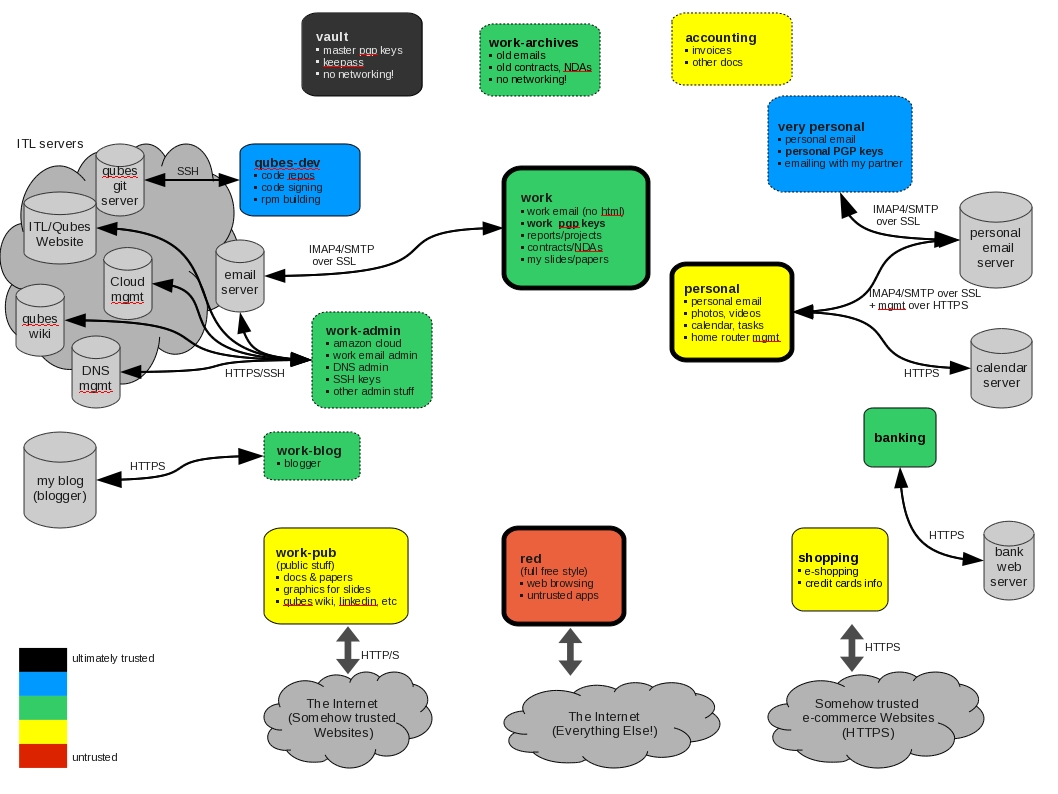
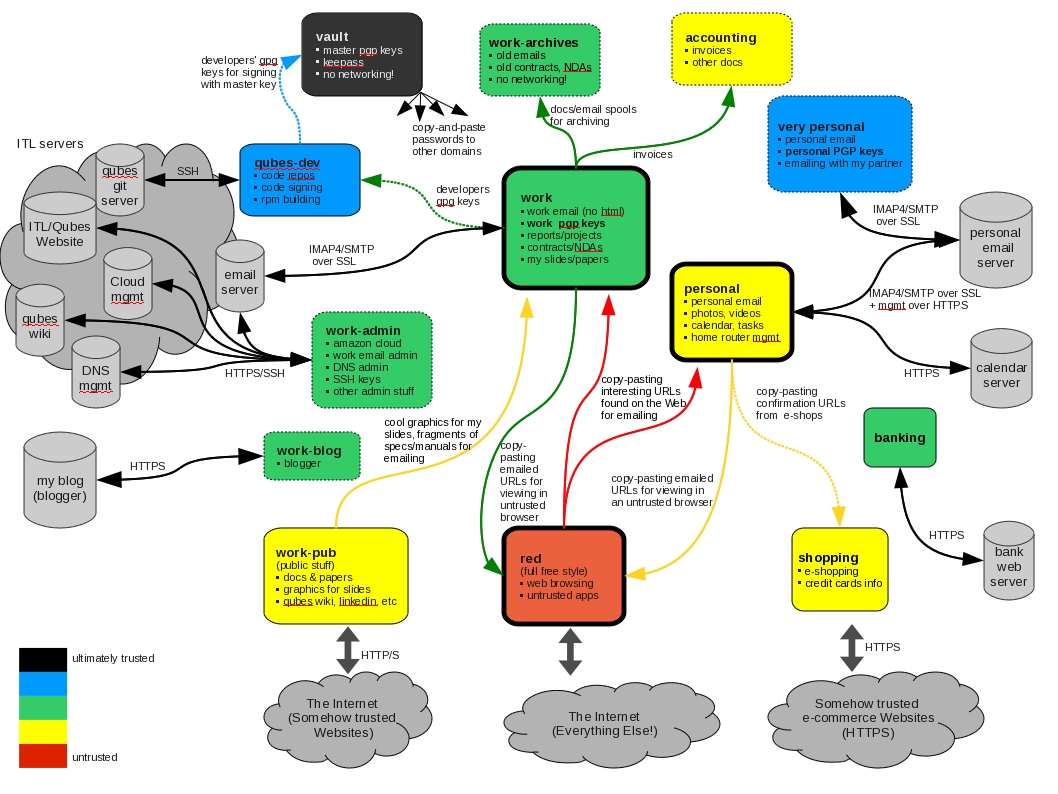
diff --git a/_posts/2007-01-03-towards-verifiable-operating-systems.html b/_posts/2007-01-03-towards-verifiable-operating-systems.html
index b8b0c60..851b7c2 100644
--- a/_posts/2007-01-03-towards-verifiable-operating-systems.html
+++ b/_posts/2007-01-03-towards-verifiable-operating-systems.html
@@ -9,4 +9,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2007/01/towards-verifiable-operating-systems.html
---
-Last week I gave a presentation at the 23rd Chaos Communication Congress in Berlin. Originally the presentation was supposed to be titled "Stealth malware - can good guys win?", but in the very last moment I decided to redesign it completely and gave it a new title: "Fighting Stealth Malware – Towards Verifiable OSes". You can download it from here.
The presentation first debunks The 4 Myths About Stealth Malware Fighting that surprisingly many people believe in. Then my stealth malware classification is briefly described, presenting the malware of type 0, I and II and challenges with their detection (mainly with type II). Finally I talk about what changes into the OS design are needed to make our systems verifiable. If the OS were designed in such a way, then detection of type I and type II malware would be a trivial task...
There are only four requirements that an OS must satisfy to become easily verifiable, these are:
- The underlying processors must support non-executable attribute on a per-page level,
- OS design must maintain strong code and data separation on a per-page level (this could be first only in kernel and later might be extended to include sensitive applications),
- All code sections should be verifiable on a per-page level (usually this means some signing or hashing scheme implemented),
- OS must allow to safely read physical memory by a 3rd party application (kernel driver/module) and for each page allow for reliable determination whether it is executable or not.
The first three requirements are becoming more and more popular these days in various operating systems, as a side effect of introducing anti-exploitation/anti-malware technologies (which is a good thing, BTW). However, the 4th requirement presents a big challenge and it is not clear now whether it would be feasible on some architectures.
Still, I think that it's possible to redesign our systems in order to make them verifiable. If we don't do that, then we will always have to rely on a bunch of "hacks" to check for some known rootktis and we will be taking part in endless arm race with the bad guys. On the other hand, such situation is very convenient for the security vendors, as they can always improve their "Advanced Rootkit Detection Technology" and sell some updates... ;)
Happy New Year!
\ No newline at end of file
+Last week I gave a presentation at the 23rd Chaos Communication Congress in Berlin. Originally the presentation was supposed to be titled "Stealth malware - can good guys win?", but in the very last moment I decided to redesign it completely and gave it a new title: "Fighting Stealth Malware – Towards Verifiable OSes". You can download it from here.
The presentation first debunks The 4 Myths About Stealth Malware Fighting that surprisingly many people believe in. Then my stealth malware classification is briefly described, presenting the malware of type 0, I and II and challenges with their detection (mainly with type II). Finally I talk about what changes into the OS design are needed to make our systems verifiable. If the OS were designed in such a way, then detection of type I and type II malware would be a trivial task...
There are only four requirements that an OS must satisfy to become easily verifiable, these are:
- The underlying processors must support non-executable attribute on a per-page level,
- OS design must maintain strong code and data separation on a per-page level (this could be first only in kernel and later might be extended to include sensitive applications),
- All code sections should be verifiable on a per-page level (usually this means some signing or hashing scheme implemented),
- OS must allow to safely read physical memory by a 3rd party application (kernel driver/module) and for each page allow for reliable determination whether it is executable or not.
The first three requirements are becoming more and more popular these days in various operating systems, as a side effect of introducing anti-exploitation/anti-malware technologies (which is a good thing, BTW). However, the 4th requirement presents a big challenge and it is not clear now whether it would be feasible on some architectures.
Still, I think that it's possible to redesign our systems in order to make them verifiable. If we don't do that, then we will always have to rely on a bunch of "hacks" to check for some known rootktis and we will be taking part in endless arm race with the bad guys. On the other hand, such situation is very convenient for the security vendors, as they can always improve their "Advanced Rootkit Detection Technology" and sell some updates... ;)
Happy New Year!
\ No newline at end of file
diff --git a/_posts/2007-02-04-running-vista-every-day.html b/_posts/2007-02-04-running-vista-every-day.html
index e97ea65..22b4dd3 100644
--- a/_posts/2007-02-04-running-vista-every-day.html
+++ b/_posts/2007-02-04-running-vista-every-day.html
@@ -10,4 +10,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2007/02/running-vista-every-day.html
---
-More then a month ago I have installed Vista RTM on my primary laptop (x86 machine) and have been running it since that time almost every day. Below are some of my reflections about the new security model introduced in Vista, its limitations, a few flaws and some practical info about how I configured my system.
UAC – The Good and The Bad
User Account Control (UAC) is a new security mechanism introduced in Vista, whose primary goal is to force users to work using restricted accounts, instead working as administrators. This is, in my opinion the most important security mechanism introduced in Vista. That doesn’t mean it can not be bypassed in many ways (due to implementation flaws), but just the fact that such a design change has been made into Windows is, without doubt, a great step towards securing consumer OSes.
When UAC is active (which is a default setting) even when user logs in as an administrator, most of her programs run as restricted processes, i.e. they have only some very limited subset of privileges in their process token. Also, they run at, so called, Medium integrity level, which, among other things, should prevent those applications from interacting with higher integrity level processes via Window messages. This mechanism also got a nice marketing acronym, UIPI, which stands for User Interface Privilege Isolation. Once the system determines that a given program (or a given action) requires administrative privileges, because e.g. the user wants to change system time, it displays a consent window to the user, asking her whether she really wants to proceed. In case the user logged in as a normal user (i.e. the account does not belong to the Administrators group), then the user is also asked to enter password for the one of the administrator's accounts. You can find more background information about UAC, e.g. at this page.
Many people complain about UAC, saying that it’s very annoying for them to see UAC consent dialog box to appear every few minutes or so, and claim that this will discourage users from using this mechanism at all (and yes, there’s an option to disable UAC). I strongly disagree with such opinion - I’ve been running Vista more then a month now and, besides the first few days when I was installing various applications, I now do not see UAC prompt more then 1-2 times per day. So, I really wonder what those people are doing that they see UAC constantly appearing every other minute…
One thing that I found particularly annoying though, is that Vista automatically assumes that all setup programs (application installers) should be run with administrator privileges. So, when you try to run such a program, you get a UAC prompt and you have only two choices: either to agree to run this application as administrator or to disallow running it at all. That means that if you downloaded some freeware Tetris game, you will have to run its installer as administrator, giving it not only full access to all your file system and registry, but also allowing e.g. to load kernel drivers! Why Tetris installer should be allowed to load kernel drivers?
How Vista recognizes installer executables? It has a compatibility database as well as uses several heuristics to do that, e.g. if the file name contains the string “setup” (Really, I’m not kidding!). Finally it looks at the executable’s manifest and most of the modern installers are expected to have such manifest embedded, which may indicate that the executable should be run as administrator.
To get around this problem, e.g. on XP, I would normally just add appropriate permissions to my normal (restricted) user account, in such a way that this account would be ale to add new directories under C:\Program Files and to add new keys under HKLM\Software (in most cases this is just enough), but still would not be able to modify any global files nor registry keys nor, heaven forbid, to load drivers. More paranoid people could chose to create a separate account, called e.g. installer and use it to install most of the applications. Of course, the real life is not that beautiful and you sometimes need to play a bit with regmon to tweak the permissions, but, in general it works for majority of applications and I have been successfully using this approach for years now on my XP box.
That approach would not work on Vista, because every time Vista detects that an executable is a setup program (and believe me Vista is really good at doing this), it will only allow running it as administrator… Even though it’s possible to disable heuristics-based installer detection via local policy settings – see picture below:

that doesn’t seem to work for those installer executables which have embedded manifest saying that they should be run as administrator.
I see the above limitation as a very severe hole in the design of UAC. After all, I would like to be offered a choice whether to fully trust given installer executable (and run it as full administrator) or just allow it to add a folder in C:\Program Files and some keys under HKLM\Software and do nothing more. I could do that under XP, but apparently I can’t under Vista, which is a bit disturbing (unless I’m missing some secret option to change that behavior).
Integrity Levels – Protect the OS but not your data!
Integrity Levels (IL) mechanism has been introduced to help implementing UAC. This mechanism is very simple – every process can be assigned one of the four possible integrity levels:
• Low
• Medium
• High
• System
Similarly, every securable object in the system, like e.g. a directory, file or registry key, can also be assigned an integrity level. Integrity level is nothing else then just an ACE of a special type assigned to the SACL list. If there’s no such ACE at all, then the integrity level of the object is assumed to be Medium. You can use icacls command to see integrity levels on file system objects:
C:\>icacls \Users\joanna\AppData\LocalLow
\Users\joanna\AppData\LocalLow silverose\joanna:(F)
silverose\joanna:(OI)(CI)(IO)(F)
NT AUTHORITY\SYSTEM:(F)
NT AUTHORITY\SYSTEM:(OI)(CI)(IO)(F)
BUILTIN\Administrators:(F)
BUILTIN\Administrators:(OI)(CI)(IO)(F)
Mandatory Label\Low Mandatory Level:(OI)(CI)(NW)
BTW, I don’t know any tool/command to see and modify integrity levels assigned to registry keys (I think I know how to do this in C though). Anybody?
Now, the whole concept behind IL is that a process can only get write-access to those objects which have the same or lower integrity level then the process itself.
Update (March 5th, 2007): This is the default behavior of IL and is indicated by the “(NW)” symbol on the picture above, which stands for NoWriteUp policy. I have just learned that one can use the chml tool by Mark Minasi to set also a different policy, i.e. NoReadUp (NR) or NoExecuteUp (NX), which would result that IL mechanism will not allow a lower integrity process to read or execute the objects marked with higher IL. See also my recent post about this tool.
UAC is implemented using IL – even if you log in as administrator, all your processes (like e.g. explorer.exe) run with Medium IL. Once you elevated to the “real admin” your process runs at High IL. System processes, like e.g. services, runs at System IL. From the security point of view High IL seems to be equivalent to System IL, because once you are allowed to execute code at High IL you can compromise the whole system.
Internet Explorer’s protected mode is implemented using the IL mechanism. The iexplore.exe process runs at Low IL and, in a system with default configuration, can only write to %USERPROFILE%\AppData\LocalLow and HKCU\Software\AppDataLow because all other objects have higher ILs (usually Medium).
If you don’t like surfing using IE, you can very easily setup your Firefox (or other browser of your choice) to run as Low integrity process (here we assume that Firefox user’s profile is in j:\config\firefox-profile):
C:\Program Files\Mozilla Firefox>icacls firefox.exe /setintegritylevel low
J:\config>icacls firefox-profile /setintegritylevel (OI)(CI)low
Because firefox.exe is now marked as a Low integrity file, Vista will also create a Low integrity process from this file, unless you are going to start this executable from a High integrity process (e.g. elevated command prompt). Also, if you, for some reason (see below), wanted to use runas or psexec to start a Low integrity process, it won’t work and will start the process as Medium, regardless that the executable is marked as Low integrity.
It should be stressed that IL, by default, protects only against modifications of higher integrity objects. It’s perfectly ok for the Low IL process to read e.g. files, even if they are marked as Medium or High IL. In other words, if somebody exploits IE running in Protected Mode (at Low IL), she will be able to read (i.e. steal) all user’s data.
This is not an implementation bug, this is a design decision and it’s cleverly called the “read-up policy”. If we think about it for a while, it should become clear why Microsoft decided to do it that way. First, we should observe, that what Microsoft is most concerned about, is malware which permanently installs itself in the system and that could later be detected by some anti-malware programs. Microsoft doesn’t like it, because it’s the source of all the complains about how insecure Windows is and also the A/V companies can publish their statistics about how many percent of computers is compromised, etc… All in all, a very uncomfortable situation, not only for Microsoft but also for all those poor users, who now need to try all the various methods (read buy A/V programs) to remove the malware, instead just focus on their work…
On the other hand, imagine a reliable exploit (i.e. not crashing a target too often) which, after exploiting e.g. IE Protected Mode process, steals all the user’s DOC and XLS files, sends them back somewhere and afterwards disappears in an elegant fashion. Our user, busy with his every day work, does not even notice anything, so he can continue working undisturbed and focus on his real job. The A/V programs do not detect the exploit (why should they? – after all there’s no signature for it nor the shellcode uses any suspicious API) so they do not report the machine as infected – because, after all it’s not infected. So, the statistics look better and everybody is generally happier. Including the competition, who now has access to stolen data ;)
User Interface Privilege Isolation and some little Fun
UAC and Integrity Levels mechanism makes it possible for processes running with different ILs to share the same desktop. This raises potential security problem, because Windows implements a mechanism to allow one process to send a “window message”, like e.g. WM_SETTEXT, to another process. Moreover, some messages, like e.g. the infamous WM_TIMER, could be used the redirect execution flow of the target thread. This has been popular a few years ago in so called “Shatter Attacks”.
UIPI, introduced in Vista, is for the rescue. UIPI basically enforces the obvious policy that lower integrity processes can not send messages to higher integrity processes.
Interestingly, UIPI implementation is a bit “unfinished” I would say… For example, in contrast to design assumption, on my system at least, it is possible for the Low integrity process to send e.g. WM_KEYDOWN to e.g. open Administrative shell (cmd.exe) running at High IL and gets arbitrary commands executed.
One simple scenario of the attack is that a malicious program, running at Low IL, can wait for the user to open elevated command prompt – it can e.g. poll the open window handles e.g. every second or so (Window enumeration is allowed even at Low IL). Once it finds the window, it can send commands to execute… Probably not that cool as the recent “Vista Speech Exploit”, but still something to play with ;)
It’s my feeling that there are more holes in UAC, but I will leave finding them all as an exercise for the readers...
Do-It-Yourself: Implementing Privilege Separation
Because of the limitations of the UAC and IL mentioned above (i.e. the read-up policy), I decided to implement a little privilege-separation policy in my system. The first thing we need, is to create a few more accounts, each for a specific type of applications or tasks. E.g. I decided that I want a separate account to run my web browser, a different one for running my email client as well as IM client (which I occasionally run) and a whole other account to deal with my super-secret projects. And, of course, I need a main account, that is, the one which I will use to log in to the system. All in all, here is the list of all the accounts on my Vista laptop:
• admin
• joanna
• joanna.web
• joanna.email
• joanna.sensitive
So, joanna is used to log into system (this is, BTW, a truly limited account, i.e. it doesn’t belong to the Administrators group) and Explorer and all applications like e.g. Picassa are started using this account. Firefox and Thunderbird run as joanna.web and joanna.email respectively. However, a little trick is needed here, if we want to start those applications as Low IL processes (and we want to do this, because we want UIPI to protect, at least in theory, other applications from web and mail clients if they got compromised somehow). As it was mentioned above, if one uses runas or psexec the created process will run as Medium IL, regardless the integrity level assigned to the executable. We can get around this, buy using this simple trick (note the nested quotations):runas /user:joanna.web "cmd /c start \"c:\Program Files\Mozilla Firefox\firefox.exe\""
c:\tools\psexec -d -e -u joanna.web -p l33tp4ssw0rd "cmd" "/c start "c:\Program Files\Mozilla Firefox\firefox.exe""
Obviously, we also need to set appropriate ACLs on the directories containing Firefox and Thunderbird user’s profiles, so that each of those two users get full access to the respective directories as well as to a \tmp folder, used to store email attachments and downloaded files. No other personal files should be accessible to joanna.web and joanna.email.
Finally, being a paranoid person as I am, I have also a special user joanna.sensitive, which is the only one granted access to my \projects directory. It may come as a surprise, but I decided to make joanna.sensitve a member of the Administrators group. The reason for that is that I need to make all the applications which run as joanna.sensitve (e.g. gvim, cmd, Visual Studio, KeePass, etc) to have their UI isolated from all other normal applications, which run as joanna at Medium IL. It seems like the only way to start a processes at High IL is to make it part of the Administrators group and then use ‘Run As Administrator’ or runas command to start it.
That way we have the highly dangerous applications, like web browser or email client, run at Low IL and as very limited users (joanna.web and joanna.email), who have access only to the necessary profile directories (the restriction, this time, applies both to read- and write- accesses, because it’s enforced by normal ACLs on file system objects and not by IL mechanism). Then we have all other applications, like Explorer, various Office applications, etc. running as joanna at Medium IL and finally the most critical programs, those running as joanna.sensitve, like KeePass and those which get access to my \projects directory, they all run at High IL.
Thunderbird, GPG and Smart Cards
Even though the above configuration might look good, there’s still a problem with it I haven’t solved yet. The problem is related to mail encryption and how to isolate email client from my PGP private keys. I use Thunderbird together with Enigmail’s OpenPGP extension. The extension is just a wrapper around gpg.exe, a GnuPG implementation of PGP. When I open encrypted email, my Thunderbird processes spawns a new gpg.exe process and passes the passphrase to it as an argument. There are two alarming things here – first Thunderbird process needs to know my passphrase (in fact I enter it into a dialog box displayed by the Enigmail’s extension) and second, the gpg.exe process runs as the same user and at the same IL level as the thunderbird.exe process. So, if thunderbird.exe gets compromised, the malicious code executing inside thunderbird.exe will not only be able to get to know my passphrase, but will also be free to read my private key from disk (because it has the same rights as gpg.exe).
Theoretically it should be possible to solve the problem with passphrase stealing by using GPG Agent, which could run in the background as a service and gpg.exe would ask the agent for the passphrase instead asking thunderbird.exe process, which will never be in possession of the passphrase. Ignoring the fact that there doesn’t seem to be a working GPG Agent implementation for Win32 environment, this still is not a good solution, because thunderbird.exe still gets access to gpg.exe process, which is its own child after all – so it’s possible for thunderbird.exe to read the contents of gpg.exe memory and to find a decrypted PGP private key there.
It would help if GPG was implemented as a service running in the background and thunderbird.exe would only communicate with it using some sort of LPC to send request to encrypt, decrypt, sign and verify buffers. Unfortunately I’m not aware of such implementation, especially for Win32.
The only practical solution seems to be to use a Smart Card, which would perform all the
necessary crypto operations using its own processor. Unfortunately, GnuPG supports only, a so called, OpenPGP smart cards, but it seems that the only two cards which implements this standard (i.e. Fellowship card and the g10 card) implement only 1024 bits RSA keys, which is definitely not enough for even a moderately paranoid person ;)
In the last hope, I turned to commercial PGP, downloaded the trial of PGP Desktop and… it turned out that it doesn’t support Vista yet (what a shame, BTW).
So, for the time being I’m defenseless like a baby against all those mean people who would try to exploit my thunderbird.exe and steal my private PGP key :(
The forgotten part: Detection
One might think that it’s a pretty secure system configuration… Well, more precisely, it could be considered as pretty secure, if UIPI was not buggy and UAC didn’t force me to run random setup programs with full administrator rights and if GPG supported Smart Cards with RSA keys > 1024 (or alternatively PGP Desktop supported Vista). But let’s not be that scrupulous and forgot about those minor problems…
Still, even though that might look like a secure configuration, this is all just an illusion of security! The whole security of the system can be compromised if attacker finds and exploits e.g. a bug in kernel driver.
It should be noted that Microsoft has also implemented several anti-exploitation techniques in Vista, the two most advertised are Address Space Layout Randomization (ASLR) and Data Execution Prevention (DEP). However, ASLR does not protect against local kernel exploitation, because it’s possible, even for the Low IL process, to query system about the list of loaded kernel modules together with their base addresses (using ZwQuerySystemInformation function). Also, hardware DEP, which works only on 64-bit processors, is not applied to the whole non-paged pool (as well as some other areas, but non-paged pool is the biggest one). In other words, the hardware NX bit is not set on all pages comprising the non-paged pool. BTW, there is a reason for Microsoft doing this and this is not due to compatibility issues (at least I believe so). I wonder who else can guess... ;)
UPDATE (see above): David Solomon, pointed out, that Hardware DEP is also available on many modern 32-bit processors (as the NX bit is implemented in PAE mode).
It’s very good that Microsoft implemented those anti-exploitation technologies (besides ASLR and NX, there are also some others). However the point is, they could be bypassed by a clever attacker under some circumstances. Now think about how many 3rd party kernel drivers are typically present in an average Windows systems – all those graphics card drivers, audio drivers, SATA drivers, A/V drivers, etc... and try answering the question how many possible bugs could be there? (BTW, it should be mentioned that Microsoft did a clever step by moving some classes of kernel drivers into user mode, like e.g. USB drivers – this is called UMDF).
When attacker successfully exploits kernel bug, then all the security scheme implemented by the OS is just worth nothing. So, what can we do? Well, we need to complement all those cool prevention technologies with effective detection technology. But has Microsoft done anything to make systematic detection possible? This is a rhetoric question of course and the negative answer applies unfortunately not only to Microsoft products but also to all other general purpose operating systems I’m aware of :(
My favorite quote of all those people who negate the value of detection is this: “once the system is compromised we can’t do anything!”. BS! Even though it might be true today – because the Operating System are not designed to be verifiable, but that doesn’t mean we can’t change this!
Bottom Line
Microsoft did a good job with securing Vista. They could do better, of course, but remember that Windows is a system for masses and also that they need to take care about compatibility issues, which sometimes can be a real pain. If you want to run Microsoft OS, then I believe that Vista is definitely a better choice then XP from a security standpoint. It has bugs, but which OS doesn't? What I wish for, is that they paid more attention to make their system verifiable...Acknowledgements
I would like to thank John Lambert and Andrew Roths, both of Microsoft, for answering my questions about UAC design.
\ No newline at end of file
+More then a month ago I have installed Vista RTM on my primary laptop (x86 machine) and have been running it since that time almost every day. Below are some of my reflections about the new security model introduced in Vista, its limitations, a few flaws and some practical info about how I configured my system.
UAC – The Good and The Bad
User Account Control (UAC) is a new security mechanism introduced in Vista, whose primary goal is to force users to work using restricted accounts, instead working as administrators. This is, in my opinion the most important security mechanism introduced in Vista. That doesn’t mean it can not be bypassed in many ways (due to implementation flaws), but just the fact that such a design change has been made into Windows is, without doubt, a great step towards securing consumer OSes.
When UAC is active (which is a default setting) even when user logs in as an administrator, most of her programs run as restricted processes, i.e. they have only some very limited subset of privileges in their process token. Also, they run at, so called, Medium integrity level, which, among other things, should prevent those applications from interacting with higher integrity level processes via Window messages. This mechanism also got a nice marketing acronym, UIPI, which stands for User Interface Privilege Isolation. Once the system determines that a given program (or a given action) requires administrative privileges, because e.g. the user wants to change system time, it displays a consent window to the user, asking her whether she really wants to proceed. In case the user logged in as a normal user (i.e. the account does not belong to the Administrators group), then the user is also asked to enter password for the one of the administrator's accounts. You can find more background information about UAC, e.g. at this page.
Many people complain about UAC, saying that it’s very annoying for them to see UAC consent dialog box to appear every few minutes or so, and claim that this will discourage users from using this mechanism at all (and yes, there’s an option to disable UAC). I strongly disagree with such opinion - I’ve been running Vista more then a month now and, besides the first few days when I was installing various applications, I now do not see UAC prompt more then 1-2 times per day. So, I really wonder what those people are doing that they see UAC constantly appearing every other minute…
One thing that I found particularly annoying though, is that Vista automatically assumes that all setup programs (application installers) should be run with administrator privileges. So, when you try to run such a program, you get a UAC prompt and you have only two choices: either to agree to run this application as administrator or to disallow running it at all. That means that if you downloaded some freeware Tetris game, you will have to run its installer as administrator, giving it not only full access to all your file system and registry, but also allowing e.g. to load kernel drivers! Why Tetris installer should be allowed to load kernel drivers?
How Vista recognizes installer executables? It has a compatibility database as well as uses several heuristics to do that, e.g. if the file name contains the string “setup” (Really, I’m not kidding!). Finally it looks at the executable’s manifest and most of the modern installers are expected to have such manifest embedded, which may indicate that the executable should be run as administrator.
To get around this problem, e.g. on XP, I would normally just add appropriate permissions to my normal (restricted) user account, in such a way that this account would be ale to add new directories under C:\Program Files and to add new keys under HKLM\Software (in most cases this is just enough), but still would not be able to modify any global files nor registry keys nor, heaven forbid, to load drivers. More paranoid people could chose to create a separate account, called e.g. installer and use it to install most of the applications. Of course, the real life is not that beautiful and you sometimes need to play a bit with regmon to tweak the permissions, but, in general it works for majority of applications and I have been successfully using this approach for years now on my XP box.
That approach would not work on Vista, because every time Vista detects that an executable is a setup program (and believe me Vista is really good at doing this), it will only allow running it as administrator… Even though it’s possible to disable heuristics-based installer detection via local policy settings – see picture below:
that doesn’t seem to work for those installer executables which have embedded manifest saying that they should be run as administrator.
I see the above limitation as a very severe hole in the design of UAC. After all, I would like to be offered a choice whether to fully trust given installer executable (and run it as full administrator) or just allow it to add a folder in C:\Program Files and some keys under HKLM\Software and do nothing more. I could do that under XP, but apparently I can’t under Vista, which is a bit disturbing (unless I’m missing some secret option to change that behavior).
Integrity Levels – Protect the OS but not your data!
Integrity Levels (IL) mechanism has been introduced to help implementing UAC. This mechanism is very simple – every process can be assigned one of the four possible integrity levels:
• Low
• Medium
• High
• System
Similarly, every securable object in the system, like e.g. a directory, file or registry key, can also be assigned an integrity level. Integrity level is nothing else then just an ACE of a special type assigned to the SACL list. If there’s no such ACE at all, then the integrity level of the object is assumed to be Medium. You can use icacls command to see integrity levels on file system objects:
C:\>icacls \Users\joanna\AppData\LocalLow
\Users\joanna\AppData\LocalLow silverose\joanna:(F)
silverose\joanna:(OI)(CI)(IO)(F)
NT AUTHORITY\SYSTEM:(F)
NT AUTHORITY\SYSTEM:(OI)(CI)(IO)(F)
BUILTIN\Administrators:(F)
BUILTIN\Administrators:(OI)(CI)(IO)(F)
Mandatory Label\Low Mandatory Level:(OI)(CI)(NW)
BTW, I don’t know any tool/command to see and modify integrity levels assigned to registry keys (I think I know how to do this in C though). Anybody?
Now, the whole concept behind IL is that a process can only get write-access to those objects which have the same or lower integrity level then the process itself.
Update (March 5th, 2007): This is the default behavior of IL and is indicated by the “(NW)” symbol on the picture above, which stands for NoWriteUp policy. I have just learned that one can use the chml tool by Mark Minasi to set also a different policy, i.e. NoReadUp (NR) or NoExecuteUp (NX), which would result that IL mechanism will not allow a lower integrity process to read or execute the objects marked with higher IL. See also my recent post about this tool.
UAC is implemented using IL – even if you log in as administrator, all your processes (like e.g. explorer.exe) run with Medium IL. Once you elevated to the “real admin” your process runs at High IL. System processes, like e.g. services, runs at System IL. From the security point of view High IL seems to be equivalent to System IL, because once you are allowed to execute code at High IL you can compromise the whole system.
Internet Explorer’s protected mode is implemented using the IL mechanism. The iexplore.exe process runs at Low IL and, in a system with default configuration, can only write to %USERPROFILE%\AppData\LocalLow and HKCU\Software\AppDataLow because all other objects have higher ILs (usually Medium).
If you don’t like surfing using IE, you can very easily setup your Firefox (or other browser of your choice) to run as Low integrity process (here we assume that Firefox user’s profile is in j:\config\firefox-profile):
C:\Program Files\Mozilla Firefox>icacls firefox.exe /setintegritylevel low
J:\config>icacls firefox-profile /setintegritylevel (OI)(CI)low
Because firefox.exe is now marked as a Low integrity file, Vista will also create a Low integrity process from this file, unless you are going to start this executable from a High integrity process (e.g. elevated command prompt). Also, if you, for some reason (see below), wanted to use runas or psexec to start a Low integrity process, it won’t work and will start the process as Medium, regardless that the executable is marked as Low integrity.
It should be stressed that IL, by default, protects only against modifications of higher integrity objects. It’s perfectly ok for the Low IL process to read e.g. files, even if they are marked as Medium or High IL. In other words, if somebody exploits IE running in Protected Mode (at Low IL), she will be able to read (i.e. steal) all user’s data.
This is not an implementation bug, this is a design decision and it’s cleverly called the “read-up policy”. If we think about it for a while, it should become clear why Microsoft decided to do it that way. First, we should observe, that what Microsoft is most concerned about, is malware which permanently installs itself in the system and that could later be detected by some anti-malware programs. Microsoft doesn’t like it, because it’s the source of all the complains about how insecure Windows is and also the A/V companies can publish their statistics about how many percent of computers is compromised, etc… All in all, a very uncomfortable situation, not only for Microsoft but also for all those poor users, who now need to try all the various methods (read buy A/V programs) to remove the malware, instead just focus on their work…
On the other hand, imagine a reliable exploit (i.e. not crashing a target too often) which, after exploiting e.g. IE Protected Mode process, steals all the user’s DOC and XLS files, sends them back somewhere and afterwards disappears in an elegant fashion. Our user, busy with his every day work, does not even notice anything, so he can continue working undisturbed and focus on his real job. The A/V programs do not detect the exploit (why should they? – after all there’s no signature for it nor the shellcode uses any suspicious API) so they do not report the machine as infected – because, after all it’s not infected. So, the statistics look better and everybody is generally happier. Including the competition, who now has access to stolen data ;)
User Interface Privilege Isolation and some little Fun
UAC and Integrity Levels mechanism makes it possible for processes running with different ILs to share the same desktop. This raises potential security problem, because Windows implements a mechanism to allow one process to send a “window message”, like e.g. WM_SETTEXT, to another process. Moreover, some messages, like e.g. the infamous WM_TIMER, could be used the redirect execution flow of the target thread. This has been popular a few years ago in so called “Shatter Attacks”.
UIPI, introduced in Vista, is for the rescue. UIPI basically enforces the obvious policy that lower integrity processes can not send messages to higher integrity processes.
Interestingly, UIPI implementation is a bit “unfinished” I would say… For example, in contrast to design assumption, on my system at least, it is possible for the Low integrity process to send e.g. WM_KEYDOWN to e.g. open Administrative shell (cmd.exe) running at High IL and gets arbitrary commands executed.
One simple scenario of the attack is that a malicious program, running at Low IL, can wait for the user to open elevated command prompt – it can e.g. poll the open window handles e.g. every second or so (Window enumeration is allowed even at Low IL). Once it finds the window, it can send commands to execute… Probably not that cool as the recent “Vista Speech Exploit”, but still something to play with ;)
It’s my feeling that there are more holes in UAC, but I will leave finding them all as an exercise for the readers...
Do-It-Yourself: Implementing Privilege Separation
Because of the limitations of the UAC and IL mentioned above (i.e. the read-up policy), I decided to implement a little privilege-separation policy in my system. The first thing we need, is to create a few more accounts, each for a specific type of applications or tasks. E.g. I decided that I want a separate account to run my web browser, a different one for running my email client as well as IM client (which I occasionally run) and a whole other account to deal with my super-secret projects. And, of course, I need a main account, that is, the one which I will use to log in to the system. All in all, here is the list of all the accounts on my Vista laptop:
• admin
• joanna
• joanna.web
• joanna.email
• joanna.sensitive
So, joanna is used to log into system (this is, BTW, a truly limited account, i.e. it doesn’t belong to the Administrators group) and Explorer and all applications like e.g. Picassa are started using this account. Firefox and Thunderbird run as joanna.web and joanna.email respectively. However, a little trick is needed here, if we want to start those applications as Low IL processes (and we want to do this, because we want UIPI to protect, at least in theory, other applications from web and mail clients if they got compromised somehow). As it was mentioned above, if one uses runas or psexec the created process will run as Medium IL, regardless the integrity level assigned to the executable. We can get around this, buy using this simple trick (note the nested quotations):runas /user:joanna.web "cmd /c start \"c:\Program Files\Mozilla Firefox\firefox.exe\""
c:\tools\psexec -d -e -u joanna.web -p l33tp4ssw0rd "cmd" "/c start "c:\Program Files\Mozilla Firefox\firefox.exe""
Obviously, we also need to set appropriate ACLs on the directories containing Firefox and Thunderbird user’s profiles, so that each of those two users get full access to the respective directories as well as to a \tmp folder, used to store email attachments and downloaded files. No other personal files should be accessible to joanna.web and joanna.email.
Finally, being a paranoid person as I am, I have also a special user joanna.sensitive, which is the only one granted access to my \projects directory. It may come as a surprise, but I decided to make joanna.sensitve a member of the Administrators group. The reason for that is that I need to make all the applications which run as joanna.sensitve (e.g. gvim, cmd, Visual Studio, KeePass, etc) to have their UI isolated from all other normal applications, which run as joanna at Medium IL. It seems like the only way to start a processes at High IL is to make it part of the Administrators group and then use ‘Run As Administrator’ or runas command to start it.
That way we have the highly dangerous applications, like web browser or email client, run at Low IL and as very limited users (joanna.web and joanna.email), who have access only to the necessary profile directories (the restriction, this time, applies both to read- and write- accesses, because it’s enforced by normal ACLs on file system objects and not by IL mechanism). Then we have all other applications, like Explorer, various Office applications, etc. running as joanna at Medium IL and finally the most critical programs, those running as joanna.sensitve, like KeePass and those which get access to my \projects directory, they all run at High IL.
Thunderbird, GPG and Smart Cards
Even though the above configuration might look good, there’s still a problem with it I haven’t solved yet. The problem is related to mail encryption and how to isolate email client from my PGP private keys. I use Thunderbird together with Enigmail’s OpenPGP extension. The extension is just a wrapper around gpg.exe, a GnuPG implementation of PGP. When I open encrypted email, my Thunderbird processes spawns a new gpg.exe process and passes the passphrase to it as an argument. There are two alarming things here – first Thunderbird process needs to know my passphrase (in fact I enter it into a dialog box displayed by the Enigmail’s extension) and second, the gpg.exe process runs as the same user and at the same IL level as the thunderbird.exe process. So, if thunderbird.exe gets compromised, the malicious code executing inside thunderbird.exe will not only be able to get to know my passphrase, but will also be free to read my private key from disk (because it has the same rights as gpg.exe).
Theoretically it should be possible to solve the problem with passphrase stealing by using GPG Agent, which could run in the background as a service and gpg.exe would ask the agent for the passphrase instead asking thunderbird.exe process, which will never be in possession of the passphrase. Ignoring the fact that there doesn’t seem to be a working GPG Agent implementation for Win32 environment, this still is not a good solution, because thunderbird.exe still gets access to gpg.exe process, which is its own child after all – so it’s possible for thunderbird.exe to read the contents of gpg.exe memory and to find a decrypted PGP private key there.
It would help if GPG was implemented as a service running in the background and thunderbird.exe would only communicate with it using some sort of LPC to send request to encrypt, decrypt, sign and verify buffers. Unfortunately I’m not aware of such implementation, especially for Win32.
The only practical solution seems to be to use a Smart Card, which would perform all the
necessary crypto operations using its own processor. Unfortunately, GnuPG supports only, a so called, OpenPGP smart cards, but it seems that the only two cards which implements this standard (i.e. Fellowship card and the g10 card) implement only 1024 bits RSA keys, which is definitely not enough for even a moderately paranoid person ;)
In the last hope, I turned to commercial PGP, downloaded the trial of PGP Desktop and… it turned out that it doesn’t support Vista yet (what a shame, BTW).
So, for the time being I’m defenseless like a baby against all those mean people who would try to exploit my thunderbird.exe and steal my private PGP key :(
The forgotten part: Detection
One might think that it’s a pretty secure system configuration… Well, more precisely, it could be considered as pretty secure, if UIPI was not buggy and UAC didn’t force me to run random setup programs with full administrator rights and if GPG supported Smart Cards with RSA keys > 1024 (or alternatively PGP Desktop supported Vista). But let’s not be that scrupulous and forgot about those minor problems…
Still, even though that might look like a secure configuration, this is all just an illusion of security! The whole security of the system can be compromised if attacker finds and exploits e.g. a bug in kernel driver.
It should be noted that Microsoft has also implemented several anti-exploitation techniques in Vista, the two most advertised are Address Space Layout Randomization (ASLR) and Data Execution Prevention (DEP). However, ASLR does not protect against local kernel exploitation, because it’s possible, even for the Low IL process, to query system about the list of loaded kernel modules together with their base addresses (using ZwQuerySystemInformation function). Also, hardware DEP, which works only on 64-bit processors, is not applied to the whole non-paged pool (as well as some other areas, but non-paged pool is the biggest one). In other words, the hardware NX bit is not set on all pages comprising the non-paged pool. BTW, there is a reason for Microsoft doing this and this is not due to compatibility issues (at least I believe so). I wonder who else can guess... ;)
UPDATE (see above): David Solomon, pointed out, that Hardware DEP is also available on many modern 32-bit processors (as the NX bit is implemented in PAE mode).
It’s very good that Microsoft implemented those anti-exploitation technologies (besides ASLR and NX, there are also some others). However the point is, they could be bypassed by a clever attacker under some circumstances. Now think about how many 3rd party kernel drivers are typically present in an average Windows systems – all those graphics card drivers, audio drivers, SATA drivers, A/V drivers, etc... and try answering the question how many possible bugs could be there? (BTW, it should be mentioned that Microsoft did a clever step by moving some classes of kernel drivers into user mode, like e.g. USB drivers – this is called UMDF).
When attacker successfully exploits kernel bug, then all the security scheme implemented by the OS is just worth nothing. So, what can we do? Well, we need to complement all those cool prevention technologies with effective detection technology. But has Microsoft done anything to make systematic detection possible? This is a rhetoric question of course and the negative answer applies unfortunately not only to Microsoft products but also to all other general purpose operating systems I’m aware of :(
My favorite quote of all those people who negate the value of detection is this: “once the system is compromised we can’t do anything!”. BS! Even though it might be true today – because the Operating System are not designed to be verifiable, but that doesn’t mean we can’t change this!
Bottom Line
Microsoft did a good job with securing Vista. They could do better, of course, but remember that Windows is a system for masses and also that they need to take care about compatibility issues, which sometimes can be a real pain. If you want to run Microsoft OS, then I believe that Vista is definitely a better choice then XP from a security standpoint. It has bugs, but which OS doesn't? What I wish for, is that they paid more attention to make their system verifiable...Acknowledgements
I would like to thank John Lambert and Andrew Roths, both of Microsoft, for answering my questions about UAC design.
\ No newline at end of file
diff --git a/_posts/2007-02-12-vista-security-model-big-joke.html b/_posts/2007-02-12-vista-security-model-big-joke.html
index a48607b..7a294de 100644
--- a/_posts/2007-02-12-vista-security-model-big-joke.html
+++ b/_posts/2007-02-12-vista-security-model-big-joke.html
@@ -9,4 +9,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2007/02/vista-security-model-big-joke.html
---
-[Update: if you came here from ZDNet or Slashdot - see the post about confusion above!]
Today I saw a new post at Mark Russinovich’s blog which I take as a response to my recent musings about Vista security features, where I pointed out several problems with UAC, like e.g. the attack that allows for a low integrity process to hijack the high integrity level command prompt. Those who read the whole article undoubtedly noticed that my overall opinion of vista security changes was still very positive – after all everybody can do mistakes and the fact UAC is not perfect, doesn’t diminish the fact that it’s a step into the right direction, i.e. implementing least-privilege policy in Windows OS.
However, I now read this post by Mark Russinovich (a Microsoft employee), which says:
"It should be clear then, that neither UAC elevations nor Protected Mode IE define new Windows security boundaries. Microsoft has been communicating this but I want to make sure that the point is clearly heard. Further, as Jim Allchin pointed out in his blog post Security Features vs Convenience, Vista makes tradeoffs between security and convenience, and both UAC and Protected Mode IE have design choices that required paths to be opened in the IL wall for application compatibility and ease of use."
And then we read:
"Because elevations and ILs don’t define a security boundary, potential avenues of attack, regardless of ease or scope, are not security bugs. So if you aren’t guaranteed that your elevated processes aren’t susceptible to compromise by those running at a lower IL, why did Windows Vista go to the trouble of introducing elevations and ILs? To get us to a world where everyone runs as standard user by default and all software is written with that assumption."
Oh, excuse me, is this supposed be a joke? We all remember all those Microsoft’s statements about how serious Microsoft is about security in Vista and how all those new cool security features like UAC or Protected Mode IE will improve the world’s security. And now we hear what? That this flagship security technology (UAC) is in fact… not a security technology!
I understand that implementing UAC, UIPI and Integrity Levels mechanisms on top of the existing Windows OS infrastructure is a hard task and it would be much easier to design the whole new OS from scratch and that Microsoft can’t do this for various of reasons. I understand that all, but that doesn’t mean that once more people at Microsoft realized that too, they should turn everything into a big joke? Or maybe I’m too much of an idealist…
So, I will say this: If Microsoft won’t change their attitude soon, then in a couple of months the security of Vista (from the typical malware’s point of view) will be equal to the security of current XP systems (which means, not too impressive).
\ No newline at end of file
+[Update: if you came here from ZDNet or Slashdot - see the post about confusion above!]
Today I saw a new post at Mark Russinovich’s blog which I take as a response to my recent musings about Vista security features, where I pointed out several problems with UAC, like e.g. the attack that allows for a low integrity process to hijack the high integrity level command prompt. Those who read the whole article undoubtedly noticed that my overall opinion of vista security changes was still very positive – after all everybody can do mistakes and the fact UAC is not perfect, doesn’t diminish the fact that it’s a step into the right direction, i.e. implementing least-privilege policy in Windows OS.
However, I now read this post by Mark Russinovich (a Microsoft employee), which says:
"It should be clear then, that neither UAC elevations nor Protected Mode IE define new Windows security boundaries. Microsoft has been communicating this but I want to make sure that the point is clearly heard. Further, as Jim Allchin pointed out in his blog post Security Features vs Convenience, Vista makes tradeoffs between security and convenience, and both UAC and Protected Mode IE have design choices that required paths to be opened in the IL wall for application compatibility and ease of use."
And then we read:
"Because elevations and ILs don’t define a security boundary, potential avenues of attack, regardless of ease or scope, are not security bugs. So if you aren’t guaranteed that your elevated processes aren’t susceptible to compromise by those running at a lower IL, why did Windows Vista go to the trouble of introducing elevations and ILs? To get us to a world where everyone runs as standard user by default and all software is written with that assumption."
Oh, excuse me, is this supposed be a joke? We all remember all those Microsoft’s statements about how serious Microsoft is about security in Vista and how all those new cool security features like UAC or Protected Mode IE will improve the world’s security. And now we hear what? That this flagship security technology (UAC) is in fact… not a security technology!
I understand that implementing UAC, UIPI and Integrity Levels mechanisms on top of the existing Windows OS infrastructure is a hard task and it would be much easier to design the whole new OS from scratch and that Microsoft can’t do this for various of reasons. I understand that all, but that doesn’t mean that once more people at Microsoft realized that too, they should turn everything into a big joke? Or maybe I’m too much of an idealist…
So, I will say this: If Microsoft won’t change their attitude soon, then in a couple of months the security of Vista (from the typical malware’s point of view) will be equal to the security of current XP systems (which means, not too impressive).
\ No newline at end of file
diff --git a/_posts/2007-02-13-confiusion-about-joke.html b/_posts/2007-02-13-confiusion-about-joke.html
index 74260ea..9d2595a 100644
--- a/_posts/2007-02-13-confiusion-about-joke.html
+++ b/_posts/2007-02-13-confiusion-about-joke.html
@@ -9,4 +9,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2007/02/confiusion-about-joke.html
---
-It seems that many people didn’t fully understand why I wrote the previous post – Vista Security Model – A Big Joke... There are two things which should be distinguished:
1) The fact that UAC design assumes that every setup executable should be run elevated (and that a user doesn't really have a choice to run it from a non-elevated account),
2) The fact that UAC implementation contains bug(s), like e.g. the bug I pointed out in my article, which allows a low integrity level process to send WM_KEYDOWN messages to a command prompt window running at high integrity level.
I was pissed off not because of #1, but because Microsoft employee - Mark Russinovich - declared that all implementation bugs in UAC are not to be considered as security bugs.
True, I also don't like the fact that UAC forces users to run every setup program with elevated privileges (fact #1), but I can understand such a design decision (as being a compromise between usability and security) and this was not the reason why I wrote "The Joke Post".
\ No newline at end of file
+It seems that many people didn’t fully understand why I wrote the previous post – Vista Security Model – A Big Joke... There are two things which should be distinguished:
1) The fact that UAC design assumes that every setup executable should be run elevated (and that a user doesn't really have a choice to run it from a non-elevated account),
2) The fact that UAC implementation contains bug(s), like e.g. the bug I pointed out in my article, which allows a low integrity level process to send WM_KEYDOWN messages to a command prompt window running at high integrity level.
I was pissed off not because of #1, but because Microsoft employee - Mark Russinovich - declared that all implementation bugs in UAC are not to be considered as security bugs.
True, I also don't like the fact that UAC forces users to run every setup program with elevated privileges (fact #1), but I can understand such a design decision (as being a compromise between usability and security) and this was not the reason why I wrote "The Joke Post".
\ No newline at end of file
diff --git a/_posts/2007-03-05-handy-tool-to-play-with-windows.html b/_posts/2007-03-05-handy-tool-to-play-with-windows.html
index f9c25aa..0dabf44 100644
--- a/_posts/2007-03-05-handy-tool-to-play-with-windows.html
+++ b/_posts/2007-03-05-handy-tool-to-play-with-windows.html
@@ -9,4 +9,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2007/03/handy-tool-to-play-with-windows.html
---
-Mark Minasi wrote to me recently to point out that his new tool, chml, is capable of setting NoReadUp and NoExecuteUp policy on file objects, in addition to the standard NoWriteUp policy, which is used by default on Vista.
As I wrote before the default IL policy used on Vista assumes only the NoWriteUp policy. That means that all objects which do not have assigned any IL explicitly (and consequently are treated as if they were marked with Medium IL) can be read by low integrity processes (only writes are prevented). Also, the standard Windows icacls command, which allows to set IL for file objects, assumes always the NoWriteUp policy only (unless I’m missing some secret switch).
However, it’s possible, for each object, to define not only the integrity level but also the policy which will be used to access it. All this information is stored in the same SACE which also defines the IL.
There doesn’t seem to be too much documentation from Microsoft about how to set those permissions, except this paper about Protected Mode IE and the sddl.h file itself.
Anyway, it’s good to see a tool like chml as it allows to do some cool things in a very simple way. E.g. consider that you have some secret documents in the folder c:\secretes and that you don’t feel like sharing those files with anybody who can exploit your Protected Mode IE. As I pointed out in my previous article, by default all your personal files are accessible to your Protected Mode IE low integrity process, so in the event of successful exploitation the attacker is free to steal them all. However now, using Mark Minasi’s tool, you can just do this:
chml.exe c:\secrets -i:m -nr -nx
This should prevent all the low IL processes, like e.g. Protected Mode IE, from reading the contents of your secret directory.
BTW, you can use chml to also examine the SACE which was created:
chml.exe c:\secrets -showsddl
and you should get something like that as a result:
SDDL string for c:\secrets's integrity label=S:(ML;OICI;NRNX;;;ME)
Where S means that it’s an SACE (in contrast to e.g. DACE), ML says that this ACE defines mandatory label, OICI means “Object Inherit” and “Container Inherit”, NRNX defines that to access this object the NoReadUp and NoExecuteUp policies should be used (which also implies the NoWriteUp BTW) and finally the ME stands for Medium Integrity Level.
All credits go to Mark Minasi and the Windows IL team :)
As a side note: the updated slides for my recent Black Hat DC talk about cheating hardware based memory acquisition can be found here. You can also get the demo movies here.
\ No newline at end of file
+Mark Minasi wrote to me recently to point out that his new tool, chml, is capable of setting NoReadUp and NoExecuteUp policy on file objects, in addition to the standard NoWriteUp policy, which is used by default on Vista.
As I wrote before the default IL policy used on Vista assumes only the NoWriteUp policy. That means that all objects which do not have assigned any IL explicitly (and consequently are treated as if they were marked with Medium IL) can be read by low integrity processes (only writes are prevented). Also, the standard Windows icacls command, which allows to set IL for file objects, assumes always the NoWriteUp policy only (unless I’m missing some secret switch).
However, it’s possible, for each object, to define not only the integrity level but also the policy which will be used to access it. All this information is stored in the same SACE which also defines the IL.
There doesn’t seem to be too much documentation from Microsoft about how to set those permissions, except this paper about Protected Mode IE and the sddl.h file itself.
Anyway, it’s good to see a tool like chml as it allows to do some cool things in a very simple way. E.g. consider that you have some secret documents in the folder c:\secretes and that you don’t feel like sharing those files with anybody who can exploit your Protected Mode IE. As I pointed out in my previous article, by default all your personal files are accessible to your Protected Mode IE low integrity process, so in the event of successful exploitation the attacker is free to steal them all. However now, using Mark Minasi’s tool, you can just do this:
chml.exe c:\secrets -i:m -nr -nx
This should prevent all the low IL processes, like e.g. Protected Mode IE, from reading the contents of your secret directory.
BTW, you can use chml to also examine the SACE which was created:
chml.exe c:\secrets -showsddl
and you should get something like that as a result:
SDDL string for c:\secrets's integrity label=S:(ML;OICI;NRNX;;;ME)
Where S means that it’s an SACE (in contrast to e.g. DACE), ML says that this ACE defines mandatory label, OICI means “Object Inherit” and “Container Inherit”, NRNX defines that to access this object the NoReadUp and NoExecuteUp policies should be used (which also implies the NoWriteUp BTW) and finally the ME stands for Medium Integrity Level.
All credits go to Mark Minasi and the Windows IL team :)
As a side note: the updated slides for my recent Black Hat DC talk about cheating hardware based memory acquisition can be found here. You can also get the demo movies here.
\ No newline at end of file
diff --git a/_posts/2007-03-26-game-is-over.html b/_posts/2007-03-26-game-is-over.html
index ac8c977..b5a33ce 100644
--- a/_posts/2007-03-26-game-is-over.html
+++ b/_posts/2007-03-26-game-is-over.html
@@ -10,4 +10,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2007/03/game-is-over.html
---
-People often say that once an attacker gets access to the kernel the game is over! That’s true indeed these days, and most of the research I have done over the past two years or so, was about proofing just that. Some people, however, go a bit further and say, that thus there is no point in researching ways to detect system compromises and, once an attacker got in, you should simply assume everything has been compromised and replace all the components, i.e. buy new machine (as the attacker might have modified the BIOS or re-flashed PCI EEPROMs), reinstall OS, all applications, etc.

However, they miss one little detail – how can they actually know that the attacker got access to the system and that the game is over indeed and we need to reinstall just now?
Well, we simply assume that the attacker had to make some mistake and that we, sooner or later, will find out. But what if she didn’t make a mistake?
There are several trends of how this problem should be addressed in a more general and elegant way though. Most of them are based on a proactive approach. Let’s have a quick look at them…
- One generic solution is to build in a prevention technology into the OS. That includes all the anti-exploitation mechanisms, like e.g. ASLR, Non Executable memory, Stack Guard/GS, and others, as well as some little design changes into OS, like e.g. implementation of least-privilege principle (think e.g. UAC in Vista) and some sort of kernel protection (e.g. securelevel in BSD, grsecurity on Linux, signed drivers in Vista, etc).
This has been undoubtedly the most popular approach for the last couple of years and recently it gets even more popular, as Microsoft implemented most of those techniques in Vista.
However, everybody who follows the security research for at least several years should know that all those clever mechanisms have all been bypassed at least once in their history. That includes attacks against Stack Guard protection presented back in 2000 by Bulba and Kil3r, several ways to bypass PaX ASLR, like those described by Nergal in 2001 and by others several months later as well as exploiting the privilege elevation bug in PaX discovered by its author in 2005. Also the Microsoft's Hardware DEP (AKA NX) has been demonstrated to be bypassable by skape and Skywing in 2005.
Similarly, kernel protection mechanisms have also been bypassed over the past years, starting e.g. with this nice attack against grsecurity /dev/(k)mem protection presented by Guillaume Pelat in 2002. In 2006 Loic Duflot demonstrated that BSD's famous securelevel mechanism can also be bypassed. And, also last year, I showed that Vista x64 kernel protection is not foolproof either.
The point is – all those hardening techniques are designed to make exploitation harder or to limit the damage after a successful exploitation, but not to be 100% foolproof. On the other hand, it must be said, that they probably represent the best prevention solutions available for us these days.
- Another approach is to dramatically redesign the whole OS in such a way that all components (like e.g. drivers and serves) are compartmentalized, e.g. run as separate processes in usermode, and consequently are isolated not only from each other but also from the OS kernel (micro kernel). The idea here is that the most critical components, i.e. the micro kernel, is very small and can be easily verified. Example of such OS is Minix3 which is still under development though.
Undoubtedly this is a very good approach to minimize impact from system or driver faults, but does not protect us against malicious system compromises. After all if an attacker exploits a bug in a web browser, she may only be interested in modifying the browser’s code. Sure, she probably would not be able to get access to the micro kernel, but why would she really need it?
Imagine, for example, the following common scenario: many online banking systems require users to use smart cards to sign all transaction requests (e.g. money transfers). This usually works by having a browser (more specifically an ActiveX control or Firefox’s plugin) to display a message to a user that he or she is about to make e.g. a wire transfer to a given account number for a given amount of money. If the user confirms that action, they should press an ‘Accept’ button, which instructs browser to send the message to the smart card for signing. The message itself is usually just some kind of formatted text message specifying the source and destination account numbers, amount of money, date and time stamp etc. Then the user is asked to insert the smart card, which contains his or her private key (issued by the bank) and to also enter the PIN code. The latter can be done either by using the same browser applet or, in slightly more secure implementations, by the smart card reader itself, if it has a pad for entering PINs.
Obviously the point here is that malware should not be able to forge the digital signature and only the legitimate user has access to the smart card and also knows the card’s PIN, so nobody else will be able to sign that message with the user’s key.
However, it’s just enough for the attacker to replace the message while it’s being send to the card, while displaying the original message in the browser’s window. This all can be done by just modifying (“hooking”) the browser’s in-memory code and/or data. No need for kernel malware, yet the system (the browser more specifically) is compromised!
Still, one good thing about such a system design is that if we don’t allow an attacker to compromise the microkernel, then, at least in theory, we can write a detector capable of finding that some (malicious) changes to the browsers memory have been introduced indeed. However, in practice, we would have to know how exactly the browser’s memory should look like, e.g. which function pointers in Firefox’s code should be verified in order to find out whether such a compromise has indeed occurred. Unfortunately we can not do that today.
- Alternative approach to the above two, which does not require any dramatic changes into OS, is to make use of so called sound static code analyzers to verify all sensitive code in OS and applications. The soundness property assures that the analyzer has been mathematically proven not to miss even a single potential run time error, which includes e.g. unintentional execution flow modifications. The catch here is that soundness doesn’t mean that the analyzer doesn’t generate false positives. It’s actually mathematically proven that we can’t have such an ideal tool (i.e. with zero false positive rate), as the problem of analyzing all possible program execution paths is incomputable. Thus, the practical analyzers always consider some superset of all possible execution flows, which is easy to compute, yet may introduce some false alarms and the whole trick is how to choose that superset so that the number of false positives is minimal.
ASTREE is an example of a sound static code analyzer for the C language (although it doesn’t support programs which make use of dynamic memory allocation) and it apparently has been used to verify the primary flight control software for Airbus A340 and A380. Unfortunately, there doesn’t seem to be any publicly available sound binary code static analyzers… (if anybody knows any links, you’re more then welcome to paste the links under this post – just please make sure you’re referring to sound analyzers).
If we had such sound and precise (i.e. with minimal rate of false alarms) binary static code analyzer that could be a big breakthrough in the OS and application security.
We could imagine, for example, a special authority for signing device drivers for various OSes and that they would first perform such a formal static validation on submitted drivers and, once passed the test, the drivers would be digitally signed. Plus, the OS kernel itself would be validated itself by the vendor and would accept only those drivers which were signed by the driver verification authority. The authority could be an OS vendor itself or a separate 3rd party organization. Additionally we could also require that the code of all security critical applications, like e.g. web browser be also signed by such an authority and set a special policy in our OS to allow e.g. only signed applications to access network.
The only one week point here is, that if the private key used by the certification authority gets compromised, then the game is over and nobody really knows that… For this reason it would be good, to have more then one certification authority and require that each driver/application be signed by at least two independent authorities.
From the above three approaches only the last one can guarantee that our system will not get compromised ever. The only problem here is that… there are no tools today for static binary code analysis that would be proved to be sound and also precise enough to be used in practice…
So, today, as far as proactive solutions are considered, we’re left only with solutions #1 and #2, which, as discussed above, can not protect OS and applications from compromises in 100%. And, to make it worse, do not offer any clue, whether the compromise actually occurred.
That’s why I’m trying so much to promote the idea of Verifiable Operating Systems, which should allow to at least find out (in a systematic way) whether the system in question has been compromised or not (but, unfortunately not to find whether the single-shot incident occurred). The point is that the number of required design changes should be fairly small. There are some problems with it too, like e.g. verifying JIT-like code, but hopefully they can be solved in the near feature. Expect me to write more on this topic in the near feature.
Special thanks to Halvar Flake for eye-opening discussions about sound code analyzers and OS security in general.
\ No newline at end of file
+People often say that once an attacker gets access to the kernel the game is over! That’s true indeed these days, and most of the research I have done over the past two years or so, was about proofing just that. Some people, however, go a bit further and say, that thus there is no point in researching ways to detect system compromises and, once an attacker got in, you should simply assume everything has been compromised and replace all the components, i.e. buy new machine (as the attacker might have modified the BIOS or re-flashed PCI EEPROMs), reinstall OS, all applications, etc.
However, they miss one little detail – how can they actually know that the attacker got access to the system and that the game is over indeed and we need to reinstall just now?
Well, we simply assume that the attacker had to make some mistake and that we, sooner or later, will find out. But what if she didn’t make a mistake?
There are several trends of how this problem should be addressed in a more general and elegant way though. Most of them are based on a proactive approach. Let’s have a quick look at them…
- One generic solution is to build in a prevention technology into the OS. That includes all the anti-exploitation mechanisms, like e.g. ASLR, Non Executable memory, Stack Guard/GS, and others, as well as some little design changes into OS, like e.g. implementation of least-privilege principle (think e.g. UAC in Vista) and some sort of kernel protection (e.g. securelevel in BSD, grsecurity on Linux, signed drivers in Vista, etc).
This has been undoubtedly the most popular approach for the last couple of years and recently it gets even more popular, as Microsoft implemented most of those techniques in Vista.
However, everybody who follows the security research for at least several years should know that all those clever mechanisms have all been bypassed at least once in their history. That includes attacks against Stack Guard protection presented back in 2000 by Bulba and Kil3r, several ways to bypass PaX ASLR, like those described by Nergal in 2001 and by others several months later as well as exploiting the privilege elevation bug in PaX discovered by its author in 2005. Also the Microsoft's Hardware DEP (AKA NX) has been demonstrated to be bypassable by skape and Skywing in 2005.
Similarly, kernel protection mechanisms have also been bypassed over the past years, starting e.g. with this nice attack against grsecurity /dev/(k)mem protection presented by Guillaume Pelat in 2002. In 2006 Loic Duflot demonstrated that BSD's famous securelevel mechanism can also be bypassed. And, also last year, I showed that Vista x64 kernel protection is not foolproof either.
The point is – all those hardening techniques are designed to make exploitation harder or to limit the damage after a successful exploitation, but not to be 100% foolproof. On the other hand, it must be said, that they probably represent the best prevention solutions available for us these days.
- Another approach is to dramatically redesign the whole OS in such a way that all components (like e.g. drivers and serves) are compartmentalized, e.g. run as separate processes in usermode, and consequently are isolated not only from each other but also from the OS kernel (micro kernel). The idea here is that the most critical components, i.e. the micro kernel, is very small and can be easily verified. Example of such OS is Minix3 which is still under development though.
Undoubtedly this is a very good approach to minimize impact from system or driver faults, but does not protect us against malicious system compromises. After all if an attacker exploits a bug in a web browser, she may only be interested in modifying the browser’s code. Sure, she probably would not be able to get access to the micro kernel, but why would she really need it?
Imagine, for example, the following common scenario: many online banking systems require users to use smart cards to sign all transaction requests (e.g. money transfers). This usually works by having a browser (more specifically an ActiveX control or Firefox’s plugin) to display a message to a user that he or she is about to make e.g. a wire transfer to a given account number for a given amount of money. If the user confirms that action, they should press an ‘Accept’ button, which instructs browser to send the message to the smart card for signing. The message itself is usually just some kind of formatted text message specifying the source and destination account numbers, amount of money, date and time stamp etc. Then the user is asked to insert the smart card, which contains his or her private key (issued by the bank) and to also enter the PIN code. The latter can be done either by using the same browser applet or, in slightly more secure implementations, by the smart card reader itself, if it has a pad for entering PINs.
Obviously the point here is that malware should not be able to forge the digital signature and only the legitimate user has access to the smart card and also knows the card’s PIN, so nobody else will be able to sign that message with the user’s key.
However, it’s just enough for the attacker to replace the message while it’s being send to the card, while displaying the original message in the browser’s window. This all can be done by just modifying (“hooking”) the browser’s in-memory code and/or data. No need for kernel malware, yet the system (the browser more specifically) is compromised!
Still, one good thing about such a system design is that if we don’t allow an attacker to compromise the microkernel, then, at least in theory, we can write a detector capable of finding that some (malicious) changes to the browsers memory have been introduced indeed. However, in practice, we would have to know how exactly the browser’s memory should look like, e.g. which function pointers in Firefox’s code should be verified in order to find out whether such a compromise has indeed occurred. Unfortunately we can not do that today.
- Alternative approach to the above two, which does not require any dramatic changes into OS, is to make use of so called sound static code analyzers to verify all sensitive code in OS and applications. The soundness property assures that the analyzer has been mathematically proven not to miss even a single potential run time error, which includes e.g. unintentional execution flow modifications. The catch here is that soundness doesn’t mean that the analyzer doesn’t generate false positives. It’s actually mathematically proven that we can’t have such an ideal tool (i.e. with zero false positive rate), as the problem of analyzing all possible program execution paths is incomputable. Thus, the practical analyzers always consider some superset of all possible execution flows, which is easy to compute, yet may introduce some false alarms and the whole trick is how to choose that superset so that the number of false positives is minimal.
ASTREE is an example of a sound static code analyzer for the C language (although it doesn’t support programs which make use of dynamic memory allocation) and it apparently has been used to verify the primary flight control software for Airbus A340 and A380. Unfortunately, there doesn’t seem to be any publicly available sound binary code static analyzers… (if anybody knows any links, you’re more then welcome to paste the links under this post – just please make sure you’re referring to sound analyzers).
If we had such sound and precise (i.e. with minimal rate of false alarms) binary static code analyzer that could be a big breakthrough in the OS and application security.
We could imagine, for example, a special authority for signing device drivers for various OSes and that they would first perform such a formal static validation on submitted drivers and, once passed the test, the drivers would be digitally signed. Plus, the OS kernel itself would be validated itself by the vendor and would accept only those drivers which were signed by the driver verification authority. The authority could be an OS vendor itself or a separate 3rd party organization. Additionally we could also require that the code of all security critical applications, like e.g. web browser be also signed by such an authority and set a special policy in our OS to allow e.g. only signed applications to access network.
The only one week point here is, that if the private key used by the certification authority gets compromised, then the game is over and nobody really knows that… For this reason it would be good, to have more then one certification authority and require that each driver/application be signed by at least two independent authorities.
