diff --git a/en/use-dify/nodes/trigger/plugin-trigger.mdx b/en/use-dify/nodes/trigger/plugin-trigger.mdx
index a12dc6854..153d4aa18 100644
--- a/en/use-dify/nodes/trigger/plugin-trigger.mdx
+++ b/en/use-dify/nodes/trigger/plugin-trigger.mdx
@@ -19,7 +19,7 @@ For example, suppose you have installed a GitHub trigger plugin. It provides a l
- If there's no suitable trigger plugin for your target external system, you can [request one from the community](https://github.com/langgenius/dify-plugins/issues/new?template=plugin_request.yaml), [develop one yourself](/en/develop-plugin/dev-guides-and-walkthroughs/trigger-plugin), or use a [webhook trigger](/en/use-dify/nodes/trigger/webhook-trigger) instead.
- - A workflow can have multiple plugin triggers running in parallel. When the parallel branches contain identical consecutive nodes, you can add a [Variable Aggregator](/en/use-dify/nodes/variable-aggregator) node to merge the branches before the common section, without duplicating the same nodes across each branch.
+ - A workflow can have multiple plugin triggers. If these trigger branches share identical downstream nodes, add a [Variable Aggregator](/en/use-dify/nodes/variable-aggregator) to converge them and avoid duplicating those nodes on each branch.
2. Select an existing subscription or [create a new one](#create-a-new-subscription).
diff --git a/en/use-dify/nodes/trigger/webhook-trigger.mdx b/en/use-dify/nodes/trigger/webhook-trigger.mdx
index 2f7dbc521..e5cd892fc 100644
--- a/en/use-dify/nodes/trigger/webhook-trigger.mdx
+++ b/en/use-dify/nodes/trigger/webhook-trigger.mdx
@@ -38,9 +38,7 @@ Following the same mechanism, webhook triggers enable your workflow to run in re
On the workflow canvas, right-click and select **Add Node** > **Start** > **Webhook Trigger**.
- A workflow can have multiple webhook triggers running in parallel.
-
- When the parallel branches contain identical consecutive nodes, you can add a [Variable Aggregator](/en/use-dify/nodes/variable-aggregator) node to merge the branches before the common section, without duplicating the same nodes across each branch.
+ A workflow can have multiple webhook triggers. If these trigger branches share identical downstream nodes, add a [Variable Aggregator](/en/use-dify/nodes/variable-aggregator) to converge them and avoid duplicating those nodes on each branch.
## Configure a Webhook Trigger
diff --git a/en/use-dify/nodes/variable-aggregator.mdx b/en/use-dify/nodes/variable-aggregator.mdx
index f552c6255..33cdafac1 100644
--- a/en/use-dify/nodes/variable-aggregator.mdx
+++ b/en/use-dify/nodes/variable-aggregator.mdx
@@ -1,67 +1,38 @@
---
title: "Variable Aggregator"
-description: "Combine variables from different workflow branches into unified outputs"
+description: "Converge exclusive workflow branches into a single output"
---
-The Variable Aggregator node combines variables from different execution paths into a single unified output. When multiple branches produce similar outputs, this node eliminates the need for duplicate downstream processing by creating one consistent variable reference.
+Use the Variable Aggregator node to converge **exclusive** workflow branches into a single output, so you only need to define downstream processing once.
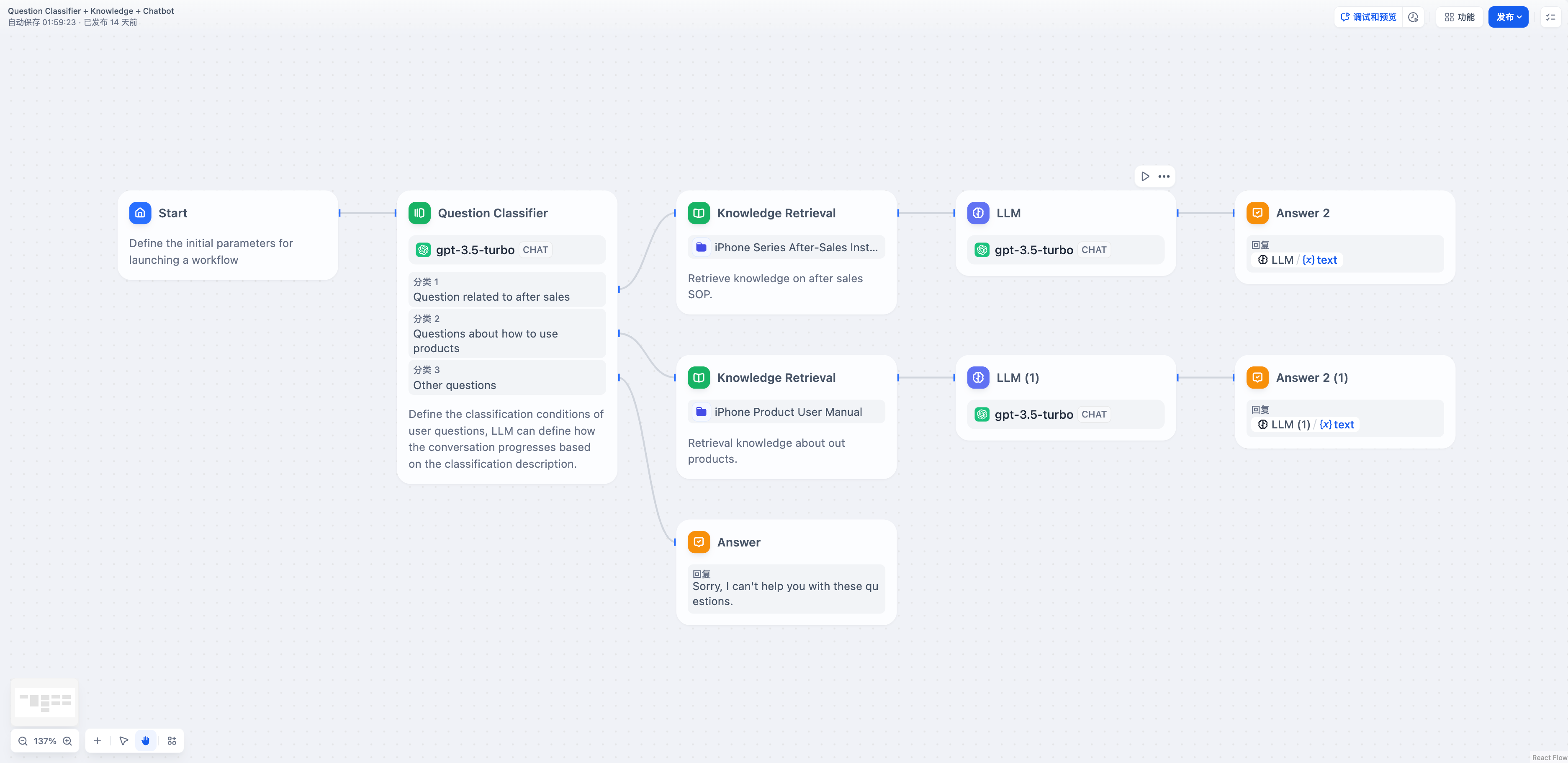
-## The Branching Problem
+Nodes like If/Else and Question Classifier create exclusive branches—only one path executes per run. When these branches produce the same type of output, you would normally duplicate downstream nodes on every branch.
