer = attention(query_states, key_states, value_states)
+
+ output = self.projection(context_layer)
+ outputs = (output, None)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_blip2_QFormer_self_output_forward():
+
+ from transformers.models.blip_2.modeling_blip_2 import Blip2QFormerSelfOutput
+
+ def forward(self: Blip2QFormerSelfOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+ return forward
+
+
+def get_jit_fused_blip2_QFormer_output_forward():
+
+ from transformers.models.blip_2.modeling_blip_2 import Blip2QFormerOutput
+
+ def forward(self: Blip2QFormerOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/modeling/bloom.py b/colossalai/shardformer/modeling/bloom.py
index a3d774ff2abb..12276635ecfa 100644
--- a/colossalai/shardformer/modeling/bloom.py
+++ b/colossalai/shardformer/modeling/bloom.py
@@ -1,6 +1,28 @@
+import warnings
+from typing import List, Optional, Tuple, Union
+
import torch
import torch.distributed as dist
from torch.distributed import ProcessGroup
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from torch.nn import functional as F
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPastAndCrossAttentions,
+ CausalLMOutputWithCrossAttentions,
+ QuestionAnsweringModelOutput,
+ SequenceClassifierOutputWithPast,
+ TokenClassifierOutput,
+)
+from transformers.models.bloom.modeling_bloom import (
+ BloomForCausalLM,
+ BloomForQuestionAnswering,
+ BloomForSequenceClassification,
+ BloomForTokenClassification,
+ BloomModel,
+)
+from transformers.utils import logging
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
def build_bloom_alibi_tensor_fn(process_group: ProcessGroup) -> torch.Tensor:
@@ -67,3 +89,810 @@ def build_bloom_alibi_tensor(self, attention_mask: torch.Tensor, num_heads: int,
return alibi.reshape(batch_size * num_heads, 1, seq_length).to(dtype)
return build_bloom_alibi_tensor
+
+
+class BloomPipelineForwards:
+ '''
+ This class serves as a micro library for bloom pipeline forwards.
+ '''
+
+ @staticmethod
+ def bloom_model_forward(
+ self: BloomModel,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ **deprecated_arguments,
+ ) -> Union[Tuple[torch.Tensor, ...], 'BaseModelOutputWithPastAndCrossAttentions']:
+
+ logger = logging.get_logger(__name__)
+
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+ if len(deprecated_arguments) > 0:
+ raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # add warnings here
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once('use_cache=True is not supported for pipeline models at the moment.')
+ use_cache = False
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape batch_size x num_heads x N x N
+
+ # head_mask has shape n_layer x batch x num_heads x N x N
+ head_mask = self.get_head_mask(head_mask, self.config.n_layer)
+
+ # case: First stage of training
+ if stage_manager.is_first_stage():
+ # check input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+
+ hidden_states = self.word_embeddings_layernorm(inputs_embeds)
+ # initialize in the first stage and then pass to the next stage
+ else:
+ input_shape = hidden_states.shape[:-1]
+ batch_size, seq_length = input_shape
+
+ # extra recording tensor should be generated in the first stage
+
+ presents = () if use_cache else None
+ all_self_attentions = () if output_attentions else None
+ all_hidden_states = () if output_hidden_states else None
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+
+ if past_key_values is None:
+ past_key_values = tuple([None] * len(self.h))
+ # Compute alibi tensor: check build_alibi_tensor documentation,build for every stage
+ seq_length_with_past = seq_length
+ past_key_values_length = 0
+ if past_key_values[0] is not None:
+ past_key_values_length = past_key_values[0][0].shape[2] # source_len
+
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, seq_length_with_past), device=hidden_states.device)
+ else:
+ attention_mask = attention_mask.to(hidden_states.device)
+
+ alibi = self.build_alibi_tensor(attention_mask, self.num_heads, dtype=hidden_states.dtype)
+
+ # causal_mask is constructed every stage and its input is passed through different stages
+ causal_mask = self._prepare_attn_mask(
+ attention_mask,
+ input_shape=(batch_size, seq_length),
+ past_key_values_length=past_key_values_length,
+ )
+
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ for i, (block, layer_past) in enumerate(zip(self.h[start_idx:end_idx], past_key_values[start_idx:end_idx]),
+ start=start_idx):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ # None for past_key_value
+ return module(*inputs, use_cache=use_cache, output_attentions=output_attentions)
+
+ return custom_forward
+
+ outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(block),
+ hidden_states,
+ alibi,
+ causal_mask,
+ layer_past,
+ head_mask[i],
+ )
+ else:
+ outputs = block(
+ hidden_states,
+ layer_past=layer_past,
+ attention_mask=causal_mask,
+ head_mask=head_mask[i],
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ alibi=alibi,
+ )
+
+ hidden_states = outputs[0]
+
+ if use_cache is True:
+ presents = presents + (outputs[1],)
+ if output_attentions:
+ all_self_attentions = all_self_attentions + \
+ (outputs[2 if use_cache else 1],)
+
+ if stage_manager.is_last_stage():
+ # Add last hidden state
+ hidden_states = self.ln_f(hidden_states)
+
+ # TODO(jianghai): deal with all_hidden_states, all_self_attentions, presents
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if stage_manager.is_last_stage():
+ if not return_dict:
+ return tuple(
+ v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
+
+ # attention_mask is not returned ; presents = past_key_values
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=presents,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+ else:
+ # always return dict for imediate stage
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def bloom_for_causal_lm_forward(self: BloomForCausalLM,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ **deprecated_arguments):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
+ `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
+ are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
+ """
+ logger = logging.get_logger(__name__)
+
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+ if len(deprecated_arguments) > 0:
+ raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ transformer_outputs = BloomPipelineForwards.bloom_model_forward(self.transformer,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index)
+ past_key_values = None
+ all_hidden_states = None
+ all_self_attentions = None
+ all_cross_attentions = None
+ if stage_manager.is_last_stage():
+ hidden_states = transformer_outputs[0]
+ lm_logits = self.lm_head(hidden_states)
+
+ loss = None
+ if labels is not None:
+ # move labels to correct device to enable model parallelism
+ labels = labels.to(lm_logits.device)
+ # Shift so that tokens < n predict n
+ shift_logits = lm_logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ batch_size, seq_length, vocab_size = shift_logits.shape
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(shift_logits.view(batch_size * seq_length, vocab_size),
+ shift_labels.view(batch_size * seq_length))
+
+ if not return_dict:
+ output = (lm_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return CausalLMOutputWithCrossAttentions(
+ loss=loss,
+ logits=lm_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
+ else:
+ hidden_states = transformer_outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def bloom_for_sequence_classification_forward(
+ self: BloomForSequenceClassification,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ **deprecated_arguments,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ logger = logging.get_logger(__name__)
+
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+ if len(deprecated_arguments) > 0:
+ raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ transformer_outputs = BloomPipelineForwards.bloom_model_forward(
+ self.transformer,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ )
+ past_key_values = None
+ all_hidden_states = None
+ all_self_attentions = None
+ all_cross_attentions = None
+ if stage_manager.is_last_stage():
+ batch_size = hidden_states.shape[0]
+ # update batch size
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ sequence_lengths = (torch.ne(input_ids, self.config.pad_token_id).sum(-1) - 1).to(logits.device)
+ else:
+ sequence_lengths = -1
+ logger.warning(
+ f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be "
+ "unexpected if using padding tokens in conjunction with `inputs_embeds.`")
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
+ else:
+ hidden_states = transformer_outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def bloom_for_token_classification_forward(
+ self: BloomForTokenClassification,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ **deprecated_arguments,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ logger = logging.get_logger(__name__)
+
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+ if len(deprecated_arguments) > 0:
+ raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ transformer_outputs = BloomPipelineForwards.bloom_model_forward(
+ self.transformer,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ )
+ past_key_values = None
+ all_hidden_states = None
+ all_self_attentions = None
+ all_cross_attentions = None
+
+ if stage_manager.is_last_stage():
+ hidden_states = transformer_outputs[0]
+ hidden_states = self.dropout(hidden_states)
+ logits = self.classifier(hidden_states)
+
+ loss = None
+ if labels is not None:
+ # move labels to correct device to enable model parallelism
+ labels = labels.to(logits.device)
+ batch_size, seq_length = labels.shape
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(batch_size * seq_length, self.num_labels),
+ labels.view(batch_size * seq_length))
+
+ if not return_dict:
+ output = (logits,) + transformer_outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return TokenClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
+ else:
+ hidden_states = transformer_outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def bloom_for_question_answering_forward(
+ self: BloomForQuestionAnswering,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ start_positions: Optional[torch.LongTensor] = None,
+ end_positions: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ r"""
+ start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the start of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+ end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the end of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+ """
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ outputs = BloomPipelineForwards.bloom_model_forward(
+ self.transformer,
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ )
+ past_key_values = None
+ all_hidden_states = None
+ all_self_attentions = None
+ all_cross_attentions = None
+
+ if stage_manager.is_last_stage():
+ sequence_output = outputs[0]
+ logits = self.qa_outputs(sequence_output)
+ start_logits, end_logits = logits.split(1, dim=-1)
+ start_logits = start_logits.squeeze(-1).contiguous()
+ end_logits = end_logits.squeeze(-1).contiguous()
+
+ total_loss = None
+ if start_positions is not None and end_positions is not None:
+ # If we are on multi-GPU, split add a dimension
+ if len(start_positions.size()) > 1:
+ start_positions = start_positions.squeeze(-1)
+ if len(end_positions.size()) > 1:
+ end_positions = end_positions.squeeze(-1)
+ # sometimes the start/end positions are outside our model inputs, we ignore these terms
+ ignored_index = start_logits.size(1)
+ start_positions = start_positions.clamp(0, ignored_index)
+ end_positions = end_positions.clamp(0, ignored_index)
+
+ loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
+ start_loss = loss_fct(start_logits, start_positions)
+ end_loss = loss_fct(end_logits, end_positions)
+ total_loss = (start_loss + end_loss) / 2
+
+ if not return_dict:
+ output = (start_logits, end_logits) + outputs[2:]
+ return ((total_loss,) + output) if total_loss is not None else output
+
+ return QuestionAnsweringModelOutput(
+ loss=total_loss,
+ start_logits=start_logits,
+ end_logits=end_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+
+def get_bloom_flash_attention_forward(enabel_jit_fused=False):
+
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+ from transformers.models.bloom.modeling_bloom import BloomAttention
+
+ def forward(
+ self: BloomAttention,
+ hidden_states: torch.Tensor,
+ residual: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ ):
+
+ fused_qkv = self.query_key_value(hidden_states)
+ (query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
+ batch_size, tgt_len, _ = hidden_states.size()
+ assert tgt_len % 4 == 0, "Flash Attention Error: The sequence length should be a multiple of 4."
+
+ _, kv_length, _, _ = key_layer.size()
+
+ proj_shape = (batch_size, tgt_len, self.num_heads, self.head_dim)
+ query_layer = query_layer.contiguous().view(*proj_shape)
+ key_layer = key_layer.contiguous().view(*proj_shape)
+ value_layer = value_layer.contiguous().view(*proj_shape)
+
+ if layer_past is not None:
+ past_key, past_value = layer_past
+ # concatenate along seq_length dimension:
+ # - key: [batch_size * self.num_heads, head_dim, kv_length]
+ # - value: [batch_size * self.num_heads, kv_length, head_dim]
+ key_layer = torch.cat((past_key, key_layer), dim=1)
+ value_layer = torch.cat((past_value, value_layer), dim=1)
+
+ if use_cache is True:
+ present = (key_layer, value_layer)
+ else:
+ present = None
+
+ tgt_len = key_layer.size()[1]
+
+ attention_numerical_mask = torch.zeros((batch_size, self.num_heads, tgt_len, kv_length),
+ dtype=torch.float32,
+ device=query_layer.device,
+ requires_grad=True)
+ attention_numerical_mask = attention_numerical_mask + alibi.view(batch_size, self.num_heads, 1,
+ kv_length) * self.beta
+ attention_numerical_mask = torch.masked_fill(attention_numerical_mask, attention_mask,
+ torch.finfo(torch.float32).min)
+
+ context_layer = me_attention(query_layer,
+ key_layer,
+ value_layer,
+ attn_bias=attention_numerical_mask,
+ scale=self.inv_norm_factor,
+ p=self.attention_dropout.p)
+ context_layer = context_layer.reshape(-1, kv_length, self.hidden_size)
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ slices = self.hidden_size / self.pretraining_tp
+ output_tensor = torch.zeros_like(context_layer)
+ for i in range(self.pretraining_tp):
+ output_tensor = output_tensor + F.linear(
+ context_layer[:, :, int(i * slices):int((i + 1) * slices)],
+ self.dense.weight[:, int(i * slices):int((i + 1) * slices)],
+ )
+ else:
+ output_tensor = self.dense(context_layer)
+
+ # TODO to replace with the bias_dropout_add function in jit
+ output_tensor = self.dropout_add(output_tensor, residual, self.hidden_dropout, self.training)
+ outputs = (output_tensor, present, None)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_bloom_attention_forward():
+
+ from transformers.models.bloom.modeling_bloom import BloomAttention
+
+ def forward(
+ self: BloomAttention,
+ hidden_states: torch.Tensor,
+ residual: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ ):
+ fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
+
+ # 3 x [batch_size, seq_length, num_heads, head_dim]
+ (query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
+
+ batch_size, q_length, _, _ = query_layer.shape
+
+ query_layer = query_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
+ key_layer = key_layer.permute(0, 2, 3, 1).reshape(batch_size * self.num_heads, self.head_dim, q_length)
+ value_layer = value_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
+ if layer_past is not None:
+ past_key, past_value = layer_past
+ # concatenate along seq_length dimension:
+ # - key: [batch_size * self.num_heads, head_dim, kv_length]
+ # - value: [batch_size * self.num_heads, kv_length, head_dim]
+ key_layer = torch.cat((past_key, key_layer), dim=2)
+ value_layer = torch.cat((past_value, value_layer), dim=1)
+
+ _, _, kv_length = key_layer.shape
+
+ if use_cache is True:
+ present = (key_layer, value_layer)
+ else:
+ present = None
+
+ # [batch_size * num_heads, q_length, kv_length]
+ # we use `torch.Tensor.baddbmm` instead of `torch.baddbmm` as the latter isn't supported by TorchScript v1.11
+ matmul_result = alibi.baddbmm(
+ batch1=query_layer,
+ batch2=key_layer,
+ beta=self.beta,
+ alpha=self.inv_norm_factor,
+ )
+
+ # change view to [batch_size, num_heads, q_length, kv_length]
+ attention_scores = matmul_result.view(batch_size, self.num_heads, q_length, kv_length)
+
+ # cast attention scores to fp32, compute scaled softmax and cast back to initial dtype - [batch_size, num_heads, q_length, kv_length]
+ input_dtype = attention_scores.dtype
+ # `float16` has a minimum value of -65504.0, whereas `bfloat16` and `float32` have a minimum value of `-3.4e+38`
+ if input_dtype == torch.float16:
+ attention_scores = attention_scores.to(torch.float)
+ attn_weights = torch.masked_fill(attention_scores, attention_mask, torch.finfo(attention_scores.dtype).min)
+ attention_probs = F.softmax(attn_weights, dim=-1, dtype=torch.float32).to(input_dtype)
+
+ # [batch_size, num_heads, q_length, kv_length]
+ attention_probs = self.attention_dropout(attention_probs)
+
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ # change view [batch_size x num_heads, q_length, kv_length]
+ attention_probs_reshaped = attention_probs.view(batch_size * self.num_heads, q_length, kv_length)
+
+ # matmul: [batch_size * num_heads, q_length, head_dim]
+ context_layer = torch.bmm(attention_probs_reshaped, value_layer)
+
+ # change view [batch_size, num_heads, q_length, head_dim]
+ context_layer = self._merge_heads(context_layer)
+
+ # aggregate results across tp ranks. See here: https://github.com/pytorch/pytorch/issues/76232
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ slices = self.hidden_size / self.pretraining_tp
+ output_tensor = torch.zeros_like(context_layer)
+ for i in range(self.pretraining_tp):
+ output_tensor = output_tensor + F.linear(
+ context_layer[:, :, int(i * slices):int((i + 1) * slices)],
+ self.dense.weight[:, int(i * slices):int((i + 1) * slices)],
+ )
+ else:
+ output_tensor = self.dense(context_layer)
+
+ output_tensor = self.dropout_add(output_tensor, residual, self.hidden_dropout, self.training)
+
+ outputs = (output_tensor, present)
+ if output_attentions:
+ outputs += (attention_probs,)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_bloom_mlp_forward():
+
+ from transformers.models.bloom.modeling_bloom import BloomMLP
+
+ def forward(self: BloomMLP, hidden_states: torch.Tensor, residual: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.gelu_impl(self.dense_h_to_4h(hidden_states))
+
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ intermediate_output = torch.zeros_like(residual)
+ slices = self.dense_4h_to_h.weight.shape[-1] / self.pretraining_tp
+ for i in range(self.pretraining_tp):
+ intermediate_output = intermediate_output + F.linear(
+ hidden_states[:, :, int(i * slices):int((i + 1) * slices)],
+ self.dense_4h_to_h.weight[:, int(i * slices):int((i + 1) * slices)],
+ )
+ else:
+ intermediate_output = self.dense_4h_to_h(hidden_states)
+ output = self.dropout_add(intermediate_output, residual, self.hidden_dropout, self.training)
+ return output
+
+ return forward
+
+
+def get_jit_fused_bloom_gelu_forward():
+
+ from transformers.models.bloom.modeling_bloom import BloomGelu
+
+ from colossalai.kernel.jit.bias_gelu import GeLUFunction as JitGeLUFunction
+
+ def forward(self: BloomGelu, x: torch.Tensor) -> torch.Tensor:
+ bias = torch.zeros_like(x)
+ if self.training:
+ return JitGeLUFunction.apply(x, bias)
+ else:
+ return self.bloom_gelu_forward(x, bias)
+
+ return forward
diff --git a/colossalai/shardformer/modeling/chatglm.py b/colossalai/shardformer/modeling/chatglm.py
new file mode 100644
index 000000000000..409e2e1f5497
--- /dev/null
+++ b/colossalai/shardformer/modeling/chatglm.py
@@ -0,0 +1,298 @@
+""" PyTorch ChatGLM model. """
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from torch.nn import CrossEntropyLoss, LayerNorm
+from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
+from transformers.utils import logging
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer.modeling.chatglm2_6b.configuration_chatglm import ChatGLMConfig
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
+ ChatGLMForConditionalGeneration,
+ ChatGLMModel,
+ GLMBlock,
+)
+
+
+def get_flash_core_attention_forward():
+
+ from colossalai.kernel.cuda_native import AttnMaskType, ColoAttention
+
+ from .chatglm2_6b.modeling_chatglm import CoreAttention
+
+ def forward(self: CoreAttention, query_layer, key_layer, value_layer, attention_mask):
+ pytorch_major_version = int(torch.__version__.split(".")[0])
+ if pytorch_major_version >= 2:
+ query_layer, key_layer, value_layer = [k.permute(1, 2, 0, 3) for k in [query_layer, key_layer, value_layer]]
+ if attention_mask is None and query_layer.shape[2] == key_layer.shape[2]:
+ context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer,
+ key_layer,
+ value_layer,
+ is_causal=True)
+ else:
+ if attention_mask is not None:
+ attention_mask = ~attention_mask
+ context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
+ attention_mask)
+ context_layer = context_layer.permute(2, 0, 1, 3)
+ new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
+ context_layer = context_layer.reshape(*new_context_layer_shape)
+ else:
+ # Raw attention scores
+ query_layer = query_layer.permute(1, 0, 2, 3).contiguous()
+ key_layer = key_layer.permute(1, 0, 2, 3).contiguous()
+ value_layer = value_layer.permute(1, 0, 2, 3).contiguous()
+
+ scale = 1.0 / self.norm_factor
+ if self.coeff is not None:
+ scale = scale * self.coeff
+
+ flash_attention_mask = None
+ attn_mask_type = None
+ if attention_mask is None:
+ attn_mask_type = AttnMaskType.causal
+ else:
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool)).contiguous()
+ attn_mask_type = AttnMaskType.paddedcausal
+
+ attention = ColoAttention(embed_dim=self.hidden_size_per_partition,
+ num_heads=self.num_attention_heads_per_partition,
+ dropout=self.attention_dropout.p,
+ scale=scale)
+ context_layer = attention(query_layer,
+ key_layer,
+ value_layer,
+ attn_mask=flash_attention_mask,
+ attn_mask_type=attn_mask_type)
+
+ context_layer = context_layer.permute(1, 0, -1).contiguous()
+
+ return context_layer
+
+ return forward
+
+
+def get_jit_fused_glm_block_forward():
+
+ from .chatglm2_6b.modeling_chatglm import GLMBlock
+
+ def forward(
+ self: GLMBlock,
+ hidden_states,
+ attention_mask,
+ rotary_pos_emb,
+ kv_cache=None,
+ use_cache=True,
+ ):
+ # hidden_states: [s, b, h]
+ # Layer norm at the beginning of the transformer layer.
+ layernorm_output = self.input_layernorm(hidden_states)
+ # Self attention.
+ attention_output, kv_cache = self.self_attention(
+ layernorm_output,
+ attention_mask,
+ rotary_pos_emb,
+ kv_cache=kv_cache,
+ use_cache=use_cache,
+ )
+
+ # Residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = hidden_states
+
+ layernorm_input = self.dropout_add(attention_output, residual, self.hidden_dropout, self.training)
+
+ # Layer norm post the self attention.
+ layernorm_output = self.post_attention_layernorm(layernorm_input)
+
+ # MLP.
+ mlp_output = self.mlp(layernorm_output)
+
+ # Second residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = layernorm_input
+
+ output = self.dropout_add(mlp_output, residual, self.hidden_dropout, self.training)
+
+ return output, kv_cache
+
+ return forward
+
+
+class ChatGLMPipelineForwards:
+ '''
+ This class serves as a micro library for ChatGLM model forwards under pipeline parallelism.
+ '''
+
+ @staticmethod
+ def chatglm_model_forward(
+ self: ChatGLMModel,
+ input_ids,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.BoolTensor] = None,
+ full_attention_mask: Optional[torch.BoolTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ logger = logging.get_logger(__name__)
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if past_key_values:
+ logger.warning_once('Non-empty past_key_values is not supported for pipeline models at the moment.')
+ past_key_values = None
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once('use_cache=True is not supported for pipeline models at the moment.')
+ use_cache = False
+ if stage_manager.is_first_stage():
+ batch_size, seq_length = input_ids.shape
+ if inputs_embeds is None:
+ inputs_embeds = self.embedding(input_ids)
+ hidden_states = inputs_embeds
+ else:
+ seq_length, batch_size = hidden_states.shape[:2]
+ if self.pre_seq_len is not None:
+ if past_key_values is None:
+ past_key_values = self.get_prompt(batch_size=batch_size,
+ device=input_ids.device,
+ dtype=inputs_embeds.dtype)
+ if attention_mask is not None:
+ attention_mask = torch.cat([attention_mask.new_ones((batch_size, self.pre_seq_len)), attention_mask],
+ dim=-1)
+ if full_attention_mask is None:
+ if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
+ full_attention_mask = self.get_masks(input_ids, past_key_values, padding_mask=attention_mask)
+ # Rotary positional embeddings
+ rotary_pos_emb = self.rotary_pos_emb(self.seq_length)
+ if position_ids is not None:
+ rotary_pos_emb = rotary_pos_emb[position_ids]
+ else:
+ rotary_pos_emb = rotary_pos_emb[None, :seq_length]
+ rotary_pos_emb = rotary_pos_emb.transpose(0, 1).contiguous()
+ if not past_key_values:
+ past_key_values = [None for _ in range(self.num_layers)]
+ presents = () if use_cache else None
+ if self.encoder.gradient_checkpointing and self.encoder.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+ all_self_attentions = None
+ all_hidden_states = () if output_hidden_states else None
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ for idx in range(start_idx, end_idx):
+ layer = self.encoder._get_layer(idx)
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+ if self.encoder.gradient_checkpointing and self.encoder.training:
+ layer_ret = torch.utils.checkpoint.checkpoint(layer, hidden_states, attention_mask, rotary_pos_emb,
+ past_key_values[idx], use_cache)
+ else:
+ layer_ret = layer(hidden_states,
+ full_attention_mask,
+ rotary_pos_emb,
+ kv_cache=past_key_values[idx],
+ use_cache=use_cache)
+ hidden_states, kv_cache = layer_ret
+ if use_cache:
+ presents = presents + (kv_cache,)
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+ if stage_manager.is_last_stage():
+ # final layer_norm
+ if self.encoder.post_layer_norm:
+ hidden_states = self.encoder.final_layernorm(hidden_states)
+ if not return_dict:
+ return tuple(
+ v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=presents,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+ else:
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def chatglm_for_conditional_generation_forward(
+ self: ChatGLMForConditionalGeneration,
+ input_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ return_last_logit: Optional[bool] = False,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ logger = logging.get_logger(__name__)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = (return_dict if return_dict is not None else self.config.use_return_dict)
+ transformer_outputs = ChatGLMPipelineForwards.chatglm_model_forward(
+ self.transformer,
+ input_ids=input_ids,
+ position_ids=position_ids,
+ attention_mask=attention_mask,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ )
+ if stage_manager.is_last_stage():
+ hidden_states = transformer_outputs[0]
+ if return_last_logit:
+ hidden_states = hidden_states[-1:]
+ lm_logits = self.transformer.output_layer(hidden_states)
+ lm_logits = lm_logits.transpose(0, 1).contiguous()
+ loss = None
+ if labels is not None:
+ lm_logits = lm_logits.to(torch.float32)
+ # Shift so that tokens < n predict n
+ shift_logits = lm_logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss(ignore_index=-100)
+ loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
+ lm_logits = lm_logits.to(hidden_states.dtype)
+ loss = loss.to(hidden_states.dtype)
+ if not return_dict:
+ output = (lm_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=lm_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
+ else:
+ return transformer_outputs
diff --git a/colossalai/shardformer/modeling/chatglm2_6b/configuration_chatglm.py b/colossalai/shardformer/modeling/chatglm2_6b/configuration_chatglm.py
new file mode 100644
index 000000000000..3e78732be2da
--- /dev/null
+++ b/colossalai/shardformer/modeling/chatglm2_6b/configuration_chatglm.py
@@ -0,0 +1,58 @@
+from transformers import PretrainedConfig
+
+
+class ChatGLMConfig(PretrainedConfig):
+ model_type = "chatglm"
+
+ def __init__(self,
+ num_layers=28,
+ padded_vocab_size=65024,
+ hidden_size=4096,
+ ffn_hidden_size=13696,
+ kv_channels=128,
+ num_attention_heads=32,
+ seq_length=2048,
+ hidden_dropout=0.0,
+ attention_dropout=0.0,
+ layernorm_epsilon=1e-5,
+ rmsnorm=True,
+ apply_residual_connection_post_layernorm=False,
+ post_layer_norm=True,
+ add_bias_linear=False,
+ add_qkv_bias=False,
+ bias_dropout_fusion=True,
+ multi_query_attention=False,
+ multi_query_group_num=1,
+ apply_query_key_layer_scaling=True,
+ attention_softmax_in_fp32=True,
+ fp32_residual_connection=False,
+ quantization_bit=0,
+ pre_seq_len=None,
+ prefix_projection=False,
+ **kwargs):
+ self.num_layers = num_layers
+ self.vocab_size = padded_vocab_size
+ self.padded_vocab_size = padded_vocab_size
+ self.hidden_size = hidden_size
+ self.ffn_hidden_size = ffn_hidden_size
+ self.kv_channels = kv_channels
+ self.num_attention_heads = num_attention_heads
+ self.seq_length = seq_length
+ self.hidden_dropout = hidden_dropout
+ self.attention_dropout = attention_dropout
+ self.layernorm_epsilon = layernorm_epsilon
+ self.rmsnorm = rmsnorm
+ self.apply_residual_connection_post_layernorm = apply_residual_connection_post_layernorm
+ self.post_layer_norm = post_layer_norm
+ self.add_bias_linear = add_bias_linear
+ self.add_qkv_bias = add_qkv_bias
+ self.bias_dropout_fusion = bias_dropout_fusion
+ self.multi_query_attention = multi_query_attention
+ self.multi_query_group_num = multi_query_group_num
+ self.apply_query_key_layer_scaling = apply_query_key_layer_scaling
+ self.attention_softmax_in_fp32 = attention_softmax_in_fp32
+ self.fp32_residual_connection = fp32_residual_connection
+ self.quantization_bit = quantization_bit
+ self.pre_seq_len = pre_seq_len
+ self.prefix_projection = prefix_projection
+ super().__init__(**kwargs)
diff --git a/colossalai/shardformer/modeling/chatglm2_6b/modeling_chatglm.py b/colossalai/shardformer/modeling/chatglm2_6b/modeling_chatglm.py
new file mode 100644
index 000000000000..a21ee0231422
--- /dev/null
+++ b/colossalai/shardformer/modeling/chatglm2_6b/modeling_chatglm.py
@@ -0,0 +1,1373 @@
+"""
+The ChatGLM2-6B License
+
+1. Definitions
+
+“Licensor” means the ChatGLM2-6B Model Team that distributes its Software.
+
+“Software” means the ChatGLM2-6B model parameters made available under this license.
+
+2. License Grant
+
+Subject to the terms and conditions of this License, the Licensor hereby grants to you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty-free copyright license to use the Software solely for your non-commercial research purposes.
+
+The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
+
+3. Restriction
+
+You will not use, copy, modify, merge, publish, distribute, reproduce, or create derivative works of the Software, in whole or in part, for any commercial, military, or illegal purposes.
+
+You will not use the Software for any act that may undermine China's national security and national unity, harm the public interest of society, or infringe upon the rights and interests of human beings.
+
+4. Disclaimer
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+
+5. Limitation of Liability
+
+EXCEPT TO THE EXTENT PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL THEORY, WHETHER BASED IN TORT, NEGLIGENCE, CONTRACT, LIABILITY, OR OTHERWISE WILL ANY LICENSOR BE LIABLE TO YOU FOR ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES, OR ANY OTHER COMMERCIAL LOSSES, EVEN IF THE LICENSOR HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
+
+6. Dispute Resolution
+
+This license shall be governed and construed in accordance with the laws of People’s Republic of China. Any dispute arising from or in connection with this License shall be submitted to Haidian District People's Court in Beijing.
+
+Note that the license is subject to update to a more comprehensive version. For any questions related to the license and copyright, please contact us at glm-130b@googlegroups.com.
+"""
+""" PyTorch ChatGLM model. """
+
+import copy
+import math
+import re
+import sys
+import warnings
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import CrossEntropyLoss, LayerNorm
+from torch.nn.utils import skip_init
+from transformers.generation.logits_process import LogitsProcessor
+from transformers.generation.utils import GenerationConfig, LogitsProcessorList, ModelOutput, StoppingCriteriaList
+from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
+from transformers.modeling_utils import PreTrainedModel
+from transformers.utils import logging
+
+from .configuration_chatglm import ChatGLMConfig
+
+# flags required to enable jit fusion kernels
+
+if sys.platform != "darwin":
+ torch._C._jit_set_profiling_mode(False)
+ torch._C._jit_set_profiling_executor(False)
+ torch._C._jit_override_can_fuse_on_cpu(True)
+ torch._C._jit_override_can_fuse_on_gpu(True)
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "THUDM/ChatGLM2-6B"
+_CONFIG_FOR_DOC = "ChatGLM6BConfig"
+
+CHATGLM_6B_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "THUDM/chatglm2-6b",
+ # See all ChatGLM models at https://huggingface.co/models?filter=chatglm
+]
+
+
+def default_init(cls, *args, **kwargs):
+ return cls(*args, **kwargs)
+
+
+class InvalidScoreLogitsProcessor(LogitsProcessor):
+
+ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
+ if torch.isnan(scores).any() or torch.isinf(scores).any():
+ scores.zero_()
+ scores[..., 5] = 5e4
+ return scores
+
+
+class PrefixEncoder(torch.nn.Module):
+ """
+ The torch.nn model to encode the prefix
+ Input shape: (batch-size, prefix-length)
+ Output shape: (batch-size, prefix-length, 2*layers*hidden)
+ """
+
+ def __init__(self, config: ChatGLMConfig):
+ super().__init__()
+ self.prefix_projection = config.prefix_projection
+ if self.prefix_projection:
+ # Use a two-layer MLP to encode the prefix
+ kv_size = (config.num_layers * config.kv_channels * config.multi_query_group_num * 2)
+ self.embedding = torch.nn.Embedding(config.pre_seq_len, kv_size)
+ self.trans = torch.nn.Sequential(
+ torch.nn.Linear(kv_size, config.hidden_size),
+ torch.nn.Tanh(),
+ torch.nn.Linear(config.hidden_size, kv_size),
+ )
+ else:
+ self.embedding = torch.nn.Embedding(
+ config.pre_seq_len,
+ config.num_layers * config.kv_channels * config.multi_query_group_num * 2,
+ )
+
+ def forward(self, prefix: torch.Tensor):
+ if self.prefix_projection:
+ prefix_tokens = self.embedding(prefix)
+ past_key_values = self.trans(prefix_tokens)
+ else:
+ past_key_values = self.embedding(prefix)
+ return past_key_values
+
+
+def split_tensor_along_last_dim(
+ tensor: torch.Tensor,
+ num_partitions: int,
+ contiguous_split_chunks: bool = False,
+) -> List[torch.Tensor]:
+ """Split a tensor along its last dimension.
+
+ Arguments:
+ tensor: input tensor.
+ num_partitions: number of partitions to split the tensor
+ contiguous_split_chunks: If True, make each chunk contiguous
+ in memory.
+
+ Returns:
+ A list of Tensors
+ """
+ # Get the size and dimension.
+ last_dim = tensor.dim() - 1
+ last_dim_size = tensor.size()[last_dim] // num_partitions
+ # Split.
+ tensor_list = torch.split(tensor, last_dim_size, dim=last_dim)
+ # Note: torch.split does not create contiguous tensors by default.
+ if contiguous_split_chunks:
+ return tuple(chunk.contiguous() for chunk in tensor_list)
+
+ return tensor_list
+
+
+class RotaryEmbedding(nn.Module):
+
+ def __init__(self, dim, original_impl=False, device=None, dtype=None):
+ super().__init__()
+ inv_freq = 1.0 / (10000**(torch.arange(0, dim, 2, device=device).to(dtype=dtype) / dim))
+ self.register_buffer("inv_freq", inv_freq)
+ self.dim = dim
+ self.original_impl = original_impl
+
+ def forward_impl(
+ self,
+ seq_len: int,
+ n_elem: int,
+ dtype: torch.dtype,
+ device: torch.device,
+ base: int = 10000,
+ ):
+ """Enhanced Transformer with Rotary Position Embedding.
+
+ Derived from: https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/labml_nn/
+ transformers/rope/__init__.py. MIT License:
+ https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/license.
+ """
+ # $\Theta = {\theta_i = 10000^{\frac{2(i-1)}{d}}, i \in [1, 2, ..., \frac{d}{2}]}$
+ theta = 1.0 / (base**(torch.arange(0, n_elem, 2, dtype=dtype, device=device) / n_elem))
+
+ # Create position indexes `[0, 1, ..., seq_len - 1]`
+ seq_idx = torch.arange(seq_len, dtype=dtype, device=device)
+
+ # Calculate the product of position index and $\theta_i$
+ idx_theta = torch.outer(seq_idx, theta).float()
+
+ cache = torch.stack([torch.cos(idx_theta), torch.sin(idx_theta)], dim=-1)
+
+ # this is to mimic the behaviour of complex32, else we will get different results
+ if dtype in (torch.float16, torch.bfloat16, torch.int8):
+ cache = cache.bfloat16() if dtype == torch.bfloat16 else cache.half()
+ return cache
+
+ def forward(self, max_seq_len, offset=0):
+ return self.forward_impl(
+ max_seq_len,
+ self.dim,
+ dtype=self.inv_freq.dtype,
+ device=self.inv_freq.device,
+ )
+
+
+@torch.jit.script
+def apply_rotary_pos_emb(x: torch.Tensor, rope_cache: torch.Tensor) -> torch.Tensor:
+ # x: [sq, b, np, hn]
+ sq, b, np, hn = x.size(0), x.size(1), x.size(2), x.size(3)
+ rot_dim = rope_cache.shape[-2] * 2
+ x, x_pass = x[..., :rot_dim], x[..., rot_dim:]
+ # truncate to support variable sizes
+ rope_cache = rope_cache[:sq]
+ xshaped = x.reshape(sq, -1, np, rot_dim // 2, 2)
+ rope_cache = rope_cache.view(sq, -1, 1, xshaped.size(3), 2)
+ x_out2 = torch.stack(
+ [
+ xshaped[..., 0] * rope_cache[..., 0] - xshaped[..., 1] * rope_cache[..., 1],
+ xshaped[..., 1] * rope_cache[..., 0] + xshaped[..., 0] * rope_cache[..., 1],
+ ],
+ -1,
+ )
+ x_out2 = x_out2.flatten(3)
+ return torch.cat((x_out2, x_pass), dim=-1)
+
+
+class RMSNorm(torch.nn.Module):
+
+ def __init__(self, normalized_shape, eps=1e-5, device=None, dtype=None, **kwargs):
+ super().__init__()
+ self.elementwise_affine = True
+ self.normalized_shape = normalized_shape
+ self.weight = torch.nn.Parameter(torch.ones(normalized_shape, device=device, dtype=dtype))
+ self.eps = eps
+
+ def forward(self, hidden_states: torch.Tensor):
+ input_dtype = hidden_states.dtype
+ variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.eps)
+ return (self.weight * hidden_states).to(input_dtype)
+
+
+class CoreAttention(torch.nn.Module):
+
+ def __init__(self, config: ChatGLMConfig, layer_number):
+ super(CoreAttention, self).__init__()
+
+ self.apply_query_key_layer_scaling = config.apply_query_key_layer_scaling
+ self.attention_softmax_in_fp32 = config.attention_softmax_in_fp32
+ if self.apply_query_key_layer_scaling:
+ self.attention_softmax_in_fp32 = True
+ self.layer_number = max(1, layer_number)
+
+ projection_size = config.kv_channels * config.num_attention_heads
+
+ # Per attention head and per partition values.
+ self.hidden_size_per_partition = projection_size
+ self.hidden_size_per_attention_head = (projection_size // config.num_attention_heads)
+ self.num_attention_heads_per_partition = config.num_attention_heads
+
+ coeff = None
+ self.norm_factor = math.sqrt(self.hidden_size_per_attention_head)
+ if self.apply_query_key_layer_scaling:
+ coeff = self.layer_number
+ self.norm_factor *= coeff
+ self.coeff = coeff
+
+ self.attention_dropout = torch.nn.Dropout(config.attention_dropout)
+
+ def forward(self, query_layer, key_layer, value_layer, attention_mask):
+ pytorch_major_version = int(torch.__version__.split(".")[0])
+ if pytorch_major_version >= 2:
+ query_layer, key_layer, value_layer = [k.permute(1, 2, 0, 3) for k in [query_layer, key_layer, value_layer]]
+ if attention_mask is None and query_layer.shape[2] == key_layer.shape[2]:
+ context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer,
+ key_layer,
+ value_layer,
+ is_causal=True)
+ else:
+ if attention_mask is not None:
+ attention_mask = ~attention_mask
+ context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
+ attention_mask)
+ context_layer = context_layer.permute(2, 0, 1, 3)
+ new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
+ context_layer = context_layer.reshape(*new_context_layer_shape)
+ else:
+ # Raw attention scores
+
+ # [b, np, sq, sk]
+ output_size = (
+ query_layer.size(1),
+ query_layer.size(2),
+ query_layer.size(0),
+ key_layer.size(0),
+ )
+
+ # [sq, b, np, hn] -> [sq, b * np, hn]
+ query_layer = query_layer.view(output_size[2], output_size[0] * output_size[1], -1)
+ # [sk, b, np, hn] -> [sk, b * np, hn]
+ key_layer = key_layer.view(output_size[3], output_size[0] * output_size[1], -1)
+
+ # preallocting input tensor: [b * np, sq, sk]
+ matmul_input_buffer = torch.empty(
+ output_size[0] * output_size[1],
+ output_size[2],
+ output_size[3],
+ dtype=query_layer.dtype,
+ device=query_layer.device,
+ )
+
+ # Raw attention scores. [b * np, sq, sk]
+ matmul_result = torch.baddbmm(
+ matmul_input_buffer,
+ query_layer.transpose(0, 1), # [b * np, sq, hn]
+ key_layer.transpose(0, 1).transpose(1, 2), # [b * np, hn, sk]
+ beta=0.0,
+ alpha=(1.0 / self.norm_factor),
+ )
+
+ # change view to [b, np, sq, sk]
+ attention_scores = matmul_result.view(*output_size)
+
+ # ===========================
+ # Attention probs and dropout
+ # ===========================
+
+ # attention scores and attention mask [b, np, sq, sk]
+ if self.attention_softmax_in_fp32:
+ attention_scores = attention_scores.float()
+ if self.coeff is not None:
+ attention_scores = attention_scores * self.coeff
+ if (attention_mask is None and attention_scores.shape[2] == attention_scores.shape[3]):
+ attention_mask = torch.ones(
+ output_size[0],
+ 1,
+ output_size[2],
+ output_size[3],
+ device=attention_scores.device,
+ dtype=torch.bool,
+ )
+ attention_mask.tril_()
+ attention_mask = ~attention_mask
+ if attention_mask is not None:
+ attention_scores = attention_scores.masked_fill(attention_mask, float("-inf"))
+ attention_probs = F.softmax(attention_scores, dim=-1)
+ attention_probs = attention_probs.type_as(value_layer)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.attention_dropout(attention_probs)
+ # =========================
+ # Context layer. [sq, b, hp]
+ # =========================
+
+ # value_layer -> context layer.
+ # [sk, b, np, hn] --> [b, np, sq, hn]
+
+ # context layer shape: [b, np, sq, hn]
+ output_size = (
+ value_layer.size(1),
+ value_layer.size(2),
+ query_layer.size(0),
+ value_layer.size(3),
+ )
+ # change view [sk, b * np, hn]
+ value_layer = value_layer.view(value_layer.size(0), output_size[0] * output_size[1], -1)
+ # change view [b * np, sq, sk]
+ attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)
+ # matmul: [b * np, sq, hn]
+ context_layer = torch.bmm(attention_probs, value_layer.transpose(0, 1))
+ # change view [b, np, sq, hn]
+ context_layer = context_layer.view(*output_size)
+ # [b, np, sq, hn] --> [sq, b, np, hn]
+ context_layer = context_layer.permute(2, 0, 1, 3).contiguous()
+ # [sq, b, np, hn] --> [sq, b, hp]
+ new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
+ context_layer = context_layer.view(*new_context_layer_shape)
+
+ return context_layer
+
+
+class SelfAttention(torch.nn.Module):
+ """Parallel self-attention layer abstract class.
+
+ Self-attention layer takes input with size [s, b, h]
+ and returns output of the same size.
+ """
+
+ def __init__(self, config: ChatGLMConfig, layer_number, device=None):
+ super(SelfAttention, self).__init__()
+ self.layer_number = max(1, layer_number)
+
+ self.projection_size = config.kv_channels * config.num_attention_heads
+ # Per attention head and per partition values.
+ self.hidden_size_per_attention_head = (self.projection_size // config.num_attention_heads)
+ self.num_attention_heads_per_partition = config.num_attention_heads
+
+ self.multi_query_attention = config.multi_query_attention
+ self.qkv_hidden_size = 3 * self.projection_size
+ if self.multi_query_attention:
+ self.num_multi_query_groups_per_partition = config.multi_query_group_num
+ self.qkv_hidden_size = (self.projection_size +
+ 2 * self.hidden_size_per_attention_head * config.multi_query_group_num)
+ self.query_key_value = nn.Linear(
+ config.hidden_size,
+ self.qkv_hidden_size,
+ bias=config.add_bias_linear or config.add_qkv_bias,
+ device=device,
+ **_config_to_kwargs(config),
+ )
+
+ self.core_attention = CoreAttention(config, self.layer_number)
+
+ # Output.
+ self.dense = nn.Linear(
+ self.projection_size,
+ config.hidden_size,
+ bias=config.add_bias_linear,
+ device=device,
+ **_config_to_kwargs(config),
+ )
+
+ def _allocate_memory(self, inference_max_sequence_len, batch_size, device=None, dtype=None):
+ if self.multi_query_attention:
+ num_attention_heads = self.num_multi_query_groups_per_partition
+ else:
+ num_attention_heads = self.num_attention_heads_per_partition
+ return torch.empty(
+ inference_max_sequence_len,
+ batch_size,
+ num_attention_heads,
+ self.hidden_size_per_attention_head,
+ dtype=dtype,
+ device=device,
+ )
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask,
+ rotary_pos_emb,
+ kv_cache=None,
+ use_cache=True,
+ ):
+ # hidden_states: [sq, b, h]
+
+ # =================================================
+ # Pre-allocate memory for key-values for inference.
+ # =================================================
+ # =====================
+ # Query, Key, and Value
+ # =====================
+
+ # Attention heads [sq, b, h] --> [sq, b, (np * 3 * hn)]
+ mixed_x_layer = self.query_key_value(hidden_states)
+
+ if self.multi_query_attention:
+ (query_layer, key_layer, value_layer) = mixed_x_layer.split(
+ [
+ self.num_attention_heads_per_partition * self.hidden_size_per_attention_head,
+ self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
+ self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
+ ],
+ dim=-1,
+ )
+ query_layer = query_layer.view(query_layer.size()[:-1] + (
+ self.num_attention_heads_per_partition,
+ self.hidden_size_per_attention_head,
+ ))
+ key_layer = key_layer.view(key_layer.size()[:-1] + (
+ self.num_multi_query_groups_per_partition,
+ self.hidden_size_per_attention_head,
+ ))
+ value_layer = value_layer.view(value_layer.size()[:-1] + (
+ self.num_multi_query_groups_per_partition,
+ self.hidden_size_per_attention_head,
+ ))
+ else:
+ new_tensor_shape = mixed_x_layer.size()[:-1] + (
+ self.num_attention_heads_per_partition,
+ 3 * self.hidden_size_per_attention_head,
+ )
+ mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
+ # [sq, b, np, 3 * hn] --> 3 [sq, b, np, hn]
+ (query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
+
+ # apply relative positional encoding (rotary embedding)
+ if rotary_pos_emb is not None:
+ query_layer = apply_rotary_pos_emb(query_layer, rotary_pos_emb)
+ key_layer = apply_rotary_pos_emb(key_layer, rotary_pos_emb)
+
+ # adjust key and value for inference
+ if kv_cache is not None:
+ cache_k, cache_v = kv_cache
+ key_layer = torch.cat((cache_k, key_layer), dim=0)
+ value_layer = torch.cat((cache_v, value_layer), dim=0)
+ if use_cache:
+ kv_cache = (key_layer, value_layer)
+ else:
+ kv_cache = None
+
+ if self.multi_query_attention:
+ key_layer = key_layer.unsqueeze(-2)
+ key_layer = key_layer.expand(
+ -1,
+ -1,
+ -1,
+ self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition,
+ -1,
+ )
+ key_layer = key_layer.contiguous().view(key_layer.size()[:2] + (
+ self.num_attention_heads_per_partition,
+ self.hidden_size_per_attention_head,
+ ))
+ value_layer = value_layer.unsqueeze(-2)
+ value_layer = value_layer.expand(
+ -1,
+ -1,
+ -1,
+ self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition,
+ -1,
+ )
+ value_layer = value_layer.contiguous().view(value_layer.size()[:2] + (
+ self.num_attention_heads_per_partition,
+ self.hidden_size_per_attention_head,
+ ))
+
+ # ==================================
+ # core attention computation
+ # ==================================
+
+ context_layer = self.core_attention(query_layer, key_layer, value_layer, attention_mask)
+
+ # =================
+ # Output. [sq, b, h]
+ # =================
+
+ output = self.dense(context_layer)
+
+ return output, kv_cache
+
+
+def _config_to_kwargs(args):
+ common_kwargs = {
+ "dtype": args.torch_dtype,
+ }
+ return common_kwargs
+
+
+class MLP(torch.nn.Module):
+ """MLP.
+
+ MLP will take the input with h hidden state, project it to 4*h
+ hidden dimension, perform nonlinear transformation, and project the
+ state back into h hidden dimension.
+ """
+
+ def __init__(self, config: ChatGLMConfig, device=None):
+ super(MLP, self).__init__()
+
+ self.add_bias = config.add_bias_linear
+
+ # Project to 4h. If using swiglu double the output width, see https://arxiv.org/pdf/2002.05202.pdf
+ self.dense_h_to_4h = nn.Linear(
+ config.hidden_size,
+ config.ffn_hidden_size * 2,
+ bias=self.add_bias,
+ device=device,
+ **_config_to_kwargs(config),
+ )
+
+ def swiglu(x):
+ x = torch.chunk(x, 2, dim=-1)
+ return F.silu(x[0]) * x[1]
+
+ self.activation_func = swiglu
+
+ # Project back to h.
+ self.dense_4h_to_h = nn.Linear(
+ config.ffn_hidden_size,
+ config.hidden_size,
+ bias=self.add_bias,
+ device=device,
+ **_config_to_kwargs(config),
+ )
+
+ def forward(self, hidden_states):
+ # [s, b, 4hp]
+ intermediate_parallel = self.dense_h_to_4h(hidden_states)
+ intermediate_parallel = self.activation_func(intermediate_parallel)
+ # [s, b, h]
+ output = self.dense_4h_to_h(intermediate_parallel)
+ return output
+
+
+class GLMBlock(torch.nn.Module):
+ """A single transformer layer.
+
+ Transformer layer takes input with size [s, b, h] and returns an
+ output of the same size.
+ """
+
+ def __init__(self, config: ChatGLMConfig, layer_number, device=None):
+ super(GLMBlock, self).__init__()
+ self.layer_number = layer_number
+
+ self.apply_residual_connection_post_layernorm = (config.apply_residual_connection_post_layernorm)
+
+ self.fp32_residual_connection = config.fp32_residual_connection
+
+ LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
+ # Layernorm on the input data.
+ self.input_layernorm = LayerNormFunc(
+ config.hidden_size,
+ eps=config.layernorm_epsilon,
+ device=device,
+ dtype=config.torch_dtype,
+ )
+
+ # Self attention.
+ self.self_attention = SelfAttention(config, layer_number, device=device)
+ self.hidden_dropout = config.hidden_dropout
+
+ # Layernorm on the attention output
+ self.post_attention_layernorm = LayerNormFunc(
+ config.hidden_size,
+ eps=config.layernorm_epsilon,
+ device=device,
+ dtype=config.torch_dtype,
+ )
+
+ # MLP
+ self.mlp = MLP(config, device=device)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask,
+ rotary_pos_emb,
+ kv_cache=None,
+ use_cache=True,
+ ):
+ # hidden_states: [s, b, h]
+
+ # Layer norm at the beginning of the transformer layer.
+ layernorm_output = self.input_layernorm(hidden_states)
+ # Self attention.
+ attention_output, kv_cache = self.self_attention(
+ layernorm_output,
+ attention_mask,
+ rotary_pos_emb,
+ kv_cache=kv_cache,
+ use_cache=use_cache,
+ )
+
+ # Residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = hidden_states
+
+ layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
+ layernorm_input = residual + layernorm_input
+
+ # Layer norm post the self attention.
+ layernorm_output = self.post_attention_layernorm(layernorm_input)
+
+ # MLP.
+ mlp_output = self.mlp(layernorm_output)
+
+ # Second residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = layernorm_input
+
+ output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
+ output = residual + output
+
+ return output, kv_cache
+
+
+class GLMTransformer(torch.nn.Module):
+ """Transformer class."""
+
+ def __init__(self, config: ChatGLMConfig, device=None):
+ super(GLMTransformer, self).__init__()
+
+ self.fp32_residual_connection = config.fp32_residual_connection
+ self.post_layer_norm = config.post_layer_norm
+
+ # Number of layers.
+ self.num_layers = config.num_layers
+
+ # Transformer layers.
+ def build_layer(layer_number):
+ return GLMBlock(config, layer_number, device=device)
+
+ self.layers = torch.nn.ModuleList([build_layer(i + 1) for i in range(self.num_layers)])
+
+ if self.post_layer_norm:
+ LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
+ # Final layer norm before output.
+ self.final_layernorm = LayerNormFunc(
+ config.hidden_size,
+ eps=config.layernorm_epsilon,
+ device=device,
+ dtype=config.torch_dtype,
+ )
+
+ self.gradient_checkpointing = False
+
+ def _get_layer(self, layer_number):
+ return self.layers[layer_number]
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask,
+ rotary_pos_emb,
+ kv_caches=None,
+ use_cache: Optional[bool] = True,
+ output_hidden_states: Optional[bool] = False,
+ ):
+ if not kv_caches:
+ kv_caches = [None for _ in range(self.num_layers)]
+ presents = () if use_cache else None
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+
+ all_self_attentions = None
+ all_hidden_states = () if output_hidden_states else None
+ for index in range(self.num_layers):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer = self._get_layer(index)
+ if self.gradient_checkpointing and self.training:
+ layer_ret = torch.utils.checkpoint.checkpoint(
+ layer,
+ hidden_states,
+ attention_mask,
+ rotary_pos_emb,
+ kv_caches[index],
+ use_cache,
+ )
+ else:
+ layer_ret = layer(
+ hidden_states,
+ attention_mask,
+ rotary_pos_emb,
+ kv_cache=kv_caches[index],
+ use_cache=use_cache,
+ )
+ hidden_states, kv_cache = layer_ret
+ if use_cache:
+ presents = presents + (kv_cache,)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ # Final layer norm.
+ if self.post_layer_norm:
+ hidden_states = self.final_layernorm(hidden_states)
+
+ return hidden_states, presents, all_hidden_states, all_self_attentions
+
+
+class ChatGLMPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and
+ a simple interface for downloading and loading pretrained models.
+ """
+
+ is_parallelizable = False
+ supports_gradient_checkpointing = True
+ config_class = ChatGLMConfig
+ base_model_prefix = "transformer"
+ _no_split_modules = ["GLMBlock"]
+
+ def _init_weights(self, module: nn.Module):
+ """Initialize the weights."""
+ return
+
+ def get_masks(self, input_ids, past_key_values, padding_mask=None):
+ batch_size, seq_length = input_ids.shape
+ full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
+ full_attention_mask.tril_()
+ past_length = 0
+ if past_key_values:
+ past_length = past_key_values[0][0].shape[0]
+ if past_length:
+ full_attention_mask = torch.cat(
+ (
+ torch.ones(batch_size, seq_length, past_length, device=input_ids.device),
+ full_attention_mask,
+ ),
+ dim=-1,
+ )
+ if padding_mask is not None:
+ full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
+ if not past_length and padding_mask is not None:
+ full_attention_mask -= padding_mask.unsqueeze(-1) - 1
+ full_attention_mask = (full_attention_mask < 0.5).bool()
+ full_attention_mask.unsqueeze_(1)
+ return full_attention_mask
+
+ def get_position_ids(self, input_ids, device):
+ batch_size, seq_length = input_ids.shape
+ position_ids = (torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1))
+ return position_ids
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, GLMTransformer):
+ module.gradient_checkpointing = value
+
+
+class Embedding(torch.nn.Module):
+ """Language model embeddings."""
