diff --git a/.github/workflows/README.md b/.github/workflows/README.md
index 9634b84b8ff8..a46d8b1c24d0 100644
--- a/.github/workflows/README.md
+++ b/.github/workflows/README.md
@@ -30,7 +30,7 @@ In the section below, we will dive into the details of different workflows avail
Refer to this [documentation](https://docs.github.com/en/actions/managing-workflow-runs/manually-running-a-workflow) on how to manually trigger a workflow.
I will provide the details of each workflow below.
-**A PR which changes the `version.txt` is considered as a release PR in the following coontext.**
+**A PR which changes the `version.txt` is considered as a release PR in the following context.**
### Code Style Check
@@ -58,15 +58,15 @@ I will provide the details of each workflow below.
#### Example Test on Dispatch
This workflow is triggered by manually dispatching the workflow. It has the following input parameters:
-- `example_directory`: the example directory to test. Multiple directories are supported and must be separated b$$y comma. For example, language/gpt, images/vit. Simply input language or simply gpt does not work.
+- `example_directory`: the example directory to test. Multiple directories are supported and must be separated by comma. For example, language/gpt, images/vit. Simply input language or simply gpt does not work.
### Compatibility Test
| Workflow Name | File name | Description |
| -------------------------------- | ------------------------------------ | -------------------------------------------------------------------------------------------------------------------- |
-| `Compatibility Test on PR` | `compatibility_test_on_pr.yml` | Check Colossal-AI's compatiblity when `version.txt` is changed in a PR. |
-| `Compatibility Test on Schedule` | `compatibility_test_on_schedule.yml` | This workflow will check the compatiblity of Colossal-AI against PyTorch specified in `.compatibility` every Sunday. |
-| `Compatiblity Test on Dispatch` | `compatibility_test_on_dispatch.yml` | Test PyTorch Compatibility manually. |
+| `Compatibility Test on PR` | `compatibility_test_on_pr.yml` | Check Colossal-AI's compatibility when `version.txt` is changed in a PR. |
+| `Compatibility Test on Schedule` | `compatibility_test_on_schedule.yml` | This workflow will check the compatibility of Colossal-AI against PyTorch specified in `.compatibility` every Sunday. |
+| `Compatibility Test on Dispatch` | `compatibility_test_on_dispatch.yml` | Test PyTorch Compatibility manually. |
#### Compatibility Test on Dispatch
@@ -74,7 +74,7 @@ This workflow is triggered by manually dispatching the workflow. It has the foll
- `torch version`:torch version to test against, multiple versions are supported but must be separated by comma. The default is value is all, which will test all available torch versions listed in this [repository](https://github.com/hpcaitech/public_assets/tree/main/colossalai/torch_build/torch_wheels).
- `cuda version`: cuda versions to test against, multiple versions are supported but must be separated by comma. The CUDA versions must be present in our [DockerHub repository](https://hub.docker.com/r/hpcaitech/cuda-conda).
-> It only test the compatiblity of the main branch
+> It only test the compatibility of the main branch
### Release
@@ -113,7 +113,7 @@ This `.compatibility` file is to tell GitHub Actions which PyTorch and CUDA vers
2. `.cuda_ext.json`
-This file controls which CUDA versions will be checked against CUDA extenson built. You can add a new entry according to the json schema below to check the AOT build of PyTorch extensions before release.
+This file controls which CUDA versions will be checked against CUDA extension built. You can add a new entry according to the json schema below to check the AOT build of PyTorch extensions before release.
```json
{
@@ -144,7 +144,7 @@ This file controls which CUDA versions will be checked against CUDA extenson bui
- [x] check on PR
- [x] regular check
- [x] manual dispatch
-- [x] compatiblity check
+- [x] compatibility check
- [x] check on PR
- [x] manual dispatch
- [x] auto test when release
diff --git a/.github/workflows/run_chatgpt_examples.yml b/.github/workflows/run_chatgpt_examples.yml
index 51bb9d074644..1d8240ad4631 100644
--- a/.github/workflows/run_chatgpt_examples.yml
+++ b/.github/workflows/run_chatgpt_examples.yml
@@ -4,10 +4,10 @@ on:
pull_request:
types: [synchronize, opened, reopened]
paths:
- - 'applications/ChatGPT/chatgpt/**'
- - 'applications/ChatGPT/requirements.txt'
- - 'applications/ChatGPT/setup.py'
- - 'applications/ChatGPT/examples/**'
+ - 'applications/Chat/coati/**'
+ - 'applications/Chat/requirements.txt'
+ - 'applications/Chat/setup.py'
+ - 'applications/Chat/examples/**'
jobs:
@@ -16,7 +16,7 @@ jobs:
runs-on: [self-hosted, gpu]
container:
image: hpcaitech/pytorch-cuda:1.12.0-11.3.0
- options: --gpus all --rm -v /data/scratch/chatgpt:/data/scratch/chatgpt
+ options: --gpus all --rm -v /data/scratch/github_actions/chat:/data/scratch/github_actions/chat
timeout-minutes: 30
defaults:
run:
@@ -27,17 +27,26 @@ jobs:
- name: Install ColossalAI and ChatGPT
run: |
- pip install -v .
- cd applications/ChatGPT
+ pip install -e .
+ cd applications/Chat
pip install -v .
pip install -r examples/requirements.txt
+ - name: Install Transformers
+ run: |
+ cd applications/Chat
+ git clone https://github.com/hpcaitech/transformers
+ cd transformers
+ pip install -v .
+
- name: Execute Examples
run: |
- cd applications/ChatGPT
+ cd applications/Chat
rm -rf ~/.cache/colossalai
./examples/test_ci.sh
env:
NCCL_SHM_DISABLE: 1
MAX_JOBS: 8
- PROMPT_PATH: /data/scratch/chatgpt/prompts.csv
+ SFT_DATASET: /data/scratch/github_actions/chat/data.json
+ PROMPT_PATH: /data/scratch/github_actions/chat/prompts_en.jsonl
+ PRETRAIN_DATASET: /data/scratch/github_actions/chat/alpaca_data.json
diff --git a/applications/Chat/.gitignore b/applications/Chat/.gitignore
index 1ec5f53a8b8d..2b9b4f345d0f 100644
--- a/applications/Chat/.gitignore
+++ b/applications/Chat/.gitignore
@@ -144,3 +144,5 @@ docs/.build
# wandb log
example/wandb/
+
+examples/awesome-chatgpt-prompts/
\ No newline at end of file
diff --git a/applications/Chat/README.md b/applications/Chat/README.md
index 8f22084953ba..dea562c4d2ad 100644
--- a/applications/Chat/README.md
+++ b/applications/Chat/README.md
@@ -15,19 +15,18 @@
- [Install the Transformers](#install-the-transformers)
- [How to use?](#how-to-use)
- [Supervised datasets collection](#supervised-datasets-collection)
- - [Stage1 - Supervised instructs tuning](#stage1---supervised-instructs-tuning)
- - [Stage2 - Training reward model](#stage2---training-reward-model)
- - [Stage3 - Training model with reinforcement learning by human feedback](#stage3---training-model-with-reinforcement-learning-by-human-feedback)
- - [Inference - After Training](#inference---after-training)
- - [8-bit setup](#8-bit-setup)
- - [4-bit setup](#4-bit-setup)
+ - [RLHF Training Stage1 - Supervised instructs tuning](#RLHF-training-stage1---supervised-instructs-tuning)
+ - [RLHF Training Stage2 - Training reward model](#RLHF-training-stage2---training-reward-model)
+ - [RLHF Training Stage3 - Training model with reinforcement learning by human feedback](#RLHF-training-stage3---training-model-with-reinforcement-learning-by-human-feedback)
+ - [Inference Quantization and Serving - After Training](#inference-quantization-and-serving---after-training)
- [Coati7B examples](#coati7b-examples)
- [Generation](#generation)
- [Open QA](#open-qa)
- - [Limitation for LLaMA-finetuned models](#limitation-for-llama-finetuned-models)
- - [Limitation of dataset](#limitation-of-dataset)
+ - [Limitation for LLaMA-finetuned models](#limitation)
+ - [Limitation of dataset](#limitation)
- [FAQ](#faq)
- - [How to save/load checkpoint](#how-to-saveload-checkpoint)
+ - [How to save/load checkpoint](#faq)
+ - [How to train with limited resources](#faq)
- [The Plan](#the-plan)
- [Real-time progress](#real-time-progress)
- [Invitation to open-source contribution](#invitation-to-open-source-contribution)
@@ -82,6 +81,8 @@ Due to resource constraints, we will only provide this service from 29th Mar 202
```shell
conda create -n coati
conda activate coati
+git clone https://github.com/hpcaitech/ColossalAI.git
+cd ColossalAI/applications/Chat
pip install .
```
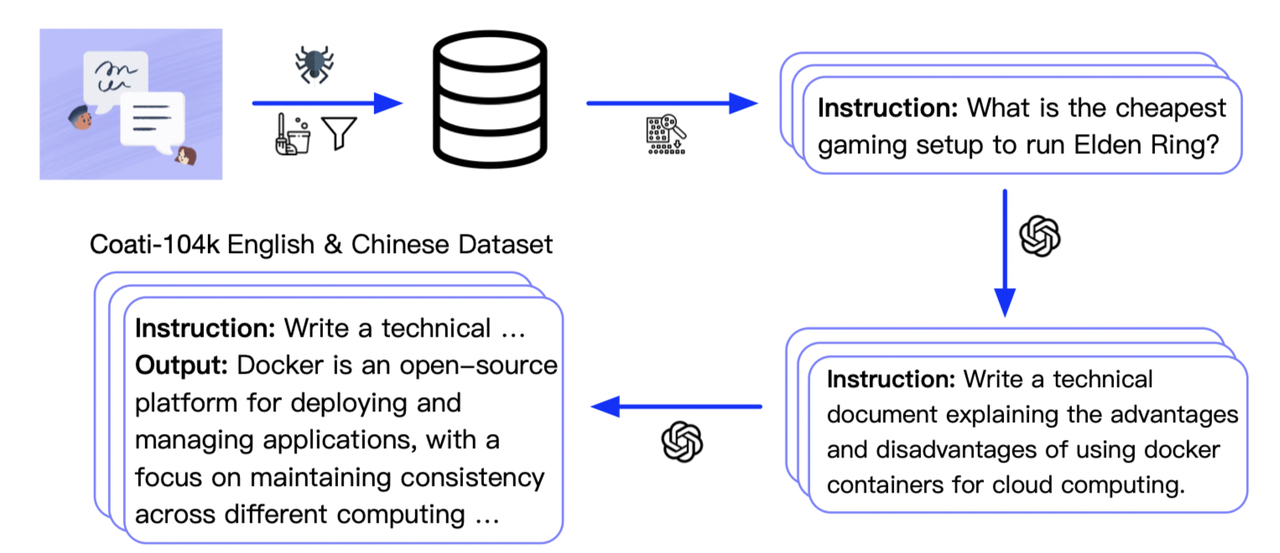
@@ -106,43 +107,19 @@ Here is how we collected the data
 -### Stage1 - Supervised instructs tuning
+### RLHF Training Stage1 - Supervised instructs tuning
-Stage1 is supervised instructs fine-tuning, which uses the datasets mentioned earlier to fine-tune the model
+Stage1 is supervised instructs fine-tuning, which uses the datasets mentioned earlier to fine-tune the model.
-you can run the `examples/train_sft.sh` to start a supervised instructs fine-tuning
+You can run the `examples/train_sft.sh` to start a supervised instructs fine-tuning.
-```
-torchrun --standalone --nproc_per_node=4 train_sft.py \
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --log_interval 10 \
- --save_path /path/to/Coati-7B \
- --dataset /path/to/data.json \
- --batch_size 4 \
- --accimulation_steps 8 \
- --lr 2e-5 \
- --max_datasets_size 512 \
- --max_epochs 1 \
-```
-
-### Stage2 - Training reward model
+### RLHF Training Stage2 - Training reward model
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model
-you can run the `examples/train_rm.sh` to start a reward model training
+You can run the `examples/train_rm.sh` to start a reward model training.
-```
-torchrun --standalone --nproc_per_node=4 train_reward_model.py
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --loss_fn 'log_exp'\
- --save_path 'rmstatic.pt' \
-```
-
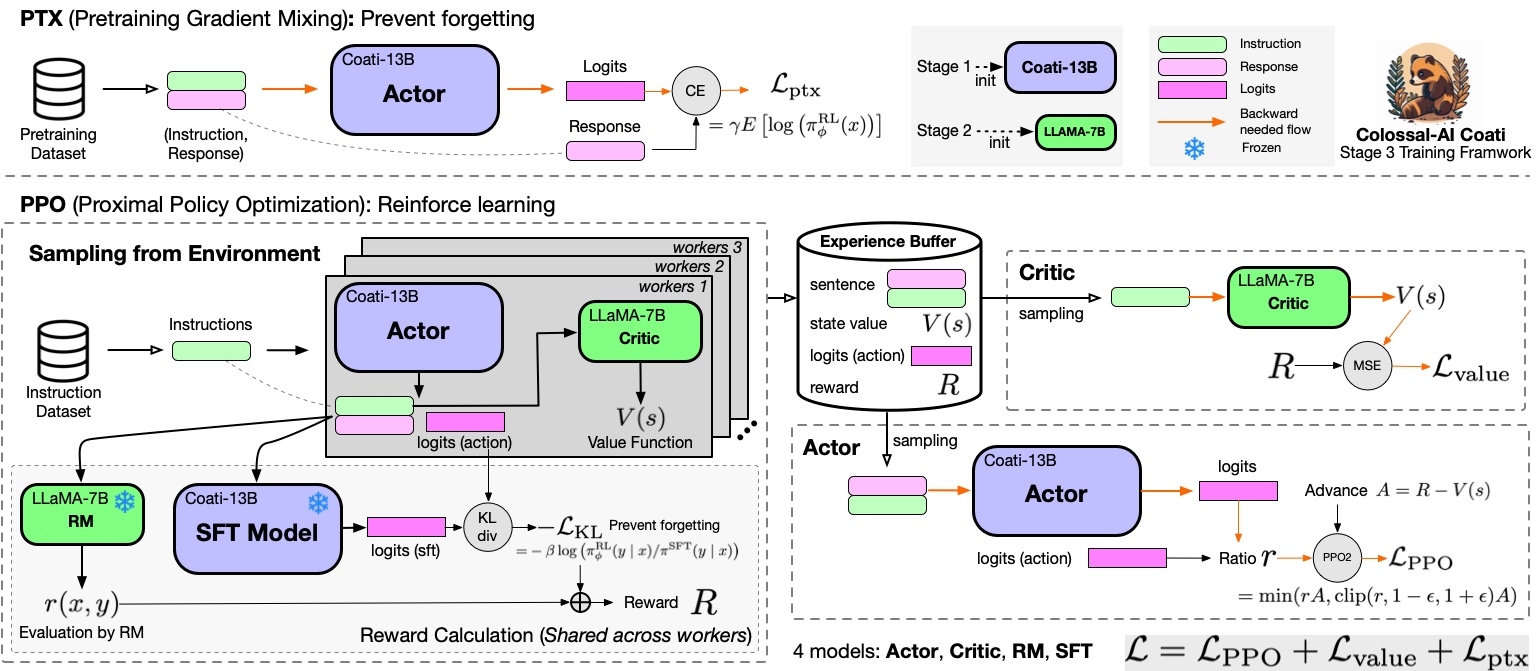
-### Stage3 - Training model with reinforcement learning by human feedback
+### RLHF Training Stage3 - Training model with reinforcement learning by human feedback
Stage3 uses reinforcement learning algorithm, which is the most complex part of the training process:
@@ -150,63 +127,16 @@ Stage3 uses reinforcement learning algorithm, which is the most complex part of
-### Stage1 - Supervised instructs tuning
+### RLHF Training Stage1 - Supervised instructs tuning
-Stage1 is supervised instructs fine-tuning, which uses the datasets mentioned earlier to fine-tune the model
+Stage1 is supervised instructs fine-tuning, which uses the datasets mentioned earlier to fine-tune the model.
-you can run the `examples/train_sft.sh` to start a supervised instructs fine-tuning
+You can run the `examples/train_sft.sh` to start a supervised instructs fine-tuning.
-```
-torchrun --standalone --nproc_per_node=4 train_sft.py \
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --log_interval 10 \
- --save_path /path/to/Coati-7B \
- --dataset /path/to/data.json \
- --batch_size 4 \
- --accimulation_steps 8 \
- --lr 2e-5 \
- --max_datasets_size 512 \
- --max_epochs 1 \
-```
-
-### Stage2 - Training reward model
+### RLHF Training Stage2 - Training reward model
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model
-you can run the `examples/train_rm.sh` to start a reward model training
+You can run the `examples/train_rm.sh` to start a reward model training.
-```
-torchrun --standalone --nproc_per_node=4 train_reward_model.py
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --loss_fn 'log_exp'\
- --save_path 'rmstatic.pt' \
-```
-
-### Stage3 - Training model with reinforcement learning by human feedback
+### RLHF Training Stage3 - Training model with reinforcement learning by human feedback
Stage3 uses reinforcement learning algorithm, which is the most complex part of the training process:
@@ -150,63 +127,16 @@ Stage3 uses reinforcement learning algorithm, which is the most complex part of
 -you can run the `examples/train_prompts.sh` to start training PPO with human feedback
-
-```
-torchrun --standalone --nproc_per_node=4 train_prompts.py \
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --prompt_path /path/to/your/prompt_dataset \
- --pretrain_dataset /path/to/your/pretrain_dataset \
- --rm_pretrain /your/pretrain/rm/defination \
- --rm_path /your/rm/model/path
-```
+You can run the `examples/train_prompts.sh` to start training PPO with human feedback.
For more details, see [`examples/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples).
-### Inference - After Training
-#### 8-bit setup
-
-8-bit quantization is originally supported by the latest [transformers](https://github.com/huggingface/transformers). Please install it from source.
+### Inference Quantization and Serving - After Training
-Please ensure you have downloaded HF-format model weights of LLaMA models.
+We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
-Usage:
-
-```python
-from transformers import LlamaForCausalLM
-USE_8BIT = True # use 8-bit quantization; otherwise, use fp16
-model = LlamaForCausalLM.from_pretrained(
- "pretrained/path",
- load_in_8bit=USE_8BIT,
- torch_dtype=torch.float16,
- device_map="auto",
- )
-if not USE_8BIT:
- model.half() # use fp16
-model.eval()
-```
-
-**Troubleshooting**: if you get errors indicating your CUDA-related libraries are not found when loading the 8-bit model, you can check whether your `LD_LIBRARY_PATH` is correct.
-
-E.g. you can set `export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH`.
-
-#### 4-bit setup
-
-Please ensure you have downloaded the HF-format model weights of LLaMA models first.
-
-Then you can follow [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). This lib provides efficient CUDA kernels and weight conversion scripts.
-
-After installing this lib, we may convert the original HF-format LLaMA model weights to a 4-bit version.
-
-```shell
-CUDA_VISIBLE_DEVICES=0 python llama.py /path/to/pretrained/llama-7b c4 --wbits 4 --groupsize 128 --save llama7b-4bit.pt
-```
-
-Run this command in your cloned `GPTQ-for-LLaMa` directory, then you will get a 4-bit weight file `llama7b-4bit-128g.pt`.
-
-**Troubleshooting**: if you get errors about `position_ids`, you can checkout to commit `50287c3b9ae4a3b66f6b5127c643ec39b769b155`(`GPTQ-for-LLaMa` repo).
+We support 8-bit quantization (RTN), 4-bit quantization (GPTQ), and FP16 inference. You can
+Online inference server scripts can help you deploy your own services.
For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
@@ -282,24 +212,27 @@ For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tre
You can find more examples in this [repo](https://github.com/XueFuzhao/InstructionWild/blob/main/comparison.md).
-### Limitation for LLaMA-finetuned models
+### Limitation
+
-you can run the `examples/train_prompts.sh` to start training PPO with human feedback
-
-```
-torchrun --standalone --nproc_per_node=4 train_prompts.py \
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --prompt_path /path/to/your/prompt_dataset \
- --pretrain_dataset /path/to/your/pretrain_dataset \
- --rm_pretrain /your/pretrain/rm/defination \
- --rm_path /your/rm/model/path
-```
+You can run the `examples/train_prompts.sh` to start training PPO with human feedback.
For more details, see [`examples/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples).
-### Inference - After Training
-#### 8-bit setup
-
-8-bit quantization is originally supported by the latest [transformers](https://github.com/huggingface/transformers). Please install it from source.
+### Inference Quantization and Serving - After Training
-Please ensure you have downloaded HF-format model weights of LLaMA models.
+We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
-Usage:
-
-```python
-from transformers import LlamaForCausalLM
-USE_8BIT = True # use 8-bit quantization; otherwise, use fp16
-model = LlamaForCausalLM.from_pretrained(
- "pretrained/path",
- load_in_8bit=USE_8BIT,
- torch_dtype=torch.float16,
- device_map="auto",
- )
-if not USE_8BIT:
- model.half() # use fp16
-model.eval()
-```
-
-**Troubleshooting**: if you get errors indicating your CUDA-related libraries are not found when loading the 8-bit model, you can check whether your `LD_LIBRARY_PATH` is correct.
-
-E.g. you can set `export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH`.
-
-#### 4-bit setup
-
-Please ensure you have downloaded the HF-format model weights of LLaMA models first.
-
-Then you can follow [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). This lib provides efficient CUDA kernels and weight conversion scripts.
-
-After installing this lib, we may convert the original HF-format LLaMA model weights to a 4-bit version.
-
-```shell
-CUDA_VISIBLE_DEVICES=0 python llama.py /path/to/pretrained/llama-7b c4 --wbits 4 --groupsize 128 --save llama7b-4bit.pt
-```
-
-Run this command in your cloned `GPTQ-for-LLaMa` directory, then you will get a 4-bit weight file `llama7b-4bit-128g.pt`.
-
-**Troubleshooting**: if you get errors about `position_ids`, you can checkout to commit `50287c3b9ae4a3b66f6b5127c643ec39b769b155`(`GPTQ-for-LLaMa` repo).
+We support 8-bit quantization (RTN), 4-bit quantization (GPTQ), and FP16 inference. You can
+Online inference server scripts can help you deploy your own services.
For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
@@ -282,24 +212,27 @@ For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tre
You can find more examples in this [repo](https://github.com/XueFuzhao/InstructionWild/blob/main/comparison.md).
-### Limitation for LLaMA-finetuned models
+### Limitation
+Limitation for LLaMA-finetuned models
- Both Alpaca and ColossalChat are based on LLaMA. It is hard to compensate for the missing knowledge in the pre-training stage.
- Lack of counting ability: Cannot count the number of items in a list.
- Lack of Logics (reasoning and calculation)
- Tend to repeat the last sentence (fail to produce the end token).
- Poor multilingual results: LLaMA is mainly trained on English datasets (Generation performs better than QA).
+Limitation of dataset
- Lack of summarization ability: No such instructions in finetune datasets.
- Lack of multi-turn chat: No such instructions in finetune datasets
- Lack of self-recognition: No such instructions in finetune datasets
- Lack of Safety:
- When the input contains fake facts, the model makes up false facts and explanations.
- Cannot abide by OpenAI's policy: When generating prompts from OpenAI API, it always abides by its policy. So no violation case is in the datasets.
+How to save/load checkpoint
We have integrated the Transformers save and load pipeline, allowing users to freely call Hugging Face's language models and save them in the HF format.
@@ -324,6 +257,63 @@ trainer.fit()
trainer.save_model(path=args.save_path, only_rank0=True, tokenizer=tokenizer)
```
+How to train with limited resources
+
+Here are some examples that can allow you to train a 7B model on a single or multiple consumer-grade GPUs.
+
+If you only have a single 24G GPU, you can use the following script. `batch_size` and `lora_rank` are the most important parameters to successfully train the model.
+```
+torchrun --standalone --nproc_per_node=1 train_sft.py \
+ --pretrain "/path/to/LLaMa-7B/" \
+ --model 'llama' \
+ --strategy naive \
+ --log_interval 10 \
+ --save_path /path/to/Coati-7B \
+ --dataset /path/to/data.json \
+ --batch_size 1 \
+ --accimulation_steps 8 \
+ --lr 2e-5 \
+ --max_datasets_size 512 \
+ --max_epochs 1 \
+ --lora_rank 16 \
+```
+
+`colossalai_gemini` strategy can enable a single 24G GPU to train the whole model without using LoRA if you have sufficient CPU memory. You can use the following script.
+```
+torchrun --standalone --nproc_per_node=1 train_sft.py \
+ --pretrain "/path/to/LLaMa-7B/" \
+ --model 'llama' \
+ --strategy colossalai_gemini \
+ --log_interval 10 \
+ --save_path /path/to/Coati-7B \
+ --dataset /path/to/data.json \
+ --batch_size 1 \
+ --accimulation_steps 8 \
+ --lr 2e-5 \
+ --max_datasets_size 512 \
+ --max_epochs 1 \
+```
+
+If you have 4x32 GB GPUs, you can even train the whole 7B model using our `colossalai_zero2_cpu` strategy! The script is given as follows.
+```
+torchrun --standalone --nproc_per_node=4 train_sft.py \
+ --pretrain "/path/to/LLaMa-7B/" \
+ --model 'llama' \
+ --strategy colossalai_zero2_cpu \
+ --log_interval 10 \
+ --save_path /path/to/Coati-7B \
+ --dataset /path/to/data.json \
+ --batch_size 1 \
+ --accimulation_steps 8 \
+ --lr 2e-5 \
+ --max_datasets_size 512 \
+ --max_epochs 1 \
+```
+

@@ -375,6 +373,13 @@ Thanks so much to all of our amazing contributors!
- Increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU
- Keep in a sufficiently high running speed
+| Model Pair | Alpaca-7B ⚔ Coati-7B | Coati-7B ⚔ Alpaca-7B |
+| :-----------: | :------------------: | :------------------: |
+| Better Cases | 38 ⚔ **41** | **45** ⚔ 33 |
+| Win Rate | 48% ⚔ **52%** | **58%** ⚔ 42% |
+| Average Score | 7.06 ⚔ **7.13** | **7.31** ⚔ 6.82 |
+- Our Coati-7B model performs better than Alpaca-7B when using GPT-4 to evaluate model performance. The Coati-7B model we evaluate is an old version we trained a few weeks ago and the new version is around the corner.
+
## Authors
Coati is developed by ColossalAI Team:
diff --git a/applications/Chat/benchmarks/benchmark_gpt_dummy.py b/applications/Chat/benchmarks/benchmark_gpt_dummy.py
index c0d8b1c377aa..e41ef239d378 100644
--- a/applications/Chat/benchmarks/benchmark_gpt_dummy.py
+++ b/applications/Chat/benchmarks/benchmark_gpt_dummy.py
@@ -156,8 +156,10 @@ def main(args):
eos_token_id=tokenizer.eos_token_id,
callbacks=[performance_evaluator])
- random_prompts = torch.randint(tokenizer.vocab_size, (1000, 400), device=torch.cuda.current_device())
- trainer.fit(random_prompts,
+ random_prompts = torch.randint(tokenizer.vocab_size, (1000, 1, 400), device=torch.cuda.current_device())
+ random_attention_mask = torch.randint(1, (1000, 1, 400), device=torch.cuda.current_device()).to(torch.bool)
+ random_pretrain = [{'input_ids':random_prompts[i], 'labels':random_prompts[i], 'attention_mask':random_attention_mask[i]} for i in range(1000)]
+ trainer.fit(random_prompts, random_pretrain,
num_episodes=args.num_episodes,
max_timesteps=args.max_timesteps,
update_timesteps=args.update_timesteps)
diff --git a/applications/Chat/benchmarks/benchmark_opt_lora_dummy.py b/applications/Chat/benchmarks/benchmark_opt_lora_dummy.py
index 42df2e1f28cb..c79435ec63c5 100644
--- a/applications/Chat/benchmarks/benchmark_opt_lora_dummy.py
+++ b/applications/Chat/benchmarks/benchmark_opt_lora_dummy.py
@@ -149,8 +149,10 @@ def main(args):
eos_token_id=tokenizer.eos_token_id,
callbacks=[performance_evaluator])
- random_prompts = torch.randint(tokenizer.vocab_size, (1000, 400), device=torch.cuda.current_device())
- trainer.fit(random_prompts,
+ random_prompts = torch.randint(tokenizer.vocab_size, (1000, 1, 400), device=torch.cuda.current_device())
+ random_attention_mask = torch.randint(1, (1000, 1, 400), device=torch.cuda.current_device()).to(torch.bool)
+ random_pretrain = [{'input_ids':random_prompts[i], 'labels':random_prompts[i], 'attention_mask':random_attention_mask[i]} for i in range(1000)]
+ trainer.fit(random_prompts, random_pretrain,
num_episodes=args.num_episodes,
max_timesteps=args.max_timesteps,
update_timesteps=args.update_timesteps)
diff --git a/applications/Chat/coati/dataset/sft_dataset.py b/applications/Chat/coati/dataset/sft_dataset.py
index 91e38f06daba..3e2453468bbc 100644
--- a/applications/Chat/coati/dataset/sft_dataset.py
+++ b/applications/Chat/coati/dataset/sft_dataset.py
@@ -53,29 +53,25 @@ class SFTDataset(Dataset):
def __init__(self, dataset, tokenizer: Callable, max_length: int = 512) -> None:
super().__init__()
- # self.prompts = []
self.input_ids = []
for data in tqdm(dataset, disable=not is_rank_0()):
- prompt = data['prompt'] + data['completion'] + "<|endoftext|>"
+ prompt = data['prompt'] + data['completion'] + tokenizer.eos_token
prompt_token = tokenizer(prompt,
max_length=max_length,
padding="max_length",
truncation=True,
return_tensors="pt")
- # self.prompts.append(prompt_token)s
- self.input_ids.append(prompt_token)
- self.labels = copy.deepcopy(self.input_ids)
+ self.input_ids.append(prompt_token['input_ids'][0])
+ self.labels = copy.deepcopy(self.input_ids)
def __len__(self):
- length = len(self.prompts)
+ length = len(self.input_ids)
return length
def __getitem__(self, idx):
- # dict(input_ids=self.input_ids[i], labels=self.labels[i])
return dict(input_ids=self.input_ids[idx], labels=self.labels[idx])
- # return dict(self.prompts[idx], self.prompts[idx])
def _tokenize_fn(strings: Sequence[str], tokenizer: transformers.PreTrainedTokenizer, max_length: int) -> Dict:
diff --git a/applications/Chat/coati/experience_maker/base.py b/applications/Chat/coati/experience_maker/base.py
index 61fd4f6744dc..ff75852576c8 100644
--- a/applications/Chat/coati/experience_maker/base.py
+++ b/applications/Chat/coati/experience_maker/base.py
@@ -18,7 +18,7 @@ class Experience:
action_log_probs: (B, A)
values: (B)
reward: (B)
- advatanges: (B)
+ advantages: (B)
attention_mask: (B, S)
action_mask: (B, A)
diff --git a/applications/Chat/coati/models/gpt/gpt_actor.py b/applications/Chat/coati/models/gpt/gpt_actor.py
index 6a53ad40b817..ae9d669f1f56 100644
--- a/applications/Chat/coati/models/gpt/gpt_actor.py
+++ b/applications/Chat/coati/models/gpt/gpt_actor.py
@@ -23,7 +23,8 @@ def __init__(self,
config: Optional[GPT2Config] = None,
checkpoint: bool = False,
lora_rank: int = 0,
- lora_train_bias: str = 'none') -> None:
+ lora_train_bias: str = 'none',
+ **kwargs) -> None:
if pretrained is not None:
model = GPT2LMHeadModel.from_pretrained(pretrained)
elif config is not None:
@@ -32,4 +33,4 @@ def __init__(self,
model = GPT2LMHeadModel(GPT2Config())
if checkpoint:
model.gradient_checkpointing_enable()
- super().__init__(model, lora_rank, lora_train_bias)
+ super().__init__(model, lora_rank, lora_train_bias, **kwargs)
diff --git a/applications/Chat/coati/models/gpt/gpt_critic.py b/applications/Chat/coati/models/gpt/gpt_critic.py
index 25bb1ed94de4..2e70f5f1fc96 100644
--- a/applications/Chat/coati/models/gpt/gpt_critic.py
+++ b/applications/Chat/coati/models/gpt/gpt_critic.py
@@ -24,7 +24,8 @@ def __init__(self,
config: Optional[GPT2Config] = None,
checkpoint: bool = False,
lora_rank: int = 0,
- lora_train_bias: str = 'none') -> None:
+ lora_train_bias: str = 'none',
+ **kwargs) -> None:
if pretrained is not None:
model = GPT2Model.from_pretrained(pretrained)
elif config is not None:
@@ -34,4 +35,4 @@ def __init__(self,
if checkpoint:
model.gradient_checkpointing_enable()
value_head = nn.Linear(model.config.n_embd, 1)
- super().__init__(model, value_head, lora_rank, lora_train_bias)
+ super().__init__(model, value_head, lora_rank, lora_train_bias, **kwargs)
diff --git a/applications/Chat/coati/models/lora.py b/applications/Chat/coati/models/lora.py
index f8f7a1cb5d81..7f6eb73262fa 100644
--- a/applications/Chat/coati/models/lora.py
+++ b/applications/Chat/coati/models/lora.py
@@ -108,7 +108,7 @@ def convert_to_lora_recursively(module: nn.Module, lora_rank: int) -> None:
class LoRAModule(nn.Module):
"""A LoRA module base class. All derived classes should call `convert_to_lora()` at the bottom of `__init__()`.
- This calss will convert all torch.nn.Linear layer to LoraLinear layer.
+ This class will convert all torch.nn.Linear layer to LoraLinear layer.
Args:
lora_rank (int, optional): LoRA rank. 0 means LoRA is not applied. Defaults to 0.
diff --git a/applications/Chat/coati/ray/__init__.py b/applications/Chat/coati/ray/__init__.py
new file mode 100644
index 000000000000..5802c05bc03f
--- /dev/null
+++ b/applications/Chat/coati/ray/__init__.py
@@ -0,0 +1,2 @@
+from .src.detached_replay_buffer import DetachedReplayBuffer
+from .src.detached_trainer_ppo import DetachedPPOTrainer
diff --git a/applications/Chat/coati/ray/example/1m1t.py b/applications/Chat/coati/ray/example/1m1t.py
new file mode 100644
index 000000000000..a6527370505b
--- /dev/null
+++ b/applications/Chat/coati/ray/example/1m1t.py
@@ -0,0 +1,153 @@
+import argparse
+from copy import deepcopy
+
+import pandas as pd
+import torch
+from coati.trainer import PPOTrainer
+
+
+from coati.ray.src.experience_maker_holder import ExperienceMakerHolder
+from coati.ray.src.detached_trainer_ppo import DetachedPPOTrainer
+
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.experience_maker import NaiveExperienceMaker
+from torch.optim import Adam
+from transformers import AutoTokenizer, BloomTokenizerFast
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.nn.optimizer import HybridAdam
+
+import ray
+import os
+import socket
+
+def get_free_port():
+ with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
+ s.bind(('', 0))
+ return s.getsockname()[1]
+
+
+def get_local_ip():
+ with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s:
+ s.connect(('8.8.8.8', 80))
+ return s.getsockname()[0]
+
+def main(args):
+ master_addr = str(get_local_ip())
+ # trainer_env_info
+ trainer_port = str(get_free_port())
+ env_info_trainer = {'local_rank' : '0',
+ 'rank' : '0',
+ 'world_size' : '1',
+ 'master_port' : trainer_port,
+ 'master_addr' : master_addr}
+
+ # maker_env_info
+ maker_port = str(get_free_port())
+ env_info_maker = {'local_rank' : '0',
+ 'rank' : '0',
+ 'world_size' : '1',
+ 'master_port' : maker_port,
+ 'master_addr' : master_addr}
+
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ # configure Trainer
+ trainer_ref = DetachedPPOTrainer.options(name="trainer1", num_gpus=1, max_concurrency=2).remote(
+ experience_maker_holder_name_list=["maker1"],
+ strategy=args.trainer_strategy,
+ model=args.model,
+ env_info = env_info_trainer,
+ pretrained=args.pretrain,
+ lora_rank=args.lora_rank,
+ train_batch_size=args.train_batch_size,
+ buffer_limit=16,
+ experience_batch_size=args.experience_batch_size,
+ max_epochs=args.max_epochs,
+ #kwargs:
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ debug=args.debug,
+ )
+
+ # configure Experience Maker
+ experience_holder_ref = ExperienceMakerHolder.options(name="maker1", num_gpus=1, max_concurrency=2).remote(
+ detached_trainer_name_list=["trainer1"],
+ strategy=args.maker_strategy,
+ env_info = env_info_maker,
+ experience_batch_size=args.experience_batch_size,
+ kl_coef=0.1,
+ #kwargs:
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ debug=args.debug,
+ )
+
+ # trainer send its actor and critic to experience holders.
+ ray.get(trainer_ref.initialize_remote_makers.remote())
+
+ # configure sampler
+ dataset = pd.read_csv(args.prompt_path)['prompt']
+
+ def tokenize_fn(texts):
+ # MUST padding to max length to ensure inputs of all ranks have the same length
+ # Different length may lead to hang when using gemini, as different generation steps
+ batch = tokenizer(texts, return_tensors='pt', max_length=96, padding='max_length', truncation=True)
+ return {k: v.cuda() for k, v in batch.items()}
+
+ trainer_done_ref = trainer_ref.fit.remote(num_episodes=args.num_episodes, max_timesteps=args.max_timesteps, update_timesteps=args.update_timesteps)
+ num_exp_per_maker = args.num_episodes * args.max_timesteps // args.update_timesteps * args.max_epochs + 3 # +3 for fault tolerance
+ maker_done_ref = experience_holder_ref.workingloop.remote(dataset, tokenize_fn, times=num_exp_per_maker)
+
+ ray.get([trainer_done_ref, maker_done_ref])
+
+ # save model checkpoint after fitting
+ trainer_ref.strategy_save_actor.remote(args.save_path, only_rank0=True)
+ # save optimizer checkpoint on all ranks
+ if args.need_optim_ckpt:
+ trainer_ref.strategy_save_actor_optim.remote('actor_optim_checkpoint_prompts_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('prompt_path')
+ parser.add_argument('--trainer_strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--maker_strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt'])
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--save_path', type=str, default='actor_checkpoint_prompts.pt')
+ parser.add_argument('--need_optim_ckpt', type=bool, default=False)
+ parser.add_argument('--num_episodes', type=int, default=10)
+ parser.add_argument('--max_timesteps', type=int, default=10)
+ parser.add_argument('--update_timesteps', type=int, default=10)
+ parser.add_argument('--max_epochs', type=int, default=5)
+ parser.add_argument('--train_batch_size', type=int, default=8)
+ parser.add_argument('--experience_batch_size', type=int, default=8)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+
+ parser.add_argument('--debug', action='store_true')
+ args = parser.parse_args()
+ ray.init(namespace=os.environ["RAY_NAMESPACE"])
+ main(args)
diff --git a/applications/Chat/coati/ray/example/1m1t.sh b/applications/Chat/coati/ray/example/1m1t.sh
new file mode 100644
index 000000000000..f7c5054c800e
--- /dev/null
+++ b/applications/Chat/coati/ray/example/1m1t.sh
@@ -0,0 +1,23 @@
+set_n_least_used_CUDA_VISIBLE_DEVICES() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
+
+set_n_least_used_CUDA_VISIBLE_DEVICES 2
+
+export RAY_NAMESPACE="admin"
+
+python 1m1t.py "/path/to/prompts.csv" \
+ --trainer_strategy colossalai_zero2 --maker_strategy naive --lora_rank 2 --pretrain "facebook/opt-350m" --model 'opt' \
+ --num_episodes 10 --max_timesteps 10 --update_timesteps 10 \
+ --max_epochs 10 --debug
diff --git a/applications/Chat/coati/ray/example/1m2t.py b/applications/Chat/coati/ray/example/1m2t.py
new file mode 100644
index 000000000000..3883c364a8e0
--- /dev/null
+++ b/applications/Chat/coati/ray/example/1m2t.py
@@ -0,0 +1,186 @@
+import argparse
+from copy import deepcopy
+
+import pandas as pd
+import torch
+from coati.trainer import PPOTrainer
+
+
+from coati.ray.src.experience_maker_holder import ExperienceMakerHolder
+from coati.ray.src.detached_trainer_ppo import DetachedPPOTrainer
+
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.experience_maker import NaiveExperienceMaker
+from torch.optim import Adam
+from transformers import AutoTokenizer, BloomTokenizerFast
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.nn.optimizer import HybridAdam
+
+import ray
+import os
+import socket
+
+
+def get_free_port():
+ with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
+ s.bind(('', 0))
+ return s.getsockname()[1]
+
+
+def get_local_ip():
+ with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s:
+ s.connect(('8.8.8.8', 80))
+ return s.getsockname()[0]
+
+def main(args):
+ master_addr = str(get_local_ip())
+ # trainer_env_info
+ trainer_port = str(get_free_port())
+ env_info_trainer_1 = {'local_rank' : '0',
+ 'rank' : '0',
+ 'world_size' : '2',
+ 'master_port' : trainer_port,
+ 'master_addr' : master_addr}
+ env_info_trainer_2 = {'local_rank' : '0',
+ 'rank' : '1',
+ 'world_size' : '2',
+ 'master_port' : trainer_port,
+ 'master_addr' : master_addr}
+ # maker_env_info
+ maker_port = str(get_free_port())
+ env_info_maker_1 = {'local_rank' : '0',
+ 'rank' : '0',
+ 'world_size' : '2',
+ 'master_port' : maker_port,
+ 'master_addr' : master_addr}
+ print([env_info_trainer_1,
+ env_info_trainer_2,
+ env_info_maker_1])
+ ray.init(dashboard_port = 1145)
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ # configure Trainer
+ trainer_1_ref = DetachedPPOTrainer.options(name="trainer1", namespace=os.environ["RAY_NAMESPACE"], num_gpus=1, max_concurrency=2).remote(
+ experience_maker_holder_name_list=["maker1"],
+ strategy=args.trainer_strategy,
+ model=args.model,
+ env_info=env_info_trainer_1,
+ pretrained=args.pretrain,
+ lora_rank=args.lora_rank,
+ train_batch_size=args.train_batch_size,
+ buffer_limit=16,
+ experience_batch_size=args.experience_batch_size,
+ max_epochs=args.max_epochs,
+ #kwargs:
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ debug=args.debug,
+ )
+
+ trainer_2_ref = DetachedPPOTrainer.options(name="trainer2", namespace=os.environ["RAY_NAMESPACE"], num_gpus=1, max_concurrency=2).remote(
+ experience_maker_holder_name_list=["maker1"],
+ strategy=args.trainer_strategy,
+ model=args.model,
+ env_info=env_info_trainer_2,
+ pretrained=args.pretrain,
+ lora_rank=args.lora_rank,
+ train_batch_size=args.train_batch_size,
+ buffer_limit=16,
+ experience_batch_size=args.experience_batch_size,
+ max_epochs=args.max_epochs,
+ #kwargs:
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ debug= args.debug,
+ )
+
+ # configure Experience Maker
+ experience_holder_1_ref = ExperienceMakerHolder.options(name="maker1", namespace=os.environ["RAY_NAMESPACE"], num_gpus=1, max_concurrency=2).remote(
+ detached_trainer_name_list=["trainer1", "trainer2"],
+ strategy=args.maker_strategy,
+ env_info=env_info_maker_1,
+ experience_batch_size=args.experience_batch_size,
+ kl_coef=0.1,
+ #kwargs:
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ debug=args.debug,
+ )
+
+ # trainer send its actor and critic to experience holders.
+ # TODO: balance duty
+ ray.get(trainer_1_ref.initialize_remote_makers.remote())
+
+ # configure sampler
+ dataset = pd.read_csv(args.prompt_path)['prompt']
+
+ def tokenize_fn(texts):
+ # MUST padding to max length to ensure inputs of all ranks have the same length
+ # Different length may lead to hang when using gemini, as different generation steps
+ batch = tokenizer(texts, return_tensors='pt', max_length=96, padding='max_length', truncation=True)
+ return {k: v.cuda() for k, v in batch.items()}
+
+ trainer_1_done_ref = trainer_1_ref.fit.remote(num_episodes=args.num_episodes, max_timesteps=args.max_timesteps, update_timesteps=args.update_timesteps)
+ trainer_2_done_ref = trainer_2_ref.fit.remote(num_episodes=args.num_episodes, max_timesteps=args.max_timesteps, update_timesteps=args.update_timesteps)
+ num_exp_per_maker = args.num_episodes * args.max_timesteps // args.update_timesteps * args.max_epochs * 2 + 3 # +3 for fault tolerance
+ maker_1_done_ref = experience_holder_1_ref.workingloop.remote(dataset, tokenize_fn, times=num_exp_per_maker)
+
+ ray.get([trainer_1_done_ref, trainer_2_done_ref, maker_1_done_ref])
+ # save model checkpoint after fitting
+ trainer_1_ref.strategy_save_actor.remote(args.save_path, only_rank0=True)
+ trainer_2_ref.strategy_save_actor.remote(args.save_path, only_rank0=True)
+ # save optimizer checkpoint on all ranks
+ if args.need_optim_ckpt:
+ trainer_1_ref.strategy_save_actor_optim.remote('actor_optim_checkpoint_prompts_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+ trainer_2_ref.strategy_save_actor_optim.remote('actor_optim_checkpoint_prompts_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('prompt_path')
+ parser.add_argument('--trainer_strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--maker_strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt'])
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--save_path', type=str, default='actor_checkpoint_prompts.pt')
+ parser.add_argument('--need_optim_ckpt', type=bool, default=False)
+ parser.add_argument('--num_episodes', type=int, default=10)
+ parser.add_argument('--max_timesteps', type=int, default=10)
+ parser.add_argument('--update_timesteps', type=int, default=10)
+ parser.add_argument('--max_epochs', type=int, default=5)
+ parser.add_argument('--train_batch_size', type=int, default=8)
+ parser.add_argument('--experience_batch_size', type=int, default=8)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+
+ parser.add_argument('--debug', action='store_true')
+ args = parser.parse_args()
+ main(args)
diff --git a/applications/Chat/coati/ray/example/1m2t.sh b/applications/Chat/coati/ray/example/1m2t.sh
new file mode 100644
index 000000000000..669f4141026c
--- /dev/null
+++ b/applications/Chat/coati/ray/example/1m2t.sh
@@ -0,0 +1,23 @@
+set_n_least_used_CUDA_VISIBLE_DEVICES() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
+
+set_n_least_used_CUDA_VISIBLE_DEVICES 2
+
+export RAY_NAMESPACE="admin"
+
+python 1m2t.py "/path/to/prompts.csv" --model gpt2 \
+ --maker_strategy naive --trainer_strategy ddp --lora_rank 2 \
+ --num_episodes 10 --max_timesteps 10 --update_timesteps 10 \
+ --max_epochs 10 #--debug
\ No newline at end of file
diff --git a/applications/Chat/coati/ray/example/2m1t.py b/applications/Chat/coati/ray/example/2m1t.py
new file mode 100644
index 000000000000..b655de1ab1fa
--- /dev/null
+++ b/applications/Chat/coati/ray/example/2m1t.py
@@ -0,0 +1,140 @@
+import argparse
+from copy import deepcopy
+
+import pandas as pd
+import torch
+from coati.trainer import PPOTrainer
+
+
+from coati.ray.src.experience_maker_holder import ExperienceMakerHolder
+from coati.ray.src.detached_trainer_ppo import DetachedPPOTrainer
+
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.experience_maker import NaiveExperienceMaker
+from torch.optim import Adam
+from transformers import AutoTokenizer, BloomTokenizerFast
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.nn.optimizer import HybridAdam
+
+import ray
+import os
+import socket
+
+
+def main(args):
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ # configure Trainer
+ trainer_ref = DetachedPPOTrainer.options(name="trainer1", num_gpus=1, max_concurrency=2).remote(
+ experience_maker_holder_name_list=["maker1", "maker2"],
+ strategy=args.trainer_strategy,
+ model=args.model,
+ pretrained=args.pretrain,
+ lora_rank=args.lora_rank,
+ train_batch_size=args.train_batch_size,
+ buffer_limit=16,
+ experience_batch_size=args.experience_batch_size,
+ max_epochs=args.max_epochs,
+ #kwargs:
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ debug=args.debug,
+ )
+
+ # configure Experience Maker
+ experience_holder_1_ref = ExperienceMakerHolder.options(name="maker1", num_gpus=1, max_concurrency=2).remote(
+ detached_trainer_name_list=["trainer1"],
+ strategy=args.maker_strategy,
+ experience_batch_size=args.experience_batch_size,
+ kl_coef=0.1,
+ #kwargs:
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ debug=args.debug,
+ )
+
+ experience_holder_2_ref = ExperienceMakerHolder.options(name="maker2", num_gpus=1, max_concurrency=2).remote(
+ detached_trainer_name_list=["trainer1"],
+ strategy=args.maker_strategy,
+ experience_batch_size=args.experience_batch_size,
+ kl_coef=0.1,
+ #kwargs:
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ debug=args.debug,
+ )
+
+ # trainer send its actor and critic to experience holders.
+ ray.get(trainer_ref.initialize_remote_makers.remote())
+
+ # configure sampler
+ dataset = pd.read_csv(args.prompt_path)['prompt']
+
+ def tokenize_fn(texts):
+ # MUST padding to max length to ensure inputs of all ranks have the same length
+ # Different length may lead to hang when using gemini, as different generation steps
+ batch = tokenizer(texts, return_tensors='pt', max_length=96, padding='max_length', truncation=True)
+ return {k: v.cuda() for k, v in batch.items()}
+
+ trainer_done_ref = trainer_ref.fit.remote(num_episodes=args.num_episodes, max_timesteps=args.max_timesteps, update_timesteps=args.update_timesteps)
+ num_exp_per_maker = args.num_episodes * args.max_timesteps // args.update_timesteps * args.max_epochs // 2 + 3 # +3 for fault tolerance
+ maker_1_done_ref = experience_holder_1_ref.workingloop.remote(dataset, tokenize_fn, times=num_exp_per_maker)
+ maker_2_done_ref = experience_holder_2_ref.workingloop.remote(dataset, tokenize_fn, times=num_exp_per_maker)
+
+ ray.get([trainer_done_ref, maker_1_done_ref, maker_2_done_ref])
+
+ # save model checkpoint after fitting
+ trainer_ref.strategy_save_actor.remote(args.save_path, only_rank0=True)
+ # save optimizer checkpoint on all ranks
+ if args.need_optim_ckpt:
+ trainer_ref.strategy_save_actor_optim.remote('actor_optim_checkpoint_prompts_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('prompt_path')
+ parser.add_argument('--trainer_strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--maker_strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt'])
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--save_path', type=str, default='actor_checkpoint_prompts.pt')
+ parser.add_argument('--need_optim_ckpt', type=bool, default=False)
+ parser.add_argument('--num_episodes', type=int, default=10)
+ parser.add_argument('--max_timesteps', type=int, default=10)
+ parser.add_argument('--update_timesteps', type=int, default=10)
+ parser.add_argument('--max_epochs', type=int, default=5)
+ parser.add_argument('--train_batch_size', type=int, default=8)
+ parser.add_argument('--experience_batch_size', type=int, default=8)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+
+ parser.add_argument('--debug', action='store_true')
+ args = parser.parse_args()
+ ray.init(namespace=os.environ["RAY_NAMESPACE"])
+ main(args)
diff --git a/applications/Chat/coati/ray/example/2m1t.sh b/applications/Chat/coati/ray/example/2m1t.sh
new file mode 100644
index 000000000000..a207d4118d60
--- /dev/null
+++ b/applications/Chat/coati/ray/example/2m1t.sh
@@ -0,0 +1,23 @@
+set_n_least_used_CUDA_VISIBLE_DEVICES() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
+
+set_n_least_used_CUDA_VISIBLE_DEVICES 3
+
+export RAY_NAMESPACE="admin"
+
+python 2m1t.py "/path/to/prompts.csv" \
+ --trainer_strategy naive --maker_strategy naive --lora_rank 2 --pretrain "facebook/opt-350m" --model 'opt' \
+ --num_episodes 10 --max_timesteps 10 --update_timesteps 10 \
+ --max_epochs 10 # --debug
diff --git a/applications/Chat/coati/ray/example/2m2t.py b/applications/Chat/coati/ray/example/2m2t.py
new file mode 100644
index 000000000000..435c71915fc2
--- /dev/null
+++ b/applications/Chat/coati/ray/example/2m2t.py
@@ -0,0 +1,209 @@
+import argparse
+from copy import deepcopy
+
+import pandas as pd
+import torch
+from coati.trainer import PPOTrainer
+
+
+from coati.ray.src.experience_maker_holder import ExperienceMakerHolder
+from coati.ray.src.detached_trainer_ppo import DetachedPPOTrainer
+
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.experience_maker import NaiveExperienceMaker
+from torch.optim import Adam
+from transformers import AutoTokenizer, BloomTokenizerFast
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.nn.optimizer import HybridAdam
+
+import ray
+import os
+import socket
+
+
+def get_free_port():
+ with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
+ s.bind(('', 0))
+ return s.getsockname()[1]
+
+
+def get_local_ip():
+ with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s:
+ s.connect(('8.8.8.8', 80))
+ return s.getsockname()[0]
+
+def main(args):
+ master_addr = str(get_local_ip())
+ # trainer_env_info
+ trainer_port = str(get_free_port())
+ env_info_trainer_1 = {'local_rank' : '0',
+ 'rank' : '0',
+ 'world_size' : '2',
+ 'master_port' : trainer_port,
+ 'master_addr' : master_addr}
+ env_info_trainer_2 = {'local_rank' : '0',
+ 'rank' : '1',
+ 'world_size' : '2',
+ 'master_port' : trainer_port,
+ 'master_addr' : master_addr}
+ # maker_env_info
+ maker_port = str(get_free_port())
+ env_info_maker_1 = {'local_rank' : '0',
+ 'rank' : '0',
+ 'world_size' : '2',
+ 'master_port' : maker_port,
+ 'master_addr' : master_addr}
+ env_info_maker_2 = {'local_rank' : '0',
+ 'rank' : '1',
+ 'world_size' : '2',
+ 'master_port': maker_port,
+ 'master_addr' : master_addr}
+ print([env_info_trainer_1,
+ env_info_trainer_2,
+ env_info_maker_1,
+ env_info_maker_2])
+ ray.init()
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ # configure Trainer
+ trainer_1_ref = DetachedPPOTrainer.options(name="trainer1", namespace=os.environ["RAY_NAMESPACE"], num_gpus=1, max_concurrency=2).remote(
+ experience_maker_holder_name_list=["maker1", "maker2"],
+ strategy=args.trainer_strategy,
+ model=args.model,
+ env_info=env_info_trainer_1,
+ pretrained=args.pretrain,
+ lora_rank=args.lora_rank,
+ train_batch_size=args.train_batch_size,
+ buffer_limit=16,
+ experience_batch_size=args.experience_batch_size,
+ max_epochs=args.max_epochs,
+ #kwargs:
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ debug=args.debug,
+ )
+
+ trainer_2_ref = DetachedPPOTrainer.options(name="trainer2", namespace=os.environ["RAY_NAMESPACE"], num_gpus=1, max_concurrency=2).remote(
+ experience_maker_holder_name_list=["maker1", "maker2"],
+ strategy=args.trainer_strategy,
+ model=args.model,
+ env_info=env_info_trainer_2,
+ pretrained=args.pretrain,
+ lora_rank=args.lora_rank,
+ train_batch_size=args.train_batch_size,
+ buffer_limit=16,
+ experience_batch_size=args.experience_batch_size,
+ max_epochs=args.max_epochs,
+ #kwargs:
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ debug=args.debug,
+ )
+
+ # configure Experience Maker
+ experience_holder_1_ref = ExperienceMakerHolder.options(name="maker1", namespace=os.environ["RAY_NAMESPACE"], num_gpus=1, max_concurrency=2).remote(
+ detached_trainer_name_list=["trainer1", "trainer2"],
+ strategy=args.maker_strategy,
+ env_info=env_info_maker_1,
+ experience_batch_size=args.experience_batch_size,
+ kl_coef=0.1,
+ #kwargs:
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ debug=args.debug,
+ )
+
+ experience_holder_2_ref = ExperienceMakerHolder.options(name="maker2", namespace=os.environ["RAY_NAMESPACE"], num_gpus=1, max_concurrency=2).remote(
+ detached_trainer_name_list=["trainer1", "trainer2"],
+ strategy=args.maker_strategy,
+ env_info=env_info_maker_2,
+ experience_batch_size=args.experience_batch_size,
+ kl_coef=0.1,
+ #kwargs:
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ debug=args.debug,
+ )
+
+ # trainer send its actor and critic to experience holders.
