diff --git a/.github/workflows/README.md b/.github/workflows/README.md
index 8fc14e0d531a..f40f4cc86d1b 100644
--- a/.github/workflows/README.md
+++ b/.github/workflows/README.md
@@ -14,7 +14,7 @@
- [Compatibility Test on Dispatch](#compatibility-test-on-dispatch)
- [Release](#release)
- [User Friendliness](#user-friendliness)
- - [Commmunity](#commmunity)
+ - [Community](#community)
- [Configuration](#configuration)
- [Progress Log](#progress-log)
@@ -97,7 +97,7 @@ This workflow is triggered by manually dispatching the workflow. It has the foll
| `Synchronize submodule` | `submodule.yml` | This workflow will check if any git submodule is updated. If so, it will create a PR to update the submodule pointers. |
| `Close inactive issues` | `close_inactive.yml` | This workflow will close issues which are stale for 14 days. |
-### Commmunity
+### Community
| Workflow Name | File name | Description |
| -------------------------------------------- | -------------------------------- | -------------------------------------------------------------------------------- |
diff --git a/.github/workflows/build_on_pr.yml b/.github/workflows/build_on_pr.yml
index a9e50e231164..a5a17d176c9d 100644
--- a/.github/workflows/build_on_pr.yml
+++ b/.github/workflows/build_on_pr.yml
@@ -3,24 +3,27 @@ name: Build on PR
on:
pull_request:
types: [synchronize, opened, reopened]
+ branches:
+ - "main"
+ - "develop"
+ - "feature/**"
paths:
- - '.github/workflows/build_on_pr.yml' # run command & env variables change
- - 'colossalai/**' # source code change
- - '!colossalai/**.md' # ignore doc change
- - 'op_builder/**' # cuda extension change
- - '!op_builder/**.md' # ignore doc change
- - 'requirements/**' # requirements change
- - 'tests/**' # test change
- - '!tests/**.md' # ignore doc change
- - 'pytest.ini' # test config change
- - 'setup.py' # install command change
+ - ".github/workflows/build_on_pr.yml" # run command & env variables change
+ - "colossalai/**" # source code change
+ - "!colossalai/**.md" # ignore doc change
+ - "op_builder/**" # cuda extension change
+ - "!op_builder/**.md" # ignore doc change
+ - "requirements/**" # requirements change
+ - "tests/**" # test change
+ - "!tests/**.md" # ignore doc change
+ - "pytest.ini" # test config change
+ - "setup.py" # install command change
jobs:
detect:
name: Detect file change
if: |
github.event.pull_request.draft == false &&
- github.base_ref == 'main' &&
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
outputs:
changedExtenisonFiles: ${{ steps.find-extension-change.outputs.all_changed_files }}
@@ -133,7 +136,7 @@ jobs:
- name: Restore Testmon Cache
run: |
if [ -d /github/home/testmon_cache ]; then
- [ ! -z "$(ls -A /github/home/testmon_cache)" ] && cp -p -r /github/home/testmon_cache/.testmondata /__w/ColossalAI/ColossalAI/
+ [ ! -z "$(ls -A /github/home/testmon_cache)" ] && cp -p -r /github/home/testmon_cache/.testmondata* /__w/ColossalAI/ColossalAI/
fi
- name: Execute Unit Testing
@@ -147,7 +150,7 @@ jobs:
- name: Store Testmon Cache
run: |
[ -d /github/home/testmon_cache ] || mkdir /github/home/testmon_cache
- cp -p -r /__w/ColossalAI/ColossalAI/.testmondata /github/home/testmon_cache/
+ cp -p -r /__w/ColossalAI/ColossalAI/.testmondata* /github/home/testmon_cache/
- name: Collate artifact
env:
diff --git a/.github/workflows/compatiblity_test_on_dispatch.yml b/.github/workflows/compatiblity_test_on_dispatch.yml
index 717cf729b3f3..3dcc4dfd182a 100644
--- a/.github/workflows/compatiblity_test_on_dispatch.yml
+++ b/.github/workflows/compatiblity_test_on_dispatch.yml
@@ -19,26 +19,26 @@ jobs:
outputs:
matrix: ${{ steps.set-matrix.outputs.matrix }}
steps:
- - id: set-matrix
- env:
- TORCH_VERSIONS: ${{ inputs.torch_version }}
- CUDA_VERSIONS: ${{ inputs.cuda_version }}
- run: |
- IFS=','
- DOCKER_IMAGE=()
+ - id: set-matrix
+ env:
+ TORCH_VERSIONS: ${{ inputs.torch_version }}
+ CUDA_VERSIONS: ${{ inputs.cuda_version }}
+ run: |
+ IFS=','
+ DOCKER_IMAGE=()
- for tv in $TORCH_VERSIONS
- do
- for cv in $CUDA_VERSIONS
- do
- DOCKER_IMAGE+=("\"hpcaitech/pytorch-cuda:${tv}-${cv}\"")
- done
- done
+ for tv in $TORCH_VERSIONS
+ do
+ for cv in $CUDA_VERSIONS
+ do
+ DOCKER_IMAGE+=("\"hpcaitech/pytorch-cuda:${tv}-${cv}\"")
+ done
+ done
- container=$( IFS=',' ; echo "${DOCKER_IMAGE[*]}" )
- container="[${container}]"
- echo "$container"
- echo "::set-output name=matrix::{\"container\":$(echo "$container")}"
+ container=$( IFS=',' ; echo "${DOCKER_IMAGE[*]}" )
+ container="[${container}]"
+ echo "$container"
+ echo "::set-output name=matrix::{\"container\":$(echo "$container")}"
build:
name: Test for PyTorch Compatibility
@@ -70,6 +70,17 @@ jobs:
- uses: actions/checkout@v2
with:
ssh-key: ${{ secrets.SSH_KEY_FOR_CI }}
+ - name: Download cub for CUDA 10.2
+ run: |
+ CUDA_VERSION=$(cat $CUDA_HOME/version.txt | grep "CUDA Version" | awk '{print $NF}' | cut -d. -f1,2)
+
+ # check if it is CUDA 10.2
+ # download cub
+ if [ "$CUDA_VERSION" = "10.2" ]; then
+ wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip
+ unzip 1.8.0.zip
+ cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
+ fi
- name: Install Colossal-AI
run: |
pip install -r requirements/requirements.txt
diff --git a/.github/workflows/compatiblity_test_on_pr.yml b/.github/workflows/compatiblity_test_on_pr.yml
index 2fca67b820a1..94a723388872 100644
--- a/.github/workflows/compatiblity_test_on_pr.yml
+++ b/.github/workflows/compatiblity_test_on_pr.yml
@@ -3,8 +3,8 @@ name: Compatibility Test on PR
on:
pull_request:
paths:
- - 'version.txt'
- - '.compatibility'
+ - "version.txt"
+ - ".compatibility"
jobs:
matrix_preparation:
@@ -58,6 +58,18 @@ jobs:
- uses: actions/checkout@v2
with:
ssh-key: ${{ secrets.SSH_KEY_FOR_CI }}
+ - name: Download cub for CUDA 10.2
+ run: |
+ CUDA_VERSION=$(cat $CUDA_HOME/version.txt | grep "CUDA Version" | awk '{print $NF}' | cut -d. -f1,2)
+
+ # check if it is CUDA 10.2
+ # download cub
+ if [ "$CUDA_VERSION" = "10.2" ]; then
+ wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip
+ unzip 1.8.0.zip
+ cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
+ fi
+
- name: Install Colossal-AI
run: |
pip install -v --no-cache-dir .
diff --git a/.github/workflows/doc_build_after_merge.yml b/.github/workflows/doc_build_on_schedule_after_release.yml
similarity index 69%
rename from .github/workflows/doc_build_after_merge.yml
rename to .github/workflows/doc_build_on_schedule_after_release.yml
index ede04b336620..62dfdc67257c 100644
--- a/.github/workflows/doc_build_after_merge.yml
+++ b/.github/workflows/doc_build_on_schedule_after_release.yml
@@ -1,18 +1,16 @@
-name: Build Documentation After Merge
+name: Build Documentation On Schedule & After Release
on:
workflow_dispatch:
- pull_request:
- paths:
- - 'version.txt'
- - 'docs/**'
- types:
- - closed
+ schedule:
+ - cron: "0 12 * * *" # build doc every day at 8pm Singapore time (12pm UTC time)
+ release:
+ types: [published]
jobs:
build-doc:
name: Trigger Documentation Build Workflow
- if: ( github.event_name == 'workflow_dispatch' || github.event.pull_request.merged == true ) && github.repository == 'hpcaitech/ColossalAI'
+ if: github.repository == 'hpcaitech/ColossalAI'
runs-on: ubuntu-latest
steps:
- name: trigger workflow in ColossalAI-Documentation
diff --git a/.github/workflows/doc_check_on_pr.yml b/.github/workflows/doc_check_on_pr.yml
index a863fcd70b44..992cc93b008c 100644
--- a/.github/workflows/doc_check_on_pr.yml
+++ b/.github/workflows/doc_check_on_pr.yml
@@ -2,47 +2,49 @@ name: Check Documentation on PR
on:
pull_request:
+ branches:
+ - "main"
+ - "develop"
+ - "feature/**"
paths:
- - 'docs/**'
+ - "docs/**"
jobs:
check-i18n:
name: Check docs in diff languages
if: |
- github.event.pull_request.draft == false &&
- github.base_ref == 'main' &&
- github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
+ github.event.pull_request.draft == false &&
+ github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: actions/setup-python@v2
with:
- python-version: '3.8.14'
+ python-version: "3.8.14"
- run: python .github/workflows/scripts/check_doc_i18n.py -d docs/source
check-doc-build:
name: Test if the docs can be built
if: |
- github.event.pull_request.draft == false &&
- github.base_ref == 'main' &&
- github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
+ github.event.pull_request.draft == false &&
+ github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
with:
- path: './ColossalAI'
+ path: "./ColossalAI"
fetch-depth: 0
- uses: actions/checkout@v2
with:
- path: './ColossalAI-Documentation'
- repository: 'hpcaitech/ColossalAI-Documentation'
+ path: "./ColossalAI-Documentation"
+ repository: "hpcaitech/ColossalAI-Documentation"
- uses: actions/setup-python@v2
with:
- python-version: '3.8.14'
+ python-version: "3.8.14"
# we use the versions in the main branch as the guide for versions to display
# checkout will give your merged branch
@@ -57,7 +59,6 @@ jobs:
git config user.name 'github-actions'
git config user.email 'github-actions@github.com'
-
- name: Build docs
run: |
cache_dir=ColossalAI-Documentation/doc-build/.cache
diff --git a/.github/workflows/doc_test_on_pr.yml b/.github/workflows/doc_test_on_pr.yml
index fb2e28cd9b2e..325e2a7c95a4 100644
--- a/.github/workflows/doc_test_on_pr.yml
+++ b/.github/workflows/doc_test_on_pr.yml
@@ -1,17 +1,20 @@
name: Test Documentation on PR
on:
pull_request:
+ branches:
+ - "main"
+ - "develop"
+ - "feature/**"
# any change in the examples folder will trigger check for the corresponding example.
paths:
- - 'docs/source/**.md'
+ - "docs/source/**.md"
jobs:
# This is for changed example files detect and output a matrix containing all the corresponding directory name.
detect-changed-doc:
if: |
- github.event.pull_request.draft == false &&
- github.base_ref == 'main' &&
- github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' && github.event_name == 'pull_request'
+ github.event.pull_request.draft == false &&
+ github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' && github.event_name == 'pull_request'
runs-on: ubuntu-latest
outputs:
any_changed: ${{ steps.changed-files.outputs.any_changed }}
@@ -26,10 +29,10 @@ jobs:
- name: Locate base commit
id: locate-base-sha
run: |
- curBranch=$(git rev-parse --abbrev-ref HEAD)
- commonCommit=$(git merge-base origin/main $curBranch)
- echo $commonCommit
- echo "baseSHA=$commonCommit" >> $GITHUB_OUTPUT
+ curBranch=$(git rev-parse --abbrev-ref HEAD)
+ commonCommit=$(git merge-base origin/main $curBranch)
+ echo $commonCommit
+ echo "baseSHA=$commonCommit" >> $GITHUB_OUTPUT
- name: Get all changed example files
id: changed-files
@@ -43,10 +46,9 @@ jobs:
check-changed-doc:
# Add this condition to avoid executing this job if the trigger event is workflow_dispatch.
if: |
- github.event.pull_request.draft == false &&
- github.base_ref == 'main' &&
- github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' && github.event_name == 'pull_request' &&
- needs.detect-changed-doc.outputs.any_changed == 'true'
+ github.event.pull_request.draft == false &&
+ github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' && github.event_name == 'pull_request' &&
+ needs.detect-changed-doc.outputs.any_changed == 'true'
name: Test the changed Doc
needs: detect-changed-doc
runs-on: [self-hosted, gpu]
@@ -61,8 +63,8 @@ jobs:
- name: Checkout ColossalAI-Documentation
uses: actions/checkout@v2
with:
- path: './ColossalAI-Documentation'
- repository: 'hpcaitech/ColossalAI-Documentation'
+ path: "./ColossalAI-Documentation"
+ repository: "hpcaitech/ColossalAI-Documentation"
- name: Install Docer
run: |
diff --git a/.github/workflows/example_check_on_pr.yml b/.github/workflows/example_check_on_pr.yml
index b22664ee47cc..31dbf7540091 100644
--- a/.github/workflows/example_check_on_pr.yml
+++ b/.github/workflows/example_check_on_pr.yml
@@ -1,17 +1,20 @@
name: Test Example on PR
on:
pull_request:
+ branches:
+ - "main"
+ - "develop"
+ - "feature/**"
# any change in the examples folder will trigger check for the corresponding example.
paths:
- - 'examples/**'
+ - "examples/**"
jobs:
# This is for changed example files detect and output a matrix containing all the corresponding directory name.
detect-changed-example:
if: |
- github.event.pull_request.draft == false &&
- github.base_ref == 'main' &&
- github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' && github.event_name == 'pull_request'
+ github.event.pull_request.draft == false &&
+ github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' && github.event_name == 'pull_request'
runs-on: ubuntu-latest
outputs:
matrix: ${{ steps.setup-matrix.outputs.matrix }}
@@ -26,10 +29,10 @@ jobs:
- name: Locate base commit
id: locate-base-sha
run: |
- curBranch=$(git rev-parse --abbrev-ref HEAD)
- commonCommit=$(git merge-base origin/main $curBranch)
- echo $commonCommit
- echo "baseSHA=$commonCommit" >> $GITHUB_OUTPUT
+ curBranch=$(git rev-parse --abbrev-ref HEAD)
+ commonCommit=$(git merge-base origin/main $curBranch)
+ echo $commonCommit
+ echo "baseSHA=$commonCommit" >> $GITHUB_OUTPUT
- name: Get all changed example files
id: changed-files
@@ -61,10 +64,9 @@ jobs:
check-changed-example:
# Add this condition to avoid executing this job if the trigger event is workflow_dispatch.
if: |
- github.event.pull_request.draft == false &&
- github.base_ref == 'main' &&
- github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' && github.event_name == 'pull_request' &&
- needs.detect-changed-example.outputs.anyChanged == 'true'
+ github.event.pull_request.draft == false &&
+ github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI' && github.event_name == 'pull_request' &&
+ needs.detect-changed-example.outputs.anyChanged == 'true'
name: Test the changed example
needs: detect-changed-example
runs-on: [self-hosted, gpu]
diff --git a/.github/workflows/release_docker_after_merge.yml b/.github/workflows/release_docker_after_publish.yml
similarity index 84%
rename from .github/workflows/release_docker_after_merge.yml
rename to .github/workflows/release_docker_after_publish.yml
index 607c19b05472..22698ca192ed 100644
--- a/.github/workflows/release_docker_after_merge.yml
+++ b/.github/workflows/release_docker_after_publish.yml
@@ -1,17 +1,14 @@
-name: Publish Docker Image to DockerHub after Merge
+name: Publish Docker Image to DockerHub after Publish
on:
workflow_dispatch:
- pull_request:
- paths:
- - 'version.txt'
- types:
- - closed
+ release:
+ types: [published]
jobs:
release:
name: Publish Docker Image to DockerHub
- if: ( github.event_name == 'workflow_dispatch' || github.event.pull_request.merged == true ) && github.repository == 'hpcaitech/ColossalAI'
+ if: github.repository == 'hpcaitech/ColossalAI'
runs-on: [self-hosted, gpu]
container:
image: "hpcaitech/docker-in-docker:latest"
@@ -26,7 +23,7 @@ jobs:
run: |
version=$(cat version.txt)
tag=hpcaitech/colossalai:$version
- docker build --build-arg http_proxy=http://172.17.0.1:7890 --build-arg https_proxy=http://172.17.0.1:7890 -t $tag ./docker
+ docker build --build-arg http_proxy=http://172.17.0.1:7890 --build-arg https_proxy=http://172.17.0.1:7890 --build-arg VERSION=v${version} -t $tag ./docker
echo "tag=${tag}" >> $GITHUB_OUTPUT
- name: Log in to Docker Hub
@@ -50,7 +47,7 @@ jobs:
- uses: actions/setup-python@v2
with:
- python-version: '3.8.14'
+ python-version: "3.8.14"
- name: Install requests
run: pip install requests
diff --git a/.github/workflows/report_test_coverage.yml b/.github/workflows/report_test_coverage.yml
index bbada74e6850..d9b131fd994c 100644
--- a/.github/workflows/report_test_coverage.yml
+++ b/.github/workflows/report_test_coverage.yml
@@ -10,7 +10,7 @@ jobs:
report-test-coverage:
runs-on: ubuntu-latest
steps:
- - name: 'Download artifact'
+ - name: "Download artifact"
uses: actions/github-script@v6
with:
script: |
@@ -31,7 +31,7 @@ jobs:
let fs = require('fs');
fs.writeFileSync(`${process.env.GITHUB_WORKSPACE}/report.zip`, Buffer.from(download.data));
- - name: 'Unzip artifact'
+ - name: "Unzip artifact"
id: unzip
run: |
unzip report.zip
@@ -58,7 +58,7 @@ jobs:
echo "" >> coverage_report.txt
mv coverage_report.txt coverage.txt
- - name: 'Comment on PR'
+ - name: "Comment on PR"
if: steps.unzip.outputs.hasReport == 'true'
uses: actions/github-script@v6
with:
diff --git a/.gitignore b/.gitignore
index bf74a753894f..81113fa99dd5 100644
--- a/.gitignore
+++ b/.gitignore
@@ -155,3 +155,7 @@ colossalai/version.py
# ignore coverage test file
coverage.lcov
coverage.xml
+
+# ignore testmon and coverage files
+.coverage
+.testmondata*
diff --git a/README.md b/README.md
index 2e6dcaa1eaf4..34c8a6b730a3 100644
--- a/README.md
+++ b/README.md
@@ -132,9 +132,9 @@ distributed training and inference in a few lines.
-[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline.
-[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
-[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline.
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
+[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
[[demo]](https://www.youtube.com/watch?v=HcTiHzApHm0)
[[tutorial]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
@@ -362,6 +362,22 @@ If you want to install and enable CUDA kernel fusion (compulsory installation wh
CUDA_EXT=1 pip install .
```
+For Users with CUDA 10.2, you can still build ColossalAI from source. However, you need to manually download the cub library and copy it to the corresponding directory.
+
+```bash
+# clone the repository
+git clone https://github.com/hpcaitech/ColossalAI.git
+cd ColossalAI
+
+# download the cub library
+wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip
+unzip 1.8.0.zip
+cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
+
+# install
+CUDA_EXT=1 pip install .
+```
+
(back to top)
## Use Docker
diff --git a/applications/Chat/README.md b/applications/Chat/README.md
index bc8481d96de3..29cd581d7cc9 100644
--- a/applications/Chat/README.md
+++ b/applications/Chat/README.md
@@ -73,9 +73,9 @@ More details can be found in the latest news.
-[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline.
-[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
-[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline.
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
+[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
[[demo]](https://www.youtube.com/watch?v=HcTiHzApHm0)
[[tutorial]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
diff --git a/applications/Chat/coati/dataset/reward_dataset.py b/applications/Chat/coati/dataset/reward_dataset.py
index faa1c94d2728..5dacf7e81464 100644
--- a/applications/Chat/coati/dataset/reward_dataset.py
+++ b/applications/Chat/coati/dataset/reward_dataset.py
@@ -6,7 +6,7 @@
from .utils import is_rank_0
-# Dahaos/rm-static
+# Dahoas/rm-static
class RmStaticDataset(Dataset):
"""
Dataset for reward model
diff --git a/applications/Chat/coati/ray/src/detached_replay_buffer.py b/applications/Chat/coati/ray/src/detached_replay_buffer.py
index 855eee48c5a5..18c8db388e88 100644
--- a/applications/Chat/coati/ray/src/detached_replay_buffer.py
+++ b/applications/Chat/coati/ray/src/detached_replay_buffer.py
@@ -34,7 +34,7 @@ def __init__(self, sample_batch_size: int, tp_world_size: int = 1, limit : int =
'''
Workers in the same tp group share this buffer and need same sample for one step.
Therefore a held_sample should be returned tp_world_size times before it could be dropped.
- worker_state records wheter a worker got the held_sample
+ worker_state records whether a worker got the held_sample
'''
self.tp_world_size = tp_world_size
self.worker_state = [False] * self.tp_world_size
diff --git a/applications/Chat/coati/ray/src/experience_maker_holder.py b/applications/Chat/coati/ray/src/experience_maker_holder.py
index 94e4a3d537a5..0ae4e3125b70 100644
--- a/applications/Chat/coati/ray/src/experience_maker_holder.py
+++ b/applications/Chat/coati/ray/src/experience_maker_holder.py
@@ -22,7 +22,7 @@
class ExperienceMakerHolder:
'''
Args:
- detached_trainer_name_list: str list to get ray actor handleskkk
+ detached_trainer_name_list: str list to get ray actor handles
strategy:
experience_batch_size: batch size of generated experience
kl_coef: the coefficient of kl divergence loss
diff --git a/applications/Chat/coati/ray/src/pipeline_strategy.py b/applications/Chat/coati/ray/src/pipeline_strategy.py
index 1780839c62ee..7ecb5d7d86d6 100644
--- a/applications/Chat/coati/ray/src/pipeline_strategy.py
+++ b/applications/Chat/coati/ray/src/pipeline_strategy.py
@@ -26,7 +26,7 @@
class PipelineModel(torch.nn.Module):
'''
Actor has 2 kinds of jobs: forward and generate.
- better to just pipelinize the inner model
+ better to just pipeline the inner model
'''
def __init__(self,
model: torch.nn.Module,
diff --git a/applications/Chat/evaluate/README.md b/applications/Chat/evaluate/README.md
index 7ace4bfe6d18..ae3499bf268c 100644
--- a/applications/Chat/evaluate/README.md
+++ b/applications/Chat/evaluate/README.md
@@ -1,182 +1,329 @@
-# Evaluation
-
-In this directory, we introduce how you can evaluate your model with GPT-4.
-
-## Evaluation Pipeline
-
-The whole evaluation process undergoes the following three steps:
-1. Prepare the questions following the internal data structure in the data format section (described below).
-2. Generate answers from different models:
- * Generate answers using GPT-3.5: [`generate_gpt35_answers.py`](generate_gpt35_answers.py).
- * Generate answers using your own models: [`generate_answers.py`](generate_answers.py).
-3. Evaluate models using GPT-4: [`evaluate.py`](evaluate.py).
-
-### Generate Answers
-#### Generate Answers Using GPT-3.5
-You can provide your own OpenAI key to generate answers from GPT-3.5 using [`generate_gpt35_answers.py`](./generate_gpt35_answers.py).
-
-An example script is provided as follows:
-```shell
-python generate_gpt35_answers.py \
- --dataset "path to the question dataset" \
- --answer_path "path to answer folder" \
- --num_workers 4 \
- --openai_key "your openai key" \
- --max_tokens 512 \
-```
-
-#### Generate Answers Using our Own Model
-You can also generate answers using your own models. The generation process is divided into two stages:
-1. Generate answers using multiple GPUs (optional) with batch processing: [`generate_answers.py`](./generate_answers.py).
-2. Merge multiple shards and output a single file: [`merge.py`](./merge.py).
-
-An example script is given as follows:
-
-```shell
-device_number=number of your devices
-model_name="name of your model"
-model_path="path to your model"
-dataset="path to the question dataset"
-answer_path="path to save the model answers"
-
-torchrun --standalone --nproc_per_node=$device_number generate_answers.py \
- --model 'llama' \
- --strategy ddp \
- --model_path $model_path \
- --model_name $model_name \
- --dataset $dataset \
- --batch_size 8 \
- --max_datasets_size 80 \
- --answer_path $answer_path \
- --max_length 512
-
-python merge.py \
- --model_name $model_name \
- --shards $device_number \
- --answer_path $answer_path \
-
-for (( i=0; iDescription |
+| :-----------------: | :----------------------------------------------------------- |
+| Brainstorming | Models are asked to generate a range of creative and diverse ideas according to the question. The capability of creativity is required. |
+| Chat | Models are asked to continue a multi-round dialogue given the roles involved. The capability of understanding, memorizing previous rounds of the dialogue and answering according to the persona provided is required. |
+| Classification | Models are asked to do classification tasks. The capability of accurate classification is required. |
+| Closed QA | Models are asked to answer a closed QA question. The capability of answering questions with limited scope (such as single/multiple choice question) is required. |
+| Extraction | Models are asked to extract information from a given material. The capability of extracting required information is required. |
+| Generation | Models are asked to generate an email, letter, article, etc. The capability of generating texts in a high quality and human-written way is required. |
+| Open QA | Models are asked to answer an open QA question(without context provided). The capability of answering questions with the models' own knowledge base is required. |
+| Roleplay | Models are asked to play the role provided. The capability of engaging in the scenario and effectively interacting with the user is required. |
+| Rewriting | Models are asked to do rewriting tasks such as translation and grammar correction. The capability of rewriting according to different instructions is required. |
+| Summarization | Models are asked to summarize the given paragraph or passage. The capability of summarization is required. |
+
+To better understand each evaluation category, here are some example questions provided.
+
+
+| Evaluation Category | Chinese Example | English Example |
+| :-----------------: | :----------------------------------------------------------- | :----------------------------------------------------------- |
+| Brainstorming | **Example 1:**
请介绍一下人工智能的多个领域。
**Example 2:**
请给出管理家庭财务的3个小技巧。
| **Example 1:**
How can I improve my memory? Any useful techniques you can suggest?
**Example 2:**
What are some ways to increase productivity while working from home? |
+| Chat | **Example 1:**
基于以下角色信息完成一段对话。小张是一名新手爱好者,对养鸡有浓厚的兴趣。老李是一名有丰富经验的养鸡大师。
小张:您好,老李,我最近开始对养鸡感兴趣了,想请教您一些问题。
老李:你好,小张,我很乐意帮助你。你想问些什么?
小张:我想知道如何确定鸡的品种和性别?
老李:确切的品种可以通过鸡的外貌特征来确定,而性别一般是通过鸡卵的大小和形状来判断。还有什么问题吗?
小张:
**Example 2:**
基于以下角色信息完成一段对话。小明是一名医生,一位老年病患者想要停药,但他对病情有所忽视并有担忧;王叔叔是老年病患者的儿子,希望能够听取医生的建议。
小明:你好,王叔叔,我了解你想要让你父亲停药。
王叔叔:是的,我父亲已经吃了那么久的药,我担心药物对他的身体会有副作用。
小明: | **Example 1:**
Complete a conversation based on the following character information. Amy is a 30-year-old chef who runs her own restaurant. Jack is a food blogger who specializes in reviewing local restaurants.
Amy: Hi Jack, I heard that you're a food blogger. Nice to meet you.
Jack: Hi Amy, yes I am. Your restaurant has been receiving a lot of good reviews lately.
Amy: Yes, we use only fresh and quality ingredients, and every dish is carefully crafted.
Jack:
**Example 2:**
Complete a dialogue based on the following role information. A: Elementary student B: Teacher
B: Good morning, Student A. Today we're going to learn about addition and subtraction.
A: Teacher, I already know this very well. Why do I need to learn it again?
B: |
+| Classification | **Example 1:**
新闻标题:今日立夏,有一上联,立夏万物并秀,下联怎么对?
请根据以上新闻标题判断新闻所属的分类,你需要从文化,娱乐,体育,财经,房产,教育,科技,旅游,游戏,军事这十类中选择一个答案。
**Example 2:**
新闻标题:赵丽颖很久没有登上微博热搜了,但你们别急,她只是在憋大招而已。
请根据新闻标题判断新闻所属的分类,你需要从文化,娱乐,体育,财经,房产,教育,科技,旅游,游戏,军事这十类中选择一个答案。 | **Example 1:**
Title: Fighting for Love (2020)
Description: Jasmine got obsessed with a man and now he's obsessed with her. Steamy nights, kisses and rules being broken awaits them. She turned his whole world upside down and now he's doing it to hers. In this free fall, can they survive each others love?\"
Based on the above information, determine which genre the work of art belongs to. You can only choose one from \"sport\", \"horror\", \"drama\", \"history\", \"romance\", \"biography\", \"science fiction\", \"comedy\", \"animation\", \"documentary\", \"music\" and \"news\".
**Example2:**
Title: Summer Breeze: The Isley Brothers Greatest Hits Live (2005)
Description: Filmed in the US in 2005 and captured in excellent form led by Ron Isley's vocals and Ernie Isley's hard edged guitar. Virtually every track is a hit including Shout, Who's That Lady, Twist And Shout, Summer Breeze and Harvest For The World.
Based on the above information, determine which genre the work of art belongs to. You can only choose one from \"sport\", \"horror\", \"drama\", \"history\", \"romance\", \"biography\", \"science fiction\", \"comedy\", \"animation\", \"documentary\", \"music\" and \"news\"." |
+| Closed QA | **Example 1:**
请从以下选项中选择正确答案。以下哪个是世界上最高山峰?
A. 长城
B. 泰山
C. 珠穆朗玛峰
D. 黄山
**Example 2:**
请从以下选项中选择一个最佳答案回答下面的问题。问题:非洲最高的山是哪座山?
选项:
A. 麦金利山
B. 喜马拉雅山
C. 乞力马扎罗山 | **Example 1:**
Which of the following options is NOT a primary color?
(a) yellow
(b) blue
(c) orange
(d) red
**Example 2:**
Choose the correct option to complete the following sentence: \"Harry Potter and the Chamber of Secrets\" is the ________ book in the Harry Potter series.
(A) first
(B) second
(C) third
(D) fourth |
+| Extraction | **Example 1:**
根据以下新闻文本,提取新闻报道时间,例如回答时按照格式“新闻报道时间:2007年8月10日”
新闻文本如下:2007-4-7中新网4月7日电据中国消防在线消息,4月4日晚上7时30分左右,湖南长潭高速公路上发生一起6车连环相撞失火事故。长株潭三地消防部门共出动消防车21台,警力100余人。经过消防官兵近2个小时奋力扑救,大火被成功扑灭。据初步调查,有1人在此次事故中死亡。
**Example 2:**
根据以下新闻文本,提取新闻报道时间,例如回答时按照格式“新闻报道时间:2007年8月10日”
新闻文本如下:2014年1月15日,据外媒《俄罗斯报》报道称,位于北半球的澳大利亚现在正处于炎热的夏季,而近日也到了高温酷暑的时候,当地时间1月14日晚,澳大利亚南部一夜间发生至少250起火灾。受炎热天气及雷雨天气影响,澳大利亚南部一夜间发生至少250起火灾,灾情多集中在维多利亚州。火灾发生后,救援人员立即展开救灾行动。目前,大部分起火点火势已被控制。 | **Example 1:**
Ernest Hemingway, an American literary giant known for his spare and direct writing style, has penned timeless works such as 'The Old Man and the Sea', 'For Whom the Bell Tolls', and 'A Farewell to Arms', which have made a profound impact on the literary world and continue to be widely read and admired today.