+
+ def __init__(self, config: ChatGLMConfig, device=None):
+ super(Embedding, self).__init__()
+
+ self.hidden_size = config.hidden_size
+ # Word embeddings (parallel).
+ self.word_embeddings = nn.Embedding(
+ config.padded_vocab_size,
+ self.hidden_size,
+ dtype=config.torch_dtype,
+ device=device,
+ )
+ self.fp32_residual_connection = config.fp32_residual_connection
+
+ def forward(self, input_ids):
+ # Embeddings.
+ words_embeddings = self.word_embeddings(input_ids)
+ embeddings = words_embeddings
+ # Data format change to avoid explicit tranposes : [b s h] --> [s b h].
+ embeddings = embeddings.transpose(0, 1).contiguous()
+ # If the input flag for fp32 residual connection is set, convert for float.
+ if self.fp32_residual_connection:
+ embeddings = embeddings.float()
+ return embeddings
+
+
+class ChatGLMModel(ChatGLMPreTrainedModel):
+
+ def __init__(self, config: ChatGLMConfig, device=None, empty_init=True):
+ super().__init__(config)
+ if empty_init:
+ init_method = skip_init
+ else:
+ init_method = default_init
+ init_kwargs = {}
+ if device is not None:
+ init_kwargs["device"] = device
+ self.embedding = init_method(Embedding, config, **init_kwargs)
+ self.num_layers = config.num_layers
+ self.multi_query_group_num = config.multi_query_group_num
+ self.kv_channels = config.kv_channels
+
+ # Rotary positional embeddings
+ self.seq_length = config.seq_length
+ rotary_dim = (config.hidden_size //
+ config.num_attention_heads if config.kv_channels is None else config.kv_channels)
+
+ self.rotary_pos_emb = RotaryEmbedding(
+ rotary_dim // 2,
+ original_impl=config.original_rope,
+ device=device,
+ dtype=config.torch_dtype,
+ )
+ self.encoder = init_method(GLMTransformer, config, **init_kwargs)
+ self.output_layer = init_method(
+ nn.Linear,
+ config.hidden_size,
+ config.padded_vocab_size,
+ bias=False,
+ dtype=config.torch_dtype,
+ **init_kwargs,
+ )
+ self.pre_seq_len = config.pre_seq_len
+ self.prefix_projection = config.prefix_projection
+ if self.pre_seq_len is not None:
+ for param in self.parameters():
+ param.requires_grad = False
+ self.prefix_tokens = torch.arange(self.pre_seq_len).long()
+ self.prefix_encoder = PrefixEncoder(config)
+ self.dropout = torch.nn.Dropout(0.1)
+
+ def get_input_embeddings(self):
+ return self.embedding.word_embeddings
+
+ def get_prompt(self, batch_size, device, dtype=torch.half):
+ prefix_tokens = (self.prefix_tokens.unsqueeze(0).expand(batch_size, -1).to(device))
+ past_key_values = self.prefix_encoder(prefix_tokens).type(dtype)
+ past_key_values = past_key_values.view(
+ batch_size,
+ self.pre_seq_len,
+ self.num_layers * 2,
+ self.multi_query_group_num,
+ self.kv_channels,
+ )
+ # seq_len, b, nh, hidden_size
+ past_key_values = self.dropout(past_key_values)
+ past_key_values = past_key_values.permute([2, 1, 0, 3, 4]).split(2)
+ return past_key_values
+
+ def forward(
+ self,
+ input_ids,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.BoolTensor] = None,
+ full_attention_mask: Optional[torch.BoolTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = (return_dict if return_dict is not None else self.config.use_return_dict)
+
+ batch_size, seq_length = input_ids.shape
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embedding(input_ids)
+
+ if self.pre_seq_len is not None:
+ if past_key_values is None:
+ past_key_values = self.get_prompt(
+ batch_size=batch_size,
+ device=input_ids.device,
+ dtype=inputs_embeds.dtype,
+ )
+ if attention_mask is not None:
+ attention_mask = torch.cat(
+ [
+ attention_mask.new_ones((batch_size, self.pre_seq_len)),
+ attention_mask,
+ ],
+ dim=-1,
+ )
+
+ if full_attention_mask is None:
+ if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
+ full_attention_mask = self.get_masks(input_ids, past_key_values, padding_mask=attention_mask)
+
+ # Rotary positional embeddings
+ rotary_pos_emb = self.rotary_pos_emb(self.seq_length)
+ if position_ids is not None:
+ rotary_pos_emb = rotary_pos_emb[position_ids]
+ else:
+ rotary_pos_emb = rotary_pos_emb[None, :seq_length]
+ rotary_pos_emb = rotary_pos_emb.transpose(0, 1).contiguous()
+
+ # Run encoder.
+ hidden_states, presents, all_hidden_states, all_self_attentions = self.encoder(
+ inputs_embeds,
+ full_attention_mask,
+ rotary_pos_emb=rotary_pos_emb,
+ kv_caches=past_key_values,
+ use_cache=use_cache,
+ output_hidden_states=output_hidden_states,
+ )
+
+ if not return_dict:
+ return tuple(v for v in [
+ hidden_states,
+ presents,
+ all_hidden_states,
+ all_self_attentions,
+ ] if v is not None)
+
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=presents,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+ def quantize(self, weight_bit_width: int):
+ from .quantization import quantize
+
+ quantize(self.encoder, weight_bit_width)
+ return self
+
+
+class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
+
+ def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
+ super().__init__(config)
+
+ self.max_sequence_length = config.max_length
+ self.transformer = ChatGLMModel(config, empty_init=empty_init, device=device)
+ self.config = config
+ self.quantized = False
+
+ if self.config.quantization_bit:
+ self.quantize(self.config.quantization_bit, empty_init=True)
+
+ def _update_model_kwargs_for_generation(
+ self,
+ outputs: ModelOutput,
+ model_kwargs: Dict[str, Any],
+ is_encoder_decoder: bool = False,
+ standardize_cache_format: bool = False,
+ ) -> Dict[str, Any]:
+ # update past_key_values
+ model_kwargs["past_key_values"] = self._extract_past_from_model_output(
+ outputs, standardize_cache_format=standardize_cache_format)
+
+ # update attention mask
+ if "attention_mask" in model_kwargs:
+ attention_mask = model_kwargs["attention_mask"]
+ model_kwargs["attention_mask"] = torch.cat(
+ [attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))],
+ dim=-1,
+ )
+
+ # update position ids
+ if "position_ids" in model_kwargs:
+ position_ids = model_kwargs["position_ids"]
+ new_position_id = position_ids[..., -1:].clone()
+ new_position_id += 1
+ model_kwargs["position_ids"] = torch.cat([position_ids, new_position_id], dim=-1)
+
+ model_kwargs["is_first_forward"] = False
+ return model_kwargs
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids: torch.LongTensor,
+ past_key_values: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ is_first_forward: bool = True,
+ **kwargs,
+ ) -> dict:
+ # only last token for input_ids if past is not None
+ if position_ids is None:
+ position_ids = self.get_position_ids(input_ids, device=input_ids.device)
+ if not is_first_forward:
+ position_ids = position_ids[..., -1:]
+ input_ids = input_ids[:, -1:]
+ return {
+ "input_ids": input_ids,
+ "past_key_values": past_key_values,
+ "position_ids": position_ids,
+ "attention_mask": attention_mask,
+ "return_last_logit": True,
+ }
+
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ return_last_logit: Optional[bool] = False,
+ ):
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = (return_dict if return_dict is not None else self.config.use_return_dict)
+
+ transformer_outputs = self.transformer(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ attention_mask=attention_mask,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = transformer_outputs[0]
+ if return_last_logit:
+ hidden_states = hidden_states[-1:]
+ lm_logits = self.transformer.output_layer(hidden_states)
+ lm_logits = lm_logits.transpose(0, 1).contiguous()
+
+ loss = None
+ if labels is not None:
+ lm_logits = lm_logits.to(torch.float32)
+
+ # Shift so that tokens < n predict n
+ shift_logits = lm_logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss(ignore_index=-100)
+ loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
+
+ lm_logits = lm_logits.to(hidden_states.dtype)
+ loss = loss.to(hidden_states.dtype)
+
+ if not return_dict:
+ output = (lm_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=lm_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
+
+ @staticmethod
+ def _reorder_cache(past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...],
+ beam_idx: torch.LongTensor) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
+ """
+ This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
+ [`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
+ beam_idx at every generation step.
+
+ Output shares the same memory storage as `past`.
+ """
+ return tuple((
+ layer_past[0].index_select(1, beam_idx.to(layer_past[0].device)),
+ layer_past[1].index_select(1, beam_idx.to(layer_past[1].device)),
+ ) for layer_past in past)
+
+ def process_response(self, response):
+ response = response.strip()
+ response = response.replace("[[训练时间]]", "2023年")
+ return response
+
+ def build_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = None):
+ prompt = tokenizer.build_prompt(query, history=history)
+ inputs = tokenizer([prompt], return_tensors="pt")
+ inputs = inputs.to(self.device)
+ return inputs
+
+ def build_stream_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = None):
+ if history:
+ prompt = "\n\n[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
+ input_ids = tokenizer.encode(prompt, add_special_tokens=False)
+ input_ids = input_ids[1:]
+ inputs = tokenizer.batch_encode_plus([(input_ids, None)], return_tensors="pt", add_special_tokens=False)
+ else:
+ prompt = "[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
+ inputs = tokenizer([prompt], return_tensors="pt")
+ inputs = inputs.to(self.device)
+ return inputs
+
+ @torch.no_grad()
+ def chat(
+ self,
+ tokenizer,
+ query: str,
+ history: List[Tuple[str, str]] = None,
+ max_length: int = 8192,
+ num_beams=1,
+ do_sample=True,
+ top_p=0.8,
+ temperature=0.8,
+ logits_processor=None,
+ **kwargs,
+ ):
+ if history is None:
+ history = []
+ if logits_processor is None:
+ logits_processor = LogitsProcessorList()
+ logits_processor.append(InvalidScoreLogitsProcessor())
+ gen_kwargs = {
+ "max_length": max_length,
+ "num_beams": num_beams,
+ "do_sample": do_sample,
+ "top_p": top_p,
+ "temperature": temperature,
+ "logits_processor": logits_processor,
+ **kwargs,
+ }
+ inputs = self.build_inputs(tokenizer, query, history=history)
+ outputs = self.generate(**inputs, **gen_kwargs)
+ outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):]
+ response = tokenizer.decode(outputs)
+ response = self.process_response(response)
+ history = history + [(query, response)]
+ return response, history
+
+ @torch.no_grad()
+ def stream_chat(
+ self,
+ tokenizer,
+ query: str,
+ history: List[Tuple[str, str]] = None,
+ past_key_values=None,
+ max_length: int = 8192,
+ do_sample=True,
+ top_p=0.8,
+ temperature=0.8,
+ logits_processor=None,
+ return_past_key_values=False,
+ **kwargs,
+ ):
+ if history is None:
+ history = []
+ if logits_processor is None:
+ logits_processor = LogitsProcessorList()
+ logits_processor.append(InvalidScoreLogitsProcessor())
+ gen_kwargs = {
+ "max_length": max_length,
+ "do_sample": do_sample,
+ "top_p": top_p,
+ "temperature": temperature,
+ "logits_processor": logits_processor,
+ **kwargs,
+ }
+ if past_key_values is None and not return_past_key_values:
+ inputs = self.build_inputs(tokenizer, query, history=history)
+ else:
+ inputs = self.build_stream_inputs(tokenizer, query, history=history)
+ if past_key_values is not None:
+ past_length = past_key_values[0][0].shape[0]
+ if self.transformer.pre_seq_len is not None:
+ past_length -= self.transformer.pre_seq_len
+ inputs.position_ids += past_length
+ attention_mask = inputs.attention_mask
+ attention_mask = torch.cat((attention_mask.new_ones(1, past_length), attention_mask), dim=1)
+ inputs["attention_mask"] = attention_mask
+ for outputs in self.stream_generate(
+ **inputs,
+ past_key_values=past_key_values,
+ return_past_key_values=return_past_key_values,
+ **gen_kwargs,
+ ):
+ if return_past_key_values:
+ outputs, past_key_values = outputs
+ outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):]
+ response = tokenizer.decode(outputs)
+ if response and response[-1] != "�":
+ response = self.process_response(response)
+ new_history = history + [(query, response)]
+ if return_past_key_values:
+ yield response, new_history, past_key_values
+ else:
+ yield response, new_history
+
+ @torch.no_grad()
+ def stream_generate(
+ self,
+ input_ids,
+ generation_config: Optional[GenerationConfig] = None,
+ logits_processor: Optional[LogitsProcessorList] = None,
+ stopping_criteria: Optional[StoppingCriteriaList] = None,
+ prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
+ return_past_key_values=False,
+ **kwargs,
+ ):
+ batch_size, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
+
+ if generation_config is None:
+ generation_config = self.generation_config
+ generation_config = copy.deepcopy(generation_config)
+ model_kwargs = generation_config.update(**kwargs)
+ bos_token_id, eos_token_id = (
+ generation_config.bos_token_id,
+ generation_config.eos_token_id,
+ )
+
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+
+ has_default_max_length = (kwargs.get("max_length") is None and generation_config.max_length is not None)
+ if has_default_max_length and generation_config.max_new_tokens is None:
+ warnings.warn(
+ f"Using `max_length`'s default ({generation_config.max_length}) to control the generation length. "
+ "This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we"
+ " recommend using `max_new_tokens` to control the maximum length of the generation.",
+ UserWarning,
+ )
+ elif generation_config.max_new_tokens is not None:
+ generation_config.max_length = (generation_config.max_new_tokens + input_ids_seq_length)
+ if not has_default_max_length:
+ logger.warn(
+ f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="
+ f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. "
+ "Please refer to the documentation for more information. "
+ "(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)",
+ UserWarning,
+ )
+
+ if input_ids_seq_length >= generation_config.max_length:
+ input_ids_string = ("decoder_input_ids" if self.config.is_encoder_decoder else "input_ids")
+ logger.warning(f"Input length of {input_ids_string} is {input_ids_seq_length}, but `max_length` is set to"
+ f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"
+ " increasing `max_new_tokens`.")
+
+ # 2. Set generation parameters if not already defined
+ logits_processor = (logits_processor if logits_processor is not None else LogitsProcessorList())
+ stopping_criteria = (stopping_criteria if stopping_criteria is not None else StoppingCriteriaList())
+
+ logits_processor = self._get_logits_processor(
+ generation_config=generation_config,
+ input_ids_seq_length=input_ids_seq_length,
+ encoder_input_ids=input_ids,
+ prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
+ logits_processor=logits_processor,
+ )
+
+ stopping_criteria = self._get_stopping_criteria(generation_config=generation_config,
+ stopping_criteria=stopping_criteria)
+ logits_warper = self._get_logits_warper(generation_config)
+
+ unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
+ scores = None
+ while True:
+ model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
+ # forward pass to get next token
+ outputs = self(
+ **model_inputs,
+ return_dict=True,
+ output_attentions=False,
+ output_hidden_states=False,
+ )
+
+ next_token_logits = outputs.logits[:, -1, :]
+
+ # pre-process distribution
+ next_token_scores = logits_processor(input_ids, next_token_logits)
+ next_token_scores = logits_warper(input_ids, next_token_scores)
+
+ # sample
+ probs = nn.functional.softmax(next_token_scores, dim=-1)
+ if generation_config.do_sample:
+ next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
+ else:
+ next_tokens = torch.argmax(probs, dim=-1)
+
+ # update generated ids, model inputs, and length for next step
+ input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
+ model_kwargs = self._update_model_kwargs_for_generation(outputs,
+ model_kwargs,
+ is_encoder_decoder=self.config.is_encoder_decoder)
+ unfinished_sequences = unfinished_sequences.mul((sum(next_tokens != i for i in eos_token_id)).long())
+ if return_past_key_values:
+ yield input_ids, outputs.past_key_values
+ else:
+ yield input_ids
+ # stop when each sentence is finished, or if we exceed the maximum length
+ if unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):
+ break
+
+ def quantize(self, bits: int, empty_init=False, device=None, **kwargs):
+ if bits == 0:
+ return
+
+ from .quantization import quantize
+
+ if self.quantized:
+ logger.info("Already quantized.")
+ return self
+
+ self.quantized = True
+
+ self.config.quantization_bit = bits
+
+ self.transformer.encoder = quantize(
+ self.transformer.encoder,
+ bits,
+ empty_init=empty_init,
+ device=device,
+ **kwargs,
+ )
+ return self
diff --git a/colossalai/shardformer/modeling/gpt2.py b/colossalai/shardformer/modeling/gpt2.py
new file mode 100644
index 000000000000..47835d5d5468
--- /dev/null
+++ b/colossalai/shardformer/modeling/gpt2.py
@@ -0,0 +1,755 @@
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPastAndCrossAttentions,
+ CausalLMOutputWithCrossAttentions,
+ QuestionAnsweringModelOutput,
+ SequenceClassifierOutputWithPast,
+ TokenClassifierOutput,
+)
+from transformers.models.gpt2.modeling_gpt2 import (
+ GPT2DoubleHeadsModel,
+ GPT2DoubleHeadsModelOutput,
+ GPT2ForQuestionAnswering,
+ GPT2ForSequenceClassification,
+ GPT2ForTokenClassification,
+ GPT2LMHeadModel,
+ GPT2Model,
+)
+from transformers.utils import logging
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+
+class GPT2PipelineForwards:
+ '''
+ This class serves as a micro library for forward function substitution of GPT2 models
+ under pipeline setting.
+ '''
+
+ @staticmethod
+ def gpt2_model_forward(
+ self: GPT2Model,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None) -> Union[Dict, Tuple, BaseModelOutputWithPastAndCrossAttentions]:
+
+ # This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2Model.forward.
+ # Please refer to original code of transformers for more details.
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ logger = logging.get_logger(__name__)
+
+ # Preprocess passed in arguments
+ # TODO(baizhou): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if past_key_values:
+ logger.warning_once('Non-empty past_key_values is not supported for pipeline models at the moment.')
+ past_key_values = None
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once('use_cache=True is not supported for pipeline models at the moment.')
+ use_cache = False
+
+ if stage_manager.is_first_stage():
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ input_shape = input_ids.size()
+ input_ids = input_ids.view(-1, seq_length)
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ batch_size = inputs_embeds.shape[0]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ if token_type_ids is not None:
+ token_type_ids = token_type_ids.view(-1, seq_length)
+ else:
+ if hidden_states is None:
+ raise ValueError("hidden_states shouldn't be None for stages other than the first stage.")
+ input_shape = hidden_states.size()[:-1]
+ batch_size, seq_length = input_shape[0], input_shape[1]
+ device = hidden_states.device
+
+ # GPT2Attention mask.
+ if attention_mask is not None:
+ if batch_size <= 0:
+ raise ValueError("batch_size has to be defined and > 0")
+ attention_mask = attention_mask.view(batch_size, -1)
+ # We create a 3D attention mask from a 2D tensor mask.
+ # Sizes are [batch_size, 1, 1, to_seq_length]
+ # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
+ # this attention mask is more simple than the triangular masking of causal attention
+ # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
+ attention_mask = attention_mask[:, None, None, :]
+
+ # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
+ # masked positions, this operation will create a tensor which is 0.0 for
+ # positions we want to attend and the dtype's smallest value for masked positions.
+ # Since we are adding it to the raw scores before the softmax, this is
+ # effectively the same as removing these entirely.
+ attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
+ attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
+
+ # If a 2D or 3D attention mask is provided for the cross-attention
+ # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if self.config.add_cross_attention and encoder_hidden_states is not None:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
+ encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
+ if encoder_attention_mask is None:
+ encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
+ encoder_attention_mask = self.invert_attention_mask(encoder_attention_mask)
+ else:
+ encoder_attention_mask = None
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # head_mask has shape n_layer x batch x n_heads x N x N
+ head_mask = self.get_head_mask(head_mask, self.config.n_layer)
+
+ if stage_manager.is_first_stage():
+ if position_ids is not None:
+ position_ids = position_ids.view(-1, seq_length)
+ else:
+ position_ids = torch.arange(0, seq_length, dtype=torch.long, device=device)
+ position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
+
+ if inputs_embeds is None:
+ inputs_embeds = self.wte(input_ids)
+ position_embeds = self.wpe(position_ids)
+ hidden_states = inputs_embeds + position_embeds
+ if token_type_ids is not None:
+ token_type_embeds = self.wte(token_type_ids)
+ hidden_states = hidden_states + token_type_embeds
+ hidden_states = self.drop(hidden_states)
+
+ output_shape = input_shape + (hidden_states.size(-1),)
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+ presents = () if use_cache else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
+ all_hidden_states = () if output_hidden_states else None
+
+ # Going through held blocks.
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ for i in range(start_idx, end_idx):
+ block = self.h[i]
+ torch.cuda.set_device(hidden_states.device)
+ # Ensure that attention_mask is always on the same device as hidden_states
+ if attention_mask is not None:
+ attention_mask = attention_mask.to(hidden_states.device)
+ if isinstance(head_mask, torch.Tensor):
+ head_mask = head_mask.to(hidden_states.device)
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ # None for past_key_value
+ return module(*inputs, use_cache, output_attentions)
+
+ return custom_forward
+
+ outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(block),
+ hidden_states,
+ None,
+ attention_mask,
+ head_mask[i],
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+ else:
+ outputs = block(
+ hidden_states,
+ layer_past=None,
+ attention_mask=attention_mask,
+ head_mask=head_mask[i],
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = outputs[0]
+ if use_cache is True:
+ presents = presents + (outputs[1],)
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
+ if self.config.add_cross_attention:
+ all_cross_attentions = all_cross_attentions + (outputs[3 if use_cache else 2],)
+
+ if stage_manager.is_last_stage():
+ hidden_states = self.ln_f(hidden_states)
+
+ hidden_states = hidden_states.view(output_shape)
+
+ # Add last hidden state
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if stage_manager.is_last_stage():
+ if not return_dict:
+ return tuple(
+ v for v in [hidden_states, presents, all_hidden_states, all_self_attentions, all_cross_attentions]
+ if v is not None)
+
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=presents,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+ else:
+ # always return dict for intermediate stage
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def gpt2_lmhead_model_forward(
+ self: GPT2LMHeadModel,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None) -> Union[Dict, Tuple, CausalLMOutputWithCrossAttentions]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
+ `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
+ are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
+
+ This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2LMHeadModel.forward.
+ Please refer to original code of transformers for more details.
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = GPT2PipelineForwards.gpt2_model_forward(self.transformer,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index)
+
+ # If not at the last stage, return hidden_states as in GPT2Model
+ if not stage_manager.is_last_stage():
+ return {'hidden_states': outputs['hidden_states']}
+
+ hidden_states = outputs[0]
+ lm_logits = self.lm_head(hidden_states)
+ loss = None
+ if labels is not None:
+ # move labels to correct device to enable model parallelism
+ labels = labels.to(lm_logits.device)
+ # Shift so that tokens < n predict n
+ shift_logits = lm_logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
+ if not return_dict:
+ output = (lm_logits,) + outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return CausalLMOutputWithCrossAttentions(
+ loss=loss,
+ logits=lm_logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ cross_attentions=outputs.cross_attentions,
+ )
+
+ @staticmethod
+ def gpt2_double_heads_model_forward(
+ self: GPT2DoubleHeadsModel,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ mc_token_ids: Optional[torch.LongTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ mc_labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None) -> Union[Dict, Tuple, GPT2DoubleHeadsModelOutput]:
+ r"""
+ mc_token_ids (`torch.LongTensor` of shape `(batch_size, num_choices)`, *optional*, default to index of the last token of the input):
+ Index of the classification token in each input sequence. Selected in the range `[0, input_ids.size(-1) -
+ 1]`.
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
+ `labels = input_ids`. Indices are selected in `[-100, 0, ..., config.vocab_size - 1]`. All labels set to
+ `-100` are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size - 1]`
+ mc_labels (`torch.LongTensor` of shape `(batch_size)`, *optional*):
+ Labels for computing the multiple choice classification loss. Indices should be in `[0, ..., num_choices]`
+ where *num_choices* is the size of the second dimension of the input tensors. (see *input_ids* above)
+
+ This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2DoubleHeadsModel.forward.
+ Please refer to original code of transformers for more details.
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = GPT2PipelineForwards.gpt2_model_forward(self.transformer,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index)
+
+ # If not at the last stage, return hidden_states as in GPT2Model
+ if not stage_manager.is_last_stage():
+ return {'hidden_states': outputs['hidden_states']}
+
+ hidden_states = outputs[0]
+ lm_logits = self.lm_head(hidden_states)
+ mc_logits = self.multiple_choice_head(hidden_states, mc_token_ids).squeeze(-1)
+
+ mc_loss = None
+ if mc_labels is not None:
+ loss_fct = CrossEntropyLoss()
+ mc_loss = loss_fct(mc_logits.view(-1, mc_logits.size(-1)), mc_labels.view(-1))
+ lm_loss = None
+ if labels is not None:
+ labels = labels.to(lm_logits.device)
+ shift_logits = lm_logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ loss_fct = CrossEntropyLoss()
+ lm_loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
+
+ if not return_dict:
+ output = (lm_logits, mc_logits) + outputs[1:]
+ if mc_loss is not None:
+ output = (mc_loss,) + output
+ return ((lm_loss,) + output) if lm_loss is not None else output
+
+ return GPT2DoubleHeadsModelOutput(
+ loss=lm_loss,
+ mc_loss=mc_loss,
+ logits=lm_logits,
+ mc_logits=mc_logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ @staticmethod
+ def gpt2_for_question_answering_forward(
+ self: GPT2ForQuestionAnswering,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ start_positions: Optional[torch.LongTensor] = None,
+ end_positions: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None) -> Union[Dict, Tuple, QuestionAnsweringModelOutput]:
+ r"""
+ start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the start of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+ end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the end of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+
+ # This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2ForQuestionAnswering.forward.
+ # Please refer to original code of transformers for more details.
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = GPT2PipelineForwards.gpt2_model_forward(self.transformer,
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index)
+
+ # If not at the last stage, return hidden_states as in GPT2Model
+ if not stage_manager.is_last_stage():
+ return {'hidden_states': outputs['hidden_states']}
+
+ sequence_output = outputs[0]
+
+ logits = self.qa_outputs(sequence_output)
+ start_logits, end_logits = logits.split(1, dim=-1)
+ start_logits = start_logits.squeeze(-1).contiguous()
+ end_logits = end_logits.squeeze(-1).contiguous()
+
+ total_loss = None
+ if start_positions is not None and end_positions is not None:
+ # If we are on multi-GPU, split add a dimension
+ if len(start_positions.size()) > 1:
+ start_positions = start_positions.squeeze(-1).to(start_logits.device)
+ if len(end_positions.size()) > 1:
+ end_positions = end_positions.squeeze(-1).to(end_logits.device)
+ # sometimes the start/end positions are outside our model inputs, we ignore these terms
+ ignored_index = start_logits.size(1)
+ start_positions = start_positions.clamp(0, ignored_index)
+ end_positions = end_positions.clamp(0, ignored_index)
+
+ loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
+ start_loss = loss_fct(start_logits, start_positions)
+ end_loss = loss_fct(end_logits, end_positions)
+ total_loss = (start_loss + end_loss) / 2
+
+ if not return_dict:
+ output = (start_logits, end_logits) + outputs[2:]
+ return ((total_loss,) + output) if total_loss is not None else output
+
+ return QuestionAnsweringModelOutput(
+ loss=total_loss,
+ start_logits=start_logits,
+ end_logits=end_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ @staticmethod
+ def gpt2_for_token_classification_forward(
+ self: GPT2ForTokenClassification,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None) -> Union[Dict, Tuple, TokenClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+
+ # This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2ForTokenClassification.forward.
+ # Please refer to original code of transformers for more details.
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = GPT2PipelineForwards.gpt2_model_forward(self.transformer,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index)
+
+ # If not at the last stage, return hidden_states as in GPT2Model
+ if not stage_manager.is_last_stage():
+ return {'hidden_states': outputs['hidden_states']}
+
+ hidden_states = outputs[0]
+ hidden_states = self.dropout(hidden_states)
+ logits = self.classifier(hidden_states)
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return TokenClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ @staticmethod
+ def gpt2_for_sequence_classification_forward(
+ self: GPT2ForSequenceClassification,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None) -> Union[Dict, Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+
+ # This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2ForSequenceClassification.forward.
+ # Please refer to original code of transformers for more details.
+ """
+ logger = logging.get_logger(__name__)
+
+ if input_ids is not None:
+ batch_size, _ = input_ids.shape[:2]
+ else:
+ batch_size, _ = hidden_states.shape[:2]
+ assert (self.config.pad_token_id is not None
+ or batch_size == 1), "Cannot handle batch sizes > 1 if no padding token is defined."
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = GPT2PipelineForwards.gpt2_model_forward(self.transformer,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index)
+
+ # If not at the last stage, return hidden_states as in GPT2Model
+ if not stage_manager.is_last_stage():
+ return {'hidden_states': outputs['hidden_states']}
+
+ hidden_states = outputs[0]
+ logits = self.score(hidden_states)
+
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ sequence_lengths = (torch.ne(input_ids, self.config.pad_token_id).sum(-1) - 1).to(logits.device)
+ else:
+ sequence_lengths = -1
+ logger.warning_once(
+ f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be "
+ "unexpected if using padding tokens in conjunction with `inputs_embeds.`")
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits,) + outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+def get_gpt2_flash_attention_forward():
+
+ from transformers.models.gpt2.modeling_gpt2 import GPT2Attention
+
+ from colossalai.kernel.cuda_native import AttnMaskType, ColoAttention
+
+ def split_heads(tensor, num_heads, attn_head_size):
+ """
+ Splits hidden_size dim into attn_head_size and num_heads
+ """
+ new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
+ tensor = tensor.view(new_shape)
+ return tensor
+
+ def forward(
+ self: GPT2Attention,
+ hidden_states: Optional[Tuple[torch.FloatTensor]],
+ layer_past: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = False,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:
+ _, tgt_len, _ = hidden_states.size()
+ assert tgt_len % 4 == 0, "Flash Attention Error: The sequence length should be a multiple of 4."
+
+ if encoder_hidden_states is not None:
+ if not hasattr(self, "q_attn"):
+ raise ValueError(
+ "If class is used as cross attention, the weights `q_attn` have to be defined. "
+ "Please make sure to instantiate class with `GPT2Attention(..., is_cross_attention=True)`.")
+
+ query = self.q_attn(hidden_states)
+ key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
+ attention_mask = encoder_attention_mask
+ else:
+ query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
+
+ query = split_heads(query, self.num_heads, self.head_dim)
+ key = split_heads(key, self.num_heads, self.head_dim)
+ value = split_heads(value, self.num_heads, self.head_dim)
+
+ if layer_past is not None:
+ past_key, past_value = layer_past
+ key = torch.cat((past_key, key), dim=1)
+ value = torch.cat((past_value, value), dim=1)
+
+ if use_cache is True:
+ present = (key, value)
+ else:
+ present = None
+
+ if not self.is_cross_attention:
+ attn_mask_type = AttnMaskType.causal
+ flash_attention_mask = None
+ if attention_mask != None:
+ if attn_mask_type == AttnMaskType.causal:
+ attn_mask_type == AttnMaskType.paddedcausal
+ else:
+ attn_mask_type = AttnMaskType.padding
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool)).contiguous()
+
+ scale = value.size(-1)**-0.5
+ if self.scale_attn_by_inverse_layer_idx:
+ scale = scale * (1 / float(self.layer_idx + 1))
+
+ # use coloattention
+ attention = ColoAttention(embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ dropout=self.attn_dropout.p,
+ scale=scale)
+
+ attn_output = attention(query, key, value, attn_mask=flash_attention_mask, attn_mask_type=attn_mask_type)
+
+ attn_output = self.c_proj(attn_output)
+ attn_output = self.resid_dropout(attn_output)
+ outputs = (attn_output, present, None)
+
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/modeling/jit.py b/colossalai/shardformer/modeling/jit.py
new file mode 100644
index 000000000000..6434348ef823
--- /dev/null
+++ b/colossalai/shardformer/modeling/jit.py
@@ -0,0 +1,34 @@
+import torch
+
+
+def get_dropout_add_func():
+
+ from transformers.models.bloom.modeling_bloom import dropout_add
+
+ def self_dropout_add(self, x: torch.Tensor, residual: torch.Tensor, prob: float, training: bool) -> torch.Tensor:
+ return dropout_add(x, residual, prob, training)
+
+ return self_dropout_add
+
+
+def get_jit_fused_dropout_add_func():
+
+ from colossalai.kernel.jit import bias_dropout_add_fused_inference, bias_dropout_add_fused_train
+
+ def self_dropout_add(self, x: torch.Tensor, residual: torch.Tensor, prob: float, training: bool) -> torch.Tensor:
+ bias = torch.zeros_like(x)
+ if training:
+ return bias_dropout_add_fused_train(x, bias, residual, prob)
+ return bias_dropout_add_fused_inference(x, bias, residual, prob)
+
+ return self_dropout_add
+
+
+def get_jit_fused_gelu_forward_func():
+
+ from colossalai.kernel.jit.bias_gelu import bias_gelu
+
+ def bloom_gelu_forward(x: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:
+ return bias_gelu(bias, x)
+
+ return bloom_gelu_forward
diff --git a/colossalai/shardformer/modeling/llama.py b/colossalai/shardformer/modeling/llama.py
new file mode 100644
index 000000000000..f1d2998bbee4
--- /dev/null
+++ b/colossalai/shardformer/modeling/llama.py
@@ -0,0 +1,452 @@
+from typing import Callable, List, Optional, Tuple
+
+import torch
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPast,
+ CausalLMOutputWithPast,
+ SequenceClassifierOutputWithPast,
+)
+from transformers.models.llama.modeling_llama import LlamaForCausalLM, LlamaForSequenceClassification, LlamaModel
+from transformers.utils import logging
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+
+class LlamaPipelineForwards:
+ '''
+ This class serves as a micro library for forward function substitution of Llama models
+ under pipeline setting.
+ '''
+
+ def llama_model_forward(
+ self: LlamaModel,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ logger = logging.get_logger(__name__)
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if stage_manager.is_first_stage():
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+ hidden_states = inputs_embeds
+ else:
+ input_shape = hidden_states.shape[:-1]
+ batch_size, seq_length = input_shape
+ device = hidden_states.device
+
+ seq_length_with_past = seq_length
+ past_key_values_length = 0
+
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once('use_cache=True is not supported for pipeline models at the moment.')
+ use_cache = False
+
+ if past_key_values is not None:
+ past_key_values_length = past_key_values[0][0].shape[2]
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+
+ if position_ids is None:
+ position_ids = torch.arange(past_key_values_length,
+ seq_length + past_key_values_length,
+ dtype=torch.long,
+ device=device)
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ # embed positions, for the first stage, hidden_states is the input embeddings,
+ # for the other stages, hidden_states is the output of the previous stage
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, seq_length_with_past),
+ dtype=torch.bool,
+ device=hidden_states.device)
+ attention_mask = self._prepare_decoder_attention_mask(attention_mask, (batch_size, seq_length), hidden_states,
+ past_key_values_length)
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = () if use_cache else None
+
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ for idx, decoder_layer in enumerate(self.layers[start_idx:end_idx], start=start_idx):
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ past_key_value = past_key_values[idx] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ # None for past_key_value
+ return module(*inputs, output_attentions, None)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(decoder_layer),
+ hidden_states,
+ attention_mask,
+ position_ids,
+ None,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ if stage_manager.is_last_stage():
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+ next_cache = next_decoder_cache if use_cache else None
+ if stage_manager.is_last_stage():
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+ # always return dict for imediate stage
+ return {'hidden_states': hidden_states}
+
+ def llama_for_causal_lm_forward(
+ self: LlamaForCausalLM,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, LlamaForCausalLM
+
+ >>> model = LlamaForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
+ >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+
+ >>> prompt = "Hey, are you consciours? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you consciours? Can you talk to me?\nI'm not consciours, but I can talk to you."
+ ```"""
+ logger = logging.get_logger(__name__)
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = LlamaPipelineForwards.llama_model_forward(
+ self.model,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ )
+ past_key_values = None
+ all_hidden_states = None
+ all_self_attentions = None
+ all_cross_attentions = None
+
+ if stage_manager.is_last_stage():
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return (loss,) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+ def llama_for_sequence_classification_forward(
+ self: LlamaForSequenceClassification,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+
+ transformer_outputs = LlamaPipelineForwards.llama_model_forward(
+ self.model,
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ )
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ elif inputs_embeds is not None:
+ batch_size = inputs_embeds.shape[0]
+ else:
+ batch_size = hidden_states.shape[0]
+
+ if stage_manager.is_last_stage():
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ sequence_lengths = (torch.ne(input_ids, self.config.pad_token_id).sum(-1) - 1).to(logits.device)
+ else:
+ sequence_lengths = -1
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
+
+ else:
+ hidden_states = transformer_outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+
+def get_llama_flash_attention_forward():
+
+ from transformers.models.llama.modeling_llama import LlamaAttention, apply_rotary_pos_emb
+
+ from colossalai.kernel.cuda_native import AttnMaskType, ColoAttention
+
+ def forward(
+ self: LlamaAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+ assert q_len % 4 == 0, "Flash Attention Error: The sequence length should be a multiple of 4."
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ me_input_shape = (bsz, q_len, self.num_heads, self.head_dim)
+ query_states = query_states.transpose(1, 2).contiguous().view(*me_input_shape)
+ key_states = key_states.transpose(1, 2).contiguous().view(*me_input_shape)
+ value_states = value_states.transpose(1, 2).contiguous().view(*me_input_shape)
+
+ flash_attention_mask = None
+ attn_mask_type = AttnMaskType.causal
+ if attention_mask != None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}")
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool)).contiguous()
+ attn_mask_type = AttnMaskType.paddedcausal
+
+ attention = ColoAttention(embed_dim=self.hidden_size, num_heads=self.num_heads)
+ attn_output = attention(query_states,
+ key_states,
+ value_states,
+ attn_mask=flash_attention_mask,
+ attn_mask_type=attn_mask_type)
+
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+ return forward
diff --git a/colossalai/shardformer/modeling/opt.py b/colossalai/shardformer/modeling/opt.py
new file mode 100644
index 000000000000..b4251f33b457
--- /dev/null
+++ b/colossalai/shardformer/modeling/opt.py
@@ -0,0 +1,667 @@
+import random
+from typing import List, Optional, Tuple, Union
+
+import torch
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPast,
+ CausalLMOutputWithPast,
+ QuestionAnsweringModelOutput,
+ SequenceClassifierOutputWithPast,
+)
+from transformers.models.opt.modeling_opt import (
+ OPTForCausalLM,
+ OPTForQuestionAnswering,
+ OPTForSequenceClassification,
+ OPTModel,
+)
+from transformers.utils import logging
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+
+class OPTPipelineForwards:
+ '''
+ This class serves as a micro library for forward function substitution of OPT models
+ under pipeline setting.
+ '''
+
+ @staticmethod
+ def _prepare_decoder_attention_mask(attention_mask, input_shape, _dtype, device, past_key_values_length):
+ # create causal mask
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ from transformers.models.opt.modeling_opt import _make_causal_mask
+ combined_attention_mask = None
+ if input_shape[-1] > 1:
+ combined_attention_mask = _make_causal_mask(
+ input_shape,
+ _dtype,
+ device,
+ past_key_values_length=past_key_values_length,
+ )
+
+ if attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ expanded_attn_mask = OPTPipelineForwards._expand_mask(attention_mask, _dtype,
+ tgt_len=input_shape[-1]).to(device)
+ combined_attention_mask = (expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask +
+ combined_attention_mask)
+
+ return combined_attention_mask
+
+ @staticmethod
+ def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
+ """
+ Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
+ """
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
+
+ inverted_mask = 1.0 - expanded_mask
+
+ return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
+
+ @staticmethod
+ def opt_model_forward(
+ self: OPTModel,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ '''
+ This forward method is modified based on transformers.models.opt.modeling_opt.OPTModel.forward
+ '''
+
+ from transformers.modeling_outputs import BaseModelOutputWithPast
+ from transformers.utils import logging
+ logger = logging.get_logger(__name__)
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ decoder = self.decoder
+ if stage_manager.is_first_stage():
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ input_shape = input_ids.size()
+ input_ids = input_ids.view(-1, input_shape[-1])
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+
+ batch_size, seq_length = input_shape
+
+ if inputs_embeds is None:
+ inputs_embeds = decoder.embed_tokens(input_ids)
+
+ if decoder.project_in is not None:
+ inputs_embeds = decoder.project_in(inputs_embeds)
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ _dtype = inputs_embeds.dtype
+
+ else:
+ if hidden_states is None:
+ raise ValueError("hidden_states shouln't be None for intermediate stages.")
+ input_shape = hidden_states.size()[:-1]
+ batch_size, seq_length = input_shape[0], input_shape[1]
+ device = hidden_states.device
+ _dtype = hidden_states.dtype
+
+ past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
+ # required mask seq length can be calculated via length of past
+ mask_seq_length = past_key_values_length + seq_length
+ # embed positions
+ if attention_mask is None:
+ attention_mask = torch.ones(batch_size, mask_seq_length, device=device)
+ elif attention_mask.shape[1] != mask_seq_length:
+ raise ValueError(
+ f"The provided attention mask has length {attention_mask.shape[1]}, but its length should be "
+ f"{mask_seq_length} (sum of the lengths of current and past inputs)")
+
+ causal_attention_mask = OPTPipelineForwards._prepare_decoder_attention_mask(attention_mask, input_shape, _dtype,
+ device, past_key_values_length)
+
+ if stage_manager.is_first_stage():
+ pos_embeds = decoder.embed_positions(attention_mask, past_key_values_length)
+ hidden_states = inputs_embeds + pos_embeds
+
+ if decoder.gradient_checkpointing and decoder.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+
+ # TODO(baizhou): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if past_key_values:
+ logger.warning_once('Non-empty past_key_values is not supported for pipeline models at the moment.')
+ past_key_values = None
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once('use_cache=True is not supported for pipeline models at the moment.')
+ use_cache = False
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = () if use_cache else None
+
+ # check if head_mask has a correct number of layers specified if desired
+ for attn_mask, mask_name in zip([head_mask], ["head_mask"]):
+ if attn_mask is not None:
+ if attn_mask.size()[0] != (len(decoder.layers)):
+ raise ValueError(
+ f"The `{mask_name}` should be specified for {len(decoder.layers)} layers, but it is for"
+ f" {head_mask.size()[0]}.")
+
+ start_idx, end_idx = stage_index[0], stage_index[1]
+
+ torch.cuda.set_device(device)
+
+ for idx in range(start_idx, end_idx):
+ # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ decoder_layer = decoder.layers[idx]
+
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ dropout_probability = random.uniform(0, 1)
+ if decoder.training and (dropout_probability < decoder.layerdrop):
+ continue
+
+ past_key_value = past_key_values[idx] if past_key_values is not None else None
+
+ if decoder.gradient_checkpointing and decoder.training:
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ # None for past_key_value
+ return module(*inputs, output_attentions, None)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(decoder_layer),
+ hidden_states,
+ causal_attention_mask,
+ head_mask[idx] if head_mask is not None else None,
+ None,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=causal_attention_mask,
+ layer_head_mask=(head_mask[idx] if head_mask is not None else None),
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ if stage_manager.is_last_stage():
+ if decoder.final_layer_norm is not None:
+ hidden_states = decoder.final_layer_norm(hidden_states)
+ if decoder.project_out is not None:
+ hidden_states = decoder.project_out(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = next_decoder_cache if use_cache else None
+
+ if stage_manager.is_last_stage():
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+ else:
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def opt_for_causal_lm_forward(
+ self: OPTForCausalLM,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ This function is modified on the basis of transformers.models.opt.modeling_opt.OPTForCausalLM.forward.
+ Please refer to original code of transformers for more details.
+ """
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = OPTPipelineForwards.opt_model_forward(
+ self.model,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ )
+ if stage_manager.is_last_stage():
+ logits = self.lm_head(outputs[0]).contiguous()
+ loss = None
+ if labels is not None:
+ # move labels to correct device to enable model parallelism
+ labels = labels.to(logits.device)
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(shift_logits.view(-1, self.config.vocab_size), shift_labels.view(-1))
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return (loss,) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+ else:
+ hidden_states = outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def opt_for_sequence_classification_forward(
+ self: OPTForSequenceClassification,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ This function is modified on the basis of transformers.models.opt.modeling_opt.OPTForSequenceClassification.forward.
+ Please refer to original code of transformers for more details.
+ """
+
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_outputs = OPTPipelineForwards.opt_model_forward(self.model,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index)
+
+ if stage_manager.is_last_stage():
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ batch_size = input_ids.shape[0] if input_ids is not None else hidden_states.shape[0]
+
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ sequence_lengths = (torch.ne(input_ids, self.config.pad_token_id).sum(-1) - 1).to(logits.device)
+ else:
+ sequence_lengths = -1
+ logger.warning(
+ f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be "
+ "unexpected if using padding tokens in conjunction with `inputs_embeds.`")
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+
+ if not return_dict:
+ output = (pooled_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
+ else:
+ hidden_states = transformer_outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+ @staticmethod
+ def opt_for_question_answering_forward(
+ self: OPTForQuestionAnswering,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ start_positions: Optional[torch.LongTensor] = None,
+ end_positions: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ) -> Union[Tuple, QuestionAnsweringModelOutput]:
+ r"""
+ This function is modified on the basis of transformers.models.opt.modeling_opt.OPTForQuestionAnswering.forward.
+ Please refer to original code of transformers for more details.
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_outputs = OPTPipelineForwards.opt_model_forward(self.model,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index)
+ if stage_manager.is_last_stage():
+ hidden_states = transformer_outputs[0]
+
+ logits = self.qa_outputs(hidden_states)
+ start_logits, end_logits = logits.split(1, dim=-1)
+ start_logits = start_logits.squeeze(-1).contiguous()
+ end_logits = end_logits.squeeze(-1).contiguous()
+
+ total_loss = None
+ if start_positions is not None and end_positions is not None:
+ # If we are on multi-GPU, split add a dimension
+ if len(start_positions.size()) > 1:
+ start_positions = start_positions.squeeze(-1)
+ if len(end_positions.size()) > 1:
+ end_positions = end_positions.squeeze(-1)
+ # sometimes the start/end positions are outside our model inputs, we ignore these terms
+ ignored_index = start_logits.size(1)
+ start_positions = start_positions.clamp(0, ignored_index)
+ end_positions = end_positions.clamp(0, ignored_index)
+
+ loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
+ start_loss = loss_fct(start_logits, start_positions)
+ end_loss = loss_fct(end_logits, end_positions)
+ total_loss = (start_loss + end_loss) / 2
+
+ if not return_dict:
+ output = (start_logits, end_logits) + transformer_outputs[2:]
+ return ((total_loss,) + output) if total_loss is not None else output
+
+ return QuestionAnsweringModelOutput(
+ loss=total_loss,
+ start_logits=start_logits,
+ end_logits=end_logits,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
+ else:
+ hidden_states = transformer_outputs.get('hidden_states')
+ return {'hidden_states': hidden_states}
+
+
+def get_opt_flash_attention_forward():
+
+ from transformers.models.opt.modeling_opt import OPTAttention
+
+ from colossalai.kernel.cuda_native import AttnMaskType, ColoAttention
+
+ def forward(
+ self: OPTAttention,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+ bsz, tgt_len, _ = hidden_states.size()
+ assert tgt_len % 4 == 0, "Flash Attention Error: The sequence length should be a multiple of 4."
+
+ attention_input_shape = (bsz, -1, self.num_heads, self.head_dim)
+ # get query proj
+ query_states = self.q_proj(hidden_states).view(*attention_input_shape)
+ # get key, value proj
+ if is_cross_attention and past_key_value is not None:
+ # reuse k, v, cross_attentions
+ key_states = past_key_value[0].transpose(1, 2).contiguous().view(*attention_input_shape)
+ value_states = past_key_value[1].transpose(1, 2).contiguous().view(*attention_input_shape)
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self.k_proj(key_value_states).view(*attention_input_shape)
+ value_states = self.v_proj(key_value_states).view(*attention_input_shape)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self.k_proj(hidden_states).view(*attention_input_shape)
+ value_states = self.v_proj(hidden_states).view(*attention_input_shape)
+ key_states = torch.cat([past_key_value[0], key_states], dim=1)
+ value_states = torch.cat([past_key_value[1], value_states], dim=1)
+ else:
+ # self_attention
+ key_states = self.k_proj(hidden_states).view(*attention_input_shape)
+ value_states = self.v_proj(hidden_states).view(*attention_input_shape)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ src_len = key_states.size(1)
+ if layer_head_mask != None:
+ if layer_head_mask.size() != (self.num_heads,):
+ raise ValueError(f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
+ f" {layer_head_mask.size()}")
+
+ flash_attention_mask = None
+ attn_mask_type = AttnMaskType.causal
+ if attention_mask != None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}")
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool)).contiguous()
+ attn_mask_type = AttnMaskType.paddedcausal
+
+ attention = ColoAttention(embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ dropout=self.dropout,
+ scale=self.scaling)
+ attn_output = attention(query_states,
+ key_states,
+ value_states,
+ attn_mask=flash_attention_mask,
+ attn_mask_type=attn_mask_type)
+
+ attn_output = self.out_proj(attn_output)
+ return attn_output, None, past_key_value
+
+ return forward
+
+
+def get_jit_fused_opt_decoder_layer_forward():
+
+ from transformers.models.opt.modeling_opt import OPTDecoderLayer
+
+ def forward(
+ self: OPTDecoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`, *optional*): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+
+ residual = hidden_states
+
+ # 125m, 1.7B, ..., 175B applies layer norm BEFORE attention
+ if self.do_layer_norm_before:
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ past_key_value=past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ # 350m applies layer norm AFTER attention
+ if not self.do_layer_norm_before:
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Fully Connected
+ hidden_states_shape = hidden_states.shape
+ hidden_states = hidden_states.reshape(-1, hidden_states.size(-1))
+ residual = hidden_states
+
+ # 125m, 1.7B, ..., 175B applies layer norm BEFORE attention
+ if self.do_layer_norm_before:
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ hidden_states = self.fc1(hidden_states)
+ hidden_states = self.activation_fn(hidden_states)
+
+ hidden_states = self.fc2(hidden_states)
+
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training).view(hidden_states_shape)
+
+ # 350m applies layer norm AFTER attention
+ if not self.do_layer_norm_before:
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/modeling/sam.py b/colossalai/shardformer/modeling/sam.py
new file mode 100644
index 000000000000..c40c02ec411a
--- /dev/null
+++ b/colossalai/shardformer/modeling/sam.py
@@ -0,0 +1,203 @@
+import math
+from typing import Tuple
+
+import torch
+import torch.nn.functional as F
+from torch import Tensor
+
+
+def forward_fn():
+
+ def forward(self, hidden_states: torch.Tensor, output_attentions=False) -> torch.Tensor:
+ batch_size, height, width, _ = hidden_states.shape
+ # qkv with shape (3, batch_size, nHead, height * width, channel)
+ qkv = (self.qkv(hidden_states).reshape(batch_size, height * width, 3, self.num_attention_heads,
+ -1).permute(2, 0, 3, 1, 4))
+ # q, k, v with shape (batch_size * nHead, height * width, channel)
+ query, key, value = qkv.reshape(3, batch_size * self.num_attention_heads, height * width, -1).unbind(0)
+
+ attn_weights = (query * self.scale) @ key.transpose(-2, -1)
+
+ if self.use_rel_pos:
+ attn_weights = self.add_decomposed_rel_pos(attn_weights, query, self.rel_pos_h, self.rel_pos_w,
+ (height, width), (height, width))
+
+ attn_weights = torch.nn.functional.softmax(attn_weights, dtype=torch.float32, dim=-1).to(query.dtype)
+
+ # replace dropout process with added DropoutForParallelInput layer
+ # origin code:
+ # attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
+ attn_probs = self.dropout_layer(attn_weights)
+
+ attn_output = (attn_probs @ value).reshape(batch_size, self.num_attention_heads, height, width, -1)
+ attn_output = attn_output.permute(0, 2, 3, 1, 4).reshape(batch_size, height, width, -1)
+
+ attn_output = self.proj(attn_output)
+
+ if output_attentions:
+ outputs = (attn_output, attn_weights)
+ else:
+ outputs = (attn_output, None)
+
+ return outputs
+
+ return forward
+
+
+def get_sam_flash_attention_forward():
+
+ from transformers.models.sam.modeling_sam import SamAttention
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+
+ def _separate_heads(hidden_states: Tensor, num_attention_heads: int) -> Tensor:
+ batch, point_batch_size, n_tokens, channel = hidden_states.shape
+ c_per_head = channel // num_attention_heads
+ hidden_states = hidden_states.reshape(batch * point_batch_size, n_tokens, num_attention_heads, c_per_head)
+ return hidden_states
+
+ def _recombine_heads(hidden_states: Tensor, point_batch_size: int) -> Tensor:
+ batch, n_tokens, n_heads, c_per_head = hidden_states.shape
+ return hidden_states.reshape(batch // point_batch_size, point_batch_size, n_tokens, n_heads * c_per_head)
+
+ def forward(self: SamAttention,
+ query: Tensor,
+ key: Tensor,
+ value: Tensor,
+ attention_similarity: Tensor = None) -> Tensor:
+ # Input projections
+ query = self.q_proj(query)
+ key = self.k_proj(key)
+ value = self.v_proj(value)
+
+ point_batch_size = query.shape[1]
+ # Separate into heads
+ query = _separate_heads(query, self.num_attention_heads)
+ key = _separate_heads(key, self.num_attention_heads)
+ value = _separate_heads(value, self.num_attention_heads)
+
+ # SamAttention
+ _, _, _, c_per_head = query.shape
+ bias = None
+ if attention_similarity is not None:
+ bias = attention_similarity
+
+ scale = 1.0 / math.sqrt(c_per_head)
+ out = me_attention(query, key, value, attn_bias=bias, scale=scale)
+
+ out = _recombine_heads(out, point_batch_size)
+ out = self.out_proj(out)
+
+ return out
+
+ return forward
+
+
+def get_sam_vision_flash_attention_forward():
+
+ from transformers.models.sam.modeling_sam import SamVisionAttention
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+
+ def add_decomposed_rel_pos(
+ query: torch.Tensor,
+ rel_pos_h: torch.Tensor,
+ rel_pos_w: torch.Tensor,
+ q_size: Tuple[int, int],
+ k_size: Tuple[int, int],
+ ) -> torch.Tensor:
+ """
+ Calculate decomposed Relative Positional Embeddings from :paper:`mvitv2`.
