Dict[str, Any]:
+ """
+ Get evaluation from GPT-4.
+
+ Args:
+ sys_prompt: prompt for the system.
+ user_prompt: prompt for the user.
+ id: id of the answers for comparison.
+ max_tokens: the maximum number of tokens to generate in the chat completion.
+
+ Returns:
+ An evaluation of one comparison.
+ """
+
+ MAX_API_RETRY = 3
+ for _ in range(MAX_API_RETRY):
+ try:
+ response = openai.ChatCompletion.create(
+ model="gpt-4",
+ messages=[
+ {
+ "role": "system",
+ "content": sys_prompt
+ },
+ {
+ "role": "user",
+ "content": user_prompt,
+ },
+ ],
+ temperature=0.2,
+ max_tokens=max_tokens,
+ )
+ evaluation = response["choices"][0]["message"]["content"]
+ return {"evaluation": evaluation, "id": id}
+ except Exception as e:
+ print(e)
+ time.sleep(1)
+ print(f" Evaluation {id} failed after {MAX_API_RETRY} retries.")
+ return {"evaluation": "", "id": id}
+
+
+def parse_battle_score(evaluation: str) -> List[float]:
+ """
+ Parse evaluation from GPT-4 and get the scores of model 1 and 2.
+
+ Args:
+ evaluation: evaluation from GPT-4.
+
+ Returns:
+ A score pair of two different model answers.
+ """
+
+ try:
+ pattern = re.compile("([0-9]|10) out of 10")
+ sp = re.findall(pattern, evaluation)
+ if len(re.findall(pattern, evaluation)) == 2:
+ return [float(sp[0]), float(sp[1])]
+
+ pattern = re.compile("a score of ([0-9]|10)")
+ sp = re.findall(pattern, evaluation)
+ if len(re.findall(pattern, evaluation)) == 2:
+ return [float(sp[0]), float(sp[1])]
+
+ pattern = re.compile("([0-9]|10)/10")
+ sp = re.findall(pattern, evaluation)
+ if len(re.findall(pattern, evaluation)) == 2:
+ return [float(sp[0]), float(sp[1])]
+
+ score_pair = evaluation.split("\n")[0]
+ score_pair = score_pair.replace(",", " ")
+ sp = score_pair.split(" ")
+ if len(sp) == 2:
+ return [float(sp[0]), float(sp[1])]
+ else:
+ raise Exception(f"Invalid score pair. Got {evaluation}.")
+ except Exception as e:
+ return [-1, -1]
+
+
+def battle(answer1: List[Dict], answer2: List[Dict], prompt_dict: Dict[str, Any]) -> List[Dict]:
+ """
+ Use GPT-4 to compare answers of two different models.
+
+ Args:
+ answer1: answers of model 1.
+ answer2: answers of model 2.
+ prompt_dict: prompt for battle.
+
+ Returns:
+ Evaluations of all comparison pairs.
+ """
+
+ assert len(answer1) == len(answer2)
+
+ handles = []
+ evaluation_file = []
+
+ total_len = len(answer1)
+ question_idx_list = list(range(total_len))
+
+ print(f" Total number of answers: {len(answer1)}.")
+
+ evaluations = []
+ with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
+ futures = []
+ for i in question_idx_list:
+ assert answer1[i]["id"] == answer2[i]["id"]
+ answer_id = answer1[i]["id"]
+
+ ques = answer1[i]["instruction"] if answer1[i][
+ "input"] == "" else answer1[i]["instruction"] + " " + answer1[i]["input"]
+ cat = answer1[i]["category"]
+ ans1 = answer1[i]["output"]
+ ans2 = answer2[i]["output"]
+
+ sys_prompt = prompt_dict["system_prompt"]
+ prompt_template = prompt_dict["prompt_template"]
+ prompt = prompt_template.format(
+ question=ques,
+ answer_1=ans1,
+ answer_2=ans2,
+ prompt=prompt_dict["prompt"],
+ )
+
+ future = executor.submit(get_battle_result, sys_prompt, prompt, answer_id, 2048)
+ futures.append(future)
+
+ for future in tqdm.tqdm(concurrent.futures.as_completed(futures), total=len(futures)):
+ evaluations.append(future.result())
+
+ evaluations.sort(key=lambda x: x["id"])
+
+ return evaluations
+
+
+def save_battle_results(evaluations: List[Dict], name1: str, name2: str, save_path: str) -> None:
+ """
+ Save evaluation results (model 1 vs model 2) from GPT-4.
+
+ Args:
+ evaluations: evaluation results from GPT-4.
+ name1: model 1 's name.
+ name2: model 2 's name.
+ save_path: path to save battle results.
+ """
+
+ evaluation_file = deepcopy(evaluations)
+
+ ans1_score = 0
+ ans2_score = 0
+ better_count = 0
+ worse_count = 0
+ tie_count = 0
+ invalid_count = 0
+
+ better_file = []
+ worse_file = []
+ tie_file = []
+ invalid_file = []
+
+ for idx, evaluation in enumerate(evaluations):
+ scores = parse_battle_score(evaluation["evaluation"])
+ evaluation_file[idx]["score"] = scores
+
+ if scores[0] == -1 and scores[1] == -1:
+ invalid_count += 1
+ invalid_file.append(evaluation_file[idx])
+ print(f'Invalid score pair: {evaluation_file[idx]["id"]}.')
+ else:
+ if scores[0] > scores[1]:
+ worse_count += 1
+ worse_file.append(evaluation_file[idx])
+ elif scores[0] < scores[1]:
+ better_count += 1
+ better_file.append(evaluation_file[idx])
+ else:
+ tie_count += 1
+ tie_file.append(evaluation_file[idx])
+ ans1_score += scores[0]
+ ans2_score += scores[1]
+
+ prefix = f"{name1}_vs_{name2}"
+
+ if not os.path.exists(save_path):
+ os.makedirs(save_path)
+
+ jdump(better_file, os.path.join(save_path, prefix, f"{name2}_better.json"))
+ jdump(worse_file, os.path.join(save_path, prefix, f"{name2}_worse.json"))
+ jdump(tie_file, os.path.join(save_path, prefix, f"{prefix}_tie.json"))
+ jdump(invalid_file, os.path.join(save_path, prefix, f"{prefix}_invalid.json"))
+ jdump(evaluation_file, os.path.join(save_path, prefix, f"{prefix}_evaluations.json"))
+
+ if os.path.exists(os.path.join(save_path, "battle_results.json")):
+ results = jload(os.path.join(save_path, "battle_results.json"))
+ else:
+ results = {}
+
+ results[prefix] = {
+ "model": [name1, name2],
+ "better": better_count,
+ "worse": worse_count,
+ "tie": tie_count,
+ "win_rate": better_count / (len(evaluations) - invalid_count),
+ "score": [
+ ans1_score / (len(evaluations) - invalid_count),
+ ans2_score / (len(evaluations) - invalid_count),
+ ],
+ }
+ jdump(results, os.path.join(save_path, "battle_results.json"))
+
+ print(f"Total {invalid_count} invalid score pair(s).")
+ print(f"Model {name2} has {better_count} better answer(s).")
+ print(f"Model {name2} has {worse_count} worse answer(s).")
+ print(f"{tie_count} answer(s) play(s) to a tie.")
+ print(f"Win rate of model {name2}: {better_count/(len(evaluations)-invalid_count):.2f}")
+ print(f"Model {name1} average score: {ans1_score/(len(evaluations)-invalid_count):.2f}")
+ print(f"Model {name2} average score: {ans2_score/(len(evaluations)-invalid_count):.2f}")
+
+
+def get_gpt35_evaluation(prompt: Dict[str, Any],
+ inst: Dict[str, Any],
+ metrics: List[str],
+ max_tokens: int = 2048) -> Dict[str, Any]:
+ """
+ Use GPT-3.5 to evaluate one model answer.
+
+ Args:
+ prompt: a dictionary including prompt template, CoT and metrics.
+ inst: the instruction that is needed to be evaluated.
+ metrics: the metrics for evaluation.
+ max_tokens: the maximum number of tokens to generate in the completion.
+
+ Returns:
+ An evaluation of one answer.
+ """
+
+ MAX_API_RETRY = 3
+
+ question = (inst["instruction"] if inst["input"] == "" else inst["instruction"] + " " + inst["input"])
+ answer = inst["output"]
+ inst["evaluation"] = {}
+
+ for metric in metrics:
+ if prompt["metrics"].get(metric, None) is None:
+ raise Exception(
+ f"Unsupported metric {metric} for category {inst['category']}! You should add this metric in the prompt file!"
+ )
+ for i in range(MAX_API_RETRY):
+ try:
+ response = openai.Completion.create(
+ model="text-davinci-003",
+ prompt=prompt["prompt"].format(
+ question=question,
+ answer=answer,
+ metric=prompt["metrics"][metric],
+ steps=prompt["CoT"][metric],
+ ),
+ logprobs=5,
+ temperature=0,
+ max_tokens=max_tokens,
+ )
+ inst["evaluation"][metric] = {
+ "response": response["choices"][0]["text"],
+ "logprobs": response["choices"][0]["logprobs"]["top_logprobs"],
+ }
+ break
+ except Exception as e:
+ print(e)
+ time.sleep(1)
+ return inst
+
+
+def gpt35_evaluate(
+ answers: List[Dict],
+ prompt: Dict[str, Any],
+ metrics: List[str],
+ category: str,
+) -> List[Dict]:
+ """
+ Use GPT-3.5 to evaluate model answers and save evaluation results.
+
+ Args:
+ answers: model answers.
+ prompt: prompt for GPT-3.5 evaluation.
+ metrics: metrics for GPT-3.5 evaluation.
+ category: the category of the model answers for evaluation.
+
+ Returns:
+ Evaluations of the given answers.
+ """
+
+ print(f"The number of instances of category {category}'s is {len(answers)}.")
+
+ evaluations = []
+
+ metrics_str = ", ".join(x for x in metrics)
+ print(f"Category {category}'s metrics are {metrics_str}.")
+
+ with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
+ futures = []
+ for inst in answers:
+ future = executor.submit(get_gpt35_evaluation, prompt, inst, metrics, 1)
+ futures.append(future)
+
+ for future in tqdm.tqdm(
+ concurrent.futures.as_completed(futures),
+ desc=f"{category}: ",
+ total=len(futures),
+ ):
+ evaluations.append(future.result())
+
+ evaluations.sort(key=lambda x: x["id"])
+
+ print(f"{category} done.")
+
+ return evaluations
+
+
+def calculate_scores_form_logprobs(logprobs: Dict[str, Any]) -> float:
+ """
+ Calculate score from log probabilities returned by text-davinci-003.
+ Only openai.Completion can return logprobs.
+
+ Calculation formula:
+ score = sum(score_i * exp(value)) where score_i is the score which corresponds to the key(predicted token) and value is its log probability.
+
+ Ref: https://arxiv.org/abs/2303.16634
+ This paper proposes NLG evaluation methods using GPT-3.5(logprobs returned by openai api) and GPT-4(logprobs obtained by sampling).
+
+ Args:
+ logprobs: logprobs returned by openai.Completion.
+
+ Returns:
+ Score of one answer.
+ """
+
+ # GPT-3.5 only returns score of 1 to 5.
+ prob = np.zeros(5)
+
+ for key, value in logprobs.items():
+ # Sometimes the key will be one byte of a unicode character which takes the form of "bytes:\\xe7".
+ # It is meaningless and thus we don't calculate probability.
+ if "bytes" in key:
+ continue
+ # results[0] is the score which corresponds to the key(predicted token).
+ # For example, key "5" corresponds to score 5.
+ results = re.findall(r"\d", key)
+ if len(results) == 1:
+ prob[int(results[0]) - 1] = prob[int(results[0]) - 1] + np.exp(value)
+
+ score = np.dot(np.arange(1, 6), prob)
+
+ return score
+
+
+def save_gpt35_evaluation_statistics(model_name: str, evaluations: List[Dict], save_path: str) -> None:
+ """
+ Generate statistics for one model.
+
+ Args:
+ model_name: name of the model for saving statistics.
+ evaluations: evaluations for all of the model answers.
+ save_path: path to save GPT-3.5 evaluation statistics.
+ """
+
+ if not os.path.exists(save_path):
+ os.makedirs(save_path)
+
+ data_per_category = {}
+ for evaluation in evaluations:
+ category = evaluation["category"]
+ if evaluation["category"] in data_per_category.keys():
+ data_per_category[category].append(evaluation)
+ else:
+ data_per_category[category] = [evaluation]
+
+ all_statistics = {}
+ for category, data in data_per_category.items():
+ metrics = data[0]["evaluation"].keys()
+ scores = {metric: [] for metric in metrics}
+ for evaluation in data:
+ for metric in metrics:
+ scores[metric].append(calculate_scores_form_logprobs(evaluation["evaluation"][metric]["logprobs"][0]))
+
+ statistics = {}
+ for metric in metrics:
+ arg_sort = np.argsort(scores[metric])
+ statistics[metric] = {}
+ statistics[metric]["avg_score"] = sum(scores[metric]) / len(data)
+ statistics[metric]["best_3"] = {data[i]["id"]: scores[metric][i] for i in arg_sort[-3:][::-1]}
+ statistics[metric]["worst_3"] = {data[i]["id"]: scores[metric][i] for i in arg_sort[:3]}
+
+ all_statistics[category] = statistics
+
+ jdump(
+ all_statistics,
+ os.path.join(save_path, f"{model_name}_evaluation_statistics.json"),
+ )
+
+
+def analyze_gpt35_evaluation_statistics(statistics_path: str, save_path: str) -> None:
+ """
+ Analyze and visualize all GPT-3.5 evaluation statistics in the given directory.
+
+ Args:
+ statistics_path: path to all the models' statistics.
+ save_path: path to save table and visualization results.
+ """
+
+ if not os.path.exists(statistics_path):
+ raise Exception(f'The given directory "{statistics_path}" doesn\'t exist! No statistics found!')
+
+ all_statistics = {}
+
+ for file_name in os.listdir(statistics_path):
+ if file_name.endswith("_evaluation_statistics.json"):
+ model_name = file_name.split("_evaluation_statistics.json")[0]
+ all_statistics[model_name] = jload(os.path.join(statistics_path, file_name))
+
+ if len(list(all_statistics.keys())) == 0:
+ raise Exception(f'There are no statistics in the given directory "{statistics_path}"!')
+
+ frame_all = {
+ "model": [],
+ "category": [],
+ "metric": [],
+ "avg_score": [],
+ "best_3": [],
+ "worst_3": [],
+ }
+ frame_per_category = {}
+ for model_name, model_statistics in all_statistics.items():
+ for category, category_statistics in model_statistics.items():
+ if frame_per_category.get(category) is None:
+ frame_per_category[category] = {
+ "model": [],
+ "metric": [],
+ "avg_score": [],
+ "best_3": [],
+ "worst_3": [],
+ }
+
+ for metric, metric_statistics in category_statistics.items():
+ frame_all["model"].append(model_name)
+ frame_all["category"].append(category)
+ frame_all["metric"].append(metric)
+ frame_all["avg_score"].append(metric_statistics["avg_score"])
+ frame_all["best_3"].append(metric_statistics["best_3"])
+ frame_all["worst_3"].append(metric_statistics["worst_3"])
+
+ frame_per_category[category]["model"].append(model_name)
+ frame_per_category[category]["metric"].append(metric)
+ frame_per_category[category]["avg_score"].append(metric_statistics["avg_score"])
+ frame_per_category[category]["best_3"].append(metric_statistics["best_3"])
+ frame_per_category[category]["worst_3"].append(metric_statistics["worst_3"])
+
+ if not os.path.exists(save_path):
+ os.makedirs(save_path)
+
+ frame_all = pd.DataFrame(frame_all)
+ frame_all.to_csv(os.path.join(save_path, "gpt35_evaluation_statistics.csv"))
+
+ for category in tqdm.tqdm(
+ frame_per_category.keys(),
+ desc=f"category: ",
+ total=len(frame_per_category.keys()),
+ ):
+ data = pd.DataFrame(frame_per_category[category])
+
+ sns.set()
+ fig = plt.figure(figsize=(16, 10))
+ plt.ylim((0, 5))
+
+ fig = sns.barplot(x="metric", y="avg_score", hue="model", data=data, dodge=True)
+ fig.set_title(f"Comparison between Different Models for Category {category.title()}")
+ plt.xlabel("Evaluation Metric")
+ plt.ylabel("Average Score")
+
+ figure = fig.get_figure()
+ figure.savefig(os.path.join(save_path, f"{category}.png"), dpi=400)
diff --git a/applications/Chat/evaluate/merge.py b/applications/Chat/evaluate/merge.py
deleted file mode 100644
index 295dd7fa7cb3..000000000000
--- a/applications/Chat/evaluate/merge.py
+++ /dev/null
@@ -1,25 +0,0 @@
-import argparse
-import os
-
-from utils import jload, jdump
-
-
-def generate(args):
- dataset = []
- for i in range(args.shards):
- shard = jload(os.path.join(args.answer_path,
- f'{args.model_name}_answers_rank{i}.json'))
- dataset.extend(shard)
-
- dataset.sort(key=lambda x: x['id'])
- jdump(dataset, os.path.join(args.answer_path,
- f'{args.model_name}_answers.json'))
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--model_name', type=str, default='model')
- parser.add_argument('--shards', type=int, default=4)
- parser.add_argument('--answer_path', type=str, default="answer")
- args = parser.parse_args()
- generate(args)
diff --git a/applications/Chat/evaluate/metrics.py b/applications/Chat/evaluate/metrics.py
new file mode 100644
index 000000000000..5e657234c61a
--- /dev/null
+++ b/applications/Chat/evaluate/metrics.py
@@ -0,0 +1,169 @@
+import statistics
+
+import jieba
+from bert_score import score
+from nltk.translate.bleu_score import sentence_bleu
+from rouge_chinese import Rouge as Rouge_cn
+from sklearn.metrics import f1_score, precision_score, recall_score
+
+
+def bleu_score(preds: list, targets: list) -> dict:
+ """Calculate BLEU Score Metric
+
+ The calculation includes BLEU-1 for unigram, BLEU-2 for bigram,
+ BLEU-3 for trigram and BLEU-4 for 4-gram. Unigram evaluates the
+ accuracy in word level, other n-gram evaluate the fluency in
+ sentence level.
+ """
+ bleu_scores = {"bleu1": 0, "bleu2": 0, "bleu3": 0, "bleu4": 0}
+ cumulative_bleu = [0] * 4
+ weights = [(1. / 1., 0., 0., 0.), (1. / 2., 1. / 2., 0., 0.), (1. / 3., 1. / 3., 1. / 3., 0.),
+ (1. / 4., 1. / 4., 1. / 4., 1. / 4.)]
+
+ for pred, target in zip(preds, targets):
+ pred_list = (' '.join(jieba.cut(pred))).split()
+ target_list = [(' '.join(jieba.cut(target))).split()]
+
+ bleu = sentence_bleu(target_list, pred_list, weights=weights)
+ cumulative_bleu = [a + b for a, b in zip(cumulative_bleu, bleu)]
+
+ for i in range(len(cumulative_bleu)):
+ bleu_scores[f"bleu{i+1}"] = cumulative_bleu[i] / len(preds)
+
+ return bleu_scores
+
+
+def rouge_cn_score(preds: list, targets: list) -> dict:
+ """Calculate Chinese ROUGE Score Metric
+
+ The calculation includes ROUGE-1 for unigram, ROUGE-2 for bigram
+ and ROUGE-L. ROUGE-N evaluates the number of matching n-grams between
+ the preds and targets. ROUGE-L measures the number of matching
+ longest common subsequence (LCS) between preds and targets.
+ """
+ rouge_scores = {"rouge1": {}, "rouge2": {}, "rougeL": {}}
+ all_preds = []
+ all_targets = []
+
+ for pred, target in zip(preds, targets):
+ pred_list = ' '.join(jieba.cut(pred))
+ target_list = ' '.join(jieba.cut(target))
+ all_preds.append(pred_list)
+ all_targets.append(target_list)
+
+ rouge_cn = Rouge_cn()
+ rouge_avg = rouge_cn.get_scores(all_preds, all_targets, avg=True)
+
+ rouge_scores["rouge1"] = rouge_avg["rouge-1"]["f"]
+ rouge_scores["rouge2"] = rouge_avg["rouge-2"]["f"]
+ rouge_scores["rougeL"] = rouge_avg["rouge-l"]["f"]
+
+ return rouge_scores
+
+
+def distinct_score(preds: list) -> dict:
+ """Calculate Distinct Score Metric
+
+ This metric refers to https://arxiv.org/abs/1510.03055.
+ It evaluates the diversity of generation text by counting
+ the unique n-grams.
+ """
+ distinct_score = {"distinct": 0}
+ cumulative_distinct = []
+
+ for pred in preds:
+ pred_seg_list = list(' '.join(jieba.cut(pred)))
+ count_segs = len(pred_seg_list)
+ unique_segs = set(pred_seg_list)
+ count_unique_chars = len(unique_segs)
+
+ cumulative_distinct.append(count_unique_chars / count_segs)
+
+ distinct_score["distinct"] = statistics.mean(cumulative_distinct)
+
+ return distinct_score
+
+
+def bert_score(preds: list, targets: list) -> dict:
+ """Calculate BERTScore Metric
+
+ The BERTScore evaluates the semantic similarity between
+ tokens of preds and targets with BERT.
+ """
+ bert_score = {"bert_score": 0}
+ pred_list = []
+ target_list = []
+
+ for pred, target in zip(preds, targets):
+ pred_list.append(' '.join(jieba.cut(pred)))
+ target_list.append(' '.join(jieba.cut(target)))
+
+ _, _, F = score(pred_list, target_list, lang="zh", verbose=True)
+
+ bert_score["bert_score"] = F.mean().item()
+
+ return bert_score
+
+
+def calculate_precision_recall_f1(preds: list, targets: list) -> dict:
+ """Precision, Recall and F1-Score Calculation
+
+ The calculation of precision, recall and f1-score is realized by counting
+ the number f overlaps between the preds and target. The comparison length
+ limited by the shorter one of preds and targets. This design is mainly
+ considered for classification and extraction categories.
+ """
+ precision_recall_f1 = {"precision": 0, "recall": 0, "f1_score": 0}
+ precision_scores = []
+ recall_scores = []
+ f1_scores = []
+
+ for pred, target in zip(preds, targets):
+ pred_list = [char for char in pred]
+ target_list = [char for char in target]
+
+ target_labels = [1] * min(len(target_list), len(pred_list))
+ pred_labels = [int(pred_list[i] == target_list[i]) for i in range(0, min(len(target_list), len(pred_list)))]
+
+ precision_scores.append(precision_score(target_labels, pred_labels, zero_division=0))
+ recall_scores.append(recall_score(target_labels, pred_labels, zero_division=0))
+ f1_scores.append(f1_score(target_labels, pred_labels, zero_division=0))
+
+ precision_recall_f1["precision"] = statistics.mean(precision_scores)
+ precision_recall_f1["recall"] = statistics.mean(recall_scores)
+ precision_recall_f1["f1_score"] = statistics.mean(f1_scores)
+
+ return precision_recall_f1
+
+
+def precision(preds: list, targets: list) -> dict:
+ """Calculate Precision Metric
+ (design for classification and extraction categories)
+
+ Calculating precision by counting the number of overlaps between the preds and target.
+ """
+ precision = {"precision": 0}
+ precision["precision"] = calculate_precision_recall_f1(preds, targets)["precision"]
+ return precision
+
+
+def recall(preds: list, targets: list) -> dict:
+ """Calculate Recall Metric
+ (design for classification and extraction categories)
+
+ Calculating recall by counting the number of overlaps between the preds and target.
+ """
+ recall = {"recall": 0}
+ recall["recall"] = calculate_precision_recall_f1(preds, targets)["recall"]
+ return recall
+
+
+def F1_score(preds: list, targets: list) -> dict:
+ """Calculate F1-score Metric
+ (design for classification and extraction categories)
+
+ Calculating f1-score by counting the number of overlaps between the preds and target.
+ """
+ f1 = {"f1_score": 0}
+ f1["f1_score"] = calculate_precision_recall_f1(preds, targets)["f1_score"]
+ return f1
diff --git a/applications/Chat/evaluate/prompt/battle_prompt/battle_prompt_cn.json b/applications/Chat/evaluate/prompt/battle_prompt/battle_prompt_cn.json
new file mode 100644
index 000000000000..ca66afd7e464
--- /dev/null
+++ b/applications/Chat/evaluate/prompt/battle_prompt/battle_prompt_cn.json
@@ -0,0 +1,6 @@
+{
+ "id": 1,
+ "system_prompt": "你是一个检查回答质量的好助手。",
+ "prompt_template": "[问题]\n{question}\n\n[1号AI助手的答案]\n{answer_1}\n\n[1号AI助手答案终止]\n\n[2号AI助手的答案]\n{answer_2}\n\n[2号AI助手答案终止]\n\n[要求]\n{prompt}\n\n",
+ "prompt": "我们需要你评价这两个AI助手回答的性能。\n请对他们的回答的有用性、相关性、准确性、详细程度进行评分。每个AI助手都会得到一个1到10分的总分,分数越高表示整体表现越好。\n请首先输出一行,该行只包含两个数值,分别表示1号和2号AI助手的分数。这两个分数之间要有一个空格。在随后的一行中,请对你的评价作出全面的解释,避免任何潜在的偏见,并确保AI助手回答的顺序不会影响您的判断。"
+}
diff --git a/applications/Chat/evaluate/prompt/evaluation_prompt/evaluation_prompt_cn.json b/applications/Chat/evaluate/prompt/evaluation_prompt/evaluation_prompt_cn.json
new file mode 100644
index 000000000000..d4b8d143eadf
--- /dev/null
+++ b/applications/Chat/evaluate/prompt/evaluation_prompt/evaluation_prompt_cn.json
@@ -0,0 +1,179 @@
+[
+ {
+ "id": 1,
+ "category": "brainstorming",
+ "metrics": {
+ "language organization": "语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。",
+ "relevance": "切题(1-5):答案内容是否切题,不答非所问,并且严格遵照题目要求。",
+ "creativity": "创意性(1-5):某些头脑风暴问题可能需要答案具有创意,提出新的思路。",
+ "practicality": "实用性(1-5):某些头脑风暴问题可能需要答案提出实用的建议或解决方法。",
+ "correctness": "正确性(1-5):答案应该符合常识、生活实际等等。"
+ },
+ "CoT": {
+ "language organization": "1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。\n2. 检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说。\n3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。\n4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。\n5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。\n6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。\n\n语言组织:",
+ "relevance": "1. 阅读题目,确定题目所问的问题是什么,以及需要回答哪些方面的问题。\n2. 阅读答案,确认答案是否直接回答了题目所问的问题。\n3. 检查答案是否严格遵照了题目的要求,包括答题方式、答题长度、答题格式等等。\n4. 根据以上因素综合评估答案的切题程度,并给出一个1到5的分数,其中5表示答案非常切题,而1表示答案完全没有切题。\n\n切题:",
+ "creativity": "1. 仔细阅读所提供的头脑风暴问题,确保你理解问题的要点和背景。\n2. 根据你的知识和经验,判断所提供的答案是否可行。如果答案不可行,则创意性评分可能会受到影响。\n3. 考虑答案中是否包含新颖的想法或独特的思路。答案可能与已知的解决方案有所重叠,但仍然可以被认为是有创意的,只要它提供了新的角度或方法来解决问题。\n4. 根据答案的创意性,给出一个1到5的评分。如果答案缺乏创意,则应给出一个较低的评分。如果答案具有创意并提供了新的思路,应给出一个较高的评分。\n\n创意性:",
+ "practicality": "1. 仔细阅读所提供的头脑风暴问题,确保你理解问题的要点和背景。\n2. 根据你的知识和经验,判断所提供的答案是否可行。如果答案不可行,则实用性评分可能会受到影响。\n3. 考虑答案中提出的建议或解决方法是否实用并可行。答案可能看起来很好,但如果无法实现或应用,则实用性评分可能会受到影响。\n4. 根据答案的实用性,给出一个1到5的评分。如果答案缺乏实用性,则应给出一个较低的评分。如果答案提出了实用的建议或解决方法,并且可以很好地解决问题,则应给出一个较高的评分。\n\n实用性:",
+ "correctness": "1. 仔细阅读所提供的头脑风暴问题,确保你理解问题的要点和背景。\n2. 根据你的知识和经验,判断所提供的答案是否可行。如果答案不可行,则正确性评分可能会受到影响。\n3. 考虑答案中所提供的信息是否正确、符合常识、生活实际等等。如果答案中存在明显的错误或不合理之处,则正确性评分可能会受到影响。\n4. 根据答案的正确性,给出一个1到5的评分。如果答案存在明显的错误或不合理之处,则应给出一个较低的评分。如果答案正确、符合常识、生活实际等等,则应给出一个较高的评分。\n\n正确性:"
+ },
+ "prompt": "你是一个好助手。请你为下面“头脑风暴”问题的答案打分。\n\n问题如下:\n\n{question}\n\n答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ },
+ {
+ "id": 2,
+ "category": "chat",
+ "metrics": {
+ "language organization": "语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。",
+ "relevance": "切题(1-5):答案内容是否切题,不答非所问,并且严格遵照题目要求。",
+ "naturalness": "自然(1-5):答案是否自然,并且符合问题给定的身份。",
+ "engagingness": "参与感(1-5):答案是否对前面的对话内容做出了恰当的反应,是否理解对话的语境和背景。",
+ "reasonableness": "合理性(1-5):答案是否能够与前面的对话内容形成逻辑上的衔接,是否符合常理,能否在这个上下文中合理存在。"
+ },
+ "CoT": {
+ "language organization": "1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。\n2. 检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说。\n3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。\n4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。\n5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。\n6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。\n\n语言组织:",
+ "relevance": "1. 阅读题目,确定题目所问的问题是什么,以及需要回答哪些方面的问题。\n2. 阅读答案,确认答案是否直接回答了题目所问的问题。\n3. 检查答案是否严格遵照了题目的要求,包括答题方式、答题长度、答题格式等等。\n4. 根据以上因素综合评估答案的切题程度,并给出一个1到5的分数,其中5表示答案非常切题,而1表示答案完全没有切题。\n\n切题:",
+ "naturalness": "1. 阅读题目,确定题目提供的身份信息。\n2. 检查答案内容是否符合题目给定的身份。\n3. 根据以上因素,对该回答的自然性进行打分,分数从1到5,其中1表示不自然,5表示非常自然,并符合问题给定的身份。\n\n自然:",
+ "engagingness": "1. 阅读题目,确定对话的语境和背景。\n2. 检查答案是否充分理解对话的语境和背景,能否自然地融入到对话中而不显得突兀。\n3. 根据以上因素,对该回答的参与感进行打分,分数从1到5,其中1表示没有参与感,5表示非常有参与感,并且恰当地理解了对话的语境和背景。\n\n参与感:",
+ "reasonableness": "1. 阅读题目,确定对话的主题以及问题期望的回答方向。\n2. 判断答案是否能够与前面的对话内容形成逻辑上的衔接,是否符合常理,能否在这个上下文中合理存在。\n3. 根据以上因素,对该回答的合理性进行打分,分数从1到5,其中1表示不合理,5表示非常合理,并且能够与前面的对话内容形成逻辑上的衔接,并符合常理。\n\n合理性:"
+ },
+ "prompt": "你是一个好助手。请你为下面的“补全对话”问题的答案打分。\n\n问题如下:\n\n{question}\n\n答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ },
+ {
+ "id": 3,
+ "category": "classification",
+ "metrics": {
+ "language organization": "语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。",
+ "relevance": "切题(1-5):答案内容是否切题,不答非所问,并且严格遵照题目要求。",
+ "correctness": "正确性(1-5):答案是否正确。"
+ },
+ "CoT": {
+ "language organization": "1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。\n2. 检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说。\n3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。\n4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。\n5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。\n6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。\n\n语言组织:",
+ "relevance": "1. 阅读题目,确定题目所问的问题是什么,以及需要回答哪些方面的问题。\n2. 阅读答案,确认答案是否直接回答了题目所问的问题。\n3. 检查答案是否严格遵照了题目的要求,包括答题方式、答题长度、答题格式等等。\n4. 根据以上因素综合评估答案的切题程度,并给出一个1到5的分数,其中5表示答案非常切题,而1表示答案完全没有切题。\n\n切题:",
+ "correctness": "1. 仔细阅读题目,尝试自己回答该问题。\n2. 检查答案的准确性。您可以使用已知的事实或研究来验证答案是否正确。如果答案是正确的,则可以将正确性得分为5分。如果答案是部分正确的,则可以给予适当的得分,例如2分、3分或4分。如果答案完全不正确,则只得1分。\n\n正确性:"
+ },
+ "prompt": "你是一个好助手。请你为下面的“分类“问题的答案打分。\n\n问题如下:\n\n{question}\n\n答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ },
+ {
+ "id": 4,
+ "category": "closed_qa",
+ "metrics": {
+ "language organization": "语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。",
+ "relevance": "切题(1-5):答案内容是否切题,不答非所问,并且严格遵照题目要求。",
+ "correctness": "正确性(1-5):答案是否正确。"
+ },
+ "CoT": {
+ "language organization": "1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。\n2. 检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说。\n3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。\n4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。\n5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。\n6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。\n\n语言组织:",
+ "relevance": "1. 阅读题目,确定题目所问的问题是什么,以及需要回答哪些方面的问题。\n2. 阅读答案,确认答案是否直接回答了题目所问的问题。\n3. 检查答案是否严格遵照了题目的要求,包括答题方式、答题长度、答题格式等等。\n4. 根据以上因素综合评估答案的切题程度,并给出一个1到5的分数,其中5表示答案非常切题,而1表示答案完全没有切题。\n\n切题:",
+ "correctness": "1. 仔细阅读题目,尝试自己回答该问题。\n2. 检查答案的准确性。您可以使用已知的事实或研究来验证答案是否正确。如果答案是正确的,则可以将正确性得分为5分。如果答案是部分正确的,则可以给予适当的得分,例如2分、3分或4分。如果答案完全不正确,则只得1分。\n\n正确性:"
+ },
+ "prompt": "你是一个好助手。请你为下面问题的答案打分。\n\n问题如下:\n\n{question}\n\n需要你评分的答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ },
+ {
+ "id": 5,
+ "category": "extraction",
+ "metrics": {
+ "language organization": "语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。",
+ "relevance": "切题(1-5):答案内容是否切题,不答非所问,并且严格遵照题目要求。",
+ "correctness": "准确性(1-5):回答应该准确无误地提取出所需信息,不应该包含任何错误或误导性信息。"
+ },
+ "CoT": {
+ "language organization": "1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。\n2. 检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说。\n3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。\n4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。\n5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。\n6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。\n\n语言组织:",
+ "relevance": "1. 阅读题目,确定题目所问的问题是什么,以及需要回答哪些方面的问题。\n2. 阅读答案,确认答案是否直接回答了题目所问的问题。\n3. 检查答案是否严格遵照了题目的要求,包括答题方式、答题长度、答题格式等等。\n4. 根据以上因素综合评估答案的切题程度,并给出一个1到5的分数,其中5表示答案非常切题,而1表示答案完全没有切题。\n\n切题:",
+ "correctness": "1. 仔细阅读问题并确定需要从材料中提取的信息。\n2. 仔细阅读回答并确保它涵盖了所有需要提取的信息。\n3. 使用所提供的材料来验证回答的准确性。如果回答不准确或包含错误或误导性信息,则无法给出高分。\n4. 检查回答是否包含所有要求提取的信息,不要漏掉任何重要细节。\n5. 根据回答的准确性和完整性,给出一个介于1和5之间的分数,5分表示回答非常准确且完整,1分表示回答几乎没有提取出所需信息。\n\n准确性:"
+ },
+ "prompt": "你是一个好助手。请你为下面的“提取”问题的答案打分。\n\n问题如下:\n\n{question}\n\n答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ },
+ {
+ "id": 6,
+ "category": "generation",
+ "metrics": {
+ "language organization": "语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。",
+ "relevance": "切题(1-5):答案内容是否切题,不答非所问,并且严格遵照题目要求。",
+ "diversity": "多样性(1-5):答案使用语言是否优美,具有有一定的创造性和想象力。然而,回答也应该保持合理和适度,不要过于夸张或离题。"
+ },
+ "CoT": {
+ "language organization": "1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。\n2. 检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说。\n3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。\n4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。\n5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。\n6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。\n\n语言组织:",
+ "relevance": "1. 阅读题目,确定题目所问的问题是什么,以及需要回答哪些方面的问题。\n2. 阅读答案,确认答案是否直接回答了题目所问的问题。\n3. 检查答案是否严格遵照了题目的要求,包括答题方式、答题长度、答题格式等等。\n4. 根据以上因素综合评估答案的切题程度,并给出一个1到5的分数,其中5表示答案非常切题,而1表示答案完全没有切题。\n\n切题:",
+ "diversity": "1. 仔细阅读整个回答,确保完全理解回答所表达的内容和主题。\n2. 在阅读回答的同时,注意语言的质量,例如措辞是否正确,语言是否生动等。\n3. 检查回答的创造性和想象力,看看回答是否能够吸引人阅读下去。\n4. 检查回答的合理性和适度,看看回答是否夸张或离题。\n5. 将多样性的评分打分在1到5之间,5分表示回答的质量很好,能够吸引人阅读,1分表示回答的内容生硬或者有离题的问题。\n\n多样性:"
+ },
+ "prompt": "你是一个好助手。请你为下面的“生成”问题的答案打分。\n\n问题如下:\n\n{question}\n\n答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ },
+ {
+ "id": 7,
+ "category": "open_qa",
+ "metrics": {
+ "language organization": "语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。",
+ "relevance": "切题(1-5):答案内容是否切题,不答非所问,并且严格遵照题目要求。",
+ "correctness": "正确性(1-5):答案是否正确。"
+ },
+ "CoT": {
+ "language organization": "1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。\n2. 检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说。\n3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。\n4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。\n5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。\n6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。\n\n语言组织:",
+ "relevance": "1. 阅读题目,确定题目所问的问题是什么,以及需要回答哪些方面的问题。\n2. 阅读答案,确认答案是否直接回答了题目所问的问题。\n3. 检查答案是否严格遵照了题目的要求,包括答题方式、答题长度、答题格式等等。\n4. 根据以上因素综合评估答案的切题程度,并给出一个1到5的分数,其中5表示答案非常切题,而1表示答案完全没有切题。\n\n切题:",
+ "correctness": "1. 仔细阅读题目,尝试自己回答该问题。\n2. 检查答案的准确性。您可以使用已知的事实或研究来验证答案是否正确。如果答案是正确的,则可以将正确性得分为5分。如果答案是部分正确的,则可以给予适当的得分,例如2分、3分或4分。如果答案完全不正确,则只得1分。\n\n正确性:"
+ },
+ "prompt": "你是一个好助手。请你为下面的问题的答案打分。\n\n问题如下:\n\n{question}\n\n答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ },
+ {
+ "id": 8,
+ "category": "rewriting",
+ "metrics": {
+ "language organization": "语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。",
+ "relevance": "切题(1-5):答案内容是否切题,不答非所问,并且严格遵照题目要求。",
+ "correctness": "正确性(1-5):答案是否正确。"
+ },
+ "CoT": {
+ "language organization": "1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。\n2. 检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说。\n3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。\n4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。\n5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。\n6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。\n\n语言组织:",
+ "relevance": "1. 阅读题目,确定题目所问的问题是什么,以及需要回答哪些方面的问题。\n2. 阅读答案,确认答案是否直接回答了题目所问的问题。\n3. 检查答案是否严格遵照了题目的要求,包括答题方式、答题长度、答题格式等等。\n4. 根据以上因素综合评估答案的切题程度,并给出一个1到5的分数,其中5表示答案非常切题,而1表示答案完全没有切题。\n\n切题:",
+ "correctness": "1. 仔细阅读题目,尝试自己回答该问题。\n2. 检查答案的准确性。您可以使用已知的事实或研究来验证答案是否正确。如果答案是正确的,则可以将正确性得分为5分。如果答案是部分正确的,则可以给予适当的得分,例如2分、3分或4分。如果答案完全不正确,则只得1分。\n\n正确性:"
+ },
+ "prompt": "你是一个好助手。请你为下面的问题的答案打分。\n\n问题如下:\n\n{question}\n\n答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ },
+ {
+ "id": 9,
+ "category": "roleplay",
+ "metrics": {
+ "language organization": "语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。",
+ "relevance": "切题(1-5):答案内容是否切题,不答非所问,并且严格遵照题目要求。",
+ "fidelity": "保真度(1-5):答案是否能够严格遵守角色的设定回答给定的请求。",
+ "creativity": "创意性(1-5):角色扮演问题的回答需要具有一定创意,但同时需要遵守角色的设定。"
+ },
+ "CoT": {
+ "language organization": "1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。\n2. 检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说。\n3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。\n4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。\n5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。\n6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。\n\n语言组织:",
+ "relevance": "1. 阅读题目,确定题目所问的问题是什么,以及需要回答哪些方面的问题。\n2. 阅读答案,确认答案是否直接回答了题目所问的问题。\n3. 检查答案是否严格遵照了题目的要求,包括答题方式、答题长度、答题格式等等。\n4. 根据以上因素综合评估答案的切题程度,并给出一个1到5的分数,其中5表示答案非常切题,而1表示答案完全没有切题。\n\n切题:",
+ "fidelity": "1. 仔细阅读问题,了解角色在问题中的设定和表现,包括职业、背景、观点、性格等方面。\n2. 阅读题目的请求,确认回答请求时需要注意的细节。\n3. 对比提供的回答与该角色的设定,评估回答是否能够严格遵守角色的设定。\n4. 结合以上评估结果给出保真度的评分,范围从1到5分,其中1分表示回答与角色设定完全不符,5分表示回答完全符合角色设定且满足给定请求。\n\n保真度:",
+ "creativity": "1. 仔细阅读问题,了解角色在问题中的设定和表现,包括职业、背景、观点、性格等方面。\n2. 评估回答是否具有独特的思路和建议,是否能够给提问者带来新的想法和启示。\n3. 对比回答中的创意和该角色的设定,评估回答是否遵守了该角色的设定和基本特征。\n4. 对回答的质量进行总体评估,并结合以上评估结果给出创意性的评分,范围从1到5分,其中1分表示回答缺乏创意,5分表示回答具有独特的思路和建议,并且能够遵守该角色的设定。\n\n创意性:"
+ },
+ "prompt": "你是一个好助手。请你为下面的“角色扮演”问题的答案打分。\n\n问题如下:\n\n{question}\n\n答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ },
+ {
+ "id": 10,
+ "category": "summarization",
+ "metrics": {
+ "language organization": "语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。",
+ "relevance": "切题(1-5):答案内容是否切题,不答非所问,并且严格遵照题目要求。",
+ "correctness": "准确性(1-5):回答应该准确无误地总结出材料的重点。",
+ "conciseness": "简明扼要(1-5):答案是否简明扼要,没有冗余内容。"
+ },
+ "CoT": {
+ "language organization": "1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。\n2. 检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说。\n3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。\n4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。\n5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。\n6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。\n\n语言组织:",
+ "relevance": "1. 阅读题目,确定题目所问的问题是什么,以及需要回答哪些方面的问题。\n2. 阅读答案,确认答案是否直接回答了题目所问的问题。\n3. 检查答案是否严格遵照了题目的要求,包括答题方式、答题长度、答题格式等等。\n4. 根据以上因素综合评估答案的切题程度,并给出一个1到5的分数,其中5表示答案非常切题,而1表示答案完全没有切题。\n\n切题:",
+ "correctness": "1. 仔细阅读问题给的材料,理解其内容和要点。\n2. 评估回答是否准确地总结出原始材料的重点。\n3. 评估回答是否包含原始材料中的所有关键信息。\n4. 根据以上步骤,给出一个1-5的分数,其中1表示回答不能准确地总结出材料的重点,5表示回答完全准确地总结出材料的重点。\n\n准确性:",
+ "conciseness": "1. 阅读题目,提取出材料的重点。\n2. 阅读该总结,并注意其中的主要观点和信息。\n3. 评估总结的长度。一个简明扼要的总结通常应该在几句话或几段文字内传达关键信息,而不是冗长的段落或文章。\n4. 检查总结是否包含与主要观点无关的信息或冗余信息。\n5.确定总结涵盖了材料中的关键信息,并且没有忽略任何重要细节。\n6.给总结打出1-5的分数,其中5表示总结简明扼要,没有冗余内容,而1表示总结冗长或包含不必要的信息,难以理解或记忆。根据您的判断,打出适当的得分。\n\n简明扼要:"
+ },
+ "prompt": "你是一个好助手。请你为下面的“总结”问题的答案打分。\n\n问题如下:\n\n{question}\n\n答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ },
+ {
+ "id": 11,
+ "category": "general",
+ "metrics": {
+ "language organization": "语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。",
+ "relevance": "切题(1-5):答案内容是否切题,不答非所问,并且严格遵照题目要求。",
+ "correctness": "正确性(1-5):答案是否正确。"
+ },
+ "CoT": {
+ "language organization": "1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。\n2. 检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说。\n3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。\n4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。\n5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。\n6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。\n\n语言组织:",
+ "relevance": "1. 阅读题目,确定题目所问的问题是什么,以及需要回答哪些方面的问题。\n2. 阅读答案,确认答案是否直接回答了题目所问的问题。\n3. 检查答案是否严格遵照了题目的要求,包括答题方式、答题长度、答题格式等等。\n4. 根据以上因素综合评估答案的切题程度,并给出一个1到5的分数,其中5表示答案非常切题,而1表示答案完全没有切题。\n\n切题:",
+ "correctness": "1. 仔细阅读题目,尝试自己回答该问题。\n2. 检查答案的准确性。您可以使用已知的事实或研究来验证答案是否正确。如果答案是正确的,则可以将正确性得分为5分。如果答案是部分正确的,则可以给予适当的得分,例如2分、3分或4分。如果答案完全不正确,则只得1分。\n\n正确性:"
+ },
+ "prompt": "你是一个好助手。请你为下面问题的答案打分。\n\n问题如下:\n\n{question}\n\n需要你评分的答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ }
+]
diff --git a/applications/Chat/evaluate/requirements.txt b/applications/Chat/evaluate/requirements.txt
new file mode 100644
index 000000000000..b0301c2f17f8
--- /dev/null
+++ b/applications/Chat/evaluate/requirements.txt
@@ -0,0 +1,10 @@
+jieba
+bert-score
+rouge_chinese
+scikit-metrics
+nltk
+openai
+seaborn
+pandas
+matplotlib
+numpy
diff --git a/applications/Chat/evaluate/sample/questions.json b/applications/Chat/evaluate/sample/questions.json
deleted file mode 100644
index e9ef9f8b1c66..000000000000
--- a/applications/Chat/evaluate/sample/questions.json
+++ /dev/null
@@ -1,9 +0,0 @@
-[
- {
- "id": 0,
- "instruction": "Help me summarize the following news?",
- "input": "National Commercial Bank (NCB), Saudi Arabia's largest lender by assets, agreed to buy rival Samba Financial Group for $15 billion in the biggest banking takeover this year.NCB will pay 28.45 riyals ($7.58) for each Samba share, according to a statement on Sunday, valuing it at about 55.7 billion riyals. NCB will offer 0.739 new shares for each Samba share, at the lower end of the 0.736-0.787 ratio the banks set when they signed an initial framework agreement in June.The offer is a 3.5% premium to Samba's Oct. 8 closing price of 27.50 riyals and about 24% higher than the level the shares traded at before the talks were made public. Bloomberg News first reported the merger discussions.The new bank will have total assets of more than $220 billion, creating the Gulf region's third-largest lender. The entity's $46 billion market capitalization nearly matches that of Qatar National Bank QPSC, which is still the Middle East's biggest lender with about $268 billion of assets.",
- "output": "NCB to pay 28.45 riyals for each Samba share. Deal will create Gulf region's third-largest lender",
- "category": "closed qa"
- }
-]
\ No newline at end of file
diff --git a/applications/Chat/evaluate/utils.py b/applications/Chat/evaluate/utils.py
index 692ee007c080..e855cd45221c 100644
--- a/applications/Chat/evaluate/utils.py
+++ b/applications/Chat/evaluate/utils.py
@@ -2,10 +2,6 @@
import json
import os
-import torch.distributed as dist
-
-def is_rank_0() -> bool:
- return not dist.is_initialized() or dist.get_rank() == 0
def _make_w_io_base(f, mode: str):
if not isinstance(f, io.IOBase):
@@ -15,11 +11,13 @@ def _make_w_io_base(f, mode: str):
f = open(f, mode=mode)
return f
+
def _make_r_io_base(f, mode: str):
if not isinstance(f, io.IOBase):
f = open(f, mode=mode)
return f
+
def jdump(obj, f, mode="w", indent=4, default=str):
"""Dump a str or dictionary to a file in json format.
Args:
@@ -38,6 +36,7 @@ def jdump(obj, f, mode="w", indent=4, default=str):
raise ValueError(f"Unexpected type: {type(obj)}")
f.close()
+
def jload(f, mode="r"):
"""Load a .json file into a dictionary."""
f = _make_r_io_base(f, mode)
@@ -45,9 +44,19 @@ def jload(f, mode="r"):
f.close()
return jdict
+
def get_json_list(file_path):
with open(file_path, 'r') as f:
json_list = []
for line in f:
json_list.append(json.loads(line))
return json_list
+
+
+def get_data_per_category(data, categories):
+ data_per_category = {category: [] for category in categories}
+ for item in data:
+ category = item["category"]
+ data_per_category[category].append(item)
+
+ return data_per_category
diff --git a/applications/Chat/examples/README.md b/applications/Chat/examples/README.md
index 2a2128e25a62..72810738d017 100644
--- a/applications/Chat/examples/README.md
+++ b/applications/Chat/examples/README.md
@@ -48,6 +48,7 @@ The following pic shows how we collected the data.
## Stage1 - Supervised instructs tuning
Stage1 is supervised instructs fine-tuning, which uses the datasets mentioned earlier to fine-tune the model.
+[[Stage1 tutorial video]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
You can run the `examples/train_sft.sh` to start a supervised instructs fine-tuning.
@@ -83,6 +84,7 @@ torchrun --standalone --nproc_per_node=4 train_sft.py \
## Stage2 - Training reward model
We train a reward model in stage 2, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model.
+[[Stage2 tutorial video]](https://www.youtube.com/watch?v=gMx2CApKhuo)
You can run the `examples/train_rm.sh` to start a reward model training.
@@ -141,6 +143,7 @@ Stage3 uses reinforcement learning algorithm, which is the most complex part of
You can run the `examples/train_prompts.sh` to start PPO training.
You can also use the cmd following to start PPO training.
+[[Stage3 tutorial video]](https://www.youtube.com/watch?v=Z8wwSHxPL9g)
```
torchrun --standalone --nproc_per_node=4 train_prompts.py \
@@ -153,7 +156,7 @@ torchrun --standalone --nproc_per_node=4 train_prompts.py \
--rm_path /your/rm/model/path
```
-Prompt dataset: the instruction dataset mentioned in the above figure which includes the instructions, e.g. you can use the [script](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/example_data_reformat.py) to reformat [seed_prompts_ch.jsonl](https://github.com/XueFuzhao/InstructionWild/blob/main/data/seed_prompts_ch.jsonl) or [seed_prompts_en.jsonl](https://github.com/XueFuzhao/InstructionWild/blob/main/data/seed_prompts_en.jsonl) in InstructionWild.
+Prompt dataset: the instruction dataset mentioned in the above figure which includes the instructions, e.g. you can use the [script](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/generate_prompt_dataset.py) which samples `instinwild_en.json` or `instinwild_ch.json` in [InstructionWild](https://github.com/XueFuzhao/InstructionWild/tree/main/data#instructwild-data) to generate the prompt dataset.
Pretrain dataset: the pretrain dataset including the instruction and corresponding response, e.g. you can use the [InstructWild Data](https://github.com/XueFuzhao/InstructionWild/tree/main/data) in stage 1 supervised instructs tuning.
