diff --git a/content/blogposts/2018/how-to-support-your-employee-through-pregnancy-maternity-leave-and-the.md b/content/blogposts/2018/how-to-support-your-employee-through-pregnancy-maternity-leave-and-the.md
index dbff7b02..f488d1cb 100644
--- a/content/blogposts/2018/how-to-support-your-employee-through-pregnancy-maternity-leave-and-the.md
+++ b/content/blogposts/2018/how-to-support-your-employee-through-pregnancy-maternity-leave-and-the.md
@@ -1,5 +1,7 @@
---
-title: 'How To Support Your Employee Through Pregnancy, Maternity Leave and the Transition Back To Work'
+title: 'How to support your employee through pregnancy, maternity leave, and the transition back to work'
+externalTitle: 'Welcome back from maternity leave: How to support a returning employee'
+externalDescription: 'Working parents need time off to care for their children and a positive welcome back from maternity leave. Learn how to support them here.'
author: 'Vanesa Ortiz'
publishDate: 2018-08-28T09:00-06:00
tags: [
@@ -10,11 +12,12 @@ heroImage: https://images.ctfassets.net/le3mxztn6yoo/luDj9P2olaGusw64m4koA/c3b44
published: true
---
-Today was my first day back to work at [Sourcegraph](https://sourcegraph.com) after my 3 1/2 months* long maternity leave. I consider myself lucky to be working at a company that is family friendly and has made my journey to parenthood much easier than expected. I decided to share some of the points I believe Sourcegraph and others do right and I encourage companies to follow.
+Today was my first day back to work at [Sourcegraph](https://sourcegraph.com) after my 3 1/2 months* long maternity leave. I consider myself lucky to be working at a company that is family friendly, has made my journey to parenthood much easier than expected, and has made for a warm welcome back from maternity leave. I decided to share some of the points I believe Sourcegraph and others do right and I encourage companies to follow.
+## 13 tips for an effective welcome back from maternity leave
1. Have a parental leave policy ready and help your employee file the correct forms at the [Employment Development Department](https://www.edd.ca.gov/). I was hired pregnant and despite having the first pregnancy in the company, Sourcegraph had its parental policy in place and I was supported throughout the entire process of filing for State Disability Insurance (SDI) and Paid Family Leave (PFL) claims. This turned out to be a blessing, as the application process was quite cumbersome and confusing.
-2. Be supportive of your pregnant employees: Creating a baby is hard! The more the pregnancy progresses, the bigger toll it will take on your employee. Have a supportive environment in which your employee feels safe sharing their needs and struggles. Offer to adapt their workload/focus accordingly.
+2. Be supportive of your pregnant employees: Creating a baby is hard! The more the pregnancy progresses, the bigger toll it will take on your employee. Have a supportive environment in which your employee feels safe sharing their needs and struggles, especially after you welcome them back from maternity leave. Offer to adapt their workload/focus accordingly.
3. Get necessary props: There are numerous props that can make pregnancy way more comfortable for your employee and help them maintain productivity. E.g.: A standing desk with foot pad helps against back pain. An ergonomic mouse will prevent carpal tunnel (a common issue during pregnancy), etc.
@@ -22,7 +25,7 @@ Today was my first day back to work at [Sourcegraph](https://sourcegraph.com) af
5. Your employee has the right to take up to 4 weeks pregnancy related disability leave before the due date in California. Make sure they feel safe enough to take this leave without worrying about their job/position/career development. The last pregnancy month is the hardest.
-6. Respect your employee’s wish to work until they feel ready to take their leave. I was able and wanting to work up to 3 days before giving birth due to an “easy” pregnancy with no complications. I’m glad I got to work so long, though I know other moms-to-be need the time off due to more difficult pregnancies. It was great that my team was supportive of my decision, didn't make me feel uncomfortable or was judgmental about my choice. Every pregnancy is different.
+6. Respect your employee’s wish to work until they feel ready to take their leave. I was able and wanting to work up to 3 days before giving birth due to an “easy” pregnancy with no complications. I’m glad I got to work so long, though I know other moms-to-be need the time off due to more difficult pregnancies. It was great that my team was supportive of my decision, didn't make me feel uncomfortable or was judgmental about my choice. Every pregnancy is different and every welcome back from maternity leave should be, too.
7. After birth: A no-brainer, but FYI: Your employee just created a little miracle (or maybe even more than one)! Rejoice and welcome the new life with a thoughtful gift that will help the new parents: baby clothes/props are great and also something nice for the new mama like a beautiful flower bouquet**!
@@ -34,7 +37,7 @@ Today was my first day back to work at [Sourcegraph](https://sourcegraph.com) af
10. Prepare the lactation room: Ask your employee what they need to make pumping at work as efficient and comfortable as possible, e.g.: a hospital grade pump or/and a hands free willow pump, a freezer to store the milk longer, a baby bottle cooler, a comfy chair etc.
-11. Once the employee goes back to work, plan together how the first weeks will look like to help their transition back to the original workflow. Temporary part time work or 4 days work week can help adding back the full time work to the new full time parent situation.
+11. Once you welcome the employee back from maternity leave and they go back to work, plan together how the first weeks will look like to help their transition back to the original workflow. Temporary part time work or 4 days work week can help adding back the full time work to the new full time parent situation.
12. Encourage them to block time in their calendar for pumping sessions. Not pumping enough at work can lead to painful mastitis, engorgement and a significant drop of their breast milk production, so things you don’t want your employee to be worrying about while working.
@@ -51,3 +54,10 @@ _\*\*Ask the new parents beforehand if they are ok with fresh flowers, as some p
---
_PS: We are [hiring](https://boards.greenhouse.io/sourcegraph91)!_
+
+---
+
+### More posts like this
+- [Let's talk about release anxiety](blog/release-anxiety)
+- [How we built our software engineering career framework](/blog/software-engineer-career-ladder)
+- [Async, remote, and flexible: How 7 engineers rethought their work calendars](/blog/remote-work-calendar)
diff --git a/content/blogposts/2021/continuous_delivery.md b/content/blogposts/2021/continuous_delivery.md
index d18270dd..b0ecbc89 100644
--- a/content/blogposts/2021/continuous_delivery.md
+++ b/content/blogposts/2021/continuous_delivery.md
@@ -131,7 +131,7 @@ One mental model through which you can look at this is one that both [GitLab](ht
Releases should be a true snapshot of your current work. Shift from “Will X be merged?” to “Is X merged?” As Jez Humble, SRE at Google, [tweeted](https://twitter.com/jezhumble/status/1448318922713821186?s=21), continuous delivery is not about “taking whatever crap you have in version control & shipping it into prod as fast as possible so you can test in prod” but is about “making it SAFE to ship your code into prod quickly.”
-
It’s come to my attention that many people think continuous delivery/deployment is about taking whatever crap you have in version control & shipping it into prod as fast as possible so you can test in prod NO CD is about making it SAFE to ship your code into prod quickly by:
It’s come to my attention that many people think continuous delivery/deployment is about taking whatever crap you have in version control & shipping it into prod as fast as possible so you can test in prod NO CD is about making it SAFE to ship your code into prod quickly by:
Your ultimate metric of success won’t be a poll of emotions among your teammates but will be how often your customers upgrade. An uneventful release for you is one that’s uneventful for your customers, too. If your customers are regularly upgrading and consistently keeping up with new releases, then you can trust you’ve reached a point where your releases are uneventful.
diff --git a/content/blogposts/2021/how-to-not-break-a-search-engine-or-what-i-learned-about-unglamorous-engineering.md b/content/blogposts/2021/how-to-not-break-a-search-engine-or-what-i-learned-about-unglamorous-engineering.md
index e0d6274e..8b13292b 100644
--- a/content/blogposts/2021/how-to-not-break-a-search-engine-or-what-i-learned-about-unglamorous-engineering.md
+++ b/content/blogposts/2021/how-to-not-break-a-search-engine-or-what-i-learned-about-unglamorous-engineering.md
@@ -8,12 +8,12 @@ authorUrl: https://twitter.com/rvtond
publishDate: 2021-06-25T10:00-07:00
tags: [blog, code, search, software, engineering, testing]
slug: how-not-to-break-a-search-engine-unglamorous-engineering
-heroImage: https://sourcegraphstatic.com/blog/how-not-to-break-a-search-engine-unglamorous-engineering.jpg
-socialImage: https://sourcegraphstatic.com/blog/how-not-to-break-a-search-engine-unglamorous-engineering.jpg
+heroImage: https://storage.googleapis.com/sourcegraph-assets/blog/how-not-to-break-a-search-engine-new.png
+socialImage: https://storage.googleapis.com/sourcegraph-assets/blog/how-not-to-break-a-search-engine-new.png
published: true
---
-
+
> _"In 2020 I flipped the switch to use a completely rewritten parser for
> Sourcegraph search queries. It serves tens of thousands of users and processes
@@ -26,7 +26,7 @@ Sourcegraph—the bit that users type into the search bar. This component
processes every single input that goes into the search bar when users search
for code:
-
+
When the switch activated the new parser in September 2020, you'd never know
that anything had changed. This is an account of the invisible, rigorous
@@ -87,7 +87,7 @@ defense for testing correctness. I reused some of our existing parser tests
lot of additional tests for new parts of the syntax. You bet there's test
coverage.
-
+
### Part 2: Integration testing
@@ -100,16 +100,11 @@ representation. I'd abstracted out a common interface for our backend to access
the new data structure under the feature-flagged code path to test on.
-
- Integration testing abstracts a common interface for our backend
- to access query values.
- We test that the backend produces the same search results for
- simple queries (ones that don't have, e.g.,
- or
- -operators), irrespective of whether those values originate from the existing parser's output or the new one.
+
+ Integration testing abstracts a common interface for our backend to access query values. We test that the backend produces the same search results for simple queries (ones that don't have, e.g., or -operators), irrespective of whether those values originate from the existing parser's output or the new one.
-
+
When I got to this part, we didn't have a good way to run integration tests. We
had browser-based end-to-end testing that was onerous to set up, time-consuming
@@ -206,7 +201,7 @@ There's unglamorous engineering in the software all around us. For all its lack
of recognition, I wish we grasped its value a bit better. I'm reminded of a
tweet by a former colleague who researched donations for open source projects:
-
I can tell you from some informal interviews we did outside that paper, that people spend the money on gruntwork — the stuff that’s fun they’re more likely to do anyway, money or not.
I can tell you from some informal interviews we did outside that paper, that people spend the money on gruntwork — the stuff that’s fun they’re more likely to do anyway, money or not.
This suggests that gruntwork, if not glamorous, is certainly valuable (and
perhaps, even disproportionately so). At the same time, I wouldn't necessarily
@@ -260,7 +255,7 @@ other engineers at Sourcegraph doing momentous but unglamorous things that most
of the organization is blissfully unaware of. And the Twitterverse suggests
there's more of it happening in software all around us:
-
A huge problem in software companies is that large new features get praise, promotions, accolades... while migrating off a legacy system, increasing performance 2,4,10X, or reducing error rates, pages, or alerts by X% is often only recognized by peers and not leadership.
A huge problem in software companies is that large new features get praise, promotions, accolades... while migrating off a legacy system, increasing performance 2,4,10X, or reducing error rates, pages, or alerts by X% is often only recognized by peers and not leadership.
I empathize with the engineers who don't have an audience for their unglamorous
work, who want to say, "I did A Thing, there's nothing to see, but more people
diff --git a/content/blogposts/2021/integration-testing.md b/content/blogposts/2021/integration-testing.md
index e8ba3df2..8c70ea93 100644
--- a/content/blogposts/2021/integration-testing.md
+++ b/content/blogposts/2021/integration-testing.md
@@ -7,12 +7,15 @@ author: Joe Chen
publishDate: 2022-01-13T18:00+02:00
tags: [blog]
slug: integration-testing
-heroImage: https://storage.googleapis.com/sourcegraph-assets/blog/how-not-to-break-a-search-engine-unglamorous-engineering.jpg
-socialImage: https://storage.googleapis.com/sourcegraph-assets/blog/how-not-to-break-a-search-engine-unglamorous-engineering.jpg
+heroImage: https://storage.googleapis.com/sourcegraph-assets/blog/backend-integration-testing/backend-integration-testing.png
+socialImage: https://storage.googleapis.com/sourcegraph-assets/blog/backend-integration-testing/backend-integration-testing.png
published: true
---
-
+
My name is Joe Chen and I was on the Core Application team at Sourcegraph (before it split into Repo Management and Cloud SaaS––I'm on the latter at the time of writing). Our responsibility was to build and maintain the infrastructure of the Sourcegraph application for other teams. Some of our previous work includes licensing enforcement, background permissions syncing, and explicit permissions APIs.
diff --git a/content/blogposts/2021/sourcegraph-cloud-teams-beta.md b/content/blogposts/2021/sourcegraph-cloud-teams-beta.md
index 476599a4..9c507218 100644
--- a/content/blogposts/2021/sourcegraph-cloud-teams-beta.md
+++ b/content/blogposts/2021/sourcegraph-cloud-teams-beta.md
@@ -12,13 +12,12 @@ published: true

-Sign up to get instant access to code navigation and intelligence across your team’s private code and 2M open source repositories. Sourcegraph Cloud for teams brings enterprise advantages to small teams. Not ready to bring your team along? You can use [Sourcegraph.com](https://sourcegraph.com) to search your personal repos and the open source universe today.
+
+ Update: The Sourcegraph Cloud private beta (for teams) is now closed to new signups. If you are interested in using Sourcegraph for your team, you can get started via self-hosting or get in contact with us for a demo.
+Sourcegraph Cloud is still available for individuals at Sourcegraph.com.
+
+Sourcegraph Cloud for teams brings enterprise advantages to small teams. Not ready to bring your team along? You can use [Sourcegraph.com](https://sourcegraph.com) to search your personal repos and the open source universe today.
The tools you have access to matter. A lot. According to a recent [McKinsey study](https://www.mckinsey.com/industries/technology-media-and-telecommunications/our-insights/developer-velocity-how-software-excellence-fuels-business-performance), “best-in-class tools are the primary driver of developer velocity... The ability to access relevant tools for each stage of the software lifecycle contributes to developer satisfaction and retention rates that are 47 percent higher for top-quartile companies compared to bottom-quartile performers.”
@@ -32,12 +31,6 @@ While code search isn’t new, access to its advantages has been limited to comp
We [recently announced](/blog/why-index-the-oss-universe/) a public beta for private code on Sourcegraph Cloud and we’re expanding access to small teams. With this release of Sourcegraph Cloud for teams, teams of up to 25 developers who use GitHub.com and GitLab.com can adopt Sourcegraph and gain the benefits of universal code search in minutes without needing to self-host.
-
-
## Code search for small teams
Access to advanced code search gives teams a massive productivity boost. For small teams, these gains can have a huge impact on scale, velocity, and team morale: it facilitates faster code discovery, streamlines collaboration, and helps to mitigate risks. We designed Sourcegraph Cloud for teams specifically for small engineering teams so you can understand, share, and navigate code without needing to invest time and effort into setting up and maintaining a self-hosted tool.
@@ -79,4 +72,4 @@ For teams leveraging open source projects and packages, the ability to track dep
With Sourcegraph, you and your team can perform your best work. Understanding new code, collaboration, and code reviews are faster and more efficient when you can search your entire graph of code for answers. Sourcegraph allows you to never miss anything when understanding your code, so you can do your best work.
-Interested in Sourcegraph Cloud for your team? You can [read more and sign up here](/cloud-beta/?&utm_medium=direct-traffic&utm_source=blog&utm_content=cloud-product-beta-teams). You can also learn more about [how we approached expanding an on-premise product to SaaS here](/blog/expanding-sourcegraph-from-on-premise-to-saas/).
+Learn more about [how we approached expanding an on-premise product to SaaS here](/blog/expanding-sourcegraph-from-on-premise-to-saas/).
diff --git a/content/blogposts/2021/tackling-the-long-tail.md b/content/blogposts/2021/tackling-the-long-tail.md
index 46060371..6b84ee46 100644
--- a/content/blogposts/2021/tackling-the-long-tail.md
+++ b/content/blogposts/2021/tackling-the-long-tail.md
@@ -1,5 +1,5 @@
---
-title: 'How we’re tackling the long tail of tiny repos with shard merging'
+title: 'Using shard merging to tackle the long tail of tiny and stale repos'
description: 'Sourcegraph is on track to grow its index of open source repositories significantly, with the aim of indexing the OSS universe. This post dives into the motivations behind introducing shard merging to our search backend.'
author: Stefan Hengl
publishDate: 2021-11-09T10:00-07:00
diff --git a/content/blogposts/2022/developer-productivity.md b/content/blogposts/2022/developer-productivity.md
new file mode 100644
index 00000000..6348662f
--- /dev/null
+++ b/content/blogposts/2022/developer-productivity.md
@@ -0,0 +1,134 @@
+---
+title: "A dev's thoughts on developer productivity"
+description: 'Developers are systems thinkers and yet, most measures of developer productivity are metrics-based, instead of systems-based. In this post, Sourcegraph co-founder and CTO Beyang Liu presents five charts that visualize what really matters for developer productivity.'
+author: Beyang Liu
+authorUrl: https://twitter.com/beyang
+publishDate: 2022-05-10T18:00+02:00
+tags: [blog]
+slug: developer-productivity-thoughts
+heroImage: https://storage.googleapis.com/sourcegraph-assets/blog/default_hero_social.png
+socialImage: https://storage.googleapis.com/sourcegraph-assets/blog/developer-productivity/Troy-overlay.jpeg
+published: true
+---
+
+Why don't we hear more developer voices in the conversation about "developer productivity"? Most self-styled experts on developer productivity seem more interested in selling something rather than painting an accurate picture of how devs really work. Perhaps as a consequence, we're swimming in acronyms, magic metrics, and methodologies, but not a lot of rigorous systems thinking.
+
+Devs are systems thinkers. Our job is to model and build systems, and we often draw out diagrams and schematics to illustrate how those systems work. But when it comes to our own work, we are letting others draw the pictures—and they've done a poor job. I doubt that I'm the only dev who feels a little wary of what the "experts" on my productivity have had to say.
+
+Instead, shouldn't we start from direct experience, our own mental models of how we work? Shouldn't _we_ be drawing pictures and diagrams that actually approximate the world in which we live? Here's an attempt to do so.
+
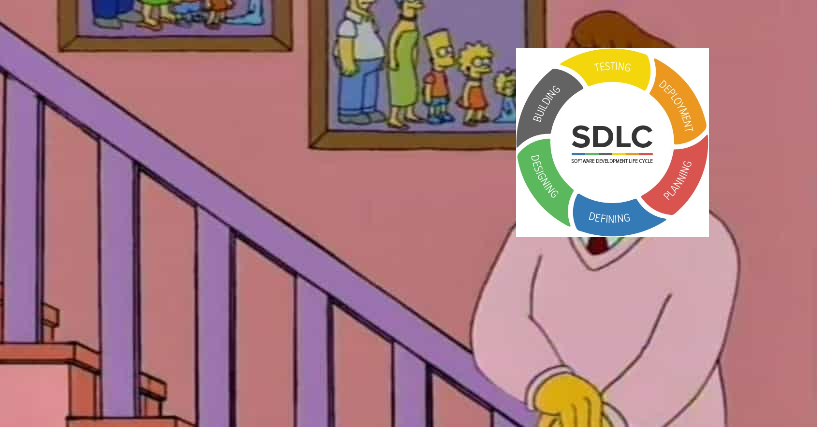
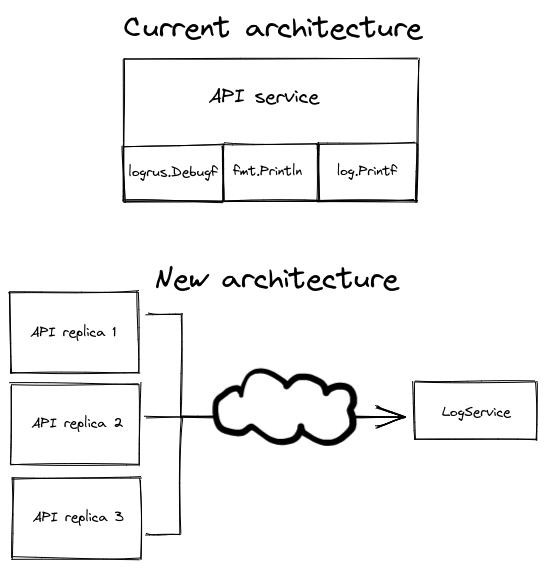
+### Picture 1: The inner loop and outer loop
+
+
+
+Hi, I'm the SDLC. You may remember me from such developer marketing campaigns as Shift Left, DORA the DevOps Explorer, and Agile Waterfalls.
+
+
+The common picture of the software development process is the SDLC. A mainstay of DevOps marketing campaigns, the SDLC does a good job of highlighting the many stages involved in bringing code to production. The SDLC, however, leaves the most critical step in software development undefined: how the code, itself, is understood and written.
+
+When I think of my own work as a developer, there isn't just one big loop, as pictured in the SDLC, but two nested loops:
+
+- The outer loop maps roughly to the SDLC and happens at the level of sprints, projects, or releases.
+- The inner one is the read-write-run loop that happens many times per day when you're in the thick of understanding code, writing code, running tests, and repeating until you're happy with the code.
+
+
+
+You enter the inner loop whenever you get "close to the source" in the development process. This happens at multiple points in the outer loop, such as when you’re:
+
+- Onboarding to the code you're about to change.
+- Authoring a new feature or bug fix.
+- Fixing a test that broke in CI.
+- Reviewing a patch or responding to a review.
+- Debugging what went wrong in a failed deployment.
+- Remediating an incident in production.
+
+It's important to talk about the inner loop. It's the heart of software creation. If you don't talk about it, then your organization will treat it as if it doesn't matter.
+
+### Picture 2: Reaching flow state
+
+Inside the inner loop is the golden state: [Flow](https://stackoverflow.blog/2018/09/10/developer-flow-state-and-its-impact-on-productivity/). Flow state is that state of focus and productivity that you attain when you're feeling inspired and motivated. It’s when you have "paged in" all the necessary context and can actually have fun. It's when you're _coding at the speed of thought_. The ideal path to Flow is represented in this first graph:
+
+
+
+Reaching flow state accelerates the inner loop. But flow state takes uninterrupted time to reach. Mental context switches take you out of it. The most common complaint I hear from developers struggling to get things done is that there are too many interruptions. Many devs' day-to-day sadly looks more like this graph:
+
+
+
+Flow-destroying interruptions can be internal or external.
+
+- An external context switch is triggered by an external factor, like a scheduled meeting or an impromptu question from a teammate.
+- An internal context switch is triggered by a necessary side quest, such as the need to understand how to use a library, the need to set up a tool, or the need to resolve a blocking issue.
+
+I suspect that every programmer has experienced the 1st graph at some point in their lives, probably early enough to suck them into programming—that feeling of flow can be quite the gateway drug. But many get stuck in the second graph when they code professionally, and that is a great source of developer misery and lost productivity.
+
+#### A unit for developer productivity
+
+The above charts reveal a question we should ponder before proceeding: **What exactly is "productivity", the y-axis in our chart above?** Many developers can describe how it _feels_, but can we arrive at a more precise definition? Lines of code? Number of commits? Some synthetic metric derived from version control history? All these seem like poor measures of developer productivity.
+
+Software development is at its core an innovative endeavor. Unlike the manufacture of physical things, the goal is not to produce something that has been produced before. The goal is to produce _new and useful_ knowledge. The atomic unit of innovation is iteration—the cycling of the inner loop.
+
+The atomic unit of developer productivity ought then to be one iteration of the inner loop. The appropriate unit is not code quantity, but iteration frequency. We might call this unit of quantity **developer hertz**.
+
+### Picture 3: Progress is a vector sum in codespace
+
+In the physical world, velocity has two components: direction and speed. Analogously, developer velocity can also be broken down into a direction and a magnitude.
+
+
+
+The speed component indicates how quickly you're cycling through the inner loop. The more you reach flow state, the faster you iterate, and the sooner you’re able to ship your new feature or patch.
+
+The directional component reflects the technical direction taken—whether you use library X or Y, for example. Picking a good direction might provide a critical shortcut. Picking a bad direction might mean you have to retrace your steps later.
+
+Great direction-setting means making the choices that get an end-to-end system up and running as quickly as possible. Getting an end-to-end system up quickly de-risks the overall project. Reaching a shippable state well before the appointed deadline means you can make further improvements in the time remaining. It's helpful to view the destination not as a single point, but as a zone of acceptable outcomes. Get into the acceptable zone first and then improve your position.
+
+### Picture 4: Team velocity is the low-variance sum of high-variance individuals
+
+So far, our pictures have treated software development as a solo endeavor. But most software is made in teams. Teamwork leads to more robust and consistent progress. As the old adage says, "If you want to go fast, go alone. If you want to go far, go together."
+
+Individual velocity tends to be choppy. There are inevitably days spent mostly onboarding to unfamiliar code or where external factors interrupt regularly scheduled programming. But individual bumps smooth out when you add them together.
+
+
+
+If a team suffers from a sustained period of low productivity, it's worthwhile to ask what factor caused a correlated drop in productivity across all members of the team. Sometimes, there's a natural explanation—perhaps a new quarterly planning process took up an inordinate amount of time. And sometimes there is a more serious cause—morale issues, technical debt, or a lack of clear goals and priorities.
+
+### Picture 5: Concurrency is not parallelism
+
+It's generally believed that the productivity of a software team scales sub-linearly—and eventually decreases—with the size of the team. There are analogs here to parallel computing and [Amdahl's law](https://en.wikipedia.org/wiki/Amdahl%27s_law). If you double the number of CPUs on a machine, programs may get faster, but almost never twice as fast.
+
+In computers, the factors that slow down parallelization are CPU context switching and how work is broken into independently processable chunks. In software teams, the primary factors are communication overhead, the dependency structure of the work, domain expertise, and the speed of context acquisition.
+
+You can draw this out in a picture where you've broken down a project into different deliverables. The finished product is a pyramid of sorts, where the blocks at the bottom have to be laid before the ones on top:
+
+
+
+The colors map to different areas of domain expertise. If you are a developer with expertise in multiple areas, you could build the entire project yourself. Or you could delegate the task to two other developers who each have expertise in a single area:
+
+
+
+The two developers have the advantage that they can build separate blocks in parallel, but their parallelism is constrained by serial dependencies (some blocks must be laid before others), the friction of onboarding to unfamiliar parts of the code, and communication overhead.
+
+It is wishful thinking that the project will be completed twice as fast by two developers as by one. Indeed, even net speedup is no guarantee. But some amount of net speedup is well within reach if there is good division of labor and team rapport.
+
+Each added person, however, increases the complexity of the coordination task and most teams see vastly diminishing returns with each additional person. This is why many organizations prioritize hiring and retaining the best developers over just expanding the size of the team. They also invest in tooling that enables greater individual productivity and helps with the coordination of software development at scale.
+
+### If we don't talk about developer productivity, someone else will
+
+Earlier, I said that if developers didn't talk about these elements of our productivity, then our organizations wouldn't realize they matter.
+
+Even worse, however, is someone else coming along and convincing our organizations that other things matter more. Too often, we find ourselves crammed into a framework that views software creation not as a journey of discovery, but as an unimaginative widget factory. Rather than value the inner loop, where all code is understood and created, we're asked to think only in terms of the mechanical outer loop. What good is "change failure rate" if you can't even jump-to-def across your code? Rather than invest in quality tools that improve our lives as engineers, we're compelled toward the classic Mythical Man Month fallacy that leads to more people, more code, and more problems.
+
+It is to our benefit, and to the benefit of our industry and society at large, to advance mental models that reflect the reality of our work and honor its essential creativity.
+
+In this post, I've sketched out some pictures that resonate with one developer—me. What about you? When you think about your own creative process and that of your team, what pictures do you see?
+
+_Huge thanks to Dan Robinson, Thorsten Ball, Stephen Gutekanst, Timothy Liu, and Nick Moore for providing feedback on this post._
+
+#### About the author
+
+_Beyang Liu is the CTO and co-founder of Sourcegraph, the code intelligence platform for dev teams and making coding more accessible to more people. Prior to Sourcegraph, Beyang was a software engineer at Palantir Technologies, where he developed new data analysis software for Fortune 500 companies. Beyang studied Computer Science at Stanford, where he published research in probabilistic graphical models and computer vision at the Stanford AI Lab._
+
+### More posts like this
+
+- [5 key elements of successful monolith-to-microservices migrations](https://about.sourcegraph.com/blog/monolith-microservices-migration/)
+- [An ex-Googler's guide to dev tools](https://about.sourcegraph.com/blog/ex-googler-guide-dev-tools/)
+- [How we migrated entirely to CSS Modules using codemods and Sourcegraph Code Insights](https://about.sourcegraph.com/blog/migrating-to-css-modules-with-codemods-and-code-insights/)
diff --git a/content/blogposts/2022/monolith-microservices.md b/content/blogposts/2022/monolith-microservices.md
new file mode 100644
index 00000000..816efda1
--- /dev/null
+++ b/content/blogposts/2022/monolith-microservices.md
@@ -0,0 +1,125 @@
+---
+title: '5 key elements of successful monolith-to-microservices migrations'
+description: "At Sourcegraph, we've helped enable some of the best engineering organizations in the world to perform major architectural migrations. In this post, we present five lessons, five elements of a successful monolith to microservices migration."
+author: Beyang Liu
+authorUrl: https://twitter.com/beyang
+publishDate: 2022-04-28T18:00+02:00
+tags: [blog]
+slug: monolith-microservices-migration
+heroImage: https://storage.googleapis.com/sourcegraph-assets/blog/monolith-microservices/image5.png
+socialImage: https://storage.googleapis.com/sourcegraph-assets/blog/monolith-microservices/image5.png
+published: true
+---
+
+Ah, microservices.
+
+In the grand Hegelian tradition of programmer dialectics—React vs. Angular, Emacs vs. Vim, Tabs vs. Spaces—the great debate of Microservices vs. Monoliths rages on.
+
+Generally speaking, "doing microservices" at inception is premature abstraction. Therefore, most microservice architectures emerge through migrations from a monolithic architecture. This migration is often a make-or-break moment for a software organization. Migrate well and you'll unlock the ability to maintain velocity as your app serves more and more users. Migrate poorly and your entire engineering team could be stuck in stasis for months or years, bogged down in a never-ending slog that blocks critical features and hamstrings your ability to scale.
+
+At Sourcegraph, we've had the privilege of working with some of the best engineering organizations in the world and have enabled major architectural migrations across many different industries. Here, we share a common template we've discovered after witnessing what works and what doesn't.
+
+Here are five critical elements to a successful, large-scale architectural migration:
+
+1. Designate a single owner and identify all the stakeholders
+2. Define what success is and isn't
+3. Alternate between big non-breaking changes and small breaking ones
+4. Automate with the human in the loop
+5. Track progress
+
+### 1. Designate a single owner and identify all stakeholders
+
+Identify a single team or person who will be responsible for driving the migration. A common choice is the leader of the developer experience team. This person must understand that the task at hand is not just a technical one, but one of stakeholder alignment and communication. They will be pushing changes that impact the work of many teams. It's important they are able and willing to help those teams understand the importance the change and enlist their cooperation in the effort.
+
+Tactically, it's important for the owner to identify all the stakeholders whose input is necessary as early as possible. This will ensure those stakeholders will support the effort as something they helped define, instead of something that feels like it’s being imposed on them without their input. The stakeholders list should include all the owners of the code that will need to be modified. The "find-references" feature of your editor or code browser is your friend in this endeavor!
+
+
+
+Find all the locations in code that will need to change and identify the owners of those locations. Then, make a list or spreadsheet of owners whose approval you'll need.
+
+### 2. Define success
+
+Lay out a clear vision for what the end state of the migration looks like and tie this to the goals you want to achieve. A lot of big migrations drag on because the original objectives were not clearly defined. The migration may also be abandoned if it has dragged on and it remains unclear how far away the finish line is.
+
+Defining the end state also helps you justify the bigger changes that are necessary to make a real difference. Avoid the inertia of incrementalism by picking a desired end state that reflects your true architectural goals. For example, if your goal is to modularize the major components of a monolith, some pretty big changes will be necessary and you're unlikely to reach your goal if you limit yourself to local, conservative changes.
+
+Here is [a template](https://docs.google.com/document/d/1TbsQC7fFVdMKjkfNegU7OwUUglfB8j-jOeoN6ULAgE0/edit#) derived from a few examples of planning docs for large-scale migrations.
+
+
+
+A sample architecture diagram showing the high-level change being implemented.
+
+
+Share this document with the list of stakeholders you created in step 1. Feedback serves two purposes:
+
+1. Feedback will improve the proposal by calling out difficulties one person alone couldn't foresee.
+2. Feedback will strengthen stakeholder buy-in needed to follow through on changes across the codebase.
+
+### 3. Alternate between big non-breaking and small breaking changes
+
+Once you've decided on the end state, break things down into more manageable, intermediate milestones. In your roadmap, avoid making changes that are big, breaking, and irreversible. These kinds of changes can disrupt development or bring down prod for an extended period of time.
+
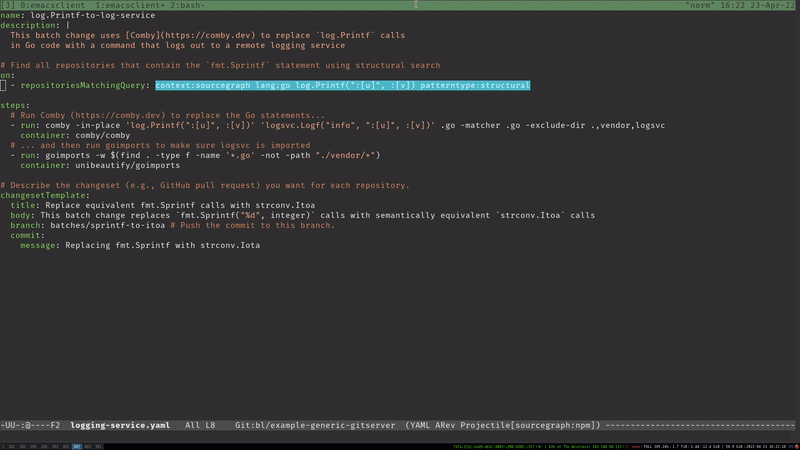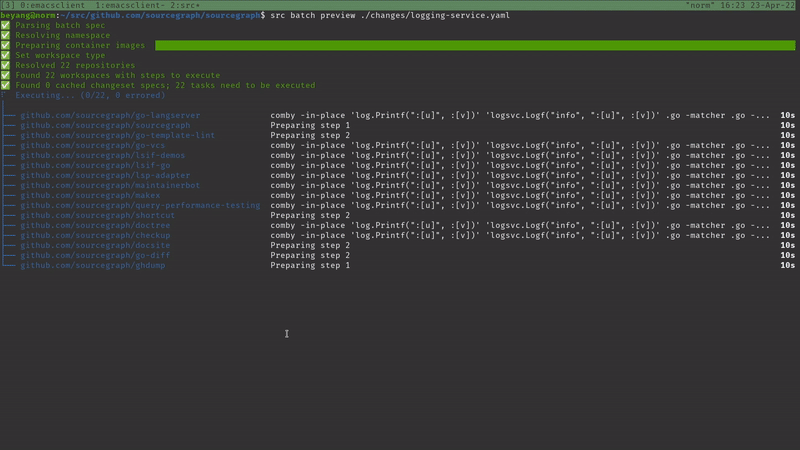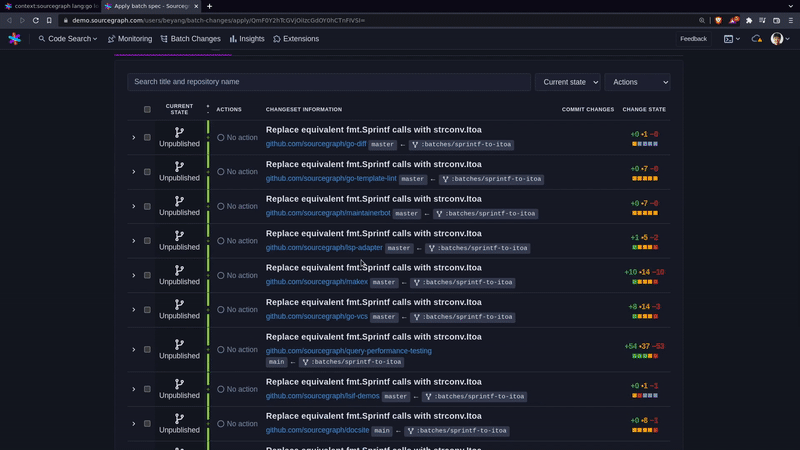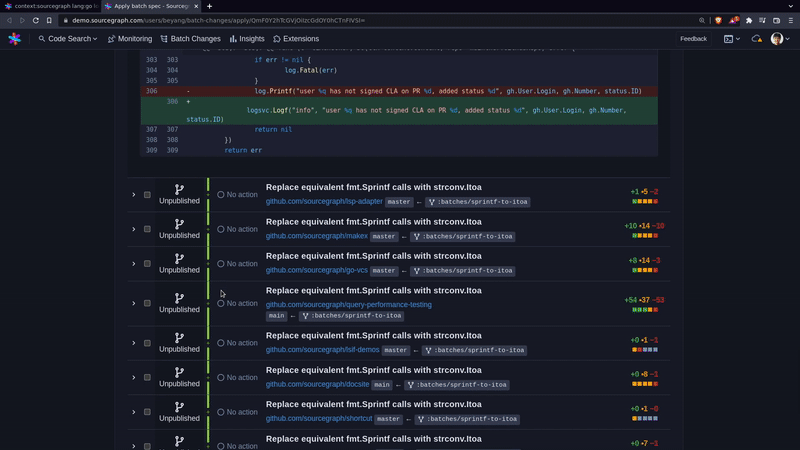
+A common pattern is to alternate between big changes that preserve backcompat and small, atomic (and ideally reversible) ones that break it. Many efforts will cycle through the following steps:
+
+1. Build the new service without changing the existing system.
+2. Introduce a conditional switch between the old and new code paths. (This may involve introducing a new interface or feature toggle, or it might just be a simple `if` statement.)
+3. Make the small, backcompat-breaking change. (For example, switch the interface implementation or flip the feature toggle.) Ideally, you've designed this so that it's easy to rollback if something goes wrong.
+4. Clean up the old code that's no longer used.
+
+This cycle may repeat once or dozens of times over the course of the migration. It's not uncommon for a full migration to take years from start to finish if the monolith is big and complex enough. If that's the case, you'll definitely want shorter-term, intermediate milestones that leave both dev and prod in a working state.
+
+
+
+Feature flags are a common way to make breaking changes small and atomic.
+
+### 4. Automate with a human in the loop
+
+Steps 2 (add conditional switch) and 4 (clean up old code) from the migration cycle often involve making a simple refactor at a very large scale across the codebase. You'll want to automate these steps because it will otherwise become a tedious "death by a thousand patches."
+
+First, try making the necessary change in one or two places manually to get a sense of what needs to be automated.
+
+Then, scale that change across the entire codebase.
+
+It's important the tool you use permits feedback and adjustments along the way, because there will invariably be edge cases you didn't foresee.
+
+
+
+In a microservices migration, it’s common to need to make simple changes to numerous places in the code. Automation can help with an otherwise tedious process, but it’s important to keep the human in the loop because the changes can sometimes be subtly different or can require conversations with the teams that own the code being updated.
+
+
+Here are the tools that we've seen used to shepherd such large-scale migrations:
+
+- Ad hoc scripts that clone down the affected repositories and apply the change using a command-line code modification tool like sed, codemod, or Comby.
