
logging — Logging facility for Python¶
+Source code: Lib/logging/__init__.py
+ ++
This module defines functions and classes which implement a flexible event +logging system for applications and libraries.
+The key benefit of having the logging API provided by a standard library module +is that all Python modules can participate in logging, so your application log +can include your own messages integrated with messages from third-party +modules.
+The simplest example:
+>>> import logging
+>>> logging.warning('Watch out!')
+WARNING:root:Watch out!
+The module provides a lot of functionality and flexibility. If you are +unfamiliar with logging, the best way to get to grips with it is to view the +tutorials (see the links above and on the right).
+The basic classes defined by the module, together with their functions, are +listed below.
+-
+
Loggers expose the interface that application code directly uses.
+Handlers send the log records (created by loggers) to the appropriate +destination.
+Filters provide a finer grained facility for determining which log records +to output.
+Formatters specify the layout of log records in the final output.
+
Logger Objects¶
+Loggers have the following attributes and methods. Note that Loggers should
+NEVER be instantiated directly, but always through the module-level function
+logging.getLogger(name). Multiple calls to getLogger() with the same
+name will always return a reference to the same Logger object.
The name is potentially a period-separated hierarchical value, like
+foo.bar.baz (though it could also be just plain foo, for example).
+Loggers that are further down in the hierarchical list are children of loggers
+higher up in the list. For example, given a logger with a name of foo,
+loggers with names of foo.bar, foo.bar.baz, and foo.bam are all
+descendants of foo. The logger name hierarchy is analogous to the Python
+package hierarchy, and identical to it if you organise your loggers on a
+per-module basis using the recommended construction
+logging.getLogger(__name__). That’s because in a module, __name__
+is the module’s name in the Python package namespace.
-
+
- +class logging.Logger¶ +
-
+
- +propagate¶ +
If this attribute evaluates to true, events logged to this logger will be +passed to the handlers of higher level (ancestor) loggers, in addition to +any handlers attached to this logger. Messages are passed directly to the +ancestor loggers’ handlers - neither the level nor filters of the ancestor +loggers in question are considered.
+If this evaluates to false, logging messages are not passed to the handlers +of ancestor loggers.
+Spelling it out with an example: If the propagate attribute of the logger named +
+A.B.Cevaluates to true, any event logged toA.B.Cvia a method call such as +logging.getLogger('A.B.C').error(...)will [subject to passing that logger’s +level and filter settings] be passed in turn to any handlers attached to loggers +namedA.B,Aand the root logger, after first being passed to any handlers +attached toA.B.C. If any logger in the chainA.B.C,A.B,Ahas its +propagateattribute set to false, then that is the last logger whose handlers +are offered the event to handle, and propagation stops at that point.The constructor sets this attribute to
+True.++Note
+If you attach a handler to a logger and one or more of its +ancestors, it may emit the same record multiple times. In general, you +should not need to attach a handler to more than one logger - if you just +attach it to the appropriate logger which is highest in the logger +hierarchy, then it will see all events logged by all descendant loggers, +provided that their propagate setting is left set to
+True. A common +scenario is to attach handlers only to the root logger, and to let +propagation take care of the rest.
-
+
- +setLevel(level)¶ +
Sets the threshold for this logger to level. Logging messages which are less +severe than level will be ignored; logging messages which have severity level +or higher will be emitted by whichever handler or handlers service this logger, +unless a handler’s level has been set to a higher severity level than level.
+When a logger is created, the level is set to
+NOTSET(which causes +all messages to be processed when the logger is the root logger, or delegation +to the parent when the logger is a non-root logger). Note that the root logger +is created with levelWARNING.The term ‘delegation to the parent’ means that if a logger has a level of +NOTSET, its chain of ancestor loggers is traversed until either an ancestor with +a level other than NOTSET is found, or the root is reached.
+If an ancestor is found with a level other than NOTSET, then that ancestor’s +level is treated as the effective level of the logger where the ancestor search +began, and is used to determine how a logging event is handled.
+If the root is reached, and it has a level of NOTSET, then all messages will be +processed. Otherwise, the root’s level will be used as the effective level.
+See Logging Levels for a list of levels.
+++Changed in version 3.2: The level parameter now accepts a string representation of the +level such as ‘INFO’ as an alternative to the integer constants +such as
+INFO. Note, however, that levels are internally stored +as integers, and methods such as e.g.getEffectiveLevel()and +isEnabledFor()will return/expect to be passed integers.
-
+
- +isEnabledFor(level)¶ +
Indicates if a message of severity level would be processed by this logger. +This method checks first the module-level level set by +
+logging.disable(level)and then the logger’s effective level as determined +bygetEffectiveLevel().
-
+
- +getEffectiveLevel()¶ +
Indicates the effective level for this logger. If a value other than +
+NOTSEThas been set usingsetLevel(), it is returned. Otherwise, +the hierarchy is traversed towards the root until a value other than +NOTSETis found, and that value is returned. The value returned is +an integer, typically one oflogging.DEBUG,logging.INFO+etc.
-
+
- +getChild(suffix)¶ +
Returns a logger which is a descendant to this logger, as determined by the suffix. +Thus,
+logging.getLogger('abc').getChild('def.ghi')would return the same +logger as would be returned bylogging.getLogger('abc.def.ghi'). This is a +convenience method, useful when the parent logger is named using e.g.__name__+rather than a literal string.++New in version 3.2.
+
-
+
- +debug(msg, *args, **kwargs)¶ +
Logs a message with level
+DEBUGon this logger. The msg is the +message format string, and the args are the arguments which are merged into +msg using the string formatting operator. (Note that this means that you can +use keywords in the format string, together with a single dictionary argument.) +No % formatting operation is performed on msg when no args are supplied.There are four keyword arguments in kwargs which are inspected: +exc_info, stack_info, stacklevel and extra.
+If exc_info does not evaluate as false, it causes exception information to be +added to the logging message. If an exception tuple (in the format returned by +
+sys.exc_info()) or an exception instance is provided, it is used; +otherwise,sys.exc_info()is called to get the exception information.The second optional keyword argument is stack_info, which defaults to +
+False. If true, stack information is added to the logging +message, including the actual logging call. Note that this is not the same +stack information as that displayed through specifying exc_info: The +former is stack frames from the bottom of the stack up to the logging call +in the current thread, whereas the latter is information about stack frames +which have been unwound, following an exception, while searching for +exception handlers.You can specify stack_info independently of exc_info, e.g. to just show +how you got to a certain point in your code, even when no exceptions were +raised. The stack frames are printed following a header line which says:
+++Stack (most recent call last): +
This mimics the
+Traceback (most recent call last):which is used when +displaying exception frames.The third optional keyword argument is stacklevel, which defaults to
+1. +If greater than 1, the corresponding number of stack frames are skipped +when computing the line number and function name set in theLogRecord+created for the logging event. This can be used in logging helpers so that +the function name, filename and line number recorded are not the information +for the helper function/method, but rather its caller. The name of this +parameter mirrors the equivalent one in thewarningsmodule.The fourth keyword argument is extra which can be used to pass a +dictionary which is used to populate the __dict__ of the
+LogRecord+created for the logging event with user-defined attributes. These custom +attributes can then be used as you like. For example, they could be +incorporated into logged messages. For example:++FORMAT = '%(asctime)s %(clientip)-15s %(user)-8s %(message)s' +logging.basicConfig(format=FORMAT) +d = {'clientip': '192.168.0.1', 'user': 'fbloggs'} +logger = logging.getLogger('tcpserver') +logger.warning('Protocol problem: %s', 'connection reset', extra=d) +
would print something like
+++2006-02-08 22:20:02,165 192.168.0.1 fbloggs Protocol problem: connection reset +
The keys in the dictionary passed in extra should not clash with the keys used +by the logging system. (See the section on LogRecord attributes for more +information on which keys are used by the logging system.)
+If you choose to use these attributes in logged messages, you need to exercise +some care. In the above example, for instance, the
+Formatterhas been +set up with a format string which expects ‘clientip’ and ‘user’ in the attribute +dictionary of theLogRecord. If these are missing, the message will +not be logged because a string formatting exception will occur. So in this case, +you always need to pass the extra dictionary with these keys.While this might be annoying, this feature is intended for use in specialized +circumstances, such as multi-threaded servers where the same code executes in +many contexts, and interesting conditions which arise are dependent on this +context (such as remote client IP address and authenticated user name, in the +above example). In such circumstances, it is likely that specialized +
+Formatters would be used with particularHandlers.If no handler is attached to this logger (or any of its ancestors, +taking into account the relevant
+Logger.propagateattributes), +the message will be sent to the handler set onlastResort.++Changed in version 3.2: The stack_info parameter was added.
+++Changed in version 3.5: The exc_info parameter can now accept exception instances.
+++Changed in version 3.8: The stacklevel parameter was added.
+
-
+
- +info(msg, *args, **kwargs)¶ +
Logs a message with level
+INFOon this logger. The arguments are +interpreted as fordebug().
-
+
- +warning(msg, *args, **kwargs)¶ +
Logs a message with level
+WARNINGon this logger. The arguments are +interpreted as fordebug().++Note
+There is an obsolete method
+warnwhich is functionally +identical towarning. Aswarnis deprecated, please do not use +it - usewarninginstead.
-
+
- +error(msg, *args, **kwargs)¶ +
Logs a message with level
+ERRORon this logger. The arguments are +interpreted as fordebug().
-
+
- +critical(msg, *args, **kwargs)¶ +
Logs a message with level
+CRITICALon this logger. The arguments are +interpreted as fordebug().
-
+
- +log(level, msg, *args, **kwargs)¶ +
Logs a message with integer level level on this logger. The other arguments are +interpreted as for
+debug().
-
+
- +exception(msg, *args, **kwargs)¶ +
Logs a message with level
+ERRORon this logger. The arguments are +interpreted as fordebug(). Exception info is added to the logging +message. This method should only be called from an exception handler.
-
+
- +addFilter(filter)¶ +
Adds the specified filter filter to this logger.
+
-
+
- +removeFilter(filter)¶ +
Removes the specified filter filter from this logger.
+
-
+
- +filter(record)¶ +
Apply this logger’s filters to the record and return
+Trueif the +record is to be processed. The filters are consulted in turn, until one of +them returns a false value. If none of them return a false value, the record +will be processed (passed to handlers). If one returns a false value, no +further processing of the record occurs.
-
+
- +addHandler(hdlr)¶ +
Adds the specified handler hdlr to this logger.
+
-
+
- +removeHandler(hdlr)¶ +
Removes the specified handler hdlr from this logger.
+
-
+
- +findCaller(stack_info=False, stacklevel=1)¶ +
Finds the caller’s source filename and line number. Returns the filename, line +number, function name and stack information as a 4-element tuple. The stack +information is returned as
+Noneunless stack_info isTrue.The stacklevel parameter is passed from code calling the
+debug()+and other APIs. If greater than 1, the excess is used to skip stack frames +before determining the values to be returned. This will generally be useful +when calling logging APIs from helper/wrapper code, so that the information +in the event log refers not to the helper/wrapper code, but to the code that +calls it.
-
+
- +handle(record)¶ +
Handles a record by passing it to all handlers associated with this logger and +its ancestors (until a false value of propagate is found). This method is used +for unpickled records received from a socket, as well as those created locally. +Logger-level filtering is applied using
+filter().
-
+
- +makeRecord(name, level, fn, lno, msg, args, exc_info, func=None, extra=None, sinfo=None)¶ +
This is a factory method which can be overridden in subclasses to create +specialized
+LogRecordinstances.
-
+
- +hasHandlers()¶ +
Checks to see if this logger has any handlers configured. This is done by +looking for handlers in this logger and its parents in the logger hierarchy. +Returns
+Trueif a handler was found, elseFalse. The method stops searching +up the hierarchy whenever a logger with the ‘propagate’ attribute set to +false is found - that will be the last logger which is checked for the +existence of handlers.++New in version 3.2.
+
++Changed in version 3.7: Loggers can now be pickled and unpickled.
+
Logging Levels¶
+The numeric values of logging levels are given in the following table. These are +primarily of interest if you want to define your own levels, and need them to +have specific values relative to the predefined levels. If you define a level +with the same numeric value, it overwrites the predefined value; the predefined +name is lost.
+Level |
+Numeric value |
+What it means / When to use it |
+
|---|---|---|
|
+0 |
+When set on a logger, indicates that
+ancestor loggers are to be consulted
+to determine the effective level.
+If that still resolves to
+ |
+
|
+10 |
+Detailed information, typically only +of interest to a developer trying to +diagnose a problem. |
+
|
+20 |
+Confirmation that things are working +as expected. |
+
|
+30 |
+An indication that something +unexpected happened, or that a +problem might occur in the near +future (e.g. ‘disk space low’). The +software is still working as +expected. |
+
|
+40 |
+Due to a more serious problem, the +software has not been able to +perform some function. |
+
|
+50 |
+A serious error, indicating that the +program itself may be unable to +continue running. |
+
Handler Objects¶
+Handlers have the following attributes and methods. Note that Handler
+is never instantiated directly; this class acts as a base for more useful
+subclasses. However, the __init__() method in subclasses needs to call
+Handler.__init__().
-
+
- +class logging.Handler¶ +
-
+
- +__init__(level=NOTSET)¶ +
Initializes the
+Handlerinstance by setting its level, setting the list +of filters to the empty list and creating a lock (usingcreateLock()) for +serializing access to an I/O mechanism.
-
+
- +createLock()¶ +
Initializes a thread lock which can be used to serialize access to underlying +I/O functionality which may not be threadsafe.
+
-
+
- +acquire()¶ +
Acquires the thread lock created with
+createLock().
-
+
- +setLevel(level)¶ +
Sets the threshold for this handler to level. Logging messages which are +less severe than level will be ignored. When a handler is created, the +level is set to
+NOTSET(which causes all messages to be +processed).See Logging Levels for a list of levels.
+++Changed in version 3.2: The level parameter now accepts a string representation of the +level such as ‘INFO’ as an alternative to the integer constants +such as
+INFO.
-
+
- +addFilter(filter)¶ +
Adds the specified filter filter to this handler.
+
-
+
- +removeFilter(filter)¶ +
Removes the specified filter filter from this handler.
+
-
+
- +filter(record)¶ +
Apply this handler’s filters to the record and return
+Trueif the +record is to be processed. The filters are consulted in turn, until one of +them returns a false value. If none of them return a false value, the record +will be emitted. If one returns a false value, the handler will not emit the +record.
-
+
- +flush()¶ +
Ensure all logging output has been flushed. This version does nothing and is +intended to be implemented by subclasses.
+
-
+
- +close()¶ +
Tidy up any resources used by the handler. This version does no output but +removes the handler from an internal list of handlers which is closed when +
+shutdown()is called. Subclasses should ensure that this gets called +from overriddenclose()methods.
-
+
- +handle(record)¶ +
Conditionally emits the specified logging record, depending on filters which may +have been added to the handler. Wraps the actual emission of the record with +acquisition/release of the I/O thread lock.
+
-
+
- +handleError(record)¶ +
This method should be called from handlers when an exception is encountered +during an
+emit()call. If the module-level attribute +raiseExceptionsisFalse, exceptions get silently ignored. This is +what is mostly wanted for a logging system - most users will not care about +errors in the logging system, they are more interested in application +errors. You could, however, replace this with a custom handler if you wish. +The specified record is the one which was being processed when the exception +occurred. (The default value ofraiseExceptionsisTrue, as that is +more useful during development).
-
+
- +format(record)¶ +
Do formatting for a record - if a formatter is set, use it. Otherwise, use the +default formatter for the module.
+
-
+
- +emit(record)¶ +
Do whatever it takes to actually log the specified logging record. This version +is intended to be implemented by subclasses and so raises a +
+NotImplementedError.++Warning
+This method is called after a handler-level lock is acquired, which +is released after this method returns. When you override this method, note +that you should be careful when calling anything that invokes other parts of +the logging API which might do locking, because that might result in a +deadlock. Specifically:
+-
+
Logging configuration APIs acquire the module-level lock, and then +individual handler-level locks as those handlers are configured.
+Many logging APIs lock the module-level lock. If such an API is called +from this method, it could cause a deadlock if a configuration call is +made on another thread, because that thread will try to acquire the +module-level lock before the handler-level lock, whereas this thread +tries to acquire the module-level lock after the handler-level lock +(because in this method, the handler-level lock has already been acquired).
+
For a list of handlers included as standard, see logging.handlers.
Formatter Objects¶
+Formatter objects have the following attributes and methods. They are
+responsible for converting a LogRecord to (usually) a string which can
+be interpreted by either a human or an external system. The base
+Formatter allows a formatting string to be specified. If none is
+supplied, the default value of '%(message)s' is used, which just includes
+the message in the logging call. To have additional items of information in the
+formatted output (such as a timestamp), keep reading.
A Formatter can be initialized with a format string which makes use of knowledge
+of the LogRecord attributes - such as the default value mentioned above
+making use of the fact that the user’s message and arguments are pre-formatted
+into a LogRecord’s message attribute. This format string contains
+standard Python %-style mapping keys. See section printf-style String Formatting
+for more information on string formatting.
The useful mapping keys in a LogRecord are given in the section on
+LogRecord attributes.
-
+
- +class logging.Formatter(fmt=None, datefmt=None, style='%', validate=True, *, defaults=None)¶ +
Returns a new instance of the
+Formatterclass. The instance is +initialized with a format string for the message as a whole, as well as a +format string for the date/time portion of a message. If no fmt is +specified,'%(message)s'is used. If no datefmt is specified, a format +is used which is described in theformatTime()documentation.The style parameter can be one of ‘%’, ‘{’ or ‘$’ and determines how +the format string will be merged with its data: using one of %-formatting, +
+str.format()orstring.Template. This only applies to the +format string fmt (e.g.'%(message)s'or{message}), not to the +actual log messages passed toLogger.debugetc; see +Using particular formatting styles throughout your application for more information on using {- and $-formatting +for log messages.The defaults parameter can be a dictionary with default values to use in +custom fields. For example: +
+logging.Formatter('%(ip)s %(message)s', defaults={"ip": None})++Changed in version 3.2: The style parameter was added.
+++Changed in version 3.8: The validate parameter was added. Incorrect or mismatched style and fmt +will raise a
+ValueError. +For example:logging.Formatter('%(asctime)s - %(message)s', style='{').++Changed in version 3.10: The defaults parameter was added.
+-
+
- +format(record)¶ +
The record’s attribute dictionary is used as the operand to a string +formatting operation. Returns the resulting string. Before formatting the +dictionary, a couple of preparatory steps are carried out. The message +attribute of the record is computed using msg % args. If the +formatting string contains
+'(asctime)',formatTime()is called +to format the event time. If there is exception information, it is +formatted usingformatException()and appended to the message. Note +that the formatted exception information is cached in attribute +exc_text. This is useful because the exception information can be +pickled and sent across the wire, but you should be careful if you have +more than oneFormattersubclass which customizes the formatting +of exception information. In this case, you will have to clear the cached +value (by setting the exc_text attribute toNone) after a formatter +has done its formatting, so that the next formatter to handle the event +doesn’t use the cached value, but recalculates it afresh.If stack information is available, it’s appended after the exception +information, using
+formatStack()to transform it if necessary.
-
+
- +formatTime(record, datefmt=None)¶ +
This method should be called from
+format()by a formatter which +wants to make use of a formatted time. This method can be overridden in +formatters to provide for any specific requirement, but the basic behavior +is as follows: if datefmt (a string) is specified, it is used with +time.strftime()to format the creation time of the +record. Otherwise, the format ‘%Y-%m-%d %H:%M:%S,uuu’ is used, where the +uuu part is a millisecond value and the other letters are as per the +time.strftime()documentation. An example time in this format is +2003-01-23 00:29:50,411. The resulting string is returned.This function uses a user-configurable function to convert the creation +time to a tuple. By default,
+time.localtime()is used; to change +this for a particular formatter instance, set theconverterattribute +to a function with the same signature astime.localtime()or +time.gmtime(). To change it for all formatters, for example if you +want all logging times to be shown in GMT, set theconverter+attribute in theFormatterclass.++Changed in version 3.3: Previously, the default format was hard-coded as in this example: +
+2010-09-06 22:38:15,292where the part before the comma is +handled by a strptime format string ('%Y-%m-%d %H:%M:%S'), and the +part after the comma is a millisecond value. Because strptime does not +have a format placeholder for milliseconds, the millisecond value is +appended using another format string,'%s,%03d'— and both of these +format strings have been hardcoded into this method. With the change, +these strings are defined as class-level attributes which can be +overridden at the instance level when desired. The names of the +attributes aredefault_time_format(for the strptime format string) +anddefault_msec_format(for appending the millisecond value).++Changed in version 3.9: The
+default_msec_formatcan beNone.
-
+
- +formatException(exc_info)¶ +
Formats the specified exception information (a standard exception tuple as +returned by
+sys.exc_info()) as a string. This default implementation +just usestraceback.print_exception(). The resulting string is +returned.
-
+
- +formatStack(stack_info)¶ +
Formats the specified stack information (a string as returned by +
+traceback.print_stack(), but with the last newline removed) as a +string. This default implementation just returns the input value.
-
+
- +class logging.BufferingFormatter(linefmt=None)¶ +
A base formatter class suitable for subclassing when you want to format a +number of records. You can pass a
+Formatterinstance which you want +to use to format each line (that corresponds to a single record). If not +specified, the default formatter (which just outputs the event message) is +used as the line formatter.-
+
- +formatHeader(records)¶ +
Return a header for a list of records. The base implementation just +returns the empty string. You will need to override this method if you +want specific behaviour, e.g. to show the count of records, a title or a +separator line.
+
-
+
+
Return a footer for a list of records. The base implementation just +returns the empty string. You will need to override this method if you +want specific behaviour, e.g. to show the count of records or a separator +line.
+
-
+
- +format(records)¶ +
Return formatted text for a list of records. The base implementation +just returns the empty string if there are no records; otherwise, it +returns the concatenation of the header, each record formatted with the +line formatter, and the footer.
+
Filter Objects¶
+Filters can be used by Handlers and Loggers for more sophisticated
+filtering than is provided by levels. The base filter class only allows events
+which are below a certain point in the logger hierarchy. For example, a filter
+initialized with ‘A.B’ will allow events logged by loggers ‘A.B’, ‘A.B.C’,
+‘A.B.C.D’, ‘A.B.D’ etc. but not ‘A.BB’, ‘B.A.B’ etc. If initialized with the
+empty string, all events are passed.
-
+
- +class logging.Filter(name='')¶ +
Returns an instance of the
+Filterclass. If name is specified, it +names a logger which, together with its children, will have its events allowed +through the filter. If name is the empty string, allows every event.-
+
- +filter(record)¶ +
Is the specified record to be logged? Returns zero for no, nonzero for +yes. If deemed appropriate, the record may be modified in-place by this +method.
+
Note that filters attached to handlers are consulted before an event is
+emitted by the handler, whereas filters attached to loggers are consulted
+whenever an event is logged (using debug(), info(),
+etc.), before sending an event to handlers. This means that events which have
+been generated by descendant loggers will not be filtered by a logger’s filter
+setting, unless the filter has also been applied to those descendant loggers.
You don’t actually need to subclass Filter: you can pass any instance
+which has a filter method with the same semantics.
Changed in version 3.2: You don’t need to create specialized Filter classes, or use other
+classes with a filter method: you can use a function (or other
+callable) as a filter. The filtering logic will check to see if the filter
+object has a filter attribute: if it does, it’s assumed to be a
+Filter and its filter() method is called. Otherwise, it’s
+assumed to be a callable and called with the record as the single
+parameter. The returned value should conform to that returned by
+filter().
Although filters are used primarily to filter records based on more
+sophisticated criteria than levels, they get to see every record which is
+processed by the handler or logger they’re attached to: this can be useful if
+you want to do things like counting how many records were processed by a
+particular logger or handler, or adding, changing or removing attributes in
+the LogRecord being processed. Obviously changing the LogRecord needs
+to be done with some care, but it does allow the injection of contextual
+information into logs (see Using Filters to impart contextual information).
LogRecord Objects¶
+LogRecord instances are created automatically by the Logger
+every time something is logged, and can be created manually via
+makeLogRecord() (for example, from a pickled event received over the
+wire).
-
+
- +class logging.LogRecord(name, level, pathname, lineno, msg, args, exc_info, func=None, sinfo=None)¶ +
Contains all the information pertinent to the event being logged.
+The primary information is passed in msg and args, +which are combined using
+msg % argsto create +themessageattribute of the record.-
+
- Parameters +
-
+
name (str) – The name of the logger used to log the event +represented by this
LogRecord. +Note that the logger name in theLogRecord+will always have this value, +even though it may be emitted by a handler +attached to a different (ancestor) logger.
+level (int) – The numeric level of the logging event +(such as
10forDEBUG,20forINFO, etc). +Note that this is converted to two attributes of the LogRecord: +levelnofor the numeric value +andlevelnamefor the corresponding level name.
+pathname (str) – The full string path of the source file +where the logging call was made.
+lineno (int) – The line number in the source file +where the logging call was made.
+msg (Any) – The event description message, +which can be a %-format string with placeholders for variable data, +or an arbitrary object (see Using arbitrary objects as messages).
+args (tuple | dict[str, Any]) – Variable data to merge into the msg argument +to obtain the event description.
+exc_info (tuple[type[BaseException], BaseException, types.TracebackType] | None) – An exception tuple with the current exception information, +as returned by
sys.exc_info(), +orNoneif no exception information is available.
+func (str | None) – The name of the function or method +from which the logging call was invoked.
+sinfo (str | None) – A text string representing stack information +from the base of the stack in the current thread, +up to the logging call.
+
+
-
+
- +getMessage()¶ +
Returns the message for this
+LogRecordinstance after merging any +user-supplied arguments with the message. If the user-supplied message +argument to the logging call is not a string,str()is called on it to +convert it to a string. This allows use of user-defined classes as +messages, whose__str__method can return the actual format string to +be used.
++Changed in version 3.2: The creation of a
+LogRecordhas been made more configurable by +providing a factory which is used to create the record. The factory can be +set usinggetLogRecordFactory()andsetLogRecordFactory()+(see this for the factory’s signature).This functionality can be used to inject your own values into a +
+LogRecordat creation time. You can use the following pattern:++old_factory = logging.getLogRecordFactory() + +def record_factory(*args, **kwargs): + record = old_factory(*args, **kwargs) + record.custom_attribute = 0xdecafbad + return record + +logging.setLogRecordFactory(record_factory) +
With this pattern, multiple factories could be chained, and as long +as they don’t overwrite each other’s attributes or unintentionally +overwrite the standard attributes listed above, there should be no +surprises.
+
LogRecord attributes¶
+The LogRecord has a number of attributes, most of which are derived from the +parameters to the constructor. (Note that the names do not always correspond +exactly between the LogRecord constructor parameters and the LogRecord +attributes.) These attributes can be used to merge data from the record into +the format string. The following table lists (in alphabetical order) the +attribute names, their meanings and the corresponding placeholder in a %-style +format string.
+If you are using {}-formatting (str.format()), you can use
+{attrname} as the placeholder in the format string. If you are using
+$-formatting (string.Template), use the form ${attrname}. In
+both cases, of course, replace attrname with the actual attribute name
+you want to use.
In the case of {}-formatting, you can specify formatting flags by placing them
+after the attribute name, separated from it with a colon. For example: a
+placeholder of {msecs:03d} would format a millisecond value of 4 as
+004. Refer to the str.format() documentation for full details on
+the options available to you.
Attribute name |
+Format |
+Description |
+
|---|---|---|
args |
+You shouldn’t need to +format this yourself. |
+The tuple of arguments merged into |
+
asctime |
+
|
+Human-readable time when the
+ |
+
created |
+
|
+Time when the |
+
exc_info |
+You shouldn’t need to +format this yourself. |
+Exception tuple (à la |
+
filename |
+
|
+Filename portion of |
+
funcName |
+
|
+Name of function containing the logging call. |
+
levelname |
+
|
+Text logging level for the message
+( |
+
levelno |
+
|
+Numeric logging level for the message
+( |
+
lineno |
+
|
+Source line number where the logging call was +issued (if available). |
+
message |
+
|
+The logged message, computed as |
+
module |
+
|
+Module (name portion of |
+
msecs |
+
|
+Millisecond portion of the time when the
+ |
+
msg |
+You shouldn’t need to +format this yourself. |
+The format string passed in the original
+logging call. Merged with |
+
name |
+
|
+Name of the logger used to log the call. |
+
pathname |
+
|
+Full pathname of the source file where the +logging call was issued (if available). |
+
process |
+
|
+Process ID (if available). |
+
processName |
+
|
+Process name (if available). |
+
relativeCreated |
+
|
+Time in milliseconds when the LogRecord was +created, relative to the time the logging +module was loaded. |
+
stack_info |
+You shouldn’t need to +format this yourself. |
+Stack frame information (where available) +from the bottom of the stack in the current +thread, up to and including the stack frame +of the logging call which resulted in the +creation of this record. |
+
thread |
+
|
+Thread ID (if available). |
+
threadName |
+
|
+Thread name (if available). |
+
Changed in version 3.1: processName was added.
+LoggerAdapter Objects¶
+LoggerAdapter instances are used to conveniently pass contextual
+information into logging calls. For a usage example, see the section on
+adding contextual information to your logging output.
-
+
- +class logging.LoggerAdapter(logger, extra)¶ +
Returns an instance of
+LoggerAdapterinitialized with an +underlyingLoggerinstance and a dict-like object.-
+
- +process(msg, kwargs)¶ +
Modifies the message and/or keyword arguments passed to a logging call in +order to insert contextual information. This implementation takes the object +passed as extra to the constructor and adds it to kwargs using key +‘extra’. The return value is a (msg, kwargs) tuple which has the +(possibly modified) versions of the arguments passed in.
+
-
+
- +manager¶ +
Delegates to the underlying
+manager`on logger.
-
+
- +_log¶ +
Delegates to the underlying
+_log`()method on logger.
In addition to the above,
+LoggerAdaptersupports the following +methods ofLogger:debug(),info(), +warning(),error(),exception(), +critical(),log(),isEnabledFor(), +getEffectiveLevel(),setLevel()and +hasHandlers(). These methods have the same signatures as their +counterparts inLogger, so you can use the two types of instances +interchangeably.++Changed in version 3.2: The
+isEnabledFor(),getEffectiveLevel(), +setLevel()andhasHandlers()methods were added +toLoggerAdapter. These methods delegate to the underlying logger.++Changed in version 3.6: Attribute
+managerand method_log()were added, which +delegate to the underlying logger and allow adapters to be nested.
Thread Safety¶
+The logging module is intended to be thread-safe without any special work +needing to be done by its clients. It achieves this though using threading +locks; there is one lock to serialize access to the module’s shared data, and +each handler also creates a lock to serialize access to its underlying I/O.
+If you are implementing asynchronous signal handlers using the signal
+module, you may not be able to use logging from within such handlers. This is
+because lock implementations in the threading module are not always
+re-entrant, and so cannot be invoked from such signal handlers.
Module-Level Functions¶
+In addition to the classes described above, there are a number of module-level +functions.
+-
+
- +logging.getLogger(name=None)¶ +
Return a logger with the specified name or, if name is
+None, return a +logger which is the root logger of the hierarchy. If specified, the name is +typically a dot-separated hierarchical name like ‘a’, ‘a.b’ or ‘a.b.c.d’. +Choice of these names is entirely up to the developer who is using logging.All calls to this function with a given name return the same logger instance. +This means that logger instances never need to be passed between different parts +of an application.
+
-
+
- +logging.getLoggerClass()¶ +
Return either the standard
+Loggerclass, or the last class passed to +setLoggerClass(). This function may be called from within a new class +definition, to ensure that installing a customizedLoggerclass will +not undo customizations already applied by other code. For example:++class MyLogger(logging.getLoggerClass()): + # ... override behaviour here +
-
+
- +logging.getLogRecordFactory()¶ +
Return a callable which is used to create a
+LogRecord.++New in version 3.2: This function has been provided, along with
+setLogRecordFactory(), +to allow developers more control over how theLogRecord+representing a logging event is constructed.See
+setLogRecordFactory()for more information about the how the +factory is called.
-
+
- +logging.debug(msg, *args, **kwargs)¶ +
Logs a message with level
+DEBUGon the root logger. The msg is the +message format string, and the args are the arguments which are merged into +msg using the string formatting operator. (Note that this means that you can +use keywords in the format string, together with a single dictionary argument.)There are three keyword arguments in kwargs which are inspected: exc_info +which, if it does not evaluate as false, causes exception information to be +added to the logging message. If an exception tuple (in the format returned by +
+sys.exc_info()) or an exception instance is provided, it is used; +otherwise,sys.exc_info()is called to get the exception information.The second optional keyword argument is stack_info, which defaults to +
+False. If true, stack information is added to the logging +message, including the actual logging call. Note that this is not the same +stack information as that displayed through specifying exc_info: The +former is stack frames from the bottom of the stack up to the logging call +in the current thread, whereas the latter is information about stack frames +which have been unwound, following an exception, while searching for +exception handlers.You can specify stack_info independently of exc_info, e.g. to just show +how you got to a certain point in your code, even when no exceptions were +raised. The stack frames are printed following a header line which says:
+++Stack (most recent call last): +
This mimics the
+Traceback (most recent call last):which is used when +displaying exception frames.The third optional keyword argument is extra which can be used to pass a +dictionary which is used to populate the __dict__ of the LogRecord created for +the logging event with user-defined attributes. These custom attributes can then +be used as you like. For example, they could be incorporated into logged +messages. For example:
+++FORMAT = '%(asctime)s %(clientip)-15s %(user)-8s %(message)s' +logging.basicConfig(format=FORMAT) +d = {'clientip': '192.168.0.1', 'user': 'fbloggs'} +logging.warning('Protocol problem: %s', 'connection reset', extra=d) +
would print something like:
+++2006-02-08 22:20:02,165 192.168.0.1 fbloggs Protocol problem: connection reset +
The keys in the dictionary passed in extra should not clash with the keys used +by the logging system. (See the
+Formatterdocumentation for more +information on which keys are used by the logging system.)If you choose to use these attributes in logged messages, you need to exercise +some care. In the above example, for instance, the
+Formatterhas been +set up with a format string which expects ‘clientip’ and ‘user’ in the attribute +dictionary of the LogRecord. If these are missing, the message will not be +logged because a string formatting exception will occur. So in this case, you +always need to pass the extra dictionary with these keys.While this might be annoying, this feature is intended for use in specialized +circumstances, such as multi-threaded servers where the same code executes in +many contexts, and interesting conditions which arise are dependent on this +context (such as remote client IP address and authenticated user name, in the +above example). In such circumstances, it is likely that specialized +
+Formatters would be used with particularHandlers.This function (as well as
+info(),warning(),error()and +critical()) will callbasicConfig()if the root logger doesn’t +have any handler attached.++Changed in version 3.2: The stack_info parameter was added.
+
-
+
- +logging.info(msg, *args, **kwargs)¶ +
Logs a message with level
+INFOon the root logger. The arguments are +interpreted as fordebug().
-
+
- +logging.warning(msg, *args, **kwargs)¶ +
Logs a message with level
+WARNINGon the root logger. The arguments +are interpreted as fordebug().++Note
+There is an obsolete function
+warnwhich is functionally +identical towarning. Aswarnis deprecated, please do not use +it - usewarninginstead.
-
+
- +logging.error(msg, *args, **kwargs)¶ +
Logs a message with level
+ERRORon the root logger. The arguments are +interpreted as fordebug().
-
+
- +logging.critical(msg, *args, **kwargs)¶ +
Logs a message with level
+CRITICALon the root logger. The arguments +are interpreted as fordebug().
-
+
- +logging.exception(msg, *args, **kwargs)¶ +
Logs a message with level
+ERRORon the root logger. The arguments are +interpreted as fordebug(). Exception info is added to the logging +message. This function should only be called from an exception handler.
-
+
- +logging.log(level, msg, *args, **kwargs)¶ +
Logs a message with level level on the root logger. The other arguments are +interpreted as for
+debug().
-
+
- +logging.disable(level=CRITICAL)¶ +
Provides an overriding level level for all loggers which takes precedence over +the logger’s own level. When the need arises to temporarily throttle logging +output down across the whole application, this function can be useful. Its +effect is to disable all logging calls of severity level and below, so that +if you call it with a value of INFO, then all INFO and DEBUG events would be +discarded, whereas those of severity WARNING and above would be processed +according to the logger’s effective level. If +
+logging.disable(logging.NOTSET)is called, it effectively removes this +overriding level, so that logging output again depends on the effective +levels of individual loggers.Note that if you have defined any custom logging level higher than +
+CRITICAL(this is not recommended), you won’t be able to rely on the +default value for the level parameter, but will have to explicitly supply a +suitable value.++Changed in version 3.7: The level parameter was defaulted to level
+CRITICAL. See +bpo-28524 for more information about this change.
-
+
- +logging.addLevelName(level, levelName)¶ +
Associates level level with text levelName in an internal dictionary, which is +used to map numeric levels to a textual representation, for example when a +
+Formatterformats a message. This function can also be used to define +your own levels. The only constraints are that all levels used must be +registered using this function, levels should be positive integers and they +should increase in increasing order of severity.++Note
+If you are thinking of defining your own levels, please see the +section on Custom Levels.
+
-
+
- +logging.getLevelNamesMapping()¶ +
Returns a mapping from level names to their corresponding logging levels. For example, the +string “CRITICAL” maps to
+CRITICAL. The returned mapping is copied from an internal +mapping on each call to this function.++New in version 3.11.
+
-
+
- +logging.getLevelName(level)¶ +
Returns the textual or numeric representation of logging level level.
+If level is one of the predefined levels
+CRITICAL,ERROR, +WARNING,INFOorDEBUGthen you get the +corresponding string. If you have associated levels with names using +addLevelName()then the name you have associated with level is +returned. If a numeric value corresponding to one of the defined levels is +passed in, the corresponding string representation is returned.The level parameter also accepts a string representation of the level such +as ‘INFO’. In such cases, this functions returns the corresponding numeric +value of the level.
+If no matching numeric or string value is passed in, the string +‘Level %s’ % level is returned.
+++Note
+Levels are internally integers (as they need to be compared in the +logging logic). This function is used to convert between an integer level +and the level name displayed in the formatted log output by means of the +
+%(levelname)sformat specifier (see LogRecord attributes), and +vice versa.++Changed in version 3.4: In Python versions earlier than 3.4, this function could also be passed a +text level, and would return the corresponding numeric value of the level. +This undocumented behaviour was considered a mistake, and was removed in +Python 3.4, but reinstated in 3.4.2 due to retain backward compatibility.
+
-
+
- +logging.makeLogRecord(attrdict)¶ +
Creates and returns a new
+LogRecordinstance whose attributes are +defined by attrdict. This function is useful for taking a pickled +LogRecordattribute dictionary, sent over a socket, and reconstituting +it as aLogRecordinstance at the receiving end.
-
+
- +logging.basicConfig(**kwargs)¶ +
Does basic configuration for the logging system by creating a +
+StreamHandlerwith a defaultFormatterand adding it to the +root logger. The functionsdebug(),info(),warning(), +error()andcritical()will callbasicConfig()automatically +if no handlers are defined for the root logger.This function does nothing if the root logger already has handlers +configured, unless the keyword argument force is set to
+True.++Note
+This function should be called from the main thread +before other threads are started. In versions of Python prior to +2.7.1 and 3.2, if this function is called from multiple threads, +it is possible (in rare circumstances) that a handler will be added +to the root logger more than once, leading to unexpected results +such as messages being duplicated in the log.
+The following keyword arguments are supported.
+++
+ + ++ + Format
Description
filename
Specifies that a
FileHandlerbe +created, using the specified filename, +rather than aStreamHandler.filemode
If filename is specified, open the file +in this mode. Defaults +to
'a'.format
Use the specified format string for the +handler. Defaults to attributes +
levelname,nameandmessage+separated by colons.datefmt
Use the specified date/time format, as +accepted by
time.strftime().style
If format is specified, use this style +for the format string. One of
'%', +'{'or'$'for printf-style, +str.format()or +string.Templaterespectively. +Defaults to'%'.level
Set the root logger level to the specified +level.
stream
Use the specified stream to initialize the +
StreamHandler. Note that this +argument is incompatible with filename - +if both are present, aValueErroris +raised.handlers
If specified, this should be an iterable of +already created handlers to add to the root +logger. Any handlers which don’t already +have a formatter set will be assigned the +default formatter created in this function. +Note that this argument is incompatible +with filename or stream - if both +are present, a
ValueErroris raised.force
If this keyword argument is specified as +true, any existing handlers attached to the +root logger are removed and closed, before +carrying out the configuration as specified +by the other arguments.
encoding
If this keyword argument is specified along +with filename, its value is used when the +
FileHandleris created, and thus +used when opening the output file.errors
If this keyword argument is specified along +with filename, its value is used when the +
FileHandleris created, and thus +used when opening the output file. If not +specified, the value ‘backslashreplace’ is +used. Note that ifNoneis specified, +it will be passed as such toopen(), +which means that it will be treated the +same as passing ‘errors’.++Changed in version 3.2: The style argument was added.
+++Changed in version 3.3: The handlers argument was added. Additional checks were added to +catch situations where incompatible arguments are specified (e.g. +handlers together with stream or filename, or stream +together with filename).
+++Changed in version 3.8: The force argument was added.
+++Changed in version 3.9: The encoding and errors arguments were added.
+
-
+
- +logging.shutdown()¶ +
Informs the logging system to perform an orderly shutdown by flushing and +closing all handlers. This should be called at application exit and no +further use of the logging system should be made after this call.
+When the logging module is imported, it registers this function as an exit +handler (see
+atexit), so normally there’s no need to do that +manually.