From the above three approaches only the last one can guarantee that our system will not get compromised ever. The only problem here is that… there are no tools today for static binary code analysis that would be proved to be sound and also precise enough to be used in practice…
So, today, as far as proactive solutions are considered, we’re left only with solutions #1 and #2, which, as discussed above, can not protect OS and applications from compromises in 100%. And, to make it worse, do not offer any clue, whether the compromise actually occurred.
That’s why I’m trying so much to promote the idea of Verifiable Operating Systems, which should allow to at least find out (in a systematic way) whether the system in question has been compromised or not (but, unfortunately not to find whether the single-shot incident occurred). The point is that the number of required design changes should be fairly small. There are some problems with it too, like e.g. verifying JIT-like code, but hopefully they can be solved in the near feature. Expect me to write more on this topic in the near feature.
Special thanks to Halvar Flake for eye-opening discussions about sound code analyzers and OS security in general.
\ No newline at end of file
diff --git a/_posts/2007-04-01-human-factor.html b/_posts/2007-04-01-human-factor.html
index 2423c6e..1d5968b 100644
--- a/_posts/2007-04-01-human-factor.html
+++ b/_posts/2007-04-01-human-factor.html
@@ -9,4 +9,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2007/04/human-factor.html
---
-When you go to some security conferences, especially those targeted for management staff, you might get the impression that the only problem in the security field that mankind is facing today is… that we’re too stupid and we do not know how to use the technology properly. So, we, use those silly simple passwords, allow strangers to look at our laptop screens over our shoulders, happily provide our e-bank credentials or credit card numbers to whoever asks for them, etc… Sure, that’s true indeed – many people (both administrators and users) do silly mistakes and this is very bad and, of course, they should be trained not to do them.
However, we also face another problem these days… A problem of no less importance then “the human factor”. Namely, even if we were perfectly trained to use the technology and understood it very well, we would still be defenseless in many areas. Just because the technology is flawed!
Think about all those exploitable bugs in WiFi drivers in your laptop or email clients vulnerabilities (e.g. in your GPG/PGP software). The point is, you, as a user can not do anything to prevent exploitation of such bugs. And, of course, the worst thing is, that you don’t even have any reliable way to tell whether somebody actually successfully attacked you or not – see my previous post. None of the so called “industry best practices” can help – you just need to hope that your system hasn’t been 0wned. And this is really disturbing…
Of course, you can chose to believe in all this risk assessment pseudo-science, which can tell you that your system is “non-compromised with 98% probability” or you can try to comfort yourself because you know that your competition has no better security they you… ;)
\ No newline at end of file
+When you go to some security conferences, especially those targeted for management staff, you might get the impression that the only problem in the security field that mankind is facing today is… that we’re too stupid and we do not know how to use the technology properly. So, we, use those silly simple passwords, allow strangers to look at our laptop screens over our shoulders, happily provide our e-bank credentials or credit card numbers to whoever asks for them, etc… Sure, that’s true indeed – many people (both administrators and users) do silly mistakes and this is very bad and, of course, they should be trained not to do them.
However, we also face another problem these days… A problem of no less importance then “the human factor”. Namely, even if we were perfectly trained to use the technology and understood it very well, we would still be defenseless in many areas. Just because the technology is flawed!
Think about all those exploitable bugs in WiFi drivers in your laptop or email clients vulnerabilities (e.g. in your GPG/PGP software). The point is, you, as a user can not do anything to prevent exploitation of such bugs. And, of course, the worst thing is, that you don’t even have any reliable way to tell whether somebody actually successfully attacked you or not – see my previous post. None of the so called “industry best practices” can help – you just need to hope that your system hasn’t been 0wned. And this is really disturbing…
Of course, you can chose to believe in all this risk assessment pseudo-science, which can tell you that your system is “non-compromised with 98% probability” or you can try to comfort yourself because you know that your competition has no better security they you… ;)
\ No newline at end of file
diff --git a/_posts/2007-08-03-virtualization-detection-vs-blue-pill.html b/_posts/2007-08-03-virtualization-detection-vs-blue-pill.html
index 902bd1d..6ef6ba2 100644
--- a/_posts/2007-08-03-virtualization-detection-vs-blue-pill.html
+++ b/_posts/2007-08-03-virtualization-detection-vs-blue-pill.html
@@ -9,4 +9,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2007/08/virtualization-detection-vs-blue-pill.html
---
-So, it’s all over the press now, but, as usual, many people didn’t quite get the main points of our Black Hat talk. So, let’s clear things up... First, please note that the talk was divided into two separate, independent, parts – the first one about bypassing vista kernel protection and the second one about virtualization based malware.
The message of the first part was that we don’t believe it’s possible to implement effective kernel protection on any general purpose OS based on monolithic kernel design.
The second part, the one about virtualization, had several messages...
- The main point was that detecting virtualization is not the same as detecting virtualization based malware. As hardware virtualization technology gets more and more widespread, many machines will be running with virtualization mode enabled, no matter whether blue pilled or not. In that case blue pill-like malware doesn’t need to cheat that virtualization is not enabled, as it’s actually expected that virtualization is being used for some legitimate purposes. In that case using a "blue pill detector", that in fact is just a generic virtualization detector is completely pointless.
Obviously in such scenarios blue pill-like malware must support nested hypervisors. And this is what we have implemented in our New Blue Pill. We can run tens of blue pills inside each other and they all work! You can try it by yourself, but you should disable comport debug output to do more then twenty nested pills. We still fail at running Virtual PC 2007 as a nested hypervisor (when it’s guest switches to protected mode), but we hope to have this fixed in the coming weeks (please note that VPC’s hypervisor doesn’t block blue pill from loading – see our slides for more info).
In other words, if somebody announces to the world that they can fight virtualization based malware using generic virtualization detectors, it’s like if they said that they can detect e.g. a botnet agent, just by detecting that an executable is using networking!
- We have also decided to discuss how blue pill could potentially cheat those generic virtualization detectors, even though we don’t believe it would be necessary in the coming years, as everything will be virtualized anyways (see previous point). But, we still decided to look into some of the SVM detection methods. First, we found out that many methods that people described as a way to detect virtualization do not work in the simple form as they were described. We took a closer look e.g. at the TLB profiling methods that were suggested by several researchers as a reliable method for virtualization detection. However all the papers that were describing this method missed the fact that some of the caches are not fully associative and one needs to use special effort (which means additional complexity) to make sure to e.g. fill the whole TLB L2 buffer. Obviously we provided all the necessary details of how to write those detectors properly (we even posted one such detector).
In other words - we believe that it will always be possible to detect virtualization mode using various tricks and hacks, but: 1) those hacks could be forced to be very complex and 2) in case virtualization is being used on the target computer for some legitimate purposes all those methods fail anyway (see point 1).
- Some people might argue that maybe then we should build these virtualization detectors into all the legitimate hypervisors (e.g. Virtual PC hypervisor), so that they know at least whether they are being run on a native machine or maybe inside blue pill. However this approach contradicts the rules we use to build secure and effective hypervisors. These rules say that hypervisors should be as small as possible and there should be no 3rd party code allowed there.
Now imagine that A/V company try to insert their virtualization detectors (which BTW would have to be updated from time to time to support e.g. new processor models) into hypervisors – if that ever happened, it would be a failure of our industry. We need other methods to address this threat, methods that would be based on documented, robust and simple methods. Security should not be built on bugs, hacks and tricks!
We posted the full source code of out New Blue Pill here. We believe that it will help other researchers to to analyze this threat and hopefully we will find a good solution soon, before this ever become widespread.
Happy bluepilling!
On a side note: now I can also explain (if this is not clear already) how we were planning to beat our challengers. We would simply ask them to install Virtual Server 2005 R2 on all the test machines and we would install our New Blue Pill on just a few of them. Then their wonderful detectors would simply detect that all the machines have SVM mode enabled, but that would be a completely useless information. Yes, we still believe we would need a couple of months to get our proof-of-concept to the level we would be confident that we will win anyway (e.g. if they used memory scanning for some “signature).
BTW, you might be wondering why I introduced the “no CPU peek for more then 1s” requirement? I will leave finding an answer as an exercise from a psychology to my dear readers ;)
\ No newline at end of file
+So, it’s all over the press now, but, as usual, many people didn’t quite get the main points of our Black Hat talk. So, let’s clear things up... First, please note that the talk was divided into two separate, independent, parts – the first one about bypassing vista kernel protection and the second one about virtualization based malware.
The message of the first part was that we don’t believe it’s possible to implement effective kernel protection on any general purpose OS based on monolithic kernel design.
The second part, the one about virtualization, had several messages...
- The main point was that detecting virtualization is not the same as detecting virtualization based malware. As hardware virtualization technology gets more and more widespread, many machines will be running with virtualization mode enabled, no matter whether blue pilled or not. In that case blue pill-like malware doesn’t need to cheat that virtualization is not enabled, as it’s actually expected that virtualization is being used for some legitimate purposes. In that case using a "blue pill detector", that in fact is just a generic virtualization detector is completely pointless.
Obviously in such scenarios blue pill-like malware must support nested hypervisors. And this is what we have implemented in our New Blue Pill. We can run tens of blue pills inside each other and they all work! You can try it by yourself, but you should disable comport debug output to do more then twenty nested pills. We still fail at running Virtual PC 2007 as a nested hypervisor (when it’s guest switches to protected mode), but we hope to have this fixed in the coming weeks (please note that VPC’s hypervisor doesn’t block blue pill from loading – see our slides for more info).
In other words, if somebody announces to the world that they can fight virtualization based malware using generic virtualization detectors, it’s like if they said that they can detect e.g. a botnet agent, just by detecting that an executable is using networking!
- We have also decided to discuss how blue pill could potentially cheat those generic virtualization detectors, even though we don’t believe it would be necessary in the coming years, as everything will be virtualized anyways (see previous point). But, we still decided to look into some of the SVM detection methods. First, we found out that many methods that people described as a way to detect virtualization do not work in the simple form as they were described. We took a closer look e.g. at the TLB profiling methods that were suggested by several researchers as a reliable method for virtualization detection. However all the papers that were describing this method missed the fact that some of the caches are not fully associative and one needs to use special effort (which means additional complexity) to make sure to e.g. fill the whole TLB L2 buffer. Obviously we provided all the necessary details of how to write those detectors properly (we even posted one such detector).
In other words - we believe that it will always be possible to detect virtualization mode using various tricks and hacks, but: 1) those hacks could be forced to be very complex and 2) in case virtualization is being used on the target computer for some legitimate purposes all those methods fail anyway (see point 1).
- Some people might argue that maybe then we should build these virtualization detectors into all the legitimate hypervisors (e.g. Virtual PC hypervisor), so that they know at least whether they are being run on a native machine or maybe inside blue pill. However this approach contradicts the rules we use to build secure and effective hypervisors. These rules say that hypervisors should be as small as possible and there should be no 3rd party code allowed there.
Now imagine that A/V company try to insert their virtualization detectors (which BTW would have to be updated from time to time to support e.g. new processor models) into hypervisors – if that ever happened, it would be a failure of our industry. We need other methods to address this threat, methods that would be based on documented, robust and simple methods. Security should not be built on bugs, hacks and tricks!
We posted the full source code of out New Blue Pill here. We believe that it will help other researchers to to analyze this threat and hopefully we will find a good solution soon, before this ever become widespread.
Happy bluepilling!
On a side note: now I can also explain (if this is not clear already) how we were planning to beat our challengers. We would simply ask them to install Virtual Server 2005 R2 on all the test machines and we would install our New Blue Pill on just a few of them. Then their wonderful detectors would simply detect that all the machines have SVM mode enabled, but that would be a completely useless information. Yes, we still believe we would need a couple of months to get our proof-of-concept to the level we would be confident that we will win anyway (e.g. if they used memory scanning for some “signature).
BTW, you might be wondering why I introduced the “no CPU peek for more then 1s” requirement? I will leave finding an answer as an exercise from a psychology to my dear readers ;)
\ No newline at end of file
diff --git a/_posts/2007-10-17-thoughts-on-browser-rootkits.html b/_posts/2007-10-17-thoughts-on-browser-rootkits.html
index df2e147..abe2cdf 100644
--- a/_posts/2007-10-17-thoughts-on-browser-rootkits.html
+++ b/_posts/2007-10-17-thoughts-on-browser-rootkits.html
@@ -9,4 +9,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2007/10/thoughts-on-browser-rootkits.html
---
-Petko D. Petkov from GNUCITIZEN wrote a post about Browser Rootkits, which inspired me to give some more thoughts on this subject. Petko is an active researcher in the field of client-side exploits (e.g. recent Adobe Acrobat PDF flaw), so it’s not a surprise that he’s thinking about browsers as a natural environment for rootkits or malware. Also it’s quite common to hear an opinion these days that browsers become so complicated and so universal that they are almost like operating systems rather than just standard applications.
Petko in his post gives several ideas of how browser-based malware could be created and I’m sure that we will see more and more such malware in the near future (I would actually be surprised if it didn’t exist already). His main argument for creating “Browser Rootkits” is that they would be “closer to the data”, which is, of course, undisputable.
The other argument is the complexity of a typical browser like e.g. Firefox or Internet Explorer. It seems like we have a very similar situation here to what we have with "classic" operating systems like e.g. Windows. Windows is so complex that nobody (including Microsoft) can really spot all the sensitive places in the kernel where a rootkit might "hook" – thus it’s not possible to effectively monitor all those places. We have a similar problem with Firefox and IE because of their extensible architecture (think about all those plugins, add-ons, etc) – although we could examine the whole memory of firefox.exe process, we still would not be able to decide whether something bad is there or not.
I’m even quite sure that my little malware taxonomy could be used here to classify Firefox or IE infections. E.g. the browser malware of type 0, would be nothing else then just additional plugins, installed using official API and not trying to hide from browser reporting mechanisms (in other words they still will be visible to users when they will ask the browser to list all the installed plugins). And we will have type I and type II infections, the former would be simply modifying some code (be that a code of a browser or maybe of some other plugin) while the latter would be hooking some function pointers or changing some data only – this all to hide the offensive module.
BTW, there is a little problem with classifying JIT-generated code – should it be type I or type II infection? I don’t know the answer for now and I welcome all the feedback on this. And we can even imagine type III infections of browsers, but I will leave it as an exercise for my readers :)
So, should we expect the classic, OS-based rootkits to die and the efforts in the malware community to move towards creating Browser-based rootkits? I don’t think so. While the browser-based malware is and will definitely be more and more important problem, it has one disadvantage comparing to classic OS-based malware. Namely it’s quite easy to avoid, or at least minimize the impact from browser-based rootkits. It’s just enough to use two different browsers – one for sensitive and the other one for non-sensitive operations.
So, for example, I use IE to do all my sensitive browsing (e.g. online banking, blogger access, etc), while Firefox to do all the casual browsing, which includes morning press reading, google searching, etc. The reason I use Firefox for non-sensitive browsing doesn’t come from the fact that I think it’s more secure (or better written) then IE, but because I like using NoScript and there is no similar plugin for IE...
Of course, an attacker still might exploit my non-sensitive browser (Firefox) and then modify configuration or executable files that are being used by my sensitive browser (IE). However this would require write-access to those files. This is yet another reason why one should run the non-sensitive browser with limited privileges and technologies like UAC in Vista help to achieve it. I wrote an article some time ago about how one can configure Vista to implement almost-full privilege separation.
Of course, even if we decide to use 2 different browsers - one for sensitive and the other one for non-sensitive browsing, an attacker still might be able to break out from account protection via a kernel mode exploit (e.g. exploiting one of the bug that Alex and I presented in Vegas this year). However this would not be a browser malware anymore – this would be a good old kernel-mode malware :)
A solution to this problem will probably be the use of a Virtual Machine to run the non-sensitive browser. Even today one might download e.g. the Browser Appliance from VMWare and we will see more and more solutions like this in the coming years I think. This BTW, will probably stimulate more research into VM escaping and virtualization-based malware.
Of course, the very important and sometimes non-trivial question is how to decide which type of browsing is sensitive and which is non-sensitive. E.g. most people will agree the online banking is a sensitive browsing, but what about webmail? Should I use my sensitive or non-sensitive browser for accessing my mail via web? Using a sensitive browser for webmail is dangerous, as it’s quite possible that it could be infected via some malicious mail that would be in our inbox. While using the non-sensitive browser for webmail is also not a good solution, as most people would like to consider mail as sensitive and would not like to allow the possibly-compromised browser to learn the password for the mailbox.
I avoid this problem by not using a browser for webmail and by having a special account just for running a thunderbird application (see again my article on how to do this in Vista). It works well for me.
Of course, one could also do the same for browser – i.e. instead of having 2 browsers (i.e. sensitive and non-sensitive), one could have 3 or more (maybe even 3 different virtual machines). But the question is how many accounts should we use? One for email, one for sensitive browsing, one for non-sensitive, one for accessing personal data (e.g. pictures)...? I guess there is no good answer for this and it depends on the specific situation (i.e. different configuration for home user that uses computer mostly for "fun" and different for somebody using the same computer for both work and "fun", etc...)
On a side note – I really don’t like the idea of using a web browser to do "everything" – I like using browser to do browsing, while to do other things to use specialized applications. I like having my data on my local hard drive. It’s quite amazing that so many people these days use Google not only for searching, but also for email, calendaring and documents editing – it’s like giving all your life secretes on a plate! Google can now correlate all your web search queries with a specific email account and even see who are you meeting with next evening and also know what a new product your company will be presenting next week, as you prepared you presentation using Google Documents. I’m not sure whether it’s Google or the people’s naivety that disturbs me more...
\ No newline at end of file
+Petko D. Petkov from GNUCITIZEN wrote a post about Browser Rootkits, which inspired me to give some more thoughts on this subject. Petko is an active researcher in the field of client-side exploits (e.g. recent Adobe Acrobat PDF flaw), so it’s not a surprise that he’s thinking about browsers as a natural environment for rootkits or malware. Also it’s quite common to hear an opinion these days that browsers become so complicated and so universal that they are almost like operating systems rather than just standard applications.
Petko in his post gives several ideas of how browser-based malware could be created and I’m sure that we will see more and more such malware in the near future (I would actually be surprised if it didn’t exist already). His main argument for creating “Browser Rootkits” is that they would be “closer to the data”, which is, of course, undisputable.
The other argument is the complexity of a typical browser like e.g. Firefox or Internet Explorer. It seems like we have a very similar situation here to what we have with "classic" operating systems like e.g. Windows. Windows is so complex that nobody (including Microsoft) can really spot all the sensitive places in the kernel where a rootkit might "hook" – thus it’s not possible to effectively monitor all those places. We have a similar problem with Firefox and IE because of their extensible architecture (think about all those plugins, add-ons, etc) – although we could examine the whole memory of firefox.exe process, we still would not be able to decide whether something bad is there or not.
I’m even quite sure that my little malware taxonomy could be used here to classify Firefox or IE infections. E.g. the browser malware of type 0, would be nothing else then just additional plugins, installed using official API and not trying to hide from browser reporting mechanisms (in other words they still will be visible to users when they will ask the browser to list all the installed plugins). And we will have type I and type II infections, the former would be simply modifying some code (be that a code of a browser or maybe of some other plugin) while the latter would be hooking some function pointers or changing some data only – this all to hide the offensive module.
BTW, there is a little problem with classifying JIT-generated code – should it be type I or type II infection? I don’t know the answer for now and I welcome all the feedback on this. And we can even imagine type III infections of browsers, but I will leave it as an exercise for my readers :)
So, should we expect the classic, OS-based rootkits to die and the efforts in the malware community to move towards creating Browser-based rootkits? I don’t think so. While the browser-based malware is and will definitely be more and more important problem, it has one disadvantage comparing to classic OS-based malware. Namely it’s quite easy to avoid, or at least minimize the impact from browser-based rootkits. It’s just enough to use two different browsers – one for sensitive and the other one for non-sensitive operations.
So, for example, I use IE to do all my sensitive browsing (e.g. online banking, blogger access, etc), while Firefox to do all the casual browsing, which includes morning press reading, google searching, etc. The reason I use Firefox for non-sensitive browsing doesn’t come from the fact that I think it’s more secure (or better written) then IE, but because I like using NoScript and there is no similar plugin for IE...
Of course, an attacker still might exploit my non-sensitive browser (Firefox) and then modify configuration or executable files that are being used by my sensitive browser (IE). However this would require write-access to those files. This is yet another reason why one should run the non-sensitive browser with limited privileges and technologies like UAC in Vista help to achieve it. I wrote an article some time ago about how one can configure Vista to implement almost-full privilege separation.
Of course, even if we decide to use 2 different browsers - one for sensitive and the other one for non-sensitive browsing, an attacker still might be able to break out from account protection via a kernel mode exploit (e.g. exploiting one of the bug that Alex and I presented in Vegas this year). However this would not be a browser malware anymore – this would be a good old kernel-mode malware :)
A solution to this problem will probably be the use of a Virtual Machine to run the non-sensitive browser. Even today one might download e.g. the Browser Appliance from VMWare and we will see more and more solutions like this in the coming years I think. This BTW, will probably stimulate more research into VM escaping and virtualization-based malware.
Of course, the very important and sometimes non-trivial question is how to decide which type of browsing is sensitive and which is non-sensitive. E.g. most people will agree the online banking is a sensitive browsing, but what about webmail? Should I use my sensitive or non-sensitive browser for accessing my mail via web? Using a sensitive browser for webmail is dangerous, as it’s quite possible that it could be infected via some malicious mail that would be in our inbox. While using the non-sensitive browser for webmail is also not a good solution, as most people would like to consider mail as sensitive and would not like to allow the possibly-compromised browser to learn the password for the mailbox.
I avoid this problem by not using a browser for webmail and by having a special account just for running a thunderbird application (see again my article on how to do this in Vista). It works well for me.
Of course, one could also do the same for browser – i.e. instead of having 2 browsers (i.e. sensitive and non-sensitive), one could have 3 or more (maybe even 3 different virtual machines). But the question is how many accounts should we use? One for email, one for sensitive browsing, one for non-sensitive, one for accessing personal data (e.g. pictures)...? I guess there is no good answer for this and it depends on the specific situation (i.e. different configuration for home user that uses computer mostly for "fun" and different for somebody using the same computer for both work and "fun", etc...)
On a side note – I really don’t like the idea of using a web browser to do "everything" – I like using browser to do browsing, while to do other things to use specialized applications. I like having my data on my local hard drive. It’s quite amazing that so many people these days use Google not only for searching, but also for email, calendaring and documents editing – it’s like giving all your life secretes on a plate! Google can now correlate all your web search queries with a specific email account and even see who are you meeting with next evening and also know what a new product your company will be presenting next week, as you prepared you presentation using Google Documents. I’m not sure whether it’s Google or the people’s naivety that disturbs me more...
\ No newline at end of file
diff --git a/_posts/2008-04-14-research-obfuscated.html b/_posts/2008-04-14-research-obfuscated.html
index 4d2cb51..1954236 100644
--- a/_posts/2008-04-14-research-obfuscated.html
+++ b/_posts/2008-04-14-research-obfuscated.html
@@ -10,4 +10,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2008/04/research-obfuscated.html
---
-Update 07-Sept-2008: Four months later after writing his open letter to me (see below), Christofer Hoff experienced on his own difficult it is for one to control the press, making sure it correctly reports what you say. In this blog entry he describes how he was terribly misquoted by a report after his Black Hat presentation and he also explicitly admits that "[I] was essentially correct in [my] assertion during our last debate that you cannot control the press, despite best efforts." and that "[he] humbly submit[s] to [me] on that point." :)
This article has been brought to my attention recently. It’s an “Open Letter to Joanna Rutkowska”, by Christofer Hoff over at the “Rational Survivability” blog. I decided to spend time reading and answering this piece as 1) technorati.com reported the blog’s authority as above 100 which suggests it has a reasonable number of readers, and also 2) because I believe this is a good example of the social engineering techniques used by my opponents and I couldn’t refrain myself from not commenting about this. Besides I felt a bit flattered that some individual decided to write an “Open Letter” to me, sort of like if I was a prime minister or some other important person ;)
Let me now analyze the letter, point by point:- Fire rules! The first thing that Hoff accuses me of in his letter is myself being an irresponsible individual, not caring about safety of my audience (not a joke!):
“As the room filled to over capacity before your talk began, you were upset and couldn't seem to understand why the conference organizers would not let people spill over from seats and sit on the floor and in the aisles to hear you speak. The fact that fire and safety codes prohibit packing a room beyond capacity was something you attributed to people being "...crazy in America." Go figure.”
Dear Christofer, if you only read my recent blog post about this very specific incident, read thoroughly shall I say, you would notice this paragraph undoubtedly:
“Interestingly it was perfectly ok for the additional people to stay in the room, provided they arranged for additional chairs for themselves. In other words it was fine for people to sit and block the main aisle, provided they sit on chairs, but they couldn’t stay and sit on the same aisle without having a chair (maybe a "certificated" chair also), as that would be against the fire regulations!”
Conclusion: I was not so much picking upon the fire regulations that forced people to leave the room, but rather on the idiotic rule, that allowed those same people to stay in this very same room, provided they also had additional chairs with them.
- Type I vs. Type II hypervisors confusion. Hoff then switches to the actual content of the presentation and writes this:
“When I spoke to you at the end of your presentation and made sure that I understood correctly that you were referring specifically to type-2 hosted virtualization on specific Intel and AMD chipsets, you conceded that this was the case.”
This simply is an incorrect statement! On the contrary, when describing the security implications of nested virtualization (which was the actual new thing I was presenting at the RSA), I explicitly gave an example of how this could be used to compromise type I hypervisors. Kindly refer to slides 85-90 of my presentation that can be downloaded here.
I said that the code we posted on bluepillproject.org indeed targets type II hypervisors and the only reason for that being that it has been built on top of our New Blue Pill code that was designed as a Windows kernel driver.
- Shit not giving. Mr. Hoff goes even further:
“When I attempted to suggest that while really interesting and intriguing, your presentation was not only confusing to many people but also excluded somewhere north of 80% of how most adopters have deployed virtualization (type-1 "bare-metal" vs. type-2 hosted) as well as excluding the market-leading virtualization platform, your response (and I quote directly) was: I don't give a shit, I'm a researcher.”
Now that was a hard blow! I understand that the usage of such a slang expression by an Eastern European female during an informal conversation with a native speaker must have made an impression on him! However, I couldn’t give such an answer to this very question, simply because of the reasons given in point #2 (see above).
If I remember correctly, I indeed used this very American expression to answer somebody’s concern (undoubtedly our Christofer Hoff’s) that most of the type I hypervisors out there are based on monolithic hypervisor architecture, and not on the micro-hypervisor architecture (and that I should not try to convince people to switch to micro-hypervisor architecture). In that context it makes it more logical for me to use the “I’m a researcher” as an excuse for not caring so much that most people use monolithic based hypervisors. Obviously, the usage of micro-hypervisors would allow to better secure the whole VMM infrastructure. And I also said, that I don’t care what people are using today, because I try to help to build a product that would be secure in the future (Phoenix’s HyperCore).
- No obfuscation postulate. Hoff then comes up with some postulates that:
“[I], as a researcher who is also actively courting publicity for commercial gain and speaking at conferences like RSA which are less technical and more "executive" in nature, you have a responsibility to clarify and not obfuscate (intentionally or otherwise) the facts surrounding your research.”
This postulate is cleverly constructed because it also contains an embedded accusation of me being a commercially motivated researcher. Well, I never tried to hide that fact, and the reason for this is very simple: I consider security research as my job, and one of the primary goals of any job is to… bring commercial gain to the individual doing the job.
Second, I really don’t understand what Hoff means by asking me to not obfuscate my research?! Maybe he was just disappointed that the presentation was too technical for an average CISSP to understand it? But, well, this presentation was classified as “Advanced Technical”, which was displayed in the conference program. I still did my best so that, say 70% of the material, was understandable to an average IT people, but, come on, there always must be some deep technical meat in any non-keynote-presentation, at least this is my idea for how a conference should look like.
- Commercially motivated. Hoff accuses me of presenting commercial product, i.e. the Phoenix’s HyperSpace, during my speech:
“No less than five times during your presentation, you highlighted marketing material in the form of graphics from Phoenix, positioned their upcoming products and announced/credited both Phoenix and AMD as funding your research.”
Well, let me tell you this – this was one of the main reasons why I decided to speak at the RSA – just to announce this very product that I try to help to secure. Why would that be wrong?
BTW, I have no idea how Mr. Hoff concluded that AMD was founding my research. I never said that, nor did I have it in my slides. Needles to say, AMD has not been founding my research. NOTE: interestingly I consider this particular mistake by Hoff to be accidental – at least I don’t see how this could be connected to any PR campaign, in contrast to all the other incorrectness he made use of.
- Independence. Hoff, for some reason, apparently known only to him, tries to argue that I’m not an “independent researcher”:
“I think it's only fair to point out that given your performance, you're not only an "independent researcher" but more so an "independent contractor." Using the "I'm a researcher" excuse doesn't cut it.”
“I know it's subtle and lots of folks are funded by third parties, but they also do a much better job of drawing the line than you do.”
Well, I found this one to be particularly amusing, as, for at least several years now, I have not claimed I have been an independent researcher.
- Final hit. You might have been wondering by now – why this gentleman, nah, I think “the guy” would fit better here, so why the guy decided to spent so much time to write all those points, all those quasi-arguments and why he made so many “mistakes”? Well he seems to give an answer right in this paragraph:
“I care very much that your research as presented to the press and at conferences like RSA isn't only built to be understood by highly skilled technicians or researchers because the continued thrashing that they generate without recourse is doing more harm than good, quite frankly.”
Aha, now all is clear. May I ask then, which virtualization vendor you write PR for? ;)
So, then Hoff quotes the Forbes article that was written after my presentation and accuses me that the article (written by some Forbes reporter) was too sensationalist. I definitely agree the article was very sensationalist (but correct) and when I saw the article I even got angry and even wanted to write a blog about it (but as the article was actually correct, I had no good arguments to use against it). And you know why I was so angry? Because I actually spent over 40 minutes with this very Forbes reporter in the RSA’s speaker’s lounge just after my speech, I spent that time on clarifying to that guy what my presentation was about and what it was not about and what was the main message of the presentation. Still, the reporter had his own vision of how to write about it (i.e. make it into a sensation) and I hardly, as it turned out, could do anything about it…
So, what was the main massage of my presentation? Interestingly Mr. Hoff forgot to mention that… Let me then remind it here (a curious reader might want to have a look at the the slide #96 in my presentation):
- Virtualization technology could be used to improve security on desktop systems
- However there are non-trivial challenges in making this all working well...
- ... and not to introduce security problems instead...
Additionally, the message I was trying to pass during the whole presentation was:
“Keep hypervisors simple, do not put drivers there, as otherwise we would get to the same point where we are with current OSes these days, i.e. no kernel security at all!”
Now I wonder, maybe Christofer Hoff doesn’t do PR for any VMM vendor, maybe he just didn’t listen carefully to my presentation. Maybe he’s just one of those many guys who always know in advance what they want to hear and selectively pick up only those facts that match their state of mind? Otherwise, why would he not realize that my presentation was actually a pro-virtualization one and needed no (false) counter-arguments?
\ No newline at end of file
+Update 07-Sept-2008: Four months later after writing his open letter to me (see below), Christofer Hoff experienced on his own difficult it is for one to control the press, making sure it correctly reports what you say. In this blog entry he describes how he was terribly misquoted by a report after his Black Hat presentation and he also explicitly admits that "[I] was essentially correct in [my] assertion during our last debate that you cannot control the press, despite best efforts." and that "[he] humbly submit[s] to [me] on that point." :)
This article has been brought to my attention recently. It’s an “Open Letter to Joanna Rutkowska”, by Christofer Hoff over at the “Rational Survivability” blog. I decided to spend time reading and answering this piece as 1) technorati.com reported the blog’s authority as above 100 which suggests it has a reasonable number of readers, and also 2) because I believe this is a good example of the social engineering techniques used by my opponents and I couldn’t refrain myself from not commenting about this. Besides I felt a bit flattered that some individual decided to write an “Open Letter” to me, sort of like if I was a prime minister or some other important person ;)
Let me now analyze the letter, point by point:- Fire rules! The first thing that Hoff accuses me of in his letter is myself being an irresponsible individual, not caring about safety of my audience (not a joke!):
“As the room filled to over capacity before your talk began, you were upset and couldn't seem to understand why the conference organizers would not let people spill over from seats and sit on the floor and in the aisles to hear you speak. The fact that fire and safety codes prohibit packing a room beyond capacity was something you attributed to people being "...crazy in America." Go figure.”
Dear Christofer, if you only read my recent blog post about this very specific incident, read thoroughly shall I say, you would notice this paragraph undoubtedly:
“Interestingly it was perfectly ok for the additional people to stay in the room, provided they arranged for additional chairs for themselves. In other words it was fine for people to sit and block the main aisle, provided they sit on chairs, but they couldn’t stay and sit on the same aisle without having a chair (maybe a "certificated" chair also), as that would be against the fire regulations!”
Conclusion: I was not so much picking upon the fire regulations that forced people to leave the room, but rather on the idiotic rule, that allowed those same people to stay in this very same room, provided they also had additional chairs with them.
- Type I vs. Type II hypervisors confusion. Hoff then switches to the actual content of the presentation and writes this:
“When I spoke to you at the end of your presentation and made sure that I understood correctly that you were referring specifically to type-2 hosted virtualization on specific Intel and AMD chipsets, you conceded that this was the case.”
This simply is an incorrect statement! On the contrary, when describing the security implications of nested virtualization (which was the actual new thing I was presenting at the RSA), I explicitly gave an example of how this could be used to compromise type I hypervisors. Kindly refer to slides 85-90 of my presentation that can be downloaded here.
I said that the code we posted on bluepillproject.org indeed targets type II hypervisors and the only reason for that being that it has been built on top of our New Blue Pill code that was designed as a Windows kernel driver.
- Shit not giving. Mr. Hoff goes even further:
“When I attempted to suggest that while really interesting and intriguing, your presentation was not only confusing to many people but also excluded somewhere north of 80% of how most adopters have deployed virtualization (type-1 "bare-metal" vs. type-2 hosted) as well as excluding the market-leading virtualization platform, your response (and I quote directly) was: I don't give a shit, I'm a researcher.”
Now that was a hard blow! I understand that the usage of such a slang expression by an Eastern European female during an informal conversation with a native speaker must have made an impression on him! However, I couldn’t give such an answer to this very question, simply because of the reasons given in point #2 (see above).
If I remember correctly, I indeed used this very American expression to answer somebody’s concern (undoubtedly our Christofer Hoff’s) that most of the type I hypervisors out there are based on monolithic hypervisor architecture, and not on the micro-hypervisor architecture (and that I should not try to convince people to switch to micro-hypervisor architecture). In that context it makes it more logical for me to use the “I’m a researcher” as an excuse for not caring so much that most people use monolithic based hypervisors. Obviously, the usage of micro-hypervisors would allow to better secure the whole VMM infrastructure. And I also said, that I don’t care what people are using today, because I try to help to build a product that would be secure in the future (Phoenix’s HyperCore).
- No obfuscation postulate. Hoff then comes up with some postulates that:
“[I], as a researcher who is also actively courting publicity for commercial gain and speaking at conferences like RSA which are less technical and more "executive" in nature, you have a responsibility to clarify and not obfuscate (intentionally or otherwise) the facts surrounding your research.”
This postulate is cleverly constructed because it also contains an embedded accusation of me being a commercially motivated researcher. Well, I never tried to hide that fact, and the reason for this is very simple: I consider security research as my job, and one of the primary goals of any job is to… bring commercial gain to the individual doing the job.
Second, I really don’t understand what Hoff means by asking me to not obfuscate my research?! Maybe he was just disappointed that the presentation was too technical for an average CISSP to understand it? But, well, this presentation was classified as “Advanced Technical”, which was displayed in the conference program. I still did my best so that, say 70% of the material, was understandable to an average IT people, but, come on, there always must be some deep technical meat in any non-keynote-presentation, at least this is my idea for how a conference should look like.
- Commercially motivated. Hoff accuses me of presenting commercial product, i.e. the Phoenix’s HyperSpace, during my speech:
“No less than five times during your presentation, you highlighted marketing material in the form of graphics from Phoenix, positioned their upcoming products and announced/credited both Phoenix and AMD as funding your research.”
Well, let me tell you this – this was one of the main reasons why I decided to speak at the RSA – just to announce this very product that I try to help to secure. Why would that be wrong?
BTW, I have no idea how Mr. Hoff concluded that AMD was founding my research. I never said that, nor did I have it in my slides. Needles to say, AMD has not been founding my research. NOTE: interestingly I consider this particular mistake by Hoff to be accidental – at least I don’t see how this could be connected to any PR campaign, in contrast to all the other incorrectness he made use of.
- Independence. Hoff, for some reason, apparently known only to him, tries to argue that I’m not an “independent researcher”:
“I think it's only fair to point out that given your performance, you're not only an "independent researcher" but more so an "independent contractor." Using the "I'm a researcher" excuse doesn't cut it.”
“I know it's subtle and lots of folks are funded by third parties, but they also do a much better job of drawing the line than you do.”
Well, I found this one to be particularly amusing, as, for at least several years now, I have not claimed I have been an independent researcher.
- Final hit. You might have been wondering by now – why this gentleman, nah, I think “the guy” would fit better here, so why the guy decided to spent so much time to write all those points, all those quasi-arguments and why he made so many “mistakes”? Well he seems to give an answer right in this paragraph:
“I care very much that your research as presented to the press and at conferences like RSA isn't only built to be understood by highly skilled technicians or researchers because the continued thrashing that they generate without recourse is doing more harm than good, quite frankly.”
Aha, now all is clear. May I ask then, which virtualization vendor you write PR for? ;)
So, then Hoff quotes the Forbes article that was written after my presentation and accuses me that the article (written by some Forbes reporter) was too sensationalist. I definitely agree the article was very sensationalist (but correct) and when I saw the article I even got angry and even wanted to write a blog about it (but as the article was actually correct, I had no good arguments to use against it). And you know why I was so angry? Because I actually spent over 40 minutes with this very Forbes reporter in the RSA’s speaker’s lounge just after my speech, I spent that time on clarifying to that guy what my presentation was about and what it was not about and what was the main message of the presentation. Still, the reporter had his own vision of how to write about it (i.e. make it into a sensation) and I hardly, as it turned out, could do anything about it…
So, what was the main massage of my presentation? Interestingly Mr. Hoff forgot to mention that… Let me then remind it here (a curious reader might want to have a look at the the slide #96 in my presentation):
- Virtualization technology could be used to improve security on desktop systems
- However there are non-trivial challenges in making this all working well...
- ... and not to introduce security problems instead...
Additionally, the message I was trying to pass during the whole presentation was:
“Keep hypervisors simple, do not put drivers there, as otherwise we would get to the same point where we are with current OSes these days, i.e. no kernel security at all!”
Now I wonder, maybe Christofer Hoff doesn’t do PR for any VMM vendor, maybe he just didn’t listen carefully to my presentation. Maybe he’s just one of those many guys who always know in advance what they want to hear and selectively pick up only those facts that match their state of mind? Otherwise, why would he not realize that my presentation was actually a pro-virtualization one and needed no (false) counter-arguments?
\ No newline at end of file
diff --git a/_posts/2008-07-07-0wning-xen-in-vegas.html b/_posts/2008-07-07-0wning-xen-in-vegas.html
index 54d62fd..ab5474f 100644
--- a/_posts/2008-07-07-0wning-xen-in-vegas.html
+++ b/_posts/2008-07-07-0wning-xen-in-vegas.html
@@ -13,4 +13,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2008/07/0wning-xen-in-vegas.html
---
- At this year’s Black Hat conference in Las Vegas in August we will be presenting three talks about the Xen hypervisor (in)security. The three presentations have been designed in such a way that they complement each other and create one bigger entirety, thus they can be referred as “Xen 0wning Trilogy” for brevity.
At this year’s Black Hat conference in Las Vegas in August we will be presenting three talks about the Xen hypervisor (in)security. The three presentations have been designed in such a way that they complement each other and create one bigger entirety, thus they can be referred as “Xen 0wning Trilogy” for brevity.
In the first presentation, Subverting the Xen hypervisor, Rafal will discuss how to modify the Xen’s hypervisor memory and consequently how to use this ability to plant hypervisor rootkits inside Xen (everything on the fly, without rebooting Xen). Hypervisor rootkits are very different creatures from virtualization based rootkits (e.g. Bluepill). This will be the first public demonstration of practical VMM 0wning (proof of concept code will be released, of course).
In the second talk, Detecting and Preventing the Xen hypervisor subversions, Rafal and I will discuss various anti-subverting techniques (IOMMU, Xen’s driver- and stub- domains) and whether they really can protect the Xen (or similar) hypervisor from compromises. After demonstrating that those mechanisms can be bypassed, we will switch to discussing hypervisor integrity scanning and will present some prototype solutions to this problem.
Our trilogy wouldn’t be complete without discussing virtualization based malware in the context of bare-metal hypervisor compromises. Thus, in the third speech, Bluepilling the Xen hypervisor, Alex and I will discuss how to insert Bluepill on top of the running Xen hypervisor. We will show how to do that both with and without restart (i.e. on the fly). To make this possible, our Bluepill needs to support full nested virtualization, so that Xen can still function properly. We will also discuss how the “Bluepill detection” methods proposed over the last 2 years, as well as the integrity scanning methods discussed in the previous speech, fit into this new scenario and how far we are from the stealth malware’s Holy Grail ;)
Special thanks to Black Hat organizers for scheduling all the three presentations one after another in a dedicated Virtualization track on the 2nd day of the conference (August 7th).
It’s worth noting that we chose Xen as the target not because we think it’s insecure and worthless. On the contrary, we believe Xen is the most secure bare-metal hypervisor out there (especially with all the goodies in the upcoming Xen 3.3). Still we believe that it needs some improvements when it comes to security. We hope that our presentations will help making Xen (and similar hypervisors) more secure.
\ No newline at end of file
+At this year’s Black Hat conference in Las Vegas in August we will be presenting three talks about the Xen hypervisor (in)security. The three presentations have been designed in such a way that they complement each other and create one bigger entirety, thus they can be referred as “Xen 0wning Trilogy” for brevity.
In the first presentation, Subverting the Xen hypervisor, Rafal will discuss how to modify the Xen’s hypervisor memory and consequently how to use this ability to plant hypervisor rootkits inside Xen (everything on the fly, without rebooting Xen). Hypervisor rootkits are very different creatures from virtualization based rootkits (e.g. Bluepill). This will be the first public demonstration of practical VMM 0wning (proof of concept code will be released, of course).
In the second talk, Detecting and Preventing the Xen hypervisor subversions, Rafal and I will discuss various anti-subverting techniques (IOMMU, Xen’s driver- and stub- domains) and whether they really can protect the Xen (or similar) hypervisor from compromises. After demonstrating that those mechanisms can be bypassed, we will switch to discussing hypervisor integrity scanning and will present some prototype solutions to this problem.
Our trilogy wouldn’t be complete without discussing virtualization based malware in the context of bare-metal hypervisor compromises. Thus, in the third speech, Bluepilling the Xen hypervisor, Alex and I will discuss how to insert Bluepill on top of the running Xen hypervisor. We will show how to do that both with and without restart (i.e. on the fly). To make this possible, our Bluepill needs to support full nested virtualization, so that Xen can still function properly. We will also discuss how the “Bluepill detection” methods proposed over the last 2 years, as well as the integrity scanning methods discussed in the previous speech, fit into this new scenario and how far we are from the stealth malware’s Holy Grail ;)
Special thanks to Black Hat organizers for scheduling all the three presentations one after another in a dedicated Virtualization track on the 2nd day of the conference (August 7th).
It’s worth noting that we chose Xen as the target not because we think it’s insecure and worthless. On the contrary, we believe Xen is the most secure bare-metal hypervisor out there (especially with all the goodies in the upcoming Xen 3.3). Still we believe that it needs some improvements when it comes to security. We hope that our presentations will help making Xen (and similar hypervisors) more secure.
\ No newline at end of file
diff --git a/_posts/2008-08-31-teamwork-crediting.html b/_posts/2008-08-31-teamwork-crediting.html
index e55ad38..1596133 100644
--- a/_posts/2008-08-31-teamwork-crediting.html
+++ b/_posts/2008-08-31-teamwork-crediting.html
@@ -10,4 +10,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2008/08/teamwork-crediting.html
---
-As the technology is getting more and more complex, security research, especially offensive security research on a system level, becoming more and more difficult to be done by one person. NX/XD, ASLR, various StackGuard-like things, VT-d, TXT, etc... - all those technologies leave less and less space for the interesting system-level attacks. On the other hand, the widespread "deployment" of Web 2.0 creates a whole new area to explore, but that is a whole different world (plus there are still all those "human factor" attacks that exploit user stupidity, but again, this is a different area).
Our Xen 0wning Trilogy is a good example of how a team of researchers can still come up with interesting new system-level attacks against the very recent and securely design system. Take XenBluePill as an example.
It has first been months of research and coding done by Alex and myself to support nested hardware virtualization on AMD. Then there was months of Rafal's research about how to load code into the running Xen on the fly ("Xen Loadable Modules"). That required ability to access Xen's memory in the first place and Rafal's way for doing that was to use the DMA attack. But then it turned out that the Xen 3.3 uses VT-d protection to protect against this very kind of attacks. So then I came up with the "Q35 attack" that exploited a problem with recent Intel BIOSes on recent motherboards (details are coming this week). But I based my attack on a similar SMM attack that Rafal came up with a few months earlier on a different chipset, when he was looking into ways to compromise SMM handler, as we started thinking about HyperGuard project back then and Rafal was curious reliable the SMM protection is. In the meantime, Alex "converted" our working New Blue Pill that had full support for nested virtualization but was essentially a Windows driver, into a piece of code that was completely OS-independent (own memory management, etc.). Then I finally took Rafal's XLM framework, added a few minor things that were needed to load our "Windows-independent Windows driver" into Xen using XLM, fixed some minor stuff and... it finally worked! But that was possible only because of the joint work by all the three people together.
So, it is simply unfair to attribute all the glory and fame for our research to "Rutkowska" or "Rutkowska and team", as many news portals did. Please don't forget to credit all the co-authors! If you really would like to use a generic term, then "Invisible Things Lab team" would probably serve better.
Speaking of our team, I also have an announcement that starting this month our team has officially been extended by yet another person: Rong Fan from Beijing, China.
Rong is a software engineer, focusing on Intel's hardware virtualization technology (VT). A few months ago he wrote to me with some advanced questions regarding the implementation of our New BluePill that we published after the last year's Black Hat. Turned out that Rong, as part of his after-hour activity, is porting Bluepill to VT-x. After he succeeded, we decided to share our nested virtualization code for AMD with him so that he could investigate how to do it on VT-x. And about 2 months ago Rong succeeded with implementing full nested virtualization support for our NBP on Intel VT-x! During that time Rong has had an opportunity to find out that working with ITL is quite fun, so he decided to quit his job at Lenovo and joined ITL full time. Right now Rong is busy adding nested VT-x support to a normal Xen hypervisor.
So, Invisible Things Lab is all about the team work. The whole idea behind ITL is to gather together a bunch of smart people, so that we could all work on the most exciting problems together. Problems that might be too complex or time-consuming for just one person to solve. But it takes more then just money to get people to be creative and devote themselves to work. Getting recognition is one of the additional factors often needed. That's why ITL is not interested in "hiding" its employees, but rather in promoting their work and fairly crediting them.
\ No newline at end of file
+As the technology is getting more and more complex, security research, especially offensive security research on a system level, becoming more and more difficult to be done by one person. NX/XD, ASLR, various StackGuard-like things, VT-d, TXT, etc... - all those technologies leave less and less space for the interesting system-level attacks. On the other hand, the widespread "deployment" of Web 2.0 creates a whole new area to explore, but that is a whole different world (plus there are still all those "human factor" attacks that exploit user stupidity, but again, this is a different area).
Our Xen 0wning Trilogy is a good example of how a team of researchers can still come up with interesting new system-level attacks against the very recent and securely design system. Take XenBluePill as an example.
It has first been months of research and coding done by Alex and myself to support nested hardware virtualization on AMD. Then there was months of Rafal's research about how to load code into the running Xen on the fly ("Xen Loadable Modules"). That required ability to access Xen's memory in the first place and Rafal's way for doing that was to use the DMA attack. But then it turned out that the Xen 3.3 uses VT-d protection to protect against this very kind of attacks. So then I came up with the "Q35 attack" that exploited a problem with recent Intel BIOSes on recent motherboards (details are coming this week). But I based my attack on a similar SMM attack that Rafal came up with a few months earlier on a different chipset, when he was looking into ways to compromise SMM handler, as we started thinking about HyperGuard project back then and Rafal was curious reliable the SMM protection is. In the meantime, Alex "converted" our working New Blue Pill that had full support for nested virtualization but was essentially a Windows driver, into a piece of code that was completely OS-independent (own memory management, etc.). Then I finally took Rafal's XLM framework, added a few minor things that were needed to load our "Windows-independent Windows driver" into Xen using XLM, fixed some minor stuff and... it finally worked! But that was possible only because of the joint work by all the three people together.
So, it is simply unfair to attribute all the glory and fame for our research to "Rutkowska" or "Rutkowska and team", as many news portals did. Please don't forget to credit all the co-authors! If you really would like to use a generic term, then "Invisible Things Lab team" would probably serve better.
Speaking of our team, I also have an announcement that starting this month our team has officially been extended by yet another person: Rong Fan from Beijing, China.
Rong is a software engineer, focusing on Intel's hardware virtualization technology (VT). A few months ago he wrote to me with some advanced questions regarding the implementation of our New BluePill that we published after the last year's Black Hat. Turned out that Rong, as part of his after-hour activity, is porting Bluepill to VT-x. After he succeeded, we decided to share our nested virtualization code for AMD with him so that he could investigate how to do it on VT-x. And about 2 months ago Rong succeeded with implementing full nested virtualization support for our NBP on Intel VT-x! During that time Rong has had an opportunity to find out that working with ITL is quite fun, so he decided to quit his job at Lenovo and joined ITL full time. Right now Rong is busy adding nested VT-x support to a normal Xen hypervisor.
So, Invisible Things Lab is all about the team work. The whole idea behind ITL is to gather together a bunch of smart people, so that we could all work on the most exciting problems together. Problems that might be too complex or time-consuming for just one person to solve. But it takes more then just money to get people to be creative and devote themselves to work. Getting recognition is one of the additional factors often needed. That's why ITL is not interested in "hiding" its employees, but rather in promoting their work and fairly crediting them.
\ No newline at end of file
diff --git a/_posts/2008-09-06-xen-0wning-trilogy-code-demos-and-q35.html b/_posts/2008-09-06-xen-0wning-trilogy-code-demos-and-q35.html
index 32ed18b..037cd73 100644
--- a/_posts/2008-09-06-xen-0wning-trilogy-code-demos-and-q35.html
+++ b/_posts/2008-09-06-xen-0wning-trilogy-code-demos-and-q35.html
@@ -13,4 +13,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2008/09/xen-0wning-trilogy-code-demos-and-q35.html
---
-We have posted all the code that we used last month during our Black Hat presentations about Xen security, and you can get it here. This includes the full source code for:
1) The generic Xen Loadable Modules framework
2) Implementation of the two Xen Hypervisor Rootkits
3) The Q35 exploit
4) The FLASK heap overflow exploit
5) The BluePillBoot (with nested virtualization support on SVM)
6) The XenBluePill (with nested virtualization support on SVM)
Beware the code is by far not user-friendly, it requires advanced Linux/Xen, C and system-level programming skills in order to tweak some constants and run it successfully on your system. Do not send us questions how to compile/run it, as we don’t have time to answer such questions. Also do not send questions how the code works – if you can’t figure it out by reading our slides and the source code, then it means you should probably spend more time on this yourself. On the other hand, we would appreciate any constructive feedback.
The code is our gift to the research community. There is no warranty and Invisible Things Lab takes no responsibility for any potential damage that this code might cause (e.g. by rebooting your machine) or any potential malicious usage of this code, or any other code built on top of this code. We believe that by publishing this code we help to create more secure systems in the future.
Additionally, we also posted the full version of our second Black Hat talk, which now includes all the slides about the Q35 bug and how we exploited it. Those slides had to be previously removed during our Black Hat presentation, as the patch was still unavailable during that time.
\ No newline at end of file
+We have posted all the code that we used last month during our Black Hat presentations about Xen security, and you can get it here. This includes the full source code for:
1) The generic Xen Loadable Modules framework
2) Implementation of the two Xen Hypervisor Rootkits
3) The Q35 exploit
4) The FLASK heap overflow exploit
5) The BluePillBoot (with nested virtualization support on SVM)
6) The XenBluePill (with nested virtualization support on SVM)
Beware the code is by far not user-friendly, it requires advanced Linux/Xen, C and system-level programming skills in order to tweak some constants and run it successfully on your system. Do not send us questions how to compile/run it, as we don’t have time to answer such questions. Also do not send questions how the code works – if you can’t figure it out by reading our slides and the source code, then it means you should probably spend more time on this yourself. On the other hand, we would appreciate any constructive feedback.
The code is our gift to the research community. There is no warranty and Invisible Things Lab takes no responsibility for any potential damage that this code might cause (e.g. by rebooting your machine) or any potential malicious usage of this code, or any other code built on top of this code. We believe that by publishing this code we help to create more secure systems in the future.
Additionally, we also posted the full version of our second Black Hat talk, which now includes all the slides about the Q35 bug and how we exploited it. Those slides had to be previously removed during our Black Hat presentation, as the patch was still unavailable during that time.
\ No newline at end of file
diff --git a/_posts/2008-09-07-microsoft-executive-rebuts-our-research.html b/_posts/2008-09-07-microsoft-executive-rebuts-our-research.html
index 4c01adf..18b1429 100644
--- a/_posts/2008-09-07-microsoft-executive-rebuts-our-research.html
+++ b/_posts/2008-09-07-microsoft-executive-rebuts-our-research.html
@@ -11,4 +11,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2008/09/microsoft-executive-rebuts-our-research.html
---
-Ah, there is no feeling like seeing your name in the news when drinking your morning coffee... In this piece some Steve Riley, a senior security strategist at Microsoft, decided to "rebute" our recent Black Hat presentations research results.
Mr. Riley had been quoted by ZDnet as saying:
"Her [Joanna Rutkowska] insistence is that you can replace the hypervisor without anybody knowing... Our assertion is that this is incorrect," Riley told the audience. "First of all, to do these attacks you need to become administrator at the root. So that's going to be, on an appropriately configured machine, an exceedingly difficult thing to happen."
Apparently, Mr. Riley has never seen our Black Hat presentations (or slides at least) that he is referring to (oh, wait, that is the typical case with all our "refuters", how come?)...
First, we never said anything about replacing the hypervisor. I really have no idea how this idea was born in Mr. Riley's head? Replacing the hypervisor - that would indeed be insane for us to do!
Second, it is not true that the attacker needs to become an administrator "at the root" (he mean the root partition or administrative domain here I assume). The attack we presented in our second speech, that exploited a heap overflow in the Xen hypervisor FLASK module, could have been conducted from the unprivileged domain, as we demonstrated during the presentation.
Mr. Riley continues with his vision:
"Because you [the attacker] didn't subject your own replacement hypervisor through the thorough design review that ours did, I'll bet your hypervisor is probably not going to implement 100 percent of the functionality as the original one," Riley said. "There will be a gap or two and we will be able to detect that."
Well, if he only took the effort of looking into our slides, he would realize that, in case of XenBluePill, we were slipping it beneath (not replacing!) the original hypervisor, and then run the original one as nested. So, all the functionality of the original hypervisor was preserved.
Mr. Riley also shares some other ground breaking thoughts in this article, but I think we can leave them uncommented ;)
This situation is pretty funny actually - we have here the words and feelings of some Microsoft executive vs. our three technical presentations, all the code that we released for those presentations, and also a few of our demos. Yet, it's apparently still worth getting into the news and reporting what the feeling of Mr. Riley are...
Let me, however, write one more time, that I'm (still) not a Microsoft hater. There are many people at Microsoft that I respect: Brandon Baker, Neil Clift, the LSD guys, Mark Russinovich, and probably a few more that I just haven't had occasion to meet in person or maybe forgot about at the moment. It's thus even more sad that people like Mr. Riley are also associated with Microsoft, even more they are the face of Microsoft for the majority of people. Throwing a party in Vegas and Amsterdam once a year certainly is not enough to change the Microsoft's image in this case...
Interestingly, if Mr. Riley only attended our Xen 0wning Trilogy at Black Hat, then he would notice that we were actually very positive about Hyper-V. Of course, I pointed out that Xen 3.3 certainly has a more secure architecture right now, but I also said that I knew (from talking to some MS engineers from the virtualization group) that Hyper-V is going to implement similar features in the next version(s) and that this is very good. I also prized the fact it has only about 100k LOC (vs. about 300k LOC in Xen 3.3).
So, Mr. Senior Security Strategist, I suggest you do your homework more carefully next time before throwing mud at others and trying to negate the value of their work (and all the efforts of Microsoft's PR people).
On a separate note, I found it quite unprofessional that ZDNet's Liam Tung and Tom Espiner, the authors of the news, didn't ask me for a commentary before publishing this. Not to mention that they also misspelled Rafal's name and forgot to mention about Alex, the third co-author of the presentations.
\ No newline at end of file
+Ah, there is no feeling like seeing your name in the news when drinking your morning coffee... In this piece some Steve Riley, a senior security strategist at Microsoft, decided to "rebute" our recent Black Hat presentations research results.
Mr. Riley had been quoted by ZDnet as saying:
"Her [Joanna Rutkowska] insistence is that you can replace the hypervisor without anybody knowing... Our assertion is that this is incorrect," Riley told the audience. "First of all, to do these attacks you need to become administrator at the root. So that's going to be, on an appropriately configured machine, an exceedingly difficult thing to happen."
Apparently, Mr. Riley has never seen our Black Hat presentations (or slides at least) that he is referring to (oh, wait, that is the typical case with all our "refuters", how come?)...
First, we never said anything about replacing the hypervisor. I really have no idea how this idea was born in Mr. Riley's head? Replacing the hypervisor - that would indeed be insane for us to do!
Second, it is not true that the attacker needs to become an administrator "at the root" (he mean the root partition or administrative domain here I assume). The attack we presented in our second speech, that exploited a heap overflow in the Xen hypervisor FLASK module, could have been conducted from the unprivileged domain, as we demonstrated during the presentation.
Mr. Riley continues with his vision:
"Because you [the attacker] didn't subject your own replacement hypervisor through the thorough design review that ours did, I'll bet your hypervisor is probably not going to implement 100 percent of the functionality as the original one," Riley said. "There will be a gap or two and we will be able to detect that."
Well, if he only took the effort of looking into our slides, he would realize that, in case of XenBluePill, we were slipping it beneath (not replacing!) the original hypervisor, and then run the original one as nested. So, all the functionality of the original hypervisor was preserved.
Mr. Riley also shares some other ground breaking thoughts in this article, but I think we can leave them uncommented ;)
This situation is pretty funny actually - we have here the words and feelings of some Microsoft executive vs. our three technical presentations, all the code that we released for those presentations, and also a few of our demos. Yet, it's apparently still worth getting into the news and reporting what the feeling of Mr. Riley are...
Let me, however, write one more time, that I'm (still) not a Microsoft hater. There are many people at Microsoft that I respect: Brandon Baker, Neil Clift, the LSD guys, Mark Russinovich, and probably a few more that I just haven't had occasion to meet in person or maybe forgot about at the moment. It's thus even more sad that people like Mr. Riley are also associated with Microsoft, even more they are the face of Microsoft for the majority of people. Throwing a party in Vegas and Amsterdam once a year certainly is not enough to change the Microsoft's image in this case...
Interestingly, if Mr. Riley only attended our Xen 0wning Trilogy at Black Hat, then he would notice that we were actually very positive about Hyper-V. Of course, I pointed out that Xen 3.3 certainly has a more secure architecture right now, but I also said that I knew (from talking to some MS engineers from the virtualization group) that Hyper-V is going to implement similar features in the next version(s) and that this is very good. I also prized the fact it has only about 100k LOC (vs. about 300k LOC in Xen 3.3).
So, Mr. Senior Security Strategist, I suggest you do your homework more carefully next time before throwing mud at others and trying to negate the value of their work (and all the efforts of Microsoft's PR people).
On a separate note, I found it quite unprofessional that ZDNet's Liam Tung and Tom Espiner, the authors of the news, didn't ask me for a commentary before publishing this. Not to mention that they also misspelled Rafal's name and forgot to mention about Alex, the third co-author of the presentations.
\ No newline at end of file
diff --git a/_posts/2009-01-21-why-do-i-miss-microsoft-bitlocker.html b/_posts/2009-01-21-why-do-i-miss-microsoft-bitlocker.html
index 2565217..ad42264 100644
--- a/_posts/2009-01-21-why-do-i-miss-microsoft-bitlocker.html
+++ b/_posts/2009-01-21-why-do-i-miss-microsoft-bitlocker.html
@@ -14,4 +14,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2009/01/why-do-i-miss-microsoft-bitlocker.html
---
-In the previous post, I wrote the only one thing I really miss after I've switched from Vista to Mac is the BitLocker Driver Encryption. I thought it might be interesting for others to understand my position, so below I describe why I think BitLocker is so cool, and why I think other system disk encryption software sucks.
So, it's all about the Trusted Boot. BitLocker does make use of a trusted boot process, while all the other system encryption software I'm aware of, does not. But why the trusted boot feature is so useful? Let's start with a quick digression about what the trusted boot process is…
Trusted boot can be implemented using either a Static Root of Trust or a Dynamic Root of Trust.
The Static Root of Trust approach (also known as Static Root of Trust Measurement or SRTM) is pretty straightforward — the system starts booting from some immutable piece of firmware code that we assume is always trusted (hence the static root) and that initiates the measurement process, in which each component measures the next one in a chain. So, e.g. this immutable piece of firmware will first calculate the hash of the BIOS and extend a TPM's PCR register with the value of this hash. Then the BIOS does the same with the PCI EEPROMs and the MBR, before handling execution to them. Then the bootloader measures the OS loader before executing it. And so on.
An alternative method to implementing trusted boot is to use Dynamic Root of Trust (often called Dynamic Root of Trust Measurement or DRTM). Intel's TXT technology, formerly LaGrande, is an example of a DRTM (more precisely: TXT is more than just DRTM, but DRTM is the central concept on which TXT is built). We will be talking a lot about TXT next month at Black Hat in DC :) This will include discussion of why DRTM might sometimes be preferred over SRTM and, of course, what are the challenges with both.
Essentially, both SRTM and DRTM, in the context of a trusted boot, are supposed to provide the same: assurance the system that just booted is actually the system that we wanted to boot (i.e. the trusted one) and not some modified system (e.g. compromised by an MBR virus).
BitLocker uses the Static Root of Trust Measurement. SRTM can really make sense when we combine it with either TPM sealing or attestation feature. BitLocker uses the former to make sure that only the trusted system can get access to the disk decryption key. In other words: BitLocker relies on the TPM that it will unseal (release) the decryption key (needed to decrypt the system partition) when and only when the state of chosen PCR registers is the same is it was when the decryption key was sealed into the TPM.
Ok, why is this trusted boot process so important for the system disk encryption software? Because it protects against a simple two-stage attack:
- You leave your laptop (can be even fully powered down) in a hotel room and go down for a breakfast… Meanwhile an Evil Maid enters your room. She holds an Evil USB stick in her hand and plugs it into your laptop and presses the power button. The system starts and boots from the USB. An Evil version of something similar to our BluePillBoot gets installed into the MBR (or to a PCI EEPROM). This Evil Program has only one task — to sniff out the encryption software's password/PIN and then report it back to the maid next time she comes...
- So, you come back to your room to brush your teeth after the breakfast. Obviously you cannot refrain from not turning on your laptop for a while. You just need to enter your disk encryption passphrase/PIN/whatever. Your encryption software happily displays the prompt, like if nothing happened. After all how could it possibly know the Evil Program, like BluePillBoot, has just been loaded a moment ago from the MBR or a PCI EEPROM? It can not! So, you enter the valid password, your system gets the decryption key and you can get access to your encrypted system...
- But then you have an appointment at the hotel SPA (at least this little fun you can have on a business trip, right?). Obviously you don't want to look so geeky and you won't take your laptop with you to the SPA, will you? The Evil Maid just waited for this occasion… She sneaks again into your room and powers up your laptop. She presses a magic key combo, which results in the Evil Program displaying the sniffed decryption password. Now, depending on their level of subtleness, she could either steal your whole laptop or only some more important data from the laptop. Your system disk encryption software is completely useless against her now.
(Yes, I know that's 3 bullets, but the Evil Maid had to sneak into your room only twice:)
So, why the BitLocker would not allow for this simple attack? Because the BitLocker software should actually be able to know that the system gets compromised (by the Evil Program) since the last boot. BitLocker should then refuse to display a password prompt. And even if it didn't and asked the user for the password, still it should not be able to get the actual decryption key out from the TPM, because the values in the certain PCR register(s) will be wrong (they will now account for the modified hashes of the MBR or PCI EEPROM or BIOS). The bottom line is: the maid is not getting the decryption key (just as the user now), which is what this is all about.
 At least this is how the BitLocker should work. I shall add a disclaimer here, that neither myself, nor anybody from my team, have looked into the BitLocker implementation. We have not, because, as of yet, there have been no customers interested in this kind of BitLocker implementation evaluation. Also, I should add that Microsoft has not paid me to write this article. I simply hope this might positively stimulate other vendors, like e.g. TrueCrypt (Hi David!), or Apple, to add SRTM or, better yet, DRTM, to their system encryption products.
At least this is how the BitLocker should work. I shall add a disclaimer here, that neither myself, nor anybody from my team, have looked into the BitLocker implementation. We have not, because, as of yet, there have been no customers interested in this kind of BitLocker implementation evaluation. Also, I should add that Microsoft has not paid me to write this article. I simply hope this might positively stimulate other vendors, like e.g. TrueCrypt (Hi David!), or Apple, to add SRTM or, better yet, DRTM, to their system encryption products.
Of course, when we consider an idiot-attack, that involves simply garbbing somebody's laptop and running away with it (i.e. without any prior preparation like our Evil Maid did), then probably all system disk encryption software would be just good enough (assuming it doesn't have any bugs in the crypto code).
Some people might argue that using a BIOS password would be just as good as using trusted boot. After all, if we disable booting from alternate media in BIOS (e.g. from USB sticks) and lock down the BIOS using a password (i.e. using the Power-On password, not just the BIOS supervisor password), then the above two-stage attacks should not be feasible. Those people might argue, that even if the Evil Maid had cleared the CMOS memory (by removing the CMOS battery from the motherboard), still they would be able to notice that something is wrong — the BIOS would not longer be asking for the password, or the password would be different from what they used before.
That is a valid point, but relaying on the BIOS password to provide security for all your data might not be such a good idea. First problem is that all the BIOSes have had a long history of various default or "maintenance" passwords (I actually do not know how the situation looks today with those default passwords). Another problem is that the attacker might first clear the CMOS memory, and then modify her Evil MBR program to also display a fake BIOS password prompt, that would accept anything the user enters. This way the user will not be alerted that something is wrong and will be willing to provide the real password for drive decryption when prompted later by the actual drive encryption software.
One might ask why can't the attacker use the similar attack against BitLocker? Even if the real BitLocker uses trusted boot process, we can still infect the MBR, display the fake BitLocker PIN prompt and this way get into the possession of the user's PIN.
This attack, however, can be spotted by an inquisitive user — after all, if he or she knows they provided the correct PIN, then it would be suspicious not to see the system being booted (and it won't boot, because the fake BitLocker will not be able to retrieve the password from the TPM). If the fake BitLocker wanted to boot the OS (so that user didn't suspect anything), it would have to remove itself from the system and then reboot the system. Again this should alert the user that something wrong is going on.
There is also a much more elegant way of defending against the above attack (with fake BitLocker prompt) — but I'd rather let Microsoft to figure it out by themselves ;)
By the way, contrary to a popular belief the BitLocker doesn't protect your computer from boot-stage infections, e.g. MBR viruses or BIOS/PCI rootkits. As we have been pointing out since the first edition of our Understanding Stealth Malware training at Black Hat in August 2007, BitLocker should not be thought as of a system integrity protection. This is because it is trivial, for any malware that already got access to the running Vista, to re-seal the BitLocker key to arbitrary new system firmware/MBR configuration. Everybody can try it by going to Control Panel/BitLocker Driver Encryption, then clicking on the "Turn Off BitLocker" and choosing "Disable BitLocker Drive Encryption". This will simply save your disk decryption key in plaintext, allowing you to e.g. reflash your BIOS, boot Vista again and then to enable BitLocker again (this would generate a new key and seal it to the TPM with the new PCR values).

This functionality has been provided obviously to allow user to update his or her firmware. But what is important to keep in mind is that this process of disabling BitLocker doesn't involve entering any special password or PIN (e.g. the BitLocker's PIN). It just enough that you are the default user with admin rights or some malware running in this context. Pity they decided on the simplest solution here. But still BitLocker is simply the one coolest thing in Vista and something I really miss on all other OSes...
\ No newline at end of file
+In the previous post, I wrote the only one thing I really miss after I've switched from Vista to Mac is the BitLocker Driver Encryption. I thought it might be interesting for others to understand my position, so below I describe why I think BitLocker is so cool, and why I think other system disk encryption software sucks.