Extract the name of the author mentioned above.
**Example 2:**
In the epic fantasy series 'A Song of Ice and Fire', George R.R. Martin weaves a complex web of political intrigue, war, and magic across the fictional continents of Westeros and Essos. Martin's richly developed characters and intricate plotlines have captivated readers worldwide, much like his other acclaimed works such as 'A Clash of Kings' and 'A Storm of Swords'.
Extract the name of the author in the above material. |
+| Generation | **Example 1:**
请撰写一篇文章,介绍如何通过改善生活习惯来预防疾病和延长寿命。
**Example 2:**
请根据以下情节撰写一篇短篇小说:一名年轻人被困在一个荒岛上,他必须想办法生存下去直到被救援。但他很快发现自己并不孤单。 | **Example 1:**
Write a descriptive paragraph about an island to relax and unwind, including details about the location and atmosphere.
**Example 2:**
Can you help me write a persuasive email to my colleagues encouraging them to participate in a charitable fundraising event? |
+| Open QA | **Example 1:**
请问万有引力定律由谁提出的?
**Example 2:**
哪些国家参与了第一次世界大战? | **Example 1:**
What are the four basic tastes of the human palate?
**Example 2:**
Who painted the The Scream? |
+| Rewriting | **Example 1:**
请将以下句子改为正确的语序。
生日快乐你祝他了吗?
**Example 2:**
将以下文本翻译成英语:
“这个周末我要去海边玩” | **Example 1:**
Please translate the following sentences, which are a mixture of Chinese and English, into full English.
我需要买一些healthy snacks,比如nuts和dried fruits,作为我的office的午餐.
**Example 2:**
Please rewrite the sentence using an inverted sentence structure.
We won't begin our journey until the sun sets. |
+| Roleplay | **Example 1:**
我想让你担任Android开发工程师面试官。我将成为候选人,您将向我询问Android开发工程师职位的面试问题。我希望你只作为面试官回答。不要一次写出所有的问题。我希望你只对我进行采访。问我问题,等待我的回答。不要写解释。像面试官一样一个一个问我,等我回答。我的第一句话是“面试官你好”。
**Example 2:**
我想让你扮演讲故事的角色。你会想出引人入胜、富有想象力和吸引观众的有趣故事。它可以是童话故事、教育故事或任何其他类型的有潜力的故事以吸引人们的注意力和想象力。根据目标受众,您可以为您的讲故事环节选择特定的主题或主题,例如,如果是儿童,那么您可以谈论动物;如果是成人,那么基于历史的故事可能会更好地吸引他们等。我的第一个请求是我需要一个关于毅力的有趣故事。 | **Example 1:**
Assume the role of a marriage counselor. Develop a series of communication exercises for a couple who are experiencing difficulties in their relationship. These exercises should promote active listening, empathy, and effective expression of emotions. Your first assignment is to provide a set of three exercises that focus on resolving conflicts and rebuilding trust.
**Example 2: **
I want you to act as a travel agent. I will tell you my desired destination, travel dates, and budget, and it will be your job to suggest the best travel itinerary for me. Your recommendations should include the best transportation options, hotel accommodations, and any popular tourist attractions nearby. My first request is "I want to plan a trip to Tokyo for a week, with a budget of $2000. I want to explore the culture and food of the city." |
+| Summarization | **Example 1:**
请简要总结概括以下段落材料。
当地时间29日,泰国卫生部通报,新增143名新冠肺炎确诊病例和1名死亡病例。截止到当地时间29日上午,泰国累计确诊病例1388例,其中泰国籍1172例,非泰国籍216例。死亡病例累计7例。(原题为《泰国新增143例新冠肺炎确诊病例累计确诊1388例》)
**Example 2:**
请简要总结概括以下段落材料。
近期,参与京雄高铁站站房建设的中铁十二局,因在施工过程中存在环境违法行为被雄安新区公开通报。通报发出后,引起社会广泛关注。近日,人民网记者从雄安新区相关部门及中铁十二局获悉,新区有关部门已经集中约谈了中铁十二局等24个参与雄安建设的项目单位。对于约谈内容和结果,中铁十二局有关宣传负责人回应:“具体内容不清楚,最好找雄安新区相关部门了解情况。”新区有关部门负责人表示,此前涉及的环境违法行为,中铁十二局已基本整改到位,但约谈内容和结果暂不公开,接下来,将按部就班推进环境治理工作。(原题为《雄安新区:中铁十二局涉环境违法已基本整改到位》) | **Example 1:**
The 21 year-old-woman was treated by paramedics after the kitchen fire in Botfield Road in Shifnal, Shropshire. West Mercia Police said it is treating Wednesday morning's incident as arson and are appealing for any witnesses to contact them.The 50-year-old man has been arrested on suspicion of arson with intent to endanger life. For more on this and other stories from Shropshire.
Please briefly summarize the above material within 20 words.
**Example 2:**
South Wales Police were called to a property in Heolgerrig, Merthyr Tydfil, at about 13:40 BST on Sunday. The child was airlifted to Prince Charles Hospital but died shortly afterwards. Police are investigating the circumstances surrounding the incident and have appealed for witnesses. The girl's family are being supported by specially trained officers.
Please briefly summarize the above material within 20 words. |
+
+
+### Evaluation Metrics
+
+#### GPT Evaluation
+
+GPT evaluation uses GPT models to evaluate the prediction of different models and different pre-defined evaluation metrics are applied to different categories. The following table shows the 11 pre-defined evaluation metrics in Chinese:
+
+| Evaluation Metric | Prompt Words | CoT(Chain-of-Thought) |
+| :-------------------: | :----------------------------------------------------------- | :----------------------------------------------------------- |
+| Language organization | 语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。 | 1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。
2.检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说
3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。
4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。
5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。
6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。 |
+| Relevance | 切题(1-5):答案内容是否切题,不答非所问,并且严格遵照题目要求。 | 1. 阅读题目,确定题目所问的问题是什么,以及需要回答哪些方面的问题。
2. 阅读答案,确认答案是否直接回答了题目所问的问题。
3. 检查答案是否严格遵照了题目的要求,包括答题方式、答题长度、答题格式等等。
4. 根据以上因素综合评估答案的切题程度,并给出一个1到5的分数,其中5表示答案非常切题,而1表示答案完全没有切题。 |
+| Creativity | 创意性(1-5):某些头脑风暴问题可能需要答案具有创意,提出新的思路。 | 1. 仔细阅读所提供的头脑风暴问题,确保你理解问题的要点和背景。
2. 根据你的知识和经验,判断所提供的答案是否可行。如果答案不可行,则创意性评分可能会受到影响。
3. 考虑答案中是否包含新颖的想法或独特的思路。答案可能与已知的解决方案有所重叠,但仍然可以被认为是有创意的,只要它提供了新的角度或方法来解决问题。
4. 根据答案的创意性,给出一个1到5的评分。如果答案缺乏创意,则应给出一个较低的评分。如果答案具有创意并提供了新的思路,应给出一个较高的评分。 |
+| Practicality | 实用性(1-5):某些头脑风暴问题可能需要答案提出实用的建议或解决方法。 | 1. 仔细阅读所提供的头脑风暴问题,确保你理解问题的要点和背景。
2. 根据你的知识和经验,判断所提供的答案是否可行。如果答案不可行,则实用性评分可能会受到影响。
3. 考虑答案中提出的建议或解决方法是否实用并可行。答案可能看起来很好,但如果无法实现或应用,则实用性评分可能会受到影响。
4. 根据答案的实用性,给出一个1到5的评分。如果答案缺乏实用性,则应给出一个较低的评分。如果答案提出了实用的建议或解决方法,并且可以很好地解决问题,则应给出一个较高的评分。 |
+| Correctness | 正确性(1-5):答案应该符合常识、生活实际等等 | 1. 仔细阅读所提供的头脑风暴问题,确保你理解问题的要点和背景。
2. 根据你的知识和经验,判断所提供的答案是否可行。如果答案不可行,则正确性评分可能会受到影响。
3. 考虑答案中所提供的信息是否正确、符合常识、生活实际等等。如果答案中存在明显的错误或不合理之处,则正确性评分可能会受到影响。
4. 根据答案的正确性,给出一个1到5的评分。如果答案存在明显的错误或不合理之处,则应给出一个较低的评分。如果答案正确、符合常识、生活实际等等,则应给出一个较高的评分。 |
+| Naturalness | 自然(1-5):答案是否自然,并且符合问题给定的身份。 | 1. 阅读题目,确定题目提供的身份信息。
2. 检查答案内容是否符合题目给定的身份。
3. 根据以上因素,对该回答的自然性进行打分,分数从1到5,其中1表示不自然,5表示非常自然,并符合问题给定的身份。 |
+| Engagingness | 参与感(1-5):答案是否对前面的对话内容做出了恰当的反应,是否理解对话的语境和背景。 | 1. 阅读题目,确定对话的语境和背景。
2. 检查答案是否充分理解对话的语境和背景,能否自然地融入到对话中而不显得突兀。
3. 根据以上因素,对该回答的参与感进行打分,分数从1到5,其中1表示没有参与感,5表示非常有参与感,并且恰当地理解了对话的语境和背景。 |
+| Reasonableness | 合理性(1-5):答案是否能够与前面的对话内容形成逻辑上的衔接,是否符合常理,能否在这个上下文中合理存在。 | 1. 阅读题目,确定对话的主题以及问题期望的回答方向。
2. 判断答案是否能够与前面的对话内容形成逻辑上的衔接,是否符合常理,能否在这个上下文中合理存在。
3. 根据以上因素,对该回答的合理性进行打分,分数从1到5,其中1表示不合理,5表示非常合理,并且能够与前面的对话内容形成逻辑上的衔接,并符合常理。 |
+| Diversity | 多样性(1-5):答案使用语言是否优美,具有有一定的创造性和想象力。然而,回答也应该保持合理和适度,不要过于夸张或离题。 | 1. 仔细阅读整个回答,确保完全理解回答所表达的内容和主题。
2. 在阅读回答的同时,注意语言的质量,例如措辞是否正确,语言是否生动等。
3. 检查回答的创造性和想象力,看看回答是否能够吸引人阅读下去。
4. 检查回答的合理性和适度,看看回答是否夸张或离题。5. 将多样性的评分打分在1到5之间,5分表示回答的质量很好,能够吸引人阅读,1分表示回答的内容生硬或者有离题的问题。 |
+| Fidelity | 保真度(1-5):答案是否能够严格遵守角色的设定回答给定的请求。 | 1. 仔细阅读问题,了解角色在问题中的设定和表现,包括职业、背景、观点、性格等方面。
阅读题目的请求,确认回答请求时需要注意的细节。
3. 对比提供的回答与该角色的设定,评估回答是否能够严格遵守角色的设定。
4. 结合以上评估结果给出保真度的评分,范围从1到5分,其中1分表示回答与角色设定完全不符,5分表示回答完全符合角色设定且满足给定请求。 |
+| Conciseness | 简明扼要(1-5):答案是否简明扼要,没有冗余内容。 | 1. 阅读题目,提取出材料的重点。
2. 阅读该总结,并注意其中的主要观点和信息。
3. 评估总结的长度。一个简明扼要的总结通常应该在几句话或几段文字内传达关键信息,而不是冗长的段落或文章。
4. 检查总结是否包含与主要观点无关的信息或冗余信息。
5. 确定总结涵盖了材料中的关键信息,并且没有忽略任何重要细节。
6. 给总结打出1-5的分数,其中5表示总结简明扼要,没有冗余内容,而1表示总结冗长或包含不必要的信息,难以理解或记忆。根据您的判断,打出适当的得分。 |
+
+GPT models evaluate the quality of model predictions based on the given prompt words and gives a score between 1-5.
+
+#### Automatic Evaluation
+
+Automated metrics evaluate the capability of a model by comparing model predictions with reference answers.
+There are two ways to obtain reference answers:
+
+* For instruction coming from human-designed problems, the reference answers are generated by GPT-3.5, such as roleplay, chat.
+* For instruction related with classic NLP problems, the reference answers are collected from open-sourced dataset with target answers, such as classification, extraction, summarization.
+
+There are 5 types of automatic evaluation metrics listed in the table below:
+
+| Automatic Evaluation Metric | Description |
+| :---------------------------------: | :----------------------------------------------------------- |
+| BLEU-n | Measure the accuracy between prediction and reference.
BLEU-1 (Unigram) evaluates accuracy in word level.
BLEU-n (n-gram) evaluate the fluency in sentence level. |
+| ROUGE | ROUGE-N measures the number of matching n-grams between prediction and reference.
ROUGE-L measures the number of matching longest common subsequence (LCS) between prediction and reference. |
+| Distinct | Measure the diversity of generation text by counting the unique n-grams. |
+| BERTScore | Measure the semantic similarity between tokens of predictions and references with BERT. |
+| Precision
Recall
F1 Score | Measure the number of overlaps between prediction and reference (design for classification and extraction categories). |
+
+## Evaluation Process
+
+### Data Format
+
+#### Target Answers / Predictions
+
+A JSON file contains one list. Each element in the list is a target answer / prediction record for one instruction / question.
+An element should have the following fields:
+
+* `category` (str, compulsory): The category of the instruction / question.
+* `instruction` (str, compulsory): The instruction / question for the LLM.
+* `input` (str, optional): The additional context of the instruction / question.
+* `output` (str, optional): The sample output of the instruction (default: GPT-3.5).
+* `target` (str, optional): The target answer for the instruction.
+* `id` (int, compulsory): The ID of the instruction / question.
+
+If the `input` has a target answer, the `output` can be empty. Otherwise, we generate answers from GPT-3.5 as the `output`, and the `target` field is empty.
+
+Example:
+
+```json
+[
+ {
+ "category": "brainstorming",
+ "instruction": "请介绍一下人工智能的多个领域。",
+ "input": "",
+ "output": "{GPT-3.5 Answers}",
+ "target": "",
+ "id": 1
+ },
+ {
+ "category": "classification",
+ "instruction": "新闻标题:为什么电影《倩女幽魂》中燕赤霞一个道士却拿着金刚经?请根据新闻标题判断新闻所属的分类,你需要从文化,娱乐,体育,财经,房产,教育,科技,旅游,游戏,军事这十类中选择一个答案。",
+ "input": "",
+ "output": "",
+ "target": "{target answer}",
+ "id": 2
+ }
+]
+```
+
+#### Model Answers / Predictions
+
+A JSON file contains one list. Each element in the list is a model answer / prediction record for one instruction / question.
+
+An element should have the following fields:
+
+* `category` (str, compulsory): The category of the instruction / question.
+* `instruction` (str, compulsory): The instruction / question for the LLM.
+* `input` (str, optional): The additional context of the instruction / question.
+* `output` (str, compulsory): The output from the LLM.
+* `target` (str, optional): The target answer for the instruction.
+* `id` (int, compulsory): The ID of the instruction / question.
+
+Example:
+
+```json
+[
+ {
+ "category": "brainstorming",
+ "instruction": "请介绍一下人工智能的多个领域。",
+ "input": "",
+ "output": "{Model Answers / Predictions}",
+ "target": "",
+ "id": 1
+ },
+ {
+ "category": "classification",
+ "instruction": "新闻标题:为什么电影《倩女幽魂》中燕赤霞一个道士却拿着金刚经?请根据新闻标题判断新闻所属的分类,你需要从文化,娱乐,体育,财经,房产,教育,科技,旅游,游戏,军事这十类中选择一个答案。",
+ "input": "",
+ "output": "{Model Answers / Predictions}",
+ "target": "{target answer}",
+ "id": 2
+ }
+]
+```
+
+### Prompt
+
+#### Battle Prompt
+
+The following is the Chinese battle prompt. In the battle prompt, the question and answers from two different models are fed into the prompt template. You can find an example battle prompt file in `prompt/battle_prompt`.
+
+```json
+{
+ "id": 1,
+ "system_prompt": "你是一个检查回答质量的好助手。",
+ "prompt_template": "[问题]\n{question}\n\n[1号AI助手的答案]\n{answer_1}\n\n[1号AI助手答案终止]\n\n[2号AI助手的答 案]\n{answer_2}\n\n[2号AI助手答案终止]\n\n[要求]\n{prompt}\n\n",
+ "prompt": "我们需要你评价这两个AI助手回答的性能。\n请对他们的回答的有用性、相关性、准确性、详细程度进行评分。每个AI助手都会得到一个1到10分的总分,分数越高表示整体表现越好。\n请首先输出一行,该行只包含两个数值,分别表示1号和2号AI助手的分数。这两个分数之间要有一个空格。在随后的一行中,请对你的评价作出全面的解释,避免任何潜在的偏见,并确保AI助手回答的顺序不会影响您的判断。"
+}
+```
+
+#### Evaluation Prompt
+
+The following is an example of a Chinese GPT evaluation prompt. In an evaluation prompt, you should define your metrics in `metrics` and provide CoT(Chain-of-Thought) in `CoT`. You can find an example evaluation prompt file in `prompt/evaluation_prompt`.
+
+```json
+{
+ "brainstorming": {
+ "id": 1,
+ "category": "brainstorming",
+ "metrics": {
+ "language organization": "语言组织(1-5):答案语言是否流畅、连贯,使用正确的语法,具有一定逻辑性,使用恰当的连接词、过渡词等等。"
+ },
+ "CoT": {
+ "language organization": "1. 阅读答案,并检查是否有语法错误、用词不当或其他显著的错误。\n2. 检查答案是否具有逻辑性,能够按照合理的顺序传达信息并且能够自圆其说。\n3. 确定答案是否与问题或主题相关,并且能够传达清晰的信息。\n4. 检查答案是否连贯,是否使用适当的转换和过渡来保持句子和段落之间的连贯性。\n5. 检查答案是否具有明确的结构和组织方式,使得读者可以轻松理解信息的层次和结构。\n6. 根据以上因素综合评估答案的语言组织,并给出一个1到5的分数,其中5表示语言组织非常好,而1表示语言组织非常差。\n\n语言组织:"
+ },
+ "prompt": "你是一个好助手。请你为下面“头脑风暴”问题的答案打分。\n\n问题如下:\n\n{question}\n\n答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ }
+}
+```
+
+`"metrics"`: the metrics that can be used in GPT evaluation. This field determines which metrics can be added to your config file.
+
+`"CoT"`: evaluation steps you prompt to GPT models for each metric defined in `"metrics"`.
+
+### Evaluation
+
+#### Configuration
+
+The following is an example of a Chinese config file. The configuration file can control how the pipeline evaluates the model. You need to specify GPT evaluation metrics and automatic metrics in key `GPT` and `Metrics`. You can find an example Chinese config file in `config`.
+
+```json
+{
+ "language": "cn",
+ "category": {
+ "brainstorming": {
+ "GPT": ["relevance", "creativity", "practicality", "correctness"],
+ "Metrics": ["Distinct"]
+ },
+ "chat": {
+ "GPT": [ "relevance", "naturalness", "engagingness", "reasonableness"],
+ "Metrics": ["Distinct"]
+ }
+ }
+}
+```
+
+`"language"`: the language used to evaluate the model capability. We only support Chinese `"cn"` for now.
+
+`"category"`: the category/categories needed to evaluate the model capability.
+
+`"GPT"`: the metrics you want to use for GPT evaluation.
+
+`"Metrics"`: the metrics you want to use for automatic metrics evaluation.
+
+You can create your config file based on available settings listed in following table.
+
+| "category" | "GPT" | "Metrics" |
+| :--------------: | :---------------------: | :---------: |
+| "brainstorming" | "language organization" | "BLEU" |
+| "chat" | "relevance" | "ROUGE" |
+| "classification" | "creativity" | "Distinct" |
+| "closed_qa" | "practicality" | "BERTScore" |
+| "extraction" | "correctness" | "Precision" |
+| "generation" | "naturalness" | "Recall" |
+| "open_qa" | "engagingness" | "F1 score" |
+| "rewriting" | "reasonableness" | |
+| "roleplay" | "diversity" | |
+| "summarization" | "fidelity" | |
+| | "conciseness" | |
+
+> **NOTE:** For categories which don't have standard answers such as `brainstorming`, you should avoid using automatic metrics such as `BLEU` and `ROUGE` which are based on similarity measures and you should use `Distinct` instead in your config file.
+
+#### Evaluate
+
+After setting the configuration file, you can evaluate the model using `eval.py`. If you want to make comparisons between answers of two different models, you should specify two answer files in the argument `answer_file_list` and two model names in the argument `model_name_list`. If you want to evaluate one answer file, the length of both `answer_file_list` and `model_name_list` should be 1 and the program will perform evaluation using automatic metrics and GPT models.
+
+An example script is provided as follows:
+
+```shell
+python eval.py \
+ --config_file "path to the config file" \
+ --battle_prompt_file "path to the prompt file for battle" \
+ --gpt_evaluation_prompt_file "path to the prompt file for gpt evaluation" \
+ --target_file "path to the target answer file" \
+ --answer_file_list "path to the answer files of at most 2 models" \
+ --model_name_list "the names of at most 2 models" \
+ --gpt_model "which GPT model to use for evaluation" \
+ --save_path "path to save results" \
+ --openai_key "your openai key" \
+```
+
+## FAQ
+
+How can I add a new GPT evaluation metric?
+
+For example, if you want to add a new metric `persuasiveness` into category `brainstorming`, you should add the metric definition and its corresponding CoT(Chain-of-thought) in the evaluation prompt file in `prompt/evaluation_promt`. The CoT can be generated using ChatGPT. You can prompt ChatGPT to generate evaluation steps for the new metric.
+
+```json
+{
+ "brainstorming": {
+ "id": 1,
+ "category": "brainstorming",
+ "metrics": {
+ "persuasiveness": "说服力(1-5):XXX"
+ },
+ "CoT": {
+ "persuasiveness": "XXX\n\n说服力:"
+ },
+ "prompt": "你是一个好助手。请你为下面“头脑风暴”问题的答案打分。\n\n问题如下:\n\n{question}\n\n答案如下:\n\n{answer}\n\n评分的指标如下:\n\n{metric}\n\n请你遵照以下的评分步骤:\n\n{steps}"
+ }
+}
+```
+
+ @@ -175,11 +175,11 @@ In this way, users can train their models as usual.
In our latest example, a Gemini + ZeRO DDP model is also defined to reduce overhead and improve efficiency.For the details of this part, please refer to [ZeRO](../features/zero_with_chunk.md). You can combine these two parts to understand our entire training process:
```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
return model
diff --git a/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md b/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md
index b26599740c5f..6adfe4f113da 100644
--- a/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md
+++ b/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md
@@ -195,7 +195,7 @@ def build_cifar(batch_size):
## Training ViT using pipeline
-You can set the size of pipeline parallel and number of microbatches in config. `NUM_CHUNKS` is useful when using interleved-pipeline (for more details see [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://arxiv.org/abs/2104.04473) ). The original batch will be split into `num_microbatches`, and each stage will load a micro batch each time. Then we will generate an approriate schedule for you to execute the pipeline training. If you don't need the output and label of model, you can set `return_output_label` to `False` when calling `trainer.fit()` which can further reduce GPU memory usage.
+You can set the size of pipeline parallel and number of microbatches in config. `NUM_CHUNKS` is useful when using interleaved-pipeline (for more details see [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://arxiv.org/abs/2104.04473) ). The original batch will be split into `num_microbatches`, and each stage will load a micro batch each time. Then we will generate an appropriate schedule for you to execute the pipeline training. If you don't need the output and label of model, you can set `return_output_label` to `False` when calling `trainer.fit()` which can further reduce GPU memory usage.
You should `export DATA=/path/to/cifar`.
diff --git a/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md b/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
index b2438a1cf562..a2deaeb88893 100644
--- a/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
+++ b/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
@@ -16,14 +16,14 @@ In this example for ViT model, Colossal-AI provides three different parallelism
We will show you how to train ViT on CIFAR-10 dataset with these parallelism techniques. To run this example, you will need 2-4 GPUs.
-## Tabel of Contents
+## Table of Contents
1. Colossal-AI installation
2. Steps to train ViT with data parallelism
3. Steps to train ViT with pipeline parallelism
4. Steps to train ViT with tensor parallelism or hybrid parallelism
## Colossal-AI Installation
-You can install Colossal-AI pacakage and its dependencies with PyPI.
+You can install Colossal-AI package and its dependencies with PyPI.
```bash
pip install colossalai
```
@@ -31,7 +31,7 @@ pip install colossalai
## Data Parallelism
-Data parallism is one basic way to accelerate model training process. You can apply data parallelism to training by only two steps:
+Data parallelism is one basic way to accelerate model training process. You can apply data parallelism to training by only two steps:
1. Define a configuration file
2. Change a few lines of code in train script
@@ -94,7 +94,7 @@ from torchvision import transforms
from torchvision.datasets import CIFAR10
```
-#### Lauch Colossal-AI
+#### Launch Colossal-AI
In train script, you need to initialize the distributed environment for Colossal-AI after your config file is prepared. We call this process `launch`. In Colossal-AI, we provided several launch methods to initialize the distributed backend. In most cases, you can use `colossalai.launch` and `colossalai.get_default_parser` to pass the parameters via command line. Besides, Colossal-AI can utilize the existing launch tool provided by PyTorch as many users are familiar with by using `colossalai.launch_from_torch`. For more details, you can view the related [documents](https://www.colossalai.org/docs/basics/launch_colossalai).
@@ -613,7 +613,7 @@ NUM_MICRO_BATCHES = parallel['pipeline']
TENSOR_SHAPE = (BATCH_SIZE // NUM_MICRO_BATCHES, SEQ_LENGTH, HIDDEN_SIZE)
```
-Ohter configs:
+Other configs:
```python
# hyper parameters
# BATCH_SIZE is as per GPU
diff --git a/docs/source/en/basics/booster_api.md b/docs/source/en/basics/booster_api.md
index 18dec4500f76..a446ff31be83 100644
--- a/docs/source/en/basics/booster_api.md
+++ b/docs/source/en/basics/booster_api.md
@@ -14,9 +14,9 @@ In our new design, `colossalai.booster` replaces the role of `colossalai.initial
### Plugin
Plugin is an important component that manages parallel configuration (eg: The gemini plugin encapsulates the gemini acceleration solution). Currently supported plugins are as follows:
-***GeminiPlugin:*** This plugin wrapps the Gemini acceleration solution, that ZeRO with chunk-based memory management.
+***GeminiPlugin:*** This plugin wraps the Gemini acceleration solution, that ZeRO with chunk-based memory management.
-***TorchDDPPlugin:*** This plugin wrapps the DDP acceleration solution, it implements data parallelism at the module level which can run across multiple machines.
+***TorchDDPPlugin:*** This plugin wraps the DDP acceleration solution, it implements data parallelism at the module level which can run across multiple machines.
***LowLevelZeroPlugin:*** This plugin wraps the 1/2 stage of Zero Redundancy Optimizer. Stage 1 : Shards optimizer states across data parallel workers/GPUs. Stage 2 : Shards optimizer states + gradients across data parallel workers/GPUs.
@@ -25,24 +25,6 @@ Plugin is an important component that manages parallel configuration (eg: The ge
{{ autodoc:colossalai.booster.Booster }}
-{{ autodoc:colossalai.booster.Booster.boost }}
-
-{{ autodoc:colossalai.booster.Booster.backward }}
-
-{{ autodoc:colossalai.booster.Booster.no_sync }}
-
-{{ autodoc:colossalai.booster.Booster.save_model }}
-
-{{ autodoc:colossalai.booster.Booster.load_model }}
-
-{{ autodoc:colossalai.booster.Booster.save_optimizer }}
-
-{{ autodoc:colossalai.booster.Booster.load_optimizer }}
-
-{{ autodoc:colossalai.booster.Booster.save_lr_scheduler }}
-
-{{ autodoc:colossalai.booster.Booster.load_lr_scheduler }}
-
## Usage
In a typical workflow, you should launch distributed environment at the beginning of training script and create objects needed (such as models, optimizers, loss function, data loaders etc.) firstly, then call `colossalai.booster` to inject features into these objects, After that, you can use our booster APIs and these returned objects to continue the rest of your training processes.
diff --git a/docs/source/en/basics/booster_plugins.md b/docs/source/en/basics/booster_plugins.md
index 0362f095af2b..5e2586b836ad 100644
--- a/docs/source/en/basics/booster_plugins.md
+++ b/docs/source/en/basics/booster_plugins.md
@@ -63,6 +63,10 @@ More details can be found in [Pytorch Docs](https://pytorch.org/docs/main/genera
> ⚠ This plugin is not available when torch version is lower than 1.12.0.
+> ⚠ This plugin does not support save/load sharded model checkpoint now.
+
+> ⚠ This plugin does not support optimizer that use multi params group.
+
More details can be found in [Pytorch Docs](https://pytorch.org/docs/main/fsdp.html).
{{ autodoc:colossalai.booster.plugin.TorchFSDPPlugin }}
diff --git a/docs/source/en/basics/colotensor_concept.md b/docs/source/en/basics/colotensor_concept.md
index 909c5e4d3c6f..abe470fe0794 100644
--- a/docs/source/en/basics/colotensor_concept.md
+++ b/docs/source/en/basics/colotensor_concept.md
@@ -2,6 +2,8 @@
Author: [Jiarui Fang](https://github.com/feifeibear), [Hongxin Liu](https://github.com/ver217) and [Haichen Huang](https://github.com/1SAA)
+> ⚠️ The information on this page is outdated and will be deprecated.
+
**Prerequisite:**
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
- [Distributed Training](../concepts/distributed_training.md)
@@ -50,7 +52,7 @@ An instance of class [ComputeSpec](https://colossalai.readthedocs.io/en/latest/c
## Example
-Let's see an example. A ColoTensor is initialized and sharded on 8 GPUs using tp_degree=4, dp_dgree=2. And then the tensor is sharded along the last dim among the TP process groups. Finally, we reshard it along the first dim (0 dim) among the TP process groups. We encourage users to run the code and observe the shape of each tensor.
+Let's see an example. A ColoTensor is initialized and sharded on 8 GPUs using tp_degree=4, dp_degree=2. And then the tensor is sharded along the last dim among the TP process groups. Finally, we reshard it along the first dim (0 dim) among the TP process groups. We encourage users to run the code and observe the shape of each tensor.
```python
diff --git a/docs/source/en/basics/configure_parallelization.md b/docs/source/en/basics/configure_parallelization.md
index 4ac0299eac14..fd1e72ccd45a 100644
--- a/docs/source/en/basics/configure_parallelization.md
+++ b/docs/source/en/basics/configure_parallelization.md
@@ -2,6 +2,8 @@
Author: Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster Plugins](../basics/booster_plugins.md) for more information.
+
**Prerequisite:**
- [Distributed Training](../concepts/distributed_training.md)
- [Paradigms of Parallelism](../concepts/paradigms_of_parallelism.md)
diff --git a/docs/source/en/basics/define_your_config.md b/docs/source/en/basics/define_your_config.md
index d2569691b7dc..048ffcacbb8f 100644
--- a/docs/source/en/basics/define_your_config.md
+++ b/docs/source/en/basics/define_your_config.md
@@ -2,6 +2,9 @@
Author: Guangyang Lu, Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster API](../basics/booster_api.md) for more information.
+
+
**Prerequisite:**
- [Distributed Training](../concepts/distributed_training.md)
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
diff --git a/docs/source/en/basics/engine_trainer.md b/docs/source/en/basics/engine_trainer.md
index bbe32ed5a3b5..d2f99563f042 100644
--- a/docs/source/en/basics/engine_trainer.md
+++ b/docs/source/en/basics/engine_trainer.md
@@ -2,6 +2,8 @@
Author: Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster API](../basics/booster_api.md) for more information.
+
**Prerequisite:**
- [Initialize Features](./initialize_features.md)
diff --git a/docs/source/en/basics/initialize_features.md b/docs/source/en/basics/initialize_features.md
index e768d2022ad8..b89017427476 100644
--- a/docs/source/en/basics/initialize_features.md
+++ b/docs/source/en/basics/initialize_features.md
@@ -2,6 +2,8 @@
Author: Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster API](../basics/booster_api.md) for more information.