-
+
- +logging.setLoggerClass(klass)¶ +
Tells the logging system to use the class klass when instantiating a logger. +The class should define
+__init__()such that only a name argument is +required, and the__init__()should callLogger.__init__(). This +function is typically called before any loggers are instantiated by applications +which need to use custom logger behavior. After this call, as at any other +time, do not instantiate loggers directly using the subclass: continue to use +thelogging.getLogger()API to get your loggers.
-
+
- +logging.setLogRecordFactory(factory)¶ +
Set a callable which is used to create a
+LogRecord.-
+
- Parameters +
factory – The factory callable to be used to instantiate a log record.
+
+
++New in version 3.2: This function has been provided, along with
+getLogRecordFactory(), to +allow developers more control over how theLogRecordrepresenting +a logging event is constructed.The factory has the following signature:
+
+factory(name, level, fn, lno, msg, args, exc_info, func=None, sinfo=None, **kwargs)+
+-
+
- name +
The logger name.
+
+- level +
The logging level (numeric).
+
+- fn +
The full pathname of the file where the logging call was made.
+
+- lno +
The line number in the file where the logging call was made.
+
+- msg +
The logging message.
+
+- args +
The arguments for the logging message.
+
+- exc_info +
An exception tuple, or
+None.
+- func +
The name of the function or method which invoked the logging +call.
+
+- sinfo +
A stack traceback such as is provided by +
+traceback.print_stack(), showing the call hierarchy.
+- kwargs +
Additional keyword arguments.
+
+
Module-Level Attributes¶
+-
+
- +logging.lastResort¶ +
A “handler of last resort” is available through this attribute. This +is a
+StreamHandlerwriting tosys.stderrwith a level of +WARNING, and is used to handle logging events in the absence of any +logging configuration. The end result is to just print the message to +sys.stderr. This replaces the earlier error message saying that +“no handlers could be found for logger XYZ”. If you need the earlier +behaviour for some reason,lastResortcan be set toNone.++New in version 3.2.
+
Integration with the warnings module¶
+The captureWarnings() function can be used to integrate logging
+with the warnings module.
-
+
- +logging.captureWarnings(capture)¶ +
This function is used to turn the capture of warnings by logging on and +off.
+If capture is
+True, warnings issued by thewarningsmodule will +be redirected to the logging system. Specifically, a warning will be +formatted usingwarnings.formatwarning()and the resulting string +logged to a logger named'py.warnings'with a severity ofWARNING.If capture is
+False, the redirection of warnings to the logging system +will stop, and warnings will be redirected to their original destinations +(i.e. those in effect beforecaptureWarnings(True)was called).
See also
+-
+
- Module
logging.config Configuration API for the logging module.
+
+- Module
logging.handlers Useful handlers included with the logging module.
+
+- PEP 282 - A Logging System
The proposal which described this feature for inclusion in the Python standard +library.
+
+- Original Python logging package
This is the original source for the
+loggingpackage. The version of the +package available from this site is suitable for use with Python 1.5.2, 2.1.x +and 2.2.x, which do not include theloggingpackage in the standard +library.
+
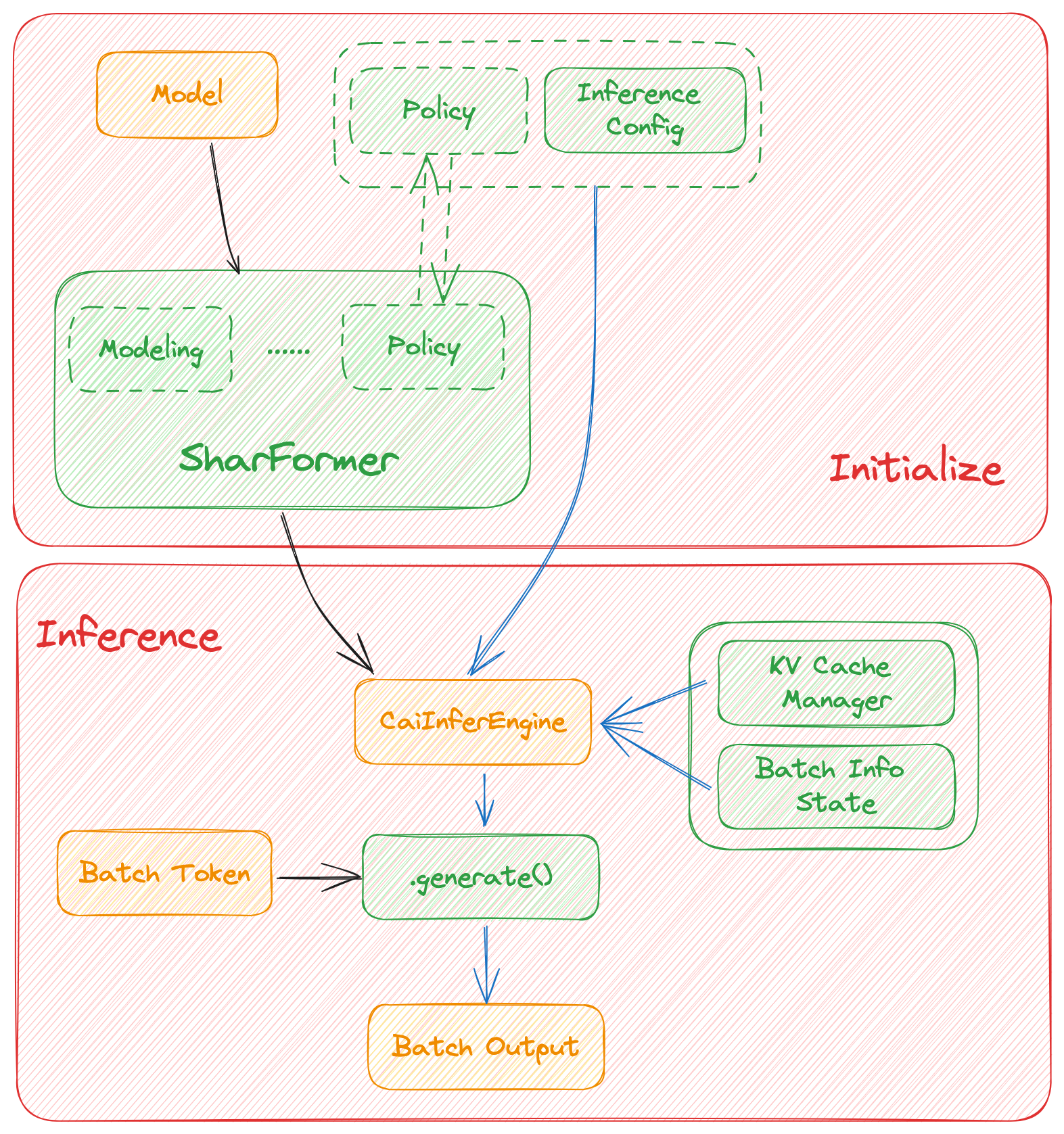 ## Roadmap of our implementation
@@ -34,11 +43,15 @@ In this section we discuss how the colossal inference works and integrates with
- [x] policy
- [x] context forward
- [x] token forward
-- [ ] Replace the kernels with `faster-transformer` in token-forward stage
-- [ ] Support all models
+ - [x] support flash-decoding
+- [x] Support all models
- [x] Llama
+ - [x] Llama-2
- [x] Bloom
- - [ ] Chatglm2
+ - [x] Chatglm2
+- [x] Quantization
+ - [x] GPTQ
+ - [x] SmoothQuant
- [ ] Benchmarking for all models
## Get started
@@ -51,23 +64,19 @@ pip install -e .
### Requirements
-dependencies
+Install dependencies.
```bash
-pytorch= 1.13.1 (gpu)
-cuda>= 11.6
-transformers= 4.30.2
-triton==2.0.0.dev20221202
-# for install vllm, please use this branch to install https://github.com/tiandiao123/vllm/tree/setup_branch
-vllm
-# for install flash-attention, please use commit hash: 67ae6fd74b4bc99c36b2ce524cf139c35663793c
-flash-attention
-
-# install lightllm since we depend on lightllm triton kernels
-git clone https://github.com/ModelTC/lightllm
-git checkout 28c1267cfca536b7b4f28e921e03de735b003039
-cd lightllm
-pip3 install -e .
+pip install -r requirements/requirements-infer.txt
+
+# if you want use smoothquant quantization, please install torch-int
+git clone --recurse-submodules https://github.com/Guangxuan-Xiao/torch-int.git
+cd torch-int
+git checkout 65266db1eadba5ca78941b789803929e6e6c6856
+pip install -r requirements.txt
+source environment.sh
+bash build_cutlass.sh
+python setup.py install
```
### Docker
@@ -83,22 +92,60 @@ docker run -it --gpus all --name ANY_NAME -v $PWD:/workspace -w /workspace hpcai
cd /path/to/CollossalAI
pip install -e .
-# install lightllm
-git clone https://github.com/ModelTC/lightllm
-git checkout 28c1267cfca536b7b4f28e921e03de735b003039
-cd lightllm
-pip3 install -e .
-
-
```
-### Dive into fast-inference!
+## Usage
+### Quick start
example files are in
```bash
-cd colossalai.examples
-python xx
+cd ColossalAI/examples
+python hybrid_llama.py --path /path/to/model --tp_size 2 --pp_size 2 --batch_size 4 --max_input_size 32 --max_out_len 16 --micro_batch_size 2
+```
+
+
+
+### Example
+```python
+# import module
+from colossalai.inference import CaiInferEngine
+import colossalai
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+#launch distributed environment
+colossalai.launch_from_torch(config={})
+
+# load original model and tokenizer
+model = LlamaForCausalLM.from_pretrained("/path/to/model")
+tokenizer = LlamaTokenizer.from_pretrained("/path/to/model")
+
+# generate token ids
+input = ["Introduce a landmark in London","Introduce a landmark in Singapore"]
+data = tokenizer(input, return_tensors='pt')
+
+# set parallel parameters
+tp_size=2
+pp_size=2
+max_output_len=32
+micro_batch_size=1
+
+# initial inference engine
+engine = CaiInferEngine(
+ tp_size=tp_size,
+ pp_size=pp_size,
+ model=model,
+ max_output_len=max_output_len,
+ micro_batch_size=micro_batch_size,
+)
+
+# inference
+output = engine.generate(data)
+
+# get results
+if dist.get_rank() == 0:
+ assert len(output[0]) == max_output_len, f"{len(output)}, {max_output_len}"
+
```
## Performance
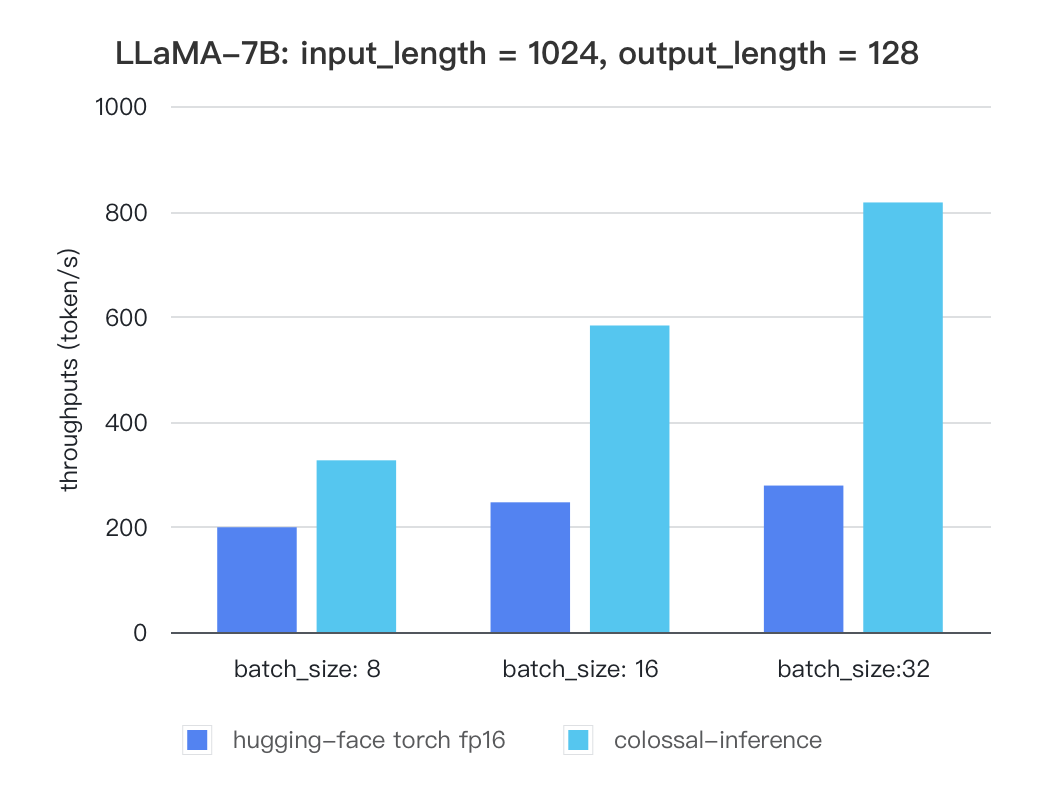
@@ -113,7 +160,9 @@ For various models, experiments were conducted using multiple batch sizes under
Currently the stats below are calculated based on A100 (single GPU), and we calculate token latency based on average values of context-forward and decoding forward process, which means we combine both of processes to calculate token generation times. We are actively developing new features and methods to further optimize the performance of LLM models. Please stay tuned.
-#### Llama
+### Tensor Parallelism Inference
+
+##### Llama
| batch_size | 8 | 16 | 32 |
| :---------------------: | :----: | :----: | :----: |
@@ -122,7 +171,7 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc
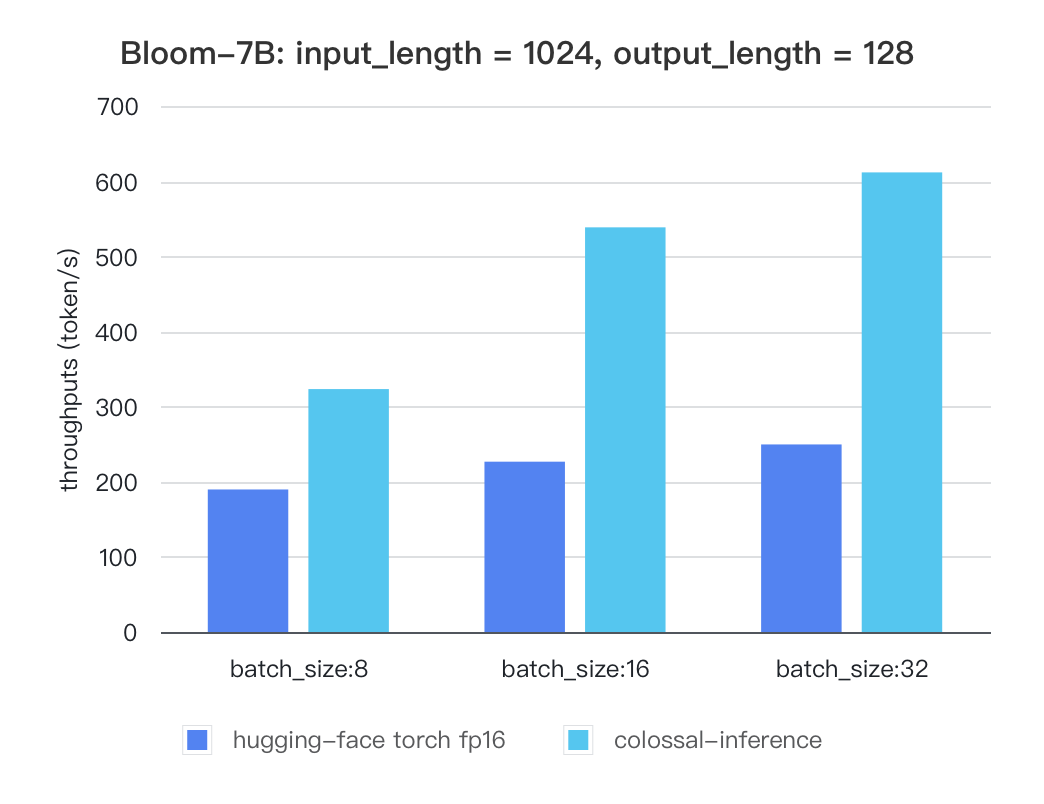
-### Bloom
+#### Bloom
| batch_size | 8 | 16 | 32 |
| :---------------------: | :----: | :----: | :----: |
@@ -131,4 +180,50 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc
+
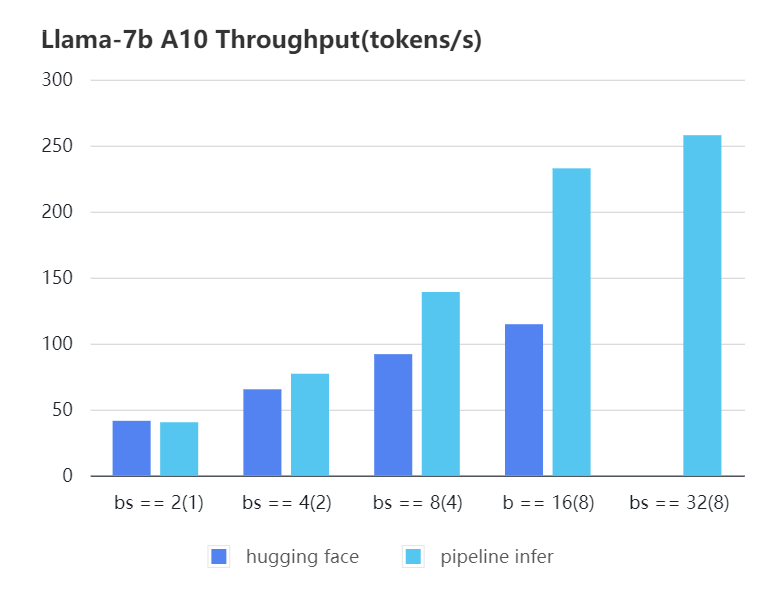
+### Pipline Parallelism Inference
+We conducted multiple benchmark tests to evaluate the performance. We compared the inference `latency` and `throughputs` between `Pipeline Inference` and `hugging face` pipeline. The test environment is 2 * A10, 20G / 2 * A800, 80G. We set input length=1024, output length=128.
+
+
+#### A10 7b, fp16
+
+| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16)|
+| :-------------------------: | :---: | :---:| :---: | :---: | :---: | :---: |
+| Pipeline Inference | 40.35 | 77.10| 139.03| 232.70| 257.81| OOM |
+| Hugging Face | 41.43 | 65.30| 91.93 | 114.62| OOM | OOM |
+
+
+
+
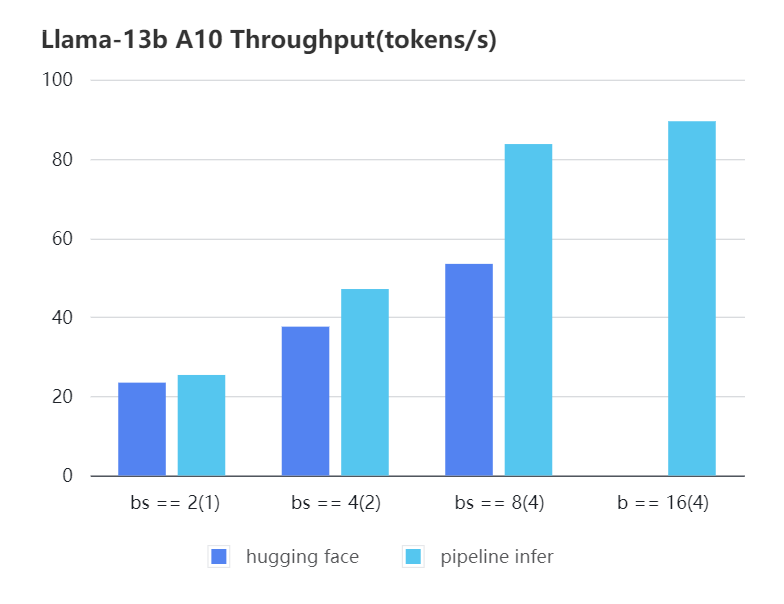
+#### A10 13b, fp16
+
+| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(4) |
+| :---: | :---: | :---: | :---: | :---: |
+| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
+| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
+
+
+
+
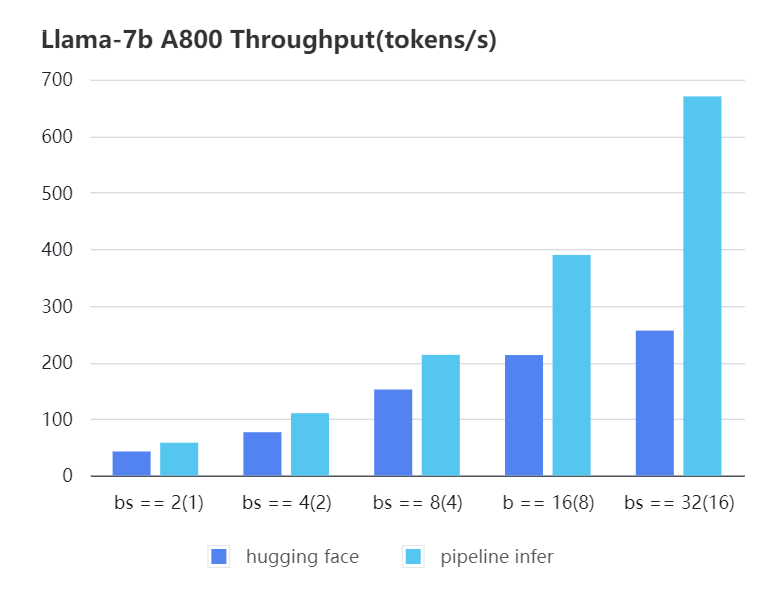
+#### A800 7b, fp16
+
+| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
+| :---: | :---: | :---: | :---: | :---: | :---: |
+| Pipeline Inference| 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
+| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
+
+
+
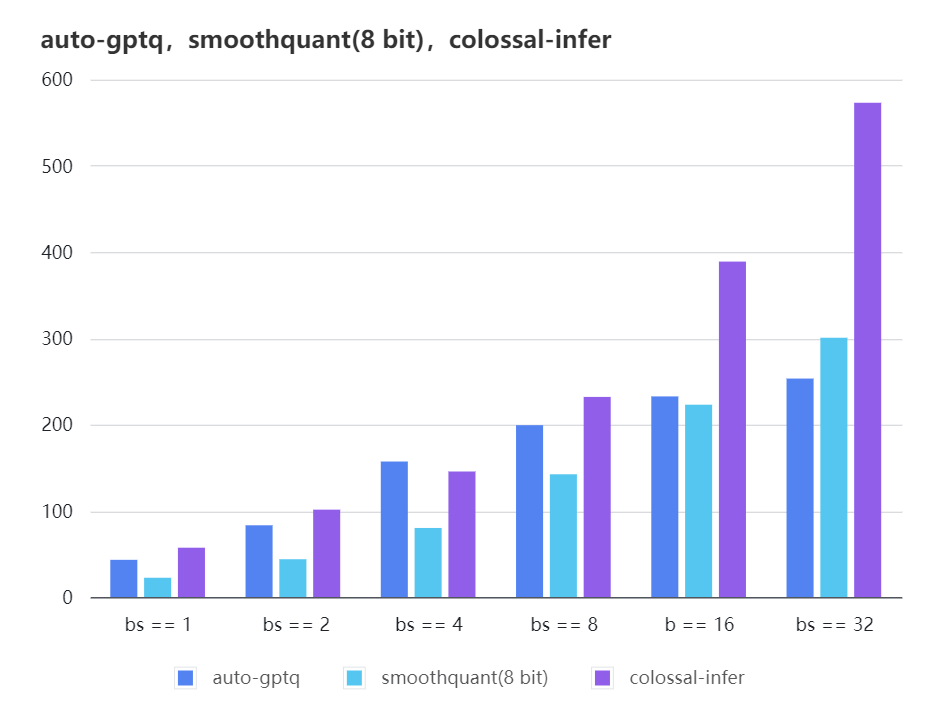
+### Quantization LLama
+
+| batch_size | 8 | 16 | 32 |
+| :---------------------: | :----: | :----: | :----: |
+| auto-gptq | 199.20 | 232.56 | 253.26 |
+| smooth-quant | 142.28 | 222.96 | 300.59 |
+| colossal-gptq | 231.98 | 388.87 | 573.03 |
+
+
+
+
+
The results of more models are coming soon!
diff --git a/colossalai/inference/__init__.py b/colossalai/inference/__init__.py
index 35891307e754..a95205efaa78 100644
--- a/colossalai/inference/__init__.py
+++ b/colossalai/inference/__init__.py
@@ -1,3 +1,4 @@
-from .pipeline import PPInferEngine
+from .engine import InferenceEngine
+from .engine.policies import BloomModelInferPolicy, ChatGLM2InferPolicy, LlamaModelInferPolicy
-__all__ = ["PPInferEngine"]
+__all__ = ["InferenceEngine", "LlamaModelInferPolicy", "BloomModelInferPolicy", "ChatGLM2InferPolicy"]
diff --git a/colossalai/inference/engine/__init__.py b/colossalai/inference/engine/__init__.py
new file mode 100644
index 000000000000..6e60da695a22
--- /dev/null
+++ b/colossalai/inference/engine/__init__.py
@@ -0,0 +1,3 @@
+from .engine import InferenceEngine
+
+__all__ = ["InferenceEngine"]
diff --git a/colossalai/inference/engine/engine.py b/colossalai/inference/engine/engine.py
new file mode 100644
index 000000000000..61da5858aa86
--- /dev/null
+++ b/colossalai/inference/engine/engine.py
@@ -0,0 +1,195 @@
+from typing import Union
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from transformers.utils import logging
+
+from colossalai.cluster import ProcessGroupMesh
+from colossalai.pipeline.schedule.generate import GenerateSchedule
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer import ShardConfig, ShardFormer
+from colossalai.shardformer.policies.base_policy import Policy
+
+from ..kv_cache import MemoryManager
+from .microbatch_manager import MicroBatchManager
+from .policies import model_policy_map
+
+PP_AXIS, TP_AXIS = 0, 1
+
+_supported_models = [
+ "LlamaForCausalLM",
+ "BloomForCausalLM",
+ "LlamaGPTQForCausalLM",
+ "SmoothLlamaForCausalLM",
+ "ChatGLMForConditionalGeneration",
+]
+
+
+class InferenceEngine:
+ """
+ InferenceEngine is a class that handles the pipeline parallel inference.
+
+ Args:
+ tp_size (int): the size of tensor parallelism.
+ pp_size (int): the size of pipeline parallelism.
+ dtype (str): the data type of the model, should be one of 'fp16', 'fp32', 'bf16'.
+ model (`nn.Module`): the model not in pipeline style, and will be modified with `ShardFormer`.
+ model_policy (`colossalai.shardformer.policies.base_policy.Policy`): the policy to shardformer model. It will be determined by the model type if not provided.
+ micro_batch_size (int): the micro batch size. Only useful when `pp_size` > 1.
+ micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
+ max_batch_size (int): the maximum batch size.
+ max_input_len (int): the maximum input length.
+ max_output_len (int): the maximum output length.
+ quant (str): the quantization method, should be one of 'smoothquant', 'gptq', None.
+ verbose (bool): whether to return the time cost of each step.
+
+ """
+
+ def __init__(
+ self,
+ tp_size: int = 1,
+ pp_size: int = 1,
+ dtype: str = "fp16",
+ model: nn.Module = None,
+ model_policy: Policy = None,
+ micro_batch_size: int = 1,
+ micro_batch_buffer_size: int = None,
+ max_batch_size: int = 4,
+ max_input_len: int = 32,
+ max_output_len: int = 32,
+ quant: str = None,
+ verbose: bool = False,
+ # TODO: implement early_stopping, and various gerneration options
+ early_stopping: bool = False,
+ do_sample: bool = False,
+ num_beams: int = 1,
+ ) -> None:
+ if quant == "gptq":
+ from ..quant.gptq import GPTQManager
+
+ self.gptq_manager = GPTQManager(model.quantize_config, max_input_len=max_input_len)
+ model = model.model
+ elif quant == "smoothquant":
+ model = model.model
+
+ assert model.__class__.__name__ in _supported_models, f"Model {model.__class__.__name__} is not supported."
+ assert (
+ tp_size * pp_size == dist.get_world_size()
+ ), f"TP size({tp_size}) * PP size({pp_size}) should be equal to the global world size ({dist.get_world_size()})"
+ assert model, "Model should be provided."
+ assert dtype in ["fp16", "fp32", "bf16"], "dtype should be one of 'fp16', 'fp32', 'bf16'"
+
+ assert max_batch_size <= 64, "Max batch size exceeds the constraint"
+ assert max_input_len + max_output_len <= 4096, "Max length exceeds the constraint"
+ assert quant in ["smoothquant", "gptq", None], "quant should be one of 'smoothquant', 'gptq'"
+ self.pp_size = pp_size
+ self.tp_size = tp_size
+ self.quant = quant
+
+ logger = logging.get_logger(__name__)
+ if quant == "smoothquant" and dtype != "fp32":
+ dtype = "fp32"
+ logger.warning_once("Warning: smoothquant only support fp32 and int8 mix precision. set dtype to fp32")
+
+ if dtype == "fp16":
+ self.dtype = torch.float16
+ model.half()
+ elif dtype == "bf16":
+ self.dtype = torch.bfloat16
+ model.to(torch.bfloat16)
+ else:
+ self.dtype = torch.float32
+
+ if model_policy is None:
+ model_policy = model_policy_map[model.config.model_type]()
+
+ # Init pg mesh
+ pg_mesh = ProcessGroupMesh(pp_size, tp_size)
+
+ stage_manager = PipelineStageManager(pg_mesh, PP_AXIS, True if pp_size * tp_size > 1 else False)
+ self.cache_manager_list = [
+ self._init_manager(model, max_batch_size, max_input_len, max_output_len)
+ for _ in range(micro_batch_buffer_size or pp_size)
+ ]
+ self.mb_manager = MicroBatchManager(
+ stage_manager.stage,
+ micro_batch_size,
+ micro_batch_buffer_size or pp_size,
+ max_input_len,
+ max_output_len,
+ self.cache_manager_list,
+ )
+ self.verbose = verbose
+ self.schedule = GenerateSchedule(stage_manager, self.mb_manager, verbose)
+
+ self.model = self._shardformer(
+ model, model_policy, stage_manager, pg_mesh.get_group_along_axis(TP_AXIS) if pp_size * tp_size > 1 else None
+ )
+ if quant == "gptq":
+ self.gptq_manager.post_init_gptq_buffer(self.model)
+
+ def generate(self, input_list: Union[list, dict]):
+ """
+ Args:
+ input_list (list): a list of input data, each element is a `BatchEncoding` or `dict`.
+
+ Returns:
+ out (list): a list of output data, each element is a list of token.
+ timestamp (float): the time cost of the inference, only return when verbose is `True`.
+ """
+
+ out, timestamp = self.schedule.generate_step(self.model, iter([input_list]))
+ if self.verbose:
+ return out, timestamp
+ else:
+ return out
+
+ def _shardformer(self, model, model_policy, stage_manager, tp_group):
+ shardconfig = ShardConfig(
+ tensor_parallel_process_group=tp_group,
+ pipeline_stage_manager=stage_manager,
+ enable_tensor_parallelism=(self.tp_size > 1),
+ enable_fused_normalization=False,
+ enable_all_optimization=False,
+ enable_flash_attention=False,
+ enable_jit_fused=False,
+ enable_sequence_parallelism=False,
+ extra_kwargs={"quant": self.quant},
+ )
+ shardformer = ShardFormer(shard_config=shardconfig)
+ shard_model, _ = shardformer.optimize(model, model_policy)
+ return shard_model.cuda()
+
+ def _init_manager(self, model, max_batch_size: int, max_input_len: int, max_output_len: int) -> None:
+ max_total_token_num = max_batch_size * (max_input_len + max_output_len)
+ if model.config.model_type == "llama":
+ head_dim = model.config.hidden_size // model.config.num_attention_heads
+ head_num = model.config.num_key_value_heads // self.tp_size
+ num_hidden_layers = (
+ model.config.num_hidden_layers
+ if hasattr(model.config, "num_hidden_layers")
+ else model.config.num_layers
+ )
+ layer_num = num_hidden_layers // self.pp_size
+ elif model.config.model_type == "bloom":
+ head_dim = model.config.hidden_size // model.config.n_head
+ head_num = model.config.n_head // self.tp_size
+ num_hidden_layers = model.config.n_layer
+ layer_num = num_hidden_layers // self.pp_size
+ elif model.config.model_type == "chatglm":
+ head_dim = model.config.hidden_size // model.config.num_attention_heads
+ if model.config.multi_query_attention:
+ head_num = model.config.multi_query_group_num // self.tp_size
+ else:
+ head_num = model.config.num_attention_heads // self.tp_size
+ num_hidden_layers = model.config.num_layers
+ layer_num = num_hidden_layers // self.pp_size
+ else:
+ raise NotImplementedError("Only support llama, bloom and chatglm model.")
+
+ if self.quant == "smoothquant":
+ cache_manager = MemoryManager(max_total_token_num, torch.int8, head_num, head_dim, layer_num)
+ else:
+ cache_manager = MemoryManager(max_total_token_num, self.dtype, head_num, head_dim, layer_num)
+ return cache_manager
diff --git a/colossalai/inference/pipeline/microbatch_manager.py b/colossalai/inference/engine/microbatch_manager.py
similarity index 72%
rename from colossalai/inference/pipeline/microbatch_manager.py
rename to colossalai/inference/engine/microbatch_manager.py
index 49d1bf3f42cb..d698c89f9936 100644
--- a/colossalai/inference/pipeline/microbatch_manager.py
+++ b/colossalai/inference/engine/microbatch_manager.py
@@ -1,8 +1,10 @@
from enum import Enum
-from typing import Dict, Tuple
+from typing import Dict
import torch
+from ..kv_cache import BatchInferState, MemoryManager
+
__all__ = "MicroBatchManager"
@@ -27,21 +29,19 @@ class MicroBatchDescription:
def __init__(
self,
inputs_dict: Dict[str, torch.Tensor],
- output_dict: Dict[str, torch.Tensor],
- new_length: int,
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
) -> None:
- assert output_dict.get("hidden_states") is not None
- self.mb_length = output_dict["hidden_states"].shape[-2]
- self.target_length = self.mb_length + new_length
- self.kv_cache = ()
-
- def update(self, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
- if output_dict is not None:
- self._update_kvcache(output_dict["past_key_values"])
+ self.mb_length = inputs_dict["input_ids"].shape[-1]
+ self.target_length = self.mb_length + max_output_len
+ self.infer_state = BatchInferState.init_from_batch(
+ batch=inputs_dict, max_input_len=max_input_len, max_output_len=max_output_len, cache_manager=cache_manager
+ )
+ # print(f"[init] {inputs_dict}, {max_input_len}, {max_output_len}, {cache_manager}, {self.infer_state}")
- def _update_kvcache(self, kv_cache: Tuple):
- assert type(kv_cache) == tuple
- self.kv_cache = kv_cache
+ def update(self, *args, **kwargs):
+ pass
@property
def state(self):
@@ -75,22 +75,24 @@ class HeadMicroBatchDescription(MicroBatchDescription):
Args:
inputs_dict (Dict[str, torch.Tensor]): the inputs of current stage. The key should have `input_ids` and `attention_mask`.
output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
- new_length (int): the new length of the input sequence.
"""
def __init__(
- self, inputs_dict: Dict[str, torch.Tensor], output_dict: Dict[str, torch.Tensor], new_length: int
+ self,
+ inputs_dict: Dict[str, torch.Tensor],
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
) -> None:
- super().__init__(inputs_dict, output_dict, new_length)
+ super().__init__(inputs_dict, max_input_len, max_output_len, cache_manager)
assert inputs_dict is not None
assert inputs_dict.get("input_ids") is not None and inputs_dict.get("attention_mask") is not None
self.input_ids = inputs_dict["input_ids"]
self.attn_mask = inputs_dict["attention_mask"]
self.new_tokens = None
- def update(self, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
- super().update(output_dict, new_token)
+ def update(self, new_token: torch.Tensor = None):
if new_token is not None:
self._update_newtokens(new_token)
if self.state is not Status.DONE and new_token is not None:
@@ -125,16 +127,16 @@ class BodyMicroBatchDescription(MicroBatchDescription):
Args:
inputs_dict (Dict[str, torch.Tensor]): will always be `None`. Other stages only receive hiddenstates from previous stage.
- output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
"""
def __init__(
- self, inputs_dict: Dict[str, torch.Tensor], output_dict: Dict[str, torch.Tensor], new_length: int
+ self,
+ inputs_dict: Dict[str, torch.Tensor],
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
) -> None:
- super().__init__(inputs_dict, output_dict, new_length)
-
- def update(self, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
- super().update(output_dict, new_token)
+ super().__init__(inputs_dict, max_input_len, max_output_len, cache_manager)
@property
def cur_length(self):
@@ -142,10 +144,7 @@ def cur_length(self):
When there is no kv_cache, the length is mb_length, otherwise the sequence length is `kv_cache[0][0].shape[-2]` plus 1
"""
- if len(self.kv_cache) == 0:
- return self.mb_length
- else:
- return self.kv_cache[0][0].shape[-2] + 1
+ return self.infer_state.seq_len.max().item()
class MicroBatchManager:
@@ -154,22 +153,41 @@ class MicroBatchManager:
Args:
stage (int): stage id of current stage.
- new_length (int): the new length of the input sequence.
micro_batch_size (int): the micro batch size.
micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
"""
- def __init__(self, stage: int, new_length: int, micro_batch_size: int, micro_batch_buffer_size: int):
+ def __init__(
+ self,
+ stage: int,
+ micro_batch_size: int,
+ micro_batch_buffer_size: int,
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager_list: MemoryManager,
+ ):
self.stage = stage
- self.new_length = new_length
self.micro_batch_size = micro_batch_size
self.buffer_size = micro_batch_buffer_size
+ self.max_input_len = max_input_len
+ self.max_output_len = max_output_len
+ self.cache_manager_list = cache_manager_list
self.mb_descrption_buffer = {}
self.new_tokens_buffer = {}
self.idx = 0
- def step(self, inputs_dict=None, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
+ def add_descrption(self, inputs_dict: Dict[str, torch.Tensor]):
+ if self.stage == 0:
+ self.mb_descrption_buffer[self.idx] = HeadMicroBatchDescription(
+ inputs_dict, self.max_input_len, self.max_output_len, self.cache_manager_list[self.idx]
+ )
+ else:
+ self.mb_descrption_buffer[self.idx] = BodyMicroBatchDescription(
+ inputs_dict, self.max_input_len, self.max_output_len, self.cache_manager_list[self.idx]
+ )
+
+ def step(self, new_token: torch.Tensor = None):
"""
Update the state if microbatch manager, 2 conditions.
1. For first stage in PREFILL, receive inputs and outputs, `_add_descrption` will save its inputs.
@@ -181,11 +199,7 @@ def step(self, inputs_dict=None, output_dict: Dict[str, torch.Tensor] = None, ne
new_token (torch.Tensor): the new token generated by current stage.
"""
# Add descrption first if the descrption is None
- if inputs_dict is None and output_dict is None and new_token is None:
- return Status.PREFILL
- if self.mb_descrption_buffer.get(self.idx) is None:
- self._add_descrption(inputs_dict, output_dict)
- self.cur_descrption.update(output_dict, new_token)
+ self.cur_descrption.update(new_token)
return self.cur_state
def export_new_tokens(self):
@@ -204,16 +218,12 @@ def is_micro_batch_done(self):
def clear(self):
self.mb_descrption_buffer.clear()
+ for cache in self.cache_manager_list:
+ cache.free_all()
def next(self):
self.idx = (self.idx + 1) % self.buffer_size
- def _add_descrption(self, inputs_dict: Dict[str, torch.Tensor], output_dict: Dict[str, torch.Tensor]):
- if self.stage == 0:
- self.mb_descrption_buffer[self.idx] = HeadMicroBatchDescription(inputs_dict, output_dict, self.new_length)
- else:
- self.mb_descrption_buffer[self.idx] = BodyMicroBatchDescription(inputs_dict, output_dict, self.new_length)
-
def _remove_descrption(self):
self.mb_descrption_buffer.pop(self.idx)
@@ -222,10 +232,10 @@ def cur_descrption(self) -> MicroBatchDescription:
return self.mb_descrption_buffer.get(self.idx)
@property
- def cur_kv_cache(self):
+ def cur_infer_state(self):
if self.cur_descrption is None:
return None
- return self.cur_descrption.kv_cache
+ return self.cur_descrption.infer_state
@property
def cur_state(self):
diff --git a/colossalai/inference/engine/modeling/__init__.py b/colossalai/inference/engine/modeling/__init__.py
new file mode 100644
index 000000000000..8a9e9999d3c5
--- /dev/null
+++ b/colossalai/inference/engine/modeling/__init__.py
@@ -0,0 +1,5 @@
+from .bloom import BloomInferenceForwards
+from .chatglm2 import ChatGLM2InferenceForwards
+from .llama import LlamaInferenceForwards
+
+__all__ = ["LlamaInferenceForwards", "BloomInferenceForwards", "ChatGLM2InferenceForwards"]
diff --git a/colossalai/inference/tensor_parallel/modeling/_utils.py b/colossalai/inference/engine/modeling/_utils.py
similarity index 100%
rename from colossalai/inference/tensor_parallel/modeling/_utils.py
rename to colossalai/inference/engine/modeling/_utils.py
diff --git a/colossalai/inference/engine/modeling/bloom.py b/colossalai/inference/engine/modeling/bloom.py
new file mode 100644
index 000000000000..4c098d3e4c80
--- /dev/null
+++ b/colossalai/inference/engine/modeling/bloom.py
@@ -0,0 +1,452 @@
+import math
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.distributed as dist
+from torch.nn import functional as F
+from transformers.models.bloom.modeling_bloom import (
+ BaseModelOutputWithPastAndCrossAttentions,
+ BloomAttention,
+ BloomBlock,
+ BloomForCausalLM,
+ BloomModel,
+)
+from transformers.utils import logging
+
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
+from colossalai.kernel.triton import bloom_context_attn_fwd, copy_kv_cache_to_dest, token_attention_fwd
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+try:
+ from lightllm.models.bloom.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_bloom_context_attention_fwd,
+ )
+
+ HAS_LIGHTLLM_KERNEL = True
+except:
+ HAS_LIGHTLLM_KERNEL = False
+
+
+def generate_alibi(n_head, dtype=torch.float16):
+ """
+ This method is adapted from `_generate_alibi` function
+ in `lightllm/models/bloom/layer_weights/transformer_layer_weight.py`
+ of the ModelTC/lightllm GitHub repository.
