`_.
+
+ Returns:
+ :class:`torch.utils.data.DataLoader`: A DataLoader used for training or testing.
+ """
+ _kwargs = kwargs.copy()
+ sampler = DistributedSampler(dataset, num_replicas=self.world_size, rank=self.rank, shuffle=shuffle)
+
+ # Deterministic dataloader
+ def seed_worker(worker_id):
+ worker_seed = seed
+ np.random.seed(worker_seed)
+ torch.manual_seed(worker_seed)
+ random.seed(worker_seed)
+
+ return DataLoader(dataset,
+ batch_size=batch_size,
+ sampler=sampler,
+ worker_init_fn=seed_worker,
+ drop_last=drop_last,
+ pin_memory=pin_memory,
+ num_workers=num_workers,
+ **_kwargs)
+
+ def configure(
+ self,
+ model: nn.Module,
+ optimizer: Optimizer,
+ criterion: Callable = None,
+ dataloader: DataLoader = None,
+ lr_scheduler: LRScheduler = None,
+ ) -> Tuple[Union[nn.Module, OptimizerWrapper, LRScheduler, DataLoader]]:
+
+ if not isinstance(model, ModelWrapper):
+ # convert model to sync bn
+ # FIXME(ver217): gemini does not support sync bn
+ # In torch/nn/modules/_functions.py, line 22, ``mean, invstd = torch.batch_norm_stats(input, eps)`` will get fp32 mean and invstd even though the input is fp16.
+ # This inconsistency of dtype will cause the error.
+ # We have two possible solutions:
+ # 1. keep batch norm always in fp32. This is hard for gemini, as it use chunks.
+ # 2. patch sync bn or write a new on. This is relatively easy, but we need to test it.
+ # model = nn.SyncBatchNorm.convert_sync_batchnorm(model, None)
+
+ # wrap the model with Gemini
+ model = GeminiModel(model, self.gemini_config)
+
+ if not isinstance(optimizer, OptimizerWrapper):
+ optimizer = GeminiOptimizer(model.unwrap(), optimizer, self.zero_optim_config, self.optim_kwargs)
+
+ return model, optimizer, criterion, dataloader, lr_scheduler
+
+ def control_checkpoint_io(self) -> bool:
+ return True
+
+ def get_checkpoint_io(self) -> CheckpointIO:
+ return GeminiCheckpointIO()
diff --git a/colossalai/cli/benchmark/models.py b/colossalai/cli/benchmark/models.py
index 38ea54188b8c..f8fd1c41a059 100644
--- a/colossalai/cli/benchmark/models.py
+++ b/colossalai/cli/benchmark/models.py
@@ -1,4 +1,5 @@
import torch
+
import colossalai.nn as col_nn
diff --git a/colossalai/context/parallel_context.py b/colossalai/context/parallel_context.py
index dd12dad6d347..0cd533fdef1a 100644
--- a/colossalai/context/parallel_context.py
+++ b/colossalai/context/parallel_context.py
@@ -10,15 +10,16 @@
import numpy as np
import torch
import torch.distributed as dist
+
from colossalai.constants import ALLOWED_MODES, INITIALIZER_MAPPING
from colossalai.context.config import Config
+from colossalai.context.singleton_meta import SingletonMeta
from colossalai.global_variables import tensor_parallel_env as env
from colossalai.logging import get_dist_logger
from colossalai.registry import DIST_GROUP_INITIALIZER
from .parallel_mode import ParallelMode
from .random import add_seed, get_seeds, set_mode
-from colossalai.context.singleton_meta import SingletonMeta
class ParallelContext(metaclass=SingletonMeta):
diff --git a/colossalai/context/process_group_initializer/initializer_3d.py b/colossalai/context/process_group_initializer/initializer_3d.py
index b752b8f45654..1ed8eec86efc 100644
--- a/colossalai/context/process_group_initializer/initializer_3d.py
+++ b/colossalai/context/process_group_initializer/initializer_3d.py
@@ -4,6 +4,7 @@
import math
import torch.distributed as dist
+
from colossalai.global_variables import tensor_parallel_env as env
from colossalai.registry import DIST_GROUP_INITIALIZER
@@ -213,7 +214,8 @@ def init_dist_group(self):
for h in range(self.num_group):
for k in range(self.depth):
ranks = [
- h * self.depth**3 + i + self.depth * (j + self.depth * k) for j in range(self.depth)
+ h * self.depth**3 + i + self.depth * (j + self.depth * k)
+ for j in range(self.depth)
for i in range(self.depth)
]
group = dist.new_group(ranks)
@@ -266,7 +268,8 @@ def init_dist_group(self):
for h in range(self.num_group):
for j in range(self.depth):
ranks = [
- h * self.depth**3 + i + self.depth * (j + self.depth * k) for k in range(self.depth)
+ h * self.depth**3 + i + self.depth * (j + self.depth * k)
+ for k in range(self.depth)
for i in range(self.depth)
]
group = dist.new_group(ranks)
diff --git a/colossalai/context/process_group_initializer/initializer_data.py b/colossalai/context/process_group_initializer/initializer_data.py
index 0b8b0d91fcb9..9715ebff7f00 100644
--- a/colossalai/context/process_group_initializer/initializer_data.py
+++ b/colossalai/context/process_group_initializer/initializer_data.py
@@ -4,8 +4,9 @@
from torch import distributed as dist
from colossalai.registry import DIST_GROUP_INITIALIZER
-from .process_group_initializer import ProcessGroupInitializer
+
from ..parallel_mode import ParallelMode
+from .process_group_initializer import ProcessGroupInitializer
@DIST_GROUP_INITIALIZER.register_module
diff --git a/colossalai/context/random/__init__.py b/colossalai/context/random/__init__.py
index 422c3676c09d..d64b993257c1 100644
--- a/colossalai/context/random/__init__.py
+++ b/colossalai/context/random/__init__.py
@@ -1,5 +1,16 @@
-from ._helper import (seed, set_mode, with_seed, add_seed, get_seeds, get_states, get_current_mode, set_seed_states,
- sync_states, moe_set_seed, reset_seeds)
+from ._helper import (
+ add_seed,
+ get_current_mode,
+ get_seeds,
+ get_states,
+ moe_set_seed,
+ reset_seeds,
+ seed,
+ set_mode,
+ set_seed_states,
+ sync_states,
+ with_seed,
+)
__all__ = [
'seed', 'set_mode', 'with_seed', 'add_seed', 'get_seeds', 'get_states', 'get_current_mode', 'set_seed_states',
diff --git a/colossalai/engine/gradient_accumulation/_gradient_accumulation.py b/colossalai/engine/gradient_accumulation/_gradient_accumulation.py
index 89c28c3be87a..cf66be1cd821 100644
--- a/colossalai/engine/gradient_accumulation/_gradient_accumulation.py
+++ b/colossalai/engine/gradient_accumulation/_gradient_accumulation.py
@@ -1,21 +1,22 @@
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
-from typing import Union
+from typing import Any, Iterable, Tuple, Union
+
import torch.nn as nn
from torch import Tensor
-from typing import Iterable, Any, Tuple
-from colossalai.nn.optimizer import ColossalaiOptimizer
from torch.nn.parallel.distributed import DistributedDataParallel
from torch.optim import Optimizer
from torch.optim.lr_scheduler import _LRScheduler
from torch.utils.data import DataLoader
-from colossalai.utils import conditional_context
+
from colossalai.engine import BaseGradientHandler
+from colossalai.nn.optimizer import ColossalaiOptimizer
+from colossalai.utils import conditional_context
class GradAccumOptimizer(ColossalaiOptimizer):
- """A wrapper for the optimizer to enable gradient accumulation by skipping the steps
+ """A wrapper for the optimizer to enable gradient accumulation by skipping the steps
before accumulation size is reached.
Args:
@@ -161,7 +162,7 @@ def __next__(self) -> Union[Tensor, Tuple[Tensor]]:
class GradAccumLrSchedulerByStep(_LRScheduler):
- """A wrapper for the LR scheduler to enable gradient accumulation by skipping the steps
+ """A wrapper for the LR scheduler to enable gradient accumulation by skipping the steps
before accumulation size is reached.
Args:
diff --git a/colossalai/engine/gradient_handler/__init__.py b/colossalai/engine/gradient_handler/__init__.py
index 6177da69ba5b..2dea768bad7e 100644
--- a/colossalai/engine/gradient_handler/__init__.py
+++ b/colossalai/engine/gradient_handler/__init__.py
@@ -1,10 +1,9 @@
from ._base_gradient_handler import BaseGradientHandler
from ._data_parallel_gradient_handler import DataParallelGradientHandler
-from ._zero_gradient_handler import ZeROGradientHandler
-from ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler
-from ._pipeline_parallel_gradient_handler import PipelineSharedModuleGradientHandler
from ._moe_gradient_handler import MoeGradientHandler
+from ._pipeline_parallel_gradient_handler import PipelineSharedModuleGradientHandler
from ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler
+from ._zero_gradient_handler import ZeROGradientHandler
__all__ = [
'BaseGradientHandler', 'DataParallelGradientHandler', 'ZeROGradientHandler', 'PipelineSharedModuleGradientHandler',
diff --git a/colossalai/engine/gradient_handler/_moe_gradient_handler.py b/colossalai/engine/gradient_handler/_moe_gradient_handler.py
index 02cea5e67a12..b499345d4e18 100644
--- a/colossalai/engine/gradient_handler/_moe_gradient_handler.py
+++ b/colossalai/engine/gradient_handler/_moe_gradient_handler.py
@@ -1,45 +1,46 @@
-from colossalai.core import global_context as gpc
-from colossalai.registry import GRADIENT_HANDLER
-from colossalai.utils.moe import get_moe_epsize_param_dict
-from ._base_gradient_handler import BaseGradientHandler
-from ...context.parallel_mode import ParallelMode
-from .utils import bucket_allreduce
-from colossalai.context.moe_context import MOE_CONTEXT
-
-
-@GRADIENT_HANDLER.register_module
-class MoeGradientHandler(BaseGradientHandler):
- """A helper class to handle all-reduce operations in a data parallel group and
- moe model parallel. A all-reduce collective communication will be operated in
- :func:`handle_gradient` among a data parallel group.
- For better performance, it bucketizes the gradients of all parameters that are
- the same type to improve the efficiency of communication.
-
- Args:
- model (Module): Model where the gradients accumulate.
- optimizer (Optimizer): Optimizer for updating the parameters.
- """
-
- def __init__(self, model, optimizer=None):
- super().__init__(model, optimizer)
-
- def handle_gradient(self):
- """A method running an all-reduce operation in a data parallel group.
- Then running an all-reduce operation for all parameters in experts
- across moe model parallel group
- """
- global_data = gpc.data_parallel_size
-
- if global_data > 1:
- epsize_param_dict = get_moe_epsize_param_dict(self._model)
-
- # epsize is 1, indicating the params are replicated among processes in data parallelism
- # use the ParallelMode.DATA to get data parallel group
- # reduce gradients for all parameters in data parallelism
- if 1 in epsize_param_dict:
- bucket_allreduce(param_list=epsize_param_dict[1], group=gpc.get_group(ParallelMode.DATA))
-
- for ep_size in epsize_param_dict:
- if ep_size != 1 and ep_size != MOE_CONTEXT.world_size:
- bucket_allreduce(param_list=epsize_param_dict[ep_size],
- group=MOE_CONTEXT.parallel_info_dict[ep_size].dp_group)
+from colossalai.context.moe_context import MOE_CONTEXT
+from colossalai.core import global_context as gpc
+from colossalai.registry import GRADIENT_HANDLER
+from colossalai.utils.moe import get_moe_epsize_param_dict
+
+from ...context.parallel_mode import ParallelMode
+from ._base_gradient_handler import BaseGradientHandler
+from .utils import bucket_allreduce
+
+
+@GRADIENT_HANDLER.register_module
+class MoeGradientHandler(BaseGradientHandler):
+ """A helper class to handle all-reduce operations in a data parallel group and
+ moe model parallel. A all-reduce collective communication will be operated in
+ :func:`handle_gradient` among a data parallel group.
+ For better performance, it bucketizes the gradients of all parameters that are
+ the same type to improve the efficiency of communication.
+
+ Args:
+ model (Module): Model where the gradients accumulate.
+ optimizer (Optimizer): Optimizer for updating the parameters.
+ """
+
+ def __init__(self, model, optimizer=None):
+ super().__init__(model, optimizer)
+
+ def handle_gradient(self):
+ """A method running an all-reduce operation in a data parallel group.
+ Then running an all-reduce operation for all parameters in experts
+ across moe model parallel group
+ """
+ global_data = gpc.data_parallel_size
+
+ if global_data > 1:
+ epsize_param_dict = get_moe_epsize_param_dict(self._model)
+
+ # epsize is 1, indicating the params are replicated among processes in data parallelism
+ # use the ParallelMode.DATA to get data parallel group
+ # reduce gradients for all parameters in data parallelism
+ if 1 in epsize_param_dict:
+ bucket_allreduce(param_list=epsize_param_dict[1], group=gpc.get_group(ParallelMode.DATA))
+
+ for ep_size in epsize_param_dict:
+ if ep_size != 1 and ep_size != MOE_CONTEXT.world_size:
+ bucket_allreduce(param_list=epsize_param_dict[ep_size],
+ group=MOE_CONTEXT.parallel_info_dict[ep_size].dp_group)
diff --git a/colossalai/engine/schedule/_pipeline_schedule_v2.py b/colossalai/engine/schedule/_pipeline_schedule_v2.py
index 50a87aafad02..28c58bd82b5c 100644
--- a/colossalai/engine/schedule/_pipeline_schedule_v2.py
+++ b/colossalai/engine/schedule/_pipeline_schedule_v2.py
@@ -1,11 +1,12 @@
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
-from typing import Tuple, Iterable
+from typing import Iterable, Tuple
-from colossalai import engine
-import colossalai.communication.p2p_v2 as comm
import torch.cuda
+
+import colossalai.communication.p2p_v2 as comm
+from colossalai import engine
from colossalai.context.parallel_mode import ParallelMode
from colossalai.core import global_context as gpc
from colossalai.utils.cuda import get_current_device
@@ -35,7 +36,7 @@ def pack_return_tensors(return_tensors):
class PipelineScheduleV2(PipelineSchedule):
"""Derived class of PipelineSchedule, the only difference is that
forward_backward_step is reconstructed with p2p_v2
-
+
Args:
num_microbatches (int): The number of microbatches.
data_process_func (Callable, optional):
@@ -43,9 +44,9 @@ class PipelineScheduleV2(PipelineSchedule):
tensor_shape (torch.Size, optional): Specified shape in pipeline communication.
scatter_gather_tensors (bool, optional):
If set to `True`, communication will be reduced over pipeline when using 1D tensor parallelization.
-
+
Example:
-
+
# this shows an example of customized data_process_func
def data_process_func(stage_output, dataloader_output):
output1, output2 = stage_output
diff --git a/colossalai/fx/_compatibility.py b/colossalai/fx/_compatibility.py
index 6caad920d2ae..0444a4816273 100644
--- a/colossalai/fx/_compatibility.py
+++ b/colossalai/fx/_compatibility.py
@@ -14,9 +14,7 @@
from . import _meta_regist_13
META_COMPATIBILITY = True
elif TORCH_MAJOR == 2:
- from . import _meta_regist_13
META_COMPATIBILITY = True
- raise UserWarning("Colossalai is not tested with torch2.0 yet!!!")
def compatibility(is_backward_compatible: bool = False) -> Callable:
diff --git a/colossalai/fx/_meta_regist_12.py b/colossalai/fx/_meta_regist_12.py
index 153214447223..52e8d63ae543 100644
--- a/colossalai/fx/_meta_regist_12.py
+++ b/colossalai/fx/_meta_regist_12.py
@@ -386,7 +386,7 @@ def meta_local_scalar_dense(self: torch.Tensor):
@register_meta(aten.where.self)
def meta_where_self(condition: torch.Tensor, self: torch.Tensor, other: torch.Tensor):
result_type = torch.result_type(self, other)
- return torch.empty_like(self, dtype=result_type)
+ return torch.empty_like(condition + self + other, dtype=result_type)
@register_meta(aten.index.Tensor)
diff --git a/colossalai/fx/passes/passes_for_gpt2_test.py b/colossalai/fx/passes/passes_for_gpt2_test.py
index f98fcd686ea4..abc1a089e9a9 100644
--- a/colossalai/fx/passes/passes_for_gpt2_test.py
+++ b/colossalai/fx/passes/passes_for_gpt2_test.py
@@ -1,14 +1,15 @@
+import inspect
+from typing import Any, Callable, Dict, List, Optional
+
import torch
-from torch.fx.graph_module import GraphModule
-from typing import Callable, List, Dict, Any, Optional
-from torch.fx._compatibility import compatibility
from packaging import version
+from torch.fx._compatibility import compatibility
+from torch.fx.graph_module import GraphModule
+from torch.fx.node import Node
+
+from colossalai.fx.passes.adding_split_node_pass import balanced_split_pass, pipe_split
from colossalai.fx.passes.meta_info_prop import TensorMetadata
-import inspect
-from typing import List
from colossalai.fx.passes.split_module import Partition
-from colossalai.fx.passes.adding_split_node_pass import pipe_split, balanced_split_pass
-from torch.fx.node import Node
def customized_split_pass_for_gpt2(gm: torch.fx.GraphModule, pp_size: int, partition_list: List[int]):
diff --git a/colossalai/fx/passes/split_module.py b/colossalai/fx/passes/split_module.py
index bc257edc8c89..9bc4bf1f5c42 100644
--- a/colossalai/fx/passes/split_module.py
+++ b/colossalai/fx/passes/split_module.py
@@ -1,9 +1,10 @@
+import inspect
+from typing import Any, Callable, Dict, List, Optional
+
import torch
-from torch.fx.graph_module import GraphModule
-from typing import Callable, List, Dict, Any, Optional
-from torch.fx._compatibility import compatibility
from packaging import version
-import inspect
+from torch.fx._compatibility import compatibility
+from torch.fx.graph_module import GraphModule
@compatibility(is_backward_compatible=True)
@@ -38,7 +39,7 @@ def split_module(
m: GraphModule,
root_m: torch.nn.Module,
split_callback: Callable[[torch.fx.node.Node], int],
- merge_output = False,
+ merge_output=False,
):
"""
Adapted from https://github.com/pytorch/pytorch/blob/master/torch/fx/passes/split_module.py
@@ -132,10 +133,8 @@ def record_cross_partition_use(def_node: torch.fx.node.Node,
use_partition.inputs.setdefault(def_node.name)
if def_partition_name is not None:
use_partition.partitions_dependent_on.setdefault(def_partition_name)
-
- def record_output(
- def_node: torch.fx.node.Node, use_node: Optional[torch.fx.node.Node]
- ): # noqa: B950
+
+ def record_output(def_node: torch.fx.node.Node, use_node: Optional[torch.fx.node.Node]): # noqa: B950
def_partition_name = getattr(def_node, "_fx_partition", None)
use_partition_name = getattr(use_node, "_fx_partition", None)
if def_partition_name != use_partition_name:
@@ -291,7 +290,7 @@ def record_output(
for partition_name in sorted_partitions:
partition = partitions[partition_name]
-
+
new_gm = torch.fx.graph_module.GraphModule(base_mod_attrs, base_mod_graph)
return new_gm
diff --git a/colossalai/fx/profiler/experimental/profiler_module/embedding.py b/colossalai/fx/profiler/experimental/profiler_module/embedding.py
index dca6f9453af3..a1ade5d3ad93 100644
--- a/colossalai/fx/profiler/experimental/profiler_module/embedding.py
+++ b/colossalai/fx/profiler/experimental/profiler_module/embedding.py
@@ -1,5 +1,7 @@
from typing import Tuple
+
import torch
+
from ..registry import meta_profiler_module
@@ -8,4 +10,4 @@ def torch_nn_embedding(self: torch.nn.Embedding, input: torch.Tensor) -> Tuple[i
# nn.Embedding is a dictionary lookup, so technically it has 0 FLOPs. (https://discuss.pytorch.org/t/correct-way-to-calculate-flops-in-model/67198/6)
flops = 0
macs = 0
- return flops, macs
\ No newline at end of file
+ return flops, macs
diff --git a/colossalai/fx/profiler/opcount.py b/colossalai/fx/profiler/opcount.py
index 407a6bed5200..ba090a2ec51b 100644
--- a/colossalai/fx/profiler/opcount.py
+++ b/colossalai/fx/profiler/opcount.py
@@ -223,7 +223,8 @@ def zero_flop_jit(*args):
return 0
-if version.parse(torch.__version__) >= version.parse('1.12.0'):
+if version.parse(torch.__version__) >= version.parse('1.12.0') and version.parse(
+ torch.__version__) < version.parse('2.0.0'):
flop_mapping = {
# gemm, gemv and dot
aten.mm.default: matmul_flop_jit,
diff --git a/colossalai/fx/proxy.py b/colossalai/fx/proxy.py
index 06272c48f852..7317072c6298 100644
--- a/colossalai/fx/proxy.py
+++ b/colossalai/fx/proxy.py
@@ -1,7 +1,9 @@
import operator
+from typing import Any, List, Union
+
import torch
-from torch.fx.proxy import Proxy, Attribute
-from typing import List, Union, Any
+from torch.fx.proxy import Attribute, Proxy
+
from colossalai.fx.tracer.meta_patch import meta_patched_function
__all__ = ['ColoProxy']
diff --git a/colossalai/fx/tracer/_tracer_utils.py b/colossalai/fx/tracer/_tracer_utils.py
index 0ec49a90a133..e160497a7444 100644
--- a/colossalai/fx/tracer/_tracer_utils.py
+++ b/colossalai/fx/tracer/_tracer_utils.py
@@ -1,6 +1,8 @@
-from typing import List, Union, Any
-from ..proxy import ColoProxy, ColoAttribute
+from typing import Any, List, Union
+
import torch
+
+from ..proxy import ColoAttribute, ColoProxy
from .meta_patch import meta_patched_function, meta_patched_module
__all__ = ['is_element_in_list', 'extract_meta']
diff --git a/colossalai/gemini/paramhooks/_param_hookmgr.py b/colossalai/gemini/paramhooks/_param_hookmgr.py
index ee57cb46a90d..84f32be358e3 100644
--- a/colossalai/gemini/paramhooks/_param_hookmgr.py
+++ b/colossalai/gemini/paramhooks/_param_hookmgr.py
@@ -1,6 +1,7 @@
+import functools
from typing import Callable, List
+
import torch
-import functools
class BaseParamHookMgr(object):
diff --git a/colossalai/gemini/tensor_placement_policy.py b/colossalai/gemini/tensor_placement_policy.py
index cfcfb385667c..0e575254c0b6 100644
--- a/colossalai/gemini/tensor_placement_policy.py
+++ b/colossalai/gemini/tensor_placement_policy.py
@@ -1,15 +1,15 @@
+import functools
from abc import ABC, abstractmethod
from time import time
-from typing import List, Optional
+from typing import List, Optional, Type
+
import torch
-from colossalai.utils import get_current_device
-from colossalai.utils.memory import colo_device_memory_capacity
-from colossalai.gemini.tensor_utils import colo_model_data_tensor_move_inline, colo_tensor_mem_usage
-from colossalai.gemini.stateful_tensor import StatefulTensor
from colossalai.gemini.memory_tracer import MemStatsCollector
-from typing import Type
-import functools
+from colossalai.gemini.stateful_tensor import StatefulTensor
+from colossalai.gemini.tensor_utils import colo_model_data_tensor_move_inline, colo_tensor_mem_usage
+from colossalai.utils import get_current_device
+from colossalai.utils.memory import colo_device_memory_capacity
class TensorPlacementPolicy(ABC):
diff --git a/colossalai/global_variables.py b/colossalai/global_variables.py
index e3575ea12ad0..61b31965e2e6 100644
--- a/colossalai/global_variables.py
+++ b/colossalai/global_variables.py
@@ -1,56 +1,56 @@
-from typing import Optional
-
-
-class TensorParallelEnv(object):
- _instance = None
-
- def __new__(cls, *args, **kwargs):
- if cls._instance is None:
- cls._instance = object.__new__(cls, *args, **kwargs)
- return cls._instance
-
- def __init__(self, *args, **kwargs):
- self.load(*args, **kwargs)
-
- def load(self,
- mode: Optional[str] = None,
- vocab_parallel: bool = False,
- parallel_input_1d: bool = False,
- summa_dim: int = None,
- tesseract_dim: int = None,
- tesseract_dep: int = None,
- depth_3d: int = None,
- input_group_3d=None,
- weight_group_3d=None,
- output_group_3d=None,
- input_x_weight_group_3d=None,
- output_x_weight_group_3d=None):
- self.mode = mode
- self.vocab_parallel = vocab_parallel
- self.parallel_input_1d = parallel_input_1d
- self.summa_dim = summa_dim
- self.tesseract_dim = tesseract_dim
- self.tesseract_dep = tesseract_dep
- self.depth_3d = depth_3d
- self.input_group_3d = input_group_3d
- self.weight_group_3d = weight_group_3d
- self.output_group_3d = output_group_3d
- self.input_x_weight_group_3d = input_x_weight_group_3d
- self.output_x_weight_group_3d = output_x_weight_group_3d
-
- def save(self):
- return dict(mode=self.mode,
- vocab_parallel=self.vocab_parallel,
- parallel_input_1d=self.parallel_input_1d,
- summa_dim=self.summa_dim,
- tesseract_dim=self.tesseract_dim,
- tesseract_dep=self.tesseract_dep,
- depth_3d=self.depth_3d,
- input_group_3d=self.input_group_3d,
- weight_group_3d=self.weight_group_3d,
- output_group_3d=self.output_group_3d,
- input_x_weight_group_3d=self.input_x_weight_group_3d,
- output_x_weight_group_3d=self.output_x_weight_group_3d)
-
-
-tensor_parallel_env = TensorParallelEnv()
+from typing import Optional
+
+
+class TensorParallelEnv(object):
+ _instance = None
+
+ def __new__(cls, *args, **kwargs):
+ if cls._instance is None:
+ cls._instance = object.__new__(cls, *args, **kwargs)
+ return cls._instance
+
+ def __init__(self, *args, **kwargs):
+ self.load(*args, **kwargs)
+
+ def load(self,
+ mode: Optional[str] = None,
+ vocab_parallel: bool = False,
+ parallel_input_1d: bool = False,
+ summa_dim: int = None,
+ tesseract_dim: int = None,
+ tesseract_dep: int = None,
+ depth_3d: int = None,
+ input_group_3d=None,
+ weight_group_3d=None,
+ output_group_3d=None,
+ input_x_weight_group_3d=None,
+ output_x_weight_group_3d=None):
+ self.mode = mode
+ self.vocab_parallel = vocab_parallel
+ self.parallel_input_1d = parallel_input_1d
+ self.summa_dim = summa_dim
+ self.tesseract_dim = tesseract_dim
+ self.tesseract_dep = tesseract_dep
+ self.depth_3d = depth_3d
+ self.input_group_3d = input_group_3d
+ self.weight_group_3d = weight_group_3d
+ self.output_group_3d = output_group_3d
+ self.input_x_weight_group_3d = input_x_weight_group_3d
+ self.output_x_weight_group_3d = output_x_weight_group_3d
+
+ def save(self):
+ return dict(mode=self.mode,
+ vocab_parallel=self.vocab_parallel,
+ parallel_input_1d=self.parallel_input_1d,
+ summa_dim=self.summa_dim,
+ tesseract_dim=self.tesseract_dim,
+ tesseract_dep=self.tesseract_dep,
+ depth_3d=self.depth_3d,
+ input_group_3d=self.input_group_3d,
+ weight_group_3d=self.weight_group_3d,
+ output_group_3d=self.output_group_3d,
+ input_x_weight_group_3d=self.input_x_weight_group_3d,
+ output_x_weight_group_3d=self.output_x_weight_group_3d)
+
+
+tensor_parallel_env = TensorParallelEnv()
diff --git a/colossalai/nn/_ops/_utils.py b/colossalai/nn/_ops/_utils.py
index 56bb5f465184..24877bbb552f 100644
--- a/colossalai/nn/_ops/_utils.py
+++ b/colossalai/nn/_ops/_utils.py
@@ -1,12 +1,11 @@
-import torch
-from typing import Union, Optional, List
-from colossalai.tensor import ColoTensor
+from typing import List, Optional, Union
+
import torch
import torch.distributed as dist
-from colossalai.global_variables import tensor_parallel_env as env
+from colossalai.global_variables import tensor_parallel_env as env
from colossalai.nn.layer.utils import divide
-from colossalai.tensor import ProcessGroup, ColoTensorSpec
+from colossalai.tensor import ColoTensor, ColoTensorSpec, ProcessGroup
GeneralTensor = Union[ColoTensor, torch.Tensor]
Number = Union[int, float]
@@ -135,7 +134,7 @@ def backward(ctx, grad_output):
class _SplitForwardGatherBackward(torch.autograd.Function):
"""
Split the input and keep only the corresponding chuck to the rank.