+
**Prerequisite:**
- [Distributed Training](../concepts/distributed_training.md)
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
diff --git a/docs/source/en/basics/model_checkpoint.md b/docs/source/en/basics/model_checkpoint.md
index 09d44e7c2709..70334f1c41e7 100644
--- a/docs/source/en/basics/model_checkpoint.md
+++ b/docs/source/en/basics/model_checkpoint.md
@@ -2,6 +2,8 @@
Author : Guangyang Lu
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster Checkpoint](../basics/booster_checkpoint.md) for more information.
+
**Prerequisite:**
- [Launch Colossal-AI](./launch_colossalai.md)
- [Initialize Colossal-AI](./initialize_features.md)
diff --git a/docs/source/en/features/3D_tensor_parallel.md b/docs/source/en/features/3D_tensor_parallel.md
index b9e98eac9350..0e28f08b23c9 100644
--- a/docs/source/en/features/3D_tensor_parallel.md
+++ b/docs/source/en/features/3D_tensor_parallel.md
@@ -67,7 +67,7 @@ Given $P=q \times q \times q$ processors, we present the theoretical computation
## Usage
-To enable 3D tensor parallelism for our model, e.g. on 8 GPUs, we need to configure the parallism setting as below.
+To enable 3D tensor parallelism for our model, e.g. on 8 GPUs, we need to configure the parallelism setting as below.
```python
CONFIG = dict(parallel=dict(
data=1,
diff --git a/docs/source/en/features/cluster_utils.md b/docs/source/en/features/cluster_utils.md
index 1903d64d2563..7331d5e73ae0 100644
--- a/docs/source/en/features/cluster_utils.md
+++ b/docs/source/en/features/cluster_utils.md
@@ -13,20 +13,4 @@ We provide a utility class `colossalai.cluster.DistCoordinator` to coordinate di
{{ autodoc:colossalai.cluster.DistCoordinator }}
-{{ autodoc:colossalai.cluster.DistCoordinator.is_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.is_node_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.is_last_process }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.print_on_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.print_on_node_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.priority_execution }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.destroy }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.block_all }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.on_master_only }}
+
diff --git a/docs/source/en/features/gradient_accumulation.md b/docs/source/en/features/gradient_accumulation.md
index ecc209fbac8d..91d89b815bf7 100644
--- a/docs/source/en/features/gradient_accumulation.md
+++ b/docs/source/en/features/gradient_accumulation.md
@@ -1,4 +1,4 @@
-# Gradient Accumulation
+# Gradient Accumulation (Outdated)
Author: Shenggui Li, Yongbin Li
@@ -43,3 +43,5 @@ iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0
iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
```
+
+
diff --git a/docs/source/en/features/gradient_accumulation_with_booster.md b/docs/source/en/features/gradient_accumulation_with_booster.md
new file mode 100644
index 000000000000..201e3bc2b643
--- /dev/null
+++ b/docs/source/en/features/gradient_accumulation_with_booster.md
@@ -0,0 +1,144 @@
+# Gradient Accumulation (Latest)
+
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+## Introduction
+
+Gradient accumulation is a common way to enlarge your batch size for training. When training large-scale models, memory can easily become the bottleneck and the batch size can be very small, (e.g. 2), leading to unsatisfactory convergence. Gradient accumulation works by adding up the gradients calculated in multiple iterations, and only update the parameters in the preset iteration.
+
+## Usage
+
+It is simple to use gradient accumulation in Colossal-AI. Just call `booster.no_sync()` which returns a context manager. It accumulate gradients without synchronization, meanwhile you should not update the weights.
+
+## Hands-on Practice
+
+We now demonstrate gradient accumulation. In this example, we let the gradient accumulation size to be 4.
+
+### Step 1. Import libraries in train.py
+Create a `train.py` and import the necessary dependencies. The version of `torch` should not be lower than 1.8.1.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet18
+from torch.utils.data import DataLoader
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.cluster.dist_coordinator import priority_execution
+```
+
+### Step 2. Initialize Distributed Environment
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md) for other initialization methods.
+
+```python
+# initialize distributed setting
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+```
+
+### Step 3. Create training components
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])` to a path on your machine. Data will be automatically downloaded to the root path.
+
+```python
+# define the training hyperparameters
+BATCH_SIZE = 128
+GRADIENT_ACCUMULATION = 4
+
+# build resnet
+model = resnet18(num_classes=10)
+
+# build dataloaders
+with priority_execution():
+ train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+```
+
+### Step 4. Inject Feature
+Create a `TorchDDPPlugin` object to instantiate a `Booster`, and boost these training components.
+
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, _ = booster.boost(model=model,
+ optimizer=optimizer,
+ criterion=criterion,
+ dataloader=train_dataloader)
+```
+
+### Step 5. Train with Booster
+Use booster in a normal training loops, and verify gradient accumulation. `param_by_iter` is to record the distributed training information.
+```python
+optimizer.zero_grad()
+for idx, (img, label) in enumerate(train_dataloader):
+ sync_context = booster.no_sync(model)
+ img = img.cuda()
+ label = label.cuda()
+ if idx % (GRADIENT_ACCUMULATION - 1) != 0:
+ with sync_context:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ else:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.step()
+ optimizer.zero_grad()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ param_by_iter.append(str(ele_1st.item()))
+
+ if idx != 0 and idx % (GRADIENT_ACCUMULATION - 1) == 0:
+ break
+
+ for iteration, val in enumerate(param_by_iter):
+ print(f'iteration {iteration} - value: {val}')
+
+ if param_by_iter[-1] != param_by_iter[0]:
+ print('The parameter is only updated in the last iteration')
+
+```
+
+### Step 6. Invoke Training Scripts
+To verify gradient accumulation, we can just check the change of parameter values. When gradient accumulation is set, parameters are only updated in the last step. You can run the script using this command:
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
+You will see output similar to the text below. This shows gradient is indeed accumulated as the parameter is not updated
+in the first 3 steps, but only updated in the last step.
+
+```text
+iteration 0, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
+```
+
+
diff --git a/docs/source/en/features/gradient_clipping.md b/docs/source/en/features/gradient_clipping.md
index f606dde6c393..5a23c68e3e27 100644
--- a/docs/source/en/features/gradient_clipping.md
+++ b/docs/source/en/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# Gradient Clipping
+# Gradient Clipping (Outdated)
Author: Boxiang Wang, Haichen Huang, Yongbin Li
@@ -60,3 +60,5 @@ to demonstrate gradient clipping. In this example, we set the gradient clipping
```shell
python -m torch.distributed.launch --nproc_per_node 1 --master_addr localhost --master_port 29500 train_with_engine.py
```
+
+
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
new file mode 100644
index 000000000000..341a608a5c7b
--- /dev/null
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -0,0 +1,142 @@
+# Gradient Clipping (Latest)
+
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+**Related Paper**
+- [On the difficulty of training Recurrent Neural Networks](https://arxiv.org/abs/1211.5063)
+
+## Introduction
+
+In order to speed up training process and seek global optimum for better performance, more and more learning rate schedulers have been proposed. People turn to control learning rate to adjust descent pace during training, which makes gradient vector better to be uniformed in every step. In that case, the descent pace can be controlled as expected. As a result, gradient clipping, a technique which can normalize the gradient vector to circumscribe it in a uniformed length, becomes indispensable for those who desire their better performance of their models.
+
+You do not have to worry about implementing gradient clipping when using Colossal-AI, we support gradient clipping in a powerful and convenient way. All you need is just an additional command in your configuration file.
+
+## Why you should use gradient clipping provided by Colossal-AI
+
+The reason of why we do not recommend users to write gradient clipping by themselves is that naive gradient clipping may fail when applying tensor parallelism, pipeline parallelism or MoE.
+
+According to the illustration below, each GPU only owns a portion of parameters of the weight in a linear layer. To get correct norm of gradient vector of the weight of the linear layer, the norm of every gradient vector in each GPU should be summed together. More complicated thing is that the distribution of bias is different from the distribution of the weight. The communication group is different in the sum operation.
+
+(PS: This situation is an old version of 2D parallelism, the implementation in the code is not the same. But it is a good example about the difficulty to unify all communication in gradient clipping.)
+
+
+
@@ -175,11 +175,11 @@ In this way, users can train their models as usual.
In our latest example, a Gemini + ZeRO DDP model is also defined to reduce overhead and improve efficiency.For the details of this part, please refer to [ZeRO](../features/zero_with_chunk.md). You can combine these two parts to understand our entire training process:
```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
return model
diff --git a/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md b/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md
index b26599740c5f..6adfe4f113da 100644
--- a/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md
+++ b/docs/source/en/advanced_tutorials/train_vit_using_pipeline_parallelism.md
@@ -195,7 +195,7 @@ def build_cifar(batch_size):
## Training ViT using pipeline
-You can set the size of pipeline parallel and number of microbatches in config. `NUM_CHUNKS` is useful when using interleved-pipeline (for more details see [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://arxiv.org/abs/2104.04473) ). The original batch will be split into `num_microbatches`, and each stage will load a micro batch each time. Then we will generate an approriate schedule for you to execute the pipeline training. If you don't need the output and label of model, you can set `return_output_label` to `False` when calling `trainer.fit()` which can further reduce GPU memory usage.
+You can set the size of pipeline parallel and number of microbatches in config. `NUM_CHUNKS` is useful when using interleaved-pipeline (for more details see [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://arxiv.org/abs/2104.04473) ). The original batch will be split into `num_microbatches`, and each stage will load a micro batch each time. Then we will generate an appropriate schedule for you to execute the pipeline training. If you don't need the output and label of model, you can set `return_output_label` to `False` when calling `trainer.fit()` which can further reduce GPU memory usage.
You should `export DATA=/path/to/cifar`.
diff --git a/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md b/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
index b2438a1cf562..a2deaeb88893 100644
--- a/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
+++ b/docs/source/en/advanced_tutorials/train_vit_with_hybrid_parallelism.md
@@ -16,14 +16,14 @@ In this example for ViT model, Colossal-AI provides three different parallelism
We will show you how to train ViT on CIFAR-10 dataset with these parallelism techniques. To run this example, you will need 2-4 GPUs.
-## Tabel of Contents
+## Table of Contents
1. Colossal-AI installation
2. Steps to train ViT with data parallelism
3. Steps to train ViT with pipeline parallelism
4. Steps to train ViT with tensor parallelism or hybrid parallelism
## Colossal-AI Installation
-You can install Colossal-AI pacakage and its dependencies with PyPI.
+You can install Colossal-AI package and its dependencies with PyPI.
```bash
pip install colossalai
```
@@ -31,7 +31,7 @@ pip install colossalai
## Data Parallelism
-Data parallism is one basic way to accelerate model training process. You can apply data parallelism to training by only two steps:
+Data parallelism is one basic way to accelerate model training process. You can apply data parallelism to training by only two steps:
1. Define a configuration file
2. Change a few lines of code in train script
@@ -94,7 +94,7 @@ from torchvision import transforms
from torchvision.datasets import CIFAR10
```
-#### Lauch Colossal-AI
+#### Launch Colossal-AI
In train script, you need to initialize the distributed environment for Colossal-AI after your config file is prepared. We call this process `launch`. In Colossal-AI, we provided several launch methods to initialize the distributed backend. In most cases, you can use `colossalai.launch` and `colossalai.get_default_parser` to pass the parameters via command line. Besides, Colossal-AI can utilize the existing launch tool provided by PyTorch as many users are familiar with by using `colossalai.launch_from_torch`. For more details, you can view the related [documents](https://www.colossalai.org/docs/basics/launch_colossalai).
@@ -613,7 +613,7 @@ NUM_MICRO_BATCHES = parallel['pipeline']
TENSOR_SHAPE = (BATCH_SIZE // NUM_MICRO_BATCHES, SEQ_LENGTH, HIDDEN_SIZE)
```
-Ohter configs:
+Other configs:
```python
# hyper parameters
# BATCH_SIZE is as per GPU
diff --git a/docs/source/en/basics/booster_api.md b/docs/source/en/basics/booster_api.md
index 18dec4500f76..a446ff31be83 100644
--- a/docs/source/en/basics/booster_api.md
+++ b/docs/source/en/basics/booster_api.md
@@ -14,9 +14,9 @@ In our new design, `colossalai.booster` replaces the role of `colossalai.initial
### Plugin
Plugin is an important component that manages parallel configuration (eg: The gemini plugin encapsulates the gemini acceleration solution). Currently supported plugins are as follows:
-***GeminiPlugin:*** This plugin wrapps the Gemini acceleration solution, that ZeRO with chunk-based memory management.
+***GeminiPlugin:*** This plugin wraps the Gemini acceleration solution, that ZeRO with chunk-based memory management.
-***TorchDDPPlugin:*** This plugin wrapps the DDP acceleration solution, it implements data parallelism at the module level which can run across multiple machines.
+***TorchDDPPlugin:*** This plugin wraps the DDP acceleration solution, it implements data parallelism at the module level which can run across multiple machines.
***LowLevelZeroPlugin:*** This plugin wraps the 1/2 stage of Zero Redundancy Optimizer. Stage 1 : Shards optimizer states across data parallel workers/GPUs. Stage 2 : Shards optimizer states + gradients across data parallel workers/GPUs.
@@ -25,24 +25,6 @@ Plugin is an important component that manages parallel configuration (eg: The ge
{{ autodoc:colossalai.booster.Booster }}
-{{ autodoc:colossalai.booster.Booster.boost }}
-
-{{ autodoc:colossalai.booster.Booster.backward }}
-
-{{ autodoc:colossalai.booster.Booster.no_sync }}
-
-{{ autodoc:colossalai.booster.Booster.save_model }}
-
-{{ autodoc:colossalai.booster.Booster.load_model }}
-
-{{ autodoc:colossalai.booster.Booster.save_optimizer }}
-
-{{ autodoc:colossalai.booster.Booster.load_optimizer }}
-
-{{ autodoc:colossalai.booster.Booster.save_lr_scheduler }}
-
-{{ autodoc:colossalai.booster.Booster.load_lr_scheduler }}
-
## Usage
In a typical workflow, you should launch distributed environment at the beginning of training script and create objects needed (such as models, optimizers, loss function, data loaders etc.) firstly, then call `colossalai.booster` to inject features into these objects, After that, you can use our booster APIs and these returned objects to continue the rest of your training processes.
diff --git a/docs/source/en/basics/booster_plugins.md b/docs/source/en/basics/booster_plugins.md
index 0362f095af2b..5e2586b836ad 100644
--- a/docs/source/en/basics/booster_plugins.md
+++ b/docs/source/en/basics/booster_plugins.md
@@ -63,6 +63,10 @@ More details can be found in [Pytorch Docs](https://pytorch.org/docs/main/genera
> ⚠ This plugin is not available when torch version is lower than 1.12.0.
+> ⚠ This plugin does not support save/load sharded model checkpoint now.
+
+> ⚠ This plugin does not support optimizer that use multi params group.
+
More details can be found in [Pytorch Docs](https://pytorch.org/docs/main/fsdp.html).
{{ autodoc:colossalai.booster.plugin.TorchFSDPPlugin }}
diff --git a/docs/source/en/basics/colotensor_concept.md b/docs/source/en/basics/colotensor_concept.md
index 909c5e4d3c6f..abe470fe0794 100644
--- a/docs/source/en/basics/colotensor_concept.md
+++ b/docs/source/en/basics/colotensor_concept.md
@@ -2,6 +2,8 @@
Author: [Jiarui Fang](https://github.com/feifeibear), [Hongxin Liu](https://github.com/ver217) and [Haichen Huang](https://github.com/1SAA)
+> ⚠️ The information on this page is outdated and will be deprecated.
+
**Prerequisite:**
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
- [Distributed Training](../concepts/distributed_training.md)
@@ -50,7 +52,7 @@ An instance of class [ComputeSpec](https://colossalai.readthedocs.io/en/latest/c
## Example
-Let's see an example. A ColoTensor is initialized and sharded on 8 GPUs using tp_degree=4, dp_dgree=2. And then the tensor is sharded along the last dim among the TP process groups. Finally, we reshard it along the first dim (0 dim) among the TP process groups. We encourage users to run the code and observe the shape of each tensor.
+Let's see an example. A ColoTensor is initialized and sharded on 8 GPUs using tp_degree=4, dp_degree=2. And then the tensor is sharded along the last dim among the TP process groups. Finally, we reshard it along the first dim (0 dim) among the TP process groups. We encourage users to run the code and observe the shape of each tensor.
```python
diff --git a/docs/source/en/basics/configure_parallelization.md b/docs/source/en/basics/configure_parallelization.md
index 4ac0299eac14..fd1e72ccd45a 100644
--- a/docs/source/en/basics/configure_parallelization.md
+++ b/docs/source/en/basics/configure_parallelization.md
@@ -2,6 +2,8 @@
Author: Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster Plugins](../basics/booster_plugins.md) for more information.
+
**Prerequisite:**
- [Distributed Training](../concepts/distributed_training.md)
- [Paradigms of Parallelism](../concepts/paradigms_of_parallelism.md)
diff --git a/docs/source/en/basics/define_your_config.md b/docs/source/en/basics/define_your_config.md
index d2569691b7dc..048ffcacbb8f 100644
--- a/docs/source/en/basics/define_your_config.md
+++ b/docs/source/en/basics/define_your_config.md
@@ -2,6 +2,9 @@
Author: Guangyang Lu, Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster API](../basics/booster_api.md) for more information.
+
+
**Prerequisite:**
- [Distributed Training](../concepts/distributed_training.md)
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
diff --git a/docs/source/en/basics/engine_trainer.md b/docs/source/en/basics/engine_trainer.md
index bbe32ed5a3b5..d2f99563f042 100644
--- a/docs/source/en/basics/engine_trainer.md
+++ b/docs/source/en/basics/engine_trainer.md
@@ -2,6 +2,8 @@
Author: Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster API](../basics/booster_api.md) for more information.
+
**Prerequisite:**
- [Initialize Features](./initialize_features.md)
diff --git a/docs/source/en/basics/initialize_features.md b/docs/source/en/basics/initialize_features.md
index e768d2022ad8..b89017427476 100644
--- a/docs/source/en/basics/initialize_features.md
+++ b/docs/source/en/basics/initialize_features.md
@@ -2,6 +2,8 @@
Author: Shenggui Li, Siqi Mai
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster API](../basics/booster_api.md) for more information.
+
**Prerequisite:**
- [Distributed Training](../concepts/distributed_training.md)
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
diff --git a/docs/source/en/basics/model_checkpoint.md b/docs/source/en/basics/model_checkpoint.md
index 09d44e7c2709..70334f1c41e7 100644
--- a/docs/source/en/basics/model_checkpoint.md
+++ b/docs/source/en/basics/model_checkpoint.md
@@ -2,6 +2,8 @@
Author : Guangyang Lu
+> ⚠️ The information on this page is outdated and will be deprecated. Please check [Booster Checkpoint](../basics/booster_checkpoint.md) for more information.
+
**Prerequisite:**
- [Launch Colossal-AI](./launch_colossalai.md)
- [Initialize Colossal-AI](./initialize_features.md)
diff --git a/docs/source/en/features/3D_tensor_parallel.md b/docs/source/en/features/3D_tensor_parallel.md
index b9e98eac9350..0e28f08b23c9 100644
--- a/docs/source/en/features/3D_tensor_parallel.md
+++ b/docs/source/en/features/3D_tensor_parallel.md
@@ -67,7 +67,7 @@ Given $P=q \times q \times q$ processors, we present the theoretical computation
## Usage
-To enable 3D tensor parallelism for our model, e.g. on 8 GPUs, we need to configure the parallism setting as below.
+To enable 3D tensor parallelism for our model, e.g. on 8 GPUs, we need to configure the parallelism setting as below.
```python
CONFIG = dict(parallel=dict(
data=1,
diff --git a/docs/source/en/features/cluster_utils.md b/docs/source/en/features/cluster_utils.md
index 1903d64d2563..7331d5e73ae0 100644
--- a/docs/source/en/features/cluster_utils.md
+++ b/docs/source/en/features/cluster_utils.md
@@ -13,20 +13,4 @@ We provide a utility class `colossalai.cluster.DistCoordinator` to coordinate di
{{ autodoc:colossalai.cluster.DistCoordinator }}
-{{ autodoc:colossalai.cluster.DistCoordinator.is_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.is_node_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.is_last_process }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.print_on_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.print_on_node_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.priority_execution }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.destroy }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.block_all }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.on_master_only }}
+
diff --git a/docs/source/en/features/gradient_accumulation.md b/docs/source/en/features/gradient_accumulation.md
index ecc209fbac8d..91d89b815bf7 100644
--- a/docs/source/en/features/gradient_accumulation.md
+++ b/docs/source/en/features/gradient_accumulation.md
@@ -1,4 +1,4 @@
-# Gradient Accumulation
+# Gradient Accumulation (Outdated)
Author: Shenggui Li, Yongbin Li
@@ -43,3 +43,5 @@ iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0
iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
```
+
+
diff --git a/docs/source/en/features/gradient_accumulation_with_booster.md b/docs/source/en/features/gradient_accumulation_with_booster.md
new file mode 100644
index 000000000000..201e3bc2b643
--- /dev/null
+++ b/docs/source/en/features/gradient_accumulation_with_booster.md
@@ -0,0 +1,144 @@
+# Gradient Accumulation (Latest)
+
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+## Introduction
+
+Gradient accumulation is a common way to enlarge your batch size for training. When training large-scale models, memory can easily become the bottleneck and the batch size can be very small, (e.g. 2), leading to unsatisfactory convergence. Gradient accumulation works by adding up the gradients calculated in multiple iterations, and only update the parameters in the preset iteration.
+
+## Usage
+
+It is simple to use gradient accumulation in Colossal-AI. Just call `booster.no_sync()` which returns a context manager. It accumulate gradients without synchronization, meanwhile you should not update the weights.
+
+## Hands-on Practice
+
+We now demonstrate gradient accumulation. In this example, we let the gradient accumulation size to be 4.
+
+### Step 1. Import libraries in train.py
+Create a `train.py` and import the necessary dependencies. The version of `torch` should not be lower than 1.8.1.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet18
+from torch.utils.data import DataLoader
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.cluster.dist_coordinator import priority_execution
+```
+
+### Step 2. Initialize Distributed Environment
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md) for other initialization methods.
+
+```python
+# initialize distributed setting
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+```
+
+### Step 3. Create training components
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])` to a path on your machine. Data will be automatically downloaded to the root path.
+
+```python
+# define the training hyperparameters
+BATCH_SIZE = 128
+GRADIENT_ACCUMULATION = 4
+
+# build resnet
+model = resnet18(num_classes=10)
+
+# build dataloaders
+with priority_execution():
+ train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+```
+
+### Step 4. Inject Feature
+Create a `TorchDDPPlugin` object to instantiate a `Booster`, and boost these training components.
+
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, _ = booster.boost(model=model,
+ optimizer=optimizer,
+ criterion=criterion,
+ dataloader=train_dataloader)
+```
+
+### Step 5. Train with Booster
+Use booster in a normal training loops, and verify gradient accumulation. `param_by_iter` is to record the distributed training information.
+```python
+optimizer.zero_grad()
+for idx, (img, label) in enumerate(train_dataloader):
+ sync_context = booster.no_sync(model)
+ img = img.cuda()
+ label = label.cuda()
+ if idx % (GRADIENT_ACCUMULATION - 1) != 0:
+ with sync_context:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ else:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.step()
+ optimizer.zero_grad()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ param_by_iter.append(str(ele_1st.item()))
+
+ if idx != 0 and idx % (GRADIENT_ACCUMULATION - 1) == 0:
+ break
+
+ for iteration, val in enumerate(param_by_iter):
+ print(f'iteration {iteration} - value: {val}')
+
+ if param_by_iter[-1] != param_by_iter[0]:
+ print('The parameter is only updated in the last iteration')
+
+```
+
+### Step 6. Invoke Training Scripts
+To verify gradient accumulation, we can just check the change of parameter values. When gradient accumulation is set, parameters are only updated in the last step. You can run the script using this command:
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
+You will see output similar to the text below. This shows gradient is indeed accumulated as the parameter is not updated
+in the first 3 steps, but only updated in the last step.
+
+```text
+iteration 0, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
+```
+
+
diff --git a/docs/source/en/features/gradient_clipping.md b/docs/source/en/features/gradient_clipping.md
index f606dde6c393..5a23c68e3e27 100644
--- a/docs/source/en/features/gradient_clipping.md
+++ b/docs/source/en/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# Gradient Clipping
+# Gradient Clipping (Outdated)
Author: Boxiang Wang, Haichen Huang, Yongbin Li
@@ -60,3 +60,5 @@ to demonstrate gradient clipping. In this example, we set the gradient clipping
```shell
python -m torch.distributed.launch --nproc_per_node 1 --master_addr localhost --master_port 29500 train_with_engine.py
```
+
+
diff --git a/docs/source/en/features/gradient_clipping_with_booster.md b/docs/source/en/features/gradient_clipping_with_booster.md
new file mode 100644
index 000000000000..341a608a5c7b
--- /dev/null
+++ b/docs/source/en/features/gradient_clipping_with_booster.md
@@ -0,0 +1,142 @@
+# Gradient Clipping (Latest)
+
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+**Related Paper**
+- [On the difficulty of training Recurrent Neural Networks](https://arxiv.org/abs/1211.5063)
+
+## Introduction
+
+In order to speed up training process and seek global optimum for better performance, more and more learning rate schedulers have been proposed. People turn to control learning rate to adjust descent pace during training, which makes gradient vector better to be uniformed in every step. In that case, the descent pace can be controlled as expected. As a result, gradient clipping, a technique which can normalize the gradient vector to circumscribe it in a uniformed length, becomes indispensable for those who desire their better performance of their models.
+
+You do not have to worry about implementing gradient clipping when using Colossal-AI, we support gradient clipping in a powerful and convenient way. All you need is just an additional command in your configuration file.
+
+## Why you should use gradient clipping provided by Colossal-AI
+
+The reason of why we do not recommend users to write gradient clipping by themselves is that naive gradient clipping may fail when applying tensor parallelism, pipeline parallelism or MoE.
+
+According to the illustration below, each GPU only owns a portion of parameters of the weight in a linear layer. To get correct norm of gradient vector of the weight of the linear layer, the norm of every gradient vector in each GPU should be summed together. More complicated thing is that the distribution of bias is different from the distribution of the weight. The communication group is different in the sum operation.
+
+(PS: This situation is an old version of 2D parallelism, the implementation in the code is not the same. But it is a good example about the difficulty to unify all communication in gradient clipping.)
+
+
+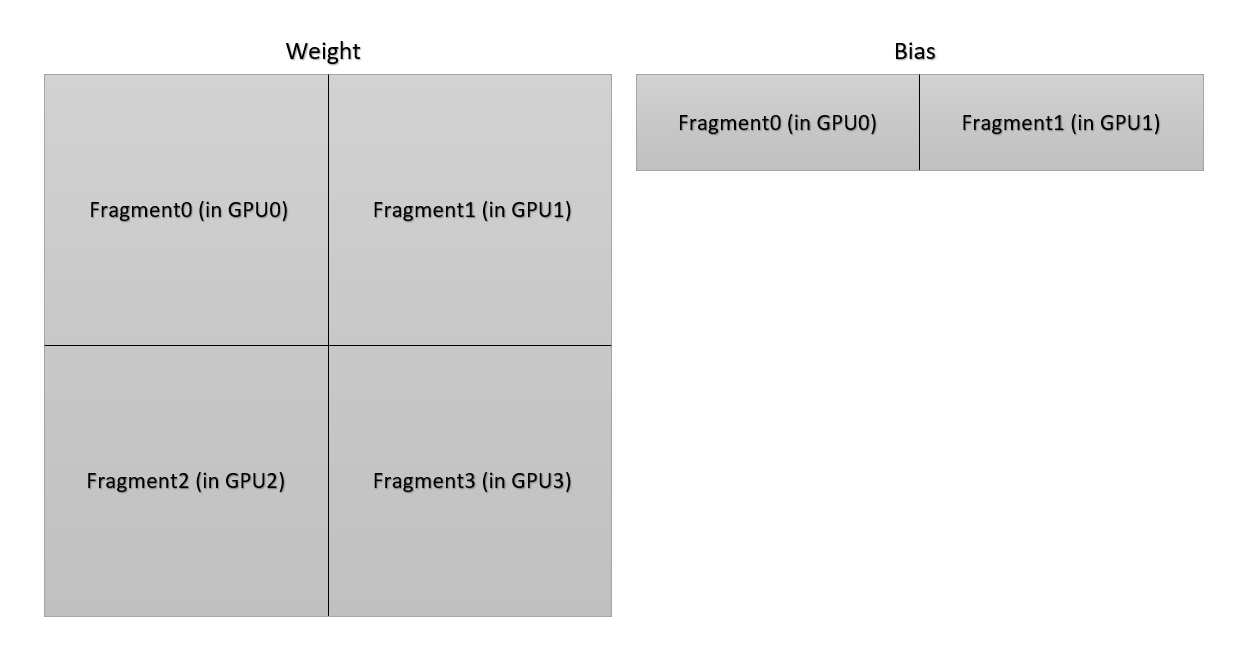 +Layout of parameters
+
+
+Do not worry about it, since Colossal-AI have handled it for you.
+
+## Usage
+To use gradient clipping, you can just add the following code to your configuration file, and after boosted, you can call `clip_grad_by_norm` or `clip_grad_by_value` method of optimizer, if it support clip gradients.
+
+## Hands-On Practice
+
+We now demonstrate how to use gradient clipping. In this example, we set the gradient clipping vector norm to be 1.0.
+
+### step 1. Import libraries in train.py
+Create a `train.py` and import the necessary dependencies.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet34
+from tqdm import tqdm
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import CosineAnnealingLR
+```
+
+### Step 2. Initialize Distributed Environment
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md)
+for other initialization methods.
+
+```python
+colossalai.launch_from_torch(config=dict())
+logger = get_dist_logger()
+```
+
+
+### Step 3. Create training components
+
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])` to a path on your machine. Data will be automatically downloaded to the root path.
+```python
+# define training hyperparameters
+NUM_EPOCHS = 200
+BATCH_SIZE = 128
+GRADIENT_CLIPPING = 0.1
+# build resnet
+model = resnet34(num_classes=10)
+# build dataloaders
+train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+# lr_scheduler
+lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+
+```
+### Step 4. Inject Gradient Clipping Feature
+
+Create a `TorchDDPPlugin` object and `Booster` object, get a data loader from plugin, then boost all training components.
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+
+```
+
+### Step 5. Train with Booster
+Use booster in a normal training loops.
+```python
+# verify gradient clipping
+model.train()
+for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
+```
+
+### Step 6. Invoke Training Scripts
+You can run the script using this command:
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
+
diff --git a/docs/source/en/features/mixed_precision_training.md b/docs/source/en/features/mixed_precision_training.md
index 11aa5235301a..8579d586ed5f 100644
--- a/docs/source/en/features/mixed_precision_training.md
+++ b/docs/source/en/features/mixed_precision_training.md
@@ -1,4 +1,4 @@
-# Auto Mixed Precision Training
+# Auto Mixed Precision Training (Outdated)
Author: Chuanrui Wang, Shenggui Li, Yongbin Li
@@ -362,6 +362,7 @@ for epoch in range(gpc.config.NUM_EPOCHS):
Use the following command to start the training scripts. You can change `--nproc_per_node` to use a different number of GPUs.
-```python
+```shell
python -m torch.distributed.launch --nproc_per_node 4 --master_addr localhost --master_port 29500 train_with_engine.py --config config/config_AMP_torch.py
```
+
diff --git a/docs/source/en/features/mixed_precision_training_with_booster.md b/docs/source/en/features/mixed_precision_training_with_booster.md
new file mode 100644
index 000000000000..e9b6f684f613
--- /dev/null
+++ b/docs/source/en/features/mixed_precision_training_with_booster.md
@@ -0,0 +1,251 @@
+# Auto Mixed Precision Training (Latest)
+
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+**Related Paper**
+- [Accelerating Scientific Computations with Mixed Precision Algorithms](https://arxiv.org/abs/0808.2794)
+
+
+## Introduction
+
+AMP stands for automatic mixed precision training.