+ This method is originally the `build_alibi_tensor` function
+ in `transformers/models/bloom/modeling_bloom.py`
+ of the huggingface/transformers GitHub repository.
+ """
+
+ def get_slopes_power_of_2(n):
+ start = 2 ** (-(2 ** -(math.log2(n) - 3)))
+ return [start * start**i for i in range(n)]
+
+ def get_slopes(n):
+ if math.log2(n).is_integer():
+ return get_slopes_power_of_2(n)
+ else:
+ closest_power_of_2 = 2 ** math.floor(math.log2(n))
+ slopes_power_of_2 = get_slopes_power_of_2(closest_power_of_2)
+ slopes_double = get_slopes(2 * closest_power_of_2)
+ slopes_combined = slopes_power_of_2 + slopes_double[0::2][: n - closest_power_of_2]
+ return slopes_combined
+
+ slopes = get_slopes(n_head)
+ return torch.tensor(slopes, dtype=dtype)
+
+
+class BloomInferenceForwards:
+ """
+ This class serves a micro library for bloom inference forwards.
+ We intend to replace the forward methods for BloomForCausalLM, BloomModel, BloomBlock, and BloomAttention,
+ as well as prepare_inputs_for_generation method for BloomForCausalLM.
+ For future improvement, we might want to skip replacing methods for BloomForCausalLM,
+ and call BloomModel.forward iteratively in TpInferEngine
+ """
+
+ @staticmethod
+ def bloom_for_causal_lm_forward(
+ self: BloomForCausalLM,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = False,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = False,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ tp_group: Optional[dist.ProcessGroup] = None,
+ **deprecated_arguments,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
+ `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
+ are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
+ """
+ logger = logging.get_logger(__name__)
+
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+
+ # If is first stage and hidden_states is not None, go throught lm_head first
+ if stage_manager.is_first_stage() and hidden_states is not None:
+ lm_logits = self.lm_head(hidden_states)
+ return {"logits": lm_logits}
+
+ outputs = BloomInferenceForwards.bloom_model_forward(
+ self.transformer,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ tp_group=tp_group,
+ )
+
+ return outputs
+
+ @staticmethod
+ def bloom_model_forward(
+ self: BloomModel,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ tp_group: Optional[dist.ProcessGroup] = None,
+ **deprecated_arguments,
+ ) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
+ logger = logging.get_logger(__name__)
+
+ # add warnings here
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once("use_cache=True is not supported for pipeline models at the moment.")
+ use_cache = False
+
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+ if len(deprecated_arguments) > 0:
+ raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape batch_size x num_heads x N x N
+ # head_mask has shape n_layer x batch x num_heads x N x N
+ head_mask = self.get_head_mask(head_mask, self.config.n_layer)
+
+ # first stage
+ if stage_manager.is_first_stage():
+ # check inputs and inputs embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+
+ hidden_states = self.word_embeddings_layernorm(inputs_embeds)
+ # other stage
+ else:
+ input_shape = hidden_states.shape[:-1]
+ batch_size, seq_length = input_shape
+
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
+
+ if seq_length != 1:
+ # prefill stage
+ infer_state.is_context_stage = True # set prefill stage, notify attention layer
+ infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
+ BatchInferState.init_block_loc(
+ infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
+ )
+ else:
+ infer_state.is_context_stage = False
+ alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
+ if alloc_mem is not None:
+ infer_state.decode_is_contiguous = True
+ infer_state.decode_mem_index = alloc_mem[0]
+ infer_state.decode_mem_start = alloc_mem[1]
+ infer_state.decode_mem_end = alloc_mem[2]
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+ else:
+ print(f" *** Encountered allocation non-contiguous")
+ print(f" infer_state.max_len_in_batch : {infer_state.max_len_in_batch}")
+ infer_state.decode_is_contiguous = False
+ alloc_mem = infer_state.cache_manager.alloc(batch_size)
+ infer_state.decode_mem_index = alloc_mem
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, infer_state.max_len_in_batch), device=hidden_states.device)
+ else:
+ attention_mask = attention_mask.to(hidden_states.device)
+
+ # NOTE revise: we might want to store a single 1D alibi(length is #heads) in model,
+ # or store to BatchInferState to prevent re-calculating
+ # When we have multiple process group (e.g. dp together with tp), we need to pass the pg to here
+ tp_size = dist.get_world_size(tp_group) if tp_group is not None else 1
+ curr_tp_rank = dist.get_rank(tp_group) if tp_group is not None else 0
+ alibi = (
+ generate_alibi(self.num_heads * tp_size)
+ .contiguous()[curr_tp_rank * self.num_heads : (curr_tp_rank + 1) * self.num_heads]
+ .cuda()
+ )
+ causal_mask = self._prepare_attn_mask(
+ attention_mask,
+ input_shape=(batch_size, seq_length),
+ past_key_values_length=past_key_values_length,
+ )
+
+ infer_state.decode_layer_id = 0
+
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ if past_key_values is None:
+ past_key_values = tuple([None] * (end_idx - start_idx + 1))
+
+ for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
+ block = self.h[idx]
+ outputs = block(
+ hidden_states,
+ layer_past=past_key_value,
+ attention_mask=causal_mask,
+ head_mask=head_mask[idx],
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ alibi=alibi,
+ infer_state=infer_state,
+ )
+
+ infer_state.decode_layer_id += 1
+ hidden_states = outputs[0]
+
+ if stage_manager.is_last_stage() or stage_manager.num_stages == 1:
+ hidden_states = self.ln_f(hidden_states)
+
+ # update indices
+ infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
+
+ # always return dict for imediate stage
+ return {"hidden_states": hidden_states}
+
+ @staticmethod
+ def bloom_block_forward(
+ self: BloomBlock,
+ hidden_states: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ # hidden_states: [batch_size, seq_length, hidden_size]
+
+ # Layer norm at the beginning of the transformer layer.
+ layernorm_output = self.input_layernorm(hidden_states)
+
+ # Layer norm post the self attention.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = hidden_states
+
+ # Self attention.
+ attn_outputs = self.self_attention(
+ layernorm_output,
+ residual,
+ layer_past=layer_past,
+ attention_mask=attention_mask,
+ alibi=alibi,
+ head_mask=head_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ infer_state=infer_state,
+ )
+
+ attention_output = attn_outputs[0]
+
+ outputs = attn_outputs[1:]
+
+ layernorm_output = self.post_attention_layernorm(attention_output)
+
+ # Get residual
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = attention_output
+
+ # MLP.
+ output = self.mlp(layernorm_output, residual)
+
+ if use_cache:
+ outputs = (output,) + outputs
+ else:
+ outputs = (output,) + outputs[1:]
+
+ return outputs # hidden_states, present, attentions
+
+ @staticmethod
+ def bloom_attention_forward(
+ self: BloomAttention,
+ hidden_states: torch.Tensor,
+ residual: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
+
+ # 3 x [batch_size, seq_length, num_heads, head_dim]
+ (query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
+ batch_size, q_length, H, D_HEAD = query_layer.shape
+ k = key_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
+ v = value_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
+
+ mem_manager = infer_state.cache_manager
+ layer_id = infer_state.decode_layer_id
+
+ if infer_state.is_context_stage:
+ # context process
+ max_input_len = q_length
+ b_start_loc = infer_state.start_loc
+ b_seq_len = infer_state.seq_len[:batch_size]
+ q = query_layer.reshape(-1, H, D_HEAD)
+
+ copy_kv_cache_to_dest(k, infer_state.context_mem_index, mem_manager.key_buffer[layer_id])
+ copy_kv_cache_to_dest(v, infer_state.context_mem_index, mem_manager.value_buffer[layer_id])
+
+ # output = self.output[:batch_size*q_length, :, :]
+ output = torch.empty_like(q)
+
+ if HAS_LIGHTLLM_KERNEL:
+ lightllm_bloom_context_attention_fwd(q, k, v, output, alibi, b_start_loc, b_seq_len, max_input_len)
+ else:
+ bloom_context_attn_fwd(q, k, v, output, b_start_loc, b_seq_len, max_input_len, alibi)
+
+ context_layer = output.view(batch_size, q_length, H * D_HEAD)
+ else:
+ # query_layer = query_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
+ # need shape: batch_size, H, D_HEAD (q_length == 1), input q shape : (batch_size, q_length(1), H, D_HEAD)
+ assert q_length == 1, "for non-context process, we only support q_length == 1"
+ q = query_layer.reshape(-1, H, D_HEAD)
+
+ if infer_state.decode_is_contiguous:
+ # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
+ cache_k = infer_state.cache_manager.key_buffer[layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_k.copy_(k)
+ cache_v.copy_(v)
+ else:
+ # if decode is not contiguous, use triton kernel to copy key and value cache
+ # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head]
+ copy_kv_cache_to_dest(k, infer_state.decode_mem_index, mem_manager.key_buffer[layer_id])
+ copy_kv_cache_to_dest(v, infer_state.decode_mem_index, mem_manager.value_buffer[layer_id])
+
+ b_start_loc = infer_state.start_loc
+ b_loc = infer_state.block_loc
+ b_seq_len = infer_state.seq_len
+ output = torch.empty_like(q)
+ token_attention_fwd(
+ q,
+ mem_manager.key_buffer[layer_id],
+ mem_manager.value_buffer[layer_id],
+ output,
+ b_loc,
+ b_start_loc,
+ b_seq_len,
+ infer_state.max_len_in_batch,
+ alibi,
+ )
+
+ context_layer = output.view(batch_size, q_length, H * D_HEAD)
+
+ # NOTE: always set present as none for now, instead of returning past key value to the next decoding,
+ # we create the past key value pair from the cache manager
+ present = None
+
+ # aggregate results across tp ranks. See here: https://github.com/pytorch/pytorch/issues/76232
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ slices = self.hidden_size / self.pretraining_tp
+ output_tensor = torch.zeros_like(context_layer)
+ for i in range(self.pretraining_tp):
+ output_tensor = output_tensor + F.linear(
+ context_layer[:, :, int(i * slices) : int((i + 1) * slices)],
+ self.dense.weight[:, int(i * slices) : int((i + 1) * slices)],
+ )
+ else:
+ output_tensor = self.dense(context_layer)
+
+ # dropout is not required here during inference
+ output_tensor = residual + output_tensor
+
+ outputs = (output_tensor, present)
+ assert output_attentions is False, "we do not support output_attentions at this time"
+
+ return outputs
diff --git a/colossalai/inference/engine/modeling/chatglm2.py b/colossalai/inference/engine/modeling/chatglm2.py
new file mode 100644
index 000000000000..56e777bb2b87
--- /dev/null
+++ b/colossalai/inference/engine/modeling/chatglm2.py
@@ -0,0 +1,492 @@
+from typing import List, Optional, Tuple
+
+import torch
+from transformers.utils import logging
+
+from colossalai.inference.kv_cache import BatchInferState
+from colossalai.kernel.triton.token_attention_kernel import Llama2TokenAttentionForwards
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer import ShardConfig
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
+ ChatGLMForConditionalGeneration,
+ ChatGLMModel,
+ GLMBlock,
+ GLMTransformer,
+ SelfAttention,
+ split_tensor_along_last_dim,
+)
+
+from ._utils import copy_kv_to_mem_cache
+
+try:
+ from lightllm.models.chatglm2.triton_kernel.rotary_emb import rotary_emb_fwd as chatglm2_rotary_emb_fwd
+ from lightllm.models.llama2.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_llama2_context_attention_fwd,
+ )
+
+ HAS_LIGHTLLM_KERNEL = True
+except:
+ print("please install lightllm from source to run inference: https://github.com/ModelTC/lightllm")
+ HAS_LIGHTLLM_KERNEL = False
+
+
+def get_masks(self, input_ids, past_length, padding_mask=None):
+ batch_size, seq_length = input_ids.shape
+ full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
+ full_attention_mask.tril_()
+ if past_length:
+ full_attention_mask = torch.cat(
+ (
+ torch.ones(batch_size, seq_length, past_length, device=input_ids.device),
+ full_attention_mask,
+ ),
+ dim=-1,
+ )
+
+ if padding_mask is not None:
+ full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
+ if not past_length and padding_mask is not None:
+ full_attention_mask -= padding_mask.unsqueeze(-1) - 1
+ full_attention_mask = (full_attention_mask < 0.5).bool()
+ full_attention_mask.unsqueeze_(1)
+ return full_attention_mask
+
+
+def get_position_ids(batch_size, seq_length, device):
+ position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
+ return position_ids
+
+
+class ChatGLM2InferenceForwards:
+ """
+ This class holds forwards for Chatglm2 inference.
+ We intend to replace the forward methods for ChatGLMModel, ChatGLMEecoderLayer, and ChatGLMAttention.
+ """
+
+ @staticmethod
+ def chatglm_for_conditional_generation_forward(
+ self: ChatGLMForConditionalGeneration,
+ input_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = True,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ return_last_logit: Optional[bool] = False,
+ infer_state: Optional[BatchInferState] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ shard_config: ShardConfig = None,
+ ):
+ logger = logging.get_logger(__name__)
+
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+
+ # If is first stage and hidden_states is not None, go throught lm_head first
+ if stage_manager.is_first_stage() and hidden_states is not None:
+ if return_last_logit:
+ hidden_states = hidden_states[-1:]
+ lm_logits = self.transformer.output_layer(hidden_states)
+ lm_logits = lm_logits.transpose(0, 1).contiguous()
+ return {"logits": lm_logits}
+
+ outputs = self.transformer(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ attention_mask=attention_mask,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ shard_config=shard_config,
+ )
+
+ return outputs
+
+ @staticmethod
+ def chatglm_model_forward(
+ self: ChatGLMModel,
+ input_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.BoolTensor] = None,
+ full_attention_mask: Optional[torch.BoolTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ shard_config: ShardConfig = None,
+ ):
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+
+ if stage_manager.is_first_stage():
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+ if inputs_embeds is None:
+ inputs_embeds = self.embedding(input_ids)
+ if position_ids is None:
+ position_ids = get_position_ids(batch_size, seq_length, input_ids.device)
+ hidden_states = inputs_embeds
+ else:
+ assert hidden_states is not None, "hidden_states should not be None in non-first stage"
+ seq_length, batch_size, _ = hidden_states.shape
+ if position_ids is None:
+ position_ids = get_position_ids(batch_size, seq_length, hidden_states.device)
+
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
+
+ seq_length_with_past = seq_length + past_key_values_length
+
+ # prefill stage at first
+ if seq_length != 1:
+ infer_state.is_context_stage = True
+ infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
+ infer_state.init_block_loc(
+ infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
+ )
+ else:
+ infer_state.is_context_stage = False
+ alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
+ if alloc_mem is not None:
+ infer_state.decode_is_contiguous = True
+ infer_state.decode_mem_index = alloc_mem[0]
+ infer_state.decode_mem_start = alloc_mem[1]
+ infer_state.decode_mem_end = alloc_mem[2]
+ infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
+ else:
+ print(f" *** Encountered allocation non-contiguous")
+ print(
+ f" infer_state.cache_manager.past_key_values_length: {infer_state.cache_manager.past_key_values_length}"
+ )
+ infer_state.decode_is_contiguous = False
+ alloc_mem = infer_state.cache_manager.alloc(batch_size)
+ infer_state.decode_mem_index = alloc_mem
+ infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
+
+ # related to rotary embedding
+ if infer_state.is_context_stage:
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+ else:
+ seq_len = infer_state.seq_len
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.other_kv_index = infer_state.block_loc[0, infer_state.max_len_in_batch - 1].item()
+
+ if self.pre_seq_len is not None:
+ if past_key_values is None:
+ past_key_values = self.get_prompt(
+ batch_size=batch_size,
+ device=input_ids.device,
+ dtype=inputs_embeds.dtype,
+ )
+ if attention_mask is not None:
+ attention_mask = torch.cat(
+ [
+ attention_mask.new_ones((batch_size, self.pre_seq_len)),
+ attention_mask,
+ ],
+ dim=-1,
+ )
+ if full_attention_mask is None:
+ if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
+ full_attention_mask = get_masks(
+ self, input_ids, infer_state.cache_manager.past_key_values_length, padding_mask=attention_mask
+ )
+
+ # Run encoder.
+ hidden_states = self.encoder(
+ hidden_states,
+ full_attention_mask,
+ kv_caches=past_key_values,
+ use_cache=use_cache,
+ output_hidden_states=output_hidden_states,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ stage_index=stage_index,
+ shard_config=shard_config,
+ )
+
+ # update indices
+ infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
+
+ return {"hidden_states": hidden_states}
+
+ @staticmethod
+ def chatglm_encoder_forward(
+ self: GLMTransformer,
+ hidden_states,
+ attention_mask,
+ kv_caches=None,
+ use_cache: Optional[bool] = True,
+ output_hidden_states: Optional[bool] = False,
+ infer_state: Optional[BatchInferState] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ stage_index: Optional[List[int]] = None,
+ shard_config: ShardConfig = None,
+ ):
+ hidden_states = hidden_states.transpose(0, 1).contiguous()
+
+ infer_state.decode_layer_id = 0
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ if kv_caches is None:
+ kv_caches = tuple([None] * (end_idx - start_idx + 1))
+
+ for idx, kv_cache in zip(range(start_idx, end_idx), kv_caches):
+ layer = self.layers[idx]
+ layer_ret = layer(
+ hidden_states,
+ attention_mask,
+ kv_cache=kv_cache,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+ infer_state.decode_layer_id += 1
+
+ hidden_states, _ = layer_ret
+
+ hidden_states = hidden_states.transpose(0, 1).contiguous()
+
+ if self.post_layer_norm and (stage_manager.is_last_stage() or stage_manager.num_stages == 1):
+ # Final layer norm.
+ hidden_states = self.final_layernorm(hidden_states)
+
+ return hidden_states
+
+ @staticmethod
+ def chatglm_glmblock_forward(
+ self: GLMBlock,
+ hidden_states,
+ attention_mask,
+ kv_cache=None,
+ use_cache=True,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ # hidden_states: [s, b, h]
+
+ # Layer norm at the beginning of the transformer layer.
+ layernorm_output = self.input_layernorm(hidden_states)
+ # Self attention.
+ attention_output, kv_cache = self.self_attention(
+ layernorm_output,
+ attention_mask,
+ kv_cache=kv_cache,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+ # Residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = hidden_states
+ layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
+ layernorm_input = residual + layernorm_input
+ # Layer norm post the self attention.
+ layernorm_output = self.post_attention_layernorm(layernorm_input)
+ # MLP.
+ mlp_output = self.mlp(layernorm_output)
+
+ # Second residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = layernorm_input
+
+ output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
+ output = residual + output
+ return output, kv_cache
+
+ @staticmethod
+ def chatglm_flash_attn_kvcache_forward(
+ self: SelfAttention,
+ hidden_states,
+ attention_mask,
+ kv_cache=None,
+ use_cache=True,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ assert use_cache is True, "use_cache should be set to True using this chatglm attention"
+ # hidden_states: original :[sq, b, h] --> this [b, sq, h]
+ batch_size = hidden_states.shape[0]
+ hidden_size = hidden_states.shape[-1]
+ # Attention heads [sq, b, h] --> [sq, b, (np * 3 * hn)]
+ mixed_x_layer = self.query_key_value(hidden_states)
+ if self.multi_query_attention:
+ (query_layer, key_layer, value_layer) = mixed_x_layer.split(
+ [
+ self.num_attention_heads_per_partition * self.hidden_size_per_attention_head,
+ self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
+ self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
+ ],
+ dim=-1,
+ )
+ query_layer = query_layer.view(
+ query_layer.size()[:-1]
+ + (
+ self.num_attention_heads_per_partition,
+ self.hidden_size_per_attention_head,
+ )
+ )
+ key_layer = key_layer.view(
+ key_layer.size()[:-1]
+ + (
+ self.num_multi_query_groups_per_partition,
+ self.hidden_size_per_attention_head,
+ )
+ )
+ value_layer = value_layer.view(
+ value_layer.size()[:-1]
+ + (
+ self.num_multi_query_groups_per_partition,
+ self.hidden_size_per_attention_head,
+ )
+ )
+
+ else:
+ new_tensor_shape = mixed_x_layer.size()[:-1] + (
+ self.num_attention_heads_per_partition,
+ 3 * self.hidden_size_per_attention_head,
+ )
+ mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
+ # [sq, b, np, 3 * hn] --> 3 [sq, b, np, hn]
+ (query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
+ cos, sin = infer_state.position_cos, infer_state.position_sin
+
+ chatglm2_rotary_emb_fwd(
+ query_layer.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head), cos, sin
+ )
+ if self.multi_query_attention:
+ chatglm2_rotary_emb_fwd(
+ key_layer.view(-1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head),
+ cos,
+ sin,
+ )
+ else:
+ chatglm2_rotary_emb_fwd(
+ key_layer.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head),
+ cos,
+ sin,
+ )
+
+ # reshape q k v to [bsz*sql, num_heads, head_dim] 2*1 ,32/2 ,128
+ query_layer = query_layer.reshape(
+ -1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head
+ )
+ key_layer = key_layer.reshape(
+ -1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head
+ )
+ value_layer = value_layer.reshape(
+ -1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head
+ )
+
+ if infer_state.is_context_stage:
+ # first token generation:
+ # copy key and value calculated in current step to memory manager
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_layer,
+ value_layer,
+ infer_state.context_mem_index,
+ infer_state.cache_manager,
+ )
+ attn_output = torch.empty_like(query_layer.contiguous().view(-1, self.projection_size))
+
+ # NOTE: no bug in context attn fwd (del it )
+ lightllm_llama2_context_attention_fwd(
+ query_layer,
+ key_layer,
+ value_layer,
+ attn_output.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head),
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+
+ else:
+ if infer_state.decode_is_contiguous:
+ # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_k.copy_(key_layer)
+ cache_v.copy_(value_layer)
+ else:
+ # if decode is not contiguous, use triton kernel to copy key and value cache
+ # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_layer,
+ value_layer,
+ infer_state.decode_mem_index,
+ infer_state.cache_manager,
+ )
+
+ # second token and follows
+ attn_output = torch.empty_like(query_layer.contiguous().view(-1, self.projection_size))
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
+ : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
+ : infer_state.decode_mem_end, :, :
+ ]
+
+ # ==================================
+ # core attention computation is replaced by triton kernel
+ # ==================================
+ Llama2TokenAttentionForwards.token_attn(
+ query_layer,
+ cache_k,
+ cache_v,
+ attn_output,
+ infer_state.block_loc,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ infer_state.other_kv_index,
+ )
+
+ # =================
+ # Output:[b,sq, h]
+ # =================
+ output = self.dense(attn_output).reshape(batch_size, -1, hidden_size)
+
+ return output, kv_cache
diff --git a/colossalai/inference/engine/modeling/llama.py b/colossalai/inference/engine/modeling/llama.py
new file mode 100644
index 000000000000..b7bc94d0eae0
--- /dev/null
+++ b/colossalai/inference/engine/modeling/llama.py
@@ -0,0 +1,492 @@
+# This code is adapted from huggingface transformers: https://github.com/huggingface/transformers/blob/v4.34.1/src/transformers/models/llama/modeling_llama.py
+import math
+from typing import List, Optional, Tuple
+
+import torch
+from transformers.models.llama.modeling_llama import LlamaAttention, LlamaDecoderLayer, LlamaForCausalLM, LlamaModel
+from transformers.utils import logging
+
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
+from colossalai.kernel.triton import llama_context_attn_fwd, token_attention_fwd
+from colossalai.kernel.triton.token_attention_kernel import Llama2TokenAttentionForwards
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+from ._utils import copy_kv_to_mem_cache
+
+try:
+ from lightllm.models.llama2.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_llama2_context_attention_fwd,
+ )
+ from lightllm.models.llama.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_context_attention_fwd,
+ )
+ from lightllm.models.llama.triton_kernel.rotary_emb import rotary_emb_fwd as llama_rotary_embedding_fwd
+
+ HAS_LIGHTLLM_KERNEL = True
+except:
+ print("please install lightllm from source to run inference: https://github.com/ModelTC/lightllm")
+ HAS_LIGHTLLM_KERNEL = False
+
+try:
+ from colossalai.kernel.triton.flash_decoding import token_flash_decoding
+ HAS_TRITON_FLASH_DECODING_KERNEL = True
+except:
+ print("no triton flash decoding support, please install lightllm from https://github.com/ModelTC/lightllm/blob/ece7b43f8a6dfa74027adc77c2c176cff28c76c8")
+ HAS_TRITON_FLASH_DECODING_KERNEL = False
+
+try:
+ from flash_attn import flash_attn_with_kvcache
+ HAS_FLASH_KERNEL = True
+except:
+ HAS_FLASH_KERNEL = False
+ print("please install flash attentiom from https://github.com/Dao-AILab/flash-attention")
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
+ # The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
+ cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
+ sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
+ cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def llama_triton_context_attention(
+ query_states, key_states, value_states, attn_output, infer_state, num_key_value_groups=1
+):
+ if num_key_value_groups == 1:
+ if HAS_LIGHTLLM_KERNEL is False:
+ llama_context_attn_fwd(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+ else:
+ lightllm_context_attention_fwd(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+ else:
+ assert HAS_LIGHTLLM_KERNEL is True, "You have to install lightllm kernels to run llama2 model"
+ lightllm_llama2_context_attention_fwd(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+
+def llama_triton_token_attention(query_states, attn_output, infer_state, num_key_value_groups=1, q_head_num = -1, head_dim = -1):
+ if HAS_TRITON_FLASH_DECODING_KERNEL and q_head_num != -1 and head_dim != -1:
+ token_flash_decoding(q = query_states,
+ o_tensor = attn_output,
+ infer_state = infer_state,
+ q_head_num = q_head_num,
+ head_dim = head_dim,
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id])
+ return
+
+ if num_key_value_groups == 1:
+ token_attention_fwd(
+ query_states,
+ infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
+ infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
+ attn_output,
+ infer_state.block_loc,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+ else:
+ Llama2TokenAttentionForwards.token_attn(
+ query_states,
+ infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
+ infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
+ attn_output,
+ infer_state.block_loc,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ infer_state.other_kv_index,
+ )
+
+
+class LlamaInferenceForwards:
+ """
+ This class holds forwards for llama inference.
+ We intend to replace the forward methods for LlamaModel, LlamaDecoderLayer, and LlamaAttention for LlamaForCausalLM.
+ """
+
+ @staticmethod
+ def llama_causal_lm_forward(
+ self: LlamaForCausalLM,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ """
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+
+ # If is first stage and hidden_states is None, go throught lm_head first
+ if stage_manager.is_first_stage() and hidden_states is not None:
+ lm_logits = self.lm_head(hidden_states)
+ return {"logits": lm_logits}
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = LlamaInferenceForwards.llama_model_forward(
+ self.model,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ )
+
+ return outputs
+
+ @staticmethod
+ def llama_model_forward(
+ self: LlamaModel,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ # retrieve input_ids and inputs_embeds
+ if stage_manager is None or stage_manager.is_first_stage():
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+ hidden_states = inputs_embeds
+ else:
+ assert stage_manager is not None
+ assert hidden_states is not None, f"hidden_state should not be none in stage {stage_manager.stage}"
+ input_shape = hidden_states.shape[:-1]
+ batch_size, seq_length = input_shape
+ device = hidden_states.device
+
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
+
+ # NOTE: differentiate with prefill stage
+ # block_loc require different value-assigning method for two different stage
+ if use_cache and seq_length != 1:
+ # NOTE assume prefill stage
+ # allocate memory block
+ infer_state.is_context_stage = True # set prefill stage, notify attention layer
+ infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
+ infer_state.init_block_loc(
+ infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
+ )
+ else:
+ infer_state.is_context_stage = False
+ alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
+ if alloc_mem is not None:
+ infer_state.decode_is_contiguous = True
+ infer_state.decode_mem_index = alloc_mem[0]
+ infer_state.decode_mem_start = alloc_mem[1]
+ infer_state.decode_mem_end = alloc_mem[2]
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+ else:
+ infer_state.decode_is_contiguous = False
+ alloc_mem = infer_state.cache_manager.alloc(batch_size)
+ infer_state.decode_mem_index = alloc_mem
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+
+ if position_ids is None:
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.repeat(batch_size, 1)
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ if infer_state.is_context_stage:
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+
+ else:
+ seq_len = infer_state.seq_len
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.other_kv_index = infer_state.block_loc[0, infer_state.max_len_in_batch - 1].item()
+
+ # embed positions
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ (batch_size, infer_state.max_len_in_batch), dtype=torch.bool, device=hidden_states.device
+ )
+
+ attention_mask = self._prepare_decoder_attention_mask(
+ attention_mask, (batch_size, seq_length), hidden_states, past_key_values_length
+ )
+
+ # decoder layers
+ infer_state.decode_layer_id = 0
+
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ if past_key_values is None:
+ past_key_values = tuple([None] * (end_idx - start_idx + 1))
+
+ for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
+ decoder_layer = self.layers[idx]
+ # NOTE: modify here for passing args to decoder layer
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+ infer_state.decode_layer_id += 1
+ hidden_states = layer_outputs[0]
+
+ if stage_manager.is_last_stage() or stage_manager.num_stages == 1:
+ hidden_states = self.norm(hidden_states)
+
+ # update indices
+ # infer_state.block_loc[:, infer_state.max_len_in_batch-1] = infer_state.total_token_num + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.start_loc += torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
+
+ return {"hidden_states": hidden_states}
+
+ @staticmethod
+ def llama_decoder_layer_forward(
+ self: LlamaDecoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ infer_state: Optional[BatchInferState] = None,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+ @staticmethod
+ def llama_flash_attn_kvcache_forward(
+ self: LlamaAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ infer_state: Optional[BatchInferState] = None,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ assert use_cache is True, "use_cache should be set to True using this llama attention"
+
+ bsz, q_len, _ = hidden_states.size()
+
+ # NOTE might think about better way to handle transposed k and v
+ # key_states [bs, seq_len, num_heads, head_dim/embed_size_per_head]
+ # key_states_transposed [bs, num_heads, seq_len, head_dim/embed_size_per_head]
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim)
+
+ # NOTE might want to revise
+ # need some way to record the length of past key values cache
+ # since we won't return past_key_value_cache right now
+
+ cos, sin = infer_state.position_cos, infer_state.position_sin
+
+ llama_rotary_embedding_fwd(query_states.view(-1, self.num_heads, self.head_dim), cos, sin)
+ llama_rotary_embedding_fwd(key_states.view(-1, self.num_key_value_heads, self.head_dim), cos, sin)
+
+ query_states = query_states.reshape(-1, self.num_heads, self.head_dim)
+ key_states = key_states.reshape(-1, self.num_key_value_heads, self.head_dim)
+ value_states = value_states.reshape(-1, self.num_key_value_heads, self.head_dim)
+
+ if infer_state.is_context_stage:
+ # first token generation
+ # copy key and value calculated in current step to memory manager
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_states,
+ value_states,
+ infer_state.context_mem_index,
+ infer_state.cache_manager,
+ )
+ attn_output = torch.empty_like(query_states)
+
+ llama_triton_context_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state,
+ num_key_value_groups=self.num_key_value_groups,
+ )
+ else:
+ if infer_state.decode_is_contiguous:
+ # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_k.copy_(key_states)
+ cache_v.copy_(value_states)
+ else:
+ # if decode is not contiguous, use triton kernel to copy key and value cache
+ # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_states,
+ value_states,
+ infer_state.decode_mem_index,
+ infer_state.cache_manager,
+ )
+
+ if HAS_LIGHTLLM_KERNEL:
+
+ attn_output = torch.empty_like(query_states)
+ llama_triton_token_attention(query_states = query_states,
+ attn_output = attn_output,
+ infer_state = infer_state,
+ num_key_value_groups = self.num_key_value_groups,
+ q_head_num = q_len * self.num_heads,
+ head_dim = self.head_dim)
+ else:
+ self.num_heads // self.num_key_value_heads
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id]
+
+ query_states = query_states.view(bsz, -1, self.num_heads, self.head_dim)
+ copy_cache_k = cache_k.view(bsz, -1, self.num_key_value_heads, self.head_dim)
+ copy_cache_v = cache_v.view(bsz, -1, self.num_key_value_heads, self.head_dim)
+
+ attn_output = flash_attn_with_kvcache(
+ q=query_states,
+ k_cache=copy_cache_k,
+ v_cache=copy_cache_v,
+ softmax_scale=1 / math.sqrt(self.head_dim),
+ causal=True,
+ )
+
+ attn_output = attn_output.view(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ # return past_key_value as None
+ return attn_output, None, None
diff --git a/colossalai/inference/engine/policies/__init__.py b/colossalai/inference/engine/policies/__init__.py
new file mode 100644
index 000000000000..269d1c57b276
--- /dev/null
+++ b/colossalai/inference/engine/policies/__init__.py
@@ -0,0 +1,11 @@
+from .bloom import BloomModelInferPolicy
+from .chatglm2 import ChatGLM2InferPolicy
+from .llama import LlamaModelInferPolicy
+
+model_policy_map = {
+ "llama": LlamaModelInferPolicy,
+ "bloom": BloomModelInferPolicy,
+ "chatglm": ChatGLM2InferPolicy,
+}
+
+__all__ = ["LlamaModelInferPolicy", "BloomModelInferPolicy", "ChatGLM2InferPolicy", "model_polic_map"]
diff --git a/colossalai/inference/engine/policies/bloom.py b/colossalai/inference/engine/policies/bloom.py
new file mode 100644
index 000000000000..f35b50189e82
--- /dev/null
+++ b/colossalai/inference/engine/policies/bloom.py
@@ -0,0 +1,127 @@
+from functools import partial
+from typing import List
+
+import torch
+from torch.nn import LayerNorm, Module
+
+import colossalai.shardformer.layer as col_nn
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
+from colossalai.shardformer.policies.bloom import BloomForCausalLMPolicy
+
+from ..modeling.bloom import BloomInferenceForwards
+
+try:
+ from colossalai.kernel.triton import layer_norm
+
+ HAS_TRITON_NORM = True
+except:
+ print("Some of our kernels require triton. You might want to install triton from https://github.com/openai/triton")
+ HAS_TRITON_NORM = False
+
+
+def get_triton_layernorm_forward():
+ if HAS_TRITON_NORM:
+
+ def _triton_layernorm_forward(self: LayerNorm, hidden_states: torch.Tensor):
+ return layer_norm(hidden_states, self.weight.data, self.bias, self.eps)
+
+ return _triton_layernorm_forward
+ else:
+ return None
+
+
+class BloomModelInferPolicy(BloomForCausalLMPolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ from transformers.models.bloom.modeling_bloom import BloomAttention, BloomBlock, BloomForCausalLM, BloomModel
+
+ policy = super().module_policy()
+ if self.shard_config.extra_kwargs.get("quant", None) == "gptq":
+ from colossalai.inference.quant.gptq.cai_gptq import ColCaiQuantLinear, RowCaiQuantLinear
+
+ policy[BloomBlock] = ModulePolicyDescription(
+ attribute_replacement={
+ "self_attention.hidden_size": self.model.config.hidden_size
+ // self.shard_config.tensor_parallel_size,
+ "self_attention.split_size": self.model.config.hidden_size
+ // self.shard_config.tensor_parallel_size,
+ "self_attention.num_heads": self.model.config.n_head // self.shard_config.tensor_parallel_size,
+ },
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attention.query_key_value",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 3},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attention.dense", target_module=RowCaiQuantLinear, kwargs={"split_num": 1}
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attention.attention_dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.dense_h_to_4h", target_module=ColCaiQuantLinear, kwargs={"split_num": 1}
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.dense_4h_to_h", target_module=RowCaiQuantLinear, kwargs={"split_num": 1}
+ ),
+ ],
+ )
+ # NOTE set inference mode to shard config
+ self.shard_config._infer()
+
+ # set as default, in inference we also use pipeline style forward, just setting stage as 1
+ self.set_pipeline_forward(
+ model_cls=BloomForCausalLM,
+ new_forward=partial(
+ BloomInferenceForwards.bloom_for_causal_lm_forward,
+ tp_group=self.shard_config.tensor_parallel_process_group,
+ ),
+ policy=policy,
+ )
+
+ method_replacement = {"forward": BloomInferenceForwards.bloom_model_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomModel)
+
+ method_replacement = {"forward": BloomInferenceForwards.bloom_block_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomBlock)
+
+ method_replacement = {"forward": BloomInferenceForwards.bloom_attention_forward}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=BloomAttention
+ )
+
+ if HAS_TRITON_NORM:
+ infer_method = get_triton_layernorm_forward()
+ method_replacement = {"forward": partial(infer_method)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LayerNorm
+ )
+
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == "BloomModel":
+ module = self.model
+ else:
+ module = self.model.transformer
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(len(module.h), stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.word_embeddings)
+ held_layers.append(module.word_embeddings_layernorm)
+ held_layers.append(self.model.lm_head)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.h[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.ln_f)
+
+ return held_layers
diff --git a/colossalai/inference/engine/policies/chatglm2.py b/colossalai/inference/engine/policies/chatglm2.py
new file mode 100644
index 000000000000..3e1d94f4785c
--- /dev/null
+++ b/colossalai/inference/engine/policies/chatglm2.py
@@ -0,0 +1,89 @@
+from typing import List
+
+import torch.nn as nn
+
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
+ ChatGLMForConditionalGeneration,
+ ChatGLMModel,
+ GLMBlock,
+ GLMTransformer,
+ SelfAttention,
+)
+
+# import colossalai
+from colossalai.shardformer.policies.chatglm2 import ChatGLMModelPolicy
+
+from ..modeling._utils import init_to_get_rotary
+from ..modeling.chatglm2 import ChatGLM2InferenceForwards
+
+try:
+ HAS_TRITON_RMSNORM = True
+except:
+ print("you should install triton from https://github.com/openai/triton")
+ HAS_TRITON_RMSNORM = False
+
+
+class ChatGLM2InferPolicy(ChatGLMModelPolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ policy = super().module_policy()
+ self.shard_config._infer()
+
+ model_infer_forward = ChatGLM2InferenceForwards.chatglm_model_forward
+ method_replacement = {"forward": model_infer_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=ChatGLMModel)
+
+ encoder_infer_forward = ChatGLM2InferenceForwards.chatglm_encoder_forward
+ method_replacement = {"forward": encoder_infer_forward}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=GLMTransformer
+ )
+
+ encoder_layer_infer_forward = ChatGLM2InferenceForwards.chatglm_glmblock_forward
+ method_replacement = {"forward": encoder_layer_infer_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=GLMBlock)
+
+ attn_infer_forward = ChatGLM2InferenceForwards.chatglm_flash_attn_kvcache_forward
+ method_replacement = {"forward": attn_infer_forward}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=SelfAttention
+ )
+ if self.shard_config.enable_tensor_parallelism:
+ policy[GLMBlock].attribute_replacement["self_attention.num_multi_query_groups_per_partition"] = (
+ self.model.config.multi_query_group_num // self.shard_config.tensor_parallel_size
+ )
+ # for rmsnorm and others, we need to check the shape
+
+ self.set_pipeline_forward(
+ model_cls=ChatGLMForConditionalGeneration,
+ new_forward=ChatGLM2InferenceForwards.chatglm_for_conditional_generation_forward,
+ policy=policy,
+ )
+
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ module = self.model.transformer
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(module.num_layers, stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embedding)
+ held_layers.append(module.output_layer)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.encoder.layers[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ if module.encoder.post_layer_norm:
+ held_layers.append(module.encoder.final_layernorm)
+
+ # rotary_pos_emb is needed for all stages
+ held_layers.append(module.rotary_pos_emb)
+
+ return held_layers
+
+ def postprocess(self):
+ init_to_get_rotary(self.model.transformer)
+ return self.model
diff --git a/colossalai/inference/engine/policies/llama.py b/colossalai/inference/engine/policies/llama.py
new file mode 100644
index 000000000000..11517d7e8a13
--- /dev/null
+++ b/colossalai/inference/engine/policies/llama.py
@@ -0,0 +1,206 @@
+from functools import partial
+from typing import List
+
+import torch
+from torch.nn import Module
+from transformers.models.llama.modeling_llama import (
+ LlamaAttention,
+ LlamaDecoderLayer,
+ LlamaForCausalLM,
+ LlamaModel,
+ LlamaRMSNorm,
+)
+
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
+
+# import colossalai
+from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy
+
+from ..modeling._utils import init_to_get_rotary
+from ..modeling.llama import LlamaInferenceForwards
+
+try:
+ from colossalai.kernel.triton import rmsnorm_forward
+
+ HAS_TRITON_RMSNORM = True
+except:
+ print("you should install triton from https://github.com/openai/triton")
+ HAS_TRITON_RMSNORM = False
+
+
+def get_triton_rmsnorm_forward():
+ if HAS_TRITON_RMSNORM:
+
+ def _triton_rmsnorm_forward(self: LlamaRMSNorm, hidden_states: torch.Tensor):
+ return rmsnorm_forward(hidden_states, self.weight.data, self.variance_epsilon)
+
+ return _triton_rmsnorm_forward
+ else:
+ return None
+
+
+class LlamaModelInferPolicy(LlamaForCausalLMPolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ policy = super().module_policy()
+ decoder_attribute_replacement = {
+ "self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "self_attn.num_key_value_heads": self.model.config.num_key_value_heads
+ // self.shard_config.tensor_parallel_size,
+ }
+ if self.shard_config.extra_kwargs.get("quant", None) == "gptq":
+ from colossalai.inference.quant.gptq.cai_gptq import ColCaiQuantLinear, RowCaiQuantLinear
+
+ policy[LlamaDecoderLayer] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=RowCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.gate_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.up_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.down_proj",
+ target_module=RowCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ ],
+ )
+
+ elif self.shard_config.extra_kwargs.get("quant", None) == "smoothquant":
+ from colossalai.inference.quant.smoothquant.models.llama import LlamaSmoothquantDecoderLayer
+ from colossalai.inference.quant.smoothquant.models.parallel_linear import (
+ ColW8A8BFP32OFP32Linear,
+ RowW8A8B8O8Linear,
+ RowW8A8BFP32O32LinearSiLU,
+ RowW8A8BFP32OFP32Linear,
+ )
+
+ policy[LlamaSmoothquantDecoderLayer] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=RowW8A8B8O8Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=RowW8A8B8O8Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=RowW8A8B8O8Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=ColW8A8BFP32OFP32Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.gate_proj",
+ target_module=RowW8A8BFP32O32LinearSiLU,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.up_proj",
+ target_module=RowW8A8BFP32OFP32Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.down_proj",
+ target_module=ColW8A8BFP32OFP32Linear,
+ kwargs={"split_num": 1},
+ ),
+ ],
+ )
+ self.shard_config._infer()
+
+ infer_forward = LlamaInferenceForwards.llama_model_forward
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaModel)
+
+ infer_forward = LlamaInferenceForwards.llama_decoder_layer_forward
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LlamaDecoderLayer
+ )
+
+ infer_forward = LlamaInferenceForwards.llama_flash_attn_kvcache_forward
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LlamaAttention
+ )
+
+ # set as default, in inference we also use pipeline style forward, just setting stage as 1
+ self.set_pipeline_forward(
+ model_cls=LlamaForCausalLM, new_forward=LlamaInferenceForwards.llama_causal_lm_forward, policy=policy
+ )
+
+ infer_forward = None
+ if HAS_TRITON_RMSNORM:
+ infer_forward = get_triton_rmsnorm_forward()
+
+ if infer_forward is not None:
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LlamaRMSNorm
+ )
+
+ return policy
+
+ def postprocess(self):
+ init_to_get_rotary(self.model.model)
+ return self.model
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == "LlamaModel":
+ module = self.model
+ else:
+ module = self.model.model
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(len(module.layers), stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embed_tokens)
+ held_layers.append(self.model.lm_head)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.layers[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.norm)
+
+ return held_layers
diff --git a/colossalai/inference/kv_cache/__init__.py b/colossalai/inference/kv_cache/__init__.py
new file mode 100644
index 000000000000..5b6ca182efae
--- /dev/null
+++ b/colossalai/inference/kv_cache/__init__.py
@@ -0,0 +1,2 @@
+from .batch_infer_state import BatchInferState
+from .kvcache_manager import MemoryManager
diff --git a/colossalai/inference/kv_cache/batch_infer_state.py b/colossalai/inference/kv_cache/batch_infer_state.py
new file mode 100644
index 000000000000..f707a86df37e
--- /dev/null
+++ b/colossalai/inference/kv_cache/batch_infer_state.py
@@ -0,0 +1,118 @@
+# might want to consider combine with InferenceConfig in colossalai/ppinference/inference_config.py later
+from dataclasses import dataclass
+
+import torch
+from transformers.tokenization_utils_base import BatchEncoding
+
+from .kvcache_manager import MemoryManager
+
+
+# adapted from: lightllm/server/router/model_infer/infer_batch.py
+@dataclass
+class BatchInferState:
+ r"""
+ Information to be passed and used for a batch of inputs during
+ a single model forward
+ """
+ batch_size: int
+ max_len_in_batch: int
+
+ cache_manager: MemoryManager = None
+
+ block_loc: torch.Tensor = None
+ start_loc: torch.Tensor = None
+ seq_len: torch.Tensor = None
+ past_key_values_len: int = None
+
+ is_context_stage: bool = False
+ context_mem_index: torch.Tensor = None
+ decode_is_contiguous: bool = None
+ decode_mem_start: int = None
+ decode_mem_end: int = None
+ decode_mem_index: torch.Tensor = None
+ decode_layer_id: int = None
+
+ device: torch.device = torch.device("cuda")
+
+ @property
+ def total_token_num(self):
+ # return self.batch_size * self.max_len_in_batch
+ assert self.seq_len is not None and self.seq_len.size(0) > 0
+ return int(torch.sum(self.seq_len))
+
+ def set_cache_manager(self, manager: MemoryManager):
+ self.cache_manager = manager
+
+ # adapted from: https://github.com/ModelTC/lightllm/blob/28c1267cfca536b7b4f28e921e03de735b003039/lightllm/common/infer_utils.py#L1
+ @staticmethod
+ def init_block_loc(
+ b_loc: torch.Tensor, seq_len: torch.Tensor, max_len_in_batch: int, alloc_mem_index: torch.Tensor
+ ):
+ """in-place update block loc mapping based on the sequence length of the inputs in current bath"""
+ start_index = 0
+ seq_len_numpy = seq_len.cpu().numpy()
+ for i, cur_seq_len in enumerate(seq_len_numpy):
+ b_loc[i, max_len_in_batch - cur_seq_len : max_len_in_batch] = alloc_mem_index[
+ start_index : start_index + cur_seq_len
+ ]
+ start_index += cur_seq_len
+ return
+
+ @classmethod
+ def init_from_batch(
+ cls,
+ batch: torch.Tensor,
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
+ ):
+ if not isinstance(batch, (BatchEncoding, dict, list, torch.Tensor)):
+ raise TypeError(f"batch type {type(batch)} is not supported in prepare_batch_state")
+
+ input_ids_list = None
+ attention_mask = None
+
+ if isinstance(batch, (BatchEncoding, dict)):
+ input_ids_list = batch["input_ids"]
+ attention_mask = batch["attention_mask"]
+ else:
+ input_ids_list = batch
+ if isinstance(input_ids_list[0], int): # for a single input
+ input_ids_list = [input_ids_list]
+ attention_mask = [attention_mask] if attention_mask is not None else attention_mask
+
+ batch_size = len(input_ids_list)
+
+ seq_start_indexes = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
+ seq_lengths = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
+ start_index = 0
+
+ max_len_in_batch = -1
+ if isinstance(batch, (BatchEncoding, dict)):
+ for i, attn_mask in enumerate(attention_mask):
+ curr_seq_len = len(attn_mask)
+ seq_lengths[i] = curr_seq_len
+ seq_start_indexes[i] = start_index
+ start_index += curr_seq_len
+ max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
+ else:
+ length = max(len(input_id) for input_id in input_ids_list)
+ for i, input_ids in enumerate(input_ids_list):
+ curr_seq_len = length
+ seq_lengths[i] = curr_seq_len
+ seq_start_indexes[i] = start_index
+ start_index += curr_seq_len
+ max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
+ block_loc = torch.zeros((batch_size, max_input_len + max_output_len), dtype=torch.long, device="cuda")
+
+ return cls(
+ batch_size=batch_size,
+ max_len_in_batch=max_len_in_batch,
+ seq_len=seq_lengths.to("cuda"),
+ start_loc=seq_start_indexes.to("cuda"),
+ block_loc=block_loc,
+ decode_layer_id=0,
+ past_key_values_len=0,
+ is_context_stage=True,
+ cache_manager=cache_manager,
+ )
diff --git a/colossalai/inference/kv_cache/kvcache_manager.py b/colossalai/inference/kv_cache/kvcache_manager.py
new file mode 100644
index 000000000000..dda46a756cc3
--- /dev/null
+++ b/colossalai/inference/kv_cache/kvcache_manager.py
@@ -0,0 +1,106 @@
+"""
+Refered/Modified from lightllm/common/mem_manager.py
+of the ModelTC/lightllm GitHub repository
+https://github.com/ModelTC/lightllm/blob/050af3ce65edca617e2f30ec2479397d5bb248c9/lightllm/common/mem_manager.py
+we slightly changed it to make it suitable for our colossal-ai shardformer TP-engine design.