+ https://github.com/facebookresearch/mvit/blob/19786631e330df9f3622e5402b4a419a263a2c80/mvit/models/attention.py
+
+ Args:
+ attn (`torch.Tensor`):
+ attention map.
+ query (`torch.Tensor`):
+ query q in the attention layer with shape (batch_size, query_height * query_width, channel).
+ rel_pos_h (`torch.Tensor`):
+ relative position embeddings (Lh, channel) for height axis.
+ rel_pos_w (`torch.Tensor`):
+ relative position embeddings (Lw, channel) for width axis.
+ q_size (tuple):
+ spatial sequence size of query q with (query_height, query_width).
+ k_size (tuple):
+ spatial sequence size of key k with (key_height, key_width).
+
+ Returns:
+ attn (`torch.Tensor`):
+ attention map with added relative positional embeddings.
+ """
+
+ query_height, query_width = q_size
+ key_height, key_width = k_size
+ relative_position_height = get_rel_pos(query_height, key_height, rel_pos_h)
+ relative_position_width = get_rel_pos(query_width, key_width, rel_pos_w)
+
+ batch_size, _, nHead, dim = query.shape
+ reshaped_query = query.transpose(1, 2).reshape(batch_size * nHead, query_height, query_width, dim)
+ rel_h = torch.einsum("bhwc,hkc->bhwk", reshaped_query, relative_position_height)
+ rel_w = torch.einsum("bhwc,wkc->bhwk", reshaped_query, relative_position_width)
+ rel_pos = rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :]
+ rel_pos = rel_pos.reshape(batch_size, nHead, query_height * query_width, key_height * key_width)
+ return rel_pos
+
+ def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torch.Tensor:
+ """
+ Get relative positional embeddings according to the relative positions of
+ query and key sizes.
+
+ Args:
+ q_size (int):
+ size of the query.
+ k_size (int):
+ size of key k.
+ rel_pos (`torch.Tensor`):
+ relative position embeddings (L, channel).
+
+ Returns:
+ Extracted positional embeddings according to relative positions.
+ """
+ max_rel_dist = int(2 * max(q_size, k_size) - 1)
+ # Interpolate rel pos.
+ rel_pos_resized = F.interpolate(
+ rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1),
+ size=max_rel_dist,
+ mode="linear",
+ )
+ rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0)
+
+ # Scale the coords with short length if shapes for q and k are different.
+ q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0)
+ k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0)
+ relative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0)
+
+ return rel_pos_resized[relative_coords.long()]
+
+ def forward(self: SamVisionAttention, hidden_states: torch.Tensor, output_attentions=False) -> torch.Tensor:
+ batch_size, height, width, _ = hidden_states.shape
+ # qkv with shape (3, batch_size, nHead, height * width, channel)
+ qkv = (self.qkv(hidden_states).reshape(batch_size, height * width, 3, self.num_attention_heads,
+ -1).permute(2, 0, 1, 3, 4))
+
+ query, key, value = qkv.reshape(3, batch_size, height * width, self.num_attention_heads, -1).unbind(0)
+
+ rel_pos = None
+ if self.use_rel_pos:
+ rel_pos = add_decomposed_rel_pos(query, self.rel_pos_h, self.rel_pos_w, (height, width), (height, width))
+
+ attn_output = me_attention(query, key, value, attn_bias=rel_pos, p=self.dropout, scale=self.scale)
+
+ attn_output = attn_output.reshape(batch_size, height, width, -1)
+
+ attn_output = self.proj(attn_output)
+
+ outputs = (attn_output, None)
+
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/modeling/t5.py b/colossalai/shardformer/modeling/t5.py
new file mode 100644
index 000000000000..9cc071f91dfc
--- /dev/null
+++ b/colossalai/shardformer/modeling/t5.py
@@ -0,0 +1,786 @@
+import warnings
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+from torch.nn import CrossEntropyLoss
+from torch.utils.checkpoint import checkpoint
+from transformers.modeling_outputs import (
+ BaseModelOutput,
+ BaseModelOutputWithPastAndCrossAttentions,
+ Seq2SeqLMOutput,
+ Seq2SeqModelOutput,
+)
+from transformers.models.t5.modeling_t5 import T5EncoderModel, T5ForConditionalGeneration, T5Model, T5Stack
+from transformers.utils import logging
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+
+class T5PipelineForwards:
+ '''
+ This class serves as a micro library for forward function substitution of
+ T5 models under pipeline setting.
+ '''
+
+ @staticmethod
+ def t5_stack_forward(
+ self: T5Stack,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ cross_attn_head_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ use_cache: Optional[bool] = False,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ encoder_decoder_position_bias: Optional[torch.Tensor] = None,
+ stage_index: Optional[List[int]] = None,
+ decoder_starting_stage: Optional[int] = None,
+ ) -> Union[Dict, Tuple, BaseModelOutputWithPastAndCrossAttentions]:
+
+ # This function is modified on the basis of transformers.models.t5.modeling_t5.T5Stack.forward.
+ # Please refer to original code of transformers for more details.
+
+ logger = logging.get_logger(__name__)
+
+ # TODO(baizhou): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if past_key_values:
+ logger.warning_once('Non-empty past_key_values is not supported for pipeline models at the moment.')
+ past_key_values = None
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once('use_cache=True is not supported for pipeline models at the moment.')
+ use_cache = False
+ if use_cache is True:
+ if not in_decoder:
+ raise ValueError(f"`use_cache` can only be set to `True` if {self} is used as a decoder")
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+
+ stage = stage_manager.stage
+ in_decoder = self.is_decoder
+ if in_decoder != (stage >= decoder_starting_stage):
+ raise ValueError("Config in T5Stack is not aligned with pipeline setting.")
+
+ # at_first_stage: current stage is the first stage of encoder/decoder, taking input_ids/input_embedds
+ # at_last_stage: current stage is the last stage of encoder/decoder, making outputs the same form as huggingface
+ at_first_stage = (stage == 0) or (stage == decoder_starting_stage)
+ at_last_stage = (stage == decoder_starting_stage - 1) or (stage == stage_manager.num_stages - 1)
+
+ # Process inputs if at the first stage of encoder/decoder.
+ if at_first_stage:
+ if input_ids is not None and inputs_embeds is not None:
+ err_msg_prefix = "decoder_" if in_decoder else ""
+ raise ValueError(
+ f"You cannot specify both {err_msg_prefix}input_ids and {err_msg_prefix}inputs_embeds at the same time"
+ )
+ elif input_ids is not None:
+ input_shape = input_ids.size()
+ input_ids = input_ids.view(-1, input_shape[-1])
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ err_msg_prefix = "decoder_" if in_decoder else ""
+ raise ValueError(
+ f"You have to specify either {err_msg_prefix}input_ids or {err_msg_prefix}inputs_embeds")
+ if inputs_embeds is None:
+ if self.embed_tokens is None:
+ raise ValueError("You have to initialize the model with valid token embeddings")
+ inputs_embeds = self.embed_tokens(input_ids)
+ batch_size, seq_length = input_shape
+ device = inputs_embeds.device
+ hidden_states = self.dropout(inputs_embeds)
+ else:
+ if hidden_states is None:
+ raise ValueError(
+ "hidden_states shouldn't be None for stages other than the first stage of encoder/decoder.")
+ input_shape = hidden_states.size()[:-1]
+ batch_size, seq_length = input_shape[0], input_shape[1]
+ device = hidden_states.device
+
+ # required mask seq length can be calculated via length of past
+ mask_seq_length = past_key_values[0][0].shape[2] + seq_length if past_key_values is not None else seq_length
+
+ if attention_mask is None:
+ attention_mask = torch.ones(batch_size, mask_seq_length, device=device)
+ if in_decoder and encoder_attention_mask is None and encoder_hidden_states is not None:
+ encoder_seq_length = encoder_hidden_states.shape[1]
+ encoder_attention_mask = torch.ones(batch_size, encoder_seq_length, device=device, dtype=torch.long)
+
+ # initialize past_key_values with `None` if past does not exist
+ if past_key_values is None:
+ past_key_values = [None] * len(self.block)
+
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask = self.get_extended_attention_mask(attention_mask, input_shape)
+
+ # If a 2D or 3D attention mask is provided for the cross-attention
+ # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if self.is_decoder and encoder_hidden_states is not None:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
+ encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
+ if encoder_attention_mask is None:
+ encoder_attention_mask = torch.ones(encoder_hidden_shape, device=inputs_embeds.device)
+ encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ head_mask = self.get_head_mask(head_mask, self.config.num_layers)
+ cross_attn_head_mask = self.get_head_mask(cross_attn_head_mask, self.config.num_layers)
+ present_key_value_states = () if use_cache else None
+ all_hidden_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+ all_cross_attentions = () if (output_attentions and self.is_decoder) else None
+
+ # Going through held blocks.
+ start_idx, end_idx = stage_index[0], stage_index[1]
+
+ for i in range(start_idx, end_idx):
+
+ past_key_value = past_key_values[i]
+ layer_module = self.block[i]
+ layer_head_mask = head_mask[i]
+ cross_attn_layer_head_mask = cross_attn_head_mask[i]
+ torch.cuda.set_device(hidden_states.device)
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ return tuple(module(*inputs, use_cache, output_attentions))
+
+ return custom_forward
+
+ layer_outputs = checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ extended_attention_mask,
+ position_bias,
+ encoder_hidden_states,
+ encoder_extended_attention_mask,
+ encoder_decoder_position_bias,
+ layer_head_mask,
+ cross_attn_layer_head_mask,
+ None, # past_key_value is always None with gradient checkpointing
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask=extended_attention_mask,
+ position_bias=position_bias,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_extended_attention_mask,
+ encoder_decoder_position_bias=encoder_decoder_position_bias,
+ layer_head_mask=layer_head_mask,
+ cross_attn_layer_head_mask=cross_attn_layer_head_mask,
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+
+ # layer_outputs is a tuple with:
+ # hidden-states, key-value-states, (self-attention position bias), (self-attention weights), (cross-attention position bias), (cross-attention weights)
+
+ if use_cache is False or use_cache is None:
+ layer_outputs = layer_outputs[:1] + (None,) + layer_outputs[1:]
+ hidden_states, present_key_value_state = layer_outputs[:2]
+
+ # We share the position biases between the layers - the first layer store them
+ # layer_outputs = hidden-states, key-value-states (self-attention position bias), (self-attention weights),
+ # (cross-attention position bias), (cross-attention weights)
+ position_bias = layer_outputs[2]
+
+ if in_decoder and encoder_hidden_states is not None:
+ encoder_decoder_position_bias = layer_outputs[4 if output_attentions else 3]
+ # append next layer key value states
+ if use_cache:
+ present_key_value_states = present_key_value_states + (present_key_value_state,)
+
+ # last layer
+ if at_last_stage:
+ hidden_states = self.final_layer_norm(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ if not return_dict:
+ return tuple(v for v in [
+ hidden_states,
+ present_key_value_states,
+ all_hidden_states,
+ all_attentions,
+ all_cross_attentions,
+ ] if v is not None)
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=present_key_value_states,
+ hidden_states=all_hidden_states,
+ attentions=all_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+ else:
+ return {
+ 'hidden_states': hidden_states,
+ 'position_bias': position_bias,
+ 'encoder_decoder_position_bias': encoder_decoder_position_bias,
+ 'backward_tensor_keys': ['hidden_states']
+ }
+
+ @staticmethod
+ def t5_model_forward(
+ self: T5Model,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ decoder_input_ids: Optional[torch.LongTensor] = None,
+ decoder_attention_mask: Optional[torch.BoolTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ decoder_head_mask: Optional[torch.FloatTensor] = None,
+ cross_attn_head_mask: Optional[torch.Tensor] = None,
+ encoder_outputs: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ decoder_inputs_embeds: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ encoder_decoder_position_bias: Optional[torch.Tensor] = None,
+ backward_tensor_keys: Optional[List[str]] = None,
+ stage_index: Optional[List[int]] = None,
+ decoder_starting_stage: Optional[int] = None,
+ ) -> Union[Tuple[torch.FloatTensor], Seq2SeqModelOutput]:
+
+ # This function is modified on the basis of transformers.models.t5.modeling_t5.T5Model.forward.
+ # Please refer to original code of transformers for more details.
+
+ __HEAD_MASK_WARNING_MSG = """
+ The input argument `head_mask` was split into two arguments `head_mask` and `decoder_head_mask`. Currently,
+ `decoder_head_mask` is set to copy `head_mask`, but this feature is deprecated and will be removed in future versions.
+ If you do not want to use any `decoder_head_mask` now, please set `decoder_head_mask = torch.ones(num_layers,
+ num_heads)`.
+ """
+
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ logger = logging.get_logger(__name__)
+
+ # TODO(baizhou): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if past_key_values:
+ logger.warning_once('Non-empty past_key_values is not supported for pipeline models at the moment.')
+ past_key_values = None
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once('use_cache=True is not supported for pipeline models at the moment.')
+ use_cache = False
+
+ # FutureWarning: head_mask was separated into two input args - head_mask, decoder_head_mask
+ if head_mask is not None and decoder_head_mask is None:
+ if self.config.num_layers == self.config.num_decoder_layers:
+ warnings.warn(__HEAD_MASK_WARNING_MSG, FutureWarning)
+ decoder_head_mask = head_mask
+
+ in_decoder = stage_manager.stage >= decoder_starting_stage
+ # Stage is in encoder, directly return the output of t5_stack_forward
+ if not in_decoder:
+ encoder_outputs = T5PipelineForwards.t5_stack_forward(
+ self.encoder,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ inputs_embeds=inputs_embeds,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ position_bias=position_bias,
+ encoder_decoder_position_bias=encoder_decoder_position_bias,
+ stage_index=stage_index,
+ decoder_starting_stage=decoder_starting_stage)
+ if stage_manager.stage == decoder_starting_stage - 1:
+ # last stage of encoder
+ return {'encoder_hidden_states': encoder_outputs[0]}
+ else:
+ return encoder_outputs
+
+ at_last_decoder_stage = stage_manager.is_last_stage()
+ at_first_decoder_stage = stage_manager.stage == decoder_starting_stage
+
+ if encoder_outputs is not None:
+ encoder_hidden_states = encoder_outputs[0]
+ elif encoder_hidden_states is None:
+ raise ValueError("Non-empty encoder_hidden_states should be passed in at decoder stages.")
+
+ if not at_first_decoder_stage and hidden_states is None:
+ raise ValueError("If not at the first layer of decoder, non-empty hidden_states must be provided.")
+
+ # Decode
+ decoder_outputs = T5PipelineForwards.t5_stack_forward(
+ self.decoder,
+ input_ids=decoder_input_ids,
+ attention_mask=decoder_attention_mask,
+ inputs_embeds=decoder_inputs_embeds,
+ past_key_values=past_key_values,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=attention_mask,
+ head_mask=decoder_head_mask,
+ cross_attn_head_mask=cross_attn_head_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ position_bias=position_bias,
+ encoder_decoder_position_bias=encoder_decoder_position_bias,
+ stage_index=stage_index,
+ decoder_starting_stage=decoder_starting_stage)
+
+ # Directly return outputs of overloaded T5Stack forward if not at last stage.
+ if not at_last_decoder_stage:
+ # encoder_hidden_states should be passed to the next stage
+ decoder_outputs['encoder_hidden_states'] = encoder_hidden_states
+ return decoder_outputs
+
+ if not return_dict:
+ return decoder_outputs + encoder_hidden_states
+ else:
+ return Seq2SeqModelOutput(last_hidden_state=decoder_outputs.last_hidden_state,
+ past_key_values=decoder_outputs.past_key_values,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
+ encoder_last_hidden_state=encoder_hidden_states)
+
+ @staticmethod
+ def t5_for_conditional_generation_forward(
+ self: T5ForConditionalGeneration,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ decoder_input_ids: Optional[torch.LongTensor] = None,
+ decoder_attention_mask: Optional[torch.BoolTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ decoder_head_mask: Optional[torch.FloatTensor] = None,
+ cross_attn_head_mask: Optional[torch.Tensor] = None,
+ encoder_outputs: Optional[Tuple[Tuple[torch.Tensor]]] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ decoder_inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ encoder_decoder_position_bias: Optional[torch.Tensor] = None,
+ backward_tensor_keys: Optional[List[str]] = None,
+ stage_index: Optional[List[int]] = None,
+ decoder_starting_stage: Optional[int] = None,
+ ) -> Union[Tuple[torch.FloatTensor], Seq2SeqLMOutput]:
+
+ # This function is modified on the basis of transformers.models.t5.modeling_t5.T5ForConditionalGeneration.forward.
+ # Please refer to original code of transformers for more details.
+
+ __HEAD_MASK_WARNING_MSG = """
+ The input argument `head_mask` was split into two arguments `head_mask` and `decoder_head_mask`. Currently,
+ `decoder_head_mask` is set to copy `head_mask`, but this feature is deprecated and will be removed in future versions.
+ If you do not want to use any `decoder_head_mask` now, please set `decoder_head_mask = torch.ones(num_layers,
+ num_heads)`.
+ """
+
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ logger = logging.get_logger(__name__)
+
+ # TODO(baizhou): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if past_key_values:
+ logger.warning_once('Non-empty past_key_values is not supported for pipeline models at the moment.')
+ past_key_values = None
+ if output_attentions:
+ logger.warning_once('output_attentions=True is not supported for pipeline models at the moment.')
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once('output_hidden_states=True is not supported for pipeline models at the moment.')
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once('use_cache=True is not supported for pipeline models at the moment.')
+ use_cache = False
+
+ # FutureWarning: head_mask was separated into two input args - head_mask, decoder_head_mask
+ if head_mask is not None and decoder_head_mask is None:
+ if self.config.num_layers == self.config.num_decoder_layers:
+ warnings.warn(__HEAD_MASK_WARNING_MSG, FutureWarning)
+ decoder_head_mask = head_mask
+
+ in_decoder = stage_manager.stage >= decoder_starting_stage
+
+ # Stage is in encoder, directly return the output of t5_stack_forward
+ if not in_decoder:
+ encoder_outputs = T5PipelineForwards.t5_stack_forward(
+ self.encoder,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ inputs_embeds=inputs_embeds,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ position_bias=position_bias,
+ encoder_decoder_position_bias=encoder_decoder_position_bias,
+ stage_index=stage_index,
+ decoder_starting_stage=decoder_starting_stage)
+ if stage_manager.stage == decoder_starting_stage - 1:
+ # last stage of encoder
+ return {'encoder_hidden_states': encoder_outputs[0]}
+ else:
+ return encoder_outputs
+
+ at_last_decoder_stage = stage_manager.is_last_stage()
+ at_first_decoder_stage = stage_manager.stage == decoder_starting_stage
+
+ if encoder_outputs is not None:
+ encoder_hidden_states = encoder_outputs[0]
+ elif encoder_hidden_states is None:
+ raise ValueError("Non-empty encoder_hidden_states should be passed in at decoder stages.")
+
+ if not at_first_decoder_stage and hidden_states is None:
+ raise ValueError("If not at the first layer of decoder, non-empty hidden_states must be provided.")
+
+ if labels is not None and decoder_input_ids is None and decoder_inputs_embeds is None:
+ # get decoder inputs from shifting lm labels to the right
+ decoder_input_ids = self._shift_right(labels)
+
+ # Decode
+ decoder_outputs = T5PipelineForwards.t5_stack_forward(
+ self.decoder,
+ input_ids=decoder_input_ids,
+ attention_mask=decoder_attention_mask,
+ inputs_embeds=decoder_inputs_embeds,
+ past_key_values=past_key_values,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=attention_mask,
+ head_mask=decoder_head_mask,
+ cross_attn_head_mask=cross_attn_head_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ position_bias=position_bias,
+ encoder_decoder_position_bias=encoder_decoder_position_bias,
+ stage_index=stage_index,
+ decoder_starting_stage=decoder_starting_stage)
+
+ # Directly return outputs of overloaded T5Stack forward if not at last stage.
+ if not at_last_decoder_stage:
+ # encoder_hidden_states should be passed to the next stage
+ decoder_outputs['encoder_hidden_states'] = encoder_hidden_states
+ return decoder_outputs
+
+ sequence_output = decoder_outputs[0]
+
+ if self.config.tie_word_embeddings:
+ # Rescale output before projecting on vocab
+ # See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/transformer/transformer.py#L586
+ sequence_output = sequence_output * (self.model_dim**-0.5)
+
+ lm_logits = self.lm_head(sequence_output)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss(ignore_index=-100)
+ # move labels to correct device to enable PP
+ labels = labels.to(lm_logits.device)
+ loss = loss_fct(lm_logits.view(-1, lm_logits.size(-1)), labels.view(-1))
+
+ if not return_dict:
+ output = (lm_logits,) + decoder_outputs[1:] + encoder_hidden_states
+ return ((loss,) + output) if loss is not None else output
+
+ return Seq2SeqLMOutput(loss=loss,
+ logits=lm_logits,
+ past_key_values=decoder_outputs.past_key_values,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
+ encoder_last_hidden_state=encoder_hidden_states)
+
+ @staticmethod
+ def t5_encoder_model_forward(
+ self: T5EncoderModel,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ encoder_decoder_position_bias: Optional[torch.Tensor] = None,
+ backward_tensor_keys: Optional[List[str]] = None,
+ stage_index: Optional[List[int]] = None,
+ decoder_starting_stage: Optional[int] = None,
+ ) -> Union[Tuple[torch.FloatTensor], BaseModelOutput]:
+ r"""
+ This function is modified on the basis of transformers.models.t5.modeling_gpt2.T5EncoderModel.forward.
+ Please refer to original code of transformers for more details.
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = T5PipelineForwards.t5_stack_forward(self.encoder,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ inputs_embeds=inputs_embeds,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ position_bias=position_bias,
+ encoder_decoder_position_bias=encoder_decoder_position_bias,
+ stage_index=stage_index,
+ decoder_starting_stage=decoder_starting_stage)
+
+ return outputs
+
+
+def get_t5_flash_attention_forward():
+
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+ from transformers.models.t5.modeling_t5 import T5Attention
+
+ def forward(
+ self: T5Attention,
+ hidden_states: torch.Tensor,
+ mask: Optional[torch.Tensor] = None,
+ key_value_states: Optional[torch.Tensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ query_length: Optional[int] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]:
+ """
+ Self-attention (if key_value_states is None) or attention over source sentence (provided by key_value_states).
+ """
+ # Input is (batch_size, seq_length, dim)
+ # Mask is (batch_size, key_length) (non-causal) or (batch_size, key_length, key_length)
+ # past_key_value[0] is (batch_size, n_heads, q_len - 1, dim_per_head)
+ batch_size, seq_length = hidden_states.shape[:2]
+
+ real_seq_length = seq_length
+
+ if past_key_value is not None:
+ if len(past_key_value) != 2:
+ raise ValueError(
+ f"past_key_value should have 2 past states: keys and values. Got { len(past_key_value)} past states"
+ )
+ real_seq_length += past_key_value[0].shape[2] if query_length is None else query_length
+
+ key_length = real_seq_length if key_value_states is None else key_value_states.shape[1]
+
+ def shape(states):
+ """projection"""
+ return states.view(batch_size, -1, self.n_heads, self.key_value_proj_dim)
+
+ def unshape(states):
+ """reshape"""
+ return states.view(batch_size, -1, self.inner_dim)
+
+ def project(hidden_states, proj_layer, key_value_states, past_key_value):
+ """projects hidden states correctly to key/query states"""
+ if key_value_states is None:
+ # self-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(hidden_states))
+ elif past_key_value is None:
+ # cross-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(key_value_states))
+
+ if past_key_value is not None:
+ if key_value_states is None:
+ # self-attn
+ # (batch_size, n_heads, key_length, dim_per_head)
+ hidden_states = torch.cat([past_key_value, hidden_states], dim=1)
+ elif past_key_value.shape[1] != key_value_states.shape[1]:
+ # checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ # cross-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(key_value_states))
+ else:
+ # cross-attn
+ hidden_states = past_key_value
+ return hidden_states
+
+ # get query states
+ query_states = shape(self.q(hidden_states)) # (batch_size, n_heads, seq_length, dim_per_head)
+
+ # get key/value states
+ key_states = project(hidden_states, self.k, key_value_states,
+ past_key_value[0] if past_key_value is not None else None)
+ value_states = project(hidden_states, self.v, key_value_states,
+ past_key_value[1] if past_key_value is not None else None)
+
+ if position_bias is None:
+ if not self.has_relative_attention_bias:
+ position_bias = torch.zeros((1, self.n_heads, real_seq_length, key_length),
+ device=query_states.device,
+ dtype=query_states.dtype)
+ if self.gradient_checkpointing and self.training:
+ position_bias.requires_grad = True
+ else:
+ position_bias = self.compute_bias(real_seq_length, key_length, device=query_states.device)
+
+ # if key and values are already calculated
+ # we want only the last query position bias
+ if past_key_value is not None:
+ position_bias = position_bias[:, :, -hidden_states.size(1):, :]
+
+ if mask is not None:
+ position_bias = position_bias + mask # (batch_size, n_heads, seq_length, key_length)
+
+ if self.pruned_heads:
+ mask = torch.ones(position_bias.shape[1])
+ mask[list(self.pruned_heads)] = 0
+ position_bias_masked = position_bias[:, mask.bool()]
+ else:
+ position_bias_masked = position_bias
+
+ position_bias_masked = position_bias_masked.contiguous()
+ attn_output = me_attention(query_states,
+ key_states,
+ value_states,
+ attn_bias=position_bias_masked,
+ p=self.dropout,
+ scale=1.0)
+ attn_output = unshape(attn_output)
+ attn_output = self.o(attn_output)
+
+ present_key_value_state = (key_states, value_states) if (self.is_decoder and use_cache) else None
+
+ outputs = (attn_output,) + (present_key_value_state,) + (position_bias,)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_T5_layer_ff_forward():
+
+ from transformers.models.t5.modeling_t5 import T5LayerFF
+
+ def forward(self: T5LayerFF, hidden_states: torch.Tensor) -> torch.Tensor:
+ forwarded_states = self.layer_norm(hidden_states)
+ forwarded_states = self.DenseReluDense(forwarded_states)
+ hidden_states = self.dropout_add(forwarded_states, hidden_states, self.dropout.p, self.dropout.training)
+ return hidden_states
+
+ return forward
+
+
+def get_T5_layer_self_attention_forward():
+
+ from transformers.models.t5.modeling_t5 import T5LayerSelfAttention
+
+ def forward(
+ self: T5LayerSelfAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]:
+ normed_hidden_states = self.layer_norm(hidden_states)
+ attention_output = self.SelfAttention(
+ normed_hidden_states,
+ mask=attention_mask,
+ position_bias=position_bias,
+ layer_head_mask=layer_head_mask,
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.dropout_add(attention_output[0], hidden_states, self.dropout.p, self.dropout.training)
+ outputs = (hidden_states,) + attention_output[1:] # add attentions if we output them
+ return outputs
+
+ return forward
+
+
+def get_T5_layer_cross_attention_forward():
+
+ from transformers.models.t5.modeling_t5 import T5LayerCrossAttention
+
+ def forward(
+ self: T5LayerCrossAttention,
+ hidden_states: torch.Tensor,
+ key_value_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ use_cache: bool = False,
+ query_length: Optional[int] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]:
+ normed_hidden_states = self.layer_norm(hidden_states)
+ attention_output = self.EncDecAttention(
+ normed_hidden_states,
+ mask=attention_mask,
+ key_value_states=key_value_states,
+ position_bias=position_bias,
+ layer_head_mask=layer_head_mask,
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ query_length=query_length,
+ output_attentions=output_attentions,
+ )
+ layer_output = self.dropout_add(attention_output[0], hidden_states, self.dropout.p, self.dropout.training)
+ outputs = (layer_output,) + attention_output[1:] # add attentions if we output them
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/modeling/vit.py b/colossalai/shardformer/modeling/vit.py
new file mode 100644
index 000000000000..9fc0b7488803
--- /dev/null
+++ b/colossalai/shardformer/modeling/vit.py
@@ -0,0 +1,386 @@
+import logging
+import math
+from typing import Dict, List, Optional, Set, Tuple, Union
+
+import torch
+from transformers.models.vit.modeling_vit import BaseModelOutput, ViTEncoder
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+
+def _encoder_forward(
+ encoder: ViTEncoder,
+ start_idx: int,
+ end_idx: int,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ stage_manager: PipelineStageManager = None,
+) -> Union[tuple, BaseModelOutput]:
+
+ for i in range(start_idx, end_idx):
+ layer_module = encoder.layer[i]
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if encoder.gradient_checkpointing and encoder.training:
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ return module(*inputs, False)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ layer_head_mask,
+ )
+ else:
+ layer_outputs = layer_module(hidden_states, layer_head_mask, False)
+
+ hidden_states = layer_outputs[0]
+ if not stage_manager.is_last_stage():
+ return hidden_states
+ else:
+ if not return_dict:
+ return tuple(hidden_states)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=None,
+ attentions=None,
+ )
+
+
+def ViTModel_pipeline_forward(stage_manager: PipelineStageManager, stage_index: List[int]):
+
+ from transformers.models.vit.modeling_vit import BaseModelOutputWithPooling
+
+ def pp_forward(
+ self,
+ pixel_values: Optional[torch.Tensor] = None,
+ bool_masked_pos: Optional[torch.BoolTensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ interpolate_pos_encoding: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ bool_masked_pos (`torch.BoolTensor` of shape `(batch_size, num_patches)`, *optional*):
+ Boolean masked positions. Indicates which patches are masked (1) and which aren't (0).
+ """
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if output_attentions is not None:
+ logging.warning('Non-empty output_attentions is not supported for pipeline models at the moment.')
+ output_attentions = None
+ if output_hidden_states is not None:
+ logging.warning('Non-empty output_hidden_states is not supported for pipeline models at the moment.')
+ output_hidden_states = None
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ if stage_manager.is_first_stage():
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ # TODO(FoolPlayer): maybe have a cleaner way to cast the input (from `ImageProcessor` side?)
+ expected_dtype = self.embeddings.patch_embeddings.projection.weight.dtype
+ if pixel_values.dtype != expected_dtype:
+ pixel_values = pixel_values.to(expected_dtype)
+
+ embedding_output = self.embeddings(pixel_values,
+ bool_masked_pos=bool_masked_pos,
+ interpolate_pos_encoding=interpolate_pos_encoding)
+ else:
+ assert hidden_states is not None, f"Current stage is {stage_manager.stage}, hidden_states should not be None"
+
+ # Go through encoder
+ if not stage_manager.is_last_stage():
+ hidden_states = _encoder_forward(
+ encoder=self.encoder,
+ start_idx=stage_index[0],
+ end_idx=stage_index[1],
+ hidden_states=embedding_output,
+ head_mask=head_mask,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ )
+ return {'hidden_states': hidden_states}
+ else:
+ encoder_outputs = _encoder_forward(
+ encoder=self.encoder,
+ start_idx=stage_index[0],
+ end_idx=stage_index[1],
+ hidden_states=hidden_states,
+ head_mask=head_mask,
+ return_dict=return_dict,
+ stage_manager=stage_manager,
+ )
+
+ # Go through rest layers
+ sequence_output = encoder_outputs[0]
+ sequence_output = self.layernorm(sequence_output)
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+
+ if not return_dict:
+ head_outputs = (sequence_output, pooled_output) if pooled_output is not None else (sequence_output,)
+ return head_outputs + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+ return pp_forward
+
+
+def ViTForImageClassification_pipeline_forward(stage_manager: PipelineStageManager, stage_index: List[int]):
+
+ from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+ from transformers.models.vit.modeling_vit import ImageClassifierOutput
+
+ def pp_forward(
+ self,
+ pixel_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ interpolate_pos_encoding: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ ) -> Union[tuple, ImageClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if not stage_manager.is_first_stage():
+ assert hidden_states is not None, f"Current stage is {stage_manager.stage}, hidden_states should not be None"
+
+ outputs = self.vit(
+ pixel_values,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ interpolate_pos_encoding=interpolate_pos_encoding,
+ return_dict=return_dict,
+ hidden_states=hidden_states,
+ )
+
+ # not last stage, return hidden_states
+ if not stage_manager.is_last_stage():
+ return outputs
+ else:
+ sequence_output = outputs[0]
+
+ # last stage
+ logits = self.classifier(sequence_output[:, 0, :])
+
+ loss = None
+ if labels is not None:
+ # move labels to correct device to enable model parallelism
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return ImageClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ return pp_forward
+
+
+def ViTForMaskedImageModeling_pipeline_forward(stage_manager: PipelineStageManager, stage_index: List[int]):
+
+ import math
+
+ import torch.nn as nn
+ from transformers.models.vit.modeling_vit import ImageClassifierOutput, MaskedImageModelingOutput
+
+ def pp_forward(
+ self,
+ pixel_values: Optional[torch.Tensor] = None,
+ bool_masked_pos: Optional[torch.BoolTensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ interpolate_pos_encoding: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ ) -> Union[tuple, ImageClassifierOutput]:
+ r"""
+ bool_masked_pos (`torch.BoolTensor` of shape `(batch_size, num_patches)`):
+ Boolean masked positions. Indicates which patches are masked (1) and which aren't (0).
+
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import AutoImageProcessor, ViTForMaskedImageModeling
+ >>> import torch
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> model = ViTForMaskedImageModeling.from_pretrained("google/vit-base-patch16-224-in21k")
+
+ >>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
+ >>> pixel_values = image_processor(images=image, return_tensors="pt").pixel_values
+ >>> # create random boolean mask of shape (batch_size, num_patches)
+ >>> bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
+
+ >>> outputs = model(pixel_values, bool_masked_pos=bool_masked_pos)
+ >>> loss, reconstructed_pixel_values = outputs.loss, outputs.reconstruction
+ >>> list(reconstructed_pixel_values.shape)
+ [1, 3, 224, 224]
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if bool_masked_pos is not None and (self.config.patch_size != self.config.encoder_stride):
+ raise ValueError(
+ "When `bool_masked_pos` is provided, `patch_size` must be equal to `encoder_stride` to ensure that "
+ "the reconstructed image has the same dimensions as the input."
+ f"Got `patch_size` = {self.config.patch_size} and `encoder_stride` = {self.config.encoder_stride}.")
+
+ if not stage_manager.is_first_stage():
+ assert hidden_states is not None, f"Current stage is {stage_manager.stage}, hidden_states should not be None"
+
+ outputs = self.vit(pixel_values,
+ bool_masked_pos=bool_masked_pos,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ interpolate_pos_encoding=interpolate_pos_encoding,
+ return_dict=return_dict,
+ hidden_states=hidden_states)
+ if not stage_manager.is_last_stage():
+ return outputs
+ else:
+ sequence_output = outputs[0]
+
+ # Reshape to (batch_size, num_channels, height, width)
+ sequence_output = sequence_output[:, 1:]
+ batch_size, sequence_length, num_channels = sequence_output.shape
+ height = width = math.floor(sequence_length**0.5)
+ sequence_output = sequence_output.permute(0, 2, 1).reshape(batch_size, num_channels, height, width)
+
+ # Reconstruct pixel values
+ reconstructed_pixel_values = self.decoder(sequence_output)
+
+ masked_im_loss = None
+ if bool_masked_pos is not None:
+ size = self.config.image_size // self.config.patch_size
+ bool_masked_pos = bool_masked_pos.reshape(-1, size, size)
+ mask = (bool_masked_pos.repeat_interleave(self.config.patch_size,
+ 1).repeat_interleave(self.config.patch_size,
+ 2).unsqueeze(1).contiguous())
+ reconstruction_loss = nn.functional.l1_loss(pixel_values, reconstructed_pixel_values, reduction="none")
+ masked_im_loss = (reconstruction_loss * mask).sum() / (mask.sum() + 1e-5) / self.config.num_channels
+
+ if not return_dict:
+ output = (reconstructed_pixel_values,) + outputs[1:]
+ return ((masked_im_loss,) + output) if masked_im_loss is not None else output
+
+ return MaskedImageModelingOutput(
+ loss=masked_im_loss,
+ reconstruction=reconstructed_pixel_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ return pp_forward
+
+
+def get_vit_flash_self_attention_forward():
+
+ from transformers.models.vit.modeling_vit import ViTSelfAttention
+
+ from colossalai.kernel.cuda_native import ColoAttention
+
+ def transpose_for_scores(x: torch.Tensor, num_attention_heads, attention_head_size) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (num_attention_heads, attention_head_size)
+ x = x.view(new_x_shape)
+ return x
+
+ def forward(self: ViTSelfAttention,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = transpose_for_scores(self.key(hidden_states), self.num_attention_heads, self.attention_head_size)
+ value_layer = transpose_for_scores(self.value(hidden_states), self.num_attention_heads,
+ self.attention_head_size)
+ query_layer = transpose_for_scores(mixed_query_layer, self.num_attention_heads, self.attention_head_size)
+
+ scale = 1.0 / math.sqrt(self.attention_head_size)
+ attention = ColoAttention(embed_dim=self.all_head_size,
+ num_heads=self.num_attention_heads,
+ dropout=self.dropout.p,
+ scale=scale)
+ context_layer = attention(query_layer, key_layer, value_layer)
+
+ outputs = (context_layer,)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_vit_output_forward():
+
+ from transformers.models.vit.modeling_vit import ViTOutput
+
+ def forward(self: ViTOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/modeling/whisper.py b/colossalai/shardformer/modeling/whisper.py
new file mode 100644
index 000000000000..0a16c6f788da
--- /dev/null
+++ b/colossalai/shardformer/modeling/whisper.py
@@ -0,0 +1,249 @@
+from typing import Optional, Tuple
+
+import torch
+from torch import nn
+
+
+def get_whisper_flash_attention_forward():
+
+ from transformers.models.whisper.modeling_whisper import WhisperAttention
+
+ from colossalai.kernel.cuda_native import AttnMaskType, ColoAttention
+
+ def shape(tensor: torch.Tensor, seq_len: int, bsz: int, num_heads: int, head_dim: int):
+ return tensor.view(bsz, seq_len, num_heads, head_dim).contiguous()
+
+ def forward(
+ self: WhisperAttention,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ # get key, value proj
+ # `past_key_value[0].shape[2] == key_value_states.shape[1]`
+ # is checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ if (is_cross_attention and past_key_value is not None
+ and past_key_value[0].shape[1] == key_value_states.shape[1]):
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0]
+ value_states = past_key_value[1]
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = shape(self.k_proj(key_value_states), -1, bsz, self.num_heads, self.head_dim)
+ value_states = shape(self.v_proj(key_value_states), -1, bsz, self.num_heads, self.head_dim)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = shape(self.k_proj(hidden_states), -1, bsz, self.num_heads, self.head_dim)
+ value_states = shape(self.v_proj(hidden_states), -1, bsz, self.num_heads, self.head_dim)
+ key_states = torch.cat([past_key_value[0], key_states], dim=1)
+ value_states = torch.cat([past_key_value[1], value_states], dim=1)
+ else:
+ # self_attention
+ key_states = shape(self.k_proj(hidden_states), -1, bsz, self.num_heads, self.head_dim)
+ value_states = shape(self.v_proj(hidden_states), -1, bsz, self.num_heads, self.head_dim)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ # get query proj
+ query_states = shape(self.q_proj(hidden_states), tgt_len, bsz, self.num_heads, self.head_dim)
+
+ src_len = key_states.size(1)
+ if layer_head_mask is not None:
+ if layer_head_mask.size() != (self.num_heads,):
+ raise ValueError(f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
+ f" {layer_head_mask.size()}")
+
+ attn_type = None
+ flash_attention_mask = None
+
+ if self.is_decoder:
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
+ )
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool).contiguous())
+ attn_type = AttnMaskType.paddedcausal
+
+ attention = ColoAttention(embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ dropout=self.dropout,
+ scale=self.scaling)
+ attn_output = attention(query_states,
+ key_states,
+ value_states,
+ attn_mask=flash_attention_mask,
+ attn_mask_type=attn_type)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+ return forward
+
+
+def get_jit_fused_whisper_encoder_layer_forward():
+
+ from transformers.models.whisper.modeling_whisper import WhisperEncoderLayer
+
+ def forward(
+ self: WhisperEncoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_head_mask: torch.Tensor,
+ output_attentions: bool = False,
+ ) -> torch.Tensor:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+ hidden_states, attn_weights, _ = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ residual = hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ if hidden_states.dtype == torch.float16 and (torch.isinf(hidden_states).any()
+ or torch.isnan(hidden_states).any()):
+ clamp_value = torch.finfo(hidden_states.dtype).max - 1000
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_whisper_decoder_layer_forward():
+
+ from transformers.models.whisper.modeling_whisper import WhisperDecoderLayer
+
+ def forward(
+ self: WhisperDecoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ cross_attn_layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = True,
+ ) -> torch.Tensor:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ encoder_hidden_states (`torch.FloatTensor`):
+ cross attention input to the layer of shape `(batch, seq_len, embed_dim)`
+ encoder_attention_mask (`torch.FloatTensor`): encoder attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ cross_attn_layer_head_mask (`torch.FloatTensor`): mask for cross-attention heads in a given layer of
+ size `(decoder_attention_heads,)`.
+ past_key_value (`Tuple(torch.FloatTensor)`): cached past key and value projection states
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Self Attention
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
+ # add present self-attn cache to positions 1,2 of present_key_value tuple
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ past_key_value=self_attn_past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ # Cross-Attention Block
+ cross_attn_present_key_value = None
+ cross_attn_weights = None
+ if encoder_hidden_states is not None:
+ residual = hidden_states
+ hidden_states = self.encoder_attn_layer_norm(hidden_states)
+
+ # cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
+ cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
+ hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
+ hidden_states=hidden_states,
+ key_value_states=encoder_hidden_states,
+ attention_mask=encoder_attention_mask,
+ layer_head_mask=cross_attn_layer_head_mask,
+ past_key_value=cross_attn_past_key_value,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ # add cross-attn to positions 3,4 of present_key_value tuple
+ present_key_value = present_key_value + cross_attn_present_key_value
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights, cross_attn_weights)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/policies/autopolicy.py b/colossalai/shardformer/policies/auto_policy.py
similarity index 72%
rename from colossalai/shardformer/policies/autopolicy.py
rename to colossalai/shardformer/policies/auto_policy.py
index 085e3150c697..eec339c02872 100644
--- a/colossalai/shardformer/policies/autopolicy.py
+++ b/colossalai/shardformer/policies/auto_policy.py
@@ -3,7 +3,7 @@
import torch.nn as nn
-from .basepolicy import Policy
+from .base_policy import Policy
__all__ = ["PolicyLocation", "get_autopolicy", "import_policy"]
@@ -29,7 +29,7 @@ class PolicyLocation:
"transformers.models.bert.modeling_bert.BertModel":
PolicyLocation(file_name="bert", class_name="BertModelPolicy"),
"transformers.models.bert.modeling_bert.BertForPreTraining":
- PolicyLocation(file_name="bert", class_name="BertForPretrainingPolicy"),
+ PolicyLocation(file_name="bert", class_name="BertForPreTrainingPolicy"),
"transformers.models.bert.modeling_bert.BertLMHeadModel":
PolicyLocation(file_name="bert", class_name="BertLMHeadModelPolicy"),
"transformers.models.bert.modeling_bert.BertForMaskedLM":
@@ -42,10 +42,12 @@ class PolicyLocation:
PolicyLocation(file_name="bert", class_name="BertForNextSentencePredictionPolicy"),
"transformers.models.bert.modeling_bert.BertForMultipleChoice":
PolicyLocation(file_name="bert", class_name="BertForMultipleChoicePolicy"),
+ "transformers.models.bert.modeling_bert.BertForQuestionAnswering":
+ PolicyLocation(file_name="bert", class_name="BertForQuestionAnsweringPolicy"),
# LLaMA
"transformers.models.llama.modeling_llama.LlamaModel":
- PolicyLocation(file_name="llama", class_name="LlamaPolicy"),
+ PolicyLocation(file_name="llama", class_name="LlamaModelPolicy"),
"transformers.models.llama.modeling_llama.LlamaForCausalLM":
PolicyLocation(file_name="llama", class_name="LlamaForCausalLMPolicy"),
"transformers.models.llama.modeling_llama.LlamaForSequenceClassification":
@@ -66,11 +68,21 @@ class PolicyLocation:
PolicyLocation(file_name="gpt2", class_name="GPT2LMHeadModelPolicy"),
"transformers.models.gpt2.modeling_gpt2.GPT2DoubleHeadsModel":
PolicyLocation(file_name="gpt2", class_name="GPT2DoubleHeadsModelPolicy"),
+ "transformers.models.gpt2.modeling_gpt2.GPT2ForQuestionAnswering":
+ PolicyLocation(file_name="gpt2", class_name="GPT2ForQuestionAnsweringPolicy"),
"transformers.models.gpt2.modeling_gpt2.GPT2ForTokenClassification":
PolicyLocation(file_name="gpt2", class_name="GPT2ForTokenClassificationPolicy"),
"transformers.models.gpt2.modeling_gpt2.GPT2ForSequenceClassification":
PolicyLocation(file_name="gpt2", class_name="GPT2ForSequenceClassificationPolicy"),
+ # ViT
+ "transformers.models.vit.modeling_vit.ViTModel":
+ PolicyLocation(file_name="vit", class_name="ViTModelPolicy"),
+ "transformers.models.vit.modeling_vit.ViTForImageClassification":
+ PolicyLocation(file_name="vit", class_name="ViTForImageClassificationPolicy"),
+ "transformers.models.vit.modeling_vit.ViTForMaskedImageModeling":
+ PolicyLocation(file_name="vit", class_name="ViTForMaskedImageModelingPolicy"),
+
# OPT
"transformers.models.opt.modeling_opt.OPTModel":
PolicyLocation(file_name="opt", class_name="OPTModelPolicy"),
@@ -92,6 +104,30 @@ class PolicyLocation:
PolicyLocation(file_name="bloom", class_name="BloomForTokenClassificationPolicy"),
"transformers.models.bloom.modeling_bloom.BloomForQuestionAnswering":
PolicyLocation(file_name="bloom", class_name="BloomForQuestionAnsweringPolicy"),
+
+ # Whisper
+ "transformers.models.whisper.modeling_whisper.WhisperModel":
+ PolicyLocation(file_name="whisper", class_name="WhisperModelPolicy"),
+ "transformers.models.whisper.modeling_whisper.WhisperForConditionalGeneration":
+ PolicyLocation(file_name="whisper", class_name="WhisperForConditionalGenerationPolicy"),
+ "transformers.models.whisper.modeling_whisper.WhisperForAudioClassification":
+ PolicyLocation(file_name="whisper", class_name="WhisperForAudioClassificationPolicy"),
+
+ # Sam
+ "transformers.models.sam.modeling_sam.SamModel":
+ PolicyLocation(file_name="sam", class_name="SamModelPolicy"),
+
+ # Blip2
+ "transformers.models.blip_2.modeling_blip_2.Blip2Model":
+ PolicyLocation(file_name="blip2", class_name="Blip2ModelPolicy"),
+ "transformers.models.blip_2.modeling_blip_2.Blip2ForConditionalGeneration":
+ PolicyLocation(file_name="blip2", class_name="Blip2ForConditionalGenerationPolicy"),
+
+ # ChatGLM
+ "colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm.ChatGLMModel":
+ PolicyLocation(file_name="chatglm", class_name="ChatGLMModelPolicy"),
+ "colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm.ChatGLMForConditionalGeneration":
+ PolicyLocation(file_name="chatglm", class_name="ChatGLMForConditionalGenerationPolicy"),
}
diff --git a/colossalai/shardformer/policies/basepolicy.py b/colossalai/shardformer/policies/base_policy.py
similarity index 62%
rename from colossalai/shardformer/policies/basepolicy.py
rename to colossalai/shardformer/policies/base_policy.py
index 2d347542fa7a..69493bfb6007 100644
--- a/colossalai/shardformer/policies/basepolicy.py
+++ b/colossalai/shardformer/policies/base_policy.py
@@ -2,9 +2,14 @@
from abc import ABC, abstractmethod
from dataclasses import dataclass
-from typing import Any, Callable, Dict, List, Type, Union
+from typing import Any, Callable, Dict, List, Optional, Union
+import numpy as np
import torch.nn as nn
+from torch import Tensor
+from torch.nn import Module
+
+from colossalai.pipeline.stage_manager import PipelineStageManager
from ..shard.shard_config import ShardConfig
@@ -71,9 +76,8 @@ class Policy(ABC):
"""
def __init__(self) -> None:
- self.shard_config = None
- self.model = None
- self.shard_config = None
+ self.shard_config: Optional[ShardConfig] = None
+ self.model: Optional[Module] = None
def set_model(self, model: nn.Module) -> None:
r"""
@@ -94,6 +98,12 @@ def set_shard_config(self, shard_config: ShardConfig) -> None:
self.shard_config = shard_config
self.config_sanity_check()
+ @property
+ def pipeline_stage_manager(self) -> Optional[PipelineStageManager]:
+ if self.shard_config is not None:
+ return self.shard_config.pipeline_stage_manager
+ return None
+
@abstractmethod
def config_sanity_check(self):
"""
@@ -146,8 +156,78 @@ def append_or_create_submodule_replacement(
# append or create a new description
if target_key in policy:
- policy[target_key].sub_module_replacement.extend(description)
+ if policy[target_key].sub_module_replacement is None:
+ policy[target_key].sub_module_replacement = description
+ else:
+ policy[target_key].sub_module_replacement.extend(description)
else:
policy[target_key] = ModulePolicyDescription(sub_module_replacement=description)
return policy
+
+ def append_or_create_method_replacement(
+ self, description: Dict[str, Callable], policy: Dict[Union[str, nn.Module], ModulePolicyDescription],
+ target_key: Union[str, nn.Module]) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
+ r"""
+ Append or create a new method replacement description to the policy for the given key.
+
+ Args:
+ description (Union[SubModuleReplacementDescription, List[SubModuleReplacementDescription]]): the submodule replacement description to be appended
+ policy (Dict[Union[str, nn.Module], ModulePolicyDescription]): the policy to be updated
+ target_key (Union[str, nn.Module]): the key of the policy to be updated
+ """
+ if target_key in policy:
+ if policy[target_key].method_replacement is None:
+ policy[target_key].method_replacement = description
+ else:
+ policy[target_key].method_replacement.update(description)
+ else:
+ policy[target_key] = ModulePolicyDescription(method_replacement=description)
+
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """Get layers that should be held in current stage. This method should be implemented by subclass.
+
+ Returns:
+ List[Module]: List of layers that should be hold in current stage
+ """
+ raise NotImplementedError
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """Get parameters that should be shared across stages. This method should be implemented by subclass.
+
+ Returns:
+ List[Dict[int, Tensor]]: List of parameters that should be shared across stages. E.g. [{0: module.model.embed_tokens.weight, 3: module.lm_head.weight}]
+ """
+ return []
+
+ @staticmethod
+ def distribute_layers(num_layers: int, num_stages: int) -> List[int]:
+ """Divide layers into stages
+
+ """
+ quotient = num_layers // num_stages
+ remainder = num_layers % num_stages
+
+ # calculate the num_layers per stage
+ layers_per_stage = [quotient] * num_stages
+
+ # deal with the rest layers
+ if remainder > 0:
+ start_position = num_stages // 2 - remainder // 2
+ for i in range(start_position, start_position + remainder):
+ layers_per_stage[i] += 1
+ return layers_per_stage
+
+ @staticmethod
+ def get_stage_index(layers_per_stage: List[int], stage: int) -> List[int]:
+ """
+ get the start index and end index of layers for each stage.
+ """
+ num_layers_per_stage_accumulated = np.insert(np.cumsum(layers_per_stage), 0, 0)
+
+ start_idx = num_layers_per_stage_accumulated[stage]
+ end_idx = num_layers_per_stage_accumulated[stage + 1]
+
+ return [start_idx, end_idx]
diff --git a/colossalai/shardformer/policies/bert.py b/colossalai/shardformer/policies/bert.py
index 9c2736cc64d3..ace9ada3904f 100644
--- a/colossalai/shardformer/policies/bert.py
+++ b/colossalai/shardformer/policies/bert.py
@@ -1,14 +1,26 @@
+from functools import partial
+from typing import Callable, Dict, List
+
import torch.nn as nn
+from torch import Tensor
+from torch.nn import Module
import colossalai.shardformer.layer as col_nn
from .._utils import getattr_, setattr_
-from .basepolicy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
+from ..modeling.bert import (
+ BertPipelineForwards,
+ get_bert_flash_attention_forward,
+ get_jit_fused_bert_output_forward,
+ get_jit_fused_bert_self_output_forward,
+)
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = [
- 'BertPolicy', 'BertModelPolicy', 'BertForPretrainingPolicy', 'BertLMHeadModelPolicy', 'BertForMaskedLMPolicy',
+ 'BertPolicy', 'BertModelPolicy', 'BertForPreTrainingPolicy', 'BertLMdHeadModelPolicy', 'BertForMaskedLMPolicy',
'BertForNextSentencePredictionPolicy', 'BertForSequenceClassificationPolicy', 'BertForTokenClassificationPolicy',
- 'BertForMultipleChoicePolicy'
+ 'BertForMultipleChoicePolicy', 'BertForQuestionAnsweringPolicy'
]
@@ -23,15 +35,22 @@ def preprocess(self):
Reshape the Embedding layer to make the embedding dimension divisible by world_size
"""
# TODO:
- vocab_size = self.model.config.vocab_size
- world_size = self.shard_config.tensor_parallel_size
- if vocab_size % world_size != 0:
- new_vocab_size = vocab_size + world_size - vocab_size % world_size
- self.model.resize_token_embeddings(new_vocab_size)
+ if self.shard_config.enable_tensor_parallelism:
+ vocab_size = self.model.config.vocab_size
+ world_size = self.shard_config.tensor_parallel_size
+ if vocab_size % world_size != 0:
+ new_vocab_size = vocab_size + world_size - vocab_size % world_size
+ self.model.resize_token_embeddings(new_vocab_size)
return self.model
def module_policy(self):
- from transformers.models.bert.modeling_bert import BertEmbeddings, BertLayer
+ from transformers.models.bert.modeling_bert import (
+ BertEmbeddings,
+ BertLayer,
+ BertOutput,
+ BertSelfAttention,
+ BertSelfOutput,
+ )
policy = {}
@@ -111,7 +130,6 @@ def module_policy(self):
],
policy=policy,
target_key=BertLayer)
-
# handle embedding layer
self.append_or_create_submodule_replacement(
description=[SubModuleReplacementDescription(
@@ -120,6 +138,24 @@ def module_policy(self):
)],
policy=policy,
target_key=BertEmbeddings)
+
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[BertSelfAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_bert_flash_attention_forward(),
+ })
+
+ # use jit operator
+ if self.shard_config.enable_jit_fused:
+ policy[BertSelfOutput] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bert_self_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[BertOutput] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bert_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
return policy
def add_lm_head_policy(self, base_policy):
@@ -143,9 +179,60 @@ def add_lm_head_policy(self, base_policy):
target_key=BertLMPredictionHead)
return base_policy
+ def add_lm_prediction_policy(self, base_policy):
+ from transformers.models.bert.modeling_bert import BertLMPredictionHead
+ method_replacement = {
+ '_save_to_state_dict': col_nn.ParallelModule._save_to_state_dict,
+ '_load_from_state_dict': col_nn.ParallelModule._load_from_state_dict,
+ }
+ self.append_or_create_method_replacement(description=method_replacement,
+ policy=base_policy,
+ target_key=BertLMPredictionHead)
+ return base_policy
+
def postprocess(self):
return self.model
+ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
+ """If under pipeline parallel setting, replacing the original forward method of huggingface
+ to customized forward method, and add this changing to policy."""