-
+
Args:
input_: input matrix.
process_group: parallel mode.
diff --git a/colossalai/nn/_ops/addmm.py b/colossalai/nn/_ops/addmm.py
index fe2eb0c999a1..660b48a71d57 100644
--- a/colossalai/nn/_ops/addmm.py
+++ b/colossalai/nn/_ops/addmm.py
@@ -1,9 +1,9 @@
import torch
+
+from colossalai.tensor import ColoTensor, ColoTensorSpec, ComputePattern, ComputeSpec, ReplicaSpec, ShardSpec, distspec
from colossalai.tensor.op_wrapper import colo_op_impl
-from colossalai.tensor import ComputePattern, ComputePattern, ComputeSpec, ColoTensor
-from colossalai.tensor import distspec, ColoTensorSpec, ShardSpec, ReplicaSpec
-from ._utils import GeneralTensor, Number, convert_to_colo_tensor
-from ._utils import reduce_input, reduce_grad
+
+from ._utils import GeneralTensor, Number, convert_to_colo_tensor, reduce_grad, reduce_input
def colo_addmm_1Drow(input_tensor: ColoTensor, mat1: ColoTensor, mat2: ColoTensor, beta: Number,
@@ -69,9 +69,13 @@ def colo_addmm(input_tensor: GeneralTensor,
if not mat2.has_compute_spec(): # No Model Parallel Applied
assert mat2.is_replicate(), 'Invalid mat2 spec for native addmm op'
assert input_tensor.is_replicate(), 'Invalid input spec for native addmm op'
- ret_tensor = ColoTensor.from_torch_tensor(
- tensor=torch.addmm(input_tensor, mat1, mat2, beta=beta, alpha=alpha, **kargs),
- spec=ColoTensorSpec(mat2.get_process_group()))
+ ret_tensor = ColoTensor.from_torch_tensor(tensor=torch.addmm(input_tensor,
+ mat1,
+ mat2,
+ beta=beta,
+ alpha=alpha,
+ **kargs),
+ spec=ColoTensorSpec(mat2.get_process_group()))
elif mat2.has_compute_pattern(ComputePattern.TP1D): # Single Model Parallel Applied
if mat2.is_shard_1drow() and input_tensor.is_replicate():
mode = 'row'
diff --git a/colossalai/nn/layer/moe/__init__.py b/colossalai/nn/layer/moe/__init__.py
index 2a51344c31a4..05333fe965f1 100644
--- a/colossalai/nn/layer/moe/__init__.py
+++ b/colossalai/nn/layer/moe/__init__.py
@@ -1,9 +1,10 @@
-from .experts import Experts, FFNExperts, TPExperts
-from .layers import MoeLayer, MoeModule
-from .routers import MoeRouter, Top1Router, Top2Router
-from .utils import NormalNoiseGenerator, UniformNoiseGenerator, build_ffn_experts
-
-__all__ = [
- 'Experts', 'FFNExperts', 'TPExperts', 'Top1Router', 'Top2Router', 'MoeLayer', 'NormalNoiseGenerator',
- 'UniformNoiseGenerator', 'build_ffn_experts', 'MoeModule', 'MoeRouter'
-]
+from .checkpoint import load_moe_model, save_moe_model
+from .experts import Experts, FFNExperts, TPExperts
+from .layers import MoeLayer, MoeModule
+from .routers import MoeRouter, Top1Router, Top2Router
+from .utils import NormalNoiseGenerator, UniformNoiseGenerator, build_ffn_experts
+
+__all__ = [
+ 'Experts', 'FFNExperts', 'TPExperts', 'Top1Router', 'Top2Router', 'MoeLayer', 'NormalNoiseGenerator',
+ 'UniformNoiseGenerator', 'build_ffn_experts', 'MoeModule', 'MoeRouter', 'save_moe_model', 'load_moe_model'
+]
diff --git a/colossalai/nn/layer/moe/checkpoint.py b/colossalai/nn/layer/moe/checkpoint.py
new file mode 100644
index 000000000000..efda1f22252d
--- /dev/null
+++ b/colossalai/nn/layer/moe/checkpoint.py
@@ -0,0 +1,40 @@
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+
+from .experts import MoeExperts
+
+
+def save_moe_model(model: nn.Module, save_path: str):
+ state_dict = model.state_dict()
+ if dist.get_rank() == 0:
+ torch.save(state_dict, save_path)
+ dist.barrier()
+
+
+def load_moe_model(model: nn.Module, load_path: str):
+ state_dict = torch.load(load_path)
+
+ for prefix, module in model.named_modules():
+ if prefix.endswith('.moe_layer.experts'):
+ # this module should be an Experts instance
+ assert isinstance(module, MoeExperts)
+
+ ep_rank = dist.get_rank(module.dist_info.ep_group)
+ num_local = module.num_local_experts
+ for i in range(num_local):
+ expert_id = ep_rank * num_local + i
+ for name, _ in module.experts[i].named_parameters():
+ cur_key = f'{prefix}.experts.{i}.{name}'
+ param_key = f'{prefix}.experts.{expert_id}.{name}'
+ load_param = state_dict[param_key]
+ state_dict[cur_key] = load_param
+
+ for name, _ in module.experts[0].named_parameters():
+ pop_pre = f'{prefix}.experts.'
+ pop_suf = f'.{name}'
+ for i in range(num_local, module.num_total_experts):
+ pop_key = f'{pop_pre}{i}{pop_suf}'
+ state_dict.pop(pop_key)
+
+ model.load_state_dict(state_dict)
diff --git a/colossalai/nn/layer/moe/experts.py b/colossalai/nn/layer/moe/experts.py
index 055afded9a20..4fb9ad332c24 100644
--- a/colossalai/nn/layer/moe/experts.py
+++ b/colossalai/nn/layer/moe/experts.py
@@ -1,172 +1,203 @@
-import math
-
-import torch
-import torch.nn as nn
-from colossalai.context import ParallelMode, seed
-from colossalai.utils import get_current_device
-from colossalai.context.moe_context import MOE_CONTEXT
-from colossalai.zero.init_ctx import no_shard_zero_decrator
-from typing import Type
-
-
-class MoeExperts(nn.Module):
- """Basic class for experts in MoE. It stores what kind of communication expersts use
- to exchange tokens, how many experts in a single GPU and parallel information such as
- expert parallel size, data parallel size and their distributed communication groups.
- """
-
- def __init__(self, comm_name: str, num_experts: int):
- super().__init__()
- assert comm_name in {"all_to_all", "all_gather"}, \
- "This kind of communication has not been implemented yet.\n Please use Experts build function."
- self.comm_name = comm_name
- # Get the configuration of experts' deployment and parallel information from moe contex
- self.num_local_experts, self.dist_info = MOE_CONTEXT.get_info(num_experts)
-
-
-@no_shard_zero_decrator(is_replicated=False)
-class Experts(MoeExperts):
- """A wrapper class to create experts. It will create E experts across the
- moe model parallel group, where E is the number of experts. Every expert
- is a instence of the class, 'expert' in initialization parameters.
-
- Args:
- expert_cls (:class:`torch.nn.Module`): The class of all experts
- num_experts (int): The number of experts
- expert_args: Args used to initialize experts, the args could be found in corresponding expert class
- """
-
- def __init__(self, expert_cls: Type[nn.Module], num_experts: int, **expert_args):
- super().__init__("all_to_all", num_experts)
-
- # Use seed to make every expert different from others
- with seed(ParallelMode.TENSOR):
- self.experts = nn.ModuleList([expert_cls(**expert_args) for _ in range(self.num_local_experts)])
-
- # Attach parallel information for all parameters in Experts
- for exp in self.experts:
- for param in exp.parameters():
- param.__setattr__('moe_info', self.dist_info)
-
- def forward(self, inputs: torch.Tensor):
- # Split inputs for each expert
- expert_input = torch.chunk(inputs, self.num_local_experts, dim=1)
- expert_output = []
-
- # Get outputs from each expert
- for i in range(self.num_local_experts):
- expert_output.append(self.experts[i](expert_input[i]))
-
- # Concatenate all outputs together
- output = torch.cat(expert_output, dim=1).contiguous()
- return output
-
-
-class FFNExperts(MoeExperts):
- """Use torch.bmm to speed up for multiple experts.
- """
-
- def __init__(self, num_experts: int, d_model: int, d_ff: int, activation=None, drop_rate: float = 0):
- super().__init__("all_to_all", num_experts)
-
- self.w1 = nn.Parameter(torch.empty(self.num_local_experts, d_model, d_ff, device=get_current_device()))
- self.b1 = nn.Parameter(torch.empty(self.num_local_experts, 1, d_ff, device=get_current_device()))
-
- self.w2 = nn.Parameter(torch.empty(self.num_local_experts, d_ff, d_model, device=get_current_device()))
- self.b2 = nn.Parameter(torch.empty(self.num_local_experts, 1, d_model, device=get_current_device()))
-
- s1 = math.sqrt(0.1 / d_model)
- s2 = math.sqrt(0.1 / d_ff)
-
- with seed(ParallelMode.TENSOR):
- nn.init.trunc_normal_(self.w1, std=s1)
- nn.init.trunc_normal_(self.b1, std=s1)
- nn.init.trunc_normal_(self.w2, std=s2)
- nn.init.trunc_normal_(self.b2, std=s2)
-
- self.act = nn.GELU() if activation is None else activation
- self.drop = nn.Dropout(p=drop_rate)
-
- for param in self.parameters():
- param.__setattr__('moe_info', self.dist_info)
-
- def forward(self, inputs): # inputs [g, el, c, h]
-
- el = inputs.size(1)
- h = inputs.size(-1)
-
- inputs = inputs.transpose(0, 1)
- inshape = inputs.shape
- inputs = inputs.reshape(el, -1, h)
-
- out_ff = torch.baddbmm(self.b1, inputs, self.w1)
- out_act = self.act(out_ff)
- with seed(ParallelMode.TENSOR):
- out_inter = self.drop(out_act)
-
- out_model = torch.baddbmm(self.b2, out_inter, self.w2)
- with seed(ParallelMode.TENSOR):
- outputs = self.drop(out_model) # outputs [el, gc, h]
-
- outputs = outputs.reshape(inshape)
- outputs = outputs.transpose(0, 1).contiguous()
- return outputs
-
-
-class TPExperts(MoeExperts):
- """Use tensor parallelism to split each expert evenly, which can deploy experts in
- case that the number of experts can't be divied by maximum expert parallel size or
- maximum expert parallel size can't be divied by the number of experts.
- """
-
- def __init__(self, num_experts: int, d_model: int, d_ff: int, activation=None, drop_rate: float = 0):
- super().__init__("all_gather", MOE_CONTEXT.max_ep_size)
-
- assert d_ff % MOE_CONTEXT.max_ep_size == 0, \
- "d_ff should be divied by maximum expert parallel size"
-
- p_ff = d_ff // MOE_CONTEXT.max_ep_size
-
- self.w1 = nn.Parameter(torch.empty(num_experts, d_model, p_ff, device=get_current_device()))
- self.b1 = nn.Parameter(torch.empty(num_experts, 1, p_ff, device=get_current_device()))
-
- self.w2 = nn.Parameter(torch.empty(num_experts, p_ff, d_model, device=get_current_device()))
- self.b2 = nn.Parameter(torch.empty(num_experts, 1, d_model, device=get_current_device()))
-
- s1 = math.sqrt(0.1 / d_model)
- s2 = math.sqrt(0.1 / d_ff)
-
- with seed(ParallelMode.TENSOR):
- nn.init.trunc_normal_(self.w1, std=s1)
- nn.init.trunc_normal_(self.b1, std=s1)
- nn.init.trunc_normal_(self.w2, std=s2)
-
- nn.init.trunc_normal_(self.b2, std=s2)
-
- self.act = nn.GELU() if activation is None else activation
- self.drop = nn.Dropout(p=drop_rate)
-
- self.w1.__setattr__('moe_info', self.dist_info)
- self.w2.__setattr__('moe_info', self.dist_info)
- self.b1.__setattr__('moe_info', self.dist_info)
-
- def forward(self, inputs): # inputs [g, e, c, h]
-
- e = inputs.size(1)
- h = inputs.size(-1)
-
- inputs = inputs.transpose(0, 1)
- inshape = inputs.shape
- inputs = inputs.reshape(e, -1, h)
-
- out_ff = torch.baddbmm(self.b1, inputs, self.w1)
- out_act = self.act(out_ff)
- with seed(ParallelMode.TENSOR):
- out_inter = self.drop(out_act)
-
- out_model = torch.baddbmm(self.b2, out_inter, self.w2)
- outputs = self.drop(out_model) # outputs [e, gc, h]
-
- outputs = outputs.reshape(inshape)
- outputs = outputs.transpose(0, 1).contiguous()
- return outputs # outputs [g, e, c, h]
+import math
+from copy import deepcopy
+from typing import Type
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+
+from colossalai.context import ParallelMode, seed
+from colossalai.context.moe_context import MOE_CONTEXT
+from colossalai.utils import get_current_device
+from colossalai.zero.init_ctx import no_shard_zero_decrator
+
+
+class MoeExperts(nn.Module):
+ """Basic class for experts in MoE. It stores what kind of communication expersts use
+ to exchange tokens, how many experts in a single GPU and parallel information such as
+ expert parallel size, data parallel size and their distributed communication groups.
+ """
+
+ def __init__(self, comm_name: str, num_experts: int):
+ super().__init__()
+ assert comm_name in {"all_to_all", "all_gather"}, \
+ "This kind of communication has not been implemented yet.\n Please use Experts build function."
+ self.comm_name = comm_name
+ self.num_total_experts = num_experts
+ # Get the configuration of experts' deployment and parallel information from moe contex
+ self.num_local_experts, self.dist_info = MOE_CONTEXT.get_info(num_experts)
+
+
+@no_shard_zero_decrator(is_replicated=False)
+class Experts(MoeExperts):
+ """A wrapper class to create experts. It will create E experts across the
+ moe model parallel group, where E is the number of experts. Every expert
+ is a instence of the class, 'expert' in initialization parameters.
+
+ Args:
+ expert_cls (:class:`torch.nn.Module`): The class of all experts
+ num_experts (int): The number of experts
+ expert_args: Args used to initialize experts, the args could be found in corresponding expert class
+ """
+
+ def __init__(self, expert_cls: Type[nn.Module], num_experts: int, **expert_args):
+ super().__init__("all_to_all", num_experts)
+
+ # Use seed to make every expert different from others
+ with seed(ParallelMode.TENSOR):
+ self.experts = nn.ModuleList([expert_cls(**expert_args) for _ in range(self.num_local_experts)])
+
+ # Attach parallel information for all parameters in Experts
+ for exp in self.experts:
+ for param in exp.parameters():
+ param.__setattr__('moe_info', self.dist_info)
+
+ def forward(self, inputs: torch.Tensor):
+ # Split inputs for each expert
+ expert_input = torch.chunk(inputs, self.num_local_experts, dim=1)
+ expert_output = []
+
+ # Get outputs from each expert
+ for i in range(self.num_local_experts):
+ expert_output.append(self.experts[i](expert_input[i]))
+
+ # Concatenate all outputs together
+ output = torch.cat(expert_output, dim=1).contiguous()
+ return output
+
+ def state_dict(self, destination=None, prefix='', keep_vars=False):
+ assert keep_vars == False, "Only support keep_vars=False now"
+ dp_rank = dist.get_rank(self.dist_info.dp_group)
+ ep_rank = dist.get_rank(self.dist_info.ep_group)
+ submodule_dict = dict()
+ example_submodule = None
+ for name, subm in self.experts.named_modules():
+ if subm is self.experts:
+ continue
+ module_number = self.num_local_experts * ep_rank + int(name)
+ submodule_dict[module_number] = subm
+ example_submodule = subm
+
+ if dp_rank == 0:
+ local_prefix = prefix + 'experts.'
+ buffer_module = deepcopy(example_submodule)
+ for i in range(self.num_total_experts):
+ source_rank = i // self.num_local_experts
+ current_prefix = local_prefix + str(i) + '.'
+ comm_module = submodule_dict.get(i, buffer_module)
+ for name, param in comm_module.named_parameters():
+ dist.broadcast(param.data, src=source_rank, group=self.dist_info.ep_group)
+ if ep_rank == 0:
+ destination[current_prefix + name] = param.data.cpu()
+
+ dist.barrier()
+
+
+class FFNExperts(MoeExperts):
+ """Use torch.bmm to speed up for multiple experts.
+ """
+
+ def __init__(self, num_experts: int, d_model: int, d_ff: int, activation=None, drop_rate: float = 0):
+ super().__init__("all_to_all", num_experts)
+
+ self.w1 = nn.Parameter(torch.empty(self.num_local_experts, d_model, d_ff, device=get_current_device()))
+ self.b1 = nn.Parameter(torch.empty(self.num_local_experts, 1, d_ff, device=get_current_device()))
+
+ self.w2 = nn.Parameter(torch.empty(self.num_local_experts, d_ff, d_model, device=get_current_device()))
+ self.b2 = nn.Parameter(torch.empty(self.num_local_experts, 1, d_model, device=get_current_device()))
+
+ s1 = math.sqrt(0.1 / d_model)
+ s2 = math.sqrt(0.1 / d_ff)
+
+ with seed(ParallelMode.TENSOR):
+ nn.init.trunc_normal_(self.w1, std=s1)
+ nn.init.trunc_normal_(self.b1, std=s1)
+ nn.init.trunc_normal_(self.w2, std=s2)
+ nn.init.trunc_normal_(self.b2, std=s2)
+
+ self.act = nn.GELU() if activation is None else activation
+ self.drop = nn.Dropout(p=drop_rate)
+
+ for param in self.parameters():
+ param.__setattr__('moe_info', self.dist_info)
+
+ def forward(self, inputs): # inputs [g, el, c, h]
+
+ el = inputs.size(1)
+ h = inputs.size(-1)
+
+ inputs = inputs.transpose(0, 1)
+ inshape = inputs.shape
+ inputs = inputs.reshape(el, -1, h)
+
+ out_ff = torch.baddbmm(self.b1, inputs, self.w1)
+ out_act = self.act(out_ff)
+ with seed(ParallelMode.TENSOR):
+ out_inter = self.drop(out_act)
+
+ out_model = torch.baddbmm(self.b2, out_inter, self.w2)
+ with seed(ParallelMode.TENSOR):
+ outputs = self.drop(out_model) # outputs [el, gc, h]
+
+ outputs = outputs.reshape(inshape)
+ outputs = outputs.transpose(0, 1).contiguous()
+ return outputs
+
+
+class TPExperts(MoeExperts):
+ """Use tensor parallelism to split each expert evenly, which can deploy experts in
+ case that the number of experts can't be divied by maximum expert parallel size or
+ maximum expert parallel size can't be divied by the number of experts.
+ """
+
+ def __init__(self, num_experts: int, d_model: int, d_ff: int, activation=None, drop_rate: float = 0):
+ super().__init__("all_gather", MOE_CONTEXT.max_ep_size)
+
+ assert d_ff % MOE_CONTEXT.max_ep_size == 0, \
+ "d_ff should be divied by maximum expert parallel size"
+
+ p_ff = d_ff // MOE_CONTEXT.max_ep_size
+
+ self.w1 = nn.Parameter(torch.empty(num_experts, d_model, p_ff, device=get_current_device()))
+ self.b1 = nn.Parameter(torch.empty(num_experts, 1, p_ff, device=get_current_device()))
+
+ self.w2 = nn.Parameter(torch.empty(num_experts, p_ff, d_model, device=get_current_device()))
+ self.b2 = nn.Parameter(torch.empty(num_experts, 1, d_model, device=get_current_device()))
+
+ s1 = math.sqrt(0.1 / d_model)
+ s2 = math.sqrt(0.1 / d_ff)
+
+ with seed(ParallelMode.TENSOR):
+ nn.init.trunc_normal_(self.w1, std=s1)
+ nn.init.trunc_normal_(self.b1, std=s1)
+ nn.init.trunc_normal_(self.w2, std=s2)
+
+ nn.init.trunc_normal_(self.b2, std=s2)
+
+ self.act = nn.GELU() if activation is None else activation
+ self.drop = nn.Dropout(p=drop_rate)
+
+ self.w1.__setattr__('moe_info', self.dist_info)
+ self.w2.__setattr__('moe_info', self.dist_info)
+ self.b1.__setattr__('moe_info', self.dist_info)
+
+ def forward(self, inputs): # inputs [g, e, c, h]
+
+ e = inputs.size(1)
+ h = inputs.size(-1)
+
+ inputs = inputs.transpose(0, 1)
+ inshape = inputs.shape
+ inputs = inputs.reshape(e, -1, h)
+
+ out_ff = torch.baddbmm(self.b1, inputs, self.w1)
+ out_act = self.act(out_ff)
+ with seed(ParallelMode.TENSOR):
+ out_inter = self.drop(out_act)
+
+ out_model = torch.baddbmm(self.b2, out_inter, self.w2)
+ outputs = self.drop(out_model) # outputs [e, gc, h]
+
+ outputs = outputs.reshape(inshape)
+ outputs = outputs.transpose(0, 1).contiguous()
+ return outputs # outputs [g, e, c, h]
diff --git a/colossalai/nn/layer/moe/layers.py b/colossalai/nn/layer/moe/layers.py
index 259f53f1adf5..0969eb818229 100644
--- a/colossalai/nn/layer/moe/layers.py
+++ b/colossalai/nn/layer/moe/layers.py
@@ -1,203 +1,210 @@
-import math
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from colossalai.context.moe_context import MOE_CONTEXT
-from colossalai.utils import get_current_device
-from colossalai.nn.layer.moe._operation import COL_MOE_KERNEL_FLAG, AllToAll, AllGather, \
- ReduceScatter, MoeDispatch, MoeCombine
-from colossalai.nn.layer.moe.experts import MoeExperts, Experts
-from colossalai.nn.layer.moe.utils import UniformNoiseGenerator, NormalNoiseGenerator
-from colossalai.nn.layer.moe.routers import MoeRouter, Top1Router, Top2Router
-from colossalai.zero.init_ctx import no_shard_zero_context, no_shard_zero_decrator
-from typing import Optional, Type, Tuple
-
-
-@no_shard_zero_decrator(is_replicated=True)
-class MoeLayer(nn.Module):
- """A MoE layer, that puts its input tensor to its gate and uses the output logits
- to router all tokens, is mainly used to exchange all tokens for every expert across
- the moe tensor group by all to all comunication. Then it will get the output of all
- experts and exchange the output. At last returns the output of the moe system.