So, it's all about the Trusted Boot. BitLocker does make use of a trusted boot process, while all the other system encryption software I'm aware of, does not. But why the trusted boot feature is so useful? Let's start with a quick digression about what the trusted boot process is…
Trusted boot can be implemented using either a Static Root of Trust or a Dynamic Root of Trust.
The Static Root of Trust approach (also known as Static Root of Trust Measurement or SRTM) is pretty straightforward — the system starts booting from some immutable piece of firmware code that we assume is always trusted (hence the static root) and that initiates the measurement process, in which each component measures the next one in a chain. So, e.g. this immutable piece of firmware will first calculate the hash of the BIOS and extend a TPM's PCR register with the value of this hash. Then the BIOS does the same with the PCI EEPROMs and the MBR, before handling execution to them. Then the bootloader measures the OS loader before executing it. And so on.
An alternative method to implementing trusted boot is to use Dynamic Root of Trust (often called Dynamic Root of Trust Measurement or DRTM). Intel's TXT technology, formerly LaGrande, is an example of a DRTM (more precisely: TXT is more than just DRTM, but DRTM is the central concept on which TXT is built). We will be talking a lot about TXT next month at Black Hat in DC :) This will include discussion of why DRTM might sometimes be preferred over SRTM and, of course, what are the challenges with both.
Essentially, both SRTM and DRTM, in the context of a trusted boot, are supposed to provide the same: assurance the system that just booted is actually the system that we wanted to boot (i.e. the trusted one) and not some modified system (e.g. compromised by an MBR virus).
BitLocker uses the Static Root of Trust Measurement. SRTM can really make sense when we combine it with either TPM sealing or attestation feature. BitLocker uses the former to make sure that only the trusted system can get access to the disk decryption key. In other words: BitLocker relies on the TPM that it will unseal (release) the decryption key (needed to decrypt the system partition) when and only when the state of chosen PCR registers is the same is it was when the decryption key was sealed into the TPM.
Ok, why is this trusted boot process so important for the system disk encryption software? Because it protects against a simple two-stage attack:
- You leave your laptop (can be even fully powered down) in a hotel room and go down for a breakfast… Meanwhile an Evil Maid enters your room. She holds an Evil USB stick in her hand and plugs it into your laptop and presses the power button. The system starts and boots from the USB. An Evil version of something similar to our BluePillBoot gets installed into the MBR (or to a PCI EEPROM). This Evil Program has only one task — to sniff out the encryption software's password/PIN and then report it back to the maid next time she comes...
- So, you come back to your room to brush your teeth after the breakfast. Obviously you cannot refrain from not turning on your laptop for a while. You just need to enter your disk encryption passphrase/PIN/whatever. Your encryption software happily displays the prompt, like if nothing happened. After all how could it possibly know the Evil Program, like BluePillBoot, has just been loaded a moment ago from the MBR or a PCI EEPROM? It can not! So, you enter the valid password, your system gets the decryption key and you can get access to your encrypted system...
- But then you have an appointment at the hotel SPA (at least this little fun you can have on a business trip, right?). Obviously you don't want to look so geeky and you won't take your laptop with you to the SPA, will you? The Evil Maid just waited for this occasion… She sneaks again into your room and powers up your laptop. She presses a magic key combo, which results in the Evil Program displaying the sniffed decryption password. Now, depending on their level of subtleness, she could either steal your whole laptop or only some more important data from the laptop. Your system disk encryption software is completely useless against her now.
(Yes, I know that's 3 bullets, but the Evil Maid had to sneak into your room only twice:)
So, why the BitLocker would not allow for this simple attack? Because the BitLocker software should actually be able to know that the system gets compromised (by the Evil Program) since the last boot. BitLocker should then refuse to display a password prompt. And even if it didn't and asked the user for the password, still it should not be able to get the actual decryption key out from the TPM, because the values in the certain PCR register(s) will be wrong (they will now account for the modified hashes of the MBR or PCI EEPROM or BIOS). The bottom line is: the maid is not getting the decryption key (just as the user now), which is what this is all about.
At least this is how the BitLocker should work. I shall add a disclaimer here, that neither myself, nor anybody from my team, have looked into the BitLocker implementation. We have not, because, as of yet, there have been no customers interested in this kind of BitLocker implementation evaluation. Also, I should add that Microsoft has not paid me to write this article. I simply hope this might positively stimulate other vendors, like e.g. TrueCrypt (Hi David!), or Apple, to add SRTM or, better yet, DRTM, to their system encryption products.
Of course, when we consider an idiot-attack, that involves simply garbbing somebody's laptop and running away with it (i.e. without any prior preparation like our Evil Maid did), then probably all system disk encryption software would be just good enough (assuming it doesn't have any bugs in the crypto code).
Some people might argue that using a BIOS password would be just as good as using trusted boot. After all, if we disable booting from alternate media in BIOS (e.g. from USB sticks) and lock down the BIOS using a password (i.e. using the Power-On password, not just the BIOS supervisor password), then the above two-stage attacks should not be feasible. Those people might argue, that even if the Evil Maid had cleared the CMOS memory (by removing the CMOS battery from the motherboard), still they would be able to notice that something is wrong — the BIOS would not longer be asking for the password, or the password would be different from what they used before.
That is a valid point, but relaying on the BIOS password to provide security for all your data might not be such a good idea. First problem is that all the BIOSes have had a long history of various default or "maintenance" passwords (I actually do not know how the situation looks today with those default passwords). Another problem is that the attacker might first clear the CMOS memory, and then modify her Evil MBR program to also display a fake BIOS password prompt, that would accept anything the user enters. This way the user will not be alerted that something is wrong and will be willing to provide the real password for drive decryption when prompted later by the actual drive encryption software.
One might ask why can't the attacker use the similar attack against BitLocker? Even if the real BitLocker uses trusted boot process, we can still infect the MBR, display the fake BitLocker PIN prompt and this way get into the possession of the user's PIN.
This attack, however, can be spotted by an inquisitive user — after all, if he or she knows they provided the correct PIN, then it would be suspicious not to see the system being booted (and it won't boot, because the fake BitLocker will not be able to retrieve the password from the TPM). If the fake BitLocker wanted to boot the OS (so that user didn't suspect anything), it would have to remove itself from the system and then reboot the system. Again this should alert the user that something wrong is going on.
There is also a much more elegant way of defending against the above attack (with fake BitLocker prompt) — but I'd rather let Microsoft to figure it out by themselves ;)
By the way, contrary to a popular belief the BitLocker doesn't protect your computer from boot-stage infections, e.g. MBR viruses or BIOS/PCI rootkits. As we have been pointing out since the first edition of our Understanding Stealth Malware training at Black Hat in August 2007, BitLocker should not be thought as of a system integrity protection. This is because it is trivial, for any malware that already got access to the running Vista, to re-seal the BitLocker key to arbitrary new system firmware/MBR configuration. Everybody can try it by going to Control Panel/BitLocker Driver Encryption, then clicking on the "Turn Off BitLocker" and choosing "Disable BitLocker Drive Encryption". This will simply save your disk decryption key in plaintext, allowing you to e.g. reflash your BIOS, boot Vista again and then to enable BitLocker again (this would generate a new key and seal it to the TPM with the new PCR values).
This functionality has been provided obviously to allow user to update his or her firmware. But what is important to keep in mind is that this process of disabling BitLocker doesn't involve entering any special password or PIN (e.g. the BitLocker's PIN). It just enough that you are the default user with admin rights or some malware running in this context. Pity they decided on the simplest solution here. But still BitLocker is simply the one coolest thing in Vista and something I really miss on all other OSes...
\ No newline at end of file
diff --git a/_posts/2009-01-26-closed-source-conspiracy.html b/_posts/2009-01-26-closed-source-conspiracy.html
index cdc991b..a17d7ab 100644
--- a/_posts/2009-01-26-closed-source-conspiracy.html
+++ b/_posts/2009-01-26-closed-source-conspiracy.html
@@ -10,4 +10,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2009/01/closed-source-conspiracy.html
---
-Many people in the industry have an innate fear of closed source (AKA proprietary software), which especially applies to everything crypto-related.
The usual arguments go this way: this (proprietary) crypto software is bad, because the vendor might have put some backdoors in there. And: only the open source crypto software, which can be reviewed by anyone, can be trusted! So, after my recent post, quite a few people wrote to me and asked how I could defend such an evil thing as BitLocker, which is proprietary, and, even worse, comes from Microsoft?
I personally think this way of reasoning sucks. In majority of cases, the fact something is distributed without the accompanying source code does not prevent others from analyzing the code. We do have advanced disassemblers and debuggers, and it is really not that difficult to make use of them as many people think.
Of course, some heavily obfuscated programs can be extremely difficult to analyze. Also, analyzing a chipset's firmware, when you do not even know the underlying CPU architecture and the I/O map might be hard. But these are special cases and do not apply to majority of software, that usually is not obfuscated at all.
It seems like the argument of Backdoored Proprietary Software usually comes from the open-source people, who are used to unlimited accesses to the source code, and consequently do not usually have much experience with advanced reverse engineer techniques, simply because they do not need them in their happy "Open Source Life". It's all Darwinism, after all ;)
On the other hand, some things are hard to analyze, regardless of whether the source code is available or not, think: crypto. Also, how many of you who actively use open source crypto software, e.g. TrueCrypt or GnuPG, have actually reviewed the source code? Anyone?
You might be thinking — maybe I haven't looked at the source code myself, but because it is open source, zillions of other users already have reviewed it. And if there was some backdoor in there, they would undoubtedly have found it already! Well, for all those open source fetishists, who blindly negate the value of anything that is not open source, I have only one word to say: Debian.
Keep in mind: I do not say closed source is more secure than open source — I only resist the open-source fundamentalism, that defines every proprietary software as inherently insecure, and everything open source as ultimately secure.
So, how should one (e.g. a government institution) verify security-level of a given crypto software, e.g. to ensure there are no built-in backdoors in there? I personally doubt it could be performed by one team, as it just usually happens that the same people who might be exceptionally skilled in code review, system-level security, etc, at the same time are average cryptographers and vice-versa.
Imagine e.g. that you need to find out if there are any weaknesses in your system drive encryption software, something like BitLocker. Even if you get access to the source code, you still would have to analyze a lot of system-level details — how is the trusted boot implemented (SRTM? DRTM? TPM interaction?), which system software is trusted, how the implementation withstands various not-crypto-related attacks (e.g. some of the attacks I described in my previous post), etc…
But this all is just system-level evaluation. What should come later is to analyze the actual crypto algorithms and protocols. Those later tasks fall into cryptography field and not into system-level security discipline, and consequently should be performed by some other team, the crypto experts.
So, no doubt, it is not an easy task, and the fact if there is or there is not C/C++ source code available, is usually one of the minor headaches (a good example is our attack on TXT, where we were able to discover bugs in Intel's specific system software, which, of course, is not open source).
\ No newline at end of file
+Many people in the industry have an innate fear of closed source (AKA proprietary software), which especially applies to everything crypto-related.
The usual arguments go this way: this (proprietary) crypto software is bad, because the vendor might have put some backdoors in there. And: only the open source crypto software, which can be reviewed by anyone, can be trusted! So, after my recent post, quite a few people wrote to me and asked how I could defend such an evil thing as BitLocker, which is proprietary, and, even worse, comes from Microsoft?
I personally think this way of reasoning sucks. In majority of cases, the fact something is distributed without the accompanying source code does not prevent others from analyzing the code. We do have advanced disassemblers and debuggers, and it is really not that difficult to make use of them as many people think.
Of course, some heavily obfuscated programs can be extremely difficult to analyze. Also, analyzing a chipset's firmware, when you do not even know the underlying CPU architecture and the I/O map might be hard. But these are special cases and do not apply to majority of software, that usually is not obfuscated at all.
It seems like the argument of Backdoored Proprietary Software usually comes from the open-source people, who are used to unlimited accesses to the source code, and consequently do not usually have much experience with advanced reverse engineer techniques, simply because they do not need them in their happy "Open Source Life". It's all Darwinism, after all ;)
On the other hand, some things are hard to analyze, regardless of whether the source code is available or not, think: crypto. Also, how many of you who actively use open source crypto software, e.g. TrueCrypt or GnuPG, have actually reviewed the source code? Anyone?
You might be thinking — maybe I haven't looked at the source code myself, but because it is open source, zillions of other users already have reviewed it. And if there was some backdoor in there, they would undoubtedly have found it already! Well, for all those open source fetishists, who blindly negate the value of anything that is not open source, I have only one word to say: Debian.
Keep in mind: I do not say closed source is more secure than open source — I only resist the open-source fundamentalism, that defines every proprietary software as inherently insecure, and everything open source as ultimately secure.
So, how should one (e.g. a government institution) verify security-level of a given crypto software, e.g. to ensure there are no built-in backdoors in there? I personally doubt it could be performed by one team, as it just usually happens that the same people who might be exceptionally skilled in code review, system-level security, etc, at the same time are average cryptographers and vice-versa.
Imagine e.g. that you need to find out if there are any weaknesses in your system drive encryption software, something like BitLocker. Even if you get access to the source code, you still would have to analyze a lot of system-level details — how is the trusted boot implemented (SRTM? DRTM? TPM interaction?), which system software is trusted, how the implementation withstands various not-crypto-related attacks (e.g. some of the attacks I described in my previous post), etc…
But this all is just system-level evaluation. What should come later is to analyze the actual crypto algorithms and protocols. Those later tasks fall into cryptography field and not into system-level security discipline, and consequently should be performed by some other team, the crypto experts.
So, no doubt, it is not an easy task, and the fact if there is or there is not C/C++ source code available, is usually one of the minor headaches (a good example is our attack on TXT, where we were able to discover bugs in Intel's specific system software, which, of course, is not open source).
\ No newline at end of file
diff --git a/_posts/2009-02-10-nesting-vmms-reloaded.html b/_posts/2009-02-10-nesting-vmms-reloaded.html
index 2eb5f40..a313e4c 100644
--- a/_posts/2009-02-10-nesting-vmms-reloaded.html
+++ b/_posts/2009-02-10-nesting-vmms-reloaded.html
@@ -12,4 +12,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2009/02/nesting-vmms-reloaded.html
---
-Besides breaking the Intel's stuff, we have also been doing other things over at our lab. Thought I would share this cool screenshot of a Virtual PC running inside Xen. More precisely what you see on the pic is: Windows XP running inside Virtual PC, that runs inside Vista, which itself runs inside a Xen's HVM VM. Both the Virtual PC and Xen are using the Intel's hardware virtualization (VT-x is always used for HVM guests on Xen).
Our Nested Xen patch is part of a work done for a customer, so it is not going to be published. Besides it is currently a bit unstable ;) It's just a prototype that shows such a thing could be done.
 \ No newline at end of file
+Besides breaking the Intel's stuff, we have also been doing other things over at our lab. Thought I would share this cool screenshot of a Virtual PC running inside Xen. More precisely what you see on the pic is: Windows XP running inside Virtual PC, that runs inside Vista, which itself runs inside a Xen's HVM VM. Both the Virtual PC and Xen are using the Intel's hardware virtualization (VT-x is always used for HVM guests on Xen).
\ No newline at end of file
+Besides breaking the Intel's stuff, we have also been doing other things over at our lab. Thought I would share this cool screenshot of a Virtual PC running inside Xen. More precisely what you see on the pic is: Windows XP running inside Virtual PC, that runs inside Vista, which itself runs inside a Xen's HVM VM. Both the Virtual PC and Xen are using the Intel's hardware virtualization (VT-x is always used for HVM guests on Xen).
Our Nested Xen patch is part of a work done for a customer, so it is not going to be published. Besides it is currently a bit unstable ;) It's just a prototype that shows such a thing could be done.
\ No newline at end of file
diff --git a/_posts/2009-03-19-attacking-smm-memory-via-intel-cpu.html b/_posts/2009-03-19-attacking-smm-memory-via-intel-cpu.html
index d4080c9..39798f2 100644
--- a/_posts/2009-03-19-attacking-smm-memory-via-intel-cpu.html
+++ b/_posts/2009-03-19-attacking-smm-memory-via-intel-cpu.html
@@ -12,4 +12,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2009/03/attacking-smm-memory-via-intel-cpu.html
---
-As promised, the paper and the proof of concept code has just been posted on the ITL website here.
A quote from the paper:
In this paper we have described practical exploitation of the CPU cache poisoning in order to read or write into (otherwise protected) SMRAM memory. We have implemented two working exploits: one for dumping the content of SMRAM and the other one for arbitrary code execution in SMRAM. This is the third attack on SMM memory our team has found within the last 10 months, affecting Intel-based systems. It seems that current state of firmware security, even in case of such reputable vendors as Intel, is quite unsatisfying.
The potential consequence of attacks on SMM might include SMM rootkits [9], hypervisor compromises [8], or OS kernel protection bypassing [2].
Don't worry, the shellcode we use in the exploit is totally harmless (have really no idea how some people concluded we were going to release an SMM rootkit today?) — it only increases an internal counter on every SMI and jumps back to the original handler. If you want something more fancy, AKA SMM rootkits, you might want to re-read Sherri's and Shawn's last year's Black Hat paper and try writing something they describe there.
The attack presented in the paper has been fixed on some systems according to Intel. We have however found out that even the relatively new boards, like e.g. Intel DQ35 are still vulnerable (the very recent Intel DQ45 doesn't seem to be vulnerable though). The exploit attached is for DQ35 board — the offsets would have to be changed to work on other boards (please do not ask how to do this).
Keep in mind this is a different SMM attack than the one we mentioned during our last month's Black Hat presentation on TXT bypassing (the VU#127284). We are planning to present that other attack at the upcoming Black Hat Vegas. Hopefully this will not be the only one thing that ITL will entertain you with in Vegas — Alex and Rafal are already working now on something even cooler (and even lower level) for the show, so cross your fingers!
And good luck to Loic with his presentation that is about to start just now...
\ No newline at end of file
+As promised, the paper and the proof of concept code has just been posted on the ITL website here.
A quote from the paper:
In this paper we have described practical exploitation of the CPU cache poisoning in order to read or write into (otherwise protected) SMRAM memory. We have implemented two working exploits: one for dumping the content of SMRAM and the other one for arbitrary code execution in SMRAM. This is the third attack on SMM memory our team has found within the last 10 months, affecting Intel-based systems. It seems that current state of firmware security, even in case of such reputable vendors as Intel, is quite unsatisfying.
The potential consequence of attacks on SMM might include SMM rootkits [9], hypervisor compromises [8], or OS kernel protection bypassing [2].
Don't worry, the shellcode we use in the exploit is totally harmless (have really no idea how some people concluded we were going to release an SMM rootkit today?) — it only increases an internal counter on every SMI and jumps back to the original handler. If you want something more fancy, AKA SMM rootkits, you might want to re-read Sherri's and Shawn's last year's Black Hat paper and try writing something they describe there.
The attack presented in the paper has been fixed on some systems according to Intel. We have however found out that even the relatively new boards, like e.g. Intel DQ35 are still vulnerable (the very recent Intel DQ45 doesn't seem to be vulnerable though). The exploit attached is for DQ35 board — the offsets would have to be changed to work on other boards (please do not ask how to do this).
Keep in mind this is a different SMM attack than the one we mentioned during our last month's Black Hat presentation on TXT bypassing (the VU#127284). We are planning to present that other attack at the upcoming Black Hat Vegas. Hopefully this will not be the only one thing that ITL will entertain you with in Vegas — Alex and Rafal are already working now on something even cooler (and even lower level) for the show, so cross your fingers!
And good luck to Loic with his presentation that is about to start just now...
\ No newline at end of file
diff --git a/_posts/2009-03-20-sky-is-falling.html b/_posts/2009-03-20-sky-is-falling.html
index 8cdec2b..8d31b46 100644
--- a/_posts/2009-03-20-sky-is-falling.html
+++ b/_posts/2009-03-20-sky-is-falling.html
@@ -11,4 +11,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2009/03/sky-is-falling.html
---
-A few reporters asked me if our recent paper on SMM attacking via CPU cache poisoning means the sky is really falling now?
Interestingly, not many people seem to have noticed that this is the 3rd attack against SMM our team has found in the last 10 months. OMG :o
But anyway, does the fact we can easily compromise the SMM today, and write SMM-based malware, does that mean the sky is falling for the average computer user?
No! The sky has actually fallen many years ago… Default users with admin privileges, monolithic kernels everywhere, most software unsigned and downloadable over plaintext HTTP — these are the main reasons we cannot trust our systems today. And those pathetic attempts to fix it, e.g. via restricting admin users on Vista, but still requiring full admin rights to install any piece of stupid software. Or selling people illusion of security via A/V programs, that cannot even protect themselves properly…
It's also funny how so many people focus on solving the security problems by "Security by Correctness" or "Security by Obscurity" approaches — patches, patches, NX and ASLR — all good, but it is not gonna work as an ultimate protection (if it could, it would worked out already).
On the other hand, there are some emerging technologies out there that could allow us to implement effective "Security by Isolation" approach. Such technologies as VT-x/AMD-V, VT-d/IOMMU or Intel TXT and TPM.
So we, at ITL, focus on analyzing those new technologies, even though almost nobody uses them today. Because those technologies could actually make the difference. Unlike A/V programs or Patch Tuesdays, those technologies can change the level of sophistication required for the attacker dramatically.
The attacks we focus on are important for those new technologies — e.g. today Intel TXT is pretty much useless without protection from SMM attacks. And currently there is no such protection, which sucks. SMM rootkits sound sexy, but, frankly, the bad guys are doing just fine using traditional kernel mode malware (due to the fact that A/V is not effective). Of course, SMM rootkits are just yet another annoyance for the traditional A/V programs, which is good, but they might not be the most important consequence of SMM attacks.
So, should the average Joe Dow care about our SMM attacks? Absolutely not!
\ No newline at end of file
+A few reporters asked me if our recent paper on SMM attacking via CPU cache poisoning means the sky is really falling now?
Interestingly, not many people seem to have noticed that this is the 3rd attack against SMM our team has found in the last 10 months. OMG :o
But anyway, does the fact we can easily compromise the SMM today, and write SMM-based malware, does that mean the sky is falling for the average computer user?
No! The sky has actually fallen many years ago… Default users with admin privileges, monolithic kernels everywhere, most software unsigned and downloadable over plaintext HTTP — these are the main reasons we cannot trust our systems today. And those pathetic attempts to fix it, e.g. via restricting admin users on Vista, but still requiring full admin rights to install any piece of stupid software. Or selling people illusion of security via A/V programs, that cannot even protect themselves properly…
It's also funny how so many people focus on solving the security problems by "Security by Correctness" or "Security by Obscurity" approaches — patches, patches, NX and ASLR — all good, but it is not gonna work as an ultimate protection (if it could, it would worked out already).
On the other hand, there are some emerging technologies out there that could allow us to implement effective "Security by Isolation" approach. Such technologies as VT-x/AMD-V, VT-d/IOMMU or Intel TXT and TPM.
So we, at ITL, focus on analyzing those new technologies, even though almost nobody uses them today. Because those technologies could actually make the difference. Unlike A/V programs or Patch Tuesdays, those technologies can change the level of sophistication required for the attacker dramatically.
The attacks we focus on are important for those new technologies — e.g. today Intel TXT is pretty much useless without protection from SMM attacks. And currently there is no such protection, which sucks. SMM rootkits sound sexy, but, frankly, the bad guys are doing just fine using traditional kernel mode malware (due to the fact that A/V is not effective). Of course, SMM rootkits are just yet another annoyance for the traditional A/V programs, which is good, but they might not be the most important consequence of SMM attacks.
So, should the average Joe Dow care about our SMM attacks? Absolutely not!
\ No newline at end of file
diff --git a/_posts/2009-06-02-more-thoughts-on-cpu-backdoors.html b/_posts/2009-06-02-more-thoughts-on-cpu-backdoors.html
index 7f0569c..73359f3 100644
--- a/_posts/2009-06-02-more-thoughts-on-cpu-backdoors.html
+++ b/_posts/2009-06-02-more-thoughts-on-cpu-backdoors.html
@@ -11,4 +11,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2009/06/more-thoughts-on-cpu-backdoors.html
---
-I've recently exchanged a few emails with Loic Duflot about CPU-based backdoors. It turned out that he recently wrote a paper about hypothetical CPU-backdoors and also implemented some proof-of-concept ones using QEMU (for he doesn't happen to own a private CPU production line). The paper can be bought here. (Loic is an academic, and so he must follow some of the strange customs in the academic world, one of them being that papers are not freely published, but rather being sold on a publisher website… Heck, even we, the ultimately commercialized researchers, still publish our papers and code for free).
Let me stress that what Loic writes about in the paper are only hypothetical backdoors, i.e. no actual backdoors have been found on any real CPU (ever, AFAIK!). What he does is he considers how Intel or AMD could implement a backdoor, and then he simulate this process by using QEMU and implementing those backdoors inside QEMU.
Loic also focuses on local privilege escalation backdoors only. You should however not underestimate a good local privilege escalation — such things could be used to break out of any virtual machine, like VMWare, or potentially even out of a software VMs like e.g. Java VM.
The backdoors Loic considers are somewhat similar in principle to the simple pseudo-code one-liner backdoor I used in my previous post about hardware backdoors, only more complicated in the actual implementation, as he took care about a few important details, that I naturally didn't concern. (BTW, the main message of my previous post about was how cool technology this VT-d is, being able to prevent PCI-based backdoors, and not about how doomed we are because of Intel- or AMD-induced potential backdoors).
Some people believe that processor backdoors do not exist in reality, because if they did, the competing CPU makers would be able to find them in each others' products, and later would likely cause a "leak" to the public about such backdoors (think: Black PR). Here people make an assumption that AMD or Intel is technically capable of reversing each others processors, which seems to be a natural consequence of them being able to produce them.
I don't think I fully agree with such an assumption though. Just the fact that you are capable of designing and producing a CPU, doesn't mean you can also reverse engineer it. Just the fact that Adobe can write a few hundred megabyte application, doesn't mean they are automatically capable of also reverse engineering similar applications of that size. Even if we assumed that it is technically feasible to use some electron microscope to scan and map all the electronic elements from the processor, there is still a problem of interpreting of how all those hundreds of millions of transistors actually work.
Anyway, a few more thoughts about properties of a hypothetical backdoors that Intel or AMD might use (be using).
First, I think that in such a backdoor scenario everything besides the "trigger" would be encrypted. The trigger is something that you must execute first, in order to activate the backdoor (e.g. the CMP instruction with particular, i.e. magic, values of some registers, say EAX, EBX, ECX, EDX). Only then the backdoor gets activated and e.g. the processor auto-magically escalates into Ring 0. Loic considers this in more detail in his paper. So, my point is that all the attacker's code that executes afterwards, think of it as of a shellcode for the backdoor, that is specific for the OS, is fetched by the processor in an encrypted form and decrypted only internally inside the CPU. That should be trivial to implement, while at the same time should complicate any potential forensic analysis afterwards — it would be highly non-trivial to understand what the backdoor actually have done.
Another crucial thing for a processor backdoor, I think, should be some sort of an anti-reply attack protection. Normally, if a smart admin had been recording all the network traffic, and also all the executables that ever got executed on the host, chances are that he or she would catch the triggering code and the shellcode (which might be encrypted, but still). So, no matter how subtle the trigger is, it is still quite possible that a curious admin will eventually find out that some tetris.exe somehow managed to breakout of a hardware VM and did something strange, e.g. installed a rootkit in a hypervisor (or some Java code somehow was able to send over all our DOCX files from our home directory).
Eventually the curious admin will find out that strange CPU instruction (the trigger) after which all the strange things had happened. Now, if the admin was able to take this code and replicate it, post it to Daily Dave, then, assuming his message would pass through the Moderator (Hi Dave), he would effectively compromise the processor vendor's reputation.
An anti-replay mechanism could ideally be some sort of a challenge-response protocol used in a trigger. So, instead having you always to put 0xdeadbeaf, 0xbabecafe, and 0x41414141 into EAX, EBX and EDX and execute some magic instruction (say CMP), you would have to put a magic that is a result of some crypto operation, taking current date and magic key as input:
Magic = MAGIC (Date, IntelSecretKey).
The obvious problem is how the processor can obtain current date? It would have to talk to the south-bridge at best, which is 1) nontrivial, and 2) observable on a bus, and 3) spoof'able.
A much better idea would be to equip a processor with some sort of an eeprom memory, say big enough to hold one 64-bit or maybe 128-bit value. Each processor would get a different value flashed there when leaving the factory. Now, in order to trigger the backdoor, the processor vendor (or backdoor operator, think: NSA) would have to do the following:
1) First execute some code that would read this unique value stored in eeprom for the particular target processor, and send this back to them,
2) Now, they could generate the actual magic for the trigger:
Magic = MAGIC (UniqeValueInEeprom, IntelSecretKey)
3) ...and send the actual code to execute the backdoor and shellcode, with the correct trigger embedded, based on the magic value.
Now, the point is that the processor will automatically increment the unique number stored in the eeprom, so the same backdoor-exploiting code would not work twice for the same processor (while at the same time it would be easy for NSA to send another exploit, as they know what the next value in the eeprom should be). Also, such a customized exploit would not work on any other CPU, as the assumption was that each CPU gets a different value at the factory, so again it would not be possible to replicate the attack and proved that the particular code has ever done something wrong.
So, the moment I learn that processors have built-in eeprom memory, I will start thinking seriously there are backdoors out there :)
One thing that bothers me with all those divagations about hypothetical backdoors in processors is that I find them pretty useless in at the end of the day. After all, by talking about those backdoors, and how they might be created, we do not make it any easier to protect against them, as there simply is no possible defense here. Also this doesn't make it any easier for us to build such backdoors (if we wanted to become the bad guys for a change). It might only be of an interest to Intel or AMD, or whatever else processor maker, but I somewhat feel they have already spent much more time thinking about it, and chances are they probably can only laugh at what we are saying here, seeing how unsophisticated our proposed backdoors are. So, my Dear Reader, I think you've been just wasting time reading this post ;) Sorry for tricking you into this and I hope to write something more practical next time :)
\ No newline at end of file
+I've recently exchanged a few emails with Loic Duflot about CPU-based backdoors. It turned out that he recently wrote a paper about hypothetical CPU-backdoors and also implemented some proof-of-concept ones using QEMU (for he doesn't happen to own a private CPU production line). The paper can be bought here. (Loic is an academic, and so he must follow some of the strange customs in the academic world, one of them being that papers are not freely published, but rather being sold on a publisher website… Heck, even we, the ultimately commercialized researchers, still publish our papers and code for free).
Let me stress that what Loic writes about in the paper are only hypothetical backdoors, i.e. no actual backdoors have been found on any real CPU (ever, AFAIK!). What he does is he considers how Intel or AMD could implement a backdoor, and then he simulate this process by using QEMU and implementing those backdoors inside QEMU.
Loic also focuses on local privilege escalation backdoors only. You should however not underestimate a good local privilege escalation — such things could be used to break out of any virtual machine, like VMWare, or potentially even out of a software VMs like e.g. Java VM.
The backdoors Loic considers are somewhat similar in principle to the simple pseudo-code one-liner backdoor I used in my previous post about hardware backdoors, only more complicated in the actual implementation, as he took care about a few important details, that I naturally didn't concern. (BTW, the main message of my previous post about was how cool technology this VT-d is, being able to prevent PCI-based backdoors, and not about how doomed we are because of Intel- or AMD-induced potential backdoors).
Some people believe that processor backdoors do not exist in reality, because if they did, the competing CPU makers would be able to find them in each others' products, and later would likely cause a "leak" to the public about such backdoors (think: Black PR). Here people make an assumption that AMD or Intel is technically capable of reversing each others processors, which seems to be a natural consequence of them being able to produce them.
I don't think I fully agree with such an assumption though. Just the fact that you are capable of designing and producing a CPU, doesn't mean you can also reverse engineer it. Just the fact that Adobe can write a few hundred megabyte application, doesn't mean they are automatically capable of also reverse engineering similar applications of that size. Even if we assumed that it is technically feasible to use some electron microscope to scan and map all the electronic elements from the processor, there is still a problem of interpreting of how all those hundreds of millions of transistors actually work.
Anyway, a few more thoughts about properties of a hypothetical backdoors that Intel or AMD might use (be using).
First, I think that in such a backdoor scenario everything besides the "trigger" would be encrypted. The trigger is something that you must execute first, in order to activate the backdoor (e.g. the CMP instruction with particular, i.e. magic, values of some registers, say EAX, EBX, ECX, EDX). Only then the backdoor gets activated and e.g. the processor auto-magically escalates into Ring 0. Loic considers this in more detail in his paper. So, my point is that all the attacker's code that executes afterwards, think of it as of a shellcode for the backdoor, that is specific for the OS, is fetched by the processor in an encrypted form and decrypted only internally inside the CPU. That should be trivial to implement, while at the same time should complicate any potential forensic analysis afterwards — it would be highly non-trivial to understand what the backdoor actually have done.
Another crucial thing for a processor backdoor, I think, should be some sort of an anti-reply attack protection. Normally, if a smart admin had been recording all the network traffic, and also all the executables that ever got executed on the host, chances are that he or she would catch the triggering code and the shellcode (which might be encrypted, but still). So, no matter how subtle the trigger is, it is still quite possible that a curious admin will eventually find out that some tetris.exe somehow managed to breakout of a hardware VM and did something strange, e.g. installed a rootkit in a hypervisor (or some Java code somehow was able to send over all our DOCX files from our home directory).
Eventually the curious admin will find out that strange CPU instruction (the trigger) after which all the strange things had happened. Now, if the admin was able to take this code and replicate it, post it to Daily Dave, then, assuming his message would pass through the Moderator (Hi Dave), he would effectively compromise the processor vendor's reputation.
An anti-replay mechanism could ideally be some sort of a challenge-response protocol used in a trigger. So, instead having you always to put 0xdeadbeaf, 0xbabecafe, and 0x41414141 into EAX, EBX and EDX and execute some magic instruction (say CMP), you would have to put a magic that is a result of some crypto operation, taking current date and magic key as input:
Magic = MAGIC (Date, IntelSecretKey).
The obvious problem is how the processor can obtain current date? It would have to talk to the south-bridge at best, which is 1) nontrivial, and 2) observable on a bus, and 3) spoof'able.
A much better idea would be to equip a processor with some sort of an eeprom memory, say big enough to hold one 64-bit or maybe 128-bit value. Each processor would get a different value flashed there when leaving the factory. Now, in order to trigger the backdoor, the processor vendor (or backdoor operator, think: NSA) would have to do the following:
1) First execute some code that would read this unique value stored in eeprom for the particular target processor, and send this back to them,
2) Now, they could generate the actual magic for the trigger:
Magic = MAGIC (UniqeValueInEeprom, IntelSecretKey)
3) ...and send the actual code to execute the backdoor and shellcode, with the correct trigger embedded, based on the magic value.
Now, the point is that the processor will automatically increment the unique number stored in the eeprom, so the same backdoor-exploiting code would not work twice for the same processor (while at the same time it would be easy for NSA to send another exploit, as they know what the next value in the eeprom should be). Also, such a customized exploit would not work on any other CPU, as the assumption was that each CPU gets a different value at the factory, so again it would not be possible to replicate the attack and proved that the particular code has ever done something wrong.
So, the moment I learn that processors have built-in eeprom memory, I will start thinking seriously there are backdoors out there :)
One thing that bothers me with all those divagations about hypothetical backdoors in processors is that I find them pretty useless in at the end of the day. After all, by talking about those backdoors, and how they might be created, we do not make it any easier to protect against them, as there simply is no possible defense here. Also this doesn't make it any easier for us to build such backdoors (if we wanted to become the bad guys for a change). It might only be of an interest to Intel or AMD, or whatever else processor maker, but I somewhat feel they have already spent much more time thinking about it, and chances are they probably can only laugh at what we are saying here, seeing how unsophisticated our proposed backdoors are. So, my Dear Reader, I think you've been just wasting time reading this post ;) Sorry for tricking you into this and I hope to write something more practical next time :)
\ No newline at end of file
diff --git a/_posts/2009-08-25-vegas-toys-part-i-ring-3-tools.html b/_posts/2009-08-25-vegas-toys-part-i-ring-3-tools.html
index 77b4c28..b163768 100644
--- a/_posts/2009-08-25-vegas-toys-part-i-ring-3-tools.html
+++ b/_posts/2009-08-25-vegas-toys-part-i-ring-3-tools.html
@@ -13,4 +13,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2009/08/vegas-toys-part-i-ring-3-tools.html
---
-We've just published the proof of concept code for the Alex's and Rafal's "Ring -3 Rootkits" talk, presented last month at the Black Hat conference in Vegas. You can download the code from our website here. It's highly recommended that one (re)reads the slides before playing with the code.
In short, the code demonstrates injection of an arbitrary ARC4 code into a vPro-compatible chipset AMT/ME memory using the chipset memory reclaiming attack. Check the README and the slides for more information.

The actual ARC4 code we distribute here is very simple: it sets a DMA write transaction to the host memory every ca. 15 seconds in order to write the "ITL" string at the predefined physical addresses (increased by 4 with every iteration). Of course one can do DMA read as well.

The ability to do DMA from the ARC4 code to/from the host memory is, in fact, all that is necessary to write a sophisticated rootkit or any sort of malware, from funny jokers to sophisticated secret sniffers. Your imagination (and good pattern searching) is the only limit here.
The OS, nor any software running on the host OS, cannot access our rootkit code, unless, of course, it used the same remapping attack we used to insert our code there :) But the rootkit might even cut off this way by locking down the remapping registers, so fixing the vulnerability on the fly, after exploiting it (of course it would be insane for any AV to use our remapping attack in order to scan ME space, but just for completeness;)
An OS might attempt to protect itself from DMA accesses from the rootkit in the chipset by carefully setting VT-d protections. Xen 3.3/3.4, for example, sets VT-d protections in such a way that our rootkit cannot access the Xen hypervisor memory. We can, however, access all the other parts of the system which includes all the domains memory (i.e. where all the interesting data are located). Still, it should be possible to modify Xen so that it set VT-d mappings in such a strict way, that the AMT code (and the AMT rootkit) could not access any useful information in any of the domains. This, in fact, would be a good idea anyway, as it would also prevent any sort of hardware-based backdoors (except for the backdoors in the CPU).
An AMT rootkit can, however, get around such a savvy OS because it can modify the OS's VT-d initialization code before it sets the VT-d protections. Alternatively, if the protections are set before the rootkit was activated, the rootkit can force the system to reboot and boot it from the AMT Virtual CDROM (In fact AMT has been designed to be able to do exactly that), which would contain rootkit agent code that would modify the OS/VMM to-be-loaded image, so that it doesn't setup VT-d properly.
Of course, the proper solution against such an attack would be to use e.g. Intel TXT to assure trusted boot of the system. In theory this should work. In practice, as you might recall, we have already shown how to bypass Intel TXT. This TXT bypass attack still works on most (all?) hardware, as there is still no STM available in the wild (all that is needed for the attack is to have a working SMM attack, and last month we showed 2 such attacks — see the slides for the BIOS talk).
Intel has released a patch a day before our presentation at Black Hat. This is a cumulative patch that is also targeting a few other, unrelated, problems, like e.g. the SMM caching attack (also reported by Loic), the SMM nvacpi attack, and the Q45 BIOS reflashing attack (for which the code will be also published shortly).
Some of you might remember that Intel has patched this very remapping bug last year, after our Xen 0wning Trilogy presentations, where we used the very same bug to get around Xen hypervisor protections. However, Intel forgot about one small detail — namely it was perfectly possible for malware to downgrade BIOS to the previous, pre-Black-Hat-2008 version, without any user consent (after all this old BIO file was also digitally signed by Intel). So, with just one additional reboot (but without a user intervention needed) malware could still use the old remapping bug, this time to get access to the AMT memory. The recent patch mentioned above solves this problem by displaying a prompt during reflash boot, if reflashing to an older version of BIOS. So now it requires user intervention (a physical presence). This "downgrade protection" works, however, only if we have administrator password enabled in BIOS.
We could get into the AMT memory on Q35, however, even if the downgrade attack was not possible. In that case we could use our BIOS reflashing exploit (the other Black Hat presentation).
However, this situation looks differently on Intel latest Q45 chipsets (that also have AMT). As explained in the presentation, we were unable to get access to the AMT memory on those chipsets, even though we can reflash the BIOS there, and consequently, even though we can get rid of all the chipset locks (e.g. the remapping locks). Still, the remapping doesn't seem to work for this one memory range, where the AMT code resides.
This suggest Intel added some additional hardware to the Q45 chipset (and other Series 4 chipsets) to prevent this very type of attacks. But we're not giving up on Q45 yet, and we will be trying other attacks, as soon as we recover from the holiday laziness ;)
Finally, the nice picture of the Q35 chipset (MCH), where our rootkit lives :) The ARC4 processor is somewhere inside...
 \ No newline at end of file
+We've just published the proof of concept code for the Alex's and Rafal's "Ring -3 Rootkits" talk, presented last month at the Black Hat conference in Vegas. You can download the code from our website here. It's highly recommended that one (re)reads the slides before playing with the code.
\ No newline at end of file
+We've just published the proof of concept code for the Alex's and Rafal's "Ring -3 Rootkits" talk, presented last month at the Black Hat conference in Vegas. You can download the code from our website here. It's highly recommended that one (re)reads the slides before playing with the code.
In short, the code demonstrates injection of an arbitrary ARC4 code into a vPro-compatible chipset AMT/ME memory using the chipset memory reclaiming attack. Check the README and the slides for more information.
The actual ARC4 code we distribute here is very simple: it sets a DMA write transaction to the host memory every ca. 15 seconds in order to write the "ITL" string at the predefined physical addresses (increased by 4 with every iteration). Of course one can do DMA read as well.
The ability to do DMA from the ARC4 code to/from the host memory is, in fact, all that is necessary to write a sophisticated rootkit or any sort of malware, from funny jokers to sophisticated secret sniffers. Your imagination (and good pattern searching) is the only limit here.
The OS, nor any software running on the host OS, cannot access our rootkit code, unless, of course, it used the same remapping attack we used to insert our code there :) But the rootkit might even cut off this way by locking down the remapping registers, so fixing the vulnerability on the fly, after exploiting it (of course it would be insane for any AV to use our remapping attack in order to scan ME space, but just for completeness;)
An OS might attempt to protect itself from DMA accesses from the rootkit in the chipset by carefully setting VT-d protections. Xen 3.3/3.4, for example, sets VT-d protections in such a way that our rootkit cannot access the Xen hypervisor memory. We can, however, access all the other parts of the system which includes all the domains memory (i.e. where all the interesting data are located). Still, it should be possible to modify Xen so that it set VT-d mappings in such a strict way, that the AMT code (and the AMT rootkit) could not access any useful information in any of the domains. This, in fact, would be a good idea anyway, as it would also prevent any sort of hardware-based backdoors (except for the backdoors in the CPU).
An AMT rootkit can, however, get around such a savvy OS because it can modify the OS's VT-d initialization code before it sets the VT-d protections. Alternatively, if the protections are set before the rootkit was activated, the rootkit can force the system to reboot and boot it from the AMT Virtual CDROM (In fact AMT has been designed to be able to do exactly that), which would contain rootkit agent code that would modify the OS/VMM to-be-loaded image, so that it doesn't setup VT-d properly.
Of course, the proper solution against such an attack would be to use e.g. Intel TXT to assure trusted boot of the system. In theory this should work. In practice, as you might recall, we have already shown how to bypass Intel TXT. This TXT bypass attack still works on most (all?) hardware, as there is still no STM available in the wild (all that is needed for the attack is to have a working SMM attack, and last month we showed 2 such attacks — see the slides for the BIOS talk).
Intel has released a patch a day before our presentation at Black Hat. This is a cumulative patch that is also targeting a few other, unrelated, problems, like e.g. the SMM caching attack (also reported by Loic), the SMM nvacpi attack, and the Q45 BIOS reflashing attack (for which the code will be also published shortly).
Some of you might remember that Intel has patched this very remapping bug last year, after our Xen 0wning Trilogy presentations, where we used the very same bug to get around Xen hypervisor protections. However, Intel forgot about one small detail — namely it was perfectly possible for malware to downgrade BIOS to the previous, pre-Black-Hat-2008 version, without any user consent (after all this old BIO file was also digitally signed by Intel). So, with just one additional reboot (but without a user intervention needed) malware could still use the old remapping bug, this time to get access to the AMT memory. The recent patch mentioned above solves this problem by displaying a prompt during reflash boot, if reflashing to an older version of BIOS. So now it requires user intervention (a physical presence). This "downgrade protection" works, however, only if we have administrator password enabled in BIOS.
We could get into the AMT memory on Q35, however, even if the downgrade attack was not possible. In that case we could use our BIOS reflashing exploit (the other Black Hat presentation).
However, this situation looks differently on Intel latest Q45 chipsets (that also have AMT). As explained in the presentation, we were unable to get access to the AMT memory on those chipsets, even though we can reflash the BIOS there, and consequently, even though we can get rid of all the chipset locks (e.g. the remapping locks). Still, the remapping doesn't seem to work for this one memory range, where the AMT code resides.
This suggest Intel added some additional hardware to the Q45 chipset (and other Series 4 chipsets) to prevent this very type of attacks. But we're not giving up on Q45 yet, and we will be trying other attacks, as soon as we recover from the holiday laziness ;)
Finally, the nice picture of the Q35 chipset (MCH), where our rootkit lives :) The ARC4 processor is somewhere inside...
\ No newline at end of file
diff --git a/_posts/2009-09-02-about-apples-security-foundations-or.html b/_posts/2009-09-02-about-apples-security-foundations-or.html
index ff6eb54..646eee6 100644
--- a/_posts/2009-09-02-about-apples-security-foundations-or.html
+++ b/_posts/2009-09-02-about-apples-security-foundations-or.html
@@ -12,4 +12,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2009/09/about-apples-security-foundations-or.html
---
-Every once in a while it’s healthy to reinstall your system... I know, I know, it’s almost a heresy to say that, but that’s reality in the world where our systems are totally unverifiable. In fact I don’t even attempt to verify if my Mac laptop has been compromised in any way (most system files are not signed anyway). But sometimes, you got this feeling that something might be wrong and you decide to reinstall to start your (digital) life all over again :)
So, every time I (re)install a Mac-based system, I end up cursing horribly at Apple’s architects. Why? Because in the Apple World they seem to totally ignore the concept of files integrity, to such extent that it’s virtually impossible to get any assurance that the programs I install are in any way authentic (i.e. not tampered by some 3rd party, e.g. by somebody controlling my Internet connection).
Take any Apple installer package, e.g. Thunderbird. In most cases an installer package on Mac is a .dmg file, that represents an installation disk image. Now, when you open such a file under Mac, the OS will never display any information about if this file is somehow signed (e.g. by who) or not. In fact, I’m pretty sure it’s never signed. What you end up with, is a .dmg file that you just downloaded over plaintext HTTP and you have absolutely no way of verifying if it is the original file the vendor really published. And you’re just about to grant admin privileges to the installer program that is inside this file -- after all it’s an installer, so must got root privileges, right (well, not quite maybe)? Beautiful...
Interestingly, this very same Thunderbird installer, but for Windows, is correctly signed, and Windows, correctly, displays that information (together with the ability to examine the certificate) and allows the user to make a choice of whether to allow it to run or not.
Sure, the certificate doesn’t guarantee that Mozilla didn’t put a nasty backdoor in there, nor that the file was not compromised due to Mozilla’s internal server compromise. Or that the certificate (the private key) wasn’t somehow stolen from Mozilla, or that the issuing authority didn’t make a mistake and maybe issued this certificate to some random guy, who just happened to be named Mozilla.
But the certificate provides liability. If it indeed turns out that this very Thunderbird installer was somehow malicious, I could take this signed file to the court and sue either Mozilla, or the certification authority for all the damages it might have done to me. Without the certificate I cannot do that, because I (and nobody) cannot know if the file was tampered while being downloaded (e.g. malicious ISP) or maybe because my system was already compromised.
But in case of Apple, we have no such choice -- we need to take the risk every time we download a program from the Internet. We must bet the security of our whole system, that at this very moment nobody is tampering with out (unsecured) HTTP connection, and also that nobody compromised the vendor’s Web Server, and, of course, we hope that the vendor didn’t put any malicious code into its product (as we could not sue them for it).
So that sucks. That sucks terribly! Without ability to check the integrity of programs we want to install, we cannot build any solid foundations. It’s funny how people divagate whether Apple implemented ASLR correctly in Snow Leopard, or not? Or whether NX is bypassable. It’s meaningless to dive into such advanced topics, if we cannot even assure that at the day 0 our system is clean. We need to start building our systems from the ground up, and not starting from the roof! Ability to assure the software we install is not tampered seems like a reasonable very first step. (Sure it could be compromised 5 minutes later, and to protect against this we should have other mechanisms, like e.g. mentioned above ASLR and NX).
And Apple should not blame the vendors for such a situation (“Vendors would never pay $300 for a certificate”, blah, blah), as it is just enough to have a look at the Windows versions of the same products, and that most of them do have signed installers (gee, even open-source TrueCrypt, has a signed installer for Windows!).
One should say that a few vendors, seeing this problem on Mac, do publish PGP signatures for their installation files. This includes e.g. PGP Desktop for Mac, KeePassX, TrueCrypt for Mac, and a few others. But these are just exceptions and I wonder how many users will be disciplined (and savvy) enough to correctly verify those PGP signatures (in general it requires you to download the vendor keys many months before, keep it in your ring, to minimize possibility that somebody alters both the installer files and the keys you download). Some other vendors offer pseudo-integrity by displaying MD5/SHA1 sums on their websites. That would make some sense only if the website on which the hashes are displayed was itself SSL-protected (still the file signature is a better option), as otherwise we can be sure that the attacker that is tampering with the installer file, will also take care about adjusting the hash on the website... But of course this never is the case -- have a look e.g. at the VMWare download page for the Mac Fusion (one need to register first). Very smart, VMWare! (Needles to say, the VMWare Workstation installer for Windows is properly signed).
BTW, anybody checked if the Apple updates are digitally signed somehow?
All I wrote here in this post is just trivial. It should be just obvious for every decently educated software engineer. Believe me it’s really is much more fun for me to write about things like new attacks on chipsets or virtualization. But I have this little hope that maybe somebody at Apple will read this little post and fix their OS. Because I really like Apple products for their aesthetics...
\ No newline at end of file
+Every once in a while it’s healthy to reinstall your system... I know, I know, it’s almost a heresy to say that, but that’s reality in the world where our systems are totally unverifiable. In fact I don’t even attempt to verify if my Mac laptop has been compromised in any way (most system files are not signed anyway). But sometimes, you got this feeling that something might be wrong and you decide to reinstall to start your (digital) life all over again :)
So, every time I (re)install a Mac-based system, I end up cursing horribly at Apple’s architects. Why? Because in the Apple World they seem to totally ignore the concept of files integrity, to such extent that it’s virtually impossible to get any assurance that the programs I install are in any way authentic (i.e. not tampered by some 3rd party, e.g. by somebody controlling my Internet connection).
Take any Apple installer package, e.g. Thunderbird. In most cases an installer package on Mac is a .dmg file, that represents an installation disk image. Now, when you open such a file under Mac, the OS will never display any information about if this file is somehow signed (e.g. by who) or not. In fact, I’m pretty sure it’s never signed. What you end up with, is a .dmg file that you just downloaded over plaintext HTTP and you have absolutely no way of verifying if it is the original file the vendor really published. And you’re just about to grant admin privileges to the installer program that is inside this file -- after all it’s an installer, so must got root privileges, right (well, not quite maybe)? Beautiful...
Interestingly, this very same Thunderbird installer, but for Windows, is correctly signed, and Windows, correctly, displays that information (together with the ability to examine the certificate) and allows the user to make a choice of whether to allow it to run or not.
Sure, the certificate doesn’t guarantee that Mozilla didn’t put a nasty backdoor in there, nor that the file was not compromised due to Mozilla’s internal server compromise. Or that the certificate (the private key) wasn’t somehow stolen from Mozilla, or that the issuing authority didn’t make a mistake and maybe issued this certificate to some random guy, who just happened to be named Mozilla.
But the certificate provides liability. If it indeed turns out that this very Thunderbird installer was somehow malicious, I could take this signed file to the court and sue either Mozilla, or the certification authority for all the damages it might have done to me. Without the certificate I cannot do that, because I (and nobody) cannot know if the file was tampered while being downloaded (e.g. malicious ISP) or maybe because my system was already compromised.
But in case of Apple, we have no such choice -- we need to take the risk every time we download a program from the Internet. We must bet the security of our whole system, that at this very moment nobody is tampering with out (unsecured) HTTP connection, and also that nobody compromised the vendor’s Web Server, and, of course, we hope that the vendor didn’t put any malicious code into its product (as we could not sue them for it).
So that sucks. That sucks terribly! Without ability to check the integrity of programs we want to install, we cannot build any solid foundations. It’s funny how people divagate whether Apple implemented ASLR correctly in Snow Leopard, or not? Or whether NX is bypassable. It’s meaningless to dive into such advanced topics, if we cannot even assure that at the day 0 our system is clean. We need to start building our systems from the ground up, and not starting from the roof! Ability to assure the software we install is not tampered seems like a reasonable very first step. (Sure it could be compromised 5 minutes later, and to protect against this we should have other mechanisms, like e.g. mentioned above ASLR and NX).
And Apple should not blame the vendors for such a situation (“Vendors would never pay $300 for a certificate”, blah, blah), as it is just enough to have a look at the Windows versions of the same products, and that most of them do have signed installers (gee, even open-source TrueCrypt, has a signed installer for Windows!).
One should say that a few vendors, seeing this problem on Mac, do publish PGP signatures for their installation files. This includes e.g. PGP Desktop for Mac, KeePassX, TrueCrypt for Mac, and a few others. But these are just exceptions and I wonder how many users will be disciplined (and savvy) enough to correctly verify those PGP signatures (in general it requires you to download the vendor keys many months before, keep it in your ring, to minimize possibility that somebody alters both the installer files and the keys you download). Some other vendors offer pseudo-integrity by displaying MD5/SHA1 sums on their websites. That would make some sense only if the website on which the hashes are displayed was itself SSL-protected (still the file signature is a better option), as otherwise we can be sure that the attacker that is tampering with the installer file, will also take care about adjusting the hash on the website... But of course this never is the case -- have a look e.g. at the VMWare download page for the Mac Fusion (one need to register first). Very smart, VMWare! (Needles to say, the VMWare Workstation installer for Windows is properly signed).
BTW, anybody checked if the Apple updates are digitally signed somehow?
All I wrote here in this post is just trivial. It should be just obvious for every decently educated software engineer. Believe me it’s really is much more fun for me to write about things like new attacks on chipsets or virtualization. But I have this little hope that maybe somebody at Apple will read this little post and fix their OS. Because I really like Apple products for their aesthetics...
\ No newline at end of file
diff --git a/_posts/2009-10-16-evil-maid-goes-after-truecrypt.html b/_posts/2009-10-16-evil-maid-goes-after-truecrypt.html
index c26d3c0..f23e185 100644
--- a/_posts/2009-10-16-evil-maid-goes-after-truecrypt.html
+++ b/_posts/2009-10-16-evil-maid-goes-after-truecrypt.html
@@ -15,4 +15,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2009/10/evil-maid-goes-after-truecrypt.html
---
-From time to time it’s good to take a break from all the ultra-low-level stuff, like e.g. chipset or TXT hacking, and do something simple, yet still important. Recently Alex Tereshkin and I got some spare time and we implemented the Evil Maid Attack against TrueCrypt system disk encryption in a form of a small bootable USB stick image that allows to perform the attack in an easy “plug-and-play” way. The whole infection process takes about 1 minute, and it’s well suited to be used by hotel maids.
The Attack
Let’s quickly recap the Evil Maid Attack. The scenario we consider is when somebody left an encrypted laptop e.g. in a hotel room. Let’s assume the laptop uses full disk encryption like e.g. this provided by TrueCrypt or PGP Whole Disk Encryption.
Many people believe, including some well known security experts, that it is advisable to fully power down your laptop when you use full disk encryption in order to prevent attacks via FireWire/PCMCIA or ”Coldboot” attacks.
So, let’s assume we have a reasonably paranoid user, that uses full disk encryption on his or her laptop, and also powers it down every time they leave it alone in a hotel room, or somewhere else.
Now, this is where our Evil Maid stick comes into play. All the attacker needs to do is to sneak into the user’s hotel room and boot the laptop from the Evil Maid USB Stick. After some 1-2 minutes, the target laptop’s gets infected with Evil Maid Sniffer that will record the disk encryption passphrase when the user enters it next time. As any smart user might have guessed already, this part is ideally suited to be performed by hotel maids, or people pretending to be them.
So, after our victim gets back to the hotel room and powers up his or her laptop, the passphrase will be recorded and e.g. stored somewhere on the disk, or maybe transmitted over the network (not implemented in current version).
 Now we can safely steal/confiscate the user’s laptop, as we know how to decrypt it. End of story.
Now we can safely steal/confiscate the user’s laptop, as we know how to decrypt it. End of story.
Quick Start
Download the USB image here. In order to “burn” the Evil Maid use the following commands on Linux (you need to be root to do dd):
dd if=evilmaidusb.img of=/dev/sdX
Where /dev/sdX should be replaced with the device representing your USB stick, e.g. /dev/sdb. Please be careful, as choosing a wrong device might result in damaging your hard disk or other media! Also, make sure to use the device representing the whole disk (e.g. /dev/sdb), rather than a disk partition (e.g. /dev/sdb1).
On Windows you would need to get a dd-like program, e.g. this one, and the command would look more or less like this one (depending on the actual dd implementation you use):
dd if=evilmaidusb.img of=\\?\Device\HarddiskX\Partition0 bs=1M
where HarddiskX should be replaced with the actual device the represents your stick.
After preparing the Evil Maid USB stick, you’re ready to test it against some TrueCrypt-encrypted laptop (more technically: a laptop that uses TrueCrypt system disk encryption). Just boot the laptop from the stick, confirm you want to run the tool (press ‘E’) and the TrueCrypt loader on your laptop should be infected.
 Now, Evil Maid will be logging the passphrases provided during the boot time. To retrieve the recorded passphrase just boot again from the Evil Maid USB -- it should detect that the target is already infected and display the sniffed password.
Now, Evil Maid will be logging the passphrases provided during the boot time. To retrieve the recorded passphrase just boot again from the Evil Maid USB -- it should detect that the target is already infected and display the sniffed password.
 The current implementation of Evil Maid always stores the last passphrase entered, assuming this is the correct one, in case the user entered the passphrase incorrectly at earlier attempts.
The current implementation of Evil Maid always stores the last passphrase entered, assuming this is the correct one, in case the user entered the passphrase incorrectly at earlier attempts.
NOTE: It’s probably illegal to use Evil Maid to obtain password from other people without their consent. You should always obtain permission from other people before testing Evil Maid against their laptops!
CAUTION: The provided USB image and source code should be considered proof-of-concept only. Use this code at your own risk, and never run it against a production system. Invisible Things Lab cannot be held responsible for any potential damages this code or its derivates might cause.
How the Evil Maid USB works
The provided implementation is extremely simple. It first reads the first 63 sectors of the primary disk (/dev/sda) and checks (looking at the first sector) if the code there looks like a valid TrueCrypt loader. If it does, the rest of the code is unpacked (using gzip) and hooked. Evil Maid hooks the TC’s function that asks user for the passphrase, so that the hook records whatever passphrase is provided to this function. We also take care about adjusting some fields in the MBR, like the boot loader size and its checksum. After the hooking is done, the loader is packed again and written back to the disk.
You can get the source code for the Evil Maid infector here.
Possible Workarounds
So, how should we protect against such Evil Maid attacks? There are a few approaches...
1. Protect your laptop when you leave it alone
Several months ago I had a discussion with one of the TrueCrypt developers about possible means of preventing the Evil Maid Attack, perhaps using TPM (see below). Our dialog went like this (reproduced here with permission from the TrueCrypt developer):
TrueCrypt Developer: We generally disregard "janitor" attacks since they inherently make the machine untrusted. We never consider the feasibility of hardware attacks; we simply have to assume the worst. After an attacker has "worked" with your hardware, you have to stop using it for sensitive data. It is impossible for TPM to prevent hardware attacks (for example, using hardware key loggers, which are readily available to average Joe users in computer shops, etc.)
Joanna Rutkowska: And how can you determine that the attacker have or have not "worked" with your hardware? Do you carry your laptop with you all the time?
TrueCrypt Developer: Given the scope of our product, how the user ensures physical security is not our problem. Anyway, to answer your question (as a side note), you could use e.g. a proper safety case with a proper lock (or, when you cannot have it with you, store it in a good strongbox).
Joanna Rutkowska: If I could arrange for a proper lock or an impenetrable strongbox, then why in the world should I need encryption?
TrueCrypt Developer: Your question was: "And how can you determine that the attacker has or has not worked with your hardware?" My answer was a good safety case or strongbox with a good lock. If you use it, then you will notice that the attacker has accessed your notebook inside (as the case or strongbox will be damaged and it cannot be replaced because you had the correct key with you). If the safety case or strongbox can be opened without getting damaged & unusable, then it's not a good safety case or strongbox. ;-)
That's a fair point, but this means that for the security of our data we must relay on the infeasibility to open our strongbox lock in a "clean" way, i.e. without visually damaging it. Plus it means we need to carry a good strongbox with us to any travel we go. I think we need a better solution...
Note that TrueCrypt authors do mention the possibility of physical attacks in the documentation:
If an attacker can physically access the computer hardware and you use it after the attacker has physically accessed it, then TrueCrypt may become unable to secure data on the computer. This is because the attacker may modify the hardware or attach a malicious hardware component to it (such as a hardware keystroke logger) that will capture the password or encryption key (e.g. when you mount a TrueCrypt volume) or otherwise compromise the security of the computer.
However, they do not explicitly warn users of a possibility of something as simple and cheap as the Evil Maid Attack. Sure, they write "or otherwise compromise the security of the computer", which does indeed cover e.g. the Evil Maid Attack, but my bet is that very few users would realize what it really means. The examples of physical attacks given in the documentation, e.g. modifying the hardware or attaching a malicious hardware, is something that most users would disregard as too expensive an attack to be afraid of. But note that our Evil Maid attack is an example of a “physical” attack, that doesn’t require any hardware modification and is extremely cheap.
Of course it is a valid point, that if we allow a possibility of a physical attack, then the attacker can e.g. install a hardware keylogger. But doing that is really not so easy as we discuss in the next paragraph. On the other hand, spending two minutes to boot the machine from an Evil Maid USB stick is just trivial and is very cheap (the price of the USB stick, plus the tip for the maid).
2. The Trusted Computing Approach
As explained a few months ago on this blog, a reasonably good solution against Evil Maid attack seems to be to take advantage of either static or dynamic root of trust offered by TPM. The first approach (SRTM) is what has been implemented in Vista Bitlocker. However Bitlocker doesn’t try to authenticate to the user (e.g. via displaying a custom picture shot by the user, with the picture decrypted using a key unsealed from a TPM), so it’s still possible to create a similar attack against Bitlocker, but with a bit different user experience. Namely the Evil Maid for Bitlocker would have to display a fake Bitlocker prompt (that could be identical to the real Bitlocker prompt), but after obtaining a correct password from the user Evil Maid would not be able to pass the execution to the real Bitlocker code, as the SRTM chain will be broken. Instead, Evil Maid would have to pretend that the password was wrong, uninstall itself, and then reboot the platform. Thus, a Bitlocker user that is confident that he or she entered the correct password, but the OS didn’t boot correctly, should destroy the laptop.
The dynamic root of trust approach (DRTM) is possible thanks to Intel TXT technology, but currently there is no full disk encryption software that would make use of it. One can try to implement it using Intel’s tboot and some Linux disk encryption, e.g. LUKS.
Please also note that even if we assume somebody “cracked” the TPM chip (e.g. using an electron microscope, or NSA backdoor), that doesn’t mean this person can automatically get access to the encrypted disk contents. This is not the case, as the TPM is used only for ensuring trusted boot. After cracking the TPM, the attacker would still have to mount an Evil Maid attack in order to obtain the passphrase or key. Without TPM this attack is always possible.
Are those trusted computing-based approaches 100% foolproof? Of course not. As signalized in the previous paragraph, if an attacker was able to mount a hardware-based keylogger into your laptop (which is non-trivial, but possible), then the attacker would be able to capture your passphrase regardless of the trusted boot. A user can prevent such an attack by using two-factor authentication (RSA challenge-response implemented in a USB token) or e.g. one-time passwords, so that there is no benefit for the attacker to capture the keystrokes. But the attacker might go to the extreme and e.g. replace the DRAM, or even the CPU with malicious DRAM or CPU that would sniff and store the decryption key for later access. We’re talking here about attack that very few entities can probably afford (think NSA), but nevertheless they are theoretically possible. (Note that an attack with inserting a malicious PCI device that would try to sniff the key using DMA can be prevented using TXT+VT-d technology).
However, just because the NSA can theoretically replace your CPU with a malicious one, doesn’t mean TPM-based solutions are useless. As for the great majority of other people that do not happen to be on the Terrorist Top 10, these represent a reasonable solution that could prevent Evil Maid attacks, and, when combined with a proper two-factor authentication, also simple hardware based attacks, e.g. keylogger, cameras, remote keystroke sniffing using laser, etc. I really cannot think of a more reasonable solution here.
3. The Poor Man’s Solution
Personally I would love to see TrueCrypt implementing TPM-based trusted boot for its loader, but, well, what can I do? Keep bothering TrueCrypt developers with Evil Maid attacks and hope they will eventually consider implementing TPM support...
So, in the meantime we have come up with a temporary poor man’s solution that we use at our lab. We call it Disk Hasher. It’s a bootable Linux-based USB stick that can be configured in quite a flexible way to calculate hashes of selected disk sectors and partitions. The correct hashes are stored also on the stick (of course everything is encrypted with a custom laptop-specific passphrase). We use this stick to verify the unencrypted portions of our laptops (typically the first 63 sectors of sda, and also the whole /boot partition in case of Linux-based laptops where we use LUKS/dm-crypt).
Of course there are many problems with such a solution. E.g. somebody who can get access to my Disk Hasher USB (e.g. when I’m in a swimming pool), can infect it in such a way that it would report correct hashes, even though the disk of my laptop would be “evilmaided”...
Another problem with Disk Hasher solution is that it only looks at the disk, but cannot validate e.g. the BIOS. So if the attacker found a way to bypass the BIOS reflashing protection on my laptop, then he or she can install a rootkit there that would sniff my passphrase or the decryption key (in case I used one time passwords).
Nevertheless, our Disk Hasher stick seems like a reasonable solution and we use it often internally at ITL to validate our laptops. In fact this is the most we can do, if we want to use TrueCrypt, PGP WDE, or LUKS/dm-crypt.
FAQ
Q: Is this Evil Maid Attack some l33t new h4ck?
Nope, the concept behind the Evil Maid Attack is neither new, nor l33t in any way.
Q: So, why did you write it?
Because we believe it demonstrates an important problem, and we would like more attention to be paid in the industry to solving it.
Q: I’m using two-factor authentication, am I protected against EM?
While a two-factor authentication or one time passwords are generally a good idea (e.g. they can prevent various keylogger attacks), they alone do not provide protection from Evil Maid-like attacks, because the attacker might modify his or her sniffer to look for the final decryption key (that would be calculated after the 2-factor authentication completes).
Q: How is Evil Maid different from Stoned-Bootkit?
The Stoned Bootkit, released a few months ago by an individual describing himself as “Software Dev. Guru in Vienna”, is also claimed to be capable of "bypassing TrueCrypt", which we take to mean a capability to sniff TC's passphrases or keys. Still, the biggest difference between Stoned Bootkit and Evil Maid USB is that in case of our attack you don’t need to start the victim's OS in order to install Evil Maid, all you need to do is to boot from a USB stick, wait about 1 minute for the minimal Linux to start, and then press ‘E’, wait some 2 more seconds, and you’re done. With the Stoned Bootkit, according to the author’s description, you need to get admin access to the target OS in order to install it, so you either need to know the Windows admin password first, or use some exploit to get the installer executing on the target OS. Alternatively, you can install it from a bootable Windows CD, but this, according to the author, works only against unencrypted volumes, so no use in case of TrueCrypt compromise.
Q: I've disabled boot from USB in BIOS and my BIOS is password protected, am I protected against EM?
No. Taking out your HDD, hooking it up to a USB enclosure case and later installing it back to your laptop increases the attack time by some 5-15 minutes at most. A maid has to carry her own laptop to do this though.
Q: What about using a HDD with built-in hardware-based encryption?
We haven’t tested such encryption systems, so we don’t know. There are many open questions here: how is the passphrase obtained from the user? Using software stored on the disk or in the BIOS? If on the disk, is this portion of disk made read-only? If so, does it mean it is non-updatable? Even if it is truly read-only, if the attacker can reflash the BIOS, then he or she can install a passphrase sniffer there in the BIOS. Of course that would make the attack non-trivial and much more expensive than the original Evil Maid USB we presented here.
Q: Which TrueCrypt versions are supported by the current Evil Maid USB?
