모듈로 개발하면 의존성 그래프를 빌드한다. 의존성 연결은 import에서 시작한다. import문들로 브라우저나 Node는 정확히 어떤 코드를 불러와야하는지 알 수 있다. 그래프의 진입점으로 파일을 제공할 수 있다. 진입점부터 import문을 따라가며 다른 코드를 찾는다.
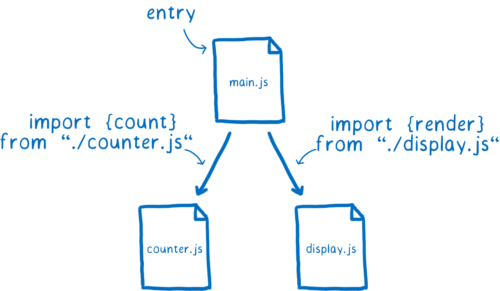
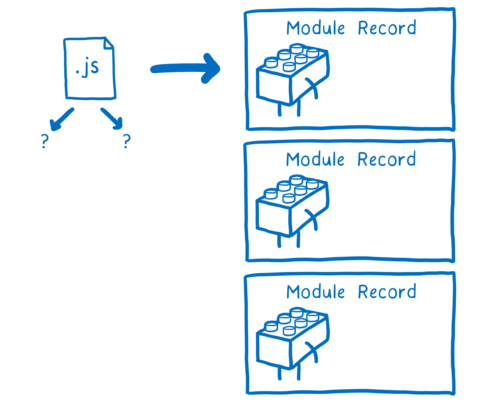
파일 자체는 브라우저가 쓸 수 없다. 파일은 모듈 레코드라는 자료구조로 파싱되야한다. 파싱을 통해 파일에서 무슨 일이 일어나는지 브라우저가 알 수 있다.
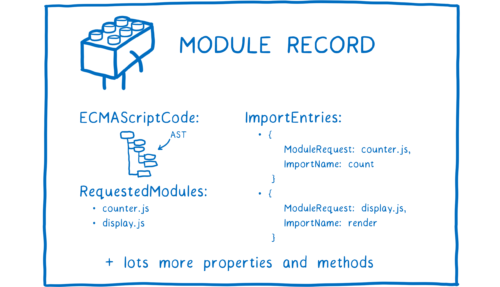
그 다음 모듈 레코드를 모듈 인스턴스로 변환한다. 모듈 인스턴스는 코드(일련의 명령어)와 상태(변수 값)의 조합이다.
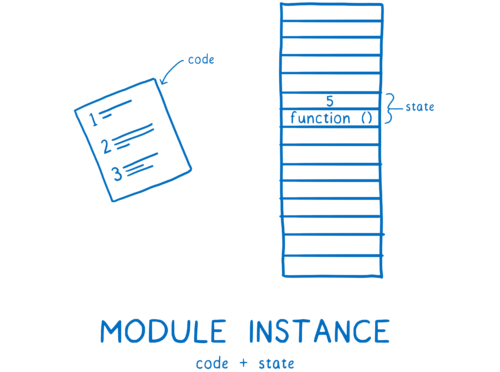
모듈마다 모듈 인스턴스를 만들어야한다. 모듈 로딩은 진입점부터 모듈 인스턴스로 이루어진 전체 그래프를 만드는 과정이다.
ES 모듈에서 모듈 로딩은 세 단계로 이루어진다.
- 구성(construction). 모든 파일을 찾고, 다운로드하고, 파싱해서 모듈 레코드로 만든다.
- 인스턴스화(instantiation): export된 값을 채우기 위한 메모리 공간을 찾는다. export와 import 지점을 해당 메모리 공간에 연결한다. 링킹(linking)이라고 한다.
- 평가(evaluation): 코드를 실행하여 실제 변수값으로 메모리 공간을 채운다.
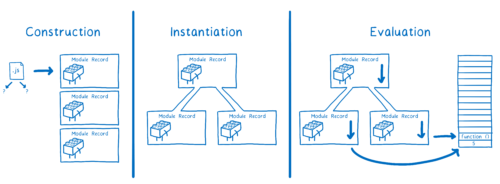
ES 모듈은 비동기적이라고 말한다. 모듈 로딩이 세 단계로 나뉘고 각 단계가 독립적으로 실행될 수 있기 때문이다.
CommonJS에서는 없는 비동기적인 사양이다. CommonJS는 모듈과 의존성을 로딩하고 인스턴스화하고 평가하는 것이 한 번에 이루어진다. (단계로 나누어져있지 않고 한 과정이라는 뜻)
그러나 단계 자체가 반드시 비동기적인 것은 아니다. 동기적으로 이루어질 수 있다. 무엇을 로딩하느냐에 달려있다. 왜냐면 모든 것이 ES 모듈 사양을 따르고 있진 않기 때문이다. 모듈 로딩은 실제로 두 개의 작업인데 서로 다른 스펙에 의해 처리된다.
- ES 모듈 스펙은 어떻게 파일을 모듈 레코드로 파싱하는지, 어떻게 모듈을 인스턴스화하고 평가하는지 명시한다. 파일을 가져오는 방법은 다루지 않는다.
- 파일을 fetch하는 것은 로더이다. 로더에 대한 명세는 다양한데, 브라우저의 경우 HTML 스펙을 따른다.