+ # TODO: balance duty
+ ray.get(trainer_1_ref.initialize_remote_makers.remote())
+
+ # configure sampler
+ dataset = pd.read_csv(args.prompt_path)['prompt']
+
+ def tokenize_fn(texts):
+ # MUST padding to max length to ensure inputs of all ranks have the same length
+ # Different length may lead to hang when using gemini, as different generation steps
+ batch = tokenizer(texts, return_tensors='pt', max_length=96, padding='max_length', truncation=True)
+ return {k: v.cuda() for k, v in batch.items()}
+
+ trainer_1_done_ref = trainer_1_ref.fit.remote(num_episodes=args.num_episodes, max_timesteps=args.max_timesteps, update_timesteps=args.update_timesteps)
+ trainer_2_done_ref = trainer_2_ref.fit.remote(num_episodes=args.num_episodes, max_timesteps=args.max_timesteps, update_timesteps=args.update_timesteps)
+ num_exp_per_maker = args.num_episodes * args.max_timesteps // args.update_timesteps * args.max_epochs + 3 # +3 for fault tolerance
+ maker_1_done_ref = experience_holder_1_ref.workingloop.remote(dataset, tokenize_fn, times=num_exp_per_maker)
+ maker_2_done_ref = experience_holder_2_ref.workingloop.remote(dataset, tokenize_fn, times=num_exp_per_maker)
+
+ ray.get([trainer_1_done_ref, trainer_2_done_ref, maker_1_done_ref, maker_2_done_ref])
+ # save model checkpoint after fitting
+ trainer_1_ref.strategy_save_actor.remote(args.save_path, only_rank0=True)
+ trainer_2_ref.strategy_save_actor.remote(args.save_path, only_rank0=True)
+ # save optimizer checkpoint on all ranks
+ if args.need_optim_ckpt:
+ trainer_1_ref.strategy_save_actor_optim.remote('actor_optim_checkpoint_prompts_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+ trainer_2_ref.strategy_save_actor_optim.remote('actor_optim_checkpoint_prompts_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('prompt_path')
+ parser.add_argument('--trainer_strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--maker_strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt'])
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--save_path', type=str, default='actor_checkpoint_prompts.pt')
+ parser.add_argument('--need_optim_ckpt', type=bool, default=False)
+ parser.add_argument('--num_episodes', type=int, default=10)
+ parser.add_argument('--max_timesteps', type=int, default=10)
+ parser.add_argument('--update_timesteps', type=int, default=10)
+ parser.add_argument('--max_epochs', type=int, default=5)
+ parser.add_argument('--train_batch_size', type=int, default=8)
+ parser.add_argument('--experience_batch_size', type=int, default=8)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+
+ parser.add_argument('--debug', action='store_true')
+ args = parser.parse_args()
+ main(args)
diff --git a/applications/Chat/coati/ray/example/2m2t.sh b/applications/Chat/coati/ray/example/2m2t.sh
new file mode 100644
index 000000000000..fb4024766c54
--- /dev/null
+++ b/applications/Chat/coati/ray/example/2m2t.sh
@@ -0,0 +1,23 @@
+set_n_least_used_CUDA_VISIBLE_DEVICES() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
+
+set_n_least_used_CUDA_VISIBLE_DEVICES 2
+
+export RAY_NAMESPACE="admin"
+
+python 2m2t.py "path/to/prompts.csv" \
+ --maker_strategy naive --trainer_strategy colossalai_zero2 --lora_rank 2 \
+ --num_episodes 10 --max_timesteps 10 --update_timesteps 10 \
+ --max_epochs 10 --debug
\ No newline at end of file
diff --git a/applications/Chat/coati/ray/src/__init__.py b/applications/Chat/coati/ray/src/__init__.py
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/applications/Chat/coati/ray/src/detached_replay_buffer.py b/applications/Chat/coati/ray/src/detached_replay_buffer.py
new file mode 100644
index 000000000000..855eee48c5a5
--- /dev/null
+++ b/applications/Chat/coati/ray/src/detached_replay_buffer.py
@@ -0,0 +1,88 @@
+import torch
+import random
+from typing import List, Any
+# from torch.multiprocessing import Queue
+from ray.util.queue import Queue
+import ray
+import asyncio
+from coati.experience_maker.base import Experience
+from coati.replay_buffer.utils import BufferItem, make_experience_batch, split_experience_batch
+from coati.replay_buffer import ReplayBuffer
+from threading import Lock
+import copy
+
+class DetachedReplayBuffer:
+ '''
+ Detached replay buffer. Share Experience across workers on the same node.
+ Therefore a trainer node is expected to have only one instance.
+ It is ExperienceMakerHolder's duty to call append(exp) method, remotely.
+
+ Args:
+ sample_batch_size: Batch size when sampling. Exp won't enqueue until they formed a batch.
+ tp_world_size: Number of workers in the same tp group
+ limit: Limit of number of experience sample BATCHs. A number <= 0 means unlimited. Defaults to 0.
+ cpu_offload: Whether to offload experience to cpu when sampling. Defaults to True.
+ '''
+
+ def __init__(self, sample_batch_size: int, tp_world_size: int = 1, limit : int = 0, cpu_offload: bool = True) -> None:
+ self.cpu_offload = cpu_offload
+ self.sample_batch_size = sample_batch_size
+ self.limit = limit
+ self.items = Queue(self.limit, actor_options={"num_cpus":1})
+ self.batch_collector : List[BufferItem] = []
+
+ '''
+ Workers in the same tp group share this buffer and need same sample for one step.
+ Therefore a held_sample should be returned tp_world_size times before it could be dropped.
+ worker_state records wheter a worker got the held_sample
+ '''
+ self.tp_world_size = tp_world_size
+ self.worker_state = [False] * self.tp_world_size
+ self.held_sample = None
+ self._worker_state_lock = Lock()
+
+ @torch.no_grad()
+ def append(self, experience: Experience) -> None:
+ '''
+ Expected to be called remotely.
+ '''
+ if self.cpu_offload:
+ experience.to_device(torch.device('cpu'))
+ items = split_experience_batch(experience)
+ self.batch_collector.extend(items)
+ while len(self.batch_collector) >= self.sample_batch_size:
+ items = self.batch_collector[:self.sample_batch_size]
+ experience = make_experience_batch(items)
+ self.items.put(experience, block=True)
+ self.batch_collector = self.batch_collector[self.sample_batch_size:]
+
+ def clear(self) -> None:
+ # self.items.close()
+ self.items.shutdown()
+ self.items = Queue(self.limit)
+ self.worker_state = [False] * self.tp_world_size
+ self.batch_collector = []
+
+ @torch.no_grad()
+ def sample(self, worker_rank = 0, to_device = "cpu") -> Experience:
+ self._worker_state_lock.acquire()
+ if not any(self.worker_state):
+ self.held_sample = self._sample_and_erase()
+ self.worker_state[worker_rank] = True
+ if all(self.worker_state):
+ self.worker_state = [False] * self.tp_world_size
+ ret = self.held_sample
+ else:
+ ret = copy.deepcopy(self.held_sample)
+ self._worker_state_lock.release()
+ ret.to_device(to_device)
+ return ret
+
+ @torch.no_grad()
+ def _sample_and_erase(self) -> Experience:
+ ret = self.items.get(block=True)
+ return ret
+
+ def get_length(self) -> int:
+ ret = self.items.qsize()
+ return ret
\ No newline at end of file
diff --git a/applications/Chat/coati/ray/src/detached_trainer_base.py b/applications/Chat/coati/ray/src/detached_trainer_base.py
new file mode 100644
index 000000000000..f1ed1ec71499
--- /dev/null
+++ b/applications/Chat/coati/ray/src/detached_trainer_base.py
@@ -0,0 +1,121 @@
+from abc import ABC, abstractmethod
+from typing import Any, Callable, Dict, List, Optional, Union
+from tqdm import tqdm
+from coati.trainer.callbacks import Callback
+from coati.experience_maker import Experience
+import ray
+import os
+
+from .detached_replay_buffer import DetachedReplayBuffer
+from .utils import is_rank_0
+
+class DetachedTrainer(ABC):
+ '''
+ Base class for detached rlhf trainers.
+ 'detach' means that the experience maker is detached compared to a normal Trainer.
+ Please set name attribute during init:
+ >>> trainer = DetachedTrainer.options(..., name = "xxx", ...).remote()
+ So an ExperienceMakerHolder can reach the detached_replay_buffer by Actor's name.
+ Args:
+ detached_strategy (DetachedStrategy): the strategy to use for training
+ detached_replay_buffer_ref (ObjectRef[DetachedReplayBuffer]): the replay buffer to use for training
+ experience_batch_size (int, defaults to 8): the batch size to use for experience generation
+ max_epochs (int, defaults to 1): the number of epochs of training process
+ data_loader_pin_memory (bool, defaults to True): whether to pin memory for data loader
+ callbacks (List[Callback], defaults to []): the callbacks to call during training process
+ generate_kwargs (dict, optional): the kwargs to use while model generating
+ '''
+
+ def __init__(self,
+ experience_maker_holder_name_list: List[str],
+ train_batch_size: int = 8,
+ buffer_limit: int = 0,
+ buffer_cpu_offload: bool = True,
+ experience_batch_size: int = 8,
+ max_epochs: int = 1,
+ dataloader_pin_memory: bool = True,
+ callbacks: List[Callback] = [],
+ **generate_kwargs) -> None:
+ super().__init__()
+ self.detached_replay_buffer = DetachedReplayBuffer(train_batch_size, limit=buffer_limit, cpu_offload=buffer_cpu_offload)
+ self.experience_batch_size = experience_batch_size
+ self.max_epochs = max_epochs
+ self.dataloader_pin_memory = dataloader_pin_memory
+ self.callbacks = callbacks
+ self.generate_kwargs = generate_kwargs
+ self.target_holder_name_list = experience_maker_holder_name_list
+ self.target_holder_list = []
+
+ def update_target_holder_list(self, experience_maker_holder_name_list):
+ self.target_holder_name_list = experience_maker_holder_name_list
+ self.target_holder_list = []
+ for name in self.target_holder_name_list:
+ self.target_holder_list.append(ray.get_actor(name, namespace=os.environ["RAY_NAMESPACE"]))
+
+ @abstractmethod
+ def _update_remote_makers(self):
+ pass
+
+ @abstractmethod
+ def training_step(self, experience: Experience) -> Dict[str, Any]:
+ pass
+
+ def _learn(self):
+ pbar = tqdm(range(self.max_epochs), desc='Train epoch', disable=not is_rank_0())
+ for _ in pbar:
+ if 'debug' in self.generate_kwargs and self.generate_kwargs['debug'] == True:
+ print("[trainer] sampling exp")
+ experience = self._buffer_sample()
+ if 'debug' in self.generate_kwargs and self.generate_kwargs['debug'] == True:
+ print("[trainer] training step")
+ metrics = self.training_step(experience)
+ if 'debug' in self.generate_kwargs and self.generate_kwargs['debug'] == True:
+ print("[trainer] step over")
+ pbar.set_postfix(metrics)
+
+ def fit(self, num_episodes: int = 50000, max_timesteps: int = 500, update_timesteps: int = 5000) -> None:
+ self._on_fit_start()
+ for episode in range(num_episodes):
+ self._on_episode_start(episode)
+ for timestep in tqdm(range(max_timesteps // update_timesteps),
+ desc=f'Episode [{episode+1}/{num_episodes}]',
+ disable=not is_rank_0()):
+ self._learn()
+ self._update_remote_makers()
+ self._on_episode_end(episode)
+ self._on_fit_end()
+
+ @ray.method(concurrency_group="buffer_length")
+ def buffer_get_length(self):
+ # called by ExperienceMakerHolder
+ if 'debug' in self.generate_kwargs and self.generate_kwargs['debug'] == True:
+ print("[trainer] telling length")
+ return self.detached_replay_buffer.get_length()
+
+ @ray.method(concurrency_group="buffer_append")
+ def buffer_append(self, experience: Experience):
+ # called by ExperienceMakerHolder
+ if 'debug' in self.generate_kwargs and self.generate_kwargs['debug'] == True:
+ # print(f"[trainer] receiving exp. Current buffer length: {self.detached_replay_buffer.get_length()}")
+ print(f"[trainer] receiving exp.")
+ self.detached_replay_buffer.append(experience)
+
+ @ray.method(concurrency_group="buffer_sample")
+ def _buffer_sample(self):
+ return self.detached_replay_buffer.sample()
+
+ def _on_fit_start(self) -> None:
+ for callback in self.callbacks:
+ callback.on_fit_start()
+
+ def _on_fit_end(self) -> None:
+ for callback in self.callbacks:
+ callback.on_fit_end()
+
+ def _on_episode_start(self, episode: int) -> None:
+ for callback in self.callbacks:
+ callback.on_episode_start(episode)
+
+ def _on_episode_end(self, episode: int) -> None:
+ for callback in self.callbacks:
+ callback.on_episode_end(episode)
diff --git a/applications/Chat/coati/ray/src/detached_trainer_ppo.py b/applications/Chat/coati/ray/src/detached_trainer_ppo.py
new file mode 100644
index 000000000000..838e82d07f4a
--- /dev/null
+++ b/applications/Chat/coati/ray/src/detached_trainer_ppo.py
@@ -0,0 +1,192 @@
+from typing import Any, Callable, Dict, List, Optional
+import torch
+from torch.optim import Adam
+
+from coati.experience_maker import Experience, NaiveExperienceMaker
+from coati.models.base import Actor, Critic
+from coati.models.generation_utils import update_model_kwargs_fn
+from coati.models.loss import PolicyLoss, ValueLoss
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy, Strategy
+from coati.trainer.callbacks import Callback
+
+from colossalai.nn.optimizer import HybridAdam
+
+import ray
+
+
+from .utils import is_rank_0, get_cuda_actor_critic_from_args, get_strategy_from_args, set_dist_env
+from .detached_trainer_base import DetachedTrainer
+
+
+@ray.remote(concurrency_groups={"buffer_length": 1, "buffer_append":1, "buffer_sample":1,"model_io": 1, "compute": 1})
+class DetachedPPOTrainer(DetachedTrainer):
+ '''
+ Detached Trainer for PPO algorithm
+ Args:
+ strategy (Strategy): the strategy to use for training
+ model (str) : for actor / critic init
+ pretrained (str) : for actor / critic init
+ lora_rank (int) : for actor / critic init
+ train_batch_size (int, defaults to 8): the batch size to use for training
+ train_batch_size (int, defaults to 8): the batch size to use for training
+ buffer_limit (int, defaults to 0): the max_size limitation of replay buffer
+ buffer_cpu_offload (bool, defaults to True): whether to offload replay buffer to cpu
+ eps_clip (float, defaults to 0.2): the clip coefficient of policy loss
+ value_clip (float, defaults to 0.4): the clip coefficient of value loss
+ experience_batch_size (int, defaults to 8): the batch size to use for experience generation
+ max_epochs (int, defaults to 1): the number of epochs of training process
+ dataloader_pin_memory (bool, defaults to True): whether to pin memory for data loader
+ callbacks (List[Callback], defaults to []): the callbacks to call during training process
+ generate_kwargs (dict, optional): the kwargs to use while model generating
+ '''
+
+ def __init__(self,
+ experience_maker_holder_name_list: List[str],
+ strategy: str,
+ model: str,
+ env_info: Dict[str, str] = None,
+ pretrained: str = None,
+ lora_rank: int = 0,
+ train_batch_size: int = 8,
+ buffer_limit: int = 0,
+ buffer_cpu_offload: bool = True,
+ eps_clip: float = 0.2,
+ value_clip: float = 0.4,
+ experience_batch_size: int = 8,
+ max_epochs: int = 10,
+ dataloader_pin_memory: bool = True,
+ callbacks: List[Callback] = [],
+ **generate_kwargs) -> None:
+ # set environment variables
+ if env_info:
+ set_dist_env(env_info=env_info)
+ # configure strategy
+ self.strategy = get_strategy_from_args(strategy)
+ # configure models, loss and optimizers
+ with self.strategy.model_init_context():
+ self.actor, self.critic = get_cuda_actor_critic_from_args(model, pretrained, lora_rank)
+
+ if strategy != 'colossalai_gemini':
+ self.actor.to(torch.float16).to(torch.cuda.current_device())
+ self.critic.to(torch.float16).to(torch.cuda.current_device())
+
+ if strategy.startswith('colossalai'):
+ self.actor_optim = HybridAdam(self.actor.parameters(), lr=5e-6)
+ self.critic_optim = HybridAdam(self.critic.parameters(), lr=5e-6)
+ else:
+ self.actor_optim = Adam(self.actor.parameters(), lr=5e-6)
+ self.critic_optim = Adam(self.critic.parameters(), lr=5e-6)
+
+ (self.actor, self.actor_optim), (self.critic, self.critic_optim) = \
+ self.strategy.prepare((self.actor, self.actor_optim), (self.critic, self.critic_optim))
+ generate_kwargs = _set_default_generate_kwargs(self.strategy, generate_kwargs, self.actor)
+
+ self.actor_loss_fn = PolicyLoss(eps_clip)
+ self.critic_loss_fn = ValueLoss(value_clip)
+
+ super().__init__(experience_maker_holder_name_list,
+ train_batch_size=train_batch_size,
+ buffer_limit=buffer_limit,
+ buffer_cpu_offload=buffer_cpu_offload,
+ experience_batch_size=experience_batch_size,
+ max_epochs=max_epochs,
+ dataloader_pin_memory=dataloader_pin_memory,
+ callbacks=callbacks,
+ **generate_kwargs)
+
+ @ray.method(concurrency_group="model_io")
+ def _update_remote_makers(self):
+ # TODO: balance duties
+ if is_rank_0():
+ self.update_target_holder_list(self.target_holder_name_list)
+ for target_holder in self.target_holder_list:
+ # TODO: reduce malloc
+ with torch.no_grad():
+ ray.get(target_holder.update_experience_maker.remote(self._get_unwrapped_actor(), self._get_unwrapped_critic()))
+
+ @ray.method(concurrency_group="model_io")
+ def initialize_remote_makers(self):
+ # TODO: balance duties
+ if is_rank_0():
+ self.update_target_holder_list(self.target_holder_name_list)
+ for target_holder in self.target_holder_list:
+ # TODO: reduce malloc
+ with torch.no_grad():
+ ray.get(target_holder.initialize_experience_maker.remote(self._get_unwrapped_actor(), self._get_unwrapped_critic()))
+
+ @ray.method(concurrency_group="compute")
+ def training_step(self, experience: Experience) -> Dict[str, float]:
+ self.actor.train()
+ self.critic.train()
+
+ experience.to_device(torch.cuda.current_device())
+ num_actions = experience.action_mask.size(1)
+ action_log_probs = self.actor(experience.sequences, num_actions, attention_mask=experience.attention_mask)
+ actor_loss = self.actor_loss_fn(action_log_probs,
+ experience.action_log_probs,
+ experience.advantages,
+ action_mask=experience.action_mask)
+ self.strategy.backward(actor_loss, self.actor, self.actor_optim)
+ self.strategy.optimizer_step(self.actor_optim)
+ self.actor_optim.zero_grad()
+
+ values = self.critic(experience.sequences,
+ action_mask=experience.action_mask,
+ attention_mask=experience.attention_mask)
+ critic_loss = self.critic_loss_fn(values,
+ experience.values,
+ experience.reward,
+ action_mask=experience.action_mask)
+
+ self.strategy.backward(critic_loss, self.critic, self.critic_optim)
+ self.strategy.optimizer_step(self.critic_optim)
+ self.critic_optim.zero_grad()
+ return {'actor_loss': actor_loss.item(), 'critic_loss': critic_loss.item()}
+
+ def strategy_save_actor(self, path: str, only_rank0: bool = False) -> None:
+ self.strategy.save_model(self.actor, path, only_rank0)
+
+ def strategy_save_critic(self, path: str, only_rank0: bool = False) -> None:
+ self.strategy.save_model(self.critic, path, only_rank0)
+
+ def strategy_save_actor_optim(self, path: str, only_rank0: bool = False) -> None:
+ self.strategy.save_optimizer(self.actor_optim, path, only_rank0)
+
+ def strategy_save_critic_optim(self, path: str, only_rank0: bool = False) -> None:
+ self.strategy.save_optimizer(self.critic_optim, path, only_rank0)
+
+ def _get_unwrapped_actor(self):
+ if False:
+ pass
+ elif isinstance(self.strategy, ColossalAIStrategy):
+ ret = Actor(self.strategy._unwrap_model(self.actor))
+ return ret
+ elif isinstance(self.strategy, DDPStrategy):
+ return Actor(self.strategy._unwrap_actor(self.actor))
+ elif isinstance(self.strategy, NaiveStrategy):
+ return self.actor
+
+ def _get_unwrapped_critic(self):
+ if False:
+ pass
+ elif isinstance(self.strategy, ColossalAIStrategy):
+ ret = self.strategy._unwrap_model(self.critic)
+ return ret
+ elif isinstance(self.strategy, DDPStrategy):
+ return self.critic.module
+ elif isinstance(self.strategy, NaiveStrategy):
+ return self.critic
+
+
+def _set_default_generate_kwargs(strategy: Strategy, generate_kwargs: dict, actor: Actor) -> None:
+ origin_model = strategy._unwrap_actor(actor)
+ new_kwargs = {**generate_kwargs}
+ # use huggingface models method directly
+ if 'prepare_inputs_fn' not in generate_kwargs and hasattr(origin_model, 'prepare_inputs_for_generation'):
+ new_kwargs['prepare_inputs_fn'] = origin_model.prepare_inputs_for_generation
+
+ if 'update_model_kwargs_fn' not in generate_kwargs:
+ new_kwargs['update_model_kwargs_fn'] = update_model_kwargs_fn
+
+ return new_kwargs
+
\ No newline at end of file
diff --git a/applications/Chat/coati/ray/src/experience_maker_holder.py b/applications/Chat/coati/ray/src/experience_maker_holder.py
new file mode 100644
index 000000000000..94e4a3d537a5
--- /dev/null
+++ b/applications/Chat/coati/ray/src/experience_maker_holder.py
@@ -0,0 +1,172 @@
+import torch
+from typing import Any, Callable, Dict, List, Optional, Union
+import ray
+from ray.exceptions import GetTimeoutError
+from torch import Tensor
+import torch.nn as nn
+from coati.models.base import Actor, Critic, RewardModel
+from coati.trainer.strategies.sampler import DistributedSampler
+from coati.trainer.strategies import Strategy
+from coati.experience_maker import NaiveExperienceMaker, Experience, ExperienceMaker
+
+from copy import deepcopy
+from threading import Lock
+import time
+import os
+
+
+from .utils import is_rank_0, get_strategy_from_args, set_dist_env
+
+
+@ray.remote(concurrency_groups={"experience_io": 1, "model_io": 1, "compute": 1})
+class ExperienceMakerHolder:
+ '''
+ Args:
+ detached_trainer_name_list: str list to get ray actor handleskkk
+ strategy:
+ experience_batch_size: batch size of generated experience
+ kl_coef: the coefficient of kl divergence loss
+ '''
+
+ def __init__(self,
+ detached_trainer_name_list: List[str],
+ strategy: str,
+ env_info: Dict[str, str] = None,
+ experience_batch_size: int = 8,
+ kl_coef: float = 0.1,
+ **generate_kwargs):
+ # set environment variables
+ if env_info:
+ set_dist_env(env_info=env_info)
+ self.target_trainer_list = []
+ for name in detached_trainer_name_list:
+ self.target_trainer_list.append(ray.get_actor(name, namespace=os.environ["RAY_NAMESPACE"]))
+ self.strategy_str = strategy
+ self.strategy = get_strategy_from_args(strategy)
+ self.experience_batch_size = experience_batch_size
+ self.kl_coef = kl_coef
+ self.generate_kwargs = generate_kwargs
+ # Need a trainer to give an actor and a critic via initialize_experience_maker(...)
+ actor, critic, reward_model, initial_model = None, None, None, None
+ self.experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model, self.kl_coef)
+ self._model_visit_lock = Lock()
+ self.fully_initialized = False
+ if 'debug' in self.generate_kwargs and self.generate_kwargs['debug'] == True:
+ print('[maker] Waiting for INIT')
+
+ def _get_ready(self):
+ while not self.fully_initialized:
+ time.sleep(1.0)
+
+ def update_target_trainer_list(self, detached_trainer_name_list):
+ self.target_trainer_list = []
+ for name in detached_trainer_name_list:
+ self.target_trainer_list.append(ray.get_actor(name))
+
+ # copy from ../trainer/base.py
+ @ray.method(concurrency_group="compute")
+ def _make_experience(self, inputs: Union[Tensor, Dict[str, Tensor]]) -> Experience:
+ self._get_ready()
+ if isinstance(inputs, Tensor):
+ return self.experience_maker.make_experience(inputs, **self.generate_kwargs)
+ elif isinstance(inputs, dict):
+ return self.experience_maker.make_experience(**inputs, **self.generate_kwargs)
+ else:
+ raise ValueError(f'Unsupported input type "{type(inputs)}"')
+
+ @ray.method(concurrency_group="experience_io")
+ def _send_experience(self, experience):
+ '''
+ ignore it
+
+ # choose a trainer that has the least experience batch in its detached_replay_buffer
+ chosen_trainer = None
+ min_length = None
+ if 'debug' in self.generate_kwargs and self.generate_kwargs['debug'] == True:
+ print("[maker] choosing target trainer")
+ while chosen_trainer is None:
+ for target_trainer in self.target_trainer_list:
+ try:
+ temp_length = ray.get(target_trainer.buffer_get_length.remote(), timeout=0.1)
+ if min_length is None:
+ min_length = temp_length
+ chosen_trainer = target_trainer
+ else:
+ if temp_length < min_length:
+ min_length = temp_length
+ chosen_trainer = target_trainer
+ except GetTimeoutError:
+ pass
+
+ if 'debug' in self.generate_kwargs and self.generate_kwargs['debug'] == True:
+ print(f"[maker] sending exp to {chosen_trainer}")
+ chosen_trainer.buffer_append.remote(experience)
+ '''
+ #
+ if not hasattr(self, "_target_idx"):
+ self._target_idx = 0
+ chosen_trainer = self.target_trainer_list[self._target_idx]
+ if 'debug' in self.generate_kwargs and self.generate_kwargs['debug'] == True:
+ print(f"[maker] sending exp to {chosen_trainer}")
+ chosen_trainer.buffer_append.remote(experience)
+ self._target_idx = (self._target_idx + 1) % len(self.target_trainer_list)
+
+ def workingloop(self, dataset, tokenizer: Optional[Callable[[Any], dict]] = None, times=5000 * 50000):
+ self._get_ready()
+ sampler = self.strategy.setup_sampler(dataset)
+ for _ in range(times):
+ rand_prompts = sampler.sample(self.experience_batch_size)
+ if tokenizer is not None:
+ inputs = tokenizer(rand_prompts)
+ else:
+ inputs = rand_prompts
+ self._model_visit_lock.acquire()
+ experience = self._make_experience(inputs=inputs)
+ self._model_visit_lock.release()
+ self._send_experience(experience=experience)
+
+ @ray.method(concurrency_group="model_io")
+ def initialize_experience_maker(self, init_actor: Actor, init_critic: Critic):
+ '''
+ called by trainer. Only once.
+ '''
+ # TODO: reduce malloc
+ if self.fully_initialized:
+ return
+ if 'debug' in self.generate_kwargs and self.generate_kwargs['debug'] == True:
+ print('[maker] INIT')
+ with torch.no_grad():
+ with self.strategy.model_init_context():
+ actor = init_actor
+ critic = init_critic
+ initial_model = deepcopy(actor)
+ reward_model = RewardModel(deepcopy(critic.model),
+ deepcopy(critic.value_head)).to(torch.cuda.current_device())
+ if self.strategy_str != 'colossalai_gemini':
+ actor.to(torch.float16).to(torch.cuda.current_device())
+ critic.to(torch.float16).to(torch.cuda.current_device())
+ initial_model.to(torch.float16).to(torch.cuda.current_device())
+ reward_model.to(torch.float16).to(torch.cuda.current_device())
+
+ self.experience_maker.actor = self.strategy.prepare(actor)
+ self.experience_maker.critic = self.strategy.prepare(critic)
+ self.experience_maker.initial_model = self.strategy.prepare(initial_model)
+ self.experience_maker.reward_model = self.strategy.prepare(reward_model)
+ self.fully_initialized = True
+
+ @ray.method(concurrency_group="model_io")
+ def update_experience_maker(self, new_actor: Actor, new_critic: Critic):
+ '''
+ called by trainer
+ '''
+ # TODO: reduce malloc
+ self._model_visit_lock.acquire()
+ with torch.no_grad():
+ if 'debug' in self.generate_kwargs and self.generate_kwargs['debug'] == True:
+ print("[maker] UPDATE ")
+ if self.strategy_str != 'colossalai_gemini':
+ new_actor.to(torch.float16).to(torch.cuda.current_device())
+ new_critic.to(torch.float16).to(torch.cuda.current_device())
+ self.experience_maker.actor = self.strategy.prepare(new_actor)
+ self.experience_maker.critic = self.strategy.prepare(new_critic)
+ self._model_visit_lock.release()
diff --git a/applications/Chat/coati/ray/src/pipeline_strategy.py b/applications/Chat/coati/ray/src/pipeline_strategy.py
new file mode 100644
index 000000000000..1780839c62ee
--- /dev/null
+++ b/applications/Chat/coati/ray/src/pipeline_strategy.py
@@ -0,0 +1,105 @@
+# WIP
+
+
+from coati.trainer.strategies import Strategy
+from coati.trainer.strategies import NaiveStrategy
+from coati.models.base import Actor, RewardModel, Critic
+
+import numpy as np
+import torch
+from torch._C._distributed_rpc import _is_current_rpc_agent_set
+
+import colossalai
+from colossalai.pipeline.pipeline_process_group import ppg
+from colossalai.pipeline.rpc._pipeline_schedule import OneFOneBPipelineEngine
+from colossalai.fx import ColoTracer
+from colossalai.fx.passes.adding_split_node_pass import balanced_split_pass, split_with_split_nodes_pass
+from colossalai.pipeline.middleware.adaptor import get_fx_topology
+
+
+import os
+from functools import partial
+import random
+
+rpc_is_initialized = _is_current_rpc_agent_set
+
+class PipelineModel(torch.nn.Module):
+ '''
+ Actor has 2 kinds of jobs: forward and generate.
+ better to just pipelinize the inner model
+ '''
+ def __init__(self,
+ model: torch.nn.Module,
+ stage_num: int,
+ num_microbatches: int,
+ data_kwargs = None,
+ ):
+ super().__init__()
+ # create partition module
+ def create_partition_module(pp_rank:int, stage_num: int, model, data_kwargs):
+ model.eval()
+ tracer = ColoTracer()
+ meta_args = {k: v.to('meta') for k, v in data_kwargs.items()}
+ graph = tracer.trace(root=model, meta_args=meta_args)
+ gm = torch.fx.GraphModule(model, graph, model.__class__.__name__)
+ annotated_model = balanced_split_pass(gm, stage_num)
+ top_module, split_submodules = split_with_split_nodes_pass(annotated_model, merge_output=True)
+ topo = get_fx_topology(top_module)
+ for submodule in split_submodules:
+ if isinstance(submodule, torch.fx.GraphModule):
+ setattr(submodule, '_topo', topo)
+ return split_submodules[pp_rank + 1]
+
+ def partition(model, data_kwargs: dict, pp_rank: int, chunk: int, stage_num: int):
+ partition = create_partition_module(pp_rank, stage_num, model, data_kwargs)
+ return partition
+ self.inference_engine = OneFOneBPipelineEngine(
+ partition_fn=partial(partition, model, data_kwargs),
+ stage_num=stage_num,
+ num_microbatches=num_microbatches,
+ device='cuda',
+ )
+
+ def forward(self,
+ **model_inputs):
+ return self.inference_engine.forward_backward(**model_inputs, forward_only=True)
+
+
+
+class PPStrategy(NaiveStrategy):
+ """
+ Strategy for Pipeline inference (inference only!)
+
+ master node only
+ """
+ def __init__(
+ self,
+ seed: int = 42
+ ):
+ self.seed = seed
+ super().__init__()
+
+
+ def setup_distributed(self) -> None:
+ colossalai.launch_from_torch({}, seed=self.seed)
+ ppg.set_global_info(rank = int(os.environ['RANK']),
+ world_size=int(os.environ['WORLD_SIZE']),
+ dp_degree=1,
+ tp_degree=1,
+ num_worker_threads=128,
+ device="cuda")
+
+ def model_init_context(self):
+ return super().model_init_context()
+
+ def setup_model(self, model: torch.nn.Module) -> torch.nn.Module:
+ if isinstance(model, Actor) or \
+ isinstance(model, RewardModel) or \
+ isinstance(model, Critic):
+ model.model = PipelineModel(model.model)
+
+ def set_seed(self, seed: int) -> None:
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+
diff --git a/applications/Chat/coati/ray/src/utils.py b/applications/Chat/coati/ray/src/utils.py
new file mode 100644
index 000000000000..c750879b6d18
--- /dev/null
+++ b/applications/Chat/coati/ray/src/utils.py
@@ -0,0 +1,48 @@
+import torch.distributed as dist
+from typing import Any, Callable, Dict, List, Optional
+from coati.models.bloom import BLOOMActor, BLOOMCritic
+from coati.models.gpt import GPTActor, GPTCritic
+from coati.models.opt import OPTActor, OPTCritic
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+import torch
+import os
+
+def is_rank_0() -> bool:
+ return not dist.is_initialized() or dist.get_rank() == 0
+
+
+def get_cuda_actor_critic_from_args(model: str, pretrained: str = None, lora_rank=0):
+ if model == 'gpt2':
+ actor = GPTActor(pretrained=pretrained, lora_rank=lora_rank).to(torch.cuda.current_device())
+ critic = GPTCritic(pretrained=pretrained, lora_rank=lora_rank).to(torch.cuda.current_device())
+ elif model == 'bloom':
+ actor = BLOOMActor(pretrained=pretrained, lora_rank=lora_rank).to(torch.cuda.current_device())
+ critic = BLOOMCritic(pretrained=pretrained, lora_rank=lora_rank).to(torch.cuda.current_device())
+ elif model == 'opt':
+ actor = OPTActor(pretrained=pretrained, lora_rank=lora_rank).to(torch.cuda.current_device())
+ critic = OPTCritic(pretrained=pretrained, lora_rank=lora_rank).to(torch.cuda.current_device())
+ else:
+ raise ValueError(f'Unsupported model "{model}"')
+ return actor, critic
+
+
+def get_strategy_from_args(strategy: str):
+ if strategy == 'naive':
+ strategy_ = NaiveStrategy()
+ elif strategy == 'ddp':
+ strategy_ = DDPStrategy()
+ elif strategy == 'colossalai_gemini':
+ strategy_ = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
+ elif strategy == 'colossalai_zero2':
+ strategy_ = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{strategy}"')
+ return strategy_
+
+
+def set_dist_env(env_info: Dict[str, str]):
+ os.environ["RANK"] = env_info['rank']
+ os.environ["LOCAL_RANK"] = env_info['local_rank']
+ os.environ["WORLD_SIZE"] = env_info['world_size']
+ os.environ['MASTER_PORT'] = env_info['master_port']
+ os.environ['MASTER_ADDR'] = env_info['master_addr']
diff --git a/applications/Chat/coati/replay_buffer/utils.py b/applications/Chat/coati/replay_buffer/utils.py
index 55ddb2ae8191..6ad0db2c3b60 100644
--- a/applications/Chat/coati/replay_buffer/utils.py
+++ b/applications/Chat/coati/replay_buffer/utils.py
@@ -15,7 +15,7 @@ class BufferItem:
action_log_probs: (A)
values: (1)
reward: (1)
- advatanges: (1)
+ advantages: (1)
attention_mask: (S)
action_mask: (A)
diff --git a/applications/Chat/coati/trainer/base.py b/applications/Chat/coati/trainer/base.py
index 610bb5111976..d676799496dd 100644
--- a/applications/Chat/coati/trainer/base.py
+++ b/applications/Chat/coati/trainer/base.py
@@ -2,15 +2,10 @@
from typing import Any, Callable, Dict, List, Optional, Union
import torch
-from coati.experience_maker import Experience, ExperienceMaker
-from coati.replay_buffer import ReplayBuffer
-from torch import Tensor
-from torch.utils.data import DistributedSampler
-from tqdm import tqdm
+from coati.experience_maker import Experience
from .callbacks import Callback
from .strategies import Strategy
-from .utils import is_rank_0
class Trainer(ABC):
@@ -19,113 +14,28 @@ class Trainer(ABC):
Args:
strategy (Strategy):the strategy to use for training
- experience_maker (ExperienceMaker): the experience maker to use for produce experience to fullfill replay buffer
- replay_buffer (ReplayBuffer): the replay buffer to use for training
- experience_batch_size (int, defaults to 8): the batch size to use for experience generation
max_epochs (int, defaults to 1): the number of epochs of training process
tokenizer (Callable, optional): the tokenizer to use for tokenizing the input
- sample_replay_buffer (bool, defaults to False): whether to sample from replay buffer
- data_loader_pin_memory (bool, defaults to True): whether to pin memory for data loader
+ dataloader_pin_memory (bool, defaults to True): whether to pin memory for data loader
callbacks (List[Callback], defaults to []): the callbacks to call during training process
generate_kwargs (dict, optional): the kwargs to use while model generating
"""
def __init__(self,
strategy: Strategy,
- experience_maker: ExperienceMaker,
- replay_buffer: ReplayBuffer,
- experience_batch_size: int = 8,
max_epochs: int = 1,
tokenizer: Optional[Callable[[Any], dict]] = None,
- sample_replay_buffer: bool = False,
dataloader_pin_memory: bool = True,
callbacks: List[Callback] = [],
**generate_kwargs) -> None:
super().__init__()
self.strategy = strategy
- self.experience_maker = experience_maker
- self.replay_buffer = replay_buffer
- self.experience_batch_size = experience_batch_size
self.max_epochs = max_epochs
self.tokenizer = tokenizer
self.generate_kwargs = generate_kwargs
- self.sample_replay_buffer = sample_replay_buffer
self.dataloader_pin_memory = dataloader_pin_memory
self.callbacks = callbacks
- @abstractmethod
- def training_step(self, experience: Experience) -> Dict[str, Any]:
- pass
-
- def _make_experience(self, inputs: Union[Tensor, Dict[str, Tensor]]) -> Experience:
- if isinstance(inputs, Tensor):
- return self.experience_maker.make_experience(inputs, **self.generate_kwargs)
- elif isinstance(inputs, dict):
- return self.experience_maker.make_experience(**inputs, **self.generate_kwargs)
- else:
- raise ValueError(f'Unsupported input type "{type(inputs)}"')
-
- def _sample_prompts(self, prompts) -> list:
- indices = list(range(len(prompts)))
- sampled_indices = self.strategy.experience_sampler.choice(indices, self.experience_batch_size, replace=False)
- return [prompts[i] for i in sampled_indices]
-
- def _learn(self):
- # replay buffer may be empty at first, we should rebuild at each training
- if not self.sample_replay_buffer:
- dataloader = self.strategy.setup_dataloader(self.replay_buffer, self.dataloader_pin_memory)
- device = torch.cuda.current_device()
- if self.sample_replay_buffer:
- pbar = tqdm(range(self.max_epochs), desc='Train epoch', disable=not is_rank_0())
- for _ in pbar:
- experience = self.replay_buffer.sample()
- metrics = self.training_step(experience)
- pbar.set_postfix(metrics)
- else:
- for epoch in range(self.max_epochs):
- self._on_learn_epoch_start(epoch)
- if isinstance(dataloader.sampler, DistributedSampler):
- dataloader.sampler.set_epoch(epoch)
- pbar = tqdm(dataloader, desc=f'Train epoch [{epoch+1}/{self.max_epochs}]', disable=not is_rank_0())
- for experience in pbar:
- self._on_learn_batch_start()
- experience.to_device(device)
- metrics = self.training_step(experience)
- self._on_learn_batch_end(metrics, experience)
- pbar.set_postfix(metrics)
- self._on_learn_epoch_end(epoch)
-
- def fit(self,
- prompt_dataloader,
- pretrain_dataloader,
- num_episodes: int = 50000,
- max_timesteps: int = 500,
- update_timesteps: int = 5000) -> None:
- time = 0
- self.pretrain_dataloader = pretrain_dataloader
- self.prompt_dataloader = prompt_dataloader
- self._on_fit_start()
- for episode in range(num_episodes):
- self._on_episode_start(episode)
- for timestep in tqdm(range(max_timesteps),
- desc=f'Episode [{episode+1}/{num_episodes}]',
- disable=not is_rank_0()):
- time += 1
- prompts = next(iter(self.prompt_dataloader))
- self._on_make_experience_start()
- self.experience_maker.initial_model.to(torch.cuda.current_device())
- self.experience_maker.reward_model.to(torch.cuda.current_device())
- experience = self._make_experience(prompts)
- self._on_make_experience_end(experience)
- self.replay_buffer.append(experience)
- if time % update_timesteps == 0:
- self.experience_maker.initial_model.to('cpu')
- self.experience_maker.reward_model.to('cpu')
- self._learn()
- self.replay_buffer.clear()
- self._on_episode_end(episode)
- self._on_fit_end()
-
# TODO(ver217): maybe simplify these code using context
def _on_fit_start(self) -> None:
for callback in self.callbacks:
diff --git a/applications/Chat/coati/trainer/callbacks/performance_evaluator.py b/applications/Chat/coati/trainer/callbacks/performance_evaluator.py
index 0fc3b077a1d1..5ca44a52d6e7 100644
--- a/applications/Chat/coati/trainer/callbacks/performance_evaluator.py
+++ b/applications/Chat/coati/trainer/callbacks/performance_evaluator.py
@@ -114,7 +114,7 @@ def on_learn_batch_end(self, metrics: dict, experience: Experience) -> None:
# actor forward-backward, 3 means forward(1) + backward(2)
self.learn_flop += self.actor_num_params * batch_size * seq_len * 2 * (3 + int(self.enable_grad_checkpoint))
- # critic foward-backward
+ # critic forward-backward
self.learn_flop += self.critic_num_params * batch_size * seq_len * 2 * (3 + int(self.enable_grad_checkpoint))
def on_fit_end(self) -> None:
diff --git a/applications/Chat/coati/trainer/ppo.py b/applications/Chat/coati/trainer/ppo.py
index d58e437e6e61..2db604fc9b74 100644
--- a/applications/Chat/coati/trainer/ppo.py
+++ b/applications/Chat/coati/trainer/ppo.py
@@ -1,4 +1,4 @@
-from typing import Any, Callable, Dict, List, Optional
+from typing import Any, Callable, Dict, List, Optional, Union
import torch
import torch.nn as nn
@@ -7,12 +7,16 @@
from coati.models.generation_utils import update_model_kwargs_fn
from coati.models.loss import PolicyLoss, ValueLoss
from coati.replay_buffer import NaiveReplayBuffer
+from torch import Tensor
from torch.optim import Optimizer
+from torch.utils.data import DistributedSampler
from transformers.tokenization_utils_base import PreTrainedTokenizerBase
+from tqdm import tqdm
from .base import Trainer
from .callbacks import Callback
from .strategies import Strategy
+from .utils import is_rank_0
class PPOTrainer(Trainer):
@@ -24,19 +28,20 @@ class PPOTrainer(Trainer):
actor (Actor): the actor model in ppo algorithm
critic (Critic): the critic model in ppo algorithm
reward_model (nn.Module): the reward model in rlhf algorithm to make reward of sentences
- initial_model (Actor): the initial model in rlhf algorithm to generate reference logits to limit the update of actor
+ initial_model (Actor): the initial model in rlhf algorithm to generate reference logics to limit the update of actor
actor_optim (Optimizer): the optimizer to use for actor model
critic_optim (Optimizer): the optimizer to use for critic model
kl_coef (float, defaults to 0.1): the coefficient of kl divergence loss
train_batch_size (int, defaults to 8): the batch size to use for training
- buffer_limit (int, defaults to 0): the max_size limitaiton of replay buffer
+ buffer_limit (int, defaults to 0): the max_size limitation of replay buffer
buffer_cpu_offload (bool, defaults to True): whether to offload replay buffer to cpu
eps_clip (float, defaults to 0.2): the clip coefficient of policy loss
vf_coef (float, defaults to 1.0): the coefficient of value loss
+ ptx_coef (float, defaults to 0.9): the coefficient of ptx loss
value_clip (float, defaults to 0.4): the clip coefficient of value loss
experience_batch_size (int, defaults to 8): the batch size to use for experience generation
max_epochs (int, defaults to 1): the number of epochs of training process
- tokenier (Callable, optional): the tokenizer to use for tokenizing the input
+ tokenizer (Callable, optional): the tokenizer to use for tokenizing the input
sample_replay_buffer (bool, defaults to False): whether to sample from replay buffer
dataloader_pin_memory (bool, defaults to True): whether to pin memory for data loader
callbacks (List[Callback], defaults to []): the callbacks to call during training process
@@ -69,8 +74,13 @@ def __init__(self,
experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model, kl_coef)
replay_buffer = NaiveReplayBuffer(train_batch_size, buffer_limit, buffer_cpu_offload)
generate_kwargs = _set_default_generate_kwargs(strategy, generate_kwargs, actor)
- super().__init__(strategy, experience_maker, replay_buffer, experience_batch_size, max_epochs, tokenizer,
- sample_replay_buffer, dataloader_pin_memory, callbacks, **generate_kwargs)
+ super().__init__(strategy, max_epochs, tokenizer, dataloader_pin_memory, callbacks, **generate_kwargs)
+
+ self.experience_maker = experience_maker
+ self.replay_buffer = replay_buffer
+ self.experience_batch_size = experience_batch_size
+ self.sample_replay_buffer = sample_replay_buffer
+
self.actor = actor
self.critic = critic
@@ -82,6 +92,81 @@ def __init__(self,
self.actor_optim = actor_optim
self.critic_optim = critic_optim
+ def _make_experience(self, inputs: Union[Tensor, Dict[str, Tensor]]) -> Experience:
+ if isinstance(inputs, Tensor):
+ return self.experience_maker.make_experience(inputs, **self.generate_kwargs)
+ elif isinstance(inputs, dict):
+ return self.experience_maker.make_experience(**inputs, **self.generate_kwargs)
+ else:
+ raise ValueError(f'Unsupported input type "{type(inputs)}"')
+
+ def _sample_prompts(self, prompts) -> list:
+ indices = list(range(len(prompts)))
+ sampled_indices = self.strategy.experience_sampler.choice(
+ indices, self.experience_batch_size, replace=False)
+ return [prompts[i] for i in sampled_indices]
+
+ def _learn(self):
+ # replay buffer may be empty at first, we should rebuild at each training
+ if not self.sample_replay_buffer:
+ dataloader = self.strategy.setup_dataloader(
+ self.replay_buffer, self.dataloader_pin_memory)
+ device = torch.cuda.current_device()
+ if self.sample_replay_buffer:
+ pbar = tqdm(range(self.max_epochs), desc='Train epoch',
+ disable=not is_rank_0())
+ for _ in pbar:
+ experience = self.replay_buffer.sample()
+ metrics = self.training_step(experience)
+ pbar.set_postfix(metrics)
+ else:
+ for epoch in range(self.max_epochs):
+ self._on_learn_epoch_start(epoch)
+ if isinstance(dataloader.sampler, DistributedSampler):
+ dataloader.sampler.set_epoch(epoch)
+ pbar = tqdm(
+ dataloader, desc=f'Train epoch [{epoch+1}/{self.max_epochs}]', disable=not is_rank_0())
+ for experience in pbar:
+ self._on_learn_batch_start()
+ experience.to_device(device)
+ metrics = self.training_step(experience)
+ self._on_learn_batch_end(metrics, experience)
+ pbar.set_postfix(metrics)
+ self._on_learn_epoch_end(epoch)
+
+ def fit(self,
+ prompt_dataloader,
+ pretrain_dataloader,
+ num_episodes: int = 50000,
+ max_timesteps: int = 500,
+ update_timesteps: int = 5000) -> None:
+ time = 0
+ self.pretrain_dataloader = pretrain_dataloader
+ self.prompt_dataloader = prompt_dataloader
+ self._on_fit_start()
+ for episode in range(num_episodes):
+ self._on_episode_start(episode)
+ for timestep in tqdm(range(max_timesteps),
+ desc=f'Episode [{episode+1}/{num_episodes}]',
+ disable=not is_rank_0()):
+ time += 1
+ prompts = next(iter(self.prompt_dataloader))
+ self._on_make_experience_start()
+ self.experience_maker.initial_model.to(
+ torch.cuda.current_device())
+ self.experience_maker.reward_model.to(
+ torch.cuda.current_device())
+ experience = self._make_experience(prompts)
+ self._on_make_experience_end(experience)
+ self.replay_buffer.append(experience)
+ if time % update_timesteps == 0:
+ self.experience_maker.initial_model.to('cpu')
+ self.experience_maker.reward_model.to('cpu')
+ self._learn()
+ self.replay_buffer.clear()
+ self._on_episode_end(episode)
+ self._on_fit_end()
+
def training_step(self, experience: Experience) -> Dict[str, float]:
self.actor.train()
self.critic.train()
diff --git a/applications/Chat/coati/trainer/rm.py b/applications/Chat/coati/trainer/rm.py
index 0cf09b0410d2..ed6720abc2af 100644
--- a/applications/Chat/coati/trainer/rm.py
+++ b/applications/Chat/coati/trainer/rm.py
@@ -1,6 +1,5 @@
-from abc import ABC
from datetime import datetime
-from typing import Optional
+from typing import Optional, List
import pandas as pd
import torch
@@ -10,11 +9,13 @@
from tqdm import tqdm
from transformers.tokenization_utils_base import PreTrainedTokenizerBase
+from .callbacks import Callback
+from .base import Trainer
from .strategies import Strategy
from .utils import is_rank_0
-class RewardModelTrainer(ABC):
+class RewardModelTrainer(Trainer):
"""
Trainer to use while training reward model.