### Arg List
diff --git a/applications/Chat/examples/community/peft/README.md b/applications/Chat/examples/community/peft/README.md
index eabb56fd8294..844bfd3d22c3 100644
--- a/applications/Chat/examples/community/peft/README.md
+++ b/applications/Chat/examples/community/peft/README.md
@@ -18,7 +18,7 @@ For SFT training, just call train_peft_sft.py
Its arguments are almost identical to train_sft.py instead adding a new eval_dataset if you have a eval_dataset file. The data file is just a plain datafile, please check the format in the easy_dataset.py.
For stage-3 rlhf training, call train_peft_prompts.py.
-Its arguments are almost idential to train_prompts.py. The only difference is that I use text files to indicate the prompt and pretrained data file. The models are included in easy_models.py. Currently only bloom models are tested, but technically gpt2/opt/llama should be supported.
+Its arguments are almost identical to train_prompts.py. The only difference is that I use text files to indicate the prompt and pretrained data file. The models are included in easy_models.py. Currently only bloom models are tested, but technically gpt2/opt/llama should be supported.
# Dataformat
Please refer the formats in test_sft.txt, test_prompts.txt, test_pretrained.txt.
diff --git a/applications/Chat/examples/example_data_reformat.py b/applications/Chat/examples/example_data_reformat.py
deleted file mode 100644
index dc83b29b525b..000000000000
--- a/applications/Chat/examples/example_data_reformat.py
+++ /dev/null
@@ -1,12 +0,0 @@
-jsonl_file = 'seed_prompts_xx.jsonl' # seed_prompts_en.jsonl or seed_prompts_ch.json from InstructionWild
-reformat_file = 'prompts_xx.jsonl' # reformat jsonl file used as Prompt dataset in Stage3
-
-data = ''
-with open(jsonl_file, 'r', encoding="utf-8") as f1:
- for jsonstr in f1.readlines():
- jsonstr = '\t' + jsonstr.strip('\n') + ',\n'
- data = data + jsonstr
- data = '[\n' + data + ']'
-
-with open(reformat_file, 'w') as f2:
- f2.write(data)
\ No newline at end of file
diff --git a/applications/Chat/examples/generate_prompt_dataset.py b/applications/Chat/examples/generate_prompt_dataset.py
new file mode 100644
index 000000000000..95e40fefe7ff
--- /dev/null
+++ b/applications/Chat/examples/generate_prompt_dataset.py
@@ -0,0 +1,30 @@
+import argparse
+
+import random
+import json
+
+random.seed(42)
+
+
+def sample(args):
+ with open(args.dataset_path, mode='r') as f:
+ dataset_list = json.load(f)
+
+ sampled_dataset = [{"instruction": sample["instruction"], "id":idx}
+ for idx, sample in enumerate(random.sample(dataset_list, args.sample_size))]
+
+ with open(args.save_path, mode='w') as f:
+ json.dump(sampled_dataset, f, indent=4,
+ default=str, ensure_ascii=False)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--dataset_path', type=str, default=None,
+ required=True, help="path to the pretrain dataset")
+ parser.add_argument('--save_path', type=str, default='prompt.json',
+ help="path to save the prompt dataset")
+ parser.add_argument('--sample_size', type=int,
+ default=16384, help="size of the prompt dataset")
+ args = parser.parse_args()
+ sample(args)
diff --git a/applications/Chat/inference/README.md b/applications/Chat/inference/README.md
index 434677c98fa5..4848817e0fd1 100644
--- a/applications/Chat/inference/README.md
+++ b/applications/Chat/inference/README.md
@@ -75,7 +75,7 @@ E.g. you can set `export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH`.
Please ensure you have downloaded HF-format model weights of LLaMA models first.
-Then you can follow [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). This lib provides efficient CUDA kernels and weight convertion script.
+Then you can follow [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). This lib provides efficient CUDA kernels and weight conversion script.
After installing this lib, we may convert the original HF-format LLaMA model weights to 4-bit version.
diff --git a/applications/Chat/inference/benchmark.py b/applications/Chat/inference/benchmark.py
index 59cd1eeea2aa..a8485f588705 100644
--- a/applications/Chat/inference/benchmark.py
+++ b/applications/Chat/inference/benchmark.py
@@ -123,7 +123,7 @@ def evaluate(
start = time()
for instruction in instructions:
print(f"Instruction: {instruction}")
- resp, tokens = evaluate(model, tokenizer, instruction, temparature=0.2, num_beams=1)
+ resp, tokens = evaluate(model, tokenizer, instruction, temperature=0.2, num_beams=1)
total_tokens += tokens
print(f"Response: {resp}")
print('\n----------------------------\n')
diff --git a/colossalai/amp/torch_amp/_grad_scaler.py b/colossalai/amp/torch_amp/_grad_scaler.py
index 7b78998fb8c2..ed4b8e484436 100644
--- a/colossalai/amp/torch_amp/_grad_scaler.py
+++ b/colossalai/amp/torch_amp/_grad_scaler.py
@@ -240,7 +240,7 @@ def _unscale_grads_(self, optimizer, inv_scale, found_inf, allow_fp16):
for grads in per_dtype_grads.values():
torch._amp_foreach_non_finite_check_and_unscale_(grads, per_device_found_inf.get(device),
per_device_inv_scale.get(device))
- # For tensor parallel paramters it should be all-reduced over tensor parallel process group
+ # For tensor parallel parameters it should be all-reduced over tensor parallel process group
if gpc.is_initialized(ParallelMode.MODEL) and gpc.get_world_size(ParallelMode.MODEL) > 1:
vals = [val for val in per_device_found_inf._per_device_tensors.values()]
coalesced = _flatten_dense_tensors(vals)
diff --git a/colossalai/auto_parallel/README.md b/colossalai/auto_parallel/README.md
index 8e47e1bb0b4a..f011ec8ccbd7 100644
--- a/colossalai/auto_parallel/README.md
+++ b/colossalai/auto_parallel/README.md
@@ -16,8 +16,8 @@ A *symbolic profiler* for collecting computing and memory overhead related to st
### Solver
**Solver** is designed to find the optimal execution plan for a given computation graph and cluster in two stages:
-1) *Intra-op parallelism stage* is to find the plan with the minimum total execution time of all nodes with respect to the constraint of the memory budget. The optimaztion goal of intra-op parallelism solver is modified from Alpa 's intra-op parallelsim ILP solver.
-2) *Activation checkpoint stage* is to search for the fastest execution plan that meets the memory budget on the computation graph after inserting the communication nodes by the intra-op parallelism stage. The algorithm to find optimial activation checkpoint is modified from Rotor . The reason we use two-stage optimization is that if the two tasks are formulated together, the solving time will be significantly increased, which will greatly affect the user experience of the system. On the contrary, solving in two hierarchical levels has many advantages. Firstly, compared with the computation graph with activation checkpointing, the original graph has fewer nodes, which can reduce the solving cost of intra-op parallelism solver. In addition, a more optimal solution can be found by adding the communication overhead into the activation checkpoint modeling.
+1) *Intra-op parallelism stage* is to find the plan with the minimum total execution time of all nodes with respect to the constraint of the memory budget. The optimization goal of intra-op parallelism solver is modified from Alpa 's intra-op parallelism ILP solver.
+2) *Activation checkpoint stage* is to search for the fastest execution plan that meets the memory budget on the computation graph after inserting the communication nodes by the intra-op parallelism stage. The algorithm to find optimal activation checkpoint is modified from Rotor . The reason we use two-stage optimization is that if the two tasks are formulated together, the solving time will be significantly increased, which will greatly affect the user experience of the system. On the contrary, solving in two hierarchical levels has many advantages. Firstly, compared with the computation graph with activation checkpointing, the original graph has fewer nodes, which can reduce the solving cost of intra-op parallelism solver. In addition, a more optimal solution can be found by adding the communication overhead into the activation checkpoint modeling.
### Generator
**Generator** applies the searched execution plan to the computation graph and recompiles the computation graph to optimized PyTorch code. It has *a series compile pass* to insert a communication node or do the kernel substitution as the intra-op parallelism solver required. Additionally, we implement a *code generation* feature to recognize the annotation from the activation checkpoint solver and inject the activation checkpoint block following annotation instructions.
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/linear.py b/colossalai/auto_parallel/meta_profiler/meta_registry/linear.py
index 7697fc6c383d..94dd9143e0ae 100644
--- a/colossalai/auto_parallel/meta_profiler/meta_registry/linear.py
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/linear.py
@@ -325,7 +325,7 @@ def matmul_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, L
else:
_is_batch_dims_same = False
- # retireve dimensions
+ # retrieve dimensions
input_dim_00 = input_tensors[0].shape[-2]
input_dim_01 = input_tensors[0].shape[-1]
input_dim_10 = input_tensors[1].shape[-2]
diff --git a/colossalai/auto_parallel/passes/meta_info_prop.py b/colossalai/auto_parallel/passes/meta_info_prop.py
index bc0960483980..0673b767de7b 100644
--- a/colossalai/auto_parallel/passes/meta_info_prop.py
+++ b/colossalai/auto_parallel/passes/meta_info_prop.py
@@ -148,7 +148,7 @@ def node_handler(self, node: Node) -> None:
graph_info.fwd_tmp = buffer_tensors
graph_info.fwd_out = output_tensors
- # fetch other memory informations
+ # fetch other memory information
memory_cost = meta_info.memory_cost
graph_info.fwd_mem_tmp = memory_cost.fwd.temp
graph_info.fwd_mem_out = memory_cost.fwd.activation
diff --git a/colossalai/auto_parallel/passes/runtime_apply_pass.py b/colossalai/auto_parallel/passes/runtime_apply_pass.py
index a473bb6e973d..2049a06187d2 100644
--- a/colossalai/auto_parallel/passes/runtime_apply_pass.py
+++ b/colossalai/auto_parallel/passes/runtime_apply_pass.py
@@ -219,7 +219,7 @@ def _comm_spec_apply(gm: torch.fx.GraphModule):
return gm
-def _act_annotataion_pass(gm: torch.fx.GraphModule):
+def _act_annotation_pass(gm: torch.fx.GraphModule):
"""
This pass is used to add the act annotation to the new inserted nodes.
"""
diff --git a/colossalai/auto_parallel/passes/runtime_preparation_pass.py b/colossalai/auto_parallel/passes/runtime_preparation_pass.py
index 08af846b221d..9a2314826448 100644
--- a/colossalai/auto_parallel/passes/runtime_preparation_pass.py
+++ b/colossalai/auto_parallel/passes/runtime_preparation_pass.py
@@ -54,7 +54,7 @@ def size_processing(size: Union[int, torch.Size],
return size
-def solution_annotatation_pass(gm: torch.fx.GraphModule, solution: List[int],
+def solution_annotation_pass(gm: torch.fx.GraphModule, solution: List[int],
strategies_constructor: StrategiesConstructor):
"""
This method is used to stick the solution strategy to the nodes and add the information
@@ -169,7 +169,7 @@ def _post_processing(node, size_processing_node):
This function is used to process the dependency between the size node and its users after
inserting the size_process_node.
'''
- # store original node and processing node pair in node_pairs dictioanry
+ # store original node and processing node pair in node_pairs dictionary
# It will be used to replace the original node with processing node in slice object
node_pairs[node] = size_processing_node
size_processing_node._meta_data = node._meta_data
@@ -388,7 +388,7 @@ def module_params_sharding_pass(gm: torch.fx.GraphModule, device_mesh: DeviceMes
"""
mod_graph = gm.graph
nodes = tuple(mod_graph.nodes)
- # This stream is created for overlaping the communication and computation.
+ # This stream is created for overlapping the communication and computation.
reduction_stream = torch.cuda.Stream()
def _add_hook_for_grad_communication(node, param, name=None):
@@ -496,7 +496,7 @@ def runtime_preparation_pass(gm: torch.fx.GraphModule,
device_mesh: DeviceMesh,
strategies_constructor: StrategiesConstructor,
overlap=False):
- gm, sharding_spec_convert_dict, origin_node_sharding_spec_dict, comm_actions_dict = solution_annotatation_pass(
+ gm, sharding_spec_convert_dict, origin_node_sharding_spec_dict, comm_actions_dict = solution_annotation_pass(
gm, solution, strategies_constructor)
gm = size_value_converting_pass(gm, device_mesh)
gm = node_args_converting_pass(gm, device_mesh)
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/embedding_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/embedding_handler.py
index e154105b672d..112ee194b4ec 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/embedding_handler.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/embedding_handler.py
@@ -155,7 +155,7 @@ def post_process(self, strategy: ShardingStrategy) -> Union[ShardingStrategy, Li
Convert the sharding spec from the logical shape to the physical shape.
"""
# create multiple sharding strategies for the inputs
- # as input can be multi-dimensinal and the partition dim is only 2D,
+ # as input can be multi-dimensional and the partition dim is only 2D,
# we need to map the partition at logical dim 0 to one of the first few dimensions of the input and output
strategies = _convert_logical_sharding_to_physical_sharding_spec_for_embedding(strategy=strategy,
input_name=str(
@@ -221,7 +221,7 @@ def post_process(self, strategy: ShardingStrategy):
Convert the sharding spec from the logical shape to the physical shape.
"""
# create multiple sharding strategies for the inputs
- # as input can be multi-dimensinal and the partition dim is only 2D,
+ # as input can be multi-dimensional and the partition dim is only 2D,
# we need to map the partition at logical dim 0 to one of the first few dimensions of the input and output
strategies = _convert_logical_sharding_to_physical_sharding_spec_for_embedding(strategy=strategy,
input_name=str(
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/linear_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/linear_handler.py
index 59091dab519f..ea541e434009 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/linear_handler.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/linear_handler.py
@@ -23,7 +23,7 @@ def _update_sharding_spec_for_transposed_weight_for_linear(strategy: ShardingStr
weight_name: str) -> ShardingStrategy:
"""
This function is a helper function used by both module node handler and function node handler. This function will
- convert the sharding spec for the transposed weight to the correct partititon spec.
+ convert the sharding spec for the transposed weight to the correct partition spec.
Args:
strategy (ShardingStrategy): the strategy generated by the strategy generator.
@@ -197,7 +197,7 @@ def post_process(self, strategy: ShardingStrategy) -> Union[ShardingStrategy, Li
strategy = _update_sharding_spec_for_transposed_weight_for_linear(strategy=strategy, weight_name='weight')
# create multiple sharding strategies for the inputs
- # as input can be multi-dimensinal and the partition dim is only 2D,
+ # as input can be multi-dimensional and the partition dim is only 2D,
# we need to map the partition at dim 0 to one of the first few dimensions of the input
strategies = _convert_logical_sharding_to_physical_sharding_spec_for_linear(strategy=strategy,
input_name=str(self.node.args[0]),
@@ -267,7 +267,7 @@ def post_process(self, strategy: ShardingStrategy):
strategy = _update_sharding_spec_for_transposed_weight_for_linear(strategy=strategy,
weight_name=str(self.node.args[1]))
# create multiple sharding strategies for the inputs
- # as input can be multi-dimensinal and the partition dim is only 2D,
+ # as input can be multi-dimensional and the partition dim is only 2D,
# we need to map the partition at dim 0 to one of the first few dimensions of the input
strategies = _convert_logical_sharding_to_physical_sharding_spec_for_linear(strategy=strategy,
input_name=str(self.node.args[0]),
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/matmul_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/matmul_handler.py
index f3c9d0cbf826..fa51114a5c94 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/matmul_handler.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/matmul_handler.py
@@ -48,8 +48,8 @@ def get_matmul_type(input_dim: int, other_dim: int):
Determine which type of matmul operation should be executed for the given tensor dimensions.
Args:
- input_dim (int): the number of dimensions for the input tenosr
- other_dim (int): the number of dimensions for the other tenosr
+ input_dim (int): the number of dimensions for the input tensor
+ other_dim (int): the number of dimensions for the other tensor
"""
if input_dim == 1 and other_dim == 1:
matmul_type = MatMulType.DOT
@@ -206,7 +206,7 @@ def _remove_sharding_on_broadcast_dim(key, strategy):
# e.g. [1, 2, 4] x [4, 4, 8] -> [4, 2, 8]
# the dim 0 of [1, 2, 4] is multiplied to 4
tensor_shape[dim_idx] = 1
- elif broadcast_type == BroadcastType.PADDDING:
+ elif broadcast_type == BroadcastType.PADDING:
# if the dim is padded
# we remove its sharding
tensor_shape[dim_idx] = None
@@ -268,13 +268,13 @@ def _update_sharding_spec(key, strategy, physical_batch_dim):
dim_partition_dict = sharding_spec.dim_partition_dict
entire_shape = sharding_spec.entire_shape
- # upddate the dimension index for the matrix dimensions
+ # update the dimension index for the matrix dimensions
if 2 in dim_partition_dict:
dim_partition_dict[len(self.batch_dims_before_view) + 1] = dim_partition_dict.pop(2)
if 1 in dim_partition_dict:
dim_partition_dict[len(self.batch_dims_before_view)] = dim_partition_dict.pop(1)
- # map the logical batch dim to phyiscal batch dim
+ # map the logical batch dim to physical batch dim
if 0 in dim_partition_dict:
batch_dim_shard = dim_partition_dict.pop(0)
dim_partition_dict[physical_batch_dim] = batch_dim_shard
@@ -414,7 +414,7 @@ def _get_logical_shape_for_dot(self):
def _get_logical_shape_for_mm(self):
"""
- We need to handle the input tensor for a matrix-matrix multiplcation as the input
+ We need to handle the input tensor for a matrix-matrix multiplication as the input
tensor can be a 1D or 2D tensor. If it is a 1D tensor, 1 will be prepended to its shape
(e.g. [4] -> [1, 4]).
"""
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py
index ab391ebfaf80..4262d76173e4 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py
@@ -75,7 +75,7 @@ def update_resharding_cost(self, strategy: ShardingStrategy) -> None:
prev_strategy.get_sharding_spec_by_name(node_name) for prev_strategy in prev_strategy_vector
]
- # create data structrure to store costs
+ # create data structure to store costs
if node not in resharding_costs:
resharding_costs[node] = []
@@ -212,7 +212,7 @@ def register_strategy(self, compute_resharding_cost: bool = True) -> StrategiesV
return self.strategies_vector
def post_process(self, strategy: ShardingStrategy) -> Union[ShardingStrategy, List[ShardingStrategy]]:
- # tranform the strategy generated
+ # transform the strategy generated
# e.g. to process the sharding strategy for the transposed weights
return strategy
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/batch_norm_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/batch_norm_generator.py
index 1f3812429fc2..416dc9c29cad 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/batch_norm_generator.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/batch_norm_generator.py
@@ -24,7 +24,7 @@ class BatchNormStrategyGenerator(StrategyGenerator):
To keep the math consistency, there are two way to do BatchNorm if the input
shards on batch dimension:
1. We gather the input partitions through batch dimension, then do the normal BatchNorm.
- 2. We do the SyncBatchNorm on the each input partition seperately, the SyncBN op will help
+ 2. We do the SyncBatchNorm on the each input partition separately, the SyncBN op will help
us to keep the computing correctness.
In this generator, both methods will be considered.
"""
@@ -44,7 +44,7 @@ def update_compute_cost(self, strategy: ShardingStrategy):
'''
Compute the computation cost per device with this specific strategy.
- Note: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ Note: compute_cost need to be divided by TFLOPS, now it just shows the computation size.
'''
# TODO: a constant coefficient need to be added.
# 1D: (L) * N * Cin
@@ -212,7 +212,7 @@ def split_input_batch(self, mesh_dim_0):
# set communication action
# For SyncBN case, we don't need to do communication for weight and bias.
- # TODO: the communication happens interally at SyncBN operation. We need to replace the BN operation
+ # TODO: the communication happens internally at SyncBN operation. We need to replace the BN operation
# to SyncBN operation instead of inserting a communication node.
output_comm_action = self.get_communication_action(
sharding_spec=sharding_spec_mapping["output"],
@@ -250,7 +250,7 @@ def split_input_batch_1d(self, mesh_dim_0, mesh_dim_1):
# set communication action
# For SyncBN case, we don't need to do communication for gradients of weight and bias.
- # TODO: the communication happens interally at SyncBN operation. We need to replace the BN operation
+ # TODO: the communication happens internally at SyncBN operation. We need to replace the BN operation
# to SyncBN operation instead of inserting a communication node.
output_comm_action = self.get_communication_action(
sharding_spec=sharding_spec_mapping["output"],
@@ -298,7 +298,7 @@ def split_input_both_dim(self, mesh_dim_0, mesh_dim_1):
# set communication action
# For SyncBN case, we don't need to do communication for gradients of weight and bias.
- # TODO: the communication happens interally at SyncBN operation. We need to replace the BN operation
+ # TODO: the communication happens internally at SyncBN operation. We need to replace the BN operation
# to SyncBN operation instead of inserting a communication node.
output_comm_action = self.get_communication_action(
sharding_spec=sharding_spec_mapping["output"],
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/binary_elementwise_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/binary_elementwise_generator.py
index fd7f811c8972..d27cc046eaf3 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/binary_elementwise_generator.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/binary_elementwise_generator.py
@@ -51,7 +51,7 @@ def update_memory_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
# compute fwd memory cost in bytes
# as the elementwise ops are not memory-intensive
- # we approximate the fwd memroy cost to be the output
+ # we approximate the fwd memory cost to be the output
# and the backward memory cost to be grad of input and other
input_bytes = self._compute_size_in_bytes(strategy, 'input')
other_bytes = self._compute_size_in_bytes(strategy, 'other')
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/conv_strategy_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/conv_strategy_generator.py
index c2154b3104d3..e605a68a326b 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/conv_strategy_generator.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/conv_strategy_generator.py
@@ -38,9 +38,9 @@ def update_compute_cost(self, strategy: ShardingStrategy):
'''
Compute the computation cost per device with this specific strategy.
- Note: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ Note: compute_cost need to be divided by TFLOPS, now it just shows the computation size.
'''
- # TODO: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ # TODO: compute_cost need to be divided by TFLOPS, now it just shows the computation size.
# 1D: (L) * N * Cout * Cin * kernel
# 2D: (H * W) * N * Cout * Cin * kernel
# 3D: (H * W * D) * N * Cout * Cin * kernel
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/layer_norm_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/layer_norm_generator.py
index fbb6070f7e82..65b173bbf65d 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/layer_norm_generator.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/layer_norm_generator.py
@@ -34,9 +34,9 @@ def update_compute_cost(self, strategy: ShardingStrategy):
'''
Compute the computation cost per device with this specific strategy.
- Note: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ Note: compute_cost need to be divided by TFLOPS, now it just shows the computation size.
'''
- # TODO: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ # TODO: compute_cost need to be divided by TFLOPS, now it just shows the computation size.
# TODO: a constant coefficient need to be added.
sharded_input_shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/normal_pooling_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/normal_pooling_generator.py
index 9df6d2fbfa12..b7db42f8f67e 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/normal_pooling_generator.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/normal_pooling_generator.py
@@ -17,7 +17,7 @@ class NormalPoolStrategyGenerator(StrategyGenerator):
"""
NormalPoolStrategyGenerator is a generic class to generate strategies for pool operation like MaxPoolxd.
The reason we call this normal pool is AvgPoolxd and MaxPoolxd are taking the kernel size element from image,
- and reduce them depening on the operation type.
+ and reduce them depending on the operation type.
"""
def validate(self) -> bool:
@@ -35,9 +35,9 @@ def update_compute_cost(self, strategy: ShardingStrategy) -> TrainCycleItem:
'''
Compute the computation cost per device with this specific strategy.
- Note: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ Note: compute_cost need to be divided by TFLOPS, now it just shows the computation size.
'''
- # TODO: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ # TODO: compute_cost need to be divided by TFLOPS, now it just shows the computation size.
# 1D: (Lout) * N * C * kernel
# 2D: (H * W) * N * Cout * Cin * kernel
# 3D: (H * W * D) * N * Cout * Cin * kernel
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/strategy_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/strategy_generator.py
index 6d68521aaea7..d42429745c61 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/strategy_generator.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/strategy_generator.py
@@ -225,7 +225,7 @@ def _compute_size_in_bytes_helper(sharding_spec, meta_data):
if isinstance(meta_data, torch.Tensor):
element_bytes = _compute_size_in_bytes_helper(sharding_spec, meta_data)
else:
- # if meta_data is not a tensor, we count the memroy as 0
+ # if meta_data is not a tensor, we count the memory as 0
element_bytes = 0
total_bytes += element_bytes
@@ -233,7 +233,7 @@ def _compute_size_in_bytes_helper(sharding_spec, meta_data):
if isinstance(op_data.data, torch.Tensor):
total_bytes = _compute_size_in_bytes_helper(strategy.sharding_specs[op_data], op_data.data)
else:
- # if op_data.data is not a tensor, we count the memroy as 0
+ # if op_data.data is not a tensor, we count the memory as 0
total_bytes = 0
return total_bytes
diff --git a/colossalai/auto_parallel/tensor_shard/solver/cost_graph.py b/colossalai/auto_parallel/tensor_shard/solver/cost_graph.py
index 74290453ca0c..1b2d3ad57407 100644
--- a/colossalai/auto_parallel/tensor_shard/solver/cost_graph.py
+++ b/colossalai/auto_parallel/tensor_shard/solver/cost_graph.py
@@ -9,7 +9,7 @@ class CostGraph:
1. To feed the quadratic resharding costs into solver, we need to linearize it. We build edge_cost in
CostGraph, and it stored every combinations of strategies for a src-dst node pair in an 1D list.
2. To reduce the searching space, we merge computationally-trivial operators, such as
- element-wise operators, transpose, and reduction, into their following nodes. The merging infomation will
+ element-wise operators, transpose, and reduction, into their following nodes. The merging information will
be given by the StrategiesVector depending on the type of target node and following nodes.
Argument:
@@ -90,7 +90,7 @@ def _check_tensor_in_node(data):
if self.simplify and strategies_vector.check_merge():
for followed_node in strategies_vector.predecessor_nodes:
# we only merge node pairs which src node has a tensor element inside.
- # This is necessay because the node without a tensor element inside will not
+ # This is necessary because the node without a tensor element inside will not
# be assigned any strategy.
if _check_tensor_in_node(followed_node._meta_data):
self.merge_pair.append((followed_node, dst_node))
diff --git a/colossalai/auto_parallel/tensor_shard/solver/graph_analysis.py b/colossalai/auto_parallel/tensor_shard/solver/graph_analysis.py
index be39a74cb237..171aa8b3399f 100644
--- a/colossalai/auto_parallel/tensor_shard/solver/graph_analysis.py
+++ b/colossalai/auto_parallel/tensor_shard/solver/graph_analysis.py
@@ -83,7 +83,7 @@ def graph(self) -> Graph:
def liveness_analysis(self) -> List[LiveStage]:
"""
- Analyse the graph to obtain the variable liveness information. This function returns
+ Analyses the graph to obtain the variable liveness information. This function returns
an ordered dictionary where the key is the compute stage ID and the value is a LivenessStage object.
"""
compute_nodes = self.graph.nodes
@@ -91,7 +91,7 @@ def liveness_analysis(self) -> List[LiveStage]:
# checked: record all variables created since the first stage
# all: record the live variables only exist until the current stage.
- # this can be different from the `checked list`` as some varialbes may be destroyed prior to this stage.
+ # this can be different from the `checked list`` as some variables may be destroyed prior to this stage.
# unique: record the unique live variables only exist until the current stage.
# this is different from `all list` as some variables are duplicated.
checked_variables = LiveVariableVector()
@@ -103,7 +103,7 @@ def liveness_analysis(self) -> List[LiveStage]:
# find new living variables #
#############################
# detect whether the current op is an in-place op
- # if it is an in-place op, we would deem it as a duplciate var
+ # if it is an in-place op, we would deem it as a duplicate var
is_inplace = False
if node.op == 'call_function':
# check if this is an inplace op such as torch.nn.functional.relu(x, inplace=True)
diff --git a/colossalai/auto_parallel/tensor_shard/solver/solver.py b/colossalai/auto_parallel/tensor_shard/solver/solver.py
index f5c6663dce80..564c5f09220c 100644
--- a/colossalai/auto_parallel/tensor_shard/solver/solver.py
+++ b/colossalai/auto_parallel/tensor_shard/solver/solver.py
@@ -44,7 +44,7 @@ def __init__(self,
graph: The computing graph to be optimized.
strategies_constructor: It will provide all the possible strategies for each node in the computing graph.
cost_graph: A graph data structure to simplify the edge cost graph.
- graph_analyser: graph_analyser will analyse the graph to obtain the variable liveness information, which will be used to generate memory constraints.
+ graph_analyser: graph_analyser will analyses the graph to obtain the variable liveness information, which will be used to generate memory constraints.
memory_budget: Memory constraint for the solution.
solution_numbers: If solution_numbers is larger than one, solver will us a serious of solutions based on different memory budget.
memory_increasing_coefficient: If solution_numbers is larger than one, we will use this coefficient to generate new memory budget.
diff --git a/colossalai/auto_parallel/tensor_shard/utils/broadcast.py b/colossalai/auto_parallel/tensor_shard/utils/broadcast.py
index 28aa551328d7..307348ea1eaf 100644
--- a/colossalai/auto_parallel/tensor_shard/utils/broadcast.py
+++ b/colossalai/auto_parallel/tensor_shard/utils/broadcast.py
@@ -21,7 +21,7 @@
class BroadcastType(Enum):
EQUAL = auto()
- PADDDING = auto()
+ PADDING = auto()
MULTIPLE = auto()
@@ -69,18 +69,18 @@ def get_broadcast_dim_info(logical_shape, physical_shape):
for i in range(logical_num_dims):
# get the trailing dim size
logical_dim_idx = logical_num_dims - i - 1
- phyiscal_dim_idx = physical_num_dims - i - 1
+ physical_dim_idx = physical_num_dims - i - 1
logical_dim_size = logical_shape[logical_dim_idx]
- if phyiscal_dim_idx >= 0:
- physical_dim_size = physical_shape[phyiscal_dim_idx]
+ if physical_dim_idx >= 0:
+ physical_dim_size = physical_shape[physical_dim_idx]
if physical_dim_size == logical_dim_size:
logical_dim_broadcast_info[logical_dim_idx] = BroadcastType.EQUAL
elif physical_dim_size == 1 and physical_dim_size != logical_dim_size:
logical_dim_broadcast_info[logical_dim_idx] = BroadcastType.MULTIPLE
else:
- logical_dim_broadcast_info[logical_dim_idx] = BroadcastType.PADDDING
+ logical_dim_broadcast_info[logical_dim_idx] = BroadcastType.PADDING
return logical_dim_broadcast_info
@@ -117,7 +117,7 @@ def recover_sharding_spec_for_broadcast_shape(logical_sharding_spec: ShardingSpe
for shape_dim, mesh_dim in logical_dim_partition.items():
logical_broadcast_type = logical_dim_broadcast_info[shape_dim]
- if logical_broadcast_type == BroadcastType.PADDDING or logical_broadcast_type == BroadcastType.MULTIPLE:
+ if logical_broadcast_type == BroadcastType.PADDING or logical_broadcast_type == BroadcastType.MULTIPLE:
removed_dims.extend(mesh_dim)
else:
# get the corresponding physical dim
diff --git a/colossalai/auto_parallel/tensor_shard/utils/factory.py b/colossalai/auto_parallel/tensor_shard/utils/factory.py
index 05331e560001..347c10aa102d 100644
--- a/colossalai/auto_parallel/tensor_shard/utils/factory.py
+++ b/colossalai/auto_parallel/tensor_shard/utils/factory.py
@@ -30,7 +30,7 @@ def generate_sharding_spec(input_: Union[Node, torch.Tensor], device_mesh: Devic
"""
if isinstance(input_, Node):
- assert hasattr(input_, '_meta_data'), f'The given node has no attribte _meta_data'
+ assert hasattr(input_, '_meta_data'), f'The given node has no attribute _meta_data'
meta_tensor = input_._meta_data
assert meta_tensor is not None, "The given node's _meta_data attribute is None"
shape = meta_tensor.shape
diff --git a/colossalai/auto_parallel/tensor_shard/utils/reshape.py b/colossalai/auto_parallel/tensor_shard/utils/reshape.py
index a32a14bf7d57..d0ebbd7e8b1b 100644
--- a/colossalai/auto_parallel/tensor_shard/utils/reshape.py
+++ b/colossalai/auto_parallel/tensor_shard/utils/reshape.py
@@ -6,12 +6,12 @@
class PreviousStatus(Enum):
"""
- This class shows the status of previous comparision.
+ This class shows the status of previous comparison.
"""
RESET = 0
- # ORIGIN means the dimension size of original tensor is larger in the previous comparision.
+ # ORIGIN means the dimension size of original tensor is larger in the previous comparison.
ORIGIN = 1
- # TGT means the dimension size of target tensor is larger in the previous comparision.
+ # TGT means the dimension size of target tensor is larger in the previous comparison.
TGT = 2
@@ -91,7 +91,7 @@ def detect_reshape_mapping(origin_shape: torch.Size, tgt_shape: torch.Size) -> D
tgt_index += 1
if previous_label == PreviousStatus.TGT:
- # if the target dimension size is larger in the previous comparision, which means
+ # if the target dimension size is larger in the previous comparison, which means
# the origin dimension size has already accumulated larger than target dimension size, so
# we need to offload the origin dims and tgt dims into the reshape_mapping_dict.
reshape_mapping_dict[tuple(origin_dims)] = tuple(tgt_dims)
@@ -111,7 +111,7 @@ def detect_reshape_mapping(origin_shape: torch.Size, tgt_shape: torch.Size) -> D
origin_index += 1
if previous_label == PreviousStatus.ORIGIN:
- # if the origin element is larger in the previous comparision, which means
+ # if the origin element is larger in the previous comparison, which means
# the target element has already accumulated larger than origin element, so
# we need to offload the origin dims and tgt dims into the reshape_mapping_dict.
reshape_mapping_dict[tuple(origin_dims)] = tuple(tgt_dims)
@@ -139,7 +139,7 @@ def check_keep_sharding_status(input_dim_partition_dict: Dict[int, List[int]],
Rule:
For a sharded dimension of input tensor, if it is not the minimum element of the input tuple,
the function will return false.
- To illustrate this issue, there are two cases to analyse:
+ To illustrate this issue, there are two cases to analyze:
1. no sharded dims in the input tuple: we could do the reshape operation safely just as the normal
operation without distributed tensor.
2. sharded dims in the input tuple: the sharded dim must be the minimum element, then during shape
diff --git a/colossalai/autochunk/autochunk_codegen.py b/colossalai/autochunk/autochunk_codegen.py
index d0a467254d72..cc98c1570b4a 100644
--- a/colossalai/autochunk/autochunk_codegen.py
+++ b/colossalai/autochunk/autochunk_codegen.py
@@ -40,7 +40,7 @@ def _gen_chunk_slice_dim(chunk_dim: int, chunk_indice_name: str, shape: List) ->
return new_shape
-def _gen_loop_start(chunk_input: List[Node], chunk_output: List[Node], chunk_ouput_dim: int, chunk_size=2) -> str:
+def _gen_loop_start(chunk_input: List[Node], chunk_output: List[Node], chunk_output_dim: int, chunk_size=2) -> str:
"""
Generate chunk loop start
@@ -52,7 +52,7 @@ def _gen_loop_start(chunk_input: List[Node], chunk_output: List[Node], chunk_oup
Args:
chunk_input (List[Node]): chunk input node
chunk_output (Node): chunk output node
- chunk_ouput_dim (int): chunk output node chunk dim
+ chunk_output_dim (int): chunk output node chunk dim
chunk_size (int): chunk size. Defaults to 2.
Returns:
@@ -74,7 +74,7 @@ def _gen_loop_start(chunk_input: List[Node], chunk_output: List[Node], chunk_oup
input_node.name, input_node.name)
out_shape = get_node_shape(chunk_output[0])
- chunk_shape = out_shape[chunk_ouput_dim[0]]
+ chunk_shape = out_shape[chunk_output_dim[0]]
context += "chunk_size = %d\nfor chunk_idx in range(0, %d, chunk_size):\n" % (chunk_size, chunk_shape)
return context
diff --git a/colossalai/autochunk/trace_flow.py b/colossalai/autochunk/trace_flow.py
index db25267e9b42..a1080fda1541 100644
--- a/colossalai/autochunk/trace_flow.py
+++ b/colossalai/autochunk/trace_flow.py
@@ -64,7 +64,7 @@ def check_index_compute(self, start_idx, end_dim, end_node, end_idx):
return False
return True
- def _assgin_single_node_flow(
+ def _assign_single_node_flow(
self,
arg_node: Node,
start_idx: int,
@@ -177,7 +177,7 @@ def _get_all_node_info(self, end_dim, start_idx, end_idx):
if get_node_shape(arg) is None:
continue
arg_list.append(arg)
- flow_flag = self._assgin_single_node_flow(
+ flow_flag = self._assign_single_node_flow(
arg,
start_idx,
end_idx,
@@ -315,7 +315,7 @@ def _get_prepose_nodes(self, all_node_info: Dict, start_idx: int, end_idx: int,
chunk_info["args"]["prepose_nodes"] = prepose_nodes
def _get_non_chunk_inputs(self, chunk_info, start_idx, end_idx):
- # we need to log input nodes to avoid deleteing them in the loop
+ # we need to log input nodes to avoid deleting them in the loop
chunk_node_list = self.node_mgr.get_node_slice_by_idx(start_idx, end_idx + 1)
# also need to get some prepose node's arg out of non_chunk_inputs
for n in chunk_info["args"]["prepose_nodes"]:
@@ -366,8 +366,8 @@ def flow_search(self, start_idx, start_dim, end_idx, end_dim):
# find non chunk inputs
chunk_info = self._get_non_chunk_inputs(chunk_info, start_idx, end_idx)
- # reassgin reshape size, some size may have changed due to chunk
- chunk_info = self._reassgin_reshape_size(chunk_info)
+ # reassign reshape size, some size may have changed due to chunk
+ chunk_info = self._reassign_reshape_size(chunk_info)
return chunk_info
@@ -428,10 +428,10 @@ def _update_chunk_info(self, chunk_info: Dict, new_all_node_info: Dict, output:
chunk_info["outputs_dim"].append(output_dim)
return True
- def _reassgin_reshape_size(self, chunk_info):
+ def _reassign_reshape_size(self, chunk_info):
"""
Some shape args in reshape may have changed due to chunk
- reassgin those changed shape
+ reassign those changed shape
"""
chunk_region = chunk_info["region"]
reshape_size = {}
diff --git a/colossalai/autochunk/trace_indice.py b/colossalai/autochunk/trace_indice.py
index c7fce4c8bee1..fbe0741b8827 100644
--- a/colossalai/autochunk/trace_indice.py
+++ b/colossalai/autochunk/trace_indice.py
@@ -18,7 +18,7 @@ class TraceIndice(object):
dim(x1)=dim(x2)=dim(x3)=[a, b, c]
This class will record every node's dims' indice, compute and source.
- Attibutes:
+ Attributes:
node_list (List)
indice_trace_list (List): [{"indice": [...], "compute": [...], "source": [...]}, {...}]
indice_view_list (Dict): not used for now
@@ -397,7 +397,7 @@ def _assign_conv2d_indice(self, node: Node, node_idx: int) -> None:
input_node = node.args[0]
assert len(get_node_shape(input_node)) == 4
- # assgin index
+ # assign index
self._assign_indice_as_input(node, node_idx, input_node)
self._del_dim(node_idx, 1)
self._add_dim(node_idx, 1)
@@ -415,7 +415,7 @@ def _assign_interpolate_indice(self, node: Node, node_idx: int) -> None:
assert node.kwargs['size'] is None
assert len(get_node_shape(node)) == 4
- # assgin index
+ # assign index
self._assign_indice_as_input(node, node_idx)
self._mark_computation(node, node_idx, [-1, -2])
@@ -461,7 +461,7 @@ def _assign_elementwise_indice(self, node, idx):
nodes_in.append(node_in)
self._inherit_more_indice_from_node_with_exclude(node_in, node)
- def _assgin_no_change_indice(self, node, idx):
+ def _assign_no_change_indice(self, node, idx):
self._assign_indice_as_input(node, idx)
for node_in in node.args:
if type(node_in) == type(node):
@@ -792,7 +792,7 @@ def _assign_view_reshape_indice(self, node: Node, node_idx: int) -> None:
self._add_dim(node_idx, i)
dim_from.reverse()
- # inheirt indice from current node
+ # inherit indice from current node
if len(dim_from) != 0 and len(dim_to) != 0:
if dim_diff == 1:
if origin_shape[dim_from[0]] == 1:
@@ -852,7 +852,7 @@ def trace_indice(self) -> None:
elif "split" == node_name:
self._assign_split_indice(node, idx)
elif any(i == node_name for i in ["to", "contiguous", "clone", "type", "float"]):
- self._assgin_no_change_indice(node, idx)
+ self._assign_no_change_indice(node, idx)
elif "new_ones" == node_name:
self._assign_all_indice(node, idx)
elif "flatten" == node_name:
@@ -914,7 +914,7 @@ def trace_indice(self) -> None:
elif "conv2d" == node_name:
self._assign_conv2d_indice(node, idx)
elif "identity" == node_name:
- self._assgin_no_change_indice(node, idx)
+ self._assign_no_change_indice(node, idx)
elif any(n == node_name for n in ["sigmoid", "dropout", "relu", "silu", "gelu"]):
self._assign_elementwise_indice(node, idx)
else:
diff --git a/colossalai/booster/booster.py b/colossalai/booster/booster.py
index c14e602deaf5..61d912157449 100644
--- a/colossalai/booster/booster.py
+++ b/colossalai/booster/booster.py
@@ -23,27 +23,28 @@ class Booster:
training with different precision, accelerator, and plugin.
Examples:
- >>> colossalai.launch(...)
- >>> plugin = GeminiPlugin(stage=3, ...)
- >>> booster = Booster(precision='fp16', plugin=plugin)
- >>>
- >>> model = GPT2()
- >>> optimizer = Adam(model.parameters())
- >>> dataloader = Dataloader(Dataset)
- >>> lr_scheduler = LinearWarmupScheduler()
- >>> criterion = GPTLMLoss()
- >>>
- >>> model, optimizer, lr_scheduler, dataloader = booster.boost(model, optimizer, lr_scheduler, dataloader)
- >>>
- >>> for epoch in range(max_epochs):
- >>> for input_ids, attention_mask in dataloader:
- >>> outputs = model(input_ids, attention_mask)
- >>> loss = criterion(outputs.logits, input_ids)
- >>> booster.backward(loss, optimizer)
- >>> optimizer.step()
- >>> lr_scheduler.step()
- >>> optimizer.zero_grad()
-
+ ```python
+ colossalai.launch(...)
+ plugin = GeminiPlugin(stage=3, ...)
+ booster = Booster(precision='fp16', plugin=plugin)
+
+ model = GPT2()
+ optimizer = Adam(model.parameters())
+ dataloader = Dataloader(Dataset)
+ lr_scheduler = LinearWarmupScheduler()
+ criterion = GPTLMLoss()
+
+ model, optimizer, lr_scheduler, dataloader = booster.boost(model, optimizer, lr_scheduler, dataloader)
+
+ for epoch in range(max_epochs):
+ for input_ids, attention_mask in dataloader:
+ outputs = model(input_ids, attention_mask)
+ loss = criterion(outputs.logits, input_ids)
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ ```
Args:
device (str or torch.device): The device to run the training. Default: 'cuda'.
@@ -130,6 +131,12 @@ def boost(
return model, optimizer, criterion, dataloader, lr_scheduler
def backward(self, loss: torch.Tensor, optimizer: Optimizer) -> None:
+ """Backward pass.
+
+ Args:
+ loss (torch.Tensor): The loss to be backpropagated.
+ optimizer (Optimizer): The optimizer to be updated.
+ """
# TODO: implement this method with plugin
optimizer.backward(loss)
@@ -146,11 +153,29 @@ def execute_pipeline(self,
pass
def no_sync(self, model: nn.Module) -> contextmanager:
+ """Context manager to disable gradient synchronization across DP process groups.
+
+ Args:
+ model (nn.Module): The model to be disabled gradient synchronization.
+
+ Returns:
+ contextmanager: Context to disable gradient synchronization.
+ """
assert self.plugin is not None, f'no_sync is only enabled when a plugin is provided and the plugin supports no_sync.'
assert self.plugin.support_no_sync, f'The plugin {self.plugin.__class__.__name__} does not support no_sync.'
return self.plugin.no_sync(model)
def load_model(self, model: nn.Module, checkpoint: str, strict: bool = True):
+ """Load model from checkpoint.
+
+ Args:
+ model (nn.Module): A model boosted by Booster.
+ checkpoint (str): Path to the checkpoint. It must be a local path.
+ It should be a directory path if the checkpoint is sharded. Otherwise, it should be a file path.
+ strict (bool, optional): whether to strictly enforce that the keys
+ in :attr:`state_dict` match the keys returned by this module's
+ :meth:`~torch.nn.Module.state_dict` function. Defaults to True.
+ """
self.checkpoint_io.load_model(model, checkpoint, strict)
def save_model(self,
@@ -159,16 +184,58 @@ def save_model(self,
prefix: str = None,
shard: bool = False,
size_per_shard: int = 1024):
- self.checkpoint_io.save_model(model, checkpoint, prefix, shard, size_per_shard)
+ """Save model to checkpoint.
+
+ Args:
+ model (nn.Module): A model boosted by Booster.
+ checkpoint (str): Path to the checkpoint. It must be a local path.
+ It is a file path if ``shard=False``. Otherwise, it is a directory path.
+ prefix (str, optional): A prefix added to parameter and buffer
+ names to compose the keys in state_dict. Defaults to None.
+ shard (bool, optional): Whether to save checkpoint a sharded way.
+ If true, the checkpoint will be a folder. Otherwise, it will be a single file. Defaults to False.
+ size_per_shard (int, optional): Maximum size of checkpoint shard file in MB. This is useful only when ``shard=True``. Defaults to 1024.
+ """
+ self.checkpoint_io.save_model(model, checkpoint=checkpoint, shard=shard, size_per_shard=size_per_shard)
def load_optimizer(self, optimizer: Optimizer, checkpoint: str):
+ """Load optimizer from checkpoint.
+
+ Args:
+ optimizer (Optimizer): An optimizer boosted by Booster.
+ checkpoint (str): Path to the checkpoint. It must be a local path.
+ It should be a directory path if the checkpoint is sharded. Otherwise, it should be a file path.
+ """
self.checkpoint_io.load_optimizer(optimizer, checkpoint)
def save_optimizer(self, optimizer: Optimizer, checkpoint: str, shard: bool = False, size_per_shard: int = 1024):
+ """Save optimizer to checkpoint.
+ Warning: Saving sharded optimizer checkpoint is not supported yet.
+
+ Args:
+ optimizer (Optimizer): An optimizer boosted by Booster.
+ checkpoint (str): Path to the checkpoint. It must be a local path.
+ It is a file path if ``shard=False``. Otherwise, it is a directory path.
+ shard (bool, optional): Whether to save checkpoint a sharded way.
+ If true, the checkpoint will be a folder. Otherwise, it will be a single file. Defaults to False.
+ size_per_shard (int, optional): Maximum size of checkpoint shard file in MB. This is useful only when ``shard=True``. Defaults to 1024.
+ """
self.checkpoint_io.save_optimizer(optimizer, checkpoint, shard, size_per_shard)
def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ """Save lr scheduler to checkpoint.
+
+ Args:
+ lr_scheduler (LRScheduler): A lr scheduler boosted by Booster.
+ checkpoint (str): Path to the checkpoint. It must be a local file path.
+ """
self.checkpoint_io.save_lr_scheduler(lr_scheduler, checkpoint)
def load_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ """Load lr scheduler from checkpoint.
+
+ Args:
+ lr_scheduler (LRScheduler): A lr scheduler boosted by Booster.
+ checkpoint (str): Path to the checkpoint. It must be a local file path.
+ """
self.checkpoint_io.load_lr_scheduler(lr_scheduler, checkpoint)
diff --git a/colossalai/booster/mixed_precision/__init__.py b/colossalai/booster/mixed_precision/__init__.py
index 3cf0ad28cdbe..0df9d84159f9 100644
--- a/colossalai/booster/mixed_precision/__init__.py
+++ b/colossalai/booster/mixed_precision/__init__.py
@@ -1,17 +1,19 @@
from .bf16 import BF16MixedPrecision
from .fp8 import FP8MixedPrecision
from .fp16_apex import FP16ApexMixedPrecision
+from .fp16_naive import FP16NaiveMixedPrecision
from .fp16_torch import FP16TorchMixedPrecision
from .mixed_precision_base import MixedPrecision
__all__ = [
'MixedPrecision', 'mixed_precision_factory', 'FP16_Apex_MixedPrecision', 'FP16_Torch_MixedPrecision',
- 'FP32_MixedPrecision', 'BF16_MixedPrecision', 'FP8_MixedPrecision'
+ 'FP32_MixedPrecision', 'BF16_MixedPrecision', 'FP8_MixedPrecision', 'FP16NaiveMixedPrecision'
]
_mixed_precision_mapping = {
'fp16': FP16TorchMixedPrecision,
'fp16_apex': FP16ApexMixedPrecision,
+ 'fp16_naive': FP16NaiveMixedPrecision,
'bf16': BF16MixedPrecision,
'fp8': FP8MixedPrecision
}
diff --git a/colossalai/booster/mixed_precision/fp16_apex.py b/colossalai/booster/mixed_precision/fp16_apex.py
index 266a750734b1..e184271e932a 100644
--- a/colossalai/booster/mixed_precision/fp16_apex.py
+++ b/colossalai/booster/mixed_precision/fp16_apex.py
@@ -1,5 +1,38 @@
+from typing import Any, Optional, Union
+
+import torch
+
from .mixed_precision_base import MixedPrecision
class FP16ApexMixedPrecision(MixedPrecision):
- pass
+ """
+ Precision for mixed precision training in FP16 using apex AMP.
+
+ Args:
+ opt_level(str, optional, default="O1" ): Pure or mixed precision optimization level. Accepted values are “O0”, “O1”, “O2”, and “O3”, explained in detail above Apex AMP Documentation.
+ cast_model_type (torch.dtype, optional, default=None): Casts your model’s parameters and buffers to the desired type.
+ patch_torch_functions (bool, optional, default=None): Patch all Torch functions and Tensor methods to perform Tensor Core-friendly ops like GEMMs and convolutions in FP16, and any ops that benefit from FP32 precision in FP32.
+ keep_batchnorm_fp32 (bool or str, optional, default=None): To enhance precision and enable cudnn batchnorm (which improves performance), it’s often beneficial to keep batchnorm weights in FP32 even if the rest of the model is FP16.
+ master_weights (bool, optional, default=None): Maintain FP32 master weights to accompany any FP16 model weights. FP32 master weights are stepped by the optimizer to enhance precision and capture small gradients.
+ loss_scale (float or str, optional, default=None): If loss_scale is a float value, use this value as the static (fixed) loss scale. If loss_scale is the string "dynamic", adaptively adjust the loss scale over time. Dynamic loss scale adjustments are performed by Amp automatically.
+ cast_model_outputs (torch.dpython:type, optional, default=None): Option to ensure that the outputs of your model(s) are always cast to a particular type regardless of opt_level.
+ num_losses(int, optional, default=1): Option to tell AMP in advance how many losses/backward passes you plan to use. When used in conjunction with the loss_id argument to `amp.scale_loss`, enables Amp to use a different loss scale per loss/backward pass, which can improve stability. If num_losses is left to 1, Amp will still support multiple losses/backward passes, but use a single global loss scale for all of them.
+ verbosity(int, default=1): Set to 0 to suppress Amp-related output.
+ min_loss_scale(float, default=None): Sets a floor for the loss scale values that can be chosen by dynamic loss scaling. The default value of None means that no floor is imposed. If dynamic loss scaling is not used, min_loss_scale is ignored.
+ max_loss_scale(float, default=2.**24 ): Sets a ceiling for the loss scale values that can be chosen by dynamic loss scaling. If dynamic loss scaling is not used, max_loss_scale is ignored.