+"""
+import torch
+from transformers.utils import logging
+
+
+class MemoryManager:
+ r"""
+ Manage token block indexes and allocate physical memory for key and value cache
+
+ Args:
+ size: maximum token number used as the size of key and value buffer
+ dtype: data type of cached key and value
+ head_num: number of heads the memory manager is responsible for
+ head_dim: embedded size per head
+ layer_num: the number of layers in the model
+ device: device used to store the key and value cache
+ """
+
+ def __init__(
+ self,
+ size: int,
+ dtype: torch.dtype,
+ head_num: int,
+ head_dim: int,
+ layer_num: int,
+ device: torch.device = torch.device("cuda"),
+ ):
+ self.logger = logging.get_logger(__name__)
+ self.available_size = size
+ self.max_len_in_batch = 0
+ self._init_mem_states(size, device)
+ self._init_kv_buffers(size, device, dtype, head_num, head_dim, layer_num)
+
+ def _init_mem_states(self, size, device):
+ """Initialize tensors used to manage memory states"""
+ self.mem_state = torch.ones((size,), dtype=torch.bool, device=device)
+ self.mem_cum_sum = torch.empty((size,), dtype=torch.int32, device=device)
+ self.indexes = torch.arange(0, size, dtype=torch.long, device=device)
+
+ def _init_kv_buffers(self, size, device, dtype, head_num, head_dim, layer_num):
+ """Initialize key buffer and value buffer on specified device"""
+ self.key_buffer = [
+ torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
+ ]
+ self.value_buffer = [
+ torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
+ ]
+
+ @torch.no_grad()
+ def alloc(self, required_size):
+ """allocate space of required_size by providing indexes representing available physical spaces"""
+ if required_size > self.available_size:
+ self.logger.warning(f"No enough cache: required_size {required_size} " f"left_size {self.available_size}")
+ return None
+ torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
+ select_index = torch.logical_and(self.mem_cum_sum <= required_size, self.mem_state == 1)
+ select_index = self.indexes[select_index]
+ self.mem_state[select_index] = 0
+ self.available_size -= len(select_index)
+ return select_index
+
+ @torch.no_grad()
+ def alloc_contiguous(self, required_size):
+ """allocate contiguous space of required_size"""
+ if required_size > self.available_size:
+ self.logger.warning(f"No enough cache: required_size {required_size} " f"left_size {self.available_size}")
+ return None
+ torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
+ sum_size = len(self.mem_cum_sum)
+ loc_sums = (
+ self.mem_cum_sum[required_size - 1 :]
+ - self.mem_cum_sum[0 : sum_size - required_size + 1]
+ + self.mem_state[0 : sum_size - required_size + 1]
+ )
+ can_used_loc = self.indexes[0 : sum_size - required_size + 1][loc_sums == required_size]
+ if can_used_loc.shape[0] == 0:
+ self.logger.info(
+ f"No enough contiguous cache: required_size {required_size} " f"left_size {self.available_size}"
+ )
+ return None
+ start_loc = can_used_loc[0]
+ select_index = self.indexes[start_loc : start_loc + required_size]
+ self.mem_state[select_index] = 0
+ self.available_size -= len(select_index)
+ start = start_loc.item()
+ end = start + required_size
+ return select_index, start, end
+
+ @torch.no_grad()
+ def free(self, free_index):
+ """free memory by updating memory states based on given indexes"""
+ self.available_size += free_index.shape[0]
+ self.mem_state[free_index] = 1
+
+ @torch.no_grad()
+ def free_all(self):
+ """free all memory by updating memory states"""
+ self.available_size = len(self.mem_state)
+ self.mem_state[:] = 1
+ self.max_len_in_batch = 0
+ # self.logger.info("freed all space of memory manager")
diff --git a/colossalai/inference/pipeline/__init__.py b/colossalai/inference/pipeline/__init__.py
deleted file mode 100644
index 41af9f3ef948..000000000000
--- a/colossalai/inference/pipeline/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .engine import PPInferEngine
-
-__all__ = ["PPInferEngine"]
diff --git a/colossalai/inference/pipeline/engine.py b/colossalai/inference/pipeline/engine.py
deleted file mode 100644
index 4f42385caf8f..000000000000
--- a/colossalai/inference/pipeline/engine.py
+++ /dev/null
@@ -1,97 +0,0 @@
-import torch
-import torch.nn as nn
-
-from colossalai.cluster import ProcessGroupMesh
-from colossalai.pipeline.schedule.generate import GenerateSchedule
-from colossalai.pipeline.stage_manager import PipelineStageManager
-from colossalai.shardformer import ShardConfig, ShardFormer
-from colossalai.shardformer.policies.base_policy import Policy
-
-from .microbatch_manager import MicroBatchManager
-
-
-class PPInferEngine:
- """
- PPInferEngine is a class that handles the pipeline parallel inference.
-
- Args:
- pp_size (int): the number of pipeline stages.
- pp_model (`nn.Module`): the model already in pipeline parallelism style.
- model (`nn.Module`): the model not in pipeline style, and will be modified with `ShardFormer`.
- model_policy (`colossalai.shardformer.policies.base_policy.Policy`): the policy to shardformer model.
- micro_batch_size (int): the micro batch size.
- micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
- new_length (int): the new length of the input sequence.
- early_stopping (bool): whether to stop early.
-
- Example:
-
- ```python
- from colossalai.ppinference import PPInferEngine
- from transformers import GPT2LMHeadModel, GPT2Tokenizer
-
- model = transformers.GPT2LMHeadModel.from_pretrained('gpt2')
- # assume the model is infered with 4 pipeline stages
- inferengine = PPInferEngine(pp_size=4, model=model, model_policy={Your own policy for pipeline sharding})
-
- input = ["Hello, my dog is cute, and I like"]
- tokenized_input = tokenizer(input, return_tensors='pt')
- output = engine.inference([tokenized_input])
- ```
-
- """
-
- def __init__(
- self,
- pp_size: int,
- dtype: str = "fp16",
- pp_model: nn.Module = None,
- model: nn.Module = None,
- model_policy: Policy = None,
- new_length: int = 32,
- micro_batch_size: int = 1,
- micro_batch_buffer_size: int = None,
- verbose: bool = False,
- # TODO: implement early_stopping, and various gerneration options
- early_stopping: bool = False,
- do_sample: bool = False,
- num_beams: int = 1,
- ) -> None:
- assert pp_model or (model and model_policy), "Either pp_model or model with model_policy should be provided."
- self.pp_size = pp_size
- self.pg_mesh = ProcessGroupMesh(pp_size)
- self.stage_manager = PipelineStageManager(self.pg_mesh, 0, True)
- self.mb_manager = MicroBatchManager(
- self.stage_manager.stage, new_length, micro_batch_size, micro_batch_buffer_size or pp_size
- )
- self.verbose = verbose
- self.schedule = GenerateSchedule(self.stage_manager, self.mb_manager, verbose)
-
- assert dtype in ["fp16", "fp32", "bf16"], "dtype should be one of 'fp16', 'fp32', 'bf16'"
- if dtype == "fp16":
- model.half()
- elif dtype == "bf16":
- model.to(torch.bfloat16)
- self.model = pp_model or self._shardformer(model, model_policy)
-
- def inference(self, input_list):
- out, timestamp = self.schedule.generate_step(self.model, iter(input_list))
- if self.verbose:
- return out, timestamp
- else:
- return out
-
- def _shardformer(self, model, model_policy):
- shardconfig = ShardConfig(
- tensor_parallel_process_group=None,
- pipeline_stage_manager=self.stage_manager,
- enable_tensor_parallelism=False,
- enable_fused_normalization=False,
- enable_all_optimization=False,
- enable_flash_attention=False,
- enable_jit_fused=False,
- enable_sequence_parallelism=False,
- )
- shardformer = ShardFormer(shard_config=shardconfig)
- shard_model, _ = shardformer.optimize(model, model_policy)
- return shard_model.cuda()
diff --git a/colossalai/inference/pipeline/modeling/gpt2.py b/colossalai/inference/pipeline/modeling/gpt2.py
deleted file mode 100644
index d2bfcb8b6842..000000000000
--- a/colossalai/inference/pipeline/modeling/gpt2.py
+++ /dev/null
@@ -1,280 +0,0 @@
-from typing import Dict, List, Optional, Tuple, Union
-
-import torch
-from transformers.modeling_outputs import BaseModelOutputWithPastAndCrossAttentions, CausalLMOutputWithCrossAttentions
-from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel, GPT2Model
-from transformers.utils import logging
-
-from colossalai.pipeline.stage_manager import PipelineStageManager
-
-
-class GPT2PipelineForwards:
- """
- This class serves as a micro library for forward function substitution of GPT2 models
- under pipeline setting.
- """
-
- @staticmethod
- def gpt2_model_forward(
- self: GPT2Model,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- encoder_hidden_states: Optional[torch.Tensor] = None,
- encoder_attention_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ) -> Union[Dict, Tuple, BaseModelOutputWithPastAndCrossAttentions]:
- # This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2Model.forward.
- # Please refer to original code of transformers for more details.
- logger = logging.get_logger(__name__)
-
- # Preprocess passed in arguments
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if past_key_values is None:
- past_length = 0
- past_key_values = tuple([None] * len(self.h))
- else:
- past_length = past_key_values[0][0].size(-2)
-
- if stage_manager.is_first_stage():
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- input_shape = input_ids.size()
- input_ids = input_ids.view(-1, input_shape[-1])
- batch_size = input_ids.shape[0]
- elif inputs_embeds is not None:
- input_shape = inputs_embeds.size()[:-1]
- batch_size = inputs_embeds.shape[0]
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- device = input_ids.device if input_ids is not None else inputs_embeds.device
- if token_type_ids is not None:
- token_type_ids = token_type_ids.view(-1, input_shape[-1])
- else:
- if hidden_states is None:
- raise ValueError("hidden_states shouldn't be None for stages other than the first stage.")
- input_shape = hidden_states.size()[:-1]
- batch_size, seq_length = input_shape[0], input_shape[1]
- device = hidden_states.device
-
- # GPT2Attention mask.
- if attention_mask is not None:
- if batch_size <= 0:
- raise ValueError("batch_size has to be defined and > 0")
- attention_mask = attention_mask.view(batch_size, -1)
- # We create a 3D attention mask from a 2D tensor mask.
- # Sizes are [batch_size, 1, 1, to_seq_length]
- # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
- # this attention mask is more simple than the triangular masking of causal attention
- # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
- attention_mask = attention_mask[:, None, None, :]
-
- # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
- # masked positions, this operation will create a tensor which is 0.0 for
- # positions we want to attend and the dtype's smallest value for masked positions.
- # Since we are adding it to the raw scores before the softmax, this is
- # effectively the same as removing these entirely.
- attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
- attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
-
- # If a 2D or 3D attention mask is provided for the cross-attention
- # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
- if self.config.add_cross_attention and encoder_hidden_states is not None:
- encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
- encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
- if encoder_attention_mask is None:
- encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
- encoder_attention_mask = self.invert_attention_mask(encoder_attention_mask)
- else:
- encoder_attention_mask = None
-
- # Prepare head mask if needed
- # 1.0 in head_mask indicate we keep the head
- # attention_probs has shape bsz x n_heads x N x N
- # head_mask has shape n_layer x batch x n_heads x N x N
- head_mask = self.get_head_mask(head_mask, self.config.n_layer)
-
- if stage_manager.is_first_stage():
- if position_ids is not None:
- position_ids = position_ids.view(-1, input_shape[-1])
- else:
- position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
- position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
-
- if inputs_embeds is None:
- inputs_embeds = self.wte(input_ids)
- position_embeds = self.wpe(position_ids)
- hidden_states = inputs_embeds + position_embeds
- if token_type_ids is not None:
- token_type_embeds = self.wte(token_type_ids)
- hidden_states = hidden_states + token_type_embeds
- hidden_states = self.drop(hidden_states)
-
- output_shape = input_shape + (hidden_states.size(-1),)
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
- )
- use_cache = False
-
- presents = () if use_cache else None
- all_self_attentions = () if output_attentions else None
- all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
- all_hidden_states = () if output_hidden_states else None
-
- # Going through held blocks.
- start_idx, end_idx = stage_index[0], stage_index[1]
- for i, layer_past in zip(range(start_idx, end_idx), past_key_values):
- block = self.h[i]
- # Model parallel
- if self.model_parallel:
- torch.cuda.set_device(hidden_states.device)
- # Ensure layer_past is on same device as hidden_states (might not be correct)
- if layer_past is not None:
- layer_past = tuple(past_state.to(hidden_states.device) for past_state in layer_past)
- # Ensure that attention_mask is always on the same device as hidden_states
- if attention_mask is not None:
- attention_mask = attention_mask.to(hidden_states.device)
- if isinstance(head_mask, torch.Tensor):
- head_mask = head_mask.to(hidden_states.device)
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, use_cache, output_attentions)
-
- return custom_forward
-
- outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(block),
- hidden_states,
- None,
- attention_mask,
- head_mask[i],
- encoder_hidden_states,
- encoder_attention_mask,
- )
- else:
- outputs = block(
- hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- head_mask=head_mask[i],
- encoder_hidden_states=encoder_hidden_states,
- encoder_attention_mask=encoder_attention_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
-
- hidden_states = outputs[0]
- if use_cache is True:
- presents = presents + (outputs[1],)
-
- if output_attentions:
- all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
- if self.config.add_cross_attention:
- all_cross_attentions = all_cross_attentions + (outputs[3 if use_cache else 2],)
-
- # Model Parallel: If it's the last layer for that device, put things on the next device
- if self.model_parallel:
- for k, v in self.device_map.items():
- if i == v[-1] and "cuda:" + str(k) != self.last_device:
- hidden_states = hidden_states.to("cuda:" + str(k + 1))
-
- if stage_manager.is_last_stage():
- hidden_states = self.ln_f(hidden_states)
-
- hidden_states = hidden_states.view(output_shape)
-
- # Add last hidden state
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- return {"hidden_states": hidden_states, "past_key_values": presents}
-
- @staticmethod
- def gpt2_lmhead_model_forward(
- self: GPT2LMHeadModel,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- encoder_hidden_states: Optional[torch.Tensor] = None,
- encoder_attention_mask: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ) -> Union[Dict, Tuple, CausalLMOutputWithCrossAttentions]:
- r"""
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
- `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
- are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
-
- This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2LMHeadModel.forward.
- Please refer to original code of transformers for more details.
- """
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- # If is first stage and after warmup, go throught lm_head first
- if stage_manager.is_first_stage() and hidden_states is not None:
- lm_logits = self.lm_head(hidden_states)
- return {"logits": lm_logits}
-
- # Not first stage or before warmup, go through gpt2 model
- outputs = GPT2PipelineForwards.gpt2_model_forward(
- self.transformer,
- input_ids,
- past_key_values=past_key_values,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- encoder_hidden_states=encoder_hidden_states,
- encoder_attention_mask=encoder_attention_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- stage_manager=stage_manager,
- hidden_states=hidden_states,
- stage_index=stage_index,
- )
-
- return outputs
diff --git a/colossalai/inference/pipeline/modeling/llama.py b/colossalai/inference/pipeline/modeling/llama.py
deleted file mode 100644
index f46e1fbdd7b3..000000000000
--- a/colossalai/inference/pipeline/modeling/llama.py
+++ /dev/null
@@ -1,229 +0,0 @@
-from typing import List, Optional
-
-import torch
-from transformers.models.llama.modeling_llama import LlamaForCausalLM, LlamaModel
-from transformers.utils import logging
-
-from colossalai.pipeline.stage_manager import PipelineStageManager
-
-
-class LlamaPipelineForwards:
- """
- This class serves as a micro library for forward function substitution of Llama models
- under pipeline setting.
- """
-
- def llama_model_forward(
- self: LlamaModel,
- input_ids: torch.LongTensor = None,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ):
- logger = logging.get_logger(__name__)
-
- # Preprocess passed in arguments
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- # retrieve input_ids and inputs_embeds
- if stage_manager.is_first_stage():
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
- elif input_ids is not None:
- batch_size, seq_length = input_ids.shape
- elif inputs_embeds is not None:
- batch_size, seq_length, _ = inputs_embeds.shape
- else:
- raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
- device = input_ids.device if input_ids is not None else inputs_embeds.device
- if inputs_embeds is None:
- inputs_embeds = self.embed_tokens(input_ids)
- hidden_states = inputs_embeds
- else:
- input_shape = hidden_states.shape[:-1]
- batch_size, seq_length = input_shape
- device = hidden_states.device
-
- seq_length_with_past = seq_length
- past_key_values_length = 0
-
- if past_key_values is not None:
- past_key_values_length = past_key_values[0][0].shape[2]
- seq_length_with_past = seq_length_with_past + past_key_values_length
-
- if position_ids is None:
- position_ids = torch.arange(
- past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
- )
- position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
- else:
- position_ids = position_ids.view(-1, seq_length).long()
-
- # embed positions, for the first stage, hidden_states is the input embeddings,
- # for the other stages, hidden_states is the output of the previous stage
- if attention_mask is None:
- attention_mask = torch.ones(
- (batch_size, seq_length_with_past), dtype=torch.bool, device=hidden_states.device
- )
- attention_mask = self._prepare_decoder_attention_mask(
- attention_mask, (batch_size, seq_length), hidden_states, past_key_values_length
- )
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
- )
- use_cache = False
-
- # decoder layers
- all_hidden_states = () if output_hidden_states else None
- all_self_attns = () if output_attentions else None
- next_decoder_cache = () if use_cache else None
-
- start_idx, end_idx = stage_index[0], stage_index[1]
- if past_key_values is None:
- past_key_values = tuple([None] * (end_idx - start_idx + 1))
-
- for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
- decoder_layer = self.layers[idx]
- if output_hidden_states:
- all_hidden_states += (hidden_states,)
-
- # past_key_value = past_key_values[idx] if past_key_values is not None else None
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, output_attentions, None)
-
- return custom_forward
-
- layer_outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(decoder_layer),
- hidden_states,
- attention_mask,
- position_ids,
- None,
- )
- else:
- layer_outputs = decoder_layer(
- hidden_states,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_value=past_key_value,
- output_attentions=output_attentions,
- use_cache=use_cache,
- )
-
- hidden_states = layer_outputs[0]
-
- if use_cache:
- next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
- if output_attentions:
- all_self_attns += (layer_outputs[1],)
-
- if stage_manager.is_last_stage():
- hidden_states = self.norm(hidden_states)
-
- # add hidden states from the last decoder layer
- if output_hidden_states:
- all_hidden_states += (hidden_states,)
- next_cache = next_decoder_cache if use_cache else None
-
- # always return dict for imediate stage
- return {"hidden_states": hidden_states, "past_key_values": next_cache}
-
- def llama_for_causal_lm_forward(
- self: LlamaForCausalLM,
- input_ids: torch.LongTensor = None,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ):
- r"""
- Args:
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
- config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
- (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
-
- Returns:
-
- Example:
-
- ```python
- >>> from transformers import AutoTokenizer, LlamaForCausalLM
-
- >>> model = LlamaForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
- >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
-
- >>> prompt = "Hey, are you consciours? Can you talk to me?"
- >>> inputs = tokenizer(prompt, return_tensors="pt")
-
- >>> # Generate
- >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
- >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
- "Hey, are you consciours? Can you talk to me?\nI'm not consciours, but I can talk to you."
- ```"""
- logger = logging.get_logger(__name__)
-
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- # If is first stage and after warmup, go throught lm_head first
- if stage_manager.is_first_stage() and hidden_states is not None:
- lm_logits = self.lm_head(hidden_states)
- return {"logits": lm_logits}
-
- # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
- outputs = LlamaPipelineForwards.llama_model_forward(
- self.model,
- input_ids=input_ids,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_values=past_key_values,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- stage_manager=stage_manager,
- hidden_states=hidden_states,
- stage_index=stage_index,
- )
-
- return outputs
diff --git a/colossalai/inference/pipeline/policy/gpt2_ppinfer.py b/colossalai/inference/pipeline/policy/gpt2_ppinfer.py
deleted file mode 100644
index 51e6425b113e..000000000000
--- a/colossalai/inference/pipeline/policy/gpt2_ppinfer.py
+++ /dev/null
@@ -1,74 +0,0 @@
-from functools import partial
-from typing import Callable, Dict, List
-
-from torch import Tensor, nn
-
-import colossalai.shardformer.layer as col_nn
-from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
-from colossalai.shardformer.policies.gpt2 import GPT2Policy
-
-from ..modeling.gpt2 import GPT2PipelineForwards
-
-
-class GPT2LMHeadModelPipelinePolicy(GPT2Policy):
- def __init__(self) -> None:
- super().__init__()
-
- def module_policy(self):
- from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
-
- module_policy = super().module_policy()
-
- if self.shard_config.enable_tensor_parallelism:
- addon_module = {
- GPT2LMHeadModel: ModulePolicyDescription(
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="lm_head", target_module=col_nn.Linear1D_Col, kwargs={"gather_output": True}
- )
- ]
- )
- }
- module_policy.update(addon_module)
-
- if self.pipeline_stage_manager is not None:
- self.set_pipeline_forward(
- model_cls=GPT2LMHeadModel,
- new_forward=GPT2PipelineForwards.gpt2_lmhead_model_forward,
- policy=module_policy,
- )
- return module_policy
-
- def get_held_layers(self) -> List[nn.Module]:
- held_layers = super().get_held_layers()
- # make the tie weight lm_head and embedding in the same device to save memory
- # if self.pipeline_stage_manager.is_first_stage():
- if self.pipeline_stage_manager.is_first_stage():
- held_layers.append(self.model.lm_head)
- return held_layers
-
- def get_shared_params(self) -> List[Dict[int, Tensor]]:
- """The weights of wte and lm_head are shared."""
- module = self.model
- stage_manager = self.pipeline_stage_manager
- if stage_manager is not None:
- if stage_manager.num_stages > 1 and id(module.transformer.wte.weight) == id(module.lm_head.weight):
- first_stage, last_stage = 0, stage_manager.num_stages - 1
- return [{first_stage: module.transformer.wte.weight, last_stage: module.lm_head.weight}]
- return []
-
- def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
- """If under pipeline parallel setting, replacing the original forward method of huggingface
- to customized forward method, and add this changing to policy."""
- if not self.pipeline_stage_manager:
- raise ValueError("set_pipeline_forward method can only be called when pipeline parallel is enabled.")
- stage_manager = self.pipeline_stage_manager
- if self.model.__class__.__name__ == "GPT2Model":
- module = self.model
- else:
- module = self.model.transformer
-
- layers_per_stage = Policy.distribute_layers(len(module.h), stage_manager.num_stages)
- stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
- method_replacement = {"forward": partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}
- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=model_cls)
diff --git a/colossalai/inference/pipeline/policy/llama_ppinfer.py b/colossalai/inference/pipeline/policy/llama_ppinfer.py
deleted file mode 100644
index 6e12ed61bf7b..000000000000
--- a/colossalai/inference/pipeline/policy/llama_ppinfer.py
+++ /dev/null
@@ -1,48 +0,0 @@
-from typing import List
-
-from torch.nn import Module
-
-from colossalai.shardformer.layer import Linear1D_Col
-from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
-from colossalai.shardformer.policies.llama import LlamaPolicy
-
-from ..modeling.llama import LlamaPipelineForwards
-
-
-class LlamaForCausalLMPipelinePolicy(LlamaPolicy):
- def __init__(self) -> None:
- super().__init__()
-
- def module_policy(self):
- from transformers import LlamaForCausalLM
-
- policy = super().module_policy()
-
- if self.shard_config.enable_tensor_parallelism:
- # add a new item for casual lm
- new_item = {
- LlamaForCausalLM: ModulePolicyDescription(
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="lm_head", target_module=Linear1D_Col, kwargs=dict(gather_output=True)
- )
- ]
- )
- }
- policy.update(new_item)
-
- if self.pipeline_stage_manager:
- # set None as default
- self.set_pipeline_forward(
- model_cls=LlamaForCausalLM, new_forward=LlamaPipelineForwards.llama_for_causal_lm_forward, policy=policy
- )
-
- return policy
-
- def get_held_layers(self) -> List[Module]:
- """Get pipeline layers for current stage."""
- stage_manager = self.pipeline_stage_manager
- held_layers = super().get_held_layers()
- if stage_manager.is_first_stage():
- held_layers.append(self.model.lm_head)
- return held_layers
diff --git a/colossalai/inference/pipeline/utils.py b/colossalai/inference/pipeline/utils.py
deleted file mode 100644
index c26aa4e40b71..000000000000
--- a/colossalai/inference/pipeline/utils.py
+++ /dev/null
@@ -1,35 +0,0 @@
-from typing import Set
-
-import torch.nn as nn
-
-from colossalai.shardformer._utils import getattr_, setattr_
-
-
-def set_tensors_to_none(model: nn.Module, include: Set[str] = set()) -> None:
- """
- Set all parameters and buffers of model to None
-
- Args:
- model (nn.Module): The model to set
- """
- for module_suffix in include:
- set_module = getattr_(model, module_suffix)
- for n, p in set_module.named_parameters():
- setattr_(set_module, n, None)
- for n, buf in set_module.named_buffers():
- setattr_(set_module, n, None)
- setattr_(model, module_suffix, None)
-
-
-def get_suffix_name(suffix: str, name: str):
- """
- Get the suffix name of the module, as `suffix.name` when name is string or `suffix[name]` when name is a digit,
- and 'name' when `suffix` is empty.
-
- Args:
- suffix (str): The suffix of the suffix module
- name (str): The name of the current module
- """
- point = "" if suffix is "" else "."
- suffix_name = suffix + f"[{name}]" if name.isdigit() else suffix + f"{point}{name}"
- return suffix_name
diff --git a/colossalai/inference/quant/__init__.py b/colossalai/inference/quant/__init__.py
new file mode 100644
index 000000000000..18e0de9cc9fc
--- /dev/null
+++ b/colossalai/inference/quant/__init__.py
@@ -0,0 +1 @@
+from .smoothquant.models.llama import SmoothLlamaForCausalLM
diff --git a/colossalai/inference/quant/gptq/__init__.py b/colossalai/inference/quant/gptq/__init__.py
index c035f397923a..4cf1fd658a41 100644
--- a/colossalai/inference/quant/gptq/__init__.py
+++ b/colossalai/inference/quant/gptq/__init__.py
@@ -2,3 +2,4 @@
if HAS_AUTO_GPTQ:
from .cai_gptq import CaiGPTQLinearOp, CaiQuantLinear
+ from .gptq_manager import GPTQManager
diff --git a/colossalai/inference/quant/gptq/gptq_manager.py b/colossalai/inference/quant/gptq/gptq_manager.py
new file mode 100644
index 000000000000..2d352fbef2b9
--- /dev/null
+++ b/colossalai/inference/quant/gptq/gptq_manager.py
@@ -0,0 +1,61 @@
+import torch
+
+
+class GPTQManager:
+ def __init__(self, quant_config, max_input_len: int = 1):
+ self.max_dq_buffer_size = 1
+ self.max_inner_outer_dim = 1
+ self.bits = quant_config.bits
+ self.use_act_order = quant_config.desc_act
+ self.max_input_len = 1
+ self.gptq_temp_state_buffer = None
+ self.gptq_temp_dq_buffer = None
+ self.quant_config = quant_config
+
+ def post_init_gptq_buffer(self, model: torch.nn.Module) -> None:
+ from .cai_gptq import CaiQuantLinear
+
+ HAS_GPTQ_CUDA = False
+ try:
+ from colossalai.kernel.op_builder.gptq import GPTQBuilder
+
+ gptq_cuda = GPTQBuilder().load()
+ HAS_GPTQ_CUDA = True
+ except ImportError:
+ warnings.warn("CUDA gptq is not installed")
+ HAS_GPTQ_CUDA = False
+
+ for name, submodule in model.named_modules():
+ if isinstance(submodule, CaiQuantLinear):
+ self.max_dq_buffer_size = max(self.max_dq_buffer_size, submodule.qweight.numel() * 8)
+
+ if self.use_act_order:
+ self.max_inner_outer_dim = max(
+ self.max_inner_outer_dim, submodule.infeatures, submodule.outfeatures
+ )
+ self.bits = submodule.bits
+ if not (HAS_GPTQ_CUDA and self.bits == 4):
+ return
+
+ max_input_len = 1
+ if self.use_act_order:
+ max_input_len = self.max_input_len
+ # The temp_state buffer is required to reorder X in the act-order case.
+ # The temp_dq buffer is required to dequantize weights when using cuBLAS, typically for the prefill.
+ self.gptq_temp_state_buffer = torch.zeros(
+ (max_input_len, self.max_inner_outer_dim), dtype=torch.float16, device=torch.cuda.current_device()
+ )
+ self.gptq_temp_dq_buffer = torch.zeros(
+ (1, self.max_dq_buffer_size), dtype=torch.float16, device=torch.cuda.current_device()
+ )
+
+ gptq_cuda.prepare_buffers(
+ torch.device(torch.cuda.current_device()), self.gptq_temp_state_buffer, self.gptq_temp_dq_buffer
+ )
+ # Using the default from exllama repo here.
+ matmul_recons_thd = 8
+ matmul_fused_remap = False
+ matmul_no_half2 = False
+ gptq_cuda.set_tuning_params(matmul_recons_thd, matmul_fused_remap, matmul_no_half2)
+
+ torch.cuda.empty_cache()
diff --git a/colossalai/inference/quant/smoothquant/models/__init__.py b/colossalai/inference/quant/smoothquant/models/__init__.py
index 77541d8610c5..1663028da138 100644
--- a/colossalai/inference/quant/smoothquant/models/__init__.py
+++ b/colossalai/inference/quant/smoothquant/models/__init__.py
@@ -4,9 +4,7 @@
HAS_TORCH_INT = True
except ImportError:
HAS_TORCH_INT = False
- raise ImportError(
- "Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int"
- )
+ print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
if HAS_TORCH_INT:
from .llama import LLamaSmoothquantAttention, LlamaSmoothquantMLP
diff --git a/colossalai/inference/quant/smoothquant/models/base_model.py b/colossalai/inference/quant/smoothquant/models/base_model.py
index 6a1d96ecec8f..f3afe5d83bb0 100644
--- a/colossalai/inference/quant/smoothquant/models/base_model.py
+++ b/colossalai/inference/quant/smoothquant/models/base_model.py
@@ -9,7 +9,6 @@
from os.path import isdir, isfile, join
from typing import Dict, List, Optional, Union
-import accelerate
import numpy as np
import torch
import torch.nn as nn
@@ -21,8 +20,16 @@
from transformers.utils.generic import ContextManagers
from transformers.utils.hub import PushToHubMixin, cached_file
-from colossalai.inference.tensor_parallel.batch_infer_state import BatchInferState
-from colossalai.inference.tensor_parallel.kvcache_manager import MemoryManager
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState, MemoryManager
+
+try:
+ import accelerate
+
+ HAS_ACCELERATE = True
+except ImportError:
+ HAS_ACCELERATE = False
+ print("accelerate is not installed.")