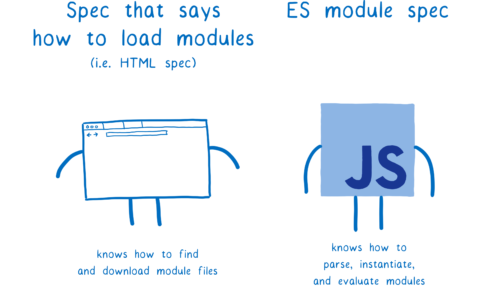
로더는 파일을 어떻게 로딩할 것인지도 제어한다. ES 모듈 메서드— ParseModule, Module.Instantiate, Module.Evaluate를 호출한다. 로더는 JS 엔진의 문자열을 제어하는 일종의 인형사이다.
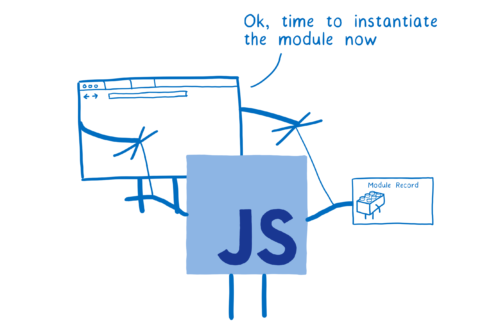
Construction 단계에서는 각 모듈마다 세 가지 일이 일어난다.
- 어디서 모듈이 든 파일을 다운로드받아야하는지 파악한다. 모듈 경로 해석(module resolution)이라고 한다.
- URL로부터 파일을 다운로드하고 파일 시스템으로부터 불러옴으로써 파일을 fetch한다.
- 파일을 모듈 레코드로 파싱한다.
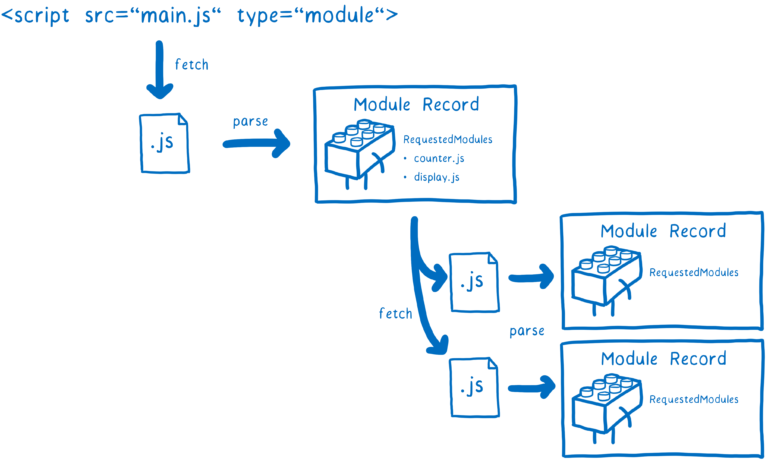
로더는 파일을 찾고 다운로드한다. 가장 먼저 필요한 것은 진입점이 되는 파일을 찾는 것이다. HTML에서 script 태그를 사용하여 로더에게 어디서 진입점을 찾을 수 있는지 알려줄 수 있다.
<script type="module" src="main.js" />로더가 main.js가 의존하고 있는 모듈들은 import문을 사용하여 찾는다. import문의 모듈 지정자(module specifier)은 로더에게 다음 모듈을 어디서 찾을 수있는지 알려준다.
import { counter } from './counter.js';
// ^^^module specifier^^^모듈 지정자는 브라우저와 노드에서 서로 다르게 처리되기도 한다. 호스트는 모듈 지정자 문자열을 해석하는 서로 다른 방법을 가진다. 이를 위해 플랫폼마다 다른 모듈 경로 해석 알고리즘(module resolution algorithm)을 호출한다. 현재 Node에서는 사용 가능하지만 브라우저에서 사용할 수 없는 모듈 지정자는 해결 중이라고 한다.
그게 달성되기 전까지는 브라우저는 모듈 지정자로 URL만 허용하고 있다. 브라우저는 URL로부터 모듈 파일을 로딩한다. 하지만 모든 모듈 그래프에서 동시에 일어날 순 없다. 파일을 파싱하기 전까지는 fetch 해와야할 의존성이 무엇인지 알 수 없고 fetch하기 전까지는 파일을 파싱할 수 없다.
이것은 파일을 파싱한 후에 그 파일의 의존성을 파악하고, 그 후에 그 의존성들을 찾고 로딩해야한다는 것을 의미한다.
메인 스레드가 각각의 파일이 다운로드되는 것을 기다린다면, 많은 작업에 큐에 쌓이게 될 것이다. 브라우저는 다운로드에 많은 시간을 사용하기 때문이다. (메모리에서 찾아오는 것보다 인터넷에서 가져오는 게 훨씬 오래 걸린다.)
이처럼 메인 스레드를 블로킹하면 모듈을 사용하는 앱을 너무 느리게 만든다. 이것이 ES 모듈 사양이 알고리즘을 여러 개의 단계로 나누는 이유이다. 구성 단계를 여러 개의 단계로 쪼갬으로써 브라우저는 동기적인 인스턴스화가 시작되기 전에 파일들을 fetch하고 모듈 그래프를 빌드한다.
이처럼 알고리즘을 여러 개의 단계로 나누는 접근이 ES 모듈과 CJS 모듈의 주요한 차이점이다.