+- In-house tools such as Google's [Rosie](https://cacm.acm.org/magazines/2016/7/204032-why-google-stores-billions-of-lines-of-code-in-a-single-repository/fulltext).
+- Sourcegraph [Batch Changes](https://sourcegraph.com/batch-changes).
+
+### 5. Track progress
+
+Finally, track progress toward your end goal. Engineering leaders, developers working in the codebase, and stakeholders from Product, Sales, and other departments will want to know how the migration is progressing, especially if it’s blocking other product development efforts they care about.
+
+You will want to track progress at two levels:
+
+1. Progress of every intermediate milestone, each of which may involve many code reviews that all of the teams affected by the changeset must approve.
+2. Progress toward the overall end goal, which may play out over the course of months or years. If you don’t clearly define this progress meter, you will waste a lot of time explaining and communicating progress to increasingly skeptical stakeholders.
+
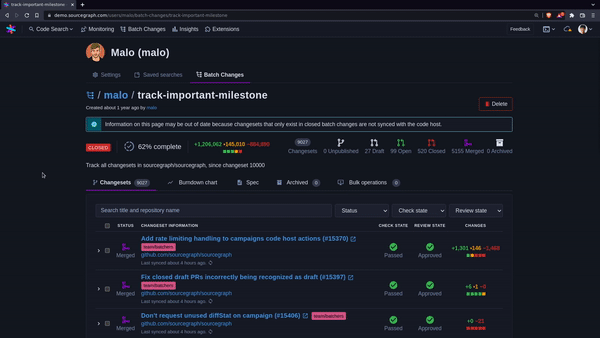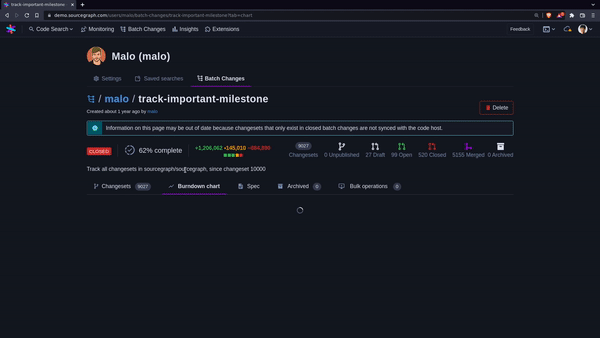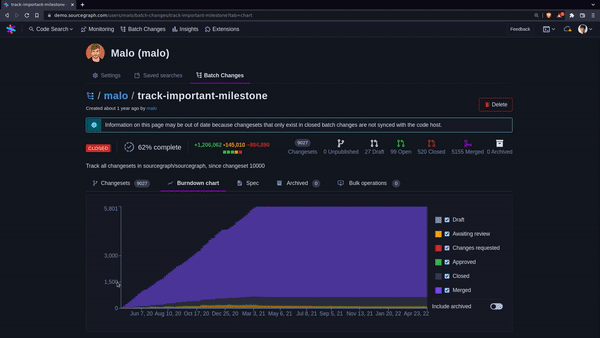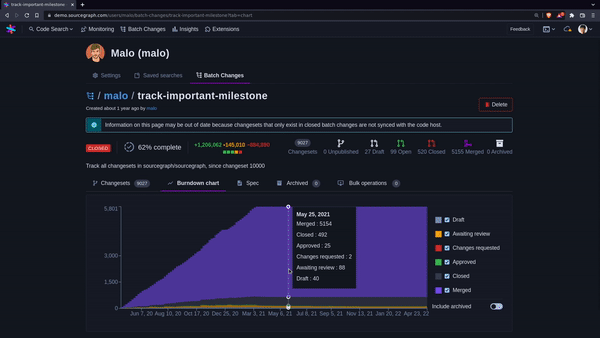
+
+
+One way to track the progress of a migration underway is through a burndown chart.
+
+
+
+A burndown chart tracks the progress of a single change campaign, but many microservices migrations will be broken down into multiple milestones. To track overall progress toward the target architecture, it can be helpful to plot the occurrence of patterns in the code that indicate the use of both the old and new architecture.
+
+### It's not about the journey
+
+When it comes to big refactors and migrations, it really is about defining your destination and getting there as quickly as possible—with buy-in from all stakeholders. The good news is that many organizations have already undertaken such migrations. These 5 elements for successful monolith-to-microservices migrations come from the collective experiences of some of the best engineering organizations we've worked with. There has clearly been [a lot of pain](https://twitter.com/beyang/status/1517569661650362368). Let's learn from it.
+
+#### About the author
+
+_Beyang Liu is the CTO and co-founder of Sourcegraph, the code intelligence platform for dev teams and making coding more accessible to more people. Prior to Sourcegraph, Beyang was a software engineer at Palantir Technologies, where he developed new data analysis software for Fortune 500 companies. Beyang studied Computer Science at Stanford, where he published research in probabilistic graphical models and computer vision at the Stanford AI Lab._
+
+### More posts like this
+
+- [An ex-Googler's guide to dev tools](https://about.sourcegraph.com/blog/ex-googler-guide-dev-tools/)
+- [How we migrated entirely to CSS Modules using codemods and Sourcegraph Code Insights](https://about.sourcegraph.com/blog/migrating-to-css-modules-with-codemods-and-code-insights/)
+- [Broken database migrations: How we finally fixed an embarrassing problem](https://about.sourcegraph.com/blog/introducing-migrator-service/)
diff --git a/content/blogposts/2022/notebooks-ci.md b/content/blogposts/2022/notebooks-ci.md
new file mode 100644
index 00000000..77f5713b
--- /dev/null
+++ b/content/blogposts/2022/notebooks-ci.md
@@ -0,0 +1,93 @@
+---
+title: 'How we used Notebooks to make our CI more accessible and understandable'
+description: 'The Sourcegraph CI is complex and customized. To make it more accessible, software engineer Robert Lin used the new Sourcegraph feature, Notebooks, to make living documentation.'
+author: Robert Lin
+authorUrl: https://handbook.sourcegraph.com/team/#robert-lin
+publishDate: 2022-04-28T18:00+02:00
+tags: [blog]
+slug: notebooks-ci
+heroImage: https://storage.googleapis.com/sourcegraph-assets/blog/Notebooks/sg-notebooks-landingpage-desktop%20copy.jpg
+socialImage: https://storage.googleapis.com/sourcegraph-assets/blog/Notebooks/sg-notebooks-landingpage-desktop%20copy.jpg
+published: true
+---
+
+Today, Sourcegraph is announcing the general availability of Notebooks. Notebooks allows developers to integrate code search queries with text, so you can create living documentation that always references live code. I remember when I first tried Notebooks shortly after it was announced internally. My reaction was something along the lines of “I didn’t know I needed this!” Now, it’s a vital part of my collaborative workflow.
+
+In this post, I’m going to walk through two ways I use Notebooks here at Sourcegraph. In both cases, I’m using Notebooks to capture and share code examples but in one, I’m embedding Sourcegraph search queries into documentation and in the other, I’m assembling code examples on the fly to make parts of our codebase more understandable to other developers.
+
+## Our continuous integration pipeline and the tradeoffs of complexity
+
+The advantage of customization is flexibility but the tradeoff is complexity–complexity that we can combat with live documentation using Notebooks.
+
+Typically, continuous integration (CI) pipelines are specified by committing a YAML file to your repository that CI services pick up and run. This YAML file will specify what commands should get run over your codebase and will usually support some simple conditions, and is an easy way to get started. However, running certain tasks or combinations of checks based on whether particular sets of files have been changed or other complex conditions can quickly become quite gnarly to describe in YAML–especially in a large monorepo. So instead, we generate the entire Sourcegraph pipeline on the fly, allowing us to easily customize builds based on an array of conditions such as diffs, branch names, and commit messages, and hook into what developers provide the pipeline generator in interesting ways.
+
+Customizability has advantages and disadvantages: the major advantage is that you can build precisely what you want and the major disadvantage is that the more unique something is, the harder you have to work to explain it.
+
+Notebooks fit into this gap perfectly, and it naturally became very important to my workflow.
+
+## Notebooks augment documentation with live code examples
+
+Documentation can easily go stale and lag behind the code it documents, especially for internal tools and libraries where APIs can change liberally. Example code is especially at risk unless special care is taken to ensure documentation is updated in lock-step with your code.
+
+With Notebooks, you can embed code directly into your documentation (and other internal knowledge management systems) and run Sourcegraph searches without having to leave whatever page you’re on. Notebooks augment our existing documentation, allowing developers to read static, explanatory text as well as run searches that return live code results. Developers can read _about_ code and then see the actual code with just a click.
+
+Take a look at the [CI pipeline development documentation](https://docs.sourcegraph.com/dev/background-information/ci/development), where I've embedded notebooks that further explain, and demonstrate, the [Run types](https://docs.sourcegraph.com/dev/background-information/ci/development#run-types) and [Diff types](https://docs.sourcegraph.com/dev/background-information/ci/development#diff-types) used internally by the pipeline generator.
+
+
+
+You can read about these in detail in the docs, but the idea is that the pipeline generator primarily determines what gets run over contributions based on:
+
+1. Run types, which are determined by branch naming conventions, tags, and environment variables; and
+2. Diff types, which are determined by what files have been changed in a given branch.
+
+I created notebooks for Run types and Diff types so that Sourcegraph developers can see them in action and in the code. The notebook for Run types includes both a search that shows Run types in the codebase and a search for RunTypeMatcher, which further shows how each RunType declares the conditions under which it should be used.
+
+Our static CI documentation now contains living documentation–code pulled directly from the current state of the codebase, complete with hover tooltips and jump-to-definition for an IDE-like experience–enabling developers to understand these concepts in theory and in practice. The end result is that our developers will spend fewer hours onboarding and combing through documentation for up-to-date information.
+
+## Notebooks provide a place for on-the-fly, ephemeral documentation
+
+I spend a lot of time explaining code and having code explained to me. One brain can’t hold an entire codebase so we’re always reliant on other developers to know, explain, and document other parts of a codebase. Documentation is rarely sufficient, however, and that often means a call with a shared screen is most effective as one of us walks through code and the other listens.
+
+The trouble with this workflow is that it typically leaves no trace and must happen synchronously, which goes against [Sourcegraph’s async-first aspirations](https://handbook.sourcegraph.com/company-info-and-process/communication/asynchronous-communication/). That’s why I started using Notebooks to build code walkthroughs on the fly.
+
+I found this really useful because it fills a gap I noticed between permanent documentation, which tends to take a while to produce, and synchronous discussions, which can be tough to arrange in a globally remote team. I call it ephemeral documentation.
+
+Let’s walk through a couple of examples. In this notebook, [Usages of soft failures in Buildkite pipelines](https://sourcegraph.com/notebooks/Tm90ZWJvb2s6NzU1), you can see a brief explanation of soft failures (basically, soft failures don’t cause the entire build to fail) and searches that show soft failures in the Sourcegraph pipeline generator and soft failures in our Buildkite YAML pipelines.
+
+This notebook came about because a coworker was asking about how we use soft failures in our pipelines, and how they work. Rather than try to list out their usages, I simply wrote a notebook with some searches that easily captured all usages. From this notebook, you can use these two searches and see live code that shows exactly what we mean by soft failures.
+
+
+
+Another example: I created this notebook, [Buildkite command tracing](https://sourcegraph.com/notebooks/Tm90ZWJvb2s6NzU0), when a coworker asked how our CI command tracing worked. This coworker was on another team and only knew, vaguely, that we had some sort of command tracing. They knew how they might implement command tracing in code but didn’t know how we had implemented it in the pipeline, especially considering things are typically scripted as shell commands in a pipeline.
+
+I walked through the code myself to jog my memory, and, along the way, using the notepad, collected links and added comments.
+
+
+
+With a single click, I was able to create a notebook that hooked up to live code from my collected links and comments. I could then share the notebook with my teammate and they could refer to it whenever they wanted to.
+
+Codebases often have lots of levels to them and each feature can be a vertical that touches many different levels of abstraction. With Notebooks, you can easily enable someone, even if they’re unfamiliar with that part of the codebase, to drill down through these layers of abstraction.
+
+## No more band-aids
+
+Our CI pipeline generator is a good example of what happens to code as a company grows up. It was once owned by a team that has since been reshaped and looks different today. Along the way, the pipeline generator has received numerous band-aids over the years to accommodate various use cases. Until I refactored it, the pipeline generator was both messy and inaccessible. Developers struggled to understand and extend it.
+
+Now, the pipeline generator is much cleaner, functional, and extensible. I used notebooks throughout the refactor because they made that work more accessible and easier to understand, the result being a project that receives many more internal contributions than it used to. Teams are now customizing CI pipelines for their needs and making improvements.
+
+As time goes on, I expect the benefits of creating notebooks to compound. Now, when someone refers to the CI documentation, they can see Run types and Diff types in action. Or, when someone else needs to understand soft failures or command tracing, I can just send them the relevant notebooks.
+
+All in all, I’m excited to create and share more notebooks, and excited to see how other developers use them. I think it’s the kind of feature that reveals more power and more use cases as time goes on and more people use it. I can’t wait to see what you create.
+
+Notebooks is now available on Sourcegraph 3.39. If you'd like to try out Notebooks on Sourcegraph Cloud, [you can try them here](https://sourcegraph.com/notebooks).
+
+### More posts like this
+
+- [How we migrated entirely to CSS Modules using codemods and Sourcegraph Code Insights](https://about.sourcegraph.com/blog/migrating-to-css-modules-with-codemods-and-code-insights/)
+- [Broken database migrations: How we finally fixed an embarrassing problem](https://about.sourcegraph.com/blog/introducing-migrator-service/)
+- [How I use the Sourcegraph extension for VS Code](https://about.sourcegraph.com/blog/ways-to-use-sourcegraph-extension-for-vs-code/)
diff --git a/content/blogposts/2022/please-save-git-io.md b/content/blogposts/2022/please-save-git-io.md
new file mode 100644
index 00000000..dbbd06a6
--- /dev/null
+++ b/content/blogposts/2022/please-save-git-io.md
@@ -0,0 +1,45 @@
+---
+title: "Please save git.io: GitHub's link shortener is being shut down in 3 days"
+author: Stephen Gutekanst
+authorUrl: https://github.com/slimsag
+publishDate: 2022-04-26T12:00-00:00
+tags: [blog]
+slug: please-save-git-io
+heroImage: https://user-images.githubusercontent.com/3173176/165389559-26ee5644-e9db-4c95-b042-e6d72a825e9e.png
+socialImage: https://user-images.githubusercontent.com/3173176/165389559-26ee5644-e9db-4c95-b042-e6d72a825e9e.png
+published: true
+description: Yesterday, GitHub announced that it intends to shut down git.io, its link-shortener service, in just 3 days time. Please help us save git.io and the hundreds of thousands of links that will be broken!
+---
+
+Yesterday, [GitHub announced](https://news.ycombinator.com/item?id=31162829) that it intends to shut down git.io, its link-shortener service, in just 3 days time:
+
+> What began as an experiment was only lightly documented and was not widely adopted.
+> In January 2022, we announced that git.io was becoming read-only. As notified in January, we shared our plans to deprecate the service. Out of an abundance of caution due to the security of the links redirected with the current git.io infrastructure, we have decided to accelerate the timeline. We will be removing all existing link redirection from git.io on April 29, 2022.
+
+## Why this matters
+
+Git.io is widely used and extinguishing this service will result in hundreds of thousands of links becoming broken:
+
+- [Thousands of scientific papers](https://scholar.google.com/scholar?hl=en&q=git.io) reference git.io URLs and cannot be updated
+- [29,000+ repositories that use git.io links will need to be updated](https://sourcegraph.com/search?q=context:global+https://git.io+count:100000+select:repo&patternType=literal)
+- 704k+ code files mention git.io [according to GitHub search](https://github.com/search?q=git.io&type=code)
+- [Google reports](https://www.google.com/search?client=firefox-b-1-d&q=site%3Agit.io) 10,300+ results for `site:git.io`
+
+## What we’re doing
+
+When some friends and I first heard this news, we thought we had to do everything we could to save it. Sourcegraph agreed, so we’re urgently trying to do everything we can to save git.io:
+
+- Setting up a [Discord server / working group](https://discord.gg/MRJyav9GCf) to discuss what we can do to save it, including scraping as many git.io links as we can before the service is extinguished.
+- Creating a public data set of each URL -> it's redirect in an open source project so we can [work with Archive.org](https://tracker.archiveteam.org:1338/status) once we have the data, or set up a savegit.io domain if needed.
+
+We’re also trying[[0](https://twitter.com/beyang/status/1519017460623499267)][[1](https://twitter.com/slimsag/status/1519023870962929664)] to see if we can get in contact with folks over at GitHub to see if:
+
+- GitHub can open-source the database to avoid a central point of failure
+- GitHub can transfer the data to the community so we can find alternative ways to keep it running
+- We could handle maintenance and run git.io for them at Sourcegraph
+
+## How you can help
+
+If you think you can help out at all, please join the [Save git.io Discord group](https://discord.gg/MRJyav9GCf) where we’re coordinating, discussing scraping strategies, and more.
+
+We’ve only got 3 days, please save git.io!
diff --git a/content/blogposts/2022/release-3.38.md b/content/blogposts/2022/release-3.38.md
new file mode 100644
index 00000000..1d9af405
--- /dev/null
+++ b/content/blogposts/2022/release-3.38.md
@@ -0,0 +1,72 @@
+---
+title: 'Sourcegraph 3.38 release'
+publishDate: 2022-03-21T10:00-07:00
+description: 'Sourcegraph 3.38 introduces improved Notebooks, faster Code Intelligence for large repositories, dependencies search, and custom file syntax highlighting.'
+tags: [blog, release]
+slug: 'release/3.38'
+published: true
+heroImage: https://storage.googleapis.com/sourcegraph-assets/blog/3.38/sourcegraph-3-38-release.png
+socialImage: https://storage.googleapis.com/sourcegraph-assets/blog/3.38/sourcegraph-3-38-release.png
+changelogItems:
+ - description: Code Insights will now periodically clean up data series that are not in use. There is a one-hour grace period where the series can be reattached to a view, after which all of the time series data and metadata will be deleted. This means customers deploying their own instance won't be storing data that has no use.
+ url: https://github.com/sourcegraph/sourcegraph/pull/32094
+ category: Code Insights
+ - description: 'Notebooks from private enterprise instances can now be embedded in external sites by enabling the `enable-embed-route` feature flag. This allows you to embed Notebooks within existing technical documentation to see your documentation and code side by side.'
+ url: https://docs.sourcegraph.com/notebooks/notebook-embedding
+ category: Notebooks
+ - description: LSIF upload pages now include a section listing the reasons and related retention policies resulting in an upload being retained and not expired.
+ url: https://github.com/sourcegraph/sourcegraph/pull/30864
+ category: Code Intelligence
+ - description: 'Code monitoring now has a Logs tab enabled as a beta feature. This lets you see recent runs of your code monitors and determine if any notifications were sent or if there were any errors during the run.'
+ url: https://github.com/sourcegraph/sourcegraph/pull/32292
+ category: Admin
+ - description: 'Searching for the pattern `//` with regular expression search is now interpreted literally and will search for `//`. Previously, the `//` pattern was interpreted as our regular expression syntax `//` which would in turn be interpreted as the empty string. Since searching for an empty string is not very useful, we now instead interpret `//` as searching for its literal meaning in regular expression search.'
+ url: https://github.com/sourcegraph/sourcegraph/pull/31520
+ category: Search
+---
+
+Sourcegraph 3.38 is now available! In this release:
+
+## Code Insights is generally available
+
+[Code Insights](https://docs.sourcegraph.com/code_insights) transforms any search query into customizable, visual dashboards in seconds. This feature surfaces high-level information about your codebase, based on both how your code changes over time and its current state. You can learn more about why we built Code Insights in [the announcement from our CEO](https://about.sourcegraph.com/blog/announcing-code-insights/).
+
+Any Sourcegraph instance can create up to two code insights, even without a trial or license. Reach out to your account team to purchase access to the full version.
+
+
+
+
+
+## Notebooks are improved with a host of new features
+
+Notebooks have several new features in 3.38 to help your team better understand your codebase:
+
+- You can now copy any existing Notebook to your own collection of Notebooks.
+- We've created a new symbol block type. This block lets you find any symbol in a repository, and the block will display that symbol no matter where it moves within a file.
+- Code Intelligence is now available in Notebook blocks, making Notebooks more intuitive to be used for onboarding and learning about your codebase.
+- Embedding Notebooks is here! You can now easily embed Notebooks from any Sourcegraph instance by embedding an iFrame anywhere, and setting `src` to `https://sourcegraph.com/notebooks/embed/`.
+
+## Improved Code Intelligence performance for large repositories
+
+We're introducing a new backend service, Rockskip, for search-based Code Intelligence, the symbol sidebar, and symbol search. Rockskip was architected with monorepos in mind, and it can index new commits much faster than the existing SQLite backend.
+
+From 3.38 onwards, Rockskip can be turned on for specific repositories and it will make the symbol sidebar and search-based Code Intelligence much faster. If you're interested in turning this on for your repositories, read more in the [Rockskip docs](https://docs.sourcegraph.com/code_intelligence/explanations/rockskip) or [contact us](mailto:support@sourcegraph.com).
+
+## Search your project dependencies for better incident resolution
+
+[Dependencies search](https://docs.sourcegraph.com/code_search/how-to/dependencies_search) is a new beta feature that lets you search through the dependency packages of your repositories. Looking into the code of your dependencies is particularly useful when you're trying to resolve incidents as fast as possible.
+
+Dependencies search currently supports NPM, and more dependency repositories are coming soon.
+
+## Configure custom language highlighting for files & extensions
+
+In the past, it was not possible to configure what language a file was highlighted as without sending a pull request to Sourcegraph to update our global configuration for language detection. Now, if you have specific extensions or files that you want highlighted as a particular language, you can easily configure that in the site settings. This allows you to get accurate highlighting for custom languages, for example.
+
+To learn more and set up custom language highlight, see our [documentation](https://docs.sourcegraph.com/dev/how-to/add_support_for_a_language#syntax-highlighting-support).
diff --git a/content/blogposts/2022/release-3.39.md b/content/blogposts/2022/release-3.39.md
new file mode 100644
index 00000000..ad89c89b
--- /dev/null
+++ b/content/blogposts/2022/release-3.39.md
@@ -0,0 +1,75 @@
+---
+title: 'Sourcegraph 3.39 release'
+publishDate: 2022-04-21T10:00-07:00
+description: 'Sourcegraph 3.39 introduces Notebooks, Code Insights on native PostgreSQL, faster Code Intelligence for Java, and dependencies search for Go.'
+tags: [blog, release]
+slug: 'release/3.39'
+published: true
+heroImage: https://storage.googleapis.com/sourcegraph-assets/blog/3.39/sourcegraph-3-39-release.png
+socialImage: https://storage.googleapis.com/sourcegraph-assets/blog/3.39/sourcegraph-3-39-release.png
+changelogItems:
+ - description: 'The repository page has been redesigned and now includes information such as recent commits and Code Intelligence availability. To use this feature, enable the `new-repo-page` feature flag.'
+ url: https://github.com/sourcegraph/sourcegraph/pull/33319
+ category: Repositories
+ - description: 'The Code Insights GraphQL API now accepts search contexts as filters. Using a search context as a filter will extract the `repo` and `-repo` search query fields from the context and apply it, allowing you to scope your insights and only return data relevant to the repositories you care about.'
+ url: https://github.com/sourcegraph/sourcegraph/pull/33866
+ category: Code Insights
+ - description: 'The Code Insights commit indexer can now index commits in smaller batches to ensure it succeeds for repositories with many commits. Set the number of days per batch in the site setting `insights.commit.indexer.windowDuration`. A value of 0 (default) will disable batching.'
+ url: https://github.com/sourcegraph/sourcegraph/pull/33666
+ category: Code Insights
+ - description: 'Code Insights series data is now sorted by semantic version and then alphabetically to make it easier to understand data in order of earliest to latest versions.'
+ url: https://github.com/sourcegraph/sourcegraph/pull/33454
+ category: Code Insights
+ - description: "We've optimized search patterns containing `and` and `not` expressions. These kinds of queries now generally execute 10 times faster than before. Previous cases where no results were returned due to hitting the file limit should now work and return results quickly."
+ url: https://github.com/sourcegraph/sourcegraph/pull/33308
+ category: Search
+ - description: 'Built-in authentication (i.e. username and password) now supports account lockout after consecutive failed sign-in attempts. New config options have been added under `auth.lockout` to customize the threshold for failed attempts and length of lockouts.'
+ url: https://github.com/sourcegraph/sourcegraph/pull/33999
+ category: Admin
+---
+
+Sourcegraph 3.39 is now available! Here are some highlights from this release:
+
+## Onboard developers fast with Notebooks
+
+Built with onboarding in mind, the Notebooks feature allows you to integrate search results and Markdown to enable documentation that is easy to create and doesn't get stale. The feature is inspired by the Jupyter Notebooks project and features four unique block types, an intelligent notepad for creating notebooks on the fly, and deep integration with Code Search, so you can always find the code you need.
+
+
+
+Web-based notebooks are the easiest way to create and share new documentation with your team, but we also support file-based notebooks via a special `.snb.md` file type. With file-based notebooks, you can transform your existing documentation and augment it with Sourcegraph query blocks. You can also embed notebooks on any web page, enabling easy integration with your own knowledge management systems, so you can meet your developers where they are.
+
+Notebooks are now available for free for all users in Sourcegraph 3.39, and you can also explore some of our [public notebooks on Sourcegraph Cloud](https://sourcegraph.com/notebooks?tab=explore) with no account required.
+
+To learn more, [read the Notebooks docs](https://docs.sourcegraph.com/notebooks).
+
+## Filter Code Insights using search contexts
+
+
+
+
+
+[Search contexts](https://docs.sourcegraph.com/code_search/explanations/features#search-contexts) are pre-set repository groups that make it easy to scope your Sourcegraph searches, and you can now apply search contexts to Code Insights as well. Then, by updating your search contexts, your filtered insights will automatically update to reflect the changes as well. Using search contexts is a fast, succinct way to reuse complex repository filters.
+
+In this initial release, you can use the `repo:` or `-repo:` field of [query-based search contexts](https://docs.sourcegraph.com/code_search/how-to/search_contexts#beta-query-based-search-contexts) to filter your insights. We're continuing to explore enabling other capabilities of search contexts to use as filters. To learn more, [read the search context filters docs](https://docs.sourcegraph.com/code_insights/explanations/code_insights_filters#context-query-based-search-context-filters).
+
+## Code Insights no longer requires a Timescale database
+
+Code Insights can now be used with managed database solutions that do not support [Timescale](https://www.timescale.com/), like Amazon RDS. It now uses native PostgreSQL.
+
+This migration has been applied over 3.37 and 3.38, and should be seamless if you are running infrastructure as described by the [official Sourcegraph deployment repositories](https://sourcegraph.com/search?q=context:global+repo:%5Egithub%5C.com/sourcegraph/deploy-sourcegraph+select:repo&patternType=literal). If you have a customized deployment, you may need to incorporate some changes into your configuration ([more details and examples here](https://github.com/sourcegraph/sourcegraph/issues/32271#issuecomment-1086328666)).
+
+Any managed database solution that supports the [official Sourcegraph PostgreSQL version requirements](https://docs.sourcegraph.com/admin/postgres#version-requirements) is now suitable for Code Insights. Migration from a self-hosted database is not performed automatically, and will need to be performed by a Sourcegraph admin at your own discretion.
+
+## Local navigation for Java code is now faster and more accurate
+
+We've added tree-sitter to our search-based Code Intelligence, meaning that local navigation for Java is now faster and more precise.
+
+
+
+## Search your Go dependencies natively in Sourcegraph
+
+Dependencies search, introduced for NPM in Sourcegraph 3.38, allows you to quickly search through your repository dependencies for faster incident and vulnerability resolution. Dependencies search has been expanded to now support Go dependencies as well. You can [read the dependencies search docs here](https://docs.sourcegraph.com/code_search/how-to/dependencies_search) or [try it out yourself on Sourcegraph Cloud](https://sourcegraph.com/search?q=context:global+r:deps%28%5Egithub%5C.com/sourcegraph/sourcegraph%24%403.37%29+r:%5Ego+fmt.Println&patternType=literal).
diff --git a/content/blogposts/2022/third-party-vulnerabilities-process.md b/content/blogposts/2022/third-party-vulnerabilities-process.md
new file mode 100644
index 00000000..ef4bcc5b
--- /dev/null
+++ b/content/blogposts/2022/third-party-vulnerabilities-process.md
@@ -0,0 +1,66 @@
+---
+title: 'The real weakest link in software supply chain security (it’s not open source)'
+description: 'When a critical security vulnerability is identified, your response time is everything. There are probably shortcomings in your response process itself that are slowing you down—find out where they are and how you can be better prepared for the next third-party vulnerability.'
+author: Rebecca Dodd, André Eleuterio
+authorUrl: https://handbook.sourcegraph.com/team/#andr%C3%A9-eleuterio
+publishDate: 2022-03-21T18:00+02:00
+tags: [blog]
+slug: real-weakest-link-in-software-supply-chain-security
+heroImage: https://storage.googleapis.com/sourcegraph-assets/blog/third-party-open-source-vulnerabilities.png
+socialImage: https://storage.googleapis.com/sourcegraph-assets/blog/third-party-open-source-vulnerabilities.png
+published: true
+---
+
+
+
+Open source code is both treasure chest and Pandora’s Box. Instead of starting from scratch when building an application or program, software developers can draw from third-party libraries and packages to jump-start development. These shortcuts come with risk though, as packages often contain yet more packages within, and these dependencies could harbor malicious code planted by bad actors, or vulnerabilities that leave your code open to exploitation. The [node-ipc malware/protestware incident](https://gist.github.com/MidSpike/f7ae3457420af78a54b38a31cc0c809c) surfaced in early March and the [Lodash](https://dev.to/jmimoni/lodash-understanding-the-recent-vulnerability-and-how-we-can-rally-behind-packages-48kc) and [log4j](https://about.sourcegraph.com/blog/log4j-log4shell-0-day/) vulnerabilities are more examples from recent memory. According to the [2021 Open Source Security and Risk Analysis report](https://www.synopsys.com/blogs/software-security/open-source-trends-ossra-report/), “An alarming 91% of the codebases contained open source dependencies that had no development activity in the last two years—meaning no code improvements and no security fixes.” 85% of audited codebases contained open source dependencies more than _four years_ out of date.
+
+These unmaintained open source components pose a risk to the company and your end users if vulnerabilities are discovered, but it’s time consuming and unrealistic for developers to vet every bit of third-party code in the codebase. Bluntly, it’s a pain for developers to keep track of all dependencies, keep them up to date, and when vulnerabilities are identified, even more of a pain for security teams to comb the codebase to determine if the vulnerability is even relevant to their code and then apply fixes across multiple repositories.
+
+It’s easy to blame poorly maintained open source projects and make that [random person in Nebraska](https://xkcd.com/2347/) the scapegoat here, but don’t write off third-party code. The alternative is reinventing the wheel every time and is likely to be frustrating for your engineering teams as they work on solving problems they know someone else has fixed already instead of writing new code. So, how do you balance the velocity unlocked by using third-party libraries with the risk posed by unaudited code? The answer is in your vulnerability management process.
+
+## 1. You lack visibility into your dependencies
+
+You can’t change what you don’t acknowledge. Dr Phil isn’t known for thought leadership on software supply chains, but he has a point here. Let’s imagine it’s December 2021 and you’ve just raised the alarm about the Log4Shell vulnerability. It’s most likely that your security team is now scrambling to figure out if and where you’re using log4j. Security engineers often have to dive into parts of the codebase they’re unfamiliar with because they didn’t write the code themselves, which limits their ability to act quickly. They will likely check the lock files in your repositories for instances of the vulnerable package using your code host’s native search, an IDE, or a tool like grep or [Sourcegraph](https://about.sourcegraph.com/blog/log4j-log4shell-0-day/#Find-everywhere-log4j-is-used-across-all-your-code). Dependencies can go many layers deep though, so security engineers need to be careful they don’t miss a vulnerable sub-dependency (referred to as transitive or indirect dependencies).
+
+### How to fix it
+
+In an ideal state, your engineering teams have been keeping thorough documentation of the open source software you’re using (also known as a software bill of materials) and updating it whenever they add a new dependency, so you already know if and where you’re using log4j. This isn’t consistently practiced though, so making sure your response team has access to robust code search to scour your repositories efficiently is critical. Some engineering orgs use dependency management software such as Snyk, Sonatype, or GitHub’s Dependabot to proactively alert you when you’re on a vulnerable version.
+
+## 2. It takes too long to understand if you’re affected by a vulnerability
+
+The next step is to determine if you’re actually using the dangerous code. You might be on a different, safe version of Log4j, or simply not using the affected code within the compromised version. It can be painfully time consuming to confirm if you’re impacted by a third-party vulnerability. In cases where you use the third-party code, but the vulnerability doesn’t affect your codebase, you have a false positive. This is ideal because no patching is required, but it’s hard to have full confidence in a false positive _and_ communicate that confidently to your users and customers.
+
+Again, the teams tasked with mitigation will need to watch out for those pesky transitive dependencies. This might require combing through an open source project’s repository in addition to your own.
+
+### How to fix it
+
+The solutions here will be largely the same as those for #1, with thorough code search playing a key role in sweeping your codebase or that of your dependencies for instances of the vulnerable code. [Nutanix](https://www.nutanix.com/) used Sourcegraph for its Log4Shell management process: “Isn’t it nice, when you can just run a report and say, ‘Here it is’ or ‘Here it isn’t’?” said Jon Kohler, Technical Director of Solution Engineering. Much better than having to say “‘Well, boss, I think we got it all.’”
+
+
+
+There’s also a cultural shift you can make: making fixing vulnerabilities an engineering-wide effort instead of the burden of a small team or lone security engineer can exponentially speed up your response time, as in addition to more people tackling the problem, the developers themselves may be able to work faster as they’re more familiar with the parts of the codebase they’re investigating.
+
+## 3. Mitigation is too time consuming
+
+If you _do_ have exploitable code, you’ll need to upgrade to the next safe version as soon as possible. If doing so is going to introduce breaking changes though, you may need more fine-grained mitigation that refactors the vulnerable code, wherever it’s being used. In either case, this can be a tedious, manual process involving dozens of pull requests across multiple repositories.
+
+### How to fix it
+
+The cultural shift of making remediation everyone’s responsibility can drastically speed up your response time here too. You can also programmatically create GitHub pull requests or GitLab merge requests with your mitigations using Sourcegraph Batch Changes, reducing the manual effort of creating and applying individual fixes. You can see [how this worked for Log4j mitigation here](https://about.sourcegraph.com/blog/log4j-log4shell-0-day/#Automate-PRs-to-fixmitigate-the-log4j-0-day-across-all-your-code).
+
+## 4. You’re not prepared for future vulnerabilities
+
+Vulnerabilities in third-party code are inevitable, but stripping your codebase of open source software isn’t the answer, unless you want to stifle innovation and frustrate all your developers. The challenge is in keeping dependencies manageable and up to date and ensuring consistency in your use of shared libraries. If left unchecked, you’re in for [dependency hell](https://about.sourcegraph.com/blog/nine-circles-of-dependency-hell/): package bloat, circular dependencies, and reckless monkey-patching are just some of the symptoms.
+
+### How to fix it
+
+You can proactively reduce your dependencies by committing to a culture of code reuse in your engineering organization. Code reuse doesn’t just narrow the scope of your dependencies, but reduces time spent on writing duplicative code and streamlines maintenance of shared code. Code search can help engineers discover reliable, reusable code already in your codebase. Using code notebooks to document how and where code is used in your organization also makes it easier for developers to reuse shared libraries confidently, reducing your overall dependency burden.
+
+### More posts like this
+
+- [How to remove secrets from your codebase](https://about.sourcegraph.com/blog/eliminate-secrets-from-codebase-with-universal-code-search/)
+- [The Nine Circles of Dependency Hell (and a roadmap out)](https://about.sourcegraph.com/blog/nine-circles-of-dependency-hell/)
+- [Log4j Log4Shell 0-day: find, fix, and track affected code](https://about.sourcegraph.com/blog/log4j-log4shell-0-day/)
diff --git a/content/blogposts/2022/why-fig-autocomplete-is-awesome.md b/content/blogposts/2022/why-fig-autocomplete-is-awesome.md
new file mode 100644
index 00000000..8423c729
--- /dev/null
+++ b/content/blogposts/2022/why-fig-autocomplete-is-awesome.md
@@ -0,0 +1,60 @@
+---
+title: 'Interact with Sourcegraph from the command line faster with Fig'
+description: "Sourcegraph teamed up with Fig to enhance 'src' the CLI that allows you to search code and more from your terminal."
+author: Justin Dorfman
+authorUrl: https://twitter.com/jdorfman
+publishDate: 2022-04-21T11:25-07:00
+tags: [blog]
+slug: why-fig-autocomplete-is-awesome
+heroImage:
+socialImage: https://storage.googleapis.com/sourcegraph-assets/blog/042222-fig-blog-post-social-og.png
+published: true
+---
+
+
+
+We are really excited to announce our latest [integration with Fig](https://fig.io/manual/src)! For those of you who don’t know about Fig, it is a tool that adds IDE-style autocomplete to your existing terminal (currently on macOS.)
+
+When I was onboarding at Sourcegraph one of my todos was to install and learn how to use `src`, a [command-line interface to Sourcegraph](https://docs.sourcegraph.com/cli). The installation was straightforward, but I couldn’t remember all of the different subcommands so I found myself typing `src --help` and [hitting the up arrow](https://www.commitstrip.com/en/2017/02/28/definitely-not-lazy/?) a lot.
+
+Then I remembered Zeno Rocha [tweeting about Fig](https://twitter.com/zenorocha/status/1432709006854869002) and I thought this might be a good opportunity to write an integration. After demoing the proof of concept to my team I got a lot of great feedback and decided to make a [pull request](https://github.com/withfig/autocomplete/pull/1081) to Fig on GitHub.
+
+## Let’s see this in action!
+
+I’m in the process of creating a budget for sponsoring the dependencies that Sourcegraph uses via Open Collective. Here is a real-world example of how I accomplish that.
+
+
+
+
+
+### Want to try it out?
+
+We got you covered. Install `src` (no login required):
+
+```shell
+# via Curl
+curl -L https://sourcegraph.com/.api/src-cli/src_darwin_amd64 -o /usr/local/bin/src
+chmod +x /usr/local/bin/src
+
+# via Brew
+brew install sourcegraph/src-cli/src-cli
+```
+
+Next, [download Fig](https://fig.io/invite/?code=DQnRfmaxLn) and open/restart your terminal.
+
+Then type `src` and you should see an IDE-style autocomplete with subcommands and options.
+
+Let us know what you think on [Twitter](https://twitter.com/intent/tweet?url=https%3A%2F%2Fabout.sourcegraph.com%2Fblog%2Fwhy-fig-autocomplete-is-awesome%2F&text=See%20why%20@sourcegraph%20thinks%20@fig%20is%20awesome%21) or our [Community Slack](https://srcgr.ph/jd-sourcegraph-slack-invite).
+
+Last but not least, a huge thanks to the Fig team ◧ especially [Federico Ciardi](https://twitter.com/fedeci_) for their help. We look forward to working together again!
