We also train the reward model based on LLaMA-7B, which reaches the ACC of 72.06% after 1 epoch, performing almost the same as Anthropic's best RM.
+
+### Arg List
+- --strategy: the strategy using for training, choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'], default='naive'
+- --model: model type, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
+- --pretrain: pretrain model, type=str, default=None
+- --model_path: the path of rm model(if continue to train), type=str, default=None
+- --save_path: path to save the model, type=str, default='output'
+- --need_optim_ckpt: whether to save optim ckpt, type=bool, default=False
+- --max_epochs: max epochs for training, type=int, default=3
+- --dataset: dataset name, type=str, choices=['Anthropic/hh-rlhf', 'Dahoas/rm-static']
+- --subset: subset of the dataset, type=str, default=None
+- --batch_size: batch size while training, type=int, default=4
+- --lora_rank: low-rank adaptation matrices rank, type=int, default=0
+- --loss_func: which kind of loss function, choices=['log_sig', 'log_exp']
+- --max_len: max sentence length for generation, type=int, default=512
+- --test: whether is only tesing, if it's ture, the dataset will be small
+
+## Stage3 - Training model using prompts with RL
+
+Stage3 uses reinforcement learning algorithm, which is the most complex part of the training process, as shown below:
+
+
+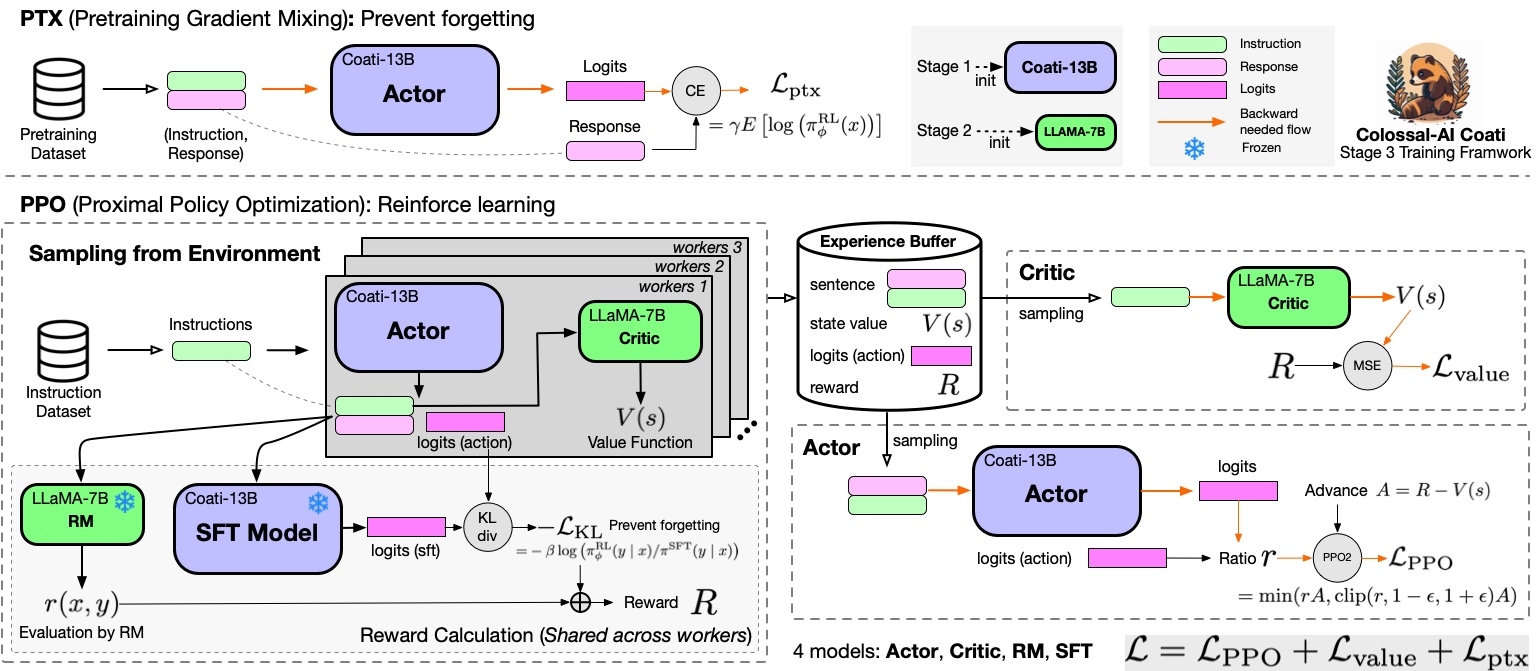 +
+
+
+You can run the `examples/train_prompts.sh` to start PPO training.
+You can also use the cmd following to start PPO training.
+
+```
+torchrun --standalone --nproc_per_node=4 train_prompts.py \
+ --pretrain "/path/to/LLaMa-7B/" \
+ --model 'llama' \
+ --strategy colossalai_zero2 \
+ --prompt_path /path/to/your/prompt_dataset \
+ --pretrain_dataset /path/to/your/pretrain_dataset \
+ --rm_pretrain /your/pretrain/rm/defination \
+ --rm_path /your/rm/model/path
+```
+### Arg List
+- --strategy: the strategy using for training, choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'], default='naive'
+- --model: model type of actor, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
+- --pretrain: pretrain model, type=str, default=None
+- --rm_pretrain: pretrain model for reward model, type=str, default=None
+- --rm_path: the path of rm model, type=str, default=None
+- --save_path: path to save the model, type=str, default='output'
+- --prompt_path: path of the prompt dataset, type=str, default=None
+- --pretrain_dataset: path of the ptx dataset, type=str, default=None
+- --need_optim_ckpt: whether to save optim ckpt, type=bool, default=False
+- --num_episodes: num of episodes for training, type=int, default=10
+- --max_epochs: max epochs for training in one episode, type=int, default=5
+- --max_timesteps: max episodes in one batch, type=int, default=10
+- --update_timesteps: timesteps to update, type=int, default=10
+- --train_batch_size: batch size while training, type=int, default=8
+- --ptx_batch_size: batch size to compute ptx loss, type=int, default=1
+- --experience_batch_size: batch size to make experience, type=int, default=8
+- --lora_rank: low-rank adaptation matrices rank, type=int, default=0
+- --kl_coef: kl_coef using for computing reward, type=float, default=0.1
+- --ptx_coef: ptx_coef using for computing policy loss, type=float, default=0.9
+
+## Inference example - After Stage3
+We support different inference options, including int8 and int4 quantization.
+For details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
+
+
+## Attention
+The examples are demos for the whole training process.You need to change the hyper-parameters to reach great performance.
+
+#### data
+- [x] [rm-static](https://huggingface.co/datasets/Dahoas/rm-static)
+- [x] [hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)
+- [ ] [openai/summarize_from_feedback](https://huggingface.co/datasets/openai/summarize_from_feedback)
+- [ ] [openai/webgpt_comparisons](https://huggingface.co/datasets/openai/webgpt_comparisons)
+- [ ] [Dahoas/instruct-synthetic-prompt-responses](https://huggingface.co/datasets/Dahoas/instruct-synthetic-prompt-responses)
+
+## Support Model
+
+### GPT
+- [x] GPT2-S (s)
+- [x] GPT2-M (m)
+- [x] GPT2-L (l)
+- [ ] GPT2-XL (xl)
+- [x] GPT2-4B (4b)
+- [ ] GPT2-6B (6b)
+
+### BLOOM
+- [x] [BLOOM-560m](https://huggingface.co/bigscience/bloom-560m)
+- [x] [BLOOM-1b1](https://huggingface.co/bigscience/bloom-1b1)
+- [x] [BLOOM-3b](https://huggingface.co/bigscience/bloom-3b)
+- [x] [BLOOM-7b](https://huggingface.co/bigscience/bloom-7b1)
+- [ ] [BLOOM-175b](https://huggingface.co/bigscience/bloom)
+
+### OPT
+- [x] [OPT-125M](https://huggingface.co/facebook/opt-125m)
+- [x] [OPT-350M](https://huggingface.co/facebook/opt-350m)
+- [ ] [OPT-1.3B](https://huggingface.co/facebook/opt-1.3b)
+- [ ] [OPT-2.7B](https://huggingface.co/facebook/opt-2.7b)
+- [ ] [OPT-6.7B](https://huggingface.co/facebook/opt-6.7b)
+- [ ] [OPT-13B](https://huggingface.co/facebook/opt-13b)
+- [ ] [OPT-30B](https://huggingface.co/facebook/opt-30b)
+
+### [LLaMA](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md)
+- [x] LLaMA-7B
+- [x] LLaMA-13B
+- [ ] LLaMA-33B
+- [ ] LLaMA-65B
diff --git a/applications/ChatGPT/examples/inference.py b/applications/Chat/examples/inference.py
similarity index 94%
rename from applications/ChatGPT/examples/inference.py
rename to applications/Chat/examples/inference.py
index 08885c33b194..f75950804d2e 100644
--- a/applications/ChatGPT/examples/inference.py
+++ b/applications/Chat/examples/inference.py
@@ -1,9 +1,9 @@
import argparse
import torch
-from chatgpt.models.bloom import BLOOMActor
-from chatgpt.models.gpt import GPTActor
-from chatgpt.models.opt import OPTActor
+from coati.models.bloom import BLOOMActor
+from coati.models.gpt import GPTActor
+from coati.models.opt import OPTActor
from transformers import AutoTokenizer
from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
diff --git a/applications/ChatGPT/examples/requirements.txt b/applications/Chat/examples/requirements.txt
similarity index 100%
rename from applications/ChatGPT/examples/requirements.txt
rename to applications/Chat/examples/requirements.txt
diff --git a/applications/ChatGPT/examples/test_ci.sh b/applications/Chat/examples/test_ci.sh
similarity index 99%
rename from applications/ChatGPT/examples/test_ci.sh
rename to applications/Chat/examples/test_ci.sh
index 1d05c4c58341..db1d0b64e3b3 100755
--- a/applications/ChatGPT/examples/test_ci.sh
+++ b/applications/Chat/examples/test_ci.sh
@@ -81,7 +81,7 @@ torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
--pretrain 'gpt2' --model 'gpt2' \
--strategy colossalai_gemini --loss_fn 'log_exp'\
--dataset 'Dahoas/rm-static' --test True --lora_rank 4
-
+
torchrun --standalone --nproc_per_node=2 ${BASE}/train_reward_model.py \
--pretrain 'bigscience/bloom-560m' --model 'bloom' \
--strategy colossalai_zero2 --loss_fn 'log_sig'\
diff --git a/applications/ChatGPT/examples/train_dummy.py b/applications/Chat/examples/train_dummy.py
similarity index 93%
rename from applications/ChatGPT/examples/train_dummy.py
rename to applications/Chat/examples/train_dummy.py
index c0ebf8f9b7b6..d944b018de8f 100644
--- a/applications/ChatGPT/examples/train_dummy.py
+++ b/applications/Chat/examples/train_dummy.py
@@ -2,13 +2,13 @@
from copy import deepcopy
import torch
-from chatgpt.models.base import RewardModel
-from chatgpt.models.bloom import BLOOMActor, BLOOMCritic
-from chatgpt.models.gpt import GPTActor, GPTCritic
-from chatgpt.models.opt import OPTActor, OPTCritic
-from chatgpt.trainer import PPOTrainer
-from chatgpt.trainer.callbacks import SaveCheckpoint
-from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.models.base import RewardModel
+from coati.models.bloom import BLOOMActor, BLOOMCritic
+from coati.models.gpt import GPTActor, GPTCritic
+from coati.models.opt import OPTActor, OPTCritic
+from coati.trainer import PPOTrainer
+from coati.trainer.callbacks import SaveCheckpoint
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
from torch.optim import Adam
from transformers import AutoTokenizer, BloomTokenizerFast
from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
@@ -115,7 +115,7 @@ def main(args):
update_timesteps=args.update_timesteps)
# save model checkpoint after fitting
- strategy.save_model(actor, args.save_path, only_rank0=True)
+ trainer.save_model(args.save_path, only_rank0=True)
# save optimizer checkpoint on all ranks
if args.need_optim_ckpt:
strategy.save_optimizer(actor_optim,
diff --git a/applications/ChatGPT/examples/train_dummy.sh b/applications/Chat/examples/train_dummy.sh
similarity index 100%
rename from applications/ChatGPT/examples/train_dummy.sh
rename to applications/Chat/examples/train_dummy.sh
diff --git a/applications/Chat/examples/train_prompts.py b/applications/Chat/examples/train_prompts.py
new file mode 100644
index 000000000000..c573f5e6fae8
--- /dev/null
+++ b/applications/Chat/examples/train_prompts.py
@@ -0,0 +1,199 @@
+import argparse
+
+import pandas as pd
+import torch
+import torch.distributed as dist
+from coati.dataset import DataCollatorForSupervisedDataset, PromptDataset, SupervisedDataset
+from coati.models.bloom import BLOOMRM, BLOOMActor, BLOOMCritic
+from coati.models.gpt import GPTRM, GPTActor, GPTCritic
+from coati.models.llama import LlamaActor
+from coati.models.opt import OPTRM, OPTActor, OPTCritic
+from coati.trainer import PPOTrainer
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.utils import prepare_llama_tokenizer_and_embedding
+from torch.optim import Adam
+from torch.utils.data import DataLoader
+from torch.utils.data.distributed import DistributedSampler
+from transformers import AutoTokenizer, BloomTokenizerFast, GPT2Tokenizer, LlamaTokenizer
+
+from colossalai.nn.optimizer import HybridAdam
+
+
+def main(args):
+ # configure strategy
+ if args.strategy == 'naive':
+ strategy = NaiveStrategy()
+ elif args.strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif args.strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
+ elif args.strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{args.strategy}"')
+
+ if args.rm_path is not None:
+ state_dict = torch.load(args.rm_path, map_location='cpu')
+
+ # configure model
+ if args.model == 'gpt2':
+ initial_model = GPTActor(pretrained=args.pretrain)
+ reward_model = GPTRM(pretrained=args.rm_pretrain)
+ elif args.model == 'bloom':
+ initial_model = BLOOMActor(pretrained=args.pretrain)
+ reward_model = BLOOMRM(pretrained=args.rm_pretrain)
+ elif args.model == 'opt':
+ initial_model = OPTActor(pretrained=args.pretrain)
+ reward_model = OPTRM(pretrained=args.rm_pretrain)
+ elif args.model == 'llama':
+ initial_model = LlamaActor(pretrained=args.pretrain)
+ reward_model = BLOOMRM(pretrained=args.rm_pretrain)
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+ if args.rm_path is not None:
+ reward_model.load_state_dict(state_dict)
+
+ if args.strategy != 'colossalai_gemini':
+ initial_model.to(torch.float16).to(torch.cuda.current_device())
+ reward_model.to(torch.float16).to(torch.cuda.current_device())
+
+ with strategy.model_init_context():
+ if args.model == 'gpt2':
+ actor = GPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
+ critic = GPTCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank, use_action_mask=True)
+ elif args.model == 'bloom':
+ actor = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
+ critic = BLOOMCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank, use_action_mask=True)
+ elif args.model == 'opt':
+ actor = OPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
+ critic = OPTCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank, use_action_mask=True)
+ elif args.model == 'llama':
+ actor = LlamaActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
+ critic = BLOOMCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank, use_action_mask=True)
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+ if args.rm_path is not None:
+ critic.load_state_dict(state_dict)
+ del state_dict
+
+ if args.strategy != 'colossalai_gemini':
+ critic.to(torch.float16).to(torch.cuda.current_device())
+ actor.to(torch.float16).to(torch.cuda.current_device())
+
+ # configure optimizer
+ if args.strategy.startswith('colossalai'):
+ actor_optim = HybridAdam(actor.parameters(), lr=1e-7)
+ critic_optim = HybridAdam(critic.parameters(), lr=1e-7)
+ else:
+ actor_optim = Adam(actor.parameters(), lr=1e-7)
+ critic_optim = Adam(critic.parameters(), lr=1e-7)
+
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained('bigscience/bloom-560m')
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ elif args.model == 'llama':
+ tokenizer = LlamaTokenizer.from_pretrained(args.pretrain)
+ tokenizer.eos_token = '<\s>'
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ if args.model == 'llama':
+ tokenizer = prepare_llama_tokenizer_and_embedding(tokenizer, actor)
+ else:
+ tokenizer.pad_token = tokenizer.eos_token
+
+ data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
+
+ prompt_dataset = PromptDataset(tokenizer=tokenizer, data_path=args.prompt_path, max_datasets_size=16384)
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ prompt_sampler = DistributedSampler(prompt_dataset, shuffle=True, seed=42, drop_last=True)
+ prompt_dataloader = DataLoader(prompt_dataset,
+ shuffle=(prompt_sampler is None),
+ sampler=prompt_sampler,
+ batch_size=args.train_batch_size)
+
+ pretrain_dataset = SupervisedDataset(tokenizer=tokenizer, data_path=args.pretrain_dataset, max_datasets_size=16384)
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ pretrain_sampler = DistributedSampler(pretrain_dataset, shuffle=True, seed=42, drop_last=True)
+ pretrain_dataloader = DataLoader(pretrain_dataset,
+ shuffle=(pretrain_sampler is None),
+ sampler=pretrain_sampler,
+ batch_size=args.ptx_batch_size,
+ collate_fn=data_collator)
+
+ def tokenize_fn(texts):
+ # MUST padding to max length to ensure inputs of all ranks have the same length
+ # Different length may lead to hang when using gemini, as different generation steps
+ batch = tokenizer(texts, return_tensors='pt', max_length=96, padding='max_length', truncation=True)
+ return {k: v.to(torch.cuda.current_device()) for k, v in batch.items()}
+
+ (actor, actor_optim), (critic, critic_optim) = strategy.prepare((actor, actor_optim), (critic, critic_optim))
+
+ # configure trainer
+ trainer = PPOTrainer(
+ strategy,
+ actor,
+ critic,
+ reward_model,
+ initial_model,
+ actor_optim,
+ critic_optim,
+ kl_coef=args.kl_coef,
+ ptx_coef=args.ptx_coef,
+ max_epochs=args.max_epochs,
+ train_batch_size=args.train_batch_size,
+ experience_batch_size=args.experience_batch_size,
+ tokenizer=tokenize_fn,
+ max_length=128,
+ do_sample=True,
+ temperature=1.0,
+ top_k=50,
+ pad_token_id=tokenizer.pad_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ )
+
+ trainer.fit(prompt_dataloader=prompt_dataloader,
+ pretrain_dataloader=pretrain_dataloader,
+ num_episodes=args.num_episodes,
+ max_timesteps=args.max_timesteps,
+ update_timesteps=args.update_timesteps)
+
+ # save model checkpoint after fitting
+ trainer.save_model(args.save_path, only_rank0=True, tokenizer=tokenizer)
+ # save optimizer checkpoint on all ranks
+ if args.need_optim_ckpt:
+ strategy.save_optimizer(actor_optim,
+ 'actor_optim_checkpoint_prompts_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--prompt_path', type=str, default=None, help='path to the prompt dataset')
+ parser.add_argument('--pretrain_dataset', type=str, default=None, help='path to the pretrained dataset')
+ parser.add_argument('--strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive',
+ help='strategy to use')
+ parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt', 'llama'])
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--rm_path', type=str, default=None)
+ parser.add_argument('--rm_pretrain', type=str, default=None)
+ parser.add_argument('--save_path', type=str, default='actor_checkpoint_prompts')
+ parser.add_argument('--need_optim_ckpt', type=bool, default=False)
+ parser.add_argument('--num_episodes', type=int, default=10)
+ parser.add_argument('--max_timesteps', type=int, default=10)
+ parser.add_argument('--update_timesteps', type=int, default=10)
+ parser.add_argument('--max_epochs', type=int, default=5)
+ parser.add_argument('--train_batch_size', type=int, default=8)
+ parser.add_argument('--ptx_batch_size', type=int, default=1)
+ parser.add_argument('--experience_batch_size', type=int, default=8)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+ parser.add_argument('--kl_coef', type=float, default=0.1)
+ parser.add_argument('--ptx_coef', type=float, default=0.9)
+ args = parser.parse_args()
+ main(args)
diff --git a/applications/ChatGPT/examples/train_prompts.sh b/applications/Chat/examples/train_prompts.sh
similarity index 100%
rename from applications/ChatGPT/examples/train_prompts.sh
rename to applications/Chat/examples/train_prompts.sh
diff --git a/applications/ChatGPT/examples/train_reward_model.py b/applications/Chat/examples/train_reward_model.py
similarity index 77%
rename from applications/ChatGPT/examples/train_reward_model.py
rename to applications/Chat/examples/train_reward_model.py
index a9c844b7b1f8..729dfa23128f 100644
--- a/applications/ChatGPT/examples/train_reward_model.py
+++ b/applications/Chat/examples/train_reward_model.py
@@ -1,24 +1,27 @@
import argparse
+from random import randint
import loralib as lora
import torch
-from chatgpt.dataset import HhRlhfDataset, RmStaticDataset
-from chatgpt.models import LogSigLoss, LogExpLoss
-from chatgpt.models.base import RewardModel
-from chatgpt.models.bloom import BLOOMRM
-from chatgpt.models.gpt import GPTRM
-from chatgpt.models.opt import OPTRM
-from chatgpt.models.deberta import DebertaRM
-from chatgpt.trainer import RewardModelTrainer
-from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.dataset import HhRlhfDataset, RmStaticDataset
+from coati.models import LogExpLoss, LogSigLoss
+from coati.models.base import RewardModel
+from coati.models.bloom import BLOOMRM
+from coati.models.deberta import DebertaRM
+from coati.models.gpt import GPTRM
+from coati.models.llama import LlamaRM
+from coati.models.opt import OPTRM
+from coati.trainer import RewardModelTrainer
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.utils import prepare_llama_tokenizer_and_embedding
from datasets import load_dataset
-from random import randint
from torch.optim import Adam
-from transformers import AutoTokenizer, BloomTokenizerFast, DebertaV2Tokenizer
+from transformers import AutoTokenizer, BloomTokenizerFast, DebertaV2Tokenizer, LlamaTokenizer
from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
from colossalai.nn.optimizer import HybridAdam
+
def train(args):
# configure strategy
if args.strategy == 'naive':
@@ -42,33 +45,43 @@ def train(args):
model = GPTRM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
elif args.model == 'deberta':
model = DebertaRM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'llama':
+ model = LlamaRM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
else:
raise ValueError(f'Unsupported model "{args.model}"')
-
+
if args.model_path is not None:
state_dict = torch.load(args.model_path)
model.load_state_dict(state_dict)
-
+
+ model = model.to(torch.float16)
+
# configure tokenizer
if args.model == 'gpt2':
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
- tokenizer.pad_token = tokenizer.eos_token
elif args.model == 'bloom':
tokenizer = BloomTokenizerFast.from_pretrained('bigscience/bloom-560m')
elif args.model == 'opt':
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
elif args.model == 'deberta':
tokenizer = DebertaV2Tokenizer.from_pretrained('microsoft/deberta-v3-large')
+ elif args.model == 'llama':
+ tokenizer = LlamaTokenizer.from_pretrained(args.pretrain)
else:
raise ValueError(f'Unsupported model "{args.model}"')
max_len = args.max_len
+ if args.model == 'llama':
+ tokenizer = prepare_llama_tokenizer_and_embedding(tokenizer, model)
+ else:
+ tokenizer.pad_token = tokenizer.eos_token
+
# configure optimizer
if args.strategy.startswith('colossalai'):
- optim = HybridAdam(model.parameters(), lr=1.5e-5)
+ optim = HybridAdam(model.parameters(), lr=5e-6)
else:
- optim = Adam(model.parameters(), lr=1.5e-5)
-
+ optim = Adam(model.parameters(), lr=5e-6)
+
# configure loss function
if args.loss_fn == 'log_sig':
loss_fn = LogSigLoss()
@@ -76,21 +89,21 @@ def train(args):
loss_fn = LogExpLoss()
else:
raise ValueError(f'Unsupported loss function "{args.loss_fn}"')
-
+
# prepare for data and dataset
if args.subset is not None:
data = load_dataset(args.dataset, data_dir=args.subset)
else:
data = load_dataset(args.dataset)
-
+
if args.test:
train_data = data['train'].select(range(100))
- eval_data = data['test'].select(range(10))
+ eval_data = data['test'].select(range(10))
else:
train_data = data['train']
eval_data = data['test']
- valid_data = data['test'].select((randint(0, len(eval_data) - 1) for _ in range(len(eval_data)//10)))
-
+ valid_data = data['test'].select((randint(0, len(eval_data) - 1) for _ in range(len(eval_data) // 5)))
+
if args.dataset == 'Dahoas/rm-static':
train_dataset = RmStaticDataset(train_data, tokenizer, max_len)
valid_dataset = RmStaticDataset(valid_data, tokenizer, max_len)
@@ -101,11 +114,11 @@ def train(args):
eval_dataset = HhRlhfDataset(eval_data, tokenizer, max_len)
else:
raise ValueError(f'Unsupported dataset "{args.dataset}"')
-
+
trainer = RewardModelTrainer(model=model,
strategy=strategy,
optim=optim,
- loss_fn = loss_fn,
+ loss_fn=loss_fn,
train_dataset=train_dataset,
valid_dataset=valid_dataset,
eval_dataset=eval_dataset,
@@ -114,25 +127,29 @@ def train(args):
trainer.fit()
# save model checkpoint after fitting on only rank0
- strategy.save_model(trainer.model, args.save_path, only_rank0=True)
+ trainer.save_model(path=args.save_path, only_rank0=True, tokenizer=tokenizer)
# save optimizer checkpoint on all ranks
if args.need_optim_ckpt:
- strategy.save_optimizer(trainer.optimizer, 'rm_optim_checkpoint_%d.pt' % (torch.cuda.current_device()), only_rank0=False)
+ strategy.save_optimizer(trainer.optimizer,
+ 'rm_optim_checkpoint_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--strategy',
choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
default='naive')
- parser.add_argument('--model', choices=['gpt2', 'bloom', 'opt', 'deberta'], default='bloom')
+ parser.add_argument('--model', choices=['gpt2', 'bloom', 'opt', 'deberta', 'llama'], default='bloom')
parser.add_argument('--pretrain', type=str, default=None)
parser.add_argument('--model_path', type=str, default=None)
parser.add_argument('--need_optim_ckpt', type=bool, default=False)
- parser.add_argument('--dataset', type=str,
+ parser.add_argument('--dataset',
+ type=str,
choices=['Anthropic/hh-rlhf', 'Dahoas/rm-static'],
default='Dahoas/rm-static')
parser.add_argument('--subset', type=str, default=None)
- parser.add_argument('--save_path', type=str, default='rm_ckpt.pt')
+ parser.add_argument('--save_path', type=str, default='rm_ckpt')
parser.add_argument('--max_epochs', type=int, default=1)
parser.add_argument('--batch_size', type=int, default=1)
parser.add_argument('--max_len', type=int, default=512)
diff --git a/applications/ChatGPT/examples/train_rm.sh b/applications/Chat/examples/train_rm.sh
similarity index 100%
rename from applications/ChatGPT/examples/train_rm.sh
rename to applications/Chat/examples/train_rm.sh
diff --git a/applications/Chat/examples/train_sft.py b/applications/Chat/examples/train_sft.py
new file mode 100644
index 000000000000..035d5a1ded1d
--- /dev/null
+++ b/applications/Chat/examples/train_sft.py
@@ -0,0 +1,184 @@
+import argparse
+import os
+
+import loralib as lora
+import torch
+import torch.distributed as dist
+from coati.dataset import DataCollatorForSupervisedDataset, SFTDataset, SupervisedDataset
+from coati.models.base import RewardModel
+from coati.models.bloom import BLOOMLM
+from coati.models.gpt import GPTLM
+from coati.models.llama import LlamaLM
+from coati.models.opt import OPTLM
+from coati.trainer import SFTTrainer
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.utils import prepare_llama_tokenizer_and_embedding
+from datasets import load_dataset
+from torch.optim import Adam
+from torch.utils.data import DataLoader
+from torch.utils.data.distributed import DistributedSampler
+from transformers import AutoTokenizer, BloomTokenizerFast
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+
+from colossalai.logging import get_dist_logger
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.tensor import ColoParameter
+
+
+def train(args):
+ # configure strategy
+ if args.strategy == 'naive':
+ strategy = NaiveStrategy()
+ elif args.strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif args.strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{args.strategy}"')
+
+ # configure model
+ with strategy.model_init_context():
+ if args.model == 'bloom':
+ model = BLOOMLM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'opt':
+ model = OPTLM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'gpt2':
+ model = GPTLM(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
+ elif args.model == 'llama':
+ model = LlamaLM(pretrained=args.pretrain, lora_rank=args.lora_rank,
+ checkpoint=True).to(torch.float16).to(torch.cuda.current_device())
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ elif args.model == 'llama':
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.pretrain,
+ padding_side="right",
+ use_fast=False,
+ )
+ tokenizer.eos_token = '<\s>'
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+ tokenizer.pad_token = tokenizer.eos_token
+ if args.model == 'llama':
+ tokenizer = prepare_llama_tokenizer_and_embedding(tokenizer, model)
+
+ if args.strategy == 'colossalai_gemini':
+ # this is a hack to deal with the resized embedding
+ # to make sure all parameters are ColoParameter for Colossal-AI Gemini Compatiblity
+ for name, param in model.named_parameters():
+ if not isinstance(param, ColoParameter):
+ sub_module_name = '.'.join(name.split('.')[:-1])
+ weight_name = name.split('.')[-1]
+ sub_module = model.get_submodule(sub_module_name)
+ setattr(sub_module, weight_name, ColoParameter(param))
+ else:
+ tokenizer.pad_token = tokenizer.eos_token
+
+ # configure optimizer
+ if args.strategy.startswith('colossalai'):
+ optim = HybridAdam(model.parameters(), lr=args.lr, clipping_norm=1.0)
+ else:
+ optim = Adam(model.parameters(), lr=args.lr)
+
+ logger = get_dist_logger()
+
+ # configure dataset
+ if args.dataset == 'yizhongw/self_instruct':
+ train_data = load_dataset(args.dataset, 'super_natural_instructions', split='train')
+ eval_data = load_dataset(args.dataset, 'super_natural_instructions', split='test')
+
+ train_dataset = SFTDataset(train_data, tokenizer)
+ eval_dataset = SFTDataset(eval_data, tokenizer)
+
+ else:
+ train_dataset = SupervisedDataset(tokenizer=tokenizer,
+ data_path=args.dataset,
+ max_datasets_size=args.max_datasets_size)
+ eval_dataset = None
+ data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
+
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ train_sampler = DistributedSampler(train_dataset,
+ shuffle=True,
+ seed=42,
+ drop_last=True,
+ rank=dist.get_rank(),
+ num_replicas=dist.get_world_size())
+ if eval_dataset is not None:
+ eval_sampler = DistributedSampler(eval_dataset,
+ shuffle=False,
+ seed=42,
+ drop_last=False,
+ rank=dist.get_rank(),
+ num_replicas=dist.get_world_size())
+ else:
+ train_sampler = None
+ eval_sampler = None
+
+ train_dataloader = DataLoader(train_dataset,
+ shuffle=(train_sampler is None),
+ sampler=train_sampler,
+ batch_size=args.batch_size,
+ collate_fn=data_collator,
+ pin_memory=True)
+ if eval_dataset is not None:
+ eval_dataloader = DataLoader(eval_dataset,
+ shuffle=(eval_sampler is None),
+ sampler=eval_sampler,
+ batch_size=args.batch_size,
+ collate_fn=data_collator,
+ pin_memory=True)
+ else:
+ eval_dataloader = None
+
+ trainer = SFTTrainer(model=model,
+ strategy=strategy,
+ optim=optim,
+ train_dataloader=train_dataloader,
+ eval_dataloader=eval_dataloader,
+ batch_size=args.batch_size,
+ max_epochs=args.max_epochs,
+ accimulation_steps=args.accimulation_steps)
+
+ trainer.fit(logger=logger, log_interval=args.log_interval)
+
+ # save model checkpoint after fitting on only rank0
+ trainer.save_model(path=args.save_path, only_rank0=True, tokenizer=tokenizer)
+ # save optimizer checkpoint on all ranks
+ if args.need_optim_ckpt:
+ strategy.save_optimizer(trainer.optimizer,
+ 'rm_optim_checkpoint_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
+ default='naive')
+ parser.add_argument('--model', choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom')
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--dataset', type=str, default=None)
+ parser.add_argument('--max_datasets_size', type=int, default=None)
+ parser.add_argument('--save_path', type=str, default='output')
+ parser.add_argument('--need_optim_ckpt', type=bool, default=False)
+ parser.add_argument('--max_epochs', type=int, default=3)
+ parser.add_argument('--batch_size', type=int, default=4)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+ parser.add_argument('--log_interval', type=int, default=100, help="how many steps to log")
+ parser.add_argument('--lr', type=float, default=5e-6)
+ parser.add_argument('--accimulation_steps', type=int, default=8)
+ args = parser.parse_args()
+ train(args)
diff --git a/applications/Chat/examples/train_sft.sh b/applications/Chat/examples/train_sft.sh
new file mode 100755
index 000000000000..73710d1b19f8
--- /dev/null
+++ b/applications/Chat/examples/train_sft.sh
@@ -0,0 +1,12 @@
+torchrun --standalone --nproc_per_node=4 train_sft.py \
+ --pretrain "/path/to/LLaMa-7B/" \
+ --model 'llama' \
+ --strategy colossalai_zero2 \
+ --log_interval 10 \
+ --save_path /path/to/Coati-7B \
+ --dataset /path/to/data.json \
+ --batch_size 4 \
+ --accimulation_steps 8 \
+ --lr 2e-5 \
+ --max_datasets_size 512 \
+ --max_epochs 1 \
diff --git a/applications/Chat/inference/README.md b/applications/Chat/inference/README.md
new file mode 100644
index 000000000000..6c23bc73cd60
--- /dev/null
+++ b/applications/Chat/inference/README.md
@@ -0,0 +1,117 @@
+# Inference
+
+We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
+
+We support 8-bit quantization (RTN), which is powered by [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) and [transformers](https://github.com/huggingface/transformers). And 4-bit quantization (GPTQ), which is powered by [gptq](https://github.com/IST-DASLab/gptq) and [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). We also support FP16 inference.