-Conditional workflows create parallel execution paths where only one branch runs at a time. Without aggregation, you'd need duplicate downstream nodes for each possible branch outcome, creating complex and maintenance-heavy workflows.
+The Variable Aggregator eliminates this duplication. It provides a single output variable for downstream nodes to reference, regardless of which branch ran.
-The Variable Aggregator acts as a merge point, collecting branch outputs into a single variable that downstream nodes can reference consistently, regardless of which branch actually executed.
-
-## Classification Workflow Example
-
-When user input is classified and each category requires different knowledge retrieval, the Variable Aggregator combines the results:
-
-**Without Aggregation** - Complex workflow requiring duplicate LLM nodes:
-
-
-  +
+ 
-**With Aggregation** - Simplified workflow with single downstream processing:
-
-
-
+
+ 
-**With Aggregation** - Simplified workflow with single downstream processing:
-
-
-  +
+ 
-The aggregated workflow uses one LLM node instead of duplicating it for each classification branch, significantly reducing complexity while maintaining the same functionality.
-
-## Conditional Processing Example
-
-Similar benefits apply to If-Else branches that produce comparable outputs:
-
-
-
+
+ 
-The aggregated workflow uses one LLM node instead of duplicating it for each classification branch, significantly reducing complexity while maintaining the same functionality.
-
-## Conditional Processing Example
-
-Similar benefits apply to If-Else branches that produce comparable outputs:
-
-
-  -
-
-## Configuration
-
-### Variable Selection
-
-Connect variables from different workflow branches that you want to combine. Each connected variable becomes a potential input to the aggregated output.
-
-### Type Constraints
+
+The Variable Aggregator is designed for exclusive branches where **only one path runs at a time**. It does not combine outputs from multiple branches that execute in parallel.
-**Same Type Rule** - All aggregated variables must be the same data type. Once you connect the first variable (e.g., String), the node only accepts variables of the same type from other branches.
+To merge results from parallel branches, use a [Code](/en/use-dify/nodes/code) or [Template](/en/use-dify/nodes/template) node.
+
-**Supported Types:**
-- **String** - Text outputs from different processing branches
-- **Number** - Numeric calculations, scores, or measurements
-- **Object** - Structured data objects with similar schemas
-- **Boolean** - True/false values
-- **Array** - Lists, collections, or multiple results
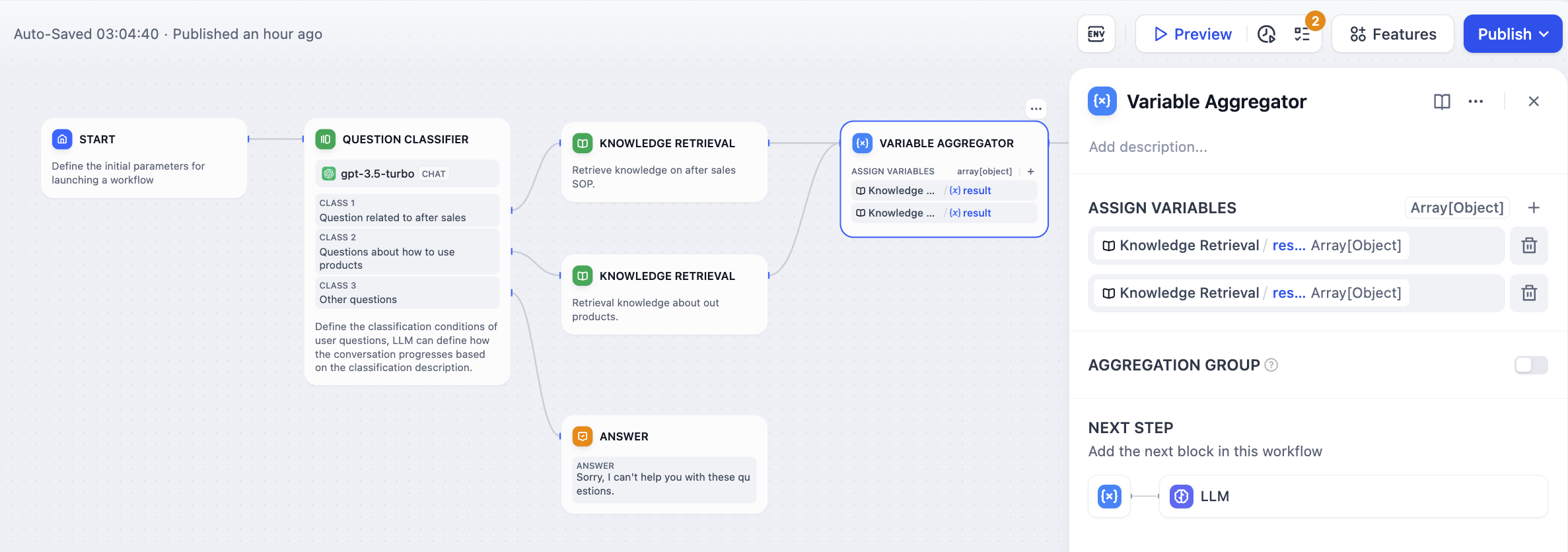
+## Select the Variables to Converge
-### Output Behavior
+From each branch, add variables that need the same downstream processing. All variables must share the same data type.
-The Variable Aggregator outputs the value from whichever branch actually executed. Since only one branch runs in conditional workflows, only one input variable will have a value during execution.