We have tested our Evil Maid USB against TrueCrypt versions 6.0a - 6.2a (the latest version currently available). Of course, if the “shape” of the TrueCrypt loader changed dramatically in the future, then Evil Maid USB would require updating.
Q: Why did you choose TrueCrypt and not some other product?
Because we believe TrueCrypt is a great product, we use it often in our lab, and we would love to see it getting some better protection against such attacks.
Q: Why there is no TPM support in TrueCrypt?
The TrueCrypt Foundation published official generalized response to TPM-related feature requests here.
Acknowledgments
Thanks to the ennead@truecrypt.org for all the polemics we had which allowed me to better gather my thoughts on the topic. The same thanks to Alex and Rafal, for all the polemics I have had with them (it's customary for ITL to spend a lot of time finding bugs in each other's reasoning).
\ No newline at end of file
+From time to time it’s good to take a break from all the ultra-low-level stuff, like e.g. chipset or TXT hacking, and do something simple, yet still important. Recently Alex Tereshkin and I got some spare time and we implemented the Evil Maid Attack against TrueCrypt system disk encryption in a form of a small bootable USB stick image that allows to perform the attack in an easy “plug-and-play” way. The whole infection process takes about 1 minute, and it’s well suited to be used by hotel maids.
The Attack
Let’s quickly recap the Evil Maid Attack. The scenario we consider is when somebody left an encrypted laptop e.g. in a hotel room. Let’s assume the laptop uses full disk encryption like e.g. this provided by TrueCrypt or PGP Whole Disk Encryption.
Many people believe, including some well known security experts, that it is advisable to fully power down your laptop when you use full disk encryption in order to prevent attacks via FireWire/PCMCIA or ”Coldboot” attacks.
So, let’s assume we have a reasonably paranoid user, that uses full disk encryption on his or her laptop, and also powers it down every time they leave it alone in a hotel room, or somewhere else.
Now, this is where our Evil Maid stick comes into play. All the attacker needs to do is to sneak into the user’s hotel room and boot the laptop from the Evil Maid USB Stick. After some 1-2 minutes, the target laptop’s gets infected with Evil Maid Sniffer that will record the disk encryption passphrase when the user enters it next time. As any smart user might have guessed already, this part is ideally suited to be performed by hotel maids, or people pretending to be them.
So, after our victim gets back to the hotel room and powers up his or her laptop, the passphrase will be recorded and e.g. stored somewhere on the disk, or maybe transmitted over the network (not implemented in current version).
Now we can safely steal/confiscate the user’s laptop, as we know how to decrypt it. End of story.
Quick Start
Download the USB image here. In order to “burn” the Evil Maid use the following commands on Linux (you need to be root to do dd):
dd if=evilmaidusb.img of=/dev/sdX
Where /dev/sdX should be replaced with the device representing your USB stick, e.g. /dev/sdb. Please be careful, as choosing a wrong device might result in damaging your hard disk or other media! Also, make sure to use the device representing the whole disk (e.g. /dev/sdb), rather than a disk partition (e.g. /dev/sdb1).
On Windows you would need to get a dd-like program, e.g. this one, and the command would look more or less like this one (depending on the actual dd implementation you use):
dd if=evilmaidusb.img of=\\?\Device\HarddiskX\Partition0 bs=1M
where HarddiskX should be replaced with the actual device the represents your stick.
After preparing the Evil Maid USB stick, you’re ready to test it against some TrueCrypt-encrypted laptop (more technically: a laptop that uses TrueCrypt system disk encryption). Just boot the laptop from the stick, confirm you want to run the tool (press ‘E’) and the TrueCrypt loader on your laptop should be infected.
Now, Evil Maid will be logging the passphrases provided during the boot time. To retrieve the recorded passphrase just boot again from the Evil Maid USB -- it should detect that the target is already infected and display the sniffed password.
The current implementation of Evil Maid always stores the last passphrase entered, assuming this is the correct one, in case the user entered the passphrase incorrectly at earlier attempts.
NOTE: It’s probably illegal to use Evil Maid to obtain password from other people without their consent. You should always obtain permission from other people before testing Evil Maid against their laptops!
CAUTION: The provided USB image and source code should be considered proof-of-concept only. Use this code at your own risk, and never run it against a production system. Invisible Things Lab cannot be held responsible for any potential damages this code or its derivates might cause.
How the Evil Maid USB works
The provided implementation is extremely simple. It first reads the first 63 sectors of the primary disk (/dev/sda) and checks (looking at the first sector) if the code there looks like a valid TrueCrypt loader. If it does, the rest of the code is unpacked (using gzip) and hooked. Evil Maid hooks the TC’s function that asks user for the passphrase, so that the hook records whatever passphrase is provided to this function. We also take care about adjusting some fields in the MBR, like the boot loader size and its checksum. After the hooking is done, the loader is packed again and written back to the disk.
You can get the source code for the Evil Maid infector here.
Possible Workarounds
So, how should we protect against such Evil Maid attacks? There are a few approaches...
1. Protect your laptop when you leave it alone
Several months ago I had a discussion with one of the TrueCrypt developers about possible means of preventing the Evil Maid Attack, perhaps using TPM (see below). Our dialog went like this (reproduced here with permission from the TrueCrypt developer):
TrueCrypt Developer: We generally disregard "janitor" attacks since they inherently make the machine untrusted. We never consider the feasibility of hardware attacks; we simply have to assume the worst. After an attacker has "worked" with your hardware, you have to stop using it for sensitive data. It is impossible for TPM to prevent hardware attacks (for example, using hardware key loggers, which are readily available to average Joe users in computer shops, etc.)
Joanna Rutkowska: And how can you determine that the attacker have or have not "worked" with your hardware? Do you carry your laptop with you all the time?
TrueCrypt Developer: Given the scope of our product, how the user ensures physical security is not our problem. Anyway, to answer your question (as a side note), you could use e.g. a proper safety case with a proper lock (or, when you cannot have it with you, store it in a good strongbox).
Joanna Rutkowska: If I could arrange for a proper lock or an impenetrable strongbox, then why in the world should I need encryption?
TrueCrypt Developer: Your question was: "And how can you determine that the attacker has or has not worked with your hardware?" My answer was a good safety case or strongbox with a good lock. If you use it, then you will notice that the attacker has accessed your notebook inside (as the case or strongbox will be damaged and it cannot be replaced because you had the correct key with you). If the safety case or strongbox can be opened without getting damaged & unusable, then it's not a good safety case or strongbox. ;-)
That's a fair point, but this means that for the security of our data we must relay on the infeasibility to open our strongbox lock in a "clean" way, i.e. without visually damaging it. Plus it means we need to carry a good strongbox with us to any travel we go. I think we need a better solution...
Note that TrueCrypt authors do mention the possibility of physical attacks in the documentation:
If an attacker can physically access the computer hardware and you use it after the attacker has physically accessed it, then TrueCrypt may become unable to secure data on the computer. This is because the attacker may modify the hardware or attach a malicious hardware component to it (such as a hardware keystroke logger) that will capture the password or encryption key (e.g. when you mount a TrueCrypt volume) or otherwise compromise the security of the computer.
However, they do not explicitly warn users of a possibility of something as simple and cheap as the Evil Maid Attack. Sure, they write "or otherwise compromise the security of the computer", which does indeed cover e.g. the Evil Maid Attack, but my bet is that very few users would realize what it really means. The examples of physical attacks given in the documentation, e.g. modifying the hardware or attaching a malicious hardware, is something that most users would disregard as too expensive an attack to be afraid of. But note that our Evil Maid attack is an example of a “physical” attack, that doesn’t require any hardware modification and is extremely cheap.
Of course it is a valid point, that if we allow a possibility of a physical attack, then the attacker can e.g. install a hardware keylogger. But doing that is really not so easy as we discuss in the next paragraph. On the other hand, spending two minutes to boot the machine from an Evil Maid USB stick is just trivial and is very cheap (the price of the USB stick, plus the tip for the maid).
2. The Trusted Computing Approach
As explained a few months ago on this blog, a reasonably good solution against Evil Maid attack seems to be to take advantage of either static or dynamic root of trust offered by TPM. The first approach (SRTM) is what has been implemented in Vista Bitlocker. However Bitlocker doesn’t try to authenticate to the user (e.g. via displaying a custom picture shot by the user, with the picture decrypted using a key unsealed from a TPM), so it’s still possible to create a similar attack against Bitlocker, but with a bit different user experience. Namely the Evil Maid for Bitlocker would have to display a fake Bitlocker prompt (that could be identical to the real Bitlocker prompt), but after obtaining a correct password from the user Evil Maid would not be able to pass the execution to the real Bitlocker code, as the SRTM chain will be broken. Instead, Evil Maid would have to pretend that the password was wrong, uninstall itself, and then reboot the platform. Thus, a Bitlocker user that is confident that he or she entered the correct password, but the OS didn’t boot correctly, should destroy the laptop.
The dynamic root of trust approach (DRTM) is possible thanks to Intel TXT technology, but currently there is no full disk encryption software that would make use of it. One can try to implement it using Intel’s tboot and some Linux disk encryption, e.g. LUKS.
Please also note that even if we assume somebody “cracked” the TPM chip (e.g. using an electron microscope, or NSA backdoor), that doesn’t mean this person can automatically get access to the encrypted disk contents. This is not the case, as the TPM is used only for ensuring trusted boot. After cracking the TPM, the attacker would still have to mount an Evil Maid attack in order to obtain the passphrase or key. Without TPM this attack is always possible.
Are those trusted computing-based approaches 100% foolproof? Of course not. As signalized in the previous paragraph, if an attacker was able to mount a hardware-based keylogger into your laptop (which is non-trivial, but possible), then the attacker would be able to capture your passphrase regardless of the trusted boot. A user can prevent such an attack by using two-factor authentication (RSA challenge-response implemented in a USB token) or e.g. one-time passwords, so that there is no benefit for the attacker to capture the keystrokes. But the attacker might go to the extreme and e.g. replace the DRAM, or even the CPU with malicious DRAM or CPU that would sniff and store the decryption key for later access. We’re talking here about attack that very few entities can probably afford (think NSA), but nevertheless they are theoretically possible. (Note that an attack with inserting a malicious PCI device that would try to sniff the key using DMA can be prevented using TXT+VT-d technology).
However, just because the NSA can theoretically replace your CPU with a malicious one, doesn’t mean TPM-based solutions are useless. As for the great majority of other people that do not happen to be on the Terrorist Top 10, these represent a reasonable solution that could prevent Evil Maid attacks, and, when combined with a proper two-factor authentication, also simple hardware based attacks, e.g. keylogger, cameras, remote keystroke sniffing using laser, etc. I really cannot think of a more reasonable solution here.
3. The Poor Man’s Solution
Personally I would love to see TrueCrypt implementing TPM-based trusted boot for its loader, but, well, what can I do? Keep bothering TrueCrypt developers with Evil Maid attacks and hope they will eventually consider implementing TPM support...
So, in the meantime we have come up with a temporary poor man’s solution that we use at our lab. We call it Disk Hasher. It’s a bootable Linux-based USB stick that can be configured in quite a flexible way to calculate hashes of selected disk sectors and partitions. The correct hashes are stored also on the stick (of course everything is encrypted with a custom laptop-specific passphrase). We use this stick to verify the unencrypted portions of our laptops (typically the first 63 sectors of sda, and also the whole /boot partition in case of Linux-based laptops where we use LUKS/dm-crypt).
Of course there are many problems with such a solution. E.g. somebody who can get access to my Disk Hasher USB (e.g. when I’m in a swimming pool), can infect it in such a way that it would report correct hashes, even though the disk of my laptop would be “evilmaided”...
Another problem with Disk Hasher solution is that it only looks at the disk, but cannot validate e.g. the BIOS. So if the attacker found a way to bypass the BIOS reflashing protection on my laptop, then he or she can install a rootkit there that would sniff my passphrase or the decryption key (in case I used one time passwords).
Nevertheless, our Disk Hasher stick seems like a reasonable solution and we use it often internally at ITL to validate our laptops. In fact this is the most we can do, if we want to use TrueCrypt, PGP WDE, or LUKS/dm-crypt.
FAQ
Q: Is this Evil Maid Attack some l33t new h4ck?
Nope, the concept behind the Evil Maid Attack is neither new, nor l33t in any way.
Q: So, why did you write it?
Because we believe it demonstrates an important problem, and we would like more attention to be paid in the industry to solving it.
Q: I’m using two-factor authentication, am I protected against EM?
While a two-factor authentication or one time passwords are generally a good idea (e.g. they can prevent various keylogger attacks), they alone do not provide protection from Evil Maid-like attacks, because the attacker might modify his or her sniffer to look for the final decryption key (that would be calculated after the 2-factor authentication completes).
Q: How is Evil Maid different from Stoned-Bootkit?
The Stoned Bootkit, released a few months ago by an individual describing himself as “Software Dev. Guru in Vienna”, is also claimed to be capable of "bypassing TrueCrypt", which we take to mean a capability to sniff TC's passphrases or keys. Still, the biggest difference between Stoned Bootkit and Evil Maid USB is that in case of our attack you don’t need to start the victim's OS in order to install Evil Maid, all you need to do is to boot from a USB stick, wait about 1 minute for the minimal Linux to start, and then press ‘E’, wait some 2 more seconds, and you’re done. With the Stoned Bootkit, according to the author’s description, you need to get admin access to the target OS in order to install it, so you either need to know the Windows admin password first, or use some exploit to get the installer executing on the target OS. Alternatively, you can install it from a bootable Windows CD, but this, according to the author, works only against unencrypted volumes, so no use in case of TrueCrypt compromise.
Q: I've disabled boot from USB in BIOS and my BIOS is password protected, am I protected against EM?
No. Taking out your HDD, hooking it up to a USB enclosure case and later installing it back to your laptop increases the attack time by some 5-15 minutes at most. A maid has to carry her own laptop to do this though.
Q: What about using a HDD with built-in hardware-based encryption?
We haven’t tested such encryption systems, so we don’t know. There are many open questions here: how is the passphrase obtained from the user? Using software stored on the disk or in the BIOS? If on the disk, is this portion of disk made read-only? If so, does it mean it is non-updatable? Even if it is truly read-only, if the attacker can reflash the BIOS, then he or she can install a passphrase sniffer there in the BIOS. Of course that would make the attack non-trivial and much more expensive than the original Evil Maid USB we presented here.
Q: Which TrueCrypt versions are supported by the current Evil Maid USB?
We have tested our Evil Maid USB against TrueCrypt versions 6.0a - 6.2a (the latest version currently available). Of course, if the “shape” of the TrueCrypt loader changed dramatically in the future, then Evil Maid USB would require updating.
Q: Why did you choose TrueCrypt and not some other product?
Because we believe TrueCrypt is a great product, we use it often in our lab, and we would love to see it getting some better protection against such attacks.
Q: Why there is no TPM support in TrueCrypt?
The TrueCrypt Foundation published official generalized response to TPM-related feature requests here.
Acknowledgments
Thanks to the ennead@truecrypt.org for all the polemics we had which allowed me to better gather my thoughts on the topic. The same thanks to Alex and Rafal, for all the polemics I have had with them (it's customary for ITL to spend a lot of time finding bugs in each other's reasoning).
\ No newline at end of file
diff --git a/_posts/2009-12-21-another-txt-attack.html b/_posts/2009-12-21-another-txt-attack.html
index e712b5c..d5c528a 100644
--- a/_posts/2009-12-21-another-txt-attack.html
+++ b/_posts/2009-12-21-another-txt-attack.html
@@ -14,4 +14,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2009/12/another-txt-attack.html
---
- Earlier this year our team has presented an attack against Intel TXT that exploited a design problem with SMM mode being over privileged on PC platforms and able to interfere with the SENTER instruction. The Intel response was two-fold: to patch the SMM implementation bugs we used for the attack (this patch was for both the NVACPI SMM attacks, as well as for the SMM caching attack), and also to start (intensify?) working on STM specification, that is, we heard, planned to be published sometime in the near future. STM is a thin hypervisor concept that is supposed to provide protection against (potentially) malicious SMMs.
Earlier this year our team has presented an attack against Intel TXT that exploited a design problem with SMM mode being over privileged on PC platforms and able to interfere with the SENTER instruction. The Intel response was two-fold: to patch the SMM implementation bugs we used for the attack (this patch was for both the NVACPI SMM attacks, as well as for the SMM caching attack), and also to start (intensify?) working on STM specification, that is, we heard, planned to be published sometime in the near future. STM is a thin hypervisor concept that is supposed to provide protection against (potentially) malicious SMMs.
Today we present a totally different attack that allows an attacker to trick the SENTER instruction into misconfiguring the VT-d engine, so that it doesn’t protect the newly loaded hypervisor or kernel. This attack exploits an implementation flaw in a SINIT AC module. This new attack also allows for full TXT circumvention, using a software-only attack. This attack doesn't require any SMM bugs to succeed and is totally independent from the previous one.
The press release is here.
The full paper is here.
The advisory published by Intel today can be found here.
Enjoy.
\ No newline at end of file
+Earlier this year our team has presented an attack against Intel TXT that exploited a design problem with SMM mode being over privileged on PC platforms and able to interfere with the SENTER instruction. The Intel response was two-fold: to patch the SMM implementation bugs we used for the attack (this patch was for both the NVACPI SMM attacks, as well as for the SMM caching attack), and also to start (intensify?) working on STM specification, that is, we heard, planned to be published sometime in the near future. STM is a thin hypervisor concept that is supposed to provide protection against (potentially) malicious SMMs.
Today we present a totally different attack that allows an attacker to trick the SENTER instruction into misconfiguring the VT-d engine, so that it doesn’t protect the newly loaded hypervisor or kernel. This attack exploits an implementation flaw in a SINIT AC module. This new attack also allows for full TXT circumvention, using a software-only attack. This attack doesn't require any SMM bugs to succeed and is totally independent from the previous one.
The press release is here.
The full paper is here.
The advisory published by Intel today can be found here.
Enjoy.
\ No newline at end of file
diff --git a/_posts/2010-05-03-on-formally-verified-microkernels-and.html b/_posts/2010-05-03-on-formally-verified-microkernels-and.html
index 8a0598e..1dd7e89 100644
--- a/_posts/2010-05-03-on-formally-verified-microkernels-and.html
+++ b/_posts/2010-05-03-on-formally-verified-microkernels-and.html
@@ -13,4 +13,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2010/05/on-formally-verified-microkernels-and.html
---
-Update May 14th, 2010: Gerwin Klein, a project lead for L4.verified, has posted some insightful comments. Also it's worth reading their website here that clearly explains what assumptions they make, and what they really prove, and what they don't.
You must have heard about it before: formally verified microkernels that offer 100% security... Why don't we use such a microkernel in Qubes then? (The difference between a micro-kernel and a type I hypervisor is blurry. Especially in case of a type I hypervisor used for running para-virtualized VMs, such as Xen used in Qubes. So I would call Xen a micro-kernel in this case, although it can also run fully-virtualized VMs, in which case it should be called a hypervisor I think.)
In order to formally prove some property of any piece of code, you need to first assume certain things. One such thing is the correctness of a compiler, so that you can be sure that all the properties you proved for the source code, still hold true for the binary generated from this source code. But let's say it's a feasible assumption -- we do have mature compilers indeed.
Another important assumption you need, and this is especially important in proving kernels/microkernels/hypervisors, is the model of the hardware your kernel interacts with. Not necessarily all the hardware, but at least the CPU (e.g. MMU, mode transitions, etc) and the Chipset.
While the CPUs are rather well understood today, and their architecture (we're talking IA32 here) doesn't change so dramatically from season to season. The chipsets, however, are a whole different story. If you take a spec for any modern chipset, let's say only the MCH part, the one closer to the processor (on Core i5/i7 even integrated on the same die), there are virtually hundreds of configuration registers there. Those registers are used for all sorts of different purposes -- they configure DRAM parameters, PCIe bridges, various system memory map characteristics (e.g. the memory reclaiming feature), access to the infamous SMM memory, and finally VT-d and TXT configuration.
So, how are all those details modeled in microkernels formal verification process? Well, as far as I'm aware, they are not! They are simply ignored. The nice way of saying this in academic papers is to say that "we trust the hardware". This, however, might be incorrectly understood by readers to mean "we don't consider physical attacks". But this is not equal! And I will give a practical example in a moment.
I can bet that even the chipset manufactures (think e.g. Intel) do not have formal models for their chipsets (again, I will give a good example to support this thesis below).
But why are the chipsets so important? Perhaps they are configured "safe by default" on power on, so even if we don't model all the configuration registers, and their effects on the system, and if we won't be playing with them, maybe it's safe to assume all will be fine then?
Well, it might be that way, if we could have secure microkernels without IOMMU/VT-d and without some trusted boot mechanism.
But we need IOMMU. Without IOMMU there is no security benefit of having a microkernel vs. having a good-old monolithic kernel. Let me repeat this statement again: there is no point in building a microkernel-based system, if we don't correctly use IOMMU to sandbox all the drivers.
Now, setting up IOMMU/VT-d permissions require programming the chipset's registers, and is by no means a trivial task (see the the Intel VT-d spec to get an impression, if you don't believe me). Correctly setting up IOMMU is one of the most security-critical tasks to be done by a hypervisor/microkernel, and so it would be logical to expect that they also formally prove that this part is done flawlessly...
The next thing is the trusted boot. I will argue that without proper trusted boot implementation, the system cannot be made secure. And I'm not talking about physical attacks, like Evil Maid. I'm talking about true, remote, software attacks. If you haven't read it already, please go back and read my very recent post on "Remotely Attacking Network Cards". Building on Loic's and Yves-Alexis' recent research, I describe there a scenario how we could take their attack further to compromise even such a securely designed system as Qubes. And this could be possible, because of a flaw in TXT implementation. And, indeed, we demonstrated an attack on Intel Trusted Execution Technology that exploits one such flaw before.
Let's quickly sketch the whole attack in points:
- The attacker attacks a flaw in the network card processing code (Loic and Yves-Alexis)
- The attacker replaces the NIC's firmware in EEPROM to survive the reboot (Loic and Yves-Alexis)
- The new firmware attacks the system trusted boot via a flaw in Intel TXT (ITL)
- If the system uses SRTM instead, it's even easier -- see the previous post (ITL)
- If you have new SINIT module that patched our attack, there is still an avenue to attack TXT via SMM (ITL)
- The microkernel/hypervisor gets compromised with a rootkit and the attacker gets full control over the system:o
And this is the practical example I mentioned above. I'm sure readers understand that this is just one example, of what could go wrong on the hardware level (and be reachable to a software-only attacker). Don't ignore hardware security! Even for software attacks!
A good question to ask is: would a system with a formally verified microkernel also be vulnerable to such an attack? And the answer is yes! Yes, unless we could model and prove correctness of the whole chipset and the CPU. But nobody can do that today, because it is impossible to build such a model. If it was, I'm pretty sure Intel would already have such a model and they would not release an SINIT module with this stupid implementation bug we found and exploited in our attack.
So, we see an example of a practical attack that could be used to fully compromise a well designed system, even if it had a formally verified microkernel/hypervisor. Compromise it remotely, over the network!
So, are all those whole microkernel/hypervisor formal verification attempts just a waste of time? Are they only good for academics so that they could write more papers for conferences? Or for some companies to use them in marketing?
Perhaps the formal verification of system software will never be able to catch up with the pace of hardware development... By the time people will learn how to build models (and how to solve them) for hardware used today, the hardware manufactures, in the meantime, will present a few new generations of the hardware. For which the academics will need another 5 years to catch up, and so on.
Perhaps the industry will take a different approach. Perhaps in the coming years we will get hardware that would allow us to create untrusted hypervisors/kernels that would not be able to read/write usermode pages (Hey Howard;)? This is currently not possible with the hardware we have, but, hey, why would a hypervisor need access to the Firefox pages?
And how this all will affect Qubes? Well, the Qubes project is not about building a hypervisor or a microkernel. Qubes is about how to take a secure hypervisor/microkernel, and how to build the rest of the system in a secure, and easy to use, way, using the isolation properties that this hypervisor/microkernel is expected to provide. So, whatever kernels we will have in the future (better formally verified, e.g. including the hardware in the model), or based on some exciting new hardware features, still Qubes architecture would make perfect sense, I think.
\ No newline at end of file
+Update May 14th, 2010: Gerwin Klein, a project lead for L4.verified, has posted some insightful comments. Also it's worth reading their website here that clearly explains what assumptions they make, and what they really prove, and what they don't.
You must have heard about it before: formally verified microkernels that offer 100% security... Why don't we use such a microkernel in Qubes then? (The difference between a micro-kernel and a type I hypervisor is blurry. Especially in case of a type I hypervisor used for running para-virtualized VMs, such as Xen used in Qubes. So I would call Xen a micro-kernel in this case, although it can also run fully-virtualized VMs, in which case it should be called a hypervisor I think.)
In order to formally prove some property of any piece of code, you need to first assume certain things. One such thing is the correctness of a compiler, so that you can be sure that all the properties you proved for the source code, still hold true for the binary generated from this source code. But let's say it's a feasible assumption -- we do have mature compilers indeed.
Another important assumption you need, and this is especially important in proving kernels/microkernels/hypervisors, is the model of the hardware your kernel interacts with. Not necessarily all the hardware, but at least the CPU (e.g. MMU, mode transitions, etc) and the Chipset.
While the CPUs are rather well understood today, and their architecture (we're talking IA32 here) doesn't change so dramatically from season to season. The chipsets, however, are a whole different story. If you take a spec for any modern chipset, let's say only the MCH part, the one closer to the processor (on Core i5/i7 even integrated on the same die), there are virtually hundreds of configuration registers there. Those registers are used for all sorts of different purposes -- they configure DRAM parameters, PCIe bridges, various system memory map characteristics (e.g. the memory reclaiming feature), access to the infamous SMM memory, and finally VT-d and TXT configuration.
So, how are all those details modeled in microkernels formal verification process? Well, as far as I'm aware, they are not! They are simply ignored. The nice way of saying this in academic papers is to say that "we trust the hardware". This, however, might be incorrectly understood by readers to mean "we don't consider physical attacks". But this is not equal! And I will give a practical example in a moment.
I can bet that even the chipset manufactures (think e.g. Intel) do not have formal models for their chipsets (again, I will give a good example to support this thesis below).
But why are the chipsets so important? Perhaps they are configured "safe by default" on power on, so even if we don't model all the configuration registers, and their effects on the system, and if we won't be playing with them, maybe it's safe to assume all will be fine then?
Well, it might be that way, if we could have secure microkernels without IOMMU/VT-d and without some trusted boot mechanism.
But we need IOMMU. Without IOMMU there is no security benefit of having a microkernel vs. having a good-old monolithic kernel. Let me repeat this statement again: there is no point in building a microkernel-based system, if we don't correctly use IOMMU to sandbox all the drivers.
Now, setting up IOMMU/VT-d permissions require programming the chipset's registers, and is by no means a trivial task (see the the Intel VT-d spec to get an impression, if you don't believe me). Correctly setting up IOMMU is one of the most security-critical tasks to be done by a hypervisor/microkernel, and so it would be logical to expect that they also formally prove that this part is done flawlessly...
The next thing is the trusted boot. I will argue that without proper trusted boot implementation, the system cannot be made secure. And I'm not talking about physical attacks, like Evil Maid. I'm talking about true, remote, software attacks. If you haven't read it already, please go back and read my very recent post on "Remotely Attacking Network Cards". Building on Loic's and Yves-Alexis' recent research, I describe there a scenario how we could take their attack further to compromise even such a securely designed system as Qubes. And this could be possible, because of a flaw in TXT implementation. And, indeed, we demonstrated an attack on Intel Trusted Execution Technology that exploits one such flaw before.
Let's quickly sketch the whole attack in points:
- The attacker attacks a flaw in the network card processing code (Loic and Yves-Alexis)
- The attacker replaces the NIC's firmware in EEPROM to survive the reboot (Loic and Yves-Alexis)
- The new firmware attacks the system trusted boot via a flaw in Intel TXT (ITL)
- If the system uses SRTM instead, it's even easier -- see the previous post (ITL)
- If you have new SINIT module that patched our attack, there is still an avenue to attack TXT via SMM (ITL)
- The microkernel/hypervisor gets compromised with a rootkit and the attacker gets full control over the system:o
And this is the practical example I mentioned above. I'm sure readers understand that this is just one example, of what could go wrong on the hardware level (and be reachable to a software-only attacker). Don't ignore hardware security! Even for software attacks!
A good question to ask is: would a system with a formally verified microkernel also be vulnerable to such an attack? And the answer is yes! Yes, unless we could model and prove correctness of the whole chipset and the CPU. But nobody can do that today, because it is impossible to build such a model. If it was, I'm pretty sure Intel would already have such a model and they would not release an SINIT module with this stupid implementation bug we found and exploited in our attack.
So, we see an example of a practical attack that could be used to fully compromise a well designed system, even if it had a formally verified microkernel/hypervisor. Compromise it remotely, over the network!
So, are all those whole microkernel/hypervisor formal verification attempts just a waste of time? Are they only good for academics so that they could write more papers for conferences? Or for some companies to use them in marketing?
Perhaps the formal verification of system software will never be able to catch up with the pace of hardware development... By the time people will learn how to build models (and how to solve them) for hardware used today, the hardware manufactures, in the meantime, will present a few new generations of the hardware. For which the academics will need another 5 years to catch up, and so on.
Perhaps the industry will take a different approach. Perhaps in the coming years we will get hardware that would allow us to create untrusted hypervisors/kernels that would not be able to read/write usermode pages (Hey Howard;)? This is currently not possible with the hardware we have, but, hey, why would a hypervisor need access to the Firefox pages?
And how this all will affect Qubes? Well, the Qubes project is not about building a hypervisor or a microkernel. Qubes is about how to take a secure hypervisor/microkernel, and how to build the rest of the system in a secure, and easy to use, way, using the isolation properties that this hypervisor/microkernel is expected to provide. So, whatever kernels we will have in the future (better formally verified, e.g. including the hardware in the model), or based on some exciting new hardware features, still Qubes architecture would make perfect sense, I think.
\ No newline at end of file
diff --git a/_posts/2010-08-19-ms-dos-security-model.html b/_posts/2010-08-19-ms-dos-security-model.html
index 784a509..abff873 100644
--- a/_posts/2010-08-19-ms-dos-security-model.html
+++ b/_posts/2010-08-19-ms-dos-security-model.html
@@ -12,4 +12,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2010/08/ms-dos-security-model.html
---
-Back in the '80s, there was an operating system called MS-DOS. This ancient OS, some readers might not even remember it today, had a very simple security model: every application had access to all the user files and other applications.
Today, over two decades later, overwhelming majority of people still use the very same security model... Why? Because on any modern, mainstream OS, be that Linux, Mac, or Windows, all the user applications still have full access to all the user's files, and can manipulate all the other user's applications.
Does it mean we haven't progressed anywhere from the MS-DOS age? Not quite. Modern OSes do have various anti-exploitation mechanisms, such as ASLR, NX, guard pages (well, Linux has it since last week at least), and even some more.
But in my opinion there has been too much focus on anti-exploitation, and on bug finding, (and on patching, of course), while almost nothing has been done on the OS architecture level.
Does anybody know why Linux Desktops offer ability to create different user accounts? What a stupid question, I hear you saying - different accounts allow to run some applications isolated from user's other applications! Really? No! The X server, by design, allows any GUI application to mess with all the other GUI applications being displayed by the same X server (on the same desktop). So, what good it is to have a "random_web_browsing" user, if the Firefox run under this user account would still be able to sniff or inject keystrokes to all my other GUI applications, take screenshots of them, etc...?
[Yes, I know, the user accounts allows also to theoretically share a single desktop computer among more than one physical users (also known as: people), but, come on, these days it's that a single person has many computers, and not the other way around.]
One might argue that the progress in the anti-exploitation, and also safe languages, would make it nearly impossible to e.g. exploit a Web browser in the next few years, so there would be no need to have a "random_web_browsing" user in the first place. But, we need isolation not only to protect ourselves when somebody exploits one of our application (e.g. a Web Browser, or a PDF viewer), but also, and perhaps most importantly, to protect from maliciously written applications.
Take summer holiday example: imagine you're a scuba diver - now, being also a decently geeky person, no doubt you will want to have some dive log manager application to store the history of your dives on a computer. There are a dozen of such applications on the web, so all you need to do is to pick one (you know, the one with the nicest screenshots), and... well you need to install it on your laptop now. But, hey, why this little, made by nobody-knows-who, dive application should be given unlimited access to all your personal files, work email, bank account, and god-know-what-else-you-keep-on-your-laptop? Anti-exploitation technology would do exactly nothing to prevent your files in this case.
Aha, it would be so nice if we could just create a user "diving", and run the app under this account. In the future, you could throw in some advanced deco planning application into the same account, still separated from all the other applications.
But, sorry, that would not work, because the X server doesn't provide isolation on the GUI-level. So, again, why should anybody bother creating any additional user accounts on a Linux Desktop?
Windows Vista made a little step forward in this area by introducing integrity levels, that, at least theoretically, were supposed to prevent GUI applications from messing with each other. But they didn't scale well (IIRC there were just 3 or 4 integrity levels available), and it still isn't really clear if Microsoft treats them seriously.
So, why do we have user accounts on Linux Desktops and Macs is beyond me (I guess Mac's X server doesn't implement any GUI-level isolation either - if I'm wrong, please point me out to the appropriate reference)?
And we haven't even touched the problems that might arise from the attacker exploiting a bug in the (over-complex) GUI server/API, or in the (big fat) kernel (with hundreds of drivers). In order for those attacks to become really interesting (like the Rafal's attack we presented yesterday), the user would have to already be using e.g. different X servers (and switch between them using Ctrl-Shift-Fn), or some sandboxing mechanisms, such as SELinux sandbox, or, in case of Vista, a scheme similar to this one.
\ No newline at end of file
+Back in the '80s, there was an operating system called MS-DOS. This ancient OS, some readers might not even remember it today, had a very simple security model: every application had access to all the user files and other applications.
Today, over two decades later, overwhelming majority of people still use the very same security model... Why? Because on any modern, mainstream OS, be that Linux, Mac, or Windows, all the user applications still have full access to all the user's files, and can manipulate all the other user's applications.
Does it mean we haven't progressed anywhere from the MS-DOS age? Not quite. Modern OSes do have various anti-exploitation mechanisms, such as ASLR, NX, guard pages (well, Linux has it since last week at least), and even some more.
But in my opinion there has been too much focus on anti-exploitation, and on bug finding, (and on patching, of course), while almost nothing has been done on the OS architecture level.
Does anybody know why Linux Desktops offer ability to create different user accounts? What a stupid question, I hear you saying - different accounts allow to run some applications isolated from user's other applications! Really? No! The X server, by design, allows any GUI application to mess with all the other GUI applications being displayed by the same X server (on the same desktop). So, what good it is to have a "random_web_browsing" user, if the Firefox run under this user account would still be able to sniff or inject keystrokes to all my other GUI applications, take screenshots of them, etc...?
[Yes, I know, the user accounts allows also to theoretically share a single desktop computer among more than one physical users (also known as: people), but, come on, these days it's that a single person has many computers, and not the other way around.]
One might argue that the progress in the anti-exploitation, and also safe languages, would make it nearly impossible to e.g. exploit a Web browser in the next few years, so there would be no need to have a "random_web_browsing" user in the first place. But, we need isolation not only to protect ourselves when somebody exploits one of our application (e.g. a Web Browser, or a PDF viewer), but also, and perhaps most importantly, to protect from maliciously written applications.
Take summer holiday example: imagine you're a scuba diver - now, being also a decently geeky person, no doubt you will want to have some dive log manager application to store the history of your dives on a computer. There are a dozen of such applications on the web, so all you need to do is to pick one (you know, the one with the nicest screenshots), and... well you need to install it on your laptop now. But, hey, why this little, made by nobody-knows-who, dive application should be given unlimited access to all your personal files, work email, bank account, and god-know-what-else-you-keep-on-your-laptop? Anti-exploitation technology would do exactly nothing to prevent your files in this case.
Aha, it would be so nice if we could just create a user "diving", and run the app under this account. In the future, you could throw in some advanced deco planning application into the same account, still separated from all the other applications.
But, sorry, that would not work, because the X server doesn't provide isolation on the GUI-level. So, again, why should anybody bother creating any additional user accounts on a Linux Desktop?
Windows Vista made a little step forward in this area by introducing integrity levels, that, at least theoretically, were supposed to prevent GUI applications from messing with each other. But they didn't scale well (IIRC there were just 3 or 4 integrity levels available), and it still isn't really clear if Microsoft treats them seriously.
So, why do we have user accounts on Linux Desktops and Macs is beyond me (I guess Mac's X server doesn't implement any GUI-level isolation either - if I'm wrong, please point me out to the appropriate reference)?
And we haven't even touched the problems that might arise from the attacker exploiting a bug in the (over-complex) GUI server/API, or in the (big fat) kernel (with hundreds of drivers). In order for those attacks to become really interesting (like the Rafal's attack we presented yesterday), the user would have to already be using e.g. different X servers (and switch between them using Ctrl-Shift-Fn), or some sandboxing mechanisms, such as SELinux sandbox, or, in case of Vista, a scheme similar to this one.
\ No newline at end of file
diff --git a/_posts/2010-09-02-qubes-qubes-pro-and-future.html b/_posts/2010-09-02-qubes-qubes-pro-and-future.html
index 00b3710..196bebb 100644
--- a/_posts/2010-09-02-qubes-qubes-pro-and-future.html
+++ b/_posts/2010-09-02-qubes-qubes-pro-and-future.html
@@ -12,4 +12,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2010/09/qubes-qubes-pro-and-future.html
---
-The work on Qubes OS has been extremely exciting and also very challenging for us. While most of the work we have been doing so far relates to solving various technical, under-the-hood challenges, the more important goals in the long-term are related more to mitigating the so called "human factor", i.e. making the system not only easy to use, but tolerant to user absentmindedness. This includes e.g. ensuring the user uses a correct AppVM (e.g. do the banking in the "banking" AppVM, and not in the "random web browsing" AppVM, and also not the other way around: don't do random surfing in the "banking" AppVM), and generally making the whole isolation between AppVMs as seamless as possible, but without sacrificing the security at the same time.
This is becoming very important, as the technical level of security in Qubes is already very high, and so the "human factor" might easily become a low hanging fruit for the attacker. (In contrast to other OSes)
But for Qubes to become something more than just an interesting OS for Linux geeks and security enthusiasts, it is also critical to have better application support. Right now Qubes lets users run Linux apps, because each AppVM is Linux-based. But, and let's not be afraid to admit this: Linux sucks when it comes to application support! (Take Open Office as an example - it not only looks like MS Office 97, but is also terribly user-unfriendly, especially their presentation program, the Impress. Why is it so difficult to make it look and behave more like Apple Keynote?)
There is only one way to provide better application support to Qubes: make it support Windows-based, or Mac-based, AppVMs. Just imagine that: being able to run most of your Windows (or Mac) applications, but at the same time benefit from the Qubes strong isolation and seamless integration on one common desktop...
In order to implement support for Windows-based AppVMs (or alternatively Mac-based AppVM) we would need to engage significant resources (5+ very skilled developers, working full time for 1+ year), and so we're currently looking for an investor that would be able to provide funding for such an endeavor. The idea is to create a dedicated spin-off company that would focus entirely on Qubes and Qubes Pro, and in the future will make a profit from selling Qubes Pro licenses. Qubes Pro will become a commercial product, still based on the open source Qubes, but adding support for Windows-based or Mac-based AppVMs. I would be happy to discuss the details and business plan via email with interested potential investors.
Speaking about the future of Qubes: next week I will speak at the European Trusted Infrastructure Summer School, where I will talk about some general stuff like why we need secure desktop systems and why trusted computing might be a way to go, but will also dive a little bit into some new things we plan for Qubes 2.0, such as storage domain and split I/O graphics model. The conference features some very reputable speakers in system-level security field, such as David Grawrock (the father of Intel TXT and TPM), and Loic Duflot (our venerable competitor in the filed of offensive system-level research), so I consider a honour to deliver an opening keynote there (Check the agenda here).
I will have my Qubes laptop with me, of course, so if anybody is interested to see Qubes OS live (including Disposable VMs!), I would be happy to do a quick demo on the spot.
\ No newline at end of file
+The work on Qubes OS has been extremely exciting and also very challenging for us. While most of the work we have been doing so far relates to solving various technical, under-the-hood challenges, the more important goals in the long-term are related more to mitigating the so called "human factor", i.e. making the system not only easy to use, but tolerant to user absentmindedness. This includes e.g. ensuring the user uses a correct AppVM (e.g. do the banking in the "banking" AppVM, and not in the "random web browsing" AppVM, and also not the other way around: don't do random surfing in the "banking" AppVM), and generally making the whole isolation between AppVMs as seamless as possible, but without sacrificing the security at the same time.
This is becoming very important, as the technical level of security in Qubes is already very high, and so the "human factor" might easily become a low hanging fruit for the attacker. (In contrast to other OSes)
But for Qubes to become something more than just an interesting OS for Linux geeks and security enthusiasts, it is also critical to have better application support. Right now Qubes lets users run Linux apps, because each AppVM is Linux-based. But, and let's not be afraid to admit this: Linux sucks when it comes to application support! (Take Open Office as an example - it not only looks like MS Office 97, but is also terribly user-unfriendly, especially their presentation program, the Impress. Why is it so difficult to make it look and behave more like Apple Keynote?)
There is only one way to provide better application support to Qubes: make it support Windows-based, or Mac-based, AppVMs. Just imagine that: being able to run most of your Windows (or Mac) applications, but at the same time benefit from the Qubes strong isolation and seamless integration on one common desktop...
In order to implement support for Windows-based AppVMs (or alternatively Mac-based AppVM) we would need to engage significant resources (5+ very skilled developers, working full time for 1+ year), and so we're currently looking for an investor that would be able to provide funding for such an endeavor. The idea is to create a dedicated spin-off company that would focus entirely on Qubes and Qubes Pro, and in the future will make a profit from selling Qubes Pro licenses. Qubes Pro will become a commercial product, still based on the open source Qubes, but adding support for Windows-based or Mac-based AppVMs. I would be happy to discuss the details and business plan via email with interested potential investors.
Speaking about the future of Qubes: next week I will speak at the European Trusted Infrastructure Summer School, where I will talk about some general stuff like why we need secure desktop systems and why trusted computing might be a way to go, but will also dive a little bit into some new things we plan for Qubes 2.0, such as storage domain and split I/O graphics model. The conference features some very reputable speakers in system-level security field, such as David Grawrock (the father of Intel TXT and TPM), and Loic Duflot (our venerable competitor in the filed of offensive system-level research), so I consider a honour to deliver an opening keynote there (Check the agenda here).
I will have my Qubes laptop with me, of course, so if anybody is interested to see Qubes OS live (including Disposable VMs!), I would be happy to do a quick demo on the spot.
\ No newline at end of file
diff --git a/_posts/2010-10-06-qubes-alpha-3.html b/_posts/2010-10-06-qubes-alpha-3.html
index 5b2296a..8f4a84d 100644
--- a/_posts/2010-10-06-qubes-alpha-3.html
+++ b/_posts/2010-10-06-qubes-alpha-3.html
@@ -11,4 +11,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2010/10/qubes-alpha-3.html
---
-We have just uploaded the new packages for the Qubes Alpha 3 milestone. A lot of under the hood work went into this release, including:
- Redesigned networking and NetVM support (for VT-d system)
- Reasonably stable S3 sleep support (suspend-to-RAM), that works even with a NetVM!
- Improved GUI virtualization (all known bugs fixed finally!)
Disposable VMs are really a killer feature IMO. The screenshot below shows the user's experience:
 The user righ-clicks on a PDF file, chooses "Open in Disposable VM", and then waits 1... 2... 3... 4 seconds (assuming a reasonably modern laptop) and the document automagically opens in a fresh new Disposable VM. If you make some changes to the document (e.g. if it was a PDF form, and you edited it), those changes will propagate back to the original file in the original AppVM.
The user righ-clicks on a PDF file, chooses "Open in Disposable VM", and then waits 1... 2... 3... 4 seconds (assuming a reasonably modern laptop) and the document automagically opens in a fresh new Disposable VM. If you make some changes to the document (e.g. if it was a PDF form, and you edited it), those changes will propagate back to the original file in the original AppVM.
So, within 4-5 seconds, Qubes creates a new VM, boots it up (actually refreshes from a savefile), copies the file in question to the VM, and finally opens the application that is a registered MIME handler for this type of documents, e.g. a PDF viewer. We're pretty confident this time could be further decreased down to some 2 seconds, or maybe even less. This is planned for some later Beta release.
Dynamic memory balancing allows to better utilize system physical memory by moving it between running AppVMs in realtime, according to the VM's real needs. This allows to run more VMs, compared to a scheme with static memory allocation, and also dramatically eliminates system hiccups, that otherwise occur often in a static scheme when one of the VMs is short of memory and initiates swapping.
 The screenshot above shows the memory usage on my 6GB laptop when writing this blog post. As you can see I can easily run a dozen of AppVMs (most users will not need that many, but I'm a bit more paranoid I guess ;) and could probably even start a few more if there was such a need (e.g. open some Disposable VMs). Of course, this all depends on the actual type of workload the user runs in each VM - most of my AppVMs run just one or two applications, usually a Web browser (Firefox), but some, e.g. the work, and personal AppVMs run much more memory-hungry applications such as Open Office, or Picasa Photo Browser. I very rarely see more than 1 GB of memory allocated to a single VM, though. Generally speaking, the new memory management in Qubes works pretty nice.
The screenshot above shows the memory usage on my 6GB laptop when writing this blog post. As you can see I can easily run a dozen of AppVMs (most users will not need that many, but I'm a bit more paranoid I guess ;) and could probably even start a few more if there was such a need (e.g. open some Disposable VMs). Of course, this all depends on the actual type of workload the user runs in each VM - most of my AppVMs run just one or two applications, usually a Web browser (Firefox), but some, e.g. the work, and personal AppVMs run much more memory-hungry applications such as Open Office, or Picasa Photo Browser. I very rarely see more than 1 GB of memory allocated to a single VM, though. Generally speaking, the new memory management in Qubes works pretty nice.
Currently, the biggest slow-down factor for Qubes is somehow poor disk performance, most likely caused by the joint impact of the Xen backend, Linux dm, and kcryptd (we use the simplest possible Xen block backend for security reasons, will move to more sophisticated backends when we introduce untrusted storage domain in Qubes 2.0).
Now, most of the under-the-hood work for Qubes 1.0 seems to be complete, and now it time for all the polishing of the user experience, which will be the main focus of the upcoming Beta development. Just reminding that we're currently looking to hire developers for this effort.
The Installation instructions can be found here. Enjoy!
\ No newline at end of file
+We have just uploaded the new packages for the Qubes Alpha 3 milestone. A lot of under the hood work went into this release, including:
- Redesigned networking and NetVM support (for VT-d system)
- Reasonably stable S3 sleep support (suspend-to-RAM), that works even with a NetVM!
- Improved GUI virtualization (all known bugs fixed finally!)
Disposable VMs are really a killer feature IMO. The screenshot below shows the user's experience:
The user righ-clicks on a PDF file, chooses "Open in Disposable VM", and then waits 1... 2... 3... 4 seconds (assuming a reasonably modern laptop) and the document automagically opens in a fresh new Disposable VM. If you make some changes to the document (e.g. if it was a PDF form, and you edited it), those changes will propagate back to the original file in the original AppVM.
So, within 4-5 seconds, Qubes creates a new VM, boots it up (actually refreshes from a savefile), copies the file in question to the VM, and finally opens the application that is a registered MIME handler for this type of documents, e.g. a PDF viewer. We're pretty confident this time could be further decreased down to some 2 seconds, or maybe even less. This is planned for some later Beta release.
Dynamic memory balancing allows to better utilize system physical memory by moving it between running AppVMs in realtime, according to the VM's real needs. This allows to run more VMs, compared to a scheme with static memory allocation, and also dramatically eliminates system hiccups, that otherwise occur often in a static scheme when one of the VMs is short of memory and initiates swapping.
The screenshot above shows the memory usage on my 6GB laptop when writing this blog post. As you can see I can easily run a dozen of AppVMs (most users will not need that many, but I'm a bit more paranoid I guess ;) and could probably even start a few more if there was such a need (e.g. open some Disposable VMs). Of course, this all depends on the actual type of workload the user runs in each VM - most of my AppVMs run just one or two applications, usually a Web browser (Firefox), but some, e.g. the work, and personal AppVMs run much more memory-hungry applications such as Open Office, or Picasa Photo Browser. I very rarely see more than 1 GB of memory allocated to a single VM, though. Generally speaking, the new memory management in Qubes works pretty nice.
Currently, the biggest slow-down factor for Qubes is somehow poor disk performance, most likely caused by the joint impact of the Xen backend, Linux dm, and kcryptd (we use the simplest possible Xen block backend for security reasons, will move to more sophisticated backends when we introduce untrusted storage domain in Qubes 2.0).
Now, most of the under-the-hood work for Qubes 1.0 seems to be complete, and now it time for all the polishing of the user experience, which will be the main focus of the upcoming Beta development. Just reminding that we're currently looking to hire developers for this effort.
The Installation instructions can be found here. Enjoy!
\ No newline at end of file
diff --git a/_posts/2011-03-13-partitioning-my-digital-life-into.html b/_posts/2011-03-13-partitioning-my-digital-life-into.html
index 66cddc9..6bf1419 100644
--- a/_posts/2011-03-13-partitioning-my-digital-life-into.html
+++ b/_posts/2011-03-13-partitioning-my-digital-life-into.html
@@ -13,4 +13,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2011/03/partitioning-my-digital-life-into.html
---
-The diagram below illustrates how I have decomposed my digital life into security domains. This is a quite sophisticated scheme and most users would probably want something simpler, but I think it's still interesting to discuss it. The domains are implemented as lightweight AppVMs on Qubes OS. The diagram also shows what type of networking connectivity each domain is allowed.
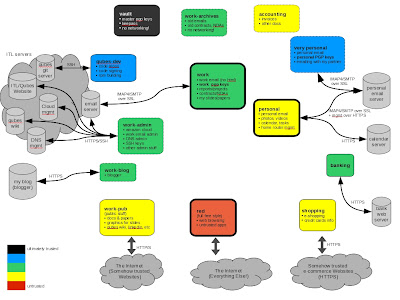
Let's discuss this diagram bit by bit. The three basic domains are work (the green label), personal (the yellow label), and red (for doing all the untrusted, insensitive things) – these are marked on the diagram with bold frames.
A quick digression on domain labels (colors) – in Qubes OS each domain, apart form having a distinct name, is also assigned a label, which basically is one of the several per-defined colors. These colors, which are used for drawing window decorations by the trusted Window Manager (color frames), are supposed to be user friendly, easy noticeable, indicators of how trusted a given window is. It's totally up to the user how he or she interprets these colors. For me, it has been somehow obvious to associate the red color with something that is untrusted and dangerous (the “red light” -- stop! danger!), green with something that is safe and trusted, while yellow and orange with something in the middle. I have also extended this scheme, to also include blue, and black, which I interpret as indicating progressively more trusted domains than green, with black being something ultimately trusted.
Back to my domains: the work domain is where I have access to my work email, where I keep my work PGP keys, where I prepare reports, slides, papers, etc. I also keep various contracts and NDAs here (yes, these are PDFs, but received from trusted parties via encrypted and signed email – otherwise I open them in Disposable VMs). The work domain has only network access to my work email server (SMTP/IMAP4 over SSL), and nothing more.
For other work-related tasks that require some Web access, such as editing Qubes Wiki, or accepting LinkedIn invites, or downloading cool pictures from fotolia.com for my presentations, or specs and manuals from intel.com, for all this I use work-pub domain, which I have assigned the yellow label, meaning I consider it only somehow trusted, and I would certainly never put my PGP keys there, or any work-related confidential information.
The personal domain is where all my non-work related stuff, such as personal email and calendar, holiday photos, videos, etc, are held. It doesn't really have access to the Web, but if I was into social networking I would then probably allow HTTPS to something like Facebook.
Being somehow on the paranoid side, I also have a special very-personal domain, which I use for the communication with my partner when I'm away from home. We use PGP, of course, and I have a separate PGP keys for this purpose. While we don't discuss any secret and sensitive stuff there, we still prefer to keep our intimate conversations private.
I use shopping for accessing all the internet e-commerce sites. Basically what defines this domain is access to my credit card numbers and my personal address (for shipping). Because I don't really have a dedicated “corporate” credit card, I do all the shopping in this domain, from groceries, through sports equipment, on hotel/plane reservations ending. If I had separate business credit cards, then I would probably split my shopping domain into personal-shopping and work-shopping. I also have banking domain, which I use only for managing my bank account (which again combines both my personal and company accounts).
I also have a few specialized work-related domains, that I rarely use. The work-admin domain is used to manage almost all of the ITL servers, such as our webserver, Qubes repo & wiki servers, email server and DNS management, etc. This domain is allowed only SSH traffic to those server, and HTTPS to a few Web-based management servers. The work-blog is used to manage this very blog you're reading now. The reason why it is separate from work-admin or work, is because I'm over paranoid, and because I fear that if somebody compromises the blogger service, and subsequently exploits a bug in my browser that I use for editing my blog, than I don't want this person to be able to also get admin access to all the ITL servers.
Similarly, if somebody somehow compromised e.g. the Amazon Web Management Console, and then exploited my browser in work-admin, then I would like at least to retain access to my blog. If I used twitter, I would probably also manage it from this work-blog domain, unless it was a personal twitter account, in which case I would run it from personal.
The qubes-dev domain is used for all the Qubes development, merging other developers' branches (after I verify signatures on their tags, of course!), building RPMs/ISOs (yes, Qubes Beta 1 will ship as a DVD ISO!), and finally signing them. Because the signing keys are there, this domain is very sensitive. This domain is allowed only SSH network access to our Qubes git server. Again, even if somebody compromised this Git server, it still would not be a big problem for us, because we sign and verify all the tags in each others repos (unless somebody could also modify the SSH/Git daemons running there so that they subsequently exploit a hypothetical bug in my git client software when I connect to the server).
I also decided to keep all the accounting-related stuff in a separate domain – whenever I get an invoice I copy it to the accounting domain. The rationale for this is that I trust those PDFs much less than I trust the PDFs I keep in my work domain.
Once a year I move the old stuff from my work domain, such as old email spools, old contracts and NDAs, to the work-archives domain. This is to minimize the potential impact of the potential attack on my work domain (my work domain could be attacked e.g. by exploiting a hypothetical bug in Thunderbird's protocol handshake using a MITM attack, or a hypothetical bug in GPG).
The vault domain is an ultimately trusted one where I generate and keep all my passwords (using keepass) and master GPG keys. Of course, this vault domain has no networking access. Most of those passwords, such as the email server access password is also kept in the specific domains which uses them, such as the work domain, and more specifically in the Thunderbird client (there is absolutely no point in not allowing e.g. Thunderbird to remember the password – if it got compromised it would just steal it the next time I manually enter it)
And finally, there is the previously mentioned red domain (I have tried to call it junk or random in the past, but I think red is still a better name after all). The red domain is totally untrusted – if it gets compromised, I don't care – I would just recreate it within seconds. I don't even back it up! Basically I do there everything that doesn't fit into other domains, and which doesn't require me to provide any sensitive information. I don't differentiate between work-related and personal-related surfing even – I don't care about anonymity for all those tasks I do there. If I was concerned about anonymity, I would create a separate anonymous domain, and proxy all the traffic through a tor proxy from there.
Now, this all looks nice and easy ;) but there is one thing that complicates the above picture...
Data flows between the domains
The diagram below shows the same domains, but additionally with arrows symbolizing typical data flows between them.
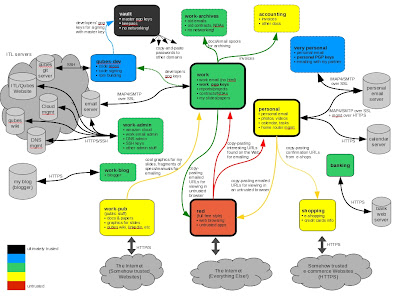
You can see that most of the usual data flows are from more trusted domains to less trusted domains – e.g. copy and pasting a URL that I receive via email in my work domain, so that I could open it in my untrusted browser in red, or moving invoices from my work domain (where I receive them via email) to the accounting domain.
But there are, unfortunately, also some transfers from less trusted domains to more trusted ones. One example is copy and pasting an interesting URL that I just stumbled upon when surfing in the red domain, and that I would like to share with a college at work, or a friend, and so I need to copy and paste it to my email client in either work (colleague) or personal (friend) domain.
Now, copying data from less trusted domains to more trusted ones presents a significant problem. While one could think that pasting an URL into Thunderbird email editor is a pretty harmless operation, it's still is an untrusted input – and we don't really know what the red domain really pasted into its local clipboard, and so what we will paste into the work domain's Thunderbird email editor (perhaps 64kB of some junk that will overflow some undo buffer in the editor?). And even more scary is the example with copying the cool-looking graphics file from the Web into my work domain so that I could use it in my presentation slides (e.g. an xkcd . Attacks originating through malicious JPEGs or other graphics format, and exploiting bugs in rendering code have been known for more than a decade.
But this problem – how to handle data flows from less trusted systems to more trusted ones – is not easily solvable in practice, unfortunately...
Some people who design and build high-security systems for use by military and government takes a somehow opposite approach – they say they are not concerned about less-trusted-to-more-trusted data transfers as long as they could assure there is no way to perform a transfer in the opposite direction.
So, if we could build a system that guarantees that a more trusted domain can never transfer data to a less trusted domain (even if both of those domains are compromised!), then they are happy to allow one-way “up transfers”. In practice this means we need to eliminate all the covert channels between two cooperating domains. The word cooperating is a key word here, and which makes this whole idea not practical at all, IMHO.
Elimination of the covert channels between cooperating domains is indeed required in this scheme, because the assumption is that the data transfer from the less trusted domain could have indeed compromised the more trusted domain. But this, at least, should not result in any data leak back to the originating domain, and later to the less-classified network, which this less-trusted domain is presumably connected to. One of the assumptions here is that the user of such a system is connected to more than one, isolated networks. Even in that case, elimination of all the covert channels between domains (or at least minimizing their bandwith to something unusable – what is unusable, really?) is a big challenge, and can probably only could be done when we're ready to significantly sacrifice the system's performance (smart scheduling tricks are needed to minimize temporal covert channels).
I would like to make it clear that we are not interested in eliminating cooperative covert channels between domains in Qubes any time in the near future, and perhaps in the long term as well. I just don't believe into such approach, and I also don't like that this approach does nothing to preserve the integrity of the more-trusted domain – it only focuses on the isolation aspect. So, perhaps the attacker might not be able to leak secrets back to the less trusted domain, but he or she can do everything else in this more trusted domain. What good is isolation, if we don't maintain integrity?
An alternative solution to handling the less-trusted-to-more-trusted data transfers, is to have trusted “converters” or “verifiers” that could handle specific file types, such as JPEGs, and ensure we get a non-malicious file in the destination domain. While this might remind the bad-old A/V technology, it is something different. Here, the trusted converters would likely be some programs written in a safe language, running in another trusted domain, rather than a big ugly A/V with a huge database of signatures of “bad” patterns of what might appear in a JPEG file. The obvious problem with such an approach is that somebody must write those converters, and write them for all file types that we wish to allow to be transferred to more trusted domains. Perhaps doable in the longer-term, and perhaps we will do it in some future version of Qubes...
Right now we are ignoring this problem, and we say that all less-trusted-to-more-trusted transfers are to be done on the user's own risk :) You're welcome to submit trusted converters for your favorite file type(s) in the meantime!
Copying files between domains
Speaking of copying files between domains, there is another security catch here. If we imagined two physically separated machines that share no common network resources, the only way to move files between those two air-gaped machines would be via something like a USB stick or a CDROM or DVD disc. But inserting a USB drive or CDROM into a machine triggers a whole lot of actions: from parsing device-provided information, loading required drivers (for USB), parsing the driver's partition table, mounting and finally parsing the filesystem. Each of this stage requires the machine's OS to perform a lot of untrusted input processing, and the potential attack space here is quite large. So, even if we could limit ourselves to copy only harmless files between machines/domains (perhaps they were somehow verified by a trusted party in-between, as discussed above), still there is a huge opportunity that the originating domain could compromise the target domain.
In Qubes Alpha we have been using a similar file copy mechanism, using a virtual stick for file copy between domains. In Qubes Beta 1 we will provide a new scheme based on same shared memory channel that we use for GUI virtualization – the technical details of this solution will be available soon in
our wiki. The most sensitive element in this new scheme is the un-cpio-like utility that runs in the target domain and unpacks the incoming blob into the pre-defined directory tree (e.g.
/home/user/incoming/from-{domainname}/). We believe we can write pretty safe un-cpio-like utility, in contrast to secure all the previously mentioned elements (USB device parsing, partition parsing, fs parsing). The Qubes Beta 1 is planned to be released at the end of March, BTW.
Partitioning enforcement and easy of use
For any security partitioning scheme to make sense in real life, it is necessary to have some enforcement mechanism that would ensure that the user doesn't mistakenly bypass it. Specifically for this purpose we have come up with special, previously-mentioned firewalling support in Qubes Beta 1, that I will cover in a separate article soon.
Anther thing is to make the partitioning easy to use. For instance, I would like to be able to setup a hint in the policy, that when I click on an URL in an email I received in my work domain that it should be automatically opened in the red domain's default Web browser. Currently we don't do that in Qubes, but we're thinking about doing it in the near future.
Summary
Partitioning one's digital life into security domains is certainly not an easy process and requires some thinking. This process is also very user-specific. The partitioning scheme that I've come up for myself is quite sophisticated, and most people would probably want something much simpler. In case of corporate deployments, the scheme would be designed by CIO or IT admins, and enforced on users automatically. Much bigger problem are home and small business users, who would need to come up with the partitioning themselves. Perhaps in future versions of Qubes we will provide some ready to use templates for select "typical" groups of users.
\ No newline at end of file
+The diagram below illustrates how I have decomposed my digital life into security domains. This is a quite sophisticated scheme and most users would probably want something simpler, but I think it's still interesting to discuss it. The domains are implemented as lightweight AppVMs on Qubes OS. The diagram also shows what type of networking connectivity each domain is allowed.
Let's discuss this diagram bit by bit. The three basic domains are work (the green label), personal (the yellow label), and red (for doing all the untrusted, insensitive things) – these are marked on the diagram with bold frames.
A quick digression on domain labels (colors) – in Qubes OS each domain, apart form having a distinct name, is also assigned a label, which basically is one of the several per-defined colors. These colors, which are used for drawing window decorations by the trusted Window Manager (color frames), are supposed to be user friendly, easy noticeable, indicators of how trusted a given window is. It's totally up to the user how he or she interprets these colors. For me, it has been somehow obvious to associate the red color with something that is untrusted and dangerous (the “red light” -- stop! danger!), green with something that is safe and trusted, while yellow and orange with something in the middle. I have also extended this scheme, to also include blue, and black, which I interpret as indicating progressively more trusted domains than green, with black being something ultimately trusted.
Back to my domains: the work domain is where I have access to my work email, where I keep my work PGP keys, where I prepare reports, slides, papers, etc. I also keep various contracts and NDAs here (yes, these are PDFs, but received from trusted parties via encrypted and signed email – otherwise I open them in Disposable VMs). The work domain has only network access to my work email server (SMTP/IMAP4 over SSL), and nothing more.
For other work-related tasks that require some Web access, such as editing Qubes Wiki, or accepting LinkedIn invites, or downloading cool pictures from fotolia.com for my presentations, or specs and manuals from intel.com, for all this I use work-pub domain, which I have assigned the yellow label, meaning I consider it only somehow trusted, and I would certainly never put my PGP keys there, or any work-related confidential information.
The personal domain is where all my non-work related stuff, such as personal email and calendar, holiday photos, videos, etc, are held. It doesn't really have access to the Web, but if I was into social networking I would then probably allow HTTPS to something like Facebook.
Being somehow on the paranoid side, I also have a special very-personal domain, which I use for the communication with my partner when I'm away from home. We use PGP, of course, and I have a separate PGP keys for this purpose. While we don't discuss any secret and sensitive stuff there, we still prefer to keep our intimate conversations private.
I use shopping for accessing all the internet e-commerce sites. Basically what defines this domain is access to my credit card numbers and my personal address (for shipping). Because I don't really have a dedicated “corporate” credit card, I do all the shopping in this domain, from groceries, through sports equipment, on hotel/plane reservations ending. If I had separate business credit cards, then I would probably split my shopping domain into personal-shopping and work-shopping. I also have banking domain, which I use only for managing my bank account (which again combines both my personal and company accounts).
I also have a few specialized work-related domains, that I rarely use. The work-admin domain is used to manage almost all of the ITL servers, such as our webserver, Qubes repo & wiki servers, email server and DNS management, etc. This domain is allowed only SSH traffic to those server, and HTTPS to a few Web-based management servers. The work-blog is used to manage this very blog you're reading now. The reason why it is separate from work-admin or work, is because I'm over paranoid, and because I fear that if somebody compromises the blogger service, and subsequently exploits a bug in my browser that I use for editing my blog, than I don't want this person to be able to also get admin access to all the ITL servers.
Similarly, if somebody somehow compromised e.g. the Amazon Web Management Console, and then exploited my browser in work-admin, then I would like at least to retain access to my blog. If I used twitter, I would probably also manage it from this work-blog domain, unless it was a personal twitter account, in which case I would run it from personal.
The qubes-dev domain is used for all the Qubes development, merging other developers' branches (after I verify signatures on their tags, of course!), building RPMs/ISOs (yes, Qubes Beta 1 will ship as a DVD ISO!), and finally signing them. Because the signing keys are there, this domain is very sensitive. This domain is allowed only SSH network access to our Qubes git server. Again, even if somebody compromised this Git server, it still would not be a big problem for us, because we sign and verify all the tags in each others repos (unless somebody could also modify the SSH/Git daemons running there so that they subsequently exploit a hypothetical bug in my git client software when I connect to the server).
I also decided to keep all the accounting-related stuff in a separate domain – whenever I get an invoice I copy it to the accounting domain. The rationale for this is that I trust those PDFs much less than I trust the PDFs I keep in my work domain.
Once a year I move the old stuff from my work domain, such as old email spools, old contracts and NDAs, to the work-archives domain. This is to minimize the potential impact of the potential attack on my work domain (my work domain could be attacked e.g. by exploiting a hypothetical bug in Thunderbird's protocol handshake using a MITM attack, or a hypothetical bug in GPG).
The vault domain is an ultimately trusted one where I generate and keep all my passwords (using keepass) and master GPG keys. Of course, this vault domain has no networking access. Most of those passwords, such as the email server access password is also kept in the specific domains which uses them, such as the work domain, and more specifically in the Thunderbird client (there is absolutely no point in not allowing e.g. Thunderbird to remember the password – if it got compromised it would just steal it the next time I manually enter it)
And finally, there is the previously mentioned red domain (I have tried to call it junk or random in the past, but I think red is still a better name after all). The red domain is totally untrusted – if it gets compromised, I don't care – I would just recreate it within seconds. I don't even back it up! Basically I do there everything that doesn't fit into other domains, and which doesn't require me to provide any sensitive information. I don't differentiate between work-related and personal-related surfing even – I don't care about anonymity for all those tasks I do there. If I was concerned about anonymity, I would create a separate anonymous domain, and proxy all the traffic through a tor proxy from there.
Now, this all looks nice and easy ;) but there is one thing that complicates the above picture...
Data flows between the domains
The diagram below shows the same domains, but additionally with arrows symbolizing typical data flows between them.
You can see that most of the usual data flows are from more trusted domains to less trusted domains – e.g. copy and pasting a URL that I receive via email in my work domain, so that I could open it in my untrusted browser in red, or moving invoices from my work domain (where I receive them via email) to the accounting domain.
But there are, unfortunately, also some transfers from less trusted domains to more trusted ones. One example is copy and pasting an interesting URL that I just stumbled upon when surfing in the red domain, and that I would like to share with a college at work, or a friend, and so I need to copy and paste it to my email client in either work (colleague) or personal (friend) domain.
Now, copying data from less trusted domains to more trusted ones presents a significant problem. While one could think that pasting an URL into Thunderbird email editor is a pretty harmless operation, it's still is an untrusted input – and we don't really know what the red domain really pasted into its local clipboard, and so what we will paste into the work domain's Thunderbird email editor (perhaps 64kB of some junk that will overflow some undo buffer in the editor?). And even more scary is the example with copying the cool-looking graphics file from the Web into my work domain so that I could use it in my presentation slides (e.g. an xkcd . Attacks originating through malicious JPEGs or other graphics format, and exploiting bugs in rendering code have been known for more than a decade.
But this problem – how to handle data flows from less trusted systems to more trusted ones – is not easily solvable in practice, unfortunately...
Some people who design and build high-security systems for use by military and government takes a somehow opposite approach – they say they are not concerned about less-trusted-to-more-trusted data transfers as long as they could assure there is no way to perform a transfer in the opposite direction.
So, if we could build a system that guarantees that a more trusted domain can never transfer data to a less trusted domain (even if both of those domains are compromised!), then they are happy to allow one-way “up transfers”. In practice this means we need to eliminate all the covert channels between two cooperating domains. The word cooperating is a key word here, and which makes this whole idea not practical at all, IMHO.