+
+---
+
+_Thanks to the following people for helping with this post: Rebecca Dodd, Eric Fritz, and Stephen Gutekanst._
diff --git a/content/podcast/2.7-2.md b/content/podcast/2.7-2.md
new file mode 100644
index 00000000..89f9c40a
--- /dev/null
+++ b/content/podcast/2.7-2.md
@@ -0,0 +1,433 @@
+---
+title: 'Decomposing a massive Rails monolith with Kirsten Westeinde, software development manager, Shopify'
+publishDate: 2021-08-17T10:01-07:00
+tags: [podcast]
+author: ['Kirsten Westeinde', 'Beyang Liu']
+slug: refactoring-shopify-codebase-kirsten-westeinde
+published: true
+description: "What's it like to deconstruct one of the largest Rails codebases (3 million lines of code, 500,000+ lifetime commits, 40,000 files) on the planet? And why didn't Shopify follow the standard path to microservices, but instead choose to modularize their monolith?
+
+In this episode, [Kirsten Westeinde](https://www.kirstenwesteinde.com/), software development manager at Shopify, describes how her team led the charge in refactoring and re-architecting Shopify's massive codebase, sharing the winding path they took to make this massive change and the way they tackled both the technical and human sides of this challenge."
+audioSrc: "https://www.buzzsprout.com/1097978/9020726-kirsten-westeinde-shopify.mp3"
+---
+
+What's it like to deconstruct one of the largest Rails codebases (3 million lines of code, 500,000+ lifetime commits, 40,000 files) on the planet? And why didn't Shopify follow the standard path to microservices, but instead choose to modularize their monolith?
+
+In this episode, [Kirsten Westeinde](https://www.kirstenwesteinde.com/), software development manager at Shopify, describes how her team led the charge in refactoring and re-architecting Shopify's massive codebase, sharing the winding path they took to make this massive change and the way they tackled both the technical and human sides of this challenge.
+
+
+
+Ruby on Rails: https://rubyonrails.org/
+
+React: https://reactjs.org/
+
+React Native: https://reactnative.dev/
+
+Go: https://golang.org/
+
+Python: https://www.python.org/
+
+Scala: https://www.scala-lang.org/
+
+Kirsten Westeinde: https://www.kirstenwesteinde.com/
+
+(Blog post) Deconstructing the Monolith: Designing Software that Maximizes Developer Productivity by Kirsten Westeinde: https://shopify.engineering/deconstructing-monolith-designing-software-maximizes-developer-productivity
+
+(2019 Shopify Unite conference talk) Deconstructing the Monolith: https://www.youtube.com/watch?v=ISYKx8sa53g
+
+(Blog post) Under Deconstruction: The State of Shopify’s Monolith by Philip
+Müller: https://shopify.engineering/shopify-monolith
+
+Wedge: Deprecated internal Shopify tool that was built to score engineering teams on how well they are doing on their componentization journey.
+
+Packwerk: https://github.com/Shopify/packwerk
+
+Shipit presents Packwerk: https://www.youtube.com/watch?v=olEA157z7kU
+
+(Blog post) Enforcing Modularity in Rails App with Packwerk by Maple Ong: https://shopify.engineering/enforcing-modularity-rails-apps-packwerk
+
+Zeitwerk: https://github.com/fxn/zeitwerk
+
+Martin Fowler’s design stamina hypothesis: https://martinfowler.com/bliki/DesignStaminaHypothesis.html
+
+Shopify Fulfillment Network (SFN): https://www.shopify.com/fulfillment
+
+Kafka: https://kafka.apache.org/
+
+
+
+**Beyang Liu:**
+All right. I'm here with Kirsten Westeinde. Kirsten is a software development manager at Shopify where I understand, Kirsten, you've been involved in a years-long effort to decompose Shopify's massive Rails monolith, or perhaps like multiple monoliths now, into smaller, modular components. Is that right?
+
+**Kirsten Westeinde:**
+That's right.
+
+**Beyang Liu:**
+Cool. Thanks so much for taking the time. Sounds like a massive effort and I'll bet that Shopify engineering has been very busy over the past year. So I really appreciate you taking the time to come chat with us and share things that you've learned along the way.
+
+**Kirsten Westeinde:**
+Absolutely. Thanks for having me.
+
+**Beyang Liu:**
+So I think the focal point of our conversation is really going to be this massive decomposition effort. It's going to be very fascinating to hear about because I think a lot of engineering teams try to undertake projects like this, especially as the company grows and some succeed, but a lot end in failure. And so I think you have a lot to share in terms of how you can pull this off successfully. But before we dive into all of that, we have kind of a tradition on the podcast of first asking people how they got into programming. Right now you're this software development manager who's in charge of this very complex project. You have a lot of responsibility, but at some point you had your first contact with code. So, for you, what was that? And how did that start your journey into this world of bits and ones and zeros that we live in?
+
+**Kirsten Westeinde:**
+Absolutely. Yeah. If you had asked me when I was a kid, I definitely would not have thought that this would have been where I ended up. I actually didn't even really know what programming was before I went into university, but I did end up studying engineering just because of my love for math and science. And the school that I went to ended up doing a general first year where we basically took classes from all of the different engineering tracks to kind of learn a bit about them and decide where we wanted to go. And so in my first year I took a programming class, we learned C++ and it turns out that I really enjoyed it and I was really good at it. And the more that I looked into it, it seemed like a really interesting field to be in. So I had originally thought I would be a civil engineer, but I'm very glad that I ended up going the direction I did.
+
+**Beyang Liu:**
+C++—that's kind of like diving off the deep end as your first programming language.
+
+**Kirsten Westeinde:**
+Yeah. It's always funny to hear what people learn in school. It's rarely what we end up using in the field I find.
+
+**Beyang Liu:**
+Okay, cool. So from your start in university, what was kind of like the rough journey from there to joining Shopify?
+
+**Kirsten Westeinde:**
+I actually joined Shopify as an intern while I was still in school. So I did two internships with other companies, but I joined Shopify in 2013 out of the Ottawa office as an intern. And then I ended up doing three different internships with Shopify before joining full-time after I graduated. And through those internships, I really used the time to try out different things and try to understand where my interests lay. So I did some web development using Rails, I did some mobile development, and I worked on some internal tools and external products. So I've really had my hands in a lot of different places at Shopify over the years.
+
+**Beyang Liu:**
+Awesome. So you've been there since 2013, which means you've kind of had a front-row seat to this whole rocket ship trajectory that the company has been on.
+
+**Kirsten Westeinde:**
+Yeah, it's been crazy. When I joined, I think we had 150 people working for the company and we're a private company. We had only a handful of merchants. We had one small office and fast forward to today, we're an international company. We have... It's hard to keep track of it, but I think like 7,000+ employees. At this time, we're a public company, so much has changed. I like to tell people I haven't worked at the same company for eight years, I've actually worked at like eight different companies because it really has been changing that quickly.
+
+**Beyang Liu:**
+Yeah, that's crazy. And you know, I bet most of our listeners don't need any introduction to Shopify, but you know, for the one or two people who've been living under a rock for the past seven years. Chances are... If you bought anything on the internet, chances are you use Shopify, right? Because you power a lot of the kind of small businesses and independent operators that sell things online right?
+
+**Kirsten Westeinde:**
+Yeah, that's correct. We actually don't force the Shopify brand on our merchant sites. So a lot of people buy things from Shopify stores without actually knowing that they have. But basically if you bought something from Amazon and it was enjoyable or—sorry—from anything other than Amazon and it was an enjoyable experience, that was probably a Shopify store.
+
+**Beyang Liu:**
+Yeah. And actually for me personally, increasingly I find myself buying more and more things off Amazon because there's like... A lot of times the things that you can get in these kinds of independent stores are just like higher quality or it just feels closer to the seller. And so thank you for enabling all that. So diving into this large-scale refactoring and re-architecture project, I thought maybe we could start off by giving people an overview of what Shopify looks like as an engineering organization and as a codebase. So in broad strokes, what are the major teams and what are the major parts of the code, and what does it all kind of do as an engineering system?
+
+**Kirsten Westeinde:**
+Definitely. So we talk about the core Shopify product as the core codebase. And so that's basically what powers merchants to manage their orders, to manage shipping, etc. So all of the core pieces of the product live in one Rails codebase. And it's actually one of the largest, probably the largest Rails codebase on the planet because we got started with Rails like right when Rails became a thing, and it's been under continuous development since at least 2006. And the last time I checked, we were pushing like 3 million lines of code, more than 500,000 lifetime commits and about 40,000 files. So it's massive. And in terms of an engineering org, I think we're at about 1,500 or so engineers and we're actually aiming to hire another 2021 this year, so it'll be continuing on this massive pace of growth. And if I had to guess, I'd guess probably about half of the engineering team works daily in the core codebase and the other half works on applications outside of core.
+
+**Beyang Liu:**
+That's crazy, that's so much code. Does it... Have you gotten to the point where Git operations start to slow down at all? Like if you were to clone the entire codebase to your local machine... Like do people even do that? Or how long does that take?
+
+**Kirsten Westeinde:**
+Yeah, people do it, it works. The test suite definitely can get slow, but development itself is not a problem. We actually... We always joke, like we host Kylie Jenner's shop on Shopify and it's like one of the largest stores. And we joke that like we are the Kylie to so many other systems that we use. So we're hosted on Google Cloud and like we are by far the largest product hosted on Google Cloud and so we're often stretching the boundaries of their systems. And similarly, like with Rails itself, we are often the ones that find those bugs that you only find when you're operating at this scale. And so what we do is we really make choices about what technologies we want to use and then really double down on them. So we actually have a full team at Shopify who are Rails core contributors, and we try to actually just evolve the tools that we use to be better and to be better able to support us and others.
+
+**Beyang Liu:**
+What languages are in use? So with Rails, I assume Ruby is a big language, are there any others that are big parts of the stack?
+
+**Kirsten Westeinde:**
+Yeah. Shopify has always been very opinionated about technology choices. So essentially any problem that can be solved with Ruby on Rails should be, there are some exceptions. If applications have really, really high performance constraints or need parallelization, sometimes we use Go, the front ends are in React. And for mobile development, we've just standardized around React Native going forward as well. And then in data land, we have some Python and Scala and in infrastructure we have Go and Lua as well.
+
+**Beyang Liu:**
+So you wrote this blog post about how you were in charge of this project to kind of decompose Shopify’s main Ruby on Rails monolith into smaller, more modular components, not microservices, but different modularized components, we'll get into that later. Tell us at a high level, what was the mandate of that project and how did you come to be involved in that.
+
+**Kirsten Westeinde:**
+Yeah. So in, I think it was around early 2017, it was becoming very clear that our core codebase was reaching a tipping point. Where it was becoming more and more challenging to build functionality into it because of all of the interdependencies. So projects were taking longer, adding things that used to be simple were causing test failures and big headaches. And also it was really... We're finding it really challenging to onboard new people into the codebase because there was just so much to learn. And so we knew we had all of these problems, but we didn't want to get into solutioning without really understanding what the problems were. So we actually sent out a large survey to all the engineers working in the core codebase to hear their feedback about what the pain points were before deciding what to do.
+
+**Kirsten Westeinde:**
+And it was that survey that actually led us to start this project. We originally called it a very clever name of, "Break core up into multiple pieces." But that name eventually evolved into componentization where essentially we wanted to make this one large codebase feel like many smaller codebases. And so we wanted to separate the code by business domain basically because that is the code that more often needs to change together. And so what that would mean is if we were hiring someone onto say the shipping team, they should be able to just understand the shipping component without having to understand all of the other elements of the core codebase. So at a high level, that was the goal.
+
+**Beyang Liu:**
+Got it. So if I were a buzzword-driven engineering manager and you came to me and said, "Let's decompose this monolith into different independent components." I would say, "Well, that's obvious, you know, we live in 2021 and the obvious solution to decomposing a monolith is to break it down into these things called microservices. But I understand that that's not the approach that you ended up taking. So can you talk about why you didn't follow the naive path of like, let's write a bunch of microservices. What did you end up with instead? What is this modular monolith that you talk about?
+
+**Kirsten Westeinde:**
+Yeah. I mean, I think for one thing we had been developing on Shopify core for so long that pausing everything and building out net new microservices just wasn't feasible for us. Whereas the direction we ended up going was making incremental changes in the existing codebase while teams continued to develop and add features to it. So that was a big reason, but the other thing is that unless we wanted to start from scratch, to be able to start extracting some of these pieces out into microservices, we would need to have them well encapsulated and have boundaries in place, which is what we ended up doing. But we ended up deciding that we wanted to stop there because monoliths have a lot of pros, a lot of benefits.
+
+**Kirsten Westeinde:**
+Having only one codebase means you only have to do all of your gem bumps and your security fixes in one place. It also means you only have to manage one deployment infrastructure and one test pipeline. There's also a lot less surface area in terms of places that you could be attacked, and I think that makes the system a lot more resilient. And we found it helpful to keep all of our data in one place, in one database and allow the different components to have access to the data that they needed instead of trying to synchronize it across many different systems.
+
+**Beyang Liu:**
+Yeah.
+
+**Kirsten Westeinde:**
+And lastly, with microservices, the communication between the different components has to happen over the network, which introduces a whole bunch of complexity around API version management and backwards compatibility, as well as just dealing with the network in general. It can be slow. There's lots of ways it can fail. So those were all the things that we liked about the monolith and didn't want to just give those all up. And we kind of felt like moving to microservices was more of a topology change whereas what we wanted was an architecture change. There was nothing necessarily wrong with our monolith, it was just that there were no well-defined boundaries between different things.
+
+**Beyang Liu:**
+So you had this principled, thoughtful approach of "We have developer pain, let's address that directly, but we're not going to involve it with changing the topology of production, introducing all these unnecessary network boundaries because that introduces its own complexity and its own baggage" in a way.
+
+**Kirsten Westeinde:**
+Yeah, exactly. Our monolith had gotten us so far. We, I think, had learned so much about what is good about it, that it gave us pause to really ask the question and really think through whether microservices were right for us. And the answer at the time was no.
+
+**Kirsten Westeinde:**
+That being said, we are believers of service-oriented architecture, so we do have other applications outside of the core codebase. However, everything related to the core functionalities of commerce, we keep in one place. But there have been some examples where we actually have extracted components out of the core codebase because they weren't related to the core functionality of commerce and we pulled them out into their own services, but that was exponentially easier to do post componentization.
+
+**Beyang Liu:**
+So what did this modularization of the monolith actually entail? I assume you started with... My knowledge of Ruby On Rails is fairly limited, but I understand the standard directly out is: you have a model directory, you have a view directory, you have a controller directory. Was that the structure of the codebase at the start of the project?
+
+**Kirsten Westeinde:**
+Yeah, that's correct. So we started before this, we basically just had a Rails app out of the box, so you're exactly right. They were organized by our software concepts, but the first thing that we wanted to do was restructure our codebase to be organized by real-world concepts like orders, shipping, inventory, billing. And what we ended up doing was we actually audited every single Ruby class in the code base, which was like 6,000 at the time, in a spreadsheet and manually labeled which component we thought that they belonged in based on the initial list of components we had. And then we built up one massive PR with automated scripts from the spreadsheet to basically just create those top-level folders. And then within the orders folder it would still be models, views, controllers, but we would just move all of the specific models, views and controls into that folder. So we did that all in one big PR, which was kind of terrifying, but ended up being fine. We have good test coverage. So it is all good.
+
+**Beyang Liu:**
+What was the size of that diff? It must have been like...
+
+**Kirsten Westeinde:**
+It was every file, every file was touched.
+
+**Beyang Liu:**
+Wow.
+
+**Kirsten Westeinde:**
+Yeah. So that was the first step.
+
+**Beyang Liu:**
+Why wasn't that sufficient? The straw man is like, "Okay, if we put everything in its own directories and now each team gets to work in their own directory and that's done. They're like separate codebases." Why was that not just the end of the project?
+
+**Kirsten Westeinde:**
+Well, all that had achieved was moving files around, right? Like in Ruby On Rails, everything is automatically globally accessible. So just because all the code for orders was within an orders folder, it could still use whatever it wanted from any of the other folders. So we still had all the same problems with fragility of the test suite and really if I was working in the orders component, I still had to understand about the taxes component and the shipping component because of how tightly coupled they were and how there was no clearly defined API for them to communicate between the folders. Nothing had structurally changed about how the code was interacting.
+
+**Kirsten Westeinde:**
+So it was a great first step in the sense that I now knew if I'm looking for something orders related, I can find it. And that the top-level component folders had explicit owners, which was actually a huge win. But beyond that, we still hadn't solved a lot of the existing problems.
+
+**Beyang Liu:**
+You mentioned something in your blog post about how one of the initial pain points was as the codebase grew, the amount of code that a given developer would have to understand to get a thing done was like something like O of N, it grew linearly with the size of the codebase. And that obviously is untenable as you grow, because it just means your productivity approaches asymptotically down to zero. So how'd you go from O of N to sub linear? What were the things that you had to make in terms of codebase structure to enable that?
+
+**Kirsten Westeinde:**
+Yeah, definitely. So once we moved all the code into their separate folders, the next ask was for each component to define a public API. And ideally that public API should be easy enough to understand that I can understand what it's doing without having to go under the hood and look into the component. And so that would allow me to get to know one component really well. We also asked each component to explicitly say which other components they depended on. So say I was joining the orders team, I could really deeply get to know the orders component. And then as my next step, I could look at what the dependency is listed out for the orders component is, and maybe just start getting to know their public API so I know what methods are available to me from those components without needing to understand all the nuances of how they get the things done exposing the public API.
+
+**Beyang Liu:**
+Yeah. What about the human side of this kind of change? In the organizations that we've worked with that have attempted something like this, there's the technical side, which involves making the proper changes to the code, in this case, introducing a bunch of interfaces and making those interface boundaries well-defined, but then there's also this human, semi-political aspect to it where you're going to each of these engineering teams and each of them has their own goals and objectives that they're working toward, business goals, and you're coming to them and essentially asking them to add work onto their plate to satisfy this change.
+
+**Beyang Liu:**
+Can you talk about that element of it? Did you have to do a lot of horse trading or, "Do me a favor and I'll do you a favor?" What does that look like from your perspective?
+
+**Kirsten Westeinde:**
+Yeah, it's interesting. I've actually talked about this project at a few different conferences and the two questions I always get are, "How did you get buy-in from the business to invest in this? And how did you get buy-in from the individual teams to invest in this?" I guess there's no really easy answer or perfect way to do it and it's going to be so nuanced depending on the organization that you're within. But one of Shopify's core cultural values that were kind of taught from the beginning, is build for the long term. And it's really driven home that we're trying to build this business for a hundred years, not for 10 years. And so with that kind of mindset, it is easier to get buy-in for these short-term pain for long-term gain type projects.
+
+**Kirsten Westeinde:**
+I think as well, the developers that had been working in the core codebase had all been feeling this pain. And so they were eager for opportunities to make it better and easier to develop within. So it wasn't always easy. And to be honest with you, different components are at completely different points in their componentization journey based on how well their team has been able to prioritize this type of work. One thing that we did was we built this tool called Wedge, a lot of complexity under the hood, but it basically gave components scores as to how well they were doing on their componentization journey. And we made it like a little fun competition between teams.
+
+**Beyang Liu:**
+You gamified it.
+
+**Kirsten Westeinde:**
+Exactly. Yeah. As a technical initiative that the whole engineering org was working towards.
+
+**Beyang Liu:**
+That's really interesting. So you kind of built a tool that condensed all these complex refactorings into something that you can measure, like a numerical score and that made it easier to track and also verify. How did you do that? How do you convert adding an interface or defining a good interface or eliminating a cyclical dependency or something into a number that is meaningful that the engineering teams don't shake their heads at and that also is useful for tracking it at a top level.
+
+**Kirsten Westeinde:**
+Yeah. So, Wedge is a really interesting tool. What we did was we used it to hook into Ruby trace points during our test suite run to get a full call graph of all the calls that were being made as our code was being executed. And then we sorted the callers and callees by component and basically pulled out all of the calls that were happening across component boundaries and then sent them to Wedge. And we'd also send some other data like code analysis and active record associations and inheritance and such. And then Wedge basically just went through everything that was sent to it and determined which of these things were okay, and which ones were violating. So if a cross-component call was being made, if there was no dependency explicitly declared between those two components, it would be violating. And if it was anything other than the public interface it would be violating.
+
+**Kirsten Westeinde:**
+We actually found though that it really is hard to get a number that is right. Especially with as much complexity as there is in call graph logging. So in the end we actually ended up canning Wedge because we didn't find it to be a useful feedback cycle. And also mostly because we had to run the full test suite to get this feedback and that takes way too long for it to be helpful. So we ended up going in a different direction. But in the early days it was really helpful to, like you said, gamify it.
+
+**Beyang Liu:**
+Yeah. That makes a lot of sense. As you learn more about what was useful and productive, what kind of stepped into the place that Wedge occupied? Was there another tool that you used or was there some different set of criteria that you used to gauge overall progress and success?
+
+**Kirsten Westeinde:**
+Yeah. We ended up building this tool called Packwerk, which actually as of September of last year is open source. And it's a really cool tool that basically analyzes static constant references. So we found that there's less ambiguity in static references and because these references are always explicitly introduced by developers, it's more actionable to highlight them, and it's much faster. So we're able to run a full analysis on our largest codebase in a few minutes, which means that we can actually put it in as part of our pull request workflow, which is a way more helpful feedback loop for developers.
+
+**Beyang Liu:**
+That's really interesting. So the Wedge was this dynamic tool. It kind of built up this call graph or reference graph from runtime by observing what actually got called and then Packwerk was building up that graph, but statically based on imports and references in source code. Is that right?
+
+**Kirsten Westeinde:**
+Yeah, that's correct. Packwerk uses the same assumptions as Zeitwerk, which is the Rails code loader. And the way that Rails is able to make constants globally accessible is it basically infers the file location based on the constant's name. And we did the exact same thing with Packwerk.
+
+**Beyang Liu:**
+So the programming languages part of my brain is saying, "But wait a minute, Ruby is a dynamically typed language, not all types are known at compile time." But were you able to solve that problem in Packwerk? Like inferring types or was it some element of best effort? Like, this is good enough.
+
+**Kirsten Westeinde:**
+Yeah. A hundred percent the latter. We understand that it's an imperfect solution and there's a lot of crazy stuff that can happen in Rails that will not be detected through this, but it's good enough essentially. And it does catch a lot of things. So we decided that the fact that it can happen so much faster and provide that faster feedback loop is a trade-off we're willing to accept for the fact that yes, maybe some things will slide under the radar.
+
+**Beyang Liu:**
+I guess it's important to recognize that there's humans in the loop in this process. So in some sense, it'd be a much harder problem to completely automate it because then you'd have to get everything precise. But as long as there's humans in the loop, they can step in and say, "Well, we recognize this tool's a little bit fuzzy, as long as the signal to noise ratio is decently high, we can work with this."
+
+**Kirsten Westeinde:**
+Absolutely, and the magic of this tool is not only within the tool itself, but it's within the conversations that it sparks, because if on my PR I get told, this is a cross-component violation, and maybe I don't know what that is, or maybe I'm a more junior programmer, and I don't have an idea of how to do inversion of control, for example, there's been a lot more conversations around software architecture across Shopify because of this tool.
+
+**Kirsten Westeinde:**
+So, what that means is sometimes maybe the tool won't catch cross-component boundaries, but because it's now becoming a part of our engineering culture, maybe someone will in a PR review. Building that muscle of good software design really is the overarching goal of this whole thing. So, yes, the tool's not perfect, but it's been really valuable for us.
+
+**Beyang Liu:**
+You just mentioned inversion of control, and I think that along with some other things you called out in your blog post were good rules of thumb or good general principles that you may have discovered along the way of doing this. Can you talk about some of those principles or maybe empirical patterns, in terms of if someone were to attempt this on a Rails codebase in general, what are the maybe tactical things? Tactical things, tricks that you can apply to make the codebase more decomposed and modular.
+
+**Kirsten Westeinde:**
+Yeah. I think the first thing I would say is that if someone's going to be trying this on a Rails codebase, they'll probably be in a similar situation that we are, or that we were, which is basically, if you look at the dependency graph that has just naturally happened, it's crazy. Every component was basically depending on every other component. There's a ton of cyclic dependency. Rails lends itself naturally to have high dependency.
+
+**Kirsten Westeinde:**
+So, I'll say that first. Even just being able to visualize that dependency graph allows you to reason at a much higher level about, does it make sense for this thing to depend on this thing? Sometimes it does, and other times it doesn't, but when it doesn't, that's when you start to use some of these tactical approaches for decoupling those things.
+
+**Kirsten Westeinde:**
+I mentioned inversion of control, which basically is saying ... So, I'll give an example. I work on a product called the Shopify Fulfillment Network, where, basically, some merchants, we host their products on their behalf. When orders come in, we'll choose the most optimal warehouse to fulfill it out of to get it to the buyer as quickly as possible.
+
+**Kirsten Westeinde:**
+SFN, that's the acronym for the Shopify Fulfillment Network. It needs to know when an order comes in on a merchant store. One way to do that could be for the orders component to make a call to a method in SFN and say, "New order has been created," and then SFN responds with, like, "Great. We got it."
+
+**Kirsten Westeinde:**
+That's a hard dependency from the orders component to SFN, whereas if we want to get rid of that dependency, we can actually just use a method like a publish subscribe mechanism. There's a bunch of different ones to do that, but at Shopify, we use Kafka events a lot. Basically, the orders component can just say, like, "An order happened," and then SFN can choose to subscribe to that and do its processing without needing to necessarily reply, and that has now broken that dependency between the two.
+
+**Beyang Liu:**
+It's like, at run time, you want this one thing to provide behavior to this other thing that is going to run, but at compile time, you don't actually want an import going from that thing to this other thing, because that adds a hard dependency, and it means that someone working on the first thing will have to go through the second thing and understand how it behaves. There's not this interface boundary that says, "Okay, don't worry about the stuff behind this curtain."
+
+**Kirsten Westeinde:**
+Yeah. That's exactly right, and had there been a hard dependency, like, say, from the orders component to SFN, then the orders component would have to care every time SFN changed. Now, having done this inversion of control, it does not at all. It just has to fire its event.
+
+**Beyang Liu:**
+Another thing that you talked about in the post was this kind of loose coupling, but high cohesion pattern that got adopted. Do you mind explaining what that means?
+
+**Kirsten Westeinde:**
+Absolutely, yeah. This was one of the core principles of this project that we were striving towards. Coupling is basically the level of dependency between modules, or classes, or in this case, components. So, you want that to be low, because you want your dependency graph to be as light as possible, but you want the cohesion to be high. The cohesion is basically the measure of how much elements within a certain encapsulation belong together. So, whether you're looking at a module level, a class level, or the package level.
+
+**Kirsten Westeinde:**
+One thing to note is that it's really hard to get the component interface right when the classes within it have interfaces that are not well-defined, and the modules within it. It really starts with good software design from the bottom up. That makes it easier, a lot easier to get the component interfaces right.
+
+**Kirsten Westeinde:**
+Then, on the point of cohesion, there’s two different types of cohesion that we think about. The first is functional cohesion, so that basically means code that performs the same task list together. You can think of service objects as being functionally cohesive, whereas data or informational cohesion is code that operates on the same object living together.
+
+**Kirsten Westeinde:**
+Again, Rails really lends itself to data or informational cohesion, because of the way that active record models are built up to interact with one database model. We often add a lot of methods relating to that object on its model, even though they might be parts of completing completely different tasks. I'm sure different languages lend themselves to different ones, but we found ourselves way over-skewed in the direction of data and informational cohesion.
+
+**Beyang Liu:**
+Where is this project today? You mentioned it started in 2017, and it's been a multi-years-long effort. Are things still being componentized in the main Rails codebase, or at this point, has it been componentized, and it's more or less in a done state, you just have to maintain the status quo?
+
+**Kirsten Westeinde:**
+Yeah, I wish I could tell you we were in a done state, but the reality is that we're not. All of the code has been moved into components, and all of the components do have publicly defined entry points, but the reality was that we were starting from a place where a lot of these calls were already violating the rules. So, one of the nice features that Packwerk built was that you could essentially declare bankruptcy, and start from a certain point, and only start tracking violations beyond that. We have a list of deprecated references, and the rule is basically that you can't add any new violations.
+
+**Beyang Liu:**
+Got it.
+
+**Kirsten Westeinde:**
+We know that there are some existing ones, but no new ones can be added. Over time, that deprecated references list basically gives us a tech debt to-do list to work off of. Like I said, different components are in different shape, but we haven't yet gotten to the point where all of those violations are gone. Only once all of those violations are gone will we be able to actually enforce those boundaries.
+
+**Beyang Liu:**
+Fascinating. You have this list of tech debt to-do items. In a given iteration cycle, how do you decide how many of those to tackle versus how many, I guess, more product-oriented things to tackle? Because that's something that our teams at Sourcegraph, I assume, like probably any software team struggles with. What is the right balance of tech debt versus new feature development to take on?
+
+**Kirsten Westeinde:**
+Yeah. That's a hard question.
+
+**Beyang Liu:**
+Can you put a price on a tech debt item? It's almost an impossible exercise.
+
+**Kirsten Westeinde:**
+Yeah, no, it's really a hard question. Honestly, the answer's going to be different team to team at Shopify. One of the patterns that I've seen in my years at Shopify is that we built a lot of features. We move really quickly leading up to Black Friday and Cyber Monday, because that's when our merchants make the vast majority of their sales for the year. So, it's really important that we've given them the tools that they need to be successful during that time.
+
+**Kirsten Westeinde:**
+Come the holiday season, we actually tend to cool down a bit on feature development, just because we don't want to be breaking things when our merchants are having their most important sales of the year. So, often, that feature cooldown can be a good time to tackle some of these larger units of tech debt. That said, I'm not saying that we just leave tech debt to do at one point in the year. We definitely try to find some pause between projects, or even just parallel tracks of work, where some people are working on more technical debt, and some people are working on product features. It's definitely a hard balance, but we have been slowly chipping away at it.
+
+**Beyang Liu:**
+I understand that the Shopify Fulfillment Network, which you mentioned earlier, that's a separate codebase. It also is or was a Rails monolith. You're currently tackling a similar project in that codebase, but adjusting some things based on what you've learned from this first major...
+
+**Kirsten Westeinde:**
+Decomposition.
+
+**Beyang Liu:**
+... decomposition componentization effort.
+
+**Kirsten Westeinde:**
+Exactly.
+
+**Beyang Liu:**
+Tell me about round two. What's different this time in the sequel?
+
+**Kirsten Westeinde:**
+Yeah. We actually took a pretty different philosophical approach. What we did in Core was we moved all of the code into the components, and then slowly, over time, started trying to break some of those dependencies, whereas what we've done in the Shopify Fulfillment Network was we've introduced separate components. We've actually used Rails engines, which are like the one modularity feature that comes out of the box with Rails, and that can allow us to enforce those boundaries a little bit more strictly. Then, over time, piece by piece, moved bits of code into it that are always respecting the boundaries.
+
+**Kirsten Westeinde:**
+So, we flipped it on its head that way, whereas we still do have the main app controllers, models, etc., but the hard rule is we can't add any more code into the app folder. All new code goes into component folders. Over time, we're pulling code from the app folder out into its, basically, correct component, so that anything that's in a component is respecting the component boundaries, whereas that is not the case in Core.
+
+**Beyang Liu:**
+Interesting, so, with Core, the approach was move all the files around into their appropriate directories, and then, over time, reduce the linkedness or monolithic-ness of each component, whereas with Fulfillment, you basically said, keep the existing monolith as is, but each new feature has to be added to something that's external in a Rails engine. Then, we'll have some connection between the two, so that the functionality makes it into the application, but we always preserve this, I guess, invariance because all of the new components are modularized. Is that about right?
+
+**Kirsten Westeinde:**
+Yeah, that's right. One of the main benefits of that is that with so many developers working in a codebase, people tend to want to follow the patterns that they see existing. In Core, there is a mix of good patterns and bad patterns, because some stuff has been adjusted to break that interdependency, and some stuff hasn't. So, it's hard to know which pattern to follow, which way is the right way, when there are both examples, whereas in SFN, anything that has been componentized is following the patterns that we're wanting to strive for, so there's more good examples to be able to learn from, and demonstrate to other developers, and follow.
+
+**Beyang Liu:**
+I get all the learnings here. This is really fantastic insight. One thing I'd love to hear about is like, what is the process on the ground that you arrive at these insights? Like, for this new project, we don't want to move a bunch of stuff in the existing codebase around, but we want to start with something new, or moving from the dynamic dependency call graph to the static version, what are those conversations like? Is it you and a bunch of other engineers or engineering managers in a room, whiteboarding, or someone coming up with a bright idea, and slowly convincing other people? Are there any, I guess, war stories that come to mind when you reach these insights?
+
+**Kirsten Westeinde:**
+Yeah. It's always a conclusion that we come to over time. In the example of Wedge, it was working well for a while, but over time, the problems with it became louder, and louder, and louder until we couldn't ignore them. So with that one, it was really, as our test suite was getting larger and slower, it was really just that it wasn't a helpful feedback loop to have to wait for that entire test suite to run to be able to get that insight. And so we knew there was a problem with that. But then the question is, what's the solution?
+
+**Kirsten Westeinde:**
+So we have a few different avenues for brainstorming these ideas. One is actually a team whose mandate is architecture patterns, and they're the ones that built Packwerk and provided a lot of the patterns to follow. And so sometimes it's just projects that get resourced, and we do explore and prototype phases. And so being armed with the learnings from Wedge, it led us down the road to Packwerk.
+
+**Kirsten Westeinde:**
+But the other thing is we have a software architecture guild at Shopify, which is basically anyone from the company who is interested in software architecture. We have a Slack channel and a bi-weekly meetup. And that's where a lot of these conversations come to a head. Because I think there were a lot of learnings from Core, but then for example, the developers who were starting to build out SFN may not have had access to that frontline information.
+
+**Kirsten Westeinde:**
+And so we did a lot of pairing actually as a way to share this knowledge and have a lot of discussions with the architecture guild. Because Shopify is very, I guess each team has a lot of autonomy. So the SFN team had the autonomy to decide what the right solution for it was, but definitely wanted to leverage the learnings that were present from Core. So that's the type of discussion that we would have at an architecture guild. Or we also do technical design reviews for any big tech projects we're kicking off. So that would be another. We have templates for those, and we have filled those templates with some prompting and questions to try to make people think about modularization as part of the upfront design.
+
+**Beyang Liu:**
+Interesting. Tell me more about this guild. So what is a guild exactly? Is it just a collection of individuals who have a common technical interest area? Or how is it organized? Is there a process associated with it? How does it fit into the overall org structure of the engineering team?
+
+**Kirsten Westeinde:**
+Yeah. Actually it doesn't fit into the org structure of the engineering team. It's composed of people from across everywhere in the engineering organization. It's completely opt-in, and it grew organically from people who were curious to be having conversations like this. I think one big learning actually that my coworker Phillip called out in his blog post was that he wished that we had started this sooner in the componentization process. So more minds could be involved and had buy-in basically for them to apply the approach that we were aligning upon in their different areas of the company.
+
+**Kirsten Westeinde:**
+But it really is just people that want to nerd out about software architecture, and people come with presentations every other week. Sometimes we'll just share the architecture of one of our systems. Sometimes we'll have more pointed discussions about certain software design strategies. It's pretty organic, but people like it.
+
+**Beyang Liu:**
+That's awesome. So the guild formed after the start of the original project.
+
+**Kirsten Westeinde:**
+Yeah. That's right.
+
+**Beyang Liu:**
+At what stage do you think it makes sense to form a guild? I think that we run into the same issue, and I think a lot of other engineering organizations run into this issue, where you have your org chart and you try your best to produce an org chart that reflects the needs of the product and how knowledge and information needs to flow. But no chart is ever going to be perfect, and there's all these areas of expertise that don't neatly fit into that. And I guess the question in my mind has always been, at what point do you start to need these guild structures? Is it at 100 engineers? Is it at 1,000 engineers? Or what, in your mind, is the right size?
+
+**Kirsten Westeinde:**
+Yeah. We've actually experimented with a few different things. The guild is more of a meetup. We less drive change through the guild, I would say, other than grassroots movements. But we also have what we call a technical leadership team, which is on a rotational basis. Technical leaders from across the company will be on that team. And anytime we're doing a tech design review, you'll get paired up with someone from the technical leadership team. You can bring them your gnarliest problems, and it's made up of people from all different parts of the org with all different perspectives on the problem.
+
+**Kirsten Westeinde:**
+So it's a way to try to, I guess, make sure that we're leveraging the learnings that are available at the company level. And then there's also what we were chatting about before, I forget what it's... the tools and patterns team. And their actual mandate and what they work on day in and day out is building out some of these tools and patterns.
+
+**Kirsten Westeinde:**
+And I think I would guess that team spun up probably in 2018 just based on this project having started in 2017. And yeah, we were probably 500 to 600 engineers around then. It's going to be different for every organization, and I think it depends on how much your organization already has it baked into their DNA to be thinking about these things, to be thinking about good software design, technical initiatives, etc., or not. Sometimes it might make sense to start earlier if that's not as organically present.
+
+**Kirsten Westeinde:**
+There's trade-offs to each approach. One of the challenges that the tools and patterns team has is that they're just building tools and patterns, but they aren't necessarily using those tools and patterns to build a product. So they need to make sure that they are in touch with the people that are using those tools and patterns and actually solving the right problems. And so we do that through pairing and internal documentation presentations, etc. But we really try to make sure that the problems that need to be solved are being solved, and we're not just adding friction to developers' lives because we think it's nicer.
+
+**Beyang Liu:**
+Yeah. That makes a ton of sense. Looking back on both projects that you've been involved in with decomposition, to what extent are the patterns that you discovered, do you think, specific to those particular codebases? And to what extent do you feel like there's some general principles here that would be widely applicable? That's one question. A more proximal question would be the way that you're approaching modularization on the fulfillment network codebase. Do you wish that you had done that with the main codebase initially, knowing what you know now? Or do you think that each codebase found its proper approach?
+
+**Kirsten Westeinde:**
+Yeah. It's a challenging question because they both have their trade-offs. So I think that you just need to know in your situation which trade-offs you're willing to accept. For the Shopify Core case, what we were really struggling with and really wanting to optimize for was that we had a lot of code that didn't have ownership. And so having moved the code into folders that have explicit owners is a big win for that. Whereas in SFN, we still have a lot of code living in the app component that doesn't have as clear owners, but for us that's okay because it's a smaller group of people working on it. And so it's easier to share the load across our team, which is smaller. Whereas for core, it was really important that we get it right in terms of code ownership.
+
+**Kirsten Westeinde:**
+So I think you really have to ask yourself, what is the intermediate state that you're most comfortable with? Because these things take a long time. And so I think Phillip has an amazing quote in his blog post. He says, "My experience tells me that a temporary incomplete state will at least last longer than you expect. So choose an approach based on which intermediate state is most useful for your situation." And it's 100% true in this case. Both of those codebases are in intermediate states that are correct for them, and I think you just need to think about what that means for your codebase.
+
+**Beyang Liu:**
+Yeah. That's very fair. Somewhere out there there's a person listening who wants to propose a big refactoring re-architecture project, but you often run into resistance from Product, from other stakeholders in the business because the value of such a project is not always clear. What advice would you have for people in that position, just in the very early stages of thinking through starting such a project and getting organizational buy-in?
+
+**Kirsten Westeinde:**
+Yeah. One thing that I think about often as it relates to this is, I don't know if you're familiar with Martin Fowler's design stamina hypothesis, but it basically says that in the beginning—
+
+**Beyang Liu:**
+I read that in your post.
+
+**Kirsten Westeinde:**
+Yeah, I love it. I talk about it all the time. It basically says that in the beginning, no design is actually the best design, and you'll be able to move more quickly without design. But at some point you're going to reach a point where not having a design is going to slow you down more and more and more, and adding incremental functionality just gets harder and harder.
+
+**Kirsten Westeinde:**
+So the first question that I would ask is, are we past that point? He calls it the design payoff line. Are we really at a point where we need this design? Because honestly, it's worse to have a bad design than to have no design, in my opinion. So you want to make sure that you have enough information and have built enough features to understand what design your codebase needs. So that's the first thing.
