diff --git a/.github/workflows/README.md b/.github/workflows/README.md
index a46d8b1c24d0..8fc14e0d531a 100644
--- a/.github/workflows/README.md
+++ b/.github/workflows/README.md
@@ -43,7 +43,7 @@ I will provide the details of each workflow below.
| Workflow Name | File name | Description |
| ---------------------- | -------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------- |
-| `Build on PR` | `build_on_pr.yml` | This workflow is triggered when the label `Run build and Test` is assigned to a PR. It will run all the unit tests in the repository with 4 GPUs. |
+| `Build on PR` | `build_on_pr.yml` | This workflow is triggered when a PR changes essential files. It will run all the unit tests in the repository with 4 GPUs. |
| `Build on Schedule` | `build_on_schedule.yml` | This workflow will run the unit tests everyday with 8 GPUs. The result is sent to Lark. |
| `Report test coverage` | `report_test_coverage.yml` | This PR will put up a comment to report the test coverage results when `Build` is done. |
diff --git a/.github/workflows/build_on_pr.yml b/.github/workflows/build_on_pr.yml
index 7419b59ca007..a9e50e231164 100644
--- a/.github/workflows/build_on_pr.yml
+++ b/.github/workflows/build_on_pr.yml
@@ -2,7 +2,18 @@ name: Build on PR
on:
pull_request:
- types: [synchronize, labeled]
+ types: [synchronize, opened, reopened]
+ paths:
+ - '.github/workflows/build_on_pr.yml' # run command & env variables change
+ - 'colossalai/**' # source code change
+ - '!colossalai/**.md' # ignore doc change
+ - 'op_builder/**' # cuda extension change
+ - '!op_builder/**.md' # ignore doc change
+ - 'requirements/**' # requirements change
+ - 'tests/**' # test change
+ - '!tests/**.md' # ignore doc change
+ - 'pytest.ini' # test config change
+ - 'setup.py' # install command change
jobs:
detect:
@@ -10,8 +21,7 @@ jobs:
if: |
github.event.pull_request.draft == false &&
github.base_ref == 'main' &&
- github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' &&
- contains( github.event.pull_request.labels.*.name, 'Run Build and Test')
+ github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
outputs:
changedExtenisonFiles: ${{ steps.find-extension-change.outputs.all_changed_files }}
anyExtensionFileChanged: ${{ steps.find-extension-change.outputs.any_changed }}
@@ -66,6 +76,7 @@ jobs:
build:
name: Build and Test Colossal-AI
needs: detect
+ if: needs.detect.outputs.anyLibraryFileChanged == 'true'
runs-on: [self-hosted, gpu]
container:
image: hpcaitech/pytorch-cuda:1.12.0-11.3.0
@@ -110,7 +121,6 @@ jobs:
[ ! -z "$(ls -A /github/home/cuda_ext_cache/)" ] && cp -p -r /github/home/cuda_ext_cache/* /__w/ColossalAI/ColossalAI/
- name: Install Colossal-AI
- if: needs.detect.outputs.anyLibraryFileChanged == 'true'
run: |
CUDA_EXT=1 pip install -v -e .
pip install -r requirements/requirements-test.txt
@@ -127,7 +137,6 @@ jobs:
fi
- name: Execute Unit Testing
- if: needs.detect.outputs.anyLibraryFileChanged == 'true'
run: |
CURL_CA_BUNDLE="" PYTHONPATH=$PWD pytest --testmon --testmon-cov=. tests/
env:
diff --git a/.github/workflows/doc_check_on_pr.yml b/.github/workflows/doc_check_on_pr.yml
index 2022c957fba8..a863fcd70b44 100644
--- a/.github/workflows/doc_check_on_pr.yml
+++ b/.github/workflows/doc_check_on_pr.yml
@@ -47,12 +47,16 @@ jobs:
# we use the versions in the main branch as the guide for versions to display
# checkout will give your merged branch
# therefore, we need to make the merged branch as the main branch
+ # there is no main branch, so it's safe to checkout the main branch from the merged branch
+ # docer will rebase the remote main branch to the merged branch, so we have to config user
- name: Make the merged branch main
run: |
cd ColossalAI
- curBranch=$(git rev-parse --abbrev-ref HEAD)
- git checkout main
- git merge $curBranch # fast-forward master up to the merge
+ git checkout -b main
+ git branch -u origin/main
+ git config user.name 'github-actions'
+ git config user.email 'github-actions@github.com'
+
- name: Build docs
run: |
diff --git a/.github/workflows/doc_test_on_pr.yml b/.github/workflows/doc_test_on_pr.yml
index fbe669582c20..fb2e28cd9b2e 100644
--- a/.github/workflows/doc_test_on_pr.yml
+++ b/.github/workflows/doc_test_on_pr.yml
@@ -86,7 +86,7 @@ jobs:
- name: Test the Doc
run: |
source activate pytorch
- for file in ${{ steps.changed-files.outputs.all_changed_files }}; do
+ for file in ${{ needs.detect-changed-doc.outputs.changed_files }}; do
echo "Testing $file now..."
docer test -p $file
done
diff --git a/README.md b/README.md
index 79f733122cb3..2e6dcaa1eaf4 100644
--- a/README.md
+++ b/README.md
@@ -127,12 +127,22 @@ distributed training and inference in a few lines.
### ColossalChat
-[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline. [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) [[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b) [[demo]](https://chat.colossalai.org)
+[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline.
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
+[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+[[demo]](https://www.youtube.com/watch?v=HcTiHzApHm0)
+[[tutorial]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
+
+
+ +
+
+
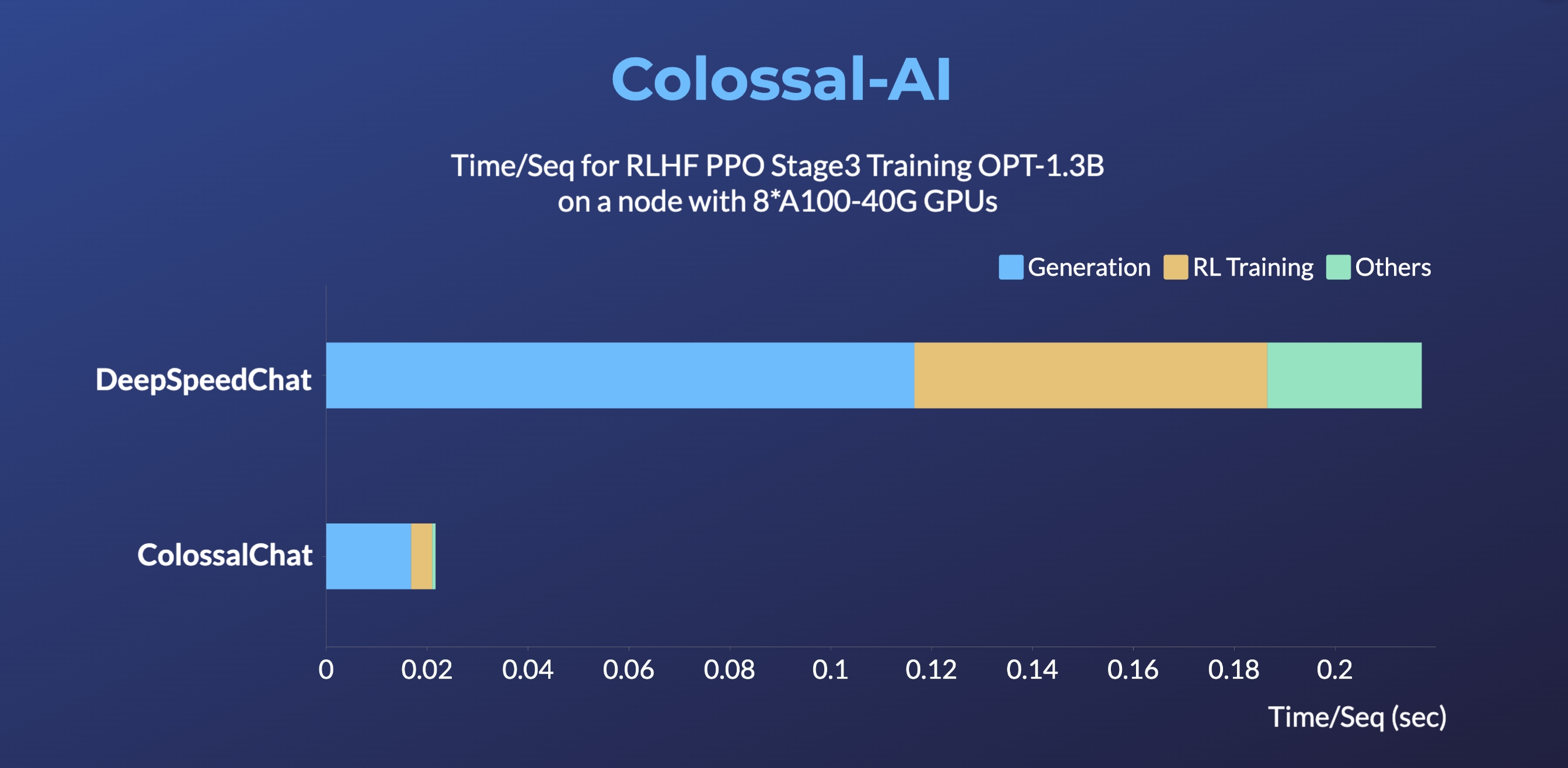
+- Up to 10 times faster for RLHF PPO Stage3 Training
 diff --git a/applications/Chat/README.md b/applications/Chat/README.md
index 9ba831973b6c..bc8481d96de3 100644
--- a/applications/Chat/README.md
+++ b/applications/Chat/README.md
@@ -67,13 +67,24 @@ More details can be found in the latest news.
* [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
## Online demo
-You can experience the performance of Coati7B on this page.
+
diff --git a/applications/Chat/README.md b/applications/Chat/README.md
index 9ba831973b6c..bc8481d96de3 100644
--- a/applications/Chat/README.md
+++ b/applications/Chat/README.md
@@ -67,13 +67,24 @@ More details can be found in the latest news.
* [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
## Online demo
-You can experience the performance of Coati7B on this page.
+
-[chat.colossalai.org](https://chat.colossalai.org/)
+[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline.
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
+[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+[[demo]](https://www.youtube.com/watch?v=HcTiHzApHm0)
+[[tutorial]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
+
+
+
+
-Due to resource constraints, we will only provide this service from 29th Mar 2023 to 5 April 2023. However, we have provided the inference code in the [inference](./inference/) folder. The WebUI will be open-sourced soon as well.
+> DeepSpeedChat performance comes from its blog on 2023 April 12, ColossalChat performance can be reproduced on an AWS p4d.24xlarge node with 8 A100-40G GPUs with the following command: torchrun --standalone --nproc_per_node 8 benchmark_opt_lora_dummy.py --max_timesteps 1 --update_timesteps 1 --use_kernels --strategy colossalai_zero2 --experience_batch_size 64 --train_batch_size 32
-> Warning: Due to model and dataset size limitations, Coati is just a baby model, Coati7B may output incorrect information and lack the ability for multi-turn dialogue. There is still significant room for improvement.
## Install
### Install the environment
@@ -112,12 +123,14 @@ Here is how we collected the data
Stage1 is supervised instructs fine-tuning, which uses the datasets mentioned earlier to fine-tune the model.
You can run the `examples/train_sft.sh` to start a supervised instructs fine-tuning.
+[[Stage1 tutorial video]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
### RLHF Training Stage2 - Training reward model
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model
You can run the `examples/train_rm.sh` to start a reward model training.
+[[Stage2 tutorial video]](https://www.youtube.com/watch?v=gMx2CApKhuo)
### RLHF Training Stage3 - Training model with reinforcement learning by human feedback
@@ -128,6 +141,7 @@ Stage3 uses reinforcement learning algorithm, which is the most complex part of
You can run the `examples/train_prompts.sh` to start training PPO with human feedback.
+[[Stage3 tutorial video]](https://www.youtube.com/watch?v=Z8wwSHxPL9g)
For more details, see [`examples/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples).
diff --git a/applications/Chat/coati/dataset/prompt_dataset.py b/applications/Chat/coati/dataset/prompt_dataset.py
index f8ab2346c4b7..5858052c836a 100644
--- a/applications/Chat/coati/dataset/prompt_dataset.py
+++ b/applications/Chat/coati/dataset/prompt_dataset.py
@@ -45,7 +45,7 @@ def __init__(self,
self.keyed_prompt[k].extend(tensor.to(torch.cuda.current_device()).unbind())
def __len__(self):
- return len(self.keyed_prompt)
+ return len(self.keyed_prompt["input_ids"])
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
return {k: v[i] for k, v in self.keyed_prompt.items()}
diff --git a/applications/Chat/examples/README.md b/applications/Chat/examples/README.md
index 2a2128e25a62..72810738d017 100644
--- a/applications/Chat/examples/README.md
+++ b/applications/Chat/examples/README.md
@@ -48,6 +48,7 @@ The following pic shows how we collected the data.
## Stage1 - Supervised instructs tuning
Stage1 is supervised instructs fine-tuning, which uses the datasets mentioned earlier to fine-tune the model.
+[[Stage1 tutorial video]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
You can run the `examples/train_sft.sh` to start a supervised instructs fine-tuning.
@@ -83,6 +84,7 @@ torchrun --standalone --nproc_per_node=4 train_sft.py \
## Stage2 - Training reward model
We train a reward model in stage 2, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model.
+[[Stage2 tutorial video]](https://www.youtube.com/watch?v=gMx2CApKhuo)
You can run the `examples/train_rm.sh` to start a reward model training.
@@ -141,6 +143,7 @@ Stage3 uses reinforcement learning algorithm, which is the most complex part of
You can run the `examples/train_prompts.sh` to start PPO training.
You can also use the cmd following to start PPO training.
+[[Stage3 tutorial video]](https://www.youtube.com/watch?v=Z8wwSHxPL9g)
```
torchrun --standalone --nproc_per_node=4 train_prompts.py \
@@ -153,7 +156,7 @@ torchrun --standalone --nproc_per_node=4 train_prompts.py \
--rm_path /your/rm/model/path
```
-Prompt dataset: the instruction dataset mentioned in the above figure which includes the instructions, e.g. you can use the [script](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/example_data_reformat.py) to reformat [seed_prompts_ch.jsonl](https://github.com/XueFuzhao/InstructionWild/blob/main/data/seed_prompts_ch.jsonl) or [seed_prompts_en.jsonl](https://github.com/XueFuzhao/InstructionWild/blob/main/data/seed_prompts_en.jsonl) in InstructionWild.
+Prompt dataset: the instruction dataset mentioned in the above figure which includes the instructions, e.g. you can use the [script](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/generate_prompt_dataset.py) which samples `instinwild_en.json` or `instinwild_ch.json` in [InstructionWild](https://github.com/XueFuzhao/InstructionWild/tree/main/data#instructwild-data) to generate the prompt dataset.