+ """
+
+ def __init__(self,
+ opt_level: Optional[str] = "O1",
+ cast_model_type: torch.dtype = None,
+ patch_torch_functions: bool = None,
+ keep_batchnorm_fp32: Union[bool, str] = None,
+ master_weights: bool = None,
+ loss_scale: Union[float, str] = None,
+ cast_model_outputs: Any = None,
+ num_losses: Optional[int] = 1,
+ verbosity: int = 1,
+ min_loss_scale: float = None,
+ max_loss_scale: float = 2.**24) -> None:
+ pass
diff --git a/colossalai/booster/mixed_precision/fp16_naive.py b/colossalai/booster/mixed_precision/fp16_naive.py
new file mode 100644
index 000000000000..5d0d815257f3
--- /dev/null
+++ b/colossalai/booster/mixed_precision/fp16_naive.py
@@ -0,0 +1,26 @@
+from .mixed_precision_base import MixedPrecision
+
+
+class FP16NaiveMixedPrecision(MixedPrecision):
+ """
+ Precision for mixed precision training in FP16 using naive AMP.
+
+ Args:
+ log_num_zeros_in_grad(bool): return number of zeros in the gradients.
+ initial_scale(int): initial scale of gradient scaler.
+ growth_factor(int): the growth rate of loss scale.
+ backoff_factor(float): the decrease rate of loss scale.
+ hysteresis(int): delay shift in dynamic loss scaling.
+ max_scale(int): maximum loss scale allowed.
+ verbose(bool): if set to `True`, will print debug info.
+ """
+
+ def __init__(self,
+ log_num_zeros_in_grad: bool,
+ initial_scale: int,
+ growth_factor: int,
+ backoff_factor: float,
+ hysteresis: int,
+ max_scale: int,
+ verbose: bool = None) -> None:
+ pass
diff --git a/colossalai/booster/plugin/__init__.py b/colossalai/booster/plugin/__init__.py
index aa45bcb59ad7..a3b87b5f11d3 100644
--- a/colossalai/booster/plugin/__init__.py
+++ b/colossalai/booster/plugin/__init__.py
@@ -4,3 +4,10 @@
from .torch_ddp_plugin import TorchDDPPlugin
__all__ = ['Plugin', 'TorchDDPPlugin', 'GeminiPlugin', 'LowLevelZeroPlugin']
+
+import torch
+from packaging import version
+
+if version.parse(torch.__version__) >= version.parse('1.12.0'):
+ from .torch_fsdp_plugin import TorchFSDPPlugin
+ __all__.append('TorchFSDPPlugin')
diff --git a/colossalai/booster/plugin/gemini_plugin.py b/colossalai/booster/plugin/gemini_plugin.py
index a3789a39d94b..adbf4803eefe 100644
--- a/colossalai/booster/plugin/gemini_plugin.py
+++ b/colossalai/booster/plugin/gemini_plugin.py
@@ -52,8 +52,16 @@ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather
Save optimizer to checkpoint but only on master process.
"""
# TODO(ver217): optimizer state dict is sharded
+ warnings.warn('GeminiPlugin does not support save full optimizer checkpoint now. Save it on every process.')
+ checkpoint = f'{checkpoint}.rank{self.coordinator.rank}'
super().save_unsharded_optimizer(optimizer, checkpoint, gather_dtensor)
+ def load_optimizer(self, optimizer: Optimizer, checkpoint: str):
+ warnings.warn(
+ 'GeminiPlugin can only load optimizer checkpoint saved by itself with the same number of processes.')
+ checkpoint = f'{checkpoint}.rank{self.coordinator.rank}'
+ super().load_optimizer(optimizer, checkpoint)
+
def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
"""
Save model to checkpoint but only on master process.
@@ -171,7 +179,7 @@ class GeminiPlugin(DPPluginBase):
Users can provide this argument to speed up searching.
If users do not know this argument before training, it is ok. We will use a default value 1024.
min_chunk_size_mb (float, optional): the minimum chunk size in MegaByte.
- If the aggregate size of parameters is still samller than the minimum chunk size,
+ If the aggregate size of parameters is still smaller than the minimum chunk size,
all parameters will be compacted into one small chunk.
memstats (MemStats, optional) the memory statistics collector by a runtime memory tracer.
gpu_margin_mem_ratio (float, optional): The ratio of GPU remaining memory (after the first forward-backward)
diff --git a/colossalai/booster/plugin/low_level_zero_plugin.py b/colossalai/booster/plugin/low_level_zero_plugin.py
index edc0b7679686..5d93cf0e33be 100644
--- a/colossalai/booster/plugin/low_level_zero_plugin.py
+++ b/colossalai/booster/plugin/low_level_zero_plugin.py
@@ -9,7 +9,7 @@
from torch.utils._pytree import tree_map
from torch.utils.data import DataLoader
-from colossalai.checkpoint_io import CheckpointIO
+from colossalai.checkpoint_io import CheckpointIO, GeneralCheckpointIO
from colossalai.interface import ModelWrapper, OptimizerWrapper
from colossalai.utils import get_current_device
from colossalai.zero import zero_model_wrapper, zero_optim_wrapper
@@ -32,8 +32,17 @@ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather
"""
Save optimizer to checkpoint but only on master process.
"""
- # TODO(ver217): optimizer state dict is sharded
- super().save_unsharded_optimizer(optimizer, checkpoint, gather_dtensor)
+ # TODO(ver217): optimizer state dict is sharded, and cannot get full state dict now
+ warnings.warn(
+ 'LowLevelZeroPlugin does not support save full optimizer checkpoint now. Save it on every process.')
+ checkpoint = f'{checkpoint}.rank{self.coordinator.rank}'
+ GeneralCheckpointIO.save_unsharded_optimizer(self, optimizer, checkpoint, gather_dtensor)
+
+ def load_optimizer(self, optimizer: Optimizer, checkpoint: str):
+ warnings.warn(
+ 'LowLevelZeroPlugin can only load optimizer checkpoint saved by itself with the same number of processes.')
+ checkpoint = f'{checkpoint}.rank{self.coordinator.rank}'
+ super().load_optimizer(optimizer, checkpoint)
class LowLevelZeroModel(ModelWrapper):
diff --git a/colossalai/booster/plugin/torch_ddp_plugin.py b/colossalai/booster/plugin/torch_ddp_plugin.py
index 99cd2f7791d3..b317ccf48ad9 100644
--- a/colossalai/booster/plugin/torch_ddp_plugin.py
+++ b/colossalai/booster/plugin/torch_ddp_plugin.py
@@ -1,4 +1,4 @@
-from typing import Callable, Iterator, List, Tuple, Union
+from typing import Callable, Iterator, List, Optional, Tuple, Union
import torch.nn as nn
from torch.nn.parallel import DistributedDataParallel as DDP
@@ -50,6 +50,16 @@ def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
if self.coordinator.is_master():
super().save_lr_scheduler(lr_scheduler, checkpoint)
+ def save_sharded_model(self,
+ model: nn.Module,
+ checkpoint_path: str,
+ gather_dtensor: bool = False,
+ variant: Optional[str] = None,
+ max_shard_size: int = 1024,
+ use_safetensors: bool = False):
+ if self.coordinator.is_master():
+ super().save_sharded_model(model, checkpoint_path, gather_dtensor, variant, max_shard_size, use_safetensors)
+
class TorchDDPModel(ModelWrapper):
diff --git a/colossalai/booster/plugin/torch_fsdp_plugin.py b/colossalai/booster/plugin/torch_fsdp_plugin.py
new file mode 100644
index 000000000000..8d534ea4c061
--- /dev/null
+++ b/colossalai/booster/plugin/torch_fsdp_plugin.py
@@ -0,0 +1,221 @@
+from pathlib import Path
+from typing import Callable, Iterable, Iterator, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import warnings
+from packaging import version
+from torch.distributed import ProcessGroup
+
+if version.parse(torch.__version__) >= version.parse('1.12.0'):
+ from torch.distributed.fsdp import FullStateDictConfig
+ from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
+ from torch.distributed.fsdp import StateDictType
+ from torch.distributed.fsdp.fully_sharded_data_parallel import (
+ BackwardPrefetch,
+ CPUOffload,
+ FullStateDictConfig,
+ MixedPrecision,
+ ShardingStrategy,
+ )
+else:
+ raise RuntimeError("FSDP is not supported while torch version under 1.12.0.")
+
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
+from torch.utils.data import DataLoader
+
+from colossalai.checkpoint_io import CheckpointIO, GeneralCheckpointIO, utils
+from colossalai.cluster import DistCoordinator
+from colossalai.interface import ModelWrapper, OptimizerWrapper
+
+from .dp_plugin_base import DPPluginBase
+
+__all__ = ['TorchFSDPPlugin']
+
+
+class TorchFSDPCheckpointIO(GeneralCheckpointIO):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.coordinator = DistCoordinator()
+
+ def load_unsharded_model(self, model: nn.Module, checkpoint: str, strict: bool):
+ checkpoint = utils.load_state_dict(checkpoint)
+ model.load_state_dict(checkpoint)
+
+ def load_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: Path):
+ checkpoint = utils.load_state_dict(checkpoint)
+ fsdp_model = optimizer.unwrap_model()
+ sharded_osd = FSDP.scatter_full_optim_state_dict(checkpoint, fsdp_model)
+ optimizer.load_state_dict(sharded_osd)
+
+ def save_unsharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, use_safetensors: bool):
+ """
+ Save model to checkpoint but only on master process.
+ """
+ # the model should be unwrapped in self.load_model via ModelWrapper.unwrap
+ cfg = FullStateDictConfig(offload_to_cpu=True, rank0_only=True)
+ with FSDP.state_dict_type(model, StateDictType.FULL_STATE_DICT, cfg):
+ full_model_state = model.state_dict()
+ utils.save_state_dict(full_model_state, checkpoint_file_path=checkpoint, use_safetensors=use_safetensors)
+
+ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather_dtensor: bool):
+ """
+ Save optimizer to checkpoint but only on master process.
+ """
+ assert isinstance(optimizer, FSDPOptimizerWrapper)
+ fsdp_model = optimizer.unwrap_model()
+ full_optimizer_state = FSDP.full_optim_state_dict(fsdp_model, optim=optimizer, rank0_only=True)
+ utils.save_state_dict(full_optimizer_state, checkpoint_file_path=checkpoint, use_safetensors=False)
+
+ def save_sharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, variant: Optional[str],
+ size_per_shard: int, use_safetensors: bool):
+ """
+ Save model to checkpoint but only on master process.
+ """
+ raise NotImplementedError("Sharded model checkpoint is not supported yet.")
+
+ def load_sharded_model(self,
+ model: nn.Module,
+ checkpoint_index_file: Path,
+ strict: bool = False,
+ use_safetensors: bool = False,
+ load_sub_module: bool = True):
+ """
+ Load model to checkpoint but only on master process.
+ """
+ raise NotImplementedError("Sharded model checkpoint is not supported yet.")
+
+ def save_sharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather_dtensor: bool):
+ """
+ Save optimizer to checkpoint but only on master process.
+ """
+ raise NotImplementedError("Sharded optimizer checkpoint is not supported yet.")
+
+ def load_sharded_optimizer(self, optimizer: Optimizer, index_file_path: str, prefix: str, size_per_shard: int):
+ """
+ Load optimizer to checkpoint but only on master process.
+ """
+ raise NotImplementedError("Sharded optimizer checkpoint is not supported yet.")
+
+ def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ """
+ Save model to checkpoint but only on master process.
+ """
+ if self.coordinator.is_master():
+ super().save_lr_scheduler(lr_scheduler, checkpoint)
+
+
+class TorchFSDPModel(ModelWrapper):
+
+ def __init__(self, module: nn.Module, *args, **kwargs) -> None:
+ super().__init__(module)
+ self.module = FSDP(module, *args, **kwargs)
+
+ def unwrap(self):
+ return self.module
+
+
+class FSDPOptimizerWrapper(OptimizerWrapper):
+
+ def __init__(self, optimizer: Optimizer, model: nn.Module):
+ self.model = model
+ super().__init__(optimizer)
+
+ def unwrap_model(self) -> nn.Module:
+ return self.model
+
+
+class TorchFSDPPlugin(DPPluginBase):
+ """
+ Plugin for PyTorch FSDP.
+
+ Example:
+ >>> from colossalai.booster import Booster
+ >>> from colossalai.booster.plugin import TorchFSDPPlugin
+ >>>
+ >>> model, train_dataset, optimizer, criterion = ...
+ >>> plugin = TorchFSDPPlugin()
+
+ >>> train_dataloader = plugin.prepare_train_dataloader(train_dataset, batch_size=8)
+ >>> booster = Booster(plugin=plugin)
+ >>> model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
+
+ Args:
+ See https://pytorch.org/docs/stable/fsdp.html for details.
+ """
+
+ if version.parse(torch.__version__) >= version.parse('1.12.0'):
+
+ def __init__(
+ self,
+ process_group: Optional[ProcessGroup] = None,
+ sharding_strategy: Optional[ShardingStrategy] = None,
+ cpu_offload: Optional[CPUOffload] = None,
+ auto_wrap_policy: Optional[Callable] = None,
+ backward_prefetch: Optional[BackwardPrefetch] = None,
+ mixed_precision: Optional[MixedPrecision] = None,
+ ignored_modules: Optional[Iterable[torch.nn.Module]] = None,
+ param_init_fn: Optional[Callable[[nn.Module], None]] = None,
+ sync_module_states: bool = False,
+ ):
+ super().__init__()
+ self.fsdp_kwargs = dict(process_group=process_group,
+ sharding_strategy=sharding_strategy,
+ cpu_offload=cpu_offload,
+ auto_wrap_policy=auto_wrap_policy,
+ backward_prefetch=backward_prefetch,
+ mixed_precision=mixed_precision,
+ ignored_modules=ignored_modules,
+ param_init_fn=param_init_fn,
+ sync_module_states=sync_module_states)
+ else:
+ raise RuntimeError("FSDP is not supported while torch version under 1.12.0.")
+
+ def support_no_sync(self) -> bool:
+ False
+
+ def no_sync(self, model: nn.Module) -> Iterator[None]:
+ raise NotImplementedError("Torch fsdp no_sync func not supported yet.")
+
+ def control_precision(self) -> bool:
+ return True
+
+ def supported_precisions(self) -> List[str]:
+ return ['fp16', 'bf16']
+
+ def control_device(self) -> bool:
+ return True
+
+ def supported_devices(self) -> List[str]:
+ return ['cuda']
+
+ def configure(
+ self,
+ model: nn.Module,
+ optimizer: Optimizer,
+ criterion: Callable = None,
+ dataloader: DataLoader = None,
+ lr_scheduler: LRScheduler = None,
+ ) -> Tuple[Union[nn.Module, OptimizerWrapper, LRScheduler, DataLoader]]:
+
+ # wrap the model with PyTorch FSDP
+ fsdp_model = TorchFSDPModel(model, device_id=torch.cuda.current_device(), **self.fsdp_kwargs)
+
+ if len(optimizer.param_groups) > 1:
+ warnings.warn(
+ 'TorchFSDPPlugin does not support optimizer that use multi param groups. The results may not be as expected if used.'
+ )
+ optimizer.__init__(fsdp_model.parameters(), **optimizer.defaults)
+
+ if not isinstance(optimizer, FSDPOptimizerWrapper):
+ optimizer = FSDPOptimizerWrapper(optimizer, fsdp_model)
+
+ return fsdp_model, optimizer, criterion, dataloader, lr_scheduler
+
+ def control_checkpoint_io(self) -> bool:
+ return True
+
+ def get_checkpoint_io(self) -> CheckpointIO:
+ return TorchFSDPCheckpointIO()
diff --git a/colossalai/checkpoint_io/checkpoint_io_base.py b/colossalai/checkpoint_io/checkpoint_io_base.py
index 9cf344ecc41b..fbc8fc5429ad 100644
--- a/colossalai/checkpoint_io/checkpoint_io_base.py
+++ b/colossalai/checkpoint_io/checkpoint_io_base.py
@@ -1,7 +1,6 @@
from abc import ABC, abstractmethod
from pathlib import Path
-from typing import Union
-from typing import Optional
+from typing import Optional, Union
import torch
import torch.nn as nn
@@ -84,9 +83,8 @@ def load_model(self,
# containing no distributed tensors, dtensor -> full tensor conversion
# should be done offline via our CLI
# the existence of index file means it is a sharded checkpoint
- ckpt_path = Path(checkpoint)
index_file_exists, index_file_path = has_index_file(checkpoint)
-
+
# return the origin model instead of the unwrapped model
origin_model = model
diff --git a/colossalai/checkpoint_io/general_checkpoint_io.py b/colossalai/checkpoint_io/general_checkpoint_io.py
index 96a883fdb42a..2cc9c3faa12b 100644
--- a/colossalai/checkpoint_io/general_checkpoint_io.py
+++ b/colossalai/checkpoint_io/general_checkpoint_io.py
@@ -1,26 +1,26 @@
-from pathlib import Path
+import gc
+import logging
+import os
from functools import reduce
+from pathlib import Path
+from typing import Iterator, Optional, OrderedDict, Tuple
import torch.nn as nn
from torch.optim import Optimizer
-import logging
-import os
-import gc
-from typing import Optional, Iterator, OrderedDict, Tuple
from .checkpoint_io_base import CheckpointIO
from .index_file import CheckpointIndexFile
from .utils import (
- has_index_file,
- load_state_dict,
- save_state_dict,
+ get_base_filenames,
+ get_shard_filename,
+ has_index_file,
is_safetensors_available,
- shard_checkpoint,
load_shard_state_dict,
+ load_state_dict,
load_state_dict_into_model,
- get_shard_filename,
- get_base_filenames
- )
+ save_state_dict,
+ shard_checkpoint,
+)
__all__ = ['GeneralCheckpointIO']
@@ -29,6 +29,7 @@ class GeneralCheckpointIO(CheckpointIO):
"""
Checkpoint IO
"""
+
def load_unsharded_model(self, model: nn.Module, checkpoint: str, strict: bool):
checkpoint = load_state_dict(checkpoint)
model.load_state_dict(checkpoint, strict=strict)
@@ -69,19 +70,23 @@ def save_unsharded_optimizer(
# TODO(FrankLeeeee): handle distributed tensors
save_state_dict(optimizer.state_dict(), checkpoint, use_safetensors=False)
-
- def save_sharded_model(self, model: nn.Module, checkpoint_path: str, gather_dtensor:bool = False,
- variant: Optional[str] = None, max_shard_size: int = 1024, use_safetensors: bool = False):
- """
+ def save_sharded_model(self,
+ model: nn.Module,
+ checkpoint_path: str,
+ gather_dtensor: bool = False,
+ variant: Optional[str] = None,
+ max_shard_size: int = 1024,
+ use_safetensors: bool = False):
+ """
implement this method as it can be supported by Huggingface model,
save shard model, save model to multiple files
"""
if os.path.isfile(checkpoint_path):
logging.error(f"Provided path ({checkpoint_path}) should be a directory, not a file")
return
-
+
Path(checkpoint_path).mkdir(parents=True, exist_ok=True)
-
+
# shard checkpoint
state_dict = model.state_dict()
state_dict_shard = shard_checkpoint(state_dict, max_shard_size=max_shard_size)
@@ -95,21 +100,22 @@ def save_sharded_model(self, model: nn.Module, checkpoint_path: str, gather_dten
total_size = total_size + shard_pair[1]
for key in shard.keys():
index_file.append_weight_map(key, shard_file)
-
+
checkpoint_file_path = os.path.join(checkpoint_path, shard_file)
save_state_dict(shard, checkpoint_file_path, use_safetensors)
-
+
index_file.append_meta_data("total_size", total_size)
index_file.write_index_file(save_index_file)
- logging.info(
- f"The model is going to be split to checkpoint shards. "
- f"You can find where each parameters has been saved in the "
- f"index located at {save_index_file}."
- )
-
-
- def load_sharded_model(self, model: nn.Module, checkpoint_index_file: Path, strict: bool = False,
- use_safetensors: bool = False, load_sub_module: bool = True):
+ logging.info(f"The model is going to be split to checkpoint shards. "
+ f"You can find where each parameters has been saved in the "
+ f"index located at {save_index_file}.")
+
+ def load_sharded_model(self,
+ model: nn.Module,
+ checkpoint_index_file: Path,
+ strict: bool = False,
+ use_safetensors: bool = False,
+ load_sub_module: bool = True):
"""
load shard model, load model from multiple files
"""
@@ -119,7 +125,7 @@ def load_sharded_model(self, model: nn.Module, checkpoint_index_file: Path, stri
if use_safetensors and not is_safetensors_available():
raise ImportError("`safe_serialization` requires the `safetensors` library: `pip install safetensors`.")
-
+
# read checkpoint index file
ckpt_index_file = CheckpointIndexFile.from_file(checkpoint_index_file)
checkpoint_files, _ = ckpt_index_file.get_checkpoint_fileanames()
@@ -134,10 +140,7 @@ def load_sharded_model(self, model: nn.Module, checkpoint_index_file: Path, stri
if strict:
remain_keys = reduce(lambda a, b: a & b, map(set, missing_keys))
if len(remain_keys) > 0:
- error_msgs = 'Missing key(s) in state_dict: {}. '.format(
- ', '.join('"{}"'.format(k) for k in missing_keys))
+ error_msgs = 'Missing key(s) in state_dict: {}. '.format(', '.join(
+ '"{}"'.format(k) for k in missing_keys))
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
- self.__class__.__name__, "\n\t".join(error_msgs)))
-
-
-
+ self.__class__.__name__, "\n\t".join(error_msgs)))
diff --git a/colossalai/checkpoint_io/index_file.py b/colossalai/checkpoint_io/index_file.py
index 15a6d09f3b5e..334ecbc04738 100644
--- a/colossalai/checkpoint_io/index_file.py
+++ b/colossalai/checkpoint_io/index_file.py
@@ -159,7 +159,7 @@ def get_all_param_names(self):
def write_index_file(self, save_index_file):
"""
- Wriete index file.
+ Write index file.
"""
save_index_file = os.path.join(self.root_path, save_index_file)
index = {"metadata": self.metadata, "weight_map": self.weight_map}
diff --git a/colossalai/checkpoint_io/utils.py b/colossalai/checkpoint_io/utils.py
index 16e41631f0d5..435feda4ac6a 100644
--- a/colossalai/checkpoint_io/utils.py
+++ b/colossalai/checkpoint_io/utils.py
@@ -1,10 +1,12 @@
# coding=utf-8
+import re
from pathlib import Path
+from typing import Iterator, List, Mapping, Optional, OrderedDict, Tuple
+
import torch
import torch.nn as nn
-from typing import List, Mapping, OrderedDict, Optional, Tuple, Iterator
+
from colossalai.tensor.d_tensor.d_tensor import DTensor
-import re
SAFE_WEIGHTS_NAME = "model.safetensors"
WEIGHTS_NAME = "pytorch_model.bin"
@@ -15,19 +17,21 @@
# General helper functions
# ======================================
+
def calculate_tensor_size(tensor: torch.Tensor) -> float:
"""
Calculate the size of a parameter in MB. Used to compute whether a group of params exceed the shard size.
If so, a new shard should be created.
Args:
- tenosr (torch.Tensor): the tensor to calculate size for.
+ tensor (torch.Tensor): the tensor to calculate size for.
Returns:
float: size of the tensor in MB.
"""
return tensor.numel() * tensor.element_size() / 1024 / 1024
+
def is_safetensors_available() -> bool:
"""
Check whether safetensors is available.
@@ -78,7 +82,6 @@ def is_safetensor_checkpoint(checkpoint_file_path: str) -> bool:
# Helper functions for saving shard file
# ======================================
def shard_checkpoint(state_dict: torch.Tensor, max_shard_size: int = 1024) -> Iterator[Tuple[OrderedDict, int]]:
-
"""
Splits a model state dictionary in sub-checkpoints so that the final size of each sub-checkpoint does not exceed a
given size.
@@ -100,35 +103,39 @@ def shard_checkpoint(state_dict: torch.Tensor, max_shard_size: int = 1024) -> It
current_block_size = 0
current_block[key] = weight
current_block_size += weight_size
-
+
if ret_block != None:
yield ret_block, ret_block_size
yield current_block, current_block_size
-def load_shard_state_dict(checkpoint_file: Path, use_safetensors: bool =False):
+def load_shard_state_dict(checkpoint_file: Path, use_safetensors: bool = False):
"""
load shard state dict into model
"""
if use_safetensors and not checkpoint_file.suffix == ".safetensors":
raise Exception("load the model using `safetensors`, but no file endwith .safetensors")
if use_safetensors:
- from safetensors.torch import safe_open
from safetensors.torch import load_file as safe_load_file
+ from safetensors.torch import safe_open
with safe_open(checkpoint_file, framework="pt") as f:
metadata = f.metadata()
if metadata["format"] != "pt":
raise NotImplementedError(
- f"Conversion from a {metadata['format']} safetensors archive to PyTorch is not implemented yet."
- )
+ f"Conversion from a {metadata['format']} safetensors archive to PyTorch is not implemented yet.")
return safe_load_file(checkpoint_file)
else:
return torch.load(checkpoint_file)
-
-def load_state_dict_into_model(model: nn.Module, state_dict: torch.Tensor, missing_keys: List, strict: bool = False, load_sub_module: bool = True):
+
+
+def load_state_dict_into_model(model: nn.Module,
+ state_dict: torch.Tensor,
+ missing_keys: List,
+ strict: bool = False,
+ load_sub_module: bool = True):
r"""Copies parameters and buffers from :attr:`state_dict` into
- this module and its descendants.
+ this module and its descendants.
Args:
state_dict (dict): a dict containing parameters and
@@ -166,11 +173,12 @@ def load(module: nn.Module, state_dict, prefix="", load_sub_module: bool = True)
if strict:
if len(unexpected_keys) > 0:
- error_msgs = 'Unexpected key(s) in state_dict: {}. '.format(
- ', '.join('"{}"'.format(k) for k in unexpected_keys))
+ error_msgs = 'Unexpected key(s) in state_dict: {}. '.format(', '.join(
+ '"{}"'.format(k) for k in unexpected_keys))
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
- model.__class__.__name__, "\n\t".join(error_msgs)))
-
+ model.__class__.__name__, "\n\t".join(error_msgs)))
+
+
# ======================================
# Helper functions for saving state dict
# ======================================
@@ -350,6 +358,8 @@ def has_index_file(checkpoint_path: str) -> Tuple[bool, Optional[Path]]:
return True, index_files[0]
else:
return False, None
+ else:
+ raise RuntimeError(f'Invalid checkpoint path {checkpoint_path}. Expected a file or a directory.')
def load_state_dict(checkpoint_file_path: Path):
@@ -380,7 +390,6 @@ def load_state_dict(checkpoint_file_path: Path):
else:
# load with torch
return torch.load(checkpoint_file_path)
-
def add_variant(weights_name: str, variant: Optional[str] = None) -> str:
@@ -392,17 +401,18 @@ def add_variant(weights_name: str, variant: Optional[str] = None) -> str:
return weights_name
-def get_base_filenames(variant: str=None, use_safetensors: bool=False):
- """
- generate base weight filenames
- """
- weights_name = SAFE_WEIGHTS_NAME if use_safetensors else WEIGHTS_NAME
- weights_name = add_variant(weights_name, variant)
+def get_base_filenames(variant: str = None, use_safetensors: bool = False):
+ """
+ generate base weight filenames
+ """
+ weights_name = SAFE_WEIGHTS_NAME if use_safetensors else WEIGHTS_NAME
+ weights_name = add_variant(weights_name, variant)
+
+ save_index_file = SAFE_WEIGHTS_INDEX_NAME if use_safetensors else WEIGHTS_INDEX_NAME
+ save_index_file = add_variant(save_index_file, variant)
- save_index_file = SAFE_WEIGHTS_INDEX_NAME if use_safetensors else WEIGHTS_INDEX_NAME
- save_index_file = add_variant(save_index_file, variant)
+ return weights_name, save_index_file
- return weights_name, save_index_file
def get_shard_filename(weights_name: str, idx: int):
"""
@@ -410,4 +420,4 @@ def get_shard_filename(weights_name: str, idx: int):
"""
shard_file = weights_name.replace(".bin", f"-{idx+1:05d}.bin")
shard_file = shard_file.replace(".safetensors", f"-{idx + 1:05d}.safetensors")
- return shard_file
\ No newline at end of file
+ return shard_file
diff --git a/colossalai/cli/check/check_installation.py b/colossalai/cli/check/check_installation.py
index cb3dbbc09301..4a481f3bd122 100644
--- a/colossalai/cli/check/check_installation.py
+++ b/colossalai/cli/check/check_installation.py
@@ -31,7 +31,7 @@ def check_installation():
found_aot_cuda_ext = _check_aot_built_cuda_extension_installed()
cuda_version = _check_cuda_version()
torch_version, torch_cuda_version = _check_torch_version()
- colossalai_verison, prebuilt_torch_version_required, prebuilt_cuda_version_required = _parse_colossalai_version()
+ colossalai_version, prebuilt_torch_version_required, prebuilt_cuda_version_required = _parse_colossalai_version()
# if cuda_version is None, that means either
# CUDA_HOME is not found, thus cannot compare the version compatibility
@@ -57,7 +57,7 @@ def check_installation():
click.echo(f'#### Installation Report ####')
click.echo(f'\n------------ Environment ------------')
- click.echo(f"Colossal-AI version: {to_click_output(colossalai_verison)}")
+ click.echo(f"Colossal-AI version: {to_click_output(colossalai_version)}")
click.echo(f"PyTorch version: {to_click_output(torch_version)}")
click.echo(f"System CUDA version: {to_click_output(cuda_version)}")
click.echo(f"CUDA version required by PyTorch: {to_click_output(torch_cuda_version)}")
@@ -137,7 +137,7 @@ def _parse_colossalai_version():
# 1. X.X.X+torchX.XXcuXX.X (when colossalai is installed with CUDA extensions)
# 2. X.X.X (when colossalai is not installed with CUDA extensions)
# where X represents an integer.
- colossalai_verison = colossalai.__version__.split('+')[0]
+ colossalai_version = colossalai.__version__.split('+')[0]
try:
torch_version_for_aot_build = colossalai.__version__.split('torch')[1].split('cu')[0]
@@ -145,7 +145,7 @@ def _parse_colossalai_version():
except:
torch_version_for_aot_build = None
cuda_version_for_aot_build = None
- return colossalai_verison, torch_version_for_aot_build, cuda_version_for_aot_build
+ return colossalai_version, torch_version_for_aot_build, cuda_version_for_aot_build
def _check_aot_built_cuda_extension_installed():
diff --git a/colossalai/cluster/dist_coordinator.py b/colossalai/cluster/dist_coordinator.py
index 99dde810e112..3ee364ec3364 100644
--- a/colossalai/cluster/dist_coordinator.py
+++ b/colossalai/cluster/dist_coordinator.py
@@ -181,7 +181,7 @@ def on_master_only(self, process_group: ProcessGroup = None):
"""
is_master = self.is_master(process_group)
- # define an inner functiuon
+ # define an inner function
def decorator(func):
@functools.wraps(func)
diff --git a/colossalai/device/alpha_beta_profiler.py b/colossalai/device/alpha_beta_profiler.py
index af2b10928c6f..f8b20de9bc37 100644
--- a/colossalai/device/alpha_beta_profiler.py
+++ b/colossalai/device/alpha_beta_profiler.py
@@ -381,7 +381,7 @@ def _extract_alpha_beta(pg, pg_handler):
first_latency, first_bandwidth = _extract_alpha_beta(first_axis, first_axis_process_group)
second_latency, second_bandwidth = _extract_alpha_beta(second_axis, second_axis_process_group)
mesh_alpha = [first_latency, second_latency]
- # The beta values have been enlarged by 1e10 times temporarilly because the computation cost
+ # The beta values have been enlarged by 1e10 times temporarily because the computation cost
# is still estimated in the unit of TFLOPs instead of time. We will remove this factor in future.
mesh_beta = [1e10 / first_bandwidth, 1e10 / second_bandwidth]
diff --git a/colossalai/engine/schedule/_pipeline_schedule.py b/colossalai/engine/schedule/_pipeline_schedule.py
index 38175fe0941c..9fc301a26559 100644
--- a/colossalai/engine/schedule/_pipeline_schedule.py
+++ b/colossalai/engine/schedule/_pipeline_schedule.py
@@ -152,9 +152,9 @@ def _get_data_slice(self, data, offset):
raise TypeError(f"Expected data to be of type torch.Tensor, list, tuple, or dict, but got {type(data)}")
def load_micro_batch(self):
- mciro_batch_data = self._get_data_slice(self.batch_data, self.microbatch_offset)
+ micro_batch_data = self._get_data_slice(self.batch_data, self.microbatch_offset)
self.microbatch_offset += self.microbatch_size
- return self._move_to_device(mciro_batch_data)
+ return self._move_to_device(micro_batch_data)
def pre_processing(self, engine):
from colossalai.zero.legacy import ShardedModelV2
diff --git a/colossalai/engine/schedule/_pipeline_schedule_v2.py b/colossalai/engine/schedule/_pipeline_schedule_v2.py
index 28c58bd82b5c..89e45c7aacec 100644
--- a/colossalai/engine/schedule/_pipeline_schedule_v2.py
+++ b/colossalai/engine/schedule/_pipeline_schedule_v2.py
@@ -84,7 +84,7 @@ def forward_backward_step(self,
'The argument \'return_loss\' has to be True when \'forward_only\' is False, but got False.'
self.load_batch(data_iter)
- # num_warmup_microbatches is the step when not all the processers are working
+ # num_warmup_microbatches is the step when not all the processes are working
num_warmup_microbatches = \
(gpc.get_world_size(ParallelMode.PIPELINE)
- gpc.get_local_rank(ParallelMode.PIPELINE) - 1)
diff --git a/colossalai/fx/codegen/activation_checkpoint_codegen.py b/colossalai/fx/codegen/activation_checkpoint_codegen.py
index 5a72cb9ca923..33b164800262 100644
--- a/colossalai/fx/codegen/activation_checkpoint_codegen.py
+++ b/colossalai/fx/codegen/activation_checkpoint_codegen.py
@@ -523,7 +523,7 @@ def emit_code_with_activation_checkpoint(body, ckpt_func, nodes, emit_node_func,
# append code text to body
for idx, node in enumerate(node_list):
# if this is the first node of the ckpt region
- # append the ckpt function defition
+ # append the ckpt function definition
if idx in start_idx:
label = start_idx.index(idx)
ckpt_fn_def = _gen_ckpt_fn_def(label, input_vars[label])
diff --git a/colossalai/fx/passes/adding_split_node_pass.py b/colossalai/fx/passes/adding_split_node_pass.py
index 2c7b842b530c..245ba5d776da 100644
--- a/colossalai/fx/passes/adding_split_node_pass.py
+++ b/colossalai/fx/passes/adding_split_node_pass.py
@@ -206,7 +206,7 @@ def avgcompute_split_pass(gm: torch.fx.GraphModule, pp_size: int):
def avgnode_split_pass(gm: torch.fx.GraphModule, pp_size: int):
"""
- In avgnode_split_pass, simpliy split graph by node number.
+ In avgnode_split_pass, simply split graph by node number.
"""
mod_graph = gm.graph
avg_num_node = len(mod_graph.nodes) // pp_size
diff --git a/colossalai/fx/passes/experimental/adding_shape_consistency_pass.py b/colossalai/fx/passes/experimental/adding_shape_consistency_pass.py
index f28d65e2668a..4571bd93a790 100644
--- a/colossalai/fx/passes/experimental/adding_shape_consistency_pass.py
+++ b/colossalai/fx/passes/experimental/adding_shape_consistency_pass.py
@@ -16,7 +16,7 @@ def apply(*args, **kwargs):
return shape_consistency_manager.apply(*args, **kwargs)
-def solution_annotatation_pass(gm: torch.fx.GraphModule, solution: List[int], device_mesh):
+def solution_annotation_pass(gm: torch.fx.GraphModule, solution: List[int], device_mesh):
mod_graph = gm.graph
nodes = tuple(mod_graph.nodes)
diff --git a/colossalai/fx/passes/meta_info_prop.py b/colossalai/fx/passes/meta_info_prop.py
index 2b4a8749cfd7..ab203dfd7440 100644
--- a/colossalai/fx/passes/meta_info_prop.py
+++ b/colossalai/fx/passes/meta_info_prop.py
@@ -31,7 +31,7 @@ class TensorMetadata(NamedTuple):
numel: int
is_tensor: bool
# TODO: we can add a list of sharding spec here, and record the sharding
- # behaviour by appending sharding spec into list.
+ # behavior by appending sharding spec into list.
def _extract_tensor_metadata(result: torch.Tensor) -> TensorMetadata:
diff --git a/colossalai/fx/passes/passes_for_gpt2_test.py b/colossalai/fx/passes/passes_for_gpt2_test.py
index abc1a089e9a9..efdd34a01fe0 100644
--- a/colossalai/fx/passes/passes_for_gpt2_test.py
+++ b/colossalai/fx/passes/passes_for_gpt2_test.py
@@ -230,7 +230,7 @@ def record_cross_partition_use(def_node: torch.fx.node.Node,
use_partition.partitions_dependent_on.setdefault(def_partition_name)
node_process_list = list(m.graph.nodes)
- # split nodes into parititons
+ # split nodes into partitions
while node_process_list:
node = node_process_list.pop(0)
orig_nodes[node.name] = node
@@ -277,7 +277,7 @@ def record_cross_partition_use(def_node: torch.fx.node.Node,
if len(sorted_partitions) != len(partitions):
raise RuntimeError("cycle exists between partitions!")
- # add placeholders to parititons
+ # add placeholders to partitions
for partition_name in sorted_partitions:
partition = partitions[partition_name]
for input in partition.inputs:
diff --git a/colossalai/fx/passes/split_module.py b/colossalai/fx/passes/split_module.py
index 5ce5b969cbde..61ed037ab7a1 100644
--- a/colossalai/fx/passes/split_module.py
+++ b/colossalai/fx/passes/split_module.py
@@ -29,8 +29,8 @@ def __repr__(self) -> str:
f" nodes: {self.node_names},\n" \
f" inputs: {self.inputs},\n" \
f" outputs: {self.outputs},\n" \
- f" partitions depenent on: {self.partitions_dependent_on},\n" \
- f" parition dependents: {self.partition_dependents}"
+ f" partitions dependent on: {self.partitions_dependent_on},\n" \
+ f" partition dependents: {self.partition_dependents}"
# Creates subgraphs out of main graph
diff --git a/colossalai/nn/optimizer/cpu_adam.py b/colossalai/nn/optimizer/cpu_adam.py
index 54036973e1e3..bb561a106515 100644
--- a/colossalai/nn/optimizer/cpu_adam.py
+++ b/colossalai/nn/optimizer/cpu_adam.py
@@ -13,7 +13,7 @@
class CPUAdam(NVMeOptimizer):
"""Implements Adam algorithm.
- Supports parameters updating on both GPU and CPU, depanding on the device of paramters.
+ Supports parameters updating on both GPU and CPU, depanding on the device of parameters.
But the parameters and gradients should on the same device:
* Parameters on CPU and gradients on CPU is allowed.
* Parameters on GPU and gradients on GPU is allowed.
diff --git a/colossalai/nn/optimizer/hybrid_adam.py b/colossalai/nn/optimizer/hybrid_adam.py
index 1d0fb92de499..be6311c6c29f 100644
--- a/colossalai/nn/optimizer/hybrid_adam.py
+++ b/colossalai/nn/optimizer/hybrid_adam.py
@@ -13,19 +13,19 @@
class HybridAdam(NVMeOptimizer):
"""Implements Adam algorithm.
- Supports parameters updating on both GPU and CPU, depanding on the device of paramters.
+ Supports parameters updating on both GPU and CPU, depanding on the device of parameters.
But the parameters and gradients should on the same device:
* Parameters on CPU and gradients on CPU is allowed.
* Parameters on GPU and gradients on GPU is allowed.
* Parameters on GPU and gradients on CPU is **not** allowed.
- `HybriadAdam` requires CUDA extensions which can be built during installation or runtime.
+ `HybridAdam` requires CUDA extensions which can be built during installation or runtime.
This version of Hybrid Adam is an hybrid of CPUAdam and FusedAdam.
* For parameters updating on CPU, it uses CPUAdam.
* For parameters updating on GPU, it uses FusedAdam.
- * Hybird precision calculation of fp16 and fp32 is supported, eg fp32 parameters and fp16 gradients.
+ * Hybrid precision calculation of fp16 and fp32 is supported, eg fp32 parameters and fp16 gradients.
:class:`colossalai.nn.optimizer.HybridAdam` may be used as a drop-in replacement for ``torch.optim.AdamW``,
or ``torch.optim.Adam`` with ``adamw_mode=False``
@@ -131,7 +131,7 @@ def step(self, closure=None, div_scale: float = -1):
assert state['exp_avg'].device.type == 'cuda', "exp_avg should stay on cuda"
assert state['exp_avg_sq'].device.type == 'cuda', "exp_avg should stay on cuda"
- # record the state by gruop and update at once
+ # record the state by group and update at once
g_l.append(p.grad.data)
p_l.append(p.data)
m_l.append(state['exp_avg'])
diff --git a/colossalai/nn/parallel/layers/cache_embedding/cache_mgr.py b/colossalai/nn/parallel/layers/cache_embedding/cache_mgr.py
index da043df368ae..a6159856dcce 100644
--- a/colossalai/nn/parallel/layers/cache_embedding/cache_mgr.py
+++ b/colossalai/nn/parallel/layers/cache_embedding/cache_mgr.py
@@ -20,8 +20,8 @@ def _wait_for_data(t, stream: Optional[torch.cuda.streams.Stream]) -> None:
return
torch.cuda.current_stream().wait_stream(stream)
# As mentioned in https://pytorch.org/docs/stable/generated/torch.Tensor.record_stream.html,
- # PyTorch uses the "caching allocator" for memroy allocation for tensors. When a tensor is
- # freed, its memory is likely to be reused by newly constructed tenosrs. By default,
+ # PyTorch uses the "caching allocator" for memory allocation for tensors. When a tensor is
+ # freed, its memory is likely to be reused by newly constructed tensors. By default,
# this allocator traces whether a tensor is still in use by only the CUDA stream where it
# was created. When a tensor is used by additional CUDA streams, we need to call record_stream
# to tell the allocator about all these streams. Otherwise, the allocator might free the
@@ -294,7 +294,7 @@ def print_comm_stats(self):
print(
f"CPU->CUDA BWD {self._cpu_to_cuda_numel * self.elem_size_in_byte / 1e6 / elapsed} MB/s {self._cpu_to_cuda_numel / 1e6} M elem"
)
- print(f'cpu_to_cuda_elpase {elapsed} sec')
+ print(f'cpu_to_cuda_elapse {elapsed} sec')
for k, v in self._elapsed_dict.items():
print(f'{k}: {v}')
diff --git a/colossalai/testing/pytest_wrapper.py b/colossalai/testing/pytest_wrapper.py
index a472eb3723ec..b264b009028a 100644
--- a/colossalai/testing/pytest_wrapper.py
+++ b/colossalai/testing/pytest_wrapper.py
@@ -33,7 +33,7 @@ def test_for_something():
assert isinstance(name, str)
flag = os.environ.get(name.upper(), '0')
- reason = f'Environment varialbe {name} is {flag}'
+ reason = f'Environment variable {name} is {flag}'
if flag == '1':
return pytest.mark.skipif(False, reason=reason)
else:
diff --git a/colossalai/testing/utils.py b/colossalai/testing/utils.py
index 6583eeb12bf4..a4370a8d4933 100644
--- a/colossalai/testing/utils.py
+++ b/colossalai/testing/utils.py
@@ -167,10 +167,10 @@ def test_something():
"""
# check version
torch_version = version.parse(torch.__version__)
- assert torch_version.major == 1
+ assert torch_version.major >= 1
# only torch >= 1.8 has ProcessRaisedException
- if torch_version.minor >= 8:
+ if torch_version >= version.parse("1.8.0"):
exception = torch.multiprocessing.ProcessRaisedException
else:
exception = Exception
diff --git a/colossalai/utils/common.py b/colossalai/utils/common.py
index 95b3b8014af1..8022e84dc24b 100644
--- a/colossalai/utils/common.py
+++ b/colossalai/utils/common.py
@@ -324,7 +324,7 @@ def clip_grad_norm_fp32(parameters, max_norm, norm_type=2):
norm_type = float(norm_type)
# Parameters can be on CPU or CUDA
- # If parameters are on CPU, disable CUDA kernerls
+ # If parameters are on CPU, disable CUDA kernels
# Calculate norm.
if norm_type == inf:
diff --git a/colossalai/utils/tensor_detector/readme.md b/colossalai/utils/tensor_detector/readme.md
index 840dc8f4eca6..d6852ea55b54 100644
--- a/colossalai/utils/tensor_detector/readme.md
+++ b/colossalai/utils/tensor_detector/readme.md
@@ -46,7 +46,7 @@ detector.detect()
I have made some comments on the right of the output for your understanding.
-Note that the total `Mem` of all the tensors and parameters is not equal to `Total GPU Memery Allocated`. PyTorch's memory management is really complicated, and for models of a large scale, it's impossible to figure out clearly.
+Note that the total `Mem` of all the tensors and parameters is not equal to `Total GPU Memory Allocated`. PyTorch's memory management is really complicated, and for models of a large scale, it's impossible to figure out clearly.
**The order of print is not equal to the order the tensor creates, but they are really close.**
@@ -61,7 +61,7 @@ Note that the total `Mem` of all the tensors and parameters is not equal to `Tot
+ mlp.2.bias cuda:0 (32,) True torch.float32 128 B
------------------------------------------------------------------------------------------------------------
Detect Location: "test_tensor_detector.py" line 27
-Totle GPU Memery Allocated on cuda:0 is 4.5 KB
+Total GPU Memory Allocated on cuda:0 is 4.5 KB
------------------------------------------------------------------------------------------------------------
@@ -72,7 +72,7 @@ Totle GPU Memery Allocated on cuda:0 is 4.5 KB
+ Tensor cuda:0 (32,) True torch.float32 128 B # output
------------------------------------------------------------------------------------------------------------
Detect Location: "test_tensor_detector.py" line 30
-Totle GPU Memery Allocated on cuda:0 is 5.5 KB
+Total GPU Memory Allocated on cuda:0 is 5.5 KB
------------------------------------------------------------------------------------------------------------
@@ -82,7 +82,7 @@ Totle GPU Memery Allocated on cuda:0 is 5.5 KB
+ Tensor cuda:0 () True torch.float32 4 B # loss
------------------------------------------------------------------------------------------------------------
Detect Location: "test_tensor_detector.py" line 32
-Totle GPU Memery Allocated on cuda:0 is 6.0 KB
+Total GPU Memory Allocated on cuda:0 is 6.0 KB
------------------------------------------------------------------------------------------------------------
@@ -103,7 +103,7 @@ Totle GPU Memery Allocated on cuda:0 is 6.0 KB
- Tensor cuda:0 (8,) True torch.float32 32 B # deleted activation
------------------------------------------------------------------------------------------------------------
Detect Location: "test_tensor_detector.py" line 34
-Totle GPU Memery Allocated on cuda:0 is 10.0 KB
+Total GPU Memory Allocated on cuda:0 is 10.0 KB
------------------------------------------------------------------------------------------------------------
@@ -117,7 +117,7 @@ Totle GPU Memery Allocated on cuda:0 is 10.0 KB
+ Tensor cuda:0 (32,) False torch.float32 128 B
------------------------------------------------------------------------------------------------------------
Detect Location: "test_tensor_detector.py" line 36
-Totle GPU Memery Allocated on cuda:0 is 14.0 KB
+Total GPU Memory Allocated on cuda:0 is 14.0 KB
------------------------------------------------------------------------------------------------------------
```
diff --git a/colossalai/utils/tensor_detector/tensor_detector.py b/colossalai/utils/tensor_detector/tensor_detector.py
index a8186f76834c..cfcd4e47b4cb 100644
--- a/colossalai/utils/tensor_detector/tensor_detector.py
+++ b/colossalai/utils/tensor_detector/tensor_detector.py
@@ -55,7 +55,7 @@ def get_tensor_mem(self, tensor):
return self.mem_format(memory_size)
def mem_format(self, real_memory_size):
- # format the tensor memory into a reasonal magnitude
+ # format the tensor memory into a reasonable magnitude
if real_memory_size >= 2**30:
return str(real_memory_size / (2**30)) + ' GB'
if real_memory_size >= 2**20:
@@ -71,7 +71,7 @@ def collect_tensors_state(self):
if (not self.include_cpu) and obj.device == torch.device('cpu'):
continue
self.detected.append(id(obj))
- # skip paramters we had added in __init__ when module is an instance of nn.Module for the first epoch
+ # skip parameters we had added in __init__ when module is an instance of nn.Module for the first epoch
if id(obj) not in self.tensor_info:
name = type(obj).__name__
@@ -84,7 +84,7 @@ def collect_tensors_state(self):
name = par_name + ' (with grad)'
else:
# with no grad attached
- # there will be no new paramters created during running
+ # there will be no new parameters created during running
# so it must be in saved_tensor_info
continue
# we can also marked common tensors as tensor(with grad)
@@ -155,7 +155,7 @@ def print_tensors_state(self):
if device == torch.device('cpu'):
continue
gpu_mem_alloc = self.mem_format(torch.cuda.memory_allocated(device))
- self.info += f"Totle GPU Memery Allocated on {device} is {gpu_mem_alloc}\n"
+ self.info += f"Total GPU Memory Allocated on {device} is {gpu_mem_alloc}\n"
self.info += LINE
self.info += '\n\n'
if self.show_info:
diff --git a/colossalai/zero/gemini/chunk/manager.py b/colossalai/zero/gemini/chunk/manager.py
index d85df0b00476..77368d06d255 100644
--- a/colossalai/zero/gemini/chunk/manager.py
+++ b/colossalai/zero/gemini/chunk/manager.py
@@ -102,7 +102,7 @@ def access_chunk(self, chunk: Chunk) -> None:
"""
if chunk in self.accessed_chunks:
return
- self.__sub_memroy_usage(chunk.memory_usage)
+ self.__sub_memory_usage(chunk.memory_usage)
if chunk.device_type == 'cpu':
chunk.shard_move(get_current_device())
self.__add_accessed_chunk(chunk)
@@ -114,7 +114,7 @@ def release_chunk(self, chunk: Chunk) -> None:
if chunk not in self.accessed_chunks:
return
if chunk.can_release:
- self.__sub_memroy_usage(chunk.memory_usage)
+ self.__sub_memory_usage(chunk.memory_usage)
self.__sub_accessed_chunk(chunk)
self.__add_memory_usage(chunk.memory_usage)
@@ -123,7 +123,7 @@ def move_chunk(self, chunk: Chunk, device: torch.device, force_copy: bool = Fals
"""
if not chunk.can_move or chunk.device_type == device.type:
return
- self.__sub_memroy_usage(chunk.memory_usage)
+ self.__sub_memory_usage(chunk.memory_usage)
chunk.shard_move(device, force_copy)
self.__add_memory_usage(chunk.memory_usage)
@@ -138,7 +138,7 @@ def reduce_chunk(self, chunk: Chunk) -> bool:
"""
if not chunk.can_reduce:
return False
- self.__sub_memroy_usage(chunk.memory_usage)
+ self.__sub_memory_usage(chunk.memory_usage)
chunk.reduce()
self.__sub_accessed_chunk(chunk)
self.__add_memory_usage(chunk.memory_usage)
@@ -228,11 +228,11 @@ def __get_chunk_group(self, group_name: str) -> Deque:
return self.chunk_groups[group_name]
def __close_one_chunk(self, chunk: Chunk):
- self.__sub_memroy_usage(chunk.memory_usage)
+ self.__sub_memory_usage(chunk.memory_usage)
chunk.close_chunk()
self.__add_memory_usage(chunk.memory_usage)
- def __sub_memroy_usage(self, usage: Dict[str, int]):
+ def __sub_memory_usage(self, usage: Dict[str, int]):
for k, v in usage.items():
self.total_mem[k] -= v
diff --git a/colossalai/zero/gemini/chunk/search_utils.py b/colossalai/zero/gemini/chunk/search_utils.py
index da58e038c879..881ceb0b3b97 100644
--- a/colossalai/zero/gemini/chunk/search_utils.py
+++ b/colossalai/zero/gemini/chunk/search_utils.py
@@ -85,7 +85,7 @@ def classify_params_by_dp_degree(param_order: OrderedParamGenerator,
Classify the parameters by their dp degree
Args:
- param_order (OrderedParamGenerator): the order of param be visied
+ param_order (OrderedParamGenerator): the order of param be vised
strict_ddp_flag (bool, optional): whether to enable the strict ddp mode. Defaults to False.