+
SUPPORTED_MODELS = ["llama"]
@@ -87,7 +94,6 @@ def init_batch_state(self, max_output_len=256, **kwargs):
batch_infer_state.start_loc = seq_start_indexes.to("cuda")
batch_infer_state.block_loc = block_loc
batch_infer_state.decode_layer_id = 0
- batch_infer_state.past_key_values_len = 0
batch_infer_state.is_context_stage = True
batch_infer_state.set_cache_manager(self.cache_manager)
batch_infer_state.cache_manager.free_all()
diff --git a/colossalai/inference/quant/smoothquant/models/linear.py b/colossalai/inference/quant/smoothquant/models/linear.py
index 969c390a0849..03d994b32489 100644
--- a/colossalai/inference/quant/smoothquant/models/linear.py
+++ b/colossalai/inference/quant/smoothquant/models/linear.py
@@ -1,17 +1,25 @@
# modified from torch-int: https://github.com/Guangxuan-Xiao/torch-int/blob/main/torch_int/nn/linear.py
import torch
-from torch_int._CUDA import linear_a8_w8_b8_o8, linear_a8_w8_bfp32_ofp32
-from torch_int.functional.quantization import quantize_per_tensor_absmax
+
+try:
+ from torch_int._CUDA import linear_a8_w8_b8_o8, linear_a8_w8_bfp32_ofp32
+ from torch_int.functional.quantization import quantize_per_tensor_absmax
+
+ HAS_TORCH_INT = True
+except ImportError:
+ HAS_TORCH_INT = False
+ print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
+
try:
from colossalai.kernel.op_builder.smoothquant import SmoothquantBuilder
smoothquant_cuda = SmoothquantBuilder().load()
HAS_SMOOTHQUANT_CUDA = True
-except ImportError:
+except:
HAS_SMOOTHQUANT_CUDA = False
- raise ImportError("CUDA smoothquant linear is not installed")
+ print("CUDA smoothquant linear is not installed")
class W8A8BFP32O32LinearSiLU(torch.nn.Module):
@@ -138,21 +146,23 @@ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
)
self.register_buffer(
"bias",
- torch.zeros(self.out_features, dtype=torch.float32, requires_grad=False),
+ torch.zeros((1, self.out_features), dtype=torch.float32, requires_grad=False),
)
self.register_buffer("a", torch.tensor(alpha))
def _apply(self, fn):
# prevent the bias from being converted to half
super()._apply(fn)
- self.bias = self.bias.to(torch.float32)
+ if self.bias is not None:
+ self.bias = self.bias.to(torch.float32)
return self
def to(self, *args, **kwargs):
super().to(*args, **kwargs)
self.weight = self.weight.to(*args, **kwargs)
- self.bias = self.bias.to(*args, **kwargs)
- self.bias = self.bias.to(torch.float32)
+ if self.bias is not None:
+ self.bias = self.bias.to(*args, **kwargs)
+ self.bias = self.bias.to(torch.float32)
return self
@torch.no_grad()
diff --git a/colossalai/inference/quant/smoothquant/models/llama.py b/colossalai/inference/quant/smoothquant/models/llama.py
index 4c3d6dcc0b23..bb74dc49d7af 100644
--- a/colossalai/inference/quant/smoothquant/models/llama.py
+++ b/colossalai/inference/quant/smoothquant/models/llama.py
@@ -8,7 +8,6 @@
import torch
import torch.nn as nn
import torch.nn.functional as F
-from torch_int.nn.bmm import BMM_S8T_S8N_F32T, BMM_S8T_S8N_S8T
from transformers import PreTrainedModel
from transformers.modeling_outputs import BaseModelOutputWithPast
from transformers.models.llama.configuration_llama import LlamaConfig
@@ -18,12 +17,11 @@
LlamaDecoderLayer,
LlamaMLP,
LlamaRotaryEmbedding,
- repeat_kv,
rotate_half,
)
from transformers.utils import add_start_docstrings_to_model_forward
-from colossalai.inference.tensor_parallel.batch_infer_state import BatchInferState
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
from colossalai.kernel.triton import (
copy_kv_cache_to_dest,
int8_rotary_embedding_fwd,
@@ -31,10 +29,31 @@
smooth_token_attention_fwd,
)
+try:
+ from torch_int.nn.bmm import BMM_S8T_S8N_F32T, BMM_S8T_S8N_S8T
+
+ HAS_TORCH_INT = True
+except ImportError:
+ HAS_TORCH_INT = False
+ print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
+
+
from .base_model import BaseSmoothForCausalLM
from .linear import W8A8B8O8Linear, W8A8BFP32O32LinearSiLU, W8A8BFP32OFP32Linear
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
class LLamaSmoothquantAttention(nn.Module):
def __init__(
self,
@@ -116,7 +135,6 @@ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
def forward(
self,
hidden_states: torch.Tensor,
- rotary_emb: Tuple[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
@@ -131,8 +149,7 @@ def forward(
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
- cos = rotary_emb[0]
- sin = rotary_emb[1]
+ cos, sin = infer_state.position_cos, infer_state.position_sin
int8_rotary_embedding_fwd(
query_states.view(-1, self.num_heads, self.head_dim),
@@ -149,12 +166,6 @@ def forward(
self.k_rotary_output_scale.item(),
)
- # NOTE might want to revise
- # need some way to record the length of past key values cache
- # since we won't return past_key_value_cache right now
- if infer_state.decode_layer_id == 0: # once per model.forward
- infer_state.cache_manager.past_key_values_length += q_len # seq_len
-
def _copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index, mem_manager):
copy_kv_cache_to_dest(key_buffer, context_mem_index, mem_manager.key_buffer[layer_id])
copy_kv_cache_to_dest(value_buffer, context_mem_index, mem_manager.value_buffer[layer_id])
@@ -229,7 +240,7 @@ def _copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index,
infer_state.block_loc,
infer_state.start_loc,
infer_state.seq_len,
- infer_state.cache_manager.past_key_values_length,
+ infer_state.max_len_in_batch,
)
attn_output = attn_output.view(bsz, q_len, self.num_heads * self.head_dim)
@@ -354,7 +365,6 @@ def pack(
def forward(
self,
hidden_states: torch.Tensor,
- rotary_emb: Tuple[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
@@ -384,7 +394,6 @@ def forward(
# Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
- rotary_emb=rotary_emb,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
@@ -592,17 +601,13 @@ def llama_model_forward(
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
- seq_length_with_past = seq_length
- past_key_values_length = 0
-
infer_state = self.infer_state
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
- if past_key_values is not None:
- # NOT READY FOR PRIME TIME
- # dummy but work, revise it
- past_key_values_length = infer_state.cache_manager.past_key_values_length
- # past_key_values_length = past_key_values[0][0].shape[2]
- seq_length_with_past = seq_length_with_past + past_key_values_length
+ seq_length_with_past = seq_length + past_key_values_length
# NOTE: differentiate with prefill stage
# block_loc require different value-assigning method for two different stage
@@ -623,9 +628,7 @@ def llama_model_forward(
infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
else:
print(f" *** Encountered allocation non-contiguous")
- print(
- f" infer_state.cache_manager.past_key_values_length: {infer_state.cache_manager.past_key_values_length}"
- )
+ print(f" infer_state.cache_manager.max_len_in_batch: {infer_state.max_len_in_batch}")
infer_state.decode_is_contiguous = False
alloc_mem = infer_state.cache_manager.alloc(batch_size)
infer_state.decode_mem_index = alloc_mem
@@ -662,15 +665,15 @@ def llama_model_forward(
raise NotImplementedError("not implement gradient_checkpointing and training options ")
if past_key_values_length == 0:
- position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
position_ids.view(-1).shape[0], -1
)
- position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
position_ids.view(-1).shape[0], -1
)
else:
- position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(batch_size, -1)
- position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(batch_size, -1)
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(batch_size, -1)
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(batch_size, -1)
# decoder layers
all_hidden_states = () if output_hidden_states else None
@@ -685,7 +688,6 @@ def llama_model_forward(
layer_outputs = decoder_layer(
hidden_states,
- rotary_emb=(position_cos, position_sin),
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
@@ -713,6 +715,7 @@ def llama_model_forward(
infer_state.is_context_stage = False
infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
next_cache = next_decoder_cache if use_cache else None
if not return_dict:
diff --git a/colossalai/inference/quant/smoothquant/models/parallel_linear.py b/colossalai/inference/quant/smoothquant/models/parallel_linear.py
new file mode 100644
index 000000000000..962b687a1d05
--- /dev/null
+++ b/colossalai/inference/quant/smoothquant/models/parallel_linear.py
@@ -0,0 +1,264 @@
+from typing import List, Union
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from torch.distributed import ProcessGroup
+
+from colossalai.lazy import LazyInitContext
+from colossalai.shardformer.layer import ParallelModule
+
+from .linear import W8A8B8O8Linear, W8A8BFP32O32LinearSiLU, W8A8BFP32OFP32Linear
+
+
+def split_row_copy(smooth_linear, para_linear, tp_size=1, tp_rank=0, split_num=1):
+ qweights = smooth_linear.weight.split(smooth_linear.out_features // split_num, dim=0)
+ if smooth_linear.bias is not None:
+ bias = smooth_linear.bias.split(smooth_linear.out_features // split_num, dim=0)
+
+ smooth_split_out_features = para_linear.out_features // split_num
+
+ for i in range(split_num):
+ para_linear.weight[i * smooth_split_out_features : (i + 1) * smooth_split_out_features, :] = qweights[i][
+ tp_rank * smooth_split_out_features : (tp_rank + 1) * smooth_split_out_features, :
+ ]
+
+ if para_linear.bias is not None:
+ para_linear.bias[:, i * smooth_split_out_features : (i + 1) * smooth_split_out_features] = bias[i][
+ :, tp_rank * smooth_split_out_features : (tp_rank + 1) * smooth_split_out_features
+ ]
+
+
+def split_column_copy(smooth_linear, para_linear, tp_rank=0, split_num=1):
+ qweights = smooth_linear.weight.split(smooth_linear.in_features // split_num, dim=-1)
+
+ smooth_split_in_features = para_linear.in_features // split_num
+
+ for i in range(split_num):
+ para_linear.weight[:, i * smooth_split_in_features : (i + 1) * smooth_split_in_features] = qweights[i][
+ :, tp_rank * smooth_split_in_features : (tp_rank + 1) * smooth_split_in_features
+ ]
+
+ if smooth_linear.bias is not None:
+ para_linear.bias.copy_(smooth_linear.bias)
+
+
+class RowW8A8B8O8Linear(W8A8B8O8Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ out_features = module.out_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = RowW8A8B8O8Linear(module.in_features, module.out_features // tp_size)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+ linear_1d.b = module.b.clone().detach()
+ split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ return linear_1d
+
+
+class ColW8A8B8O8Linear(W8A8B8O8Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ in_features = module.in_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if in_features < tp_size:
+ return module
+
+ if in_features % tp_size != 0:
+ raise ValueError(
+ f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = ColW8A8B8O8Linear(module.in_features // tp_size, module.out_features)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = torch.tensor(module.a)
+ linear_1d.b = torch.tensor(module.b)
+
+ split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ if linear_1d.bias is not None:
+ linear_1d.bias = linear_1d.bias // tp_size
+
+ return linear_1d
+
+ @torch.no_grad()
+ def forward(self, x):
+ output = super().forward(x)
+ if self.tp_size > 1:
+ dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
+ return output
+
+
+class RowW8A8BFP32O32LinearSiLU(W8A8BFP32O32LinearSiLU, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ out_features = module.out_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = RowW8A8BFP32O32LinearSiLU(module.in_features, module.out_features // tp_size)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+
+ split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ return linear_1d
+
+
+class RowW8A8BFP32OFP32Linear(W8A8BFP32OFP32Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ out_features = module.out_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = RowW8A8BFP32OFP32Linear(module.in_features, module.out_features // tp_size)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+
+ split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ return linear_1d
+
+
+class ColW8A8BFP32OFP32Linear(W8A8BFP32OFP32Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ in_features = module.in_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if in_features < tp_size:
+ return module
+
+ if in_features % tp_size != 0:
+ raise ValueError(
+ f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = ColW8A8BFP32OFP32Linear(module.in_features // tp_size, module.out_features)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+
+ split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ if linear_1d.bias is not None:
+ linear_1d.bias = linear_1d.bias / tp_size
+
+ return linear_1d
+
+ @torch.no_grad()
+ def forward(self, x):
+ output = super().forward(x)
+ if self.tp_size > 1:
+ dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
+ return output
diff --git a/colossalai/inference/tensor_parallel/batch_infer_state.py b/colossalai/inference/tensor_parallel/batch_infer_state.py
deleted file mode 100644
index de150311cc08..000000000000
--- a/colossalai/inference/tensor_parallel/batch_infer_state.py
+++ /dev/null
@@ -1,57 +0,0 @@
-# might want to consider combine with InferenceConfig in colossalai/ppinference/inference_config.py later
-from dataclasses import dataclass
-
-import torch
-
-from .kvcache_manager import MemoryManager
-
-# adapted from: lightllm/server/router/model_infer/infer_batch.py
-@dataclass
-class BatchInferState:
- r"""
- Information to be passed and used for a batch of inputs during
- a single model forward
- """
- batch_size: int
- max_len_in_batch: int
-
- cache_manager: MemoryManager = None
-
- block_loc: torch.Tensor = None
- start_loc: torch.Tensor = None
- seq_len: torch.Tensor = None
- past_key_values_len: int = None
-
- is_context_stage: bool = False
- context_mem_index: torch.Tensor = None
- decode_is_contiguous: bool = None
- decode_mem_start: int = None
- decode_mem_end: int = None
- decode_mem_index: torch.Tensor = None
- decode_layer_id: int = None
-
- device: torch.device = torch.device("cuda")
-
- @property
- def total_token_num(self):
- # return self.batch_size * self.max_len_in_batch
- assert self.seq_len is not None and self.seq_len.size(0) > 0
- return int(torch.sum(self.seq_len))
-
- def set_cache_manager(self, manager: MemoryManager):
- self.cache_manager = manager
-
- # adapted from: https://github.com/ModelTC/lightllm/blob/28c1267cfca536b7b4f28e921e03de735b003039/lightllm/common/infer_utils.py#L1
- @staticmethod
- def init_block_loc(
- b_loc: torch.Tensor, seq_len: torch.Tensor, max_len_in_batch: int, alloc_mem_index: torch.Tensor
- ):
- """in-place update block loc mapping based on the sequence length of the inputs in current bath"""
- start_index = 0
- seq_len_numpy = seq_len.cpu().numpy()
- for i, cur_seq_len in enumerate(seq_len_numpy):
- b_loc[i, max_len_in_batch - cur_seq_len : max_len_in_batch] = alloc_mem_index[
- start_index : start_index + cur_seq_len
- ]
- start_index += cur_seq_len
- return
diff --git a/colossalai/initialize.py b/colossalai/initialize.py
index aac57d34a2c1..25076b742c26 100644
--- a/colossalai/initialize.py
+++ b/colossalai/initialize.py
@@ -11,7 +11,7 @@
from colossalai.context import Config
from colossalai.logging import get_dist_logger
-from colossalai.utils import set_device, set_seed
+from colossalai.utils import IS_NPU_AVAILABLE, set_device, set_seed
def launch(
@@ -47,12 +47,15 @@ def launch(
if rank == 0:
warnings.warn("`config` is deprecated and will be removed soon.")
+ if IS_NPU_AVAILABLE and backend == "nccl":
+ backend = "hccl"
+
# init default process group
init_method = f"tcp://[{host}]:{port}"
dist.init_process_group(rank=rank, world_size=world_size, backend=backend, init_method=init_method)
# set cuda device
- if torch.cuda.is_available():
+ if torch.cuda.is_available() or IS_NPU_AVAILABLE:
# if local rank is not given, calculate automatically
set_device(local_rank)
diff --git a/colossalai/kernel/cuda_native/csrc/cpu_adam.h b/colossalai/kernel/cuda_native/csrc/cpu_adam.h
index bf9b85997c78..db1f26d5f6da 100644
--- a/colossalai/kernel/cuda_native/csrc/cpu_adam.h
+++ b/colossalai/kernel/cuda_native/csrc/cpu_adam.h
@@ -142,6 +142,7 @@ class Adam_Optimizer {
}
}
+#if defined(__AVX512__) or defined(__AVX256__) or defined(__AVX2__)
inline void simd_load(bool is_half, float *ptr, __half *h_ptr,
AVX_Data &data) {
if (is_half) {
@@ -159,6 +160,7 @@ class Adam_Optimizer {
SIMD_STORE(ptr, data.data);
}
}
+#endif
void step(size_t step, float lr, float beta1, float beta2, float epsilon,
float weight_decay, bool bias_correction, torch::Tensor ¶ms,
diff --git a/colossalai/kernel/cuda_native/csrc/cpu_adam_arm.cpp b/colossalai/kernel/cuda_native/csrc/cpu_adam_arm.cpp
new file mode 100644
index 000000000000..a715a2711576
--- /dev/null
+++ b/colossalai/kernel/cuda_native/csrc/cpu_adam_arm.cpp
@@ -0,0 +1,304 @@
+#include "cpu_adam_arm.h"
+
+void AdamOptimizer::Step_1(void *_params, void *grads, void *_exp_avg,
+ void *_exp_avg_sq, size_t _param_size,
+ at::ScalarType param_dtype,
+ at::ScalarType grad_dtype,
+ at::ScalarType exp_avg_dtype,
+ at::ScalarType exp_avg_sq_dtype, float loss_scale) {
+ size_t rounded_size = 0;
+#if defined(__aarch64__)
+ rounded_size = ROUND_DOWN(_param_size, SIMD_WIDTH);
+#endif
+
+ float betta1_minus1 = 1 - _betta1;
+ float betta2_minus1 = 1 - _betta2;
+ float step_size = -1 * _alpha / _bias_correction1;
+ float w_decay = -1 * _alpha * _weight_decay;
+
+#if defined(__aarch64__)
+ float32x4_t betta1_4 = simd_set(_betta1);
+ float32x4_t betta2_4 = simd_set(_betta2);
+ float32x4_t betta1_minus1_4 = simd_set(betta1_minus1);
+ float32x4_t betta2_minus1_4 = simd_set(betta2_minus1);
+ float32x4_t bias2_sqrt = simd_set(_bias_correction2);
+ float32x4_t eps_4 = simd_set(_eps);
+ float32x4_t step_size_4 = simd_set(step_size);
+ float32x4_t weight_decay_4;
+ if (_weight_decay > 0) {
+ weight_decay_4 = _adamw_mode ? simd_set(w_decay) : simd_set(_weight_decay);
+ }
+ for (size_t t = 0; t < rounded_size; t += TILE) {
+ size_t copy_size = TILE;
+ if ((t + TILE) > rounded_size) copy_size = rounded_size - t;
+ size_t offset = copy_size + t;
+
+#pragma omp parallel for
+ for (size_t i = t; i < offset; i += SIMD_WIDTH) {
+ float32x4_t grad_4 = simd_load_offset(grads, grad_dtype, i);
+ if (loss_scale > 0) {
+ float32x4_t loss_scale_vec = simd_set(loss_scale);
+ grad_4 = vdivq_f32(grad_4, loss_scale_vec);
+ }
+ float32x4_t momentum_4 = simd_load_offset(_exp_avg, exp_avg_dtype, i);
+ float32x4_t variance_4 =
+ simd_load_offset(_exp_avg_sq, exp_avg_sq_dtype, i);
+ float32x4_t param_4 = simd_load_offset(_params, param_dtype, i);
+ if (_weight_decay > 0 && !_adamw_mode) {
+ grad_4 = vfmaq_f32(grad_4, param_4, weight_decay_4);
+ }
+ momentum_4 = vmulq_f32(momentum_4, betta1_4);
+ momentum_4 = vfmaq_f32(momentum_4, grad_4, betta1_minus1_4);
+ variance_4 = vmulq_f32(variance_4, betta2_4);
+ grad_4 = vmulq_f32(grad_4, grad_4);
+ variance_4 = vfmaq_f32(variance_4, grad_4, betta2_minus1_4);
+ grad_4 = vsqrtq_f32(variance_4);
+ grad_4 = vfmaq_f32(eps_4, grad_4, bias2_sqrt);
+ grad_4 = vdivq_f32(momentum_4, grad_4);
+ if (_weight_decay > 0 && _adamw_mode) {
+ param_4 = vfmaq_f32(param_4, param_4, weight_decay_4);
+ }
+ param_4 = vfmaq_f32(param_4, grad_4, step_size_4);
+ simd_store_offset(_params, param_dtype, param_4, i);
+ simd_store_offset(_exp_avg, exp_avg_dtype, momentum_4, i);
+ simd_store_offset(_exp_avg_sq, exp_avg_sq_dtype, variance_4, i);
+ }
+ }
+#endif
+ if (_param_size > rounded_size) {
+ for (size_t t = rounded_size; t < _param_size; t += TILE) {
+ size_t copy_size = TILE;
+ if ((t + TILE) > _param_size) copy_size = _param_size - t;
+ size_t offset = copy_size + t;
+
+#pragma omp parallel for
+ for (size_t k = t; k < offset; k++) {
+ float grad = scalar_load_offset(grads, grad_dtype, k);
+ if (loss_scale > 0) {
+ grad /= loss_scale;
+ }
+ float param = scalar_load_offset(_params, param_dtype, k);
+ float momentum = scalar_load_offset(_exp_avg, exp_avg_dtype, k);
+ float variance = scalar_load_offset(_exp_avg_sq, exp_avg_sq_dtype, k);
+ if (_weight_decay > 0 && !_adamw_mode) {
+ grad = param * _weight_decay + grad;
+ }
+ momentum = momentum * _betta1;
+ momentum = grad * betta1_minus1 + momentum;
+
+ variance = variance * _betta2;
+ grad = grad * grad;
+ variance = grad * betta2_minus1 + variance;
+
+ grad = sqrt(variance);
+ grad = grad * _bias_correction2 + _eps;
+ grad = momentum / grad;
+ if (_weight_decay > 0 && _adamw_mode) {
+ param += w_decay * param;
+ }
+ param = grad * step_size + param;
+
+ scalar_store_offset(_params, param_dtype, param, k);
+ scalar_store_offset(_exp_avg, exp_avg_dtype, momentum, k);
+ scalar_store_offset(_exp_avg_sq, exp_avg_sq_dtype, variance, k);
+ }
+ }
+ }
+}
+
+void AdamOptimizer::Step_4(void *_params, void *grads, void *_exp_avg,
+ void *_exp_avg_sq, size_t _param_size,
+ at::ScalarType param_dtype,
+ at::ScalarType grad_dtype,
+ at::ScalarType exp_avg_dtype,
+ at::ScalarType exp_avg_sq_dtype, float loss_scale) {
+ size_t rounded_size = 0;
+#if defined(__aarch64__)
+ rounded_size = ROUND_DOWN(_param_size, SIMD_WIDTH * 4);
+#endif
+
+ float betta1_minus1 = 1 - _betta1;
+ float betta2_minus1 = 1 - _betta2;
+ float step_size = -1 * _alpha / _bias_correction1;
+ float w_decay = -1 * _alpha * _weight_decay;
+
+#if defined(__aarch64__)
+ float32x4_t betta1_4 = simd_set(_betta1);
+ float32x4_t betta2_4 = simd_set(_betta2);
+ float32x4_t betta1_minus1_4 = simd_set(betta1_minus1);
+ float32x4_t betta2_minus1_4 = simd_set(betta2_minus1);
+ float32x4_t bias2_sqrt = simd_set(_bias_correction2);
+ float32x4_t eps_4 = simd_set(_eps);
+ float32x4_t step_size_4 = simd_set(step_size);
+ float32x4_t weight_decay_4;
+ if (_weight_decay > 0) {
+ weight_decay_4 = _adamw_mode ? simd_set(w_decay) : simd_set(_weight_decay);
+ }
+
+ for (size_t t = 0; t < rounded_size; t += TILE) {
+ size_t copy_size = TILE;
+ if ((t + TILE) > rounded_size) copy_size = rounded_size - t;
+ size_t offset = copy_size + t;
+
+#pragma omp parallel for
+ for (size_t i = t; i < offset; i += SIMD_WIDTH * 4) {
+ float32x4_t grad_4[4];
+ float32x4_t momentum_4[4];
+ float32x4_t variance_4[4];
+ float32x4_t param_4[4];
+#pragma unroll 4
+ for (int j = 0; j < 4; j++) {
+ grad_4[j] = simd_load_offset(grads, grad_dtype, i + SIMD_WIDTH * j);
+ if (loss_scale > 0) {
+ float32x4_t loss_scale_vec = simd_set(loss_scale);
+ grad_4[j] = vdivq_f32(grad_4[j], loss_scale_vec);
+ }
+ momentum_4[j] =
+ simd_load_offset(_exp_avg, exp_avg_dtype, i + SIMD_WIDTH * j);
+ variance_4[j] =
+ simd_load_offset(_exp_avg_sq, exp_avg_sq_dtype, i + SIMD_WIDTH * j);
+ param_4[j] = simd_load_offset(_params, param_dtype, i + SIMD_WIDTH * j);
+ if (_weight_decay > 0 && !_adamw_mode) {
+ grad_4[j] = vfmaq_f32(grad_4[j], param_4[j], weight_decay_4);
+ }
+ momentum_4[j] = vmulq_f32(momentum_4[j], betta1_4);
+ momentum_4[j] = vfmaq_f32(momentum_4[j], grad_4[j], betta1_minus1_4);
+ variance_4[j] = vmulq_f32(variance_4[j], betta2_4);
+ grad_4[j] = vmulq_f32(grad_4[j], grad_4[j]);
+ variance_4[j] = vfmaq_f32(variance_4[j], grad_4[j], betta2_minus1_4);
+ grad_4[j] = vsqrtq_f32(variance_4[j]);
+ grad_4[j] = vfmaq_f32(eps_4, grad_4[j], bias2_sqrt);
+ grad_4[j] = vdivq_f32(momentum_4[j], grad_4[j]);
+ if (_weight_decay > 0 && _adamw_mode) {
+ param_4[j] = vfmaq_f32(param_4[j], param_4[j], weight_decay_4);
+ }
+ param_4[j] = vfmaq_f32(param_4[j], grad_4[j], step_size_4);
+ simd_store_offset(_params, param_dtype, param_4[j], i + SIMD_WIDTH * j);
+ simd_store_offset(_exp_avg, exp_avg_dtype, momentum_4[j],
+ i + SIMD_WIDTH * j);
+ simd_store_offset(_exp_avg_sq, exp_avg_sq_dtype, variance_4[j],
+ i + SIMD_WIDTH * j);
+ }
+ }
+ }
+#endif
+ if (_param_size > rounded_size) {
+ Step_1(scalar_seek_offset(_params, param_dtype, rounded_size),
+ scalar_seek_offset(grads, grad_dtype, rounded_size),
+ scalar_seek_offset(_exp_avg, exp_avg_dtype, rounded_size),
+ scalar_seek_offset(_exp_avg_sq, exp_avg_sq_dtype, rounded_size),
+ (_param_size - rounded_size), param_dtype, grad_dtype, exp_avg_dtype,
+ exp_avg_sq_dtype, loss_scale);
+ }
+}
+
+void AdamOptimizer::Step_8(void *_params, void *grads, void *_exp_avg,
+ void *_exp_avg_sq, size_t _param_size,
+ at::ScalarType param_dtype,
+ at::ScalarType grad_dtype,
+ at::ScalarType exp_avg_dtype,
+ at::ScalarType exp_avg_sq_dtype, float loss_scale) {
+ size_t rounded_size = 0;
+#if defined(__aarch64__)
+ rounded_size = ROUND_DOWN(_param_size, SIMD_WIDTH * 8);
+#endif
+
+ float betta1_minus1 = 1 - _betta1;
+ float betta2_minus1 = 1 - _betta2;
+ float step_size = -1 * _alpha / _bias_correction1;
+ float w_decay = -1 * _alpha * _weight_decay;
+#if defined(__aarch64__)
+ float32x4_t betta1_4 = simd_set(_betta1);
+ float32x4_t betta2_4 = simd_set(_betta2);
+ float32x4_t betta1_minus1_4 = simd_set(betta1_minus1);
+ float32x4_t betta2_minus1_4 = simd_set(betta2_minus1);
+ float32x4_t bias2_sqrt = simd_set(_bias_correction2);
+ float32x4_t eps_4 = simd_set(_eps);
+ float32x4_t step_size_4 = simd_set(step_size);
+ float32x4_t weight_decay_4;
+ if (_weight_decay > 0) {
+ weight_decay_4 = _adamw_mode ? simd_set(w_decay) : simd_set(_weight_decay);
+ }
+
+ for (size_t t = 0; t < rounded_size; t += TILE) {
+ size_t copy_size = TILE;
+ if ((t + TILE) > rounded_size) copy_size = rounded_size - t;
+ size_t offset = copy_size + t;
+
+#pragma omp parallel for
+ for (size_t i = t; i < offset; i += SIMD_WIDTH * 8) {
+ float32x4_t grad_4[8];
+ float32x4_t momentum_4[8];
+ float32x4_t variance_4[8];
+ float32x4_t param_4[8];
+#pragma unroll 4
+ for (int j = 0; j < 8; j++) {
+ grad_4[j] = simd_load_offset(grads, grad_dtype, i + SIMD_WIDTH * j);
+ if (loss_scale > 0) {
+ float32x4_t loss_scale_vec = simd_set(loss_scale);
+ grad_4[j] = vdivq_f32(grad_4[j], loss_scale_vec);
+ }
+ momentum_4[j] =
+ simd_load_offset(_exp_avg, exp_avg_dtype, i + SIMD_WIDTH * j);
+ variance_4[j] =
+ simd_load_offset(_exp_avg_sq, exp_avg_sq_dtype, i + SIMD_WIDTH * j);
+ param_4[j] = simd_load_offset(_params, param_dtype, i + SIMD_WIDTH * j);
+ if (_weight_decay > 0 && !_adamw_mode) {
+ grad_4[j] = vfmaq_f32(grad_4[j], param_4[j], weight_decay_4);
+ }
+ momentum_4[j] = vmulq_f32(momentum_4[j], betta1_4);
+ momentum_4[j] = vfmaq_f32(momentum_4[j], grad_4[j], betta1_minus1_4);
+ variance_4[j] = vmulq_f32(variance_4[j], betta2_4);
+ grad_4[j] = vmulq_f32(grad_4[j], grad_4[j]);
+ variance_4[j] = vfmaq_f32(variance_4[j], grad_4[j], betta2_minus1_4);
+ grad_4[j] = vsqrtq_f32(variance_4[j]);
+ grad_4[j] = vfmaq_f32(eps_4, grad_4[j], bias2_sqrt);
+ grad_4[j] = vdivq_f32(momentum_4[j], grad_4[j]);
+ if (_weight_decay > 0 && _adamw_mode) {
+ param_4[j] = vfmaq_f32(param_4[j], param_4[j], weight_decay_4);
+ }
+ param_4[j] = vfmaq_f32(param_4[j], grad_4[j], step_size_4);
+ simd_store_offset(_params, param_dtype, param_4[j], i + SIMD_WIDTH * j);
+ simd_store_offset(_exp_avg, exp_avg_dtype, momentum_4[j],
+ i + SIMD_WIDTH * j);
+ simd_store_offset(_exp_avg_sq, exp_avg_sq_dtype, variance_4[j],
+ i + SIMD_WIDTH * j);
+ }
+ }
+ }
+#endif
+ if (_param_size > rounded_size) {
+ Step_4(scalar_seek_offset(_params, param_dtype, rounded_size),
+ scalar_seek_offset(grads, grad_dtype, rounded_size),
+ scalar_seek_offset(_exp_avg, exp_avg_dtype, rounded_size),
+ scalar_seek_offset(_exp_avg_sq, exp_avg_sq_dtype, rounded_size),
+ (_param_size - rounded_size), param_dtype, grad_dtype, exp_avg_dtype,
+ exp_avg_sq_dtype, loss_scale);
+ }
+}
+
+void AdamOptimizer::step(size_t step, float lr, float beta1, float beta2,
+ float epsilon, float weight_decay,
+ bool bias_correction, torch::Tensor ¶ms,
+ torch::Tensor &grads, torch::Tensor &exp_avg,
+ torch::Tensor &exp_avg_sq, float loss_scale) {
+ auto params_c = params.contiguous();
+ auto grads_c = grads.contiguous();
+ auto exp_avg_c = exp_avg.contiguous();
+ auto exp_avg_sq_c = exp_avg_sq.contiguous();
+
+ this->IncrementStep(step, beta1, beta2);
+ this->update_state(lr, epsilon, weight_decay, bias_correction);
+ this->Step_8(params_c.data_ptr(), grads_c.data_ptr(), exp_avg_c.data_ptr(),
+ exp_avg_sq_c.data_ptr(), params_c.numel(),
+ params_c.scalar_type(), grads_c.scalar_type(),
+ exp_avg_c.scalar_type(), exp_avg_sq_c.scalar_type(), loss_scale);
+}
+
+namespace py = pybind11;
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ py::class_
## Roadmap of our implementation
@@ -34,11 +43,15 @@ In this section we discuss how the colossal inference works and integrates with
- [x] policy
- [x] context forward
- [x] token forward
-- [ ] Replace the kernels with `faster-transformer` in token-forward stage
-- [ ] Support all models
+ - [x] support flash-decoding
+- [x] Support all models
- [x] Llama
+ - [x] Llama-2
- [x] Bloom
- - [ ] Chatglm2
+ - [x] Chatglm2
+- [x] Quantization
+ - [x] GPTQ
+ - [x] SmoothQuant
- [ ] Benchmarking for all models
## Get started
@@ -51,23 +64,19 @@ pip install -e .
### Requirements
-dependencies
+Install dependencies.
```bash
-pytorch= 1.13.1 (gpu)
-cuda>= 11.6
-transformers= 4.30.2
-triton==2.0.0.dev20221202
-# for install vllm, please use this branch to install https://github.com/tiandiao123/vllm/tree/setup_branch
-vllm
-# for install flash-attention, please use commit hash: 67ae6fd74b4bc99c36b2ce524cf139c35663793c
-flash-attention
-
-# install lightllm since we depend on lightllm triton kernels
-git clone https://github.com/ModelTC/lightllm
-git checkout 28c1267cfca536b7b4f28e921e03de735b003039
-cd lightllm
-pip3 install -e .
+pip install -r requirements/requirements-infer.txt
+
+# if you want use smoothquant quantization, please install torch-int
+git clone --recurse-submodules https://github.com/Guangxuan-Xiao/torch-int.git
+cd torch-int
+git checkout 65266db1eadba5ca78941b789803929e6e6c6856
+pip install -r requirements.txt
+source environment.sh
+bash build_cutlass.sh
+python setup.py install
```
### Docker
@@ -83,22 +92,60 @@ docker run -it --gpus all --name ANY_NAME -v $PWD:/workspace -w /workspace hpcai
cd /path/to/CollossalAI
pip install -e .
-# install lightllm
-git clone https://github.com/ModelTC/lightllm
-git checkout 28c1267cfca536b7b4f28e921e03de735b003039
-cd lightllm
-pip3 install -e .
-
-
```
-### Dive into fast-inference!
+## Usage
+### Quick start
example files are in
```bash
-cd colossalai.examples
-python xx
+cd ColossalAI/examples
+python hybrid_llama.py --path /path/to/model --tp_size 2 --pp_size 2 --batch_size 4 --max_input_size 32 --max_out_len 16 --micro_batch_size 2
+```
+
+
+
+### Example
+```python
+# import module
+from colossalai.inference import CaiInferEngine
+import colossalai
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+#launch distributed environment
+colossalai.launch_from_torch(config={})
+
+# load original model and tokenizer
+model = LlamaForCausalLM.from_pretrained("/path/to/model")
+tokenizer = LlamaTokenizer.from_pretrained("/path/to/model")
+
+# generate token ids
+input = ["Introduce a landmark in London","Introduce a landmark in Singapore"]
+data = tokenizer(input, return_tensors='pt')
+
+# set parallel parameters
+tp_size=2
+pp_size=2
+max_output_len=32
+micro_batch_size=1
+
+# initial inference engine
+engine = CaiInferEngine(
+ tp_size=tp_size,
+ pp_size=pp_size,
+ model=model,
+ max_output_len=max_output_len,
+ micro_batch_size=micro_batch_size,
+)
+
+# inference
+output = engine.generate(data)
+
+# get results
+if dist.get_rank() == 0:
+ assert len(output[0]) == max_output_len, f"{len(output)}, {max_output_len}"
+
```
## Performance
@@ -113,7 +160,9 @@ For various models, experiments were conducted using multiple batch sizes under
Currently the stats below are calculated based on A100 (single GPU), and we calculate token latency based on average values of context-forward and decoding forward process, which means we combine both of processes to calculate token generation times. We are actively developing new features and methods to further optimize the performance of LLM models. Please stay tuned.
-#### Llama
+### Tensor Parallelism Inference
+
+##### Llama
| batch_size | 8 | 16 | 32 |
| :---------------------: | :----: | :----: | :----: |
@@ -122,7 +171,7 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc

-### Bloom
+#### Bloom
| batch_size | 8 | 16 | 32 |
| :---------------------: | :----: | :----: | :----: |
@@ -131,4 +180,50 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc

+
+### Pipline Parallelism Inference
+We conducted multiple benchmark tests to evaluate the performance. We compared the inference `latency` and `throughputs` between `Pipeline Inference` and `hugging face` pipeline. The test environment is 2 * A10, 20G / 2 * A800, 80G. We set input length=1024, output length=128.
+
+
+#### A10 7b, fp16
+
+| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16)|
+| :-------------------------: | :---: | :---:| :---: | :---: | :---: | :---: |
+| Pipeline Inference | 40.35 | 77.10| 139.03| 232.70| 257.81| OOM |
+| Hugging Face | 41.43 | 65.30| 91.93 | 114.62| OOM | OOM |
+
+
+
+
+#### A10 13b, fp16
+
+| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(4) |
+| :---: | :---: | :---: | :---: | :---: |
+| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
+| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
+
+
+
+
+#### A800 7b, fp16
+
+| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
+| :---: | :---: | :---: | :---: | :---: | :---: |
+| Pipeline Inference| 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
+| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
+
+
+
+### Quantization LLama
+
+| batch_size | 8 | 16 | 32 |
+| :---------------------: | :----: | :----: | :----: |
+| auto-gptq | 199.20 | 232.56 | 253.26 |
+| smooth-quant | 142.28 | 222.96 | 300.59 |
+| colossal-gptq | 231.98 | 388.87 | 573.03 |
+
+
+
+
+
The results of more models are coming soon!
diff --git a/colossalai/inference/__init__.py b/colossalai/inference/__init__.py
index 35891307e754..a95205efaa78 100644
--- a/colossalai/inference/__init__.py
+++ b/colossalai/inference/__init__.py
@@ -1,3 +1,4 @@
-from .pipeline import PPInferEngine
+from .engine import InferenceEngine
+from .engine.policies import BloomModelInferPolicy, ChatGLM2InferPolicy, LlamaModelInferPolicy
-__all__ = ["PPInferEngine"]
+__all__ = ["InferenceEngine", "LlamaModelInferPolicy", "BloomModelInferPolicy", "ChatGLM2InferPolicy"]
diff --git a/colossalai/inference/engine/__init__.py b/colossalai/inference/engine/__init__.py
new file mode 100644
index 000000000000..6e60da695a22
--- /dev/null
+++ b/colossalai/inference/engine/__init__.py
@@ -0,0 +1,3 @@
+from .engine import InferenceEngine
+
+__all__ = ["InferenceEngine"]
diff --git a/colossalai/inference/engine/engine.py b/colossalai/inference/engine/engine.py
new file mode 100644
index 000000000000..61da5858aa86
--- /dev/null
+++ b/colossalai/inference/engine/engine.py
@@ -0,0 +1,195 @@
+from typing import Union
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from transformers.utils import logging
+
+from colossalai.cluster import ProcessGroupMesh
+from colossalai.pipeline.schedule.generate import GenerateSchedule
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer import ShardConfig, ShardFormer
+from colossalai.shardformer.policies.base_policy import Policy
+
+from ..kv_cache import MemoryManager
+from .microbatch_manager import MicroBatchManager
+from .policies import model_policy_map
+
+PP_AXIS, TP_AXIS = 0, 1
+
+_supported_models = [
+ "LlamaForCausalLM",
+ "BloomForCausalLM",
+ "LlamaGPTQForCausalLM",
+ "SmoothLlamaForCausalLM",
+ "ChatGLMForConditionalGeneration",
+]
+
+
+class InferenceEngine:
+ """
+ InferenceEngine is a class that handles the pipeline parallel inference.
+
+ Args:
+ tp_size (int): the size of tensor parallelism.
+ pp_size (int): the size of pipeline parallelism.
+ dtype (str): the data type of the model, should be one of 'fp16', 'fp32', 'bf16'.
+ model (`nn.Module`): the model not in pipeline style, and will be modified with `ShardFormer`.
+ model_policy (`colossalai.shardformer.policies.base_policy.Policy`): the policy to shardformer model. It will be determined by the model type if not provided.
+ micro_batch_size (int): the micro batch size. Only useful when `pp_size` > 1.
+ micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
+ max_batch_size (int): the maximum batch size.
+ max_input_len (int): the maximum input length.
+ max_output_len (int): the maximum output length.
+ quant (str): the quantization method, should be one of 'smoothquant', 'gptq', None.
+ verbose (bool): whether to return the time cost of each step.
+
+ """
+
+ def __init__(
+ self,
+ tp_size: int = 1,
+ pp_size: int = 1,
+ dtype: str = "fp16",
+ model: nn.Module = None,
+ model_policy: Policy = None,
+ micro_batch_size: int = 1,
+ micro_batch_buffer_size: int = None,
+ max_batch_size: int = 4,
+ max_input_len: int = 32,
+ max_output_len: int = 32,
+ quant: str = None,
+ verbose: bool = False,
+ # TODO: implement early_stopping, and various gerneration options
+ early_stopping: bool = False,
+ do_sample: bool = False,
+ num_beams: int = 1,
+ ) -> None:
+ if quant == "gptq":
+ from ..quant.gptq import GPTQManager
+
+ self.gptq_manager = GPTQManager(model.quantize_config, max_input_len=max_input_len)
+ model = model.model
+ elif quant == "smoothquant":
+ model = model.model
+
+ assert model.__class__.__name__ in _supported_models, f"Model {model.__class__.__name__} is not supported."
+ assert (
+ tp_size * pp_size == dist.get_world_size()
+ ), f"TP size({tp_size}) * PP size({pp_size}) should be equal to the global world size ({dist.get_world_size()})"
+ assert model, "Model should be provided."
+ assert dtype in ["fp16", "fp32", "bf16"], "dtype should be one of 'fp16', 'fp32', 'bf16'"
+
+ assert max_batch_size <= 64, "Max batch size exceeds the constraint"
+ assert max_input_len + max_output_len <= 4096, "Max length exceeds the constraint"
+ assert quant in ["smoothquant", "gptq", None], "quant should be one of 'smoothquant', 'gptq'"
+ self.pp_size = pp_size
+ self.tp_size = tp_size
+ self.quant = quant
+
+ logger = logging.get_logger(__name__)
+ if quant == "smoothquant" and dtype != "fp32":
+ dtype = "fp32"
+ logger.warning_once("Warning: smoothquant only support fp32 and int8 mix precision. set dtype to fp32")
+
+ if dtype == "fp16":
+ self.dtype = torch.float16
+ model.half()
+ elif dtype == "bf16":
+ self.dtype = torch.bfloat16
+ model.to(torch.bfloat16)
+ else:
+ self.dtype = torch.float32
+
+ if model_policy is None:
+ model_policy = model_policy_map[model.config.model_type]()
+
+ # Init pg mesh
+ pg_mesh = ProcessGroupMesh(pp_size, tp_size)
+
+ stage_manager = PipelineStageManager(pg_mesh, PP_AXIS, True if pp_size * tp_size > 1 else False)
+ self.cache_manager_list = [
+ self._init_manager(model, max_batch_size, max_input_len, max_output_len)
+ for _ in range(micro_batch_buffer_size or pp_size)
+ ]
+ self.mb_manager = MicroBatchManager(
+ stage_manager.stage,
+ micro_batch_size,
+ micro_batch_buffer_size or pp_size,
+ max_input_len,
+ max_output_len,
+ self.cache_manager_list,
+ )
+ self.verbose = verbose
+ self.schedule = GenerateSchedule(stage_manager, self.mb_manager, verbose)
+
+ self.model = self._shardformer(
+ model, model_policy, stage_manager, pg_mesh.get_group_along_axis(TP_AXIS) if pp_size * tp_size > 1 else None
+ )
+ if quant == "gptq":
+ self.gptq_manager.post_init_gptq_buffer(self.model)
+
+ def generate(self, input_list: Union[list, dict]):
+ """
+ Args:
+ input_list (list): a list of input data, each element is a `BatchEncoding` or `dict`.