+ if self.pipeline_stage_manager:
+ stage_manager = self.pipeline_stage_manager
+ if self.model.__class__.__name__ == "BertModel":
+ module = self.model
+ else:
+ module = self.model.bert
+
+ layers_per_stage = Policy.distribute_layers(len(module.encoder.layer), stage_manager.num_stages)
+ stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
+ method_replacement = {'forward': partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}
+ self.append_or_create_method_replacement(description=method_replacement,
+ policy=policy,
+ target_key=model_cls)
+
+ return
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == 'BertModel':
+ module = self.model
+ else:
+ module = self.model.bert
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(len(module.encoder.layer), stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embeddings)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.encoder.layer[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.pooler)
+
+ return held_layers
+
# BertModel
class BertModelPolicy(BertPolicy):
@@ -153,24 +240,61 @@ class BertModelPolicy(BertPolicy):
def __init__(self) -> None:
super().__init__()
+ def module_policy(self):
+ policy = super().module_policy()
+ from transformers.models.bert.modeling_bert import BertModel
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BertModel,
+ new_forward=BertPipelineForwards.bert_model_forward,
+ policy=policy)
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ held_layers = super().get_held_layers()
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in bert model"""
+ return []
+
# BertForPreTraining
-class BertForPretrainingPolicy(BertPolicy):
+class BertForPreTrainingPolicy(BertPolicy):
def __init__(self) -> None:
super().__init__()
def module_policy(self):
- module_policy = super().module_policy()
- module_policy = self.add_lm_head_policy(module_policy)
- return module_policy
+ policy = super().module_policy()
+ policy = self.add_lm_head_policy(policy)
+ policy = self.add_lm_prediction_policy(policy)
+ from transformers.models.bert.modeling_bert import BertForPreTraining
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BertForPreTraining,
+ new_forward=BertPipelineForwards.bert_for_pretraining_forward,
+ policy=policy)
+ return policy
- def postprocess(self):
- binding_map = {"bert.embeddings.word_embeddings.weight": "cls.predictions.decoder.weight"}
- for k, v in binding_map.items():
- param = getattr_(self.model, k)
- setattr_(self.model, v, param)
- return self.model
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage"""
+ held_layers = super().get_held_layers()
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.cls)
+
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ model = self.model
+ if self.pipeline_stage_manager and self.pipeline_stage_manager.num_stages > 1:
+ if id(model.bert.embeddings.word_embeddings.weight) == id(model.cls.predictions.decoder.weight):
+ # tie weights
+ return [{
+ 0: model.bert.embeddings.word_embeddings.weight,
+ self.pipeline_stage_manager.num_stages - 1: model.cls.predictions.decoder.weight
+ }]
+ return []
# BertLMHeadModel
@@ -180,16 +304,36 @@ def __init__(self) -> None:
super().__init__()
def module_policy(self):
- module_policy = super().module_policy()
- module_policy = self.add_lm_head_policy(module_policy)
- return module_policy
+ policy = super().module_policy()
+ policy = self.add_lm_head_policy(policy)
+ policy = self.add_lm_prediction_policy(policy)
+ from transformers.models.bert.modeling_bert import BertLMHeadModel
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BertLMHeadModel,
+ new_forward=BertPipelineForwards.bert_lm_head_model_forward,
+ policy=policy)
+ return policy
- def postprocess(self):
- binding_map = {"bert.embeddings.word_embeddings.weight": "cls.predictions.decoder.weight"}
- for k, v in binding_map.items():
- param = getattr_(self.model, k)
- setattr_(self.model, v, param)
- return self.model
+ def get_held_layers(self) -> List[Module]:
+ """
+ get pipeline layers for current stage
+ """
+ held_layers = super().get_held_layers()
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.cls)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ bert_model = self.model.bert
+ if self.pipeline_stage_manager and self.pipeline_stage_manager.num_stages > 1:
+ if id(bert_model.embeddings.word_embeddings.weight) == id(self.model.cls.predictions.decoder.weight):
+ # tie weights
+ return [{
+ 0: bert_model.embeddings.word_embeddings.weight,
+ self.pipeline_stage_manager.num_stages - 1: self.model.cls.predictions.decoder.weight
+ }]
+ return []
# BertForMaskedLM
@@ -199,16 +343,36 @@ def __init__(self) -> None:
super().__init__()
def module_policy(self):
- module_policy = super().module_policy()
- module_policy = self.add_lm_head_policy(module_policy)
- return module_policy
+ policy = super().module_policy()
+ policy = self.add_lm_head_policy(policy)
+ policy = self.add_lm_prediction_policy(policy)
+ from transformers.models.bert.modeling_bert import BertForMaskedLM
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BertForMaskedLM,
+ new_forward=BertPipelineForwards.bert_for_masked_lm_forward,
+ policy=policy)
+ return policy
- def postprocess(self):
- binding_map = {"bert.embeddings.word_embeddings.weight": "cls.predictions.decoder.weight"}
- for k, v in binding_map.items():
- param = getattr_(self.model, k)
- setattr_(self.model, v, param)
- return self.model
+ def get_held_layers(self) -> List[Module]:
+ """
+ get pipeline layers for current stage
+ """
+ held_layers = super().get_held_layers()
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.cls)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ bert_model = self.model.bert
+ if self.pipeline_stage_manager and self.pipeline_stage_manager.num_stages > 1:
+ if id(bert_model.embeddings.word_embeddings.weight) == id(self.model.cls.predictions.decoder.weight):
+ # tie weights
+ return [{
+ 0: bert_model.embeddings.word_embeddings.weight,
+ self.pipeline_stage_manager.num_stages - 1: self.model.cls.predictions.decoder.weight
+ }]
+ return []
# BertForSequenceClassification
@@ -220,7 +384,7 @@ def __init__(self) -> None:
def module_policy(self):
from transformers.models.bert.modeling_bert import BertForSequenceClassification
- module_policy = super().module_policy()
+ policy = super().module_policy()
if self.shard_config.enable_tensor_parallelism:
addon_module = {
@@ -232,8 +396,28 @@ def module_policy(self):
)
])
}
- module_policy.update(addon_module)
- return module_policy
+ policy.update(addon_module)
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BertForSequenceClassification,
+ new_forward=BertPipelineForwards.bert_for_sequence_classification_forward,
+ policy=policy)
+
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """
+ get pipeline layers for current stage
+ """
+ held_layers = super().get_held_layers()
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.dropout)
+ held_layers.append(self.model.classifier)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ # no shared params for sequence classification model
+ return []
# BertForTokenClassification
@@ -245,7 +429,7 @@ def __init__(self) -> None:
def module_policy(self):
from transformers.models.bert.modeling_bert import BertForTokenClassification
- module_policy = super().module_policy()
+ policy = super().module_policy()
if self.shard_config.enable_tensor_parallelism:
addon_module = {
@@ -257,8 +441,28 @@ def module_policy(self):
)
])
}
- module_policy.update(addon_module)
- return module_policy
+ policy.update(addon_module)
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BertForTokenClassification,
+ new_forward=BertPipelineForwards.bert_for_token_classification_forward,
+ policy=policy)
+
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """
+ get pipeline layers for current stage
+ """
+ held_layers = super().get_held_layers()
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.dropout)
+ held_layers.append(self.model.classifier)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ # no shared params for sequence classification model
+ return []
# BertForNextSentencePrediction
@@ -267,6 +471,30 @@ class BertForNextSentencePredictionPolicy(BertPolicy):
def __init__(self) -> None:
super().__init__()
+ def module_policy(self):
+ policy = super().module_policy()
+ from transformers.models.bert.modeling_bert import BertForNextSentencePrediction
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BertForNextSentencePrediction,
+ new_forward=BertPipelineForwards.bert_for_next_sentence_prediction_forward,
+ policy=policy)
+
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """
+ get pipeline layers for current stage
+ """
+ held_layers = super().get_held_layers()
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.cls)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ # no shared params for sequence classification model
+ return []
+
# BertForMultipleChoice
class BertForMultipleChoicePolicy(BertPolicy):
@@ -277,7 +505,7 @@ def __init__(self) -> None:
def module_policy(self):
from transformers.models.bert.modeling_bert import BertForMultipleChoice
- module_policy = super().module_policy()
+ policy = super().module_policy()
if self.shard_config.enable_tensor_parallelism:
addon_module = {
@@ -289,5 +517,55 @@ def module_policy(self):
)
])
}
- module_policy.update(addon_module)
- return module_policy
+ policy.update(addon_module)
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BertForMultipleChoice,
+ new_forward=BertPipelineForwards.bert_for_multiple_choice_forward,
+ policy=policy)
+
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """
+ get pipeline layers for current stage
+ """
+ held_layers = super().get_held_layers()
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.dropout)
+ held_layers.append(self.model.classifier)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ # no shared params for sequence classification model
+ return []
+
+
+class BertForQuestionAnsweringPolicy(BertPolicy):
+
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ from transformers.models.bert.modeling_bert import BertForQuestionAnswering
+ policy = super().module_policy()
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BertForQuestionAnswering,
+ new_forward=BertPipelineForwards.bert_for_question_answering_forward,
+ policy=policy)
+
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """
+ get pipeline layers for current stage
+ """
+ held_layers = super().get_held_layers()
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.qa_outputs)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ # no shared params for sequence classification model
+ return []
diff --git a/colossalai/shardformer/policies/blip2.py b/colossalai/shardformer/policies/blip2.py
new file mode 100644
index 000000000000..50356302e93e
--- /dev/null
+++ b/colossalai/shardformer/policies/blip2.py
@@ -0,0 +1,330 @@
+import torch.nn as nn
+
+import colossalai.shardformer.layer as col_nn
+
+from .._utils import getattr_, setattr_
+from ..modeling.blip2 import (
+ forward_fn,
+ get_blip2_flash_attention_forward,
+ get_jit_fused_blip2_QFormer_output_forward,
+ get_jit_fused_blip2_QFormer_self_output_forward,
+)
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
+
+__all__ = ['BlipPolicy', 'BlipModelPolicy']
+
+
+class BlipPolicy(Policy):
+
+ def config_sanity_check(self):
+ pass
+
+ def preprocess(self):
+ # reshape the embedding layer
+ r"""
+ Reshape the Embedding layer to make the embedding dimension divisible by world_size
+ """
+ # TODO:
+ vocab_size = self.model.config.qformer_config.vocab_size
+ world_size = self.shard_config.tensor_parallel_size
+ if vocab_size % world_size != 0:
+ new_vocab_size = vocab_size + world_size - vocab_size % world_size
+ self.model.resize_token_embeddings(new_vocab_size)
+ return self.model
+
+ def module_policy(self):
+ from transformers.models.blip_2.modeling_blip_2 import (
+ Blip2Attention,
+ Blip2EncoderLayer,
+ Blip2QFormerLayer,
+ Blip2QFormerModel,
+ Blip2QFormerOutput,
+ Blip2QFormerSelfOutput,
+ Blip2VisionModel,
+ )
+ from transformers.models.opt.modeling_opt import OPTDecoderLayer, OPTForCausalLM
+
+ policy = {}
+
+ if self.shard_config.enable_tensor_parallelism:
+ policy[Blip2EncoderLayer] = ModulePolicyDescription(attribute_replacement={
+ "self_attn.num_heads":
+ self.model.config.vision_config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "self_attn.embed_dim":
+ self.model.config.vision_config.hidden_size // self.shard_config.tensor_parallel_size,
+ },
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.qkv",
+ target_module=col_nn.FusedLinear1D_Col,
+ kwargs={
+ "n_fused": 3,
+ }),
+ SubModuleReplacementDescription(
+ suffix="self_attn.projection",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.fc1",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.fc2",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ ])
+
+ policy[Blip2QFormerModel] = ModulePolicyDescription(sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ ])
+
+ policy[Blip2QFormerLayer] = ModulePolicyDescription(attribute_replacement={
+ "attention.attention.num_attention_heads":
+ self.model.config.qformer_config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "attention.attention.all_head_size":
+ self.model.config.qformer_config.hidden_size // self.shard_config.tensor_parallel_size,
+ "crossattention.attention.num_attention_heads":
+ self.model.config.qformer_config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "crossattention.attention.all_head_size":
+ self.model.config.qformer_config.hidden_size // self.shard_config.tensor_parallel_size,
+ },
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="attention.attention.query",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attention.attention.key",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attention.attention.value",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attention.attention.dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attention.output.dense",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attention.output.dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="crossattention.attention.query",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="crossattention.attention.key",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="crossattention.attention.value",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="crossattention.attention.dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="crossattention.output.dense",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="crossattention.output.dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="intermediate_query.dense",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="output_query.dense",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="output_query.dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ )
+ ])
+
+ policy[OPTDecoderLayer] = ModulePolicyDescription(attribute_replacement={
+ "self_attn.embed_dim":
+ self.model.config.text_config.hidden_size // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads":
+ self.model.config.text_config.num_attention_heads // self.shard_config.tensor_parallel_size
+ },
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.out_proj",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="fc1",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="fc2",
+ target_module=col_nn.Linear1D_Row,
+ )
+ ])
+
+ policy[OPTForCausalLM] = ModulePolicyDescription(sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="model.decoder.embed_tokens",
+ target_module=col_nn.VocabParallelEmbedding1D,
+ ),
+ SubModuleReplacementDescription(
+ suffix="lm_head",
+ target_module=col_nn.Linear1D_Col,
+ kwargs={"gather_output": True},
+ ),
+ ])
+
+ policy[Blip2Attention] = ModulePolicyDescription(method_replacement={"forward": forward_fn()})
+
+ # optimization configuration
+ if self.shard_config.enable_fused_normalization:
+ # Handle Blip2EncoderLayer layer
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(
+ suffix="layer_norm1",
+ target_module=col_nn.FusedLayerNorm,
+ ),
+ SubModuleReplacementDescription(
+ suffix="layer_norm2",
+ target_module=col_nn.FusedLayerNorm,
+ )
+ ],
+ policy=policy,
+ target_key=Blip2EncoderLayer)
+
+ # handle Blip2VisionModel layer
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(
+ suffix="post_layernorm",
+ target_module=col_nn.FusedLayerNorm,
+ )
+ ],
+ policy=policy,
+ target_key=Blip2VisionModel)
+
+ # handle Blip2VisionModel layer
+ self.append_or_create_submodule_replacement(
+ description=[SubModuleReplacementDescription(
+ suffix="layernorm",
+ target_module=col_nn.FusedLayerNorm,
+ )],
+ policy=policy,
+ target_key=Blip2QFormerModel)
+
+ # handle Blip2QFormerLayer layer
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(
+ suffix="attention.output.LayerNorm",
+ target_module=col_nn.FusedLayerNorm,
+ ),
+ SubModuleReplacementDescription(
+ suffix="crossattention.output.LayerNorm",
+ target_module=col_nn.FusedLayerNorm,
+ ),
+ SubModuleReplacementDescription(
+ suffix="output_query.LayerNorm",
+ target_module=col_nn.FusedLayerNorm,
+ )
+ ],
+ policy=policy,
+ target_key=Blip2QFormerLayer)
+
+ # handle OPTForCausalLM layer
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(
+ suffix="model.decoder.final_layer_norm",
+ target_module=col_nn.FusedLayerNorm,
+ )
+ ],
+ policy=policy,
+ target_key=OPTForCausalLM)
+
+ # handle OPTDecoderLayer layer
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(
+ suffix="self_attn_layer_norm",
+ target_module=col_nn.FusedLayerNorm,
+ ),
+ SubModuleReplacementDescription(
+ suffix="final_layer_norm",
+ target_module=col_nn.FusedLayerNorm,
+ )
+ ],
+ policy=policy,
+ target_key=OPTDecoderLayer)
+
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[Blip2Attention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_blip2_flash_attention_forward(),
+ })
+
+ # use jit operator
+ if self.shard_config.enable_jit_fused:
+ policy[Blip2QFormerSelfOutput] = ModulePolicyDescription(
+ method_replacement={
+ 'forward': get_jit_fused_blip2_QFormer_self_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[Blip2QFormerOutput] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_blip2_QFormer_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
+ return policy
+
+ def postprocess(self):
+ binding_map = {
+ 'language_model.model.decoder.embed_tokens': 'language_model.lm_head',
+ }
+
+ for k, v in binding_map.items():
+ src_mod = getattr_(self.model, k)
+ dst_mod = getattr_(self.model, v)
+ dst_mod.weight = src_mod.weight
+
+ return self.model
+
+
+# Blip2Model
+class Blip2ModelPolicy(BlipPolicy):
+
+ def __init__(self) -> None:
+ super().__init__()
+
+
+# Blip2ForConditionalGeneration
+class Blip2ForConditionalGenerationPolicy(BlipPolicy):
+
+ def __init__(self) -> None:
+ super().__init__()
diff --git a/colossalai/shardformer/policies/bloom.py b/colossalai/shardformer/policies/bloom.py
index a0b5340f72bc..b35764db3870 100644
--- a/colossalai/shardformer/policies/bloom.py
+++ b/colossalai/shardformer/policies/bloom.py
@@ -1,10 +1,23 @@
+from functools import partial
+from typing import Callable, Dict, List, Optional, Tuple, Union
+
import torch.nn as nn
+from torch import Tensor
+from torch.nn import Module
import colossalai.shardformer.layer as col_nn
from .._utils import getattr_, setattr_
-from ..modeling.bloom import build_bloom_alibi_tensor_fn
-from .basepolicy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
+from ..modeling.bloom import (
+ BloomPipelineForwards,
+ build_bloom_alibi_tensor_fn,
+ get_bloom_flash_attention_forward,
+ get_jit_fused_bloom_attention_forward,
+ get_jit_fused_bloom_gelu_forward,
+ get_jit_fused_bloom_mlp_forward,
+)
+from ..modeling.jit import get_dropout_add_func, get_jit_fused_dropout_add_func, get_jit_fused_gelu_forward_func
+from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
class BloomPolicy(Policy):
@@ -17,15 +30,16 @@ def preprocess(self):
r"""
Reshape the Embedding layer to make the embedding dimension divisible by world_size
"""
- vocab_size = self.model.config.vocab_size
- world_size = self.shard_config.tensor_parallel_size
- if vocab_size % world_size != 0:
- new_vocab_size = vocab_size + world_size - vocab_size % world_size
- self.model.resize_token_embeddings(new_vocab_size)
+ if self.shard_config.enable_tensor_parallelism:
+ vocab_size = self.model.config.vocab_size
+ world_size = self.shard_config.tensor_parallel_size
+ if vocab_size % world_size != 0:
+ new_vocab_size = vocab_size + world_size - vocab_size % world_size
+ self.model.resize_token_embeddings(new_vocab_size)
return self.model
def module_policy(self):
- from transformers.models.bloom.modeling_bloom import BloomBlock, BloomModel
+ from transformers.models.bloom.modeling_bloom import BloomAttention, BloomBlock, BloomGelu, BloomMLP, BloomModel
policy = {}
@@ -102,14 +116,97 @@ def module_policy(self):
policy=policy,
target_key=BloomBlock)
+ if self.shard_config.enable_flash_attention:
+ policy[BloomAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_bloom_flash_attention_forward(),
+ 'dropout_add': get_dropout_add_func()
+ })
+
+ # enable jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[BloomAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bloom_attention_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[BloomMLP] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bloom_mlp_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[BloomGelu] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bloom_gelu_forward(),
+ 'bloom_gelu_forward': get_jit_fused_gelu_forward_func(),
+ })
+
return policy
def postprocess(self):
return self.model
+ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
+ """If under pipeline parallel setting, replacing the original forward method of huggingface
+ to customized forward method, and add this changing to policy."""
+ if self.pipeline_stage_manager:
+ stage_manager = self.pipeline_stage_manager
+ if self.model.__class__.__name__ == "BloomModel":
+ module = self.model
+ else:
+ module = self.model.transformer
+
+ layers_per_stage = Policy.distribute_layers(len(module.h), stage_manager.num_stages)
+ stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
+ method_replacement = {'forward': partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}
+ self.append_or_create_method_replacement(description=method_replacement,
+ policy=policy,
+ target_key=model_cls)
+ return
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == 'BloomModel':
+ module = self.model
+ else:
+ module = self.model.transformer
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(len(module.h), stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.word_embeddings)
+ held_layers.append(module.word_embeddings_layernorm)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.h[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.ln_f)
+
+ return held_layers
+
class BloomModelPolicy(BloomPolicy):
- pass
+
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ policy = super().module_policy()
+ from transformers.models.bloom.modeling_bloom import BloomModel
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BloomModel,
+ new_forward=BloomPipelineForwards.bloom_model_forward,
+ policy=policy)
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """
+ get pipeline layers for current stage
+ """
+ held_layers = super().get_held_layers()
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ '''no shared params in bloom model'''
+ return []
class BloomForCausalLMPolicy(BloomPolicy):
@@ -124,21 +221,30 @@ def module_policy(self):
suffix="lm_head", target_module=col_nn.Linear1D_Col, kwargs=dict(gather_output=True)),
policy=policy,
target_key=BloomForCausalLM)
-
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BloomForCausalLM,
+ new_forward=BloomPipelineForwards.bloom_for_causal_lm_forward,
+ policy=policy)
return policy
- def postprocess(self):
- binding_map = {"transformer.word_embeddings.weight": "lm_head.weight"}
-
- for k, v in binding_map.items():
- param = getattr_(self.model, k)
-
- if not isinstance(param, nn.Parameter):
- param = nn.Parameter(param)
-
- # tie weights
- setattr_(self.model, v, param)
- return self.model
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ stage_manager = self.pipeline_stage_manager
+ held_layers = super().get_held_layers()
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.lm_head)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ bloom_model = self.model
+ if self.pipeline_stage_manager and self.pipeline_stage_manager.num_stages > 1:
+ if id(bloom_model.transformer.word_embeddings.weight) == id(bloom_model.lm_head.weight):
+ # tie weights
+ return [{
+ 0: bloom_model.transformer.word_embeddings.weight,
+ self.pipeline_stage_manager.num_stages - 1: bloom_model.lm_head.weight
+ }]
+ return []
class BloomForSequenceClassificationPolicy(BloomPolicy):
@@ -153,9 +259,24 @@ def module_policy(self):
suffix="score", target_module=col_nn.Linear1D_Col, kwargs=dict(gather_output=True)),
policy=policy,
target_key=BloomForSequenceClassification)
-
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BloomForSequenceClassification,
+ new_forward=BloomPipelineForwards.bloom_for_sequence_classification_forward,
+ policy=policy)
return policy
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ stage_manager = self.pipeline_stage_manager
+ held_layers = super().get_held_layers()
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.score)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in bloom for sequence classification model"""
+ return []
+
class BloomForTokenClassificationPolicy(BloomPolicy):
@@ -176,10 +297,46 @@ def module_policy(self):
],
policy=policy,
target_key=BloomForTokenClassification)
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BloomForTokenClassification,
+ new_forward=BloomPipelineForwards.bloom_for_token_classification_forward,
+ policy=policy)
return policy
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ stage_manager = self.pipeline_stage_manager
+ held_layers = super().get_held_layers()
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.dropout)
+ held_layers.append(self.model.classifier)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in bloom for token classification model"""
+ return []
+
class BloomForQuestionAnsweringPolicy(BloomPolicy):
# No head sharding as the output features is only 2
- pass
+ def module_policy(self):
+ from transformers.models.bloom.modeling_bloom import BloomForQuestionAnswering
+ policy = super().module_policy()
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=BloomForQuestionAnswering,
+ new_forward=BloomPipelineForwards.bloom_for_question_answering_forward,
+ policy=policy)
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ held_layers = super().get_held_layers()
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.qa_outputs)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in bloom for question answering model"""
+ return []
diff --git a/colossalai/shardformer/policies/chatglm.py b/colossalai/shardformer/policies/chatglm.py
new file mode 100644
index 000000000000..e6b458936637
--- /dev/null
+++ b/colossalai/shardformer/policies/chatglm.py
@@ -0,0 +1,228 @@
+from functools import partial
+from typing import Callable, Dict, List, Optional, Tuple, Union
+
+import torch.nn as nn
+from torch import Tensor
+from transformers.modeling_outputs import BaseModelOutputWithPast
+
+import colossalai.shardformer.layer as col_nn
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer.modeling.chatglm import ChatGLMPipelineForwards
+from colossalai.shardformer.modeling.chatglm2_6b.configuration_chatglm import ChatGLMConfig
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
+ ChatGLMForConditionalGeneration,
+ ChatGLMModel,
+ GLMBlock,
+)
+
+from ..modeling.chatglm import get_flash_core_attention_forward, get_jit_fused_glm_block_forward
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
+
+__all__ = ['ChatGLMPolicy', 'ChatGLMModelPolicy', 'ChatGLMForConditionalGenerationPolicy']
+
+
+class ChatGLMPolicy(Policy):
+
+ def config_sanity_check(self):
+ pass
+
+ def preprocess(self):
+ # Resize embedding
+ if self.shard_config.enable_tensor_parallelism:
+ vocab_size = self.model.config.padded_vocab_size
+ world_size = self.shard_config.tensor_parallel_size
+
+ if vocab_size % world_size != 0:
+ new_vocab_size = vocab_size + world_size - vocab_size % world_size
+ self.model.resize_token_embeddings(new_vocab_size)
+
+ return self.model
+
+ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
+
+ from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import ChatGLMModel, CoreAttention, GLMBlock
+
+ policy = {}
+
+ if self.shard_config.enable_tensor_parallelism:
+
+ policy[ChatGLMModel] = ModulePolicyDescription(attribute_replacement={},
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="embedding.word_embeddings",
+ target_module=col_nn.VocabParallelEmbedding1D,
+ )
+ ])
+
+ policy[GLMBlock] = ModulePolicyDescription(attribute_replacement={
+ "self_attention.num_attention_heads_per_partition":
+ self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "self_attention.projection_size":
+ (self.model.config.kv_channels * self.model.config.num_attention_heads) //
+ self.shard_config.tensor_parallel_size,
+ "self_attention.qkv_hidden_size":
+ (self.model.config.kv_channels * self.model.config.num_attention_heads * 3) //
+ self.shard_config.tensor_parallel_size,
+ "self_attention.core_attention.num_attention_heads_per_partition":
+ self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "self_attention.core_attention.hidden_size_per_partition":
+ self.model.config.kv_channels * self.model.config.num_attention_heads //
+ self.shard_config.tensor_parallel_size,
+ },
+ param_replacement=[],
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attention.query_key_value",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attention.dense",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attention.core_attention.attention_dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ ])
+ # optimization configuration
+ if self.shard_config.enable_fused_normalization:
+ if not self.model.config.rmsnorm:
+
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(suffix="input_layernorm", target_module=col_nn.FusedLayerNorm),
+ SubModuleReplacementDescription(suffix="post_attention_layernorm",
+ target_module=col_nn.FusedLayerNorm)
+ ],
+ policy=policy,
+ target_key=GLMBlock)
+
+ if self.model.config.post_layer_norm:
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(suffix="encoder.final_layernorm",
+ target_module=col_nn.FusedLayerNorm)
+ ],
+ policy=policy,
+ target_key=ChatGLMModel)
+
+ else:
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(suffix="input_layernorm", target_module=col_nn.FusedRMSNorm),
+ SubModuleReplacementDescription(suffix="post_attention_layernorm",
+ target_module=col_nn.FusedRMSNorm)
+ ],
+ policy=policy,
+ target_key=GLMBlock)
+
+ if self.model.config.post_layer_norm:
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(suffix="encoder.final_layernorm",
+ target_module=col_nn.FusedRMSNorm)
+ ],
+ policy=policy,
+ target_key=ChatGLMModel)
+
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[CoreAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_flash_core_attention_forward(),
+ })
+
+ # use jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[GLMBlock] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_glm_block_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
+ return policy
+
+ def postprocess(self):
+ return self.model
+
+ def get_held_layers(self) -> List[nn.Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == 'ChatGLMModel':
+ module = self.model
+ else:
+ module = self.model.transformer
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(module.num_layers, stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embedding)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.encoder.layers[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ if module.encoder.post_layer_norm:
+ held_layers.append(module.encoder.final_layernorm)
+
+ # rotary_pos_emb is needed for all stages
+ held_layers.append(module.rotary_pos_emb)
+
+ return held_layers
+
+ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
+ """If under pipeline parallel setting, replacing the original forward method of huggingface
+ to customized forward method, and add this changing to policy."""
+ if not self.pipeline_stage_manager:
+ raise ValueError("set_pipeline_forward method can only be called when pipeline parallel is enabled.")
+ stage_manager = self.pipeline_stage_manager
+ if self.model.__class__.__name__ == 'ChatGLMModel':
+ module = self.model
+ else:
+ module = self.model.transformer
+
+ layers_per_stage = Policy.distribute_layers(module.num_layers, stage_manager.num_stages)
+ stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
+ method_replacement = {'forward': partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=model_cls)
+
+
+class ChatGLMModelPolicy(ChatGLMPolicy):
+
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ from transformers.models.gpt2.modeling_gpt2 import GPT2Model
+
+ policy = super().module_policy()
+
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=ChatGLMModel,
+ new_forward=ChatGLMPipelineForwards.chatglm_model_forward,
+ policy=policy)
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ return super().get_held_layers()
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in ChatGLMModel."""
+ return []
+
+
+class ChatGLMForConditionalGenerationPolicy(ChatGLMModelPolicy):
+
+ def module_policy(self):
+ policy = super().module_policy()
+
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=ChatGLMForConditionalGeneration,
+ new_forward=ChatGLMPipelineForwards.chatglm_for_conditional_generation_forward,
+ policy=policy)
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ if self.pipeline_stage_manager.is_last_stage():
+ held_layers.append(self.model.transformer.output_layer)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in ChatGLMForConditionalGenerationModel."""
+ return []
diff --git a/colossalai/shardformer/policies/gpt2.py b/colossalai/shardformer/policies/gpt2.py
index 549cdbf87a80..20e5fa372c8f 100644
--- a/colossalai/shardformer/policies/gpt2.py
+++ b/colossalai/shardformer/policies/gpt2.py
@@ -1,9 +1,13 @@
-import torch.nn as nn
+from functools import partial
+from typing import Callable, Dict, List
+
+from torch import Tensor, nn
import colossalai.shardformer.layer as col_nn
from .._utils import getattr_, setattr_
-from .basepolicy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
+from ..modeling.gpt2 import GPT2PipelineForwards, get_gpt2_flash_attention_forward
+from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = [
'GPT2Policy', 'GPT2ModelPolicy', 'GPT2LMHeadModelPolicy', 'GPT2DoubleHeadsModelPolicy',
@@ -21,15 +25,16 @@ def preprocess(self):
r"""
Reshape the Embedding layer to make the embedding dimension divisible by world_size
"""
- vocab_size = self.model.config.vocab_size
- world_size = self.shard_config.tensor_parallel_size
- if vocab_size % world_size != 0:
- new_vocab_size = vocab_size + world_size - vocab_size % world_size
- self.model.resize_token_embeddings(new_vocab_size)
+ if self.shard_config.enable_tensor_parallelism:
+ vocab_size = self.model.config.vocab_size
+ world_size = self.shard_config.tensor_parallel_size
+ if vocab_size % world_size != 0:
+ new_vocab_size = vocab_size + world_size - vocab_size % world_size
+ self.model.resize_token_embeddings(new_vocab_size)
return self.model
def module_policy(self):
- from transformers.models.gpt2.modeling_gpt2 import GPT2Block, GPT2Model
+ from transformers.models.gpt2.modeling_gpt2 import GPT2Attention, GPT2Block, GPT2Model
policy = {}
@@ -39,6 +44,10 @@ def module_policy(self):
suffix="wte",
target_module=col_nn.VocabParallelEmbedding1D,
),
+ SubModuleReplacementDescription(
+ suffix="drop",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
])
policy[GPT2Block] = ModulePolicyDescription(attribute_replacement={
"attn.embed_dim": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
@@ -106,11 +115,54 @@ def module_policy(self):
],
policy=policy,
target_key=GPT2Block)
+
+ if self.shard_config.enable_flash_attention:
+ policy[GPT2Attention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_gpt2_flash_attention_forward(),
+ })
return policy
def postprocess(self):
return self.model
+ def get_held_layers(self) -> List[nn.Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == 'GPT2Model':
+ module = self.model
+ else:
+ module = self.model.transformer
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(len(module.h), stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.wte)
+ held_layers.append(module.wpe)
+ held_layers.append(module.drop)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.h[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.ln_f)
+ return held_layers
+
+ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
+ """If under pipeline parallel setting, replacing the original forward method of huggingface
+ to customized forward method, and add this changing to policy."""
+ if not self.pipeline_stage_manager:
+ raise ValueError("set_pipeline_forward method can only be called when pipeline parallel is enabled.")
+ stage_manager = self.pipeline_stage_manager
+ if self.model.__class__.__name__ == 'GPT2Model':
+ module = self.model
+ else:
+ module = self.model.transformer
+
+ layers_per_stage = Policy.distribute_layers(len(module.h), stage_manager.num_stages)
+ stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
+ method_replacement = {'forward': partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=model_cls)
+
# GPT2Model
class GPT2ModelPolicy(GPT2Policy):
@@ -118,6 +170,24 @@ class GPT2ModelPolicy(GPT2Policy):
def __init__(self) -> None:
super().__init__()
+ def module_policy(self):
+ from transformers.models.gpt2.modeling_gpt2 import GPT2Model
+
+ policy = super().module_policy()
+
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=GPT2Model,
+ new_forward=GPT2PipelineForwards.gpt2_model_forward,
+ policy=policy)
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ return super().get_held_layers()
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in GPT2Model."""
+ return []
+
# GPT2LMHeadModel
class GPT2LMHeadModelPolicy(GPT2Policy):
@@ -139,17 +209,31 @@ def module_policy(self):
])
}
module_policy.update(addon_module)
+
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=GPT2LMHeadModel,
+ new_forward=GPT2PipelineForwards.gpt2_lmhead_model_forward,
+ policy=module_policy)
return module_policy
- def postprocess(self):
- binding_map = {"transformer.wte.weight": "lm_head.weight"}
- for k, v in binding_map.items():
- param = getattr_(self.model, k)
- setattr_(self.model, v, param)
- return self.model
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ if self.pipeline_stage_manager.is_last_stage():
+ held_layers.append(self.model.lm_head)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ '''The weights of wte and lm_head are shared.'''
+ module = self.model
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager is not None:
+ if stage_manager.num_stages > 1 and id(module.transformer.wte.weight) == id(module.lm_head.weight):
+ first_stage, last_stage = 0, stage_manager.num_stages - 1
+ return [{first_stage: module.transformer.wte.weight, last_stage: module.lm_head.weight}]
+ return []
-# GPT22DoubleHeadsModel
+# GPT2DoubleHeadsModel
class GPT2DoubleHeadsModelPolicy(GPT2Policy):
def __init__(self) -> None:
@@ -169,14 +253,64 @@ def module_policy(self):
])
}
module_policy.update(addon_module)
+
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=GPT2DoubleHeadsModel,
+ new_forward=GPT2PipelineForwards.gpt2_double_heads_model_forward,
+ policy=module_policy)
+
return module_policy
- def postprocess(self):
- binding_map = {"transformer.wte.weight": "lm_head.weight"}
- for k, v in binding_map.items():
- param = getattr_(self.model, k)
- setattr_(self.model, v, param)
- return self.model
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ if self.pipeline_stage_manager.is_last_stage():
+ multiple_choice_head = self.model.multiple_choice_head
+ held_layers.append(self.model.lm_head)
+ held_layers.append(multiple_choice_head.summary)
+ held_layers.append(multiple_choice_head.activation)
+ held_layers.append(multiple_choice_head.first_dropout)
+ held_layers.append(multiple_choice_head.last_dropout)
+
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ '''The weights of wte and lm_head are shared.'''
+ module = self.model
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager is not None:
+ if stage_manager.num_stages > 1 and id(module.transformer.wte.weight) == id(module.lm_head.weight):
+ first_stage, last_stage = 0, stage_manager.num_stages - 1
+ return [{first_stage: module.transformer.wte.weight, last_stage: module.lm_head.weight}]
+ return []
+
+
+# GPT2ForQuestionAnswering
+class GPT2ForQuestionAnsweringPolicy(GPT2Policy):
+
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ from transformers.models.gpt2.modeling_gpt2 import GPT2ForQuestionAnswering
+
+ module_policy = super().module_policy()
+
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=GPT2ForQuestionAnswering,
+ new_forward=GPT2PipelineForwards.gpt2_for_question_answering_forward,
+ policy=module_policy)
+
+ return module_policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ if self.pipeline_stage_manager.is_last_stage():
+ held_layers.append(self.model.qa_outputs)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ '''No shared_params in gpt2 for QA.'''
+ return []
# GPT2ForTokenClassification
@@ -185,9 +319,61 @@ class GPT2ForTokenClassificationPolicy(GPT2Policy):
def __init__(self) -> None:
super().__init__()
+ def module_policy(self):
+ from transformers.models.gpt2.modeling_gpt2 import GPT2ForTokenClassification
+
+ module_policy = super().module_policy()
+
+ if self.shard_config.enable_tensor_parallelism:
+ addon_module = {
+ GPT2ForTokenClassification:
+ ModulePolicyDescription(sub_module_replacement=[
+ SubModuleReplacementDescription(suffix="dropout", target_module=col_nn.DropoutForParallelInput)
+ ])
+ }
+ module_policy.update(addon_module)
+
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=GPT2ForTokenClassification,
+ new_forward=GPT2PipelineForwards.gpt2_for_token_classification_forward,
+ policy=module_policy)
+ return module_policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ if self.pipeline_stage_manager.is_last_stage():
+ held_layers.append(self.model.dropout)
+ held_layers.append(self.model.classifier)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in GPT2ForTokenClassification."""
+ return []
+
# GPT2ForSequenceClassification
class GPT2ForSequenceClassificationPolicy(GPT2Policy):
def __init__(self) -> None:
super().__init__()
+
+ def module_policy(self):
+ from transformers.models.gpt2.modeling_gpt2 import GPT2ForSequenceClassification
+
+ module_policy = super().module_policy()
+
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=GPT2ForSequenceClassification,
+ new_forward=GPT2PipelineForwards.gpt2_for_sequence_classification_forward,
+ policy=module_policy)
+ return module_policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ if self.pipeline_stage_manager.is_last_stage():
+ held_layers.append(self.model.score)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in GPT2ForTokenClassification."""
+ return []
diff --git a/colossalai/shardformer/policies/llama.py b/colossalai/shardformer/policies/llama.py
index 157785bdcf13..5ee95f3be8fa 100644
--- a/colossalai/shardformer/policies/llama.py
+++ b/colossalai/shardformer/policies/llama.py
@@ -1,10 +1,14 @@
-from typing import Dict, Union
+from functools import partial
+from typing import Callable, Dict, List, Union
import torch.nn as nn
+from torch import Tensor
+from torch.nn import Module
from colossalai.shardformer.layer import FusedRMSNorm, Linear1D_Col, Linear1D_Row, VocabParallelEmbedding1D
-from .basepolicy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
+from ..modeling.llama import LlamaPipelineForwards, get_llama_flash_attention_forward
+from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ['LlamaPolicy', 'LlamaForCausalLMPolicy', 'LlamaForSequenceClassificationPolicy']
@@ -15,18 +19,19 @@ def config_sanity_check(self):
pass
def preprocess(self):
- # Resize embedding
- vocab_size = self.model.config.vocab_size
- world_size = self.shard_config.tensor_parallel_size
+ if self.shard_config.enable_tensor_parallelism:
+ # Resize embedding
+ vocab_size = self.model.config.vocab_size
+ world_size = self.shard_config.tensor_parallel_size
- if vocab_size % world_size != 0:
- new_vocab_size = vocab_size + world_size - vocab_size % world_size
- self.model.resize_token_embeddings(new_vocab_size)
+ if vocab_size % world_size != 0:
+ new_vocab_size = vocab_size + world_size - vocab_size % world_size
+ self.model.resize_token_embeddings(new_vocab_size)
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
- from transformers.models.llama.modeling_llama import LlamaDecoderLayer, LlamaModel
+ from transformers.models.llama.modeling_llama import LlamaAttention, LlamaDecoderLayer, LlamaModel
policy = {}
@@ -99,11 +104,81 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
policy=policy,
target_key=LlamaModel)
+ if self.shard_config.enable_flash_attention:
+ policy[LlamaAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_llama_flash_attention_forward(),
+ })
+
return policy
def postprocess(self):
return self.model
+ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
+ """If under pipeline parallel setting, replacing the original forward method of huggingface
+ to customized forward method, and add this changing to policy."""
+ if self.pipeline_stage_manager:
+ stage_manager = self.pipeline_stage_manager
+ if self.model.__class__.__name__ == "LlamaModel":
+ module = self.model
+ else:
+ module = self.model.model
+
+ layers_per_stage = Policy.distribute_layers(len(module.layers), stage_manager.num_stages)
+ stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
+ method_replacement = {'forward': partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}
+ self.append_or_create_method_replacement(description=method_replacement,
+ policy=policy,
+ target_key=model_cls)
+
+ return
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == 'LlamaModel':
+ module = self.model
+ else:
+ module = self.model.model
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(len(module.layers), stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embed_tokens)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.layers[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.norm)
+
+ return held_layers
+
+
+class LlamaModelPolicy(LlamaPolicy):
+
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ policy = super().module_policy()
+ from transformers.models.llama.modeling_llama import LlamaModel
+ if self.pipeline_stage_manager:
+ # set None as default
+ self.set_pipeline_forward(model_cls=LlamaModel,
+ new_forward=LlamaPipelineForwards.llama_model_forward,
+ policy=policy)
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ held_layers = super().get_held_layers()
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in llama model"""
+ return []
+
class LlamaForCausalLMPolicy(LlamaPolicy):
@@ -122,8 +197,35 @@ def module_policy(self):
])
}
policy.update(new_item)
+
+ if self.pipeline_stage_manager:
+ # set None as default
+ self.set_pipeline_forward(model_cls=LlamaForCausalLM,
+ new_forward=LlamaPipelineForwards.llama_for_causal_lm_forward,
+ policy=policy)
+
return policy
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ stage_manager = self.pipeline_stage_manager
+ held_layers = super().get_held_layers()
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.lm_head)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ llama_model = self.model.model
+ if self.pipeline_stage_manager and self.pipeline_stage_manager.num_stages > 1:
+ if id(llama_model.embed_tokens.weight) == id(
+ self.model.lm_head.weight) and self.pipeline_stage_manager.num_stages > 1:
+ # tie weights
+ return [{
+ 0: llama_model.embed_tokens.weight,
+ self.pipeline_stage_manager.num_stages - 1: self.model.lm_head.weight
+ }]
+ return []
+
class LlamaForSequenceClassificationPolicy(LlamaPolicy):
@@ -142,4 +244,22 @@ def module_policy(self):
])
}
policy.update(new_item)
+ # to be confirmed
+ if self.pipeline_stage_manager:
+ # set None as default
+ self.set_pipeline_forward(model_cls=LlamaForSequenceClassification,
+ new_forward=LlamaPipelineForwards.llama_for_sequence_classification_forward,
+ policy=policy)
return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ stage_manager = self.pipeline_stage_manager
+ held_layers = super().get_held_layers()
+ if stage_manager.is_last_stage():
+ held_layers.append(self.model.score)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in llama for sequence classification model"""
+ return []
diff --git a/colossalai/shardformer/policies/opt.py b/colossalai/shardformer/policies/opt.py
index b87db53f45f1..ba6036bd0658 100644
--- a/colossalai/shardformer/policies/opt.py
+++ b/colossalai/shardformer/policies/opt.py
@@ -1,7 +1,15 @@
+from functools import partial
+from typing import Callable, Dict, List
+
+import torch.nn as nn
+from torch import Tensor, nn
+
from colossalai.shardformer.layer import FusedLayerNorm, Linear1D_Col, Linear1D_Row, VocabParallelEmbedding1D
-from .._utils import getattr_, setattr_
-from .basepolicy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
+from .._utils import getattr_
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from ..modeling.opt import OPTPipelineForwards, get_jit_fused_opt_decoder_layer_forward, get_opt_flash_attention_forward
+from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = [
'OPTPolicy', 'OPTModelPolicy', 'OPTForCausalLMPolicy', 'OPTForSequenceClassificationPolicy',
@@ -19,11 +27,12 @@ def preprocess(self):
r"""
Reshape the Embedding layer to make the embedding dimension divisible by world_size
"""
- vocab_size = self.model.config.vocab_size
- world_size = self.shard_config.tensor_parallel_size
- if vocab_size % world_size != 0:
- new_vocab_size = vocab_size + world_size - vocab_size % world_size
- self.model.resize_token_embeddings(new_vocab_size)
+ if self.shard_config.enable_tensor_parallelism:
+ vocab_size = self.model.config.vocab_size
+ world_size = self.shard_config.tensor_parallel_size
+ if vocab_size % world_size != 0:
+ new_vocab_size = vocab_size + world_size - vocab_size % world_size
+ self.model.resize_token_embeddings(new_vocab_size)
return self.model
def module_policy(self):
@@ -89,17 +98,87 @@ def module_policy(self):
policy=policy,
target_key=OPTDecoderLayer)
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[OPTAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_opt_flash_attention_forward(),
+ })
+
+ # use jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[OPTDecoderLayer] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_opt_decoder_layer_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
return policy
def postprocess(self):
return self.model
+ def get_held_layers(self) -> List[nn.Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == 'OPTModel':
+ module = self.model.decoder
+ else:
+ module = self.model.model.decoder
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(len(module.layers), stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embed_tokens)
+ held_layers.append(module.embed_positions)
+ held_layers.append(module.project_in)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.layers[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.final_layer_norm)
+ held_layers.append(module.project_out)
+ return held_layers
+
+ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
+ """If under pipeline parallel setting, replacing the original forward method of huggingface
+ to customized forward method, and add this changing to policy."""
+ if self.pipeline_stage_manager:
+ stage_manager = self.pipeline_stage_manager
+ if self.model.__class__.__name__ == 'OPTModel':
+ module = self.model.decoder
+ else:
+ module = self.model.model.decoder
+
+ layers_per_stage = Policy.distribute_layers(len(module.layers), stage_manager.num_stages)
+ stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
+ method_replacement = {'forward': partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}
+ self.append_or_create_method_replacement(description=method_replacement,
+ policy=policy,
+ target_key=model_cls)
+
class OPTModelPolicy(OPTPolicy):
def __init__(self) -> None:
super().__init__()
+ def module_policy(self):
+ from transformers.models.opt.modeling_opt import OPTModel
+
+ policy = super().module_policy()
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=OPTModel,
+ new_forward=OPTPipelineForwards.opt_model_forward,
+ policy=policy)
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ return super().get_held_layers()
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in OPTModel."""
+ return []
+
class OPTForCausalLMPolicy(OPTPolicy):
@@ -107,23 +186,42 @@ def module_policy(self):
from transformers.models.opt.modeling_opt import OPTForCausalLM
policy = super().module_policy()
-
if self.shard_config.enable_tensor_parallelism:
self.append_or_create_submodule_replacement(description=SubModuleReplacementDescription(
suffix="lm_head", target_module=Linear1D_Col, kwargs=dict(gather_output=True)),
policy=policy,
target_key=OPTForCausalLM)
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=OPTForCausalLM,
+ new_forward=OPTPipelineForwards.opt_for_causal_lm_forward,
+ policy=policy)
+
return policy
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ if self.pipeline_stage_manager.is_last_stage():
+ held_layers.append(self.model.lm_head)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ opt_model = self.model
+ if self.pipeline_stage_manager and self.pipeline_stage_manager.num_stages > 1:
+ num_stages = self.pipeline_stage_manager.num_stages
+ if id(opt_model.model.decoder.embed_tokens.weight) == id(opt_model.lm_head.weight):
+ return [{0: opt_model.model.decoder.embed_tokens.weight, num_stages - 1: opt_model.lm_head.weight}]
+ return []
+
def postprocess(self):
- binding_map = {
- 'model.decoder.embed_tokens': 'lm_head',
- }
+ if self.shard_config.enable_tensor_parallelism and self.pipeline_stage_manager is None:
+ binding_map = {
+ 'model.decoder.embed_tokens': 'lm_head',
+ }
- for k, v in binding_map.items():
- src_mod = getattr_(self.model, k)
- dst_mod = getattr_(self.model, v)
- dst_mod.weight = src_mod.weight
+ for k, v in binding_map.items():
+ src_mod = getattr_(self.model, k)
+ dst_mod = getattr_(self.model, v)
+ dst_mod.weight = src_mod.weight
return self.model
@@ -133,8 +231,50 @@ class OPTForSequenceClassificationPolicy(OPTPolicy):
def __init__(self) -> None:
super().__init__()
+ def module_policy(self):
+ from transformers.models.opt.modeling_opt import OPTForSequenceClassification
+
+ policy = super().module_policy()
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=OPTForSequenceClassification,
+ new_forward=OPTPipelineForwards.opt_for_sequence_classification_forward,
+ policy=policy)
+
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ if self.pipeline_stage_manager.is_last_stage():
+ held_layers.append(self.model.score)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ "no shared params in OPTForSequenceClassification"
+ return []
+
class OPTForQuestionAnsweringPolicy(OPTPolicy):
def __init__(self) -> None:
super().__init__()
+
+ def module_policy(self):
+ from transformers.models.opt.modeling_opt import OPTForQuestionAnswering
+
+ policy = super().module_policy()
+ if self.pipeline_stage_manager:
+ self.set_pipeline_forward(model_cls=OPTForQuestionAnswering,
+ new_forward=OPTPipelineForwards.opt_for_question_answering_forward,
+ policy=policy)
+
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ if self.pipeline_stage_manager.is_last_stage():
+ held_layers.append(self.model.qa_outputs)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ "no shared params in OPTForSequenceClassification"
+ return []
diff --git a/colossalai/shardformer/policies/sam.py b/colossalai/shardformer/policies/sam.py
new file mode 100644
index 000000000000..b1eba0432b49
--- /dev/null
+++ b/colossalai/shardformer/policies/sam.py
@@ -0,0 +1,219 @@
+import torch.nn as nn
+
+import colossalai.shardformer.layer as col_nn
+
+from .._utils import getattr_, setattr_
+from ..modeling.sam import forward_fn, get_sam_flash_attention_forward, get_sam_vision_flash_attention_forward
+from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
+
+__all__ = ['SamPolicy', 'SamModelPolicy']
+
+
+class SamPolicy(Policy):
+
+ def config_sanity_check(self):
+ pass
+
+ def preprocess(self):
+ return self.model
+
+ def module_policy(self):
+ from transformers.models.sam.modeling_sam import (
+ SamAttention,
+ SamFeedForward,
+ SamTwoWayAttentionBlock,
+ SamTwoWayTransformer,
+ SamVisionAttention,
+ SamVisionLayer,
+ )
+
+ policy = {}
+
+ if self.shard_config.enable_tensor_parallelism:
+ policy[SamVisionLayer] = ModulePolicyDescription(attribute_replacement={
+ "attn.num_attention_heads":
+ self.model.config.vision_config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ },
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="attn.qkv",
+ target_module=col_nn.FusedLinear1D_Col,
+ kwargs={
+ "n_fused": 3,
+ },
+ ),
+ SubModuleReplacementDescription(
+ suffix="attn.proj",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.lin1",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.lin2",
+ target_module=col_nn.Linear1D_Row,
+ )
+ ])
+ policy[SamTwoWayAttentionBlock] = ModulePolicyDescription(
+ attribute_replacement={
+ "self_attn.num_attention_heads":
+ self.model.config.mask_decoder_config.num_attention_heads //
+ self.shard_config.tensor_parallel_size,
+ },
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.out_proj",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="cross_attn_token_to_image.q_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="cross_attn_token_to_image.k_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="cross_attn_token_to_image.v_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="cross_attn_token_to_image.out_proj",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.lin1",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.lin2",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="cross_attn_image_to_token.q_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="cross_attn_image_to_token.k_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="cross_attn_image_to_token.v_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="cross_attn_image_to_token.out_proj",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ ])
+ policy[SamTwoWayTransformer] = ModulePolicyDescription(attribute_replacement={
+ "final_attn_token_to_image.num_attention_heads":
+ self.model.config.mask_decoder_config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ },
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="final_attn_token_to_image.q_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="final_attn_token_to_image.k_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="final_attn_token_to_image.v_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="final_attn_token_to_image.out_proj",
+ target_module=col_nn.Linear1D_Row,
+ )
+ ])
+
+ # add `DropoutForParallelInput` layer to replace the useage of `nn.functional.dropout`
+ policy[SamVisionAttention] = ModulePolicyDescription(attribute_replacement={
+ "dropout_layer": col_nn.DropoutForParallelInput(self.model.config.vision_config.attention_dropout)
+ },
+ method_replacement={"forward": forward_fn()},
+ sub_module_replacement=[])
+
+ # optimization configuration
+ if self.shard_config.enable_fused_normalization:
+ # Handle SamVisionLayer
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(
+ suffix="layer_norm1",
+ target_module=col_nn.FusedLayerNorm,
+ ),
+ SubModuleReplacementDescription(
+ suffix="layer_norm2",
+ target_module=col_nn.FusedLayerNorm,
+ )
+ ],
+ policy=policy,
+ target_key=SamVisionLayer)
+
+ # Handle SamTwoWayAttentionBlock
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(
+ suffix="layer_norm1",
+ target_module=col_nn.FusedLayerNorm,
+ ),
+ SubModuleReplacementDescription(
+ suffix="layer_norm2",
+ target_module=col_nn.FusedLayerNorm,
+ ),
+ SubModuleReplacementDescription(
+ suffix="layer_norm3",
+ target_module=col_nn.FusedLayerNorm,
+ ),
+ SubModuleReplacementDescription(
+ suffix="layer_norm4",
+ target_module=col_nn.FusedLayerNorm,
+ )
+ ],
+ policy=policy,
+ target_key=SamTwoWayAttentionBlock)
+
+ # Handle SamTwoWayTransformer
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(
+ suffix="layer_norm_final_attn",
+ target_module=col_nn.FusedLayerNorm,
+ )
+ ],
+ policy=policy,
+ target_key=SamTwoWayTransformer)
+
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[SamAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_sam_flash_attention_forward(),
+ })
+ policy[SamVisionAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_sam_vision_flash_attention_forward(),
+ })
+
+ return policy
+
+ def postprocess(self):
+ return self.model
+
+
+# SamModel
+class SamModelPolicy(SamPolicy):
+
+ def __init__(self) -> None:
+ super().__init__()
diff --git a/colossalai/shardformer/policies/t5.py b/colossalai/shardformer/policies/t5.py
index cde59ab77042..2ef52c214c6b 100644
--- a/colossalai/shardformer/policies/t5.py
+++ b/colossalai/shardformer/policies/t5.py
@@ -1,3 +1,8 @@
+from functools import partial
+from typing import Callable, Dict, List, Optional, Tuple
+
+from torch import Tensor, nn
+
from colossalai.shardformer.layer import (
DropoutForParallelInput,
Embedding1D,
@@ -6,12 +11,20 @@
Linear1D_Row,
VocabParallelEmbedding1D,
)
-from colossalai.shardformer.policies.basepolicy import ModulePolicyDescription
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription
from .._utils import getattr_, setattr_
-from .basepolicy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from ..modeling.t5 import (
+ T5PipelineForwards,
+ get_jit_fused_T5_layer_ff_forward,
+ get_t5_flash_attention_forward,
+ get_T5_layer_cross_attention_forward,
+ get_T5_layer_self_attention_forward,
+)
+from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
-__all__ = ["T5ModelPolicy", "T5ForConditionalGenerationPolicy", "T5EncoderPolicy"]
+__all__ = ["distribute_t5_layers", "T5ModelPolicy", "T5ForConditionalGenerationPolicy", "T5EncoderPolicy"]
class T5BasePolicy(Policy):
@@ -24,11 +37,12 @@ def preprocess(self):
r"""
Reshape the Embedding layer to make the embedding dimension divisible by world_size
"""
- vocab_size = self.model.config.vocab_size
- world_size = self.shard_config.tensor_parallel_size
- if vocab_size % world_size != 0:
- new_vocab_size = vocab_size + world_size - vocab_size % world_size
- self.model.resize_token_embeddings(new_vocab_size)
+ if self.shard_config.enable_tensor_parallelism:
+ vocab_size = self.model.config.vocab_size
+ world_size = self.shard_config.tensor_parallel_size
+ if vocab_size % world_size != 0:
+ new_vocab_size = vocab_size + world_size - vocab_size % world_size
+ self.model.resize_token_embeddings(new_vocab_size)
return self.model
def module_policy(self):
@@ -52,7 +66,7 @@ def module_policy(self):
),
SubModuleReplacementDescription(
suffix="embed_tokens",
- target_module=Embedding1D,
+ target_module=VocabParallelEmbedding1D,
)
])
policy[T5LayerSelfAttention] = ModulePolicyDescription(sub_module_replacement=[
@@ -106,7 +120,7 @@ def module_policy(self):
])
policy[T5DenseGatedActDense] = ModulePolicyDescription(sub_module_replacement=[
SubModuleReplacementDescription(
- suffix="wi_0",
+ suffix="wi_0 ",
target_module=Linear1D_Col,
),
SubModuleReplacementDescription(
@@ -161,35 +175,192 @@ def module_policy(self):
suffix="final_layer_norm", target_module=FusedRMSNorm),
policy=policy,
target_key=T5Stack)
+
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[T5Attention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_t5_flash_attention_forward(),
+ })
+
+ # use jit operator
+ if self.shard_config.enable_jit_fused:
+ policy[T5LayerFF] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_T5_layer_ff_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[T5LayerSelfAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_T5_layer_self_attention_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[T5LayerCrossAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_T5_layer_cross_attention_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
return policy
def postprocess(self):
- binding_map = [["shared", "encoder.embed_tokens"], ["shared", "decoder.embed_tokens"]]
-
- for k, v in binding_map:
- mod = getattr_(self.model, k)
- setattr_(self.model, v, mod)
return self.model
+ @staticmethod
+ def distribute_t5_layers(num_encoder_layers: int, num_decoder_layers: int,
+ num_stages: int) -> Tuple[List[int], int]:
+ """
+ Distribute t5 layers into stages when pipeline parallel is used.