Elimination of the covert channels between cooperating domains is indeed required in this scheme, because the assumption is that the data transfer from the less trusted domain could have indeed compromised the more trusted domain. But this, at least, should not result in any data leak back to the originating domain, and later to the less-classified network, which this less-trusted domain is presumably connected to. One of the assumptions here is that the user of such a system is connected to more than one, isolated networks. Even in that case, elimination of all the covert channels between domains (or at least minimizing their bandwith to something unusable – what is unusable, really?) is a big challenge, and can probably only could be done when we're ready to significantly sacrifice the system's performance (smart scheduling tricks are needed to minimize temporal covert channels).
I would like to make it clear that we are not interested in eliminating cooperative covert channels between domains in Qubes any time in the near future, and perhaps in the long term as well. I just don't believe into such approach, and I also don't like that this approach does nothing to preserve the integrity of the more-trusted domain – it only focuses on the isolation aspect. So, perhaps the attacker might not be able to leak secrets back to the less trusted domain, but he or she can do everything else in this more trusted domain. What good is isolation, if we don't maintain integrity?
An alternative solution to handling the less-trusted-to-more-trusted data transfers, is to have trusted “converters” or “verifiers” that could handle specific file types, such as JPEGs, and ensure we get a non-malicious file in the destination domain. While this might remind the bad-old A/V technology, it is something different. Here, the trusted converters would likely be some programs written in a safe language, running in another trusted domain, rather than a big ugly A/V with a huge database of signatures of “bad” patterns of what might appear in a JPEG file. The obvious problem with such an approach is that somebody must write those converters, and write them for all file types that we wish to allow to be transferred to more trusted domains. Perhaps doable in the longer-term, and perhaps we will do it in some future version of Qubes...
Right now we are ignoring this problem, and we say that all less-trusted-to-more-trusted transfers are to be done on the user's own risk :) You're welcome to submit trusted converters for your favorite file type(s) in the meantime!
Copying files between domains
Speaking of copying files between domains, there is another security catch here. If we imagined two physically separated machines that share no common network resources, the only way to move files between those two air-gaped machines would be via something like a USB stick or a CDROM or DVD disc. But inserting a USB drive or CDROM into a machine triggers a whole lot of actions: from parsing device-provided information, loading required drivers (for USB), parsing the driver's partition table, mounting and finally parsing the filesystem. Each of this stage requires the machine's OS to perform a lot of untrusted input processing, and the potential attack space here is quite large. So, even if we could limit ourselves to copy only harmless files between machines/domains (perhaps they were somehow verified by a trusted party in-between, as discussed above), still there is a huge opportunity that the originating domain could compromise the target domain.
In Qubes Alpha we have been using a similar file copy mechanism, using a virtual stick for file copy between domains. In Qubes Beta 1 we will provide a new scheme based on same shared memory channel that we use for GUI virtualization – the technical details of this solution will be available soon in
our wiki. The most sensitive element in this new scheme is the un-cpio-like utility that runs in the target domain and unpacks the incoming blob into the pre-defined directory tree (e.g.
/home/user/incoming/from-{domainname}/). We believe we can write pretty safe un-cpio-like utility, in contrast to secure all the previously mentioned elements (USB device parsing, partition parsing, fs parsing). The Qubes Beta 1 is planned to be released at the end of March, BTW.
Partitioning enforcement and easy of use
For any security partitioning scheme to make sense in real life, it is necessary to have some enforcement mechanism that would ensure that the user doesn't mistakenly bypass it. Specifically for this purpose we have come up with special, previously-mentioned firewalling support in Qubes Beta 1, that I will cover in a separate article soon.
Anther thing is to make the partitioning easy to use. For instance, I would like to be able to setup a hint in the policy, that when I click on an URL in an email I received in my work domain that it should be automatically opened in the red domain's default Web browser. Currently we don't do that in Qubes, but we're thinking about doing it in the near future.
Summary
Partitioning one's digital life into security domains is certainly not an easy process and requires some thinking. This process is also very user-specific. The partitioning scheme that I've come up for myself is quite sophisticated, and most people would probably want something much simpler. In case of corporate deployments, the scheme would be designed by CIO or IT admins, and enforced on users automatically. Much bigger problem are home and small business users, who would need to come up with the partitioning themselves. Perhaps in future versions of Qubes we will provide some ready to use templates for select "typical" groups of users.
\ No newline at end of file
diff --git a/_posts/2011-04-23-linux-security-circus-on-gui-isolation.html b/_posts/2011-04-23-linux-security-circus-on-gui-isolation.html
index cabed3a..3b36c19 100644
--- a/_posts/2011-04-23-linux-security-circus-on-gui-isolation.html
+++ b/_posts/2011-04-23-linux-security-circus-on-gui-isolation.html
@@ -11,4 +11,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2011/04/linux-security-circus-on-gui-isolation.html
---
-There certainly is one thing that most Linux users don't realize about their Linux systems... this is the lack of GUI-level isolation, and how it essentially nullifies all the desktop security. I wrote about it a few times, I spoke about it a few times, yet I still come across people who don't realize it all the time.
So, let me stress this one more time: if you have two GUI applications, e.g. an OpenOffice Word Processor, and a stupid Tetris game, both of which granted access to your screen (your X server), then there is no isolation between those two apps. Even if they run as different user accounts! Even if they are somehow sandboxed by SELinux or whatever! None, zero, null, nil!
The X server architecture, designed long time ago by some happy hippies who just thought all the people apps are good and non-malicious, simply allows any GUI application to control any other one. No bugs, no exploits, no tricks, are required. This is all by design. One application can sniff or inject keystrokes to another one, can take snapshots of the screen occupied by windows belonging to another one, etc.
If you don't believe me, I suggest you do a simple experiment. Open a terminal window, as normal user, and run xinput list, which is a standard diagnostic program for Xorg (on Fedora you will likely need to install it first: yum install xorg-x11-apps):
$ xinput list
It will show you all the pointer and keyboard devices that your Xorg knows about. Note the ID of the device listed as “AT keyboard” and then run (as normal user!):
$ xinput test id
It should now start displaying the scancodes for all the keys you press on the keyboard. If it doesn't, it means you used a wrong device ID.
Now, for the best, start another terminal window, and switch to root (e.g. using su, or sudo). Notice how the xinput running as user is able to sniff all your keystrokes, including root password (for su), and then all the keystrokes you enter in your root session. Start some GUI app as root, or as different user, again notice how your xinput can sniff all the keystrokes you enter to this other app!
Yes, I can understand what is happening in your mind and heart right now... Don't worry, others have also passed through it. Feel free to hate me, throw out insults at me, etc. I don't mind, really (I just won't moderate them). When you calm down, continue reading.
In Qubes the above problem doesn't exist, because each domain (each AppVM) has it own local, isolated, dummy X server. The main X server, that runs in Dom0 and that handles the real display is never exposed to any of the AppVMs directly (AppVMs cannot connect to it via the X protocol). For details see this
technical overview.
You can repeat the same experiment in Qubes. You just need to use the ID of the “qubesdev” device, as shown by xinput list (should be 7). Run the xinput in one of your domains, e.g. in the “red” one. Because we actually use the same device for both mouse and keystrokes, you should now see both the key scancodes, as well as all the mouse events. Notice how your xinput is able to sniff all the events that are destined for other apps belonging to the same domain where you run xinput, and how it is unable to sniff anything targeted to other domains, or Dom0.
BTW, Windows is the only one mainstream OS I'm aware of, that actually attempts to implement some form of GUI-level isolation, starting from Windows Vista. See e.g. this
ancient article I wrote in the days when I used Vista at my primary laptop. Of course, it's still easy to bypass this isolation, because of the huge interface that is exposed to each GUI client (that also includes GPU API). Nevertheless, they at least attempt to prevent this at the architecture level.
There certainly is one thing that most Linux users don't realize about their Linux systems... this is the lack of GUI-level isolation, and how it essentially nullifies all the desktop security. I wrote about it a few times, I spoke about it a few times, yet I still come across people who don't realize it all the time.
So, let me stress this one more time: if you have two GUI applications, e.g. an OpenOffice Word Processor, and a stupid Tetris game, both of which granted access to your screen (your X server), then there is no isolation between those two apps. Even if they run as different user accounts! Even if they are somehow sandboxed by SELinux or whatever! None, zero, null, nil!
The X server architecture, designed long time ago by some happy hippies who just thought all the people apps are good and non-malicious, simply allows any GUI application to control any other one. No bugs, no exploits, no tricks, are required. This is all by design. One application can sniff or inject keystrokes to another one, can take snapshots of the screen occupied by windows belonging to another one, etc.
If you don't believe me, I suggest you do a simple experiment. Open a terminal window, as normal user, and run xinput list, which is a standard diagnostic program for Xorg (on Fedora you will likely need to install it first: yum install xorg-x11-apps):
$ xinput list
It will show you all the pointer and keyboard devices that your Xorg knows about. Note the ID of the device listed as “AT keyboard” and then run (as normal user!):
$ xinput test id
It should now start displaying the scancodes for all the keys you press on the keyboard. If it doesn't, it means you used a wrong device ID.
Now, for the best, start another terminal window, and switch to root (e.g. using su, or sudo). Notice how the xinput running as user is able to sniff all your keystrokes, including root password (for su), and then all the keystrokes you enter in your root session. Start some GUI app as root, or as different user, again notice how your xinput can sniff all the keystrokes you enter to this other app!
Yes, I can understand what is happening in your mind and heart right now... Don't worry, others have also passed through it. Feel free to hate me, throw out insults at me, etc. I don't mind, really (I just won't moderate them). When you calm down, continue reading.
In Qubes the above problem doesn't exist, because each domain (each AppVM) has it own local, isolated, dummy X server. The main X server, that runs in Dom0 and that handles the real display is never exposed to any of the AppVMs directly (AppVMs cannot connect to it via the X protocol). For details see this
technical overview.
You can repeat the same experiment in Qubes. You just need to use the ID of the “qubesdev” device, as shown by xinput list (should be 7). Run the xinput in one of your domains, e.g. in the “red” one. Because we actually use the same device for both mouse and keystrokes, you should now see both the key scancodes, as well as all the mouse events. Notice how your xinput is able to sniff all the events that are destined for other apps belonging to the same domain where you run xinput, and how it is unable to sniff anything targeted to other domains, or Dom0.
BTW, Windows is the only one mainstream OS I'm aware of, that actually attempts to implement some form of GUI-level isolation, starting from Windows Vista. See e.g. this
ancient article I wrote in the days when I used Vista at my primary laptop. Of course, it's still easy to bypass this isolation, because of the huge interface that is exposed to each GUI client (that also includes GPU API). Nevertheless, they at least attempt to prevent this at the architecture level.
When we think about “USB Security” there are lots of things that come to mind...
First there are all the
physical attacks that could be conducted with the help of USB devices. These are generally not so interesting, because if one includes physical attacks in the threat model, then it really opens up lots of possibilities of various attacks, and generally a physical attacker always wins. Still, there are a few very cheap and easy physical attacks that one would like to avoid, or make harder, such as the Evil Maid Attacks or the Cold Boot Attacks. Strictly speaking these are not problems inherent to USB itself, but rather with lack of Trusted Boot, or OS not cleaning properly secrets from memory upon shutdown. They are just made simple thanks to bootable USB sticks.
Much more interesting USB-related physical attacks are those that take advantage of the specifics of the USB standard. One
example here would be a malicious USB device that exposes intentionally malformed info about itself in order to exploit a potential flaw in a USB Host Controller driver that processes this info upon each new USB device connect.
Or a malicious USB device that would trick the OS (Windows at least) into downloading a known buggy USB driver (or even an intentionally malicious driver, legally submitted to WHQL by the attacker) and then exploit the driver.
Another class of physical attacks made possible by the USB specification are malicious USB devices that
pretend to be a keyboard or mouse. The input devices, such as keyboard, are actually the most security sensitive devices
, because an attacker who controls the keyboard can do everything the user can do, which basically means: can do everything, at least with regards to the user's data.
Finally, the USB, as the names stands, is a bus interconnect, which means all the USB devices sharing the same USB controller are capable of sniffing and spoofing signals on the bus. This is one of the key differences between USB and PCI Express standards, where the latter uses a peer-to-peer interconnect architecture.
Ok, so these all above were physical attacks. Let's now look at, much more fatal, software attacks.
The infamous class of attacks exploiting various autorun or auto-preview behaviors is the most known example, but also the easiest, at least in theory, to protect against.
Much more interesting are software attacks that attempt to exploit potential flaws in the USB stacks – similarly like the physical attacks mentioned above, just that this time not requiring any hardware-level modifications to the USB device. Exposing a malformed partition table is a great example of such an attack. Even if we have all the autorun mechanisms disabled, still, when we're inserting a storage medium the OS always attempts to parse the partition table in order to e.g. create devices symbolizing each partition/volume (e.g. /dev/sdbX devices).
Now, this is really a problematic attack, because the malformed partition table can be written onto a fully legitimate USB stick by malware. Imagine e.g. you have two physically separated machines (air-gapped), belonging to two different security domains, and you want to transfer files from one to another. You insert the USB stick into the first machine, copy files, and then insert the stick to the second machine. If the first machine was compromised, it could have altered the partition table on the USB stick, and now when this stick is inserted into the other machine its malformed partition table might exploit a buffer overflow in the code used by the second OS to parse the stick's partition information. Air-gapped systems, huh? We avoid this attack vector in Qubes by using a special inter-domain file copy mechanism that doesn't require any metadata parsing.
A variation of the above attack would be to expose a malicious file system metadata, but this time the target OS would have to actually mount the partition for the attack to work (and, of course, there would have to be bugs in the OS file system parsing code, although these seem to be quite common on most OSes).
Having quickly summarized the USB security-related threats, let's now think about how we could design an OS to mitigate most of those attacks, and at the very least the software-based attacks. This is, in fact, precisely the challenge we've been facing in Qubes, so the divagations below necessarily focus mostly on the Qubes architecture.
First we should realize that USB devices, unlike PCI Express devices, cannot be independently delegated to different domains (VMs). This is because IOMMU technologies, such as Intel VT-d, operate only on PCIe device granularity. This means we can only delegate a whole USB controller to a domain, including all of the USB devices connected to this controller/hub.
Imagine now two internal devices, both connected via internal USB bus: a keyboard, and a 3G wireless modem. Chances are high that you will have those two devices connected to the same USB controller – usually one controller is used for all the internal devices, like those I just mentioned, plus camera, fingerprint reader, etc, and the other controller is used for all the externally visible USB connectors (at least this is true for modern systems: Intel Series 5 chipsets and newer).
We would like to be able to delegate the 3G modem to the NetVM (an untrusted domain on Qubes where all the networking drivers and stacks are kept; it's considered untrusted because its compromise is equivalent to a compromise of a WiFi network or home router, or some other router, and any reasonable person always assumes that the network is compromised, and deals with that using crypto, such as SSL or SSH). But assigning the USB controller, to which the 3G modem is connected to, to the NetVM, would also assign the USB keyboard to the NetVM! And this is precisely what we don't want to do, because control over the keyboard is equivalent to the control over the whole system!
Currently, in Qubes Beta 1, we keep all the USB controllers assigned to Dom0. This, however, causes two annoyances:
First, the user cannot use any of the USB-connected networking devices, such as 3G modems (because there is no networking in Dom0).
Second, if somebody connects a USB disk and later delegates it to some domain (this could easily be done via block-attach mechanism, supported by the same backend that handles storage virtualization for domains), and this domain turns out to be compromised, it might alter e.g. the stick's partition table and later attack Dom0 as explained above.
We can eliminate the second problem by modifying the Dom0's kernel to not parse the partition table of any removable devices automatically, and instead expect some kind of explicit consent from user to actually do that (we still must allow to mount USB disks in Dom0 to allow easy backups of all domains at once).
To allow the use of USB-connected networking devices in NetVM, we could use a PVUSB backend that can virtualize single USB devices without moving the whole USB controller to the domain. But that would require introducing a whole lot of new code to Dom0 – code that would be directly reachable from VMs (in other words that would be processing lots of untrusted input coming from untrusted domains).
So another option is to delegate all the non-security-critical USB controllers, i.e. those controllers that don't have any security-sensitive USB devices connected, such as keyboard, to a dedicated “USB” domain, and later share the USB devices via PVUSB backend from this USB domain. This time, the extra PVUSB backend runs in the USB domain, not in Dom0, so we don't worry that much about potential bugs in this backend. Of course, this way you cannot delegate the USB controller to which the keyboard, and potentially also other security-critical devices, such as camera, are connected to, which in practice rules out the integrated3G modem. Fortunately many modern laptops do not use USB-connected keyboard and touchpad (they use PS/2-connected keyboards instead), and the face camera can be easily disabled with a piece of sticker (although that sucks, because it means we cannot really use the camera).
With this approach (a dedicated USB domain) you can now delegate your 3G modem to the NetVM, and other USB devices, such as removable disks to other domains, e.g. for file exchange. This seems the most reasonable setup, although it requires that either 1) your laptop doesn't have USB-connected keyboard, or 2) you don't use internal USB devices connected to the same controller that your USB keyboard/touchpad from other domains than Dom0 (in practice: no 3G modem in NetVM).
As we can see proper handling of USB devices is quite a challenge for OS architects. It might have been much less of a challenge if the engineers designing the USB, chipsets, and motherboards were a bit more security-conscious. Even such simple practice as never mixing security critical devices (keyboard, touchpad, camera, fingerprint reader), with non-security ones (3G modem), onto the same USB controller, would help tremendously. Or ability to somehow dynamically configure their connectivity, e.g. in BIOS?
\ No newline at end of file
+
When we think about “USB Security” there are lots of things that come to mind...
First there are all the
physical attacks that could be conducted with the help of USB devices. These are generally not so interesting, because if one includes physical attacks in the threat model, then it really opens up lots of possibilities of various attacks, and generally a physical attacker always wins. Still, there are a few very cheap and easy physical attacks that one would like to avoid, or make harder, such as the Evil Maid Attacks or the Cold Boot Attacks. Strictly speaking these are not problems inherent to USB itself, but rather with lack of Trusted Boot, or OS not cleaning properly secrets from memory upon shutdown. They are just made simple thanks to bootable USB sticks.
Much more interesting USB-related physical attacks are those that take advantage of the specifics of the USB standard. One
example here would be a malicious USB device that exposes intentionally malformed info about itself in order to exploit a potential flaw in a USB Host Controller driver that processes this info upon each new USB device connect.
Or a malicious USB device that would trick the OS (Windows at least) into downloading a known buggy USB driver (or even an intentionally malicious driver, legally submitted to WHQL by the attacker) and then exploit the driver.
Another class of physical attacks made possible by the USB specification are malicious USB devices that
pretend to be a keyboard or mouse. The input devices, such as keyboard, are actually the most security sensitive devices
, because an attacker who controls the keyboard can do everything the user can do, which basically means: can do everything, at least with regards to the user's data.
Finally, the USB, as the names stands, is a bus interconnect, which means all the USB devices sharing the same USB controller are capable of sniffing and spoofing signals on the bus. This is one of the key differences between USB and PCI Express standards, where the latter uses a peer-to-peer interconnect architecture.
Ok, so these all above were physical attacks. Let's now look at, much more fatal, software attacks.
The infamous class of attacks exploiting various autorun or auto-preview behaviors is the most known example, but also the easiest, at least in theory, to protect against.
Much more interesting are software attacks that attempt to exploit potential flaws in the USB stacks – similarly like the physical attacks mentioned above, just that this time not requiring any hardware-level modifications to the USB device. Exposing a malformed partition table is a great example of such an attack. Even if we have all the autorun mechanisms disabled, still, when we're inserting a storage medium the OS always attempts to parse the partition table in order to e.g. create devices symbolizing each partition/volume (e.g. /dev/sdbX devices).
Now, this is really a problematic attack, because the malformed partition table can be written onto a fully legitimate USB stick by malware. Imagine e.g. you have two physically separated machines (air-gapped), belonging to two different security domains, and you want to transfer files from one to another. You insert the USB stick into the first machine, copy files, and then insert the stick to the second machine. If the first machine was compromised, it could have altered the partition table on the USB stick, and now when this stick is inserted into the other machine its malformed partition table might exploit a buffer overflow in the code used by the second OS to parse the stick's partition information. Air-gapped systems, huh? We avoid this attack vector in Qubes by using a special inter-domain file copy mechanism that doesn't require any metadata parsing.
A variation of the above attack would be to expose a malicious file system metadata, but this time the target OS would have to actually mount the partition for the attack to work (and, of course, there would have to be bugs in the OS file system parsing code, although these seem to be quite common on most OSes).
Having quickly summarized the USB security-related threats, let's now think about how we could design an OS to mitigate most of those attacks, and at the very least the software-based attacks. This is, in fact, precisely the challenge we've been facing in Qubes, so the divagations below necessarily focus mostly on the Qubes architecture.
First we should realize that USB devices, unlike PCI Express devices, cannot be independently delegated to different domains (VMs). This is because IOMMU technologies, such as Intel VT-d, operate only on PCIe device granularity. This means we can only delegate a whole USB controller to a domain, including all of the USB devices connected to this controller/hub.
Imagine now two internal devices, both connected via internal USB bus: a keyboard, and a 3G wireless modem. Chances are high that you will have those two devices connected to the same USB controller – usually one controller is used for all the internal devices, like those I just mentioned, plus camera, fingerprint reader, etc, and the other controller is used for all the externally visible USB connectors (at least this is true for modern systems: Intel Series 5 chipsets and newer).
We would like to be able to delegate the 3G modem to the NetVM (an untrusted domain on Qubes where all the networking drivers and stacks are kept; it's considered untrusted because its compromise is equivalent to a compromise of a WiFi network or home router, or some other router, and any reasonable person always assumes that the network is compromised, and deals with that using crypto, such as SSL or SSH). But assigning the USB controller, to which the 3G modem is connected to, to the NetVM, would also assign the USB keyboard to the NetVM! And this is precisely what we don't want to do, because control over the keyboard is equivalent to the control over the whole system!
Currently, in Qubes Beta 1, we keep all the USB controllers assigned to Dom0. This, however, causes two annoyances:
First, the user cannot use any of the USB-connected networking devices, such as 3G modems (because there is no networking in Dom0).
Second, if somebody connects a USB disk and later delegates it to some domain (this could easily be done via block-attach mechanism, supported by the same backend that handles storage virtualization for domains), and this domain turns out to be compromised, it might alter e.g. the stick's partition table and later attack Dom0 as explained above.
We can eliminate the second problem by modifying the Dom0's kernel to not parse the partition table of any removable devices automatically, and instead expect some kind of explicit consent from user to actually do that (we still must allow to mount USB disks in Dom0 to allow easy backups of all domains at once).
To allow the use of USB-connected networking devices in NetVM, we could use a PVUSB backend that can virtualize single USB devices without moving the whole USB controller to the domain. But that would require introducing a whole lot of new code to Dom0 – code that would be directly reachable from VMs (in other words that would be processing lots of untrusted input coming from untrusted domains).
So another option is to delegate all the non-security-critical USB controllers, i.e. those controllers that don't have any security-sensitive USB devices connected, such as keyboard, to a dedicated “USB” domain, and later share the USB devices via PVUSB backend from this USB domain. This time, the extra PVUSB backend runs in the USB domain, not in Dom0, so we don't worry that much about potential bugs in this backend. Of course, this way you cannot delegate the USB controller to which the keyboard, and potentially also other security-critical devices, such as camera, are connected to, which in practice rules out the integrated3G modem. Fortunately many modern laptops do not use USB-connected keyboard and touchpad (they use PS/2-connected keyboards instead), and the face camera can be easily disabled with a piece of sticker (although that sucks, because it means we cannot really use the camera).
With this approach (a dedicated USB domain) you can now delegate your 3G modem to the NetVM, and other USB devices, such as removable disks to other domains, e.g. for file exchange. This seems the most reasonable setup, although it requires that either 1) your laptop doesn't have USB-connected keyboard, or 2) you don't use internal USB devices connected to the same controller that your USB keyboard/touchpad from other domains than Dom0 (in practice: no 3G modem in NetVM).
As we can see proper handling of USB devices is quite a challenge for OS architects. It might have been much less of a challenge if the engineers designing the USB, chipsets, and motherboards were a bit more security-conscious. Even such simple practice as never mixing security critical devices (keyboard, touchpad, camera, fingerprint reader), with non-security ones (3G modem), onto the same USB controller, would help tremendously. Or ability to somehow dynamically configure their connectivity, e.g. in BIOS?
\ No newline at end of file
diff --git a/_posts/2011-06-03-from-slides-to-silicon-in-3-years.html b/_posts/2011-06-03-from-slides-to-silicon-in-3-years.html
index af87804..120d81b 100644
--- a/_posts/2011-06-03-from-slides-to-silicon-in-3-years.html
+++ b/_posts/2011-06-03-from-slides-to-silicon-in-3-years.html
@@ -12,4 +12,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2011/06/from-slides-to-silicon-in-3-years.html
---
-
One of the things we were discussing there was a proposal to include an additional restriction to Intel processors that would disallow execution of usermode pages from within supervisor mode (ring0). Such a feature, we argued, apart from obviously making many ring3-to-ring0 exploits much harder, including the very Xen heap overflow exploit we presented in the slides, would also bring us closer to efficient runtime code integrity checkers for kernels and hypervisors, as discussed in the slides.
 |
| Slide #97, Detecting and Preventing Xen Hypervisor Subversions, Black Hat USA, July, 2008 |
Fast forward 3 years. On June 1st, 2011, an Intel engineer is submitting a patch for Xen to support a mysterious new processor feature called SMEP (Supervisor Mode Execution Protection). He writes the feature is not yet documented in SDM, but soon will be. In fact, the May 2011 update of Intel SDM already contains the details: |
| Intel SDM, vol. 3a, May 2011, source: intel.com |
Some other people spotted this feature earlier, because of another patch submitted by another Intel engineer to Linux kernel a few weeks ago. Here's a good write up by Dan Rosenberg discussing how this patch makes writing Linux kernel exploits harder, and how it's still possible to write them.
The SMEP feature still doesn't seem to be present in the processors available on the market, including the latest Sand Bridge processors, but there's no question it's coming, now that the feature made it into SDM.
It is quite rewarding to see your idea implemented in a processor... I guess this is how physicists feel when they introduce a new particle as part of a new quantum model, and later discover evidences to support the existence of this very particle in the wild...
\ No newline at end of file
+
One of the things we were discussing there was a proposal to include an additional restriction to Intel processors that would disallow execution of usermode pages from within supervisor mode (ring0). Such a feature, we argued, apart from obviously making many ring3-to-ring0 exploits much harder, including the very Xen heap overflow exploit we presented in the slides, would also bring us closer to efficient runtime code integrity checkers for kernels and hypervisors, as discussed in the slides.
|
| Slide #97, Detecting and Preventing Xen Hypervisor Subversions, Black Hat USA, July, 2008 |
Fast forward 3 years. On June 1st, 2011, an Intel engineer is submitting a patch for Xen to support a mysterious new processor feature called SMEP (Supervisor Mode Execution Protection). He writes the feature is not yet documented in SDM, but soon will be. In fact, the May 2011 update of Intel SDM already contains the details: |
| Intel SDM, vol. 3a, May 2011, source: intel.com |
Some other people spotted this feature earlier, because of another patch submitted by another Intel engineer to Linux kernel a few weeks ago. Here's a good write up by Dan Rosenberg discussing how this patch makes writing Linux kernel exploits harder, and how it's still possible to write them.
The SMEP feature still doesn't seem to be present in the processors available on the market, including the latest Sand Bridge processors, but there's no question it's coming, now that the feature made it into SDM.
It is quite rewarding to see your idea implemented in a processor... I guess this is how physicists feel when they introduce a new particle as part of a new quantum model, and later discover evidences to support the existence of this very particle in the wild...
\ No newline at end of file
diff --git a/_posts/2011-09-07-anti-evil-maid.html b/_posts/2011-09-07-anti-evil-maid.html
index bdbe54c..15383a5 100644
--- a/_posts/2011-09-07-anti-evil-maid.html
+++ b/_posts/2011-09-07-anti-evil-maid.html
@@ -14,4 +14,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2011/09/anti-evil-maid.html
---
-
Anti Evil Maid is an implementation of a TPM-based static trusted boot with a primary goal to prevent
Evil Maid attacks.
The adjective trusted, in trusted boot, means that the goal of the mechanism is to somehow attest to a user that only desired (trusted) components have been loaded and executed during the system boot. It's a common mistake to confuse it with what is sometimes called secure boot, whose purpure is to prevent any unauthorized component from executing. Secure boot is problematic to implement in practice, because there must be a way to tell which components are authorized for execution. This might be done using digital signatures and some kind of CA infrastructure, but this gets us into problems such as who should run the CA, what should be the policy for issuing certificates, etc.
The adjective static means that the whole chain of trust is anchored in a special code that executes before all other code on the platform, and which is kept in a non re-flashable memory, whose sole purpure is to make the initial measurement of the next component that is going to be executed, which is the BIOS code. This special code, also known as Core Root of Trust for Measurement (CRTM), might be part of the BIOS (but kept on a special read-only memory, or implemented by some other entity that executes before the BIOS reset vector, such as e.g. Intel ME or the processor microcode even. Once measured, the BIOS code is executed, and it is now its turn to measures the platform configuration, Option ROM code, and MBR. Then the loader (stored in the MBR), such as Trusted GRUB, takes over and measures its own next stages (other than the MBR sector), and the hypervisor, kernel, and initramfs images that are to be loaded, together with their configuration (e.g. kernel arguments).
As explained above, trusted boot can only retrospectively tell the user whether correct (trusted) software has booted or not, but cannot prevent any software from executing. But how can it communicate anything reliably to the user, if it might have just been compromised? This is possible thanks to the TPM unseal operation that releases secrets to software only if correct software has booted (as indicated by correct hashes in select PCR registers).
So the idea is that if a user can see correct secret message (or perhaps a photo) being displayed on the screen, then it means that correct software must have booted, or otherwise the TPM would not release (unseal) the secret. Of course we assume the adversary had no other way to sniff this secret and couldn't simply hardcode it into the Evil Maid – more on this later.
Another way to look at it is to realize that Anti Evil Maid is all about authenticating machine to the user, as opposed to the usual case of authenticating the user to the machine/OS (login and password, decryption key, token, etc). We proceed with booting the machine and entering sensitive information, only after we get confidence it is still our trusted machine and not some compromised one.
Installing Anti Evil Maid
Anti Evil Maid should work for any Linux system that uses dracut/initramfs, which includes Qubes, Fedora and probably many other distros. You can find the Anti Evil Maid source code in a git repository
here.
You can also download a tarball with sources and prebuilt rpm packages from here (they all should be signed with the Qubes signing key). Qubes Beta 2, that is coming soon, will have those RPMs already per-installed.
To install Anti Evil Maid, follow the instructions in the README file.
Some Practical considerations
If you decided to use no password for your TPM SRK key (so, you passed '-z' to tpm_takeownership, see the README), then you should definitely install Anti Evil Maid on a removable USB stick. Otherwise, if you installed it on your disk boot partition, the attacker would be able to just boot your computer and note down the secret passphrase that will be displayed on the screen. Then the attacker can compromise your BIOS/MBR/kernel images however she likes, and just hardcode the secret passphrase to make it look like if your system was fine.
If you decided to use custom TPM SRK password (so, you did not pass -z to tpm_takeownership), then you can install Anti Evil Maid onto your regular boot partition. The attacker would not be able to see your secret passphrase without knowing the SRK password. Now, the attacker can try another Evil Maid attack to steal this password, but this attack is easy to spot and prevent (see the discussion in the next section).
However, there is still a good argument to install Anti Evil Maid on a separate USB stick rather than on your built-in disk boot partition. This is because you can use Anti Evil Maid as a provider of a keyfile to your LUKS disk encryption (as an additional file unsealable by the TPM). This way you could also stop adversary that is able to sniff your keystrokes (e.g. using hidden camera, or electromagnetic leak), and capture your disk decryption passphrase (see the discussion in the next section).
In any case it probably would be a good idea to make a backup stick that you might want to use in case you lose or somehow damage your primary stick. In that case you should have a way to figure out if your system has been compromised in the meantime or not. Use another stick, with another passphrase, and keep it in a vault for this occasion.
Finally, be aware that, depending on which PCRs you decided to seal your secrets to, you might be unable to see the secret even after you changed some minor thing in your BIOS config, such as e.g. the order of boot devices. Every time you change something in your system that affects the boot process, you would need to reseal your secrets to new PCR values as described in the installation instructions.
Attacks prevented by Anti Evil Maid
The classic Evil Maid attack is fully prevented.
If the attacker is able to steal your Anti Evil Maid stick, and the attacker gets access to your computer, then the attacker would be able to learn your secret passphrase by just booting from the stolen stick. This is not fatal, because user should get alarmed seeing that the stick has been stolen, and use the backup stick to verify the system (with a different secret messages, of course), and later create a new stick for every day use with a new secret message.
A variation of the above attack is when the attacker silently copies the content of the stick, so that the user cannot realize that someone got access to the stick. Attacker then uses the copied stick to boot the user's computer and this way can learn the secret passphrase. Now, the attacker can infect the computer with Evil Maid, and can also bypass Anti Evil Maid verification by just hardcoding the secret message into Evil Maid. So, even though TPM would know that incorrect software has booted, and even though it would not unseal the secret, the user would have no way of knowing this (as the secret would still be displayed on screen).
In order to protect against this attack, one might want to use a non-default SRK password – see the installation instructions. Now an extra SRK password would be needed to unseal any secret from the TPM (in addition to PCRs being correct). So the attacker, who doesn't know the SRK password, is now not able to see the secret message and cannot prepare the Evil Maid Attack (doesn't know what secret passphrase to hardcode there).
The attacker might want to perform an additional Evil Maid attack targeted at capturing this SRK password, e.g. by infecting the user's stick. This, however, could be immediately detected by the user, because the user would see that after entering the correct SRK password, there was no correct secret passphrase displayed. The user should then assume the stick got compromised together with the SRK password, and should start the machine from the backup stick, verify that the backup secret is correct, and then create new AEM stick for daily usage.
If an attacker is able to capture the user's keystrokes (hidden camera, electromagnetic leaks), the attacker doesn't need Evil Maid attack anymore, and so doesn't need to bother with compromising the system boot anymore. This is because the attacker can just sniff the disk decryption password, and then steal the laptop and will get full access to all user data.
In order to prevent such a “keystroke sniffing” attack, one can use an additional sealed secret on the Anti Evil Maid stick that would be used as a keyfile for LUKS (in addition to passphrase). In this case the knowledge of the sniffed LUKS passphrase would not be enough for the attacker to decrypt the disk. This has not been implemented, although would be a simple modification to
dracut-antievilmaid module. If you decided to use this approach, don't forget to also create a backup passphrase that doesn't need a keyfile, so that you don't lock yourself from access to your data in case you lose your stick, or upgrade your BIOS, or something! You have been warned, anyway.
Attacks that are still possible
An adversary that is able to both: sniff your keystrokes (hidden camera, electromagnetic leak) and is also able to copy/steal/seize your Anti Evil Maid stick, can not be stopped. If a non-democratic government is your adversary, perhaps because you're a freedom fighter in one of those dark countries, then you likely cannot ignore this type of attacks. The only thing you can do, I think, is to use some kind of easy-to-destroy USB stick for keeping Anti Evil Maid. A digestible USB stick, anyone?
Another type of attack that is not addressed by Anti Evil Maid is an attack that works by removing the “gears” from your laptop (the motherboard and disk at the very least), putting there a fake board with a transmitter that connects back to the attacker's system via some radio link and proxies all the keyboard/screen events and USB ports back to the original “gears” that execute now under supervision of the attacker. Another way of thinking about this attack is as if we took the motherboard and disk away, but kept all the cables connecting them with the laptop's keyboard, screen, and other ports, such as USB (yes, very long cables). The attacker then waits until the user boots the machine, passes the machine-to-user authentications (however sophisticated it was), and finally enters the disk decryption key. In practice I wouldn't worry that much about such an attack, but just mentioning it here for completeness.
Finally, if our adversary is able to extract secret keys from the TPM somehow, e.g. using electron microscope, or via some secret backdoor in the TPM, or alternatively is able to install some hardware device on the motherboard that would be performing TPM reset without resetting the platform, then such an attacker would be able to install Evil Maid program and avoid its detection by SRTM. Still, this doesn't automatically give access to the user data, as the attacker would need to obtain the decryption key first (e.g. using Evil Maid attack).
Implementation Specific Attacks
In the discussion above we assumed that the trusted boot has been correctly implemented. This might not be true, especially in case of the BIOS. In that case we would be talking about attacks against a particular implementation of your BIOS (or TrustedGRUB), and not against Anti Evil Maid approach.
One typical problem might be related to how CRTM is implemented – if it is kept in a regular BIOS reflashable memory, than the attacker who can find a way to reflash the BIOS (which might be trivial in case your BIOS doesn't check digital signatures on updates) would be able to install Evil Maid in the BIOS but pretend that all hashes are correct, because the attacker controls the root of trust.
Another possible implementation problem might be similar to the
attack we used some years ago to reflash a secure Intel BIOS (that verified digital signatures on updates) by presenting a malformed input to the BIOS that caused a buffer overflow and allowed to execute arbitrary code within the BIOS. For such an attack to work, however, the BIOS should not measure the input that is used as an attack vector. I think this was the situation with the logo picture that was used in our attack. Otherwise, even if there was a buffer overflow, the chain of trust would be broken and thus the attack detected. In other words, the possibility of such an attack seems to be rather slim in practice.
What about Intel TXT?
Intel TXT takes an alternative approach to trusted boot. It relies on a Dynamic instead of Static Root of Trust for Measurement (DRTM vs. SRTM), which is implemented by the SENTER instruction and special dynamic PCR registers that can be set to zero only by SENTER. Intel TXT doesn't rely anymore on the BIOS or CRTM. This offers a huge advantage that one doesn't need to trust the BIOS, nor the boot loader, and yet can still perform a trusted boot. Amazing, huh?
Unfortunately, this amazing property doesn't hold in practice. As
we have demonstrated almost 3 years ago (!), it is not really true that Intel TXT can remove the BIOS away from the chain of trust. This is because Intel TXT is prone to attacks through a compromised SMM, and anybody who managed to compromise the BIOS would be trivially able to also compromise the SMM (because it is the BIOS that is supposed to provide the SMI handler).
Thus, if one compares SRTM with Intel TXT, then the conclusion is that Intel TXT cannot be more secure than SRTM. This is because if an attacker can compromise the BIOS, then the attacker can also bypass Intel TXT (via a SMM attack). On the other hand, a BIOS compromise alone doesn't automatically allow to bypass SRTM, as it has been discussed in a paragraph above.
It really is a pity, because otherwise Intel TXT would be just a great technology. Shame on you Intel, really!
Alternative approaches to mitigate Evil Maid Attacks
Various people suggested other methods to prevent Evil Maid attacks, so lets quickly recap and discuss some of them...
The most straight forward approach suggested by most people, has been to disable booting from external devices in BIOS, together with locking the BIOS setup with an admin password.
There are two problems with such an approach. First, all the BIOSes have a long history of so called default passwords (AKA maintenance passwords). You don't want to rely on the lack of BIOS default passwords when protecting your sensitive data, do you?
Second, even if your BIOS doesn't have a backdoor (maintenance password), it is still possible to just take your disk away and connect to another laptop and infect its boot partition.
Another suggested approach has been to keep your boot partition on a separate USB stick. This solution obviously doesn't take into account the fact that the attacker might install Evil Maid into your BIOS. Many consumer laptop BIOSes do not require digital signatures on BIOS firmware updates (my Sony Vaio Z, a rather high-end machine, is among them), making it simple to install Evil Maid there (the most trivial attack is to make the BIOS always boot from the HDD instead of whatever other device the user wanted to boot from).
Finally, some people pointed out that many modern laptops comes with SATA disks that offer ability to “lock” the disk so that it could only be used with a specific SATA controller. Using this, combined with setting your BIOS to only boot from your internal disk, plus locking access to BIOS setup, should provide reasonable protection. This solution, of course, doesn't solve the problem of a potential maintenance password in your BIOS. Also being skeptical and paranoid as I am, I would not trust this mechanism to be really robust – I would expect it would be fairly simple to unlock the disk so that it could be paired with another, unauthorized controller, and that this probably is a matter of NOP-ing a few instructions in the controller firmware... In fact it seems like you can buy
software to unlock this mechanism for some $50... And apparently (and not very surprisingly)
some drives seems to continue on the 'default passwords' tradition.
FAQ
Q: Bitlocker implemented this already several years ago, right?
A: No.
Q: But, two-factor authentication can also be used to prevent Evil Maid, right?
A: No.
Q: Does it make any sense to use Anti Evil Maid without a full disk encryption?
A: No.
Q: Are you going to answer 'no' for each question I ask?
A: No.
Q: Why there are no negative indicators (e.g. a big scary warning) when the unseal process fails?
A: The lack of negative indicators is intentional. The user should keep in mind that if somebody compromised their computer, then the attacker would be able to display whatever she wants on the screen, and especially to skip displaying of any warning messages. The only thing the attacker would not be able to display would be the secret message. Thus, it would make no sense to use negative indicators, as they would likely not work in case of a real attack. One solution here would be to use the unsealed secret as a keyfile for disk encryption (as discussed above), which would make it impossible to decrypt the user disk (and so generally proceed with the boot) without successfully unsealing the secret from the TPM.
\ No newline at end of file
+
Anti Evil Maid is an implementation of a TPM-based static trusted boot with a primary goal to prevent
Evil Maid attacks.
The adjective trusted, in trusted boot, means that the goal of the mechanism is to somehow attest to a user that only desired (trusted) components have been loaded and executed during the system boot. It's a common mistake to confuse it with what is sometimes called secure boot, whose purpure is to prevent any unauthorized component from executing. Secure boot is problematic to implement in practice, because there must be a way to tell which components are authorized for execution. This might be done using digital signatures and some kind of CA infrastructure, but this gets us into problems such as who should run the CA, what should be the policy for issuing certificates, etc.
The adjective static means that the whole chain of trust is anchored in a special code that executes before all other code on the platform, and which is kept in a non re-flashable memory, whose sole purpure is to make the initial measurement of the next component that is going to be executed, which is the BIOS code. This special code, also known as Core Root of Trust for Measurement (CRTM), might be part of the BIOS (but kept on a special read-only memory, or implemented by some other entity that executes before the BIOS reset vector, such as e.g. Intel ME or the processor microcode even. Once measured, the BIOS code is executed, and it is now its turn to measures the platform configuration, Option ROM code, and MBR. Then the loader (stored in the MBR), such as Trusted GRUB, takes over and measures its own next stages (other than the MBR sector), and the hypervisor, kernel, and initramfs images that are to be loaded, together with their configuration (e.g. kernel arguments).
As explained above, trusted boot can only retrospectively tell the user whether correct (trusted) software has booted or not, but cannot prevent any software from executing. But how can it communicate anything reliably to the user, if it might have just been compromised? This is possible thanks to the TPM unseal operation that releases secrets to software only if correct software has booted (as indicated by correct hashes in select PCR registers).
So the idea is that if a user can see correct secret message (or perhaps a photo) being displayed on the screen, then it means that correct software must have booted, or otherwise the TPM would not release (unseal) the secret. Of course we assume the adversary had no other way to sniff this secret and couldn't simply hardcode it into the Evil Maid – more on this later.
Another way to look at it is to realize that Anti Evil Maid is all about authenticating machine to the user, as opposed to the usual case of authenticating the user to the machine/OS (login and password, decryption key, token, etc). We proceed with booting the machine and entering sensitive information, only after we get confidence it is still our trusted machine and not some compromised one.
Installing Anti Evil Maid
Anti Evil Maid should work for any Linux system that uses dracut/initramfs, which includes Qubes, Fedora and probably many other distros. You can find the Anti Evil Maid source code in a git repository
here.
You can also download a tarball with sources and prebuilt rpm packages from here (they all should be signed with the Qubes signing key). Qubes Beta 2, that is coming soon, will have those RPMs already per-installed.
To install Anti Evil Maid, follow the instructions in the README file.
Some Practical considerations
If you decided to use no password for your TPM SRK key (so, you passed '-z' to tpm_takeownership, see the README), then you should definitely install Anti Evil Maid on a removable USB stick. Otherwise, if you installed it on your disk boot partition, the attacker would be able to just boot your computer and note down the secret passphrase that will be displayed on the screen. Then the attacker can compromise your BIOS/MBR/kernel images however she likes, and just hardcode the secret passphrase to make it look like if your system was fine.
If you decided to use custom TPM SRK password (so, you did not pass -z to tpm_takeownership), then you can install Anti Evil Maid onto your regular boot partition. The attacker would not be able to see your secret passphrase without knowing the SRK password. Now, the attacker can try another Evil Maid attack to steal this password, but this attack is easy to spot and prevent (see the discussion in the next section).
However, there is still a good argument to install Anti Evil Maid on a separate USB stick rather than on your built-in disk boot partition. This is because you can use Anti Evil Maid as a provider of a keyfile to your LUKS disk encryption (as an additional file unsealable by the TPM). This way you could also stop adversary that is able to sniff your keystrokes (e.g. using hidden camera, or electromagnetic leak), and capture your disk decryption passphrase (see the discussion in the next section).
In any case it probably would be a good idea to make a backup stick that you might want to use in case you lose or somehow damage your primary stick. In that case you should have a way to figure out if your system has been compromised in the meantime or not. Use another stick, with another passphrase, and keep it in a vault for this occasion.
Finally, be aware that, depending on which PCRs you decided to seal your secrets to, you might be unable to see the secret even after you changed some minor thing in your BIOS config, such as e.g. the order of boot devices. Every time you change something in your system that affects the boot process, you would need to reseal your secrets to new PCR values as described in the installation instructions.
Attacks prevented by Anti Evil Maid
The classic Evil Maid attack is fully prevented.
If the attacker is able to steal your Anti Evil Maid stick, and the attacker gets access to your computer, then the attacker would be able to learn your secret passphrase by just booting from the stolen stick. This is not fatal, because user should get alarmed seeing that the stick has been stolen, and use the backup stick to verify the system (with a different secret messages, of course), and later create a new stick for every day use with a new secret message.
A variation of the above attack is when the attacker silently copies the content of the stick, so that the user cannot realize that someone got access to the stick. Attacker then uses the copied stick to boot the user's computer and this way can learn the secret passphrase. Now, the attacker can infect the computer with Evil Maid, and can also bypass Anti Evil Maid verification by just hardcoding the secret message into Evil Maid. So, even though TPM would know that incorrect software has booted, and even though it would not unseal the secret, the user would have no way of knowing this (as the secret would still be displayed on screen).
In order to protect against this attack, one might want to use a non-default SRK password – see the installation instructions. Now an extra SRK password would be needed to unseal any secret from the TPM (in addition to PCRs being correct). So the attacker, who doesn't know the SRK password, is now not able to see the secret message and cannot prepare the Evil Maid Attack (doesn't know what secret passphrase to hardcode there).
The attacker might want to perform an additional Evil Maid attack targeted at capturing this SRK password, e.g. by infecting the user's stick. This, however, could be immediately detected by the user, because the user would see that after entering the correct SRK password, there was no correct secret passphrase displayed. The user should then assume the stick got compromised together with the SRK password, and should start the machine from the backup stick, verify that the backup secret is correct, and then create new AEM stick for daily usage.
If an attacker is able to capture the user's keystrokes (hidden camera, electromagnetic leaks), the attacker doesn't need Evil Maid attack anymore, and so doesn't need to bother with compromising the system boot anymore. This is because the attacker can just sniff the disk decryption password, and then steal the laptop and will get full access to all user data.
In order to prevent such a “keystroke sniffing” attack, one can use an additional sealed secret on the Anti Evil Maid stick that would be used as a keyfile for LUKS (in addition to passphrase). In this case the knowledge of the sniffed LUKS passphrase would not be enough for the attacker to decrypt the disk. This has not been implemented, although would be a simple modification to
dracut-antievilmaid module. If you decided to use this approach, don't forget to also create a backup passphrase that doesn't need a keyfile, so that you don't lock yourself from access to your data in case you lose your stick, or upgrade your BIOS, or something! You have been warned, anyway.
Attacks that are still possible
An adversary that is able to both: sniff your keystrokes (hidden camera, electromagnetic leak) and is also able to copy/steal/seize your Anti Evil Maid stick, can not be stopped. If a non-democratic government is your adversary, perhaps because you're a freedom fighter in one of those dark countries, then you likely cannot ignore this type of attacks. The only thing you can do, I think, is to use some kind of easy-to-destroy USB stick for keeping Anti Evil Maid. A digestible USB stick, anyone?
Another type of attack that is not addressed by Anti Evil Maid is an attack that works by removing the “gears” from your laptop (the motherboard and disk at the very least), putting there a fake board with a transmitter that connects back to the attacker's system via some radio link and proxies all the keyboard/screen events and USB ports back to the original “gears” that execute now under supervision of the attacker. Another way of thinking about this attack is as if we took the motherboard and disk away, but kept all the cables connecting them with the laptop's keyboard, screen, and other ports, such as USB (yes, very long cables). The attacker then waits until the user boots the machine, passes the machine-to-user authentications (however sophisticated it was), and finally enters the disk decryption key. In practice I wouldn't worry that much about such an attack, but just mentioning it here for completeness.
Finally, if our adversary is able to extract secret keys from the TPM somehow, e.g. using electron microscope, or via some secret backdoor in the TPM, or alternatively is able to install some hardware device on the motherboard that would be performing TPM reset without resetting the platform, then such an attacker would be able to install Evil Maid program and avoid its detection by SRTM. Still, this doesn't automatically give access to the user data, as the attacker would need to obtain the decryption key first (e.g. using Evil Maid attack).
Implementation Specific Attacks
In the discussion above we assumed that the trusted boot has been correctly implemented. This might not be true, especially in case of the BIOS. In that case we would be talking about attacks against a particular implementation of your BIOS (or TrustedGRUB), and not against Anti Evil Maid approach.
One typical problem might be related to how CRTM is implemented – if it is kept in a regular BIOS reflashable memory, than the attacker who can find a way to reflash the BIOS (which might be trivial in case your BIOS doesn't check digital signatures on updates) would be able to install Evil Maid in the BIOS but pretend that all hashes are correct, because the attacker controls the root of trust.
Another possible implementation problem might be similar to the
attack we used some years ago to reflash a secure Intel BIOS (that verified digital signatures on updates) by presenting a malformed input to the BIOS that caused a buffer overflow and allowed to execute arbitrary code within the BIOS. For such an attack to work, however, the BIOS should not measure the input that is used as an attack vector. I think this was the situation with the logo picture that was used in our attack. Otherwise, even if there was a buffer overflow, the chain of trust would be broken and thus the attack detected. In other words, the possibility of such an attack seems to be rather slim in practice.
What about Intel TXT?
Intel TXT takes an alternative approach to trusted boot. It relies on a Dynamic instead of Static Root of Trust for Measurement (DRTM vs. SRTM), which is implemented by the SENTER instruction and special dynamic PCR registers that can be set to zero only by SENTER. Intel TXT doesn't rely anymore on the BIOS or CRTM. This offers a huge advantage that one doesn't need to trust the BIOS, nor the boot loader, and yet can still perform a trusted boot. Amazing, huh?
Unfortunately, this amazing property doesn't hold in practice. As
we have demonstrated almost 3 years ago (!), it is not really true that Intel TXT can remove the BIOS away from the chain of trust. This is because Intel TXT is prone to attacks through a compromised SMM, and anybody who managed to compromise the BIOS would be trivially able to also compromise the SMM (because it is the BIOS that is supposed to provide the SMI handler).
Thus, if one compares SRTM with Intel TXT, then the conclusion is that Intel TXT cannot be more secure than SRTM. This is because if an attacker can compromise the BIOS, then the attacker can also bypass Intel TXT (via a SMM attack). On the other hand, a BIOS compromise alone doesn't automatically allow to bypass SRTM, as it has been discussed in a paragraph above.
It really is a pity, because otherwise Intel TXT would be just a great technology. Shame on you Intel, really!
Alternative approaches to mitigate Evil Maid Attacks
Various people suggested other methods to prevent Evil Maid attacks, so lets quickly recap and discuss some of them...
The most straight forward approach suggested by most people, has been to disable booting from external devices in BIOS, together with locking the BIOS setup with an admin password.
There are two problems with such an approach. First, all the BIOSes have a long history of so called default passwords (AKA maintenance passwords). You don't want to rely on the lack of BIOS default passwords when protecting your sensitive data, do you?
Second, even if your BIOS doesn't have a backdoor (maintenance password), it is still possible to just take your disk away and connect to another laptop and infect its boot partition.
Another suggested approach has been to keep your boot partition on a separate USB stick. This solution obviously doesn't take into account the fact that the attacker might install Evil Maid into your BIOS. Many consumer laptop BIOSes do not require digital signatures on BIOS firmware updates (my Sony Vaio Z, a rather high-end machine, is among them), making it simple to install Evil Maid there (the most trivial attack is to make the BIOS always boot from the HDD instead of whatever other device the user wanted to boot from).
Finally, some people pointed out that many modern laptops comes with SATA disks that offer ability to “lock” the disk so that it could only be used with a specific SATA controller. Using this, combined with setting your BIOS to only boot from your internal disk, plus locking access to BIOS setup, should provide reasonable protection. This solution, of course, doesn't solve the problem of a potential maintenance password in your BIOS. Also being skeptical and paranoid as I am, I would not trust this mechanism to be really robust – I would expect it would be fairly simple to unlock the disk so that it could be paired with another, unauthorized controller, and that this probably is a matter of NOP-ing a few instructions in the controller firmware... In fact it seems like you can buy
software to unlock this mechanism for some $50... And apparently (and not very surprisingly)
some drives seems to continue on the 'default passwords' tradition.
FAQ
Q: Bitlocker implemented this already several years ago, right?
A: No.
Q: But, two-factor authentication can also be used to prevent Evil Maid, right?
A: No.
Q: Does it make any sense to use Anti Evil Maid without a full disk encryption?
A: No.
Q: Are you going to answer 'no' for each question I ask?
A: No.
Q: Why there are no negative indicators (e.g. a big scary warning) when the unseal process fails?
A: The lack of negative indicators is intentional. The user should keep in mind that if somebody compromised their computer, then the attacker would be able to display whatever she wants on the screen, and especially to skip displaying of any warning messages. The only thing the attacker would not be able to display would be the secret message. Thus, it would make no sense to use negative indicators, as they would likely not work in case of a real attack. One solution here would be to use the unsealed secret as a keyfile for disk encryption (as discussed above), which would make it impossible to decrypt the user disk (and so generally proceed with the boot) without successfully unsealing the secret from the TPM.
\ No newline at end of file
diff --git a/_posts/2011-12-13-trusted-execution-in-untrusted-cloud.html b/_posts/2011-12-13-trusted-execution-in-untrusted-cloud.html
index cd2fc39..814d72f 100644
--- a/_posts/2011-12-13-trusted-execution-in-untrusted-cloud.html
+++ b/_posts/2011-12-13-trusted-execution-in-untrusted-cloud.html
@@ -12,4 +12,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2011/12/trusted-execution-in-untrusted-cloud.html
---
-
Wouldn't it be nice if we could actually own our data and programs in the cloud? By “owning” here I mean to have control over their confidentiality and integrity. When it comes to confidentiality and integrity for the
data,it's not much of a rocket since, as the classic crypto (and secure client systems) is all that we need.
I have already wrote about it in an earlier post.
But it would also be nice, if we could somehow get the same confidentiality and integrity assurance for our programsthat we upload for the execution in the cloud...
For example, a company might want take their database application, that deal with all sorts of corporate critical sensitive data, and then upload and safely run this application on e.g. Amazon's EC2, or maybe even to some China-based EC2-clone. Currently there is really nothing that could stop the provider, who has a full control over the kernel or the hypervisor under which our application (or our VM) executes, from reading the contents of our process' memory and stealing the secrets from there. This is all easy stuff to do from the technical point of view, and this is also
not just my own paranoia...
Plus, there are the usual concerns, such as: is the infrastructure of the cloud provider really that safe and secure, as it is advertised? How do we know nobody found an exploitable bug in the hypervisor and was not able to compromise other customer's VMs from within the attacker-hired VM? Perhaps the same question applies if we didn't decided to outsource the apps to a 3rdparty cloud, but in case of a 3rdparty clouds we really don't know about what measures have been applied. E.g. does the physical server on which my VMs are hosted also used to host some foreign customers? From China maybe? You get the point.
Sometimes all we really need is just integrity, e.g. if we wanted to host an open source code revision system, e.g. a git repository or a file server. Remember the kernel.org incident? On a side note, I find the Jonathan Corbet's self-comforting remarks on how there was really nothing to worry about, to be strikingly naive... I could easily think of a few examples of how the attacker(s) could have exploited this incident, so that Linus & co. would never (not soon) find out. But that's another story...
But, how can one protect a running process, or a VM, from a potentially compromised OS, or a hypervisor/VMM?
To some extent, at least theoretically, Intel Trusted Execution Technology (TXT), could be used to implement such protection. Intel TXT can attest to a remote entity, in that case this would be the cloud customer, about the hash of the hypervisor (or kernel) that has been loaded on the platform. This means it should be possible for the user to know that the cloud provider uses the unmodified Xen 4.1.1 binary as the hypervisor and not some modified version, with a built-in FBI backdoor for memory inspection. Ok, it's a poor example, because the Xen architecture (and any other commercially used VMM) allow the administrator who controls Dom0 (or equivalent) to essentially inspect and modify all the memory in the system, also that belonging to other VMs, and no special backdoors in the hypervisor are needed for this.
But let's assume hypothetically that Xen 5.0 would change that architecture, and so the Dom0 would not be able to access any other VM's memory anymore. Additionally, if we also assumed that the Xen hypervisor was secure, so that it was not possible to exploit any flaw in the hypervior, then we should be fine. Of course, assuming also there were also no flaws in the TXT implementation, and that the SMM was properly sandboxed, or that we trusted (some parts of) the BIOS (these are really complex problems to solve in practice, but I know there is some work going on in this area, so there is some hope).
Such a TXT-bases solution, although a step forward, still requires us to trust the cloud provider a bit... First, TXT doesn't protect against bus-level physical attacks – think of an attacker who replaces the DRAM dies with some kind of DRAM emulator – a device that looks like DRAM to the host, but on the other end allows full inspection/modification of its contents (well, ok, this is still a bit tricky, because of the lack of synchronization, but doable).
Additionally for Remote Attestation to make any sense, we must somehow know that we “talk to” a real TPM, and not to some software-emulated TPM. The idea here is that only a “real” TPM would have access to a private key, called Endorsement Key, used for signing during Remote Attestation procedure (or used during the generation of the AIK key, that can be used alternatively for Remote Attestation). But then again who generates (and so: owns) the private endorsement keys? Well, the TPM manufacturer, that can be... some Asian company that we not necessarily want to trust that much...
Now we see it would really be advantageous for customers, if Intel decided to return to the practice of implementing TPM internally inside the chipset, as they did in the past for their Series 4 chipsets (e.g. Q45). This would also protect against the LCP bus-level attacks against TPM (although somebody told me recently that TPM in current systems cannot be so easily attacked from LCP bus, because of some authentication protocol being used there – I really don't know, as physical attacks have not been the area we ever looked at extensively; any comments on that?).
But then again, the problem of DRAM content sniffing always remains, although I would consider this to be a complex and expensive attack. So, it seems to me that most governments would be able to bypass such TXT-ensured guarantees in order to “tap” the user's programs executing in the cloud provides that operate within their jurisdictions. But at least this could stop malicious companies from staring up fake cloud services with an intent to easily harvest some sensitive data from unsuspecting users.
It seems that the only way to solve the above problem of DRAM sniffing attacks is to add some protection at the processor level. We can imagine two solutions that processor vendors could implement:
First, they could opt for adding an in-processor hardware mechanism for encrypting all the data that leave the processor, to ensure that everything the is kept in the DRAM is encrypted (and, of course, also integrity-protected), with some private key that never leave the processor. This could be seen as an extension to the Intel TXT.
This would mean, however, we still needed to relay on: 1) the hypervisor to not contain bugs, 2) the whole VMM architecture to properly protect VM's memory, specifically against the Dom0, 3) Intel TXT to not be buggy either, 4) SMM being properly sandboxed, or alternatively to trust (some parts of) the BIOS and SMI handler, 5) TPM's EK key to be non-compromised and verifiable as genuine, and 6) TPM bus attacks made impossible (those two could be achieved by moving the TPM back onto the chipset, as mentioned above), and finally, 7) on the encryption key used by the processor for data encryption to be safely kept in the processor.
That's still quite a lot of things to trust, and it requires quite a lot of work to make it practically really secure...
The other option is a bit more crazy, but also more powerful. The idea is that the processor might allow to create untrusted supervisors (or hypervisors). Bringing this down to x86 nomenclature, it would mean that kernel mode (or VT-x root) code cannot sniff or inject code into (crypto-protected) memory of the usermode processes (or VT-x guests). This idea is not as crazy as you might think, and there has even been some academic work done in this area. Of course, there are many catches here, as this would require specifically written and designed applications. And if we ever considered to use this technology also for client systems (how nice it would be if we could just get rid of some 200-300 kLOC of the Xen hypervisor from the TCB in Qubes OS!), the challenges are even bigger, mostly relating to safe and secure trusted output (screen) and, especially, input (keyboard, mouse).
If this worked out, then we would need to trust just one element: the processor. But we need to trust it anyway. Of course, we also need to trust some software stack, e.g. the compilers we use at home to build our application, and the libraries it uses, but that's somehow an unrelated issue. What is important is that we now would be able to choose that (important) software stack ourselves, and don't care about all the other software used by the cloud provider.
As I wrote above, the processor is this final element we always need to rust. In practice this comes down to also trusting the US government :) But we might imagine users consciously choosing e.g. China-based, or Russia-based cloud providers and require (cryptographically) to run their hosted programs on US-made processors. I guess this could provide reasonable politically-based safety. And there is also ARM, with its licensable processor cores, where, I can imagine, the licensee (e.g. an EU state) would be able to put their own private key, not known to any other government (here I assume the licensee also audits the processor RTL for any signs of backdoors). I'm not sure if it would be possible to hide such a private key from a foundry in Hong Kong, or somewhere, but luckily there are also some foundries within the EU.
In any case, it seems like we could make our cloud computing orders of magnitude safer and more secure than what is now. Let's see whether the industry will follow this path...
\ No newline at end of file
+
Wouldn't it be nice if we could actually own our data and programs in the cloud? By “owning” here I mean to have control over their confidentiality and integrity. When it comes to confidentiality and integrity for the
data,it's not much of a rocket since, as the classic crypto (and secure client systems) is all that we need.
I have already wrote about it in an earlier post.
But it would also be nice, if we could somehow get the same confidentiality and integrity assurance for our programsthat we upload for the execution in the cloud...
For example, a company might want take their database application, that deal with all sorts of corporate critical sensitive data, and then upload and safely run this application on e.g. Amazon's EC2, or maybe even to some China-based EC2-clone. Currently there is really nothing that could stop the provider, who has a full control over the kernel or the hypervisor under which our application (or our VM) executes, from reading the contents of our process' memory and stealing the secrets from there. This is all easy stuff to do from the technical point of view, and this is also
not just my own paranoia...
Plus, there are the usual concerns, such as: is the infrastructure of the cloud provider really that safe and secure, as it is advertised? How do we know nobody found an exploitable bug in the hypervisor and was not able to compromise other customer's VMs from within the attacker-hired VM? Perhaps the same question applies if we didn't decided to outsource the apps to a 3rdparty cloud, but in case of a 3rdparty clouds we really don't know about what measures have been applied. E.g. does the physical server on which my VMs are hosted also used to host some foreign customers? From China maybe? You get the point.
Sometimes all we really need is just integrity, e.g. if we wanted to host an open source code revision system, e.g. a git repository or a file server. Remember the kernel.org incident? On a side note, I find the Jonathan Corbet's self-comforting remarks on how there was really nothing to worry about, to be strikingly naive... I could easily think of a few examples of how the attacker(s) could have exploited this incident, so that Linus & co. would never (not soon) find out. But that's another story...
But, how can one protect a running process, or a VM, from a potentially compromised OS, or a hypervisor/VMM?
To some extent, at least theoretically, Intel Trusted Execution Technology (TXT), could be used to implement such protection. Intel TXT can attest to a remote entity, in that case this would be the cloud customer, about the hash of the hypervisor (or kernel) that has been loaded on the platform. This means it should be possible for the user to know that the cloud provider uses the unmodified Xen 4.1.1 binary as the hypervisor and not some modified version, with a built-in FBI backdoor for memory inspection. Ok, it's a poor example, because the Xen architecture (and any other commercially used VMM) allow the administrator who controls Dom0 (or equivalent) to essentially inspect and modify all the memory in the system, also that belonging to other VMs, and no special backdoors in the hypervisor are needed for this.
But let's assume hypothetically that Xen 5.0 would change that architecture, and so the Dom0 would not be able to access any other VM's memory anymore. Additionally, if we also assumed that the Xen hypervisor was secure, so that it was not possible to exploit any flaw in the hypervior, then we should be fine. Of course, assuming also there were also no flaws in the TXT implementation, and that the SMM was properly sandboxed, or that we trusted (some parts of) the BIOS (these are really complex problems to solve in practice, but I know there is some work going on in this area, so there is some hope).
Such a TXT-bases solution, although a step forward, still requires us to trust the cloud provider a bit... First, TXT doesn't protect against bus-level physical attacks – think of an attacker who replaces the DRAM dies with some kind of DRAM emulator – a device that looks like DRAM to the host, but on the other end allows full inspection/modification of its contents (well, ok, this is still a bit tricky, because of the lack of synchronization, but doable).
Additionally for Remote Attestation to make any sense, we must somehow know that we “talk to” a real TPM, and not to some software-emulated TPM. The idea here is that only a “real” TPM would have access to a private key, called Endorsement Key, used for signing during Remote Attestation procedure (or used during the generation of the AIK key, that can be used alternatively for Remote Attestation). But then again who generates (and so: owns) the private endorsement keys? Well, the TPM manufacturer, that can be... some Asian company that we not necessarily want to trust that much...
Now we see it would really be advantageous for customers, if Intel decided to return to the practice of implementing TPM internally inside the chipset, as they did in the past for their Series 4 chipsets (e.g. Q45). This would also protect against the LCP bus-level attacks against TPM (although somebody told me recently that TPM in current systems cannot be so easily attacked from LCP bus, because of some authentication protocol being used there – I really don't know, as physical attacks have not been the area we ever looked at extensively; any comments on that?).
But then again, the problem of DRAM content sniffing always remains, although I would consider this to be a complex and expensive attack. So, it seems to me that most governments would be able to bypass such TXT-ensured guarantees in order to “tap” the user's programs executing in the cloud provides that operate within their jurisdictions. But at least this could stop malicious companies from staring up fake cloud services with an intent to easily harvest some sensitive data from unsuspecting users.
It seems that the only way to solve the above problem of DRAM sniffing attacks is to add some protection at the processor level. We can imagine two solutions that processor vendors could implement:
First, they could opt for adding an in-processor hardware mechanism for encrypting all the data that leave the processor, to ensure that everything the is kept in the DRAM is encrypted (and, of course, also integrity-protected), with some private key that never leave the processor. This could be seen as an extension to the Intel TXT.
This would mean, however, we still needed to relay on: 1) the hypervisor to not contain bugs, 2) the whole VMM architecture to properly protect VM's memory, specifically against the Dom0, 3) Intel TXT to not be buggy either, 4) SMM being properly sandboxed, or alternatively to trust (some parts of) the BIOS and SMI handler, 5) TPM's EK key to be non-compromised and verifiable as genuine, and 6) TPM bus attacks made impossible (those two could be achieved by moving the TPM back onto the chipset, as mentioned above), and finally, 7) on the encryption key used by the processor for data encryption to be safely kept in the processor.
That's still quite a lot of things to trust, and it requires quite a lot of work to make it practically really secure...
The other option is a bit more crazy, but also more powerful. The idea is that the processor might allow to create untrusted supervisors (or hypervisors). Bringing this down to x86 nomenclature, it would mean that kernel mode (or VT-x root) code cannot sniff or inject code into (crypto-protected) memory of the usermode processes (or VT-x guests). This idea is not as crazy as you might think, and there has even been some academic work done in this area. Of course, there are many catches here, as this would require specifically written and designed applications. And if we ever considered to use this technology also for client systems (how nice it would be if we could just get rid of some 200-300 kLOC of the Xen hypervisor from the TCB in Qubes OS!), the challenges are even bigger, mostly relating to safe and secure trusted output (screen) and, especially, input (keyboard, mouse).
If this worked out, then we would need to trust just one element: the processor. But we need to trust it anyway. Of course, we also need to trust some software stack, e.g. the compilers we use at home to build our application, and the libraries it uses, but that's somehow an unrelated issue. What is important is that we now would be able to choose that (important) software stack ourselves, and don't care about all the other software used by the cloud provider.