+
+ Returns:
+ out (list): a list of output data, each element is a list of token.
+ timestamp (float): the time cost of the inference, only return when verbose is `True`.
+ """
+
+ out, timestamp = self.schedule.generate_step(self.model, iter([input_list]))
+ if self.verbose:
+ return out, timestamp
+ else:
+ return out
+
+ def _shardformer(self, model, model_policy, stage_manager, tp_group):
+ shardconfig = ShardConfig(
+ tensor_parallel_process_group=tp_group,
+ pipeline_stage_manager=stage_manager,
+ enable_tensor_parallelism=(self.tp_size > 1),
+ enable_fused_normalization=False,
+ enable_all_optimization=False,
+ enable_flash_attention=False,
+ enable_jit_fused=False,
+ enable_sequence_parallelism=False,
+ extra_kwargs={"quant": self.quant},
+ )
+ shardformer = ShardFormer(shard_config=shardconfig)
+ shard_model, _ = shardformer.optimize(model, model_policy)
+ return shard_model.cuda()
+
+ def _init_manager(self, model, max_batch_size: int, max_input_len: int, max_output_len: int) -> None:
+ max_total_token_num = max_batch_size * (max_input_len + max_output_len)
+ if model.config.model_type == "llama":
+ head_dim = model.config.hidden_size // model.config.num_attention_heads
+ head_num = model.config.num_key_value_heads // self.tp_size
+ num_hidden_layers = (
+ model.config.num_hidden_layers
+ if hasattr(model.config, "num_hidden_layers")
+ else model.config.num_layers
+ )
+ layer_num = num_hidden_layers // self.pp_size
+ elif model.config.model_type == "bloom":
+ head_dim = model.config.hidden_size // model.config.n_head
+ head_num = model.config.n_head // self.tp_size
+ num_hidden_layers = model.config.n_layer
+ layer_num = num_hidden_layers // self.pp_size
+ elif model.config.model_type == "chatglm":
+ head_dim = model.config.hidden_size // model.config.num_attention_heads
+ if model.config.multi_query_attention:
+ head_num = model.config.multi_query_group_num // self.tp_size
+ else:
+ head_num = model.config.num_attention_heads // self.tp_size
+ num_hidden_layers = model.config.num_layers
+ layer_num = num_hidden_layers // self.pp_size
+ else:
+ raise NotImplementedError("Only support llama, bloom and chatglm model.")
+
+ if self.quant == "smoothquant":
+ cache_manager = MemoryManager(max_total_token_num, torch.int8, head_num, head_dim, layer_num)
+ else:
+ cache_manager = MemoryManager(max_total_token_num, self.dtype, head_num, head_dim, layer_num)
+ return cache_manager
diff --git a/colossalai/inference/pipeline/microbatch_manager.py b/colossalai/inference/engine/microbatch_manager.py
similarity index 72%
rename from colossalai/inference/pipeline/microbatch_manager.py
rename to colossalai/inference/engine/microbatch_manager.py
index 49d1bf3f42cb..d698c89f9936 100644
--- a/colossalai/inference/pipeline/microbatch_manager.py
+++ b/colossalai/inference/engine/microbatch_manager.py
@@ -1,8 +1,10 @@
from enum import Enum
-from typing import Dict, Tuple
+from typing import Dict
import torch
+from ..kv_cache import BatchInferState, MemoryManager
+
__all__ = "MicroBatchManager"
@@ -27,21 +29,19 @@ class MicroBatchDescription:
def __init__(
self,
inputs_dict: Dict[str, torch.Tensor],
- output_dict: Dict[str, torch.Tensor],
- new_length: int,
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
) -> None:
- assert output_dict.get("hidden_states") is not None
- self.mb_length = output_dict["hidden_states"].shape[-2]
- self.target_length = self.mb_length + new_length
- self.kv_cache = ()
-
- def update(self, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
- if output_dict is not None:
- self._update_kvcache(output_dict["past_key_values"])
+ self.mb_length = inputs_dict["input_ids"].shape[-1]
+ self.target_length = self.mb_length + max_output_len
+ self.infer_state = BatchInferState.init_from_batch(
+ batch=inputs_dict, max_input_len=max_input_len, max_output_len=max_output_len, cache_manager=cache_manager
+ )
+ # print(f"[init] {inputs_dict}, {max_input_len}, {max_output_len}, {cache_manager}, {self.infer_state}")
- def _update_kvcache(self, kv_cache: Tuple):
- assert type(kv_cache) == tuple
- self.kv_cache = kv_cache
+ def update(self, *args, **kwargs):
+ pass
@property
def state(self):
@@ -75,22 +75,24 @@ class HeadMicroBatchDescription(MicroBatchDescription):
Args:
inputs_dict (Dict[str, torch.Tensor]): the inputs of current stage. The key should have `input_ids` and `attention_mask`.
output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
- new_length (int): the new length of the input sequence.
"""
def __init__(
- self, inputs_dict: Dict[str, torch.Tensor], output_dict: Dict[str, torch.Tensor], new_length: int
+ self,
+ inputs_dict: Dict[str, torch.Tensor],
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
) -> None:
- super().__init__(inputs_dict, output_dict, new_length)
+ super().__init__(inputs_dict, max_input_len, max_output_len, cache_manager)
assert inputs_dict is not None
assert inputs_dict.get("input_ids") is not None and inputs_dict.get("attention_mask") is not None
self.input_ids = inputs_dict["input_ids"]
self.attn_mask = inputs_dict["attention_mask"]
self.new_tokens = None
- def update(self, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
- super().update(output_dict, new_token)
+ def update(self, new_token: torch.Tensor = None):
if new_token is not None:
self._update_newtokens(new_token)
if self.state is not Status.DONE and new_token is not None:
@@ -125,16 +127,16 @@ class BodyMicroBatchDescription(MicroBatchDescription):
Args:
inputs_dict (Dict[str, torch.Tensor]): will always be `None`. Other stages only receive hiddenstates from previous stage.
- output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
"""
def __init__(
- self, inputs_dict: Dict[str, torch.Tensor], output_dict: Dict[str, torch.Tensor], new_length: int
+ self,
+ inputs_dict: Dict[str, torch.Tensor],
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
) -> None:
- super().__init__(inputs_dict, output_dict, new_length)
-
- def update(self, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
- super().update(output_dict, new_token)
+ super().__init__(inputs_dict, max_input_len, max_output_len, cache_manager)
@property
def cur_length(self):
@@ -142,10 +144,7 @@ def cur_length(self):
When there is no kv_cache, the length is mb_length, otherwise the sequence length is `kv_cache[0][0].shape[-2]` plus 1
"""
- if len(self.kv_cache) == 0:
- return self.mb_length
- else:
- return self.kv_cache[0][0].shape[-2] + 1
+ return self.infer_state.seq_len.max().item()
class MicroBatchManager:
@@ -154,22 +153,41 @@ class MicroBatchManager:
Args:
stage (int): stage id of current stage.
- new_length (int): the new length of the input sequence.
micro_batch_size (int): the micro batch size.
micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
"""
- def __init__(self, stage: int, new_length: int, micro_batch_size: int, micro_batch_buffer_size: int):
+ def __init__(
+ self,
+ stage: int,
+ micro_batch_size: int,
+ micro_batch_buffer_size: int,
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager_list: MemoryManager,
+ ):
self.stage = stage
- self.new_length = new_length
self.micro_batch_size = micro_batch_size
self.buffer_size = micro_batch_buffer_size
+ self.max_input_len = max_input_len
+ self.max_output_len = max_output_len
+ self.cache_manager_list = cache_manager_list
self.mb_descrption_buffer = {}
self.new_tokens_buffer = {}
self.idx = 0
- def step(self, inputs_dict=None, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
+ def add_descrption(self, inputs_dict: Dict[str, torch.Tensor]):
+ if self.stage == 0:
+ self.mb_descrption_buffer[self.idx] = HeadMicroBatchDescription(
+ inputs_dict, self.max_input_len, self.max_output_len, self.cache_manager_list[self.idx]
+ )
+ else:
+ self.mb_descrption_buffer[self.idx] = BodyMicroBatchDescription(
+ inputs_dict, self.max_input_len, self.max_output_len, self.cache_manager_list[self.idx]
+ )
+
+ def step(self, new_token: torch.Tensor = None):
"""
Update the state if microbatch manager, 2 conditions.
1. For first stage in PREFILL, receive inputs and outputs, `_add_descrption` will save its inputs.
@@ -181,11 +199,7 @@ def step(self, inputs_dict=None, output_dict: Dict[str, torch.Tensor] = None, ne
new_token (torch.Tensor): the new token generated by current stage.
"""
# Add descrption first if the descrption is None
- if inputs_dict is None and output_dict is None and new_token is None:
- return Status.PREFILL
- if self.mb_descrption_buffer.get(self.idx) is None:
- self._add_descrption(inputs_dict, output_dict)
- self.cur_descrption.update(output_dict, new_token)
+ self.cur_descrption.update(new_token)
return self.cur_state
def export_new_tokens(self):
@@ -204,16 +218,12 @@ def is_micro_batch_done(self):
def clear(self):
self.mb_descrption_buffer.clear()
+ for cache in self.cache_manager_list:
+ cache.free_all()
def next(self):
self.idx = (self.idx + 1) % self.buffer_size
- def _add_descrption(self, inputs_dict: Dict[str, torch.Tensor], output_dict: Dict[str, torch.Tensor]):
- if self.stage == 0:
- self.mb_descrption_buffer[self.idx] = HeadMicroBatchDescription(inputs_dict, output_dict, self.new_length)
- else:
- self.mb_descrption_buffer[self.idx] = BodyMicroBatchDescription(inputs_dict, output_dict, self.new_length)
-
def _remove_descrption(self):
self.mb_descrption_buffer.pop(self.idx)
@@ -222,10 +232,10 @@ def cur_descrption(self) -> MicroBatchDescription:
return self.mb_descrption_buffer.get(self.idx)
@property
- def cur_kv_cache(self):
+ def cur_infer_state(self):
if self.cur_descrption is None:
return None
- return self.cur_descrption.kv_cache
+ return self.cur_descrption.infer_state
@property
def cur_state(self):
diff --git a/colossalai/inference/engine/modeling/__init__.py b/colossalai/inference/engine/modeling/__init__.py
new file mode 100644
index 000000000000..8a9e9999d3c5
--- /dev/null
+++ b/colossalai/inference/engine/modeling/__init__.py
@@ -0,0 +1,5 @@
+from .bloom import BloomInferenceForwards
+from .chatglm2 import ChatGLM2InferenceForwards
+from .llama import LlamaInferenceForwards
+
+__all__ = ["LlamaInferenceForwards", "BloomInferenceForwards", "ChatGLM2InferenceForwards"]
diff --git a/colossalai/inference/tensor_parallel/modeling/_utils.py b/colossalai/inference/engine/modeling/_utils.py
similarity index 100%
rename from colossalai/inference/tensor_parallel/modeling/_utils.py
rename to colossalai/inference/engine/modeling/_utils.py
diff --git a/colossalai/inference/engine/modeling/bloom.py b/colossalai/inference/engine/modeling/bloom.py
new file mode 100644
index 000000000000..4c098d3e4c80
--- /dev/null
+++ b/colossalai/inference/engine/modeling/bloom.py
@@ -0,0 +1,452 @@
+import math
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.distributed as dist
+from torch.nn import functional as F
+from transformers.models.bloom.modeling_bloom import (
+ BaseModelOutputWithPastAndCrossAttentions,
+ BloomAttention,
+ BloomBlock,
+ BloomForCausalLM,
+ BloomModel,
+)
+from transformers.utils import logging
+
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
+from colossalai.kernel.triton import bloom_context_attn_fwd, copy_kv_cache_to_dest, token_attention_fwd
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+try:
+ from lightllm.models.bloom.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_bloom_context_attention_fwd,
+ )
+
+ HAS_LIGHTLLM_KERNEL = True
+except:
+ HAS_LIGHTLLM_KERNEL = False
+
+
+def generate_alibi(n_head, dtype=torch.float16):
+ """
+ This method is adapted from `_generate_alibi` function
+ in `lightllm/models/bloom/layer_weights/transformer_layer_weight.py`
+ of the ModelTC/lightllm GitHub repository.
+ This method is originally the `build_alibi_tensor` function
+ in `transformers/models/bloom/modeling_bloom.py`
+ of the huggingface/transformers GitHub repository.
+ """
+
+ def get_slopes_power_of_2(n):
+ start = 2 ** (-(2 ** -(math.log2(n) - 3)))
+ return [start * start**i for i in range(n)]
+
+ def get_slopes(n):
+ if math.log2(n).is_integer():
+ return get_slopes_power_of_2(n)
+ else:
+ closest_power_of_2 = 2 ** math.floor(math.log2(n))
+ slopes_power_of_2 = get_slopes_power_of_2(closest_power_of_2)
+ slopes_double = get_slopes(2 * closest_power_of_2)
+ slopes_combined = slopes_power_of_2 + slopes_double[0::2][: n - closest_power_of_2]
+ return slopes_combined
+
+ slopes = get_slopes(n_head)
+ return torch.tensor(slopes, dtype=dtype)
+
+
+class BloomInferenceForwards:
+ """
+ This class serves a micro library for bloom inference forwards.
+ We intend to replace the forward methods for BloomForCausalLM, BloomModel, BloomBlock, and BloomAttention,
+ as well as prepare_inputs_for_generation method for BloomForCausalLM.
+ For future improvement, we might want to skip replacing methods for BloomForCausalLM,
+ and call BloomModel.forward iteratively in TpInferEngine
+ """
+
+ @staticmethod
+ def bloom_for_causal_lm_forward(
+ self: BloomForCausalLM,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = False,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = False,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ tp_group: Optional[dist.ProcessGroup] = None,
+ **deprecated_arguments,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
+ `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
+ are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
+ """
+ logger = logging.get_logger(__name__)
+
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+
+ # If is first stage and hidden_states is not None, go throught lm_head first
+ if stage_manager.is_first_stage() and hidden_states is not None:
+ lm_logits = self.lm_head(hidden_states)
+ return {"logits": lm_logits}
+
+ outputs = BloomInferenceForwards.bloom_model_forward(
+ self.transformer,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ tp_group=tp_group,
+ )
+
+ return outputs
+
+ @staticmethod
+ def bloom_model_forward(
+ self: BloomModel,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ tp_group: Optional[dist.ProcessGroup] = None,
+ **deprecated_arguments,
+ ) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
+ logger = logging.get_logger(__name__)
+
+ # add warnings here
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once("use_cache=True is not supported for pipeline models at the moment.")
+ use_cache = False
+
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+ if len(deprecated_arguments) > 0:
+ raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape batch_size x num_heads x N x N
+ # head_mask has shape n_layer x batch x num_heads x N x N
+ head_mask = self.get_head_mask(head_mask, self.config.n_layer)
+
+ # first stage
+ if stage_manager.is_first_stage():
+ # check inputs and inputs embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+
+ hidden_states = self.word_embeddings_layernorm(inputs_embeds)
+ # other stage
+ else:
+ input_shape = hidden_states.shape[:-1]
+ batch_size, seq_length = input_shape
+
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
+
+ if seq_length != 1:
+ # prefill stage
+ infer_state.is_context_stage = True # set prefill stage, notify attention layer
+ infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
+ BatchInferState.init_block_loc(
+ infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
+ )
+ else:
+ infer_state.is_context_stage = False
+ alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
+ if alloc_mem is not None:
+ infer_state.decode_is_contiguous = True
+ infer_state.decode_mem_index = alloc_mem[0]
+ infer_state.decode_mem_start = alloc_mem[1]
+ infer_state.decode_mem_end = alloc_mem[2]
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+ else:
+ print(f" *** Encountered allocation non-contiguous")
+ print(f" infer_state.max_len_in_batch : {infer_state.max_len_in_batch}")
+ infer_state.decode_is_contiguous = False
+ alloc_mem = infer_state.cache_manager.alloc(batch_size)
+ infer_state.decode_mem_index = alloc_mem
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, infer_state.max_len_in_batch), device=hidden_states.device)
+ else:
+ attention_mask = attention_mask.to(hidden_states.device)
+
+ # NOTE revise: we might want to store a single 1D alibi(length is #heads) in model,
+ # or store to BatchInferState to prevent re-calculating
+ # When we have multiple process group (e.g. dp together with tp), we need to pass the pg to here
+ tp_size = dist.get_world_size(tp_group) if tp_group is not None else 1
+ curr_tp_rank = dist.get_rank(tp_group) if tp_group is not None else 0
+ alibi = (
+ generate_alibi(self.num_heads * tp_size)
+ .contiguous()[curr_tp_rank * self.num_heads : (curr_tp_rank + 1) * self.num_heads]
+ .cuda()
+ )
+ causal_mask = self._prepare_attn_mask(
+ attention_mask,
+ input_shape=(batch_size, seq_length),
+ past_key_values_length=past_key_values_length,
+ )
+
+ infer_state.decode_layer_id = 0
+
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ if past_key_values is None:
+ past_key_values = tuple([None] * (end_idx - start_idx + 1))
+
+ for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
+ block = self.h[idx]
+ outputs = block(
+ hidden_states,
+ layer_past=past_key_value,
+ attention_mask=causal_mask,
+ head_mask=head_mask[idx],
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ alibi=alibi,
+ infer_state=infer_state,
+ )
+
+ infer_state.decode_layer_id += 1
+ hidden_states = outputs[0]
+
+ if stage_manager.is_last_stage() or stage_manager.num_stages == 1:
+ hidden_states = self.ln_f(hidden_states)
+
+ # update indices
+ infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
+
+ # always return dict for imediate stage
+ return {"hidden_states": hidden_states}
+
+ @staticmethod
+ def bloom_block_forward(
+ self: BloomBlock,
+ hidden_states: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ # hidden_states: [batch_size, seq_length, hidden_size]
+
+ # Layer norm at the beginning of the transformer layer.
+ layernorm_output = self.input_layernorm(hidden_states)
+
+ # Layer norm post the self attention.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = hidden_states
+
+ # Self attention.
+ attn_outputs = self.self_attention(
+ layernorm_output,
+ residual,
+ layer_past=layer_past,
+ attention_mask=attention_mask,
+ alibi=alibi,
+ head_mask=head_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ infer_state=infer_state,
+ )
+
+ attention_output = attn_outputs[0]
+
+ outputs = attn_outputs[1:]
+
+ layernorm_output = self.post_attention_layernorm(attention_output)
+
+ # Get residual
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = attention_output
+
+ # MLP.
+ output = self.mlp(layernorm_output, residual)
+
+ if use_cache:
+ outputs = (output,) + outputs
+ else:
+ outputs = (output,) + outputs[1:]
+
+ return outputs # hidden_states, present, attentions
+
+ @staticmethod
+ def bloom_attention_forward(
+ self: BloomAttention,
+ hidden_states: torch.Tensor,
+ residual: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
+
+ # 3 x [batch_size, seq_length, num_heads, head_dim]
+ (query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
+ batch_size, q_length, H, D_HEAD = query_layer.shape
+ k = key_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
+ v = value_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
+
+ mem_manager = infer_state.cache_manager
+ layer_id = infer_state.decode_layer_id
+
+ if infer_state.is_context_stage:
+ # context process
+ max_input_len = q_length
+ b_start_loc = infer_state.start_loc
+ b_seq_len = infer_state.seq_len[:batch_size]
+ q = query_layer.reshape(-1, H, D_HEAD)
+
+ copy_kv_cache_to_dest(k, infer_state.context_mem_index, mem_manager.key_buffer[layer_id])
+ copy_kv_cache_to_dest(v, infer_state.context_mem_index, mem_manager.value_buffer[layer_id])
+
+ # output = self.output[:batch_size*q_length, :, :]
+ output = torch.empty_like(q)
+
+ if HAS_LIGHTLLM_KERNEL:
+ lightllm_bloom_context_attention_fwd(q, k, v, output, alibi, b_start_loc, b_seq_len, max_input_len)
+ else:
+ bloom_context_attn_fwd(q, k, v, output, b_start_loc, b_seq_len, max_input_len, alibi)
+
+ context_layer = output.view(batch_size, q_length, H * D_HEAD)
+ else:
+ # query_layer = query_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
+ # need shape: batch_size, H, D_HEAD (q_length == 1), input q shape : (batch_size, q_length(1), H, D_HEAD)
+ assert q_length == 1, "for non-context process, we only support q_length == 1"
+ q = query_layer.reshape(-1, H, D_HEAD)
+
+ if infer_state.decode_is_contiguous:
+ # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
+ cache_k = infer_state.cache_manager.key_buffer[layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_k.copy_(k)
+ cache_v.copy_(v)
+ else:
+ # if decode is not contiguous, use triton kernel to copy key and value cache
+ # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head]
+ copy_kv_cache_to_dest(k, infer_state.decode_mem_index, mem_manager.key_buffer[layer_id])
+ copy_kv_cache_to_dest(v, infer_state.decode_mem_index, mem_manager.value_buffer[layer_id])
+
+ b_start_loc = infer_state.start_loc
+ b_loc = infer_state.block_loc
+ b_seq_len = infer_state.seq_len
+ output = torch.empty_like(q)
+ token_attention_fwd(
+ q,
+ mem_manager.key_buffer[layer_id],
+ mem_manager.value_buffer[layer_id],
+ output,
+ b_loc,
+ b_start_loc,
+ b_seq_len,
+ infer_state.max_len_in_batch,
+ alibi,
+ )
+
+ context_layer = output.view(batch_size, q_length, H * D_HEAD)
+
+ # NOTE: always set present as none for now, instead of returning past key value to the next decoding,
+ # we create the past key value pair from the cache manager
+ present = None
+
+ # aggregate results across tp ranks. See here: https://github.com/pytorch/pytorch/issues/76232
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ slices = self.hidden_size / self.pretraining_tp
+ output_tensor = torch.zeros_like(context_layer)
+ for i in range(self.pretraining_tp):
+ output_tensor = output_tensor + F.linear(
+ context_layer[:, :, int(i * slices) : int((i + 1) * slices)],
+ self.dense.weight[:, int(i * slices) : int((i + 1) * slices)],
+ )
+ else:
+ output_tensor = self.dense(context_layer)
+
+ # dropout is not required here during inference
+ output_tensor = residual + output_tensor
+
+ outputs = (output_tensor, present)
+ assert output_attentions is False, "we do not support output_attentions at this time"
+
+ return outputs
diff --git a/colossalai/inference/engine/modeling/chatglm2.py b/colossalai/inference/engine/modeling/chatglm2.py
new file mode 100644
index 000000000000..56e777bb2b87
--- /dev/null
+++ b/colossalai/inference/engine/modeling/chatglm2.py
@@ -0,0 +1,492 @@
+from typing import List, Optional, Tuple
+
+import torch
+from transformers.utils import logging
+
+from colossalai.inference.kv_cache import BatchInferState
+from colossalai.kernel.triton.token_attention_kernel import Llama2TokenAttentionForwards
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer import ShardConfig
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
+ ChatGLMForConditionalGeneration,
+ ChatGLMModel,
+ GLMBlock,
+ GLMTransformer,
+ SelfAttention,
+ split_tensor_along_last_dim,
+)
+
+from ._utils import copy_kv_to_mem_cache
+
+try:
+ from lightllm.models.chatglm2.triton_kernel.rotary_emb import rotary_emb_fwd as chatglm2_rotary_emb_fwd
+ from lightllm.models.llama2.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_llama2_context_attention_fwd,
+ )
+
+ HAS_LIGHTLLM_KERNEL = True
+except:
+ print("please install lightllm from source to run inference: https://github.com/ModelTC/lightllm")
+ HAS_LIGHTLLM_KERNEL = False
+
+
+def get_masks(self, input_ids, past_length, padding_mask=None):
+ batch_size, seq_length = input_ids.shape
+ full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
+ full_attention_mask.tril_()
+ if past_length:
+ full_attention_mask = torch.cat(
+ (
+ torch.ones(batch_size, seq_length, past_length, device=input_ids.device),
+ full_attention_mask,
+ ),
+ dim=-1,
+ )
+
+ if padding_mask is not None:
+ full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
+ if not past_length and padding_mask is not None:
+ full_attention_mask -= padding_mask.unsqueeze(-1) - 1
+ full_attention_mask = (full_attention_mask < 0.5).bool()
+ full_attention_mask.unsqueeze_(1)
+ return full_attention_mask
+
+
+def get_position_ids(batch_size, seq_length, device):
+ position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
+ return position_ids
+
+
+class ChatGLM2InferenceForwards:
+ """
+ This class holds forwards for Chatglm2 inference.
+ We intend to replace the forward methods for ChatGLMModel, ChatGLMEecoderLayer, and ChatGLMAttention.
+ """
+
+ @staticmethod
+ def chatglm_for_conditional_generation_forward(
+ self: ChatGLMForConditionalGeneration,
+ input_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = True,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ return_last_logit: Optional[bool] = False,
+ infer_state: Optional[BatchInferState] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ shard_config: ShardConfig = None,
+ ):
+ logger = logging.get_logger(__name__)
+
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+
+ # If is first stage and hidden_states is not None, go throught lm_head first
+ if stage_manager.is_first_stage() and hidden_states is not None:
+ if return_last_logit:
+ hidden_states = hidden_states[-1:]
+ lm_logits = self.transformer.output_layer(hidden_states)
+ lm_logits = lm_logits.transpose(0, 1).contiguous()
+ return {"logits": lm_logits}
+
+ outputs = self.transformer(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ attention_mask=attention_mask,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ shard_config=shard_config,
+ )
+
+ return outputs
+
+ @staticmethod
+ def chatglm_model_forward(
+ self: ChatGLMModel,
+ input_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.BoolTensor] = None,
+ full_attention_mask: Optional[torch.BoolTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ shard_config: ShardConfig = None,
+ ):
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+
+ if stage_manager.is_first_stage():
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+ if inputs_embeds is None:
+ inputs_embeds = self.embedding(input_ids)
+ if position_ids is None:
+ position_ids = get_position_ids(batch_size, seq_length, input_ids.device)
+ hidden_states = inputs_embeds
+ else:
+ assert hidden_states is not None, "hidden_states should not be None in non-first stage"
+ seq_length, batch_size, _ = hidden_states.shape
+ if position_ids is None:
+ position_ids = get_position_ids(batch_size, seq_length, hidden_states.device)
+
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
+
+ seq_length_with_past = seq_length + past_key_values_length
+
+ # prefill stage at first
+ if seq_length != 1:
+ infer_state.is_context_stage = True
+ infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
+ infer_state.init_block_loc(
+ infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
+ )
+ else:
+ infer_state.is_context_stage = False
+ alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
+ if alloc_mem is not None:
+ infer_state.decode_is_contiguous = True
+ infer_state.decode_mem_index = alloc_mem[0]
+ infer_state.decode_mem_start = alloc_mem[1]
+ infer_state.decode_mem_end = alloc_mem[2]
+ infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
+ else:
+ print(f" *** Encountered allocation non-contiguous")
+ print(
+ f" infer_state.cache_manager.past_key_values_length: {infer_state.cache_manager.past_key_values_length}"
+ )
+ infer_state.decode_is_contiguous = False
+ alloc_mem = infer_state.cache_manager.alloc(batch_size)
+ infer_state.decode_mem_index = alloc_mem
+ infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
+
+ # related to rotary embedding
+ if infer_state.is_context_stage:
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+ else:
+ seq_len = infer_state.seq_len
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.other_kv_index = infer_state.block_loc[0, infer_state.max_len_in_batch - 1].item()
+
+ if self.pre_seq_len is not None:
+ if past_key_values is None:
+ past_key_values = self.get_prompt(
+ batch_size=batch_size,
+ device=input_ids.device,
+ dtype=inputs_embeds.dtype,
+ )
+ if attention_mask is not None:
+ attention_mask = torch.cat(
+ [
+ attention_mask.new_ones((batch_size, self.pre_seq_len)),
+ attention_mask,
+ ],
+ dim=-1,
+ )
+ if full_attention_mask is None:
+ if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
+ full_attention_mask = get_masks(
+ self, input_ids, infer_state.cache_manager.past_key_values_length, padding_mask=attention_mask
+ )
+
+ # Run encoder.
+ hidden_states = self.encoder(
+ hidden_states,
+ full_attention_mask,
+ kv_caches=past_key_values,
+ use_cache=use_cache,
+ output_hidden_states=output_hidden_states,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ stage_index=stage_index,
+ shard_config=shard_config,
+ )
+
+ # update indices
+ infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
+
+ return {"hidden_states": hidden_states}
+
+ @staticmethod
+ def chatglm_encoder_forward(
+ self: GLMTransformer,
+ hidden_states,
+ attention_mask,
+ kv_caches=None,
+ use_cache: Optional[bool] = True,
+ output_hidden_states: Optional[bool] = False,
+ infer_state: Optional[BatchInferState] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ stage_index: Optional[List[int]] = None,
+ shard_config: ShardConfig = None,
+ ):
+ hidden_states = hidden_states.transpose(0, 1).contiguous()
+
+ infer_state.decode_layer_id = 0
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ if kv_caches is None:
+ kv_caches = tuple([None] * (end_idx - start_idx + 1))
+
+ for idx, kv_cache in zip(range(start_idx, end_idx), kv_caches):
+ layer = self.layers[idx]
+ layer_ret = layer(
+ hidden_states,
+ attention_mask,
+ kv_cache=kv_cache,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+ infer_state.decode_layer_id += 1
+
+ hidden_states, _ = layer_ret
+
+ hidden_states = hidden_states.transpose(0, 1).contiguous()
+
+ if self.post_layer_norm and (stage_manager.is_last_stage() or stage_manager.num_stages == 1):
+ # Final layer norm.
+ hidden_states = self.final_layernorm(hidden_states)
+
+ return hidden_states
+
+ @staticmethod
+ def chatglm_glmblock_forward(
+ self: GLMBlock,
+ hidden_states,
+ attention_mask,
+ kv_cache=None,
+ use_cache=True,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ # hidden_states: [s, b, h]
+
+ # Layer norm at the beginning of the transformer layer.
+ layernorm_output = self.input_layernorm(hidden_states)
+ # Self attention.
+ attention_output, kv_cache = self.self_attention(
+ layernorm_output,
+ attention_mask,
+ kv_cache=kv_cache,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+ # Residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = hidden_states
+ layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
+ layernorm_input = residual + layernorm_input
+ # Layer norm post the self attention.
+ layernorm_output = self.post_attention_layernorm(layernorm_input)
+ # MLP.
+ mlp_output = self.mlp(layernorm_output)
+
+ # Second residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = layernorm_input
+
+ output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
+ output = residual + output
+ return output, kv_cache
+
+ @staticmethod
+ def chatglm_flash_attn_kvcache_forward(
+ self: SelfAttention,
+ hidden_states,
+ attention_mask,
+ kv_cache=None,
+ use_cache=True,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ assert use_cache is True, "use_cache should be set to True using this chatglm attention"
+ # hidden_states: original :[sq, b, h] --> this [b, sq, h]
+ batch_size = hidden_states.shape[0]
+ hidden_size = hidden_states.shape[-1]
+ # Attention heads [sq, b, h] --> [sq, b, (np * 3 * hn)]
+ mixed_x_layer = self.query_key_value(hidden_states)
+ if self.multi_query_attention:
+ (query_layer, key_layer, value_layer) = mixed_x_layer.split(
+ [
+ self.num_attention_heads_per_partition * self.hidden_size_per_attention_head,
+ self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
+ self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
+ ],
+ dim=-1,
+ )
+ query_layer = query_layer.view(
+ query_layer.size()[:-1]
+ + (
+ self.num_attention_heads_per_partition,
+ self.hidden_size_per_attention_head,
+ )
+ )
+ key_layer = key_layer.view(
+ key_layer.size()[:-1]
+ + (
+ self.num_multi_query_groups_per_partition,
+ self.hidden_size_per_attention_head,
+ )
+ )
+ value_layer = value_layer.view(
+ value_layer.size()[:-1]
+ + (
+ self.num_multi_query_groups_per_partition,
+ self.hidden_size_per_attention_head,
+ )
+ )
+
+ else:
+ new_tensor_shape = mixed_x_layer.size()[:-1] + (
+ self.num_attention_heads_per_partition,
+ 3 * self.hidden_size_per_attention_head,
+ )
+ mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
+ # [sq, b, np, 3 * hn] --> 3 [sq, b, np, hn]
+ (query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
+ cos, sin = infer_state.position_cos, infer_state.position_sin
+
+ chatglm2_rotary_emb_fwd(
+ query_layer.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head), cos, sin
+ )
+ if self.multi_query_attention:
+ chatglm2_rotary_emb_fwd(
+ key_layer.view(-1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head),
+ cos,
+ sin,
+ )
+ else:
+ chatglm2_rotary_emb_fwd(
+ key_layer.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head),
+ cos,
+ sin,
+ )
+
+ # reshape q k v to [bsz*sql, num_heads, head_dim] 2*1 ,32/2 ,128
+ query_layer = query_layer.reshape(
+ -1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head
+ )
+ key_layer = key_layer.reshape(
+ -1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head
+ )
+ value_layer = value_layer.reshape(
+ -1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head
+ )
+
+ if infer_state.is_context_stage:
+ # first token generation:
+ # copy key and value calculated in current step to memory manager
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_layer,
+ value_layer,
+ infer_state.context_mem_index,
+ infer_state.cache_manager,
+ )
+ attn_output = torch.empty_like(query_layer.contiguous().view(-1, self.projection_size))
+
+ # NOTE: no bug in context attn fwd (del it )
+ lightllm_llama2_context_attention_fwd(
+ query_layer,
+ key_layer,
+ value_layer,
+ attn_output.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head),
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+
+ else:
+ if infer_state.decode_is_contiguous:
+ # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_k.copy_(key_layer)
+ cache_v.copy_(value_layer)
+ else:
+ # if decode is not contiguous, use triton kernel to copy key and value cache
+ # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_layer,
+ value_layer,
+ infer_state.decode_mem_index,
+ infer_state.cache_manager,
+ )
+
+ # second token and follows
+ attn_output = torch.empty_like(query_layer.contiguous().view(-1, self.projection_size))
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
+ : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
+ : infer_state.decode_mem_end, :, :
+ ]
+
+ # ==================================
+ # core attention computation is replaced by triton kernel
+ # ==================================
+ Llama2TokenAttentionForwards.token_attn(
+ query_layer,
+ cache_k,
+ cache_v,
+ attn_output,
+ infer_state.block_loc,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ infer_state.other_kv_index,
+ )
+
+ # =================
+ # Output:[b,sq, h]
+ # =================
+ output = self.dense(attn_output).reshape(batch_size, -1, hidden_size)
+
+ return output, kv_cache
diff --git a/colossalai/inference/engine/modeling/llama.py b/colossalai/inference/engine/modeling/llama.py
new file mode 100644
index 000000000000..b7bc94d0eae0
--- /dev/null
+++ b/colossalai/inference/engine/modeling/llama.py
@@ -0,0 +1,492 @@
+# This code is adapted from huggingface transformers: https://github.com/huggingface/transformers/blob/v4.34.1/src/transformers/models/llama/modeling_llama.py
+import math
+from typing import List, Optional, Tuple
+
+import torch
+from transformers.models.llama.modeling_llama import LlamaAttention, LlamaDecoderLayer, LlamaForCausalLM, LlamaModel
+from transformers.utils import logging
+
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
+from colossalai.kernel.triton import llama_context_attn_fwd, token_attention_fwd
+from colossalai.kernel.triton.token_attention_kernel import Llama2TokenAttentionForwards
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+from ._utils import copy_kv_to_mem_cache
+
+try:
+ from lightllm.models.llama2.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_llama2_context_attention_fwd,
+ )
+ from lightllm.models.llama.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_context_attention_fwd,
+ )
+ from lightllm.models.llama.triton_kernel.rotary_emb import rotary_emb_fwd as llama_rotary_embedding_fwd
+
+ HAS_LIGHTLLM_KERNEL = True
+except:
+ print("please install lightllm from source to run inference: https://github.com/ModelTC/lightllm")
+ HAS_LIGHTLLM_KERNEL = False
+
+try:
+ from colossalai.kernel.triton.flash_decoding import token_flash_decoding
+ HAS_TRITON_FLASH_DECODING_KERNEL = True
+except:
+ print("no triton flash decoding support, please install lightllm from https://github.com/ModelTC/lightllm/blob/ece7b43f8a6dfa74027adc77c2c176cff28c76c8")
+ HAS_TRITON_FLASH_DECODING_KERNEL = False
+
+try:
+ from flash_attn import flash_attn_with_kvcache
+ HAS_FLASH_KERNEL = True
+except:
+ HAS_FLASH_KERNEL = False
+ print("please install flash attentiom from https://github.com/Dao-AILab/flash-attention")
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
+ # The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
+ cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
+ sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
+ cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def llama_triton_context_attention(
+ query_states, key_states, value_states, attn_output, infer_state, num_key_value_groups=1
+):
+ if num_key_value_groups == 1:
+ if HAS_LIGHTLLM_KERNEL is False:
+ llama_context_attn_fwd(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+ else:
+ lightllm_context_attention_fwd(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+ else:
+ assert HAS_LIGHTLLM_KERNEL is True, "You have to install lightllm kernels to run llama2 model"
+ lightllm_llama2_context_attention_fwd(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+
+def llama_triton_token_attention(query_states, attn_output, infer_state, num_key_value_groups=1, q_head_num = -1, head_dim = -1):
+ if HAS_TRITON_FLASH_DECODING_KERNEL and q_head_num != -1 and head_dim != -1:
+ token_flash_decoding(q = query_states,
+ o_tensor = attn_output,
+ infer_state = infer_state,
+ q_head_num = q_head_num,
+ head_dim = head_dim,
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id])
+ return
+
+ if num_key_value_groups == 1:
+ token_attention_fwd(
+ query_states,
+ infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
+ infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
+ attn_output,
+ infer_state.block_loc,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+ else:
+ Llama2TokenAttentionForwards.token_attn(
+ query_states,
+ infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
+ infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
+ attn_output,
+ infer_state.block_loc,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ infer_state.other_kv_index,
+ )
+
+
+class LlamaInferenceForwards:
+ """
+ This class holds forwards for llama inference.
+ We intend to replace the forward methods for LlamaModel, LlamaDecoderLayer, and LlamaAttention for LlamaForCausalLM.