+Supported types: `string`, `number`, `object`, `boolean`, `array`, `file`.
-## Advanced Features
+The node outputs whichever variable has a value at runtime. Since only one branch executes, only one variable will have a value, and that value becomes the node's output.
-### Multiple Aggregation Groups
+## Converge Multiple Sets of Variables
-Advanced workflows (v0.6.10+) can aggregate multiple groups of variables simultaneously. Each group maintains its own type constraint, allowing you to aggregate different data types in parallel within the same node.
+When you have multiple sets of variables that each need to be converged separately, enable **Aggregation Group** to create groups within a single Variable Aggregator.
-This is useful when branches produce multiple related outputs that need to be combined separately - for example, aggregating both text summaries and numeric scores from different processing paths.
+Each group converges its own set of variables and produces a separate output.
\ No newline at end of file
diff --git a/images/with-variable-aggregator.png b/images/with-variable-aggregator.png
new file mode 100644
index 000000000..60d78abf8
Binary files /dev/null and b/images/with-variable-aggregator.png differ
diff --git a/images/without-variable-aggregator.png b/images/without-variable-aggregator.png
new file mode 100644
index 000000000..3b723897c
Binary files /dev/null and b/images/without-variable-aggregator.png differ
diff --git a/ja/use-dify/nodes/trigger/plugin-trigger.mdx b/ja/use-dify/nodes/trigger/plugin-trigger.mdx
index 5d912d3b8..7864c3ae4 100644
--- a/ja/use-dify/nodes/trigger/plugin-trigger.mdx
+++ b/ja/use-dify/nodes/trigger/plugin-trigger.mdx
@@ -21,7 +21,7 @@ title: プラグイントリガー
- 対象の外部システムに適切なトリガープラグインがない場合は、[コミュニティにリクエスト](https://github.com/langgenius/dify-plugins/issues/new?template=plugin_request.yaml)したり、[自分で開発](/ja/develop-plugin/dev-guides-and-walkthroughs/trigger-plugin)したり、代わりに [Webhook トリガー](/ja/use-dify/nodes/trigger/webhook-trigger)を使用したりできます。
- - 1 つのワークフローは、並行して実行される複数のプラグイントリガーで開始できます。並行分岐に同一の連続したノードが含まれている場合、共通セクションの前に[変数集約](/ja/use-dify/nodes/variable-aggregator)ノードを追加して分岐をマージできます。これにより、各分岐で同じノードを個別に重複して追加することを回避できます。
+ - 1 つのワークフローに複数のプラグイントリガーを含めることができます。これらのトリガーブランチが同じ下流ノードを共有する場合、[変数集約器](/ja/use-dify/nodes/variable-aggregator) を追加してそれらを集約し、各ブランチでノードを重複させないようにします。
2. 既存のサブスクリプションを選択するか、[新しいサブスクリプションを作成](#新しいサブスクリプションを作成)します。
diff --git a/ja/use-dify/nodes/trigger/webhook-trigger.mdx b/ja/use-dify/nodes/trigger/webhook-trigger.mdx
index 48f3da2b6..9b03f6e02 100644
--- a/ja/use-dify/nodes/trigger/webhook-trigger.mdx
+++ b/ja/use-dify/nodes/trigger/webhook-trigger.mdx
@@ -38,9 +38,7 @@ Webhook を使用すると、あるシステムが別のシステムにリアル
workflow キャンバスで右クリックし、**ブロックを追加** > **始める** > **Webhook トリガー**を選択します。
- 1 つの workflow は、並行して実行される複数の Webhook トリガーで開始できます。
-
- 並行分岐に同一の連続したノードが含まれている場合、共通セクションの前に[変数集約](/ja/use-dify/nodes/variable-aggregator)ノードを追加して分岐をマージできます。これにより、各分岐で同じノードを個別に重複して追加することを回避できます。
+ 1 つのワークフローに複数の Webhook トリガーを含めることができます。これらのトリガーブランチが同じ下流ノードを共有する場合、[変数集約器](/ja/use-dify/nodes/variable-aggregator) を追加してそれらを集約し、各ブランチでノードを重複させないようにします。
## Webhook トリガーの設定
diff --git a/ja/use-dify/nodes/variable-aggregator.mdx b/ja/use-dify/nodes/variable-aggregator.mdx
index 94968efde..92189e066 100644
--- a/ja/use-dify/nodes/variable-aggregator.mdx
+++ b/ja/use-dify/nodes/variable-aggregator.mdx
@@ -1,69 +1,40 @@
---
-title: "変数アグリゲーター"
-description: "異なるワークフローブランチからの変数を統一された出力に結合"
+title: "変数集約器"
+description: "排他的なワークフローブランチを単一の出力に集約"
---
⚠️ このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/variable-aggregator)を参照してください。
-変数アグリゲーターノードは、異なる実行パスからの変数を単一の統一された出力に結合します。複数のブランチが類似の出力を生成する場合、このノードは一つの一貫した変数参照を作成することで、下流での重複処理の必要性を排除します。
+変数集約器ノードを使用すると、**排他的な** ワークフローブランチを単一の出力に集約し、下流の処理を一度だけ定義すれば済むようになります。
-## 分岐の問題
+IF/ELSE や質問分類器などのノードは排他的なブランチを作成し、実行ごとに 1 つのパスのみが実行されます。これらのブランチが同じ型の出力を生成する場合、通常はすべてのブランチに下流ノードを重複して配置する必要があります。
-条件付きワークフローでは、並列実行パスが作成され、一度に一つのブランチのみが実行されます。集約なしでは、各可能なブランチ結果に対して重複した下流ノードが必要となり、複雑でメンテナンスが困難なワークフローが生成されます。
+変数集約器はこの重複を解消します。実際にどのブランチが実行されたかに関係なく、下流ノードが参照できる単一の出力変数を提供します。
-変数アグリゲーターはマージポイントとして機能し、ブランチ出力を単一の変数に収集することで、実際にどのブランチが実行されたかに関係なく、下流ノードが一貫して参照できるようにします。
-