Returns:
diff --git a/colossalai/zero/gemini/memory_tracer/memory_stats.py b/colossalai/zero/gemini/memory_tracer/memory_stats.py
index 9a45034ee27e..41d7e5754e96 100644
--- a/colossalai/zero/gemini/memory_tracer/memory_stats.py
+++ b/colossalai/zero/gemini/memory_tracer/memory_stats.py
@@ -59,7 +59,7 @@ def increase_preop_step(self, param_list: List[torch.nn.Parameter]):
time step.
Args:
- param_list (List[torch.nn.Parameter]): a list of torch paramters.
+ param_list (List[torch.nn.Parameter]): a list of torch parameters.
"""
for p in param_list:
if p not in self._param_step_dict:
diff --git a/docker/Dockerfile b/docker/Dockerfile
index 49ff9b344268..2c7bafd9604c 100644
--- a/docker/Dockerfile
+++ b/docker/Dockerfile
@@ -8,14 +8,19 @@ LABEL org.opencontainers.image.base.name = "docker.io/library/hpcaitech/cuda-con
# install torch
RUN conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
+# install ninja
+RUN apt-get install -y --no-install-recommends ninja-build
+
# install apex
RUN git clone https://github.com/NVIDIA/apex && \
cd apex && \
+ git checkout 91fcaa && \
pip install packaging && \
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" --global-option="--fast_layer_norm" ./
# install colossalai
-RUN git clone https://github.com/hpcaitech/ColossalAI.git \
+ARG VERSION=1
+RUN git clone -b ${VERSION} https://github.com/hpcaitech/ColossalAI.git \
&& cd ./ColossalAI \
&& CUDA_EXT=1 pip install -v --no-cache-dir .
diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md
index 9d5bcfe3f974..1dde7a816676 100644
--- a/docs/README-zh-Hans.md
+++ b/docs/README-zh-Hans.md
@@ -121,12 +121,22 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
### ColossalChat
-[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): 完整RLHF流程0门槛克隆 [ChatGPT](https://openai.com/blog/chatgpt/) [[代码]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) [[博客]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b) [[在线样例]](https://chat.colossalai.org)
+[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): 完整RLHF流程0门槛克隆 [ChatGPT](https://openai.com/blog/chatgpt/)
+[[代码]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
+[[博客]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+[[在线样例]](https://www.youtube.com/watch?v=HcTiHzApHm0)
+[[教程]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
+
+
+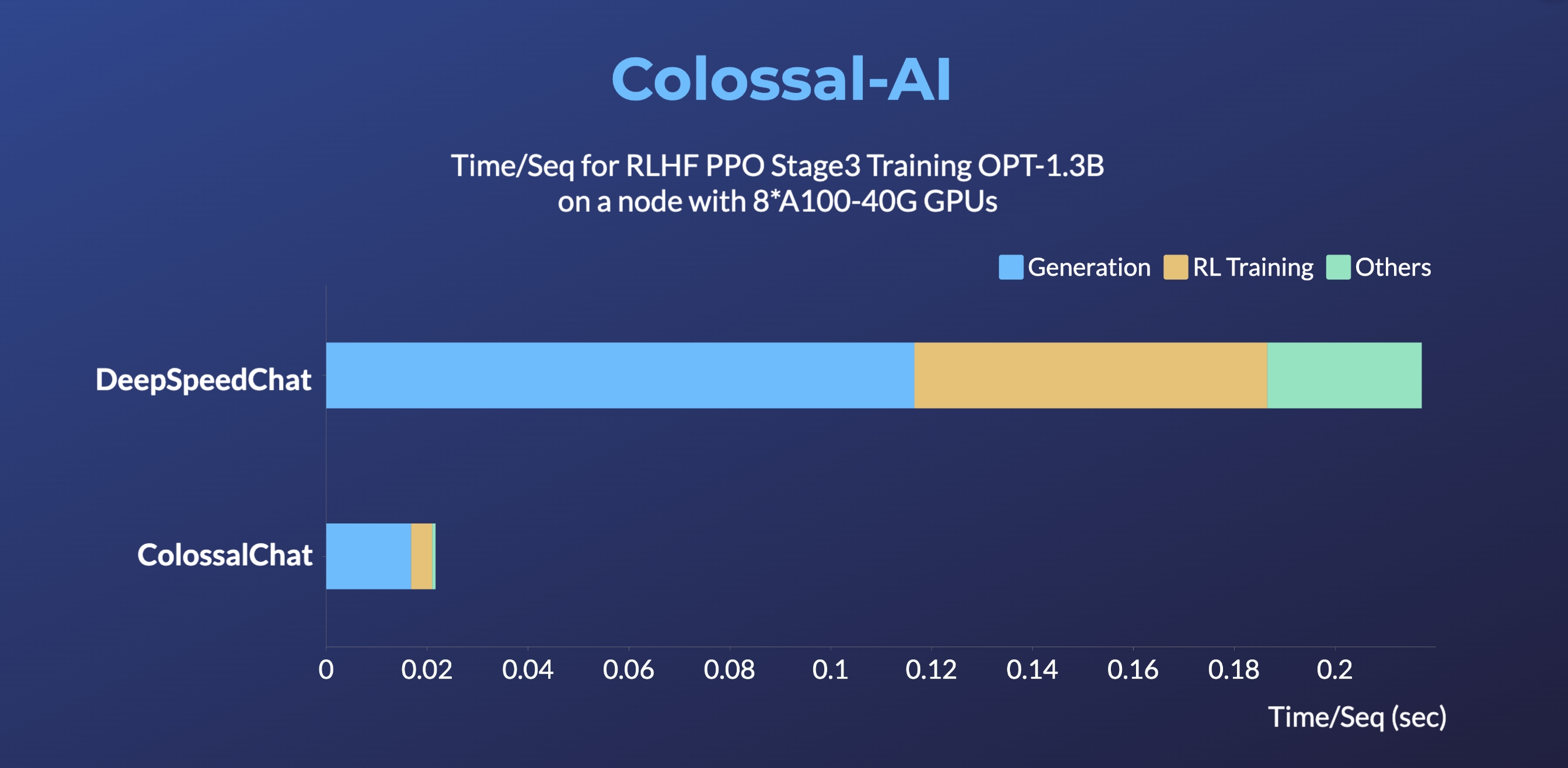 +
+
+
+- 最高可提升RLHF PPO阶段3训练速度10倍
 diff --git a/docs/README.md b/docs/README.md
index f520608d552c..f0cb50ffe217 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -98,7 +98,7 @@ Lastly, if you want to skip some code, you just need to add the following annota
```
-If you have any dependency required, please add it to `requriements-doc-test.txt` for pip and `conda-doc-test-deps.yml` for Conda.
+If you have any dependency required, please add it to `requirements-doc-test.txt` for pip and `conda-doc-test-deps.yml` for Conda.
### 💉 Auto Documentation
diff --git a/docs/REFERENCE.md b/docs/REFERENCE.md
index 2681198191cb..0984b2dc3f28 100644
--- a/docs/REFERENCE.md
+++ b/docs/REFERENCE.md
@@ -1,6 +1,6 @@
# References
-The Colossal-AI project aims to provide a wide array of parallelism techniques for the machine learning community in the big-model era. This project is inspired by quite a few reserach works, some are conducted by some of our developers and the others are research projects open-sourced by other organizations. We would like to credit these amazing projects below in the IEEE citation format.
+The Colossal-AI project aims to provide a wide array of parallelism techniques for the machine learning community in the big-model era. This project is inspired by quite a few research works, some are conducted by some of our developers and the others are research projects open-sourced by other organizations. We would like to credit these amazing projects below in the IEEE citation format.
## By Our Team
diff --git a/docs/sidebars.json b/docs/sidebars.json
index 44287c17eadf..8be40e4512f9 100644
--- a/docs/sidebars.json
+++ b/docs/sidebars.json
@@ -26,8 +26,11 @@
"collapsed": true,
"items": [
"basics/command_line_tool",
- "basics/define_your_config",
"basics/launch_colossalai",
+ "basics/booster_api",
+ "basics/booster_plugins",
+ "basics/booster_checkpoint",
+ "basics/define_your_config",
"basics/initialize_features",
"basics/engine_trainer",
"basics/configure_parallelization",
@@ -40,8 +43,11 @@
"label": "Features",
"collapsed": true,
"items": [
+ "features/mixed_precision_training_with_booster",
"features/mixed_precision_training",
+ "features/gradient_accumulation_with_booster",
"features/gradient_accumulation",
+ "features/gradient_clipping_with_booster",
"features/gradient_clipping",
"features/gradient_handler",
"features/zero_with_chunk",
@@ -57,7 +63,8 @@
]
},
"features/pipeline_parallel",
- "features/nvme_offload"
+ "features/nvme_offload",
+ "features/cluster_utils"
]
},
{
diff --git a/docs/source/en/advanced_tutorials/add_your_parallel.md b/docs/source/en/advanced_tutorials/add_your_parallel.md
index be7284a7ab64..1caf58c8734e 100644
--- a/docs/source/en/advanced_tutorials/add_your_parallel.md
+++ b/docs/source/en/advanced_tutorials/add_your_parallel.md
@@ -56,7 +56,7 @@ follow the steps below to create a new distributed initialization.
world_size: int,
config: Config,
data_parallel_size: int,
- pipeline_parlalel_size: int,
+ pipeline_parallel_size: int,
tensor_parallel_size: int,
arg1,
arg2):
diff --git a/docs/source/en/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md b/docs/source/en/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
index e01caf76d2b3..d5edd135c079 100644
--- a/docs/source/en/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
+++ b/docs/source/en/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
@@ -121,7 +121,7 @@ Inside the initialization of Experts, the local expert number of each GPU will b
## Train Your Model
-Do not to forget to use `colossalai.initialize` function in `colosalai` to add gradient handler for the engine.
+Do not to forget to use `colossalai.initialize` function in `colossalai` to add gradient handler for the engine.
We handle the back-propagation of MoE models for you.
In `colossalai.initialize`, we will automatically create a `MoeGradientHandler` object to process gradients.
You can find more information about the handler `MoeGradientHandler` in colossal directory.
diff --git a/docs/source/en/advanced_tutorials/meet_gemini.md b/docs/source/en/advanced_tutorials/meet_gemini.md
index 8afb6705b6ae..c1c23a355efa 100644
--- a/docs/source/en/advanced_tutorials/meet_gemini.md
+++ b/docs/source/en/advanced_tutorials/meet_gemini.md
@@ -9,16 +9,21 @@ When you only have a few GPUs for large model training tasks, **heterogeneous tr
## Usage
-At present, Gemini supports compatibility with ZeRO parallel mode, and it is really simple to use Gemini. Set attribute of zero model_config, i.e., tensor_placement_policy='auto'.
-
-```
-zero = dict(
- model_config=dict(
- tensor_placement_policy='auto',
- shard_strategy=BucketTensorShardStrategy()
- ),
- optimizer_config=dict(
- ...)
+At present, Gemini supports compatibility with ZeRO parallel mode, and it is really simple to use Gemini: Inject the feathures of `GeminiPlugin` into training components with `booster`. More instructions of `booster` please refer to [**usage of booster**](../basics/booster_api.md).
+
+```python
+from torchvision.models import resnet18
+from colossalai.booster import Booster
+from colossalai.zero import ColoInitContext
+from colossalai.booster.plugin import GeminiPlugin
+plugin = GeminiPlugin(placement_policy='cuda', strict_ddp_mode=True, max_norm=1.0, initial_scale=2**5)
+booster = Booster(plugin=plugin)
+ctx = ColoInitContext()
+with ctx:
+ model = resnet18()
+optimizer = HybridAdam(model.parameters(), lr=1e-3)
+criterion = lambda x: x.mean()
+model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
)
```
@@ -86,3 +91,5 @@ The important duty of MSC is to adjust the tensor layout position. For example,
In the warmup stage, since we haven't finished a complete iteration yet, we don't know actual memory occupation. At this time, we limit the upper bound of memory usage of the model data. For example, only 30% of the GPU memory can be used. This ensures that we can successfully complete the warmup state.
In the non-warmup stage, we need to use the memory information of non-model data collected in the warm-up stage to reserve the peak memory required by the computing device for the next Period, which requires us to move some model tensors. In order to avoid frequent replacement of the same tensor in and out of the CPU-GPU, causing a phenomenon similar to [cache thrashing](https://en.wikipedia.org/wiki/Thrashing_(computer_science)). Using the iterative characteristics of DNN training, we design the OPT cache swap out strategy. Specifically, in the warmup stage, we record the sampling time required by each tensor computing device. If we need to expel some HOLD tensors, we will choose the latest tensor needed on this device as the victim.
+
+
diff --git a/docs/source/en/advanced_tutorials/opt_service.md b/docs/source/en/advanced_tutorials/opt_service.md
index a43ec7fdd1fe..eccfa12f9389 100644
--- a/docs/source/en/advanced_tutorials/opt_service.md
+++ b/docs/source/en/advanced_tutorials/opt_service.md
@@ -53,7 +53,7 @@ export CHECKPOINT_DIR="your_opt_checkpoint_path"
# the ${CONFIG_DIR} must contain a server.sh file as the entry of service
export CONFIG_DIR="config_file_path"
-docker run --gpus all --rm -it -p 8020:8020 -v ${CHECKPOINT_DIR}:/model_checkpoint -v ${CONFIG_DIR}:/config --ipc=host energonai:lastest
+docker run --gpus all --rm -it -p 8020:8020 -v ${CHECKPOINT_DIR}:/model_checkpoint -v ${CONFIG_DIR}:/config --ipc=host energonai:latest
```
Then open `https://[IP-ADDRESS]:8020/docs#` in your browser to try out!
diff --git a/docs/source/en/advanced_tutorials/parallelize_your_training_like_Megatron.md b/docs/source/en/advanced_tutorials/parallelize_your_training_like_Megatron.md
index e7698e5e9d1b..22d52fb3cd1a 100644
--- a/docs/source/en/advanced_tutorials/parallelize_your_training_like_Megatron.md
+++ b/docs/source/en/advanced_tutorials/parallelize_your_training_like_Megatron.md
@@ -69,7 +69,7 @@ After the forward operation of the embedding module, each word in all sequences
The embedding module
-Each transformer layer contains two blocks. The self-attention operation is called in the first block and a two-layer percepton is located in the second block.
+Each transformer layer contains two blocks. The self-attention operation is called in the first block and a two-layer perception is located in the second block.
diff --git a/docs/README.md b/docs/README.md
index f520608d552c..f0cb50ffe217 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -98,7 +98,7 @@ Lastly, if you want to skip some code, you just need to add the following annota
```
-If you have any dependency required, please add it to `requriements-doc-test.txt` for pip and `conda-doc-test-deps.yml` for Conda.
+If you have any dependency required, please add it to `requirements-doc-test.txt` for pip and `conda-doc-test-deps.yml` for Conda.
### 💉 Auto Documentation
diff --git a/docs/REFERENCE.md b/docs/REFERENCE.md
index 2681198191cb..0984b2dc3f28 100644
--- a/docs/REFERENCE.md
+++ b/docs/REFERENCE.md
@@ -1,6 +1,6 @@
# References
-The Colossal-AI project aims to provide a wide array of parallelism techniques for the machine learning community in the big-model era. This project is inspired by quite a few reserach works, some are conducted by some of our developers and the others are research projects open-sourced by other organizations. We would like to credit these amazing projects below in the IEEE citation format.
+The Colossal-AI project aims to provide a wide array of parallelism techniques for the machine learning community in the big-model era. This project is inspired by quite a few research works, some are conducted by some of our developers and the others are research projects open-sourced by other organizations. We would like to credit these amazing projects below in the IEEE citation format.
## By Our Team
diff --git a/docs/sidebars.json b/docs/sidebars.json
index 44287c17eadf..8be40e4512f9 100644
--- a/docs/sidebars.json
+++ b/docs/sidebars.json
@@ -26,8 +26,11 @@
"collapsed": true,
"items": [
"basics/command_line_tool",
- "basics/define_your_config",
"basics/launch_colossalai",
+ "basics/booster_api",
+ "basics/booster_plugins",
+ "basics/booster_checkpoint",
+ "basics/define_your_config",
"basics/initialize_features",
"basics/engine_trainer",
"basics/configure_parallelization",
@@ -40,8 +43,11 @@
"label": "Features",
"collapsed": true,
"items": [
+ "features/mixed_precision_training_with_booster",
"features/mixed_precision_training",
+ "features/gradient_accumulation_with_booster",
"features/gradient_accumulation",
+ "features/gradient_clipping_with_booster",
"features/gradient_clipping",
"features/gradient_handler",
"features/zero_with_chunk",
@@ -57,7 +63,8 @@
]
},
"features/pipeline_parallel",
- "features/nvme_offload"
+ "features/nvme_offload",
+ "features/cluster_utils"
]
},
{
diff --git a/docs/source/en/advanced_tutorials/add_your_parallel.md b/docs/source/en/advanced_tutorials/add_your_parallel.md
index be7284a7ab64..1caf58c8734e 100644
--- a/docs/source/en/advanced_tutorials/add_your_parallel.md
+++ b/docs/source/en/advanced_tutorials/add_your_parallel.md
@@ -56,7 +56,7 @@ follow the steps below to create a new distributed initialization.
world_size: int,
config: Config,
data_parallel_size: int,
- pipeline_parlalel_size: int,
+ pipeline_parallel_size: int,
tensor_parallel_size: int,
arg1,
arg2):
diff --git a/docs/source/en/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md b/docs/source/en/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
index e01caf76d2b3..d5edd135c079 100644
--- a/docs/source/en/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
+++ b/docs/source/en/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
@@ -121,7 +121,7 @@ Inside the initialization of Experts, the local expert number of each GPU will b
## Train Your Model
-Do not to forget to use `colossalai.initialize` function in `colosalai` to add gradient handler for the engine.
+Do not to forget to use `colossalai.initialize` function in `colossalai` to add gradient handler for the engine.
We handle the back-propagation of MoE models for you.
In `colossalai.initialize`, we will automatically create a `MoeGradientHandler` object to process gradients.
You can find more information about the handler `MoeGradientHandler` in colossal directory.
diff --git a/docs/source/en/advanced_tutorials/meet_gemini.md b/docs/source/en/advanced_tutorials/meet_gemini.md
index 8afb6705b6ae..c1c23a355efa 100644
--- a/docs/source/en/advanced_tutorials/meet_gemini.md
+++ b/docs/source/en/advanced_tutorials/meet_gemini.md
@@ -9,16 +9,21 @@ When you only have a few GPUs for large model training tasks, **heterogeneous tr
## Usage
-At present, Gemini supports compatibility with ZeRO parallel mode, and it is really simple to use Gemini. Set attribute of zero model_config, i.e., tensor_placement_policy='auto'.
-
-```
-zero = dict(
- model_config=dict(
- tensor_placement_policy='auto',
- shard_strategy=BucketTensorShardStrategy()
- ),
- optimizer_config=dict(
- ...)
+At present, Gemini supports compatibility with ZeRO parallel mode, and it is really simple to use Gemini: Inject the feathures of `GeminiPlugin` into training components with `booster`. More instructions of `booster` please refer to [**usage of booster**](../basics/booster_api.md).
+
+```python
+from torchvision.models import resnet18
+from colossalai.booster import Booster
+from colossalai.zero import ColoInitContext
+from colossalai.booster.plugin import GeminiPlugin
+plugin = GeminiPlugin(placement_policy='cuda', strict_ddp_mode=True, max_norm=1.0, initial_scale=2**5)
+booster = Booster(plugin=plugin)
+ctx = ColoInitContext()
+with ctx:
+ model = resnet18()
+optimizer = HybridAdam(model.parameters(), lr=1e-3)
+criterion = lambda x: x.mean()
+model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
)
```
@@ -86,3 +91,5 @@ The important duty of MSC is to adjust the tensor layout position. For example,
In the warmup stage, since we haven't finished a complete iteration yet, we don't know actual memory occupation. At this time, we limit the upper bound of memory usage of the model data. For example, only 30% of the GPU memory can be used. This ensures that we can successfully complete the warmup state.
In the non-warmup stage, we need to use the memory information of non-model data collected in the warm-up stage to reserve the peak memory required by the computing device for the next Period, which requires us to move some model tensors. In order to avoid frequent replacement of the same tensor in and out of the CPU-GPU, causing a phenomenon similar to [cache thrashing](https://en.wikipedia.org/wiki/Thrashing_(computer_science)). Using the iterative characteristics of DNN training, we design the OPT cache swap out strategy. Specifically, in the warmup stage, we record the sampling time required by each tensor computing device. If we need to expel some HOLD tensors, we will choose the latest tensor needed on this device as the victim.
+
+
diff --git a/docs/source/en/advanced_tutorials/opt_service.md b/docs/source/en/advanced_tutorials/opt_service.md
index a43ec7fdd1fe..eccfa12f9389 100644
--- a/docs/source/en/advanced_tutorials/opt_service.md
+++ b/docs/source/en/advanced_tutorials/opt_service.md
@@ -53,7 +53,7 @@ export CHECKPOINT_DIR="your_opt_checkpoint_path"
# the ${CONFIG_DIR} must contain a server.sh file as the entry of service
export CONFIG_DIR="config_file_path"
-docker run --gpus all --rm -it -p 8020:8020 -v ${CHECKPOINT_DIR}:/model_checkpoint -v ${CONFIG_DIR}:/config --ipc=host energonai:lastest
+docker run --gpus all --rm -it -p 8020:8020 -v ${CHECKPOINT_DIR}:/model_checkpoint -v ${CONFIG_DIR}:/config --ipc=host energonai:latest
```
Then open `https://[IP-ADDRESS]:8020/docs#` in your browser to try out!
diff --git a/docs/source/en/advanced_tutorials/parallelize_your_training_like_Megatron.md b/docs/source/en/advanced_tutorials/parallelize_your_training_like_Megatron.md
index e7698e5e9d1b..22d52fb3cd1a 100644
--- a/docs/source/en/advanced_tutorials/parallelize_your_training_like_Megatron.md
+++ b/docs/source/en/advanced_tutorials/parallelize_your_training_like_Megatron.md
@@ -69,7 +69,7 @@ After the forward operation of the embedding module, each word in all sequences
The embedding module
-Each transformer layer contains two blocks. The self-attention operation is called in the first block and a two-layer percepton is located in the second block.
+Each transformer layer contains two blocks. The self-attention operation is called in the first block and a two-layer perception is located in the second block.
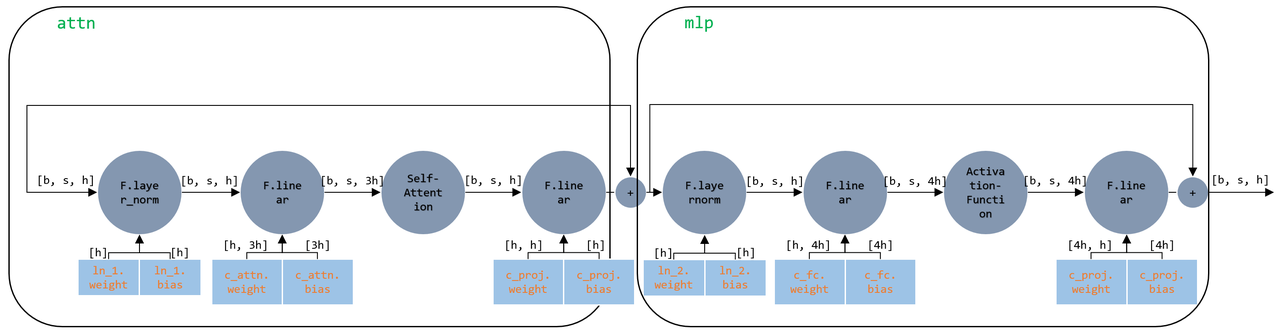 @@ -175,11 +175,11 @@ In this way, users can train their models as usual.
In our latest example, a Gemini + ZeRO DDP model is also defined to reduce overhead and improve efficiency.For the details of this part, please refer to [ZeRO](../features/zero_with_chunk.md). You can combine these two parts to understand our entire training process:
```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
return model
diff --git a/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md b/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md
index b26599740c5f..6adfe4f113da 100644
--- a/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md
+++ b/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md
@@ -195,7 +195,7 @@ def build_cifar(batch_size):
## Training ViT using pipeline
-You can set the size of pipeline parallel and number of microbatches in config. `NUM_CHUNKS` is useful when using interleved-pipeline (for more details see [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://arxiv.org/abs/2104.04473) ). The original batch will be split into `num_microbatches`, and each stage will load a micro batch each time. Then we will generate an approriate schedule for you to execute the pipeline training. If you don't need the output and label of model, you can set `return_output_label` to `False` when calling `trainer.fit()` which can further reduce GPU memory usage.
+You can set the size of pipeline parallel and number of microbatches in config. `NUM_CHUNKS` is useful when using interleaved-pipeline (for more details see [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://arxiv.org/abs/2104.04473) ). The original batch will be split into `num_microbatches`, and each stage will load a micro batch each time. Then we will generate an appropriate schedule for you to execute the pipeline training. If you don't need the output and label of model, you can set `return_output_label` to `False` when calling `trainer.fit()` which can further reduce GPU memory usage.
You should `export DATA=/path/to/cifar`.
diff --git a/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md b/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
index b2438a1cf562..a2deaeb88893 100644
--- a/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
+++ b/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
@@ -16,14 +16,14 @@ In this example for ViT model, Colossal-AI provides three different parallelism
We will show you how to train ViT on CIFAR-10 dataset with these parallelism techniques. To run this example, you will need 2-4 GPUs.
-## Tabel of Contents
+## Table of Contents
1. Colossal-AI installation
2. Steps to train ViT with data parallelism
3. Steps to train ViT with pipeline parallelism
4. Steps to train ViT with tensor parallelism or hybrid parallelism
## Colossal-AI Installation
-You can install Colossal-AI pacakage and its dependencies with PyPI.
+You can install Colossal-AI package and its dependencies with PyPI.
```bash
pip install colossalai
```
@@ -31,7 +31,7 @@ pip install colossalai
## Data Parallelism
-Data parallism is one basic way to accelerate model training process. You can apply data parallelism to training by only two steps:
+Data parallelism is one basic way to accelerate model training process. You can apply data parallelism to training by only two steps:
1. Define a configuration file
2. Change a few lines of code in train script
@@ -94,7 +94,7 @@ from torchvision import transforms
from torchvision.datasets import CIFAR10
```
-#### Lauch Colossal-AI
+#### Launch Colossal-AI
In train script, you need to initialize the distributed environment for Colossal-AI after your config file is prepared. We call this process `launch`. In Colossal-AI, we provided several launch methods to initialize the distributed backend. In most cases, you can use `colossalai.launch` and `colossalai.get_default_parser` to pass the parameters via command line. Besides, Colossal-AI can utilize the existing launch tool provided by PyTorch as many users are familiar with by using `colossalai.launch_from_torch`. For more details, you can view the related [documents](https://www.colossalai.org/docs/basics/launch_colossalai).
@@ -613,7 +613,7 @@ NUM_MICRO_BATCHES = parallel['pipeline']
TENSOR_SHAPE = (BATCH_SIZE // NUM_MICRO_BATCHES, SEQ_LENGTH, HIDDEN_SIZE)
```
-Ohter configs:
+Other configs:
```python
# hyper parameters
# BATCH_SIZE is as per GPU
diff --git a/docs/source/en/basics/booster_api.md b/docs/source/en/basics/booster_api.md
new file mode 100644
index 000000000000..a446ff31be83
--- /dev/null
+++ b/docs/source/en/basics/booster_api.md
@@ -0,0 +1,71 @@
+# Booster API
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite:**
+- [Distributed Training](../concepts/distributed_training.md)
+- [Colossal-AI Overview](../concepts/colossalai_overview.md)
+
+**Example Code**
+- [Train with Booster](https://github.com/hpcaitech/ColossalAI/blob/main/examples/tutorial/new_api/cifar_resnet/README.md)
+
+## Introduction
+In our new design, `colossalai.booster` replaces the role of `colossalai.initialize` to inject features into your training components (e.g. model, optimizer, dataloader) seamlessly. With these new APIs, you can integrate your model with our parallelism features more friendly. Also calling `colossalai.booster` is the standard procedure before you run into your training loops. In the sections below, I will cover how `colossalai.booster` works and what we should take note of.
+
+### Plugin
+Plugin is an important component that manages parallel configuration (eg: The gemini plugin encapsulates the gemini acceleration solution). Currently supported plugins are as follows:
+
+***GeminiPlugin:*** This plugin wraps the Gemini acceleration solution, that ZeRO with chunk-based memory management.
+
+***TorchDDPPlugin:*** This plugin wraps the DDP acceleration solution, it implements data parallelism at the module level which can run across multiple machines.
+
+***LowLevelZeroPlugin:*** This plugin wraps the 1/2 stage of Zero Redundancy Optimizer. Stage 1 : Shards optimizer states across data parallel workers/GPUs. Stage 2 : Shards optimizer states + gradients across data parallel workers/GPUs.
+
+### API of booster
+
+
+{{ autodoc:colossalai.booster.Booster }}
+
+## Usage
+In a typical workflow, you should launch distributed environment at the beginning of training script and create objects needed (such as models, optimizers, loss function, data loaders etc.) firstly, then call `colossalai.booster` to inject features into these objects, After that, you can use our booster APIs and these returned objects to continue the rest of your training processes.
+
+A pseudo-code example is like below:
+
+```python
+import torch
+from torch.optim import SGD
+from torchvision.models import resnet18
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+
+def train():
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ plugin = TorchDDPPlugin()
+ booster = Booster(plugin=plugin)
+ model = resnet18()
+ criterion = lambda x: x.mean()
+ optimizer = SGD((model.parameters()), lr=0.001)
+ scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1)
+ model, optimizer, criterion, _, scheduler = booster.boost(model, optimizer, criterion, lr_scheduler=scheduler)
+
+ x = torch.randn(4, 3, 224, 224)
+ x = x.to('cuda')
+ output = model(x)
+ loss = criterion(output)
+ booster.backward(loss, optimizer)
+ optimizer.clip_grad_by_norm(1.0)
+ optimizer.step()
+ scheduler.step()
+
+ save_path = "./model"
+ booster.save_model(model, save_path, True, True, "", 10, use_safetensors=use_safetensors)
+
+ new_model = resnet18()
+ booster.load_model(new_model, save_path)
+```
+
+[more design details](https://github.com/hpcaitech/ColossalAI/discussions/3046)
+
+
+
diff --git a/docs/source/en/basics/booster_checkpoint.md b/docs/source/en/basics/booster_checkpoint.md
new file mode 100644
index 000000000000..adc0af60b7de
--- /dev/null
+++ b/docs/source/en/basics/booster_checkpoint.md
@@ -0,0 +1,48 @@
+# Booster Checkpoint
+
+Author: [Hongxin Liu](https://github.com/ver217)
+
+**Prerequisite:**
+- [Booster API](./booster_api.md)
+
+## Introduction
+
+We've introduced the [Booster API](./booster_api.md) in the previous tutorial. In this tutorial, we will introduce how to save and load checkpoints using booster.
+
+## Model Checkpoint
+
+{{ autodoc:colossalai.booster.Booster.save_model }}
+
+Model must be boosted by `colossalai.booster.Booster` before saving. `checkpoint` is the path to saved checkpoint. It can be a file, if `shard=False`. Otherwise, it should be a directory. If `shard=True`, the checkpoint will be saved in a sharded way. This is useful when the checkpoint is too large to be saved in a single file. Our sharded checkpoint format is compatible with [huggingface/transformers](https://github.com/huggingface/transformers).
+
+{{ autodoc:colossalai.booster.Booster.load_model }}
+
+Model must be boosted by `colossalai.booster.Booster` before loading. It will detect the checkpoint format automatically, and load in corresponding way.
+
+## Optimizer Checkpoint
+
+> ⚠ Saving optimizer checkpoint in a sharded way is not supported yet.
+
+{{ autodoc:colossalai.booster.Booster.save_optimizer }}
+
+Optimizer must be boosted by `colossalai.booster.Booster` before saving.
+
+{{ autodoc:colossalai.booster.Booster.load_optimizer }}
+
+Optimizer must be boosted by `colossalai.booster.Booster` before loading.
+
+## LR Scheduler Checkpoint
+
+{{ autodoc:colossalai.booster.Booster.save_lr_scheduler }}
+
+LR scheduler must be boosted by `colossalai.booster.Booster` before saving. `checkpoint` is the local path to checkpoint file.
+
+{{ autodoc:colossalai.booster.Booster.load_lr_scheduler }}
+
+LR scheduler must be boosted by `colossalai.booster.Booster` before loading. `checkpoint` is the local path to checkpoint file.
+
+## Checkpoint design
+
+More details about checkpoint design can be found in our discussion [A Unified Checkpoint System Design](https://github.com/hpcaitech/ColossalAI/discussions/3339).
+
+
diff --git a/docs/source/en/basics/booster_plugins.md b/docs/source/en/basics/booster_plugins.md
new file mode 100644
index 000000000000..5e2586b836ad
--- /dev/null
+++ b/docs/source/en/basics/booster_plugins.md
@@ -0,0 +1,74 @@
+# Booster Plugins
+
+Author: [Hongxin Liu](https://github.com/ver217)
+
+**Prerequisite:**
+- [Booster API](./booster_api.md)
+
+## Introduction
+
+As mentioned in [Booster API](./booster_api.md), we can use booster plugins to customize the parallel training. In this tutorial, we will introduce how to use booster plugins.
+
+We currently provide the following plugins:
+
+- [Low Level Zero Plugin](#low-level-zero-plugin): It wraps the `colossalai.zero.low_level.LowLevelZeroOptimizer` and can be used to train models with zero-dp. It only supports zero stage-1 and stage-2.
+- [Gemini Plugin](#gemini-plugin): It wraps the [Gemini](../features/zero_with_chunk.md) which implements Zero-3 with chunk-based and heterogeneous memory management.
+- [Torch DDP Plugin](#torch-ddp-plugin): It is a wrapper of `torch.nn.parallel.DistributedDataParallel` and can be used to train models with data parallelism.
+- [Torch FSDP Plugin](#torch-fsdp-plugin): It is a wrapper of `torch.distributed.fsdp.FullyShardedDataParallel` and can be used to train models with zero-dp.
+
+More plugins are coming soon.
+
+## Plugins
+
+### Low Level Zero Plugin
+
+This plugin implements Zero-1 and Zero-2 (w/wo CPU offload), using `reduce` and `gather` to synchronize gradients and weights.
+
+Zero-1 can be regarded as a better substitute of Torch DDP, which is more memory efficient and faster. It can be easily used in hybrid parallelism.
+
+Zero-2 does not support local gradient accumulation. Though you can accumulate gradient if you insist, it cannot reduce communication cost. That is to say, it's not a good idea to use Zero-2 with pipeline parallelism.
+
+{{ autodoc:colossalai.booster.plugin.LowLevelZeroPlugin }}
+
+We've tested compatibility on some famous models, following models may not be supported:
+
+- `timm.models.convit_base`
+- dlrm and deepfm models in `torchrec`
+- `diffusers.VQModel`
+- `transformers.AlbertModel`
+- `transformers.AlbertForPreTraining`
+- `transformers.BertModel`
+- `transformers.BertForPreTraining`
+- `transformers.GPT2DoubleHeadsModel`
+
+Compatibility problems will be fixed in the future.
+
+> ⚠ This plugin can only load optimizer checkpoint saved by itself with the same number of processes now. This will be fixed in the future.
+
+### Gemini Plugin
+
+This plugin implements Zero-3 with chunk-based and heterogeneous memory management. It can train large models without much loss in speed. It also does not support local gradient accumulation. More details can be found in [Gemini Doc](../features/zero_with_chunk.md).
+
+{{ autodoc:colossalai.booster.plugin.GeminiPlugin }}
+
+> ⚠ This plugin can only load optimizer checkpoint saved by itself with the same number of processes now. This will be fixed in the future.
+
+### Torch DDP Plugin
+
+More details can be found in [Pytorch Docs](https://pytorch.org/docs/main/generated/torch.nn.parallel.DistributedDataParallel.html#torch.nn.parallel.DistributedDataParallel).
+
+{{ autodoc:colossalai.booster.plugin.TorchDDPPlugin }}
+
+### Torch FSDP Plugin
+
+> ⚠ This plugin is not available when torch version is lower than 1.12.0.
+
+> ⚠ This plugin does not support save/load sharded model checkpoint now.
+
+> ⚠ This plugin does not support optimizer that use multi params group.
+
+More details can be found in [Pytorch Docs](https://pytorch.org/docs/main/fsdp.html).
+
+{{ autodoc:colossalai.booster.plugin.TorchFSDPPlugin }}
+
+
diff --git a/docs/source/en/basics/colotensor_concept.md b/docs/source/en/basics/colotensor_concept.md
index 909c5e4d3c6f..abe470fe0794 100644
--- a/docs/source/en/basics/colotensor_concept.md
+++ b/docs/source/en/basics/colotensor_concept.md
@@ -2,6 +2,8 @@
Author: [Jiarui Fang](https://github.com/feifeibear), [Hongxin Liu](https://github.com/ver217) and [Haichen Huang](https://github.com/1SAA)
+> ⚠️ The information on this page is outdated and will be deprecated.
+
**Prerequisite:**
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
- [Distributed Training](../concepts/distributed_training.md)
@@ -50,7 +52,7 @@ An instance of class [ComputeSpec](https://colossalai.readthedocs.io/en/latest/c
## Example
-Let's see an example. A ColoTensor is initialized and sharded on 8 GPUs using tp_degree=4, dp_dgree=2. And then the tensor is sharded along the last dim among the TP process groups. Finally, we reshard it along the first dim (0 dim) among the TP process groups. We encourage users to run the code and observe the shape of each tensor.
+Let's see an example. A ColoTensor is initialized and sharded on 8 GPUs using tp_degree=4, dp_degree=2. And then the tensor is sharded along the last dim among the TP process groups. Finally, we reshard it along the first dim (0 dim) among the TP process groups. We encourage users to run the code and observe the shape of each tensor.
```python
diff --git a/docs/source/en/basics/configure_parallelization.md b/docs/source/en/basics/configure_parallelization.md
index 4ac0299eac14..fd1e72ccd45a 100644
--- a/docs/source/en/basics/configure_parallelization.md
+++ b/docs/source/en/basics/configure_parallelization.md
@@ -2,6 +2,8 @@
Author: Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster Plugins](../basics/booster_plugins.md) for more information.
+
**Prerequisite:**
- [Distributed Training](../concepts/distributed_training.md)
- [Paradigms of Parallelism](../concepts/paradigms_of_parallelism.md)
diff --git a/docs/source/en/basics/define_your_config.md b/docs/source/en/basics/define_your_config.md
index d2569691b7dc..048ffcacbb8f 100644
--- a/docs/source/en/basics/define_your_config.md
+++ b/docs/source/en/basics/define_your_config.md
@@ -2,6 +2,9 @@
Author: Guangyang Lu, Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster API](../basics/booster_api.md) for more information.
+
+
**Prerequisite:**
- [Distributed Training](../concepts/distributed_training.md)
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
diff --git a/docs/source/en/basics/engine_trainer.md b/docs/source/en/basics/engine_trainer.md
index bbe32ed5a3b5..d2f99563f042 100644
--- a/docs/source/en/basics/engine_trainer.md
+++ b/docs/source/en/basics/engine_trainer.md
@@ -2,6 +2,8 @@
Author: Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster API](../basics/booster_api.md) for more information.
+
**Prerequisite:**
- [Initialize Features](./initialize_features.md)
diff --git a/docs/source/en/basics/initialize_features.md b/docs/source/en/basics/initialize_features.md
index e768d2022ad8..b89017427476 100644
--- a/docs/source/en/basics/initialize_features.md
+++ b/docs/source/en/basics/initialize_features.md
@@ -2,6 +2,8 @@
Author: Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster API](../basics/booster_api.md) for more information.
+
**Prerequisite:**
- [Distributed Training](../concepts/distributed_training.md)
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
diff --git a/docs/source/en/basics/launch_colossalai.md b/docs/source/en/basics/launch_colossalai.md
index be487f8539a5..334757ea75af 100644
--- a/docs/source/en/basics/launch_colossalai.md
+++ b/docs/source/en/basics/launch_colossalai.md
@@ -87,14 +87,13 @@ import colossalai
args = colossalai.get_default_parser().parse_args()
# launch distributed environment
-colossalai.launch(config=,
+colossalai.launch(config=args.config,
rank=args.rank,
world_size=args.world_size,
host=args.host,
port=args.port,
backend=args.backend
)
-
```
@@ -107,12 +106,21 @@ First, we need to set the launch method in our code. As this is a wrapper of the
use `colossalai.launch_from_torch`. The arguments required for distributed environment such as rank, world size, host and port are all set by the PyTorch
launcher and can be read from the environment variable directly.
+config.py
+```python
+BATCH_SIZE = 512
+LEARNING_RATE = 3e-3
+WEIGHT_DECAY = 0.3
+NUM_EPOCHS = 2
+```
+train.py
```python
import colossalai
colossalai.launch_from_torch(
- config=,
+ config="./config.py",
)
+...
```
Next, we can easily start multiple processes with `colossalai run` in your terminal. Below is an example to run the code
diff --git a/docs/source/en/basics/model_checkpoint.md b/docs/source/en/basics/model_checkpoint.md
index 09d44e7c2709..70334f1c41e7 100644
--- a/docs/source/en/basics/model_checkpoint.md
+++ b/docs/source/en/basics/model_checkpoint.md
@@ -2,6 +2,8 @@
Author : Guangyang Lu
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster Checkpoint](../basics/booster_checkpoint.md) for more information.
+
**Prerequisite:**
- [Launch Colossal-AI](./launch_colossalai.md)
- [Initialize Colossal-AI](./initialize_features.md)
diff --git a/docs/source/en/features/1D_tensor_parallel.md b/docs/source/en/features/1D_tensor_parallel.md
index 7577e50400e9..7157af210bc5 100644
--- a/docs/source/en/features/1D_tensor_parallel.md
+++ b/docs/source/en/features/1D_tensor_parallel.md
@@ -7,7 +7,7 @@ Author: Zhengda Bian, Yongbin Li
- [Configure Parallelization](../basics/configure_parallelization.md)
**Example Code**
-- [ColossalAI-Examples 1D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_1d.py)
+- [ColossalAI-Examples 1D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**Related Paper**
- [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://deepakn94.github.io/assets/papers/megatron-sc21.pdf)
@@ -19,15 +19,15 @@ An efficient 1D tensor parallelism implementation was introduced by [Megatron-LM
Let's take a linear layer as an example, which consists of a GEMM $Y = XA$. Given 2 processors, we split the columns of $A$ into $[A_1 ~ A_2]$, and calculate $Y_i = XA_i$ on each processor, which then forms $[Y_1 ~ Y_2] = [XA_1 ~ XA_2]$. This is called a column-parallel fashion.
-When a second linear layer $Z=YB$ follows the column-parallel one, we split $B$ into
-```math
+When a second linear layer $Z=YB$ follows the column-parallel one, we split $B$ into
+$$
\left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
-```
+$$
which is called a row-parallel fashion.
-To calculate
-```math
+To calculate
+$$
Z = [Y_1 ~ Y_2] \left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
-```
+$$
we first calculate $Y_iB_i$ on each processor, then use an all-reduce to aggregate the results as $Z=Y_1B_1+Y_2B_2$.
We also need to note that in the backward pass, the column-parallel linear layer needs to aggregate the gradients of the input tensor $X$, because on each processor $i$ we only have $\dot{X_i}=\dot{Y_i}A_i^T$.
diff --git a/docs/source/en/features/2D_tensor_parallel.md b/docs/source/en/features/2D_tensor_parallel.md
index 7b6c10766099..aae8cc9eef97 100644
--- a/docs/source/en/features/2D_tensor_parallel.md
+++ b/docs/source/en/features/2D_tensor_parallel.md
@@ -8,7 +8,7 @@ Author: Zhengda Bian, Yongbin Li
- [1D Tensor Parallelism](./1D_tensor_parallel.md)
**Example Code**
-- [ColossalAI-Examples - 2D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_2d.py)
+- [ColossalAI-Examples - 2D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**Related Paper**
- [An Efficient 2D Method for Training Super-Large Deep Learning Models](https://arxiv.org/pdf/2104.05343.pdf)
@@ -22,33 +22,33 @@ Let's still take a linear layer $Y = XA$ as an example.
Given $P=q\times q$ processors (necessary condition), e.g. $q=2$, we split both the input $X$ and weight $A$ into
$$
-\left[\begin{matrix} X_{10} & X_{11} \\ X_{00} & X_{01} \end{matrix} \right]
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \end{matrix} \right]
\text{~and~}
-\left[\begin{matrix} A_{10} & A_{11} \\ A_{00} & A_{01} \end{matrix} \right].
+\left[\begin{matrix} A_{00} & A_{01} \\ A_{10} & A_{11} \end{matrix} \right].
$$
The calculation includes $q$ steps. When $t=1$, $X_{i0}$ is broadcasted in its row, and $A_{0j}$ is broadcasted in its column. So, we have
$$
-\left[\begin{matrix} X_{10},A_{00} & X_{10},A_{01} \\ X_{00},A_{00} & X_{00},A_{01} \end{matrix} \right].
+\left[\begin{matrix} X_{00},A_{00} & X_{00},A_{01} \\ X_{10},A_{00} & X_{10},A_{01} \end{matrix} \right].
$$
Then we multiply $X_{i0}$ and $A_{0j}$ on each processor $(i, j)$ as
$$
-\left[\begin{matrix} X_{10}A_{00} & X_{10}A_{01} \\ X_{00}A_{00} & X_{00}A_{01} \end{matrix} \right] (1).
+\left[\begin{matrix} X_{00}A_{00} & X_{00}A_{01} \\ X_{10}A_{00} & X_{10}A_{01} \end{matrix} \right] (1).
$$
Similarly, when $t=2$, $X_{i1}$ is broadcasted in its row, $A_{1j}$ is broadcasted in its column, and we multiply them as
$$
-\left[\begin{matrix} X_{11}A_{10} & X_{11}A_{11} \\ X_{01}A_{10} & X_{01}A_{11} \end{matrix} \right] (2).
+\left[\begin{matrix} X_{01}A_{10} & X_{01}A_{11} \\ X_{11}A_{10} & X_{11}A_{11} \end{matrix} \right] (2).
$$
By adding $(1)$ and $(2)$ up, we have
$$
-Y = XA = \left[\begin{matrix} X_{10}A_{00}+X_{11}A_{10} & X_{10}A_{01}+X_{11}A_{11} \\ X_{00}A_{00}+X_{01}A_{10} & X_{00}A_{01}+X_{01}A_{11} \end{matrix} \right].
+Y = XA = \left[\begin{matrix} X_{00}A_{00}+X_{01}A_{10} & X_{00}A_{01}+X_{01}A_{11} \\ X_{10}A_{00}+X_{11}A_{10} & X_{10}A_{01}+X_{11}A_{11} \end{matrix} \right].
$$
## Efficiency
diff --git a/docs/source/en/features/2p5D_tensor_parallel.md b/docs/source/en/features/2p5D_tensor_parallel.md
index 6076562e6dca..a81d14f10627 100644
--- a/docs/source/en/features/2p5D_tensor_parallel.md
+++ b/docs/source/en/features/2p5D_tensor_parallel.md
@@ -9,7 +9,7 @@ Author: Zhengda Bian, Yongbin Li
- [2D Tensor Parallelism](./2D_tensor_parallel.md)
**Example Code**
-- [ColossalAI-Examples - 2.5D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_2p5d.py)
+- [ColossalAI-Examples - 2.5D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**Related Paper**
- [2.5-dimensional distributed model training](https://arxiv.org/pdf/2105.14500.pdf)
@@ -23,29 +23,30 @@ Let's still take a linear layer $Y = XA$ as an example.
Given $P=q \times q \times d$ processors (necessary condition), e.g. $q=d=2$, we split the input $X$ into $d\times q$ rows and $q$ columns as
$$
-\left[\begin{matrix} X_{30} & X_{31} \\ X_{20} & X_{21} \\ X_{10} & X_{11} \\ X_{00} & X_{01}\end{matrix} \right],
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \\ X_{20} & X_{21} \\ X_{30} & X_{31}\end{matrix} \right],
$$
+
which can be reshaped into $d$ layers as
$$
-\left[\begin{matrix} X_{10} & X_{11} \\ X_{00} & X_{01} \end{matrix} \right] \text{~and~}\left[\begin{matrix} X_{30} & X_{31} \\ X_{20} & X_{21} \end{matrix} \right].
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \end{matrix} \right] \text{~and~}\left[\begin{matrix} X_{20} & X_{21} \\ X_{30} & X_{31} \end{matrix} \right].
$$
Also, the weight $A$ is split into
$$
-\left[\begin{matrix} A_{10} & A_{11} \\ A_{00} & A_{01} \end{matrix} \right].
+\left[\begin{matrix} A_{00} & A_{01} \\ A_{10} & A_{11} \end{matrix} \right].
$$
For each layer of $X$, we use the SUMMA algorithm to multiply $X$ and $A$.
Then, we have the output
$$
-\left[\begin{matrix} Y_{10}=X_{10}A_{00}+X_{11}A_{10} & Y_{11}=X_{10}A_{01}+X_{11}A_{11} \\ Y_{00}=X_{00}A_{00}+X_{01}A_{10} & Y_{01}=X_{00}A_{01}+X_{01}A_{11} \end{matrix} \right]
+\left[\begin{matrix} Y_{00}=X_{00}A_{00}+X_{01}A_{10} & Y_{01}=X_{00}A_{01}+X_{01}A_{11} \\ Y_{10}=X_{10}A_{00}+X_{11}A_{10} & Y_{11}=X_{10}A_{01}+X_{11}A_{11} \end{matrix} \right]
\text{~and~}
$$
$$
-\left[\begin{matrix} Y_{30}=X_{30}A_{00}+X_{31}A_{10} & Y_{31}=X_{30}A_{01}+X_{31}A_{11} \\ Y_{20}=X_{20}A_{00}+X_{21}A_{10} & Y_{21}=X_{20}A_{01}+X_{21}A_{11} \end{matrix} \right].
+\left[\begin{matrix} Y_{20}=X_{20}A_{00}+X_{21}A_{10} & Y_{21}=X_{20}A_{01}+X_{21}A_{11} \\ Y_{30}=X_{30}A_{00}+X_{31}A_{10} & Y_{31}=X_{30}A_{01}+X_{31}A_{11} \end{matrix} \right].
$$
## Efficiency
diff --git a/docs/source/en/features/3D_tensor_parallel.md b/docs/source/en/features/3D_tensor_parallel.md
index 1207376335ce..0e28f08b23c9 100644
--- a/docs/source/en/features/3D_tensor_parallel.md
+++ b/docs/source/en/features/3D_tensor_parallel.md
@@ -9,7 +9,7 @@ Author: Zhengda Bian, Yongbin Li
- [2D Tensor Parallelism](./2D_tensor_parallel.md)
**Example Code**
-- [ColossalAI-Examples - 3D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_3d.py)
+- [ColossalAI-Examples - 3D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**Related Paper**
- [Maximizing Parallelism in Distributed Training for Huge Neural Networks](https://arxiv.org/pdf/2105.14450.pdf)
@@ -67,7 +67,7 @@ Given $P=q \times q \times q$ processors, we present the theoretical computation
## Usage
-To enable 3D tensor parallelism for our model, e.g. on 8 GPUs, we need to configure the parallism setting as below.
+To enable 3D tensor parallelism for our model, e.g. on 8 GPUs, we need to configure the parallelism setting as below.