+ """
+
+ @staticmethod
+ def llama_causal_lm_forward(
+ self: LlamaForCausalLM,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ """
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+
+ # If is first stage and hidden_states is None, go throught lm_head first
+ if stage_manager.is_first_stage() and hidden_states is not None:
+ lm_logits = self.lm_head(hidden_states)
+ return {"logits": lm_logits}
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = LlamaInferenceForwards.llama_model_forward(
+ self.model,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ )
+
+ return outputs
+
+ @staticmethod
+ def llama_model_forward(
+ self: LlamaModel,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ # retrieve input_ids and inputs_embeds
+ if stage_manager is None or stage_manager.is_first_stage():
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+ hidden_states = inputs_embeds
+ else:
+ assert stage_manager is not None
+ assert hidden_states is not None, f"hidden_state should not be none in stage {stage_manager.stage}"
+ input_shape = hidden_states.shape[:-1]
+ batch_size, seq_length = input_shape
+ device = hidden_states.device
+
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
+
+ # NOTE: differentiate with prefill stage
+ # block_loc require different value-assigning method for two different stage
+ if use_cache and seq_length != 1:
+ # NOTE assume prefill stage
+ # allocate memory block
+ infer_state.is_context_stage = True # set prefill stage, notify attention layer
+ infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
+ infer_state.init_block_loc(
+ infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
+ )
+ else:
+ infer_state.is_context_stage = False
+ alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
+ if alloc_mem is not None:
+ infer_state.decode_is_contiguous = True
+ infer_state.decode_mem_index = alloc_mem[0]
+ infer_state.decode_mem_start = alloc_mem[1]
+ infer_state.decode_mem_end = alloc_mem[2]
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+ else:
+ infer_state.decode_is_contiguous = False
+ alloc_mem = infer_state.cache_manager.alloc(batch_size)
+ infer_state.decode_mem_index = alloc_mem
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+
+ if position_ids is None:
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.repeat(batch_size, 1)
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ if infer_state.is_context_stage:
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+
+ else:
+ seq_len = infer_state.seq_len
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.other_kv_index = infer_state.block_loc[0, infer_state.max_len_in_batch - 1].item()
+
+ # embed positions
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ (batch_size, infer_state.max_len_in_batch), dtype=torch.bool, device=hidden_states.device
+ )
+
+ attention_mask = self._prepare_decoder_attention_mask(
+ attention_mask, (batch_size, seq_length), hidden_states, past_key_values_length
+ )
+
+ # decoder layers
+ infer_state.decode_layer_id = 0
+
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ if past_key_values is None:
+ past_key_values = tuple([None] * (end_idx - start_idx + 1))
+
+ for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
+ decoder_layer = self.layers[idx]
+ # NOTE: modify here for passing args to decoder layer
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+ infer_state.decode_layer_id += 1
+ hidden_states = layer_outputs[0]
+
+ if stage_manager.is_last_stage() or stage_manager.num_stages == 1:
+ hidden_states = self.norm(hidden_states)
+
+ # update indices
+ # infer_state.block_loc[:, infer_state.max_len_in_batch-1] = infer_state.total_token_num + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.start_loc += torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
+
+ return {"hidden_states": hidden_states}
+
+ @staticmethod
+ def llama_decoder_layer_forward(
+ self: LlamaDecoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ infer_state: Optional[BatchInferState] = None,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+ @staticmethod
+ def llama_flash_attn_kvcache_forward(
+ self: LlamaAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ infer_state: Optional[BatchInferState] = None,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ assert use_cache is True, "use_cache should be set to True using this llama attention"
+
+ bsz, q_len, _ = hidden_states.size()
+
+ # NOTE might think about better way to handle transposed k and v
+ # key_states [bs, seq_len, num_heads, head_dim/embed_size_per_head]
+ # key_states_transposed [bs, num_heads, seq_len, head_dim/embed_size_per_head]
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim)
+
+ # NOTE might want to revise
+ # need some way to record the length of past key values cache
+ # since we won't return past_key_value_cache right now
+
+ cos, sin = infer_state.position_cos, infer_state.position_sin
+
+ llama_rotary_embedding_fwd(query_states.view(-1, self.num_heads, self.head_dim), cos, sin)
+ llama_rotary_embedding_fwd(key_states.view(-1, self.num_key_value_heads, self.head_dim), cos, sin)
+
+ query_states = query_states.reshape(-1, self.num_heads, self.head_dim)
+ key_states = key_states.reshape(-1, self.num_key_value_heads, self.head_dim)
+ value_states = value_states.reshape(-1, self.num_key_value_heads, self.head_dim)
+
+ if infer_state.is_context_stage:
+ # first token generation
+ # copy key and value calculated in current step to memory manager
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_states,
+ value_states,
+ infer_state.context_mem_index,
+ infer_state.cache_manager,
+ )
+ attn_output = torch.empty_like(query_states)
+
+ llama_triton_context_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state,
+ num_key_value_groups=self.num_key_value_groups,
+ )
+ else:
+ if infer_state.decode_is_contiguous:
+ # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_k.copy_(key_states)
+ cache_v.copy_(value_states)
+ else:
+ # if decode is not contiguous, use triton kernel to copy key and value cache
+ # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_states,
+ value_states,
+ infer_state.decode_mem_index,
+ infer_state.cache_manager,
+ )
+
+ if HAS_LIGHTLLM_KERNEL:
+
+ attn_output = torch.empty_like(query_states)
+ llama_triton_token_attention(query_states = query_states,
+ attn_output = attn_output,
+ infer_state = infer_state,
+ num_key_value_groups = self.num_key_value_groups,
+ q_head_num = q_len * self.num_heads,
+ head_dim = self.head_dim)
+ else:
+ self.num_heads // self.num_key_value_heads
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id]
+
+ query_states = query_states.view(bsz, -1, self.num_heads, self.head_dim)
+ copy_cache_k = cache_k.view(bsz, -1, self.num_key_value_heads, self.head_dim)
+ copy_cache_v = cache_v.view(bsz, -1, self.num_key_value_heads, self.head_dim)
+
+ attn_output = flash_attn_with_kvcache(
+ q=query_states,
+ k_cache=copy_cache_k,
+ v_cache=copy_cache_v,
+ softmax_scale=1 / math.sqrt(self.head_dim),
+ causal=True,
+ )
+
+ attn_output = attn_output.view(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ # return past_key_value as None
+ return attn_output, None, None
diff --git a/colossalai/inference/engine/policies/__init__.py b/colossalai/inference/engine/policies/__init__.py
new file mode 100644
index 000000000000..269d1c57b276
--- /dev/null
+++ b/colossalai/inference/engine/policies/__init__.py
@@ -0,0 +1,11 @@
+from .bloom import BloomModelInferPolicy
+from .chatglm2 import ChatGLM2InferPolicy
+from .llama import LlamaModelInferPolicy
+
+model_policy_map = {
+ "llama": LlamaModelInferPolicy,
+ "bloom": BloomModelInferPolicy,
+ "chatglm": ChatGLM2InferPolicy,
+}
+
+__all__ = ["LlamaModelInferPolicy", "BloomModelInferPolicy", "ChatGLM2InferPolicy", "model_polic_map"]
diff --git a/colossalai/inference/engine/policies/bloom.py b/colossalai/inference/engine/policies/bloom.py
new file mode 100644
index 000000000000..f35b50189e82
--- /dev/null
+++ b/colossalai/inference/engine/policies/bloom.py
@@ -0,0 +1,127 @@
+from functools import partial
+from typing import List
+
+import torch
+from torch.nn import LayerNorm, Module
+
+import colossalai.shardformer.layer as col_nn
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
+from colossalai.shardformer.policies.bloom import BloomForCausalLMPolicy
+
+from ..modeling.bloom import BloomInferenceForwards
+
+try:
+ from colossalai.kernel.triton import layer_norm
+
+ HAS_TRITON_NORM = True
+except:
+ print("Some of our kernels require triton. You might want to install triton from https://github.com/openai/triton")
+ HAS_TRITON_NORM = False
+
+
+def get_triton_layernorm_forward():
+ if HAS_TRITON_NORM:
+
+ def _triton_layernorm_forward(self: LayerNorm, hidden_states: torch.Tensor):
+ return layer_norm(hidden_states, self.weight.data, self.bias, self.eps)
+
+ return _triton_layernorm_forward
+ else:
+ return None
+
+
+class BloomModelInferPolicy(BloomForCausalLMPolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ from transformers.models.bloom.modeling_bloom import BloomAttention, BloomBlock, BloomForCausalLM, BloomModel
+
+ policy = super().module_policy()
+ if self.shard_config.extra_kwargs.get("quant", None) == "gptq":
+ from colossalai.inference.quant.gptq.cai_gptq import ColCaiQuantLinear, RowCaiQuantLinear
+
+ policy[BloomBlock] = ModulePolicyDescription(
+ attribute_replacement={
+ "self_attention.hidden_size": self.model.config.hidden_size
+ // self.shard_config.tensor_parallel_size,
+ "self_attention.split_size": self.model.config.hidden_size
+ // self.shard_config.tensor_parallel_size,
+ "self_attention.num_heads": self.model.config.n_head // self.shard_config.tensor_parallel_size,
+ },
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attention.query_key_value",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 3},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attention.dense", target_module=RowCaiQuantLinear, kwargs={"split_num": 1}
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attention.attention_dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.dense_h_to_4h", target_module=ColCaiQuantLinear, kwargs={"split_num": 1}
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.dense_4h_to_h", target_module=RowCaiQuantLinear, kwargs={"split_num": 1}
+ ),
+ ],
+ )
+ # NOTE set inference mode to shard config
+ self.shard_config._infer()
+
+ # set as default, in inference we also use pipeline style forward, just setting stage as 1
+ self.set_pipeline_forward(
+ model_cls=BloomForCausalLM,
+ new_forward=partial(
+ BloomInferenceForwards.bloom_for_causal_lm_forward,
+ tp_group=self.shard_config.tensor_parallel_process_group,
+ ),
+ policy=policy,
+ )
+
+ method_replacement = {"forward": BloomInferenceForwards.bloom_model_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomModel)
+
+ method_replacement = {"forward": BloomInferenceForwards.bloom_block_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomBlock)
+
+ method_replacement = {"forward": BloomInferenceForwards.bloom_attention_forward}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=BloomAttention
+ )
+
+ if HAS_TRITON_NORM:
+ infer_method = get_triton_layernorm_forward()
+ method_replacement = {"forward": partial(infer_method)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LayerNorm
+ )
+
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == "BloomModel":
+ module = self.model
+ else:
+ module = self.model.transformer
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(len(module.h), stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.word_embeddings)
+ held_layers.append(module.word_embeddings_layernorm)
+ held_layers.append(self.model.lm_head)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.h[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.ln_f)
+
+ return held_layers
diff --git a/colossalai/inference/engine/policies/chatglm2.py b/colossalai/inference/engine/policies/chatglm2.py
new file mode 100644
index 000000000000..3e1d94f4785c
--- /dev/null
+++ b/colossalai/inference/engine/policies/chatglm2.py
@@ -0,0 +1,89 @@
+from typing import List
+
+import torch.nn as nn
+
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
+ ChatGLMForConditionalGeneration,
+ ChatGLMModel,
+ GLMBlock,
+ GLMTransformer,
+ SelfAttention,
+)
+
+# import colossalai
+from colossalai.shardformer.policies.chatglm2 import ChatGLMModelPolicy
+
+from ..modeling._utils import init_to_get_rotary
+from ..modeling.chatglm2 import ChatGLM2InferenceForwards
+
+try:
+ HAS_TRITON_RMSNORM = True
+except:
+ print("you should install triton from https://github.com/openai/triton")
+ HAS_TRITON_RMSNORM = False
+
+
+class ChatGLM2InferPolicy(ChatGLMModelPolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ policy = super().module_policy()
+ self.shard_config._infer()
+
+ model_infer_forward = ChatGLM2InferenceForwards.chatglm_model_forward
+ method_replacement = {"forward": model_infer_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=ChatGLMModel)
+
+ encoder_infer_forward = ChatGLM2InferenceForwards.chatglm_encoder_forward
+ method_replacement = {"forward": encoder_infer_forward}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=GLMTransformer
+ )
+
+ encoder_layer_infer_forward = ChatGLM2InferenceForwards.chatglm_glmblock_forward
+ method_replacement = {"forward": encoder_layer_infer_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=GLMBlock)
+
+ attn_infer_forward = ChatGLM2InferenceForwards.chatglm_flash_attn_kvcache_forward
+ method_replacement = {"forward": attn_infer_forward}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=SelfAttention
+ )
+ if self.shard_config.enable_tensor_parallelism:
+ policy[GLMBlock].attribute_replacement["self_attention.num_multi_query_groups_per_partition"] = (
+ self.model.config.multi_query_group_num // self.shard_config.tensor_parallel_size
+ )
+ # for rmsnorm and others, we need to check the shape
+
+ self.set_pipeline_forward(
+ model_cls=ChatGLMForConditionalGeneration,
+ new_forward=ChatGLM2InferenceForwards.chatglm_for_conditional_generation_forward,
+ policy=policy,
+ )
+
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ module = self.model.transformer
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(module.num_layers, stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embedding)
+ held_layers.append(module.output_layer)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.encoder.layers[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ if module.encoder.post_layer_norm:
+ held_layers.append(module.encoder.final_layernorm)
+
+ # rotary_pos_emb is needed for all stages
+ held_layers.append(module.rotary_pos_emb)
+
+ return held_layers
+
+ def postprocess(self):
+ init_to_get_rotary(self.model.transformer)
+ return self.model
diff --git a/colossalai/inference/engine/policies/llama.py b/colossalai/inference/engine/policies/llama.py
new file mode 100644
index 000000000000..11517d7e8a13
--- /dev/null
+++ b/colossalai/inference/engine/policies/llama.py
@@ -0,0 +1,206 @@
+from functools import partial
+from typing import List
+
+import torch
+from torch.nn import Module
+from transformers.models.llama.modeling_llama import (
+ LlamaAttention,
+ LlamaDecoderLayer,
+ LlamaForCausalLM,
+ LlamaModel,
+ LlamaRMSNorm,
+)
+
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
+
+# import colossalai
+from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy
+
+from ..modeling._utils import init_to_get_rotary
+from ..modeling.llama import LlamaInferenceForwards
+
+try:
+ from colossalai.kernel.triton import rmsnorm_forward
+
+ HAS_TRITON_RMSNORM = True
+except:
+ print("you should install triton from https://github.com/openai/triton")
+ HAS_TRITON_RMSNORM = False
+
+
+def get_triton_rmsnorm_forward():
+ if HAS_TRITON_RMSNORM:
+
+ def _triton_rmsnorm_forward(self: LlamaRMSNorm, hidden_states: torch.Tensor):
+ return rmsnorm_forward(hidden_states, self.weight.data, self.variance_epsilon)
+
+ return _triton_rmsnorm_forward
+ else:
+ return None
+
+
+class LlamaModelInferPolicy(LlamaForCausalLMPolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ policy = super().module_policy()
+ decoder_attribute_replacement = {
+ "self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "self_attn.num_key_value_heads": self.model.config.num_key_value_heads
+ // self.shard_config.tensor_parallel_size,
+ }
+ if self.shard_config.extra_kwargs.get("quant", None) == "gptq":
+ from colossalai.inference.quant.gptq.cai_gptq import ColCaiQuantLinear, RowCaiQuantLinear
+
+ policy[LlamaDecoderLayer] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=RowCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.gate_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.up_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.down_proj",
+ target_module=RowCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ ],
+ )
+
+ elif self.shard_config.extra_kwargs.get("quant", None) == "smoothquant":
+ from colossalai.inference.quant.smoothquant.models.llama import LlamaSmoothquantDecoderLayer
+ from colossalai.inference.quant.smoothquant.models.parallel_linear import (
+ ColW8A8BFP32OFP32Linear,
+ RowW8A8B8O8Linear,
+ RowW8A8BFP32O32LinearSiLU,
+ RowW8A8BFP32OFP32Linear,
+ )
+
+ policy[LlamaSmoothquantDecoderLayer] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=RowW8A8B8O8Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=RowW8A8B8O8Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=RowW8A8B8O8Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=ColW8A8BFP32OFP32Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.gate_proj",
+ target_module=RowW8A8BFP32O32LinearSiLU,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.up_proj",
+ target_module=RowW8A8BFP32OFP32Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.down_proj",
+ target_module=ColW8A8BFP32OFP32Linear,
+ kwargs={"split_num": 1},
+ ),
+ ],
+ )
+ self.shard_config._infer()
+
+ infer_forward = LlamaInferenceForwards.llama_model_forward
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaModel)
+
+ infer_forward = LlamaInferenceForwards.llama_decoder_layer_forward
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LlamaDecoderLayer
+ )
+
+ infer_forward = LlamaInferenceForwards.llama_flash_attn_kvcache_forward
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LlamaAttention
+ )
+
+ # set as default, in inference we also use pipeline style forward, just setting stage as 1
+ self.set_pipeline_forward(
+ model_cls=LlamaForCausalLM, new_forward=LlamaInferenceForwards.llama_causal_lm_forward, policy=policy
+ )
+
+ infer_forward = None
+ if HAS_TRITON_RMSNORM:
+ infer_forward = get_triton_rmsnorm_forward()
+
+ if infer_forward is not None:
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LlamaRMSNorm
+ )
+
+ return policy
+
+ def postprocess(self):
+ init_to_get_rotary(self.model.model)
+ return self.model
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == "LlamaModel":
+ module = self.model
+ else:
+ module = self.model.model
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = self.distribute_layers(len(module.layers), stage_manager.num_stages)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embed_tokens)
+ held_layers.append(self.model.lm_head)
+ start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
+ held_layers.extend(module.layers[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.norm)
+
+ return held_layers
diff --git a/colossalai/inference/kv_cache/__init__.py b/colossalai/inference/kv_cache/__init__.py
new file mode 100644
index 000000000000..5b6ca182efae
--- /dev/null
+++ b/colossalai/inference/kv_cache/__init__.py
@@ -0,0 +1,2 @@
+from .batch_infer_state import BatchInferState
+from .kvcache_manager import MemoryManager
diff --git a/colossalai/inference/kv_cache/batch_infer_state.py b/colossalai/inference/kv_cache/batch_infer_state.py
new file mode 100644
index 000000000000..f707a86df37e
--- /dev/null
+++ b/colossalai/inference/kv_cache/batch_infer_state.py
@@ -0,0 +1,118 @@
+# might want to consider combine with InferenceConfig in colossalai/ppinference/inference_config.py later
+from dataclasses import dataclass
+
+import torch
+from transformers.tokenization_utils_base import BatchEncoding
+
+from .kvcache_manager import MemoryManager
+
+
+# adapted from: lightllm/server/router/model_infer/infer_batch.py
+@dataclass
+class BatchInferState:
+ r"""
+ Information to be passed and used for a batch of inputs during
+ a single model forward
+ """
+ batch_size: int
+ max_len_in_batch: int
+
+ cache_manager: MemoryManager = None
+
+ block_loc: torch.Tensor = None
+ start_loc: torch.Tensor = None
+ seq_len: torch.Tensor = None
+ past_key_values_len: int = None
+
+ is_context_stage: bool = False
+ context_mem_index: torch.Tensor = None
+ decode_is_contiguous: bool = None
+ decode_mem_start: int = None
+ decode_mem_end: int = None
+ decode_mem_index: torch.Tensor = None
+ decode_layer_id: int = None
+
+ device: torch.device = torch.device("cuda")
+
+ @property
+ def total_token_num(self):
+ # return self.batch_size * self.max_len_in_batch
+ assert self.seq_len is not None and self.seq_len.size(0) > 0
+ return int(torch.sum(self.seq_len))
+
+ def set_cache_manager(self, manager: MemoryManager):
+ self.cache_manager = manager
+
+ # adapted from: https://github.com/ModelTC/lightllm/blob/28c1267cfca536b7b4f28e921e03de735b003039/lightllm/common/infer_utils.py#L1
+ @staticmethod
+ def init_block_loc(
+ b_loc: torch.Tensor, seq_len: torch.Tensor, max_len_in_batch: int, alloc_mem_index: torch.Tensor
+ ):
+ """in-place update block loc mapping based on the sequence length of the inputs in current bath"""
+ start_index = 0
+ seq_len_numpy = seq_len.cpu().numpy()
+ for i, cur_seq_len in enumerate(seq_len_numpy):
+ b_loc[i, max_len_in_batch - cur_seq_len : max_len_in_batch] = alloc_mem_index[
+ start_index : start_index + cur_seq_len
+ ]
+ start_index += cur_seq_len
+ return
+
+ @classmethod
+ def init_from_batch(
+ cls,
+ batch: torch.Tensor,
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
+ ):
+ if not isinstance(batch, (BatchEncoding, dict, list, torch.Tensor)):
+ raise TypeError(f"batch type {type(batch)} is not supported in prepare_batch_state")
+
+ input_ids_list = None
+ attention_mask = None
+
+ if isinstance(batch, (BatchEncoding, dict)):
+ input_ids_list = batch["input_ids"]
+ attention_mask = batch["attention_mask"]
+ else:
+ input_ids_list = batch
+ if isinstance(input_ids_list[0], int): # for a single input
+ input_ids_list = [input_ids_list]
+ attention_mask = [attention_mask] if attention_mask is not None else attention_mask
+
+ batch_size = len(input_ids_list)
+
+ seq_start_indexes = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
+ seq_lengths = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
+ start_index = 0
+
+ max_len_in_batch = -1
+ if isinstance(batch, (BatchEncoding, dict)):
+ for i, attn_mask in enumerate(attention_mask):
+ curr_seq_len = len(attn_mask)
+ seq_lengths[i] = curr_seq_len
+ seq_start_indexes[i] = start_index
+ start_index += curr_seq_len
+ max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
+ else:
+ length = max(len(input_id) for input_id in input_ids_list)
+ for i, input_ids in enumerate(input_ids_list):
+ curr_seq_len = length
+ seq_lengths[i] = curr_seq_len
+ seq_start_indexes[i] = start_index
+ start_index += curr_seq_len
+ max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
+ block_loc = torch.zeros((batch_size, max_input_len + max_output_len), dtype=torch.long, device="cuda")
+
+ return cls(
+ batch_size=batch_size,
+ max_len_in_batch=max_len_in_batch,
+ seq_len=seq_lengths.to("cuda"),
+ start_loc=seq_start_indexes.to("cuda"),
+ block_loc=block_loc,
+ decode_layer_id=0,
+ past_key_values_len=0,
+ is_context_stage=True,
+ cache_manager=cache_manager,
+ )
diff --git a/colossalai/inference/kv_cache/kvcache_manager.py b/colossalai/inference/kv_cache/kvcache_manager.py
new file mode 100644
index 000000000000..dda46a756cc3
--- /dev/null
+++ b/colossalai/inference/kv_cache/kvcache_manager.py
@@ -0,0 +1,106 @@
+"""
+Refered/Modified from lightllm/common/mem_manager.py
+of the ModelTC/lightllm GitHub repository
+https://github.com/ModelTC/lightllm/blob/050af3ce65edca617e2f30ec2479397d5bb248c9/lightllm/common/mem_manager.py
+we slightly changed it to make it suitable for our colossal-ai shardformer TP-engine design.
+"""
+import torch
+from transformers.utils import logging
+
+
+class MemoryManager:
+ r"""
+ Manage token block indexes and allocate physical memory for key and value cache
+
+ Args:
+ size: maximum token number used as the size of key and value buffer
+ dtype: data type of cached key and value
+ head_num: number of heads the memory manager is responsible for
+ head_dim: embedded size per head
+ layer_num: the number of layers in the model
+ device: device used to store the key and value cache
+ """
+
+ def __init__(
+ self,
+ size: int,
+ dtype: torch.dtype,
+ head_num: int,
+ head_dim: int,
+ layer_num: int,
+ device: torch.device = torch.device("cuda"),
+ ):
+ self.logger = logging.get_logger(__name__)
+ self.available_size = size
+ self.max_len_in_batch = 0
+ self._init_mem_states(size, device)
+ self._init_kv_buffers(size, device, dtype, head_num, head_dim, layer_num)
+
+ def _init_mem_states(self, size, device):
+ """Initialize tensors used to manage memory states"""
+ self.mem_state = torch.ones((size,), dtype=torch.bool, device=device)
+ self.mem_cum_sum = torch.empty((size,), dtype=torch.int32, device=device)
+ self.indexes = torch.arange(0, size, dtype=torch.long, device=device)
+
+ def _init_kv_buffers(self, size, device, dtype, head_num, head_dim, layer_num):
+ """Initialize key buffer and value buffer on specified device"""
+ self.key_buffer = [
+ torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
+ ]
+ self.value_buffer = [
+ torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
+ ]
+
+ @torch.no_grad()
+ def alloc(self, required_size):
+ """allocate space of required_size by providing indexes representing available physical spaces"""
+ if required_size > self.available_size:
+ self.logger.warning(f"No enough cache: required_size {required_size} " f"left_size {self.available_size}")
+ return None
+ torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
+ select_index = torch.logical_and(self.mem_cum_sum <= required_size, self.mem_state == 1)
+ select_index = self.indexes[select_index]
+ self.mem_state[select_index] = 0
+ self.available_size -= len(select_index)
+ return select_index
+
+ @torch.no_grad()
+ def alloc_contiguous(self, required_size):
+ """allocate contiguous space of required_size"""
+ if required_size > self.available_size:
+ self.logger.warning(f"No enough cache: required_size {required_size} " f"left_size {self.available_size}")
+ return None
+ torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
+ sum_size = len(self.mem_cum_sum)
+ loc_sums = (
+ self.mem_cum_sum[required_size - 1 :]
+ - self.mem_cum_sum[0 : sum_size - required_size + 1]
+ + self.mem_state[0 : sum_size - required_size + 1]
+ )
+ can_used_loc = self.indexes[0 : sum_size - required_size + 1][loc_sums == required_size]
+ if can_used_loc.shape[0] == 0:
+ self.logger.info(
+ f"No enough contiguous cache: required_size {required_size} " f"left_size {self.available_size}"
+ )
+ return None
+ start_loc = can_used_loc[0]
+ select_index = self.indexes[start_loc : start_loc + required_size]
+ self.mem_state[select_index] = 0
+ self.available_size -= len(select_index)
+ start = start_loc.item()
+ end = start + required_size
+ return select_index, start, end
+
+ @torch.no_grad()
+ def free(self, free_index):
+ """free memory by updating memory states based on given indexes"""
+ self.available_size += free_index.shape[0]
+ self.mem_state[free_index] = 1
+
+ @torch.no_grad()
+ def free_all(self):
+ """free all memory by updating memory states"""
+ self.available_size = len(self.mem_state)
+ self.mem_state[:] = 1
+ self.max_len_in_batch = 0
+ # self.logger.info("freed all space of memory manager")
diff --git a/colossalai/inference/pipeline/__init__.py b/colossalai/inference/pipeline/__init__.py
deleted file mode 100644
index 41af9f3ef948..000000000000
--- a/colossalai/inference/pipeline/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .engine import PPInferEngine
-
-__all__ = ["PPInferEngine"]
diff --git a/colossalai/inference/pipeline/engine.py b/colossalai/inference/pipeline/engine.py
deleted file mode 100644
index 4f42385caf8f..000000000000
--- a/colossalai/inference/pipeline/engine.py
+++ /dev/null
@@ -1,97 +0,0 @@
-import torch
-import torch.nn as nn
-
-from colossalai.cluster import ProcessGroupMesh
-from colossalai.pipeline.schedule.generate import GenerateSchedule
-from colossalai.pipeline.stage_manager import PipelineStageManager
-from colossalai.shardformer import ShardConfig, ShardFormer
-from colossalai.shardformer.policies.base_policy import Policy
-
-from .microbatch_manager import MicroBatchManager
-
-
-class PPInferEngine:
- """
- PPInferEngine is a class that handles the pipeline parallel inference.
-
- Args:
- pp_size (int): the number of pipeline stages.
- pp_model (`nn.Module`): the model already in pipeline parallelism style.
- model (`nn.Module`): the model not in pipeline style, and will be modified with `ShardFormer`.
- model_policy (`colossalai.shardformer.policies.base_policy.Policy`): the policy to shardformer model.
- micro_batch_size (int): the micro batch size.
- micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
- new_length (int): the new length of the input sequence.
- early_stopping (bool): whether to stop early.
-
- Example:
-
- ```python
- from colossalai.ppinference import PPInferEngine
- from transformers import GPT2LMHeadModel, GPT2Tokenizer
-
- model = transformers.GPT2LMHeadModel.from_pretrained('gpt2')
- # assume the model is infered with 4 pipeline stages
- inferengine = PPInferEngine(pp_size=4, model=model, model_policy={Your own policy for pipeline sharding})
-
- input = ["Hello, my dog is cute, and I like"]
- tokenized_input = tokenizer(input, return_tensors='pt')
- output = engine.inference([tokenized_input])
- ```
-
- """
-
- def __init__(
- self,
- pp_size: int,
- dtype: str = "fp16",
- pp_model: nn.Module = None,
- model: nn.Module = None,
- model_policy: Policy = None,
- new_length: int = 32,
- micro_batch_size: int = 1,
- micro_batch_buffer_size: int = None,
- verbose: bool = False,
- # TODO: implement early_stopping, and various gerneration options
- early_stopping: bool = False,
- do_sample: bool = False,
- num_beams: int = 1,
- ) -> None:
- assert pp_model or (model and model_policy), "Either pp_model or model with model_policy should be provided."
- self.pp_size = pp_size
- self.pg_mesh = ProcessGroupMesh(pp_size)
- self.stage_manager = PipelineStageManager(self.pg_mesh, 0, True)
- self.mb_manager = MicroBatchManager(
- self.stage_manager.stage, new_length, micro_batch_size, micro_batch_buffer_size or pp_size
- )
- self.verbose = verbose
- self.schedule = GenerateSchedule(self.stage_manager, self.mb_manager, verbose)
-
- assert dtype in ["fp16", "fp32", "bf16"], "dtype should be one of 'fp16', 'fp32', 'bf16'"
- if dtype == "fp16":
- model.half()
- elif dtype == "bf16":
- model.to(torch.bfloat16)
- self.model = pp_model or self._shardformer(model, model_policy)
-
- def inference(self, input_list):
- out, timestamp = self.schedule.generate_step(self.model, iter(input_list))
- if self.verbose:
- return out, timestamp
- else:
- return out
-
- def _shardformer(self, model, model_policy):
- shardconfig = ShardConfig(
- tensor_parallel_process_group=None,
- pipeline_stage_manager=self.stage_manager,
- enable_tensor_parallelism=False,
- enable_fused_normalization=False,
- enable_all_optimization=False,
- enable_flash_attention=False,
- enable_jit_fused=False,
- enable_sequence_parallelism=False,
- )
- shardformer = ShardFormer(shard_config=shardconfig)
- shard_model, _ = shardformer.optimize(model, model_policy)
- return shard_model.cuda()
diff --git a/colossalai/inference/pipeline/modeling/gpt2.py b/colossalai/inference/pipeline/modeling/gpt2.py
deleted file mode 100644
index d2bfcb8b6842..000000000000
--- a/colossalai/inference/pipeline/modeling/gpt2.py
+++ /dev/null
@@ -1,280 +0,0 @@
-from typing import Dict, List, Optional, Tuple, Union
-
-import torch
-from transformers.modeling_outputs import BaseModelOutputWithPastAndCrossAttentions, CausalLMOutputWithCrossAttentions
-from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel, GPT2Model
-from transformers.utils import logging
-
-from colossalai.pipeline.stage_manager import PipelineStageManager
-
-
-class GPT2PipelineForwards:
- """
- This class serves as a micro library for forward function substitution of GPT2 models
- under pipeline setting.
- """
-
- @staticmethod
- def gpt2_model_forward(
- self: GPT2Model,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- encoder_hidden_states: Optional[torch.Tensor] = None,
- encoder_attention_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ) -> Union[Dict, Tuple, BaseModelOutputWithPastAndCrossAttentions]:
- # This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2Model.forward.
- # Please refer to original code of transformers for more details.
- logger = logging.get_logger(__name__)
-
- # Preprocess passed in arguments
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if past_key_values is None:
- past_length = 0
- past_key_values = tuple([None] * len(self.h))
- else:
- past_length = past_key_values[0][0].size(-2)
-
- if stage_manager.is_first_stage():
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- input_shape = input_ids.size()
- input_ids = input_ids.view(-1, input_shape[-1])
- batch_size = input_ids.shape[0]
- elif inputs_embeds is not None:
- input_shape = inputs_embeds.size()[:-1]
- batch_size = inputs_embeds.shape[0]
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- device = input_ids.device if input_ids is not None else inputs_embeds.device
- if token_type_ids is not None:
- token_type_ids = token_type_ids.view(-1, input_shape[-1])
- else:
- if hidden_states is None:
- raise ValueError("hidden_states shouldn't be None for stages other than the first stage.")
- input_shape = hidden_states.size()[:-1]
- batch_size, seq_length = input_shape[0], input_shape[1]
- device = hidden_states.device
-
- # GPT2Attention mask.
- if attention_mask is not None:
- if batch_size <= 0:
- raise ValueError("batch_size has to be defined and > 0")
- attention_mask = attention_mask.view(batch_size, -1)
- # We create a 3D attention mask from a 2D tensor mask.
- # Sizes are [batch_size, 1, 1, to_seq_length]
- # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
- # this attention mask is more simple than the triangular masking of causal attention
- # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
- attention_mask = attention_mask[:, None, None, :]
-
- # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
- # masked positions, this operation will create a tensor which is 0.0 for
- # positions we want to attend and the dtype's smallest value for masked positions.
- # Since we are adding it to the raw scores before the softmax, this is
- # effectively the same as removing these entirely.
- attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
- attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
-
- # If a 2D or 3D attention mask is provided for the cross-attention
- # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
- if self.config.add_cross_attention and encoder_hidden_states is not None:
- encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
- encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
- if encoder_attention_mask is None:
- encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
- encoder_attention_mask = self.invert_attention_mask(encoder_attention_mask)
- else:
- encoder_attention_mask = None
-
- # Prepare head mask if needed
- # 1.0 in head_mask indicate we keep the head
- # attention_probs has shape bsz x n_heads x N x N
- # head_mask has shape n_layer x batch x n_heads x N x N
- head_mask = self.get_head_mask(head_mask, self.config.n_layer)
-
- if stage_manager.is_first_stage():
- if position_ids is not None:
- position_ids = position_ids.view(-1, input_shape[-1])
- else:
- position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
- position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
-
- if inputs_embeds is None:
- inputs_embeds = self.wte(input_ids)
- position_embeds = self.wpe(position_ids)
- hidden_states = inputs_embeds + position_embeds
- if token_type_ids is not None:
- token_type_embeds = self.wte(token_type_ids)
- hidden_states = hidden_states + token_type_embeds
- hidden_states = self.drop(hidden_states)
-
- output_shape = input_shape + (hidden_states.size(-1),)
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
- )
- use_cache = False
-
- presents = () if use_cache else None
- all_self_attentions = () if output_attentions else None
- all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
- all_hidden_states = () if output_hidden_states else None
-
- # Going through held blocks.
- start_idx, end_idx = stage_index[0], stage_index[1]
- for i, layer_past in zip(range(start_idx, end_idx), past_key_values):
- block = self.h[i]
- # Model parallel
- if self.model_parallel:
- torch.cuda.set_device(hidden_states.device)
- # Ensure layer_past is on same device as hidden_states (might not be correct)
- if layer_past is not None:
- layer_past = tuple(past_state.to(hidden_states.device) for past_state in layer_past)
- # Ensure that attention_mask is always on the same device as hidden_states
- if attention_mask is not None:
- attention_mask = attention_mask.to(hidden_states.device)
- if isinstance(head_mask, torch.Tensor):
- head_mask = head_mask.to(hidden_states.device)
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, use_cache, output_attentions)
-
- return custom_forward
-
- outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(block),
- hidden_states,
- None,
- attention_mask,
- head_mask[i],
- encoder_hidden_states,
- encoder_attention_mask,
- )
- else:
- outputs = block(
- hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- head_mask=head_mask[i],
- encoder_hidden_states=encoder_hidden_states,
- encoder_attention_mask=encoder_attention_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
-
- hidden_states = outputs[0]
- if use_cache is True:
- presents = presents + (outputs[1],)
-
- if output_attentions:
- all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
- if self.config.add_cross_attention:
- all_cross_attentions = all_cross_attentions + (outputs[3 if use_cache else 2],)
-
- # Model Parallel: If it's the last layer for that device, put things on the next device
- if self.model_parallel:
- for k, v in self.device_map.items():
- if i == v[-1] and "cuda:" + str(k) != self.last_device:
- hidden_states = hidden_states.to("cuda:" + str(k + 1))
-
- if stage_manager.is_last_stage():
- hidden_states = self.ln_f(hidden_states)
-
- hidden_states = hidden_states.view(output_shape)
-
- # Add last hidden state
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- return {"hidden_states": hidden_states, "past_key_values": presents}
-
- @staticmethod
- def gpt2_lmhead_model_forward(
- self: GPT2LMHeadModel,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- encoder_hidden_states: Optional[torch.Tensor] = None,
- encoder_attention_mask: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ) -> Union[Dict, Tuple, CausalLMOutputWithCrossAttentions]:
- r"""
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
- `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
- are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
-
- This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2LMHeadModel.forward.
- Please refer to original code of transformers for more details.
- """
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- # If is first stage and after warmup, go throught lm_head first
- if stage_manager.is_first_stage() and hidden_states is not None:
- lm_logits = self.lm_head(hidden_states)
- return {"logits": lm_logits}
-
- # Not first stage or before warmup, go through gpt2 model
- outputs = GPT2PipelineForwards.gpt2_model_forward(
- self.transformer,
- input_ids,
- past_key_values=past_key_values,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- encoder_hidden_states=encoder_hidden_states,
- encoder_attention_mask=encoder_attention_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- stage_manager=stage_manager,
- hidden_states=hidden_states,
- stage_index=stage_index,
- )
-
- return outputs
diff --git a/colossalai/inference/pipeline/modeling/llama.py b/colossalai/inference/pipeline/modeling/llama.py
deleted file mode 100644
index f46e1fbdd7b3..000000000000
--- a/colossalai/inference/pipeline/modeling/llama.py
+++ /dev/null
@@ -1,229 +0,0 @@
-from typing import List, Optional
-
-import torch
-from transformers.models.llama.modeling_llama import LlamaForCausalLM, LlamaModel
-from transformers.utils import logging
-
-from colossalai.pipeline.stage_manager import PipelineStageManager
-
-
-class LlamaPipelineForwards:
- """
- This class serves as a micro library for forward function substitution of Llama models
- under pipeline setting.
- """
-
- def llama_model_forward(
- self: LlamaModel,
- input_ids: torch.LongTensor = None,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ):
- logger = logging.get_logger(__name__)
-
- # Preprocess passed in arguments
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- # retrieve input_ids and inputs_embeds
- if stage_manager.is_first_stage():
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
- elif input_ids is not None:
- batch_size, seq_length = input_ids.shape
- elif inputs_embeds is not None:
- batch_size, seq_length, _ = inputs_embeds.shape
- else:
- raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
- device = input_ids.device if input_ids is not None else inputs_embeds.device
- if inputs_embeds is None:
- inputs_embeds = self.embed_tokens(input_ids)
- hidden_states = inputs_embeds
- else:
- input_shape = hidden_states.shape[:-1]
- batch_size, seq_length = input_shape
- device = hidden_states.device
-
- seq_length_with_past = seq_length
- past_key_values_length = 0
-
- if past_key_values is not None:
- past_key_values_length = past_key_values[0][0].shape[2]
- seq_length_with_past = seq_length_with_past + past_key_values_length
-
- if position_ids is None:
- position_ids = torch.arange(
- past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
- )
- position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
- else:
- position_ids = position_ids.view(-1, seq_length).long()
-
- # embed positions, for the first stage, hidden_states is the input embeddings,
- # for the other stages, hidden_states is the output of the previous stage
- if attention_mask is None:
- attention_mask = torch.ones(
- (batch_size, seq_length_with_past), dtype=torch.bool, device=hidden_states.device
- )
- attention_mask = self._prepare_decoder_attention_mask(
- attention_mask, (batch_size, seq_length), hidden_states, past_key_values_length
- )
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
- )
- use_cache = False
-
- # decoder layers
- all_hidden_states = () if output_hidden_states else None
- all_self_attns = () if output_attentions else None
- next_decoder_cache = () if use_cache else None
-
- start_idx, end_idx = stage_index[0], stage_index[1]
- if past_key_values is None:
- past_key_values = tuple([None] * (end_idx - start_idx + 1))
-
- for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
- decoder_layer = self.layers[idx]
- if output_hidden_states:
- all_hidden_states += (hidden_states,)
-
- # past_key_value = past_key_values[idx] if past_key_values is not None else None
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, output_attentions, None)
-
- return custom_forward
-
- layer_outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(decoder_layer),
- hidden_states,
- attention_mask,
- position_ids,
- None,
- )
- else:
- layer_outputs = decoder_layer(
- hidden_states,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_value=past_key_value,
- output_attentions=output_attentions,
- use_cache=use_cache,
- )
-
- hidden_states = layer_outputs[0]
-
- if use_cache:
- next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
- if output_attentions:
- all_self_attns += (layer_outputs[1],)
-
- if stage_manager.is_last_stage():
- hidden_states = self.norm(hidden_states)
-
- # add hidden states from the last decoder layer
- if output_hidden_states:
- all_hidden_states += (hidden_states,)
- next_cache = next_decoder_cache if use_cache else None
-
- # always return dict for imediate stage
- return {"hidden_states": hidden_states, "past_key_values": next_cache}
-
- def llama_for_causal_lm_forward(
- self: LlamaForCausalLM,
- input_ids: torch.LongTensor = None,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ):
- r"""
- Args:
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
- config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
- (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
-
- Returns:
-
- Example:
-
- ```python
- >>> from transformers import AutoTokenizer, LlamaForCausalLM
-
- >>> model = LlamaForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
- >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
-
- >>> prompt = "Hey, are you consciours? Can you talk to me?"
- >>> inputs = tokenizer(prompt, return_tensors="pt")
-
- >>> # Generate
- >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
- >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
- "Hey, are you consciours? Can you talk to me?\nI'm not consciours, but I can talk to you."
- ```"""
- logger = logging.get_logger(__name__)
-
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- # If is first stage and after warmup, go throught lm_head first
- if stage_manager.is_first_stage() and hidden_states is not None:
- lm_logits = self.lm_head(hidden_states)
- return {"logits": lm_logits}
-
- # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
- outputs = LlamaPipelineForwards.llama_model_forward(
- self.model,
- input_ids=input_ids,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_values=past_key_values,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- stage_manager=stage_manager,
- hidden_states=hidden_states,
- stage_index=stage_index,
- )
-
- return outputs
diff --git a/colossalai/inference/pipeline/policy/gpt2_ppinfer.py b/colossalai/inference/pipeline/policy/gpt2_ppinfer.py
deleted file mode 100644
index 51e6425b113e..000000000000
--- a/colossalai/inference/pipeline/policy/gpt2_ppinfer.py
+++ /dev/null
@@ -1,74 +0,0 @@
-from functools import partial
-from typing import Callable, Dict, List
-
-from torch import Tensor, nn
-
-import colossalai.shardformer.layer as col_nn
-from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
-from colossalai.shardformer.policies.gpt2 import GPT2Policy
-
-from ..modeling.gpt2 import GPT2PipelineForwards
-
-
-class GPT2LMHeadModelPipelinePolicy(GPT2Policy):
- def __init__(self) -> None:
- super().__init__()
-
- def module_policy(self):
- from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
-
- module_policy = super().module_policy()
-
- if self.shard_config.enable_tensor_parallelism:
- addon_module = {
- GPT2LMHeadModel: ModulePolicyDescription(
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="lm_head", target_module=col_nn.Linear1D_Col, kwargs={"gather_output": True}
- )
- ]
- )
- }
- module_policy.update(addon_module)
-
- if self.pipeline_stage_manager is not None:
- self.set_pipeline_forward(
- model_cls=GPT2LMHeadModel,
- new_forward=GPT2PipelineForwards.gpt2_lmhead_model_forward,
- policy=module_policy,
- )
- return module_policy
-
- def get_held_layers(self) -> List[nn.Module]:
- held_layers = super().get_held_layers()
- # make the tie weight lm_head and embedding in the same device to save memory
- # if self.pipeline_stage_manager.is_first_stage():
- if self.pipeline_stage_manager.is_first_stage():
- held_layers.append(self.model.lm_head)
- return held_layers
-
- def get_shared_params(self) -> List[Dict[int, Tensor]]:
- """The weights of wte and lm_head are shared."""
- module = self.model
- stage_manager = self.pipeline_stage_manager
- if stage_manager is not None:
- if stage_manager.num_stages > 1 and id(module.transformer.wte.weight) == id(module.lm_head.weight):
- first_stage, last_stage = 0, stage_manager.num_stages - 1
- return [{first_stage: module.transformer.wte.weight, last_stage: module.lm_head.weight}]
- return []
-
- def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
- """If under pipeline parallel setting, replacing the original forward method of huggingface
- to customized forward method, and add this changing to policy."""
