+ - LLaMA
- GPT-3
- GPT-2
- BERT
@@ -216,6 +218,15 @@ Acceleration of [AlphaFold Protein Structure](https://alphafold.ebi.ac.uk/)
## Parallel Training Demo
+### LLaMA
+
+ +
+
+
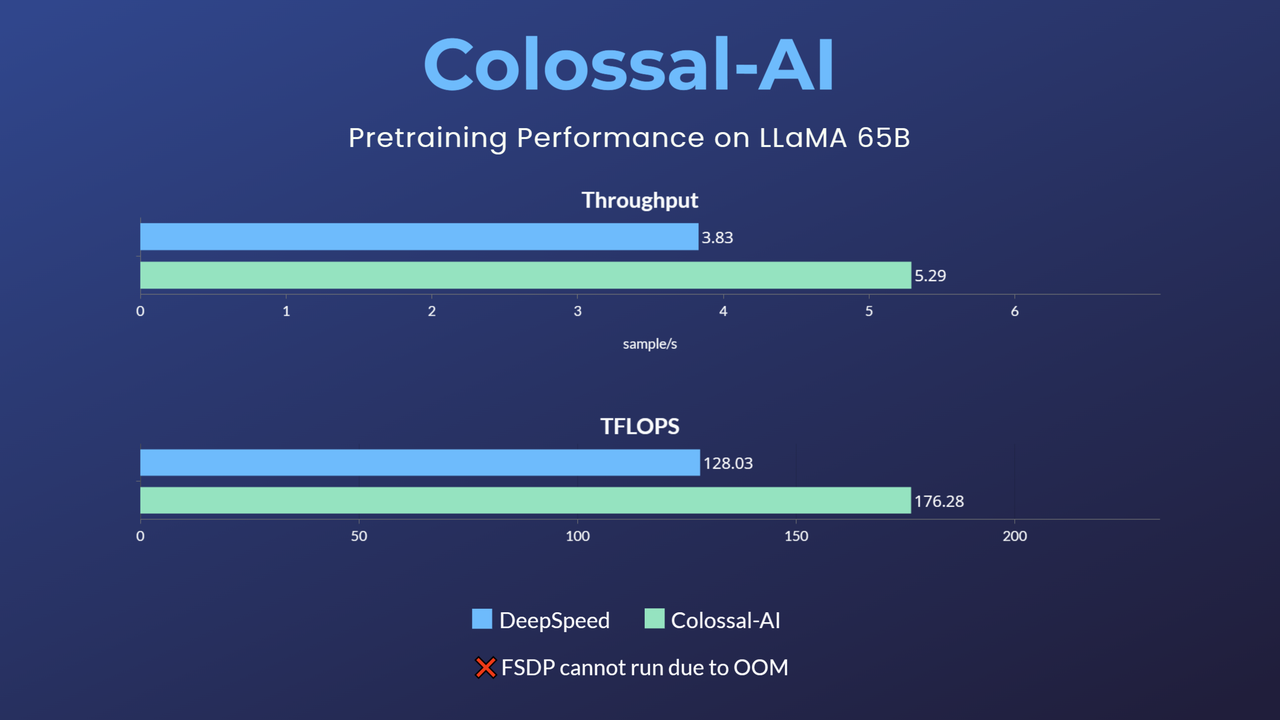
+- 65-billion-parameter large model pretraining accelerated by 38%
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/example/llama/examples/language/llama)
+[[blog]](https://www.hpc-ai.tech/blog/large-model-pretraining)
+
### GPT-3
 diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md
index 1dde7a816676..e229c65d890c 100644
--- a/docs/README-zh-Hans.md
+++ b/docs/README-zh-Hans.md
@@ -24,6 +24,7 @@
## 新闻
+* [2023/07] [65B Model Pretraining Accelerated by 38%, Best Practices for Building LLaMA-Like Base Models Open-Source](https://www.hpc-ai.tech/blog/large-model-pretraining)
* [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
* [2023/03] [Intel and Colossal-AI Partner to Deliver Cost-Efficient Open-Source Solution for Protein Folding Structure Prediction](https://www.hpc-ai.tech/blog/intel-habana)
* [2023/03] [AWS and Google Fund Colossal-AI with Startup Cloud Programs](https://www.hpc-ai.tech/blog/aws-and-google-fund-colossal-ai-with-startup-cloud-programs)
@@ -49,6 +50,7 @@
diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md
index 1dde7a816676..e229c65d890c 100644
--- a/docs/README-zh-Hans.md
+++ b/docs/README-zh-Hans.md
@@ -24,6 +24,7 @@
## 新闻
+* [2023/07] [65B Model Pretraining Accelerated by 38%, Best Practices for Building LLaMA-Like Base Models Open-Source](https://www.hpc-ai.tech/blog/large-model-pretraining)
* [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
* [2023/03] [Intel and Colossal-AI Partner to Deliver Cost-Efficient Open-Source Solution for Protein Folding Structure Prediction](https://www.hpc-ai.tech/blog/intel-habana)
* [2023/03] [AWS and Google Fund Colossal-AI with Startup Cloud Programs](https://www.hpc-ai.tech/blog/aws-and-google-fund-colossal-ai-with-startup-cloud-programs)
@@ -49,6 +50,7 @@
-
并行训练样例展示
+ - LLaMA
- GPT-3
- GPT-2
- BERT
@@ -209,6 +211,14 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
(返回顶端)
## 并行训练样例展示
+### LLaMA
+
+
+
+
+- 650亿参数大模型预训练加速38%
+[[代码]](https://github.com/hpcaitech/ColossalAI/tree/example/llama/examples/language/llama)
+[[博客]](https://www.hpc-ai.tech/blog/large-model-pretraining)
### GPT-3
diff --git a/examples/language/llama/README.md b/examples/language/llama/README.md
new file mode 100644
index 000000000000..871804f2ca86
--- /dev/null
+++ b/examples/language/llama/README.md
@@ -0,0 +1,11 @@
+# Pretraining LLaMA: best practices for building LLaMA-like base models
+
+
+
+
+
+- 65-billion-parameter large model pretraining accelerated by 38%
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/example/llama/examples/language/llama)
+[[blog]](https://www.hpc-ai.tech/blog/large-model-pretraining)
+
+> Since the main branch is being updated, in order to maintain the stability of the code, this example is temporarily kept as an [independent branch](https://github.com/hpcaitech/ColossalAI/tree/example/llama/examples/language/llama).