Pretrain dataset: the pretrain dataset including the instruction and corresponding response, e.g. you can use the [InstructWild Data](https://github.com/XueFuzhao/InstructionWild/tree/main/data) in stage 1 supervised instructs tuning.
### Arg List
diff --git a/applications/Chat/examples/example_data_reformat.py b/applications/Chat/examples/example_data_reformat.py
deleted file mode 100644
index dc83b29b525b..000000000000
--- a/applications/Chat/examples/example_data_reformat.py
+++ /dev/null
@@ -1,12 +0,0 @@
-jsonl_file = 'seed_prompts_xx.jsonl' # seed_prompts_en.jsonl or seed_prompts_ch.json from InstructionWild
-reformat_file = 'prompts_xx.jsonl' # reformat jsonl file used as Prompt dataset in Stage3
-
-data = ''
-with open(jsonl_file, 'r', encoding="utf-8") as f1:
- for jsonstr in f1.readlines():
- jsonstr = '\t' + jsonstr.strip('\n') + ',\n'
- data = data + jsonstr
- data = '[\n' + data + ']'
-
-with open(reformat_file, 'w') as f2:
- f2.write(data)
\ No newline at end of file
diff --git a/applications/Chat/examples/generate_prompt_dataset.py b/applications/Chat/examples/generate_prompt_dataset.py
new file mode 100644
index 000000000000..95e40fefe7ff
--- /dev/null
+++ b/applications/Chat/examples/generate_prompt_dataset.py
@@ -0,0 +1,30 @@
+import argparse
+
+import random
+import json
+
+random.seed(42)
+
+
+def sample(args):
+ with open(args.dataset_path, mode='r') as f:
+ dataset_list = json.load(f)
+
+ sampled_dataset = [{"instruction": sample["instruction"], "id":idx}
+ for idx, sample in enumerate(random.sample(dataset_list, args.sample_size))]
+
+ with open(args.save_path, mode='w') as f:
+ json.dump(sampled_dataset, f, indent=4,
+ default=str, ensure_ascii=False)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--dataset_path', type=str, default=None,
+ required=True, help="path to the pretrain dataset")
+ parser.add_argument('--save_path', type=str, default='prompt.json',
+ help="path to save the prompt dataset")
+ parser.add_argument('--sample_size', type=int,
+ default=16384, help="size of the prompt dataset")
+ args = parser.parse_args()
+ sample(args)
diff --git a/colossalai/amp/torch_amp/_grad_scaler.py b/colossalai/amp/torch_amp/_grad_scaler.py
index 7b78998fb8c2..ed4b8e484436 100644
--- a/colossalai/amp/torch_amp/_grad_scaler.py
+++ b/colossalai/amp/torch_amp/_grad_scaler.py
@@ -240,7 +240,7 @@ def _unscale_grads_(self, optimizer, inv_scale, found_inf, allow_fp16):
for grads in per_dtype_grads.values():
torch._amp_foreach_non_finite_check_and_unscale_(grads, per_device_found_inf.get(device),
per_device_inv_scale.get(device))
- # For tensor parallel paramters it should be all-reduced over tensor parallel process group
+ # For tensor parallel parameters it should be all-reduced over tensor parallel process group
if gpc.is_initialized(ParallelMode.MODEL) and gpc.get_world_size(ParallelMode.MODEL) > 1:
vals = [val for val in per_device_found_inf._per_device_tensors.values()]
coalesced = _flatten_dense_tensors(vals)
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/linear.py b/colossalai/auto_parallel/meta_profiler/meta_registry/linear.py
index 7697fc6c383d..94dd9143e0ae 100644
--- a/colossalai/auto_parallel/meta_profiler/meta_registry/linear.py
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/linear.py
@@ -325,7 +325,7 @@ def matmul_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, L
else:
_is_batch_dims_same = False
- # retireve dimensions
+ # retrieve dimensions
input_dim_00 = input_tensors[0].shape[-2]
input_dim_01 = input_tensors[0].shape[-1]
input_dim_10 = input_tensors[1].shape[-2]
diff --git a/colossalai/auto_parallel/passes/runtime_apply_pass.py b/colossalai/auto_parallel/passes/runtime_apply_pass.py
index a473bb6e973d..2049a06187d2 100644
--- a/colossalai/auto_parallel/passes/runtime_apply_pass.py
+++ b/colossalai/auto_parallel/passes/runtime_apply_pass.py
@@ -219,7 +219,7 @@ def _comm_spec_apply(gm: torch.fx.GraphModule):
return gm
-def _act_annotataion_pass(gm: torch.fx.GraphModule):
+def _act_annotation_pass(gm: torch.fx.GraphModule):
"""
This pass is used to add the act annotation to the new inserted nodes.
"""
diff --git a/colossalai/auto_parallel/passes/runtime_preparation_pass.py b/colossalai/auto_parallel/passes/runtime_preparation_pass.py
index 177f3765f5a0..9a2314826448 100644
--- a/colossalai/auto_parallel/passes/runtime_preparation_pass.py
+++ b/colossalai/auto_parallel/passes/runtime_preparation_pass.py
@@ -54,7 +54,7 @@ def size_processing(size: Union[int, torch.Size],
return size
-def solution_annotatation_pass(gm: torch.fx.GraphModule, solution: List[int],
+def solution_annotation_pass(gm: torch.fx.GraphModule, solution: List[int],
strategies_constructor: StrategiesConstructor):
"""
This method is used to stick the solution strategy to the nodes and add the information
@@ -496,7 +496,7 @@ def runtime_preparation_pass(gm: torch.fx.GraphModule,
device_mesh: DeviceMesh,
strategies_constructor: StrategiesConstructor,
overlap=False):
- gm, sharding_spec_convert_dict, origin_node_sharding_spec_dict, comm_actions_dict = solution_annotatation_pass(
+ gm, sharding_spec_convert_dict, origin_node_sharding_spec_dict, comm_actions_dict = solution_annotation_pass(
gm, solution, strategies_constructor)
gm = size_value_converting_pass(gm, device_mesh)
gm = node_args_converting_pass(gm, device_mesh)
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py
index ab391ebfaf80..d3d09a9dcf65 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py
@@ -75,7 +75,7 @@ def update_resharding_cost(self, strategy: ShardingStrategy) -> None:
prev_strategy.get_sharding_spec_by_name(node_name) for prev_strategy in prev_strategy_vector
]
- # create data structrure to store costs
+ # create data structure to store costs
if node not in resharding_costs:
resharding_costs[node] = []
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/batch_norm_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/batch_norm_generator.py
index 1f3812429fc2..79b69acb25b3 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/batch_norm_generator.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/batch_norm_generator.py
@@ -24,7 +24,7 @@ class BatchNormStrategyGenerator(StrategyGenerator):
To keep the math consistency, there are two way to do BatchNorm if the input
shards on batch dimension:
1. We gather the input partitions through batch dimension, then do the normal BatchNorm.
- 2. We do the SyncBatchNorm on the each input partition seperately, the SyncBN op will help
+ 2. We do the SyncBatchNorm on the each input partition separately, the SyncBN op will help
us to keep the computing correctness.
In this generator, both methods will be considered.
"""
@@ -212,7 +212,7 @@ def split_input_batch(self, mesh_dim_0):
# set communication action
# For SyncBN case, we don't need to do communication for weight and bias.
- # TODO: the communication happens interally at SyncBN operation. We need to replace the BN operation
+ # TODO: the communication happens internally at SyncBN operation. We need to replace the BN operation
# to SyncBN operation instead of inserting a communication node.
output_comm_action = self.get_communication_action(
sharding_spec=sharding_spec_mapping["output"],
@@ -250,7 +250,7 @@ def split_input_batch_1d(self, mesh_dim_0, mesh_dim_1):
# set communication action
# For SyncBN case, we don't need to do communication for gradients of weight and bias.
- # TODO: the communication happens interally at SyncBN operation. We need to replace the BN operation
+ # TODO: the communication happens internally at SyncBN operation. We need to replace the BN operation
# to SyncBN operation instead of inserting a communication node.
output_comm_action = self.get_communication_action(
sharding_spec=sharding_spec_mapping["output"],
@@ -298,7 +298,7 @@ def split_input_both_dim(self, mesh_dim_0, mesh_dim_1):
# set communication action
# For SyncBN case, we don't need to do communication for gradients of weight and bias.
- # TODO: the communication happens interally at SyncBN operation. We need to replace the BN operation
+ # TODO: the communication happens internally at SyncBN operation. We need to replace the BN operation
# to SyncBN operation instead of inserting a communication node.
output_comm_action = self.get_communication_action(
sharding_spec=sharding_spec_mapping["output"],
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/binary_elementwise_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/binary_elementwise_generator.py
index fd7f811c8972..d27cc046eaf3 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/binary_elementwise_generator.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/binary_elementwise_generator.py
@@ -51,7 +51,7 @@ def update_memory_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
# compute fwd memory cost in bytes
# as the elementwise ops are not memory-intensive
- # we approximate the fwd memroy cost to be the output
+ # we approximate the fwd memory cost to be the output
# and the backward memory cost to be grad of input and other
input_bytes = self._compute_size_in_bytes(strategy, 'input')
other_bytes = self._compute_size_in_bytes(strategy, 'other')
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/strategy_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/strategy_generator.py
index 6d68521aaea7..d42429745c61 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/strategy_generator.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/strategy_generator.py
@@ -225,7 +225,7 @@ def _compute_size_in_bytes_helper(sharding_spec, meta_data):
if isinstance(meta_data, torch.Tensor):
element_bytes = _compute_size_in_bytes_helper(sharding_spec, meta_data)
else:
- # if meta_data is not a tensor, we count the memroy as 0
+ # if meta_data is not a tensor, we count the memory as 0
element_bytes = 0
total_bytes += element_bytes
@@ -233,7 +233,7 @@ def _compute_size_in_bytes_helper(sharding_spec, meta_data):
if isinstance(op_data.data, torch.Tensor):
total_bytes = _compute_size_in_bytes_helper(strategy.sharding_specs[op_data], op_data.data)
else:
- # if op_data.data is not a tensor, we count the memroy as 0
+ # if op_data.data is not a tensor, we count the memory as 0
total_bytes = 0
return total_bytes
diff --git a/colossalai/auto_parallel/tensor_shard/solver/cost_graph.py b/colossalai/auto_parallel/tensor_shard/solver/cost_graph.py
index 74290453ca0c..1b2d3ad57407 100644
--- a/colossalai/auto_parallel/tensor_shard/solver/cost_graph.py
+++ b/colossalai/auto_parallel/tensor_shard/solver/cost_graph.py
@@ -9,7 +9,7 @@ class CostGraph:
1. To feed the quadratic resharding costs into solver, we need to linearize it. We build edge_cost in
CostGraph, and it stored every combinations of strategies for a src-dst node pair in an 1D list.
2. To reduce the searching space, we merge computationally-trivial operators, such as
- element-wise operators, transpose, and reduction, into their following nodes. The merging infomation will
+ element-wise operators, transpose, and reduction, into their following nodes. The merging information will
be given by the StrategiesVector depending on the type of target node and following nodes.
Argument:
@@ -90,7 +90,7 @@ def _check_tensor_in_node(data):
if self.simplify and strategies_vector.check_merge():
for followed_node in strategies_vector.predecessor_nodes:
# we only merge node pairs which src node has a tensor element inside.
- # This is necessay because the node without a tensor element inside will not
+ # This is necessary because the node without a tensor element inside will not
# be assigned any strategy.
if _check_tensor_in_node(followed_node._meta_data):
self.merge_pair.append((followed_node, dst_node))
diff --git a/colossalai/auto_parallel/tensor_shard/solver/graph_analysis.py b/colossalai/auto_parallel/tensor_shard/solver/graph_analysis.py
index be39a74cb237..171aa8b3399f 100644
--- a/colossalai/auto_parallel/tensor_shard/solver/graph_analysis.py
+++ b/colossalai/auto_parallel/tensor_shard/solver/graph_analysis.py
@@ -83,7 +83,7 @@ def graph(self) -> Graph:
def liveness_analysis(self) -> List[LiveStage]:
"""
- Analyse the graph to obtain the variable liveness information. This function returns
+ Analyses the graph to obtain the variable liveness information. This function returns
an ordered dictionary where the key is the compute stage ID and the value is a LivenessStage object.
"""
compute_nodes = self.graph.nodes
@@ -91,7 +91,7 @@ def liveness_analysis(self) -> List[LiveStage]:
# checked: record all variables created since the first stage
# all: record the live variables only exist until the current stage.
- # this can be different from the `checked list`` as some varialbes may be destroyed prior to this stage.
+ # this can be different from the `checked list`` as some variables may be destroyed prior to this stage.
# unique: record the unique live variables only exist until the current stage.
# this is different from `all list` as some variables are duplicated.
checked_variables = LiveVariableVector()
@@ -103,7 +103,7 @@ def liveness_analysis(self) -> List[LiveStage]:
# find new living variables #
#############################
# detect whether the current op is an in-place op
- # if it is an in-place op, we would deem it as a duplciate var
+ # if it is an in-place op, we would deem it as a duplicate var
is_inplace = False
if node.op == 'call_function':
# check if this is an inplace op such as torch.nn.functional.relu(x, inplace=True)
diff --git a/colossalai/auto_parallel/tensor_shard/solver/solver.py b/colossalai/auto_parallel/tensor_shard/solver/solver.py
index f5c6663dce80..564c5f09220c 100644
--- a/colossalai/auto_parallel/tensor_shard/solver/solver.py
+++ b/colossalai/auto_parallel/tensor_shard/solver/solver.py
@@ -44,7 +44,7 @@ def __init__(self,
graph: The computing graph to be optimized.
strategies_constructor: It will provide all the possible strategies for each node in the computing graph.
cost_graph: A graph data structure to simplify the edge cost graph.
- graph_analyser: graph_analyser will analyse the graph to obtain the variable liveness information, which will be used to generate memory constraints.