+ Return the layer distribution as a list and the starting stage of decoder.
+ If decoder doesn't exist, returned decoder starting stage is set to num_encoder_layers.
+ """
+
+ # number of encoder layers must be a positive integer
+ if num_encoder_layers <= 0:
+ raise ValueError("The number of encoder layers for T5 must be a positive integer.")
+
+ # number of layers should be large enough to fill in every stage
+ if num_encoder_layers + num_decoder_layers < num_stages:
+ raise ValueError("The total number of layers can't be smaller than number of stages.")
+
+ # in the case of T5EncoderModel, set decoder starting stage to num_stages since it doesn't exist
+ if num_decoder_layers == 0:
+ return Policy.distribute_layers(num_encoder_layers, num_stages), num_stages
+
+ # the number of stages distributed between encoder and decoder is optmized in this way:
+ # num_encoder_stages = argmin(abs(num_encoder_layers / encoder_stages - num_decoder_layers / decoder_stages))
+ # s.t. num_encoder_stages + num_decoder_stages = num_stages, num_encoder_stages >= 1, num_decoder_stages >= 1
+ def objective(num_encoder_stages):
+ return abs(num_encoder_layers / num_encoder_stages - num_decoder_layers / (num_stages - num_encoder_stages))
+
+ num_encoder_stages = 0
+ optimal_diff = 2**31 - 1
+ for i in range(1, num_stages):
+ attempt = objective(i)
+ if attempt < optimal_diff:
+ num_encoder_stages = i
+ optimal_diff = attempt
+ num_decoder_stages = num_stages - num_encoder_stages
+
+ encoder_distribution = Policy.distribute_layers(num_encoder_layers, num_encoder_stages)
+ decoder_distribution = Policy.distribute_layers(num_decoder_layers, num_decoder_stages)
+ return encoder_distribution + decoder_distribution, num_encoder_stages
+
+ @staticmethod
+ def get_t5_stage_index(layers_per_stage: List[int], stage: int,
+ decoder_starting_stage: int) -> Tuple[bool, int, int]:
+ """
+ Input the distribution of layers among stages, the current stage and the first stage of decoder.
+ Return the starting/ending idx of layers in encoder/decoder
+ """
+ if stage < decoder_starting_stage:
+ return Policy.get_stage_index(layers_per_stage[:decoder_starting_stage], stage)
+ else:
+ return Policy.get_stage_index(layers_per_stage[decoder_starting_stage:], stage - decoder_starting_stage)
+
+ def get_held_layers(self) -> List[nn.Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+ stage_manager = self.pipeline_stage_manager
+
+ model = self.model
+ encoder = self.model.encoder
+ decoder = getattr(self.model, 'decoder', None)
+
+ num_encoder_layers = len(encoder.block)
+ num_decoder_layers = len(decoder.block) if decoder else 0
+
+ held_layers = []
+ layers_per_stage, decoder_starting_stage = T5BasePolicy.distribute_t5_layers(
+ num_encoder_layers, num_decoder_layers, stage_manager.num_stages)
+ start_idx, end_idx = T5BasePolicy.get_t5_stage_index(layers_per_stage, stage_manager.stage,
+ decoder_starting_stage)
+
+ if stage_manager.stage < decoder_starting_stage:
+ # current stage is in t5's encoder
+ if stage_manager.is_first_stage():
+ held_layers.append(model.shared)
+ held_layers.append(encoder.embed_tokens)
+ held_layers.append(encoder.dropout)
+ if stage_manager.stage == decoder_starting_stage - 1:
+ held_layers.append(encoder.final_layer_norm)
+ held_layers.append(encoder.dropout)
+ held_layers.extend(encoder.block[start_idx:end_idx])
+ else:
+ # current stage is in t5's decoder
+ if stage_manager.stage == decoder_starting_stage:
+ held_layers.append(decoder.embed_tokens)
+ held_layers.append(decoder.dropout)
+ if stage_manager.is_last_stage():
+ held_layers.append(decoder.final_layer_norm)
+ held_layers.append(decoder.dropout)
+ held_layers.extend(decoder.block[start_idx:end_idx])
+ return held_layers
+
+ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
+ """If under pipeline parallel setting, replacing the original forward method of huggingface
+ to customized forward method, and add this changing to policy."""
+ if not self.pipeline_stage_manager:
+ raise ValueError("set_pipeline_forward method can only be called when pipeline parallel is enabled.")
+ stage_manager = self.pipeline_stage_manager
+
+ encoder = self.model.encoder
+ decoder = getattr(self.model, 'decoder', None)
+
+ num_encoder_layers = len(encoder.block)
+ num_decoder_layers = len(decoder.block) if decoder else 0
+
+ layers_per_stage, decoder_starting_stage = T5BasePolicy.distribute_t5_layers(
+ num_encoder_layers, num_decoder_layers, stage_manager.num_stages)
+ stage_index = T5BasePolicy.get_t5_stage_index(layers_per_stage, stage_manager.stage, decoder_starting_stage)
+
+ method_replacement = {
+ 'forward':
+ partial(new_forward,
+ stage_manager=stage_manager,
+ stage_index=stage_index,
+ decoder_starting_stage=decoder_starting_stage)
+ }
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=model_cls)
+
class T5ModelPolicy(T5BasePolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
def module_policy(self):
from transformers import T5Model
- base_policy = super().module_policy()
+ policy = super().module_policy()
if self.shard_config.enable_tensor_parallelism:
self.append_or_create_submodule_replacement(description=SubModuleReplacementDescription(
suffix="shared",
target_module=VocabParallelEmbedding1D,
),
- policy=base_policy,
+ policy=policy,
target_key=T5Model)
- return base_policy
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=T5Model, new_forward=T5PipelineForwards.t5_model_forward, policy=policy)
+
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ return super().get_held_layers()
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ module = self.model
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager is not None and stage_manager.num_stages > 1:
+ _, decoder_starting_stage = T5BasePolicy.distribute_t5_layers(len(module.encoder.block),
+ len(module.decoder.block),
+ stage_manager.num_stages)
+
+ if id(module.decoder.embed_tokens.weight) == id(module.shared.weight):
+ return [{0: module.shared.weight, decoder_starting_stage: module.decoder.embed_tokens.weight}]
+ return []
class T5ForConditionalGenerationPolicy(T5BasePolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
def module_policy(self):
from transformers import T5ForConditionalGeneration
@@ -207,43 +378,71 @@ def module_policy(self):
],
policy=policy,
target_key=T5ForConditionalGeneration)
+
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=T5ForConditionalGeneration,
+ new_forward=T5PipelineForwards.t5_for_conditional_generation_forward,
+ policy=policy)
return policy
- def postprocess(self):
- super().postprocess()
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ if self.pipeline_stage_manager.is_last_stage():
+ held_layers.append(self.model.lm_head)
+ return held_layers
- binding_map = {"shared": "lm_head"}
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ module = self.model
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager is not None and stage_manager.num_stages > 1:
+ _, decoder_starting_stage = T5BasePolicy.distribute_t5_layers(len(module.encoder.block),
+ len(module.decoder.block),
+ stage_manager.num_stages)
- for k, v in binding_map.items():
- src_mod = getattr_(self.model, k)
- dst_mod = getattr_(self.model, v)
- dst_mod.weight = src_mod.weight
+ shared_params = []
+ shared_embedding = {}
+ if id(module.decoder.embed_tokens.weight) == id(module.shared.weight):
+ shared_embedding[0] = module.shared.weight
+ shared_embedding[decoder_starting_stage] = module.decoder.embed_tokens.weight
- return self.model
+ if id(module.lm_head.weight) == id(module.shared.weight):
+ shared_embedding[0] = module.shared.weight
+ shared_embedding[stage_manager.num_stages - 1] = module.lm_head.weight
+
+ if len(shared_embedding) > 0:
+ shared_params.append(shared_embedding)
+
+ return shared_params
+
+ return []
class T5EncoderPolicy(T5BasePolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
def module_policy(self):
from transformers import T5EncoderModel
- base_policy = super().module_policy()
+ policy = super().module_policy()
if self.shard_config.enable_tensor_parallelism:
self.append_or_create_submodule_replacement(description=SubModuleReplacementDescription(
suffix="shared",
target_module=VocabParallelEmbedding1D,
),
- policy=base_policy,
+ policy=policy,
target_key=T5EncoderModel)
- return base_policy
- def postprocess(self):
- binding_map = [
- ["shared", "encoder.embed_tokens"],
- ]
+ if self.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=T5EncoderModel,
+ new_forward=T5PipelineForwards.t5_encoder_model_forward,
+ policy=policy)
+ return policy
- for k, v in binding_map:
- mod = getattr_(self.model, k)
- setattr_(self.model, v, mod)
- return self.model
+ def get_held_layers(self) -> List[nn.Module]:
+ return super().get_held_layers()
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ return []
diff --git a/colossalai/shardformer/policies/vit.py b/colossalai/shardformer/policies/vit.py
index eaebe2eee0ba..26fcb6e77d35 100644
--- a/colossalai/shardformer/policies/vit.py
+++ b/colossalai/shardformer/policies/vit.py
@@ -1,12 +1,21 @@
-from typing import Dict, Union
+from typing import Callable, Dict, List, Union
import torch.nn as nn
-from colossalai.shardformer.layer import DropoutForReplicatedInput, FusedLayerNorm, Linear1D_Col, Linear1D_Row
+import colossalai.shardformer.layer as col_nn
+from colossalai.shardformer.layer import DropoutForReplicatedInput, Linear1D_Col
-from .basepolicy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from ..modeling.vit import (
+ ViTForImageClassification_pipeline_forward,
+ ViTForMaskedImageModeling_pipeline_forward,
+ ViTModel_pipeline_forward,
+ get_jit_fused_vit_output_forward,
+ get_vit_flash_self_attention_forward,
+)
+from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
-__all__ = ['ViTPolicy']
+__all__ = ['ViTPolicy', 'ViTModelPolicy', 'ViTForImageClassificationPolicy', 'ViTForMaskedImageModelingPolicy']
class ViTPolicy(Policy):
@@ -15,96 +24,216 @@ def config_sanity_check(self):
pass
def preprocess(self):
- # Resize embedding
- vocab_size = self.model.config.vocab_size
- world_size = self.shard_config.tensor_parallel_size
-
- if vocab_size % world_size != 0:
- new_vocab_size = vocab_size + world_size - vocab_size % world_size
- self.model.resize_token_embeddings(new_vocab_size)
-
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
- from transformers.models.vit.modeling_vit import ViTEmbeddings, ViTLayer
-
- base_policy = {
- ViTEmbeddings:
- ModulePolicyDescription(sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="dropout",
- target_module=DropoutForReplicatedInput,
- )
- ]),
- ViTLayer:
- ModulePolicyDescription(attribute_replacement={
- "attention.attention.num_attention_heads":
- self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
- "attention.attention.all_head_size":
- self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
- },
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="attention.attention.query",
- target_module=Linear1D_Col,
- ),
- SubModuleReplacementDescription(
- suffix="attention.attention.key",
- target_module=Linear1D_Col,
- ),
- SubModuleReplacementDescription(
- suffix="attention.attention.value",
- target_module=Linear1D_Col,
- ),
- SubModuleReplacementDescription(
- suffix="attention.attention.dropout",
- target_module=DropoutForParallelInput,
- ),
- SubModuleReplacementDescription(
- suffix="attention.output.dense",
- target_module=Linear1D_Row,
- ),
- SubModuleReplacementDescription(
- suffix="attention.output.dropout",
- target_module=DropoutForParallelInput,
- ),
- SubModuleReplacementDescription(
- suffix="intermediate.dense",
- target_module=Linear1D_Col,
- ),
- SubModuleReplacementDescription(
- suffix="output.dense",
- target_module=Linear1D_Row,
- ),
- SubModuleReplacementDescription(
- suffix="output.dropout",
- target_module=DropoutForParallelInput,
- ),
- ]),
- }
-
- # optimization configuration
- if self.shard_config.enable_fused_normalization:
- base_policy[ViTAttention].sub_module_replacement.extend([
+
+ from transformers.models.vit.modeling_vit import ViTEmbeddings, ViTLayer, ViTModel, ViTOutput, ViTSelfAttention
+
+ policy = {}
+
+ if self.shard_config.enable_tensor_parallelism:
+ policy[ViTEmbeddings] = ModulePolicyDescription(attribute_replacement={},
+ param_replacement=[],
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="dropout",
+ target_module=DropoutForReplicatedInput,
+ )
+ ])
+
+ policy[ViTLayer] = ModulePolicyDescription(attribute_replacement={
+ "attention.attention.num_attention_heads":
+ self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "attention.attention.all_head_size":
+ self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
+ },
+ param_replacement=[],
+ sub_module_replacement=[
SubModuleReplacementDescription(
- suffix="layernorm_before",
- target_module=FusedLayerNorm,
+ suffix="attention.attention.query",
+ target_module=col_nn.Linear1D_Col,
),
SubModuleReplacementDescription(
- suffix="layernorm_after",
- target_module=FusedLayerNorm,
- )
- ])
- base_policy[ViTModel].sub_module_replacement.append(
+ suffix="attention.attention.key",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attention.attention.value",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attention.attention.dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attention.output.dense",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attention.output.dropout",
+ target_module=col_nn.DropoutForReplicatedInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="intermediate.dense",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="output.dense",
+ target_module=col_nn.Linear1D_Row,
+ ),
SubModuleReplacementDescription(
- suffix="layernorm",
- target_module=FusedLayerNorm,
- ))
+ suffix="output.dropout",
+ target_module=col_nn.DropoutForReplicatedInput,
+ ),
+ ])
- return base_policy
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[ViTSelfAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_vit_flash_self_attention_forward(),
+ })
+
+ # use jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[ViTOutput] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_vit_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ return policy
def new_model_class(self):
return None
def postprocess(self):
return self.model
+
+ def get_held_layers(self) -> List[nn.Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None, "pipeline_stage_manager is None"
+
+ if self.model.__class__.__name__ == 'ViTModel':
+ module = self.model
+ else:
+ module = self.model.vit
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(len(module.encoder.layer), stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embeddings)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.encoder.layer[start_idx:end_idx])
+ return held_layers
+
+ def set_pipeline_forward(self, model_cls: nn.Module, pipeline_forward: Callable, policy: Dict):
+ if self.pipeline_stage_manager:
+ stage_manager = self.pipeline_stage_manager
+ if self.model.__class__.__name__ == 'ViTModel':
+ module = self.model
+ else:
+ module = self.model.vit
+
+ layers_per_stage = Policy.distribute_layers(len(module.encoder.layer), stage_manager.num_stages)
+ stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
+ method_replacement = {'forward': pipeline_forward(stage_manager=stage_manager, stage_index=stage_index)}
+ self.append_or_create_method_replacement(description=method_replacement,
+ policy=policy,
+ target_key=model_cls)
+
+
+# ViTModel
+class ViTModelPolicy(ViTPolicy):
+
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ from transformers.models.vit.modeling_vit import ViTModel
+
+ policy = super().module_policy()
+
+ if self.shard_config.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=ViTModel, pipeline_forward=ViTModel_pipeline_forward, policy=policy)
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ assert self.pipeline_stage_manager is not None, "pipeline_stage_manager is None"
+
+ module = self.model
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager.is_last_stage():
+ held_layers.append(module.layernorm)
+ held_layers.append(module.pooler)
+
+ return held_layers
+
+
+# ViTForImageClassification
+class ViTForImageClassificationPolicy(ViTPolicy):
+
+ def module_policy(self):
+ from transformers.models.vit.modeling_vit import ViTForImageClassification, ViTModel
+
+ policy = super().module_policy()
+ if self.shard_config.enable_tensor_parallelism:
+ new_item = {
+ ViTForImageClassification:
+ ModulePolicyDescription(sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="classifier", target_module=Linear1D_Col, kwargs=dict(gather_output=True))
+ ])
+ }
+ policy.update(new_item)
+
+ if self.shard_config.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=ViTModel, pipeline_forward=ViTModel_pipeline_forward, policy=policy)
+ self.set_pipeline_forward(model_cls=ViTForImageClassification,
+ pipeline_forward=ViTForImageClassification_pipeline_forward,
+ policy=policy)
+
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ assert self.pipeline_stage_manager is not None, "pipeline_stage_manager is None"
+
+ module = self.model.vit
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager.is_last_stage():
+ held_layers.append(module.layernorm)
+ held_layers.append(self.model.classifier)
+
+ return held_layers
+
+
+# ViTForMaskedImageModeling
+class ViTForMaskedImageModelingPolicy(ViTPolicy):
+
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ from transformers.models.vit.modeling_vit import ViTForMaskedImageModeling, ViTModel
+
+ policy = super().module_policy()
+
+ if self.shard_config.pipeline_stage_manager is not None:
+ self.set_pipeline_forward(model_cls=ViTModel, pipeline_forward=ViTModel_pipeline_forward, policy=policy)
+ self.set_pipeline_forward(model_cls=ViTForMaskedImageModeling,
+ pipeline_forward=ViTForMaskedImageModeling_pipeline_forward,
+ policy=policy)
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ held_layers = super().get_held_layers()
+ assert self.pipeline_stage_manager is not None, "pipeline_stage_manager is None"
+
+ module = self.model.vit
+ stage_manager = self.pipeline_stage_manager
+ if stage_manager.is_last_stage():
+ held_layers.append(module.layernorm)
+ held_layers.append(self.model.decoder)
+
+ return held_layers
diff --git a/colossalai/shardformer/policies/whisper.py b/colossalai/shardformer/policies/whisper.py
new file mode 100644
index 000000000000..2ac7a49fd27b
--- /dev/null
+++ b/colossalai/shardformer/policies/whisper.py
@@ -0,0 +1,257 @@
+import torch.nn as nn
+
+import colossalai.shardformer.layer as col_nn
+
+from .._utils import getattr_, setattr_
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from ..modeling.whisper import (
+ get_jit_fused_whisper_decoder_layer_forward,
+ get_jit_fused_whisper_encoder_layer_forward,
+ get_whisper_flash_attention_forward,
+)
+from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
+
+__all__ = [
+ 'WhisperPolicy', 'WhisperModelPolicy', 'WhisperForConditionalGenerationPolicy', 'WhisperForAudioClassification'
+]
+
+
+class WhisperPolicy(Policy):
+
+ def config_sanity_check(self):
+ pass
+
+ def preprocess(self):
+ # reshape the embedding layer
+ r"""
+ Reshape the Embedding layer to make the embedding dimension divisible by world_size
+ """
+ # TODO:
+ vocab_size = self.model.config.vocab_size
+ world_size = self.shard_config.tensor_parallel_size
+ if vocab_size % world_size != 0:
+ new_vocab_size = vocab_size + world_size - vocab_size % world_size
+ self.model.resize_token_embeddings(new_vocab_size)
+ return self.model
+
+ def module_policy(self):
+ from transformers.models.whisper.modeling_whisper import (
+ WhisperAttention,
+ WhisperDecoder,
+ WhisperDecoderLayer,
+ WhisperEncoder,
+ WhisperEncoderLayer,
+ )
+
+ policy = {}
+
+ if self.shard_config.enable_tensor_parallelism:
+ policy[WhisperEncoderLayer] = ModulePolicyDescription(attribute_replacement={
+ "self_attn.embed_dim":
+ self.model.config.d_model // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads":
+ self.model.config.encoder_attention_heads // self.shard_config.tensor_parallel_size,
+ },
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.out_proj",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="fc1",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="fc2",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ ])
+
+ policy[WhisperDecoderLayer] = ModulePolicyDescription(attribute_replacement={
+ "self_attn.embed_dim":
+ self.model.config.d_model // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads":
+ self.model.config.decoder_attention_heads // self.shard_config.tensor_parallel_size,
+ "encoder_attn.embed_dim":
+ self.model.config.d_model // self.shard_config.tensor_parallel_size,
+ "encoder_attn.num_heads":
+ self.model.config.encoder_attention_heads // self.shard_config.tensor_parallel_size,
+ },
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.out_proj",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="encoder_attn.q_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="encoder_attn.k_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="encoder_attn.v_proj",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="encoder_attn.out_proj",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="fc1",
+ target_module=col_nn.Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="fc2",
+ target_module=col_nn.Linear1D_Row,
+ ),
+ ])
+
+ policy[WhisperDecoder] = ModulePolicyDescription(sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="embed_tokens",
+ target_module=col_nn.VocabParallelEmbedding1D,
+ ),
+ ])
+
+ # optimization configuration
+ if self.shard_config.enable_fused_normalization:
+ # Handle encoder layer
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(
+ suffix="self_attn_layer_norm",
+ target_module=col_nn.FusedLayerNorm,
+ ),
+ SubModuleReplacementDescription(
+ suffix="final_layer_norm",
+ target_module=col_nn.FusedLayerNorm,
+ )
+ ],
+ policy=policy,
+ target_key=WhisperEncoderLayer)
+
+ # Handle decoder layer
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(
+ suffix="self_attn_layer_norm",
+ target_module=col_nn.FusedLayerNorm,
+ ),
+ SubModuleReplacementDescription(
+ suffix="final_layer_norm",
+ target_module=col_nn.FusedLayerNorm,
+ )
+ ],
+ policy=policy,
+ target_key=WhisperDecoderLayer)
+
+ # handle encoder layer
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(
+ suffix="layer_norm",
+ target_module=col_nn.FusedLayerNorm,
+ )
+ ],
+ policy=policy,
+ target_key=WhisperEncoder)
+
+ # handle decoder layer
+ self.append_or_create_submodule_replacement(description=[
+ SubModuleReplacementDescription(
+ suffix="layer_norm",
+ target_module=col_nn.FusedLayerNorm,
+ )
+ ],
+ policy=policy,
+ target_key=WhisperDecoder)
+
+ # enable flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[WhisperAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_whisper_flash_attention_forward(),
+ })
+
+ # use jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[WhisperEncoderLayer] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_whisper_encoder_layer_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[WhisperDecoderLayer] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_whisper_decoder_layer_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
+ return policy
+
+ def add_lm_head_policy(self, base_policy):
+ from transformers.models.whisper.modeling_whisper import WhisperForConditionalGeneration
+
+ # optimize for tensor parallelism
+ if self.shard_config.enable_tensor_parallelism:
+ self.append_or_create_submodule_replacement(description=SubModuleReplacementDescription(
+ suffix="proj_out", target_module=col_nn.Linear1D_Col, kwargs={"gather_output": True}),
+ policy=base_policy,
+ target_key=WhisperForConditionalGeneration)
+
+ return base_policy
+
+ def postprocess(self):
+ return self.model
+
+
+# WhisperModel
+class WhisperModelPolicy(WhisperPolicy):
+
+ def __init__(self) -> None:
+ super().__init__()
+
+
+# WhisperForConditionalGeneration
+class WhisperForConditionalGenerationPolicy(WhisperPolicy):
+
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ module_policy = super().module_policy()
+ module_policy = self.add_lm_head_policy(module_policy)
+ return module_policy
+
+ def postprocess(self):
+ binding_map = {"model.decoder.embed_tokens.weight": "proj_out.weight"}
+ for k, v in binding_map.items():
+ param = getattr_(self.model, k)
+ setattr_(self.model, v, param)
+ return self.model
+
+
+# WhisperForAudioClassification
+class WhisperForAudioClassificationPolicy(WhisperPolicy):
+
+ def __init__(self) -> None:
+ super().__init__()
diff --git a/colossalai/shardformer/shard/shard_config.py b/colossalai/shardformer/shard/shard_config.py
index 83c08d275df3..0c28f115d018 100644
--- a/colossalai/shardformer/shard/shard_config.py
+++ b/colossalai/shardformer/shard/shard_config.py
@@ -1,8 +1,11 @@
from dataclasses import dataclass
+from typing import Optional
import torch.distributed as dist
from torch.distributed import ProcessGroup
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
__all__ = ['ShardConfig']
@@ -12,17 +15,20 @@ class ShardConfig:
The config for sharding the huggingface model
Args:
- tensor_parallel_process_group (int): The process group for tensor parallelism, defaults to None, which is the global process group.
+ tensor_parallel_process_group (Optional[ProcessGroup]): The process group for tensor parallelism, defaults to None, which is the global process group.
+ pipeline_stage_manager (Optional[PipelineStageManager]): The pipeline stage manager, defaults to None, which means no pipeline.
enable_tensor_parallelism (bool): Whether to turn on tensor parallelism, default is True.
enable_fused_normalization (bool): Whether to use fused layernorm, default is False.
enable_all_optimization (bool): Whether to turn on all optimization, default is False.
"""
- tensor_parallel_process_group: ProcessGroup = None
+ tensor_parallel_process_group: Optional[ProcessGroup] = None
+ pipeline_stage_manager: Optional[PipelineStageManager] = None
enable_tensor_parallelism: bool = True
enable_fused_normalization: bool = False
enable_all_optimization: bool = False
+ enable_flash_attention: bool = False
+ enable_jit_fused: bool = False
- # TODO: add support for tensor parallel
# pipeline_parallel_size: int
# data_parallel_size: int
# tensor_parallel_mode: Literal['1d', '2d', '2.5d', '3d']
@@ -39,7 +45,6 @@ def __post_init__(self):
else:
# get the parallel size
self._tensor_parallel_size = dist.get_world_size(self.tensor_parallel_process_group)
-
# turn on all optimization if all_optimization is set to True
if self.enable_all_optimization:
self._turn_on_all_optimization()
@@ -50,3 +55,5 @@ def _turn_on_all_optimization(self):
"""
# you can add all the optimization flag here
self.enable_fused_normalization = True
+ self.enable_flash_attention = True
+ self.enable_jit_fused = True
diff --git a/colossalai/shardformer/shard/sharder.py b/colossalai/shardformer/shard/sharder.py
index 201e0a08cbfe..0ed745a1fc4a 100644
--- a/colossalai/shardformer/shard/sharder.py
+++ b/colossalai/shardformer/shard/sharder.py
@@ -1,11 +1,16 @@
-from typing import Any, Callable, Dict, List, Union
+from types import MethodType
+from typing import Any, Callable, Dict, List, Optional, Set, Union
import torch.nn as nn
+from torch import Tensor
+
+from colossalai.lazy import LazyInitContext
from .._utils import getattr_, setattr_
-from ..policies.autopolicy import get_autopolicy
-from ..policies.basepolicy import Policy, SubModuleReplacementDescription
+from ..policies.auto_policy import get_autopolicy
+from ..policies.base_policy import Policy, SubModuleReplacementDescription
from .shard_config import ShardConfig
+from .utils import set_tensors_to_none
__all__ = ['ModelSharder', 'shard_model']
@@ -25,15 +30,20 @@ def __init__(self, model: nn.Module, policy: Policy, shard_config: ShardConfig =
self.policy = get_autopolicy(self.model) if policy is None else policy
self.shard_config = shard_config
- def shard(self) -> None:
+ def shard(self) -> List[Dict[int, Tensor]]:
r"""
Shard the model according to the policy
"""
self.policy.set_model(self.model)
self.policy.set_shard_config(self.shard_config)
self._preprocess()
- self._replace_module()
+ # get shared params before release unheld layers, this avoid misjudgement of shared params (None is None)
+ shared_params = self.policy.get_shared_params()
+ held_layers = self._release_unheld_layers()
+ self._replace_module(include=held_layers)
+ self._materialize()
self._postprocess()
+ return shared_params
def _preprocess(self) -> None:
self.model = self.policy.preprocess()
@@ -41,7 +51,7 @@ def _preprocess(self) -> None:
def _postprocess(self) -> None:
self.model = self.policy.postprocess()
- def _replace_module(self,) -> None:
+ def _replace_module(self, include: Optional[Set[nn.Module]] = None) -> None:
r"""
Replace the module according to the policy, and replace the module one by one
@@ -54,8 +64,13 @@ def _replace_module(self,) -> None:
param_replacement = module_description.param_replacement
sub_module_replacement = module_description.sub_module_replacement
method_replacement = module_description.method_replacement
- self._recursive_replace_layer(self.model, layer_cls, attr_replacement, param_replacement,
- method_replacement, sub_module_replacement)
+ self._recursive_replace_layer(self.model,
+ layer_cls,
+ attr_replacement,
+ param_replacement,
+ method_replacement,
+ sub_module_replacement,
+ include=include)
def _recursive_replace_layer(
self,
@@ -64,35 +79,44 @@ def _recursive_replace_layer(
attr_replacement: Dict[str, Any],
param_replacement: List[Callable],
method_replacement: Dict[str, Callable],
- sub_module_replacement: List[Callable],
+ sub_module_replacement: List[SubModuleReplacementDescription],
+ include: Optional[Set[nn.Module]] = None,
) -> None:
r"""
Reverse the replace layer operation
Args:
- layer (torch.nn.Module): The object of layer to shard
- origin_cls (Union[str, torch.nn.Module]): The origin layer class or a string of layer class name.
- attr_replacement (Dict): The attribute dict to modify
+ module (torch.nn.Module): The object of layer to shard
+ origin_cls (Union[str, torch.nn.Module]): The origin layer class or a string of layer class name
+ attr_replacement (Dict[str, Any]): The attribute dict to modify
param_replacement (List[Callable]): The function list to get parameter shard information in policy
- sub_module_replacement (List[Callable]): The function list to get sub module shard information in policy
+ method_replacement (Dict[str, Callable]): Key is the method name, value is the method for replacement
+ sub_module_replacement ((List[SubModuleReplacementDescription]): The function list to get sub module shard information in policy
"""
+ # released layers are not shardable
+ can_replace_param_or_layer = include is None or module in include
if (isinstance(origin_cls, str) and origin_cls == module.__class__.__name__) or \
(module.__class__ == origin_cls):
if attr_replacement is not None:
self._replace_attr(module, attr_replacement)
- if param_replacement is not None:
+ if param_replacement is not None and can_replace_param_or_layer:
self._replace_param(module, param_replacement)
if method_replacement is not None:
self._replace_method(module, method_replacement)
- if sub_module_replacement is not None:
+ if sub_module_replacement is not None and can_replace_param_or_layer:
self._replace_sub_module(module, sub_module_replacement)
for name, child in module.named_children():
- self._recursive_replace_layer(child, origin_cls, attr_replacement, param_replacement, method_replacement,
- sub_module_replacement)
+ self._recursive_replace_layer(child,
+ origin_cls,
+ attr_replacement,
+ param_replacement,
+ method_replacement,
+ sub_module_replacement,
+ include=include)
def _replace_attr(
self,
@@ -103,7 +127,7 @@ def _replace_attr(
Replace the attribute of the layer
Args:
- layer (:class:`torch.nn.Module`): The object of layer to shard
+ module (:class:`torch.nn.Module`): The object of layer to shard
attr_replacement (Dict): The attribute dict to modify
"""
for k, v in attr_replacement.items():
@@ -118,7 +142,7 @@ def _replace_param(
Replace the parameter of the layer
Args:
- layer (:class:`torch.nn.Module`): The object of layer to shard
+ module (:class:`torch.nn.Module`): The object of layer to shard
param_replacement (List[Callable]): The function list to get parameter shard information in policy
"""
for param_func in param_replacement:
@@ -127,7 +151,8 @@ def _replace_param(
def _replace_method(self, module: nn.Module, method_replacement: Dict[str, Callable]):
for method_name, new_method in method_replacement.items():
# bind the new method to the module
- setattr(module, method_name, new_method.__get__(module, module.__class__))
+ bound_method = MethodType(new_method, module)
+ setattr(module, method_name, bound_method)
def _replace_sub_module(
self,
@@ -172,3 +197,33 @@ def _replace_sub_module(
)
setattr_(org_layer, suffix, replace_layer)
+
+ def _get_recursive_held_layers(self, held_layers: Optional[List[nn.Module]]) -> Optional[List[nn.Module]]:
+
+ def collect_sub_modules(module: nn.Module):
+ if module is None:
+ return
+ recursive_held_layers.append(module)
+ for name, child in module.named_children():
+ collect_sub_modules(child)
+
+ recursive_held_layers = []
+ for module in held_layers:
+ collect_sub_modules(module)
+ return recursive_held_layers
+
+ def _release_unheld_layers(self) -> Optional[Set[nn.Module]]:
+ r"""
+ Release the unheld layers in the model
+ """
+ if self.shard_config and self.shard_config.pipeline_stage_manager:
+ held_layers = self.policy.get_held_layers()
+ set_tensors_to_none(self.model, exclude=set(held_layers))
+ return set(self._get_recursive_held_layers(held_layers))
+ return None
+
+ def _materialize(self) -> None:
+ r"""
+ Materialize the model if lazy initialization is used
+ """
+ LazyInitContext.materialize(self.model)
diff --git a/colossalai/shardformer/shard/shardformer.py b/colossalai/shardformer/shard/shardformer.py
index 3fce12463414..7a0d75bf2f2a 100644
--- a/colossalai/shardformer/shard/shardformer.py
+++ b/colossalai/shardformer/shard/shardformer.py
@@ -1,8 +1,11 @@
+from typing import Dict, List, Tuple
+
import torch.nn as nn
+from torch import Tensor
from colossalai.cluster import DistCoordinator
-from ..policies.basepolicy import Policy
+from ..policies.base_policy import Policy
from .shard_config import ShardConfig
from .sharder import ModelSharder
@@ -24,7 +27,7 @@ class ShardFormer:
org_model = BertForMaskedLM.from_pretrained('bert-base-uncased')
shard_config = ShardConfig()
shard_former = ShardFormer(shard_config=shard_config)
- model = shard_former.optimize(org_model)
+ model, shared_params = shard_former.optimize(org_model)
```
"""
@@ -32,7 +35,7 @@ def __init__(self, shard_config: ShardConfig):
self.coordinator = DistCoordinator()
self.shard_config = shard_config
- def optimize(self, model: nn.Module, policy: Policy = None):
+ def optimize(self, model: nn.Module, policy: Policy = None) -> Tuple[nn.Module, List[Dict[int, Tensor]]]:
r"""
This method will optimize the model based on the given policy.
@@ -40,7 +43,9 @@ def optimize(self, model: nn.Module, policy: Policy = None):
model (`torch.nn.Model`): the origin huggingface model
shard_config (`ShardConfig`): the config for distribute information
policy (`Policy`): the custom policy for sharding
+
+ Returns: the sharded model and the shared parameters
"""
sharder = ModelSharder(model=model, shard_config=self.shard_config, policy=policy)
- sharder.shard()
- return model
+ shared_params = sharder.shard()
+ return model, shared_params
diff --git a/colossalai/shardformer/shard/utils.py b/colossalai/shardformer/shard/utils.py
new file mode 100644
index 000000000000..2bac37bfedda
--- /dev/null
+++ b/colossalai/shardformer/shard/utils.py
@@ -0,0 +1,19 @@
+from typing import Set
+
+import torch.nn as nn
+
+
+def set_tensors_to_none(model: nn.Module, exclude: Set[nn.Module] = set()) -> None:
+ """Set all parameters and buffers of model to None
+
+ Args:
+ model (nn.Module): The model to set
+ """
+ if model in exclude:
+ return
+ for child in model.children():
+ set_tensors_to_none(child, exclude=exclude)
+ for n, p in model.named_parameters(recurse=False):
+ setattr(model, n, None)
+ for n, buf in model.named_buffers(recurse=False):
+ setattr(model, n, None)
diff --git a/colossalai/tensor/d_tensor/api.py b/colossalai/tensor/d_tensor/api.py
index 95a44e09e16a..9848e4ca423e 100644
--- a/colossalai/tensor/d_tensor/api.py
+++ b/colossalai/tensor/d_tensor/api.py
@@ -16,6 +16,11 @@
layout_converter = LayoutConverter()
+def clear_layout_converter():
+ global layout_converter
+ layout_converter.cached_solution.clear()
+
+
def is_distributed_tensor(tensor: torch.Tensor) -> bool:
"""
Check whether the given tensor is a distributed tensor.
@@ -235,6 +240,14 @@ def sharded_tensor_to_param(dtensor: torch.Tensor, requires_grad: bool = True):
return param
+def sharded_tensor_to_existing_param(dtensor: torch.Tensor, param: torch.nn.Parameter) -> None:
+ assert is_distributed_tensor(dtensor), 'The input tensor is not a distributed tensor.'
+ param.data = dtensor
+ # make it distributed as well
+ param.dist_layout = dtensor.dist_layout
+ _hijack_detach_and_clone(param)
+
+
def compute_global_numel(dtensor: torch.Tensor) -> int:
"""
Compute the global number of elements in the distributed tensor.
@@ -432,3 +445,15 @@ def customized_distributed_tensor_to_param(dtensor: torch.Tensor, requires_grad:
param.gather_fn = dtensor.gather_fn
_hijack_detach_and_clone_for_customized_distributed_tensor(param)
return param
+
+
+def customized_distributed_tensor_to_existing_param(dtensor: torch.Tensor, param: torch.nn.Parameter):
+ """
+ Convert the given customized distributed tensor to an existing parameter.
+ """
+ assert is_customized_distributed_tensor(dtensor), 'The input tensor is not a customized distributed tensor.'
+
+ param.data = dtensor.data
+ param.shard_fn = dtensor.shard_fn
+ param.gather_fn = dtensor.gather_fn
+ _hijack_detach_and_clone_for_customized_distributed_tensor(param)
diff --git a/colossalai/zero/gemini/gemini_optimizer.py b/colossalai/zero/gemini/gemini_optimizer.py
index 7d0db6b1fa23..a2085323f83e 100644
--- a/colossalai/zero/gemini/gemini_optimizer.py
+++ b/colossalai/zero/gemini/gemini_optimizer.py
@@ -1,6 +1,5 @@
# this code is inspired by the DeepSpeed library and implemented with our own design from scratch
import copy
-import gc
import math
import warnings
from typing import Any, Dict, Iterator, OrderedDict, Set, Tuple
@@ -468,11 +467,6 @@ def collect_states(self, param_id: int, only_rank_0: bool = True) -> dict:
self.load_from_compacted_states(compacted_states, collected_states, state_names, shard_offset,
shard_size)
- # Clean gathered states
- for state_shard in gathered_state_shards:
- del state_shard[0]
- gc.collect()
-
# Reshape tensors
if is_collector:
for state_name, state_tensor in collected_states.items():
diff --git a/colossalai/zero/low_level/bookkeeping/bucket_store.py b/colossalai/zero/low_level/bookkeeping/bucket_store.py
index 98f1b78d0049..0ab10e25d407 100644
--- a/colossalai/zero/low_level/bookkeeping/bucket_store.py
+++ b/colossalai/zero/low_level/bookkeeping/bucket_store.py
@@ -13,15 +13,20 @@ class BucketStore(BaseStore):
def __init__(self, torch_pg: ProcessGroup):
super().__init__(torch_pg)
- # init and reset
+ # init
self.current_group_id = 0
+ self._num_elements_in_bucket = 0
# mapping gardient slices and parameter
self.grad_to_param_mapping = dict()
+ self._grad_in_bucket = dict()
self._param_list = []
self._padding_size = []
+ for rank in range(self._world_size):
+ self._grad_in_bucket[rank] = []
- self.reset()
+ # offset_list records number of tensors in the bucket before each reduction
+ self.offset_list = [0]
def num_elements_in_bucket(self) -> int:
"""Return the total number of elements in bucket
@@ -32,6 +37,12 @@ def num_elements_in_bucket(self) -> int:
return self._num_elements_in_bucket
+ def reset_num_elements_in_bucket(self):
+ """Set the number of elements in bucket to zero.
+ """
+
+ self._num_elements_in_bucket = 0
+
def add_param_grad(self, group_id: int, param: Tensor, padding_size: int):
"""Add a param to bucket and record the padding size of a param for gradient padding
@@ -46,28 +57,32 @@ def add_param_grad(self, group_id: int, param: Tensor, padding_size: int):
self._num_elements_in_bucket += (param.numel() + padding_size)
self.current_group_id = group_id
+ # number of tensors in current bucket
+ self.offset_list[-1] += 1
+
def build_grad_in_bucket(self):
"""Orgnize parameters' gradient(padding and split), follows the paramters' splitting method
Data structure of self._grad_in_bucket:
{
rank0: [grad0_rank0, grad1_rank0, ...]
- rank1: [grad1_rank1, grad1_rank1, ...]
+ rank1: [grad0_rank1, grad1_rank1, ...]
}
"""
-
for param, padding_size in zip(self._param_list, self._padding_size):
- with torch.no_grad():
- grad = param.grad.detach().flatten()
- if padding_size > 0:
- grad = torch.nn.functional.pad(grad, [0, padding_size])
- grad_list = grad.split(grad.numel() // self._world_size)
- for rank in range(self._world_size):
- grad_current_rank = grad_list[rank].detach()
- self.grad_to_param_mapping[id(grad_current_rank)] = id(param)
- self._grad_in_bucket[rank].append(grad_current_rank)
+ grad = param.grad.clone().detach().flatten()
+ if padding_size > 0:
+ with torch.no_grad():
+ grad = torch.nn.functional.pad(grad.view(-1), [0, padding_size])
+ grad_list = grad.split(grad.numel() // self._world_size)
+ for rank in range(self._world_size):
+ grad_current_rank = grad_list[rank].clone().detach()
+ self.grad_to_param_mapping[id(grad_current_rank)] = id(param)
+ self._grad_in_bucket[rank].append(grad_current_rank)
param.grad = None
+ self.offset_list.append(0)
+
def get_grad(self) -> Dict:
"""Return the dictionary of gradients slices, of which the keys are ranks
@@ -104,10 +119,12 @@ def get_param_id_of_grad(self, grad: Tensor) -> int:
return self.grad_to_param_mapping[id(grad)]
def reset(self):
- self.grad_to_param_mapping = dict()
- self._num_elements_in_bucket = 0
- self._param_list = []
- self._padding_size = []
- self._grad_in_bucket = dict()
+ """Reset the bucket storage after reduction, only release the tensors have been reduced
+ """
+ cur_offset = self.offset_list.pop(0)
+ self._param_list = self._param_list[cur_offset:]
+ self._padding_size = self._padding_size[cur_offset:]
+ for _ in range(cur_offset):
+ del self.grad_to_param_mapping[next(iter(self.grad_to_param_mapping))]
for rank in range(self._world_size):
- self._grad_in_bucket[rank] = []
+ self._grad_in_bucket[rank] = self._grad_in_bucket[rank][cur_offset:]
diff --git a/colossalai/zero/low_level/low_level_optim.py b/colossalai/zero/low_level/low_level_optim.py
index 2b3f50ed4fd4..64d6a5395120 100644
--- a/colossalai/zero/low_level/low_level_optim.py
+++ b/colossalai/zero/low_level/low_level_optim.py
@@ -242,10 +242,19 @@ def _attach_reduction_hook(self):
def _run_reduction(self):
if self._bucket_store.num_elements_in_bucket() > 0:
self._bucket_store.build_grad_in_bucket()
+
flat_grads = self._bucket_store.get_flatten_grad()
flat_grads /= self._world_size
+
+ # ready to add other tensors to bucket
+ self._bucket_store.reset_num_elements_in_bucket()
+
if self._overlap_communication:
stream = self._comm_stream
+ # in case of the memory being reused in the default stream
+ flat_grads.record_stream(stream)
+ # waiting for ops in the default stream finishing
+ stream.wait_stream(torch.cuda.current_stream())
else:
stream = torch.cuda.current_stream()
diff --git a/examples/tutorial/auto_parallel/README.md b/examples/tutorial/auto_parallel/README.md
index 6a12e0dd5a48..13561567636e 100644
--- a/examples/tutorial/auto_parallel/README.md
+++ b/examples/tutorial/auto_parallel/README.md
@@ -13,7 +13,7 @@
## 📚 Overview
-This tutorial folder contains a simple demo to run auto-parallelism with ResNet. Meanwhile, this diretory also contains demo scripts to run automatic activation checkpointing, but both features are still experimental for now and no guarantee that they will work for your version of Colossal-AI.
+This tutorial folder contains a simple demo to run auto-parallelism with ResNet. Meanwhile, this directory also contains demo scripts to run automatic activation checkpointing, but both features are still experimental for now and no guarantee that they will work for your version of Colossal-AI.