From 4b977541a86c90946badc77a6a77fee64fdc8cce Mon Sep 17 00:00:00 2001
From: Cuiqing Li
Date: Tue, 18 Jul 2023 23:53:38 +0800
Subject: [PATCH 3/6] [Kernels] added triton-implemented of self attention for
colossal-ai (#4241)
* added softmax kernel
* added qkv_kernel
* added ops
* adding tests
* upload tets
* fix tests
* debugging
* debugging tests
* debugging
* added
* fixed errors
* added softmax kernel
* clean codes
* added tests
* update tests
* update tests
* added attention
* add
* fixed pytest checking
* add cuda check
* fix cuda version
* fix typo
---
colossalai/kernel/triton/ops.py | 209 ++++++++++++++++++
colossalai/kernel/triton/qkv_matmul_kernel.py | 109 +++++++++
colossalai/kernel/triton/softmax_kernel.py | 44 ++++
tests/test_kernels/test_self_attention.py | 136 ++++++++++++
tests/test_kernels/test_softmax.py | 27 +++
5 files changed, 525 insertions(+)
create mode 100644 colossalai/kernel/triton/ops.py
create mode 100644 colossalai/kernel/triton/qkv_matmul_kernel.py
create mode 100644 colossalai/kernel/triton/softmax_kernel.py
create mode 100644 tests/test_kernels/test_self_attention.py
create mode 100644 tests/test_kernels/test_softmax.py
diff --git a/colossalai/kernel/triton/ops.py b/colossalai/kernel/triton/ops.py
new file mode 100644
index 000000000000..5e8d4ba3ec99
--- /dev/null
+++ b/colossalai/kernel/triton/ops.py
@@ -0,0 +1,209 @@
+import torch
+from torch import nn
+
+try:
+ import triton
+ import triton.language as tl
+ HAS_TRITON = True
+except ImportError:
+ HAS_TRITON = False
+ print("please install triton from https://github.com/openai/triton")
+
+if HAS_TRITON:
+ from .qkv_matmul_kernel import qkv_gemm_4d_kernel
+ from .softmax_kernel import softmax_kernel
+
+ def self_attention_forward_without_fusion(q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, input_mask: torch.Tensor, scale: float):
+ r""" A function to do QKV Attention calculation by calling GEMM and softmax triton kernels
+ Args:
+ q (torch.Tensor): Q embedding in attention layer, shape should be (batch, seq_len, num_heads, head_size)
+ k (torch.Tensor): K embedding in attention layer, shape should be (batch, seq_len, num_heads, head_size)
+ v (torch.Tensor): V embedding in attention layer, shape should be (batch, seq_len, num_heads, head_size)
+ input_mask (torch.Tensor): mask for softmax layer, shape should be (batch, num_heads, seq_lem, seq_len)
+ scale: the float scale value which is used to multiply with Q*K^T before doing softmax
+
+ Return:
+ output (Torch.Tensor): The output shape is (batch, seq_len, num_heads, head_size)
+ """
+ assert len(q.shape) == 4, "the shape of q val must be 4"
+ batches, M, H, K = q.shape
+ assert q.shape == k.shape, "the shape of q and the shape of k must be equal"
+ assert q.shape == v.shape, "the shape of q and the shape of v must be equal"
+ assert q.shape[-1] == k.shape[-1], "the last dimension of q and k must be equal"
+
+ N = k.shape[1]
+
+ # head_size * num_of_head
+ d_model = q.shape[-1] * q.shape[-2]
+
+ score_output = torch.empty(
+ (batches, H, M, N), device=q.device, dtype=q.dtype)
+
+ grid = lambda meta: (
+ batches,
+ H,
+ triton.cdiv(M, meta["BLOCK_SIZE_M"]) *
+ triton.cdiv(N, meta["BLOCK_SIZE_N"]),
+ )
+
+ qkv_gemm_4d_kernel[grid](
+ q, k, score_output,
+ M, N, K,
+ q.stride(0), q.stride(2), q.stride(1), q.stride(3),
+ k.stride(0), k.stride(2), k.stride(3), k.stride(1),
+ score_output.stride(0), score_output.stride(1), score_output.stride(2), score_output.stride(3),
+ scale=scale,
+ # currently manually setting, later on we can use auto-tune config to match best setting
+ BLOCK_SIZE_M=64,
+ BLOCK_SIZE_N=32,
+ BLOCK_SIZE_K=32,
+ GROUP_SIZE_M=8,
+ )
+
+ softmax_output = torch.empty(
+ score_output.shape, device=score_output.device, dtype=score_output.dtype)
+ score_output_shape = score_output.shape
+
+ score_output = score_output.view(-1, score_output.shape[-1])
+ n_rows, n_cols = score_output.shape
+
+ if n_rows <= 350000:
+
+ block_size = max(triton.next_power_of_2(n_cols), 2)
+ num_warps = 4
+ if block_size >= 4096:
+ num_warps = 16
+ elif block_size >= 2048:
+ num_warps = 8
+ else:
+ num_warps = 4
+
+ softmax_kernel[(n_rows, )](
+ softmax_output,
+ score_output,
+ score_output.stride(0),
+ n_cols,
+ mask_ptr = input_mask,
+ num_warps=num_warps,
+ BLOCK_SIZE=block_size,
+ )
+
+ else:
+ #TODO: change softmax kernel functions to make it suitable for large size dimension
+ softmax_output = torch.nn.functional.softmax(score_output, dim=-1)
+ softmax_output = softmax_output.view(*score_output_shape)
+
+ batches, H, M, K = softmax_output.shape
+ N = v.shape[-1]
+
+ output = torch.empty(
+ (batches, M, H, N), device=softmax_output.device, dtype=softmax_output.dtype)
+
+ grid = lambda meta: (
+ batches,
+ H,
+ triton.cdiv(M, meta["BLOCK_SIZE_M"]) *
+ triton.cdiv(N, meta["BLOCK_SIZE_N"]),
+ )
+
+ qkv_gemm_4d_kernel[grid](
+ softmax_output, v, output,
+ M, N, K,
+ softmax_output.stride(0),
+ softmax_output.stride(1),
+ softmax_output.stride(2),
+ softmax_output.stride(3),
+ v.stride(0),
+ v.stride(2),
+ v.stride(1),
+ v.stride(3),
+ output.stride(0),
+ output.stride(2),
+ output.stride(1),
+ output.stride(3),
+ BLOCK_SIZE_M=128,
+ BLOCK_SIZE_N=64,
+ BLOCK_SIZE_K=64,
+ GROUP_SIZE_M=8,
+ scale=-1,
+ )
+ return output.view(batches, -1, d_model)
+
+
+ def self_attention_compute_using_triton(qkv,
+ input_mask,
+ layer_past,
+ alibi,
+ scale,
+ head_size,
+ triangular=False,
+ use_flash=False):
+
+ assert qkv.is_contiguous()
+ assert alibi is None, "current triton self-attention does not support alibi"
+ batches = qkv.shape[0]
+ d_model = qkv.shape[-1] // 3
+ num_of_heads = d_model // head_size
+
+ q = qkv[:, :, :d_model]
+ k = qkv[:, :, d_model:d_model * 2]
+ v = qkv[:, :, d_model * 2:]
+ q = q.view(batches, -1, num_of_heads, head_size)
+ k = k.view(batches, -1, num_of_heads, head_size)
+ v = v.view(batches, -1, num_of_heads, head_size)
+
+ data_output_triton = self_attention_forward_without_fusion(
+ q, k, v, input_mask, scale)
+
+ return data_output_triton
+
+
+ def softmax(input: torch.Tensor, mask: torch.Tensor = None, dim=-1) -> torch.Tensor:
+ if mask is not None:
+ assert input[-1] == mask[-1], "the last dimentions should be the same for input and mask"
+ assert dim == -1 or dim == len(input.shape)-1, "currently softmax layer only support last dimention"
+
+ hidden_dim = input.shape[-1]
+ output = torch.empty_like(input)
+ input = input.view(-1, hidden_dim)
+ if mask is not None:
+ mask = mask.view(-1, hidden_dim)
+ assert input.shape[0] == mask.shape[0], "the fist dimention of mask and input should be the same"
+
+ num_rows, num_cols = input.shape
+ block_size = max(triton.next_power_of_2(num_cols), 2)
+ num_warps = 16
+ if block_size >= 4096:
+ num_warps = 16
+ elif block_size >= 2048:
+ num_warps = 8
+ else:
+ num_warps = 4
+
+ if num_rows <= 350000:
+ grid = (num_rows,)
+ softmax_kernel[grid](output, input, input.stride(0), num_cols, mask, BLOCK_SIZE = block_size, num_warps=num_warps)
+ else:
+ grid = lambda meta: ()
+
+ grid = lambda meta: (
+ triton.cdiv(num_rows, meta["BLOCK_M"]),
+ )
+
+ BLOCK_M = 32
+ if block_size >= 4096:
+ BLOCK_M = 4
+ elif block_size >= 2048:
+ BLOCK_M = 8
+
+ softmax_kernel_2[grid](output_ptr = output,
+ input_ptr = input,
+ row_stride = input.stride(0),
+ n_rows = num_rows,
+ n_cols = num_cols,
+ mask_ptr = mask,
+ # currently manually setting up size
+ BLOCK_M = 32,
+ BLOCK_SIZE = block_size)
+
+ return output
\ No newline at end of file
diff --git a/colossalai/kernel/triton/qkv_matmul_kernel.py b/colossalai/kernel/triton/qkv_matmul_kernel.py
new file mode 100644
index 000000000000..62fc6bba0360
--- /dev/null
+++ b/colossalai/kernel/triton/qkv_matmul_kernel.py
@@ -0,0 +1,109 @@
+import torch
+try:
+ import triton
+ import triton.language as tl
+ HAS_TRITON = True
+except ImportError:
+ HAS_TRITON = False
+ print("please install triton from https://github.com/openai/triton")
+
+
+if HAS_TRITON:
+ '''
+ this kernel function is modified from https://triton-lang.org/main/getting-started/tutorials/03-matrix-multiplication.html
+ '''
+ @triton.jit
+ def qkv_gemm_4d_kernel(
+ a_ptr,
+ b_ptr,
+ c_ptr,
+ M,
+ N,
+ K,
+ stride_ab,
+ stride_ah,
+ stride_am,
+ stride_ak,
+ stride_bb,
+ stride_bh,
+ stride_bk,
+ stride_bn,
+ stride_cb,
+ stride_ch,
+ stride_cm,
+ stride_cn,
+ scale,
+ # Meta-parameters
+ BLOCK_SIZE_M : tl.constexpr = 64,
+ BLOCK_SIZE_N : tl.constexpr = 32,
+ BLOCK_SIZE_K : tl.constexpr = 32,
+ GROUP_SIZE_M : tl.constexpr = 8,
+ ):
+ r""" A kernel function which is used to do batch-matmul for Q*K^T or score_matrix * V for attention layer,
+ where score_matrix is softmax(Q*V^T/sqrt(hidden_size))
+ Args:
+ a_ptr(torch.Tensor): pointer to input tensor array (bs, M, h, K) or (bs, h, M, K)
+ b_ptr(torch.Tensor): pointer to input tensor array (bs, N, h, K) or (bs, h, N, K)
+ c_ptr(torch.Tensor): pointer to output tensor array (bs, M, h, N) or (bs, h, M, N)
+ stride_ab(tl.constexpr): stride for bs-dimention for tensor array A
+ stride_ah(tl.constexpr): stride for h-dimention for tensor array A
+ stride_am(tl.constexpr): stride for m-dimention for tensor array A
+ stride_ak(tl.constexpr): stride for k-dimention for tensor array A
+ stride_bb(tl.constexpr): stride for bs-dimention for tensor array B
+ stride_bh(tl.constexpr): stride for h-dimention for tensor array B
+ stride_bk(tl.constexpr): stride for k-dimention for tensor array B
+ stride_bn(tl.constexpr): stride for n-dimention for tensor array B
+ stride_cb(tl.constexpr): stride for bs-dimention for tensor array output
+ stride_ch(tl.constexpr): stride for h-dimention for tensor array output
+ stride_cm(tl.constexpr): stride for m-dimention for tensor array output
+ stride_cn(tl.constexpr): stride for n-dimention for tensor array output
+ BLOCK_SIZE_M : tiling size for M-dimension of tensor Array a
+ BLOCK_SIZE_N : tiling size for N-dimension of tensor Array b
+ BLOCK_SIZE_K : tiling size for K-dimension of a and b
+ GROUP_SIZE_M : group size for reducing cache miss, more details:
+ """
+
+ num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
+ num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
+ batch = tl.program_id(axis = 0)
+ head = tl.program_id(axis = 1)
+ pid = tl.program_id(axis = 2)
+
+ # the following is from tutorial: https://triton-lang.org/main/getting-started/tutorials/03-matrix-multiplication.html
+ num_pid_in_group = GROUP_SIZE_M * num_pid_n
+ group_id = pid // num_pid_in_group
+ first_pid_m = group_id * GROUP_SIZE_M
+ group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
+ pid_m = first_pid_m + (pid % group_size_m)
+ pid_n = (pid % num_pid_in_group) // group_size_m
+
+
+ offs_am = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
+ offs_bn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
+ offs_k = tl.arange(0, BLOCK_SIZE_K)
+ a_ptrs = (a_ptr + batch * stride_ab + head * stride_ah +
+ (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak))
+ b_ptrs = (b_ptr + batch * stride_bb + head * stride_bh +
+ (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn))
+
+ accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
+ for k in range(0, K, BLOCK_SIZE_K):
+ a_mask = (offs_am[:, None] < M) & (offs_k[None, :] + k < K)
+ b_mask = (offs_k[:, None] + k < K) & (offs_bn[None, :] < N)
+ a = tl.load(a_ptrs, mask=a_mask, other=0.)