-## 分類ワークフローの例
-
-ユーザー入力が分類され、各カテゴリが異なる知識検索を必要とする場合、変数アグリゲーターが結果を結合します:
-
-**集約なし** - 重複したLLMノードを必要とする複雑なワークフロー:
-
-
-
+
+ 
-**集約あり** - 単一の下流処理による簡素化されたワークフロー:
-
-
-
+
+ 
-集約されたワークフローでは、各分類ブランチに対してLLMノードを複製する代わりに一つのLLMノードを使用し、同じ機能を維持しながら複雑さを大幅に削減します。
-
-## 条件処理の例
-
-同様の利点は、類似の出力を生成するIf-Elseブランチにも適用されます:
-
-
-
-
-
-## 設定
-
-### 変数選択
-
-結合したい異なるワークフローブランチからの変数を接続します。接続された各変数は、集約された出力への潜在的な入力となります。
-
-### 型制約
+
+変数集約器は、**一度に 1 つのパスのみが実行される** 排他的なブランチ向けに設計されています。複数のブランチが同時に実行される並列ブランチの出力を結合することはできません。
-**同一型ルール** - すべての集約された変数は同じデータ型である必要があります。最初の変数(例:文字列)を接続すると、ノードは他のブランチから同じ型の変数のみを受け入れます。
+並列ブランチの結果をマージするには、[コード実行](/ja/use-dify/nodes/code) または [テンプレート](/ja/use-dify/nodes/template) ノードを使用してください。
+
-**サポートされる型:**
-- **文字列** - 異なる処理ブランチからのテキスト出力
-- **数値** - 数値計算、スコア、または測定値
-- **オブジェクト** - 類似のスキーマを持つ構造化データオブジェクト
-- **ブール値** - True/false値
-- **配列** - リスト、コレクション、または複数の結果
+## 集約する変数の選択
-### 出力動作
+各ブランチから、同じ下流処理が必要な変数を追加します。すべての変数は同じデータ型である必要があります。
-変数アグリゲーターは、実際に実行されたブランチからの値を出力します。条件付きワークフローでは一つのブランチのみが実行されるため、実行中は一つの入力変数のみが値を持ちます。
+サポートされる型:`string`、`number`、`object`、`boolean`、`array`、`file`。
-## 高度な機能
+ノードは実行時に値を持つ変数を出力します。排他的なブランチでは 1 つのブランチのみが実行されるため、値を持つ変数は 1 つだけであり、その値がノードの出力になります。
-### 複数集約グループ
+## 複数の変数セットの集約
-高度なワークフロー(v0.6.10+)では、複数の変数グループを同時に集約できます。各グループは独自の型制約を維持し、同一ノード内で異なるデータ型を並行して集約することができます。
+複数の変数セットをそれぞれ個別に集約する必要がある場合は、**グループ** を有効にして、単一の変数集約器内にグループを作成します。
-これは、ブランチが複数の関連する出力を生成し、それらを個別に結合する必要がある場合に便利です - たとえば、異なる処理パスからのテキスト要約と数値スコアの両方を集約する場合です。
\ No newline at end of file
+各グループはそれぞれの変数セットを独立して集約し、個別の出力を生成します。
diff --git a/tools/translate/formatting-ja.md b/tools/translate/formatting-ja.md
index a79d4bfd5..d08a1dd74 100644
--- a/tools/translate/formatting-ja.md
+++ b/tools/translate/formatting-ja.md
@@ -167,6 +167,16 @@ Use minimal honorifics. Be polite but not overly formal.
**Exception:** ご利用 is idiomatic and reads naturally (e.g., ご利用のブラウザ).
+## Translation Disclaimer
+
+Every translated page must include the translation disclaimer directly below the frontmatter, before any body content:
+
+```mdx
+ ⚠️ このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/path/to/page)を参照してください。
+```
+
+Keep the disclaimer regardless of whether the page has been human-reviewed. The English source is always the canonical version, and readers benefit from a consistent pointer to it on every translated page.
+
## Translatable Elements
These elements must be translated, not left in English:
diff --git a/tools/translate/formatting-zh.md b/tools/translate/formatting-zh.md
index fb8416603..3ed0ebfdb 100644
--- a/tools/translate/formatting-zh.md
+++ b/tools/translate/formatting-zh.md
@@ -131,6 +131,16 @@ Do not end headings with sentence-ending punctuation (`。,、;:`). Paired
- If list items are short phrases or fragments, omit trailing punctuation.
- Never mix the two styles within a single list.
+## Translation Disclaimer
+
+Every translated page must include the translation disclaimer directly below the frontmatter, before any body content:
+
+```mdx
+ ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考 [英文原版](/en/path/to/page)。
+```
+
+Keep the disclaimer regardless of whether the page has been human-reviewed. The English source is always the canonical version, and readers benefit from a consistent pointer to it on every translated page.
+
## Translatable Elements
These elements must be translated, not left in English:
diff --git a/writing-guides/style-guide.md b/writing-guides/style-guide.md
index f7db87a1b..6a4dacf7a 100644
--- a/writing-guides/style-guide.md
+++ b/writing-guides/style-guide.md
@@ -14,6 +14,8 @@ Express ideas clearly and concisely. Every sentence should add value. Cut unnece
Choose precision when it prevents confusion. A specific, descriptive term is better than a shorthand that assumes shared context with the reader.
+Keep paragraphs under 50 words. On Mintlify's content width, longer paragraphs exceed four rendered lines and become visually dense. When a paragraph runs long, split it at a natural boundary—typically where the topic shifts from setup to payoff, or from problem to solution.
+
When a heading already states the topic, the first sentence should add new information—not restate the heading.