```python
CONFIG = dict(parallel=dict(
data=1,
diff --git a/docs/source/en/features/cluster_utils.md b/docs/source/en/features/cluster_utils.md
new file mode 100644
index 000000000000..7331d5e73ae0
--- /dev/null
+++ b/docs/source/en/features/cluster_utils.md
@@ -0,0 +1,16 @@
+# Cluster Utilities
+
+Author: [Hongxin Liu](https://github.com/ver217)
+
+**Prerequisite:**
+- [Distributed Training](../concepts/distributed_training.md)
+
+## Introduction
+
+We provide a utility class `colossalai.cluster.DistCoordinator` to coordinate distributed training. It's useful to get various information about the cluster, such as the number of nodes, the number of processes per node, etc.
+
+## API Reference
+
+{{ autodoc:colossalai.cluster.DistCoordinator }}
+
+
diff --git a/docs/source/en/features/gradient_accumulation.md b/docs/source/en/features/gradient_accumulation.md
index ecc209fbac8d..91d89b815bf7 100644
--- a/docs/source/en/features/gradient_accumulation.md
+++ b/docs/source/en/features/gradient_accumulation.md
@@ -1,4 +1,4 @@
-# Gradient Accumulation
+# Gradient Accumulation (Outdated)
Author: Shenggui Li, Yongbin Li
@@ -43,3 +43,5 @@ iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0
iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
```
+
+
diff --git a/docs/source/en/features/gradient_accumulation_with_booster.md b/docs/source/en/features/gradient_accumulation_with_booster.md
new file mode 100644
index 000000000000..201e3bc2b643
--- /dev/null
+++ b/docs/source/en/features/gradient_accumulation_with_booster.md
@@ -0,0 +1,144 @@
+# Gradient Accumulation (Latest)
+
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+## Introduction
+
+Gradient accumulation is a common way to enlarge your batch size for training. When training large-scale models, memory can easily become the bottleneck and the batch size can be very small, (e.g. 2), leading to unsatisfactory convergence. Gradient accumulation works by adding up the gradients calculated in multiple iterations, and only update the parameters in the preset iteration.
+
+## Usage
+
+It is simple to use gradient accumulation in Colossal-AI. Just call `booster.no_sync()` which returns a context manager. It accumulate gradients without synchronization, meanwhile you should not update the weights.
+
+## Hands-on Practice
+
+We now demonstrate gradient accumulation. In this example, we let the gradient accumulation size to be 4.
+
+### Step 1. Import libraries in train.py
+Create a `train.py` and import the necessary dependencies. The version of `torch` should not be lower than 1.8.1.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet18
+from torch.utils.data import DataLoader
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.cluster.dist_coordinator import priority_execution
+```
+
+### Step 2. Initialize Distributed Environment
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md) for other initialization methods.
+
+```python
+# initialize distributed setting
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+```
+
+### Step 3. Create training components
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])` to a path on your machine. Data will be automatically downloaded to the root path.
+
+```python
+# define the training hyperparameters
+BATCH_SIZE = 128
+GRADIENT_ACCUMULATION = 4
+
+# build resnet
+model = resnet18(num_classes=10)
+
+# build dataloaders
+with priority_execution():
+ train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+```
+
+### Step 4. Inject Feature
+Create a `TorchDDPPlugin` object to instantiate a `Booster`, and boost these training components.
+
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, _ = booster.boost(model=model,
+ optimizer=optimizer,
+ criterion=criterion,
+ dataloader=train_dataloader)
+```
+
+### Step 5. Train with Booster
+Use booster in a normal training loops, and verify gradient accumulation. `param_by_iter` is to record the distributed training information.
+```python
+optimizer.zero_grad()
+for idx, (img, label) in enumerate(train_dataloader):
+ sync_context = booster.no_sync(model)
+ img = img.cuda()
+ label = label.cuda()
+ if idx % (GRADIENT_ACCUMULATION - 1) != 0:
+ with sync_context:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ else:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.step()
+ optimizer.zero_grad()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ param_by_iter.append(str(ele_1st.item()))
+
+ if idx != 0 and idx % (GRADIENT_ACCUMULATION - 1) == 0:
+ break
+
+ for iteration, val in enumerate(param_by_iter):
+ print(f'iteration {iteration} - value: {val}')
+
+ if param_by_iter[-1] != param_by_iter[0]:
+ print('The parameter is only updated in the last iteration')
+
+```
+
+### Step 6. Invoke Training Scripts
+To verify gradient accumulation, we can just check the change of parameter values. When gradient accumulation is set, parameters are only updated in the last step. You can run the script using this command:
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
+You will see output similar to the text below. This shows gradient is indeed accumulated as the parameter is not updated
+in the first 3 steps, but only updated in the last step.
+
+```text
+iteration 0, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
+```
+
+
diff --git a/docs/source/en/features/gradient_clipping.md b/docs/source/en/features/gradient_clipping.md
index f606dde6c393..5a23c68e3e27 100644
--- a/docs/source/en/features/gradient_clipping.md
+++ b/docs/source/en/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# Gradient Clipping
+# Gradient Clipping (Outdated)
Author: Boxiang Wang, Haichen Huang, Yongbin Li
@@ -60,3 +60,5 @@ to demonstrate gradient clipping. In this example, we set the gradient clipping
```shell
python -m torch.distributed.launch --nproc_per_node 1 --master_addr localhost --master_port 29500 train_with_engine.py
```
+
+
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
new file mode 100644
index 000000000000..341a608a5c7b
--- /dev/null
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -0,0 +1,142 @@
+# Gradient Clipping (Latest)
+
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+**Related Paper**
+- [On the difficulty of training Recurrent Neural Networks](https://arxiv.org/abs/1211.5063)
+
+## Introduction
+
+In order to speed up training process and seek global optimum for better performance, more and more learning rate schedulers have been proposed. People turn to control learning rate to adjust descent pace during training, which makes gradient vector better to be uniformed in every step. In that case, the descent pace can be controlled as expected. As a result, gradient clipping, a technique which can normalize the gradient vector to circumscribe it in a uniformed length, becomes indispensable for those who desire their better performance of their models.
+
+You do not have to worry about implementing gradient clipping when using Colossal-AI, we support gradient clipping in a powerful and convenient way. All you need is just an additional command in your configuration file.
+
+## Why you should use gradient clipping provided by Colossal-AI
+
+The reason of why we do not recommend users to write gradient clipping by themselves is that naive gradient clipping may fail when applying tensor parallelism, pipeline parallelism or MoE.
+
+According to the illustration below, each GPU only owns a portion of parameters of the weight in a linear layer. To get correct norm of gradient vector of the weight of the linear layer, the norm of every gradient vector in each GPU should be summed together. More complicated thing is that the distribution of bias is different from the distribution of the weight. The communication group is different in the sum operation.
+
+(PS: This situation is an old version of 2D parallelism, the implementation in the code is not the same. But it is a good example about the difficulty to unify all communication in gradient clipping.)
+
+
+
@@ -175,11 +175,11 @@ In this way, users can train their models as usual.
In our latest example, a Gemini + ZeRO DDP model is also defined to reduce overhead and improve efficiency.For the details of this part, please refer to [ZeRO](../features/zero_with_chunk.md). You can combine these two parts to understand our entire training process:
```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
return model
diff --git a/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md b/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md
index b26599740c5f..6adfe4f113da 100644
--- a/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md
+++ b/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md
@@ -195,7 +195,7 @@ def build_cifar(batch_size):
## Training ViT using pipeline
-You can set the size of pipeline parallel and number of microbatches in config. `NUM_CHUNKS` is useful when using interleved-pipeline (for more details see [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://arxiv.org/abs/2104.04473) ). The original batch will be split into `num_microbatches`, and each stage will load a micro batch each time. Then we will generate an approriate schedule for you to execute the pipeline training. If you don't need the output and label of model, you can set `return_output_label` to `False` when calling `trainer.fit()` which can further reduce GPU memory usage.
+You can set the size of pipeline parallel and number of microbatches in config. `NUM_CHUNKS` is useful when using interleaved-pipeline (for more details see [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://arxiv.org/abs/2104.04473) ). The original batch will be split into `num_microbatches`, and each stage will load a micro batch each time. Then we will generate an appropriate schedule for you to execute the pipeline training. If you don't need the output and label of model, you can set `return_output_label` to `False` when calling `trainer.fit()` which can further reduce GPU memory usage.
You should `export DATA=/path/to/cifar`.
diff --git a/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md b/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
index b2438a1cf562..a2deaeb88893 100644
--- a/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
+++ b/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
@@ -16,14 +16,14 @@ In this example for ViT model, Colossal-AI provides three different parallelism
We will show you how to train ViT on CIFAR-10 dataset with these parallelism techniques. To run this example, you will need 2-4 GPUs.
-## Tabel of Contents
+## Table of Contents
1. Colossal-AI installation
2. Steps to train ViT with data parallelism
3. Steps to train ViT with pipeline parallelism
4. Steps to train ViT with tensor parallelism or hybrid parallelism
## Colossal-AI Installation
-You can install Colossal-AI pacakage and its dependencies with PyPI.
+You can install Colossal-AI package and its dependencies with PyPI.
```bash
pip install colossalai
```
@@ -31,7 +31,7 @@ pip install colossalai
## Data Parallelism
-Data parallism is one basic way to accelerate model training process. You can apply data parallelism to training by only two steps:
+Data parallelism is one basic way to accelerate model training process. You can apply data parallelism to training by only two steps:
1. Define a configuration file
2. Change a few lines of code in train script
@@ -94,7 +94,7 @@ from torchvision import transforms
from torchvision.datasets import CIFAR10
```
-#### Lauch Colossal-AI
+#### Launch Colossal-AI
In train script, you need to initialize the distributed environment for Colossal-AI after your config file is prepared. We call this process `launch`. In Colossal-AI, we provided several launch methods to initialize the distributed backend. In most cases, you can use `colossalai.launch` and `colossalai.get_default_parser` to pass the parameters via command line. Besides, Colossal-AI can utilize the existing launch tool provided by PyTorch as many users are familiar with by using `colossalai.launch_from_torch`. For more details, you can view the related [documents](https://www.colossalai.org/docs/basics/launch_colossalai).
@@ -613,7 +613,7 @@ NUM_MICRO_BATCHES = parallel['pipeline']
TENSOR_SHAPE = (BATCH_SIZE // NUM_MICRO_BATCHES, SEQ_LENGTH, HIDDEN_SIZE)
```
-Ohter configs:
+Other configs:
```python
# hyper parameters
# BATCH_SIZE is as per GPU
diff --git a/docs/source/en/basics/booster_api.md b/docs/source/en/basics/booster_api.md
new file mode 100644
index 000000000000..a446ff31be83
--- /dev/null
+++ b/docs/source/en/basics/booster_api.md
@@ -0,0 +1,71 @@
+# Booster API
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite:**
+- [Distributed Training](../concepts/distributed_training.md)
+- [Colossal-AI Overview](../concepts/colossalai_overview.md)
+
+**Example Code**
+- [Train with Booster](https://github.com/hpcaitech/ColossalAI/blob/main/examples/tutorial/new_api/cifar_resnet/README.md)
+
+## Introduction
+In our new design, `colossalai.booster` replaces the role of `colossalai.initialize` to inject features into your training components (e.g. model, optimizer, dataloader) seamlessly. With these new APIs, you can integrate your model with our parallelism features more friendly. Also calling `colossalai.booster` is the standard procedure before you run into your training loops. In the sections below, I will cover how `colossalai.booster` works and what we should take note of.
+
+### Plugin
+Plugin is an important component that manages parallel configuration (eg: The gemini plugin encapsulates the gemini acceleration solution). Currently supported plugins are as follows:
+
+***GeminiPlugin:*** This plugin wraps the Gemini acceleration solution, that ZeRO with chunk-based memory management.
+
+***TorchDDPPlugin:*** This plugin wraps the DDP acceleration solution, it implements data parallelism at the module level which can run across multiple machines.
+
+***LowLevelZeroPlugin:*** This plugin wraps the 1/2 stage of Zero Redundancy Optimizer. Stage 1 : Shards optimizer states across data parallel workers/GPUs. Stage 2 : Shards optimizer states + gradients across data parallel workers/GPUs.
+
+### API of booster
+
+
+{{ autodoc:colossalai.booster.Booster }}
+
+## Usage
+In a typical workflow, you should launch distributed environment at the beginning of training script and create objects needed (such as models, optimizers, loss function, data loaders etc.) firstly, then call `colossalai.booster` to inject features into these objects, After that, you can use our booster APIs and these returned objects to continue the rest of your training processes.
+
+A pseudo-code example is like below:
+
+```python
+import torch
+from torch.optim import SGD
+from torchvision.models import resnet18
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+
+def train():
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ plugin = TorchDDPPlugin()
+ booster = Booster(plugin=plugin)
+ model = resnet18()
+ criterion = lambda x: x.mean()
+ optimizer = SGD((model.parameters()), lr=0.001)
+ scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1)
+ model, optimizer, criterion, _, scheduler = booster.boost(model, optimizer, criterion, lr_scheduler=scheduler)
+
+ x = torch.randn(4, 3, 224, 224)
+ x = x.to('cuda')
+ output = model(x)
+ loss = criterion(output)
+ booster.backward(loss, optimizer)
+ optimizer.clip_grad_by_norm(1.0)
+ optimizer.step()
+ scheduler.step()
+
+ save_path = "./model"
+ booster.save_model(model, save_path, True, True, "", 10, use_safetensors=use_safetensors)
+
+ new_model = resnet18()
+ booster.load_model(new_model, save_path)
+```
+
+[more design details](https://github.com/hpcaitech/ColossalAI/discussions/3046)
+
+
+
diff --git a/docs/source/en/basics/booster_checkpoint.md b/docs/source/en/basics/booster_checkpoint.md
new file mode 100644
index 000000000000..adc0af60b7de
--- /dev/null
+++ b/docs/source/en/basics/booster_checkpoint.md
@@ -0,0 +1,48 @@
+# Booster Checkpoint
+
+Author: [Hongxin Liu](https://github.com/ver217)
+
+**Prerequisite:**
+- [Booster API](./booster_api.md)
+
+## Introduction
+
+We've introduced the [Booster API](./booster_api.md) in the previous tutorial. In this tutorial, we will introduce how to save and load checkpoints using booster.
+
+## Model Checkpoint
+
+{{ autodoc:colossalai.booster.Booster.save_model }}
+
+Model must be boosted by `colossalai.booster.Booster` before saving. `checkpoint` is the path to saved checkpoint. It can be a file, if `shard=False`. Otherwise, it should be a directory. If `shard=True`, the checkpoint will be saved in a sharded way. This is useful when the checkpoint is too large to be saved in a single file. Our sharded checkpoint format is compatible with [huggingface/transformers](https://github.com/huggingface/transformers).
+
+{{ autodoc:colossalai.booster.Booster.load_model }}
+
+Model must be boosted by `colossalai.booster.Booster` before loading. It will detect the checkpoint format automatically, and load in corresponding way.
+
+## Optimizer Checkpoint
+
+> ⚠ Saving optimizer checkpoint in a sharded way is not supported yet.
+
+{{ autodoc:colossalai.booster.Booster.save_optimizer }}
+
+Optimizer must be boosted by `colossalai.booster.Booster` before saving.
+
+{{ autodoc:colossalai.booster.Booster.load_optimizer }}
+
+Optimizer must be boosted by `colossalai.booster.Booster` before loading.
+
+## LR Scheduler Checkpoint
+
+{{ autodoc:colossalai.booster.Booster.save_lr_scheduler }}
+
+LR scheduler must be boosted by `colossalai.booster.Booster` before saving. `checkpoint` is the local path to checkpoint file.
+
+{{ autodoc:colossalai.booster.Booster.load_lr_scheduler }}
+
+LR scheduler must be boosted by `colossalai.booster.Booster` before loading. `checkpoint` is the local path to checkpoint file.
+
+## Checkpoint design
+
+More details about checkpoint design can be found in our discussion [A Unified Checkpoint System Design](https://github.com/hpcaitech/ColossalAI/discussions/3339).
+
+
diff --git a/docs/source/en/basics/booster_plugins.md b/docs/source/en/basics/booster_plugins.md
new file mode 100644
index 000000000000..5e2586b836ad
--- /dev/null
+++ b/docs/source/en/basics/booster_plugins.md
@@ -0,0 +1,74 @@
+# Booster Plugins
+
+Author: [Hongxin Liu](https://github.com/ver217)
+
+**Prerequisite:**
+- [Booster API](./booster_api.md)
+
+## Introduction
+
+As mentioned in [Booster API](./booster_api.md), we can use booster plugins to customize the parallel training. In this tutorial, we will introduce how to use booster plugins.
+
+We currently provide the following plugins:
+
+- [Low Level Zero Plugin](#low-level-zero-plugin): It wraps the `colossalai.zero.low_level.LowLevelZeroOptimizer` and can be used to train models with zero-dp. It only supports zero stage-1 and stage-2.
+- [Gemini Plugin](#gemini-plugin): It wraps the [Gemini](../features/zero_with_chunk.md) which implements Zero-3 with chunk-based and heterogeneous memory management.
+- [Torch DDP Plugin](#torch-ddp-plugin): It is a wrapper of `torch.nn.parallel.DistributedDataParallel` and can be used to train models with data parallelism.
+- [Torch FSDP Plugin](#torch-fsdp-plugin): It is a wrapper of `torch.distributed.fsdp.FullyShardedDataParallel` and can be used to train models with zero-dp.
+
+More plugins are coming soon.
+
+## Plugins
+
+### Low Level Zero Plugin
+
+This plugin implements Zero-1 and Zero-2 (w/wo CPU offload), using `reduce` and `gather` to synchronize gradients and weights.
+
+Zero-1 can be regarded as a better substitute of Torch DDP, which is more memory efficient and faster. It can be easily used in hybrid parallelism.
+
+Zero-2 does not support local gradient accumulation. Though you can accumulate gradient if you insist, it cannot reduce communication cost. That is to say, it's not a good idea to use Zero-2 with pipeline parallelism.
+
+{{ autodoc:colossalai.booster.plugin.LowLevelZeroPlugin }}
+
+We've tested compatibility on some famous models, following models may not be supported:
+
+- `timm.models.convit_base`
+- dlrm and deepfm models in `torchrec`
+- `diffusers.VQModel`
+- `transformers.AlbertModel`
+- `transformers.AlbertForPreTraining`
+- `transformers.BertModel`
+- `transformers.BertForPreTraining`
+- `transformers.GPT2DoubleHeadsModel`
+
+Compatibility problems will be fixed in the future.
+
+> ⚠ This plugin can only load optimizer checkpoint saved by itself with the same number of processes now. This will be fixed in the future.
+
+### Gemini Plugin
+
+This plugin implements Zero-3 with chunk-based and heterogeneous memory management. It can train large models without much loss in speed. It also does not support local gradient accumulation. More details can be found in [Gemini Doc](../features/zero_with_chunk.md).
+
+{{ autodoc:colossalai.booster.plugin.GeminiPlugin }}
+
+> ⚠ This plugin can only load optimizer checkpoint saved by itself with the same number of processes now. This will be fixed in the future.
+
+### Torch DDP Plugin
+
+More details can be found in [Pytorch Docs](https://pytorch.org/docs/main/generated/torch.nn.parallel.DistributedDataParallel.html#torch.nn.parallel.DistributedDataParallel).
+
+{{ autodoc:colossalai.booster.plugin.TorchDDPPlugin }}
+
+### Torch FSDP Plugin
+
+> ⚠ This plugin is not available when torch version is lower than 1.12.0.
+
+> ⚠ This plugin does not support save/load sharded model checkpoint now.
+
+> ⚠ This plugin does not support optimizer that use multi params group.
+
+More details can be found in [Pytorch Docs](https://pytorch.org/docs/main/fsdp.html).
+
+{{ autodoc:colossalai.booster.plugin.TorchFSDPPlugin }}
+
+
diff --git a/docs/source/en/basics/colotensor_concept.md b/docs/source/en/basics/colotensor_concept.md
index 909c5e4d3c6f..abe470fe0794 100644
--- a/docs/source/en/basics/colotensor_concept.md
+++ b/docs/source/en/basics/colotensor_concept.md
@@ -2,6 +2,8 @@
Author: [Jiarui Fang](https://github.com/feifeibear), [Hongxin Liu](https://github.com/ver217) and [Haichen Huang](https://github.com/1SAA)
+> ⚠️ The information on this page is outdated and will be deprecated.
+
**Prerequisite:**
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
- [Distributed Training](../concepts/distributed_training.md)
@@ -50,7 +52,7 @@ An instance of class [ComputeSpec](https://colossalai.readthedocs.io/en/latest/c
## Example
-Let's see an example. A ColoTensor is initialized and sharded on 8 GPUs using tp_degree=4, dp_dgree=2. And then the tensor is sharded along the last dim among the TP process groups. Finally, we reshard it along the first dim (0 dim) among the TP process groups. We encourage users to run the code and observe the shape of each tensor.
+Let's see an example. A ColoTensor is initialized and sharded on 8 GPUs using tp_degree=4, dp_degree=2. And then the tensor is sharded along the last dim among the TP process groups. Finally, we reshard it along the first dim (0 dim) among the TP process groups. We encourage users to run the code and observe the shape of each tensor.
```python
diff --git a/docs/source/en/basics/configure_parallelization.md b/docs/source/en/basics/configure_parallelization.md
index 4ac0299eac14..fd1e72ccd45a 100644
--- a/docs/source/en/basics/configure_parallelization.md
+++ b/docs/source/en/basics/configure_parallelization.md
@@ -2,6 +2,8 @@
Author: Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster Plugins](../basics/booster_plugins.md) for more information.
+
**Prerequisite:**
- [Distributed Training](../concepts/distributed_training.md)
- [Paradigms of Parallelism](../concepts/paradigms_of_parallelism.md)
diff --git a/docs/source/en/basics/define_your_config.md b/docs/source/en/basics/define_your_config.md
index d2569691b7dc..048ffcacbb8f 100644
--- a/docs/source/en/basics/define_your_config.md
+++ b/docs/source/en/basics/define_your_config.md
@@ -2,6 +2,9 @@
Author: Guangyang Lu, Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster API](../basics/booster_api.md) for more information.
+
+
**Prerequisite:**
- [Distributed Training](../concepts/distributed_training.md)
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
diff --git a/docs/source/en/basics/engine_trainer.md b/docs/source/en/basics/engine_trainer.md
index bbe32ed5a3b5..d2f99563f042 100644
--- a/docs/source/en/basics/engine_trainer.md
+++ b/docs/source/en/basics/engine_trainer.md
@@ -2,6 +2,8 @@
Author: Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster API](../basics/booster_api.md) for more information.
+
**Prerequisite:**
- [Initialize Features](./initialize_features.md)
diff --git a/docs/source/en/basics/initialize_features.md b/docs/source/en/basics/initialize_features.md
index e768d2022ad8..b89017427476 100644
--- a/docs/source/en/basics/initialize_features.md
+++ b/docs/source/en/basics/initialize_features.md
@@ -2,6 +2,8 @@
Author: Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster API](../basics/booster_api.md) for more information.
+
**Prerequisite:**
- [Distributed Training](../concepts/distributed_training.md)
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
diff --git a/docs/source/en/basics/launch_colossalai.md b/docs/source/en/basics/launch_colossalai.md
index be487f8539a5..334757ea75af 100644
--- a/docs/source/en/basics/launch_colossalai.md
+++ b/docs/source/en/basics/launch_colossalai.md
@@ -87,14 +87,13 @@ import colossalai
args = colossalai.get_default_parser().parse_args()
# launch distributed environment
-colossalai.launch(config=,
+colossalai.launch(config=args.config,
rank=args.rank,
world_size=args.world_size,
host=args.host,
port=args.port,
backend=args.backend
)
-
```
@@ -107,12 +106,21 @@ First, we need to set the launch method in our code. As this is a wrapper of the
use `colossalai.launch_from_torch`. The arguments required for distributed environment such as rank, world size, host and port are all set by the PyTorch
launcher and can be read from the environment variable directly.
+config.py
+```python
+BATCH_SIZE = 512
+LEARNING_RATE = 3e-3
+WEIGHT_DECAY = 0.3
+NUM_EPOCHS = 2
+```
+train.py
```python
import colossalai
colossalai.launch_from_torch(
- config=,
+ config="./config.py",
)
+...
```
Next, we can easily start multiple processes with `colossalai run` in your terminal. Below is an example to run the code
diff --git a/docs/source/en/basics/model_checkpoint.md b/docs/source/en/basics/model_checkpoint.md
index 09d44e7c2709..70334f1c41e7 100644
--- a/docs/source/en/basics/model_checkpoint.md
+++ b/docs/source/en/basics/model_checkpoint.md
@@ -2,6 +2,8 @@
Author : Guangyang Lu
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster Checkpoint](../basics/booster_checkpoint.md) for more information.
+
**Prerequisite:**
- [Launch Colossal-AI](./launch_colossalai.md)
- [Initialize Colossal-AI](./initialize_features.md)
diff --git a/docs/source/en/features/1D_tensor_parallel.md b/docs/source/en/features/1D_tensor_parallel.md
index 7577e50400e9..7157af210bc5 100644
--- a/docs/source/en/features/1D_tensor_parallel.md
+++ b/docs/source/en/features/1D_tensor_parallel.md
@@ -7,7 +7,7 @@ Author: Zhengda Bian, Yongbin Li
- [Configure Parallelization](../basics/configure_parallelization.md)
**Example Code**
-- [ColossalAI-Examples 1D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_1d.py)
+- [ColossalAI-Examples 1D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**Related Paper**
- [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://deepakn94.github.io/assets/papers/megatron-sc21.pdf)
@@ -19,15 +19,15 @@ An efficient 1D tensor parallelism implementation was introduced by [Megatron-LM
Let's take a linear layer as an example, which consists of a GEMM $Y = XA$. Given 2 processors, we split the columns of $A$ into $[A_1 ~ A_2]$, and calculate $Y_i = XA_i$ on each processor, which then forms $[Y_1 ~ Y_2] = [XA_1 ~ XA_2]$. This is called a column-parallel fashion.
-When a second linear layer $Z=YB$ follows the column-parallel one, we split $B$ into
-```math
+When a second linear layer $Z=YB$ follows the column-parallel one, we split $B$ into
+$$
\left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
-```
+$$
which is called a row-parallel fashion.
-To calculate
-```math
+To calculate
+$$
Z = [Y_1 ~ Y_2] \left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
-```
+$$
we first calculate $Y_iB_i$ on each processor, then use an all-reduce to aggregate the results as $Z=Y_1B_1+Y_2B_2$.
We also need to note that in the backward pass, the column-parallel linear layer needs to aggregate the gradients of the input tensor $X$, because on each processor $i$ we only have $\dot{X_i}=\dot{Y_i}A_i^T$.
diff --git a/docs/source/en/features/2D_tensor_parallel.md b/docs/source/en/features/2D_tensor_parallel.md
index 7b6c10766099..aae8cc9eef97 100644
--- a/docs/source/en/features/2D_tensor_parallel.md
+++ b/docs/source/en/features/2D_tensor_parallel.md
@@ -8,7 +8,7 @@ Author: Zhengda Bian, Yongbin Li
- [1D Tensor Parallelism](./1D_tensor_parallel.md)
**Example Code**
-- [ColossalAI-Examples - 2D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_2d.py)
+- [ColossalAI-Examples - 2D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**Related Paper**
- [An Efficient 2D Method for Training Super-Large Deep Learning Models](https://arxiv.org/pdf/2104.05343.pdf)
@@ -22,33 +22,33 @@ Let's still take a linear layer $Y = XA$ as an example.
Given $P=q\times q$ processors (necessary condition), e.g. $q=2$, we split both the input $X$ and weight $A$ into
$$
-\left[\begin{matrix} X_{10} & X_{11} \\ X_{00} & X_{01} \end{matrix} \right]
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \end{matrix} \right]
\text{~and~}
-\left[\begin{matrix} A_{10} & A_{11} \\ A_{00} & A_{01} \end{matrix} \right].
+\left[\begin{matrix} A_{00} & A_{01} \\ A_{10} & A_{11} \end{matrix} \right].
$$
The calculation includes $q$ steps. When $t=1$, $X_{i0}$ is broadcasted in its row, and $A_{0j}$ is broadcasted in its column. So, we have
$$
-\left[\begin{matrix} X_{10},A_{00} & X_{10},A_{01} \\ X_{00},A_{00} & X_{00},A_{01} \end{matrix} \right].
+\left[\begin{matrix} X_{00},A_{00} & X_{00},A_{01} \\ X_{10},A_{00} & X_{10},A_{01} \end{matrix} \right].
$$
Then we multiply $X_{i0}$ and $A_{0j}$ on each processor $(i, j)$ as
$$
-\left[\begin{matrix} X_{10}A_{00} & X_{10}A_{01} \\ X_{00}A_{00} & X_{00}A_{01} \end{matrix} \right] (1).
+\left[\begin{matrix} X_{00}A_{00} & X_{00}A_{01} \\ X_{10}A_{00} & X_{10}A_{01} \end{matrix} \right] (1).
$$
Similarly, when $t=2$, $X_{i1}$ is broadcasted in its row, $A_{1j}$ is broadcasted in its column, and we multiply them as
$$
-\left[\begin{matrix} X_{11}A_{10} & X_{11}A_{11} \\ X_{01}A_{10} & X_{01}A_{11} \end{matrix} \right] (2).
+\left[\begin{matrix} X_{01}A_{10} & X_{01}A_{11} \\ X_{11}A_{10} & X_{11}A_{11} \end{matrix} \right] (2).
$$
By adding $(1)$ and $(2)$ up, we have
$$
-Y = XA = \left[\begin{matrix} X_{10}A_{00}+X_{11}A_{10} & X_{10}A_{01}+X_{11}A_{11} \\ X_{00}A_{00}+X_{01}A_{10} & X_{00}A_{01}+X_{01}A_{11} \end{matrix} \right].
+Y = XA = \left[\begin{matrix} X_{00}A_{00}+X_{01}A_{10} & X_{00}A_{01}+X_{01}A_{11} \\ X_{10}A_{00}+X_{11}A_{10} & X_{10}A_{01}+X_{11}A_{11} \end{matrix} \right].
$$
## Efficiency
diff --git a/docs/source/en/features/2p5D_tensor_parallel.md b/docs/source/en/features/2p5D_tensor_parallel.md
index 6076562e6dca..a81d14f10627 100644
--- a/docs/source/en/features/2p5D_tensor_parallel.md
+++ b/docs/source/en/features/2p5D_tensor_parallel.md
@@ -9,7 +9,7 @@ Author: Zhengda Bian, Yongbin Li
- [2D Tensor Parallelism](./2D_tensor_parallel.md)
**Example Code**
-- [ColossalAI-Examples - 2.5D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_2p5d.py)
+- [ColossalAI-Examples - 2.5D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**Related Paper**
- [2.5-dimensional distributed model training](https://arxiv.org/pdf/2105.14500.pdf)
@@ -23,29 +23,30 @@ Let's still take a linear layer $Y = XA$ as an example.
Given $P=q \times q \times d$ processors (necessary condition), e.g. $q=d=2$, we split the input $X$ into $d\times q$ rows and $q$ columns as
$$
-\left[\begin{matrix} X_{30} & X_{31} \\ X_{20} & X_{21} \\ X_{10} & X_{11} \\ X_{00} & X_{01}\end{matrix} \right],
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \\ X_{20} & X_{21} \\ X_{30} & X_{31}\end{matrix} \right],
$$
+
which can be reshaped into $d$ layers as
$$
-\left[\begin{matrix} X_{10} & X_{11} \\ X_{00} & X_{01} \end{matrix} \right] \text{~and~}\left[\begin{matrix} X_{30} & X_{31} \\ X_{20} & X_{21} \end{matrix} \right].
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \end{matrix} \right] \text{~and~}\left[\begin{matrix} X_{20} & X_{21} \\ X_{30} & X_{31} \end{matrix} \right].
$$
Also, the weight $A$ is split into
$$
-\left[\begin{matrix} A_{10} & A_{11} \\ A_{00} & A_{01} \end{matrix} \right].
+\left[\begin{matrix} A_{00} & A_{01} \\ A_{10} & A_{11} \end{matrix} \right].
$$
For each layer of $X$, we use the SUMMA algorithm to multiply $X$ and $A$.
Then, we have the output
$$
-\left[\begin{matrix} Y_{10}=X_{10}A_{00}+X_{11}A_{10} & Y_{11}=X_{10}A_{01}+X_{11}A_{11} \\ Y_{00}=X_{00}A_{00}+X_{01}A_{10} & Y_{01}=X_{00}A_{01}+X_{01}A_{11} \end{matrix} \right]
+\left[\begin{matrix} Y_{00}=X_{00}A_{00}+X_{01}A_{10} & Y_{01}=X_{00}A_{01}+X_{01}A_{11} \\ Y_{10}=X_{10}A_{00}+X_{11}A_{10} & Y_{11}=X_{10}A_{01}+X_{11}A_{11} \end{matrix} \right]
\text{~and~}
$$
$$
-\left[\begin{matrix} Y_{30}=X_{30}A_{00}+X_{31}A_{10} & Y_{31}=X_{30}A_{01}+X_{31}A_{11} \\ Y_{20}=X_{20}A_{00}+X_{21}A_{10} & Y_{21}=X_{20}A_{01}+X_{21}A_{11} \end{matrix} \right].
+\left[\begin{matrix} Y_{20}=X_{20}A_{00}+X_{21}A_{10} & Y_{21}=X_{20}A_{01}+X_{21}A_{11} \\ Y_{30}=X_{30}A_{00}+X_{31}A_{10} & Y_{31}=X_{30}A_{01}+X_{31}A_{11} \end{matrix} \right].
$$
## Efficiency
diff --git a/docs/source/en/features/3D_tensor_parallel.md b/docs/source/en/features/3D_tensor_parallel.md
index 1207376335ce..0e28f08b23c9 100644
--- a/docs/source/en/features/3D_tensor_parallel.md
+++ b/docs/source/en/features/3D_tensor_parallel.md
@@ -9,7 +9,7 @@ Author: Zhengda Bian, Yongbin Li
- [2D Tensor Parallelism](./2D_tensor_parallel.md)
**Example Code**
-- [ColossalAI-Examples - 3D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_3d.py)
+- [ColossalAI-Examples - 3D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**Related Paper**
- [Maximizing Parallelism in Distributed Training for Huge Neural Networks](https://arxiv.org/pdf/2105.14450.pdf)
@@ -67,7 +67,7 @@ Given $P=q \times q \times q$ processors, we present the theoretical computation
## Usage
-To enable 3D tensor parallelism for our model, e.g. on 8 GPUs, we need to configure the parallism setting as below.
+To enable 3D tensor parallelism for our model, e.g. on 8 GPUs, we need to configure the parallelism setting as below.
```python
CONFIG = dict(parallel=dict(
data=1,
diff --git a/docs/source/en/features/cluster_utils.md b/docs/source/en/features/cluster_utils.md
new file mode 100644
index 000000000000..7331d5e73ae0
--- /dev/null
+++ b/docs/source/en/features/cluster_utils.md
@@ -0,0 +1,16 @@
+# Cluster Utilities
+
+Author: [Hongxin Liu](https://github.com/ver217)
+
+**Prerequisite:**
+- [Distributed Training](../concepts/distributed_training.md)
+
+## Introduction
+
+We provide a utility class `colossalai.cluster.DistCoordinator` to coordinate distributed training. It's useful to get various information about the cluster, such as the number of nodes, the number of processes per node, etc.
+
+## API Reference
+
+{{ autodoc:colossalai.cluster.DistCoordinator }}
+
+
diff --git a/docs/source/en/features/gradient_accumulation.md b/docs/source/en/features/gradient_accumulation.md
index ecc209fbac8d..91d89b815bf7 100644
--- a/docs/source/en/features/gradient_accumulation.md
+++ b/docs/source/en/features/gradient_accumulation.md
@@ -1,4 +1,4 @@
-# Gradient Accumulation
+# Gradient Accumulation (Outdated)
Author: Shenggui Li, Yongbin Li
@@ -43,3 +43,5 @@ iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0
iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
```
+
+
diff --git a/docs/source/en/features/gradient_accumulation_with_booster.md b/docs/source/en/features/gradient_accumulation_with_booster.md
new file mode 100644
index 000000000000..201e3bc2b643
--- /dev/null
+++ b/docs/source/en/features/gradient_accumulation_with_booster.md
@@ -0,0 +1,144 @@
+# Gradient Accumulation (Latest)
+
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+## Introduction
+
+Gradient accumulation is a common way to enlarge your batch size for training. When training large-scale models, memory can easily become the bottleneck and the batch size can be very small, (e.g. 2), leading to unsatisfactory convergence. Gradient accumulation works by adding up the gradients calculated in multiple iterations, and only update the parameters in the preset iteration.
+
+## Usage
+
+It is simple to use gradient accumulation in Colossal-AI. Just call `booster.no_sync()` which returns a context manager. It accumulate gradients without synchronization, meanwhile you should not update the weights.
+
+## Hands-on Practice
+
+We now demonstrate gradient accumulation. In this example, we let the gradient accumulation size to be 4.
+
+### Step 1. Import libraries in train.py
+Create a `train.py` and import the necessary dependencies. The version of `torch` should not be lower than 1.8.1.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet18
+from torch.utils.data import DataLoader
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.cluster.dist_coordinator import priority_execution
+```
+
+### Step 2. Initialize Distributed Environment
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md) for other initialization methods.
+
+```python
+# initialize distributed setting
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+```
+
+### Step 3. Create training components
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])` to a path on your machine. Data will be automatically downloaded to the root path.
+
+```python
+# define the training hyperparameters
+BATCH_SIZE = 128
+GRADIENT_ACCUMULATION = 4
+
+# build resnet
+model = resnet18(num_classes=10)
+
+# build dataloaders
+with priority_execution():
+ train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+```
+
+### Step 4. Inject Feature
+Create a `TorchDDPPlugin` object to instantiate a `Booster`, and boost these training components.
+
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, _ = booster.boost(model=model,
+ optimizer=optimizer,
+ criterion=criterion,
+ dataloader=train_dataloader)
+```
+
+### Step 5. Train with Booster
+Use booster in a normal training loops, and verify gradient accumulation. `param_by_iter` is to record the distributed training information.
+```python
+optimizer.zero_grad()
+for idx, (img, label) in enumerate(train_dataloader):
+ sync_context = booster.no_sync(model)
+ img = img.cuda()
+ label = label.cuda()
+ if idx % (GRADIENT_ACCUMULATION - 1) != 0:
+ with sync_context:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ else:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.step()
+ optimizer.zero_grad()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ param_by_iter.append(str(ele_1st.item()))
+
+ if idx != 0 and idx % (GRADIENT_ACCUMULATION - 1) == 0:
+ break
+
+ for iteration, val in enumerate(param_by_iter):
+ print(f'iteration {iteration} - value: {val}')
+
+ if param_by_iter[-1] != param_by_iter[0]:
+ print('The parameter is only updated in the last iteration')
+
+```
+
+### Step 6. Invoke Training Scripts
+To verify gradient accumulation, we can just check the change of parameter values. When gradient accumulation is set, parameters are only updated in the last step. You can run the script using this command:
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
+You will see output similar to the text below. This shows gradient is indeed accumulated as the parameter is not updated
+in the first 3 steps, but only updated in the last step.
+
+```text
+iteration 0, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
+```
+
+
diff --git a/docs/source/en/features/gradient_clipping.md b/docs/source/en/features/gradient_clipping.md
index f606dde6c393..5a23c68e3e27 100644
--- a/docs/source/en/features/gradient_clipping.md
+++ b/docs/source/en/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# Gradient Clipping
+# Gradient Clipping (Outdated)
Author: Boxiang Wang, Haichen Huang, Yongbin Li
@@ -60,3 +60,5 @@ to demonstrate gradient clipping. In this example, we set the gradient clipping
```shell
python -m torch.distributed.launch --nproc_per_node 1 --master_addr localhost --master_port 29500 train_with_engine.py
```
+
+
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
new file mode 100644
index 000000000000..341a608a5c7b
--- /dev/null
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -0,0 +1,142 @@
+# Gradient Clipping (Latest)
+
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+**Related Paper**
+- [On the difficulty of training Recurrent Neural Networks](https://arxiv.org/abs/1211.5063)
+
+## Introduction
+
+In order to speed up training process and seek global optimum for better performance, more and more learning rate schedulers have been proposed. People turn to control learning rate to adjust descent pace during training, which makes gradient vector better to be uniformed in every step. In that case, the descent pace can be controlled as expected. As a result, gradient clipping, a technique which can normalize the gradient vector to circumscribe it in a uniformed length, becomes indispensable for those who desire their better performance of their models.
+
+You do not have to worry about implementing gradient clipping when using Colossal-AI, we support gradient clipping in a powerful and convenient way. All you need is just an additional command in your configuration file.
+
+## Why you should use gradient clipping provided by Colossal-AI
+
+The reason of why we do not recommend users to write gradient clipping by themselves is that naive gradient clipping may fail when applying tensor parallelism, pipeline parallelism or MoE.
+
+According to the illustration below, each GPU only owns a portion of parameters of the weight in a linear layer. To get correct norm of gradient vector of the weight of the linear layer, the norm of every gradient vector in each GPU should be summed together. More complicated thing is that the distribution of bias is different from the distribution of the weight. The communication group is different in the sum operation.
+
+(PS: This situation is an old version of 2D parallelism, the implementation in the code is not the same. But it is a good example about the difficulty to unify all communication in gradient clipping.)
+
+
+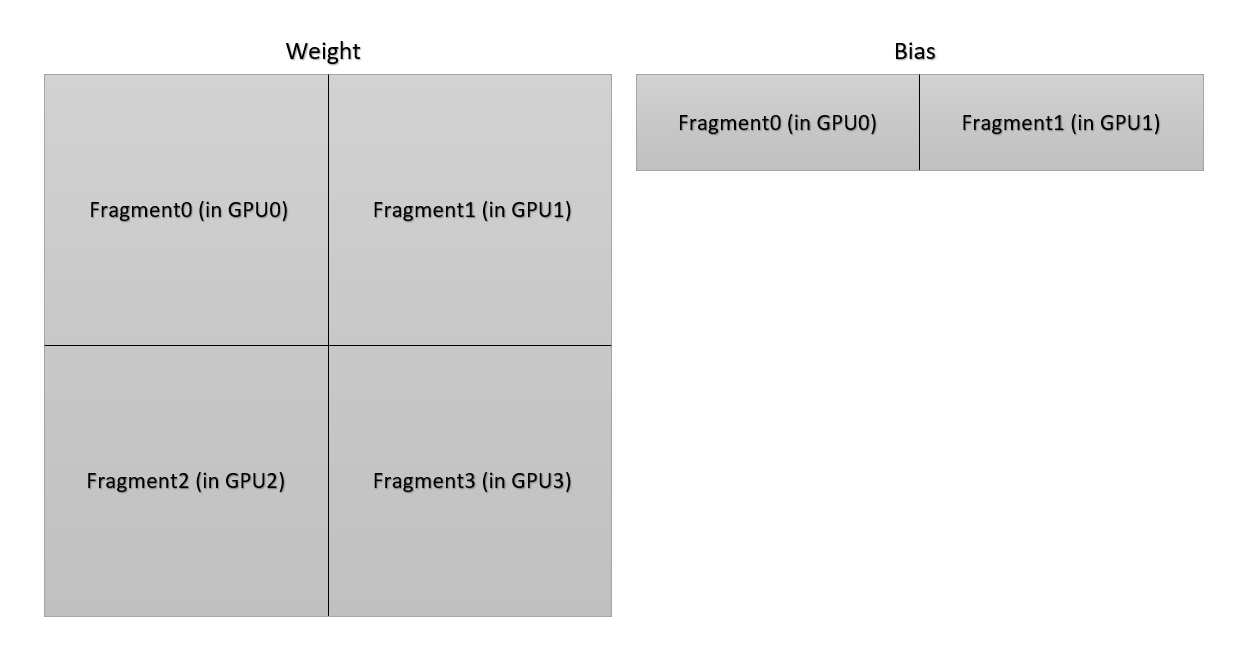 +Layout of parameters
+
+
+Do not worry about it, since Colossal-AI have handled it for you.
+
+## Usage
+To use gradient clipping, you can just add the following code to your configuration file, and after boosted, you can call `clip_grad_by_norm` or `clip_grad_by_value` method of optimizer, if it support clip gradients.
+
+## Hands-On Practice
+
+We now demonstrate how to use gradient clipping. In this example, we set the gradient clipping vector norm to be 1.0.
+
+### step 1. Import libraries in train.py
+Create a `train.py` and import the necessary dependencies.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet34
+from tqdm import tqdm
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import CosineAnnealingLR
+```
+
+### Step 2. Initialize Distributed Environment
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md)
+for other initialization methods.
+
+```python
+colossalai.launch_from_torch(config=dict())
+logger = get_dist_logger()
+```
+
+
+### Step 3. Create training components
+
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])` to a path on your machine. Data will be automatically downloaded to the root path.
+```python
+# define training hyperparameters
+NUM_EPOCHS = 200
+BATCH_SIZE = 128
+GRADIENT_CLIPPING = 0.1
+# build resnet
+model = resnet34(num_classes=10)
+# build dataloaders
+train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+# lr_scheduler
+lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+
+```
+### Step 4. Inject Gradient Clipping Feature
+
+Create a `TorchDDPPlugin` object and `Booster` object, get a data loader from plugin, then boost all training components.
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+
+```
+
+### Step 5. Train with Booster
+Use booster in a normal training loops.
+```python
+# verify gradient clipping
+model.train()
+for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
+```
+
+### Step 6. Invoke Training Scripts
+You can run the script using this command:
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
+
diff --git a/docs/source/en/features/mixed_precision_training.md b/docs/source/en/features/mixed_precision_training.md
index 11aa5235301a..8579d586ed5f 100644
--- a/docs/source/en/features/mixed_precision_training.md
+++ b/docs/source/en/features/mixed_precision_training.md
@@ -1,4 +1,4 @@
-# Auto Mixed Precision Training
+# Auto Mixed Precision Training (Outdated)
Author: Chuanrui Wang, Shenggui Li, Yongbin Li
@@ -362,6 +362,7 @@ for epoch in range(gpc.config.NUM_EPOCHS):
Use the following command to start the training scripts. You can change `--nproc_per_node` to use a different number of GPUs.
-```python
+```shell
python -m torch.distributed.launch --nproc_per_node 4 --master_addr localhost --master_port 29500 train_with_engine.py --config config/config_AMP_torch.py
```
+
diff --git a/docs/source/en/features/mixed_precision_training_with_booster.md b/docs/source/en/features/mixed_precision_training_with_booster.md
new file mode 100644
index 000000000000..e9b6f684f613
--- /dev/null
+++ b/docs/source/en/features/mixed_precision_training_with_booster.md
@@ -0,0 +1,251 @@
+# Auto Mixed Precision Training (Latest)
+
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+**Related Paper**
+- [Accelerating Scientific Computations with Mixed Precision Algorithms](https://arxiv.org/abs/0808.2794)
+
+
+## Introduction
+
+AMP stands for automatic mixed precision training.
+In Colossal-AI, we have incorporated different implementations of mixed precision training:
+
+1. torch.cuda.amp
+2. apex.amp
+3. naive amp
+
+
+| Colossal-AI | support tensor parallel | support pipeline parallel | fp16 extent |
+| ----------- | ----------------------- | ------------------------- | ----------- |
+| AMP_TYPE.TORCH | ✅ | ❌ | Model parameters, activation, gradients are downcast to fp16 during forward and backward propagation |
+| AMP_TYPE.APEX | ❌ | ❌ | More fine-grained, we can choose opt_level O0, O1, O2, O3 |
+| AMP_TYPE.NAIVE | ✅ | ✅ | Model parameters, forward and backward operations are all downcast to fp16 |
+
+The first two rely on the original implementation of PyTorch (version 1.6 and above) and NVIDIA Apex.
+The last method is similar to Apex O2 level.
+Among these methods, apex AMP is not compatible with tensor parallelism.
+This is because that tensors are split across devices in tensor parallelism, thus, it is required to communicate among different processes to check if inf or nan occurs in the whole model weights.
+We modified the torch amp implementation so that it is compatible with tensor parallelism now.
+
+> ❌️ fp16 and zero are not compatible
+>
+> ⚠️ Pipeline only support naive AMP currently
+
+We recommend you to use torch AMP as it generally gives better accuracy than naive AMP if no pipeline is used.
+
+## Table of Contents
+
+In this tutorial we will cover:
+
+1. [AMP introduction](#amp-introduction)
+2. [AMP in Colossal-AI](#amp-in-colossal-ai)
+3. [Hands-on Practice](#hands-on-practice)
+
+## AMP Introduction
+
+Automatic Mixed Precision training is a mixture of FP16 and FP32 training.
+
+Half-precision float point format (FP16) has lower arithmetic complexity and higher compute efficiency. Besides, fp16 requires half of the storage needed by fp32 and saves memory & network bandwidth, which makes more memory available for large batch size and model size.
+
+However, there are other operations, like reductions, which require the dynamic range of fp32 to avoid numeric overflow/underflow. That's the reason why we introduce automatic mixed precision, attempting to match each operation to its appropriate data type, which can reduce the memory footprint and augment training efficiency.
+
+
+
+Layout of parameters
+
+
+Do not worry about it, since Colossal-AI have handled it for you.
+
+## Usage
+To use gradient clipping, you can just add the following code to your configuration file, and after boosted, you can call `clip_grad_by_norm` or `clip_grad_by_value` method of optimizer, if it support clip gradients.
+
+## Hands-On Practice
+
+We now demonstrate how to use gradient clipping. In this example, we set the gradient clipping vector norm to be 1.0.
+
+### step 1. Import libraries in train.py
+Create a `train.py` and import the necessary dependencies.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet34
+from tqdm import tqdm
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import CosineAnnealingLR
+```
+
+### Step 2. Initialize Distributed Environment
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md)
+for other initialization methods.
+
+```python
+colossalai.launch_from_torch(config=dict())
+logger = get_dist_logger()
+```
+
+
+### Step 3. Create training components
+
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])` to a path on your machine. Data will be automatically downloaded to the root path.
+```python
+# define training hyperparameters
+NUM_EPOCHS = 200
+BATCH_SIZE = 128
+GRADIENT_CLIPPING = 0.1
+# build resnet
+model = resnet34(num_classes=10)
+# build dataloaders
+train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+# lr_scheduler
+lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+
+```
+### Step 4. Inject Gradient Clipping Feature
+
+Create a `TorchDDPPlugin` object and `Booster` object, get a data loader from plugin, then boost all training components.
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+
+```
+
+### Step 5. Train with Booster
+Use booster in a normal training loops.
+```python
+# verify gradient clipping
+model.train()
+for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
+```
+
+### Step 6. Invoke Training Scripts
+You can run the script using this command:
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
+
diff --git a/docs/source/en/features/mixed_precision_training.md b/docs/source/en/features/mixed_precision_training.md
index 11aa5235301a..8579d586ed5f 100644
--- a/docs/source/en/features/mixed_precision_training.md
+++ b/docs/source/en/features/mixed_precision_training.md
@@ -1,4 +1,4 @@
-# Auto Mixed Precision Training
+# Auto Mixed Precision Training (Outdated)
Author: Chuanrui Wang, Shenggui Li, Yongbin Li
@@ -362,6 +362,7 @@ for epoch in range(gpc.config.NUM_EPOCHS):
Use the following command to start the training scripts. You can change `--nproc_per_node` to use a different number of GPUs.
-```python
+```shell
python -m torch.distributed.launch --nproc_per_node 4 --master_addr localhost --master_port 29500 train_with_engine.py --config config/config_AMP_torch.py
```
+
diff --git a/docs/source/en/features/mixed_precision_training_with_booster.md b/docs/source/en/features/mixed_precision_training_with_booster.md
new file mode 100644
index 000000000000..e9b6f684f613
--- /dev/null
+++ b/docs/source/en/features/mixed_precision_training_with_booster.md
@@ -0,0 +1,251 @@
+# Auto Mixed Precision Training (Latest)
+
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+**Related Paper**
+- [Accelerating Scientific Computations with Mixed Precision Algorithms](https://arxiv.org/abs/0808.2794)
+
+
+## Introduction
+
+AMP stands for automatic mixed precision training.