CJS는 파일 시스템으로부터 로딩을 불러오는 것이 인터넷에서 불러오는 것보다 훨씬 시간이 적게들기 때문에 다르게 처리한다. Node는 파일을 로딩하는 동안 메인 스레드를 블록할 수 있다는 뜻이다. 파일이 이미 로딩되어있으므로 단순히 인스턴스화하고 평가하는게 당연하다(CJS에서는 별개의 단계로 나누지 않는다). 또한 이것은 모듈 인스턴스를 반환하기 전에 전체 트리를 순회하고, 모든 의존성을 로딩하고, 인스턴스화하고 평가할 수 있다는 것을 의미한다.
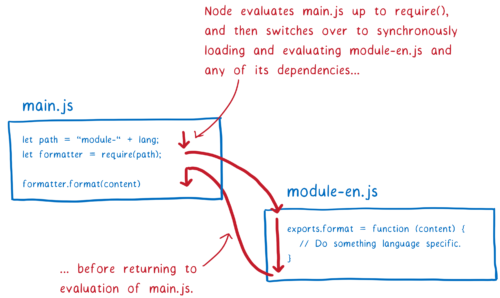
CJS식 접근은 여러 암시를 가지고 있지만 나중에 설명하겠다. 어쨌든 CJS 모듈을 Node.js에서 사용하는 것은 모듈 지정자에 변수를 사용할 수 있다는 것을 의미한다. 다음 모듈을 탐색하기 전에 require식까지 코드가 실행되어 모듈 경로를 해석하러갈 때 변수에 값이 있다.
하지만 ES 모듈은 어떤 평가가 이뤄지기 전 전체 모듈 그래프를 빌드해야한다. 이것은 모듈 지정자에 변수를 사용할 수 없다는 것을 의미한다. 변수들에 아직 값이 없기 때문이다.

하지만 이따금 모듈 경로에 변수를 사용하는 것은 매우 유용하다. 예를 들어 코드가 무엇을 하는지 혹은 코드가 실행되는 환경에 따라 로딩할 모듈을 바꾸고 싶을 수 있기 때문이다.
ES 모듈에서는 dynamic import를 통해 이것이 가능하다. import문을 import(${path}/foo.js) 처럼 쓰면 된다.
이것이 작동하는 방법은 import()를 사용하여 로딩되는 모든 파일을 별개의 그래프의 진입점으로 처리하는 것이다. 동적으로 불러온 모듈은 새로운 그래프에서 시작하여 독립적으로 처리된다.
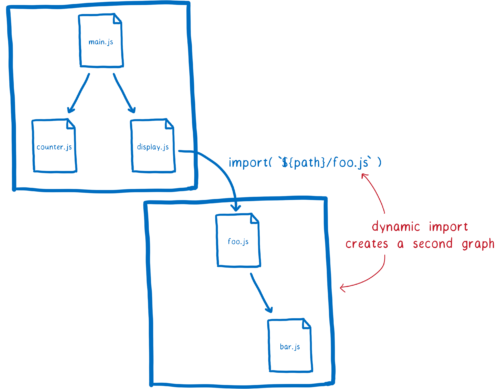
알아야할 것은, 두 그래프에 속한 모듈은 모듈 인스턴스를 공유한다는 점이다. 로더가 모듈 인스턴스를 캐시하기 때문이다. 특정 전역 스코프에 있는 각각의 모듈은 단 하나의 모듈 인스턴스가 된다.
이를 통해 엔진은 일을 덜 할 수 있다. 예를 들어, 여러 개의 모듈이 의존하는 모듈을 단 한 번만 fetch한다는 뜻이다. (모듈을 캐싱하는 이유 중 하나이다. 다른 이유는 평가 섹션에서 다룬다)
로더는 모듈맵이라는 것을 이용하여 캐시를 관리한다. 각각의 전역은 별개의 모듈맵으로 모듈을 추적한다.
로더가 URL을 fetch해올 때 모듈 맵에 그 URL을 넣고 그 파일을 현재 fetching하는 중이라고 표시한다. 그다음 요청을 보내고 다음 파일을 fetching하기 시작한다.
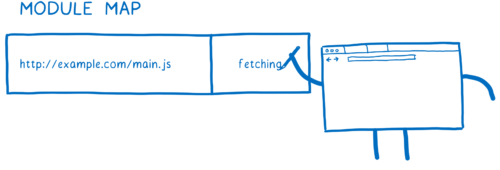
다른 모듈이 같은 파일에 의존하면 어떻게 될까? 로더는 모듈맵에서 각각의 URL을 탐색한다. fetching 표시를 보면, 그냥 다음 URL로 넘어간다.
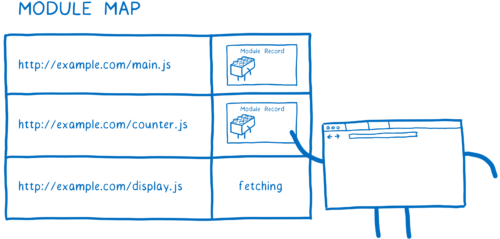
하지만 모듈맵은 fetching이 완료된 파일은 더이상 추적하지 않는다. 모듈맵은 또한 모듈에 대한 캐시 역할을 하는데, 다음에 보겠다.
이제 파일을 fetching해왔으니, 모듈 레코드로 파싱해야한다. 이것은 브라우저가 모듈의 다른 부분을 이해하는데 도움을 준다.
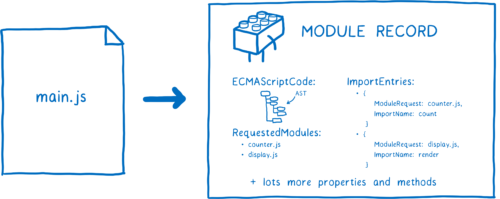
모듈 레코드가 생성되면, 모듈 맵에 저장된다.이것은 앞으로 모듈이 요청될 때마다 맵에서 가져올 수 있다는 것을 말한다.