## Formatting Principles
diff --git a/zh/use-dify/nodes/trigger/plugin-trigger.mdx b/zh/use-dify/nodes/trigger/plugin-trigger.mdx
index a383b4cef..45d0f72ba 100644
--- a/zh/use-dify/nodes/trigger/plugin-trigger.mdx
+++ b/zh/use-dify/nodes/trigger/plugin-trigger.mdx
@@ -21,7 +21,7 @@ title: 插件触发器
- 若未找到合适的触发器插件,你可以 [向社区请求](https://github.com/langgenius/dify-plugins/issues/new?template=plugin_request.yaml)、[自行开发](/zh/develop-plugin/dev-guides-and-walkthroughs/trigger-plugin),或者改用 [Webhook 触发器](/zh/use-dify/nodes/trigger/webhook-trigger)。
- - 一个工作流可同时拥有多个并行的插件触发器。当并行的分支连续包含相同节点时,可在相同部分之前添加 [变量聚合节点](/zh/use-dify/nodes/variable-aggregator) 以合并分支,而无需在每个分支中分别重复添加相同的节点。
+ - 一个工作流可以包含多个插件触发器。如果这些触发器分支共享相同的下游节点,可以添加 [变量聚合器](/zh/use-dify/nodes/variable-aggregator) 将它们汇聚,避免在每条分支上重复配置相同的节点。
2. 选择一个现有订阅或 [创建新订阅](#创建新订阅)。
diff --git a/zh/use-dify/nodes/trigger/webhook-trigger.mdx b/zh/use-dify/nodes/trigger/webhook-trigger.mdx
index 094924d4d..ab87a5246 100644
--- a/zh/use-dify/nodes/trigger/webhook-trigger.mdx
+++ b/zh/use-dify/nodes/trigger/webhook-trigger.mdx
@@ -36,7 +36,7 @@ Webhook 允许一个系统自动向另一个系统发送实时数据。当某个
在 Workflow 画布上,单击右键并选择 **添加节点** > **开始** > **Webhook 触发器**。
- 一个 Workflow 可同时拥有多个并行的 Webhook 触发器。当并行的分支连续包含相同节点时,可在相同部分之前添加 [变量聚合节点](/zh/use-dify/nodes/variable-aggregator) 以合并分支,而无需在每个分支中分别重复添加相同的节点。
+ 一个工作流可以包含多个 Webhook 触发器。如果这些触发器分支共享相同的下游节点,可以添加 [变量聚合器](/zh/use-dify/nodes/variable-aggregator) 将它们汇聚,避免在每条分支上重复配置相同的节点。
## 配置 Webhook 触发器
diff --git a/zh/use-dify/nodes/variable-aggregator.mdx b/zh/use-dify/nodes/variable-aggregator.mdx
index 672ce02a7..c2fef1cd5 100644
--- a/zh/use-dify/nodes/variable-aggregator.mdx
+++ b/zh/use-dify/nodes/variable-aggregator.mdx
@@ -1,69 +1,40 @@
---
title: "变量聚合器"
-description: "将来自不同工作流分支的变量组合成统一输出"
+description: "将互斥工作流分支汇聚为单一输出"
---
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考 [英文原版](/en/use-dify/nodes/variable-aggregator)。
-变量聚合器节点将来自不同执行路径的变量组合成单一的统一输出。当多个分支产生相似输出时,该节点通过创建一个一致的变量引用,消除了对重复下游处理的需求。
+使用变量聚合器节点将 **互斥** 的工作流分支汇聚为单一输出,这样只需定义一次下游处理逻辑。
-## 分支问题
+条件分支和问题分类器等节点会创建互斥分支,每次运行只有一条路径会执行。当这些分支产生相同类型的输出时,通常需要在每条分支上重复配置下游节点。
-条件工作流创建并行执行路径,其中每次只有一个分支运行。没有聚合的情况下,你需要为每个可能的分支结果设置重复的下游节点,这会创建复杂且难以维护的工作流。
+变量聚合器消除了这种重复,提供一个统一的输出变量供下游节点引用,无论实际执行的是哪条分支。
-变量聚合器充当合并点,将分支输出收集到单个变量中,下游节点可以一致地引用该变量,无论实际执行的是哪个分支。
-
-## 分类工作流示例
-
-当用户输入被分类且每个类别需要不同的知识检索时,变量聚合器将结果组合:
-
-**无聚合** - 需要重复大型语言模型节点的复杂工作流:
-
-
-
+
+ 
-**有聚合** - 使用单一下游处理的简化工作流:
-
-
-
+
+ 
-聚合的工作流使用一个大型语言模型节点,而不是为每个分类分支重复设置,显著降低了复杂性,同时保持相同的功能。
-
-## 条件处理示例
-
-对于产生类似输出的If-Else分支,也有类似的好处:
-
-
-
-
-
-## 配置
-
-### 变量选择
-
-连接来自不同工作流分支的变量,你希望将这些变量组合。每个连接的变量都成为聚合输出的潜在输入。
-
-### 类型约束
+
+变量聚合器仅适用于 **每次只有一条路径会执行** 的互斥分支。它不会合并同时执行的多条并行分支的输出。
-**相同类型规则** - 所有聚合的变量必须是相同的数据类型。一旦你连接第一个变量(例如字符串),节点只接受来自其他分支的相同类型变量。
+如需合并并行分支的结果,请使用 [代码执行](/zh/use-dify/nodes/code) 或 [模板转换](/zh/use-dify/nodes/template) 节点。
+
-**支持的类型:**
-- **String** - 来自不同处理分支的文本输出
-- **Number** - 数值计算、分数或测量值
-- **Object** - 具有相似架构的结构化数据对象
-- **Boolean** - 真/假值
-- **Array** - 列表、集合或多个结果
+## 选择要汇聚的变量
-### 输出行为
+从每条分支中添加需要相同下游处理的变量。所有变量必须具有相同的数据类型。
-变量聚合器输出实际执行的分支的值。由于在条件工作流中只有一个分支运行,因此在执行期间只有一个输入变量会有值。
+支持的类型:`string`、`number`、`object`、`boolean`、`array`、`file`。
-## 高级功能
+节点在运行时输出有值的变量。由于只有一条分支会执行,因此只有一个变量会有值,该值即为节点的输出。
-### 多个聚合组
+## 汇聚多组变量
-高级工作流(v0.6.10+)可以同时聚合多组变量。每组都保持自己的类型约束,允许你在同一节点内并行聚合不同的数据类型。
+当有多组变量需要分别汇聚时,启用 **聚合分组** 在单个变量聚合器中创建分组。
-这在分支产生需要单独组合的多个相关输出时很有用 - 例如,从不同处理路径聚合文本摘要和数值分数。
\ No newline at end of file
+每个分组独立汇聚各自的变量,并产生单独的输出。
-
-
-## Configuration
-
-### Variable Selection
-
-Connect variables from different workflow branches that you want to combine. Each connected variable becomes a potential input to the aggregated output.
-
-### Type Constraints
+
+The Variable Aggregator is designed for exclusive branches where **only one path runs at a time**. It does not combine outputs from multiple branches that execute in parallel.
-**Same Type Rule** - All aggregated variables must be the same data type. Once you connect the first variable (e.g., String), the node only accepts variables of the same type from other branches.
+To merge results from parallel branches, use a [Code](/en/use-dify/nodes/code) or [Template](/en/use-dify/nodes/template) node.