As I wrote above, the processor is this final element we always need to rust. In practice this comes down to also trusting the US government :) But we might imagine users consciously choosing e.g. China-based, or Russia-based cloud providers and require (cryptographically) to run their hosted programs on US-made processors. I guess this could provide reasonable politically-based safety. And there is also ARM, with its licensable processor cores, where, I can imagine, the licensee (e.g. an EU state) would be able to put their own private key, not known to any other government (here I assume the licensee also audits the processor RTL for any signs of backdoors). I'm not sure if it would be possible to hide such a private key from a foundry in Hong Kong, or somewhere, but luckily there are also some foundries within the EU.
In any case, it seems like we could make our cloud computing orders of magnitude safer and more secure than what is now. Let's see whether the industry will follow this path...
\ No newline at end of file
diff --git a/_posts/2012-02-06-qubes-beta-3.html b/_posts/2012-02-06-qubes-beta-3.html
index 5449396..aabe1f4 100644
--- a/_posts/2012-02-06-qubes-beta-3.html
+++ b/_posts/2012-02-06-qubes-beta-3.html
@@ -10,4 +10,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2012/02/qubes-beta-3.html
---
- -->
A new ISO with the just released Qubes Beta 3 is now available for download
here.
Beta 3 fixes lots of annoying problems discovered in Beta 2 and earlier releases, and also implements a bunch of useful feature:
This includes the
qvm-block tool and infrastructure for easy attachment of block devices to any AppVM, no matter which system VM is handling the actual USB controller. So, this allows to have untrusted USB domain(s), almost seamlessly integrated in the desktop system. One can consider to use it in order to prevent
various USB attacks. The next release (the 1.0) will bring this feature to the Qubes GUI manager as well, making it easy to use for non-command-line users too.
Also, we have now introduced fully automatic Qubes build system, that allows to build all the Qubes packages, and also create the installation ISO, with just one command. More information on this system and on how to use it can be found in the
wiki.
We have also updated to Fedora 15-based template as a default. Unfortunately F16-based template would require too much work to get all the Gnome 3 stuff working correctly. (The challenge here, is that we don't run a normal Windows and Desktop manager in every domain, in order to make the VMs light weight, and so we need to sometimes work around various problems this causes...).
Finally, we have added two new Qubes-specific applications:
- A plugin for Thunderbird (it is automatically installed in the template), that allows for one click opening of attachments in Disposable VMs, as well as one-click saving of the attachment to select VM.
- And something we call “split GPG”, that I will describe in a separate article later.
Those Qubes-specific applications are based on our Qubes RPC, introduced in Beta 2.
This is likely the last release before the “final 1.0”, that is scheduled to follow soon(TM). The only major work for 1.0 is GUI manager improvements to expose most of the Qubes functionality via clickable GUI, and command line tools cleanup and documentation. Plus testing and bugfixing :)
And then, the next thing we will be working on will be support for HVM domains, e.g. Windows. This work is starting actually just about now, but code will be released only after Qubes 1.0.
\ No newline at end of file
+ -->
A new ISO with the just released Qubes Beta 3 is now available for download
here.
Beta 3 fixes lots of annoying problems discovered in Beta 2 and earlier releases, and also implements a bunch of useful feature:
This includes the
qvm-block tool and infrastructure for easy attachment of block devices to any AppVM, no matter which system VM is handling the actual USB controller. So, this allows to have untrusted USB domain(s), almost seamlessly integrated in the desktop system. One can consider to use it in order to prevent
various USB attacks. The next release (the 1.0) will bring this feature to the Qubes GUI manager as well, making it easy to use for non-command-line users too.
Also, we have now introduced fully automatic Qubes build system, that allows to build all the Qubes packages, and also create the installation ISO, with just one command. More information on this system and on how to use it can be found in the
wiki.
We have also updated to Fedora 15-based template as a default. Unfortunately F16-based template would require too much work to get all the Gnome 3 stuff working correctly. (The challenge here, is that we don't run a normal Windows and Desktop manager in every domain, in order to make the VMs light weight, and so we need to sometimes work around various problems this causes...).
Finally, we have added two new Qubes-specific applications:
- A plugin for Thunderbird (it is automatically installed in the template), that allows for one click opening of attachments in Disposable VMs, as well as one-click saving of the attachment to select VM.
- And something we call “split GPG”, that I will describe in a separate article later.
Those Qubes-specific applications are based on our Qubes RPC, introduced in Beta 2.
This is likely the last release before the “final 1.0”, that is scheduled to follow soon(TM). The only major work for 1.0 is GUI manager improvements to expose most of the Qubes functionality via clickable GUI, and command line tools cleanup and documentation. Plus testing and bugfixing :)
And then, the next thing we will be working on will be support for HVM domains, e.g. Windows. This work is starting actually just about now, but code will be released only after Qubes 1.0.
\ No newline at end of file
diff --git a/_posts/2012-03-03-windows-support-coming-to-qubes.html b/_posts/2012-03-03-windows-support-coming-to-qubes.html
index 0d939bc..90ce430 100644
--- a/_posts/2012-03-03-windows-support-coming-to-qubes.html
+++ b/_posts/2012-03-03-windows-support-coming-to-qubes.html
@@ -11,4 +11,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2012/03/windows-support-coming-to-qubes.html
---
-Ok, let's start with a screenshot :)
While the “Qubes 1.0” branch is currently in the final development and testing, we have already started working on the Next Big Feature, which is a support for HVM domains (hardware, or VT-x virtualized domains). This allows to run e.g. Windows VMs under Qubes. You might be wondering what so special about this, if Xen has been supporting HVM domains, and specifically Windows VMs for a long time, and Qubes uses Xen hypervisor, so why haven't we had Windows support since day one?
The are a couple of things that we don't like about HVM support in Xen (and also in other VMMs), which include: the need to run device emulator (AKA qemu) in Dom0, the need to use crappy VNC, or a similar protocol to access the VM's framebuffer, or alternatively, the crazy idea (from security point of view, that is) of using a pass-through graphics for a VM, the lack of support for disaggregated architecture where backends, e.g. network backends, run in other domains than Dom0. In fact even the Xen “stubdomain” feature, introduced a few years ago, that was supposed to be a solution allowing to move the qemu out of Dom0, in practice turned out to be quite disappointing, as the qemu in the stub domain still requires an accompanying process of another qemu in Dom0, somehow negating all the security benefits this architecture is supposed to bring... And not to mention the omni present assumption that backends run always in Dom0, hardcoded in a few places in the stubdomain code.
So, we didn't like it and that's why Qubes had no Windows support for long time. But this has now changed, as we have just finished the 1
st stage implementation of HVM support in Qubes, the way we like it, without any security compromises. In our implementation we've completely eliminated all the qemu remains from Dom0 (it's running in a micro stub domain), the graphics virtualization fully integrates with our very slim GUI daemon (we didn't have to modify our GUI daemon at all!), using our Xen-optimized, zero-copy,
minimalist GUI protocol, and the networking is also fully integrated with the
Qubes diaggregated networking architecturethat uses isolated domains for all the networking stacks and drivers. Of course, there are still some rough edges, such as no clipboard support, and the virtualization is currently in a “per-desktop” mode, rather than in a “per-window” mode, which is used for PV domains. But, rest assured, we are working on those things right now...
This code is currently not public, and the plan is to release it only after Qubes 1.0 release, either as an upgrade, or as Qubes 2.0. All the dom0 code for HVM support will likely remain GPL, while any Windows-specific code (agent code) will likely be proprietary.
\ No newline at end of file
+Ok, let's start with a screenshot :)
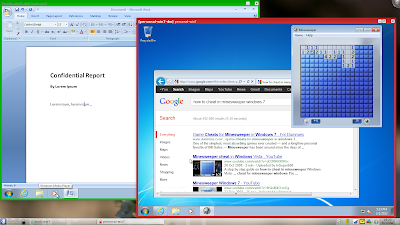
While the “Qubes 1.0” branch is currently in the final development and testing, we have already started working on the Next Big Feature, which is a support for HVM domains (hardware, or VT-x virtualized domains). This allows to run e.g. Windows VMs under Qubes. You might be wondering what so special about this, if Xen has been supporting HVM domains, and specifically Windows VMs for a long time, and Qubes uses Xen hypervisor, so why haven't we had Windows support since day one?
The are a couple of things that we don't like about HVM support in Xen (and also in other VMMs), which include: the need to run device emulator (AKA qemu) in Dom0, the need to use crappy VNC, or a similar protocol to access the VM's framebuffer, or alternatively, the crazy idea (from security point of view, that is) of using a pass-through graphics for a VM, the lack of support for disaggregated architecture where backends, e.g. network backends, run in other domains than Dom0. In fact even the Xen “stubdomain” feature, introduced a few years ago, that was supposed to be a solution allowing to move the qemu out of Dom0, in practice turned out to be quite disappointing, as the qemu in the stub domain still requires an accompanying process of another qemu in Dom0, somehow negating all the security benefits this architecture is supposed to bring... And not to mention the omni present assumption that backends run always in Dom0, hardcoded in a few places in the stubdomain code.
So, we didn't like it and that's why Qubes had no Windows support for long time. But this has now changed, as we have just finished the 1
st stage implementation of HVM support in Qubes, the way we like it, without any security compromises. In our implementation we've completely eliminated all the qemu remains from Dom0 (it's running in a micro stub domain), the graphics virtualization fully integrates with our very slim GUI daemon (we didn't have to modify our GUI daemon at all!), using our Xen-optimized, zero-copy,
minimalist GUI protocol, and the networking is also fully integrated with the
Qubes diaggregated networking architecturethat uses isolated domains for all the networking stacks and drivers. Of course, there are still some rough edges, such as no clipboard support, and the virtualization is currently in a “per-desktop” mode, rather than in a “per-window” mode, which is used for PV domains. But, rest assured, we are working on those things right now...
This code is currently not public, and the plan is to release it only after Qubes 1.0 release, either as an upgrade, or as Qubes 2.0. All the dom0 code for HVM support will likely remain GPL, while any Windows-specific code (agent code) will likely be proprietary.
\ No newline at end of file
diff --git a/_posts/2012-06-27-some-comments-on-operation-high-roller.html b/_posts/2012-06-27-some-comments-on-operation-high-roller.html
index 4f26f55..d74eb86 100644
--- a/_posts/2012-06-27-some-comments-on-operation-high-roller.html
+++ b/_posts/2012-06-27-some-comments-on-operation-high-roller.html
@@ -9,4 +9,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2012/06/some-comments-on-operation-high-roller.html
---
-About a year ago I wrote about Why the US "password revolution" won't work, where I pointed out that a massive move towards two-factor authentication will not solve any of the identity theft problems that users experience today. Specifically, I wrote:
[People] don't understand that the [compromised] operating system can impersonate the user at will!
The compromised OS could have saved your PIN to this [smart] card when you used it previously (even if you configured it not to do so!) and now, immediately, it could use the inserted card to authenticate as you to the bank and start issuing transactions on your behalf. And you won't even notice this all, because in the meantime it will show you a faked screen of your banking account. After all, it fully controls the screen.
The bottom line is that we cannot secure our digital lives, if our client operating systems could not be secured first.
But introduction of tokens won't make our operating systems any more secure!
This article sparked lots of controversy with many people, who considered it a fallacy to criticize two factor authentication...
Today, I came across the news about Operation High Roller, discovered recently by McAfee and Guardian Analytics. They released a paper with some details about the attacks and the malware deployed. Some interesting quotes:
All of the instances that involved High Roller malware could bypass complex multi-stage authentication. Unlike recent attacks that collect simple form authentication data—a security challenge question, a one-time token, or PIN—this attack can get past the extensive physical (“something you have”) authentication required by swiping a card in a reader and typing the input into a field (see Two-factor Authentication sidebar).
The attack asks the victim to supply the information required to get around the physical controls of smartcard reader plus pin pad entry to generate a one-time password (or digital token).
Having collected all the information it requires for the entire transfer, the malware stalls the user and executes its transaction in the background using the legitimate digital token.
Multiple after-the-theft behaviors hide evidence of the transaction from the user. For example, the client-side malware kills the links to printable statements. It also searches for and erases confirmation
emails and email copies of the statement. Finally, it also changes the transactions, transaction values, and account balance in the statement displayed on the victim’s screen so the amounts are what the account holder expects to see.
Defensive security is a difficult game, because one doesn't immediately see whether a given solution works or not. This is in stark contrast to other engineering disciplines (and to offensive security) where one usually have immediate feedback on whether something works well or not.
Say you want to build a redundant long-range video downlink for your unmanned, remotely operated helicopter -- you can throw in lots of money buying various high-gain antennas, circular antennas, antenna trackers, diversity systems, etc., but then ultimately you can verify your creation immediately by going into a field and trying to fly a few miles away, and see whether you loose the vision (usually in the middle of some life-threatening manoeuvre) or not. At least you can draw some lines of how good your solution is ("I can fly up to one mile away, but not more, unless there aren't that many trees around and the air is dry enough").
With security, especially with computer security, it is so different, because there is no immediate feedback. This results in various vendors pitching their products as wonderful solutions that just solve all the worlds problems, even though what they're saying in those marketing materials might be pure nonsense... (BTW, congrats to Simon Crosby for apparently creating a Windows-hosted VMM in below 10k LOC! ;)
The often made mistake is to say: "Perhaps there is a way to attack this solution, but then again, how much of the malware in the wild implements such attacks?" This is a classical thinking in our industry, and in my opinion, an inexcusable mistake! Let me say it clearly:
It doesn't matter whether what the malware in the wild does -- it matters what it could potentially do!
So, if we can do a quick brainstorming session and point out potential attacks within 1 hour against some technology/product X, then, if we don't see a solution how to prevent them generically, we should not bother and implement product X, because it will be defeated, sooner or later. Let's not waste time on useless solutions, life's too short!
\ No newline at end of file
+About a year ago I wrote about Why the US "password revolution" won't work, where I pointed out that a massive move towards two-factor authentication will not solve any of the identity theft problems that users experience today. Specifically, I wrote:
[People] don't understand that the [compromised] operating system can impersonate the user at will!
The compromised OS could have saved your PIN to this [smart] card when you used it previously (even if you configured it not to do so!) and now, immediately, it could use the inserted card to authenticate as you to the bank and start issuing transactions on your behalf. And you won't even notice this all, because in the meantime it will show you a faked screen of your banking account. After all, it fully controls the screen.
The bottom line is that we cannot secure our digital lives, if our client operating systems could not be secured first.
But introduction of tokens won't make our operating systems any more secure!
This article sparked lots of controversy with many people, who considered it a fallacy to criticize two factor authentication...
Today, I came across the news about Operation High Roller, discovered recently by McAfee and Guardian Analytics. They released a paper with some details about the attacks and the malware deployed. Some interesting quotes:
All of the instances that involved High Roller malware could bypass complex multi-stage authentication. Unlike recent attacks that collect simple form authentication data—a security challenge question, a one-time token, or PIN—this attack can get past the extensive physical (“something you have”) authentication required by swiping a card in a reader and typing the input into a field (see Two-factor Authentication sidebar).
The attack asks the victim to supply the information required to get around the physical controls of smartcard reader plus pin pad entry to generate a one-time password (or digital token).
Having collected all the information it requires for the entire transfer, the malware stalls the user and executes its transaction in the background using the legitimate digital token.
Multiple after-the-theft behaviors hide evidence of the transaction from the user. For example, the client-side malware kills the links to printable statements. It also searches for and erases confirmation
emails and email copies of the statement. Finally, it also changes the transactions, transaction values, and account balance in the statement displayed on the victim’s screen so the amounts are what the account holder expects to see.
Defensive security is a difficult game, because one doesn't immediately see whether a given solution works or not. This is in stark contrast to other engineering disciplines (and to offensive security) where one usually have immediate feedback on whether something works well or not.
Say you want to build a redundant long-range video downlink for your unmanned, remotely operated helicopter -- you can throw in lots of money buying various high-gain antennas, circular antennas, antenna trackers, diversity systems, etc., but then ultimately you can verify your creation immediately by going into a field and trying to fly a few miles away, and see whether you loose the vision (usually in the middle of some life-threatening manoeuvre) or not. At least you can draw some lines of how good your solution is ("I can fly up to one mile away, but not more, unless there aren't that many trees around and the air is dry enough").
With security, especially with computer security, it is so different, because there is no immediate feedback. This results in various vendors pitching their products as wonderful solutions that just solve all the worlds problems, even though what they're saying in those marketing materials might be pure nonsense... (BTW, congrats to Simon Crosby for apparently creating a Windows-hosted VMM in below 10k LOC! ;)
The often made mistake is to say: "Perhaps there is a way to attack this solution, but then again, how much of the malware in the wild implements such attacks?" This is a classical thinking in our industry, and in my opinion, an inexcusable mistake! Let me say it clearly:
It doesn't matter whether what the malware in the wild does -- it matters what it could potentially do!
So, if we can do a quick brainstorming session and point out potential attacks within 1 hour against some technology/product X, then, if we don't see a solution how to prevent them generically, we should not bother and implement product X, because it will be defeated, sooner or later. Let's not waste time on useless solutions, life's too short!
\ No newline at end of file
diff --git a/_posts/2012-07-21-qubes-10-release-candidate-1.html b/_posts/2012-07-21-qubes-10-release-candidate-1.html
index eb1b798..fe3a656 100644
--- a/_posts/2012-07-21-qubes-10-release-candidate-1.html
+++ b/_posts/2012-07-21-qubes-10-release-candidate-1.html
@@ -10,4 +10,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2012/07/qubes-10-release-candidate-1.html
---
- I would like to announce the release of Qubes RC1. The installation ISO and instructions can be found
here.
This release is expected to essentially be identical to the final 1.0 release, which will likely follow in the coming weeks, except for some minor, cosmetic fixes.
Comparing to the previous
Beta 3 release, the major changes and improvements in this version include:
A much improved Qubes Manager, that now allows to configure and manage almost every aspect of the Qubes system using a simple and intuitive GUI.
All the VMs are now based on Fedora 17 template.
Cleaned up and improved command lines tools for both
Dom0 and for the
VMs.
Updated Dom0 and VM kernels are now based on 3.2.7-pvops kernel, which offer better hardware and power management support.
Convenient menu improvements, that include e.g. a handy icon for launching a Disposable Web browser in a Disposable VM.
Support for “yum proxy”, which smartly allows to update packages in a template VM (or other updateable VM), without requiring to grant general HTTP access for this VM. This has been a problem before, as the Fedora repos use hundreds of mirrored yum servers, and it wasn't possible to setup a single rule in the firewall VM to allow only access to the yum servers, and nothing else. Now, this is possible, and the primary application is to prevent user mistakes, e.g. against using the temaplate VM for Web Browsing.
...plus lots of other improvements and fixes under the hood. As
can be seen in the wiki, there has been over 200 tickets closed as part of the work on this release!
So, again, this is almost the final release, please test it and report any problems to the mailing list, so that we could fix them before Qubes 1.0 comes out officially.
\ No newline at end of file
+ I would like to announce the release of Qubes RC1. The installation ISO and instructions can be found
here.
This release is expected to essentially be identical to the final 1.0 release, which will likely follow in the coming weeks, except for some minor, cosmetic fixes.
Comparing to the previous
Beta 3 release, the major changes and improvements in this version include:
A much improved Qubes Manager, that now allows to configure and manage almost every aspect of the Qubes system using a simple and intuitive GUI.
All the VMs are now based on Fedora 17 template.
Cleaned up and improved command lines tools for both
Dom0 and for the
VMs.
Updated Dom0 and VM kernels are now based on 3.2.7-pvops kernel, which offer better hardware and power management support.
Convenient menu improvements, that include e.g. a handy icon for launching a Disposable Web browser in a Disposable VM.
Support for “yum proxy”, which smartly allows to update packages in a template VM (or other updateable VM), without requiring to grant general HTTP access for this VM. This has been a problem before, as the Fedora repos use hundreds of mirrored yum servers, and it wasn't possible to setup a single rule in the firewall VM to allow only access to the yum servers, and nothing else. Now, this is possible, and the primary application is to prevent user mistakes, e.g. against using the temaplate VM for Web Browsing.
...plus lots of other improvements and fixes under the hood. As
can be seen in the wiki, there has been over 200 tickets closed as part of the work on this release!
So, again, this is almost the final release, please test it and report any problems to the mailing list, so that we could fix them before Qubes 1.0 comes out officially.
\ No newline at end of file
diff --git a/_posts/2012-09-03-introducing-qubes-10.html b/_posts/2012-09-03-introducing-qubes-10.html
index 457f67d..0ffaf5b 100644
--- a/_posts/2012-09-03-introducing-qubes-10.html
+++ b/_posts/2012-09-03-introducing-qubes-10.html
@@ -9,4 +9,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2012/09/introducing-qubes-10.html
---
-After nearly three years of work, I have a pleasure to announce that Qubes 1.0 has finally been released! To see the installation instructions and to get an ISO, please go to this page.
I would like to thank all the developers who have worked on this project. Creating Qubes OS has been a great challenge, especially for such a small team as ours, but ultimately, I'm very glad with the final outcome – it really is a stable and reasonably secure desktop OS. In fact I cannot think of any more secure alternative...
I use the term “reasonably secure”, because when it comes to defensive security it's difficult to use definite statements (“secure”, “unbreakable”, etc), unless one can formally prove the whole design and implementation to be 100% secure.
Unfortunately, contrary to common belief, there are no general purpose, desktop OSes, that would be formally proven to be secure. At the very best, there are some
partsthat are formally verified, such as some microkernels, but not whole OSes. And what good is saying that our microkernel is formally verified, if we continue to use a bloated and buggy X server as our GUI subsystem? After all, a GUI subsystem has access to all the user inputs and output, thus it is as much security sensitive, as is the the microkernel! Or power management subsystem, or filesystem server, or trusted boot scheme, or ... a dozens of other elements, which just cannot be forgotten if one wants to talk about a truly secure OS. As said before, I know of no general-purpose desktop OS that would be formally proven, and thus that could be called “secure”. You can also read more about challenges with formal verification microkernels in this article, and especially in this comment from the seL4 project leader.
In Qubes OS we took a practical approach and we have tried to focus on all those sensitive parts of the OS, and to make them reasonably secure. And, of course, in the first place, we tried to minimize the amount of those trusted parts, in which Qubes really stands out, I think.
So, we believe Qubes OS represents a reasonably secure OS. In fact I'm not aware of any other solution currently on the market that would come close when it comes to secure desktop environment. But then again, I'm biased, of course ;)
I wouldn't call Qubes OS “safe”, however, at least not at this stage. By “safe” I mean a product that is “safe to use”, which also implies “easy to use”, “not requiring special skills”, and thus harmless in the hands of an inexperienced user. I think that Apple iOS is a good example of such a “safe” OS – it automatically puts each application into its own sandbox, essentially not relaying on the user to make any security decisions. However, the isolation that each such sandbox provides is far from being secure, as various practical attacks have proven, and which is mostly a result of exposing too fat APIs to each sandbox, as I understand. In Qubes OS, it's the user that is responsible for making all the security decisions – how to partition her digital life into security domains, what networkand other permissions each domain might have, whether to open a given document in a Disposable VM, etc. This provides for great flexibility for more advanced users, but the price to pay is that Qubes OS requires some skills and thinking to actually make the user's data more secure.
Generally Qubes OS is an advanced tool for implementing Security by Isolation approach on your desktop, using domains implemented as lightweight Xen VMs. It tries to marry two contradictory goals: how to make the isolation between domains as strong as possible, mainly due to clever architecture that minimizes the amount of trusted code, and how to make this isolation as seamless and easy as possible. Again, how the user is going to take advantage of this isolation is totally left up to the user. I realize this might be a tricky part for some users and some usage scenarios, yet, on the other hand, this seems to be the most flexible and powerful approach we could provide.
Thus people should realize that by mere fact of using Qubes OS they won't become automatically more secure – it's
how they are going to use it might make them significantly more secure. A hypothetical exploit for your favourite web browser would work against Firefox running inside one of the Qubes VMs just as well as it worked for the same browser running on normal Linux. The
difference that Qubes makes, is that this attacked browser might be just your for-personal-use-only browser which is isolated from your for-work-use-only-browser, and for-banking-use-only-browser.
Finally, even though Qubes has been created by a reasonably skilled team of people, it should not be considered bug free. In fact, over the last 3 years we
already found 3 serious bugs/attacks affecting Qubes OS – one of them in the very code we created, and two other in Intel hardware. Again, we tried as much as possible to limit the amount of code that is security sensitive in the first place, yet we are just humans ;) So, I'm very curious to see others' attempts to break Qubes – I think it might make for a very interesting research. A good starting point for such research might be
this page. And I know there are individuals out there who apparently only been waiting for Qubes 1.0 to come out, to
get some glory(yet, it's not clear to me why to attack qemu, which is not part of the TCB in Qubes, but I guess great minds have their own mysteries ;)
In other words, please enjoy Qubes OS 1.0, hopefully it could make your digital life safer!
Please send all the
technical questions regarding Qubes to the
qubes-devel mailing list. Do not send them to me directly, nor post them in this blog's comments.
I would like to thank all the developers who have worked on this project. Creating Qubes OS has been a great challenge, especially for such a small team as ours, but ultimately, I'm very glad with the final outcome – it really is a stable and reasonably secure desktop OS. In fact I cannot think of any more secure alternative...
I use the term “reasonably secure”, because when it comes to defensive security it's difficult to use definite statements (“secure”, “unbreakable”, etc), unless one can formally prove the whole design and implementation to be 100% secure.
Unfortunately, contrary to common belief, there are no general purpose, desktop OSes, that would be formally proven to be secure. At the very best, there are some
partsthat are formally verified, such as some microkernels, but not whole OSes. And what good is saying that our microkernel is formally verified, if we continue to use a bloated and buggy X server as our GUI subsystem? After all, a GUI subsystem has access to all the user inputs and output, thus it is as much security sensitive, as is the the microkernel! Or power management subsystem, or filesystem server, or trusted boot scheme, or ... a dozens of other elements, which just cannot be forgotten if one wants to talk about a truly secure OS. As said before, I know of no general-purpose desktop OS that would be formally proven, and thus that could be called “secure”. You can also read more about challenges with formal verification microkernels in this article, and especially in this comment from the seL4 project leader.
In Qubes OS we took a practical approach and we have tried to focus on all those sensitive parts of the OS, and to make them reasonably secure. And, of course, in the first place, we tried to minimize the amount of those trusted parts, in which Qubes really stands out, I think.
So, we believe Qubes OS represents a reasonably secure OS. In fact I'm not aware of any other solution currently on the market that would come close when it comes to secure desktop environment. But then again, I'm biased, of course ;)
I wouldn't call Qubes OS “safe”, however, at least not at this stage. By “safe” I mean a product that is “safe to use”, which also implies “easy to use”, “not requiring special skills”, and thus harmless in the hands of an inexperienced user. I think that Apple iOS is a good example of such a “safe” OS – it automatically puts each application into its own sandbox, essentially not relaying on the user to make any security decisions. However, the isolation that each such sandbox provides is far from being secure, as various practical attacks have proven, and which is mostly a result of exposing too fat APIs to each sandbox, as I understand. In Qubes OS, it's the user that is responsible for making all the security decisions – how to partition her digital life into security domains, what networkand other permissions each domain might have, whether to open a given document in a Disposable VM, etc. This provides for great flexibility for more advanced users, but the price to pay is that Qubes OS requires some skills and thinking to actually make the user's data more secure.
Generally Qubes OS is an advanced tool for implementing Security by Isolation approach on your desktop, using domains implemented as lightweight Xen VMs. It tries to marry two contradictory goals: how to make the isolation between domains as strong as possible, mainly due to clever architecture that minimizes the amount of trusted code, and how to make this isolation as seamless and easy as possible. Again, how the user is going to take advantage of this isolation is totally left up to the user. I realize this might be a tricky part for some users and some usage scenarios, yet, on the other hand, this seems to be the most flexible and powerful approach we could provide.
Thus people should realize that by mere fact of using Qubes OS they won't become automatically more secure – it's
how they are going to use it might make them significantly more secure. A hypothetical exploit for your favourite web browser would work against Firefox running inside one of the Qubes VMs just as well as it worked for the same browser running on normal Linux. The
difference that Qubes makes, is that this attacked browser might be just your for-personal-use-only browser which is isolated from your for-work-use-only-browser, and for-banking-use-only-browser.
Finally, even though Qubes has been created by a reasonably skilled team of people, it should not be considered bug free. In fact, over the last 3 years we
already found 3 serious bugs/attacks affecting Qubes OS – one of them in the very code we created, and two other in Intel hardware. Again, we tried as much as possible to limit the amount of code that is security sensitive in the first place, yet we are just humans ;) So, I'm very curious to see others' attempts to break Qubes – I think it might make for a very interesting research. A good starting point for such research might be
this page. And I know there are individuals out there who apparently only been waiting for Qubes 1.0 to come out, to
get some glory(yet, it's not clear to me why to attack qemu, which is not part of the TCB in Qubes, but I guess great minds have their own mysteries ;)
In other words, please enjoy Qubes OS 1.0, hopefully it could make your digital life safer!
Please send all the
technical questions regarding Qubes to the
qubes-devel mailing list. Do not send them to me directly, nor post them in this blog's comments.
- Why bother with Qubes OS, if any Linux/BSD already allows to setup different user accounts, or some form of light-weight containers or sandboxes, such as chroot, LXC, SELinux?
First, if you use Xorg or similar X-based server as your GUI server, and this is what nearly all Linux, and most of the other non-Windows OSes use, then you don't have any form of GUI-level isolation, which is essential for a desktop system. I wrote more about this surprising problem some time ago. Proper GUI-level isolation was one of the main goals for Qubes.
Second, all mainstream desktop OSes, such as Windows, Linux, BSD, even OSX, are all based on a monolithic kernels, which present a significant security problem. This is because a typical monolithic kernel of a contemporary desktop OS contains tens of millions of lines of code, and to make it worse, most of this code is reachable from (untrusted) applications via all sorts of APIs, making the attack surface on the kernel huge. And it requires just one successful kernel exploit to own the whole system, bypassing any security mechanisms that might have been built on top of it, such as SELinux, LXC, etc.
Additionally, all the various drivers, networking and USB stacks, are also hosted in the kernel, making attacks via buggy networking (e.g. via
buggy 802.11 stacksor
buggy firmware) or
USB stacks a practical possibility. And there is essentially nothing one can do about it, when using an OS based on a monolithic kernel.
In Qubes, on the other hand, we use Xen hypervisor to provide security isolation between domains, and Xen is just a few hundred of thousands lines of code. It also doesn't need to provide all sorts of APIs to applications, because the Xen hypervisor is essentially only interested in CPU scheduling, memory management and power management, and very few things beyond that. Most notably, the Xen hypervisor knows nothing about networking, disk storage, filesystems, USB stacks, etc, as all those tasks are delegated to (often untrusted) service VMs.
- How is Qubes better than just running a bunch of VMs in VMWare or Virtual Box?
First, products such as VMWare Workstation or Fusion, or Virtual Box, are all examples of type II hypervisors (sometimes called “hosted VMMs”), which means that they run inside a normal OS, such as Windows, as ordinary processes and/or kernel modules. This means that they use the OS-provided services for all sorts of things, from networking, USB stacks, to graphics output and keyboard and mouse input, which in turn implies they can be only as secure as the hosting OS is. If the hosting OS got compromised, perhaps via a bug in its DHCP client, or USB driver, then it is a game over, also for all your VMs.
Second, those popular consumer type II VMM systems have not been designed with security as a primary goal. Instead, their main focus has been on easy of use, performance, and providing seamless integration of the guest OS(es) with the host OS. Especially the latter, which involves lack of good method to identify which domain a given application belongs to (so, lack of trusted Window Manager), support for shared clipboards which every other VM can steal, insecure file sharing methods, and others, all make it not a very desirable solution when strong domain isolation is important. (This is not to imply that Qubes doesn't support clipboard or file sharing between domains, it does – it's just that we do it in a secure way, at least so we believe). On the other hand, there are many usability improvements in Qubes that are specific to multi-domain system, and which you won't find in the above mentioned products, such as
trusted Window Manager that, while maintaining great seamless integration of all the applications onto a common desktop, still allows the user to always know which domain owns which window, support for
advanced networking setups, per-domain policies, the just mentioned secure mechanisms for clipboard and filesystem sharing, and many other. Qubes also focuses on making the VMs light-weight so that it was possible to run really a lot of them at the same time, and also on mechanism to allow for secure filesystem sharing between domains (templates).
Finally, the commercial hosted VMMs are really bloated pieces of code. They support everything and the kitchen sink (e.g. Open GL exposed to VMs, and various additional interfaces to allow e.g. drag and drop of files to/from the VM), and so, the attack surface on such a VMM system is orders of magnitude bigger than in case of Qubes OS.
- How does Qubes compare to [your favourite academic microkernel]?
While the Xen hypervisor can indeed be considered a microkernel if you're not a strict terminology freak, Qubes itself is much more than just the hypervisor. Qubes is everything that is needed to build a reasonably secure desktop OS on top ofa baremetal hypervisor (or microkernel). Theoretically, with just a few cosmetic changes (at least architecture-wise), Qubes could perhaps swap the Xen hypervisor for some other hypervisor or microkernel, such as perhaps Hyper-V, KVM, or some more exotic one. Thus, it makes little sense to compare Qubes with a hypervisor or microkernel project. What makes sense is to compare the Xen hypervisor, as used in Qubes, with some other hypervisor or microkernel.
Ok, so how does Xen compare with other hypervisors or microkernels out there? We think Xen is unique because it combines an elegant architecture (type I, baremetal, hypervisor) with a number of practical features, such as power management, support for Intel VT-d and driver domains, support for both para-virtualizaed, and fully-virtualized VMs, and many more, not found in e.g. academic microkernels/hypervisor projects, that otherwise seem attractive from the architecture point of view.
- How is Qubes better than Google Chrome OS?
First, Chrome OS is not a general purpose OS. Second, it's based on Linux with all its security limitation that are a result of using a monolithic kernel described above (e.g. all the networking and USB stacks in the kernel without a possibility to deprivilige them). Not being a traditional general purpose OS, Chrome is able to avoid many of the challenges of desktop computing, such as the need to define security domains, inter-domain file exchange (as there is essentially no filesystem visible to the user), and others, which is good, of course. But then again, Chrome OS is essentially just an environment to run the Chrome Browser, so the comparison to Qubes is a bit of a misunderstanding.
Technical aspects aside, there is always the privacy concern associated with running everything in a browser – why would all my private data be managed and accessible to some 3rd party organizations and
their administrators?
- How is Qubes better than [your favorite commercial military-grade certified secure OS]?
You must have heard about the super secure military-grade, formally verified, 100% certified, and generally “unbreakable” operating systems made by companies such as Green Hills, Lynx Works, and others. How do they compare to Qubes OS?
Really, I have no idea. For a mere mortal like myself (and perhaps not a US citizen), it seems impossible to get any more technical documentation of those systems (anything beyond the marketing pseudo-technical gibberish), not to mention a trial copy to play with...
Thus, from my point of view, those systems are just a vaporware. If you, my dear reader, are privileged enough to have access to such system, then good for you, but don't expect me to treat seriously a security product that is not available for a wider audience to touch and play with... (And the Chineese surely have the copies already to play with ;)
- How is Qubes different than Bromium's “micro virtualization” solution?
Many people asked recently about the Bromium's upcoming product and how it differs from Qubes OS. Unfortunately there are few public information available on this product – essentially there is one not-very-technical whitepaperand there are Ian Pratt's presentation slides from the recent XenSummit about u-Xen, apparently a hypervisor that is to be ultimately used in their upcoming product.
The whitepaper suggests that Bromium is based on a hosted (type II) hypervisor running within a normal Window OS, and that this hypervisor is used to spawn a new “micro VM” for each new “task”, where apparently the task might be something as granular as opening a new tab in a Web browser, which makes it somehow similar to Google Chrome's approach. Clearly, the Bromium's main goal seem to be to automate the process of creating separation domains, which is in contrast with what we do on Qubes OS, where the user is required to define the domains explicitly.
The Pratt's slides provide also some technical insight into how Bromium intends to secure their hypervisor. As just discussed above, a hosted hypervisor must normally trust the hosting OS, in this case Windows, which, for obvious reasons, is not a good idea from the security standpoint. Pratt, however, clearly states that “host (...) can not interfere with the privacy or integrity of the hypervisor or other guests” (slide #8). This is a strong statement, so let's take a closer look at their approach to this problem.
The Bromium's idea of how to make their hypervisor (and the VMs) protected from a potentially malicious host OS is not really breakthrough: the slides suggest to “deprivilege the host into a VT-container” (I think the verb to bluepillis now an accepted term for such action ;), and to remove the host's access to the hypervisor pages (via EPT), as well as protect DMA access from devices via VT-d, plus to make this all sensible, use DRTM scheme such as Intel TXT, to load such a hypervisor from within a potentially untrusted OS.
So, what's wrong with the idea of a load-on-the-fly-secure-VMM-system? Isn't Ian Pratt correct that one could protect its memory and execution from the interference of the host? Actually that is possible – Intel TXT, VT-x, VT-d, and EPT give us means to achieve that (although there are a number of catches here). But he's missing one important point: it's the untrusted OS that still owns and manages the input devices (e.g. via USB stacks and drivers) and, most importantly, the output (via the GUI subsystem and drivers). Ensuring that the host OS cannot interfere (e.g. sniff the screen of trusted applications) might be very difficult, or even impossible, in practice.
If I ever was to break the security of such a system, I would just follow the simple way:
1) Infect the host e.g. via one of the many USB attacks (remember they cannot have sandboxed USB driver domain, as they have only a type II hosted hypervisor), 2) Hook somewhere into the GUI subsystem and keep recoding all the interesting data from the screen...
... or something like that ;)
There are also many other things that needs to be answered and which the publicly available documents are silent about, such as e.g. how does the system handle installation of new applications? How is clipboard and file exchange between (micro)VMs handled? How large are the interfaces exposed to each (micro)VM? For now, without a solid documentation available, and without any code to play with, it is just another vaporware for me. (Interestingly there seem to be Bromium's Beta program, which however doesn't seem to be working, at least not for me -- I tried to signup twice, but never got any confirmation or response...?)
- How is Qubes different from Xen Client?
In many aspects, Xen Clientmight be the most similar product to Qubes OS. Like Qubes, it is based on the Xen hypervisor and so it is also a standalone OS, that one must install instead of one's favorite system, and also, like Qubes, it is targeted for desktop systems, and also offers a possibility to run a few VMs at a time.
However, XenClient has been designed with a different goal in mind, namely as a “Virtual Desktops To Go” solution, while Qubes has been designed to provide seamless experience for secure multi-domain desktop system. As a result, lots of focus in Qubes has been put on creating trusted GUI subsystem, support for advanced networking configurations, secure inter-VM clipboard and file sharing, secure method to reuse the same filesystem as a basis for the AppVMs, and also to optimize the AppVMs so they start almost instantly and take little memory, so that one could easily run many of them at the same time. All those things seem to be missing from Xen Client (as well as solid technical documentation about its design).
***
I surely have missed a few other products or approaches -- feel free to point them out in the comments, and I might write a continuation post one day.
\ No newline at end of file
+Many people ask how does Qubes OS differ from other approaches to desktop security. Today I'm trying to answer the most popular questions.
- Why bother with Qubes OS, if any Linux/BSD already allows to setup different user accounts, or some form of light-weight containers or sandboxes, such as chroot, LXC, SELinux?
First, if you use Xorg or similar X-based server as your GUI server, and this is what nearly all Linux, and most of the other non-Windows OSes use, then you don't have any form of GUI-level isolation, which is essential for a desktop system. I wrote more about this surprising problem some time ago. Proper GUI-level isolation was one of the main goals for Qubes.
Second, all mainstream desktop OSes, such as Windows, Linux, BSD, even OSX, are all based on a monolithic kernels, which present a significant security problem. This is because a typical monolithic kernel of a contemporary desktop OS contains tens of millions of lines of code, and to make it worse, most of this code is reachable from (untrusted) applications via all sorts of APIs, making the attack surface on the kernel huge. And it requires just one successful kernel exploit to own the whole system, bypassing any security mechanisms that might have been built on top of it, such as SELinux, LXC, etc.
Additionally, all the various drivers, networking and USB stacks, are also hosted in the kernel, making attacks via buggy networking (e.g. via
buggy 802.11 stacksor
buggy firmware) or
USB stacks a practical possibility. And there is essentially nothing one can do about it, when using an OS based on a monolithic kernel.
In Qubes, on the other hand, we use Xen hypervisor to provide security isolation between domains, and Xen is just a few hundred of thousands lines of code. It also doesn't need to provide all sorts of APIs to applications, because the Xen hypervisor is essentially only interested in CPU scheduling, memory management and power management, and very few things beyond that. Most notably, the Xen hypervisor knows nothing about networking, disk storage, filesystems, USB stacks, etc, as all those tasks are delegated to (often untrusted) service VMs.
- How is Qubes better than just running a bunch of VMs in VMWare or Virtual Box?
First, products such as VMWare Workstation or Fusion, or Virtual Box, are all examples of type II hypervisors (sometimes called “hosted VMMs”), which means that they run inside a normal OS, such as Windows, as ordinary processes and/or kernel modules. This means that they use the OS-provided services for all sorts of things, from networking, USB stacks, to graphics output and keyboard and mouse input, which in turn implies they can be only as secure as the hosting OS is. If the hosting OS got compromised, perhaps via a bug in its DHCP client, or USB driver, then it is a game over, also for all your VMs.
Second, those popular consumer type II VMM systems have not been designed with security as a primary goal. Instead, their main focus has been on easy of use, performance, and providing seamless integration of the guest OS(es) with the host OS. Especially the latter, which involves lack of good method to identify which domain a given application belongs to (so, lack of trusted Window Manager), support for shared clipboards which every other VM can steal, insecure file sharing methods, and others, all make it not a very desirable solution when strong domain isolation is important. (This is not to imply that Qubes doesn't support clipboard or file sharing between domains, it does – it's just that we do it in a secure way, at least so we believe). On the other hand, there are many usability improvements in Qubes that are specific to multi-domain system, and which you won't find in the above mentioned products, such as
trusted Window Manager that, while maintaining great seamless integration of all the applications onto a common desktop, still allows the user to always know which domain owns which window, support for
advanced networking setups, per-domain policies, the just mentioned secure mechanisms for clipboard and filesystem sharing, and many other. Qubes also focuses on making the VMs light-weight so that it was possible to run really a lot of them at the same time, and also on mechanism to allow for secure filesystem sharing between domains (templates).
Finally, the commercial hosted VMMs are really bloated pieces of code. They support everything and the kitchen sink (e.g. Open GL exposed to VMs, and various additional interfaces to allow e.g. drag and drop of files to/from the VM), and so, the attack surface on such a VMM system is orders of magnitude bigger than in case of Qubes OS.
- How does Qubes compare to [your favourite academic microkernel]?
While the Xen hypervisor can indeed be considered a microkernel if you're not a strict terminology freak, Qubes itself is much more than just the hypervisor. Qubes is everything that is needed to build a reasonably secure desktop OS on top ofa baremetal hypervisor (or microkernel). Theoretically, with just a few cosmetic changes (at least architecture-wise), Qubes could perhaps swap the Xen hypervisor for some other hypervisor or microkernel, such as perhaps Hyper-V, KVM, or some more exotic one. Thus, it makes little sense to compare Qubes with a hypervisor or microkernel project. What makes sense is to compare the Xen hypervisor, as used in Qubes, with some other hypervisor or microkernel.
Ok, so how does Xen compare with other hypervisors or microkernels out there? We think Xen is unique because it combines an elegant architecture (type I, baremetal, hypervisor) with a number of practical features, such as power management, support for Intel VT-d and driver domains, support for both para-virtualizaed, and fully-virtualized VMs, and many more, not found in e.g. academic microkernels/hypervisor projects, that otherwise seem attractive from the architecture point of view.
- How is Qubes better than Google Chrome OS?
First, Chrome OS is not a general purpose OS. Second, it's based on Linux with all its security limitation that are a result of using a monolithic kernel described above (e.g. all the networking and USB stacks in the kernel without a possibility to deprivilige them). Not being a traditional general purpose OS, Chrome is able to avoid many of the challenges of desktop computing, such as the need to define security domains, inter-domain file exchange (as there is essentially no filesystem visible to the user), and others, which is good, of course. But then again, Chrome OS is essentially just an environment to run the Chrome Browser, so the comparison to Qubes is a bit of a misunderstanding.
Technical aspects aside, there is always the privacy concern associated with running everything in a browser – why would all my private data be managed and accessible to some 3rd party organizations and
their administrators?
- How is Qubes better than [your favorite commercial military-grade certified secure OS]?
You must have heard about the super secure military-grade, formally verified, 100% certified, and generally “unbreakable” operating systems made by companies such as Green Hills, Lynx Works, and others. How do they compare to Qubes OS?
Really, I have no idea. For a mere mortal like myself (and perhaps not a US citizen), it seems impossible to get any more technical documentation of those systems (anything beyond the marketing pseudo-technical gibberish), not to mention a trial copy to play with...
Thus, from my point of view, those systems are just a vaporware. If you, my dear reader, are privileged enough to have access to such system, then good for you, but don't expect me to treat seriously a security product that is not available for a wider audience to touch and play with... (And the Chineese surely have the copies already to play with ;)
- How is Qubes different than Bromium's “micro virtualization” solution?
Many people asked recently about the Bromium's upcoming product and how it differs from Qubes OS. Unfortunately there are few public information available on this product – essentially there is one not-very-technical whitepaperand there are Ian Pratt's presentation slides from the recent XenSummit about u-Xen, apparently a hypervisor that is to be ultimately used in their upcoming product.
The whitepaper suggests that Bromium is based on a hosted (type II) hypervisor running within a normal Window OS, and that this hypervisor is used to spawn a new “micro VM” for each new “task”, where apparently the task might be something as granular as opening a new tab in a Web browser, which makes it somehow similar to Google Chrome's approach. Clearly, the Bromium's main goal seem to be to automate the process of creating separation domains, which is in contrast with what we do on Qubes OS, where the user is required to define the domains explicitly.
The Pratt's slides provide also some technical insight into how Bromium intends to secure their hypervisor. As just discussed above, a hosted hypervisor must normally trust the hosting OS, in this case Windows, which, for obvious reasons, is not a good idea from the security standpoint. Pratt, however, clearly states that “host (...) can not interfere with the privacy or integrity of the hypervisor or other guests” (slide #8). This is a strong statement, so let's take a closer look at their approach to this problem.
The Bromium's idea of how to make their hypervisor (and the VMs) protected from a potentially malicious host OS is not really breakthrough: the slides suggest to “deprivilege the host into a VT-container” (I think the verb to bluepillis now an accepted term for such action ;), and to remove the host's access to the hypervisor pages (via EPT), as well as protect DMA access from devices via VT-d, plus to make this all sensible, use DRTM scheme such as Intel TXT, to load such a hypervisor from within a potentially untrusted OS.
So, what's wrong with the idea of a load-on-the-fly-secure-VMM-system? Isn't Ian Pratt correct that one could protect its memory and execution from the interference of the host? Actually that is possible – Intel TXT, VT-x, VT-d, and EPT give us means to achieve that (although there are a number of catches here). But he's missing one important point: it's the untrusted OS that still owns and manages the input devices (e.g. via USB stacks and drivers) and, most importantly, the output (via the GUI subsystem and drivers). Ensuring that the host OS cannot interfere (e.g. sniff the screen of trusted applications) might be very difficult, or even impossible, in practice.
If I ever was to break the security of such a system, I would just follow the simple way:
1) Infect the host e.g. via one of the many USB attacks (remember they cannot have sandboxed USB driver domain, as they have only a type II hosted hypervisor), 2) Hook somewhere into the GUI subsystem and keep recoding all the interesting data from the screen...
... or something like that ;)
There are also many other things that needs to be answered and which the publicly available documents are silent about, such as e.g. how does the system handle installation of new applications? How is clipboard and file exchange between (micro)VMs handled? How large are the interfaces exposed to each (micro)VM? For now, without a solid documentation available, and without any code to play with, it is just another vaporware for me. (Interestingly there seem to be Bromium's Beta program, which however doesn't seem to be working, at least not for me -- I tried to signup twice, but never got any confirmation or response...?)
- How is Qubes different from Xen Client?
In many aspects, Xen Clientmight be the most similar product to Qubes OS. Like Qubes, it is based on the Xen hypervisor and so it is also a standalone OS, that one must install instead of one's favorite system, and also, like Qubes, it is targeted for desktop systems, and also offers a possibility to run a few VMs at a time.
However, XenClient has been designed with a different goal in mind, namely as a “Virtual Desktops To Go” solution, while Qubes has been designed to provide seamless experience for secure multi-domain desktop system. As a result, lots of focus in Qubes has been put on creating trusted GUI subsystem, support for advanced networking configurations, secure inter-VM clipboard and file sharing, secure method to reuse the same filesystem as a basis for the AppVMs, and also to optimize the AppVMs so they start almost instantly and take little memory, so that one could easily run many of them at the same time. All those things seem to be missing from Xen Client (as well as solid technical documentation about its design).
***
I surely have missed a few other products or approaches -- feel free to point them out in the comments, and I might write a continuation post one day.
\ No newline at end of file
diff --git a/_posts/2012-12-14-qubes-2-beta-1-with-initial-windows.html b/_posts/2012-12-14-qubes-2-beta-1-with-initial-windows.html
index aa50324..754cc9c 100644
--- a/_posts/2012-12-14-qubes-2-beta-1-with-initial-windows.html
+++ b/_posts/2012-12-14-qubes-2-beta-1-with-initial-windows.html
@@ -9,4 +9,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2012/12/qubes-2-beta-1-with-initial-windows.html
---
-
It's my pleasure to announce the first Beta for Qubes Release 2 is now available for
download.
This release introduces generic support for fully virtualized AppVMs (called HVMs in Xen parlance), and specifically initial support for Windows-based AppVMs integration. It's been quite a challenge to add support for secure HVMs to Qubes without breaking its security architecture, and I already wrote about it
in the past.
Generic support for HVMs means you can now install many different OSes as Qubes VMs, such as various Linux distros, BSD systems, and, of course, Windows. Essentially all you need is an installation ISO and the whole process is similar to creating a VM in a program like Virtual Box or VMWare Workstation (although we believe the underlying architecture for this is more secure in Qubes).
Additionally we provide a set of tools for Windows-based AppVMs (Windows 7 specifically) which allow for tight integration with the rest of the Qubes system. This currently includes support for secure (and policy controllable) clipboard and file exchanges between the Windows-based AppVMs and other AppVMs, integration with Qubes advanced networking infrastructure, and PV drivers for faster operation. As of now there is still no seamless app integration for Windows applications, so Windows VMs are presented as full-desktop-within-a-window, but we're aiming to add support for this in the next Betas.
Unlike the rest of Qubes, which is distributed under a GPL v2 license, the Qubes Windows Support Tools are not open sourced and are distributed as binaries only, under a proprietary license. They are free to use for any Qubes 2 user. The tools are not part of the Qubes 2 installation ISO (which is GPL), and are down loadable on demand.
More information about creating and using HVM domains, including Windows-based AppVMs, can be found in the wiki
here.
To summary, here's a quick list of some of the exciting new features that toady's release brings in:
Support for generic fully virtualized VMs (without qemu in the TCB!)
Support for Windows-based AppVMs integration (clipboard, file exchange, qrexec, pv drivers)
Secure audio input to select AppVMs (Hello Skype users!)
Clipboard is now also controlled by central policies, unified with other qrexec policies.
Out of the box TorVM support
Experimental support for PVUSB
Updated Xorg packages in Dom0 to support new GPUs
DisposableVM customization support
... and, as usual, various fixes and other improvements :)
Existing users of Qubes R1 can upgrade without needing to reinstall – the upgrade procedure is described
here. Standard installation is described
here.
Enjoy!
PS. Please send all the technical questions to the
qubes-devel mailing list, instead posting them as comments to this blog. Keep the comments here for more generic discussions.
PS2. As usual, I would like to remind that we have little control over the servers that are used for Qubes ISO distributions and that the downloads should be verified according to the procedure described
here. We always assume that even our own servers (git, wiki, yum) could be compromised, and yet this should not affect Qubes security in any way, because of the extensive use of digital signatures everywhere in the development and distribution process.
It's my pleasure to announce the first Beta for Qubes Release 2 is now available for
download.
This release introduces generic support for fully virtualized AppVMs (called HVMs in Xen parlance), and specifically initial support for Windows-based AppVMs integration. It's been quite a challenge to add support for secure HVMs to Qubes without breaking its security architecture, and I already wrote about it
in the past.
Generic support for HVMs means you can now install many different OSes as Qubes VMs, such as various Linux distros, BSD systems, and, of course, Windows. Essentially all you need is an installation ISO and the whole process is similar to creating a VM in a program like Virtual Box or VMWare Workstation (although we believe the underlying architecture for this is more secure in Qubes).
Additionally we provide a set of tools for Windows-based AppVMs (Windows 7 specifically) which allow for tight integration with the rest of the Qubes system. This currently includes support for secure (and policy controllable) clipboard and file exchanges between the Windows-based AppVMs and other AppVMs, integration with Qubes advanced networking infrastructure, and PV drivers for faster operation. As of now there is still no seamless app integration for Windows applications, so Windows VMs are presented as full-desktop-within-a-window, but we're aiming to add support for this in the next Betas.
Unlike the rest of Qubes, which is distributed under a GPL v2 license, the Qubes Windows Support Tools are not open sourced and are distributed as binaries only, under a proprietary license. They are free to use for any Qubes 2 user. The tools are not part of the Qubes 2 installation ISO (which is GPL), and are down loadable on demand.
More information about creating and using HVM domains, including Windows-based AppVMs, can be found in the wiki
here.
To summary, here's a quick list of some of the exciting new features that toady's release brings in:
Support for generic fully virtualized VMs (without qemu in the TCB!)
Support for Windows-based AppVMs integration (clipboard, file exchange, qrexec, pv drivers)
Secure audio input to select AppVMs (Hello Skype users!)
Clipboard is now also controlled by central policies, unified with other qrexec policies.
Out of the box TorVM support
Experimental support for PVUSB
Updated Xorg packages in Dom0 to support new GPUs
DisposableVM customization support
... and, as usual, various fixes and other improvements :)
Existing users of Qubes R1 can upgrade without needing to reinstall – the upgrade procedure is described
here. Standard installation is described
here.
Enjoy!
PS. Please send all the technical questions to the
qubes-devel mailing list, instead posting them as comments to this blog. Keep the comments here for more generic discussions.
PS2. As usual, I would like to remind that we have little control over the servers that are used for Qubes ISO distributions and that the downloads should be verified according to the procedure described
here. We always assume that even our own servers (git, wiki, yum) could be compromised, and yet this should not affect Qubes security in any way, because of the extensive use of digital signatures everywhere in the development and distribution process.
Arguably one of the biggest challenges for desktop security is how to handle those overly complex PDFs, DOCs, and similar files, that are so often exchanged by people, or downloaded from the Web, and that often provide a way for the attacker to
compromise the user's desktop system.
Today I would like to discuss a recent innovation we created for Qubes OS that allows to securely convert those pesky PDFs (as well as essentially any graphics files) into trusted PDFs. Here by a “trusted PDF” I mean a file that should be harmlessto the user's system, so, a non-malicious PDF.
A few years ago, we have already introduced a mechanism in Qubes OS called Disposable VMs, that can be used to safelyopen any file, including PDFs, DOCs, etc. The file is being opened in a... well a dedicated disposable VM that is created within seconds (typically below 5 seconds) and all the file processing and rendering happens inside this VM. Once the document is closed, the disposable VM is automatically destroyed, and any changes to the file (e.g. if the was an editable DOC file) are automatically propagated back into the original file. This mechanism is very powerful, and I often use it for my daily work. However, it surely is a bit cumbersome – who wants to wait 5 seconds for the PDF to open, especially if I have a dozen of invoices to look through! So, today I present an alternative approach...
Approaches to converting PDFs
The problem of converting a potentially untrusted PDF into a harmless one is certainly not a new one. Some tools have already be created for this task.
The typical approach is to parse the original PDF, look for “potentially dangerous things” there, and remove them. As simple as that! This is, of course, a typical AntiVirus approach to the problem. And, typically as it is for most AV approaches, it's completely useless against any more skilled and determined attacker (and these are the ones we fear the most, don't we?).
A somehow better approach is to parse the original PDF, disassemble it into pieces, and then reassemble them into a new PDF only using the “trusted” pieces – this, I think, could be called a whitelisting approach.
Anyway, the fundamental problem with the approaches mentioned above, is that all of them require parsingof the original PDF file. And parsing is where the “big bang” usually happens. Parsing is where our, normally pretty decent, code, comes in close, intimate contact with some unknown complex input data, which often leads to a successful abuse or exploitation.
Parsing PDFs safely
So, how to perform parsing safely? Of course, that's simple! Let's run the parser in an isolated container – in case of Qubes we already have an ideal such container: it's the Disposable VMs.
But, before we get too excited, let's think more about it – say we run the parser safely isolated in a Disposable VM, meaning it couldn't harm any of the rest of the system, except for the Disposable VM itself, which we however won't worry much about, because it is disposable... But then what?
We want our PDF back in our original VM, to actually use it, right? But we cannot just copy the result from the Disposable VM, because if it got compromised, as a result of parsing of the malicious PDF, then we would like get... a compromised converted PDF. So, this approach gives us nothing!
(Even though our “solution” incorporates all the obligatory buzzwords: “Disposable VMs” (“Micro Disposable VMs”?), “VMs isolated using hardware Intel vPRO technology” and, of course, the “hypervisor”! Sometime just the mere fact we use “hardware virtualization” buys us nothing... People seem to forget about this sometimes.)
So, the trick to make this approach meaningful is to introduce what I will call a “Simple Representation” of the input file. More on this, straightforward concept, below. The idea is that our parser (that runs in a Disposable VM) will be expectedto return the Simple Representation of the original PDF. Of course, it might very well go wild (as a result of exploitation by the PDF it parses), and don't obey our expectations, and instead return something totally different and potentially malicious. But that doesn't matter! The whole point of the Simple Representation is that it should be, well... simple to parse it safely and discard in case what we're getting doesn't look like the Simple Representation.
Ok, so what's the simplest possible representation of an arbitrary PDF file? Yes, it's the RGB format, which is essentially just a raw array of RGB values for each pixel. In fact, I'm not sure there could be anything simpler in the Known Universe to represent a PDF file...
Now this is all becoming simple: we would expect our parser to send us just two things: the dimensions (W x H) of the bitmap representation of each of the page of the PDF in question, and each of the PDF page itself converted into a raw RGB format. If the parser didn't obey, we would still interpret whatever stream of bytes we get as a RGB bitmap – in the worst case the PDF we create would look like un-tuned analog TV screen.
The diagram below summaries this idea:
Implementing this all on Qubes
Now I would like to show how easy it is to implement such PDF converter service using the Qubes advanced infrastructure that we call qrexec, and which is part of Qubes core for quite some time now. First, let's choose the PDF and image conversion tools. The choice of PDF converter is not security critical, because it will run in an isolated Disposable VM. Here I decided to use pdftocairo converter, which is part of the poppler-utils package on Fedora. We will also use ImageMagick's “convert” command to convert the PNG files (produced by pdftocairo, one for each PDF page) to the raw RGB format. Incidentally ImageMagick supports RGB format natively. As mentioned above, in addition to sending the raw RGB file, we would also need to send the width and height of the pixmap – those can easily be obtained using ImageMagick's “identify” command. Again, all those programs discussed so far are not security critical – they might get exploited during the processing of the untrusted input PDF file, and we don't worry about that at all.
On the receiving side, however, we need to use a foolproof parser for the RGB format. Again, this is what we gain in this whole process – instead of requiring a foolproof-and-also-being-able-to-produce-non-malicious-PDFs parser, we only require a foolproof RGB parses, and that's quite a gain! The ImageMagick's convert comes to mind again here, and one might want to use it like this:
convert page.rgb page.pdf
Unfortunately this would be wrong, because the convert program would still try to detect the “real” format of the page.rgb file, and, if it looked more like, say, JPEG or PDF, it would parse it accordingly, compromising all our careful plan! What we really need is to tell our convert program to always treat the input as raw RGB file, instead of trying to be (too) smart and trying to guess the format by itself. This can be achieved by adding the “rgb:” prefix in front of the input argument, which provides explicit input format specification:
convert -size ${IMG_WIDTH}x${IMG_HEIGHT} -depth ${IMG_DEPTH} rgb:$RGB_FILE pdf:$PDF_FILE
Now also needed to add size and depth explicitly, because the raw RGB format doesn't convey such information (well, it has no header of any sort at all!). Of course we need to obtain the width and height from the parser, but we can validate such input rather easily. In addition we make sure that the received RGB file has exactly the size as indicated by width and height. With those precautions in place, there would have to be really a gappinghole in the ImageMagic's RGB parsing code for the attacker to exploit this. Perhaps instead of using the ImageMagick's convert I should have written a small script in python that would parse the received RGB file (and save it into a... RGB file, for later processing by ImageMagick), but I sincerely think this would be an overkill here.
Additionally we also need to create a policy file in Dom0 in
/etc/qubes_rpc/policy/to allow to use this service. The policy file content for this service should look like this:
$anyvm $dispvm allow
... which is pretty self explanatory. When I do development I also add another line to the policy file like this:
$anyvm devel-vm ask
... to allow me to run the server inside my 'devel-vm' VM, instead of running it in Disposable VM every time, which would be very inconvenient for development, as it would require me to update the Disposable VM template each time I wanted to test a new version of qpdf-convert-server.
The policy file should be placed in Dom0 in /etc/qubes_rpc/policy/qubes.PdfConvertfile – here the name of the file must be the same as the name of the service, as invoked via qrexec_client_vmcommand, discussed below.
And, one last thing, in the destination VM we must also create a file that will map the service name (so, the
qubes.PdfConvert in our example) to the actual binary that should be called in the VM when the service is invoked. So, the file should be named:
/etc/qubes_rpc/qubes.PdfConvert(again, this is now in a VM, not in Dom0, also note the lack of
policy/ subdir), and it is another one-liner with the following content:
/usr/lib/qubes/qpdf-convert-server
The full source code of qpdf-converter can be seen and downloaded from
this git repo.
We're ready now to test our qubes.PdfConvert service: in the requesting VM, i.e. the one from which we want to initiate the conversion process we do:
[user@work Downloads]$ /usr/lib/qubes/qrexec_client_vm '$dispvm' qubes.PdfConvert /usr/lib/qubes/qpdf-convert-client ITLquote.pdf
-> Sending file to remote VM...
-> Waiting for converted samples...
-> Receving page 2 out of 2...
-> Merging pages into a single PDF document...
-> Converted PDF saved as: ITLquote.trusted.pdf
-> Original file saved as .ITLquote.pdf
Again, for development process I would replace '$dispvm' with something like 'devel-vm'.
The
qrexec_client_vmcommand, used above, is not actually intended to be used by user directly (that's why it's installed in /usr/lib/qubes instead of /usr/bin/), and so when one creates a Qubes qrexec service, it's customary to create also a small wrapper around qrexec, like
this one, that makes using the service simple.
The presented converter saves the original file as .${original_pdf}making it a hidden file to help the user avoid accidental opening. The new, converted file gets .trusted.pdfsuffix appended to the base name of the original file. I discuss more issues regarding the human factor and avoiding accidental opening in one of the next paragraphs below. The converter can also be used to convert essentially any image file, such as JPEG, PNG, etc, into a PDF, using the same method.
As you can see creating client-server services in Qubes is very simple – in fact it took me just one afternoon to get the inital working version of the converter (with subsequent "polishing" over the next 2 days).
The qrexec infrastructure takes care about all the under-the-hood tasks, such as starting the necessary VMs, e.g. creating Disposable VM to handle the service request,establishing communication channels between VMs (which are ultimately implemented on top of Xen's shared memory), redirecting client and server's stdin and stdout to each other, so that writing services is very simple, even in shell, and, of course, obeying policies defined centrally in Dom0.
Most “inter-VM” features in Qubes, such as secure file copy between domains, opening files in Disposable VMs, time synchronization, appmenus synchronization, etc, are all implemented on top of qrexec. A notable exception is clipboard exchange, which is implemented as part of the GUI protocol, but still uses the same common qrexec code for policy processing (e.g. I use this policy to block clipboard and file exchanges between my work and personal domains).
Limitations, other Simple Representations
The obvious disadvantage of converting a PDF to an RGB representation is that one looses text search, as well as copy and edit capabilities (e.g. in case of PDF forms). So, converting Intel's IA32 Software Developer's Manual this way would certainly not be a good idea... But, hey, such large PDFs can always be opened in a Disposable VM – they would be fully functional then, only that you would need to wait a few seconds for the PDF window to pop up. Or, better yet, why not keep all such PDFs in a dedicated domain? E.g. I have a VM called “work-pub” where I keep tons of various, publicly available PDFs, such as the mentioned Intel's SDM, as well as various chipset docs, conferences papers and slides, and generally lots of stuff. The key point is that all in this VM is public material (and also all is related to my work), so that I don't really care if any of those PDFs compromises my work-pub domain. In the worst case, I will revert the VM from backup and download any missing PDFs again from the web. They are public after all.
But the PDF conversion described above comes extremely useful in case of all the various invoices, Purchase Orders, NDAs, contracts, and god-knows-what-else PDF documents, which I'm forced to deal with in my “work” domain (where my email client runs). Most of those are one pagers, or maximum a few pages long documents, so the fact that they got converted to a bitmap provides me with very little discomfort. At the same time I gain incredible freedom in opening all those documents natively in my work VM, without fearing that one of those invoices will comrpomise my work domain (which would be a rather sad thing for me, although the really sensitive stuff is still in some other domains ;)
An interesting question is, however, can we come up with another form of Simple Representation that would allow e.g. to preserve the text searching ability of the converted PDFs (and DOCs, PPTs)? Probably... yes. The choice of the Simple Representation should be thought of as of a trade-off between security and document's features preservation. I'm not an expert on PDF and DOC formats (and I'm not sure I want to be) but it seems plausible that one could disassemble PDF into simple pieces, select the really simple ones, send those pieces as a Simple Representation back to client, and have them reassembled back into a almost-fully-functional PDF. Here, again, the point is that the PDF parsing is done in isolated Disposable VM, while the reassembly in the trusted VM. Anyway, let me leave it as a exercise for the reader :)
Preventing user mistakes
Being able to right-click on a PDF file and have it converted into a trusted PDF is one thing. Having this mechanism adopted by users and actually making their daily computing safer, is another story.
Users will likely have hundreds of PDF spread over their home directories, and the real challenge is how to make sure that the user never accidentally opens the unconverted, untrusted PDF. We can think of several approaches to this problem:
We modify the Thunderbird, Firefox, etc, e.g. by providing specific plugins, to always perform PDF conversion on each file that we got via email or downloaded from the Web. Additionally we convert all the already present PDFs in the user's home directory (file system?). And, additionally, we modify Qubes file copy operation to also always do automatic PDF conversion whenever one transfers files from other domains (if Qubes qrexec policy allows for such transfer in the first place, of course).
This approach would not be optimal, because some PDFs, as we discussed above, might not be well suited for conversion-through-bitmap process – they might be large PDFs where text search is crucial, some conference papers for review, where text copy is crucial, or some editable forms. That's why it seems better to take a slightly different approach:
We modify mime handlers for PDF files (as well as any other files that our converter supports) and then upon every opening of the file (e.g. via mouse click in a file manager) our program gets to run and its job is to determine whether the file should be opened natively, converted to a trusted PDF, or perhaps opened in a Disposable VM. Of course, upon “first” opening we should probably ask the user about the decision, if this cannot be determined automatically. E.g. if we can reliably determine the file is already converted, we can safely open it without prompting the user, but if it's not, we should ask – perhaps the user would like to open it in a Disposable VM instead of converting, or perhaps the file should be considered trusted anyway, because it was created by the user herself.
This second approach seems like a way to go, and we will likely implement it sooner or later (probably sooner, but after the upcoming R2 Beta2). It should also be noted, that typically user would need such mechanism only in some domains – e.g. I really feel the need for such protection in my “work” domain, but not in any other. But that, of course, depends on how one partitions their digital life into security domains.
One important detail worth mentioning here, is that we should unconditionally disable “Thumbnail View” in whatever file manager we use (which itself is really a stupid feature – can people not read filenames anymore or something?).
Qubes: from containers isolation down to apps protection
The mechanism introduced today, in addition to the Disposable VMs mechanism introduced earlier, represents a trend in Qubes development of “stepping down” into AppVMs in order to also make the VMs themselves somehow more secure (in addition to the isolation between the VMs).
Originally Qubes aimed at containers isolation only. This included protecting the system TCB where techniques such as deprivileged networking stacks (and optionally also deprivileged USB stacks) have been deployed, as well as custom GUI virtualization, and generally somehow “hardened” Xen configuration. This also included protecting the VMs from each other, where techniques such as secure clipboard, secure file copy and generally secure qrexec infrastructure have been introduced, as well as trusted GUI subsystem with explicit domain decorations.
But now, Qubes is stepping down into the AppVMs in order to make the VMs themselves also less prone to compromise. We surely will be working on more such mechanisms in the future. We still are only at the beginning of the quest to create a Reasonably Secure Desktop OS!