파싱 과정에서 사소해보일 수 있는 디테일이 있는데, 사실 매우 큰 암시를 가지고 있다. 모든 모듈은 최상위에 "use strict"를 가진 것처럼 파싱된다. 그 외의 다른 차이점도 가진다. 예를 들어, 키워드 await는 모듈의 최상단 코드에 예약되어있고 this의 값은 undefined이다.
이렇게 파싱을 다르게 하는 것을 "parse goal"이라고 한다. 동일한 파일을 파싱해도 다른 goal을 사용하면, 다른 결과를 얻게 될 것이다. 따라서 파싱을 하기 전에 파일이 어떤 종류인지, 즉 모듈인지 아닌지 알아야한다.
브라우저에서는 꽤 쉽다. script 태그에 type="module"이라고 적기만 해도 된다. 이것은 브라우저에게 파일이 모듈로 파싱되어야한다는 것을 알린다. 모듈만 import될 수 있기 때문에, 브라우저는 모든 import가 모듈이라는 것을 알 수 있다.

하지만 Node는 HTML 태그를 사용할 수 없으므로 type 속성과 같은 선택지가 없다. 커뮤니티가 이 문제를 해결하기 위해 사용하는 방법 중 하나는 .mjs 확장자를 사용하는 것이다. 이 확장자를 사용하는 것은 Node에게 "이 파일은 모듈이야"라고 말하는 것이다. 사람들이 이것이 parse goal에 대한 신호라고 말하는 것을 볼 수 있다. 관련 토론은 계속되고 있어 Node 커뮤니티가 무엇을 최종적으로 goal에 대한 신호로 결정할지는 분명하지 않다.
어느 쪽이든, 로더는 파일을 모듈로 파싱할지 아닐지를 결정한다. 모듈이고 import가 있으면 모든 파일을 fetch하고 파싱할 때까지 과정을 반복한다.
그리고 끝이다! 로딩 프로세스가 끝나면 진입점 파일만 가졌던 것에서 무더기의 모듈 레코드를 가지게 될 것이다.
다음 단계는 이 모듈을 인스턴스화하고 모든 인스턴스를 링크하는 것이다.
일전에 언급했듯, 인스턴스는 코드와 상태를 결합한 것이다. 이 상태는 메모리에 존재하므로 인스턴스화 단계는 모두 메모리에 상태를 쓰는 것에 관련한 것이다.
먼저 자바스크립트 엔진이 모듈 환경 레코드를 생성한다. 이것은 모듈 레코드에 대한 변수를 관리한다. 그리고 엔진은 모든 export에 대한 메모리 공간을 찾는다. 모듈 환경 레코드는 어떤 메모리 공간이 각각의 export와 연관되어있는지 추적할 것이다.
메모리 공간들은 아직 값을 가지고 있진 않다. 실제 값이 채워지는 평가 후에야 그럴 것이다. 한가지 경고할 것이 있다. 모든 export된 함수 선언문은 이 단계에서 초기화된다. 이것은 평가를 더욱 쉽게 만든다.
모듈 그래프를 인스턴스화하기 위해 엔진은 DFS를 시작한다. 그래프의 가장 밑-아무것도 의존하지 않는 의존성-까지 순회하고 export를 설정한다. (각각의 모듈 레코드에 대한 모듈 환경 레코드를 메모리 공간에 연결)
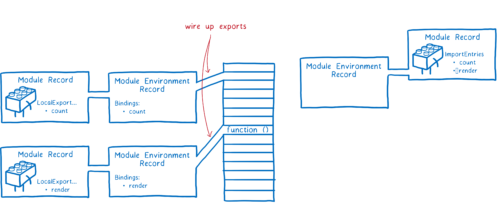
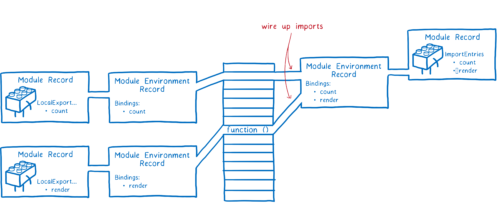
엔진은 모듈 내부의 모든 export-모듈이 의존하는 모든 export- 작성을 끝낸다. 그리고 나서 이전 레벨로 돌아가 그 모듈로부터 import된 것을 연결한다.
export와 import가 모두 메모리에서 동일한 위치를 가리키고 있다는 것을 기억하라. export를 먼저 연결하는 것은 모든 import가 대응하는 export에 연결된다는 것을 보장한다.
이것이 CJS 모듈과의 차이점이다. CJS는 export 객체 전체를 export에 복사한다. export되는 값은 종류가 무엇이든(숫자 같은 것도) 복사된다는 뜻이다.
이것은 export되는 모듈이 나중에 값을 바꾸면, import하는 모듈은 그 변화를 보지 못한다는 것과 같다.
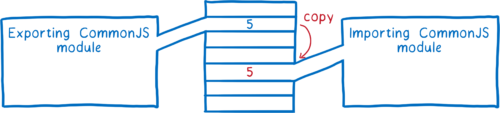
그에 반하여 ES 모듈은 라이브 바인딩(live binding)한다. 동일한 모듈은 항상 메모리 공간에서 동일한 위치를 가리킨다. export되는 모듈이 값을 바꾸면, 그 변화는 import되는 모듈에서도 가시적이다.