+In Colossal-AI, we have incorporated different implementations of mixed precision training:
+
+1. torch.cuda.amp
+2. apex.amp
+3. naive amp
+
+
+| Colossal-AI | support tensor parallel | support pipeline parallel | fp16 extent |
+| ----------- | ----------------------- | ------------------------- | ----------- |
+| AMP_TYPE.TORCH | ✅ | ❌ | Model parameters, activation, gradients are downcast to fp16 during forward and backward propagation |
+| AMP_TYPE.APEX | ❌ | ❌ | More fine-grained, we can choose opt_level O0, O1, O2, O3 |
+| AMP_TYPE.NAIVE | ✅ | ✅ | Model parameters, forward and backward operations are all downcast to fp16 |
+
+The first two rely on the original implementation of PyTorch (version 1.6 and above) and NVIDIA Apex.
+The last method is similar to Apex O2 level.
+Among these methods, apex AMP is not compatible with tensor parallelism.
+This is because that tensors are split across devices in tensor parallelism, thus, it is required to communicate among different processes to check if inf or nan occurs in the whole model weights.
+We modified the torch amp implementation so that it is compatible with tensor parallelism now.
+
+> ❌️ fp16 and zero are not compatible
+>
+> ⚠️ Pipeline only support naive AMP currently
+
+We recommend you to use torch AMP as it generally gives better accuracy than naive AMP if no pipeline is used.
+
+## Table of Contents
+
+In this tutorial we will cover:
+
+1. [AMP introduction](#amp-introduction)
+2. [AMP in Colossal-AI](#amp-in-colossal-ai)
+3. [Hands-on Practice](#hands-on-practice)
+
+## AMP Introduction
+
+Automatic Mixed Precision training is a mixture of FP16 and FP32 training.
+
+Half-precision float point format (FP16) has lower arithmetic complexity and higher compute efficiency. Besides, fp16 requires half of the storage needed by fp32 and saves memory & network bandwidth, which makes more memory available for large batch size and model size.
+
+However, there are other operations, like reductions, which require the dynamic range of fp32 to avoid numeric overflow/underflow. That's the reason why we introduce automatic mixed precision, attempting to match each operation to its appropriate data type, which can reduce the memory footprint and augment training efficiency.
+
+
+
+Layout of parameters
+
+
+Do not worry about it, since Colossal-AI have handled it for you.
+
+## Usage
+To use gradient clipping, you can just add the following code to your configuration file, and after boosted, you can call `clip_grad_by_norm` or `clip_grad_by_value` method of optimizer, if it support clip gradients.
+
+## Hands-On Practice
+
+We now demonstrate how to use gradient clipping. In this example, we set the gradient clipping vector norm to be 1.0.
+
+### step 1. Import libraries in train.py
+Create a `train.py` and import the necessary dependencies.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet34
+from tqdm import tqdm
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import CosineAnnealingLR
+```
+
+### Step 2. Initialize Distributed Environment
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md)
+for other initialization methods.
+
+```python
+colossalai.launch_from_torch(config=dict())
+logger = get_dist_logger()
+```
+
+
+### Step 3. Create training components
+
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])` to a path on your machine. Data will be automatically downloaded to the root path.
+```python
+# define training hyperparameters
+NUM_EPOCHS = 200
+BATCH_SIZE = 128
+GRADIENT_CLIPPING = 0.1
+# build resnet
+model = resnet34(num_classes=10)
+# build dataloaders
+train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+# lr_scheduler
+lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+
+```
+### Step 4. Inject Gradient Clipping Feature
+
+Create a `TorchDDPPlugin` object and `Booster` object, get a data loader from plugin, then boost all training components.
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+
+```
+
+### Step 5. Train with Booster
+Use booster in a normal training loops.
+```python
+# verify gradient clipping
+model.train()
+for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
+```
+
+### Step 6. Invoke Training Scripts
+You can run the script using this command:
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
+
diff --git a/docs/source/en/features/mixed_precision_training.md b/docs/source/en/features/mixed_precision_training.md
index 11aa5235301a..8579d586ed5f 100644
--- a/docs/source/en/features/mixed_precision_training.md
+++ b/docs/source/en/features/mixed_precision_training.md
@@ -1,4 +1,4 @@
-# Auto Mixed Precision Training
+# Auto Mixed Precision Training (Outdated)
Author: Chuanrui Wang, Shenggui Li, Yongbin Li
@@ -362,6 +362,7 @@ for epoch in range(gpc.config.NUM_EPOCHS):
Use the following command to start the training scripts. You can change `--nproc_per_node` to use a different number of GPUs.
-```python
+```shell
python -m torch.distributed.launch --nproc_per_node 4 --master_addr localhost --master_port 29500 train_with_engine.py --config config/config_AMP_torch.py
```
+
diff --git a/docs/source/en/features/mixed_precision_training_with_booster.md b/docs/source/en/features/mixed_precision_training_with_booster.md
new file mode 100644
index 000000000000..e9b6f684f613
--- /dev/null
+++ b/docs/source/en/features/mixed_precision_training_with_booster.md
@@ -0,0 +1,251 @@
+# Auto Mixed Precision Training (Latest)
+
+Author: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**Prerequisite**
+- [Define Your Configuration](../basics/define_your_config.md)
+- [Training Booster](../basics/booster_api.md)
+
+**Related Paper**
+- [Accelerating Scientific Computations with Mixed Precision Algorithms](https://arxiv.org/abs/0808.2794)
+
+
+## Introduction
+
+AMP stands for automatic mixed precision training.
+In Colossal-AI, we have incorporated different implementations of mixed precision training:
+
+1. torch.cuda.amp
+2. apex.amp
+3. naive amp
+
+
+| Colossal-AI | support tensor parallel | support pipeline parallel | fp16 extent |
+| ----------- | ----------------------- | ------------------------- | ----------- |
+| AMP_TYPE.TORCH | ✅ | ❌ | Model parameters, activation, gradients are downcast to fp16 during forward and backward propagation |
+| AMP_TYPE.APEX | ❌ | ❌ | More fine-grained, we can choose opt_level O0, O1, O2, O3 |
+| AMP_TYPE.NAIVE | ✅ | ✅ | Model parameters, forward and backward operations are all downcast to fp16 |
+
+The first two rely on the original implementation of PyTorch (version 1.6 and above) and NVIDIA Apex.
+The last method is similar to Apex O2 level.
+Among these methods, apex AMP is not compatible with tensor parallelism.
+This is because that tensors are split across devices in tensor parallelism, thus, it is required to communicate among different processes to check if inf or nan occurs in the whole model weights.
+We modified the torch amp implementation so that it is compatible with tensor parallelism now.
+
+> ❌️ fp16 and zero are not compatible
+>
+> ⚠️ Pipeline only support naive AMP currently
+
+We recommend you to use torch AMP as it generally gives better accuracy than naive AMP if no pipeline is used.
+
+## Table of Contents
+
+In this tutorial we will cover:
+
+1. [AMP introduction](#amp-introduction)
+2. [AMP in Colossal-AI](#amp-in-colossal-ai)
+3. [Hands-on Practice](#hands-on-practice)
+
+## AMP Introduction
+
+Automatic Mixed Precision training is a mixture of FP16 and FP32 training.
+
+Half-precision float point format (FP16) has lower arithmetic complexity and higher compute efficiency. Besides, fp16 requires half of the storage needed by fp32 and saves memory & network bandwidth, which makes more memory available for large batch size and model size.
+
+However, there are other operations, like reductions, which require the dynamic range of fp32 to avoid numeric overflow/underflow. That's the reason why we introduce automatic mixed precision, attempting to match each operation to its appropriate data type, which can reduce the memory footprint and augment training efficiency.
+
+
+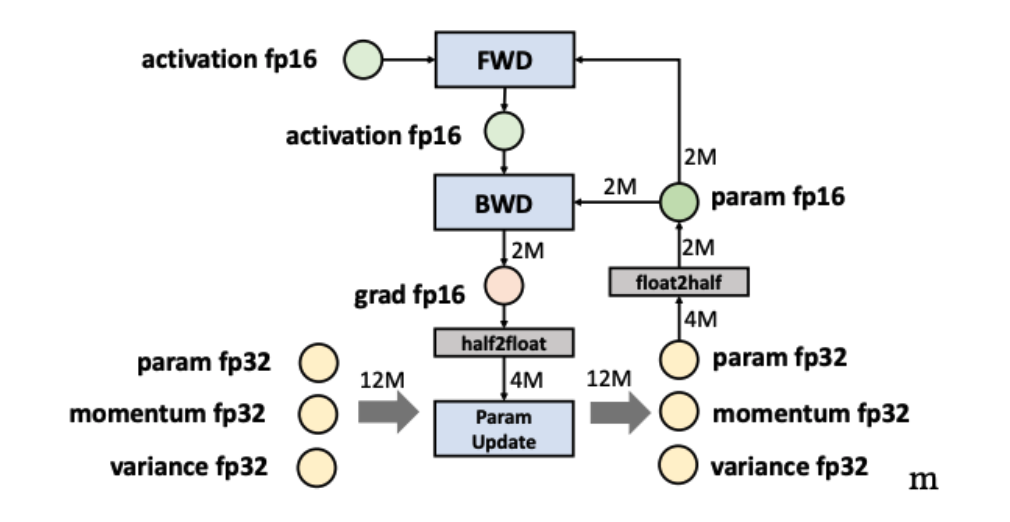 +Illustration of an ordinary AMP (figure from PatrickStar paper)
+
+
+## AMP in Colossal-AI
+
+We supported three AMP training methods and allowed the user to train with AMP with no code. If you want to train with amp, just assign `mixed_precision` with `fp16` when you instantiate the `Booster`. Now booster support torch amp, the other two(apex amp, naive amp) are still started by `colossalai.initialize`, if needed, please refer to [this](./mixed_precision_training.md). Next we will support `bf16`, `fp8`.
+
+### Start with Booster
+instantiate `Booster` with `mixed_precision="fp16"`, then you can train with torch amp.
+
+```python
+"""
+ Mapping:
+ 'fp16': torch amp
+ 'fp16_apex': apex amp,
+ 'bf16': bf16,
+ 'fp8': fp8,
+ 'fp16_naive': naive amp
+"""
+from colossalai import Booster
+booster = Booster(mixed_precision='fp16',...)
+```
+
+or you can create a `FP16TorchMixedPrecision` object, such as:
+
+```python
+from colossalai.mixed_precision import FP16TorchMixedPrecision
+mixed_precision = FP16TorchMixedPrecision(
+ init_scale=2.**16,
+ growth_factor=2.0,
+ backoff_factor=0.5,
+ growth_interval=2000)
+booster = Booster(mixed_precision=mixed_precision,...)
+```
+
+The same goes for other types of amps.
+
+
+### Torch AMP Configuration
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16TorchMixedPrecision }}
+
+### Apex AMP Configuration
+
+For this mode, we rely on the Apex implementation for mixed precision training.
+We support this plugin because it allows for finer control on the granularity of mixed precision.
+For example, O2 level (optimization level 2) will keep batch normalization in fp32.
+
+If you look for more details, please refer to [Apex Documentation](https://nvidia.github.io/apex/).
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16ApexMixedPrecision }}
+
+### Naive AMP Configuration
+
+In Naive AMP mode, we achieved mixed precision training while maintaining compatibility with complex tensor and pipeline parallelism.
+This AMP mode will cast all operations into fp16.
+The following code block shows the mixed precision api for this mode.
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16NaiveMixedPrecision }}
+
+When using `colossalai.booster`, you are required to first instantiate a model, an optimizer and a criterion.
+The output model is converted to AMP model of smaller memory consumption.
+If your input model is already too large to fit in a GPU, please instantiate your model weights in `dtype=torch.float16`.
+Otherwise, try smaller models or checkout more parallelization training techniques!
+
+
+## Hands-on Practice
+
+Now we will introduce the use of AMP with Colossal-AI. In this practice, we will use Torch AMP as an example.
+
+### Step 1. Import libraries in train.py
+
+Create a `train.py` and import the necessary dependencies. Remember to install `scipy` and `timm` by running
+`pip install timm scipy`.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from timm.models import vit_base_patch16_224
+from titans.utils import barrier_context
+from torchvision import datasets, transforms
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import LinearWarmupLR
+```
+
+### Step 2. Initialize Distributed Environment
+
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md)
+for other initialization methods.
+
+```python
+# initialize distributed setting
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+
+```
+
+### Step 3. Create training components
+
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is
+obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])`
+to a path on your machine. Data will be automatically downloaded to the root path.
+
+```python
+# define the constants
+NUM_EPOCHS = 2
+BATCH_SIZE = 128
+
+# build model
+model = vit_base_patch16_224(drop_rate=0.1)
+
+# build dataloader
+train_dataset = datasets.Caltech101(
+ root=Path(os.environ['DATA']),
+ download=True,
+ transform=transforms.Compose([
+ transforms.Resize(256),
+ transforms.RandomResizedCrop(224),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ Gray2RGB(),
+ transforms.Normalize([0.5, 0.5, 0.5],
+ [0.5, 0.5, 0.5])
+ ]))
+
+# build optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, weight_decay=0.1)
+
+# build loss
+criterion = torch.nn.CrossEntropyLoss()
+
+# lr_scheduler
+lr_scheduler = LinearWarmupLR(optimizer, warmup_steps=50, total_steps=NUM_EPOCHS)
+```
+
+### Step 4. Inject AMP Feature
+
+Create a `MixedPrecision`(if needed) and `TorchDDPPlugin` object, call `colossalai.boost` convert the training components to be running with FP16.
+
+```python
+plugin = TorchDDPPlugin()
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+
+# if you need to customize the config, do like this
+# >>> from colossalai.mixed_precision import FP16TorchMixedPrecision
+# >>> mixed_precision = FP16TorchMixedPrecision(
+# >>> init_scale=2.**16,
+# >>> growth_factor=2.0,
+# >>> backoff_factor=0.5,
+# >>> growth_interval=2000)
+# >>> plugin = TorchDDPPlugin()
+# >>> booster = Booster(mixed_precision=mixed_precision, plugin=plugin)
+
+# boost model, optimizer, criterion, dataloader, lr_scheduler
+model, optimizer, criterion, dataloader, lr_scheduler = booster.boost(model, optimizer, criterion, dataloader, lr_scheduler)
+```
+
+### Step 5. Train with Booster
+
+Use booster in a normal training loops.
+
+```python
+model.train()
+for epoch in range(NUM_EPOCHS):
+ for img, label in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+ optimizer.zero_grad()
+ output = model(img)
+ loss = criterion(output, label)
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ lr_scheduler.step()
+```
+
+### Step 6. Invoke Training Scripts
+
+Use the following command to start the training scripts. You can change `--nproc_per_node` to use a different number of GPUs.
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
diff --git a/docs/source/en/features/nvme_offload.md b/docs/source/en/features/nvme_offload.md
index 4374da3c9c45..6ed6f2dee5d6 100644
--- a/docs/source/en/features/nvme_offload.md
+++ b/docs/source/en/features/nvme_offload.md
@@ -53,7 +53,7 @@ It's compatible with all parallel methods in ColossalAI.
> ⚠ It only offloads optimizer states on CPU. This means it only affects CPU training or Zero/Gemini with offloading.
-## Exampls
+## Examples
Let's start from two simple examples -- training GPT with different methods. These examples relies on `transformers`.
@@ -78,8 +78,9 @@ from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
import colossalai
from colossalai.nn.optimizer import HybridAdam
-from colossalai.zero import zero_model_wrapper, zero_optim_wrapper
from colossalai.utils.model.colo_init_context import ColoInitContext
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin
```
Then we define a loss function:
@@ -192,17 +193,23 @@ def train_gemini_cpu(nvme_offload_fraction: float = 0.0):
optimizer = HybridAdam(model.parameters(), nvme_offload_fraction=nvme_offload_fraction)
print(f'Model numel: {get_model_numel(model) / 1024**3:.3f} B')
- gemini_config = dict(strict_ddp_mode=True, device=torch.cuda.current_device(),
- placement_policy='cpu', pin_memory=True, hidden_dim=config.n_embd)
- model = zero_model_wrapper(model, zero_stage=3, gemini_config=gemini_config)
- optimizer = zero_optim_wrapper(model, optimizer, initial_scale=2**5)
+ plugin = GeminiPlugin(
+ strict_ddp_mode=True,
+ device=torch.cuda.current_device(),
+ placement_policy='cpu',
+ pin_memory=True,
+ hidden_dim=config.n_embd,
+ initial_scale=2**5
+ )
+ booster = Booster(plugin)
+ model, optimizer, criterion, _* = booster.boost(model, optimizer, criterion)
start = time.time()
for step in range(3):
data = get_data(4, 128, config.vocab_size)
outputs = model(**data)
loss = criterion(outputs.logits, data['input_ids'])
- optimizer.backward(loss)
+ booster.backward(loss, optimizer)
optimizer.step()
optimizer.zero_grad()
print(f'[{step}] loss: {loss.item():.3f}')
diff --git a/docs/source/en/features/pipeline_parallel.md b/docs/source/en/features/pipeline_parallel.md
index ac49863b3c71..30654b0b0195 100644
--- a/docs/source/en/features/pipeline_parallel.md
+++ b/docs/source/en/features/pipeline_parallel.md
@@ -156,4 +156,4 @@ trainer.fit(train_dataloader=train_dataloader,
display_progress=True)
```
-We use `2` pipeline stages and the batch will be splitted into `4` micro batches.
+We use `2` pipeline stages and the batch will be split into `4` micro batches.
diff --git a/docs/source/en/features/zero_with_chunk.md b/docs/source/en/features/zero_with_chunk.md
index a105831a5409..d6f6f611a64c 100644
--- a/docs/source/en/features/zero_with_chunk.md
+++ b/docs/source/en/features/zero_with_chunk.md
@@ -3,7 +3,7 @@
Author: [Hongxiu Liu](https://github.com/ver217), [Jiarui Fang](https://github.com/feifeibear), [Zijian Ye](https://github.com/ZijianYY)
**Prerequisite:**
-- [Define Your Configuration](../basics/define_your_config.md)
+- [Train with booster](../basics/booster_api.md)
**Example Code**
@@ -72,7 +72,7 @@ chunk_manager = init_chunk_manager(model=module,
gemini_manager = GeminiManager(placement_policy, chunk_manager)
```
-`hidden_dim` is the hidden dimension of DNN. Users can provide this argument to speed up searching. If users do not know this argument before training, it is ok. We will use a default value 1024. `min_chunk_size_mb` is the the minimum chunk size in MegaByte. If the aggregate size of parameters is still samller than the minimum chunk size, all parameters will be compacted into one small chunk.
+`hidden_dim` is the hidden dimension of DNN. Users can provide this argument to speed up searching. If users do not know this argument before training, it is ok. We will use a default value 1024. `min_chunk_size_mb` is the the minimum chunk size in MegaByte. If the aggregate size of parameters is still smaller than the minimum chunk size, all parameters will be compacted into one small chunk.
Initialization of the optimizer.
```python
@@ -97,6 +97,7 @@ For simplicity, we just use randomly generated data here.
First we only need to import `GPT2LMHeadModel` from `Huggingface transformers` to define our model, which does not require users to define or modify the model, so that users can use it more conveniently.
+Define a GPT model:
```python
class GPTLMModel(nn.Module):
@@ -182,34 +183,6 @@ def split_param_col_tp1d(param: ColoParameter, pg: ProcessGroup):
split_param_single_dim_tp1d(-1, param, pg)
```
-Define a model which uses Gemini + ZeRO DDP:
-
-```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
- cai_version = colossalai.__version__
- if version.parse(cai_version) > version.parse("0.1.10"):
- from colossalai.nn.parallel import GeminiDDP
- model = GeminiDDP(model,
- device=get_current_device(),
- placement_policy=placememt_policy,
- pin_memory=True,
- search_range_mb=32)
- elif version.parse(cai_version) <= version.parse("0.1.10") and version.parse(cai_version) >= version.parse("0.1.9"):
- from colossalai.gemini import ChunkManager, GeminiManager
- chunk_size = ChunkManager.search_chunk_size(model, 64 * 1024**2, 32)
- gemini_manager = GeminiManager(placememt_policy, chunk_manager)
- chunk_manager = ChunkManager(chunk_size,
- pg,
- enable_distributed_storage=True,
- init_device=GeminiManager.get_default_device(placememt_policy))
- model = ZeroDDP(model, gemini_manager)
- else:
- raise NotImplemented(f"CAI version {cai_version} is not supported")
- return model
-```
-
-As we pre-train GPT in this example, we just use a simple language model loss.
-
Write a function to get random inputs:
```python
@@ -219,9 +192,15 @@ def get_data(batch_size, seq_len, vocab_size):
return input_ids, attention_mask
```
-Finally, we can define our training loop:
+Finally, we define a model which uses Gemini + ZeRO DDP and define our training loop, As we pre-train GPT in this example, we just use a simple language model loss:
```python
+from torch.optim import Adam
+
+from colossalai.booster import Booster
+from colossalai.zero import ColoInitContext
+from colossalai.booster.plugin import GeminiPlugin
+
def main():
args = parse_args()
BATCH_SIZE = 8
@@ -232,22 +211,23 @@ def main():
# build criterion
criterion = GPTLMLoss()
+ optimizer = Adam(model.parameters(), lr=0.001)
torch.manual_seed(123)
default_pg = ProcessGroup(tp_degree=args.tp_degree)
- default_dist_spec = ShardSpec([-1], [args.tp_degree]) if args.shardinit else None
+ default_dist_spec = ShardSpec([-1], [args.tp_degree])
# build GPT model
with ColoInitContext(device='cpu', default_dist_spec=default_dist_spec, default_pg=default_pg):
model = gpt2_medium(checkpoint=True)
pg = default_pg
# Tensor Parallelism (TP)
tensor_parallelize(model, pg)
+
# Gemini + ZeRO DP, Note it must be used after TP
- model = gemini_zero_dpp(model, pg, args.placement)
- # build optimizer
- optimizer = GeminiAdamOptimizer(model, lr=1e-3, initial_scale=2**5)
- numel = sum([p.numel() for p in model.parameters()])
- get_tflops_func = partial(get_tflops, numel, BATCH_SIZE, SEQ_LEN)
+ plugin = GeminiPlugin(placement_policy='cuda', max_norm=1.0, initial_scale=2**5)
+ booster = Booster(plugin=plugin)
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+
torch.cuda.synchronize()
model.train()
for n in range(NUM_STEPS):
@@ -256,10 +236,12 @@ def main():
optimizer.zero_grad()
outputs = model(input_ids, attn_mask)
loss = criterion(outputs, input_ids)
- optimizer.backward(loss)
+ booster.backward(loss, optimizer)
optimizer.step()
torch.cuda.synchronize()
```
> ⚠️ Note: If you want to use the Gemini module, please do not use the [Gradient Accumulation](../features/gradient_accumulation.md) we mentioned before。
The complete example can be found on [Train GPT with Colossal-AI](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/gpt).
+
+
diff --git a/docs/source/en/get_started/installation.md b/docs/source/en/get_started/installation.md
index b626edb19e8e..6fc4ce2c922a 100644
--- a/docs/source/en/get_started/installation.md
+++ b/docs/source/en/get_started/installation.md
@@ -48,5 +48,20 @@ If you don't want to install and enable CUDA kernel fusion (compulsory installat
pip install .
```
+For Users with CUDA 10.2, you can still build ColossalAI from source. However, you need to manually download the cub library and copy it to the corresponding directory.
+
+```bash
+# clone the repository
+git clone https://github.com/hpcaitech/ColossalAI.git
+cd ColossalAI
+
+# download the cub library
+wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip
+unzip 1.8.0.zip
+cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
+
+# install
+CUDA_EXT=1 pip install .
+```
diff --git a/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md b/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md
index 4825a6fa1d6c..059eb014affd 100644
--- a/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md
+++ b/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md
@@ -48,7 +48,7 @@ Colossal-AI 为用户提供了一个全局 context,使他们能够轻松地管
world_size: int,
config: Config,
data_parallel_size: int,
- pipeline_parlalel_size: int,
+ pipeline_parallel_size: int,
tensor_parallel_size: int,
arg1,
arg2):
diff --git a/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md b/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
index 456878caa147..276fcc2619e0 100644
--- a/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
+++ b/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
@@ -122,7 +122,7 @@ Inside the initialization of Experts, the local expert number of each GPU will b
## Train Your Model
-Do not to forget to use `colossalai.initialize` function in `colosalai` to add gradient handler for the engine.
+Do not to forget to use `colossalai.initialize` function in `colossalai` to add gradient handler for the engine.
We handle the back-propagation of MoE models for you.
In `colossalai.initialize`, we will automatically create a `MoeGradientHandler` object to process gradients.
You can find more information about the handler `MoeGradientHandler` in colossal directory.
diff --git a/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md b/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md
index 2bf0a9c98c3f..594823862de1 100644
--- a/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md
+++ b/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md
@@ -8,21 +8,21 @@
## 用法
-目前Gemini支持和ZeRO并行方式兼容,它的使用方法很简单,在训练策略的配置文件里设置zero的model_config属性tensor_placement_policy='auto'
-
-```
-zero = dict(
- model_config=dict(
- reduce_scatter_bucket_size_mb=25,
- fp32_reduce_scatter=False,
- gradient_predivide_factor=1.0,
- tensor_placement_policy="auto",
- shard_strategy=TensorShardStrategy(),
- ...
- ),
- optimizer_config=dict(
- ...
- )
+目前Gemini支持和ZeRO并行方式兼容,它的使用方法很简单:使用booster将`GeminiPlugin`中的特性注入到训练组件中。更多`booster`介绍请参考[booster使用](../basics/booster_api.md)。
+
+```python
+from torchvision.models import resnet18
+from colossalai.booster import Booster
+from colossalai.zero import ColoInitContext
+from colossalai.booster.plugin import GeminiPlugin
+plugin = GeminiPlugin(placement_policy='cuda', strict_ddp_mode=True, max_norm=1.0, initial_scale=2**5)
+booster = Booster(plugin=plugin)
+ctx = ColoInitContext()
+with ctx:
+ model = resnet18()
+optimizer = HybridAdam(model.parameters(), lr=1e-3)
+criterion = lambda x: x.mean()
+model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
)
```
@@ -48,7 +48,7 @@ zero = dict(
-ColossalAI设计了Gemini,就像双子星一样,它管理CPU和GPU二者内存空间。它可以让张量在训练过程中动态分布在CPU-GPU的存储空间内,从而让模型训练突破GPU的内存墙。内存管理器由两部分组成,分别是MemStatsCollector(MSC)和StatefuleTensorMgr(STM)。
+ColossalAI设计了Gemini,就像双子星一样,它管理CPU和GPU二者内存空间。它可以让张量在训练过程中动态分布在CPU-GPU的存储空间内,从而让模型训练突破GPU的内存墙。内存管理器由两部分组成,分别是MemStatsCollector(MSC)和StatefulTensorMgr(STM)。
我们利用了深度学习网络训练过程的迭代特性。我们将迭代分为warmup和non-warmup两个阶段,开始时的一个或若干迭代步属于预热阶段,其余的迭代步属于正式阶段。在warmup阶段我们为MSC收集信息,而在non-warmup阶段STM入去MSC收集的信息来移动tensor,以达到最小化CPU-GPU数据移动volume的目的。
@@ -75,7 +75,7 @@ STM管理所有model data tensor的信息。在模型的构造过程中,Coloss
我们在算子的开始和结束计算时,触发内存采样操作,我们称这个时间点为**采样时刻(sampling moment)**,两个采样时刻之间的时间我们称为**period**。计算过程是一个黑盒,由于可能分配临时buffer,内存使用情况很复杂。但是,我们可以较准确的获取period的系统最大内存使用。非模型数据的使用可以通过两个统计时刻之间系统最大内存使用-模型内存使用获得。
-我们如何设计采样时刻呢。我们选择preOp的model data layout adjust之前。如下图所示。我们采样获得上一个period的system memory used,和下一个period的model data memoy used。并行策略会给MSC的工作造成障碍。如图所示,比如对于ZeRO或者Tensor Parallel,由于Op计算前需要gather模型数据,会带来额外的内存需求。因此,我们要求在模型数据变化前进行采样系统内存,这样在一个period内,MSC会把preOp的模型变化内存捕捉。比如在period 2-3内,我们考虑的tensor gather和shard带来的内存变化。
+我们如何设计采样时刻呢。我们选择preOp的model data layout adjust之前。如下图所示。我们采样获得上一个period的system memory used,和下一个period的model data memory used。并行策略会给MSC的工作造成障碍。如图所示,比如对于ZeRO或者Tensor Parallel,由于Op计算前需要gather模型数据,会带来额外的内存需求。因此,我们要求在模型数据变化前进行采样系统内存,这样在一个period内,MSC会把preOp的模型变化内存捕捉。比如在period 2-3内,我们考虑的tensor gather和shard带来的内存变化。
尽管可以将采样时刻放在其他位置,比如排除gather buffer的变动新信息,但是会给造成麻烦。不同并行方式Op的实现有差异,比如对于Linear Op,Tensor Parallel中gather buffer的分配在Op中。而对于ZeRO,gather buffer的分配是在PreOp中。将放在PreOp开始时采样有利于将两种情况统一。
@@ -94,3 +94,5 @@ MSC的重要职责是在调整tensor layout位置,比如在上图S2时刻,
在non-warmup阶段,我们需要利用预热阶段采集的非模型数据内存信息,预留出下一个Period在计算设备上需要的峰值内存,这需要我们移动出一些模型张量。
为了避免频繁在CPU-GPU换入换出相同的tensor,引起类似[cache thrashing](https://en.wikipedia.org/wiki/Thrashing_(computer_science))的现象。我们利用DNN训练迭代特性,设计了OPT cache换出策略。具体来说,在warmup阶段,我们记录每个tensor被计算设备需要的采样时刻。如果我们需要驱逐一些HOLD tensor,那么我们选择在本设备上最晚被需要的tensor作为受害者。
+
+
diff --git a/docs/source/zh-Hans/advanced_tutorials/opt_service.md b/docs/source/zh-Hans/advanced_tutorials/opt_service.md
index a213584fd41d..1f8324a53ecb 100644
--- a/docs/source/zh-Hans/advanced_tutorials/opt_service.md
+++ b/docs/source/zh-Hans/advanced_tutorials/opt_service.md
@@ -52,7 +52,7 @@ export CHECKPOINT_DIR="your_opt_checkpoint_path"
# the ${CONFIG_DIR} must contain a server.sh file as the entry of service
export CONFIG_DIR="config_file_path"
-docker run --gpus all --rm -it -p 8020:8020 -v ${CHECKPOINT_DIR}:/model_checkpoint -v ${CONFIG_DIR}:/config --ipc=host energonai:lastest
+docker run --gpus all --rm -it -p 8020:8020 -v ${CHECKPOINT_DIR}:/model_checkpoint -v ${CONFIG_DIR}:/config --ipc=host energonai:latest
```
接下来,您就可以在您的浏览器中打开 `https://[IP-ADDRESS]:8020/docs#` 进行测试。
diff --git a/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md b/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md
index f3c6247c38e4..c4131e593437 100644
--- a/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md
+++ b/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md
@@ -159,11 +159,11 @@ for mn, module in model.named_modules():
在我们最新示例中还定义了一个Gemini + ZeRO DDP 的模型从而减小开销,提升效率。这一部分的详细内容可以参考[ZeRO](../features/zero_with_chunk.md),你可以将这两部分内容结合起来看从而理解我们整个训练流程:
```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
return model
diff --git a/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md b/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
index 6dc5eccf4421..e2f2c90a3791 100644
--- a/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
+++ b/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
@@ -477,7 +477,7 @@ def build_cifar(batch_size):
return train_dataloader, test_dataloader
-# craete dataloaders
+# create dataloaders
train_dataloader , test_dataloader = build_cifar()
# create loss function
criterion = CrossEntropyLoss(label_smoothing=0.1)
@@ -492,7 +492,7 @@ lr_scheduler = CosineAnnealingWarmupLR(optimizer=optimizer,
#### 启动 Colossal-AI 引擎
```python
-# intiailize
+# initialize
engine, train_dataloader, test_dataloader, _ = colossalai.initialize(model=model,
optimizer=optimizer,
criterion=criterion,
diff --git a/docs/source/zh-Hans/basics/booster_api.md b/docs/source/zh-Hans/basics/booster_api.md
index 5410cc213fd2..1bb5fd69bd15 100644
--- a/docs/source/zh-Hans/basics/booster_api.md
+++ b/docs/source/zh-Hans/basics/booster_api.md
@@ -25,24 +25,6 @@ Booster插件是管理并行配置的重要组件(eg:gemini插件封装了ge
{{ autodoc:colossalai.booster.Booster }}
-{{ autodoc:colossalai.booster.Booster.boost }}
-
-{{ autodoc:colossalai.booster.Booster.backward }}
-
-{{ autodoc:colossalai.booster.Booster.no_sync }}
-
-{{ autodoc:colossalai.booster.Booster.save_model }}
-
-{{ autodoc:colossalai.booster.Booster.load_model }}
-
-{{ autodoc:colossalai.booster.Booster.save_optimizer }}
-
-{{ autodoc:colossalai.booster.Booster.load_optimizer }}
-
-{{ autodoc:colossalai.booster.Booster.save_lr_scheduler }}
-
-{{ autodoc:colossalai.booster.Booster.load_lr_scheduler }}
-
## 使用方法及示例
在使用colossalai训练时,首先需要在训练脚本的开头启动分布式环境,并创建需要使用的模型、优化器、损失函数、数据加载器等对象。之后,调用`colossalai.booster` 将特征注入到这些对象中,您就可以使用我们的booster API去进行您接下来的训练流程。
diff --git a/docs/source/zh-Hans/basics/booster_plugins.md b/docs/source/zh-Hans/basics/booster_plugins.md
index b15ceb1e3ad5..5bd88b679000 100644
--- a/docs/source/zh-Hans/basics/booster_plugins.md
+++ b/docs/source/zh-Hans/basics/booster_plugins.md
@@ -63,6 +63,10 @@ Zero-2 不支持局部梯度累积。如果您坚持使用,虽然可以积累
> ⚠ 如果 torch 版本低于 1.12.0,此插件将不可用。
+> ⚠ 该插件现在还不支持保存/加载分片的模型 checkpoint。
+
+> ⚠ 该插件现在还不支持使用了multi params group的optimizer。
+
更多详细信息,请参阅 [Pytorch 文档](https://pytorch.org/docs/main/fsdp.html).