+
+We only support LLaMA family models now.
+
+## Choosing precision (quantization)
+
+**FP16**: Fastest, best output quality, highest memory usage
+
+**8-bit**: Slow, easier setup (originally supported by transformers), lower output quality (due to RTN), **recommended for first-timers**
+
+**4-bit**: Faster, lowest memory usage, higher output quality (due to GPTQ), but more difficult setup
+
+## Hardware requirements for LLaMA
+
+Tha data is from [LLaMA Int8 4bit ChatBot Guide v2](https://rentry.org/llama-tard-v2).
+
+### 8-bit
+
+| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
+| :---: | :---: | :---: | :---: | :---: |
+| LLaMA-7B | 9.2GB | 10GB | 24GB | 3060 12GB, RTX 3080 10GB, RTX 3090 |
+| LLaMA-13B | 16.3GB | 20GB | 32GB | RTX 3090 Ti, RTX 4090 |
+| LLaMA-30B | 36GB | 40GB | 64GB | A6000 48GB, A100 40GB |
+| LLaMA-65B | 74GB | 80GB | 128GB | A100 80GB |
+
+### 4-bit
+
+| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
+| :---: | :---: | :---: | :---: | :---: |
+| LLaMA-7B | 3.5GB | 6GB | 16GB | RTX 1660, 2060, AMD 5700xt, RTX 3050, 3060 |
+| LLaMA-13B | 6.5GB | 10GB | 32GB | AMD 6900xt, RTX 2060 12GB, 3060 12GB, 3080, A2000 |
+| LLaMA-30B | 15.8GB | 20GB | 64GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 |
+| LLaMA-65B | 31.2GB | 40GB | 128GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000, Titan Ada |
+
+## General setup
+
+```shell
+pip install -r requirements.txt
+```
+
+## 8-bit setup
+
+8-bit quantization is originally supported by the latest [transformers](https://github.com/huggingface/transformers). Please install it from source.
+
+Please ensure you have downloaded HF-format model weights of LLaMA models.
+
+Usage:
+
+```python
+from transformers import LlamaForCausalLM
+
+USE_8BIT = True # use 8-bit quantization; otherwise, use fp16
+
+model = LlamaForCausalLM.from_pretrained(
+ "pretrained/path",
+ load_in_8bit=USE_8BIT,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ )
+if not USE_8BIT:
+ model.half() # use fp16
+model.eval()
+```
+
+**Troubleshooting**: if you get error indicating your CUDA-related libraries not found when loading 8-bit model, you can check whether your `LD_LIBRARY_PATH` is correct.
+
+E.g. you can set `export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH`.
+
+## 4-bit setup
+
+Please ensure you have downloaded HF-format model weights of LLaMA models first.
+
+Then you can follow [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). This lib provides efficient CUDA kernels and weight convertion script.
+
+After installing this lib, we may convert the original HF-format LLaMA model weights to 4-bit version.
+
+```shell
+CUDA_VISIBLE_DEVICES=0 python llama.py /path/to/pretrained/llama-7b c4 --wbits 4 --groupsize 128 --save llama7b-4bit.pt
+```
+
+Run this command in your cloned `GPTQ-for-LLaMa` directory, then you will get a 4-bit weight file `llama7b-4bit-128g.pt`.
+
+**Troubleshooting**: if you get error about `position_ids`, you can checkout to commit `50287c3b9ae4a3b66f6b5127c643ec39b769b155`(`GPTQ-for-LLaMa` repo).
+
+## Online inference server
+
+In this directory:
+
+```shell
+export CUDA_VISIBLE_DEVICES=0
+# fp16, will listen on 0.0.0.0:7070 by default
+python server.py /path/to/pretrained
+# 8-bit, will listen on localhost:8080
+python server.py /path/to/pretrained --quant 8bit --http_host localhost --http_port 8080
+# 4-bit
+python server.py /path/to/pretrained --quant 4bit --gptq_checkpoint /path/to/llama7b-4bit-128g.pt --gptq_group_size 128
+```
+
+## Benchmark
+
+In this directory:
+
+```shell
+export CUDA_VISIBLE_DEVICES=0
+# fp16
+python benchmark.py /path/to/pretrained
+# 8-bit
+python benchmark.py /path/to/pretrained --quant 8bit
+# 4-bit
+python benchmark.py /path/to/pretrained --quant 4bit --gptq_checkpoint /path/to/llama7b-4bit-128g.pt --gptq_group_size 128
+```
+
+This benchmark will record throughput and peak CUDA memory usage.
diff --git a/applications/Chat/inference/benchmark.py b/applications/Chat/inference/benchmark.py
new file mode 100644
index 000000000000..59cd1eeea2aa
--- /dev/null
+++ b/applications/Chat/inference/benchmark.py
@@ -0,0 +1,132 @@
+# Adapted from https://github.com/tloen/alpaca-lora/blob/main/generate.py
+
+import argparse
+from time import time
+
+import torch
+from llama_gptq import load_quant
+from transformers import AutoTokenizer, GenerationConfig, LlamaForCausalLM
+
+
+def generate_prompt(instruction, input=None):
+ if input:
+ return f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
+
+### Instruction:
+{instruction}
+
+### Input:
+{input}
+
+### Response:"""
+ else:
+ return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
+
+### Instruction:
+{instruction}
+
+### Response:"""
+
+
+@torch.no_grad()
+def evaluate(
+ model,
+ tokenizer,
+ instruction,
+ input=None,
+ temperature=0.1,
+ top_p=0.75,
+ top_k=40,
+ num_beams=4,
+ max_new_tokens=128,
+ **kwargs,
+):
+ prompt = generate_prompt(instruction, input)
+ inputs = tokenizer(prompt, return_tensors="pt")
+ input_ids = inputs["input_ids"].cuda()
+ generation_config = GenerationConfig(
+ temperature=temperature,
+ top_p=top_p,
+ top_k=top_k,
+ num_beams=num_beams,
+ **kwargs,
+ )
+ generation_output = model.generate(
+ input_ids=input_ids,
+ generation_config=generation_config,
+ return_dict_in_generate=True,
+ output_scores=True,
+ max_new_tokens=max_new_tokens,
+ do_sample=True,
+ )
+ s = generation_output.sequences[0]
+ output = tokenizer.decode(s)
+ n_new_tokens = s.size(0) - input_ids.size(1)
+ return output.split("### Response:")[1].strip(), n_new_tokens
+
+
+instructions = [
+ "Tell me about alpacas.",
+ "Tell me about the president of Mexico in 2019.",
+ "Tell me about the king of France in 2019.",
+ "List all Canadian provinces in alphabetical order.",
+ "Write a Python program that prints the first 10 Fibonacci numbers.",
+ "Write a program that prints the numbers from 1 to 100. But for multiples of three print 'Fizz' instead of the number and for the multiples of five print 'Buzz'. For numbers which are multiples of both three and five print 'FizzBuzz'.",
+ "Tell me five words that rhyme with 'shock'.",
+ "Translate the sentence 'I have no mouth but I must scream' into Spanish.",
+ "Count up from 1 to 500.",
+ # ===
+ "How to play support in legends of league",
+ "Write a Python program that calculate Fibonacci numbers.",
+]
+inst = [instructions[0]] * 4
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ 'pretrained',
+ help='Path to pretrained model. Can be a local path or a model name from the HuggingFace model hub.')
+ parser.add_argument('--quant',
+ choices=['8bit', '4bit'],
+ default=None,
+ help='Quantization mode. Default: None (no quantization, fp16).')
+ parser.add_argument(
+ '--gptq_checkpoint',
+ default=None,
+ help='Path to GPTQ checkpoint. This is only useful when quantization mode is 4bit. Default: None.')
+ parser.add_argument('--gptq_group_size',
+ type=int,
+ default=128,
+ help='Group size for GPTQ. This is only useful when quantization mode is 4bit. Default: 128.')
+ args = parser.parse_args()
+
+ if args.quant == '4bit':
+ assert args.gptq_checkpoint is not None, 'Please specify a GPTQ checkpoint.'
+
+ tokenizer = AutoTokenizer.from_pretrained(args.pretrained)
+
+ if args.quant == '4bit':
+ model = load_quant(args.pretrained, args.gptq_checkpoint, 4, args.gptq_group_size)
+ model.cuda()
+ else:
+ model = LlamaForCausalLM.from_pretrained(
+ args.pretrained,
+ load_in_8bit=(args.quant == '8bit'),
+ torch_dtype=torch.float16,
+ device_map="auto",
+ )
+ if args.quant != '8bit':
+ model.half() # seems to fix bugs for some users.
+ model.eval()
+
+ total_tokens = 0
+ start = time()
+ for instruction in instructions:
+ print(f"Instruction: {instruction}")
+ resp, tokens = evaluate(model, tokenizer, instruction, temparature=0.2, num_beams=1)
+ total_tokens += tokens
+ print(f"Response: {resp}")
+ print('\n----------------------------\n')
+ duration = time() - start
+ print(f'Total time: {duration:.3f} s, {total_tokens/duration:.3f} tokens/s')
+ print(f'Peak CUDA mem: {torch.cuda.max_memory_allocated()/1024**3:.3f} GB')
diff --git a/applications/Chat/inference/llama_gptq/__init__.py b/applications/Chat/inference/llama_gptq/__init__.py
new file mode 100644
index 000000000000..51c8d6316290
--- /dev/null
+++ b/applications/Chat/inference/llama_gptq/__init__.py
@@ -0,0 +1,5 @@
+from .loader import load_quant
+
+__all__ = [
+ 'load_quant',
+]
diff --git a/applications/Chat/inference/llama_gptq/loader.py b/applications/Chat/inference/llama_gptq/loader.py
new file mode 100644
index 000000000000..a5c6ac7d1589
--- /dev/null
+++ b/applications/Chat/inference/llama_gptq/loader.py
@@ -0,0 +1,41 @@
+import torch
+import torch.nn as nn
+import transformers
+from transformers import LlamaConfig, LlamaForCausalLM
+
+from .model_utils import find_layers
+from .quant import make_quant
+
+
+def load_quant(pretrained: str, checkpoint: str, wbits: int, groupsize: int):
+ config = LlamaConfig.from_pretrained(pretrained)
+
+ def noop(*args, **kwargs):
+ pass
+
+ torch.nn.init.kaiming_uniform_ = noop
+ torch.nn.init.uniform_ = noop
+ torch.nn.init.normal_ = noop
+
+ torch.set_default_dtype(torch.half)
+ transformers.modeling_utils._init_weights = False
+ torch.set_default_dtype(torch.half)
+ model = LlamaForCausalLM(config)
+ torch.set_default_dtype(torch.float)
+ model = model.eval()
+ layers = find_layers(model)
+ for name in ['lm_head']:
+ if name in layers:
+ del layers[name]
+ make_quant(model, layers, wbits, groupsize)
+
+ print(f'Loading model with {wbits} bits...')
+ if checkpoint.endswith('.safetensors'):
+ from safetensors.torch import load_file as safe_load
+ model.load_state_dict(safe_load(checkpoint))
+ else:
+ model.load_state_dict(torch.load(checkpoint))
+ model.seqlen = 2048
+ print('Done.')
+
+ return model
diff --git a/applications/Chat/inference/llama_gptq/model_utils.py b/applications/Chat/inference/llama_gptq/model_utils.py
new file mode 100644
index 000000000000..62db171abb52
--- /dev/null
+++ b/applications/Chat/inference/llama_gptq/model_utils.py
@@ -0,0 +1,13 @@
+# copied from https://github.com/qwopqwop200/GPTQ-for-LLaMa/blob/past/modelutils.py
+
+import torch
+import torch.nn as nn
+
+
+def find_layers(module, layers=[nn.Conv2d, nn.Linear], name=''):
+ if type(module) in layers:
+ return {name: module}
+ res = {}
+ for name1, child in module.named_children():
+ res.update(find_layers(child, layers=layers, name=name + '.' + name1 if name != '' else name1))
+ return res
diff --git a/applications/Chat/inference/llama_gptq/quant.py b/applications/Chat/inference/llama_gptq/quant.py
new file mode 100644
index 000000000000..f7d5b7ce4bd8
--- /dev/null
+++ b/applications/Chat/inference/llama_gptq/quant.py
@@ -0,0 +1,283 @@
+# copied from https://github.com/qwopqwop200/GPTQ-for-LLaMa/blob/past/quant.py
+
+import math
+
+import numpy as np
+import torch
+import torch.nn as nn
+
+
+def quantize(x, scale, zero, maxq):
+ q = torch.clamp(torch.round(x / scale) + zero, 0, maxq)
+ return scale * (q - zero)
+
+
+class Quantizer(nn.Module):
+
+ def __init__(self, shape=1):
+ super(Quantizer, self).__init__()
+ self.register_buffer('maxq', torch.tensor(0))
+ self.register_buffer('scale', torch.zeros(shape))
+ self.register_buffer('zero', torch.zeros(shape))
+
+ def configure(self, bits, perchannel=False, sym=True, mse=False, norm=2.4, grid=100, maxshrink=.8):
+ self.maxq = torch.tensor(2**bits - 1)
+ self.perchannel = perchannel
+ self.sym = sym
+ self.mse = mse
+ self.norm = norm
+ self.grid = grid
+ self.maxshrink = maxshrink
+
+ def find_params(self, x, weight=False):
+ dev = x.device
+ self.maxq = self.maxq.to(dev)
+
+ shape = x.shape
+ if self.perchannel:
+ if weight:
+ x = x.flatten(1)
+ else:
+ if len(shape) == 4:
+ x = x.permute([1, 0, 2, 3])
+ x = x.flatten(1)
+ if len(shape) == 3:
+ x = x.reshape((-1, shape[-1])).t()
+ if len(shape) == 2:
+ x = x.t()
+ else:
+ x = x.flatten().unsqueeze(0)
+
+ tmp = torch.zeros(x.shape[0], device=dev)
+ xmin = torch.minimum(x.min(1)[0], tmp)
+ xmax = torch.maximum(x.max(1)[0], tmp)
+
+ if self.sym:
+ xmax = torch.maximum(torch.abs(xmin), xmax)
+ tmp = xmin < 0
+ if torch.any(tmp):
+ xmin[tmp] = -xmax[tmp]
+ tmp = (xmin == 0) & (xmax == 0)
+ xmin[tmp] = -1
+ xmax[tmp] = +1
+
+ self.scale = (xmax - xmin) / self.maxq
+ if self.sym:
+ self.zero = torch.full_like(self.scale, (self.maxq + 1) / 2)
+ else:
+ self.zero = torch.round(-xmin / self.scale)
+
+ if self.mse:
+ best = torch.full([x.shape[0]], float('inf'), device=dev)
+ for i in range(int(self.maxshrink * self.grid)):
+ p = 1 - i / self.grid
+ xmin1 = p * xmin
+ xmax1 = p * xmax
+ scale1 = (xmax1 - xmin1) / self.maxq
+ zero1 = torch.round(-xmin1 / scale1) if not self.sym else self.zero
+ q = quantize(x, scale1.unsqueeze(1), zero1.unsqueeze(1), self.maxq)
+ q -= x
+ q.abs_()
+ q.pow_(self.norm)
+ err = torch.sum(q, 1)
+ tmp = err < best
+ if torch.any(tmp):
+ best[tmp] = err[tmp]
+ self.scale[tmp] = scale1[tmp]
+ self.zero[tmp] = zero1[tmp]
+ if not self.perchannel:
+ if weight:
+ tmp = shape[0]
+ else:
+ tmp = shape[1] if len(shape) != 3 else shape[2]
+ self.scale = self.scale.repeat(tmp)
+ self.zero = self.zero.repeat(tmp)
+
+ if weight:
+ shape = [-1] + [1] * (len(shape) - 1)
+ self.scale = self.scale.reshape(shape)
+ self.zero = self.zero.reshape(shape)
+ return
+ if len(shape) == 4:
+ self.scale = self.scale.reshape((1, -1, 1, 1))
+ self.zero = self.zero.reshape((1, -1, 1, 1))
+ if len(shape) == 3:
+ self.scale = self.scale.reshape((1, 1, -1))
+ self.zero = self.zero.reshape((1, 1, -1))
+ if len(shape) == 2:
+ self.scale = self.scale.unsqueeze(0)
+ self.zero = self.zero.unsqueeze(0)
+
+ def quantize(self, x):
+ if self.ready():
+ return quantize(x, self.scale, self.zero, self.maxq)
+ return x
+
+ def enabled(self):
+ return self.maxq > 0
+
+ def ready(self):
+ return torch.all(self.scale != 0)
+
+
+try:
+ import quant_cuda
+except:
+ print('CUDA extension not installed.')
+
+# Assumes layer is perfectly divisible into 256 * 256 blocks
+
+
+class QuantLinear(nn.Module):
+
+ def __init__(self, bits, groupsize, infeatures, outfeatures):
+ super().__init__()
+ if bits not in [2, 3, 4, 8]:
+ raise NotImplementedError("Only 2,3,4,8 bits are supported.")
+ self.infeatures = infeatures
+ self.outfeatures = outfeatures
+ self.bits = bits
+ if groupsize != -1 and groupsize < 32 and groupsize != int(math.pow(2, int(math.log2(groupsize)))):
+ raise NotImplementedError("groupsize supports powers of 2 greater than 32. (e.g. : 32,64,128,etc)")
+ groupsize = groupsize if groupsize != -1 else infeatures
+ self.groupsize = groupsize
+ self.register_buffer(
+ 'qzeros', torch.zeros((math.ceil(infeatures / groupsize), outfeatures // 256 * (bits * 8)),
+ dtype=torch.int))
+ self.register_buffer('scales', torch.zeros((math.ceil(infeatures / groupsize), outfeatures)))
+ self.register_buffer('bias', torch.zeros(outfeatures))
+ self.register_buffer('qweight', torch.zeros((infeatures // 256 * (bits * 8), outfeatures), dtype=torch.int))
+ self._initialized_quant_state = False
+
+ def pack(self, linear, scales, zeros):
+ scales = scales.t().contiguous()
+ zeros = zeros.t().contiguous()
+ scale_zeros = zeros * scales
+ self.scales = scales.clone()
+ if linear.bias is not None:
+ self.bias = linear.bias.clone()
+
+ intweight = []
+ for idx in range(self.infeatures):
+ g_idx = idx // self.groupsize
+ intweight.append(
+ torch.round((linear.weight.data[:, idx] + scale_zeros[g_idx]) / self.scales[g_idx]).to(torch.int)[:,
+ None])
+ intweight = torch.cat(intweight, dim=1)
+ intweight = intweight.t().contiguous()
+ intweight = intweight.numpy().astype(np.uint32)
+ qweight = np.zeros((intweight.shape[0] // 256 * (self.bits * 8), intweight.shape[1]), dtype=np.uint32)
+ i = 0
+ row = 0
+ while row < qweight.shape[0]:
+ if self.bits in [2, 4, 8]:
+ for j in range(i, i + (32 // self.bits)):
+ qweight[row] |= intweight[j] << (self.bits * (j - i))
+ i += 32 // self.bits
+ row += 1
+ elif self.bits == 3:
+ for j in range(i, i + 10):
+ qweight[row] |= intweight[j] << (3 * (j - i))
+ i += 10
+ qweight[row] |= intweight[i] << 30
+ row += 1
+ qweight[row] |= (intweight[i] >> 2) & 1
+ i += 1
+ for j in range(i, i + 10):
+ qweight[row] |= intweight[j] << (3 * (j - i) + 1)
+ i += 10
+ qweight[row] |= intweight[i] << 31
+ row += 1
+ qweight[row] |= (intweight[i] >> 1) & 0x3
+ i += 1
+ for j in range(i, i + 10):
+ qweight[row] |= intweight[j] << (3 * (j - i) + 2)
+ i += 10
+ row += 1
+ else:
+ raise NotImplementedError("Only 2,3,4,8 bits are supported.")