+ graph_analyser: graph_analyser will analyses the graph to obtain the variable liveness information, which will be used to generate memory constraints.
memory_budget: Memory constraint for the solution.
solution_numbers: If solution_numbers is larger than one, solver will us a serious of solutions based on different memory budget.
memory_increasing_coefficient: If solution_numbers is larger than one, we will use this coefficient to generate new memory budget.
diff --git a/colossalai/autochunk/trace_flow.py b/colossalai/autochunk/trace_flow.py
index db25267e9b42..11a7e62ff37c 100644
--- a/colossalai/autochunk/trace_flow.py
+++ b/colossalai/autochunk/trace_flow.py
@@ -64,7 +64,7 @@ def check_index_compute(self, start_idx, end_dim, end_node, end_idx):
return False
return True
- def _assgin_single_node_flow(
+ def _assign_single_node_flow(
self,
arg_node: Node,
start_idx: int,
@@ -177,7 +177,7 @@ def _get_all_node_info(self, end_dim, start_idx, end_idx):
if get_node_shape(arg) is None:
continue
arg_list.append(arg)
- flow_flag = self._assgin_single_node_flow(
+ flow_flag = self._assign_single_node_flow(
arg,
start_idx,
end_idx,
@@ -315,7 +315,7 @@ def _get_prepose_nodes(self, all_node_info: Dict, start_idx: int, end_idx: int,
chunk_info["args"]["prepose_nodes"] = prepose_nodes
def _get_non_chunk_inputs(self, chunk_info, start_idx, end_idx):
- # we need to log input nodes to avoid deleteing them in the loop
+ # we need to log input nodes to avoid deleting them in the loop
chunk_node_list = self.node_mgr.get_node_slice_by_idx(start_idx, end_idx + 1)
# also need to get some prepose node's arg out of non_chunk_inputs
for n in chunk_info["args"]["prepose_nodes"]:
diff --git a/colossalai/autochunk/trace_indice.py b/colossalai/autochunk/trace_indice.py
index d56bf843f18d..8e6cd3e29bea 100644
--- a/colossalai/autochunk/trace_indice.py
+++ b/colossalai/autochunk/trace_indice.py
@@ -461,7 +461,7 @@ def _assign_elementwise_indice(self, node, idx):
nodes_in.append(node_in)
self._inherit_more_indice_from_node_with_exclude(node_in, node)
- def _assgin_no_change_indice(self, node, idx):
+ def _assign_no_change_indice(self, node, idx):
self._assign_indice_as_input(node, idx)
for node_in in node.args:
if type(node_in) == type(node):
@@ -792,7 +792,7 @@ def _assign_view_reshape_indice(self, node: Node, node_idx: int) -> None:
self._add_dim(node_idx, i)
dim_from.reverse()
- # inheirt indice from current node
+ # inherit indice from current node
if len(dim_from) != 0 and len(dim_to) != 0:
if dim_diff == 1:
if origin_shape[dim_from[0]] == 1:
@@ -852,7 +852,7 @@ def trace_indice(self) -> None:
elif "split" == node_name:
self._assign_split_indice(node, idx)
elif any(i == node_name for i in ["to", "contiguous", "clone", "type", "float"]):
- self._assgin_no_change_indice(node, idx)
+ self._assign_no_change_indice(node, idx)
elif "new_ones" == node_name:
self._assign_all_indice(node, idx)
elif "flatten" == node_name:
@@ -914,7 +914,7 @@ def trace_indice(self) -> None:
elif "conv2d" == node_name:
self._assign_conv2d_indice(node, idx)
elif "identity" == node_name:
- self._assgin_no_change_indice(node, idx)
+ self._assign_no_change_indice(node, idx)
elif any(n == node_name for n in ["sigmoid", "dropout", "relu", "silu", "gelu"]):
self._assign_elementwise_indice(node, idx)
else:
diff --git a/colossalai/booster/booster.py b/colossalai/booster/booster.py
index c14e602deaf5..6f2adaf03074 100644
--- a/colossalai/booster/booster.py
+++ b/colossalai/booster/booster.py
@@ -151,6 +151,16 @@ def no_sync(self, model: nn.Module) -> contextmanager:
return self.plugin.no_sync(model)
def load_model(self, model: nn.Module, checkpoint: str, strict: bool = True):
+ """Load model from checkpoint.
+
+ Args:
+ model (nn.Module): A model boosted by Booster.
+ checkpoint (str): Path to the checkpoint. It must be a local path.
+ It should be a directory path if the checkpoint is sharded. Otherwise, it should be a file path.
+ strict (bool, optional): whether to strictly enforce that the keys
+ in :attr:`state_dict` match the keys returned by this module's
+ :meth:`~torch.nn.Module.state_dict` function. Defaults to True.
+ """
self.checkpoint_io.load_model(model, checkpoint, strict)
def save_model(self,
@@ -159,16 +169,58 @@ def save_model(self,
prefix: str = None,
shard: bool = False,
size_per_shard: int = 1024):
+ """Save model to checkpoint.
+
+ Args:
+ model (nn.Module): A model boosted by Booster.
+ checkpoint (str): Path to the checkpoint. It must be a local path.
+ It is a file path if ``shard=False``. Otherwise, it is a directory path.
+ prefix (str, optional): A prefix added to parameter and buffer
+ names to compose the keys in state_dict. Defaults to None.
+ shard (bool, optional): Whether to save checkpoint a sharded way.
+ If true, the checkpoint will be a folder. Otherwise, it will be a single file. Defaults to False.
+ size_per_shard (int, optional): Maximum size of checkpoint shard file in MB. This is useful only when ``shard=True``. Defaults to 1024.
+ """
self.checkpoint_io.save_model(model, checkpoint, prefix, shard, size_per_shard)
def load_optimizer(self, optimizer: Optimizer, checkpoint: str):
+ """Load optimizer from checkpoint.
+
+ Args:
+ optimizer (Optimizer): An optimizer boosted by Booster.
+ checkpoint (str): Path to the checkpoint. It must be a local path.
+ It should be a directory path if the checkpoint is sharded. Otherwise, it should be a file path.
+ """
self.checkpoint_io.load_optimizer(optimizer, checkpoint)
def save_optimizer(self, optimizer: Optimizer, checkpoint: str, shard: bool = False, size_per_shard: int = 1024):
+ """Save optimizer to checkpoint.
+ Warning: Saving sharded optimizer checkpoint is not supported yet.
+
+ Args:
+ optimizer (Optimizer): An optimizer boosted by Booster.
+ checkpoint (str): Path to the checkpoint. It must be a local path.
+ It is a file path if ``shard=False``. Otherwise, it is a directory path.
+ shard (bool, optional): Whether to save checkpoint a sharded way.
+ If true, the checkpoint will be a folder. Otherwise, it will be a single file. Defaults to False.
+ size_per_shard (int, optional): Maximum size of checkpoint shard file in MB. This is useful only when ``shard=True``. Defaults to 1024.
+ """
self.checkpoint_io.save_optimizer(optimizer, checkpoint, shard, size_per_shard)
def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ """Save lr scheduler to checkpoint.
+
+ Args:
+ lr_scheduler (LRScheduler): A lr scheduler boosted by Booster.
+ checkpoint (str): Path to the checkpoint. It must be a local file path.
+ """
self.checkpoint_io.save_lr_scheduler(lr_scheduler, checkpoint)
def load_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ """Load lr scheduler from checkpoint.
+
+ Args:
+ lr_scheduler (LRScheduler): A lr scheduler boosted by Booster.
+ checkpoint (str): Path to the checkpoint. It must be a local file path.
+ """
self.checkpoint_io.load_lr_scheduler(lr_scheduler, checkpoint)
diff --git a/colossalai/booster/mixed_precision/__init__.py b/colossalai/booster/mixed_precision/__init__.py
index 3cf0ad28cdbe..0df9d84159f9 100644
--- a/colossalai/booster/mixed_precision/__init__.py
+++ b/colossalai/booster/mixed_precision/__init__.py
@@ -1,17 +1,19 @@
from .bf16 import BF16MixedPrecision
from .fp8 import FP8MixedPrecision
from .fp16_apex import FP16ApexMixedPrecision
+from .fp16_naive import FP16NaiveMixedPrecision
from .fp16_torch import FP16TorchMixedPrecision
from .mixed_precision_base import MixedPrecision
__all__ = [
'MixedPrecision', 'mixed_precision_factory', 'FP16_Apex_MixedPrecision', 'FP16_Torch_MixedPrecision',
- 'FP32_MixedPrecision', 'BF16_MixedPrecision', 'FP8_MixedPrecision'
+ 'FP32_MixedPrecision', 'BF16_MixedPrecision', 'FP8_MixedPrecision', 'FP16NaiveMixedPrecision'
]
_mixed_precision_mapping = {
'fp16': FP16TorchMixedPrecision,
'fp16_apex': FP16ApexMixedPrecision,
+ 'fp16_naive': FP16NaiveMixedPrecision,
'bf16': BF16MixedPrecision,
'fp8': FP8MixedPrecision
}
diff --git a/colossalai/booster/mixed_precision/fp16_naive.py b/colossalai/booster/mixed_precision/fp16_naive.py
new file mode 100644
index 000000000000..ef1ec1f42d70
--- /dev/null
+++ b/colossalai/booster/mixed_precision/fp16_naive.py
@@ -0,0 +1,5 @@
+from .mixed_precision_base import MixedPrecision
+
+
+class FP16NaiveMixedPrecision(MixedPrecision):
+ pass
diff --git a/colossalai/booster/plugin/gemini_plugin.py b/colossalai/booster/plugin/gemini_plugin.py
index a3789a39d94b..bb3124642ccf 100644
--- a/colossalai/booster/plugin/gemini_plugin.py
+++ b/colossalai/booster/plugin/gemini_plugin.py
@@ -52,8 +52,16 @@ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather
Save optimizer to checkpoint but only on master process.
"""
# TODO(ver217): optimizer state dict is sharded
+ warnings.warn('GeminiPlugin does not support save full optimizer checkpoint now. Save it on every process.')
+ checkpoint = f'{checkpoint}.rank{self.coordinator.rank}'
super().save_unsharded_optimizer(optimizer, checkpoint, gather_dtensor)
+ def load_optimizer(self, optimizer: Optimizer, checkpoint: str):
+ warnings.warn(
+ 'GeminiPlugin can only load optimizer checkpoint saved by itself with the same number of processes.')
+ checkpoint = f'{checkpoint}.rank{self.coordinator.rank}'
+ super().load_optimizer(optimizer, checkpoint)
+
def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
"""
Save model to checkpoint but only on master process.
diff --git a/colossalai/booster/plugin/low_level_zero_plugin.py b/colossalai/booster/plugin/low_level_zero_plugin.py
index edc0b7679686..5d93cf0e33be 100644
--- a/colossalai/booster/plugin/low_level_zero_plugin.py
+++ b/colossalai/booster/plugin/low_level_zero_plugin.py
@@ -9,7 +9,7 @@
from torch.utils._pytree import tree_map
from torch.utils.data import DataLoader
-from colossalai.checkpoint_io import CheckpointIO
+from colossalai.checkpoint_io import CheckpointIO, GeneralCheckpointIO
from colossalai.interface import ModelWrapper, OptimizerWrapper
from colossalai.utils import get_current_device
from colossalai.zero import zero_model_wrapper, zero_optim_wrapper
@@ -32,8 +32,17 @@ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather
"""
Save optimizer to checkpoint but only on master process.
"""
- # TODO(ver217): optimizer state dict is sharded
- super().save_unsharded_optimizer(optimizer, checkpoint, gather_dtensor)
+ # TODO(ver217): optimizer state dict is sharded, and cannot get full state dict now
+ warnings.warn(
+ 'LowLevelZeroPlugin does not support save full optimizer checkpoint now. Save it on every process.')
+ checkpoint = f'{checkpoint}.rank{self.coordinator.rank}'
+ GeneralCheckpointIO.save_unsharded_optimizer(self, optimizer, checkpoint, gather_dtensor)
+
+ def load_optimizer(self, optimizer: Optimizer, checkpoint: str):
+ warnings.warn(
+ 'LowLevelZeroPlugin can only load optimizer checkpoint saved by itself with the same number of processes.')
+ checkpoint = f'{checkpoint}.rank{self.coordinator.rank}'
+ super().load_optimizer(optimizer, checkpoint)
class LowLevelZeroModel(ModelWrapper):
diff --git a/colossalai/booster/plugin/torch_ddp_plugin.py b/colossalai/booster/plugin/torch_ddp_plugin.py
index 99cd2f7791d3..b317ccf48ad9 100644
--- a/colossalai/booster/plugin/torch_ddp_plugin.py
+++ b/colossalai/booster/plugin/torch_ddp_plugin.py
@@ -1,4 +1,4 @@
-from typing import Callable, Iterator, List, Tuple, Union
+from typing import Callable, Iterator, List, Optional, Tuple, Union
import torch.nn as nn
from torch.nn.parallel import DistributedDataParallel as DDP
@@ -50,6 +50,16 @@ def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
if self.coordinator.is_master():
super().save_lr_scheduler(lr_scheduler, checkpoint)
+ def save_sharded_model(self,
+ model: nn.Module,
+ checkpoint_path: str,
+ gather_dtensor: bool = False,
+ variant: Optional[str] = None,
+ max_shard_size: int = 1024,
+ use_safetensors: bool = False):
+ if self.coordinator.is_master():
+ super().save_sharded_model(model, checkpoint_path, gather_dtensor, variant, max_shard_size, use_safetensors)
+
class TorchDDPModel(ModelWrapper):
diff --git a/colossalai/checkpoint_io/checkpoint_io_base.py b/colossalai/checkpoint_io/checkpoint_io_base.py
index 9cf344ecc41b..fbc8fc5429ad 100644
--- a/colossalai/checkpoint_io/checkpoint_io_base.py
+++ b/colossalai/checkpoint_io/checkpoint_io_base.py
@@ -1,7 +1,6 @@
from abc import ABC, abstractmethod
from pathlib import Path
-from typing import Union
-from typing import Optional
+from typing import Optional, Union
import torch
import torch.nn as nn
@@ -84,9 +83,8 @@ def load_model(self,
# containing no distributed tensors, dtensor -> full tensor conversion
# should be done offline via our CLI
# the existence of index file means it is a sharded checkpoint
- ckpt_path = Path(checkpoint)
index_file_exists, index_file_path = has_index_file(checkpoint)
-
+
# return the origin model instead of the unwrapped model
origin_model = model
diff --git a/colossalai/checkpoint_io/utils.py b/colossalai/checkpoint_io/utils.py
index ee4bd72e89ec..435feda4ac6a 100644
--- a/colossalai/checkpoint_io/utils.py
+++ b/colossalai/checkpoint_io/utils.py
@@ -1,10 +1,12 @@
# coding=utf-8
+import re
from pathlib import Path
+from typing import Iterator, List, Mapping, Optional, OrderedDict, Tuple
+
import torch
import torch.nn as nn
-from typing import List, Mapping, OrderedDict, Optional, Tuple, Iterator
+
from colossalai.tensor.d_tensor.d_tensor import DTensor
-import re
SAFE_WEIGHTS_NAME = "model.safetensors"
WEIGHTS_NAME = "pytorch_model.bin"
@@ -15,6 +17,7 @@
# General helper functions
# ======================================
+
def calculate_tensor_size(tensor: torch.Tensor) -> float:
"""
Calculate the size of a parameter in MB. Used to compute whether a group of params exceed the shard size.
@@ -28,6 +31,7 @@ def calculate_tensor_size(tensor: torch.Tensor) -> float:
"""
return tensor.numel() * tensor.element_size() / 1024 / 1024
+
def is_safetensors_available() -> bool:
"""
Check whether safetensors is available.