-
- Args:
- dim_model (int): Dimension of model.
- num_experts (int): The number of experts.
- router (MoeRouter): Instance of router used in routing.
- experts (MoeExperts): Instance of experts generated by Expert.
- """
-
- def __init__(self, dim_model: int, num_experts: int, router: MoeRouter, experts: MoeExperts):
- super().__init__()
- self.d_model = dim_model
- self.num_experts = num_experts
- self.gate_weight = torch.nn.Parameter(torch.empty(num_experts, dim_model))
- self.router: MoeRouter = router
- self.experts: MoeExperts = experts
- self.use_kernel = True if COL_MOE_KERNEL_FLAG and MOE_CONTEXT.use_kernel_optim else False
- self.ep_group = experts.dist_info.ep_group
- self.ep_size = experts.dist_info.ep_size
- self.num_local_experts = experts.num_local_experts
-
- nn.init.trunc_normal_(self.gate_weight, std=math.sqrt(0.1 / dim_model))
-
- def a2a_process(self, dispatch_data: torch.Tensor):
- expert_input = AllToAll.apply(dispatch_data, self.ep_group)
- input_shape = expert_input.shape
- expert_input = expert_input.reshape(self.ep_size, self.num_local_experts, -1, self.d_model)
- expert_output = self.experts(expert_input)
- expert_output = expert_output.reshape(input_shape)
- expert_output = AllToAll.apply(expert_output, self.ep_group)
- return expert_output
-
- def tp_process(self, dispatch_data: torch.Tensor):
- expert_in = AllGather.apply(dispatch_data, self.ep_group)
- expert_out = self.experts(expert_in)
- expert_out = ReduceScatter.apply(expert_out, self.ep_group)
- return expert_out
-
- def forward(self, inputs: torch.Tensor) -> Tuple:
- # reshape the input tokens
- tokens = inputs.reshape(-1, self.d_model)
-
- # the data type of the inputs in the gating should be fp32
- fp32_input = tokens.to(torch.float)
- fp32_weight = self.gate_weight.to(torch.float)
- gate_output = F.linear(fp32_input, fp32_weight)
-
- # the result from the router
- route_result_list = self.router(inputs=gate_output, use_kernel=self.use_kernel, ep_group=self.ep_group)
-
- if self.use_kernel:
- dispatch_data = MoeDispatch.apply(tokens, *route_result_list[1:])
- dispatch_data = dispatch_data.reshape(self.num_experts, -1, self.d_model)
- else:
- sec_mask_f = route_result_list[1].type_as(inputs)
- dispatch_data = torch.matmul(sec_mask_f.permute(1, 2, 0), tokens)
-
- # dispatch_data [e, c, h]
- if self.experts.comm_name == "all_to_all":
- expert_output = self.a2a_process(dispatch_data)
- elif self.experts.comm_name == "all_gather":
- expert_output = self.tp_process(dispatch_data)
- else:
- raise NotImplementedError("This kind of communication has not been implemented yet.\n Please use Experts "
- "build function.")
- # expert_output [e, c, h]
- if self.use_kernel:
- expert_output = expert_output.reshape(-1, self.d_model)
- ans = MoeCombine.apply(expert_output, *route_result_list)
- else:
- combine_weights = route_result_list[0].type_as(inputs)
- combine_weights = combine_weights.view(combine_weights.shape[0], -1)
- expert_output = expert_output.view(-1, expert_output.shape[-1])
- ans = torch.matmul(combine_weights, expert_output)
-
- ans = ans.reshape(inputs.shape)
- l_aux = self.router.pop_routing_loss()
- return ans, l_aux
-
-
-class MoeModule(nn.Module):
- """A class for users to create MoE modules in their models.
-
- Args:
- dim_model (int): Hidden dimension of training model
- num_experts (int): The number experts
- top_k (int, optional): The number of experts for dispatchment of each token
- capacity_factor_train (float, optional): Capacity factor in routing during training
- capacity_factor_eval (float, optional): Capacity factor in routing during evaluation
- min_capacity (int, optional): The minimum number of the capacity of each expert
- noisy_policy (str, optional): The policy of noisy function. Now we have 'Jitter' and 'Gaussian'.
- 'Jitter' can be found in `Switch Transformer paper`_.
- 'Gaussian' can be found in `ViT-MoE paper`_.
- drop_tks (bool, optional): Whether drops tokens in evaluation
- use_residual (bool, optional): Makes this MoE layer a Residual MoE.
- More information can be found in `Microsoft paper`_.
- residual_instance (nn.Module, optional): The instance of residual module in Resiual MoE
- expert_instance (MoeExperts, optional): The instance of experts module in MoeLayer
- expert_cls (Type[nn.Module], optional): The class of each expert when no instance is given
- expert_args (optional): The args of expert when no instance is given
-
- .. _Switch Transformer paper:
- https://arxiv.org/abs/2101.03961
- .. _ViT-MoE paper:
- https://arxiv.org/abs/2106.05974
- .. _Microsoft paper:
- https://arxiv.org/abs/2201.05596
- """
-
- def __init__(self,
- dim_model: int,
- num_experts: int,
- top_k: int = 1,
- capacity_factor_train: float = 1.25,
- capacity_factor_eval: float = 2.0,
- min_capacity: int = 4,
- noisy_policy: Optional[str] = None,
- drop_tks: bool = True,
- use_residual: bool = False,
- residual_instance: Optional[nn.Module] = None,
- expert_instance: Optional[MoeExperts] = None,
- expert_cls: Optional[Type[nn.Module]] = None,
- **expert_args):
- super().__init__()
-
- noisy_func = None
- if noisy_policy is not None:
- if noisy_policy == 'Jitter':
- noisy_func = UniformNoiseGenerator()
- elif noisy_policy == 'Gaussian':
- noisy_func = NormalNoiseGenerator(num_experts)
- else:
- raise NotImplementedError("Unsupported input noisy policy")
-
- if top_k == 1:
- moe_router_cls = Top1Router
- elif top_k == 2:
- moe_router_cls = Top2Router
- else:
- raise NotImplementedError("top_k > 2 is not supported yet")
-
- self.moe_router = moe_router_cls(capacity_factor_train=capacity_factor_train,
- capacity_factor_eval=capacity_factor_eval,
- min_capacity=min_capacity,
- noisy_func=noisy_func,
- drop_tks=drop_tks)
- self.use_residual = use_residual
- if use_residual:
- if residual_instance is not None:
- self.residual_module = residual_instance
- else:
- assert expert_cls is not None, \
- "Expert class can't be None when residual instance is not given"
- self.residual_module = expert_cls(**expert_args)
-
- with no_shard_zero_context():
- self.residual_combine = nn.Linear(dim_model, 2, device=get_current_device())
-
- if expert_instance is not None:
- self.experts = expert_instance
- else:
- assert expert_cls is not None, \
- "Expert class can't be None when experts instance is not given"
- self.experts = Experts(expert_cls, num_experts, **expert_args)
-
- self.moe_layer = MoeLayer(dim_model=dim_model,
- num_experts=num_experts,
- router=self.moe_router,
- experts=self.experts)
-
- def forward(self, inputs: torch.Tensor):
- moe_output, l_aux = self.moe_layer(inputs)
-
- if self.use_residual:
- residual_output = self.residual_module(inputs)
- combine_coef = self.residual_combine(inputs)
- combine_coef = F.softmax(combine_coef, dim=-1)
- output = moe_output * combine_coef[..., 0:1] + residual_output * combine_coef[..., 1:]
- else:
- output = moe_output
-
- return output, l_aux
+import math
+from typing import Optional, Tuple, Type
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from colossalai.context.moe_context import MOE_CONTEXT
+from colossalai.nn.layer.moe._operation import (
+ COL_MOE_KERNEL_FLAG,
+ AllGather,
+ AllToAll,
+ MoeCombine,
+ MoeDispatch,
+ ReduceScatter,
+)
+from colossalai.nn.layer.moe.experts import Experts, MoeExperts
+from colossalai.nn.layer.moe.routers import MoeRouter, Top1Router, Top2Router
+from colossalai.nn.layer.moe.utils import NormalNoiseGenerator, UniformNoiseGenerator
+from colossalai.utils import get_current_device
+from colossalai.zero.init_ctx import no_shard_zero_context, no_shard_zero_decrator
+
+
+@no_shard_zero_decrator(is_replicated=True)
+class MoeLayer(nn.Module):
+ """A MoE layer, that puts its input tensor to its gate and uses the output logits
+ to router all tokens, is mainly used to exchange all tokens for every expert across
+ the moe tensor group by all to all comunication. Then it will get the output of all
+ experts and exchange the output. At last returns the output of the moe system.
+
+ Args:
+ dim_model (int): Dimension of model.
+ num_experts (int): The number of experts.
+ router (MoeRouter): Instance of router used in routing.
+ experts (MoeExperts): Instance of experts generated by Expert.
+ """
+
+ def __init__(self, dim_model: int, num_experts: int, router: MoeRouter, experts: MoeExperts):
+ super().__init__()
+ self.d_model = dim_model
+ self.num_experts = num_experts
+ self.gate_weight = torch.nn.Parameter(torch.empty(num_experts, dim_model))
+ self.router: MoeRouter = router
+ self.experts: MoeExperts = experts
+ self.use_kernel = True if COL_MOE_KERNEL_FLAG and MOE_CONTEXT.use_kernel_optim else False
+ self.ep_group = experts.dist_info.ep_group
+ self.ep_size = experts.dist_info.ep_size
+ self.num_local_experts = experts.num_local_experts
+
+ nn.init.trunc_normal_(self.gate_weight, std=math.sqrt(0.1 / dim_model))
+
+ def a2a_process(self, dispatch_data: torch.Tensor):
+ expert_input = AllToAll.apply(dispatch_data, self.ep_group)
+ input_shape = expert_input.shape
+ expert_input = expert_input.reshape(self.ep_size, self.num_local_experts, -1, self.d_model)
+ expert_output = self.experts(expert_input)
+ expert_output = expert_output.reshape(input_shape)
+ expert_output = AllToAll.apply(expert_output, self.ep_group)
+ return expert_output
+
+ def tp_process(self, dispatch_data: torch.Tensor):
+ expert_in = AllGather.apply(dispatch_data, self.ep_group)
+ expert_out = self.experts(expert_in)
+ expert_out = ReduceScatter.apply(expert_out, self.ep_group)
+ return expert_out
+
+ def forward(self, inputs: torch.Tensor) -> Tuple:
+ # reshape the input tokens
+ tokens = inputs.reshape(-1, self.d_model)
+
+ # the data type of the inputs in the gating should be fp32
+ fp32_input = tokens.to(torch.float)
+ fp32_weight = self.gate_weight.to(torch.float)
+ gate_output = F.linear(fp32_input, fp32_weight)
+
+ # the result from the router
+ route_result_list = self.router(inputs=gate_output, use_kernel=self.use_kernel, ep_group=self.ep_group)
+
+ if self.use_kernel:
+ dispatch_data = MoeDispatch.apply(tokens, *route_result_list[1:])
+ dispatch_data = dispatch_data.reshape(self.num_experts, -1, self.d_model)
+ else:
+ sec_mask_f = route_result_list[1].type_as(inputs)
+ dispatch_data = torch.matmul(sec_mask_f.permute(1, 2, 0), tokens)
+
+ # dispatch_data [e, c, h]
+ if self.experts.comm_name == "all_to_all":
+ expert_output = self.a2a_process(dispatch_data)
+ elif self.experts.comm_name == "all_gather":
+ expert_output = self.tp_process(dispatch_data)
+ else:
+ raise NotImplementedError("This kind of communication has not been implemented yet.\n Please use Experts "
+ "build function.")
+ # expert_output [e, c, h]
+ if self.use_kernel:
+ expert_output = expert_output.reshape(-1, self.d_model)
+ ans = MoeCombine.apply(expert_output, *route_result_list)
+ else:
+ combine_weights = route_result_list[0].type_as(inputs)
+ combine_weights = combine_weights.view(combine_weights.shape[0], -1)
+ expert_output = expert_output.view(-1, expert_output.shape[-1])
+ ans = torch.matmul(combine_weights, expert_output)
+
+ ans = ans.reshape(inputs.shape)
+ l_aux = self.router.pop_routing_loss()
+ return ans, l_aux
+
+
+class MoeModule(nn.Module):
+ """A class for users to create MoE modules in their models.
+
+ Args:
+ dim_model (int): Hidden dimension of training model
+ num_experts (int): The number experts
+ top_k (int, optional): The number of experts for dispatchment of each token
+ capacity_factor_train (float, optional): Capacity factor in routing during training
+ capacity_factor_eval (float, optional): Capacity factor in routing during evaluation
+ min_capacity (int, optional): The minimum number of the capacity of each expert
+ noisy_policy (str, optional): The policy of noisy function. Now we have 'Jitter' and 'Gaussian'.
+ 'Jitter' can be found in `Switch Transformer paper`_.
+ 'Gaussian' can be found in `ViT-MoE paper`_.
+ drop_tks (bool, optional): Whether drops tokens in evaluation
+ use_residual (bool, optional): Makes this MoE layer a Residual MoE.
+ More information can be found in `Microsoft paper`_.
+ residual_instance (nn.Module, optional): The instance of residual module in Resiual MoE
+ expert_instance (MoeExperts, optional): The instance of experts module in MoeLayer
+ expert_cls (Type[nn.Module], optional): The class of each expert when no instance is given
+ expert_args (optional): The args of expert when no instance is given
+
+ .. _Switch Transformer paper:
+ https://arxiv.org/abs/2101.03961
+ .. _ViT-MoE paper:
+ https://arxiv.org/abs/2106.05974
+ .. _Microsoft paper:
+ https://arxiv.org/abs/2201.05596
+ """
+
+ def __init__(self,
+ dim_model: int,
+ num_experts: int,
+ top_k: int = 1,
+ capacity_factor_train: float = 1.25,
+ capacity_factor_eval: float = 2.0,
+ min_capacity: int = 4,
+ noisy_policy: Optional[str] = None,
+ drop_tks: bool = True,
+ use_residual: bool = False,
+ residual_instance: Optional[nn.Module] = None,
+ expert_instance: Optional[MoeExperts] = None,
+ expert_cls: Optional[Type[nn.Module]] = None,
+ **expert_args):
+ super().__init__()
+
+ noisy_func = None
+ if noisy_policy is not None:
+ if noisy_policy == 'Jitter':
+ noisy_func = UniformNoiseGenerator()
+ elif noisy_policy == 'Gaussian':
+ noisy_func = NormalNoiseGenerator(num_experts)
+ else:
+ raise NotImplementedError("Unsupported input noisy policy")
+
+ if top_k == 1:
+ moe_router_cls = Top1Router
+ elif top_k == 2:
+ moe_router_cls = Top2Router
+ else:
+ raise NotImplementedError("top_k > 2 is not supported yet")
+
+ self.moe_router = moe_router_cls(capacity_factor_train=capacity_factor_train,
+ capacity_factor_eval=capacity_factor_eval,
+ min_capacity=min_capacity,
+ noisy_func=noisy_func,
+ drop_tks=drop_tks)
+ self.use_residual = use_residual
+ if use_residual:
+ if residual_instance is not None:
+ self.residual_module = residual_instance
+ else:
+ assert expert_cls is not None, \
+ "Expert class can't be None when residual instance is not given"
+ self.residual_module = expert_cls(**expert_args)
+
+ with no_shard_zero_context():
+ self.residual_combine = nn.Linear(dim_model, 2, device=get_current_device())
+
+ if expert_instance is not None:
+ my_experts = expert_instance
+ else:
+ assert expert_cls is not None, \
+ "Expert class can't be None when experts instance is not given"
+ my_experts = Experts(expert_cls, num_experts, **expert_args)
+
+ self.moe_layer = MoeLayer(dim_model=dim_model,
+ num_experts=num_experts,
+ router=self.moe_router,
+ experts=my_experts)
+
+ def forward(self, inputs: torch.Tensor):
+ moe_output, l_aux = self.moe_layer(inputs)
+
+ if self.use_residual:
+ residual_output = self.residual_module(inputs)
+ combine_coef = self.residual_combine(inputs)
+ combine_coef = F.softmax(combine_coef, dim=-1)
+ output = moe_output * combine_coef[..., 0:1] + residual_output * combine_coef[..., 1:]
+ else:
+ output = moe_output
+
+ return output, l_aux
diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md
index 4be923eca024..3630e8539a8b 100644
--- a/docs/README-zh-Hans.md
+++ b/docs/README-zh-Hans.md
@@ -24,8 +24,10 @@
## 新闻
+* [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+* [2023/03] [Intel and Colossal-AI Partner to Deliver Cost-Efficient Open-Source Solution for Protein Folding Structure Prediction](https://www.hpc-ai.tech/blog/intel-habana)
* [2023/03] [AWS and Google Fund Colossal-AI with Startup Cloud Programs](https://www.hpc-ai.tech/blog/aws-and-google-fund-colossal-ai-with-startup-cloud-programs)
-* [2023/02] [Open source solution replicates ChatGPT training process! Ready to go with only 1.6GB GPU memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
+* [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
* [2023/01] [Hardware Savings Up to 46 Times for AIGC and Automatic Parallelism](https://medium.com/pytorch/latest-colossal-ai-boasts-novel-automatic-parallelism-and-offers-savings-up-to-46x-for-stable-1453b48f3f02)
* [2022/11] [Diffusion Pretraining and Hardware Fine-Tuning Can Be Almost 7X Cheaper](https://www.hpc-ai.tech/blog/diffusion-pretraining-and-hardware-fine-tuning-can-be-almost-7x-cheaper)
* [2022/10] [Use a Laptop to Analyze 90% of Proteins, With a Single-GPU Inference Sequence Exceeding 10,000](https://www.hpc-ai.tech/blog/use-a-laptop-to-analyze-90-of-proteins-with-a-single-gpu-inference-sequence-exceeding)
@@ -220,7 +222,7 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
-[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): 完整RLHF流程0门槛克隆 [ChatGPT](https://openai.com/blog/chatgpt/) [[代码]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) [[博客]](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt) [[在线样例]](https://chat.colossalai.org)
+[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): 完整RLHF流程0门槛克隆 [ChatGPT](https://openai.com/blog/chatgpt/) [[代码]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) [[博客]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b) [[在线样例]](https://chat.colossalai.org)
 diff --git a/examples/images/diffusion/README.md b/examples/images/diffusion/README.md
index 3f9690500130..0c7f42ded318 100644
--- a/examples/images/diffusion/README.md
+++ b/examples/images/diffusion/README.md
@@ -37,7 +37,7 @@ This project is in rapid development.
## Installation
-### Option #1: install from source
+### Option #1: Install from source
#### Step 1: Requirements
To begin with, make sure your operating system has the cuda version suitable for this exciting training session, which is cuda11.6/11.8. For your convience, we have set up the rest of packages here. You can create and activate a suitable [conda](https://conda.io/) environment named `ldm` :
@@ -54,11 +54,11 @@ conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit
pip install transformers diffusers invisible-watermark
```
-#### Step 2:Install [Colossal-AI](https://colossalai.org/download/) From Our Official Website
+#### Step 2: Install [Colossal-AI](https://colossalai.org/download/) From Our Official Website
You can install the latest version (0.2.7) from our official website or from source. Notice that the suitable version for this training is colossalai(0.2.5), which stands for torch(1.12.1).
-##### Download suggested verision for this training
+##### Download suggested version for this training
```
pip install colossalai==0.2.5
@@ -80,9 +80,9 @@ cd ColossalAI
CUDA_EXT=1 pip install .
```
-#### Step 3:Accelerate with flash attention by xformers(Optional)
+#### Step 3: Accelerate with flash attention by xformers (Optional)
-Notice that xformers will accelerate the training process in cost of extra disk space. The suitable version of xformers for this training process is 0.12.0. You can download xformers directly via pip. For more release versions, feel free to check its official website: [XFormers](./https://pypi.org/project/xformers/)
+Notice that xformers will accelerate the training process at the cost of extra disk space. The suitable version of xformers for this training process is 0.0.12, which can be downloaded directly via pip. For more release versions, feel free to check its official website: [XFormers](https://pypi.org/project/xformers/)
```
pip install xformers==0.0.12
@@ -120,7 +120,7 @@ docker run --rm \
/bin/bash
########################
-# Insider Container #
+# Inside a Container #
########################
# Once you have entered the docker container, go to the stable diffusion directory for training
cd examples/images/diffusion/
@@ -132,14 +132,14 @@ bash train_colossalai.sh
```
It is important for you to configure your volume mapping in order to get the best training experience.
-1. **Mandatory**, mount your prepared data to `/data/scratch` via `-v :/data/scratch`, where you need to replace `` with the actual data path on your machine. Notice that within docker we need to transform Win expresison into Linuxd, e.g. C:\User\Desktop into /c/User/Desktop.
+1. **Mandatory**, mount your prepared data to `/data/scratch` via `-v :/data/scratch`, where you need to replace `` with the actual data path on your machine. Notice that within docker we need to transform the Windows path to a Linux one, e.g. `C:\User\Desktop` into `/mnt/c/User/Desktop`.
2. **Recommended**, store the downloaded model weights to your host machine instead of the container directory via `-v :/root/.cache/huggingface`, where you need to replace the `` with the actual path. In this way, you don't have to repeatedly download the pretrained weights for every `docker run`.
3. **Optional**, if you encounter any problem stating that shared memory is insufficient inside container, please add `-v /dev/shm:/dev/shm` to your `docker run` command.
## Download the model checkpoint from pretrained
-### stable-diffusion-v2-base(Recommand)
+### stable-diffusion-v2-base (Recommended)
```
wget https://huggingface.co/stabilityai/stable-diffusion-2-base/resolve/main/512-base-ema.ckpt
@@ -182,12 +182,12 @@ python main.py --logdir /tmp/ --train --base configs/train_colossalai.yaml --ckp
### Training config
-You can change the trainging config in the yaml file
+You can change the training config in the yaml file
- devices: device number used for training, default = 8
- max_epochs: max training epochs, default = 2
- precision: the precision type used in training, default = 16 (fp16), you must use fp16 if you want to apply colossalai
-- placement_policy: the training strategy supported by Colossal AI, defult = 'cuda', which refers to loading all the parameters into cuda memory. On the other hand, 'cpu' refers to 'cpu offload' strategy while 'auto' enables 'Gemini', both featured by Colossal AI.
+- placement_policy: the training strategy supported by Colossal AI, default = 'cuda', which refers to loading all the parameters into cuda memory. On the other hand, 'cpu' refers to 'cpu offload' strategy while 'auto' enables 'Gemini', both featured by Colossal AI.