## 🚀 Quick Start
diff --git a/requirements/requirements-test.txt b/requirements/requirements-test.txt
index e65271621ddd..ba5ea0936010 100644
--- a/requirements/requirements-test.txt
+++ b/requirements/requirements-test.txt
@@ -16,4 +16,5 @@ triton==2.0.0.dev20221202
requests==2.27.1 # downgrade to avoid huggingface error https://github.com/huggingface/transformers/issues/17611
SentencePiece
ninja
-flash_attn>=2.0
+flash_attn==2.0.5
+datasets
diff --git a/requirements/requirements.txt b/requirements/requirements.txt
index 65eecce2c34f..9aa5f2822e40 100644
--- a/requirements/requirements.txt
+++ b/requirements/requirements.txt
@@ -8,7 +8,6 @@ click
fabric
contexttimer
ninja
-torch>=1.11
+torch>=1.12
safetensors
-flash_attn>=2.0
einops
diff --git a/tests/kit/model_zoo/transformers/__init__.py b/tests/kit/model_zoo/transformers/__init__.py
index 4aa01abe13ee..823ca032fc30 100644
--- a/tests/kit/model_zoo/transformers/__init__.py
+++ b/tests/kit/model_zoo/transformers/__init__.py
@@ -1,7 +1,12 @@
from .albert import *
from .bert import *
+from .blip2 import *
from .bloom import *
+from .chatglm import *
from .gpt import *
from .llama import *
from .opt import *
+from .sam import *
from .t5 import *
+from .vit import *
+from .whisper import *
diff --git a/tests/kit/model_zoo/transformers/bert.py b/tests/kit/model_zoo/transformers/bert.py
index d2d3de7b7bee..e16d3b269ba0 100644
--- a/tests/kit/model_zoo/transformers/bert.py
+++ b/tests/kit/model_zoo/transformers/bert.py
@@ -20,7 +20,7 @@ def data_gen():
# token_type_ids = tokenized_input['token_type_ids']
input_ids = torch.tensor([[101, 7592, 1010, 2026, 3899, 2003, 10140, 102]], dtype=torch.int64)
token_type_ids = torch.tensor([[0, 0, 0, 0, 0, 0, 0, 0]], dtype=torch.int64)
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 0]], dtype=torch.int64)
return dict(input_ids=input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
@@ -69,29 +69,52 @@ def data_gen_for_mcq():
# data['labels'] = torch.tensor([0], dtype=torch.int64)
input_ids = torch.tensor([[[
101, 1999, 3304, 1010, 10733, 2366, 1999, 5337, 10906, 1010, 2107, 2004, 2012, 1037, 4825, 1010, 2003, 3591,
- 4895, 14540, 6610, 2094, 1012, 102, 2009, 2003, 8828, 2007, 1037, 9292, 1998, 1037, 5442, 1012, 102
+ 4895, 14540, 6610, 2094, 1012, 102, 2009, 2003, 8828, 2007, 1037, 9292, 1998, 1037, 5442, 1012, 102, 102, 5442,
+ 1012, 102, 102
],
[
101, 1999, 3304, 1010, 10733, 2366, 1999, 5337, 10906, 1010, 2107, 2004, 2012, 1037,
4825, 1010, 2003, 3591, 4895, 14540, 6610, 2094, 1012, 102, 2009, 2003, 8828, 2096,
- 2218, 1999, 1996, 2192, 1012, 102, 0
+ 2218, 1999, 1996, 2192, 1012, 102, 0, 0, 1012, 102, 0, 0
]]])
- token_type_ids = torch.tensor(
- [[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
- [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]]])
- attention_mask = torch.tensor(
- [[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]]])
+ token_type_ids = torch.tensor([[[
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1
+ ],
+ [
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0
+ ]]])
+ attention_mask = torch.tensor([[[
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1
+ ],
+ [
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0
+ ]]])
labels = torch.tensor([0], dtype=torch.int64)
return dict(input_ids=input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask, labels=labels)
+def data_gen_for_qa():
+ # generating data for question answering
+ # no need for labels and use start and end position instead
+ data = data_gen()
+ start_positions = torch.tensor([0], dtype=torch.int64)
+ data['start_positions'] = start_positions
+ end_positions = torch.tensor([1], dtype=torch.int64)
+ data['end_positions'] = end_positions
+ return data
+
+
# define output transform function
output_transform_fn = lambda x: x
# define loss funciton
-loss_fn_for_bert_model = lambda x: x.pooler_output.mean()
+loss_fn_for_bert_model = lambda x: torch.nn.functional.mse_loss(x.last_hidden_state, torch.ones_like(x.last_hidden_state
+ ))
loss_fn = lambda x: x.loss
config = transformers.BertConfig(hidden_size=128,
@@ -150,3 +173,9 @@ def data_gen_for_mcq():
output_transform_fn=output_transform_fn,
loss_fn=loss_fn,
model_attribute=ModelAttribute(has_control_flow=True))
+model_zoo.register(name='transformers_bert_for_question_answering',
+ model_fn=lambda: transformers.BertForQuestionAnswering(config),
+ data_gen_fn=data_gen_for_qa,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn,
+ model_attribute=ModelAttribute(has_control_flow=True))
diff --git a/tests/kit/model_zoo/transformers/blip2.py b/tests/kit/model_zoo/transformers/blip2.py
new file mode 100644
index 000000000000..984a6ffa920d
--- /dev/null
+++ b/tests/kit/model_zoo/transformers/blip2.py
@@ -0,0 +1,62 @@
+import torch
+import transformers
+
+from ..registry import ModelAttribute, model_zoo
+
+# ===============================
+# Register single-image SAM
+# ===============================
+
+
+# define data gen function
+def data_gen():
+ # Generated from following code snippet
+ #
+ # from PIL import Image
+ # import requests
+ # from transformers import Blip2Processor, Blip2Model
+ # import torch
+
+ # processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
+ # url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ # image = Image.open(requests.get(url, stream=True).raw)
+
+ # prompt = "Question: how many cats are there? Answer:"
+ # inputs = processor(images=image, text=prompt, return_tensors="pt").to(device, torch.float16)
+
+ pixel_values = torch.rand(1, 3, 224, 224, dtype=torch.float32)
+ input_ids = torch.tensor([[2, 45641, 35, 141, 171, 10017, 32, 89, 116, 31652, 35]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ labels = torch.tensor([[34, 56]], dtype=torch.int64)
+ return dict(pixel_values=pixel_values, input_ids=input_ids, attention_mask=attention_mask, labels=labels)
+
+
+# define output transform function
+output_transform_fn = lambda x: x
+
+# define loss funciton
+loss_fn_blip2_model = lambda x: x.loss
+
+config = transformers.Blip2Config()
+config.vision_config.patch_size = 14
+config.text_config.num_hidden_layers = 1
+config.qformer_config.num_hidden_layers = 1
+config.vision_config.num_hidden_layers = 1
+config.qformer_config.attention_probs_dropout_prob = 0
+config.qformer_config.hidden_dropout_prob = 0
+config.text_config.dropout = 0
+
+# register the blip2 variants
+model_zoo.register(name='transformers_blip2',
+ model_fn=lambda: transformers.Blip2Model(config),
+ data_gen_fn=data_gen,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn_blip2_model,
+ model_attribute=ModelAttribute(has_control_flow=True))
+
+model_zoo.register(name='transformers_blip2_conditional_gerneration',
+ model_fn=lambda: transformers.Blip2ForConditionalGeneration(config),
+ data_gen_fn=data_gen,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn_blip2_model,
+ model_attribute=ModelAttribute(has_control_flow=True))
diff --git a/tests/kit/model_zoo/transformers/bloom.py b/tests/kit/model_zoo/transformers/bloom.py
index 71146c0b9819..2d9c882089cb 100644
--- a/tests/kit/model_zoo/transformers/bloom.py
+++ b/tests/kit/model_zoo/transformers/bloom.py
@@ -16,8 +16,8 @@ def data_gen():
# tokenized_input = tokenizer(input, return_tensors='pt')
# input_ids = tokenized_input['input_ids']
# attention_mask = tokenized_input['attention_mask']
- input_ids = torch.tensor([[59414, 15, 2670, 35433, 632, 207595]], dtype=torch.int64)
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ input_ids = torch.tensor([[59414, 15, 2670, 35433, 632, 207595, 632, 207595]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
return dict(input_ids=input_ids, attention_mask=attention_mask)
@@ -33,7 +33,7 @@ def data_gen_for_token_classification():
# token classification data gen
# `labels` is the type not the token id for token classification, 0 or 1
data = data_gen()
- data['labels'] = torch.tensor([[0, 0, 0, 0, 0, 0]], dtype=torch.int64)
+ data['labels'] = torch.tensor([[0, 0, 0, 0, 0, 0, 0, 0]], dtype=torch.int64)
return data
@@ -53,26 +53,34 @@ def data_gen_for_question_answering():
# inputs = tokenizer(question, text, return_tensors="pt")
input_ids = torch.tensor(
- [[57647, 1620, 23967, 620, 107373, 34, 91514, 620, 107373, 1620, 267, 35378, 48946, 18161]], dtype=torch.int64)
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
- return dict(input_ids=input_ids, attention_mask=attention_mask)
+ [[57647, 1620, 23967, 620, 107373, 34, 91514, 620, 107373, 1620, 267, 35378, 48946, 18161, 48946, 18161]],
+ dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ start_positions = torch.tensor([1], dtype=torch.int64)
+ end_positions = torch.tensor([10], dtype=torch.int64)
+ return dict(input_ids=input_ids,
+ attention_mask=attention_mask,
+ start_positions=start_positions,
+ end_positions=end_positions)
# define output transform function
output_transform_fn = lambda x: x
# define loss function
-loss_fn_for_bloom_model = lambda x: x.last_hidden_state.mean()
+loss_fn_for_bloom_model = lambda x: torch.nn.functional.mse_loss(x.last_hidden_state,
+ torch.ones_like(x.last_hidden_state))
loss_fn_for_causal_lm = lambda x: x.loss
-loss_fn_for_classification = lambda x: x.logits.mean()
-loss_fn_for_question_answering = lambda x: x.end_logits.mean()
+loss_fn_for_classification = lambda x: x.loss
+loss_fn_for_question_answering = lambda x: x.loss
-config = transformers.BloomConfig(n_layer=1,
+config = transformers.BloomConfig(n_layer=2,
n_head=4,
vocab_size=250880,
hidden_dropout=0,
attention_dropout=0,
- hidden_size=64)
+ hidden_size=64,
+ pad_token_id=50256)
# register the following models
model_zoo.register(name='transformers_bloom',
diff --git a/tests/kit/model_zoo/transformers/chatglm.py b/tests/kit/model_zoo/transformers/chatglm.py
new file mode 100644
index 000000000000..c6473ee2a025
--- /dev/null
+++ b/tests/kit/model_zoo/transformers/chatglm.py
@@ -0,0 +1,58 @@
+import torch
+import transformers
+
+from colossalai.shardformer.modeling.chatglm2_6b.configuration_chatglm import ChatGLMConfig
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import ChatGLMForConditionalGeneration, ChatGLMModel
+
+from ..registry import ModelAttribute, model_zoo
+
+# ================================
+# Register single-sentence ChatGLM
+# ================================
+
+
+def data_gen():
+ input_ids = torch.tensor([[5941, 15, 2670, 3543, 632, 2075]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1]])
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def data_gen_for_conditional_generation():
+ # token classification data gen
+ # `labels` is the type not the token id for token classification, 0 or 1
+ data = data_gen()
+ labels = data['input_ids'].clone()
+ data['labels'] = labels
+ return data
+
+
+# define output transform function
+output_transform_fn = lambda x: x
+
+# define loss function
+loss_fn_for_chatglm_model = lambda x: torch.nn.functional.mse_loss(x.last_hidden_state,
+ torch.ones_like(x.last_hidden_state))
+loss_fn = lambda x: x.loss
+
+config = ChatGLMConfig(num_layers=2,
+ padded_vocab_size=65024,
+ hidden_size=64,
+ num_attention_heads=8,
+ rmsnorm=True,
+ original_rope=True,
+ use_cache=True,
+ torch_dtype=torch.float32)
+
+model_zoo.register(name='transformers_chatglm',
+ model_fn=lambda: ChatGLMModel(config, empty_init=False),
+ data_gen_fn=data_gen,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn_for_chatglm_model,
+ model_attribute=ModelAttribute(has_control_flow=True))
+
+model_zoo.register(name="transformers_chatglm_for_conditional_generation",
+ model_fn=lambda: ChatGLMForConditionalGeneration(config, empty_init=False),
+ data_gen_fn=data_gen_for_conditional_generation,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn,
+ model_attribute=ModelAttribute(has_control_flow=True))
diff --git a/tests/kit/model_zoo/transformers/gpt.py b/tests/kit/model_zoo/transformers/gpt.py
index b9e0310780af..5c3eb4438bc8 100644
--- a/tests/kit/model_zoo/transformers/gpt.py
+++ b/tests/kit/model_zoo/transformers/gpt.py
@@ -1,3 +1,5 @@
+import copy
+
import torch
import transformers
@@ -16,8 +18,8 @@ def data_gen():
# tokenized_input = tokenizer(input, return_tensors='pt')
# input_ids = tokenized_input['input_ids']
# attention_mask = tokenized_input['attention_mask']
- input_ids = torch.tensor([[15496, 11, 616, 3290, 318, 13779]], dtype=torch.int64)
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ input_ids = torch.tensor([[15496, 11, 616, 3290, 318, 13779, 318, 13779]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
return dict(input_ids=input_ids, attention_mask=attention_mask)
@@ -29,18 +31,29 @@ def data_gen_for_lm():
return data
+def data_gen_for_question_answering():
+ # question answering data gen
+ # `labels` is the type not the token id for token classification, 0 or 1
+ data = data_gen()
+ start_positions = torch.tensor([0], dtype=torch.int64)
+ data['start_positions'] = start_positions
+ end_positions = torch.tensor([1], dtype=torch.int64)
+ data['end_positions'] = end_positions
+ return data
+
+
def data_gen_for_token_classification():
# token classification data gen
# `labels` is the type not the token id for token classification, 0 or 1
data = data_gen()
- data['labels'] = torch.tensor([[0, 0, 0, 0, 0, 0]], dtype=torch.int64)
+ data['labels'] = torch.tensor([[0, 0, 0, 0, 0, 0, 0, 1]], dtype=torch.int64)
return data
def data_gen_for_sequence_classification():
# sequence classification data gen
data = data_gen()
- data['labels'] = torch.tensor([0], dtype=torch.int64)
+ data['labels'] = torch.tensor([1], dtype=torch.int64)
return data
@@ -48,7 +61,8 @@ def data_gen_for_sequence_classification():
output_transform_fn = lambda x: x
# define loss function
-loss_fn_for_gpt2_model = lambda x: x.last_hidden_state.mean()
+loss_fn_for_gpt2_model = lambda x: torch.nn.functional.mse_loss(x.last_hidden_state, torch.ones_like(x.last_hidden_state
+ ))
loss_fn = lambda x: x.loss
config = transformers.GPT2Config(n_layer=2,
@@ -59,7 +73,11 @@ def data_gen_for_sequence_classification():
resid_pdrop=0,
summary_first_dropout=0,
hidden_dropout=0,
- problem_type="single_label_classification")
+ problem_type="single_label_classification",
+ pad_token_id=50256)
+
+config_for_token_classification = copy.deepcopy(config)
+config_for_token_classification.num_labels = 2
# register the following models
model_zoo.register(name='transformers_gpt',
@@ -80,14 +98,20 @@ def data_gen_for_sequence_classification():
output_transform_fn=output_transform_fn,
loss_fn=loss_fn,
model_attribute=ModelAttribute(has_control_flow=True))
+model_zoo.register(name='transformers_gpt_for_question_answering',
+ model_fn=lambda: transformers.GPT2ForQuestionAnswering(config),
+ data_gen_fn=data_gen_for_question_answering,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn,
+ model_attribute=ModelAttribute(has_control_flow=True))
model_zoo.register(name='transformers_gpt_for_token_classification',
- model_fn=lambda: transformers.GPT2ForTokenClassification(config),
+ model_fn=lambda: transformers.GPT2ForTokenClassification(config_for_token_classification),
data_gen_fn=data_gen_for_token_classification,
output_transform_fn=output_transform_fn,
loss_fn=loss_fn,
model_attribute=ModelAttribute(has_control_flow=True))
model_zoo.register(name='transformers_gpt_for_sequence_classification',
- model_fn=lambda: transformers.GPT2ForSequenceClassification(config),
+ model_fn=lambda: transformers.GPT2ForSequenceClassification(config_for_token_classification),
data_gen_fn=data_gen_for_sequence_classification,
output_transform_fn=output_transform_fn,
loss_fn=loss_fn,
diff --git a/tests/kit/model_zoo/transformers/opt.py b/tests/kit/model_zoo/transformers/opt.py
index 4463ae12b901..29430afc0661 100644
--- a/tests/kit/model_zoo/transformers/opt.py
+++ b/tests/kit/model_zoo/transformers/opt.py
@@ -44,7 +44,8 @@ def data_gen_for_question_answering():
output_transform_fn = lambda x: x
-loss_fn_for_opt_model = lambda x: x.last_hidden_state.mean()
+loss_fn_for_opt_model = lambda x: torch.nn.functional.mse_loss(x.last_hidden_state, torch.ones_like(x.last_hidden_state)
+ )
loss_fn_for_lm = lambda x: x.loss
config = transformers.OPTConfig(
hidden_size=128,
diff --git a/tests/kit/model_zoo/transformers/sam.py b/tests/kit/model_zoo/transformers/sam.py
new file mode 100644
index 000000000000..d850623f368f
--- /dev/null
+++ b/tests/kit/model_zoo/transformers/sam.py
@@ -0,0 +1,52 @@
+import torch
+import transformers
+
+from ..registry import ModelAttribute, model_zoo
+
+# ===============================
+# Register single-image SAM
+# ===============================
+
+
+# define data gen function
+def data_gen():
+ # Generated from following code snippet
+ #
+ # from PIL import Image
+ # import requests
+ # from transformers import SamModel, SamProcessor
+ #
+ # model = SamModel.from_pretrained("facebook/sam-vit-base")
+ # processor = SamProcessor.from_pretrained("facebook/sam-vit-base")
+ #
+ # img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
+ # raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
+ # input_points = [[[450, 600]]] # 2D localization of a window
+ # inputs = processor(raw_image, input_points=input_points, return_tensors="pt")
+
+ pixel_values = torch.rand(1, 3, 1024, 1024, dtype=torch.float32)
+ original_sizes = torch.tensor([[1764, 2646]], dtype=torch.int64)
+ reshaped_input_sizes = torch.tensor([[683, 1024]], dtype=torch.int64)
+ input_points = torch.tensor([[[[174.1497, 232.3129]]]], dtype=torch.float64)
+ return dict(pixel_values=pixel_values,
+ original_sizes=original_sizes,
+ reshaped_input_sizes=reshaped_input_sizes,
+ input_points=input_points)
+
+
+# define output transform function
+output_transform_fn = lambda x: x
+
+# define loss funciton
+loss_fn = lambda x: x.iou_scores.mean()
+
+config = transformers.SamConfig()
+config.vision_config.num_hidden_layers = 2
+
+# register the BERT variants
+model_zoo.register(name='transformers_sam',
+ model_fn=lambda: transformers.SamModel(config),
+ data_gen_fn=data_gen,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn,
+ model_attribute=ModelAttribute(has_control_flow=True))
diff --git a/tests/kit/model_zoo/transformers/t5.py b/tests/kit/model_zoo/transformers/t5.py
index 689db2c40abb..175d48963480 100644
--- a/tests/kit/model_zoo/transformers/t5.py
+++ b/tests/kit/model_zoo/transformers/t5.py
@@ -16,8 +16,9 @@ def data_gen_for_encoder_only():
# config = T5Config(decoder_start_token_id=0)
# tokenizer = T5Tokenizer.from_pretrained("t5-small")
# input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
- input_ids = torch.Tensor([[13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5, 1]]).long()
- return dict(input_ids=input_ids)
+ input_ids = torch.Tensor([[13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5, 1, 12, 1627, 5, 1, 12]]).long()
+ attention_mask = torch.Tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]]).long()
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
def data_gen_for_conditional_generation():
@@ -25,17 +26,16 @@ def data_gen_for_conditional_generation():
#
# labels = tokenizer("Das Haus ist wunderbar.", return_tensors="pt").input_ids
data = data_gen_for_encoder_only()
- labels = torch.Tensor([[644, 4598, 229, 19250, 5, 1]]).long()
+ labels = torch.Tensor([[644, 4598, 229, 19250, 5, 1, 644, 4598, 229, 19250, 5, 1, 229, 19250, 5, 1]]).long()
data['labels'] = labels
return data
def data_gen_for_t5_model():
# decoder_inputs_ids is obtained with the following code
- #
# decoder_input_ids = model._shift_right(input_ids)
data = data_gen_for_encoder_only()
- decoder_input_ids = torch.Tensor([[0, 13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5]]).long()
+ decoder_input_ids = torch.Tensor([[0, 13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5, 5, 19, 1627, 5, 5]]).long()
data['decoder_input_ids'] = decoder_input_ids
return data
diff --git a/tests/kit/model_zoo/transformers/vit.py b/tests/kit/model_zoo/transformers/vit.py
new file mode 100644
index 000000000000..a84b8d31c284
--- /dev/null
+++ b/tests/kit/model_zoo/transformers/vit.py
@@ -0,0 +1,64 @@
+import torch
+import transformers
+
+from ..registry import ModelAttribute, model_zoo
+
+# ===============================
+# Register single-sentence VIT
+# ===============================
+
+config = transformers.ViTConfig(num_hidden_layers=4, hidden_size=128, intermediate_size=256, num_attention_heads=4)
+
+
+# define data gen function
+def data_gen():
+ pixel_values = torch.randn(1, 3, 224, 224)
+ return dict(pixel_values=pixel_values)
+
+
+def data_gen_for_image_classification():
+ data = data_gen()
+ data['labels'] = torch.tensor([0])
+ return data
+
+
+def data_gen_for_masked_image_modeling():
+ data = data_gen()
+ num_patches = (config.image_size // config.patch_size)**2
+ bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
+ data['bool_masked_pos'] = bool_masked_pos
+ return data
+
+
+# define output transform function
+output_transform_fn = lambda x: x
+
+# function to get the loss
+loss_fn_for_vit_model = lambda x: x.pooler_output.mean()
+loss_fn_for_image_classification = lambda x: x.logits.mean()
+loss_fn_for_masked_image_modeling = lambda x: x.loss
+
+# register the following models
+# transformers.ViTModel,
+# transformers.ViTForMaskedImageModeling,
+# transformers.ViTForImageClassification,
+model_zoo.register(name='transformers_vit',
+ model_fn=lambda: transformers.ViTModel(config),
+ data_gen_fn=data_gen,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn_for_vit_model,
+ model_attribute=ModelAttribute(has_control_flow=True))
+
+model_zoo.register(name='transformers_vit_for_masked_image_modeling',
+ model_fn=lambda: transformers.ViTForMaskedImageModeling(config),
+ data_gen_fn=data_gen_for_masked_image_modeling,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn_for_masked_image_modeling,
+ model_attribute=ModelAttribute(has_control_flow=True))
+
+model_zoo.register(name='transformers_vit_for_image_classification',
+ model_fn=lambda: transformers.ViTForImageClassification(config),
+ data_gen_fn=data_gen_for_image_classification,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn_for_image_classification,
+ model_attribute=ModelAttribute(has_control_flow=True))
diff --git a/tests/kit/model_zoo/transformers/whisper.py b/tests/kit/model_zoo/transformers/whisper.py
new file mode 100644
index 000000000000..f7cdc052aaf0
--- /dev/null
+++ b/tests/kit/model_zoo/transformers/whisper.py
@@ -0,0 +1,91 @@
+import torch
+import transformers
+
+from ..registry import ModelAttribute, model_zoo
+
+# ===============================
+# Register single-sentence Whisper
+# ===============================
+
+
+# define data gen function
+def data_gen():
+ # Generated from following code snippet
+ #
+ # from transformers import AutoFeatureExtractor, WhisperModel
+ # from datasets import load_dataset
+
+ # model = WhisperModel.from_pretrained("openai/whisper-base")
+ # feature_extractor = AutoFeatureExtractor.from_pretrained("openai/whisper-base")
+ # ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ # inputs = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt")
+ # input_features = inputs.input_features
+ # decoder_input_ids = torch.tensor([[1, 1]]) * model.config.decoder_start_token_id
+
+ input_features = torch.rand(1, 80, 3000)
+ decoder_input_ids = torch.tensor([[1, 1]]) * 50258
+ return dict(input_features=input_features, decoder_input_ids=decoder_input_ids)
+
+
+def data_gen_for_conditional_generation():
+ # labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ # Labels for computing the language modeling loss. Indices should either be in `[0, ..., config.vocab_size]`
+ # or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored (masked), the loss is
+ # only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+ data = data_gen()
+ data['labels'] = torch.tensor([[0, 1]], dtype=torch.int64)
+ return data
+
+
+def data_gen_for_audio_classification():
+ # labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ # Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ # config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ # `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ # `WhisperForAudioClassification` does not need `decoder_input_ids`
+ data = data_gen()
+ data.pop('decoder_input_ids')
+ data['labels'] = torch.tensor([1], dtype=torch.int64)
+ return data
+
+
+# define output transform function
+output_transform_fn = lambda x: x
+
+# define loss funciton
+loss_fn = lambda x: torch.nn.functional.mse_loss(x.last_hidden_state, torch.ones_like(x.last_hidden_state))
+loss_fn_attr = lambda x: x.loss
+
+config = transformers.WhisperConfig(
+ classifier_proj_size=256,
+ d_model=256,
+ decoder_attention_heads=4,
+ decoder_ffn_dim=1536,
+ decoder_layers=2,
+ encoder_attention_heads=4,
+ encoder_ffn_dim=1536,
+ encoder_layers=2,
+ vocab_size=51866,
+)
+
+# register the Whisper variants
+model_zoo.register(name='transformers_whisper',
+ model_fn=lambda: transformers.WhisperModel(config),
+ data_gen_fn=data_gen,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn,
+ model_attribute=ModelAttribute(has_control_flow=True))
+
+model_zoo.register(name='transformers_whisper_for_conditional_generation',
+ model_fn=lambda: transformers.WhisperForConditionalGeneration(config),
+ data_gen_fn=data_gen_for_conditional_generation,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn_attr,
+ model_attribute=ModelAttribute(has_control_flow=True))
+
+model_zoo.register(name='transformers_whisper_for_audio_classification',
+ model_fn=lambda: transformers.WhisperForAudioClassification(config),
+ data_gen_fn=data_gen_for_audio_classification,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn_attr,
+ model_attribute=ModelAttribute(has_control_flow=True))
diff --git a/tests/test_booster/test_plugin/test_3d_plugin.py b/tests/test_booster/test_plugin/test_3d_plugin.py
new file mode 100644
index 000000000000..a58afac810d7
--- /dev/null
+++ b/tests/test_booster/test_plugin/test_3d_plugin.py
@@ -0,0 +1,99 @@
+from contextlib import nullcontext
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import HybridParallelPlugin
+from colossalai.fx import is_compatible_with_meta
+from colossalai.lazy.lazy_init import LazyInitContext
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+from tests.kit.model_zoo import model_zoo
+
+
+def run_fn(init_method, model_fn, data_gen_fn, output_transform_fn) -> Optional[str]:
+ try:
+ if init_method == 'lazy':
+ ctx = LazyInitContext()
+ else:
+ ctx = nullcontext()
+ plugin = HybridParallelPlugin(tp_size=2, pp_size=2, num_microbatches=4, precision='bf16')
+ booster = Booster(plugin=plugin)
+ with ctx:
+ model = model_fn()
+ optimizer = HybridAdam(model.parameters(), lr=1e-3)
+ criterion = lambda x: x.mean()
+ data = data_gen_fn()
+
+ data = {
+ k: v.to('cuda').repeat(4, 1) if torch.is_tensor(v) or 'Tensor' in v.__class__.__name__ else v
+ for k, v in data.items()
+ }
+
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+
+ data_iter = iter([data])
+
+ def _criterion(outputs, inputs):
+ outputs = output_transform_fn(outputs)
+ output_key = list(outputs.keys())[0]
+ loss = criterion(outputs[output_key])
+ return loss
+
+ booster.execute_pipeline(data_iter, model, _criterion, optimizer, return_loss=True, return_outputs=False)
+ optimizer.step()
+
+ except Exception as e:
+ return repr(e)
+
+
+@parameterize('init_method', ['none', 'lazy'])
+def check_3d_plugin(init_method: str = 'none', early_stop: bool = True):
+ """check gemini plugin over model zoo
+
+ Args:
+ early_stop (bool, optional): Whether to stop when getting the first error. Defaults to True.
+ """
+ is_support_meta = is_compatible_with_meta()
+ if not is_support_meta and init_method == 'lazy':
+ return
+
+ passed_models = []
+ failed_info = {} # (model_name, error) pair
+
+ # TODO(ver217): add more models
+ for name, (model_fn, data_gen_fn, output_transform_fn, _,
+ _) in model_zoo.get_sub_registry('transformers_llama_for_casual_lm').items():
+ err = run_fn(init_method, model_fn, data_gen_fn, output_transform_fn)
+ torch.cuda.empty_cache()
+
+ if err is None:
+ passed_models.append(name)
+ else:
+ failed_info[name] = err
+ if early_stop:
+ break
+
+ if dist.get_rank() == 0:
+ print(f'Init method: {init_method}')
+ print(f'Passed models({len(passed_models)}): {passed_models}\n\n')
+ print(f'Failed models({len(failed_info)}): {list(failed_info.keys())}\n\n')
+ assert len(failed_info) == 0, '\n'.join([f'{k}: {v}' for k, v in failed_info.items()])
+
+
+def run_dist(rank, world_size, port, early_stop: bool = True):
+ # init dist env
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ check_3d_plugin(early_stop=early_stop)
+
+
+@rerun_if_address_is_in_use()
+def test_gemini_plugin(early_stop: bool = True):
+ spawn(run_dist, 4, early_stop=early_stop)
+
+
+if __name__ == '__main__':
+ test_gemini_plugin(early_stop=False)
diff --git a/tests/test_booster/test_plugin/test_gemini_plugin.py b/tests/test_booster/test_plugin/test_gemini_plugin.py
index d29c92926066..fee153baf1ac 100644
--- a/tests/test_booster/test_plugin/test_gemini_plugin.py
+++ b/tests/test_booster/test_plugin/test_gemini_plugin.py
@@ -88,7 +88,12 @@ def check_gemini_plugin(init_method: str = 'none', early_stop: bool = True):
'torchvision_vit_b_16', 'torchvision_convnext_base', 'torchvision_swin_s', 'transformers_albert',
'transformers_albert_for_pretraining', 'transformers_bert', 'transformers_bert_for_pretraining',
'transformers_gpt_double_heads', 'torchaudio_hubert_base', 'torchaudio_wav2vec2_base',
- 'transformers_t5_for_conditional_generation', 'transformers_t5', 'transformers_t5_encoder_model'
+ 'transformers_t5_for_conditional_generation', 'transformers_t5', 'transformers_t5_encoder_model',
+ 'transformers_vit', 'transformers_vit_for_masked_image_modeling',
+ 'transformers_vit_for_image_classification', 'transformers_chatglm',
+ 'transformers_chatglm_for_conditional_generation', 'transformers_blip2',
+ 'transformers_blip2_conditional_gerneration', 'transformers_sam', 'transformers_whisper',
+ 'transformers_whisper_for_conditional_generation', 'transformers_whisper_for_audio_classification'
]:
continue
@@ -99,7 +104,6 @@ def check_gemini_plugin(init_method: str = 'none', early_stop: bool = True):
'torchvision_shufflenet_v2_x0_5', 'torchvision_efficientnet_v2_s'
]:
continue
-
err = run_fn(init_method, model_fn, data_gen_fn, output_transform_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_cluster/test_process_group_mesh.py b/tests/test_cluster/test_process_group_mesh.py
new file mode 100644
index 000000000000..13b7119424e4
--- /dev/null
+++ b/tests/test_cluster/test_process_group_mesh.py
@@ -0,0 +1,151 @@
+import pytest
+import torch.distributed as dist
+
+import colossalai
+from colossalai.cluster import ProcessGroupMesh
+from colossalai.testing import spawn
+
+
+def check_process_group_mesh_with_gpc():
+ from colossalai.context import ParallelMode
+ from colossalai.core import global_context as gpc
+
+ DP_DIM, PP_DIM, TP_DIM = 0, 1, 2
+ pg_mesh = ProcessGroupMesh(1, 2, 2)
+
+ # check world size
+ assert gpc.get_world_size(ParallelMode.TENSOR) == pg_mesh.size(
+ TP_DIM), f'{gpc.get_world_size(ParallelMode.TENSOR)} != {pg_mesh.size(TP_DIM)}'
+ assert gpc.get_world_size(ParallelMode.PIPELINE) == pg_mesh.size(PP_DIM)
+ assert gpc.get_world_size(ParallelMode.DATA) == pg_mesh.size(DP_DIM)
+
+ # check locak rank (coordinate)
+ assert gpc.get_local_rank(ParallelMode.TENSOR) == pg_mesh.coordinate(
+ TP_DIM), f'{gpc.get_local_rank(ParallelMode.TENSOR)} != {pg_mesh.coordinate(TP_DIM)}'
+ assert gpc.get_local_rank(ParallelMode.PIPELINE) == pg_mesh.coordinate(PP_DIM)
+ assert gpc.get_local_rank(ParallelMode.DATA) == pg_mesh.coordinate(DP_DIM)
+
+ # check ranks in group
+ tp_group = pg_mesh.get_group_along_axis(TP_DIM)
+ assert gpc.get_ranks_in_group(ParallelMode.TENSOR) == pg_mesh.get_ranks_in_group(tp_group)
+ pp_group = pg_mesh.get_group_along_axis(PP_DIM)
+ assert gpc.get_ranks_in_group(ParallelMode.PIPELINE) == pg_mesh.get_ranks_in_group(pp_group)
+ dp_group = pg_mesh.get_group_along_axis(DP_DIM)
+ assert gpc.get_ranks_in_group(ParallelMode.DATA) == pg_mesh.get_ranks_in_group(dp_group)
+
+ # check prev rank
+ coord = pg_mesh.coordinate()
+ if not gpc.is_first_rank(ParallelMode.TENSOR):
+ assert coord[TP_DIM] != 0
+ prev_coord = coord[:TP_DIM] + (coord[TP_DIM] - 1,) + coord[TP_DIM + 1:]
+ assert gpc.get_prev_global_rank(ParallelMode.TENSOR) == pg_mesh.ravel(prev_coord, pg_mesh.shape)
+ if not gpc.is_first_rank(ParallelMode.PIPELINE):
+ assert coord[PP_DIM] != 0
+ prev_coord = coord[:PP_DIM] + (coord[PP_DIM] - 1,) + coord[PP_DIM + 1:]
+ assert gpc.get_prev_global_rank(ParallelMode.PIPELINE) == pg_mesh.ravel(prev_coord, pg_mesh.shape)
+
+ # check next rank
+ if not gpc.is_last_rank(ParallelMode.TENSOR):
+ assert coord[TP_DIM] != pg_mesh.size(TP_DIM) - 1
+ next_coord = coord[:TP_DIM] + (coord[TP_DIM] + 1,) + coord[TP_DIM + 1:]
+ assert gpc.get_next_global_rank(ParallelMode.TENSOR) == pg_mesh.ravel(next_coord, pg_mesh.shape)
+ if not gpc.is_last_rank(ParallelMode.PIPELINE):
+ assert coord[PP_DIM] != pg_mesh.size(PP_DIM) - 1
+ next_coord = coord[:PP_DIM] + (coord[PP_DIM] + 1,) + coord[PP_DIM + 1:]
+ assert gpc.get_next_global_rank(ParallelMode.PIPELINE) == pg_mesh.ravel(next_coord, pg_mesh.shape)
+
+
+def check_process_group_mesh_with_cases():
+ DP_DIM, PP_DIM, TP_DIM = 0, 1, 2
+ DP_SIZE, PP_SIZE, TP_SIZE = 1, 2, 2
+ RANK_TO_COORDINATE = {
+ 0: (0, 0, 0),
+ 1: (0, 0, 1),
+ 2: (0, 1, 0),
+ 3: (0, 1, 1),
+ }
+ TP_RANKS_IN_GROUP = {
+ 0: [0, 1],
+ 1: [0, 1],
+ 2: [2, 3],
+ 3: [2, 3],
+ }
+ PP_RANKS_IN_GROUP = {
+ 0: [0, 2],
+ 1: [1, 3],
+ 2: [0, 2],
+ 3: [1, 3],
+ }
+ DP_RANKS_IN_GROUP = {
+ 0: [0],
+ 1: [1],
+ 2: [2],
+ 3: [3],
+ }
+
+ pg_mesh = ProcessGroupMesh(DP_SIZE, PP_SIZE, TP_SIZE)
+
+ rank = dist.get_rank()
+ assert rank == pg_mesh.rank
+
+ # check world size
+ assert pg_mesh.size(TP_DIM) == 2
+ assert pg_mesh.size(PP_DIM) == 2
+ assert pg_mesh.size(DP_DIM) == 1
+
+ # check coordinate
+ assert pg_mesh.coordinate(TP_DIM) == RANK_TO_COORDINATE[rank][TP_DIM]
+ assert pg_mesh.coordinate(PP_DIM) == RANK_TO_COORDINATE[rank][PP_DIM]
+ assert pg_mesh.coordinate(DP_DIM) == RANK_TO_COORDINATE[rank][DP_DIM]
+
+ # check ranks in group
+ tp_group = pg_mesh.get_group_along_axis(TP_DIM)
+ assert pg_mesh.get_ranks_in_group(tp_group) == TP_RANKS_IN_GROUP[rank]
+ pp_group = pg_mesh.get_group_along_axis(PP_DIM)
+ assert pg_mesh.get_ranks_in_group(pp_group) == PP_RANKS_IN_GROUP[rank]
+ dp_group = pg_mesh.get_group_along_axis(DP_DIM)
+ assert pg_mesh.get_ranks_in_group(dp_group) == DP_RANKS_IN_GROUP[rank]
+
+ # check prev rank
+ if RANK_TO_COORDINATE[rank][TP_DIM] != 0:
+ prev_coord = RANK_TO_COORDINATE[rank][:TP_DIM] + (RANK_TO_COORDINATE[rank][TP_DIM] - 1,) + \
+ RANK_TO_COORDINATE[rank][TP_DIM + 1:]
+ prev_rank = TP_RANKS_IN_GROUP[rank][TP_RANKS_IN_GROUP[rank].index(rank) - 1]
+ assert pg_mesh.ravel(prev_coord, pg_mesh.shape) == prev_rank
+ if RANK_TO_COORDINATE[rank][PP_DIM] != 0:
+ prev_coord = RANK_TO_COORDINATE[rank][:PP_DIM] + (RANK_TO_COORDINATE[rank][PP_DIM] - 1,) + \
+ RANK_TO_COORDINATE[rank][PP_DIM + 1:]
+ prev_rank = PP_RANKS_IN_GROUP[rank][PP_RANKS_IN_GROUP[rank].index(rank) - 1]
+ assert pg_mesh.ravel(prev_coord, pg_mesh.shape) == prev_rank
+
+ # check next rank
+ if RANK_TO_COORDINATE[rank][TP_DIM] != TP_SIZE - 1:
+ next_coord = RANK_TO_COORDINATE[rank][:TP_DIM] + (RANK_TO_COORDINATE[rank][TP_DIM] + 1,) + \
+ RANK_TO_COORDINATE[rank][TP_DIM + 1:]
+ next_rank = TP_RANKS_IN_GROUP[rank][TP_RANKS_IN_GROUP[rank].index(rank) + 1]
+ assert pg_mesh.ravel(next_coord, pg_mesh.shape) == next_rank
+ if RANK_TO_COORDINATE[rank][PP_DIM] != PP_SIZE - 1:
+ next_coord = RANK_TO_COORDINATE[rank][:PP_DIM] + (RANK_TO_COORDINATE[rank][PP_DIM] + 1,) + \
+ RANK_TO_COORDINATE[rank][PP_DIM + 1:]
+ next_rank = PP_RANKS_IN_GROUP[rank][PP_RANKS_IN_GROUP[rank].index(rank) + 1]
+ assert pg_mesh.ravel(next_coord, pg_mesh.shape) == next_rank
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(config=dict(parallel=dict(data=1, pipeline=2, tensor=dict(mode='1d', size=2))),
+ rank=rank,
+ world_size=world_size,
+ port=port,
+ host='localhost')
+ # TODO(ver217): this function should be removed when gpc is removed
+ check_process_group_mesh_with_gpc()
+ check_process_group_mesh_with_cases()
+
+
+@pytest.mark.dist
+def test_process_group_mesh():
+ spawn(run_dist, 4)
+
+
+if __name__ == '__main__':
+ test_process_group_mesh()
diff --git a/tests/test_fx/test_tracer/test_hf_model/hf_tracer_utils.py b/tests/test_fx/test_tracer/test_hf_model/hf_tracer_utils.py
index 58c8132e1490..e6f8df2e0af7 100644
--- a/tests/test_fx/test_tracer/test_hf_model/hf_tracer_utils.py
+++ b/tests/test_fx/test_tracer/test_hf_model/hf_tracer_utils.py
@@ -22,6 +22,7 @@ def trace_model_and_compare_output(model, data_gen, ignore_data: List[str] = Non
try:
meta_args = {k: v.to('meta') for k, v in inputs.items()}
gm = symbolic_trace(model, meta_args=meta_args)
+
except Exception as e:
raise RuntimeError(f"Failed to trace {model.__class__.__name__}, error: {e}")
diff --git a/tests/test_fx/test_tracer/test_hf_model/test_hf_bert.py b/tests/test_fx/test_tracer/test_hf_model/test_hf_bert.py
index 632ad366ccc4..7773de480302 100644
--- a/tests/test_fx/test_tracer/test_hf_model/test_hf_bert.py
+++ b/tests/test_fx/test_tracer/test_hf_model/test_hf_bert.py
@@ -14,6 +14,8 @@ def test_bert():
for name, (model_fn, data_gen_fn, _, _, _) in sub_registry.items():
model = model_fn()
+ if model.__class__.__name__ == "BertForQuestionAnswering":
+ continue
trace_model_and_compare_output(model, data_gen_fn, ignore_data=['labels', 'next_sentence_label'])
diff --git a/tests/test_fx/test_tracer/test_hf_model/test_hf_gpt.py b/tests/test_fx/test_tracer/test_hf_model/test_hf_gpt.py
index 31bcb7028e25..1cd3b90db917 100644
--- a/tests/test_fx/test_tracer/test_hf_model/test_hf_gpt.py
+++ b/tests/test_fx/test_tracer/test_hf_model/test_hf_gpt.py
@@ -15,10 +15,10 @@ def test_gpt():
for name, (model_fn, data_gen_fn, _, _, _) in sub_registry.items():
model = model_fn()
- # TODO: support the following models
+ # TODO(ver217): support the following models
# 1. GPT2DoubleHeadsModel
# as they are not supported, let's skip them
- if model.__class__.__name__ in ['GPT2DoubleHeadsModel']:
+ if model.__class__.__name__ in ['GPT2DoubleHeadsModel', 'GPT2ForQuestionAnswering']:
continue
trace_model_and_compare_output(model, data_gen_fn, ignore_data=['labels'])
diff --git a/tests/test_lazy/test_models.py b/tests/test_lazy/test_models.py
index e37184125d21..18a737fcec85 100644
--- a/tests/test_lazy/test_models.py
+++ b/tests/test_lazy/test_models.py
@@ -11,7 +11,9 @@ def test_torchvision_models_lazy_init(subset, default_device):
sub_model_zoo = model_zoo.get_sub_registry(subset)
for name, entry in sub_model_zoo.items():
# TODO(ver217): lazy init does not support weight norm, skip these models
- if name in ('torchaudio_wav2vec2_base', 'torchaudio_hubert_base') or name.startswith('transformers_llama'):
+ if name in ('torchaudio_wav2vec2_base',
+ 'torchaudio_hubert_base') or name.startswith('transformers_llama') or name.startswith(
+ ('transformers_vit', 'transformers_blip2')):
continue
check_lazy_init(entry, verbose=True, default_device=default_device)
diff --git a/tests/test_pipeline/test_p2p_communication.py b/tests/test_pipeline/test_p2p_communication.py
new file mode 100644
index 000000000000..71946f6b988a
--- /dev/null
+++ b/tests/test_pipeline/test_p2p_communication.py
@@ -0,0 +1,59 @@
+import pytest
+import torch
+import torch.distributed as dist
+
+import colossalai
+from colossalai.cluster import ProcessGroupMesh
+from colossalai.pipeline.p2p import PipelineP2PCommunication
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.testing import rerun_if_address_is_in_use, spawn
+from colossalai.utils import get_current_device
+
+
+def check_p2p_communication():
+ pg_mesh = ProcessGroupMesh(2)
+ stage_manager = PipelineStageManager(pg_mesh, 0)
+ p2p = PipelineP2PCommunication(stage_manager)
+
+ rank = dist.get_rank()
+
+ tensor = torch.ones(1, device=get_current_device())
+
+ if rank == 0:
+ p2p.send_forward(tensor)
+ p2p.send_forward([tensor])
+ p2p.send_forward({'tensor': tensor})
+ else:
+ obj = p2p.recv_forward()
+ assert torch.equal(obj, tensor)
+ obj = p2p.recv_forward()
+ assert type(obj) == list and len(obj) == 1 and torch.equal(obj[0], tensor)
+ obj = p2p.recv_forward()
+ assert type(obj) == dict and 'tensor' in obj and torch.equal(obj['tensor'], tensor)
+
+ if rank == 1:
+ p2p.send_backward(tensor)
+ p2p.send_backward([tensor])
+ p2p.send_backward({'tensor': tensor})
+ else:
+ obj = p2p.recv_backward()
+ assert torch.equal(obj, tensor)
+ obj = p2p.recv_backward()
+ assert type(obj) == list and len(obj) == 1 and torch.equal(obj[0], tensor)
+ obj = p2p.recv_backward()
+ assert type(obj) == dict and 'tensor' in obj and torch.equal(obj['tensor'], tensor)
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(config={}, rank=rank, world_size=world_size, port=port, host='localhost')
+ check_p2p_communication()
+
+
+@pytest.mark.dist
+@rerun_if_address_is_in_use()
+def test_pipeline_p2p():
+ spawn(run_dist, 2)
+
+
+if __name__ == '__main__':
+ test_pipeline_p2p()
diff --git a/tests/test_pipeline/test_schedule/test_oneF_oneB.py b/tests/test_pipeline/test_schedule/test_oneF_oneB.py
new file mode 100644
index 000000000000..542116a1da75
--- /dev/null
+++ b/tests/test_pipeline/test_schedule/test_oneF_oneB.py
@@ -0,0 +1,134 @@
+import copy
+from functools import partial
+from types import MethodType
+
+import pytest
+import torch
+import torch.nn as nn
+
+import colossalai
+from colossalai.cluster import ProcessGroupMesh
+from colossalai.interface import OptimizerWrapper
+from colossalai.pipeline.schedule.one_f_one_b import OneForwardOneBackwardSchedule
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.testing import rerun_if_address_is_in_use, spawn
+from colossalai.testing.random import seed_all
+
+
+class MlpModel(nn.Module):
+
+ def __init__(self):
+ super(MlpModel, self).__init__()
+ self.linear1 = nn.Linear(4, 8)
+ self.linear2 = nn.Linear(8, 4)
+
+ def forward(self, x):
+ x = self.linear1(x)
+ x = self.linear2(x)
+ return x
+
+
+def pp_linear_fwd(forward,
+ data: torch.Tensor = None,
+ input_obj: torch.Tensor = None,
+ stage_mgr: PipelineStageManager = None):
+
+ if stage_mgr.is_first_stage():
+ return {'input_obj': forward(data)}
+ elif stage_mgr.is_last_stage():
+ return forward(input_obj)
+ else:
+ return {'input_obj': forward(input_obj)}
+
+
+def examine_pp():
+ """
+ This test is to examine the correctness of 1F1B, compared with torch.
+ Be aware it contains some hardcodes.
+ """
+ world_size = torch.distributed.get_world_size()
+ local_rank = torch.distributed.get_rank()
+ seed_all(1453)
+
+ NUM_MICRO_BATCHS = 4
+ BATCH_SIZE = 4
+
+ # create models
+ torch_model = MlpModel().cuda()
+
+ pp_model = copy.deepcopy(torch_model).cuda()
+
+ DP_DIM, PP_DIM, TP_DIM = 0, 1, 2
+ pg_mesh = ProcessGroupMesh(1, world_size, 1)
+ stage_manager = PipelineStageManager(pg_mesh, PP_DIM)
+ schedule = OneForwardOneBackwardSchedule(NUM_MICRO_BATCHS, stage_manager)
+
+ for idx, (_, sub_model) in enumerate(pp_model.named_children()):
+ if idx % (world_size) == local_rank:
+ sharded_model = sub_model.cuda()
+
+ sharded_model._forward = sharded_model.forward
+ sharded_model.forward = MethodType(partial(pp_linear_fwd, stage_mgr=stage_manager), sharded_model._forward)
+
+ # create optimizer
+ torch_optimizer = torch.optim.SGD(torch_model.parameters(), lr=1)
+ pp_optimizer = OptimizerWrapper(torch.optim.SGD(sharded_model.parameters(), lr=1))
+
+ # create
+ seed_all(1453)
+ if stage_manager.is_first_stage():
+ input_list = [torch.rand(BATCH_SIZE, 4).cuda()]
+ else:
+ input_list = [torch.zeros(BATCH_SIZE, 4).cuda()]
+ torch.distributed.all_reduce(input_list[0])
+
+ criterion = lambda x, y: torch.mean(x)
+
+ # forward and backward
+ torch_output = torch_model(input_list[0])
+ torch_loss = criterion(torch_output, _)
+ torch_loss.backward()
+
+ pp_ret = schedule.forward_backward_step(sharded_model,
+ pp_optimizer,
+ iter(input_list),
+ criterion,
+ return_loss=True,
+ return_outputs=True)
+
+ # check loss
+ if stage_manager.is_last_stage():
+ assert torch.allclose(torch_loss, pp_ret['loss'])
+
+ # check gradients
+ torch_grad = []
+ for torch_p in torch_model.parameters():
+ torch_grad.append(torch_p.grad.data)
+ for idx, pp_p in enumerate(sharded_model.parameters()):
+ assert torch.allclose(torch_grad[idx + local_rank * 2], pp_p.grad.data)
+
+ # step
+ torch_optimizer.step()
+ pp_optimizer.step()
+
+ # check updated param
+ torch_param = []
+ for torch_p in torch_model.parameters():
+ torch_param.append(torch_p.data)
+ for idx, pp_p in enumerate(sharded_model.parameters()):
+ assert torch.allclose(torch_param[idx + local_rank * 2], pp_p.data)
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ examine_pp()
+
+
+@pytest.mark.dist
+@rerun_if_address_is_in_use()
+def test_pp():
+ spawn(run_dist, 2)
+
+
+if __name__ == '__main__':
+ test_pp()
diff --git a/tests/test_pipeline/test_schedule/test_pipeline_schedule_utils.py b/tests/test_pipeline/test_schedule/test_pipeline_schedule_utils.py
new file mode 100644
index 000000000000..4c23a23ebaba
--- /dev/null
+++ b/tests/test_pipeline/test_schedule/test_pipeline_schedule_utils.py
@@ -0,0 +1,47 @@
+import torch
+
+from colossalai.pipeline.schedule._utils import get_batch_size, get_micro_batch, merge_batch
+
+
+def test_get_batch_size():
+ tensor = torch.rand(2, 3)
+ assert get_batch_size(tensor) == 2
+ assert get_batch_size([tensor]) == 2
+ assert get_batch_size((1, tensor)) == 2
+ assert get_batch_size({'tensor': tensor}) == 2
+ assert get_batch_size({'dummy': [1], 'tensor': tensor}) == 2
+ assert get_batch_size({'tensor': [tensor]}) == 2
+
+
+def test_get_micro_batch():
+ x = torch.rand(2, 1)
+ y = torch.rand(2, 3)
+ micro_batch = get_micro_batch(x, 0, 1)
+ assert torch.equal(micro_batch, x[0:1])
+ micro_batch = get_micro_batch(x, 1, 1)
+ assert torch.equal(micro_batch, x[1:2])
+ micro_batch = get_micro_batch([x, y], 0, 1)
+ assert torch.equal(micro_batch[0], x[0:1])
+ assert torch.equal(micro_batch[1], y[0:1])
+ micro_batch = get_micro_batch([x, y], 1, 1)
+ assert torch.equal(micro_batch[0], x[1:2])
+ assert torch.equal(micro_batch[1], y[1:2])
+ micro_batch = get_micro_batch({'x': x, 'y': y}, 0, 1)
+ assert torch.equal(micro_batch['x'], x[0:1])
+ assert torch.equal(micro_batch['y'], y[0:1])
+ micro_batch = get_micro_batch({'x': x, 'y': y}, 1, 1)
+ assert torch.equal(micro_batch['x'], x[1:2])
+ assert torch.equal(micro_batch['y'], y[1:2])
+
+
+def test_merge_batch():
+ x = torch.rand(2, 1)
+ y = torch.rand(2, 3)
+ merged = merge_batch([x[0:1], x[1:2]])
+ assert torch.equal(merged, x)
+ merged = merge_batch([[x[0:1], y[0:1]], [x[1:2], y[1:2]]])
+ assert torch.equal(merged[0], x)
+ assert torch.equal(merged[1], y)
+ merged = merge_batch([{'x': x[0:1], 'y': y[0:1]}, {'x': x[1:2], 'y': y[1:2]}])
+ assert torch.equal(merged['x'], x)
+ assert torch.equal(merged['y'], y)
diff --git a/tests/test_pipeline/test_stage_manager.py b/tests/test_pipeline/test_stage_manager.py
new file mode 100644
index 000000000000..67a2e90532e2
--- /dev/null
+++ b/tests/test_pipeline/test_stage_manager.py
@@ -0,0 +1,87 @@
+import pytest
+import torch.distributed as dist
+
+import colossalai
+from colossalai.cluster import ProcessGroupMesh
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.testing import rerun_if_address_is_in_use, spawn
+
+
+def check_stage_manager():
+ DP_DIM, PP_DIM = 0, 1
+ DP_SIZE, PP_SIZE = 2, 2
+ RANK_TO_COORDINATE = {
+ 0: (0, 0),
+ 1: (0, 1),
+ 2: (1, 0),
+ 3: (1, 1),
+ }
+ PP_RANKS_IN_GROUP = {
+ 0: [0, 1],
+ 1: [0, 1],
+ 2: [2, 3],
+ 3: [2, 3],
+ }
+ pg_mesh = ProcessGroupMesh(DP_SIZE, PP_SIZE)
+ stage_manager = PipelineStageManager(pg_mesh, PP_DIM)
+ rank = dist.get_rank()
+
+ # check stage info
+ assert stage_manager.num_stages == PP_SIZE
+ assert stage_manager.stage == RANK_TO_COORDINATE[rank][PP_DIM]
+
+ # check is_first_stage
+ ranks_in_group = PP_RANKS_IN_GROUP[rank]
+ is_first_stage = ranks_in_group.index(rank) == 0
+ assert stage_manager.is_first_stage() == is_first_stage
+
+ # check is_last_stage
+ is_last_stage = ranks_in_group.index(rank) == len(ranks_in_group) - 1
+ assert stage_manager.is_last_stage() == is_last_stage
+
+ # check prev rank
+ if not is_first_stage:
+ prev_rank = ranks_in_group[ranks_in_group.index(rank) - 1]
+ assert stage_manager.get_prev_rank() == prev_rank
+
+ # check next rank
+ if not is_last_stage:
+ next_rank = ranks_in_group[ranks_in_group.index(rank) + 1]
+ assert stage_manager.get_next_rank() == next_rank
+
+ # check virtual stage
+ stage_manager.set_num_virtual_stages(PP_SIZE * 2)
+ assert stage_manager.num_virtual_stages == PP_SIZE * 2
+ stage_manager.set_virtual_stage(stage_manager.stage * 2)
+ assert stage_manager.virtual_stage == stage_manager.stage * 2
+ with stage_manager.switch_virtual_stage(stage_manager.stage * 2 + 1):
+ assert stage_manager.virtual_stage == stage_manager.stage * 2 + 1
+ assert stage_manager.virtual_stage == stage_manager.stage * 2
+
+ # check p2p groups
+ for prev, cur in zip(ranks_in_group[:-1], ranks_in_group[1:]):
+ if rank in [prev, cur]:
+ group = stage_manager.get_p2p_process_group(prev, cur)
+ dist.barrier(group=group)
+
+ # check stage groups
+ pg_mesh = ProcessGroupMesh(4)
+ stage_manager = PipelineStageManager(pg_mesh, 0)
+ group = stage_manager.init_process_group_by_stages([0, 2])
+ if rank in [0, 2]:
+ dist.barrier(group=group)
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(config={}, rank=rank, world_size=world_size, port=port, host='localhost')
+ check_stage_manager()
+
+
+@pytest.mark.dist
+@rerun_if_address_is_in_use()
+def test_pipeline_stage_manager():
+ spawn(run_dist, 4)
+
+
+if __name__ == '__main__':
+ test_pipeline_stage_manager()
diff --git a/tests/test_shardformer/test_layer/test_embedding.py b/tests/test_shardformer/test_layer/test_embedding.py
index 8a6aa42a42f2..d62dba7ea92a 100644
--- a/tests/test_shardformer/test_layer/test_embedding.py
+++ b/tests/test_shardformer/test_layer/test_embedding.py
@@ -1,18 +1,27 @@
+from contextlib import nullcontext
+
import torch
import torch.distributed as dist
import torch.nn as nn
from torch.testing import assert_close
import colossalai
+from colossalai.lazy import LazyInitContext
from colossalai.shardformer.layer import Embedding1D
-from colossalai.testing import rerun_if_address_is_in_use, spawn
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+
+@parameterize('lazy_init', [False, True])
+def check_embedding_1d(lazy_init: bool):
+ ctx = LazyInitContext() if lazy_init else nullcontext()
-def check_embedding_1d():
embedding = nn.Embedding(32, 128).cuda()
- embedding_1d = Embedding1D.from_native_module(embedding, process_group=None)
+ with ctx:
+ embedding_copy = nn.Embedding(32, 128).cuda()
+ embedding_1d = Embedding1D.from_native_module(embedding_copy, process_group=None)
assert embedding_1d.weight.shape == torch.Size([32, 64])
+ assert embedding_1d.weight is embedding_copy.weight
# ensure state dict is reversibly loadable
embedding.load_state_dict(embedding_1d.state_dict())
diff --git a/tests/test_shardformer/test_layer/test_gpt2_qkv_fused_linear_1d.py b/tests/test_shardformer/test_layer/test_gpt2_qkv_fused_linear_1d.py
new file mode 100644
index 000000000000..b45cd172c3ca
--- /dev/null
+++ b/tests/test_shardformer/test_layer/test_gpt2_qkv_fused_linear_1d.py
@@ -0,0 +1,140 @@
+from contextlib import nullcontext
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from torch.testing import assert_close
+
+import colossalai
+from colossalai.lazy import LazyInitContext
+from colossalai.shardformer.layer import GPT2FusedLinearConv1D_Col, GPT2FusedLinearConv1D_Row
+from colossalai.shardformer.layer.qkv_fused_linear import split_fused_qkv_in_gpt2_style
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+
+
+# This code is copied from https://github.com/huggingface/transformers
+class Conv1D(nn.Module):
+ """
+ 1D-convolutional layer as defined by Radford et al. for OpenAI GPT (and also used in GPT-2).
+
+ Basically works like a linear layer but the weights are transposed.
+
+ Args:
+ nf (`int`): The number of output features.
+ nx (`int`): The number of input features.