@@ -78,7 +82,6 @@ def is_safetensor_checkpoint(checkpoint_file_path: str) -> bool:
# Helper functions for saving shard file
# ======================================
def shard_checkpoint(state_dict: torch.Tensor, max_shard_size: int = 1024) -> Iterator[Tuple[OrderedDict, int]]:
-
"""
Splits a model state dictionary in sub-checkpoints so that the final size of each sub-checkpoint does not exceed a
given size.
@@ -100,35 +103,39 @@ def shard_checkpoint(state_dict: torch.Tensor, max_shard_size: int = 1024) -> It
current_block_size = 0
current_block[key] = weight
current_block_size += weight_size
-
+
if ret_block != None:
yield ret_block, ret_block_size
yield current_block, current_block_size
-def load_shard_state_dict(checkpoint_file: Path, use_safetensors: bool =False):
+def load_shard_state_dict(checkpoint_file: Path, use_safetensors: bool = False):
"""
load shard state dict into model
"""
if use_safetensors and not checkpoint_file.suffix == ".safetensors":
raise Exception("load the model using `safetensors`, but no file endwith .safetensors")
if use_safetensors:
- from safetensors.torch import safe_open
from safetensors.torch import load_file as safe_load_file
+ from safetensors.torch import safe_open
with safe_open(checkpoint_file, framework="pt") as f:
metadata = f.metadata()
if metadata["format"] != "pt":
raise NotImplementedError(
- f"Conversion from a {metadata['format']} safetensors archive to PyTorch is not implemented yet."
- )
+ f"Conversion from a {metadata['format']} safetensors archive to PyTorch is not implemented yet.")
return safe_load_file(checkpoint_file)
else:
return torch.load(checkpoint_file)
-
-def load_state_dict_into_model(model: nn.Module, state_dict: torch.Tensor, missing_keys: List, strict: bool = False, load_sub_module: bool = True):
+
+
+def load_state_dict_into_model(model: nn.Module,
+ state_dict: torch.Tensor,
+ missing_keys: List,
+ strict: bool = False,
+ load_sub_module: bool = True):
r"""Copies parameters and buffers from :attr:`state_dict` into
- this module and its descendants.
+ this module and its descendants.
Args:
state_dict (dict): a dict containing parameters and
@@ -166,11 +173,12 @@ def load(module: nn.Module, state_dict, prefix="", load_sub_module: bool = True)
if strict:
if len(unexpected_keys) > 0:
- error_msgs = 'Unexpected key(s) in state_dict: {}. '.format(
- ', '.join('"{}"'.format(k) for k in unexpected_keys))
+ error_msgs = 'Unexpected key(s) in state_dict: {}. '.format(', '.join(
+ '"{}"'.format(k) for k in unexpected_keys))
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
- model.__class__.__name__, "\n\t".join(error_msgs)))
-
+ model.__class__.__name__, "\n\t".join(error_msgs)))
+
+
# ======================================
# Helper functions for saving state dict
# ======================================
@@ -350,6 +358,8 @@ def has_index_file(checkpoint_path: str) -> Tuple[bool, Optional[Path]]:
return True, index_files[0]
else:
return False, None
+ else:
+ raise RuntimeError(f'Invalid checkpoint path {checkpoint_path}. Expected a file or a directory.')
def load_state_dict(checkpoint_file_path: Path):
@@ -380,7 +390,6 @@ def load_state_dict(checkpoint_file_path: Path):
else:
# load with torch
return torch.load(checkpoint_file_path)
-
def add_variant(weights_name: str, variant: Optional[str] = None) -> str:
@@ -392,17 +401,18 @@ def add_variant(weights_name: str, variant: Optional[str] = None) -> str:
return weights_name
-def get_base_filenames(variant: str=None, use_safetensors: bool=False):
- """
- generate base weight filenames
- """
- weights_name = SAFE_WEIGHTS_NAME if use_safetensors else WEIGHTS_NAME
- weights_name = add_variant(weights_name, variant)
+def get_base_filenames(variant: str = None, use_safetensors: bool = False):
+ """
+ generate base weight filenames
+ """
+ weights_name = SAFE_WEIGHTS_NAME if use_safetensors else WEIGHTS_NAME
+ weights_name = add_variant(weights_name, variant)
+
+ save_index_file = SAFE_WEIGHTS_INDEX_NAME if use_safetensors else WEIGHTS_INDEX_NAME
+ save_index_file = add_variant(save_index_file, variant)
- save_index_file = SAFE_WEIGHTS_INDEX_NAME if use_safetensors else WEIGHTS_INDEX_NAME
- save_index_file = add_variant(save_index_file, variant)
+ return weights_name, save_index_file
- return weights_name, save_index_file
def get_shard_filename(weights_name: str, idx: int):
"""
@@ -410,4 +420,4 @@ def get_shard_filename(weights_name: str, idx: int):
"""
shard_file = weights_name.replace(".bin", f"-{idx+1:05d}.bin")
shard_file = shard_file.replace(".safetensors", f"-{idx + 1:05d}.safetensors")
- return shard_file
\ No newline at end of file
+ return shard_file
diff --git a/colossalai/testing/pytest_wrapper.py b/colossalai/testing/pytest_wrapper.py
index a472eb3723ec..b264b009028a 100644
--- a/colossalai/testing/pytest_wrapper.py
+++ b/colossalai/testing/pytest_wrapper.py
@@ -33,7 +33,7 @@ def test_for_something():
assert isinstance(name, str)
flag = os.environ.get(name.upper(), '0')
- reason = f'Environment varialbe {name} is {flag}'
+ reason = f'Environment variable {name} is {flag}'
if flag == '1':
return pytest.mark.skipif(False, reason=reason)
else:
diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md
index 9d5bcfe3f974..c3deca7e9c17 100644
--- a/docs/README-zh-Hans.md
+++ b/docs/README-zh-Hans.md
@@ -121,12 +121,22 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
### ColossalChat
-[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): 完整RLHF流程0门槛克隆 [ChatGPT](https://openai.com/blog/chatgpt/) [[代码]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) [[博客]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b) [[在线样例]](https://chat.colossalai.org)
+[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): 完整RLHF流程0门槛克隆 [ChatGPT](https://openai.com/blog/chatgpt/)
+[[代码]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
+[[博客]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+[[在线样例]](https://www.youtube.com/watch?v=HcTiHzApHm0)
+[[教程]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
+
+
+
+
+
+- 最高可提升RLHF PPO阶段3训练速度10倍
diff --git a/docs/sidebars.json b/docs/sidebars.json
index 44287c17eadf..94f79dcd3509 100644
--- a/docs/sidebars.json
+++ b/docs/sidebars.json
@@ -26,8 +26,11 @@
"collapsed": true,
"items": [
"basics/command_line_tool",
- "basics/define_your_config",
"basics/launch_colossalai",
+ "basics/booster_api",
+ "basics/booster_plugins",
+ "basics/booster_checkpoint",
+ "basics/define_your_config",
"basics/initialize_features",
"basics/engine_trainer",
"basics/configure_parallelization",
@@ -57,7 +60,8 @@
]
},
"features/pipeline_parallel",
- "features/nvme_offload"
+ "features/nvme_offload",
+ "features/cluster_utils"
]
},
{
diff --git a/docs/source/en/basics/booster_api.md b/docs/source/en/basics/booster_api.md
new file mode 100644
index 000000000000..18dec4500f76
--- /dev/null
+++ b/docs/source/en/basics/booster_api.md
@@ -0,0 +1,89 @@
+# Booster API
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite:**
+- [Distributed Training](../concepts/distributed_training.md)
+- [Colossal-AI Overview](../concepts/colossalai_overview.md)
+
+**Example Code**
+- [Train with Booster](https://github.com/hpcaitech/ColossalAI/blob/main/examples/tutorial/new_api/cifar_resnet/README.md)
+
+## Introduction
+In our new design, `colossalai.booster` replaces the role of `colossalai.initialize` to inject features into your training components (e.g. model, optimizer, dataloader) seamlessly. With these new APIs, you can integrate your model with our parallelism features more friendly. Also calling `colossalai.booster` is the standard procedure before you run into your training loops. In the sections below, I will cover how `colossalai.booster` works and what we should take note of.
+
+### Plugin
+Plugin is an important component that manages parallel configuration (eg: The gemini plugin encapsulates the gemini acceleration solution). Currently supported plugins are as follows:
+
+***GeminiPlugin:*** This plugin wrapps the Gemini acceleration solution, that ZeRO with chunk-based memory management.
+
+***TorchDDPPlugin:*** This plugin wrapps the DDP acceleration solution, it implements data parallelism at the module level which can run across multiple machines.
+
+***LowLevelZeroPlugin:*** This plugin wraps the 1/2 stage of Zero Redundancy Optimizer. Stage 1 : Shards optimizer states across data parallel workers/GPUs. Stage 2 : Shards optimizer states + gradients across data parallel workers/GPUs.
+
+### API of booster
+
+
+{{ autodoc:colossalai.booster.Booster }}
+
+{{ autodoc:colossalai.booster.Booster.boost }}
+
+{{ autodoc:colossalai.booster.Booster.backward }}
+
+{{ autodoc:colossalai.booster.Booster.no_sync }}
+
+{{ autodoc:colossalai.booster.Booster.save_model }}
+
+{{ autodoc:colossalai.booster.Booster.load_model }}
+
+{{ autodoc:colossalai.booster.Booster.save_optimizer }}
+
+{{ autodoc:colossalai.booster.Booster.load_optimizer }}
+
+{{ autodoc:colossalai.booster.Booster.save_lr_scheduler }}
+
+{{ autodoc:colossalai.booster.Booster.load_lr_scheduler }}
+
+## Usage
+In a typical workflow, you should launch distributed environment at the beginning of training script and create objects needed (such as models, optimizers, loss function, data loaders etc.) firstly, then call `colossalai.booster` to inject features into these objects, After that, you can use our booster APIs and these returned objects to continue the rest of your training processes.
+
+A pseudo-code example is like below:
+
+```python
+import torch
+from torch.optim import SGD
+from torchvision.models import resnet18
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+
+def train():
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ plugin = TorchDDPPlugin()
+ booster = Booster(plugin=plugin)
+ model = resnet18()
+ criterion = lambda x: x.mean()
+ optimizer = SGD((model.parameters()), lr=0.001)
+ scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1)
+ model, optimizer, criterion, _, scheduler = booster.boost(model, optimizer, criterion, lr_scheduler=scheduler)
+
+ x = torch.randn(4, 3, 224, 224)
+ x = x.to('cuda')
+ output = model(x)
+ loss = criterion(output)
+ booster.backward(loss, optimizer)
+ optimizer.clip_grad_by_norm(1.0)
+ optimizer.step()
+ scheduler.step()
+
+ save_path = "./model"
+ booster.save_model(model, save_path, True, True, "", 10, use_safetensors=use_safetensors)
+
+ new_model = resnet18()
+ booster.load_model(new_model, save_path)
+```
+
+[more design details](https://github.com/hpcaitech/ColossalAI/discussions/3046)
+
+
+
diff --git a/docs/source/en/basics/booster_checkpoint.md b/docs/source/en/basics/booster_checkpoint.md
new file mode 100644
index 000000000000..adc0af60b7de
--- /dev/null
+++ b/docs/source/en/basics/booster_checkpoint.md
@@ -0,0 +1,48 @@
+# Booster Checkpoint
+
+Author: [Hongxin Liu](https://github.com/ver217)
+
+**Prerequisite:**
+- [Booster API](./booster_api.md)
+
+## Introduction
+
+We've introduced the [Booster API](./booster_api.md) in the previous tutorial. In this tutorial, we will introduce how to save and load checkpoints using booster.
+
+## Model Checkpoint
+
+{{ autodoc:colossalai.booster.Booster.save_model }}
+
+Model must be boosted by `colossalai.booster.Booster` before saving. `checkpoint` is the path to saved checkpoint. It can be a file, if `shard=False`. Otherwise, it should be a directory. If `shard=True`, the checkpoint will be saved in a sharded way. This is useful when the checkpoint is too large to be saved in a single file. Our sharded checkpoint format is compatible with [huggingface/transformers](https://github.com/huggingface/transformers).
+
+{{ autodoc:colossalai.booster.Booster.load_model }}
+
+Model must be boosted by `colossalai.booster.Booster` before loading. It will detect the checkpoint format automatically, and load in corresponding way.
+
+## Optimizer Checkpoint
+
+> ⚠ Saving optimizer checkpoint in a sharded way is not supported yet.
+
+{{ autodoc:colossalai.booster.Booster.save_optimizer }}
+
+Optimizer must be boosted by `colossalai.booster.Booster` before saving.
+
+{{ autodoc:colossalai.booster.Booster.load_optimizer }}
+
+Optimizer must be boosted by `colossalai.booster.Booster` before loading.
+
+## LR Scheduler Checkpoint
+
+{{ autodoc:colossalai.booster.Booster.save_lr_scheduler }}
+
+LR scheduler must be boosted by `colossalai.booster.Booster` before saving. `checkpoint` is the local path to checkpoint file.
+
+{{ autodoc:colossalai.booster.Booster.load_lr_scheduler }}
+
+LR scheduler must be boosted by `colossalai.booster.Booster` before loading. `checkpoint` is the local path to checkpoint file.
+
+## Checkpoint design
+
+More details about checkpoint design can be found in our discussion [A Unified Checkpoint System Design](https://github.com/hpcaitech/ColossalAI/discussions/3339).
+
+
diff --git a/docs/source/en/basics/booster_plugins.md b/docs/source/en/basics/booster_plugins.md
new file mode 100644
index 000000000000..0362f095af2b
--- /dev/null
+++ b/docs/source/en/basics/booster_plugins.md
@@ -0,0 +1,70 @@
+# Booster Plugins
+
+Author: [Hongxin Liu](https://github.com/ver217)
+
+**Prerequisite:**
+- [Booster API](./booster_api.md)
+
+## Introduction
+
+As mentioned in [Booster API](./booster_api.md), we can use booster plugins to customize the parallel training. In this tutorial, we will introduce how to use booster plugins.
+
+We currently provide the following plugins:
+
+- [Low Level Zero Plugin](#low-level-zero-plugin): It wraps the `colossalai.zero.low_level.LowLevelZeroOptimizer` and can be used to train models with zero-dp. It only supports zero stage-1 and stage-2.
+- [Gemini Plugin](#gemini-plugin): It wraps the [Gemini](../features/zero_with_chunk.md) which implements Zero-3 with chunk-based and heterogeneous memory management.
+- [Torch DDP Plugin](#torch-ddp-plugin): It is a wrapper of `torch.nn.parallel.DistributedDataParallel` and can be used to train models with data parallelism.