+
+ qweight = qweight.astype(np.int32)
+ self.qweight = torch.from_numpy(qweight)
+
+ zeros -= 1
+ zeros = zeros.numpy().astype(np.uint32)
+ qzeros = np.zeros((zeros.shape[0], zeros.shape[1] // 256 * (self.bits * 8)), dtype=np.uint32)
+ i = 0
+ col = 0
+ while col < qzeros.shape[1]:
+ if self.bits in [2, 4, 8]:
+ for j in range(i, i + (32 // self.bits)):
+ qzeros[:, col] |= zeros[:, j] << (self.bits * (j - i))
+ i += 32 // self.bits
+ col += 1
+ elif self.bits == 3:
+ for j in range(i, i + 10):
+ qzeros[:, col] |= zeros[:, j] << (3 * (j - i))
+ i += 10
+ qzeros[:, col] |= zeros[:, i] << 30
+ col += 1
+ qzeros[:, col] |= (zeros[:, i] >> 2) & 1
+ i += 1
+ for j in range(i, i + 10):
+ qzeros[:, col] |= zeros[:, j] << (3 * (j - i) + 1)
+ i += 10
+ qzeros[:, col] |= zeros[:, i] << 31
+ col += 1
+ qzeros[:, col] |= (zeros[:, i] >> 1) & 0x3
+ i += 1
+ for j in range(i, i + 10):
+ qzeros[:, col] |= zeros[:, j] << (3 * (j - i) + 2)
+ i += 10
+ col += 1
+ else:
+ raise NotImplementedError("Only 2,3,4,8 bits are supported.")
+
+ qzeros = qzeros.astype(np.int32)
+ self.qzeros = torch.from_numpy(qzeros)
+
+ def forward(self, x):
+ intermediate_dtype = torch.float32
+
+ if not self._initialized_quant_state:
+ # Do we even have a bias? Check for at least one non-zero element.
+ if self.bias is not None and bool(torch.any(self.bias != 0)):
+ # Then make sure it's the right type.
+ self.bias.data = self.bias.data.to(intermediate_dtype)
+ else:
+ self.bias = None
+
+ outshape = list(x.shape)
+ outshape[-1] = self.outfeatures
+ x = x.reshape(-1, x.shape[-1])
+ if self.bias is None:
+ y = torch.zeros(x.shape[0], outshape[-1], dtype=intermediate_dtype, device=x.device)
+ else:
+ y = self.bias.clone().repeat(x.shape[0], 1)
+
+ output_dtype = x.dtype
+ x = x.to(intermediate_dtype)
+ if self.bits == 2:
+ quant_cuda.vecquant2matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
+ elif self.bits == 3:
+ quant_cuda.vecquant3matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
+ elif self.bits == 4:
+ quant_cuda.vecquant4matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
+ elif self.bits == 8:
+ quant_cuda.vecquant8matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
+ else:
+ raise NotImplementedError("Only 2,3,4,8 bits are supported.")
+ y = y.to(output_dtype)
+ return y.reshape(outshape)
+
+
+def make_quant(module, names, bits, groupsize, name=''):
+ if isinstance(module, QuantLinear):
+ return
+ for attr in dir(module):
+ tmp = getattr(module, attr)
+ name1 = name + '.' + attr if name != '' else attr
+ if name1 in names:
+ setattr(module, attr, QuantLinear(bits, groupsize, tmp.in_features, tmp.out_features))
+ for name1, child in module.named_children():
+ make_quant(child, names, bits, groupsize, name + '.' + name1 if name != '' else name1)
diff --git a/applications/Chat/inference/locustfile.py b/applications/Chat/inference/locustfile.py
new file mode 100644
index 000000000000..51cdc68125bb
--- /dev/null
+++ b/applications/Chat/inference/locustfile.py
@@ -0,0 +1,27 @@
+from json import JSONDecodeError
+
+from locust import HttpUser, task
+
+samples = [[
+ dict(
+ instruction='Who is the best player in the history of NBA?',
+ response=
+ 'The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1'
+ ),
+ dict(instruction='continue this talk', response=''),
+], [
+ dict(instruction='Who is the best player in the history of NBA?', response=''),
+]]
+
+
+class GenerationUser(HttpUser):
+
+ @task
+ def generate(self):
+ for sample in samples:
+ data = {'max_new_tokens': 64, 'history': sample}
+ with self.client.post('/generate', json=data, catch_response=True) as response:
+ if response.status_code in (200, 406):
+ response.success()
+ else:
+ response.failure('Response wrong')
diff --git a/applications/Chat/inference/requirements.txt b/applications/Chat/inference/requirements.txt
new file mode 100644
index 000000000000..511fe1a4f1f3
--- /dev/null
+++ b/applications/Chat/inference/requirements.txt
@@ -0,0 +1,13 @@
+fastapi
+locust
+numpy
+pydantic
+safetensors
+slowapi
+sse_starlette
+torch
+uvicorn
+git+https://github.com/huggingface/transformers
+accelerate
+bitsandbytes
+jieba
\ No newline at end of file
diff --git a/applications/Chat/inference/server.py b/applications/Chat/inference/server.py
new file mode 100644
index 000000000000..b4627299397e
--- /dev/null
+++ b/applications/Chat/inference/server.py
@@ -0,0 +1,178 @@
+import argparse
+import os
+from threading import Lock
+from typing import Dict, Generator, List, Optional
+
+import torch
+import uvicorn
+from fastapi import FastAPI, HTTPException, Request
+from fastapi.middleware.cors import CORSMiddleware
+from llama_gptq import load_quant
+from pydantic import BaseModel, Field
+from slowapi import Limiter, _rate_limit_exceeded_handler
+from slowapi.errors import RateLimitExceeded
+from slowapi.util import get_remote_address
+from sse_starlette.sse import EventSourceResponse
+from transformers import AutoTokenizer, GenerationConfig, LlamaForCausalLM
+from utils import ChatPromptProcessor, Dialogue, LockedIterator, sample_streamingly, update_model_kwargs_fn, load_json
+
+CONTEXT = 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.'
+MAX_LEN = 512
+running_lock = Lock()
+
+
+class GenerationTaskReq(BaseModel):
+ max_new_tokens: int = Field(gt=0, le=512, example=64)
+ history: List[Dialogue] = Field(min_items=1)
+ top_k: Optional[int] = Field(default=None, gt=0, example=50)
+ top_p: Optional[float] = Field(default=None, gt=0.0, lt=1.0, example=0.5)
+ temperature: Optional[float] = Field(default=None, gt=0.0, lt=1.0, example=0.7)
+ repetition_penalty: Optional[float] = Field(default=None, gt=1.0, example=1.2)
+
+
+limiter = Limiter(key_func=get_remote_address)
+app = FastAPI()
+app.state.limiter = limiter
+app.add_exception_handler(RateLimitExceeded, _rate_limit_exceeded_handler)
+
+# set CORS
+origin_spec_from_env = os.environ.get('CORS_ORIGIN', None)
+
+if origin_spec_from_env is not None:
+ # allow CORS from the specified origins
+ origins = os.environ['CORS_ORIGIN'].split(',')
+else:
+ # allow CORS from all origins
+ origins = ["*"]
+
+app.add_middleware(
+ CORSMiddleware,
+ allow_origins=origins,
+ allow_credentials=True,
+ allow_methods=["*"],
+ allow_headers=["*"],
+)
+
+
+def generate_streamingly(prompt, max_new_tokens, top_k, top_p, temperature):
+ inputs = {k: v.cuda() for k, v in tokenizer(prompt, return_tensors="pt").items()}
+ #TODO(ver217): streaming generation does not support repetition_penalty now
+ model_kwargs = {
+ 'max_generate_tokens': max_new_tokens,
+ 'early_stopping': True,
+ 'top_k': top_k,
+ 'top_p': top_p,
+ 'temperature': temperature,
+ 'prepare_inputs_fn': model.prepare_inputs_for_generation,
+ 'update_model_kwargs_fn': update_model_kwargs_fn,
+ }
+ is_first_word = True
+ generator = LockedIterator(sample_streamingly(model, **inputs, **model_kwargs), running_lock)
+ for output in generator:
+ output = output.cpu()
+ tokens = tokenizer.convert_ids_to_tokens(output, skip_special_tokens=True)
+ current_sub_tokens = []
+ for token in tokens:
+ if token in tokenizer.all_special_tokens:
+ continue
+ current_sub_tokens.append(token)
+ if current_sub_tokens:
+ out_string = tokenizer.sp_model.decode(current_sub_tokens)
+ if is_first_word:
+ out_string = out_string.lstrip()
+ is_first_word = False
+ elif current_sub_tokens[0].startswith('▁'):
+ # whitespace will be ignored by the frontend
+ out_string = ' ' + out_string
+ yield out_string
+
+
+async def event_generator(request: Request, generator: Generator):
+ while True:
+ if await request.is_disconnected():
+ break
+ try:
+ yield {'event': 'generate', 'data': next(generator)}
+ except StopIteration:
+ yield {'event': 'end', 'data': ''}
+ break
+
+
+@app.post('/generate/stream')
+@limiter.limit('1/second')
+def generate(data: GenerationTaskReq, request: Request):
+ prompt = prompt_processor.preprocess_prompt(data.history, data.max_new_tokens)
+ event_source = event_generator(
+ request, generate_streamingly(prompt, data.max_new_tokens, data.top_k, data.top_p, data.temperature))
+ return EventSourceResponse(event_source)
+
+
+@app.post('/generate')
+@limiter.limit('1/second')
+def generate_no_stream(data: GenerationTaskReq, request: Request):
+ prompt = prompt_processor.preprocess_prompt(data.history, data.max_new_tokens)
+ if prompt_processor.has_censored_words(prompt):
+ return prompt_processor.SAFE_RESPONSE
+ inputs = {k: v.cuda() for k, v in tokenizer(prompt, return_tensors="pt").items()}
+ with running_lock:
+ output = model.generate(**inputs, **data.dict(exclude={'history'}))
+ output = output.cpu()
+ prompt_len = inputs['input_ids'].size(1)
+ response = output[0, prompt_len:]
+ out_string = tokenizer.decode(response, skip_special_tokens=True)
+ out_string = prompt_processor.postprocess_output(out_string)
+ if prompt_processor.has_censored_words(out_string):
+ return prompt_processor.SAFE_RESPONSE
+ return out_string
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ 'pretrained',
+ help='Path to pretrained model. Can be a local path or a model name from the HuggingFace model hub.')
+ parser.add_argument('--quant',
+ choices=['8bit', '4bit'],
+ default=None,
+ help='Quantization mode. Default: None (no quantization, fp16).')
+ parser.add_argument(
+ '--gptq_checkpoint',
+ default=None,
+ help='Path to GPTQ checkpoint. This is only useful when quantization mode is 4bit. Default: None.')
+ parser.add_argument('--gptq_group_size',
+ type=int,
+ default=128,
+ help='Group size for GPTQ. This is only useful when quantization mode is 4bit. Default: 128.')
+ parser.add_argument('--http_host', default='0.0.0.0')
+ parser.add_argument('--http_port', type=int, default=7070)
+ parser.add_argument('--profanity_file', default=None, help='Path to profanity words list. It should be a JSON file containing a list of words.')
+ args = parser.parse_args()
+
+ if args.quant == '4bit':
+ assert args.gptq_checkpoint is not None, 'Please specify a GPTQ checkpoint.'
+
+ tokenizer = AutoTokenizer.from_pretrained(args.pretrained)
+
+ if args.profanity_file is not None:
+ censored_words = load_json(args.profanity_file)
+ else:
+ censored_words = []
+ prompt_processor = ChatPromptProcessor(tokenizer, CONTEXT, MAX_LEN, censored_words=censored_words)
+
+ if args.quant == '4bit':
+ model = load_quant(args.pretrained, args.gptq_checkpoint, 4, args.gptq_group_size)
+ model.cuda()
+ else:
+ model = LlamaForCausalLM.from_pretrained(
+ args.pretrained,
+ load_in_8bit=(args.quant == '8bit'),
+ torch_dtype=torch.float16,
+ device_map="auto",
+ )
+ if args.quant != '8bit':
+ model.half() # seems to fix bugs for some users.
+ model.eval()
+
+ config = uvicorn.Config(app, host=args.http_host, port=args.http_port)
+ server = uvicorn.Server(config=config)
+ server.run()
diff --git a/applications/Chat/inference/tests/test_chat_prompt.py b/applications/Chat/inference/tests/test_chat_prompt.py
new file mode 100644
index 000000000000..f5737ebe8c09
--- /dev/null
+++ b/applications/Chat/inference/tests/test_chat_prompt.py
@@ -0,0 +1,56 @@
+import os
+
+from transformers import AutoTokenizer
+from utils import ChatPromptProcessor, Dialogue
+
+CONTEXT = 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.'
+tokenizer = AutoTokenizer.from_pretrained(os.environ['PRETRAINED_PATH'])
+
+samples = [
+ ([
+ Dialogue(
+ instruction='Who is the best player in the history of NBA?',
+ response=
+ 'The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1'
+ ),
+ Dialogue(instruction='continue this talk', response=''),
+ ], 128,
+ 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\nWho is the best player in the history of NBA?\n\n### Response:\nThe best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1\n\n### Instruction:\ncontinue this talk\n\n### Response:\n'
+ ),
+ ([
+ Dialogue(
+ instruction='Who is the best player in the history of NBA?',
+ response=
+ 'The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1'
+ ),
+ Dialogue(instruction='continue this talk', response=''),
+ ], 200,
+ 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\ncontinue this talk\n\n### Response:\n'
+ ),
+ ([
+ Dialogue(
+ instruction='Who is the best player in the history of NBA?',
+ response=
+ 'The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1'
+ ),
+ Dialogue(instruction='continue this talk', response=''),
+ ], 211,
+ 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\ncontinue this\n\n### Response:\n'
+ ),
+ ([
+ Dialogue(instruction='Who is the best player in the history of NBA?', response=''),
+ ], 128,
+ 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\nWho is the best player in the history of NBA?\n\n### Response:\n'
+ ),
+]
+
+
+def test_chat_prompt_processor():
+ processor = ChatPromptProcessor(tokenizer, CONTEXT, 256)
+ for history, max_new_tokens, result in samples:
+ prompt = processor.preprocess_prompt(history, max_new_tokens)
+ assert prompt == result
+
+
+if __name__ == '__main__':
+ test_chat_prompt_processor()
diff --git a/applications/Chat/inference/utils.py b/applications/Chat/inference/utils.py
new file mode 100644
index 000000000000..37944be70a3b
--- /dev/null
+++ b/applications/Chat/inference/utils.py
@@ -0,0 +1,200 @@
+import re
+from threading import Lock
+from typing import Any, Callable, Generator, List, Optional
+import json
+import jieba
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from pydantic import BaseModel, Field
+
+try:
+ from transformers.generation_logits_process import (
+ LogitsProcessorList,
+ TemperatureLogitsWarper,
+ TopKLogitsWarper,
+ TopPLogitsWarper,
+ )
+except ImportError:
+ from transformers.generation import LogitsProcessorList, TemperatureLogitsWarper, TopKLogitsWarper, TopPLogitsWarper
+
+
+def prepare_logits_processor(top_k: Optional[int] = None,
+ top_p: Optional[float] = None,
+ temperature: Optional[float] = None) -> LogitsProcessorList:
+ processor_list = LogitsProcessorList()
+ if temperature is not None and temperature != 1.0:
+ processor_list.append(TemperatureLogitsWarper(temperature))
+ if top_k is not None and top_k != 0:
+ processor_list.append(TopKLogitsWarper(top_k))
+ if top_p is not None and top_p < 1.0:
+ processor_list.append(TopPLogitsWarper(top_p))
+ return processor_list
+
+
+def _is_sequence_finished(unfinished_sequences: torch.Tensor) -> bool:
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ # consider DP
+ unfinished_sequences = unfinished_sequences.clone()
+ dist.all_reduce(unfinished_sequences)
+ return unfinished_sequences.max() == 0
+
+
+def sample_streamingly(model: nn.Module,
+ input_ids: torch.Tensor,
+ max_generate_tokens: int,
+ early_stopping: bool = False,
+ eos_token_id: Optional[int] = None,
+ pad_token_id: Optional[int] = None,
+ top_k: Optional[int] = None,
+ top_p: Optional[float] = None,
+ temperature: Optional[float] = None,
+ prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
+ update_model_kwargs_fn: Optional[Callable[[dict, Any], dict]] = None,
+ **model_kwargs) -> Generator:
+
+ logits_processor = prepare_logits_processor(top_k, top_p, temperature)
+ unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
+
+ for _ in range(max_generate_tokens):
+ model_inputs = prepare_inputs_fn(input_ids, **model_kwargs) if prepare_inputs_fn is not None else {
+ 'input_ids': input_ids
+ }
+ outputs = model(**model_inputs)
+
+ next_token_logits = outputs['logits'][:, -1, :]
+ # pre-process distribution
+ next_token_logits = logits_processor(input_ids, next_token_logits)
+ # sample
+ probs = torch.softmax(next_token_logits, dim=-1, dtype=torch.float)
+ next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
+
+ # finished sentences should have their next token be a padding token
+ if eos_token_id is not None:
+ if pad_token_id is None:
+ raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
+ next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
+
+ yield next_tokens
+
+ # update generated ids, model inputs for next step
+ input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
+ if update_model_kwargs_fn is not None:
+ model_kwargs = update_model_kwargs_fn(outputs, **model_kwargs)
+
+ # if eos_token was found in one sentence, set sentence to finished
+ if eos_token_id is not None:
+ unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
+
+ # stop when each sentence is finished if early_stopping=True
+ if early_stopping and _is_sequence_finished(unfinished_sequences):
+ break
+
+
+def update_model_kwargs_fn(outputs: dict, **model_kwargs) -> dict:
+ if "past_key_values" in outputs:
+ model_kwargs["past"] = outputs["past_key_values"]
+ else:
+ model_kwargs["past"] = None
+
+ # update token_type_ids with last value
+ if "token_type_ids" in model_kwargs:
+ token_type_ids = model_kwargs["token_type_ids"]
+ model_kwargs["token_type_ids"] = torch.cat([token_type_ids, token_type_ids[:, -1].unsqueeze(-1)], dim=-1)
+
+ # update attention mask
+ if "attention_mask" in model_kwargs:
+ attention_mask = model_kwargs["attention_mask"]
+ model_kwargs["attention_mask"] = torch.cat(
+ [attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1)
+
+ return model_kwargs
+
+
+class Dialogue(BaseModel):
+ instruction: str = Field(min_length=1, example='Count up from 1 to 500.')
+ response: str = Field(example='')
+
+
+def _format_dialogue(instruction: str, response: str = ''):
+ return f'\n\n### Instruction:\n{instruction}\n\n### Response:\n{response}'
+
+
+STOP_PAT = re.compile(r'(###|instruction:).*', flags=(re.I | re.S))
+
+
+class ChatPromptProcessor:
+ SAFE_RESPONSE = 'The input/response contains inappropriate content, please rephrase your prompt.'
+
+ def __init__(self, tokenizer, context: str, max_len: int = 2048, censored_words: List[str]=[]):
+ self.tokenizer = tokenizer
+ self.context = context
+ self.max_len = max_len
+ self.censored_words = set([word.lower() for word in censored_words])
+ # These will be initialized after the first call of preprocess_prompt()
+ self.context_len: Optional[int] = None
+ self.dialogue_placeholder_len: Optional[int] = None
+
+ def preprocess_prompt(self, history: List[Dialogue], max_new_tokens: int) -> str:
+ if self.context_len is None:
+ self.context_len = len(self.tokenizer(self.context)['input_ids'])
+ if self.dialogue_placeholder_len is None:
+ self.dialogue_placeholder_len = len(
+ self.tokenizer(_format_dialogue(''), add_special_tokens=False)['input_ids'])
+ prompt = self.context
+ # the last dialogue must be in the prompt
+ last_dialogue = history.pop()
+ # the response of the last dialogue is empty
+ assert last_dialogue.response == ''
+ if len(self.tokenizer(_format_dialogue(last_dialogue.instruction), add_special_tokens=False)
+ ['input_ids']) + max_new_tokens + self.context_len >= self.max_len:
+ # to avoid truncate placeholder, apply truncate to the original instruction
+ instruction_truncated = self.tokenizer(last_dialogue.instruction,
+ add_special_tokens=False,
+ truncation=True,
+ max_length=(self.max_len - max_new_tokens - self.context_len -
+ self.dialogue_placeholder_len))['input_ids']
+ instruction_truncated = self.tokenizer.decode(instruction_truncated).lstrip()
+ prompt += _format_dialogue(instruction_truncated)
+ return prompt
+
+ res_len = self.max_len - max_new_tokens - len(self.tokenizer(prompt)['input_ids'])
+
+ rows = []
+ for dialogue in history[::-1]:
+ text = _format_dialogue(dialogue.instruction, dialogue.response)
+ cur_len = len(self.tokenizer(text, add_special_tokens=False)['input_ids'])
+ if res_len - cur_len < 0:
+ break
+ res_len -= cur_len
+ rows.insert(0, text)
+ prompt += ''.join(rows) + _format_dialogue(last_dialogue.instruction)
+ return prompt
+
+ def postprocess_output(self, output: str) -> str:
+ output = STOP_PAT.sub('', output)
+ return output.strip()
+
+ def has_censored_words(self, text: str) -> bool:
+ if len(self.censored_words) == 0:
+ return False
+ intersection = set(jieba.cut(text.lower())) & self.censored_words
+ return len(intersection) > 0
+
+class LockedIterator:
+
+ def __init__(self, it, lock: Lock) -> None:
+ self.lock = lock
+ self.it = iter(it)
+
+ def __iter__(self):
+ return self
+
+ def __next__(self):
+ with self.lock:
+ return next(self.it)
+
+def load_json(path: str):
+ with open(path) as f:
+ return json.load(f)
\ No newline at end of file
diff --git a/applications/ChatGPT/pytest.ini b/applications/Chat/pytest.ini
similarity index 100%
rename from applications/ChatGPT/pytest.ini
rename to applications/Chat/pytest.ini
diff --git a/applications/ChatGPT/requirements-test.txt b/applications/Chat/requirements-test.txt
similarity index 100%
rename from applications/ChatGPT/requirements-test.txt
rename to applications/Chat/requirements-test.txt
diff --git a/applications/Chat/requirements.txt b/applications/Chat/requirements.txt
new file mode 100644
index 000000000000..af7ff67861eb
--- /dev/null
+++ b/applications/Chat/requirements.txt
@@ -0,0 +1,13 @@
+transformers>=4.20.1
+tqdm
+datasets
+loralib
+colossalai>=0.2.4
+torch<2.0.0, >=1.12.1
+langchain
+tokenizers
+fastapi
+sse_starlette
+wandb
+sentencepiece
+gpustat
diff --git a/applications/ChatGPT/setup.py b/applications/Chat/setup.py
similarity index 87%
rename from applications/ChatGPT/setup.py
rename to applications/Chat/setup.py
index deec10e0c841..a285a6dff4bf 100644
--- a/applications/ChatGPT/setup.py
+++ b/applications/Chat/setup.py
@@ -17,18 +17,18 @@ def fetch_version():
setup(
- name='chatgpt',
+ name='coati',
version=fetch_version(),
packages=find_packages(exclude=(
'tests',
'benchmarks',
'*.egg-info',
)),
- description='A RLFH implementation (ChatGPT) powered by ColossalAI',
+ description='Colossal-AI Talking Intelligence',
long_description=fetch_readme(),
long_description_content_type='text/markdown',
license='Apache Software License 2.0',
- url='https://github.com/hpcaitech/ChatGPT',
+ url='https://github.com/hpcaitech/Coati',
install_requires=fetch_requirements('requirements.txt'),
python_requires='>=3.6',
classifiers=[
diff --git a/applications/ChatGPT/tests/__init__.py b/applications/Chat/tests/__init__.py
similarity index 100%
rename from applications/ChatGPT/tests/__init__.py
rename to applications/Chat/tests/__init__.py
diff --git a/applications/ChatGPT/tests/test_checkpoint.py b/applications/Chat/tests/test_checkpoint.py
similarity index 96%
rename from applications/ChatGPT/tests/test_checkpoint.py
rename to applications/Chat/tests/test_checkpoint.py
index 1bbd133f76d3..8c7848525201 100644
--- a/applications/ChatGPT/tests/test_checkpoint.py
+++ b/applications/Chat/tests/test_checkpoint.py
@@ -7,8 +7,8 @@
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
-from chatgpt.models.gpt import GPTActor
-from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy
+from coati.models.gpt import GPTActor
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy
from transformers.models.gpt2.configuration_gpt2 import GPT2Config
from colossalai.nn.optimizer import HybridAdam
diff --git a/applications/ChatGPT/tests/test_data.py b/applications/Chat/tests/test_data.py
similarity index 94%
rename from applications/ChatGPT/tests/test_data.py
rename to applications/Chat/tests/test_data.py
index 3d8fe912cb27..577309a0fceb 100644
--- a/applications/ChatGPT/tests/test_data.py
+++ b/applications/Chat/tests/test_data.py
@@ -6,11 +6,11 @@
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
-from chatgpt.experience_maker import NaiveExperienceMaker
-from chatgpt.models.base import RewardModel
-from chatgpt.models.gpt import GPTActor, GPTCritic
-from chatgpt.replay_buffer import NaiveReplayBuffer
-from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy
+from coati.experience_maker import NaiveExperienceMaker
+from coati.models.base import RewardModel
+from coati.models.gpt import GPTActor, GPTCritic
+from coati.replay_buffer import NaiveReplayBuffer
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy
from transformers.models.gpt2.configuration_gpt2 import GPT2Config
from colossalai.testing import rerun_if_address_is_in_use
diff --git a/applications/Chat/version.txt b/applications/Chat/version.txt
new file mode 100644
index 000000000000..3eefcb9dd5b3
--- /dev/null
+++ b/applications/Chat/version.txt
@@ -0,0 +1 @@
+1.0.0
diff --git a/applications/ChatGPT/README.md b/applications/ChatGPT/README.md
deleted file mode 100644
index 206ede5f1843..000000000000
--- a/applications/ChatGPT/README.md
+++ /dev/null
@@ -1,209 +0,0 @@
-# RLHF - Colossal-AI
-
-## Table of Contents
-
-- [What is RLHF - Colossal-AI?](#intro)
-- [How to Install?](#install)
-- [The Plan](#the-plan)
-- [How can you partcipate in open source?](#invitation-to-open-source-contribution)
----
-## Intro
-Implementation of RLHF (Reinforcement Learning with Human Feedback) powered by Colossal-AI. It supports distributed training and offloading, which can fit extremly large models. More details can be found in the [blog](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt).