+ """
+
+ def __init__(self, nf, nx):
+ super().__init__()
+ self.nf = nf
+ self.weight = nn.Parameter(torch.empty(nx, nf))
+ self.bias = nn.Parameter(torch.zeros(nf))
+ nn.init.normal_(self.weight, std=0.02)
+
+ def forward(self, x):
+ size_out = x.size()[:-1] + (self.nf,)
+ x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
+ x = x.view(size_out)
+ return x
+
+
+def rearrange(tensor: torch.Tensor, dim: int):
+ tensor = tensor.clone()
+ world_size = 2
+ order = torch.arange(world_size * 3)
+ new_order = []
+ for i in range(world_size):
+ new_order.append(order[i::world_size])
+ new_order = torch.cat(new_order)
+
+ tensor_chunks = torch.chunk(tensor, world_size * 3, dim=dim)
+ rearanged_tensor_chunks = [tensor_chunks[i] for i in new_order]
+ rearanged_tensor = torch.cat(rearanged_tensor_chunks, dim=dim)
+ return rearanged_tensor
+
+
+@parameterize('lazy_init', [False, True])
+def check_linear_conv_1d_col(lazy_init: bool):
+ ctx = LazyInitContext() if lazy_init else nullcontext()
+ linear = Conv1D(192, 48).cuda()
+ with ctx:
+ linear_copy = Conv1D(192, 48).cuda()
+ linear_conv_col = GPT2FusedLinearConv1D_Col.from_native_module(linear_copy,
+ process_group=None,
+ gather_output=True,
+ n_fused=3)
+
+ assert linear.weight.shape == torch.Size([48, 192])
+ assert linear.bias.shape == torch.Size([192])
+ assert linear_conv_col.weight.shape == torch.Size([48, 96])
+ assert linear_conv_col.bias.shape == torch.Size([96])
+ assert linear_copy.weight is linear_conv_col.weight
+ assert linear_copy.bias is linear_conv_col.bias
+
+ # ensure weights are reversibly loadable
+ linear_conv_col.load_state_dict(linear.state_dict())
+ linear.load_state_dict(linear_conv_col.state_dict())
+
+ # check computation correctness
+ x = torch.rand(4, 48).cuda()
+ out = linear(x)
+ gather_out = linear_conv_col(x)
+ assert_close(rearrange(out, 1), gather_out)
+
+ # check backward correctness
+ out.sum().backward()
+ gather_out.sum().backward()
+
+ target_grad = split_fused_qkv_in_gpt2_style(linear.weight.grad, 3, None, True)
+ assert_close(target_grad, linear_conv_col.weight.grad)
+
+
+@parameterize('lazy_init', [False, True])
+def check_linear_conv_1d_row(lazy_init: bool):
+ ctx = LazyInitContext() if lazy_init else nullcontext()
+
+ linear = Conv1D(192, 48).cuda()
+ with ctx:
+ linear_copy = Conv1D(192, 48).cuda()
+ linear_row = GPT2FusedLinearConv1D_Row.from_native_module(linear_copy, process_group=None, parallel_input=False)
+
+ assert linear.weight.shape == torch.Size([48, 192])
+ assert linear_row.weight.shape == torch.Size([24, 192])
+ assert linear_row.bias.shape == torch.Size([192])
+ assert linear_copy.weight is linear_row.weight
+ assert linear_copy.bias is linear_row.bias
+
+ # ensure weights are reversibly loadable
+ linear_row.load_state_dict(linear.state_dict())
+ linear.load_state_dict(linear_row.state_dict())
+
+ # check computation correctness
+ x = torch.rand(4, 48).cuda()
+ out = linear(x)
+ gather_out = linear_row(x)
+ assert_close(out, gather_out)
+
+ # check backward correctness
+ out.sum().backward()
+ gather_out.sum().backward()
+
+ rank = dist.get_rank()
+ target_grad = torch.chunk(linear.weight.grad, 2, dim=0)[rank]
+ assert_close(target_grad, linear_row.weight.grad)
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+
+ # test for linear conv
+ check_linear_conv_1d_col()
+ check_linear_conv_1d_row()
+
+
+@rerun_if_address_is_in_use()
+def test_linearconv():
+ spawn(run_dist, nprocs=2)
+
+
+if __name__ == '__main__':
+ test_linearconv()
diff --git a/tests/test_shardformer/test_layer/test_layernorm.py b/tests/test_shardformer/test_layer/test_layernorm.py
index a117845545be..f9c21b82a282 100644
--- a/tests/test_shardformer/test_layer/test_layernorm.py
+++ b/tests/test_shardformer/test_layer/test_layernorm.py
@@ -1,17 +1,27 @@
+from contextlib import nullcontext
+
import torch
import torch.nn as nn
from torch.testing import assert_close
import colossalai
+from colossalai.lazy import LazyInitContext
from colossalai.shardformer.layer import FusedLayerNorm
-from colossalai.testing import rerun_if_address_is_in_use, spawn
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+
+@parameterize('lazy_init', [False, True])
+def check_layernorm(lazy_init: bool):
+ ctx = LazyInitContext() if lazy_init else nullcontext()
-def check_layernorm():
norm = nn.LayerNorm(128, 0.00001).cuda()
- norm1d = FusedLayerNorm.from_native_module(norm, process_group=None)
+ with ctx:
+ norm_copy = nn.LayerNorm(128, 0.00001).cuda()
+ norm1d = FusedLayerNorm.from_native_module(norm_copy, process_group=None)
assert norm1d.weight.shape == torch.Size([128])
+ assert norm_copy.weight is norm1d.weight
+ assert norm_copy.bias is norm1d.bias
# ensure state dict is reversibly loadable
norm.load_state_dict(norm1d.state_dict())
@@ -41,4 +51,4 @@ def test_layernorm():
if __name__ == '__main__':
- test_layernorm_1d()
+ test_layernorm()
diff --git a/tests/test_shardformer/test_layer/test_linear_1d.py b/tests/test_shardformer/test_layer/test_linear_1d.py
index da3bdc1d78d3..aa75879e0313 100644
--- a/tests/test_shardformer/test_layer/test_linear_1d.py
+++ b/tests/test_shardformer/test_layer/test_linear_1d.py
@@ -1,21 +1,30 @@
+from contextlib import nullcontext
+
import torch
import torch.distributed as dist
import torch.nn as nn
from torch.testing import assert_close
import colossalai
+from colossalai.lazy import LazyInitContext
from colossalai.shardformer.layer import Linear1D_Col, Linear1D_Row
from colossalai.tensor.d_tensor import is_distributed_tensor
-from colossalai.testing import rerun_if_address_is_in_use, spawn
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
-def check_linear_1d_col():
+@parameterize('lazy_init', [False, True])
+def check_linear_1d_col(lazy_init: bool):
+ ctx = LazyInitContext() if lazy_init else nullcontext()
linear = nn.Linear(32, 128).cuda()
- linear_col = Linear1D_Col.from_native_module(linear, process_group=None, gather_output=True)
+ with ctx:
+ linear_copy = nn.Linear(32, 128).cuda()
+ linear_col = Linear1D_Col.from_native_module(linear_copy, process_group=None, gather_output=True)
# ensure that the parameters are distributed
assert is_distributed_tensor(linear_col.weight)
assert is_distributed_tensor(linear_col.bias)
+ assert linear_copy.weight is linear_col.weight
+ assert linear_copy.bias is linear_col.bias
# ensure the shape is correct
assert linear_col.weight.shape == torch.Size([64, 32])
@@ -50,12 +59,22 @@ def check_linear_1d_col():
assert_close(x_for_unshard.grad, x_for_shard.grad)
-def check_linear_1d_row():
+@parameterize('lazy_init', [False, True])
+def check_linear_1d_row(lazy_init: bool):
+ ctx = LazyInitContext() if lazy_init else nullcontext()
+
linear = nn.Linear(32, 128).cuda()
- linear_row = Linear1D_Row.from_native_module(linear, process_group=None, parallel_input=False)
+ with ctx:
+ linear_copy = nn.Linear(32, 128).cuda()
+ linear_row = Linear1D_Row.from_native_module(linear_copy, process_group=None, parallel_input=False)
assert linear_row.weight.shape == torch.Size([128, 16])
assert linear_row.bias.shape == torch.Size([128])
+ assert linear_copy.weight is linear_row.weight
+ assert linear_copy.bias is linear_row.bias
+
+ linear.load_state_dict(linear_row.state_dict())
+ linear_row.load_state_dict(linear.state_dict())
# check computation correctness
x = torch.rand(4, 32).cuda()
@@ -83,11 +102,23 @@ def check_linear_1d_row():
assert_close(x_for_unshard.grad, x_for_shard.grad)
-def check_linear_col_plus_row():
+@parameterize('lazy_init', [False, True])
+def check_linear_col_plus_row(lazy_init: bool):
+ ctx = LazyInitContext() if lazy_init else nullcontext()
+
linear_1 = nn.Linear(32, 128).cuda()
linear_2 = nn.Linear(128, 32).cuda()
- linear_col = Linear1D_Col.from_native_module(linear_1, process_group=None, gather_output=False)
- linear_row = Linear1D_Row.from_native_module(linear_2, process_group=None, parallel_input=True)
+
+ with ctx:
+ linear_1_copy = nn.Linear(32, 128).cuda()
+ linear_2_copy = nn.Linear(128, 32).cuda()
+ linear_col = Linear1D_Col.from_native_module(linear_1_copy, process_group=None, gather_output=False)
+ linear_row = Linear1D_Row.from_native_module(linear_2_copy, process_group=None, parallel_input=True)
+
+ linear_1.load_state_dict(linear_col.state_dict())
+ linear_col.load_state_dict(linear_1.state_dict())
+ linear_2.load_state_dict(linear_row.state_dict())
+ linear_row.load_state_dict(linear_2.state_dict())
# check computation correctness
x = torch.rand(4, 32).cuda()
diff --git a/tests/test_shardformer/test_layer/test_qkv_fused_linear_1d.py b/tests/test_shardformer/test_layer/test_qkv_fused_linear_1d.py
index 681c4f6dd9f1..b45cd172c3ca 100644
--- a/tests/test_shardformer/test_layer/test_qkv_fused_linear_1d.py
+++ b/tests/test_shardformer/test_layer/test_qkv_fused_linear_1d.py
@@ -1,12 +1,15 @@
+from contextlib import nullcontext
+
import torch
import torch.distributed as dist
import torch.nn as nn
from torch.testing import assert_close
import colossalai
+from colossalai.lazy import LazyInitContext
from colossalai.shardformer.layer import GPT2FusedLinearConv1D_Col, GPT2FusedLinearConv1D_Row
from colossalai.shardformer.layer.qkv_fused_linear import split_fused_qkv_in_gpt2_style
-from colossalai.testing import rerun_if_address_is_in_use, spawn
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
# This code is copied from https://github.com/huggingface/transformers
@@ -50,9 +53,13 @@ def rearrange(tensor: torch.Tensor, dim: int):
return rearanged_tensor
-def check_linear_conv_1d_col():
+@parameterize('lazy_init', [False, True])
+def check_linear_conv_1d_col(lazy_init: bool):
+ ctx = LazyInitContext() if lazy_init else nullcontext()
linear = Conv1D(192, 48).cuda()
- linear_conv_col = GPT2FusedLinearConv1D_Col.from_native_module(linear,
+ with ctx:
+ linear_copy = Conv1D(192, 48).cuda()
+ linear_conv_col = GPT2FusedLinearConv1D_Col.from_native_module(linear_copy,
process_group=None,
gather_output=True,
n_fused=3)
@@ -61,6 +68,8 @@ def check_linear_conv_1d_col():
assert linear.bias.shape == torch.Size([192])
assert linear_conv_col.weight.shape == torch.Size([48, 96])
assert linear_conv_col.bias.shape == torch.Size([96])
+ assert linear_copy.weight is linear_conv_col.weight
+ assert linear_copy.bias is linear_conv_col.bias
# ensure weights are reversibly loadable
linear_conv_col.load_state_dict(linear.state_dict())
@@ -80,13 +89,24 @@ def check_linear_conv_1d_col():
assert_close(target_grad, linear_conv_col.weight.grad)
-def check_linear_conv_1d_row():
+@parameterize('lazy_init', [False, True])
+def check_linear_conv_1d_row(lazy_init: bool):
+ ctx = LazyInitContext() if lazy_init else nullcontext()
+
linear = Conv1D(192, 48).cuda()
- linear_row = GPT2FusedLinearConv1D_Row.from_native_module(linear, process_group=None, parallel_input=False)
+ with ctx:
+ linear_copy = Conv1D(192, 48).cuda()
+ linear_row = GPT2FusedLinearConv1D_Row.from_native_module(linear_copy, process_group=None, parallel_input=False)
assert linear.weight.shape == torch.Size([48, 192])
assert linear_row.weight.shape == torch.Size([24, 192])
assert linear_row.bias.shape == torch.Size([192])
+ assert linear_copy.weight is linear_row.weight
+ assert linear_copy.bias is linear_row.bias
+
+ # ensure weights are reversibly loadable
+ linear_row.load_state_dict(linear.state_dict())
+ linear.load_state_dict(linear_row.state_dict())
# check computation correctness
x = torch.rand(4, 48).cuda()
diff --git a/tests/test_shardformer/test_layer/test_vocab_parallel_embedding_1d.py b/tests/test_shardformer/test_layer/test_vocab_parallel_embedding_1d.py
index 8991d9b304f5..6d2f087302d9 100644
--- a/tests/test_shardformer/test_layer/test_vocab_parallel_embedding_1d.py
+++ b/tests/test_shardformer/test_layer/test_vocab_parallel_embedding_1d.py
@@ -1,20 +1,29 @@
+from contextlib import nullcontext
+
import torch
import torch.distributed as dist
import torch.nn as nn
from torch.testing import assert_close
import colossalai
+from colossalai.lazy import LazyInitContext
from colossalai.shardformer.layer import VocabParallelEmbedding1D
from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
-def check_vocab_embedding_1d():
+@parameterize('lazy_init', [False, True])
+def check_vocab_embedding_1d(lazy_init: bool):
+ ctx = LazyInitContext() if lazy_init else nullcontext()
+
embedding = nn.Embedding(128, 32).to('cuda')
- dist_embedding_1d = VocabParallelEmbedding1D.from_native_module(embedding, process_group=None)
+ with ctx:
+ embedding_copy = nn.Embedding(128, 32).to('cuda')
+ dist_embedding_1d = VocabParallelEmbedding1D.from_native_module(embedding_copy, process_group=None)
assert dist_embedding_1d.weight.shape == torch.Size([64, 32])
assert dist_embedding_1d.num_embeddings == 64
assert dist_embedding_1d.embedding_dim == 32
+ assert embedding_copy.weight is dist_embedding_1d.weight
# ensure state dict is reversibly loadable
embedding.load_state_dict(dist_embedding_1d.state_dict())
diff --git a/tests/test_shardformer/test_model/_utils.py b/tests/test_shardformer/test_model/_utils.py
index d83d9ecd39e0..921af2a8b1d0 100644
--- a/tests/test_shardformer/test_model/_utils.py
+++ b/tests/test_shardformer/test_model/_utils.py
@@ -1,26 +1,78 @@
import copy
+from contextlib import nullcontext
+from typing import Any, Callable, Dict, List, Optional
+import torch
+import torch.distributed as dist
+from torch import Tensor
+from torch import distributed as dist
+from torch.distributed import ProcessGroup
+from torch.nn import Module
+from torch.optim import Adam, Optimizer
+
+from colossalai.booster import Booster
+from colossalai.booster.plugin import HybridParallelPlugin
+from colossalai.lazy import LazyInitContext
+from colossalai.pipeline.stage_manager import PipelineStageManager
from colossalai.shardformer import ShardConfig, ShardFormer
+from colossalai.shardformer._utils import getattr_
+from colossalai.shardformer.policies.auto_policy import Policy
+from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
-def build_model(model_fn, enable_fused_normalization=True, enable_tensor_parallelism=True):
+def build_model(model_fn,
+ enable_fused_normalization=True,
+ enable_tensor_parallelism=True,
+ enable_flash_attention=False,
+ enable_jit_fused=False,
+ use_lazy_init: bool = False):
# create new model
- org_model = model_fn().cuda()
-
+ ctx = LazyInitContext() if use_lazy_init else nullcontext()
+ with ctx:
+ # create new model
+ org_model = model_fn()
+ model_copy = copy.deepcopy(org_model)
+ if use_lazy_init:
+ ctx.materialize(org_model)
# shard model
shard_config = ShardConfig(enable_fused_normalization=enable_fused_normalization,
- enable_tensor_parallelism=enable_tensor_parallelism)
+ enable_tensor_parallelism=enable_tensor_parallelism,
+ enable_flash_attention=enable_flash_attention,
+ enable_jit_fused=enable_jit_fused)
model_copy = copy.deepcopy(org_model)
shard_former = ShardFormer(shard_config=shard_config)
- sharded_model = shard_former.optimize(model_copy).cuda()
- return org_model, sharded_model
+ sharded_model, shared_params = shard_former.optimize(model_copy)
+ return org_model.cuda(), sharded_model.cuda()
+
+
+def build_pipeline_model(model_fn,
+ stage_manager=None,
+ enable_fused_normalization=False,
+ enable_tensor_parallelism=False,
+ use_lazy_init: bool = False,
+ policy: Optional[Policy] = None):
+ ctx = LazyInitContext() if use_lazy_init else nullcontext()
+ with ctx:
+ # create new model
+ org_model = model_fn()
+ model_copy = copy.deepcopy(org_model)
+ if use_lazy_init:
+ ctx.materialize(org_model)
+
+ # shard model
+ shard_config = ShardConfig(enable_fused_normalization=enable_fused_normalization,
+ enable_tensor_parallelism=enable_tensor_parallelism,
+ pipeline_stage_manager=stage_manager)
+
+ shard_former = ShardFormer(shard_config=shard_config)
+ sharded_model, shared_params = shard_former.optimize(model_copy, policy=policy)
+ return org_model.cuda(), sharded_model.cuda()
def run_forward(original_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
# prepare input
data = data_gen_fn()
data = {k: v.cuda() for k, v in data.items()}
-
# switch to train mode
original_model.train()
sharded_model.train()
@@ -33,3 +85,164 @@ def run_forward(original_model, sharded_model, data_gen_fn, output_transform_fn,
shard_output = output_transform_fn(shard_output)
shard_loss = loss_fn(shard_output)
return org_output, org_loss, shard_output, shard_loss
+
+
+def check_state_dict(org_model: Module, sharded_model: Module, name: str = ''):
+ org_sd = org_model.state_dict()
+ shard_sd = sharded_model.state_dict()
+ for k, v in org_sd.items():
+ assert k in shard_sd, f'{name} {k} not in sharded model'
+ shard_v = shard_sd[k]
+ assert v.shape == shard_v.shape, f'{name} {k} shape mismatch, {v.shape} vs {shard_v.shape}'
+ assert v.dtype == shard_v.dtype, f'{name} {k} dtype mismatch, {v.dtype} vs {shard_v.dtype}'
+ assert torch.equal(v, shard_v), f'{name} {k} value mismatch'
+
+
+def build_model_from_hybrid_plugin(model_fn: Callable, loss_fn: Callable, test_config: Dict[str, Any]):
+
+ use_lazy_init = False
+ if 'use_lazy_init' in test_config:
+ use_lazy_init = test_config.pop('use_lazy_init')
+
+ ctx = LazyInitContext() if use_lazy_init else nullcontext()
+ with ctx:
+ org_model = model_fn()
+ sharded_model = copy.deepcopy(org_model)
+ if use_lazy_init:
+ ctx.materialize(org_model)
+
+ org_model = org_model.cuda()
+ org_optimizer = Adam(org_model.parameters(), lr=1e-3)
+ sharded_optimizer = Adam(sharded_model.parameters(), lr=1e-3)
+ criterion = loss_fn
+
+ plugin = HybridParallelPlugin(**test_config)
+ booster = Booster(plugin=plugin)
+
+ sharded_model, sharded_optimizer, criterion, _, _ = booster.boost(sharded_model, sharded_optimizer, criterion)
+ return org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster
+
+
+def run_forward_backward_with_hybrid_plugin(org_model: Module, sharded_model: Module, sharded_optimizer: Optimizer,
+ data_gen_fn: Callable, output_transform_fn: Callable, criterion: Callable,
+ booster: Booster):
+ org_model.cuda()
+ sharded_model.cuda()
+
+ def _criterion(outputs, inputs):
+ outputs = output_transform_fn(outputs)
+ loss = criterion(outputs)
+ return loss
+
+ data = data_gen_fn()
+ sharded_model.train()
+ if booster.plugin.stage_manager is not None:
+ for k, v in data.items():
+ if torch.is_tensor(v) or 'Tensor' in v.__class__.__name__:
+ new_shape = [1] * v.dim()
+ new_shape[0] = 4
+ data[k] = v.to('cuda').repeat(*new_shape)
+
+ data_iter = iter([data])
+ sharded_output = booster.execute_pipeline(data_iter,
+ sharded_model,
+ _criterion,
+ sharded_optimizer,
+ return_loss=True,
+ return_outputs=True)
+ sharded_loss = sharded_output['loss']
+ else:
+ data = {k: v.cuda() for k, v in data.items()}
+ sharded_output = sharded_model(**data)
+
+ sharded_loss = criterion(sharded_output)
+ sharded_optimizer.backward(sharded_loss)
+
+ org_model.train()
+ data = {k: v.cuda() for k, v in data.items()}
+ org_output = org_model(**data)
+
+ org_loss = criterion(org_output)
+ org_loss.backward()
+
+ return org_loss, org_output, sharded_loss, sharded_output
+
+
+def check_output_hidden_state(org_output: Tensor,
+ sharded_output: Tensor,
+ stage_manager: Optional[PipelineStageManager] = None,
+ atol: float = 1e-5,
+ rtol: float = 1e-3,
+ dim: int = 0):
+
+ org_hidden_state = org_output.last_hidden_state
+
+ if stage_manager is None:
+ sharded_hidden_state = sharded_output.last_hidden_state
+
+ if stage_manager and stage_manager.is_last_stage():
+ sharded_hidden_state = torch.cat([output.last_hidden_state for output in sharded_output['outputs']], dim=dim)
+
+ assert torch.allclose(org_hidden_state.float(), sharded_hidden_state.float(), atol=atol, rtol=rtol), \
+ f"shard model's output hidden state is not equal to origin model's last hidden state\n{org_hidden_state}\n{sharded_hidden_state}"
+
+
+def check_loss(org_loss: Tensor, sharded_loss: Tensor, atol: float = 1e-5, rtol: float = 1e-3):
+ assert torch.allclose(org_loss.float(), sharded_loss.float(), atol=atol, rtol=rtol), \
+ f"shard model loss is not equal to origin model loss\n{org_loss}\n{sharded_loss}"
+
+
+def check_weight(org_model: Module,
+ sharded_model: Module,
+ layer_suffix: List[str],
+ tp_group: Optional[ProcessGroup] = None,
+ dim: int = 0,
+ atol: float = 1e-5,
+ rtol: float = 1e-3,
+ verbose: bool = False):
+
+ for suffix in layer_suffix:
+ org_weight = getattr_(org_model, suffix).weight
+ sharded_weight = getattr_(sharded_model, suffix).weight
+
+ if is_distributed_tensor(sharded_weight) or is_customized_distributed_tensor(sharded_weight):
+ sharded_weight_list = [
+ torch.zeros_like(sharded_weight).to('cuda') for _ in range(dist.get_world_size(tp_group))
+ ]
+ dist.all_gather(sharded_weight_list, sharded_weight, tp_group)
+ sharded_weight = torch.cat(sharded_weight_list, dim=dim)
+
+ if verbose and dist.get_rank() == 0:
+ print(f"'{suffix}' weight: {org_weight}, {sharded_weight}")
+
+ assert torch.allclose(org_weight.float(), sharded_weight.float(), atol=atol, rtol=rtol), \
+ f"shard model weight {suffix} is not equal to origin model weight\n{org_weight}\n{sharded_weight}"
+
+
+def check_grad(org_model: Module,
+ sharded_model: Module,
+ layer_suffix: List[str],
+ tp_group: ProcessGroup = None,
+ dim: int = 0,
+ atol: float = 1e-5,
+ rtol: float = 1e-3,
+ verbose: bool = False):
+ for suffix in layer_suffix:
+ org_grad = getattr_(org_model, suffix).weight.grad
+ shard_grad = getattr_(sharded_model, suffix).weight.grad
+ shard_weight = getattr_(sharded_model, suffix).weight
+
+ if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
+ shard_grad_list = [torch.zeros_like(shard_grad).to('cuda') for _ in range(dist.get_world_size(tp_group))]
+ dist.all_gather(shard_grad_list, shard_grad, tp_group)
+ shard_grad = torch.cat(shard_grad_list, dim=dim)
+
+ # embedding may be resized when using tensor parallel
+ if shard_grad.shape[0] > org_grad.shape[0]:
+ shard_grad = shard_grad[:org_grad.shape[0], :]
+ if verbose and dist.get_rank() == 0:
+ print(f"'{suffix}' grad: {org_grad}, {shard_grad}")
+
+ assert torch.allclose(
+ org_grad.float(), shard_grad.float(), rtol=rtol, atol=atol
+ ), f"error attribute '{suffix}', orgin model grad is not equal to shard model grad\n{org_grad}\n{shard_grad}"
diff --git a/tests/test_shardformer/test_model/test_shard_bert.py b/tests/test_shardformer/test_model/test_shard_bert.py
index 1afedb7079ea..0a24e46d28f2 100644
--- a/tests/test_shardformer/test_model/test_shard_bert.py
+++ b/tests/test_shardformer/test_model/test_shard_bert.py
@@ -1,80 +1,113 @@
import pytest
import torch
+from torch import distributed as dist
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
-from colossalai.testing import (
- assert_hf_output_close,
- clear_cache_before_run,
- parameterize,
- rerun_if_address_is_in_use,
- spawn,
-)
+from colossalai.shardformer.layer.utils import Randomizer
+from colossalai.tensor.d_tensor.api import clear_layout_converter
+from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, run_forward
-
-
-def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
- # check forward
- org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
- output_transform_fn, loss_fn)
- assert_hf_output_close(org_output, shard_output)
-
- # do backward
- org_loss.backward()
- shard_loss.backward()
-
- assert torch.allclose(org_loss, shard_loss,
- atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
+from tests.test_shardformer.test_model._utils import (
+ build_model_from_hybrid_plugin,
+ check_grad,
+ check_loss,
+ check_output_hidden_state,
+ check_weight,
+ run_forward_backward_with_hybrid_plugin,
+)
- # check grad
+def check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config):
+
+ org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster = \
+ build_model_from_hybrid_plugin(model_fn, loss_fn, test_config)
+
+ org_loss, org_output, sharded_loss, sharded_output = \
+ run_forward_backward_with_hybrid_plugin(
+ org_model,
+ sharded_model,
+ sharded_optimizer,
+ data_gen_fn,
+ output_transform_fn,
+ criterion,
+ booster)
+ stage_manager = booster.plugin.stage_manager
+ tp_group = booster.plugin.tp_group
+ # check last hidden state & loss
+ if stage_manager is None or stage_manager.is_last_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-5, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+ if org_model.__class__.__name__ == 'BertModel':
+ check_output_hidden_state(org_output, sharded_output, stage_manager, atol=atol, rtol=rtol)
+
+ check_loss(org_loss, sharded_loss, atol=atol, rtol=rtol)
+ # unwrap model
if org_model.__class__.__name__ == 'BertModel':
bert = org_model
- sharded_bert = sharded_model
+ sharded_bert = sharded_model.unwrap()
else:
bert = org_model.bert
- sharded_bert = sharded_model.bert
+ sharded_bert = sharded_model.unwrap().bert
- # compare self attention grad
- org_grad = bert.encoder.layer[0].attention.self.query.weight.grad
- shard_grad = sharded_bert.encoder.layer[0].attention.self.query.weight.grad
- shard_weight = sharded_bert.encoder.layer[0].attention.self.query.weight
+ col_layer_for_check = ['encoder.layer[0].output.dense']
+ row_layer_for_check = ['embeddings.word_embeddings', 'encoder.layer[0].intermediate.dense']
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-4, 1e-3
else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
-
- # compare embedding grad
- org_grad = bert.embeddings.word_embeddings.weight.grad
- shard_grad = sharded_bert.embeddings.word_embeddings.weight.grad
- shard_weight = sharded_bert.embeddings.word_embeddings.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
+ atol, rtol = 5e-3, 5e-3
+ if stage_manager is None or stage_manager.is_first_stage():
+ #check_weight(bert.embeddings.word_embeddings, sharded_bert.embeddings.word_embeddings, tp_group, atol=1e-5, rtol=1e-3)
+ #check_weight(bert.encoder.layer[0].attention.self.query, sharded_bert.encoder.layer[0].attention.self.query, tp_group, atol=5e-3, rtol=1e-3)
+ check_grad(bert, sharded_bert, col_layer_for_check, tp_group, atol=atol, rtol=rtol, dim=1, verbose=False)
+ check_grad(bert, sharded_bert, row_layer_for_check, tp_group, atol=atol, rtol=rtol, dim=0, verbose=False)
+
+ # check weights after optimizer.step()
+ org_optimizer.step()
+ sharded_optimizer.step()
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 5e-3, 1e-3
else:
- all_shard_grad = shard_grad
+ atol, rtol = 5e-3, 5e-3
+ if stage_manager is None or stage_manager.is_first_stage():
+ check_weight(bert, sharded_bert, col_layer_for_check, tp_group, atol=atol, rtol=rtol, dim=1, verbose=False)
+
+ torch.cuda.empty_cache()
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+@parameterize('test_config', [{
+ 'tp_size': 1,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'use_lazy_init': True,
+ 'precision': 'fp32',
+}, {
+ 'tp_size': 2,
+ 'pp_size': 2,
+ 'num_microbatches': 2,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': True,
+ 'precision': 'fp16',
+ 'initial_scale': 1,
+}, {
+ 'tp_size': 4,
+ 'pp_size': 1,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}])
+def run_bert_test(test_config):
-@parameterize('enable_fused_normalization', [True, False])
-@parameterize('enable_tensor_parallelism', [True, False])
-def run_bert_test(enable_fused_normalization, enable_tensor_parallelism):
sub_model_zoo = model_zoo.get_sub_registry('transformers_bert')
+
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism)
- check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
+ check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config)
+ clear_layout_converter()
+ Randomizer.reset_index()
torch.cuda.empty_cache()
@@ -88,7 +121,7 @@ def check_bert(rank, world_size, port):
@rerun_if_address_is_in_use()
@clear_cache_before_run()
def test_bert():
- spawn(check_bert, 2)
+ spawn(check_bert, 4)
if __name__ == "__main__":
diff --git a/tests/test_shardformer/test_model/test_shard_blip2.py b/tests/test_shardformer/test_model/test_shard_blip2.py
new file mode 100644
index 000000000000..cd034d0c139a
--- /dev/null
+++ b/tests/test_shardformer/test_model/test_shard_blip2.py
@@ -0,0 +1,76 @@
+import pytest
+import torch
+
+import colossalai
+from colossalai.logging import disable_existing_loggers
+from colossalai.testing import (
+ assert_hf_output_close,
+ clear_cache_before_run,
+ parameterize,
+ rerun_if_address_is_in_use,
+ spawn,
+)
+from tests.kit.model_zoo import model_zoo
+from tests.test_shardformer.test_model._utils import build_model, check_grad, run_forward
+
+
+def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
+ # check forward
+ org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
+ output_transform_fn, loss_fn)
+ assert_hf_output_close(org_output, shard_output, ignore_keys=['past_key_values'])
+
+ # do backward
+ org_loss.backward()
+ shard_loss.backward()
+
+ assert torch.allclose(org_loss, shard_loss,
+ atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
+
+ # check grad
+
+ blip2 = org_model
+ sharded_blip2 = sharded_model
+
+ # check grad
+ col_layer_for_check = [
+ 'vision_model.encoder.layers[0].self_attn.qkv', 'qformer.encoder.layer[0].attention.attention.query',
+ 'language_model.model.decoder.layers[0].self_attn.k_proj'
+ ]
+ row_layer_for_check = [
+ 'vision_model.encoder.layers[0].self_attn.projection', 'qformer.encoder.layer[0].attention.output.dense',
+ 'language_model.model.decoder.layers[0].self_attn.out_proj'
+ ]
+ check_grad(blip2, sharded_blip2, col_layer_for_check, atol=1e-6, rtol=1e-5, dim=0, verbose=False)
+ check_grad(blip2, sharded_blip2, row_layer_for_check, atol=1e-6, rtol=1e-5, dim=1, verbose=False)
+
+
+@parameterize('enable_fused_normalization', [True, False])
+@parameterize('enable_tensor_parallelism', [True, False])
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_blip2_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused):
+ sub_model_zoo = model_zoo.get_sub_registry('transformers_blip2')
+ for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
+ org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
+ enable_flash_attention, enable_jit_fused)
+ check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
+
+ torch.cuda.empty_cache()
+
+
+def check_blip2(rank, world_size, port):
+ disable_existing_loggers()
+ colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ run_blip2_test()
+
+
+@pytest.mark.dist
+@rerun_if_address_is_in_use()
+@clear_cache_before_run()
+def test_blip2():
+ spawn(check_blip2, 2)
+
+
+if __name__ == "__main__":
+ test_blip2()
diff --git a/tests/test_shardformer/test_model/test_shard_bloom.py b/tests/test_shardformer/test_model/test_shard_bloom.py
index a3389652269c..ed0d1d8e401d 100644
--- a/tests/test_shardformer/test_model/test_shard_bloom.py
+++ b/tests/test_shardformer/test_model/test_shard_bloom.py
@@ -3,77 +3,112 @@
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
-from colossalai.testing import (
- assert_hf_output_close,
- clear_cache_before_run,
- parameterize,
- rerun_if_address_is_in_use,
- spawn,
-)
+from colossalai.tensor.d_tensor.api import clear_layout_converter
+from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, run_forward
+from tests.test_shardformer.test_model._utils import (
+ build_model_from_hybrid_plugin,
+ check_grad,
+ check_loss,
+ check_output_hidden_state,
+ check_weight,
+ run_forward_backward_with_hybrid_plugin,
+)
+
+
+def check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config):
+ org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster = \
+ build_model_from_hybrid_plugin(model_fn, loss_fn, test_config)
-def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
- # check forward
- org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
- output_transform_fn, loss_fn)
- assert_hf_output_close(org_output, shard_output, ignore_keys=['past_key_values'])
+ org_loss, org_output, sharded_loss, sharded_output = \
+ run_forward_backward_with_hybrid_plugin(
+ org_model,
+ sharded_model,
+ sharded_optimizer,
+ data_gen_fn,
+ output_transform_fn,
+ criterion,
+ booster)
- # do backward
- org_loss.backward()
- shard_loss.backward()
+ stage_manager = booster.plugin.stage_manager
+ tp_group = booster.plugin.tp_group
- assert torch.allclose(org_loss, shard_loss,
- atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
+ # check last hidden state & loss
+ if stage_manager is None or stage_manager.is_last_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-5, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+ if org_model.__class__.__name__ == 'BloomModel':
+ check_output_hidden_state(org_output, sharded_output, stage_manager, atol=atol, rtol=rtol)
+
+ check_loss(org_loss, sharded_loss, atol=atol, rtol=rtol)
# unwrap model
if org_model.__class__.__name__ == 'BloomModel':
bloom = org_model
- sharded_bloom = sharded_model
+ sharded_bloom = sharded_model.unwrap()
else:
bloom = org_model.transformer
- sharded_bloom = sharded_model.transformer
-
- # check attention grad
- org_grad = bloom.h[0].self_attention.query_key_value.weight.grad
- shard_grad = sharded_bloom.h[0].self_attention.query_key_value.weight.grad
- shard_weight = sharded_bloom.h[0].self_attention.query_key_value.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
-
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+ sharded_bloom = sharded_model.unwrap().transformer
+
+ # check grad
+ row_layer_for_check = ['h[0].self_attention.query_key_value', 'word_embeddings']
+ col_layer_for_check = ['h[0].self_attention.dense']
+ if stage_manager is None or stage_manager.is_first_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-6, 1e-5
+ else:
+ atol, rtol = 5e-3, 5e-3
+ check_grad(bloom, sharded_bloom, row_layer_for_check, tp_group, atol=atol, rtol=rtol, dim=0, verbose=False)
+ check_grad(bloom, sharded_bloom, col_layer_for_check, tp_group, atol=atol, rtol=rtol, dim=1, verbose=False)
+
+ # check weights after optimizer.step()
+ org_optimizer.step()
+ sharded_optimizer.step()
+ if stage_manager is None or stage_manager.is_first_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-4, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+ check_weight(bloom, sharded_bloom, col_layer_for_check, tp_group, atol=atol, rtol=rtol, dim=1, verbose=False)
- # check embedding weights
- org_grad = bloom.word_embeddings.weight.grad
- shard_grad = sharded_bloom.word_embeddings.weight.grad
- shard_weight = sharded_bloom.word_embeddings.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
+ torch.cuda.empty_cache()
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+@parameterize('test_config', [{
+ 'tp_size': 2,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': True,
+ 'precision': 'fp16',
+ 'initial_scale': 1,
+}, {
+ 'tp_size': 1,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'enable_all_optimization': False,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}, {
+ 'tp_size': 4,
+ 'pp_size': 1,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}])
+def run_bloom_test(test_config):
+
+ # TODO(baizhou): add test_config for TP+DP after supporting & debugging it
-@parameterize('enable_fused_normalization', [True, False])
-@parameterize('enable_tensor_parallelism', [True, False])
-def run_bloom_test(enable_fused_normalization, enable_tensor_parallelism):
sub_model_zoo = model_zoo.get_sub_registry('transformers_bloom')
+
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism)
- check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
+ check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config)
+
+ clear_layout_converter()
torch.cuda.empty_cache()
@@ -87,7 +122,7 @@ def check_bloom(rank, world_size, port):
@rerun_if_address_is_in_use()
@clear_cache_before_run()
def test_bloom():
- spawn(check_bloom, 2)
+ spawn(check_bloom, 4)
if __name__ == "__main__":
diff --git a/tests/test_shardformer/test_model/test_shard_chatglm.py b/tests/test_shardformer/test_model/test_shard_chatglm.py
new file mode 100644
index 000000000000..bb77759048b3
--- /dev/null
+++ b/tests/test_shardformer/test_model/test_shard_chatglm.py
@@ -0,0 +1,153 @@
+import pytest
+import torch
+from torch import distributed as dist
+
+import colossalai
+from colossalai.logging import disable_existing_loggers
+from colossalai.tensor.d_tensor.api import clear_layout_converter
+from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
+from tests.kit.model_zoo import model_zoo
+from tests.test_shardformer.test_model._utils import (
+ build_model_from_hybrid_plugin,
+ check_grad,
+ check_loss,
+ check_output_hidden_state,
+ check_weight,
+ run_forward_backward_with_hybrid_plugin,
+)
+
+
+def check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config):
+
+ org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster = \
+ build_model_from_hybrid_plugin(model_fn, loss_fn, test_config)
+
+ org_loss, org_output, sharded_loss, sharded_output = \
+ run_forward_backward_with_hybrid_plugin(
+ org_model,
+ sharded_model,
+ sharded_optimizer,
+ data_gen_fn,
+ output_transform_fn,
+ criterion,
+ booster)
+
+ stage_manager = booster.plugin.stage_manager
+ tp_group = booster.plugin.tp_group
+
+ # check last hidden state & loss
+ if stage_manager is None or stage_manager.is_last_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-5, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+
+ if org_model.__class__.__name__ == 'ChatGLMModel':
+ check_output_hidden_state(org_output, sharded_output, stage_manager, atol=atol, rtol=rtol, dim=1)
+
+ check_loss(org_loss, sharded_loss, atol=atol, rtol=rtol)
+
+ # unwrap model
+ if org_model.__class__.__name__ == 'ChatGLMModel':
+ chatglm_model = org_model
+ shard_chatglm_model = sharded_model.unwrap()
+ else:
+ chatglm_model = org_model.transformer
+ shard_chatglm_model = sharded_model.unwrap().transformer
+
+ # check grad
+ row_layer_for_check = ['encoder.layers[0].self_attention.query_key_value', 'embedding.word_embeddings']
+ col_layer_for_check = ['encoder.layers[0].self_attention.dense']
+ if stage_manager is None or stage_manager.is_first_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-6, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+ check_grad(chatglm_model,
+ shard_chatglm_model,
+ row_layer_for_check,
+ tp_group,
+ atol=atol,
+ rtol=rtol,
+ dim=0,
+ verbose=False)
+
+ check_grad(chatglm_model,
+ shard_chatglm_model,
+ col_layer_for_check,
+ tp_group,
+ atol=atol,
+ rtol=rtol,
+ dim=1,
+ verbose=False)
+
+ # check weights after optimizer.step()
+ org_optimizer.step()
+ sharded_optimizer.step()
+ if stage_manager is None or stage_manager.is_first_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-4, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+ check_weight(chatglm_model,
+ shard_chatglm_model,
+ col_layer_for_check,
+ tp_group,
+ atol=atol,
+ rtol=rtol,
+ dim=1,
+ verbose=False)
+
+ torch.cuda.empty_cache()
+
+
+@parameterize('test_config', [{
+ 'tp_size': 2,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': True,
+ 'precision': 'fp16',
+ 'initial_scale': 1,
+}, {
+ 'tp_size': 1,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'enable_all_optimization': False,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}, {
+ 'tp_size': 4,
+ 'pp_size': 1,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}])
+def run_chatglm_test(test_config):
+
+ # TODO(baizhou): add test_config for TP+DP after supporting & debugging it
+
+ sub_model_zoo = model_zoo.get_sub_registry('transformers_chatglm')
+
+ for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
+ check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config)
+
+ clear_layout_converter()
+ torch.cuda.empty_cache()
+
+
+def check_chatglm(rank, world_size, port):
+ disable_existing_loggers()
+ colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ run_chatglm_test()
+
+
+@pytest.mark.dist
+@rerun_if_address_is_in_use()
+@clear_cache_before_run()
+def test_chatglm():
+ spawn(check_chatglm, 4)
+
+
+if __name__ == "__main__":
+ test_chatglm()
diff --git a/tests/test_shardformer/test_model/test_shard_gpt2.py b/tests/test_shardformer/test_model/test_shard_gpt2.py
index ee7737687d99..ca086bf12776 100644
--- a/tests/test_shardformer/test_model/test_shard_gpt2.py
+++ b/tests/test_shardformer/test_model/test_shard_gpt2.py
@@ -1,79 +1,123 @@
import pytest
import torch
+from torch import distributed as dist
import colossalai
+from colossalai.booster.plugin.hybrid_parallel_plugin import HybridParallelModule
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
-from colossalai.testing import (
- assert_hf_output_close,
- clear_cache_before_run,
- parameterize,
- rerun_if_address_is_in_use,
- spawn,
-)
+from colossalai.tensor.d_tensor.api import clear_layout_converter
+from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, run_forward
+from tests.test_shardformer.test_model._utils import (
+ build_model_from_hybrid_plugin,
+ check_grad,
+ check_loss,
+ check_output_hidden_state,
+ check_weight,
+ run_forward_backward_with_hybrid_plugin,
+)
+
+
+def check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config):
+ org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster = \
+ build_model_from_hybrid_plugin(model_fn, loss_fn, test_config)
-def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
- # check forward
- org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
- output_transform_fn, loss_fn)
- assert_hf_output_close(org_output, shard_output, ignore_keys=['past_key_values'])
+ org_loss, org_output, sharded_loss, sharded_output = \
+ run_forward_backward_with_hybrid_plugin(
+ org_model,
+ sharded_model,
+ sharded_optimizer,
+ data_gen_fn,
+ output_transform_fn,
+ criterion,
+ booster)
- # do backward
- org_loss.backward()
- shard_loss.backward()
+ stage_manager = booster.plugin.stage_manager
+ tp_group = booster.plugin.tp_group
- assert torch.allclose(org_loss, shard_loss,
- atol=1e-5), f"shard model loss is not equal to origin model loss\n{org_loss}\n{shard_loss}"
+ # check last hidden state & loss
+ if stage_manager is None or stage_manager.is_last_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-5, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+
+ if org_model.__class__.__name__ == 'GPT2Model':
+ check_output_hidden_state(org_output, sharded_output, stage_manager, atol=atol, rtol=rtol)
+
+ check_loss(org_loss, sharded_loss, atol=atol, rtol=rtol)
+
+ def unwrap(module):
+ if isinstance(module, HybridParallelModule):
+ module = module.unwrap()
+ if module.__class__.__name__ == 'GPT2Model':
+ return module
+ return module.transformer
# unwrap model
- if org_model.__class__.__name__ == 'GPT2Model':
- org_model = org_model
- sharded_model = sharded_model
- else:
- org_model = org_model.transformer
- sharded_model = sharded_model.transformer
-
- # check mlp grad
- org_grad = org_model.h[0].mlp.c_fc.weight.grad
- shard_grad = sharded_model.h[0].mlp.c_fc.weight.grad
- shard_weight = sharded_model.h[0].mlp.c_fc.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=1)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(
- org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to origin model grad\n{org_grad}\n{all_shard_grad}"
-
- # check embedding weights
- org_grad = org_model.wte.weight.grad
- shard_grad = sharded_model.wte.weight.grad
- shard_weight = sharded_model.wte.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(
- org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to origin model grad\n{org_grad}\n{all_shard_grad}"
-
-
-@parameterize('enable_fused_normalization', [True, False])
-@parameterize('enable_tensor_parallelism', [True, False])
-def run_gpt2_test(enable_fused_normalization, enable_tensor_parallelism):
+ gpt2 = unwrap(org_model)
+ sharded_gpt2 = unwrap(sharded_model)
+
+ col_layer_for_check = ['h[0].mlp.c_fc']
+ row_layer_for_check = ['wte', 'h[0].mlp.c_proj']
+
+ # check grad
+ if stage_manager is None or stage_manager.is_first_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-4, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+ check_grad(gpt2, sharded_gpt2, col_layer_for_check, tp_group, atol=atol, rtol=rtol, dim=1, verbose=False)
+ check_grad(gpt2, sharded_gpt2, row_layer_for_check, tp_group, atol=atol, rtol=rtol, dim=0, verbose=False)
+
+ # check weights after optimizer.step()
+ org_optimizer.step()
+ sharded_optimizer.step()
+ if stage_manager is None or stage_manager.is_first_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 5e-3, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+ check_weight(gpt2, sharded_gpt2, col_layer_for_check, tp_group, atol=atol, rtol=rtol, dim=1, verbose=False)
+
+ torch.cuda.empty_cache()
+
+
+@parameterize('test_config', [{
+ 'tp_size': 2,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': True,
+ 'precision': 'fp16',
+ 'initial_scale': 1,
+}, {
+ 'tp_size': 1,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': True,
+ 'precision': 'fp16',
+ 'initial_scale': 1,
+}, {
+ 'tp_size': 4,
+ 'pp_size': 1,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}])
+@clear_cache_before_run()
+def run_gpt2_test(test_config):
+
+ # TODO(baizhou): add test_config for TP+DP after supporting & debugging it
+
sub_model_zoo = model_zoo.get_sub_registry('transformers_gpt')
+
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism)
- check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
+ check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config)
+
+ clear_layout_converter()
torch.cuda.empty_cache()
@@ -87,7 +131,7 @@ def check_gpt2(rank, world_size, port):
@rerun_if_address_is_in_use()
@clear_cache_before_run()
def test_gpt2():
- spawn(check_gpt2, 2)
+ spawn(check_gpt2, 4)
if __name__ == "__main__":
diff --git a/tests/test_shardformer/test_model/test_shard_llama.py b/tests/test_shardformer/test_model/test_shard_llama.py
index 74b5fdd18af8..30ebdfbe5cd9 100644
--- a/tests/test_shardformer/test_model/test_shard_llama.py
+++ b/tests/test_shardformer/test_model/test_shard_llama.py
@@ -2,88 +2,152 @@
import pytest
import torch
+from torch import distributed as dist
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
-from colossalai.testing import (
- assert_hf_output_close,
- clear_cache_before_run,
- parameterize,
- rerun_if_address_is_in_use,
- spawn,
-)
+from colossalai.tensor.d_tensor.api import clear_layout_converter
+from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, run_forward
+from tests.test_shardformer.test_model._utils import (
+ build_model_from_hybrid_plugin,
+ check_grad,
+ check_loss,
+ check_output_hidden_state,
+ check_weight,
+ run_forward_backward_with_hybrid_plugin,
+)
os.environ['TRANSFORMERS_NO_ADVISORY_WARNINGS'] = 'true'
-def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
- org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
- output_transform_fn, loss_fn)
+def check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config):
+
+ org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster = \
+ build_model_from_hybrid_plugin(model_fn, loss_fn, test_config)
+
+ org_loss, org_output, sharded_loss, sharded_output = \
+ run_forward_backward_with_hybrid_plugin(
+ org_model,
+ sharded_model,
+ sharded_optimizer,
+ data_gen_fn,
+ output_transform_fn,
+ criterion,
+ booster)
- # forward check
- assert_hf_output_close(org_output, shard_output, ignore_keys=['past_key_values'], rtol=1e-4)
+ stage_manager = booster.plugin.stage_manager
+ tp_group = booster.plugin.tp_group
- # run backward
- org_loss.backward()
- shard_loss.backward()
+ # check last hidden state & loss
+ if stage_manager is None or stage_manager.is_last_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-5, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
- assert torch.allclose(org_loss, shard_loss,
- atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
+ if org_model.__class__.__name__ == 'LlamaModel':
+ check_output_hidden_state(org_output, sharded_output, stage_manager, atol=atol, rtol=rtol)
+
+ check_loss(org_loss, sharded_loss, atol=atol, rtol=rtol)
# unwrap model
- if hasattr(org_model, 'model'):
- llama_model = org_model.model
- shard_llama_model = sharded_model.model
- else:
+ if org_model.__class__.__name__ == 'LlamaModel':
llama_model = org_model
- shard_llama_model = sharded_model
+ shard_llama_model = sharded_model.unwrap()
+ else:
+ llama_model = org_model.model
+ shard_llama_model = sharded_model.unwrap().model
+
+ # check grad
+ row_layer_for_check = ['layers[0].self_attn.q_proj', 'embed_tokens']
+ col_layer_for_check = ['layers[0].self_attn.o_proj']
+ if stage_manager is None or stage_manager.is_first_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-6, 1e-4
+ else:
+ atol, rtol = 5e-3, 5e-3
+ check_grad(llama_model,
+ shard_llama_model,
+ row_layer_for_check,
+ tp_group,
+ atol=atol,
+ rtol=rtol,
+ dim=0,
+ verbose=False)
+ check_grad(llama_model,
+ shard_llama_model,
+ col_layer_for_check,
+ tp_group,
+ atol=atol,
+ rtol=rtol,
+ dim=1,
+ verbose=False)
+
+ # check weights after optimizer.step()
+ org_optimizer.step()
+ sharded_optimizer.step()
+ if stage_manager is None or stage_manager.is_first_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-4, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+ check_weight(llama_model,
+ shard_llama_model,
+ col_layer_for_check,
+ tp_group,
+ atol=atol,
+ rtol=rtol,
+ dim=1,
+ verbose=False)
- # check attention grad
- org_grad = llama_model.layers[0].self_attn.q_proj.weight.grad
- shard_grad = shard_llama_model.layers[0].self_attn.q_proj.weight.grad
- shard_weight = shard_llama_model.layers[0].self_attn.q_proj.weight
+ torch.cuda.empty_cache()