+In Colossal-AI, we have incorporated different implementations of mixed precision training:
+
+1. torch.cuda.amp
+2. apex.amp
+3. naive amp
+
+
+| Colossal-AI | support tensor parallel | support pipeline parallel | fp16 extent |
+| ----------- | ----------------------- | ------------------------- | ----------- |
+| AMP_TYPE.TORCH | ✅ | ❌ | Model parameters, activation, gradients are downcast to fp16 during forward and backward propagation |
+| AMP_TYPE.APEX | ❌ | ❌ | More fine-grained, we can choose opt_level O0, O1, O2, O3 |
+| AMP_TYPE.NAIVE | ✅ | ✅ | Model parameters, forward and backward operations are all downcast to fp16 |
+
+The first two rely on the original implementation of PyTorch (version 1.6 and above) and NVIDIA Apex.
+The last method is similar to Apex O2 level.
+Among these methods, apex AMP is not compatible with tensor parallelism.
+This is because that tensors are split across devices in tensor parallelism, thus, it is required to communicate among different processes to check if inf or nan occurs in the whole model weights.
+We modified the torch amp implementation so that it is compatible with tensor parallelism now.
+
+> ❌️ fp16 and zero are not compatible
+>
+> ⚠️ Pipeline only support naive AMP currently
+
+We recommend you to use torch AMP as it generally gives better accuracy than naive AMP if no pipeline is used.
+
+## Table of Contents
+
+In this tutorial we will cover:
+
+1. [AMP introduction](#amp-introduction)
+2. [AMP in Colossal-AI](#amp-in-colossal-ai)
+3. [Hands-on Practice](#hands-on-practice)
+
+## AMP Introduction
+
+Automatic Mixed Precision training is a mixture of FP16 and FP32 training.
+
+Half-precision float point format (FP16) has lower arithmetic complexity and higher compute efficiency. Besides, fp16 requires half of the storage needed by fp32 and saves memory & network bandwidth, which makes more memory available for large batch size and model size.
+
+However, there are other operations, like reductions, which require the dynamic range of fp32 to avoid numeric overflow/underflow. That's the reason why we introduce automatic mixed precision, attempting to match each operation to its appropriate data type, which can reduce the memory footprint and augment training efficiency.
+
+
+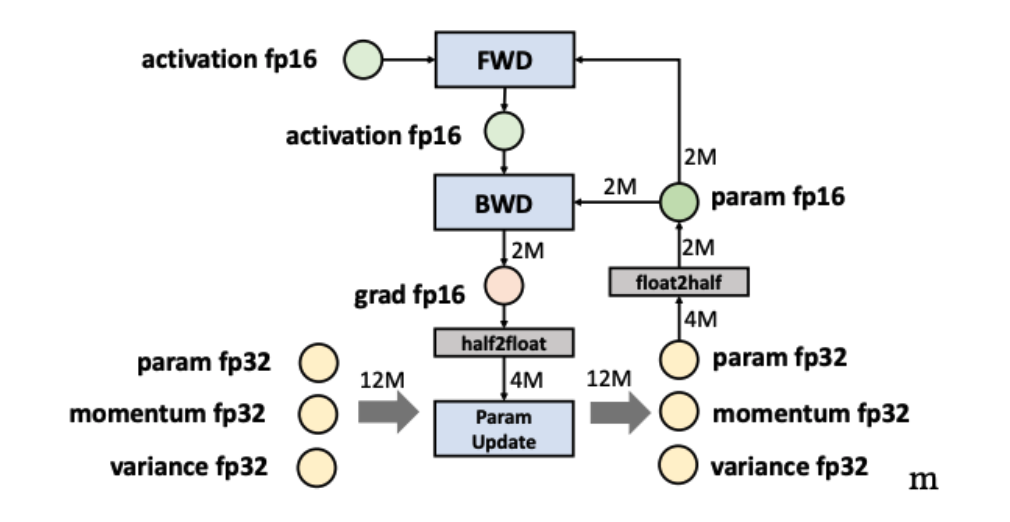 +Illustration of an ordinary AMP (figure from PatrickStar paper)
+
+
+## AMP in Colossal-AI
+
+We supported three AMP training methods and allowed the user to train with AMP with no code. If you want to train with amp, just assign `mixed_precision` with `fp16` when you instantiate the `Booster`. Now booster support torch amp, the other two(apex amp, naive amp) are still started by `colossalai.initialize`, if needed, please refer to [this](./mixed_precision_training.md). Next we will support `bf16`, `fp8`.
+
+### Start with Booster
+instantiate `Booster` with `mixed_precision="fp16"`, then you can train with torch amp.
+
+```python
+"""
+ Mapping:
+ 'fp16': torch amp
+ 'fp16_apex': apex amp,
+ 'bf16': bf16,
+ 'fp8': fp8,
+ 'fp16_naive': naive amp
+"""
+from colossalai import Booster
+booster = Booster(mixed_precision='fp16',...)
+```
+
+or you can create a `FP16TorchMixedPrecision` object, such as:
+
+```python
+from colossalai.mixed_precision import FP16TorchMixedPrecision
+mixed_precision = FP16TorchMixedPrecision(
+ init_scale=2.**16,
+ growth_factor=2.0,
+ backoff_factor=0.5,
+ growth_interval=2000)
+booster = Booster(mixed_precision=mixed_precision,...)
+```
+
+The same goes for other types of amps.
+
+
+### Torch AMP Configuration
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16TorchMixedPrecision }}
+
+### Apex AMP Configuration
+
+For this mode, we rely on the Apex implementation for mixed precision training.
+We support this plugin because it allows for finer control on the granularity of mixed precision.
+For example, O2 level (optimization level 2) will keep batch normalization in fp32.
+
+If you look for more details, please refer to [Apex Documentation](https://nvidia.github.io/apex/).
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16ApexMixedPrecision }}
+
+### Naive AMP Configuration
+
+In Naive AMP mode, we achieved mixed precision training while maintaining compatibility with complex tensor and pipeline parallelism.
+This AMP mode will cast all operations into fp16.
+The following code block shows the mixed precision api for this mode.
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16NaiveMixedPrecision }}
+
+When using `colossalai.booster`, you are required to first instantiate a model, an optimizer and a criterion.
+The output model is converted to AMP model of smaller memory consumption.
+If your input model is already too large to fit in a GPU, please instantiate your model weights in `dtype=torch.float16`.
+Otherwise, try smaller models or checkout more parallelization training techniques!
+
+
+## Hands-on Practice
+
+Now we will introduce the use of AMP with Colossal-AI. In this practice, we will use Torch AMP as an example.
+
+### Step 1. Import libraries in train.py
+
+Create a `train.py` and import the necessary dependencies. Remember to install `scipy` and `timm` by running
+`pip install timm scipy`.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from timm.models import vit_base_patch16_224
+from titans.utils import barrier_context
+from torchvision import datasets, transforms
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import LinearWarmupLR
+```
+
+### Step 2. Initialize Distributed Environment
+
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md)
+for other initialization methods.
+
+```python
+# initialize distributed setting
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+
+```
+
+### Step 3. Create training components
+
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is
+obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])`
+to a path on your machine. Data will be automatically downloaded to the root path.
+
+```python
+# define the constants
+NUM_EPOCHS = 2
+BATCH_SIZE = 128
+
+# build model
+model = vit_base_patch16_224(drop_rate=0.1)
+
+# build dataloader
+train_dataset = datasets.Caltech101(
+ root=Path(os.environ['DATA']),
+ download=True,
+ transform=transforms.Compose([
+ transforms.Resize(256),
+ transforms.RandomResizedCrop(224),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ Gray2RGB(),
+ transforms.Normalize([0.5, 0.5, 0.5],
+ [0.5, 0.5, 0.5])
+ ]))
+
+# build optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, weight_decay=0.1)
+
+# build loss
+criterion = torch.nn.CrossEntropyLoss()
+
+# lr_scheduler
+lr_scheduler = LinearWarmupLR(optimizer, warmup_steps=50, total_steps=NUM_EPOCHS)
+```
+
+### Step 4. Inject AMP Feature
+
+Create a `MixedPrecision`(if needed) and `TorchDDPPlugin` object, call `colossalai.boost` convert the training components to be running with FP16.
+
+```python
+plugin = TorchDDPPlugin()
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+
+# if you need to customize the config, do like this
+# >>> from colossalai.mixed_precision import FP16TorchMixedPrecision
+# >>> mixed_precision = FP16TorchMixedPrecision(
+# >>> init_scale=2.**16,
+# >>> growth_factor=2.0,
+# >>> backoff_factor=0.5,
+# >>> growth_interval=2000)
+# >>> plugin = TorchDDPPlugin()
+# >>> booster = Booster(mixed_precision=mixed_precision, plugin=plugin)
+
+# boost model, optimizer, criterion, dataloader, lr_scheduler
+model, optimizer, criterion, dataloader, lr_scheduler = booster.boost(model, optimizer, criterion, dataloader, lr_scheduler)
+```
+
+### Step 5. Train with Booster
+
+Use booster in a normal training loops.
+
+```python
+model.train()
+for epoch in range(NUM_EPOCHS):
+ for img, label in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+ optimizer.zero_grad()
+ output = model(img)
+ loss = criterion(output, label)
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ lr_scheduler.step()
+```
+
+### Step 6. Invoke Training Scripts
+
+Use the following command to start the training scripts. You can change `--nproc_per_node` to use a different number of GPUs.
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
diff --git a/docs/source/en/features/nvme_offload.md b/docs/source/en/features/nvme_offload.md
index 4374da3c9c45..6ed6f2dee5d6 100644
--- a/docs/source/en/features/nvme_offload.md
+++ b/docs/source/en/features/nvme_offload.md
@@ -53,7 +53,7 @@ It's compatible with all parallel methods in ColossalAI.
> ⚠ It only offloads optimizer states on CPU. This means it only affects CPU training or Zero/Gemini with offloading.
-## Exampls
+## Examples
Let's start from two simple examples -- training GPT with different methods. These examples relies on `transformers`.
@@ -78,8 +78,9 @@ from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
import colossalai
from colossalai.nn.optimizer import HybridAdam
-from colossalai.zero import zero_model_wrapper, zero_optim_wrapper
from colossalai.utils.model.colo_init_context import ColoInitContext
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin
```
Then we define a loss function:
@@ -192,17 +193,23 @@ def train_gemini_cpu(nvme_offload_fraction: float = 0.0):
optimizer = HybridAdam(model.parameters(), nvme_offload_fraction=nvme_offload_fraction)
print(f'Model numel: {get_model_numel(model) / 1024**3:.3f} B')
- gemini_config = dict(strict_ddp_mode=True, device=torch.cuda.current_device(),
- placement_policy='cpu', pin_memory=True, hidden_dim=config.n_embd)
- model = zero_model_wrapper(model, zero_stage=3, gemini_config=gemini_config)
- optimizer = zero_optim_wrapper(model, optimizer, initial_scale=2**5)
+ plugin = GeminiPlugin(
+ strict_ddp_mode=True,
+ device=torch.cuda.current_device(),
+ placement_policy='cpu',
+ pin_memory=True,
+ hidden_dim=config.n_embd,
+ initial_scale=2**5
+ )
+ booster = Booster(plugin)
+ model, optimizer, criterion, _* = booster.boost(model, optimizer, criterion)
start = time.time()
for step in range(3):
data = get_data(4, 128, config.vocab_size)
outputs = model(**data)
loss = criterion(outputs.logits, data['input_ids'])
- optimizer.backward(loss)
+ booster.backward(loss, optimizer)
optimizer.step()
optimizer.zero_grad()
print(f'[{step}] loss: {loss.item():.3f}')
diff --git a/docs/source/en/features/pipeline_parallel.md b/docs/source/en/features/pipeline_parallel.md
index ac49863b3c71..30654b0b0195 100644
--- a/docs/source/en/features/pipeline_parallel.md
+++ b/docs/source/en/features/pipeline_parallel.md
@@ -156,4 +156,4 @@ trainer.fit(train_dataloader=train_dataloader,
display_progress=True)
```
-We use `2` pipeline stages and the batch will be splitted into `4` micro batches.
+We use `2` pipeline stages and the batch will be split into `4` micro batches.
diff --git a/docs/source/en/features/zero_with_chunk.md b/docs/source/en/features/zero_with_chunk.md
index a105831a5409..d7a99f2fbbfd 100644
--- a/docs/source/en/features/zero_with_chunk.md
+++ b/docs/source/en/features/zero_with_chunk.md
@@ -72,7 +72,7 @@ chunk_manager = init_chunk_manager(model=module,
gemini_manager = GeminiManager(placement_policy, chunk_manager)
```
-`hidden_dim` is the hidden dimension of DNN. Users can provide this argument to speed up searching. If users do not know this argument before training, it is ok. We will use a default value 1024. `min_chunk_size_mb` is the the minimum chunk size in MegaByte. If the aggregate size of parameters is still samller than the minimum chunk size, all parameters will be compacted into one small chunk.
+`hidden_dim` is the hidden dimension of DNN. Users can provide this argument to speed up searching. If users do not know this argument before training, it is ok. We will use a default value 1024. `min_chunk_size_mb` is the the minimum chunk size in MegaByte. If the aggregate size of parameters is still smaller than the minimum chunk size, all parameters will be compacted into one small chunk.
Initialization of the optimizer.
```python
@@ -185,23 +185,23 @@ def split_param_col_tp1d(param: ColoParameter, pg: ProcessGroup):
Define a model which uses Gemini + ZeRO DDP:
```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
cai_version = colossalai.__version__
if version.parse(cai_version) > version.parse("0.1.10"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
elif version.parse(cai_version) <= version.parse("0.1.10") and version.parse(cai_version) >= version.parse("0.1.9"):
from colossalai.gemini import ChunkManager, GeminiManager
chunk_size = ChunkManager.search_chunk_size(model, 64 * 1024**2, 32)
- gemini_manager = GeminiManager(placememt_policy, chunk_manager)
+ gemini_manager = GeminiManager(placement_policy, chunk_manager)
chunk_manager = ChunkManager(chunk_size,
pg,
enable_distributed_storage=True,
- init_device=GeminiManager.get_default_device(placememt_policy))
+ init_device=GeminiManager.get_default_device(placement_policy))
model = ZeroDDP(model, gemini_manager)
else:
raise NotImplemented(f"CAI version {cai_version} is not supported")
diff --git a/docs/source/en/get_started/installation.md b/docs/source/en/get_started/installation.md
index 290879219074..6fc4ce2c922a 100644
--- a/docs/source/en/get_started/installation.md
+++ b/docs/source/en/get_started/installation.md
@@ -29,7 +29,7 @@ CUDA_EXT=1 pip install colossalai
## Download From Source
-> The version of Colossal-AI will be in line with the main branch of the repository. Feel free to raise an issue if you encounter any problem. :)
+> The version of Colossal-AI will be in line with the main branch of the repository. Feel free to raise an issue if you encounter any problem.
```shell
git clone https://github.com/hpcaitech/ColossalAI.git
@@ -39,14 +39,29 @@ cd ColossalAI
pip install -r requirements/requirements.txt
# install colossalai
-pip install .
+CUDA_EXT=1 pip install .
```
-If you don't want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer):
+If you don't want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer), just don't specify the `CUDA_EXT`:
```shell
-CUDA_EXT=1 pip install .
+pip install .
```
+For Users with CUDA 10.2, you can still build ColossalAI from source. However, you need to manually download the cub library and copy it to the corresponding directory.
+
+```bash
+# clone the repository
+git clone https://github.com/hpcaitech/ColossalAI.git
+cd ColossalAI
+
+# download the cub library
+wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip
+unzip 1.8.0.zip
+cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
+
+# install
+CUDA_EXT=1 pip install .
+```
diff --git a/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md b/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md
index 4825a6fa1d6c..059eb014affd 100644
--- a/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md
+++ b/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md
@@ -48,7 +48,7 @@ Colossal-AI 为用户提供了一个全局 context,使他们能够轻松地管
world_size: int,
config: Config,
data_parallel_size: int,
- pipeline_parlalel_size: int,
+ pipeline_parallel_size: int,
tensor_parallel_size: int,
arg1,
arg2):
diff --git a/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md b/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
index 456878caa147..276fcc2619e0 100644
--- a/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
+++ b/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
@@ -122,7 +122,7 @@ Inside the initialization of Experts, the local expert number of each GPU will b
## Train Your Model
-Do not to forget to use `colossalai.initialize` function in `colosalai` to add gradient handler for the engine.
+Do not to forget to use `colossalai.initialize` function in `colossalai` to add gradient handler for the engine.
We handle the back-propagation of MoE models for you.
In `colossalai.initialize`, we will automatically create a `MoeGradientHandler` object to process gradients.
You can find more information about the handler `MoeGradientHandler` in colossal directory.
diff --git a/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md b/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md
index 2bf0a9c98c3f..594823862de1 100644
--- a/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md
+++ b/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md
@@ -8,21 +8,21 @@
## 用法
-目前Gemini支持和ZeRO并行方式兼容,它的使用方法很简单,在训练策略的配置文件里设置zero的model_config属性tensor_placement_policy='auto'
-
-```
-zero = dict(
- model_config=dict(
- reduce_scatter_bucket_size_mb=25,
- fp32_reduce_scatter=False,
- gradient_predivide_factor=1.0,
- tensor_placement_policy="auto",
- shard_strategy=TensorShardStrategy(),
- ...
- ),
- optimizer_config=dict(
- ...
- )
+目前Gemini支持和ZeRO并行方式兼容,它的使用方法很简单:使用booster将`GeminiPlugin`中的特性注入到训练组件中。更多`booster`介绍请参考[booster使用](../basics/booster_api.md)。
+
+```python
+from torchvision.models import resnet18
+from colossalai.booster import Booster
+from colossalai.zero import ColoInitContext
+from colossalai.booster.plugin import GeminiPlugin
+plugin = GeminiPlugin(placement_policy='cuda', strict_ddp_mode=True, max_norm=1.0, initial_scale=2**5)
+booster = Booster(plugin=plugin)
+ctx = ColoInitContext()
+with ctx:
+ model = resnet18()
+optimizer = HybridAdam(model.parameters(), lr=1e-3)
+criterion = lambda x: x.mean()
+model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
)
```
@@ -48,7 +48,7 @@ zero = dict(
-ColossalAI设计了Gemini,就像双子星一样,它管理CPU和GPU二者内存空间。它可以让张量在训练过程中动态分布在CPU-GPU的存储空间内,从而让模型训练突破GPU的内存墙。内存管理器由两部分组成,分别是MemStatsCollector(MSC)和StatefuleTensorMgr(STM)。
+ColossalAI设计了Gemini,就像双子星一样,它管理CPU和GPU二者内存空间。它可以让张量在训练过程中动态分布在CPU-GPU的存储空间内,从而让模型训练突破GPU的内存墙。内存管理器由两部分组成,分别是MemStatsCollector(MSC)和StatefulTensorMgr(STM)。
我们利用了深度学习网络训练过程的迭代特性。我们将迭代分为warmup和non-warmup两个阶段,开始时的一个或若干迭代步属于预热阶段,其余的迭代步属于正式阶段。在warmup阶段我们为MSC收集信息,而在non-warmup阶段STM入去MSC收集的信息来移动tensor,以达到最小化CPU-GPU数据移动volume的目的。
@@ -75,7 +75,7 @@ STM管理所有model data tensor的信息。在模型的构造过程中,Coloss
我们在算子的开始和结束计算时,触发内存采样操作,我们称这个时间点为**采样时刻(sampling moment)**,两个采样时刻之间的时间我们称为**period**。计算过程是一个黑盒,由于可能分配临时buffer,内存使用情况很复杂。但是,我们可以较准确的获取period的系统最大内存使用。非模型数据的使用可以通过两个统计时刻之间系统最大内存使用-模型内存使用获得。
-我们如何设计采样时刻呢。我们选择preOp的model data layout adjust之前。如下图所示。我们采样获得上一个period的system memory used,和下一个period的model data memoy used。并行策略会给MSC的工作造成障碍。如图所示,比如对于ZeRO或者Tensor Parallel,由于Op计算前需要gather模型数据,会带来额外的内存需求。因此,我们要求在模型数据变化前进行采样系统内存,这样在一个period内,MSC会把preOp的模型变化内存捕捉。比如在period 2-3内,我们考虑的tensor gather和shard带来的内存变化。
+我们如何设计采样时刻呢。我们选择preOp的model data layout adjust之前。如下图所示。我们采样获得上一个period的system memory used,和下一个period的model data memory used。并行策略会给MSC的工作造成障碍。如图所示,比如对于ZeRO或者Tensor Parallel,由于Op计算前需要gather模型数据,会带来额外的内存需求。因此,我们要求在模型数据变化前进行采样系统内存,这样在一个period内,MSC会把preOp的模型变化内存捕捉。比如在period 2-3内,我们考虑的tensor gather和shard带来的内存变化。
尽管可以将采样时刻放在其他位置,比如排除gather buffer的变动新信息,但是会给造成麻烦。不同并行方式Op的实现有差异,比如对于Linear Op,Tensor Parallel中gather buffer的分配在Op中。而对于ZeRO,gather buffer的分配是在PreOp中。将放在PreOp开始时采样有利于将两种情况统一。
@@ -94,3 +94,5 @@ MSC的重要职责是在调整tensor layout位置,比如在上图S2时刻,
在non-warmup阶段,我们需要利用预热阶段采集的非模型数据内存信息,预留出下一个Period在计算设备上需要的峰值内存,这需要我们移动出一些模型张量。
为了避免频繁在CPU-GPU换入换出相同的tensor,引起类似[cache thrashing](https://en.wikipedia.org/wiki/Thrashing_(computer_science))的现象。我们利用DNN训练迭代特性,设计了OPT cache换出策略。具体来说,在warmup阶段,我们记录每个tensor被计算设备需要的采样时刻。如果我们需要驱逐一些HOLD tensor,那么我们选择在本设备上最晚被需要的tensor作为受害者。
+
+
diff --git a/docs/source/zh-Hans/advanced_tutorials/opt_service.md b/docs/source/zh-Hans/advanced_tutorials/opt_service.md
index a213584fd41d..1f8324a53ecb 100644
--- a/docs/source/zh-Hans/advanced_tutorials/opt_service.md
+++ b/docs/source/zh-Hans/advanced_tutorials/opt_service.md
@@ -52,7 +52,7 @@ export CHECKPOINT_DIR="your_opt_checkpoint_path"
# the ${CONFIG_DIR} must contain a server.sh file as the entry of service
export CONFIG_DIR="config_file_path"
-docker run --gpus all --rm -it -p 8020:8020 -v ${CHECKPOINT_DIR}:/model_checkpoint -v ${CONFIG_DIR}:/config --ipc=host energonai:lastest
+docker run --gpus all --rm -it -p 8020:8020 -v ${CHECKPOINT_DIR}:/model_checkpoint -v ${CONFIG_DIR}:/config --ipc=host energonai:latest
```
接下来,您就可以在您的浏览器中打开 `https://[IP-ADDRESS]:8020/docs#` 进行测试。
diff --git a/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md b/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md
index f3c6247c38e4..c4131e593437 100644
--- a/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md
+++ b/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md
@@ -159,11 +159,11 @@ for mn, module in model.named_modules():
在我们最新示例中还定义了一个Gemini + ZeRO DDP 的模型从而减小开销,提升效率。这一部分的详细内容可以参考[ZeRO](../features/zero_with_chunk.md),你可以将这两部分内容结合起来看从而理解我们整个训练流程:
```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
return model
diff --git a/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md b/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
index 6dc5eccf4421..e2f2c90a3791 100644
--- a/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
+++ b/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
@@ -477,7 +477,7 @@ def build_cifar(batch_size):
return train_dataloader, test_dataloader
-# craete dataloaders
+# create dataloaders
train_dataloader , test_dataloader = build_cifar()
# create loss function
criterion = CrossEntropyLoss(label_smoothing=0.1)
@@ -492,7 +492,7 @@ lr_scheduler = CosineAnnealingWarmupLR(optimizer=optimizer,
#### 启动 Colossal-AI 引擎
```python
-# intiailize
+# initialize
engine, train_dataloader, test_dataloader, _ = colossalai.initialize(model=model,
optimizer=optimizer,
criterion=criterion,
diff --git a/docs/source/zh-Hans/basics/booster_api.md b/docs/source/zh-Hans/basics/booster_api.md
new file mode 100644
index 000000000000..1bb5fd69bd15
--- /dev/null
+++ b/docs/source/zh-Hans/basics/booster_api.md
@@ -0,0 +1,71 @@
+# booster 使用
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**预备知识:**
+- [分布式训练](../concepts/distributed_training.md)
+- [Colossal-AI 总览](../concepts/colossalai_overview.md)
+
+**示例代码**
+- [使用booster训练](https://github.com/hpcaitech/ColossalAI/blob/main/examples/tutorial/new_api/cifar_resnet/README.md)
+
+## 简介
+在我们的新设计中, `colossalai.booster` 代替 `colossalai.initialize` 将特征(例如,模型、优化器、数据加载器)无缝注入您的训练组件中。 使用booster API, 您可以更友好地将我们的并行策略整合到待训练模型中. 调用 `colossalai.booster` 是您进入训练循环前的基本操作。
+在下面的章节中,我们将介绍 `colossalai.booster` 是如何工作的以及使用时我们要注意的细节。
+
+### Booster插件
+Booster插件是管理并行配置的重要组件(eg:gemini插件封装了gemini加速方案)。目前支持的插件如下:
+
+***GeminiPlugin:*** GeminiPlugin插件封装了 gemini 加速解决方案,即基于块内存管理的 ZeRO优化方案。
+
+***TorchDDPPlugin:*** TorchDDPPlugin插件封装了DDP加速方案,实现了模型级别的数据并行,可以跨多机运行。
+
+***LowLevelZeroPlugin:*** LowLevelZeroPlugin插件封装了零冗余优化器的 1/2 阶段。阶段 1:切分优化器参数,分发到各并发进程或并发GPU上。阶段 2:切分优化器参数及梯度,分发到各并发进程或并发GPU上。
+
+### Booster接口
+
+{{ autodoc:colossalai.booster.Booster }}
+
+## 使用方法及示例
+
+在使用colossalai训练时,首先需要在训练脚本的开头启动分布式环境,并创建需要使用的模型、优化器、损失函数、数据加载器等对象。之后,调用`colossalai.booster` 将特征注入到这些对象中,您就可以使用我们的booster API去进行您接下来的训练流程。
+
+以下是一个伪代码示例,将展示如何使用我们的booster API进行模型训练:
+
+```python
+import torch
+from torch.optim import SGD
+from torchvision.models import resnet18
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+
+def train():
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ plugin = TorchDDPPlugin()
+ booster = Booster(plugin=plugin)
+ model = resnet18()
+ criterion = lambda x: x.mean()
+ optimizer = SGD((model.parameters()), lr=0.001)
+ scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1)
+ model, optimizer, criterion, _, scheduler = booster.boost(model, optimizer, criterion, lr_scheduler=scheduler)
+
+ x = torch.randn(4, 3, 224, 224)
+ x = x.to('cuda')
+ output = model(x)
+ loss = criterion(output)
+ booster.backward(loss, optimizer)
+ optimizer.clip_grad_by_norm(1.0)
+ optimizer.step()
+ scheduler.step()
+
+ save_path = "./model"
+ booster.save_model(model, save_path, True, True, "", 10, use_safetensors=use_safetensors)
+
+ new_model = resnet18()
+ booster.load_model(new_model, save_path)
+```
+
+[更多的设计细节请参考](https://github.com/hpcaitech/ColossalAI/discussions/3046)
+
+
diff --git a/docs/source/zh-Hans/basics/booster_checkpoint.md b/docs/source/zh-Hans/basics/booster_checkpoint.md
new file mode 100644
index 000000000000..d75f18c908ba
--- /dev/null
+++ b/docs/source/zh-Hans/basics/booster_checkpoint.md
@@ -0,0 +1,48 @@
+# Booster Checkpoint
+
+作者: [Hongxin Liu](https://github.com/ver217)
+
+**前置教程:**
+- [Booster API](./booster_api.md)
+
+## 引言
+
+我们在之前的教程中介绍了 [Booster API](./booster_api.md)。在本教程中,我们将介绍如何使用 booster 保存和加载 checkpoint。
+
+## 模型 Checkpoint
+
+{{ autodoc:colossalai.booster.Booster.save_model }}
+
+模型在保存前必须被 `colossalai.booster.Booster` 加速。 `checkpoint` 是要保存的 checkpoint 的路径。 如果 `shard=False`,它就是文件。 否则, 它就是文件夹。如果 `shard=True`,checkpoint 将以分片方式保存。当 checkpoint 太大而无法保存在单个文件中时,这很有用。我们的分片 checkpoint 格式与 [huggingface/transformers](https://github.com/huggingface/transformers) 兼容。
+
+{{ autodoc:colossalai.booster.Booster.load_model }}
+
+模型在加载前必须被 `colossalai.booster.Booster` 加速。它会自动检测 checkpoint 格式,并以相应的方式加载。
+
+## 优化器 Checkpoint
+
+> ⚠ 尚不支持以分片方式保存优化器 Checkpoint。
+
+{{ autodoc:colossalai.booster.Booster.save_optimizer }}
+
+优化器在保存前必须被 `colossalai.booster.Booster` 加速。
+
+{{ autodoc:colossalai.booster.Booster.load_optimizer }}
+
+优化器在加载前必须被 `colossalai.booster.Booster` 加速。
+
+## 学习率调度器 Checkpoint
+
+{{ autodoc:colossalai.booster.Booster.save_lr_scheduler }}
+
+学习率调度器在保存前必须被 `colossalai.booster.Booster` 加速。 `checkpoint` 是 checkpoint 文件的本地路径.
+
+{{ autodoc:colossalai.booster.Booster.load_lr_scheduler }}
+
+学习率调度器在加载前必须被 `colossalai.booster.Booster` 加速。 `checkpoint` 是 checkpoint 文件的本地路径.
+
+## Checkpoint 设计
+
+有关 Checkpoint 设计的更多详细信息,请参见我们的讨论 [A Unified Checkpoint System Design](https://github.com/hpcaitech/ColossalAI/discussions/3339).
+
+
diff --git a/docs/source/zh-Hans/basics/booster_plugins.md b/docs/source/zh-Hans/basics/booster_plugins.md
new file mode 100644
index 000000000000..5bd88b679000
--- /dev/null
+++ b/docs/source/zh-Hans/basics/booster_plugins.md
@@ -0,0 +1,74 @@
+# Booster 插件
+
+作者: [Hongxin Liu](https://github.com/ver217)
+
+**前置教程:**
+- [Booster API](./booster_api.md)
+
+## 引言
+
+正如 [Booster API](./booster_api.md) 中提到的,我们可以使用 booster 插件来自定义并行训练。在本教程中,我们将介绍如何使用 booster 插件。
+
+我们现在提供以下插件:
+
+- [Low Level Zero 插件](#low-level-zero-plugin): 它包装了 `colossalai.zero.low_level.LowLevelZeroOptimizer`,可用于使用 Zero-dp 训练模型。它仅支持 Zero 阶段1和阶段2。
+- [Gemini 插件](#gemini-plugin): 它包装了 [Gemini](../features/zero_with_chunk.md),Gemini 实现了基于Chunk内存管理和异构内存管理的 Zero-3。
+- [Torch DDP 插件](#torch-ddp-plugin): 它包装了 `torch.nn.parallel.DistributedDataParallel` 并且可用于使用数据并行训练模型。
+- [Torch FSDP 插件](#torch-fsdp-plugin): 它包装了 `torch.distributed.fsdp.FullyShardedDataParallel` 并且可用于使用 Zero-dp 训练模型。
+
+更多插件即将推出。
+
+## 插件
+
+### Low Level Zero 插件
+
+该插件实现了 Zero-1 和 Zero-2(使用/不使用 CPU 卸载),使用`reduce`和`gather`来同步梯度和权重。
+
+Zero-1 可以看作是 Torch DDP 更好的替代品,内存效率更高,速度更快。它可以很容易地用于混合并行。
+
+Zero-2 不支持局部梯度累积。如果您坚持使用,虽然可以积累梯度,但不能降低通信成本。也就是说,同时使用流水线并行和 Zero-2 并不是一个好主意。
+
+{{ autodoc:colossalai.booster.plugin.LowLevelZeroPlugin }}
+
+我们已经测试了一些主流模型的兼容性,可能不支持以下模型:
+
+- `timm.models.convit_base`
+- dlrm and deepfm models in `torchrec`
+- `diffusers.VQModel`
+- `transformers.AlbertModel`
+- `transformers.AlbertForPreTraining`
+- `transformers.BertModel`
+- `transformers.BertForPreTraining`
+- `transformers.GPT2DoubleHeadsModel`
+
+兼容性问题将在未来修复。
+
+> ⚠ 该插件现在只能加载自己保存的且具有相同进程数的优化器 Checkpoint。这将在未来得到解决。
+
+### Gemini 插件
+
+这个插件实现了基于Chunk内存管理和异构内存管理的 Zero-3。它可以训练大型模型而不会损失太多速度。它也不支持局部梯度累积。更多详细信息,请参阅 [Gemini 文档](../features/zero_with_chunk.md).
+
+{{ autodoc:colossalai.booster.plugin.GeminiPlugin }}
+
+> ⚠ 该插件现在只能加载自己保存的且具有相同进程数的优化器 Checkpoint。这将在未来得到解决。
+
+### Torch DDP 插件
+
+更多详细信息,请参阅 [Pytorch 文档](https://pytorch.org/docs/main/generated/torch.nn.parallel.DistributedDataParallel.html#torch.nn.parallel.DistributedDataParallel).
+
+{{ autodoc:colossalai.booster.plugin.TorchDDPPlugin }}
+
+### Torch FSDP 插件
+
+> ⚠ 如果 torch 版本低于 1.12.0,此插件将不可用。
+
+> ⚠ 该插件现在还不支持保存/加载分片的模型 checkpoint。
+
+> ⚠ 该插件现在还不支持使用了multi params group的optimizer。
+
+更多详细信息,请参阅 [Pytorch 文档](https://pytorch.org/docs/main/fsdp.html).
+
+{{ autodoc:colossalai.booster.plugin.TorchFSDPPlugin }}
+
+
diff --git a/docs/source/zh-Hans/basics/colotensor_concept.md b/docs/source/zh-Hans/basics/colotensor_concept.md
index d6a332df2e9c..ab2413e990f7 100644
--- a/docs/source/zh-Hans/basics/colotensor_concept.md
+++ b/docs/source/zh-Hans/basics/colotensor_concept.md
@@ -2,6 +2,8 @@
Author: [Jiarui Fang](https://github.com/feifeibear), [Hongxin Liu](https://github.com/ver217) and [Haichen Huang](https://github.com/1SAA)
+> ⚠️ 此页面上的信息已经过时并将被废弃。
+
**Prerequisite:**
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
- [Distributed Training](../concepts/distributed_training.md)
@@ -51,7 +53,7 @@ ColoTensor 包含额外的属性[ColoTensorSpec](https://colossalai.readthedocs.
## Example
-让我们看一个例子。 使用 tp_degree=4, dp_dgree=2 在 8 个 GPU 上初始化并Shard一个ColoTensor。 然后tensor被沿着 TP 进程组中的最后一个维度进行分片。 最后,我们沿着 TP 进程组中的第一个维度(dim 0)对其进行重新Shard。 我们鼓励用户运行代码并观察每个张量的形状。
+让我们看一个例子。 使用 tp_degree=4, dp_degree=2 在 8 个 GPU 上初始化并Shard一个ColoTensor。 然后tensor被沿着 TP 进程组中的最后一个维度进行分片。 最后,我们沿着 TP 进程组中的第一个维度(dim 0)对其进行重新Shard。 我们鼓励用户运行代码并观察每个张量的形状。
```python
diff --git a/docs/source/zh-Hans/basics/configure_parallelization.md b/docs/source/zh-Hans/basics/configure_parallelization.md
index eb4b38f48ddb..0c2a66572d60 100644
--- a/docs/source/zh-Hans/basics/configure_parallelization.md
+++ b/docs/source/zh-Hans/basics/configure_parallelization.md
@@ -2,6 +2,8 @@
作者: Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster插件](../basics/booster_plugins.md)页面查阅更新。
+
**预备知识:**
- [分布式训练](../concepts/distributed_training.md)
- [并行技术](../concepts/paradigms_of_parallelism.md)
diff --git a/docs/source/zh-Hans/basics/define_your_config.md b/docs/source/zh-Hans/basics/define_your_config.md
index d7e49cbf23de..720e75805e8d 100644
--- a/docs/source/zh-Hans/basics/define_your_config.md
+++ b/docs/source/zh-Hans/basics/define_your_config.md
@@ -2,6 +2,8 @@
作者: Guangyang Lu, Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster API](../basics/booster_api.md)页面查阅更新。
+
**预备知识:**
- [分布式训练](../concepts/distributed_training.md)
- [Colossal-AI 总览](../concepts/colossalai_overview.md)
diff --git a/docs/source/zh-Hans/basics/engine_trainer.md b/docs/source/zh-Hans/basics/engine_trainer.md
index a7519bfca14f..a35bd87c44e1 100644
--- a/docs/source/zh-Hans/basics/engine_trainer.md
+++ b/docs/source/zh-Hans/basics/engine_trainer.md
@@ -2,6 +2,8 @@
作者: Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster API](../basics/booster_api.md)页面查阅更新。
+
**预备知识:**
- [初始化功能](./initialize_features.md)
diff --git a/docs/source/zh-Hans/basics/initialize_features.md b/docs/source/zh-Hans/basics/initialize_features.md
index 67ea114b42b2..1c28d658e1bc 100644
--- a/docs/source/zh-Hans/basics/initialize_features.md
+++ b/docs/source/zh-Hans/basics/initialize_features.md
@@ -2,6 +2,8 @@
作者: Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster API](../basics/booster_api.md)页面查阅更新。
+
**预备知识:**
- [分布式训练](../concepts/distributed_training.md)
- [Colossal-AI 总览](../concepts/colossalai_overview.md)
diff --git a/docs/source/zh-Hans/basics/launch_colossalai.md b/docs/source/zh-Hans/basics/launch_colossalai.md
index ca927de578d5..39b09deae085 100644
--- a/docs/source/zh-Hans/basics/launch_colossalai.md
+++ b/docs/source/zh-Hans/basics/launch_colossalai.md
@@ -74,7 +74,7 @@ import colossalai
args = colossalai.get_default_parser().parse_args()
# launch distributed environment
-colossalai.launch(config=,
+colossalai.launch(config=args.config,
rank=args.rank,
world_size=args.world_size,
host=args.host,
@@ -93,12 +93,21 @@ PyTorch自带的启动器需要在每个节点上都启动命令才能启动多
首先,我们需要在代码里指定我们的启动方式。由于这个启动器是PyTorch启动器的封装,那么我们自然而然应该使用`colossalai.launch_from_torch`。
分布式环境所需的参数,如 rank, world size, host 和 port 都是由 PyTorch 启动器设置的,可以直接从环境变量中读取。
+config.py
+```python
+BATCH_SIZE = 512
+LEARNING_RATE = 3e-3
+WEIGHT_DECAY = 0.3
+NUM_EPOCHS = 2
+```
+train.py
```python
import colossalai
colossalai.launch_from_torch(
- config=,
+ config="./config.py",
)
+...
```
接下来,我们可以轻松地在终端使用`colossalai run`来启动训练。下面的命令可以在当前机器上启动一个4卡的训练任务。
diff --git a/docs/source/zh-Hans/basics/model_checkpoint.md b/docs/source/zh-Hans/basics/model_checkpoint.md
index cec12d451989..a5374b7509c9 100644
--- a/docs/source/zh-Hans/basics/model_checkpoint.md
+++ b/docs/source/zh-Hans/basics/model_checkpoint.md
@@ -1,7 +1,9 @@
-# 模型检查点
+# 模型Checkpoint
作者 : Guangyang Lu
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster Checkpoint](../basics/booster_checkpoint.md)页面查阅更新。
+
**预备知识:**
- [Launch Colossal-AI](./launch_colossalai.md)
- [Initialize Colossal-AI](./initialize_features.md)
@@ -13,9 +15,9 @@
## 简介
-本教程将介绍如何保存和加载模型检查点。
+本教程将介绍如何保存和加载模型Checkpoint。
-为了充分利用Colossal-AI的强大并行策略,我们需要修改模型和张量,可以直接使用 `torch.save` 或者 `torch.load` 保存或加载模型检查点。在Colossal-AI中,我们提供了应用程序接口实现上述同样的效果。
+为了充分利用Colossal-AI的强大并行策略,我们需要修改模型和张量,可以直接使用 `torch.save` 或者 `torch.load` 保存或加载模型Checkpoint。在Colossal-AI中,我们提供了应用程序接口实现上述同样的效果。
但是,在加载时,你不需要使用与存储相同的保存策略。
@@ -24,7 +26,7 @@
### 保存
有两种方法可以使用Colossal-AI训练模型,即使用engine或使用trainer。
-**注意我们只保存 `state_dict`.** 因此,在加载检查点时,需要首先定义模型。
+**注意我们只保存 `state_dict`.** 因此,在加载Checkpoint时,需要首先定义模型。
#### 同 engine 保存
diff --git a/docs/source/zh-Hans/features/1D_tensor_parallel.md b/docs/source/zh-Hans/features/1D_tensor_parallel.md
index 2ddc27c7b50f..4dd45e8783c3 100644
--- a/docs/source/zh-Hans/features/1D_tensor_parallel.md
+++ b/docs/source/zh-Hans/features/1D_tensor_parallel.md
@@ -7,7 +7,7 @@
- [并行配置](../basics/configure_parallelization.md)
**示例代码**
-- [ColossalAI-Examples 1D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_1d.py)
+- [ColossalAI-Examples 1D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**相关论文**
- [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://deepakn94.github.io/assets/papers/megatron-sc21.pdf)
@@ -20,15 +20,16 @@
让我们以一个线性层为例,它包括一个 GEMM $Y = XA$。 给定2个处理器,我们把列 $A$ 划分为 $[A_1 ~ A_2]$, 并在每个处理器上计算 $Y_i = XA_i$ , 然后形成 $[Y_1 ~ Y_2] = [XA_1 ~ XA_2]$. 这被称为列并行方式。
当第二个线性层 $Z=YB$ 跟随上述列并行层的时候, 我们把 $B$ 划分为
-```math
+$$
\left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
```
-这就是所谓的行并行方式.
+Illustration of an ordinary AMP (figure from PatrickStar paper)
+
+
+## AMP in Colossal-AI
+
+We supported three AMP training methods and allowed the user to train with AMP with no code. If you want to train with amp, just assign `mixed_precision` with `fp16` when you instantiate the `Booster`. Now booster support torch amp, the other two(apex amp, naive amp) are still started by `colossalai.initialize`, if needed, please refer to [this](./mixed_precision_training.md). Next we will support `bf16`, `fp8`.
+
+### Start with Booster
+instantiate `Booster` with `mixed_precision="fp16"`, then you can train with torch amp.
+
+```python
+"""
+ Mapping:
+ 'fp16': torch amp
+ 'fp16_apex': apex amp,
+ 'bf16': bf16,
+ 'fp8': fp8,
+ 'fp16_naive': naive amp
+"""
+from colossalai import Booster
+booster = Booster(mixed_precision='fp16',...)
+```
+
+or you can create a `FP16TorchMixedPrecision` object, such as:
+
+```python
+from colossalai.mixed_precision import FP16TorchMixedPrecision
+mixed_precision = FP16TorchMixedPrecision(
+ init_scale=2.**16,
+ growth_factor=2.0,
+ backoff_factor=0.5,
+ growth_interval=2000)
+booster = Booster(mixed_precision=mixed_precision,...)
+```
+
+The same goes for other types of amps.
+
+
+### Torch AMP Configuration
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16TorchMixedPrecision }}
+
+### Apex AMP Configuration
+
+For this mode, we rely on the Apex implementation for mixed precision training.
+We support this plugin because it allows for finer control on the granularity of mixed precision.
+For example, O2 level (optimization level 2) will keep batch normalization in fp32.
+
+If you look for more details, please refer to [Apex Documentation](https://nvidia.github.io/apex/).
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16ApexMixedPrecision }}
+
+### Naive AMP Configuration
+
+In Naive AMP mode, we achieved mixed precision training while maintaining compatibility with complex tensor and pipeline parallelism.
+This AMP mode will cast all operations into fp16.
+The following code block shows the mixed precision api for this mode.
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16NaiveMixedPrecision }}
+
+When using `colossalai.booster`, you are required to first instantiate a model, an optimizer and a criterion.
+The output model is converted to AMP model of smaller memory consumption.
+If your input model is already too large to fit in a GPU, please instantiate your model weights in `dtype=torch.float16`.
+Otherwise, try smaller models or checkout more parallelization training techniques!
+
+
+## Hands-on Practice
+
+Now we will introduce the use of AMP with Colossal-AI. In this practice, we will use Torch AMP as an example.
+
+### Step 1. Import libraries in train.py
+
+Create a `train.py` and import the necessary dependencies. Remember to install `scipy` and `timm` by running
+`pip install timm scipy`.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from timm.models import vit_base_patch16_224
+from titans.utils import barrier_context
+from torchvision import datasets, transforms
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import LinearWarmupLR
+```
+
+### Step 2. Initialize Distributed Environment
+
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md)
+for other initialization methods.
+
+```python
+# initialize distributed setting
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+
+```
+
+### Step 3. Create training components
+
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is
+obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])`
+to a path on your machine. Data will be automatically downloaded to the root path.
+
+```python
+# define the constants
+NUM_EPOCHS = 2
+BATCH_SIZE = 128
+
+# build model
+model = vit_base_patch16_224(drop_rate=0.1)
+
+# build dataloader
+train_dataset = datasets.Caltech101(
+ root=Path(os.environ['DATA']),
+ download=True,
+ transform=transforms.Compose([
+ transforms.Resize(256),
+ transforms.RandomResizedCrop(224),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ Gray2RGB(),
+ transforms.Normalize([0.5, 0.5, 0.5],
+ [0.5, 0.5, 0.5])
+ ]))
+
+# build optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, weight_decay=0.1)
+
+# build loss
+criterion = torch.nn.CrossEntropyLoss()
+
+# lr_scheduler
+lr_scheduler = LinearWarmupLR(optimizer, warmup_steps=50, total_steps=NUM_EPOCHS)
+```
+
+### Step 4. Inject AMP Feature
+
+Create a `MixedPrecision`(if needed) and `TorchDDPPlugin` object, call `colossalai.boost` convert the training components to be running with FP16.
+
+```python
+plugin = TorchDDPPlugin()
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+
+# if you need to customize the config, do like this
+# >>> from colossalai.mixed_precision import FP16TorchMixedPrecision
+# >>> mixed_precision = FP16TorchMixedPrecision(
+# >>> init_scale=2.**16,
+# >>> growth_factor=2.0,
+# >>> backoff_factor=0.5,
+# >>> growth_interval=2000)
+# >>> plugin = TorchDDPPlugin()
+# >>> booster = Booster(mixed_precision=mixed_precision, plugin=plugin)
+
+# boost model, optimizer, criterion, dataloader, lr_scheduler
+model, optimizer, criterion, dataloader, lr_scheduler = booster.boost(model, optimizer, criterion, dataloader, lr_scheduler)
+```
+
+### Step 5. Train with Booster
+
+Use booster in a normal training loops.
+
+```python
+model.train()
+for epoch in range(NUM_EPOCHS):
+ for img, label in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+ optimizer.zero_grad()
+ output = model(img)
+ loss = criterion(output, label)
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ lr_scheduler.step()
+```
+
+### Step 6. Invoke Training Scripts
+
+Use the following command to start the training scripts. You can change `--nproc_per_node` to use a different number of GPUs.
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
diff --git a/docs/source/en/features/nvme_offload.md b/docs/source/en/features/nvme_offload.md
index 4374da3c9c45..6ed6f2dee5d6 100644
--- a/docs/source/en/features/nvme_offload.md
+++ b/docs/source/en/features/nvme_offload.md
@@ -53,7 +53,7 @@ It's compatible with all parallel methods in ColossalAI.
> ⚠ It only offloads optimizer states on CPU. This means it only affects CPU training or Zero/Gemini with offloading.
-## Exampls
+## Examples
Let's start from two simple examples -- training GPT with different methods. These examples relies on `transformers`.
@@ -78,8 +78,9 @@ from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
import colossalai
from colossalai.nn.optimizer import HybridAdam
-from colossalai.zero import zero_model_wrapper, zero_optim_wrapper
from colossalai.utils.model.colo_init_context import ColoInitContext
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin
```
Then we define a loss function:
@@ -192,17 +193,23 @@ def train_gemini_cpu(nvme_offload_fraction: float = 0.0):
optimizer = HybridAdam(model.parameters(), nvme_offload_fraction=nvme_offload_fraction)
print(f'Model numel: {get_model_numel(model) / 1024**3:.3f} B')
- gemini_config = dict(strict_ddp_mode=True, device=torch.cuda.current_device(),
- placement_policy='cpu', pin_memory=True, hidden_dim=config.n_embd)
- model = zero_model_wrapper(model, zero_stage=3, gemini_config=gemini_config)
- optimizer = zero_optim_wrapper(model, optimizer, initial_scale=2**5)
+ plugin = GeminiPlugin(
+ strict_ddp_mode=True,
+ device=torch.cuda.current_device(),
+ placement_policy='cpu',
+ pin_memory=True,
+ hidden_dim=config.n_embd,
+ initial_scale=2**5
+ )
+ booster = Booster(plugin)
+ model, optimizer, criterion, _* = booster.boost(model, optimizer, criterion)
start = time.time()
for step in range(3):
data = get_data(4, 128, config.vocab_size)
outputs = model(**data)
loss = criterion(outputs.logits, data['input_ids'])
- optimizer.backward(loss)
+ booster.backward(loss, optimizer)
optimizer.step()
optimizer.zero_grad()
print(f'[{step}] loss: {loss.item():.3f}')
diff --git a/docs/source/en/features/pipeline_parallel.md b/docs/source/en/features/pipeline_parallel.md
index ac49863b3c71..30654b0b0195 100644
--- a/docs/source/en/features/pipeline_parallel.md
+++ b/docs/source/en/features/pipeline_parallel.md
@@ -156,4 +156,4 @@ trainer.fit(train_dataloader=train_dataloader,
display_progress=True)
```
-We use `2` pipeline stages and the batch will be splitted into `4` micro batches.
+We use `2` pipeline stages and the batch will be split into `4` micro batches.
diff --git a/docs/source/en/features/zero_with_chunk.md b/docs/source/en/features/zero_with_chunk.md
index a105831a5409..d7a99f2fbbfd 100644
--- a/docs/source/en/features/zero_with_chunk.md
+++ b/docs/source/en/features/zero_with_chunk.md
@@ -72,7 +72,7 @@ chunk_manager = init_chunk_manager(model=module,
gemini_manager = GeminiManager(placement_policy, chunk_manager)
```
-`hidden_dim` is the hidden dimension of DNN. Users can provide this argument to speed up searching. If users do not know this argument before training, it is ok. We will use a default value 1024. `min_chunk_size_mb` is the the minimum chunk size in MegaByte. If the aggregate size of parameters is still samller than the minimum chunk size, all parameters will be compacted into one small chunk.
+`hidden_dim` is the hidden dimension of DNN. Users can provide this argument to speed up searching. If users do not know this argument before training, it is ok. We will use a default value 1024. `min_chunk_size_mb` is the the minimum chunk size in MegaByte. If the aggregate size of parameters is still smaller than the minimum chunk size, all parameters will be compacted into one small chunk.
Initialization of the optimizer.