-
-
- -
-
-
-## Training process (step 3)
-
-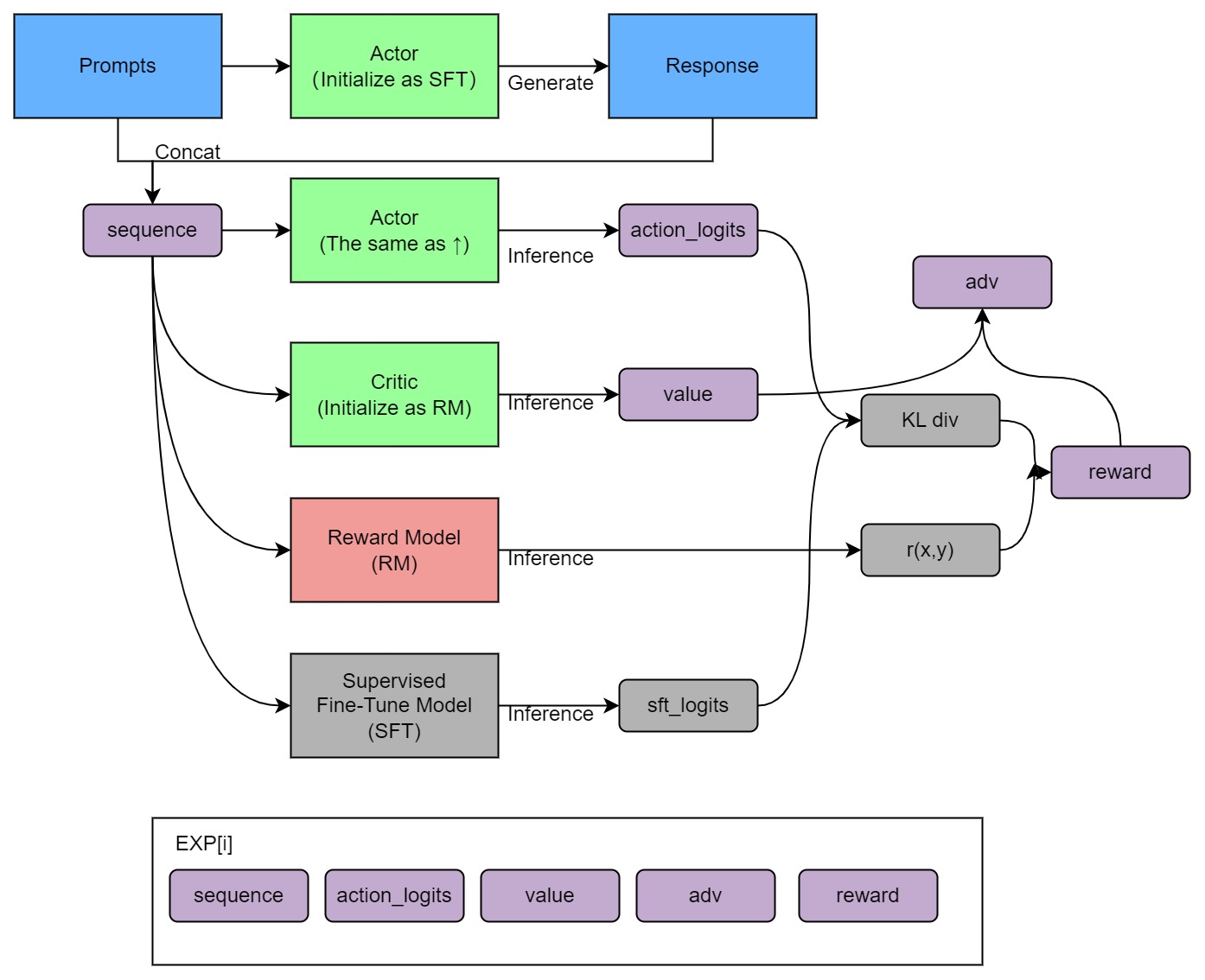 -
-
-
-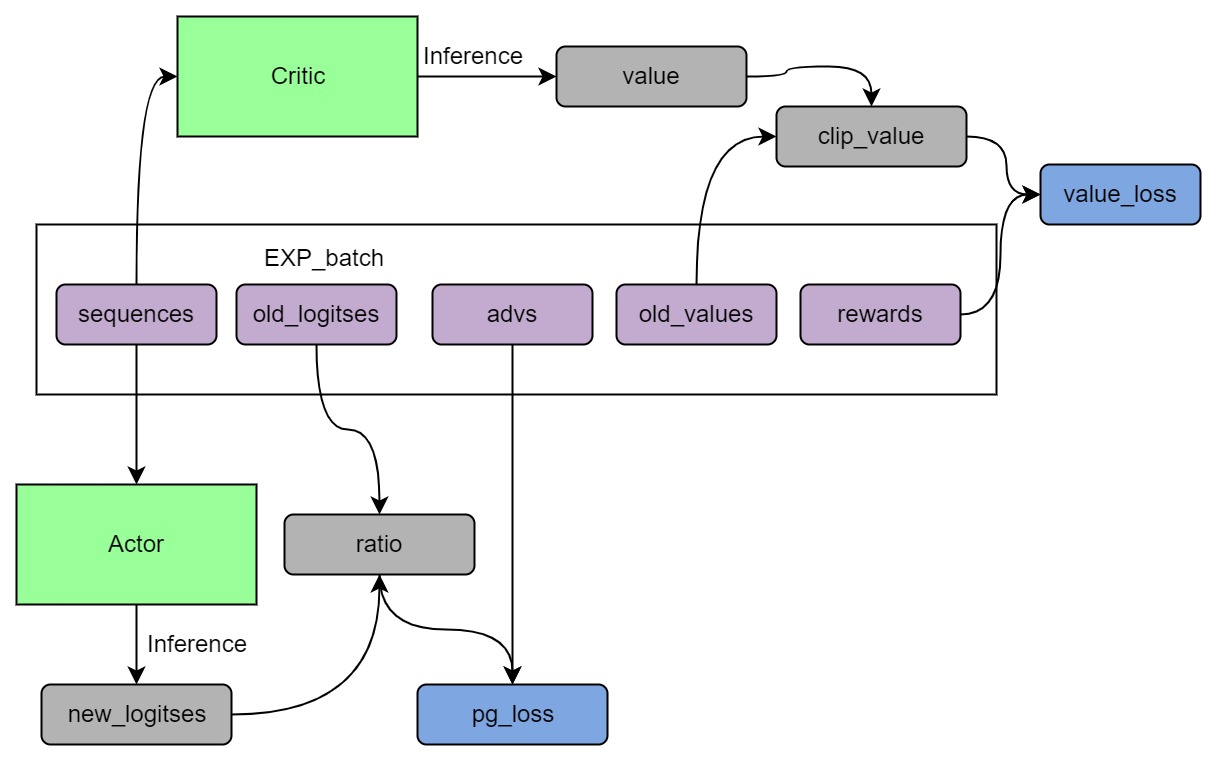 -
-
-
-
-## Install
-```shell
-pip install .
-```
-
-## Usage
-
-The main entrypoint is `Trainer`. We only support PPO trainer now. We support many training strategies:
-
-- NaiveStrategy: simplest strategy. Train on single GPU.
-- DDPStrategy: use `torch.nn.parallel.DistributedDataParallel`. Train on multi GPUs.
-- ColossalAIStrategy: use Gemini and Zero of ColossalAI. It eliminates model duplication on each GPU and supports offload. It's very useful when training large models on multi GPUs.
-
-Simplest usage:
-
-```python
-from chatgpt.trainer import PPOTrainer
-from chatgpt.trainer.strategies import ColossalAIStrategy
-from chatgpt.models.gpt import GPTActor, GPTCritic
-from chatgpt.models.base import RewardModel
-from copy import deepcopy
-from colossalai.nn.optimizer import HybridAdam
-
-strategy = ColossalAIStrategy()
-
-with strategy.model_init_context():
- # init your model here
- # load pretrained gpt2
- actor = GPTActor(pretrained='gpt2')
- critic = GPTCritic()
- initial_model = deepcopy(actor).cuda()
- reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).cuda()
-
-actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
-critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
-
-# prepare models and optimizers
-(actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
- (actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
-
-# load saved model checkpoint after preparing
-strategy.load_model(actor, 'actor_checkpoint.pt', strict=False)
-# load saved optimizer checkpoint after preparing
-strategy.load_optimizer(actor_optim, 'actor_optim_checkpoint.pt')
-
-trainer = PPOTrainer(strategy,
- actor,
- critic,
- reward_model,
- initial_model,
- actor_optim,
- critic_optim,
- ...)
-
-trainer.fit(dataset, ...)
-
-# save model checkpoint after fitting on only rank0
-strategy.save_model(actor, 'actor_checkpoint.pt', only_rank0=True)
-# save optimizer checkpoint on all ranks
-strategy.save_optimizer(actor_optim, 'actor_optim_checkpoint.pt', only_rank0=False)
-```
-
-For more details, see `examples/`.
-
-We also support training reward model with true-world data. See `examples/train_reward_model.py`.
-
-## FAQ
-
-### How to save/load checkpoint
-
-To load pretrained model, you can simply use huggingface pretrained models:
-
-```python
-# load OPT-350m pretrained model
-actor = OPTActor(pretrained='facebook/opt-350m')
-```
-
-To save model checkpoint:
-
-```python
-# save model checkpoint on only rank0
-strategy.save_model(actor, 'actor_checkpoint.pt', only_rank0=True)
-```
-
-This function must be called after `strategy.prepare()`.
-
-For DDP strategy, model weights are replicated on all ranks. And for ColossalAI strategy, model weights may be sharded, but all-gather will be applied before returning state dict. You can set `only_rank0=True` for both of them, which only saves checkpoint on rank0, to save disk space usage. The checkpoint is float32.
-
-To save optimizer checkpoint:
-
-```python
-# save optimizer checkpoint on all ranks
-strategy.save_optimizer(actor_optim, 'actor_optim_checkpoint.pt', only_rank0=False)
-```
-
-For DDP strategy, optimizer states are replicated on all ranks. You can set `only_rank0=True`. But for ColossalAI strategy, optimizer states are sharded over all ranks, and no all-gather will be applied. So for ColossalAI strategy, you can only set `only_rank0=False`. That is to say, each rank will save a cehckpoint. When loading, each rank should load the corresponding part.
-
-Note that different stategy may have different shapes of optimizer checkpoint.
-
-To load model checkpoint:
-
-```python
-# load saved model checkpoint after preparing
-strategy.load_model(actor, 'actor_checkpoint.pt', strict=False)
-```
-
-To load optimizer checkpoint:
-
-```python
-# load saved optimizer checkpoint after preparing
-strategy.load_optimizer(actor_optim, 'actor_optim_checkpoint.pt')
-```
-
-## The Plan
-
-- [x] implement PPO fine-tuning
-- [x] implement training reward model
-- [x] support LoRA
-- [x] support inference
-- [ ] open source the reward model weight
-- [ ] support llama from [facebook](https://github.com/facebookresearch/llama)
-- [ ] support BoN(best of N sample)
-- [ ] implement PPO-ptx fine-tuning
-- [ ] integrate with Ray
-- [ ] support more RL paradigms, like Implicit Language Q-Learning (ILQL),
-- [ ] support chain of throught by [langchain](https://github.com/hwchase17/langchain)
-
-### Real-time progress
-You will find our progress in github project broad
-
-[Open ChatGPT](https://github.com/orgs/hpcaitech/projects/17/views/1)
-
-## Invitation to open-source contribution
-Referring to the successful attempts of [BLOOM](https://bigscience.huggingface.co/) and [Stable Diffusion](https://en.wikipedia.org/wiki/Stable_Diffusion), any and all developers and partners with computing powers, datasets, models are welcome to join and build the Colossal-AI community, making efforts towards the era of big AI models from the starting point of replicating ChatGPT!
-
-You may contact us or participate in the following ways:
-1. [Leaving a Star ⭐](https://github.com/hpcaitech/ColossalAI/stargazers) to show your like and support. Thanks!
-2. Posting an [issue](https://github.com/hpcaitech/ColossalAI/issues/new/choose), or submitting a PR on GitHub follow the guideline in [Contributing](https://github.com/hpcaitech/ColossalAI/blob/main/CONTRIBUTING.md).
-3. Join the Colossal-AI community on
-[Slack](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w),
-and [WeChat(微信)](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png "qrcode") to share your ideas.
-4. Send your official proposal to email contact@hpcaitech.com
-
-Thanks so much to all of our amazing contributors!
-
-## Quick Preview
-
- -
-
-
-- Up to 7.73 times faster for single server training and 1.42 times faster for single-GPU inference
-
-
-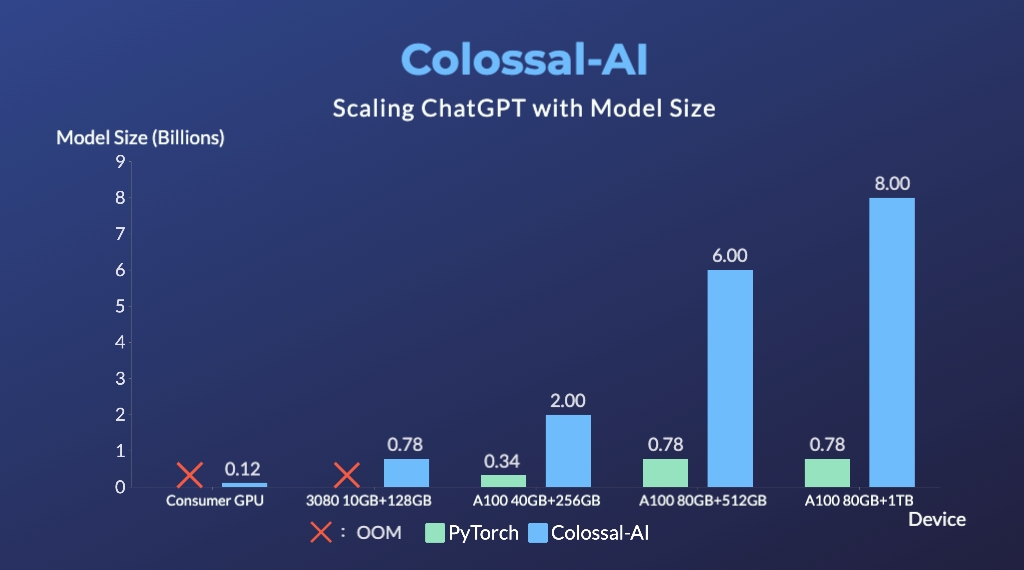 -
-
-
-- Up to 10.3x growth in model capacity on one GPU
-- A mini demo training process requires only 1.62GB of GPU memory (any consumer-grade GPU)
-
-
-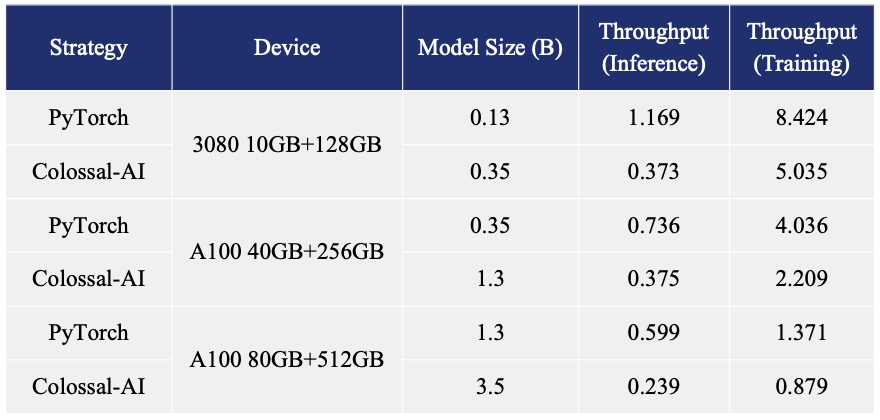 -
-
-
-- Increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU
-- Keep in a sufficiently high running speed
-
-## Citations
-
-```bibtex
-@article{Hu2021LoRALA,
- title = {LoRA: Low-Rank Adaptation of Large Language Models},
- author = {Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen},
- journal = {ArXiv},
- year = {2021},
- volume = {abs/2106.09685}
-}
-
-@article{ouyang2022training,
- title={Training language models to follow instructions with human feedback},
- author={Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others},
- journal={arXiv preprint arXiv:2203.02155},
- year={2022}
-}
-```
diff --git a/applications/ChatGPT/chatgpt/dataset/__init__.py b/applications/ChatGPT/chatgpt/dataset/__init__.py
deleted file mode 100644
index df484f46d24c..000000000000
--- a/applications/ChatGPT/chatgpt/dataset/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-from .reward_dataset import RmStaticDataset, HhRlhfDataset
-from .utils import is_rank_0
-from .sft_dataset import SFTDataset, AlpacaDataset, AlpacaDataCollator
-
-__all__ = ['RmStaticDataset', 'HhRlhfDataset','is_rank_0', 'SFTDataset', 'AlpacaDataset', 'AlpacaDataCollator']
diff --git a/applications/ChatGPT/chatgpt/trainer/sft.py b/applications/ChatGPT/chatgpt/trainer/sft.py
deleted file mode 100644
index 3b35f516816f..000000000000
--- a/applications/ChatGPT/chatgpt/trainer/sft.py
+++ /dev/null
@@ -1,101 +0,0 @@
-from abc import ABC
-from typing import Optional
-import loralib as lora
-import torch
-from chatgpt.models.loss import GPTLMLoss
-from torch.optim import Adam, Optimizer
-from torch.utils.data import DataLoader
-from torch.utils.data.distributed import DistributedSampler
-from tqdm import tqdm
-import torch.distributed as dist
-from .strategies import Strategy
-from .utils import is_rank_0
-from colossalai.logging import get_dist_logger
-
-
-class SFTTrainer(ABC):
- """
- Trainer to use while training reward model.
-
- Args:
- model (torch.nn.Module): the model to train
- strategy (Strategy): the strategy to use for training
- optim(Optimizer): the optimizer to use for training
- train_dataloader: the dataloader to use for training
- eval_dataloader: the dataloader to use for evaluation
- batch_size (int, defaults to 1): the batch size while training
- max_epochs (int, defaults to 2): the number of epochs to train
- optim_kwargs (dict, defaults to {'lr':1e-4}): the kwargs to use while initializing optimizer
- """
-
- def __init__(
- self,
- model,
- strategy: Strategy,
- optim: Optimizer,
- train_dataloader: DataLoader,
- eval_dataloader: DataLoader = None,
- sampler: Optional[DistributedSampler] = None,
- batch_size: int = 1,
- max_epochs: int = 2,
- ) -> None:
- super().__init__()
- self.strategy = strategy
- self.epochs = max_epochs
- self.sampler = sampler
-
- self.train_dataloader = train_dataloader
- self.eval_dataloader = eval_dataloader
-
- self.model = strategy.setup_model(model)
- if "DDP" in str(self.strategy):
- self.model = self.model.module
- self.loss_fn = GPTLMLoss()
- self.optimizer = strategy.setup_optimizer(optim, self.model)
-
- def fit(self, logger, use_lora, log_interval=10):
- epoch_bar = tqdm(range(self.epochs), desc='Train epoch', disable=not is_rank_0())
- for epoch in range(self.epochs):
- if isinstance(self.sampler, DistributedSampler):
- self.sampler.set_epoch(epoch)
- # train
- self.model.train()
- for batch_id, batch in enumerate(self.train_dataloader):
- prompt_ids = batch["input_ids"]
- p_mask = batch["attention_mask"]
- labels = batch["labels"]
- prompt_ids = prompt_ids.squeeze(1).cuda()
- p_mask = p_mask.squeeze(1).cuda()
- # prompt_logits = self.model(prompt_ids, attention_mask=p_mask, labels=labels)
- loss, prompt_logits = self.model(prompt_ids, attention_mask=p_mask, labels=labels)
-
- # loss = self.loss_fn(prompt_logits, labels)
- self.strategy.backward(loss, self.model, self.optimizer)
- self.strategy.optimizer_step(self.optimizer)
- self.optimizer.zero_grad()
- if batch_id % log_interval == 0:
- logger.info(f'Train Epoch {epoch}/{self.epochs} Batch {batch_id} Rank {dist.get_rank()} loss {loss.item()}')
-
- # eval
- if self.eval_dataloader is not None:
- self.model.eval()
- with torch.no_grad():
- loss_sum = 0
- num_seen = 0
- for batch in self.eval_dataloader:
- prompt_ids = batch["input_ids"]
- p_mask = batch["attention_mask"]
- prompt_ids = prompt_ids.squeeze(1).cuda()
- p_mask = p_mask.squeeze(1).cuda()
-
- prompt_logits = self.model(prompt_ids, attention_mask=p_mask)
- loss = self.loss_fn(prompt_logits, prompt_ids)
- loss_sum += loss.item()
- num_seen += prompt_ids.size(0)
-
- loss_mean = loss_sum / num_seen
- if dist.get_rank() == 0:
- logger.info(f'Eval Epoch {epoch}/{self.epochs} loss {loss_mean}')
-
- epoch_bar.update()
-
diff --git a/applications/ChatGPT/chatgpt/utils/__init__.py b/applications/ChatGPT/chatgpt/utils/__init__.py
deleted file mode 100644
index 8f526d7efdad..000000000000
--- a/applications/ChatGPT/chatgpt/utils/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .tokenizer_utils import smart_tokenizer_and_embedding_resize, prepare_llama_tokenizer_and_embedding
-
-__all__ = ['smart_tokenizer_and_embedding_resize', 'prepare_llama_tokenizer_and_embedding']
\ No newline at end of file
diff --git a/applications/ChatGPT/examples/README.md b/applications/ChatGPT/examples/README.md
deleted file mode 100644
index ce73a5407944..000000000000
--- a/applications/ChatGPT/examples/README.md
+++ /dev/null
@@ -1,141 +0,0 @@
-# Examples
-
-## Install requirements
-
-```shell
-pip install -r requirements.txt
-```
-
-## Train the reward model (Stage 2)
-Use these code to train your reward model.
-```shell
-# Take naive reward model training with opt-350m as example
-python train_reward_model.py --pretrain "facebook/opt-350m" --model 'opt' --strategy naive
-# use colossalai_zero2
-torchrun --standalone --nproc_per_node=2 train_reward_model.py --pretrain "facebook/opt-350m" --model 'opt' --strategy colossalai_zero2
-```
-
-### Features and tricks in RM training
-- We support [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)and[rm-static](https://huggingface.co/datasets/Dahoas/rm-static) datasets.
-- We support 2 kinds of loss_function named 'log_sig'(used by OpenAI) and 'log_exp'(used by Anthropic).
-- We change the loss to valid_acc and pair_dist to monitor progress during training.
-- We add special token to the end of the sequence to get better result.
-- We use cosine-reducing lr-scheduler for RM training.
-- We set value_head as 1 liner layer and initialize the weight of value_head using N(0,1/(d_model + 1)) distribution.
-- We train a Bloom-560m reward model for 1 epoch and find the test acc of the model achieve the performance mentions in [Anthropics paper](https://arxiv.org/abs/2112.00861).
-
-### Experiment result
-Model performance in [Anthropics paper](https://arxiv.org/abs/2112.00861):
-
-

-
-
Our training & test result of bloom-560m for 1 epoch:
-
-
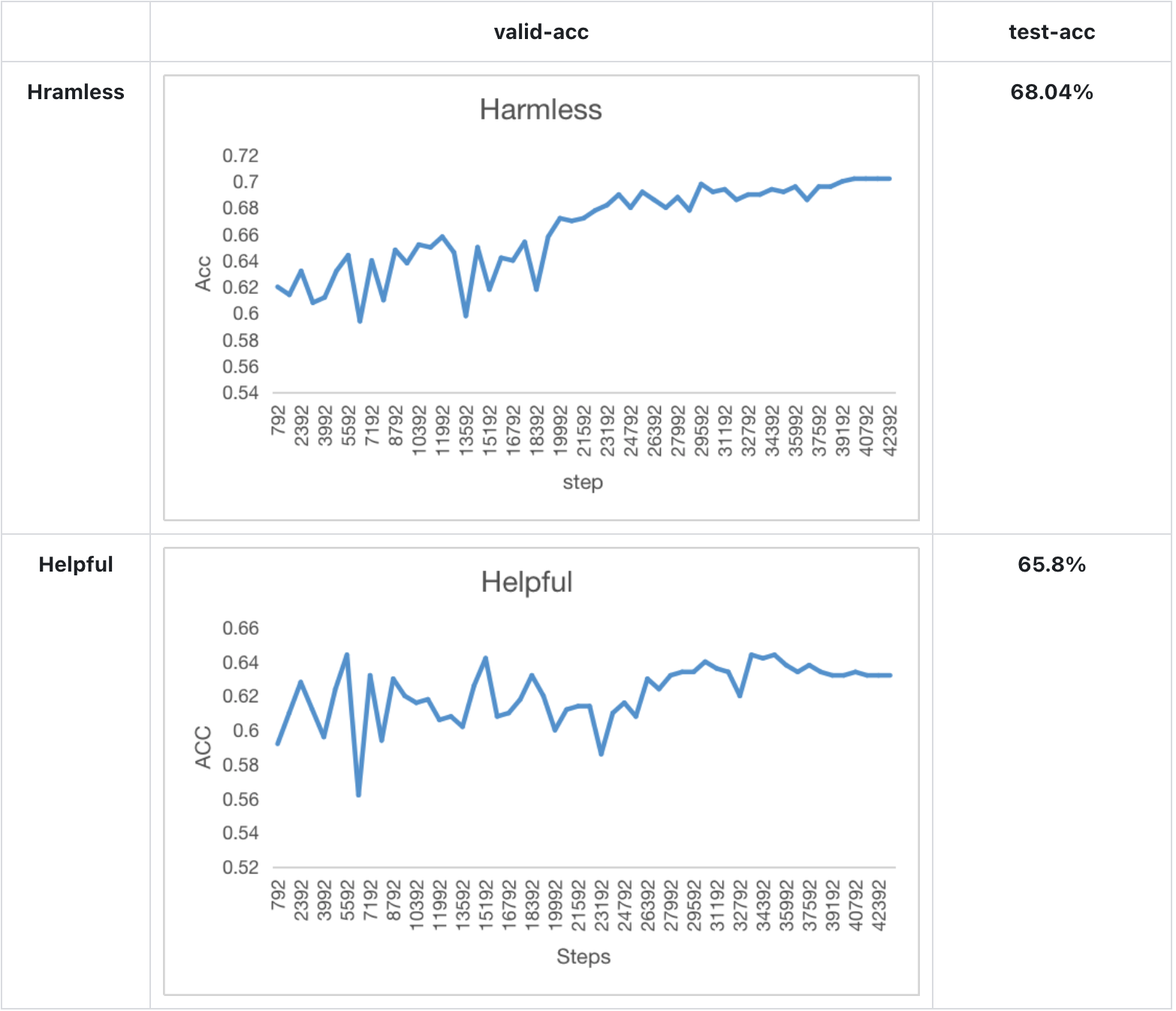
-
-
-
-## Train with dummy prompt data (Stage 3)
-
-This script supports 4 kinds of strategies:
-
-- naive
-- ddp
-- colossalai_zero2
-- colossalai_gemini
-
-It uses random generated prompt data.