+
-**Supported Types:**
-- **String** - Text outputs from different processing branches
-- **Number** - Numeric calculations, scores, or measurements
-- **Object** - Structured data objects with similar schemas
-- **Boolean** - True/false values
-- **Array** - Lists, collections, or multiple results
+## Select the Variables to Converge
-### Output Behavior
+From each branch, add variables that need the same downstream processing. All variables must share the same data type.
-The Variable Aggregator outputs the value from whichever branch actually executed. Since only one branch runs in conditional workflows, only one input variable will have a value during execution.
+Supported types: `string`, `number`, `object`, `boolean`, `array`, `file`.
-## Advanced Features
+The node outputs whichever variable has a value at runtime. Since only one branch executes, only one variable will have a value, and that value becomes the node's output.
-### Multiple Aggregation Groups
+## Converge Multiple Sets of Variables
-Advanced workflows (v0.6.10+) can aggregate multiple groups of variables simultaneously. Each group maintains its own type constraint, allowing you to aggregate different data types in parallel within the same node.
+When you have multiple sets of variables that each need to be converged separately, enable **Aggregation Group** to create groups within a single Variable Aggregator.
-This is useful when branches produce multiple related outputs that need to be combined separately - for example, aggregating both text summaries and numeric scores from different processing paths.
+Each group converges its own set of variables and produces a separate output.
\ No newline at end of file
diff --git a/images/with-variable-aggregator.png b/images/with-variable-aggregator.png
new file mode 100644
index 000000000..60d78abf8
Binary files /dev/null and b/images/with-variable-aggregator.png differ
diff --git a/images/without-variable-aggregator.png b/images/without-variable-aggregator.png
new file mode 100644
index 000000000..3b723897c
Binary files /dev/null and b/images/without-variable-aggregator.png differ
diff --git a/ja/use-dify/nodes/trigger/plugin-trigger.mdx b/ja/use-dify/nodes/trigger/plugin-trigger.mdx
index 5d912d3b8..7864c3ae4 100644
--- a/ja/use-dify/nodes/trigger/plugin-trigger.mdx
+++ b/ja/use-dify/nodes/trigger/plugin-trigger.mdx
@@ -21,7 +21,7 @@ title: プラグイントリガー
- 対象の外部システムに適切なトリガープラグインがない場合は、[コミュニティにリクエスト](https://github.com/langgenius/dify-plugins/issues/new?template=plugin_request.yaml)したり、[自分で開発](/ja/develop-plugin/dev-guides-and-walkthroughs/trigger-plugin)したり、代わりに [Webhook トリガー](/ja/use-dify/nodes/trigger/webhook-trigger)を使用したりできます。
- - 1 つのワークフローは、並行して実行される複数のプラグイントリガーで開始できます。並行分岐に同一の連続したノードが含まれている場合、共通セクションの前に[変数集約](/ja/use-dify/nodes/variable-aggregator)ノードを追加して分岐をマージできます。これにより、各分岐で同じノードを個別に重複して追加することを回避できます。
+ - 1 つのワークフローに複数のプラグイントリガーを含めることができます。これらのトリガーブランチが同じ下流ノードを共有する場合、[変数集約器](/ja/use-dify/nodes/variable-aggregator) を追加してそれらを集約し、各ブランチでノードを重複させないようにします。
2. 既存のサブスクリプションを選択するか、[新しいサブスクリプションを作成](#新しいサブスクリプションを作成)します。
diff --git a/ja/use-dify/nodes/trigger/webhook-trigger.mdx b/ja/use-dify/nodes/trigger/webhook-trigger.mdx
index 48f3da2b6..9b03f6e02 100644
--- a/ja/use-dify/nodes/trigger/webhook-trigger.mdx
+++ b/ja/use-dify/nodes/trigger/webhook-trigger.mdx
@@ -38,9 +38,7 @@ Webhook を使用すると、あるシステムが別のシステムにリアル
workflow キャンバスで右クリックし、**ブロックを追加** > **始める** > **Webhook トリガー**を選択します。
- 1 つの workflow は、並行して実行される複数の Webhook トリガーで開始できます。
-
- 並行分岐に同一の連続したノードが含まれている場合、共通セクションの前に[変数集約](/ja/use-dify/nodes/variable-aggregator)ノードを追加して分岐をマージできます。これにより、各分岐で同じノードを個別に重複して追加することを回避できます。
+ 1 つのワークフローに複数の Webhook トリガーを含めることができます。これらのトリガーブランチが同じ下流ノードを共有する場合、[変数集約器](/ja/use-dify/nodes/variable-aggregator) を追加してそれらを集約し、各ブランチでノードを重複させないようにします。
## Webhook トリガーの設定
diff --git a/ja/use-dify/nodes/variable-aggregator.mdx b/ja/use-dify/nodes/variable-aggregator.mdx
index 94968efde..92189e066 100644
--- a/ja/use-dify/nodes/variable-aggregator.mdx
+++ b/ja/use-dify/nodes/variable-aggregator.mdx
@@ -1,69 +1,40 @@
---
-title: "変数アグリゲーター"
-description: "異なるワークフローブランチからの変数を統一された出力に結合"
+title: "変数集約器"
+description: "排他的なワークフローブランチを単一の出力に集約"
---
⚠️ このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/variable-aggregator)を参照してください。
-変数アグリゲーターノードは、異なる実行パスからの変数を単一の統一された出力に結合します。複数のブランチが類似の出力を生成する場合、このノードは一つの一貫した変数参照を作成することで、下流での重複処理の必要性を排除します。
+変数集約器ノードを使用すると、**排他的な** ワークフローブランチを単一の出力に集約し、下流の処理を一度だけ定義すれば済むようになります。
-## 分岐の問題