```python
@@ -185,23 +185,23 @@ def split_param_col_tp1d(param: ColoParameter, pg: ProcessGroup):
Define a model which uses Gemini + ZeRO DDP:
```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
cai_version = colossalai.__version__
if version.parse(cai_version) > version.parse("0.1.10"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
elif version.parse(cai_version) <= version.parse("0.1.10") and version.parse(cai_version) >= version.parse("0.1.9"):
from colossalai.gemini import ChunkManager, GeminiManager
chunk_size = ChunkManager.search_chunk_size(model, 64 * 1024**2, 32)
- gemini_manager = GeminiManager(placememt_policy, chunk_manager)
+ gemini_manager = GeminiManager(placement_policy, chunk_manager)
chunk_manager = ChunkManager(chunk_size,
pg,
enable_distributed_storage=True,
- init_device=GeminiManager.get_default_device(placememt_policy))
+ init_device=GeminiManager.get_default_device(placement_policy))
model = ZeroDDP(model, gemini_manager)
else:
raise NotImplemented(f"CAI version {cai_version} is not supported")
diff --git a/docs/source/en/get_started/installation.md b/docs/source/en/get_started/installation.md
index 290879219074..6fc4ce2c922a 100644
--- a/docs/source/en/get_started/installation.md
+++ b/docs/source/en/get_started/installation.md
@@ -29,7 +29,7 @@ CUDA_EXT=1 pip install colossalai
## Download From Source
-> The version of Colossal-AI will be in line with the main branch of the repository. Feel free to raise an issue if you encounter any problem. :)
+> The version of Colossal-AI will be in line with the main branch of the repository. Feel free to raise an issue if you encounter any problem.
```shell
git clone https://github.com/hpcaitech/ColossalAI.git
@@ -39,14 +39,29 @@ cd ColossalAI
pip install -r requirements/requirements.txt
# install colossalai
-pip install .
+CUDA_EXT=1 pip install .
```
-If you don't want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer):
+If you don't want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer), just don't specify the `CUDA_EXT`:
```shell
-CUDA_EXT=1 pip install .
+pip install .
```
+For Users with CUDA 10.2, you can still build ColossalAI from source. However, you need to manually download the cub library and copy it to the corresponding directory.
+
+```bash
+# clone the repository
+git clone https://github.com/hpcaitech/ColossalAI.git
+cd ColossalAI
+
+# download the cub library
+wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip
+unzip 1.8.0.zip
+cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
+
+# install
+CUDA_EXT=1 pip install .
+```
diff --git a/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md b/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md
index 4825a6fa1d6c..059eb014affd 100644
--- a/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md
+++ b/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md
@@ -48,7 +48,7 @@ Colossal-AI 为用户提供了一个全局 context,使他们能够轻松地管
world_size: int,
config: Config,
data_parallel_size: int,
- pipeline_parlalel_size: int,
+ pipeline_parallel_size: int,
tensor_parallel_size: int,
arg1,
arg2):
diff --git a/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md b/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
index 456878caa147..276fcc2619e0 100644
--- a/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
+++ b/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
@@ -122,7 +122,7 @@ Inside the initialization of Experts, the local expert number of each GPU will b
## Train Your Model
-Do not to forget to use `colossalai.initialize` function in `colosalai` to add gradient handler for the engine.
+Do not to forget to use `colossalai.initialize` function in `colossalai` to add gradient handler for the engine.
We handle the back-propagation of MoE models for you.
In `colossalai.initialize`, we will automatically create a `MoeGradientHandler` object to process gradients.
You can find more information about the handler `MoeGradientHandler` in colossal directory.
diff --git a/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md b/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md
index 2bf0a9c98c3f..594823862de1 100644
--- a/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md
+++ b/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md
@@ -8,21 +8,21 @@
## 用法
-目前Gemini支持和ZeRO并行方式兼容,它的使用方法很简单,在训练策略的配置文件里设置zero的model_config属性tensor_placement_policy='auto'
-
-```
-zero = dict(
- model_config=dict(
- reduce_scatter_bucket_size_mb=25,
- fp32_reduce_scatter=False,
- gradient_predivide_factor=1.0,
- tensor_placement_policy="auto",
- shard_strategy=TensorShardStrategy(),
- ...
- ),
- optimizer_config=dict(
- ...
- )
+目前Gemini支持和ZeRO并行方式兼容,它的使用方法很简单:使用booster将`GeminiPlugin`中的特性注入到训练组件中。更多`booster`介绍请参考[booster使用](../basics/booster_api.md)。
+
+```python
+from torchvision.models import resnet18
+from colossalai.booster import Booster
+from colossalai.zero import ColoInitContext
+from colossalai.booster.plugin import GeminiPlugin
+plugin = GeminiPlugin(placement_policy='cuda', strict_ddp_mode=True, max_norm=1.0, initial_scale=2**5)
+booster = Booster(plugin=plugin)
+ctx = ColoInitContext()
+with ctx:
+ model = resnet18()
+optimizer = HybridAdam(model.parameters(), lr=1e-3)
+criterion = lambda x: x.mean()
+model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
)
```
@@ -48,7 +48,7 @@ zero = dict(
-ColossalAI设计了Gemini,就像双子星一样,它管理CPU和GPU二者内存空间。它可以让张量在训练过程中动态分布在CPU-GPU的存储空间内,从而让模型训练突破GPU的内存墙。内存管理器由两部分组成,分别是MemStatsCollector(MSC)和StatefuleTensorMgr(STM)。
+ColossalAI设计了Gemini,就像双子星一样,它管理CPU和GPU二者内存空间。它可以让张量在训练过程中动态分布在CPU-GPU的存储空间内,从而让模型训练突破GPU的内存墙。内存管理器由两部分组成,分别是MemStatsCollector(MSC)和StatefulTensorMgr(STM)。
我们利用了深度学习网络训练过程的迭代特性。我们将迭代分为warmup和non-warmup两个阶段,开始时的一个或若干迭代步属于预热阶段,其余的迭代步属于正式阶段。在warmup阶段我们为MSC收集信息,而在non-warmup阶段STM入去MSC收集的信息来移动tensor,以达到最小化CPU-GPU数据移动volume的目的。
@@ -75,7 +75,7 @@ STM管理所有model data tensor的信息。在模型的构造过程中,Coloss
我们在算子的开始和结束计算时,触发内存采样操作,我们称这个时间点为**采样时刻(sampling moment)**,两个采样时刻之间的时间我们称为**period**。计算过程是一个黑盒,由于可能分配临时buffer,内存使用情况很复杂。但是,我们可以较准确的获取period的系统最大内存使用。非模型数据的使用可以通过两个统计时刻之间系统最大内存使用-模型内存使用获得。
-我们如何设计采样时刻呢。我们选择preOp的model data layout adjust之前。如下图所示。我们采样获得上一个period的system memory used,和下一个period的model data memoy used。并行策略会给MSC的工作造成障碍。如图所示,比如对于ZeRO或者Tensor Parallel,由于Op计算前需要gather模型数据,会带来额外的内存需求。因此,我们要求在模型数据变化前进行采样系统内存,这样在一个period内,MSC会把preOp的模型变化内存捕捉。比如在period 2-3内,我们考虑的tensor gather和shard带来的内存变化。
+我们如何设计采样时刻呢。我们选择preOp的model data layout adjust之前。如下图所示。我们采样获得上一个period的system memory used,和下一个period的model data memory used。并行策略会给MSC的工作造成障碍。如图所示,比如对于ZeRO或者Tensor Parallel,由于Op计算前需要gather模型数据,会带来额外的内存需求。因此,我们要求在模型数据变化前进行采样系统内存,这样在一个period内,MSC会把preOp的模型变化内存捕捉。比如在period 2-3内,我们考虑的tensor gather和shard带来的内存变化。
尽管可以将采样时刻放在其他位置,比如排除gather buffer的变动新信息,但是会给造成麻烦。不同并行方式Op的实现有差异,比如对于Linear Op,Tensor Parallel中gather buffer的分配在Op中。而对于ZeRO,gather buffer的分配是在PreOp中。将放在PreOp开始时采样有利于将两种情况统一。
@@ -94,3 +94,5 @@ MSC的重要职责是在调整tensor layout位置,比如在上图S2时刻,
在non-warmup阶段,我们需要利用预热阶段采集的非模型数据内存信息,预留出下一个Period在计算设备上需要的峰值内存,这需要我们移动出一些模型张量。
为了避免频繁在CPU-GPU换入换出相同的tensor,引起类似[cache thrashing](https://en.wikipedia.org/wiki/Thrashing_(computer_science))的现象。我们利用DNN训练迭代特性,设计了OPT cache换出策略。具体来说,在warmup阶段,我们记录每个tensor被计算设备需要的采样时刻。如果我们需要驱逐一些HOLD tensor,那么我们选择在本设备上最晚被需要的tensor作为受害者。
+
+
diff --git a/docs/source/zh-Hans/advanced_tutorials/opt_service.md b/docs/source/zh-Hans/advanced_tutorials/opt_service.md
index a213584fd41d..1f8324a53ecb 100644
--- a/docs/source/zh-Hans/advanced_tutorials/opt_service.md
+++ b/docs/source/zh-Hans/advanced_tutorials/opt_service.md
@@ -52,7 +52,7 @@ export CHECKPOINT_DIR="your_opt_checkpoint_path"
# the ${CONFIG_DIR} must contain a server.sh file as the entry of service
export CONFIG_DIR="config_file_path"
-docker run --gpus all --rm -it -p 8020:8020 -v ${CHECKPOINT_DIR}:/model_checkpoint -v ${CONFIG_DIR}:/config --ipc=host energonai:lastest
+docker run --gpus all --rm -it -p 8020:8020 -v ${CHECKPOINT_DIR}:/model_checkpoint -v ${CONFIG_DIR}:/config --ipc=host energonai:latest
```
接下来,您就可以在您的浏览器中打开 `https://[IP-ADDRESS]:8020/docs#` 进行测试。
diff --git a/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md b/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md
index f3c6247c38e4..c4131e593437 100644
--- a/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md
+++ b/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md
@@ -159,11 +159,11 @@ for mn, module in model.named_modules():
在我们最新示例中还定义了一个Gemini + ZeRO DDP 的模型从而减小开销,提升效率。这一部分的详细内容可以参考[ZeRO](../features/zero_with_chunk.md),你可以将这两部分内容结合起来看从而理解我们整个训练流程:
```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
return model
diff --git a/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md b/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
index 6dc5eccf4421..e2f2c90a3791 100644
--- a/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
+++ b/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
@@ -477,7 +477,7 @@ def build_cifar(batch_size):
return train_dataloader, test_dataloader
-# craete dataloaders
+# create dataloaders
train_dataloader , test_dataloader = build_cifar()
# create loss function
criterion = CrossEntropyLoss(label_smoothing=0.1)
@@ -492,7 +492,7 @@ lr_scheduler = CosineAnnealingWarmupLR(optimizer=optimizer,
#### 启动 Colossal-AI 引擎
```python
-# intiailize
+# initialize
engine, train_dataloader, test_dataloader, _ = colossalai.initialize(model=model,
optimizer=optimizer,
criterion=criterion,
diff --git a/docs/source/zh-Hans/basics/booster_api.md b/docs/source/zh-Hans/basics/booster_api.md
new file mode 100644
index 000000000000..1bb5fd69bd15
--- /dev/null
+++ b/docs/source/zh-Hans/basics/booster_api.md
@@ -0,0 +1,71 @@
+# booster 使用
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**预备知识:**
+- [分布式训练](../concepts/distributed_training.md)
+- [Colossal-AI 总览](../concepts/colossalai_overview.md)
+
+**示例代码**
+- [使用booster训练](https://github.com/hpcaitech/ColossalAI/blob/main/examples/tutorial/new_api/cifar_resnet/README.md)
+
+## 简介
+在我们的新设计中, `colossalai.booster` 代替 `colossalai.initialize` 将特征(例如,模型、优化器、数据加载器)无缝注入您的训练组件中。 使用booster API, 您可以更友好地将我们的并行策略整合到待训练模型中. 调用 `colossalai.booster` 是您进入训练循环前的基本操作。
+在下面的章节中,我们将介绍 `colossalai.booster` 是如何工作的以及使用时我们要注意的细节。
+
+### Booster插件
+Booster插件是管理并行配置的重要组件(eg:gemini插件封装了gemini加速方案)。目前支持的插件如下:
+
+***GeminiPlugin:*** GeminiPlugin插件封装了 gemini 加速解决方案,即基于块内存管理的 ZeRO优化方案。
+
+***TorchDDPPlugin:*** TorchDDPPlugin插件封装了DDP加速方案,实现了模型级别的数据并行,可以跨多机运行。
+
+***LowLevelZeroPlugin:*** LowLevelZeroPlugin插件封装了零冗余优化器的 1/2 阶段。阶段 1:切分优化器参数,分发到各并发进程或并发GPU上。阶段 2:切分优化器参数及梯度,分发到各并发进程或并发GPU上。
+
+### Booster接口
+
+{{ autodoc:colossalai.booster.Booster }}
+
+## 使用方法及示例
+
+在使用colossalai训练时,首先需要在训练脚本的开头启动分布式环境,并创建需要使用的模型、优化器、损失函数、数据加载器等对象。之后,调用`colossalai.booster` 将特征注入到这些对象中,您就可以使用我们的booster API去进行您接下来的训练流程。
+
+以下是一个伪代码示例,将展示如何使用我们的booster API进行模型训练:
+
+```python
+import torch
+from torch.optim import SGD
+from torchvision.models import resnet18
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+
+def train():
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ plugin = TorchDDPPlugin()
+ booster = Booster(plugin=plugin)
+ model = resnet18()
+ criterion = lambda x: x.mean()
+ optimizer = SGD((model.parameters()), lr=0.001)
+ scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1)
+ model, optimizer, criterion, _, scheduler = booster.boost(model, optimizer, criterion, lr_scheduler=scheduler)
+
+ x = torch.randn(4, 3, 224, 224)
+ x = x.to('cuda')
+ output = model(x)
+ loss = criterion(output)
+ booster.backward(loss, optimizer)
+ optimizer.clip_grad_by_norm(1.0)
+ optimizer.step()
+ scheduler.step()
+
+ save_path = "./model"
+ booster.save_model(model, save_path, True, True, "", 10, use_safetensors=use_safetensors)
+
+ new_model = resnet18()
+ booster.load_model(new_model, save_path)
+```
+
+[更多的设计细节请参考](https://github.com/hpcaitech/ColossalAI/discussions/3046)
+
+
diff --git a/docs/source/zh-Hans/basics/booster_checkpoint.md b/docs/source/zh-Hans/basics/booster_checkpoint.md
new file mode 100644
index 000000000000..d75f18c908ba
--- /dev/null
+++ b/docs/source/zh-Hans/basics/booster_checkpoint.md
@@ -0,0 +1,48 @@
+# Booster Checkpoint
+
+作者: [Hongxin Liu](https://github.com/ver217)
+
+**前置教程:**
+- [Booster API](./booster_api.md)
+
+## 引言
+
+我们在之前的教程中介绍了 [Booster API](./booster_api.md)。在本教程中,我们将介绍如何使用 booster 保存和加载 checkpoint。
+
+## 模型 Checkpoint
+
+{{ autodoc:colossalai.booster.Booster.save_model }}
+
+模型在保存前必须被 `colossalai.booster.Booster` 加速。 `checkpoint` 是要保存的 checkpoint 的路径。 如果 `shard=False`,它就是文件。 否则, 它就是文件夹。如果 `shard=True`,checkpoint 将以分片方式保存。当 checkpoint 太大而无法保存在单个文件中时,这很有用。我们的分片 checkpoint 格式与 [huggingface/transformers](https://github.com/huggingface/transformers) 兼容。
+
+{{ autodoc:colossalai.booster.Booster.load_model }}
+
+模型在加载前必须被 `colossalai.booster.Booster` 加速。它会自动检测 checkpoint 格式,并以相应的方式加载。
+
+## 优化器 Checkpoint
+
+> ⚠ 尚不支持以分片方式保存优化器 Checkpoint。
+
+{{ autodoc:colossalai.booster.Booster.save_optimizer }}
+
+优化器在保存前必须被 `colossalai.booster.Booster` 加速。
+
+{{ autodoc:colossalai.booster.Booster.load_optimizer }}
+
+优化器在加载前必须被 `colossalai.booster.Booster` 加速。
+
+## 学习率调度器 Checkpoint
+
+{{ autodoc:colossalai.booster.Booster.save_lr_scheduler }}
+
+学习率调度器在保存前必须被 `colossalai.booster.Booster` 加速。 `checkpoint` 是 checkpoint 文件的本地路径.
+
+{{ autodoc:colossalai.booster.Booster.load_lr_scheduler }}
+
+学习率调度器在加载前必须被 `colossalai.booster.Booster` 加速。 `checkpoint` 是 checkpoint 文件的本地路径.
+
+## Checkpoint 设计
+
+有关 Checkpoint 设计的更多详细信息,请参见我们的讨论 [A Unified Checkpoint System Design](https://github.com/hpcaitech/ColossalAI/discussions/3339).
+
+
diff --git a/docs/source/zh-Hans/basics/booster_plugins.md b/docs/source/zh-Hans/basics/booster_plugins.md
new file mode 100644
index 000000000000..5bd88b679000
--- /dev/null
+++ b/docs/source/zh-Hans/basics/booster_plugins.md
@@ -0,0 +1,74 @@
+# Booster 插件
+
+作者: [Hongxin Liu](https://github.com/ver217)
+
+**前置教程:**
+- [Booster API](./booster_api.md)
+
+## 引言
+
+正如 [Booster API](./booster_api.md) 中提到的,我们可以使用 booster 插件来自定义并行训练。在本教程中,我们将介绍如何使用 booster 插件。
+
+我们现在提供以下插件:
+
+- [Low Level Zero 插件](#low-level-zero-plugin): 它包装了 `colossalai.zero.low_level.LowLevelZeroOptimizer`,可用于使用 Zero-dp 训练模型。它仅支持 Zero 阶段1和阶段2。
+- [Gemini 插件](#gemini-plugin): 它包装了 [Gemini](../features/zero_with_chunk.md),Gemini 实现了基于Chunk内存管理和异构内存管理的 Zero-3。
+- [Torch DDP 插件](#torch-ddp-plugin): 它包装了 `torch.nn.parallel.DistributedDataParallel` 并且可用于使用数据并行训练模型。
+- [Torch FSDP 插件](#torch-fsdp-plugin): 它包装了 `torch.distributed.fsdp.FullyShardedDataParallel` 并且可用于使用 Zero-dp 训练模型。
+
+更多插件即将推出。
+
+## 插件
+
+### Low Level Zero 插件
+
+该插件实现了 Zero-1 和 Zero-2(使用/不使用 CPU 卸载),使用`reduce`和`gather`来同步梯度和权重。
+
+Zero-1 可以看作是 Torch DDP 更好的替代品,内存效率更高,速度更快。它可以很容易地用于混合并行。
+
+Zero-2 不支持局部梯度累积。如果您坚持使用,虽然可以积累梯度,但不能降低通信成本。也就是说,同时使用流水线并行和 Zero-2 并不是一个好主意。
+
+{{ autodoc:colossalai.booster.plugin.LowLevelZeroPlugin }}
+
+我们已经测试了一些主流模型的兼容性,可能不支持以下模型:
+
+- `timm.models.convit_base`
+- dlrm and deepfm models in `torchrec`
+- `diffusers.VQModel`
+- `transformers.AlbertModel`
+- `transformers.AlbertForPreTraining`
+- `transformers.BertModel`
+- `transformers.BertForPreTraining`
+- `transformers.GPT2DoubleHeadsModel`
+
+兼容性问题将在未来修复。
+
+> ⚠ 该插件现在只能加载自己保存的且具有相同进程数的优化器 Checkpoint。这将在未来得到解决。
+
+### Gemini 插件
+
+这个插件实现了基于Chunk内存管理和异构内存管理的 Zero-3。它可以训练大型模型而不会损失太多速度。它也不支持局部梯度累积。更多详细信息,请参阅 [Gemini 文档](../features/zero_with_chunk.md).
+
+{{ autodoc:colossalai.booster.plugin.GeminiPlugin }}
+
+> ⚠ 该插件现在只能加载自己保存的且具有相同进程数的优化器 Checkpoint。这将在未来得到解决。
+
+### Torch DDP 插件
+
+更多详细信息,请参阅 [Pytorch 文档](https://pytorch.org/docs/main/generated/torch.nn.parallel.DistributedDataParallel.html#torch.nn.parallel.DistributedDataParallel).
+
+{{ autodoc:colossalai.booster.plugin.TorchDDPPlugin }}
+
+### Torch FSDP 插件
+
+> ⚠ 如果 torch 版本低于 1.12.0,此插件将不可用。
+
+> ⚠ 该插件现在还不支持保存/加载分片的模型 checkpoint。
+
+> ⚠ 该插件现在还不支持使用了multi params group的optimizer。
+
+更多详细信息,请参阅 [Pytorch 文档](https://pytorch.org/docs/main/fsdp.html).
+
+{{ autodoc:colossalai.booster.plugin.TorchFSDPPlugin }}
+
+
diff --git a/docs/source/zh-Hans/basics/colotensor_concept.md b/docs/source/zh-Hans/basics/colotensor_concept.md
index d6a332df2e9c..ab2413e990f7 100644
--- a/docs/source/zh-Hans/basics/colotensor_concept.md
+++ b/docs/source/zh-Hans/basics/colotensor_concept.md
@@ -2,6 +2,8 @@
Author: [Jiarui Fang](https://github.com/feifeibear), [Hongxin Liu](https://github.com/ver217) and [Haichen Huang](https://github.com/1SAA)
+> ⚠️ 此页面上的信息已经过时并将被废弃。
+
**Prerequisite:**
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
- [Distributed Training](../concepts/distributed_training.md)
@@ -51,7 +53,7 @@ ColoTensor 包含额外的属性[ColoTensorSpec](https://colossalai.readthedocs.
## Example
-让我们看一个例子。 使用 tp_degree=4, dp_dgree=2 在 8 个 GPU 上初始化并Shard一个ColoTensor。 然后tensor被沿着 TP 进程组中的最后一个维度进行分片。 最后,我们沿着 TP 进程组中的第一个维度(dim 0)对其进行重新Shard。 我们鼓励用户运行代码并观察每个张量的形状。
+让我们看一个例子。 使用 tp_degree=4, dp_degree=2 在 8 个 GPU 上初始化并Shard一个ColoTensor。 然后tensor被沿着 TP 进程组中的最后一个维度进行分片。 最后,我们沿着 TP 进程组中的第一个维度(dim 0)对其进行重新Shard。 我们鼓励用户运行代码并观察每个张量的形状。
```python
diff --git a/docs/source/zh-Hans/basics/configure_parallelization.md b/docs/source/zh-Hans/basics/configure_parallelization.md
index eb4b38f48ddb..0c2a66572d60 100644
--- a/docs/source/zh-Hans/basics/configure_parallelization.md
+++ b/docs/source/zh-Hans/basics/configure_parallelization.md
@@ -2,6 +2,8 @@
作者: Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster插件](../basics/booster_plugins.md)页面查阅更新。
+
**预备知识:**
- [分布式训练](../concepts/distributed_training.md)
- [并行技术](../concepts/paradigms_of_parallelism.md)
diff --git a/docs/source/zh-Hans/basics/define_your_config.md b/docs/source/zh-Hans/basics/define_your_config.md
index d7e49cbf23de..720e75805e8d 100644
--- a/docs/source/zh-Hans/basics/define_your_config.md
+++ b/docs/source/zh-Hans/basics/define_your_config.md
@@ -2,6 +2,8 @@
作者: Guangyang Lu, Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster API](../basics/booster_api.md)页面查阅更新。
+
**预备知识:**
- [分布式训练](../concepts/distributed_training.md)
- [Colossal-AI 总览](../concepts/colossalai_overview.md)
diff --git a/docs/source/zh-Hans/basics/engine_trainer.md b/docs/source/zh-Hans/basics/engine_trainer.md
index a7519bfca14f..a35bd87c44e1 100644
--- a/docs/source/zh-Hans/basics/engine_trainer.md
+++ b/docs/source/zh-Hans/basics/engine_trainer.md
@@ -2,6 +2,8 @@
作者: Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster API](../basics/booster_api.md)页面查阅更新。
+
**预备知识:**
- [初始化功能](./initialize_features.md)
diff --git a/docs/source/zh-Hans/basics/initialize_features.md b/docs/source/zh-Hans/basics/initialize_features.md
index 67ea114b42b2..1c28d658e1bc 100644
--- a/docs/source/zh-Hans/basics/initialize_features.md
+++ b/docs/source/zh-Hans/basics/initialize_features.md
@@ -2,6 +2,8 @@
作者: Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster API](../basics/booster_api.md)页面查阅更新。
+
**预备知识:**
- [分布式训练](../concepts/distributed_training.md)
- [Colossal-AI 总览](../concepts/colossalai_overview.md)
diff --git a/docs/source/zh-Hans/basics/launch_colossalai.md b/docs/source/zh-Hans/basics/launch_colossalai.md
index ca927de578d5..39b09deae085 100644
--- a/docs/source/zh-Hans/basics/launch_colossalai.md
+++ b/docs/source/zh-Hans/basics/launch_colossalai.md
@@ -74,7 +74,7 @@ import colossalai
args = colossalai.get_default_parser().parse_args()
# launch distributed environment
-colossalai.launch(config=,
+colossalai.launch(config=args.config,
rank=args.rank,
world_size=args.world_size,
host=args.host,
@@ -93,12 +93,21 @@ PyTorch自带的启动器需要在每个节点上都启动命令才能启动多
首先,我们需要在代码里指定我们的启动方式。由于这个启动器是PyTorch启动器的封装,那么我们自然而然应该使用`colossalai.launch_from_torch`。
分布式环境所需的参数,如 rank, world size, host 和 port 都是由 PyTorch 启动器设置的,可以直接从环境变量中读取。
+config.py
+```python
+BATCH_SIZE = 512
+LEARNING_RATE = 3e-3
+WEIGHT_DECAY = 0.3
+NUM_EPOCHS = 2
+```
+train.py
```python
import colossalai
colossalai.launch_from_torch(
- config=,
+ config="./config.py",
)
+...
```
接下来,我们可以轻松地在终端使用`colossalai run`来启动训练。下面的命令可以在当前机器上启动一个4卡的训练任务。
diff --git a/docs/source/zh-Hans/basics/model_checkpoint.md b/docs/source/zh-Hans/basics/model_checkpoint.md
index cec12d451989..a5374b7509c9 100644
--- a/docs/source/zh-Hans/basics/model_checkpoint.md
+++ b/docs/source/zh-Hans/basics/model_checkpoint.md
@@ -1,7 +1,9 @@
-# 模型检查点
+# 模型Checkpoint
作者 : Guangyang Lu
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster Checkpoint](../basics/booster_checkpoint.md)页面查阅更新。
+
**预备知识:**
- [Launch Colossal-AI](./launch_colossalai.md)
- [Initialize Colossal-AI](./initialize_features.md)
@@ -13,9 +15,9 @@
## 简介
-本教程将介绍如何保存和加载模型检查点。
+本教程将介绍如何保存和加载模型Checkpoint。
-为了充分利用Colossal-AI的强大并行策略,我们需要修改模型和张量,可以直接使用 `torch.save` 或者 `torch.load` 保存或加载模型检查点。在Colossal-AI中,我们提供了应用程序接口实现上述同样的效果。
+为了充分利用Colossal-AI的强大并行策略,我们需要修改模型和张量,可以直接使用 `torch.save` 或者 `torch.load` 保存或加载模型Checkpoint。在Colossal-AI中,我们提供了应用程序接口实现上述同样的效果。
但是,在加载时,你不需要使用与存储相同的保存策略。
@@ -24,7 +26,7 @@
### 保存
有两种方法可以使用Colossal-AI训练模型,即使用engine或使用trainer。
-**注意我们只保存 `state_dict`.** 因此,在加载检查点时,需要首先定义模型。
+**注意我们只保存 `state_dict`.** 因此,在加载Checkpoint时,需要首先定义模型。
#### 同 engine 保存
diff --git a/docs/source/zh-Hans/features/1D_tensor_parallel.md b/docs/source/zh-Hans/features/1D_tensor_parallel.md
index 2ddc27c7b50f..4dd45e8783c3 100644
--- a/docs/source/zh-Hans/features/1D_tensor_parallel.md
+++ b/docs/source/zh-Hans/features/1D_tensor_parallel.md
@@ -7,7 +7,7 @@
- [并行配置](../basics/configure_parallelization.md)
**示例代码**
-- [ColossalAI-Examples 1D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_1d.py)
+- [ColossalAI-Examples 1D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**相关论文**
- [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://deepakn94.github.io/assets/papers/megatron-sc21.pdf)
@@ -20,15 +20,16 @@
让我们以一个线性层为例,它包括一个 GEMM $Y = XA$。 给定2个处理器,我们把列 $A$ 划分为 $[A_1 ~ A_2]$, 并在每个处理器上计算 $Y_i = XA_i$ , 然后形成 $[Y_1 ~ Y_2] = [XA_1 ~ XA_2]$. 这被称为列并行方式。
当第二个线性层 $Z=YB$ 跟随上述列并行层的时候, 我们把 $B$ 划分为
-```math
+$$
\left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
```
-这就是所谓的行并行方式.
+这就是所谓的行并行方式.
+$$
为了计算
-```math
+$$
Z = [Y_1 ~ Y_2] \left[\begin{matrix} B_1 \\ B_2 \end{matrix} \right]
-```
+$$
我们首先在每个处理器上计算 $Y_iB_i$ 然后使用一个all-reduce操作将结果汇总为 $Z=Y_1B_1+Y_2B_2$。
我们还需要注意,在后向计算中,列并行线性层需要聚合输入张量 $X$, 因为在每个处理器 $i$ 上,我们只有 $\dot{X_i}=\dot{Y_i}A_i^T$,因此,我们在各处理器之间进行all-reduce,得到 $\dot{X}=\dot{Y}A^T=\dot{Y_1}A_1^T+\dot{Y_2}A_2^T$。
diff --git a/docs/source/zh-Hans/features/2D_tensor_parallel.md b/docs/source/zh-Hans/features/2D_tensor_parallel.md
index c942f82bf9d2..f163432ecceb 100644
--- a/docs/source/zh-Hans/features/2D_tensor_parallel.md
+++ b/docs/source/zh-Hans/features/2D_tensor_parallel.md
@@ -8,7 +8,7 @@
- [1D 张量并行](./1D_tensor_parallel.md)
**示例代码**
-- [ColossalAI-Examples - 2D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_2d.py)
+- [ColossalAI-Examples - 2D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**相关论文**
- [An Efficient 2D Method for Training Super-Large Deep Learning Models](https://arxiv.org/pdf/2104.05343.pdf)
@@ -22,33 +22,33 @@
给定 $P=q\times q$ 个处理器(必要条件), 如 $q=2$, 我们把输入 $X$ 和权重A $A$ 都划分为
$$
-\left[\begin{matrix} X_{10} & X_{11} \\ X_{00} & X_{01} \end{matrix} \right]
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \end{matrix} \right]
\text{~and~}
-\left[\begin{matrix} A_{10} & A_{11} \\ A_{00} & A_{01} \end{matrix} \right]。
+\left[\begin{matrix} A_{00} & A_{01} \\ A_{10} & A_{11} \end{matrix} \right].
$$
该计算包括 $q$ 步。 当 $t=1$ 时, $X_{i0}$ 在其行中被广播, 而 $A_{0j}$ 在其列中被广播。因此,我们有
$$
-\left[\begin{matrix} X_{10},A_{00} & X_{10},A_{01} \\ X_{00},A_{00} & X_{00},A_{01} \end{matrix} \right]。
+\left[\begin{matrix} X_{00},A_{00} & X_{00},A_{01} \\ X_{10},A_{00} & X_{10},A_{01} \end{matrix} \right].
$$
然后我们在每个处理器 $(i, j)$ 上将 $X_{i0}$ 和 $A_{0j}$ 相乘为
$$
-\left[\begin{matrix} X_{10}A_{00} & X_{10}A_{01} \\ X_{00}A_{00} & X_{00}A_{01} \end{matrix} \right] (1)。
+\left[\begin{matrix} X_{00}A_{00} & X_{00}A_{01} \\ X_{10}A_{00} & X_{10}A_{01} \end{matrix} \right] (1).
$$
同样,当 $t=2$ 时, $X_{i1}$ 在其行中被广播, $A_{1j}$ 在其列中被广播, 我们将它们相乘为
$$
-\left[\begin{matrix} X_{11}A_{10} & X_{11}A_{11} \\ X_{01}A_{10} & X_{01}A_{11} \end{matrix} \right] (2)。
+\left[\begin{matrix} X_{01}A_{10} & X_{01}A_{11} \\ X_{11}A_{10} & X_{11}A_{11} \end{matrix} \right] (2).
$$
通过将 $(1)$ 和 $(2)$ 相加,我们有
$$
-Y = XA = \left[\begin{matrix} X_{10}A_{00}+X_{11}A_{10} & X_{10}A_{01}+X_{11}A_{11} \\ X_{00}A_{00}+X_{01}A_{10} & X_{00}A_{01}+X_{01}A_{11} \end{matrix} \right]。
+Y = XA = \left[\begin{matrix} X_{00}A_{00}+X_{01}A_{10} & X_{00}A_{01}+X_{01}A_{11} \\ X_{10}A_{00}+X_{11}A_{10} & X_{10}A_{01}+X_{11}A_{11} \end{matrix} \right].
$$
## 效率
diff --git a/docs/source/zh-Hans/features/2p5D_tensor_parallel.md b/docs/source/zh-Hans/features/2p5D_tensor_parallel.md
index 59a4be02ce47..5f15202729a7 100644
--- a/docs/source/zh-Hans/features/2p5D_tensor_parallel.md
+++ b/docs/source/zh-Hans/features/2p5D_tensor_parallel.md
@@ -9,7 +9,7 @@
- [2D 张量并行](./2D_tensor_parallel.md)
**示例代码**
-- [ColossalAI-Examples - 2.5D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_2p5d.py)
+- [ColossalAI-Examples - 2.5D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**相关论文**
- [2.5-dimensional distributed model training](https://arxiv.org/pdf/2105.14500.pdf)
@@ -22,29 +22,29 @@
给定 $P=q \times q \times d$ 个处理器(必要条件), 如 $q=d=2$, 我们把输入 $X$ 划分为 $d\times q$ 行和 $q$ 列
$$
-\left[\begin{matrix} X_{30} & X_{31} \\ X_{20} & X_{21} \\ X_{10} & X_{11} \\ X_{00} & X_{01}\end{matrix} \right],
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \\ X_{20} & X_{21} \\ X_{30} & X_{31}\end{matrix} \right],
$$
它可以被重塑为 $d$ 层
$$
-\left[\begin{matrix} X_{10} & X_{11} \\ X_{00} & X_{01} \end{matrix} \right] \text{~and~}\left[\begin{matrix} X_{30} & X_{31} \\ X_{20} & X_{21} \end{matrix} \right].
+\left[\begin{matrix} X_{00} & X_{01} \\ X_{10} & X_{11} \end{matrix} \right] \text{~and~}\left[\begin{matrix} X_{20} & X_{21} \\ X_{30} & X_{31} \end{matrix} \right].
$$
另外,权重 $A$ 被分割为
$$
-\left[\begin{matrix} A_{10} & A_{11} \\ A_{00} & A_{01} \end{matrix} \right].
+\left[\begin{matrix} A_{00} & A_{01} \\ A_{10} & A_{11} \end{matrix} \right].
$$
对于 $X$ 相关的每一层, 我们使用SUMMA算法将 $X$ 与 $A$ 相乘。
然后,我们得到输出
$$
-\left[\begin{matrix} Y_{10}=X_{10}A_{00}+X_{11}A_{10} & Y_{11}=X_{10}A_{01}+X_{11}A_{11} \\ Y_{00}=X_{00}A_{00}+X_{01}A_{10} & Y_{01}=X_{00}A_{01}+X_{01}A_{11} \end{matrix} \right]
+\left[\begin{matrix} Y_{00}=X_{00}A_{00}+X_{01}A_{10} & Y_{01}=X_{00}A_{01}+X_{01}A_{11} \\ Y_{10}=X_{10}A_{00}+X_{11}A_{10} & Y_{11}=X_{10}A_{01}+X_{11}A_{11} \end{matrix} \right]
\text{~and~}
$$
$$
-\left[\begin{matrix} Y_{30}=X_{30}A_{00}+X_{31}A_{10} & Y_{31}=X_{30}A_{01}+X_{31}A_{11} \\ Y_{20}=X_{20}A_{00}+X_{21}A_{10} & Y_{21}=X_{20}A_{01}+X_{21}A_{11} \end{matrix} \right].
+\left[\begin{matrix} Y_{20}=X_{20}A_{00}+X_{21}A_{10} & Y_{21}=X_{20}A_{01}+X_{21}A_{11} \\ Y_{30}=X_{30}A_{00}+X_{31}A_{10} & Y_{31}=X_{30}A_{01}+X_{31}A_{11} \end{matrix} \right].
$$
## 效率
diff --git a/docs/source/zh-Hans/features/3D_tensor_parallel.md b/docs/source/zh-Hans/features/3D_tensor_parallel.md
index 440121c94243..5ce0cdf6c068 100644
--- a/docs/source/zh-Hans/features/3D_tensor_parallel.md
+++ b/docs/source/zh-Hans/features/3D_tensor_parallel.md
@@ -9,7 +9,7 @@
- [2D 张量并行](./2D_tensor_parallel.md)
**示例代码**
-- [ColossalAI-Examples - 3D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/tensor_parallel/tensor_parallel_3d.py)
+- [ColossalAI-Examples - 3D Tensor Parallelism](https://github.com/hpcaitech/ColossalAI-Examples/blob/main/features/tensor_parallel/README.md)
**相关论文**
- [Maximizing Parallelism in Distributed Training for Huge Neural Networks](https://arxiv.org/pdf/2105.14450.pdf)
diff --git a/docs/source/zh-Hans/features/cluster_utils.md b/docs/source/zh-Hans/features/cluster_utils.md
new file mode 100644
index 000000000000..f54a72c63a66
--- /dev/null
+++ b/docs/source/zh-Hans/features/cluster_utils.md
@@ -0,0 +1,16 @@
+# 集群实用程序
+
+作者: [Hongxin Liu](https://github.com/ver217)
+
+**前置教程:**
+- [分布式训练](../concepts/distributed_training.md)
+
+## 引言
+
+我们提供了一个实用程序类 `colossalai.cluster.DistCoordinator` 来协调分布式训练。它对于获取有关集群的各种信息很有用,例如节点数、每个节点的进程数等。
+
+## API 参考
+
+{{ autodoc:colossalai.cluster.DistCoordinator }}
+
+
diff --git a/docs/source/zh-Hans/features/gradient_accumulation.md b/docs/source/zh-Hans/features/gradient_accumulation.md
index e21e5fcd43d8..fc8b29bbe8f1 100644
--- a/docs/source/zh-Hans/features/gradient_accumulation.md
+++ b/docs/source/zh-Hans/features/gradient_accumulation.md
@@ -1,4 +1,4 @@
-# 梯度累积
+# 梯度累积 (旧版本)
作者: Shenggui Li, Yongbin Li
@@ -38,3 +38,4 @@ iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0
iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
```
+
diff --git a/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md b/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md
new file mode 100644
index 000000000000..ab86f34f2dec
--- /dev/null
+++ b/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md
@@ -0,0 +1,146 @@
+# 梯度累积 (最新版本)
+
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**前置教程**
+- [定义配置文件](../basics/define_your_config.md)
+- [训练中使用Booster](../basics/booster_api.md)
+
+## 引言
+
+梯度累积是一种常见的增大训练 batch size 的方式。 在训练大模型时,内存经常会成为瓶颈,并且 batch size 通常会很小(如2),这导致收敛性无法保证。梯度累积将多次迭代的梯度累加,并仅在达到预设迭代次数时更新参数。
+
+## 使用
+
+在 Colossal-AI 中使用梯度累积非常简单,booster提供no_sync返回一个上下文管理器,在该上下文管理器下取消同步并且累积梯度。
+
+## 实例
+
+我们将介绍如何使用梯度累积。在这个例子中,梯度累积次数被设置为4。
+
+### 步骤 1. 在 train.py 导入相关库
+创建train.py并导入必要依赖。 `torch` 的版本应不低于1.8.1。
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet18
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.cluster.dist_coordinator import priority_execution
+```
+
+### 步骤 2. 初始化分布式环境
+
+我们需要初始化分布式环境。为了快速演示,我们使用`launch_from_torch`。你可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)使用其他初始化方法。
+
+```python
+# initialize distributed setting
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+
+```
+
+### 步骤 3. 创建训练组件
+
+构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`,在你的机器上设置路径。数据将会被自动下载到该路径。
+
+```python
+# define the training hyperparameters
+BATCH_SIZE = 128
+GRADIENT_ACCUMULATION = 4
+
+# build resnet
+model = resnet18(num_classes=10)
+
+# build dataloaders
+with priority_execution():
+ train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+```
+
+### 步骤 4. 注入特性
+创建一个`TorchDDPPlugin`对象,并作为参实例化`Booster`, 调用`booster.boost`注入特性。
+
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, _ = booster.boost(model=model,
+ optimizer=optimizer,
+ criterion=criterion,
+ dataloader=train_dataloader)
+```
+
+### 步骤 5. 使用booster训练
+使用booster构建一个普通的训练循环,验证梯度累积。 `param_by_iter` 记录分布训练的信息。
+```python
+optimizer.zero_grad()
+for idx, (img, label) in enumerate(train_dataloader):
+ sync_context = booster.no_sync(model)
+ img = img.cuda()
+ label = label.cuda()
+ if idx % (GRADIENT_ACCUMULATION - 1) != 0:
+ with sync_context:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ else:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.step()
+ optimizer.zero_grad()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ param_by_iter.append(str(ele_1st.item()))
+
+ if idx != 0 and idx % (GRADIENT_ACCUMULATION - 1) == 0:
+ break
+
+ for iteration, val in enumerate(param_by_iter):
+ print(f'iteration {iteration} - value: {val}')
+
+ if param_by_iter[-1] != param_by_iter[0]:
+ print('The parameter is only updated in the last iteration')
+
+```
+
+### 步骤 6. 启动训练脚本
+为了验证梯度累积,我们可以只检查参数值的变化。当设置梯度累加时,仅在最后一步更新参数。您可以使用以下命令运行脚本:
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
+你将会看到类似下方的文本输出。这展现了梯度虽然在前3个迭代中被计算,但直到最后一次迭代,参数才被更新。
+
+```text
+iteration 0, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
+```
+
+
diff --git a/docs/source/zh-Hans/features/gradient_clipping.md b/docs/source/zh-Hans/features/gradient_clipping.md
index 203f66a3fea2..2f62c31766a6 100644
--- a/docs/source/zh-Hans/features/gradient_clipping.md
+++ b/docs/source/zh-Hans/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# 梯度裁剪
+# 梯度裁剪(旧版本)
作者: Boxiang Wang, Haichen Huang, Yongbin Li
@@ -49,3 +49,5 @@ clip_grad_norm = 1.0
```shell
python -m torch.distributed.launch --nproc_per_node 1 --master_addr localhost --master_port 29500 train_with_engine.py
```
+
+
diff --git a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
new file mode 100644
index 000000000000..3c61356dd0d5
--- /dev/null
+++ b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
@@ -0,0 +1,140 @@
+# 梯度裁剪 (新版本)
+
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**前置教程**
+- [定义配置文件](../basics/define_your_config.md)
+- [booster使用](../basics/booster_api.md)
+
+**相关论文**
+- [On the difficulty of training Recurrent Neural Networks](https://arxiv.org/abs/1211.5063)
+
+## 引言
+
+为了加快训练过程和寻求全局最优以获得更好的性能,越来越多的学习率调度器被提出。人们通过控制学习率来调整训练中的下降速度。这使得梯度向量在每一步都能更好地统一。在这种情况下,下降速度可以按预期被控制。
+因此,梯度裁剪,一种可以将梯度向量归一化,以将其限制在统一长度的技术,对于那些希望模型性能更好的人来说是不可或缺的。
+
+在使用 Colossal-AI 时,你不必担心实现梯度剪裁,我们以一种有效而方便的方式支持梯度剪裁。你所需要的只是在你的配置文件中增加一个命令。
+
+## 为什么应该使用 Colossal-AI 中的梯度裁剪
+
+我们不建议用户自己编写梯度剪裁,因为朴素的梯度剪裁在应用张量并行、流水线并行、MoE 等功能时可能会失败。
+
+根据下图,每个 GPU 只拥有线性层中权重的一部分参数。为了得到线性层权重的梯度向量的正确范数,每个 GPU 中的每个梯度向量的范数应该相加。更复杂的是,偏置的分布不同于权重的分布。通信组在求和运算中有所不同。
+
+(注: 这种情况是旧版本的 2D 并行,在代码中的实现是不一样的。但这是一个很好的例子,能够说明在梯度剪裁中统一所有通信的困难。)
+
+
+
+参数分布
+
+
+不用担心它,因为 Colossal-AI 已经为你处理好。
+
+### 使用
+要使用梯度裁剪,只需在使用booster注入特性之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。
+
+### 实例
+
+下面我们将介绍如何使用梯度裁剪,在本例中,我们将梯度裁剪范数设置为1.0。
+
+### 步骤 1. 在训练中导入相关库
+创建`train.py`并导入相关库。
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet34
+from tqdm import tqdm
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import CosineAnnealingLR
+```
+
+### 步骤 2. 初始化分布式环境
+我们需要初始化分布式环境. 为了快速演示,我们使用`launch_from_torch`. 您可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)
+
+```python
+colossalai.launch_from_torch(config=dict())
+logger = get_dist_logger()
+```
+
+### 步骤 3. 创建训练组件
+
+构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`在你的机器上设置路径。数据将会被自动下载到该路径。
+```python
+# define training hyperparameters
+NUM_EPOCHS = 200
+BATCH_SIZE = 128
+GRADIENT_CLIPPING = 0.1
+# build resnet
+model = resnet34(num_classes=10)
+# build dataloaders
+train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+# lr_scheduler
+lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+
+```
+### 步骤 4. 注入梯度裁剪特性
+
+创建`TorchDDPPlugin`对象并初始化`Booster`, 使用booster注入相关特性。
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+
+```
+
+### 步骤 5. 使用booster训练
+使用booster进行训练。
+```python
+# verify gradient clipping
+model.train()
+for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
+```
+
+### 步骤 6. 启动训练脚本
+你可以使用以下命令运行脚本:
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
diff --git a/docs/source/zh-Hans/features/mixed_precision_training.md b/docs/source/zh-Hans/features/mixed_precision_training.md
index c9db3a59c1c3..4628b09cd910 100644
--- a/docs/source/zh-Hans/features/mixed_precision_training.md
+++ b/docs/source/zh-Hans/features/mixed_precision_training.md
@@ -1,4 +1,4 @@
-# 自动混合精度训练 (AMP)
+# 自动混合精度训练 (旧版本)
作者: Chuanrui Wang, Shenggui Li, Yongbin Li
@@ -203,7 +203,7 @@ Naive AMP 的默认参数:
- initial_scale(int): gradient scaler 的初始值
- growth_factor(int): loss scale 的增长率
- backoff_factor(float): loss scale 的下降率
-- hysterisis(int): 动态 loss scaling 的延迟偏移
+- hysteresis(int): 动态 loss scaling 的延迟偏移
- max_scale(int): loss scale 的最大允许值
- verbose(bool): 如果被设为`True`,将打印调试信息
@@ -339,6 +339,7 @@ for epoch in range(gpc.config.NUM_EPOCHS):
使用下列命令启动训练脚本,你可以改变 `--nproc_per_node` 以使用不同数量的 GPU。
-```python
+```shell
python -m torch.distributed.launch --nproc_per_node 4 --master_addr localhost --master_port 29500 train_with_engine.py --config config/config_AMP_torch.py
```
+
diff --git a/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md b/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md
new file mode 100644
index 000000000000..6954556a8e9a
--- /dev/null
+++ b/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md
@@ -0,0 +1,235 @@
+# 自动混合精度训练 (最新版本)
+
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**前置教程**
+- [定义配置文件](../basics/define_your_config.md)
+- [booster使用](../basics/booster_api.md)
+
+**相关论文**
+- [Accelerating Scientific Computations with Mixed Precision Algorithms](https://arxiv.org/abs/0808.2794)
+
+
+## 引言
+
+AMP 代表自动混合精度训练。
+在 Colossal-AI 中, 我们结合了混合精度训练的不同实现:
+
+1. torch.cuda.amp
+2. apex.amp
+3. naive amp
+
+
+| Colossal-AI | 支持张量并行 | 支持流水并行 | fp16范围 |
+| ----------- | ----------------------- | ------------------------- | ----------- |
+| AMP_TYPE.TORCH | ✅ | ❌ | 在前向和反向传播期间,模型参数、激活和梯度向下转换至fp16 |
+| AMP_TYPE.APEX | ❌ | ❌ | 更细粒度,我们可以选择 opt_level O0, O1, O2, O3 |
+| AMP_TYPE.NAIVE | ✅ | ✅ | 模型参数、前向和反向操作,全都向下转换至fp16 |
+
+前两个依赖于 PyTorch (1.6及以上) 和 NVIDIA Apex 的原始实现。最后一种方法类似 Apex O2。在这些方法中,Apex-AMP 与张量并行不兼容。这是因为张量是以张量并行的方式在设备之间拆分的,因此,需要在不同的进程之间进行通信,以检查整个模型权重中是否出现inf或nan。我们修改了torch amp实现,使其现在与张量并行兼容。
+
+> ❌️ fp16与ZeRO不兼容
+>
+> ⚠️ 流水并行目前仅支持naive amp
+
+我们建议使用 torch AMP,因为在不使用流水并行时,它通常比 NVIDIA AMP 提供更好的准确性。
+
+## 目录
+
+在本教程中,我们将介绍:
+
+1. [AMP 介绍](#amp-介绍)
+2. [Colossal-AI 中的 AMP](#colossal-ai-中的-amp)
+3. [练习实例](#实例)
+
+## AMP 介绍
+
+自动混合精度训练是混合 FP16 和 FP32 训练。
+
+半精度浮点格式(FP16)具有较低的算法复杂度和较高的计算效率。此外,FP16 仅需要 FP32 所需的一半存储空间,并节省了内存和网络带宽,从而为大 batch size 和大模型提供了更多内存。
+
+然而,还有其他操作,如缩减,需要 FP32 的动态范围,以避免数值溢出/下溢。因此,我们引入自动混合精度,尝试将每个操作与其相应的数据类型相匹配,这可以减少内存占用并提高训练效率。
+
+
+
+AMP 示意图 (图片来自 PatrickStar 论文)
+
+
+## Colossal-AI 中的 AMP
+
+我们支持三种 AMP 训练方法,并允许用户在没有改变代码的情况下使用 AMP 进行训练。booster支持amp特性注入,如果您要使用混合精度训练,则在创建booster实例时指定`mixed_precision`参数,我们现已支持torch amp,apex amp, naive amp(现已移植torch amp至booster,apex amp, naive amp仍由`colossalai.initialize`方式启动,如您需使用,请[参考](./mixed_precision_training.md);后续将会拓展`bf16`,`pf8`的混合精度训练.
+
+#### booster启动方式
+您可以在创建booster实例时,指定`mixed_precision="fp16"`即使用torch amp。
+
+```python
+"""
+ 初始化映射关系如下:
+ 'fp16': torch amp
+ 'fp16_apex': apex amp,
+ 'bf16': bf16,
+ 'fp8': fp8,
+ 'fp16_naive': naive amp
+"""
+from colossalai import Booster
+booster = Booster(mixed_precision='fp16',...)
+```
+
+或者您可以自定义一个`FP16TorchMixedPrecision`对象,如
+
+```python
+from colossalai.mixed_precision import FP16TorchMixedPrecision
+mixed_precision = FP16TorchMixedPrecision(
+ init_scale=2.**16,
+ growth_factor=2.0,
+ backoff_factor=0.5,
+ growth_interval=2000)
+booster = Booster(mixed_precision=mixed_precision,...)