-
-Naive strategy only support single GPU training:
-
-```shell
-python train_dummy.py --strategy naive
-# display cli help
-python train_dummy.py -h
-```
-
-DDP strategy and ColossalAI strategy support multi GPUs training:
-
-```shell
-# run DDP on 2 GPUs
-torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy ddp
-# run ColossalAI on 2 GPUs
-torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy colossalai_zero2
-```
-
-## Train with real prompt data (Stage 3)
-
-We use [awesome-chatgpt-prompts](https://huggingface.co/datasets/fka/awesome-chatgpt-prompts) as example dataset. It is a small dataset with hundreds of prompts.
-
-You should download `prompts.csv` first.
-
-This script also supports 4 strategies.
-
-```shell
-# display cli help
-python train_dummy.py -h
-# run naive on 1 GPU
-python train_prompts.py prompts.csv --strategy naive
-# run DDP on 2 GPUs
-torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy ddp
-# run ColossalAI on 2 GPUs
-torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai_zero2
-```
-
-## Inference example(After Stage3)
-We support naive inference demo after training.
-```shell
-# inference, using pretrain path to configure model
-python inference.py --model_path
--model --pretrain
-# example
-python inference.py --model_path ./actor_checkpoint_prompts.pt --pretrain bigscience/bloom-560m --model bloom
-```
-
-## Attention
-The examples is just a demo for testing our progress of RM and PPO training.
-
-
-#### data
-- [x] [rm-static](https://huggingface.co/datasets/Dahoas/rm-static)
-- [x] [hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)
-- [ ] [openai/summarize_from_feedback](https://huggingface.co/datasets/openai/summarize_from_feedback)
-- [ ] [openai/webgpt_comparisons](https://huggingface.co/datasets/openai/webgpt_comparisons)
-- [ ] [Dahoas/instruct-synthetic-prompt-responses](https://huggingface.co/datasets/Dahoas/instruct-synthetic-prompt-responses)
-
-## Support Model
-
-### GPT
-- [x] GPT2-S (s)
-- [x] GPT2-M (m)
-- [x] GPT2-L (l)
-- [ ] GPT2-XL (xl)
-- [x] GPT2-4B (4b)
-- [ ] GPT2-6B (6b)
-- [ ] GPT2-8B (8b)
-- [ ] GPT2-10B (10b)
-- [ ] GPT2-12B (12b)
-- [ ] GPT2-15B (15b)
-- [ ] GPT2-18B (18b)
-- [ ] GPT2-20B (20b)
-- [ ] GPT2-24B (24b)
-- [ ] GPT2-28B (28b)
-- [ ] GPT2-32B (32b)
-- [ ] GPT2-36B (36b)
-- [ ] GPT2-40B (40b)
-- [ ] GPT3 (175b)
-
-### BLOOM
-- [x] [BLOOM-560m](https://huggingface.co/bigscience/bloom-560m)
-- [x] [BLOOM-1b1](https://huggingface.co/bigscience/bloom-1b1)
-- [x] [BLOOM-3b](https://huggingface.co/bigscience/bloom-3b)
-- [x] [BLOOM-7b](https://huggingface.co/bigscience/bloom-7b1)
-- [ ] BLOOM-175b
-
-### OPT
-- [x] [OPT-125M](https://huggingface.co/facebook/opt-125m)
-- [x] [OPT-350M](https://huggingface.co/facebook/opt-350m)
-- [ ] [OPT-1.3B](https://huggingface.co/facebook/opt-1.3b)
-- [ ] [OPT-2.7B](https://huggingface.co/facebook/opt-2.7b)
-- [ ] [OPT-6.7B](https://huggingface.co/facebook/opt-6.7b)
-- [ ] [OPT-13B](https://huggingface.co/facebook/opt-13b)
-- [ ] [OPT-30B](https://huggingface.co/facebook/opt-30b)
diff --git a/applications/ChatGPT/examples/train_prompts.py b/applications/ChatGPT/examples/train_prompts.py
deleted file mode 100644
index 8f48a11c33e8..000000000000
--- a/applications/ChatGPT/examples/train_prompts.py
+++ /dev/null
@@ -1,132 +0,0 @@
-import argparse
-from copy import deepcopy
-
-import pandas as pd
-import torch
-from chatgpt.models.base import RewardModel
-from chatgpt.models.bloom import BLOOMActor, BLOOMCritic
-from chatgpt.models.gpt import GPTActor, GPTCritic
-from chatgpt.models.opt import OPTActor, OPTCritic
-from chatgpt.trainer import PPOTrainer
-from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
-from torch.optim import Adam
-from transformers import AutoTokenizer, BloomTokenizerFast
-from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
-
-from colossalai.nn.optimizer import HybridAdam
-
-
-def main(args):
- # configure strategy
- if args.strategy == 'naive':
- strategy = NaiveStrategy()
- elif args.strategy == 'ddp':
- strategy = DDPStrategy()
- elif args.strategy == 'colossalai_gemini':
- strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
- elif args.strategy == 'colossalai_zero2':
- strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
- else:
- raise ValueError(f'Unsupported strategy "{args.strategy}"')
-
- # configure model
- with strategy.model_init_context():
- if args.model == 'gpt2':
- actor = GPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- critic = GPTCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- elif args.model == 'bloom':
- actor = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- critic = BLOOMCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- elif args.model == 'opt':
- actor = OPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- critic = OPTCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- initial_model = deepcopy(actor)
- reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).to(torch.cuda.current_device())
-
- # configure optimizer
- if args.strategy.startswith('colossalai'):
- actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
- critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
- else:
- actor_optim = Adam(actor.parameters(), lr=5e-6)
- critic_optim = Adam(critic.parameters(), lr=5e-6)
-
- # configure tokenizer
- if args.model == 'gpt2':
- tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'bloom':
- tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'opt':
- tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- dataset = pd.read_csv(args.prompt_path)['prompt']
-
- def tokenize_fn(texts):
- # MUST padding to max length to ensure inputs of all ranks have the same length
- # Different length may lead to hang when using gemini, as different generation steps
- batch = tokenizer(texts, return_tensors='pt', max_length=96, padding='max_length', truncation=True)
- return {k: v.cuda() for k, v in batch.items()}
-
- (actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
- (actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
-
- # configure trainer
- trainer = PPOTrainer(
- strategy,
- actor,
- critic,
- reward_model,
- initial_model,
- actor_optim,
- critic_optim,
- max_epochs=args.max_epochs,
- train_batch_size=args.train_batch_size,
- experience_batch_size=args.experience_batch_size,
- tokenizer=tokenize_fn,
- max_length=128,
- do_sample=True,
- temperature=1.0,
- top_k=50,
- pad_token_id=tokenizer.pad_token_id,
- eos_token_id=tokenizer.eos_token_id,
- )
-
- trainer.fit(dataset,
- num_episodes=args.num_episodes,
- max_timesteps=args.max_timesteps,
- update_timesteps=args.update_timesteps)
- # save model checkpoint after fitting
- strategy.save_model(actor, args.save_path, only_rank0=True)
- # save optimizer checkpoint on all ranks
- if args.need_optim_ckpt:
- strategy.save_optimizer(actor_optim,
- 'actor_optim_checkpoint_prompts_%d.pt' % (torch.cuda.current_device()),
- only_rank0=False)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('prompt_path')
- parser.add_argument('--strategy',
- choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
- default='naive')
- parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt'])
- parser.add_argument('--pretrain', type=str, default=None)
- parser.add_argument('--save_path', type=str, default='actor_checkpoint_prompts.pt')
- parser.add_argument('--need_optim_ckpt', type=bool, default=False)
- parser.add_argument('--num_episodes', type=int, default=10)
- parser.add_argument('--max_timesteps', type=int, default=10)
- parser.add_argument('--update_timesteps', type=int, default=10)
- parser.add_argument('--max_epochs', type=int, default=5)
- parser.add_argument('--train_batch_size', type=int, default=8)
- parser.add_argument('--experience_batch_size', type=int, default=8)
- parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
- args = parser.parse_args()
- main(args)
diff --git a/applications/ChatGPT/examples/train_sft.py b/applications/ChatGPT/examples/train_sft.py
deleted file mode 100644
index 83b34f9dd1ea..000000000000
--- a/applications/ChatGPT/examples/train_sft.py
+++ /dev/null
@@ -1,141 +0,0 @@
-import argparse
-
-import loralib as lora
-import torch
-import torch.distributed as dist
-from torch.utils.data.distributed import DistributedSampler
-from chatgpt.dataset import SFTDataset, AlpacaDataset, AlpacaDataCollator
-from chatgpt.models.base import RewardModel
-from chatgpt.models.bloom import BLOOMLM
-from chatgpt.models.gpt import GPTLM
-from chatgpt.models.opt import OPTLM
-from chatgpt.models.llama import LlamaLM
-from chatgpt.trainer import SFTTrainer
-from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
-from chatgpt.utils import prepare_llama_tokenizer_and_embedding
-from datasets import load_dataset
-from torch.optim import Adam
-from torch.utils.data import DataLoader
-from transformers import AutoTokenizer, BloomTokenizerFast
-from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
-
-from colossalai.nn.optimizer import HybridAdam
-from colossalai.logging import get_dist_logger
-
-
-def train(args):
- # configure strategy
- if args.strategy == 'naive':
- strategy = NaiveStrategy()
- elif args.strategy == 'ddp':
- strategy = DDPStrategy()
- elif args.strategy == 'colossalai_gemini':
- strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
- elif args.strategy == 'colossalai_zero2':
- strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
- else:
- raise ValueError(f'Unsupported strategy "{args.strategy}"')
-
- # configure model
- with strategy.model_init_context():
- if args.model == 'bloom':
- model = BLOOMLM(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
- elif args.model == 'opt':
- model = OPTLM(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
- elif args.model == 'gpt2':
- model = GPTLM(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
- elif args.model == 'llama':
- model = LlamaLM(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- # configure tokenizer
- if args.model == 'gpt2':
- tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'bloom':
- tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == 'opt':
- tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
- elif args.model == 'llama':
- tokenizer = AutoTokenizer.from_pretrained(
- args.pretrain,
- padding_side="right",
- use_fast=False,
- )
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- if args.model == 'llama':
- tokenizer = prepare_llama_tokenizer_and_embedding(tokenizer, model)
- else:
- tokenizer.pad_token = tokenizer.eos_token
-
- max_len = 512
-
- # configure optimizer
- if args.strategy.startswith('colossalai'):
- optim = HybridAdam(model.parameters(), lr=5e-5)
- else:
- optim = Adam(model.parameters(), lr=5e-5)
-
- logger = get_dist_logger()
-
- # configure dataset
- if args.dataset == 'yizhongw/self_instruct':
- train_data = load_dataset(args.dataset, 'super_natural_instructions', split='train')
- eval_data = load_dataset(args.dataset, 'super_natural_instructions', split='test')
-
- train_dataset = SFTDataset(train_data, tokenizer, max_len)
- eval_dataset = SFTDataset(eval_data, tokenizer, max_len)
-
- elif 'alpaca' in args.dataset:
- train_dataset = AlpacaDataset(tokenizer=tokenizer, data_path=args.dataset)
- eval_dataset = None
- eval_dataset
- data_collator = AlpacaDataCollator(tokenizer=tokenizer)
-
- if dist.is_initialized() and dist.get_world_size() > 1:
- sampler = DistributedSampler(train_dataset, shuffle=True, seed=42, drop_last=True)
- logger.info("Using Distributed Sampler")
- else:
- sampler = None
-
- train_dataloader = DataLoader(train_dataset, shuffle=(sampler is None), sampler=sampler, batch_size=args.batch_size)
- if eval_dataset is not None:
- eval_dataloader = DataLoader(eval_dataset, batch_size=args.batch_size)
-
- trainer = SFTTrainer(model=model,
- strategy=strategy,
- optim=optim,
- train_dataloader=train_dataloader,
- eval_dataloader=eval_dataloader,
- sampler=sampler,
- batch_size=args.batch_size,
- max_epochs=args.max_epochs)
-
- trainer.fit(logger=logger, use_lora=args.lora_rank, log_interval=args.log_interval)
-
- # save model checkpoint after fitting on only rank0
- strategy.save_model(model, 'sft_checkpoint.pt', only_rank0=True)
- # save optimizer checkpoint on all ranks
- strategy.save_optimizer(optim, 'sft_optim_checkpoint_%d.pt' % (torch.cuda.current_device()), only_rank0=False)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--strategy',
- choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
- default='naive')
- parser.add_argument('--model', choices=['gpt2', 'bloom', 'opt'], default='bloom')
- parser.add_argument('--pretrain', type=str, default=None)
- parser.add_argument('--dataset', type=str, default='yizhongw/self_instruct')
- parser.add_argument('--save_path', type=str, default='sft_ckpt.pth')
- parser.add_argument('--max_epochs', type=int, default=1)
- parser.add_argument('--batch_size', type=int, default=4)
- parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
- parser.add_argument('--log_interval', type=int, default=100, help="how many steps to log")
- args = parser.parse_args()
- train(args)
-
diff --git a/applications/ChatGPT/examples/train_sft.sh b/applications/ChatGPT/examples/train_sft.sh
deleted file mode 100755
index 9f747b24689e..000000000000
--- a/applications/ChatGPT/examples/train_sft.sh
+++ /dev/null
@@ -1,20 +0,0 @@
-set_n_least_used_CUDA_VISIBLE_DEVICES() {
- local n=${1:-"9999"}
- echo "GPU Memory Usage:"
- local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
- | tail -n +2 \
- | nl -v 0 \
- | tee /dev/tty \
- | sort -g -k 2 \
- | awk '{print $1}' \
- | head -n $n)
- export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
- echo "Now CUDA_VISIBLE_DEVICES is set to:"
- echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
-}
-
-set_n_least_used_CUDA_VISIBLE_DEVICES 8
-
-#torchrun --standalone --nproc_per_node=2 train_sft.py --pretrain 'bigscience/bloomz-560m' --model 'bloom' --strategy colossalai_zero2 --log_interval 10
-#torchrun --standalone --nproc_per_node=8 train_sft.py --model 'gpt2' --strategy colossalai_zero2 --batch_size 1 --log_interval 10
-torchrun --standalone --nproc_per_node=2 train_sft.py --pretrain "facebook/opt-350m" --model 'opt' --strategy colossalai_zero2 --log_interval 10
diff --git a/applications/ChatGPT/requirements.txt b/applications/ChatGPT/requirements.txt
deleted file mode 100644
index 3469111925ff..000000000000
--- a/applications/ChatGPT/requirements.txt
+++ /dev/null
@@ -1,7 +0,0 @@
-transformers>=4.20.1
-tqdm
-datasets
-loralib
-colossalai>=0.2.4
-torch==1.12.1
-langchain
diff --git a/applications/ChatGPT/version.txt b/applications/ChatGPT/version.txt
deleted file mode 100644
index 6e8bf73aa550..000000000000
--- a/applications/ChatGPT/version.txt
+++ /dev/null
@@ -1 +0,0 @@
-0.1.0
diff --git a/colossalai/booster/__init__.py b/colossalai/booster/__init__.py
index 3b3f45bb0fe2..841054a9c672 100644
--- a/colossalai/booster/__init__.py
+++ b/colossalai/booster/__init__.py
@@ -1,4 +1,3 @@
from .accelerator import Accelerator
from .booster import Booster
-from .environment_table import EnvironmentTable
from .plugin import Plugin
diff --git a/colossalai/booster/booster.py b/colossalai/booster/booster.py
index 230c65a9e0a1..1ad9f7f20ec1 100644
--- a/colossalai/booster/booster.py
+++ b/colossalai/booster/booster.py
@@ -8,6 +8,8 @@
from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
from torch.utils.data import DataLoader
+from colossalai.checkpoint_io import GeneralCheckpointIO
+
from .accelerator import Accelerator
from .mixed_precision import MixedPrecision, mixed_precision_factory
from .plugin import Plugin
@@ -61,19 +63,21 @@ def __init__(self,
self.plugin = plugin
# set accelerator
- if self.plugin and self.plugin.control_device:
+ if self.plugin and self.plugin.control_device():
self.accelerator = None
warnings.warn('The plugin will control the accelerator, so the device argument will be ignored.')
else:
self.accelerator = Accelerator(device)
# set precision
- if mixed_precision is None or (self.plugin and self.plugin.control_precision):
- self.mixed_precision = None
+ if self.plugin and self.plugin.control_precision():
warnings.warn('The plugin will control the precision, so the mixed_precision argument will be ignored.')
+ self.mixed_precision = None
+ elif mixed_precision is None:
+ self.mixed_precision = None
else:
# validate and set precision
- if isinstance(MixedPrecision, str):
+ if isinstance(mixed_precision, str):
# the user will take the default arguments for amp training
self.mixed_precision = mixed_precision_factory(mixed_precision)
elif isinstance(mixed_precision, MixedPrecision):
@@ -84,6 +88,11 @@ def __init__(self,
f'Expected the argument mixed_precision to be a string or an instance of Precision, but got {type(mixed_precision)}.'
)
+ if self.plugin is not None and self.plugin.control_checkpoint_io():
+ self.checkpoint_io = self.plugin.get_checkpoint_io()
+ else:
+ self.checkpoint_io = GeneralCheckpointIO()
+
def boost(
self,
model: nn.Module,
@@ -109,12 +118,13 @@ def boost(
model, optimizer, criterion, dataloader, lr_scheduler = self.plugin.configure(
model, optimizer, criterion, dataloader, lr_scheduler)
- if self.plugin and not self.plugin.control_device:
+ if self.plugin and not self.plugin.control_device():
# transform model for accelerator
model = self.accelerator.configure(model)
- if self.mixed_precision and self.plugin and not self.plugin.control_precision:
+ if self.mixed_precision and (self.plugin is None or self.plugin and not self.plugin.control_precision()):
# transform model for mixed precision
+ # when mixed_precision is specified and the plugin is not given or does not control the precision
model, optimizer, criterion = self.mixed_precision.configure(model, optimizer, criterion)
return model, optimizer, criterion, dataloader, lr_scheduler
@@ -140,18 +150,25 @@ def no_sync(self, model: nn.Module) -> contextmanager:
assert self.plugin.support_no_sync, f'The plugin {self.plugin.__class__.__name__} does not support no_sync.'
return self.plugin.no_sync(model)
- def save(self,
- obj: Union[nn.Module, Optimizer, LRScheduler],
- path_like: str,
- plan: str = 'torch',
- **kwargs) -> None:
- # TODO: implement this method
- pass
+ def load_model(self, model: nn.Module, checkpoint: str, strict: bool = True):
+ self.checkpoint_io.load_model(model, checkpoint, strict)
- def load(self,
- obj: Union[nn.Module, Optimizer, LRScheduler],
- path_like: str,
- plan: str = 'torch',
- **kwargs) -> None:
- # TODO: implement this method
- pass
+ def save_model(self,
+ model: nn.Module,
+ checkpoint: str,
+ prefix: str = None,
+ shard: bool = False,
+ size_per_shard: int = 1024):
+ self.checkpoint_io.save_model(model, checkpoint, prefix, shard, size_per_shard)
+
+ def load_optimizer(self, optimizer: Optimizer, checkpoint: str):
+ self.checkpoint_io.load_optimizer(optimizer, checkpoint)
+
+ def save_optimizer(self, optimizer: Optimizer, checkpoint: str, shard: bool = False, size_per_shard: int = 1024):
+ self.checkpoint_io.save_optimizer(optimizer, checkpoint, shard, size_per_shard)
+
+ def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ self.checkpoint_io.save_lr_scheduler(lr_scheduler, checkpoint)
+
+ def load_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ self.checkpoint_io.load_lr_scheduler(lr_scheduler, checkpoint)
diff --git a/colossalai/booster/environment_table.py b/colossalai/booster/environment_table.py
deleted file mode 100644
index 4b16f120c1b9..000000000000
--- a/colossalai/booster/environment_table.py
+++ /dev/null
@@ -1,18 +0,0 @@
-from typing import List
-
-__all__ = ['EnvironmentTable']
-
-
-class EnvironmentTable:
-
- def __init__(self, intra_op_world_sizes: List[int]):
- # TODO: implement this method
- pass
-
- @property
- def is_master(self) -> bool:
- # TODO: implement this method
- pass
-
- # TODO: implement more utility methods as given in
- # https://github.com/hpcaitech/ColossalAI/issues/3051
diff --git a/colossalai/booster/interface/__init__.py b/colossalai/booster/interface/__init__.py
deleted file mode 100644
index 8892a13e1814..000000000000
--- a/colossalai/booster/interface/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .optimizer import OptimizerWrapper
-
-__all__ = ['OptimizerWrapper']
diff --git a/colossalai/booster/mixed_precision/fp16_torch.py b/colossalai/booster/mixed_precision/fp16_torch.py
index 054f78d2e226..9999aa5e0eb4 100644
--- a/colossalai/booster/mixed_precision/fp16_torch.py
+++ b/colossalai/booster/mixed_precision/fp16_torch.py
@@ -5,7 +5,8 @@
from torch import Tensor
from torch.optim import Optimizer
-from ..interface import OptimizerWrapper
+from colossalai.interface import ModelWrapper, OptimizerWrapper
+
from .mixed_precision_base import MixedPrecision
__all__ = ['FP16_Torch_MixedPrecision', 'TorchAMPOptimizer', 'TorchAMPModule']
@@ -45,7 +46,9 @@ def backward(self, loss: Tensor, *args, **kwargs) -> None:
scaled_loss.backward(*args, **kwargs)
def step(self, *args, **kwargs) -> Optional[float]:
- return self.scaler.step(self.optim, *args, **kwargs)
+ out = self.scaler.step(self.optim, *args, **kwargs)
+ self.scaler.update()
+ return out
def scale_loss(self, loss: Tensor) -> Tensor:
return self.scaler.scale(loss)
@@ -67,7 +70,7 @@ def clip_grad_by_norm(self,
super().clip_grad_by_norm(max_norm, norm_type, error_if_nonfinite, *args, **kwargs)
-class TorchAMPModule(nn.Module):
+class TorchAMPModule(ModelWrapper):
"""
Module wrapper for mixed precision training in FP16 using PyTorch AMP.
@@ -76,8 +79,7 @@ class TorchAMPModule(nn.Module):
"""
def __init__(self, module: nn.Module):
- super().__init__()
- self.module = module
+ super().__init__(module)
def forward(self, *args, **kwargs):
with torch.cuda.amp.autocast():
diff --git a/colossalai/booster/mixed_precision/mixed_precision_base.py b/colossalai/booster/mixed_precision/mixed_precision_base.py
index d1e8acc82cc6..2490e9811ccf 100644
--- a/colossalai/booster/mixed_precision/mixed_precision_base.py
+++ b/colossalai/booster/mixed_precision/mixed_precision_base.py
@@ -4,7 +4,7 @@
import torch.nn as nn
from torch.optim import Optimizer
-from ..interface import OptimizerWrapper
+from colossalai.interface import OptimizerWrapper
class MixedPrecision(ABC):
diff --git a/colossalai/booster/plugin/plugin_base.py b/colossalai/booster/plugin/plugin_base.py
index 3c347cb4252d..7a222022c1b2 100644
--- a/colossalai/booster/plugin/plugin_base.py
+++ b/colossalai/booster/plugin/plugin_base.py
@@ -6,34 +6,30 @@
from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
from torch.utils.data import DataLoader
-from colossalai.booster.interface import OptimizerWrapper
+from colossalai.checkpoint_io import CheckpointIO
+from colossalai.interface import OptimizerWrapper
__all__ = ['Plugin']
class Plugin(ABC):
- @property
@abstractmethod
def supported_devices(self) -> List[str]:
pass
- @property
@abstractmethod
def supported_precisions(self) -> List[str]:
pass
- @property
@abstractmethod
def control_precision(self) -> bool:
pass
- @property
@abstractmethod
def control_device(self) -> bool:
pass
- @property
@abstractmethod
def support_no_sync(self) -> bool:
pass
@@ -49,3 +45,17 @@ def configure(
) -> Tuple[Union[nn.Module, OptimizerWrapper, LRScheduler, DataLoader]]:
# implement this method
pass
+
+ @abstractmethod
+ def control_checkpoint_io(self) -> bool:
+ """
+ Whether the plugin controls the checkpoint io
+ """
+ pass
+
+ @abstractmethod
+ def get_checkpoint_io(self) -> CheckpointIO:
+ """
+ Get checkpoint io object for this plugin, only invoked when control_checkpoint_io is True.
+ """
+ pass
diff --git a/colossalai/booster/plugin/torch_ddp_plugin.py b/colossalai/booster/plugin/torch_ddp_plugin.py
index 07d6be8c748d..d7f3d22d93cc 100644
--- a/colossalai/booster/plugin/torch_ddp_plugin.py
+++ b/colossalai/booster/plugin/torch_ddp_plugin.py
@@ -11,13 +11,61 @@
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
-from colossalai.booster.interface import OptimizerWrapper
+from colossalai.checkpoint_io import CheckpointIO, GeneralCheckpointIO
+from colossalai.cluster import DistCoordinator
+from colossalai.interface import ModelWrapper, OptimizerWrapper
from .plugin_base import Plugin
__all__ = ['TorchDDPPlugin']
+class TorchDDPCheckpointIO(GeneralCheckpointIO):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.coordinator = DistCoordinator()
+
+ def load_unsharded_model(self, model: nn.Module, checkpoint: str, strict: bool = True):
+ """
+ Load model from checkpoint with automatic unwrapping.