@@ -23,11 +24,12 @@ class RewardModelTrainer(ABC):
strategy (Strategy): the strategy to use for training
optim(Optimizer): the optimizer to use for training
loss_fn (callable): the loss function to use for training
- train_dataset (Dataset): the dataset to use for training
- valid_dataset (Dataset): the dataset to use for validation
- eval_dataset (Dataset): the dataset to use for evaluation
+ train_dataloader (DataLoader): the dataloader to use for training
+ valid_dataloader (DataLoader): the dataloader to use for validation
+ eval_dataloader (DataLoader): the dataloader to use for evaluation
batch_size (int, defaults to 1): the batch size while training
max_epochs (int, defaults to 2): the number of epochs to train
+ callbacks (List[Callback], defaults to []): the callbacks to call during training process
"""
def __init__(
@@ -36,25 +38,19 @@ def __init__(
strategy: Strategy,
optim: Optimizer,
loss_fn,
- train_dataset: Dataset,
- valid_dataset: Dataset,
- eval_dataset: Dataset,
+ train_dataloader: DataLoader,
+ valid_dataloader: DataLoader,
+ eval_dataloader: DataLoader,
batch_size: int = 1,
max_epochs: int = 1,
+ callbacks: List[Callback] = [],
) -> None:
- super().__init__()
- self.strategy = strategy
- self.epochs = max_epochs
+ super().__init__(strategy, max_epochs, callbacks=callbacks)
train_sampler = None
- if dist.is_initialized() and dist.get_world_size() > 1:
- train_sampler = DistributedSampler(train_dataset, shuffle=True, seed=42, drop_last=True)
- self.train_dataloader = DataLoader(train_dataset,
- shuffle=(train_sampler is None),
- sampler=train_sampler,
- batch_size=batch_size)
- self.valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=True)
- self.eval_dataloader = DataLoader(eval_dataset, batch_size=batch_size, shuffle=True)
+ self.train_dataloader = train_dataloader
+ self.valid_dataloader = valid_dataloader
+ self.eval_dataloader = eval_dataloader
self.model = strategy.setup_model(model)
self.loss_fn = loss_fn
@@ -86,8 +82,8 @@ def eval_acc(self, dataloader):
def fit(self):
time = datetime.now()
- epoch_bar = tqdm(range(self.epochs), desc='Train epoch', disable=not is_rank_0())
- for epoch in range(self.epochs):
+ epoch_bar = tqdm(range(self.max_epochs), desc='Train epoch', disable=not is_rank_0())
+ for epoch in range(self.max_epochs):
step_bar = tqdm(range(self.train_dataloader.__len__()),
desc='Train step of epoch %d' % epoch,
disable=not is_rank_0())
diff --git a/applications/Chat/coati/trainer/sft.py b/applications/Chat/coati/trainer/sft.py
index 8eeffea48bdd..350553108e68 100644
--- a/applications/Chat/coati/trainer/sft.py
+++ b/applications/Chat/coati/trainer/sft.py
@@ -1,7 +1,6 @@
import math
import time
-from abc import ABC
-from typing import Optional
+from typing import Optional, List
import loralib as lora
import torch
@@ -19,11 +18,13 @@
from colossalai.logging import get_dist_logger
+from .callbacks import Callback
+from .base import Trainer
from .strategies import Strategy
from .utils import is_rank_0
-class SFTTrainer(ABC):
+class SFTTrainer(Trainer):
"""
Trainer to use while training reward model.
@@ -35,6 +36,7 @@ class SFTTrainer(ABC):
eval_dataloader: the dataloader to use for evaluation
batch_size (int, defaults to 1): the batch size while training
max_epochs (int, defaults to 2): the number of epochs to train
+ callbacks (List[Callback], defaults to []): the callbacks to call during training process
optim_kwargs (dict, defaults to {'lr':1e-4}): the kwargs to use while initializing optimizer
"""
@@ -48,10 +50,9 @@ def __init__(
batch_size: int = 1,
max_epochs: int = 2,
accimulation_steps: int = 8,
+ callbacks: List[Callback] = [],
) -> None:
- super().__init__()
- self.strategy = strategy
- self.epochs = max_epochs
+ super().__init__(strategy, max_epochs, callbacks=callbacks)
self.train_dataloader = train_dataloader
self.eval_dataloader = eval_dataloader
@@ -62,7 +63,7 @@ def __init__(
self.accimulation_steps = accimulation_steps
num_update_steps_per_epoch = len(train_dataloader) // self.accimulation_steps
- max_steps = math.ceil(self.epochs * num_update_steps_per_epoch)
+ max_steps = math.ceil(self.max_epochs * num_update_steps_per_epoch)
self.scheduler = get_scheduler("cosine",
self.optimizer,
@@ -74,10 +75,10 @@ def fit(self, logger, log_interval=10):
wandb.watch(self.model)
total_loss = 0
# epoch_bar = tqdm(range(self.epochs), desc='Epochs', disable=not is_rank_0())
- step_bar = tqdm(range(len(self.train_dataloader) // self.accimulation_steps * self.epochs),
+ step_bar = tqdm(range(len(self.train_dataloader) // self.accimulation_steps * self.max_epochs),
desc=f'steps',
disable=not is_rank_0())
- for epoch in range(self.epochs):
+ for epoch in range(self.max_epochs):
# process_bar = tqdm(range(len(self.train_dataloader)), desc=f'Train process for{epoch}', disable=not is_rank_0())
# train
@@ -96,7 +97,7 @@ def fit(self, logger, log_interval=10):
loss = outputs.loss
prompt_logits = outputs.logits
- if loss >= 2.5:
+ if loss >= 2.5 and is_rank_0():
logger.warning(f"batch_id:{batch_id}, abnormal loss: {loss}")
loss = loss / self.accimulation_steps
@@ -110,12 +111,13 @@ def fit(self, logger, log_interval=10):
self.strategy.optimizer_step(self.optimizer)
self.optimizer.zero_grad()
self.scheduler.step()
- wandb.log({
- "loss": total_loss / self.accimulation_steps,
- "lr": self.scheduler.get_last_lr()[0],
- "epoch": epoch,
- "batch_id": batch_id
- })
+ if is_rank_0():
+ wandb.log({
+ "loss": total_loss / self.accimulation_steps,
+ "lr": self.scheduler.get_last_lr()[0],
+ "epoch": epoch,
+ "batch_id": batch_id
+ })
total_loss = 0
step_bar.update()
@@ -147,7 +149,7 @@ def fit(self, logger, log_interval=10):
loss_mean = loss_sum / num_seen
if dist.get_rank() == 0:
- logger.info(f'Eval Epoch {epoch}/{self.epochs} loss {loss_mean}')
+ logger.info(f'Eval Epoch {epoch}/{self.max_epochs} loss {loss_mean}')
# epoch_bar.update()
diff --git a/applications/Chat/coati/trainer/utils.py b/applications/Chat/coati/trainer/utils.py
index 6c9f7f085f8c..1b17a0421656 100644
--- a/applications/Chat/coati/trainer/utils.py
+++ b/applications/Chat/coati/trainer/utils.py
@@ -1,5 +1,14 @@
import torch.distributed as dist
+from typing import Any, Callable, Dict, List, Optional
+from coati.models.bloom import BLOOMActor, BLOOMCritic
+from coati.models.gpt import GPTActor, GPTCritic
+from coati.models.opt import OPTActor, OPTCritic
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+import torch
+import os
def is_rank_0() -> bool:
return not dist.is_initialized() or dist.get_rank() == 0
+
+
diff --git a/applications/Chat/coati/utils/__init__.py b/applications/Chat/coati/utils/__init__.py
index e75401d382a8..112b82b97064 100644
--- a/applications/Chat/coati/utils/__init__.py
+++ b/applications/Chat/coati/utils/__init__.py
@@ -1,3 +1,3 @@
from .tokenizer_utils import prepare_llama_tokenizer_and_embedding, smart_tokenizer_and_embedding_resize
-__all__ = ['smart_tokenizer_and_embedding_resize', 'prepare_llama_tokenizer_and_embedding']
+__all__ = ['smart_tokenizer_and_embedding_resize', 'prepare_llama_tokenizer_and_embedding']
\ No newline at end of file
diff --git a/applications/Chat/evaluate/README.md b/applications/Chat/evaluate/README.md
new file mode 100644
index 000000000000..6113dbbb1ef2
--- /dev/null
+++ b/applications/Chat/evaluate/README.md
@@ -0,0 +1,181 @@
+# Evaluation
+
+In this directory we will introduce how you can evaluate your model with GPT-4.
+
+## Evaluation Pipeline
+
+The whole evaluation process undergoes two steps.
+
+1. Generate answers from different models: Use `generate_gpt35_answers.py` to generate answers of GPT 3.5 and use `generate_answers.py` to generate answers of your own models.
+2. Evaluate models using GPT 4: Use `evaluate.py` to evaluate model answers with GPT-4.
+
+### Generate Answers
+
+To generate answers, you should first format [FastChat's]([FastChat/question.jsonl at main · lm-sys/FastChat (github.com)](https://github.com/lm-sys/FastChat/blob/main/fastchat/eval/table/question.jsonl)) `question.jsonl` file. We do this formatting because we would like to add more questions later and the pipeline for generating new questions may follow that of Self-Instruct and Stanford Alpaca. An example script is given as follows.
+
+```shell
+python format_questions.py \
+ --questions_path "path to FastChat's question.jsonl" \
+ --save_path "path to the formatted file" \
+
+```
+
+In `generate_answers.py`, the model will generate answers in a batch way and different GPU processes will do inference on different shards of the given questions. Once all GPU process generate its answers, `merge.py` will merge different shards of answers and output a single answer file. Finally, the script will also remove the answer shards. An example script is given as follows.
+
+```shell
+device_number=number of your devices
+model_name="name of your model"
+model_path="path to your model"
+dataset="path to the question dataset"
+answer_path="path to save the model answers"
+
+torchrun --standalone --nproc_per_node=$device_number generate_answers.py \
+ --model 'llama' \
+ --strategy ddp \
+ --model_path $model_path \
+ --model_name $model_name \
+ --dataset $dataset \
+ --batch_size 8 \
+ --max_datasets_size 80 \
+ --answer_path $answer_path \
+ --max_length 512
+
+python merge.py \
+ --model_name $model_name \
+ --shards $device_number \
+ --answer_path $answer_path \
+
+for (( i=0; i scores[1]:
+ worse_count += 1
+ worse_file.append(review_jsons[idx])
+ elif scores[0] < scores[1]:
+ better_count += 1
+ better_file.append(review_jsons[idx])
+ else:
+ tie_count += 1
+ tie_file.append(review_jsons[idx])
+ ans1_score += scores[0]
+ ans2_score += scores[1]
+
+ output_review_file.append(review_jsons[idx])
+
+ better_file.sort(key=lambda x: x['id'])
+ worse_file.sort(key=lambda x: x['id'])
+ tie_file.sort(key=lambda x: x['id'])
+ invalid_file.sort(key=lambda x: x['id'])
+ output_review_file.sort(key=lambda x: x['id'])
+
+ name1 = os.path.basename(args.answer_file_list[0]).split("_answers")[0]
+ name2 = os.path.basename(args.answer_file_list[1]).split("_answers")[0]
+ prefix = f"{name1}_vs_{name2}"
+
+ jdump(better_file, os.path.join(
+ args.output_folder, prefix, f"{prefix}_better.json"))
+ jdump(worse_file, os.path.join(
+ args.output_folder, prefix, f"{prefix}_worse.json"))
+ jdump(tie_file, os.path.join(
+ args.output_folder, prefix, f"{prefix}_tie.json"))
+ jdump(invalid_file, os.path.join(
+ args.output_folder, prefix, f"{prefix}_invalid.json"))
+ jdump(output_review_file, os.path.join(
+ args.output_folder, prefix, f"{prefix}_review.json"))
+
+ if os.path.exists(os.path.join(args.output_folder, "results.json")):
+ results = jload(os.path.join(args.output_folder, "results.json"))
+ else:
+ results = {}
+ results[prefix] = {'model': [name1, name2], 'better': better_count, 'worse': worse_count, 'tie': tie_count, 'win_rate': better_count /
+ (len(reviews)-invalid_count), 'score': [ans1_score/(len(reviews)-invalid_count), ans2_score/(len(reviews)-invalid_count)]}
+ jdump(results, os.path.join(args.output_folder, "results.json"))
+
+ logger.info(f' Total {invalid_count} invalid score pair(s).')
+ logger.info(f' Model {name2} has {better_count} better answer(s).')
+ logger.info(f' Model {name2} has {worse_count} worse answer(s).')
+ logger.info(f' {tie_count} answer(s) play(s) to a tie.')
+ logger.info(
+ f' Win rate of model {name2}: {better_count/(len(reviews)-invalid_count):.2f}')
+ logger.info(
+ f' Model {name1} average score: {ans1_score/(len(reviews)-invalid_count):.2f}')
+ logger.info(
+ f' Model {name2} average score: {ans2_score/(len(reviews)-invalid_count):.2f}')
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(
+ description='Model evaluation.')
+ parser.add_argument('--answer_file_list', nargs='+', default=[])
+ parser.add_argument('--prompt_file')
+ parser.add_argument('--reviewer_file')
+ parser.add_argument('--output_folder', type=str, default="./output")
+ parser.add_argument('--openai_key', type=str, default=None)
+ parser.add_argument('--model', type=str, default="gpt-4")
+ parser.add_argument('--num_workers', type=int, default=8)
+ parser.add_argument('--max_tokens', type=int, default=512,
+ help='maximum number of tokens produced in the output')
+ args = parser.parse_args()
+
+ if args.openai_key is not None:
+ os.environ["OPENAI_API_KEY"] = args.openai_key
+ openai.api_key = os.getenv("OPENAI_API_KEY")
+
+ evaluate(args)
diff --git a/applications/Chat/evaluate/evaluate.sh b/applications/Chat/evaluate/evaluate.sh
new file mode 100755
index 000000000000..c51aa941019e
--- /dev/null
+++ b/applications/Chat/evaluate/evaluate.sh
@@ -0,0 +1,9 @@
+python evaluate.py \
+ --answer_file_list "path to answers of model 1" "path to answers of model 2" \
+ --prompt_file "path to prompt file" \
+ --reviewer_file "path to reviewer file" \
+ --output_folder "path to output folder" \
+ --openai_key "your openai key" \
+ --model "gpt-4" \
+ --num_workers 8 \
+ --max_tokens 512 \
diff --git a/applications/Chat/evaluate/format_questions.py b/applications/Chat/evaluate/format_questions.py
new file mode 100644
index 000000000000..9b47907c34bf
--- /dev/null
+++ b/applications/Chat/evaluate/format_questions.py
@@ -0,0 +1,31 @@
+import argparse
+import os
+import json
+import copy
+
+from utils import jdump, get_json_list
+
+
+def format_questions(args):
+ questions = get_json_list(args.questions_path)
+ keys=questions[0].keys()
+
+ formatted_questions=copy.deepcopy(questions)
+ for i in range(len(formatted_questions)):
+ formatted_questions[i]['instruction']=questions[i]['text']
+ formatted_questions[i]['input']=""
+ formatted_questions[i]['output']=""
+ formatted_questions[i]['id']=questions[i]['question_id']
+ for key in keys:
+ if key=="category":
+ continue
+ del formatted_questions[i][key]
+
+ jdump(formatted_questions, args.save_path)
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--questions_path', type=str, default='table/question.jsonl')
+ parser.add_argument('--save_path', type=str, default="table/questions.json")
+ args = parser.parse_args()
+ format_questions(args)
\ No newline at end of file
diff --git a/applications/Chat/evaluate/format_questions.sh b/applications/Chat/evaluate/format_questions.sh
new file mode 100755
index 000000000000..a7568da364ad
--- /dev/null
+++ b/applications/Chat/evaluate/format_questions.sh
@@ -0,0 +1,3 @@
+python format_questions.py \
+ --questions_path "path to FastChat's question.jsonl" \
+ --save_path "path to the formatted file" \
diff --git a/applications/Chat/evaluate/generate_answers.py b/applications/Chat/evaluate/generate_answers.py
new file mode 100644
index 000000000000..fbebf5c5e6f6
--- /dev/null
+++ b/applications/Chat/evaluate/generate_answers.py
@@ -0,0 +1,173 @@
+import argparse
+import os
+import random
+import copy
+import math
+from tqdm import tqdm
+
+import torch
+import torch.distributed as dist
+import transformers
+
+from coati.models.bloom import BLOOMActor
+from coati.models.gpt import GPTActor
+from coati.models.opt import OPTActor
+from coati.models.roberta import RoBERTaActor
+from coati.models.llama import LlamaActor
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from transformers import AutoTokenizer, RobertaTokenizer
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.logging import get_dist_logger
+
+from utils import jload, jdump, is_rank_0
+
+
+logger = get_dist_logger()
+
+PROMPT_DICT = {
+ "prompt_input":
+ ("Below is an instruction that describes a task, paired with an input that provides further context. "
+ "Write a response that appropriately completes the request.\n\n"
+ "### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:"),
+ "prompt_no_input": ("Below is an instruction that describes a task. "
+ "Write a response that appropriately completes the request.\n\n"
+ "### Instruction:\n{instruction}\n\n### Response:"),
+}
+
+
+def generate(args):
+ # torch.cuda.set_per_process_memory_fraction(0.4)
+ if args.strategy == 'naive':
+ strategy = NaiveStrategy()
+ elif args.strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif args.strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero2_cpu':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cpu')
+ else:
+ raise ValueError(f'Unsupported strategy "{args.strategy}"')
+
+ world_size = dist.get_world_size()
+ rank = dist.get_rank()
+
+ with strategy.model_init_context():
+ if args.model == 'gpt2':
+ actor = GPTActor(pretrained=args.model_path).to(
+ torch.cuda.current_device())
+ elif args.model == 'bloom':
+ actor = BLOOMActor(pretrained=args.model_path).to(
+ torch.cuda.current_device())
+ elif args.model == 'opt':
+ actor = OPTActor(pretrained=args.model_path).to(
+ torch.cuda.current_device())
+ elif args.model == 'roberta':
+ actor = RoBERTaActor(pretrained=args.model_path).to(
+ torch.cuda.current_device())
+ elif args.model == 'llama':
+ actor = LlamaActor(pretrained=args.model_path).to(
+ torch.float16).to(torch.cuda.current_device())
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'bloom':
+ tokenizer = AutoTokenizer.from_pretrained('bigscience/bloom-560m')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained('facebook/opt-350m')
+ elif args.model == 'roberta':
+ tokenizer = RobertaTokenizer.from_pretrained("roberta-base")
+ elif args.model == 'llama':
+ tokenizer = AutoTokenizer.from_pretrained(args.model_path,
+ padding_side="right",
+ use_fast=False,
+ )
+ tokenizer.eos_token = '<\s>'
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ questions = []
+ if args.max_datasets_size is not None:
+ questions = random.sample(jload(args.dataset), args.max_datasets_size)
+ if is_rank_0():
+ logger.info(
+ f"Limiting dataset to {args.max_datasets_size} examples.")
+ questions = questions[rank:args.max_datasets_size:world_size]
+
+ answers = copy.deepcopy(questions)
+
+ prompt_input, prompt_no_input = PROMPT_DICT["prompt_input"], PROMPT_DICT["prompt_no_input"]
+ sources = [
+ prompt_input.format_map(example) if example.get(
+ "input", "") != "" else prompt_no_input.format_map(example)
+ for example in questions
+ ]
+
+ if is_rank_0():
+ logger.info("Tokenizing inputs... This may take some time...")
+
+ input_ids_list = []
+
+ for string in sources:
+ input_ids = tokenizer.encode(string, return_tensors='pt').squeeze(0)
+ input_ids_list.append(input_ids)
+
+ bar = tqdm(range(math.ceil(len(input_ids_list)/args.batch_size)),
+ desc=f'steps', disable=not is_rank_0())
+
+ actor.eval()
+ with torch.no_grad():
+ for i in range(0, len(input_ids_list), args.batch_size):
+ batch = input_ids_list[i:i+args.batch_size]
+ batch = [i.flip(dims=[0]) for i in batch]
+ batch = torch.nn.utils.rnn.pad_sequence(batch,
+ batch_first=True,
+ padding_value=tokenizer.pad_token_id if tokenizer.pad_token_id is not None else 0).to(torch.cuda.current_device())
+ batch = batch.flip(dims=[1])
+ attention_mask = batch.ne(tokenizer.pad_token_id if tokenizer.pad_token_id is not None else 0)
+
+ outputs = actor.model.generate(batch, attention_mask=attention_mask,
+ max_length=args.max_length,
+ do_sample=True,
+ top_k=50,
+ top_p=0.95,
+ num_return_sequences=1)
+
+ outputs = tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ for j in range(batch.size(0)):
+ answers[i +
+ j]['output'] = outputs[j].split("### Response:")[1].strip()
+
+ bar.update()
+
+ jdump(answers, os.path.join(args.answer_path,
+ f'{args.model_name}_answers_rank{rank}.json'))
+
+ if is_rank_0():
+ logger.info(
+ f'Peak CUDA mem: {torch.cuda.max_memory_allocated()/1024**3:.3f} GB')
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini',
+ 'colossalai_zero2', 'colossalai_zero2_cpu'],
+ default='naive')
+ parser.add_argument('--model', default='gpt2',
+ choices=['gpt2', 'bloom', 'opt', 'roberta', 'llama'])
+ parser.add_argument('--model_path', type=str, default=None)
+ parser.add_argument('--model_name', type=str, default='model')
+ parser.add_argument('--dataset', type=str, default=None)
+ parser.add_argument('--batch_size', type=int, default=1)
+ parser.add_argument('--max_datasets_size', type=int, default=None)
+ parser.add_argument('--answer_path', type=str, default="answer")
+ parser.add_argument('--max_length', type=int, default=1024)
+ args = parser.parse_args()
+ generate(args)
diff --git a/applications/Chat/evaluate/generate_answers.sh b/applications/Chat/evaluate/generate_answers.sh
new file mode 100755
index 000000000000..36881f5f4f29
--- /dev/null
+++ b/applications/Chat/evaluate/generate_answers.sh
@@ -0,0 +1,25 @@
+device_number=number of your devices
+model_name="name of your model"
+model_path="path to your model"
+dataset="path to the question dataset"
+answer_path="path to save the model answers"
+
+torchrun --standalone --nproc_per_node=$device_number generate_answers.py \
+ --model 'llama' \
+ --strategy ddp \
+ --model_path $model_path \
+ --model_name $model_name \
+ --dataset $dataset \
+ --batch_size 8 \
+ --max_datasets_size 80 \
+ --answer_path $answer_path \
+ --max_length 512
+
+python merge.py \
+ --model_name $model_name \
+ --shards $device_number \
+ --answer_path $answer_path \
+
+for (( i=0; i bool:
+ return not dist.is_initialized() or dist.get_rank() == 0
+
+def _make_w_io_base(f, mode: str):
+ if not isinstance(f, io.IOBase):
+ f_dirname = os.path.dirname(f)
+ if f_dirname != "":
+ os.makedirs(f_dirname, exist_ok=True)
+ f = open(f, mode=mode)
+ return f
+
+def _make_r_io_base(f, mode: str):
+ if not isinstance(f, io.IOBase):
+ f = open(f, mode=mode)
+ return f
+
+def jdump(obj, f, mode="w", indent=4, default=str):
+ """Dump a str or dictionary to a file in json format.
+ Args:
+ obj: An object to be written.
+ f: A string path to the location on disk.
+ mode: Mode for opening the file.
+ indent: Indent for storing json dictionaries.
+ default: A function to handle non-serializable entries; defaults to `str`.
+ """
+ f = _make_w_io_base(f, mode)
+ if isinstance(obj, (dict, list)):
+ json.dump(obj, f, indent=indent, default=default)
+ elif isinstance(obj, str):
+ f.write(obj)
+ else:
+ raise ValueError(f"Unexpected type: {type(obj)}")
+ f.close()
+
+def jload(f, mode="r"):
+ """Load a .json file into a dictionary."""
+ f = _make_r_io_base(f, mode)
+ jdict = json.load(f)
+ f.close()
+ return jdict
+
+def get_json_list(file_path):
+ with open(file_path, 'r') as f:
+ json_list = []
+ for line in f:
+ json_list.append(json.loads(line))
+ return json_list
diff --git a/applications/Chat/examples/README.md b/applications/Chat/examples/README.md
index 6c02606eab93..af8ded005600 100644
--- a/applications/Chat/examples/README.md
+++ b/applications/Chat/examples/README.md
@@ -1,5 +1,35 @@
# Examples
+## Table of Contents
+
+- [Examples](#examples)
+ - [Table of Contents](#table-of-contents)
+ - [Install requirements](#install-requirements)
+ - [Supervised datasets collection](#supervised-datasets-collection)
+ - [Stage1 - Supervised instructs tuning](#stage1---supervised-instructs-tuning)
+ - [Arg List](#arg-list)
+ - [Stage2 - Training reward model](#stage2---training-reward-model)
+ - [Features and tricks in RM training](#features-and-tricks-in-rm-training)
+ - [Experiment result](#experiment-result)
+ - [Arg List](#arg-list-1)
+ - [Stage3 - Training model using prompts with RL](#stage3---training-model-using-prompts-with-rl)
+ - [Arg List](#arg-list-2)
+ - [Inference example - After Stage3](#inference-example---after-stage3)
+ - [Attention](#attention)
+ - [data](#data)
+ - [Support Model](#support-model)
+ - [GPT](#gpt)
+ - [BLOOM](#bloom)
+ - [OPT](#opt)
+ - [LLaMA](#llama)
+ - [Add your own models](#add-your-own-models)
+ - [Actor model](#actor-model)
+ - [LM model](#lm-model)
+ - [Reward model](#reward-model)
+ - [Critic model](#critic-model)
+
+
+---
## Install requirements
```shell
@@ -8,7 +38,7 @@ pip install -r requirements.txt
## Supervised datasets collection
-We colllected 104K bilingual dataset of Chinese and English, and you can find the datasets in this repo
+We collected 104K bilingual dataset of Chinese and English, and you can find the datasets in this repo
[InstructionWild](https://github.com/XueFuzhao/InstructionWild).
The following pic shows how we collected the data.
@@ -98,7 +128,7 @@ Model performance in [Anthropics paper](https://arxiv.org/abs/2204.05862):
- --lora_rank: low-rank adaptation matrices rank, type=int, default=0
- --loss_func: which kind of loss function, choices=['log_sig', 'log_exp']
- --max_len: max sentence length for generation, type=int, default=512
-- --test: whether is only tesing, if it's ture, the dataset will be small
+- --test: whether is only testing, if it's true, the dataset will be small
## Stage3 - Training model using prompts with RL
@@ -164,7 +194,7 @@ The examples are demos for the whole training process.You need to change the hyp
- [x] GPT2-S (s)
- [x] GPT2-M (m)
- [x] GPT2-L (l)
-- [ ] GPT2-XL (xl)
+- [x] GPT2-XL (xl)
- [x] GPT2-4B (4b)
- [ ] GPT2-6B (6b)
@@ -178,9 +208,9 @@ The examples are demos for the whole training process.You need to change the hyp
### OPT
- [x] [OPT-125M](https://huggingface.co/facebook/opt-125m)
- [x] [OPT-350M](https://huggingface.co/facebook/opt-350m)
-- [ ] [OPT-1.3B](https://huggingface.co/facebook/opt-1.3b)
-- [ ] [OPT-2.7B](https://huggingface.co/facebook/opt-2.7b)
-- [ ] [OPT-6.7B](https://huggingface.co/facebook/opt-6.7b)
+- [x] [OPT-1.3B](https://huggingface.co/facebook/opt-1.3b)
+- [x] [OPT-2.7B](https://huggingface.co/facebook/opt-2.7b)
+- [x] [OPT-6.7B](https://huggingface.co/facebook/opt-6.7b)
- [ ] [OPT-13B](https://huggingface.co/facebook/opt-13b)
- [ ] [OPT-30B](https://huggingface.co/facebook/opt-30b)
@@ -189,3 +219,101 @@ The examples are demos for the whole training process.You need to change the hyp
- [x] LLaMA-13B
- [ ] LLaMA-33B
- [ ] LLaMA-65B
+
+## Add your own models
+
+If you want to support your own model in Coati, please refer the pull request for RoBERTa support as an example --[[chatgpt] add pre-trained model RoBERTa for RLHF stage 2 & 3](https://github.com/hpcaitech/ColossalAI/pull/3223), and submit a PR to us.
+
+You should complete the implementation of four model classes, including Reward model, Critic model, LM model, Actor model
+
+here are some example code for a NewModel named `Coati`.
+if it is supported in huggingaface [transformers](https://github.com/huggingface/transformers), you can load it by `from_pretrained`, o
+r you can build your own model by yourself.
+
+### Actor model
+```
+from ..base import Actor
+from transformers.models.coati import CoatiModel
+
+class CoatiActor(Actor):
+
+ def __init__(self,
+ pretrained: Optional[str] = None,
+ checkpoint: bool = False,
+ lora_rank: int = 0,
+ lora_train_bias: str = 'none') -> None:
+ if pretrained is not None:
+ model = CoatiModel.from_pretrained(pretrained)
+ else:
+ model = build_model() # load your own model if it is not support in transformers
+
+ super().__init__(model, lora_rank, lora_train_bias)
+```
+
+### LM model
+
+```
+from ..base import LM
+from transformers.models.coati import CoatiModel
+
+class GPTLM(LM):
+
+ def __init__(self,
+ pretrained: Optional[str] = None,
+ checkpoint: bool = False,
+ lora_rank: int = 0,
+ lora_train_bias: str = 'none') -> None:
+ if pretrained is not None:
+ model = CoatiModel.from_pretrained(pretrained)
+ else:
+ model = build_model() # load your own model if it is not support in transformers
+
+ super().__init__(model, lora_rank, lora_train_bias)
+
+ def forward(self, input_ids, attention_mask=None, labels=None, **kwargs):
+ return self.model(input_ids, attention_mask=attention_mask, labels=labels, **kwargs)
+```
+### Reward model
+```
+from ..base import RewardModel
+from transformers.models.coati import CoatiModel
+
+class CoatiRM(RewardModel):
+
+ def __init__(self,
+ pretrained: Optional[str] = None,
+ checkpoint: bool = False,
+ lora_rank: int = 0,
+ lora_train_bias: str = 'none') -> None:
+ if pretrained is not None:
+ model = CoatiModel.from_pretrained(pretrained)
+ else:
+ model = build_model() # load your own model if it is not support in transformers
+
+ value_head = nn.Linear(model.config.n_embd, 1)
+ value_head.weight.data.normal_(mean=0.0, std=1 / (model.config.n_embd + 1))
+ super().__init__(model, value_head, lora_rank, lora_train_bias)
+```
+
+### Critic model
+
+```
+from ..base import Critic
+from transformers.models.coati import CoatiModel
+
+class CoatiCritic(Critic):
+
+ def __init__(self,
+ pretrained: Optional[str] = None,
+ checkpoint: bool = False,
+ lora_rank: int = 0,
+ lora_train_bias: str = 'none') -> None:
+ if pretrained is not None:
+ model = CoatiModel.from_pretrained(pretrained)
+ else:
+ model = build_model() # load your own model if it is not support in transformers
+
+ value_head = nn.Linear(model.config.n_embd, 1)
+ value_head.weight.data.normal_(mean=0.0, std=1 / (model.config.n_embd + 1))
+ super().__init__(model, value_head, lora_rank, lora_train_bias)
+```
diff --git a/applications/Chat/examples/community/README.md b/applications/Chat/examples/community/README.md
index 905418892611..c9c645032288 100644
--- a/applications/Chat/examples/community/README.md
+++ b/applications/Chat/examples/community/README.md
@@ -1,6 +1,6 @@
# Community Examples
---
-We are thrilled to announce the latest updates to ColossalChat, an open-source solution for cloning ChatGPT with a complete RLHF (Reinforcement Learning with Human Feedback) pipeline.
+We are thrilled to announce the latest updates to ColossalChat, an open-source solution for cloning ChatGPT with a complete RLHF (Reinforcement Learning with Human Feedback) pipeline.
As Colossal-AI undergoes major updates, we are actively maintaining ColossalChat to stay aligned with the project's progress. With the introduction of Community-driven example, we aim to create a collaborative platform for developers to contribute exotic features built on top of ColossalChat.
@@ -16,7 +16,8 @@ Community examples consist of both inference and training examples that have bee
| Example | Description | Code Example | Colab | Author |
|:---------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------:|
-| Peft | Adding Peft support for SFT and Prompts model training | [Huggingface Peft](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/peft) | - | [YY Lin](https://github.com/yynil) |
+| Peft | Adding Peft support for SFT and Prompts model training | [Huggingface Peft](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/peft) | - | [YY Lin](https://github.com/yynil) |
+| Train prompts on Ray | A Ray based implementation of Train prompts example | [Huggingface Peft](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/ray) | - | [MisterLin1995](https://github.com/MisterLin1995) |
|...|...|...|...|...|
### How to get involved
diff --git a/applications/Chat/examples/community/peft/README.md b/applications/Chat/examples/community/peft/README.md
index a82f02a87317..eabb56fd8294 100644
--- a/applications/Chat/examples/community/peft/README.md
+++ b/applications/Chat/examples/community/peft/README.md
@@ -1,10 +1,10 @@
# Add Peft support for SFT and Prompts model training
-The orginal implementation just adopts the loralib and merges the layers into the final model. The huggingface peft is a better lora model implementation and can be easily training and distributed.
+The original implementation just adopts the loralib and merges the layers into the final model. The huggingface peft is a better lora model implementation and can be easily training and distributed.
Since reward model is relative small, I just keep it as original one. I suggest train full model to get the proper reward/critic model.
-# Prelimenary installation
+# Preliminary installation
Since the current pypi peft package(0.2) has some bugs, please install the peft package using source.
```
git clone https://github.com/huggingface/peft
diff --git a/applications/Chat/examples/community/peft/easy_dataset.py b/applications/Chat/examples/community/peft/easy_dataset.py
index 13dceef79145..24ea4f0a8618 100644
--- a/applications/Chat/examples/community/peft/easy_dataset.py
+++ b/applications/Chat/examples/community/peft/easy_dataset.py
@@ -166,7 +166,7 @@ def __str__(self):
'''
-Easy SFT just accept a text file which can be read line by line. However the datasest will group texts together to max_length so LLM will learn the texts meaning better.
+Easy SFT just accept a text file which can be read line by line. However the datasets will group texts together to max_length so LLM will learn the texts meaning better.
If individual lines are not related, just set is_group_texts to False.
'''
diff --git a/applications/Chat/examples/community/ray/README.md b/applications/Chat/examples/community/ray/README.md
new file mode 100644
index 000000000000..64360bd73ddc
--- /dev/null
+++ b/applications/Chat/examples/community/ray/README.md
@@ -0,0 +1,17 @@
+# ColossalAI on Ray
+## Abstract
+This is an experimental effort to run ColossalAI Chat training on Ray
+## How to use?
+### 1. Setup Ray clusters
+Please follow the official [Ray cluster setup instructions](https://docs.ray.io/en/latest/cluster/getting-started.html) to setup an cluster with GPU support. Record the cluster's api server endpoint, it should be something similar to http://your.head.node.addrees:8265
+### 2. Clone repo
+Clone this project:
+```shell
+git clone https://github.com/hpcaitech/ColossalAI.git
+```
+### 3. Submit the ray job
+```shell
+python applications/Chat/examples/community/ray/ray_job_script.py http://your.head.node.addrees:8265
+```
+### 4. View your job on the Ray Dashboard
+Open your ray cluster dashboard http://your.head.node.addrees:8265 to view your submitted training job.
diff --git a/applications/Chat/examples/community/ray/ray_job_script.py b/applications/Chat/examples/community/ray/ray_job_script.py
new file mode 100644
index 000000000000..53f304d379fe
--- /dev/null
+++ b/applications/Chat/examples/community/ray/ray_job_script.py
@@ -0,0 +1,22 @@
+import sys
+
+from ray.job_submission import JobSubmissionClient
+
+
+def main(api_server_endpoint="http://127.0.0.1:8265"):
+ client = JobSubmissionClient(api_server_endpoint)
+ client.submit_job(
+ entrypoint=
+ "python experimental/ray/train_prompts_on_ray.py --strategy colossalai_zero2 --prompt_csv_url https://huggingface.co/datasets/fka/awesome-chatgpt-prompts/resolve/main/prompts.csv",
+ runtime_env={
+ "working_dir":
+ "applications/Chat",
+ "pip": [
+ "torch==1.13.1", "transformers>=4.20.1", "datasets", "loralib", "colossalai>=0.2.4", "langchain",
+ "tokenizers", "fastapi", "sse_starlette", "wandb", "sentencepiece", "gpustat"
+ ]
+ })
+
+
+if __name__ == "__main__":
+ main(sys.argv[1])
diff --git a/applications/Chat/examples/community/ray/train_prompts_on_ray.py b/applications/Chat/examples/community/ray/train_prompts_on_ray.py
new file mode 100644
index 000000000000..289330ad8415
--- /dev/null
+++ b/applications/Chat/examples/community/ray/train_prompts_on_ray.py
@@ -0,0 +1,555 @@
+import argparse
+import logging
+import os
+import socket
+from copy import deepcopy
+from typing import Type
+
+import ray
+import torch
+from coati.experience_maker.base import Experience
+from coati.models.base import RewardModel
+from coati.models.bloom import BLOOMActor, BLOOMCritic
+from coati.models.gpt import GPTActor, GPTCritic
+from coati.models.lora import LoRAModule
+from coati.models.loss import PolicyLoss, ValueLoss
+from coati.models.opt import OPTActor, OPTCritic
+from coati.models.utils import compute_reward
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from ray.util.placement_group import placement_group
+from ray.util.scheduling_strategies import PlacementGroupSchedulingStrategy
+from torch.optim import Adam
+from transformers import AutoTokenizer, BloomTokenizerFast
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.nn.optimizer import HybridAdam
+
+
+class ExperienceCompositionRefs:
+
+ def __init__(self, sequences_attention_mask_action_mask_ref: ray.ObjectRef, action_log_probs_ref: ray.ObjectRef,
+ base_action_log_probs_ref: ray.ObjectRef, value_ref: ray.ObjectRef, r_ref: ray.ObjectRef) -> None:
+ self.sequences_attention_mask_action_mask_ref = sequences_attention_mask_action_mask_ref
+ self.action_log_probs_ref = action_log_probs_ref
+ self.base_action_log_probs_ref = base_action_log_probs_ref
+ self.value_ref = value_ref
+ self.r_ref = r_ref
+
+
+class ExperienceMaker:
+
+ def __init__(self, kl_coef) -> None:
+ self.kl_coef = kl_coef
+
+ @torch.no_grad()
+ def make_experience(self, experiment_computation_refs: ExperienceCompositionRefs):
+ sequences, attention_mask, action_mask = ray.get(
+ experiment_computation_refs.sequences_attention_mask_action_mask_ref)
+ action_log_probs = ray.get(experiment_computation_refs.action_log_probs_ref)
+ base_action_log_probs = ray.get(experiment_computation_refs.base_action_log_probs_ref)
+ r = ray.get(experiment_computation_refs.r_ref)
+ reward = compute_reward(r, self.kl_coef, action_log_probs, base_action_log_probs, action_mask=action_mask)
+ value = ray.get(experiment_computation_refs.value_ref)
+ advantage = reward - value
+ if advantage.ndim == 1:
+ advantage = advantage.unsqueeze(-1)
+ experience = Experience(sequences, action_log_probs, value, reward, advantage, attention_mask, action_mask)
+ return experience
+
+
+class DistributedTorchRayActor:
+
+ def __init__(self, world_size, rank, local_rank, master_addr, master_port):
+ logging.basicConfig(format='%(asctime)s %(levelname)-8s %(message)s',
+ level=logging.INFO,
+ datefmt='%Y-%m-%d %H:%M:%S')
+ self._model = None
+ self._world_size = world_size
+ self._rank = rank
+ self._local_rank = local_rank
+ self._master_addr = master_addr if master_addr else self._get_current_node_ip()
+ self._master_port = master_port if master_port else self._get_free_port()
+ os.environ["MASTER_ADDR"] = self._master_addr
+ os.environ["MASTER_PORT"] = str(self._master_port)
+ os.environ["WORLD_SIZE"] = str(self._world_size)
+ os.environ["RANK"] = str(self._rank)
+ os.environ["LOCAL_RANK"] = str(self._local_rank)
+
+ @staticmethod
+ def _get_current_node_ip():
+ return ray._private.services.get_node_ip_address()
+
+ @staticmethod
+ def _get_free_port():
+ with socket.socket() as sock:
+ sock.bind(('', 0))
+ return sock.getsockname()[1]
+
+ def get_master_addr_port(self):
+ return self._master_addr, self._master_port
+
+
+class BasePPORole(DistributedTorchRayActor):
+
+ def add_experience_maker(self, kl_coef: float = 0.1):
+ self._experience_maker = ExperienceMaker(kl_coef)
+
+ def make_experience(self, experience_computation_ref: ExperienceCompositionRefs):
+ return self._experience_maker.make_experience(experience_computation_ref)
+
+ def _init_strategy(self, strategy: str):
+ # configure strategy
+ if strategy == 'naive':
+ self._strategy = NaiveStrategy()
+ elif strategy == 'ddp':
+ self._strategy = DDPStrategy()
+ elif strategy == 'colossalai_gemini':
+ self._strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
+ elif strategy == 'colossalai_zero2':
+ self._strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{strategy}"')
+
+ def _init_optimizer(self):
+ if isinstance(self._strategy, ColossalAIStrategy):
+ self._optimizer = HybridAdam(self._model.parameters(), lr=5e-6)
+ else:
+ self._optimizer = Adam(self._model.parameters(), lr=5e-6)
+
+ def _prepare_model_with_strategy(self, has_optimizer: bool):
+ if has_optimizer:
+ self._init_optimizer()
+ (self._model, self._optimizer) = self._strategy.prepare((self._model, self._optimizer))
+ else:
+ self._model = self._strategy.prepare(self._model)
+
+ def _load_model_from_pretrained(self, model_class: Type[LoRAModule], pretrain: str):
+ raise NotImplementedError()
+
+ def init_model_from_pretrained(self,
+ strategy: str,
+ model_class: Type[LoRAModule],
+ pretrain: str,
+ has_optimizer=False):
+ self._init_strategy(strategy)
+ self._load_model_from_pretrained(model_class, pretrain)
+ self._prepare_model_with_strategy(has_optimizer)
+
+ def eval(self):
+ self._model.eval()
+
+
+class TrainablePPORole(BasePPORole):
+
+ def _load_model_from_pretrained(self, model_class, pretrain):
+ with self._strategy.model_init_context():
+ self._model = model_class(pretrain).to(torch.cuda.current_device())
+
+ def _train(self):
+ self._model.train()
+
+ def _training_step(self, experience: Experience):
+ raise NotImplementedError()
+
+ def learn_on_experiences(self, experience_refs):
+ experiences = ray.get(experience_refs)
+ device = torch.cuda.current_device()
+ self._train()
+ for exp in experiences:
+ exp.to_device(device)
+ self._training_step(exp)
+ self.eval()
+
+
+@ray.remote(num_gpus=1)
+class RayPPOActor(TrainablePPORole):
+
+ def set_loss_function(self, eps_clip: float):
+ self._actor_loss_fn = PolicyLoss(eps_clip)
+
+ def load_tokenizer_from_pretrained(self, model_type: str, pretrained):
+ if model_type == 'gpt2':
+ self._model_tokenizer = GPT2Tokenizer.from_pretrained(pretrained)
+ self._model_tokenizer.pad_token = self._model_tokenizer.eos_token
+ elif model_type == 'bloom':
+ self._model_tokenizer = BloomTokenizerFast.from_pretrained(pretrained)
+ self._model_tokenizer.pad_token = self._model_tokenizer.eos_token
+ elif model_type == 'opt':
+ self._model_tokenizer = AutoTokenizer.from_pretrained(pretrained)
+ else:
+ raise ValueError(f'Unsupported model "{model_type}"')
+
+ # Set tokenize function for sequence generation
+ def _text_input_tokenize_fn(texts):
+ batch = self._model_tokenizer(texts, return_tensors='pt', max_length=96, padding=True, truncation=True)
+ return {k: v.cuda() for k, v in batch.items()}
+
+ self._sample_tokenize_function = _text_input_tokenize_fn
+
+ def setup_generate_kwargs(self, generate_kwargs: dict):
+ from coati.trainer.ppo import _set_default_generate_kwargs
+ self._generate_kwargs = _set_default_generate_kwargs(self._strategy, generate_kwargs, self._model)
+ self._generate_kwargs['pad_token_id'] = self._model_tokenizer.pad_token_id
+ self._generate_kwargs['eos_token_id'] = self._model_tokenizer.eos_token_id
+
+ def load_csv_prompt_file_from_url_to_sampler(self, prompt_url):
+ import pandas as pd
+ prompts = pd.read_csv(prompt_url)['prompt']
+ self._sampler = self._strategy.setup_sampler(prompts)
+
+ def _generate(self, input_ids, **generate_kwargs):
+ return self._model.generate(input_ids, return_action_mask=True, **generate_kwargs)
+
+ def sample_prompts_and_make_sequence(self, experience_batch_size):
+ sampled_prompts = self._sampler.sample(experience_batch_size)
+ input_ids = self._sample_tokenize_function(sampled_prompts)
+ if isinstance(input_ids, dict):
+ return self._generate(**input_ids, **self._generate_kwargs)
+ else:
+ return self._generate(input_ids, **self._generate_kwargs)
+
+ @torch.no_grad()
+ def calculate_action_log_probs(self, sequence_attention_action_mask):
+ sequences, attention_mask, action_mask = sequence_attention_action_mask
+ return self._model.forward(sequences, action_mask.size(1), attention_mask)
+
+ def _training_step(self, experience):
+ num_actions = experience.action_mask.size(1)
+ action_log_probs = self._model(experience.sequences, num_actions, attention_mask=experience.attention_mask)
+ actor_loss = self._actor_loss_fn(action_log_probs,
+ experience.action_log_probs,
+ experience.advantages,
+ action_mask=experience.action_mask)
+ self._strategy.backward(actor_loss, self._model, self._optimizer)
+ self._strategy.optimizer_step(self._optimizer)
+ self._optimizer.zero_grad()
+ logging.info("actor_loss: {}".format(actor_loss))
+
+ def save_checkpoint(self, save_path, should_save_optimizer: bool):
+ if self._rank == 0:
+ # save model checkpoint only on rank 0
+ self._strategy.save_model(self._model, save_path, only_rank0=True)
+ # save optimizer checkpoint on all ranks
+ if should_save_optimizer:
+ self._strategy.save_optimizer(self._optimizer,
+ 'actor_optim_checkpoint_prompts_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
+ def generate_answer(self, prompt, max_length=30, num_return_sequences=5):
+ encoded_input = self._model_tokenizer(prompt, return_tensors='pt')
+ input_ids = {k: v.cuda() for k, v in encoded_input.items()}
+ sequence, _ = self._model.generate(**input_ids,
+ max_length=max_length,
+ return_action_mask=False,
+ num_return_sequences=num_return_sequences)
+ token_list = list(sequence.data[0])
+ output = " ".join([self._model_tokenizer.decode(token) for token in token_list])
+ return output
+
+
+@ray.remote(num_gpus=1)
+class RayPPOCritic(TrainablePPORole):
+
+ def set_loss_function(self, value_clip: float):
+ self._critic_loss_fn = ValueLoss(value_clip)
+
+ def _training_step(self, experience):
+ values = self._model(experience.sequences,
+ action_mask=experience.action_mask,
+ attention_mask=experience.attention_mask)
+ critic_loss = self._critic_loss_fn(values,
+ experience.values,
+ experience.reward,
+ action_mask=experience.action_mask)
+ self._strategy.backward(critic_loss, self._model, self._optimizer)
+ self._strategy.optimizer_step(self._optimizer)
+ self._optimizer.zero_grad()
+ logging.info("critic_loss: {}".format(critic_loss))
+
+ @torch.no_grad()
+ def calculate_value(self, sequence_attention_action_mask):
+ sequences, attention_mask, action_mask = sequence_attention_action_mask
+ return self._model(sequences, action_mask, attention_mask)
+
+
+@ray.remote(num_gpus=1)
+class RayPPORewardModel(BasePPORole):
+
+ def _load_model_from_pretrained(self, model_class, pretrain):
+ with self._strategy.model_init_context():
+ critic = model_class(pretrained=pretrain).to(torch.cuda.current_device())
+ self._model = RewardModel(deepcopy(critic.model),
+ deepcopy(critic.value_head)).to(torch.cuda.current_device())
+
+ @torch.no_grad()
+ def calculate_r(self, sequence_attention_action_mask):
+ sequences, attention_mask, _ = sequence_attention_action_mask
+ return self._model(sequences, attention_mask)
+
+
+@ray.remote(num_gpus=1)
+class RayPPOInitialModel(BasePPORole):
+
+ def _load_model_from_pretrained(self, model_class, pretrain):
+ with self._strategy.model_init_context():
+ self._model = model_class(pretrain).to(torch.cuda.current_device())
+
+ @torch.no_grad()
+ def calculate_base_action_log_probs(self, sequence_attention_action_mask):
+ sequences, attention_mask, action_mask = sequence_attention_action_mask
+ return self._model(sequences, action_mask.size(1), attention_mask)
+
+
+class PPORayActorGroup:
+ """
+ A group of ray actors
+ Functions start with 'async' should return list of object refs
+ """
+
+ def __init__(self, num_nodes, num_gpus_per_node, ray_actor_type: Type[BasePPORole]) -> None:
+ self._num_nodes = num_nodes
+ self._num_gpus_per_node = num_gpus_per_node
+ self.ray_actor_type = ray_actor_type
+ self._initiate_actors()
+
+ def _initiate_actors(self):
+ world_size = self._num_nodes * self._num_gpus_per_node
+ # Use placement group to lock resources for models of same type
+ pg = None
+ if self._num_gpus_per_node > 1:
+ bundles = [{"GPU": self._num_gpus_per_node, "CPU": self._num_gpus_per_node} for _ in range(self._num_nodes)]
+ pg = placement_group(bundles, strategy="STRICT_SPREAD")
+ ray.get(pg.ready())
+ if pg:
+ master_actor = self.ray_actor_type.options(scheduling_strategy=PlacementGroupSchedulingStrategy(
+ placement_group=pg, placement_group_bundle_index=0)).remote(world_size, 0, 0, None, None)
+ else:
+ master_actor = self.ray_actor_type.options(num_gpus=1).remote(world_size, 0, 0, None, None)
+ self._actor_handlers = [master_actor]
+
+ # Create worker actors
+ if world_size > 1:
+ master_addr, master_port = ray.get(master_actor.get_master_addr_port.remote())
+ for rank in range(1, world_size):
+ local_rank = rank % self._num_gpus_per_node
+ if pg:
+ worker_actor = self.ray_actor_type.options(scheduling_strategy=PlacementGroupSchedulingStrategy(
+ placement_group=pg, placement_group_bundle_index=rank // self._num_gpus_per_node)).remote(
+ world_size, rank, local_rank, master_addr, master_port)
+ else:
+ worker_actor = self.ray_actor_type.options(num_gpus=1).remote(world_size, rank, local_rank,
+ master_addr, master_port)
+ self._actor_handlers.append(worker_actor)
+
+ def async_init_model_from_pretrained(self, strategy: str, model_class: Type[LoRAModule], pretrain: str,
+ has_optimizer: bool):
+ return [
+ actor.init_model_from_pretrained.remote(strategy, model_class, pretrain, has_optimizer)
+ for actor in self._actor_handlers
+ ]
+
+
+class TrainableModelRayActorGroup(PPORayActorGroup):
+
+ def async_learn_on_experiences(self, experience_refs):
+ num_actors = len(self._actor_handlers)
+ learn_result_refs = []
+ for i in range(num_actors):
+ exp_refs_batch = experience_refs[i::num_actors]
+ learn_result_refs.append(self._actor_handlers[i].learn_on_experiences.remote(exp_refs_batch))
+ return learn_result_refs
+
+
+class PPOActorRayActorGroup(TrainableModelRayActorGroup):
+
+ def __init__(self, num_nodes, num_gpus_per_node) -> None:
+ super().__init__(num_nodes, num_gpus_per_node, RayPPOActor)
+
+ def async_prepare_for_sequence_generation(self, model: str, pretrain: str, generation_kwargs: dict):
+ refs = []
+ for actor in self._actor_handlers:
+ refs.append(actor.load_tokenizer_from_pretrained.remote(model, pretrain))
+ refs.append(actor.setup_generate_kwargs.remote(generation_kwargs))
+ return refs
+
+ def load_csv_prompt_file_from_url_to_sampler(self, csv_url):
+ ray.get([actor.load_csv_prompt_file_from_url_to_sampler.remote(csv_url) for actor in self._actor_handlers])
+
+ def async_sample_prompts_and_make_sequence(self, experience_batch_size):
+ return [actor.sample_prompts_and_make_sequence.remote(experience_batch_size) for actor in self._actor_handlers]
+
+ def async_calculate_action_log_probs(self, sequences_attention_mask_action_mask_refs):
+ num_actors = len(self._actor_handlers)
+ action_log_probs_refs = []
+ for i in range(len(sequences_attention_mask_action_mask_refs)):
+ action_log_probs_ref = self._actor_handlers[i % num_actors].calculate_action_log_probs.remote(
+ sequences_attention_mask_action_mask_refs[i])
+ action_log_probs_refs.append(action_log_probs_ref)
+ return action_log_probs_refs
+
+ def set_loss_function(self, eps_clip: float = 0.2):
+ ray.get([actor.set_loss_function.remote(eps_clip) for actor in self._actor_handlers])
+
+ def save_checkpoint(self, save_path, should_save_optimizer):
+ ray.get([actor.save_checkpoint.remote(save_path, should_save_optimizer) for actor in self._actor_handlers])
+
+
+class PPOCriticRayActorGroup(TrainableModelRayActorGroup):
+
+ def __init__(self, num_nodes, num_gpus_per_node) -> None:
+ super().__init__(num_nodes, num_gpus_per_node, RayPPOCritic)
+
+ def async_calculate_value(self, sequences_attention_mask_action_mask_refs):
+ num_actors = len(self._actor_handlers)
+ value_refs = []
+ for i in range(len(sequences_attention_mask_action_mask_refs)):
+ value_ref = self._actor_handlers[i % num_actors].calculate_value.remote(
+ sequences_attention_mask_action_mask_refs[i])
+ value_refs.append(value_ref)
+ return value_refs
+
+ def set_loss_function(self, value_clip: float = 0.4):
+ ray.get([actor.set_loss_function.remote(value_clip) for actor in self._actor_handlers])
+
+
+class PPOInitialRayActorGroup(PPORayActorGroup):
+
+ def __init__(self, num_nodes, num_gpus_per_node) -> None:
+ super().__init__(num_nodes, num_gpus_per_node, RayPPOInitialModel)
+
+ def async_calculate_base_action_log_probs(self, sequences_attention_mask_action_mask_refs):
+ num_actors = len(self._actor_handlers)
+ base_action_log_probs_refs = []
+ for i in range(len(sequences_attention_mask_action_mask_refs)):
+ base_action_log_probs_ref = self._actor_handlers[i % num_actors].calculate_base_action_log_probs.remote(
+ sequences_attention_mask_action_mask_refs[i])
+ base_action_log_probs_refs.append(base_action_log_probs_ref)
+ return base_action_log_probs_refs
+
+
+class PPORewardRayActorGroup(PPORayActorGroup):
+
+ def __init__(self, num_nodes, num_gpus_per_node) -> None:
+ super().__init__(num_nodes, num_gpus_per_node, RayPPORewardModel)
+
+ def async_calculate_r(self, sequences_attention_mask_action_mask_refs):
+ num_actors = len(self._actor_handlers)
+ r_refs = []
+ for i in range(len(sequences_attention_mask_action_mask_refs)):
+ r_ref = self._actor_handlers[i % num_actors].calculate_r.remote(
+ sequences_attention_mask_action_mask_refs[i])
+ r_refs.append(r_ref)
+ return r_refs
+
+
+def main(args):
+ logging.basicConfig(format='%(asctime)s %(levelname)-8s %(message)s',
+ level=logging.INFO,
+ datefmt='%Y-%m-%d %H:%M:%S')
+ if args.model == 'gpt2':
+ actor_model_class, critic_model_class = GPTActor, GPTCritic
+ elif args.model == 'bloom':
+ actor_model_class, critic_model_class = BLOOMActor, BLOOMCritic
+ elif args.model == 'opt':
+ actor_model_class, critic_model_class = OPTActor, OPTCritic
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ logging.info("Start creating actors")
+ # Initialize 4 models (actor, critic, initial_model and reward_model)
+ actor_group = PPOActorRayActorGroup(num_nodes=args.num_actor_nodes, num_gpus_per_node=args.num_gpus_per_node)
+ critic_group = PPOCriticRayActorGroup(num_nodes=args.num_critic_nodes, num_gpus_per_node=args.num_gpus_per_node)
+ initial_group = PPOInitialRayActorGroup(num_nodes=args.num_initial_nodes, num_gpus_per_node=args.num_gpus_per_node)
+ reward_group = PPORewardRayActorGroup(num_nodes=args.num_reward_nodes, num_gpus_per_node=args.num_gpus_per_node)
+ logging.info("Actors created")
+
+ # Prepare model for training
+ generate_kwargs = {'max_length': 128, 'do_sample': True, 'temperature': 1.0, 'top_k': 50}
+ ray.get(
+ actor_group.async_init_model_from_pretrained(args.strategy, actor_model_class, args.pretrain, True) +
+ critic_group.async_init_model_from_pretrained(args.strategy, critic_model_class, args.pretrain, True) +
+ initial_group.async_init_model_from_pretrained(args.strategy, actor_model_class, args.pretrain, False) +
+ reward_group.async_init_model_from_pretrained(args.strategy, critic_model_class, args.pretrain, False) +
+ actor_group.async_prepare_for_sequence_generation(args.model, args.pretrain, generate_kwargs))
+ logging.info("Models prepared for training")
+
+ # Prepare models for training
+ actor_group.load_csv_prompt_file_from_url_to_sampler(args.prompt_csv_url)
+ actor_group.set_loss_function()
+ critic_group.set_loss_function()
+ # Training parameter
+ num_episodes = args.num_episodes
+ max_timesteps = args.max_timesteps
+ update_timesteps = args.update_timesteps
+ experience_batch_size = args.experience_batch_size
+ # Start training
+ logging.info("Training start")
+ # Set all models to eval and add experience maker
+ all_ray_actors = actor_group._actor_handlers + critic_group._actor_handlers + \
+ initial_group._actor_handlers + reward_group._actor_handlers
+ num_ray_actors = len(all_ray_actors)
+ ray.get([ray_actor.eval.remote() for ray_actor in all_ray_actors])
+ ray.get([ray_actor.add_experience_maker.remote() for ray_actor in all_ray_actors])
+ # Used as a queue to coordinate experience making
+ experience_composition_refs = []
+ time = 0
+ for episode in range(num_episodes):
+ logging.info("episode {} started".format(episode))
+ for _ in range(max_timesteps):
+ time += 1
+ # Experience queueing stage
+ sequences_attention_mask_action_mask_refs = actor_group.async_sample_prompts_and_make_sequence(
+ experience_batch_size)
+ base_action_log_probs_refs = initial_group.async_calculate_base_action_log_probs(
+ sequences_attention_mask_action_mask_refs)
+ values_refs = critic_group.async_calculate_value(sequences_attention_mask_action_mask_refs)
+ r_refs = reward_group.async_calculate_r(sequences_attention_mask_action_mask_refs)
+ action_log_probs_refs = actor_group.async_calculate_action_log_probs(
+ sequences_attention_mask_action_mask_refs)
+ experience_composition_refs.extend([
+ ExperienceCompositionRefs(sequences_attention_mask_action_mask_refs[i], action_log_probs_refs[i],
+ base_action_log_probs_refs[i], values_refs[i], r_refs[i])
+ for i in range(len(sequences_attention_mask_action_mask_refs))
+ ])
+ # Learning stage
+ if time % update_timesteps == 0:
+ experience_refs = []
+ # calculate experiences
+ for i, experience_composition_ref in enumerate(experience_composition_refs):
+ exp_composition_ref = experience_composition_ref
+ selected_ray_actor = all_ray_actors[i % num_ray_actors]
+ experience_refs.append(selected_ray_actor.make_experience.remote(exp_composition_ref))
+ # backward
+ ray.get(
+ actor_group.async_learn_on_experiences(experience_refs) +
+ critic_group.async_learn_on_experiences(experience_refs))
+ # clear refs queue
+ experience_composition_refs.clear()
+ logging.info("Training finished")
+ # Save checkpoint
+ actor_group.save_checkpoint(args.save_path, args.need_optim_ckpt)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--prompt_csv_url', type=str)
+ parser.add_argument('--strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt'])
+ parser.add_argument('--pretrain', type=str, default='gpt2')
+ parser.add_argument('--save_path', type=str, default='actor_checkpoint_prompts.pt')
+ parser.add_argument('--need_optim_ckpt', type=bool, default=False)
+ parser.add_argument('--num_episodes', type=int, default=10)
+ parser.add_argument('--max_timesteps', type=int, default=10)
+ parser.add_argument('--update_timesteps', type=int, default=10)
+ parser.add_argument('--train_batch_size', type=int, default=8)
+ parser.add_argument('--experience_batch_size', type=int, default=8)
+ parser.add_argument('--num_actor_nodes', type=int, help='num of nodes to use to host actor model', default=1)
+ parser.add_argument('--num_critic_nodes', type=int, help='num of nodes to use to host critic model', default=1)
+ parser.add_argument('--num_initial_nodes', type=int, help='num of nodes to use to host initial model', default=1)
+ parser.add_argument('--num_reward_nodes', type=int, help='num of nodes to use to host reward model', default=1)
+ parser.add_argument('--num_gpus_per_node', type=int, help='num of gpus on a ray node', default=1)
+ args = parser.parse_args()
+ ray.init()
+ main(args)
diff --git a/applications/Chat/examples/test_ci.sh b/applications/Chat/examples/test_ci.sh
index 64cf68a0a13f..32f5858a51b6 100755
--- a/applications/Chat/examples/test_ci.sh
+++ b/applications/Chat/examples/test_ci.sh
@@ -2,11 +2,21 @@
set -xue
+if [ -z "$SFT_DATASET" ]; then
+ echo "Please set \$SFT_DATASET to the path to sft dataset."