PS. The presenetd converter will be part of the Qubes R2 Beta 2, that is expected to be released... in the comming days. Experienced users of Qubes R1 and R2 Beta 1 can install the converter immediately by building the rpms from the git repo.
PS. WTF is happening with the Blogger web interface? Seriously, I don't remember being so frustrated using any software in the recent years that I am right now, when editing this post (as well as the last several ones). It sometimes honours the line breaks, sometimes do not, sometimes inserts a couple of new lines, sometime removes them, sometime mysterious spaces appear at the end of lines, sometime those cannot be removed... It doesn't allow to paste pre-formatted code-listing (at least I couldn't figure out how to make it honour tabs). And yes, I'm using the "Compose mode", because when I try to switch to the HTML mode, not only I'm overwhelmed with tons of HTML markups, nobody knows what for, but also when I switch back to the Compose mode, my article tends to get even more fucked up! Really, a shame. I wish I could go away to some other blogging service, but I'm afraid that converting all my posts would be even a bigger PITA... Sigh.
\ No newline at end of file
+
Arguably one of the biggest challenges for desktop security is how to handle those overly complex PDFs, DOCs, and similar files, that are so often exchanged by people, or downloaded from the Web, and that often provide a way for the attacker to
compromise the user's desktop system.
Today I would like to discuss a recent innovation we created for Qubes OS that allows to securely convert those pesky PDFs (as well as essentially any graphics files) into trusted PDFs. Here by a “trusted PDF” I mean a file that should be harmlessto the user's system, so, a non-malicious PDF.
A few years ago, we have already introduced a mechanism in Qubes OS called Disposable VMs, that can be used to safelyopen any file, including PDFs, DOCs, etc. The file is being opened in a... well a dedicated disposable VM that is created within seconds (typically below 5 seconds) and all the file processing and rendering happens inside this VM. Once the document is closed, the disposable VM is automatically destroyed, and any changes to the file (e.g. if the was an editable DOC file) are automatically propagated back into the original file. This mechanism is very powerful, and I often use it for my daily work. However, it surely is a bit cumbersome – who wants to wait 5 seconds for the PDF to open, especially if I have a dozen of invoices to look through! So, today I present an alternative approach...
Approaches to converting PDFs
The problem of converting a potentially untrusted PDF into a harmless one is certainly not a new one. Some tools have already be created for this task.
The typical approach is to parse the original PDF, look for “potentially dangerous things” there, and remove them. As simple as that! This is, of course, a typical AntiVirus approach to the problem. And, typically as it is for most AV approaches, it's completely useless against any more skilled and determined attacker (and these are the ones we fear the most, don't we?).
A somehow better approach is to parse the original PDF, disassemble it into pieces, and then reassemble them into a new PDF only using the “trusted” pieces – this, I think, could be called a whitelisting approach.
Anyway, the fundamental problem with the approaches mentioned above, is that all of them require parsingof the original PDF file. And parsing is where the “big bang” usually happens. Parsing is where our, normally pretty decent, code, comes in close, intimate contact with some unknown complex input data, which often leads to a successful abuse or exploitation.
Parsing PDFs safely
So, how to perform parsing safely? Of course, that's simple! Let's run the parser in an isolated container – in case of Qubes we already have an ideal such container: it's the Disposable VMs.
But, before we get too excited, let's think more about it – say we run the parser safely isolated in a Disposable VM, meaning it couldn't harm any of the rest of the system, except for the Disposable VM itself, which we however won't worry much about, because it is disposable... But then what?
We want our PDF back in our original VM, to actually use it, right? But we cannot just copy the result from the Disposable VM, because if it got compromised, as a result of parsing of the malicious PDF, then we would like get... a compromised converted PDF. So, this approach gives us nothing!
(Even though our “solution” incorporates all the obligatory buzzwords: “Disposable VMs” (“Micro Disposable VMs”?), “VMs isolated using hardware Intel vPRO technology” and, of course, the “hypervisor”! Sometime just the mere fact we use “hardware virtualization” buys us nothing... People seem to forget about this sometimes.)
So, the trick to make this approach meaningful is to introduce what I will call a “Simple Representation” of the input file. More on this, straightforward concept, below. The idea is that our parser (that runs in a Disposable VM) will be expectedto return the Simple Representation of the original PDF. Of course, it might very well go wild (as a result of exploitation by the PDF it parses), and don't obey our expectations, and instead return something totally different and potentially malicious. But that doesn't matter! The whole point of the Simple Representation is that it should be, well... simple to parse it safely and discard in case what we're getting doesn't look like the Simple Representation.
Ok, so what's the simplest possible representation of an arbitrary PDF file? Yes, it's the RGB format, which is essentially just a raw array of RGB values for each pixel. In fact, I'm not sure there could be anything simpler in the Known Universe to represent a PDF file...
Now this is all becoming simple: we would expect our parser to send us just two things: the dimensions (W x H) of the bitmap representation of each of the page of the PDF in question, and each of the PDF page itself converted into a raw RGB format. If the parser didn't obey, we would still interpret whatever stream of bytes we get as a RGB bitmap – in the worst case the PDF we create would look like un-tuned analog TV screen.
The diagram below summaries this idea:
Implementing this all on Qubes
Now I would like to show how easy it is to implement such PDF converter service using the Qubes advanced infrastructure that we call qrexec, and which is part of Qubes core for quite some time now. First, let's choose the PDF and image conversion tools. The choice of PDF converter is not security critical, because it will run in an isolated Disposable VM. Here I decided to use pdftocairo converter, which is part of the poppler-utils package on Fedora. We will also use ImageMagick's “convert” command to convert the PNG files (produced by pdftocairo, one for each PDF page) to the raw RGB format. Incidentally ImageMagick supports RGB format natively. As mentioned above, in addition to sending the raw RGB file, we would also need to send the width and height of the pixmap – those can easily be obtained using ImageMagick's “identify” command. Again, all those programs discussed so far are not security critical – they might get exploited during the processing of the untrusted input PDF file, and we don't worry about that at all.
On the receiving side, however, we need to use a foolproof parser for the RGB format. Again, this is what we gain in this whole process – instead of requiring a foolproof-and-also-being-able-to-produce-non-malicious-PDFs parser, we only require a foolproof RGB parses, and that's quite a gain! The ImageMagick's convert comes to mind again here, and one might want to use it like this:
convert page.rgb page.pdf
Unfortunately this would be wrong, because the convert program would still try to detect the “real” format of the page.rgb file, and, if it looked more like, say, JPEG or PDF, it would parse it accordingly, compromising all our careful plan! What we really need is to tell our convert program to always treat the input as raw RGB file, instead of trying to be (too) smart and trying to guess the format by itself. This can be achieved by adding the “rgb:” prefix in front of the input argument, which provides explicit input format specification:
convert -size ${IMG_WIDTH}x${IMG_HEIGHT} -depth ${IMG_DEPTH} rgb:$RGB_FILE pdf:$PDF_FILE
Now also needed to add size and depth explicitly, because the raw RGB format doesn't convey such information (well, it has no header of any sort at all!). Of course we need to obtain the width and height from the parser, but we can validate such input rather easily. In addition we make sure that the received RGB file has exactly the size as indicated by width and height. With those precautions in place, there would have to be really a gappinghole in the ImageMagic's RGB parsing code for the attacker to exploit this. Perhaps instead of using the ImageMagick's convert I should have written a small script in python that would parse the received RGB file (and save it into a... RGB file, for later processing by ImageMagick), but I sincerely think this would be an overkill here.
Additionally we also need to create a policy file in Dom0 in
/etc/qubes_rpc/policy/to allow to use this service. The policy file content for this service should look like this:
$anyvm $dispvm allow
... which is pretty self explanatory. When I do development I also add another line to the policy file like this:
$anyvm devel-vm ask
... to allow me to run the server inside my 'devel-vm' VM, instead of running it in Disposable VM every time, which would be very inconvenient for development, as it would require me to update the Disposable VM template each time I wanted to test a new version of qpdf-convert-server.
The policy file should be placed in Dom0 in /etc/qubes_rpc/policy/qubes.PdfConvertfile – here the name of the file must be the same as the name of the service, as invoked via qrexec_client_vmcommand, discussed below.
And, one last thing, in the destination VM we must also create a file that will map the service name (so, the
qubes.PdfConvert in our example) to the actual binary that should be called in the VM when the service is invoked. So, the file should be named:
/etc/qubes_rpc/qubes.PdfConvert(again, this is now in a VM, not in Dom0, also note the lack of
policy/ subdir), and it is another one-liner with the following content:
/usr/lib/qubes/qpdf-convert-server
The full source code of qpdf-converter can be seen and downloaded from
this git repo.
We're ready now to test our qubes.PdfConvert service: in the requesting VM, i.e. the one from which we want to initiate the conversion process we do:
[user@work Downloads]$ /usr/lib/qubes/qrexec_client_vm '$dispvm' qubes.PdfConvert /usr/lib/qubes/qpdf-convert-client ITLquote.pdf
-> Sending file to remote VM...
-> Waiting for converted samples...
-> Receving page 2 out of 2...
-> Merging pages into a single PDF document...
-> Converted PDF saved as: ITLquote.trusted.pdf
-> Original file saved as .ITLquote.pdf
Again, for development process I would replace '$dispvm' with something like 'devel-vm'.
The
qrexec_client_vmcommand, used above, is not actually intended to be used by user directly (that's why it's installed in /usr/lib/qubes instead of /usr/bin/), and so when one creates a Qubes qrexec service, it's customary to create also a small wrapper around qrexec, like
this one, that makes using the service simple.
The presented converter saves the original file as .${original_pdf}making it a hidden file to help the user avoid accidental opening. The new, converted file gets .trusted.pdfsuffix appended to the base name of the original file. I discuss more issues regarding the human factor and avoiding accidental opening in one of the next paragraphs below. The converter can also be used to convert essentially any image file, such as JPEG, PNG, etc, into a PDF, using the same method.
As you can see creating client-server services in Qubes is very simple – in fact it took me just one afternoon to get the inital working version of the converter (with subsequent "polishing" over the next 2 days).
The qrexec infrastructure takes care about all the under-the-hood tasks, such as starting the necessary VMs, e.g. creating Disposable VM to handle the service request,establishing communication channels between VMs (which are ultimately implemented on top of Xen's shared memory), redirecting client and server's stdin and stdout to each other, so that writing services is very simple, even in shell, and, of course, obeying policies defined centrally in Dom0.
Most “inter-VM” features in Qubes, such as secure file copy between domains, opening files in Disposable VMs, time synchronization, appmenus synchronization, etc, are all implemented on top of qrexec. A notable exception is clipboard exchange, which is implemented as part of the GUI protocol, but still uses the same common qrexec code for policy processing (e.g. I use this policy to block clipboard and file exchanges between my work and personal domains).
Limitations, other Simple Representations
The obvious disadvantage of converting a PDF to an RGB representation is that one looses text search, as well as copy and edit capabilities (e.g. in case of PDF forms). So, converting Intel's IA32 Software Developer's Manual this way would certainly not be a good idea... But, hey, such large PDFs can always be opened in a Disposable VM – they would be fully functional then, only that you would need to wait a few seconds for the PDF window to pop up. Or, better yet, why not keep all such PDFs in a dedicated domain? E.g. I have a VM called “work-pub” where I keep tons of various, publicly available PDFs, such as the mentioned Intel's SDM, as well as various chipset docs, conferences papers and slides, and generally lots of stuff. The key point is that all in this VM is public material (and also all is related to my work), so that I don't really care if any of those PDFs compromises my work-pub domain. In the worst case, I will revert the VM from backup and download any missing PDFs again from the web. They are public after all.
But the PDF conversion described above comes extremely useful in case of all the various invoices, Purchase Orders, NDAs, contracts, and god-knows-what-else PDF documents, which I'm forced to deal with in my “work” domain (where my email client runs). Most of those are one pagers, or maximum a few pages long documents, so the fact that they got converted to a bitmap provides me with very little discomfort. At the same time I gain incredible freedom in opening all those documents natively in my work VM, without fearing that one of those invoices will comrpomise my work domain (which would be a rather sad thing for me, although the really sensitive stuff is still in some other domains ;)
An interesting question is, however, can we come up with another form of Simple Representation that would allow e.g. to preserve the text searching ability of the converted PDFs (and DOCs, PPTs)? Probably... yes. The choice of the Simple Representation should be thought of as of a trade-off between security and document's features preservation. I'm not an expert on PDF and DOC formats (and I'm not sure I want to be) but it seems plausible that one could disassemble PDF into simple pieces, select the really simple ones, send those pieces as a Simple Representation back to client, and have them reassembled back into a almost-fully-functional PDF. Here, again, the point is that the PDF parsing is done in isolated Disposable VM, while the reassembly in the trusted VM. Anyway, let me leave it as a exercise for the reader :)
Preventing user mistakes
Being able to right-click on a PDF file and have it converted into a trusted PDF is one thing. Having this mechanism adopted by users and actually making their daily computing safer, is another story.
Users will likely have hundreds of PDF spread over their home directories, and the real challenge is how to make sure that the user never accidentally opens the unconverted, untrusted PDF. We can think of several approaches to this problem:
We modify the Thunderbird, Firefox, etc, e.g. by providing specific plugins, to always perform PDF conversion on each file that we got via email or downloaded from the Web. Additionally we convert all the already present PDFs in the user's home directory (file system?). And, additionally, we modify Qubes file copy operation to also always do automatic PDF conversion whenever one transfers files from other domains (if Qubes qrexec policy allows for such transfer in the first place, of course).
This approach would not be optimal, because some PDFs, as we discussed above, might not be well suited for conversion-through-bitmap process – they might be large PDFs where text search is crucial, some conference papers for review, where text copy is crucial, or some editable forms. That's why it seems better to take a slightly different approach:
We modify mime handlers for PDF files (as well as any other files that our converter supports) and then upon every opening of the file (e.g. via mouse click in a file manager) our program gets to run and its job is to determine whether the file should be opened natively, converted to a trusted PDF, or perhaps opened in a Disposable VM. Of course, upon “first” opening we should probably ask the user about the decision, if this cannot be determined automatically. E.g. if we can reliably determine the file is already converted, we can safely open it without prompting the user, but if it's not, we should ask – perhaps the user would like to open it in a Disposable VM instead of converting, or perhaps the file should be considered trusted anyway, because it was created by the user herself.
This second approach seems like a way to go, and we will likely implement it sooner or later (probably sooner, but after the upcoming R2 Beta2). It should also be noted, that typically user would need such mechanism only in some domains – e.g. I really feel the need for such protection in my “work” domain, but not in any other. But that, of course, depends on how one partitions their digital life into security domains.
One important detail worth mentioning here, is that we should unconditionally disable “Thumbnail View” in whatever file manager we use (which itself is really a stupid feature – can people not read filenames anymore or something?).
Qubes: from containers isolation down to apps protection
The mechanism introduced today, in addition to the Disposable VMs mechanism introduced earlier, represents a trend in Qubes development of “stepping down” into AppVMs in order to also make the VMs themselves somehow more secure (in addition to the isolation between the VMs).
Originally Qubes aimed at containers isolation only. This included protecting the system TCB where techniques such as deprivileged networking stacks (and optionally also deprivileged USB stacks) have been deployed, as well as custom GUI virtualization, and generally somehow “hardened” Xen configuration. This also included protecting the VMs from each other, where techniques such as secure clipboard, secure file copy and generally secure qrexec infrastructure have been introduced, as well as trusted GUI subsystem with explicit domain decorations.
But now, Qubes is stepping down into the AppVMs in order to make the VMs themselves also less prone to compromise. We surely will be working on more such mechanisms in the future. We still are only at the beginning of the quest to create a Reasonably Secure Desktop OS!
PS. The presenetd converter will be part of the Qubes R2 Beta 2, that is expected to be released... in the comming days. Experienced users of Qubes R1 and R2 Beta 1 can install the converter immediately by building the rpms from the git repo.
PS. WTF is happening with the Blogger web interface? Seriously, I don't remember being so frustrated using any software in the recent years that I am right now, when editing this post (as well as the last several ones). It sometimes honours the line breaks, sometimes do not, sometimes inserts a couple of new lines, sometime removes them, sometime mysterious spaces appear at the end of lines, sometime those cannot be removed... It doesn't allow to paste pre-formatted code-listing (at least I couldn't figure out how to make it honour tabs). And yes, I'm using the "Compose mode", because when I try to switch to the HTML mode, not only I'm overwhelmed with tons of HTML markups, nobody knows what for, but also when I switch back to the Compose mode, my article tends to get even more fucked up! Really, a shame. I wish I could go away to some other blogging service, but I'm afraid that converting all my posts would be even a bigger PITA... Sigh.
\ No newline at end of file
diff --git a/_posts/2013-02-28-qubes-2-beta-2-has-been-released.html b/_posts/2013-02-28-qubes-2-beta-2-has-been-released.html
index efa579f..e925167 100644
--- a/_posts/2013-02-28-qubes-2-beta-2-has-been-released.html
+++ b/_posts/2013-02-28-qubes-2-beta-2-has-been-released.html
@@ -10,4 +10,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2013/02/qubes-2-beta-2-has-been-released.html
---
-
We're progressing fast and today I would like to announce the release of Qubes R2 Beta 2 ISO. The installation and upgrade instructions, as well as the ISO itself, can be found via the
our wiki page. As usual, please remember to verify the digital signature of the downloaded ISO.
The major changes in this beta release include:
Upgraded Dom0 distribution to the latest Fedora 18 (all previous releases used Fedora 13 for Dom0!)
Upgraded default VM template also to Fedora 18
Upgraded Dom0 kernel to 3.7.6
Upgraded KDE environment in Dom0 (KDE 4.9)
Introduced Xfce 4.10 environment for Dom0 as an alternative to KDE
A few other fixes and improvements, including the recently discussed Disposable VM-based
PDF converter
The upgrade of the Dom0 distribution and kernel should significantly improve hardware compatibility – one of the major problems with Qubes adoption so far, as we hear. Now, with the latest GPU drivers and Xorg packages, I hope we will be able to cover a much boarder range of hardware (especially all the newer GPUs).
The upgrade of KDE in Dom0 is mostly an eye-candy type of improvement (but then, who doesn't like eye candies!), as is the introduction of the Xfce4 as its alternative, although, arguably, Xfce4 is considered faster and lighter than KDE. In Qubes the choice of an actual desktop environment that runs in Dom0 is not as important as it is on traditional Linux systems, I think, simply because most of the functionality, typically provided by such environments, such as apps and file management, is simply... disabled, because on Qubes there are no user apps or files in Dom0.
Nevertheless people love and hate particular window managers and environments, and we hope that now, by supporting alternative environments, we could appeal to even more users.
I'm glad that we just completed this difficult phase of upgrading Qubes Dom0 distribution (for the first time since Qubes R1 Beta 1!) -- this forced us to clean up the code and prepare for some even bigger and bolder changes in the near future. But those will come only in Release 3. As far as Release 2 is considered, we do have quite
a few more tickets scheduled for R2 Beta 3 milestone, but most of those represent various addons, rather than modifications to Qubes core software.
So what are those brave changes that are to happen in Release 3? That I will write about in a separate blog post... Stay tuned!
So, please enjoy this latest Qubes R2 beta release, and be sure to send all your questions and comments, as well as the HCL info, to the
qubes-devel mailing list. I have already upgraded my primary laptop to this release a few days ago and everything seems to be working fine, so fear not!
We're progressing fast and today I would like to announce the release of Qubes R2 Beta 2 ISO. The installation and upgrade instructions, as well as the ISO itself, can be found via the
our wiki page. As usual, please remember to verify the digital signature of the downloaded ISO.
The major changes in this beta release include:
Upgraded Dom0 distribution to the latest Fedora 18 (all previous releases used Fedora 13 for Dom0!)
Upgraded default VM template also to Fedora 18
Upgraded Dom0 kernel to 3.7.6
Upgraded KDE environment in Dom0 (KDE 4.9)
Introduced Xfce 4.10 environment for Dom0 as an alternative to KDE
A few other fixes and improvements, including the recently discussed Disposable VM-based
PDF converter
The upgrade of the Dom0 distribution and kernel should significantly improve hardware compatibility – one of the major problems with Qubes adoption so far, as we hear. Now, with the latest GPU drivers and Xorg packages, I hope we will be able to cover a much boarder range of hardware (especially all the newer GPUs).
The upgrade of KDE in Dom0 is mostly an eye-candy type of improvement (but then, who doesn't like eye candies!), as is the introduction of the Xfce4 as its alternative, although, arguably, Xfce4 is considered faster and lighter than KDE. In Qubes the choice of an actual desktop environment that runs in Dom0 is not as important as it is on traditional Linux systems, I think, simply because most of the functionality, typically provided by such environments, such as apps and file management, is simply... disabled, because on Qubes there are no user apps or files in Dom0.
Nevertheless people love and hate particular window managers and environments, and we hope that now, by supporting alternative environments, we could appeal to even more users.
I'm glad that we just completed this difficult phase of upgrading Qubes Dom0 distribution (for the first time since Qubes R1 Beta 1!) -- this forced us to clean up the code and prepare for some even bigger and bolder changes in the near future. But those will come only in Release 3. As far as Release 2 is considered, we do have quite
a few more tickets scheduled for R2 Beta 3 milestone, but most of those represent various addons, rather than modifications to Qubes core software.
So what are those brave changes that are to happen in Release 3? That I will write about in a separate blog post... Stay tuned!
So, please enjoy this latest Qubes R2 beta release, and be sure to send all your questions and comments, as well as the HCL info, to the
qubes-devel mailing list. I have already upgraded my primary laptop to this release a few days ago and everything seems to be working fine, so fear not!
Qubes OS is becoming
more and more advanced, polished, and user friendly OS.
But Qubes OS, even as advanced as it is now, surely have its limitations. Limitations, that for some users might be difficult to accept, and might discourage them from even trying out the OS. One such limitation is lack of 3D graphics support for applications running in AppVMs. Another one is still-far-from-ideal hardware compatibility – a somehow inherent problem for most (all?) Linux-based systems.
There is also one more “limitation” of Qubes OS, particularly difficult to overcome... Namely that it is a standalone Operating System, not an application that could be installed inside the user's existing OS. While installing a new application that increases system's security is a no-brianer for most people, switching to a new, exotic OS, is quite a different story...
Before I discuss how we plan to address those limitations, let's first make a quick digression about what Qubes reallyis, as many people often get that wrong...
What Qubes IS, and what Qubes IS NOT?
Qubes surely is not Xen! Qubes only usesXen to create isolatedcontainers – security domains (or zones). Qubes also is not a Linux distribution! Sure, we currently use Fedora 18 as the default template for AppVMs, but at the same time we also support Windows VMs. And while we also use Linux as GUI and admin domain, we could really use something different – e.g. Windows as GUI domain.
So, what is Qubes then? Qubes (note how I've suddenly dropped the OS suffix) is several things:
The way how to configure, harden, and use the VMM (e.g. Xen) to create isolated security domains, and to minimize overall system TCB.
Secure GUI virtualization that provides strong gui isolation, while at the same time, provides also seamless integration of all applications running in different VMs onto one common desktop. Plus a customized GUI environment, including trusted Window Manager that provides unspoofable decorations for the applications' windows.
Secure inter-domain communication and services infrastructure with centrally enforced policy engine. Plus some “core” services built on top of this, such as secure file exchange between domains.
Various additional services, or “addons”, built on top of Qubes infrastructure, such as Disposable VMs, Split GPG, TorVM, Trusted PDF converter, etc. These are just few examples, as basically the sky is the limit here.
Various additional customizations to all the guest OSes that run in various domains: GUI, Admin, ServiceVMs, and AppVMs.
Introducing Qubes HAL: Hypervisor Abstraction Layer
Because Qubes is a bunch of technologies and approaches that are mostly independent from the underlying hypervisor, as discussed above, it's quite natural to consider if we could easily build an abstraction layer to allow the use of different VMMs with Qubes, instead of just Xen? Turns out this is not as difficult as we originally thought, and this is exactly the direction we're taking right now with Qubes Odyssey! To make this possible we're going to use the libvirt project.
So, we might imagine Qubes that is based on Hyper-V or even Virtual Box or VMWare Workstation. In the case of the last two Qubes would no longer be a standalone OS, but rather an “application” that one installs on top of an existing OS, such as Windows. The obvious advantage we're gaining here is improved hardware compatibility, and ease of deployment.
And we can go even further and ask: why not use Windows Native Isolation, i.e. mechanisms such as user account separation, process isolation, and ACLs, to implement domain isolation? In other words why not use Windows OS as a kind of “VMM”? This would further dramatically improve then lightness of the system...
Of course the price we pay for all this is progressively degraded security, as e.g. Virtual Box cannot be a match to Xen in terms of security, both architecturally and implementation-wise, and not to mention the quality of isolation provided by the Windows kernel, which is even less.
But on the other hand, it's still better than using “just Windows” which offers essentially only one “zone”, so no domain isolation at all! And if we can get, with minimal effort, most of our Qubes code to work with all those various isolation providers then... why not?
Being able to seamlessly switch between various hypervisors is only part of the story, of course. The remaining part is the support for different OSes used for various Qubes domains. Currently we use Linux, specifically Fedora 18, in our GUI & Admin domain, but there is no fundamental reason why we couldn't use Windows there instead. We discuss this more in-depth in one of the paragraphs below.
The diagram below tries to illustrate the trade-offs between hardware compatibility and ease of deployment vs. security when using different isolation backends with Qubes. Some variants might also offer additional benefits, such as “super-lightness” in terms of CPU and memory resources required, as is the case with Windows Native Isolation.
Some example configurations
Let's now discuss two extreme variants of Qubes – one based on the baremetal Xen hypervisor and the other one based on Windows Native Isolation, so a variant from the opposite endof the spectrum (as shown on the illustration above).
The diagram below shows a configuration that uses a decent baremetal hypervisor, such as Xen, with abilities to securely assign devices to untrusted service domains(NetVM, UsbVM). So, this is very similar to the current Qubes OS.
Additionally weseeseparate GUI and Admin domains:the GUI domain might perhaps be based on Windows, to provide users with a familiar UI, while the Admin domain, tasked with domain management and policy enforcement,might be based on some minimal Linux distribution.
In the current Qubes OS there is no distinction between a GUI and an Admin domain --both are hosted within one domain called “dom0”. But in some cases there are benefits of separating the GUI domain from the Admin domain. In a corporate scenario, for example, the Admin domain might be accessible only to the IT department and not to the end user. This way the user wouldhave no way of modifying system-wide policies, and e.g. allowing their “work” domain to suddenly talk to the wild open Internet, or to copy workproject files from “work” to “personal” domains(save for the exotic, low-bandwidthcovert channels, such as through CPU cache).
The ability to deprivilege networking and USB stacks by assigning corresponding devices (NICs, and USB controllers) to untrusted, or semi-trused, domains provides great security benefits. This automatically prevents various attacks against the bugs in WiFi stacks or USB stacks. What is not seen on the diagram, but what is typical for baremetal hypervisors is that they are usually much smaller than hosted hypervisors, implementing less services, and delegating most tasks, such as the infamous I/O emulation to (often)unprivileged VMs.
Let's now look at the other extreme example of using Qubes – the diagram below shows an architecture of a “Qubized” Windows system that uses either a hosted VMM, such as Virtual Box or VMWare Workstation, or even the previously mentioned Windows Native Isolation mechanisms, as an isolation provider for domains.
Of course this architecture lacks many benefits discussed above, such as untrusted domains for networking and USB stacks, small hypervisors, etc. But it still can be used to implement multiple security domains, at amuch lower “price”: better hardware compatibility, easier deployment, and in case of Windows Native Isolation – excellent performance.
And it really can be made reasonable, although it might require more effort than it might seem at first sight. Take Windows Native Isolation – of course just creating different user accounts to represent different domains is not enough, because Windows still doesn't implement true GUI-level isolation. Nor network isolation. So, there is a challenge to do it right, and “right” in this case means to make the isolation as good as the Windows kernel can isolate processes from different users from each other.
Sure, a single kernel exploit destroys this all, but it's still better than “one application can (legally) read all my files” policy that 99% of all desktop OSes out there essentially implement today.
Now, probably the best thing with all this is that once we implement a product based on, say, Qubes for Windows, together with various cool “addons” that will take advantage of the Qubes services infrastructure, and which shall be product-specific, it should then be really easy to upgrade to another VMM, say Hyper-V to boost security. And the users shall not even notice a change in the UI, save for the performance degradation perhaps (well, clearly automatic creation of VMs to handle various users tasks would be more costly on Hyper-V than with Windows Native Isolation, where “VMs” are just... processes).
Qubes building blocks – implementation details
Let's have a look now at the repository layout for the latest Qubes OSsources – every name listed below represents a separate code repository that corresponds to a logical module, or a building block of a Qubes system:
core-admin
core-admin-linux
core-agent-linux
core-agent-windows
core-vchan-xen
desktop-linux-kde
desktop-linux-xfce4
gui-agent-linux
gui-agent-windows
gui-agent-xen-hvm-stubdom
gui-common
gui-daemon
linux-dom0-updates
linux-installer-qubes-os
linux-kernel
linux-template-builder
linux-utils
linux-yum
qubes-app-linux-pdf-converter
qubes-app-linux-split-gpg
qubes-app-linux-tor
qubes-app-thunderbird
qubes-builder
qubes-manager
vmm-xen
vmm-xen-windows-pvdrivers
Because current Qubes R2 still doesn't use HAL layer to support different hypervisors, it can currently be used with only one hypervisor, namely Xen, whose code is provided by the vmm-xenrepository (in an ideal world we would be just using vanilla Xen instead of buildingour own from sources, but in reality we like the ability to build it ourselves, slightly modifying some things).
Once we move towards the Qubes Odyssey architecture (essentially by replacing thehardcoded calls to Xen's management stack, in the core-adminmodule, with libvirt calls), we could then easily switch Xen for other hypervisors, such as Hyper-V or Virtual Box. In case of Hyper-V we would not have access to the sources of the VMM, of course, so would just be using the stock binaries, although we still might want to maintain thevmm-hyperv repository that could contain various hardening scripts and configuration files for this VMM. Or might not. Also, chances are high that we would be just able to use the stock libvirt driversfor Hyper-V or Virtual Box,so no need for creating core-libvirt-hypervor core-libvirt-virtualboxbackends.
What we will need to provide, is ourcustom inter-domaincommunication library for each hypervisor supported.This means we will need to write core-vchan-hypervor core-vchan-virtualbox. Most (all?) VMMs do provide some kind of API for inter-VM communication (or at least VM-host communication), so the main task of such component is to wrap the VMM-custom mechanism with Qubes-standarizedAPI for vchan (and this standardization is one thing we're currently working on). All in all, in most cases this will be asimple task.
If we, on the other hand, wanted to support an “exotic” VMM, such as the previously mentioned Windows Native Isolation, which is not really a true VMM, then we will need to write our own libvirt backend to support is:
core-libvirt-windows
... as well as the corresponding vchan module (which should be especially trivial to write in this case):
core-vchan-windows
Additionally, if we're building a system where the Admin domain is not based on Linux, which would likely be the case if we used Hyper-V, or Virtual Box for Windows, or, especially, Windows Native Isolation, then we should also provide core-admin-windowsmodule, that, among other things, should provide Qubes qrexecimplementation, something that is highly OS-dependent. As can be seen above, we currently only have core-admin-linux, which is understandable as we currently use Linux in Dom0. But the good news is that we only need to write core-admin-XXXonce for each OS that is to be supported as an Admin domain, asthis code should not be depend on the actual VMM used (thanks to our smart HAL).
Similarly, we also need to assure that our gui-daemoncan run on the OS that is to be used as a GUI domain (again, in most cases GUI domain would be the same as Admin domain, but not always). Here the situation is generally much easier because “with just a few #ifdefs” our current GUIdaemon should compile and run on most OSes, from Linux/Xorg to Windows and Macs (which is the reason we only have one gui-daemonrepository, instead of several gui-daemon-XXX).
Finally we should provide some code that will gather all the components neededfor our specific product and package this all into either an installable ISO, if Qubes is to be a standalone OS, like current Qubes,or into an executable, in case Qubes is to be an “application”. The installer, depending on the product, might do some cool things, such as e.g. take current user system and automatically move it into one of Qubes domains.
To summary, these would be the components needed to build “Qubes for Windows” product:
core-admin
core-admin-windows
core-agent-windows
core-vchan-windows
core-libvirt-windows
desktop-windows
gui-agent-windows
gui-common
gui-daemon
windows-installer-qubes-for-windows
qubes-builder
qubes-manager
Additionally we will likely need a few qubes-app-*modules that would implement some "addons", such as perhaps automatic links and documents opening in specific VMs, e.g.:
qubes-app-windows-mime-handlers
Here, again, the sky's the limit and this is specifically the area where each vendor can go to great lenghts and build killer apps using our Qubes framework.
Now, if we wanted to create "Qubes for Hyper-V" we would need the following components:
core-admin
core-admin-windows
core-agent-linux
core-agent-windows
core-vchan-hyperv
desktop-windows
gui-agent-linux
gui-agent-windows
gui-common
gui-daemon
windows-installer-qubes-hyperv
qubes-app-XXX
qubes-builder
qubes-manager
vmm-hyperv
Here, as an example, I also left optional core-agent-linux and gui-agent-linux components (the same that are to be used with Xen-based Qubes OS) to allow support for also Linux-based VMs – if we can get those “for free”, then why not!
It should be striking how many of those components are the same in both of those two cases – essentially the only differences are made by the use of different vmm-* components and, of course, the different installer
It should be also clear now how this framework now enables seamless upgrades from one product (say Qubes for Windows) to another (say Qubes for Hyper-V).
Licensing
Our business model assumes working with vendors, as opposed to end users, and licensing to them various code modules needed to create products based on Qubes.
All the code that comprises the base foundation needed for creation of any Qubes variant (so core-admin, gui-common, gui-daemon, qubes-builderand qubes-manager) will be kept open source, GPL specifically. Additionally all the code needed for building of Xen-based Qubes OS with Linux-based AppVMs and Linux-based GUI and Admin domains, will continue to be available as open source. This is to ensure Qubes OS R3 that will be based on this framework, can remain fully open source (GPL).
Additionally we plan to double-license this core open source code to vendors who would like to use it in proprietary products and who would not like to be forced, by the GPL license, to share the (modified) sources.
All the other modules, especially those developed to support other VMMs (Hyper-V, Virtual Box, Windows Native Isolation), as well as those to support Windows OS (gui-agent-windows, core-agent-windows, core-admin-windows, etc) will most likely be proprietary and will be available only to vendors who decide to work with us and buy a license.
So, if you want to develop an open source product that uses Qubes framework, then you can freely do that as all the required core components for this will be open sourced. But if you would like to make a proprietary product, then you should buy a license from us. I think this is a pretty fair deal.
Current status and roadmap
We're currently working on two fronts: one is rewriting current Qubes code to support Qubes HAL, while the other one is adding a backend for Windows Native Isolation (which also involves doing things such as GUI isolation right on Windows).
We believe that by implementing two such extreme backends: Xen and Windows Native Isolation we can best show the flexibility of the framework (plus our customer is especially interested in this backend;)
We should be able to publish some code, i.e. the framework together with early Qubes OS R3 that will be based on it, sometime in fall or maybe earlier.
We obviously are determined to further develop Xen-based Qubes OS, because we believe this is the most practically secure OS available today, and we believe such OS should be open source.
Qubes R2 will still be based on the Xen-hardcoded code, because it's close to the final release and we don't want to introduce such drastic changes at this stage. The only thing that Qubes R2 will get in common with Qubes Odyssey is this new source code layout as presented above (but still with hardcoded xl calls and xen-vchan).
So, this is all really exciting and a big thing, let's see if we can change the industry with this :)
Oh, and BTW, some readers might be wondering why the framework was codenamed “Odyssey” -- this is obviously because of the “HAL” which plays a central role here, and which, of course, also brings to mind the famous Kubrick's movie.
\ No newline at end of file
+
Qubes OS is becoming
more and more advanced, polished, and user friendly OS.
But Qubes OS, even as advanced as it is now, surely have its limitations. Limitations, that for some users might be difficult to accept, and might discourage them from even trying out the OS. One such limitation is lack of 3D graphics support for applications running in AppVMs. Another one is still-far-from-ideal hardware compatibility – a somehow inherent problem for most (all?) Linux-based systems.
There is also one more “limitation” of Qubes OS, particularly difficult to overcome... Namely that it is a standalone Operating System, not an application that could be installed inside the user's existing OS. While installing a new application that increases system's security is a no-brianer for most people, switching to a new, exotic OS, is quite a different story...
Before I discuss how we plan to address those limitations, let's first make a quick digression about what Qubes reallyis, as many people often get that wrong...
What Qubes IS, and what Qubes IS NOT?
Qubes surely is not Xen! Qubes only usesXen to create isolatedcontainers – security domains (or zones). Qubes also is not a Linux distribution! Sure, we currently use Fedora 18 as the default template for AppVMs, but at the same time we also support Windows VMs. And while we also use Linux as GUI and admin domain, we could really use something different – e.g. Windows as GUI domain.
So, what is Qubes then? Qubes (note how I've suddenly dropped the OS suffix) is several things:
The way how to configure, harden, and use the VMM (e.g. Xen) to create isolated security domains, and to minimize overall system TCB.
Secure GUI virtualization that provides strong gui isolation, while at the same time, provides also seamless integration of all applications running in different VMs onto one common desktop. Plus a customized GUI environment, including trusted Window Manager that provides unspoofable decorations for the applications' windows.
Secure inter-domain communication and services infrastructure with centrally enforced policy engine. Plus some “core” services built on top of this, such as secure file exchange between domains.
Various additional services, or “addons”, built on top of Qubes infrastructure, such as Disposable VMs, Split GPG, TorVM, Trusted PDF converter, etc. These are just few examples, as basically the sky is the limit here.
Various additional customizations to all the guest OSes that run in various domains: GUI, Admin, ServiceVMs, and AppVMs.
Introducing Qubes HAL: Hypervisor Abstraction Layer
Because Qubes is a bunch of technologies and approaches that are mostly independent from the underlying hypervisor, as discussed above, it's quite natural to consider if we could easily build an abstraction layer to allow the use of different VMMs with Qubes, instead of just Xen? Turns out this is not as difficult as we originally thought, and this is exactly the direction we're taking right now with Qubes Odyssey! To make this possible we're going to use the libvirt project.
So, we might imagine Qubes that is based on Hyper-V or even Virtual Box or VMWare Workstation. In the case of the last two Qubes would no longer be a standalone OS, but rather an “application” that one installs on top of an existing OS, such as Windows. The obvious advantage we're gaining here is improved hardware compatibility, and ease of deployment.
And we can go even further and ask: why not use Windows Native Isolation, i.e. mechanisms such as user account separation, process isolation, and ACLs, to implement domain isolation? In other words why not use Windows OS as a kind of “VMM”? This would further dramatically improve then lightness of the system...
Of course the price we pay for all this is progressively degraded security, as e.g. Virtual Box cannot be a match to Xen in terms of security, both architecturally and implementation-wise, and not to mention the quality of isolation provided by the Windows kernel, which is even less.
But on the other hand, it's still better than using “just Windows” which offers essentially only one “zone”, so no domain isolation at all! And if we can get, with minimal effort, most of our Qubes code to work with all those various isolation providers then... why not?
Being able to seamlessly switch between various hypervisors is only part of the story, of course. The remaining part is the support for different OSes used for various Qubes domains. Currently we use Linux, specifically Fedora 18, in our GUI & Admin domain, but there is no fundamental reason why we couldn't use Windows there instead. We discuss this more in-depth in one of the paragraphs below.
The diagram below tries to illustrate the trade-offs between hardware compatibility and ease of deployment vs. security when using different isolation backends with Qubes. Some variants might also offer additional benefits, such as “super-lightness” in terms of CPU and memory resources required, as is the case with Windows Native Isolation.
Some example configurations
Let's now discuss two extreme variants of Qubes – one based on the baremetal Xen hypervisor and the other one based on Windows Native Isolation, so a variant from the opposite endof the spectrum (as shown on the illustration above).
The diagram below shows a configuration that uses a decent baremetal hypervisor, such as Xen, with abilities to securely assign devices to untrusted service domains(NetVM, UsbVM). So, this is very similar to the current Qubes OS.
Additionally weseeseparate GUI and Admin domains:the GUI domain might perhaps be based on Windows, to provide users with a familiar UI, while the Admin domain, tasked with domain management and policy enforcement,might be based on some minimal Linux distribution.
In the current Qubes OS there is no distinction between a GUI and an Admin domain --both are hosted within one domain called “dom0”. But in some cases there are benefits of separating the GUI domain from the Admin domain. In a corporate scenario, for example, the Admin domain might be accessible only to the IT department and not to the end user. This way the user wouldhave no way of modifying system-wide policies, and e.g. allowing their “work” domain to suddenly talk to the wild open Internet, or to copy workproject files from “work” to “personal” domains(save for the exotic, low-bandwidthcovert channels, such as through CPU cache).
The ability to deprivilege networking and USB stacks by assigning corresponding devices (NICs, and USB controllers) to untrusted, or semi-trused, domains provides great security benefits. This automatically prevents various attacks against the bugs in WiFi stacks or USB stacks. What is not seen on the diagram, but what is typical for baremetal hypervisors is that they are usually much smaller than hosted hypervisors, implementing less services, and delegating most tasks, such as the infamous I/O emulation to (often)unprivileged VMs.
Let's now look at the other extreme example of using Qubes – the diagram below shows an architecture of a “Qubized” Windows system that uses either a hosted VMM, such as Virtual Box or VMWare Workstation, or even the previously mentioned Windows Native Isolation mechanisms, as an isolation provider for domains.
Of course this architecture lacks many benefits discussed above, such as untrusted domains for networking and USB stacks, small hypervisors, etc. But it still can be used to implement multiple security domains, at amuch lower “price”: better hardware compatibility, easier deployment, and in case of Windows Native Isolation – excellent performance.
And it really can be made reasonable, although it might require more effort than it might seem at first sight. Take Windows Native Isolation – of course just creating different user accounts to represent different domains is not enough, because Windows still doesn't implement true GUI-level isolation. Nor network isolation. So, there is a challenge to do it right, and “right” in this case means to make the isolation as good as the Windows kernel can isolate processes from different users from each other.
Sure, a single kernel exploit destroys this all, but it's still better than “one application can (legally) read all my files” policy that 99% of all desktop OSes out there essentially implement today.
Now, probably the best thing with all this is that once we implement a product based on, say, Qubes for Windows, together with various cool “addons” that will take advantage of the Qubes services infrastructure, and which shall be product-specific, it should then be really easy to upgrade to another VMM, say Hyper-V to boost security. And the users shall not even notice a change in the UI, save for the performance degradation perhaps (well, clearly automatic creation of VMs to handle various users tasks would be more costly on Hyper-V than with Windows Native Isolation, where “VMs” are just... processes).
Qubes building blocks – implementation details
Let's have a look now at the repository layout for the latest Qubes OSsources – every name listed below represents a separate code repository that corresponds to a logical module, or a building block of a Qubes system:
core-admin
core-admin-linux
core-agent-linux
core-agent-windows
core-vchan-xen
desktop-linux-kde
desktop-linux-xfce4
gui-agent-linux
gui-agent-windows
gui-agent-xen-hvm-stubdom
gui-common
gui-daemon
linux-dom0-updates
linux-installer-qubes-os
linux-kernel
linux-template-builder
linux-utils
linux-yum
qubes-app-linux-pdf-converter
qubes-app-linux-split-gpg
qubes-app-linux-tor
qubes-app-thunderbird
qubes-builder
qubes-manager
vmm-xen
vmm-xen-windows-pvdrivers
Because current Qubes R2 still doesn't use HAL layer to support different hypervisors, it can currently be used with only one hypervisor, namely Xen, whose code is provided by the vmm-xenrepository (in an ideal world we would be just using vanilla Xen instead of buildingour own from sources, but in reality we like the ability to build it ourselves, slightly modifying some things).
Once we move towards the Qubes Odyssey architecture (essentially by replacing thehardcoded calls to Xen's management stack, in the core-adminmodule, with libvirt calls), we could then easily switch Xen for other hypervisors, such as Hyper-V or Virtual Box. In case of Hyper-V we would not have access to the sources of the VMM, of course, so would just be using the stock binaries, although we still might want to maintain thevmm-hyperv repository that could contain various hardening scripts and configuration files for this VMM. Or might not. Also, chances are high that we would be just able to use the stock libvirt driversfor Hyper-V or Virtual Box,so no need for creating core-libvirt-hypervor core-libvirt-virtualboxbackends.
What we will need to provide, is ourcustom inter-domaincommunication library for each hypervisor supported.This means we will need to write core-vchan-hypervor core-vchan-virtualbox. Most (all?) VMMs do provide some kind of API for inter-VM communication (or at least VM-host communication), so the main task of such component is to wrap the VMM-custom mechanism with Qubes-standarizedAPI for vchan (and this standardization is one thing we're currently working on). All in all, in most cases this will be asimple task.
If we, on the other hand, wanted to support an “exotic” VMM, such as the previously mentioned Windows Native Isolation, which is not really a true VMM, then we will need to write our own libvirt backend to support is:
core-libvirt-windows
... as well as the corresponding vchan module (which should be especially trivial to write in this case):
core-vchan-windows
Additionally, if we're building a system where the Admin domain is not based on Linux, which would likely be the case if we used Hyper-V, or Virtual Box for Windows, or, especially, Windows Native Isolation, then we should also provide core-admin-windowsmodule, that, among other things, should provide Qubes qrexecimplementation, something that is highly OS-dependent. As can be seen above, we currently only have core-admin-linux, which is understandable as we currently use Linux in Dom0. But the good news is that we only need to write core-admin-XXXonce for each OS that is to be supported as an Admin domain, asthis code should not be depend on the actual VMM used (thanks to our smart HAL).
Similarly, we also need to assure that our gui-daemoncan run on the OS that is to be used as a GUI domain (again, in most cases GUI domain would be the same as Admin domain, but not always). Here the situation is generally much easier because “with just a few #ifdefs” our current GUIdaemon should compile and run on most OSes, from Linux/Xorg to Windows and Macs (which is the reason we only have one gui-daemonrepository, instead of several gui-daemon-XXX).
Finally we should provide some code that will gather all the components neededfor our specific product and package this all into either an installable ISO, if Qubes is to be a standalone OS, like current Qubes,or into an executable, in case Qubes is to be an “application”. The installer, depending on the product, might do some cool things, such as e.g. take current user system and automatically move it into one of Qubes domains.
To summary, these would be the components needed to build “Qubes for Windows” product:
core-admin
core-admin-windows
core-agent-windows
core-vchan-windows
core-libvirt-windows
desktop-windows
gui-agent-windows
gui-common
gui-daemon
windows-installer-qubes-for-windows
qubes-builder
qubes-manager
Additionally we will likely need a few qubes-app-*modules that would implement some "addons", such as perhaps automatic links and documents opening in specific VMs, e.g.:
qubes-app-windows-mime-handlers
Here, again, the sky's the limit and this is specifically the area where each vendor can go to great lenghts and build killer apps using our Qubes framework.
Now, if we wanted to create "Qubes for Hyper-V" we would need the following components:
core-admin
core-admin-windows
core-agent-linux
core-agent-windows
core-vchan-hyperv
desktop-windows
gui-agent-linux
gui-agent-windows
gui-common
gui-daemon
windows-installer-qubes-hyperv
qubes-app-XXX
qubes-builder
qubes-manager
vmm-hyperv
Here, as an example, I also left optional core-agent-linux and gui-agent-linux components (the same that are to be used with Xen-based Qubes OS) to allow support for also Linux-based VMs – if we can get those “for free”, then why not!
It should be striking how many of those components are the same in both of those two cases – essentially the only differences are made by the use of different vmm-* components and, of course, the different installer
It should be also clear now how this framework now enables seamless upgrades from one product (say Qubes for Windows) to another (say Qubes for Hyper-V).
Licensing
Our business model assumes working with vendors, as opposed to end users, and licensing to them various code modules needed to create products based on Qubes.
All the code that comprises the base foundation needed for creation of any Qubes variant (so core-admin, gui-common, gui-daemon, qubes-builderand qubes-manager) will be kept open source, GPL specifically. Additionally all the code needed for building of Xen-based Qubes OS with Linux-based AppVMs and Linux-based GUI and Admin domains, will continue to be available as open source. This is to ensure Qubes OS R3 that will be based on this framework, can remain fully open source (GPL).
Additionally we plan to double-license this core open source code to vendors who would like to use it in proprietary products and who would not like to be forced, by the GPL license, to share the (modified) sources.
All the other modules, especially those developed to support other VMMs (Hyper-V, Virtual Box, Windows Native Isolation), as well as those to support Windows OS (gui-agent-windows, core-agent-windows, core-admin-windows, etc) will most likely be proprietary and will be available only to vendors who decide to work with us and buy a license.
So, if you want to develop an open source product that uses Qubes framework, then you can freely do that as all the required core components for this will be open sourced. But if you would like to make a proprietary product, then you should buy a license from us. I think this is a pretty fair deal.
Current status and roadmap
We're currently working on two fronts: one is rewriting current Qubes code to support Qubes HAL, while the other one is adding a backend for Windows Native Isolation (which also involves doing things such as GUI isolation right on Windows).
We believe that by implementing two such extreme backends: Xen and Windows Native Isolation we can best show the flexibility of the framework (plus our customer is especially interested in this backend;)
We should be able to publish some code, i.e. the framework together with early Qubes OS R3 that will be based on it, sometime in fall or maybe earlier.
We obviously are determined to further develop Xen-based Qubes OS, because we believe this is the most practically secure OS available today, and we believe such OS should be open source.
Qubes R2 will still be based on the Xen-hardcoded code, because it's close to the final release and we don't want to introduce such drastic changes at this stage. The only thing that Qubes R2 will get in common with Qubes Odyssey is this new source code layout as presented above (but still with hardcoded xl calls and xen-vchan).
So, this is all really exciting and a big thing, let's see if we can change the industry with this :)
Oh, and BTW, some readers might be wondering why the framework was codenamed “Odyssey” -- this is obviously because of the “HAL” which plays a central role here, and which, of course, also brings to mind the famous Kubrick's movie.
\ No newline at end of file
diff --git a/_posts/2013-06-21-qubes-os-r3-alpha-preview-odyssey-hal.html b/_posts/2013-06-21-qubes-os-r3-alpha-preview-odyssey-hal.html
index 0cbeb9d..1ead9cf 100644
--- a/_posts/2013-06-21-qubes-os-r3-alpha-preview-odyssey-hal.html
+++ b/_posts/2013-06-21-qubes-os-r3-alpha-preview-odyssey-hal.html
@@ -10,4 +10,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2013/06/qubes-os-r3-alpha-preview-odyssey-hal.html
---
-
In a
previous postI have outlined a new direction we're aiming with the Qubes project, which is a departure from using a “hardcoded” hypervisor with Qubes (as well as “hardcoded” Linux as Dom0, GUI domain, etc).
Today I'm happy to announce that we've already completed initial porting of the current Qubes OS into this Hypervisor-Abstraction-Layer-based framework. The new version of Qubes, that we call “R3 Alpha” for now, builds fine, installs fine, and even (mostly) works(!), as can be admired on the screenshot below :) It still uses Xen, of course, but this time in a non-hardcoded way, which allows to replace it easily with another hypervisor, as I discuss below.
Our Qubes Odyssey backendneeded to support a specific hypervisor comprises essentially three parts:
A libvirt driver to support a given VMM. In our case we got it (almost) for free, because Xen 4.2 is well supported by libvirt. I wrote “almost” for free, because some patches to libvirt were still needed, mostly to get rid of some unjustified simplifying assumptions, such as that all the backends are always in Dom0, which is not the case for Qubes OS, of course. Some of those patches were accepted into upstream libvirt, some (still) not, so we had to fork libvirt.
A VMM-specific implementation of our vchan – a simple, socket-like, VMM shared memory-based communication stack between the VMs. Again, in case of Xen 4.2 we got that (almost) for free, because Xen 4.2 has now included a libxenvchan component, which is modified (improved and cleaned up) version of our original vchan (written in early Qubes days for older Xen versions) contributed and maintained by Daniel De Graff from the NSA.
Some minor configuration files, e.g. to tell libvirt which hypervisor protocol to use (in our case: xen:///), and VM configuration template files.
Now, if one wanted to switch Xen for some other hypervisor, such as e.g. the KVM, we would need to write a KVM Odyssey backend in a form of providing the above mentioned three elements. Again, libvirt driver we would get for free, configuration files would be trivial to write, and the only task which would require some coding would be the vchan for KVM.
Ok, one thing that is left out (non-HAL'ified) for now, is the xc_map_foreign_pages() Xen-specific
function call within our GUI daemon
.
Ideally such call could also be handled by the libvirt API, however it's not clear to us whether true zero-copy page access is really supported (and intended). If it is not, we will try to contribute a patch to libvirt to add such functionality, as it is generally useful for many things that involve high-speed inter-VM communication, of which our GUI virtualization is just one example. So, at this moment, one would need to add an ugly #if (BACKEND_VMM == ...) to the code above and use another VMM's function(s), equivalent to the xc_map_foreign_pages() on Xen.
But besides the above, essentially everything else should Just Work (TM). And that's pretty amazing, I think :) While I personally can't immediately see any security benefit of switching from Xen to KVM, it might appeal to some people for other reasons (Performance? Better hardware support?). The point is: this should be now easy to do.
If one wanted to support some Windows-based hypervisor, on the other hand, such as MS Hyper-V, or Virtual Box on top of Windows, then two more things will need to be taken care of:
Our core management stack (the core-admin repository), the core RPC services (mostly the qrexec daemon, currently part of core-admin-linux repo), and the libvirt code (core-libvirt, a forked original libvirt with some custom patches I mentioned above), all would need to build and run fine on Windows. While this is not a big problem for core-admin (it's all python) and core-libvirt (it is supposed to build and run on Windows fine), the qrexec daemon would need to be rewritten with Windows OS in mind. We're currently working on this step, BTW.
The GUI daemon would also need to be ported to run on Windows, instead of on top of X Server. This is somehow orthogonal to the need to get rid of the hardcoded xc_map_foreign_pages() function as mentioned above. This step might be optional, however, if we wanted to use a Linux-based (and so Xorg-based GUI server) as a GUI domain.
Once the above two pieces are made Windows-ready (note how I wrote Windows-ready, and not specific-VMM-ready), we can then use any Windows-based hypervisor we want (i.e. for which we have libvirt driver, and can write vchan).
This is again pretty amazing, because it means we don't need N*M variations of each component (where N is the number of VMMs, and M the number of host/GUI OSes to support) – but only N+M! This is similar to how modern compilers are designed using a language-specific frontends (C, C++, Pascal, C#, etc), and architecture-specific backends (x86, x64, ARM, etc), and an Intermediate Language for internal “grinding”, again achieving this N+M number of needed variants instead of N*M, which otherwise would be just totally impractical.
One other detail I would like to point out, and which is also visible on the screenshot above, is that we also got rid of using the Xen-specific Xenstore infrastructure (a registry-like tree-based infrastructure for inter-VM configuration and status exchange), and we replaced it with our own, vchan-based Qubes DB (core-qubesdb).
One interesting thing about Qubes DB is that it get rids of the (overly complex and unnecessary) permission system that is used by xenstore, and instead uses the most simple approach: each VM has its separate Qubes DB daemon, and so a totally separate configuration/state namespace. This is inline with the rest of the Qubes philosophy, which basically says that: permissions is dead, long live separation!
So, in Qubes OS we just isolate everything by default, unless a user/configuration specifically allows an exception – e.g. no file copy operation between domains is possible, unless the user expresses an explicit consent for it.
Many old-school security people can't imagine a system without permissions, but if wethink about it more, we might get to a conclusion that: 1) permissions are complex and so often difficult to understand and set correctly, 2) require often complex code to parse and make security decisions, and 3) often are absolutely unneeded.
As a practical example of how permissions schemes might sometime trick even (otherwise somehow smart) developersinto making a mistake consider this bug in Qubes we made a long time ago when setting permissions on some xenstore key, which resulted in some information leak (not much of a security problem in general, but still). And just today, Xen.org has published this advisory, that sounds pretty serious, again caused by bad permissions on some xenstore keys. (Yes, we do have updated Xen packages to fix that, of course).
Back to Qubes R3 Alpha, the first successful Qubes based on Odyssey HAL framework. As previously mentioned, we plan to make most of the framework open sourced, specifically all the non-Windows code. However, we're not publishing this Odyssey/R3 code at this moment, mainly for two reasons: 1) we don't want people to immediately start building other backends, such as to support KVM, right at this stage, because we still might want/need to modify some interfaces slightly, e.g. for our vchan, and we don't want to tide our hands now, and 2) the other reason is that we're still in the middle of “Beta” releases for Qubes R2, and we want people to rather focus on testing that, rather stable release, than jumping onto Qubes R3 alpha.
In other news: everybody seems to be genuinely surprised that
unencrypted information can be
intercepted and analyzed without user consent... Can it be that people will "discover" cryptography now? How many of you use PGP everyday? And how long will it take then to understand that cryptography without secure client devices is useless?
In a
previous postI have outlined a new direction we're aiming with the Qubes project, which is a departure from using a “hardcoded” hypervisor with Qubes (as well as “hardcoded” Linux as Dom0, GUI domain, etc).
Today I'm happy to announce that we've already completed initial porting of the current Qubes OS into this Hypervisor-Abstraction-Layer-based framework. The new version of Qubes, that we call “R3 Alpha” for now, builds fine, installs fine, and even (mostly) works(!), as can be admired on the screenshot below :) It still uses Xen, of course, but this time in a non-hardcoded way, which allows to replace it easily with another hypervisor, as I discuss below.
Our Qubes Odyssey backendneeded to support a specific hypervisor comprises essentially three parts:
A libvirt driver to support a given VMM. In our case we got it (almost) for free, because Xen 4.2 is well supported by libvirt. I wrote “almost” for free, because some patches to libvirt were still needed, mostly to get rid of some unjustified simplifying assumptions, such as that all the backends are always in Dom0, which is not the case for Qubes OS, of course. Some of those patches were accepted into upstream libvirt, some (still) not, so we had to fork libvirt.
A VMM-specific implementation of our vchan – a simple, socket-like, VMM shared memory-based communication stack between the VMs. Again, in case of Xen 4.2 we got that (almost) for free, because Xen 4.2 has now included a libxenvchan component, which is modified (improved and cleaned up) version of our original vchan (written in early Qubes days for older Xen versions) contributed and maintained by Daniel De Graff from the NSA.
Some minor configuration files, e.g. to tell libvirt which hypervisor protocol to use (in our case: xen:///), and VM configuration template files.
Now, if one wanted to switch Xen for some other hypervisor, such as e.g. the KVM, we would need to write a KVM Odyssey backend in a form of providing the above mentioned three elements. Again, libvirt driver we would get for free, configuration files would be trivial to write, and the only task which would require some coding would be the vchan for KVM.
Ok, one thing that is left out (non-HAL'ified) for now, is the xc_map_foreign_pages() Xen-specific
function call within our GUI daemon
.
Ideally such call could also be handled by the libvirt API, however it's not clear to us whether true zero-copy page access is really supported (and intended). If it is not, we will try to contribute a patch to libvirt to add such functionality, as it is generally useful for many things that involve high-speed inter-VM communication, of which our GUI virtualization is just one example. So, at this moment, one would need to add an ugly #if (BACKEND_VMM == ...) to the code above and use another VMM's function(s), equivalent to the xc_map_foreign_pages() on Xen.
But besides the above, essentially everything else should Just Work (TM). And that's pretty amazing, I think :) While I personally can't immediately see any security benefit of switching from Xen to KVM, it might appeal to some people for other reasons (Performance? Better hardware support?). The point is: this should be now easy to do.
If one wanted to support some Windows-based hypervisor, on the other hand, such as MS Hyper-V, or Virtual Box on top of Windows, then two more things will need to be taken care of:
Our core management stack (the core-admin repository), the core RPC services (mostly the qrexec daemon, currently part of core-admin-linux repo), and the libvirt code (core-libvirt, a forked original libvirt with some custom patches I mentioned above), all would need to build and run fine on Windows. While this is not a big problem for core-admin (it's all python) and core-libvirt (it is supposed to build and run on Windows fine), the qrexec daemon would need to be rewritten with Windows OS in mind. We're currently working on this step, BTW.
The GUI daemon would also need to be ported to run on Windows, instead of on top of X Server. This is somehow orthogonal to the need to get rid of the hardcoded xc_map_foreign_pages() function as mentioned above. This step might be optional, however, if we wanted to use a Linux-based (and so Xorg-based GUI server) as a GUI domain.
Once the above two pieces are made Windows-ready (note how I wrote Windows-ready, and not specific-VMM-ready), we can then use any Windows-based hypervisor we want (i.e. for which we have libvirt driver, and can write vchan).
This is again pretty amazing, because it means we don't need N*M variations of each component (where N is the number of VMMs, and M the number of host/GUI OSes to support) – but only N+M! This is similar to how modern compilers are designed using a language-specific frontends (C, C++, Pascal, C#, etc), and architecture-specific backends (x86, x64, ARM, etc), and an Intermediate Language for internal “grinding”, again achieving this N+M number of needed variants instead of N*M, which otherwise would be just totally impractical.
One other detail I would like to point out, and which is also visible on the screenshot above, is that we also got rid of using the Xen-specific Xenstore infrastructure (a registry-like tree-based infrastructure for inter-VM configuration and status exchange), and we replaced it with our own, vchan-based Qubes DB (core-qubesdb).
One interesting thing about Qubes DB is that it get rids of the (overly complex and unnecessary) permission system that is used by xenstore, and instead uses the most simple approach: each VM has its separate Qubes DB daemon, and so a totally separate configuration/state namespace. This is inline with the rest of the Qubes philosophy, which basically says that: permissions is dead, long live separation!
So, in Qubes OS we just isolate everything by default, unless a user/configuration specifically allows an exception – e.g. no file copy operation between domains is possible, unless the user expresses an explicit consent for it.
Many old-school security people can't imagine a system without permissions, but if wethink about it more, we might get to a conclusion that: 1) permissions are complex and so often difficult to understand and set correctly, 2) require often complex code to parse and make security decisions, and 3) often are absolutely unneeded.
As a practical example of how permissions schemes might sometime trick even (otherwise somehow smart) developersinto making a mistake consider this bug in Qubes we made a long time ago when setting permissions on some xenstore key, which resulted in some information leak (not much of a security problem in general, but still). And just today, Xen.org has published this advisory, that sounds pretty serious, again caused by bad permissions on some xenstore keys. (Yes, we do have updated Xen packages to fix that, of course).
Back to Qubes R3 Alpha, the first successful Qubes based on Odyssey HAL framework. As previously mentioned, we plan to make most of the framework open sourced, specifically all the non-Windows code. However, we're not publishing this Odyssey/R3 code at this moment, mainly for two reasons: 1) we don't want people to immediately start building other backends, such as to support KVM, right at this stage, because we still might want/need to modify some interfaces slightly, e.g. for our vchan, and we don't want to tide our hands now, and 2) the other reason is that we're still in the middle of “Beta” releases for Qubes R2, and we want people to rather focus on testing that, rather stable release, than jumping onto Qubes R3 alpha.
In other news: everybody seems to be genuinely surprised that
unencrypted information can be
intercepted and analyzed without user consent... Can it be that people will "discover" cryptography now? How many of you use PGP everyday? And how long will it take then to understand that cryptography without secure client devices is useless?
In the
first part of this article published a few weeks ago, I have discussed the basics of Intel SGX technology, and also discussed challenges with using SGX for securing desktop systems, specifically focusing on the problem of trusted input and output. In this part we will look at some other aspects of Intel SGX, and we will start with a discussion of how it could be used to create a truly irreversible software.
SGX Blackboxing – Apps and malware that cannot be reverse engineered?
A nice feature of Intel SGX is that the processor automatically encrypts the content of SGX-protected memory pages whenever it leaves the processor caches and is stored in DRAM. In other words the code and data used by SGX enclaves never leave the processor in plaintext.
This feature, no doubt influenced by the DRM industry, might profoundly change our approach as to who controls our computers really. This is because it will now be easy to create an application, or malware for that matter, that just cannot be reversed engineered in any way. No more IDA, no more debuggers, not even kernel debuggers, could reveal the actual intentions of the EXE file we're about to run.
Consider the following scenario, where a user downloads an executable, say blackpill.exe, which in fact logically consists of three parts:
A 1st stage loader (SGX loader) which is unencrypted, and which task is to setup an SGX enclave, copy the rest of the code there, specifically the 2nd stage loader, and then start executing the 2nd stage loader...
The 2nd stage loader, which starts executing within the enclave, performs remote attestation with an external server and, in case the remote attestation completes successfully, obtains a secret key from the remote server. This code is also delivered in plaintext too.
Finally the encrypted blob which can only be decrypted using the key obtained by the 2nd stage loader from the remote server, and which contains the actual logic of the application (or malware).
We can easily see that there is no way for the user to figure out what the code from the encrypted blob is going to do on her computer. This is because the key will be released by the remote server only if the 2ndstage loader can prove via remote attestation that it indeed executes within a protect SGX enclave and that it is the original unmodified loader code that the application's author created. Should one bit of this loader be modified, or should it be attempted to run outside of an SGX enclave, or within a somehow misconfigured SGX enclave, then the remote attestation wouldfail and the key will not be obtained.
And once the key is obtained, it is available only within the SGX enclave. It cannot be found in DRAM or on the memory bus, even if the user had access to expensive DRAM emulators or bus sniffers. And the key cannot also be mishandled by the code that runs in the SGX enclave, because remote attestation also proved that the loader code has not been modified, and the author wrote the loader specifically not to mishandle the key in any way (e.g. not to write it out somewhere to unprotected memory, or store on the disk). Now, the loader uses the key to decrypt the payload, and this decrypted payload remains within secure enclave, never leaving it, just like the key. It's data never leaves the enclave either...
One little catch is how the key is actually sent to the SGX-protected enclave so that it could not be spoofed in the middle? Of course it must be encrypted, but to which key? Well, we can have our 2ndstage loader generate a new key pair and send the public key to the remote server – the server will then use this public key to send the actual decryption key encrypted with this loader's public key. This is almost good, except for the fact that this scheme is not immune to a classic main in the middle attack. The solution to this is easy, though – if I understand correctly the description of the new Quoting and Sealing operations performed by the Quoting Enclave – we can include the generated public key hash as part of the data that will be signed and put into the Quote message, so the remote sever can be assured also that the public key originates from the actual code running in the SGX enclave and not from Mallory somewhere in the middle.
So, what does the application really do? Does it do exactly what has been advertised by its author? Or does it also “accidentally” sniffs some system memory or even reads out disk sectors and sends the gathered data to a remote server, encrypted, of course? We cannot know this. And that's quite worrying, I think.
One might say that we do accept all the proprietary software blindly anyway – after all who fires up IDA to review MS Office before use? Or MS Windows? Or any other application? Probably very few people indeed. But the point is: this could be done, and actually some brave souls do that. This could be done even if the author used some advanced form of obfuscation. Can be done, even if taking lots of time. Now, with Intel SGX it suddenly cannot be done anymore. That's quite a revolution, complete change of the rules. We're no longer masters of our little universe – the computer system – and now somebody else is.
Unless there was a way for “Certified Antivirus companies” to get around SGX protection.... (see below for more discussion on this).
...And some good applications of SGX
The SGX blackboxing has, however, some good usages too, beyond protecting the Hollywood productions, and making malware un-analyzable...
One particularly attractive possibility is the “trusted cloud” where VMs offered to users could not be eavesdropped or tampered by the cloud provider admins.
I wrote about such possibility two years ago, but with Intel SGX this could be done much, much better. This will, of course, require a specially written hypervisor which would be setting up SGX containers for each of the VM, and then the VM could authenticate to the user and prove, via remote attestation, that it is executing inside a protected and properly set SGX enclave. Note how this time we do not require the hypervisor to authenticate to the users – we just don't care, if our code correctly attests that it is in a correct SGX, it's all fine.
Suddenly Google could no longer collect and process your calendar, email, documents, and medial records! Or how about a tor node that could prove to users that it is not backdoored by its own admin and does not keep a log of how connections were routed? Or a safe bitcoin web-based wallet? It's hard to overestimate how good such a technology might be for bringing privacy to the wide society of users...
Assuming, of course, there was no backdoor for the NSA to get around the SGX protection and ruin this all goodness...(see below for more discussion on this).
New OS and VMM architectures
In the paragraph above I mentioned that we will need specially written hypervisors (VMMs) that will be making use of SGX in order to protect the user's VMs against themselves (i.e. against the hypervisor). We could go further and put other components of a VMM into protected SGX enclaves, things that we currently, in Qubes OS, keep in separate Service VMs, such as networking stacks, USB stacks, etc. Remember that Intel SGX provides convenient mechanism to build inter-enclave secure communication channels.