{{ autodoc:colossalai.booster.plugin.TorchFSDPPlugin }}
diff --git a/docs/source/zh-Hans/basics/colotensor_concept.md b/docs/source/zh-Hans/basics/colotensor_concept.md
index d6a332df2e9c..ab2413e990f7 100644
--- a/docs/source/zh-Hans/basics/colotensor_concept.md
+++ b/docs/source/zh-Hans/basics/colotensor_concept.md
@@ -2,6 +2,8 @@
Author: [Jiarui Fang](https://github.com/feifeibear), [Hongxin Liu](https://github.com/ver217) and [Haichen Huang](https://github.com/1SAA)
+> ⚠️ 此页面上的信息已经过时并将被废弃。
+
**Prerequisite:**
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
- [Distributed Training](../concepts/distributed_training.md)
@@ -51,7 +53,7 @@ ColoTensor 包含额外的属性[ColoTensorSpec](https://colossalai.readthedocs.
## Example
-让我们看一个例子。 使用 tp_degree=4, dp_dgree=2 在 8 个 GPU 上初始化并Shard一个ColoTensor。 然后tensor被沿着 TP 进程组中的最后一个维度进行分片。 最后,我们沿着 TP 进程组中的第一个维度(dim 0)对其进行重新Shard。 我们鼓励用户运行代码并观察每个张量的形状。
+让我们看一个例子。 使用 tp_degree=4, dp_degree=2 在 8 个 GPU 上初始化并Shard一个ColoTensor。 然后tensor被沿着 TP 进程组中的最后一个维度进行分片。 最后,我们沿着 TP 进程组中的第一个维度(dim 0)对其进行重新Shard。 我们鼓励用户运行代码并观察每个张量的形状。
```python
diff --git a/docs/source/zh-Hans/basics/configure_parallelization.md b/docs/source/zh-Hans/basics/configure_parallelization.md
index eb4b38f48ddb..0c2a66572d60 100644
--- a/docs/source/zh-Hans/basics/configure_parallelization.md
+++ b/docs/source/zh-Hans/basics/configure_parallelization.md
@@ -2,6 +2,8 @@
作者: Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster插件](../basics/booster_plugins.md)页面查阅更新。
+
**预备知识:**
- [分布式训练](../concepts/distributed_training.md)
- [并行技术](../concepts/paradigms_of_parallelism.md)
diff --git a/docs/source/zh-Hans/basics/define_your_config.md b/docs/source/zh-Hans/basics/define_your_config.md
index d7e49cbf23de..720e75805e8d 100644
--- a/docs/source/zh-Hans/basics/define_your_config.md
+++ b/docs/source/zh-Hans/basics/define_your_config.md
@@ -2,6 +2,8 @@
作者: Guangyang Lu, Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster API](../basics/booster_api.md)页面查阅更新。
+
**预备知识:**
- [分布式训练](../concepts/distributed_training.md)
- [Colossal-AI 总览](../concepts/colossalai_overview.md)
diff --git a/docs/source/zh-Hans/basics/engine_trainer.md b/docs/source/zh-Hans/basics/engine_trainer.md
index a7519bfca14f..a35bd87c44e1 100644
--- a/docs/source/zh-Hans/basics/engine_trainer.md
+++ b/docs/source/zh-Hans/basics/engine_trainer.md
@@ -2,6 +2,8 @@
作者: Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster API](../basics/booster_api.md)页面查阅更新。
+
**预备知识:**
- [初始化功能](./initialize_features.md)
diff --git a/docs/source/zh-Hans/basics/initialize_features.md b/docs/source/zh-Hans/basics/initialize_features.md
index 67ea114b42b2..1c28d658e1bc 100644
--- a/docs/source/zh-Hans/basics/initialize_features.md
+++ b/docs/source/zh-Hans/basics/initialize_features.md
@@ -2,6 +2,8 @@
作者: Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster API](../basics/booster_api.md)页面查阅更新。
+
**预备知识:**
- [分布式训练](../concepts/distributed_training.md)
- [Colossal-AI 总览](../concepts/colossalai_overview.md)
diff --git a/docs/source/zh-Hans/basics/model_checkpoint.md b/docs/source/zh-Hans/basics/model_checkpoint.md
index cec12d451989..a5374b7509c9 100644
--- a/docs/source/zh-Hans/basics/model_checkpoint.md
+++ b/docs/source/zh-Hans/basics/model_checkpoint.md
@@ -1,7 +1,9 @@
-# 模型检查点
+# 模型Checkpoint
作者 : Guangyang Lu
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster Checkpoint](../basics/booster_checkpoint.md)页面查阅更新。
+
**预备知识:**
- [Launch Colossal-AI](./launch_colossalai.md)
- [Initialize Colossal-AI](./initialize_features.md)
@@ -13,9 +15,9 @@
## 简介
-本教程将介绍如何保存和加载模型检查点。
+本教程将介绍如何保存和加载模型Checkpoint。
-为了充分利用Colossal-AI的强大并行策略,我们需要修改模型和张量,可以直接使用 `torch.save` 或者 `torch.load` 保存或加载模型检查点。在Colossal-AI中,我们提供了应用程序接口实现上述同样的效果。
+为了充分利用Colossal-AI的强大并行策略,我们需要修改模型和张量,可以直接使用 `torch.save` 或者 `torch.load` 保存或加载模型Checkpoint。在Colossal-AI中,我们提供了应用程序接口实现上述同样的效果。
但是,在加载时,你不需要使用与存储相同的保存策略。
@@ -24,7 +26,7 @@
### 保存
有两种方法可以使用Colossal-AI训练模型,即使用engine或使用trainer。
-**注意我们只保存 `state_dict`.** 因此,在加载检查点时,需要首先定义模型。
+**注意我们只保存 `state_dict`.** 因此,在加载Checkpoint时,需要首先定义模型。
#### 同 engine 保存
diff --git a/docs/source/zh-Hans/features/cluster_utils.md b/docs/source/zh-Hans/features/cluster_utils.md
index ca787a869041..f54a72c63a66 100644
--- a/docs/source/zh-Hans/features/cluster_utils.md
+++ b/docs/source/zh-Hans/features/cluster_utils.md
@@ -13,20 +13,4 @@
{{ autodoc:colossalai.cluster.DistCoordinator }}
-{{ autodoc:colossalai.cluster.DistCoordinator.is_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.is_node_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.is_last_process }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.print_on_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.print_on_node_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.priority_execution }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.destroy }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.block_all }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.on_master_only }}
+
diff --git a/docs/source/zh-Hans/features/gradient_accumulation.md b/docs/source/zh-Hans/features/gradient_accumulation.md
index e21e5fcd43d8..fc8b29bbe8f1 100644
--- a/docs/source/zh-Hans/features/gradient_accumulation.md
+++ b/docs/source/zh-Hans/features/gradient_accumulation.md
@@ -1,4 +1,4 @@
-# 梯度累积
+# 梯度累积 (旧版本)
作者: Shenggui Li, Yongbin Li
@@ -38,3 +38,4 @@ iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0
iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
```
+
diff --git a/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md b/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md
new file mode 100644
index 000000000000..a8422060f0ea
--- /dev/null
+++ b/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md
@@ -0,0 +1,146 @@
+# 梯度累积 (新版本)
+
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**前置教程**
+- [定义配置文件](../basics/define_your_config.md)
+- [训练中使用Booster](../basics/booster_api.md)
+
+## 引言
+
+梯度累积是一种常见的增大训练 batch size 的方式。 在训练大模型时,内存经常会成为瓶颈,并且 batch size 通常会很小(如2),这导致收敛性无法保证。梯度累积将多次迭代的梯度累加,并仅在达到预设迭代次数时更新参数。
+
+## 使用
+
+在 Colossal-AI 中使用梯度累积非常简单,booster提供no_sync返回一个上下文管理器,在该上下文管理器下取消同步并且累积梯度。
+
+## 实例
+
+我们将介绍如何使用梯度累积。在这个例子中,梯度累积次数被设置为4。
+
+### 步骤 1. 在 train.py 导入相关库
+创建train.py并导入必要依赖。 `torch` 的版本应不低于1.8.1。
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet18
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.cluster.dist_coordinator import priority_execution
+```
+
+### 步骤 2. 初始化分布式环境
+
+我们需要初始化分布式环境。为了快速演示,我们使用`launch_from_torch`。你可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)使用其他初始化方法。
+
+```python
+# initialize distributed setting
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+
+```
+
+### 步骤 3. 创建训练组件
+
+构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`,在你的机器上设置路径。数据将会被自动下载到该路径。
+
+```python
+# define the training hyperparameters
+BATCH_SIZE = 128
+GRADIENT_ACCUMULATION = 4
+
+# build resnet
+model = resnet18(num_classes=10)
+
+# build dataloaders
+with priority_execution():
+ train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+```
+
+### 步骤 4. 注入特性
+创建一个`TorchDDPPlugin`对象,并作为参实例化`Booster`, 调用`booster.boost`注入特性。
+
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, _ = booster.boost(model=model,
+ optimizer=optimizer,
+ criterion=criterion,
+ dataloader=train_dataloader)
+```
+
+### 步骤 5. 使用booster训练
+使用booster构建一个普通的训练循环,验证梯度累积。 `param_by_iter` 记录分布训练的信息。
+```python
+optimizer.zero_grad()
+for idx, (img, label) in enumerate(train_dataloader):
+ sync_context = booster.no_sync(model)
+ img = img.cuda()
+ label = label.cuda()
+ if idx % (GRADIENT_ACCUMULATION - 1) != 0:
+ with sync_context:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ else:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.step()
+ optimizer.zero_grad()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ param_by_iter.append(str(ele_1st.item()))
+
+ if idx != 0 and idx % (GRADIENT_ACCUMULATION - 1) == 0:
+ break
+
+ for iteration, val in enumerate(param_by_iter):
+ print(f'iteration {iteration} - value: {val}')
+
+ if param_by_iter[-1] != param_by_iter[0]:
+ print('The parameter is only updated in the last iteration')
+
+```
+
+### 步骤 6. 启动训练脚本
+为了验证梯度累积,我们可以只检查参数值的变化。当设置梯度累加时,仅在最后一步更新参数。您可以使用以下命令运行脚本:
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
+你将会看到类似下方的文本输出。这展现了梯度虽然在前3个迭代中被计算,但直到最后一次迭代,参数才被更新。
+
+```text
+iteration 0, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
+```
+
+
diff --git a/docs/source/zh-Hans/features/gradient_clipping.md b/docs/source/zh-Hans/features/gradient_clipping.md
index 203f66a3fea2..2f62c31766a6 100644
--- a/docs/source/zh-Hans/features/gradient_clipping.md
+++ b/docs/source/zh-Hans/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# 梯度裁剪
+# 梯度裁剪(旧版本)
作者: Boxiang Wang, Haichen Huang, Yongbin Li
@@ -49,3 +49,5 @@ clip_grad_norm = 1.0
```shell
python -m torch.distributed.launch --nproc_per_node 1 --master_addr localhost --master_port 29500 train_with_engine.py
```
+
+
diff --git a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
new file mode 100644
index 000000000000..3c61356dd0d5
--- /dev/null
+++ b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
@@ -0,0 +1,140 @@
+# 梯度裁剪 (新版本)
+
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**前置教程**
+- [定义配置文件](../basics/define_your_config.md)
+- [booster使用](../basics/booster_api.md)
+
+**相关论文**
+- [On the difficulty of training Recurrent Neural Networks](https://arxiv.org/abs/1211.5063)
+
+## 引言
+
+为了加快训练过程和寻求全局最优以获得更好的性能,越来越多的学习率调度器被提出。人们通过控制学习率来调整训练中的下降速度。这使得梯度向量在每一步都能更好地统一。在这种情况下,下降速度可以按预期被控制。
+因此,梯度裁剪,一种可以将梯度向量归一化,以将其限制在统一长度的技术,对于那些希望模型性能更好的人来说是不可或缺的。
+
+在使用 Colossal-AI 时,你不必担心实现梯度剪裁,我们以一种有效而方便的方式支持梯度剪裁。你所需要的只是在你的配置文件中增加一个命令。
+
+## 为什么应该使用 Colossal-AI 中的梯度裁剪
+
+我们不建议用户自己编写梯度剪裁,因为朴素的梯度剪裁在应用张量并行、流水线并行、MoE 等功能时可能会失败。
+
+根据下图,每个 GPU 只拥有线性层中权重的一部分参数。为了得到线性层权重的梯度向量的正确范数,每个 GPU 中的每个梯度向量的范数应该相加。更复杂的是,偏置的分布不同于权重的分布。通信组在求和运算中有所不同。
+
+(注: 这种情况是旧版本的 2D 并行,在代码中的实现是不一样的。但这是一个很好的例子,能够说明在梯度剪裁中统一所有通信的困难。)
+
+
+
+参数分布
+
+
+不用担心它,因为 Colossal-AI 已经为你处理好。
+
+### 使用
+要使用梯度裁剪,只需在使用booster注入特性之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。
+
+### 实例
+
+下面我们将介绍如何使用梯度裁剪,在本例中,我们将梯度裁剪范数设置为1.0。
+
+### 步骤 1. 在训练中导入相关库
+创建`train.py`并导入相关库。
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet34
+from tqdm import tqdm
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import CosineAnnealingLR
+```
+
+### 步骤 2. 初始化分布式环境
+我们需要初始化分布式环境. 为了快速演示,我们使用`launch_from_torch`. 您可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)
+
+```python
+colossalai.launch_from_torch(config=dict())
+logger = get_dist_logger()
+```
+
+### 步骤 3. 创建训练组件
+
+构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`在你的机器上设置路径。数据将会被自动下载到该路径。
+```python
+# define training hyperparameters
+NUM_EPOCHS = 200
+BATCH_SIZE = 128
+GRADIENT_CLIPPING = 0.1
+# build resnet
+model = resnet34(num_classes=10)
+# build dataloaders
+train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+# lr_scheduler
+lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+
+```
+### 步骤 4. 注入梯度裁剪特性
+
+创建`TorchDDPPlugin`对象并初始化`Booster`, 使用booster注入相关特性。
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+
+```
+
+### 步骤 5. 使用booster训练
+使用booster进行训练。
+```python
+# verify gradient clipping
+model.train()
+for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
+```
+
+### 步骤 6. 启动训练脚本
+你可以使用以下命令运行脚本:
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
diff --git a/docs/source/zh-Hans/features/mixed_precision_training.md b/docs/source/zh-Hans/features/mixed_precision_training.md
index c9db3a59c1c3..4628b09cd910 100644
--- a/docs/source/zh-Hans/features/mixed_precision_training.md
+++ b/docs/source/zh-Hans/features/mixed_precision_training.md
@@ -1,4 +1,4 @@
-# 自动混合精度训练 (AMP)
+# 自动混合精度训练 (旧版本)
作者: Chuanrui Wang, Shenggui Li, Yongbin Li
@@ -203,7 +203,7 @@ Naive AMP 的默认参数:
- initial_scale(int): gradient scaler 的初始值
- growth_factor(int): loss scale 的增长率
- backoff_factor(float): loss scale 的下降率
-- hysterisis(int): 动态 loss scaling 的延迟偏移
+- hysteresis(int): 动态 loss scaling 的延迟偏移
- max_scale(int): loss scale 的最大允许值
- verbose(bool): 如果被设为`True`,将打印调试信息
@@ -339,6 +339,7 @@ for epoch in range(gpc.config.NUM_EPOCHS):
使用下列命令启动训练脚本,你可以改变 `--nproc_per_node` 以使用不同数量的 GPU。
-```python
+```shell
python -m torch.distributed.launch --nproc_per_node 4 --master_addr localhost --master_port 29500 train_with_engine.py --config config/config_AMP_torch.py
```
+
diff --git a/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md b/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md
new file mode 100644
index 000000000000..187aef1a6c4a
--- /dev/null
+++ b/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md
@@ -0,0 +1,235 @@
+# 自动混合精度训练 (新版本)
+
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**前置教程**
+- [定义配置文件](../basics/define_your_config.md)
+- [booster使用](../basics/booster_api.md)
+
+**相关论文**
+- [Accelerating Scientific Computations with Mixed Precision Algorithms](https://arxiv.org/abs/0808.2794)
+
+
+## 引言
+
+AMP 代表自动混合精度训练。
+在 Colossal-AI 中, 我们结合了混合精度训练的不同实现:
+
+1. torch.cuda.amp
+2. apex.amp
+3. naive amp
+
+
+| Colossal-AI | 支持张量并行 | 支持流水并行 | fp16范围 |
+| ----------- | ----------------------- | ------------------------- | ----------- |
+| AMP_TYPE.TORCH | ✅ | ❌ | 在前向和反向传播期间,模型参数、激活和梯度向下转换至fp16 |
+| AMP_TYPE.APEX | ❌ | ❌ | 更细粒度,我们可以选择 opt_level O0, O1, O2, O3 |
+| AMP_TYPE.NAIVE | ✅ | ✅ | 模型参数、前向和反向操作,全都向下转换至fp16 |
+
+前两个依赖于 PyTorch (1.6及以上) 和 NVIDIA Apex 的原始实现。最后一种方法类似 Apex O2。在这些方法中,Apex-AMP 与张量并行不兼容。这是因为张量是以张量并行的方式在设备之间拆分的,因此,需要在不同的进程之间进行通信,以检查整个模型权重中是否出现inf或nan。我们修改了torch amp实现,使其现在与张量并行兼容。
+
+> ❌️ fp16与ZeRO不兼容
+>
+> ⚠️ 流水并行目前仅支持naive amp
+
+我们建议使用 torch AMP,因为在不使用流水并行时,它通常比 NVIDIA AMP 提供更好的准确性。
+
+## 目录
+
+在本教程中,我们将介绍:
+
+1. [AMP 介绍](#amp-介绍)
+2. [Colossal-AI 中的 AMP](#colossal-ai-中的-amp)
+3. [练习实例](#实例)
+
+## AMP 介绍
+
+自动混合精度训练是混合 FP16 和 FP32 训练。
+
+半精度浮点格式(FP16)具有较低的算法复杂度和较高的计算效率。此外,FP16 仅需要 FP32 所需的一半存储空间,并节省了内存和网络带宽,从而为大 batch size 和大模型提供了更多内存。
+
+然而,还有其他操作,如缩减,需要 FP32 的动态范围,以避免数值溢出/下溢。因此,我们引入自动混合精度,尝试将每个操作与其相应的数据类型相匹配,这可以减少内存占用并提高训练效率。
+
+
+
+AMP 示意图 (图片来自 PatrickStar 论文)
+
+
+## Colossal-AI 中的 AMP
+
+我们支持三种 AMP 训练方法,并允许用户在没有改变代码的情况下使用 AMP 进行训练。booster支持amp特性注入,如果您要使用混合精度训练,则在创建booster实例时指定`mixed_precision`参数,我们现已支持torch amp,apex amp, naive amp(现已移植torch amp至booster,apex amp, naive amp仍由`colossalai.initialize`方式启动,如您需使用,请[参考](./mixed_precision_training.md);后续将会拓展`bf16`,`pf8`的混合精度训练.
+
+#### booster启动方式
+您可以在创建booster实例时,指定`mixed_precision="fp16"`即使用torch amp。
+
+```python
+"""
+ 初始化映射关系如下:
+ 'fp16': torch amp
+ 'fp16_apex': apex amp,
+ 'bf16': bf16,
+ 'fp8': fp8,
+ 'fp16_naive': naive amp
+"""
+from colossalai import Booster
+booster = Booster(mixed_precision='fp16',...)
+```
+
+或者您可以自定义一个`FP16TorchMixedPrecision`对象,如
+
+```python
+from colossalai.mixed_precision import FP16TorchMixedPrecision
+mixed_precision = FP16TorchMixedPrecision(
+ init_scale=2.**16,
+ growth_factor=2.0,
+ backoff_factor=0.5,
+ growth_interval=2000)
+booster = Booster(mixed_precision=mixed_precision,...)
+```
+
+其他类型的amp使用方式也是一样的。
+
+### Torch AMP 配置
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16TorchMixedPrecision }}
+
+### Apex AMP 配置
+
+对于这种模式,我们依靠 Apex 实现混合精度训练。我们支持这个插件,因为它允许对混合精度的粒度进行更精细的控制。
+例如, O2 水平 (优化器水平2) 将保持 batch normalization 为 FP32。
+
+如果你想了解更多细节,请参考 [Apex Documentation](https://nvidia.github.io/apex/)。
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16ApexMixedPrecision }}
+
+### Naive AMP 配置
+
+在 Naive AMP 模式中, 我们实现了混合精度训练,同时保持了与复杂张量和流水并行的兼容性。该 AMP 模式将所有操作转为 FP16 。下列代码块展示了该模式的booster启动方式。
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16NaiveMixedPrecision }}
+
+当使用`colossalai.booster`时, 首先需要实例化一个模型、一个优化器和一个标准。将输出模型转换为内存消耗较小的 AMP 模型。如果您的输入模型已经太大,无法放置在 GPU 中,请使用`dtype=torch.float16`实例化你的模型。或者请尝试更小的模型,或尝试更多的并行化训练技术!
+
+## 实例
+
+下面我们将展现如何在 Colossal-AI 使用 AMP。在该例程中,我们使用 Torch AMP.
+
+### 步骤 1. 在 train.py 导入相关库
+
+创建`train.py`并导入必要依赖. 请记得通过命令`pip install timm scipy`安装`scipy`和`timm`。
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from timm.models import vit_base_patch16_224
+from titans.utils import barrier_context
+from torchvision import datasets, transforms
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import LinearWarmupLR
+```
+
+### 步骤 2. 初始化分布式环境
+
+我们需要初始化分布式环境。为了快速演示,我们使用`launch_from_torch`。你可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)
+使用其他初始化方法。
+
+```python
+# 初始化分布式设置
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+
+```
+
+### 步骤 3. 创建训练组件
+
+构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`
+在你的机器上设置路径。数据将会被自动下载到该路径。
+
+```python
+# define the constants
+NUM_EPOCHS = 2
+BATCH_SIZE = 128
+# build model
+model = vit_base_patch16_224(drop_rate=0.1)
+
+# build dataloader
+train_dataset = datasets.Caltech101(
+ root=Path(os.environ['DATA']),
+ download=True,
+ transform=transforms.Compose([
+ transforms.Resize(256),
+ transforms.RandomResizedCrop(224),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ Gray2RGB(),
+ transforms.Normalize([0.5, 0.5, 0.5],
+ [0.5, 0.5, 0.5])
+ ]))
+
+# build optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, weight_decay=0.1)
+
+# build loss
+criterion = torch.nn.CrossEntropyLoss()
+
+# lr_scheduelr
+lr_scheduler = LinearWarmupLR(optimizer, warmup_steps=50, total_steps=NUM_EPOCHS)
+```
+
+### 步骤 4. 插入 AMP
+创建一个MixedPrecision对象(如果需要)及torchDDPPlugin对象,调用 `colossalai.boost` 将所有训练组件转为为FP16模式.
+
+```python
+plugin = TorchDDPPlugin()
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+
+# if you need to customize the config, do like this
+# >>> from colossalai.mixed_precision import FP16TorchMixedPrecision
+# >>> mixed_precision = FP16TorchMixedPrecision(
+# >>> init_scale=2.**16,
+# >>> growth_factor=2.0,
+# >>> backoff_factor=0.5,
+# >>> growth_interval=2000)
+# >>> plugin = TorchDDPPlugin()
+# >>> booster = Booster(mixed_precision=mixed_precision, plugin=plugin)
+
+# boost model, optimizer, criterion, dataloader, lr_scheduler
+model, optimizer, criterion, dataloader, lr_scheduler = booster.boost(model, optimizer, criterion, dataloader, lr_scheduler)
+```
+
+### 步骤 5. 使用 booster 训练
+
+使用booster构建一个普通的训练循环。
+
+```python
+model.train()
+for epoch in range(NUM_EPOCHS):
+ for img, label in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+ optimizer.zero_grad()
+ output = model(img)
+ loss = criterion(output, label)
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ lr_scheduler.step()
+```
+
+### 步骤 6. 启动训练脚本
+
+使用下列命令启动训练脚本,你可以改变 `--nproc_per_node` 以使用不同数量的 GPU。
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
diff --git a/docs/source/zh-Hans/features/nvme_offload.md b/docs/source/zh-Hans/features/nvme_offload.md
index fd75ed1f5b3e..1feb9dde5725 100644
--- a/docs/source/zh-Hans/features/nvme_offload.md
+++ b/docs/source/zh-Hans/features/nvme_offload.md
@@ -53,9 +53,8 @@ optimizer = HybridAdam(model.parameters(), lr=1e-3, nvme_offload_fraction=1.0, n
> ⚠ 它只会卸载在 CPU 上的优化器状态。这意味着它只会影响 CPU 训练或者使用卸载的 Zero/Gemini。
-## Exampls
+## Examples
-Let's start from two simple examples -- training GPT with different methods. These examples relies on `transformers`.
首先让我们从两个简单的例子开始 -- 用不同的方法训练 GPT。这些例子依赖`transformers`。
我们首先应该安装依赖:
@@ -77,8 +76,9 @@ from transformers.models.gpt2.configuration_gpt2 import GPT2Config
from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
import colossalai
from colossalai.nn.optimizer import HybridAdam
-from colossalai.zero import zero_model_wrapper, zero_optim_wrapper
from colossalai.utils.model.colo_init_context import ColoInitContext
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin
```
然后我们定义一个损失函数:
@@ -182,16 +182,24 @@ def train_gemini_cpu(nvme_offload_fraction: float = 0.0):
criterion = GPTLMLoss()
optimizer = HybridAdam(model.parameters(), nvme_offload_fraction=nvme_offload_fraction)
print(f'Model numel: {get_model_numel(model) / 1024**3:.3f} B')
- gemini_config = dict(strict_ddp_mode=True, device=torch.cuda.current_device(),
- placement_policy='cpu', pin_memory=True, hidden_dim=config.n_embd)
- model = zero_model_wrapper(model, zero_stage=3, gemini_config=gemini_config)
- optimizer = zero_optim_wrapper(model, optimizer, initial_scale=2**5)
+
+ plugin = GeminiPlugin(
+ strict_ddp_mode=True,
+ device=torch.cuda.current_device(),
+ placement_policy='cpu',
+ pin_memory=True,
+ hidden_dim=config.n_embd,
+ initial_scale=2**5
+ )
+ booster = Booster(plugin)
+ model, optimizer, criterion, _* = booster.boost(model, optimizer, criterion)
+
start = time.time()
for step in range(3):
data = get_data(4, 128, config.vocab_size)
outputs = model(**data)
loss = criterion(outputs.logits, data['input_ids'])
- optimizer.backward(loss)
+ booster.backward(loss, optimizer)
optimizer.step()
optimizer.zero_grad()
print(f'[{step}] loss: {loss.item():.3f}')
diff --git a/docs/source/zh-Hans/features/zero_with_chunk.md b/docs/source/zh-Hans/features/zero_with_chunk.md
index 72403bf610a4..9030464ddf9a 100644
--- a/docs/source/zh-Hans/features/zero_with_chunk.md
+++ b/docs/source/zh-Hans/features/zero_with_chunk.md
@@ -4,7 +4,7 @@
**前置教程:**
-- [定义配置文件](../basics/define_your_config.md)
+- [booster使用](../basics/booster_api.md)
**示例代码**
@@ -97,6 +97,8 @@ optimizer.step()
首先我们只需要引入`Huggingface transformers` 的 `GPT2LMHeadModel`来定义我们的模型,不需要用户进行模型的定义与修改,方便用户使用。
+定义GPT模型:
+
```python
class GPTLMModel(nn.Module):
@@ -182,34 +184,6 @@ def split_param_col_tp1d(param: ColoParameter, pg: ProcessGroup):
split_param_single_dim_tp1d(-1, param, pg)
```
-定义一个使用 Gemini + ZeRO DDP 的模型:
-
-```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
- cai_version = colossalai.__version__
- if version.parse(cai_version) > version.parse("0.1.10"):
- from colossalai.nn.parallel import GeminiDDP
- model = GeminiDDP(model,
- device=get_current_device(),
- placement_policy=placememt_policy,
- pin_memory=True,
- search_range_mb=32)
- elif version.parse(cai_version) <= version.parse("0.1.10") and version.parse(cai_version) >= version.parse("0.1.9"):
- from colossalai.gemini import ChunkManager, GeminiManager
- chunk_size = ChunkManager.search_chunk_size(model, 64 * 1024**2, 32)
- gemini_manager = GeminiManager(placememt_policy, chunk_manager)
- chunk_manager = ChunkManager(chunk_size,
- pg,
- enable_distributed_storage=True,
- init_device=GeminiManager.get_default_device(placememt_policy))
- model = ZeroDDP(model, gemini_manager)
- else:
- raise NotImplemented(f"CAI version {cai_version} is not supported")
- return model
-```
-
-由于我们在这个例子中对GPT进行预训练,因此只使用了一个简单的语言模型损失函数。
-
写一个获得随机输入的函数:
```python
@@ -219,9 +193,16 @@ def get_data(batch_size, seq_len, vocab_size):
return input_ids, attention_mask
```
-最后,我们可以定义我们的训练循环:
+
+最后,使用booster注入 Gemini + ZeRO DDP 特性, 并定义训练循环。由于我们在这个例子中对GPT进行预训练,因此只使用了一个简单的语言模型损失函数:
```python
+from torch.optim import Adam
+
+from colossalai.booster import Booster
+from colossalai.zero import ColoInitContext
+from colossalai.booster.plugin import GeminiPlugin
+
def main():
args = parse_args()
BATCH_SIZE = 8
@@ -232,22 +213,23 @@ def main():
# build criterion
criterion = GPTLMLoss()
+ optimizer = Adam(model.parameters(), lr=0.001)
torch.manual_seed(123)
default_pg = ProcessGroup(tp_degree=args.tp_degree)
- default_dist_spec = ShardSpec([-1], [args.tp_degree]) if args.shardinit else None
+ default_dist_spec = ShardSpec([-1], [args.tp_degree])
# build GPT model
with ColoInitContext(device='cpu', default_dist_spec=default_dist_spec, default_pg=default_pg):
model = gpt2_medium(checkpoint=True)
pg = default_pg
# Tensor Parallelism (TP)
tensor_parallelize(model, pg)
+
# Gemini + ZeRO DP, Note it must be used after TP
- model = gemini_zero_dpp(model, pg, args.placement)
- # build optimizer
- optimizer = GeminiAdamOptimizer(model, lr=1e-3, initial_scale=2**5)
- numel = sum([p.numel() for p in model.parameters()])
- get_tflops_func = partial(get_tflops, numel, BATCH_SIZE, SEQ_LEN)
+ plugin = GeminiPlugin(placement_policy='cuda', max_norm=1.0, initial_scale=2**5)
+ booster = Booster(plugin=plugin)
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+
torch.cuda.synchronize()
model.train()
for n in range(NUM_STEPS):
@@ -256,10 +238,12 @@ def main():
optimizer.zero_grad()
outputs = model(input_ids, attn_mask)
loss = criterion(outputs, input_ids)
- optimizer.backward(loss)
+ booster.backward(loss, optimizer)
optimizer.step()
torch.cuda.synchronize()
```
> ⚠️ 注意:如果你使用Gemini模块的话,请不要使用我们之前提到过的[梯度累加](../features/gradient_accumulation.md)。
完整的例子代码可以在 [Train GPT with Colossal-AI](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/gpt). 获得。
+
+
diff --git a/docs/source/zh-Hans/get_started/installation.md b/docs/source/zh-Hans/get_started/installation.md
index e0d726c74f64..a6c88672b907 100755
--- a/docs/source/zh-Hans/get_started/installation.md
+++ b/docs/source/zh-Hans/get_started/installation.md
@@ -47,4 +47,20 @@ CUDA_EXT=1 pip install .
pip install .