+ exit 1
+fi
+
if [ -z "$PROMPT_PATH" ]; then
echo "Please set \$PROMPT_PATH to the path to prompts csv."
exit 1
fi
+if [ -z "$PRETRAIN_DATASET" ]; then
+ echo "Please set \$PRETRAIN_DATASET to the path to alpaca data."
+ exit 1
+fi
+
BASE=$(realpath $(dirname $0))
export OMP_NUM_THREADS=8
@@ -14,104 +24,97 @@ export OMP_NUM_THREADS=8
# install requirements
pip install -r ${BASE}/requirements.txt
-# train dummy
-python ${BASE}/train_dummy.py --strategy naive --num_episodes 1 \
- --max_timesteps 2 --update_timesteps 2 \
- --max_epochs 1 --train_batch_size 2 --lora_rank 4
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
- --strategy colossalai_gemini --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'facebook/opt-350m' --model opt --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_dummy.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'facebook/opt-350m' --model opt
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
- --strategy ddp --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'facebook/opt-350m' --model opt --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_dummy.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'facebook/opt-350m' --model opt
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
- --strategy colossalai_zero2 --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'gpt2' --model gpt2 --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_dummy.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'gpt2' --model gpt2
+wandb init -m offline
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
- --strategy colossalai_zero2 --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'roberta-base' --model roberta --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_dummy.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'roberta-base' --model roberta
+# train sft
+torchrun --standalone --nproc_per_node=4 ${BASE}/train_sft.py --pretrain 'bigscience/bloom-560m' \
+ --model 'bloom' --strategy colossalai_zero2 --lora_rank 4\
+ --dataset $SFT_DATASET --max_datasets_size 512 --max_epochs 1 \
+ --save_path ${BASE}/output
-rm -rf ${BASE}/actor_checkpoint_dummy.pt
+torchrun --standalone --nproc_per_node=4 ${BASE}/train_sft.py --pretrain 'gpt2' \
+ --model 'gpt2' --strategy colossalai_zero2 \
+ --dataset $SFT_DATASET --max_datasets_size 512 --max_epochs 1 \
+ --save_path ${BASE}/output
-# train prompts
-python ${BASE}/train_prompts.py $PROMPT_PATH --strategy naive --num_episodes 1 \
- --max_timesteps 2 --update_timesteps 2 \
- --max_epochs 1 --train_batch_size 2 --lora_rank 4
+torchrun --standalone --nproc_per_node=4 ${BASE}/train_sft.py --pretrain 'facebook/opt-350m' \
+ --model 'opt' --strategy colossalai_zero2 --lora_rank 4\
+ --dataset $SFT_DATASET --max_datasets_size 512 --max_epochs 1 \
+ --save_path ${BASE}/output
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
- --strategy colossalai_zero2 --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'facebook/opt-350m' --model opt --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_prompts.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'facebook/opt-350m' --model opt
+torchrun --standalone --nproc_per_node=4 ${BASE}/train_sft.py --pretrain 'gpt2' \
+ --model 'gpt2' --strategy ddp --lora_rank 4\
+ --dataset $SFT_DATASET --max_datasets_size 512 --max_epochs 1 \
+ --save_path ${BASE}/output
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
- --strategy ddp --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'gpt2' --model gpt2 --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_prompts.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'gpt2' --model gpt2
+#torchrun --standalone --nproc_per_node=4 ${BASE}/train_sft.py --pretrain 'facebook/opt-350m' \
+# --model 'opt' --strategy naive \
+# --dataset $SFT_DATASET --max_datasets_size 512 --max_epochs 1 \
+# --save_path ${BASE}/output
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
- --strategy colossalai_gemini --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'gpt2' --model gpt2 --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_prompts.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'gpt2' --model gpt2
-
-torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
- --strategy colossalai_zero2 --num_episodes 1 --max_timesteps 2 \
- --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
- --pretrain 'roberta-base' --model roberta --lora_rank 4\
- --save_path ${BASE}/actor_checkpoint_prompts.pt
-python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'roberta-base' --model roberta
-
-rm -rf ${BASE}/actor_checkpoint_prompts.pt
+rm -rf ${BASE}/output
# train rm
torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
- --pretrain 'facebook/opt-350m' --model 'opt' \
- --strategy colossalai_zero2 --loss_fn 'log_sig'\
- --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base'\
- --test True --lora_rank 4
+ --pretrain 'facebook/opt-350m' --model 'opt' \
+ --strategy colossalai_zero2 --loss_fn 'log_sig'\
+ --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base' \
+ --test True --lora_rank 4 \
+ --save_path ${BASE}/rm_ckpt_opt.pt
+
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
+ --pretrain 'gpt2' --model 'gpt2' \
+ --strategy colossalai_zero2 --loss_fn 'log_exp' \
+ --dataset 'Dahoas/rm-static' \
+ --test True --lora_rank 4 \
+ --save_path ${BASE}/rm_ckpt_gpt.pt
torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
- --pretrain 'gpt2' --model 'gpt2' \
- --strategy colossalai_gemini --loss_fn 'log_exp'\
- --dataset 'Dahoas/rm-static' --test True --lora_rank 4
+ --pretrain 'gpt2' --model 'gpt2' \
+ --strategy ddp --loss_fn 'log_exp' \
+ --dataset 'Dahoas/rm-static' \
+ --test True --lora_rank 4 \
+ --save_path ${BASE}/rm_ckpt.pt
torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
- --pretrain 'bigscience/bloom-560m' --model 'bloom' \
- --strategy colossalai_zero2 --loss_fn 'log_sig'\
- --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base'\
- --test True --lora_rank 4
+ --pretrain 'bigscience/bloom-560m' --model 'bloom' \
+ --strategy colossalai_zero2 --loss_fn 'log_sig' \
+ --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base' \
+ --test True --lora_rank 4 \
+ --save_path ${BASE}/rm_ckpt.pt
torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
- --pretrain 'microsoft/deberta-v3-large' --model 'deberta' \
- --strategy colossalai_zero2 --loss_fn 'log_sig'\
- --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base'\
- --test True --lora_rank 4
+ --pretrain 'microsoft/deberta-v3-large' --model 'deberta' \
+ --strategy colossalai_zero2 --loss_fn 'log_sig' \
+ --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base' \
+ --test True --lora_rank 4 \
+ --save_path ${BASE}/rm_ckpt.pt
torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
- --pretrain 'roberta-base' --model 'roberta' \
- --strategy colossalai_zero2 --loss_fn 'log_exp'\
- --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base'\
- --test True --lora_rank 4
+ --pretrain 'roberta-base' --model 'roberta' \
+ --strategy colossalai_zero2 --loss_fn 'log_exp'\
+ --dataset 'Anthropic/hh-rlhf' --subset 'harmless-base'\
+ --test True --lora_rank 4 \
+ --save_path ${BASE}/rm_ckpt.pt
rm -rf ${BASE}/rm_ckpt.pt
+
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py --prompt_path $PROMPT_PATH --pretrain_dataset $PRETRAIN_DATASET \
+ --strategy colossalai_zero2 --num_episodes 1 --max_timesteps 2 \
+ --update_timesteps 2 --max_epochs 1 --train_batch_size 2 \
+ --pretrain 'facebook/opt-350m' --model opt \
+ --rm_pretrain 'facebook/opt-350m' \
+ --rm_path ${BASE}/rm_ckpt_opt.pt \
+ --save_path ${BASE}/actor_checkpoint_prompts.pt
+rm -rf ${BASE}/rm_ckpt_opt.pt
+
+torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py --prompt_path $PROMPT_PATH --pretrain_dataset $PRETRAIN_DATASET \
+ --strategy colossalai_zero2 --num_episodes 1 --max_timesteps 2 \
+ --update_timesteps 2 --max_epochs 1 --train_batch_size 2 \
+ --pretrain 'gpt2' --model gpt2 \
+ --rm_pretrain 'gpt2' \
+ --rm_path ${BASE}/rm_ckpt_gpt.pt \
+ --save_path ${BASE}/actor_checkpoint_prompts.pt
+rm -rf ${BASE}/rm_ckpt_gpt.pt
+
+rm -rf ${BASE}/actor_checkpoint_prompts.pt
\ No newline at end of file
diff --git a/applications/Chat/examples/train_dummy.py b/applications/Chat/examples/train_dummy.py
index 4ac7ace44803..5f34c80f0892 100644
--- a/applications/Chat/examples/train_dummy.py
+++ b/applications/Chat/examples/train_dummy.py
@@ -114,8 +114,10 @@ def main(args):
eos_token_id=tokenizer.eos_token_id,
callbacks=callbacks)
- random_prompts = torch.randint(tokenizer.vocab_size, (1000, 64), device=torch.cuda.current_device())
- trainer.fit(random_prompts,
+ random_prompts = torch.randint(tokenizer.vocab_size, (1000, 1, 64), device=torch.cuda.current_device())
+ random_attention_mask = torch.randint(1, (1000, 1, 64), device=torch.cuda.current_device()).to(torch.bool)
+ random_pretrain = [{'input_ids':random_prompts[i], 'labels':random_prompts[i], 'attention_mask':random_attention_mask[i]} for i in range(1000)]
+ trainer.fit(random_prompts, random_pretrain,
num_episodes=args.num_episodes,
max_timesteps=args.max_timesteps,
update_timesteps=args.update_timesteps)
@@ -136,7 +138,7 @@ def main(args):
default='naive')
parser.add_argument('--model', type=str, default='gpt2', choices=['gpt2', 'bloom', 'opt', 'roberta'])
parser.add_argument('--pretrain', type=str, default=None)
- parser.add_argument('--save_path', type=str, default='actor_checkpoint_dummy.pt')
+ parser.add_argument('--save_path', type=str, default='actor_checkpoint_dummy')
parser.add_argument('--need_optim_ckpt', type=bool, default=False)
parser.add_argument('--num_episodes', type=int, default=50)
parser.add_argument('--max_timesteps', type=int, default=10)
diff --git a/applications/Chat/examples/train_prompts.sh b/applications/Chat/examples/train_prompts.sh
index b750cf3581a6..8e1ce67ecc64 100755
--- a/applications/Chat/examples/train_prompts.sh
+++ b/applications/Chat/examples/train_prompts.sh
@@ -15,4 +15,6 @@ set_n_least_used_CUDA_VISIBLE_DEVICES() {
set_n_least_used_CUDA_VISIBLE_DEVICES 2
+# torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai_zero2
+
torchrun --standalone --nproc_per_node=2 train_prompts.py --prompt_path /path/to/data.json --strategy colossalai_zero2
diff --git a/applications/Chat/examples/train_reward_model.py b/applications/Chat/examples/train_reward_model.py
index aa1b51dea7f9..6a788a891ca6 100644
--- a/applications/Chat/examples/train_reward_model.py
+++ b/applications/Chat/examples/train_reward_model.py
@@ -3,6 +3,7 @@
import loralib as lora
import torch
+import torch.distributed as dist
from coati.dataset import HhRlhfDataset, RmStaticDataset
from coati.models import LogExpLoss, LogSigLoss
from coati.models.base import RewardModel
@@ -17,6 +18,8 @@
from coati.utils import prepare_llama_tokenizer_and_embedding
from datasets import load_dataset
from torch.optim import Adam
+from torch.utils.data import DataLoader
+from torch.utils.data.distributed import DistributedSampler
from transformers import AutoTokenizer, BloomTokenizerFast, DebertaV2Tokenizer, LlamaTokenizer, RobertaTokenizer
from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
@@ -120,13 +123,38 @@ def train(args):
else:
raise ValueError(f'Unsupported dataset "{args.dataset}"')
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ train_sampler = DistributedSampler(train_dataset, shuffle=True, seed=42, drop_last=True, rank=dist.get_rank(),
+ num_replicas=dist.get_world_size())
+ valid_sampler = DistributedSampler(valid_dataset, shuffle=True, seed=42, drop_last=True, rank=dist.get_rank(),
+ num_replicas=dist.get_world_size())
+ eval_sampler = DistributedSampler(eval_dataset, shuffle=True, seed=42, drop_last=True, rank=dist.get_rank(),
+ num_replicas=dist.get_world_size())
+ else:
+ train_sampler = None
+ valid_sampler = None
+ eval_sampler = None
+
+ train_dataloader = DataLoader(train_dataset,
+ shuffle=(train_sampler is None),
+ sampler=train_sampler,
+ batch_size=args.batch_size,
+ pin_memory=True)
+
+ valid_dataloader = DataLoader(valid_dataset, shuffle=(valid_sampler is None),
+ sampler=valid_sampler,
+ batch_size=args.batch_size, pin_memory=True)
+
+ eval_dataloader = DataLoader(eval_dataset, shuffle=(eval_sampler is None),
+ sampler=eval_sampler, batch_size=args.batch_size, pin_memory=True)
+
trainer = RewardModelTrainer(model=model,
strategy=strategy,
optim=optim,
loss_fn=loss_fn,
- train_dataset=train_dataset,
- valid_dataset=valid_dataset,
- eval_dataset=eval_dataset,
+ train_dataloader=train_dataloader,
+ valid_dataloader=valid_dataloader,
+ eval_dataloader=eval_dataloader,
batch_size=args.batch_size,
max_epochs=args.max_epochs)
diff --git a/applications/Chat/examples/train_rm.sh b/applications/Chat/examples/train_rm.sh
index 4f9f55b6b59a..80abe62d2a3f 100755
--- a/applications/Chat/examples/train_rm.sh
+++ b/applications/Chat/examples/train_rm.sh
@@ -1,8 +1,24 @@
-set_n_least_used_CUDA_VISIBLE_DEVICES 1
+set_n_least_used_CUDA_VISIBLE_DEVICES() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
-python train_reward_model.py --pretrain 'microsoft/deberta-v3-large' \
- --model 'deberta' \
- --strategy naive \
- --loss_fn 'log_exp'\
- --save_path 'rmstatic.pt' \
- --test True
+set_n_least_used_CUDA_VISIBLE_DEVICES 2
+
+torchrun --standalone --nproc_per_node=2 train_reward_model.py \
+ --pretrain \
+ --model 'bloom' \
+ --strategy colossalai_zero2 \
+ --loss_fn 'log_sig'\
+ --save_path \
+ --dataset 'Anthropic/hh-rlhf'\
diff --git a/applications/Chat/examples/train_sft.py b/applications/Chat/examples/train_sft.py
index 22f70e485843..d7502c23b5e6 100644
--- a/applications/Chat/examples/train_sft.py
+++ b/applications/Chat/examples/train_sft.py
@@ -111,7 +111,7 @@ def train(args):
max_datasets_size=args.max_datasets_size,
max_length=max_len)
eval_dataset = None
- data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
+ data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
if dist.is_initialized() and dist.get_world_size() > 1:
train_sampler = DistributedSampler(train_dataset,
diff --git a/colossalai/_analyzer/_subclasses/_meta_registration.py b/colossalai/_analyzer/_subclasses/_meta_registration.py
index 4b1fd28e982f..4049be79c70f 100644
--- a/colossalai/_analyzer/_subclasses/_meta_registration.py
+++ b/colossalai/_analyzer/_subclasses/_meta_registration.py
@@ -274,11 +274,15 @@ def meta_cudnn_rnn_backward(input: torch.Tensor,
aten.prelu.default,
aten.hardswish.default,
aten.hardtanh.default,
- aten.prelu_backward.default,
aten.hardswish_backward.default,
aten.hardtanh_backward.default,
]
+ if version.parse(torch.__version__) < version.parse('2.0.0'):
+ _unregistered_ewise += [
+ aten.prelu_backward.default,
+ ]
+
@register_meta(_unregistered_ewise)
def meta_unregistered_ewise(input: torch.Tensor, *args):
return new_like(input)
@@ -331,11 +335,6 @@ def meta_ln_backward(dY: torch.Tensor, input: torch.Tensor, normalized_shape, me
def meta_im2col(input: torch.Tensor, kernel_size, dilation, padding, stride):
return new_like(input)
- # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/native_functions.yaml
- @register_meta(aten.eye.m_out)
- def meta_eye(n: int, m: int, out: torch.Tensor):
- return out
-
# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/native_functions.yaml
@register_meta(aten.roll.default)
def meta_roll(input: torch.Tensor, shifts, dims):
@@ -352,97 +351,9 @@ def meta_where_self(condition: torch.Tensor, self: torch.Tensor, other: torch.Te
result_type = torch.result_type(self, other)
return new_like(condition + self + other, dtype=result_type)
- @register_meta(aten.index.Tensor)
- def meta_index_Tensor(self, indices):
- assert indices, "at least one index must be provided"
- # aten::index is the internal advanced indexing implementation
- # checkIndexTensorTypes and expandTensors
- result: List[Optional[torch.Tensor]] = []
- for i, index in enumerate(indices):
- if index is not None:
- assert index.dtype in [torch.long, torch.int8, torch.bool],\
- "tensors used as indices must be long, byte or bool tensors"
- if index.dtype in [torch.int8, torch.bool]:
- nonzero = index.nonzero()
- k = len(result)
- assert k + index.ndim <= self.ndim, f"too many indices for tensor of dimension {self.ndim}"
- for j in range(index.ndim):
- assert index.shape[j] == self.shape[
- k +
- j], f"The shape of the mask {index.shape} at index {i} does not match the shape of the indexed tensor {self.shape} at index {k + j}"
- result.append(nonzero.select(1, j))
- else:
- result.append(index)
- else:
- result.append(index)
- indices = result
- assert len(indices) <= self.ndim, f"too many indices for tensor of dimension {self.ndim} (got {len(indices)})"
- # expand_outplace
- import torch._refs as refs
-
- indices = list(refs._maybe_broadcast(*indices))
- # add missing null tensors
- while len(indices) < self.ndim:
- indices.append(None)
-
- # hasContiguousSubspace
- # true if all non-null tensors are adjacent
- # See:
- # https://numpy.org/doc/stable/user/basics.indexing.html#combining-advanced-and-basic-indexing
- # https://stackoverflow.com/questions/53841497/why-does-numpy-mixed-basic-advanced-indexing-depend-on-slice-adjacency
- state = 0
- has_contiguous_subspace = False
- for index in indices:
- if state == 0:
- if index is not None:
- state = 1
- elif state == 1:
- if index is None:
- state = 2
- else:
- if index is not None:
- break
- else:
- has_contiguous_subspace = True
-
- # transposeToFront
- # This is the logic that causes the newly inserted dimensions to show up
- # at the beginning of the tensor, if they're not contiguous
- if not has_contiguous_subspace:
- dims = []
- transposed_indices = []
- for i, index in enumerate(indices):
- if index is not None:
- dims.append(i)
- transposed_indices.append(index)
- for i, index in enumerate(indices):
- if index is None:
- dims.append(i)
- transposed_indices.append(index)
- self = self.permute(dims)
- indices = transposed_indices
-
- # AdvancedIndex::AdvancedIndex
- # Now we can assume the indices have contiguous subspace
- # This is simplified from AdvancedIndex which goes to more effort
- # to put the input and indices in a form so that TensorIterator can
- # take them. If we write a ref for this, probably that logic should
- # get implemented
- before_shape: List[int] = []
- after_shape: List[int] = []
- replacement_shape: List[int] = []
- for dim, index in enumerate(indices):
- if index is None:
- if replacement_shape:
- after_shape.append(self.shape[dim])
- else:
- before_shape.append(self.shape[dim])
- else:
- replacement_shape = list(index.shape)
- return self.new_empty(before_shape + replacement_shape + after_shape)
-
# ============================== Embedding =========================================
# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Embedding.cpp
+
@register_meta(aten.embedding_dense_backward.default)
def meta_embedding_dense_backward(grad_output: torch.Tensor, indices: torch.Tensor, num_weights, padding_idx,
scale_grad_by_freq):
@@ -459,3 +370,99 @@ def meta_native_dropout_default(input: torch.Tensor, p: float, train: bool = Fal
@register_meta(aten.native_dropout_backward.default)
def meta_native_dropout_backward_default(grad: torch.Tensor, mask: torch.Tensor, scale: float):
return new_like(grad) # (grad_in)
+
+ if version.parse(torch.__version__) < version.parse('1.13.0'):
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/native_functions.yaml
+ @register_meta(aten.eye.m_out)
+ def meta_eye(n: int, m: int, out: torch.Tensor):
+ return out
+
+ @register_meta(aten.index.Tensor)
+ def meta_index_Tensor(self, indices):
+ assert indices, "at least one index must be provided"
+ # aten::index is the internal advanced indexing implementation
+ # checkIndexTensorTypes and expandTensors
+ result: List[Optional[torch.Tensor]] = []
+ for i, index in enumerate(indices):
+ if index is not None:
+ assert index.dtype in [torch.long, torch.int8, torch.bool],\
+ "tensors used as indices must be long, byte or bool tensors"
+ if index.dtype in [torch.int8, torch.bool]:
+ nonzero = index.nonzero()
+ k = len(result)
+ assert k + index.ndim <= self.ndim, f"too many indices for tensor of dimension {self.ndim}"
+ for j in range(index.ndim):
+ assert index.shape[j] == self.shape[
+ k +
+ j], f"The shape of the mask {index.shape} at index {i} does not match the shape of the indexed tensor {self.shape} at index {k + j}"
+ result.append(nonzero.select(1, j))
+ else:
+ result.append(index)
+ else:
+ result.append(index)
+ indices = result
+ assert len(
+ indices) <= self.ndim, f"too many indices for tensor of dimension {self.ndim} (got {len(indices)})"
+ # expand_outplace
+ import torch._refs as refs
+
+ indices = list(refs._maybe_broadcast(*indices))
+ # add missing null tensors
+ while len(indices) < self.ndim:
+ indices.append(None)
+
+ # hasContiguousSubspace
+ # true if all non-null tensors are adjacent
+ # See:
+ # https://numpy.org/doc/stable/user/basics.indexing.html#combining-advanced-and-basic-indexing
+ # https://stackoverflow.com/questions/53841497/why-does-numpy-mixed-basic-advanced-indexing-depend-on-slice-adjacency
+ state = 0
+ has_contiguous_subspace = False
+ for index in indices:
+ if state == 0:
+ if index is not None:
+ state = 1
+ elif state == 1:
+ if index is None:
+ state = 2
+ else:
+ if index is not None:
+ break
+ else:
+ has_contiguous_subspace = True
+
+ # transposeToFront
+ # This is the logic that causes the newly inserted dimensions to show up
+ # at the beginning of the tensor, if they're not contiguous
+ if not has_contiguous_subspace:
+ dims = []
+ transposed_indices = []
+ for i, index in enumerate(indices):
+ if index is not None:
+ dims.append(i)
+ transposed_indices.append(index)
+ for i, index in enumerate(indices):
+ if index is None:
+ dims.append(i)
+ transposed_indices.append(index)
+ self = self.permute(dims)
+ indices = transposed_indices
+
+ # AdvancedIndex::AdvancedIndex
+ # Now we can assume the indices have contiguous subspace
+ # This is simplified from AdvancedIndex which goes to more effort
+ # to put the input and indices in a form so that TensorIterator can
+ # take them. If we write a ref for this, probably that logic should
+ # get implemented
+ before_shape: List[int] = []
+ after_shape: List[int] = []
+ replacement_shape: List[int] = []
+ for dim, index in enumerate(indices):
+ if index is None:
+ if replacement_shape:
+ after_shape.append(self.shape[dim])
+ else:
+ before_shape.append(self.shape[dim])
+ else:
+ replacement_shape = list(index.shape)
+ return self.new_empty(before_shape + replacement_shape + after_shape)
diff --git a/colossalai/_analyzer/_subclasses/_monkey_patch.py b/colossalai/_analyzer/_subclasses/_monkey_patch.py
index 7c1c3d3d8cd4..b3ec98f0811f 100644
--- a/colossalai/_analyzer/_subclasses/_monkey_patch.py
+++ b/colossalai/_analyzer/_subclasses/_monkey_patch.py
@@ -2,8 +2,6 @@
import torch.distributed as dist
from packaging import version
-aten = torch.ops.aten
-
__all__ = [
"_TorchFactoryMethod",
"_TorchOverrideableFactoryMethod",
@@ -51,6 +49,7 @@
]
if version.parse(torch.__version__) >= version.parse('1.12.0'):
+ aten = torch.ops.aten
# TODO: dive deep here
# refer to https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/TensorShape.cpp
_AliasATen = [
diff --git a/colossalai/booster/plugin/gemini_plugin.py b/colossalai/booster/plugin/gemini_plugin.py
index 6693b1f44d62..deda00d8a7b3 100644
--- a/colossalai/booster/plugin/gemini_plugin.py
+++ b/colossalai/booster/plugin/gemini_plugin.py
@@ -16,10 +16,8 @@
from colossalai.checkpoint_io.utils import save_state_dict
from colossalai.cluster import DistCoordinator
from colossalai.interface import ModelWrapper, OptimizerWrapper
-from colossalai.tensor.colo_parameter import ColoParameter
from colossalai.utils import get_current_device
from colossalai.zero import GeminiDDP, zero_model_wrapper, zero_optim_wrapper
-from colossalai.zero.gemini.colo_init_context import _convert_to_coloparam
from colossalai.zero.gemini.memory_tracer import MemStats
from .plugin_base import Plugin
@@ -27,50 +25,6 @@
__all__ = ['GeminiPlugin']
-def convert_to_colo_param(module: nn.Module) -> None:
- """Convert module's paramters to ColoParameter. This is a workaround and will be deprecated when lazy init is compatible with Gemini.
-
- Args:
- module (nn.Module): Module to be converted.
- """
- converted_modules = set() # handle shared modules
- converted_params = dict() # record mapping between (torch.Tensor, ColoTensor) to distinguish the same reference
-
- def convert_recursively(m: nn.Module):
- for child in m.children():
- if child not in converted_modules:
- converted_modules.add(child)
- convert_recursively(child)
-
- for name, p in m.named_parameters(recurse=False):
- assert not isinstance(p, ColoParameter)
- if p in converted_params:
- target = converted_params[p]
- else:
- target = _convert_to_coloparam(p, p.device, p.dtype)
- converted_params[p] = target
- setattr(m, name, target)
- target.shared_param_modules.append(m)
-
- convert_recursively(module)
-
- # optimizer should replace params in group as well. This attr should be deleted after replacing to avoid memory leak
- module._converted_params = converted_params
-
-
-def replace_param_in_group(optimizer: Optimizer, converted_params: dict) -> None:
- """Replace param in optimizer's group with converted ColoParameter.
-
- Args:
- optimizer (Optimizer): Optimizer to be replaced.
- converted_params (dict): Mapping between (torch.Tensor, ColoTensor).
- """
- for group in optimizer.param_groups:
- for i, p in enumerate(group['params']):
- if p in converted_params:
- group['params'][i] = converted_params[p]
-
-
class GeminiCheckpointIO(GeneralCheckpointIO):
def __init__(self) -> None:
@@ -111,11 +65,9 @@ def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
class GeminiModel(ModelWrapper):
- def __init__(self, module: nn.Module, gemini_config: dict) -> None:
+ def __init__(self, module: nn.Module, gemini_config: dict, verbose: bool = False) -> None:
super().__init__(module)
- # TODO(ver217): only support Gemini now
- convert_to_colo_param(module)
- self.module = zero_model_wrapper(module, zero_stage=3, gemini_config=gemini_config)
+ self.module = zero_model_wrapper(module, zero_stage=3, gemini_config=gemini_config, verbose=verbose)
def unwrap(self):
# as save/load state dict is coupled with the GeminiDDP, we only return GeminiDDP model
@@ -124,10 +76,17 @@ def unwrap(self):
class GeminiOptimizer(OptimizerWrapper):
- def __init__(self, module: GeminiDDP, optimizer: Optimizer, zero_optim_config: dict, optim_kwargs: dict) -> None:
- replace_param_in_group(optimizer, module.module._converted_params)
- del module.module._converted_params
- optimizer = zero_optim_wrapper(module, optimizer, optim_config=zero_optim_config, **optim_kwargs)
+ def __init__(self,
+ module: GeminiDDP,
+ optimizer: Optimizer,
+ zero_optim_config: dict,
+ optim_kwargs: dict,
+ verbose: bool = False) -> None:
+ optimizer = zero_optim_wrapper(module,
+ optimizer,
+ optim_config=zero_optim_config,
+ **optim_kwargs,
+ verbose=verbose)
super().__init__(optimizer)
def backward(self, loss: Tensor, *args, **kwargs):
@@ -188,6 +147,7 @@ class GeminiPlugin(Plugin):
max_norm (float, optional): max_norm used for `clip_grad_norm`. You should notice that you shall not do
clip_grad_norm by yourself when using ZeRO DDP. The ZeRO optimizer will take care of clip_grad_norm.
norm_type (float, optional): norm_type used for `clip_grad_norm`.
+ verbose (bool, optional): verbose mode. Debug info including chunk search result will be printed. Defaults to False.
"""
def __init__(
@@ -211,6 +171,7 @@ def __init__(
max_scale: float = 2**32,
max_norm: float = 0.0,
norm_type: float = 2.0,
+ verbose: bool = False,
) -> None:
assert dist.is_initialized(
@@ -238,6 +199,7 @@ def __init__(
max_scale=max_scale,
max_norm=max_norm,
norm_type=norm_type)
+ self.verbose = verbose
def support_no_sync(self) -> bool:
return False
@@ -325,10 +287,11 @@ def configure(
# model = nn.SyncBatchNorm.convert_sync_batchnorm(model, None)
# wrap the model with Gemini
- model = GeminiModel(model, self.gemini_config)
+ model = GeminiModel(model, self.gemini_config, self.verbose)
if not isinstance(optimizer, OptimizerWrapper):
- optimizer = GeminiOptimizer(model.unwrap(), optimizer, self.zero_optim_config, self.optim_kwargs)
+ optimizer = GeminiOptimizer(model.unwrap(), optimizer, self.zero_optim_config, self.optim_kwargs,
+ self.verbose)
return model, optimizer, criterion, dataloader, lr_scheduler
diff --git a/colossalai/checkpoint_io/checkpoint_io_base.py b/colossalai/checkpoint_io/checkpoint_io_base.py
index b91b00831e52..3f8b0b0a6b47 100644
--- a/colossalai/checkpoint_io/checkpoint_io_base.py
+++ b/colossalai/checkpoint_io/checkpoint_io_base.py
@@ -1,6 +1,7 @@
from abc import ABC, abstractmethod
from pathlib import Path
from typing import Union
+from typing import Optional
import torch
import torch.nn as nn
@@ -104,7 +105,7 @@ def save_model(self,
checkpoint: str,
shard: bool = False,
gather_dtensor: bool = True,
- prefix: str = None,
+ variant: str = None,
size_per_shard: int = 1024,
use_safetensors: bool = False):
"""
@@ -129,7 +130,7 @@ def save_model(self,
multiple files. The model shards will be specificed by a `model.index.json` file. When shard = True, please ensure
that the checkpoint path is a directory path instead of a file path.
gather_dtensor (bool): whether to gather the distributed tensor to the first device. Default: True.
- prefix (str): prefix for the model checkpoint file name when shard=True. Default: None.
+ variant (str): If specified, weights are saved in the format pytorch_model..bin. Default: None.
size_per_shard (int): size per shard in MB. Default: 1024. This value is only used when shard = True.
use_safetensors (bool): whether to use safe tensors. Default: False. If set to True, the checkpoint will be saved
"""
@@ -138,7 +139,7 @@ def save_model(self,
model = model.unwrap()
if shard:
- self.save_sharded_model(model, checkpoint, gather_dtensor, prefix, size_per_shard, use_safetensors)
+ self.save_sharded_model(model, checkpoint, gather_dtensor, variant, size_per_shard, use_safetensors)
else:
self.save_unsharded_model(model, checkpoint, gather_dtensor, use_safetensors)
@@ -219,7 +220,7 @@ def load_unsharded_model(self, model: nn.Module, checkpoint: str, strict: bool):
pass
@abstractmethod
- def save_sharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, prefix: str,
+ def save_sharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, variant: Optional[str],
size_per_shard: int, use_safetensors: bool):
"""
Save model to sharded checkpoint.
diff --git a/colossalai/checkpoint_io/general_checkpoint_io.py b/colossalai/checkpoint_io/general_checkpoint_io.py
index 2a76f1718469..bf584f45d045 100644
--- a/colossalai/checkpoint_io/general_checkpoint_io.py
+++ b/colossalai/checkpoint_io/general_checkpoint_io.py
@@ -6,6 +6,7 @@
import os
import json
import gc
+from typing import Optional
from .checkpoint_io_base import CheckpointIO
from .index_file import CheckpointIndexFile
@@ -16,10 +17,12 @@
is_safetensors_available,
shard_checkpoint,
load_shard_state_dict,
- load_state_dict_into_model
+ load_state_dict_into_model,
+ add_variant
)
from .utils import SAFE_WEIGHTS_NAME, WEIGHTS_NAME, SAFE_WEIGHTS_INDEX_NAME, WEIGHTS_INDEX_NAME
+
__all__ = ['GeneralCheckpointIO']
@@ -69,7 +72,7 @@ def save_unsharded_optimizer(
def save_sharded_model(self, model: nn.Module, checkpoint_path: str, gather_dtensor:bool = False,
- prefix: str = "", max_shard_size: int = 1024, use_safetensors: bool = False):
+ variant: Optional[str] = None, max_shard_size: int = 1024, use_safetensors: bool = False):
"""
implement this method as it can be supported by Huggingface model,
save shard model, save model to multiple files
@@ -83,6 +86,7 @@ def save_sharded_model(self, model: nn.Module, checkpoint_path: str, gather_dten
# shard checkpoint
state_dict = model.state_dict()
weights_name = SAFE_WEIGHTS_NAME if use_safetensors else WEIGHTS_NAME
+ weights_name = add_variant(weights_name, variant)
shards, index = shard_checkpoint(state_dict, max_shard_size=max_shard_size, weights_name=weights_name)
# Save the model
@@ -92,7 +96,8 @@ def save_sharded_model(self, model: nn.Module, checkpoint_path: str, gather_dten
# save index file
save_index_file = SAFE_WEIGHTS_INDEX_NAME if use_safetensors else WEIGHTS_INDEX_NAME
- save_index_file = os.path.join(checkpoint_path, save_index_file)
+
+ save_index_file = os.path.join(checkpoint_path, add_variant(save_index_file, variant))
with open(save_index_file, "w", encoding="utf-8") as f:
content = json.dumps(index, indent=2, sort_keys=True) + "\n"
f.write(content)
diff --git a/colossalai/checkpoint_io/utils.py b/colossalai/checkpoint_io/utils.py
index 81b666da5c78..37d22d08df40 100644
--- a/colossalai/checkpoint_io/utils.py
+++ b/colossalai/checkpoint_io/utils.py
@@ -4,11 +4,12 @@
import torch.nn as nn
from typing import List, Dict, Mapping, OrderedDict, Optional, Tuple
from colossalai.tensor.d_tensor.d_tensor import DTensor
+import re
SAFE_WEIGHTS_NAME = "model.safetensors"
-WEIGHTS_NAME = "model.bin"
+WEIGHTS_NAME = "pytorch_model.bin"
SAFE_WEIGHTS_INDEX_NAME = "model.safetensors.index.json"
-WEIGHTS_INDEX_NAME = "model.bin.index.json"
+WEIGHTS_INDEX_NAME = "pytorch_model.bin.index.json"
# ======================================
# General helper functions
@@ -27,7 +28,6 @@ def calculate_tensor_size(tensor: torch.Tensor) -> float:
"""
return tensor.numel() * tensor.element_size() / 1024 / 1024
-
def is_safetensors_available() -> bool:
"""
Check whether safetensors is available.
@@ -358,13 +358,14 @@ def has_index_file(checkpoint_path: str) -> Tuple[bool, Optional[Path]]:
checkpoint_path = Path(checkpoint_path)
if checkpoint_path.is_file():
# check if it is .index.json
- if checkpoint_path.name.endswith('.index.json'):
+ reg = re.compile("(.*?).index((\..*)?).json")
+ if reg.fullmatch(checkpoint_path.name) is not None:
return True, checkpoint_path
else:
return False, None
elif checkpoint_path.is_dir():
# check if there is only one a file ending with .index.json in this directory
- index_files = list(checkpoint_path.glob('*.index.json'))
+ index_files = list(checkpoint_path.glob('*.index.*json'))
# if we found a .index.json file, make sure there is only one
if len(index_files) > 0:
@@ -406,3 +407,13 @@ def load_state_dict(checkpoint_file_path: Path):
else:
# load with torch
return torch.load(checkpoint_file_path)
+
+
+
+def add_variant(weights_name: str, variant: Optional[str] = None) -> str:
+ if variant is not None and len(variant) > 0:
+ splits = weights_name.split(".")
+ splits = splits[:-1] + [variant] + splits[-1:]
+ weights_name = ".".join(splits)
+
+ return weights_name
diff --git a/colossalai/nn/optimizer/nvme_optimizer.py b/colossalai/nn/optimizer/nvme_optimizer.py
index cbb435a90f61..53e4a46c9741 100644
--- a/colossalai/nn/optimizer/nvme_optimizer.py
+++ b/colossalai/nn/optimizer/nvme_optimizer.py
@@ -1,9 +1,10 @@
-import torch
+import math
import os
import tempfile
-import math
+from typing import Callable, Dict, List, Optional
+
+import torch
from torch.nn.parameter import Parameter
-from typing import Optional, List, Dict, Callable
class NVMeOptimizer(torch.optim.Optimizer):
@@ -42,8 +43,9 @@ def __init__(self,
self.offloader = None
self.is_on_nvme: Dict[Parameter, bool] = {}
self.offloaded_numel: int = 0
- self.total_numel: int = self._get_numel()
- self.can_offload_numel = math.floor(self.total_numel * self.nvme_offload_fraction)
+ # As param may be not materialized here, these attributes are initalized when the first step
+ self.total_numel: Optional[int] = None
+ self.can_offload_numel: Optional[int] = None
self.prefetch_params: List[Parameter] = []
self.param_to_prefetch_idx: Dict[Parameter, int] = {}
@@ -77,6 +79,9 @@ def _setup_prefetch_params(self) -> List[Parameter]:
self.prefetch_params.append(p)
def _pre_step(self, *state_keys: str) -> None:
+ if self.total_numel is None:
+ self.total_numel = self._get_numel()
+ self.can_offload_numel = math.floor(self.total_numel * self.nvme_offload_fraction)
self._setup_prefetch_params()
if self.offloader is None or len(self.prefetch_params) == 0:
return
diff --git a/colossalai/utils/model/experimental.py b/colossalai/utils/model/experimental.py
index 6427a147a5c0..bf3e3d05b99c 100644
--- a/colossalai/utils/model/experimental.py
+++ b/colossalai/utils/model/experimental.py
@@ -7,15 +7,15 @@
from torch import Tensor
from torch.utils._pytree import tree_map
-from colossalai.fx.profiler.tensor import MetaTensor
+from colossalai._analyzer._subclasses import MetaTensor
from colossalai.tensor.d_tensor.d_tensor import DTensor
from colossalai.tensor.d_tensor.layout import Layout
# reference: https://pytorch.org/cppdocs/notes/tensor_creation.html
_NORMAL_FACTORY = [
"arange",
- "empty",
"full",
+ "empty",
"linspace",
"logspace",
"ones",
@@ -37,7 +37,7 @@
# If your intent is to change the metadata of a Tensor (such as sizes / strides / storage / storage_offset)
# without autograd tracking the change, remove the .data / .detach() call and wrap the change in a `with torch.no_grad():` block.
# These ops cannot be unwrapped using .data
-_CHANGE_META_OPS = ['_cudnn_rnn_flatten_weight', 'requires_grad_', '__get__']
+_CHANGE_META_OPS = ['_cudnn_rnn_flatten_weight', 'requires_grad_', '__get__', '__set__']
_LEGACY_TENSOR_CONSTRUCTOR = {
'FloatTensor': torch.float,
@@ -75,6 +75,12 @@ def __torch_function__(cls, func, types, args=(), kwargs=None):
return super().__torch_function__(func, types, args, kwargs)
+def _data_tolist(tensor: torch.Tensor) -> list:
+ """tolist() method is not allowed for a subclass of tensor. Tensor.data returns a Tensor.
+ """
+ return tensor.data.tolist()
+
+
def _convert_cls(tensor: 'LazyTensor', target: torch.Tensor) -> torch.Tensor:
"""Convert a lazy tensor's class to target's class, with target's data.
@@ -94,7 +100,7 @@ def _convert_cls(tensor: 'LazyTensor', target: torch.Tensor) -> torch.Tensor:
tensor.requires_grad = target.requires_grad
# subclass of torch.Tensor does not have tolist() method
# overwrite this method after materialization or distribution
- tensor.tolist = MethodType(torch.Tensor.tolist, target)
+ tensor.tolist = MethodType(_data_tolist, tensor)
return tensor
@@ -144,7 +150,7 @@ def __new__(cls, func, *args, meta_data=None, concrete_data=None, **kwargs):
if meta_data is None:
device = kwargs.get('device', 'cpu')
elem = func(*args, **{**kwargs, 'device': 'meta'})
- meta_data = MetaTensor(elem, fake_device=device)
+ meta_data = MetaTensor(elem, device=device)
elem = meta_data._tensor
# As a meta tensor cannot be modified __class__ to torch.Tensor, we should use an empty real tensor here
r = torch.Tensor._make_subclass(cls, _EMPTY_DATA, require_grad=elem.requires_grad)
@@ -255,7 +261,7 @@ def __torch_function__(cls, func, types, args=(), kwargs=None):
tree_map(cls._replace_with_materialized, args)
tree_map(cls._replace_with_materialized, kwargs)
is_inplace: bool = (func.__name__.endswith('_') and not (func.__name__.endswith('__'))
- or func.__name__ == "__setitem__")
+ or func.__name__ in ('__setitem__', '__set__'))
is_change_meta_op: bool = func.__name__ in _CHANGE_META_OPS
@@ -318,7 +324,9 @@ def __torch_dispatch__(cls, func, types, args=(), kwargs=None):
def clone(self) -> "LazyTensor":
def factory_fn():
- return self.materialize().clone()
+ # if self is materialized, return self
+ new_tensor = self.materialize() if type(self) is LazyTensor else self
+ return new_tensor.clone()
target = LazyTensor(factory_fn, meta_data=self._meta_data)
@@ -327,6 +335,26 @@ def factory_fn():
def detach(self) -> Tensor:
return self
+ def __deepcopy__(self, memo):
+ if not self.is_leaf:
+ raise RuntimeError("Only Tensors created explicitly by the user "
+ "(graph leaves) support the deepcopy protocol at the moment")
+ if id(self) in memo:
+ return memo[id(self)]
+
+ def factory_fn():
+ # if self is materialized, return self
+ new_tensor = self.materialize() if type(self) is LazyTensor else self
+ copied = new_tensor.detach().clone()
+ if new_tensor.requires_grad:
+ copied.requires_grad_()
+ return copied
+
+ target = LazyTensor(factory_fn, meta_data=self._meta_data)
+
+ memo[id(self)] = target
+ return target
+
@property
def data(self):
return self
diff --git a/colossalai/zero/gemini/chunk/search_utils.py b/colossalai/zero/gemini/chunk/search_utils.py
index a69b782ead2e..da58e038c879 100644
--- a/colossalai/zero/gemini/chunk/search_utils.py
+++ b/colossalai/zero/gemini/chunk/search_utils.py
@@ -11,8 +11,13 @@
def _filter_exlarge_params(model: nn.Module, size_dict: Dict[int, List[int]]) -> None:
- """
+ """_filter_exlarge_params
+
Filter those parameters whose size is too large (more than 3x standard deviations) from others.
+
+ Args:
+ model (nn.Module): the model.
+ size_dict (Dict[int, List[int]]): the size dict of parameters.
"""
agg_size_list = []
for key in size_dict:
@@ -33,7 +38,16 @@ def _filter_exlarge_params(model: nn.Module, size_dict: Dict[int, List[int]]) ->
def _get_unused_byte(size_list: List[int], chunk_size: int) -> int:
- """Get unused byte for a certain chunk size.
+ """_get_unused_byte
+
+ Get unused byte for a certain chunk size.
+
+ Args:
+ size_list (List[int]): the size list of parameters.
+ chunk_size (int): the chunk size.
+
+ Returns:
+ int: the unused byte.
"""
acc = 0
left = 0
@@ -45,10 +59,22 @@ def _get_unused_byte(size_list: List[int], chunk_size: int) -> int:
return left + acc
-def _tensor_numel(local_param: ColoParameter, strict_ddp_flag: bool):
- if strict_ddp_flag:
+def _tensor_numel(local_param: ColoParameter, strict_ddp_flag: bool) -> int:
+ """_tensor_numel
+
+ Get the number of elements of a tensor.