값을 export하는 모듈은 언제나 그 값들을 바꿀 수 있으나 import하는 모듈은 import한 값을 바꿀 수 없다. 모듈이 객체를 import하는 경우라면 그 객체의 프로퍼티의 값을 바꿀 수는 있다.
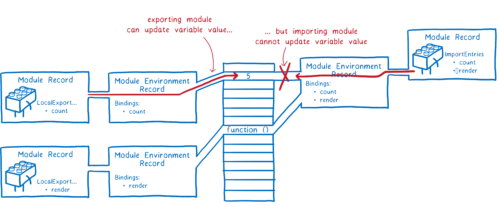
라이브 바인딩하는 이유는 모든 모듈을 코드의 실행 없이 연결할 수 있기 때문이다. 이것은 순환 의존성(cyclic dependencies)을 가질 때 평가하는 것에 도움이 된다.
이 단계가 끝나면 export,import한 변수에 대한 모든 인스턴스와 메모리 공간을 가지게 된다.
이제 코드 평가를 시작하고 메모리 공간에 값을 채워보자.
마지막 단계는 메모리 공간을 채우는 것이다 JS 엔진은 이것을 최상위 코드-함수 바깥의 코드를 실행하여 수행한다.
메모리 공간의 값을 채우는 데 더해 코드를 평가하는 것은 사이드 이펙트를 발생시킬 수 있다. 예를 들어 모듈이 서버에 대한 호출을 만들 수도 있다.

잠재적인 사이드 이펙트 때문에, 모듈은 단 한 번만 평가된다. 인스턴스화에서 진행되는 링킹(여러 번 실행되어도 정확히 같은 결과를 내는)과는 대조적으로 평가는 실행 횟수에 따라 여러 결과를 가질 수 있다.
이것이 모듈맵을 사용하는 이유 중 하나이다. 모듈맵은 표준 URL로 모듈을 캐시하여 각각의 모듈에 대해 단 하나의 모듈 레코드를 가진다. 각각의 모듈은 단 한 번 실행되는 것이 보장되고 이것은 DFS 순회에서 이루어진다.
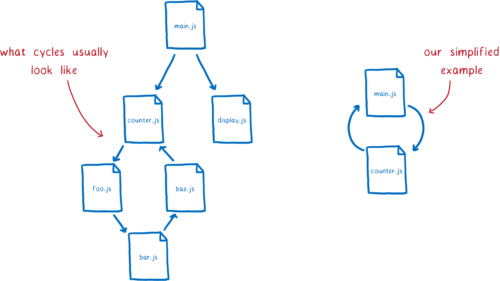
순환 의존성은 어떤가?
순환 의존성에서 그래프에 루프가 생길 수 있다. 대개 이것은 긴 루프이다. 하지만 문제를 설명하기 위해 짧은 루프를 가진 간단한 예시를 사용하겠다.
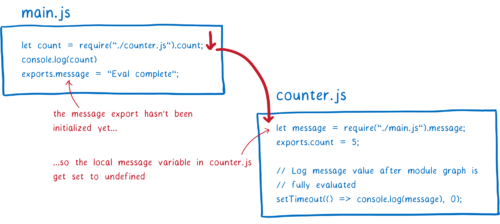
먼저 main 모듈이 require 문까지 실행된다. 그리고 counter 모듈을 로드하기 시작한다.
counter 모듈은 export 객체의 message에 접근하려 시도한다. 하지만 main 모듈에서 아직 평가되진 않았으므로 undefined를 반환한다. JS 엔진은 로컬 변수에 대한 메모리 공간을 할당하고 undefined로 설정한다.

counter 모듈의 최상위 코드의 끝까지 평가가 이루어진다. main.js가 평가된 후에 message에 알맞은 값이 들어가길 원하므로, timeout을 설정했다. 그리고 main.js에서 평가가 재개된다.
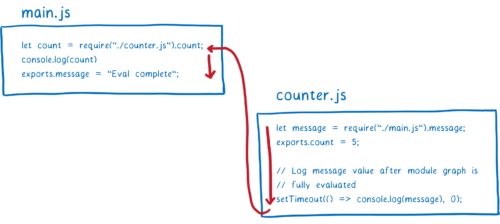
message 변수는 초기화된 후 메모리에 추가된다. 그러나 둘 사이엔 어떤 연결도 없으므로 import한 모듈에선 여전히 undefined이다.
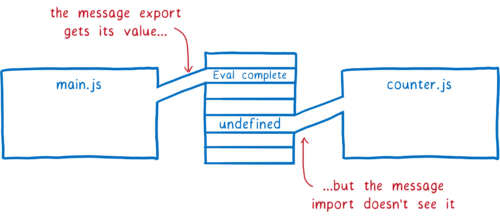
만약 export가 라이브 바인딩으로 처리되었다면 counter는 결국 알맞은 값을 보게 될 것이다. timeout이 실행되기 전, main.js의 평가는 완료되고 값이 채워질 것이다.
ES 모듈의 설계가 이렇게 된 건 순환을 제공하기 위해서라고 할 수 있다. 세 단계로 나눈 설계가 순환을 가능하게 한다.
-
rollup - ES6 모듈 여러 개를 하나의 ES5로 번들링할 수 있다. 바벨 플러그인 사용해서 타겟팅가능.