+
+**Kirsten Westeinde:**
+But if you think that you are in that position, I always find that the business and the product managers are very motivated by data. So the more data that you can capture, the better. So I don't know that your organization uses story points, but say you could point to an issue of story point three that used to take half a day. Now it takes a day-and-a-half. Anything that you can point to to show that you are getting slower is a really good starting point.
+
+**Kirsten Westeinde:**
+Often they will have been feeling similar things. It probably won't come out of left field to them. They might feel like projects are taking longer than they should and are harder than they should. So the more you socialize the idea of, "X would be easier if we did this" and really just keep being the squeaky wheel, that can be really helpful.
+
+**Kirsten Westeinde:**
+The other thing too is we would absolutely never have gotten buy-in to stop feature development and do this. So if you can do it in an incremental way that you can chip away at over time, it'll be much more likely that you can get buy-in. And if you're in the lucky situation where your company has enough engineers to be working on parallel tracks of work, then if some people can still be building features while some people do this, it's going to be a lot easier of a pill to swallow for the business.
+
+**Beyang Liu:**
+Yeah. That makes a lot of sense. Kirsten, thanks so much for taking the time today. If there's people listening to this and they're interested in learning more about this effort or more about projects and learnings that you've undertaken, where should they go on the internet to find out more and learn more?
+
+**Kirsten Westeinde:**
+Well, Shopify has an engineering blog where we've published a few different blog posts on this topic. So I would definitely start with checking those out. We also have a ShipIt Presents new YouTube series about some of the engineering efforts at Shopify, and there's an episode that speaks about this as well. So check those out. And there's lots of other interesting non-componentization-related stuff on the shelf for the engineering blog. So I would say give that a look.
+
+**Beyang Liu:**
+All right. My guest today has been Kirsten Westeinde. Kirsten, thanks for being on the show.
+
+**Kirsten Westeinde:**
+Thanks for having me. It was fun.
+
+
diff --git a/content/podcast/3.1.md b/content/podcast/3.1.md
index 89f9c40a..2547061d 100644
--- a/content/podcast/3.1.md
+++ b/content/podcast/3.1.md
@@ -1,433 +1,564 @@
---
-title: 'Decomposing a massive Rails monolith with Kirsten Westeinde, software development manager, Shopify'
-publishDate: 2021-08-17T10:01-07:00
+title: 'Max Howell, creator of Homebrew and founder of tea'
+publishDate: 2022-05-18T07:00-07:00
tags: [podcast]
-author: ['Kirsten Westeinde', 'Beyang Liu']
-slug: refactoring-shopify-codebase-kirsten-westeinde
+author: ['Max Howell', 'Beyang Liu']
+slug: max-howell
published: true
-description: "What's it like to deconstruct one of the largest Rails codebases (3 million lines of code, 500,000+ lifetime commits, 40,000 files) on the planet? And why didn't Shopify follow the standard path to microservices, but instead choose to modularize their monolith?
+description: "Beyang talks with Max Howell, creator of Homebrew, about his new package manager, tea, which aims to solve the problem of open-source funding.
-In this episode, [Kirsten Westeinde](https://www.kirstenwesteinde.com/), software development manager at Shopify, describes how her team led the charge in refactoring and re-architecting Shopify's massive codebase, sharing the winding path they took to make this massive change and the way they tackled both the technical and human sides of this challenge."
-audioSrc: "https://www.buzzsprout.com/1097978/9020726-kirsten-westeinde-shopify.mp3"
+Max shares his beginnings in programming and what led him to work on early music players in Linux, Last.fm, and eventually get into Mac development. Max discusses the frustrations he experienced in cross-platform development that were the impetus for the creation of Homebrew and explains how Homebrew became the de facto package manager for macOS.
+
+Max talks about his latest project, tea, a successor to Homebrew that aims to solve the open-source funding problem with a decentralized protocol that uses NFTs and an understanding of the package dependency graph to distribute funding to open-source maintainers."
---
-What's it like to deconstruct one of the largest Rails codebases (3 million lines of code, 500,000+ lifetime commits, 40,000 files) on the planet? And why didn't Shopify follow the standard path to microservices, but instead choose to modularize their monolith?
+Beyang talks with Max Howell, creator of Homebrew, about his new package manager, tea, which aims to solve the problem of open-source funding.
+
+Max shares his beginnings in programming and what led him to work on early music players in Linux, Last.fm, and eventually get into Mac development. Max discusses the frustrations he experienced in cross-platform development that were the impetus for the creation of Homebrew and explains how Homebrew became the de facto package manager for macOS.
+
+Max talks about his latest project, tea, a successor to Homebrew that aims to solve the open-source funding problem with a decentralized protocol that uses NFTs and an understanding of the package dependency graph to distribute funding to open-source maintainers.
+
+
+
+
+
+Beyang and Max discuss Max’s early years in programming experimenting with the BBC Micro and BBC BASIC (1:55-9:25)
+
+Max talks about his experience helping to create Amarok, an early open-source music player on Linux (9:35-13:42)
+
+Max explains how he transitioned from open source to programming for pay by getting hired at last.fm (13:47-16:52)
+
+Max discusses how his work on Last.fm apps led him into Mac development (16:54-20:13)
+
+Beyang and Max discuss user experience and Max’s work in the macOS ecosystem (20:15-24:55)
+
+Max discusses the frustrations he experienced in cross-platform development that led him to start Homebrew (27:15-33:59)
+
+Max explains how Homebrew became the de facto package manager for macOS (33:30-41:00)
+
+Max introduces his new project, a successor to Homebrew, called Tea (41:04-50:34)
+
+Beyang and Max discuss NFTs and how selling an NFT prompted Max to consider the problem of paying developers in open source (50:35- 54:00)
+
+Max discusses how Tea aims to solve the problem of compensation in open source (54:04-56:33)
+
+Max describes the “Nebraska problem” and walks through how Tea can fund projects like OpenSSL and its dependencies. (56:34-57:43)
+
+Beyang and Max discuss how NFTs and DAOs fit into the Tea protocol (57:45-1:08:20)
+
+**Beyang:** All right, welcome back to another iteration of the Sourcegraph Podcast. Today I’m here with Max Howell, creator of Homebrew, the popular package manager for macOS, a prominent contributor to the Mac and Swift open-source communities, and most recently, the founder of Tea, a new decentralized package manager that aims to solve the hairy problem of open-source funding. Max, welcome to the show.
+
+**Max:** Hey, great to be here.
+
+**Beyang:** Awesome. It’s so good to have you. We have so much ground to cover, but the way we always kick things off here on Sourcegraph Podcast is by asking people how they got into programming. So, going back to, you know, your beginnings as a programmer, what was the thing that got you into this world?
+
+**Max:** Yeah. When I was six, my dad brought home this computer that we had in the UK, called the BBC Micro, and it was, in fact, indeed made, in some manner at least, by the BBC, or they sponsored it. Certainly, they stuck ‘BBC’ all over it. And one of the things about it that was interesting, and I think is kind of a shame that this doesn’t still happen is that it booted straight into a prompt that was not, like, Bash, not a shell, it was a programming language. It was BBC BASIC, which was a very typical BASIC and probably didn’t deserve to be branded BBC. I’m sure this was like, you know, someone else’s BASIC, I’m not really sure.
+
+But because it booted straight into the prompt, my dad started playing around with it, and then he introduced me to what you could do. And obviously, the first few programs we wrote were the ones that you do see from time to time when you go to computer museums, the PRINT HELLO, on line 10, and then on line 20, GOTO 10. Because BASICs used to number all their lines, and then you referred to them that way, which was a very easy way to get the hang of what program flow was like. And it is actually kind of a shame that there isn’t any major BASICs around nowadays, I think, for people to learn from. Like, it seems a lot harder to jump straight into JavaScript or Python than it was for me to get into BASIC.
+
+So yeah, from a very young age, I was into it, but just as something that I was doing with everything else that a child does. So, I made video games. And [laugh] remember, I got in and out of it, and I remember when I was 11, 12-ish, at school, I’d go to the library at lunch and just work on this game that I was making. And me and some friends were, like, competing to figure out how to make any kind of game scroll. We started off making this, like, Asteroids kind of game, it was like a maze. You had a ship and you moved through this maze.
+
+And we couldn’t figure out how to make the screen scroll so we have this, like, little competition among us. I was the first to figure out how to make a game, like how to make it so that keypresses moved something on the screen. And this was before the internet, of course, or the internet was extremely nascent then. Like, we did not have it. So, we had to scour the manuals and figure it out.
+
+And then my friend, I came in one lunch, and he was like, “I figured out how to make it scroll.” He was just so thrilled at himself. Yeah, it opened up a whole new sort of era in our BASIC video game-making. So yeah, for a long time, like, that was it for me. I never considered it as a career because nobody in my life programmed for a job.
+
+**Beyang:** What did your parents do?
+
+**Max:** My mom was an interior designer and my dad was just like someone who did, like, construction, essentially, like, internal inside houses work. But my dad was very into math and electronics and, you know, programming to a certain extent. Like, he used to play chess with me until I got better than him and then he just suddenly stopped playing with me. [laugh].
+
+**Beyang:** [laugh].
+
+**Max:** So yeah, my mom always, like, gave me this impression that the only things worth doing were, like, being a lawyer or a doctor. It wasn’t, you know, something she did deliberately, but it never was something I considered. And I remember, I went through a career fair when I was 16, 17, and I went to the programmers who were there and talked to them. And I came away feeling that they were just so geeky that I didn’t want to do it. [laugh].
+
+**Beyang:** [laugh]. You were turned off by the nerdiness.
+
+**Max:** Yeah. Yeah.
+
+**Beyang:** It’s just not your personality type.
+
+**Max:** Well, things I was quite nerdy as a teenager, but I didn’t want to be.
+
+**Beyang:** [laugh]. It’s not really an aspirational thing. It’s just a—[laugh].
+
+**Max:** I wanted to pick a career where I was moving away from that to some extent. Well, I don’t know. I picked chemistry. So, I went to university and did a Masters in Chemistry. And well, I did one year in industry and hated it.
+
+I… I really enjoyed the first month where I got to know the machines and was measuring surfactant surface tension and, like, the organic chemistry would make me new surfactants to measure, and I’d measure them. And when I got the hang of the machine, it was really fun mastering that. And then after a month, I’d mastered it, and I realized that if I did this, as a career, I would be using this machine for the next five to ten years of my life and that’s it. There would be nothing else. I could try and write some papers and get myself, like, out there, et cetera, but I realized it was a very slow-moving area.
+
+And in a way, it’s fortunate that I ended up doing this boring physical chemistry rather than something a little more interesting because I might have stuck with it. But I became extremely depressed and started looking for other things to do. And I remembered that I really enjoyed programming. And at this point, it was possible to install Linux and then look at the source code. And I was, it seemed, like, natural for me to get into something where other people were collaborating, contributing because I wanted to understand how to be part of something like that.
+
+It was rewarding. And so, as a result, I got into programming from open-source, like that was my route. I never did computer science. I never really found it that interesting is the thing. Obviously, I’m famous for snubbing it at this point.
+
+**Beyang:** The kind of theory behind it, not your cup of tea? You’re more of kind of like—
+
+**Max:** Yeah.
+
+**Beyang:** —in practice, hands-on.
+
+**Max:** I like building things. I like making something that someone else is using, and, like, get something out of. And my [unintelligible 00:07:00] I got a design background as well. I almost went to university and did product design or industrial design. I got a scholarship… in UK we call the sixth form, which is… there isn’t really an equivalent in the States, but it’s like, after 16, 17, and 18, you can do two more years.
+
+So, I almost did that, but as result, I have a design basis; I have a product background. So, the algorithms, I find them fun occasionally. I certainly it’s not as though I haven’t had to do some algorithms of a Data Science and Computer Science, kind of, nature here and there. Like, when I need to I do. But it was never the, like, part which interested me. I like building things.
+
+**Beyang:** Nice. So, when you got into open-source, was computing just sort of this hobby that you had kept on through your college years, and your—
+
+**Max:** Mm-hm.
+
+**Beyang:** Years as a professional chemist? Were you just always, like, installing the like, how did you get introduced to Linux in the first place?
+
+**Max:** [laugh]. Yeah well, I got fed up with Windows. [laugh].
+
+**Beyang:** [laugh]. Well, a lot of people got fed up with Windows.
+
+**Max:** And the more I studied, like, what was going on in computing—like, I found Slashdot, like, one year, I remember finding Slashdot. Like, during university, I became obsessed with this mp3 player called Sonique, which was like the main competitor to Winamp, but not as popular. It was very pretty. And I think that’s probably what got me into it. But not as good, frankly, with hindsight.
+
+But there was a bunch of people that I used to hang with on those forums, and they introduced me to Linux as, like, this free version of Windows. And at the time, Microsoft was evil, right? I don’t know if people remember this, but they were a tr—
+
+**Beyang:** [laugh] the old Microsoft.
+
+**Max:** [laugh]. Yeah, right. Nowadays, I have a reasonable amount respect for them, but at the time, like, IE6 was destroying the internet and they were doing everything they could to make sure that Windows was the only operating system that existed, and that included trying to take out Linux. So like, I got into this sort of revolutionary spirit, I think, that was part of the Linux movement. And I’d watch Stallman on his movies and, like, this—for people who don’t know, the guy is kind of—you know, I don’t want to—
+
+**Beyang:** RMS.
+
+**Max:** —offend him. Yeah. He’s uh… he’s certainly passionate, and inspiring in a way. And he got me into it. Was like, “Yeah, I want to be part of freeing software.” And I read more about Unix and went back and read about, like, the people who created it and it really inspired me.
+
+So, I found this Music Player because, like I say, like, music was something that I felt that the software wasn’t very good. It was called Amarok, and it only just been released version point-six, I believe. And the guy released it, there was a mailing list for this sort of stuff—it was for Linux—and he was like, “I’d like some other people to join me and make this.” So, I found the IRC channel—I miss IRC, incidentally. [laugh]. Things aren’t quite the same without it. Like, obviously it still exists, but other technologies much better now, so I don’t dwell on stuff that has nostalgia for me. If it’s not as good. Slack is better.
+
+And I said, “I’d like to get involved.” And he’s like, “Great. Just download the source code; start doing stuff.” So, I started hacking on it. And it came to be there was three of us, and we got known as the Three Ms—because I was mxcl, and the founder—we don’t call them founders in open-source, like, [unintelligible 00:10:59]—
+
+**Beyang:** Creator?
+
+**Max:** Released initially—yeah, creator—markey and mueslix. And still great friends with mueslix. Markey kind of fell off the map about ten years ago, unfortunately. And well, I don’t know how, but none of us had jobs and [laugh] so we just worked on it the whole time. Worked on it continuously.
+
+And we made it into something that was really impressive. People loved it. At the time, I think it was probably the best music player that there was. Like, you know, Winamp had been purchased by AOL and so, like, the innovation had moved to other areas. And, you know, I’d stay up all night because we have people contributing to it from all time zones, and I never wanted to miss anything because I was worried they would ruin it. [laugh].
+
+But it was very open-source so nobody really had complete control over what was going on, which I learned from that experience is bad. Like, I took that into account and saw how Linux had Linus, and he controlled the contributions to a certain extent. He was very allowing and very open to whatever you wanted to build, but if he thought it was wrong, he’d say no. And Amarok had a problem where there wasn’t anyone who was willing to say no. Should have been markey. It was his initially, but he believed in the open-source spirit. So, I did learn that from that, but it can slow things down and derail the project. And I took that into account with Homebrew quite sincerely.
+
+**Beyang:** Yeah, yeah. So, I want to get into Homebrew and kind of how you transitioned over to the Mac. But before we get into that, like, so what was your life situation at that time? You said, “None of you had jobs,” so like, what were you doing for money at that point? And what was that like?
+
+**Max:** Yeah, so I was living with my parents. After the year in industry and quitting, and not being able to… handle the idea of going back to that, I moved back in with my parents, and, you know, just told them, I was going to try and figure out what I was doing myself. And still, I wasn’t thinking that I could make a career out of programming. But that’s all that I did. And so, I turned it into a night owl so that I wouldn’t have to see my parents and interact with them or explain to them what the hell I was doing with my life.
+
+**Beyang:** Were they understanding or were they kind of judgmental about the whole thing?
+
+**Max:** Well, first, they were understanding. And then, after about six months, and I’d been working on Amarok for, like, probably 18 months at this point, they sat me down just after I got up and just before they were about to go to bed and were like, “This cannot go on. You need to move out and get a job.” [laugh].
+
+**Beyang:** [laugh]. Oh, now. And did you or did you just kind of continue as it was?
+
+**Max:** Well, I moved out. [laugh].
+
+**Beyang:** [laugh]. Got it.
+
+**Max:** I went to live with my girlfriend at the time. She was living with her parents. Her parents were far less fussed about this sort of thing. But—
+
+**Beyang:** I can—yeah.
+
+**Max:** I don’t know why they were less fussed. Do you think they’d want me to make something with myself, but well, no, they liked me more than my parents apparently. [laugh].
+
+**Beyang:** Interesting. [laugh].
+
+**Max:** That’s not true. That’s not true. My parents have been extremely supportive. Mostly. This one exception.
+
+**Beyang:** I think they were just concer—it’s just like the parental concern, you know? They see you making a decision that they perceive to be, you know, a bad life decision and they kind of want to course correct.
+
+**Max:** Yeah. Like, they didn’t really understand what I was doing. They knew it wasn’t earning any money and they didn’t think it could. So, I lived with the girlfriend for six months and her dad gave me a job. So, you know.
+
+And I was making Excel spreadsheets [laugh] and I made them programmable, and so I was getting into that stuff. It was after about six months of that, the Last.fm, this startup in London, wrote to me and asked if I wanted to come and work for them. And it was because of Amarok. Amarok was very popular there. They were a music social network, like, early Web2.0, trying to figure out what music as a social network could be.
+
+And in many ways, really the only ones who ever figured it out, even though they’re not a big anymore, unfortunately. So, that’s how I got into doing it for pay, through open-source, so I don’t think it’s very typical.
+
+**Beyang:** Yeah, that’s interesting. And when did you get into macOS development? You know, what was that transition like? As I understand it, you’re mostly Mac these days. So, what made you kind of go from the Linux world into the very proprietary, very non-open world of Mac development?
+
+**Max:** Yeah. So, it was about the Last.fm period, and I was getting fed up with Linux because didn’t matter what you did on Linux, you had to read a tutorial or a blog post about it. Because nothing ever worked. Nothing just worked.
+
+And it’s not as though I could go back to Windows, having become a Unix diehard at this point. And it was about then, a bit before that when they—Apple announced that the next Mac would be Intel. And the fact that it was Intel and thus, all the software that I was using on Linux could easily be compiled for it—this was before it was very common for everything to be able to compile for ARM as well, although people made a lot of effort to do that. And I—and it was macOS Tiger, and it was clear that Apple were putting a lot of effort into making Mac OS X really nice, and, like, as a product person, you know, I appreciate the fact that they put all this time and effort into it, while Linux was a mess. And part of the reason I was involved in open-source on Linux is I was trying to fix it.
+
+But I kept seeing how these big organizations without anyone in charge were having trouble making something as large as a desktop environment. That’s what they call them on Linux. So, I bought one of the new Mac Minis with an Intel to see what I’d think of it. And I loved it. Every part of macOS that I looked at was clearly very well designed.
+
+Even the Unix integrations, how the file system was laid out, I just loved how everything was so consistent on the file system. There was a directory called library, and everything was capitalized, like, everything was CamelCase capitalized. Like, on Linux, everything was like whatever that particular dev liked. So, underscores, hyphens, CamelCase, spaces if they hated everybody. And Apple have chosen to CamelCase everything and very rarely put spaces in. Sometimes, sometimes there’s spaces in there, but really the spaces were more consistent, really.
+
+And I was like, okay, well, so they saying you always must quote in shell scripts. Like, I forgave them for that. I think with hindsight now, that was a bad call, but at the time, I was like, willing to, like, see how there was a positive to some of these choices. And so yeah, I really liked every part of it, but the part that was missing was a decent package manager. I came from Linux so I was used to having, like, power.
+
+I came from Arch Linux, actually, which I still think has one of the best package managers. So, that seeded the idea, certainly, that I could perhaps make the macOS Package Manager that was how I needed it to be.
+
+**Beyang:** Do you think—you know, you mentioned you had a design background. Do you think that aspect of the Mac world appealed to you? Like, do you feel like you were kind of unique in the Linux world in terms of being motivated by that, kind of like, end-user product experience?
+
+**Max:** Well, certainly at the time in Linux world. Things like Ubuntu was starting to turn up and they cared more about the user experience for their users. But yeah, it was frustrating, and I used to put a lot of effort into thinking about the usability and user experience, even though I had no formal training. I made this app, it was really the first open-source project that I made was an app called Filelight, which was this—it’s like Disk Daisy on Mac, it shows a concentric pie chart, essentially, so you can see where disk space was. And of course, back in, like, 2003 when we had 30 gigabyte hard drives, it was very important to know who was using your disk space because you needed it. [laugh]
+
+But I remember one time getting this comment from someone accusing the app of having no appreciation for user experience and it just annoyed me so much because that’s all I was thinking about. [laugh]. I was like, this is not like your other apps on Linux. Can you not see that? So, it occurred to me at that point that everyone was always complaining about the user experience on Linux, but you can’t even listen to these people because they don’t know good user experience. And that was frustrating.
+
+And I found on macOS, that the developers on macOS really cared about user experience and also really knew what it was, and the users also knew what it was. So, my work would be appreciated, rather than being told that I didn’t have a good eye for user experience by someone who didn’t know any better, apparently, what the term was. So, it’s just like, also—I hate to say it—like, the quality of developers, the quality of users, the quality of the ecosystem is excellent. And I think it’s a bit sad, actually. I don’t think Apple is that quality anymore. I don’t.
+
+**Beyang:** Interesting. So, when you got into macOS development, did you jump straight into, kind of, replicating that package manager experience? Or—
+
+**Max:** No.
+
+**Beyang:** Did you work on other things and then, you know, this became—those became motivation for developer experience?
+
+**Max:** Yeah, I certainly didn’t jump straight into it. It was years later, while I was at Last.fm, I became the lead developer for the client team there, and Last.fm had six client apps, and so—when we meant client, it was app. Last.fm was a website predominantly, but we had an app portion.
+
+And over the years, the number of apps increased from just Mac, Linux, and Windows. And you know, it’s another reason I liked Last.fm, the people there were Linux people, but—so we had apps for every platform so it meant that I would be making apps for every platform. We used this cross-platform toolkit called Qt—Q-T—which still exists, but I don’t know if it’s very—like, you know, the Bitcoin client was originally Qt—no, it wasn’t originally Qt, but it became Qt.
+
+**Beyang:** [laugh].
+
+**Max:** And so, [my friend 00:22:22]—
+
+**Beyang:** Yeah I remember using—yeah, sorry. Go ahead.
+
+**Max:** So, when iPhone came out, there was an avid community of people who reverse-engineered it in order to make apps. And I think part of the reason that the App Store came out so quickly after the iPhone was originally announced was because people were clearly showing they really wanted to make their own apps for this device. They reverse-engineered the whole thing, open-sourced that, and put it online, and you could make apps sort of. You had to jailbreak the phone, which was a lot easier back then obviously. [laugh]. But Apple were a lot less bothered about whether or not you did it.
+
+And we hired the guy who made the Last.fm app for iPhone. So, we were really early to iPhone, and so I got into iPhone development super-early relative to a lot of people which was instrumental in where my career went. And then we made Android and we also had a Blackberry app because BlackBerry did have an App Store on their, like, newer phones for a bit. It was terrible. I hated their SDK. C++ and it was gross. But, you know, iPhone dev was the first—
+
+**Beyang:** They probably had a fair bit of market share at that point. They might have still been dominant. No?
+
+**Max:** They were doing well because people didn’t want to give up their old BlackBerrys and then they made a huge mistake by removing the keyboard and trying to copy of your iPhone, and it bombed.
+
+**Beyang:** They should have—yeah, yeah.
+
+**Max:** Know why your users like your product. [laugh]. It’s very important. I think touchscreens have gone way too many places. I think it’s ludicrous that Elon Musk thinks that Tesla should have such a big touchscreen in a car when you don’t want to have to be looking at these things.
+
+**Beyang:** Tactile feedback.
+
+**Max:** Yeah. I like Elon Musk. I read his autobiography at Christmas, but I think sometimes you make bad calls. He’s not as much of a product person as he thinks he is. He needs to listen to his CPO more.
+
+On the other hand, maybe I’m completely wrong, right? Like, everyone thinks touchscreens are so great, so he put them in the Tesla, and then they think the Tesla’s great. Sometimes I’m not the best person to ask. That is certainly something I’ve learned over the years. Like, I’ll make it so the product is all that matters, and then it won’t sell because I totally misread the market.
+
+**Beyang:** Well, you know what it is? I think sometimes they’re just like, waves that sweep the collective consciousness, or whatever, where everyone just agrees, like, that’s the way it should be done. Like, my kind of like, controversial take is, like, actually, you know, computers would be easier to use if they’re more like keyboard-based inputs. You know, and that’s a very, like, developer-y, you know, mindset.
+
+**Max:** Well, you’re right, it would be easier to use, just harder to learn.
+
+**Beyang:** Yeah. Yeah.
+
+**Max:** And that’s, of course, a big factor in whether or not a product succeeds.
+
+**Beyang:** Yeah, definitely. Okay, so you were working on these different mobile clients, but you liked iOS the best for Last.fm?
+
+**Max:** Yeah, I really enjoyed Objective-C. So, my experience with Objective-C had been more limited up until then because we used this cross-platform toolkit. And even though I bought a Mac, I haven’t jumped straight into making apps on it at that point. But we used Mac for all of the development because it was the only platform where we could have a VM for Linux and a VM for Windows, and easily—you know, because the tools for making those virtual machines were great on Mac. Like, that was the thing, everything was always greatest on Mac, even if, like, it might be greater on Windows for one thing, overall it was easier to just develop on Mac. So, we all did that in the client team.
+
+Like most of the company even. Like, you know, this was right at the beginning of the era, where Mac became the choice for developers. So, we did everything on Mac, and like, you know, so like Android SDK, you didn’t need to VM it, it worked well on Mac. You could pick Mac or Windows and that was a universal thing. Even the BlackBerry SDK, like, you could pick Windows or Mac.
+
+So, at that point, we were trying to build the six different platforms and the amount of crap we had to go through to make it work on six platforms was prohibitive. Like, I estimated we were wasting 40% of our time just messing around with build systems and trying to try to make it consistently work. We had a bunch of open-source that was underpinning the whole, like, all of the work we did was open-source, all these libraries trying to make it work. And it annoyed me, you know? This led me back to thinking about doing a package manager. Well, the truth is, I’d go to the pub and complain about it every evening [laugh] until my coworkers got fed up with me complaining about it, and one of them said, “Max, maybe you should just fix this problem.” And uh, it’s—
+
+**Beyang:** And you’re like, “Challenge accepted.”
+
+**Max:** Yeah. It occurred to me that I could and that I didn’t have to just complain about it. So, that weekend, I started what would later become Homebrew. Just thinking through what, as a developer, I needed in order to do this cross-platform dev. And so, you know, this is strange how that Homebrew is not a cross-platform development tool now and indicative of how what a product is changes during its development. But that was how it started.
+
+**Beyang:** Interesting. So, what were some of the—you know, when you’re first getting the project off the ground, you know, what were the ideas that you took from your experience with the Linux package management world, and what were the changes or new ideas you brought in?
+
+**Max:** Yeah. So, most package managers are really inflexible, like, famously so. Like, at the time, apt was probably the biggest one and forums online were always filled with people trying to get something installed and failing because it had no flexibility. So, you have installed foo, and this thing you’re trying to install wants foo slightly newer and I refuse to install it. [laugh]. I will not do it for you.
+
+And now that annoyed me, I felt that developers knew what they were doing, so they needed, like, some freedom to, you know, do that, get things working, that you can trust them. So, from the go, I made like that was why the formula system was built from the go, and why I built it on top of Git. I wanted you to go in there and hack on these package recipes yourself. I wanted it to be extremely obvious how you did it and for you to have the power to do whatever you want and to make it work for you. Like, the idea originally was you cloned a version of Homebrew into your source directory and then made it install the packages you needed in order to get going.
+
+And then you could have, like, several copies of the copies of it scattered around, which meant compiling everything from source which didn’t seem a problem because unlike the main competitor to Homebrew, which is called MacPorts. I realized that the Mac itself came with a huge amount of Unix software that Apple will maintain for us, and they were obligated to make it binary compatible and safe and consistent so that all the apps that you installed would continue working, you know, for ten years. So, I took advantage of that. We didn’t reinstall all those things. And it meant using Homebrew was vastly quicker than using MacPorts, which certainly helped with early adoption.
+
+And the symlinking system, I think there was another package manager that used it, but I didn’t know about it at the time, but I had heard about the symlinking system from another tool that GNU made, but it wasn’t the [unintelligible 00:30:34] typical, it’s a typical GNU thing, right, like, almost good. [laugh].
+
+**Beyang:** [laugh].
+
+**Max:** Because I wanted to have multiple versions of things available so you could switch back and forth as you needed for different projects, or if something was broken. And I wanted the file system layout to be really nice, just like the rest of Mac. I wanted it so you could go into the cellar and there would be all the software you’d installed, and it’s all nicely versioned and you can see what each package contains. I like the idea that the file system was the database, and so I very carefully designed everything so I didn’t need another database. Because also at that point, I’d realized that every time you add a new system—call it a database or whatever—a load of stuff breaks, and you’ve added complexity that’s just going to slow down development to the rest of time.
+
+And so, if you can avoid it, like, it wasn’t going to, like, insist we avoid it. Like, if we needed it, I’d be like, “Okay, now we have a database.” But if I could think of some clever way to avoid it that worked well enough and made it so people could use regular tools to inspect what packages they’d installed, I really liked that. I liked that you could just use the terminal to see what you have installed, you can use ls, you can use find, and you didn’t have to learn a cryptic command like all the other package managers, in order to just use it. Like, I really believe that the package manager is just this fundamental tool that nobody wants.
+
+And I wanted to build something that just got out of your way so you could get on with what mattered. You wanted to build an app, you wanted to use an app, you wanted to do something else. And the package manager shouldn’t be sitting there going, “Hey, I’m important. You have to learn me. You have to understand how I work. You have to tread on eggshells while you’re using me. And if you don’t, you’re going to be sorry.” [laugh]. I didn’t want that.
+
+Another reason that it was such a successful product, I think, is because people saw just by reading the readme that I was trying to make the thing they wanted. And while everyone else who made a package manager, it became their lives. And, like, when you build something, it becomes important to you, and you want everyone to know how important this thing you’ve built is. I think, like, the human ego side of things was holding back similar tools.
+
+**Beyang:** Mm-hm. So, how did Homebrew, I guess, go from this thing was originally intended for, you know, multi-platform package management, geared towards your mobile development issues to, like, the thing that became the de facto package manager for macOS? Was that, like, a sudden transition? Was there, like, a particular inflection point where it kind of changed from one to the other? Or was it more just, like, you know, one day you woke up and you realized that this was now mainly for macOS, and it was basically ubiquitous.
+
+**Max:** Yeah, it was definitely gradual. And it was following what users wanted was the truth. So, there was huge demand for making it work on Mac and making it work as a replacement for MacPorts so it could install all the tools that people needed and not just the things you might need as a developer to build apps. So yeah, it was following the community and allowing the community to influence it. I was—from the way it was designed, I always wanted other people to get involved, like, heavily involved because there are tens of thousands of packages, and I’ll be damned if I personally had to write all the package recipes.
+
+So, I built it from the start so that it was super easy to get involved. Like, it was just a git clone. So, you could go in there, edit it, it was working out of the clone, there was no installation of the package manager itself, and you could just push back, like, straightaway, commit and push back. Now, this is also partly so that you could have maintained your own fork so that you could customize it to what you wanted, but it was also because I wanted people to get involved straight away. And so, I created two commands ‘brew create,’ which took a URL and then would download that URL, assuming it was a source tarball, and then try and create the formula, the template, the recipe—we called them formula; well, I called them formula. The namings system is something—another thing it’s famous for.
-In this episode, [Kirsten Westeinde](https://www.kirstenwesteinde.com/), software development manager at Shopify, describes how her team led the charge in refactoring and re-architecting Shopify's massive codebase, sharing the winding path they took to make this massive change and the way they tackled both the technical and human sides of this challenge.
+And it would probably work. You could probably just push that back, open a pull request—after pull requests existed; like, Homebrew was before pull requests, initially. They turned up a few months later, thank God. It was very hard to work with open-source before that. Better than SourceForge, but.
-
+And ‘brew edit,’ which meant that if something wasn’t working, you could—I wanted people to fix things themselves, and it’s still a big problem with open-source is that a lot of projects don’t tell their users, their developer—they don’t, they assume the developers who are using it, A, haven’t got the talent to fix things in the way that they present themselves, but they don’t tell the users how to get involved either or what they need to do. I still do not know how to contribute to a Ruby Gem. I built Homebrew with Ruby. I couldn’t find any documentation for it, and I gave up.
-Ruby on Rails: https://rubyonrails.org/
+How do you do it? Do you clone it somewhere? Then how do you make Ruby Gems use your version rather than vended version? I don’t know, and I never learned and I don’t really use Ruby anymore, so I’ll never know. But I think everything that’s open-source should have at the top how to get involved, how to contribute, and it should be two or three steps at most.
-React: https://reactjs.org/
+With Homebrew it was one step, so everyone got involved. And if you look up, like, the video that someone’s put online about showing how Homebrew’s contribution exploded, it’s one of those videos where people’s heads fly around and they activate dots and the dots represent files. So, the Homebrew one is for, like, the first few months while I was getting it up to speed, before I even really open-sourced, just me darting around. And then a few other people turned up, and then within no time at all, there’s thousands of people participating.
-React Native: https://reactnative.dev/
+**Beyang:** That’s awesome.
-Go: https://golang.org/
+**Max:** And it’s—I don’t think there can be another open-source project that got as many unique contributors as quickly. And it is the project that has the most unique contributors of any open-source project, and thus, almost certainly any software project that exists. Because I designed it to do that, from the get-go.
-Python: https://www.python.org/
+**Beyang:** Because the formulas for Homebrew which, you know, if you’re contributing to another package manager, you might not think of as, like, contributing per se, you’re just you know, writing a formula, but with Homebrew it’s all just in the same Git repository, so the boundaries are—
-Scala: https://www.scala-lang.org/
+**Max:** Or was.
-Kirsten Westeinde: https://www.kirstenwesteinde.com/
+**Beyang:** —kind of fuzzy—or was, sorry. But it was easy to go from one to the other. And I think this gets back to your earlier point about the advantages of just using a system that’s already there, you know, file system on your computer, or you know, Git for hosting things that matter to devs. It wasn’t some other system; it was just a Git repository so it’s easy to, like, introspect and, like, you know, pull open the covers. There were no covers; you could just see how it worked.
-(Blog post) Deconstructing the Monolith: Designing Software that Maximizes Developer Productivity by Kirsten Westeinde: https://shopify.engineering/deconstructing-monolith-designing-software-maximizes-developer-productivity
+I can think of, like, a couple other open-source projects, like, you know, TypeScript, the way they did, their type definitions with definitely typed that repository in the early days. The Go package management in the early days, where it was just a Git URL. I think there’s something to be said for just, like, using the tool that people are already familiar with instead of trying to reinvent something that people then have to learn; it becomes, like, this whole, like, thing they have to grok before they can start contributing to your tool.
-(2019 Shopify Unite conference talk) Deconstructing the Monolith: https://www.youtube.com/watch?v=ISYKx8sa53g
+**Max:** It’s absolutely true. There’s so much open-source released every week. Nobody wants to learn anything new. [laugh] so if you’re going to—
-(Blog post) Under Deconstruction: The State of Shopify’s Monolith by Philip
-Müller: https://shopify.engineering/shopify-monolith
+**Beyang:** [laugh]. We’re also busy. Yeah.
-Wedge: Deprecated internal Shopify tool that was built to score engineering teams on how well they are doing on their componentization journey.
+**Max:** You have to be extremely compelling to make them jump through hoops to learn how it works. Like, you know, we’re all lazy in that respect. But also, we don’t trust that anything is really going to be that good. You can say it’s going to be great all you want but we don’t trust it. So yeah, but people aren’t willing to sit down and read an instruction manual.
-Packwerk: https://github.com/Shopify/packwerk
+I think that’s an issue with a huge amount of software at the moment. Like, Docker is a good example of something that’s so compelling everybody uses it, but the interface that we use to interact with it is awful. I have to Google every time how to do everything. I can never remember it; it’s not intuitive in the slightest. So yeah, you’re I’d have to be so compelling—like Docker—that people willing to tolerate a terrible interface, or you have to have an incredibly good interface. And preferably both. [laugh]. Right?
-Shipit presents Packwerk: https://www.youtube.com/watch?v=olEA157z7kU
+**Beyang:** [laugh]. Yeah, that makes sense. Okay, so you’re the author of the most successful package manager on macOS. Some might argue the most successful package manager in existence, given the ubiquity it has for Mac users and Mac devs. You know, a less ambitious person might be content with that, and just, you know, ride off into the sunset being satisfied that they created this awesome package manager that everyone uses.
-(Blog post) Enforcing Modularity in Rails App with Packwerk by Maple Ong: https://shopify.engineering/enforcing-modularity-rails-apps-packwerk
+But no. You are working on a new project which in some ways is a bit of a successor to Homebrew, kind of a Homebrew 2, called Tea. So, talk a little bit about what Tea is and what the motivations were for creating this new system that you’re working on now.
-Zeitwerk: https://github.com/fxn/zeitwerk
+**Max:** Good name, right?
-Martin Fowler’s design stamina hypothesis: https://martinfowler.com/bliki/DesignStaminaHypothesis.html
+**Beyang:** Yeah. It—[laugh] I love the naming scheme throughout. Yeah.
-Shopify Fulfillment Network (SFN): https://www.shopify.com/fulfillment
+**Max:** Yeah, I’ve always been fond of names. And it goes back to intuitiveness, again. Humans need labels. Computers don’t. Like, I talk about this with my girlfriend on a regular basis about what a potential AI is going to be like, and one of the things I talked about is how it doesn’t need to name things. It will just use IDs, it will make a UUID for everything.
-Kafka: https://kafka.apache.org/
+**Beyang:** [laugh].
-
+**Max:** Humans need names in order to understand what something is, and so that limits our creative ability for sure. When everything needs a name, it means you to have less things that need names or you overload the human. So, I’m a big believer in picking names that evoke the right metaphor so that someone reading about your tool, your app, your library has a preconceived notion of what it is. Obviously, this is no good for children, but children learn things extremely quickly so I’m not worried about them. It’s adults who are the problem.
-**Beyang Liu:**
-All right. I'm here with Kirsten Westeinde. Kirsten is a software development manager at Shopify where I understand, Kirsten, you've been involved in a years-long effort to decompose Shopify's massive Rails monolith, or perhaps like multiple monoliths now, into smaller, modular components. Is that right?
+So, I’ve always been a big person for names. And Homebrew has great naming scheme; we can talk about that some other time, I guess. But yeah, Tea is, essentially Brew 2 for Web3 is what we’re saying. And the genesis of this came because I haven’t worked on Homebrew for quite a few years at this point. I burned out on the project. I felt that it was good enough, it did everything that it should do, it was extremely useful to people, and there was a limited amount of value I could continue adding to it.
-**Kirsten Westeinde:**
-That's right.