+ """
+ # the model should be unwrapped in self.load_model via ModelWrapper.unwrap
+ return super().load_unsharded_model(model, checkpoint, strict=strict)
+
+ def save_unsharded_model(self, model: nn.Module, checkpoint: str):
+ """
+ Save model to checkpoint but only on master process.
+ """
+ # the model should be unwrapped in self.load_model via ModelWrapper.unwrap
+ if self.coordinator.is_master():
+ super().save_unsharded_model(model, checkpoint)
+
+ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str):
+ """
+ Save optimizer to checkpoint but only on master process.
+ """
+ if self.coordinator.is_master():
+ super().save_unsharded_optimizer(optimizer, checkpoint)
+
+ def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ """
+ Save model to checkpoint but only on master process.
+ """
+ if self.coordinator.is_master():
+ super().save_lr_scheduler(lr_scheduler, checkpoint)
+
+
+class TorchDDPModel(ModelWrapper):
+
+ def __init__(self, module: nn.Module, *args, **kwargs) -> None:
+ super().__init__(module)
+ self.module = DDP(module, *args, **kwargs)
+
+ def unwrap(self):
+ return self.module.module
+
+
class TorchDDPPlugin(Plugin):
"""
Plugin for PyTorch DDP.
@@ -138,10 +186,19 @@ def configure(
# cast model to cuda
model = model.cuda()
+ # convert model to sync bn
+ model = nn.SyncBatchNorm.convert_sync_batchnorm(model, None)
+
# wrap the model with PyTorch DDP
- model = DDP(model, **self.ddp_kwargs)
+ model = TorchDDPModel(model, **self.ddp_kwargs)
if not isinstance(optimizer, OptimizerWrapper):
optimizer = OptimizerWrapper(optimizer)
return model, optimizer, criterion, dataloader, lr_scheduler
+
+ def control_checkpoint_io(self) -> bool:
+ return True
+
+ def get_checkpoint_io(self) -> CheckpointIO:
+ return TorchDDPCheckpointIO()
diff --git a/colossalai/checkpoint_io/checkpoint_io_base.py b/colossalai/checkpoint_io/checkpoint_io_base.py
index 00a65424bece..d6eef7a96cdc 100644
--- a/colossalai/checkpoint_io/checkpoint_io_base.py
+++ b/colossalai/checkpoint_io/checkpoint_io_base.py
@@ -1,13 +1,15 @@
import json
from abc import ABC, abstractmethod
from pathlib import Path
-from typing import Any
+from typing import Any, Union
import torch
import torch.nn as nn
from torch.optim import Optimizer
from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
+from colossalai.interface import ModelWrapper
+
__all__ = ['CheckpointIO', 'ShardCheckpointIndexFile']
@@ -37,15 +39,15 @@ class CheckpointIO(ABC):
>>>
>>> # save optimizer to checkpoint
>>> checkpoint_io.save_optimizer(optimizer, 'optimizer.pt')
-
"""
# ======================================
- # Abstract methods for implementation
+ # Public methods
# ======================================
-
- @abstractmethod
- def load_model(self, model: nn.Module, checkpoint: str, strict: bool = True):
+ def load_model(self,
+ model: Union[nn.Module, ModelWrapper],
+ checkpoint: str,
+ strict: bool = True) -> Union[nn.Module, ModelWrapper]:
"""
Load model from checkpoint.
@@ -59,14 +61,26 @@ def load_model(self, model: nn.Module, checkpoint: str, strict: bool = True):
strict (bool): whether to strictly enforce that the param name in
the checkpoint match the keys returned by this module's.
"""
- pass
+ ckpt_path = Path(checkpoint)
+ is_sharded = self.is_sharded_checkpoint(ckpt_path)
+
+ origin_model = model
+
+ if isinstance(model, ModelWrapper):
+ model = model.unwrap()
+
+ if is_sharded:
+ self.load_sharded_model(model, ckpt_path, strict)
+ else:
+ self.load_unsharded_model(model, ckpt_path, strict)
+
+ return origin_model
- @abstractmethod
def save_model(self,
- model: nn.Module,
+ model: Union[nn.Module, ModelWrapper],
checkpoint: str,
- prefix: str = None,
shard: bool = False,
+ prefix: str = None,
size_per_shard: int = 1024):
"""
Save model to checkpoint.
@@ -83,17 +97,24 @@ def save_model(self,
Args:
model (nn.Module): model to be saved.
- checkpoint: checkpoint path. The checkpoint path can be :
+ checkpoint (str): checkpoint path. The checkpoint path can be :
1. a file path, e.g. 'model.pt'
2. a directory path to save the sharded checkpoint, e.g. './checkpoints/' when shard = True.
- shard: whether to shard the checkpoint. Default: False. If set to True, the checkpoint will be sharded into
+ shard (bool): whether to shard the checkpoint. Default: False. If set to True, the checkpoint will be sharded into
multiple files. The model shards will be specificed by a `model.index.json` file. When shard = True, please ensure
that the checkpoint path is a directory path instead of a file path.
- size_per_shard (int): size per shard in MB. Default: 1024. This value is only used when shard is set to True.
+ prefix (str): prefix for the model checkpoint file name when shard=True. Default: None.
+ size_per_shard (int): size per shard in MB. Default: 1024. This value is only used when shard = True.
"""
- pass
- @abstractmethod
+ if isinstance(model, ModelWrapper):
+ model = model.unwrap()
+
+ if shard:
+ self.save_sharded_model(model, checkpoint, prefix, size_per_shard)
+ else:
+ self.save_unsharded_model(model, checkpoint)
+
def load_optimizer(self, optimizer: Optimizer, checkpoint: str):
"""
Load optimizer from checkpoint.
@@ -102,19 +123,139 @@ def load_optimizer(self, optimizer: Optimizer, checkpoint: str):
optimizer (Optimizer): optimizer to be loaded.
checkpoint (str): checkpoint path. This value is made compatiblity with the model checkpoints in the
"""
- pass
+ ckpt_path = Path(checkpoint)
+ is_sharded = self.is_sharded_checkpoint(ckpt_path)
- @abstractmethod
- def save_optimizer(self, optimizer: Optimizer, checkpoint: str, shard: bool = False, size_per_shard: int = 1024):
+ if is_sharded:
+ self.load_sharded_optimizer(optimizer, ckpt_path)
+ else:
+ self.load_unsharded_optimizer(optimizer, ckpt_path)
+
+ def save_optimizer(self,
+ optimizer: Optimizer,
+ checkpoint: str,
+ shard: bool = False,
+ prefix: str = None,
+ size_per_shard: int = 1024):
"""
Save optimizer to checkpoint.
Args:
optimizer (Optimizer): optimizer to be saved.
- checkpoint: checkpoint path. The checkpoint path can be :
+ checkpoint (str): checkpoint path. The checkpoint path can be :
1. a file path, e.g. 'model.pt'
2. a path to a json file which defines the index to the sharded checkpoint for the optimizer
3. a path to a folder containing a unique .index.json file for sharded checkpoint
+ shard (bool): whether to shard the checkpoint. Default: False. If set to True, the checkpoint will be sharded into
+ multiple files. The optimizer shards will be specificed by a `optimizer.index.json` file.
+ prefix (str): prefix for the optimizer checkpoint when shard = True. Default: None.
+ size_per_shard (int): size per shard in MB. Default: 1024. This value is only used when shard is set to True.
+ """
+ if shard:
+ self.save_sharded_optimizer(optimizer, checkpoint, prefix, size_per_shard)
+ else:
+ self.save_unsharded_optimizer(optimizer, checkpoint)
+
+ # ========================================================
+ # Abstract methods for model loading/saving implementation
+ # ========================================================
+ @abstractmethod
+ def load_sharded_model(self, model: nn.Module, checkpoint: Path, strict: bool):
+ """
+ Load model from sharded checkpoint.
+
+ Args:
+ model (nn.Module): model to be loaded.
+ checkpoint (str): checkpoint path. It should be path to the .index.json file or a path to a directory which contains a .index.json file.
+ """
+ pass
+
+ @abstractmethod
+ def load_unsharded_model(self, model: nn.Module, checkpoint: Path, strict: bool):
+ """
+ Load model from unsharded checkpoint.
+
+ Args:
+ model (nn.Module): model to be loaded.
+ checkpoint (str): checkpoint path. It should be a single file path pointing to a model weight binary.
+ strict (bool): whether to strictly enforce that the param name in
+ the checkpoint match the keys returned by this module's.
+ """
+ pass
+
+ @abstractmethod
+ def save_sharded_model(self, model: nn.Module, checkpoint: Path, prefix: str, size_per_shard: int):
+ """
+ Save model to sharded checkpoint.
+
+ Args:
+ model (nn.Module): model to be saved.
+ checkpoint (Path): checkpoint path. It should be a directory path.
+ prefix (str): prefix for the model checkpoint.
+ size_per_shard (int): size per shard in MB.
+ """
+ pass
+
+ @abstractmethod
+ def save_unsharded_model(self, model: nn.Module, checkpoint: Path):
+ """
+ Save model to unsharded checkpoint.
+
+ Args:
+ model (nn.Module): model to be saved.
+ checkpoint (Path): checkpoint path. It should be a single file path pointing to a model weight binary.
+ """
+ pass
+
+ # ========================================================
+ # Abstract methods for optimizer loading/saving implementation
+ # ========================================================
+
+ @abstractmethod
+ def load_sharded_optimizer(self, optimizer: Optimizer, checkpoint: Path, prefix: str, size_per_shard: int):
+ """
+ Load optimizer from sharded checkpoint.
+
+ Args:
+ optimizer (Optimizer): optimizer to be loaded.
+ checkpoint (str): checkpoint path. It should be path to the .index.json file or a path to a directory which contains a .index.json file.
+ prefix (str): prefix for the optimizer checkpoint.
+ size_per_shard (int): size per shard in MB.
+ """
+ pass
+
+ @abstractmethod
+ def load_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: Path):
+ """
+ Load optimizer from unsharded checkpoint.
+
+ Args:
+ optimizer (Optimizer): optimizer to be loaded.
+ checkpoint (str): checkpoint path. It should be a single file path pointing to a model weight binary.
+ """
+ pass
+
+ @abstractmethod
+ def save_sharded_optimizer(self, optimizer: Optimizer, checkpoint: Path, prefix: str, size_per_shard: int):
+ """
+ Save optimizer to sharded checkpoint.
+
+ Args:
+ optimizer (Optimizer): optimizer to be saved.
+ checkpoint (Path): checkpoint path. It should be a directory path.
+ prefix (str): prefix for the optimizer checkpoint.
+ size_per_shard (int): size per shard in MB.
+ """
+ pass
+
+ @abstractmethod
+ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: Path):
+ """
+ Save optimizer to unsharded checkpoint.
+
+ Args:
+ optimizer (Optimizer): optimizer to be saved.
+ checkpoint (str): checkpoint path. It should be a single file path pointing to a model weight binary.
"""
pass
diff --git a/colossalai/checkpoint_io/general_checkpoint_io.py b/colossalai/checkpoint_io/general_checkpoint_io.py
index 0a3636655530..cfabcfa5589f 100644
--- a/colossalai/checkpoint_io/general_checkpoint_io.py
+++ b/colossalai/checkpoint_io/general_checkpoint_io.py
@@ -10,57 +10,36 @@
class GeneralCheckpointIO(CheckpointIO):
- def load_model(self, model: nn.Module, checkpoint: str, strict: bool = True):
- checkpoint = Path(checkpoint)
- is_sharded = self.is_sharded_checkpoint(checkpoint)
+ def load_sharded_model(self, model: nn.Module, checkpoint: Path, strict: bool):
+ index_file_path = self.get_sharded_checkpoint_index_file(checkpoint)
- if not is_sharded:
- checkpoint = self.load_state_dict(checkpoint)
- model.load_state_dict(checkpoint, strict=strict)
- else:
- # find the index file
- checkpoint_path = Path(checkpoint)
- index_file_path = self.get_sharded_checkpoint_index_file(checkpoint_path)
+ # iterate over the shard checkpoint files
+ # and load each
+ shard_files = self.get_checkpoint_shard_filenames(index_file_path)
+ for shard_file in shard_files:
+ shard_checkpoint = self.load_state_dict(shard_file)
+ model.load_state_dict(shard_checkpoint, strict=strict)
- # iterate over the shard checkpoint files
- # and load each
- shard_files = self.get_checkpoint_shard_filenames(index_file_path)
- for shard_file in shard_files:
- shard_checkpoint = self.load_state_dict(shard_file)
- model.load_state_dict(shard_checkpoint, strict=strict)
+ def load_unsharded_model(self, model: nn.Module, checkpoint: Path, strict: bool):
+ checkpoint = self.load_state_dict(str(checkpoint))
+ model.load_state_dict(checkpoint, strict=strict)
- return model
+ def save_sharded_model(self, model: nn.Module, checkpoint: Path, prefix: str, size_per_shard: int):
+ # TODO(FrankLeeeee): implement this method as it can be supported by Huggingface model
+ raise NotImplementedError("Sharded model checkpoint is not supported yet.")
- def save_model(self,
- model: nn.Module,
- checkpoint: str,
- prefix: str = None,
- shard: bool = False,
- size_per_shard: int = 1024):
- checkpoint = Path(checkpoint)
- if shard:
- # TODO(FrankLeeeee): implement checkpoint saving to sharded checkpoint
- raise NotImplementedError("Not implemented yet")
- else:
- self.save_checkpoint(model.state_dict(), checkpoint)
+ def save_unsharded_model(self, model: nn.Module, checkpoint: Path):
+ self.save_checkpoint(model.state_dict(), checkpoint)
- def load_optimizer(self, optimizer: Optimizer, checkpoint: str):
- checkpoint = Path(checkpoint)
- is_sharded = self.is_sharded_checkpoint(checkpoint)
+ def load_sharded_optimizer(self, optimizer: Optimizer, checkpoint: Path, prefix: str, size_per_shard: int):
+ raise NotImplementedError("Sharded optimizer checkpoint is not supported yet.")
- if not is_sharded:
- checkpoint = self.load_state_dict(checkpoint)
- optimizer.load_state_dict(checkpoint)
- else:
- # TODO(FrankLeeeee): implement checkpoint loading from sharded checkpoint
- # This is not an urgent feature, so we can leave it for later
- # let's implement this when we test large-scale models
- pass
- return optimizer
+ def load_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: Path):
+ checkpoint = self.load_state_dict(checkpoint)
+ optimizer.load_state_dict(checkpoint)
- def save_optimizer(self, optimizer: Optimizer, checkpoint: str, shard: bool = False, size_per_shard: int = 1024):
- if shard:
- # TODO(FrankLeeeee): implement checkpoint saving to sharded checkpoint
- pass
- else:
- self.save_checkpoint(optimizer.state_dict(), checkpoint)
+ def save_sharded_optimizer(self, optimizer: Optimizer, checkpoint: Path, prefix: str, size_per_shard: int):
+ raise NotImplementedError("Sharded optimizer checkpoint is not supported yet.")
+
+ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: Path):
+ self.save_checkpoint(optimizer.state_dict(), checkpoint)
diff --git a/colossalai/cluster/device_mesh_manager.py b/colossalai/cluster/device_mesh_manager.py
index 744799182e22..8754baa19792 100644
--- a/colossalai/cluster/device_mesh_manager.py
+++ b/colossalai/cluster/device_mesh_manager.py
@@ -1,36 +1,117 @@
+from dataclasses import dataclass
+from typing import Dict, List, Tuple, Union
+
+import torch
+import torch.distributed as dist
+
+from colossalai.device.alpha_beta_profiler import AlphaBetaProfiler
from colossalai.device.device_mesh import DeviceMesh
+@dataclass
+class DeviceMeshInfo:
+ '''
+ This class is used to store the information used to initialize the device mesh.
+
+ Args:
+ physical_ids (List[int]): The physical ids of the current booster. For example, if we have the last 4 GPUs on a 8-devices cluster, then the physical ids should be [4, 5, 6, 7].
+ mesh_shapes (List[Union[torch.Size, List[int], Tuple[int]]]): The shape of the mesh. For example, if we have 4 GPUs and we want to use 2D mesh with mesh shape [2, 2], then the mesh shape should be [2, 2].
+ '''
+ physical_ids: List[int]
+ mesh_shape: Union[torch.Size, List[int], Tuple[int]] = None
+
+ def __post_init__(self):
+ if self.mesh_shape is not None:
+ world_size = len(self.physical_ids)
+ mesh_shape_numel = torch.Size(self.mesh_shape).numel()
+ assert world_size == mesh_shape_numel, f'the numel of mesh_shape should be equal to world size, but got {world_size} != {mesh_shape_numel}'
+
+
+def initialize_device_mesh(device_mesh_info: DeviceMeshInfo):
+ '''
+ This method is used to initialize the device mesh.
+
+ Args:
+ device_mesh_info (DeviceMeshInfo): The information used to initialize device mesh.
+ '''
+ # parse the device mesh info
+ physical_devices = device_mesh_info.physical_ids
+ physical_mesh = torch.tensor(physical_devices)
+ logical_mesh_shape = device_mesh_info.mesh_shape
+
+ if logical_mesh_shape is None:
+ ab_profiler = AlphaBetaProfiler(physical_devices)
+ # search for the best logical mesh shape
+ logical_mesh_id = ab_profiler.search_best_logical_mesh()
+ logical_mesh_id = torch.Tensor(logical_mesh_id).to(torch.int)
+
+ else:
+ logical_mesh_id = physical_mesh.reshape(logical_mesh_shape)
+
+ device_mesh = DeviceMesh(physical_mesh_id=physical_mesh, logical_mesh_id=logical_mesh_id, init_process_group=True)
+ return device_mesh
+
+
class DeviceMeshManager:
"""
Device mesh manager is responsible for creating and managing device meshes.
"""
def __init__(self):
- self.device_mesh_store = dict()
+ self.device_mesh_store: Dict[str, DeviceMesh] = dict()
- def create_device_mesh(self, name, *args, **kwargs) -> DeviceMesh:
+ def create_device_mesh(self, name, device_mesh_info: DeviceMeshInfo) -> DeviceMesh:
"""
Create a device mesh and store it in the manager.
Args:
name (str): name of the device mesh
- *args: args for DeviceMesh
- **kwargs: kwargs for DeviceMesh
- """
- # TODO(Yuliang): replace *args, **kwargs with explicit arguments
+ device_mesh_info (DeviceMeshInfo): the information used to initialize the device mesh
+ """
if name not in self.device_mesh_store:
- device_mesh = DeviceMesh(*args, **kwargs)
+ device_mesh = initialize_device_mesh(device_mesh_info)
self.device_mesh_store[name] = device_mesh
return device_mesh
else:
raise ValueError(f'Device mesh {name} already exists.')
def get(self, name: str) -> DeviceMesh:
- pass
+ """
+ Get a device mesh by name.
- def destroy(self):
- pass
+ Args:
+ name (str): name of the device mesh
+
+ Returns:
+ DeviceMesh: the device mesh
+ """
+ if name in self.device_mesh_store:
+ return self.device_mesh_store[name]
+ else:
+ raise ValueError(f'Device mesh {name} does not exist.')
+
+ def destroy(self, name: str) -> None:
+ """
+ Destroy a device mesh by name.
+
+ Args:
+ name (str): name of the device mesh
+ """
+ if name in self.device_mesh_store:
+ for pgs in self.device_mesh_store[name].process_groups_dict.values():
+ for pg in pgs:
+ dist.destroy_process_group(pg)
+ del self.device_mesh_store[name]
+ else:
+ raise ValueError(f'Device mesh {name} does not exist.')
def destroy_all(self):
- pass
+ """
+ Destroy all device meshes.
+ """
+ for name in self.device_mesh_store:
+ for pgs in self.device_mesh_store[name].process_groups_dict.values():
+ for pg in pgs:
+ dist.destroy_process_group(pg)
+
+ self.device_mesh_store.clear()
diff --git a/colossalai/cluster/dist_coordinator.py b/colossalai/cluster/dist_coordinator.py
index 6b48faf5b720..99dde810e112 100644
--- a/colossalai/cluster/dist_coordinator.py
+++ b/colossalai/cluster/dist_coordinator.py
@@ -1,3 +1,4 @@
+import functools
import os
from contextlib import contextmanager
@@ -141,12 +142,12 @@ def priority_execution(self, executor_rank: int = 0, process_group: ProcessGroup
should_block = rank != executor_rank
if should_block:
- dist.barrier(group=process_group)
+ self.block_all(process_group)
yield
if not should_block:
- dist.barrier(group=process_group)
+ self.block_all(process_group)
def destroy(self, process_group: ProcessGroup = None):
"""
@@ -156,3 +157,38 @@ def destroy(self, process_group: ProcessGroup = None):
process_group (ProcessGroup, optional): process group to destroy. Defaults to None, which refers to the default process group.
"""
dist.destroy_process_group(process_group)
+
+ def block_all(self, process_group: ProcessGroup = None):
+ """
+ Block all processes in the process group.
+
+ Args:
+ process_group (ProcessGroup, optional): process group to block. Defaults to None, which refers to the default process group.
+ """
+ dist.barrier(group=process_group)
+
+ def on_master_only(self, process_group: ProcessGroup = None):
+ """
+ A function wrapper that only executes the wrapped function on the master process (rank 0).
+
+ Example:
+ >>> from colossalai.cluster import DistCoordinator
+ >>> dist_coordinator = DistCoordinator()
+ >>>
+ >>> @dist_coordinator.on_master_only()
+ >>> def print_on_master(msg):
+ >>> print(msg)
+ """
+ is_master = self.is_master(process_group)
+
+ # define an inner functiuon
+ def decorator(func):
+
+ @functools.wraps(func)
+ def wrapper(*args, **kwargs):
+ if is_master:
+ return func(*args, **kwargs)
+
+ return wrapper
+
+ return decorator
diff --git a/colossalai/fx/_compatibility.py b/colossalai/fx/_compatibility.py
index 126403270301..6caad920d2ae 100644
--- a/colossalai/fx/_compatibility.py
+++ b/colossalai/fx/_compatibility.py
@@ -2,11 +2,21 @@
import torch
-try:
- from . import _meta_registrations
- META_COMPATIBILITY = True
-except:
+TORCH_MAJOR = int(torch.__version__.split('.')[0])
+TORCH_MINOR = int(torch.__version__.split('.')[1])
+
+if TORCH_MAJOR == 1 and TORCH_MINOR < 12:
META_COMPATIBILITY = False
+elif TORCH_MAJOR == 1 and TORCH_MINOR == 12:
+ from . import _meta_regist_12
+ META_COMPATIBILITY = True
+elif TORCH_MAJOR == 1 and TORCH_MINOR == 13:
+ from . import _meta_regist_13
+ META_COMPATIBILITY = True
+elif TORCH_MAJOR == 2:
+ from . import _meta_regist_13
+ META_COMPATIBILITY = True
+ raise UserWarning("Colossalai is not tested with torch2.0 yet!!!")
def compatibility(is_backward_compatible: bool = False) -> Callable:
diff --git a/colossalai/fx/_meta_registrations.py b/colossalai/fx/_meta_regist_12.py
similarity index 100%
rename from colossalai/fx/_meta_registrations.py
rename to colossalai/fx/_meta_regist_12.py
diff --git a/colossalai/fx/_meta_regist_13.py b/colossalai/fx/_meta_regist_13.py
new file mode 100644
index 000000000000..6caa87c449ab
--- /dev/null
+++ b/colossalai/fx/_meta_regist_13.py
@@ -0,0 +1,57 @@
+import torch
+from torch._meta_registrations import register_meta
+from torch._prims_common import check
+
+aten = torch.ops.aten
+
+
+# since we fix the torch version to 1.13.1, we have to add unimplemented meta ops
+# all these functions are from here https://github.com/pytorch/pytorch/blob/master/torch/_meta_registrations.py
+@register_meta([aten.convolution_backward.default])
+def meta_convolution_backward(
+ grad_output_,
+ input_,
+ weight_,
+ bias_sizes_opt,
+ stride,
+ padding,
+ dilation,
+ transposed,
+ output_padding,
+ groups,
+ output_mask,
+):
+ # High level logic taken from slow_conv3d_backward_cpu which should
+ # be representative of all convolution_backward impls
+ backend_grad_input = None
+ backend_grad_weight = None
+ backend_grad_bias = None
+
+ if output_mask[0]:
+ backend_grad_input = grad_output_.new_empty(input_.size())
+ if output_mask[1]:
+ backend_grad_weight = grad_output_.new_empty(weight_.size())
+ if output_mask[2]:
+ backend_grad_bias = grad_output_.new_empty(bias_sizes_opt)
+
+ return (backend_grad_input, backend_grad_weight, backend_grad_bias)
+
+
+@register_meta(aten._adaptive_avg_pool2d_backward.default)
+def meta__adaptive_avg_pool2d_backward(grad_out, self):
+ ndim = grad_out.ndim
+ for i in range(1, ndim):
+ check(
+ grad_out.size(i) > 0,
+ lambda: f"adaptive_avg_pool2d_backward(): Expected grad_output to have non-zero \
+ size for non-batch dimensions, {grad_out.shape} with dimension {i} being empty",
+ )
+ check(
+ ndim == 3 or ndim == 4,
+ lambda: f"adaptive_avg_pool2d_backward(): Expected 3D or 4D tensor, but got {self.shape}",
+ )
+ check(
+ self.dtype == grad_out.dtype,
+ lambda: f"expected dtype {self.dtype} for `grad_output` but got dtype {grad_out.dtype}",
+ )
+ return self.new_empty(self.shape)
diff --git a/colossalai/gemini/chunk/manager.py b/colossalai/gemini/chunk/manager.py
index 30ac4d354647..2fa65c970316 100644
--- a/colossalai/gemini/chunk/manager.py
+++ b/colossalai/gemini/chunk/manager.py
@@ -72,7 +72,7 @@ def register_tensor(self,
if tensor.numel() > chunk_size:
chunk_size = tensor.numel()
- dp_size = tensor.process_group.dp_world_size()
+ dp_size = tensor.get_dp_world_size()
chunk_size = chunk_size + (-chunk_size % dp_size)
chunk = Chunk(
diff --git a/colossalai/interface/__init__.py b/colossalai/interface/__init__.py
new file mode 100644
index 000000000000..8c658e375146
--- /dev/null
+++ b/colossalai/interface/__init__.py
@@ -0,0 +1,4 @@
+from .model import ModelWrapper
+from .optimizer import OptimizerWrapper
+
+__all__ = ['OptimizerWrapper', 'ModelWrapper']
diff --git a/colossalai/interface/model.py b/colossalai/interface/model.py
new file mode 100644
index 000000000000..a067d7671ce7
--- /dev/null
+++ b/colossalai/interface/model.py
@@ -0,0 +1,25 @@
+import torch.nn as nn
+
+
+class ModelWrapper(nn.Module):
+ """
+ A wrapper class to define the common interface used by booster.