+- [Torch FSDP Plugin](#torch-fsdp-plugin): It is a wrapper of `torch.distributed.fsdp.FullyShardedDataParallel` and can be used to train models with zero-dp.
+
+More plugins are coming soon.
+
+## Plugins
+
+### Low Level Zero Plugin
+
+This plugin implements Zero-1 and Zero-2 (w/wo CPU offload), using `reduce` and `gather` to synchronize gradients and weights.
+
+Zero-1 can be regarded as a better substitute of Torch DDP, which is more memory efficient and faster. It can be easily used in hybrid parallelism.
+
+Zero-2 does not support local gradient accumulation. Though you can accumulate gradient if you insist, it cannot reduce communication cost. That is to say, it's not a good idea to use Zero-2 with pipeline parallelism.
+
+{{ autodoc:colossalai.booster.plugin.LowLevelZeroPlugin }}
+
+We've tested compatibility on some famous models, following models may not be supported:
+
+- `timm.models.convit_base`
+- dlrm and deepfm models in `torchrec`
+- `diffusers.VQModel`
+- `transformers.AlbertModel`
+- `transformers.AlbertForPreTraining`
+- `transformers.BertModel`
+- `transformers.BertForPreTraining`
+- `transformers.GPT2DoubleHeadsModel`
+
+Compatibility problems will be fixed in the future.
+
+> ⚠ This plugin can only load optimizer checkpoint saved by itself with the same number of processes now. This will be fixed in the future.
+
+### Gemini Plugin
+
+This plugin implements Zero-3 with chunk-based and heterogeneous memory management. It can train large models without much loss in speed. It also does not support local gradient accumulation. More details can be found in [Gemini Doc](../features/zero_with_chunk.md).
+
+{{ autodoc:colossalai.booster.plugin.GeminiPlugin }}
+
+> ⚠ This plugin can only load optimizer checkpoint saved by itself with the same number of processes now. This will be fixed in the future.
+
+### Torch DDP Plugin
+
+More details can be found in [Pytorch Docs](https://pytorch.org/docs/main/generated/torch.nn.parallel.DistributedDataParallel.html#torch.nn.parallel.DistributedDataParallel).
+
+{{ autodoc:colossalai.booster.plugin.TorchDDPPlugin }}
+
+### Torch FSDP Plugin
+
+> ⚠ This plugin is not available when torch version is lower than 1.12.0.
+
+More details can be found in [Pytorch Docs](https://pytorch.org/docs/main/fsdp.html).
+
+{{ autodoc:colossalai.booster.plugin.TorchFSDPPlugin }}
+
+
diff --git a/docs/source/en/basics/launch_colossalai.md b/docs/source/en/basics/launch_colossalai.md
index be487f8539a5..334757ea75af 100644
--- a/docs/source/en/basics/launch_colossalai.md
+++ b/docs/source/en/basics/launch_colossalai.md
@@ -87,14 +87,13 @@ import colossalai
args = colossalai.get_default_parser().parse_args()
# launch distributed environment
-colossalai.launch(config=,
+colossalai.launch(config=args.config,
rank=args.rank,
world_size=args.world_size,
host=args.host,
port=args.port,
backend=args.backend
)
-
```
@@ -107,12 +106,21 @@ First, we need to set the launch method in our code. As this is a wrapper of the
use `colossalai.launch_from_torch`. The arguments required for distributed environment such as rank, world size, host and port are all set by the PyTorch
launcher and can be read from the environment variable directly.
+config.py
+```python
+BATCH_SIZE = 512
+LEARNING_RATE = 3e-3
+WEIGHT_DECAY = 0.3
+NUM_EPOCHS = 2
+```
+train.py
```python
import colossalai
colossalai.launch_from_torch(
- config=,
+ config="./config.py",
)
+...
```
Next, we can easily start multiple processes with `colossalai run` in your terminal. Below is an example to run the code
diff --git a/docs/source/en/features/1D_tensor_parallel.md b/docs/source/en/features/1D_tensor_parallel.md
index 7577e50400e9..7157af210bc5 100644
--- a/docs/source/en/features/1D_tensor_parallel.md
+++ b/docs/source/en/features/1D_tensor_parallel.md
@@ -7,7 +7,7 @@ Author: Zhengda Bian, Yongbin Li
- [Configure Parallelization](../basics/configure_parallelization.md)
**Example Code**
-- [ColossalAI-Examples 1D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_1d.py)
+- [ColossalAI-Examples 1D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**Related Paper**
- [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://deepakn94.github.io/assets/papers/megatron-sc21.pdf)
@@ -19,15 +19,15 @@ An efficient 1D tensor parallelism implementation was introduced by [Megatron-LM
Let's take a linear layer as an example, which consists of a GEMM $Y = XA$. Given 2 processors, we split the columns of $A$ into $[A_1 ~ A_2]$, and calculate $Y_i = XA_i$ on each processor, which then forms $[Y_1 ~ Y_2] = [XA_1 ~ XA_2]$. This is called a column-parallel fashion.
-When a second linear layer $Z=YB$ follows the column-parallel one, we split $B$ into
-```math
+When a second linear layer $Z=YB$ follows the column-parallel one, we split $B$ into
+$$
\left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
-```
+$$
which is called a row-parallel fashion.
-To calculate
-```math
+To calculate
+$$
Z = [Y_1 ~ Y_2] \left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
-```
+$$
we first calculate $Y_iB_i$ on each processor, then use an all-reduce to aggregate the results as $Z=Y_1B_1+Y_2B_2$.
We also need to note that in the backward pass, the column-parallel linear layer needs to aggregate the gradients of the input tensor $X$, because on each processor $i$ we only have $\dot{X_i}=\dot{Y_i}A_i^T$.
diff --git a/docs/source/en/features/2D_tensor_parallel.md b/docs/source/en/features/2D_tensor_parallel.md
index 7b6c10766099..aae8cc9eef97 100644
--- a/docs/source/en/features/2D_tensor_parallel.md
+++ b/docs/source/en/features/2D_tensor_parallel.md
@@ -8,7 +8,7 @@ Author: Zhengda Bian, Yongbin Li
- [1D Tensor Parallelism](./1D_tensor_parallel.md)
**Example Code**
-- [ColossalAI-Examples - 2D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_2d.py)
+- [ColossalAI-Examples - 2D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**Related Paper**
- [An Efficient 2D Method for Training Super-Large Deep Learning Models](https://arxiv.org/pdf/2104.05343.pdf)
@@ -22,33 +22,33 @@ Let's still take a linear layer $Y = XA$ as an example.
Given $P=q\times q$ processors (necessary condition), e.g. $q=2$, we split both the input $X$ and weight $A$ into
$$
-\left[\begin{matrix} X_{10} & X_{11} \\ X_{00} & X_{01} \end{matrix} \right]
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \end{matrix} \right]
\text{~and~}
-\left[\begin{matrix} A_{10} & A_{11} \\ A_{00} & A_{01} \end{matrix} \right].
+\left[\begin{matrix} A_{00} & A_{01} \\ A_{10} & A_{11} \end{matrix} \right].
$$
The calculation includes $q$ steps. When $t=1$, $X_{i0}$ is broadcasted in its row, and $A_{0j}$ is broadcasted in its column. So, we have
$$
-\left[\begin{matrix} X_{10},A_{00} & X_{10},A_{01} \\ X_{00},A_{00} & X_{00},A_{01} \end{matrix} \right].
+\left[\begin{matrix} X_{00},A_{00} & X_{00},A_{01} \\ X_{10},A_{00} & X_{10},A_{01} \end{matrix} \right].
$$
Then we multiply $X_{i0}$ and $A_{0j}$ on each processor $(i, j)$ as
$$
-\left[\begin{matrix} X_{10}A_{00} & X_{10}A_{01} \\ X_{00}A_{00} & X_{00}A_{01} \end{matrix} \right] (1).
+\left[\begin{matrix} X_{00}A_{00} & X_{00}A_{01} \\ X_{10}A_{00} & X_{10}A_{01} \end{matrix} \right] (1).
$$
Similarly, when $t=2$, $X_{i1}$ is broadcasted in its row, $A_{1j}$ is broadcasted in its column, and we multiply them as
$$
-\left[\begin{matrix} X_{11}A_{10} & X_{11}A_{11} \\ X_{01}A_{10} & X_{01}A_{11} \end{matrix} \right] (2).
+\left[\begin{matrix} X_{01}A_{10} & X_{01}A_{11} \\ X_{11}A_{10} & X_{11}A_{11} \end{matrix} \right] (2).
$$
By adding $(1)$ and $(2)$ up, we have
$$
-Y = XA = \left[\begin{matrix} X_{10}A_{00}+X_{11}A_{10} & X_{10}A_{01}+X_{11}A_{11} \\ X_{00}A_{00}+X_{01}A_{10} & X_{00}A_{01}+X_{01}A_{11} \end{matrix} \right].
+Y = XA = \left[\begin{matrix} X_{00}A_{00}+X_{01}A_{10} & X_{00}A_{01}+X_{01}A_{11} \\ X_{10}A_{00}+X_{11}A_{10} & X_{10}A_{01}+X_{11}A_{11} \end{matrix} \right].
$$
## Efficiency
diff --git a/docs/source/en/features/2p5D_tensor_parallel.md b/docs/source/en/features/2p5D_tensor_parallel.md
index 6076562e6dca..a81d14f10627 100644
--- a/docs/source/en/features/2p5D_tensor_parallel.md
+++ b/docs/source/en/features/2p5D_tensor_parallel.md
@@ -9,7 +9,7 @@ Author: Zhengda Bian, Yongbin Li
- [2D Tensor Parallelism](./2D_tensor_parallel.md)
**Example Code**
-- [ColossalAI-Examples - 2.5D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_2p5d.py)
+- [ColossalAI-Examples - 2.5D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**Related Paper**
- [2.5-dimensional distributed model training](https://arxiv.org/pdf/2105.14500.pdf)
@@ -23,29 +23,30 @@ Let's still take a linear layer $Y = XA$ as an example.
Given $P=q \times q \times d$ processors (necessary condition), e.g. $q=d=2$, we split the input $X$ into $d\times q$ rows and $q$ columns as
$$
-\left[\begin{matrix} X_{30} & X_{31} \\ X_{20} & X_{21} \\ X_{10} & X_{11} \\ X_{00} & X_{01}\end{matrix} \right],
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \\ X_{20} & X_{21} \\ X_{30} & X_{31}\end{matrix} \right],
$$
+
which can be reshaped into $d$ layers as
$$
-\left[\begin{matrix} X_{10} & X_{11} \\ X_{00} & X_{01} \end{matrix} \right] \text{~and~}\left[\begin{matrix} X_{30} & X_{31} \\ X_{20} & X_{21} \end{matrix} \right].
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \end{matrix} \right] \text{~and~}\left[\begin{matrix} X_{20} & X_{21} \\ X_{30} & X_{31} \end{matrix} \right].
$$
Also, the weight $A$ is split into
$$
-\left[\begin{matrix} A_{10} & A_{11} \\ A_{00} & A_{01} \end{matrix} \right].
+\left[\begin{matrix} A_{00} & A_{01} \\ A_{10} & A_{11} \end{matrix} \right].
$$
For each layer of $X$, we use the SUMMA algorithm to multiply $X$ and $A$.
Then, we have the output
$$
-\left[\begin{matrix} Y_{10}=X_{10}A_{00}+X_{11}A_{10} & Y_{11}=X_{10}A_{01}+X_{11}A_{11} \\ Y_{00}=X_{00}A_{00}+X_{01}A_{10} & Y_{01}=X_{00}A_{01}+X_{01}A_{11} \end{matrix} \right]
+\left[\begin{matrix} Y_{00}=X_{00}A_{00}+X_{01}A_{10} & Y_{01}=X_{00}A_{01}+X_{01}A_{11} \\ Y_{10}=X_{10}A_{00}+X_{11}A_{10} & Y_{11}=X_{10}A_{01}+X_{11}A_{11} \end{matrix} \right]
\text{~and~}
$$
$$
-\left[\begin{matrix} Y_{30}=X_{30}A_{00}+X_{31}A_{10} & Y_{31}=X_{30}A_{01}+X_{31}A_{11} \\ Y_{20}=X_{20}A_{00}+X_{21}A_{10} & Y_{21}=X_{20}A_{01}+X_{21}A_{11} \end{matrix} \right].
+\left[\begin{matrix} Y_{20}=X_{20}A_{00}+X_{21}A_{10} & Y_{21}=X_{20}A_{01}+X_{21}A_{11} \\ Y_{30}=X_{30}A_{00}+X_{31}A_{10} & Y_{31}=X_{30}A_{01}+X_{31}A_{11} \end{matrix} \right].
$$
## Efficiency
diff --git a/docs/source/en/features/3D_tensor_parallel.md b/docs/source/en/features/3D_tensor_parallel.md
index 1207376335ce..b9e98eac9350 100644
--- a/docs/source/en/features/3D_tensor_parallel.md
+++ b/docs/source/en/features/3D_tensor_parallel.md
@@ -9,7 +9,7 @@ Author: Zhengda Bian, Yongbin Li
- [2D Tensor Parallelism](./2D_tensor_parallel.md)
**Example Code**
-- [ColossalAI-Examples - 3D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_3d.py)
+- [ColossalAI-Examples - 3D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**Related Paper**
- [Maximizing Parallelism in Distributed Training for Huge Neural Networks](https://arxiv.org/pdf/2105.14450.pdf)
diff --git a/docs/source/en/features/cluster_utils.md b/docs/source/en/features/cluster_utils.md
new file mode 100644
index 000000000000..1903d64d2563
--- /dev/null
+++ b/docs/source/en/features/cluster_utils.md
@@ -0,0 +1,32 @@
+# Cluster Utilities
+
+Author: [Hongxin Liu](https://github.com/ver217)
+
+**Prerequisite:**
+- [Distributed Training](../concepts/distributed_training.md)
+
+## Introduction
+
+We provide a utility class `colossalai.cluster.DistCoordinator` to coordinate distributed training. It's useful to get various information about the cluster, such as the number of nodes, the number of processes per node, etc.
+
+## API Reference
+
+{{ autodoc:colossalai.cluster.DistCoordinator }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.is_master }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.is_node_master }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.is_last_process }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.print_on_master }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.print_on_node_master }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.priority_execution }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.destroy }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.block_all }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.on_master_only }}
diff --git a/docs/source/en/get_started/installation.md b/docs/source/en/get_started/installation.md
index 290879219074..b626edb19e8e 100644
--- a/docs/source/en/get_started/installation.md
+++ b/docs/source/en/get_started/installation.md
@@ -29,7 +29,7 @@ CUDA_EXT=1 pip install colossalai
## Download From Source
-> The version of Colossal-AI will be in line with the main branch of the repository. Feel free to raise an issue if you encounter any problem. :)
+> The version of Colossal-AI will be in line with the main branch of the repository. Feel free to raise an issue if you encounter any problem.