+ b = tl.load(b_ptrs, mask=b_mask, other=0.)
+ accumulator += tl.dot(a, b)
+ a_ptrs += BLOCK_SIZE_K * stride_ak
+ b_ptrs += BLOCK_SIZE_K * stride_bk
+
+ accumulator = accumulator.to(c_ptr.dtype.element_ty)
+ if scale > 0:
+ accumulator = accumulator * scale.to(c_ptr.dtype.element_ty)
+
+
+ offs_accumu_m = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
+ offs_accumu_n = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
+ c_ptrs = (c_ptr + batch * stride_cb + head * stride_ch + stride_cm * offs_accumu_m[:, None] +
+ stride_cn * offs_accumu_n[None, :])
+ accumulator_mask = (offs_accumu_m[:, None] < M) & (offs_accumu_n[None, :] < N)
+ tl.store(c_ptrs, accumulator, mask=accumulator_mask)
diff --git a/colossalai/kernel/triton/softmax_kernel.py b/colossalai/kernel/triton/softmax_kernel.py
new file mode 100644
index 000000000000..c215890badff
--- /dev/null
+++ b/colossalai/kernel/triton/softmax_kernel.py
@@ -0,0 +1,44 @@
+try:
+ import triton
+ import triton.language as tl
+ HAS_TRITON = True
+except ImportError:
+ HAS_TRITON = False
+ print("please install triton from https://github.com/openai/triton")
+
+if HAS_TRITON:
+ '''
+ softmax kernel is modified based on
+ https://github.com/openai/triton/blob/34817ecc954a6f4ca7b4dfb352fdde1f8bd49ca5/python/tutorials/02-fused-softmax.py
+ '''
+ @triton.jit
+ def softmax_kernel(output_ptr, input_ptr, row_stride, n_cols, mask_ptr, BLOCK_SIZE: tl.constexpr):
+ r""" the kernel function for implementing softmax operator
+ Args:
+ output_ptr: the output after finishing softmax operation, (N, hidden_dim)
+ input_ptr: the tensor of input, shape should be (N, hidden_dim)
+ n_cols(tl.constexpr): the number of cols of input
+ BLOCK_SIZE(tl.constexpr): the block_size of your hidden_dim dimension, typically BLOCK_SIZE >= hidden_dim
+ """
+ row_idx = tl.program_id(0)
+ row_start_ptr = input_ptr + row_idx * row_stride
+ col_offsets = tl.arange(0, BLOCK_SIZE)
+ input_ptrs = row_start_ptr + col_offsets
+ row = tl.load(input_ptrs, mask=col_offsets < n_cols, other=-float('inf')).to(tl.float32)
+ row_minus_max = row - tl.max(row, axis=0)
+
+ if mask_ptr is not None:
+ # load mask into SRAM
+ mask_ptrs = (mask_ptr + (row_indx * row_stride)) + col_offsets
+ mask = tl.load(mask_ptrs, mask=col_offsets < n_cols, other=0).to(tl.float32)
+
+ # update
+ row_minus_max = row_minus_max + mask
+
+ numerator = tl.exp(row_minus_max)
+ denominator = tl.sum(numerator, axis=0)
+ softmax_output = numerator / denominator
+ output_row_start_ptr = output_ptr + row_idx * row_stride
+ output_ptrs = output_row_start_ptr + col_offsets
+ # Write back output to DRAM
+ tl.store(output_ptrs, softmax_output, mask=col_offsets < n_cols)
\ No newline at end of file
diff --git a/tests/test_kernels/test_self_attention.py b/tests/test_kernels/test_self_attention.py
new file mode 100644
index 000000000000..b316404a58db
--- /dev/null
+++ b/tests/test_kernels/test_self_attention.py
@@ -0,0 +1,136 @@
+import pytest
+from packaging import version
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from colossalai.kernel.triton.ops import self_attention_compute_using_triton
+from colossalai.kernel.triton.qkv_matmul_kernel import qkv_gemm_4d_kernel
+
+try:
+ import triton
+ import triton.language as tl
+ HAS_TRITON = True
+except ImportError:
+ HAS_TRITON = False
+ print("please install triton from https://github.com/openai/triton")
+
+TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
+
+@pytest.mark.skipif(not TRITON_CUDA_SUPPORT, reason="triton requires cuda version to be higher than 11.4")
+def test_qkv_matmul():
+ qkv = torch.randn((4, 24, 64*3), device="cuda", dtype=torch.float16)
+ scale = 1.2
+ head_size = 32
+ batches = qkv.shape[0]
+ d_model = qkv.shape[-1] // 3
+ num_of_heads = d_model // head_size
+
+ q = qkv[:, :, :d_model]
+ k = qkv[:, :, d_model:d_model * 2]
+
+ q = q.view(batches, -1, num_of_heads, head_size)
+ k = k.view(batches, -1, num_of_heads, head_size)
+ q_copy = q.clone()
+ k_copy = k.clone()
+ q = torch.transpose(q, 1, 2).contiguous()
+ k = torch.transpose(k, 1, 2).contiguous()
+ k = torch.transpose(k, 2, 3).contiguous()
+
+ torch_ouput = torch.einsum('bnij,bnjk->bnik', q, k)
+ torch_ouput *= 1.2
+
+ q, k = q_copy, k_copy
+ batches, M, H, K = q.shape
+ N = k.shape[1]
+ score_output = torch.empty(
+ (batches, H, M, N), device=q.device, dtype=q.dtype)
+
+ grid = lambda meta: (
+ batches,
+ H,
+ triton.cdiv(M, meta["BLOCK_SIZE_M"]) *
+ triton.cdiv(N, meta["BLOCK_SIZE_N"]),
+ )
+
+ K = q.shape[3]
+ qkv_gemm_4d_kernel[grid](
+ q, k, score_output,
+ M, N, K,
+ q.stride(0), q.stride(2), q.stride(1), q.stride(3),
+ k.stride(0), k.stride(2), k.stride(3), k.stride(1),
+ score_output.stride(0), score_output.stride(1), score_output.stride(2), score_output.stride(3),
+ scale=scale,
+ # currently manually setting, later on we can use auto-tune config to match best setting
+ BLOCK_SIZE_M=64,
+ BLOCK_SIZE_N=32,
+ BLOCK_SIZE_K=32,
+ GROUP_SIZE_M=8,
+ )
+
+ check = torch.allclose(torch_ouput.cpu(), score_output.cpu(), rtol=1e-3, atol=1e-5)
+ assert check is True, "the outputs of triton and torch are not matched"
+
+
+def self_attention_compute_using_torch(qkv,
+ input_mask,
+ scale,
+ head_size
+ ):
+
+ batches = qkv.shape[0]
+ d_model = qkv.shape[-1] // 3
+ num_of_heads = d_model // head_size
+
+ q = qkv[:, :, :d_model]
+ k = qkv[:, :, d_model:d_model * 2]
+ v = qkv[:, :, d_model * 2:]
+ q = q.view(batches, -1, num_of_heads, head_size)
+ k = k.view(batches, -1, num_of_heads, head_size)
+ v = v.view(batches, -1, num_of_heads, head_size)
+
+ q = torch.transpose(q, 1, 2).contiguous()
+ k = torch.transpose(k, 1, 2).contiguous()
+ v = torch.transpose(v, 1, 2).contiguous()
+
+ k = torch.transpose(k, -1, -2).contiguous()
+
+ score_output = torch.einsum('bnij,bnjk->bnik', q, k)
+ score_output *= scale
+
+ softmax_output = F.softmax(score_output, dim = -1)
+ res = torch.einsum('bnij,bnjk->bnik', softmax_output, v)
+ res = torch.transpose(res, 1, 2)
+ res = res.contiguous()
+
+
+ return res.view(batches, -1, d_model), score_output, softmax_output
+
+@pytest.mark.skipif(not TRITON_CUDA_SUPPORT, reason="triton requires cuda version to be higher than 11.4")
+def test_self_atttention_test():
+
+ qkv = torch.randn((4, 24, 64*3), device="cuda", dtype=torch.float16)
+ data_output_torch, score_output_torch, softmax_output_torch = self_attention_compute_using_torch(
+ qkv.clone(),
+ input_mask = None,
+ scale = 1.2,
+ head_size = 32
+ )
+
+ data_output_triton = self_attention_compute_using_triton(
+ qkv.clone(),
+ alibi=None,
+ head_size=32,
+ scale=1.2,
+ input_mask=None,
+ layer_past=None,
+ use_flash=False,
+ triangular=True)
+
+ check = torch.allclose(data_output_triton.cpu(), data_output_torch.cpu(), rtol=1e-4, atol=1e-2)