+IF/ELSE や質問分類器などのノードは排他的なブランチを作成し、実行ごとに 1 つのパスのみが実行されます。これらのブランチが同じ型の出力を生成する場合、通常はすべてのブランチに下流ノードを重複して配置する必要があります。
-条件付きワークフローでは、並列実行パスが作成され、一度に一つのブランチのみが実行されます。集約なしでは、各可能なブランチ結果に対して重複した下流ノードが必要となり、複雑でメンテナンスが困難なワークフローが生成されます。
+変数集約器はこの重複を解消します。実際にどのブランチが実行されたかに関係なく、下流ノードが参照できる単一の出力変数を提供します。
-変数アグリゲーターはマージポイントとして機能し、ブランチ出力を単一の変数に収集することで、実際にどのブランチが実行されたかに関係なく、下流ノードが一貫して参照できるようにします。
-
-## 分類ワークフローの例
-
-ユーザー入力が分類され、各カテゴリが異なる知識検索を必要とする場合、変数アグリゲーターが結果を結合します:
-
-**集約なし** - 重複したLLMノードを必要とする複雑なワークフロー:
-
-
-
+
+ 
-**集約あり** - 単一の下流処理による簡素化されたワークフロー:
-
-
-
+
+ 
-集約されたワークフローでは、各分類ブランチに対してLLMノードを複製する代わりに一つのLLMノードを使用し、同じ機能を維持しながら複雑さを大幅に削減します。
-
-## 条件処理の例
-
-同様の利点は、類似の出力を生成するIf-Elseブランチにも適用されます:
-
-
-
-
-
-## 設定
-
-### 変数選択
-
-結合したい異なるワークフローブランチからの変数を接続します。接続された各変数は、集約された出力への潜在的な入力となります。
-
-### 型制約
+
+変数集約器は、**一度に 1 つのパスのみが実行される** 排他的なブランチ向けに設計されています。複数のブランチが同時に実行される並列ブランチの出力を結合することはできません。
-**同一型ルール** - すべての集約された変数は同じデータ型である必要があります。最初の変数(例:文字列)を接続すると、ノードは他のブランチから同じ型の変数のみを受け入れます。
+並列ブランチの結果をマージするには、[コード実行](/ja/use-dify/nodes/code) または [テンプレート](/ja/use-dify/nodes/template) ノードを使用してください。
+
-**サポートされる型:**
-- **文字列** - 異なる処理ブランチからのテキスト出力
-- **数値** - 数値計算、スコア、または測定値
-- **オブジェクト** - 類似のスキーマを持つ構造化データオブジェクト
-- **ブール値** - True/false値
-- **配列** - リスト、コレクション、または複数の結果
+## 集約する変数の選択
-### 出力動作
+各ブランチから、同じ下流処理が必要な変数を追加します。すべての変数は同じデータ型である必要があります。
-変数アグリゲーターは、実際に実行されたブランチからの値を出力します。条件付きワークフローでは一つのブランチのみが実行されるため、実行中は一つの入力変数のみが値を持ちます。
+サポートされる型:`string`、`number`、`object`、`boolean`、`array`、`file`。
-## 高度な機能
+ノードは実行時に値を持つ変数を出力します。排他的なブランチでは 1 つのブランチのみが実行されるため、値を持つ変数は 1 つだけであり、その値がノードの出力になります。
-### 複数集約グループ
+## 複数の変数セットの集約
-高度なワークフロー(v0.6.10+)では、複数の変数グループを同時に集約できます。各グループは独自の型制約を維持し、同一ノード内で異なるデータ型を並行して集約することができます。
+複数の変数セットをそれぞれ個別に集約する必要がある場合は、**グループ** を有効にして、単一の変数集約器内にグループを作成します。
-これは、ブランチが複数の関連する出力を生成し、それらを個別に結合する必要がある場合に便利です - たとえば、異なる処理パスからのテキスト要約と数値スコアの両方を集約する場合です。
\ No newline at end of file
+各グループはそれぞれの変数セットを独立して集約し、個別の出力を生成します。
diff --git a/tools/translate/formatting-ja.md b/tools/translate/formatting-ja.md
index a79d4bfd5..d08a1dd74 100644
--- a/tools/translate/formatting-ja.md
+++ b/tools/translate/formatting-ja.md
@@ -167,6 +167,16 @@ Use minimal honorifics. Be polite but not overly formal.
**Exception:** ご利用 is idiomatic and reads naturally (e.g., ご利用のブラウザ).
+## Translation Disclaimer
+
+Every translated page must include the translation disclaimer directly below the frontmatter, before any body content:
+
+```mdx
+ ⚠️ このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/path/to/page)を参照してください。
+```
+
+Keep the disclaimer regardless of whether the page has been human-reviewed. The English source is always the canonical version, and readers benefit from a consistent pointer to it on every translated page.
+
## Translatable Elements
These elements must be translated, not left in English:
diff --git a/tools/translate/formatting-zh.md b/tools/translate/formatting-zh.md
index fb8416603..3ed0ebfdb 100644
--- a/tools/translate/formatting-zh.md
+++ b/tools/translate/formatting-zh.md
@@ -131,6 +131,16 @@ Do not end headings with sentence-ending punctuation (`。,、;:`). Paired
- If list items are short phrases or fragments, omit trailing punctuation.
- Never mix the two styles within a single list.
+## Translation Disclaimer
+
+Every translated page must include the translation disclaimer directly below the frontmatter, before any body content:
+
+```mdx
+ ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考 [英文原版](/en/path/to/page)。
+```
+
+Keep the disclaimer regardless of whether the page has been human-reviewed. The English source is always the canonical version, and readers benefit from a consistent pointer to it on every translated page.
+
## Translatable Elements
These elements must be translated, not left in English:
diff --git a/writing-guides/style-guide.md b/writing-guides/style-guide.md
index f7db87a1b..6a4dacf7a 100644
--- a/writing-guides/style-guide.md
+++ b/writing-guides/style-guide.md
@@ -14,6 +14,8 @@ Express ideas clearly and concisely. Every sentence should add value. Cut unnece
Choose precision when it prevents confusion. A specific, descriptive term is better than a shorthand that assumes shared context with the reader.
+Keep paragraphs under 50 words. On Mintlify's content width, longer paragraphs exceed four rendered lines and become visually dense. When a paragraph runs long, split it at a natural boundary—typically where the topic shifts from setup to payoff, or from problem to solution.
+
When a heading already states the topic, the first sentence should add new information—not restate the heading.