+
+ Args:
+ module (nn.Module): The model to be wrapped.
+ """
+
+ def __init__(self, module: nn.Module) -> None:
+ super().__init__()
+ self.module = module
+
+ def unwrap(self):
+ """
+ Unwrap the model to return the original model for checkpoint saving/loading.
+ """
+ if isinstance(self.module, ModelWrapper):
+ return self.module.unwrap()
+ return self.module
+
+ def forward(self, *args, **kwargs):
+ return self.module(*args, **kwargs)
diff --git a/colossalai/booster/interface/optimizer.py b/colossalai/interface/optimizer.py
similarity index 100%
rename from colossalai/booster/interface/optimizer.py
rename to colossalai/interface/optimizer.py
diff --git a/colossalai/tensor/colo_tensor.py b/colossalai/tensor/colo_tensor.py
index bbed8847abbc..40eefc3ec5d1 100644
--- a/colossalai/tensor/colo_tensor.py
+++ b/colossalai/tensor/colo_tensor.py
@@ -138,6 +138,15 @@ def set_process_group(self, pg: ProcessGroup):
def get_tp_world_size(self) -> int:
return self.process_group.tp_world_size()
+ def get_dp_world_size(self) -> int:
+ """get_dp_world_size
+ get the dp world size of the tensor.
+
+ Returns:
+ int: dp world size
+ """
+ return self.process_group.dp_world_size()
+
def set_dist_spec(self, dist_spec: _DistSpec):
"""set_dist_spec
set dist spec and change the payloads.
diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md
index 81c45abfd833..4be923eca024 100644
--- a/docs/README-zh-Hans.md
+++ b/docs/README-zh-Hans.md
@@ -66,7 +66,7 @@
Colossal-AI 成功案例
@@ -212,22 +212,30 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
(返回顶端)
## Colossal-AI 成功案例
-### ChatGPT
-低成本复现[ChatGPT](https://openai.com/blog/chatgpt/)完整流程 [[代码]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/ChatGPT) [[博客]](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
-
+### ColossalChat
+
+
+
+[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): 完整RLHF流程0门槛克隆 [ChatGPT](https://openai.com/blog/chatgpt/) [[代码]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) [[博客]](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt) [[在线样例]](https://chat.colossalai.org)
+
+
- 最高可提升单机训练速度7.73倍,单卡推理速度1.42倍
-
+
- 单卡模型容量最多提升10.3倍
- 最小demo训练流程最低仅需1.62GB显存 (任意消费级GPU)
-
+
diff --git a/examples/images/diffusion/README.md b/examples/images/diffusion/README.md
index a70792b9f4a4..3f9690500130 100644
--- a/examples/images/diffusion/README.md
+++ b/examples/images/diffusion/README.md
@@ -47,40 +47,21 @@ conda env create -f environment.yaml
conda activate ldm
```
-You can also update an existing [latent diffusion](https://github.com/CompVis/latent-diffusion) environment by running
+You can also update an existing [latent diffusion](https://github.com/CompVis/latent-diffusion) environment by running:
```
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pip install transformers diffusers invisible-watermark
```
-#### Step 2: install lightning
-
-Install Lightning version later than 2022.01.04. We suggest you install lightning from source. Notice that the default download path of pip should be within the conda environment, or you may need to specify using 'which pip' and redirect the path into conda environment.
-
-##### From Source
-```
-git clone https://github.com/Lightning-AI/lightning.git
-pip install -r requirements.txt
-python setup.py install
-```
-
-##### From pip
-
-```
-pip install pytorch-lightning
-```
-
-#### Step 3:Install [Colossal-AI](https://colossalai.org/download/) From Our Official Website
+#### Step 2:Install [Colossal-AI](https://colossalai.org/download/) From Our Official Website
You can install the latest version (0.2.7) from our official website or from source. Notice that the suitable version for this training is colossalai(0.2.5), which stands for torch(1.12.1).
##### Download suggested verision for this training
```
-
pip install colossalai==0.2.5
-
```
##### Download the latest version from pip for latest torch version
@@ -89,7 +70,7 @@ pip install colossalai==0.2.5
pip install colossalai
```
-##### From source
+##### From source:
```
git clone https://github.com/hpcaitech/ColossalAI.git
@@ -99,7 +80,7 @@ cd ColossalAI
CUDA_EXT=1 pip install .
```
-#### Step 4:Accelerate with flash attention by xformers(Optional)
+#### Step 3:Accelerate with flash attention by xformers(Optional)
Notice that xformers will accelerate the training process in cost of extra disk space. The suitable version of xformers for this training process is 0.12.0. You can download xformers directly via pip. For more release versions, feel free to check its official website: [XFormers](./https://pypi.org/project/xformers/)
@@ -113,7 +94,7 @@ To use the stable diffusion Docker image, you can either build using the provide
```
# 1. build from dockerfile
-cd docker
+cd ColossalAI/examples/images/diffusion/docker
docker build -t hpcaitech/diffusion:0.2.0 .
# 2. pull from our docker hub
@@ -127,7 +108,7 @@ Once you have the image ready, you can launch the image with the following comma
# On Your Host Machine #
########################
# make sure you start your image in the repository root directory
-cd Colossal-AI
+cd ColossalAI
# run the docker container
docker run --rm \
@@ -144,13 +125,15 @@ docker run --rm \
# Once you have entered the docker container, go to the stable diffusion directory for training
cd examples/images/diffusion/
+# Download the model checkpoint from pretrained (See the following steps)
+# Set up your configuration the "train_colossalai.sh" (See the following steps)
# start training with colossalai
bash train_colossalai.sh
```
It is important for you to configure your volume mapping in order to get the best training experience.
-1. **Mandatory**, mount your prepared data to `/data/scratch` via `-v :/data/scratch`, where you need to replace `` with the actual data path on your machine.
-2. **Recommended**, store the downloaded model weights to your host machine instead of the container directory via `-v :/root/.cache/huggingface`, where you need to repliace the `` with the actual path. In this way, you don't have to repeatedly download the pretrained weights for every `docker run`.
+1. **Mandatory**, mount your prepared data to `/data/scratch` via `-v :/data/scratch`, where you need to replace `` with the actual data path on your machine. Notice that within docker we need to transform Win expresison into Linuxd, e.g. C:\User\Desktop into /c/User/Desktop.
+2. **Recommended**, store the downloaded model weights to your host machine instead of the container directory via `-v :/root/.cache/huggingface`, where you need to replace the `` with the actual path. In this way, you don't have to repeatedly download the pretrained weights for every `docker run`.
3. **Optional**, if you encounter any problem stating that shared memory is insufficient inside container, please add `-v /dev/shm:/dev/shm` to your `docker run` command.
diff --git a/examples/images/diffusion/ldm/data/lsun.py b/examples/images/diffusion/ldm/data/lsun.py
index 6256e45715ff..f5bf26c14254 100644
--- a/examples/images/diffusion/ldm/data/lsun.py
+++ b/examples/images/diffusion/ldm/data/lsun.py
@@ -5,87 +5,105 @@
from torch.utils.data import Dataset
from torchvision import transforms
-
+# This class is used to create a dataset of images from LSUN dataset for training
class LSUNBase(Dataset):
def __init__(self,
- txt_file,
- data_root,
- size=None,
- interpolation="bicubic",
- flip_p=0.5
+ txt_file, # path to the text file containing the list of image paths
+ data_root, # root directory of the LSUN dataset
+ size=None, # the size of images to resize to
+ interpolation="bicubic", # interpolation method to be used while resizing
+ flip_p=0.5 # probability of random horizontal flipping
):
- self.data_paths = txt_file
- self.data_root = data_root
- with open(self.data_paths, "r") as f:
- self.image_paths = f.read().splitlines()
- self._length = len(self.image_paths)
+ self.data_paths = txt_file # store path to text file containing list of images
+ self.data_root = data_root # store path to root directory of the dataset
+ with open(self.data_paths, "r") as f: # open and read the text file
+ self.image_paths = f.read().splitlines() # read the lines of the file and store as list
+ self._length = len(self.image_paths) # store the number of images
+
+ # create dictionary to hold image path information
self.labels = {
"relative_file_path_": [l for l in self.image_paths],
"file_path_": [os.path.join(self.data_root, l)
for l in self.image_paths],
}
- self.size = size
+ # set the image size to be resized
+ self.size = size
+ # set the interpolation method for resizing the image
self.interpolation = {"linear": PIL.Image.LINEAR,
"bilinear": PIL.Image.BILINEAR,
"bicubic": PIL.Image.BICUBIC,
"lanczos": PIL.Image.LANCZOS,
}[interpolation]
+ # randomly flip the image horizontally with a given probability
self.flip = transforms.RandomHorizontalFlip(p=flip_p)
def __len__(self):
+ # return the length of dataset
return self._length
+
def __getitem__(self, i):
+ # get the image path for the given index
example = dict((k, self.labels[k][i]) for k in self.labels)
image = Image.open(example["file_path_"])
+ # convert it to RGB format
if not image.mode == "RGB":
image = image.convert("RGB")
# default to score-sde preprocessing
- img = np.array(image).astype(np.uint8)
- crop = min(img.shape[0], img.shape[1])
- h, w, = img.shape[0], img.shape[1]
+
+ img = np.array(image).astype(np.uint8) # convert image to numpy array
+ crop = min(img.shape[0], img.shape[1]) # crop the image to a square shape
+ h, w, = img.shape[0], img.shape[1] # get the height and width of image
img = img[(h - crop) // 2:(h + crop) // 2,
- (w - crop) // 2:(w + crop) // 2]
+ (w - crop) // 2:(w + crop) // 2] # crop the image to a square shape
- image = Image.fromarray(img)
- if self.size is not None:
+ image = Image.fromarray(img) # create an image from numpy array
+ if self.size is not None: # if image size is provided, resize the image
image = image.resize((self.size, self.size), resample=self.interpolation)
- image = self.flip(image)
- image = np.array(image).astype(np.uint8)
- example["image"] = (image / 127.5 - 1.0).astype(np.float32)
- return example
-
+ image = self.flip(image) # flip the image horizontally with the given probability
+ image = np.array(image).astype(np.uint8)
+ example["image"] = (image / 127.5 - 1.0).astype(np.float32) # normalize the image values and convert to float32
+ return example # return the example dictionary containing the image and its file paths
+#A dataset class for LSUN Churches training set.
+# It initializes by calling the constructor of LSUNBase class and passing the appropriate arguments.
+# The text file containing the paths to the images and the root directory where the images are stored are passed as arguments. Any additional keyword arguments passed to this class will be forwarded to the constructor of the parent class.
class LSUNChurchesTrain(LSUNBase):
def __init__(self, **kwargs):
super().__init__(txt_file="data/lsun/church_outdoor_train.txt", data_root="data/lsun/churches", **kwargs)
-
+#A dataset class for LSUN Churches validation set.
+# It is similar to LSUNChurchesTrain except that it uses a different text file and sets the flip probability to zero by default.
class LSUNChurchesValidation(LSUNBase):
def __init__(self, flip_p=0., **kwargs):
super().__init__(txt_file="data/lsun/church_outdoor_val.txt", data_root="data/lsun/churches",
flip_p=flip_p, **kwargs)
-
+# A dataset class for LSUN Bedrooms training set.
+# It initializes by calling the constructor of LSUNBase class and passing the appropriate arguments.
class LSUNBedroomsTrain(LSUNBase):
def __init__(self, **kwargs):
super().__init__(txt_file="data/lsun/bedrooms_train.txt", data_root="data/lsun/bedrooms", **kwargs)
-
+# A dataset class for LSUN Bedrooms validation set.
+# It is similar to LSUNBedroomsTrain except that it uses a different text file and sets the flip probability to zero by default.
class LSUNBedroomsValidation(LSUNBase):
def __init__(self, flip_p=0.0, **kwargs):
super().__init__(txt_file="data/lsun/bedrooms_val.txt", data_root="data/lsun/bedrooms",
flip_p=flip_p, **kwargs)
-
+# A dataset class for LSUN Cats training set.
+# It initializes by calling the constructor of LSUNBase class and passing the appropriate arguments.
+# The text file containing the paths to the images and the root directory where the images are stored are passed as arguments.
class LSUNCatsTrain(LSUNBase):
def __init__(self, **kwargs):
super().__init__(txt_file="data/lsun/cat_train.txt", data_root="data/lsun/cats", **kwargs)
-
+# A dataset class for LSUN Cats validation set.
+# It is similar to LSUNCatsTrain except that it uses a different text file and sets the flip probability to zero by default.
class LSUNCatsValidation(LSUNBase):
def __init__(self, flip_p=0., **kwargs):
super().__init__(txt_file="data/lsun/cat_val.txt", data_root="data/lsun/cats",
diff --git a/examples/images/diffusion/main.py b/examples/images/diffusion/main.py
index 4dd88a5eca44..91b809d5a65c 100644
--- a/examples/images/diffusion/main.py
+++ b/examples/images/diffusion/main.py
@@ -44,14 +44,18 @@
class DataLoaderX(DataLoader):
-
+# A custom data loader class that inherits from DataLoader
def __iter__(self):
+ # Overriding the __iter__ method of DataLoader to return a BackgroundGenerator
+ #This is to enable data laoding in the background to improve training performance
return BackgroundGenerator(super().__iter__())
def get_parser(**parser_kwargs):
+ #A function to create an ArgumentParser object and add arguments to it
def str2bool(v):
+ # A helper function to parse boolean values from command line arguments
if isinstance(v, bool):
return v
if v.lower() in ("yes", "true", "t", "y", "1"):
@@ -60,8 +64,10 @@ def str2bool(v):
return False
else:
raise argparse.ArgumentTypeError("Boolean value expected.")
-
+ # Create an ArgumentParser object with specifies kwargs
parser = argparse.ArgumentParser(**parser_kwargs)
+
+ # Add vairous command line arguments with their default balues and descriptions
parser.add_argument(
"-n",
"--name",
@@ -161,14 +167,18 @@ def str2bool(v):
return parser
-
+# A function that returns the non-default arguments between two objects
def nondefault_trainer_args(opt):
+ # create an argument parsser
parser = argparse.ArgumentParser()
+ # add pytorch lightning trainer default arguments
parser = Trainer.add_argparse_args(parser)
+ # parse the empty arguments to obtain the default values
args = parser.parse_args([])
+ # return all non-default arguments
return sorted(k for k in vars(args) if getattr(opt, k) != getattr(args, k))
-
+# A dataset wrapper class to create a pytorch dataset from an arbitrary object
class WrappedDataset(Dataset):
"""Wraps an arbitrary object with __len__ and __getitem__ into a pytorch dataset"""
@@ -181,7 +191,7 @@ def __len__(self):
def __getitem__(self, idx):
return self.data[idx]
-
+# A function to initialize worker processes
def worker_init_fn(_):
worker_info = torch.utils.data.get_worker_info()
@@ -189,15 +199,18 @@ def worker_init_fn(_):
worker_id = worker_info.id
if isinstance(dataset, Txt2ImgIterableBaseDataset):
+ #divide the dataset into equal parts for each worker
split_size = dataset.num_records // worker_info.num_workers
+ #set the sample IDs for the current worker
# reset num_records to the true number to retain reliable length information
dataset.sample_ids = dataset.valid_ids[worker_id * split_size:(worker_id + 1) * split_size]
+ # set the seed for the current worker
current_id = np.random.choice(len(np.random.get_state()[1]), 1)
return np.random.seed(np.random.get_state()[1][current_id] + worker_id)
else:
return np.random.seed(np.random.get_state()[1][0] + worker_id)
-
+#Provide functionality for creating data loadedrs based on provided dataset configurations
class DataModuleFromConfig(pl.LightningDataModule):
def __init__(self,
@@ -212,10 +225,12 @@ def __init__(self,
use_worker_init_fn=False,
shuffle_val_dataloader=False):
super().__init__()
+ # Set data module attributes
self.batch_size = batch_size
self.dataset_configs = dict()
self.num_workers = num_workers if num_workers is not None else batch_size * 2
self.use_worker_init_fn = use_worker_init_fn
+ # If a dataset is passed, add it to the dataset configs and create a corresponding dataloader method
if train is not None:
self.dataset_configs["train"] = train
self.train_dataloader = self._train_dataloader
@@ -231,21 +246,28 @@ def __init__(self,
self.wrap = wrap
def prepare_data(self):
+ # Instantiate datasets
for data_cfg in self.dataset_configs.values():
instantiate_from_config(data_cfg)
def setup(self, stage=None):
+ # Instantiate datasets from the dataset configs
self.datasets = dict((k, instantiate_from_config(self.dataset_configs[k])) for k in self.dataset_configs)
+
+ # If wrap is true, create a WrappedDataset for each dataset
if self.wrap:
for k in self.datasets:
self.datasets[k] = WrappedDataset(self.datasets[k])
def _train_dataloader(self):
+ #Check if the train dataset is iterable
is_iterable_dataset = isinstance(self.datasets['train'], Txt2ImgIterableBaseDataset)
+ #Set the worker initialization function of the dataset isiterable or use_worker_init_fn is True
if is_iterable_dataset or self.use_worker_init_fn:
init_fn = worker_init_fn
else:
init_fn = None
+ # Return a DataLoaderX object for the train dataset
return DataLoaderX(self.datasets["train"],
batch_size=self.batch_size,
num_workers=self.num_workers,
@@ -253,10 +275,12 @@ def _train_dataloader(self):
worker_init_fn=init_fn)
def _val_dataloader(self, shuffle=False):
+ #Check if the validation dataset is iterable
if isinstance(self.datasets['validation'], Txt2ImgIterableBaseDataset) or self.use_worker_init_fn:
init_fn = worker_init_fn
else:
init_fn = None
+ # Return a DataLoaderX object for the validation dataset
return DataLoaderX(self.datasets["validation"],
batch_size=self.batch_size,
num_workers=self.num_workers,
@@ -264,7 +288,9 @@ def _val_dataloader(self, shuffle=False):
shuffle=shuffle)
def _test_dataloader(self, shuffle=False):
+ # Check if the test dataset is iterable
is_iterable_dataset = isinstance(self.datasets['train'], Txt2ImgIterableBaseDataset)
+ # Set the worker initialization function if the dataset is iterable or use_worker_init_fn is True
if is_iterable_dataset or self.use_worker_init_fn:
init_fn = worker_init_fn
else:
@@ -291,6 +317,7 @@ def _predict_dataloader(self, shuffle=False):
class SetupCallback(Callback):
+ # I nitialize the callback with the necessary parameters
def __init__(self, resume, now, logdir, ckptdir, cfgdir, config, lightning_config):
super().__init__()
@@ -302,12 +329,14 @@ def __init__(self, resume, now, logdir, ckptdir, cfgdir, config, lightning_confi
self.config = config
self.lightning_config = lightning_config
+ # Save a checkpoint if training is interrupted with keyboard interrupt
def on_keyboard_interrupt(self, trainer, pl_module):
if trainer.global_rank == 0:
print("Summoning checkpoint.")
ckpt_path = os.path.join(self.ckptdir, "last.ckpt")
trainer.save_checkpoint(ckpt_path)
+ # Create necessary directories and save configuration files before training starts
# def on_pretrain_routine_start(self, trainer, pl_module):
def on_fit_start(self, trainer, pl_module):
if trainer.global_rank == 0:
@@ -316,6 +345,7 @@ def on_fit_start(self, trainer, pl_module):
os.makedirs(self.ckptdir, exist_ok=True)
os.makedirs(self.cfgdir, exist_ok=True)
+ #Create trainstep checkpoint directory if necessary
if "callbacks" in self.lightning_config:
if 'metrics_over_trainsteps_checkpoint' in self.lightning_config['callbacks']:
os.makedirs(os.path.join(self.ckptdir, 'trainstep_checkpoints'), exist_ok=True)
@@ -323,11 +353,13 @@ def on_fit_start(self, trainer, pl_module):
print(OmegaConf.to_yaml(self.config))
OmegaConf.save(self.config, os.path.join(self.cfgdir, "{}-project.yaml".format(self.now)))
+ # Save project config and lightning config as YAML files
print("Lightning config")
print(OmegaConf.to_yaml(self.lightning_config))
OmegaConf.save(OmegaConf.create({"lightning": self.lightning_config}),
os.path.join(self.cfgdir, "{}-lightning.yaml".format(self.now)))
+ # Remove log directory if resuming training and directory already exists
else:
# ModelCheckpoint callback created log directory --- remove it
if not self.resume and os.path.exists(self.logdir):
@@ -346,25 +378,28 @@ def on_fit_start(self, trainer, pl_module):
# trainer.save_checkpoint(ckpt_path)
+# PyTorch Lightning callback for ogging images during training and validation of a deep learning model
class ImageLogger(Callback):
def __init__(self,
- batch_frequency,
- max_images,
- clamp=True,
- increase_log_steps=True,
- rescale=True,
- disabled=False,
- log_on_batch_idx=False,
- log_first_step=False,
- log_images_kwargs=None):
+ batch_frequency, # Frequency of batches on which to log images
+ max_images, # Maximum number of images to log
+ clamp=True, # Whether to clamp pixel values to [-1,1]
+ increase_log_steps=True, # Whether to increase frequency of log steps exponentially
+ rescale=True, # Whetehr to rescale pixel values to [0,1]
+ disabled=False, # Whether to disable logging
+ log_on_batch_idx=False, # Whether to log on baych index instead of global step
+ log_first_step=False, # Whetehr to log on the first step
+ log_images_kwargs=None): # Additional keyword arguments to pass to log_images method
super().__init__()
self.rescale = rescale
self.batch_freq = batch_frequency
self.max_images = max_images
self.logger_log_images = {
- pl.loggers.CSVLogger: self._testtube,
+ # Dictionary of logger classes and their corresponding logging methods
+ pl.loggers.CSVLogger: self._testtube,
}
+ # Create a list of exponentially increasing log steps, starting from 1 and ending at batch_frequency
self.log_steps = [2**n for n in range(int(np.log2(self.batch_freq)) + 1)]
if not increase_log_steps:
self.log_steps = [self.batch_freq]
@@ -374,17 +409,32 @@ def __init__(self,
self.log_images_kwargs = log_images_kwargs if log_images_kwargs else {}
self.log_first_step = log_first_step
- @rank_zero_only
- def _testtube(self, pl_module, images, batch_idx, split):
+ @rank_zero_only # Ensure that only the first process in distributed training executes this method
+ def _testtube(self, # The PyTorch Lightning module
+ pl_module, # A dictionary of images to log.
+ images, #
+ batch_idx, # The batch index.
+ split # The split (train/val) on which to log the images
+ ):
+ # Method for logging images using test-tube logger
for k in images:
grid = torchvision.utils.make_grid(images[k])
grid = (grid + 1.0) / 2.0 # -1,1 -> 0,1; c,h,w
tag = f"{split}/{k}"
+ # Add image grid to logger's experiment
pl_module.logger.experiment.add_image(tag, grid, global_step=pl_module.global_step)
@rank_zero_only
- def log_local(self, save_dir, split, images, global_step, current_epoch, batch_idx):
+ def log_local(self,
+ save_dir,
+ split, # The split (train/val) on which to log the images
+ images, # A dictionary of images to log
+ global_step, # The global step
+ current_epoch, # The current epoch.
+ batch_idx
+ ):
+ # Method for saving image grids to local file system
root = os.path.join(save_dir, "images", split)
for k in images:
grid = torchvision.utils.make_grid(images[k], nrow=4)
@@ -396,12 +446,16 @@ def log_local(self, save_dir, split, images, global_step, current_epoch, batch_i
filename = "{}_gs-{:06}_e-{:06}_b-{:06}.png".format(k, global_step, current_epoch, batch_idx)
path = os.path.join(root, filename)
os.makedirs(os.path.split(path)[0], exist_ok=True)
+ # Save image grid as PNG file
Image.fromarray(grid).save(path)
def log_img(self, pl_module, batch, batch_idx, split="train"):
+ #Function for logging images to both the logger and local file system.
check_idx = batch_idx if self.log_on_batch_idx else pl_module.global_step
+ # check if it's time to log an image batch
if (self.check_frequency(check_idx) and # batch_idx % self.batch_freq == 0
hasattr(pl_module, "log_images") and callable(pl_module.log_images) and self.max_images > 0):
+ # Get logger type and check if training mode is on
logger = type(pl_module.logger)
is_train = pl_module.training
@@ -409,8 +463,10 @@ def log_img(self, pl_module, batch, batch_idx, split="train"):
pl_module.eval()
with torch.no_grad():
+ # Get images from log_images method of the pl_module
images = pl_module.log_images(batch, split=split, **self.log_images_kwargs)
+ # Clip images if specified and convert to CPU tensor
for k in images:
N = min(images[k].shape[0], self.max_images)
images[k] = images[k][:N]
@@ -419,15 +475,19 @@ def log_img(self, pl_module, batch, batch_idx, split="train"):
if self.clamp:
images[k] = torch.clamp(images[k], -1., 1.)
+ # Log images locally to file system
self.log_local(pl_module.logger.save_dir, split, images, pl_module.global_step, pl_module.current_epoch,
batch_idx)
+ # log the images using the logger
logger_log_images = self.logger_log_images.get(logger, lambda *args, **kwargs: None)
logger_log_images(pl_module, images, pl_module.global_step, split)
+ # switch back to training mode if necessary
if is_train:
pl_module.train()
+ # The function checks if it's time to log an image batch
def check_frequency(self, check_idx):
if ((check_idx % self.batch_freq) == 0 or
(check_idx in self.log_steps)) and (check_idx > 0 or self.log_first_step):
@@ -439,14 +499,17 @@ def check_frequency(self, check_idx):
return True
return False
+ # Log images on train batch end if logging is not disabled
def on_train_batch_end(self, trainer, pl_module, outputs, batch, batch_idx):
# if not self.disabled and (pl_module.global_step > 0 or self.log_first_step):
# self.log_img(pl_module, batch, batch_idx, split="train")
pass
+ # Log images on validation batch end if logging is not disabled and in validation mode
def on_validation_batch_end(self, trainer, pl_module, outputs, batch, batch_idx):
if not self.disabled and pl_module.global_step > 0:
self.log_img(pl_module, batch, batch_idx, split="val")
+ # log gradients during calibration if necessary
if hasattr(pl_module, 'calibrate_grad_norm'):
if (pl_module.calibrate_grad_norm and batch_idx % 25 == 0) and batch_idx > 0:
self.log_gradients(trainer, pl_module, batch_idx=batch_idx)
@@ -458,6 +521,7 @@ class CUDACallback(Callback):
def on_train_start(self, trainer, pl_module):
rank_zero_info("Training is starting")
+ #the method is called at the end of each training epoch
def on_train_end(self, trainer, pl_module):
rank_zero_info("Training is ending")
@@ -524,6 +588,7 @@ def on_train_epoch_end(self, trainer, pl_module):
# params:
# key: value
+ # get the current time to create a new logging directory
now = datetime.datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
# add cwd for convenience and to make classes in this file available when
@@ -535,11 +600,13 @@ def on_train_epoch_end(self, trainer, pl_module):
parser = Trainer.add_argparse_args(parser)
opt, unknown = parser.parse_known_args()
+ # Veirfy the arguments are both specified
if opt.name and opt.resume:
raise ValueError("-n/--name and -r/--resume cannot be specified both."