- if not self.pipeline_stage_manager:
- raise ValueError("set_pipeline_forward method can only be called when pipeline parallel is enabled.")
- stage_manager = self.pipeline_stage_manager
- if self.model.__class__.__name__ == "GPT2Model":
- module = self.model
- else:
- module = self.model.transformer
-
- layers_per_stage = Policy.distribute_layers(len(module.h), stage_manager.num_stages)
- stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
- method_replacement = {"forward": partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}
- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=model_cls)
diff --git a/colossalai/inference/pipeline/policy/llama_ppinfer.py b/colossalai/inference/pipeline/policy/llama_ppinfer.py
deleted file mode 100644
index 6e12ed61bf7b..000000000000
--- a/colossalai/inference/pipeline/policy/llama_ppinfer.py
+++ /dev/null
@@ -1,48 +0,0 @@
-from typing import List
-
-from torch.nn import Module
-
-from colossalai.shardformer.layer import Linear1D_Col
-from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
-from colossalai.shardformer.policies.llama import LlamaPolicy
-
-from ..modeling.llama import LlamaPipelineForwards
-
-
-class LlamaForCausalLMPipelinePolicy(LlamaPolicy):
- def __init__(self) -> None:
- super().__init__()
-
- def module_policy(self):
- from transformers import LlamaForCausalLM
-
- policy = super().module_policy()
-
- if self.shard_config.enable_tensor_parallelism:
- # add a new item for casual lm
- new_item = {
- LlamaForCausalLM: ModulePolicyDescription(
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="lm_head", target_module=Linear1D_Col, kwargs=dict(gather_output=True)
- )
- ]
- )
- }
- policy.update(new_item)
-
- if self.pipeline_stage_manager:
- # set None as default
- self.set_pipeline_forward(
- model_cls=LlamaForCausalLM, new_forward=LlamaPipelineForwards.llama_for_causal_lm_forward, policy=policy
- )
-
- return policy
-
- def get_held_layers(self) -> List[Module]:
- """Get pipeline layers for current stage."""
- stage_manager = self.pipeline_stage_manager
- held_layers = super().get_held_layers()
- if stage_manager.is_first_stage():
- held_layers.append(self.model.lm_head)
- return held_layers
diff --git a/colossalai/inference/pipeline/utils.py b/colossalai/inference/pipeline/utils.py
deleted file mode 100644
index c26aa4e40b71..000000000000
--- a/colossalai/inference/pipeline/utils.py
+++ /dev/null
@@ -1,35 +0,0 @@
-from typing import Set
-
-import torch.nn as nn
-
-from colossalai.shardformer._utils import getattr_, setattr_
-
-
-def set_tensors_to_none(model: nn.Module, include: Set[str] = set()) -> None:
- """
- Set all parameters and buffers of model to None
-
- Args:
- model (nn.Module): The model to set
- """
- for module_suffix in include:
- set_module = getattr_(model, module_suffix)
- for n, p in set_module.named_parameters():
- setattr_(set_module, n, None)
- for n, buf in set_module.named_buffers():
- setattr_(set_module, n, None)
- setattr_(model, module_suffix, None)
-
-
-def get_suffix_name(suffix: str, name: str):
- """
- Get the suffix name of the module, as `suffix.name` when name is string or `suffix[name]` when name is a digit,
- and 'name' when `suffix` is empty.
-
- Args:
- suffix (str): The suffix of the suffix module
- name (str): The name of the current module
- """
- point = "" if suffix is "" else "."
- suffix_name = suffix + f"[{name}]" if name.isdigit() else suffix + f"{point}{name}"
- return suffix_name
diff --git a/colossalai/inference/quant/__init__.py b/colossalai/inference/quant/__init__.py
new file mode 100644
index 000000000000..18e0de9cc9fc
--- /dev/null
+++ b/colossalai/inference/quant/__init__.py
@@ -0,0 +1 @@
+from .smoothquant.models.llama import SmoothLlamaForCausalLM
diff --git a/colossalai/inference/quant/gptq/__init__.py b/colossalai/inference/quant/gptq/__init__.py
index c035f397923a..4cf1fd658a41 100644
--- a/colossalai/inference/quant/gptq/__init__.py
+++ b/colossalai/inference/quant/gptq/__init__.py
@@ -2,3 +2,4 @@
if HAS_AUTO_GPTQ:
from .cai_gptq import CaiGPTQLinearOp, CaiQuantLinear
+ from .gptq_manager import GPTQManager
diff --git a/colossalai/inference/quant/gptq/gptq_manager.py b/colossalai/inference/quant/gptq/gptq_manager.py
new file mode 100644
index 000000000000..2d352fbef2b9
--- /dev/null
+++ b/colossalai/inference/quant/gptq/gptq_manager.py
@@ -0,0 +1,61 @@
+import torch
+
+
+class GPTQManager:
+ def __init__(self, quant_config, max_input_len: int = 1):
+ self.max_dq_buffer_size = 1
+ self.max_inner_outer_dim = 1
+ self.bits = quant_config.bits
+ self.use_act_order = quant_config.desc_act
+ self.max_input_len = 1
+ self.gptq_temp_state_buffer = None
+ self.gptq_temp_dq_buffer = None
+ self.quant_config = quant_config
+
+ def post_init_gptq_buffer(self, model: torch.nn.Module) -> None:
+ from .cai_gptq import CaiQuantLinear
+
+ HAS_GPTQ_CUDA = False
+ try:
+ from colossalai.kernel.op_builder.gptq import GPTQBuilder
+
+ gptq_cuda = GPTQBuilder().load()
+ HAS_GPTQ_CUDA = True
+ except ImportError:
+ warnings.warn("CUDA gptq is not installed")
+ HAS_GPTQ_CUDA = False
+
+ for name, submodule in model.named_modules():
+ if isinstance(submodule, CaiQuantLinear):
+ self.max_dq_buffer_size = max(self.max_dq_buffer_size, submodule.qweight.numel() * 8)
+
+ if self.use_act_order:
+ self.max_inner_outer_dim = max(
+ self.max_inner_outer_dim, submodule.infeatures, submodule.outfeatures
+ )
+ self.bits = submodule.bits
+ if not (HAS_GPTQ_CUDA and self.bits == 4):
+ return
+
+ max_input_len = 1
+ if self.use_act_order:
+ max_input_len = self.max_input_len
+ # The temp_state buffer is required to reorder X in the act-order case.
+ # The temp_dq buffer is required to dequantize weights when using cuBLAS, typically for the prefill.
+ self.gptq_temp_state_buffer = torch.zeros(
+ (max_input_len, self.max_inner_outer_dim), dtype=torch.float16, device=torch.cuda.current_device()
+ )
+ self.gptq_temp_dq_buffer = torch.zeros(
+ (1, self.max_dq_buffer_size), dtype=torch.float16, device=torch.cuda.current_device()
+ )
+
+ gptq_cuda.prepare_buffers(
+ torch.device(torch.cuda.current_device()), self.gptq_temp_state_buffer, self.gptq_temp_dq_buffer
+ )
+ # Using the default from exllama repo here.
+ matmul_recons_thd = 8
+ matmul_fused_remap = False
+ matmul_no_half2 = False
+ gptq_cuda.set_tuning_params(matmul_recons_thd, matmul_fused_remap, matmul_no_half2)
+
+ torch.cuda.empty_cache()
diff --git a/colossalai/inference/quant/smoothquant/models/__init__.py b/colossalai/inference/quant/smoothquant/models/__init__.py
index 77541d8610c5..1663028da138 100644
--- a/colossalai/inference/quant/smoothquant/models/__init__.py
+++ b/colossalai/inference/quant/smoothquant/models/__init__.py
@@ -4,9 +4,7 @@
HAS_TORCH_INT = True
except ImportError:
HAS_TORCH_INT = False
- raise ImportError(
- "Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int"
- )
+ print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
if HAS_TORCH_INT:
from .llama import LLamaSmoothquantAttention, LlamaSmoothquantMLP
diff --git a/colossalai/inference/quant/smoothquant/models/base_model.py b/colossalai/inference/quant/smoothquant/models/base_model.py
index 6a1d96ecec8f..f3afe5d83bb0 100644
--- a/colossalai/inference/quant/smoothquant/models/base_model.py
+++ b/colossalai/inference/quant/smoothquant/models/base_model.py
@@ -9,7 +9,6 @@
from os.path import isdir, isfile, join
from typing import Dict, List, Optional, Union
-import accelerate
import numpy as np
import torch
import torch.nn as nn
@@ -21,8 +20,16 @@
from transformers.utils.generic import ContextManagers
from transformers.utils.hub import PushToHubMixin, cached_file
-from colossalai.inference.tensor_parallel.batch_infer_state import BatchInferState
-from colossalai.inference.tensor_parallel.kvcache_manager import MemoryManager
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState, MemoryManager
+
+try:
+ import accelerate
+
+ HAS_ACCELERATE = True
+except ImportError:
+ HAS_ACCELERATE = False
+ print("accelerate is not installed.")
+
SUPPORTED_MODELS = ["llama"]
@@ -87,7 +94,6 @@ def init_batch_state(self, max_output_len=256, **kwargs):
batch_infer_state.start_loc = seq_start_indexes.to("cuda")
batch_infer_state.block_loc = block_loc
batch_infer_state.decode_layer_id = 0
- batch_infer_state.past_key_values_len = 0
batch_infer_state.is_context_stage = True
batch_infer_state.set_cache_manager(self.cache_manager)
batch_infer_state.cache_manager.free_all()
diff --git a/colossalai/inference/quant/smoothquant/models/linear.py b/colossalai/inference/quant/smoothquant/models/linear.py
index 969c390a0849..03d994b32489 100644
--- a/colossalai/inference/quant/smoothquant/models/linear.py
+++ b/colossalai/inference/quant/smoothquant/models/linear.py
@@ -1,17 +1,25 @@
# modified from torch-int: https://github.com/Guangxuan-Xiao/torch-int/blob/main/torch_int/nn/linear.py
import torch
-from torch_int._CUDA import linear_a8_w8_b8_o8, linear_a8_w8_bfp32_ofp32
-from torch_int.functional.quantization import quantize_per_tensor_absmax
+
+try:
+ from torch_int._CUDA import linear_a8_w8_b8_o8, linear_a8_w8_bfp32_ofp32
+ from torch_int.functional.quantization import quantize_per_tensor_absmax
+
+ HAS_TORCH_INT = True
+except ImportError:
+ HAS_TORCH_INT = False
+ print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
+
try:
from colossalai.kernel.op_builder.smoothquant import SmoothquantBuilder
smoothquant_cuda = SmoothquantBuilder().load()
HAS_SMOOTHQUANT_CUDA = True
-except ImportError:
+except:
HAS_SMOOTHQUANT_CUDA = False
- raise ImportError("CUDA smoothquant linear is not installed")
+ print("CUDA smoothquant linear is not installed")
class W8A8BFP32O32LinearSiLU(torch.nn.Module):
@@ -138,21 +146,23 @@ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
)
self.register_buffer(
"bias",
- torch.zeros(self.out_features, dtype=torch.float32, requires_grad=False),
+ torch.zeros((1, self.out_features), dtype=torch.float32, requires_grad=False),
)
self.register_buffer("a", torch.tensor(alpha))
def _apply(self, fn):
# prevent the bias from being converted to half
super()._apply(fn)
- self.bias = self.bias.to(torch.float32)
+ if self.bias is not None:
+ self.bias = self.bias.to(torch.float32)
return self
def to(self, *args, **kwargs):
super().to(*args, **kwargs)
self.weight = self.weight.to(*args, **kwargs)
- self.bias = self.bias.to(*args, **kwargs)
- self.bias = self.bias.to(torch.float32)
+ if self.bias is not None:
+ self.bias = self.bias.to(*args, **kwargs)
+ self.bias = self.bias.to(torch.float32)
return self
@torch.no_grad()
diff --git a/colossalai/inference/quant/smoothquant/models/llama.py b/colossalai/inference/quant/smoothquant/models/llama.py
index 4c3d6dcc0b23..bb74dc49d7af 100644
--- a/colossalai/inference/quant/smoothquant/models/llama.py
+++ b/colossalai/inference/quant/smoothquant/models/llama.py
@@ -8,7 +8,6 @@
import torch
import torch.nn as nn
import torch.nn.functional as F
-from torch_int.nn.bmm import BMM_S8T_S8N_F32T, BMM_S8T_S8N_S8T
from transformers import PreTrainedModel
from transformers.modeling_outputs import BaseModelOutputWithPast
from transformers.models.llama.configuration_llama import LlamaConfig
@@ -18,12 +17,11 @@
LlamaDecoderLayer,
LlamaMLP,
LlamaRotaryEmbedding,
- repeat_kv,
rotate_half,
)
from transformers.utils import add_start_docstrings_to_model_forward
-from colossalai.inference.tensor_parallel.batch_infer_state import BatchInferState
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
from colossalai.kernel.triton import (
copy_kv_cache_to_dest,
int8_rotary_embedding_fwd,
@@ -31,10 +29,31 @@
smooth_token_attention_fwd,
)
+try:
+ from torch_int.nn.bmm import BMM_S8T_S8N_F32T, BMM_S8T_S8N_S8T
+
+ HAS_TORCH_INT = True
+except ImportError:
+ HAS_TORCH_INT = False
+ print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
+
+
from .base_model import BaseSmoothForCausalLM
from .linear import W8A8B8O8Linear, W8A8BFP32O32LinearSiLU, W8A8BFP32OFP32Linear
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
class LLamaSmoothquantAttention(nn.Module):
def __init__(
self,
@@ -116,7 +135,6 @@ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
def forward(
self,
hidden_states: torch.Tensor,
- rotary_emb: Tuple[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
@@ -131,8 +149,7 @@ def forward(
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
- cos = rotary_emb[0]
- sin = rotary_emb[1]
+ cos, sin = infer_state.position_cos, infer_state.position_sin
int8_rotary_embedding_fwd(
query_states.view(-1, self.num_heads, self.head_dim),
@@ -149,12 +166,6 @@ def forward(
self.k_rotary_output_scale.item(),
)
- # NOTE might want to revise
- # need some way to record the length of past key values cache
- # since we won't return past_key_value_cache right now
- if infer_state.decode_layer_id == 0: # once per model.forward
- infer_state.cache_manager.past_key_values_length += q_len # seq_len
-
def _copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index, mem_manager):
copy_kv_cache_to_dest(key_buffer, context_mem_index, mem_manager.key_buffer[layer_id])
copy_kv_cache_to_dest(value_buffer, context_mem_index, mem_manager.value_buffer[layer_id])
@@ -229,7 +240,7 @@ def _copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index,
infer_state.block_loc,
infer_state.start_loc,
infer_state.seq_len,
- infer_state.cache_manager.past_key_values_length,
+ infer_state.max_len_in_batch,
)
attn_output = attn_output.view(bsz, q_len, self.num_heads * self.head_dim)
@@ -354,7 +365,6 @@ def pack(
def forward(
self,
hidden_states: torch.Tensor,
- rotary_emb: Tuple[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
@@ -384,7 +394,6 @@ def forward(
# Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
- rotary_emb=rotary_emb,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
@@ -592,17 +601,13 @@ def llama_model_forward(
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
- seq_length_with_past = seq_length
- past_key_values_length = 0
-
infer_state = self.infer_state
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
- if past_key_values is not None:
- # NOT READY FOR PRIME TIME
- # dummy but work, revise it
- past_key_values_length = infer_state.cache_manager.past_key_values_length
- # past_key_values_length = past_key_values[0][0].shape[2]
- seq_length_with_past = seq_length_with_past + past_key_values_length
+ seq_length_with_past = seq_length + past_key_values_length
# NOTE: differentiate with prefill stage
# block_loc require different value-assigning method for two different stage
@@ -623,9 +628,7 @@ def llama_model_forward(
infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
else:
print(f" *** Encountered allocation non-contiguous")
- print(
- f" infer_state.cache_manager.past_key_values_length: {infer_state.cache_manager.past_key_values_length}"
- )
+ print(f" infer_state.cache_manager.max_len_in_batch: {infer_state.max_len_in_batch}")
infer_state.decode_is_contiguous = False
alloc_mem = infer_state.cache_manager.alloc(batch_size)
infer_state.decode_mem_index = alloc_mem
@@ -662,15 +665,15 @@ def llama_model_forward(
raise NotImplementedError("not implement gradient_checkpointing and training options ")
if past_key_values_length == 0:
- position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
position_ids.view(-1).shape[0], -1
)
- position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
position_ids.view(-1).shape[0], -1
)
else:
- position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(batch_size, -1)
- position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(batch_size, -1)
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(batch_size, -1)
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(batch_size, -1)
# decoder layers
all_hidden_states = () if output_hidden_states else None
@@ -685,7 +688,6 @@ def llama_model_forward(
layer_outputs = decoder_layer(
hidden_states,
- rotary_emb=(position_cos, position_sin),
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
@@ -713,6 +715,7 @@ def llama_model_forward(
infer_state.is_context_stage = False
infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
next_cache = next_decoder_cache if use_cache else None
if not return_dict:
diff --git a/colossalai/inference/quant/smoothquant/models/parallel_linear.py b/colossalai/inference/quant/smoothquant/models/parallel_linear.py
new file mode 100644
index 000000000000..962b687a1d05
--- /dev/null
+++ b/colossalai/inference/quant/smoothquant/models/parallel_linear.py
@@ -0,0 +1,264 @@
+from typing import List, Union
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from torch.distributed import ProcessGroup
+
+from colossalai.lazy import LazyInitContext
+from colossalai.shardformer.layer import ParallelModule
+
+from .linear import W8A8B8O8Linear, W8A8BFP32O32LinearSiLU, W8A8BFP32OFP32Linear
+
+
+def split_row_copy(smooth_linear, para_linear, tp_size=1, tp_rank=0, split_num=1):
+ qweights = smooth_linear.weight.split(smooth_linear.out_features // split_num, dim=0)
+ if smooth_linear.bias is not None:
+ bias = smooth_linear.bias.split(smooth_linear.out_features // split_num, dim=0)
+
+ smooth_split_out_features = para_linear.out_features // split_num
+
+ for i in range(split_num):
+ para_linear.weight[i * smooth_split_out_features : (i + 1) * smooth_split_out_features, :] = qweights[i][
+ tp_rank * smooth_split_out_features : (tp_rank + 1) * smooth_split_out_features, :
+ ]
+
+ if para_linear.bias is not None:
+ para_linear.bias[:, i * smooth_split_out_features : (i + 1) * smooth_split_out_features] = bias[i][
+ :, tp_rank * smooth_split_out_features : (tp_rank + 1) * smooth_split_out_features
+ ]
+
+
+def split_column_copy(smooth_linear, para_linear, tp_rank=0, split_num=1):
+ qweights = smooth_linear.weight.split(smooth_linear.in_features // split_num, dim=-1)
+
+ smooth_split_in_features = para_linear.in_features // split_num
+
+ for i in range(split_num):
+ para_linear.weight[:, i * smooth_split_in_features : (i + 1) * smooth_split_in_features] = qweights[i][
+ :, tp_rank * smooth_split_in_features : (tp_rank + 1) * smooth_split_in_features
+ ]
+
+ if smooth_linear.bias is not None:
+ para_linear.bias.copy_(smooth_linear.bias)
+
+
+class RowW8A8B8O8Linear(W8A8B8O8Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ out_features = module.out_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = RowW8A8B8O8Linear(module.in_features, module.out_features // tp_size)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+ linear_1d.b = module.b.clone().detach()
+ split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ return linear_1d
+
+
+class ColW8A8B8O8Linear(W8A8B8O8Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ in_features = module.in_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if in_features < tp_size:
+ return module
+
+ if in_features % tp_size != 0:
+ raise ValueError(
+ f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = ColW8A8B8O8Linear(module.in_features // tp_size, module.out_features)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = torch.tensor(module.a)
+ linear_1d.b = torch.tensor(module.b)
+
+ split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ if linear_1d.bias is not None:
+ linear_1d.bias = linear_1d.bias // tp_size
+
+ return linear_1d
+
+ @torch.no_grad()
+ def forward(self, x):
+ output = super().forward(x)
+ if self.tp_size > 1:
+ dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
+ return output
+
+
+class RowW8A8BFP32O32LinearSiLU(W8A8BFP32O32LinearSiLU, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ out_features = module.out_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = RowW8A8BFP32O32LinearSiLU(module.in_features, module.out_features // tp_size)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+
+ split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ return linear_1d
+
+
+class RowW8A8BFP32OFP32Linear(W8A8BFP32OFP32Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ out_features = module.out_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = RowW8A8BFP32OFP32Linear(module.in_features, module.out_features // tp_size)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+
+ split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ return linear_1d
+
+
+class ColW8A8BFP32OFP32Linear(W8A8BFP32OFP32Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ in_features = module.in_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if in_features < tp_size:
+ return module
+
+ if in_features % tp_size != 0:
+ raise ValueError(
+ f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = ColW8A8BFP32OFP32Linear(module.in_features // tp_size, module.out_features)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+
+ split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ if linear_1d.bias is not None:
+ linear_1d.bias = linear_1d.bias / tp_size
+
+ return linear_1d
+
+ @torch.no_grad()
+ def forward(self, x):
+ output = super().forward(x)
+ if self.tp_size > 1:
+ dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
+ return output
diff --git a/colossalai/inference/tensor_parallel/batch_infer_state.py b/colossalai/inference/tensor_parallel/batch_infer_state.py
deleted file mode 100644
index de150311cc08..000000000000
--- a/colossalai/inference/tensor_parallel/batch_infer_state.py
+++ /dev/null
@@ -1,57 +0,0 @@
-# might want to consider combine with InferenceConfig in colossalai/ppinference/inference_config.py later
-from dataclasses import dataclass
-
-import torch
-
-from .kvcache_manager import MemoryManager
-
-# adapted from: lightllm/server/router/model_infer/infer_batch.py
-@dataclass
-class BatchInferState:
- r"""
- Information to be passed and used for a batch of inputs during
- a single model forward
- """
- batch_size: int
- max_len_in_batch: int
-
- cache_manager: MemoryManager = None
-
- block_loc: torch.Tensor = None
- start_loc: torch.Tensor = None
- seq_len: torch.Tensor = None
- past_key_values_len: int = None
-
- is_context_stage: bool = False
- context_mem_index: torch.Tensor = None
- decode_is_contiguous: bool = None
- decode_mem_start: int = None
- decode_mem_end: int = None
- decode_mem_index: torch.Tensor = None
- decode_layer_id: int = None
-
- device: torch.device = torch.device("cuda")
-
- @property
- def total_token_num(self):
- # return self.batch_size * self.max_len_in_batch
- assert self.seq_len is not None and self.seq_len.size(0) > 0
- return int(torch.sum(self.seq_len))
-
- def set_cache_manager(self, manager: MemoryManager):
- self.cache_manager = manager
-
- # adapted from: https://github.com/ModelTC/lightllm/blob/28c1267cfca536b7b4f28e921e03de735b003039/lightllm/common/infer_utils.py#L1
- @staticmethod
- def init_block_loc(
- b_loc: torch.Tensor, seq_len: torch.Tensor, max_len_in_batch: int, alloc_mem_index: torch.Tensor
- ):
- """in-place update block loc mapping based on the sequence length of the inputs in current bath"""
- start_index = 0
- seq_len_numpy = seq_len.cpu().numpy()
- for i, cur_seq_len in enumerate(seq_len_numpy):
- b_loc[i, max_len_in_batch - cur_seq_len : max_len_in_batch] = alloc_mem_index[
- start_index : start_index + cur_seq_len
- ]
- start_index += cur_seq_len
- return
diff --git a/colossalai/initialize.py b/colossalai/initialize.py
index aac57d34a2c1..25076b742c26 100644
--- a/colossalai/initialize.py
+++ b/colossalai/initialize.py
@@ -11,7 +11,7 @@
from colossalai.context import Config
from colossalai.logging import get_dist_logger
-from colossalai.utils import set_device, set_seed
+from colossalai.utils import IS_NPU_AVAILABLE, set_device, set_seed
def launch(
@@ -47,12 +47,15 @@ def launch(
if rank == 0:
warnings.warn("`config` is deprecated and will be removed soon.")
+ if IS_NPU_AVAILABLE and backend == "nccl":
+ backend = "hccl"
+
# init default process group
init_method = f"tcp://[{host}]:{port}"
dist.init_process_group(rank=rank, world_size=world_size, backend=backend, init_method=init_method)
# set cuda device
- if torch.cuda.is_available():
+ if torch.cuda.is_available() or IS_NPU_AVAILABLE:
# if local rank is not given, calculate automatically
set_device(local_rank)
diff --git a/colossalai/kernel/cuda_native/csrc/cpu_adam.h b/colossalai/kernel/cuda_native/csrc/cpu_adam.h
index bf9b85997c78..db1f26d5f6da 100644
--- a/colossalai/kernel/cuda_native/csrc/cpu_adam.h
+++ b/colossalai/kernel/cuda_native/csrc/cpu_adam.h
@@ -142,6 +142,7 @@ class Adam_Optimizer {
}
}
+#if defined(__AVX512__) or defined(__AVX256__) or defined(__AVX2__)
inline void simd_load(bool is_half, float *ptr, __half *h_ptr,
AVX_Data &data) {
if (is_half) {
@@ -159,6 +160,7 @@ class Adam_Optimizer {
SIMD_STORE(ptr, data.data);
}
}
+#endif
void step(size_t step, float lr, float beta1, float beta2, float epsilon,
float weight_decay, bool bias_correction, torch::Tensor ¶ms,
diff --git a/colossalai/kernel/cuda_native/csrc/cpu_adam_arm.cpp b/colossalai/kernel/cuda_native/csrc/cpu_adam_arm.cpp
new file mode 100644
index 000000000000..a715a2711576
--- /dev/null
+++ b/colossalai/kernel/cuda_native/csrc/cpu_adam_arm.cpp
@@ -0,0 +1,304 @@
+#include "cpu_adam_arm.h"
+
+void AdamOptimizer::Step_1(void *_params, void *grads, void *_exp_avg,
+ void *_exp_avg_sq, size_t _param_size,
+ at::ScalarType param_dtype,
+ at::ScalarType grad_dtype,
+ at::ScalarType exp_avg_dtype,
+ at::ScalarType exp_avg_sq_dtype, float loss_scale) {
+ size_t rounded_size = 0;
+#if defined(__aarch64__)
+ rounded_size = ROUND_DOWN(_param_size, SIMD_WIDTH);
+#endif
+
+ float betta1_minus1 = 1 - _betta1;
+ float betta2_minus1 = 1 - _betta2;
+ float step_size = -1 * _alpha / _bias_correction1;
+ float w_decay = -1 * _alpha * _weight_decay;
+
+#if defined(__aarch64__)
+ float32x4_t betta1_4 = simd_set(_betta1);
+ float32x4_t betta2_4 = simd_set(_betta2);
+ float32x4_t betta1_minus1_4 = simd_set(betta1_minus1);
+ float32x4_t betta2_minus1_4 = simd_set(betta2_minus1);
+ float32x4_t bias2_sqrt = simd_set(_bias_correction2);
+ float32x4_t eps_4 = simd_set(_eps);
+ float32x4_t step_size_4 = simd_set(step_size);
+ float32x4_t weight_decay_4;
+ if (_weight_decay > 0) {
+ weight_decay_4 = _adamw_mode ? simd_set(w_decay) : simd_set(_weight_decay);
+ }
+ for (size_t t = 0; t < rounded_size; t += TILE) {
+ size_t copy_size = TILE;
+ if ((t + TILE) > rounded_size) copy_size = rounded_size - t;
+ size_t offset = copy_size + t;
+
+#pragma omp parallel for
+ for (size_t i = t; i < offset; i += SIMD_WIDTH) {
+ float32x4_t grad_4 = simd_load_offset(grads, grad_dtype, i);
+ if (loss_scale > 0) {
+ float32x4_t loss_scale_vec = simd_set(loss_scale);
+ grad_4 = vdivq_f32(grad_4, loss_scale_vec);
+ }
+ float32x4_t momentum_4 = simd_load_offset(_exp_avg, exp_avg_dtype, i);
+ float32x4_t variance_4 =
+ simd_load_offset(_exp_avg_sq, exp_avg_sq_dtype, i);
+ float32x4_t param_4 = simd_load_offset(_params, param_dtype, i);
+ if (_weight_decay > 0 && !_adamw_mode) {
+ grad_4 = vfmaq_f32(grad_4, param_4, weight_decay_4);
+ }
+ momentum_4 = vmulq_f32(momentum_4, betta1_4);
+ momentum_4 = vfmaq_f32(momentum_4, grad_4, betta1_minus1_4);
+ variance_4 = vmulq_f32(variance_4, betta2_4);
+ grad_4 = vmulq_f32(grad_4, grad_4);
+ variance_4 = vfmaq_f32(variance_4, grad_4, betta2_minus1_4);
+ grad_4 = vsqrtq_f32(variance_4);
+ grad_4 = vfmaq_f32(eps_4, grad_4, bias2_sqrt);
+ grad_4 = vdivq_f32(momentum_4, grad_4);
+ if (_weight_decay > 0 && _adamw_mode) {
+ param_4 = vfmaq_f32(param_4, param_4, weight_decay_4);
+ }
+ param_4 = vfmaq_f32(param_4, grad_4, step_size_4);
+ simd_store_offset(_params, param_dtype, param_4, i);
+ simd_store_offset(_exp_avg, exp_avg_dtype, momentum_4, i);
+ simd_store_offset(_exp_avg_sq, exp_avg_sq_dtype, variance_4, i);
+ }
+ }
+#endif
+ if (_param_size > rounded_size) {
+ for (size_t t = rounded_size; t < _param_size; t += TILE) {
+ size_t copy_size = TILE;
+ if ((t + TILE) > _param_size) copy_size = _param_size - t;
+ size_t offset = copy_size + t;
+
+#pragma omp parallel for
+ for (size_t k = t; k < offset; k++) {
+ float grad = scalar_load_offset(grads, grad_dtype, k);
+ if (loss_scale > 0) {
+ grad /= loss_scale;
+ }
+ float param = scalar_load_offset(_params, param_dtype, k);
+ float momentum = scalar_load_offset(_exp_avg, exp_avg_dtype, k);
+ float variance = scalar_load_offset(_exp_avg_sq, exp_avg_sq_dtype, k);
+ if (_weight_decay > 0 && !_adamw_mode) {
+ grad = param * _weight_decay + grad;
+ }
+ momentum = momentum * _betta1;
+ momentum = grad * betta1_minus1 + momentum;
+
+ variance = variance * _betta2;
+ grad = grad * grad;
+ variance = grad * betta2_minus1 + variance;
+
+ grad = sqrt(variance);
+ grad = grad * _bias_correction2 + _eps;
+ grad = momentum / grad;
+ if (_weight_decay > 0 && _adamw_mode) {
+ param += w_decay * param;
+ }
+ param = grad * step_size + param;
+
+ scalar_store_offset(_params, param_dtype, param, k);
+ scalar_store_offset(_exp_avg, exp_avg_dtype, momentum, k);
+ scalar_store_offset(_exp_avg_sq, exp_avg_sq_dtype, variance, k);
+ }
+ }
+ }
+}
+
+void AdamOptimizer::Step_4(void *_params, void *grads, void *_exp_avg,
+ void *_exp_avg_sq, size_t _param_size,
+ at::ScalarType param_dtype,
+ at::ScalarType grad_dtype,
+ at::ScalarType exp_avg_dtype,
+ at::ScalarType exp_avg_sq_dtype, float loss_scale) {
+ size_t rounded_size = 0;
+#if defined(__aarch64__)
+ rounded_size = ROUND_DOWN(_param_size, SIMD_WIDTH * 4);
+#endif
+
+ float betta1_minus1 = 1 - _betta1;
+ float betta2_minus1 = 1 - _betta2;
+ float step_size = -1 * _alpha / _bias_correction1;
+ float w_decay = -1 * _alpha * _weight_decay;
+
+#if defined(__aarch64__)
+ float32x4_t betta1_4 = simd_set(_betta1);
+ float32x4_t betta2_4 = simd_set(_betta2);
+ float32x4_t betta1_minus1_4 = simd_set(betta1_minus1);
+ float32x4_t betta2_minus1_4 = simd_set(betta2_minus1);
+ float32x4_t bias2_sqrt = simd_set(_bias_correction2);
+ float32x4_t eps_4 = simd_set(_eps);
+ float32x4_t step_size_4 = simd_set(step_size);
+ float32x4_t weight_decay_4;
+ if (_weight_decay > 0) {
+ weight_decay_4 = _adamw_mode ? simd_set(w_decay) : simd_set(_weight_decay);
+ }
+
+ for (size_t t = 0; t < rounded_size; t += TILE) {
+ size_t copy_size = TILE;
+ if ((t + TILE) > rounded_size) copy_size = rounded_size - t;
+ size_t offset = copy_size + t;
+
+#pragma omp parallel for
+ for (size_t i = t; i < offset; i += SIMD_WIDTH * 4) {
+ float32x4_t grad_4[4];
+ float32x4_t momentum_4[4];
+ float32x4_t variance_4[4];
+ float32x4_t param_4[4];
+#pragma unroll 4
+ for (int j = 0; j < 4; j++) {
+ grad_4[j] = simd_load_offset(grads, grad_dtype, i + SIMD_WIDTH * j);
+ if (loss_scale > 0) {
+ float32x4_t loss_scale_vec = simd_set(loss_scale);
+ grad_4[j] = vdivq_f32(grad_4[j], loss_scale_vec);
+ }
+ momentum_4[j] =
+ simd_load_offset(_exp_avg, exp_avg_dtype, i + SIMD_WIDTH * j);
+ variance_4[j] =
+ simd_load_offset(_exp_avg_sq, exp_avg_sq_dtype, i + SIMD_WIDTH * j);
+ param_4[j] = simd_load_offset(_params, param_dtype, i + SIMD_WIDTH * j);
+ if (_weight_decay > 0 && !_adamw_mode) {
+ grad_4[j] = vfmaq_f32(grad_4[j], param_4[j], weight_decay_4);
+ }
+ momentum_4[j] = vmulq_f32(momentum_4[j], betta1_4);
+ momentum_4[j] = vfmaq_f32(momentum_4[j], grad_4[j], betta1_minus1_4);
+ variance_4[j] = vmulq_f32(variance_4[j], betta2_4);
+ grad_4[j] = vmulq_f32(grad_4[j], grad_4[j]);
+ variance_4[j] = vfmaq_f32(variance_4[j], grad_4[j], betta2_minus1_4);
+ grad_4[j] = vsqrtq_f32(variance_4[j]);
+ grad_4[j] = vfmaq_f32(eps_4, grad_4[j], bias2_sqrt);
+ grad_4[j] = vdivq_f32(momentum_4[j], grad_4[j]);
+ if (_weight_decay > 0 && _adamw_mode) {
+ param_4[j] = vfmaq_f32(param_4[j], param_4[j], weight_decay_4);
+ }
+ param_4[j] = vfmaq_f32(param_4[j], grad_4[j], step_size_4);
+ simd_store_offset(_params, param_dtype, param_4[j], i + SIMD_WIDTH * j);
+ simd_store_offset(_exp_avg, exp_avg_dtype, momentum_4[j],
+ i + SIMD_WIDTH * j);
+ simd_store_offset(_exp_avg_sq, exp_avg_sq_dtype, variance_4[j],
+ i + SIMD_WIDTH * j);
+ }
+ }
+ }
+#endif
+ if (_param_size > rounded_size) {
+ Step_1(scalar_seek_offset(_params, param_dtype, rounded_size),
+ scalar_seek_offset(grads, grad_dtype, rounded_size),
+ scalar_seek_offset(_exp_avg, exp_avg_dtype, rounded_size),
+ scalar_seek_offset(_exp_avg_sq, exp_avg_sq_dtype, rounded_size),
+ (_param_size - rounded_size), param_dtype, grad_dtype, exp_avg_dtype,
+ exp_avg_sq_dtype, loss_scale);
+ }
+}
+
+void AdamOptimizer::Step_8(void *_params, void *grads, void *_exp_avg,
+ void *_exp_avg_sq, size_t _param_size,
+ at::ScalarType param_dtype,
+ at::ScalarType grad_dtype,
+ at::ScalarType exp_avg_dtype,
+ at::ScalarType exp_avg_sq_dtype, float loss_scale) {
+ size_t rounded_size = 0;
+#if defined(__aarch64__)
+ rounded_size = ROUND_DOWN(_param_size, SIMD_WIDTH * 8);
+#endif
+
+ float betta1_minus1 = 1 - _betta1;
+ float betta2_minus1 = 1 - _betta2;
+ float step_size = -1 * _alpha / _bias_correction1;
+ float w_decay = -1 * _alpha * _weight_decay;
+#if defined(__aarch64__)
+ float32x4_t betta1_4 = simd_set(_betta1);
+ float32x4_t betta2_4 = simd_set(_betta2);
+ float32x4_t betta1_minus1_4 = simd_set(betta1_minus1);
+ float32x4_t betta2_minus1_4 = simd_set(betta2_minus1);
+ float32x4_t bias2_sqrt = simd_set(_bias_correction2);
+ float32x4_t eps_4 = simd_set(_eps);
+ float32x4_t step_size_4 = simd_set(step_size);
+ float32x4_t weight_decay_4;
+ if (_weight_decay > 0) {
+ weight_decay_4 = _adamw_mode ? simd_set(w_decay) : simd_set(_weight_decay);
+ }
+
+ for (size_t t = 0; t < rounded_size; t += TILE) {
+ size_t copy_size = TILE;
+ if ((t + TILE) > rounded_size) copy_size = rounded_size - t;
+ size_t offset = copy_size + t;
+
+#pragma omp parallel for
+ for (size_t i = t; i < offset; i += SIMD_WIDTH * 8) {
+ float32x4_t grad_4[8];
+ float32x4_t momentum_4[8];
+ float32x4_t variance_4[8];
+ float32x4_t param_4[8];
+#pragma unroll 4
+ for (int j = 0; j < 8; j++) {
+ grad_4[j] = simd_load_offset(grads, grad_dtype, i + SIMD_WIDTH * j);
+ if (loss_scale > 0) {
+ float32x4_t loss_scale_vec = simd_set(loss_scale);
+ grad_4[j] = vdivq_f32(grad_4[j], loss_scale_vec);
+ }
+ momentum_4[j] =
+ simd_load_offset(_exp_avg, exp_avg_dtype, i + SIMD_WIDTH * j);
+ variance_4[j] =
+ simd_load_offset(_exp_avg_sq, exp_avg_sq_dtype, i + SIMD_WIDTH * j);
+ param_4[j] = simd_load_offset(_params, param_dtype, i + SIMD_WIDTH * j);
+ if (_weight_decay > 0 && !_adamw_mode) {
+ grad_4[j] = vfmaq_f32(grad_4[j], param_4[j], weight_decay_4);
+ }
+ momentum_4[j] = vmulq_f32(momentum_4[j], betta1_4);
+ momentum_4[j] = vfmaq_f32(momentum_4[j], grad_4[j], betta1_minus1_4);
+ variance_4[j] = vmulq_f32(variance_4[j], betta2_4);
+ grad_4[j] = vmulq_f32(grad_4[j], grad_4[j]);
+ variance_4[j] = vfmaq_f32(variance_4[j], grad_4[j], betta2_minus1_4);
+ grad_4[j] = vsqrtq_f32(variance_4[j]);
+ grad_4[j] = vfmaq_f32(eps_4, grad_4[j], bias2_sqrt);
+ grad_4[j] = vdivq_f32(momentum_4[j], grad_4[j]);
+ if (_weight_decay > 0 && _adamw_mode) {
+ param_4[j] = vfmaq_f32(param_4[j], param_4[j], weight_decay_4);
+ }
+ param_4[j] = vfmaq_f32(param_4[j], grad_4[j], step_size_4);
+ simd_store_offset(_params, param_dtype, param_4[j], i + SIMD_WIDTH * j);
+ simd_store_offset(_exp_avg, exp_avg_dtype, momentum_4[j],
+ i + SIMD_WIDTH * j);
+ simd_store_offset(_exp_avg_sq, exp_avg_sq_dtype, variance_4[j],
+ i + SIMD_WIDTH * j);
+ }
+ }
+ }
+#endif
+ if (_param_size > rounded_size) {
+ Step_4(scalar_seek_offset(_params, param_dtype, rounded_size),
+ scalar_seek_offset(grads, grad_dtype, rounded_size),
+ scalar_seek_offset(_exp_avg, exp_avg_dtype, rounded_size),
+ scalar_seek_offset(_exp_avg_sq, exp_avg_sq_dtype, rounded_size),
+ (_param_size - rounded_size), param_dtype, grad_dtype, exp_avg_dtype,
+ exp_avg_sq_dtype, loss_scale);
+ }
+}
+
+void AdamOptimizer::step(size_t step, float lr, float beta1, float beta2,
+ float epsilon, float weight_decay,
+ bool bias_correction, torch::Tensor ¶ms,
+ torch::Tensor &grads, torch::Tensor &exp_avg,
+ torch::Tensor &exp_avg_sq, float loss_scale) {
+ auto params_c = params.contiguous();
+ auto grads_c = grads.contiguous();
+ auto exp_avg_c = exp_avg.contiguous();
+ auto exp_avg_sq_c = exp_avg_sq.contiguous();
+
+ this->IncrementStep(step, beta1, beta2);
+ this->update_state(lr, epsilon, weight_decay, bias_correction);
+ this->Step_8(params_c.data_ptr(), grads_c.data_ptr(), exp_avg_c.data_ptr(),
+ exp_avg_sq_c.data_ptr(), params_c.numel(),
+ params_c.scalar_type(), grads_c.scalar_type(),
+ exp_avg_c.scalar_type(), exp_avg_sq_c.scalar_type(), loss_scale);
+}
+
+namespace py = pybind11;
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ py::class_ +
+