+
+ Args:
+ local_param (ColoParameter): The local parameter.
+ strict_ddp_flag (bool): whether to enable the strict ddp mode.
+
+ Returns:
+ int: the number of elements.
+ """
+ if strict_ddp_flag and type(local_param) is ColoParameter:
return local_param.numel_global()
else:
+ # if local_param is not ColoParameter, we assume it's replicated
return local_param.numel()
@@ -60,6 +86,7 @@ def classify_params_by_dp_degree(param_order: OrderedParamGenerator,
Args:
param_order (OrderedParamGenerator): the order of param be visied
+ strict_ddp_flag (bool, optional): whether to enable the strict ddp mode. Defaults to False.
Returns:
Dict[int, List[ColoParameter]]: a dict contains the classification results.
@@ -67,11 +94,13 @@ def classify_params_by_dp_degree(param_order: OrderedParamGenerator,
"""
params_dict: Dict[int, List[ColoParameter]] = dict()
for param in param_order.generate():
- assert isinstance(param, ColoParameter), "please init model in the ColoInitContext"
+ # assert isinstance(param, ColoParameter), "please init model in the ColoInitContext"
if is_ddp_ignored(param):
continue
- if strict_ddp_flag:
+ if strict_ddp_flag or type(param) is not ColoParameter:
+ # if model is not initialized with ColoInitContext, we assume it's replicated
+ # TODO(ver217): integrate DTensor
param_key = dist.get_world_size()
else:
param_key = param.process_group.dp_world_size()
@@ -93,6 +122,8 @@ def search_chunk_configuration(
memstas: Optional[MemStats] = None) -> Tuple[Dict, int, int]:
"""search_chunk_configuration
+ Search the chunk configuration for a model.
+
Args:
model (nn.Module): torch module
search_range_mb (float): searching range in mega byte.
diff --git a/colossalai/zero/gemini/chunk/utils.py b/colossalai/zero/gemini/chunk/utils.py
index 283f74203592..71242dcd6d49 100644
--- a/colossalai/zero/gemini/chunk/utils.py
+++ b/colossalai/zero/gemini/chunk/utils.py
@@ -20,6 +20,7 @@ def safe_div(a, b):
def init_chunk_manager(model: nn.Module,
init_device: Optional[torch.device] = None,
hidden_dim: Optional[int] = None,
+ verbose: bool = False,
**kwargs) -> ChunkManager:
if hidden_dim:
search_interval_byte = hidden_dim
@@ -39,7 +40,7 @@ def init_chunk_manager(model: nn.Module,
total_size /= mb_size
wasted_size /= mb_size
- if dist.get_rank() == 0:
+ if verbose and dist.get_rank() == 0:
print("searching chunk configuration is completed in {:.2f} s.\n".format(span_s),
"used number: {:.2f} MB, wasted number: {:.2f} MB\n".format(total_size, wasted_size),
"total wasted percentage is {:.2f}%".format(100 * safe_div(wasted_size, total_size + wasted_size)),
diff --git a/colossalai/zero/gemini/gemini_ddp.py b/colossalai/zero/gemini/gemini_ddp.py
index 50f1b1ef1ccc..e151f1aefb2d 100644
--- a/colossalai/zero/gemini/gemini_ddp.py
+++ b/colossalai/zero/gemini/gemini_ddp.py
@@ -1,12 +1,13 @@
import itertools
from collections import OrderedDict
from functools import partial
-from typing import Dict, List, Optional
+from typing import Dict, Iterator, List, Optional, Union
import torch
import torch.distributed as dist
import torch.nn as nn
+from colossalai.checkpoint_io.utils import calculate_tensor_size
from colossalai.logging import get_dist_logger
from colossalai.nn.parallel.data_parallel import ColoDDP, _cast_float, free_storage
from colossalai.tensor import ProcessGroup as ColoProcessGroup
@@ -14,6 +15,7 @@
from colossalai.tensor.colo_parameter import ColoParameter, ColoTensor, ColoTensorSpec
from colossalai.tensor.param_op_hook import ColoParamOpHookManager
from colossalai.utils import get_current_device, is_ddp_ignored
+from colossalai.utils.model.experimental import LazyTensor
from .chunk import Chunk, ChunkManager, TensorState, init_chunk_manager
from .gemini_hook import GeminiZeROHook
@@ -55,7 +57,6 @@ def __init__(self,
pin_memory: bool = False,
force_outputs_fp32: bool = False,
strict_ddp_mode: bool = False) -> None:
- super().__init__(module, process_group=ColoProcessGroup())
self.gemini_manager = gemini_manager
self.chunk_manager: ChunkManager = gemini_manager.chunk_manager
self.force_outputs_fp32 = force_outputs_fp32
@@ -67,7 +68,6 @@ def __init__(self,
self.param2name: Dict[nn.Parameter, str] = dict()
self.name2param: Dict[str, nn.Parameter] = dict()
- self._cast_buffers()
self._logger = get_dist_logger()
if self.gemini_manager._premade_memstats_:
@@ -91,6 +91,8 @@ def __init__(self,
for p_name, p_var in m_var.named_parameters(recurse=False):
param_name = m_name + '.' + p_name if m_name else p_name
self.name2param[param_name] = p_var
+ super().__init__(module, process_group=ColoProcessGroup())
+ self._cast_buffers()
def _post_forward(self):
"""This function is only triggered for inference.
@@ -200,7 +202,12 @@ def set_chunk_grad_device(self, chunk: Chunk, device: torch.device) -> None:
for tensor in chunk.get_tensors():
self.grads_device[tensor] = device
- def state_dict(self, destination=None, prefix='', keep_vars=False, only_rank_0: bool = True):
+ def state_dict(self,
+ destination=None,
+ prefix='',
+ keep_vars=False,
+ only_rank_0: bool = True,
+ dtype: torch.dtype = torch.float16):
"""Returns a dictionary containing a whole state of the module.
Both parameters and persistent buffers (e.g. running averages) are included.
@@ -219,7 +226,7 @@ def state_dict(self, destination=None, prefix='', keep_vars=False, only_rank_0:
destination = OrderedDict()
destination._metadata = OrderedDict()
destination._metadata[prefix[:-1]] = local_metadata = dict(version=self._version)
- self._save_to_state_dict(destination, prefix, keep_vars, only_rank_0)
+ self._save_to_state_dict(destination, prefix, keep_vars, only_rank_0, dtype)
for hook in self._state_dict_hooks.values():
hook_result = hook(self, destination, prefix, local_metadata)
@@ -227,7 +234,36 @@ def state_dict(self, destination=None, prefix='', keep_vars=False, only_rank_0:
destination = hook_result
return destination
- def _get_param_to_save_data(self, param_list: List[torch.nn.Parameter], only_rank_0: bool) -> Dict:
+ def _get_chunk_to_save_data(self, chunk: Chunk, only_rank_0: bool, dtype: torch.dtype = torch.float16) -> Dict:
+ """
+ get gathered chunk content.
+
+ Args:
+ chunk (Chunk): a chunk
+ only_rank_0 (bool): whether to only save data on rank 0
+
+ Returns:
+ Dict: a dict whose key is param name and value is param with correct payload
+ """
+ # save parameters
+ chunk_to_save_data = dict()
+ temp_chunk = get_temp_total_chunk_on_cuda(chunk)
+ if torch.is_floating_point(temp_chunk):
+ temp_chunk = temp_chunk.to(dtype)
+ for tensor, tensor_info in chunk.tensors_info.items():
+ record_tensor = torch.empty([0])
+ record_flag = (not only_rank_0) | (dist.get_rank(chunk.torch_pg) == 0)
+ if record_flag:
+ record_tensor = temp_chunk[tensor_info.offset:tensor_info.end].view(tensor.shape).cpu()
+
+ assert tensor not in chunk_to_save_data
+ chunk_to_save_data[tensor] = record_tensor
+
+ del temp_chunk
+ return chunk_to_save_data
+
+ def _get_param_to_save_data(self, param_list: List[torch.nn.Parameter], only_rank_0: bool,
+ dtype: torch.dtype) -> Dict:
"""
get param content from chunks.
@@ -242,21 +278,10 @@ def _get_param_to_save_data(self, param_list: List[torch.nn.Parameter], only_ran
param_to_save_data = dict()
chunk_list = self.chunk_manager.get_chunks(param_list)
for chunk in chunk_list:
- temp_chunk = get_temp_total_chunk_on_cuda(chunk)
-
- for tensor, tensor_info in chunk.tensors_info.items():
- record_tensor = torch.empty([0])
- record_flag = (not only_rank_0) | (dist.get_rank(chunk.torch_pg) == 0)
- if record_flag:
- record_tensor = temp_chunk[tensor_info.offset:tensor_info.end].view(tensor.shape).cpu()
-
- assert tensor not in param_to_save_data
- param_to_save_data[tensor] = record_tensor
-
- del temp_chunk
+ param_to_save_data.update(self._get_chunk_to_save_data(chunk, only_rank_0, dtype))
return param_to_save_data
- def _save_to_state_dict(self, destination, prefix, keep_vars, only_rank_0=True):
+ def _save_to_state_dict(self, destination, prefix, keep_vars, only_rank_0=True, dtype=torch.float16):
r"""Saves module state to `destination` dictionary, containing a state
of the module, but not its descendants. This is called on every
submodule in :meth:`~torch.nn.Module.state_dict`.
@@ -272,7 +297,8 @@ def _save_to_state_dict(self, destination, prefix, keep_vars, only_rank_0=True):
assert keep_vars is False, "`state_dict` with parameter, `keep_vars=True`, is not supported now."
# get copies of fp32 parameters in CPU
- param_to_save_data = self._get_param_to_save_data(self.fp32_params, only_rank_0)
+ # as memory of fp16_params may be reused by grad, it's not reliable, we should use fp32_params and convert to fp16
+ param_to_save_data = self._get_param_to_save_data(self.fp32_params, only_rank_0, dtype)
# get the mapping between copies and fp16 parameters
p_mapping = dict()
for p, fp32_p in zip(self.fp16_params, self.fp32_params):
@@ -478,7 +504,8 @@ def load_fp32_parameter(chunk_slice, data):
def _init_chunks(self, param_order, strict_ddp_mode: bool, cpu_offload: bool, pin_memory: bool):
ddp_pg = ColoProcessGroup()
for p in param_order.generate():
- assert isinstance(p, ColoParameter)
+ self._preprocess_param(p)
+ assert type(p) is ColoParameter
# gather sharded parameters in the strict ddp mode
if strict_ddp_mode:
@@ -531,10 +558,116 @@ def _init_chunks(self, param_order, strict_ddp_mode: bool, cpu_offload: bool, pi
def _cast_buffers(self):
for buffer in self.module.buffers():
+ if isinstance(buffer, LazyTensor):
+ buffer.materialize()
buffer.data = buffer.cuda()
if torch.is_floating_point(buffer):
buffer.data = buffer.half()
+ def _preprocess_param(self, p: Union[nn.Parameter, ColoParameter, 'LazyTensor']) -> None:
+ """Convert parameter to ColoParameter in-place.
+ Args:
+ p (Union[nn.Parameter, ColoParameter, LazyTensor]): parameter to be converted
+ """
+ if type(p) is ColoParameter:
+ # model is initialized with ColoInitContext
+ return
+ requires_grad = p.requires_grad
+ if isinstance(p, LazyTensor):
+ # model is initialized with LazyInitContext
+ p.materialize()
+ p.__class__ = ColoParameter
+ p.__init__(p, requires_grad=requires_grad)
+
+ def state_dict_shard(self,
+ prefix: str = '',
+ keep_vars: bool = False,
+ max_shard_size: int = 1024,
+ only_rank_0: bool = True,
+ dtype: torch.dtype = torch.float16) -> Iterator[OrderedDict]:
+ """Returns dictionaries containing a whole state of the module one by one. The max size of dictionary shard is specified by ``max_shard_size``.
+
+ Both parameters and persistent buffers (e.g. running averages) are included.
+ Keys are corresponding parameter and buffer names.
+ Parameters and buffers set to ``None`` are not included.
+
+ Args:
+ prefix (str, optional): the prefix for parameters and buffers used in this
+ module. Defaults to ''.
+ keep_vars (bool, optional): whether to keep variables. Defaults to False.
+ max_shard_size (int, optional): max size of state dict shard (in MB). Defaults to 1024.
+ only_rank_0 (bool, optional): only get data on rank0. Defaults to True.
+
+
+ Yields:
+ Iterator[OrderedDict]: A generator of state dict shard
+ """
+ sharder = _StateDictSharder(max_shard_size)
+
+ # get the mapping between copies and fp16 parameters
+ fp16_to_fp32 = dict()
+ for p, fp32_p in zip(self.fp16_params, self.fp32_params):
+ fp16_to_fp32[p] = fp32_p
+
+ # key is fp32 param, and value is gathered param on CPU
+ gathered_param_buffer = dict()
+ for name, param in self.name2param.items():
+ if param is not None:
+ if is_ddp_ignored(param):
+ # deal with ddp ignored parameters
+ gathered_param = param if keep_vars else param.detach()
+ else:
+ # as memory of fp16 param may be reused, we should use fp32 param and then convert to fp16
+ fp32_param = fp16_to_fp32[param]
+ if fp32_param not in gathered_param_buffer:
+ chunk = self.chunk_manager.get_chunk(fp32_param)
+ gathered_param_buffer.update(self._get_chunk_to_save_data(chunk, only_rank_0, dtype))
+ gathered_param = gathered_param_buffer.pop(fp32_param)
+
+ block = sharder.append(prefix + name, gathered_param)
+ if block is not None:
+ yield block
+
+ del fp16_to_fp32
+ del gathered_param_buffer
+
+ # save all buffers
+ for name, buf in self.named_buffers():
+ if buf is not None and name not in self._non_persistent_buffers_set:
+ buffer = buf if keep_vars else buf.detach()
+ block = sharder.append(prefix + name, buffer)
+ if block is not None:
+ yield block
+ # save extra states
+ extra_state_key = prefix + _EXTRA_STATE_KEY_SUFFIX
+ if getattr(self.__class__, "get_extra_state",
+ torch.nn.Module.get_extra_state) is not torch.nn.Module.get_extra_state:
+ extra_state = self.get_extra_state()
+ block = sharder.append(extra_state_key, extra_state)
+ if block is not None:
+ yield block
+
+ yield sharder.current_block
+
+
+class _StateDictSharder:
+
+ def __init__(self, max_shard_size: int) -> None:
+ self.max_shard_size = max_shard_size
+ self.current_block = OrderedDict()
+ self.current_block_size = 0
+
+ def append(self, name: str, tensor: torch.Tensor) -> Optional[OrderedDict]:
+ tensor_size = calculate_tensor_size(tensor)
+ ret_block = None
+ if self.current_block_size + tensor_size > self.max_shard_size:
+ ret_block = self.current_block
+ self.current_block = OrderedDict()
+ self.current_block_size = 0
+ self.current_block[name] = tensor
+ self.current_block_size += tensor_size
+ return ret_block
+
class GeminiDDP(ZeroDDP):
@@ -548,7 +681,8 @@ def __init__(self,
search_range_mb: int = 32,
hidden_dim: Optional[int] = None,
min_chunk_size_mb: float = 32,
- memstats: Optional[MemStats] = None) -> None:
+ memstats: Optional[MemStats] = None,
+ verbose: bool = False) -> None:
"""
A torch.Module warpper using ZeRO-DP and Genimi.
ZeRO is for parallel. Gemini is for memory management.
@@ -585,6 +719,7 @@ def __init__(self,
hidden_dim=hidden_dim,
search_range_mb=search_range_mb,
min_chunk_size_mb=min_chunk_size_mb,
- strict_ddp_flag=strict_ddp_mode)
+ strict_ddp_flag=strict_ddp_mode,
+ verbose=verbose)
gemini_manager = GeminiManager(placement_policy, chunk_manager, memstats)
super().__init__(module, gemini_manager, pin_memory, force_outputs_fp32, strict_ddp_mode)
diff --git a/colossalai/zero/gemini/gemini_optimizer.py b/colossalai/zero/gemini/gemini_optimizer.py
index 8940ab9a3251..71c4f65cb8d2 100644
--- a/colossalai/zero/gemini/gemini_optimizer.py
+++ b/colossalai/zero/gemini/gemini_optimizer.py
@@ -54,6 +54,7 @@ class ZeroOptimizer(ColossalaiOptimizer):
clipping_norm (float, optional): The norm value used to clip gradient. Defaults to 0.0.
norm_type (float, optional): The type of norm used for gradient clipping. Currently, only L2-norm (norm_type=2.0)
is supported in ZeroOptimizer. Defaults to 2.0.
+ verbose (bool, optional): Whether to print verbose information, including grad overflow info. Defaults to False.
"""
def __init__(self,
@@ -69,6 +70,7 @@ def __init__(self,
max_scale: float = 2**32,
clipping_norm: float = 0.0,
norm_type: float = 2.0,
+ verbose: bool = False,
**defaults: Any):
super().__init__(optim)
assert isinstance(module, ZeroDDP)
@@ -83,6 +85,7 @@ def __init__(self,
self.chunk16_set: Set[Chunk] = set()
self.clipping_flag = clipping_norm > 0.0
self.max_norm = clipping_norm
+ self.verbose = verbose
if self.clipping_flag:
assert norm_type == 2.0, "ZeroOptimizer only supports L2 norm now"
@@ -221,7 +224,8 @@ def step(self, *args, **kwargs):
if found_inf:
self.optim_state = OptimState.UNSCALED # no need to unscale grad
self.grad_scaler.update(found_inf) # update gradient scaler
- self._logger.info(f'Found overflow. Skip step')
+ if self.verbose:
+ self._logger.info(f'Found overflow. Skip step')
self._clear_global_norm() # clear recorded norm
self.zero_grad() # reset all gradients
self._update_fp16_params()
diff --git a/colossalai/zero/low_level/low_level_optim.py b/colossalai/zero/low_level/low_level_optim.py
index 49fb8b54b7d2..39ade27b9d98 100644
--- a/colossalai/zero/low_level/low_level_optim.py
+++ b/colossalai/zero/low_level/low_level_optim.py
@@ -440,6 +440,8 @@ def step(self, closure=None):
# update loss scale if overflow occurs
if found_inf:
self._grad_store.reset_all_average_gradients()
+ if self._verbose:
+ self._logger.info(f'Found overflow. Skip step')
self.zero_grad()
return
diff --git a/colossalai/zero/wrapper.py b/colossalai/zero/wrapper.py
index 4553249e271d..6cdb8fc59ba5 100644
--- a/colossalai/zero/wrapper.py
+++ b/colossalai/zero/wrapper.py
@@ -7,7 +7,10 @@
from .gemini import GeminiDDP
-def zero_model_wrapper(model: nn.Module, zero_stage: int = 1, gemini_config: Optional[Dict] = None):
+def zero_model_wrapper(model: nn.Module,
+ zero_stage: int = 1,
+ gemini_config: Optional[Dict] = None,
+ verbose: bool = False):
"""This wrapper function is used to wrap your training model for ZeRO DDP.
Example:
@@ -40,7 +43,7 @@ def zero_model_wrapper(model: nn.Module, zero_stage: int = 1, gemini_config: Opt
if zero_stage in [1, 2]:
wrapped_model = model
else:
- wrapped_model = GeminiDDP(model, **gemini_config)
+ wrapped_model = GeminiDDP(model, **gemini_config, verbose=verbose)
setattr(wrapped_model, "_colo_zero_stage", zero_stage)
@@ -58,7 +61,8 @@ def zero_optim_wrapper(model: nn.Module,
max_scale: float = 2**32,
max_norm: float = 0.0,
norm_type: float = 2.0,
- optim_config: Optional[Dict] = None):
+ optim_config: Optional[Dict] = None,
+ verbose: bool = False):
"""This wrapper function is used to wrap your training optimizer for ZeRO DDP.
Args:
@@ -79,6 +83,7 @@ def zero_optim_wrapper(model: nn.Module,
>>> zero2_config = dict(reduce_bucket_size=12 * 1024 * 1024, overlap_communication=True)
>>> optim = zero_optim_wrapper(model, optim, optim_config=zero2_config)
+ verbose (bool, optional): Whether to print the verbose info.
"""
assert hasattr(model, "_colo_zero_stage"), "You should use `zero_ddp_wrapper` first"
zero_stage = getattr(model, "_colo_zero_stage")
@@ -102,8 +107,8 @@ def zero_optim_wrapper(model: nn.Module,
from colossalai.zero.low_level import LowLevelZeroOptimizer
config_dict['partition_grad'] = zero_stage == 2
config_dict['clip_grad_norm'] = max_norm
- return LowLevelZeroOptimizer(optimizer, **config_dict)
+ return LowLevelZeroOptimizer(optimizer, **config_dict, verbose=verbose)
else:
from colossalai.zero.gemini.gemini_optimizer import ZeroOptimizer
config_dict['clipping_norm'] = max_norm
- return ZeroOptimizer(optimizer, model, **config_dict)
+ return ZeroOptimizer(optimizer, model, **config_dict, verbose=verbose)
diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md
index daa42412cc3a..9d5bcfe3f974 100644
--- a/docs/README-zh-Hans.md
+++ b/docs/README-zh-Hans.md
@@ -406,7 +406,7 @@ docker run -ti --gpus all --rm --ipc=host colossalai bash
## CI/CD
-我们使用[GitHub Actions](https://github.com/features/actions)来自动化大部分开发以及部署流程。如果想了解这些工作流是如何运行的,请查看这个[文档](.github/workflows/README.md).
+我们使用[GitHub Actions](https://github.com/features/actions)来自动化大部分开发以及部署流程。如果想了解这些工作流是如何运行的,请查看这个[文档](https://github.com/hpcaitech/ColossalAI/blob/main/.github/workflows/README.md).
## 引用我们
diff --git a/docs/source/en/features/1D_tensor_parallel.md b/docs/source/en/features/1D_tensor_parallel.md
index 530c2e7b64bc..695a8f31f8c5 100644
--- a/docs/source/en/features/1D_tensor_parallel.md
+++ b/docs/source/en/features/1D_tensor_parallel.md
@@ -19,9 +19,16 @@ An efficient 1D tensor parallelism implementation was introduced by [Megatron-LM
Let's take a linear layer as an example, which consists of a GEMM $Y = XA$. Given 2 processors, we split the columns of $A$ into $[A_1 ~ A_2]$, and calculate $Y_i = XA_i$ on each processor, which then forms $[Y_1 ~ Y_2] = [XA_1 ~ XA_2]$. This is called a column-parallel fashion.
-When a second linear layer $Z=YB$ follows the column-parallel one, we split $B$ into $\left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]$,
+When a second linear layer $Z=YB$ follows the column-parallel one, we split $B$ into
+```math
+\left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
+```
which is called a row-parallel fashion.
-To calculate $Z = [Y_1 ~ Y_2] \left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]$, we first calculate $Y_iB_i$ on each processor, then use an all-reduce to aggregate the results as $Z=Y_1B_1+Y_2B_2$.
+To calculate
+```math
+Z = [Y_1 ~ Y_2] \left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
+```
+we first calculate $Y_iB_i$ on each processor, then use an all-reduce to aggregate the results as $Z=Y_1B_1+Y_2B_2$.
We also need to note that in the backward pass, the column-parallel linear layer needs to aggregate the gradients of the input tensor $X$, because on each processor $i$ we only have $\dot{X_i}=\dot{Y_i}A_i^T$.
Thus, we apply an all-reduce across the processors to get $\dot{X}=\dot{Y}A^T=\dot{Y_1}A_1^T+\dot{Y_2}A_2^T$.
diff --git a/docs/source/zh-Hans/features/1D_tensor_parallel.md b/docs/source/zh-Hans/features/1D_tensor_parallel.md
index 8f3a3c6209da..2ddc27c7b50f 100644
--- a/docs/source/zh-Hans/features/1D_tensor_parallel.md
+++ b/docs/source/zh-Hans/features/1D_tensor_parallel.md
@@ -17,11 +17,19 @@
张量并行将模型参数划分到多个设备上,以减少内存负荷。
[Megatron-LM](https://deepakn94.github.io/assets/papers/megatron-sc21.pdf) 介绍了一种高效的一维张量并行化实现。
-让我们以一个线性层为例,它包括一个 GEMM $Y = XA$。 给定2个处理器,我们把列 $A$ 划分为 $[A_1 ~ A_2]$, 并在每个处理器上计算 $Y_i = XA_i$ , which then forms $[Y_1 ~ Y_2] = [XA_1 ~ XA_2]$. This is called a column-parallel fashion.
+让我们以一个线性层为例,它包括一个 GEMM $Y = XA$。 给定2个处理器,我们把列 $A$ 划分为 $[A_1 ~ A_2]$, 并在每个处理器上计算 $Y_i = XA_i$ , 然后形成 $[Y_1 ~ Y_2] = [XA_1 ~ XA_2]$. 这被称为列并行方式。
-当第二个线性层 $Z=YB$ 跟随上述列并行层的时候, 我们把 $B$ 划分为 $\left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]$,
-这就是所谓的行并行方式.
-为了计算 $Z = [Y_1 ~ Y_2] \left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]$, 我们首先在每个处理器上计算 $Y_iB_i$ 然后使用一个all-reduce操作将结果汇总为 $Z=Y_1B_1+Y_2B_2$。
+当第二个线性层 $Z=YB$ 跟随上述列并行层的时候, 我们把 $B$ 划分为
+```math
+\left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
+```
+这就是所谓的行并行方式.
+
+为了计算
+```math
+Z = [Y_1 ~ Y_2] \left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
+```
+我们首先在每个处理器上计算 $Y_iB_i$ 然后使用一个all-reduce操作将结果汇总为 $Z=Y_1B_1+Y_2B_2$。
我们还需要注意,在后向计算中,列并行线性层需要聚合输入张量 $X$, 因为在每个处理器 $i$ 上,我们只有 $\dot{X_i}=\dot{Y_i}A_i^T$,因此,我们在各处理器之间进行all-reduce,得到 $\dot{X}=\dot{Y}A^T=\dot{Y_1}A_1^T+\dot{Y_2}A_2^T$。
diff --git a/examples/README.md b/examples/README.md
index dd5e7b10ae66..142a735c6819 100644
--- a/examples/README.md
+++ b/examples/README.md
@@ -10,9 +10,12 @@
## Overview
-This folder provides several examples accelerated by Colossal-AI. The `tutorial` folder is for everyone to quickly try out the different features in Colossal-AI. Other folders such as `images` and `language` include a wide range of deep learning tasks and applications.
+This folder provides several examples accelerated by Colossal-AI.
+Folders such as `images` and `language` include a wide range of deep learning tasks and applications.
+The `community` folder aim to create a collaborative platform for developers to contribute exotic features built on top of Colossal-AI.
+The `tutorial` folder is for everyone to quickly try out the different features in Colossal-AI.
-You can find applications such as Chatbot, Stable Diffusion and Biomedicine in the [Applications](https://github.com/hpcaitech/ColossalAI/tree/main/applications) directory.
+You can find applications such as Chatbot, AIGC and Biomedicine in the [Applications](https://github.com/hpcaitech/ColossalAI/tree/main/applications) directory.
## Folder Structure
@@ -52,3 +55,10 @@ Therefore, it is essential for the example contributors to know how to integrate
2. Configure your testing parameters such as number steps, batch size in `test_ci.sh`, e.t.c. Keep these parameters small such that each example only takes several minutes.
3. Export your dataset path with the prefix `/data` and make sure you have a copy of the dataset in the `/data/scratch/examples-data` directory on the CI machine. Community contributors can contact us via slack to request for downloading the dataset on the CI machine.
4. Implement the logic such as dependency setup and example execution
+
+## Community Dependency
+We are happy to introduce the following nice community dependency repos that are powered by Colossal-AI:
+- [lightning-ColossalAI](https://github.com/Lightning-AI/lightning)
+- [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion)
+- [KoChatGPT](https://github.com/airobotlab/KoChatGPT)
+- [minichatgpt](https://github.com/juncongmoo/minichatgpt)
diff --git a/examples/community/README.md b/examples/community/README.md
new file mode 100644
index 000000000000..fb2ca37ed988
--- /dev/null
+++ b/examples/community/README.md
@@ -0,0 +1,28 @@
+## Community Examples
+
+Community-driven Examples is an initiative that allows users to share their own examples to the Colossal-AI community, fostering a sense of community and making it easy for others to access and benefit from shared work. The primary goal with community-driven examples is to have a community-maintained collection of diverse and exotic functionalities built on top of the Colossal-AI package.
+
+If a community example doesn't work as expected, you can [open an issue](https://github.com/hpcaitech/ColossalAI/issues/new/choose) and @ the author to report it.
+
+
+| Example | Description | Code Example | Colab |Author |
+|:------------------|:---------------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------|:-----------------------------------------|-----------------------------------------------------:|
+| RoBERTa | Adding RoBERTa for SFT and Prompts model training | [RoBERTa](./roberta) | - | [YY Lin](https://github.com/yynil) (Moore Threads) |
+| TransformerEngine FP8 | Adding TransformerEngine with FP8 training | [TransformerEngine FP8](./fp8) | - | [Kirthi Shankar Sivamani](https://github.com/ksivaman) (NVIDIA) |
+|...|...|...|...|...|
+
+## Looking for Examples
+* [Swin-Transformer](https://github.com/microsoft/Swin-Transformer)
+* [T-5](https://github.com/google-research/text-to-text-transfer-transformer)
+* [Segment Anything (SAM)](https://github.com/facebookresearch/segment-anything)
+* [ControlNet](https://github.com/lllyasviel/ControlNet)
+* [Consistency Models](https://github.com/openai/consistency_models)
+* [MAE](https://github.com/facebookresearch/mae)
+* [CLIP](https://github.com/openai/CLIP)
+
+Welcome to [open an issue](https://github.com/hpcaitech/ColossalAI/issues/new/choose) to share your insights and needs.
+
+## How to get involved
+To join our community-driven initiative, please visit the [Colossal-AI examples](https://github.com/hpcaitech/ColossalAI/tree/main/examples), review the provided information, and explore the codebase.
+
+To contribute, create a new issue outlining your proposed feature or enhancement, and our team will review and provide feedback. If you are confident enough you can also submit a PR directly. We look forward to collaborating with you on this exciting project!
diff --git a/examples/tutorial/fp8/mnist/README.md b/examples/community/fp8/mnist/README.md
similarity index 89%
rename from examples/tutorial/fp8/mnist/README.md
rename to examples/community/fp8/mnist/README.md
index 46711f9ebdd8..e1128c1054b7 100644
--- a/examples/tutorial/fp8/mnist/README.md
+++ b/examples/community/fp8/mnist/README.md
@@ -1,13 +1,13 @@
-# Basic MNIST Example with optional FP8 of TransformerEngine
-
-[TransformerEngine](https://github.com/NVIDIA/TransformerEngine) is a library for accelerating Transformer models on NVIDIA GPUs, including using 8-bit floating point (FP8) precision on Hopper GPUs, to provide better performance with lower memory utilization in both training and inference.
-
-Thanks for the contribution to this tutorial from NVIDIA.
-
-```bash
-python main.py
-python main.py --use-te # Linear layers from TransformerEngine
-python main.py --use-fp8 # FP8 + TransformerEngine for Linear layers
-```
-
-> We are working to integrate it with Colossal-AI and will finish it soon.
+# Basic MNIST Example with optional FP8 of TransformerEngine
+
+[TransformerEngine](https://github.com/NVIDIA/TransformerEngine) is a library for accelerating Transformer models on NVIDIA GPUs, including using 8-bit floating point (FP8) precision on Hopper GPUs, to provide better performance with lower memory utilization in both training and inference.
+
+Thanks for the contribution to this tutorial from NVIDIA.
+
+```bash
+python main.py
+python main.py --use-te # Linear layers from TransformerEngine
+python main.py --use-fp8 # FP8 + TransformerEngine for Linear layers
+```
+
+> We are working to integrate it with Colossal-AI and will finish it soon.
diff --git a/examples/tutorial/fp8/mnist/main.py b/examples/community/fp8/mnist/main.py
similarity index 81%
rename from examples/tutorial/fp8/mnist/main.py
rename to examples/community/fp8/mnist/main.py
index 000ded2f111f..a534663d380f 100644
--- a/examples/tutorial/fp8/mnist/main.py
+++ b/examples/community/fp8/mnist/main.py
@@ -3,12 +3,13 @@
# See LICENSE for license information.
import argparse
+
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
-from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
+from torchvision import datasets, transforms
try:
from transformer_engine import pytorch as te
@@ -18,6 +19,7 @@
class Net(nn.Module):
+
def __init__(self, use_te=False):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
@@ -62,12 +64,10 @@ def train(args, model, device, train_loader, optimizer, epoch, use_fp8):
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
- print(
- f"Train Epoch: {epoch} "
- f"[{batch_idx * len(data)}/{len(train_loader.dataset)} "
- f"({100. * batch_idx / len(train_loader):.0f}%)]\t"
- f"Loss: {loss.item():.6f}"
- )
+ print(f"Train Epoch: {epoch} "
+ f"[{batch_idx * len(data)}/{len(train_loader.dataset)} "
+ f"({100. * batch_idx / len(train_loader):.0f}%)]\t"
+ f"Loss: {loss.item():.6f}")
if args.dry_run:
break
@@ -83,6 +83,7 @@ def calibrate(model, device, test_loader):
with te.fp8_autocast(enabled=False, calibrating=True):
output = model(data)
+
def test(model, device, test_loader, use_fp8):
"""Testing function."""
model.eval()
@@ -93,21 +94,15 @@ def test(model, device, test_loader, use_fp8):
data, target = data.to(device), target.to(device)
with te.fp8_autocast(enabled=use_fp8):
output = model(data)
- test_loss += F.nll_loss(
- output, target, reduction="sum"
- ).item() # sum up batch loss
- pred = output.argmax(
- dim=1, keepdim=True
- ) # get the index of the max log-probability
+ test_loss += F.nll_loss(output, target, reduction="sum").item() # sum up batch loss
+ pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
- print(
- f"\nTest set: Average loss: {test_loss:.4f}, "
- f"Accuracy: {correct}/{len(test_loader.dataset)} "
- f"({100. * correct / len(test_loader.dataset):.0f}%)\n"
- )
+ print(f"\nTest set: Average loss: {test_loss:.4f}, "
+ f"Accuracy: {correct}/{len(test_loader.dataset)} "
+ f"({100. * correct / len(test_loader.dataset):.0f}%)\n")
def main():
@@ -154,9 +149,7 @@ def main():
default=False,
help="quickly check a single pass",
)
- parser.add_argument(
- "--seed", type=int, default=1, metavar="S", help="random seed (default: 1)"
- )
+ parser.add_argument("--seed", type=int, default=1, metavar="S", help="random seed (default: 1)")
parser.add_argument(
"--log-interval",
type=int,
@@ -170,15 +163,12 @@ def main():
default=False,
help="For Saving the current Model",
)
- parser.add_argument(
- "--use-fp8", action="store_true", default=False, help="Use FP8 for inference and training without recalibration"
- )
- parser.add_argument(
- "--use-fp8-infer", action="store_true", default=False, help="Use FP8 inference only"
- )
- parser.add_argument(
- "--use-te", action="store_true", default=False, help="Use Transformer Engine"
- )
+ parser.add_argument("--use-fp8",
+ action="store_true",
+ default=False,
+ help="Use FP8 for inference and training without recalibration")
+ parser.add_argument("--use-fp8-infer", action="store_true", default=False, help="Use FP8 inference only")
+ parser.add_argument("--use-te", action="store_true", default=False, help="Use Transformer Engine")
args = parser.parse_args()
use_cuda = torch.cuda.is_available()
@@ -205,9 +195,7 @@ def main():
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
- transform = transforms.Compose(
- [transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
- )
+ transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
dataset1 = datasets.MNIST("../data", train=True, download=True, transform=transform)
dataset2 = datasets.MNIST("../data", train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1, **train_kwargs)
@@ -227,7 +215,7 @@ def main():
if args.save_model or args.use_fp8_infer:
torch.save(model.state_dict(), "mnist_cnn.pt")
- print('Eval with reloaded checkpoint : fp8='+str(args.use_fp8_infer))
+ print('Eval with reloaded checkpoint : fp8=' + str(args.use_fp8_infer))
weights = torch.load("mnist_cnn.pt")
model.load_state_dict(weights)
test(model, device, test_loader, args.use_fp8_infer)
diff --git a/examples/language/roberta/README.md b/examples/community/roberta/README.md
similarity index 96%
rename from examples/language/roberta/README.md
rename to examples/community/roberta/README.md
index 0e080d00981a..8aefa327a4b4 100644
--- a/examples/language/roberta/README.md
+++ b/examples/community/roberta/README.md
@@ -11,7 +11,7 @@ ssh-keygen
ssh-copy-id -i ~/.ssh/id_rsa.pub ip_destination
```
-- In all hosts, edit /etc/hosts to record all hosts' name and ip.The example is shown below.
+- In all hosts, edit /etc/hosts to record all hosts' name and ip.The example is shown below.
```bash
192.168.2.1 GPU001
@@ -29,7 +29,7 @@ ssh-copy-id -i ~/.ssh/id_rsa.pub ip_destination
service ssh restart
```
-## 1. Corpus Preprocessing
+## 1. Corpus Preprocessing
```bash
cd preprocessing
```
diff --git a/examples/language/roberta/preprocessing/Makefile b/examples/community/roberta/preprocessing/Makefile
similarity index 100%
rename from examples/language/roberta/preprocessing/Makefile
rename to examples/community/roberta/preprocessing/Makefile
diff --git a/examples/language/roberta/preprocessing/README.md b/examples/community/roberta/preprocessing/README.md
similarity index 96%
rename from examples/language/roberta/preprocessing/README.md
rename to examples/community/roberta/preprocessing/README.md
index 1dbd745ab9bd..17cc2f4dc22c 100644
--- a/examples/language/roberta/preprocessing/README.md
+++ b/examples/community/roberta/preprocessing/README.md
@@ -21,7 +21,7 @@ This folder is used to preprocess chinese corpus with Whole Word Masked. You can
### 2.1. Split Sentence & Split data into multiple shard:
-Firstly, each file has multiple documents, and each document contains multiple sentences. Split sentence through punctuation, such as `。!`. **Secondly, split data into multiple shard based on server hardware (cpu, cpu memory, hard disk) and corpus size.** Each shard contains a part of corpus, and the model needs to train all the shards as one epoch.
+Firstly, each file has multiple documents, and each document contains multiple sentences. Split sentence through punctuation, such as `。!`. **Secondly, split data into multiple shard based on server hardware (cpu, cpu memory, hard disk) and corpus size.** Each shard contains a part of corpus, and the model needs to train all the shards as one epoch.
In this example, split 200G Corpus into 100 shard, and each shard is about 2G. The size of the shard is memory-dependent, taking into account the number of servers, the memory used by the tokenizer, and the memory used by the multi-process training to read the shard (n data parallel requires n\*shard_size memory). **To sum up, data preprocessing and model pretraining requires fighting with hardware, not just GPU.**
```python
@@ -49,7 +49,7 @@ python sentence_split.py --input_path /orginal_corpus --output_path /shard --sha
]
```
-Output txt:
+Output txt:
```
我今天去打篮球。
@@ -76,7 +76,7 @@ make
* `--input_path`: location of all shard with split sentences, e.g., /shard/0.txt, /shard/1.txt ...
* `--output_path`: location of all h5 with token_id, input_mask, segment_ids and masked_lm_positions, e.g., /h5/0.h5, /h5/1.h5 ...
-* `--tokenizer_path`: tokenizer path contains huggingface tokenizer.json. Download config.json, special_tokens_map.json, vocab.txt and tokenzier.json from [hfl/chinese-roberta-wwm-ext-large](https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/tree/main)
+* `--tokenizer_path`: tokenizer path contains huggingface tokenizer.json. Download config.json, special_tokens_map.json, vocab.txt and tokenzier.json from [hfl/chinese-roberta-wwm-ext-large](https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/tree/main)
* `--backend`: python or c++, **specifies c++ can obtain faster preprocess speed**
* `--dupe_factor`: specifies how many times the preprocessor repeats to create the input from the same article/document
* `--worker`: number of process
@@ -91,7 +91,7 @@ make
下周请假。
```
-Output h5+numpy:
+Output h5+numpy:
```
'input_ids': [[id0,id1,id2,id3,id4,id5,id6,0,0..],
@@ -102,4 +102,4 @@ make
...]
'masked_lm_positions': [[label1,-1,-1,label2,-1...],
...]
-```
\ No newline at end of file
+```
diff --git a/examples/language/roberta/preprocessing/get_mask.py b/examples/community/roberta/preprocessing/get_mask.py
similarity index 85%
rename from examples/language/roberta/preprocessing/get_mask.py
rename to examples/community/roberta/preprocessing/get_mask.py
index 869ef2cb377c..74c97a63a9f3 100644
--- a/examples/language/roberta/preprocessing/get_mask.py
+++ b/examples/community/roberta/preprocessing/get_mask.py
@@ -1,20 +1,22 @@
-import torch
+import collections
+import logging
import os
-from enum import IntEnum
-from random import choice
import random
-import collections
import time
-import logging
+from enum import IntEnum
+from random import choice
+
import jieba
+import torch
+
jieba.setLogLevel(logging.CRITICAL)
import re
-import numpy as np
+
import mask
+import numpy as np
PAD = 0
-MaskedLMInstance = collections.namedtuple("MaskedLMInstance",
- ["index", "label"])
+MaskedLMInstance = collections.namedtuple("MaskedLMInstance", ["index", "label"])
def map_to_numpy(data):
@@ -22,6 +24,7 @@ def map_to_numpy(data):
class PreTrainingDataset():
+
def __init__(self,
tokenizer,
max_seq_length,
@@ -43,17 +46,15 @@ def __init__(self,
self.mlm_tamper_p = 0.05
self.mlm_maintain_p = 0.1
-
def tokenize(self, doc):
temp = []
for d in doc:
temp.append(self.tokenizer.tokenize(d))
return temp
-
def create_training_instance(self, instance):
is_next = 1
- raw_text_list = self.get_new_segment(instance)
+ raw_text_list = self.get_new_segment(instance)
tokens_a = raw_text_list
assert len(tokens_a) == len(instance)
# tokens_a, tokens_b, is_next = instance.get_values()
@@ -83,8 +84,9 @@ def create_training_instance(self, instance):
# Get Masked LM predictions
if self.backend == 'c++':
- output_tokens, masked_lm_output = mask.create_whole_masked_lm_predictions(tokens, original_tokens, self.vocab_words,
- self.tokenizer.vocab, self.max_predictions_per_seq, self.masked_lm_prob)
+ output_tokens, masked_lm_output = mask.create_whole_masked_lm_predictions(
+ tokens, original_tokens, self.vocab_words, self.tokenizer.vocab, self.max_predictions_per_seq,
+ self.masked_lm_prob)
elif self.backend == 'python':
output_tokens, masked_lm_output = self.create_whole_masked_lm_predictions(tokens)
@@ -102,29 +104,25 @@ def create_training_instance(self, instance):
map_to_numpy(input_mask),
map_to_numpy(segment_ids),
map_to_numpy(masked_lm_output),
- map_to_numpy([is_next])
+ map_to_numpy([is_next])
])
-
def create_masked_lm_predictions(self, tokens):
cand_indexes = []
for i, token in enumerate(tokens):
if token == "[CLS]" or token == "[SEP]":
continue
- if (self.do_whole_word_mask and len(cand_indexes) >= 1 and
- token.startswith("##")):
+ if (self.do_whole_word_mask and len(cand_indexes) >= 1 and token.startswith("##")):
cand_indexes[-1].append(i)
else:
cand_indexes.append([i])
-
+
# cand_indexes.append(i)
random.shuffle(cand_indexes)
output_tokens = list(tokens)
- num_to_predict = min(
- self.max_predictions_per_seq,
- max(1, int(round(len(tokens) * self.masked_lm_prob))))
+ num_to_predict = min(self.max_predictions_per_seq, max(1, int(round(len(tokens) * self.masked_lm_prob))))
masked_lms = []
covered_indexes = set()
@@ -145,13 +143,10 @@ def create_masked_lm_predictions(self, tokens):
masked_token = tokens[index]
# 10% replace w/ random word
else:
- masked_token = self.vocab_words[random.randint(
- 0,
- len(self.vocab_words) - 1)]
+ masked_token = self.vocab_words[random.randint(0, len(self.vocab_words) - 1)]
output_tokens[index] = masked_token
- masked_lms.append(
- MaskedLMInstance(index=index, label=tokens[index]))
+ masked_lms.append(MaskedLMInstance(index=index, label=tokens[index]))
masked_lms = sorted(masked_lms, key=lambda x: x.index)
masked_lm_output = [-1] * len(output_tokens)
@@ -160,7 +155,6 @@ def create_masked_lm_predictions(self, tokens):
return (output_tokens, masked_lm_output)
-
def get_new_segment(self, segment):
"""
Input a sentence, return a processed sentence: In order to support the Chinese whole word mask, the words that are separated will be marked with a special mark ("#"), so that the subsequent processing module can know which words belong to the same word.
@@ -171,7 +165,7 @@ def get_new_segment(self, segment):
new_segment = []
i = 0
while i < len(segment):
- if len(self.rec.findall(segment[i])) == 0:
+ if len(self.rec.findall(segment[i])) == 0:
new_segment.append(segment[i])
i += 1
continue
@@ -180,10 +174,10 @@ def get_new_segment(self, segment):
for length in range(3, 0, -1):
if i + length > len(segment):
continue
- if ''.join(segment[i: i+length]) in seq_cws_dict:
+ if ''.join(segment[i:i + length]) in seq_cws_dict:
new_segment.append(segment[i])
for l in range(1, length):
- new_segment.append('##' + segment[i+l])
+ new_segment.append('##' + segment[i + l])
i += length
has_add = True
break
@@ -192,7 +186,6 @@ def get_new_segment(self, segment):
i += 1
return new_segment
-
def create_whole_masked_lm_predictions(self, tokens):
"""Creates the predictions for the masked LM objective."""
@@ -209,18 +202,16 @@ def create_whole_masked_lm_predictions(self, tokens):
# Note that Whole Word Masking does *not* change the training code
# at all -- we still predict each WordPiece independently, softmaxed
# over the entire vocabulary.
- if (self.do_whole_word_mask and len(cand_indexes) >= 1 and
- token.startswith("##")):
+ if (self.do_whole_word_mask and len(cand_indexes) >= 1 and token.startswith("##")):
cand_indexes[-1].append(i)
else:
cand_indexes.append([i])
random.shuffle(cand_indexes)
- output_tokens = [t[2:] if len(self.whole_rec.findall(t))>0 else t for t in tokens] # 去掉"##"
+ output_tokens = [t[2:] if len(self.whole_rec.findall(t)) > 0 else t for t in tokens] # 去掉"##"
- num_to_predict = min(self.max_predictions_per_seq,
- max(1, int(round(len(tokens) * self.masked_lm_prob))))
+ num_to_predict = min(self.max_predictions_per_seq, max(1, int(round(len(tokens) * self.masked_lm_prob))))
masked_lms = []
covered_indexes = set()
@@ -248,14 +239,18 @@ def create_whole_masked_lm_predictions(self, tokens):
else:
# 10% of the time, keep original
if random.random() < 0.5:
- masked_token = tokens[index][2:] if len(self.whole_rec.findall(tokens[index]))>0 else tokens[index] # 去掉"##"
+ masked_token = tokens[index][2:] if len(self.whole_rec.findall(
+ tokens[index])) > 0 else tokens[index] # 去掉"##"
# 10% of the time, replace with random word
else:
masked_token = self.vocab_words[random.randint(0, len(self.vocab_words) - 1)]
output_tokens[index] = masked_token
- masked_lms.append(MaskedLMInstance(index=index, label=tokens[index][2:] if len(self.whole_rec.findall(tokens[index]))>0 else tokens[index]))
+ masked_lms.append(
+ MaskedLMInstance(
+ index=index,
+ label=tokens[index][2:] if len(self.whole_rec.findall(tokens[index])) > 0 else tokens[index]))
assert len(masked_lms) <= num_to_predict
masked_lms = sorted(masked_lms, key=lambda x: x.index)
masked_lm_output = [-1] * len(output_tokens)
diff --git a/examples/community/roberta/preprocessing/mask.cpp b/examples/community/roberta/preprocessing/mask.cpp
new file mode 100644
index 000000000000..d44f58eccfc2
--- /dev/null
+++ b/examples/community/roberta/preprocessing/mask.cpp
@@ -0,0 +1,190 @@
+#include
+#include
+#include
+#include
+
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+
+namespace py = pybind11;
+
+const int32_t LONG_SENTENCE_LEN = 512;
+
+struct MaskedLMInstance {
+ int index;
+ std::string label;
+ MaskedLMInstance(int index, std::string label) {
+ this->index = index;
+ this->label = label;
+ }
+};
+
+auto get_new_segment(
+ std::vector segment, std::vector segment_jieba,
+ const std::vector chinese_vocab) { // const
+ // std::unordered_set
+ // &chinese_vocab
+ std::unordered_set seq_cws_dict;
+ for (auto word : segment_jieba) {
+ seq_cws_dict.insert(word);
+ }
+ int i = 0;
+ std::vector new_segment;
+ int segment_size = segment.size();
+ while (i < segment_size) {
+ if (!chinese_vocab[i]) { // chinese_vocab.find(segment[i]) ==
+ // chinese_vocab.end()
+ new_segment.emplace_back(segment[i]);
+ i += 1;
+ continue;
+ }
+ bool has_add = false;
+ for (int length = 3; length >= 1; length--) {
+ if (i + length > segment_size) {
+ continue;
+ }
+ std::string chinese_word = "";
+ for (int j = i; j < i + length; j++) {
+ chinese_word += segment[j];
+ }
+ if (seq_cws_dict.find(chinese_word) != seq_cws_dict.end()) {
+ new_segment.emplace_back(segment[i]);
+ for (int j = i + 1; j < i + length; j++) {
+ new_segment.emplace_back("##" + segment[j]);
+ }
+ i += length;
+ has_add = true;
+ break;
+ }
+ }
+ if (!has_add) {
+ new_segment.emplace_back(segment[i]);
+ i += 1;
+ }
+ }
+
+ return new_segment;
+}
+
+bool startsWith(const std::string &s, const std::string &sub) {
+ return s.find(sub) == 0 ? true : false;
+}
+
+auto create_whole_masked_lm_predictions(
+ std::vector &tokens,
+ const std::vector &original_tokens,
+ const std::vector &vocab_words,
+ std::map &vocab, const int max_predictions_per_seq,
+ const double masked_lm_prob) {
+ // for (auto item : vocab) {
+ // std::cout << "key=" << std::string(py::str(item.first)) << ", "
+ // << "value=" << std::string(py::str(item.second)) <<
+ // std::endl;
+ // }
+ std::vector > cand_indexes;
+ std::vector cand_temp;
+ int tokens_size = tokens.size();
+ std::string prefix = "##";
+ bool do_whole_masked = true;
+
+ for (int i = 0; i < tokens_size; i++) {
+ if (tokens[i] == "[CLS]" || tokens[i] == "[SEP]") {
+ continue;
+ }
+ if (do_whole_masked && (cand_indexes.size() > 0) &&
+ (tokens[i].rfind(prefix, 0) == 0)) {
+ cand_temp.emplace_back(i);
+ } else {
+ if (cand_temp.size() > 0) {
+ cand_indexes.emplace_back(cand_temp);
+ }
+ cand_temp.clear();
+ cand_temp.emplace_back(i);
+ }
+ }
+ auto seed = std::chrono::system_clock::now().time_since_epoch().count();
+ std::shuffle(cand_indexes.begin(), cand_indexes.end(),
+ std::default_random_engine(seed));
+ // for (auto i : cand_indexes) {
+ // for (auto j : i) {
+ // std::cout << tokens[j] << " ";
+ // }
+ // std::cout << std::endl;
+ // }
+ // for (auto i : output_tokens) {
+ // std::cout << i;
+ // }
+ // std::cout << std::endl;
+
+ int num_to_predict = std::min(max_predictions_per_seq,
+ std::max(1, int(tokens_size * masked_lm_prob)));
+ // std::cout << num_to_predict << std::endl;
+
+ std::set covered_indexes;
+ std::vector masked_lm_output(tokens_size, -1);
+ int vocab_words_len = vocab_words.size();
+ std::default_random_engine e(seed);
+ std::uniform_real_distribution u1(0.0, 1.0);
+ std::uniform_int_distribution u2(0, vocab_words_len - 1);
+ int mask_cnt = 0;
+ std::vector output_tokens;
+ output_tokens = original_tokens;
+
+ for (auto index_set : cand_indexes) {
+ if (mask_cnt > num_to_predict) {
+ break;
+ }
+ int index_set_size = index_set.size();
+ if (mask_cnt + index_set_size > num_to_predict) {
+ continue;
+ }
+ bool is_any_index_covered = false;
+ for (auto index : index_set) {
+ if (covered_indexes.find(index) != covered_indexes.end()) {
+ is_any_index_covered = true;
+ break;
+ }
+ }
+ if (is_any_index_covered) {
+ continue;
+ }
+ for (auto index : index_set) {
+ covered_indexes.insert(index);
+ std::string masked_token;
+ if (u1(e) < 0.8) {
+ masked_token = "[MASK]";
+ } else {
+ if (u1(e) < 0.5) {
+ masked_token = output_tokens[index];
+ } else {
+ int random_index = u2(e);
+ masked_token = vocab_words[random_index];
+ }
+ }
+ // masked_lms.emplace_back(MaskedLMInstance(index, output_tokens[index]));
+ masked_lm_output[index] = vocab[output_tokens[index]];
+ output_tokens[index] = masked_token;
+ mask_cnt++;
+ }
+ }
+
+ // for (auto p : masked_lms) {
+ // masked_lm_output[p.index] = vocab[p.label];
+ // }
+ return std::make_tuple(output_tokens, masked_lm_output);
+}
+
+PYBIND11_MODULE(mask, m) {
+ m.def("create_whole_masked_lm_predictions",
+ &create_whole_masked_lm_predictions);
+ m.def("get_new_segment", &get_new_segment);
+}
diff --git a/examples/language/roberta/preprocessing/sentence_split.py b/examples/community/roberta/preprocessing/sentence_split.py
similarity index 86%
rename from examples/language/roberta/preprocessing/sentence_split.py
rename to examples/community/roberta/preprocessing/sentence_split.py
index f0ed83f90114..76e8bd428723 100644
--- a/examples/language/roberta/preprocessing/sentence_split.py
+++ b/examples/community/roberta/preprocessing/sentence_split.py
@@ -1,28 +1,30 @@
-
+import argparse
+import functools
+import json
import multiprocessing
import os
import re
-from tqdm import tqdm
-from typing import List
-import json
import time
-import argparse
-import functools
+from typing import List
+
+from tqdm import tqdm
+
def split_sentence(document: str, flag: str = "all", limit: int = 510) -> List[str]:
sent_list = []
try:
if flag == "zh":
- document = re.sub('(?P([。?!…](?![”’"\'])))', r'\g\n', document)
+ document = re.sub('(?P([。?!…](?![”’"\'])))', r'\g\n', document)
document = re.sub('(?P([。?!]|…{1,2})[”’"\'])', r'\g\n', document)
elif flag == "en":
- document = re.sub('(?P([.?!](?![”’"\'])))', r'\g\n', document)
- document = re.sub('(?P([?!.]["\']))', r'\g\n', document) # Special quotation marks
+ document = re.sub('(?P([.?!](?![”’"\'])))', r'\g\n', document)
+ document = re.sub('(?P([?!.]["\']))', r'\g\n',
+ document) # Special quotation marks
else:
- document = re.sub('(?P([。?!….?!](?![”’"\'])))', r'\g\n', document)
-
+ document = re.sub('(?P([。?!….?!](?![”’"\'])))', r'\g\n', document)
+
document = re.sub('(?P(([。?!.!?]|…{1,2})[”’"\']))', r'\g\n',
- document) # Special quotation marks
+ document) # Special quotation marks
sent_list_ori = document.splitlines()
for sent in sent_list_ori:
@@ -43,17 +45,15 @@ def split_sentence(document: str, flag: str = "all", limit: int = 510) -> List[s
return sent_list
-def get_sent(output_path,
- input_path,
- fin_list=[], host=-1, seq_len=512) -> None:
+def get_sent(output_path, input_path, fin_list=[], host=-1, seq_len=512) -> None:
workers = 32
if input_path[-1] == '/':
input_path = input_path[:-1]
-
+
cur_path = os.path.join(output_path, str(host) + '.txt')
- new_split_sentence = functools.partial(split_sentence, limit=seq_len-2)
+ new_split_sentence = functools.partial(split_sentence, limit=seq_len - 2)
with open(cur_path, 'w', encoding='utf-8') as f:
for fi, fin_path in enumerate(fin_list):
if not os.path.exists(os.path.join(input_path, fin_path[0])):
@@ -62,7 +62,7 @@ def get_sent(output_path,
continue
print("Processing ", fin_path[0], " ", fi)
-
+
with open(os.path.join(input_path, fin_path[0]), 'r') as fin:
f_data = [l['content'] for l in json.load(fin)]
@@ -99,17 +99,17 @@ def getFileSize(filepath, shard):
real_shard.append(temp)
accu_size = 0
temp = []
-
+
if len(temp) > 0:
real_shard.append(temp)
-
+
return real_shard
def get_start_end(real_shard, base=0, server_num=10, server_name='GPU'):
import socket
host = int(socket.gethostname().split(server_name)[-1])
-
+
fin_list = real_shard[server_num * base + host - 1]
print(fin_list)
print(f'I am server {host}, process {server_num * base + host - 1}, len {len(fin_list)}')
@@ -126,28 +126,24 @@ def get_start_end(real_shard, base=0, server_num=10, server_name='GPU'):
parser.add_argument('--output_path', type=str, required=True, help='output path of shard which has split sentence')
args = parser.parse_args()
- server_num = args.server_num
+ server_num = args.server_num
seq_len = args.seq_len
- shard = args.shard
+ shard = args.shard
input_path = args.input_path
- output_path = args.output_path
+ output_path = args.output_path
real_shard = getFileSize(input_path, shard)
start = time.time()
for index, shard in enumerate(real_shard):
- get_sent(output_path,
- input_path,
- fin_list=shard,
- host=index,
- seq_len=seq_len)
+ get_sent(output_path, input_path, fin_list=shard, host=index, seq_len=seq_len)
print(f'cost {str(time.time() - start)}')
# if you have multiple server, you can use code below or modify code to openmpi
-
+
# for i in range(len(real_shard) // server_num + 1):
# fin_list, host = get_start_end(real_shard, i)
-
+
# start = time.time()
# get_sent(output_path,
# input_path,
diff --git a/examples/language/roberta/preprocessing/tokenize_mask.py b/examples/community/roberta/preprocessing/tokenize_mask.py
similarity index 76%
rename from examples/language/roberta/preprocessing/tokenize_mask.py
rename to examples/community/roberta/preprocessing/tokenize_mask.py
index 76c74868e1fc..f3d49c3d965f 100644
--- a/examples/language/roberta/preprocessing/tokenize_mask.py
+++ b/examples/community/roberta/preprocessing/tokenize_mask.py
@@ -1,19 +1,19 @@
-import time
+import argparse
+import multiprocessing
import os
-import psutil
-import h5py
import socket
-import argparse
+import time
+from random import shuffle
+
+import h5py
import numpy as np
-import multiprocessing
+import psutil
+from get_mask import PreTrainingDataset
from tqdm import tqdm
-from random import shuffle
from transformers import AutoTokenizer
-from get_mask import PreTrainingDataset
def get_raw_instance(document, max_sequence_length=512):
-
"""
Get the initial training instances, split the whole segment into multiple parts according to the max_sequence_length, and return as multiple processed instances.