```
+如果您在使用CUDA 10.2,您仍然可以从源码安装ColossalAI。但是您需要手动下载cub库并将其复制到相应的目录。
+
+```bash
+# clone the repository
+git clone https://github.com/hpcaitech/ColossalAI.git
+cd ColossalAI
+
+# download the cub library
+wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip
+unzip 1.8.0.zip
+cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
+
+# install
+CUDA_EXT=1 pip install .
+```
+
diff --git a/examples/images/dreambooth/train_dreambooth_colossalai.py b/examples/images/dreambooth/train_dreambooth_colossalai.py
index e6159e1058b9..d07febea0a84 100644
--- a/examples/images/dreambooth/train_dreambooth_colossalai.py
+++ b/examples/images/dreambooth/train_dreambooth_colossalai.py
@@ -340,12 +340,12 @@ def get_full_repo_name(model_id: str, organization: Optional[str] = None, token:
# Gemini + ZeRO DDP
-def gemini_zero_dpp(model: torch.nn.Module, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=64)
return model
diff --git a/examples/images/dreambooth/train_dreambooth_colossalai_lora.py b/examples/images/dreambooth/train_dreambooth_colossalai_lora.py
index 1b2fc778d5ed..6715b473a567 100644
--- a/examples/images/dreambooth/train_dreambooth_colossalai_lora.py
+++ b/examples/images/dreambooth/train_dreambooth_colossalai_lora.py
@@ -342,12 +342,12 @@ def get_full_repo_name(model_id: str, organization: Optional[str] = None, token:
# Gemini + ZeRO DDP
-def gemini_zero_dpp(model: torch.nn.Module, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=64)
return model
diff --git a/examples/language/gpt/gemini/test_ci.sh b/examples/language/gpt/gemini/test_ci.sh
index 6079d5ed615b..0ddfd3a6211c 100644
--- a/examples/language/gpt/gemini/test_ci.sh
+++ b/examples/language/gpt/gemini/test_ci.sh
@@ -3,7 +3,7 @@ $(cd `dirname $0`;pwd)
export TRAIN_STEP=4
for MODEL_TYPE in "gpt2_medium"; do
- for DISTPLAN in "colossalai"; do
+ for DISTPLAN in "CAI_Gemini"; do
for BATCH_SIZE in 2; do
for GPUNUM in 1 4; do
for TPDEGREE in 1 2; do
diff --git a/examples/language/gpt/gemini/train_gpt_demo.py b/examples/language/gpt/gemini/train_gpt_demo.py
index b2a7fa36d021..92751c7e2f47 100644
--- a/examples/language/gpt/gemini/train_gpt_demo.py
+++ b/examples/language/gpt/gemini/train_gpt_demo.py
@@ -11,11 +11,13 @@
from torch.nn.parallel import DistributedDataParallel as DDP
import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin, LowLevelZeroPlugin, TorchDDPPlugin
from colossalai.logging import disable_existing_loggers, get_dist_logger
from colossalai.nn.optimizer import HybridAdam
from colossalai.tensor import ColoParameter, ComputePattern, ComputeSpec, ProcessGroup, ReplicaSpec, ShardSpec
from colossalai.utils import get_current_device
-from colossalai.zero import ColoInitContext, zero_model_wrapper, zero_optim_wrapper
+from colossalai.zero import ColoInitContext
CAI_VERSION = colossalai.__version__
@@ -236,23 +238,6 @@ def main():
tensor_parallelize(model, tp_pg)
# asign running configurations
- gemini_config = None
- if args.distplan.startswith("CAI_ZeRO"):
- optim_config = dict(reduce_bucket_size=12 * 1024 * 1024, overlap_communication=True, verbose=True)
- elif args.distplan == "CAI_Gemini":
- gemini_config = dict(strict_ddp_mode=args.tp_degree == 1,
- device=get_current_device(),
- placement_policy=args.placement,
- pin_memory=True,
- hidden_dim=model.config.n_embd,
- search_range_mb=128)
- optim_config = dict(gpu_margin_mem_ratio=0.)
- else:
- raise RuntimeError
-
- # build a highly optimized gpu/cpu optimizer
- optimizer = HybridAdam(model.parameters(), lr=1e-3)
-
if args.distplan == "CAI_ZeRO1":
zero_stage = 1
elif args.distplan == "CAI_ZeRO2":
@@ -262,22 +247,42 @@ def main():
else:
raise RuntimeError
- # wrap your model and optimizer
- model = zero_model_wrapper(model, zero_stage, gemini_config)
- optimizer = zero_optim_wrapper(model, optimizer, optim_config=optim_config)
+ plugin = None
+ if args.distplan.startswith("CAI_ZeRO"):
+ plugin = LowLevelZeroPlugin(stage=zero_stage,
+ reduce_bucket_size_in_m=12 * 1024 * 1024,
+ overlap_communication=True,
+ verbose=True)
+ elif args.distplan == "CAI_Gemini":
+ plugin = GeminiPlugin(device=get_current_device(),
+ placement_policy=args.placement,
+ pin_memory=True,
+ strict_ddp_mode=args.tp_degree == 1,
+ search_range_mb=128,
+ hidden_dim=model.config.n_embd,
+ gpu_margin_mem_ratio=0.)
+ else:
+ raise RuntimeError
+
+ # build a highly optimized gpu/cpu optimizer
+ optimizer = HybridAdam(model.parameters(), lr=1e-3)
logger.info(get_mem_info(prefix='After init optim, '), ranks=[0])
elif args.distplan.startswith("Pytorch"):
assert args.tp_degree == 1, "The degree of TP should be 1 for DDP examples."
model = model_builder(args.model_type)(checkpoint=True).cuda()
- model = DDP(model)
+ plugin = TorchDDPPlugin()
if args.distplan.endswith("DDP"):
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
elif args.distplan.endswith("ZeRO"):
from torch.distributed.optim import ZeroRedundancyOptimizer
optimizer = ZeroRedundancyOptimizer(model.parameters(), optimizer_class=torch.optim.Adam, lr=1e-3)
+
else:
raise RuntimeError
+ # wrap your model and optimizer
+ booster = Booster(plugin=plugin)
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
# model is shared after TP
numel = get_model_size(model)
@@ -305,13 +310,7 @@ def train_step():
fwd_end = time()
fwd_time = fwd_end - start
logger.info(get_mem_info(prefix=f'[{n + 1}/{NUM_STEPS}] Forward '), ranks=[0])
-
- if args.distplan.startswith("CAI"):
- optimizer.backward(loss)
- elif args.distplan.startswith("Pytorch"):
- loss.backward()
- else:
- raise RuntimeError
+ booster.backward(loss, optimizer)
torch.cuda.synchronize()
bwd_end = time()
diff --git a/examples/language/palm/train.py b/examples/language/palm/train.py
index 7923e4fc855d..b16da1c7744a 100644
--- a/examples/language/palm/train.py
+++ b/examples/language/palm/train.py
@@ -102,23 +102,23 @@ def get_model_size(model: nn.Module):
# Gemini + ZeRO DDP
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
cai_version = colossalai.__version__
if version.parse(cai_version) > version.parse("0.1.10"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
elif version.parse(cai_version) <= version.parse("0.1.10") and version.parse(cai_version) >= version.parse("0.1.9"):
from colossalai.gemini import ChunkManager, GeminiManager
chunk_size = ChunkManager.search_chunk_size(model, 64 * 1024**2, 32)
- gemini_manager = GeminiManager(placememt_policy, chunk_manager)
+ gemini_manager = GeminiManager(placement_policy, chunk_manager)
chunk_manager = ChunkManager(chunk_size,
pg,
enable_distributed_storage=True,
- init_device=GeminiManager.get_default_device(placememt_policy))
+ init_device=GeminiManager.get_default_device(placement_policy))
model = ZeroDDP(model, gemini_manager)
else:
raise NotImplemented(f"CAI version {cai_version} is not supported")
diff --git a/examples/tutorial/README.md b/examples/tutorial/README.md
index 933026166d3f..0664d41fd359 100644
--- a/examples/tutorial/README.md
+++ b/examples/tutorial/README.md
@@ -29,9 +29,9 @@ quickly deploy large AI model training and inference, reducing large AI model tr
- Fine-tuning and Inference for OPT [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/opt) [[video]](https://www.youtube.com/watch?v=jbEFNVzl67Y)
- Optimized AlphaFold [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/fastfold) [[video]](https://www.youtube.com/watch?v=-zP13LfJP7w)
- Optimized Stable Diffusion [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion) [[video]](https://www.youtube.com/watch?v=8KHeUjjc-XQ)
- - ColossalChat: Cloning ChatGPT with a Complete RLHF Pipeline
-[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
-[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+ - ColossalChat: Cloning ChatGPT with a Complete RLHF Pipeline
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
+[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
[[demo]](https://www.youtube.com/watch?v=HcTiHzApHm0)
[[video]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
diff --git a/op_builder/utils.py b/op_builder/utils.py
index 2dbd976fbcbb..cb528eea66a1 100644
--- a/op_builder/utils.py
+++ b/op_builder/utils.py
@@ -110,7 +110,7 @@ def get_pytorch_version() -> List[int]:
torch_version = torch.__version__.split('+')[0]
TORCH_MAJOR = int(torch_version.split('.')[0])
TORCH_MINOR = int(torch_version.split('.')[1])
- TORCH_PATCH = int(torch_version.split('.')[2])
+ TORCH_PATCH = int(torch_version.split('.')[2], 16)
return TORCH_MAJOR, TORCH_MINOR, TORCH_PATCH
diff --git a/requirements/requirements-test.txt b/requirements/requirements-test.txt
index 55edb1b6a512..6895113bc637 100644
--- a/requirements/requirements-test.txt
+++ b/requirements/requirements-test.txt
@@ -1,6 +1,7 @@
diffusers
fbgemm-gpu==0.2.0
pytest
+coverage==7.2.3
git+https://github.com/hpcaitech/pytest-testmon
torchvision
transformers
diff --git a/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py b/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py
index 12562095c153..44767f051fdd 100644
--- a/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py
+++ b/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py
@@ -1,10 +1,6 @@
-from contextlib import nullcontext
-
import pytest
import torch
-import torch.distributed as dist
from packaging import version
-from torch import nn
from torch.optim import SGD
import colossalai
@@ -19,6 +15,7 @@
from tests.kit.model_zoo import model_zoo
+# test baisc fsdp function
def run_fn(model_fn, data_gen_fn, output_transform_fn):
plugin = TorchFSDPPlugin()
booster = Booster(plugin=plugin)
diff --git a/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py b/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py
new file mode 100644
index 000000000000..2b6090bb1e29
--- /dev/null
+++ b/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py
@@ -0,0 +1,113 @@
+import pytest
+import torch
+from packaging import version
+from torch import nn
+from torch.optim import SGD
+from torchvision.models import resnet18
+from utils import shared_tempdir
+
+import colossalai
+from colossalai.booster import Booster
+
+if version.parse(torch.__version__) >= version.parse('1.12.0'):
+ from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
+ from colossalai.booster.plugin import TorchFSDPPlugin
+
+from colossalai.testing import rerun_if_address_is_in_use, spawn, check_state_dict_equal
+
+
+def compare_nested_dict(dict1, dict2):
+ for key in dict1:
+ if key in dict2:
+ if type(dict1[key]) is dict:
+ assert type(dict2[key]) is dict
+ diff = compare_nested_dict(dict1[key], dict2[key])
+ if not diff:
+ return diff
+ elif type(dict1[key]) is list:
+ assert type(dict2[key]) is list
+ for i, val in enumerate(dict1[key]):
+ if isinstance(val, torch.Tensor):
+ if not torch.equal(dict1[key][i], dict2[key][i]):
+ return False
+ elif val != dict2[key][i]:
+ return False
+ elif type(dict1[key]) is torch.Tensor:
+ assert type(dict2[key]) is torch.Tensor
+ if not torch.equal(dict1[key], dict2[key]):
+ return False
+ else:
+ if dict1[key] != dict2[key]:
+ return False
+ else:
+ return False
+ return True
+
+
+def check_torch_fsdp_ckpt():
+ model = resnet18()
+ plugin = TorchFSDPPlugin()
+ booster = Booster(plugin=plugin)
+ optimizer = SGD(model.parameters(), lr=0.001, momentum=0.9)
+ criterion = lambda x: x.mean()
+ fsdp_model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+
+ inputs = torch.randn(4, 3, 224, 224)
+ outputs = None
+
+ def run_model():
+ nonlocal outputs
+ outputs = fsdp_model(inputs)
+ optimizer.zero_grad()
+ criterion(outputs).backward()
+ optimizer.step()
+
+ with shared_tempdir() as tempdir:
+ model_ckpt_path = f"{tempdir}/model"
+ optim_ckpt_path = f"{tempdir}/optimizer"
+
+ run_model()
+
+ booster.save_model(fsdp_model, model_ckpt_path, shard=False)
+ booster.save_optimizer(optimizer, optim_ckpt_path, shard=False)
+
+ full_msd = fsdp_model.state_dict()
+ #full_osd = FSDP.full_optim_state_dict(fsdp_model, optimizer)
+ sharded_osd = optimizer.state_dict()
+ import copy
+ sharded_osd = copy.deepcopy(sharded_osd)
+
+ run_model()
+
+ full_msd_updated = fsdp_model.state_dict()
+ #full_osd_updated = FSDP.full_optim_state_dict(fsdp_model, optimizer, rank0_only=True)
+ sharded_osd_updated = optimizer.state_dict()
+
+ assert not compare_nested_dict(sharded_osd, sharded_osd_updated)
+ assert not compare_nested_dict(full_msd_updated, full_msd)
+ outputs_first = fsdp_model(inputs)
+ assert criterion(outputs_first) != criterion(outputs)
+
+ booster.load_model(fsdp_model, model_ckpt_path)
+ booster.load_optimizer(optimizer, optim_ckpt_path)
+
+ full_msd_restore = fsdp_model.state_dict()
+ #full_osd_restore = FSDP.full_optim_state_dict(fsdp_model, optimizer, rank0_only=True)
+ sharded_osd_restore = optimizer.state_dict()
+
+ assert compare_nested_dict(sharded_osd, sharded_osd_restore)
+ assert compare_nested_dict(full_msd_restore, full_msd)
+ outputs_sec = fsdp_model(inputs)
+ assert criterion(outputs_sec) == criterion(outputs)
+
+
+def run_dist(rank, world_size, port):
+ # init dist env
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ check_torch_fsdp_ckpt()
+
+
+@pytest.mark.skipif(version.parse(torch.__version__) < version.parse('1.12.0'), reason="requires torch1.12 or higher")
+@rerun_if_address_is_in_use()
+def test_torch_fsdp_ckpt():
+ spawn(run_dist, 2)
diff --git a/tests/test_utils/test_lazy_init/utils.py b/tests/test_utils/test_lazy_init/lazy_init_utils.py
similarity index 100%
rename from tests/test_utils/test_lazy_init/utils.py
rename to tests/test_utils/test_lazy_init/lazy_init_utils.py
diff --git a/tests/test_utils/test_lazy_init/test_distribute.py b/tests/test_utils/test_lazy_init/test_distribute.py
index c15b055e8361..fd91e7e912b5 100644
--- a/tests/test_utils/test_lazy_init/test_distribute.py
+++ b/tests/test_utils/test_lazy_init/test_distribute.py
@@ -15,7 +15,7 @@
from colossalai.utils.model.experimental import LazyInitContext, LazyTensor, _MyTensor
except:
pass
-from utils import SUPPORT_LAZY, assert_dist_model_equal, set_seed
+from lazy_init_utils import SUPPORT_LAZY, assert_dist_model_equal, set_seed
from tests.kit.model_zoo import model_zoo
diff --git a/tests/test_utils/test_lazy_init/test_models.py b/tests/test_utils/test_lazy_init/test_models.py
index 4a0217b31a97..f828b23a94c4 100644
--- a/tests/test_utils/test_lazy_init/test_models.py
+++ b/tests/test_utils/test_lazy_init/test_models.py
@@ -1,5 +1,5 @@
import pytest
-from utils import SUPPORT_LAZY, check_lazy_init
+from lazy_init_utils import SUPPORT_LAZY, check_lazy_init
from tests.kit.model_zoo import model_zoo
diff --git a/version.txt b/version.txt
index a45be4627678..0d91a54c7d43 100644
--- a/version.txt
+++ b/version.txt
@@ -1 +1 @@
-0.2.8
+0.3.0
+Illustration of an ordinary AMP (figure from PatrickStar paper)
+
+
+## AMP in Colossal-AI
+
+We supported three AMP training methods and allowed the user to train with AMP with no code. If you want to train with amp, just assign `mixed_precision` with `fp16` when you instantiate the `Booster`. Now booster support torch amp, the other two(apex amp, naive amp) are still started by `colossalai.initialize`, if needed, please refer to [this](./mixed_precision_training.md). Next we will support `bf16`, `fp8`.
+
+### Start with Booster
+instantiate `Booster` with `mixed_precision="fp16"`, then you can train with torch amp.
+
+```python
+"""
+ Mapping:
+ 'fp16': torch amp
+ 'fp16_apex': apex amp,
+ 'bf16': bf16,
+ 'fp8': fp8,
+ 'fp16_naive': naive amp
+"""
+from colossalai import Booster
+booster = Booster(mixed_precision='fp16',...)
+```
+
+or you can create a `FP16TorchMixedPrecision` object, such as:
+
+```python
+from colossalai.mixed_precision import FP16TorchMixedPrecision
+mixed_precision = FP16TorchMixedPrecision(
+ init_scale=2.**16,
+ growth_factor=2.0,
+ backoff_factor=0.5,
+ growth_interval=2000)
+booster = Booster(mixed_precision=mixed_precision,...)
+```
+
+The same goes for other types of amps.
+
+
+### Torch AMP Configuration
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16TorchMixedPrecision }}
+
+### Apex AMP Configuration
+
+For this mode, we rely on the Apex implementation for mixed precision training.
+We support this plugin because it allows for finer control on the granularity of mixed precision.
+For example, O2 level (optimization level 2) will keep batch normalization in fp32.
+
+If you look for more details, please refer to [Apex Documentation](https://nvidia.github.io/apex/).
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16ApexMixedPrecision }}
+
+### Naive AMP Configuration
+
+In Naive AMP mode, we achieved mixed precision training while maintaining compatibility with complex tensor and pipeline parallelism.
+This AMP mode will cast all operations into fp16.
+The following code block shows the mixed precision api for this mode.
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16NaiveMixedPrecision }}
+
+When using `colossalai.booster`, you are required to first instantiate a model, an optimizer and a criterion.
+The output model is converted to AMP model of smaller memory consumption.
+If your input model is already too large to fit in a GPU, please instantiate your model weights in `dtype=torch.float16`.
+Otherwise, try smaller models or checkout more parallelization training techniques!
+
+
+## Hands-on Practice
+
+Now we will introduce the use of AMP with Colossal-AI. In this practice, we will use Torch AMP as an example.
+
+### Step 1. Import libraries in train.py
+
+Create a `train.py` and import the necessary dependencies. Remember to install `scipy` and `timm` by running
+`pip install timm scipy`.
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from timm.models import vit_base_patch16_224
+from titans.utils import barrier_context
+from torchvision import datasets, transforms
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import LinearWarmupLR
+```
+
+### Step 2. Initialize Distributed Environment
+
+We then need to initialize distributed environment. For demo purpose, we uses `launch_from_torch`. You can refer to [Launch Colossal-AI](../basics/launch_colossalai.md)
+for other initialization methods.
+
+```python
+# initialize distributed setting
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+
+```
+
+### Step 3. Create training components
+
+Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is
+obtained from the environment variable `DATA`. You may `export DATA=/path/to/data` or change `Path(os.environ['DATA'])`
+to a path on your machine. Data will be automatically downloaded to the root path.
+
+```python
+# define the constants
+NUM_EPOCHS = 2
+BATCH_SIZE = 128
+
+# build model
+model = vit_base_patch16_224(drop_rate=0.1)
+
+# build dataloader
+train_dataset = datasets.Caltech101(
+ root=Path(os.environ['DATA']),
+ download=True,
+ transform=transforms.Compose([
+ transforms.Resize(256),
+ transforms.RandomResizedCrop(224),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ Gray2RGB(),
+ transforms.Normalize([0.5, 0.5, 0.5],
+ [0.5, 0.5, 0.5])
+ ]))
+
+# build optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, weight_decay=0.1)
+
+# build loss
+criterion = torch.nn.CrossEntropyLoss()
+
+# lr_scheduler
+lr_scheduler = LinearWarmupLR(optimizer, warmup_steps=50, total_steps=NUM_EPOCHS)
+```
+
+### Step 4. Inject AMP Feature
+
+Create a `MixedPrecision`(if needed) and `TorchDDPPlugin` object, call `colossalai.boost` convert the training components to be running with FP16.
+
+```python
+plugin = TorchDDPPlugin()
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+
+# if you need to customize the config, do like this
+# >>> from colossalai.mixed_precision import FP16TorchMixedPrecision
+# >>> mixed_precision = FP16TorchMixedPrecision(
+# >>> init_scale=2.**16,
+# >>> growth_factor=2.0,
+# >>> backoff_factor=0.5,
+# >>> growth_interval=2000)
+# >>> plugin = TorchDDPPlugin()
+# >>> booster = Booster(mixed_precision=mixed_precision, plugin=plugin)
+
+# boost model, optimizer, criterion, dataloader, lr_scheduler
+model, optimizer, criterion, dataloader, lr_scheduler = booster.boost(model, optimizer, criterion, dataloader, lr_scheduler)
+```
+
+### Step 5. Train with Booster
+
+Use booster in a normal training loops.
+
+```python
+model.train()
+for epoch in range(NUM_EPOCHS):
+ for img, label in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+ optimizer.zero_grad()
+ output = model(img)
+ loss = criterion(output, label)
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ lr_scheduler.step()
+```
+
+### Step 6. Invoke Training Scripts
+
+Use the following command to start the training scripts. You can change `--nproc_per_node` to use a different number of GPUs.
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
diff --git a/docs/source/en/features/nvme_offload.md b/docs/source/en/features/nvme_offload.md
index 4374da3c9c45..6ed6f2dee5d6 100644
--- a/docs/source/en/features/nvme_offload.md
+++ b/docs/source/en/features/nvme_offload.md
@@ -53,7 +53,7 @@ It's compatible with all parallel methods in ColossalAI.
> ⚠ It only offloads optimizer states on CPU. This means it only affects CPU training or Zero/Gemini with offloading.
-## Exampls
+## Examples
Let's start from two simple examples -- training GPT with different methods. These examples relies on `transformers`.
@@ -78,8 +78,9 @@ from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
import colossalai
from colossalai.nn.optimizer import HybridAdam
-from colossalai.zero import zero_model_wrapper, zero_optim_wrapper
from colossalai.utils.model.colo_init_context import ColoInitContext
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin
```
Then we define a loss function:
@@ -192,17 +193,23 @@ def train_gemini_cpu(nvme_offload_fraction: float = 0.0):
optimizer = HybridAdam(model.parameters(), nvme_offload_fraction=nvme_offload_fraction)
print(f'Model numel: {get_model_numel(model) / 1024**3:.3f} B')
- gemini_config = dict(strict_ddp_mode=True, device=torch.cuda.current_device(),
- placement_policy='cpu', pin_memory=True, hidden_dim=config.n_embd)
- model = zero_model_wrapper(model, zero_stage=3, gemini_config=gemini_config)
- optimizer = zero_optim_wrapper(model, optimizer, initial_scale=2**5)
+ plugin = GeminiPlugin(
+ strict_ddp_mode=True,
+ device=torch.cuda.current_device(),
+ placement_policy='cpu',
+ pin_memory=True,
+ hidden_dim=config.n_embd,
+ initial_scale=2**5
+ )
+ booster = Booster(plugin)
+ model, optimizer, criterion, _* = booster.boost(model, optimizer, criterion)
start = time.time()
for step in range(3):
data = get_data(4, 128, config.vocab_size)
outputs = model(**data)
loss = criterion(outputs.logits, data['input_ids'])
- optimizer.backward(loss)
+ booster.backward(loss, optimizer)
optimizer.step()
optimizer.zero_grad()
print(f'[{step}] loss: {loss.item():.3f}')
diff --git a/docs/source/en/features/pipeline_parallel.md b/docs/source/en/features/pipeline_parallel.md
index ac49863b3c71..30654b0b0195 100644
--- a/docs/source/en/features/pipeline_parallel.md
+++ b/docs/source/en/features/pipeline_parallel.md
@@ -156,4 +156,4 @@ trainer.fit(train_dataloader=train_dataloader,
display_progress=True)
```
-We use `2` pipeline stages and the batch will be splitted into `4` micro batches.
+We use `2` pipeline stages and the batch will be split into `4` micro batches.
diff --git a/docs/source/en/features/zero_with_chunk.md b/docs/source/en/features/zero_with_chunk.md
index a105831a5409..d6f6f611a64c 100644
--- a/docs/source/en/features/zero_with_chunk.md
+++ b/docs/source/en/features/zero_with_chunk.md
@@ -3,7 +3,7 @@
Author: [Hongxiu Liu](https://github.com/ver217), [Jiarui Fang](https://github.com/feifeibear), [Zijian Ye](https://github.com/ZijianYY)
**Prerequisite:**
-- [Define Your Configuration](../basics/define_your_config.md)
+- [Train with booster](../basics/booster_api.md)
**Example Code**
@@ -72,7 +72,7 @@ chunk_manager = init_chunk_manager(model=module,
gemini_manager = GeminiManager(placement_policy, chunk_manager)
```
-`hidden_dim` is the hidden dimension of DNN. Users can provide this argument to speed up searching. If users do not know this argument before training, it is ok. We will use a default value 1024. `min_chunk_size_mb` is the the minimum chunk size in MegaByte. If the aggregate size of parameters is still samller than the minimum chunk size, all parameters will be compacted into one small chunk.
+`hidden_dim` is the hidden dimension of DNN. Users can provide this argument to speed up searching. If users do not know this argument before training, it is ok. We will use a default value 1024. `min_chunk_size_mb` is the the minimum chunk size in MegaByte. If the aggregate size of parameters is still smaller than the minimum chunk size, all parameters will be compacted into one small chunk.
Initialization of the optimizer.
```python
@@ -97,6 +97,7 @@ For simplicity, we just use randomly generated data here.
First we only need to import `GPT2LMHeadModel` from `Huggingface transformers` to define our model, which does not require users to define or modify the model, so that users can use it more conveniently.
+Define a GPT model:
```python
class GPTLMModel(nn.Module):
@@ -182,34 +183,6 @@ def split_param_col_tp1d(param: ColoParameter, pg: ProcessGroup):
split_param_single_dim_tp1d(-1, param, pg)
```
-Define a model which uses Gemini + ZeRO DDP:
-
-```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
- cai_version = colossalai.__version__
- if version.parse(cai_version) > version.parse("0.1.10"):
- from colossalai.nn.parallel import GeminiDDP
- model = GeminiDDP(model,
- device=get_current_device(),
- placement_policy=placememt_policy,
- pin_memory=True,
- search_range_mb=32)
- elif version.parse(cai_version) <= version.parse("0.1.10") and version.parse(cai_version) >= version.parse("0.1.9"):
- from colossalai.gemini import ChunkManager, GeminiManager
- chunk_size = ChunkManager.search_chunk_size(model, 64 * 1024**2, 32)
- gemini_manager = GeminiManager(placememt_policy, chunk_manager)
- chunk_manager = ChunkManager(chunk_size,
- pg,
- enable_distributed_storage=True,
- init_device=GeminiManager.get_default_device(placememt_policy))
- model = ZeroDDP(model, gemini_manager)
- else:
- raise NotImplemented(f"CAI version {cai_version} is not supported")
- return model
-```
-
-As we pre-train GPT in this example, we just use a simple language model loss.
-
Write a function to get random inputs:
```python
@@ -219,9 +192,15 @@ def get_data(batch_size, seq_len, vocab_size):
return input_ids, attention_mask
```
-Finally, we can define our training loop:
+Finally, we define a model which uses Gemini + ZeRO DDP and define our training loop, As we pre-train GPT in this example, we just use a simple language model loss:
```python
+from torch.optim import Adam
+
+from colossalai.booster import Booster
+from colossalai.zero import ColoInitContext
+from colossalai.booster.plugin import GeminiPlugin
+
def main():
args = parse_args()
BATCH_SIZE = 8
@@ -232,22 +211,23 @@ def main():
# build criterion
criterion = GPTLMLoss()
+ optimizer = Adam(model.parameters(), lr=0.001)
torch.manual_seed(123)
default_pg = ProcessGroup(tp_degree=args.tp_degree)
- default_dist_spec = ShardSpec([-1], [args.tp_degree]) if args.shardinit else None
+ default_dist_spec = ShardSpec([-1], [args.tp_degree])
# build GPT model
with ColoInitContext(device='cpu', default_dist_spec=default_dist_spec, default_pg=default_pg):
model = gpt2_medium(checkpoint=True)
pg = default_pg
# Tensor Parallelism (TP)
tensor_parallelize(model, pg)
+
# Gemini + ZeRO DP, Note it must be used after TP
- model = gemini_zero_dpp(model, pg, args.placement)
- # build optimizer
- optimizer = GeminiAdamOptimizer(model, lr=1e-3, initial_scale=2**5)
- numel = sum([p.numel() for p in model.parameters()])
- get_tflops_func = partial(get_tflops, numel, BATCH_SIZE, SEQ_LEN)
+ plugin = GeminiPlugin(placement_policy='cuda', max_norm=1.0, initial_scale=2**5)
+ booster = Booster(plugin=plugin)
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+
torch.cuda.synchronize()
model.train()
for n in range(NUM_STEPS):
@@ -256,10 +236,12 @@ def main():
optimizer.zero_grad()
outputs = model(input_ids, attn_mask)
loss = criterion(outputs, input_ids)
- optimizer.backward(loss)
+ booster.backward(loss, optimizer)
optimizer.step()
torch.cuda.synchronize()
```
> ⚠️ Note: If you want to use the Gemini module, please do not use the [Gradient Accumulation](../features/gradient_accumulation.md) we mentioned before。
The complete example can be found on [Train GPT with Colossal-AI](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/gpt).