## Formatting Principles
diff --git a/zh/use-dify/nodes/trigger/plugin-trigger.mdx b/zh/use-dify/nodes/trigger/plugin-trigger.mdx
index a383b4cef..45d0f72ba 100644
--- a/zh/use-dify/nodes/trigger/plugin-trigger.mdx
+++ b/zh/use-dify/nodes/trigger/plugin-trigger.mdx
@@ -21,7 +21,7 @@ title: 插件触发器
- 若未找到合适的触发器插件,你可以 [向社区请求](https://github.com/langgenius/dify-plugins/issues/new?template=plugin_request.yaml)、[自行开发](/zh/develop-plugin/dev-guides-and-walkthroughs/trigger-plugin),或者改用 [Webhook 触发器](/zh/use-dify/nodes/trigger/webhook-trigger)。
- - 一个工作流可同时拥有多个并行的插件触发器。当并行的分支连续包含相同节点时,可在相同部分之前添加 [变量聚合节点](/zh/use-dify/nodes/variable-aggregator) 以合并分支,而无需在每个分支中分别重复添加相同的节点。
+ - 一个工作流可以包含多个插件触发器。如果这些触发器分支共享相同的下游节点,可以添加 [变量聚合器](/zh/use-dify/nodes/variable-aggregator) 将它们汇聚,避免在每条分支上重复配置相同的节点。
2. 选择一个现有订阅或 [创建新订阅](#创建新订阅)。
diff --git a/zh/use-dify/nodes/trigger/webhook-trigger.mdx b/zh/use-dify/nodes/trigger/webhook-trigger.mdx
index 094924d4d..ab87a5246 100644
--- a/zh/use-dify/nodes/trigger/webhook-trigger.mdx
+++ b/zh/use-dify/nodes/trigger/webhook-trigger.mdx
@@ -36,7 +36,7 @@ Webhook 允许一个系统自动向另一个系统发送实时数据。当某个
在 Workflow 画布上,单击右键并选择 **添加节点** > **开始** > **Webhook 触发器**。
- 一个 Workflow 可同时拥有多个并行的 Webhook 触发器。当并行的分支连续包含相同节点时,可在相同部分之前添加 [变量聚合节点](/zh/use-dify/nodes/variable-aggregator) 以合并分支,而无需在每个分支中分别重复添加相同的节点。
+ 一个工作流可以包含多个 Webhook 触发器。如果这些触发器分支共享相同的下游节点,可以添加 [变量聚合器](/zh/use-dify/nodes/variable-aggregator) 将它们汇聚,避免在每条分支上重复配置相同的节点。
## 配置 Webhook 触发器
diff --git a/zh/use-dify/nodes/variable-aggregator.mdx b/zh/use-dify/nodes/variable-aggregator.mdx
index 672ce02a7..c2fef1cd5 100644
--- a/zh/use-dify/nodes/variable-aggregator.mdx
+++ b/zh/use-dify/nodes/variable-aggregator.mdx
@@ -1,69 +1,40 @@
---
title: "变量聚合器"
-description: "将来自不同工作流分支的变量组合成统一输出"
+description: "将互斥工作流分支汇聚为单一输出"
---
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考 [英文原版](/en/use-dify/nodes/variable-aggregator)。
-变量聚合器节点将来自不同执行路径的变量组合成单一的统一输出。当多个分支产生相似输出时,该节点通过创建一个一致的变量引用,消除了对重复下游处理的需求。
+使用变量聚合器节点将 **互斥** 的工作流分支汇聚为单一输出,这样只需定义一次下游处理逻辑。
-## 分支问题
+条件分支和问题分类器等节点会创建互斥分支,每次运行只有一条路径会执行。当这些分支产生相同类型的输出时,通常需要在每条分支上重复配置下游节点。
-条件工作流创建并行执行路径,其中每次只有一个分支运行。没有聚合的情况下,你需要为每个可能的分支结果设置重复的下游节点,这会创建复杂且难以维护的工作流。
+变量聚合器消除了这种重复,提供一个统一的输出变量供下游节点引用,无论实际执行的是哪条分支。
-变量聚合器充当合并点,将分支输出收集到单个变量中,下游节点可以一致地引用该变量,无论实际执行的是哪个分支。
-
-## 分类工作流示例
-
-当用户输入被分类且每个类别需要不同的知识检索时,变量聚合器将结果组合:
-
-**无聚合** - 需要重复大型语言模型节点的复杂工作流:
-
-
-
+
+ 
-**有聚合** - 使用单一下游处理的简化工作流:
-
-
-
+
+ 
-聚合的工作流使用一个大型语言模型节点,而不是为每个分类分支重复设置,显著降低了复杂性,同时保持相同的功能。
-
-## 条件处理示例
-
-对于产生类似输出的If-Else分支,也有类似的好处:
-
-
-
-
-
-## 配置
-
-### 变量选择
-
-连接来自不同工作流分支的变量,你希望将这些变量组合。每个连接的变量都成为聚合输出的潜在输入。
-
-### 类型约束
+
+变量聚合器仅适用于 **每次只有一条路径会执行** 的互斥分支。它不会合并同时执行的多条并行分支的输出。
-**相同类型规则** - 所有聚合的变量必须是相同的数据类型。一旦你连接第一个变量(例如字符串),节点只接受来自其他分支的相同类型变量。
+如需合并并行分支的结果,请使用 [代码执行](/zh/use-dify/nodes/code) 或 [模板转换](/zh/use-dify/nodes/template) 节点。
+
-**支持的类型:**
-- **String** - 来自不同处理分支的文本输出
-- **Number** - 数值计算、分数或测量值
-- **Object** - 具有相似架构的结构化数据对象
-- **Boolean** - 真/假值
-- **Array** - 列表、集合或多个结果
+## 选择要汇聚的变量
-### 输出行为
+从每条分支中添加需要相同下游处理的变量。所有变量必须具有相同的数据类型。
-变量聚合器输出实际执行的分支的值。由于在条件工作流中只有一个分支运行,因此在执行期间只有一个输入变量会有值。
+支持的类型:`string`、`number`、`object`、`boolean`、`array`、`file`。
-## 高级功能
+节点在运行时输出有值的变量。由于只有一条分支会执行,因此只有一个变量会有值,该值即为节点的输出。
-### 多个聚合组
+## 汇聚多组变量
-高级工作流(v0.6.10+)可以同时聚合多组变量。每组都保持自己的类型约束,允许你在同一节点内并行聚合不同的数据类型。
+当有多组变量需要分别汇聚时,启用 **聚合分组** 在单个变量聚合器中创建分组。
-这在分支产生需要单独组合的多个相关输出时很有用 - 例如,从不同处理路径聚合文本摘要和数值分数。
\ No newline at end of file
+每个分组独立汇聚各自的变量,并产生单独的输出。