:param document: document
@@ -26,24 +26,24 @@ def get_raw_instance(document, max_sequence_length=512):
sizes = [len(seq) for seq in document]
result_list = []
- curr_seq = []
+ curr_seq = []
sz_idx = 0
while sz_idx < len(sizes):
-
- if len(curr_seq) + sizes[sz_idx] <= max_sequence_length_allowed: # or len(curr_seq)==0:
+
+ if len(curr_seq) + sizes[sz_idx] <= max_sequence_length_allowed: # or len(curr_seq)==0:
curr_seq += document[sz_idx]
sz_idx += 1
elif sizes[sz_idx] >= max_sequence_length_allowed:
if len(curr_seq) > 0:
result_list.append(curr_seq)
curr_seq = []
- result_list.append(document[sz_idx][ : max_sequence_length_allowed])
+ result_list.append(document[sz_idx][:max_sequence_length_allowed])
sz_idx += 1
else:
result_list.append(curr_seq)
curr_seq = []
- if len(curr_seq) > max_sequence_length_allowed / 2: # /2
+ if len(curr_seq) > max_sequence_length_allowed / 2: # /2
result_list.append(curr_seq)
# num_instance=int(len(big_list)/max_sequence_length_allowed)+1
@@ -70,8 +70,7 @@ def split_numpy_chunk(path, tokenizer, pretrain_data, host):
# document = line
# if len(document.split("")) <= 3:
# continue
- if len(line
- ) > 0 and line[:2] == "]]": # This is end of document
+ if len(line) > 0 and line[:2] == "]]": # This is end of document
documents.append(document)
document = []
elif len(line) >= 2:
@@ -84,8 +83,8 @@ def split_numpy_chunk(path, tokenizer, pretrain_data, host):
# print(len(documents))
# print(len(documents[0]))
# print(documents[0][0:10])
- from typing import List
import multiprocessing
+ from typing import List
ans = []
for docs in tqdm(documents):
@@ -98,7 +97,7 @@ def split_numpy_chunk(path, tokenizer, pretrain_data, host):
raw_ins = get_raw_instance(a)
instances.extend(raw_ins)
del ans
-
+
print('len instance', len(instances))
sen_num = len(instances)
@@ -116,21 +115,15 @@ def split_numpy_chunk(path, tokenizer, pretrain_data, host):
masked_lm_output[index] = mask_dict[3]
with h5py.File(f'/output/{host}.h5', 'w') as hf:
- hf.create_dataset("input_ids", data=input_ids)
- hf.create_dataset("input_mask", data=input_ids)
- hf.create_dataset("segment_ids", data=segment_ids)
- hf.create_dataset("masked_lm_positions", data=masked_lm_output)
+ hf.create_dataset("input_ids", data=input_ids)
+ hf.create_dataset("input_mask", data=input_ids)
+ hf.create_dataset("segment_ids", data=segment_ids)
+ hf.create_dataset("masked_lm_positions", data=masked_lm_output)
del instances
-def split_numpy_chunk_pool(input_path,
- output_path,
- pretrain_data,
- worker,
- dupe_factor,
- seq_len,
- file_name):
+def split_numpy_chunk_pool(input_path, output_path, pretrain_data, worker, dupe_factor, seq_len, file_name):
if os.path.exists(os.path.join(output_path, f'{file_name}.h5')):
print(f'{file_name}.h5 exists')
@@ -144,8 +137,7 @@ def split_numpy_chunk_pool(input_path,
document = []
for i, line in enumerate(tqdm(fd)):
line = line.strip()
- if len(line
- ) > 0 and line[:2] == "]]": # This is end of document
+ if len(line) > 0 and line[:2] == "]]": # This is end of document
documents.append(document)
document = []
elif len(line) >= 2:
@@ -153,7 +145,7 @@ def split_numpy_chunk_pool(input_path,
if len(document) > 0:
documents.append(document)
print(f'read_file cost {time.time() - s}, length is {len(documents)}')
-
+
ans = []
s = time.time()
pool = multiprocessing.Pool(worker)
@@ -169,7 +161,7 @@ def split_numpy_chunk_pool(input_path,
raw_ins = get_raw_instance(a, max_sequence_length=seq_len)
instances.extend(raw_ins)
del ans
-
+
print('len instance', len(instances))
new_instances = []
@@ -199,10 +191,10 @@ def split_numpy_chunk_pool(input_path,
print((time.time() - s) / 60)
with h5py.File(os.path.join(output_path, f'{file_name}.h5'), 'w') as hf:
- hf.create_dataset("input_ids", data=input_ids)
- hf.create_dataset("input_mask", data=input_mask)
- hf.create_dataset("segment_ids", data=segment_ids)
- hf.create_dataset("masked_lm_positions", data=masked_lm_output)
+ hf.create_dataset("input_ids", data=input_ids)
+ hf.create_dataset("input_mask", data=input_mask)
+ hf.create_dataset("segment_ids", data=segment_ids)
+ hf.create_dataset("masked_lm_positions", data=masked_lm_output)
del instances
@@ -212,22 +204,31 @@ def split_numpy_chunk_pool(input_path,
parser = argparse.ArgumentParser()
parser.add_argument('--tokenizer_path', type=str, required=True, default=10, help='path of tokenizer')
parser.add_argument('--seq_len', type=int, default=512, help='sequence length')
- parser.add_argument('--max_predictions_per_seq', type=int, default=80, help='number of shards, e.g., 10, 50, or 100')
+ parser.add_argument('--max_predictions_per_seq',
+ type=int,
+ default=80,
+ help='number of shards, e.g., 10, 50, or 100')
parser.add_argument('--input_path', type=str, required=True, help='input path of shard which has split sentence')
parser.add_argument('--output_path', type=str, required=True, help='output path of h5 contains token id')
- parser.add_argument('--backend', type=str, default='python', help='backend of mask token, python, c++, numpy respectively')
- parser.add_argument('--dupe_factor', type=int, default=1, help='specifies how many times the preprocessor repeats to create the input from the same article/document')
+ parser.add_argument('--backend',
+ type=str,
+ default='python',
+ help='backend of mask token, python, c++, numpy respectively')
+ parser.add_argument(
+ '--dupe_factor',
+ type=int,
+ default=1,
+ help='specifies how many times the preprocessor repeats to create the input from the same article/document')
parser.add_argument('--worker', type=int, default=32, help='number of process')
parser.add_argument('--server_num', type=int, default=10, help='number of servers')
args = parser.parse_args()
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_path)
- pretrain_data = PreTrainingDataset(tokenizer,
- args.seq_len,
- args.backend,
- max_predictions_per_seq=args.max_predictions_per_seq)
-
-
+ pretrain_data = PreTrainingDataset(tokenizer,
+ args.seq_len,
+ args.backend,
+ max_predictions_per_seq=args.max_predictions_per_seq)
+
data_len = len(os.listdir(args.input_path))
for i in range(data_len):
@@ -235,15 +236,10 @@ def split_numpy_chunk_pool(input_path,
if os.path.exists(input_path):
start = time.time()
print(f'process {input_path}')
- split_numpy_chunk_pool(input_path,
- args.output_path,
- pretrain_data,
- args.worker,
- args.dupe_factor,
- args.seq_len,
- i)
+ split_numpy_chunk_pool(input_path, args.output_path, pretrain_data, args.worker, args.dupe_factor,
+ args.seq_len, i)
end_ = time.time()
- print(u'memory:%.4f GB' % (psutil.Process(os.getpid()).memory_info().rss / 1024 / 1024 / 1024) )
+ print(u'memory:%.4f GB' % (psutil.Process(os.getpid()).memory_info().rss / 1024 / 1024 / 1024))
print(f'has cost {(end_ - start) / 60}')
print('-' * 100)
print('')
@@ -257,9 +253,9 @@ def split_numpy_chunk_pool(input_path,
# if os.path.exists(input_path):
# start = time.time()
# print(f'I am server {host}, process {input_path}')
- # split_numpy_chunk_pool(input_path,
- # args.output_path,
- # pretrain_data,
+ # split_numpy_chunk_pool(input_path,
+ # args.output_path,
+ # pretrain_data,
# args.worker,
# args.dupe_factor,
# args.seq_len,
@@ -269,5 +265,3 @@ def split_numpy_chunk_pool(input_path,
# print(f'has cost {(end_ - start) / 60}')
# print('-' * 100)
# print('')
-
-
diff --git a/examples/language/roberta/pretraining/README.md b/examples/community/roberta/pretraining/README.md
similarity index 97%
rename from examples/language/roberta/pretraining/README.md
rename to examples/community/roberta/pretraining/README.md
index 055d6969654d..c248fc1f5708 100644
--- a/examples/language/roberta/pretraining/README.md
+++ b/examples/community/roberta/pretraining/README.md
@@ -19,6 +19,5 @@ bash run_pretrain.sh
bash run_pretrain_resume.sh
```
* `--resume_train`: whether to resume training
-* `--load_pretrain_model`: absolute path which contains model checkpoint
-* `--load_optimizer_lr`: absolute path which contains optimizer checkpoint
-
+* `--load_pretrain_model`: absolute path which contains model checkpoint
+* `--load_optimizer_lr`: absolute path which contains optimizer checkpoint
diff --git a/examples/community/roberta/pretraining/arguments.py b/examples/community/roberta/pretraining/arguments.py
new file mode 100644
index 000000000000..40210c4b1be7
--- /dev/null
+++ b/examples/community/roberta/pretraining/arguments.py
@@ -0,0 +1,87 @@
+from numpy import require
+
+import colossalai
+
+__all__ = ['parse_args']
+
+
+def parse_args():
+ parser = colossalai.get_default_parser()
+
+ parser.add_argument(
+ "--distplan",
+ type=str,
+ default='CAI_Gemini',
+ help="The distributed plan [colossalai, zero1, zero2, torch_ddp, torch_zero].",
+ )
+ parser.add_argument(
+ "--tp_degree",
+ type=int,
+ default=1,
+ help="Tensor Parallelism Degree. Valid when using colossalai as dist plan.",
+ )
+ parser.add_argument(
+ "--placement",
+ type=str,
+ default='cpu',
+ help="Placement Policy for Gemini. Valid when using colossalai as dist plan.",
+ )
+ parser.add_argument(
+ "--shardinit",
+ action='store_true',
+ help=
+ "Shard the tensors when init the model to shrink peak memory size on the assigned device. Valid when using colossalai as dist plan.",
+ )
+
+ parser.add_argument('--lr', type=float, required=True, help='initial learning rate')
+ parser.add_argument('--epoch', type=int, required=True, help='number of epoch')
+ parser.add_argument('--data_path_prefix', type=str, required=True, help="location of the train data corpus")
+ parser.add_argument('--eval_data_path_prefix',
+ type=str,
+ required=True,
+ help='location of the evaluation data corpus')
+ parser.add_argument('--tokenizer_path', type=str, required=True, help='location of the tokenizer')
+ parser.add_argument('--max_seq_length', type=int, default=512, help='sequence length')
+ parser.add_argument('--refresh_bucket_size',
+ type=int,
+ default=1,
+ help="This param makes sure that a certain task is repeated for this time steps to \
+ optimise on the back propogation speed with APEX's DistributedDataParallel")
+ parser.add_argument("--max_predictions_per_seq",
+ "--max_pred",
+ default=80,
+ type=int,
+ help="The maximum number of masked tokens in a sequence to be predicted.")
+ parser.add_argument("--gradient_accumulation_steps", default=1, type=int, help="accumulation_steps")
+ parser.add_argument("--train_micro_batch_size_per_gpu", default=2, type=int, required=True, help="train batch size")
+ parser.add_argument("--eval_micro_batch_size_per_gpu", default=2, type=int, required=True, help="eval batch size")
+ parser.add_argument("--num_workers", default=8, type=int, help="")
+ parser.add_argument("--async_worker", action='store_true', help="")
+ parser.add_argument("--bert_config", required=True, type=str, help="location of config.json")
+ parser.add_argument("--wandb", action='store_true', help="use wandb to watch model")
+ parser.add_argument("--wandb_project_name", default='roberta', help="wandb project name")
+ parser.add_argument("--log_interval", default=100, type=int, help="report interval")
+ parser.add_argument("--log_path", type=str, required=True, help="log file which records train step")
+ parser.add_argument("--tensorboard_path", type=str, required=True, help="location of tensorboard file")
+ parser.add_argument("--colossal_config",
+ type=str,
+ required=True,
+ help="colossal config, which contains zero config and so on")
+ parser.add_argument("--ckpt_path",
+ type=str,
+ required=True,
+ help="location of saving checkpoint, which contains model and optimizer")
+ parser.add_argument('--seed', type=int, default=42, help="random seed for initialization")
+ parser.add_argument('--vscode_debug', action='store_true', help="use vscode to debug")
+ parser.add_argument('--load_pretrain_model', default='', type=str, help="location of model's checkpoin")
+ parser.add_argument(
+ '--load_optimizer_lr',
+ default='',
+ type=str,
+ help="location of checkpoint, which contains optimerzier, learning rate, epoch, shard and global_step")
+ parser.add_argument('--resume_train', action='store_true', help="whether resume training from a early checkpoint")
+ parser.add_argument('--mlm', default='bert', type=str, help="model type, bert or deberta")
+ parser.add_argument('--checkpoint_activations', action='store_true', help="whether to use gradient checkpointing")
+
+ args = parser.parse_args()
+ return args
diff --git a/examples/language/roberta/pretraining/bert_dataset_provider.py b/examples/community/roberta/pretraining/bert_dataset_provider.py
similarity index 99%
rename from examples/language/roberta/pretraining/bert_dataset_provider.py
rename to examples/community/roberta/pretraining/bert_dataset_provider.py
index 1d8cf2a910e9..eaf165ed18f4 100644
--- a/examples/language/roberta/pretraining/bert_dataset_provider.py
+++ b/examples/community/roberta/pretraining/bert_dataset_provider.py
@@ -1,4 +1,5 @@
class BertDatasetProviderInterface:
+
def get_shard(self, index, shuffle=True):
raise NotImplementedError
diff --git a/examples/language/roberta/pretraining/evaluation.py b/examples/community/roberta/pretraining/evaluation.py
similarity index 74%
rename from examples/language/roberta/pretraining/evaluation.py
rename to examples/community/roberta/pretraining/evaluation.py
index 8fc019c121ac..009242cd1cf5 100644
--- a/examples/language/roberta/pretraining/evaluation.py
+++ b/examples/community/roberta/pretraining/evaluation.py
@@ -1,9 +1,11 @@
-import os
import math
+import os
+
import torch
+from nvidia_bert_dataset_provider import NvidiaBertDatasetProvider
from tqdm import tqdm
-from utils.global_vars import get_timers, get_tensorboard_writer
-from nvidia_bert_dataset_provider import NvidiaBertDatasetProvider
+from utils.global_vars import get_tensorboard_writer, get_timers
+
def evaluate(model, args, logger, global_step, criterion):
evaluate_dataset_provider = NvidiaBertDatasetProvider(args, evaluate=True)
@@ -20,16 +22,19 @@ def evaluate(model, args, logger, global_step, criterion):
for shard in range(start_shard, len(os.listdir(args.eval_data_path_prefix))):
- timers('eval_shard_time').start()
+ timers('eval_shard_time').start()
dataset_iterator, total_length = evaluate_dataset_provider.get_shard(shard)
# evaluate_dataset_provider.prefetch_shard(shard + 1)
if torch.distributed.get_rank() == 0:
- iterator_data = tqdm(enumerate(dataset_iterator), total=(total_length // args.eval_micro_batch_size_per_gpu // world_size), colour='MAGENTA', smoothing=1)
+ iterator_data = tqdm(enumerate(dataset_iterator),
+ total=(total_length // args.eval_micro_batch_size_per_gpu // world_size),
+ colour='MAGENTA',
+ smoothing=1)
else:
iterator_data = enumerate(dataset_iterator)
-
- for step, batch_data in iterator_data: #tqdm(enumerate(dataset_iterator), total=(total_length // args.train_micro_batch_size_per_gpu // world_size), colour='cyan', smoothing=1):
+
+ for step, batch_data in iterator_data: #tqdm(enumerate(dataset_iterator), total=(total_length // args.train_micro_batch_size_per_gpu // world_size), colour='cyan', smoothing=1):
# batch_data = pretrain_dataset_provider.get_batch(batch_index)
eval_step += 1
@@ -40,8 +45,8 @@ def evaluate(model, args, logger, global_step, criterion):
# nsp_label = batch_data[5].cuda()
output = model(input_ids=input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
-
- loss = criterion(output.logits, mlm_label)#prediction_scores
+
+ loss = criterion(output.logits, mlm_label) #prediction_scores
evaluate_dataset_provider.prefetch_batch()
eval_loss += loss.float().item()
@@ -54,10 +59,10 @@ def evaluate(model, args, logger, global_step, criterion):
if args.wandb and torch.distributed.get_rank() == 0:
tensorboard_log = get_tensorboard_writer()
tensorboard_log.log_eval({
- 'loss': cur_loss,
- 'ppl': ppl,
- 'mins_batch': elapsed_time_per_iteration
- }, global_step)
+ 'loss': cur_loss,
+ 'ppl': ppl,
+ 'mins_batch': elapsed_time_per_iteration
+ }, global_step)
eval_log_str = f'evaluation shard: {shard} | step: {eval_step} | elapsed_time: {elapsed_time / 60 :.3f} minutes ' + \
f'| mins/batch: {elapsed_time_per_iteration :.3f} seconds | loss: {cur_loss:.7f} | ppl: {ppl:.7f}'
@@ -68,4 +73,4 @@ def evaluate(model, args, logger, global_step, criterion):
evaluate_dataset_provider.release_shard()
model.train()
- return cur_loss
\ No newline at end of file
+ return cur_loss
diff --git a/examples/language/roberta/pretraining/hostfile b/examples/community/roberta/pretraining/hostfile
similarity index 100%
rename from examples/language/roberta/pretraining/hostfile
rename to examples/community/roberta/pretraining/hostfile
diff --git a/examples/language/roberta/pretraining/loss.py b/examples/community/roberta/pretraining/loss.py
similarity index 91%
rename from examples/language/roberta/pretraining/loss.py
rename to examples/community/roberta/pretraining/loss.py
index dc4f872a755d..989c2bd5c450 100644
--- a/examples/language/roberta/pretraining/loss.py
+++ b/examples/community/roberta/pretraining/loss.py
@@ -13,5 +13,5 @@ def __init__(self, vocab_size):
def forward(self, prediction_scores, masked_lm_labels, next_sentence_labels=None):
masked_lm_loss = self.loss_fn(prediction_scores.view(-1, self.vocab_size), masked_lm_labels.view(-1))
# next_sentence_loss = self.loss_fn(seq_relationship_score.view(-1, 2), next_sentence_labels.view(-1))
- total_loss = masked_lm_loss #+ next_sentence_loss
+ total_loss = masked_lm_loss #+ next_sentence_loss
return total_loss
diff --git a/examples/language/roberta/pretraining/model/bert.py b/examples/community/roberta/pretraining/model/bert.py
similarity index 96%
rename from examples/language/roberta/pretraining/model/bert.py
rename to examples/community/roberta/pretraining/model/bert.py
index 67c85f760776..a5da1bea6f65 100644
--- a/examples/language/roberta/pretraining/model/bert.py
+++ b/examples/community/roberta/pretraining/model/bert.py
@@ -15,7 +15,6 @@
# limitations under the License.
"""PyTorch BERT model."""
-
import math
import os
import warnings
@@ -27,7 +26,6 @@
from packaging import version
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
-
from transformers.activations import ACT2FN
from transformers.modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
@@ -41,8 +39,9 @@
TokenClassifierOutput,
)
from transformers.modeling_utils import PreTrainedModel
+from transformers.models.bert.configuration_bert import BertConfig
from transformers.pytorch_utils import apply_chunking_to_forward, find_pruneable_heads_and_indices, prune_linear_layer
-from transformers.utils import (
+from transformers.utils import (
ModelOutput,
add_code_sample_docstrings,
add_start_docstrings,
@@ -50,8 +49,6 @@
logging,
replace_return_docstrings,
)
-from transformers.models.bert.configuration_bert import BertConfig
-
logger = logging.get_logger(__name__)
@@ -62,8 +59,7 @@
# TokenClassification docstring
_CHECKPOINT_FOR_TOKEN_CLASSIFICATION = "dbmdz/bert-large-cased-finetuned-conll03-english"
_TOKEN_CLASS_EXPECTED_OUTPUT = (
- "['O', 'I-ORG', 'I-ORG', 'I-ORG', 'O', 'O', 'O', 'O', 'O', 'I-LOC', 'O', 'I-LOC', 'I-LOC'] "
-)
+ "['O', 'I-ORG', 'I-ORG', 'I-ORG', 'O', 'O', 'O', 'O', 'O', 'I-LOC', 'O', 'I-LOC', 'I-LOC'] ")
_TOKEN_CLASS_EXPECTED_LOSS = 0.01
# QuestionAnswering docstring
@@ -78,7 +74,6 @@
_SEQ_CLASS_EXPECTED_OUTPUT = "'LABEL_1'"
_SEQ_CLASS_EXPECTED_LOSS = 0.01
-
BERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
"bert-base-uncased",
"bert-large-uncased",
@@ -114,10 +109,8 @@ def load_tf_weights_in_bert(model, config, tf_checkpoint_path):
import numpy as np
import tensorflow as tf
except ImportError:
- logger.error(
- "Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
- "https://www.tensorflow.org/install/ for installation instructions."
- )
+ logger.error("Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
+ "https://www.tensorflow.org/install/ for installation instructions.")
raise
tf_path = os.path.abspath(tf_checkpoint_path)
logger.info(f"Converting TensorFlow checkpoint from {tf_path}")
@@ -135,10 +128,8 @@ def load_tf_weights_in_bert(model, config, tf_checkpoint_path):
name = name.split("/")
# adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
# which are not required for using pretrained model
- if any(
- n in ["adam_v", "adam_m", "AdamWeightDecayOptimizer", "AdamWeightDecayOptimizer_1", "global_step"]
- for n in name
- ):
+ if any(n in ["adam_v", "adam_m", "AdamWeightDecayOptimizer", "AdamWeightDecayOptimizer_1", "global_step"]
+ for n in name):
logger.info(f"Skipping {'/'.join(name)}")
continue
pointer = model
@@ -218,7 +209,7 @@ def forward(
seq_length = input_shape[1]
if position_ids is None:
- position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
+ position_ids = self.position_ids[:, past_key_values_length:seq_length + past_key_values_length]
# Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
# when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
@@ -245,13 +236,12 @@ def forward(
class BertSelfAttention(nn.Module):
+
def __init__(self, config, position_embedding_type=None):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
- raise ValueError(
- f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
- f"heads ({config.num_attention_heads})"
- )
+ raise ValueError(f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
+ f"heads ({config.num_attention_heads})")
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
@@ -262,9 +252,7 @@ def __init__(self, config, position_embedding_type=None):
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
- self.position_embedding_type = position_embedding_type or getattr(
- config, "position_embedding_type", "absolute"
- )
+ self.position_embedding_type = position_embedding_type or getattr(config, "position_embedding_type", "absolute")
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
@@ -332,7 +320,7 @@ def forward(
position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
- positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
@@ -372,6 +360,7 @@ def forward(
class BertSelfOutput(nn.Module):
+
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
@@ -386,6 +375,7 @@ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> to
class BertAttention(nn.Module):
+
def __init__(self, config, position_embedding_type=None):
super().__init__()
self.self = BertSelfAttention(config, position_embedding_type=position_embedding_type)
@@ -395,9 +385,8 @@ def __init__(self, config, position_embedding_type=None):
def prune_heads(self, heads):
if len(heads) == 0:
return
- heads, index = find_pruneable_heads_and_indices(
- heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
- )
+ heads, index = find_pruneable_heads_and_indices(heads, self.self.num_attention_heads,
+ self.self.attention_head_size, self.pruned_heads)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
@@ -430,11 +419,12 @@ def forward(
output_attentions,
)
attention_output = self.output(self_outputs[0], hidden_states)
- outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
class BertIntermediate(nn.Module):
+
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
@@ -450,6 +440,7 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
class BertOutput(nn.Module):
+
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
@@ -464,6 +455,7 @@ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> to
class BertLayer(nn.Module):
+
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
@@ -504,15 +496,14 @@ def forward(
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
- outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
if not hasattr(self, "crossattention"):
raise ValueError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
- " by setting `config.add_cross_attention=True`"
- )
+ " by setting `config.add_cross_attention=True`")
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
@@ -526,15 +517,14 @@ def forward(
output_attentions,
)
attention_output = cross_attention_outputs[0]
- outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
+ outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
- layer_output = apply_chunking_to_forward(
- self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
- )
+ layer_output = apply_chunking_to_forward(self.feed_forward_chunk, self.chunk_size_feed_forward,
+ self.seq_len_dim, attention_output)
outputs = (layer_output,) + outputs
# if decoder, return the attn key/values as the last output
@@ -550,6 +540,7 @@ def feed_forward_chunk(self, attention_output):
class BertEncoder(nn.Module):
+
def __init__(self, config):
super().__init__()
self.config = config
@@ -585,11 +576,11 @@ def forward(
if use_cache:
logger.warning(
- "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
- )
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
use_cache = False
def create_custom_forward(module):
+
def custom_forward(*inputs):
return module(*inputs, past_key_value, output_attentions)
@@ -626,17 +617,13 @@ def custom_forward(*inputs):
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
- return tuple(
- v
- for v in [
- hidden_states,
- next_decoder_cache,
- all_hidden_states,
- all_self_attentions,
- all_cross_attentions,
- ]
- if v is not None
- )
+ return tuple(v for v in [
+ hidden_states,
+ next_decoder_cache,
+ all_hidden_states,
+ all_self_attentions,
+ all_cross_attentions,
+ ] if v is not None)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
@@ -647,6 +634,7 @@ def custom_forward(*inputs):
class BertPooler(nn.Module):
+
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
@@ -662,6 +650,7 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
class BertPredictionHeadTransform(nn.Module):
+
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
@@ -679,6 +668,7 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
class BertLMPredictionHead(nn.Module):
+
def __init__(self, config):
super().__init__()
self.transform = BertPredictionHeadTransform(config)
@@ -699,6 +689,7 @@ def forward(self, hidden_states):
class BertOnlyMLMHead(nn.Module):
+
def __init__(self, config):
super().__init__()
self.predictions = BertLMPredictionHead(config)
@@ -709,6 +700,7 @@ def forward(self, sequence_output: torch.Tensor) -> torch.Tensor:
class BertOnlyNSPHead(nn.Module):
+
def __init__(self, config):
super().__init__()
self.seq_relationship = nn.Linear(config.hidden_size, 2)
@@ -719,6 +711,7 @@ def forward(self, pooled_output):
class BertPreTrainingHeads(nn.Module):
+
def __init__(self, config):
super().__init__()
self.predictions = BertLMPredictionHead(config)
@@ -950,9 +943,8 @@ def forward(
`past_key_values`).
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
- output_hidden_states = (
- output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
- )
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if self.config.is_decoder:
@@ -1051,6 +1043,7 @@ def forward(
BERT_START_DOCSTRING,
)
class BertForPreTraining(BertPreTrainedModel):
+
def __init__(self, config):
super().__init__(config)
@@ -1151,9 +1144,8 @@ def forward(
)
-@add_start_docstrings(
- """Bert Model with a `language modeling` head on top for CLM fine-tuning.""", BERT_START_DOCSTRING
-)
+@add_start_docstrings("""Bert Model with a `language modeling` head on top for CLM fine-tuning.""",
+ BERT_START_DOCSTRING)
class BertLMHeadModel(BertPreTrainedModel):
_keys_to_ignore_on_load_unexpected = [r"pooler"]
@@ -1298,10 +1290,8 @@ def __init__(self, config):
super().__init__(config)
if config.is_decoder:
- logger.warning(
- "If you want to use `BertForMaskedLM` make sure `config.is_decoder=False` for "
- "bi-directional self-attention."
- )
+ logger.warning("If you want to use `BertForMaskedLM` make sure `config.is_decoder=False` for "
+ "bi-directional self-attention.")
self.bert = BertModel(config, add_pooling_layer=False)
self.cls = BertOnlyMLMHead(config)
@@ -1367,7 +1357,7 @@ def forward(
masked_lm_loss = None
if labels is not None:
- loss_fct = CrossEntropyLoss() # -100 index = padding token
+ loss_fct = CrossEntropyLoss() # -100 index = padding token
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
@@ -1390,9 +1380,10 @@ def prepare_inputs_for_generation(self, input_ids, attention_mask=None, **model_
raise ValueError("The PAD token should be defined for generation")
attention_mask = torch.cat([attention_mask, attention_mask.new_zeros((attention_mask.shape[0], 1))], dim=-1)
- dummy_token = torch.full(
- (effective_batch_size, 1), self.config.pad_token_id, dtype=torch.long, device=input_ids.device
- )
+ dummy_token = torch.full((effective_batch_size, 1),
+ self.config.pad_token_id,
+ dtype=torch.long,
+ device=input_ids.device)
input_ids = torch.cat([input_ids, dummy_token], dim=1)
return {"input_ids": input_ids, "attention_mask": attention_mask}
@@ -1403,6 +1394,7 @@ def prepare_inputs_for_generation(self, input_ids, attention_mask=None, **model_
BERT_START_DOCSTRING,
)
class BertForNextSentencePrediction(BertPreTrainedModel):
+
def __init__(self, config):
super().__init__(config)
@@ -1508,15 +1500,15 @@ def forward(
BERT_START_DOCSTRING,
)
class BertForSequenceClassification(BertPreTrainedModel):
+
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.bert = BertModel(config)
- classifier_dropout = (
- config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
- )
+ classifier_dropout = (config.classifier_dropout
+ if config.classifier_dropout is not None else config.hidden_dropout_prob)
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
@@ -1612,13 +1604,13 @@ def forward(
BERT_START_DOCSTRING,
)
class BertForMultipleChoice(BertPreTrainedModel):
+
def __init__(self, config):
super().__init__(config)
self.bert = BertModel(config)
- classifier_dropout = (
- config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
- )
+ classifier_dropout = (config.classifier_dropout
+ if config.classifier_dropout is not None else config.hidden_dropout_prob)
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, 1)
@@ -1658,11 +1650,8 @@ def forward(
attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
- inputs_embeds = (
- inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
- if inputs_embeds is not None
- else None
- )
+ inputs_embeds = (inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
+ if inputs_embeds is not None else None)
outputs = self.bert(
input_ids,
@@ -1715,9 +1704,8 @@ def __init__(self, config):
self.num_labels = config.num_labels
self.bert = BertModel(config, add_pooling_layer=False)
- classifier_dropout = (
- config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
- )
+ classifier_dropout = (config.classifier_dropout
+ if config.classifier_dropout is not None else config.hidden_dropout_prob)
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
diff --git a/examples/language/roberta/pretraining/model/deberta_v2.py b/examples/community/roberta/pretraining/model/deberta_v2.py
similarity index 92%
rename from examples/language/roberta/pretraining/model/deberta_v2.py
rename to examples/community/roberta/pretraining/model/deberta_v2.py
index c6ce82847f75..5fc284911e38 100644
--- a/examples/language/roberta/pretraining/model/deberta_v2.py
+++ b/examples/community/roberta/pretraining/model/deberta_v2.py
@@ -23,7 +23,7 @@
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, LayerNorm, MSELoss
-
+from transformers import FillMaskPipeline, T5ForConditionalGeneration, T5Tokenizer
from transformers.activations import ACT2FN
from transformers.modeling_outputs import (
BaseModelOutput,
@@ -34,10 +34,14 @@
TokenClassifierOutput,
)
from transformers.modeling_utils import PreTrainedModel
-from transformers.pytorch_utils import softmax_backward_data
-from transformers.utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward, logging
from transformers.models.deberta_v2.configuration_deberta_v2 import DebertaV2Config
-from transformers import T5Tokenizer, T5ForConditionalGeneration, FillMaskPipeline
+from transformers.pytorch_utils import softmax_backward_data
+from transformers.utils import (
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+)
logger = logging.get_logger(__name__)
@@ -55,6 +59,7 @@
# Copied from transformers.models.deberta.modeling_deberta.ContextPooler
class ContextPooler(nn.Module):
+
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.pooler_hidden_size, config.pooler_hidden_size)
@@ -133,15 +138,15 @@ def symbolic(g, self, mask, dim):
g.op("Sub", g.op("Constant", value_t=torch.tensor(1, dtype=torch.int64)), mask_cast_value),
to_i=sym_help.cast_pytorch_to_onnx["Byte"],
)
- output = masked_fill(
- g, self, r_mask, g.op("Constant", value_t=torch.tensor(torch.finfo(self.type().dtype()).min))
- )
+ output = masked_fill(g, self, r_mask,
+ g.op("Constant", value_t=torch.tensor(torch.finfo(self.type().dtype()).min)))
output = softmax(g, output, dim)
return masked_fill(g, output, r_mask, g.op("Constant", value_t=torch.tensor(0, dtype=torch.uint8)))
# Copied from transformers.models.deberta.modeling_deberta.DropoutContext
class DropoutContext(object):
+
def __init__(self):
self.dropout = 0
self.mask = None
@@ -244,6 +249,7 @@ def get_context(self):
# Copied from transformers.models.deberta.modeling_deberta.DebertaSelfOutput with DebertaLayerNorm->LayerNorm
class DebertaV2SelfOutput(nn.Module):
+
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
@@ -259,6 +265,7 @@ def forward(self, hidden_states, input_tensor):
# Copied from transformers.models.deberta.modeling_deberta.DebertaAttention with Deberta->DebertaV2
class DebertaV2Attention(nn.Module):
+
def __init__(self, config):
super().__init__()
self.self = DisentangledSelfAttention(config)
@@ -296,6 +303,7 @@ def forward(
# Copied from transformers.models.bert.modeling_bert.BertIntermediate with Bert->DebertaV2
class DebertaV2Intermediate(nn.Module):
+
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
@@ -312,6 +320,7 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# Copied from transformers.models.deberta.modeling_deberta.DebertaOutput with DebertaLayerNorm->LayerNorm
class DebertaV2Output(nn.Module):
+
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
@@ -328,6 +337,7 @@ def forward(self, hidden_states, input_tensor):
# Copied from transformers.models.deberta.modeling_deberta.DebertaLayer with Deberta->DebertaV2
class DebertaV2Layer(nn.Module):
+
def __init__(self, config):
super().__init__()
self.attention = DebertaV2Attention(config)
@@ -362,14 +372,17 @@ def forward(
class ConvLayer(nn.Module):
+
def __init__(self, config):
super().__init__()
kernel_size = getattr(config, "conv_kernel_size", 3)
groups = getattr(config, "conv_groups", 1)
self.conv_act = getattr(config, "conv_act", "tanh")
- self.conv = nn.Conv1d(
- config.hidden_size, config.hidden_size, kernel_size, padding=(kernel_size - 1) // 2, groups=groups
- )
+ self.conv = nn.Conv1d(config.hidden_size,
+ config.hidden_size,
+ kernel_size,
+ padding=(kernel_size - 1) // 2,
+ groups=groups)
self.LayerNorm = LayerNorm(config.hidden_size, config.layer_norm_eps)
self.dropout = StableDropout(config.hidden_dropout_prob)
self.config = config
@@ -452,9 +465,10 @@ def get_attention_mask(self, attention_mask):
def get_rel_pos(self, hidden_states, query_states=None, relative_pos=None):
if self.relative_attention and relative_pos is None:
q = query_states.size(-2) if query_states is not None else hidden_states.size(-2)
- relative_pos = build_relative_position(
- q, hidden_states.size(-2), bucket_size=self.position_buckets, max_position=self.max_relative_positions
- )
+ relative_pos = build_relative_position(q,
+ hidden_states.size(-2),
+ bucket_size=self.position_buckets,
+ max_position=self.max_relative_positions)
return relative_pos
def forward(
@@ -491,6 +505,7 @@ def forward(
if self.gradient_checkpointing and self.training:
def create_custom_forward(module):
+
def custom_forward(*inputs):
return module(*inputs, output_attentions)
@@ -535,9 +550,9 @@ def custom_forward(*inputs):
if not return_dict:
return tuple(v for v in [output_states, all_hidden_states, all_attentions] if v is not None)
- return BaseModelOutput(
- last_hidden_state=output_states, hidden_states=all_hidden_states, attentions=all_attentions
- )
+ return BaseModelOutput(last_hidden_state=output_states,
+ hidden_states=all_hidden_states,
+ attentions=all_attentions)
def make_log_bucket_position(relative_pos, bucket_size, max_position):
@@ -610,10 +625,8 @@ class DisentangledSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0:
- raise ValueError(
- f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
- f"heads ({config.num_attention_heads})"
- )
+ raise ValueError(f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
+ f"heads ({config.num_attention_heads})")
self.num_attention_heads = config.num_attention_heads
_attention_head_size = config.hidden_size // config.num_attention_heads
self.attention_head_size = getattr(config, "attention_head_size", _attention_head_size)
@@ -706,28 +719,22 @@ def forward(
attention_scores = torch.bmm(query_layer, key_layer.transpose(-1, -2)) / scale
if self.relative_attention:
rel_embeddings = self.pos_dropout(rel_embeddings)
- rel_att = self.disentangled_attention_bias(
- query_layer, key_layer, relative_pos, rel_embeddings, scale_factor
- )
+ rel_att = self.disentangled_attention_bias(query_layer, key_layer, relative_pos, rel_embeddings,
+ scale_factor)
if rel_att is not None:
attention_scores = attention_scores + rel_att
attention_scores = attention_scores
- attention_scores = attention_scores.view(
- -1, self.num_attention_heads, attention_scores.size(-2), attention_scores.size(-1)
- )
+ attention_scores = attention_scores.view(-1, self.num_attention_heads, attention_scores.size(-2),
+ attention_scores.size(-1))
# bsz x height x length x dimension
attention_probs = XSoftmax.apply(attention_scores, attention_mask, -1)
attention_probs = self.dropout(attention_probs)
- context_layer = torch.bmm(
- attention_probs.view(-1, attention_probs.size(-2), attention_probs.size(-1)), value_layer
- )
- context_layer = (
- context_layer.view(-1, self.num_attention_heads, context_layer.size(-2), context_layer.size(-1))
- .permute(0, 2, 1, 3)
- .contiguous()
- )
+ context_layer = torch.bmm(attention_probs.view(-1, attention_probs.size(-2), attention_probs.size(-1)),
+ value_layer)
+ context_layer = (context_layer.view(-1, self.num_attention_heads, context_layer.size(-2),
+ context_layer.size(-1)).permute(0, 2, 1, 3).contiguous())
new_context_layer_shape = context_layer.size()[:-2] + (-1,)
context_layer = context_layer.view(new_context_layer_shape)
if output_attentions:
@@ -738,9 +745,10 @@ def forward(
def disentangled_attention_bias(self, query_layer, key_layer, relative_pos, rel_embeddings, scale_factor):
if relative_pos is None:
q = query_layer.size(-2)
- relative_pos = build_relative_position(
- q, key_layer.size(-2), bucket_size=self.position_buckets, max_position=self.max_relative_positions
- )
+ relative_pos = build_relative_position(q,
+ key_layer.size(-2),
+ bucket_size=self.position_buckets,
+ max_position=self.max_relative_positions)
if relative_pos.dim() == 2:
relative_pos = relative_pos.unsqueeze(0).unsqueeze(0)
elif relative_pos.dim() == 3:
@@ -758,25 +766,22 @@ def disentangled_attention_bias(self, query_layer, key_layer, relative_pos, rel_
# rel_embeddings = rel_embeddings.unsqueeze(0)
# rel_embeddings = rel_embeddings[0 : att_span * 2, :].unsqueeze(0)
if self.share_att_key:
- pos_query_layer = self.transpose_for_scores(
- self.query_proj(rel_embeddings), self.num_attention_heads
- ).repeat(query_layer.size(0) // self.num_attention_heads, 1, 1)
+ pos_query_layer = self.transpose_for_scores(self.query_proj(rel_embeddings),
+ self.num_attention_heads).repeat(
+ query_layer.size(0) // self.num_attention_heads, 1, 1)
pos_key_layer = self.transpose_for_scores(self.key_proj(rel_embeddings), self.num_attention_heads).repeat(
- query_layer.size(0) // self.num_attention_heads, 1, 1
- )
+ query_layer.size(0) // self.num_attention_heads, 1, 1)
else:
if "c2p" in self.pos_att_type:
- pos_key_layer = self.transpose_for_scores(
- self.pos_key_proj(rel_embeddings), self.num_attention_heads
- ).repeat(
- query_layer.size(0) // self.num_attention_heads, 1, 1
- ) # .split(self.all_head_size, dim=-1)
+ pos_key_layer = self.transpose_for_scores(self.pos_key_proj(rel_embeddings),
+ self.num_attention_heads).repeat(
+ query_layer.size(0) // self.num_attention_heads, 1,
+ 1) # .split(self.all_head_size, dim=-1)
if "p2c" in self.pos_att_type:
- pos_query_layer = self.transpose_for_scores(
- self.pos_query_proj(rel_embeddings), self.num_attention_heads
- ).repeat(
- query_layer.size(0) // self.num_attention_heads, 1, 1
- ) # .split(self.all_head_size, dim=-1)
+ pos_query_layer = self.transpose_for_scores(self.pos_query_proj(rel_embeddings),
+ self.num_attention_heads).repeat(
+ query_layer.size(0) // self.num_attention_heads, 1,
+ 1) # .split(self.all_head_size, dim=-1)
score = 0
# content->position
@@ -787,7 +792,9 @@ def disentangled_attention_bias(self, query_layer, key_layer, relative_pos, rel_
c2p_att = torch.gather(
c2p_att,
dim=-1,
- index=c2p_pos.squeeze(0).expand([query_layer.size(0), query_layer.size(1), relative_pos.size(-1)]),
+ index=c2p_pos.squeeze(0).expand([query_layer.size(0),
+ query_layer.size(1),
+ relative_pos.size(-1)]),
)
score += c2p_att / scale
@@ -810,7 +817,9 @@ def disentangled_attention_bias(self, query_layer, key_layer, relative_pos, rel_
p2c_att = torch.gather(
p2c_att,
dim=-1,
- index=p2c_pos.squeeze(0).expand([query_layer.size(0), key_layer.size(-2), key_layer.size(-2)]),
+ index=p2c_pos.squeeze(0).expand([query_layer.size(0),
+ key_layer.size(-2),
+ key_layer.size(-2)]),
).transpose(-1, -2)
score += p2c_att / scale
@@ -990,6 +999,7 @@ def _set_gradient_checkpointing(self, module, value=False):
)
# Copied from transformers.models.deberta.modeling_deberta.DebertaModel with Deberta->DebertaV2
class DebertaV2Model(DebertaV2PreTrainedModel):
+
def __init__(self, config):
super().__init__(config)
@@ -1032,9 +1042,8 @@ def forward(
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutput]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
- output_hidden_states = (
- output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
- )
+ output_hidden_states = (output_hidden_states
+ if output_hidden_states is not None else self.config.output_hidden_states)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
@@ -1091,7 +1100,7 @@ def forward(
sequence_output = encoded_layers[-1]
if not return_dict:
- return (sequence_output,) + encoder_outputs[(1 if output_hidden_states else 2) :]
+ return (sequence_output,) + encoder_outputs[(1 if output_hidden_states else 2):]
return BaseModelOutput(
last_hidden_state=sequence_output,
@@ -1165,7 +1174,7 @@ def forward(
masked_lm_loss = None
if labels is not None:
- loss_fct = CrossEntropyLoss() # -100 index = padding token
+ loss_fct = CrossEntropyLoss() # -100 index = padding token
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
@@ -1182,6 +1191,7 @@ def forward(
# copied from transformers.models.bert.BertPredictionHeadTransform with bert -> deberta
class DebertaV2PredictionHeadTransform(nn.Module):
+
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
@@ -1200,6 +1210,7 @@ def forward(self, hidden_states):
# copied from transformers.models.bert.BertLMPredictionHead with bert -> deberta
class DebertaV2LMPredictionHead(nn.Module):
+
def __init__(self, config):
super().__init__()
self.transform = DebertaV2PredictionHeadTransform(config)
@@ -1221,6 +1232,7 @@ def forward(self, hidden_states):
# copied from transformers.models.bert.BertOnlyMLMHead with bert -> deberta
class DebertaV2OnlyMLMHead(nn.Module):
+
def __init__(self, config):
super().__init__()
self.predictions = DebertaV2LMPredictionHead(config)
@@ -1239,6 +1251,7 @@ def forward(self, sequence_output):
)
# Copied from transformers.models.deberta.modeling_deberta.DebertaForSequenceClassification with Deberta->DebertaV2
class DebertaV2ForSequenceClassification(DebertaV2PreTrainedModel):
+
def __init__(self, config):
super().__init__(config)
@@ -1318,9 +1331,8 @@ def forward(
label_index = (labels >= 0).nonzero()
labels = labels.long()
if label_index.size(0) > 0:
- labeled_logits = torch.gather(
- logits, 0, label_index.expand(label_index.size(0), logits.size(1))
- )
+ labeled_logits = torch.gather(logits, 0, label_index.expand(label_index.size(0),
+ logits.size(1)))
labels = torch.gather(labels, 0, label_index.view(-1))
loss_fct = CrossEntropyLoss()
loss = loss_fct(labeled_logits.view(-1, self.num_labels).float(), labels.view(-1))
@@ -1345,9 +1357,10 @@ def forward(
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
- return SequenceClassifierOutput(
- loss=loss, logits=logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions
- )
+ return SequenceClassifierOutput(loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions)
@add_start_docstrings(
@@ -1422,9 +1435,10 @@ def forward(
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
- return TokenClassifierOutput(
- loss=loss, logits=logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions
- )
+ return TokenClassifierOutput(loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions)
@add_start_docstrings(
@@ -1536,6 +1550,7 @@ def forward(
DEBERTA_START_DOCSTRING,
)
class DebertaV2ForMultipleChoice(DebertaV2PreTrainedModel):
+
def __init__(self, config):
super().__init__(config)
@@ -1591,11 +1606,8 @@ def forward(
flat_position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
flat_token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
flat_attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
- flat_inputs_embeds = (
- inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
- if inputs_embeds is not None
- else None
- )
+ flat_inputs_embeds = (inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
+ if inputs_embeds is not None else None)
outputs = self.deberta(
flat_input_ids,
diff --git a/examples/language/roberta/pretraining/nvidia_bert_dataset_provider.py b/examples/community/roberta/pretraining/nvidia_bert_dataset_provider.py
similarity index 76%
rename from examples/language/roberta/pretraining/nvidia_bert_dataset_provider.py
rename to examples/community/roberta/pretraining/nvidia_bert_dataset_provider.py
index cce836913505..72c7bd852a40 100644
--- a/examples/language/roberta/pretraining/nvidia_bert_dataset_provider.py
+++ b/examples/community/roberta/pretraining/nvidia_bert_dataset_provider.py
@@ -1,24 +1,25 @@
+import json
+import logging
import os
import random
-import h5py
-import logging
-import json
import time
from concurrent.futures import ProcessPoolExecutor
+import h5py
import numpy as np
-
import torch
import torch.distributed as dist
+from bert_dataset_provider import BertDatasetProviderInterface
from torch.utils.data import DataLoader, Dataset
-from torch.utils.data.sampler import RandomSampler
from torch.utils.data.distributed import DistributedSampler
+from torch.utils.data.sampler import RandomSampler
-from bert_dataset_provider import BertDatasetProviderInterface
import colossalai.utils as utils
+
# Workaround because python functions are not picklable
class WorkerInitObj(object):
+
def __init__(self, seed):
self.seed = seed
@@ -27,29 +28,25 @@ def __call__(self, id):
random.seed(self.seed + id)
-def create_pretraining_dataset(input_file, max_predictions_per_seq,
- num_workers, train_batch_size, worker_init,
+def create_pretraining_dataset(input_file, max_predictions_per_seq, num_workers, train_batch_size, worker_init,
data_sampler):
- train_data = pretraining_dataset(
- input_file=input_file, max_predictions_per_seq=max_predictions_per_seq)
+ train_data = pretraining_dataset(input_file=input_file, max_predictions_per_seq=max_predictions_per_seq)
train_dataloader = DataLoader(train_data,
sampler=data_sampler(train_data),
batch_size=train_batch_size,
num_workers=num_workers,
worker_init_fn=worker_init,
- pin_memory=True
- )
+ pin_memory=True)
return train_dataloader, len(train_data)
class pretraining_dataset(Dataset):
+
def __init__(self, input_file, max_predictions_per_seq):
self.input_file = input_file
self.max_predictions_per_seq = max_predictions_per_seq
f = h5py.File(input_file, "r")
- keys = [
- 'input_ids', 'input_mask', 'segment_ids', 'masked_lm_positions'
- ]
+ keys = ['input_ids', 'input_mask', 'segment_ids', 'masked_lm_positions']
self.inputs = [np.asarray(f[key][:]) for key in keys]
f.close()
@@ -59,21 +56,16 @@ def __len__(self):
def __getitem__(self, index):
- [
- input_ids, input_mask, segment_ids, masked_lm_labels
- ] = [
- torch.from_numpy(input[index].astype(np.int64)) if indice < 5 else
- torch.from_numpy(np.asarray(input[index].astype(np.int64)))
- for indice, input in enumerate(self.inputs)
+ [input_ids, input_mask, segment_ids, masked_lm_labels] = [
+ torch.from_numpy(input[index].astype(np.int64)) if indice < 5 else torch.from_numpy(
+ np.asarray(input[index].astype(np.int64))) for indice, input in enumerate(self.inputs)
]
- return [
- input_ids, input_mask,
- segment_ids, masked_lm_labels
- ]
+ return [input_ids, input_mask, segment_ids, masked_lm_labels]
class NvidiaBertDatasetProvider(BertDatasetProviderInterface):
+
def __init__(self, args, evaluate=False):
self.num_workers = args.num_workers
self.max_seq_length = args.max_seq_length
@@ -85,22 +77,24 @@ def __init__(self, args, evaluate=False):
else:
self.train_micro_batch_size_per_gpu = args.eval_micro_batch_size_per_gpu
self.logger = args.logger
-
+
self.global_rank = dist.get_rank()
self.world_size = dist.get_world_size()
# Initialize dataset files
if not evaluate:
self.dataset_files = [
- os.path.join(args.data_path_prefix, f) for f in os.listdir(args.data_path_prefix) if
- os.path.isfile(os.path.join(args.data_path_prefix, f)) and 'h5' in f
+ os.path.join(args.data_path_prefix, f)
+ for f in os.listdir(args.data_path_prefix)
+ if os.path.isfile(os.path.join(args.data_path_prefix, f)) and 'h5' in f
]
else:
self.dataset_files = [
- os.path.join(args.eval_data_path_prefix, f) for f in os.listdir(args.eval_data_path_prefix) if
- os.path.isfile(os.path.join(args.eval_data_path_prefix, f)) and 'h5' in f
+ os.path.join(args.eval_data_path_prefix, f)
+ for f in os.listdir(args.eval_data_path_prefix)
+ if os.path.isfile(os.path.join(args.eval_data_path_prefix, f)) and 'h5' in f
]
-
+
self.dataset_files.sort()
# random.shuffle(self.dataset_files)
self.num_files = len(self.dataset_files)
@@ -114,9 +108,7 @@ def __init__(self, args, evaluate=False):
self.shuffle = True
if self.global_rank == 0:
- self.logger.info(
- f"NvidiaBertDatasetProvider - Initialization: num_files = {self.num_files}"
- )
+ self.logger.info(f"NvidiaBertDatasetProvider - Initialization: num_files = {self.num_files}")
def get_shard(self, index):
start = time.time()
@@ -130,9 +122,8 @@ def get_shard(self, index):
worker_init=self.worker_init,
data_sampler=self.data_sampler)
else:
- self.train_dataloader, sample_count = self.dataset_future.result(
- timeout=None)
-
+ self.train_dataloader, sample_count = self.dataset_future.result(timeout=None)
+
self.logger.info(
f"Data Loading Completed for Pretraining Data from {self.data_file} with {sample_count} samples took {time.time()-start:.2f}s."