```shell
git clone https://github.com/hpcaitech/ColossalAI.git
@@ -39,13 +39,13 @@ cd ColossalAI
pip install -r requirements/requirements.txt
# install colossalai
-pip install .
+CUDA_EXT=1 pip install .
```
-If you don't want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer):
+If you don't want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer), just don't specify the `CUDA_EXT`:
```shell
-CUDA_EXT=1 pip install .
+pip install .
```
diff --git a/docs/source/zh-Hans/basics/booster_api.md b/docs/source/zh-Hans/basics/booster_api.md
new file mode 100644
index 000000000000..5410cc213fd2
--- /dev/null
+++ b/docs/source/zh-Hans/basics/booster_api.md
@@ -0,0 +1,89 @@
+# booster 使用
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**预备知识:**
+- [分布式训练](../concepts/distributed_training.md)
+- [Colossal-AI 总览](../concepts/colossalai_overview.md)
+
+**示例代码**
+- [使用booster训练](https://github.com/hpcaitech/ColossalAI/blob/main/examples/tutorial/new_api/cifar_resnet/README.md)
+
+## 简介
+在我们的新设计中, `colossalai.booster` 代替 `colossalai.initialize` 将特征(例如,模型、优化器、数据加载器)无缝注入您的训练组件中。 使用booster API, 您可以更友好地将我们的并行策略整合到待训练模型中. 调用 `colossalai.booster` 是您进入训练循环前的基本操作。
+在下面的章节中,我们将介绍 `colossalai.booster` 是如何工作的以及使用时我们要注意的细节。
+
+### Booster插件
+Booster插件是管理并行配置的重要组件(eg:gemini插件封装了gemini加速方案)。目前支持的插件如下:
+
+***GeminiPlugin:*** GeminiPlugin插件封装了 gemini 加速解决方案,即基于块内存管理的 ZeRO优化方案。
+
+***TorchDDPPlugin:*** TorchDDPPlugin插件封装了DDP加速方案,实现了模型级别的数据并行,可以跨多机运行。
+
+***LowLevelZeroPlugin:*** LowLevelZeroPlugin插件封装了零冗余优化器的 1/2 阶段。阶段 1:切分优化器参数,分发到各并发进程或并发GPU上。阶段 2:切分优化器参数及梯度,分发到各并发进程或并发GPU上。
+
+### Booster接口
+
+{{ autodoc:colossalai.booster.Booster }}
+
+{{ autodoc:colossalai.booster.Booster.boost }}
+
+{{ autodoc:colossalai.booster.Booster.backward }}
+
+{{ autodoc:colossalai.booster.Booster.no_sync }}
+
+{{ autodoc:colossalai.booster.Booster.save_model }}
+
+{{ autodoc:colossalai.booster.Booster.load_model }}
+
+{{ autodoc:colossalai.booster.Booster.save_optimizer }}
+
+{{ autodoc:colossalai.booster.Booster.load_optimizer }}
+
+{{ autodoc:colossalai.booster.Booster.save_lr_scheduler }}
+
+{{ autodoc:colossalai.booster.Booster.load_lr_scheduler }}
+
+## 使用方法及示例
+
+在使用colossalai训练时,首先需要在训练脚本的开头启动分布式环境,并创建需要使用的模型、优化器、损失函数、数据加载器等对象。之后,调用`colossalai.booster` 将特征注入到这些对象中,您就可以使用我们的booster API去进行您接下来的训练流程。
+
+以下是一个伪代码示例,将展示如何使用我们的booster API进行模型训练:
+
+```python
+import torch
+from torch.optim import SGD
+from torchvision.models import resnet18
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+
+def train():
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ plugin = TorchDDPPlugin()
+ booster = Booster(plugin=plugin)
+ model = resnet18()
+ criterion = lambda x: x.mean()
+ optimizer = SGD((model.parameters()), lr=0.001)
+ scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1)
+ model, optimizer, criterion, _, scheduler = booster.boost(model, optimizer, criterion, lr_scheduler=scheduler)
+
+ x = torch.randn(4, 3, 224, 224)
+ x = x.to('cuda')
+ output = model(x)
+ loss = criterion(output)
+ booster.backward(loss, optimizer)
+ optimizer.clip_grad_by_norm(1.0)
+ optimizer.step()
+ scheduler.step()
+
+ save_path = "./model"
+ booster.save_model(model, save_path, True, True, "", 10, use_safetensors=use_safetensors)
+
+ new_model = resnet18()
+ booster.load_model(new_model, save_path)
+```
+
+[更多的设计细节请参考](https://github.com/hpcaitech/ColossalAI/discussions/3046)
+
+
diff --git a/docs/source/zh-Hans/basics/booster_checkpoint.md b/docs/source/zh-Hans/basics/booster_checkpoint.md
new file mode 100644
index 000000000000..d75f18c908ba
--- /dev/null
+++ b/docs/source/zh-Hans/basics/booster_checkpoint.md
@@ -0,0 +1,48 @@
+# Booster Checkpoint
+
+作者: [Hongxin Liu](https://github.com/ver217)
+
+**前置教程:**
+- [Booster API](./booster_api.md)
+
+## 引言
+
+我们在之前的教程中介绍了 [Booster API](./booster_api.md)。在本教程中,我们将介绍如何使用 booster 保存和加载 checkpoint。
+
+## 模型 Checkpoint
+
+{{ autodoc:colossalai.booster.Booster.save_model }}
+
+模型在保存前必须被 `colossalai.booster.Booster` 加速。 `checkpoint` 是要保存的 checkpoint 的路径。 如果 `shard=False`,它就是文件。 否则, 它就是文件夹。如果 `shard=True`,checkpoint 将以分片方式保存。当 checkpoint 太大而无法保存在单个文件中时,这很有用。我们的分片 checkpoint 格式与 [huggingface/transformers](https://github.com/huggingface/transformers) 兼容。
+
+{{ autodoc:colossalai.booster.Booster.load_model }}
+
+模型在加载前必须被 `colossalai.booster.Booster` 加速。它会自动检测 checkpoint 格式,并以相应的方式加载。
+
+## 优化器 Checkpoint
+
+> ⚠ 尚不支持以分片方式保存优化器 Checkpoint。
+
+{{ autodoc:colossalai.booster.Booster.save_optimizer }}
+
+优化器在保存前必须被 `colossalai.booster.Booster` 加速。
+
+{{ autodoc:colossalai.booster.Booster.load_optimizer }}
+
+优化器在加载前必须被 `colossalai.booster.Booster` 加速。
+
+## 学习率调度器 Checkpoint
+
+{{ autodoc:colossalai.booster.Booster.save_lr_scheduler }}
+
+学习率调度器在保存前必须被 `colossalai.booster.Booster` 加速。 `checkpoint` 是 checkpoint 文件的本地路径.
+
+{{ autodoc:colossalai.booster.Booster.load_lr_scheduler }}
+
+学习率调度器在加载前必须被 `colossalai.booster.Booster` 加速。 `checkpoint` 是 checkpoint 文件的本地路径.
+
+## Checkpoint 设计
+
+有关 Checkpoint 设计的更多详细信息,请参见我们的讨论 [A Unified Checkpoint System Design](https://github.com/hpcaitech/ColossalAI/discussions/3339).
+
+
diff --git a/docs/source/zh-Hans/basics/booster_plugins.md b/docs/source/zh-Hans/basics/booster_plugins.md
new file mode 100644
index 000000000000..b15ceb1e3ad5
--- /dev/null
+++ b/docs/source/zh-Hans/basics/booster_plugins.md
@@ -0,0 +1,70 @@
+# Booster 插件
+
+作者: [Hongxin Liu](https://github.com/ver217)
+
+**前置教程:**
+- [Booster API](./booster_api.md)
+
+## 引言
+
+正如 [Booster API](./booster_api.md) 中提到的,我们可以使用 booster 插件来自定义并行训练。在本教程中,我们将介绍如何使用 booster 插件。
+
+我们现在提供以下插件:
+
+- [Low Level Zero 插件](#low-level-zero-plugin): 它包装了 `colossalai.zero.low_level.LowLevelZeroOptimizer`,可用于使用 Zero-dp 训练模型。它仅支持 Zero 阶段1和阶段2。
+- [Gemini 插件](#gemini-plugin): 它包装了 [Gemini](../features/zero_with_chunk.md),Gemini 实现了基于Chunk内存管理和异构内存管理的 Zero-3。
+- [Torch DDP 插件](#torch-ddp-plugin): 它包装了 `torch.nn.parallel.DistributedDataParallel` 并且可用于使用数据并行训练模型。
+- [Torch FSDP 插件](#torch-fsdp-plugin): 它包装了 `torch.distributed.fsdp.FullyShardedDataParallel` 并且可用于使用 Zero-dp 训练模型。
+
+更多插件即将推出。
+
+## 插件
+
+### Low Level Zero 插件
+
+该插件实现了 Zero-1 和 Zero-2(使用/不使用 CPU 卸载),使用`reduce`和`gather`来同步梯度和权重。
+
+Zero-1 可以看作是 Torch DDP 更好的替代品,内存效率更高,速度更快。它可以很容易地用于混合并行。
+
+Zero-2 不支持局部梯度累积。如果您坚持使用,虽然可以积累梯度,但不能降低通信成本。也就是说,同时使用流水线并行和 Zero-2 并不是一个好主意。
+
+{{ autodoc:colossalai.booster.plugin.LowLevelZeroPlugin }}
+
+我们已经测试了一些主流模型的兼容性,可能不支持以下模型:
+
+- `timm.models.convit_base`
+- dlrm and deepfm models in `torchrec`
+- `diffusers.VQModel`
+- `transformers.AlbertModel`
+- `transformers.AlbertForPreTraining`
+- `transformers.BertModel`
+- `transformers.BertForPreTraining`
+- `transformers.GPT2DoubleHeadsModel`
+
+兼容性问题将在未来修复。
+
+> ⚠ 该插件现在只能加载自己保存的且具有相同进程数的优化器 Checkpoint。这将在未来得到解决。
+
+### Gemini 插件
+
+这个插件实现了基于Chunk内存管理和异构内存管理的 Zero-3。它可以训练大型模型而不会损失太多速度。它也不支持局部梯度累积。更多详细信息,请参阅 [Gemini 文档](../features/zero_with_chunk.md).
+
+{{ autodoc:colossalai.booster.plugin.GeminiPlugin }}
+
+> ⚠ 该插件现在只能加载自己保存的且具有相同进程数的优化器 Checkpoint。这将在未来得到解决。
+
+### Torch DDP 插件
+
+更多详细信息,请参阅 [Pytorch 文档](https://pytorch.org/docs/main/generated/torch.nn.parallel.DistributedDataParallel.html#torch.nn.parallel.DistributedDataParallel).
+
+{{ autodoc:colossalai.booster.plugin.TorchDDPPlugin }}
+
+### Torch FSDP 插件
+
+> ⚠ 如果 torch 版本低于 1.12.0,此插件将不可用。
+
+更多详细信息,请参阅 [Pytorch 文档](https://pytorch.org/docs/main/fsdp.html).
+
+{{ autodoc:colossalai.booster.plugin.TorchFSDPPlugin }}
+
+
diff --git a/docs/source/zh-Hans/basics/launch_colossalai.md b/docs/source/zh-Hans/basics/launch_colossalai.md
index ca927de578d5..39b09deae085 100644
--- a/docs/source/zh-Hans/basics/launch_colossalai.md
+++ b/docs/source/zh-Hans/basics/launch_colossalai.md
@@ -74,7 +74,7 @@ import colossalai
args = colossalai.get_default_parser().parse_args()
# launch distributed environment
-colossalai.launch(config=,
+colossalai.launch(config=args.config,
rank=args.rank,
world_size=args.world_size,
host=args.host,
@@ -93,12 +93,21 @@ PyTorch自带的启动器需要在每个节点上都启动命令才能启动多
首先,我们需要在代码里指定我们的启动方式。由于这个启动器是PyTorch启动器的封装,那么我们自然而然应该使用`colossalai.launch_from_torch`。
分布式环境所需的参数,如 rank, world size, host 和 port 都是由 PyTorch 启动器设置的,可以直接从环境变量中读取。
+config.py
+```python
+BATCH_SIZE = 512
+LEARNING_RATE = 3e-3
+WEIGHT_DECAY = 0.3
+NUM_EPOCHS = 2
+```
+train.py
```python
import colossalai
colossalai.launch_from_torch(
- config=,
+ config="./config.py",
)
+...
```
接下来,我们可以轻松地在终端使用`colossalai run`来启动训练。下面的命令可以在当前机器上启动一个4卡的训练任务。
diff --git a/docs/source/zh-Hans/features/1D_tensor_parallel.md b/docs/source/zh-Hans/features/1D_tensor_parallel.md
index 2ddc27c7b50f..4dd45e8783c3 100644
--- a/docs/source/zh-Hans/features/1D_tensor_parallel.md
+++ b/docs/source/zh-Hans/features/1D_tensor_parallel.md
@@ -7,7 +7,7 @@
- [并行配置](../basics/configure_parallelization.md)
**示例代码**
-- [ColossalAI-Examples 1D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_1d.py)
+- [ColossalAI-Examples 1D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**相关论文**
- [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://deepakn94.github.io/assets/papers/megatron-sc21.pdf)
@@ -20,15 +20,16 @@
让我们以一个线性层为例,它包括一个 GEMM $Y = XA$。 给定2个处理器,我们把列 $A$ 划分为 $[A_1 ~ A_2]$, 并在每个处理器上计算 $Y_i = XA_i$ , 然后形成 $[Y_1 ~ Y_2] = [XA_1 ~ XA_2]$. 这被称为列并行方式。
当第二个线性层 $Z=YB$ 跟随上述列并行层的时候, 我们把 $B$ 划分为
-```math
+$$
\left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
```
-这就是所谓的行并行方式.
+这就是所谓的行并行方式.