-
간단한 애플리케이션은 이렇게 하는 것을 추천합니다
rollup -f es로 모듈을 하나의 파일로 합치기- 트랜스파일하지 않기. 모던 브라우저는 요새 잘 지원한다.
-
이렇게 하면 어떤 장점이 있는가?
- ES 모듈을 사용하므로 트리 쉐이킹 좋다.
- 여러 개의 모듈을 사용하는데서 오는 request chain을 피할 수 있다. (HTTP/2 Push를 사용하면 해결할 수도 있다. 하지만 많은 서버가 그러한 기능을 제공하지도 않고 있고, 헤더 오버헤드가 발생할 수도 있다. 100 바이트의 파일 하나를 전송하는데 200 바이트의 헤더가 필요할 수도?)
-
모듈 실행에 대하여 알아보자.
-
모듈은 언제나 strict mode에서 실행된다.
-
모듈은 IIFE에서 실행되는 것처럼 처리된다. 즉, 글로벌 스코프에서 실행되지 않는다.
(function () {/* module code */}).call();
-
-
export와 사이드 이펙트
- 단지 사이드 이펙트를 실행하기 위해 import할 수도 있다. 이건 전통적인 JS 라이브러리의 방식이다.
-
기본적으로 모듈은 지연된다. 동기적으로 실행되지 않는다. 왜냐하면 많은 의존성을 가질 경우 (동기적으로 실행되면) 브라우저는 페이지를 실행하지 못하고 오랜 시간 동안 그것을 모두 fetching할 것이기 때문이다. (
<script defer />란? 페이지 구성을 블로킹(다운로드 되는 동안에도 HTML 파싱을 멈추지 않는다)않고 페이지 구성이 끝난 후 실행된다.) 그러나 필요한 경우<script defer />를 사용하여 빠르게 로딩되거나 캐시된 모듈이 다운로드되는 즉시 실행될 수 있다. 이건 일반적인 스크립트 태그가 작동하는 방식과 똑같다. -
모듈은 단 한 번 import된다.
- 동일한 script 태그도 단 한 번 실행된다.
- 모듈은 사실 트리 구조의 그래프라 마치 싱글톤과 같이 작동한다. 두 개의 다른 모듈이 동일한 모듈을 import해도 동일한 모듈을 받는다
- 하지만 파일이 같아도 URL이 다르면 브라우저는 다른 파일로 인식한다.
src/index.js에서../foo.js랑./src/foo.js는 같지만./foo.js?query=abc는 다르다.
-
모듈은 마치 호이스팅된 함수와 같다. 스코프의 최상단으로 올려진다. 그래프 순회로 실행된다.
-
순환 의존성이 허용된다.
-
서로를 안정적으로 import할 수 있다. 하지만 어떤 경우에는 불가능하다. 런타임에 오류를 발생시킬 것이다.
// vehicle.js import { Car } from './car.js' let id = 0; export class Vehicle { constructor() { this.id = ++id; } static build() { return new Car(); } } // car.js import { Vehicle } from './vehicle.js'; export class Car extends Vehicle { } let testCar = new Car();
왜냐하면 vehicle이 호이스팅되기 때문이다.
export class Vehicle { constructor() { this.id = ++id; } static build() { return new Car(); } } // vehicle.js import { Car } from './car.js' let id = 0;
id는 이 클래스 내부의 스코프에 존재하지 않아 레퍼런스 에러를 일으킬 것이다. => 나는 잘 돌아가는데 잘 모르겠음
-
-
Node의 기존 코드들은 어떻게 사용할까?
-
(간단한 방법) defer 옵션을 스크립트 태그에 붙이기. 왜냐하면 모듈은 기본적으로 defer이니까, es 모듈이 로딩되기전까지 이 기존 모듈도 필요하지 않다면 defer한다.
-
(추천) CommonJS 모듈을 rollup하기: CJS 의존성을 rollup해서 하나로 만들고 그것들을 ES 모듈로 만들어서 제공하기
// node_modules에 있는 require 사용 commonjs 모듈 // 브라우저에서는 지원하지 않는다. const foo = require('foo'); const bar = require('bar'); // ES 모듈로 즉시 내보내기 export { foo }; export { bar.fun as barFun };
트랜스파일 결과는 다음과 같을 것이다.
var foo = function (a) { ... } export { foo } -
혹은 노드에서 ES 모듈 사용하기: polymer를 사용하세요.
-
-
ES 모듈에 대한 것 중 가장 많은 이야기는 코드 스플리팅에 관한 것이다.
- HTML에 두 개의 진입점이 있다고 하자. 두 파일은 동일한 모듈들을 공유한다. 하지만 번들링할 경우엔, 그 이점을 누릴 수 없다. 코드의 중복이 일어난다. 하지만 어떤 모듈이 중복되는지 알 수 있으므로, 각각의 진입점에서부터 번들했을 때의 결과물에서 중복되는 모듈만 분리할 수도 있다. 그럼 남은 모듈은 어떻게 하는가? 하나의 큰 청크로 보낼 수도 있을 것이다. 하지만 ES 모듈에서는 불가능하다. 중복되는 export 이름이 존재할 수 있기 때문이다. 순진하게 번들링해서는 안된다. 어떤 식으로든 다른 이름으로 쓰게 하면 되는데, Webpack을 쓸 수도 있을 것이다. 하지만 간단하게 생각하자면, 전부 합치지 않고 의존하는 모듈끼리만 번들해서 제공할 수 있을 것이다.
모듈과 클래식 스크립트의 차이는 다음과 같다.