- more information about the configuration of ColossalAIStrategy can be found [here](https://pytorch-lightning.readthedocs.io/en/latest/advanced/model_parallel.html#colossal-ai)
@@ -202,7 +202,8 @@ python main.py --logdir /tmp/ -t -b configs/Teyvat/train_colossalai_teyvat.yaml
```
## Inference
-you can get yout training last.ckpt and train config.yaml in your `--logdir`, and run by
+
+You can get your training last.ckpt and train config.yaml in your `--logdir`, and run by
```
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
--outdir ./output \
diff --git a/requirements/requirements.txt b/requirements/requirements.txt
index e32b3ecda063..4e4f35edb2d9 100644
--- a/requirements/requirements.txt
+++ b/requirements/requirements.txt
@@ -8,4 +8,4 @@ click
fabric
contexttimer
ninja
-torch>=1.11,<2.0
+torch>=1.11
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addmm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addmm_handler.py
index aa5a57474335..35f12ce83af2 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addmm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addmm_handler.py
@@ -1,22 +1,20 @@
-from faulthandler import disable
from functools import partial
-from xml.dom import WrongDocumentErr
import pytest
import torch
import torch.multiprocessing as mp
import torch.nn as nn
-from typing_extensions import Self
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
- OperationData,
OperationDataType,
ShardingStrategy,
StrategiesVector,
)
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import parameterize, rerun_if_address_is_in_use
@@ -96,7 +94,7 @@ def check_addmm_function_handler(rank, input_shape, model_cls, world_size, port)
meta_arg_names=meta_arg_names,
node_type='bias_module')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %m1 : torch.Tensor [#users=1] = placeholder[target=m1]
@@ -109,6 +107,7 @@ def check_addmm_function_handler(rank, input_shape, model_cls, world_size, port)
# return add
graph = tracer.trace(model, meta_args=meta_args_for_tracer)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args_for_tracer.values())
# [input_1, m1, m2, addmm, output]
node_list = list(graph.nodes)
linear_node = node_list[4]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_batch_norm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_batch_norm_handler.py
index 0ab70abffb4c..2069b5e8a4de 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_batch_norm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_batch_norm_handler.py
@@ -5,10 +5,12 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.batch_norm_handler import BatchNormModuleHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -38,13 +40,15 @@ def check_bn_module_handler(rank, world_size, port):
strategy_number=strategy_number,
input_args=[input],
meta_arg_names=['input'])
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %_0 : [#users=1] = call_module[target=0](args = (%input_1,), kwargs = {})
# return _0
- graph = tracer.trace(model, meta_args={"input": torch.rand(4, 16, 64, 64).to('meta')})
+ meta_args = {"input": torch.rand(4, 16, 64, 64).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
bn_mod_node = list(graph.nodes)[1]
strategies_vector = StrategiesVector(bn_mod_node)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_function_node.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_function_node.py
index 162d1fbba295..dca5f6e227fa 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_function_node.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_function_node.py
@@ -1,14 +1,14 @@
-from faulthandler import disable
from functools import partial
-from xml.dom import WrongDocumentErr
import pytest
import torch
import torch.multiprocessing as mp
import torch.nn as nn
import torch.nn.functional as F
-from typing_extensions import Self
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import LinearFunctionHandler, LinearModuleHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
OperationData,
@@ -17,12 +17,10 @@
StrategiesVector,
)
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
from colossalai.testing.pytest_wrapper import run_on_environment_flag
-from colossalai.testing.utils import parameterize
from colossalai.utils import free_port
from tests.test_auto_parallel.test_tensor_shard.test_node_handler.utils import numerical_test_for_node_strategy
@@ -66,7 +64,7 @@ def check_linear_module_handler(rank, world_size, port):
meta_arg_names=meta_arg_names,
node_type='bias_module')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %x : torch.Tensor [#users=1] = placeholder[target=x]
# %weight : [#users=1] = get_attr[target=weight]
@@ -74,8 +72,10 @@ def check_linear_module_handler(rank, world_size, port):
# %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%x, %weight), kwargs = {})
# %add : [#users=1] = call_function[target=operator.add](args = (%linear, %bias), kwargs = {})
# return add
- graph = tracer.trace(model, meta_args={"x": torch.rand(4, 4, 4, 16).to('meta')})
+ meta_args = {"x": torch.rand(4, 4, 4, 16).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
linear_mod_node = list(graph.nodes)[3]
strategies_vector = StrategiesVector(linear_mod_node)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_module_node.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_module_node.py
index c5c3f378197e..14d4a73fb4f8 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_module_node.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_module_node.py
@@ -1,13 +1,13 @@
-from faulthandler import disable
from functools import partial
-from xml.dom import WrongDocumentErr
import pytest
import torch
import torch.multiprocessing as mp
import torch.nn as nn
-from typing_extensions import Self
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import LinearFunctionHandler, LinearModuleHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
OperationData,
@@ -16,12 +16,10 @@
StrategiesVector,
)
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
from colossalai.testing.pytest_wrapper import run_on_environment_flag
-from colossalai.testing.utils import parameterize
from colossalai.utils import free_port
from tests.test_auto_parallel.test_tensor_shard.test_node_handler.utils import numerical_test_for_node_strategy
@@ -62,9 +60,11 @@ def check_linear_module_handler(rank, bias, world_size, port):
meta_arg_names=meta_arg_names,
node_type='bias_module')
- tracer = ColoTracer()
- graph = tracer.trace(model, meta_args={"x": torch.rand(4, 4, 4, 16).to('meta')})
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {"x": torch.rand(4, 4, 4, 16).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
linear_mod_node = list(graph.nodes)[3]
strategies_vector = StrategiesVector(linear_mod_node)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py
index 50385c0450a8..2414749f60a4 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py
@@ -5,10 +5,12 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import BinaryElementwiseHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -52,10 +54,11 @@ def forward(self, x1, x2):
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
meta_args = {'x1': torch.rand(4, 4).to('meta'), 'x2': torch.rand([4] * other_dim).to('meta')}
graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
op_node = list(graph.nodes)[2]
strategies_vector = StrategiesVector(op_node)
@@ -172,12 +175,11 @@ def check_binary_elementwise_handler_with_int(rank, op, other_dim, model_cls, wo
strategy_number=strategy_number,
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
meta_args = {'x1': torch.rand(4, 4).to('meta')}
graph = tracer.trace(model, meta_args=meta_args)
- print(graph)
- # assert False
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
if model_cls == BEOpModelWithNodeConst:
op_node = list(graph.nodes)[2]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bmm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bmm_handler.py
index 02c7e0671149..34c20c1ac0fe 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bmm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bmm_handler.py
@@ -5,10 +5,12 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import BMMFunctionHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -52,13 +54,11 @@ def check_2d_device_mesh(rank, module, world_size, port):
strategy_number=strategy_number,
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
- graph = tracer.trace(model,
- meta_args={
- "x1": torch.rand(4, 8, 16).to('meta'),
- 'x2': torch.rand(4, 16, 8).to('meta')
- })
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {'x1': torch.rand(4, 8, 16).to('meta'), 'x2': torch.rand(4, 16, 8).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
linear_mod_node = list(graph.nodes)[2]
strategies_vector = StrategiesVector(linear_mod_node)
@@ -147,13 +147,11 @@ def check_1d_device_mesh(rank, module, world_size, port):
strategy_number=strategy_number,
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
- graph = tracer.trace(model,
- meta_args={
- "x1": torch.rand(4, 8, 16).to('meta'),
- 'x2': torch.rand(4, 16, 8).to('meta')
- })
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {'x1': torch.rand(4, 8, 16).to('meta'), 'x2': torch.rand(4, 16, 8).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
linear_mod_node = list(graph.nodes)[2]
strategies_vector = StrategiesVector(linear_mod_node)
@@ -205,6 +203,7 @@ def check_1d_device_mesh(rank, module, world_size, port):
@run_on_environment_flag(name='AUTO_PARALLEL')
@parameterize('module', [BMMTensorMethodModule, BMMTorchFunctionModule])
+@parameterize('module', [BMMTensorMethodModule, BMMTorchFunctionModule])
@pytest.mark.dist
@rerun_if_address_is_in_use()
def test_bmm_handler(module):
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_conv_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_conv_handler.py
index 2acd015c8f59..fe1a0d726db0 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_conv_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_conv_handler.py
@@ -5,10 +5,12 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler, ConvModuleHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -41,9 +43,11 @@ def check_conv_module_handler(rank, bias, world_size, port):
strategy_number=strategy_number,
input_args=[input],
meta_arg_names=['input'])
- tracer = ColoTracer()
- graph = tracer.trace(model, meta_args={"input": torch.rand(4, 4, 64, 64).to('meta')})
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {'input': torch.rand(4, 4, 64, 64).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
conv_mod_node = list(graph.nodes)[1]
strategies_vector = StrategiesVector(conv_mod_node)
@@ -178,7 +182,7 @@ def check_conv_function_handler(rank, bias, world_size, port):
meta_arg_names=meta_arg_names,
input_kwargs=input_kwargs)
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %others : torch.Tensor [#users=1] = placeholder[target=others]
@@ -189,6 +193,7 @@ def check_conv_function_handler(rank, bias, world_size, port):
meta_args['bias'] = torch.rand(16).to('meta')
graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
if bias:
conv_mod_node = list(graph.nodes)[3]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_default_reshape_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_default_reshape_handler.py
index ea7c2b729635..8e5b7512ca0e 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_default_reshape_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_default_reshape_handler.py
@@ -1,11 +1,13 @@
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import DefaultReshapeHandler
from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.testing.pytest_wrapper import run_on_environment_flag
@@ -23,19 +25,20 @@ def forward(self, input, other):
@run_on_environment_flag(name='AUTO_PARALLEL')
def test_reshape_handler():
model = ReshapeModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %other : torch.Tensor [#users=1] = placeholder[target=other]
# %conv2d : [#users=1] = call_function[target=torch.conv2d](args = (%input_1, %other), kwargs = {})
# %view : [#users=1] = call_method[target=view](args = (%conv2d, 2, -1), kwargs = {})
# return view
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(4, 4, 64, 64).to('meta'),
- "other": torch.rand(4, 16, 3, 3).to('meta'),
- })
+ meta_args = {
+ "input": torch.rand(4, 4, 64, 64).to('meta'),
+ "other": torch.rand(16, 4, 3, 3).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
@@ -67,13 +70,13 @@ def test_reshape_handler():
assert mapping['input'].name == "conv2d"
assert mapping['input'].data.is_meta
- assert mapping['input'].data.shape == torch.Size([4, 4, 62, 62])
+ assert mapping['input'].data.shape == torch.Size([4, 16, 62, 62])
assert mapping['input'].type == OperationDataType.ARG
- assert mapping['input'].logical_shape == torch.Size([4, 4, 62, 62])
+ assert mapping['input'].logical_shape == torch.Size([4, 16, 62, 62])
assert mapping['output'].name == "view"
assert mapping['output'].data.is_meta
- assert mapping['output'].data.shape == torch.Size([2, 30752])
+ assert mapping['output'].data.shape == torch.Size([2, 123008])
assert mapping['output'].type == OperationDataType.OUTPUT
# reshape handler is a following strategy handler, so the number of strategies is equal to the predecessor node.
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_embedding_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_embedding_handler.py
index 5bce383dd0ab..a61d2ed5c108 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_embedding_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_embedding_handler.py
@@ -5,13 +5,15 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.embedding_handler import (
EmbeddingFunctionHandler,
EmbeddingModuleHandler,
)
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -60,9 +62,11 @@ def check_embedding_module_handler(rank, world_size, port):
input_args=[input],
meta_arg_names=['input'])
- tracer = ColoTracer()
- graph = tracer.trace(model, meta_args={"input": torch.rand(4, 16, 16).to('meta')})
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {"input": torch.randint(NUM_EMBEDDINGS, (4, 16, 16)).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
embedding_node = list(graph.nodes)[1]
strategies_vector = StrategiesVector(embedding_node)
@@ -171,18 +175,19 @@ def check_embedding_function_handler(rank, world_size, port):
input_args=input_args,
meta_arg_names=meta_arg_names,
input_kwargs=input_kwargs)
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %others : torch.Tensor [#users=1] = placeholder[target=others]
# %embedding : [#users=1] = call_function[target=torch.nn.functional.embedding](args = (%input_1, %others), kwargs = {padding_idx: None, max_norm: None, norm_type: 2.0, scale_grad_by_freq: False, sparse: False})
# return embedding
meta_args = {
- "input": torch.rand(4, 16, 16).to('meta'),
+ "input": torch.randint(NUM_EMBEDDINGS, (4, 16, 16)).to('meta'),
"others": torch.rand(NUM_EMBEDDINGS, EMBEDDING_DIMS).to('meta')
}
graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
embedding_node = list(graph.nodes)[2]
strategies_vector = StrategiesVector(embedding_node)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getattr_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getattr_handler.py
index 681e93a5fe16..fb611330946a 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getattr_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getattr_handler.py
@@ -1,10 +1,13 @@
+import pytest
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.getattr_handler import GetattrHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
class GetattrModel(nn.Module):
@@ -18,15 +21,18 @@ def forward(self, input):
return weight
+@pytest.mark.skip('ShapeProp is not compatible with PyTorch 1.11.0')
def test_getattr_handler():
model = GetattrModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=0] = placeholder[target=input]
# %conv_weight : [#users=1] = get_attr[target=conv.weight]
# return conv_weight
- graph = tracer.trace(model, meta_args={'input': torch.rand(4, 4, 64, 64).to('meta')})
+ meta_args = {'input': torch.rand(4, 4, 64, 64).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
device_mesh = DeviceMesh(physical_mesh_id, mesh_shape)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getitem_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getitem_handler.py
index c72d2a6a80e8..9a29808ebb31 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getitem_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getitem_handler.py
@@ -5,13 +5,15 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.default_reshape_handler import DefaultReshapeHandler
from colossalai.auto_parallel.tensor_shard.node_handler.getitem_handler import GetItemHandler
from colossalai.auto_parallel.tensor_shard.node_handler.linear_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.placeholder_handler import PlaceholderHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.fx.tracer.meta_patch.patched_module import linear
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
@@ -58,15 +60,15 @@ def check_getitem_from_tensor_handler(rank, getitem_index, world_size, port):
meta_arg_names=['input', 'other'],
node_type='following')
- tracer = ColoTracer()
-
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 16, 64, 32).to('meta'),
- "other": torch.rand(64, 32).to('meta'),
- })
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {
+ "input": torch.rand(8, 16, 64, 32).to('meta'),
+ "other": torch.rand(64, 32).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *list(meta_args.values()))
linear_mod_node = list(graph.nodes)[2]
getitem_mod_node = list(graph.nodes)[3]
getitem_strategies_vector = StrategiesVector(getitem_mod_node)
@@ -129,10 +131,12 @@ def test_getitem_from_tuple_handler():
# %split : [#users=1] = call_function[target=torch.functional.split](args = (%conv2d, 2), kwargs = {dim: 0})
# %getitem : [#users=1] = call_function[target=operator.getitem](args = (%split, 1), kwargs = {})
# return getitem
- graph = tracer.trace(model, meta_args={
+ meta_args = {
"input": torch.rand(4, 4, 64, 64).to('meta'),
- })
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_layer_norm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_layer_norm_handler.py
index f4d0063fd6b6..edd7bae6c979 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_layer_norm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_layer_norm_handler.py
@@ -5,10 +5,12 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.layer_norm_handler import LayerNormModuleHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.fx.tracer.meta_patch.patched_module import linear
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
@@ -40,13 +42,15 @@ def check_ln_module_handler(rank, world_size, port):
strategy_number=strategy_number,
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %_0 : [#users=1] = call_module[target=0](args = (%input_1,), kwargs = {})
# return _0
- graph = tracer.trace(model, meta_args={"input": torch.rand(4, 16).to('meta')})
+ meta_args = {"input": torch.rand(4, 16).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
ln_mod_node = list(graph.nodes)[1]
strategies_vector = StrategiesVector(ln_mod_node)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_linear_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_linear_handler.py
index 18afacf56b8e..bec5c3dc5e28 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_linear_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_linear_handler.py
@@ -5,6 +5,9 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import LinearFunctionHandler, LinearModuleHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
OperationData,
@@ -13,7 +16,6 @@
StrategiesVector,
)
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -49,9 +51,11 @@ def check_linear_module_handler(rank, bias, input_shape, world_size, port):
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
- graph = tracer.trace(model, meta_args={"input": torch.rand(input_shape).to('meta')})
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {"input": torch.rand(input_shape).cuda()}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
linear_mod_node = list(graph.nodes)[1]
strategies_vector = StrategiesVector(linear_mod_node)
@@ -196,13 +200,12 @@ def check_linear_function_handler(rank, bias, input_shape, world_size, port):
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(input_shape).to('meta'),
- 'others': torch.rand(32, 16).to('meta')
- })
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {'input': torch.rand(input_shape).to('meta'), 'others': torch.rand(32, 16).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
+
if bias:
linear_func_node = list(graph.nodes)[3]
else:
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_matmul_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_matmul_handler.py
index 91b3ae27d599..46c3ff4434d7 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_matmul_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_matmul_handler.py
@@ -2,6 +2,9 @@
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.matmul_handler import (
MatMulHandler,
MatMulType,
@@ -15,7 +18,6 @@
StrategiesVector,
)
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.testing.utils import parameterize
@@ -57,9 +59,11 @@ def test_matmul_node_handler(tensor_shapes):
model = MatMulModule()
- tracer = ColoTracer()
- graph = tracer.trace(model, meta_args={"x1": x1.to('meta'), 'x2': x2.to('meta')})
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {"x1": x1.to('meta'), 'x2': x2.to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
print(graph)
@@ -124,7 +128,6 @@ def test_matmul_node_handler(tensor_shapes):
input_sharding_spec = strategy.get_sharding_spec_by_name('x1')
other_sharding_spec = strategy.get_sharding_spec_by_name('x2')
output_sharding_spec = strategy.get_sharding_spec_by_name('matmul')
-
if matmul_type == MatMulType.DOT:
# dot product will produce a scaler
# results should fulfill:
@@ -159,7 +162,10 @@ def test_matmul_node_handler(tensor_shapes):
if len(other_shape) > 1:
assert other_sharding_spec.sharding_sequence[-1] == output_sharding_spec.sharding_sequence[-1]
if len(input_shape) > 1:
- assert input_sharding_spec.sharding_sequence[-2] == output_sharding_spec.sharding_sequence[-2]
+ if len(other_shape) == 1:
+ assert input_sharding_spec.sharding_sequence[-2] == output_sharding_spec.sharding_sequence[-1]
+ else:
+ assert input_sharding_spec.sharding_sequence[-2] == output_sharding_spec.sharding_sequence[-2]
if len(other_shape) > 2:
assert other_sharding_spec.sharding_sequence[-2] == input_sharding_spec.sharding_sequence[-1]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_norm_pooling_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_norm_pooling_handler.py
index f219bc2f3976..aacc7d9aeb64 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_norm_pooling_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_norm_pooling_handler.py
@@ -2,10 +2,12 @@
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.normal_pooling_handler import NormPoolingHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.fx.tracer.meta_patch.patched_module import linear
from colossalai.testing.pytest_wrapper import run_on_environment_flag
@@ -13,14 +15,16 @@
@run_on_environment_flag(name='AUTO_PARALLEL')
def test_norm_pool_handler():
model = nn.Sequential(nn.MaxPool2d(4, padding=1).to('meta'))
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %_0 : [#users=1] = call_module[target=0](args = (%input_1,), kwargs = {})
# return _0
- graph = tracer.trace(model, meta_args={"input": torch.rand(4, 4, 64, 64).to('meta')})
+ meta_args = {"input": torch.rand(4, 4, 64, 64).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_output_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_output_handler.py
index 26376c429ebc..5efbb4f5f6a4 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_output_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_output_handler.py
@@ -1,10 +1,13 @@
+import pytest
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.output_handler import OutputHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -18,19 +21,20 @@ def forward(self, x):
return x, y
+@pytest.mark.skip('ShapeProp is not compatible with PyTorch 1.11.0')
@parameterize('output_option', ['distributed', 'replicated'])
@rerun_if_address_is_in_use()
def test_output_handler(output_option):
model = OutputModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %x : torch.Tensor [#users=2] = placeholder[target=x]
# %mul : [#users=1] = call_function[target=operator.mul](args = (%x, 2), kwargs = {})
# return (x, mul)
- graph = tracer.trace(model, meta_args={
- "x": torch.rand(4, 4, 64, 64).to('meta'),
- })
+ meta_args = {'x': torch.rand(4, 4, 64, 64).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_permute_and_transpose_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_permute_and_transpose_handler.py
index af03481d830e..0a5ad3e3523d 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_permute_and_transpose_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_permute_and_transpose_handler.py
@@ -5,12 +5,14 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import PermuteHandler, TransposeHandler
from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.linear_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -88,7 +90,7 @@ def check_view_handler(rank, call_function, reshape_dims, model_cls, world_size,
input_args=[input, other],
meta_arg_names=['input', 'other'],
node_type='following')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
if model_cls.__name__ == 'ConvReshapeModel':
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
@@ -96,11 +98,11 @@ def check_view_handler(rank, call_function, reshape_dims, model_cls, world_size,
# %conv2d : [#users=1] = call_function[target=torch.conv2d](args = (%input_1, %other), kwargs = {bias: None})
# %permute : [#users=1] = call_function[target=torch.permute](args = (%conv2d, (0, 2, 1, 3)), kwargs = {})
# return permute
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 8, 66, 66).to('meta'),
- "other": torch.rand(16, 8, 3, 3).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(8, 8, 66, 66).to('meta'),
+ 'other': torch.rand(16, 8, 3, 3).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
if model_cls.__name__ == 'LinearReshapeModel':
# graph():
@@ -109,13 +111,14 @@ def check_view_handler(rank, call_function, reshape_dims, model_cls, world_size,
# %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%input_1, %other), kwargs = {bias: None})
# %permute : [#users=1] = call_method[target=view](args = (%linear, 32, 4, 32, 32, 4), kwargs = {})
# return permute
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 16, 64, 32).to('meta'),
- "other": torch.rand(64, 32).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(8, 16, 64, 32).to('meta'),
+ 'other': torch.rand(64, 32).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
previous_mod_node = list(graph.nodes)[2]
reshape_node = list(graph.nodes)[3]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_placeholder_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_placeholder_handler.py
index 9bc453a27cdc..5e8fb51edbff 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_placeholder_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_placeholder_handler.py
@@ -1,10 +1,13 @@
+import pytest
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.placeholder_handler import PlaceholderHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -17,18 +20,21 @@ def forward(self, input):
return input
+@pytest.mark.skip('ShapeProp is not compatible with PyTorch 1.11.0')
@parameterize('placeholder_option', ['distributed', 'replicated'])
@rerun_if_address_is_in_use()
def test_placeholder_handler(placeholder_option):
model = PlaceholderModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# return input_1
- graph = tracer.trace(model, meta_args={
+ meta_args = {
"input": torch.rand(4, 4, 64, 64).to('meta'),
- })
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_shard_option.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_shard_option.py
index f6895d92ab03..e589fff996c6 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_shard_option.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_shard_option.py
@@ -1,17 +1,15 @@
-from functools import partial
-
import torch
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.options import ShardOption
from colossalai.auto_parallel.tensor_shard.sharding_strategy import StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
-from colossalai.testing import parameterize
from colossalai.testing.pytest_wrapper import run_on_environment_flag
-from colossalai.testing.utils import parameterize
class LinearModel(nn.Module):
@@ -30,13 +28,11 @@ def check_shard_option(shard_option):
mesh_shape = (2, 2)
device_mesh = DeviceMesh(physical_mesh_id, mesh_shape)
- tracer = ColoTracer()
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(4, 4, 4, 16).to('meta'),
- 'others': torch.rand(32, 16).to('meta')
- })
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {'input': torch.rand(4, 4, 4, 16).to('meta'), 'others': torch.rand(32, 16).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
linear_func_node = list(graph.nodes)[2]
strategies_vector = StrategiesVector(linear_func_node)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_softmax_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_softmax_handler.py
index c43ee292bedf..db463a4e9d6a 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_softmax_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_softmax_handler.py
@@ -6,11 +6,13 @@
import torch.nn as nn
import torch.nn.functional as F
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.linear_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.softmax_handler import SoftmaxHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -54,7 +56,7 @@ def check_split_handler(rank, softmax_dim, model_cls, world_size, port):
input_args=[input, other],
meta_arg_names=['input', 'other'],
node_type='following')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
@@ -62,13 +64,14 @@ def check_split_handler(rank, softmax_dim, model_cls, world_size, port):
# %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%input_1, %other), kwargs = {bias: None})
# %softmax : [#users=1] = call_method[target=split](args = (%linear,), kwargs = {})
# return split
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 16, 64, 32).to('meta'),
- "other": torch.rand(64, 32).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(8, 16, 64, 32).to('meta'),
+ 'other': torch.rand(64, 32).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
previous_mod_node = list(graph.nodes)[2]
split_node = list(graph.nodes)[3]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_split_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_split_handler.py
index 044aef19d38d..db59ea60ef4b 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_split_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_split_handler.py
@@ -5,12 +5,14 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import SplitHandler
from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.linear_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -76,7 +78,7 @@ def check_split_handler(rank, split_size, split_dim, model_cls, world_size, port
input_args=[input, other],
meta_arg_names=['input', 'other'],
node_type='following')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
if model_cls.__name__ == 'ConvSplitModel':
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
@@ -84,11 +86,11 @@ def check_split_handler(rank, split_size, split_dim, model_cls, world_size, port