+ assert check is True, "the triton output is not matched with torch output"
+
+
+if __name__ == "__main__":
+ test_qkv_matmul()
+ test_self_atttention_test()
\ No newline at end of file
diff --git a/tests/test_kernels/test_softmax.py b/tests/test_kernels/test_softmax.py
new file mode 100644
index 000000000000..843d811d019c
--- /dev/null
+++ b/tests/test_kernels/test_softmax.py
@@ -0,0 +1,27 @@
+import pytest
+from packaging import version
+import torch
+from torch import nn
+
+from colossalai.kernel.triton.ops import softmax
+
+TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
+
+@pytest.mark.skipif(not TRITON_CUDA_SUPPORT, reason="triton requires cuda version to be higher than 11.4")
+def test_softmax_op():
+ data_samples = [
+ torch.randn((3, 4, 5, 32), device = "cuda", dtype = torch.float32),
+ torch.randn((320, 320, 78), device = "cuda", dtype = torch.float32),
+ torch.randn((2345, 4, 5, 64), device = "cuda", dtype = torch.float16)
+ ]
+
+ for data in data_samples:
+ module = nn.Softmax(dim = -1)
+ data_torch_out = module(data)
+ data_triton_out = softmax(data)
+ check = torch.allclose(data_torch_out.cpu(), data_triton_out.cpu(), rtol=1e-3, atol=1e-3)
+ assert check is True, "softmax outputs from triton and torch are not matched"
+
+
+if __name__ == "__main__":
+ test_softmax_op()
\ No newline at end of file
From fc5cef2c79265e36b585ef22c5e1d7f18be52a4e Mon Sep 17 00:00:00 2001
From: Hongxin Liu
Date: Wed, 19 Jul 2023 16:43:01 +0800
Subject: [PATCH 4/6] [lazy] support init on cuda (#4269)
* [lazy] support init on cuda
* [test] update lazy init test
* [test] fix transformer version
---
colossalai/lazy/lazy_init.py | 28 ++++++++++++++++++++--------
requirements/requirements-test.txt | 2 +-
tests/test_lazy/lazy_init_utils.py | 10 +++++++---
tests/test_lazy/test_models.py | 5 +++--
4 files changed, 31 insertions(+), 14 deletions(-)
diff --git a/colossalai/lazy/lazy_init.py b/colossalai/lazy/lazy_init.py
index 8b911407307c..1f5345015bf2 100644
--- a/colossalai/lazy/lazy_init.py
+++ b/colossalai/lazy/lazy_init.py
@@ -1,3 +1,4 @@
+from contextlib import contextmanager
from types import MethodType
from typing import Callable, Dict, Optional, Union
@@ -61,12 +62,15 @@ class _MyTensor(Tensor):
"""
_pre_op_fn: Callable[['LazyTensor'], None] = lambda *args: None
+ default_device: Optional[torch.device] = None
+
def __new__(cls, func, *args, concrete_data=None, **kwargs) -> '_MyTensor':
cls._pre_op_fn()
if concrete_data is not None:
# uniform api as LazyTensor
data = concrete_data
else:
+ kwargs['device'] = cls.default_device
data = func(*args, **kwargs)
return Tensor._make_subclass(cls, data, require_grad=data.requires_grad)
@@ -142,6 +146,8 @@ class LazyTensor(torch.Tensor):
_meta_data: Optional[MetaTensor] = None # shape, dtype, device
_pre_op_fn: Callable[['LazyTensor'], None] = lambda *args: None
+ default_device: Optional[torch.device] = None
+
@staticmethod
def __new__(cls, func, *args, meta_data=None, concrete_data=None, **kwargs):
if concrete_data is not None:
@@ -159,6 +165,8 @@ def __new__(cls, func, *args, meta_data=None, concrete_data=None, **kwargs):
return r
def __init__(self, func, *args, meta_data=None, concrete_data=None, **kwargs):
+ if func.__name__ in _NORMAL_FACTORY:
+ kwargs = {**kwargs, 'device': LazyTensor.default_device}
self._factory_method = (func, args, kwargs) # (func, args, kwargs)
self._op_buffer = [] # (func, args, kwargs, replace)
self._materialized_data: Optional[torch.Tensor] = concrete_data # materialized data
@@ -206,16 +214,11 @@ def _materialize_data(self) -> torch.Tensor:
if self._materialized_data is None:
# apply factory method
func, args, kwargs = self._factory_method
-
# apply cached sequence
self._pre_op_fn()
- try:
- init_val = func(*tree_map(self._replace_with_materialized, args),
- **tree_map(self._replace_with_materialized, kwargs))
- except TypeError as e:
- print(f'init fn: {func.__name__}')
- raise e
+ init_val = func(*tree_map(self._replace_with_materialized, args),
+ **tree_map(self._replace_with_materialized, kwargs))
self._materialized_data = self._rerun_ops(init_val)
return self._materialized_data
@@ -305,6 +308,7 @@ def wrap(y, i=None):
else:
# out of place op, create new lazy tensor
fn = lambda *a, **kw: func(*a, **kw) if i is None else func(*a, **kw)[i]
+ fn.__name__ = func.__name__
lazy_y = LazyTensor(fn, *args, meta_data=y, **kwargs)
return lazy_y
elif type(y) is Tensor:
@@ -435,14 +439,21 @@ class LazyInitContext:
"""
_replaced: bool = False
- def __init__(self, tensor_cls: Union[_MyTensor, LazyTensor] = LazyTensor):
+ def __init__(self,
+ tensor_cls: Union[_MyTensor, LazyTensor] = LazyTensor,
+ default_device: Optional[Union[torch.device, str, int]] = None):
+ assert tensor_cls is LazyTensor or tensor_cls is _MyTensor
self.overrides = {}
self.tensor_cls = tensor_cls
+ self.old_default_device = LazyTensor.default_device
+ self.default_device = default_device
def __enter__(self):
if LazyInitContext._replaced:
raise RuntimeError(f'LazyInitContext is not reentrant')
LazyInitContext._replaced = True
+ self.old_default_device = self.tensor_cls.default_device
+ self.tensor_cls.default_device = self.default_device
def wrap_factory_method(target):
# factory functions (eg. torch.empty())
@@ -518,6 +529,7 @@ def wrapper(*args, **kwargs):
setattr(torch, name, wrapper)
def __exit__(self, exc_type, exc_val, exc_tb):
+ self.tensor_cls.default_device = self.old_default_device
LazyInitContext._replaced = False
for name, (wrapper, orig) in self.overrides.items():
setattr(torch, name, orig)
diff --git a/requirements/requirements-test.txt b/requirements/requirements-test.txt
index 50121a9283f2..9f6580c72d1b 100644
--- a/requirements/requirements-test.txt
+++ b/requirements/requirements-test.txt
@@ -4,7 +4,7 @@ pytest
coverage==7.2.3
git+https://github.com/hpcaitech/pytest-testmon
torchvision
-transformers
+transformers==4.30.2
timm
titans
torchaudio
diff --git a/tests/test_lazy/lazy_init_utils.py b/tests/test_lazy/lazy_init_utils.py
index 73c3c5422d8a..9d9e9a3a5c76 100644
--- a/tests/test_lazy/lazy_init_utils.py
+++ b/tests/test_lazy/lazy_init_utils.py
@@ -61,14 +61,18 @@ def assert_forward_equal(m1: torch.nn.Module, m2: torch.nn.Module, data_gen_fn:
f'{m1.__class__.__name__} has inconsistent outputs, {out1} vs {out2}'
-def check_lazy_init(entry: TestingEntry, seed: int = 42, verbose: bool = False, check_forward: bool = False) -> None:
+def check_lazy_init(entry: TestingEntry,
+ seed: int = 42,
+ verbose: bool = False,
+ check_forward: bool = False,
+ default_device: str = 'cpu') -> None:
model_fn, data_gen_fn, output_transform_fn, _, model_attr = entry
_MyTensor._pre_op_fn = lambda *args: set_seed(seed)
LazyTensor._pre_op_fn = lambda *args: set_seed(seed)
- ctx = LazyInitContext(tensor_cls=_MyTensor)