)
@@ -145,11 +136,9 @@ def release_shard(self):
def prefetch_shard(self, index):
self.data_file = self._get_shard_file(index)
- self.dataset_future = self.pool.submit(
- create_pretraining_dataset, self.data_file,
- self.max_predictions_per_seq, self.num_workers,
- self.train_micro_batch_size_per_gpu, self.worker_init,
- self.data_sampler)
+ self.dataset_future = self.pool.submit(create_pretraining_dataset, self.data_file, self.max_predictions_per_seq,
+ self.num_workers, self.train_micro_batch_size_per_gpu, self.worker_init,
+ self.data_sampler)
def get_batch(self, batch_iter):
return batch_iter
@@ -179,4 +168,3 @@ def shuffle_dataset(self, epoch):
indices = torch.randperm(self.num_files, generator=g).tolist()
new_dataset = [self.dataset_files[i] for i in indices]
self.dataset_files = new_dataset
-
\ No newline at end of file
diff --git a/examples/language/roberta/pretraining/pretrain_utils.py b/examples/community/roberta/pretraining/pretrain_utils.py
similarity index 77%
rename from examples/language/roberta/pretraining/pretrain_utils.py
rename to examples/community/roberta/pretraining/pretrain_utils.py
index 54fc2affe632..cea6ac2c36e5 100644
--- a/examples/language/roberta/pretraining/pretrain_utils.py
+++ b/examples/community/roberta/pretraining/pretrain_utils.py
@@ -1,35 +1,45 @@
-import transformers
import logging
-from colossalai.nn.lr_scheduler import LinearWarmupLR
-from transformers import get_linear_schedule_with_warmup
-from transformers import BertForPreTraining, RobertaForMaskedLM, RobertaConfig
-from transformers import GPT2Config, GPT2LMHeadModel
-from transformers import AutoTokenizer, AutoModelForMaskedLM
-from colossalai.nn.optimizer import FusedAdam, HybridAdam
-from torch.optim import AdamW
-from colossalai.core import global_context as gpc
-import torch
import os
import sys
-sys.path.append(os.getcwd())
-from model.deberta_v2 import DebertaV2ForMaskedLM
-from model.bert import BertForMaskedLM
-import torch.nn as nn
+import torch
+import transformers
+from torch.optim import AdamW
+from transformers import (
+ AutoModelForMaskedLM,
+ AutoTokenizer,
+ BertForPreTraining,
+ GPT2Config,
+ GPT2LMHeadModel,
+ RobertaConfig,
+ RobertaForMaskedLM,
+ get_linear_schedule_with_warmup,
+)
+
+from colossalai.core import global_context as gpc
+from colossalai.nn.lr_scheduler import LinearWarmupLR
+from colossalai.nn.optimizer import FusedAdam, HybridAdam
+
+sys.path.append(os.getcwd())
from collections import OrderedDict
+import torch.nn as nn
+from model.bert import BertForMaskedLM
+from model.deberta_v2 import DebertaV2ForMaskedLM
+
__all__ = ['get_model', 'get_optimizer', 'get_lr_scheduler', 'get_dataloader_for_pretraining']
def get_new_state_dict(state_dict, start_index=13):
- new_state_dict = OrderedDict()
+ new_state_dict = OrderedDict()
for k, v in state_dict.items():
name = k[start_index:]
- new_state_dict[name] = v
+ new_state_dict[name] = v
return new_state_dict
class LMModel(nn.Module):
+
def __init__(self, model, config, args):
super().__init__()
@@ -58,16 +68,18 @@ def get_model(args, logger):
if len(args.load_pretrain_model) > 0:
assert os.path.exists(args.load_pretrain_model)
# load_checkpoint(args.load_pretrain_model, model, strict=False)
- m_state_dict = torch.load(args.load_pretrain_model, map_location=torch.device(f"cuda:{torch.cuda.current_device()}"))
+ m_state_dict = torch.load(args.load_pretrain_model,
+ map_location=torch.device(f"cuda:{torch.cuda.current_device()}"))
# new_state_dict = get_new_state_dict(m_state_dict)
- model.load_state_dict(m_state_dict, strict=True) # must insure that every process have identical parameters !!!!!!!
+ model.load_state_dict(m_state_dict,
+ strict=True) # must insure that every process have identical parameters !!!!!!!
logger.info("load model success")
-
+
numel = sum([p.numel() for p in model.parameters()])
if args.checkpoint_activations:
model.gradient_checkpointing_enable()
# model = LMModel(model, config, args)
-
+
return config, model, numel
@@ -89,7 +101,10 @@ def get_optimizer(model, lr):
def get_lr_scheduler(optimizer, total_steps, warmup_steps=2000, last_epoch=-1):
# warmup_steps = int(total_steps * warmup_ratio)
- lr_scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=total_steps, last_epoch=last_epoch)
+ lr_scheduler = get_linear_schedule_with_warmup(optimizer,
+ num_warmup_steps=warmup_steps,
+ num_training_steps=total_steps,
+ last_epoch=last_epoch)
# lr_scheduler = LinearWarmupLR(optimizer, total_steps=total_steps, warmup_steps=warmup_steps)
return lr_scheduler
@@ -103,10 +118,7 @@ def save_ckpt(model, optimizer, lr_scheduler, path, epoch, shard, global_step):
checkpoint['epoch'] = epoch
checkpoint['shard'] = shard
checkpoint['global_step'] = global_step
- model_state = model.state_dict() #each process must run model.state_dict()
+ model_state = model.state_dict() #each process must run model.state_dict()
if gpc.get_global_rank() == 0:
torch.save(checkpoint, optimizer_lr_path)
torch.save(model_state, model_path)
-
-
-
diff --git a/examples/language/roberta/pretraining/run_pretrain.sh b/examples/community/roberta/pretraining/run_pretrain.sh
similarity index 98%
rename from examples/language/roberta/pretraining/run_pretrain.sh
rename to examples/community/roberta/pretraining/run_pretrain.sh
index 38fdefe0af8a..280dba714de5 100644
--- a/examples/language/roberta/pretraining/run_pretrain.sh
+++ b/examples/community/roberta/pretraining/run_pretrain.sh
@@ -35,4 +35,3 @@ env OMP_NUM_THREADS=40 colossalai run --hostfile ./hostfile \
--mlm bert \
--wandb \
--checkpoint_activations \
-
\ No newline at end of file
diff --git a/examples/language/roberta/pretraining/run_pretrain_resume.sh b/examples/community/roberta/pretraining/run_pretrain_resume.sh
similarity index 98%
rename from examples/language/roberta/pretraining/run_pretrain_resume.sh
rename to examples/community/roberta/pretraining/run_pretrain_resume.sh
index 351c98d3e9cb..8f443b454d7d 100644
--- a/examples/language/roberta/pretraining/run_pretrain_resume.sh
+++ b/examples/community/roberta/pretraining/run_pretrain_resume.sh
@@ -38,4 +38,3 @@ env OMP_NUM_THREADS=40 colossalai run --hostfile ./hostfile \
--resume_train \
--load_pretrain_model /ckpt/1.pt \
--load_optimizer_lr /ckpt/1.op_lrs \
-
\ No newline at end of file
diff --git a/examples/language/roberta/pretraining/run_pretraining.py b/examples/community/roberta/pretraining/run_pretraining.py
similarity index 94%
rename from examples/language/roberta/pretraining/run_pretraining.py
rename to examples/community/roberta/pretraining/run_pretraining.py
index a283c44cadbf..9a6ffc1c5661 100644
--- a/examples/language/roberta/pretraining/run_pretraining.py
+++ b/examples/community/roberta/pretraining/run_pretraining.py
@@ -4,21 +4,6 @@
from functools import partial
import torch
-from tqdm import tqdm
-import os
-import time
-from functools import partial
-from transformers import AutoTokenizer
-
-import colossalai
-from colossalai.context import ParallelMode
-from colossalai.core import global_context as gpc
-from colossalai.nn.parallel import GeminiDDP, zero_model_wrapper, zero_optim_wrapper
-from colossalai.utils import get_current_device
-from colossalai.utils.model.colo_init_context import ColoInitContext
-from colossalai.zero import ZeroOptimizer
-from colossalai.tensor import ColoParameter, ComputePattern, ComputeSpec, ProcessGroup, ReplicaSpec, ShardSpec
-
from arguments import parse_args
from evaluation import evaluate
from loss import LossForPretraining
@@ -30,6 +15,15 @@
from utils.global_vars import get_tensorboard_writer, get_timers, set_global_variables
from utils.logger import Logger
+import colossalai
+from colossalai.context import ParallelMode
+from colossalai.core import global_context as gpc
+from colossalai.nn.parallel import GeminiDDP, zero_model_wrapper, zero_optim_wrapper
+from colossalai.tensor import ColoParameter, ComputePattern, ComputeSpec, ProcessGroup, ReplicaSpec, ShardSpec
+from colossalai.utils import get_current_device
+from colossalai.utils.model.colo_init_context import ColoInitContext
+from colossalai.zero import ZeroOptimizer
+
def main():
@@ -39,7 +33,7 @@ def main():
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_path)
# os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
-
+
logger = Logger(os.path.join(args.log_path, launch_time), cuda=torch.cuda.is_available(), debug=args.vscode_debug)
if args.vscode_debug:
@@ -52,7 +46,7 @@ def main():
args.local_rank = -1
args.log_interval = 1
else:
- colossalai.launch_from_torch(config={}) #args.colossal_config
+ colossalai.launch_from_torch(config={}) #args.colossal_config
args.local_rank = int(os.environ["LOCAL_RANK"])
logger.info(
f'launch_from_torch, world size: {torch.distributed.get_world_size()} | ' +
@@ -63,7 +57,7 @@ def main():
args.tokenizer = tokenizer
args.logger = logger
set_global_variables(launch_time, args.tensorboard_path)
-
+
world_size = torch.distributed.get_world_size()
init_dev = get_current_device()
@@ -116,7 +110,7 @@ def main():
optimizer = zero_optim_wrapper(model, optimizer, optim_config=optim_config)
logger.info(get_mem_info(prefix='After init optim, '))
-
+
else:
config, model, numel = get_model(args, logger)
logger.info("no_zero")
@@ -129,7 +123,7 @@ def main():
get_tflops_func = partial(get_tflops, numel, args.train_micro_batch_size_per_gpu, args.max_seq_length)
# 144003367 is is the length of the entire dataset
- steps_per_epoch = 144003367 // world_size // args.train_micro_batch_size_per_gpu // args.gradient_accumulation_steps // args.refresh_bucket_size #len(dataloader)
+ steps_per_epoch = 144003367 // world_size // args.train_micro_batch_size_per_gpu // args.gradient_accumulation_steps // args.refresh_bucket_size #len(dataloader)
total_steps = steps_per_epoch * args.epoch
lr_scheduler = get_lr_scheduler(optimizer, total_steps=total_steps, last_epoch=-1)
@@ -156,14 +150,15 @@ def main():
start_epoch = o_l_state_dict['epoch']
start_shard = o_l_state_dict['shard'] + 1
# global_step = o_l_state_dict['global_step'] + 1
- logger.info(f'resume from epoch {start_epoch} shard {start_shard} step {lr_scheduler.last_epoch} lr {lr_scheduler.get_last_lr()[0]}')
+ logger.info(
+ f'resume from epoch {start_epoch} shard {start_shard} step {lr_scheduler.last_epoch} lr {lr_scheduler.get_last_lr()[0]}'
+ )
criterion = LossForPretraining(config.vocab_size)
# build dataloader
pretrain_dataset_provider = NvidiaBertDatasetProvider(args)
-
logger.info(get_mem_info(prefix='After init model, '))
best_loss = None
@@ -189,8 +184,8 @@ def main():
iterator_data = enumerate(dataset_iterator)
model.train()
-
- for step, batch_data in iterator_data:
+
+ for step, batch_data in iterator_data:
# batch_data = pretrain_dataset_provider.get_batch(batch_index)
input_ids = batch_data[0].cuda(f"cuda:{torch.cuda.current_device()}")
@@ -200,7 +195,7 @@ def main():
# nsp_label = batch_data[5].cuda()
output = model(input_ids=input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
-
+
loss = criterion(output.logits, mlm_label)
pretrain_dataset_provider.prefetch_batch()
@@ -210,7 +205,7 @@ def main():
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
-
+
global_step += 1
if global_step % args.log_interval == 0 and global_step != 0 \
@@ -242,9 +237,10 @@ def main():
logger.info('*' * 100)
eval_loss += evaluate(model, args, logger, global_step, criterion)
- save_ckpt(model, optimizer, lr_scheduler, os.path.join(args.ckpt_path, launch_time, f'epoch-{epoch}_shard-{shard}_' + launch_time), epoch, shard, global_step)
-
-
+ save_ckpt(model, optimizer, lr_scheduler,
+ os.path.join(args.ckpt_path, launch_time, f'epoch-{epoch}_shard-{shard}_' + launch_time), epoch,
+ shard, global_step)
+
eval_loss /= len(os.listdir(args.data_path_prefix))
logger.info(
f'epoch {epoch} | shard_length {len(os.listdir(args.data_path_prefix))} | elapsed_time: {timers("epoch_time").elapsed() / 60 :.3f} mins'
diff --git a/examples/language/roberta/pretraining/utils/WandbLog.py b/examples/community/roberta/pretraining/utils/WandbLog.py
similarity index 98%
rename from examples/language/roberta/pretraining/utils/WandbLog.py
rename to examples/community/roberta/pretraining/utils/WandbLog.py
index 9dd28a98186b..b68ba8387dcd 100644
--- a/examples/language/roberta/pretraining/utils/WandbLog.py
+++ b/examples/community/roberta/pretraining/utils/WandbLog.py
@@ -1,8 +1,10 @@
+import os
import time
+
import wandb
-import os
from torch.utils.tensorboard import SummaryWriter
+
class WandbLog:
@classmethod
@@ -15,7 +17,7 @@ def log(cls, result, model=None, gradient=None):
if model:
wandb.watch(model)
-
+
if gradient:
wandb.watch(gradient)
@@ -30,7 +32,7 @@ def __init__(self, location, name=time.strftime("%Y-%m-%d %H:%M:%S", time.localt
def log_train(self, result, step):
for k, v in result.items():
self.writer.add_scalar(f'{k}/train', v, step)
-
+
def log_eval(self, result, step):
for k, v in result.items():
self.writer.add_scalar(f'{k}/eval', v, step)
@@ -38,9 +40,3 @@ def log_eval(self, result, step):
def log_zeroshot(self, result, step):
for k, v in result.items():
self.writer.add_scalar(f'{k}_acc/eval', v, step)
-
-
-
-
-
-
diff --git a/examples/language/roberta/pretraining/utils/exp_util.py b/examples/community/roberta/pretraining/utils/exp_util.py
similarity index 86%
rename from examples/language/roberta/pretraining/utils/exp_util.py
rename to examples/community/roberta/pretraining/utils/exp_util.py
index a02b0872acbc..0cdb56bad031 100644
--- a/examples/language/roberta/pretraining/utils/exp_util.py
+++ b/examples/community/roberta/pretraining/utils/exp_util.py
@@ -1,9 +1,13 @@
import functools
-import os, shutil
-import torch
+import os
+import shutil
+
import psutil
+import torch
+
from colossalai.core import global_context as gpc
+
def logging(s, log_path, print_=True, log_=True):
if print_:
print(s)
@@ -11,9 +15,11 @@ def logging(s, log_path, print_=True, log_=True):
with open(log_path, 'a+') as f_log:
f_log.write(s + '\n')
+
def get_logger(log_path, **kwargs):
return functools.partial(logging, log_path=log_path, **kwargs)
+
def create_exp_dir(dir_path, scripts_to_save=None, debug=False):
if debug:
print('Debug Mode : no experiment dir created')
@@ -33,6 +39,7 @@ def create_exp_dir(dir_path, scripts_to_save=None, debug=False):
return get_logger(log_path=os.path.join(dir_path, 'log.txt'))
+
def get_cpu_mem():
return psutil.Process().memory_info().rss / 1024**2
@@ -52,11 +59,15 @@ def get_tflops(model_numel, batch_size, seq_len, step_time):
def get_parameters_in_billions(model, world_size=1):
gpus_per_model = world_size
- approx_parameters_in_billions = sum([sum([p.ds_numel if hasattr(p,'ds_id') else p.nelement() for p in model_module.parameters()])
- for model_module in model])
+ approx_parameters_in_billions = sum([
+ sum([p.ds_numel if hasattr(p, 'ds_id') else p.nelement()
+ for p in model_module.parameters()])
+ for model_module in model
+ ])
return approx_parameters_in_billions * gpus_per_model / (1e9)
+
def throughput_calculator(numel, args, config, iteration_time, total_iterations, world_size=1):
gpus_per_model = 1
batch_size = args.train_micro_batch_size_per_gpu
@@ -76,10 +87,13 @@ def throughput_calculator(numel, args, config, iteration_time, total_iterations,
# The factor of 4 is when used with activation check-pointing,
# otherwise it will be 3.
checkpoint_activations_factor = 4 if args.checkpoint_activations else 3
- flops_per_iteration = (24 * checkpoint_activations_factor * batch_size * args.max_seq_length * num_layers * (hidden_size**2)) * (1. + (args.max_seq_length / (6. * hidden_size)) + (vocab_size / (16. * num_layers * hidden_size)))
+ flops_per_iteration = (24 * checkpoint_activations_factor * batch_size * args.max_seq_length * num_layers *
+ (hidden_size**2)) * (1. + (args.max_seq_length / (6. * hidden_size)) +
+ (vocab_size / (16. * num_layers * hidden_size)))
tflops = flops_per_iteration / (elapsed_time_per_iter * (10**12))
return samples_per_second, tflops, approx_parameters_in_billions
+
def synchronize():
if not torch.distributed.is_available():
return
@@ -90,10 +104,11 @@ def synchronize():
return
torch.distributed.barrier()
+
def log_args(logger, args):
logger.info('--------args----------')
message = '\n'.join([f'{k:<30}: {v}' for k, v in vars(args).items()])
message += '\n'
message += '\n'.join([f'{k:<30}: {v}' for k, v in gpc.config.items()])
logger.info(message)
- logger.info('--------args----------\n')
\ No newline at end of file
+ logger.info('--------args----------\n')
diff --git a/examples/language/roberta/pretraining/utils/global_vars.py b/examples/community/roberta/pretraining/utils/global_vars.py
similarity index 91%
rename from examples/language/roberta/pretraining/utils/global_vars.py
rename to examples/community/roberta/pretraining/utils/global_vars.py
index 363cbf91c065..7b0c5a2be73d 100644
--- a/examples/language/roberta/pretraining/utils/global_vars.py
+++ b/examples/community/roberta/pretraining/utils/global_vars.py
@@ -1,5 +1,7 @@
import time
+
import torch
+
from .WandbLog import TensorboardLog
_GLOBAL_TIMERS = None
@@ -10,30 +12,34 @@ def set_global_variables(launch_time, tensorboard_path):
_set_timers()
_set_tensorboard_writer(launch_time, tensorboard_path)
+
def _set_timers():
"""Initialize timers."""
global _GLOBAL_TIMERS
_ensure_var_is_not_initialized(_GLOBAL_TIMERS, 'timers')
_GLOBAL_TIMERS = Timers()
+
def _set_tensorboard_writer(launch_time, tensorboard_path):
"""Set tensorboard writer."""
global _GLOBAL_TENSORBOARD_WRITER
- _ensure_var_is_not_initialized(_GLOBAL_TENSORBOARD_WRITER,
- 'tensorboard writer')
+ _ensure_var_is_not_initialized(_GLOBAL_TENSORBOARD_WRITER, 'tensorboard writer')
if torch.distributed.get_rank() == 0:
_GLOBAL_TENSORBOARD_WRITER = TensorboardLog(tensorboard_path + f'/{launch_time}', launch_time)
-
+
+
def get_timers():
"""Return timers."""
_ensure_var_is_initialized(_GLOBAL_TIMERS, 'timers')
return _GLOBAL_TIMERS
+
def get_tensorboard_writer():
"""Return tensorboard writer. It can be None so no need
to check if it is initialized."""
return _GLOBAL_TENSORBOARD_WRITER
+
def _ensure_var_is_initialized(var, name):
"""Make sure the input variable is not None."""
assert var is not None, '{} is not initialized.'.format(name)
@@ -115,12 +121,10 @@ def log(self, names, normalizer=1.0, reset=True):
assert normalizer > 0.0
string = 'time (ms)'
for name in names:
- elapsed_time = self.timers[name].elapsed(
- reset=reset) * 1000.0 / normalizer
+ elapsed_time = self.timers[name].elapsed(reset=reset) * 1000.0 / normalizer
string += ' | {}: {:.2f}'.format(name, elapsed_time)
if torch.distributed.is_initialized():
- if torch.distributed.get_rank() == (
- torch.distributed.get_world_size() - 1):
+ if torch.distributed.get_rank() == (torch.distributed.get_world_size() - 1):
print(string, flush=True)
else:
print(string, flush=True)
diff --git a/examples/language/roberta/pretraining/utils/logger.py b/examples/community/roberta/pretraining/utils/logger.py
similarity index 81%
rename from examples/language/roberta/pretraining/utils/logger.py
rename to examples/community/roberta/pretraining/utils/logger.py
index 481c4c6ce61b..75c9bf4bef25 100644
--- a/examples/language/roberta/pretraining/utils/logger.py
+++ b/examples/community/roberta/pretraining/utils/logger.py
@@ -1,22 +1,22 @@
-import os
import logging
+import os
+
import torch.distributed as dist
-logging.basicConfig(
- format='%(asctime)s - %(levelname)s - %(name)s - %(message)s',
- datefmt='%m/%d/%Y %H:%M:%S',
- level=logging.INFO)
+logging.basicConfig(format='%(asctime)s - %(levelname)s - %(name)s - %(message)s',
+ datefmt='%m/%d/%Y %H:%M:%S',
+ level=logging.INFO)
logger = logging.getLogger(__name__)
class Logger():
+
def __init__(self, log_path, cuda=False, debug=False):
self.logger = logging.getLogger(__name__)
self.cuda = cuda
self.log_path = log_path
self.debug = debug
-
def info(self, message, log_=True, print_=True, *args, **kwargs):
if (self.cuda and dist.get_rank() == 0) or not self.cuda:
if print_:
@@ -26,6 +26,5 @@ def info(self, message, log_=True, print_=True, *args, **kwargs):
with open(self.log_path, 'a+') as f_log:
f_log.write(message + '\n')
-
def error(self, message, *args, **kwargs):
self.logger.error(message, *args, **kwargs)
diff --git a/examples/language/roberta/requirements.txt b/examples/community/roberta/requirements.txt
similarity index 91%
rename from examples/language/roberta/requirements.txt
rename to examples/community/roberta/requirements.txt
index d351f362f3f7..de082defb14a 100644
--- a/examples/language/roberta/requirements.txt
+++ b/examples/community/roberta/requirements.txt
@@ -4,4 +4,4 @@ tqdm
tensorboard
numpy
h5py
-wandb
\ No newline at end of file
+wandb
diff --git a/examples/images/diffusion/configs/Inference/v2-inference-v.yaml b/examples/images/diffusion/configs/Inference/v2-inference-v.yaml
index 8ec8dfbfefe9..b05955d3faf7 100644
--- a/examples/images/diffusion/configs/Inference/v2-inference-v.yaml
+++ b/examples/images/diffusion/configs/Inference/v2-inference-v.yaml
@@ -1,6 +1,5 @@
model:
base_learning_rate: 1.0e-4
- target: ldm.models.diffusion.ddpm.LatentDiffusion
params:
parameterization: "v"
linear_start: 0.00085
@@ -19,50 +18,42 @@ model:
use_ema: False # we set this to false because this is an inference only config
unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- use_checkpoint: True
- use_fp16: True
- image_size: 32 # unused
- in_channels: 4
- out_channels: 4
- model_channels: 320
- attention_resolutions: [ 4, 2, 1 ]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 4, 4 ]
- num_head_channels: 64 # need to fix for flash-attn
- use_spatial_transformer: True
- use_linear_in_transformer: True
- transformer_depth: 1
- context_dim: 1024
- legacy: False
+ use_checkpoint: True
+ use_fp16: True
+ image_size: 32 # unused
+ in_channels: 4
+ out_channels: 4
+ model_channels: 320
+ attention_resolutions: [ 4, 2, 1 ]
+ num_res_blocks: 2
+ channel_mult: [ 1, 2, 4, 4 ]
+ num_head_channels: 64 # need to fix for flash-attn
+ use_spatial_transformer: True
+ use_linear_in_transformer: True
+ transformer_depth: 1
+ context_dim: 1024
+ legacy: False
first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- monitor: val/rec_loss
- ddconfig:
- #attn_type: "vanilla-xformers"
- double_z: true
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult:
- - 1
- - 2
- - 4
- - 4
- num_res_blocks: 2
- attn_resolutions: []
- dropout: 0.0
- lossconfig:
- target: torch.nn.Identity
+ embed_dim: 4
+ monitor: val/rec_loss
+ ddconfig:
+ #attn_type: "vanilla-xformers"
+ double_z: true
+ z_channels: 4
+ resolution: 256
+ in_channels: 3
+ out_ch: 3
+ ch: 128
+ ch_mult:
+ - 1
+ - 2
+ - 4
+ - 4
+ num_res_blocks: 2
+ attn_resolutions: []
+ dropout: 0.0
cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenOpenCLIPEmbedder
- params:
- freeze: True
- layer: "penultimate"
+ freeze: True
+ layer: "penultimate"
diff --git a/examples/images/diffusion/configs/Inference/v2-inference.yaml b/examples/images/diffusion/configs/Inference/v2-inference.yaml
index 152c4f3c2b36..5d8d583d06d1 100644
--- a/examples/images/diffusion/configs/Inference/v2-inference.yaml
+++ b/examples/images/diffusion/configs/Inference/v2-inference.yaml
@@ -1,6 +1,5 @@
model:
base_learning_rate: 1.0e-4
- target: ldm.models.diffusion.ddpm.LatentDiffusion
params:
linear_start: 0.00085
linear_end: 0.0120
@@ -18,50 +17,42 @@ model:
use_ema: False # we set this to false because this is an inference only config
unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- use_checkpoint: True
- use_fp16: True
- image_size: 32 # unused
- in_channels: 4
- out_channels: 4
- model_channels: 320
- attention_resolutions: [ 4, 2, 1 ]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 4, 4 ]
- num_head_channels: 64 # need to fix for flash-attn
- use_spatial_transformer: True
- use_linear_in_transformer: True
- transformer_depth: 1
- context_dim: 1024
- legacy: False
+ use_checkpoint: True
+ use_fp16: True
+ image_size: 32 # unused
+ in_channels: 4
+ out_channels: 4
+ model_channels: 320
+ attention_resolutions: [ 4, 2, 1 ]
+ num_res_blocks: 2
+ channel_mult: [ 1, 2, 4, 4 ]
+ num_head_channels: 64 # need to fix for flash-attn
+ use_spatial_transformer: True
+ use_linear_in_transformer: True
+ transformer_depth: 1
+ context_dim: 1024
+ legacy: False
first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- monitor: val/rec_loss
- ddconfig:
- #attn_type: "vanilla-xformers"
- double_z: true
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult:
- - 1
- - 2
- - 4
- - 4
- num_res_blocks: 2
- attn_resolutions: []
- dropout: 0.0
- lossconfig:
- target: torch.nn.Identity
+ embed_dim: 4
+ monitor: val/rec_loss
+ ddconfig:
+ #attn_type: "vanilla-xformers"
+ double_z: true
+ z_channels: 4
+ resolution: 256
+ in_channels: 3
+ out_ch: 3
+ ch: 128
+ ch_mult:
+ - 1
+ - 2
+ - 4
+ - 4
+ num_res_blocks: 2
+ attn_resolutions: []
+ dropout: 0.0
cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenOpenCLIPEmbedder
- params:
- freeze: True
- layer: "penultimate"
+ freeze: True
+ layer: "penultimate"
diff --git a/examples/images/diffusion/configs/Inference/v2-inpainting-inference.yaml b/examples/images/diffusion/configs/Inference/v2-inpainting-inference.yaml
index 32a9471d71b8..ffaa5e8da2ad 100644
--- a/examples/images/diffusion/configs/Inference/v2-inpainting-inference.yaml
+++ b/examples/images/diffusion/configs/Inference/v2-inpainting-inference.yaml
@@ -19,106 +19,97 @@ model:
use_ema: False
unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- use_checkpoint: True
- image_size: 32 # unused
- in_channels: 9
- out_channels: 4
- model_channels: 320
- attention_resolutions: [ 4, 2, 1 ]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 4, 4 ]
- num_head_channels: 64 # need to fix for flash-attn
- use_spatial_transformer: True
- use_linear_in_transformer: True
- transformer_depth: 1
- context_dim: 1024
- legacy: False
+ use_checkpoint: True
+ image_size: 32 # unused
+ in_channels: 9
+ out_channels: 4
+ model_channels: 320
+ attention_resolutions: [ 4, 2, 1 ]
+ num_res_blocks: 2
+ channel_mult: [ 1, 2, 4, 4 ]
+ num_head_channels: 64 # need to fix for flash-attn
+ use_spatial_transformer: True
+ use_linear_in_transformer: True
+ transformer_depth: 1
+ context_dim: 1024
+ legacy: False
first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- monitor: val/rec_loss
- ddconfig:
- #attn_type: "vanilla-xformers"
- double_z: true
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult:
- - 1
- - 2
- - 4
- - 4
- num_res_blocks: 2
- attn_resolutions: [ ]
- dropout: 0.0
- lossconfig:
- target: torch.nn.Identity
+ embed_dim: 4
+ monitor: val/rec_loss
+ ddconfig:
+ #attn_type: "vanilla-xformers"
+ double_z: true
+ z_channels: 4
+ resolution: 256
+ in_channels: 3
+ out_ch: 3
+ ch: 128
+ ch_mult:
+ - 1
+ - 2
+ - 4
+ - 4
+ num_res_blocks: 2
+ attn_resolutions: [ ]
+ dropout: 0.0
+ lossconfig:
cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenOpenCLIPEmbedder
- params:
- freeze: True
- layer: "penultimate"
+ freeze: True
+ layer: "penultimate"
data:
- target: ldm.data.laion.WebDataModuleFromConfig
- params:
- tar_base: null # for concat as in LAION-A
- p_unsafe_threshold: 0.1
- filter_word_list: "data/filters.yaml"
- max_pwatermark: 0.45
- batch_size: 8
- num_workers: 6
- multinode: True
- min_size: 512
- train:
- shards:
- - "pipe:aws s3 cp s3://stability-aws/laion-a-native/part-0/{00000..18699}.tar -"
- - "pipe:aws s3 cp s3://stability-aws/laion-a-native/part-1/{00000..18699}.tar -"
- - "pipe:aws s3 cp s3://stability-aws/laion-a-native/part-2/{00000..18699}.tar -"
- - "pipe:aws s3 cp s3://stability-aws/laion-a-native/part-3/{00000..18699}.tar -"
- - "pipe:aws s3 cp s3://stability-aws/laion-a-native/part-4/{00000..18699}.tar -" #{00000-94333}.tar"
- shuffle: 10000
- image_key: jpg
- image_transforms:
- - target: torchvision.transforms.Resize
- params:
- size: 512
- interpolation: 3
- - target: torchvision.transforms.RandomCrop
- params:
- size: 512
- postprocess:
- target: ldm.data.laion.AddMask
- params:
- mode: "512train-large"
- p_drop: 0.25
- # NOTE use enough shards to avoid empty validation loops in workers
- validation:
- shards:
- - "pipe:aws s3 cp s3://deep-floyd-s3/datasets/laion_cleaned-part5/{93001..94333}.tar - "
- shuffle: 0
- image_key: jpg
- image_transforms:
- - target: torchvision.transforms.Resize
- params:
- size: 512
- interpolation: 3
- - target: torchvision.transforms.CenterCrop
- params:
- size: 512
- postprocess:
- target: ldm.data.laion.AddMask
- params:
- mode: "512train-large"
- p_drop: 0.25
+ tar_base: null # for concat as in LAION-A
+ p_unsafe_threshold: 0.1
+ filter_word_list: "data/filters.yaml"
+ max_pwatermark: 0.45
+ batch_size: 8
+ num_workers: 6
+ multinode: True
+ min_size: 512
+ train:
+ shards:
+ - "pipe:aws s3 cp s3://stability-aws/laion-a-native/part-0/{00000..18699}.tar -"
+ - "pipe:aws s3 cp s3://stability-aws/laion-a-native/part-1/{00000..18699}.tar -"
+ - "pipe:aws s3 cp s3://stability-aws/laion-a-native/part-2/{00000..18699}.tar -"
+ - "pipe:aws s3 cp s3://stability-aws/laion-a-native/part-3/{00000..18699}.tar -"
+ - "pipe:aws s3 cp s3://stability-aws/laion-a-native/part-4/{00000..18699}.tar -" #{00000-94333}.tar"
+ shuffle: 10000
+ image_key: jpg
+ image_transforms:
+ - target: torchvision.transforms.Resize
+ params:
+ size: 512
+ interpolation: 3
+ - target: torchvision.transforms.RandomCrop
+ params:
+ size: 512
+ postprocess:
+ target: ldm.data.laion.AddMask
+ params:
+ mode: "512train-large"
+ p_drop: 0.25
+ # NOTE use enough shards to avoid empty validation loops in workers
+ validation:
+ shards:
+ - "pipe:aws s3 cp s3://deep-floyd-s3/datasets/laion_cleaned-part5/{93001..94333}.tar - "
+ shuffle: 0
+ image_key: jpg
+ image_transforms:
+ - target: torchvision.transforms.Resize
+ params:
+ size: 512
+ interpolation: 3
+ - target: torchvision.transforms.CenterCrop
+ params:
+ size: 512
+ postprocess:
+ target: ldm.data.laion.AddMask
+ params:
+ mode: "512train-large"
+ p_drop: 0.25
lightning:
find_unused_parameters: True
@@ -132,8 +123,6 @@ lightning:
every_n_train_steps: 10000
image_logger:
- target: main.ImageLogger
- params:
enable_autocast: False
disabled: False
batch_frequency: 1000
diff --git a/examples/images/diffusion/configs/Inference/v2-midas-inference.yaml b/examples/images/diffusion/configs/Inference/v2-midas-inference.yaml
index 531199de4878..01d3729f1590 100644
--- a/examples/images/diffusion/configs/Inference/v2-midas-inference.yaml
+++ b/examples/images/diffusion/configs/Inference/v2-midas-inference.yaml
@@ -19,54 +19,45 @@ model:
use_ema: False
depth_stage_config:
- target: ldm.modules.midas.api.MiDaSInference
- params:
- model_type: "dpt_hybrid"
+ model_type: "dpt_hybrid"
unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- use_checkpoint: True
- image_size: 32 # unused
- in_channels: 5
- out_channels: 4
- model_channels: 320
- attention_resolutions: [ 4, 2, 1 ]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 4, 4 ]
- num_head_channels: 64 # need to fix for flash-attn
- use_spatial_transformer: True
- use_linear_in_transformer: True
- transformer_depth: 1
- context_dim: 1024
- legacy: False
+ use_checkpoint: True
+ image_size: 32 # unused
+ in_channels: 5
+ out_channels: 4
+ model_channels: 320
+ attention_resolutions: [ 4, 2, 1 ]
+ num_res_blocks: 2
+ channel_mult: [ 1, 2, 4, 4 ]
+ num_head_channels: 64 # need to fix for flash-attn
+ use_spatial_transformer: True
+ use_linear_in_transformer: True
+ transformer_depth: 1
+ context_dim: 1024
+ legacy: False
first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- monitor: val/rec_loss
- ddconfig:
- #attn_type: "vanilla-xformers"
- double_z: true
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult:
- - 1
- - 2
- - 4
- - 4
- num_res_blocks: 2
- attn_resolutions: [ ]
- dropout: 0.0
- lossconfig:
- target: torch.nn.Identity
+ embed_dim: 4
+ monitor: val/rec_loss
+ ddconfig:
+ #attn_type: "vanilla-xformers"
+ double_z: true
+ z_channels: 4
+ resolution: 256
+ in_channels: 3
+ out_ch: 3
+ ch: 128
+ ch_mult:
+ - 1
+ - 2
+ - 4
+ - 4
+ num_res_blocks: 2
+ attn_resolutions: [ ]
+ dropout: 0.0
+ lossconfig:
cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenOpenCLIPEmbedder
- params:
- freeze: True
- layer: "penultimate"
+ freeze: True
+ layer: "penultimate"
diff --git a/examples/images/diffusion/configs/Inference/x4-upscaling.yaml b/examples/images/diffusion/configs/Inference/x4-upscaling.yaml
index 45ecbf9ad863..426d387ca611 100644
--- a/examples/images/diffusion/configs/Inference/x4-upscaling.yaml
+++ b/examples/images/diffusion/configs/Inference/x4-upscaling.yaml
@@ -20,56 +20,47 @@ model:
use_ema: False
low_scale_config:
- target: ldm.modules.diffusionmodules.upscaling.ImageConcatWithNoiseAugmentation
- params:
- noise_schedule_config: # image space
- linear_start: 0.0001
- linear_end: 0.02
- max_noise_level: 350
+ noise_schedule_config: # image space
+ linear_start: 0.0001
+ linear_end: 0.02
+ max_noise_level: 350
unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- use_checkpoint: True
- num_classes: 1000 # timesteps for noise conditioning (here constant, just need one)
- image_size: 128
- in_channels: 7
- out_channels: 4
- model_channels: 256
- attention_resolutions: [ 2,4,8]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 2, 4]
- disable_self_attentions: [True, True, True, False]
- disable_middle_self_attn: False
- num_heads: 8
- use_spatial_transformer: True
- transformer_depth: 1
- context_dim: 1024
- legacy: False
- use_linear_in_transformer: True
+ use_checkpoint: True
+ num_classes: 1000 # timesteps for noise conditioning (here constant, just need one)
+ image_size: 128
+ in_channels: 7
+ out_channels: 4
+ model_channels: 256
+ attention_resolutions: [ 2,4,8]
+ num_res_blocks: 2
+ channel_mult: [ 1, 2, 2, 4]
+ disable_self_attentions: [True, True, True, False]
+ disable_middle_self_attn: False
+ num_heads: 8
+ use_spatial_transformer: True
+ transformer_depth: 1
+ context_dim: 1024
+ legacy: False
+ use_linear_in_transformer: True
first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- ddconfig:
- # attn_type: "vanilla-xformers" this model needs efficient attention to be feasible on HR data, also the decoder seems to break in half precision (UNet is fine though)
- double_z: True
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult: [ 1,2,4 ] # num_down = len(ch_mult)-1
- num_res_blocks: 2
- attn_resolutions: [ ]
- dropout: 0.0
+ embed_dim: 4
+ ddconfig:
+ # attn_type: "vanilla-xformers" this model needs efficient attention to be feasible on HR data, also the decoder seems to break in half precision (UNet is fine though)
+ double_z: True
+ z_channels: 4
+ resolution: 256
+ in_channels: 3
+ out_ch: 3
+ ch: 128
+ ch_mult: [ 1,2,4 ] # num_down = len(ch_mult)-1
+ num_res_blocks: 2
+ attn_resolutions: [ ]
+ dropout: 0.0
+ lossconfig:
- lossconfig:
- target: torch.nn.Identity
cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenOpenCLIPEmbedder
- params:
- freeze: True
- layer: "penultimate"
+ freeze: True
+ layer: "penultimate"
diff --git a/examples/images/diffusion/configs/Teyvat/train_colossalai_teyvat.yaml b/examples/images/diffusion/configs/Teyvat/train_colossalai_teyvat.yaml
index ff0f4c5a0463..9e760124c7a4 100644
--- a/examples/images/diffusion/configs/Teyvat/train_colossalai_teyvat.yaml
+++ b/examples/images/diffusion/configs/Teyvat/train_colossalai_teyvat.yaml
@@ -1,6 +1,5 @@
model:
base_learning_rate: 1.0e-4
- target: ldm.models.diffusion.ddpm.LatentDiffusion
params:
parameterization: "v"
linear_start: 0.00085
@@ -20,81 +19,70 @@ model:
use_ema: False
scheduler_config: # 10000 warmup steps
- target: ldm.lr_scheduler.LambdaLinearScheduler
- params:
- warm_up_steps: [ 1 ] # NOTE for resuming. use 10000 if starting from scratch
- cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
- f_start: [ 1.e-6 ]
- f_max: [ 1.e-4 ]
- f_min: [ 1.e-10 ]
+ warm_up_steps: [ 1 ] # NOTE for resuming. use 10000 if starting from scratch
+ cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
+ f_start: [ 1.e-6 ]
+ f_max: [ 1.e-4 ]
+ f_min: [ 1.e-10 ]
unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- use_checkpoint: True
- use_fp16: True
- image_size: 32 # unused
- in_channels: 4
- out_channels: 4
- model_channels: 320
- attention_resolutions: [ 4, 2, 1 ]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 4, 4 ]
- num_head_channels: 64 # need to fix for flash-attn
- use_spatial_transformer: True
- use_linear_in_transformer: True
- transformer_depth: 1
- context_dim: 1024
- legacy: False
+ use_checkpoint: True
+ use_fp16: True
+ image_size: 32 # unused
+ in_channels: 4
+ out_channels: 4
+ model_channels: 320
+ attention_resolutions: [ 4, 2, 1 ]
+ num_res_blocks: 2
+ channel_mult: [ 1, 2, 4, 4 ]
+ num_head_channels: 64 # need to fix for flash-attn
+ use_spatial_transformer: True
+ use_linear_in_transformer: True
+ transformer_depth: 1
+ context_dim: 1024
+ legacy: False
first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- monitor: val/rec_loss
- ddconfig:
- #attn_type: "vanilla-xformers"
- double_z: true
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult:
- - 1
- - 2
- - 4
- - 4
- num_res_blocks: 2
- attn_resolutions: []
- dropout: 0.0
- lossconfig:
- target: torch.nn.Identity
+ embed_dim: 4
+ monitor: val/rec_loss
+ ddconfig:
+ #attn_type: "vanilla-xformers"
+ double_z: true
+ z_channels: 4
+ resolution: 256
+ in_channels: 3
+ out_ch: 3
+ ch: 128
+ ch_mult:
+ - 1
+ - 2
+ - 4
+ - 4
+ num_res_blocks: 2
+ attn_resolutions: []
+ dropout: 0.0
+ lossconfig:
cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenOpenCLIPEmbedder
- params:
- freeze: True
- layer: "penultimate"
+ freeze: True
+ layer: "penultimate"
data:
- target: main.DataModuleFromConfig
- params:
- batch_size: 16
- num_workers: 4
- train:
- target: ldm.data.teyvat.hf_dataset
- params:
- path: Fazzie/Teyvat
- image_transforms:
- - target: torchvision.transforms.Resize
- params:
- size: 512
- - target: torchvision.transforms.RandomCrop
- params:
- size: 512
- - target: torchvision.transforms.RandomHorizontalFlip
+ batch_size: 16
+ num_workers: 4
+ train:
+ target: ldm.data.teyvat.hf_dataset
+ params:
+ path: Fazzie/Teyvat
+ image_transforms:
+ - target: torchvision.transforms.Resize
+ params:
+ size: 512
+ - target: torchvision.transforms.RandomCrop
+ params:
+ size: 512
+ - target: torchvision.transforms.RandomHorizontalFlip
lightning:
trainer:
@@ -105,13 +93,11 @@ lightning:
precision: 16
auto_select_gpus: False
strategy:
- target: strategies.ColossalAIStrategy
- params:
- use_chunk: True
- enable_distributed_storage: True
- placement_policy: cuda
- force_outputs_fp32: true
- min_chunk_size: 64
+ use_chunk: True
+ enable_distributed_storage: True
+ placement_policy: cuda
+ force_outputs_fp32: true
+ min_chunk_size: 64
log_every_n_steps: 2
logger: True
@@ -120,9 +106,7 @@ lightning:
logger_config:
wandb:
- target: loggers.WandbLogger
- params:
- name: nowname
- save_dir: "/tmp/diff_log/"
- offline: opt.debug
- id: nowname
+ name: nowname
+ save_dir: "/tmp/diff_log/"
+ offline: opt.debug
+ id: nowname
diff --git a/examples/images/diffusion/configs/train_colossalai.yaml b/examples/images/diffusion/configs/train_colossalai.yaml
index 88432e978a0f..5f745286a719 100644
--- a/examples/images/diffusion/configs/train_colossalai.yaml
+++ b/examples/images/diffusion/configs/train_colossalai.yaml
@@ -1,6 +1,5 @@
model:
base_learning_rate: 1.0e-4
- target: ldm.models.diffusion.ddpm.LatentDiffusion
params:
parameterization: "v"
linear_start: 0.00085
@@ -19,95 +18,83 @@ model:
use_ema: False # we set this to false because this is an inference only config
scheduler_config: # 10000 warmup steps
- target: ldm.lr_scheduler.LambdaLinearScheduler
- params:
- warm_up_steps: [ 1 ] # NOTE for resuming. use 10000 if starting from scratch
- cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
- f_start: [ 1.e-6 ]
- f_max: [ 1.e-4 ]
- f_min: [ 1.e-10 ]
+ warm_up_steps: [ 1 ] # NOTE for resuming. use 10000 if starting from scratch
+ cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
+ f_start: [ 1.e-6 ]
+ f_max: [ 1.e-4 ]
+ f_min: [ 1.e-10 ]
unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- use_checkpoint: True
- use_fp16: True
- image_size: 32 # unused
- in_channels: 4
- out_channels: 4
- model_channels: 320
- attention_resolutions: [ 4, 2, 1 ]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 4, 4 ]
- num_head_channels: 64 # need to fix for flash-attn
- use_spatial_transformer: True
- use_linear_in_transformer: True
- transformer_depth: 1
- context_dim: 1024
- legacy: False
+ use_checkpoint: True
+ use_fp16: True
+ image_size: 32 # unused
+ in_channels: 4
+ out_channels: 4
+ model_channels: 320
+ attention_resolutions: [ 4, 2, 1 ]
+ num_res_blocks: 2
+ channel_mult: [ 1, 2, 4, 4 ]
+ num_head_channels: 64 # need to fix for flash-attn
+ use_spatial_transformer: True
+ use_linear_in_transformer: True
+ transformer_depth: 1
+ context_dim: 1024
+ legacy: False
first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- monitor: val/rec_loss
- ddconfig:
- #attn_type: "vanilla-xformers"
- double_z: true
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult:
- - 1
- - 2
- - 4
- - 4
- num_res_blocks: 2
- attn_resolutions: []
- dropout: 0.0
- lossconfig:
- target: torch.nn.Identity
+ embed_dim: 4
+ monitor: val/rec_loss
+ ddconfig:
+ #attn_type: "vanilla-xformers"
+ double_z: true
+ z_channels: 4
+ resolution: 256
+ in_channels: 3
+ out_ch: 3
+ ch: 128
+ ch_mult:
+ - 1
+ - 2
+ - 4
+ - 4
+ num_res_blocks: 2
+ attn_resolutions: []
+ dropout: 0.0
+ lossconfig:
+
cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenOpenCLIPEmbedder
- params:
- freeze: True
- layer: "penultimate"
+ freeze: True
+ layer: "penultimate"
data:
- target: main.DataModuleFromConfig
- params:
- batch_size: 128
- wrap: False
- # num_workwers should be 2 * batch_size, and total num less than 1024
- # e.g. if use 8 devices, no more than 128
- num_workers: 128
- train:
- target: ldm.data.base.Txt2ImgIterableBaseDataset
- params:
- file_path: # YOUR DATASET_PATH
- world_size: 1
- rank: 0
+ batch_size: 128
+ wrap: False
+ # num_workwers should be 2 * batch_size, and total num less than 1024
+ # e.g. if use 8 devices, no more than 128
+ num_workers: 128
+ train:
+ target: ldm.data.base.Txt2ImgIterableBaseDataset
+ params:
+ file_path: # YOUR DATASET_PATH
+ world_size: 1
+ rank: 0
lightning:
trainer:
accelerator: 'gpu'
- devices: 8
+ devices: 2
log_gpu_memory: all
max_epochs: 2
precision: 16
auto_select_gpus: False
strategy:
- target: strategies.ColossalAIStrategy
- params:
- use_chunk: True
- enable_distributed_storage: True
- placement_policy: cuda
- force_outputs_fp32: true
- min_chunk_size: 64
+ use_chunk: True
+ enable_distributed_storage: True
+ placement_policy: cuda
+ force_outputs_fp32: true
+ min_chunk_size: 64
log_every_n_steps: 2
logger: True
@@ -116,9 +103,7 @@ lightning:
logger_config:
wandb:
- target: loggers.WandbLogger
- params:
- name: nowname
- save_dir: "/tmp/diff_log/"
- offline: opt.debug
- id: nowname
+ name: nowname
+ save_dir: "/tmp/diff_log/"
+ offline: opt.debug
+ id: nowname
diff --git a/examples/images/diffusion/configs/train_colossalai_cifar10.yaml b/examples/images/diffusion/configs/train_colossalai_cifar10.yaml
index 0ba06f832178..0d0f185426c2 100644
--- a/examples/images/diffusion/configs/train_colossalai_cifar10.yaml
+++ b/examples/images/diffusion/configs/train_colossalai_cifar10.yaml
@@ -1,6 +1,5 @@
model:
base_learning_rate: 1.0e-4
- target: ldm.models.diffusion.ddpm.LatentDiffusion
params:
parameterization: "v"
linear_start: 0.00085
@@ -19,82 +18,71 @@ model:
use_ema: False # we set this to false because this is an inference only config
scheduler_config: # 10000 warmup steps
- target: ldm.lr_scheduler.LambdaLinearScheduler
- params:
- warm_up_steps: [ 1 ] # NOTE for resuming. use 10000 if starting from scratch
- cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
- f_start: [ 1.e-6 ]
- f_max: [ 1.e-4 ]
- f_min: [ 1.e-10 ]
+ warm_up_steps: [ 1 ] # NOTE for resuming. use 10000 if starting from scratch
+ cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
+ f_start: [ 1.e-6 ]
+ f_max: [ 1.e-4 ]
+ f_min: [ 1.e-10 ]
unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- use_checkpoint: True
- use_fp16: True
- image_size: 32 # unused
- in_channels: 4
- out_channels: 4
- model_channels: 320
- attention_resolutions: [ 4, 2, 1 ]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 4, 4 ]
- num_head_channels: 64 # need to fix for flash-attn
- use_spatial_transformer: True
- use_linear_in_transformer: True
- transformer_depth: 1
- context_dim: 1024
- legacy: False
+ use_checkpoint: True
+ use_fp16: True
+ image_size: 32 # unused
+ in_channels: 4
+ out_channels: 4
+ model_channels: 320
+ attention_resolutions: [ 4, 2, 1 ]
+ num_res_blocks: 2
+ channel_mult: [ 1, 2, 4, 4 ]
+ num_head_channels: 64 # need to fix for flash-attn
+ use_spatial_transformer: True
+ use_linear_in_transformer: True
+ transformer_depth: 1
+ context_dim: 1024
+ legacy: False
first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- monitor: val/rec_loss
- ddconfig:
- #attn_type: "vanilla-xformers"
- double_z: true
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult:
- - 1
- - 2
- - 4
- - 4
- num_res_blocks: 2
- attn_resolutions: []
- dropout: 0.0
- lossconfig:
- target: torch.nn.Identity
+ embed_dim: 4
+ monitor: val/rec_loss
+ ddconfig:
+ #attn_type: "vanilla-xformers"
+ double_z: true
+ z_channels: 4
+ resolution: 256
+ in_channels: 3
+ out_ch: 3
+ ch: 128
+ ch_mult:
+ - 1
+ - 2
+ - 4
+ - 4
+ num_res_blocks: 2
+ attn_resolutions: []
+ dropout: 0.0
+ lossconfig:
cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenOpenCLIPEmbedder
- params:
- freeze: True
- layer: "penultimate"
+ freeze: True
+ layer: "penultimate"
data:
- target: main.DataModuleFromConfig
- params:
- batch_size: 4
- num_workers: 4
- train:
- target: ldm.data.cifar10.hf_dataset
- params:
- name: cifar10
- image_transforms:
- - target: torchvision.transforms.Resize
- params:
- size: 512
- interpolation: 3
- - target: torchvision.transforms.RandomCrop
- params:
- size: 512
- - target: torchvision.transforms.RandomHorizontalFlip
+ batch_size: 4
+ num_workers: 4
+ train:
+ target: ldm.data.cifar10.hf_dataset
+ params:
+ name: cifar10
+ image_transforms:
+ - target: torchvision.transforms.Resize
+ params:
+ size: 512
+ interpolation: 3
+ - target: torchvision.transforms.RandomCrop
+ params:
+ size: 512
+ - target: torchvision.transforms.RandomHorizontalFlip
lightning:
trainer:
@@ -105,13 +93,11 @@ lightning:
precision: 16
auto_select_gpus: False
strategy:
- target: strategies.ColossalAIStrategy
- params:
- use_chunk: True
- enable_distributed_storage: True
- placement_policy: cuda
- force_outputs_fp32: true
- min_chunk_size: 64
+ use_chunk: True
+ enable_distributed_storage: True
+ placement_policy: cuda
+ force_outputs_fp32: true
+ min_chunk_size: 64
log_every_n_steps: 2
logger: True
@@ -120,9 +106,7 @@ lightning:
logger_config:
wandb:
- target: loggers.WandbLogger
- params:
- name: nowname
- save_dir: "/tmp/diff_log/"
- offline: opt.debug
- id: nowname
+ name: nowname
+ save_dir: "/tmp/diff_log/"
+ offline: opt.debug
+ id: nowname
diff --git a/examples/images/diffusion/configs/train_ddp.yaml b/examples/images/diffusion/configs/train_ddp.yaml
index a63df887e719..f3ae3ddb5ff6 100644
--- a/examples/images/diffusion/configs/train_ddp.yaml
+++ b/examples/images/diffusion/configs/train_ddp.yaml
@@ -1,6 +1,5 @@
model:
base_learning_rate: 1.0e-4
- target: ldm.models.diffusion.ddpm.LatentDiffusion
params:
parameterization: "v"
linear_start: 0.00085
@@ -19,77 +18,65 @@ model:
use_ema: False # we set this to false because this is an inference only config
scheduler_config: # 10000 warmup steps
- target: ldm.lr_scheduler.LambdaLinearScheduler
- params:
- warm_up_steps: [ 1 ] # NOTE for resuming. use 10000 if starting from scratch
- cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
- f_start: [ 1.e-6 ]
- f_max: [ 1.e-4 ]
- f_min: [ 1.e-10 ]
+ warm_up_steps: [ 1 ] # NOTE for resuming. use 10000 if starting from scratch
+ cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
+ f_start: [ 1.e-6 ]
+ f_max: [ 1.e-4 ]
+ f_min: [ 1.e-10 ]
unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- use_checkpoint: True
- use_fp16: True
- image_size: 32 # unused
- in_channels: 4
- out_channels: 4
- model_channels: 320
- attention_resolutions: [ 4, 2, 1 ]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 4, 4 ]
- num_head_channels: 64 # need to fix for flash-attn
- use_spatial_transformer: True
- use_linear_in_transformer: True
- transformer_depth: 1
- context_dim: 1024
- legacy: False
+ use_checkpoint: True
+ use_fp16: True
+ image_size: 32 # unused
+ in_channels: 4
+ out_channels: 4
+ model_channels: 320
+ attention_resolutions: [ 4, 2, 1 ]
+ num_res_blocks: 2
+ channel_mult: [ 1, 2, 4, 4 ]
+ num_head_channels: 64 # need to fix for flash-attn
+ use_spatial_transformer: True
+ use_linear_in_transformer: True
+ transformer_depth: 1
+ context_dim: 1024
+ legacy: False
first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- monitor: val/rec_loss
- ddconfig:
- #attn_type: "vanilla-xformers"
- double_z: true
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult:
- - 1
- - 2
- - 4
- - 4
- num_res_blocks: 2
- attn_resolutions: []
- dropout: 0.0
- lossconfig:
- target: torch.nn.Identity
+ embed_dim: 4
+ monitor: val/rec_loss
+ ddconfig:
+ #attn_type: "vanilla-xformers"
+ double_z: true
+ z_channels: 4
+ resolution: 256
+ in_channels: 3
+ out_ch: 3
+ ch: 128
+ ch_mult:
+ - 1
+ - 2
+ - 4
+ - 4
+ num_res_blocks: 2
+ attn_resolutions: []
+ dropout: 0.0
cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenOpenCLIPEmbedder
- params:
- freeze: True
- layer: "penultimate"
+ freeze: True
+ layer: "penultimate"
data:
- target: main.DataModuleFromConfig
- params:
- batch_size: 128
- # num_workwers should be 2 * batch_size, and the total num less than 1024
- # e.g. if use 8 devices, no more than 128
- num_workers: 128
- train:
- target: ldm.data.base.Txt2ImgIterableBaseDataset
- params:
- file_path: # YOUR DATAPATH
- world_size: 1
- rank: 0
+ batch_size: 128
+ # num_workwers should be 2 * batch_size, and the total num less than 1024
+ # e.g. if use 8 devices, no more than 128
+ num_workers: 128
+ train:
+ target: ldm.data.base.Txt2ImgIterableBaseDataset
+ params:
+ file_path: # YOUR DATAPATH
+ world_size: 1
+ rank: 0
lightning:
trainer:
@@ -100,9 +87,7 @@ lightning:
precision: 16
auto_select_gpus: False
strategy:
- target: strategies.DDPStrategy
- params:
- find_unused_parameters: False
+ find_unused_parameters: False
log_every_n_steps: 2
# max_steps: 6o
logger: True
@@ -111,9 +96,7 @@ lightning:
logger_config:
wandb:
- target: loggers.WandbLogger
- params:
- name: nowname
- save_dir: "/data2/tmp/diff_log/"
- offline: opt.debug
- id: nowname
+ name: nowname
+ save_dir: "/data2/tmp/diff_log/"
+ offline: opt.debug
+ id: nowname
diff --git a/examples/images/diffusion/ldm/models/autoencoder.py b/examples/images/diffusion/ldm/models/autoencoder.py
index b1bd8377835b..f0a69fe63a8c 100644
--- a/examples/images/diffusion/ldm/models/autoencoder.py
+++ b/examples/images/diffusion/ldm/models/autoencoder.py
@@ -1,16 +1,13 @@
import torch
-try:
- import lightning.pytorch as pl
-except:
- import pytorch_lightning as pl
+import lightning.pytorch as pl
-import torch.nn.functional as F
+from torch import nn
+from torch.nn import functional as F
+from torch.nn import Identity
from contextlib import contextmanager
from ldm.modules.diffusionmodules.model import Encoder, Decoder
from ldm.modules.distributions.distributions import DiagonalGaussianDistribution
-
-from ldm.util import instantiate_from_config
from ldm.modules.ema import LitEma
@@ -32,7 +29,7 @@ def __init__(self,
self.image_key = image_key
self.encoder = Encoder(**ddconfig)
self.decoder = Decoder(**ddconfig)
- self.loss = instantiate_from_config(lossconfig)
+ self.loss = Identity()
assert ddconfig["double_z"]
self.quant_conv = torch.nn.Conv2d(2*ddconfig["z_channels"], 2*embed_dim, 1)
self.post_quant_conv = torch.nn.Conv2d(embed_dim, ddconfig["z_channels"], 1)
diff --git a/examples/images/diffusion/ldm/models/diffusion/classifier.py b/examples/images/diffusion/ldm/models/diffusion/classifier.py
index 612a8371bf20..3cf12f093bea 100644
--- a/examples/images/diffusion/ldm/models/diffusion/classifier.py
+++ b/examples/images/diffusion/ldm/models/diffusion/classifier.py
@@ -9,9 +9,10 @@
from einops import rearrange
from glob import glob
from natsort import natsorted
-
+from ldm.models.diffusion.ddpm import LatentDiffusion
+from ldm.lr_scheduler import LambdaLinearScheduler
from ldm.modules.diffusionmodules.openaimodel import EncoderUNetModel, UNetModel
-from ldm.util import log_txt_as_img, default, ismap, instantiate_from_config
+from ldm.util import log_txt_as_img, default, ismap
__models__ = {
'class_label': EncoderUNetModel,
@@ -86,7 +87,7 @@ def init_from_ckpt(self, path, ignore_keys=list(), only_model=False):
print(f"Unexpected Keys: {unexpected}")
def load_diffusion(self):
- model = instantiate_from_config(self.diffusion_config)
+ model = LatentDiffusion(**self.diffusion_config.get('params',dict()))
self.diffusion_model = model.eval()
self.diffusion_model.train = disabled_train
for param in self.diffusion_model.parameters():
@@ -221,7 +222,7 @@ def configure_optimizers(self):
optimizer = AdamW(self.model.parameters(), lr=self.learning_rate, weight_decay=self.weight_decay)
if self.use_scheduler:
- scheduler = instantiate_from_config(self.scheduler_config)
+ scheduler = LambdaLinearScheduler(**self.scheduler_config.get('params',dict()))
print("Setting up LambdaLR scheduler...")