# %conv2d : [#users=1] = call_function[target=torch.conv2d](args = (%input_1, %other), kwargs = {})
# %split : [#users=1] = call_method[target=split](args = (%conv2d,), kwargs = {})
# return split
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 8, 66, 66).to('meta'),
- "other": torch.rand(16, 8, 3, 3).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(8, 8, 66, 66).to('meta'),
+ 'other': torch.rand(16, 8, 3, 3).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
if model_cls.__name__ == 'LinearSplitModel':
# graph():
@@ -97,13 +99,14 @@ def check_split_handler(rank, split_size, split_dim, model_cls, world_size, port
# %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%input_1, %other), kwargs = {bias: None})
# %split : [#users=1] = call_method[target=split](args = (%linear,), kwargs = {})
# return split
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 16, 64, 32).to('meta'),
- "other": torch.rand(64, 32).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(8, 16, 64, 32).to('meta'),
+ 'other': torch.rand(64, 32).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
previous_mod_node = list(graph.nodes)[2]
split_node = list(graph.nodes)[3]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_sum_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_sum_handler.py
index 5fda4de1a101..add51d73f2a4 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_sum_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_sum_handler.py
@@ -5,12 +5,13 @@
import torch.multiprocessing as mp
import torch.nn as nn
-from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.linear_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.sum_handler import SumHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -58,7 +59,7 @@ def check_sum_handler(rank, sum_dims, keepdim, world_size, port):
meta_arg_names=['input', 'other'],
node_type='following')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
@@ -66,12 +67,13 @@ def check_sum_handler(rank, sum_dims, keepdim, world_size, port):
# %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%input_1, %other), kwargs = {bias: None})
# %sum_1 : [#users=1] = call_function[target=torch.sum](args = (%linear,), kwargs = {})
# return sum_1
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 16, 64, 32).to('meta'),
- "other": torch.rand(64, 32).to('meta'),
- })
+ meta_args = {
+ "input": torch.rand(8, 16, 64, 32).to('meta'),
+ "other": torch.rand(64, 32).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
previous_mod_node = list(graph.nodes)[2]
sum_node = list(graph.nodes)[3]
@@ -116,107 +118,107 @@ def check_sum_handler(rank, sum_dims, keepdim, world_size, port):
# check strategy name
if sum_dims == (0, 2) and keepdim == False:
- assert '[R, R, R, S1] -> [R, S1]_0' in strategy_name_list
- assert '[R, S0, R, S1] -> [S0, S1]_1' in strategy_name_list
- assert '[R, R, R, S1] -> [R, S1]_2' in strategy_name_list
- assert '[R, R, R, S0] -> [R, S0]_3' in strategy_name_list
- assert '[R, S1, R, S0] -> [S1, S0]_4' in strategy_name_list
- assert '[R, R, R, S0] -> [R, S0]_5' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_6' in strategy_name_list
- assert '[R, S0, R, R] -> [S0, R]_7' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_0' in strategy_name_list
+ assert '[R, S01, R, R] -> [S01, R]_1' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_2' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_3' in strategy_name_list
+ assert '[R, R, R, S01] -> [R, S01]_4' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, S1]_5' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, S0]_6' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_7' in strategy_name_list
assert '[R, R, R, R] -> [R, R]_8' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_9' in strategy_name_list
- assert '[R, S1, R, R] -> [S1, R]_10' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_11' in strategy_name_list
- assert '[R, R, R, S1] -> [R, S1]_12' in strategy_name_list
- assert '[R, R, R, S0] -> [R, S0]_13' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_14' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_15' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, S0]_9' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, S1]_10' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, S1]_11' in strategy_name_list
+ assert '[R, S0, R, S1] -> [S0, S1]_12' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, S1]_13' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, S0]_14' in strategy_name_list
+ assert '[R, S1, R, S0] -> [S1, S0]_15' in strategy_name_list
assert '[R, R, R, S0] -> [R, S0]_16' in strategy_name_list
- assert '[R, R, R, S1] -> [R, S1]_17' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_18' in strategy_name_list
- assert '[R, S01, R, R] -> [S01, R]_19' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_17' in strategy_name_list
+ assert '[R, S0, R, R] -> [S0, R]_18' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_19' in strategy_name_list
assert '[R, R, R, R] -> [R, R]_20' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_21' in strategy_name_list
- assert '[R, R, R, S01] -> [R, S01]_22' in strategy_name_list
+ assert '[R, S1, R, R] -> [S1, R]_21' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_22' in strategy_name_list
assert '[R, R, R, R] -> [R, R]_23' in strategy_name_list
if sum_dims == (0, 2) and keepdim == True:
- assert '[R, R, R, S1] -> [R, R, R, S1]_0' in strategy_name_list
- assert '[R, S0, R, S1] -> [R, S0, R, S1]_1' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, R, S1]_2' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, R, S0]_3' in strategy_name_list
- assert '[R, S1, R, S0] -> [R, S1, R, S0]_4' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, R, S0]_5' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_6' in strategy_name_list
- assert '[R, S0, R, R] -> [R, S0, R, R]_7' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_0' in strategy_name_list
+ assert '[R, S01, R, R] -> [R, S01, R, R]_1' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_2' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_3' in strategy_name_list
+ assert '[R, R, R, S01] -> [R, R, R, S01]_4' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, R, S1]_5' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, R, S0]_6' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_7' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R, R]_8' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_9' in strategy_name_list
- assert '[R, S1, R, R] -> [R, S1, R, R]_10' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_11' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, R, S1]_12' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, R, S0]_13' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_14' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_15' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, R, S0]_9' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, R, S1]_10' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, R, S1]_11' in strategy_name_list
+ assert '[R, S0, R, S1] -> [R, S0, R, S1]_12' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, R, S1]_13' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, R, S0]_14' in strategy_name_list
+ assert '[R, S1, R, S0] -> [R, S1, R, S0]_15' in strategy_name_list
assert '[R, R, R, S0] -> [R, R, R, S0]_16' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, R, S1]_17' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_18' in strategy_name_list
- assert '[R, S01, R, R] -> [R, S01, R, R]_19' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_17' in strategy_name_list
+ assert '[R, S0, R, R] -> [R, S0, R, R]_18' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_19' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R, R]_20' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_21' in strategy_name_list
- assert '[R, R, R, S01] -> [R, R, R, S01]_22' in strategy_name_list
+ assert '[R, S1, R, R] -> [R, S1, R, R]_21' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_22' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R, R]_23' in strategy_name_list
if sum_dims == 1 and keepdim == False:
- assert '[S0, R, R, S1] -> [S0, R, S1]_0' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, S1]_1' in strategy_name_list
- assert '[R, R, S0, S1] -> [R, S0, S1]_2' in strategy_name_list
- assert '[S1, R, R, S0] -> [S1, R, S0]_3' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, S0]_4' in strategy_name_list
- assert '[R, R, S1, S0] -> [R, S1, S0]_5' in strategy_name_list
- assert '[S0, R, R, R] -> [S0, R, R]_6' in strategy_name_list
+ assert '[S01, R, R, R] -> [S01, R, R]_0' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R]_1' in strategy_name_list
+ assert '[R, R, S01, R] -> [R, S01, R]_2' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R]_3' in strategy_name_list
+ assert '[R, R, R, S01] -> [R, R, S01]_4' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, S1]_5' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, S0]_6' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R]_7' in strategy_name_list
- assert '[R, R, S0, R] -> [R, S0, R]_8' in strategy_name_list
- assert '[S1, R, R, R] -> [S1, R, R]_9' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R]_10' in strategy_name_list
- assert '[R, R, S1, R] -> [R, S1, R]_11' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R]_8' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, S0]_9' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, S1]_10' in strategy_name_list
+ assert '[S0, R, R, S1] -> [S0, R, S1]_11' in strategy_name_list
assert '[R, R, R, S1] -> [R, R, S1]_12' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, S0]_13' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R]_14' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R]_15' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, S0]_16' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, S1]_17' in strategy_name_list
- assert '[S01, R, R, R] -> [S01, R, R]_18' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R]_19' in strategy_name_list
- assert '[R, R, S01, R] -> [R, S01, R]_20' in strategy_name_list
+ assert '[R, R, S0, S1] -> [R, S0, S1]_13' in strategy_name_list
+ assert '[S1, R, R, S0] -> [S1, R, S0]_14' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, S0]_15' in strategy_name_list
+ assert '[R, R, S1, S0] -> [R, S1, S0]_16' in strategy_name_list
+ assert '[S0, R, R, R] -> [S0, R, R]_17' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R]_18' in strategy_name_list
+ assert '[R, R, S0, R] -> [R, S0, R]_19' in strategy_name_list
+ assert '[S1, R, R, R] -> [S1, R, R]_20' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R]_21' in strategy_name_list
- assert '[R, R, R, S01] -> [R, R, S01]_22' in strategy_name_list
+ assert '[R, R, S1, R] -> [R, S1, R]_22' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R]_23' in strategy_name_list
if sum_dims == 1 and keepdim == True:
- assert '[S0, R, R, S1] -> [S0, R, R, S1]_0' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, R, S1]_1' in strategy_name_list
- assert '[R, R, S0, S1] -> [R, R, S0, S1]_2' in strategy_name_list
- assert '[S1, R, R, S0] -> [S1, R, R, S0]_3' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, R, S0]_4' in strategy_name_list
- assert '[R, R, S1, S0] -> [R, R, S1, S0]_5' in strategy_name_list
- assert '[S0, R, R, R] -> [S0, R, R, R]_6' in strategy_name_list
+ assert '[S01, R, R, R] -> [S01, R, R, R]_0' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_1' in strategy_name_list
+ assert '[R, R, S01, R] -> [R, R, S01, R]_2' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_3' in strategy_name_list
+ assert '[R, R, R, S01] -> [R, R, R, S01]_4' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, R, S1]_5' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, R, S0]_6' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R, R]_7' in strategy_name_list
- assert '[R, R, S0, R] -> [R, R, S0, R]_8' in strategy_name_list
- assert '[S1, R, R, R] -> [S1, R, R, R]_9' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_10' in strategy_name_list
- assert '[R, R, S1, R] -> [R, R, S1, R]_11' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_8' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, R, S0]_9' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, R, S1]_10' in strategy_name_list
+ assert '[S0, R, R, S1] -> [S0, R, R, S1]_11' in strategy_name_list
assert '[R, R, R, S1] -> [R, R, R, S1]_12' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, R, S0]_13' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_14' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_15' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, R, S0]_16' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, R, S1]_17' in strategy_name_list
- assert '[S01, R, R, R] -> [S01, R, R, R]_18' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_19' in strategy_name_list
- assert '[R, R, S01, R] -> [R, R, S01, R]_20' in strategy_name_list
+ assert '[R, R, S0, S1] -> [R, R, S0, S1]_13' in strategy_name_list
+ assert '[S1, R, R, S0] -> [S1, R, R, S0]_14' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, R, S0]_15' in strategy_name_list
+ assert '[R, R, S1, S0] -> [R, R, S1, S0]_16' in strategy_name_list
+ assert '[S0, R, R, R] -> [S0, R, R, R]_17' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_18' in strategy_name_list
+ assert '[R, R, S0, R] -> [R, R, S0, R]_19' in strategy_name_list
+ assert '[S1, R, R, R] -> [S1, R, R, R]_20' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R, R]_21' in strategy_name_list
- assert '[R, R, R, S01] -> [R, R, R, S01]_22' in strategy_name_list
+ assert '[R, R, S1, R] -> [R, R, S1, R]_22' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R, R]_23' in strategy_name_list
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_tensor_constructor.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_tensor_constructor.py
index de35fe256ac7..f54b208c3380 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_tensor_constructor.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_tensor_constructor.py
@@ -1,10 +1,12 @@
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.tensor_constructor_handler import TensorConstructorHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.testing.pytest_wrapper import run_on_environment_flag
@@ -22,7 +24,7 @@ def forward(self, x):
@run_on_environment_flag(name='AUTO_PARALLEL')
def test_where_handler():
model = TensorConstructorModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %x : torch.Tensor [#users=2] = placeholder[target=x]
# %size : [#users=1] = call_method[target=size](args = (%x,), kwargs = {})
@@ -30,10 +32,10 @@ def test_where_handler():
# %arange : [#users=1] = call_function[target=torch.arange](args = (%getitem,), kwargs = {})
# %add : [#users=1] = call_function[target=operator.add](args = (%x, %arange), kwargs = {})
# return add
- graph = tracer.trace(model, meta_args={
- "x": torch.rand(10).to('meta'),
- })
+ meta_args = {'x': torch.rand(10).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_unary_element_wise_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_unary_element_wise_handler.py
index a861cb7f57f0..bd88089734a7 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_unary_element_wise_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_unary_element_wise_handler.py
@@ -1,12 +1,13 @@
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.unary_elementwise_handler import UnaryElementwiseHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
-from colossalai.fx.tracer.meta_patch.patched_module import linear
from colossalai.testing.pytest_wrapper import run_on_environment_flag
@@ -25,19 +26,20 @@ def forward(self, input, other):
@run_on_environment_flag(name='AUTO_PARALLEL')
def test_elementwise_handler():
model = ReLuModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %other : torch.Tensor [#users=1] = placeholder[target=other]
# %conv2d : [#users=1] = call_function[target=torch.conv2d](args = (%input_1, %other), kwargs = {})
# %act : [#users=1] = call_module[target=act](args = (%conv2d,), kwargs = {})
# return act
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(4, 4, 64, 64).to('meta'),
- "other": torch.rand(4, 16, 3, 3).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(4, 4, 64, 64).to('meta'),
+ 'other': torch.rand(16, 4, 3, 3).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
@@ -69,13 +71,13 @@ def test_elementwise_handler():
assert mapping['input'].name == "conv2d"
assert mapping['input'].data.is_meta
- assert mapping['input'].data.shape == torch.Size([4, 4, 62, 62])
+ assert mapping['input'].data.shape == torch.Size([4, 16, 62, 62])
assert mapping['input'].type == OperationDataType.ARG
- assert mapping['input'].logical_shape == torch.Size([4, 4, 62, 62])
+ assert mapping['input'].logical_shape == torch.Size([4, 16, 62, 62])
assert mapping['output'].name == "act"
assert mapping['output'].data.is_meta
- assert mapping['output'].data.shape == torch.Size([4, 4, 62, 62])
+ assert mapping['output'].data.shape == torch.Size([4, 16, 62, 62])
assert mapping['output'].type == OperationDataType.OUTPUT
# getitem is a following strategy handler, so the number of strategies is equal to the predecessor node.
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_view_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_view_handler.py
index 8a96ac0d66f0..300e8f94e7fe 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_view_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_view_handler.py
@@ -5,12 +5,14 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import ViewHandler
from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.linear_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -74,7 +76,7 @@ def check_view_handler(rank, tgt_shape, model_cls, world_size, port):
input_args=[input, other],
meta_arg_names=['input', 'other'],
node_type='following')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
if model_cls.__name__ == 'ConvViewModel':
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
@@ -82,11 +84,8 @@ def check_view_handler(rank, tgt_shape, model_cls, world_size, port):
# %conv2d : [#users=1] = call_function[target=torch.conv2d](args = (%input_1, %other), kwargs = {})
# %view : [#users=1] = call_method[target=view](args = (%conv2d, 2, -1), kwargs = {})
# return view
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 8, 66, 66).to('meta'),
- "other": torch.rand(16, 8, 3, 3).to('meta'),
- })
+ meta_args = {'input': torch.rand(8, 8, 66, 66).to('meta'), 'other': torch.rand(16, 8, 3, 3).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
if model_cls.__name__ == 'LinearViewModel':
# graph():
@@ -95,13 +94,14 @@ def check_view_handler(rank, tgt_shape, model_cls, world_size, port):
# %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%input_1, %other), kwargs = {bias: None})
# %view : [#users=1] = call_method[target=view](args = (%linear, 32, 4, 32, 32, 4), kwargs = {})
# return view
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 16, 64, 32).to('meta'),
- "other": torch.rand(64, 32).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(8, 16, 64, 32).to('meta'),
+ 'other': torch.rand(64, 32).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
previous_mod_node = list(graph.nodes)[2]
view_node = list(graph.nodes)[3]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_where_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_where_handler.py
index 9838e2eb01c6..c150ebd90053 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_where_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_where_handler.py
@@ -1,12 +1,13 @@
+import pytest
import torch
import torch.nn as nn
-from colossalai.auto_parallel.tensor_shard.node_handler.where_handler import \
- WhereHandler
-from colossalai.auto_parallel.tensor_shard.sharding_strategy import (OperationData, OperationDataType, StrategiesVector)
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
+from colossalai.auto_parallel.tensor_shard.node_handler.where_handler import WhereHandler
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
-from colossalai.fx.tracer.meta_patch.patched_module import linear
class ConvModel(nn.Module):
@@ -19,22 +20,24 @@ def forward(self, condition, x, y):
return output
+@pytest.mark.skip('ShapeProp is not compatible with PyTorch 1.11.0')
def test_where_handler():
model = ConvModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %condition : torch.Tensor [#users=1] = placeholder[target=condition]
# %x : torch.Tensor [#users=1] = placeholder[target=x]
# %y : torch.Tensor [#users=1] = placeholder[target=y]
# %where : [#users=1] = call_function[target=torch.where](args = (%condition, %x, %y), kwargs = {})
# return where
- graph = tracer.trace(model,
- meta_args={
- "condition": torch.rand(4, 4, 64, 64).to('meta'),
- "x": torch.rand(4, 1, 64, 64).to('meta'),
- "y": torch.rand(1, 4, 64, 64).to('meta')
- })
+ meta_args = {
+ 'condition': torch.rand(4, 4, 64, 64).to('meta'),
+ 'x': torch.rand(4, 1, 64, 64).to('meta'),
+ 'y': torch.rand(1, 4, 64, 64).to('meta')
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/utils.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/utils.py
index 0cdfdbc9d0cd..28a8bbd9a4c1 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/utils.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/utils.py
@@ -4,6 +4,9 @@
import torch
from torch.fx import GraphModule
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.passes.runtime_apply_pass import runtime_apply_pass
from colossalai.auto_parallel.passes.runtime_preparation_pass import runtime_preparation_pass
from colossalai.auto_parallel.tensor_shard.options import SolverOptions
@@ -11,7 +14,6 @@
from colossalai.auto_parallel.tensor_shard.solver.cost_graph import CostGraph
from colossalai.auto_parallel.tensor_shard.solver.solver import Solver
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx.tracer.tracer import ColoTracer
from colossalai.tensor.shape_consistency import to_global
from colossalai.testing.comparison import assert_close
@@ -79,14 +81,16 @@ def numerical_test_for_node_strategy(model: torch.nn.Module,
model_to_shard, args_to_shard, kwargs_to_shard = _build_model_to_compare(model, input_args, input_kwargs,
grad_to_shard_dict)
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
input_sample = {}
for input_arg, meta_arg_name in zip(input_args, meta_arg_names):
- input_sample[meta_arg_name] = torch.rand(input_arg.shape).to('meta')
+ input_sample[meta_arg_name] = torch.empty(input_arg.shape, dtype=input_arg.dtype).to('meta')
for meta_kwarg_name, input_kwarg in input_kwargs.items():
- input_sample[meta_kwarg_name] = torch.rand(input_kwarg.shape).to('meta')
+ input_sample[meta_kwarg_name] = torch.empty(input_kwarg.shape, dtype=input_kwarg.dtype).to('meta')
graph = tracer.trace(root=model_to_shard, meta_args=input_sample)
- gm = GraphModule(model_to_shard, graph, model_to_shard.__class__.__name__)
+ gm = ColoGraphModule(model_to_shard, graph, model_to_shard.__class__.__name__)
+ shape_prop_pass(gm, *input_sample.values())
+
solver_options = SolverOptions()
strategies_constructor = StrategiesConstructor(graph, device_mesh, solver_options)
strategies_constructor.build_strategies_and_cost()
diff --git a/tests/test_booster/test_plugin/test_gemini_plugin.py b/tests/test_booster/test_plugin/test_gemini_plugin.py
new file mode 100644
index 000000000000..7a0d4a15d53a
--- /dev/null
+++ b/tests/test_booster/test_plugin/test_gemini_plugin.py
@@ -0,0 +1,150 @@
+from functools import partial
+
+import pytest
+import torch
+import torch.distributed as dist
+import torch.multiprocessing as mp
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.tensor.colo_parameter import ColoParameter
+from colossalai.testing import rerun_if_address_is_in_use
+from colossalai.utils import free_port
+from tests.kit.model_zoo import model_zoo
+
+
+def check_gemini_plugin(early_stop: bool = True):
+ """check gemini plugin over model zoo
+
+ Args:
+ early_stop (bool, optional): Whether to stop when getting the first error. Defaults to True.
+ """
+ plugin = GeminiPlugin(placement_policy='cuda', strict_ddp_mode=True, max_norm=1.0, initial_scale=2**5)
+ booster = Booster(plugin=plugin)
+
+ passed_models = []
+ failed_info = {} # (model_name, error) pair
+
+ for name, (model_fn, data_gen_fn, output_transform_fn, _) in model_zoo.items():
+ # These models lead to CUDA error
+ if name in ('diffusers_auto_encoder_kl', 'diffusers_vq_model', 'diffusers_unet2d_model', 'timm_resmlp',
+ 'timm_gmixer_12_224', 'timm_gmlp_b16_224', 'timm_mixer_b16_224', 'timm_convnext'):
+ continue
+ # These models are not compatible with gemini
+ if name in [
+ 'diffusers_clip_vision_model',
+ 'timm_resnet',
+ 'timm_beit',
+ 'timm_beitv2',
+ 'timm_eca_nfnet',
+ 'timm_efficientformer',
+ 'timm_hrnet_w18_small',
+ 'timm_nf_ecaresnet101',
+ 'timm_nf_regnet_b0',
+ 'timm_skresnet18',
+ 'timm_wide_resnet50_2',
+ 'timm_convit',
+ 'timm_dm_nfnet',
+ 'timm_swin_transformer',
+ 'torchaudio_conformer',
+ 'torchaudio_deepspeech',
+ 'torchaudio_wavernn',
+ 'torchaudio_tacotron',
+ 'deepfm_interactionarch',
+ 'deepfm_simpledeepfmnn',
+ 'dlrm',
+ 'dlrm_interactionarch',
+ 'torchvision_googlenet',
+ 'torchvision_inception_v3',
+ 'torchvision_mobilenet_v3_small',
+ 'torchvision_resnet18',
+ 'torchvision_resnext50_32x4d',
+ 'torchvision_wide_resnet50_2',
+ 'torchvision_vit_b_16',
+ 'torchvision_convnext_base',
+ 'torchvision_swin_s',
+ 'transformers_albert',
+ 'transformers_albert_for_pretraining',
+ 'transformers_bert',
+ 'transformers_bert_for_pretraining',
+ 'transformers_gpt_double_heads',
+ 'torchaudio_hubert_base',
+ ]:
+ continue
+ try:
+ model = model_fn()
+ optimizer = HybridAdam(model.parameters(), lr=1e-3)
+ criterion = lambda x: x.mean()
+ data = data_gen_fn()
+
+ data = {
+ k: v.to('cuda') if torch.is_tensor(v) or 'Tensor' in v.__class__.__name__ else v
+ for k, v in data.items()
+ }
+
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+
+ for n, p in model.named_parameters():
+ assert isinstance(p, ColoParameter), f'{n} is not a ColoParameter'
+
+ output = model(**data)
+ output = output_transform_fn(output)
+ output_key = list(output.keys())[0]
+ loss = criterion(output[output_key])
+
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ passed_models.append(name)
+ except Exception as e:
+ failed_info[name] = e
+ if early_stop:
+ raise e
+ if dist.get_rank() == 0:
+ print(f'Passed models({len(passed_models)}): {passed_models}\n\n')
+ print(f'Failed models({len(failed_info)}): {list(failed_info.keys())}\n\n')
+ assert len(failed_info) == 0, '\n'.join([f'{k}: {v}' for k, v in failed_info.items()])
+
+
+def check_dataloader_sharding():
+ plugin = GeminiPlugin()
+
+ # create a custom dasetset with 0 to 10
+ dataset = torch.utils.data.TensorDataset(torch.arange(0, 10))
+ train_dataloader = plugin.prepare_train_dataloader(dataset, batch_size=2)
+
+ # get the first batch of data
+ batch = next(iter(train_dataloader))[0].cuda()
+ is_rank_0 = dist.get_rank() == 0
+
+ if is_rank_0:
+ batch_to_compare = batch.clone()
+ else:
+ batch_to_compare = batch
+ # pass to the rank 1 value to rank 0
+ dist.broadcast(batch_to_compare, src=1)
+
+ # compare on rank 0
+ if is_rank_0:
+ assert not torch.equal(batch,
+ batch_to_compare), 'Same number was found across ranks but expected it to be different'
+
+
+def run_dist(rank, world_size, port, early_stop: bool = True):
+ # init dist env
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ check_dataloader_sharding()
+ check_gemini_plugin(early_stop=early_stop)
+
+
+@pytest.mark.skip(reason='Skip gemini plugin test due to OOM')
+@rerun_if_address_is_in_use()
+def test_gemini_plugin(early_stop: bool = True):
+ world_size = 2
+ run_func = partial(run_dist, world_size=world_size, port=free_port(), early_stop=early_stop)
+ mp.spawn(run_func, nprocs=world_size)
+
+
+if __name__ == '__main__':
+ test_gemini_plugin(early_stop=False)
diff --git a/tests/test_fx/test_pipeline/test_topo/test_topo.py b/tests/test_fx/test_pipeline/test_topo/test_topo.py
index 75c74870523c..16da56250dc3 100644
--- a/tests/test_fx/test_pipeline/test_topo/test_topo.py
+++ b/tests/test_fx/test_pipeline/test_topo/test_topo.py
@@ -1,11 +1,13 @@
import pytest
import torch
import transformers
-from topo_utils import split_model_and_get_DAG, check_topo, MLP
+from topo_utils import MLP, check_topo, split_model_and_get_DAG
BATCH_SIZE = 1
SEQ_LENGHT = 16
+
+@pytest.mark.skip('ShapeProp is not compatible with PyTorch 1.11.0')
def test_opt():
MODEL_LIST = [
MLP,
@@ -13,7 +15,10 @@ def test_opt():
]
CONFIGS = [
- {'dim': 10, 'layers': 12},
+ {
+ 'dim': 10,
+ 'layers': 12
+ },
transformers.OPTConfig(vocab_size=100, hidden_size=128, num_hidden_layers=4, num_attention_heads=4),
]
@@ -21,15 +26,15 @@ def data_gen_MLP():
x = torch.zeros((16, 10))
kwargs = dict(x=x)
return kwargs
-
+
def data_gen_OPT():
input_ids = torch.zeros((BATCH_SIZE, SEQ_LENGHT), dtype=torch.int64)
attention_mask = torch.zeros((BATCH_SIZE, SEQ_LENGHT), dtype=torch.int64)
kwargs = dict(input_ids=input_ids, attention_mask=attention_mask)
return kwargs
-
+
DATAGEN = [
- data_gen_MLP,
+ data_gen_MLP,
data_gen_OPT,
]
@@ -39,5 +44,6 @@ def data_gen_OPT():
# print(f'{top_mod=}\n----\n{topo=}')
check_topo(top_mod, topo)
+
if __name__ == '__main__':
- test_opt()
\ No newline at end of file
+ test_opt()
diff --git a/tests/test_moe/test_moe_checkpoint.py b/tests/test_moe/test_moe_checkpoint.py
new file mode 100644
index 000000000000..f99e74ea55c1
--- /dev/null
+++ b/tests/test_moe/test_moe_checkpoint.py
@@ -0,0 +1,54 @@
+import os
+from functools import partial
+
+import pytest
+import torch
+import torch.distributed as dist
+import torch.multiprocessing as mp
+
+import colossalai
+from colossalai.context import MOE_CONTEXT
+from colossalai.nn.layer.moe import load_moe_model, save_moe_model
+from colossalai.testing import parameterize, rerun_if_address_is_in_use
+from colossalai.utils import free_port, get_current_device
+from colossalai.utils.model.colo_init_context import ColoInitContext
+from tests.test_moe.test_moe_zero_init import MoeModel
+from tests.test_tensor.common_utils import debug_print
+from tests.test_zero.common import CONFIG
+
+
+def exam_moe_checkpoint():
+ with ColoInitContext(device=get_current_device()):
+ model = MoeModel(checkpoint=True)
+ save_moe_model(model, 'temp_path.pth')
+
+ with ColoInitContext(device=get_current_device()):
+ other_model = MoeModel(checkpoint=True)
+ load_moe_model(other_model, 'temp_path.pth')
+
+ state_0 = model.state_dict()
+ state_1 = other_model.state_dict()
+ for k, v in state_0.items():
+ u = state_1.get(k)
+ assert torch.equal(u.data, v.data)
+
+ if dist.get_rank() == 0:
+ os.remove('temp_path.pth')
+
+
+def _run_dist(rank, world_size, port):
+ colossalai.launch(config=CONFIG, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ MOE_CONTEXT.setup(seed=42)
+ exam_moe_checkpoint()
+
+
+@pytest.mark.dist
+@pytest.mark.parametrize("world_size", [2, 4])
+@rerun_if_address_is_in_use()
+def test_moe_checkpoint(world_size):
+ run_func = partial(_run_dist, world_size=world_size, port=free_port())
+ mp.spawn(run_func, nprocs=world_size)
+
+
+if __name__ == '__main__':
+ test_moe_checkpoint(world_size=4)
diff --git a/version.txt b/version.txt
index b0032849c80b..a45be4627678 100644
--- a/version.txt
+++ b/version.txt
@@ -1 +1 @@
-0.2.7
+0.2.8
diff --git a/examples/images/diffusion/README.md b/examples/images/diffusion/README.md
index 3f9690500130..0c7f42ded318 100644
--- a/examples/images/diffusion/README.md
+++ b/examples/images/diffusion/README.md
@@ -37,7 +37,7 @@ This project is in rapid development.