+$$
为了计算
-```math
+$$
Z = [Y_1 ~ Y_2] \left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
-```
+$$
我们首先在每个处理器上计算 $Y_iB_i$ 然后使用一个all-reduce操作将结果汇总为 $Z=Y_1B_1+Y_2B_2$。
我们还需要注意,在后向计算中,列并行线性层需要聚合输入张量 $X$, 因为在每个处理器 $i$ 上,我们只有 $\dot{X_i}=\dot{Y_i}A_i^T$,因此,我们在各处理器之间进行all-reduce,得到 $\dot{X}=\dot{Y}A^T=\dot{Y_1}A_1^T+\dot{Y_2}A_2^T$。
diff --git a/docs/source/zh-Hans/features/2D_tensor_parallel.md b/docs/source/zh-Hans/features/2D_tensor_parallel.md
index c942f82bf9d2..f163432ecceb 100644
--- a/docs/source/zh-Hans/features/2D_tensor_parallel.md
+++ b/docs/source/zh-Hans/features/2D_tensor_parallel.md
@@ -8,7 +8,7 @@
- [1D 张量并行](./1D_tensor_parallel.md)
**示例代码**
-- [ColossalAI-Examples - 2D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_2d.py)
+- [ColossalAI-Examples - 2D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**相关论文**
- [An Efficient 2D Method for Training Super-Large Deep Learning Models](https://arxiv.org/pdf/2104.05343.pdf)
@@ -22,33 +22,33 @@
给定 $P=q\times q$ 个处理器(必要条件), 如 $q=2$, 我们把输入 $X$ 和权重A $A$ 都划分为
$$
-\left[\begin{matrix} X_{10} & X_{11} \\ X_{00} & X_{01} \end{matrix} \right]
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \end{matrix} \right]
\text{~and~}
-\left[\begin{matrix} A_{10} & A_{11} \\ A_{00} & A_{01} \end{matrix} \right]。
+\left[\begin{matrix} A_{00} & A_{01} \\ A_{10} & A_{11} \end{matrix} \right].
$$
该计算包括 $q$ 步。 当 $t=1$ 时, $X_{i0}$ 在其行中被广播, 而 $A_{0j}$ 在其列中被广播。因此,我们有
$$
-\left[\begin{matrix} X_{10},A_{00} & X_{10},A_{01} \\ X_{00},A_{00} & X_{00},A_{01} \end{matrix} \right]。
+\left[\begin{matrix} X_{00},A_{00} & X_{00},A_{01} \\ X_{10},A_{00} & X_{10},A_{01} \end{matrix} \right].
$$
然后我们在每个处理器 $(i, j)$ 上将 $X_{i0}$ 和 $A_{0j}$ 相乘为
$$
-\left[\begin{matrix} X_{10}A_{00} & X_{10}A_{01} \\ X_{00}A_{00} & X_{00}A_{01} \end{matrix} \right] (1)。
+\left[\begin{matrix} X_{00}A_{00} & X_{00}A_{01} \\ X_{10}A_{00} & X_{10}A_{01} \end{matrix} \right] (1).
$$
同样,当 $t=2$ 时, $X_{i1}$ 在其行中被广播, $A_{1j}$ 在其列中被广播, 我们将它们相乘为
$$
-\left[\begin{matrix} X_{11}A_{10} & X_{11}A_{11} \\ X_{01}A_{10} & X_{01}A_{11} \end{matrix} \right] (2)。
+\left[\begin{matrix} X_{01}A_{10} & X_{01}A_{11} \\ X_{11}A_{10} & X_{11}A_{11} \end{matrix} \right] (2).
$$
通过将 $(1)$ 和 $(2)$ 相加,我们有
$$
-Y = XA = \left[\begin{matrix} X_{10}A_{00}+X_{11}A_{10} & X_{10}A_{01}+X_{11}A_{11} \\ X_{00}A_{00}+X_{01}A_{10} & X_{00}A_{01}+X_{01}A_{11} \end{matrix} \right]。
+Y = XA = \left[\begin{matrix} X_{00}A_{00}+X_{01}A_{10} & X_{00}A_{01}+X_{01}A_{11} \\ X_{10}A_{00}+X_{11}A_{10} & X_{10}A_{01}+X_{11}A_{11} \end{matrix} \right].
$$
## 效率
diff --git a/docs/source/zh-Hans/features/2p5D_tensor_parallel.md b/docs/source/zh-Hans/features/2p5D_tensor_parallel.md
index 59a4be02ce47..5f15202729a7 100644
--- a/docs/source/zh-Hans/features/2p5D_tensor_parallel.md
+++ b/docs/source/zh-Hans/features/2p5D_tensor_parallel.md
@@ -9,7 +9,7 @@
- [2D 张量并行](./2D_tensor_parallel.md)
**示例代码**
-- [ColossalAI-Examples - 2.5D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_2p5d.py)
+- [ColossalAI-Examples - 2.5D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**相关论文**
- [2.5-dimensional distributed model training](https://arxiv.org/pdf/2105.14500.pdf)
@@ -22,29 +22,29 @@
给定 $P=q \times q \times d$ 个处理器(必要条件), 如 $q=d=2$, 我们把输入 $X$ 划分为 $d\times q$ 行和 $q$ 列
$$
-\left[\begin{matrix} X_{30} & X_{31} \\ X_{20} & X_{21} \\ X_{10} & X_{11} \\ X_{00} & X_{01}\end{matrix} \right],
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \\ X_{20} & X_{21} \\ X_{30} & X_{31}\end{matrix} \right],
$$
它可以被重塑为 $d$ 层
$$
-\left[\begin{matrix} X_{10} & X_{11} \\ X_{00} & X_{01} \end{matrix} \right] \text{~and~}\left[\begin{matrix} X_{30} & X_{31} \\ X_{20} & X_{21} \end{matrix} \right].
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \end{matrix} \right] \text{~and~}\left[\begin{matrix} X_{20} & X_{21} \\ X_{30} & X_{31} \end{matrix} \right].
$$
另外,权重 $A$ 被分割为
$$
-\left[\begin{matrix} A_{10} & A_{11} \\ A_{00} & A_{01} \end{matrix} \right].
+\left[\begin{matrix} A_{00} & A_{01} \\ A_{10} & A_{11} \end{matrix} \right].
$$
对于 $X$ 相关的每一层, 我们使用SUMMA算法将 $X$ 与 $A$ 相乘。
然后,我们得到输出
$$
-\left[\begin{matrix} Y_{10}=X_{10}A_{00}+X_{11}A_{10} & Y_{11}=X_{10}A_{01}+X_{11}A_{11} \\ Y_{00}=X_{00}A_{00}+X_{01}A_{10} & Y_{01}=X_{00}A_{01}+X_{01}A_{11} \end{matrix} \right]
+\left[\begin{matrix} Y_{00}=X_{00}A_{00}+X_{01}A_{10} & Y_{01}=X_{00}A_{01}+X_{01}A_{11} \\ Y_{10}=X_{10}A_{00}+X_{11}A_{10} & Y_{11}=X_{10}A_{01}+X_{11}A_{11} \end{matrix} \right]
\text{~and~}
$$
$$
-\left[\begin{matrix} Y_{30}=X_{30}A_{00}+X_{31}A_{10} & Y_{31}=X_{30}A_{01}+X_{31}A_{11} \\ Y_{20}=X_{20}A_{00}+X_{21}A_{10} & Y_{21}=X_{20}A_{01}+X_{21}A_{11} \end{matrix} \right].
+\left[\begin{matrix} Y_{20}=X_{20}A_{00}+X_{21}A_{10} & Y_{21}=X_{20}A_{01}+X_{21}A_{11} \\ Y_{30}=X_{30}A_{00}+X_{31}A_{10} & Y_{31}=X_{30}A_{01}+X_{31}A_{11} \end{matrix} \right].
$$
## 效率
diff --git a/docs/source/zh-Hans/features/3D_tensor_parallel.md b/docs/source/zh-Hans/features/3D_tensor_parallel.md
index 440121c94243..5ce0cdf6c068 100644
--- a/docs/source/zh-Hans/features/3D_tensor_parallel.md
+++ b/docs/source/zh-Hans/features/3D_tensor_parallel.md
@@ -9,7 +9,7 @@
- [2D 张量并行](./2D_tensor_parallel.md)
**示例代码**
-- [ColossalAI-Examples - 3D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_3d.py)
+- [ColossalAI-Examples - 3D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**相关论文**
- [Maximizing Parallelism in Distributed Training for Huge Neural Networks](https://arxiv.org/pdf/2105.14450.pdf)
diff --git a/docs/source/zh-Hans/features/cluster_utils.md b/docs/source/zh-Hans/features/cluster_utils.md
new file mode 100644
index 000000000000..ca787a869041
--- /dev/null
+++ b/docs/source/zh-Hans/features/cluster_utils.md
@@ -0,0 +1,32 @@
+# 集群实用程序
+
+作者: [Hongxin Liu](https://github.com/ver217)
+
+**前置教程:**
+- [分布式训练](../concepts/distributed_training.md)
+
+## 引言
+
+我们提供了一个实用程序类 `colossalai.cluster.DistCoordinator` 来协调分布式训练。它对于获取有关集群的各种信息很有用,例如节点数、每个节点的进程数等。
+
+## API 参考
+
+{{ autodoc:colossalai.cluster.DistCoordinator }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.is_master }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.is_node_master }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.is_last_process }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.print_on_master }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.print_on_node_master }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.priority_execution }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.destroy }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.block_all }}
+
+{{ autodoc:colossalai.cluster.DistCoordinator.on_master_only }}
diff --git a/docs/source/zh-Hans/get_started/installation.md b/docs/source/zh-Hans/get_started/installation.md
index 72f85393814f..e0d726c74f64 100755
--- a/docs/source/zh-Hans/get_started/installation.md
+++ b/docs/source/zh-Hans/get_started/installation.md
@@ -28,7 +28,7 @@ CUDA_EXT=1 pip install colossalai
## 从源安装
-> 此文档将与版本库的主分支保持一致。如果您遇到任何问题,欢迎给我们提 issue :)
+> 此文档将与版本库的主分支保持一致。如果您遇到任何问题,欢迎给我们提 issue。
```shell
git clone https://github.com/hpcaitech/ColossalAI.git
@@ -38,13 +38,13 @@ cd ColossalAI
pip install -r requirements/requirements.txt
# install colossalai
-pip install .
+CUDA_EXT=1 pip install .
```
-如果您不想安装和启用 CUDA 内核融合(使用融合优化器时强制安装):
+如果您不想安装和启用 CUDA 内核融合(使用融合优化器时强制安装),您可以不添加`CUDA_EXT=1`:
```shell
-NO_CUDA_EXT=1 pip install .
+pip install .
```
diff --git a/examples/language/gpt/experiments/auto_parallel/README.md b/examples/language/gpt/experiments/auto_parallel/README.md
index 1c8b1c35109f..32688873f8f1 100644
--- a/examples/language/gpt/experiments/auto_parallel/README.md
+++ b/examples/language/gpt/experiments/auto_parallel/README.md
@@ -13,10 +13,10 @@ conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu113
```
-### Install [Colossal-AI v0.2.0](https://colossalai.org/download/) From Official Website
+### Install Colossal-AI
```bash
-pip install colossalai==0.2.0+torch1.12cu11.3 -f https://release.colossalai.org
+pip install colossalai==0.2.0
```
### Install transformers
diff --git a/examples/tutorial/README.md b/examples/tutorial/README.md
index f4843331fd54..933026166d3f 100644
--- a/examples/tutorial/README.md
+++ b/examples/tutorial/README.md
@@ -29,7 +29,11 @@ quickly deploy large AI model training and inference, reducing large AI model tr
- Fine-tuning and Inference for OPT [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/opt) [[video]](https://www.youtube.com/watch?v=jbEFNVzl67Y)
- Optimized AlphaFold [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/fastfold) [[video]](https://www.youtube.com/watch?v=-zP13LfJP7w)
- Optimized Stable Diffusion [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion) [[video]](https://www.youtube.com/watch?v=8KHeUjjc-XQ)
-
+ - ColossalChat: Cloning ChatGPT with a Complete RLHF Pipeline
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
+[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+[[demo]](https://www.youtube.com/watch?v=HcTiHzApHm0)
+[[video]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
## Discussion
diff --git a/tests/test_booster/test_plugin/test_low_level_zero_plugin.py b/tests/test_booster/test_plugin/test_low_level_zero_plugin.py
index d84b96f77a75..f70f27be2aa7 100644
--- a/tests/test_booster/test_plugin/test_low_level_zero_plugin.py
+++ b/tests/test_booster/test_plugin/test_low_level_zero_plugin.py
@@ -11,9 +11,9 @@
from tests.kit.model_zoo import model_zoo
# These models are not compatible with AMP
-_AMP_ERR_MODELS = ['timm_convit', 'dlrm', 'deepfm_interactionarch', 'deepfm_simpledeepfmnn`']
+_AMP_ERR_MODELS = ['timm_convit', 'dlrm', 'deepfm_interactionarch', 'deepfm_simpledeepfmnn']
# These models have no parameters
-_LOW_LEVEL_ZERO_ERR_MODELS = ['dlrm_interactionarch']
+_LOW_LEVEL_ZERO_ERR_MODELS = ['dlrm_interactionarch', 'deepfm_overarch', 'deepfm_sparsearch', 'dlrm_sparsearch']
# These models will get stuck
_STUCK_MODELS = [
'diffusers_vq_model', 'transformers_albert', 'transformers_albert_for_pretraining', 'transformers_bert',
@@ -67,6 +67,7 @@ def check_low_level_zero_plugin(stage: int, early_stop: bool = True):
skipped_models.append(name)
continue
err = run_fn(stage, model_fn, data_gen_fn, output_transform_fn)
+
torch.cuda.empty_cache()
if err is None:
@@ -91,7 +92,7 @@ def run_dist(rank, world_size, port, early_stop: bool = True):
@rerun_if_address_is_in_use()
def test_low_level_zero_plugin(early_stop: bool = True):
- spawn(run_dist, 2, early_stop=early_stop)
+ spawn(run_dist, 4, early_stop=early_stop)
if __name__ == '__main__':
diff --git a/tests/test_checkpoint_io/test_gemini_checkpoint_io.py b/tests/test_checkpoint_io/test_gemini_checkpoint_io.py
index 1e5a2e1c4b44..994412bbc63f 100644
--- a/tests/test_checkpoint_io/test_gemini_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_gemini_checkpoint_io.py
@@ -1,87 +1,95 @@
-import tempfile
+import os
import pytest
import torch
+import torch.distributed as dist
+from utils import shared_tempdir
import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin
from colossalai.booster.plugin.gemini_plugin import GeminiCheckpointIO
+from colossalai.nn.optimizer import HybridAdam
from colossalai.testing import check_state_dict_equal, parameterize, rerun_if_address_is_in_use, spawn
-from colossalai.utils.cuda import get_current_device
-from colossalai.zero import ColoInitContext, ZeroDDP
+from colossalai.zero import ZeroDDP
from colossalai.zero.gemini.chunk import ChunkManager, search_chunk_configuration
from colossalai.zero.gemini.gemini_mgr import GeminiManager
-from tests.components_to_test.registry import non_distributed_component_funcs
+from tests.kit.model_zoo import model_zoo
@parameterize('placement_policy', ['cuda', 'cpu'])
-@parameterize('model_name', ['bert'])
-@parameterize('use_safetensors', [True, False])
+@parameterize('model_name', ['transformers_bert_for_sequence_classification'])
+@parameterize('use_safetensors', [False, True])
def exam_state_dict_with_origin(placement_policy, model_name, use_safetensors: bool):
from transformers import BertForSequenceClassification
+ (model_fn, data_gen_fn, output_transform_fn, _) = next(iter(model_zoo.get_sub_registry(model_name).values()))
+ bert_model = model_fn()
- model_ckpt_dir = tempfile.TemporaryDirectory()
- get_components_func = non_distributed_component_funcs.get_callable(model_name)