+
+
diff --git a/docs/source/en/get_started/installation.md b/docs/source/en/get_started/installation.md
index b626edb19e8e..6fc4ce2c922a 100644
--- a/docs/source/en/get_started/installation.md
+++ b/docs/source/en/get_started/installation.md
@@ -48,5 +48,20 @@ If you don't want to install and enable CUDA kernel fusion (compulsory installat
pip install .
```
+For Users with CUDA 10.2, you can still build ColossalAI from source. However, you need to manually download the cub library and copy it to the corresponding directory.
+
+```bash
+# clone the repository
+git clone https://github.com/hpcaitech/ColossalAI.git
+cd ColossalAI
+
+# download the cub library
+wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip
+unzip 1.8.0.zip
+cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
+
+# install
+CUDA_EXT=1 pip install .
+```
diff --git a/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md b/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md
index 4825a6fa1d6c..059eb014affd 100644
--- a/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md
+++ b/docs/source/zh-Hans/advanced_tutorials/add_your_parallel.md
@@ -48,7 +48,7 @@ Colossal-AI 为用户提供了一个全局 context,使他们能够轻松地管
world_size: int,
config: Config,
data_parallel_size: int,
- pipeline_parlalel_size: int,
+ pipeline_parallel_size: int,
tensor_parallel_size: int,
arg1,
arg2):
diff --git a/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md b/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
index 456878caa147..276fcc2619e0 100644
--- a/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
+++ b/docs/source/zh-Hans/advanced_tutorials/integrate_mixture_of_experts_into_your_model.md
@@ -122,7 +122,7 @@ Inside the initialization of Experts, the local expert number of each GPU will b
## Train Your Model
-Do not to forget to use `colossalai.initialize` function in `colosalai` to add gradient handler for the engine.
+Do not to forget to use `colossalai.initialize` function in `colossalai` to add gradient handler for the engine.
We handle the back-propagation of MoE models for you.
In `colossalai.initialize`, we will automatically create a `MoeGradientHandler` object to process gradients.
You can find more information about the handler `MoeGradientHandler` in colossal directory.
diff --git a/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md b/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md
index 2bf0a9c98c3f..594823862de1 100644
--- a/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md
+++ b/docs/source/zh-Hans/advanced_tutorials/meet_gemini.md
@@ -8,21 +8,21 @@
## 用法
-目前Gemini支持和ZeRO并行方式兼容,它的使用方法很简单,在训练策略的配置文件里设置zero的model_config属性tensor_placement_policy='auto'
-
-```
-zero = dict(
- model_config=dict(
- reduce_scatter_bucket_size_mb=25,
- fp32_reduce_scatter=False,
- gradient_predivide_factor=1.0,
- tensor_placement_policy="auto",
- shard_strategy=TensorShardStrategy(),
- ...
- ),
- optimizer_config=dict(
- ...
- )
+目前Gemini支持和ZeRO并行方式兼容,它的使用方法很简单:使用booster将`GeminiPlugin`中的特性注入到训练组件中。更多`booster`介绍请参考[booster使用](../basics/booster_api.md)。
+
+```python
+from torchvision.models import resnet18
+from colossalai.booster import Booster
+from colossalai.zero import ColoInitContext
+from colossalai.booster.plugin import GeminiPlugin
+plugin = GeminiPlugin(placement_policy='cuda', strict_ddp_mode=True, max_norm=1.0, initial_scale=2**5)
+booster = Booster(plugin=plugin)
+ctx = ColoInitContext()
+with ctx:
+ model = resnet18()
+optimizer = HybridAdam(model.parameters(), lr=1e-3)
+criterion = lambda x: x.mean()
+model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
)
```
@@ -48,7 +48,7 @@ zero = dict(
-ColossalAI设计了Gemini,就像双子星一样,它管理CPU和GPU二者内存空间。它可以让张量在训练过程中动态分布在CPU-GPU的存储空间内,从而让模型训练突破GPU的内存墙。内存管理器由两部分组成,分别是MemStatsCollector(MSC)和StatefuleTensorMgr(STM)。
+ColossalAI设计了Gemini,就像双子星一样,它管理CPU和GPU二者内存空间。它可以让张量在训练过程中动态分布在CPU-GPU的存储空间内,从而让模型训练突破GPU的内存墙。内存管理器由两部分组成,分别是MemStatsCollector(MSC)和StatefulTensorMgr(STM)。
我们利用了深度学习网络训练过程的迭代特性。我们将迭代分为warmup和non-warmup两个阶段,开始时的一个或若干迭代步属于预热阶段,其余的迭代步属于正式阶段。在warmup阶段我们为MSC收集信息,而在non-warmup阶段STM入去MSC收集的信息来移动tensor,以达到最小化CPU-GPU数据移动volume的目的。
@@ -75,7 +75,7 @@ STM管理所有model data tensor的信息。在模型的构造过程中,Coloss
我们在算子的开始和结束计算时,触发内存采样操作,我们称这个时间点为**采样时刻(sampling moment)**,两个采样时刻之间的时间我们称为**period**。计算过程是一个黑盒,由于可能分配临时buffer,内存使用情况很复杂。但是,我们可以较准确的获取period的系统最大内存使用。非模型数据的使用可以通过两个统计时刻之间系统最大内存使用-模型内存使用获得。
-我们如何设计采样时刻呢。我们选择preOp的model data layout adjust之前。如下图所示。我们采样获得上一个period的system memory used,和下一个period的model data memoy used。并行策略会给MSC的工作造成障碍。如图所示,比如对于ZeRO或者Tensor Parallel,由于Op计算前需要gather模型数据,会带来额外的内存需求。因此,我们要求在模型数据变化前进行采样系统内存,这样在一个period内,MSC会把preOp的模型变化内存捕捉。比如在period 2-3内,我们考虑的tensor gather和shard带来的内存变化。
+我们如何设计采样时刻呢。我们选择preOp的model data layout adjust之前。如下图所示。我们采样获得上一个period的system memory used,和下一个period的model data memory used。并行策略会给MSC的工作造成障碍。如图所示,比如对于ZeRO或者Tensor Parallel,由于Op计算前需要gather模型数据,会带来额外的内存需求。因此,我们要求在模型数据变化前进行采样系统内存,这样在一个period内,MSC会把preOp的模型变化内存捕捉。比如在period 2-3内,我们考虑的tensor gather和shard带来的内存变化。
尽管可以将采样时刻放在其他位置,比如排除gather buffer的变动新信息,但是会给造成麻烦。不同并行方式Op的实现有差异,比如对于Linear Op,Tensor Parallel中gather buffer的分配在Op中。而对于ZeRO,gather buffer的分配是在PreOp中。将放在PreOp开始时采样有利于将两种情况统一。
@@ -94,3 +94,5 @@ MSC的重要职责是在调整tensor layout位置,比如在上图S2时刻,
在non-warmup阶段,我们需要利用预热阶段采集的非模型数据内存信息,预留出下一个Period在计算设备上需要的峰值内存,这需要我们移动出一些模型张量。
为了避免频繁在CPU-GPU换入换出相同的tensor,引起类似[cache thrashing](https://en.wikipedia.org/wiki/Thrashing_(computer_science))的现象。我们利用DNN训练迭代特性,设计了OPT cache换出策略。具体来说,在warmup阶段,我们记录每个tensor被计算设备需要的采样时刻。如果我们需要驱逐一些HOLD tensor,那么我们选择在本设备上最晚被需要的tensor作为受害者。
+
+
diff --git a/docs/source/zh-Hans/advanced_tutorials/opt_service.md b/docs/source/zh-Hans/advanced_tutorials/opt_service.md
index a213584fd41d..1f8324a53ecb 100644
--- a/docs/source/zh-Hans/advanced_tutorials/opt_service.md
+++ b/docs/source/zh-Hans/advanced_tutorials/opt_service.md
@@ -52,7 +52,7 @@ export CHECKPOINT_DIR="your_opt_checkpoint_path"
# the ${CONFIG_DIR} must contain a server.sh file as the entry of service
export CONFIG_DIR="config_file_path"
-docker run --gpus all --rm -it -p 8020:8020 -v ${CHECKPOINT_DIR}:/model_checkpoint -v ${CONFIG_DIR}:/config --ipc=host energonai:lastest
+docker run --gpus all --rm -it -p 8020:8020 -v ${CHECKPOINT_DIR}:/model_checkpoint -v ${CONFIG_DIR}:/config --ipc=host energonai:latest
```
接下来,您就可以在您的浏览器中打开 `https://[IP-ADDRESS]:8020/docs#` 进行测试。
diff --git a/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md b/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md
index f3c6247c38e4..c4131e593437 100644
--- a/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md
+++ b/docs/source/zh-Hans/advanced_tutorials/parallelize_your_training_like_Megatron.md
@@ -159,11 +159,11 @@ for mn, module in model.named_modules():
在我们最新示例中还定义了一个Gemini + ZeRO DDP 的模型从而减小开销,提升效率。这一部分的详细内容可以参考[ZeRO](../features/zero_with_chunk.md),你可以将这两部分内容结合起来看从而理解我们整个训练流程:
```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
return model
diff --git a/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md b/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
index 6dc5eccf4421..e2f2c90a3791 100644
--- a/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
+++ b/docs/source/zh-Hans/advanced_tutorials/train_vit_with_hybrid_parallelism.md
@@ -477,7 +477,7 @@ def build_cifar(batch_size):
return train_dataloader, test_dataloader
-# craete dataloaders
+# create dataloaders
train_dataloader , test_dataloader = build_cifar()
# create loss function
criterion = CrossEntropyLoss(label_smoothing=0.1)
@@ -492,7 +492,7 @@ lr_scheduler = CosineAnnealingWarmupLR(optimizer=optimizer,
#### 启动 Colossal-AI 引擎
```python
-# intiailize
+# initialize
engine, train_dataloader, test_dataloader, _ = colossalai.initialize(model=model,
optimizer=optimizer,
criterion=criterion,
diff --git a/docs/source/zh-Hans/basics/booster_api.md b/docs/source/zh-Hans/basics/booster_api.md
index 5410cc213fd2..1bb5fd69bd15 100644
--- a/docs/source/zh-Hans/basics/booster_api.md
+++ b/docs/source/zh-Hans/basics/booster_api.md
@@ -25,24 +25,6 @@ Booster插件是管理并行配置的重要组件(eg:gemini插件封装了ge
{{ autodoc:colossalai.booster.Booster }}
-{{ autodoc:colossalai.booster.Booster.boost }}
-
-{{ autodoc:colossalai.booster.Booster.backward }}
-
-{{ autodoc:colossalai.booster.Booster.no_sync }}
-
-{{ autodoc:colossalai.booster.Booster.save_model }}
-
-{{ autodoc:colossalai.booster.Booster.load_model }}
-
-{{ autodoc:colossalai.booster.Booster.save_optimizer }}
-
-{{ autodoc:colossalai.booster.Booster.load_optimizer }}
-
-{{ autodoc:colossalai.booster.Booster.save_lr_scheduler }}
-
-{{ autodoc:colossalai.booster.Booster.load_lr_scheduler }}
-
## 使用方法及示例
在使用colossalai训练时,首先需要在训练脚本的开头启动分布式环境,并创建需要使用的模型、优化器、损失函数、数据加载器等对象。之后,调用`colossalai.booster` 将特征注入到这些对象中,您就可以使用我们的booster API去进行您接下来的训练流程。
diff --git a/docs/source/zh-Hans/basics/booster_plugins.md b/docs/source/zh-Hans/basics/booster_plugins.md
index b15ceb1e3ad5..5bd88b679000 100644
--- a/docs/source/zh-Hans/basics/booster_plugins.md
+++ b/docs/source/zh-Hans/basics/booster_plugins.md
@@ -63,6 +63,10 @@ Zero-2 不支持局部梯度累积。如果您坚持使用,虽然可以积累
> ⚠ 如果 torch 版本低于 1.12.0,此插件将不可用。
+> ⚠ 该插件现在还不支持保存/加载分片的模型 checkpoint。
+
+> ⚠ 该插件现在还不支持使用了multi params group的optimizer。
+
更多详细信息,请参阅 [Pytorch 文档](https://pytorch.org/docs/main/fsdp.html).
{{ autodoc:colossalai.booster.plugin.TorchFSDPPlugin }}
diff --git a/docs/source/zh-Hans/basics/colotensor_concept.md b/docs/source/zh-Hans/basics/colotensor_concept.md
index d6a332df2e9c..ab2413e990f7 100644
--- a/docs/source/zh-Hans/basics/colotensor_concept.md
+++ b/docs/source/zh-Hans/basics/colotensor_concept.md
@@ -2,6 +2,8 @@
Author: [Jiarui Fang](https://github.com/feifeibear), [Hongxin Liu](https://github.com/ver217) and [Haichen Huang](https://github.com/1SAA)
+> ⚠️ 此页面上的信息已经过时并将被废弃。
+
**Prerequisite:**
- [Colossal-AI Overview](../concepts/colossalai_overview.md)
- [Distributed Training](../concepts/distributed_training.md)
@@ -51,7 +53,7 @@ ColoTensor 包含额外的属性[ColoTensorSpec](https://colossalai.readthedocs.
## Example
-让我们看一个例子。 使用 tp_degree=4, dp_dgree=2 在 8 个 GPU 上初始化并Shard一个ColoTensor。 然后tensor被沿着 TP 进程组中的最后一个维度进行分片。 最后,我们沿着 TP 进程组中的第一个维度(dim 0)对其进行重新Shard。 我们鼓励用户运行代码并观察每个张量的形状。
+让我们看一个例子。 使用 tp_degree=4, dp_degree=2 在 8 个 GPU 上初始化并Shard一个ColoTensor。 然后tensor被沿着 TP 进程组中的最后一个维度进行分片。 最后,我们沿着 TP 进程组中的第一个维度(dim 0)对其进行重新Shard。 我们鼓励用户运行代码并观察每个张量的形状。
```python
diff --git a/docs/source/zh-Hans/basics/configure_parallelization.md b/docs/source/zh-Hans/basics/configure_parallelization.md
index eb4b38f48ddb..0c2a66572d60 100644
--- a/docs/source/zh-Hans/basics/configure_parallelization.md
+++ b/docs/source/zh-Hans/basics/configure_parallelization.md
@@ -2,6 +2,8 @@
作者: Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster插件](../basics/booster_plugins.md)页面查阅更新。
+
**预备知识:**
- [分布式训练](../concepts/distributed_training.md)
- [并行技术](../concepts/paradigms_of_parallelism.md)
diff --git a/docs/source/zh-Hans/basics/define_your_config.md b/docs/source/zh-Hans/basics/define_your_config.md
index d7e49cbf23de..720e75805e8d 100644
--- a/docs/source/zh-Hans/basics/define_your_config.md
+++ b/docs/source/zh-Hans/basics/define_your_config.md
@@ -2,6 +2,8 @@
作者: Guangyang Lu, Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster API](../basics/booster_api.md)页面查阅更新。
+
**预备知识:**
- [分布式训练](../concepts/distributed_training.md)
- [Colossal-AI 总览](../concepts/colossalai_overview.md)
diff --git a/docs/source/zh-Hans/basics/engine_trainer.md b/docs/source/zh-Hans/basics/engine_trainer.md
index a7519bfca14f..a35bd87c44e1 100644
--- a/docs/source/zh-Hans/basics/engine_trainer.md
+++ b/docs/source/zh-Hans/basics/engine_trainer.md
@@ -2,6 +2,8 @@
作者: Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster API](../basics/booster_api.md)页面查阅更新。
+
**预备知识:**
- [初始化功能](./initialize_features.md)
diff --git a/docs/source/zh-Hans/basics/initialize_features.md b/docs/source/zh-Hans/basics/initialize_features.md
index 67ea114b42b2..1c28d658e1bc 100644
--- a/docs/source/zh-Hans/basics/initialize_features.md
+++ b/docs/source/zh-Hans/basics/initialize_features.md
@@ -2,6 +2,8 @@
作者: Shenggui Li, Siqi Mai
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster API](../basics/booster_api.md)页面查阅更新。
+
**预备知识:**
- [分布式训练](../concepts/distributed_training.md)
- [Colossal-AI 总览](../concepts/colossalai_overview.md)
diff --git a/docs/source/zh-Hans/basics/model_checkpoint.md b/docs/source/zh-Hans/basics/model_checkpoint.md
index cec12d451989..a5374b7509c9 100644
--- a/docs/source/zh-Hans/basics/model_checkpoint.md
+++ b/docs/source/zh-Hans/basics/model_checkpoint.md
@@ -1,7 +1,9 @@
-# 模型检查点
+# 模型Checkpoint
作者 : Guangyang Lu
+> ⚠️ 此页面上的信息已经过时并将被废弃。请在[Booster Checkpoint](../basics/booster_checkpoint.md)页面查阅更新。
+
**预备知识:**
- [Launch Colossal-AI](./launch_colossalai.md)
- [Initialize Colossal-AI](./initialize_features.md)
@@ -13,9 +15,9 @@
## 简介
-本教程将介绍如何保存和加载模型检查点。
+本教程将介绍如何保存和加载模型Checkpoint。
-为了充分利用Colossal-AI的强大并行策略,我们需要修改模型和张量,可以直接使用 `torch.save` 或者 `torch.load` 保存或加载模型检查点。在Colossal-AI中,我们提供了应用程序接口实现上述同样的效果。
+为了充分利用Colossal-AI的强大并行策略,我们需要修改模型和张量,可以直接使用 `torch.save` 或者 `torch.load` 保存或加载模型Checkpoint。在Colossal-AI中,我们提供了应用程序接口实现上述同样的效果。
但是,在加载时,你不需要使用与存储相同的保存策略。
@@ -24,7 +26,7 @@
### 保存
有两种方法可以使用Colossal-AI训练模型,即使用engine或使用trainer。
-**注意我们只保存 `state_dict`.** 因此,在加载检查点时,需要首先定义模型。
+**注意我们只保存 `state_dict`.** 因此,在加载Checkpoint时,需要首先定义模型。
#### 同 engine 保存
diff --git a/docs/source/zh-Hans/features/cluster_utils.md b/docs/source/zh-Hans/features/cluster_utils.md
index ca787a869041..f54a72c63a66 100644
--- a/docs/source/zh-Hans/features/cluster_utils.md
+++ b/docs/source/zh-Hans/features/cluster_utils.md
@@ -13,20 +13,4 @@
{{ autodoc:colossalai.cluster.DistCoordinator }}
-{{ autodoc:colossalai.cluster.DistCoordinator.is_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.is_node_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.is_last_process }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.print_on_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.print_on_node_master }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.priority_execution }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.destroy }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.block_all }}
-
-{{ autodoc:colossalai.cluster.DistCoordinator.on_master_only }}
+
diff --git a/docs/source/zh-Hans/features/gradient_accumulation.md b/docs/source/zh-Hans/features/gradient_accumulation.md
index e21e5fcd43d8..fc8b29bbe8f1 100644
--- a/docs/source/zh-Hans/features/gradient_accumulation.md
+++ b/docs/source/zh-Hans/features/gradient_accumulation.md
@@ -1,4 +1,4 @@
-# 梯度累积
+# 梯度累积 (旧版本)
作者: Shenggui Li, Yongbin Li
@@ -38,3 +38,4 @@ iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0
iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
```
+
diff --git a/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md b/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md
new file mode 100644
index 000000000000..a8422060f0ea
--- /dev/null
+++ b/docs/source/zh-Hans/features/gradient_accumulation_with_booster.md
@@ -0,0 +1,146 @@
+# 梯度累积 (新版本)
+
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**前置教程**
+- [定义配置文件](../basics/define_your_config.md)
+- [训练中使用Booster](../basics/booster_api.md)
+
+## 引言
+
+梯度累积是一种常见的增大训练 batch size 的方式。 在训练大模型时,内存经常会成为瓶颈,并且 batch size 通常会很小(如2),这导致收敛性无法保证。梯度累积将多次迭代的梯度累加,并仅在达到预设迭代次数时更新参数。
+
+## 使用
+
+在 Colossal-AI 中使用梯度累积非常简单,booster提供no_sync返回一个上下文管理器,在该上下文管理器下取消同步并且累积梯度。
+
+## 实例
+
+我们将介绍如何使用梯度累积。在这个例子中,梯度累积次数被设置为4。
+
+### 步骤 1. 在 train.py 导入相关库
+创建train.py并导入必要依赖。 `torch` 的版本应不低于1.8.1。
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet18
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.cluster.dist_coordinator import priority_execution
+```
+
+### 步骤 2. 初始化分布式环境
+
+我们需要初始化分布式环境。为了快速演示,我们使用`launch_from_torch`。你可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)使用其他初始化方法。
+
+```python
+# initialize distributed setting
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+
+```
+
+### 步骤 3. 创建训练组件
+
+构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`,在你的机器上设置路径。数据将会被自动下载到该路径。
+
+```python
+# define the training hyperparameters
+BATCH_SIZE = 128
+GRADIENT_ACCUMULATION = 4
+
+# build resnet
+model = resnet18(num_classes=10)
+
+# build dataloaders
+with priority_execution():
+ train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+```
+
+### 步骤 4. 注入特性
+创建一个`TorchDDPPlugin`对象,并作为参实例化`Booster`, 调用`booster.boost`注入特性。
+
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, _ = booster.boost(model=model,
+ optimizer=optimizer,
+ criterion=criterion,
+ dataloader=train_dataloader)
+```
+
+### 步骤 5. 使用booster训练
+使用booster构建一个普通的训练循环,验证梯度累积。 `param_by_iter` 记录分布训练的信息。
+```python
+optimizer.zero_grad()
+for idx, (img, label) in enumerate(train_dataloader):
+ sync_context = booster.no_sync(model)
+ img = img.cuda()
+ label = label.cuda()
+ if idx % (GRADIENT_ACCUMULATION - 1) != 0:
+ with sync_context:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ else:
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.step()
+ optimizer.zero_grad()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ param_by_iter.append(str(ele_1st.item()))
+
+ if idx != 0 and idx % (GRADIENT_ACCUMULATION - 1) == 0:
+ break
+
+ for iteration, val in enumerate(param_by_iter):
+ print(f'iteration {iteration} - value: {val}')
+
+ if param_by_iter[-1] != param_by_iter[0]:
+ print('The parameter is only updated in the last iteration')
+
+```
+
+### 步骤 6. 启动训练脚本
+为了验证梯度累积,我们可以只检查参数值的变化。当设置梯度累加时,仅在最后一步更新参数。您可以使用以下命令运行脚本:
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
+你将会看到类似下方的文本输出。这展现了梯度虽然在前3个迭代中被计算,但直到最后一次迭代,参数才被更新。
+
+```text
+iteration 0, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 1, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 2, first 10 elements of param: tensor([-0.0208, 0.0189, 0.0234, 0.0047, 0.0116, -0.0283, 0.0071, -0.0359, -0.0267, -0.0006], device='cuda:0', grad_fn=)
+iteration 3, first 10 elements of param: tensor([-0.0141, 0.0464, 0.0507, 0.0321, 0.0356, -0.0150, 0.0172, -0.0118, 0.0222, 0.0473], device='cuda:0', grad_fn=)
+```
+
+
diff --git a/docs/source/zh-Hans/features/gradient_clipping.md b/docs/source/zh-Hans/features/gradient_clipping.md
index 203f66a3fea2..2f62c31766a6 100644
--- a/docs/source/zh-Hans/features/gradient_clipping.md
+++ b/docs/source/zh-Hans/features/gradient_clipping.md
@@ -1,4 +1,4 @@
-# 梯度裁剪
+# 梯度裁剪(旧版本)
作者: Boxiang Wang, Haichen Huang, Yongbin Li
@@ -49,3 +49,5 @@ clip_grad_norm = 1.0
```shell
python -m torch.distributed.launch --nproc_per_node 1 --master_addr localhost --master_port 29500 train_with_engine.py
```
+
+
diff --git a/docs/source/zh-Hans/features/gradient_clipping_with_booster.md b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
new file mode 100644
index 000000000000..3c61356dd0d5
--- /dev/null
+++ b/docs/source/zh-Hans/features/gradient_clipping_with_booster.md
@@ -0,0 +1,140 @@
+# 梯度裁剪 (新版本)
+
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**前置教程**
+- [定义配置文件](../basics/define_your_config.md)
+- [booster使用](../basics/booster_api.md)
+
+**相关论文**
+- [On the difficulty of training Recurrent Neural Networks](https://arxiv.org/abs/1211.5063)
+
+## 引言
+
+为了加快训练过程和寻求全局最优以获得更好的性能,越来越多的学习率调度器被提出。人们通过控制学习率来调整训练中的下降速度。这使得梯度向量在每一步都能更好地统一。在这种情况下,下降速度可以按预期被控制。
+因此,梯度裁剪,一种可以将梯度向量归一化,以将其限制在统一长度的技术,对于那些希望模型性能更好的人来说是不可或缺的。
+
+在使用 Colossal-AI 时,你不必担心实现梯度剪裁,我们以一种有效而方便的方式支持梯度剪裁。你所需要的只是在你的配置文件中增加一个命令。
+
+## 为什么应该使用 Colossal-AI 中的梯度裁剪
+
+我们不建议用户自己编写梯度剪裁,因为朴素的梯度剪裁在应用张量并行、流水线并行、MoE 等功能时可能会失败。
+
+根据下图,每个 GPU 只拥有线性层中权重的一部分参数。为了得到线性层权重的梯度向量的正确范数,每个 GPU 中的每个梯度向量的范数应该相加。更复杂的是,偏置的分布不同于权重的分布。通信组在求和运算中有所不同。
+
+(注: 这种情况是旧版本的 2D 并行,在代码中的实现是不一样的。但这是一个很好的例子,能够说明在梯度剪裁中统一所有通信的困难。)
+
+
+
+参数分布
+
+
+不用担心它,因为 Colossal-AI 已经为你处理好。
+
+### 使用
+要使用梯度裁剪,只需在使用booster注入特性之后,调用optimizer的`clip_grad_by_norm`或者`clip_grad_by_value`函数即可进行梯度裁剪。
+
+### 实例
+
+下面我们将介绍如何使用梯度裁剪,在本例中,我们将梯度裁剪范数设置为1.0。
+
+### 步骤 1. 在训练中导入相关库
+创建`train.py`并导入相关库。
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.datasets import CIFAR10
+from torchvision.models import resnet34
+from tqdm import tqdm
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import CosineAnnealingLR
+```
+
+### 步骤 2. 初始化分布式环境
+我们需要初始化分布式环境. 为了快速演示,我们使用`launch_from_torch`. 您可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)
+
+```python
+colossalai.launch_from_torch(config=dict())
+logger = get_dist_logger()
+```
+
+### 步骤 3. 创建训练组件
+
+构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`在你的机器上设置路径。数据将会被自动下载到该路径。
+```python
+# define training hyperparameters
+NUM_EPOCHS = 200
+BATCH_SIZE = 128
+GRADIENT_CLIPPING = 0.1
+# build resnet
+model = resnet34(num_classes=10)
+# build dataloaders
+train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(size=32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
+ ]))
+# build criterion
+criterion = torch.nn.CrossEntropyLoss()
+
+# optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
+
+# lr_scheduler
+lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
+
+```
+### 步骤 4. 注入梯度裁剪特性
+
+创建`TorchDDPPlugin`对象并初始化`Booster`, 使用booster注入相关特性。
+```python
+plugin = TorchDDPPlugin()
+booster = Booster(plugin=plugin)
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
+
+```
+
+### 步骤 5. 使用booster训练
+使用booster进行训练。
+```python
+# verify gradient clipping
+model.train()
+for idx, (img, label) in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+
+ model.zero_grad()
+ output = model(img)
+ train_loss = criterion(output, label)
+ booster.backward(train_loss, optimizer)
+ optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
+ optimizer.step()
+ lr_scheduler.step()
+
+ ele_1st = next(model.parameters()).flatten()[0]
+ logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
+
+ # only run for 4 iterations
+ if idx == 3:
+ break
+```
+
+### 步骤 6. 启动训练脚本
+你可以使用以下命令运行脚本:
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
diff --git a/docs/source/zh-Hans/features/mixed_precision_training.md b/docs/source/zh-Hans/features/mixed_precision_training.md
index c9db3a59c1c3..4628b09cd910 100644
--- a/docs/source/zh-Hans/features/mixed_precision_training.md
+++ b/docs/source/zh-Hans/features/mixed_precision_training.md
@@ -1,4 +1,4 @@
-# 自动混合精度训练 (AMP)
+# 自动混合精度训练 (旧版本)
作者: Chuanrui Wang, Shenggui Li, Yongbin Li
@@ -203,7 +203,7 @@ Naive AMP 的默认参数:
- initial_scale(int): gradient scaler 的初始值
- growth_factor(int): loss scale 的增长率
- backoff_factor(float): loss scale 的下降率
-- hysterisis(int): 动态 loss scaling 的延迟偏移
+- hysteresis(int): 动态 loss scaling 的延迟偏移
- max_scale(int): loss scale 的最大允许值
- verbose(bool): 如果被设为`True`,将打印调试信息
@@ -339,6 +339,7 @@ for epoch in range(gpc.config.NUM_EPOCHS):
使用下列命令启动训练脚本,你可以改变 `--nproc_per_node` 以使用不同数量的 GPU。
-```python
+```shell
python -m torch.distributed.launch --nproc_per_node 4 --master_addr localhost --master_port 29500 train_with_engine.py --config config/config_AMP_torch.py
```
+
diff --git a/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md b/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md
new file mode 100644
index 000000000000..187aef1a6c4a
--- /dev/null
+++ b/docs/source/zh-Hans/features/mixed_precision_training_with_booster.md
@@ -0,0 +1,235 @@
+# 自动混合精度训练 (新版本)
+
+作者: [Mingyan Jiang](https://github.com/jiangmingyan)
+
+**前置教程**
+- [定义配置文件](../basics/define_your_config.md)
+- [booster使用](../basics/booster_api.md)
+
+**相关论文**
+- [Accelerating Scientific Computations with Mixed Precision Algorithms](https://arxiv.org/abs/0808.2794)
+
+
+## 引言
+
+AMP 代表自动混合精度训练。
+在 Colossal-AI 中, 我们结合了混合精度训练的不同实现:
+
+1. torch.cuda.amp
+2. apex.amp
+3. naive amp
+
+
+| Colossal-AI | 支持张量并行 | 支持流水并行 | fp16范围 |
+| ----------- | ----------------------- | ------------------------- | ----------- |
+| AMP_TYPE.TORCH | ✅ | ❌ | 在前向和反向传播期间,模型参数、激活和梯度向下转换至fp16 |
+| AMP_TYPE.APEX | ❌ | ❌ | 更细粒度,我们可以选择 opt_level O0, O1, O2, O3 |
+| AMP_TYPE.NAIVE | ✅ | ✅ | 模型参数、前向和反向操作,全都向下转换至fp16 |
+
+前两个依赖于 PyTorch (1.6及以上) 和 NVIDIA Apex 的原始实现。最后一种方法类似 Apex O2。在这些方法中,Apex-AMP 与张量并行不兼容。这是因为张量是以张量并行的方式在设备之间拆分的,因此,需要在不同的进程之间进行通信,以检查整个模型权重中是否出现inf或nan。我们修改了torch amp实现,使其现在与张量并行兼容。
+
+> ❌️ fp16与ZeRO不兼容
+>
+> ⚠️ 流水并行目前仅支持naive amp
+
+我们建议使用 torch AMP,因为在不使用流水并行时,它通常比 NVIDIA AMP 提供更好的准确性。
+
+## 目录
+
+在本教程中,我们将介绍:
+
+1. [AMP 介绍](#amp-介绍)
+2. [Colossal-AI 中的 AMP](#colossal-ai-中的-amp)
+3. [练习实例](#实例)
+
+## AMP 介绍
+
+自动混合精度训练是混合 FP16 和 FP32 训练。
+
+半精度浮点格式(FP16)具有较低的算法复杂度和较高的计算效率。此外,FP16 仅需要 FP32 所需的一半存储空间,并节省了内存和网络带宽,从而为大 batch size 和大模型提供了更多内存。
+
+然而,还有其他操作,如缩减,需要 FP32 的动态范围,以避免数值溢出/下溢。因此,我们引入自动混合精度,尝试将每个操作与其相应的数据类型相匹配,这可以减少内存占用并提高训练效率。
+
+
+
+AMP 示意图 (图片来自 PatrickStar 论文)
+
+
+## Colossal-AI 中的 AMP
+
+我们支持三种 AMP 训练方法,并允许用户在没有改变代码的情况下使用 AMP 进行训练。booster支持amp特性注入,如果您要使用混合精度训练,则在创建booster实例时指定`mixed_precision`参数,我们现已支持torch amp,apex amp, naive amp(现已移植torch amp至booster,apex amp, naive amp仍由`colossalai.initialize`方式启动,如您需使用,请[参考](./mixed_precision_training.md);后续将会拓展`bf16`,`pf8`的混合精度训练.