## Installation
-### Option #1: install from source
+### Option #1: Install from source
#### Step 1: Requirements
To begin with, make sure your operating system has the cuda version suitable for this exciting training session, which is cuda11.6/11.8. For your convience, we have set up the rest of packages here. You can create and activate a suitable [conda](https://conda.io/) environment named `ldm` :
@@ -54,11 +54,11 @@ conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit
pip install transformers diffusers invisible-watermark
```
-#### Step 2:Install [Colossal-AI](https://colossalai.org/download/) From Our Official Website
+#### Step 2: Install [Colossal-AI](https://colossalai.org/download/) From Our Official Website
You can install the latest version (0.2.7) from our official website or from source. Notice that the suitable version for this training is colossalai(0.2.5), which stands for torch(1.12.1).
-##### Download suggested verision for this training
+##### Download suggested version for this training
```
pip install colossalai==0.2.5
@@ -80,9 +80,9 @@ cd ColossalAI
CUDA_EXT=1 pip install .
```
-#### Step 3:Accelerate with flash attention by xformers(Optional)
+#### Step 3: Accelerate with flash attention by xformers (Optional)
-Notice that xformers will accelerate the training process in cost of extra disk space. The suitable version of xformers for this training process is 0.12.0. You can download xformers directly via pip. For more release versions, feel free to check its official website: [XFormers](./https://pypi.org/project/xformers/)
+Notice that xformers will accelerate the training process at the cost of extra disk space. The suitable version of xformers for this training process is 0.0.12, which can be downloaded directly via pip. For more release versions, feel free to check its official website: [XFormers](https://pypi.org/project/xformers/)
```
pip install xformers==0.0.12
@@ -120,7 +120,7 @@ docker run --rm \
/bin/bash
########################
-# Insider Container #
+# Inside a Container #
########################
# Once you have entered the docker container, go to the stable diffusion directory for training
cd examples/images/diffusion/
@@ -132,14 +132,14 @@ bash train_colossalai.sh
```
It is important for you to configure your volume mapping in order to get the best training experience.
-1. **Mandatory**, mount your prepared data to `/data/scratch` via `-v :/data/scratch`, where you need to replace `` with the actual data path on your machine. Notice that within docker we need to transform Win expresison into Linuxd, e.g. C:\User\Desktop into /c/User/Desktop.
+1. **Mandatory**, mount your prepared data to `/data/scratch` via `-v :/data/scratch`, where you need to replace `` with the actual data path on your machine. Notice that within docker we need to transform the Windows path to a Linux one, e.g. `C:\User\Desktop` into `/mnt/c/User/Desktop`.
2. **Recommended**, store the downloaded model weights to your host machine instead of the container directory via `-v :/root/.cache/huggingface`, where you need to replace the `` with the actual path. In this way, you don't have to repeatedly download the pretrained weights for every `docker run`.
3. **Optional**, if you encounter any problem stating that shared memory is insufficient inside container, please add `-v /dev/shm:/dev/shm` to your `docker run` command.
## Download the model checkpoint from pretrained
-### stable-diffusion-v2-base(Recommand)
+### stable-diffusion-v2-base (Recommended)
```
wget https://huggingface.co/stabilityai/stable-diffusion-2-base/resolve/main/512-base-ema.ckpt
@@ -182,12 +182,12 @@ python main.py --logdir /tmp/ --train --base configs/train_colossalai.yaml --ckp
### Training config
-You can change the trainging config in the yaml file
+You can change the training config in the yaml file
- devices: device number used for training, default = 8
- max_epochs: max training epochs, default = 2
- precision: the precision type used in training, default = 16 (fp16), you must use fp16 if you want to apply colossalai
-- placement_policy: the training strategy supported by Colossal AI, defult = 'cuda', which refers to loading all the parameters into cuda memory. On the other hand, 'cpu' refers to 'cpu offload' strategy while 'auto' enables 'Gemini', both featured by Colossal AI.
+- placement_policy: the training strategy supported by Colossal AI, default = 'cuda', which refers to loading all the parameters into cuda memory. On the other hand, 'cpu' refers to 'cpu offload' strategy while 'auto' enables 'Gemini', both featured by Colossal AI.
- more information about the configuration of ColossalAIStrategy can be found [here](https://pytorch-lightning.readthedocs.io/en/latest/advanced/model_parallel.html#colossal-ai)
@@ -202,7 +202,8 @@ python main.py --logdir /tmp/ -t -b configs/Teyvat/train_colossalai_teyvat.yaml
```
## Inference
-you can get yout training last.ckpt and train config.yaml in your `--logdir`, and run by
+
+You can get your training last.ckpt and train config.yaml in your `--logdir`, and run by
```
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
--outdir ./output \
diff --git a/requirements/requirements.txt b/requirements/requirements.txt
index e32b3ecda063..4e4f35edb2d9 100644
--- a/requirements/requirements.txt
+++ b/requirements/requirements.txt
@@ -8,4 +8,4 @@ click
fabric
contexttimer
ninja
-torch>=1.11,<2.0
+torch>=1.11
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addmm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addmm_handler.py
index aa5a57474335..35f12ce83af2 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addmm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_addmm_handler.py
@@ -1,22 +1,20 @@
-from faulthandler import disable
from functools import partial
-from xml.dom import WrongDocumentErr
import pytest
import torch
import torch.multiprocessing as mp
import torch.nn as nn
-from typing_extensions import Self
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
- OperationData,
OperationDataType,
ShardingStrategy,
StrategiesVector,
)
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import parameterize, rerun_if_address_is_in_use
@@ -96,7 +94,7 @@ def check_addmm_function_handler(rank, input_shape, model_cls, world_size, port)
meta_arg_names=meta_arg_names,
node_type='bias_module')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %m1 : torch.Tensor [#users=1] = placeholder[target=m1]
@@ -109,6 +107,7 @@ def check_addmm_function_handler(rank, input_shape, model_cls, world_size, port)
# return add
graph = tracer.trace(model, meta_args=meta_args_for_tracer)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args_for_tracer.values())
# [input_1, m1, m2, addmm, output]
node_list = list(graph.nodes)
linear_node = node_list[4]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_batch_norm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_batch_norm_handler.py
index 0ab70abffb4c..2069b5e8a4de 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_batch_norm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_batch_norm_handler.py
@@ -5,10 +5,12 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.batch_norm_handler import BatchNormModuleHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -38,13 +40,15 @@ def check_bn_module_handler(rank, world_size, port):
strategy_number=strategy_number,
input_args=[input],
meta_arg_names=['input'])
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %_0 : [#users=1] = call_module[target=0](args = (%input_1,), kwargs = {})
# return _0
- graph = tracer.trace(model, meta_args={"input": torch.rand(4, 16, 64, 64).to('meta')})
+ meta_args = {"input": torch.rand(4, 16, 64, 64).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
bn_mod_node = list(graph.nodes)[1]
strategies_vector = StrategiesVector(bn_mod_node)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_function_node.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_function_node.py
index 162d1fbba295..dca5f6e227fa 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_function_node.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_function_node.py
@@ -1,14 +1,14 @@
-from faulthandler import disable
from functools import partial
-from xml.dom import WrongDocumentErr
import pytest
import torch
import torch.multiprocessing as mp
import torch.nn as nn
import torch.nn.functional as F
-from typing_extensions import Self
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import LinearFunctionHandler, LinearModuleHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
OperationData,
@@ -17,12 +17,10 @@
StrategiesVector,
)
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
from colossalai.testing.pytest_wrapper import run_on_environment_flag
-from colossalai.testing.utils import parameterize
from colossalai.utils import free_port
from tests.test_auto_parallel.test_tensor_shard.test_node_handler.utils import numerical_test_for_node_strategy
@@ -66,7 +64,7 @@ def check_linear_module_handler(rank, world_size, port):
meta_arg_names=meta_arg_names,
node_type='bias_module')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %x : torch.Tensor [#users=1] = placeholder[target=x]
# %weight : [#users=1] = get_attr[target=weight]
@@ -74,8 +72,10 @@ def check_linear_module_handler(rank, world_size, port):
# %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%x, %weight), kwargs = {})
# %add : [#users=1] = call_function[target=operator.add](args = (%linear, %bias), kwargs = {})
# return add
- graph = tracer.trace(model, meta_args={"x": torch.rand(4, 4, 4, 16).to('meta')})
+ meta_args = {"x": torch.rand(4, 4, 4, 16).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
linear_mod_node = list(graph.nodes)[3]
strategies_vector = StrategiesVector(linear_mod_node)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_module_node.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_module_node.py
index c5c3f378197e..14d4a73fb4f8 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_module_node.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bias_linear_module_node.py
@@ -1,13 +1,13 @@
-from faulthandler import disable
from functools import partial
-from xml.dom import WrongDocumentErr
import pytest
import torch
import torch.multiprocessing as mp
import torch.nn as nn
-from typing_extensions import Self
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import LinearFunctionHandler, LinearModuleHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
OperationData,
@@ -16,12 +16,10 @@
StrategiesVector,
)
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
from colossalai.testing.pytest_wrapper import run_on_environment_flag
-from colossalai.testing.utils import parameterize
from colossalai.utils import free_port
from tests.test_auto_parallel.test_tensor_shard.test_node_handler.utils import numerical_test_for_node_strategy
@@ -62,9 +60,11 @@ def check_linear_module_handler(rank, bias, world_size, port):
meta_arg_names=meta_arg_names,
node_type='bias_module')
- tracer = ColoTracer()
- graph = tracer.trace(model, meta_args={"x": torch.rand(4, 4, 4, 16).to('meta')})
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {"x": torch.rand(4, 4, 4, 16).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
linear_mod_node = list(graph.nodes)[3]
strategies_vector = StrategiesVector(linear_mod_node)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py
index 50385c0450a8..2414749f60a4 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py
@@ -5,10 +5,12 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import BinaryElementwiseHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -52,10 +54,11 @@ def forward(self, x1, x2):
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
meta_args = {'x1': torch.rand(4, 4).to('meta'), 'x2': torch.rand([4] * other_dim).to('meta')}
graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
op_node = list(graph.nodes)[2]
strategies_vector = StrategiesVector(op_node)
@@ -172,12 +175,11 @@ def check_binary_elementwise_handler_with_int(rank, op, other_dim, model_cls, wo
strategy_number=strategy_number,
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
meta_args = {'x1': torch.rand(4, 4).to('meta')}
graph = tracer.trace(model, meta_args=meta_args)
- print(graph)
- # assert False
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
if model_cls == BEOpModelWithNodeConst:
op_node = list(graph.nodes)[2]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bmm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bmm_handler.py
index 02c7e0671149..34c20c1ac0fe 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bmm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_bmm_handler.py
@@ -5,10 +5,12 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import BMMFunctionHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -52,13 +54,11 @@ def check_2d_device_mesh(rank, module, world_size, port):
strategy_number=strategy_number,
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
- graph = tracer.trace(model,
- meta_args={
- "x1": torch.rand(4, 8, 16).to('meta'),
- 'x2': torch.rand(4, 16, 8).to('meta')
- })
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {'x1': torch.rand(4, 8, 16).to('meta'), 'x2': torch.rand(4, 16, 8).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
linear_mod_node = list(graph.nodes)[2]
strategies_vector = StrategiesVector(linear_mod_node)
@@ -147,13 +147,11 @@ def check_1d_device_mesh(rank, module, world_size, port):
strategy_number=strategy_number,
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
- graph = tracer.trace(model,
- meta_args={
- "x1": torch.rand(4, 8, 16).to('meta'),
- 'x2': torch.rand(4, 16, 8).to('meta')
- })
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {'x1': torch.rand(4, 8, 16).to('meta'), 'x2': torch.rand(4, 16, 8).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
linear_mod_node = list(graph.nodes)[2]
strategies_vector = StrategiesVector(linear_mod_node)
@@ -205,6 +203,7 @@ def check_1d_device_mesh(rank, module, world_size, port):
@run_on_environment_flag(name='AUTO_PARALLEL')
@parameterize('module', [BMMTensorMethodModule, BMMTorchFunctionModule])
+@parameterize('module', [BMMTensorMethodModule, BMMTorchFunctionModule])
@pytest.mark.dist
@rerun_if_address_is_in_use()
def test_bmm_handler(module):
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_conv_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_conv_handler.py
index 2acd015c8f59..fe1a0d726db0 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_conv_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_conv_handler.py
@@ -5,10 +5,12 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler, ConvModuleHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -41,9 +43,11 @@ def check_conv_module_handler(rank, bias, world_size, port):
strategy_number=strategy_number,
input_args=[input],
meta_arg_names=['input'])
- tracer = ColoTracer()
- graph = tracer.trace(model, meta_args={"input": torch.rand(4, 4, 64, 64).to('meta')})
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {'input': torch.rand(4, 4, 64, 64).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
conv_mod_node = list(graph.nodes)[1]
strategies_vector = StrategiesVector(conv_mod_node)
@@ -178,7 +182,7 @@ def check_conv_function_handler(rank, bias, world_size, port):
meta_arg_names=meta_arg_names,
input_kwargs=input_kwargs)
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %others : torch.Tensor [#users=1] = placeholder[target=others]
@@ -189,6 +193,7 @@ def check_conv_function_handler(rank, bias, world_size, port):
meta_args['bias'] = torch.rand(16).to('meta')
graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
if bias:
conv_mod_node = list(graph.nodes)[3]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_default_reshape_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_default_reshape_handler.py
index ea7c2b729635..8e5b7512ca0e 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_default_reshape_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_default_reshape_handler.py
@@ -1,11 +1,13 @@
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import DefaultReshapeHandler
from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.testing.pytest_wrapper import run_on_environment_flag
@@ -23,19 +25,20 @@ def forward(self, input, other):
@run_on_environment_flag(name='AUTO_PARALLEL')
def test_reshape_handler():
model = ReshapeModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %other : torch.Tensor [#users=1] = placeholder[target=other]
# %conv2d : [#users=1] = call_function[target=torch.conv2d](args = (%input_1, %other), kwargs = {})
# %view : [#users=1] = call_method[target=view](args = (%conv2d, 2, -1), kwargs = {})
# return view
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(4, 4, 64, 64).to('meta'),
- "other": torch.rand(4, 16, 3, 3).to('meta'),
- })
+ meta_args = {
+ "input": torch.rand(4, 4, 64, 64).to('meta'),
+ "other": torch.rand(16, 4, 3, 3).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
@@ -67,13 +70,13 @@ def test_reshape_handler():
assert mapping['input'].name == "conv2d"
assert mapping['input'].data.is_meta
- assert mapping['input'].data.shape == torch.Size([4, 4, 62, 62])
+ assert mapping['input'].data.shape == torch.Size([4, 16, 62, 62])
assert mapping['input'].type == OperationDataType.ARG
- assert mapping['input'].logical_shape == torch.Size([4, 4, 62, 62])
+ assert mapping['input'].logical_shape == torch.Size([4, 16, 62, 62])
assert mapping['output'].name == "view"
assert mapping['output'].data.is_meta
- assert mapping['output'].data.shape == torch.Size([2, 30752])
+ assert mapping['output'].data.shape == torch.Size([2, 123008])
assert mapping['output'].type == OperationDataType.OUTPUT
# reshape handler is a following strategy handler, so the number of strategies is equal to the predecessor node.
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_embedding_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_embedding_handler.py
index 5bce383dd0ab..a61d2ed5c108 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_embedding_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_embedding_handler.py
@@ -5,13 +5,15 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.embedding_handler import (
EmbeddingFunctionHandler,
EmbeddingModuleHandler,
)
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -60,9 +62,11 @@ def check_embedding_module_handler(rank, world_size, port):
input_args=[input],
meta_arg_names=['input'])
- tracer = ColoTracer()
- graph = tracer.trace(model, meta_args={"input": torch.rand(4, 16, 16).to('meta')})
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {"input": torch.randint(NUM_EMBEDDINGS, (4, 16, 16)).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
embedding_node = list(graph.nodes)[1]
strategies_vector = StrategiesVector(embedding_node)
@@ -171,18 +175,19 @@ def check_embedding_function_handler(rank, world_size, port):
input_args=input_args,
meta_arg_names=meta_arg_names,
input_kwargs=input_kwargs)
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %others : torch.Tensor [#users=1] = placeholder[target=others]
# %embedding : [#users=1] = call_function[target=torch.nn.functional.embedding](args = (%input_1, %others), kwargs = {padding_idx: None, max_norm: None, norm_type: 2.0, scale_grad_by_freq: False, sparse: False})
# return embedding
meta_args = {
- "input": torch.rand(4, 16, 16).to('meta'),
+ "input": torch.randint(NUM_EMBEDDINGS, (4, 16, 16)).to('meta'),
"others": torch.rand(NUM_EMBEDDINGS, EMBEDDING_DIMS).to('meta')
}
graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
embedding_node = list(graph.nodes)[2]
strategies_vector = StrategiesVector(embedding_node)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getattr_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getattr_handler.py
index 681e93a5fe16..fb611330946a 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getattr_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getattr_handler.py
@@ -1,10 +1,13 @@
+import pytest
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.getattr_handler import GetattrHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
class GetattrModel(nn.Module):
@@ -18,15 +21,18 @@ def forward(self, input):
return weight
+@pytest.mark.skip('ShapeProp is not compatible with PyTorch 1.11.0')
def test_getattr_handler():
model = GetattrModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=0] = placeholder[target=input]
# %conv_weight : [#users=1] = get_attr[target=conv.weight]
# return conv_weight
- graph = tracer.trace(model, meta_args={'input': torch.rand(4, 4, 64, 64).to('meta')})
+ meta_args = {'input': torch.rand(4, 4, 64, 64).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
device_mesh = DeviceMesh(physical_mesh_id, mesh_shape)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getitem_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getitem_handler.py
index c72d2a6a80e8..9a29808ebb31 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getitem_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_getitem_handler.py
@@ -5,13 +5,15 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.default_reshape_handler import DefaultReshapeHandler
from colossalai.auto_parallel.tensor_shard.node_handler.getitem_handler import GetItemHandler
from colossalai.auto_parallel.tensor_shard.node_handler.linear_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.placeholder_handler import PlaceholderHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.fx.tracer.meta_patch.patched_module import linear
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
@@ -58,15 +60,15 @@ def check_getitem_from_tensor_handler(rank, getitem_index, world_size, port):
meta_arg_names=['input', 'other'],
node_type='following')
- tracer = ColoTracer()
-
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 16, 64, 32).to('meta'),
- "other": torch.rand(64, 32).to('meta'),
- })
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {
+ "input": torch.rand(8, 16, 64, 32).to('meta'),
+ "other": torch.rand(64, 32).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *list(meta_args.values()))
linear_mod_node = list(graph.nodes)[2]
getitem_mod_node = list(graph.nodes)[3]
getitem_strategies_vector = StrategiesVector(getitem_mod_node)
@@ -129,10 +131,12 @@ def test_getitem_from_tuple_handler():
# %split : [#users=1] = call_function[target=torch.functional.split](args = (%conv2d, 2), kwargs = {dim: 0})
# %getitem : [#users=1] = call_function[target=operator.getitem](args = (%split, 1), kwargs = {})
# return getitem
- graph = tracer.trace(model, meta_args={
+ meta_args = {
"input": torch.rand(4, 4, 64, 64).to('meta'),
- })
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_layer_norm_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_layer_norm_handler.py
index f4d0063fd6b6..edd7bae6c979 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_layer_norm_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_layer_norm_handler.py
@@ -5,10 +5,12 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.layer_norm_handler import LayerNormModuleHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.fx.tracer.meta_patch.patched_module import linear
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
@@ -40,13 +42,15 @@ def check_ln_module_handler(rank, world_size, port):
strategy_number=strategy_number,
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %_0 : [#users=1] = call_module[target=0](args = (%input_1,), kwargs = {})
# return _0
- graph = tracer.trace(model, meta_args={"input": torch.rand(4, 16).to('meta')})
+ meta_args = {"input": torch.rand(4, 16).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
ln_mod_node = list(graph.nodes)[1]
strategies_vector = StrategiesVector(ln_mod_node)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_linear_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_linear_handler.py
index 18afacf56b8e..bec5c3dc5e28 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_linear_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_linear_handler.py
@@ -5,6 +5,9 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import LinearFunctionHandler, LinearModuleHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
OperationData,
@@ -13,7 +16,6 @@
StrategiesVector,
)
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -49,9 +51,11 @@ def check_linear_module_handler(rank, bias, input_shape, world_size, port):
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
- graph = tracer.trace(model, meta_args={"input": torch.rand(input_shape).to('meta')})
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {"input": torch.rand(input_shape).cuda()}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
linear_mod_node = list(graph.nodes)[1]
strategies_vector = StrategiesVector(linear_mod_node)
@@ -196,13 +200,12 @@ def check_linear_function_handler(rank, bias, input_shape, world_size, port):
input_args=input_args,
meta_arg_names=meta_arg_names)
- tracer = ColoTracer()
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(input_shape).to('meta'),
- 'others': torch.rand(32, 16).to('meta')
- })
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {'input': torch.rand(input_shape).to('meta'), 'others': torch.rand(32, 16).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
+
if bias:
linear_func_node = list(graph.nodes)[3]
else:
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_matmul_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_matmul_handler.py
index 91b3ae27d599..46c3ff4434d7 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_matmul_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_matmul_handler.py
@@ -2,6 +2,9 @@
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.matmul_handler import (
MatMulHandler,
MatMulType,
@@ -15,7 +18,6 @@
StrategiesVector,
)
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.testing.utils import parameterize
@@ -57,9 +59,11 @@ def test_matmul_node_handler(tensor_shapes):
model = MatMulModule()
- tracer = ColoTracer()
- graph = tracer.trace(model, meta_args={"x1": x1.to('meta'), 'x2': x2.to('meta')})
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {"x1": x1.to('meta'), 'x2': x2.to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
print(graph)
@@ -124,7 +128,6 @@ def test_matmul_node_handler(tensor_shapes):
input_sharding_spec = strategy.get_sharding_spec_by_name('x1')
other_sharding_spec = strategy.get_sharding_spec_by_name('x2')
output_sharding_spec = strategy.get_sharding_spec_by_name('matmul')
-
if matmul_type == MatMulType.DOT:
# dot product will produce a scaler
# results should fulfill:
@@ -159,7 +162,10 @@ def test_matmul_node_handler(tensor_shapes):
if len(other_shape) > 1:
assert other_sharding_spec.sharding_sequence[-1] == output_sharding_spec.sharding_sequence[-1]
if len(input_shape) > 1:
- assert input_sharding_spec.sharding_sequence[-2] == output_sharding_spec.sharding_sequence[-2]
+ if len(other_shape) == 1:
+ assert input_sharding_spec.sharding_sequence[-2] == output_sharding_spec.sharding_sequence[-1]
+ else:
+ assert input_sharding_spec.sharding_sequence[-2] == output_sharding_spec.sharding_sequence[-2]
if len(other_shape) > 2:
assert other_sharding_spec.sharding_sequence[-2] == input_sharding_spec.sharding_sequence[-1]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_norm_pooling_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_norm_pooling_handler.py
index f219bc2f3976..aacc7d9aeb64 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_norm_pooling_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_norm_pooling_handler.py
@@ -2,10 +2,12 @@
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.normal_pooling_handler import NormPoolingHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.fx.tracer.meta_patch.patched_module import linear
from colossalai.testing.pytest_wrapper import run_on_environment_flag
@@ -13,14 +15,16 @@
@run_on_environment_flag(name='AUTO_PARALLEL')
def test_norm_pool_handler():
model = nn.Sequential(nn.MaxPool2d(4, padding=1).to('meta'))
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %_0 : [#users=1] = call_module[target=0](args = (%input_1,), kwargs = {})
# return _0
- graph = tracer.trace(model, meta_args={"input": torch.rand(4, 4, 64, 64).to('meta')})
+ meta_args = {"input": torch.rand(4, 4, 64, 64).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_output_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_output_handler.py
index 26376c429ebc..5efbb4f5f6a4 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_output_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_output_handler.py
@@ -1,10 +1,13 @@
+import pytest
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.output_handler import OutputHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -18,19 +21,20 @@ def forward(self, x):
return x, y
+@pytest.mark.skip('ShapeProp is not compatible with PyTorch 1.11.0')
@parameterize('output_option', ['distributed', 'replicated'])
@rerun_if_address_is_in_use()
def test_output_handler(output_option):
model = OutputModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %x : torch.Tensor [#users=2] = placeholder[target=x]
# %mul : [#users=1] = call_function[target=operator.mul](args = (%x, 2), kwargs = {})
# return (x, mul)
- graph = tracer.trace(model, meta_args={
- "x": torch.rand(4, 4, 64, 64).to('meta'),
- })
+ meta_args = {'x': torch.rand(4, 4, 64, 64).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_permute_and_transpose_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_permute_and_transpose_handler.py
index af03481d830e..0a5ad3e3523d 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_permute_and_transpose_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_permute_and_transpose_handler.py
@@ -5,12 +5,14 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import PermuteHandler, TransposeHandler
from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.linear_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -88,7 +90,7 @@ def check_view_handler(rank, call_function, reshape_dims, model_cls, world_size,
input_args=[input, other],
meta_arg_names=['input', 'other'],
node_type='following')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
if model_cls.__name__ == 'ConvReshapeModel':
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
@@ -96,11 +98,11 @@ def check_view_handler(rank, call_function, reshape_dims, model_cls, world_size,
# %conv2d : [#users=1] = call_function[target=torch.conv2d](args = (%input_1, %other), kwargs = {bias: None})
# %permute : [#users=1] = call_function[target=torch.permute](args = (%conv2d, (0, 2, 1, 3)), kwargs = {})
# return permute
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 8, 66, 66).to('meta'),