+ ctx = LazyInitContext(tensor_cls=_MyTensor, default_device=default_device)
with ctx:
model = model_fn()
- ctx = LazyInitContext()
+ ctx = LazyInitContext(default_device=default_device)
with ctx:
deferred_model = model_fn()
copied_deferred_model = deepcopy(deferred_model)
diff --git a/tests/test_lazy/test_models.py b/tests/test_lazy/test_models.py
index 4b7aeed73a69..e37184125d21 100644
--- a/tests/test_lazy/test_models.py
+++ b/tests/test_lazy/test_models.py
@@ -6,13 +6,14 @@
@pytest.mark.skipif(not SUPPORT_LAZY, reason='requires torch >= 1.12.0')
@pytest.mark.parametrize('subset', ['torchvision', 'diffusers', 'timm', 'transformers', 'torchaudio', 'deepfm', 'dlrm'])
-def test_torchvision_models_lazy_init(subset):
+@pytest.mark.parametrize('default_device', ['cpu', 'cuda'])
+def test_torchvision_models_lazy_init(subset, default_device):
sub_model_zoo = model_zoo.get_sub_registry(subset)
for name, entry in sub_model_zoo.items():
# TODO(ver217): lazy init does not support weight norm, skip these models
if name in ('torchaudio_wav2vec2_base', 'torchaudio_hubert_base') or name.startswith('transformers_llama'):
continue
- check_lazy_init(entry, verbose=True)
+ check_lazy_init(entry, verbose=True, default_device=default_device)
if __name__ == '__main__':
From c6f6005990b182d7ee34c1fb84762d31ce7d3616 Mon Sep 17 00:00:00 2001
From: Baizhou Zhang
Date: Fri, 21 Jul 2023 14:39:01 +0800
Subject: [PATCH 5/6] [checkpointio] Sharded Optimizer Checkpoint for Gemini
Plugin (#4302)
* sharded optimizer checkpoint for gemini plugin
* modify test to reduce testing time
* update doc
* fix bug when keep_gatherd is true under GeminiPlugin
---
colossalai/booster/plugin/gemini_plugin.py | 131 +++++++++++++---
.../checkpoint_io/general_checkpoint_io.py | 38 +++--
colossalai/checkpoint_io/utils.py | 38 +++++
colossalai/zero/gemini/gemini_optimizer.py | 140 ++++++++++++++----
docs/source/en/basics/booster_api.md | 5 +-
docs/source/en/basics/booster_checkpoint.md | 2 -
docs/source/en/basics/booster_plugins.md | 2 -
docs/source/zh-Hans/basics/booster_api.md | 5 +-
.../zh-Hans/basics/booster_checkpoint.md | 1 -
docs/source/zh-Hans/basics/booster_plugins.md | 1 -
.../test_gemini_checkpoint_io.py | 4 +-
.../test_gemini_torch_compability.py | 6 +-
12 files changed, 289 insertions(+), 84 deletions(-)
diff --git a/colossalai/booster/plugin/gemini_plugin.py b/colossalai/booster/plugin/gemini_plugin.py
index 6191f271c318..7b6e17337d36 100644
--- a/colossalai/booster/plugin/gemini_plugin.py
+++ b/colossalai/booster/plugin/gemini_plugin.py
@@ -1,3 +1,4 @@
+import gc
import logging
import os
import warnings
@@ -12,11 +13,19 @@
from torch.utils.data import DataLoader
from colossalai.checkpoint_io import CheckpointIndexFile, CheckpointIO, GeneralCheckpointIO
-from colossalai.checkpoint_io.utils import get_model_base_filenames, get_shard_filename, save_state_dict
+from colossalai.checkpoint_io.utils import (
+ get_model_base_filenames,
+ get_optimizer_base_filenames,
+ get_shard_filename,
+ load_shard_state_dict,
+ save_state_dict,
+ save_state_dict_shards,
+)
from colossalai.cluster import DistCoordinator
from colossalai.interface import ModelWrapper, OptimizerWrapper
from colossalai.utils import get_current_device
from colossalai.zero import GeminiDDP, zero_model_wrapper, zero_optim_wrapper
+from colossalai.zero.gemini import ZeroOptimizer
from colossalai.zero.gemini.memory_tracer import MemStats
from .dp_plugin_base import DPPluginBase
@@ -37,7 +46,7 @@ def save_unsharded_model(self, model: GeminiDDP, checkpoint: str, gather_dtensor
"""
Save sharded model to checkpoint but only on master process.
The model should be unwrapped in self.load_model via ModelWrapper.unwrap.
- As there is communication when getting state dict, this must be called on all processes.
+ As there is communication when getting state dict, model.state_dict() must be called on all processes.
"""
state_dict = model.state_dict(only_rank_0=True)
if self.coordinator.is_master():
@@ -54,7 +63,7 @@ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather
"""
Save unsharded optimizer state dict to checkpoint.
After calling optimizer.state_dict(), the complete optimizer states will be collected on master rank.
- As there is communication when getting state dict, this must be called on all processes.
+ As there is communication when getting state dict, optimizer.state_dict() must be called on all processes.
The saving process will only be executed by master rank.
"""
state_dict = optimizer.state_dict()
@@ -76,7 +85,8 @@ def save_sharded_model(self,
max_shard_size: int = 1024,
use_safetensors: bool = False):
"""
- Save sharded model
+ Save sharded model.
+ As there is communication when getting state dict, model.state_dict() must be called on all processes.
"""
if os.path.isfile(checkpoint_path):
logging.error(f"Provided path ({checkpoint_path}) should be a directory, not a file")
@@ -86,28 +96,24 @@ def save_sharded_model(self,
state_dict_shard = model.state_dict_shard(max_shard_size=max_shard_size, only_rank_0=True, dtype=torch.float32)
weights_name, save_index_file = get_model_base_filenames(prefix, use_safetensors)
- total_size = 0
index_file = CheckpointIndexFile(checkpoint_path)
- for idx, shard_pair in enumerate(state_dict_shard):
- if not self.coordinator.is_master():
- continue
- shard = shard_pair[0]
- shard_file = get_shard_filename(weights_name, idx)
- total_size = total_size + shard_pair[1]
- for key in shard.keys():
- index_file.append_weight_map(key, shard_file)
-
- checkpoint_file_path = os.path.join(checkpoint_path, shard_file)
- save_state_dict(shard, checkpoint_file_path, use_safetensors)
- index_file.append_meta_data("total_size", total_size)
+ # Save shards of optimizer states.
+ is_master = self.coordinator.is_master()
+ total_size = save_state_dict_shards(sharded_state_dict=state_dict_shard,
+ checkpoint=checkpoint_path,
+ index_file=index_file,
+ base_filename=weights_name,
+ is_master=is_master,
+ use_safetensors=use_safetensors)
# only save the index file on the master rank
if self.coordinator.is_master():
+ index_file.append_meta_data("total_size", total_size)
index_file.write_index_file(save_index_file)
- logging.info(f"The model is split into checkpoint shards. "
- f"You can find where each parameters has been saved in the "
- f"index located at {save_index_file}.")
+ logging.info(f"The model is split into checkpoint shards. "
+ f"You can find where each parameters has been saved in the "
+ f"index located at {save_index_file}.")
def load_sharded_model(self,
model: GeminiDDP,
@@ -115,7 +121,7 @@ def load_sharded_model(self,
strict: bool = False,
use_safetensors: bool = False):
"""
- load shard model, load model from multiple files
+ Load shard model, load model from multiple files.