- 모듈은 기본적으로 strict mode로 실행된다.
- HTML 스타일의 주석은 모듈에서 허용되지 않는다. 클래식에서는 허용된다.
- 모듈은 렉시컬 최상위 스코프를 가진다. 클래식에서와 달리
var foo = 42를 실행하는 것은window.foo로도 접근할 수 있는 전역 변수foo를 만들지 않는다. this는 더이상 전역this를 가리키지 않고undefined이다. 필요하다면globalThis를 사용하도록 한다.- 정적
import와export는 오로지 모듈에서만 사용할 수 있다. 클래식에서는 사용할 수 없다. - 클래식과 달리 모듈에서는 최상위
await가 가능하다.await는 모듈에서 변수 이름으로 사용할 수 없다. 클래식은 async 함수 내부가 아니면 변수 이름으로 사용할 수 있다.
위와 같은 차이로, 동일한 자바스크립트 코드는 모듈이냐 클래식이냐에 따라 다르게 처리되므로 런타임은 스크립트가 모듈인지 알아야한다.
<script type="module" src="main.mjs"></script>
<script nomodule src="fallback.js"></script>type="module"을 이해하는 브라우저는 nomodule 속성을 가진 스크립트를 무시한다. 모듈을 사용하지 않는 브라우저에게 폴백을 제공할 수 있다. 성능만 생각하면 매우 좋다. 모듈을 이해하는 브라우저는 다른 최신 기능도 제공하므로 트랜스파일할 필요가 없고 더 작고 덜 트랜스파일된 모듈 기반 페이로드만 브라우저에게 제공하면 된다. 참고 레거시 브라우저만 nomodule 페이로드를 사용한다.
모듈은 기본적으로 지연되므로 nomodule 스크립트도 지연되길 원할 수 있다.
<script type="module" src="main.mjs"></script>
<script nomodule defer src="fallback.js"></script>모듈은 클래식의 작동 방식은 다르고 플랫폼에 의해서도, 브라우저별로도 조금씩 다르다. 예를 들어 모듈은 한 번 평가되는 반면 클래식은 DOM에 추가될 때마다 평가된다.
<script src="classic.js"></script>
<script src="classic.js"></script>
<!-- classic.js executes multiple times. -->
<script type="module" src="module.mjs"></script>
<script type="module" src="module.mjs"></script>
<script type="module">import './module.mjs';</script>
<!-- module.mjs executes only once. -->또한 모듈과 모듈의 의존성은 CORS 옵션으로 fetch된다. 즉 모든 크로스 오리진 모듈 스크립트는 반드시 Access-Control-Allow-Origin: *와 같은 적절한 헤더로 제공되어야한다. 클래식은 그렇지 않다.
또다른 차이점은 async 속성과 관련한다. 또 다른 차이점은 비동기 속성과 관련이 있는데, 이 속성은 defer처럼 HTML 파서를 차단하지 않고 스크립트가 다운로드되도록 한다. 단, 스크립트를 보장된 순서 없이 그리고 HTML 파싱이 끝나기를 기다리지 않고 가능한 한 빨리 실행한다. async는 인라인 <script type="module"에만 동작한다. 스크립트를 실행할 수 있는대로, 정해진 순서없이 실행된다. 클래식 인라인 스크립트에는 동작하지 않는다.
모듈을 위해 .mjs 확장자를 사용한다. 웹에서 이 파일 확장자는 파일이 자바스크립트 MIME 타입 text/javascript로 제공되는 이상 문제가 되지 않는다. 브라우저는 type 어트리뷰트를 통해 모듈이라는 것을 안다.
그러나 .mjs를 사용하기를 추천한다.
.mjs를 사용하면 파일이 모듈이라는 것을 명확히 할 수 있다.- 파일이 Node.js와 d8과 같은 런타임과 Babel과 같은 빌드 툴에 의해 모듈로 파싱되는 것을 보장한다.
주의할 점! .mjs를 웹에서 사용하려면 웹 서버가 Content-Type: text/javascript 헤더와 함께 파일을 제공하도록 한다.
import에서 모듈 지정자(module specifier) 또는 import 지정자(import specifier)는 모듈의 위치를 명시하는 문자열이다.
import {shout} from './lib.mjs';
// ^^^^^^^^^^^현재 "bare"한 모듈 지정자는 브라우저에서 지원이 안된다. 미래에는 제공될 것이다.
// Not supported (yet):
import {shout} from 'jquery';
import {shout} from 'lib.mjs';
import {shout} from 'modules/lib.mjs';
// Supported:
import {shout} from './lib.mjs';
import {shout} from '../lib.mjs';
import {shout} from '/modules/lib.mjs';
import {shout} from 'https://simple.example/modules/lib.mjs';현재로서 모듈 지정자는 완전한 URL이거나, /, ./, ../로 시작하는 상대 경로 URL이다.
클래식 <script />는 기본적으로 HTML 파서를 블로킹한다. 그렇게 하려면 defer 속성을 추가하면 되는데, 이 속성은 스크립트의 다운로드와 HTML 파싱을 병렬적으로 수행하도록 한다.

모듈 스크립트는 기본적으로 지연되므로 <script type="module" />에 defer를 붙일 필요는 없다. HTML 파싱과 메인 모듈의 다운로드가 병렬적으로 수행될 뿐만 아니라 모든 의존성 모듈에 대해서 그러하다.