- model_builder, *_ = get_components_func()
- with ColoInitContext(device=(get_current_device())):
- bert_model = model_builder()
- bert_model.config.save_pretrained(save_directory=(model_ckpt_dir.name))
-
- config_dict, *_ = search_chunk_configuration(bert_model, search_range_mb=1, search_interval_byte=100)
- chunk_manager = ChunkManager(config_dict)
- gemini_manager = GeminiManager(placement_policy, chunk_manager)
- bert_model = ZeroDDP(bert_model, gemini_manager)
- bert_model.train()
-
- ckpt_io = GeminiCheckpointIO()
- if ckpt_io.coordinator.is_master():
+ with shared_tempdir() as tempdir:
+ pretrained_path = os.path.join(tempdir, 'pretrained')
+ bert_model.config.save_pretrained(save_directory=pretrained_path)
+
+ # TODO(ver217): use boost api
+ config_dict, *_ = search_chunk_configuration(bert_model, search_range_mb=1, search_interval_byte=100)
+ chunk_manager = ChunkManager(config_dict)
+ gemini_manager = GeminiManager(placement_policy, chunk_manager)
+ bert_model = ZeroDDP(bert_model, gemini_manager)
+ bert_model.train()
+
+ ckpt_io = GeminiCheckpointIO()
model_size = sum(p.numel() * p.element_size() for p in bert_model.parameters()) / 1024**2
- ckpt_io.save_model(bert_model, (model_ckpt_dir.name),
+ ckpt_io.save_model(bert_model, (pretrained_path),
True,
True,
'', (model_size / 3),
use_safetensors=use_safetensors)
- new_bert_model = BertForSequenceClassification.from_pretrained(model_ckpt_dir.name)
- check_state_dict_equal(bert_model.state_dict(only_rank_0=True, dtype=(torch.float32)),
+ dist.barrier()
+ new_bert_model = BertForSequenceClassification.from_pretrained(pretrained_path)
+ check_state_dict_equal(bert_model.state_dict(only_rank_0=False, dtype=torch.float32),
new_bert_model.state_dict(), False)
- model_ckpt_dir.cleanup()
@parameterize('placement_policy', ['cuda', 'cpu'])
-@parameterize('model_name', ['gpt2', 'bert'])
-@parameterize('use_safetensors', [True, False])
-def exam_state_dict(placement_policy, model_name: str, use_safetensors: bool):
- get_components_func = non_distributed_component_funcs.get_callable(model_name)
- model_builder, *_ = get_components_func()
- with ColoInitContext(device=(get_current_device())):
- model = model_builder()
- new_model = model_builder()
- config_dict, *_ = search_chunk_configuration(model, search_range_mb=1, search_interval_byte=100)
- chunk_manager = ChunkManager(config_dict)
- gemini_manager = GeminiManager(placement_policy, chunk_manager)
- model = ZeroDDP(model, gemini_manager)
-
- model.train()
- #new model
- new_config_dict, *_ = search_chunk_configuration(new_model, search_range_mb=1, search_interval_byte=100)
- new_chunk_manager = ChunkManager(new_config_dict)
- new_gemini_manager = GeminiManager(placement_policy, new_chunk_manager)
- new_model = ZeroDDP(new_model, new_gemini_manager)
-
- model_ckpt_dir = tempfile.TemporaryDirectory()
- ckpt_io = GeminiCheckpointIO()
- model_size = sum(p.numel() * p.element_size() for p in model.parameters()) / 1024**2
- ckpt_io.save_model(model, (model_ckpt_dir.name),
- True,
- True,
- 'epoch', (model_size / 3),
- use_safetensors=use_safetensors)
-
- if ckpt_io.coordinator.is_master():
- ckpt_io.load_model(new_model, (model_ckpt_dir.name), strict=True)
- model_dict = model.state_dict(only_rank_0=True)
- new_model_dict = new_model.state_dict(only_rank_0=True)
- check_state_dict_equal(model_dict, new_model_dict, False)
- model_ckpt_dir.cleanup()
+@parameterize('shard', [True, False])
+@parameterize('model_name', ['transformers_gpt'])
+def exam_state_dict(placement_policy, shard: bool, model_name: str):
+ (model_fn, data_gen_fn, output_transform_fn, _) = next(iter(model_zoo.get_sub_registry(model_name).values()))
+ criterion = lambda x: x.mean()
+ plugin = GeminiPlugin(placement_policy=placement_policy)
+ booster = Booster(plugin=plugin)
+
+ model = model_fn()
+ new_model = model_fn()
+ optimizer = HybridAdam(model.parameters(), lr=0.001)
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+ new_optimizer = HybridAdam(new_model.parameters(), lr=0.001)
+ new_model, new_optimizer, criterion, _, _ = booster.boost(new_model, new_optimizer, criterion)
+
+ data = data_gen_fn()
+ data = {k: v.to('cuda') if torch.is_tensor(v) or 'Tensor' in v.__class__.__name__ else v for k, v in data.items()}
+ output = model(**data)
+ output = output_transform_fn(output)
+ output_key = list(output.keys())[0]
+ loss = criterion(output[output_key])
+
+ booster.backward(loss, optimizer)
+ optimizer.step()
+
+ with shared_tempdir() as tempdir:
+ model_ckpt_path = f"{tempdir}/model"
+ optimizer_ckpt_path = f"{tempdir}/optimizer"
+ booster.save_model(model, model_ckpt_path)
+ if not shard:
+ # TODO(ver217): optimizer checkpointing is not supported for sharded checkpoint
+ booster.save_optimizer(optimizer, optimizer_ckpt_path)
+ dist.barrier()
+
+ booster.load_model(new_model, model_ckpt_path)
+ check_state_dict_equal(model.unwrap().state_dict(only_rank_0=False),
+ new_model.unwrap().state_dict(only_rank_0=False), False)
+ if not shard:
+ booster.load_optimizer(new_optimizer, optimizer_ckpt_path)
+ check_state_dict_equal(optimizer.state_dict(), new_optimizer.state_dict(), False)
def run_dist(rank, world_size, port):
@@ -92,7 +100,7 @@ def run_dist(rank, world_size, port):
@pytest.mark.dist
-@pytest.mark.parametrize('world_size', [4, 4])
+@pytest.mark.parametrize('world_size', [2])
@rerun_if_address_is_in_use()
def test_gemini_ckpIO(world_size):
spawn(run_dist, world_size)
diff --git a/tests/test_checkpoint_io/test_low_level_zero_checkpoint_io.py b/tests/test_checkpoint_io/test_low_level_zero_checkpoint_io.py
index a5a0adea91a3..c51b54c82f57 100644
--- a/tests/test_checkpoint_io/test_low_level_zero_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_low_level_zero_checkpoint_io.py
@@ -1,13 +1,11 @@
-import tempfile
-
-import pytest
import torch
+import torch.distributed as dist
from torchvision.models import resnet18
+from utils import shared_tempdir
import colossalai
from colossalai.booster import Booster
from colossalai.booster.plugin import LowLevelZeroPlugin
-from colossalai.booster.plugin.low_level_zero_plugin import LowLevelZeroCheckpointIO
from colossalai.nn.optimizer import HybridAdam
from colossalai.testing import (
check_state_dict_equal,
@@ -20,7 +18,8 @@
@clear_cache_before_run()
@parameterize('stage', [2])
-def check_low_level_zero_checkpointIO(stage: int):
+@parameterize('shard', [True, False])
+def check_low_level_zero_checkpointIO(stage: int, shard: bool):
plugin = LowLevelZeroPlugin(stage=stage, max_norm=1.0, initial_scale=32)
booster = Booster(plugin=plugin)
model = resnet18()
@@ -34,17 +33,25 @@ def check_low_level_zero_checkpointIO(stage: int):
loss = criterion(output)
booster.backward(loss, optimizer)
optimizer.step()
+ with shared_tempdir() as tempdir:
+ model_ckpt_path = f"{tempdir}/model"
+ optimizer_ckpt_path = f"{tempdir}/optimizer"
+ # lr scheduler is tested in test_torch_ddp_checkpoint_io.py and low level zero does not change it, we can skip it here
+ booster.save_model(model, model_ckpt_path, shard=shard)
+ if not shard:
+ # TODO(ver217): optimizer checkpointing is not supported for sharded checkpoint
+ booster.save_optimizer(optimizer, optimizer_ckpt_path)
+ dist.barrier()
- optimizer_ckpt_tempfile = tempfile.NamedTemporaryFile()
- ckpt_io = LowLevelZeroCheckpointIO()
- ckpt_io.save_optimizer(optimizer, optimizer_ckpt_tempfile.name)
+ new_model = resnet18()
+ new_optimizer = HybridAdam((new_model.parameters()), lr=0.001)
+ new_model, new_optimizer, _, _, _ = booster.boost(new_model, new_optimizer)
- new_model = resnet18()
- new_optimizer = HybridAdam((new_model.parameters()), lr=0.001)
- _, new_optimizer, _, _, _ = booster.boost(new_model, new_optimizer)
- if ckpt_io.coordinator.is_master():
- ckpt_io.load_optimizer(new_optimizer, optimizer_ckpt_tempfile.name)
- check_state_dict_equal(optimizer.state_dict(), new_optimizer.state_dict(), False)
+ booster.load_model(new_model, model_ckpt_path)
+ check_state_dict_equal(model.state_dict(), new_model.state_dict(), False)
+ if not shard:
+ booster.load_optimizer(new_optimizer, optimizer_ckpt_path)
+ check_state_dict_equal(optimizer.state_dict(), new_optimizer.state_dict(), False)
def run_dist(rank, world_size, port):
diff --git a/tests/test_checkpoint_io/test_torch_ddp_checkpoint_io.py b/tests/test_checkpoint_io/test_torch_ddp_checkpoint_io.py
index 3c05ea9f1b17..5501ee4e3ef2 100644
--- a/tests/test_checkpoint_io/test_torch_ddp_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_torch_ddp_checkpoint_io.py
@@ -1,19 +1,19 @@
-import tempfile
-
import torch
+import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim import SGD
from torchvision.models import resnet18
+from utils import shared_tempdir
import colossalai
from colossalai.booster import Booster
from colossalai.booster.plugin import TorchDDPPlugin
-from colossalai.booster.plugin.torch_ddp_plugin import TorchDDPCheckpointIO
from colossalai.interface import OptimizerWrapper
-from colossalai.testing import check_state_dict_equal, rerun_if_address_is_in_use, spawn
+from colossalai.testing import check_state_dict_equal, parameterize, rerun_if_address_is_in_use, spawn
-def check_torch_ddp_checkpointIO():
+@parameterize('shard', [True, False])
+def check_torch_ddp_checkpointIO(shard: bool):
plugin = TorchDDPPlugin()
booster = Booster(plugin=plugin)
model = resnet18()
@@ -34,23 +34,32 @@ def check_torch_ddp_checkpointIO():
optimizer.step()
scheduler.step()
- optimizer_ckpt_tempfile = tempfile.NamedTemporaryFile()
- lr_scheduler_ckpt_tempfile = tempfile.NamedTemporaryFile()
- ckpt_io = TorchDDPCheckpointIO()
- ckpt_io.save_optimizer(optimizer, optimizer_ckpt_tempfile.name)
- ckpt_io.save_lr_scheduler(scheduler, lr_scheduler_ckpt_tempfile.name)
+ with shared_tempdir() as tempdir:
+ model_ckpt_path = f"{tempdir}/model"
+ optimizer_ckpt_path = f"{tempdir}/optimizer"
+ lr_scheduler_ckpt_path = f"{tempdir}/lr_scheduler"
+ booster.save_model(model, model_ckpt_path, shard=shard)
+ if not shard:
+ # TODO(ver217): optimizer checkpointing is not supported for sharded checkpoint
+ booster.save_optimizer(optimizer, optimizer_ckpt_path)
+ booster.save_lr_scheduler(scheduler, lr_scheduler_ckpt_path)
+ dist.barrier()
- new_model = resnet18()
- new_optimizer = SGD((new_model.parameters()), lr=0.001)
- new_scheduler = torch.optim.lr_scheduler.StepLR(new_optimizer, step_size=1, gamma=0.1)
- _, new_optimizer, _, _, new_scheduler = booster.boost(new_model, new_optimizer, lr_scheduler=new_scheduler)
+ new_model = resnet18()
+ new_optimizer = SGD((new_model.parameters()), lr=0.001)
+ new_scheduler = torch.optim.lr_scheduler.StepLR(new_optimizer, step_size=1, gamma=0.1)
+ new_model, new_optimizer, _, _, new_scheduler = booster.boost(new_model,
+ new_optimizer,
+ lr_scheduler=new_scheduler)
- if ckpt_io.coordinator.is_master():
- ckpt_io.load_optimizer(new_optimizer, optimizer_ckpt_tempfile.name)
- check_state_dict_equal(optimizer.state_dict(), new_optimizer.state_dict(), False)
+ booster.load_model(new_model, model_ckpt_path)
+ check_state_dict_equal(model.state_dict(), new_model.state_dict(), False)
- ckpt_io.load_lr_scheduler(new_scheduler, lr_scheduler_ckpt_tempfile.name)
- check_state_dict_equal(scheduler.state_dict(), new_scheduler.state_dict(), False)
+ if not shard:
+ booster.load_optimizer(new_optimizer, optimizer_ckpt_path)
+ check_state_dict_equal(optimizer.state_dict(), new_optimizer.state_dict(), False)
+ booster.load_lr_scheduler(new_scheduler, lr_scheduler_ckpt_path)
+ check_state_dict_equal(scheduler.state_dict(), new_scheduler.state_dict(), False)
def run_dist(rank, world_size, port):
diff --git a/tests/test_checkpoint_io/utils.py b/tests/test_checkpoint_io/utils.py
new file mode 100644
index 000000000000..2d35e157f446
--- /dev/null
+++ b/tests/test_checkpoint_io/utils.py
@@ -0,0 +1,21 @@
+import tempfile
+from contextlib import contextmanager, nullcontext
+from typing import Iterator
+
+import torch.distributed as dist
+
+
+@contextmanager
+def shared_tempdir() -> Iterator[str]:
+ """
+ A temporary directory that is shared across all processes.
+ """
+ ctx_fn = tempfile.TemporaryDirectory if dist.get_rank() == 0 else nullcontext
+ with ctx_fn() as tempdir:
+ try:
+ obj = [tempdir]
+ dist.broadcast_object_list(obj, src=0)
+ tempdir = obj[0] # use the same directory on all ranks
+ yield tempdir
+ finally:
+ dist.barrier()
 +
+
+
+ 