"""
return super().load_sharded_model(model, checkpoint_index_file, strict, use_safetensors, load_sub_module=False)
@@ -125,16 +131,93 @@ def save_sharded_optimizer(self, optimizer: Optimizer, checkpoint: Path, gather_
Save sharded optimizer state dict to checkpoint folder.
As there is communication when getting state dict, this must be called on all processes.
"""
+
+ # If optimizer is wrapped, unwrap it.
+ if isinstance(optimizer, OptimizerWrapper):
+ optimizer = optimizer.unwrap()
+
+ assert isinstance(optimizer, ZeroOptimizer)
+
+ if os.path.isfile(checkpoint):
+ logging.error(f"Provided path ({checkpoint}) should be a directory, not a file")
+ return
+
Path(checkpoint).mkdir(parents=True, exist_ok=True)
- super().save_sharded_optimizer(optimizer, checkpoint, gather_dtensor, prefix, size_per_shard)
+
+ # Preparing file paths and index file.
+ states_name, save_index_file, param_group_file = get_optimizer_base_filenames(prefix)
+ index_file = CheckpointIndexFile(checkpoint)
+
+ # Store the information of param groups to param_group_file.
+ index_file.append_meta_data("param_groups", param_group_file)
+ group_file_path = os.path.join(checkpoint, param_group_file)
+ param_groups = optimizer.get_param_groups_for_saving()
+ torch.save(param_groups, group_file_path)
+
+ # States are broken into shards within max_shard_size.
+ state_dict_shard = optimizer.state_shard(prefix=prefix, max_shard_size=size_per_shard, only_rank_0=True)
+
+ # Save shards of optimizer states.
+ is_master = self.coordinator.is_master()
+ total_size = save_state_dict_shards(sharded_state_dict=state_dict_shard,
+ checkpoint=checkpoint,
+ index_file=index_file,
+ base_filename=states_name,
+ is_master=is_master,
+ use_safetensors=False)
+
+ # Wrap up index file. Only save it on master rank.
+ if self.coordinator.is_master():
+ index_file.append_meta_data("total_size", total_size)
+ index_file.write_index_file(save_index_file)
+ logging.info(f"The optimizer is going to be split to checkpoint shards. "
+ f"You can find where each parameters has been saved in the "
+ f"index located at {save_index_file}.")
def load_sharded_optimizer(self, optimizer: Optimizer, checkpoint_index_file: Path, prefix: str):
"""
Loading sharded optimizer from checkpoint folder, with index file given.
For each process, only loading optimizer states of parameters it controls.
"""
- # TODO(Baizhou): To be implemented.
- pass
+
+ if not os.path.isfile(checkpoint_index_file):
+ logging.error(f"Provided path ({checkpoint_index_file}) should be a file")
+
+ # If optimizer is wrapped, unwrap it.
+ if isinstance(optimizer, OptimizerWrapper):
+ optimizer = optimizer.unwrap()
+
+ assert isinstance(optimizer, ZeroOptimizer)
+
+ # Read checkpoint index file.
+ ckpt_index_file = CheckpointIndexFile.from_file(checkpoint_index_file)
+
+ # Load param_groups.
+ param_group_path = ckpt_index_file.get_param_group_filename()
+ if param_group_path is None:
+ raise RuntimeError(f'Invalid index file path {checkpoint_index_file} for an optimizer. \
+ Lacking param group file under current directory.')
+ saved_param_groups = torch.load(param_group_path)
+ optimizer.load_param_groups(saved_param_groups)
+
+ checkpoint_files, _ = ckpt_index_file.get_checkpoint_filenames()
+
+ # Load optimizer states from shard files under checkpoint path.
+ # For each file, only load the states managed by current process.
+ for shard_file in checkpoint_files:
+ state_dict_shard = load_shard_state_dict(Path(shard_file), use_safetensors=False)
+ optimizer.load_param_states(state_dict_shard)
+ del state_dict_shard
+ gc.collect()
+
+ optimizer.optimizer_loading_epilogue()
+
+ def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ """
+ Save model to checkpoint but only on master process.
+ """
+ if self.coordinator.is_master():
+ super().save_lr_scheduler(lr_scheduler, checkpoint)
class GeminiModel(ModelWrapper):
diff --git a/colossalai/checkpoint_io/general_checkpoint_io.py b/colossalai/checkpoint_io/general_checkpoint_io.py
index e1d9066948dd..83e4bdcc863b 100644
--- a/colossalai/checkpoint_io/general_checkpoint_io.py
+++ b/colossalai/checkpoint_io/general_checkpoint_io.py
@@ -5,6 +5,7 @@
from pathlib import Path
from typing import Iterator, Optional, OrderedDict, Tuple
+import torch.distributed as dist
import torch.nn as nn
from torch.optim import Optimizer
@@ -16,7 +17,6 @@
get_model_base_filenames,
get_optimizer_base_filenames,
get_shard_filename,
- has_index_file,
is_safetensors_available,
load_param_groups_into_optimizer,
load_shard_state_dict,
@@ -25,6 +25,7 @@
load_states_into_optimizer,
save_param_groups,
save_state_dict,
+ save_state_dict_shards,
shard_model_checkpoint,
shard_optimizer_checkpoint,
sharded_optimizer_loading_epilogue,
@@ -122,15 +123,13 @@ def save_sharded_optimizer(
save_param_groups(state_dict, group_file_path)
# Save shards of optimizer states.
- total_size = 0
- for idx, shard_pair in enumerate(sharded_state):
- shard, current_size = shard_pair
- shard_file = get_shard_filename(states_name, idx)
- total_size = total_size + current_size
- for key in shard.keys():
- index_file.append_weight_map(key, shard_file)
- checkpoint_file_path = os.path.join(checkpoint, shard_file)
- save_state_dict(shard, checkpoint_file_path, use_safetensors=False)
+ # In general cases, is_master is set to True to get the right behavior.
+ total_size = save_state_dict_shards(sharded_state_dict=sharded_state,
+ checkpoint=checkpoint,
+ index_file=index_file,
+ base_filename=states_name,
+ is_master=True,
+ use_safetensors=False)
# Wrap up index file.
index_file.append_meta_data("total_size", total_size)
@@ -172,18 +171,17 @@ def save_sharded_model(self,
# shard checkpoint
state_dict = model.state_dict()
state_dict_shard = shard_model_checkpoint(state_dict, max_shard_size=max_shard_size)
-
weights_name, save_index_file = get_model_base_filenames(prefix, use_safetensors)
- total_size = 0
index_file = CheckpointIndexFile(checkpoint_path)
- for idx, shard_pair in enumerate(state_dict_shard):
- shard = shard_pair[0]
- shard_file = get_shard_filename(weights_name, idx)
- total_size = total_size + shard_pair[1]
- for key in shard.keys():
- index_file.append_weight_map(key, shard_file)
- checkpoint_file_path = os.path.join(checkpoint_path, shard_file)
- save_state_dict(shard, checkpoint_file_path, use_safetensors)
+
+ # Save shards of optimizer states.
+ # In general cases, is_master is set to True to get the right behavior.
+ total_size = save_state_dict_shards(sharded_state_dict=state_dict_shard,
+ checkpoint=checkpoint_path,
+ index_file=index_file,
+ base_filename=weights_name,
+ is_master=True,
+ use_safetensors=use_safetensors)
index_file.append_meta_data("total_size", total_size)
index_file.write_index_file(save_index_file)
diff --git a/colossalai/checkpoint_io/utils.py b/colossalai/checkpoint_io/utils.py
index 19e28c3f7068..8837776aee4d 100644
--- a/colossalai/checkpoint_io/utils.py
+++ b/colossalai/checkpoint_io/utils.py
@@ -1,4 +1,5 @@
# coding=utf-8
+import os
import re
from collections import abc as container_abcs
from collections import defaultdict
@@ -103,6 +104,43 @@ def unwrap_optimizer(optimizer: OptimizerWrapper):
return unwrapped_optim
+def save_state_dict_shards(sharded_state_dict: Iterator[Tuple[OrderedDict, int]],
+ checkpoint: str,
+ index_file: "CheckpointIndexFile",
+ base_filename: str,
+ is_master: bool,
+ use_safetensors: bool = False) -> int:
+ '''
+ Save sharded state dict only on master rank, this method can be used by both model and optimizer states.
+ Args:
+ sharded_state_dict (Iterator[Tuple[OrderedDict, int]]): a generator of shards, each shard contains state dict and shard size.
+ checkpoint (str): The path of checkpoint directory as string.
+ index_file (CheckpointIndexFile): The index file object to be updated.
+ base_filename (str): Decides the prefix of filenames of shards.
+ is_master (bool): Whether current rank is master.
+ use_safetensors (bool): Whether to use safetensors to save checkpoint.