정적 import를 사용하면 모듈 그래프 전체가 메인 코드가 실행되기 전 다운로드되고 실행되어야한다. 하지만 모듈을 필요할 때(on-demand)만 로드해도 된다면 동적 import()를 사용한다. 초기 로드-타임(load-time) 성능을 향상시킨다.
정적 import와 달리 동적 import()는 regular 스크립트에서도 사용할 수 있다. 점진적으로 모듈을 도입하는데 도움이 될 것이다. 자세한 것은 다음을 참고하라.
주의할 점! Webpack은 자기만의 import()를 가진다. import된 모듈을 메인 번들로부터 독립된 청크로 분명하게 나누기 위해서이다.
import.meta는 현재 모듈에 대한 메타데이터를 제공한다. 정확한 메타데이터는 ECMAScript 사양에 명시되어있지 않다. 호스트 환경에 의존한다. 브라우저와 Node.js가 제공하는 메타데이터를 서로 다르다.
모듈을 사용하면 Webpack, Rollup, Parcel 없이 웹 사이트를 개발할 수 있다. 다음과 같은 경우 네이티브 JS 모듈을 직접적으로 사용해도 괜찮다.
- 로컬 개발인 경우
- 프로덕션이어도 모듈이 100개 이하이고 비교적 얕은 의존성 트리(예를 들어 최대 깊이가 5인) 작은 웹 애플리케이션을 개발하는 경우
하지만 대략 300개의 모듈로 구성된 모듈화된 라이브러리를 로딩할 때 크롬의 로딩 파이프라인의 병목 현상 분석에 의하면, 번들된 앱의 로딩 성능이 번들되지 않은 것보다 낫다.
그 이유 중 하나는 정적 import/export 문법이 정적으로 분석가능하여 번들 툴이 사용되지 않는 export를 제거하여 코드를 최적화하는데 도움이 되기 때문이다.
모듈을 프로덕션으로 배포하기 전 번들러를 사용하라. 어떤 면에서 번들링은 코드를 줄이는 최적화이다. 성능적이로 이득이니 계속 번들링하라.
데브툴로 커버리지를 측정하는 것은 사용자에게 불필요한 코드를 제공하고 있다는 것을 파악하는데 도움이 된다. 번들들을 쪼개고 우선적으로 필요하진 않지만 중요한 스크립트의 로딩을 지연하기 위해 코드 스플리팅하는 것도 추천한다.
코드 스플리팅 없이 단일하게 번들하는 것에 비교하자면, 번들되지 않은 모듈을 사용하는 것은 초기 로딩 성능에는 좋지 않지만(콜드 캐시; cold cache) 자주 사용하면 로딩 성능에는 좋다(웜 캐시; warm cache). 200KB의 코드 베이스라면 단일한 fine-grained 모듈로 바꾸고 서버에서 유일하게 fetch하는 것이 전체 번들을 re-fetch하는 것보단 낫다.
첫 방문 성능 보다 웜 캐시를 사용한 사용자 경험이 더 중요하고 꽤 많은 수의 find-grained 모듈로 이루어져있다면, 번들되지 않은 모듈을 테스트하여 콜드 캐시와 웜 로딩의 성능을 측정하고 결과에 따라 선택해볼 수 있다.
시간이 지나면 번들되지 않은 모듈을 사용하는 것이 더 많은 상황에서 적절해질 거라고 생각한다.
코드를 작고, fine-grained한 모듈로 작성하라.
export function drop() { /* … */ }
export function pluck() { /* … */ }
export function zip() { /* … */ }이런 모듈에서 pluck만 사용한다면 ./plck.mjs로 분리해라.
export function pluck() { /* … */ }소스코드를 단순하고 멋지게 만들뿐만 아니라, 번들러에 의해 수행되는 안 쓰는 코드 없애기(dead-code eliminationi)에 대한 필요도 낮춘다. 모듈은 브라우저에 의해 코드-캐싱될 수 있다.
<link rel="modulepreload">를 사용하여 모듈의 로딩을 최적화할 수 있다. 브라우저는 모듈과 의존성들을 미리 로딩하고 미리 파싱하고 미리 컴파일할 수 있다.
<link rel="modulepreload" href="lib.mjs">
<link rel="modulepreload" href="main.mjs">
<script type="module" src="main.mjs"></script>
<script nomodule src="fallback.js"></script>이것은 큰 의존성 트리를 가지고 있을 때 특히 중요하다. rel="modulepreload"가 없으면 브라우저는 여러 번의 HTTP 요청을 수행하여 전체 의존성 트리를 파악해야한다. 하지만 필요한 모듈 스크립트를 모두 rel="modulepreload"로 선언하면 브라우저는 의존성을 점진적으로 파악하지 않아도 된다.
HTTP/2의 멀티플렉싱을 사용하면 다중 요청과 다중 메시지가 동시에 날아갈 수 있어, 모듈 트리를 로딩하는데 효과적이다. 안타깝게도 크롬 팀이 HTTP/2 서버 푸쉬를 사용해보았지만 까다롭고 웹 서버와 프라우저의 구현이 현재 높은 수준으로 모듈화된 웹 앱 사례에 최적화되있지 않다. 사용자가 이미 캐시하지 않은 리소스를 푸쉬하는 것(예를 들어, 전체 캐시 상황을 서버에게 알려주는 것은 개인 보안상 문제이다)은 어렵다.
어쨌든 HTTP/2를 써라. HTTP/2 서버 푸쉬가 실버 불렛이 아니라는 것만 기억하라.
TODO: 모듈의 미래 무엇인가? https://v8.dev/features/modules#next