+```
+
+其他类型的amp使用方式也是一样的。
+
+### Torch AMP 配置
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16TorchMixedPrecision }}
+
+### Apex AMP 配置
+
+对于这种模式,我们依靠 Apex 实现混合精度训练。我们支持这个插件,因为它允许对混合精度的粒度进行更精细的控制。
+例如, O2 水平 (优化器水平2) 将保持 batch normalization 为 FP32。
+
+如果你想了解更多细节,请参考 [Apex Documentation](https://nvidia.github.io/apex/)。
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16ApexMixedPrecision }}
+
+### Naive AMP 配置
+
+在 Naive AMP 模式中, 我们实现了混合精度训练,同时保持了与复杂张量和流水并行的兼容性。该 AMP 模式将所有操作转为 FP16 。下列代码块展示了该模式的booster启动方式。
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16NaiveMixedPrecision }}
+
+当使用`colossalai.booster`时, 首先需要实例化一个模型、一个优化器和一个标准。将输出模型转换为内存消耗较小的 AMP 模型。如果您的输入模型已经太大,无法放置在 GPU 中,请使用`dtype=torch.float16`实例化你的模型。或者请尝试更小的模型,或尝试更多的并行化训练技术!
+
+## 实例
+
+下面我们将展现如何在 Colossal-AI 使用 AMP。在该例程中,我们使用 Torch AMP.
+
+### 步骤 1. 在 train.py 导入相关库
+
+创建`train.py`并导入必要依赖. 请记得通过命令`pip install timm scipy`安装`scipy`和`timm`。
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from timm.models import vit_base_patch16_224
+from titans.utils import barrier_context
+from torchvision import datasets, transforms
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import LinearWarmupLR
+```
+
+### 步骤 2. 初始化分布式环境
+
+我们需要初始化分布式环境。为了快速演示,我们使用`launch_from_torch`。你可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)
+使用其他初始化方法。
+
+```python
+# 初始化分布式设置
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+
+```
+
+### 步骤 3. 创建训练组件
+
+构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`
+在你的机器上设置路径。数据将会被自动下载到该路径。
+
+```python
+# define the constants
+NUM_EPOCHS = 2
+BATCH_SIZE = 128
+# build model
+model = vit_base_patch16_224(drop_rate=0.1)
+
+# build dataloader
+train_dataset = datasets.Caltech101(
+ root=Path(os.environ['DATA']),
+ download=True,
+ transform=transforms.Compose([
+ transforms.Resize(256),
+ transforms.RandomResizedCrop(224),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ Gray2RGB(),
+ transforms.Normalize([0.5, 0.5, 0.5],
+ [0.5, 0.5, 0.5])
+ ]))
+
+# build optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, weight_decay=0.1)
+
+# build loss
+criterion = torch.nn.CrossEntropyLoss()
+
+# lr_scheduelr
+lr_scheduler = LinearWarmupLR(optimizer, warmup_steps=50, total_steps=NUM_EPOCHS)
+```
+
+### 步骤 4. 插入 AMP
+创建一个MixedPrecision对象(如果需要)及torchDDPPlugin对象,调用 `colossalai.boost` 将所有训练组件转为为FP16模式.
+
+```python
+plugin = TorchDDPPlugin()
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+
+# if you need to customize the config, do like this
+# >>> from colossalai.mixed_precision import FP16TorchMixedPrecision
+# >>> mixed_precision = FP16TorchMixedPrecision(
+# >>> init_scale=2.**16,
+# >>> growth_factor=2.0,
+# >>> backoff_factor=0.5,
+# >>> growth_interval=2000)
+# >>> plugin = TorchDDPPlugin()
+# >>> booster = Booster(mixed_precision=mixed_precision, plugin=plugin)
+
+# boost model, optimizer, criterion, dataloader, lr_scheduler
+model, optimizer, criterion, dataloader, lr_scheduler = booster.boost(model, optimizer, criterion, dataloader, lr_scheduler)
+```
+
+### 步骤 5. 使用 booster 训练
+
+使用booster构建一个普通的训练循环。
+
+```python
+model.train()
+for epoch in range(NUM_EPOCHS):
+ for img, label in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+ optimizer.zero_grad()
+ output = model(img)
+ loss = criterion(output, label)
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ lr_scheduler.step()
+```
+
+### 步骤 6. 启动训练脚本
+
+使用下列命令启动训练脚本,你可以改变 `--nproc_per_node` 以使用不同数量的 GPU。
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
diff --git a/docs/source/zh-Hans/features/nvme_offload.md b/docs/source/zh-Hans/features/nvme_offload.md
index fd75ed1f5b3e..1feb9dde5725 100644
--- a/docs/source/zh-Hans/features/nvme_offload.md
+++ b/docs/source/zh-Hans/features/nvme_offload.md
@@ -53,9 +53,8 @@ optimizer = HybridAdam(model.parameters(), lr=1e-3, nvme_offload_fraction=1.0, n
> ⚠ 它只会卸载在 CPU 上的优化器状态。这意味着它只会影响 CPU 训练或者使用卸载的 Zero/Gemini。
-## Exampls
+## Examples
-Let's start from two simple examples -- training GPT with different methods. These examples relies on `transformers`.
首先让我们从两个简单的例子开始 -- 用不同的方法训练 GPT。这些例子依赖`transformers`。
我们首先应该安装依赖:
@@ -77,8 +76,9 @@ from transformers.models.gpt2.configuration_gpt2 import GPT2Config
from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
import colossalai
from colossalai.nn.optimizer import HybridAdam
-from colossalai.zero import zero_model_wrapper, zero_optim_wrapper
from colossalai.utils.model.colo_init_context import ColoInitContext
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin
```
然后我们定义一个损失函数:
@@ -182,16 +182,24 @@ def train_gemini_cpu(nvme_offload_fraction: float = 0.0):
criterion = GPTLMLoss()
optimizer = HybridAdam(model.parameters(), nvme_offload_fraction=nvme_offload_fraction)
print(f'Model numel: {get_model_numel(model) / 1024**3:.3f} B')
- gemini_config = dict(strict_ddp_mode=True, device=torch.cuda.current_device(),
- placement_policy='cpu', pin_memory=True, hidden_dim=config.n_embd)
- model = zero_model_wrapper(model, zero_stage=3, gemini_config=gemini_config)
- optimizer = zero_optim_wrapper(model, optimizer, initial_scale=2**5)
+
+ plugin = GeminiPlugin(
+ strict_ddp_mode=True,
+ device=torch.cuda.current_device(),
+ placement_policy='cpu',
+ pin_memory=True,
+ hidden_dim=config.n_embd,
+ initial_scale=2**5
+ )
+ booster = Booster(plugin)
+ model, optimizer, criterion, _* = booster.boost(model, optimizer, criterion)
+
start = time.time()
for step in range(3):
data = get_data(4, 128, config.vocab_size)
outputs = model(**data)
loss = criterion(outputs.logits, data['input_ids'])
- optimizer.backward(loss)
+ booster.backward(loss, optimizer)
optimizer.step()
optimizer.zero_grad()
print(f'[{step}] loss: {loss.item():.3f}')
diff --git a/docs/source/zh-Hans/features/zero_with_chunk.md b/docs/source/zh-Hans/features/zero_with_chunk.md
index 72403bf610a4..ba57ba4e8e61 100644
--- a/docs/source/zh-Hans/features/zero_with_chunk.md
+++ b/docs/source/zh-Hans/features/zero_with_chunk.md
@@ -185,23 +185,23 @@ def split_param_col_tp1d(param: ColoParameter, pg: ProcessGroup):
定义一个使用 Gemini + ZeRO DDP 的模型:
```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
cai_version = colossalai.__version__
if version.parse(cai_version) > version.parse("0.1.10"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
elif version.parse(cai_version) <= version.parse("0.1.10") and version.parse(cai_version) >= version.parse("0.1.9"):
from colossalai.gemini import ChunkManager, GeminiManager
chunk_size = ChunkManager.search_chunk_size(model, 64 * 1024**2, 32)
- gemini_manager = GeminiManager(placememt_policy, chunk_manager)
+ gemini_manager = GeminiManager(placement_policy, chunk_manager)
chunk_manager = ChunkManager(chunk_size,
pg,
enable_distributed_storage=True,
- init_device=GeminiManager.get_default_device(placememt_policy))
+ init_device=GeminiManager.get_default_device(placement_policy))
model = ZeroDDP(model, gemini_manager)
else:
raise NotImplemented(f"CAI version {cai_version} is not supported")
diff --git a/docs/source/zh-Hans/get_started/installation.md b/docs/source/zh-Hans/get_started/installation.md
index 72f85393814f..a32627db6f00 100755
--- a/docs/source/zh-Hans/get_started/installation.md
+++ b/docs/source/zh-Hans/get_started/installation.md
@@ -28,7 +28,7 @@ CUDA_EXT=1 pip install colossalai
## 从源安装
-> 此文档将与版本库的主分支保持一致。如果您遇到任何问题,欢迎给我们提 issue :)
+> 此文档将与版本库的主分支保持一致。如果您遇到任何问题,欢迎给我们提 issue。
```shell
git clone https://github.com/hpcaitech/ColossalAI.git
@@ -38,13 +38,29 @@ cd ColossalAI
pip install -r requirements/requirements.txt
# install colossalai
-pip install .
+CUDA_EXT=1 pip install .
```
-如果您不想安装和启用 CUDA 内核融合(使用融合优化器时强制安装):
+如果您不想安装和启用 CUDA 内核融合(使用融合优化器时强制安装),您可以不添加`CUDA_EXT=1`:
```shell
-NO_CUDA_EXT=1 pip install .
+pip install .
+```
+
+如果您在使用CUDA 10.2,您仍然可以从源码安装ColossalA。但是您需要手动下载cub库并将其复制到相应的目录。
+
+```bash
+# clone the repository
+git clone https://github.com/hpcaitech/ColossalAI.git
+cd ColossalAI
+
+# download the cub library
+wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip
+unzip 1.8.0.zip
+cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
+
+# install
+CUDA_EXT=1 pip install .
```
diff --git a/examples/images/dreambooth/train_dreambooth_colossalai.py b/examples/images/dreambooth/train_dreambooth_colossalai.py
index e6159e1058b9..d07febea0a84 100644
--- a/examples/images/dreambooth/train_dreambooth_colossalai.py
+++ b/examples/images/dreambooth/train_dreambooth_colossalai.py
@@ -340,12 +340,12 @@ def get_full_repo_name(model_id: str, organization: Optional[str] = None, token:
# Gemini + ZeRO DDP
-def gemini_zero_dpp(model: torch.nn.Module, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=64)
return model
diff --git a/examples/images/dreambooth/train_dreambooth_colossalai_lora.py b/examples/images/dreambooth/train_dreambooth_colossalai_lora.py
index 1b2fc778d5ed..6715b473a567 100644
--- a/examples/images/dreambooth/train_dreambooth_colossalai_lora.py
+++ b/examples/images/dreambooth/train_dreambooth_colossalai_lora.py
@@ -342,12 +342,12 @@ def get_full_repo_name(model_id: str, organization: Optional[str] = None, token:
# Gemini + ZeRO DDP
-def gemini_zero_dpp(model: torch.nn.Module, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=64)
return model
diff --git a/examples/language/gpt/experiments/auto_parallel/README.md b/examples/language/gpt/experiments/auto_parallel/README.md
index 1c8b1c35109f..32688873f8f1 100644
--- a/examples/language/gpt/experiments/auto_parallel/README.md
+++ b/examples/language/gpt/experiments/auto_parallel/README.md
@@ -13,10 +13,10 @@ conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu113
```
-### Install [Colossal-AI v0.2.0](https://colossalai.org/download/) From Official Website
+### Install Colossal-AI
```bash
-pip install colossalai==0.2.0+torch1.12cu11.3 -f https://release.colossalai.org
+pip install colossalai==0.2.0
```
### Install transformers
diff --git a/examples/language/palm/train.py b/examples/language/palm/train.py
index 7923e4fc855d..b16da1c7744a 100644
--- a/examples/language/palm/train.py
+++ b/examples/language/palm/train.py
@@ -102,23 +102,23 @@ def get_model_size(model: nn.Module):
# Gemini + ZeRO DDP
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
cai_version = colossalai.__version__
if version.parse(cai_version) > version.parse("0.1.10"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
elif version.parse(cai_version) <= version.parse("0.1.10") and version.parse(cai_version) >= version.parse("0.1.9"):
from colossalai.gemini import ChunkManager, GeminiManager
chunk_size = ChunkManager.search_chunk_size(model, 64 * 1024**2, 32)
- gemini_manager = GeminiManager(placememt_policy, chunk_manager)
+ gemini_manager = GeminiManager(placement_policy, chunk_manager)
chunk_manager = ChunkManager(chunk_size,
pg,
enable_distributed_storage=True,
- init_device=GeminiManager.get_default_device(placememt_policy))
+ init_device=GeminiManager.get_default_device(placement_policy))
model = ZeroDDP(model, gemini_manager)
else:
raise NotImplemented(f"CAI version {cai_version} is not supported")
diff --git a/examples/tutorial/README.md b/examples/tutorial/README.md
index f4843331fd54..0664d41fd359 100644
--- a/examples/tutorial/README.md
+++ b/examples/tutorial/README.md
@@ -29,7 +29,11 @@ quickly deploy large AI model training and inference, reducing large AI model tr
- Fine-tuning and Inference for OPT [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/opt) [[video]](https://www.youtube.com/watch?v=jbEFNVzl67Y)
- Optimized AlphaFold [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/fastfold) [[video]](https://www.youtube.com/watch?v=-zP13LfJP7w)
- Optimized Stable Diffusion [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion) [[video]](https://www.youtube.com/watch?v=8KHeUjjc-XQ)
-
+ - ColossalChat: Cloning ChatGPT with a Complete RLHF Pipeline
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
+[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+[[demo]](https://www.youtube.com/watch?v=HcTiHzApHm0)
+[[video]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
## Discussion
diff --git a/op_builder/utils.py b/op_builder/utils.py
index 2dbd976fbcbb..cb528eea66a1 100644
--- a/op_builder/utils.py
+++ b/op_builder/utils.py
@@ -110,7 +110,7 @@ def get_pytorch_version() -> List[int]:
torch_version = torch.__version__.split('+')[0]
TORCH_MAJOR = int(torch_version.split('.')[0])
TORCH_MINOR = int(torch_version.split('.')[1])
- TORCH_PATCH = int(torch_version.split('.')[2])
+ TORCH_PATCH = int(torch_version.split('.')[2], 16)
return TORCH_MAJOR, TORCH_MINOR, TORCH_PATCH
diff --git a/requirements/requirements-test.txt b/requirements/requirements-test.txt
index 82b6173b3517..6895113bc637 100644
--- a/requirements/requirements-test.txt
+++ b/requirements/requirements-test.txt
@@ -1,12 +1,14 @@
diffusers
fbgemm-gpu==0.2.0
pytest
-pytest-cov
+coverage==7.2.3
+git+https://github.com/hpcaitech/pytest-testmon
torchvision
transformers
timm
titans
torchaudio
+torchx-nightly==2022.6.29 # torchrec 0.2.0 requires torchx-nightly. This package is updated every day. We fix the version to a specific date to avoid breaking changes.
torchrec==0.2.0
contexttimer
einops
diff --git a/tests/test_analyzer/test_subclasses/test_flop_tensor.py b/tests/test_analyzer/test_subclasses/test_flop_tensor.py
index da3829e40146..4e9c9852649b 100644
--- a/tests/test_analyzer/test_subclasses/test_flop_tensor.py
+++ b/tests/test_analyzer/test_subclasses/test_flop_tensor.py
@@ -40,8 +40,7 @@ def test_flop_count_module(m):
@pytest.mark.skipif(version.parse(torch.__version__) < version.parse('1.12.0'), reason='torch version < 12')
-@clear_cache_before_run()
-@parameterize('func, args, kwargs', odd_cases)
+@pytest.mark.parametrize('func, args, kwargs', odd_cases)
def test_flop_count_function(func, args, kwargs):
rs_fwd, rs_bwd = flop_count(func, *args, **kwargs, verbose=True)
assert rs_fwd > 0, f'fwd flop count of {func.__name__} is {rs_fwd}'
diff --git a/tests/test_autochunk/test_autochunk_diffuser/test_autochunk_diffuser_utils.py b/tests/test_autochunk/test_autochunk_diffuser/test_autochunk_diffuser_utils.py
index e245f10d4576..b6a792f5652c 100644
--- a/tests/test_autochunk/test_autochunk_diffuser/test_autochunk_diffuser_utils.py
+++ b/tests/test_autochunk/test_autochunk_diffuser/test_autochunk_diffuser_utils.py
@@ -8,7 +8,6 @@
from colossalai.core import global_context as gpc
from colossalai.fx.graph_module import ColoGraphModule
from colossalai.fx.passes.meta_info_prop import MetaInfoProp
-from colossalai.testing import free_port
if AUTOCHUNK_AVAILABLE:
from colossalai.autochunk.autochunk_codegen import AutoChunkCodeGen
@@ -93,6 +92,8 @@ def assert_codegen_run(
def run_test(
rank: int,
+ world_size: int,
+ port: int,
model: Any,
data: tuple,
max_memory: int,
@@ -106,9 +107,9 @@ def run_test(
colossalai.launch(
config={},
rank=rank,
- world_size=1,
+ world_size=world_size,
host="localhost",
- port=free_port(),
+ port=port,
backend="nccl",
)
diff --git a/tests/test_autochunk/test_autochunk_transformer/test_autochunk_gpt.py b/tests/test_autochunk/test_autochunk_transformer/test_autochunk_gpt.py
index 384706639e10..82af6c05c6ef 100644
--- a/tests/test_autochunk/test_autochunk_transformer/test_autochunk_gpt.py
+++ b/tests/test_autochunk/test_autochunk_transformer/test_autochunk_gpt.py
@@ -30,6 +30,8 @@ def get_data(shape: tuple) -> Tuple[List, List]:
return meta_args, concrete_args, sequence
+@pytest.mark.skip("full op is not implemented now")
+# FIXME(ver217, oahzxl): implement full op
@pytest.mark.skipif(
not (AUTOCHUNK_AVAILABLE and HAS_REPO),
reason="torch version is lower than 1.12.0",
diff --git a/tests/test_autochunk/test_autochunk_transformer/test_autochunk_transformer_utils.py b/tests/test_autochunk/test_autochunk_transformer/test_autochunk_transformer_utils.py
index faba138cd42c..5c863b0df47f 100644
--- a/tests/test_autochunk/test_autochunk_transformer/test_autochunk_transformer_utils.py
+++ b/tests/test_autochunk/test_autochunk_transformer/test_autochunk_transformer_utils.py
@@ -5,10 +5,8 @@
import colossalai
from colossalai.autochunk.autochunk_codegen import AUTOCHUNK_AVAILABLE
-from colossalai.core import global_context as gpc
from colossalai.fx.graph_module import ColoGraphModule
from colossalai.fx.passes.meta_info_prop import MetaInfoProp
-from colossalai.testing import free_port
if AUTOCHUNK_AVAILABLE:
from colossalai.autochunk.autochunk_codegen import AutoChunkCodeGen
@@ -100,6 +98,8 @@ def assert_allclose(out_model: Any, out_gm: Any) -> None:
def run_test(
rank: int,
+ world_size: int,
+ port: int,
model: Any,
config: Any,
data: tuple,
@@ -116,9 +116,9 @@ def run_test(
colossalai.launch(
config={},
rank=rank,
- world_size=1,
+ world_size=world_size,
host="localhost",
- port=free_port(),
+ port=port,
backend="nccl",
)
diff --git a/tests/test_autochunk/test_autochunk_vit/test_autochunk_vit_utils.py b/tests/test_autochunk/test_autochunk_vit/test_autochunk_vit_utils.py
index 317606fc4781..3202318fb6d1 100644
--- a/tests/test_autochunk/test_autochunk_vit/test_autochunk_vit_utils.py
+++ b/tests/test_autochunk/test_autochunk_vit/test_autochunk_vit_utils.py
@@ -8,7 +8,6 @@
from colossalai.core import global_context as gpc
from colossalai.fx.graph_module import ColoGraphModule
from colossalai.fx.passes.meta_info_prop import MetaInfoProp
-from colossalai.testing import free_port
if AUTOCHUNK_AVAILABLE:
from colossalai.autochunk.autochunk_codegen import AutoChunkCodeGen
@@ -85,6 +84,8 @@ def assert_codegen_run(
def run_test(
rank: int,
+ world_size: int,
+ port: int,
model: Any,
data: tuple,
max_memory: int,
@@ -98,9 +99,9 @@ def run_test(
colossalai.launch(
config={},
rank=rank,
- world_size=1,
+ world_size=world_size,
host="localhost",
- port=free_port(),
+ port=port,
backend="nccl",
)
diff --git a/tests/test_booster/test_plugin/test_low_level_zero_plugin.py b/tests/test_booster/test_plugin/test_low_level_zero_plugin.py
index d84b96f77a75..f70f27be2aa7 100644
--- a/tests/test_booster/test_plugin/test_low_level_zero_plugin.py
+++ b/tests/test_booster/test_plugin/test_low_level_zero_plugin.py
@@ -11,9 +11,9 @@
from tests.kit.model_zoo import model_zoo
# These models are not compatible with AMP
-_AMP_ERR_MODELS = ['timm_convit', 'dlrm', 'deepfm_interactionarch', 'deepfm_simpledeepfmnn`']
+_AMP_ERR_MODELS = ['timm_convit', 'dlrm', 'deepfm_interactionarch', 'deepfm_simpledeepfmnn']
# These models have no parameters
-_LOW_LEVEL_ZERO_ERR_MODELS = ['dlrm_interactionarch']
+_LOW_LEVEL_ZERO_ERR_MODELS = ['dlrm_interactionarch', 'deepfm_overarch', 'deepfm_sparsearch', 'dlrm_sparsearch']
# These models will get stuck
_STUCK_MODELS = [
'diffusers_vq_model', 'transformers_albert', 'transformers_albert_for_pretraining', 'transformers_bert',
@@ -67,6 +67,7 @@ def check_low_level_zero_plugin(stage: int, early_stop: bool = True):
skipped_models.append(name)
continue
err = run_fn(stage, model_fn, data_gen_fn, output_transform_fn)
+
torch.cuda.empty_cache()
if err is None:
@@ -91,7 +92,7 @@ def run_dist(rank, world_size, port, early_stop: bool = True):
@rerun_if_address_is_in_use()
def test_low_level_zero_plugin(early_stop: bool = True):
- spawn(run_dist, 2, early_stop=early_stop)
+ spawn(run_dist, 4, early_stop=early_stop)
if __name__ == '__main__':
diff --git a/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py b/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py
new file mode 100644
index 000000000000..44767f051fdd
--- /dev/null
+++ b/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py
@@ -0,0 +1,64 @@
+import pytest
+import torch
+from packaging import version
+from torch.optim import SGD
+
+import colossalai
+from colossalai.booster import Booster
+
+if version.parse(torch.__version__) >= version.parse('1.12.0'):
+ from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
+ from colossalai.booster.plugin import TorchFSDPPlugin
+
+from colossalai.interface import OptimizerWrapper
+from colossalai.testing import rerun_if_address_is_in_use, spawn
+from tests.kit.model_zoo import model_zoo
+
+
+# test baisc fsdp function
+def run_fn(model_fn, data_gen_fn, output_transform_fn):
+ plugin = TorchFSDPPlugin()
+ booster = Booster(plugin=plugin)
+ model = model_fn()
+ optimizer = SGD(model.parameters(), lr=1e-3)
+ criterion = lambda x: x.mean()
+ data = data_gen_fn()
+
+ data = {k: v.to('cuda') if torch.is_tensor(v) or 'Tensor' in v.__class__.__name__ else v for k, v in data.items()}
+
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+
+ assert isinstance(model.module, FSDP)
+ assert isinstance(optimizer, OptimizerWrapper)
+
+ output = model(**data)
+ output = output_transform_fn(output)
+ output_key = list(output.keys())[0]
+ loss = criterion(output[output_key])
+
+ booster.backward(loss, optimizer)
+ optimizer.clip_grad_by_norm(1.0)
+ optimizer.step()
+
+
+def check_torch_fsdp_plugin():
+ for name, (model_fn, data_gen_fn, output_transform_fn, _) in model_zoo.items():
+ if any(element in name for element in [
+ 'diffusers', 'deepfm_sparsearch', 'dlrm_interactionarch', 'torchvision_googlenet',
+ 'torchvision_inception_v3'
+ ]):
+ continue
+ run_fn(model_fn, data_gen_fn, output_transform_fn)
+ torch.cuda.empty_cache()
+
+
+def run_dist(rank, world_size, port):
+ # init dist env
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ check_torch_fsdp_plugin()
+
+
+@pytest.mark.skipif(version.parse(torch.__version__) < version.parse('1.12.0'), reason="requires torch1.12 or higher")
+@rerun_if_address_is_in_use()
+def test_torch_fsdp_plugin():
+ spawn(run_dist, 2)
diff --git a/tests/test_checkpoint_io/test_gemini_checkpoint_io.py b/tests/test_checkpoint_io/test_gemini_checkpoint_io.py
index 1e5a2e1c4b44..994412bbc63f 100644
--- a/tests/test_checkpoint_io/test_gemini_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_gemini_checkpoint_io.py
@@ -1,87 +1,95 @@
-import tempfile
+import os
import pytest
import torch
+import torch.distributed as dist
+from utils import shared_tempdir
import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin
from colossalai.booster.plugin.gemini_plugin import GeminiCheckpointIO
+from colossalai.nn.optimizer import HybridAdam
from colossalai.testing import check_state_dict_equal, parameterize, rerun_if_address_is_in_use, spawn
-from colossalai.utils.cuda import get_current_device
-from colossalai.zero import ColoInitContext, ZeroDDP
+from colossalai.zero import ZeroDDP
from colossalai.zero.gemini.chunk import ChunkManager, search_chunk_configuration
from colossalai.zero.gemini.gemini_mgr import GeminiManager
-from tests.components_to_test.registry import non_distributed_component_funcs
+from tests.kit.model_zoo import model_zoo
@parameterize('placement_policy', ['cuda', 'cpu'])
-@parameterize('model_name', ['bert'])
-@parameterize('use_safetensors', [True, False])
+@parameterize('model_name', ['transformers_bert_for_sequence_classification'])
+@parameterize('use_safetensors', [False, True])
def exam_state_dict_with_origin(placement_policy, model_name, use_safetensors: bool):
from transformers import BertForSequenceClassification
+ (model_fn, data_gen_fn, output_transform_fn, _) = next(iter(model_zoo.get_sub_registry(model_name).values()))
+ bert_model = model_fn()
- model_ckpt_dir = tempfile.TemporaryDirectory()
- get_components_func = non_distributed_component_funcs.get_callable(model_name)
- model_builder, *_ = get_components_func()
- with ColoInitContext(device=(get_current_device())):
- bert_model = model_builder()
- bert_model.config.save_pretrained(save_directory=(model_ckpt_dir.name))
-
- config_dict, *_ = search_chunk_configuration(bert_model, search_range_mb=1, search_interval_byte=100)
- chunk_manager = ChunkManager(config_dict)
- gemini_manager = GeminiManager(placement_policy, chunk_manager)
- bert_model = ZeroDDP(bert_model, gemini_manager)
- bert_model.train()
-
- ckpt_io = GeminiCheckpointIO()
- if ckpt_io.coordinator.is_master():
+ with shared_tempdir() as tempdir:
+ pretrained_path = os.path.join(tempdir, 'pretrained')
+ bert_model.config.save_pretrained(save_directory=pretrained_path)
+
+ # TODO(ver217): use boost api
+ config_dict, *_ = search_chunk_configuration(bert_model, search_range_mb=1, search_interval_byte=100)
+ chunk_manager = ChunkManager(config_dict)
+ gemini_manager = GeminiManager(placement_policy, chunk_manager)
+ bert_model = ZeroDDP(bert_model, gemini_manager)
+ bert_model.train()
+
+ ckpt_io = GeminiCheckpointIO()
model_size = sum(p.numel() * p.element_size() for p in bert_model.parameters()) / 1024**2
- ckpt_io.save_model(bert_model, (model_ckpt_dir.name),
+ ckpt_io.save_model(bert_model, (pretrained_path),
True,
True,
'', (model_size / 3),
use_safetensors=use_safetensors)
- new_bert_model = BertForSequenceClassification.from_pretrained(model_ckpt_dir.name)
- check_state_dict_equal(bert_model.state_dict(only_rank_0=True, dtype=(torch.float32)),
+ dist.barrier()
+ new_bert_model = BertForSequenceClassification.from_pretrained(pretrained_path)
+ check_state_dict_equal(bert_model.state_dict(only_rank_0=False, dtype=torch.float32),
new_bert_model.state_dict(), False)
- model_ckpt_dir.cleanup()
@parameterize('placement_policy', ['cuda', 'cpu'])
-@parameterize('model_name', ['gpt2', 'bert'])
-@parameterize('use_safetensors', [True, False])
-def exam_state_dict(placement_policy, model_name: str, use_safetensors: bool):
- get_components_func = non_distributed_component_funcs.get_callable(model_name)
- model_builder, *_ = get_components_func()
- with ColoInitContext(device=(get_current_device())):
- model = model_builder()
- new_model = model_builder()
- config_dict, *_ = search_chunk_configuration(model, search_range_mb=1, search_interval_byte=100)
- chunk_manager = ChunkManager(config_dict)
- gemini_manager = GeminiManager(placement_policy, chunk_manager)
- model = ZeroDDP(model, gemini_manager)
-
- model.train()
- #new model
- new_config_dict, *_ = search_chunk_configuration(new_model, search_range_mb=1, search_interval_byte=100)
- new_chunk_manager = ChunkManager(new_config_dict)
- new_gemini_manager = GeminiManager(placement_policy, new_chunk_manager)
- new_model = ZeroDDP(new_model, new_gemini_manager)
-
- model_ckpt_dir = tempfile.TemporaryDirectory()
- ckpt_io = GeminiCheckpointIO()
- model_size = sum(p.numel() * p.element_size() for p in model.parameters()) / 1024**2
- ckpt_io.save_model(model, (model_ckpt_dir.name),
- True,
- True,
- 'epoch', (model_size / 3),
- use_safetensors=use_safetensors)
-
- if ckpt_io.coordinator.is_master():
- ckpt_io.load_model(new_model, (model_ckpt_dir.name), strict=True)
- model_dict = model.state_dict(only_rank_0=True)
- new_model_dict = new_model.state_dict(only_rank_0=True)
- check_state_dict_equal(model_dict, new_model_dict, False)
- model_ckpt_dir.cleanup()
+@parameterize('shard', [True, False])
+@parameterize('model_name', ['transformers_gpt'])
+def exam_state_dict(placement_policy, shard: bool, model_name: str):
+ (model_fn, data_gen_fn, output_transform_fn, _) = next(iter(model_zoo.get_sub_registry(model_name).values()))
+ criterion = lambda x: x.mean()
+ plugin = GeminiPlugin(placement_policy=placement_policy)
+ booster = Booster(plugin=plugin)
+
+ model = model_fn()
+ new_model = model_fn()
+ optimizer = HybridAdam(model.parameters(), lr=0.001)
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+ new_optimizer = HybridAdam(new_model.parameters(), lr=0.001)
+ new_model, new_optimizer, criterion, _, _ = booster.boost(new_model, new_optimizer, criterion)
+
+ data = data_gen_fn()
+ data = {k: v.to('cuda') if torch.is_tensor(v) or 'Tensor' in v.__class__.__name__ else v for k, v in data.items()}
+ output = model(**data)
+ output = output_transform_fn(output)
+ output_key = list(output.keys())[0]
+ loss = criterion(output[output_key])
+
+ booster.backward(loss, optimizer)
+ optimizer.step()
+
+ with shared_tempdir() as tempdir:
+ model_ckpt_path = f"{tempdir}/model"
+ optimizer_ckpt_path = f"{tempdir}/optimizer"
+ booster.save_model(model, model_ckpt_path)
+ if not shard:
+ # TODO(ver217): optimizer checkpointing is not supported for sharded checkpoint
+ booster.save_optimizer(optimizer, optimizer_ckpt_path)
+ dist.barrier()
+
+ booster.load_model(new_model, model_ckpt_path)
+ check_state_dict_equal(model.unwrap().state_dict(only_rank_0=False),
+ new_model.unwrap().state_dict(only_rank_0=False), False)
+ if not shard:
+ booster.load_optimizer(new_optimizer, optimizer_ckpt_path)
+ check_state_dict_equal(optimizer.state_dict(), new_optimizer.state_dict(), False)
def run_dist(rank, world_size, port):
@@ -92,7 +100,7 @@ def run_dist(rank, world_size, port):
@pytest.mark.dist
-@pytest.mark.parametrize('world_size', [4, 4])
+@pytest.mark.parametrize('world_size', [2])
@rerun_if_address_is_in_use()
def test_gemini_ckpIO(world_size):
spawn(run_dist, world_size)
diff --git a/tests/test_checkpoint_io/test_low_level_zero_checkpoint_io.py b/tests/test_checkpoint_io/test_low_level_zero_checkpoint_io.py
index 217a950d8155..c51b54c82f57 100644
--- a/tests/test_checkpoint_io/test_low_level_zero_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_low_level_zero_checkpoint_io.py
@@ -1,13 +1,11 @@
-import tempfile
-
-import pytest
import torch
+import torch.distributed as dist
from torchvision.models import resnet18
+from utils import shared_tempdir
import colossalai
from colossalai.booster import Booster
from colossalai.booster.plugin import LowLevelZeroPlugin
-from colossalai.booster.plugin.low_level_zero_plugin import LowLevelZeroCheckpointIO
from colossalai.nn.optimizer import HybridAdam
from colossalai.testing import (
check_state_dict_equal,
@@ -20,7 +18,8 @@
@clear_cache_before_run()
@parameterize('stage', [2])
-def check_low_level_zero_checkpointIO(stage: int):
+@parameterize('shard', [True, False])
+def check_low_level_zero_checkpointIO(stage: int, shard: bool):
plugin = LowLevelZeroPlugin(stage=stage, max_norm=1.0, initial_scale=32)
booster = Booster(plugin=plugin)
model = resnet18()
@@ -34,17 +33,25 @@ def check_low_level_zero_checkpointIO(stage: int):
loss = criterion(output)
booster.backward(loss, optimizer)
optimizer.step()
+ with shared_tempdir() as tempdir:
+ model_ckpt_path = f"{tempdir}/model"
+ optimizer_ckpt_path = f"{tempdir}/optimizer"
+ # lr scheduler is tested in test_torch_ddp_checkpoint_io.py and low level zero does not change it, we can skip it here
+ booster.save_model(model, model_ckpt_path, shard=shard)
+ if not shard:
+ # TODO(ver217): optimizer checkpointing is not supported for sharded checkpoint
+ booster.save_optimizer(optimizer, optimizer_ckpt_path)
+ dist.barrier()
- optimizer_ckpt_tempfile = tempfile.NamedTemporaryFile()
- ckpt_io = LowLevelZeroCheckpointIO()
- ckpt_io.save_optimizer(optimizer, optimizer_ckpt_tempfile.name)
-
- if ckpt_io.coordinator.is_master():
new_model = resnet18()
new_optimizer = HybridAdam((new_model.parameters()), lr=0.001)
- _, new_optimizer, _, _, _ = booster.boost(new_model, new_optimizer)
- ckpt_io.load_optimizer(new_optimizer, optimizer_ckpt_tempfile.name)
- check_state_dict_equal(optimizer.state_dict(), new_optimizer.state_dict(), False)
+ new_model, new_optimizer, _, _, _ = booster.boost(new_model, new_optimizer)
+
+ booster.load_model(new_model, model_ckpt_path)
+ check_state_dict_equal(model.state_dict(), new_model.state_dict(), False)
+ if not shard:
+ booster.load_optimizer(new_optimizer, optimizer_ckpt_path)
+ check_state_dict_equal(optimizer.state_dict(), new_optimizer.state_dict(), False)
def run_dist(rank, world_size, port):
diff --git a/tests/test_checkpoint_io/test_torch_ddp_checkpoint_io.py b/tests/test_checkpoint_io/test_torch_ddp_checkpoint_io.py
index 9128f8c0fe9e..5501ee4e3ef2 100644
--- a/tests/test_checkpoint_io/test_torch_ddp_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_torch_ddp_checkpoint_io.py
@@ -1,19 +1,19 @@
-import tempfile
-
import torch
+import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim import SGD
from torchvision.models import resnet18
+from utils import shared_tempdir
import colossalai
from colossalai.booster import Booster
from colossalai.booster.plugin import TorchDDPPlugin
-from colossalai.booster.plugin.torch_ddp_plugin import TorchDDPCheckpointIO
from colossalai.interface import OptimizerWrapper
-from colossalai.testing import check_state_dict_equal, rerun_if_address_is_in_use, spawn
+from colossalai.testing import check_state_dict_equal, parameterize, rerun_if_address_is_in_use, spawn
-def check_torch_ddp_checkpointIO():
+@parameterize('shard', [True, False])
+def check_torch_ddp_checkpointIO(shard: bool):
plugin = TorchDDPPlugin()
booster = Booster(plugin=plugin)
model = resnet18()
@@ -34,23 +34,32 @@ def check_torch_ddp_checkpointIO():
optimizer.step()
scheduler.step()
- optimizer_ckpt_tempfile = tempfile.NamedTemporaryFile()
- lr_scheduler_ckpt_tempfile = tempfile.NamedTemporaryFile()
- ckpt_io = TorchDDPCheckpointIO()
- ckpt_io.save_optimizer(optimizer, optimizer_ckpt_tempfile.name)
- ckpt_io.save_lr_scheduler(scheduler, lr_scheduler_ckpt_tempfile.name)
+ with shared_tempdir() as tempdir:
+ model_ckpt_path = f"{tempdir}/model"
+ optimizer_ckpt_path = f"{tempdir}/optimizer"
+ lr_scheduler_ckpt_path = f"{tempdir}/lr_scheduler"
+ booster.save_model(model, model_ckpt_path, shard=shard)
+ if not shard:
+ # TODO(ver217): optimizer checkpointing is not supported for sharded checkpoint
+ booster.save_optimizer(optimizer, optimizer_ckpt_path)
+ booster.save_lr_scheduler(scheduler, lr_scheduler_ckpt_path)
+ dist.barrier()
- if ckpt_io.coordinator.is_master():
new_model = resnet18()
new_optimizer = SGD((new_model.parameters()), lr=0.001)
new_scheduler = torch.optim.lr_scheduler.StepLR(new_optimizer, step_size=1, gamma=0.1)
- _, new_optimizer, _, _, new_scheduler = booster.boost(new_model, new_optimizer, lr_scheduler=new_scheduler)
+ new_model, new_optimizer, _, _, new_scheduler = booster.boost(new_model,
+ new_optimizer,
+ lr_scheduler=new_scheduler)
- ckpt_io.load_optimizer(new_optimizer, optimizer_ckpt_tempfile.name)
- check_state_dict_equal(optimizer.state_dict(), new_optimizer.state_dict(), False)
+ booster.load_model(new_model, model_ckpt_path)
+ check_state_dict_equal(model.state_dict(), new_model.state_dict(), False)
- ckpt_io.load_lr_scheduler(new_scheduler, lr_scheduler_ckpt_tempfile.name)
- check_state_dict_equal(scheduler.state_dict(), new_scheduler.state_dict(), False)
+ if not shard:
+ booster.load_optimizer(new_optimizer, optimizer_ckpt_path)
+ check_state_dict_equal(optimizer.state_dict(), new_optimizer.state_dict(), False)
+ booster.load_lr_scheduler(new_scheduler, lr_scheduler_ckpt_path)
+ check_state_dict_equal(scheduler.state_dict(), new_scheduler.state_dict(), False)
def run_dist(rank, world_size, port):
diff --git a/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py b/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py
new file mode 100644
index 000000000000..2b6090bb1e29
--- /dev/null
+++ b/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py
@@ -0,0 +1,113 @@
+import pytest
+import torch
+from packaging import version
+from torch import nn
+from torch.optim import SGD
+from torchvision.models import resnet18
+from utils import shared_tempdir
+
+import colossalai
+from colossalai.booster import Booster
+
+if version.parse(torch.__version__) >= version.parse('1.12.0'):
+ from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
+ from colossalai.booster.plugin import TorchFSDPPlugin
+
+from colossalai.testing import rerun_if_address_is_in_use, spawn, check_state_dict_equal
+
+
+def compare_nested_dict(dict1, dict2):
+ for key in dict1:
+ if key in dict2:
+ if type(dict1[key]) is dict:
+ assert type(dict2[key]) is dict
+ diff = compare_nested_dict(dict1[key], dict2[key])
+ if not diff:
+ return diff
+ elif type(dict1[key]) is list:
+ assert type(dict2[key]) is list
+ for i, val in enumerate(dict1[key]):
+ if isinstance(val, torch.Tensor):
+ if not torch.equal(dict1[key][i], dict2[key][i]):
+ return False
+ elif val != dict2[key][i]:
+ return False
+ elif type(dict1[key]) is torch.Tensor:
+ assert type(dict2[key]) is torch.Tensor
+ if not torch.equal(dict1[key], dict2[key]):
+ return False
+ else:
+ if dict1[key] != dict2[key]:
+ return False
+ else:
+ return False
+ return True
+
+
+def check_torch_fsdp_ckpt():
+ model = resnet18()
+ plugin = TorchFSDPPlugin()
+ booster = Booster(plugin=plugin)
+ optimizer = SGD(model.parameters(), lr=0.001, momentum=0.9)
+ criterion = lambda x: x.mean()
+ fsdp_model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+
+ inputs = torch.randn(4, 3, 224, 224)
+ outputs = None
+
+ def run_model():
+ nonlocal outputs
+ outputs = fsdp_model(inputs)
+ optimizer.zero_grad()
+ criterion(outputs).backward()
+ optimizer.step()
+
+ with shared_tempdir() as tempdir:
+ model_ckpt_path = f"{tempdir}/model"
+ optim_ckpt_path = f"{tempdir}/optimizer"
+
+ run_model()
+
+ booster.save_model(fsdp_model, model_ckpt_path, shard=False)
+ booster.save_optimizer(optimizer, optim_ckpt_path, shard=False)
+
+ full_msd = fsdp_model.state_dict()
+ #full_osd = FSDP.full_optim_state_dict(fsdp_model, optimizer)
+ sharded_osd = optimizer.state_dict()
+ import copy
+ sharded_osd = copy.deepcopy(sharded_osd)
+
+ run_model()
+
+ full_msd_updated = fsdp_model.state_dict()
+ #full_osd_updated = FSDP.full_optim_state_dict(fsdp_model, optimizer, rank0_only=True)
+ sharded_osd_updated = optimizer.state_dict()
+
+ assert not compare_nested_dict(sharded_osd, sharded_osd_updated)
+ assert not compare_nested_dict(full_msd_updated, full_msd)
+ outputs_first = fsdp_model(inputs)
+ assert criterion(outputs_first) != criterion(outputs)
+
+ booster.load_model(fsdp_model, model_ckpt_path)
+ booster.load_optimizer(optimizer, optim_ckpt_path)
+
+ full_msd_restore = fsdp_model.state_dict()
+ #full_osd_restore = FSDP.full_optim_state_dict(fsdp_model, optimizer, rank0_only=True)
+ sharded_osd_restore = optimizer.state_dict()
+
+ assert compare_nested_dict(sharded_osd, sharded_osd_restore)
+ assert compare_nested_dict(full_msd_restore, full_msd)
+ outputs_sec = fsdp_model(inputs)
+ assert criterion(outputs_sec) == criterion(outputs)
+
+
+def run_dist(rank, world_size, port):
+ # init dist env
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ check_torch_fsdp_ckpt()
+
+
+@pytest.mark.skipif(version.parse(torch.__version__) < version.parse('1.12.0'), reason="requires torch1.12 or higher")
+@rerun_if_address_is_in_use()
+def test_torch_fsdp_ckpt():
+ spawn(run_dist, 2)
diff --git a/tests/test_checkpoint_io/utils.py b/tests/test_checkpoint_io/utils.py
new file mode 100644
index 000000000000..2d35e157f446
--- /dev/null
+++ b/tests/test_checkpoint_io/utils.py
@@ -0,0 +1,21 @@
+import tempfile
+from contextlib import contextmanager, nullcontext
+from typing import Iterator
+
+import torch.distributed as dist
+
+
+@contextmanager
+def shared_tempdir() -> Iterator[str]:
+ """
+ A temporary directory that is shared across all processes.
+ """
+ ctx_fn = tempfile.TemporaryDirectory if dist.get_rank() == 0 else nullcontext
+ with ctx_fn() as tempdir:
+ try:
+ obj = [tempdir]
+ dist.broadcast_object_list(obj, src=0)
+ tempdir = obj[0] # use the same directory on all ranks
+ yield tempdir
+ finally:
+ dist.barrier()
diff --git a/tests/test_cluster/test_device_mesh_manager.py b/tests/test_cluster/test_device_mesh_manager.py
index b42ef1fe0062..bb818a275879 100644
--- a/tests/test_cluster/test_device_mesh_manager.py
+++ b/tests/test_cluster/test_device_mesh_manager.py
@@ -10,10 +10,11 @@ def check_device_mesh_manager(rank, world_size, port):
disable_existing_loggers()
launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
device_mesh_manager = DeviceMeshManager()
- device_mesh_info_auto = DeviceMeshInfo(physical_ids=[0, 1, 2, 3],)
- device_mesh_auto = device_mesh_manager.create_device_mesh('0', device_mesh_info_auto)
- assert device_mesh_auto.shape == (2, 2)
- assert device_mesh_auto._logical_mesh_id.tolist() == [[0, 1], [2, 3]]
+ # TODO(ver217): this test is strictly relies on hardware, temporary skip it
+ # device_mesh_info_auto = DeviceMeshInfo(physical_ids=[0, 1, 2, 3],)
+ # device_mesh_auto = device_mesh_manager.create_device_mesh('0', device_mesh_info_auto)
+ # assert device_mesh_auto.shape == (2, 2)
+ # assert device_mesh_auto._logical_mesh_id.tolist() == [[0, 1], [2, 3]]
device_mesh_info_with_shape = DeviceMeshInfo(
physical_ids=[0, 1, 2, 3],
diff --git a/tests/test_fx/test_tracer/test_timm_model/test_timm_model.py b/tests/test_fx/test_tracer/test_timm_model/test_timm_model.py
index aa14f514c7d6..11302e8f36b0 100644
--- a/tests/test_fx/test_tracer/test_timm_model/test_timm_model.py
+++ b/tests/test_fx/test_tracer/test_timm_model/test_timm_model.py
@@ -43,6 +43,12 @@ def trace_and_compare(model_cls, data, output_transform_fn, meta_args=None):
f'{model.__class__.__name__} has inconsistent outputs, {fx_output_val} vs {non_fx_output_val}'
+# FIXME(ver217): timm/models/convit.py:71: in forward
+# if self.rel_indices is None or self.rel_indices.shape[1] != N:
+# torch/fx/proxy.py:284: in __bool__
+# return self.tracer.to_bool(self)
+# torch.fx.proxy.TraceError: symbolically traced variables cannot be used as inputs to control flow
+@pytest.mark.skip("convit is not supported yet")
@pytest.mark.skipif(version.parse(torch.__version__) < version.parse('1.12.0'), reason='torch version < 12')
@clear_cache_before_run()
def test_timm_models():
diff --git a/tests/test_utils/test_lazy_init/utils.py b/tests/test_utils/test_lazy_init/lazy_init_utils.py
similarity index 96%
rename from tests/test_utils/test_lazy_init/utils.py
rename to tests/test_utils/test_lazy_init/lazy_init_utils.py
index 0b5f15ca5445..aa87d32a808b 100644
--- a/tests/test_utils/test_lazy_init/utils.py
+++ b/tests/test_utils/test_lazy_init/lazy_init_utils.py
@@ -3,11 +3,14 @@
import numpy as np
import torch
+from packaging import version
from colossalai.tensor.d_tensor.layout_converter import to_global
from colossalai.utils.model.experimental import LazyInitContext, LazyTensor, _MyTensor
from tests.kit.model_zoo.registry import ModelAttribute
+SUPPORT_LAZY = version.parse(torch.__version__) >= version.parse('1.12.0')
+
# model_fn, data_gen_fn, output_transform_fn, model_attr
TestingEntry = Tuple[Callable[[], torch.nn.Module], Callable[[], dict], Callable[[], dict], Optional[ModelAttribute]]
diff --git a/tests/test_utils/test_lazy_init/test_distribute.py b/tests/test_utils/test_lazy_init/test_distribute.py
index 2c15ca84efaa..fd91e7e912b5 100644
--- a/tests/test_utils/test_lazy_init/test_distribute.py
+++ b/tests/test_utils/test_lazy_init/test_distribute.py
@@ -15,9 +15,9 @@
from colossalai.utils.model.experimental import LazyInitContext, LazyTensor, _MyTensor
except:
pass
-from tests.kit.model_zoo import model_zoo
+from lazy_init_utils import SUPPORT_LAZY, assert_dist_model_equal, set_seed
-# from utils import assert_dist_model_equal, set_seed
+from tests.kit.model_zoo import model_zoo
def find_shard_dim(shape: torch.Size) -> Optional[int]:
@@ -70,9 +70,8 @@ def generate_recursively(module: nn.Module, prefix: str = ''):
def run_dist_lazy_init(subset, seed: int = 42):
sub_model_zoo = model_zoo.get_sub_registry(subset)
device_mesh = DeviceMesh(torch.Tensor([0, 1, 2, 3]), (2, 2), init_process_group=True)
- # FIXME(ver217): uncomment this line
- # _MyTensor._pre_op_fn = lambda *args: set_seed(seed)
- # LazyTensor._pre_op_fn = lambda *args: set_seed(seed)
+ _MyTensor._pre_op_fn = lambda *args: set_seed(seed)
+ LazyTensor._pre_op_fn = lambda *args: set_seed(seed)
for name, entry in sub_model_zoo.items():
# TODO(ver217): lazy init does not support weight norm, skip these models
@@ -88,8 +87,7 @@ def run_dist_lazy_init(subset, seed: int = 42):
deferred_model = model_fn()
layout_dict = generate_layout_dict(deferred_model, device_mesh)
ctx.distribute(deferred_model, layout_dict, verbose=True)
- # FIXME(ver217): uncomment this line
- # assert_dist_model_equal(model, deferred_model, layout_dict)
+ assert_dist_model_equal(model, deferred_model, layout_dict)
def run_dist(rank, world_size, port) -> None:
@@ -97,8 +95,7 @@ def run_dist(rank, world_size, port) -> None:
run_dist_lazy_init()
-# FIXME(ver217): temporarily skip this test since torch 1.11 does not fully support meta tensor
-@pytest.mark.skip
+@pytest.mark.skipif(not SUPPORT_LAZY, reason='torch version should be >= 1.12.0')
@pytest.mark.dist
@rerun_if_address_is_in_use()
def test_dist_lazy_init():
diff --git a/tests/test_utils/test_lazy_init/test_models.py b/tests/test_utils/test_lazy_init/test_models.py
index 9faddecbaca4..f828b23a94c4 100644
--- a/tests/test_utils/test_lazy_init/test_models.py
+++ b/tests/test_utils/test_lazy_init/test_models.py
@@ -1,13 +1,10 @@
import pytest
+from lazy_init_utils import SUPPORT_LAZY, check_lazy_init
from tests.kit.model_zoo import model_zoo
-# FIXME(ver217): uncomment this line
-# from utils import check_lazy_init
-
-# FIXME(ver217): temporarily skip this test since torch 1.11 does not fully support meta tensor
-@pytest.mark.skip
+@pytest.mark.skipif(not SUPPORT_LAZY, reason='requires torch >= 1.12.0')
@pytest.mark.parametrize('subset', ['torchvision', 'diffusers', 'timm', 'transformers', 'torchaudio', 'deepfm', 'dlrm'])
def test_torchvision_models_lazy_init(subset):
sub_model_zoo = model_zoo.get_sub_registry(subset)
@@ -15,8 +12,7 @@ def test_torchvision_models_lazy_init(subset):
# TODO(ver217): lazy init does not support weight norm, skip these models
if name in ('torchaudio_wav2vec2_base', 'torchaudio_hubert_base'):
continue
- # FIXME(ver217): uncomment this line
- # check_lazy_init(entry, verbose=True)
+ check_lazy_init(entry, verbose=True)
if __name__ == '__main__':
diff --git a/version.txt b/version.txt
index a45be4627678..0d91a54c7d43 100644
--- a/version.txt
+++ b/version.txt
@@ -1 +1 @@
-0.2.8
+0.3.0
 +
+
+
+ 