+
+ Returns:
+ int: the total size of shards
+ '''
+
+ total_size = 0
+ for idx, shard_pair in enumerate(sharded_state_dict):
+ if not is_master:
+ continue
+ shard, current_size = shard_pair
+ shard_file = get_shard_filename(base_filename, idx)
+ total_size = total_size + current_size
+ for key in shard.keys():
+ index_file.append_weight_map(key, shard_file)
+ checkpoint_file_path = os.path.join(checkpoint, shard_file)
+
+ # Only save on master rank.
+ save_state_dict(shard, checkpoint_file_path, use_safetensors=use_safetensors)
+
+ return total_size
+
+
def shard_model_checkpoint(state_dict: torch.Tensor, max_shard_size: int = 1024) -> Iterator[Tuple[OrderedDict, int]]:
"""
Splits a model state dictionary in sub-checkpoints so that the final size of each sub-checkpoint does not exceed a
diff --git a/colossalai/zero/gemini/gemini_optimizer.py b/colossalai/zero/gemini/gemini_optimizer.py
index 99aff6f1c527..7d0db6b1fa23 100644
--- a/colossalai/zero/gemini/gemini_optimizer.py
+++ b/colossalai/zero/gemini/gemini_optimizer.py
@@ -3,7 +3,7 @@
import gc
import math
import warnings
-from typing import Any, Dict, Set, Tuple
+from typing import Any, Dict, Iterator, OrderedDict, Set, Tuple
import torch
import torch.distributed as dist
@@ -11,8 +11,10 @@
from torch.optim import Optimizer
from colossalai.amp.naive_amp.mixed_precision_mixin import BF16MixedPrecisionMixin, FP16MixedPrecisionMixin
+from colossalai.checkpoint_io.utils import calculate_tensor_size
from colossalai.logging import get_dist_logger
from colossalai.nn.optimizer import ColossalaiOptimizer, CPUAdam, FusedAdam, HybridAdam
+from colossalai.tensor.d_tensor import is_distributed_tensor
from colossalai.utils import disposable, get_current_device, is_ddp_ignored
from .chunk import Chunk, ChunkManager
@@ -360,10 +362,12 @@ def get_offsets(self, param_id: int) -> tuple:
begin_in_chunk, end_in_chunk = self.param_to_range[fake_param]
chunk_offset = begin_in_chunk
- shard_offset = begin_in_chunk + chunk.shard_begin - param_info.offset
+ if chunk.keep_gathered:
+ shard_offset = 0
+ else:
+ shard_offset = begin_in_chunk + chunk.shard_begin - param_info.offset
shard_size = end_in_chunk - begin_in_chunk
assert chunk_offset >= 0 and shard_offset >= 0
-
return chunk_offset, shard_offset, shard_size
def collect_states(self, param_id: int, only_rank_0: bool = True) -> dict:
@@ -427,7 +431,8 @@ def collect_states(self, param_id: int, only_rank_0: bool = True) -> dict:
dtype=torch.float32,
requires_grad=False).cpu()
else:
- collected_states[state_name] = states[state_name].detach().clone().to(torch.float32).cpu()
+ state_tensor = states[state_name].detach().clone().to(torch.float32).cpu()
+ collected_states[state_name] = torch.reshape(state_tensor, param.shape)
return collected_states
# Check whether the param with given id is managed by current process.
@@ -536,6 +541,31 @@ def load_from_compacted_states(self, compacted_states: torch.Tensor, collected_s
target_segment.copy_(compacted_states[next_state_offset:next_state_offset + shard_size])
next_state_offset += shard_size
+ def get_param_groups_for_saving(self) -> list:
+ '''
+ Return the param_groups in Pytorch format when saving to checkpoint.
+ '''
+
+ param_groups = copy.deepcopy(self.param_groups_backup)
+
+ # To be compatible with pytorch checkpointing,
+ # store extra hyperparameters used by pytorch Adam optimizer.
+ torch_special_hyperparameters = {
+ 'amsgrad': False,
+ 'maximize': False,
+ 'foreach': None,
+ 'capturable': False,
+ 'differentiable': False,
+ 'fused': False
+ }
+
+ for group in param_groups:
+ for k, v in torch_special_hyperparameters.items():
+ if k not in group:
+ group[k] = v
+
+ return param_groups
+
def state_dict(self, only_rank_0: bool = True) -> dict:
"""
Args:
@@ -555,21 +585,7 @@ def state_dict(self, only_rank_0: bool = True) -> dict:
so it should be called only when memory resources are abundant.
"""
state_dict = {}
- state_dict['param_groups'] = copy.deepcopy(self.param_groups_backup)
-
- torch_special_hyperparameters = {
- 'amsgrad': False,
- 'maximize': False,
- 'foreach': None,
- 'capturable': False,
- 'differentiable': False,
- 'fused': False
- }
-
- for group in state_dict['param_groups']:
- for k, v in torch_special_hyperparameters.items():
- if k not in group:
- group[k] = v
+ state_dict['param_groups'] = self.get_param_groups_for_saving()
# Collect optimizer states.
state_dict['state'] = dict()
@@ -634,8 +650,24 @@ def cast(param, state_range, value, key=None):
del v # clean loaded states
self.optim.state[fake_param].update(updated_states)
+ def load_param_states(self, param_states: dict):
+ """Loads param states from a state_dict. The param_states can be complete or sharded.
+ During loading, filter out the part of states not considered by current process.
+
+ Args:
+ param_states (dict): A mapping from param_id to its states.
+ """
+ for param_id, states in param_states.items():
+ if param_id in self.id_to_fake_params:
+ self.load_single_param_states(param_id, states)
+
+ def optimizer_loading_epilogue(self):
+ # Epilogue when loading state_dict to pytorch optimizer.
+ self.optim._hook_for_profile() # To support multiprocessing pickle/unpickle.
+ self.optim.defaults.setdefault('differentiable', False)
+
def load_state_dict(self, state_dict: dict):
- """Loads optimizer state from whole optimizer state_dict.
+ """Loads optimizer state from complete optimizer state_dict.
During loading, filter out the part of states not considered by current process.
Args:
@@ -643,17 +675,71 @@ def load_state_dict(self, state_dict: dict):
from a call to :meth:`state_dict`.
"""
assert 'param_groups' in state_dict
+ assert 'state' in state_dict
self.load_param_groups(state_dict['param_groups'])
+ self.load_param_states(state_dict['state'])
+ self.optimizer_loading_epilogue()
- state = state_dict['state']
+ def state_shard(self,
+ prefix: str = '',
+ max_shard_size: int = 1024,
+ only_rank_0: bool = True) -> Iterator[Tuple[OrderedDict, int]]:
+ """Returns dictionaries containing shards of optimizer states one by one.
+ The max size of each dictionary shard is specified by ``max_shard_size``.
- for param_id, param_states in state.items():
- if param_id in self.id_to_fake_params:
- self.load_single_param_states(param_id, param_states)
+ Args:
+ prefix (str, optional): the prefix for states. Default to ''.
+ max_shard_size (int, optional): max size of state dict shard (in MB). Defaults to 1024.
+ only_rank_0 (bool, optional): a boolean value indicating whether the state_dict is collected
+ only on rank 0, dafault to True.
- # Epilogue for pytorch optimizer.
- self.optim._hook_for_profile() # To support multiprocessing pickle/unpickle.
- self.optim.defaults.setdefault('differentiable', False)
+ Yields:
+ Iterator[OrderedDict]: A generator of state dict shard of optimizer states.
+ """
+
+ current_block = {}
+ current_block_size = 0
+
+ for param_id in self.id_to_real_params.keys():
+
+ dist.barrier()
+ state = self.collect_states(param_id=param_id, only_rank_0=only_rank_0)
+
+ ret_block = None
+ ret_block_size = 0
+
+ # A state might contain more than one tensors.
+ # e.g. each Adam state includes: 'step', 'exp_avg', 'exp_avg_sq'
+ state_size = 0
+ isDTensor = False
+ for state_tensor in state.values():
+
+ # When state_tensor is not of Tensor class,
+ # e.g., a SGD optimizer with momentum set to 0 can have None as state
+ # The calculation of tensor size should be skipped to avoid error.
+ if not isinstance(state_tensor, torch.Tensor):
+ continue
+
+ # If the states are stored as DTensors, mark isDTensor as true.
+ if is_distributed_tensor(state_tensor):
+ isDTensor = True
+ state_size += calculate_tensor_size(state_tensor)
+
+ if not isDTensor:
+
+ if current_block_size + state_size > max_shard_size and current_block_size > 0:
+ ret_block = current_block
+ ret_block_size = current_block_size
+ current_block = {}
+ current_block_size = 0
+
+ current_block[param_id] = state
+ current_block_size += state_size
+
+ if ret_block != None:
+ yield ret_block, ret_block_size
+
+ yield current_block, current_block_size
class GeminiAdamOptimizer(ZeroOptimizer):
diff --git a/docs/source/en/basics/booster_api.md b/docs/source/en/basics/booster_api.md
index 22d5ee818019..1e75c343c14f 100644
--- a/docs/source/en/basics/booster_api.md
+++ b/docs/source/en/basics/booster_api.md
@@ -21,10 +21,13 @@ Plugin is an important component that manages parallel configuration (eg: The ge
**_GeminiPlugin:_** This plugin wraps the Gemini acceleration solution, that ZeRO with chunk-based memory management.
-**_TorchDDPPlugin:_** This plugin wraps the DDP acceleration solution, it implements data parallelism at the module level which can run across multiple machines.