- "other": torch.rand(16, 8, 3, 3).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(8, 8, 66, 66).to('meta'),
+ 'other': torch.rand(16, 8, 3, 3).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
if model_cls.__name__ == 'LinearReshapeModel':
# graph():
@@ -109,13 +111,14 @@ def check_view_handler(rank, call_function, reshape_dims, model_cls, world_size,
# %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%input_1, %other), kwargs = {bias: None})
# %permute : [#users=1] = call_method[target=view](args = (%linear, 32, 4, 32, 32, 4), kwargs = {})
# return permute
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 16, 64, 32).to('meta'),
- "other": torch.rand(64, 32).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(8, 16, 64, 32).to('meta'),
+ 'other': torch.rand(64, 32).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
previous_mod_node = list(graph.nodes)[2]
reshape_node = list(graph.nodes)[3]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_placeholder_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_placeholder_handler.py
index 9bc453a27cdc..5e8fb51edbff 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_placeholder_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_placeholder_handler.py
@@ -1,10 +1,13 @@
+import pytest
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.placeholder_handler import PlaceholderHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -17,18 +20,21 @@ def forward(self, input):
return input
+@pytest.mark.skip('ShapeProp is not compatible with PyTorch 1.11.0')
@parameterize('placeholder_option', ['distributed', 'replicated'])
@rerun_if_address_is_in_use()
def test_placeholder_handler(placeholder_option):
model = PlaceholderModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# return input_1
- graph = tracer.trace(model, meta_args={
+ meta_args = {
"input": torch.rand(4, 4, 64, 64).to('meta'),
- })
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_shard_option.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_shard_option.py
index f6895d92ab03..e589fff996c6 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_shard_option.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_shard_option.py
@@ -1,17 +1,15 @@
-from functools import partial
-
import torch
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.options import ShardOption
from colossalai.auto_parallel.tensor_shard.sharding_strategy import StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
-from colossalai.testing import parameterize
from colossalai.testing.pytest_wrapper import run_on_environment_flag
-from colossalai.testing.utils import parameterize
class LinearModel(nn.Module):
@@ -30,13 +28,11 @@ def check_shard_option(shard_option):
mesh_shape = (2, 2)
device_mesh = DeviceMesh(physical_mesh_id, mesh_shape)
- tracer = ColoTracer()
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(4, 4, 4, 16).to('meta'),
- 'others': torch.rand(32, 16).to('meta')
- })
+ tracer = ColoTracer(bias_addition_split=True)
+ meta_args = {'input': torch.rand(4, 4, 4, 16).to('meta'), 'others': torch.rand(32, 16).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
linear_func_node = list(graph.nodes)[2]
strategies_vector = StrategiesVector(linear_func_node)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_softmax_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_softmax_handler.py
index c43ee292bedf..db463a4e9d6a 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_softmax_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_softmax_handler.py
@@ -6,11 +6,13 @@
import torch.nn as nn
import torch.nn.functional as F
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.linear_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.softmax_handler import SoftmaxHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -54,7 +56,7 @@ def check_split_handler(rank, softmax_dim, model_cls, world_size, port):
input_args=[input, other],
meta_arg_names=['input', 'other'],
node_type='following')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
@@ -62,13 +64,14 @@ def check_split_handler(rank, softmax_dim, model_cls, world_size, port):
# %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%input_1, %other), kwargs = {bias: None})
# %softmax : [#users=1] = call_method[target=split](args = (%linear,), kwargs = {})
# return split
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 16, 64, 32).to('meta'),
- "other": torch.rand(64, 32).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(8, 16, 64, 32).to('meta'),
+ 'other': torch.rand(64, 32).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
previous_mod_node = list(graph.nodes)[2]
split_node = list(graph.nodes)[3]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_split_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_split_handler.py
index 044aef19d38d..db59ea60ef4b 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_split_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_split_handler.py
@@ -5,12 +5,14 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import SplitHandler
from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.linear_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -76,7 +78,7 @@ def check_split_handler(rank, split_size, split_dim, model_cls, world_size, port
input_args=[input, other],
meta_arg_names=['input', 'other'],
node_type='following')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
if model_cls.__name__ == 'ConvSplitModel':
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
@@ -84,11 +86,11 @@ def check_split_handler(rank, split_size, split_dim, model_cls, world_size, port
# %conv2d : [#users=1] = call_function[target=torch.conv2d](args = (%input_1, %other), kwargs = {})
# %split : [#users=1] = call_method[target=split](args = (%conv2d,), kwargs = {})
# return split
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 8, 66, 66).to('meta'),
- "other": torch.rand(16, 8, 3, 3).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(8, 8, 66, 66).to('meta'),
+ 'other': torch.rand(16, 8, 3, 3).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
if model_cls.__name__ == 'LinearSplitModel':
# graph():
@@ -97,13 +99,14 @@ def check_split_handler(rank, split_size, split_dim, model_cls, world_size, port
# %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%input_1, %other), kwargs = {bias: None})
# %split : [#users=1] = call_method[target=split](args = (%linear,), kwargs = {})
# return split
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 16, 64, 32).to('meta'),
- "other": torch.rand(64, 32).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(8, 16, 64, 32).to('meta'),
+ 'other': torch.rand(64, 32).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
previous_mod_node = list(graph.nodes)[2]
split_node = list(graph.nodes)[3]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_sum_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_sum_handler.py
index 5fda4de1a101..add51d73f2a4 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_sum_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_sum_handler.py
@@ -5,12 +5,13 @@
import torch.multiprocessing as mp
import torch.nn as nn
-from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.linear_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.sum_handler import SumHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -58,7 +59,7 @@ def check_sum_handler(rank, sum_dims, keepdim, world_size, port):
meta_arg_names=['input', 'other'],
node_type='following')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
@@ -66,12 +67,13 @@ def check_sum_handler(rank, sum_dims, keepdim, world_size, port):
# %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%input_1, %other), kwargs = {bias: None})
# %sum_1 : [#users=1] = call_function[target=torch.sum](args = (%linear,), kwargs = {})
# return sum_1
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 16, 64, 32).to('meta'),
- "other": torch.rand(64, 32).to('meta'),
- })
+ meta_args = {
+ "input": torch.rand(8, 16, 64, 32).to('meta'),
+ "other": torch.rand(64, 32).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
previous_mod_node = list(graph.nodes)[2]
sum_node = list(graph.nodes)[3]
@@ -116,107 +118,107 @@ def check_sum_handler(rank, sum_dims, keepdim, world_size, port):
# check strategy name
if sum_dims == (0, 2) and keepdim == False:
- assert '[R, R, R, S1] -> [R, S1]_0' in strategy_name_list
- assert '[R, S0, R, S1] -> [S0, S1]_1' in strategy_name_list
- assert '[R, R, R, S1] -> [R, S1]_2' in strategy_name_list
- assert '[R, R, R, S0] -> [R, S0]_3' in strategy_name_list
- assert '[R, S1, R, S0] -> [S1, S0]_4' in strategy_name_list
- assert '[R, R, R, S0] -> [R, S0]_5' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_6' in strategy_name_list
- assert '[R, S0, R, R] -> [S0, R]_7' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_0' in strategy_name_list
+ assert '[R, S01, R, R] -> [S01, R]_1' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_2' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_3' in strategy_name_list
+ assert '[R, R, R, S01] -> [R, S01]_4' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, S1]_5' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, S0]_6' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_7' in strategy_name_list
assert '[R, R, R, R] -> [R, R]_8' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_9' in strategy_name_list
- assert '[R, S1, R, R] -> [S1, R]_10' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_11' in strategy_name_list
- assert '[R, R, R, S1] -> [R, S1]_12' in strategy_name_list
- assert '[R, R, R, S0] -> [R, S0]_13' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_14' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_15' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, S0]_9' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, S1]_10' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, S1]_11' in strategy_name_list
+ assert '[R, S0, R, S1] -> [S0, S1]_12' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, S1]_13' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, S0]_14' in strategy_name_list
+ assert '[R, S1, R, S0] -> [S1, S0]_15' in strategy_name_list
assert '[R, R, R, S0] -> [R, S0]_16' in strategy_name_list
- assert '[R, R, R, S1] -> [R, S1]_17' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_18' in strategy_name_list
- assert '[R, S01, R, R] -> [S01, R]_19' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_17' in strategy_name_list
+ assert '[R, S0, R, R] -> [S0, R]_18' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_19' in strategy_name_list
assert '[R, R, R, R] -> [R, R]_20' in strategy_name_list
- assert '[R, R, R, R] -> [R, R]_21' in strategy_name_list
- assert '[R, R, R, S01] -> [R, S01]_22' in strategy_name_list
+ assert '[R, S1, R, R] -> [S1, R]_21' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R]_22' in strategy_name_list
assert '[R, R, R, R] -> [R, R]_23' in strategy_name_list
if sum_dims == (0, 2) and keepdim == True:
- assert '[R, R, R, S1] -> [R, R, R, S1]_0' in strategy_name_list
- assert '[R, S0, R, S1] -> [R, S0, R, S1]_1' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, R, S1]_2' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, R, S0]_3' in strategy_name_list
- assert '[R, S1, R, S0] -> [R, S1, R, S0]_4' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, R, S0]_5' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_6' in strategy_name_list
- assert '[R, S0, R, R] -> [R, S0, R, R]_7' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_0' in strategy_name_list
+ assert '[R, S01, R, R] -> [R, S01, R, R]_1' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_2' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_3' in strategy_name_list
+ assert '[R, R, R, S01] -> [R, R, R, S01]_4' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, R, S1]_5' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, R, S0]_6' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_7' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R, R]_8' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_9' in strategy_name_list
- assert '[R, S1, R, R] -> [R, S1, R, R]_10' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_11' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, R, S1]_12' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, R, S0]_13' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_14' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_15' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, R, S0]_9' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, R, S1]_10' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, R, S1]_11' in strategy_name_list
+ assert '[R, S0, R, S1] -> [R, S0, R, S1]_12' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, R, S1]_13' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, R, S0]_14' in strategy_name_list
+ assert '[R, S1, R, S0] -> [R, S1, R, S0]_15' in strategy_name_list
assert '[R, R, R, S0] -> [R, R, R, S0]_16' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, R, S1]_17' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_18' in strategy_name_list
- assert '[R, S01, R, R] -> [R, S01, R, R]_19' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_17' in strategy_name_list
+ assert '[R, S0, R, R] -> [R, S0, R, R]_18' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_19' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R, R]_20' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_21' in strategy_name_list
- assert '[R, R, R, S01] -> [R, R, R, S01]_22' in strategy_name_list
+ assert '[R, S1, R, R] -> [R, S1, R, R]_21' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_22' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R, R]_23' in strategy_name_list
if sum_dims == 1 and keepdim == False:
- assert '[S0, R, R, S1] -> [S0, R, S1]_0' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, S1]_1' in strategy_name_list
- assert '[R, R, S0, S1] -> [R, S0, S1]_2' in strategy_name_list
- assert '[S1, R, R, S0] -> [S1, R, S0]_3' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, S0]_4' in strategy_name_list
- assert '[R, R, S1, S0] -> [R, S1, S0]_5' in strategy_name_list
- assert '[S0, R, R, R] -> [S0, R, R]_6' in strategy_name_list
+ assert '[S01, R, R, R] -> [S01, R, R]_0' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R]_1' in strategy_name_list
+ assert '[R, R, S01, R] -> [R, S01, R]_2' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R]_3' in strategy_name_list
+ assert '[R, R, R, S01] -> [R, R, S01]_4' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, S1]_5' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, S0]_6' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R]_7' in strategy_name_list
- assert '[R, R, S0, R] -> [R, S0, R]_8' in strategy_name_list
- assert '[S1, R, R, R] -> [S1, R, R]_9' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R]_10' in strategy_name_list
- assert '[R, R, S1, R] -> [R, S1, R]_11' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R]_8' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, S0]_9' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, S1]_10' in strategy_name_list
+ assert '[S0, R, R, S1] -> [S0, R, S1]_11' in strategy_name_list
assert '[R, R, R, S1] -> [R, R, S1]_12' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, S0]_13' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R]_14' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R]_15' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, S0]_16' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, S1]_17' in strategy_name_list
- assert '[S01, R, R, R] -> [S01, R, R]_18' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R]_19' in strategy_name_list
- assert '[R, R, S01, R] -> [R, S01, R]_20' in strategy_name_list
+ assert '[R, R, S0, S1] -> [R, S0, S1]_13' in strategy_name_list
+ assert '[S1, R, R, S0] -> [S1, R, S0]_14' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, S0]_15' in strategy_name_list
+ assert '[R, R, S1, S0] -> [R, S1, S0]_16' in strategy_name_list
+ assert '[S0, R, R, R] -> [S0, R, R]_17' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R]_18' in strategy_name_list
+ assert '[R, R, S0, R] -> [R, S0, R]_19' in strategy_name_list
+ assert '[S1, R, R, R] -> [S1, R, R]_20' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R]_21' in strategy_name_list
- assert '[R, R, R, S01] -> [R, R, S01]_22' in strategy_name_list
+ assert '[R, R, S1, R] -> [R, S1, R]_22' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R]_23' in strategy_name_list
if sum_dims == 1 and keepdim == True:
- assert '[S0, R, R, S1] -> [S0, R, R, S1]_0' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, R, S1]_1' in strategy_name_list
- assert '[R, R, S0, S1] -> [R, R, S0, S1]_2' in strategy_name_list
- assert '[S1, R, R, S0] -> [S1, R, R, S0]_3' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, R, S0]_4' in strategy_name_list
- assert '[R, R, S1, S0] -> [R, R, S1, S0]_5' in strategy_name_list
- assert '[S0, R, R, R] -> [S0, R, R, R]_6' in strategy_name_list
+ assert '[S01, R, R, R] -> [S01, R, R, R]_0' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_1' in strategy_name_list
+ assert '[R, R, S01, R] -> [R, R, S01, R]_2' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_3' in strategy_name_list
+ assert '[R, R, R, S01] -> [R, R, R, S01]_4' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, R, S1]_5' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, R, S0]_6' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R, R]_7' in strategy_name_list
- assert '[R, R, S0, R] -> [R, R, S0, R]_8' in strategy_name_list
- assert '[S1, R, R, R] -> [S1, R, R, R]_9' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_10' in strategy_name_list
- assert '[R, R, S1, R] -> [R, R, S1, R]_11' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_8' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, R, S0]_9' in strategy_name_list
+ assert '[R, R, R, S1] -> [R, R, R, S1]_10' in strategy_name_list
+ assert '[S0, R, R, S1] -> [S0, R, R, S1]_11' in strategy_name_list
assert '[R, R, R, S1] -> [R, R, R, S1]_12' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, R, S0]_13' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_14' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_15' in strategy_name_list
- assert '[R, R, R, S0] -> [R, R, R, S0]_16' in strategy_name_list
- assert '[R, R, R, S1] -> [R, R, R, S1]_17' in strategy_name_list
- assert '[S01, R, R, R] -> [S01, R, R, R]_18' in strategy_name_list
- assert '[R, R, R, R] -> [R, R, R, R]_19' in strategy_name_list
- assert '[R, R, S01, R] -> [R, R, S01, R]_20' in strategy_name_list
+ assert '[R, R, S0, S1] -> [R, R, S0, S1]_13' in strategy_name_list
+ assert '[S1, R, R, S0] -> [S1, R, R, S0]_14' in strategy_name_list
+ assert '[R, R, R, S0] -> [R, R, R, S0]_15' in strategy_name_list
+ assert '[R, R, S1, S0] -> [R, R, S1, S0]_16' in strategy_name_list
+ assert '[S0, R, R, R] -> [S0, R, R, R]_17' in strategy_name_list
+ assert '[R, R, R, R] -> [R, R, R, R]_18' in strategy_name_list
+ assert '[R, R, S0, R] -> [R, R, S0, R]_19' in strategy_name_list
+ assert '[S1, R, R, R] -> [S1, R, R, R]_20' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R, R]_21' in strategy_name_list
- assert '[R, R, R, S01] -> [R, R, R, S01]_22' in strategy_name_list
+ assert '[R, R, S1, R] -> [R, R, S1, R]_22' in strategy_name_list
assert '[R, R, R, R] -> [R, R, R, R]_23' in strategy_name_list
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_tensor_constructor.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_tensor_constructor.py
index de35fe256ac7..f54b208c3380 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_tensor_constructor.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_tensor_constructor.py
@@ -1,10 +1,12 @@
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.tensor_constructor_handler import TensorConstructorHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.testing.pytest_wrapper import run_on_environment_flag
@@ -22,7 +24,7 @@ def forward(self, x):
@run_on_environment_flag(name='AUTO_PARALLEL')
def test_where_handler():
model = TensorConstructorModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %x : torch.Tensor [#users=2] = placeholder[target=x]
# %size : [#users=1] = call_method[target=size](args = (%x,), kwargs = {})
@@ -30,10 +32,10 @@ def test_where_handler():
# %arange : [#users=1] = call_function[target=torch.arange](args = (%getitem,), kwargs = {})
# %add : [#users=1] = call_function[target=operator.add](args = (%x, %arange), kwargs = {})
# return add
- graph = tracer.trace(model, meta_args={
- "x": torch.rand(10).to('meta'),
- })
+ meta_args = {'x': torch.rand(10).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_unary_element_wise_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_unary_element_wise_handler.py
index a861cb7f57f0..bd88089734a7 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_unary_element_wise_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_unary_element_wise_handler.py
@@ -1,12 +1,13 @@
import torch
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.unary_elementwise_handler import UnaryElementwiseHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
-from colossalai.fx.tracer.meta_patch.patched_module import linear
from colossalai.testing.pytest_wrapper import run_on_environment_flag
@@ -25,19 +26,20 @@ def forward(self, input, other):
@run_on_environment_flag(name='AUTO_PARALLEL')
def test_elementwise_handler():
model = ReLuModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
# %other : torch.Tensor [#users=1] = placeholder[target=other]
# %conv2d : [#users=1] = call_function[target=torch.conv2d](args = (%input_1, %other), kwargs = {})
# %act : [#users=1] = call_module[target=act](args = (%conv2d,), kwargs = {})
# return act
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(4, 4, 64, 64).to('meta'),
- "other": torch.rand(4, 16, 3, 3).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(4, 4, 64, 64).to('meta'),
+ 'other': torch.rand(16, 4, 3, 3).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
@@ -69,13 +71,13 @@ def test_elementwise_handler():
assert mapping['input'].name == "conv2d"
assert mapping['input'].data.is_meta
- assert mapping['input'].data.shape == torch.Size([4, 4, 62, 62])
+ assert mapping['input'].data.shape == torch.Size([4, 16, 62, 62])
assert mapping['input'].type == OperationDataType.ARG
- assert mapping['input'].logical_shape == torch.Size([4, 4, 62, 62])
+ assert mapping['input'].logical_shape == torch.Size([4, 16, 62, 62])
assert mapping['output'].name == "act"
assert mapping['output'].data.is_meta
- assert mapping['output'].data.shape == torch.Size([4, 4, 62, 62])
+ assert mapping['output'].data.shape == torch.Size([4, 16, 62, 62])
assert mapping['output'].type == OperationDataType.OUTPUT
# getitem is a following strategy handler, so the number of strategies is equal to the predecessor node.
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_view_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_view_handler.py
index 8a96ac0d66f0..300e8f94e7fe 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_view_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_view_handler.py
@@ -5,12 +5,14 @@
import torch.multiprocessing as mp
import torch.nn as nn
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.tensor_shard.node_handler import ViewHandler
from colossalai.auto_parallel.tensor_shard.node_handler.conv_handler import ConvFunctionHandler
from colossalai.auto_parallel.tensor_shard.node_handler.linear_handler import LinearFunctionHandler
from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
from colossalai.initialize import launch
from colossalai.logging import disable_existing_loggers
from colossalai.testing import assert_close, parameterize, rerun_if_address_is_in_use
@@ -74,7 +76,7 @@ def check_view_handler(rank, tgt_shape, model_cls, world_size, port):
input_args=[input, other],
meta_arg_names=['input', 'other'],
node_type='following')
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
if model_cls.__name__ == 'ConvViewModel':
# graph():
# %input_1 : torch.Tensor [#users=1] = placeholder[target=input]
@@ -82,11 +84,8 @@ def check_view_handler(rank, tgt_shape, model_cls, world_size, port):
# %conv2d : [#users=1] = call_function[target=torch.conv2d](args = (%input_1, %other), kwargs = {})
# %view : [#users=1] = call_method[target=view](args = (%conv2d, 2, -1), kwargs = {})
# return view
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 8, 66, 66).to('meta'),
- "other": torch.rand(16, 8, 3, 3).to('meta'),
- })
+ meta_args = {'input': torch.rand(8, 8, 66, 66).to('meta'), 'other': torch.rand(16, 8, 3, 3).to('meta')}
+ graph = tracer.trace(model, meta_args=meta_args)
if model_cls.__name__ == 'LinearViewModel':
# graph():
@@ -95,13 +94,14 @@ def check_view_handler(rank, tgt_shape, model_cls, world_size, port):
# %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%input_1, %other), kwargs = {bias: None})
# %view : [#users=1] = call_method[target=view](args = (%linear, 32, 4, 32, 32, 4), kwargs = {})
# return view
- graph = tracer.trace(model,
- meta_args={
- "input": torch.rand(8, 16, 64, 32).to('meta'),
- "other": torch.rand(64, 32).to('meta'),
- })
+ meta_args = {
+ 'input': torch.rand(8, 16, 64, 32).to('meta'),
+ 'other': torch.rand(64, 32).to('meta'),
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
previous_mod_node = list(graph.nodes)[2]
view_node = list(graph.nodes)[3]
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_where_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_where_handler.py
index 9838e2eb01c6..c150ebd90053 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_where_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_where_handler.py
@@ -1,12 +1,13 @@
+import pytest
import torch
import torch.nn as nn
-from colossalai.auto_parallel.tensor_shard.node_handler.where_handler import \
- WhereHandler
-from colossalai.auto_parallel.tensor_shard.sharding_strategy import (OperationData, OperationDataType, StrategiesVector)
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
+from colossalai.auto_parallel.tensor_shard.node_handler.where_handler import WhereHandler
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, StrategiesVector
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx import ColoGraphModule, ColoTracer
-from colossalai.fx.tracer.meta_patch.patched_module import linear
class ConvModel(nn.Module):
@@ -19,22 +20,24 @@ def forward(self, condition, x, y):
return output
+@pytest.mark.skip('ShapeProp is not compatible with PyTorch 1.11.0')
def test_where_handler():
model = ConvModel()
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
# graph():
# %condition : torch.Tensor [#users=1] = placeholder[target=condition]
# %x : torch.Tensor [#users=1] = placeholder[target=x]
# %y : torch.Tensor [#users=1] = placeholder[target=y]
# %where : [#users=1] = call_function[target=torch.where](args = (%condition, %x, %y), kwargs = {})
# return where
- graph = tracer.trace(model,
- meta_args={
- "condition": torch.rand(4, 4, 64, 64).to('meta'),
- "x": torch.rand(4, 1, 64, 64).to('meta'),
- "y": torch.rand(1, 4, 64, 64).to('meta')
- })
+ meta_args = {
+ 'condition': torch.rand(4, 4, 64, 64).to('meta'),
+ 'x': torch.rand(4, 1, 64, 64).to('meta'),
+ 'y': torch.rand(1, 4, 64, 64).to('meta')
+ }
+ graph = tracer.trace(model, meta_args=meta_args)
gm = ColoGraphModule(model, graph)
+ shape_prop_pass(gm, *meta_args.values())
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/utils.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/utils.py
index 0cdfdbc9d0cd..28a8bbd9a4c1 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/utils.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/utils.py
@@ -4,6 +4,9 @@
import torch
from torch.fx import GraphModule
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes.shape_prop import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
from colossalai.auto_parallel.passes.runtime_apply_pass import runtime_apply_pass
from colossalai.auto_parallel.passes.runtime_preparation_pass import runtime_preparation_pass
from colossalai.auto_parallel.tensor_shard.options import SolverOptions
@@ -11,7 +14,6 @@
from colossalai.auto_parallel.tensor_shard.solver.cost_graph import CostGraph
from colossalai.auto_parallel.tensor_shard.solver.solver import Solver
from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx.tracer.tracer import ColoTracer
from colossalai.tensor.shape_consistency import to_global
from colossalai.testing.comparison import assert_close
@@ -79,14 +81,16 @@ def numerical_test_for_node_strategy(model: torch.nn.Module,
model_to_shard, args_to_shard, kwargs_to_shard = _build_model_to_compare(model, input_args, input_kwargs,
grad_to_shard_dict)
- tracer = ColoTracer()
+ tracer = ColoTracer(bias_addition_split=True)
input_sample = {}
for input_arg, meta_arg_name in zip(input_args, meta_arg_names):
- input_sample[meta_arg_name] = torch.rand(input_arg.shape).to('meta')
+ input_sample[meta_arg_name] = torch.empty(input_arg.shape, dtype=input_arg.dtype).to('meta')
for meta_kwarg_name, input_kwarg in input_kwargs.items():
- input_sample[meta_kwarg_name] = torch.rand(input_kwarg.shape).to('meta')
+ input_sample[meta_kwarg_name] = torch.empty(input_kwarg.shape, dtype=input_kwarg.dtype).to('meta')
graph = tracer.trace(root=model_to_shard, meta_args=input_sample)
- gm = GraphModule(model_to_shard, graph, model_to_shard.__class__.__name__)
+ gm = ColoGraphModule(model_to_shard, graph, model_to_shard.__class__.__name__)
+ shape_prop_pass(gm, *input_sample.values())
+
solver_options = SolverOptions()
strategies_constructor = StrategiesConstructor(graph, device_mesh, solver_options)
strategies_constructor.build_strategies_and_cost()
diff --git a/tests/test_booster/test_plugin/test_gemini_plugin.py b/tests/test_booster/test_plugin/test_gemini_plugin.py
new file mode 100644
index 000000000000..7a0d4a15d53a
--- /dev/null
+++ b/tests/test_booster/test_plugin/test_gemini_plugin.py
@@ -0,0 +1,150 @@
+from functools import partial
+
+import pytest
+import torch
+import torch.distributed as dist
+import torch.multiprocessing as mp
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.tensor.colo_parameter import ColoParameter
+from colossalai.testing import rerun_if_address_is_in_use
+from colossalai.utils import free_port
+from tests.kit.model_zoo import model_zoo
+
+
+def check_gemini_plugin(early_stop: bool = True):
+ """check gemini plugin over model zoo
+
+ Args:
+ early_stop (bool, optional): Whether to stop when getting the first error. Defaults to True.