+But the main thing was that in order to work on it, I had to have two full-time jobs. Like, I got to confess to a lot of my past employers at this point that there was a lot of times when I was working on Homebrew and I was not working on the thing you paid me to do. [laugh]. Sorry about that, but I hope you were happy with what I produced otherwise, anyway. And so, I got into this cycle.
-**Beyang Liu:**
-Cool. Thanks so much for taking the time. Sounds like a massive effort and I'll bet that Shopify engineering has been very busy over the past year. So I really appreciate you taking the time to come chat with us and share things that you've learned along the way.
+I quit my job to work on Homebrew initially, after it became successful because it was so compelling to work on this huge project that was getting people really excited, and it was by far, like, the most interesting thing I could be working on at that point. But then I ran out of money. I remember going to the bank and asking them how going overdrawn works because I’d never done it before, and I didn’t know, like, would I be paying interest? And how much money could I go overdrawn by?
-**Kirsten Westeinde:**
-Absolutely. Thanks for having me.
+**Beyang:** Wow.
-**Beyang Liu:**
-So I think the focal point of our conversation is really going to be this massive decomposition effort. It's going to be very fascinating to hear about because I think a lot of engineering teams try to undertake projects like this, especially as the company grows and some succeed, but a lot end in failure. And so I think you have a lot to share in terms of how you can pull this off successfully. But before we dive into all of that, we have kind of a tradition on the podcast of first asking people how they got into programming. Right now you're this software development manager who's in charge of this very complex project. You have a lot of responsibility, but at some point you had your first contact with code. So, for you, what was that? And how did that start your journey into this world of bits and ones and zeros that we live in?
+**Max:** And were they going to report me to the government as some kind of delinquent? [laugh]. I was 28. So, I kept going through the cycle of getting jobs—I had to pick jobs that I liked, I can’t work on things I don’t like. That’s how I got into open-source, right? Like, chemistry didn’t turn out to be what I wanted, and it made me incredibly depressed.
-**Kirsten Westeinde:**
-Absolutely. Yeah. If you had asked me when I was a kid, I definitely would not have thought that this would have been where I ended up. I actually didn't even really know what programming was before I went into university, but I did end up studying engineering just because of my love for math and science. And the school that I went to ended up doing a general first year where we basically took classes from all of the different engineering tracks to kind of learn a bit about them and decide where we wanted to go. And so in my first year I took a programming class, we learned C++ and it turns out that I really enjoyed it and I was really good at it. And the more that I looked into it, it seemed like a really interesting field to be in. So I had originally thought I would be a civil engineer, but I'm very glad that I ended up going the direction I did.
+So, I had to find jobs that I wanted, which is difficult. And then I wanted to go back and work on Homebrew or my other open-source because that was what I felt was my calling, really. That was where I was making the most impact. So, I cycled through jobs, like, doing something for a bit, quitting, working on open-source, and then going back. And, you know, a few years ago, I was like, “This is getting ridiculous. I need to figure out how to try and make money with open-source.”
-**Beyang Liu:**
-C++—that's kind of like diving off the deep end as your first programming language.
+And there’s a few people who do and they’re quite successful, and I tried to copy their system but didn’t manage to get enough people to sponsor my Patreon and found that even marketing myself for Patreon was an enormous amount of time that I didn’t want to be spending on that.
-**Kirsten Westeinde:**
-Yeah. It's always funny to hear what people learn in school. It's rarely what we end up using in the field I find.
+**Beyang:** Yeah.
-**Beyang Liu:**
-Okay, cool. So from your start in university, what was kind of like the rough journey from there to joining Shopify?
+**Max:** So, went back to get another job.
-**Kirsten Westeinde:**
-I actually joined Shopify as an intern while I was still in school. So I did two internships with other companies, but I joined Shopify in 2013 out of the Ottawa office as an intern. And then I ended up doing three different internships with Shopify before joining full-time after I graduated. And through those internships, I really used the time to try out different things and try to understand where my interests lay. So I did some web development using Rails, I did some mobile development, and I worked on some internal tools and external products. So I've really had my hands in a lot of different places at Shopify over the years.
+**Beyang:** [laugh]. You don’t strike me much as a company man.
-**Beyang Liu:**
-Awesome. So you've been there since 2013, which means you've kind of had a front-row seat to this whole rocket ship trajectory that the company has been on.
+**Max:** No. No. No. Apple knew that full well. I feel bad for Apple, really. I worked there for a year and I just couldn’t handle it. Too corporate, at least part I was at. Tried to make something useful and important—hopefully did anyway.
-**Kirsten Westeinde:**
-Yeah, it's been crazy. When I joined, I think we had 150 people working for the company and we're a private company. We had only a handful of merchants. We had one small office and fast forward to today, we're an international company. We have... It's hard to keep track of it, but I think like 7,000+ employees. At this time, we're a public company, so much has changed. I like to tell people I haven't worked at the same company for eight years, I've actually worked at like eight different companies because it really has been changing that quickly.
+Yeah, so—well indeed. So, startups mostly. But it’s an old problem. Everyone knows it, that people who make an open-source may not find a way to get paid for that. Like, a lot of people who work on Homebrew now work at GitHub and great, I’m glad that there are companies that exist who understand the importance of open-source and willing to basically fund it.
-**Beyang Liu:**
-Yeah, that's crazy. And you know, I bet most of our listeners don't need any introduction to Shopify, but you know, for the one or two people who've been living under a rock for the past seven years. Chances are... If you bought anything on the internet, chances are you use Shopify, right? Because you power a lot of the kind of small businesses and independent operators that sell things online right?
+I don’t think that’s good for open-source to have big companies like Microsoft controlling how open-source works.
-**Kirsten Westeinde:**
-Yeah, that's correct. We actually don't force the Shopify brand on our merchant sites. So a lot of people buy things from Shopify stores without actually knowing that they have. But basically if you bought something from Amazon and it was enjoyable or—sorry—from anything other than Amazon and it was an enjoyable experience, that was probably a Shopify store.
+**Beyang:** Sure. Yeah, yeah.
-**Beyang Liu:**
-Yeah. And actually for me personally, increasingly I find myself buying more and more things off Amazon because there's like... A lot of times the things that you can get in these kinds of independent stores are just like higher quality or it just feels closer to the seller. And so thank you for enabling all that. So diving into this large-scale refactoring and re-architecture project, I thought maybe we could start off by giving people an overview of what Shopify looks like as an engineering organization and as a codebase. So in broad strokes, what are the major teams and what are the major parts of the code, and what does it all kind of do as an engineering system?
+**Max:** Like, let’s not forget what Microsoft were, like, 20 years ago. Even ten years ago. They could easily go back to that and then you have huge portions of what builds the internet. And let’s face it, there isn’t an app that exists isn’t composed of open-source in some capacity, even if it’s just the operating system itself. Like, 80, 90% of all applications are an open-source bed, and then some proprietary source code on top, which is, like, the cherry, which makes the thing into the app and makes it into Instagram.
-**Kirsten Westeinde:**
-Definitely. So we talk about the core Shopify product as the core codebase. And so that's basically what powers merchants to manage their orders, to manage shipping, etc. So all of the core pieces of the product live in one Rails codebase. And it's actually one of the largest, probably the largest Rails codebase on the planet because we got started with Rails like right when Rails became a thing, and it's been under continuous development since at least 2006. And the last time I checked, we were pushing like 3 million lines of code, more than 500,000 lifetime commits and about 40,000 files. So it's massive. And in terms of an engineering org, I think we're at about 1,500 or so engineers and we're actually aiming to hire another 2021 this year, so it'll be continuing on this massive pace of growth. And if I had to guess, I'd guess probably about half of the engineering team works daily in the core codebase and the other half works on applications outside of core.
+But a huge amount of open-source software and the people who have built this stuff often would love to work on it. They’re passionate enough they built it in the first place. But there’s no mechanism for how that works. And last year, while I was—well here’s the truth. My girlfriend and me were trying for a baby and succeeded in record time. [laugh]. The gynecologist told us it could take up to a year and not to expect anything, so like, two weeks later, when she was showing me the pregnancy tests, I was like, “Oh, great. This is what we wanted, but I thought we had a bit more time to figure out how—what I was going to do next.”
-**Beyang Liu:**
-That's crazy, that's so much code. Does it... Have you gotten to the point where Git operations start to slow down at all? Like if you were to clone the entire codebase to your local machine... Like do people even do that? Or how long does that take?
+**Beyang:** Cash flow and yeah. [laugh].
-**Kirsten Westeinde:**
-Yeah, people do it, it works. The test suite definitely can get slow, but development itself is not a problem. We actually... We always joke, like we host Kylie Jenner's shop on Shopify and it's like one of the largest stores. And we joke that like we are the Kylie to so many other systems that we use. So we're hosted on Google Cloud and like we are by far the largest product hosted on Google Cloud and so we're often stretching the boundaries of their systems. And similarly, like with Rails itself, we are often the ones that find those bugs that you only find when you're operating at this scale. And so what we do is we really make choices about what technologies we want to use and then really double down on them. So we actually have a full team at Shopify who are Rails core contributors, and we try to actually just evolve the tools that we use to be better and to be better able to support us and others.
+**Max:** Yeah, exactly. [laugh]. So, I kind of panicked and went through all the ideas I’ve ever written down. I’m a bit of an obsessive notetaker, and even though I hadn’t worked on Homebrew for, you know, five, six years at this point, I’d been recording what would be, like, a Brew 2, what I could do. And people have often asked me if I make another Brew 2, and I always said no, but I’d made the notes anyway.
-**Beyang Liu:**
-What languages are in use? So with Rails, I assume Ruby is a big language, are there any others that are big parts of the stack?
+And I said no because I didn’t see anything—like, all my ideas were good, but they weren’t good enough that it made sense for me to do something new. Homebrew is good. It’s still a great tool. And I have a friend—and he’s my co-founder—Timothy Lewis, and I’ve known him for ten years or so.
-**Kirsten Westeinde:**
-Yeah. Shopify has always been very opinionated about technology choices. So essentially any problem that can be solved with Ruby on Rails should be, there are some exceptions. If applications have really, really high performance constraints or need parallelization, sometimes we use Go, the front ends are in React. And for mobile development, we've just standardized around React Native going forward as well. And then in data land, we have some Python and Scala and in infrastructure we have Go and Lua as well.
+And he’s been trying to get me into Web3 and crypto. Crypto of course before Web3 because that’s what it was. Like, the fundamental—you know, blockchain is the technology underneath it, and for a long time, its only purpose was crypto, cryptocurrencies. And so, I started diving down there as well because it’s like, okay. You know, whatever I think about cryptocurrencies, there’s definitely money there. Like, last year was the year I think a lot of developers saw that.
-**Beyang Liu:**
-So you wrote this blog post about how you were in charge of this project to kind of decompose Shopify’s main Ruby on Rails monolith into smaller, more modular components, not microservices, but different modularized components, we'll get into that later. Tell us at a high level, what was the mandate of that project and how did you come to be involved in that.
+**Beyang:** Yeah. But you’re coming from a point of skepticism it sounds like?
-**Kirsten Westeinde:**
-Yeah. So in, I think it was around early 2017, it was becoming very clear that our core codebase was reaching a tipping point. Where it was becoming more and more challenging to build functionality into it because of all of the interdependencies. So projects were taking longer, adding things that used to be simple were causing test failures and big headaches. And also it was really... We're finding it really challenging to onboard new people into the codebase because there was just so much to learn. And so we knew we had all of these problems, but we didn't want to get into solutioning without really understanding what the problems were. So we actually sent out a large survey to all the engineers working in the core codebase to hear their feedback about what the pain points were before deciding what to do.
+**Max:** Yes.
-**Kirsten Westeinde:**
-And it was that survey that actually led us to start this project. We originally called it a very clever name of, "Break core up into multiple pieces." But that name eventually evolved into componentization where essentially we wanted to make this one large codebase feel like many smaller codebases. And so we wanted to separate the code by business domain basically because that is the code that more often needs to change together. And so what that would mean is if we were hiring someone onto say the shipping team, they should be able to just understand the shipping component without having to understand all of the other elements of the core codebase. So at a high level, that was the goal.
+**Beyang:** Like you.
-**Beyang Liu:**
-Got it. So if I were a buzzword-driven engineering manager and you came to me and said, "Let's decompose this monolith into different independent components." I would say, "Well, that's obvious, you know, we live in 2021 and the obvious solution to decomposing a monolith is to break it down into these things called microservices. But I understand that that's not the approach that you ended up taking. So can you talk about why you didn't follow the naive path of like, let's write a bunch of microservices. What did you end up with instead? What is this modular monolith that you talk about?
+**Max:** Well—
-**Kirsten Westeinde:**
-Yeah. I mean, I think for one thing we had been developing on Shopify core for so long that pausing everything and building out net new microservices just wasn't feasible for us. Whereas the direction we ended up going was making incremental changes in the existing codebase while teams continued to develop and add features to it. So that was a big reason, but the other thing is that unless we wanted to start from scratch, to be able to start extracting some of these pieces out into microservices, we would need to have them well encapsulated and have boundaries in place, which is what we ended up doing. But we ended up deciding that we wanted to stop there because monoliths have a lot of pros, a lot of benefits.
+**Beyang:** He was more—he was earlier in the space—and you were kind of—
-**Kirsten Westeinde:**
-Having only one codebase means you only have to do all of your gem bumps and your security fixes in one place. It also means you only have to manage one deployment infrastructure and one test pipeline. There's also a lot less surface area in terms of places that you could be attacked, and I think that makes the system a lot more resilient. And we found it helpful to keep all of our data in one place, in one database and allow the different components to have access to the data that they needed instead of trying to synchronize it across many different systems.
+**Max:** Yeah.
-**Beyang Liu:**
-Yeah.
+**Beyang:** “Eh, I don’t”—
-**Kirsten Westeinde:**
-And lastly, with microservices, the communication between the different components has to happen over the network, which introduces a whole bunch of complexity around API version management and backwards compatibility, as well as just dealing with the network in general. It can be slow. There's lots of ways it can fail. So those were all the things that we liked about the monolith and didn't want to just give those all up. And we kind of felt like moving to microservices was more of a topology change whereas what we wanted was an architecture change. There was nothing necessarily wrong with our monolith, it was just that there were no well-defined boundaries between different things.
+**Max:** He was there very early. Like, good on him. Like, you know, you got to say good on all the people who saw it a long time ago, at this point because they’ve done very well out of it. So, good on them. But yeah, I wasn’t so much skeptical—well, I was, but not, like, totally skeptical.
-**Beyang Liu:**
-So you had this principled, thoughtful approach of "We have developer pain, let's address that directly, but we're not going to involve it with changing the topology of production, introducing all these unnecessary network boundaries because that introduces its own complexity and its own baggage" in a way.
+I’d read the Bitcoin whitepaper years ago and I was like, “This is a good piece of technology.” Like, clearly, I liked the whitepaper format. Like, very good way for getting people who don’t know a lot about the technicalities of something. Like you didn’t have to understand crypto—cryptography, I mean—in order to understand the Bitcoin whitepaper. But I thought it was just money, and money has never really interested me as—I like having it because then I don’t have to worry about it. [laugh].
-**Kirsten Westeinde:**
-Yeah, exactly. Our monolith had gotten us so far. We, I think, had learned so much about what is good about it, that it gave us pause to really ask the question and really think through whether microservices were right for us. And the answer at the time was no.
+You know, I like the things I make. That’s my motivation. So, I didn’t realize that it had become what we’re now calling Web3, of course. And that there’s all these ways that blockchain as a base technology can be used that are exciting. And so, I dove down that rabbit hole, bought a few NFTs just to see what that was about because that was, you know, obviously it was really becoming a craze then and, like, now I honestly I think NFTs are a little bit h—
-**Kirsten Westeinde:**
-That being said, we are believers of service-oriented architecture, so we do have other applications outside of the core codebase. However, everything related to the core functionalities of commerce, we keep in one place. But there have been some examples where we actually have extracted components out of the core codebase because they weren't related to the core functionality of commerce and we pulled them out into their own services, but that was exponentially easier to do post componentization.
+**Beyang:** [laugh].
-**Beyang Liu:**
-So what did this modularization of the monolith actually entail? I assume you started with... My knowledge of Ruby On Rails is fairly limited, but I understand the standard directly out is: you have a model directory, you have a view directory, you have a controller directory. Was that the structure of the codebase at the start of the project?
+**Max:** —they’ve ha—they’ve peaked. But you know, don’t tell some other people that, I guess. But I bought them to see what it was about. And when I sold one and there was this 10% royalty that was enforced by the digital contract, I was like, “Ah, this is interesting.” There was no way to not—well, I now know there is a way to not pay the 10% but that’s because [laugh] you can—
-**Kirsten Westeinde:**
-Yeah, that's correct. So we started before this, we basically just had a Rails app out of the box, so you're exactly right. They were organized by our software concepts, but the first thing that we wanted to do was restructure our codebase to be organized by real-world concepts like orders, shipping, inventory, billing. And what we ended up doing was we actually audited every single Ruby class in the code base, which was like 6,000 at the time, in a spreadsheet and manually labeled which component we thought that they belonged in based on the initial list of components we had. And then we built up one massive PR with automated scripts from the spreadsheet to basically just create those top-level folders. And then within the orders folder it would still be models, views, controllers, but we would just move all of the specific models, views and controls into that folder. So we did that all in one big PR, which was kind of terrifying, but ended up being fine. We have good test coverage. So it is all good.
+**Beyang:** Oh, that’s interesting.
-**Beyang Liu:**
-What was the size of that diff? It must have been like...
+**Max:** Yeah.
-**Kirsten Westeinde:**
-It was every file, every file was touched.
+**Beyang:** There’s a loophole.
-**Beyang Liu:**
-Wow.
+**Max:** Yeah. Well, it’s because the NFT is on Ethereum, shall we say? So, it’s just part of the blockchain and you can just transfer that. The digital contract enforces the royalties, OpenSeas. But they’re making a new proposal which will make it so it’s part of the blockchain itself, then you won’t be able to get around it.
-**Kirsten Westeinde:**
-Yeah. So that was the first step.
+**Beyang:** Ah, I see. They had their own centralized, kind of, system of record for NFT ownership. Now, they’re decentralizing it.
-**Beyang Liu:**
-Why wasn't that sufficient? The straw man is like, "Okay, if we put everything in its own directories and now each team gets to work in their own directory and that's done. They're like separate codebases." Why was that not just the end of the project?
+**Max:** Well, essentially, you had to sell the—you still have to sell your NFT through OpenSea for the 10% royalty to be paid to the original creator because you have to use their digital contract. And some people, you know, save 10%, effectively, by going around it, and it’s just, you know, [unintelligible 00:50:42]. Shouldn’t do that.
-**Kirsten Westeinde:**
-Well, all that had achieved was moving files around, right? Like in Ruby On Rails, everything is automatically globally accessible. So just because all the code for orders was within an orders folder, it could still use whatever it wanted from any of the other folders. So we still had all the same problems with fragility of the test suite and really if I was working in the orders component, I still had to understand about the taxes component and the shipping component because of how tightly coupled they were and how there was no clearly defined API for them to communicate between the folders. Nothing had structurally changed about how the code was interacting.
+**Beyang:** Yeah. Yeah. And 10% on some of these NFT purchases, that’s quite a substantial sum of money.
-**Kirsten Westeinde:**
-So it was a great first step in the sense that I now knew if I'm looking for something orders related, I can find it. And that the top-level component folders had explicit owners, which was actually a huge win. But beyond that, we still hadn't solved a lot of the existing problems.
+**Max:** Yeah. Let’s not talk about it. I saw [unintelligible 00:50:52].
-**Beyang Liu:**
-You mentioned something in your blog post about how one of the initial pain points was as the codebase grew, the amount of code that a given developer would have to understand to get a thing done was like something like O of N, it grew linearly with the size of the codebase. And that obviously is untenable as you grow, because it just means your productivity approaches asymptotically down to zero. So how'd you go from O of N to sub linear? What were the things that you had to make in terms of codebase structure to enable that?
+**Beyang:** [laugh].
-**Kirsten Westeinde:**
-Yeah, definitely. So once we moved all the code into their separate folders, the next ask was for each component to define a public API. And ideally that public API should be easy enough to understand that I can understand what it's doing without having to go under the hood and look into the component. And so that would allow me to get to know one component really well. We also asked each component to explicitly say which other components they depended on. So say I was joining the orders team, I could really deeply get to know the orders component. And then as my next step, I could look at what the dependency is listed out for the orders component is, and maybe just start getting to know their public API so I know what methods are available to me from those components without needing to understand all the nuances of how they get the things done exposing the public API.
+**Max:** I saw some of those come and go, and I was like, “This is stupid, isn’t it?” Like everyone else, I thought it was stupid. I now understand that NFTs as a thing is more useful, and like, well, we’re going to use them for Tea, right? We’re not using JPEGed NFTs. But I’ll get to that.
-**Beyang Liu:**
-Yeah. What about the human side of this kind of change? In the organizations that we've worked with that have attempted something like this, there's the technical side, which involves making the proper changes to the code, in this case, introducing a bunch of interfaces and making those interface boundaries well-defined, but then there's also this human, semi-political aspect to it where you're going to each of these engineering teams and each of them has their own goals and objectives that they're working toward, business goals, and you're coming to them and essentially asking them to add work onto their plate to satisfy this change.
+**Beyang:** Yeah. Yeah.
-**Beyang Liu:**
-Can you talk about that element of it? Did you have to do a lot of horse trading or, "Do me a favor and I'll do you a favor?" What does that look like from your perspective?
+**Max:** [laugh]. But it occurred to me that this mandatory royalty was very interesting. And like, sponsorship and bounties are two systems people try to use to fund open-source, but it only rewards, really, the popular projects, stuff that people know about. And you know, your average node application is 600 to 1000 node dependencies and then that goes down underneath that all the way down to libc, the most fundamental ones. And you could say the kernel, even, is the most fundamental part that’s doing the literal hardware operations.
-**Kirsten Westeinde:**
-Yeah, it's interesting. I've actually talked about this project at a few different conferences and the two questions I always get are, "How did you get buy-in from the business to invest in this? And how did you get buy-in from the individual teams to invest in this?" I guess there's no really easy answer or perfect way to do it and it's going to be so nuanced depending on the organization that you're within. But one of Shopify's core cultural values that were kind of taught from the beginning, is build for the long term. And it's really driven home that we're trying to build this business for a hundred years, not for 10 years. And so with that kind of mindset, it is easier to get buy-in for these short-term pain for long-term gain type projects.
+And so, you got, you know, thousands of open-source dependencies and it’s just infeasible for anyone to sponsor their entire stack. We give these companies a hard time because they got the money to sponsor their stack, but how they literally going to do that? Like, I have this popular open-source library called PromiseKit—and I’ve used this as an example throughout talking about Tea—it’s used by 100,000 apps so if every one of those apps just give me one dollar a year—
-**Kirsten Westeinde:**
-I think as well, the developers that had been working in the core codebase had all been feeling this pain. And so they were eager for opportunities to make it better and easier to develop within. So it wasn't always easy. And to be honest with you, different components are at completely different points in their componentization journey based on how well their team has been able to prioritize this type of work. One thing that we did was we built this tool called Wedge, a lot of complexity under the hood, but it basically gave components scores as to how well they were doing on their componentization journey. And we made it like a little fun competition between teams.
+**Beyang:** [laugh].
-**Beyang Liu:**
-You gamified it.
+**Max:** All right, that’s, you know, that’s a salary.
-**Kirsten Westeinde:**
-Exactly. Yeah. As a technical initiative that the whole engineering org was working towards.
+**Beyang:** Solve your money problems. Yeah. Yeah, yeah.
-**Beyang Liu:**
-That's really interesting. So you kind of built a tool that condensed all these complex refactorings into something that you can measure, like a numerical score and that made it easier to track and also verify. How did you do that? How do you convert adding an interface or defining a good interface or eliminating a cyclical dependency or something into a number that is meaningful that the engineering teams don't shake their heads at and that also is useful for tracking it at a top level.
+**Max:** Well, it’s not a great salary. I think we have to give open-source developers good salaries, otherwise they’re not going to do open-source full-time. So—
-**Kirsten Westeinde:**
-Yeah. So, Wedge is a really interesting tool. What we did was we used it to hook into Ruby trace points during our test suite run to get a full call graph of all the calls that were being made as our code was being executed. And then we sorted the callers and callees by component and basically pulled out all of the calls that were happening across component boundaries and then sent them to Wedge. And we'd also send some other data like code analysis and active record associations and inheritance and such. And then Wedge basically just went through everything that was sent to it and determined which of these things were okay, and which ones were violating. So if a cross-component call was being made, if there was no dependency explicitly declared between those two components, it would be violating. And if it was anything other than the public interface it would be violating.
+**Beyang:** Totally. Yeah.
-**Kirsten Westeinde:**
-We actually found though that it really is hard to get a number that is right. Especially with as much complexity as there is in call graph logging. So in the end we actually ended up canning Wedge because we didn't find it to be a useful feedback cycle. And also mostly because we had to run the full test suite to get this feedback and that takes way too long for it to be helpful. So we ended up going in a different direction. But in the early days it was really helpful to, like you said, gamify it.
+**Max:** —that’s part of what we’re trying to do. So yeah, like—but the thing is, it was buried in the stack, it was hard for people to find, I got a good sponsor once and they said that they went through all their dependencies and tried to find ones to look for, and, like, it was a three to four-week process for them to figure out how to sponsor me. Now, there is GitHub sponsorship now, but still, like, difficult to figure out your whole stack. It’s impossible. So, sponsorship doesn’t work, in my opinion.
-**Beyang Liu:**
-Yeah. That makes a lot of sense. As you learn more about what was useful and productive, what kind of stepped into the place that Wedge occupied? Was there another tool that you used or was there some different set of criteria that you used to gauge overall progress and success?
+Bounties are interesting and they will continue to exist for sure. Because you should be able to provide an incentive for someone to build the future you want on [unintelligible 00:52:58] open-source. But they still mostly only reward the top of the stack. Like, no one’s going to do a bounty on, like, some random logging library that sitting underneath all there, probably.
-**Kirsten Westeinde:**
-Yeah. We ended up building this tool called Packwerk, which actually as of September of last year is open source. And it's a really cool tool that basically analyzes static constant references. So we found that there's less ambiguity in static references and because these references are always explicitly introduced by developers, it's more actionable to highlight them, and it's much faster. So we're able to run a full analysis on our largest codebase in a few minutes, which means that we can actually put it in as part of our pull request workflow, which is a way more helpful feedback loop for developers.
+**Beyang:** Sure.
-**Beyang Liu:**
-That's really interesting. So the Wedge was this dynamic tool. It kind of built up this call graph or reference graph from runtime by observing what actually got called and then Packwerk was building up that graph, but statically based on imports and references in source code. Is that right?
+**Max:** So, it occurred to me that a tool like Homebrew knows the entire open-source ecosystem, it understands the graph, it understand—it sits underneath all of those tools. And because we understand the graph, we could thus, as a result, spread some, you know, token around. So, if something at the top of the stack—let’s say React—gets some token, we can feed a percentage to its dependencies, and then a percentage of that to all their dependencies as well, and thus, like, fund the entire graph. And I was like, “Oh, wow. This is an important understanding, an important realization.”
-**Kirsten Westeinde:**
-Yeah, that's correct. Packwerk uses the same assumptions as Zeitwerk, which is the Rails code loader. And the way that Rails is able to make constants globally accessible is it basically infers the file location based on the constant's name. And we did the exact same thing with Packwerk.
+I went and woke my girlfriend up because it was like two in the morning. I told her that I had just figured out how we could fund open-source software, the entire open-source ecosystem. She does not remember this. [laugh]—
-**Beyang Liu:**
-So the programming languages part of my brain is saying, "But wait a minute, Ruby is a dynamically typed language, not all types are known at compile time." But were you able to solve that problem in Packwerk? Like inferring types or was it some element of best effort? Like, this is good enough.
+**Beyang:** [laugh].
-**Kirsten Westeinde:**
-Yeah. A hundred percent the latter. We understand that it's an imperfect solution and there's a lot of crazy stuff that can happen in Rails that will not be detected through this, but it's good enough essentially. And it does catch a lot of things. So we decided that the fact that it can happen so much faster and provide that faster feedback loop is a trade-off we're willing to accept for the fact that yes, maybe some things will slide under the radar.
+**Max:** —sadly.
-**Beyang Liu:**
-I guess it's important to recognize that there's humans in the loop in this process. So in some sense, it'd be a much harder problem to completely automate it because then you'd have to get everything precise. But as long as there's humans in the loop, they can step in and say, "Well, we recognize this tool's a little bit fuzzy, as long as the signal to noise ratio is decently high, we can work with this."
+**Beyang:** Maybe it was a dream, you know? It was late at night, and it was just you’re in a dream state. [laugh].
-**Kirsten Westeinde:**
-Absolutely, and the magic of this tool is not only within the tool itself, but it's within the conversations that it sparks, because if on my PR I get told, this is a cross-component violation, and maybe I don't know what that is, or maybe I'm a more junior programmer, and I don't have an idea of how to do inversion of control, for example, there's been a lot more conversations around software architecture across Shopify because of this tool.
+**Max:** [laugh]. Like—well, it’s a story all the same, now. [laugh].Even if it was. I guess it’s possible. It was late. Like, I’ve been staying up late just going through everything, trying to figure out what I could make into something that would be a startup or way to fund me working on open-source. And yeah, it was just a combination [crosstalk 00:54:34]—
-**Kirsten Westeinde:**
-So, what that means is sometimes maybe the tool won't catch cross-component boundaries, but because it's now becoming a part of our engineering culture, maybe someone will in a PR review. Building that muscle of good software design really is the overarching goal of this whole thing. So, yes, the tool's not perfect, but it's been really valuable for us.
+**Beyang:** So, just to clarify, the eureka moment was thinking about open-source funding and connecting some of the ideas in the Web3 space into, like, a token that kind of understands the structure of the dependency tree? Is that kind of the idea?
-**Beyang Liu:**
-You just mentioned inversion of control, and I think that along with some other things you called out in your blog post were good rules of thumb or good general principles that you may have discovered along the way of doing this. Can you talk about some of those principles or maybe empirical patterns, in terms of if someone were to attempt this on a Rails codebase in general, what are the maybe tactical things? Tactical things, tricks that you can apply to make the codebase more decomposed and modular.
+**Max:** Yes.
-**Kirsten Westeinde:**
-Yeah. I think the first thing I would say is that if someone's going to be trying this on a Rails codebase, they'll probably be in a similar situation that we are, or that we were, which is basically, if you look at the dependency graph that has just naturally happened, it's crazy. Every component was basically depending on every other component. There's a ton of cyclic dependency. Rails lends itself naturally to have high dependency.
+**Beyang:** And then you, like, fund the token and that automatically spreads the funding to all parts of the tree, not just the most prominent—
-**Kirsten Westeinde:**
-So, I'll say that first. Even just being able to visualize that dependency graph allows you to reason at a much higher level about, does it make sense for this thing to depend on this thing? Sometimes it does, and other times it doesn't, but when it doesn't, that's when you start to use some of these tactical approaches for decoupling those things.
+**Max:** Yes.
-**Kirsten Westeinde:**
-I mentioned inversion of control, which basically is saying ... So, I'll give an example. I work on a product called the Shopify Fulfillment Network, where, basically, some merchants, we host their products on their behalf. When orders come in, we'll choose the most optimal warehouse to fulfill it out of to get it to the buyer as quickly as possible.
+**Beyang:** —or the most well-known name?
-**Kirsten Westeinde:**
-SFN, that's the acronym for the Shopify Fulfillment Network. It needs to know when an order comes in on a merchant store. One way to do that could be for the orders component to make a call to a method in SFN and say, "New order has been created," and then SFN responds with, like, "Great. We got it."
+**Max:** Exactly.
-**Kirsten Westeinde:**
-That's a hard dependency from the orders component to SFN, whereas if we want to get rid of that dependency, we can actually just use a method like a publish subscribe mechanism. There's a bunch of different ones to do that, but at Shopify, we use Kafka events a lot. Basically, the orders component can just say, like, "An order happened," and then SFN can choose to subscribe to that and do its processing without needing to necessarily reply, and that has now broken that dependency between the two.
+**Beyang:** Got it.
-**Beyang Liu:**
-It's like, at run time, you want this one thing to provide behavior to this other thing that is going to run, but at compile time, you don't actually want an import going from that thing to this other thing, because that adds a hard dependency, and it means that someone working on the first thing will have to go through the second thing and understand how it behaves. There's not this interface boundary that says, "Okay, don't worry about the stuff behind this curtain."
+**Max:** Like, yeah, the top is where people will probably still target their money, but we can filter it to all the other dependencies. And because of the way the law of exponentials works, if you’re a good dependency, you’re going to get a ton of those smaller percentages anyway so the funding will be relatively equal. And, like, a good part of what we’re talking about in our whitepaper is figuring out the math so that we are funding things in a fair and reasonable way, and, like, not over-funding things as well. Like, we don’t want—although I’m—there’s all sorts of interesting things that come out of what we’re trying to do.
-**Kirsten Westeinde:**
-Yeah. That's exactly right, and had there been a hard dependency, like, say, from the orders component to SFN, then the orders component would have to care every time SFN changed. Now, having done this inversion of control, it does not at all. It just has to fire its event.
+One of the things is, so a token gets into the system, and then there’s a dependency. Let’s say, OpenSSL; it’s my favorite example. OpenSSL, it’s used by so much of the internet, very important security layer. And it’s also terrible. Every year, there’s a new exploit found that, like, causes huge problems for the entire internet.
-**Beyang Liu:**
-Another thing that you talked about in the post was this kind of loose coupling, but high cohesion pattern that got adopted. Do you mind explaining what that means?
+With our system, we would actually be incentivizing people to replace OpenSSL. That’s never happened before. Open-source, typically things get inserted into this tower of open-source—we use the XKCD comic called “Dependency” a lot are met—you know, just to demonstrate to people what we’re talking about. And it has a tower of bricks like a toddler might make, and right near the bottom, there’s this tiny little pillar that seems to be holding up, like, 80% of the internet. And has an arrow pointing to it, and it says, “This dependency is maintained by some guy from Nebraska since 2004, and thanklessly.”
-**Kirsten Westeinde:**
-Absolutely, yeah. This was one of the core principles of this project that we were striving towards. Coupling is basically the level of dependency between modules, or classes, or in this case, components. So, you want that to be low, because you want your dependency graph to be as light as possible, but you want the cohesion to be high. The cohesion is basically the measure of how much elements within a certain encapsulation belong together. So, whether you're looking at a module level, a class level, or the package level.
+**Beyang:** Yeah, and has never realized a dime from the work that has gone into that.
-**Kirsten Westeinde:**
-One thing to note is that it's really hard to get the component interface right when the classes within it have interfaces that are not well-defined, and the modules within it. It really starts with good software design from the bottom up. That makes it easier, a lot easier to get the component interfaces right.
+**Max:** Exactly. So, OpenSSL is famous, but there are examples of the Nebraska problem—that’s what we call it—and one was Log4j which had that security exploit in December. And a huge amount of the internet, a surprising amount, became suddenly zero-day exploitable. Like Minecraft, you could type something into the chat and it would root the server. Or you could, you know, you got access to do that if you wanted it to.
-**Kirsten Westeinde:**
-Then, on the point of cohesion, there’s two different types of cohesion that we think about. The first is functional cohesion, so that basically means code that performs the same task list together. You can think of service objects as being functionally cohesive, whereas data or informational cohesion is code that operates on the same object living together.
+And nobody had ever heard of this thing. It was one of those deep dependencies they didn’t even know they were using, something was built on top of it, which added a layer which made it nicer in some manner or whatever, and then like that was built into something else. And then people were angry. And there was a lot—you can look on Twitter; it was abuse. People were abusive towards these dev.
-**Kirsten Westeinde:**
-Again, Rails really lends itself to data or informational cohesion, because of the way that active record models are built up to interact with one database model. We often add a lot of methods relating to that object on its model, even though they might be parts of completing completely different tasks. I'm sure different languages lend themselves to different ones, but we found ourselves way over-skewed in the direction of data and informational cohesion.
+And they were like, “Look, we’re going to fix the bug. We’re sorry about the bug. We do care about this, but nobody’s ever given us a cent for making this thing so maybe we should fix that.” [laugh].
-**Beyang Liu:**
-Where is this project today? You mentioned it started in 2017, and it's been a multi-years-long effort. Are things still being componentized in the main Rails codebase, or at this point, has it been componentized, and it's more or less in a done state, you just have to maintain the status quo?
+**Beyang:** Yeah.
-**Kirsten Westeinde:**
-Yeah, I wish I could tell you we were in a done state, but the reality is that we're not. All of the code has been moved into components, and all of the components do have publicly defined entry points, but the reality was that we were starting from a place where a lot of these calls were already violating the rules. So, one of the nice features that Packwerk built was that you could essentially declare bankruptcy, and start from a certain point, and only start tracking violations beyond that. We have a list of deprecated references, and the rule is basically that you can't add any new violations.
+**Max:** So, with Tea, that’s our objective. We’re making this trustless decentralized protocol which understands the open-source ecosystem. Effectively, the package manager’s registry, with Homebrew was a Git repository; with Tea, it’s the blockchain. It’s a blockchain. We’re putting all the packages on-chain as NFTs. It’s a good use of NFTs.
-**Beyang Liu:**
-Got it.
+We’re not exactly calling them NFTs at this point because they’ve got so much of a bad stigma, but an NFT is just a token, right? It’s just a non-fungible token. It doesn’t have to be a JPEG. Ours are representing package releases, a very good use for NFTs. I think over the years, people will start to see that NFT is just a utility technology, and it doesn’t mean that you’re getting a Bored Ape or something else, some sort of collectible jpg.
-**Kirsten Westeinde:**
-We know that there are some existing ones, but no new ones can be added. Over time, that deprecated references list basically gives us a tech debt to-do list to work off of. Like I said, different components are in different shape, but we haven't yet gotten to the point where all of those violations are gone. Only once all of those violations are gone will we be able to actually enforce those boundaries.
+**Beyang:** Yeah.
-**Beyang Liu:**
-Fascinating. You have this list of tech debt to-do items. In a given iteration cycle, how do you decide how many of those to tackle versus how many, I guess, more product-oriented things to tackle? Because that's something that our teams at Sourcegraph, I assume, like probably any software team struggles with. What is the right balance of tech debt versus new feature development to take on?
+**Max:** And so, the NFTs are going to be on-chain will guide how a token is distributed through that network, however we decide to insert it. Now, our whitepaper is coming out soon. The way that we’re going to have insertion happen is an inflationary staking mechanism. And I’m super excited about it because it means that we’re not fundamentally changing how open-source works.
-**Kirsten Westeinde:**
-Yeah. That's a hard question.
+People have asked me this a lot, and it’s good question: “Are you going to charge for open-source now?” The answer is no, not at all. You can’t charge for open-source. No one would accept that. [laugh]. You can’t take something that has worked a certain way for more than 20 years and fundamentally change it.
-**Beyang Liu:**
-Can you put a price on a tech debt item? It's almost an impossible exercise.
+So, Tea is free to use. Our protocol is going to be run by DAO, not by the company. It’s not funded by the—it’s not run by the funded company. Obviously, initially, a few of us at the company will have large voting rights because we’re going to make sure that it goes in the right direction, but over time, our voting rights will fall to be in line with the rest of the open-source community. So, people who make open-source will get voting rights by publishing into our chain.
-**Kirsten Westeinde:**
-Yeah, no, it's really a hard question. Honestly, the answer's going to be different team to team at Shopify. One of the patterns that I've seen in my years at Shopify is that we built a lot of features. We move really quickly leading up to Black Friday and Cyber Monday, because that's when our merchants make the vast majority of their sales for the year. So, it's really important that we've given them the tools that they need to be successful during that time.