+**_TorchDDPPlugin:_** This plugin wraps the DDP acceleration solution of Pytorch. It implements data parallelism at the module level which can run across multiple machines.
**_LowLevelZeroPlugin:_** This plugin wraps the 1/2 stage of Zero Redundancy Optimizer. Stage 1 : Shards optimizer states across data parallel workers/GPUs. Stage 2 : Shards optimizer states + gradients across data parallel workers/GPUs.
+
+**_TorchFSDPPlugin:_** This plugin wraps the FSDP acceleration solution of Pytorch and can be used to train models with zero-dp.
+
### API of booster
{{ autodoc:colossalai.booster.Booster }}
diff --git a/docs/source/en/basics/booster_checkpoint.md b/docs/source/en/basics/booster_checkpoint.md
index adc0af60b7de..b2840fe87441 100644
--- a/docs/source/en/basics/booster_checkpoint.md
+++ b/docs/source/en/basics/booster_checkpoint.md
@@ -21,8 +21,6 @@ Model must be boosted by `colossalai.booster.Booster` before loading. It will de
## Optimizer Checkpoint
-> ⚠ Saving optimizer checkpoint in a sharded way is not supported yet.
-
{{ autodoc:colossalai.booster.Booster.save_optimizer }}
Optimizer must be boosted by `colossalai.booster.Booster` before saving.
diff --git a/docs/source/en/basics/booster_plugins.md b/docs/source/en/basics/booster_plugins.md
index 5e2586b836ad..c5c45abce8f7 100644
--- a/docs/source/en/basics/booster_plugins.md
+++ b/docs/source/en/basics/booster_plugins.md
@@ -51,8 +51,6 @@ This plugin implements Zero-3 with chunk-based and heterogeneous memory manageme
{{ autodoc:colossalai.booster.plugin.GeminiPlugin }}
-> ⚠ This plugin can only load optimizer checkpoint saved by itself with the same number of processes now. This will be fixed in the future.
-
### Torch DDP Plugin
More details can be found in [Pytorch Docs](https://pytorch.org/docs/main/generated/torch.nn.parallel.DistributedDataParallel.html#torch.nn.parallel.DistributedDataParallel).
diff --git a/docs/source/zh-Hans/basics/booster_api.md b/docs/source/zh-Hans/basics/booster_api.md
index 1df821ce7d6e..b2235b73bca1 100644
--- a/docs/source/zh-Hans/basics/booster_api.md
+++ b/docs/source/zh-Hans/basics/booster_api.md
@@ -24,10 +24,13 @@ Booster 插件是管理并行配置的重要组件(eg:gemini 插件封装了
**_GeminiPlugin:_** GeminiPlugin 插件封装了 gemini 加速解决方案,即基于块内存管理的 ZeRO 优化方案。
-**_TorchDDPPlugin:_** TorchDDPPlugin 插件封装了 DDP 加速方案,实现了模型级别的数据并行,可以跨多机运行。
+**_TorchDDPPlugin:_** TorchDDPPlugin 插件封装了Pytorch的DDP加速方案,实现了模型级别的数据并行,可以跨多机运行。
**_LowLevelZeroPlugin:_** LowLevelZeroPlugin 插件封装了零冗余优化器的 1/2 阶段。阶段 1:切分优化器参数,分发到各并发进程或并发 GPU 上。阶段 2:切分优化器参数及梯度,分发到各并发进程或并发 GPU 上。
+**_TorchFSDPPlugin:_** TorchFSDPPlugin封装了 Pytorch的FSDP加速方案,可以用于零冗余优化器数据并行(ZeroDP)的训练。
+
+
### Booster 接口
diff --git a/docs/source/zh-Hans/basics/booster_checkpoint.md b/docs/source/zh-Hans/basics/booster_checkpoint.md
index d75f18c908ba..4ed049dcf44f 100644
--- a/docs/source/zh-Hans/basics/booster_checkpoint.md
+++ b/docs/source/zh-Hans/basics/booster_checkpoint.md
@@ -21,7 +21,6 @@
## 优化器 Checkpoint
-> ⚠ 尚不支持以分片方式保存优化器 Checkpoint。
{{ autodoc:colossalai.booster.Booster.save_optimizer }}
diff --git a/docs/source/zh-Hans/basics/booster_plugins.md b/docs/source/zh-Hans/basics/booster_plugins.md
index 5bd88b679000..0f355c43901c 100644
--- a/docs/source/zh-Hans/basics/booster_plugins.md
+++ b/docs/source/zh-Hans/basics/booster_plugins.md
@@ -51,7 +51,6 @@ Zero-2 不支持局部梯度累积。如果您坚持使用,虽然可以积累
{{ autodoc:colossalai.booster.plugin.GeminiPlugin }}
-> ⚠ 该插件现在只能加载自己保存的且具有相同进程数的优化器 Checkpoint。这将在未来得到解决。
### Torch DDP 插件
diff --git a/tests/test_checkpoint_io/test_gemini_checkpoint_io.py b/tests/test_checkpoint_io/test_gemini_checkpoint_io.py
index 0235ff2e2c81..7b664419b405 100644
--- a/tests/test_checkpoint_io/test_gemini_checkpoint_io.py
+++ b/tests/test_checkpoint_io/test_gemini_checkpoint_io.py
@@ -52,7 +52,7 @@ def exam_state_dict_with_origin(placement_policy, model_name, use_safetensors: b
@clear_cache_before_run()
@parameterize('placement_policy', ['cuda', 'cpu'])
-@parameterize('shard', [False])
+@parameterize('shard', [False, True])
@parameterize('model_name', ['transformers_gpt'])
@parameterize('size_per_shard', [32])
def exam_state_dict(placement_policy, shard: bool, model_name: str, size_per_shard: int):
@@ -117,7 +117,7 @@ def run_dist(rank, world_size, port):
@pytest.mark.dist
-@pytest.mark.parametrize('world_size', [1, 2])
+@pytest.mark.parametrize('world_size', [2])
@rerun_if_address_is_in_use()
def test_gemini_ckpIO(world_size):
spawn(run_dist, world_size)
diff --git a/tests/test_checkpoint_io/test_gemini_torch_compability.py b/tests/test_checkpoint_io/test_gemini_torch_compability.py
index b34e3e3a1310..464fccb39103 100644
--- a/tests/test_checkpoint_io/test_gemini_torch_compability.py
+++ b/tests/test_checkpoint_io/test_gemini_torch_compability.py
@@ -19,7 +19,7 @@
@clear_cache_before_run()
-@parameterize('shard', [False])
+@parameterize('shard', [False, True])
@parameterize('model_name', ['transformers_gpt'])
def exam_torch_load_from_gemini(shard: bool, model_name: str):
@@ -83,7 +83,7 @@ def exam_torch_load_from_gemini(shard: bool, model_name: str):
@clear_cache_before_run()
-@parameterize('shard', [False])
+@parameterize('shard', [False, True])
@parameterize('model_name', ['transformers_gpt'])
def exam_gemini_load_from_torch(shard: bool, model_name: str):
@@ -165,7 +165,7 @@ def run_dist(rank, world_size, port):
@pytest.mark.dist
-@pytest.mark.parametrize('world_size', [1, 2])
+@pytest.mark.parametrize('world_size', [2])
@rerun_if_address_is_in_use()
def test_gemini_ckpIO(world_size):
spawn(run_dist, world_size)
From 02192a632e6c6f965d93ec79937f97e10e121307 Mon Sep 17 00:00:00 2001
From: Hongxin Liu
Date: Fri, 21 Jul 2023 18:36:35 +0800
Subject: [PATCH 6/6] [ci] support testmon core pkg change detection (#4305)
---
.github/workflows/build_on_pr.yml | 1 +
1 file changed, 1 insertion(+)
diff --git a/.github/workflows/build_on_pr.yml b/.github/workflows/build_on_pr.yml
index 380c8e9f882c..8a1bc8e113de 100644
--- a/.github/workflows/build_on_pr.yml
+++ b/.github/workflows/build_on_pr.yml
@@ -213,6 +213,7 @@ jobs:
DATA: /data/scratch/cifar-10
NCCL_SHM_DISABLE: 1
LD_LIBRARY_PATH: /github/home/.tensornvme/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
+ TESTMON_CORE_PKGS: /__w/ColossalAI/ColossalAI/requirements/requirements.txt,/__w/ColossalAI/ColossalAI/requirements/requirements-test.txt
- name: Store Testmon Cache
run: |