scheduler = [
diff --git a/examples/images/diffusion/ldm/models/diffusion/ddpm.py b/examples/images/diffusion/ldm/models/diffusion/ddpm.py
index b7315b048c66..842ec1371ea0 100644
--- a/examples/images/diffusion/ldm/models/diffusion/ddpm.py
+++ b/examples/images/diffusion/ldm/models/diffusion/ddpm.py
@@ -22,19 +22,22 @@
from functools import partial
from einops import rearrange, repeat
+from ldm.lr_scheduler import LambdaLinearScheduler
from ldm.models.autoencoder import *
from ldm.models.autoencoder import AutoencoderKL, IdentityFirstStage
from ldm.models.diffusion.ddim import *
from ldm.models.diffusion.ddim import DDIMSampler
+from ldm.modules.midas.api import MiDaSInference
from ldm.modules.diffusionmodules.model import *
from ldm.modules.diffusionmodules.model import Decoder, Encoder, Model
from ldm.modules.diffusionmodules.openaimodel import *
-from ldm.modules.diffusionmodules.openaimodel import AttentionPool2d
+from ldm.modules.diffusionmodules.openaimodel import AttentionPool2d, UNetModel
from ldm.modules.diffusionmodules.util import extract_into_tensor, make_beta_schedule, noise_like
from ldm.modules.distributions.distributions import DiagonalGaussianDistribution, normal_kl
+from ldm.modules.diffusionmodules.upscaling import ImageConcatWithNoiseAugmentation
from ldm.modules.ema import LitEma
from ldm.modules.encoders.modules import *
-from ldm.util import count_params, default, exists, instantiate_from_config, isimage, ismap, log_txt_as_img, mean_flat
+from ldm.util import count_params, default, exists, isimage, ismap, log_txt_as_img, mean_flat
from omegaconf import ListConfig
from torch.optim.lr_scheduler import LambdaLR
from torchvision.utils import make_grid
@@ -690,7 +693,7 @@ def register_schedule(self,
self.make_cond_schedule()
def instantiate_first_stage(self, config):
- model = instantiate_from_config(config)
+ model = AutoencoderKL(**config)
self.first_stage_model = model.eval()
self.first_stage_model.train = disabled_train
for param in self.first_stage_model.parameters():
@@ -706,15 +709,13 @@ def instantiate_cond_stage(self, config):
self.cond_stage_model = None
# self.be_unconditional = True
else:
- model = instantiate_from_config(config)
+ model = FrozenOpenCLIPEmbedder(**config)
self.cond_stage_model = model.eval()
self.cond_stage_model.train = disabled_train
for param in self.cond_stage_model.parameters():
param.requires_grad = False
else:
- assert config != '__is_first_stage__'
- assert config != '__is_unconditional__'
- model = instantiate_from_config(config)
+ model = FrozenOpenCLIPEmbedder(**config)
self.cond_stage_model = model
def _get_denoise_row_from_list(self, samples, desc='', force_no_decoder_quantization=False):
@@ -1479,8 +1480,7 @@ def configure_optimizers(self):
# opt = torch.optim.AdamW(params, lr=lr)
if self.use_scheduler:
- assert 'target' in self.scheduler_config
- scheduler = instantiate_from_config(self.scheduler_config)
+ scheduler = LambdaLinearScheduler(**self.scheduler_config)
rank_zero_info("Setting up LambdaLR scheduler...")
scheduler = [{'scheduler': LambdaLR(opt, lr_lambda=scheduler.schedule), 'interval': 'step', 'frequency': 1}]
@@ -1502,7 +1502,7 @@ class DiffusionWrapper(pl.LightningModule):
def __init__(self, diff_model_config, conditioning_key):
super().__init__()
self.sequential_cross_attn = diff_model_config.pop("sequential_crossattn", False)
- self.diffusion_model = instantiate_from_config(diff_model_config)
+ self.diffusion_model = UNetModel(**diff_model_config)
self.conditioning_key = conditioning_key
assert self.conditioning_key in [None, 'concat', 'crossattn', 'hybrid', 'adm', 'hybrid-adm', 'crossattn-adm']
@@ -1551,7 +1551,7 @@ def __init__(self, *args, low_scale_config, low_scale_key="LR", noise_level_key=
self.noise_level_key = noise_level_key
def instantiate_low_stage(self, config):
- model = instantiate_from_config(config)
+ model = ImageConcatWithNoiseAugmentation(**config)
self.low_scale_model = model.eval()
self.low_scale_model.train = disabled_train
for param in self.low_scale_model.parameters():
@@ -1933,7 +1933,7 @@ class LatentDepth2ImageDiffusion(LatentFinetuneDiffusion):
def __init__(self, depth_stage_config, concat_keys=("midas_in",), *args, **kwargs):
super().__init__(concat_keys=concat_keys, *args, **kwargs)
- self.depth_model = instantiate_from_config(depth_stage_config)
+ self.depth_model = MiDaSInference(**depth_stage_config)
self.depth_stage_key = concat_keys[0]
@torch.no_grad()
@@ -2006,7 +2006,7 @@ def __init__(self,
self.low_scale_key = low_scale_key
def instantiate_low_stage(self, config):
- model = instantiate_from_config(config)
+ model = ImageConcatWithNoiseAugmentation(**config)
self.low_scale_model = model.eval()
self.low_scale_model.train = disabled_train
for param in self.low_scale_model.parameters():
diff --git a/examples/images/diffusion/main.py b/examples/images/diffusion/main.py
index 91b809d5a65c..e31d75e0874d 100644
--- a/examples/images/diffusion/main.py
+++ b/examples/images/diffusion/main.py
@@ -10,11 +10,8 @@
import numpy as np
import torch
import torchvision
+import lightning.pytorch as pl
-try:
- import lightning.pytorch as pl
-except:
- import pytorch_lightning as pl
from functools import partial
@@ -23,19 +20,15 @@
from PIL import Image
from prefetch_generator import BackgroundGenerator
from torch.utils.data import DataLoader, Dataset, Subset, random_split
+from ldm.models.diffusion.ddpm import LatentDiffusion
-try:
- from lightning.pytorch import seed_everything
- from lightning.pytorch.callbacks import Callback, LearningRateMonitor, ModelCheckpoint
- from lightning.pytorch.trainer import Trainer
- from lightning.pytorch.utilities import rank_zero_info, rank_zero_only
- LIGHTNING_PACK_NAME = "lightning.pytorch."
-except:
- from pytorch_lightning import seed_everything
- from pytorch_lightning.callbacks import Callback, LearningRateMonitor, ModelCheckpoint
- from pytorch_lightning.trainer import Trainer
- from pytorch_lightning.utilities import rank_zero_info, rank_zero_only
- LIGHTNING_PACK_NAME = "pytorch_lightning."
+from lightning.pytorch import seed_everything
+from lightning.pytorch.callbacks import Callback, LearningRateMonitor, ModelCheckpoint
+from lightning.pytorch.trainer import Trainer
+from lightning.pytorch.utilities import rank_zero_info, rank_zero_only
+from lightning.pytorch.loggers import WandbLogger, TensorBoardLogger
+from lightning.pytorch.strategies import ColossalAIStrategy,DDPStrategy
+LIGHTNING_PACK_NAME = "lightning.pytorch."
from ldm.data.base import Txt2ImgIterableBaseDataset
from ldm.util import instantiate_from_config
@@ -687,153 +680,114 @@ def on_train_epoch_end(self, trainer, pl_module):
config.model["params"].update({"ckpt": ckpt})
rank_zero_info("Using ckpt_path = {}".format(config.model["params"]["ckpt"]))
- model = instantiate_from_config(config.model)
+ model = LatentDiffusion(**config.model.get("params", dict()))
# trainer and callbacks
trainer_kwargs = dict()
# config the logger
# Default logger configs to log training metrics during the training process.
- # These loggers are specified as targets in the dictionary, along with the configuration settings specific to each logger.
default_logger_cfgs = {
"wandb": {
- "target": LIGHTNING_PACK_NAME + "loggers.WandbLogger",
- "params": {
"name": nowname,
"save_dir": logdir,
"offline": opt.debug,
"id": nowname,
}
- },
+ ,
"tensorboard": {
- "target": LIGHTNING_PACK_NAME + "loggers.TensorBoardLogger",
- "params": {
"save_dir": logdir,
"name": "diff_tb",
"log_graph": True
}
- }
}
# Set up the logger for TensorBoard
default_logger_cfg = default_logger_cfgs["tensorboard"]
if "logger" in lightning_config:
logger_cfg = lightning_config.logger
+ trainer_kwargs["logger"] = WandbLogger(**logger_cfg)
else:
logger_cfg = default_logger_cfg
- logger_cfg = OmegaConf.merge(default_logger_cfg, logger_cfg)
- trainer_kwargs["logger"] = instantiate_from_config(logger_cfg)
+ trainer_kwargs["logger"] = TensorBoardLogger(**logger_cfg)
# config the strategy, defualt is ddp
if "strategy" in trainer_config:
strategy_cfg = trainer_config["strategy"]
- strategy_cfg["target"] = LIGHTNING_PACK_NAME + strategy_cfg["target"]
+ trainer_kwargs["strategy"] = ColossalAIStrategy(**strategy_cfg)
else:
- strategy_cfg = {
- "target": LIGHTNING_PACK_NAME + "strategies.DDPStrategy",
- "params": {
- "find_unused_parameters": False
- }
- }
-
- trainer_kwargs["strategy"] = instantiate_from_config(strategy_cfg)
+ strategy_cfg = {"find_unused_parameters": False}
+ trainer_kwargs["strategy"] = DDPStrategy(**strategy_cfg)
# Set up ModelCheckpoint callback to save best models
# modelcheckpoint - use TrainResult/EvalResult(checkpoint_on=metric) to
# specify which metric is used to determine best models
default_modelckpt_cfg = {
- "target": LIGHTNING_PACK_NAME + "callbacks.ModelCheckpoint",
- "params": {
"dirpath": ckptdir,
"filename": "{epoch:06}",
"verbose": True,
"save_last": True,
}
- }
if hasattr(model, "monitor"):
- default_modelckpt_cfg["params"]["monitor"] = model.monitor
- default_modelckpt_cfg["params"]["save_top_k"] = 3
+ default_modelckpt_cfg["monitor"] = model.monitor
+ default_modelckpt_cfg["save_top_k"] = 3
if "modelcheckpoint" in lightning_config:
- modelckpt_cfg = lightning_config.modelcheckpoint
+ modelckpt_cfg = lightning_config.modelcheckpoint["params"]
else:
modelckpt_cfg = OmegaConf.create()
modelckpt_cfg = OmegaConf.merge(default_modelckpt_cfg, modelckpt_cfg)
if version.parse(pl.__version__) < version.parse('1.4.0'):
- trainer_kwargs["checkpoint_callback"] = instantiate_from_config(modelckpt_cfg)
-
- # Set up various callbacks, including logging, learning rate monitoring, and CUDA management
- # add callback which sets up log directory
- default_callbacks_cfg = {
- "setup_callback": { # callback to set up the training
- "target": "main.SetupCallback",
- "params": {
- "resume": opt.resume, # resume training if applicable
- "now": now,
- "logdir": logdir, # directory to save the log file
- "ckptdir": ckptdir, # directory to save the checkpoint file
- "cfgdir": cfgdir, # directory to save the configuration file
- "config": config, # configuration dictionary
- "lightning_config": lightning_config, # LightningModule configuration
- }
- },
- "image_logger": { # callback to log image data
- "target": "main.ImageLogger",
- "params": {
- "batch_frequency": 750, # how frequently to log images
- "max_images": 4, # maximum number of images to log
- "clamp": True # whether to clamp pixel values to [0,1]
- }
- },
- "learning_rate_logger": { # callback to log learning rate
- "target": "main.LearningRateMonitor",
- "params": {
- "logging_interval": "step", # logging frequency (either 'step' or 'epoch')
- # "log_momentum": True # whether to log momentum (currently commented out)
- }
- },
- "cuda_callback": { # callback to handle CUDA-related operations
- "target": "main.CUDACallback"
- },
- }
-
- # If the LightningModule configuration has specified callbacks, use those
- # Otherwise, create an empty OmegaConf configuration object
- if "callbacks" in lightning_config:
- callbacks_cfg = lightning_config.callbacks
- else:
- callbacks_cfg = OmegaConf.create()
+ trainer_kwargs["checkpoint_callback"] = ModelCheckpoint(**modelckpt_cfg)
+
+ #Create an empty OmegaConf configuration object
+
+ callbacks_cfg = OmegaConf.create()
+
+ #Instantiate items according to the configs
+ trainer_kwargs.setdefault("callbacks", [])
+ setup_callback_config = {
+ "resume": opt.resume, # resume training if applicable
+ "now": now,
+ "logdir": logdir, # directory to save the log file
+ "ckptdir": ckptdir, # directory to save the checkpoint file
+ "cfgdir": cfgdir, # directory to save the configuration file
+ "config": config, # configuration dictionary
+ "lightning_config": lightning_config, # LightningModule configuration
+ }
+ trainer_kwargs["callbacks"].append(SetupCallback(**setup_callback_config))
- # If the 'metrics_over_trainsteps_checkpoint' callback is specified in the
- # LightningModule configuration, update the default callbacks configuration
- if 'metrics_over_trainsteps_checkpoint' in callbacks_cfg:
- print(
- 'Caution: Saving checkpoints every n train steps without deleting. This might require some free space.')
- default_metrics_over_trainsteps_ckpt_dict = {
- 'metrics_over_trainsteps_checkpoint': {
- "target": LIGHTNING_PACK_NAME + 'callbacks.ModelCheckpoint',
- 'params': {
- "dirpath": os.path.join(ckptdir, 'trainstep_checkpoints'),
- "filename": "{epoch:06}-{step:09}",
- "verbose": True,
- 'save_top_k': -1,
- 'every_n_train_steps': 10000,
- 'save_weights_only': True
- }
- }
+ image_logger_config = {
+
+ "batch_frequency": 750, # how frequently to log images
+ "max_images": 4, # maximum number of images to log
+ "clamp": True # whether to clamp pixel values to [0,1]
}
- default_callbacks_cfg.update(default_metrics_over_trainsteps_ckpt_dict)
+ trainer_kwargs["callbacks"].append(ImageLogger(**image_logger_config))
- # Merge the default callbacks configuration with the specified callbacks configuration, and instantiate the callbacks
- callbacks_cfg = OmegaConf.merge(default_callbacks_cfg, callbacks_cfg)
-
- trainer_kwargs["callbacks"] = [instantiate_from_config(callbacks_cfg[k]) for k in callbacks_cfg]
+ learning_rate_logger_config = {
+ "logging_interval": "step", # logging frequency (either 'step' or 'epoch')
+ # "log_momentum": True # whether to log momentum (currently commented out)
+ }
+ trainer_kwargs["callbacks"].append(LearningRateMonitor(**learning_rate_logger_config))
+
+ metrics_over_trainsteps_checkpoint_config= {
+ "dirpath": os.path.join(ckptdir, 'trainstep_checkpoints'),
+ "filename": "{epoch:06}-{step:09}",
+ "verbose": True,
+ 'save_top_k': -1,
+ 'every_n_train_steps': 10000,
+ 'save_weights_only': True
+ }
+ trainer_kwargs["callbacks"].append(ModelCheckpoint(**metrics_over_trainsteps_checkpoint_config))
+ trainer_kwargs["callbacks"].append(CUDACallback())
# Create a Trainer object with the specified command-line arguments and keyword arguments, and set the log directory
trainer = Trainer.from_argparse_args(trainer_opt, **trainer_kwargs)
trainer.logdir = logdir
# Create a data module based on the configuration file
- data = instantiate_from_config(config.data)
+ data = DataModuleFromConfig(**config.data)
+
# NOTE according to https://pytorch-lightning.readthedocs.io/en/latest/datamodules.html
# calling these ourselves should not be necessary but it is.
# lightning still takes care of proper multiprocessing though
@@ -846,7 +800,7 @@ def on_train_epoch_end(self, trainer, pl_module):
# Configure learning rate based on the batch size, base learning rate and number of GPUs
# If scale_lr is true, calculate the learning rate based on additional factors
- bs, base_lr = config.data.params.batch_size, config.model.base_learning_rate
+ bs, base_lr = config.data.batch_size, config.model.base_learning_rate
if not cpu:
ngpu = trainer_config["devices"]
else:
diff --git a/examples/images/diffusion/scripts/tests/test_checkpoint.py b/examples/images/diffusion/scripts/tests/test_checkpoint.py
index a32e66d44cf2..13622c4989fd 100644
--- a/examples/images/diffusion/scripts/tests/test_checkpoint.py
+++ b/examples/images/diffusion/scripts/tests/test_checkpoint.py
@@ -7,8 +7,9 @@
from diffusers import StableDiffusionPipeline
import torch
-from ldm.util import instantiate_from_config
+
from main import get_parser
+from ldm.modules.diffusionmodules.openaimodel import UNetModel
if __name__ == "__main__":
with torch.no_grad():
@@ -17,7 +18,7 @@
config = f.read()
base_config = yaml.load(config, Loader=yaml.FullLoader)
unet_config = base_config['model']['params']['unet_config']
- diffusion_model = instantiate_from_config(unet_config).to("cuda:0")
+ diffusion_model = UNetModel(**unet_config).to("cuda:0")
pipe = StableDiffusionPipeline.from_pretrained(
"/data/scratch/diffuser/stable-diffusion-v1-4"
diff --git a/examples/images/diffusion/train_colossalai.sh b/examples/images/diffusion/train_colossalai.sh
index c56ed7876e5a..7f1a1bd14615 100755
--- a/examples/images/diffusion/train_colossalai.sh
+++ b/examples/images/diffusion/train_colossalai.sh
@@ -3,3 +3,4 @@ TRANSFORMERS_OFFLINE=1
DIFFUSERS_OFFLINE=1
python main.py --logdir /tmp --train --base configs/Teyvat/train_colossalai_teyvat.yaml --ckpt diffuser_root_dir/512-base-ema.ckpt
+
diff --git a/examples/language/roberta/preprocessing/mask.cpp b/examples/language/roberta/preprocessing/mask.cpp
deleted file mode 100644
index 8355c45cff0a..000000000000
--- a/examples/language/roberta/preprocessing/mask.cpp
+++ /dev/null
@@ -1,184 +0,0 @@
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-
-namespace py = pybind11;
-
-const int32_t LONG_SENTENCE_LEN = 512;
-
-struct MaskedLMInstance {
- int index;
- std::string label;
- MaskedLMInstance(int index, std::string label) {
- this->index = index;
- this->label = label;
- }
-};
-
-auto get_new_segment(std::vector segment, std::vector segment_jieba, const std::vector chinese_vocab) { // const std::unordered_set &chinese_vocab
- std::unordered_set seq_cws_dict;
- for (auto word : segment_jieba) {
- seq_cws_dict.insert(word);
- }
- int i = 0;
- std::vector new_segment;
- int segment_size = segment.size();
- while (i < segment_size) {
- if (!chinese_vocab[i]) { //chinese_vocab.find(segment[i]) == chinese_vocab.end()
- new_segment.emplace_back(segment[i]);
- i += 1;
- continue;
- }
- bool has_add = false;
- for (int length = 3; length >= 1; length--) {
- if (i + length > segment_size) {
- continue;
- }
- std::string chinese_word = "";
- for (int j = i; j < i + length; j++) {
- chinese_word += segment[j];
- }
- if (seq_cws_dict.find(chinese_word) != seq_cws_dict.end()) {
- new_segment.emplace_back(segment[i]);
- for (int j = i + 1; j < i + length; j++) {
- new_segment.emplace_back("##" + segment[j]);
- }
- i += length;
- has_add = true;
- break;
- }
- }
- if (!has_add) {
- new_segment.emplace_back(segment[i]);
- i += 1;
- }
- }
-
- return new_segment;
-}
-
-bool startsWith(const std::string& s, const std::string& sub) {
- return s.find(sub) == 0 ? true : false;
-}
-
-auto create_whole_masked_lm_predictions(std::vector &tokens,
- const std::vector &original_tokens,
- const std::vector &vocab_words,
- std::map &vocab,
- const int max_predictions_per_seq,
- const double masked_lm_prob) {
- // for (auto item : vocab) {
- // std::cout << "key=" << std::string(py::str(item.first)) << ", "
- // << "value=" << std::string(py::str(item.second)) << std::endl;
- // }
- std::vector > cand_indexes;
- std::vector cand_temp;
- int tokens_size = tokens.size();
- std::string prefix = "##";
- bool do_whole_masked = true;
-
- for (int i = 0; i < tokens_size; i++) {
- if (tokens[i] == "[CLS]" || tokens[i] == "[SEP]") {
- continue;
- }
- if (do_whole_masked && (cand_indexes.size() > 0) && (tokens[i].rfind(prefix, 0) == 0)) {
- cand_temp.emplace_back(i);
- }
- else {
- if (cand_temp.size() > 0) {
- cand_indexes.emplace_back(cand_temp);
- }
- cand_temp.clear();
- cand_temp.emplace_back(i);
- }
- }
- auto seed = std::chrono::system_clock::now().time_since_epoch().count();
- std::shuffle(cand_indexes.begin(), cand_indexes.end(), std::default_random_engine(seed));
- // for (auto i : cand_indexes) {
- // for (auto j : i) {
- // std::cout << tokens[j] << " ";
- // }
- // std::cout << std::endl;
- // }
- // for (auto i : output_tokens) {
- // std::cout << i;
- // }
- // std::cout << std::endl;
-
- int num_to_predict = std::min(max_predictions_per_seq,
- std::max(1, int(tokens_size * masked_lm_prob)));
- // std::cout << num_to_predict << std::endl;
-
- std::set covered_indexes;
- std::vector masked_lm_output(tokens_size, -1);
- int vocab_words_len = vocab_words.size();
- std::default_random_engine e(seed);
- std::uniform_real_distribution u1(0.0, 1.0);
- std::uniform_int_distribution u2(0, vocab_words_len - 1);
- int mask_cnt = 0;
- std::vector output_tokens;
- output_tokens = original_tokens;
-
- for (auto index_set : cand_indexes) {
- if (mask_cnt > num_to_predict) {
- break;
- }
- int index_set_size = index_set.size();
- if (mask_cnt + index_set_size > num_to_predict) {
- continue;
- }
- bool is_any_index_covered = false;
- for (auto index : index_set) {
- if (covered_indexes.find(index) != covered_indexes.end()) {
- is_any_index_covered = true;
- break;
- }
- }
- if (is_any_index_covered) {
- continue;
- }
- for (auto index : index_set) {
-
- covered_indexes.insert(index);
- std::string masked_token;
- if (u1(e) < 0.8) {
- masked_token = "[MASK]";
- }
- else {
- if (u1(e) < 0.5) {
- masked_token = output_tokens[index];
- }
- else {
- int random_index = u2(e);
- masked_token = vocab_words[random_index];
- }
- }
- // masked_lms.emplace_back(MaskedLMInstance(index, output_tokens[index]));
- masked_lm_output[index] = vocab[output_tokens[index]];
- output_tokens[index] = masked_token;
- mask_cnt++;
- }
- }
-
- // for (auto p : masked_lms) {
- // masked_lm_output[p.index] = vocab[p.label];
- // }
- return std::make_tuple(output_tokens, masked_lm_output);
-}
-
-PYBIND11_MODULE(mask, m) {
- m.def("create_whole_masked_lm_predictions", &create_whole_masked_lm_predictions);
- m.def("get_new_segment", &get_new_segment);
-}
diff --git a/examples/language/roberta/pretraining/arguments.py b/examples/language/roberta/pretraining/arguments.py
deleted file mode 100644
index 87fa8dd8a8ae..000000000000
--- a/examples/language/roberta/pretraining/arguments.py
+++ /dev/null
@@ -1,176 +0,0 @@
-import colossalai
-from numpy import require
-
-__all__ = ['parse_args']
-
-
-def parse_args():
- parser = colossalai.get_default_parser()
-
- parser.add_argument(
- "--distplan",
- type=str,
- default='CAI_Gemini',
- help="The distributed plan [colossalai, zero1, zero2, torch_ddp, torch_zero].",
- )
- parser.add_argument(
- "--tp_degree",
- type=int,
- default=1,
- help="Tensor Parallelism Degree. Valid when using colossalai as dist plan.",
- )
- parser.add_argument(
- "--placement",
- type=str,
- default='cpu',
- help="Placement Policy for Gemini. Valid when using colossalai as dist plan.",
- )
- parser.add_argument(
- "--shardinit",
- action='store_true',
- help="Shard the tensors when init the model to shrink peak memory size on the assigned device. Valid when using colossalai as dist plan.",
- )
-
- parser.add_argument(
- '--lr',
- type=float,
- required=True,
- help='initial learning rate')
- parser.add_argument(
- '--epoch',
- type=int,
- required=True,
- help='number of epoch')
- parser.add_argument(
- '--data_path_prefix',
- type=str,
- required=True,
- help="location of the train data corpus")
- parser.add_argument(
- '--eval_data_path_prefix',
- type=str,
- required=True,
- help='location of the evaluation data corpus')
- parser.add_argument(
- '--tokenizer_path',
- type=str,
- required=True,
- help='location of the tokenizer')
- parser.add_argument(
- '--max_seq_length',
- type=int,
- default=512,
- help='sequence length')
- parser.add_argument(
- '--refresh_bucket_size',
- type=int,
- default=1,
- help=
- "This param makes sure that a certain task is repeated for this time steps to \
- optimise on the back propogation speed with APEX's DistributedDataParallel")
- parser.add_argument(
- "--max_predictions_per_seq",
- "--max_pred",
- default=80,
- type=int,
- help=
- "The maximum number of masked tokens in a sequence to be predicted.")
- parser.add_argument(
- "--gradient_accumulation_steps",
- default=1,
- type=int,
- help="accumulation_steps")
- parser.add_argument(
- "--train_micro_batch_size_per_gpu",
- default=2,
- type=int,
- required=True,
- help="train batch size")
- parser.add_argument(
- "--eval_micro_batch_size_per_gpu",
- default=2,
- type=int,
- required=True,
- help="eval batch size")
- parser.add_argument(
- "--num_workers",
- default=8,
- type=int,
- help="")
- parser.add_argument(
- "--async_worker",
- action='store_true',
- help="")
- parser.add_argument(
- "--bert_config",
- required=True,
- type=str,
- help="location of config.json")
- parser.add_argument(
- "--wandb",
- action='store_true',
- help="use wandb to watch model")
- parser.add_argument(
- "--wandb_project_name",
- default='roberta',
- help="wandb project name")
- parser.add_argument(
- "--log_interval",
- default=100,
- type=int,
- help="report interval")
- parser.add_argument(
- "--log_path",
- type=str,
- required=True,
- help="log file which records train step")
- parser.add_argument(
- "--tensorboard_path",
- type=str,
- required=True,
- help="location of tensorboard file")
- parser.add_argument(
- "--colossal_config",
- type=str,
- required=True,
- help="colossal config, which contains zero config and so on")
- parser.add_argument(
- "--ckpt_path",
- type=str,
- required=True,
- help="location of saving checkpoint, which contains model and optimizer")
- parser.add_argument(
- '--seed',
- type=int,
- default=42,
- help="random seed for initialization")
- parser.add_argument(
- '--vscode_debug',
- action='store_true',
- help="use vscode to debug")
- parser.add_argument(
- '--load_pretrain_model',
- default='',
- type=str,
- help="location of model's checkpoin")
- parser.add_argument(
- '--load_optimizer_lr',
- default='',
- type=str,
- help="location of checkpoint, which contains optimerzier, learning rate, epoch, shard and global_step")
- parser.add_argument(
- '--resume_train',
- action='store_true',
- help="whether resume training from a early checkpoint")
- parser.add_argument(
- '--mlm',
- default='bert',
- type=str,
- help="model type, bert or deberta")
- parser.add_argument(
- '--checkpoint_activations',
- action='store_true',
- help="whether to use gradient checkpointing")
-
- args = parser.parse_args()
- return args
diff --git a/examples/tutorial/fastfold/FastFold b/examples/tutorial/fastfold/FastFold
index 867587b3aa4e..05681304651b 160000
--- a/examples/tutorial/fastfold/FastFold
+++ b/examples/tutorial/fastfold/FastFold
@@ -1 +1 @@
-Subproject commit 867587b3aa4e43bdaf64f9910127842f1dfbfebd
+Subproject commit 05681304651b1b29d7d887db169045ea3dd28fce
diff --git a/op_builder/README.md b/op_builder/README.md
index b7ac6107300c..9c33a4a328d7 100644
--- a/op_builder/README.md
+++ b/op_builder/README.md
@@ -15,8 +15,8 @@ Method 2 is good because it allows the user to only build the kernel they actual
## PyTorch Extensions in Colossal-AI
-The project DeepSpeed (https://github.com/microsoft/DeepSpeed) has proposed a [solution](https://github.com/microsoft/DeepSpeed/tree/master/op_builder)) to support kernel-build during either installation or runtime.
-We have adapted from DeepSpeed's solution to build extensions. The extension build requries two main functions from PyTorch:
+The project [DeepSpeed](https://github.com/microsoft/DeepSpeed) has proposed a [solution](https://github.com/microsoft/DeepSpeed/tree/master/op_builder) to support kernel-build during either installation or runtime.
+We have adapted from DeepSpeed's solution to build extensions. The extension build requires two main functions from PyTorch:
1. `torch.utils.cpp_extension.CUDAExtension`: used to build extensions in `setup.py` during `pip install`.
2. `torch.utils.cpp_extension.load`: used to build and load extension during runtime
diff --git a/op_builder/builder.py b/op_builder/builder.py
index b9f44decc119..8396235e5cfe 100644
--- a/op_builder/builder.py
+++ b/op_builder/builder.py
@@ -7,7 +7,7 @@
import time
from abc import ABC, abstractmethod
from pathlib import Path
-from typing import List
+from typing import List, Optional
from .utils import check_cuda_availability, check_system_pytorch_cuda_match, print_rank_0
@@ -78,7 +78,7 @@ def sources_files(self) -> List[str]:
@abstractmethod
def include_dirs(self) -> List[str]:
"""
- This function should return a list of inlcude files for extensions.
+ This function should return a list of include files for extensions.
"""
pass
@@ -127,18 +127,18 @@ def check_runtime_build_environment(self):
if CUDA_HOME is None:
raise RuntimeError(
- "CUDA_HOME is not found. You need to export CUDA_HOME environment vairable or install CUDA Toolkit first in order to build CUDA extensions"
+ "CUDA_HOME is not found. You need to export CUDA_HOME environment variable or install CUDA Toolkit first in order to build CUDA extensions"
)
# make sure CUDA is available for compilation during
cuda_available = check_cuda_availability()
if not cuda_available:
- raise RuntimeError("CUDA is not available on your system as torch.cuda.is_avaible() returns False.")
+ raise RuntimeError("CUDA is not available on your system as torch.cuda.is_available() returns False.")
# make sure system CUDA and pytorch CUDA match, an error will raised inside the function if not
check_system_pytorch_cuda_match(CUDA_HOME)
- def load(self, verbose=True):
+ def load(self, verbose: Optional[bool] = None):
"""
load the kernel during runtime. If the kernel is not built during pip install, it will build the kernel.
If the kernel is built during runtime, it will be stored in `~/.cache/colossalai/torch_extensions/`. If the
@@ -149,6 +149,8 @@ def load(self, verbose=True):
Args:
verbose (bool, optional): show detailed info. Defaults to True.
"""
+ if verbose is None:
+ verbose = os.environ.get('CAI_KERNEL_VERBOSE', '0') == '1'
# if the kernel has be compiled and cached, we directly use it
if self.cached_op_module is not None:
return self.cached_op_module
@@ -159,7 +161,7 @@ def load(self, verbose=True):
op_module = self.import_op()
if verbose:
print_rank_0(
- f"[extension] OP {self.prebuilt_import_path} has been compileed ahead of time, skip building.")
+ f"[extension] OP {self.prebuilt_import_path} has been compiled ahead of time, skip building.")
except ImportError:
# check environment
self.check_runtime_build_environment()
diff --git a/op_builder/utils.py b/op_builder/utils.py
index 4029703e4829..1b1bd5f49970 100644
--- a/op_builder/utils.py
+++ b/op_builder/utils.py
@@ -90,7 +90,6 @@ def check_system_pytorch_cuda_match(cuda_dir):
'Please make sure you have set the CUDA_HOME correctly and installed the correct PyTorch in https://pytorch.org/get-started/locally/ .'
)
- print(bare_metal_minor != torch_cuda_minor)
if bare_metal_minor != torch_cuda_minor:
warnings.warn(
f"[extension] The CUDA version on the system ({bare_metal_major}.{bare_metal_minor}) does not match with the version ({torch_cuda_major}.{torch_cuda_minor}) torch was compiled with. "
@@ -156,16 +155,15 @@ def set_cuda_arch_list(cuda_dir):
# we only need to set this when CUDA is not available for cross-compilation
if not cuda_available:
- warnings.warn(
- '\n[extension] PyTorch did not find available GPUs on this system.\n'
- 'If your intention is to cross-compile, this is not an error.\n'
- 'By default, Colossal-AI will cross-compile for \n'
- '1. Pascal (compute capabilities 6.0, 6.1, 6.2),\n'
- '2. Volta (compute capability 7.0)\n'
- '3. Turing (compute capability 7.5),\n'
- '4. Ampere (compute capability 8.0, 8.6)if the CUDA version is >= 11.0\n'
- '\nIf you wish to cross-compile for a single specific architecture,\n'
- 'export TORCH_CUDA_ARCH_LIST="compute capability" before running setup.py.\n')
+ warnings.warn('\n[extension] PyTorch did not find available GPUs on this system.\n'
+ 'If your intention is to cross-compile, this is not an error.\n'
+ 'By default, Colossal-AI will cross-compile for \n'
+ '1. Pascal (compute capabilities 6.0, 6.1, 6.2),\n'
+ '2. Volta (compute capability 7.0)\n'
+ '3. Turing (compute capability 7.5),\n'
+ '4. Ampere (compute capability 8.0, 8.6)if the CUDA version is >= 11.0\n'
+ '\nIf you wish to cross-compile for a single specific architecture,\n'
+ 'export TORCH_CUDA_ARCH_LIST="compute capability" before running setup.py.\n')
if os.environ.get("TORCH_CUDA_ARCH_LIST", None) is None:
bare_metal_major, bare_metal_minor = get_cuda_bare_metal_version(cuda_dir)
diff --git a/setup.py b/setup.py
index 89a7b0de461b..5d8f831218d9 100644
--- a/setup.py
+++ b/setup.py
@@ -46,7 +46,7 @@ def environment_check_for_cuda_extension_build():
if not CUDA_HOME:
raise RuntimeError(
- "[extension] CUDA_HOME is not found while CUDA_EXT=1. You need to export CUDA_HOME environment vairable or install CUDA Toolkit first in order to build CUDA extensions"
+ "[extension] CUDA_HOME is not found while CUDA_EXT=1. You need to export CUDA_HOME environment variable or install CUDA Toolkit first in order to build CUDA extensions"
)
check_system_pytorch_cuda_match(CUDA_HOME)
diff --git a/tests/test_booster/test_plugin/test_gemini_plugin.py b/tests/test_booster/test_plugin/test_gemini_plugin.py
index a3c63fd09d26..d804c727ad3e 100644
--- a/tests/test_booster/test_plugin/test_gemini_plugin.py
+++ b/tests/test_booster/test_plugin/test_gemini_plugin.py
@@ -1,21 +1,31 @@
+from contextlib import nullcontext
+
import torch
import torch.distributed as dist
import colossalai
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin
+from colossalai.fx import is_compatible_with_meta
from colossalai.nn.optimizer import HybridAdam
from colossalai.tensor.colo_parameter import ColoParameter
-from colossalai.testing import rerun_if_address_is_in_use, spawn
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+from colossalai.zero import ColoInitContext
from tests.kit.model_zoo import model_zoo
-def check_gemini_plugin(early_stop: bool = True):
+@parameterize('init_method', ['lazy', 'none', 'colo'])
+def check_gemini_plugin(init_method: str = 'none', early_stop: bool = True):
"""check gemini plugin over model zoo
Args:
early_stop (bool, optional): Whether to stop when getting the first error. Defaults to True.
"""
+ is_support_meta = is_compatible_with_meta()
+ if not is_support_meta and init_method == 'lazy':
+ return
+
+ from colossalai.utils.model.experimental import LazyInitContext
passed_models = []
failed_info = {} # (model_name, error) pair
@@ -40,10 +50,25 @@ def check_gemini_plugin(early_stop: bool = True):
]:
continue
+ if init_method == 'lazy' and name in [
+ 'timm_convmixer', 'timm_vision_transformer', 'timm_deit', 'timm_deit3', 'timm_inception_v3',
+ 'timm_tnt_b_patch16_224', 'timm_rexnet', 'torchvision_densenet121', 'torchvision_efficientnet_b0',
+ 'torchvision_mobilenet_v2', 'torchvision_mnasnet0_5', 'torchvision_regnet_x_16gf',
+ 'torchvision_shufflenet_v2_x0_5', 'torchvision_efficientnet_v2_s'
+ ]:
+ continue
+
try:
+ if init_method == 'colo':
+ ctx = ColoInitContext()
+ elif init_method == 'lazy':
+ ctx = LazyInitContext()
+ else:
+ ctx = nullcontext()
plugin = GeminiPlugin(placement_policy='cuda', strict_ddp_mode=True, max_norm=1.0, initial_scale=2**5)
booster = Booster(plugin=plugin)
- model = model_fn()
+ with ctx:
+ model = model_fn()
optimizer = HybridAdam(model.parameters(), lr=1e-3)
criterion = lambda x: x.mean()
data = data_gen_fn()
@@ -76,6 +101,7 @@ def check_gemini_plugin(early_stop: bool = True):
torch.cuda.empty_cache()
if dist.get_rank() == 0:
+ print(f'Init method: {init_method}')
print(f'Passed models({len(passed_models)}): {passed_models}\n\n')
print(f'Failed models({len(failed_info)}): {list(failed_info.keys())}\n\n')
assert len(failed_info) == 0, '\n'.join([f'{k}: {v}' for k, v in failed_info.items()])
diff --git a/tests/test_zero/test_gemini/test_zeroddp_state_dict_shard.py b/tests/test_zero/test_gemini/test_zeroddp_state_dict_shard.py
new file mode 100644
index 000000000000..96c26a1de4df
--- /dev/null
+++ b/tests/test_zero/test_gemini/test_zeroddp_state_dict_shard.py
@@ -0,0 +1,56 @@
+import pytest
+import torch
+from torch.testing import assert_close
+
+import colossalai
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+from colossalai.utils.cuda import get_current_device
+from colossalai.zero import ColoInitContext, ZeroDDP
+from colossalai.zero.gemini.chunk import ChunkManager, search_chunk_configuration
+from colossalai.zero.gemini.gemini_mgr import GeminiManager
+from tests.components_to_test.registry import non_distributed_component_funcs
+
+
+@parameterize('placement_policy', ['cuda', 'cpu'])
+@parameterize('model_name', ['gpt2', 'bert'])
+def exam_state_dict(placement_policy, model_name: str):
+ get_components_func = non_distributed_component_funcs.get_callable(model_name)
+ model_builder, train_dataloader, test_dataloader, optimizer_class, criterion = get_components_func()
+
+ with ColoInitContext(device=get_current_device()):
+ model = model_builder()
+
+ model_size = sum(p.numel() * p.element_size() for p in model.parameters()) / 1024**2
+
+ config_dict, *_ = search_chunk_configuration(model, search_range_mb=1, search_interval_byte=100)
+ chunk_manager = ChunkManager(config_dict)
+ gemini_manager = GeminiManager(placement_policy, chunk_manager)
+ model = ZeroDDP(model, gemini_manager)
+ model.train()
+
+ zero_dict = model.state_dict(only_rank_0=False)
+ accumulated_keys = set()
+ # ensure number of shards > 1
+ for shard in model.state_dict_shard(max_shard_size=(model_size / 3), only_rank_0=False):
+ for key, value in shard.items():
+ assert key not in accumulated_keys, f"key `{key}` is duplicated."
+ accumulated_keys.add(key)
+ assert key in zero_dict, f"{key} not in ZeRO dictionary."
+ assert torch.equal(value, zero_dict[key]), f"{key} not equal."
+
+
+def run_dist(rank, world_size, port):
+ config = {}
+ colossalai.launch(config=config, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ exam_state_dict()
+
+
+@pytest.mark.dist
+@pytest.mark.parametrize('world_size', [1, 4])
+@rerun_if_address_is_in_use()
+def test_zero_ddp_state_dict_shard(world_size):
+ spawn(run_dist, world_size)
+
+
+if __name__ == '__main__':
+ test_zero_ddp_state_dict_shard(1)
 +
+
+
+