+And so, the chain itself is going to be managed by the open-source community, managed by open-source ecosystem. Tea, the package manager and the other tools that we’re going to build on top of it are just going to be clients onto that protocol. We’re hoping to make the best clients, but very much like Twitter used to be, where everyone and their son made their own Twitter app because the API was public, and it was very interesting, and like, people make better things all the time, we’re going to have the same ecosystem, except we don’t own the API like Twitter did. So, they just started closing it at one point and made it private.
-**Kirsten Westeinde:**
-Come the holiday season, we actually tend to cool down a bit on feature development, just because we don't want to be breaking things when our merchants are having their most important sales of the year. So, often, that feature cooldown can be a good time to tackle some of these larger units of tech debt. That said, I'm not saying that we just leave tech debt to do at one point in the year. We definitely try to find some pause between projects, or even just parallel tracks of work, where some people are working on more technical debt, and some people are working on product features. It's definitely a hard balance, but we have been slowly chipping away at it.
+**Beyang:** Okay. So, you’re going to have a decentralized protocol for managing package dependencies and then your client is going to be the equivalent of the Brew command-line tool, or like an apt-get where this will talk to that distributed chain and fetch the dependencies from that chain—
-**Beyang Liu:**
-I understand that the Shopify Fulfillment Network, which you mentioned earlier, that's a separate codebase. It also is or was a Rails monolith. You're currently tackling a similar project in that codebase, but adjusting some things based on what you've learned from this first major...
+**Max:** Yes.
-**Kirsten Westeinde:**
-Decomposition.
+**Beyang:** For purposes of installing an actual—okay, got it. And then you’ll also have a, sort of like, one-to-one mapping between an NFT-type token and each release of each package on this chain?
-**Beyang Liu:**
-... decomposition componentization effort.
+**Max:** Uh-huh.
-**Kirsten Westeinde:**
-Exactly.
+**Beyang:** I guess one of my questions is, for these tokens, what gives them value? Is it just like in the kind of current NFT sense of, like, you don’t technically—well, I guess, some some NFTs have rights attached to them, right? Is that kind of idea? Are there any—
-**Beyang Liu:**
-Tell me about round two. What's different this time in the sequel?
+**Max:** Yeah.
-**Kirsten Westeinde:**
-Yeah. We actually took a pretty different philosophical approach. What we did in Core was we moved all of the code into the components, and then slowly, over time, started trying to break some of those dependencies, whereas what we've done in the Shopify Fulfillment Network was we've introduced separate components. We've actually used Rails engines, which are like the one modularity feature that comes out of the box with Rails, and that can allow us to enforce those boundaries a little bit more strictly. Then, over time, piece by piece, moved bits of code into it that are always respecting the boundaries.
+**Beyang:** Like, rights or privileges or—
-**Kirsten Westeinde:**
-So, we flipped it on its head that way, whereas we still do have the main app controllers, models, etc., but the hard rule is we can't add any more code into the app folder. All new code goes into component folders. Over time, we're pulling code from the app folder out into its, basically, correct component, so that anything that's in a component is respecting the component boundaries, whereas that is not the case in Core.
+**Max:** Oh yeah.
-**Beyang Liu:**
-Interesting, so, with Core, the approach was move all the files around into their appropriate directories, and then, over time, reduce the linkedness or monolithic-ness of each component, whereas with Fulfillment, you basically said, keep the existing monolith as is, but each new feature has to be added to something that's external in a Rails engine. Then, we'll have some connection between the two, so that the functionality makes it into the application, but we always preserve this, I guess, invariance because all of the new components are modularized. Is that about right?
+**Beyang:** Like, a sense of ownership attached to owning the NFT associated with a particular open-source project in this world?
-**Kirsten Westeinde:**
-Yeah, that's right. One of the main benefits of that is that with so many developers working in a codebase, people tend to want to follow the patterns that they see existing. In Core, there is a mix of good patterns and bad patterns, because some stuff has been adjusted to break that interdependency, and some stuff hasn't. So, it's hard to know which pattern to follow, which way is the right way, when there are both examples, whereas in SFN, anything that has been componentized is following the patterns that we're wanting to strive for, so there's more good examples to be able to learn from, and demonstrate to other developers, and follow.
+**Max:** Yes. So, for it to be an NFT, it has to be transferable, and we actually expect people to do interesting things with that. Like, my chief product officer has suggested that people—someone will probably make a digital contract which allows you to lease a release of open-source. So, you can say, “Okay, I’m building this open-source package and I need, like, 100 grand now in order to build it.” It’s like, you know, writing a book and getting upfront stipend—
-**Beyang Liu:**
-I get all the learnings here. This is really fantastic insight. One thing I'd love to hear about is like, what is the process on the ground that you arrive at these insights? Like, for this new project, we don't want to move a bunch of stuff in the existing codebase around, but we want to start with something new, or moving from the dynamic dependency call graph to the static version, what are those conversations like? Is it you and a bunch of other engineers or engineering managers in a room, whiteboarding, or someone coming up with a bright idea, and slowly convincing other people? Are there any, I guess, war stories that come to mind when you reach these insights?
+**Beyang:** An advance.
-**Kirsten Westeinde:**
-Yeah. It's always a conclusion that we come to over time. In the example of Wedge, it was working well for a while, but over time, the problems with it became louder, and louder, and louder until we couldn't ignore them. So with that one, it was really, as our test suite was getting larger and slower, it was really just that it wasn't a helpful feedback loop to have to wait for that entire test suite to run to be able to get that insight. And so we knew there was a problem with that. But then the question is, what's the solution?
+**Max:** Yeah and advance. Exactly. And so, they’ll say, “Okay, for 12 months, you own the NFT or you’re leasing it from me.” And this is the beauty of digital contracts, right? You can—it’s a way to build law into the money system.
-**Kirsten Westeinde:**
-So we have a few different avenues for brainstorming these ideas. One is actually a team whose mandate is architecture patterns, and they're the ones that built Packwerk and provided a lot of the patterns to follow. And so sometimes it's just projects that get resourced, and we do explore and prototype phases. And so being armed with the learnings from Wedge, it led us down the road to Packwerk.
+And so, “Someone else is going to do this. We’re not going to do this. We’re just suggesting someone else build this system.” And so, they’ll be able to get 100 grand of token upfront and then the person who’s leasing the NFT gets all the profits off of the use.
-**Kirsten Westeinde:**
-But the other thing is we have a software architecture guild at Shopify, which is basically anyone from the company who is interested in software architecture. We have a Slack channel and a bi-weekly meetup. And that's where a lot of these conversations come to a head. Because I think there were a lot of learnings from Core, but then for example, the developers who were starting to build out SFN may not have had access to that frontline information.
+But the NFTs themselves are not the primary way that money is going to be made. We’re going to use the NFTs as, like, a map. So, they’re like signposts that show the protocol how to filter and funnel and direct token that enters it. The primary way that token—I expect—to enter it—and this is in the whitepaper, by the time this podcast is released, we should have released the whitepaper so I can go into it.
-**Kirsten Westeinde:**
-And so we did a lot of pairing actually as a way to share this knowledge and have a lot of discussions with the architecture guild. Because Shopify is very, I guess each team has a lot of autonomy. So the SFN team had the autonomy to decide what the right solution for it was, but definitely wanted to leverage the learnings that were present from Core. So that's the type of discussion that we would have at an architecture guild. Or we also do technical design reviews for any big tech projects we're kicking off. So that would be another. We have templates for those, and we have filled those templates with some prompting and questions to try to make people think about modularization as part of the upfront design.
+**Beyang:** Cool. We’ll link to it in the [show notes 01:03:12].
-**Beyang Liu:**
-Interesting. Tell me more about this guild. So what is a guild exactly? Is it just a collection of individuals who have a common technical interest area? Or how is it organized? Is there a process associated with it? How does it fit into the overall org structure of the engineering team?
+**Max:** Yeah. But we’re using a proof-of-stake chain, and the proof-of-stake system creates new token periodically at epochs. So, it’s an inflationary system. This new token is what we’re going to funnel into the open-source ecosystem. So, it’s an inflationary system. So, every epoch, we’ll give some token to the people that stake in to reward them for staking their token and securing the network. Because what you stake it, it means that you cannot spend it, you cannot use that token. You’re putting it into a digital contract that gives you 24 hours, at least, to withdraw it. It’s like a bank saying you don’t have your money for 24 hours.
-**Kirsten Westeinde:**
-Yeah. Actually it doesn't fit into the org structure of the engineering team. It's composed of people from across everywhere in the engineering organization. It's completely opt-in, and it grew organically from people who were curious to be having conversations like this. I think one big learning actually that my coworker Phillip called out in his blog post was that he wished that we had started this sooner in the componentization process. So more minds could be involved and had buy-in basically for them to apply the approach that we were aligning upon in their different areas of the company.
+**Beyang:** Sure.
-**Kirsten Westeinde:**
-But it really is just people that want to nerd out about software architecture, and people come with presentations every other week. Sometimes we'll just share the architecture of one of our systems. Sometimes we'll have more pointed discussions about certain software design strategies. It's pretty organic, but people like it.
+**Max:** And this means that the price fluctuates less so it’s good for the system. So, we reward them for doing that by giving them a bit of a token, but we’re also going to give, like, a percentage—probably half or 60%, like, we haven’t got the exact figure yet—to the graph, the open-source ecosystem graph. And the people staking would choose the packages that they’re staking against, and we’re going to incentivize staking ones that are less staked because we don’t want everyone to just stake their favorites; we want people to actively find new exciting open-source projects. So, when you find it, you’ll get a better reward initially.
-**Beyang Liu:**
-That's awesome. So the guild formed after the start of the original project.
+**Beyang:** Interesting. And what is a reward here? Like, is it—
-**Kirsten Westeinde:**
-Yeah. That's right.
+**Max:** The token.
-**Beyang Liu:**
-At what stage do you think it makes sense to form a guild? I think that we run into the same issue, and I think a lot of other engineering organizations run into this issue, where you have your org chart and you try your best to produce an org chart that reflects the needs of the product and how knowledge and information needs to flow. But no chart is ever going to be perfect, and there's all these areas of expertise that don't neatly fit into that. And I guess the question in my mind has always been, at what point do you start to need these guild structures? Is it at 100 engineers? Is it at 1,000 engineers? Or what, in your mind, is the right size?
+**Beyang:** Is it mainly just being—the token? And the token allows you to say that I am sponsoring this project?
-**Kirsten Westeinde:**
-Yeah. We've actually experimented with a few different things. The guild is more of a meetup. We less drive change through the guild, I would say, other than grassroots movements. But we also have what we call a technical leadership team, which is on a rotational basis. Technical leaders from across the company will be on that team. And anytime we're doing a tech design review, you'll get paired up with someone from the technical leadership team. You can bring them your gnarliest problems, and it's made up of people from all different parts of the org with all different perspectives on the problem.
+**Max:** Yes.
-**Kirsten Westeinde:**
-So it's a way to try to, I guess, make sure that we're leveraging the learnings that are available at the company level. And then there's also what we were chatting about before, I forget what it's... the tools and patterns team. And their actual mandate and what they work on day in and day out is building out some of these tools and patterns.
+**Beyang:** Like, I am contributing to—okay, got it.
-**Kirsten Westeinde:**
-And I think I would guess that team spun up probably in 2018 just based on this project having started in 2017. And yeah, we were probably 500 to 600 engineers around then. It's going to be different for every organization, and I think it depends on how much your organization already has it baked into their DNA to be thinking about these things, to be thinking about good software design, technical initiatives, etc., or not. Sometimes it might make sense to start earlier if that's not as organically present.
+**Max:** The token is governance so you will be able to help govern how this entire system works. And we’re going to give governance priority to open-source packages so if you have some actual NFTs in the graph that are being staked, we’re calling it ‘steeping’ incidentally, for this particular part.
-**Kirsten Westeinde:**
-There's trade-offs to each approach. One of the challenges that the tools and patterns team has is that they're just building tools and patterns, but they aren't necessarily using those tools and patterns to build a product. So they need to make sure that they are in touch with the people that are using those tools and patterns and actually solving the right problems. And so we do that through pairing and internal documentation presentations, etc. But we really try to make sure that the problems that need to be solved are being solved, and we're not just adding friction to developers' lives because we think it's nicer.
+**Beyang:** [laugh]. I love the terminology.
-**Beyang Liu:**
-Yeah. That makes a ton of sense. Looking back on both projects that you've been involved in with decomposition, to what extent are the patterns that you discovered, do you think, specific to those particular codebases? And to what extent do you feel like there's some general principles here that would be widely applicable? That's one question. A more proximal question would be the way that you're approaching modularization on the fulfillment network codebase. Do you wish that you had done that with the main codebase initially, knowing what you know now? Or do you think that each codebase found its proper approach?
+**Max:** It’s nice and the metaphor works really well. So, we have staking and steeping in our system. The whitepaper will go into a lot more detail here.
-**Kirsten Westeinde:**
-Yeah. It's a challenging question because they both have their trade-offs. So I think that you just need to know in your situation which trade-offs you're willing to accept. For the Shopify Core case, what we were really struggling with and really wanting to optimize for was that we had a lot of code that didn't have ownership. And so having moved the code into folders that have explicit owners is a big win for that. Whereas in SFN, we still have a lot of code living in the app component that doesn't have as clear owners, but for us that's okay because it's a smaller group of people working on it. And so it's easier to share the load across our team, which is smaller. Whereas for core, it was really important that we get it right in terms of code ownership.
+**Beyang:** Got it.
-**Kirsten Westeinde:**
-So I think you really have to ask yourself, what is the intermediate state that you're most comfortable with? Because these things take a long time. And so I think Phillip has an amazing quote in his blog post. He says, "My experience tells me that a temporary incomplete state will at least last longer than you expect. So choose an approach based on which intermediate state is most useful for your situation." And it's 100% true in this case. Both of those codebases are in intermediate states that are correct for them, and I think you just need to think about what that means for your codebase.
+**Max:** But in order to, like, make sure that everything is correct, like, obviously, this is easy to game; we’re going to have a slashing mechanism where we can take away your stake. And we’ll do this if packages have security exploits, for example. So, we’re going to incentivize, like, properly incentivize the open-source ecosystem to make sure that their software doesn’t have security holes. So—
-**Beyang Liu:**
-Yeah. That's very fair. Somewhere out there there's a person listening who wants to propose a big refactoring re-architecture project, but you often run into resistance from Product, from other stakeholders in the business because the value of such a project is not always clear. What advice would you have for people in that position, just in the very early stages of thinking through starting such a project and getting organizational buy-in?
+**Beyang:** Interesting.
-**Kirsten Westeinde:**
-Yeah. One thing that I think about often as it relates to this is, I don't know if you're familiar with Martin Fowler's design stamina hypothesis, but it basically says that in the beginning—
+**Max:** If a package is found have a security issue, someone can report that to the DAO. So, the DAO is a Decentralized Autonomous Organization. It’s just a governance structure that runs the protocol. If the DAO decides that it’s a legitimate security issue, we can slash that package and the people who is staking it. So, this means that if you—you get more rewards for staking new packages, but if they’re found to be, you know, either fake, for example, like, people—it isn’t a real open-source project, or there’s security issues, it’s not good quality, then you could lose your stake.
-**Beyang Liu:**
-I read that in your post.
+So, you have to make sure you’re staking the right things. So, we’re effectively making—well for a start the creator economy for open-source, but we’re also making a system where the people are actively involved in making sure open-source continues to be great and is greater and greater going forwards, as well as allowing the people who make this essential infrastructure that builds the internet, powers the internet, makes everything that happens on the internet possible, are able to do that as a job. And they don’t have to go and find someone at Facebook, who will, like, “Okay, well 70% of the time you can work on this because it’s useful, but we also want it to do this,” or, you know, beg for money, effectively, on Patreon, or find bounties. Like, I approve of bounties and I think Gitcoin is going to be a wonderful complement to what we’re doing—Gitcoin is a Web3 bounties program—but it does introduce [agenda 01:07:26]. And you shouldn’t have to chase bounties from people who are then shaping how your product goes.
-**Kirsten Westeinde:**
-Yeah, I love it. I talk about it all the time. It basically says that in the beginning, no design is actually the best design, and you'll be able to move more quickly without design. But at some point you're going to reach a point where not having a design is going to slow you down more and more and more, and adding incremental functionality just gets harder and harder.
+**Beyang:** Totally.
-**Kirsten Westeinde:**
-So the first question that I would ask is, are we past that point? He calls it the design payoff line. Are we really at a point where we need this design? Because honestly, it's worse to have a bad design than to have no design, in my opinion. So you want to make sure that you have enough information and have built enough features to understand what design your codebase needs. So that's the first thing.
+**Max:** The open-source community should shape how open-source goes, in a transparent and fair way. And I believe what we’re going to build is going to achieve that, and it’s very exciting.
-**Kirsten Westeinde:**
-But if you think that you are in that position, I always find that the business and the product managers are very motivated by data. So the more data that you can capture, the better. So I don't know that your organization uses story points, but say you could point to an issue of story point three that used to take half a day. Now it takes a day-and-a-half. Anything that you can point to to show that you are getting slower is a really good starting point.
+**Beyang:** Awesome. So, you know, we are almost out of time. I wish we had another hour to go into all the intricacies of this plan, but for those listening who want to get involved in this, you know, new package manager, this way of funding open-source, this really interesting take on Web3, from both a, I would say, like, maintainer perspective and an open-source user perspective, what’s the best way to get involved?
-**Kirsten Westeinde:**
-Often they will have been feeling similar things. It probably won't come out of left field to them. They might feel like projects are taking longer than they should and are harder than they should. So the more you socialize the idea of, "X would be easier if we did this" and really just keep being the squeaky wheel, that can be really helpful.
+**Max:** Yeah, so follow us on Twitter and follow us on GitHub. I haven’t open-sourced the package manager yet. I never open-source it before it has enough functionality because otherwise people get excited and then they lose interest waiting for it to be something.
-**Kirsten Westeinde:**
-The other thing too is we would absolutely never have gotten buy-in to stop feature development and do this. So if you can do it in an incremental way that you can chip away at over time, it'll be much more likely that you can get buy-in. And if you're in the lucky situation where your company has enough engineers to be working on parallel tracks of work, then if some people can still be building features while some people do this, it's going to be a lot easier of a pill to swallow for the business.
+So, I’m open-sourcing it hopefully in May. That’s the plan. The only reason I wouldn’t is it just doesn’t quite get ready—it’s not ready yet, or some other reason, like, there is a company behind the package manager so I have to have considerations there. So, at GitHub, we’re going to have our [test net 01:08:52] up in autumn. So, that will be run by the DAO, but company is building it initially.
-**Beyang Liu:**
-Yeah. That makes a lot of sense. Kirsten, thanks so much for taking the time today. If there's people listening to this and they're interested in learning more about this effort or more about projects and learnings that you've undertaken, where should they go on the internet to find out more and learn more?
+Whitepaper’s coming out in April so I—you know, soon. So hopefully, we’ll—everyone listening to this will read it and then give us genuine feedback. Like, this is to make a genuinely open, transparent, fair, open-source remuneration and governance system. If it doesn’t achieve those things then we failed and I want you to tell me before we build it, preferably.
-**Kirsten Westeinde:**
-Well, Shopify has an engineering blog where we've published a few different blog posts on this topic. So I would definitely start with checking those out. We also have a ShipIt Presents new YouTube series about some of the engineering efforts at Shopify, and there's an episode that speaks about this as well. So check those out. And there's lots of other interesting non-componentization-related stuff on the shelf for the engineering blog. So I would say give that a look.
+**Beyang:** And then for those listening on audio only, your Twitter handle is @teaxyz\_, right?
-**Beyang Liu:**
-All right. My guest today has been Kirsten Westeinde. Kirsten, thanks for being on the show.
+**Max:** Yes. Unfortunately, Twitter being as old as it is now, you can’t get good handles anymore, so [laugh] put the underscore in the end there. But yeah, you can go to tea.xyz and it has all our links.
-**Kirsten Westeinde:**
-Thanks for having me. It was fun.
+**Beyang:** Cool. Awesome. Max, thanks so much for coming on the show. This was an awesome conversation and I really appreciate you taking the time.
-
+**Max:** Great. Well, it’s been really good to talk through everything that we’re building. Thanks for having us on.
diff --git a/content/terms/archives/cloud/2022-02-09.md b/content/terms/archives/cloud/2022-02-09.md
new file mode 100644
index 00000000..36d367a9
--- /dev/null
+++ b/content/terms/archives/cloud/2022-02-09.md
@@ -0,0 +1,377 @@
+---
+layout: markdown
+title: Terms of Service for Sourcegraph Cloud (Archived)
+---
+
+Last modified: February 9, 2022
+
+See the [changes](https://sourcegraph.com/search?q=context:global+repo:%5Egithub%5C.com/sourcegraph/about%24+file:%5Edocs/terms-dotcom%5C.md+type:diff&patternType=literal) since the [previous version](https://about.sourcegraph.com/archives/terms-cloud/2021-12-09/) or visit our [archives](https://github.com/sourcegraph/about/tree/main/docs/archives).
+
+Thank you for using Sourcegraph! This page lays out the basic terms and conditions that apply to your use of Sourcegraph Cloud.
+
+
+
+
+## Is this the right Terms of Service for me?
+
+
+
+Are you interested in terms for...
+
+- **Sourcegraph Cloud**: You're in the right place! Read on.
+
+- **[A self-hosted Sourcegraph instance](/terms/self-hosted)**: If you’d like to use a self-hosted Sourcegraph instance (e.g. one deployed via the `docker run` command in our [Quickstart](https://docs.sourcegraph.com)) to search, navigate, and analyze your code, rather than the Sourcegraph Cloud instance, or if you’d like to use any products (e.g. browser or editor extensions) developed and distributed by us for use with your self-hosted instance, please see our terms and conditions at https://about.sourcegraph.com/terms-self-hosted.
+
+- **[Sourcegraph OSS](https://github.com/sourcegraph/sourcegraph/blob/master/LICENSE.apache)**: It is possible to run a version of Sourcegraph without some Enterprise features from our open source code available at https://github.com/sourcegraph/sourcegraph. If you want to follow the instructions there to build and run Sourcegraph OSS from source, please see the open source license (Apache 2.0) at https://github.com/sourcegraph/sourcegraph/blob/master/LICENSE.apache.
+
+- **Sourcegraph extensions**: If you’d like to use any extensions made available via our [Extension Registry](https://sourcegraph.com/extensions), please understand that extensions made available by third-parties are not provided by us and are generally governed by separate terms and conditions. Extensions that are developed and distributed by us are governed by these terms and conditions.
+
+- **[Government](/terms/gov)**: Certain features of our software may have their own terms and conditions that you must agree to when you sign up for that particular feature. As an example, if you’re using our software as an employee or contractor of the U.S. Government, our Supplemental Terms for U.S. Government Users at https://about.sourcegraph.com/terms-gov apply. Those terms and conditions supplement these terms and conditions.
+
+
+PLEASE READ THESE TERMS CAREFULLY TO ENSURE YOUR UNDERSTANDING OF EACH PROVISION. THE AGREEMENT CONTAINS A MANDATORY INDIVIDUAL ARBITRATION AND CLASS ACTION/JURY TRIAL WAIVER PROVISION THAT REQUIRES THE USE OF ARBITRATION ON AN INDIVIDUAL BASIS TO RESOLVE DISPUTES, RATHER THAN JURY TRIALS OR CLASS ACTIONS.
+
+
+
+## 0. Table of contents
+
+
+
+| Section | Description |
+| ------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------- |
+| 1. [Definitions](#1-Definitions) | Definitions of specific terms used on this page |
+| 2. [Account terms](#2-Account-terms) | Your responsibilities to use Sourcegraph |
+| 3. [Proprietary rights and licenses](#3-Proprietary-rights-and-licenses) | Your rights and ours when you use Sourcegraph |
+| 4. [Usage data](#4-Usage-data) | Data we collect on Sourcegraph |
+| 5. [Privacy and security](#5-Privacy-and-security) | Our policies for protecting your data |
+| 6. [Confidentiality](#6-Confidentiality) | The parties’ respective confidentiality obligations |
+| 7. [Term; termination](#7-Term-termination) | When and how your account can be terminated |
+| 8. [Fees](#8-Fees) | Rules for payment for paid features |
+| 9. [Third party services and software](#9-Third-party-services-and-software) | Our use of third party services and software |
+| 10. [Copyright infringement and DMCA policy](#10-Copyright-infringement-and-DMCA-policy) | How we handle IP infringment |
+| 11. [Warranties; disclaimer](#11-No-warranties-disclaimer) | Our warranties about Sourcegraph |
+| 12. [Limitation of liability](#12-Limitation-of-liability) | Our liabilities are limited |
+| 13. [Indemnification](#13-Indemnification) | The parties’ respective indemnification obligations |
+| 14. [Location of the Services; export controls](#14-Location-of-the-services-export-controls) | Usage restrictions in embargoed locations |
+| 15. [Governing law; arbitration; and class action/jury trial waiver](#15-Governing-law-arbitration-and-class-actionjury-trial-waiver) | Where and how disputes would be handled |
+| 16. [Miscellaneous](#16-Miscellaneous) | Miscellaneous topics |
+
+
+
+
+## 1. Definitions
+
+
+
+As used on this page, the following terms have the following specific meanings:
+
+1.1 **“Account”** means the account you've created via the Site in order to use the Services.
+
+1.2 **“Agreement”** means, collectively, the terms and conditions laid out on this page (these “Terms”), along with any order for Services (**“Order Form”**) and all other applicable rules, policies, and procedures that we may publish from time to time on the Site, including but not limited to our [Privacy Policy](/terms/privacy).
+
+1.3 **“Content”** means any content displayed on the Site or made available through the Services, including but not limited to text (including Documentation), data (including Code Data), articles, images, photographs, videos, applications, software (including source code), and other materials, as well as the Services themselves (with respect to us).
+
+1.4 **“Documentation”** means the documentation regarding the Services that we make available for use at https://docs.sourcegraph.com.
+
+1.5 **“Code”** means source code that we analyze in order to provide you Code Data via the Services.
+
+1.6 **“Code Data”** means the results of our analysis of Code, which we may provide to you from time to time via the Services.
+
+1.7 **“Services”** means, collectively, the applications, software, products, and services provided by us on or for use exclusively in connection with the Site, including but not limited to our browser and editor extensions (to the extent exclusively connected to the Site and not a self-hosted instance).
+
+1.8 **“Site”** means our website located at sourcegraph.com, and all content, services, and products provided by us at or through the Site (or any subdomain or successor site).
+
+1.9 **“Sourcegraph”**, **“we”**, or **“us”** refers to Sourcegraph, Inc., as well as its affiliates.
+
+1.10 **“You”** refers to the individual person, company, or organization that has visited or is using the Site or Services, that accesses an Account, or that directs the use of the Account. If you’re entering into the Agreement on behalf of your company or organization (your **“Organization”**), then (i) the Agreement is an agreement between us and you and us and that Organization and your acceptance of this Agreement binds that Organization, (ii) you represent and warrant that you’re authorized to bind that Organization to the Agreement and that you've read, understood, and agree to be bound by the Agreement on that Organization’s behalf, and (iii) references to "you" herein will mean you and that Organization.
+
+
+
+## 2. Account terms
+
+
+
+**Short version**: You are responsible for your account and its security, as well as everything posted on it. You must be 18 or over to use our services.
+
+2.1 **Account Responsibility and Security.**
+
+1. **Generally**. If you’re entering into the Agreement on behalf of your Organization, your Organization has administrative control of all Accounts tied to the Organization. Only you may use your Account, and a single Account may not be shared by multiple people. You are, or your Organization is, fully responsible for your Account and all Content posted under it.
+
+2. **Age Limitation**. In order to create an Account or use our Services, you must be at least eighteen (18) years old and, in any event, we do not permit any users under thirteen (13) years old to use our Services for any purpose. If we discover that an Account is being used by a user under thirteen (13) years old, we will terminate that Account immediately without notice to you.
+
+3. **Security**. You’re responsible for the security of your Account when using our Services. While we may offer tools to help you maintain your Account’s security, these are not guaranteed to work. Accordingly:
+
+ (i) you’re responsible for all Content posted under your Account (even if you didn't post it);
+
+ (ii) you’re responsible for maintaining the security of your Account and password and we have no liability of any kind for any loss or damage from your failure to secure them; and
+
+ (iii) you must notify us immediately on becoming aware of any unauthorized use of or access to the Services through your Account.
+
+2.2 **Required Information**. In order to register for an Account, you must provide all of the information we request during the onboarding process. We may use that information in accordance with our [Privacy Policy](/terms/privacy).
+
+
+
+## 3. Proprietary rights and licenses
+
+
+
+**Short version**: You’re allowed to use the services for any reasonable purpose (e.g. don’t use it to host illegal content). Because the services are made available on a hosted basis, we – like most sites – will collect data about your use of the services (e.g., click rates and other metadata) and can use it to run our business. If you give us a great idea about how to improve our services, we can use it.
+
+3.1 **License from Us to You**.
+
+1. **Grant**. Subject to the terms and conditions of the Agreement, we hereby grant to you a limited, revocable, non-transferable, non-sublicensable (except, with respect to Organizations, to your employees and contractors performing services for you or on your behalf) license to access and use the Services in order to review Code Data in the manner contemplated by the Agreement and the Documentation, solely for your internal business purposes. You may only use the Documentation to support your use of the Services. All rights in the Services and Code Data not expressly granted herein are hereby reserved by us.
+
+2. **Restrictions**. You may not, and may not permit any third-party to redistribute, encumber, sell, rent, lease, sublicense, or otherwise transfer rights to all or any part of the Services or Code Data without our prior written approval. Your use of the Site and Services must not violate any applicable laws, including copyright or trademark laws, export control or sanctions laws, or other laws in your jurisdiction. You are responsible for making sure that your use of the Site and Services complies with laws and any applicable regulations.
+
+3. **No Sensitive Data**. You acknowledge and agree that, (i) the Services are not designed to store Sensitive Data (as defined below), and (ii) you will not use the Services to store Sensitive Data. “Sensitive Data” means: (i) special categories of data enumerated in European Union Regulation 2016/679, Article 9(1) or any successor legislation; (ii) protected health information as defined in HIPAA; (iii) payment cardholder information or financial account information, including bank account numbers or other personally identifiable financial information; (iv) social security numbers, driver’s license numbers, or other government identification numbers; (v) other information subject to regulation or protection under specific laws such as the Children’s Online Privacy Protection Act or Gramm-Leach-Bliley Act (“GLBA”) or related rules or regulations; or (vi) any data similar to the above protected under applicable laws. You acknowledge that the Services and related features are not intended to meet any legal obligations for these uses, including HIPAA and GLBA requirements and that we are not a Business Associate as defined under HIPAA. Therefore, notwithstanding anything else in this Agreement, we have no liability for Sensitive Data processed in connection with your use of the Services.
+
+3.2 **License Grant from You to Us**.
+
+1. **User-Generated Content**. Some areas of the Services allow users to post Content such as profile information, proprietary Code, comments, reviews, etc. (**“User-Generated Content”** or **“UGC”**) (for clarity, this does not include open source Code as defined by the Open Source Initiative at https://opensource.org/osd). WE CLAIM NO OWNERSHIP OF YOUR UGC. However, you understand that other users may view and interact with your UGC in accordance with your Account settings, and you grant us rights reasonably necessary to do so. We have the right (but not the obligation) to remove any UGC at any time and for any reason.
+
+2. **Grant**. By posting UGC on or through the Services, you grant (and you represent and warrant that you have all rights necessary to grant) to Sourcegraph a royalty-free, sublicensable, transferable, perpetual, irrevocable, non-exclusive, worldwide license to use, modify, and publish all such UGC via the Services (including your name, voice, and/or likeness as contained in your UGC) for the limited purposes of:
+ (i) providing and improving the Services;
+ (ii) protecting the Services to prevent abuse;
+ (iii) tailoring the Services to you; and
+ (iv) marketing the Services.
+ We do not use any Content (including any UGC) in private repositories to market the Services. The license you give us is only for the above purposes.
+
+3. **Representations and Warranties Regarding UGC**. In connection with your UGC, you represent, warrant, and covenant that you have the right to post it, including written consent from anyone referenced or involved, it doesn't violate any laws (such as IP or privacy rights), and we won’t have to pay anybody else (including you) in order to host it and make it available to other users. You’re responsible for obtaining all necessary consents and permissions for any UGC, including Code, that you provide or make accessible to the Services.
+
+4. **Responsibility for UGC**. We take no responsibility and assume no liability for any UGC that you or any other user or third-party posts. You’re solely responsible for your UGC and the consequences of posting it, and you agree that we’re only acting as a passive conduit for your online distribution and publication of your UGC. You understand and agree that you may be exposed to UGC that is inaccurate, objectionable, inappropriate for children, or otherwise unsuited to your purpose, and we’re not liable for any damages you allege to incur as a result.
+
+5. **Private Repositories**. Some Accounts have private repositories, which allow you to control access to Content. We consider the contents of private repositories to be confidential to you. Our personnel may only access the content of your private repositories in the situations described in our Privacy Policy. In addition, you may enable additional access to your private repositories to use certain services or features. We may also be compelled by law to disclose the contents of your private repositories, in which case we will provide notice regarding our access to private repository content to the extent permitted by law.
+
+3.3 **Ownership of the Services**. The Services are owned and operated by Sourcegraph. All Content made available via the Services is owned by us or our licensors (including you, with respect to UGC) and is protected by intellectual property and other applicable laws. All of our trademarks, service marks, and trade names are proprietary to us or our affiliates.
+
+3.4 **Ideas**. You may submit comments or ideas about the Services, such as how to improve it. By submitting a comment or idea, you agree that your disclosure is gratuitous, unsolicited and without restriction and will not place us under any fiduciary or other obligation, and that we are free to use the comment or idea without any additional compensation to you. By acceptance of your submission, we do not waive any rights to use similar ideas we already had or obtained from other sources.
+
+3.5 **Extensions**. As described above, certain features of the Services may allow you to download software packages from the Extension Registry. These packages may be offered by us or by third-party providers. Packages made available by third-party providers are subject to separate terms and conditions and are not governed by these Terms.
+
+3.6 **Beta Services**. We may make beta and experimental products, features, and Documentation available to you on an early access basis (**“Beta Services”**). Beta Services are not generally available and may contain bugs, defects, and errors. We provide Beta Services “as is,” without warranties, and may discontinue the Beta Services at any time. Our service level agreements do not apply to Beta Services. If and when the Beta Services become generally available, you will have the option to pay for the software or discontinue its use. We may use your feedback about Beta Services.
+
+
+
+## 4. Usage data
+
+
+
+**Short version**: We have the right to collect usage data from Sourcegraph, as described in our [Privacy Policy](/terms/privacy).
+
+In the course of your use of the Services, we may collect certain information about your use, including aggregated data derived from you and other users’ access and use of the Services (**“Usage Data”**). You acknowledge and agree that Usage Data is owned solely and exclusively by us, and that we may use it for any legal purpose, including for purposes of operating, analyzing, improving, or marketing our products and services.
+
+If we share or publicly disclose any information constituting or derived from Usage Data (e.g., in marketing materials), we will aggregate or anonymize that information to avoid identifying you or any other individual.
+
+
+
+## 5. Privacy and security
+
+
+
+**Short version**: Our privacy policy tells you what you need to know about how we use any personal information you provide to us. The internet is a dangerous place and, while we’ve instituted safeguards to protect your information, you understand that data breaches happen and we can’t guarantee perfect security.
+
+User privacy is important to us. Please read our [Privacy Policy](/terms/privacy) carefully for details relating to how we collect, use, and disclose personal information you provide to us.
+
+We have implemented commercially reasonable technical and organizational measures designed to secure information you provide us from accidental loss and from unauthorized access, use, alteration or disclosure. However, we cannot guarantee that unauthorized third parties will never be able to defeat those measures or use your information for improper purposes. You understand that internet technologies have the inherent potential for disclosure. You acknowledge that you provide any sensitive information to us at your own risk.
+
+If you are an Organization established in the European Economic Area, the United Kingdom or Switzerland, or otherwise obliged to comply with the General Data Protection Regulation, we will process any information relating to identified or identifiable natural persons in accordance with our [Data Processing Addendum](/dpa), which will be incorporated by reference into the terms of this Agreement.
+
+
+
+## 6. Confidentiality
+
+
+
+**Short version**: We will each protect the other party's confidential information.
+
+6.1 **Definition**. **"Confidential Information"** means all non-public information disclosed by us to you, or vice-versa, that is designated by the discloser as confidential or that reasonably should be considered confidential given the nature of the information or circumstances of its disclosure.
+
+6.2 **Exclusions**. Confidential Information does not include any information that
+
+1. was or becomes publicly known through no fault of the receiving party;
+2. was rightfully known or becomes rightfully known to the receiving party without confidential restriction from a third-party that has a right to disclose it;
+3. is approved by the disclosing party for disclosure without restriction in a written document or electronic record; or
+4. the receiving party independently develops without access to or use of the other party’s Confidential Information.
+
+6.3 **Restrictions on Use and Disclosure**. Neither party will use the other party’s Confidential Information except as permitted under this Agreement. Each party agrees to maintain in confidence and protect the other party’s Confidential Information using at least the same degree of care as it uses for its own information of a similar nature, but in any event at least a reasonable degree of care. Each party agrees to take all reasonable precautions to prevent any unauthorized disclosure of the other party’s Confidential Information, including, without limitation, disclosing such Confidential Information only to its employees, independent contractors, consultants, and legal and financial advisors (collectively, **“Representatives”**) who (i) have a need to know such information, and (ii) are subject to confidentiality obligations at least as protective of the Confidential Information as the terms of this Agreement. Each party is responsible for all acts and omissions of its Representatives. The foregoing obligations will not restrict either party from disclosing Confidential Information of the other party if required by any governmental body, so long as, to the extent allowed under applicable law, the party required to make the disclosure gives reasonable notice to the other party to enable it to contest the requirement. The restrictions set forth in this Section will survive the termination or expiration of this Agreement.
+
+
+
+## 7. Term; termination
+
+
+
+**Short version**: You may shut down your Account any time. We may terminate the agreement at any time, at which point your right to use the Services will immediately expire.
+
+7.1 **Subscription Period**. Unless otherwise stated in an Order Form, this Agreement starts on the earlier of the date on which you: (a) agree to the terms and conditions of this Agreement; or (b) first register for an Account and will continue in effect until either you or we terminate it (the “Subscription Period” or “Term”).
+
+7.2 **Termination for Breach**. If a party fails to cure a material breach of the Agreement within thirty (30) days after receiving written notice of breach, the other party may then terminate the Agreement within the following thirty (30) days. We will refund you any prepaid, unused fees.
+
+7.3 **Termination for Convenience**. Either party may terminate this Agreement, for any reason or for no reason, provided that you are responsible for all prepaid fees and fees you commit to in an Order Form. If we terminate the Agreement under this section, we will refund you for all prepaid fees for the remainder of the Subscription Period.
+
+7.4 **Effect of Termination; Survival**. Upon termination of this Agreement, you may no longer use the Services, and if any fees were owed prior to termination, you must pay those fees immediately. Any provisions of this Agreement that, by their terms or their nature, should survive the termination of this Agreement shall so survive. For purposes of clarity, your right to use the Services will not survive any termination of this Agreement. Following termination of this Agreement, Sourcegraph will remove your Content from the Services.
+
+
+
+## 8. Fees
+
+
+
+**Short version**: You’re responsible for any fees associated with your use of Sourcegraph. Your subscription will automatically renew, unless an Order Form states otherwise.
+
+8.1 **Pricing**. You are responsible for paying any applicable fees as set forth on our [Pricing and Payment Terms](/pricing) or in an Order Form and applicable taxes associated with the Services in a timely manner with a valid payment method. Unless otherwise stated in an Order Form, you will pay all invoices within thirty (30) days of receipt. You agree that we may charge for any such fees owed. You are required to keep your billing information current.