"If you want to resume training in a new log folder, "
"use -n/--name in combination with --resume_from_checkpoint")
+ # Check if the "resume" option is specified, resume training from the checkpoint if it is true
ckpt = None
if opt.resume:
rank_zero_info("Resuming from {}".format(opt.resume))
@@ -557,8 +624,10 @@ def on_train_epoch_end(self, trainer, pl_module):
logdir = opt.resume.rstrip("/")
ckpt = os.path.join(logdir, "checkpoints", "last.ckpt")
+ # Finds all ".yaml" configuration files in the log directory and adds them to the list of base configurations
base_configs = sorted(glob.glob(os.path.join(logdir, "configs/*.yaml")))
opt.base = base_configs + opt.base
+ # Gets the name of the current log directory by splitting the path and taking the last element.
_tmp = logdir.split("/")
nowname = _tmp[-1]
else:
@@ -574,13 +643,17 @@ def on_train_epoch_end(self, trainer, pl_module):
nowname = now + name + opt.postfix
logdir = os.path.join(opt.logdir, nowname)
+ # Sets the checkpoint path of the 'ckpt' option is specified
if opt.ckpt:
ckpt = opt.ckpt
+ # Create the checkpoint and configuration directories within the log directory.
ckptdir = os.path.join(logdir, "checkpoints")
cfgdir = os.path.join(logdir, "configs")
+ # Sets the seed for the random number generator to ensure reproducibility
seed_everything(opt.seed)
+ # Intinalize and save configuratioon using teh OmegaConf library.
try:
# init and save configs
configs = [OmegaConf.load(cfg) for cfg in opt.base]
@@ -593,6 +666,7 @@ def on_train_epoch_end(self, trainer, pl_module):
for k in nondefault_trainer_args(opt):
trainer_config[k] = getattr(opt, k)
+ # Check whether the accelerator is gpu
if not trainer_config["accelerator"] == "gpu":
del trainer_config["accelerator"]
cpu = True
@@ -609,6 +683,7 @@ def on_train_epoch_end(self, trainer, pl_module):
config.model["params"].update({"use_fp16": False})
if ckpt is not None:
+ #If a checkpoint path is specified in the ckpt variable, the code updates the "ckpt" key in the "params" dictionary of the config.model configuration with the value of ckpt
config.model["params"].update({"ckpt": ckpt})
rank_zero_info("Using ckpt_path = {}".format(config.model["params"]["ckpt"]))
@@ -617,7 +692,8 @@ def on_train_epoch_end(self, trainer, pl_module):
trainer_kwargs = dict()
# config the logger
- # default logger configs
+ # Default logger configs to log training metrics during the training process.
+ # These loggers are specified as targets in the dictionary, along with the configuration settings specific to each logger.
default_logger_cfgs = {
"wandb": {
"target": LIGHTNING_PACK_NAME + "loggers.WandbLogger",
@@ -638,6 +714,7 @@ def on_train_epoch_end(self, trainer, pl_module):
}
}
+ # Set up the logger for TensorBoard
default_logger_cfg = default_logger_cfgs["tensorboard"]
if "logger" in lightning_config:
logger_cfg = lightning_config.logger
@@ -660,6 +737,7 @@ def on_train_epoch_end(self, trainer, pl_module):
trainer_kwargs["strategy"] = instantiate_from_config(strategy_cfg)
+ # Set up ModelCheckpoint callback to save best models
# modelcheckpoint - use TrainResult/EvalResult(checkpoint_on=metric) to
# specify which metric is used to determine best models
default_modelckpt_cfg = {
@@ -683,45 +761,50 @@ def on_train_epoch_end(self, trainer, pl_module):
if version.parse(pl.__version__) < version.parse('1.4.0'):
trainer_kwargs["checkpoint_callback"] = instantiate_from_config(modelckpt_cfg)
+ # Set up various callbacks, including logging, learning rate monitoring, and CUDA management
# add callback which sets up log directory
default_callbacks_cfg = {
- "setup_callback": {
+ "setup_callback": { # callback to set up the training
"target": "main.SetupCallback",
"params": {
- "resume": opt.resume,
- "now": now,
- "logdir": logdir,
- "ckptdir": ckptdir,
- "cfgdir": cfgdir,
- "config": config,
- "lightning_config": lightning_config,
+ "resume": opt.resume, # resume training if applicable
+ "now": now,
+ "logdir": logdir, # directory to save the log file
+ "ckptdir": ckptdir, # directory to save the checkpoint file
+ "cfgdir": cfgdir, # directory to save the configuration file
+ "config": config, # configuration dictionary
+ "lightning_config": lightning_config, # LightningModule configuration
}
},
- "image_logger": {
+ "image_logger": { # callback to log image data
"target": "main.ImageLogger",
"params": {
- "batch_frequency": 750,
- "max_images": 4,
- "clamp": True
+ "batch_frequency": 750, # how frequently to log images
+ "max_images": 4, # maximum number of images to log
+ "clamp": True # whether to clamp pixel values to [0,1]
}
},
- "learning_rate_logger": {
+ "learning_rate_logger": { # callback to log learning rate
"target": "main.LearningRateMonitor",
"params": {
- "logging_interval": "step",
- # "log_momentum": True
+ "logging_interval": "step", # logging frequency (either 'step' or 'epoch')
+ # "log_momentum": True # whether to log momentum (currently commented out)
}
},
- "cuda_callback": {
+ "cuda_callback": { # callback to handle CUDA-related operations
"target": "main.CUDACallback"
},
}
+ # If the LightningModule configuration has specified callbacks, use those
+ # Otherwise, create an empty OmegaConf configuration object
if "callbacks" in lightning_config:
callbacks_cfg = lightning_config.callbacks
else:
callbacks_cfg = OmegaConf.create()
-
+
+ # If the 'metrics_over_trainsteps_checkpoint' callback is specified in the
+ # LightningModule configuration, update the default callbacks configuration
if 'metrics_over_trainsteps_checkpoint' in callbacks_cfg:
print(
'Caution: Saving checkpoints every n train steps without deleting. This might require some free space.')
@@ -739,15 +822,17 @@ def on_train_epoch_end(self, trainer, pl_module):
}
}
default_callbacks_cfg.update(default_metrics_over_trainsteps_ckpt_dict)
-
+
+ # Merge the default callbacks configuration with the specified callbacks configuration, and instantiate the callbacks
callbacks_cfg = OmegaConf.merge(default_callbacks_cfg, callbacks_cfg)
trainer_kwargs["callbacks"] = [instantiate_from_config(callbacks_cfg[k]) for k in callbacks_cfg]
+ # Create a Trainer object with the specified command-line arguments and keyword arguments, and set the log directory
trainer = Trainer.from_argparse_args(trainer_opt, **trainer_kwargs)
trainer.logdir = logdir
- # data
+ # Create a data module based on the configuration file
data = instantiate_from_config(config.data)
# NOTE according to https://pytorch-lightning.readthedocs.io/en/latest/datamodules.html
# calling these ourselves should not be necessary but it is.
@@ -755,10 +840,12 @@ def on_train_epoch_end(self, trainer, pl_module):
data.prepare_data()
data.setup()
+ # Print some information about the datasets in the data module
for k in data.datasets:
rank_zero_info(f"{k}, {data.datasets[k].__class__.__name__}, {len(data.datasets[k])}")
- # configure learning rate
+ # Configure learning rate based on the batch size, base learning rate and number of GPUs
+ # If scale_lr is true, calculate the learning rate based on additional factors
bs, base_lr = config.data.params.batch_size, config.model.base_learning_rate
if not cpu:
ngpu = trainer_config["devices"]
@@ -780,7 +867,7 @@ def on_train_epoch_end(self, trainer, pl_module):
rank_zero_info("++++ NOT USING LR SCALING ++++")
rank_zero_info(f"Setting learning rate to {model.learning_rate:.2e}")
- # allow checkpointing via USR1
+ # Allow checkpointing via USR1
def melk(*args, **kwargs):
# run all checkpoint hooks
if trainer.global_rank == 0:
@@ -794,20 +881,23 @@ def divein(*args, **kwargs):
pudb.set_trace()
import signal
-
+ # Assign melk to SIGUSR1 signal and divein to SIGUSR2 signal
signal.signal(signal.SIGUSR1, melk)
signal.signal(signal.SIGUSR2, divein)
- # run
+ # Run the training and validation
if opt.train:
try:
trainer.fit(model, data)
except Exception:
melk()
raise
+ # Print the maximum GPU memory allocated during training
+ print(f"GPU memory usage: {torch.cuda.max_memory_allocated() / 1024**2:.0f} MB")
# if not opt.no_test and not trainer.interrupted:
# trainer.test(model, data)
except Exception:
+ # If there's an exception, debug it if opt.debug is true and the trainer's global rank is 0
if opt.debug and trainer.global_rank == 0:
try:
import pudb as debugger
@@ -816,7 +906,7 @@ def divein(*args, **kwargs):
debugger.post_mortem()
raise
finally:
- # move newly created debug project to debug_runs
+ # Move the log directory to debug_runs if opt.debug is true and the trainer's global
if opt.debug and not opt.resume and trainer.global_rank == 0:
dst, name = os.path.split(logdir)
dst = os.path.join(dst, "debug_runs", name)
diff --git a/examples/tutorial/auto_parallel/README.md b/examples/tutorial/auto_parallel/README.md
index bb014b9067b2..6a12e0dd5a48 100644
--- a/examples/tutorial/auto_parallel/README.md
+++ b/examples/tutorial/auto_parallel/README.md
@@ -45,6 +45,7 @@ colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
You should expect to the log like this. This log shows the edge cost on the computation graph as well as the sharding strategy for an operation. For example, `layer1_0_conv1 S01R = S01R X RR` means that the first dimension (batch) of the input and output is sharded while the weight is not sharded (S means sharded, R means replicated), simply equivalent to data parallel training.
+**Note: This experimental feature has been tested on torch 1.12.1 and transformer 4.22.2. If you are using other versions, you may need to modify the code to make it work.**
### Auto-Checkpoint Tutorial
diff --git a/examples/tutorial/auto_parallel/requirements.txt b/examples/tutorial/auto_parallel/requirements.txt
index ce89e7c80070..cc61362ba6f9 100644
--- a/examples/tutorial/auto_parallel/requirements.txt
+++ b/examples/tutorial/auto_parallel/requirements.txt
@@ -1,7 +1,7 @@
-torch
+torch==1.12.1
colossalai
titans
pulp
datasets
matplotlib
-transformers
+transformers==4.22.1
diff --git a/examples/tutorial/new_api/README.md b/examples/tutorial/new_api/README.md
new file mode 100644
index 000000000000..cec88f41caf1
--- /dev/null
+++ b/examples/tutorial/new_api/README.md
@@ -0,0 +1,5 @@
+# New API Features
+
+**The New API is not officially released yet.**
+
+This folder contains some of the demonstrations of the new API. The new API is still under intensive development and will be released soon.
diff --git a/examples/tutorial/new_api/test_ci.sh b/examples/tutorial/new_api/test_ci.sh
new file mode 100644
index 000000000000..8b4475e9f147
--- /dev/null
+++ b/examples/tutorial/new_api/test_ci.sh
@@ -0,0 +1,2 @@
+#!/usr/bin/env
+echo "The CI integration will be completed when the API is stable"
diff --git a/examples/tutorial/new_api/torch_ddp/.gitignore b/examples/tutorial/new_api/torch_ddp/.gitignore
new file mode 100644
index 000000000000..a79cf5236c08
--- /dev/null
+++ b/examples/tutorial/new_api/torch_ddp/.gitignore
@@ -0,0 +1,4 @@
+data
+checkpoint
+ckpt-fp16
+ckpt-fp32
diff --git a/examples/tutorial/new_api/torch_ddp/README.md b/examples/tutorial/new_api/torch_ddp/README.md
new file mode 100644
index 000000000000..62d5a083d0a1
--- /dev/null
+++ b/examples/tutorial/new_api/torch_ddp/README.md
@@ -0,0 +1,44 @@
+# Distributed Data Parallel
+
+## 🚀 Quick Start
+
+This example provides a training script and and evaluation script. The training script provides a an example of training ResNet on CIFAR10 dataset from scratch.
+
+- Training Arguments
+ - `-r, `--resume`: resume from checkpoint file path
+ - `-c`, `--checkpoint`: the folder to save checkpoints
+ - `-i`, `--interval`: epoch interval to save checkpoints
+ - `-f`, `--fp16`: use fp16
+
+- Eval Arguments
+ - `-e`, `--epoch`: select the epoch to evaluate
+ - `-c`, `--checkpoint`: the folder where checkpoints are found
+
+
+### Train
+
+```bash
+# train with torch DDP with fp32
+colossalai run --nproc_per_node 2 train.py -c ./ckpt-fp32
+
+# train with torch DDP with mixed precision training
+colossalai run --nproc_per_node 2 train.py -c ./ckpt-fp16 --fp16
+```
+
+### Eval
+
+```bash
+# evaluate fp32 training
+python eval.py -c ./ckpt-fp32 -e 80
+
+# evaluate fp16 mixed precision training
+python eval.py -c ./ckpt-fp16 -e 80
+```
+
+Expected accuracy performance will be:
+
+| Model | Single-GPU Baseline FP32 | Booster DDP with FP32 | Booster DDP with FP16 |
+| --------- | ------------------------ | --------------------- | --------------------- |
+| ResNet-18 | 85.85% | 85.03% | 85.12% |
+
+**Note: the baseline is a adapted from the [script](https://pytorch-tutorial.readthedocs.io/en/latest/tutorial/chapter03_intermediate/3_2_2_cnn_resnet_cifar10/) to use `torchvision.models.resnet18`**
diff --git a/examples/tutorial/new_api/torch_ddp/eval.py b/examples/tutorial/new_api/torch_ddp/eval.py
new file mode 100644
index 000000000000..657708ec3ff2
--- /dev/null
+++ b/examples/tutorial/new_api/torch_ddp/eval.py
@@ -0,0 +1,48 @@
+import argparse
+
+import torch
+import torch.nn as nn
+import torchvision
+import torchvision.transforms as transforms
+
+# ==============================
+# Parse Arguments
+# ==============================
+parser = argparse.ArgumentParser()
+parser.add_argument('-e', '--epoch', type=int, default=80, help="resume from the epoch's checkpoint")
+parser.add_argument('-c', '--checkpoint', type=str, default='./checkpoint', help="checkpoint directory")
+args = parser.parse_args()
+
+# ==============================
+# Prepare Test Dataset
+# ==============================
+# CIFAR-10 dataset
+test_dataset = torchvision.datasets.CIFAR10(root='./data/', train=False, transform=transforms.ToTensor())
+
+# Data loader
+test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=128, shuffle=False)
+
+# ==============================
+# Load Model
+# ==============================
+model = torchvision.models.resnet18(num_classes=10).cuda()
+state_dict = torch.load(f'{args.checkpoint}/model_{args.epoch}.pth')
+model.load_state_dict(state_dict)
+
+# ==============================
+# Run Evaluation
+# ==============================
+model.eval()
+
+with torch.no_grad():
+ correct = 0
+ total = 0
+ for images, labels in test_loader:
+ images = images.cuda()
+ labels = labels.cuda()
+ outputs = model(images)
+ _, predicted = torch.max(outputs.data, 1)
+ total += labels.size(0)
+ correct += (predicted == labels).sum().item()
+
+ print('Accuracy of the model on the test images: {} %'.format(100 * correct / total))
diff --git a/examples/tutorial/new_api/torch_ddp/train.py b/examples/tutorial/new_api/torch_ddp/train.py
new file mode 100644
index 000000000000..4741c3151cbb
--- /dev/null
+++ b/examples/tutorial/new_api/torch_ddp/train.py
@@ -0,0 +1,128 @@
+import argparse
+from pathlib import Path
+
+import torch
+import torch.nn as nn
+import torchvision
+import torchvision.transforms as transforms
+from torch.optim.lr_scheduler import MultiStepLR
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.cluster import DistCoordinator
+
+# ==============================
+# Parse Arguments
+# ==============================
+parser = argparse.ArgumentParser()
+parser.add_argument('-r', '--resume', type=int, default=-1, help="resume from the epoch's checkpoint")
+parser.add_argument('-c', '--checkpoint', type=str, default='./checkpoint', help="checkpoint directory")
+parser.add_argument('-i', '--interval', type=int, default=5, help="interval of saving checkpoint")
+parser.add_argument('-f', '--fp16', action='store_true', help="use fp16")
+args = parser.parse_args()
+
+# ==============================
+# Prepare Checkpoint Directory
+# ==============================
+Path(args.checkpoint).mkdir(parents=True, exist_ok=True)
+
+# ==============================
+# Prepare Hyperparameters
+# ==============================
+NUM_EPOCHS = 80
+LEARNING_RATE = 1e-3
+START_EPOCH = args.resume if args.resume >= 0 else 0
+
+# ==============================
+# Launch Distributed Environment
+# ==============================
+colossalai.launch_from_torch(config={})
+coordinator = DistCoordinator()
+
+# update the learning rate with linear scaling
+# old_gpu_num / old_lr = new_gpu_num / new_lr
+LEARNING_RATE *= coordinator.world_size
+
+# ==============================
+# Prepare Booster
+# ==============================
+plugin = TorchDDPPlugin()
+if args.fp16:
+ booster = Booster(mixed_precision='fp16', plugin=plugin)
+else:
+ booster = Booster(plugin=plugin)
+
+# ==============================
+# Prepare Train Dataset
+# ==============================
+transform = transforms.Compose(
+ [transforms.Pad(4),
+ transforms.RandomHorizontalFlip(),
+ transforms.RandomCrop(32),
+ transforms.ToTensor()])
+
+# CIFAR-10 dataset
+with coordinator.priority_execution():
+ train_dataset = torchvision.datasets.CIFAR10(root='./data/', train=True, transform=transform, download=True)
+
+# ====================================
+# Prepare model, optimizer, criterion
+# ====================================
+# resent50
+model = torchvision.models.resnet18(num_classes=10).cuda()
+
+# Loss and optimizer
+criterion = nn.CrossEntropyLoss()
+optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
+
+# lr scheduler
+lr_scheduler = MultiStepLR(optimizer, milestones=[20, 40, 60, 80], gamma=1 / 3)
+
+# prepare dataloader with torch ddp plugin
+train_dataloader = plugin.prepare_train_dataloader(train_dataset, batch_size=100, shuffle=True)
+
+# ==============================
+# Resume from checkpoint
+# ==============================
+if args.resume >= 0:
+ booster.load_model(model, f'{args.checkpoint}/model_{args.resume}.pth')
+ booster.load_optimizer(optimizer, f'{args.checkpoint}/optimizer_{args.resume}.pth')
+ booster.load_lr_scheduler(lr_scheduler, f'{args.checkpoint}/lr_scheduler_{args.resume}.pth')
+
+# ==============================
+# Boost with ColossalAI
+# ==============================
+model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model, optimizer, criterion,
+ train_dataloader, lr_scheduler)
+
+# ==============================
+# Train model
+# ==============================
+total_step = len(train_dataloader)
+
+for epoch in range(START_EPOCH, NUM_EPOCHS):
+ for i, (images, labels) in enumerate(train_dataloader):
+ images = images.cuda()
+ labels = labels.cuda()
+
+ # Forward pass
+ outputs = model(images)
+ loss = criterion(outputs, labels)
+
+ # Backward and optimize
+ optimizer.zero_grad()
+ booster.backward(loss, optimizer)
+ optimizer.step()
+
+ if (i + 1) % 100 == 0:
+ print("Epoch [{}/{}], Step [{}/{}] Loss: {:.4f}".format(epoch + 1, NUM_EPOCHS, i + 1, total_step,
+ loss.item()))
+
+ lr_scheduler.step()
+
+ # save checkpoint every 5 epoch
+ if (epoch + 1) % args.interval == 0:
+ booster.save_model(model, f'{args.checkpoint}/model_{epoch + 1}.pth')
+ booster.save_optimizer(optimizer, f'{args.checkpoint}/optimizer_{epoch + 1}.pth')
+ booster.save_lr_scheduler(lr_scheduler, f'{args.checkpoint}/lr_scheduler_{epoch + 1}.pth')
diff --git a/requirements/requirements.txt b/requirements/requirements.txt
index 8e619ac24477..e32b3ecda063 100644
--- a/requirements/requirements.txt
+++ b/requirements/requirements.txt
@@ -8,4 +8,4 @@ click
fabric
contexttimer
ninja
-torch
+torch>=1.11,<2.0
diff --git a/tests/test_booster/test_plugin/test_torch_ddp_plugin.py b/tests/test_booster/test_plugin/test_torch_ddp_plugin.py
index 58aef54c4967..2dcc5a5bba27 100644
--- a/tests/test_booster/test_plugin/test_torch_ddp_plugin.py
+++ b/tests/test_booster/test_plugin/test_torch_ddp_plugin.py
@@ -8,8 +8,8 @@
import colossalai
from colossalai.booster import Booster
-from colossalai.booster.interface import OptimizerWrapper
from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.interface import OptimizerWrapper
from colossalai.testing import rerun_if_address_is_in_use
from colossalai.utils import free_port
from tests.kit.model_zoo import model_zoo
@@ -34,7 +34,7 @@ def check_torch_ddp_plugin():
model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
- assert isinstance(model, DDP)
+ assert isinstance(model.module, DDP)
assert isinstance(optimizer, OptimizerWrapper)
output = model(**data)
diff --git a/tests/test_checkpoint_io/test_general_checkpoint_io.py b/tests/test_checkpoint_io/test_general_checkpoint_io.py
index 48376aaa88bf..f9f0e03c4fa1 100644
--- a/tests/test_checkpoint_io/test_general_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_general_checkpoint_io.py
@@ -42,8 +42,8 @@ def test_unsharded_checkpoint():
new_optimizer = Adam(new_model.parameters(), lr=0.001)
# load the model and optimizer
- new_model = ckpt_io.load_model(new_model, model_ckpt_tempfile.name)
- new_optimizer = ckpt_io.load_optimizer(new_optimizer, optimizer_ckpt_tempfile.name)
+ ckpt_io.load_model(new_model, model_ckpt_tempfile.name)
+ ckpt_io.load_optimizer(new_optimizer, optimizer_ckpt_tempfile.name)
# do recursive check for the optimizer state dict
# if the value is a dict, compare its values
diff --git a/tests/test_cluster/test_device_mesh_manager.py b/tests/test_cluster/test_device_mesh_manager.py
new file mode 100644
index 000000000000..b79814735325
--- /dev/null
+++ b/tests/test_cluster/test_device_mesh_manager.py
@@ -0,0 +1,40 @@
+from functools import partial
+
+import torch
+import torch.multiprocessing as mp
+
+from colossalai.cluster.device_mesh_manager import DeviceMeshInfo, DeviceMeshManager
+from colossalai.device.device_mesh import DeviceMesh
+from colossalai.fx.tracer import ColoTracer
+from colossalai.initialize import launch
+from colossalai.logging import disable_existing_loggers
+from colossalai.utils import free_port
+
+
+def check_device_mesh_manager(rank, world_size, port):
+ disable_existing_loggers()
+ launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ device_mesh_manager = DeviceMeshManager()
+ device_mesh_info_auto = DeviceMeshInfo(physical_ids=[0, 1, 2, 3],)
+ device_mesh_auto = device_mesh_manager.create_device_mesh('0', device_mesh_info_auto)
+ assert device_mesh_auto.shape == (2, 2)
+ assert device_mesh_auto._logical_mesh_id.tolist() == [[0, 1], [2, 3]]
+
+ device_mesh_info_with_shape = DeviceMeshInfo(
+ physical_ids=[0, 1, 2, 3],
+ mesh_shape=(2, 2),
+ )
+ device_mesh_with_shape = device_mesh_manager.create_device_mesh('1', device_mesh_info_with_shape)
+
+ assert device_mesh_with_shape.shape == (2, 2)
+ assert device_mesh_with_shape._logical_mesh_id.tolist() == [[0, 1], [2, 3]]
+
+
+def test_device_mesh_manager():
+ world_size = 4
+ run_func = partial(check_device_mesh_manager, world_size=world_size, port=free_port())
+ mp.spawn(run_func, nprocs=world_size)
+
+
+if __name__ == '__main__':
+ test_device_mesh_manager()
diff --git a/tests/test_fx/test_tracer/test_torchaudio_model/test_torchaudio_model.py b/tests/test_fx/test_tracer/test_torchaudio_model/test_torchaudio_model.py
index 65f9f5149dda..66f4be5a6f7f 100644
--- a/tests/test_fx/test_tracer/test_torchaudio_model/test_torchaudio_model.py
+++ b/tests/test_fx/test_tracer/test_torchaudio_model/test_torchaudio_model.py
@@ -6,7 +6,9 @@
from tests.kit.model_zoo import model_zoo
-@pytest.mark.skipif(version.parse(torch.__version__) < version.parse('1.12.0'), reason='torch version < 12')
+# We cannot handle the tensors constructed with constant during forward, such as ``torch.empty(0).to(device=Proxy.device)``
+# TODO: We could handle this case by hijacking torch.Tensor.to function.
+@pytest.mark.skip
def test_torchaudio_models():
torch.backends.cudnn.deterministic = True
diff --git a/tests/test_utils/test_lazy_init/test_distribute.py b/tests/test_utils/test_lazy_init/test_distribute.py
index 37b2c5da1efa..1e32814ab147 100644
--- a/tests/test_utils/test_lazy_init/test_distribute.py
+++ b/tests/test_utils/test_lazy_init/test_distribute.py
@@ -13,7 +13,11 @@
from colossalai.testing import parameterize, rerun_if_address_is_in_use
from colossalai.utils import free_port
from colossalai.utils.common import print_rank_0
-from colossalai.utils.model.experimental import LazyInitContext, LazyTensor, _MyTensor
+
+try:
+ from colossalai.utils.model.experimental import LazyInitContext, LazyTensor, _MyTensor
+except:
+ pass
from tests.kit.model_zoo import model_zoo
# from utils import assert_dist_model_equal, set_seed
 +
+
+
+ +
+