+ """
+ plugin = GeminiPlugin(placement_policy='cuda', strict_ddp_mode=True, max_norm=1.0, initial_scale=2**5)
+ booster = Booster(plugin=plugin)
+
+ passed_models = []
+ failed_info = {} # (model_name, error) pair
+
+ for name, (model_fn, data_gen_fn, output_transform_fn, _) in model_zoo.items():
+ # These models lead to CUDA error
+ if name in ('diffusers_auto_encoder_kl', 'diffusers_vq_model', 'diffusers_unet2d_model', 'timm_resmlp',
+ 'timm_gmixer_12_224', 'timm_gmlp_b16_224', 'timm_mixer_b16_224', 'timm_convnext'):
+ continue
+ # These models are not compatible with gemini
+ if name in [
+ 'diffusers_clip_vision_model',
+ 'timm_resnet',
+ 'timm_beit',
+ 'timm_beitv2',
+ 'timm_eca_nfnet',
+ 'timm_efficientformer',
+ 'timm_hrnet_w18_small',
+ 'timm_nf_ecaresnet101',
+ 'timm_nf_regnet_b0',
+ 'timm_skresnet18',
+ 'timm_wide_resnet50_2',
+ 'timm_convit',
+ 'timm_dm_nfnet',
+ 'timm_swin_transformer',
+ 'torchaudio_conformer',
+ 'torchaudio_deepspeech',
+ 'torchaudio_wavernn',
+ 'torchaudio_tacotron',
+ 'deepfm_interactionarch',
+ 'deepfm_simpledeepfmnn',
+ 'dlrm',
+ 'dlrm_interactionarch',
+ 'torchvision_googlenet',
+ 'torchvision_inception_v3',
+ 'torchvision_mobilenet_v3_small',
+ 'torchvision_resnet18',
+ 'torchvision_resnext50_32x4d',
+ 'torchvision_wide_resnet50_2',
+ 'torchvision_vit_b_16',
+ 'torchvision_convnext_base',
+ 'torchvision_swin_s',
+ 'transformers_albert',
+ 'transformers_albert_for_pretraining',
+ 'transformers_bert',
+ 'transformers_bert_for_pretraining',
+ 'transformers_gpt_double_heads',
+ 'torchaudio_hubert_base',
+ ]:
+ continue
+ try:
+ model = model_fn()
+ optimizer = HybridAdam(model.parameters(), lr=1e-3)
+ criterion = lambda x: x.mean()
+ data = data_gen_fn()
+
+ data = {
+ k: v.to('cuda') if torch.is_tensor(v) or 'Tensor' in v.__class__.__name__ else v
+ for k, v in data.items()
+ }
+
+ model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
+
+ for n, p in model.named_parameters():
+ assert isinstance(p, ColoParameter), f'{n} is not a ColoParameter'
+
+ output = model(**data)
+ output = output_transform_fn(output)
+ output_key = list(output.keys())[0]
+ loss = criterion(output[output_key])
+
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ passed_models.append(name)
+ except Exception as e:
+ failed_info[name] = e
+ if early_stop:
+ raise e
+ if dist.get_rank() == 0:
+ print(f'Passed models({len(passed_models)}): {passed_models}\n\n')
+ print(f'Failed models({len(failed_info)}): {list(failed_info.keys())}\n\n')
+ assert len(failed_info) == 0, '\n'.join([f'{k}: {v}' for k, v in failed_info.items()])
+
+
+def check_dataloader_sharding():
+ plugin = GeminiPlugin()
+
+ # create a custom dasetset with 0 to 10
+ dataset = torch.utils.data.TensorDataset(torch.arange(0, 10))
+ train_dataloader = plugin.prepare_train_dataloader(dataset, batch_size=2)
+
+ # get the first batch of data
+ batch = next(iter(train_dataloader))[0].cuda()
+ is_rank_0 = dist.get_rank() == 0
+
+ if is_rank_0:
+ batch_to_compare = batch.clone()
+ else:
+ batch_to_compare = batch
+ # pass to the rank 1 value to rank 0
+ dist.broadcast(batch_to_compare, src=1)
+
+ # compare on rank 0
+ if is_rank_0:
+ assert not torch.equal(batch,
+ batch_to_compare), 'Same number was found across ranks but expected it to be different'
+
+
+def run_dist(rank, world_size, port, early_stop: bool = True):
+ # init dist env
+ colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
+ check_dataloader_sharding()
+ check_gemini_plugin(early_stop=early_stop)
+
+
+@pytest.mark.skip(reason='Skip gemini plugin test due to OOM')
+@rerun_if_address_is_in_use()
+def test_gemini_plugin(early_stop: bool = True):
+ world_size = 2
+ run_func = partial(run_dist, world_size=world_size, port=free_port(), early_stop=early_stop)
+ mp.spawn(run_func, nprocs=world_size)
+
+
+if __name__ == '__main__':
+ test_gemini_plugin(early_stop=False)
diff --git a/tests/test_fx/test_pipeline/test_topo/test_topo.py b/tests/test_fx/test_pipeline/test_topo/test_topo.py
index 75c74870523c..16da56250dc3 100644
--- a/tests/test_fx/test_pipeline/test_topo/test_topo.py
+++ b/tests/test_fx/test_pipeline/test_topo/test_topo.py
@@ -1,11 +1,13 @@
import pytest
import torch
import transformers
-from topo_utils import split_model_and_get_DAG, check_topo, MLP
+from topo_utils import MLP, check_topo, split_model_and_get_DAG
BATCH_SIZE = 1
SEQ_LENGHT = 16
+
+@pytest.mark.skip('ShapeProp is not compatible with PyTorch 1.11.0')
def test_opt():
MODEL_LIST = [
MLP,
@@ -13,7 +15,10 @@ def test_opt():
]
CONFIGS = [
- {'dim': 10, 'layers': 12},
+ {
+ 'dim': 10,
+ 'layers': 12
+ },
transformers.OPTConfig(vocab_size=100, hidden_size=128, num_hidden_layers=4, num_attention_heads=4),
]
@@ -21,15 +26,15 @@ def data_gen_MLP():
x = torch.zeros((16, 10))
kwargs = dict(x=x)
return kwargs
-
+
def data_gen_OPT():
input_ids = torch.zeros((BATCH_SIZE, SEQ_LENGHT), dtype=torch.int64)
attention_mask = torch.zeros((BATCH_SIZE, SEQ_LENGHT), dtype=torch.int64)
kwargs = dict(input_ids=input_ids, attention_mask=attention_mask)
return kwargs
-
+
DATAGEN = [
- data_gen_MLP,
+ data_gen_MLP,
data_gen_OPT,
]
@@ -39,5 +44,6 @@ def data_gen_OPT():
# print(f'{top_mod=}\n----\n{topo=}')
check_topo(top_mod, topo)
+
if __name__ == '__main__':
- test_opt()
\ No newline at end of file
+ test_opt()
diff --git a/tests/test_moe/test_moe_checkpoint.py b/tests/test_moe/test_moe_checkpoint.py
new file mode 100644
index 000000000000..f99e74ea55c1
--- /dev/null
+++ b/tests/test_moe/test_moe_checkpoint.py
@@ -0,0 +1,54 @@
+import os
+from functools import partial
+
+import pytest
+import torch
+import torch.distributed as dist
+import torch.multiprocessing as mp
+
+import colossalai
+from colossalai.context import MOE_CONTEXT
+from colossalai.nn.layer.moe import load_moe_model, save_moe_model
+from colossalai.testing import parameterize, rerun_if_address_is_in_use
+from colossalai.utils import free_port, get_current_device
+from colossalai.utils.model.colo_init_context import ColoInitContext
+from tests.test_moe.test_moe_zero_init import MoeModel
+from tests.test_tensor.common_utils import debug_print
+from tests.test_zero.common import CONFIG
+
+
+def exam_moe_checkpoint():
+ with ColoInitContext(device=get_current_device()):
+ model = MoeModel(checkpoint=True)
+ save_moe_model(model, 'temp_path.pth')
+
+ with ColoInitContext(device=get_current_device()):
+ other_model = MoeModel(checkpoint=True)
+ load_moe_model(other_model, 'temp_path.pth')
+
+ state_0 = model.state_dict()
+ state_1 = other_model.state_dict()
+ for k, v in state_0.items():
+ u = state_1.get(k)
+ assert torch.equal(u.data, v.data)
+
+ if dist.get_rank() == 0:
+ os.remove('temp_path.pth')
+
+
+def _run_dist(rank, world_size, port):
+ colossalai.launch(config=CONFIG, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ MOE_CONTEXT.setup(seed=42)
+ exam_moe_checkpoint()
+
+
+@pytest.mark.dist
+@pytest.mark.parametrize("world_size", [2, 4])
+@rerun_if_address_is_in_use()
+def test_moe_checkpoint(world_size):
+ run_func = partial(_run_dist, world_size=world_size, port=free_port())
+ mp.spawn(run_func, nprocs=world_size)
+
+
+if __name__ == '__main__':
+ test_moe_checkpoint(world_size=4)
diff --git a/version.txt b/version.txt
index b0032849c80b..a45be4627678 100644
--- a/version.txt
+++ b/version.txt
@@ -1 +1 @@
-0.2.7
+0.2.8
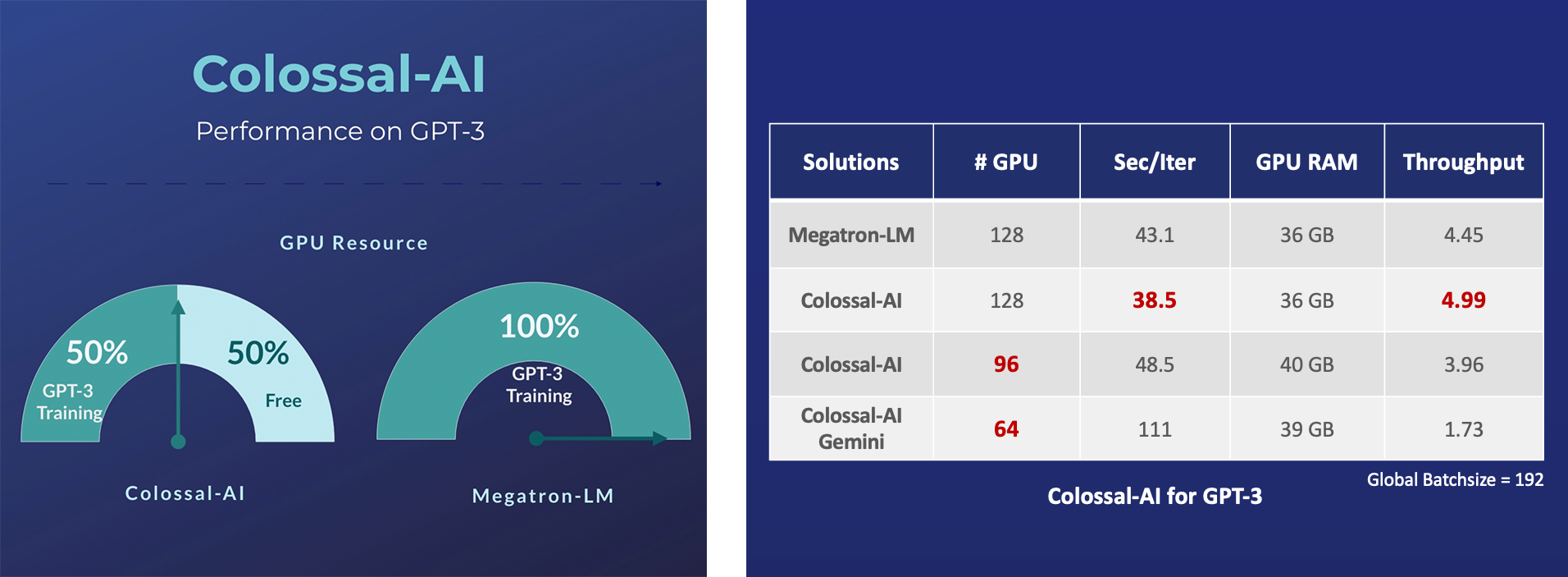 -- Save 50% GPU resources, and 10.7% acceleration
+- Save 50% GPU resources and 10.7% acceleration
### GPT-2
-- Save 50% GPU resources, and 10.7% acceleration
+- Save 50% GPU resources and 10.7% acceleration
### GPT-2
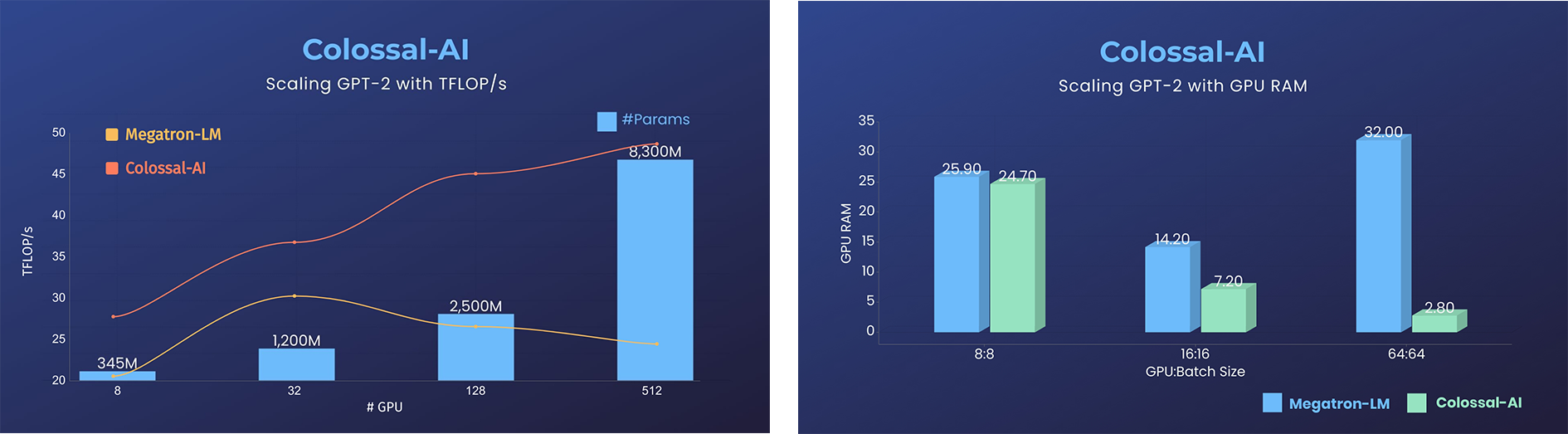 @@ -149,7 +151,7 @@ distributed training and inference in a few lines.
### OPT
@@ -149,7 +151,7 @@ distributed training and inference in a few lines.
### OPT
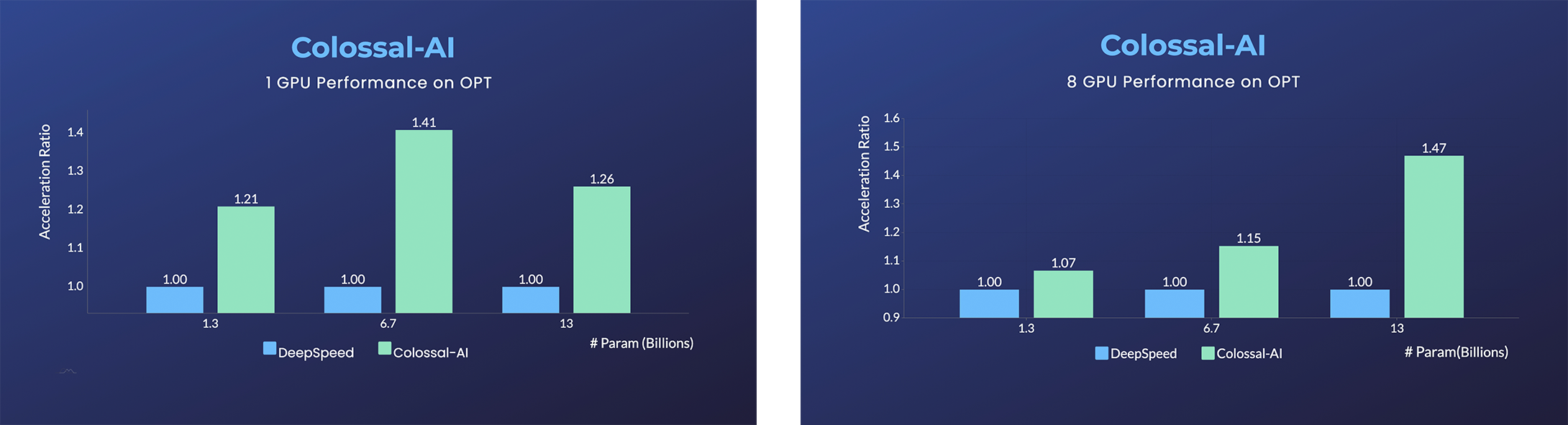 -- [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), a 175-Billion parameter AI language model released by Meta, which stimulates AI programmers to perform various downstream tasks and application deployments because public pretrained model weights.
+- [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), a 175-Billion parameter AI language model released by Meta, which stimulates AI programmers to perform various downstream tasks and application deployments because of public pre-trained model weights.
- 45% speedup fine-tuning OPT at low cost in lines. [[Example]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/opt) [[Online Serving]](https://colossalai.org/docs/advanced_tutorials/opt_service)
Please visit our [documentation](https://www.colossalai.org/) and [examples](https://github.com/hpcaitech/ColossalAI/tree/main/examples) for more details.
@@ -223,7 +225,7 @@ Please visit our [documentation](https://www.colossalai.org/) and [examples](htt
-[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline. [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) [[blog]](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt) [[demo]](https://chat.colossalai.org)
+[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline. [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) [[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b) [[demo]](https://chat.colossalai.org)
-- [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), a 175-Billion parameter AI language model released by Meta, which stimulates AI programmers to perform various downstream tasks and application deployments because public pretrained model weights.
+- [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), a 175-Billion parameter AI language model released by Meta, which stimulates AI programmers to perform various downstream tasks and application deployments because of public pre-trained model weights.
- 45% speedup fine-tuning OPT at low cost in lines. [[Example]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/opt) [[Online Serving]](https://colossalai.org/docs/advanced_tutorials/opt_service)
Please visit our [documentation](https://www.colossalai.org/) and [examples](https://github.com/hpcaitech/ColossalAI/tree/main/examples) for more details.
@@ -223,7 +225,7 @@ Please visit our [documentation](https://www.colossalai.org/) and [examples](htt
-[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline. [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) [[blog]](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt) [[demo]](https://chat.colossalai.org)
+[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline. [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) [[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b) [[demo]](https://chat.colossalai.org)
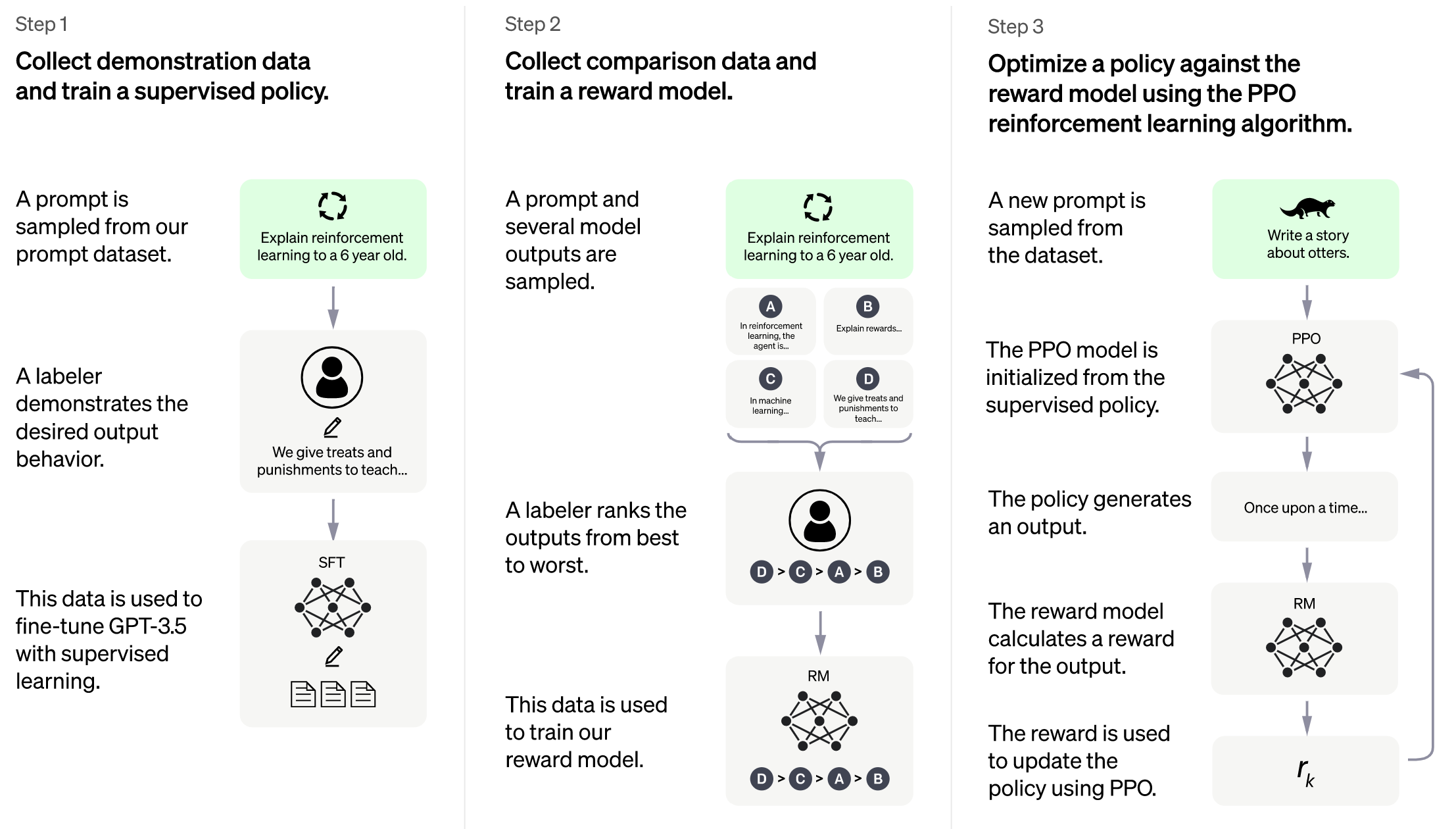 +
+