+
+8.2 **Term**. Authorization to charge your chosen payment method account will remain in effect until you cancel or modify your preference. You agree that charges may be accumulated as incurred and may be submitted as one or more aggregate charges during or at the end of the applicable billing cycle.
+
+8.3 **Responsibility for Changes**. You are responsible for all charges incurred by usage of your Account. If your payment method fails or you are past due on amounts owed, we may collect fees owed using other collection mechanisms. You are also responsible for paying any governmental taxes imposed on your use of the Services, including, but not limited to, sales, use, or value-added taxes.
+
+8.4 **No Refunds**. All fees and charges are earned upon receipt by us and are nonrefundable unless negotiated otherwise, except (a) as expressly set forth herein, and/or (b) as required by applicable law.
+
+8.5 **Renewals**. Unless otherwise stated in an Order Form, your subscription will be automatically renew for one (1) year terms at the then-current fees and your credit card account (or other payment method account) will be charged without further authorization from you, absent sixty (60) day written notice of non-renewal prior to the end of your current subscription term.
+
+
+
+## 9. Third party services and software
+
+
+
+**Short version**: Third party services and software may be necessary for Sourcegraph Cloud to work (examples include libraries Sourcegraph uses internally, code hosts, authentication providers, external code analyzers, monitoring and tracing tools, etc.). We’re not responsible for anything provided by a third party, and additional terms and conditions may apply.
+
+You may enable the Services to call the servers of other websites or services (**“Third Party Services”**) in order to help you analyze Your Code. We do not share Your Code with third-party services, unless you enable the integration or extension. We make no warranties of any kind with regard to anything that is contained on or accessible through them. Access and use of Third Party Services is solely at your own risk.
+
+The Services may contain copyrighted software of our licensors (**“Third Party Software”**). The licensors retain all right, title, and interest in and to such Third Party Software and all copies thereof. Your use of any Third Party Software is subject to the terms and conditions of this Agreement, and any other terms and conditions in any Third Party Software documentation or printed materials (including EULAs).
+
+If there's ever a conflict between the terms of this Agreement and the terms applicable to any Third Party Software, and the conflict relates to the use of that Third Party Software, their terms and conditions will govern the conflict.
+
+
+
+## 10. Copyright infringement and DMCA policy
+
+
+
+**Short version**: If you think we (or a user of the services) is infringing your copyrights, let us know and we’ll handle it in compliance with law.
+
+We respect the intellectual property of others and ask that you do too. We reserve the right to delete or disable content alleged to be infringing and terminate accounts of repeat infringers. If you believe that your copyrighted work has been copied in a way that constitutes copyright infringement and is accessible via the Services, please notify our copyright agent as set forth in the DMCA. For your complaint to be valid under the DMCA, you must provide the following information in writing:
+
+1. An electronic or physical signature of a person authorized to act on behalf of the copyright owner;
+2. Identification of the copyrighted work that you claim has been infringed;
+3. Identification of the material that is claimed to be infringing and where it is located on the Service;
+4. Information reasonably sufficient to permit us to contact you, such as your address, telephone number, and, e-mail address;
+5. A statement that you have a good faith belief that use of the material in the manner complained of is not authorized by the copyright owner, its agent, or law; and
+6. A statement, made under penalty of perjury, that the above information is accurate, and that you are the copyright owner or are authorized to act on behalf of the owner.
+
+The above information must be submitted to the following DMCA Agent:
+
+```
+Attn: DMCA Notice
+ Sourcegraph Inc.
+Address: 548 Market St PMB 20739, San Francisco, CA 94104-5401
+Tel. (650) 273-5591
+Email: legal@sourcegraph.com
+```
+
+UNDER FEDERAL LAW, IF YOU KNOWINGLY MISREPRESENT THAT ONLINE MATERIAL IS INFRINGING, YOU MAY BE SUBJECT TO CRIMINAL PROSECUTION FOR PERJURY AND CIVIL PENALTIES, INCLUDING MONETARY DAMAGES, COURT COSTS, AND ATTORNEYS’ FEES.
+
+Please note that this procedure is exclusively for notifying us that your copyrighted material has been infringed. The preceding requirements are intended to comply with our rights and obligations under the DMCA, including 17 U.S.C. §512(c), but do not constitute legal advice. It may be advisable to contact an attorney regarding your rights and obligations under the DMCA and other applicable laws.
+
+In accordance with the DMCA and other applicable law, we have adopted a policy of terminating, in appropriate circumstances, users who are deemed to be repeat infringers. We may also at our sole discretion limit access to the Services and/or terminate the Accounts of any users who infringe any intellectual property rights of others, whether or not there is any repeat infringement.
+
+
+
+## 11. Warranties; disclaimer
+
+
+
+**Short version**: Other than the warranties explicitly described in this Section, the Services and Code Data are provided “as is” with no guarantees of any kind (unless applicable law provides you additional mandatory rights). Please read this section carefully.
+
+We warrant that (1) the Services will perform materially in accordance with the applicable Documentation when accessed and used as recommended in the Documentation and in accordance with the Agreement and (2) to the best of our knowledge, the Services are free from, and we will not knowingly introduce, software viruses, worms, Trojan horses or other code, files, scripts, or agents intended to do harm. Your sole and exclusive remedy for breach of the warranties in this section is set forth in Section 7.2.
+
+OTHER THAN THE WARRANTIES EXPLICITLY SET FORTH IN THIS SECTION 11, THE SERVICES AND CODE DATA, AND ANY OTHER SOFTWARE, APPLICATIONS, PRODUCTS, AND SERVICES MADE AVAILABLE ON OR IN CONNECTION WITH THE SERVICES ARE PROVIDED ON AN “AS IS” AND “AS AVAILABLE” BASIS WITHOUT WARRANTIES OF ANY KIND, WHETHER EXPRESS, IMPLIED, OR OTHERWISE. WITHOUT LIMITING THE GENERALITY OF THE FOREGOING, TO THE FULLEST EXTENT PERMISSIBLE UNDER APPLICABLE LAW, SOURCEGRAPH DISCLAIMS, ON BEHALF OF ITSELF AND ITS LICENSORS, ALL WARRANTIES, WHETHER EXPRESS, IMPLIED, OR OTHERWISE, INCLUDING BUT NOT LIMITED TO ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, OR NONINFRINGEMENT. FURTHER, WE DO NOT WARRANT THAT THE SERVICES OR CODE DATA OR ANY PART THEREOF (OR YOUR ACCESS THERETO) WILL BE UNINTERRUPTED OR ERROR-FREE, WILL MEET YOUR REQUIREMENTS, OR THAT DEFECTS WILL BE CORRECTED.
+
+CERTAIN JURISDICTIONS DO NOT ALLOW LIMITATIONS ON IMPLIED WARRANTIES OR THE EXCLUSION OR LIMITATION OF CERTAIN DAMAGES. IF THESE LAWS APPLY TO YOU, SOME OR ALL OF THE ABOVE DISCLAIMERS, EXCLUSIONS, OR LIMITATIONS MAY NOT APPLY TO YOU, AND YOU MAY HAVE ADDITIONAL RIGHTS AS PROVIDED BY LAW.
+
+
+
+## 12. Limitation of liability
+
+
+
+**Short version**: Our liability is limited to direct damages wherever possible, and to no more than $100 or the amount you paid us for access to the services. Please read this section carefully.
+
+UNDER NO CIRCUMSTANCES WILL EITHER PARTY (OR ITS AFFILIATES, EMPLOYEES, AGENTS, LICENSORS, SUCCESSORS, OR ASSIGNS) BE LIABLE FOR ANY SPECIAL, INDIRECT, INCIDENTAL, CONSEQUENTIAL, PUNITIVE, RELIANCE, OR EXEMPLARY DAMAGES (INCLUDING WITHOUT LIMITATION LOSSES OR LIABILITY RESULTING FROM LOSS OF DATA, LOSS OF REVENUE, ANTICIPATED PROFITS, OR LOSS OF BUSINESS OPPORTUNITY) THAT RESULT FROM YOUR USE OR YOUR INABILITY TO USE THE SERVICES, OR ANY OTHER INTERACTIONS WITH US, EVEN IF WE OR A SOURCEGRAPH-AUTHORIZED REPRESENTATIVE HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
+
+APPLICABLE LAW MAY NOT ALLOW THE LIMITATION OR EXCLUSION OF LIABILITY FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES, SO THE ABOVE LIMITATION OR EXCLUSION MAY NOT APPLY. IN SUCH CASES, EACH PARTY'S LIABILITY WILL BE LIMITED TO THE FULLEST EXTENT PERMITTED BY APPLICABLE LAW.
+
+IN NO EVENT WILL EACH PARTY'S (OR ITS AFFILIATES, EMPLOYEES, AGENTS, LICENSORS, SUCCESSORS, OR ASSIGNS’) TOTAL LIABILITY FOR ALL DAMAGES, LOSSES, AND CAUSES OF ACTION ARISING OUT OF OR RELATING TO THESE TERMS OR YOUR USE OF THE SERVICES, INCLUDING WITHOUT LIMITATION YOUR INTERACTIONS WITH OTHER USERS, (WHETHER IN CONTRACT, TORT INCLUDING NEGLIGENCE, WARRANTY, OR OTHERWISE) EXCEED THE AMOUNT PAID BY YOU, IF ANY, FOR ACCESSING THE SERVICES DURING THE TWELVE (12) MONTHS IMMEDIATELY PRECEDING THE DAY THE ACT OR OMISSION OCCURRED THAT GAVE RISE TO YOUR CLAIM OR ONE HUNDRED DOLLARS ($100.00), WHICHEVER IS GREATER.
+
+You acknowledge and agree that we have offered our products and services, set our prices, and entered into the Agreement in reliance upon the disclaimers of warranty and the limitations of liability set forth herein, that the disclaimers of warranty and the limitations of liability set forth herein reflect a reasonable and fair allocation of risk between the parties (including the risk that a contract remedy may fail of its essential purpose and cause consequential loss), and that the disclaimers of warranty and the limitations of liability set forth herein form an essential basis of the bargain between you and us.
+
+
+
+## 13. Indemnification
+
+
+
+**Short version**: Each of us agrees to defend the other against third-party lawsuits that result from matters under our respective responsibility.
+
+13.1 **By You**. You agree to defend us and our affiliates, directors, officers, employees, and contractors from and against any third-party claims, proceedings, demands, and investigations and indemnify us for damages, attorney’s fees, and costs arising from Your Code or Content, your use of the Services in violation of the Agreement including any data or work transmitted or received by you, your violation of the Agreement or applicable laws, your infringement of any third-party intellectual property or other right of any person or entity, or any other party’s access and use of the Services with your unique username, password, or other appropriate security code.
+
+13.2 **By Sourcegraph**. We agree to defend you and your affiliates, directors, officers, employees, and contractors from and against any third-party claims, proceedings, demands, and investigations and indemnify you for damages, attorney’s fees, and costs arising from your use of the Services or Documentation in accordance with this Agreement that infringes or misappropriates such third-party’s intellectual property rights, except for claims arising from (a) Your Code or Content, (b) your use of the Services in violation of the Agreement, or (c) any modification, combination, or development of the Services not performed by us.
+
+13.3 **Procedure**. Each party must give the other prompt written notice of any defense or indemnity sought and reasonable cooperation in the defense. The defending party will have sole control of the defense and settlement, provided that neither party may enter into a settlement placing any material obligation of any kind, including any admission of liability or payment of any amount, on the other party without the other party’s prior written approval, not to be unreasonably withheld, conditioned, or delayed.
+
+
+
+## 14. Location of the Services; export controls
+
+
+
+**Short version**: The services are located in the US (where we’re located). Don’t use them if you’re located in an embargoed country.
+
+14.1 **Location of the Services**. The Services are controlled and operated from our facilities in the United States. We make no representations that the Services is appropriate or available for use in other locations. Those who access or use the Services from other jurisdictions do so at their own volition and are entirely responsible for compliance with local law, including but not limited to export and import regulations. You may not use the Services if you are a resident of a country embargoed by the United States, or are a foreign person or entity blocked or denied by the United States government. Unless otherwise explicitly stated, all materials found on the Services are solely directed to individuals, companies, or other entities located in the U.S. By using the Services, you are consenting to have your personal data transferred to and processed in the United States.
+
+14.2 **Export Controls**. The Services and the underlying information and technology may not be downloaded or otherwise exported or re-exported (a) into (or to a national or resident of) any country to which the U.S. has embargoed goods; or (b) to anyone on the U.S. Treasury Department's list of Specially Designated Nationals or the U.S. Commerce Department's Table of Deny Orders. By downloading or using the Services, you are agreeing to the foregoing and you represent and warrant that you are not located in, under the control of, or a national or resident of any such country or on any such list and you agree to comply with all export laws and other applicable laws.
+
+
+
+## 15. Governing law; arbitration; and class action/jury trial waiver
+
+
+
+**Short version**: We’re based in California, so the agreement is governed by California law, and all disputes must be brought there. If you have a claim against us, you’ll work with us to arbitrate it on an individual basis instead of via class action or jury trial.
+
+15.1 **Governing Law**. The Agreement shall be governed by the internal substantive laws of the State of California, without respect to its conflict of laws principles. Notwithstanding the preceding sentence with respect to the substantive law, any arbitration conducted pursuant to the terms of these Terms shall be governed by the Federal Arbitration Act (9 U.S.C. §§ 1-16). The application of the United Nations Convention on Contracts for the International Sale of Goods is expressly excluded. You agree to submit to the personal jurisdiction of the federal and state courts located in Santa Clara County, California for any actions for which we retain the right to seek injunctive or other equitable relief in a court of competent jurisdiction to prevent the actual or threatened infringement, misappropriation or violation of a our copyrights, trademarks, trade secrets, patents, or other intellectual property or proprietary rights, as set forth in the Arbitration provision below, including any provisional relief required to prevent irreparable harm. You agree that Santa Clara County, California is the proper forum for any appeals of an arbitration award or for trial court proceedings if the arbitration provision below is found to be unenforceable.
+
+15.2 **Arbitration**. Read this section carefully because it requires the parties to arbitrate their disputes and limits the manner in which you can seek relief from us. For any dispute with us, you agree to first contact us at support@sourcegraph.com and attempt to resolve the dispute with us informally. In the unlikely event that we have not been able to resolve a dispute it has with you after sixty (60) days, we each agree to resolve any claim, dispute, or controversy (excluding any claims for injunctive or other equitable relief as provided below) arising out of or in connection with or relating to the Agreement, or the breach or alleged breach thereof, by binding arbitration by JAMS, under the Optional Expedited Arbitration Procedures then in effect for JAMS, except as provided herein. JAMS may be contacted at www.jamsadr.com. The arbitration will be conducted in Santa Clara County, California, unless we agree otherwise. If you are using the Services for commercial purposes, each party will be responsible for paying any JAMS filing, administrative and arbitrator fees in accordance with JAMS rules, and the award rendered by the arbitrator shall include costs of arbitration, reasonable attorneys' fees and reasonable costs for expert and other witnesses. Any judgment on the award rendered by the arbitrator may be entered in any court of competent jurisdiction. Nothing in this section shall be deemed as preventing us from seeking injunctive or other equitable relief from the courts as necessary to prevent the actual or threatened infringement, misappropriation, or violation of our data security, intellectual property or other proprietary rights.
+
+15.3 **Class Action/Jury Trial Waiver**. WITH RESPECT TO ALL PERSONS AND ENTITIES, REGARDLESS OF WHETHER THEY HAVE OBTAINED OR USED THE SERVICES FOR PERSONAL, COMMERCIAL OR OTHER PURPOSES, ALL CLAIMS MUST BE BROUGHT IN THE PARTIES' INDIVIDUAL CAPACITY, AND NOT AS A PLAINTIFF OR CLASS MEMBER IN ANY PURPORTED CLASS ACTION, COLLECTIVE ACTION, PRIVATE ATTORNEY GENERAL ACTION OR OTHER REPRESENTATIVE PROCEEDING. THIS WAIVER APPLIES TO CLASS ARBITRATION, AND, UNLESS WE AGREE OTHERWISE, THE ARBITRATOR MAY NOT CONSOLIDATE MORE THAN ONE PERSON'S CLAIMS. YOU AGREE THAT, BY ENTERING INTO THE AGREEMENT, WE ARE EACH WAIVING THE RIGHT TO A TRIAL BY JURY OR TO PARTICIPATE IN A CLASS ACTION, COLLECTIVE ACTION, PRIVATE ATTORNEY GENERAL ACTION, OR OTHER REPRESENTATIVE PROCEEDING OF ANY KIND.
+
+
+
+## 16. Miscellaneous
+
+
+
+16.1 **Notices and Electronic Communications**. We may provide you with (and you hereby consent to our provision of) notices, including those regarding changes to our terms and conditions, by email, regular mail, or postings on the Services. Notice will be deemed given twenty-four hours after email is sent, unless we’re notified that the email address is invalid. Alternatively, we may give you legal notice by mail to a postal address, if provided by you through the Services. In such case, notice will be deemed given three days after the date of mailing. Notice posted on the Services is deemed given five (5) days following the initial posting. We reserve the right to determine the form and means of providing notifications to our users, provided that you may opt out of certain means of notification as described in the Agreement. We are not responsible for any automatic filtering you or your network provider may apply to email notifications we send to the email address you provide us.
+
+16.2 **Updates and Modifications**. We may, in our sole discretion, modify or update the Agreement (or any part thereof, including these Terms) from time to time, so you should review this page periodically. When we change the Agreement (or any part thereof, including these Terms) in a material manner, we will update the 'last modified' date at the top of this page and notify you that material changes have been made to the Agreement. Your continued use of the Services after any such change constitutes your acceptance of the new Terms of Service, unless you have signed an Order Form with us where the terms in effect as of your Order Date will apply. If you have purchased a subscription to use the Services, any change to these Terms will be effective with respect to such Services upon the renewal of your subscription, unless otherwise stated in an Order Form.
+
+16.3 **U.S. Government End Users**. The Services were developed by private financing and constitute a "Commercial Item," as that term is defined at 48 C.F.R. § 2.101. The Services and Documentation consist of "Commercial Computer Software" and "Commercial Computer Software Documentation," as such terms are used in 48 C.F.R. § 12.212. Consistent with 48 C.F.R. § 12.212 and 48 C.F.R. §§ 227.7202-1 through 227.7202-4, all U.S. Government End Users acquire only those rights in the Services and the documentation that are specifically provided by this Agreement. Consistent with 48 C.F.R. § 12.211, all U.S. Government End Users acquire only technical data and the rights in that data customarily as specifically provided in this Agreement.
+
+16.4 **Waiver**. A party's failure to exercise or enforce any right or provision of the Agreement will not constitute a waiver of such right or provision. Any waiver of any provision of the Agreement will be effective only if in writing and signed by the waiving party.
+
+16.5 **Severability**. If any provision of the Agreement is held to be unlawful, void, or for any reason unenforceable, then that provision will be limited or eliminated from the Agreement to the minimum extent necessary and will not affect the validity and enforceability of any remaining provisions; except that in the event of unenforceability of the universal Class Action/Jury Trial Waiver, the entire arbitration agreement shall be unenforceable.
+
+16.6 **Assignment**. The Agreement and any rights and licenses granted hereunder, may not be transferred or assigned by either party without written consent, except in connection with a merger, acquisition, reorganization, or sale of substantially all assets.
+
+16.7 **Survival**. Upon termination of the Agreement, any provision which, by its nature or express terms should survive, shall survive such termination or expiration.
+
+16.8 **Headings**. The heading references herein are for convenience only, do not constitute a part of the Agreement, and will not be deemed to limit or affect any of the provisions hereof.
+
+16.9 **Marketing and Publicity**. If you are an Organization, we may use your name and logo to identify you as a customer and use product testimonials and quotes your representatives may provide us.
+
+16.10 **Entire Agreement**. This, including the agreements incorporated by reference, constitutes the entire agreement between you and us relating to the subject matter herein and will not be modified except in writing, signed by both parties, or by a change made by us as set forth in the Agreement.
+
+16.11 **Claims**. To the extent permissible under applicable law, you and we agree that any cause of action you may have arising out of or related to the Services or Code Data must commence within one (1) year after the cause of action accrues. Otherwise, such cause of action is permanently barred.
+
+16.12 **Disclosures**. The Services are offered by Sourcegraph, Inc., located at 548 Market St PMB 20739, San Francisco, CA 94104-5401, and can be reached via email at support@sourcegraph.com or telephone at (650) 273-5591. If you are a California resident, (a) you may have this same information emailed to you by sending a letter to the foregoing address with your email address and a request for this information; and (b) in accordance with Cal. Civ. Code § 1789.3, you may report complaints to the Complaint Assistance Unit of the Division of Consumer Services of the California Department of Consumer Affairs by contacting them in writing at 1625 North Market Blvd., Suite N 112 Sacramento, CA 95834, or by telephone at (800) 952-5210 or (916) 445-1254.
diff --git a/content/terms/archives/privacy/2021-01-15.md b/content/terms/archives/privacy/2021-01-15.md
new file mode 100644
index 00000000..f4f1fe9e
--- /dev/null
+++ b/content/terms/archives/privacy/2021-01-15.md
@@ -0,0 +1,229 @@
+---
+layout: markdown
+title: Sourcegraph Privacy Policy (Archived)
+---
+
+Last modified: January 15, 2021
+
+Sourcegraph, Inc. (**"Sourcegraph," "we," "our,"** or **"us"**) understands that privacy is important to our online visitors to our Sourcegraph.com website and users of our online services (collectively, for the purposes of this Privacy Policy, our **"Website"**), as well as users of our private or self-hosted Sourcegraph instances (collectively with our Website, our **"Service"** or **"Services"**). This Privacy Policy explains how we collect, use, share and protect your personal information that we collect through our Service. By using our Service, you agree to the terms of this Privacy Policy and our Terms of Service.
+
+Capitalized terms that are not defined in this Privacy Policy have the meaning given them in our Terms of Service.
+
+
+
+## Data controller
+
+
+
+The Data Controller for Sourcegraph and our Services is:
+
+Sourcegraph, Inc. 981 Mission St, San Francisco, CA 94103
+
+
+
+## What types of information do we collect, and for what purpose
+
+
+
+The categories of information we collect can include:
+
+- **Information you provide to us directly:** We may collect personal information such as a username, first and last name, email address, and payment information, when you register for a Sourcegraph account, participate in forums, comment on blog posts, submit a feedback survey, or if you correspond with us.
+
+- **Information we collect from third parties and social media sites:** We may collect information about you from third-party services. For example, we may receive information about you if you interact with our site through various social media, for example, by logging in through or liking us on Facebook or following us on Twitter. The data we receive is dependent upon your privacy settings with the social network. You should always review, and if necessary, adjust your privacy settings on third-party websites and services before linking or connecting them to the Service.
+
+We use this information to operate, maintain, and provide to you the features of the Services. We may use this information to communicate with you, such as to send you email messages, and to follow up with you to offer news and information about our Services. We may also send you Service-related emails or messages (e.g., account verification, change or updates to features of the Services, technical and security notices). For more information about your communication preferences, see "Your Choices About Your Information" below.
+
+
+
+## How we use cookies and other tracking technology to collect information
+
+
+
+### Usage information from private or self-hosted Sourcegraph instances
+
+Sourcegraph collects aggregate and high-level information about usage from self-hosted Sourcegraph instances through a server ping. The server ping sends a payload containing data such as total number of users and whether certain features are enabled or in use.
+
+
+
+The only personal information collected is the email address of the initial Sourcegraph installer and site admin (or, if that user is deleted or demoted to not be an admin, the first such active site admin). This information allows us to contact the technical administrator of the Sourcegraph instance to deliver information about product updates and policy changes, and for customer development purposes. Other than the initial site admin email address, only aggregates of usage data are sent: no usernames, user emails, user personal information, code, repository names, file names, URLs, or other such private content is sent to Sourcegraph.
+
+### Information from Sourcegraph.com visitors
+
+We and our third-party partners may automatically collect certain types of usage information when you visit or use our Website.
+
+- **Cookies**. When visiting our website, we may send one or more cookies — a small text file containing a string of alphanumeric characters — to your computer that uniquely identifies your browser and lets us help you log in faster and enhance your navigation through the site. A cookie may also convey information to us about how you use the Website (e.g., the pages you view, the links you click, how frequently you access the Website, and other actions you take on the Website), and allow us to track your usage of the Website over time.
+
+- **Log file information**. We may collect log file information about your browser or mobile device each time you access the Website. Log file information may include anonymous information such as your web request, Internet Protocol ("IP") address, browser type, information about your mobile device, referring / exit pages and URLs, number of clicks and how you interact with links on the Website, domain names, landing pages, pages viewed, and other such information.
+
+- **Email beacons**. We may employ clear gifs (also known as web beacons) in HTML-based emails sent to our users to track which emails are opened and which links are clicked by recipients. The information allows for more accurate reporting and improvement of the Website.
+
+- **Web analytics**. We may also collect analytics data, or use third-party analytics tools, to help us measure traffic and usage trends for the Website. These tools collect information sent by your browser or mobile device, including the pages you visit, your use of third-party applications, and other information that assists us in analyzing and improving the Website.
+
+Although we do our best to honor the privacy preferences of our Users, we are not able to respond to Do Not Track signals from your browser at this time.
+
+We may use the data collected through cookies, log file, device identifiers, location data, and clear gifs information to:
+
+1. remember information so that you will not have to re-enter it during your visit or the next time you visit the site;
+1. provide custom, personalized content and information;
+1. provide and monitor the effectiveness of our Website;
+1. monitor aggregate metrics such as total number of visitors, traffic, usage, and demographic patterns on our website and our Service;
+1. diagnose or fix technology problems; and
+1. otherwise to plan for and enhance our service
+
+For more information on what cookies are used, visit our Cookie Policy.
+
+### Third-party services and data processors
+
+We use third-party automated devices and applications, such as Google Analytics, to evaluate usage of our Website. Google Analytics is a Web-based analysis tool provided by the Google Inc., 1600 Amphitheatre Pkwy, Mountain View, CA 94043-1351, USA. Google provides further information about its own privacy practices and offers a browser add-on to opt out of Google Analytics tracking at https://tools.google.com/dlpage/gaoptout.
+
+We use third-party applications such as Google Apps, HubSpot, GitHub, Slack, DocuSign, and more to track and manage conversations, chats, or email exchanges with our users and customers. These products and companies provide further information about their own privacy practices on their websites.
+
+We use third-party applications such as Google Cloud Platform, Honeycomb, and more to host, serve, store, and analyze our Website's operational infrastructure and operational data collected on our Website. These products and companies provide further information about their own privacy practices on their websites.
+
+We use third-party applications such as Stripe and Xero to manage corporate billing and invoicing. These companies provide further information about their own privacy practices on their websites.
+
+We and our third-party partners may also use cookies and tracking technologies for the purpose of tracking the effectiveness of our own ads placed on Google, Twitter, etc. on Sourcegraph.com (never on private or self-hosted instances). For more information about tracking technologies, please see [“Third-party tracking and online advertising”](#Third-party-tracking-and-online-advertising) below.
+
+
+
+## Bases for processing your information
+
+
+
+**Performance of a contract:** The use of your information may be necessary to perform the contract that you have with us. For example, if you use our Website to purchase Sourcegraph product subscriptions or services, create a profile, post and comment through our Website, or request information through our Website, we will use your information to carry out our obligation to complete and administer that contract or request.
+
+**Legitimate interests:** We use your information for our legitimate interests, such as to provide you with the best content through our Service and communications with users and the public, to improve and promote our products and services, and for administrative, security, fraud prevention, and legal purposes.
+
+**Consent:** We may rely on your consent to use your personal information for certain direct marketing purposes, such as sending you newsletter updates about Sourcegraph products. You may withdraw your consent at any time through the unsubscribe feature provided with each marketing email or by contacting us at the addresses given at the end of this Privacy Policy.
+
+
+
+## Sharing your information
+
+
+
+We may share your personal information in the instances described below. For further information on your choices regarding your information, see the "Your Choices About Your Information" section below.
+
+We may share your personal information with:
+
+- Other companies owned by or under common ownership with Sourcegraph. These companies will use your personal information in the same way as we can under this Privacy Policy;
+
+- Third-party vendors and other service providers that perform services on our behalf, as needed to carry out their work for us, which may include data hosting, billing, payment processing, or providing analytic services;
+
+- Other parties in connection with a company transaction, such as a merger, sale of company assets or shares, reorganization, financing, change of control, or acquisition of all or a portion of our business by another company or third party or in the event of a bankruptcy or related or similar proceedings; and
+
+- Third parties as required by law or subpoena or to if we reasonably believe that such action is necessary to (a) comply with the law, legal process and the reasonable requests of law enforcement; (b) to enforce our Terms of Service or to protect the security or integrity of our Service; and/or (c) to exercise or protect the rights, property, or personal safety of Sourcegraph, our Users, or others.
+
+We may also aggregate or otherwise strip data of all personally identifying characteristics and may share that aggregated or pseudonymized data with third parties.
+
+Any information or content that you voluntarily disclose for posting to the Website becomes available to the public, as controlled by any applicable privacy settings. If you remove information or content that you posted to the Website, copies may remain viewable in cached and archived pages of the Website, or if other Users have copied or saved that information.
+
+
+
+## Third-party tracking and online advertising
+
+
+
+We participate in interest-based advertising and use third-party advertising companies to serve you targeted advertisements based on your online browsing history and your interests. We permit third-party online advertising networks, social media companies, and other third-party services, to collect information about your use of our Service over time so that they may play or display ads for our products on other websites, apps, or services you may use and on other devices you may use. Typically, though not always, the information used for interest-based advertising is collected through cookies or similar tracking technologies. We and our third-party partners use this information to make the advertisements you see online more relevant to your interests, as well as to provide advertising-related services such as reporting, attribution, analytics and market research.
+
+To learn more about interest-based advertising and how you may be able to opt-out of some of this advertising, you may wish to visit the Network Advertising Initiative’s online resources, at http://www.networkadvertising.org/choices, and/or the DAA’s resources at www.aboutads.info/choices. You may also be able to set your browser to delete or notify you of cookies by actively managing the settings on your browser or mobile device. Please note that some advertising opt-outs may not be effective unless your browser is set to accept cookies. Furthermore, if you use a different device, change browsers or delete the opt-out cookies, you may need to perform the opt-out task again.
+
+You may also be able to limit certain interest-based mobile advertising through the settings on your mobile device by selecting “limit ad tracking” (iOS) or “opt-out of interest based ads” (Android).
+
+**Google Analytics and Advertising**. We may also utilize certain forms of display advertising and other advanced features through Google Analytics, such as Remarketing with Google Analytics, Google Display Network Impression Reporting, the DoubleClick Campaign Manager Integration, and Google Analytics Demographics and Interest Reporting. These features enable us to use first-party cookies (such as the Google Analytics cookie) and third-party cookies (such as the DoubleClick advertising cookie) or other third-party cookies together to inform, optimize, and display ads based on your past visits to the Sites. You may control your advertising preferences or opt-out of certain Google advertising products by visiting the Google Ads Preferences Manager, currently available at https://google.com/ads/preferences, or by vising NAI’s online resources at http://www.networkadvertising.org/choices.
+
+
+
+## Global privacy practices
+
+
+
+Information we collect will be stored and processed in the United States in accordance with this Privacy Policy but we understand that users from other countries may have different expectations and rights with regard to their privacy. For all Sourcegraph.com visitors, Website users, and self-hosted Sourcegraph users, no matter their country of location, we will:
+
+- provide clear methods of unambiguous, informed consent when we do collect your personal information;
+- only collect the minimum amount of personal data necessary for the purpose it is collected for, unless you choose to provide us more;
+- offer you simple methods of requesting access, correction, or deletion your information that we have collected, which we will make reasonable efforts to accommodate; and
+- provide Service users notice, choice, accountability, security, and access, and we limit the purpose for processing. We also provide our users a method of recourse and enforcement.
+
+If you are located in the European Union, you are entitled to the following rights with regard to your personal information and data:
+
+- Right of access to your personal data, to know what information about you we hold
+- Right to correct any incorrect or incomplete personal data about yourself that we hold
+- Right to restrict/suspend our processing of your personal data
+- Right to complain to a supervisory authority if you believe your privacy rights are being violated
+
+Additional rights that may apply to you in certain instances:
+
+- Right of data portability (if our processing is based on consent and automated means)
+- Right to withdraw consent at any time (if processing is based on consent)
+- Right to object to processing (if processing is based on legitimate interests)
+- Right to object to processing of personal data for direct marketing purposes
+- Right of erasure of your personal data from our system (“right to be forgotten”) if certain grounds are met
+
+To exercise your privacy rights, you can contact us directly at support@sourcegraph.com.
+
+
+
+## Your choices about your information
+
+
+
+**How to control your communications preferences:** You can stop receiving promotional email communications from us by clicking on the "unsubscribe link" provided in such communications. We make every effort to promptly process all unsubscribe requests. For as long as you are using our Services, you may not opt out of Service-related communications (e.g., account verification, changes/updates to our products or features of the Service, technical, and security notices).
+
+**Modifying or deleting your information:** If you already have an account on the Website, you may access, update, alter, or delete your basic user profile information by logging into your account and updating profile settings.
+
+Sourcegraph will retain your information for as long as your account is active or as needed to perform our contractual obligations, provide you services, to comply with legal obligations, resolve disputes, preserve legal rights, or enforce our agreements.
+
+We will delete inactive accounts and any personal information in them after a period of eighteen (18) months.
+
+If you have any questions about reviewing, modifying or deleting your account information, you can contact us directly at support@sourcegraph.com.
+
+
+
+## How we store and protect your information
+
+
+
+**Storage and processing:** Your information collected through the Service may be stored and processed in the United States or any other country in which Sourcegraph or its subsidiaries, affiliates or service providers maintain facilities. If you are located in the European Union or other regions with laws governing data collection and use that may differ from U.S. law, please note that we may transfer information, including personal information, to a country and jurisdiction that does not have the same data protection laws as your jurisdiction, and you consent to the transfer of information to the U.S. or any other country in which Sourcegraph or its parent, subsidiaries, affiliates or service providers maintain facilities and the use and disclosure of information about you as described in this Privacy Policy.
+
+**Keeping your information safe:** Sourcegraph cares about the security of your information, and uses commercially reasonable physical, administrative, and technological safeguards to preserve the integrity and security of all information collected through the Service. However, no security system is impenetrable and we cannot guarantee the security of our systems 100%. In the event that any information under our control is compromised as a result of a breach of security, Sourcegraph will take reasonable steps to investigate the situation and where appropriate, notify those individuals whose information may have been compromised and take other steps, in accordance with any applicable laws and regulations.
+
+
+
+## Usage data
+
+
+
+Sourcegraph's collection, storage, and use of Usage Data, and our responsibilities with respect to such Usage Data, are set forth in our Terms of Service and are not covered by this Privacy Policy.
+
+
+
+## Children's privacy
+
+
+
+Sourcegraph does not knowingly collect or solicit any information from anyone under the age of 13 or knowingly allow such persons to register as Users. If you are based in the European Union, we will not knowingly collect your information if you are under the age of 16. In the event that we learn that we have collected personal information from a child under age 13, we will delete that information as quickly as possible. If you believe that we might have any information from a child under 13 or child in the European Union under 16, please contact us at support@sourcegraph.com.
+
+
+
+## Links to other web sites and services
+
+
+
+Our Service may integrate with or contain links to other third-party sites and services. We are not responsible for the practices employed by third-party websites or services embedded in, linked to, or linked from the Service and your interactions with any third-party website or service are subject to that third-party's own rules and policies.
+
+
+
+## How to contact us
+
+
+
+If you have any questions about this Privacy Policy or the Service, please contact us at support@sourcegraph.com.
+
+
+
+## Changes to our privacy policy
+
+
+
+Sourcegraph may modify or update this Privacy Policy from time to time to reflect the changes in our business and practices. When we do so, we will revise the "last modified" date at the top of this page.
diff --git a/content/terms/archives/self-hosted/2021-06-24.md b/content/terms/archives/self-hosted/2021-06-24.md
index bbd7b299..aab3e921 100644
--- a/content/terms/archives/self-hosted/2021-06-24.md
+++ b/content/terms/archives/self-hosted/2021-06-24.md
@@ -18,13 +18,13 @@ Are you interested in terms for...
- **A self-hosted Sourcegraph instance**: You're in the right place! Read on.
-- **[Sourcegraph.com](https://about.sourcegraph.com/terms-dotcom)**: If you’d like to use Sourcegraph.com (the public Sourcegraph instance that can be used to search, navigate, and analyze public code) rather than a self-hosted instance, or if you’d like to use any products (e.g. browser or editor extensions) developed and distributed by us for use with sourcegraph.com, please see our Sourcegraph.com terms and conditions at https://about.sourcegraph.com/terms-dotcom.
+- **[Sourcegraph.com](/terms/cloud)**: If you’d like to use Sourcegraph.com (the public Sourcegraph instance that can be used to search, navigate, and analyze public code) rather than a self-hosted instance, or if you’d like to use any products (e.g. browser or editor extensions) developed and distributed by us for use with sourcegraph.com, please see our Sourcegraph.com terms and conditions at https://about.sourcegraph.com/terms-dotcom.
- **[Sourcegraph OSS](https://github.com/sourcegraph/sourcegraph/blob/master/LICENSE.apache)**: It is possible to run a version of Sourcegraph without some Enterprise features from our open source code available at https://github.com/sourcegraph/sourcegraph. If you want to follow the instructions there to build and run Sourcegraph OSS from source, please see the open source license (Apache 2.0) at https://github.com/sourcegraph/sourcegraph/blob/master/LICENSE.apache.
- **Sourcegraph extensions**: If you’d like to use any extensions made available via our [Extension Registry](https://sourcegraph.com/extensions), please understand that extensions made available by third-parties are not provided by us and are generally governed by separate terms and conditions. Extensions that are developed and distributed by us are governed by these terms and conditions.
-- **[Government](https://about.sourcegraph.com/terms-gov)**: Certain features of our software may have their own terms and conditions that you must agree to when you sign up for that particular feature. As an example, if you’re using our software as an employee or contractor of the U.S. Government, our Supplemental Terms for U.S. Government Users at https://about.sourcegraph.com/terms-gov apply. Those terms and conditions supplement these terms and conditions.
+- **[Government](/terms/gov)**: Certain features of our software may have their own terms and conditions that you must agree to when you sign up for that particular feature. As an example, if you’re using our software as an employee or contractor of the U.S. Government, our Supplemental Terms for U.S. Government Users at https://about.sourcegraph.com/terms-gov apply. Those terms and conditions supplement these terms and conditions.
PLEASE READ THESE TERMS CAREFULLY TO ENSURE YOUR UNDERSTANDING OF EACH PROVISION. THE AGREEMENT CONTAINS A MANDATORY INDIVIDUAL ARBITRATION AND CLASS ACTION/JURY TRIAL WAIVER PROVISION THAT REQUIRES THE USE OF ARBITRATION ON AN INDIVIDUAL BASIS TO RESOLVE DISPUTES, RATHER THAN JURY TRIALS OR CLASS ACTIONS.
diff --git a/content/terms/archives/self-hosted/2021-08-25.md b/content/terms/archives/self-hosted/2021-08-25.md
index 3de2bd02..d5237972 100644
--- a/content/terms/archives/self-hosted/2021-08-25.md
+++ b/content/terms/archives/self-hosted/2021-08-25.md
@@ -20,13 +20,13 @@ Are you interested in terms for...
- **A self-hosted Sourcegraph instance**: You're in the right place! Read on.