We could also take the “GUI domain” (currently this is just Dom0 in Qubes OS) and move it into a separate SGX enclave. If only Intel came up with solid protected input and output technologies that would work well with SGX, then this would suddenly make whole lots of sense (unlike currently where
it is very challenging). What we win this way is that no longer a bug in the hypervisor should be critical, as it would be now a long way for the attacker who compromised the hypervisor to steal any real secret of the user, because there are no secrets in the hypervisor itself.
In this setup the two most critical enclaves are: 1) the GUI enclave, of course, and 2) the admin enclave, although it is thinkable that the latter could be made reasonably deprivileged in that it might only be allowed to create/remove VMs, setup networking and other policies for them, but no longer be able to read and write memory of the VMs (Anti Snowden Protection, ASP?).
And... why use hypervisors? Why not use the same approach to compartmentalize ordinary operating systems? Well, this could be done, of course, but it would require considerable rewrite of the systems, essentially turning them into microkernels (except for the fact that the microkernel would no longer need to be trusted), as well as the applications and drivers, and we know that this will never happen. Again, let me repeat one more time: the whole point of using virtualization for security is that it wraps up all the huge APIs of an ordinary OS, like Win32 or POSIX, or OSX, into a virtual machine that itself requires orders of magnitude simpler interface to/from the outside world (especially true for paravirtualized VMs), and all this without the need to rewrite the applications.
Trusting Intel – Next Generation of Backdooring?
We have seen that SGX offers a number of attractive functionality that could potentially make our digital systems more secure and 3rdparty servers more trusted. But does it really?
The obvious question, especially in the light of recent revelations about NSA backdooring everything and the kitchen sink, is whether Intel will have backdoors allowing “privileged entities” to bypass SGX protections?
Traditional CPU backdooring
Of course they could, no question about it. But one can say that Intel (as well as AMD) might have been having backdoors in their processors for a long time, not necessarily in anything related to SGX, TPM, TXT, AMT, etc. Intel could have built backdoors into simple MOV or ADD instructions, in such a way that they would automatically disable ring/page protections whenever executed with some magic arguments.
I wrote more about this many years ago.
The problem with those “traditional” backdoors is that Intel (or a certain agency) could be caught using it, and this might have catastrophic consequences for Intel. Just imagine somebody discovered (during a forensic analysis of an incident) that doing:
MOV eax, $deadbeef
MOV ebx, $babecafe
ADD eax, ebx
...causes ring elevation for the next 1000 cycles. All the processors affected would suddenly became equivalents of the old 8086 and would have to be replaced. Quite a marketing nightmare I think, no?
Next-generation CPU backdooring
But as more and more crypto and security mechanisms got delegated from software to the processor, the more likely it becomes for Intel (or AMD) to insert really “plausibly deniable” backdoors into processors.
Consider e.g.
the recent paper on how to plant a backdoor into the Intel's Ivy Bridge's random number generator (usable via the new RDRAND instruction). The backdoor reduces the actual entropy of the generator making it feasible to later brute-force any crypto which uses keys generated via the weakened generator. The paper goes into great lengths describing how this backdoor could be injected by a malicious foundry (e.g. one in China), behind the Intel's back, which is achieved by implementing the backdoor entirely below the HDL level. The paper takes a “classic” view on the threat model with Good Americans (Intel engineers) and the Bad Chinese (foundry operators/employees). Nevertheless, it should be obvious that Intel could have planted such a backdoor without any effort or challenge described in the paper, because they could do so at any level, not necessarily below HDL.
But backdooring an RNG is still something that leaves traces. Even though the backdoored processor can apparently pass all external “randomness” testes, such as the NIST testsuite, they still might be caught. Perhaps because somebody will buy 1000 processors and will run them for a year and will note down all the numbers generated and then conclude that the distribution is quite not right. Or something like that. Or perhaps because somebody will reverse-engineer the processor and specifically the RNG circuitry and notice some gates are shorted to GND. Or perhaps because somebody at this “Bad Chinese” foundry will notice that.
Let's now get back to Intel SGX -- what is the actual Root of Trust for this technology? Of course, the processor, just like for the old ring3/ring0 separation. But for SGX there is additional Root of Trust which is used for remote attestation, and this is the private key(s) used for signing the Quote Messages.
If the signing private key somehow got into the hands of an adversary, the remote attestation breaks down completely. Suddenly the “SGX Blackboxed” apps and malware can readily be decrypted, disassembled and reverse engineered, because the adversary can now emulate their execution step by step under a debugger and still pass the remote attestation. We might say this is good, as we don't want irreversible malware and apps. But then, suddenly, we also loose our attractive “trusted cloud” too – now there is nothing that could stop the adversary, who has the private signing key, to run our trusted VM outside of SGX, yet still reporting to us that it is SGX-protected. And so, while we believe that our trusted VM should be trusted and unsniffable, and while we devote all our deepest secrets to it, the adversary can read them all like on a plate.
And the worst thing is – even if somebody took such a processor, disassembled it into pieces, analyzed transitor-by-transitor, recreated HDL, analyzed it all, then still it all would look good. Because the backdoor is... the leaked private key that is now also in the hands of the adversary, and there is no way to prove it by looking at the processor alone.
As I understand, the whole idea of having a separate TPM chip, was exactly to make such backdoor-by-leaking-keys more difficult, because, while we're all forced to use Intel or AMD processors today, it is possible that e.g. every country can produce their own TPM, as it's million times less complex than a modern processor. So, perhaps Russia could use their own TPMs, which they might be reasonably sure they use private keys which have not be handed over to the NSA.
However, as I mentioned in the first part of this article, sadly, this scheme doesn't work that well. The processor can still cheat the external TPM module. For example, in case of an Intel TXT and TPM – the processor can produce incorrect PCR values in response to certain trigger – in that case it no longer matters that the TPM is trusted and keys not leaked, because the TPM will sign wrong values. On the other hand we go back now to using “traditional” backdoors in the processors, whose main disadvantage is that people might got cought using them (e.g. somebody analyzed an exploit which turns out to be triggering correct Quote message despite incorrect PCRs).
So, perhaps, the idea of separate TPM actually does make some sense after all?
What about just accidental bugs in Intel products?
Conspiracy theories aside, what about accidental bugs? What are the chances of SGX being really foolproof, at least against those unlucky adversaries who didn't get access to the private signing keys? The Intel's processor have become quite a complex beasts these days. And if you also thrown in the Memory Controller Hub, it's unimaginably complex beast.
Let's take a quick tour back discussing some spectacular attacks against Intel “hardware” security mechanisms. I wrote “hardware” in quotation marks, because really most of these technologies is software, like most of the things in electronics these days. Nevertheless the “hardware enforced security” does have a special appeal to lots of people, often creating an impression that these must be some ultimate unbreakable technologies....
I think it all started with our
exploit against Intel Q35 chipset (slides 15+) demonstrated back in 2008 which was the first attack allowing to compromise, otherwise hardware-protected, SMM memory on Intel platforms (some other attacks against SMM shown before assumed the SMM was not protected, which was the case on many older platforms).
This was then shortly followed by
another paper from us about attacking Intel Trusted Execution Technology (TXT), which found out and exploited a fact that TXT-loaded code was not protected against code running in the SMM mode. We used our previous attack on Q35 against SMM, as well as found a couple of new ones, in order to compromise SMM, plant a backdoor there, and then compromise TXT-loaded code from there. The issue highlighted in the paper has never really been correctly patched. Intel has spent years developing something they called STM, which was supposed to be a thin hypervisor for SMM code sandboxing. I don't know if the Intel STM specification has eventually been made public, and how many bugs it might be introducing on systems using it, or how much inaccurate it might be.
In the following years we presented two more devastating attacks against Intel TXT (none of which depending on compromised SMM):
onewhich exploited a subtle bug in the processor SINIT module allowing to misconfigure VT-d protections for TXT-loaded code, and
another one exploiting a classic buffer overflow bug also in the processor's SINIT module, allowing this time not only to fully bypass TXT, but also fully bypass Intel Launch Control Policy and hijack SMM (several years after our original papers on attacking SMM the old bugs got patched and so this was also attractive as yet another way to compromise SMM for whatever other reason).
Invisible Things Lab has also
presented first, and as far as I'm aware still the only one, attack on Intel BIOS that allowed to reflash the BIOS despite Intel's strong “hardware” protection mechanism to allow only digitally signed code to be flashed. We also
found outabout secret processor in the chipset used for execution of Intel AMT code and we found a way to inject our custom code into this special AMT environment and have it executed in parallel with the main system, unconstrained by any other entity.
This is quite a list of Intel significant security failures, which I think gives something to think about. At the very least that just because something is “hardware enforced” or “hardware protected” doesn't mean it is foolproof against software exploits. Because, it should be clearly said, all our exploits mentioned above were pure software attacks.
But, to be fair, we have never been able to break Intel core memory protection (ring separation, page protection) or Intel VT-x. Rafal Wojtczuk has probably came closest with
his SYSRET attackin an attempt to break the ring separation, but ultimately the Intel's excuse was that the problem was on the side of the OS developers who didn't notice subtle differences in the behavior of SYSRET between AMD and Intel processors, and didn't make their kernel code defensive enough against Intel processor's odd behavior.
We have also
demonstrated rather impressive attacks bypassing Intel VT-d, but, again, to be fair, we should mention that the attacks were possible only on those platforms which Intel didn't equip with so called Interrupt Remapping hardware, and that Intel knew that such hardware was indeed needed and was planning it a few years before our attacks were published.
So, is Intel SGX gonna be as insecure as Intel TXT, or as secure as Intel VT-x....?
The bottom line
Intel SGX promises some incredible functionality – to create protected execution environments (called enclaves) within untrusted (compromised) Operating System. However, for SGX to be of any use on a client OS, it is important that we also have technologies to implement trusted output and input from/to the SGX enclave. Intel currently provides little details about the former and openly admits it doesn't have the later.
Still, even without trusted input and output technologies, SGX might be very useful in bringing trust to the cloud, by allowing users to create trusted VMs inside untrusted provider infrastructure. However, at the same time, it could allow to create applications and malware that could not be reversed engineered. It's quote ironic that those two applications (trusted cloud and irreversible malware) are mutually bound together, so that if one wanted to add a backdoor to allow A/V industry to be able to analyze SGX-protected malware, then this very same backdoor could be used to weaken the guarantees of the trustworthiness of the user VMs in the cloud.
Finally, a problem that is hard to ignore today, in the post-Snowden world, is the ease of backdooring this technology by Intel itself. In fact Intel doesn't need to add anything to their processors – all they need to do is to give away the private signing keys used by SGX for remote attestation. This makes for a perfectly deniable backdoor – nobody could catch Intel on this, even if the processor was analyzed transistor-by-transistor, HDL line-by-line.
As a system architect I would love to have Intel SGX, and I would love to believe it is secure. It would allow to further decompose Qubes OS, specifically get rid of the hypervisor from the TCB, and probably even more.
Special thanks to Oded Horowitz for turning my attention towards Intel SGX.
\ No newline at end of file
+
In the
first part of this article published a few weeks ago, I have discussed the basics of Intel SGX technology, and also discussed challenges with using SGX for securing desktop systems, specifically focusing on the problem of trusted input and output. In this part we will look at some other aspects of Intel SGX, and we will start with a discussion of how it could be used to create a truly irreversible software.
SGX Blackboxing – Apps and malware that cannot be reverse engineered?
A nice feature of Intel SGX is that the processor automatically encrypts the content of SGX-protected memory pages whenever it leaves the processor caches and is stored in DRAM. In other words the code and data used by SGX enclaves never leave the processor in plaintext.
This feature, no doubt influenced by the DRM industry, might profoundly change our approach as to who controls our computers really. This is because it will now be easy to create an application, or malware for that matter, that just cannot be reversed engineered in any way. No more IDA, no more debuggers, not even kernel debuggers, could reveal the actual intentions of the EXE file we're about to run.
Consider the following scenario, where a user downloads an executable, say blackpill.exe, which in fact logically consists of three parts:
A 1st stage loader (SGX loader) which is unencrypted, and which task is to setup an SGX enclave, copy the rest of the code there, specifically the 2nd stage loader, and then start executing the 2nd stage loader...
The 2nd stage loader, which starts executing within the enclave, performs remote attestation with an external server and, in case the remote attestation completes successfully, obtains a secret key from the remote server. This code is also delivered in plaintext too.
Finally the encrypted blob which can only be decrypted using the key obtained by the 2nd stage loader from the remote server, and which contains the actual logic of the application (or malware).
We can easily see that there is no way for the user to figure out what the code from the encrypted blob is going to do on her computer. This is because the key will be released by the remote server only if the 2ndstage loader can prove via remote attestation that it indeed executes within a protect SGX enclave and that it is the original unmodified loader code that the application's author created. Should one bit of this loader be modified, or should it be attempted to run outside of an SGX enclave, or within a somehow misconfigured SGX enclave, then the remote attestation wouldfail and the key will not be obtained.
And once the key is obtained, it is available only within the SGX enclave. It cannot be found in DRAM or on the memory bus, even if the user had access to expensive DRAM emulators or bus sniffers. And the key cannot also be mishandled by the code that runs in the SGX enclave, because remote attestation also proved that the loader code has not been modified, and the author wrote the loader specifically not to mishandle the key in any way (e.g. not to write it out somewhere to unprotected memory, or store on the disk). Now, the loader uses the key to decrypt the payload, and this decrypted payload remains within secure enclave, never leaving it, just like the key. It's data never leaves the enclave either...
One little catch is how the key is actually sent to the SGX-protected enclave so that it could not be spoofed in the middle? Of course it must be encrypted, but to which key? Well, we can have our 2ndstage loader generate a new key pair and send the public key to the remote server – the server will then use this public key to send the actual decryption key encrypted with this loader's public key. This is almost good, except for the fact that this scheme is not immune to a classic main in the middle attack. The solution to this is easy, though – if I understand correctly the description of the new Quoting and Sealing operations performed by the Quoting Enclave – we can include the generated public key hash as part of the data that will be signed and put into the Quote message, so the remote sever can be assured also that the public key originates from the actual code running in the SGX enclave and not from Mallory somewhere in the middle.
So, what does the application really do? Does it do exactly what has been advertised by its author? Or does it also “accidentally” sniffs some system memory or even reads out disk sectors and sends the gathered data to a remote server, encrypted, of course? We cannot know this. And that's quite worrying, I think.
One might say that we do accept all the proprietary software blindly anyway – after all who fires up IDA to review MS Office before use? Or MS Windows? Or any other application? Probably very few people indeed. But the point is: this could be done, and actually some brave souls do that. This could be done even if the author used some advanced form of obfuscation. Can be done, even if taking lots of time. Now, with Intel SGX it suddenly cannot be done anymore. That's quite a revolution, complete change of the rules. We're no longer masters of our little universe – the computer system – and now somebody else is.
Unless there was a way for “Certified Antivirus companies” to get around SGX protection.... (see below for more discussion on this).
...And some good applications of SGX
The SGX blackboxing has, however, some good usages too, beyond protecting the Hollywood productions, and making malware un-analyzable...
One particularly attractive possibility is the “trusted cloud” where VMs offered to users could not be eavesdropped or tampered by the cloud provider admins.
I wrote about such possibility two years ago, but with Intel SGX this could be done much, much better. This will, of course, require a specially written hypervisor which would be setting up SGX containers for each of the VM, and then the VM could authenticate to the user and prove, via remote attestation, that it is executing inside a protected and properly set SGX enclave. Note how this time we do not require the hypervisor to authenticate to the users – we just don't care, if our code correctly attests that it is in a correct SGX, it's all fine.
Suddenly Google could no longer collect and process your calendar, email, documents, and medial records! Or how about a tor node that could prove to users that it is not backdoored by its own admin and does not keep a log of how connections were routed? Or a safe bitcoin web-based wallet? It's hard to overestimate how good such a technology might be for bringing privacy to the wide society of users...
Assuming, of course, there was no backdoor for the NSA to get around the SGX protection and ruin this all goodness...(see below for more discussion on this).
New OS and VMM architectures
In the paragraph above I mentioned that we will need specially written hypervisors (VMMs) that will be making use of SGX in order to protect the user's VMs against themselves (i.e. against the hypervisor). We could go further and put other components of a VMM into protected SGX enclaves, things that we currently, in Qubes OS, keep in separate Service VMs, such as networking stacks, USB stacks, etc. Remember that Intel SGX provides convenient mechanism to build inter-enclave secure communication channels.
We could also take the “GUI domain” (currently this is just Dom0 in Qubes OS) and move it into a separate SGX enclave. If only Intel came up with solid protected input and output technologies that would work well with SGX, then this would suddenly make whole lots of sense (unlike currently where
it is very challenging). What we win this way is that no longer a bug in the hypervisor should be critical, as it would be now a long way for the attacker who compromised the hypervisor to steal any real secret of the user, because there are no secrets in the hypervisor itself.
In this setup the two most critical enclaves are: 1) the GUI enclave, of course, and 2) the admin enclave, although it is thinkable that the latter could be made reasonably deprivileged in that it might only be allowed to create/remove VMs, setup networking and other policies for them, but no longer be able to read and write memory of the VMs (Anti Snowden Protection, ASP?).
And... why use hypervisors? Why not use the same approach to compartmentalize ordinary operating systems? Well, this could be done, of course, but it would require considerable rewrite of the systems, essentially turning them into microkernels (except for the fact that the microkernel would no longer need to be trusted), as well as the applications and drivers, and we know that this will never happen. Again, let me repeat one more time: the whole point of using virtualization for security is that it wraps up all the huge APIs of an ordinary OS, like Win32 or POSIX, or OSX, into a virtual machine that itself requires orders of magnitude simpler interface to/from the outside world (especially true for paravirtualized VMs), and all this without the need to rewrite the applications.
Trusting Intel – Next Generation of Backdooring?
We have seen that SGX offers a number of attractive functionality that could potentially make our digital systems more secure and 3rdparty servers more trusted. But does it really?
The obvious question, especially in the light of recent revelations about NSA backdooring everything and the kitchen sink, is whether Intel will have backdoors allowing “privileged entities” to bypass SGX protections?
Traditional CPU backdooring
Of course they could, no question about it. But one can say that Intel (as well as AMD) might have been having backdoors in their processors for a long time, not necessarily in anything related to SGX, TPM, TXT, AMT, etc. Intel could have built backdoors into simple MOV or ADD instructions, in such a way that they would automatically disable ring/page protections whenever executed with some magic arguments.
I wrote more about this many years ago.
The problem with those “traditional” backdoors is that Intel (or a certain agency) could be caught using it, and this might have catastrophic consequences for Intel. Just imagine somebody discovered (during a forensic analysis of an incident) that doing:
MOV eax, $deadbeef
MOV ebx, $babecafe
ADD eax, ebx
...causes ring elevation for the next 1000 cycles. All the processors affected would suddenly became equivalents of the old 8086 and would have to be replaced. Quite a marketing nightmare I think, no?
Next-generation CPU backdooring
But as more and more crypto and security mechanisms got delegated from software to the processor, the more likely it becomes for Intel (or AMD) to insert really “plausibly deniable” backdoors into processors.
Consider e.g.
the recent paper on how to plant a backdoor into the Intel's Ivy Bridge's random number generator (usable via the new RDRAND instruction). The backdoor reduces the actual entropy of the generator making it feasible to later brute-force any crypto which uses keys generated via the weakened generator. The paper goes into great lengths describing how this backdoor could be injected by a malicious foundry (e.g. one in China), behind the Intel's back, which is achieved by implementing the backdoor entirely below the HDL level. The paper takes a “classic” view on the threat model with Good Americans (Intel engineers) and the Bad Chinese (foundry operators/employees). Nevertheless, it should be obvious that Intel could have planted such a backdoor without any effort or challenge described in the paper, because they could do so at any level, not necessarily below HDL.
But backdooring an RNG is still something that leaves traces. Even though the backdoored processor can apparently pass all external “randomness” testes, such as the NIST testsuite, they still might be caught. Perhaps because somebody will buy 1000 processors and will run them for a year and will note down all the numbers generated and then conclude that the distribution is quite not right. Or something like that. Or perhaps because somebody will reverse-engineer the processor and specifically the RNG circuitry and notice some gates are shorted to GND. Or perhaps because somebody at this “Bad Chinese” foundry will notice that.
Let's now get back to Intel SGX -- what is the actual Root of Trust for this technology? Of course, the processor, just like for the old ring3/ring0 separation. But for SGX there is additional Root of Trust which is used for remote attestation, and this is the private key(s) used for signing the Quote Messages.
If the signing private key somehow got into the hands of an adversary, the remote attestation breaks down completely. Suddenly the “SGX Blackboxed” apps and malware can readily be decrypted, disassembled and reverse engineered, because the adversary can now emulate their execution step by step under a debugger and still pass the remote attestation. We might say this is good, as we don't want irreversible malware and apps. But then, suddenly, we also loose our attractive “trusted cloud” too – now there is nothing that could stop the adversary, who has the private signing key, to run our trusted VM outside of SGX, yet still reporting to us that it is SGX-protected. And so, while we believe that our trusted VM should be trusted and unsniffable, and while we devote all our deepest secrets to it, the adversary can read them all like on a plate.
And the worst thing is – even if somebody took such a processor, disassembled it into pieces, analyzed transitor-by-transitor, recreated HDL, analyzed it all, then still it all would look good. Because the backdoor is... the leaked private key that is now also in the hands of the adversary, and there is no way to prove it by looking at the processor alone.
As I understand, the whole idea of having a separate TPM chip, was exactly to make such backdoor-by-leaking-keys more difficult, because, while we're all forced to use Intel or AMD processors today, it is possible that e.g. every country can produce their own TPM, as it's million times less complex than a modern processor. So, perhaps Russia could use their own TPMs, which they might be reasonably sure they use private keys which have not be handed over to the NSA.
However, as I mentioned in the first part of this article, sadly, this scheme doesn't work that well. The processor can still cheat the external TPM module. For example, in case of an Intel TXT and TPM – the processor can produce incorrect PCR values in response to certain trigger – in that case it no longer matters that the TPM is trusted and keys not leaked, because the TPM will sign wrong values. On the other hand we go back now to using “traditional” backdoors in the processors, whose main disadvantage is that people might got cought using them (e.g. somebody analyzed an exploit which turns out to be triggering correct Quote message despite incorrect PCRs).
So, perhaps, the idea of separate TPM actually does make some sense after all?
What about just accidental bugs in Intel products?
Conspiracy theories aside, what about accidental bugs? What are the chances of SGX being really foolproof, at least against those unlucky adversaries who didn't get access to the private signing keys? The Intel's processor have become quite a complex beasts these days. And if you also thrown in the Memory Controller Hub, it's unimaginably complex beast.
Let's take a quick tour back discussing some spectacular attacks against Intel “hardware” security mechanisms. I wrote “hardware” in quotation marks, because really most of these technologies is software, like most of the things in electronics these days. Nevertheless the “hardware enforced security” does have a special appeal to lots of people, often creating an impression that these must be some ultimate unbreakable technologies....
I think it all started with our
exploit against Intel Q35 chipset (slides 15+) demonstrated back in 2008 which was the first attack allowing to compromise, otherwise hardware-protected, SMM memory on Intel platforms (some other attacks against SMM shown before assumed the SMM was not protected, which was the case on many older platforms).
This was then shortly followed by
another paper from us about attacking Intel Trusted Execution Technology (TXT), which found out and exploited a fact that TXT-loaded code was not protected against code running in the SMM mode. We used our previous attack on Q35 against SMM, as well as found a couple of new ones, in order to compromise SMM, plant a backdoor there, and then compromise TXT-loaded code from there. The issue highlighted in the paper has never really been correctly patched. Intel has spent years developing something they called STM, which was supposed to be a thin hypervisor for SMM code sandboxing. I don't know if the Intel STM specification has eventually been made public, and how many bugs it might be introducing on systems using it, or how much inaccurate it might be.
In the following years we presented two more devastating attacks against Intel TXT (none of which depending on compromised SMM):
onewhich exploited a subtle bug in the processor SINIT module allowing to misconfigure VT-d protections for TXT-loaded code, and
another one exploiting a classic buffer overflow bug also in the processor's SINIT module, allowing this time not only to fully bypass TXT, but also fully bypass Intel Launch Control Policy and hijack SMM (several years after our original papers on attacking SMM the old bugs got patched and so this was also attractive as yet another way to compromise SMM for whatever other reason).
Invisible Things Lab has also
presented first, and as far as I'm aware still the only one, attack on Intel BIOS that allowed to reflash the BIOS despite Intel's strong “hardware” protection mechanism to allow only digitally signed code to be flashed. We also
found outabout secret processor in the chipset used for execution of Intel AMT code and we found a way to inject our custom code into this special AMT environment and have it executed in parallel with the main system, unconstrained by any other entity.
This is quite a list of Intel significant security failures, which I think gives something to think about. At the very least that just because something is “hardware enforced” or “hardware protected” doesn't mean it is foolproof against software exploits. Because, it should be clearly said, all our exploits mentioned above were pure software attacks.
But, to be fair, we have never been able to break Intel core memory protection (ring separation, page protection) or Intel VT-x. Rafal Wojtczuk has probably came closest with
his SYSRET attackin an attempt to break the ring separation, but ultimately the Intel's excuse was that the problem was on the side of the OS developers who didn't notice subtle differences in the behavior of SYSRET between AMD and Intel processors, and didn't make their kernel code defensive enough against Intel processor's odd behavior.
We have also
demonstrated rather impressive attacks bypassing Intel VT-d, but, again, to be fair, we should mention that the attacks were possible only on those platforms which Intel didn't equip with so called Interrupt Remapping hardware, and that Intel knew that such hardware was indeed needed and was planning it a few years before our attacks were published.
So, is Intel SGX gonna be as insecure as Intel TXT, or as secure as Intel VT-x....?
The bottom line
Intel SGX promises some incredible functionality – to create protected execution environments (called enclaves) within untrusted (compromised) Operating System. However, for SGX to be of any use on a client OS, it is important that we also have technologies to implement trusted output and input from/to the SGX enclave. Intel currently provides little details about the former and openly admits it doesn't have the later.
Still, even without trusted input and output technologies, SGX might be very useful in bringing trust to the cloud, by allowing users to create trusted VMs inside untrusted provider infrastructure. However, at the same time, it could allow to create applications and malware that could not be reversed engineered. It's quote ironic that those two applications (trusted cloud and irreversible malware) are mutually bound together, so that if one wanted to add a backdoor to allow A/V industry to be able to analyze SGX-protected malware, then this very same backdoor could be used to weaken the guarantees of the trustworthiness of the user VMs in the cloud.
Finally, a problem that is hard to ignore today, in the post-Snowden world, is the ease of backdooring this technology by Intel itself. In fact Intel doesn't need to add anything to their processors – all they need to do is to give away the private signing keys used by SGX for remote attestation. This makes for a perfectly deniable backdoor – nobody could catch Intel on this, even if the processor was analyzed transistor-by-transistor, HDL line-by-line.
As a system architect I would love to have Intel SGX, and I would love to believe it is secure. It would allow to further decompose Qubes OS, specifically get rid of the hypervisor from the TCB, and probably even more.
Special thanks to Oded Horowitz for turning my attention towards Intel SGX.
\ No newline at end of file
diff --git a/_posts/2013-12-11-qubes-r2-beta-3-has-been-released.html b/_posts/2013-12-11-qubes-r2-beta-3-has-been-released.html
index 07064dd..623a575 100644
--- a/_posts/2013-12-11-qubes-r2-beta-3-has-been-released.html
+++ b/_posts/2013-12-11-qubes-r2-beta-3-has-been-released.html
@@ -9,4 +9,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2013/12/qubes-r2-beta-3-has-been-released.html
---
-
Today we're releasing Qubes R2 Beta 3, one of the latest milestones on our roadmap for Qubes R2. Even though it is still called a “beta”, most users should install it, because, we believe, it is the most polished and stable Qubes edition. Looking back, I think it was a mistake to use this alpha/beta/rc nomenclature to mark Qubes releases, and so, starting with Qubes R3 we will be just using version numbers: 3.0, 3.1, etc.
Anyway, back to the R2 Beta 3 – below I discuss some of the highlights of the today's release:
The
seamless GUI virtualization for Windows 7-based AppVMs, and support for
HVM-based templates (e.g. Windows-based templates) is one of the most spectacular feature of this release, I think. It has already been discussed in an
earlier blog post, and now instructions have also been added
to the wiki for how to install and use such Windows AppVMs.
We've also introduced a much more advanced infrastructure for system backups, so it is now possible to make and restore backups to/from untrusted VMs, which allows e.g. to backup easily the whole system to a NAS, or just to an USB device, not worrying that somebody might exploit the NAS client over the network, or that plugging of the USB disk with malformed partition table or filesystem might compromise the system. The whole point here is that the VM that handles the backup storage (and which might be directing it to a NAS, or somewhere) might be compromised, and it still cannot do anything that could compromise (or even DoS) the system, neither can it sniff the data in the backup. I will write more about the challenges we had to solve and how we did it in a separate blog post. I'm very proud to note that majority of the implementation for this has been contributed by the community, specifically Oliver Medoc. Thanks!
A very simple feature, trivial almost, yet very important from the security point of view – it is now possible to set 'autostart' property on select VMs. Why is this so important for security? Because I can create e.g. UsbVM, assign all my USB controllers to it, and then once I set it as autostarting, I can have assurance that all my USB controllers will be delegated to such AppVM immediately upon each system boot. Having such a UsbVM is a very good idea, if one is afraid of physical attacks coming though USB devices. And it now could double as a BackupVM with this new backup system mentioned above!
To improve hardware compatibility we now ship the installer with multiple kernel versions (3.7, 3.9, and 3.11) allowing to run the installation using any of those, e.g. if it turned out that one kernel doesn't support the graphics card correctly -- a typical problem many users faced in the past. All the kernels are also installed in the final system, allowing the user to easily boot with a select Dom0 kernel later, choosing the one which supports their hardware best.
Another popular problem of the past now was the lack of support for dynamically changing resolution/screen layout in the AppVMs when a seccond monitor or a projector was hot-plugged in (which changed only the resolution layout in Dom0). Now this problem has been solved and the new monitor layout is dynamically propagated to the AppVMs, allowing to use all the screen real estate by the apps running there.
There has also been a significant amount of cleanups and fixes. This includes the unification of paths and command names (“The Underscore Revolution” as we call it), as well as refactoring of all the source code components (which now closely matches what we have on Qubes Odyssey/R3), and lots of various bugfixes.
We're planning one more release (Qubes R2 RC1) before the final R2, which will bring improvements mostly in the area of more polished UI, such as allowing some of the tasks that currently require commandline to be done from the Qubes Manager. So, this would mostly be a minor cosmetic upgrade, plus bugfixes. And probably we will also upgrade the default Linux template to Fedora 20.
Installation and upgrade instructions can be found
here.
Today we're releasing Qubes R2 Beta 3, one of the latest milestones on our roadmap for Qubes R2. Even though it is still called a “beta”, most users should install it, because, we believe, it is the most polished and stable Qubes edition. Looking back, I think it was a mistake to use this alpha/beta/rc nomenclature to mark Qubes releases, and so, starting with Qubes R3 we will be just using version numbers: 3.0, 3.1, etc.
Anyway, back to the R2 Beta 3 – below I discuss some of the highlights of the today's release:
The
seamless GUI virtualization for Windows 7-based AppVMs, and support for
HVM-based templates (e.g. Windows-based templates) is one of the most spectacular feature of this release, I think. It has already been discussed in an
earlier blog post, and now instructions have also been added
to the wiki for how to install and use such Windows AppVMs.
We've also introduced a much more advanced infrastructure for system backups, so it is now possible to make and restore backups to/from untrusted VMs, which allows e.g. to backup easily the whole system to a NAS, or just to an USB device, not worrying that somebody might exploit the NAS client over the network, or that plugging of the USB disk with malformed partition table or filesystem might compromise the system. The whole point here is that the VM that handles the backup storage (and which might be directing it to a NAS, or somewhere) might be compromised, and it still cannot do anything that could compromise (or even DoS) the system, neither can it sniff the data in the backup. I will write more about the challenges we had to solve and how we did it in a separate blog post. I'm very proud to note that majority of the implementation for this has been contributed by the community, specifically Oliver Medoc. Thanks!
A very simple feature, trivial almost, yet very important from the security point of view – it is now possible to set 'autostart' property on select VMs. Why is this so important for security? Because I can create e.g. UsbVM, assign all my USB controllers to it, and then once I set it as autostarting, I can have assurance that all my USB controllers will be delegated to such AppVM immediately upon each system boot. Having such a UsbVM is a very good idea, if one is afraid of physical attacks coming though USB devices. And it now could double as a BackupVM with this new backup system mentioned above!
To improve hardware compatibility we now ship the installer with multiple kernel versions (3.7, 3.9, and 3.11) allowing to run the installation using any of those, e.g. if it turned out that one kernel doesn't support the graphics card correctly -- a typical problem many users faced in the past. All the kernels are also installed in the final system, allowing the user to easily boot with a select Dom0 kernel later, choosing the one which supports their hardware best.
Another popular problem of the past now was the lack of support for dynamically changing resolution/screen layout in the AppVMs when a seccond monitor or a projector was hot-plugged in (which changed only the resolution layout in Dom0). Now this problem has been solved and the new monitor layout is dynamically propagated to the AppVMs, allowing to use all the screen real estate by the apps running there.
There has also been a significant amount of cleanups and fixes. This includes the unification of paths and command names (“The Underscore Revolution” as we call it), as well as refactoring of all the source code components (which now closely matches what we have on Qubes Odyssey/R3), and lots of various bugfixes.
We're planning one more release (Qubes R2 RC1) before the final R2, which will bring improvements mostly in the area of more polished UI, such as allowing some of the tasks that currently require commandline to be done from the Qubes Manager. So, this would mostly be a minor cosmetic upgrade, plus bugfixes. And probably we will also upgrade the default Linux template to Fedora 20.
Installation and upgrade instructions can be found
here.
Sure, the inter-process isolation provided by a monolithic kernel such as Windows or Linux could never be compared to the inter-VM isolation offered even by the most lousy hypervisors. This is simply because the sizes of the interfaces exposed to untrusted entities (processes in case of a monolithic kernel; VMs in case of a hypervisor) are just incomparable. Just think about all those Windows system calls and GDI calls which any process can call and which contains probably thousands of bugs still waiting to be discovered by some kid with IDA. And think about those tens of thousands of drivers, which also expose (often unsecured) IOCTLs, as well as parsing the incoming packets, USB devices infos, filesystem metadata, etc. And then think about various additional services exposed by system processes, which are not part of the kernel, but which are still trusted and privileged. And now think about the typical interface that needs to be exposed to a typical VM: it's “just” the virtualized CPU, some emulated devices (some old-fashined Pentium-era chipset, SVGA graphics adapter, etc) and virtualized memory.
Anyway, knowing all this, I still believed that Qubes WNI would make a whole lot of sense. This is because Qubes WNI would still offer a significant boost over the “Just Windows” default security, which is (still) essentially equivalent to the MS-DOS security model. And this is a real pity, because Windows OS has long implemented very sophisticated security mechanisms, such as complex ACLs applicable to nearly any object, as well as recent mechanisms such as UIPI/UAC, etc. So, why not use all those sophisticated security to bring some real-world security to Windows desktops!
And, best of all, once people start using Qubes WNI, and they liked it, they could then pretty seamlessly upgrade to Xen-based Qubes OS, or perhaps Hyper-V-based Qubes OS (when we implement it) and their system would look and behave very similarly. Albeit with orders of magnitude stronger security. Finally, if we could get our Odyssey Framework to be flexible enough to support both Qubes WNI, as well as Xen-based Qubes OS, we should then be able to support any hypervisor or other isolation mechanism in the future.
And so we decided to build the Qubes WNI. Lots of work we invested in building Qubes WNI was actually WNI-independent, because it e.g. covered adjusting the core Odyssey framework to be more flexible (after all “WNI” is quite a non-standard hypervisor) as well as some components that were Windows-specific, but not WNI-specific (e.g. could very well be used on Hyper-V based Qubes OS in the future). But we also invested lots of time into evaluating all those Windows security mechanisms in order to achieve our specific goals (e.g. proper GUI isolation, networking isolation, kernel object spaces isolation, etc)...
Sadly this all has turned out to be a story without a happy end, as we have finally came to the conclusion that consumer Windows OS, with all those one-would-think sophisticated security mechanisms, is just not usable for any real-world domain isolation.
And today we publish a technical paper about our findings on Windows security model and mechanisms and why we concluded they are inadequate in practice. The paper has been written by Rafał Wojdyła who joined ITL a few months ago with the main task of implementing Qubes WNI. I think most people will be able to learn a thing or two about Windows security model by reading this paper.
Also, we still do have this little hope that somebody will read the paper and then write to us: “Oh, you're guys so dumb, you could just use this and that mechanism, to solve all your problems with WNI!” :)
The paper can be downloaded from here.
\ No newline at end of file
+When I originally described the flexible Qubes Odyssey framework several months ago, I mentioned that we would even consider to use “Windows Native Isolation” mechanisms as a primitive type of isolation provider (“hypervisor”) for some basic edition of Qubes for Windows. The idea has been very attractive indeed, because with minimal effort we could allow people to install and run such Qubes WNI on their normal, consumer Windows laptops.
Sure, the inter-process isolation provided by a monolithic kernel such as Windows or Linux could never be compared to the inter-VM isolation offered even by the most lousy hypervisors. This is simply because the sizes of the interfaces exposed to untrusted entities (processes in case of a monolithic kernel; VMs in case of a hypervisor) are just incomparable. Just think about all those Windows system calls and GDI calls which any process can call and which contains probably thousands of bugs still waiting to be discovered by some kid with IDA. And think about those tens of thousands of drivers, which also expose (often unsecured) IOCTLs, as well as parsing the incoming packets, USB devices infos, filesystem metadata, etc. And then think about various additional services exposed by system processes, which are not part of the kernel, but which are still trusted and privileged. And now think about the typical interface that needs to be exposed to a typical VM: it's “just” the virtualized CPU, some emulated devices (some old-fashined Pentium-era chipset, SVGA graphics adapter, etc) and virtualized memory.
Anyway, knowing all this, I still believed that Qubes WNI would make a whole lot of sense. This is because Qubes WNI would still offer a significant boost over the “Just Windows” default security, which is (still) essentially equivalent to the MS-DOS security model. And this is a real pity, because Windows OS has long implemented very sophisticated security mechanisms, such as complex ACLs applicable to nearly any object, as well as recent mechanisms such as UIPI/UAC, etc. So, why not use all those sophisticated security to bring some real-world security to Windows desktops!
And, best of all, once people start using Qubes WNI, and they liked it, they could then pretty seamlessly upgrade to Xen-based Qubes OS, or perhaps Hyper-V-based Qubes OS (when we implement it) and their system would look and behave very similarly. Albeit with orders of magnitude stronger security. Finally, if we could get our Odyssey Framework to be flexible enough to support both Qubes WNI, as well as Xen-based Qubes OS, we should then be able to support any hypervisor or other isolation mechanism in the future.
And so we decided to build the Qubes WNI. Lots of work we invested in building Qubes WNI was actually WNI-independent, because it e.g. covered adjusting the core Odyssey framework to be more flexible (after all “WNI” is quite a non-standard hypervisor) as well as some components that were Windows-specific, but not WNI-specific (e.g. could very well be used on Hyper-V based Qubes OS in the future). But we also invested lots of time into evaluating all those Windows security mechanisms in order to achieve our specific goals (e.g. proper GUI isolation, networking isolation, kernel object spaces isolation, etc)...
Sadly this all has turned out to be a story without a happy end, as we have finally came to the conclusion that consumer Windows OS, with all those one-would-think sophisticated security mechanisms, is just not usable for any real-world domain isolation.
And today we publish a technical paper about our findings on Windows security model and mechanisms and why we concluded they are inadequate in practice. The paper has been written by Rafał Wojdyła who joined ITL a few months ago with the main task of implementing Qubes WNI. I think most people will be able to learn a thing or two about Windows security model by reading this paper.
Also, we still do have this little hope that somebody will read the paper and then write to us: “Oh, you're guys so dumb, you could just use this and that mechanism, to solve all your problems with WNI!” :)
The paper can be downloaded from here.
\ No newline at end of file
diff --git a/_posts/2014-04-20-qubes-os-r2-rc1-has-been-released.html b/_posts/2014-04-20-qubes-os-r2-rc1-has-been-released.html
index 0b86483..66ba6f8 100644
--- a/_posts/2014-04-20-qubes-os-r2-rc1-has-been-released.html
+++ b/_posts/2014-04-20-qubes-os-r2-rc1-has-been-released.html
@@ -9,4 +9,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2014/04/qubes-os-r2-rc1-has-been-released.html
---
-Today we're releasing Qubes OS R2 rc1 (release candidate), which is expected to be the last milestone before the final Qubes OS R2 release. As mentioned previously today's release is bringing mainly UI improvements and polishing and lots of bugfixes, as well as some last new features:
- Both Dom0 and VMs have been upgraded to Fedora 20.
- Support for full templates download via two new repo definitions: templates-itl and templates-community. With a bit of imagination we could call it Qubes “AppStore” for VMs :) Currently we have only published one template there – the new default fc20-based template, but we plan to upload more templates in the coming weeks (such as the community-produced Arch Linux and Debian templates). Even though we have a separate repo for community contributed templates, we still plan on building those templates ourselves, from (contributed) sources.
- Support for running Windows AppVMs in “full desktop” mode with support for arbitrary window resizing (which automatically adjusts the resolution in the VMs).
- Support for on-the-fly switching between the “full desktop” and “seamless” modes for Windows AppVMs.
The last two features require, of course, our proprietary Qubes Windows Tools to be installed in the Windows AppVMs to work, which new version we have also published to the new repositories for R2rc1.
We support smooth upgrading for current Qubes R2 Beta 3 users – the procedure is very simple, yet it will take some hours because of the Dom0 distro upgrading.
As can be seen in our ticketing system, there really are only few minor cosmetic tasks left before the final Qubes R2 release. It is expected that upgrade from today's release to the final R2 will be very simple and quick – just standard updates installation.
As usual, the detailed installation and upgrade instructions, as well as the HCL, can be found here. Note however, that the HCL for the today's release will take some days/weeks to compile, as we need to wait for reports from the community, and so for this time the HCL for the previous release (R2 Beta 3) should be used instead. It is reasonable to expect that the new HCL will be a subset of the previous one.
Also, as usual, please keep in mind that we don't control the servers from which the ISO is being served and so please always make sure to verify the digital signature on the downloaded ISO before installing it.
Please direct all the technical questions or comments regarding Qubes OS to our mailing lists.
Enjoy!
\ No newline at end of file
+Today we're releasing Qubes OS R2 rc1 (release candidate), which is expected to be the last milestone before the final Qubes OS R2 release. As mentioned previously today's release is bringing mainly UI improvements and polishing and lots of bugfixes, as well as some last new features:
- Both Dom0 and VMs have been upgraded to Fedora 20.
- Support for full templates download via two new repo definitions: templates-itl and templates-community. With a bit of imagination we could call it Qubes “AppStore” for VMs :) Currently we have only published one template there – the new default fc20-based template, but we plan to upload more templates in the coming weeks (such as the community-produced Arch Linux and Debian templates). Even though we have a separate repo for community contributed templates, we still plan on building those templates ourselves, from (contributed) sources.
- Support for running Windows AppVMs in “full desktop” mode with support for arbitrary window resizing (which automatically adjusts the resolution in the VMs).
- Support for on-the-fly switching between the “full desktop” and “seamless” modes for Windows AppVMs.
The last two features require, of course, our proprietary Qubes Windows Tools to be installed in the Windows AppVMs to work, which new version we have also published to the new repositories for R2rc1.
We support smooth upgrading for current Qubes R2 Beta 3 users – the procedure is very simple, yet it will take some hours because of the Dom0 distro upgrading.
As can be seen in our ticketing system, there really are only few minor cosmetic tasks left before the final Qubes R2 release. It is expected that upgrade from today's release to the final R2 will be very simple and quick – just standard updates installation.
As usual, the detailed installation and upgrade instructions, as well as the HCL, can be found here. Note however, that the HCL for the today's release will take some days/weeks to compile, as we need to wait for reports from the community, and so for this time the HCL for the previous release (R2 Beta 3) should be used instead. It is reasonable to expect that the new HCL will be a subset of the previous one.
Also, as usual, please keep in mind that we don't control the servers from which the ISO is being served and so please always make sure to verify the digital signature on the downloaded ISO before installing it.
Please direct all the technical questions or comments regarding Qubes OS to our mailing lists.
Enjoy!
\ No newline at end of file
diff --git a/_posts/2014-08-06-qubes-os-r2-rc2-debian-template-ssled.html b/_posts/2014-08-06-qubes-os-r2-rc2-debian-template-ssled.html
index 639bd53..0b7c889 100644
--- a/_posts/2014-08-06-qubes-os-r2-rc2-debian-template-ssled.html
+++ b/_posts/2014-08-06-qubes-os-r2-rc2-debian-template-ssled.html
@@ -13,4 +13,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2014/08/qubes-os-r2-rc2-debian-template-ssled.html
---
-Today we're release the second release candidate (rc2) for Qubes OS R2. There are currently no more open tickets for the final R2 release, and we hope that what we release today is stable enough and so will be identical, or nearly identical, to the final R2 ISO, which we plan to release after the summer holidays. Download and installation instructions are here.
After Qubes rc1 release a few months ago we have been hit by a number of problems related to unreliable VM start-ups. The most prevalent problem has been traced down to an upstream bug in systemd, which just happened to be manifesting on Qubes OS due to specific conditions imposed by our startup scripts.
Actually, it has not been the first time when some things related to VM bootup or initialization didn't work quite well on Qubes, a side effect of heavy optimizations and stripping down we do in order to make the VMs as light weight as possible. E.g. we don't start most of the Desktop Environment which otherwise is assumed to be running by various desktop-related applications and services. In most cases these are really NOTOURBUG kind of problems, yet we just happen to be unlucky they manifest on Qubes. We do need more help from the community with testing, debugging and patching such NOTOURBUG problems in the upstream. The more people use Qubes OS, the higher the chances such problems will be addressed much quicker. Ideally, in the future, we could partner with a Linux distro that would include Qubes AppVM as one of the test cases.
Speaking of different Linux distros -- we have also recently built and released an experimental (“beta”) Debian template for Qubes AppVMs, a popular request expressed by our users for quite some time. It can be readily installed with just one command, as described in the wiki. It is supposed to behave as a first class Qubes AppVM with all the Qubes signature VM integration features, such as seamless GUI virtualization, secure clipboard, secure file copy, and other integration, all working out of the box. Special thanks to our community contributors for providing most of the patches required for porting of our agents and other scripts to Debian. This template is currently provided via our templates-community repo, but it nevertheless has been built and signed by ITL, and is also configured to fetch updates (for Qubes tools) from our server, but we look forward for somebody from the community to take over from us the maintenance (building, testing) of the updates for this template.
Also in our "Templates Appstore" you can find now an experimental “minimal” fedora-based template, which might be used by more advanced users to build customized special-purpose VMs and templates.
We have also moved our Wiki server to a bigger EC2 instance so it could better handle the increased traffic and also added a real CA-signed SSL certificate! But I encourage people to read why this is mostly irrelevant from the security standpoint and why they should still be checking signatures on the ISOs.
We also got a new logo (actually we never really had our own logo before). This also means Qubes now got its own distinct set of themes for installer, plymouth and, of course, a bunch of cool wallpapers with Qubes logo nicely engraved on them. However, it turned out that convincing KDE to set our wallpaper as a default one exceeds the collective mental abilities of ITL, and so one needs to right-click on the desktop and choose one of the Qubes-branded wallpapers manually after install or upgrade.
Every once in a while people (re-)discover that monolithic kernel-based desktop operating systems are not the best solution whenever the user even remotely cares about security...
Yes, USB inherent insecurity, as well as widespread GUI insecurity, or networking stack insecurity, trivial physical insecurities, or sick permissions model as used in most desktop systems, have all been known facts for years. The recognition of these problems has been the primary motivator for us to start the work on Qubes OS back in 2009/2010.
And yes, Qubes running on an appropriate hardware (specifically with Intel VT-d) can solve most of these problems. Correction: Qubes OS can allow the user or administrator to solve these problems, as unfortunately this still requires some configuration decisions made by the human operator. So today Qubes R2 is like a sports manual transmission, which requires a bit of skill to get most out of it. In the near future I see no reason why we should not be offering the "automatic 8-speed transmission" edition of Qubes OS. We just need more time to get there. The R3 release (Odyssey-based), whose early code is planned to be released just after the "final" R2, so sometime in September, is all about bringing us closer to that "automatic transmission" version.
With my 10+ years of experience as a system-level security researcher, I believe there is no other way to go. Don't get deluded that safe languages or formally verified microkernels could solve these problems. Security by Isolation, done sensibly, is the only way to go (of course it doesn't preclude making use of some formally verified components, like e.g. microkernel in place of Xen, at least in some editions of Qubes).
Finally one more announcement for today: after writing this blog for 8 years, I've suddenly felt like I might need to try also some new form of expression... And so, for a few days, I now have a twitter account (@rootkovska), which I hope to use for updates on Qubes, as well as more general commentary on various things happening in IT security.
\ No newline at end of file
+Today we're release the second release candidate (rc2) for Qubes OS R2. There are currently no more open tickets for the final R2 release, and we hope that what we release today is stable enough and so will be identical, or nearly identical, to the final R2 ISO, which we plan to release after the summer holidays. Download and installation instructions are here.
After Qubes rc1 release a few months ago we have been hit by a number of problems related to unreliable VM start-ups. The most prevalent problem has been traced down to an upstream bug in systemd, which just happened to be manifesting on Qubes OS due to specific conditions imposed by our startup scripts.
Actually, it has not been the first time when some things related to VM bootup or initialization didn't work quite well on Qubes, a side effect of heavy optimizations and stripping down we do in order to make the VMs as light weight as possible. E.g. we don't start most of the Desktop Environment which otherwise is assumed to be running by various desktop-related applications and services. In most cases these are really NOTOURBUG kind of problems, yet we just happen to be unlucky they manifest on Qubes. We do need more help from the community with testing, debugging and patching such NOTOURBUG problems in the upstream. The more people use Qubes OS, the higher the chances such problems will be addressed much quicker. Ideally, in the future, we could partner with a Linux distro that would include Qubes AppVM as one of the test cases.
Speaking of different Linux distros -- we have also recently built and released an experimental (“beta”) Debian template for Qubes AppVMs, a popular request expressed by our users for quite some time. It can be readily installed with just one command, as described in the wiki. It is supposed to behave as a first class Qubes AppVM with all the Qubes signature VM integration features, such as seamless GUI virtualization, secure clipboard, secure file copy, and other integration, all working out of the box. Special thanks to our community contributors for providing most of the patches required for porting of our agents and other scripts to Debian. This template is currently provided via our templates-community repo, but it nevertheless has been built and signed by ITL, and is also configured to fetch updates (for Qubes tools) from our server, but we look forward for somebody from the community to take over from us the maintenance (building, testing) of the updates for this template.
Also in our "Templates Appstore" you can find now an experimental “minimal” fedora-based template, which might be used by more advanced users to build customized special-purpose VMs and templates.
We have also moved our Wiki server to a bigger EC2 instance so it could better handle the increased traffic and also added a real CA-signed SSL certificate! But I encourage people to read why this is mostly irrelevant from the security standpoint and why they should still be checking signatures on the ISOs.
We also got a new logo (actually we never really had our own logo before). This also means Qubes now got its own distinct set of themes for installer, plymouth and, of course, a bunch of cool wallpapers with Qubes logo nicely engraved on them. However, it turned out that convincing KDE to set our wallpaper as a default one exceeds the collective mental abilities of ITL, and so one needs to right-click on the desktop and choose one of the Qubes-branded wallpapers manually after install or upgrade.
Every once in a while people (re-)discover that monolithic kernel-based desktop operating systems are not the best solution whenever the user even remotely cares about security...
Yes, USB inherent insecurity, as well as widespread GUI insecurity, or networking stack insecurity, trivial physical insecurities, or sick permissions model as used in most desktop systems, have all been known facts for years. The recognition of these problems has been the primary motivator for us to start the work on Qubes OS back in 2009/2010.
And yes, Qubes running on an appropriate hardware (specifically with Intel VT-d) can solve most of these problems. Correction: Qubes OS can allow the user or administrator to solve these problems, as unfortunately this still requires some configuration decisions made by the human operator. So today Qubes R2 is like a sports manual transmission, which requires a bit of skill to get most out of it. In the near future I see no reason why we should not be offering the "automatic 8-speed transmission" edition of Qubes OS. We just need more time to get there. The R3 release (Odyssey-based), whose early code is planned to be released just after the "final" R2, so sometime in September, is all about bringing us closer to that "automatic transmission" version.
With my 10+ years of experience as a system-level security researcher, I believe there is no other way to go. Don't get deluded that safe languages or formally verified microkernels could solve these problems. Security by Isolation, done sensibly, is the only way to go (of course it doesn't preclude making use of some formally verified components, like e.g. microkernel in place of Xen, at least in some editions of Qubes).
Finally one more announcement for today: after writing this blog for 8 years, I've suddenly felt like I might need to try also some new form of expression... And so, for a few days, I now have a twitter account (@rootkovska), which I hope to use for updates on Qubes, as well as more general commentary on various things happening in IT security.
\ No newline at end of file
diff --git a/_posts/2014-09-26-announcing-qubes-os-release-2.html b/_posts/2014-09-26-announcing-qubes-os-release-2.html
index 66415f8..146dff0 100644
--- a/_posts/2014-09-26-announcing-qubes-os-release-2.html
+++ b/_posts/2014-09-26-announcing-qubes-os-release-2.html
@@ -11,4 +11,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2014/09/announcing-qubes-os-release-2.html
---
-Today we're releasing Qubes OS R2! I'm not gonna write about all the cool features in this release because you can find all this in our wiki and previous announcements (R2-beta1, R2-beta2, R2-beta3, R2-rc1, and R2-rc2). Suffice to say that we've come a long way over those 4+ years from a primitive proof of concept to a powerful desktop OS which, I believe, it is today.
One of the biggest difficulties we have been facing with Qubes since the very beginning, has been the amount of this extra, not-so-exciting, not directly security-related work, but so much needed to ensure things actually work. Yet, the line between what is, and what is not-security related, is sometimes very thin and one can easily cross it if not being careful.
It's great that we're receiving more and more community contributions. This includes not only bug fixes, but also invaluable efforts related to documentation, HCL maintenance, as well as some really non-trivial new features (advanced backups support, Debian and Arch templates, TorVM, Whonix port, etc). Thanks!
I'm also happy to announce that Caspar Bowden, a well known privacy advocate, expert on EU data protection law, member of the board of Tor, former Microsoft Chief Privacy Adviser, etc, will be taking a role as Qubes Policy Adviser, helping us to make Qubes OS more suitable for a wider audience of people interested in privacy, and be liaising with other projects that would like to build privacy services with Qubes as a base.
And there is still a lot in front of us. Using the obligatory car analogy, I would say Qubes OS is currently like a racing car that just went into production as a road vehicle: one hell of an engine under-the-hood, and powerful new technologies until now unavailable even for professional use, yet lacking leather interior with 12-speaker audio system, and still with a manual transmission... This is just the beginning for making security by isolation on the desktop as "driveable" as a [insert your fav make of German fine cars] :)
Exciting stuff is coming next: the Release 3 (“Odyssey”) and more, stay tuned!
Thanks to everyone who has made Qubes OS possible, as well as all the upstream projects without which we would probably never even try this journey: Xen, Linux, Xorg, and many others!
\ No newline at end of file
+Today we're releasing Qubes OS R2! I'm not gonna write about all the cool features in this release because you can find all this in our wiki and previous announcements (R2-beta1, R2-beta2, R2-beta3, R2-rc1, and R2-rc2). Suffice to say that we've come a long way over those 4+ years from a primitive proof of concept to a powerful desktop OS which, I believe, it is today.
One of the biggest difficulties we have been facing with Qubes since the very beginning, has been the amount of this extra, not-so-exciting, not directly security-related work, but so much needed to ensure things actually work. Yet, the line between what is, and what is not-security related, is sometimes very thin and one can easily cross it if not being careful.
It's great that we're receiving more and more community contributions. This includes not only bug fixes, but also invaluable efforts related to documentation, HCL maintenance, as well as some really non-trivial new features (advanced backups support, Debian and Arch templates, TorVM, Whonix port, etc). Thanks!
I'm also happy to announce that Caspar Bowden, a well known privacy advocate, expert on EU data protection law, member of the board of Tor, former Microsoft Chief Privacy Adviser, etc, will be taking a role as Qubes Policy Adviser, helping us to make Qubes OS more suitable for a wider audience of people interested in privacy, and be liaising with other projects that would like to build privacy services with Qubes as a base.
And there is still a lot in front of us. Using the obligatory car analogy, I would say Qubes OS is currently like a racing car that just went into production as a road vehicle: one hell of an engine under-the-hood, and powerful new technologies until now unavailable even for professional use, yet lacking leather interior with 12-speaker audio system, and still with a manual transmission... This is just the beginning for making security by isolation on the desktop as "driveable" as a [insert your fav make of German fine cars] :)
Exciting stuff is coming next: the Release 3 (“Odyssey”) and more, stay tuned!
Thanks to everyone who has made Qubes OS possible, as well as all the upstream projects without which we would probably never even try this journey: Xen, Linux, Xorg, and many others!
\ No newline at end of file
diff --git a/_posts/2014-11-27-qubes-r3odyssey-initial-source-code.html b/_posts/2014-11-27-qubes-r3odyssey-initial-source-code.html
index e673088..6d3011a 100644
--- a/_posts/2014-11-27-qubes-r3odyssey-initial-source-code.html
+++ b/_posts/2014-11-27-qubes-r3odyssey-initial-source-code.html
@@ -12,4 +12,4 @@
blogger_orig_url: http://theinvisiblethings.blogspot.com/2014/11/qubes-r3odyssey-initial-source-code.html
---
-Back in 2013 we've started the work on generalizing Qubes architecture, which we code-named “Odyssey”, to allow for use of multiple hypervisors instead of just Xen via Hypervisor Abstraction Layer (“HAL” -> “Space Odyssey”, get it? ;). The concept has been described in this post, which I recommend to re-read if you're more interested in understanding our goals.
We have been wandering here and there since that time. Lots of work has been invested in the light-weight Qubes edition for Windows, which, sadly, turned out to be a failure.
We have also done a lot of work in the meantime to polish Qubes R2 and bring it to the state of the final release, which happened earlier this fall.
We have also been heavily researching possibilities of other cool projects based on this flexible new architecture. Some of which you might hear about in the coming months, others turned out to be dead ends.
Today we're finally releasing the Qubes R3 source code to the public. The code builds fine (see here for building instruction), produces install-able ISO, and, if that was not enough, even seems to be working, mostly fine, when installed :)
However, we don't recommend users to switch to it, and we intend this release for developers only, specifically those who would like to start working towards porting of other hypervisors, or other containerization technologies, like LXC, to Qubes R3. I highly recommend these devlopers to discuss what they try to achieve on the qubes-devel mailing list, before they start the actual coding.
Currently the only implemented and supported backend is Xen, of course, specifically the Xen 4.4, currently the latest version. It should be now trivial to switch to future versions as they become available, although, a decision to rush with that might not be such a no-brainer from the security point of view. We should remember that the hypervisor, unlike Linux kernel, is not someting you would like to change every month or so. Ideally we should aim for having a stable version of Xen for desktops that would work for years without needing any updates.
But use of other hypervisors might open up lots of interesting possibilities: imagine e.g. Qubes Live USB edition that has backends for 1) Xen, 2) KVM, and 3) LXC, and choose automatically the most secure one which is still supported on the given laptop.
Major features of the current release, compared to Qubes R2:
- Hypervisor Abstraction Layer for all the core management stack (but still missing for the GUI daemon, see below)
- New implementation of vchan and qrexec. As you might know our original vchan has been rewritten and improved (better performance and flexibility) and included in the upstream Xen starting from v4.2. Now we're switching to this upstream libvchan. Also, qrexec has been slightly rewritten to utilize some new features of this libvchan, which results in much better performance for inter-VM traffic (like a few orders of magnitude better!) Especially important for things such as USB virtualization that we're testing right now (not to be confused with USB controller pass-though).
There is still some work going on which we would like to complete before we officially decide to release Qubes OS 3.0-rc1 ISO, and this includes:
- Rewrite of some internal code for the core management stack, which includes internal API of the python classes. This should mostly be of no interest to users, and even most developers working on Qubes.
Further down the road (Qubes OS 3.1) we plan to work on some really exciting things:
- More flexibility to qrexec policy (more on that in a separate post)
- More flexibility to Qubes Admin API (expose it to slelect other VMs)
- Split of Dom0 into (semi-depriviliged) GUI domain and minimal Admin domain. This would be great opportunity to also add the missing HAL support for the GUI daemon.
One of the immediate application of these features above would be to introduce support for remote management of Qubes installations, an absolutely necessary feature for corporate adoption of Qubes.
Also note how all these tasks are independent of the actual hypervisor support, meaning it's perfectly possible for other developers to work on porting other hypervisors to Qubes in the meantime.
The possibilities seems to be endless now. Join us and help us with The Revolution! :)
\ No newline at end of file
+Back in 2013 we've started the work on generalizing Qubes architecture, which we code-named “Odyssey”, to allow for use of multiple hypervisors instead of just Xen via Hypervisor Abstraction Layer (“HAL” -> “Space Odyssey”, get it? ;). The concept has been described in this post, which I recommend to re-read if you're more interested in understanding our goals.
We have been wandering here and there since that time. Lots of work has been invested in the light-weight Qubes edition for Windows, which, sadly, turned out to be a failure.
We have also done a lot of work in the meantime to polish Qubes R2 and bring it to the state of the final release, which happened earlier this fall.
We have also been heavily researching possibilities of other cool projects based on this flexible new architecture. Some of which you might hear about in the coming months, others turned out to be dead ends.
Today we're finally releasing the Qubes R3 source code to the public. The code builds fine (see here for building instruction), produces install-able ISO, and, if that was not enough, even seems to be working, mostly fine, when installed :)
However, we don't recommend users to switch to it, and we intend this release for developers only, specifically those who would like to start working towards porting of other hypervisors, or other containerization technologies, like LXC, to Qubes R3. I highly recommend these devlopers to discuss what they try to achieve on the qubes-devel mailing list, before they start the actual coding.
Currently the only implemented and supported backend is Xen, of course, specifically the Xen 4.4, currently the latest version. It should be now trivial to switch to future versions as they become available, although, a decision to rush with that might not be such a no-brainer from the security point of view. We should remember that the hypervisor, unlike Linux kernel, is not someting you would like to change every month or so. Ideally we should aim for having a stable version of Xen for desktops that would work for years without needing any updates.
But use of other hypervisors might open up lots of interesting possibilities: imagine e.g. Qubes Live USB edition that has backends for 1) Xen, 2) KVM, and 3) LXC, and choose automatically the most secure one which is still supported on the given laptop.
Major features of the current release, compared to Qubes R2:
- Hypervisor Abstraction Layer for all the core management stack (but still missing for the GUI daemon, see below)
- New implementation of vchan and qrexec. As you might know our original vchan has been rewritten and improved (better performance and flexibility) and included in the upstream Xen starting from v4.2. Now we're switching to this upstream libvchan. Also, qrexec has been slightly rewritten to utilize some new features of this libvchan, which results in much better performance for inter-VM traffic (like a few orders of magnitude better!) Especially important for things such as USB virtualization that we're testing right now (not to be confused with USB controller pass-though).
There is still some work going on which we would like to complete before we officially decide to release Qubes OS 3.0-rc1 ISO, and this includes:
- Rewrite of some internal code for the core management stack, which includes internal API of the python classes. This should mostly be of no interest to users, and even most developers working on Qubes.
Further down the road (Qubes OS 3.1) we plan to work on some really exciting things:
- More flexibility to qrexec policy (more on that in a separate post)
- More flexibility to Qubes Admin API (expose it to slelect other VMs)
- Split of Dom0 into (semi-depriviliged) GUI domain and minimal Admin domain. This would be great opportunity to also add the missing HAL support for the GUI daemon.
One of the immediate application of these features above would be to introduce support for remote management of Qubes installations, an absolutely necessary feature for corporate adoption of Qubes.
Also note how all these tasks are independent of the actual hypervisor support, meaning it's perfectly possible for other developers to work on porting other hypervisors to Qubes in the meantime.
The possibilities seems to be endless now. Join us and help us with The Revolution! :)
\ No newline at end of file

 At least this is how the BitLocker should work. I shall add a disclaimer here, that neither myself, nor anybody from my team, have looked into the BitLocker implementation. We have not, because, as of yet, there have been no customers interested in this kind of BitLocker implementation evaluation. Also, I should add that Microsoft has not paid me to write this article. I simply hope this might positively stimulate other vendors, like e.g. TrueCrypt (Hi David!), or Apple, to add SRTM or, better yet, DRTM, to their system encryption products.
At least this is how the BitLocker should work. I shall add a disclaimer here, that neither myself, nor anybody from my team, have looked into the BitLocker implementation. We have not, because, as of yet, there have been no customers interested in this kind of BitLocker implementation evaluation. Also, I should add that Microsoft has not paid me to write this article. I simply hope this might positively stimulate other vendors, like e.g. TrueCrypt (Hi David!), or Apple, to add SRTM or, better yet, DRTM, to their system encryption products.
 \ No newline at end of file
+Besides breaking the Intel's stuff, we have also been doing other things over at our lab. Thought I would share this cool screenshot of a Virtual PC running inside Xen. More precisely what you see on the pic is: Windows XP running inside Virtual PC, that runs inside Vista, which itself runs inside a Xen's HVM VM. Both the Virtual PC and Xen are using the Intel's hardware virtualization (VT-x is always used for HVM guests on Xen).
\ No newline at end of file
+Besides breaking the Intel's stuff, we have also been doing other things over at our lab. Thought I would share this cool screenshot of a Virtual PC running inside Xen. More precisely what you see on the pic is: Windows XP running inside Virtual PC, that runs inside Vista, which itself runs inside a Xen's HVM VM. Both the Virtual PC and Xen are using the Intel's hardware virtualization (VT-x is always used for HVM guests on Xen).

 \ No newline at end of file
+We've just published the proof of concept code for the Alex's and Rafal's "Ring -3 Rootkits" talk, presented last month at the Black Hat conference in Vegas. You can download the code from our website here. It's highly recommended that one (re)reads the slides before playing with the code.
\ No newline at end of file
+We've just published the proof of concept code for the Alex's and Rafal's "Ring -3 Rootkits" talk, presented last month at the Black Hat conference in Vegas. You can download the code from our website here. It's highly recommended that one (re)reads the slides before playing with the code.
 Now, Evil Maid will be logging the passphrases provided during the boot time. To retrieve the recorded passphrase just boot again from the Evil Maid USB -- it should detect that the target is already infected and display the sniffed password.
Now, Evil Maid will be logging the passphrases provided during the boot time. To retrieve the recorded passphrase just boot again from the Evil Maid USB -- it should detect that the target is already infected and display the sniffed password. The current implementation of Evil Maid always stores the last passphrase entered, assuming this is the correct one, in case the user entered the passphrase incorrectly at earlier attempts.
The current implementation of Evil Maid always stores the last passphrase entered, assuming this is the correct one, in case the user entered the passphrase incorrectly at earlier attempts. The user righ-clicks on a PDF file, chooses "Open in Disposable VM", and then waits 1... 2... 3... 4 seconds (assuming a reasonably modern laptop) and the document automagically opens in a fresh new Disposable VM. If you make some changes to the document (e.g. if it was a PDF form, and you edited it), those changes will propagate back to the original file in the original AppVM.
The user righ-clicks on a PDF file, chooses "Open in Disposable VM", and then waits 1... 2... 3... 4 seconds (assuming a reasonably modern laptop) and the document automagically opens in a fresh new Disposable VM. If you make some changes to the document (e.g. if it was a PDF form, and you edited it), those changes will propagate back to the original file in the original AppVM. The screenshot above shows the memory usage on my 6GB laptop when writing this blog post. As you can see I can easily run a dozen of AppVMs (most users will not need that many, but I'm a bit more paranoid I guess ;) and could probably even start a few more if there was such a need (e.g. open some Disposable VMs). Of course, this all depends on the actual type of workload the user runs in each VM - most of my AppVMs run just one or two applications, usually a Web browser (Firefox), but some, e.g. the work, and personal AppVMs run much more memory-hungry applications such as Open Office, or Picasa Photo Browser. I very rarely see more than 1 GB of memory allocated to a single VM, though. Generally speaking, the new memory management in Qubes works pretty nice.
The screenshot above shows the memory usage on my 6GB laptop when writing this blog post. As you can see I can easily run a dozen of AppVMs (most users will not need that many, but I'm a bit more paranoid I guess ;) and could probably even start a few more if there was such a need (e.g. open some Disposable VMs). Of course, this all depends on the actual type of workload the user runs in each VM - most of my AppVMs run just one or two applications, usually a Web browser (Firefox), but some, e.g. the work, and personal AppVMs run much more memory-hungry applications such as Open Office, or Picasa Photo Browser. I very rarely see more than 1 GB of memory allocated to a single VM, though. Generally speaking, the new memory management in Qubes works pretty nice.