+
+#### booster启动方式
+您可以在创建booster实例时,指定`mixed_precision="fp16"`即使用torch amp。
+
+```python
+"""
+ 初始化映射关系如下:
+ 'fp16': torch amp
+ 'fp16_apex': apex amp,
+ 'bf16': bf16,
+ 'fp8': fp8,
+ 'fp16_naive': naive amp
+"""
+from colossalai import Booster
+booster = Booster(mixed_precision='fp16',...)
+```
+
+或者您可以自定义一个`FP16TorchMixedPrecision`对象,如
+
+```python
+from colossalai.mixed_precision import FP16TorchMixedPrecision
+mixed_precision = FP16TorchMixedPrecision(
+ init_scale=2.**16,
+ growth_factor=2.0,
+ backoff_factor=0.5,
+ growth_interval=2000)
+booster = Booster(mixed_precision=mixed_precision,...)
+```
+
+其他类型的amp使用方式也是一样的。
+
+### Torch AMP 配置
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16TorchMixedPrecision }}
+
+### Apex AMP 配置
+
+对于这种模式,我们依靠 Apex 实现混合精度训练。我们支持这个插件,因为它允许对混合精度的粒度进行更精细的控制。
+例如, O2 水平 (优化器水平2) 将保持 batch normalization 为 FP32。
+
+如果你想了解更多细节,请参考 [Apex Documentation](https://nvidia.github.io/apex/)。
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16ApexMixedPrecision }}
+
+### Naive AMP 配置
+
+在 Naive AMP 模式中, 我们实现了混合精度训练,同时保持了与复杂张量和流水并行的兼容性。该 AMP 模式将所有操作转为 FP16 。下列代码块展示了该模式的booster启动方式。
+
+{{ autodoc:colossalai.booster.mixed_precision.FP16NaiveMixedPrecision }}
+
+当使用`colossalai.booster`时, 首先需要实例化一个模型、一个优化器和一个标准。将输出模型转换为内存消耗较小的 AMP 模型。如果您的输入模型已经太大,无法放置在 GPU 中,请使用`dtype=torch.float16`实例化你的模型。或者请尝试更小的模型,或尝试更多的并行化训练技术!
+
+## 实例
+
+下面我们将展现如何在 Colossal-AI 使用 AMP。在该例程中,我们使用 Torch AMP.
+
+### 步骤 1. 在 train.py 导入相关库
+
+创建`train.py`并导入必要依赖. 请记得通过命令`pip install timm scipy`安装`scipy`和`timm`。
+
+```python
+import os
+from pathlib import Path
+
+import torch
+from timm.models import vit_base_patch16_224
+from titans.utils import barrier_context
+from torchvision import datasets, transforms
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import TorchDDPPlugin
+from colossalai.logging import get_dist_logger
+from colossalai.nn.lr_scheduler import LinearWarmupLR
+```
+
+### 步骤 2. 初始化分布式环境
+
+我们需要初始化分布式环境。为了快速演示,我们使用`launch_from_torch`。你可以参考 [Launch Colossal-AI](../basics/launch_colossalai.md)
+使用其他初始化方法。
+
+```python
+# 初始化分布式设置
+parser = colossalai.get_default_parser()
+args = parser.parse_args()
+
+# launch from torch
+colossalai.launch_from_torch(config=dict())
+
+```
+
+### 步骤 3. 创建训练组件
+
+构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量`DATA`获得。你可以通过 `export DATA=/path/to/data` 或 `Path(os.environ['DATA'])`
+在你的机器上设置路径。数据将会被自动下载到该路径。
+
+```python
+# define the constants
+NUM_EPOCHS = 2
+BATCH_SIZE = 128
+# build model
+model = vit_base_patch16_224(drop_rate=0.1)
+
+# build dataloader
+train_dataset = datasets.Caltech101(
+ root=Path(os.environ['DATA']),
+ download=True,
+ transform=transforms.Compose([
+ transforms.Resize(256),
+ transforms.RandomResizedCrop(224),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ Gray2RGB(),
+ transforms.Normalize([0.5, 0.5, 0.5],
+ [0.5, 0.5, 0.5])
+ ]))
+
+# build optimizer
+optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, weight_decay=0.1)
+
+# build loss
+criterion = torch.nn.CrossEntropyLoss()
+
+# lr_scheduelr
+lr_scheduler = LinearWarmupLR(optimizer, warmup_steps=50, total_steps=NUM_EPOCHS)
+```
+
+### 步骤 4. 插入 AMP
+创建一个MixedPrecision对象(如果需要)及torchDDPPlugin对象,调用 `colossalai.boost` 将所有训练组件转为为FP16模式.
+
+```python
+plugin = TorchDDPPlugin()
+train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
+booster = Booster(mixed_precision='fp16', plugin=plugin)
+
+# if you need to customize the config, do like this
+# >>> from colossalai.mixed_precision import FP16TorchMixedPrecision
+# >>> mixed_precision = FP16TorchMixedPrecision(
+# >>> init_scale=2.**16,
+# >>> growth_factor=2.0,
+# >>> backoff_factor=0.5,
+# >>> growth_interval=2000)
+# >>> plugin = TorchDDPPlugin()
+# >>> booster = Booster(mixed_precision=mixed_precision, plugin=plugin)
+
+# boost model, optimizer, criterion, dataloader, lr_scheduler
+model, optimizer, criterion, dataloader, lr_scheduler = booster.boost(model, optimizer, criterion, dataloader, lr_scheduler)
+```
+
+### 步骤 5. 使用 booster 训练
+
+使用booster构建一个普通的训练循环。
+
+```python
+model.train()
+for epoch in range(NUM_EPOCHS):
+ for img, label in enumerate(train_dataloader):
+ img = img.cuda()
+ label = label.cuda()
+ optimizer.zero_grad()
+ output = model(img)
+ loss = criterion(output, label)
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ lr_scheduler.step()
+```
+
+### 步骤 6. 启动训练脚本
+
+使用下列命令启动训练脚本,你可以改变 `--nproc_per_node` 以使用不同数量的 GPU。
+
+```shell
+colossalai run --nproc_per_node 1 train.py
+```
+
diff --git a/docs/source/zh-Hans/features/nvme_offload.md b/docs/source/zh-Hans/features/nvme_offload.md
index fd75ed1f5b3e..1feb9dde5725 100644
--- a/docs/source/zh-Hans/features/nvme_offload.md
+++ b/docs/source/zh-Hans/features/nvme_offload.md
@@ -53,9 +53,8 @@ optimizer = HybridAdam(model.parameters(), lr=1e-3, nvme_offload_fraction=1.0, n
> ⚠ 它只会卸载在 CPU 上的优化器状态。这意味着它只会影响 CPU 训练或者使用卸载的 Zero/Gemini。
-## Exampls
+## Examples
-Let's start from two simple examples -- training GPT with different methods. These examples relies on `transformers`.
首先让我们从两个简单的例子开始 -- 用不同的方法训练 GPT。这些例子依赖`transformers`。
我们首先应该安装依赖:
@@ -77,8 +76,9 @@ from transformers.models.gpt2.configuration_gpt2 import GPT2Config
from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
import colossalai
from colossalai.nn.optimizer import HybridAdam
-from colossalai.zero import zero_model_wrapper, zero_optim_wrapper
from colossalai.utils.model.colo_init_context import ColoInitContext
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin
```
然后我们定义一个损失函数:
@@ -182,16 +182,24 @@ def train_gemini_cpu(nvme_offload_fraction: float = 0.0):
criterion = GPTLMLoss()
optimizer = HybridAdam(model.parameters(), nvme_offload_fraction=nvme_offload_fraction)
print(f'Model numel: {get_model_numel(model) / 1024**3:.3f} B')
- gemini_config = dict(strict_ddp_mode=True, device=torch.cuda.current_device(),
- placement_policy='cpu', pin_memory=True, hidden_dim=config.n_embd)
- model = zero_model_wrapper(model, zero_stage=3, gemini_config=gemini_config)
- optimizer = zero_optim_wrapper(model, optimizer, initial_scale=2**5)
+
+ plugin = GeminiPlugin(
+ strict_ddp_mode=True,
+ device=torch.cuda.current_device(),
+ placement_policy='cpu',
+ pin_memory=True,
+ hidden_dim=config.n_embd,
+ initial_scale=2**5
+ )
+ booster = Booster(plugin)
+ model, optimizer, criterion, _* = booster.boost(model, optimizer, criterion)
+
start = time.time()
for step in range(3):
data = get_data(4, 128, config.vocab_size)
outputs = model(**data)
loss = criterion(outputs.logits, data['input_ids'])
- optimizer.backward(loss)
+ booster.backward(loss, optimizer)
optimizer.step()
optimizer.zero_grad()
print(f'[{step}] loss: {loss.item():.3f}')
diff --git a/docs/source/zh-Hans/features/zero_with_chunk.md b/docs/source/zh-Hans/features/zero_with_chunk.md
index 72403bf610a4..9030464ddf9a 100644
--- a/docs/source/zh-Hans/features/zero_with_chunk.md
+++ b/docs/source/zh-Hans/features/zero_with_chunk.md
@@ -4,7 +4,7 @@
**前置教程:**
-- [定义配置文件](../basics/define_your_config.md)
+- [booster使用](../basics/booster_api.md)
**示例代码**
@@ -97,6 +97,8 @@ optimizer.step()
首先我们只需要引入`Huggingface transformers` 的 `GPT2LMHeadModel`来定义我们的模型,不需要用户进行模型的定义与修改,方便用户使用。
+定义GPT模型:
+
```python
class GPTLMModel(nn.Module):
@@ -182,34 +184,6 @@ def split_param_col_tp1d(param: ColoParameter, pg: ProcessGroup):
split_param_single_dim_tp1d(-1, param, pg)
```
-定义一个使用 Gemini + ZeRO DDP 的模型:
-
-```python
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
- cai_version = colossalai.__version__
- if version.parse(cai_version) > version.parse("0.1.10"):
- from colossalai.nn.parallel import GeminiDDP
- model = GeminiDDP(model,
- device=get_current_device(),
- placement_policy=placememt_policy,
- pin_memory=True,
- search_range_mb=32)
- elif version.parse(cai_version) <= version.parse("0.1.10") and version.parse(cai_version) >= version.parse("0.1.9"):
- from colossalai.gemini import ChunkManager, GeminiManager
- chunk_size = ChunkManager.search_chunk_size(model, 64 * 1024**2, 32)
- gemini_manager = GeminiManager(placememt_policy, chunk_manager)
- chunk_manager = ChunkManager(chunk_size,
- pg,
- enable_distributed_storage=True,
- init_device=GeminiManager.get_default_device(placememt_policy))
- model = ZeroDDP(model, gemini_manager)
- else:
- raise NotImplemented(f"CAI version {cai_version} is not supported")
- return model
-```
-
-由于我们在这个例子中对GPT进行预训练,因此只使用了一个简单的语言模型损失函数。
-
写一个获得随机输入的函数:
```python
@@ -219,9 +193,16 @@ def get_data(batch_size, seq_len, vocab_size):
return input_ids, attention_mask
```
-最后,我们可以定义我们的训练循环:
+
+最后,使用booster注入 Gemini + ZeRO DDP 特性, 并定义训练循环。由于我们在这个例子中对GPT进行预训练,因此只使用了一个简单的语言模型损失函数:
```python
+from torch.optim import Adam
+
+from colossalai.booster import Booster
+from colossalai.zero import ColoInitContext
+from colossalai.booster.plugin import GeminiPlugin
+
def main():
args = parse_args()
BATCH_SIZE = 8
@@ -232,22 +213,23 @@ def main():
# build criterion
criterion = GPTLMLoss()
+ optimizer = Adam(model.parameters(), lr=0.001)
torch.manual_seed(123)
default_pg = ProcessGroup(tp_degree=args.tp_degree)
- default_dist_spec = ShardSpec([-1], [args.tp_degree]) if args.shardinit else None
+ default_dist_spec = ShardSpec([-1], [args.tp_degree])
# build GPT model
with ColoInitContext(device='cpu', default_dist_spec=default_dist_spec, default_pg=default_pg):
model = gpt2_medium(checkpoint=True)
pg = default_pg
# Tensor Parallelism (TP)
tensor_parallelize(model, pg)
+
# Gemini + ZeRO DP, Note it must be used after TP
- model = gemini_zero_dpp(model, pg, args.placement)
- # build optimizer
- optimizer = GeminiAdamOptimizer(model, lr=1e-3, initial_scale=2**5)
- numel = sum([p.numel() for p in model.parameters()])
- get_tflops_func = partial(get_tflops, numel, BATCH_SIZE, SEQ_LEN)
+ plugin = GeminiPlugin(placement_policy='cuda', max_norm=1.0, initial_scale=2**5)
+ booster = Booster(plugin=plugin)
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+
torch.cuda.synchronize()
model.train()
for n in range(NUM_STEPS):
@@ -256,10 +238,12 @@ def main():
optimizer.zero_grad()
outputs = model(input_ids, attn_mask)
loss = criterion(outputs, input_ids)
- optimizer.backward(loss)
+ booster.backward(loss, optimizer)
optimizer.step()
torch.cuda.synchronize()
```
> ⚠️ 注意:如果你使用Gemini模块的话,请不要使用我们之前提到过的[梯度累加](../features/gradient_accumulation.md)。
完整的例子代码可以在 [Train GPT with Colossal-AI](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/gpt). 获得。
+
+
diff --git a/docs/source/zh-Hans/get_started/installation.md b/docs/source/zh-Hans/get_started/installation.md
index e0d726c74f64..a6c88672b907 100755
--- a/docs/source/zh-Hans/get_started/installation.md
+++ b/docs/source/zh-Hans/get_started/installation.md
@@ -47,4 +47,20 @@ CUDA_EXT=1 pip install .
pip install .
```
+如果您在使用CUDA 10.2,您仍然可以从源码安装ColossalAI。但是您需要手动下载cub库并将其复制到相应的目录。
+
+```bash
+# clone the repository
+git clone https://github.com/hpcaitech/ColossalAI.git
+cd ColossalAI
+
+# download the cub library
+wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip
+unzip 1.8.0.zip
+cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
+
+# install
+CUDA_EXT=1 pip install .
+```
+
diff --git a/examples/images/dreambooth/train_dreambooth_colossalai.py b/examples/images/dreambooth/train_dreambooth_colossalai.py
index e6159e1058b9..d07febea0a84 100644
--- a/examples/images/dreambooth/train_dreambooth_colossalai.py
+++ b/examples/images/dreambooth/train_dreambooth_colossalai.py
@@ -340,12 +340,12 @@ def get_full_repo_name(model_id: str, organization: Optional[str] = None, token:
# Gemini + ZeRO DDP
-def gemini_zero_dpp(model: torch.nn.Module, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=64)
return model
diff --git a/examples/images/dreambooth/train_dreambooth_colossalai_lora.py b/examples/images/dreambooth/train_dreambooth_colossalai_lora.py
index 1b2fc778d5ed..6715b473a567 100644
--- a/examples/images/dreambooth/train_dreambooth_colossalai_lora.py
+++ b/examples/images/dreambooth/train_dreambooth_colossalai_lora.py
@@ -342,12 +342,12 @@ def get_full_repo_name(model_id: str, organization: Optional[str] = None, token:
# Gemini + ZeRO DDP
-def gemini_zero_dpp(model: torch.nn.Module, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, placement_policy: str = "auto"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=64)
return model
diff --git a/examples/language/gpt/gemini/test_ci.sh b/examples/language/gpt/gemini/test_ci.sh
index 6079d5ed615b..0ddfd3a6211c 100644
--- a/examples/language/gpt/gemini/test_ci.sh
+++ b/examples/language/gpt/gemini/test_ci.sh
@@ -3,7 +3,7 @@ $(cd `dirname $0`;pwd)
export TRAIN_STEP=4
for MODEL_TYPE in "gpt2_medium"; do
- for DISTPLAN in "colossalai"; do
+ for DISTPLAN in "CAI_Gemini"; do
for BATCH_SIZE in 2; do
for GPUNUM in 1 4; do
for TPDEGREE in 1 2; do
diff --git a/examples/language/gpt/gemini/train_gpt_demo.py b/examples/language/gpt/gemini/train_gpt_demo.py
index b2a7fa36d021..92751c7e2f47 100644
--- a/examples/language/gpt/gemini/train_gpt_demo.py
+++ b/examples/language/gpt/gemini/train_gpt_demo.py
@@ -11,11 +11,13 @@
from torch.nn.parallel import DistributedDataParallel as DDP
import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin, LowLevelZeroPlugin, TorchDDPPlugin
from colossalai.logging import disable_existing_loggers, get_dist_logger
from colossalai.nn.optimizer import HybridAdam
from colossalai.tensor import ColoParameter, ComputePattern, ComputeSpec, ProcessGroup, ReplicaSpec, ShardSpec
from colossalai.utils import get_current_device
-from colossalai.zero import ColoInitContext, zero_model_wrapper, zero_optim_wrapper
+from colossalai.zero import ColoInitContext
CAI_VERSION = colossalai.__version__
@@ -236,23 +238,6 @@ def main():
tensor_parallelize(model, tp_pg)
# asign running configurations
- gemini_config = None
- if args.distplan.startswith("CAI_ZeRO"):
- optim_config = dict(reduce_bucket_size=12 * 1024 * 1024, overlap_communication=True, verbose=True)
- elif args.distplan == "CAI_Gemini":
- gemini_config = dict(strict_ddp_mode=args.tp_degree == 1,
- device=get_current_device(),
- placement_policy=args.placement,
- pin_memory=True,
- hidden_dim=model.config.n_embd,
- search_range_mb=128)
- optim_config = dict(gpu_margin_mem_ratio=0.)
- else:
- raise RuntimeError
-
- # build a highly optimized gpu/cpu optimizer
- optimizer = HybridAdam(model.parameters(), lr=1e-3)
-
if args.distplan == "CAI_ZeRO1":
zero_stage = 1
elif args.distplan == "CAI_ZeRO2":
@@ -262,22 +247,42 @@ def main():
else:
raise RuntimeError
- # wrap your model and optimizer
- model = zero_model_wrapper(model, zero_stage, gemini_config)
- optimizer = zero_optim_wrapper(model, optimizer, optim_config=optim_config)
+ plugin = None
+ if args.distplan.startswith("CAI_ZeRO"):
+ plugin = LowLevelZeroPlugin(stage=zero_stage,
+ reduce_bucket_size_in_m=12 * 1024 * 1024,
+ overlap_communication=True,
+ verbose=True)
+ elif args.distplan == "CAI_Gemini":
+ plugin = GeminiPlugin(device=get_current_device(),
+ placement_policy=args.placement,
+ pin_memory=True,
+ strict_ddp_mode=args.tp_degree == 1,
+ search_range_mb=128,
+ hidden_dim=model.config.n_embd,
+ gpu_margin_mem_ratio=0.)
+ else:
+ raise RuntimeError
+
+ # build a highly optimized gpu/cpu optimizer
+ optimizer = HybridAdam(model.parameters(), lr=1e-3)
logger.info(get_mem_info(prefix='After init optim, '), ranks=[0])
elif args.distplan.startswith("Pytorch"):
assert args.tp_degree == 1, "The degree of TP should be 1 for DDP examples."
model = model_builder(args.model_type)(checkpoint=True).cuda()
- model = DDP(model)
+ plugin = TorchDDPPlugin()
if args.distplan.endswith("DDP"):
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
elif args.distplan.endswith("ZeRO"):
from torch.distributed.optim import ZeroRedundancyOptimizer
optimizer = ZeroRedundancyOptimizer(model.parameters(), optimizer_class=torch.optim.Adam, lr=1e-3)
+
else:
raise RuntimeError
+ # wrap your model and optimizer
+ booster = Booster(plugin=plugin)
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
# model is shared after TP
numel = get_model_size(model)
@@ -305,13 +310,7 @@ def train_step():
fwd_end = time()
fwd_time = fwd_end - start
logger.info(get_mem_info(prefix=f'[{n + 1}/{NUM_STEPS}] Forward '), ranks=[0])
-
- if args.distplan.startswith("CAI"):
- optimizer.backward(loss)
- elif args.distplan.startswith("Pytorch"):
- loss.backward()
- else:
- raise RuntimeError
+ booster.backward(loss, optimizer)
torch.cuda.synchronize()
bwd_end = time()
diff --git a/examples/language/palm/train.py b/examples/language/palm/train.py
index 7923e4fc855d..b16da1c7744a 100644
--- a/examples/language/palm/train.py
+++ b/examples/language/palm/train.py
@@ -102,23 +102,23 @@ def get_model_size(model: nn.Module):
# Gemini + ZeRO DDP
-def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
+def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
cai_version = colossalai.__version__
if version.parse(cai_version) > version.parse("0.1.10"):
from colossalai.nn.parallel import GeminiDDP
model = GeminiDDP(model,
device=get_current_device(),
- placement_policy=placememt_policy,
+ placement_policy=placement_policy,
pin_memory=True,
search_range_mb=32)
elif version.parse(cai_version) <= version.parse("0.1.10") and version.parse(cai_version) >= version.parse("0.1.9"):
from colossalai.gemini import ChunkManager, GeminiManager
chunk_size = ChunkManager.search_chunk_size(model, 64 * 1024**2, 32)
- gemini_manager = GeminiManager(placememt_policy, chunk_manager)
+ gemini_manager = GeminiManager(placement_policy, chunk_manager)
chunk_manager = ChunkManager(chunk_size,
pg,
enable_distributed_storage=True,
- init_device=GeminiManager.get_default_device(placememt_policy))
+ init_device=GeminiManager.get_default_device(placement_policy))
model = ZeroDDP(model, gemini_manager)
else:
raise NotImplemented(f"CAI version {cai_version} is not supported")
diff --git a/examples/tutorial/README.md b/examples/tutorial/README.md
index 933026166d3f..0664d41fd359 100644
--- a/examples/tutorial/README.md
+++ b/examples/tutorial/README.md
@@ -29,9 +29,9 @@ quickly deploy large AI model training and inference, reducing large AI model tr
- Fine-tuning and Inference for OPT [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/opt) [[video]](https://www.youtube.com/watch?v=jbEFNVzl67Y)
- Optimized AlphaFold [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/fastfold) [[video]](https://www.youtube.com/watch?v=-zP13LfJP7w)
- Optimized Stable Diffusion [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion) [[video]](https://www.youtube.com/watch?v=8KHeUjjc-XQ)
- - ColossalChat: Cloning ChatGPT with a Complete RLHF Pipeline
-[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
-[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+ - ColossalChat: Cloning ChatGPT with a Complete RLHF Pipeline
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
+[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
[[demo]](https://www.youtube.com/watch?v=HcTiHzApHm0)
[[video]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
diff --git a/op_builder/utils.py b/op_builder/utils.py
index 2dbd976fbcbb..cb528eea66a1 100644
--- a/op_builder/utils.py
+++ b/op_builder/utils.py
@@ -110,7 +110,7 @@ def get_pytorch_version() -> List[int]:
torch_version = torch.__version__.split('+')[0]
TORCH_MAJOR = int(torch_version.split('.')[0])
TORCH_MINOR = int(torch_version.split('.')[1])
- TORCH_PATCH = int(torch_version.split('.')[2])
+ TORCH_PATCH = int(torch_version.split('.')[2], 16)
return TORCH_MAJOR, TORCH_MINOR, TORCH_PATCH
diff --git a/requirements/requirements-test.txt b/requirements/requirements-test.txt
index 55edb1b6a512..6895113bc637 100644
--- a/requirements/requirements-test.txt
+++ b/requirements/requirements-test.txt
@@ -1,6 +1,7 @@
diffusers
fbgemm-gpu==0.2.0
pytest
+coverage==7.2.3
git+https://github.com/hpcaitech/pytest-testmon
torchvision
transformers
diff --git a/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py b/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py
index 12562095c153..44767f051fdd 100644
--- a/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py
+++ b/tests/test_booster/test_plugin/test_torch_fsdp_plugin.py
@@ -1,10 +1,6 @@
-from contextlib import nullcontext
-
import pytest
import torch
-import torch.distributed as dist
from packaging import version
-from torch import nn
from torch.optim import SGD
import colossalai
@@ -19,6 +15,7 @@
from tests.kit.model_zoo import model_zoo
+# test baisc fsdp function
def run_fn(model_fn, data_gen_fn, output_transform_fn):
plugin = TorchFSDPPlugin()
booster = Booster(plugin=plugin)
diff --git a/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py b/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py
new file mode 100644
index 000000000000..2b6090bb1e29
--- /dev/null
+++ b/tests/test_checkpoint_io/test_torch_fsdp_checkpoint_io.py
@@ -0,0 +1,113 @@
+import pytest
+import torch
+from packaging import version
+from torch import nn
+from torch.optim import SGD
+from torchvision.models import resnet18
+from utils import shared_tempdir
+
+import colossalai
+from colossalai.booster import Booster
+
+if version.parse(torch.__version__) >= version.parse('1.12.0'):
+ from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
+ from colossalai.booster.plugin import TorchFSDPPlugin
+
+from colossalai.testing import rerun_if_address_is_in_use, spawn, check_state_dict_equal
+
+
+def compare_nested_dict(dict1, dict2):
+ for key in dict1:
+ if key in dict2:
+ if type(dict1[key]) is dict:
+ assert type(dict2[key]) is dict
+ diff = compare_nested_dict(dict1[key], dict2[key])
+ if not diff:
+ return diff
+ elif type(dict1[key]) is list:
+ assert type(dict2[key]) is list
+ for i, val in enumerate(dict1[key]):
+ if isinstance(val, torch.Tensor):
+ if not torch.equal(dict1[key][i], dict2[key][i]):
+ return False
+ elif val != dict2[key][i]:
+ return False
+ elif type(dict1[key]) is torch.Tensor:
+ assert type(dict2[key]) is torch.Tensor
+ if not torch.equal(dict1[key], dict2[key]):
+ return False
+ else:
+ if dict1[key] != dict2[key]:
+ return False
+ else:
+ return False
+ return True
+
+
+def check_torch_fsdp_ckpt():
+ model = resnet18()
+ plugin = TorchFSDPPlugin()
+ booster = Booster(plugin=plugin)
+ optimizer = SGD(model.parameters(), lr=0.001, momentum=0.9)
+ criterion = lambda x: x.mean()
+ fsdp_model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+
+ inputs = torch.randn(4, 3, 224, 224)
+ outputs = None
+
+ def run_model():
+ nonlocal outputs
+ outputs = fsdp_model(inputs)
+ optimizer.zero_grad()
+ criterion(outputs).backward()
+ optimizer.step()
+
+ with shared_tempdir() as tempdir:
+ model_ckpt_path = f"{tempdir}/model"
+ optim_ckpt_path = f"{tempdir}/optimizer"
+
+ run_model()
+
+ booster.save_model(fsdp_model, model_ckpt_path, shard=False)
+ booster.save_optimizer(optimizer, optim_ckpt_path, shard=False)
+
+ full_msd = fsdp_model.state_dict()
+ #full_osd = FSDP.full_optim_state_dict(fsdp_model, optimizer)
+ sharded_osd = optimizer.state_dict()
+ import copy
+ sharded_osd = copy.deepcopy(sharded_osd)
+
+ run_model()
+
+ full_msd_updated = fsdp_model.state_dict()
+ #full_osd_updated = FSDP.full_optim_state_dict(fsdp_model, optimizer, rank0_only=True)
+ sharded_osd_updated = optimizer.state_dict()
+
+ assert not compare_nested_dict(sharded_osd, sharded_osd_updated)
+ assert not compare_nested_dict(full_msd_updated, full_msd)
+ outputs_first = fsdp_model(inputs)
+ assert criterion(outputs_first) != criterion(outputs)
+
+ booster.load_model(fsdp_model, model_ckpt_path)
+ booster.load_optimizer(optimizer, optim_ckpt_path)
+
+ full_msd_restore = fsdp_model.state_dict()
+ #full_osd_restore = FSDP.full_optim_state_dict(fsdp_model, optimizer, rank0_only=True)
+ sharded_osd_restore = optimizer.state_dict()
+
+ assert compare_nested_dict(sharded_osd, sharded_osd_restore)
+ assert compare_nested_dict(full_msd_restore, full_msd)
+ outputs_sec = fsdp_model(inputs)
+ assert criterion(outputs_sec) == criterion(outputs)
+
+
+def run_dist(rank, world_size, port):
+ # init dist env
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ check_torch_fsdp_ckpt()
+
+
+@pytest.mark.skipif(version.parse(torch.__version__) < version.parse('1.12.0'), reason="requires torch1.12 or higher")
+@rerun_if_address_is_in_use()
+def test_torch_fsdp_ckpt():
+ spawn(run_dist, 2)
diff --git a/tests/test_utils/test_lazy_init/utils.py b/tests/test_utils/test_lazy_init/lazy_init_utils.py
similarity index 100%
rename from tests/test_utils/test_lazy_init/utils.py
rename to tests/test_utils/test_lazy_init/lazy_init_utils.py
diff --git a/tests/test_utils/test_lazy_init/test_distribute.py b/tests/test_utils/test_lazy_init/test_distribute.py
index c15b055e8361..fd91e7e912b5 100644
--- a/tests/test_utils/test_lazy_init/test_distribute.py
+++ b/tests/test_utils/test_lazy_init/test_distribute.py
@@ -15,7 +15,7 @@
from colossalai.utils.model.experimental import LazyInitContext, LazyTensor, _MyTensor
except:
pass
-from utils import SUPPORT_LAZY, assert_dist_model_equal, set_seed
+from lazy_init_utils import SUPPORT_LAZY, assert_dist_model_equal, set_seed
from tests.kit.model_zoo import model_zoo
diff --git a/tests/test_utils/test_lazy_init/test_models.py b/tests/test_utils/test_lazy_init/test_models.py
index 4a0217b31a97..f828b23a94c4 100644
--- a/tests/test_utils/test_lazy_init/test_models.py
+++ b/tests/test_utils/test_lazy_init/test_models.py
@@ -1,5 +1,5 @@
import pytest
-from utils import SUPPORT_LAZY, check_lazy_init
+from lazy_init_utils import SUPPORT_LAZY, check_lazy_init
from tests.kit.model_zoo import model_zoo
diff --git a/version.txt b/version.txt
index a45be4627678..0d91a54c7d43 100644
--- a/version.txt
+++ b/version.txt
@@ -1 +1 @@
-0.2.8
+0.3.0