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(4)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{shard_grad}"
-
- # check embedding grad
- org_grad = llama_model.embed_tokens.weight.grad
- shard_grad = shard_llama_model.embed_tokens.weight.grad
- shard_weight = shard_llama_model.embed_tokens.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(4)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{shard_grad}"
+@parameterize('test_config', [{
+ 'tp_size': 2,
+ 'pp_size': 2,
+ 'num_microbatches': 2,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': True,
+ 'precision': 'fp16',
+ 'initial_scale': 1,
+}, {
+ 'tp_size': 1,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}, {
+ 'tp_size': 4,
+ 'pp_size': 1,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}, {
+ 'tp_size': 1,
+ 'pp_size': 4,
+ 'num_microbatches': 4,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}])
+def run_llama_test(test_config):
+
+ # TODO(baizhou): add test_config for TP+DP after supporting & debugging it
-@parameterize('enable_fused_normalization', [True, False])
-@parameterize('enable_tensor_parallelism', [True, False])
-def run_gpt2_llama(enable_fused_normalization, enable_tensor_parallelism):
sub_model_zoo = model_zoo.get_sub_registry('transformers_llama')
+
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism)
- check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
+ check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config)
+
+ clear_layout_converter()
torch.cuda.empty_cache()
def check_llama(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
- run_gpt2_llama()
+ run_llama_test()
@pytest.mark.dist
diff --git a/tests/test_shardformer/test_model/test_shard_opt.py b/tests/test_shardformer/test_model/test_shard_opt.py
index 25bccb13b1a8..8d1154d82638 100644
--- a/tests/test_shardformer/test_model/test_shard_opt.py
+++ b/tests/test_shardformer/test_model/test_shard_opt.py
@@ -1,88 +1,147 @@
-import copy
import os
import pytest
import torch
+from torch import distributed as dist
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
-from colossalai.testing import (
- assert_hf_output_close,
- clear_cache_before_run,
- parameterize,
- rerun_if_address_is_in_use,
- spawn,
-)
+from colossalai.tensor.d_tensor.api import clear_layout_converter
+from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, run_forward
+from tests.test_shardformer.test_model._utils import (
+ build_model_from_hybrid_plugin,
+ check_grad,
+ check_loss,
+ check_output_hidden_state,
+ check_weight,
+ run_forward_backward_with_hybrid_plugin,
+)
os.environ['TRANSFORMERS_NO_ADVISORY_WARNINGS'] = 'true'
-def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
- org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
- output_transform_fn, loss_fn)
- assert_hf_output_close(org_output, shard_output, ignore_keys=['past_key_values'], rtol=1e-4)
+def check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config):
+
+ org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster = \
+ build_model_from_hybrid_plugin(model_fn, loss_fn, test_config)
+
+ org_loss, org_output, sharded_loss, sharded_output = \
+ run_forward_backward_with_hybrid_plugin(
+ org_model,
+ sharded_model,
+ sharded_optimizer,
+ data_gen_fn,
+ output_transform_fn,
+ criterion,
+ booster)
- # run backward
- org_loss.backward()
- shard_loss.backward()
+ stage_manager = booster.plugin.stage_manager
+ tp_group = booster.plugin.tp_group
- assert torch.allclose(org_loss, shard_loss,
- atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
+ # check last hidden state & loss
+ if stage_manager is None or stage_manager.is_last_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-5, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+ if org_model.__class__.__name__ == 'OPTModel':
+ check_output_hidden_state(org_output, sharded_output, stage_manager, atol=atol, rtol=rtol)
+
+ check_loss(org_loss, sharded_loss, atol=atol, rtol=rtol)
# unwrap model
- if hasattr(org_model, 'model'):
- opt_model = org_model.model
- shard_opt_model = sharded_model.model
- else:
+ if org_model.__class__.__name__ == 'OPTModel':
opt_model = org_model
- shard_opt_model = sharded_model
+ shard_opt_model = sharded_model.unwrap()
+ else:
+ opt_model = org_model.model
+ shard_opt_model = sharded_model.unwrap().model
+
+ # check grad
+ row_layer_for_check = ['decoder.layers[0].self_attn.q_proj', 'decoder.embed_tokens'] # 'decoder.embed_tokens'
+ col_layer_for_check = ['decoder.layers[0].self_attn.out_proj']
+ if stage_manager is None or stage_manager.is_first_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-6, 1e-3
+ else:
+ atol, rtol = 3e-2, 3e-2
+ check_grad(opt_model,
+ shard_opt_model,
+ row_layer_for_check,
+ tp_group,
+ atol=atol,
+ rtol=rtol,
+ dim=0,
+ verbose=False)
+ check_grad(opt_model,
+ shard_opt_model,
+ col_layer_for_check,
+ tp_group,
+ atol=atol,
+ rtol=rtol,
+ dim=1,
+ verbose=False)
+
+ # check weights after optimizer.step()
+ org_optimizer.step()
+ sharded_optimizer.step()
+ if stage_manager is None or stage_manager.is_first_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-3, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+ check_weight(opt_model,
+ shard_opt_model,
+ col_layer_for_check,
+ tp_group,
+ atol=atol,
+ rtol=rtol,
+ dim=1,
+ verbose=False)
- # check attention grad
- org_grad = opt_model.decoder.layers[0].self_attn.q_proj.weight.grad
- shard_grad = shard_opt_model.decoder.layers[0].self_attn.q_proj.weight.grad
- shard_weight = shard_opt_model.decoder.layers[0].self_attn.q_proj.weight
+ torch.cuda.empty_cache()
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(4)]
- torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
-
- # check embedding grad
- org_grad = opt_model.decoder.embed_tokens.weight.grad
- shard_grad = shard_opt_model.decoder.embed_tokens.weight.grad
- shard_weight = shard_opt_model.decoder.embed_tokens.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(4)]
- torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+@parameterize('test_config', [{
+ 'tp_size': 2,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': True,
+ 'precision': 'fp16',
+ 'initial_scale': 1,
+}, {
+ 'tp_size': 1,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'enable_all_optimization': False,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}, {
+ 'tp_size': 4,
+ 'pp_size': 1,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}])
+def run_opt_test(test_config):
+
+ # TODO(baizhou): add test_config for TP+DP after supporting & debugging it
-@parameterize('enable_fused_normalization', [True, False])
-@parameterize('enable_tensor_parallelism', [True, False])
-def run_t5_test(enable_fused_normalization, enable_tensor_parallelism):
sub_model_zoo = model_zoo.get_sub_registry('transformers_opt')
+
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism)
- check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
+ check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config)
+
+ clear_layout_converter()
torch.cuda.empty_cache()
def check_OPTModel(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
- run_t5_test()
+ run_opt_test()
@pytest.mark.dist
diff --git a/tests/test_shardformer/test_model/test_shard_sam.py b/tests/test_shardformer/test_model/test_shard_sam.py
new file mode 100644
index 000000000000..616104cd7828
--- /dev/null
+++ b/tests/test_shardformer/test_model/test_shard_sam.py
@@ -0,0 +1,69 @@
+import pytest
+import torch
+
+import colossalai
+from colossalai.logging import disable_existing_loggers
+from colossalai.testing import (
+ assert_hf_output_close,
+ clear_cache_before_run,
+ parameterize,
+ rerun_if_address_is_in_use,
+ spawn,
+)
+from tests.kit.model_zoo import model_zoo
+from tests.test_shardformer.test_model._utils import build_model, check_grad, run_forward
+
+
+def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
+ # check forward
+ org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
+ output_transform_fn, loss_fn)
+ assert_hf_output_close(org_output, shard_output, ignore_keys=['pred_masks'])
+
+ # do backward
+ org_loss.backward()
+ shard_loss.backward()
+
+ assert torch.allclose(org_loss, shard_loss,
+ atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
+
+ # check grad
+
+ sam = org_model
+ sharded_sam = sharded_model
+
+ # check grad
+ col_layer_for_check = ['mask_decoder.transformer.layers[0].self_attn.q_proj', 'vision_encoder.layers[0].mlp.lin1']
+ row_layer_for_check = ['mask_decoder.transformer.layers[0].self_attn.out_proj', 'vision_encoder.layers[0].mlp.lin2']
+ check_grad(sam, sharded_sam, col_layer_for_check, atol=1e-5, rtol=1e-3, dim=0, verbose=False)
+ check_grad(sam, sharded_sam, row_layer_for_check, atol=1e-3, rtol=1e-3, dim=1, verbose=False)
+
+
+@parameterize('enable_fused_normalization', [True, False])
+@parameterize('enable_tensor_parallelism', [True, False])
+@parameterize('enable_flash_attention', [True, False])
+def run_sam_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention):
+ sub_model_zoo = model_zoo.get_sub_registry('transformers_sam')
+ for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
+ org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
+ enable_flash_attention)
+ check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
+
+ torch.cuda.empty_cache()
+
+
+def check_sam(rank, world_size, port):
+ disable_existing_loggers()
+ colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ run_sam_test()
+
+
+@pytest.mark.dist
+@rerun_if_address_is_in_use()
+@clear_cache_before_run()
+def test_sam():
+ spawn(check_sam, 2)
+
+
+if __name__ == "__main__":
+ test_sam()
diff --git a/tests/test_shardformer/test_model/test_shard_t5.py b/tests/test_shardformer/test_model/test_shard_t5.py
index 0762dc09e5af..066f7ee815b4 100644
--- a/tests/test_shardformer/test_model/test_shard_t5.py
+++ b/tests/test_shardformer/test_model/test_shard_t5.py
@@ -1,92 +1,127 @@
-import os
-
import pytest
import torch
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
-from colossalai.testing import (
- assert_hf_output_close,
- clear_cache_before_run,
- parameterize,
- rerun_if_address_is_in_use,
- spawn,
-)
+from colossalai.shardformer.layer.utils import Randomizer
+from colossalai.tensor.d_tensor.api import clear_layout_converter
+from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, run_forward
+from tests.test_shardformer.test_model._utils import (
+ build_model_from_hybrid_plugin,
+ check_grad,
+ check_loss,
+ check_output_hidden_state,
+ check_weight,
+ run_forward_backward_with_hybrid_plugin,
+)
+
+
+def check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config):
+
+ org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster = \
+ build_model_from_hybrid_plugin(model_fn, loss_fn, test_config)
+
+ org_loss, org_output, sharded_loss, sharded_output = \
+ run_forward_backward_with_hybrid_plugin(
+ org_model,
+ sharded_model,
+ sharded_optimizer,
+ data_gen_fn,
+ output_transform_fn,
+ criterion,
+ booster)
+
+ stage_manager = booster.plugin.stage_manager
+ tp_group = booster.plugin.tp_group
+ # check last hidden state & loss
+ if stage_manager is None or stage_manager.is_last_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-5, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
-def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
- # check forward
- # the value "past_key_values" is sharded, so we ignore
- org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
- output_transform_fn, loss_fn)
- assert_hf_output_close(org_output, shard_output, ignore_keys=['past_key_values'])
+ if org_model.__class__.__name__ != 'T5ForConditionalGeneration':
+ check_output_hidden_state(org_output, sharded_output, stage_manager, atol=atol, rtol=rtol)
- # do backward
- org_loss.backward()
- shard_loss.backward()
+ check_loss(org_loss, sharded_loss, atol=atol, rtol=rtol)
- assert torch.allclose(org_loss, shard_loss,
- atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
+ # unwrap model
+ t5 = org_model
+ sharded_t5 = sharded_model.unwrap()
- # check attention grad
- org_grad = org_model.encoder.block[0].layer[0].SelfAttention.q.weight.grad
- shard_grad = sharded_model.encoder.block[0].layer[0].SelfAttention.q.weight.grad
- shard_weight = sharded_model.encoder.block[0].layer[0].SelfAttention.q.weight
+ row_layer_for_check = ['shared', 'encoder.block[0].layer[0].SelfAttention.q']
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
+ # check weights and gradients
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-5, 1e-3
else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{shard_grad}"
-
- # check self attention embed
- org_grad = org_model.encoder.block[0].layer[0].SelfAttention.relative_attention_bias.weight.grad
- shard_grad = sharded_model.encoder.block[0].layer[0].SelfAttention.relative_attention_bias.weight.grad
- shard_weight = sharded_model.encoder.block[0].layer[0].SelfAttention.relative_attention_bias.weight
-
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=1)
+ atol, rtol = 5e-3, 5e-3
+ if stage_manager is None or stage_manager.is_first_stage():
+ check_grad(t5, sharded_t5, row_layer_for_check, tp_group, atol=atol, rtol=rtol, dim=0)
+
+ # check weights after optimizer.step()
+ org_optimizer.step()
+ sharded_optimizer.step()
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-4, 1e-3
else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+ atol, rtol = 5e-3, 5e-3
+ if stage_manager is None or stage_manager.is_first_stage():
+ check_weight(t5, sharded_t5, row_layer_for_check, tp_group, atol=atol, rtol=rtol, dim=0, verbose=False)
- # check token embedding grad
- org_grad = org_model.shared.weight.grad
+ torch.cuda.empty_cache()
- # check weights are tied
- if hasattr(org_model, 'lm_head'):
- assert org_model.shared.weight.data.data_ptr() == org_model.lm_head.weight.data.data_ptr()
- assert sharded_model.shared.weight.data.data_ptr() == sharded_model.lm_head.weight.data.data_ptr()
- shard_grad = sharded_model.shared.weight.grad
- shard_weight = sharded_model.shared.weight
+@parameterize('test_config', [{
+ 'tp_size': 2,
+ 'pp_size': 2,
+ 'num_microbatches': 2,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': True,
+ 'precision': 'fp16',
+ 'initial_scale': 1,
+}, {
+ 'tp_size': 1,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'use_lazy_init': False,
+ 'precision': 'fp16',
+ 'initial_scale': 1,
+}, {
+ 'tp_size': 4,
+ 'pp_size': 1,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}, {
+ 'tp_size': 1,
+ 'pp_size': 4,
+ 'num_microbatches': 4,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}])
+@clear_cache_before_run()
+def run_t5_test(test_config):
- if is_distributed_tensor(shard_weight) or is_customized_distributed_tensor(shard_weight):
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
- else:
- all_shard_grad = shard_grad
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+ # TODO(baizhou): add plugin_config for TP+DP after supporting & debugging it
+ # {'tp_size': 2, 'pp_size': 1, 'enable_fused_normalization': True}
+ # TODO(baizhou): add test_config for flash attention & jit operator after supporting
-@parameterize('enable_fused_normalization', [True, False])
-@parameterize('enable_tensor_parallelism', [True, False])
-def run_t5_test(enable_fused_normalization, enable_tensor_parallelism):
sub_model_zoo = model_zoo.get_sub_registry('transformers_t5')
+
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism)
- check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
+
+ # skip 4-stage pp test for t5_encoder
+ if test_config['pp_size'] > 2 and name == 'transformers_t5_encoder_model':
+ continue
+
+ check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config)
+
+ clear_layout_converter()
+ Randomizer.reset_index()
torch.cuda.empty_cache()
@@ -100,7 +135,7 @@ def check_t5(rank, world_size, port):
@rerun_if_address_is_in_use()
@clear_cache_before_run()
def test_t5():
- spawn(check_t5, 2)
+ spawn(check_t5, 4)
if __name__ == "__main__":
diff --git a/tests/test_shardformer/test_model/test_shard_vit.py b/tests/test_shardformer/test_model/test_shard_vit.py
index af1605b6b659..18df8ef555f2 100644
--- a/tests/test_shardformer/test_model/test_shard_vit.py
+++ b/tests/test_shardformer/test_model/test_shard_vit.py
@@ -3,49 +3,147 @@
import colossalai
from colossalai.logging import disable_existing_loggers
-from colossalai.testing import assert_hf_output_close, clear_cache_before_run, rerun_if_address_is_in_use, spawn
+from colossalai.shardformer.layer.utils import Randomizer
+from colossalai.tensor.d_tensor.api import clear_layout_converter
+from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
-from tests.test_shardformer.test_model._utils import build_model, run_forward
+from tests.test_shardformer.test_model._utils import (
+ build_model_from_hybrid_plugin,
+ check_grad,
+ check_loss,
+ check_output_hidden_state,
+ check_weight,
+ run_forward_backward_with_hybrid_plugin,
+)
-def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
- # check forward
- org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
- output_transform_fn, loss_fn)
- assert_hf_output_close(org_output, shard_output)
+def check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config):
- # do backward
- org_loss.backward()
- shard_loss.backward()
+ org_model, org_optimizer, sharded_model, sharded_optimizer, criterion, booster = \
+ build_model_from_hybrid_plugin(model_fn, loss_fn, test_config)
+
+ org_loss, org_output, sharded_loss, sharded_output = \
+ run_forward_backward_with_hybrid_plugin(
+ org_model,
+ sharded_model,
+ sharded_optimizer,
+ data_gen_fn,
+ output_transform_fn,
+ criterion,
+ booster)
+
+ stage_manager = booster.plugin.stage_manager
+ tp_group = booster.plugin.tp_group
+
+ # check last hidden state & loss
+ if stage_manager is None or stage_manager.is_last_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-5, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+
+ if org_model.__class__.__name__ == 'ViTModel':
+ check_output_hidden_state(org_output, sharded_output, stage_manager, atol=atol, rtol=rtol)
+
+ check_loss(org_loss, sharded_loss, atol=atol, rtol=rtol)
+
+ # unwrap model
+ if org_model.__class__.__name__ == 'ViTModel':
+ vit_model = org_model
+ shard_vit_model = sharded_model.unwrap()
+ else:
+ vit_model = org_model.vit
+ shard_vit_model = sharded_model.unwrap().vit
# check grad
- org_grad = org_model.encoder.layer[0].attention.attention.query.weight.grad
- shard_grad = sharded_model.encoder.layer[0].attention.attention.query.weight.grad
+ row_layer_for_check = ['encoder.layer[0].attention.attention.query', 'embeddings.patch_embeddings.projection']
+ col_layer_for_check = ['encoder.layer[0].attention.output.dense']
+ if stage_manager is None or stage_manager.is_first_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 1e-5, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+ check_grad(vit_model,
+ shard_vit_model,
+ row_layer_for_check,
+ tp_group,
+ atol=atol,
+ rtol=rtol,
+ dim=0,
+ verbose=False)
+ check_grad(vit_model,
+ shard_vit_model,
+ col_layer_for_check,
+ tp_group,
+ atol=atol,
+ rtol=rtol,
+ dim=1,
+ verbose=False)
- shard_grad_list = [torch.zeros([*shard_grad.shape]).to('cuda') for _ in range(2)]
- shard_grad = torch.distributed.all_gather(shard_grad_list, shard_grad)
- all_shard_grad = torch.cat(shard_grad_list, dim=0)
+ # check weights after optimizer.step()
+ org_optimizer.step()
+ sharded_optimizer.step()
+ if stage_manager is None or stage_manager.is_first_stage():
+ if test_config['precision'] == 'fp32':
+ atol, rtol = 5e-3, 1e-3
+ else:
+ atol, rtol = 5e-3, 5e-3
+ check_weight(vit_model,
+ shard_vit_model,
+ col_layer_for_check,
+ tp_group,
+ atol=atol,
+ rtol=rtol,
+ dim=1,
+ verbose=False)
- assert torch.allclose(org_loss, shard_loss,
- atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
- assert torch.allclose(org_grad, all_shard_grad,
- atol=1e-5), f"shard model grad is not equal to orgin model grad\n{org_grad}\n{all_shard_grad}"
+ torch.cuda.empty_cache()
-def check_vit(rank, world_size, port):
- disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+@parameterize('test_config', [{
+ 'tp_size': 2,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': False,
+ 'precision': 'fp16',
+ 'initial_scale': 1,
+}, {
+ 'tp_size': 1,
+ 'pp_size': 2,
+ 'num_microbatches': 4,
+ 'enable_all_optimization': False,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}, {
+ 'tp_size': 4,
+ 'pp_size': 1,
+ 'enable_all_optimization': True,
+ 'use_lazy_init': False,
+ 'precision': 'fp32',
+}])
+def run_vit_test(test_config):
+
+ # TODO(baizhou): add test_config for TP+DP after supporting & debugging it
+ # TODO(baizhou): fix bug when settign lazy_init for Conv2D Layers in ViT models
sub_model_zoo = model_zoo.get_sub_registry('transformers_vit')
+
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(world_size, model_fn)
- check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
+ check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn, test_config)
+ clear_layout_converter()
+ Randomizer.reset_index()
torch.cuda.empty_cache()
+def check_vit(rank, world_size, port):
+ disable_existing_loggers()
+ colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ run_vit_test()
+
+
@pytest.mark.dist
-@pytest.mark.skip
@rerun_if_address_is_in_use()
@clear_cache_before_run()
def test_vit():
diff --git a/tests/test_shardformer/test_model/test_shard_whisper.py b/tests/test_shardformer/test_model/test_shard_whisper.py
new file mode 100644
index 000000000000..9b38ae07b1d6
--- /dev/null
+++ b/tests/test_shardformer/test_model/test_shard_whisper.py
@@ -0,0 +1,80 @@
+import pytest
+import torch
+
+import colossalai
+from colossalai.logging import disable_existing_loggers
+from colossalai.testing import (
+ assert_hf_output_close,
+ clear_cache_before_run,
+ parameterize,
+ rerun_if_address_is_in_use,
+ spawn,
+)
+from tests.kit.model_zoo import model_zoo
+from tests.test_shardformer.test_model._utils import build_model, check_grad, run_forward
+
+
+def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn):
+ # check forward
+ org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
+ output_transform_fn, loss_fn)
+ assert_hf_output_close(org_output, shard_output, ignore_keys='past_key_values', atol=1e-5)
+
+ # do backward
+ org_loss.backward()
+ shard_loss.backward()
+
+ assert torch.allclose(org_loss, shard_loss,
+ atol=1e-5), f"shard model loss is not equal to orgin model loss\n{org_loss}\n{shard_loss}"
+
+ # unwarp the model
+ if org_model.__class__.__name__ == 'WhisperForConditionalGeneration':
+ whisper = org_model.model
+ sharded_whisper = sharded_model.model
+ else:
+ whisper = org_model
+ sharded_whisper = sharded_model
+
+ # check grad
+ if org_model.__class__.__name__ == 'WhisperForAudioClassification':
+ col_layer_for_check = ['encoder.layers[0].self_attn.q_proj']
+ row_layer_for_check = ['encoder.layers[0].self_attn.out_proj']
+ else:
+ col_layer_for_check = ['encoder.layers[0].self_attn.q_proj', 'decoder.layers[0].self_attn.q_proj']
+ row_layer_for_check = ['encoder.layers[0].self_attn.out_proj', 'decoder.layers[0].self_attn.out_proj']
+ check_grad(whisper, sharded_whisper, col_layer_for_check, atol=1e-6, rtol=1e-5, dim=0, verbose=False)
+ check_grad(whisper, sharded_whisper, row_layer_for_check, atol=1e-6, rtol=1e-5, dim=1, verbose=False)
+
+
+@parameterize('enable_fused_normalization', [True, False])
+@parameterize('enable_tensor_parallelism', [True, False])
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_whisper_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused):
+ sub_model_zoo = model_zoo.get_sub_registry('transformers_whisper')
+ for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
+ org_model, sharded_model = build_model(model_fn,
+ enable_fused_normalization=enable_fused_normalization,
+ enable_tensor_parallelism=enable_tensor_parallelism,
+ enable_flash_attention=enable_flash_attention,
+ enable_jit_fused=enable_jit_fused)
+ check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
+
+ torch.cuda.empty_cache()
+
+
+def check_whisper(rank, world_size, port):
+ disable_existing_loggers()
+ colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ run_whisper_test()
+
+
+@pytest.mark.dist
+@rerun_if_address_is_in_use()
+@clear_cache_before_run()
+def test_whisper():
+ spawn(check_whisper, 2)
+
+
+if __name__ == "__main__":
+ test_whisper()
diff --git a/tests/test_shardformer/test_shard_utils.py b/tests/test_shardformer/test_shard_utils.py
new file mode 100644
index 000000000000..220b8291c9c6
--- /dev/null
+++ b/tests/test_shardformer/test_shard_utils.py
@@ -0,0 +1,27 @@
+import torch
+import torch.nn as nn
+
+from colossalai.shardformer.shard.utils import set_tensors_to_none
+
+
+class Net(nn.Module):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.layers = nn.Sequential(nn.Linear(1, 2), nn.Linear(2, 3))
+ self.out = nn.Linear(3, 1)
+
+
+def test_release_layer():
+ orig_cuda_allocated = torch.cuda.memory_allocated()
+ model = Net().cuda()
+ set_tensors_to_none(model, exclude={model.layers[0]})
+ assert model.layers[1].weight is None
+ assert model.layers[1].bias is None
+ assert model.out.weight is None
+ assert model.out.bias is None
+ set_tensors_to_none(model)
+ assert model.layers[0].weight is None
+ assert model.layers[0].bias is None
+ assert len(list(model.parameters())) == 0
+ assert torch.cuda.memory_allocated() == orig_cuda_allocated
diff --git a/tests/test_shardformer/test_with_torch_ddp.py b/tests/test_shardformer/test_with_torch_ddp.py
index 9f8a5db6c94f..2b6933246298 100644
--- a/tests/test_shardformer/test_with_torch_ddp.py
+++ b/tests/test_shardformer/test_with_torch_ddp.py
@@ -1,3 +1,5 @@
+from contextlib import nullcontext
+
import pytest
import torch
import torch.distributed as dist
@@ -5,15 +7,15 @@
import colossalai
from colossalai.cluster import DistCoordinator
+from colossalai.lazy import LazyInitContext
from colossalai.logging import disable_existing_loggers
from colossalai.shardformer import ShardConfig, ShardFormer
-from colossalai.testing import clear_cache_before_run, rerun_if_address_is_in_use, spawn
+from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
-def check_shardformer_with_ddp(rank, world_size, port):
- disable_existing_loggers()
- colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+@parameterize('lazy_init', [True, False])
+def check_shardformer_with_ddp(lazy_init: bool):
sub_model_zoo = model_zoo.get_sub_registry('transformers_gpt')
@@ -41,10 +43,13 @@ def check_shardformer_with_ddp(rank, world_size, port):
shard_config = ShardConfig(tensor_parallel_process_group=tp_process_group, enable_fused_normalization=True)
shardformer = ShardFormer(shard_config=shard_config)
+ ctx = LazyInitContext() if lazy_init else nullcontext()
+
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
# create and shard model
- model = model_fn().cuda()
- sharded_model = shardformer.optimize(model)
+ with ctx:
+ model = model_fn().cuda()
+ sharded_model, _ = shardformer.optimize(model)
# add ddp
sharded_ddp_model = DDP(sharded_model, process_group=dp_process_group)
@@ -65,13 +70,18 @@ def check_shardformer_with_ddp(rank, world_size, port):
torch.cuda.empty_cache()
+def run_dist(rank, world_size, port):
+ disable_existing_loggers()
+ colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ check_shardformer_with_ddp()
+
+
@pytest.mark.dist
@rerun_if_address_is_in_use()
@clear_cache_before_run()
def test_gpt2():
- spawn(check_shardformer_with_ddp, 4)
+ spawn(run_dist, 4)
if __name__ == "__main__":
test_gpt2()
- test_gpt2()
diff --git a/tests/test_utils/test_flash_attention.py b/tests/test_utils/test_flash_attention.py
index e1c7446f40db..f775710c40c2 100644
--- a/tests/test_utils/test_flash_attention.py
+++ b/tests/test_utils/test_flash_attention.py
@@ -13,7 +13,6 @@
from colossalai.kernel.cuda_native.scaled_softmax import AttnMaskType
DTYPE = [torch.float16, torch.bfloat16, torch.float32]
-FLASH_DTYPE = [torch.float16, torch.bfloat16]
def attention_ref(q, k, v, attn_mask=None, causal=False):
@@ -167,4 +166,4 @@ def test_cross_attention(proj_shape, dtype, dropout):
torch.allclose(y, out_ref, atol=1e-18), f"{(y - out_ref).abs().max()}"
torch.allclose(grad_q, grad_ref_q, atol=1e-7), f"{(grad_q - grad_ref_q).abs().max()}"
torch.allclose(grad_k, grad_ref_k, atol=1e-7), f"{(grad_k - grad_ref_k).abs().max()}"
- torch.allclose(grad_v, grad_ref_v, atol=1e-7), f"{(grad_v - grad_ref_v).abs().max()}"
\ No newline at end of file
+ torch.allclose(grad_v, grad_ref_v, atol=1e-7), f"{(grad_v - grad_ref_v).abs().max()}"
diff --git a/tests/test_zero/test_low_level/test_zero1_2.py b/tests/test_zero/test_low_level/test_zero1_2.py
index 5a0609bff192..9c4474aff5c3 100644
--- a/tests/test_zero/test_low_level/test_zero1_2.py
+++ b/tests/test_zero/test_low_level/test_zero1_2.py
@@ -137,7 +137,7 @@ def exam_zero_1_torch_ddp(world_size, dtype: torch.dtype):
zero_optimizer = LowLevelZeroOptimizer(zero_optimizer,
overlap_communication=True,
initial_scale=1,
- reduce_bucket_size=262144)
+ reduce_bucket_size=1024 * 1024)
torch_optimizer = torch.optim.SGD(torch_model.parameters(), lr=1)
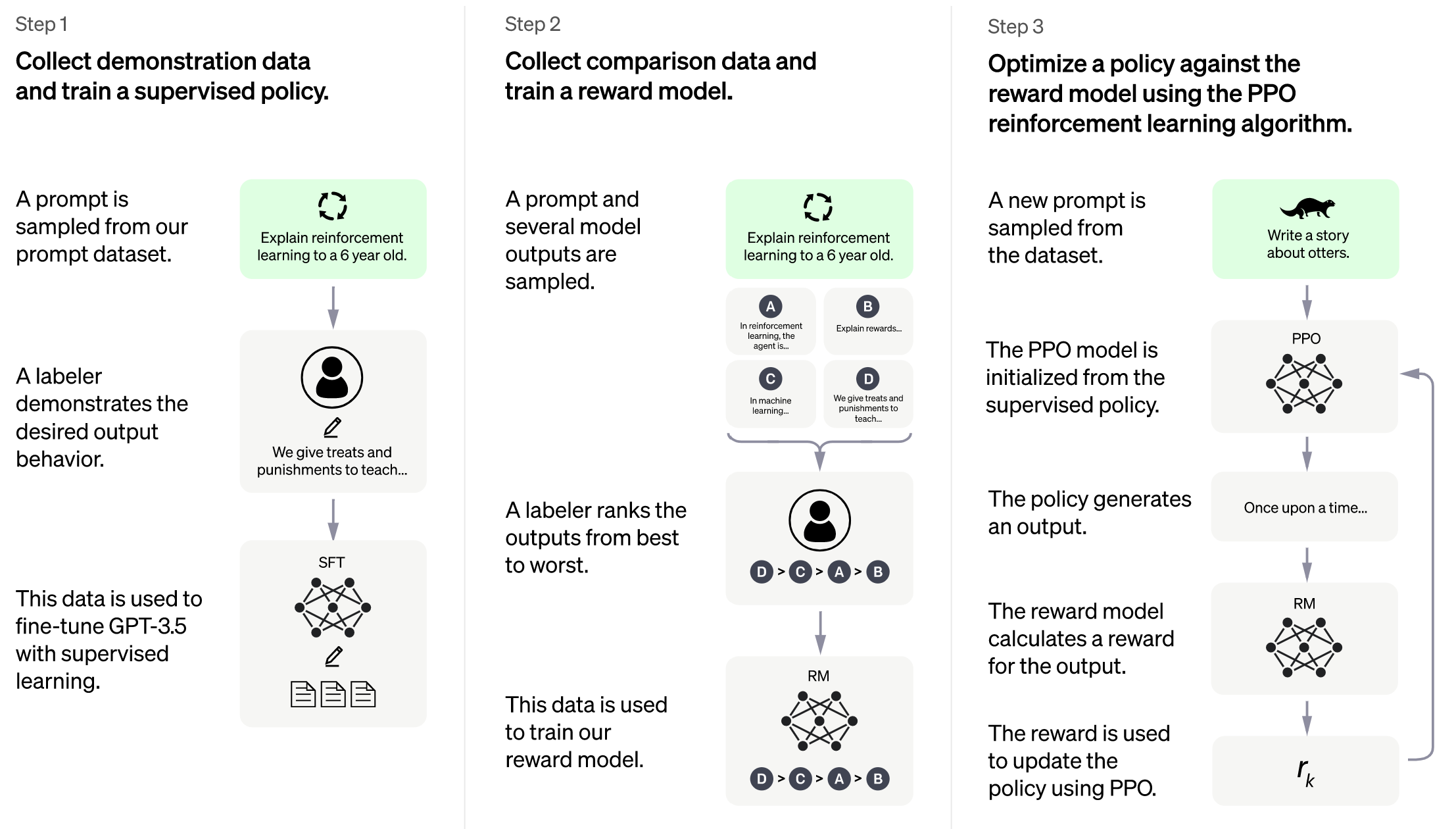 - Image source: https://openai.com/blog/chatgpt
+Image source: https://openai.com/blog/chatgpt
+
**As Colossal-AI is undergoing some major updates, this project will be actively maintained to stay in line with the Colossal-AI project.**
-
More details can be found in the latest news.
-* [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
-* [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
+
+- [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+- [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
## Online demo
+
- Image source: https://openai.com/blog/chatgpt
+Image source: https://openai.com/blog/chatgpt
+
**As Colossal-AI is undergoing some major updates, this project will be actively maintained to stay in line with the Colossal-AI project.**
-
More details can be found in the latest news.
-* [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
-* [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
+
+- [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+- [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
## Online demo
+
 @@ -83,13 +87,13 @@ More details can be found in the latest news.
@@ -83,13 +87,13 @@ More details can be found in the latest news.
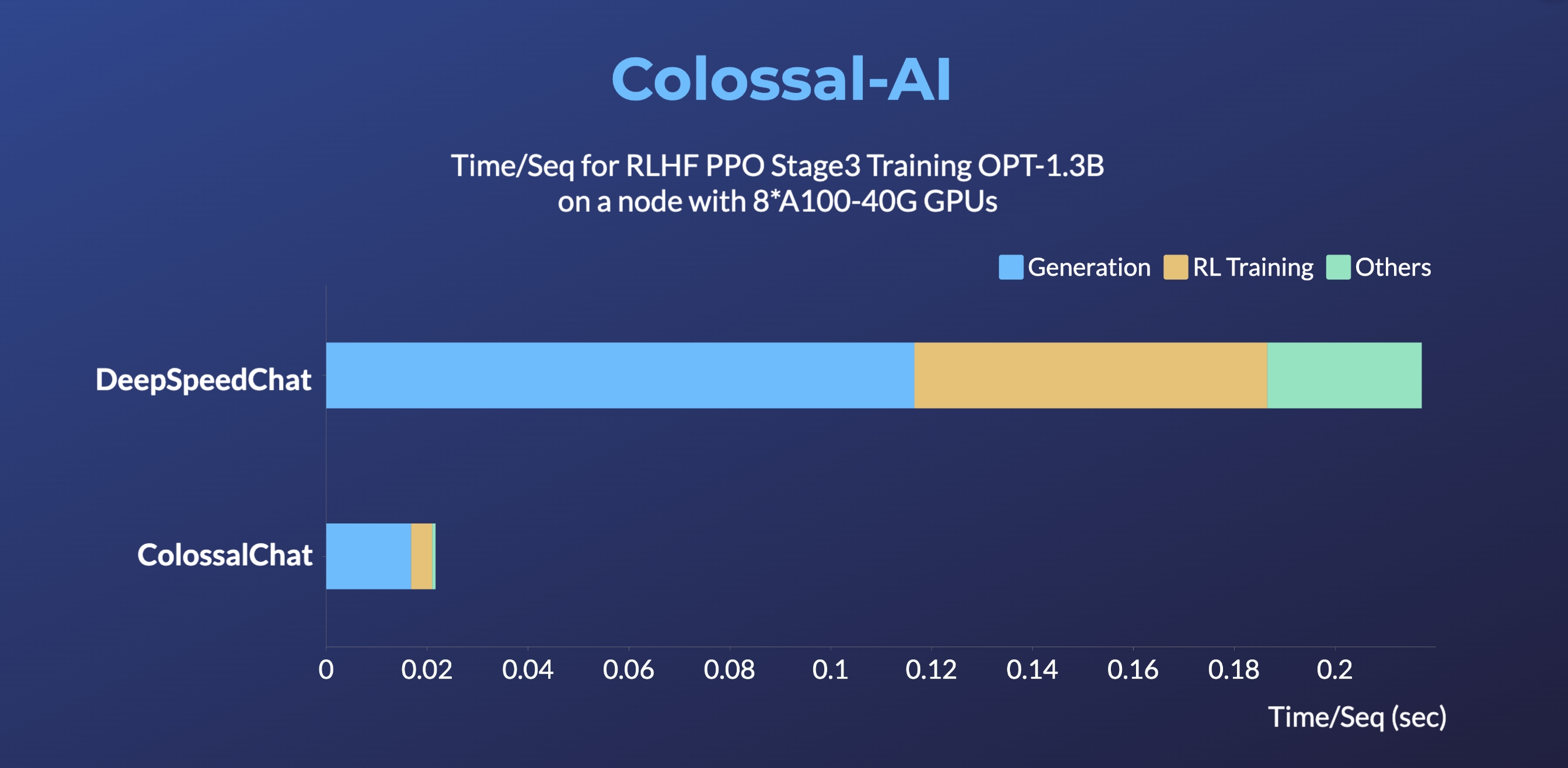 -> DeepSpeedChat performance comes from its blog on 2023 April 12, ColossalChat performance can be reproduced on an AWS p4d.24xlarge node with 8 A100-40G GPUs with the following command: torchrun --standalone --nproc_per_node 8 benchmark_opt_lora_dummy.py --num_collect_steps 1 --use_kernels --strategy colossalai_zero2 --experience_batch_size 64 --train_batch_size 32
+> DeepSpeedChat performance comes from its blog on 2023 April 12, ColossalChat performance can be reproduced on an AWS p4d.24xlarge node with 8 A100-40G GPUs with the following command: `torchrun --standalone --nproc_per_node 8 benchmark_opt_lora_dummy.py --num_collect_steps 1 --use_kernels --strategy colossalai_zero2 --experience_batch_size 64 --train_batch_size 32`
## Install
### Install the environment
-```shell
+```bash
conda create -n coati
conda activate coati
git clone https://github.com/hpcaitech/ColossalAI.git
@@ -99,7 +103,7 @@ pip install .
### Install the Transformers
-```shell
+```bash
pip install transformers==4.30.2
```
@@ -107,10 +111,11 @@ pip install transformers==4.30.2
### Supervised datasets collection
-we collected 104K bilingual datasets of Chinese and English, and you can find the datasets in this repo
-[InstructionWild](https://github.com/XueFuzhao/InstructionWild)
+We collected 104K bilingual datasets of Chinese and English, and you can find the datasets in this repo
+[InstructionWild](https://github.com/XueFuzhao/InstructionWild) and in this [file](https://github.com/XueFuzhao/InstructionWild/blob/main/data/README.md).
Here is how we collected the data
+
-> DeepSpeedChat performance comes from its blog on 2023 April 12, ColossalChat performance can be reproduced on an AWS p4d.24xlarge node with 8 A100-40G GPUs with the following command: torchrun --standalone --nproc_per_node 8 benchmark_opt_lora_dummy.py --num_collect_steps 1 --use_kernels --strategy colossalai_zero2 --experience_batch_size 64 --train_batch_size 32
+> DeepSpeedChat performance comes from its blog on 2023 April 12, ColossalChat performance can be reproduced on an AWS p4d.24xlarge node with 8 A100-40G GPUs with the following command: `torchrun --standalone --nproc_per_node 8 benchmark_opt_lora_dummy.py --num_collect_steps 1 --use_kernels --strategy colossalai_zero2 --experience_batch_size 64 --train_batch_size 32`
## Install
### Install the environment
-```shell
+```bash
conda create -n coati
conda activate coati
git clone https://github.com/hpcaitech/ColossalAI.git
@@ -99,7 +103,7 @@ pip install .
### Install the Transformers
-```shell
+```bash
pip install transformers==4.30.2
```
@@ -107,10 +111,11 @@ pip install transformers==4.30.2
### Supervised datasets collection
-we collected 104K bilingual datasets of Chinese and English, and you can find the datasets in this repo
-[InstructionWild](https://github.com/XueFuzhao/InstructionWild)
+We collected 104K bilingual datasets of Chinese and English, and you can find the datasets in this repo
+[InstructionWild](https://github.com/XueFuzhao/InstructionWild) and in this [file](https://github.com/XueFuzhao/InstructionWild/blob/main/data/README.md).
Here is how we collected the data
+
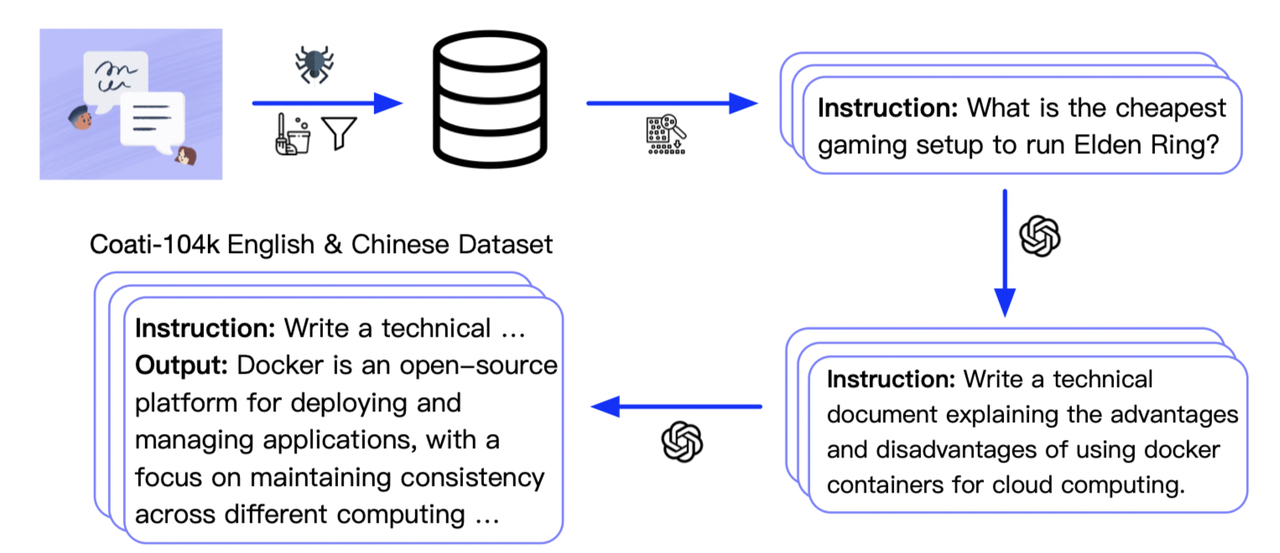
 @@ -397,18 +455,22 @@ Thanks so much to all of our amazing contributors!
| Better Cases | 38 ⚔ **41** | **45** ⚔ 33 |
| Win Rate | 48% ⚔ **52%** | **58%** ⚔ 42% |
| Average Score | 7.06 ⚔ **7.13** | **7.31** ⚔ 6.82 |
+
- Our Coati-7B model performs better than Alpaca-7B when using GPT-4 to evaluate model performance. The Coati-7B model we evaluate is an old version we trained a few weeks ago and the new version is around the corner.
## Authors
Coati is developed by ColossalAI Team:
+
- [Fazzie](https://fazzie-key.cool/about/index.html)
- [FrankLeeeee](https://github.com/FrankLeeeee)
- [BlueRum](https://github.com/ht-zhou)
- [ver217](https://github.com/ver217)
- [ofey404](https://github.com/ofey404)
+- [Wenhao Chen](https://github.com/CWHer)
The Phd student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contributed a lot to this project.
+
- [Zangwei Zheng](https://github.com/zhengzangw)
- [Xue Fuzhao](https://github.com/XueFuzhao)
diff --git a/applications/Chat/benchmarks/README.md b/applications/Chat/benchmarks/README.md
index bc8ad8ba9816..c13f3485863b 100644
--- a/applications/Chat/benchmarks/README.md
+++ b/applications/Chat/benchmarks/README.md
@@ -27,9 +27,12 @@ We also provide various training strategies:
We only support `torchrun` to launch now. E.g.
-```shell
+```bash
# run OPT-125M with no lora (lora_rank=0) on single-node single-GPU with min batch size
-torchrun --standalone --nproc_per_node 1 benchmark_opt_lora_dummy.py --model 125m --critic_model 125m --strategy ddp --experience_batch_size 1 --train_batch_size 1 --lora_rank 0
+torchrun --standalone --nproc_per_node 1 benchmark_opt_lora_dummy.py \
+ --model 125m --critic_model 125m --strategy ddp \
+ --experience_batch_size 1 --train_batch_size 1 --lora_rank 0
# run Actor (OPT-1.3B) and Critic (OPT-350M) with lora_rank=4 on single-node 4-GPU
-torchrun --standalone --nproc_per_node 4 benchmark_opt_lora_dummy.py --model 1.3b --critic_model 350m --strategy colossalai_zero2 --lora_rank 4
+torchrun --standalone --nproc_per_node 4 benchmark_opt_lora_dummy.py \
+ --model 1.3b --critic_model 350m --strategy colossalai_zero2 --lora_rank 4
```
diff --git a/applications/Chat/coati/ray/README.md b/applications/Chat/coati/ray/README.md
index 228155a6855b..79b1db347827 100644
--- a/applications/Chat/coati/ray/README.md
+++ b/applications/Chat/coati/ray/README.md
@@ -1,3 +1,5 @@
+:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
+
# Distributed PPO Training on Stage 3
## Detach Experience Makers and Trainers
@@ -26,124 +28,137 @@ See examples at `ColossalAI/application/Chat/examples/ray`
- define makers' environment variables :
- ```python
- env_info_makers = [{
- 'local_rank': '0',
- 'rank': str(rank),
- 'world_size': str(num_makers),
- 'master_port': maker_port,
- 'master_addr': master_addr
- } for rank in range(num_makers)]
+ ```python
+ env_info_makers = [{
+ 'local_rank': '0',
+ 'rank': str(rank),
+ 'world_size': str(num_makers),
+ 'master_port': maker_port,
+ 'master_addr': master_addr
+ } for rank in range(num_makers)]
+
+ ```
- ```
- define maker models :
- ```python
- def model_fn():
- actor = get_actor_from_args(...)
- critic = get_critic_from_args(...)
- reward_model = get_reward_model_from_args(...)
- initial_model = get_actor_from_args(...)
- return actor, critic, reward_model, initial_model
-
- ```
+
+ ```python
+ def model_fn():
+ actor = get_actor_from_args(...)
+ critic = get_critic_from_args(...)
+ reward_model = get_reward_model_from_args(...)
+ initial_model = get_actor_from_args(...)
+ return actor, critic, reward_model, initial_model
+
+ ```
+
- set experience_holder_refs :
- ```python
- experience_holder_refs = [
- ExperienceMakerHolder.options(
- name=f"maker_{i}",
- num_gpus=1,
- max_concurrency=2
- ).remote(
- detached_trainer_name_list=[f"trainer_{x}" for x in target_trainers(...)],
- model_fn=model_fn,
- ...)
- for i, env_info_maker in enumerate(env_info_makers)
- ]
- ```
- The names in the `detached_trainer_name_list` refer to the target trainers that the maker should send experience to.
- We set a trainer's name the same as a maker, by `.options(name="str")`. See below.
+ ```python
+ experience_holder_refs = [
+ ExperienceMakerHolder.options(
+ name=f"maker_{i}",
+ num_gpus=1,
+ max_concurrency=2
+ ).remote(
+ detached_trainer_name_list=[f"trainer_{x}" for x in target_trainers(...)],
+ model_fn=model_fn,
+ ...)
+ for i, env_info_maker in enumerate(env_info_makers)
+ ]
+ ```
+
+ The names in the `detached_trainer_name_list` refer to the target trainers that the maker should send experience to.
+ We set a trainer's name the same as a maker, by `.options(name="str")`. See below.
### Setup Trainers
- define trainers' environment variables :
- ```python
- env_info_trainers = [{
- 'local_rank': '0',
- 'rank': str(rank),
- 'world_size': str(num_trainers),
- 'master_port': trainer_port,
- 'master_addr': master_addr
- } for rank in range(num_trainers)]
- ```
+ ```python
+ env_info_trainers = [{
+ 'local_rank': '0',
+ 'rank': str(rank),
+ 'world_size': str(num_trainers),
+ 'master_port': trainer_port,
+ 'master_addr': master_addr
+ } for rank in range(num_trainers)]
+ ```
- define trainer models :
- ```python
- def trainer_model_fn():
- actor = get_actor_from_args(...)
- critic = get_critic_from_args(...)
- return actor, critic
- ```
+ ```python
+ def trainer_model_fn():
+ actor = get_actor_from_args(...)
+ critic = get_critic_from_args(...)
+ return actor, critic
+ ```
+
- set trainer_refs :
- ```python
- trainer_refs = [
- DetachedPPOTrainer.options(
- name=f"trainer{i}",
- num_gpus=1,
- max_concurrency=2
- ).remote(
- experience_maker_holder_name_list=[f"maker{x}" for x in target_makers(...)],
- model_fn = trainer_model_fn(),
- ...)
- for i, env_info_trainer in enumerate(env_info_trainers)
- ]
- ```
- The names in `experience_maker_holder_name_list` refer to the target makers that the trainer should send updated models to.
- By setting `detached_trainer_name_list` and `experience_maker_holder_name_list`, we can customize the transmission graph.
+ ```python
+ trainer_refs = [
+ DetachedPPOTrainer.options(
+ name=f"trainer{i}",
+ num_gpus=1,
+ max_concurrency=2
+ ).remote(
+ experience_maker_holder_name_list=[f"maker{x}" for x in target_makers(...)],
+ model_fn = trainer_model_fn(),
+ ...)
+ for i, env_info_trainer in enumerate(env_info_trainers)
+ ]
+ ```
+ The names in `experience_maker_holder_name_list` refer to the target makers that the trainer should send updated models to.
+ By setting `detached_trainer_name_list` and `experience_maker_holder_name_list`, we can customize the transmission graph.
### Launch Jobs
+
- define data_loader :
- ```python
- def data_loader_fn():
- return = torch.utils.data.DataLoader(dataset=dataset)
- ```
+ ```python
+ def data_loader_fn():
+ return = torch.utils.data.DataLoader(dataset=dataset)
+
+ ```
+
- launch makers :
- ```python
- wait_tasks = []
- for experience_holder_ref in experience_holder_refs:
- wait_tasks.append(
- experience_holder_ref.workingloop.remote(data_loader_fn(),
- num_steps=experience_steps))
- ```
+ ```python
+ wait_tasks = []
+ for experience_holder_ref in experience_holder_refs:
+ wait_tasks.append(
+ experience_holder_ref.workingloop.remote(data_loader_fn(),
+ num_steps=experience_steps))
+
+ ```
- launch trainers :
- ```python
- for trainer_ref in trainer_refs:
- wait_tasks.append(trainer_ref.fit.remote(total_steps, update_steps, train_epochs))
- ```
+
+ ```python
+ for trainer_ref in trainer_refs:
+ wait_tasks.append(trainer_ref.fit.remote(total_steps, update_steps, train_epochs))
+ ```
- wait for done :
- ```python
- ray.get(wait_tasks)
- ```
+ ```python
+ ray.get(wait_tasks)
+ ```
## Flexible Structure
We can deploy different strategies to makers and trainers. Here are some notions.
### 2 Makers 1 Trainer
+
@@ -397,18 +455,22 @@ Thanks so much to all of our amazing contributors!
| Better Cases | 38 ⚔ **41** | **45** ⚔ 33 |
| Win Rate | 48% ⚔ **52%** | **58%** ⚔ 42% |
| Average Score | 7.06 ⚔ **7.13** | **7.31** ⚔ 6.82 |
+
- Our Coati-7B model performs better than Alpaca-7B when using GPT-4 to evaluate model performance. The Coati-7B model we evaluate is an old version we trained a few weeks ago and the new version is around the corner.
## Authors
Coati is developed by ColossalAI Team:
+
- [Fazzie](https://fazzie-key.cool/about/index.html)
- [FrankLeeeee](https://github.com/FrankLeeeee)
- [BlueRum](https://github.com/ht-zhou)
- [ver217](https://github.com/ver217)
- [ofey404](https://github.com/ofey404)
+- [Wenhao Chen](https://github.com/CWHer)
The Phd student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contributed a lot to this project.
+
- [Zangwei Zheng](https://github.com/zhengzangw)
- [Xue Fuzhao](https://github.com/XueFuzhao)
diff --git a/applications/Chat/benchmarks/README.md b/applications/Chat/benchmarks/README.md
index bc8ad8ba9816..c13f3485863b 100644
--- a/applications/Chat/benchmarks/README.md
+++ b/applications/Chat/benchmarks/README.md
@@ -27,9 +27,12 @@ We also provide various training strategies:
We only support `torchrun` to launch now. E.g.
-```shell
+```bash
# run OPT-125M with no lora (lora_rank=0) on single-node single-GPU with min batch size
-torchrun --standalone --nproc_per_node 1 benchmark_opt_lora_dummy.py --model 125m --critic_model 125m --strategy ddp --experience_batch_size 1 --train_batch_size 1 --lora_rank 0
+torchrun --standalone --nproc_per_node 1 benchmark_opt_lora_dummy.py \
+ --model 125m --critic_model 125m --strategy ddp \
+ --experience_batch_size 1 --train_batch_size 1 --lora_rank 0
# run Actor (OPT-1.3B) and Critic (OPT-350M) with lora_rank=4 on single-node 4-GPU
-torchrun --standalone --nproc_per_node 4 benchmark_opt_lora_dummy.py --model 1.3b --critic_model 350m --strategy colossalai_zero2 --lora_rank 4
+torchrun --standalone --nproc_per_node 4 benchmark_opt_lora_dummy.py \
+ --model 1.3b --critic_model 350m --strategy colossalai_zero2 --lora_rank 4
```
diff --git a/applications/Chat/coati/ray/README.md b/applications/Chat/coati/ray/README.md
index 228155a6855b..79b1db347827 100644
--- a/applications/Chat/coati/ray/README.md
+++ b/applications/Chat/coati/ray/README.md
@@ -1,3 +1,5 @@
+:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
+
# Distributed PPO Training on Stage 3
## Detach Experience Makers and Trainers
@@ -26,124 +28,137 @@ See examples at `ColossalAI/application/Chat/examples/ray`
- define makers' environment variables :
- ```python
- env_info_makers = [{
- 'local_rank': '0',
- 'rank': str(rank),
- 'world_size': str(num_makers),
- 'master_port': maker_port,
- 'master_addr': master_addr
- } for rank in range(num_makers)]
+ ```python
+ env_info_makers = [{
+ 'local_rank': '0',
+ 'rank': str(rank),
+ 'world_size': str(num_makers),
+ 'master_port': maker_port,
+ 'master_addr': master_addr
+ } for rank in range(num_makers)]
+
+ ```
- ```
- define maker models :
- ```python
- def model_fn():
- actor = get_actor_from_args(...)
- critic = get_critic_from_args(...)
- reward_model = get_reward_model_from_args(...)
- initial_model = get_actor_from_args(...)
- return actor, critic, reward_model, initial_model
-
- ```
+
+ ```python
+ def model_fn():
+ actor = get_actor_from_args(...)
+ critic = get_critic_from_args(...)
+ reward_model = get_reward_model_from_args(...)
+ initial_model = get_actor_from_args(...)
+ return actor, critic, reward_model, initial_model
+
+ ```
+
- set experience_holder_refs :
- ```python
- experience_holder_refs = [
- ExperienceMakerHolder.options(
- name=f"maker_{i}",
- num_gpus=1,
- max_concurrency=2
- ).remote(
- detached_trainer_name_list=[f"trainer_{x}" for x in target_trainers(...)],
- model_fn=model_fn,
- ...)
- for i, env_info_maker in enumerate(env_info_makers)
- ]
- ```
- The names in the `detached_trainer_name_list` refer to the target trainers that the maker should send experience to.
- We set a trainer's name the same as a maker, by `.options(name="str")`. See below.
+ ```python
+ experience_holder_refs = [
+ ExperienceMakerHolder.options(
+ name=f"maker_{i}",
+ num_gpus=1,
+ max_concurrency=2
+ ).remote(
+ detached_trainer_name_list=[f"trainer_{x}" for x in target_trainers(...)],
+ model_fn=model_fn,
+ ...)
+ for i, env_info_maker in enumerate(env_info_makers)
+ ]
+ ```
+
+ The names in the `detached_trainer_name_list` refer to the target trainers that the maker should send experience to.
+ We set a trainer's name the same as a maker, by `.options(name="str")`. See below.
### Setup Trainers
- define trainers' environment variables :
- ```python
- env_info_trainers = [{
- 'local_rank': '0',
- 'rank': str(rank),
- 'world_size': str(num_trainers),
- 'master_port': trainer_port,
- 'master_addr': master_addr
- } for rank in range(num_trainers)]
- ```
+ ```python
+ env_info_trainers = [{
+ 'local_rank': '0',
+ 'rank': str(rank),
+ 'world_size': str(num_trainers),
+ 'master_port': trainer_port,
+ 'master_addr': master_addr
+ } for rank in range(num_trainers)]
+ ```
- define trainer models :
- ```python
- def trainer_model_fn():
- actor = get_actor_from_args(...)
- critic = get_critic_from_args(...)
- return actor, critic
- ```
+ ```python
+ def trainer_model_fn():
+ actor = get_actor_from_args(...)
+ critic = get_critic_from_args(...)
+ return actor, critic
+ ```
+
- set trainer_refs :
- ```python
- trainer_refs = [
- DetachedPPOTrainer.options(
- name=f"trainer{i}",
- num_gpus=1,
- max_concurrency=2
- ).remote(
- experience_maker_holder_name_list=[f"maker{x}" for x in target_makers(...)],
- model_fn = trainer_model_fn(),
- ...)
- for i, env_info_trainer in enumerate(env_info_trainers)
- ]
- ```
- The names in `experience_maker_holder_name_list` refer to the target makers that the trainer should send updated models to.
- By setting `detached_trainer_name_list` and `experience_maker_holder_name_list`, we can customize the transmission graph.
+ ```python
+ trainer_refs = [
+ DetachedPPOTrainer.options(
+ name=f"trainer{i}",
+ num_gpus=1,
+ max_concurrency=2
+ ).remote(
+ experience_maker_holder_name_list=[f"maker{x}" for x in target_makers(...)],
+ model_fn = trainer_model_fn(),
+ ...)
+ for i, env_info_trainer in enumerate(env_info_trainers)
+ ]
+ ```
+ The names in `experience_maker_holder_name_list` refer to the target makers that the trainer should send updated models to.
+ By setting `detached_trainer_name_list` and `experience_maker_holder_name_list`, we can customize the transmission graph.
### Launch Jobs
+
- define data_loader :
- ```python
- def data_loader_fn():
- return = torch.utils.data.DataLoader(dataset=dataset)
- ```
+ ```python
+ def data_loader_fn():
+ return = torch.utils.data.DataLoader(dataset=dataset)
+
+ ```
+
- launch makers :
- ```python
- wait_tasks = []
- for experience_holder_ref in experience_holder_refs:
- wait_tasks.append(
- experience_holder_ref.workingloop.remote(data_loader_fn(),
- num_steps=experience_steps))
- ```
+ ```python
+ wait_tasks = []
+ for experience_holder_ref in experience_holder_refs:
+ wait_tasks.append(
+ experience_holder_ref.workingloop.remote(data_loader_fn(),
+ num_steps=experience_steps))
+
+ ```
- launch trainers :
- ```python
- for trainer_ref in trainer_refs:
- wait_tasks.append(trainer_ref.fit.remote(total_steps, update_steps, train_epochs))
- ```
+
+ ```python
+ for trainer_ref in trainer_refs:
+ wait_tasks.append(trainer_ref.fit.remote(total_steps, update_steps, train_epochs))
+ ```
- wait for done :
- ```python
- ray.get(wait_tasks)
- ```
+ ```python
+ ray.get(wait_tasks)
+ ```
## Flexible Structure
We can deploy different strategies to makers and trainers. Here are some notions.
### 2 Makers 1 Trainer
+



 @@ -162,20 +184,20 @@ Model performance in [Anthropics paper](https://arxiv.org/abs/2204.05862):
@@ -162,20 +184,20 @@ Model performance in [Anthropics paper](https://arxiv.org/abs/2204.05862):