-- **[Sourcegraph.com](https://about.sourcegraph.com/terms-dotcom)**: If you’d like to use Sourcegraph.com (the public Sourcegraph instance that can be used to search, navigate, and analyze public code) rather than a self-hosted instance, or if you’d like to use any products (e.g. browser or editor extensions) developed and distributed by us for use with sourcegraph.com, please see our Sourcegraph.com terms and conditions at https://about.sourcegraph.com/terms-dotcom.
+- **[Sourcegraph.com](/terms/cloud)**: If you’d like to use Sourcegraph.com (the public Sourcegraph instance that can be used to search, navigate, and analyze public code) rather than a self-hosted instance, or if you’d like to use any products (e.g. browser or editor extensions) developed and distributed by us for use with sourcegraph.com, please see our Sourcegraph.com terms and conditions at https://about.sourcegraph.com/terms-dotcom.
- **[Sourcegraph OSS](https://github.com/sourcegraph/sourcegraph/blob/master/LICENSE.apache)**: It is possible to run a version of Sourcegraph without some Enterprise features from our open source code available at https://github.com/sourcegraph/sourcegraph. If you want to follow the instructions there to build and run Sourcegraph OSS from source, please see the open source license (Apache 2.0) at https://github.com/sourcegraph/sourcegraph/blob/master/LICENSE.apache.
- **Sourcegraph extensions**: If you’d like to use any extensions made available via our [Extension Registry](https://sourcegraph.com/extensions), please understand that extensions made available by third-parties are not provided by us and are generally governed by separate terms and conditions. Extensions that are developed and distributed by us are governed by these terms and conditions.
-- **[Government](https://about.sourcegraph.com/terms-gov)**: Certain features of our software may have their own terms and conditions that you must agree to when you sign up for that particular feature. As an example, if you’re using our software as an employee or contractor of the U.S. Government, our Supplemental Terms for U.S. Government Users at https://about.sourcegraph.com/terms-gov apply. Those terms and conditions supplement these terms and conditions.
+- **[Government](/terms/gov)**: Certain features of our software may have their own terms and conditions that you must agree to when you sign up for that particular feature. As an example, if you’re using our software as an employee or contractor of the U.S. Government, our Supplemental Terms for U.S. Government Users at https://about.sourcegraph.com/terms-gov apply. Those terms and conditions supplement these terms and conditions.
PLEASE READ THESE TERMS CAREFULLY TO ENSURE YOUR UNDERSTANDING OF EACH PROVISION. THE AGREEMENT CONTAINS A MANDATORY INDIVIDUAL ARBITRATION AND CLASS ACTION/JURY TRIAL WAIVER PROVISION THAT REQUIRES THE USE OF ARBITRATION ON AN INDIVIDUAL BASIS TO RESOLVE DISPUTES, RATHER THAN JURY TRIALS OR CLASS ACTIONS.
diff --git a/content/terms/archives/self-hosted/2021-10-11.md b/content/terms/archives/self-hosted/2021-10-11.md
index 511152cb..14a59f76 100644
--- a/content/terms/archives/self-hosted/2021-10-11.md
+++ b/content/terms/archives/self-hosted/2021-10-11.md
@@ -20,13 +20,13 @@ Are you interested in terms for...
- **A self-hosted Sourcegraph instance**: You're in the right place! Read on.
-- **[Sourcegraph.com](https://about.sourcegraph.com/terms-dotcom)**: If you’d like to use Sourcegraph.com (the public Sourcegraph instance that can be used to search, navigate, and analyze public code) rather than a self-hosted instance, or if you’d like to use any products (e.g. browser or editor extensions) developed and distributed by us for use with sourcegraph.com, please see our Sourcegraph.com terms and conditions at https://about.sourcegraph.com/terms-dotcom.
+- **[Sourcegraph.com](/terms/cloud)**: If you’d like to use Sourcegraph.com (the public Sourcegraph instance that can be used to search, navigate, and analyze public code) rather than a self-hosted instance, or if you’d like to use any products (e.g. browser or editor extensions) developed and distributed by us for use with sourcegraph.com, please see our Sourcegraph.com terms and conditions at https://about.sourcegraph.com/terms-dotcom.
- **[Sourcegraph OSS](https://github.com/sourcegraph/sourcegraph/blob/master/LICENSE.apache)**: It is possible to run a version of Sourcegraph without some Enterprise features from our open source code available at https://github.com/sourcegraph/sourcegraph. If you want to follow the instructions there to build and run Sourcegraph OSS from source, please see the open source license (Apache 2.0) at https://github.com/sourcegraph/sourcegraph/blob/master/LICENSE.apache.
- **Sourcegraph extensions**: If you’d like to use any extensions made available via our [Extension Registry](https://sourcegraph.com/extensions), please understand that extensions made available by third-parties are not provided by us and are generally governed by separate terms and conditions. Extensions that are developed and distributed by us are governed by these terms and conditions.
-- **[Government](https://about.sourcegraph.com/terms-gov)**: Certain features of our software may have their own terms and conditions that you must agree to when you sign up for that particular feature. As an example, if you’re using our software as an employee or contractor of the U.S. Government, our Supplemental Terms for U.S. Government Users at https://about.sourcegraph.com/terms-gov apply. Those terms and conditions supplement these terms and conditions.
+- **[Government](/terms/gov)**: Certain features of our software may have their own terms and conditions that you must agree to when you sign up for that particular feature. As an example, if you’re using our software as an employee or contractor of the U.S. Government, our Supplemental Terms for U.S. Government Users at https://about.sourcegraph.com/terms-gov apply. Those terms and conditions supplement these terms and conditions.
PLEASE READ THESE TERMS CAREFULLY TO ENSURE YOUR UNDERSTANDING OF EACH PROVISION. THE AGREEMENT CONTAINS A MANDATORY INDIVIDUAL ARBITRATION AND CLASS ACTION/JURY TRIAL WAIVER PROVISION THAT REQUIRES THE USE OF ARBITRATION ON AN INDIVIDUAL BASIS TO RESOLVE DISPUTES, RATHER THAN JURY TRIALS OR CLASS ACTIONS.
diff --git a/content/terms/archives/self-hosted/2022-02-10.md b/content/terms/archives/self-hosted/2022-02-10.md
new file mode 100644
index 00000000..94c36057
--- /dev/null
+++ b/content/terms/archives/self-hosted/2022-02-10.md
@@ -0,0 +1,320 @@
+---
+layout: markdown
+title: Terms of Service for Self-hosted Sourcegraph Instances (Archived)
+---
+
+Last modified: February 10, 2022
+
+See the [changes](https://sourcegraph.com/search?q=context:global+repo:%5Egithub%5C.com/sourcegraph/about%24+file:%5Edocs/terms-self-hosted%5C.md+type:diff&patternType=literal) since the [previous version](https://about.sourcegraph.com/archives/terms-self-hosted/2021-10-11/) or visit our [archives](https://github.com/sourcegraph/about/tree/main/docs/archives).
+
+Thank you for using Sourcegraph! This page lays out the basic terms and conditions that apply to your use of self-hosted Sourcegraph instances.
+
+
+
+
+
+## Is this the right Terms of Service for me?
+
+
+
+Are you interested in terms for...
+
+- **A self-hosted Sourcegraph instance**: You're in the right place! Read on.
+
+- **[Sourcegraph Cloud](/terms/cloud)**: If you’d like to use Sourcegraph Cloud (the public Sourcegraph instance that can be used to search, navigate, and analyze public code) rather than a self-hosted instance, or if you’d like to use any products (e.g. browser or editor extensions) developed and distributed by us for use with Sourcegraph Cloud, please see our Sourcegraph Cloud terms and conditions at https://about.sourcegraph.com/terms-cloud.
+
+- **[Sourcegraph OSS](https://github.com/sourcegraph/sourcegraph/blob/master/LICENSE.apache)**: It is possible to run a version of Sourcegraph without some Enterprise features from our open source code available at https://github.com/sourcegraph/sourcegraph. If you want to follow the instructions there to build and run Sourcegraph OSS from source, please see the open source license (Apache 2.0) at https://github.com/sourcegraph/sourcegraph/blob/master/LICENSE.apache.
+
+- **Sourcegraph extensions**: If you’d like to use any extensions made available via our [Extension Registry](https://sourcegraph.com/extensions), please understand that extensions made available by third-parties are not provided by us and are generally governed by separate terms and conditions. Extensions that are developed and distributed by us are governed by these terms and conditions.
+
+- **[Government](/terms/gov)**: Certain features of our software may have their own terms and conditions that you must agree to when you sign up for that particular feature. As an example, if you’re using our software as an employee or contractor of the U.S. Government, our Supplemental Terms for U.S. Government Users at https://about.sourcegraph.com/terms-gov apply. Those terms and conditions supplement these terms and conditions.
+
+
+PLEASE READ THESE TERMS CAREFULLY TO ENSURE YOUR UNDERSTANDING OF EACH PROVISION. THE AGREEMENT CONTAINS A MANDATORY INDIVIDUAL ARBITRATION AND CLASS ACTION/JURY TRIAL WAIVER PROVISION THAT REQUIRES THE USE OF ARBITRATION ON AN INDIVIDUAL BASIS TO RESOLVE DISPUTES, RATHER THAN JURY TRIALS OR CLASS ACTIONS.
+
+
+
+## 0. Table of contents
+
+
+
+| Section | Description |
+| ------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------- |
+| 1. [Definitions](#1-Definitions) | Definitions of specific terms used on this page |
+| 2. [Account terms](#2-Account-terms) | Your responsibilities to use Sourcegraph |
+| 3. [Acceptable use](#3-Acceptable-use) | Acceptable use of Sourcegraph |
+| 4. [Usage data](#4-Usage-data) | Aggregate and high-level data we collect from self-hosted Sourcegraph instances |
+| 5. [Data protection](#5-Data-protection) | Our policies for protecting your data |
+| 6. [Confidentiality](#6-Confidentiality) | Our mutual responsibilities to protect confidential data |
+| 7. [Term; termination](#7-Term-termination) | When and how your account can be terminated |
+| 8. [Fees](#8-Fees) | Rules for payment for paid and Enterprise features |
+| 9. [Third party services and software](#9-Third-party-services-and-software) | Our use of third party services and software |
+| 10. [Warranties; disclaimer](#10-Warranties-disclaimer) | Our warranties about Sourcegraph |
+| 11. [Limitation of liability](#11-Limitation-of-liability) | Our liabilities are limited |
+| 12. [Indemnification](#12-Indemnification) | The parties’ respective indemnification obligations |
+| 13. [Export controls](#13-Export-controls) | Usage restrictions in embargoed locations |
+| 14. [Governing law; arbitration; and class action/jury trial waiver](#14-Governing-law-arbitration-and-class-actionjury-trial-waiver) | Where and how disputes would be handled |
+| 15. [Miscellaneous](#15-Miscellaneous) | Miscellaneous topics |
+
+
+
+
+## 1. Definitions
+
+
+
+As used on this page, the following terms have the following specific meanings:
+
+1.1 **“Agreement”** means, collectively, the terms and conditions laid out on this page (these **“Terms”**), along with any order for Software (**“Order Form”**) and all other applicable rules, policies, and procedures that we may publish from time to time on the Site, including but not limited to our [Privacy Policy](/terms/privacy).
+
+1.2 **“Content”** means any content made available through the Software, including but not limited to text (including Documentation), data, articles, images, photographs, videos, applications, software (including source code), and other materials, as well as the Software itself (with respect to us).
+
+1.3 **“Documentation”** means the documentation regarding the Software that we make available for use at https://docs.sourcegraph.com.
+
+1.4 **“Instance”** means the self-hosted instance of the Software that you create or use in order to analyze Your Code.
+
+1.5 **“Site”** means our website located at sourcegraph.com, and all content, services, and products provided by us at or through the Site (or any subdomain or successor site).
+
+1.6 **“Software”** means, collectively, the software provided by us for download via the Site and for installation on your equipment, including but not limited to the self-hosted Sourcegraph software and our browser and editor extensions (to the extent exclusively connected to a self-hosted instance).
+
+1.7 **“Sourcegraph”**, **“we”**, or **“us”** refers to Sourcegraph, Inc., as well as its affiliates.
+
+1.8 **“You”** refers to the individual person, company, or organization that has visited or is using the Software, that accesses an Instance, or that directs the use of the Instance. If you’re entering into the Agreement on behalf of your company or organization (your **“Organization”**), you represent and warrant that you’re authorized to bind that company or organization to the Agreement and that you've read, understood, and agree to be bound by the Agreement on that company or organization’s behalf.
+
+1.9 **“Your Code”** means the source code and all source code metadata (e.g. version control system (VCS) data) that you analyze via the Software.
+
+
+
+## 2. Account terms
+
+
+
+**Short version**: You – or the organization you work for – is responsible for your instance and its security, as well as everything posted on it. You must be 18 or over to use our services.
+
+2.1 **Account Responsibility and Security.**
+
+1. **Generally**. If you’re entering into the Agreement on behalf of your Organization, your Organization has administrative control of all Instances tied to the Organization. You are or your Organization is fully responsible for your Instance and all Content posted under it.
+
+2. **Age Limitation**. In order to create an Instance, you must be at least eighteen (18) years old and we do not permit any users under thirteen (13) years old to use our Software for any purpose. If we discover that an Instance is being used by a user under thirteen (13) years old, we will notify you that the Instance must immediately be shut down.
+
+3. **Security**. You’re responsible for the security of your Instance when using our Software. While we may offer tools to help you maintain your Instance’s security, these are not guaranteed to work. You’re responsible for all Content posted on your Instance under your user account, even if you didn't post it. We have no liability of any kind for any loss or damage from your failure to secure your Instance.
+
+
+
+## 3. Acceptable use
+
+
+
+**Short version**: You’re allowed to use Sourcegraph for any reasonable purposes (e.g., don’t try to re-sell it, don’t violate your license, etc.). If you post any comments or other content, you’re responsible for it, and we have the right to display it to other users per your settings. If you give us a great idea about how to improve our services, we can use it.
+
+3.1 **License from Us to You**. The source code for our Software is publicly available at https://github.com/sourcegraph. Your rights to access and use that code is covered by the software license in that repository.
+
+3.2 **Restrictions**. You may not, and may not permit any third-party to:
+
+1. redistribute, encumber, sell, rent, lease, sublicense, or otherwise transfer rights to all or any part of the Software;
+
+2. permit a number of users of the Software more than permitted by us;
+
+3. use the Software to analyze any source code or other Content that is not Your Code; or
+
+4. use any release of the Software that is more than three (3) versions older than the then-most-current release of the Software.
+
+3.3 **No Sensitive Data**. You acknowledge and agree that, (i) the Software is not designed to store Sensitive Data (as defined below), and (ii) you will not use the Software to store Sensitive Data. “Sensitive Data” means: (i) special categories of data enumerated in European Union Regulation 2016/679, Article 9(1) or any successor legislation; (ii) protected health information as defined in HIPAA; (iii) payment cardholder information or financial account information, including bank account numbers or other personally identifiable financial information; (iv) social security numbers, driver’s license numbers, or other government identification numbers; (v) other information subject to regulation or protection under specific laws such as the Children’s Online Privacy Protection Act or Gramm-Leach-Bliley Act (“GLBA”) or related rules or regulations; or (vi) any data similar to the above protected under applicable laws. You acknowledge that the Software and related features are not intended to meet any legal obligations for these uses, including HIPAA and GLBA requirements and that we are not a Business Associate as defined under HIPAA. Therefore, notwithstanding anything else in this Agreement, we have no liability for Sensitive Data processed in connection with your use of the Software.
+
+3.4 **Ownership of the Software**. The Software is owned and operated by Sourcegraph. All Content made available via the Software is owned by us or our licensors and is protected by intellectual property and other applicable laws. All of our trademarks, service marks, and trade names are proprietary to us or our affiliates.
+
+3.5 **Ideas**. You may submit comments or ideas about the Software, such as how to improve it. By submitting a comment or idea, you agree that your disclosure is gratuitous, unsolicited and without restriction and will not place us under any fiduciary or other obligation, and that we are free to use the comment or idea without any additional compensation to you. By acceptance of your submission, we do not waive any rights to use similar ideas we already had or obtained from other sources.
+
+3.6 **Extensions**. As described above, certain features of the Software may allow you to download software packages from the Extension Registry. These packages may be offered by us or by third-party providers. Packages made available by third-party providers are subject to separate terms and conditions and are not governed by these Terms.
+
+3.7 **Beta Software**. We may make beta and experimental products, features, and Documentation available to you on an early access basis (“Beta Software”). Beta Software is not generally available and may contain bugs, defects, and errors. We provide Beta Software “as is,” without warranties, and may discontinue the Beta Software at any time. Our service level agreements do not apply to Beta Software. If and when the Beta Software becomes generally available, you will have the option to pay for the software or discontinue its use. We may use your feedback about Beta Software.
+
+
+
+## 4. Usage data
+
+
+
+**Short version**: We have the right to collect aggregate and high-level data from self-hosted Sourcegraph instances, as described in our [Privacy Policy](/terms/privacy) and specifically listed in our [product documentation](https://docs.sourcegraph.com/admin/pings).
+
+We may collect data derived from your use of the Software (**“Usage Data”**). A specific list of Usage Data that we receive from self-hosted instances is always available in our [Documentation](https://docs.sourcegraph.com/admin/pings) and in the site-admin area on your Instance. You acknowledge and agree that Usage Data is owned solely and exclusively by us, and that we may use it for any legal purpose, including for purposes of operating, analyzing, improving, or marketing our products.
+
+If we share or publicly disclose any information constituting or derived from Usage Data (e.g., in marketing materials), we will aggregate or anonymize that information to avoid identification.
+
+
+
+## 5. Data protection
+
+
+
+**Short version**: Our privacy policy tells you what you need to know about how we use any personal information you provide to us. The internet is a dangerous place and, while we’ve instituted safeguards to protect your information, you understand that data breaches happen and we can’t guarantee perfect security.
+
+Data security and user privacy are very, VERY important to us. Please read our [Privacy Policy](/terms/privacy) carefully for details relating to how we collect, use, and disclose personal information you provide to us in connection with your use of the Software.
+
+As the Software is provided in the form of a self-hosted Instance, Sourcegraph will not have access to any of Your Code unless you include Your Code via email or other support channels to Sourcegraph. We have implemented, and the Software contains, commercially reasonable technical and organizational measures designed to secure Your Code and any other information you provide that is stored on your Instance (which we do not have access to), and any information that we do have access to (such as support emails you send to us, Usage Data, etc.), from accidental loss and from unauthorized access, use, alteration or disclosure. However, we cannot guarantee that unauthorized third parties will never be able to defeat those measures or use your information for improper purposes. You understand that internet technologies have the inherent potential for disclosure. You acknowledge that you store sensitive information on your Instance, or provide any sensitive information to us at your own risk.
+
+
+
+## 6. Confidentiality
+
+
+
+**Short version**: We will each protect the other party’s confidential information.
+
+6.1 **Definition**. **"Confidential Information"** means all non-public information disclosed by us to you, or vice-versa, that is designated by the discloser as confidential or that reasonably should be considered confidential given the nature of the information or circumstances of its disclosure.
+
+6.2 **Exclusions.** Confidential Information does not include any information that
+
+1. was or becomes publicly known through no fault of the receiving party;
+
+2. was rightfully known or becomes rightfully known to the receiving party without confidential restriction from a third-party that has a right to disclose it;
+
+3. is approved by the disclosing party for disclosure without restriction in a written document or electronic record; or
+
+4. the receiving party independently develops without access to or use of the other party's Confidential Information.
+
+6.3 **Restrictions on Use and Disclosure**. Neither party will use the other party's Confidential Information except as permitted under this Agreement. Each party agrees to maintain in confidence and protect the other party's Confidential Information using at least the same degree of care as it uses for its own information of a similar nature, but in any event at least a reasonable degree of care. Each party agrees to take all reasonable precautions to prevent any unauthorized disclosure of the other party's Confidential Information, including, without limitation, disclosing such Confidential Information only to its employees, independent contractors, consultants, and legal and financial advisors (collectively, **"Representatives"**) who (i) have a need to know such information, and (ii) are subject to confidentiality obligations at least as protective of the Confidential Information as the terms of this Agreement. Each party is responsible for all acts and omissions of its Representatives. The foregoing obligations will not restrict either party from disclosing Confidential Information of the other party if required by any governmental body, so long as, to the extent allowed under applicable law, the party required to make the disclosure gives reasonable notice to the other party to enable it to contest the requirement. The restrictions set forth in this Section will survive the termination or expiration of this Agreement.
+
+
+
+## 7. Term; Termination
+
+
+
+**Short version**: You may shut down your instance any time. We may terminate the agreement at any time, at which point your right to use the software will immediately expire.
+
+7.1 **Subscription Period**. Unless otherwise stated in an Order Form, this Agreement starts on the earlier of the date on which you: (a) agree to the terms and conditions of this Agreement; or (b) first set up an Instance and will continue in effect until either you or we terminate it (the **“Subscription Period”**).
+
+7.2 **Termination for Breach**. If a party fails to cure a material breach of the Agreement within thirty (30) days after receiving written notice of breach, the other party may then terminate the Agreement within the following thirty (30) days. We will refund you any prepaid, unused fees.
+
+7.3 **Termination for Convenience**. Either party may terminate this Agreement, for any reason or for no reason, provided that you are responsible for all prepaid fees and fees you commit to in an Order Form. If we terminate the Agreement under this section, we will refund you for all prepaid fees for the remainder of the Subscription Period.
+
+7.4 **Effect of Termination; Survival**. Upon termination of this Agreement, you may no longer use the Software, and if any fees were owed prior to termination, you must pay those fees immediately. Any provisions of this Agreement that, by their terms or their nature, should survive the termination of this Agreement shall so survive. For purposes of clarity, your right to use the Software will not survive any termination of this Agreement.
+
+
+
+## 8. Fees
+
+
+
+**Short version**: You’re responsible for any fees associated with your use of Sourcegraph. Your subscription will automatically renew, unless an Order Form states otherwise.
+
+8.1 **Pricing**. You are responsible for paying any applicable fees as set forth on our [Pricing and Payment Terms](/pricing) or in an Order Form and applicable taxes associated with the Software in a timely manner with a valid payment method. Unless otherwise stated in an Order Form, you will pay all invoices within thirty (30) days of receipt. You agree that we may charge for any such fees owed. You are required to keep your billing information current.
+
+8.2 **Term**. Authorization to charge your chosen payment method account will remain in effect until you cancel or modify your preference. You agree that charges may be accumulated as incurred and may be submitted as one or more aggregate charges during or at the end of the applicable billing cycle.
+
+8.3 **Responsibility for Charges**. You are responsible for all charges incurred by usage of your Instance (whether made by you or anyone who may use your Instance, such as your co-workers, colleagues, team-members, etc.). If your payment method fails or you are past due on amounts owed, we may collect fees owed using other collection mechanisms. You are also responsible for paying any governmental taxes imposed on your use of the Software, including, but not limited to, sales, use, or value-added taxes.
+
+8.4 **No Refunds**. All fees and charges are earned upon receipt by us and are nonrefundable unless negotiated otherwise, except (a) as expressly set forth herein, and/or (b) as required by applicable law.
+
+8.5 **Renewals**. Unless otherwise stated in an Order Form, your subscription will be automatically renew for one (1) year terms at the then-current fees and your credit card account (or other payment method account) will be charged without further authorization from you, absent sixty (60) day written notice of non-renewal prior to the end of your current subscription term.
+
+
+
+## 9. Third party services and software
+
+
+
+**Short version**: Third party services and software may be necessary for Sourcegraph to work (examples include libraries Sourcegraph uses internally, code hosts, authentication providers, external code analyzers, monitoring and tracing tools, etc.). We’re not responsible for anything provided by a third party, and additional terms and conditions may apply.
+
+You may enable the Software to call the servers of other websites or services (**“Third Party Services”**) in order to help you analyze Your Code. We do not share Your Code with third-party services, unless you enable the integration or extension. We make no warranties of any kind with regard to anything that is contained on or accessible through them. Access and use of Third Party Services is solely at your own risk.
+
+The Software may contain copyrighted software of our licensors (**“Third Party Software”**). The licensors retain all right, title, and interest in and to such Third Party Software and all copies thereof. Your use of any Third Party Software is subject to the terms and conditions of this Agreement, and any other terms and conditions in any Third Party Software documentation or printed materials (including EULAs).
+
+If there's ever a conflict between the terms of this Agreement and the terms applicable to any Third Party Software, and the conflict relates to the use of that Third Party Software, their terms and conditions will govern the conflict.
+
+
+
+## 10. Warranties; disclaimer
+
+
+
+**Short version**: Other than the warranties explicitly set forth in this section, Sourcegraph is provided “as is” with no guarantees of any kind (unless applicable law provides you additional mandatory rights). Please read this section carefully.
+
+We warrant that (1) the Software will perform materially in accordance with the applicable Documentation when accessed and used as recommended in the Documentation and in accordance with the Agreement and (2) to the best of our knowledge, the Software is free from, and we will not knowingly introduce, software viruses, worms, Trojan horses or other code, files, scripts, or agents intended to do harm. Your sole and exclusive remedy for breach of the warranties in this section is set forth in Section 7.2.
+
+OTHER THAN THE WARRANTIES EXPLICITLY SET FORTH IN THIS SECTION 10, THE SOFTWARE, AND ANY OTHER SOFTWARE, APPLICATIONS, PRODUCTS, AND SOFTWARE MADE AVAILABLE ON OR IN CONNECTION WITH THE SOFTWARE ARE PROVIDED ON AN “AS IS” AND “AS AVAILABLE” BASIS WITHOUT WARRANTIES OF ANY KIND, WHETHER EXPRESS, IMPLIED, OR OTHERWISE. WITHOUT LIMITING THE GENERALITY OF THE FOREGOING, TO THE FULLEST EXTENT PERMISSIBLE UNDER APPLICABLE LAW, SOURCEGRAPH DISCLAIMS, ON BEHALF OF ITSELF AND ITS LICENSORS, ALL WARRANTIES, WHETHER EXPRESS, IMPLIED, OR OTHERWISE, INCLUDING BUT NOT LIMITED TO ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, OR NONINFRINGEMENT. FURTHER, WE DO NOT WARRANT THAT THE SOFTWARE OR ANY PART THEREOF (OR YOUR ACCESS THERETO) WILL BE UNINTERRUPTED, ERROR-FREE, OR FREE FROM VIRUSES OR OTHER HARMFUL COMPONENTS, WILL MEET YOUR REQUIREMENTS, OR THAT DEFECTS WILL BE CORRECTED.
+
+CERTAIN JURISDICTIONS DO NOT ALLOW LIMITATIONS ON IMPLIED WARRANTIES OR THE EXCLUSION OR LIMITATION OF CERTAIN DAMAGES. IF THESE LAWS APPLY TO YOU, SOME OR ALL OF THE ABOVE DISCLAIMERS, EXCLUSIONS, OR LIMITATIONS MAY NOT APPLY TO YOU, AND YOU MAY HAVE ADDITIONAL RIGHTS AS PROVIDED BY LAW.
+
+
+
+## 11. Limitation of liability
+
+
+
+**Short version**: Each party's liability is limited to direct damages wherever possible, and to no more than $100 or the amount you paid us to access the software. Please read this section carefully.
+
+UNDER NO CIRCUMSTANCES WILL EITHER PARTY (OR ITS AFFILIATES, EMPLOYEES, AGENTS, LICENSORS, SUCCESSORS, OR ASSIGNS) BE LIABLE FOR ANY SPECIAL, INDIRECT, INCIDENTAL, CONSEQUENTIAL, PUNITIVE, RELIANCE, OR EXEMPLARY DAMAGES (INCLUDING WITHOUT LIMITATION LOSSES OR LIABILITY RESULTING FROM LOSS OF DATA, LOSS OF REVENUE, ANTICIPATED PROFITS, COST OF REPLACEMENT SOFTWARE, OR LOSS OF BUSINESS OPPORTUNITY) THAT RESULT FROM YOUR USE OR YOUR INABILITY TO USE THE SOFTWARE, OR ANY OTHER INTERACTIONS WITH US, EVEN IF WE OR A SOURCEGRAPH-AUTHORIZED REPRESENTATIVE HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
+
+APPLICABLE LAW MAY NOT ALLOW THE LIMITATION OR EXCLUSION OF LIABILITY FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES, SO THE ABOVE LIMITATION OR EXCLUSION MAY NOT APPLY TO YOU. IN SUCH CASES, OUR LIABILITY WILL BE LIMITED TO THE FULLEST EXTENT PERMITTED BY APPLICABLE LAW.
+
+IN NO EVENT WILL EACH PARTY'S (OR ITS AFFILIATES, EMPLOYEES, AGENTS, LICENSORS, SUCCESSORS, OR ASSIGNS’) TOTAL LIABILITY FOR ALL DAMAGES, LOSSES, AND CAUSES OF ACTION ARISING OUT OF OR RELATING TO THESE TERMS OR YOUR USE OF THE SOFTWARE, INCLUDING WITHOUT LIMITATION YOUR INTERACTIONS WITH OTHER USERS, (WHETHER IN CONTRACT, TORT INCLUDING NEGLIGENCE, WARRANTY, OR OTHERWISE) EXCEED THE AMOUNT PAID OR PAYABLE BY YOU, IF ANY, FOR THE SOFTWARE DURING THE TWELVE (12) MONTHS IMMEDIATELY PRECEDING THE EVENT THAT GAVE RISE TO THE CLAIM OR ONE HUNDRED DOLLARS ($100.00), WHICHEVER IS GREATER.
+
+You acknowledge and agree that we have offered our products and services, set our prices, and entered into the Agreement in reliance upon the disclaimers of warranty and the limitations of liability set forth herein, that the disclaimers of warranty and the limitations of liability set forth herein reflect a reasonable and fair allocation of risk between the parties (including the risk that a contract remedy may fail of its essential purpose and cause consequential loss), and that the disclaimers of warranty and the limitations of liability set forth herein form an essential basis of the bargain between you and us.
+
+
+
+## 12. Indemnification
+
+
+
+**Short version**: Each of us agrees to defend the other against third-party lawsuits that result from matters under our respective responsibility.
+
+12.1 **By You**. You agree to defend us and our affiliates, directors, officers, employees, and contractors from and against any third-party claims, proceedings, demands, and investigations and indemnify us for damages, attorney’s fees, and costs arising from Your Code or Content, your use of the Software in violation of the Agreement including any data or work transmitted or received by you, your violation of the Agreement or applicable laws, your infringement of any third-party intellectual property or other right of any person or entity, or any other party's access and use of the Software with your unique username, password, or other appropriate security code.
+
+12.2 **By Sourcegraph**. We agree to defend you and your affiliates, directors, officers, employees, and contractors from and against any third-party claims, proceedings, demands, and investigations and indemnify you for damages, attorney’s fees, and costs arising from your use of the Software or Documentation in accordance with this Agreement that infringes or misappropriates such third-party’s intellectual property rights, except for claims arising from (a) Your Code or Content, (b) your use of the Software in violation of the Agreement, or (c) any modification, combination, or development of the Software not performed by us.
+
+12.3 **Procedure**. Each party must give the other prompt written notice of any defense or indemnity sought and reasonable cooperation in the defense. The defending party will have sole control of the defense and settlement, provided that neither party may enter into a settlement placing any material obligation of any kind, including any admission of liability or payment of any amount, on the other party without the other party’s prior written approval, not to be unreasonably withheld, conditioned, or delayed.
+
+
+
+## 13. Export controls
+
+
+
+**Short version**: Don’t use our site or software if you’re located in an embargoed country.
+
+The Software and the underlying information and technology may not be downloaded or otherwise exported or re-exported (a) into (or to a national or resident of) any country to which the U.S. has embargoed goods; or (b) to anyone on the U.S. Treasury Department's list of Specially Designated Nationals or the U.S. Commerce Department's Table of Deny Orders. By downloading or using the Software, you are agreeing to the foregoing and you represent and warrant that you are not located in, under the control of, or a national or resident of any such country or on any such list and you agree to comply with all export laws and other applicable laws.
+
+
+
+## 14. Governing law; arbitration; and class action/jury trial waiver
+
+
+
+**Short version**: We’re based in California, so the agreement is governed by California law, and all disputes must be brought there. If you have a claim against us, you’ll work with us to arbitrate it on an individual basis instead of via class action or jury trial.
+
+14.1 **Governing Law**. The Agreement shall be governed by the internal substantive laws of the State of California, without respect to its conflict of laws principles. Notwithstanding the preceding sentence with respect to the substantive law, any arbitration conducted pursuant to the terms of these Terms shall be governed by the Federal Arbitration Act (9 U.S.C. §§ 1-16). The application of the United Nations Convention on Contracts for the International Sale of Goods is expressly excluded. You agree to submit to the personal jurisdiction of the federal and state courts located in Santa Clara County, California for any actions for which we retain the right to seek injunctive or other equitable relief in a court of competent jurisdiction to prevent the actual or threatened infringement, misappropriation or violation of a our copyrights, trademarks, trade secrets, patents, or other intellectual property or proprietary rights, as set forth in the Arbitration provision below, including any provisional relief required to prevent irreparable harm. You agree that Santa Clara County, California is the proper forum for any appeals of an arbitration award or for trial court proceedings if the arbitration provision below is found to be unenforceable.
+
+14.2 **Arbitration**. Read this section carefully because it requires the parties to arbitrate their disputes and limits the manner in which you can seek relief from us. For any dispute with us, you agree to first contact us at support@sourcegraph.com and attempt to resolve the dispute with us informally. In the unlikely event that we have not been able to resolve a dispute it has with you after sixty (60) days, we each agree to resolve any claim, dispute, or controversy (excluding any claims for injunctive or other equitable relief as provided below) arising out of or in connection with or relating to the Agreement, or the breach or alleged breach thereof, by binding arbitration by JAMS, under the Optional Expedited Arbitration Procedures then in effect for JAMS, except as provided herein. JAMS may be contacted at www.jamsadr.com. The arbitration will be conducted in Santa Clara County, California, unless we agree otherwise. If you are using the Software for commercial purposes, each party will be responsible for paying any JAMS filing, administrative and arbitrator fees in accordance with JAMS rules, and the award rendered by the arbitrator shall include costs of arbitration, reasonable attorneys' fees and reasonable costs for expert and other witnesses. Any judgment on the award rendered by the arbitrator may be entered in any court of competent jurisdiction. Nothing in this section shall be deemed as preventing us from seeking injunctive or other equitable relief from the courts as necessary to prevent the actual or threatened infringement, misappropriation, or violation of our data security, intellectual property or other proprietary rights.
+
+14.3 **Class Action/Jury Trial Waiver**. WITH RESPECT TO ALL PERSONS AND ENTITIES, REGARDLESS OF WHETHER THEY HAVE OBTAINED OR USED THE SOFTWARE FOR PERSONAL, COMMERCIAL OR OTHER PURPOSES, ALL CLAIMS MUST BE BROUGHT IN THE PARTIES' INDIVIDUAL CAPACITY, AND NOT AS A PLAINTIFF OR CLASS MEMBER IN ANY PURPORTED CLASS ACTION, COLLECTIVE ACTION, PRIVATE ATTORNEY GENERAL ACTION OR OTHER REPRESENTATIVE PROCEEDING. THIS WAIVER APPLIES TO CLASS ARBITRATION, AND, UNLESS WE AGREE OTHERWISE, THE ARBITRATOR MAY NOT CONSOLIDATE MORE THAN ONE PERSON'S CLAIMS. YOU AGREE THAT, BY ENTERING INTO THE AGREEMENT, WE ARE EACH WAIVING THE RIGHT TO A TRIAL BY JURY OR TO PARTICIPATE IN A CLASS ACTION, COLLECTIVE ACTION, PRIVATE ATTORNEY GENERAL ACTION, OR OTHER REPRESENTATIVE PROCEEDING OF ANY KIND.
+
+
+
+## 15. Miscellaneous
+
+
+
+15.1 **Notices and Electronic Communications**. We may provide you with (and you hereby consent to our provision of) notices, including those regarding changes to our terms and conditions, by email, regular mail, or postings on the Site. Notice will be deemed given twenty-four hours after email is sent, unless we’re notified that the email address is invalid. Notice posted on the Site is deemed given five (5) days following the initial posting. We reserve the right to determine the form and means of providing notifications to our users, provided that you may opt out of certain means of notification as described in the Agreement. We are not responsible for any automatic filtering you or your network provider may apply to email notifications we send to the email address you provide us.
+
+15.2 **Updates and Modifications**. We may update the Agreement (including these Terms) from time to time. When we change the Agreement (including these Terms) in a material manner, we will update the 'last modified' date at the top of this page and notify you that material changes have been made to the Agreement. Your continued use of the Software after any such change constitutes your acceptance of the new Terms of Service, unless you have signed an Order Form with us where the terms in effect as of your Order Date will apply. If you have purchased a subscription to use the Software, any change to these Terms will be effective with respect to such Software upon the renewal of your subscription, unless otherwise stated in an Order Form.
+
+15.3 **U.S. Government End Users**. The Software and Documentation were developed by private financing and constitute a "Commercial Item," as that term is defined at 48 C.F.R. § 2.101. The Software and Documentation consist of "Commercial Computer Software" and "Commercial Computer Software Documentation," as such terms are used in 48 C.F.R. § 12.212. Consistent with 48 C.F.R. § 12.212 and 48 C.F.R. §§ 227.7202-1 through 227.7202-4, all U.S. Government End Users acquire only those rights in the Software and the Documentation that are specifically provided by this Agreement. Consistent with 48 C.F.R. § 12.211, all U.S. Government End Users acquire only technical data and the rights in that data customarily as specifically provided in this Agreement.
+
+15.4 **Waiver**. A party's failure to exercise or enforce any right or provision of the Agreement will not constitute a waiver of such right or provision. Any waiver of any provision of the Agreement will be effective only if in writing and signed by the waiving party.
+
+15.5 **Severability**. If any provision of the Agreement is held to be unlawful, void, or for any reason unenforceable, then that provision will be limited or eliminated from the Agreement to the minimum extent necessary and will not affect the validity and enforceability of any remaining provisions; except that in the event of unenforceability of the universal Class Action/Jury Trial Waiver, the entire arbitration agreement shall be unenforceable.
+
+15.6 **Assignment**. The Agreement and any rights and licenses granted hereunder, may not be transferred or assigned by either party without written consent, except in connection with a merger, acquisition, reorganization, or sale of substantially all assets.
+
+15.7 **Survival**. Upon termination of the Agreement, any provision which, by its nature or express terms should survive, shall survive such termination or expiration.
+
+15.8 **Headings**. The heading references herein are for convenience only, do not constitute a part of the Agreement, and will not be deemed to limit or affect any of the provisions hereof.
+
+15.9. **Marketing and Publicity**. We may freely refer to your Organization and your relationship with us in connection with publicizing and marketing our products and services, including using your Organization’s name and logo to identify your Organization as a customer and using product testimonials and quotes your Organization’s representatives may provide to us.
+
+15.10 **Entire Agreement**. This, including the agreements incorporated by reference, constitutes the entire agreement between you and us relating to the subject matter herein and will not be modified except in writing, signed by both parties, or by a change made by us as set forth in the Agreement.
+
+15.11 **Disclosures**. The Software is offered by Sourcegraph, Inc., located at 548 Market St PMB 20739, San Francisco, CA 94104-5401, and can be reached via email at support@sourcegraph.com or telephone at (650) 318-3480. If you are a California resident, (a) you may have this same information emailed to you by sending a letter to the foregoing address with your email address and a request for this information; and (b) in accordance with Cal. Civ. Code § 1789.3, you may report complaints to the Complaint Assistance Unit of the Division of Consumer Services of the California Department of Consumer Affairs by contacting them in writing at 1625 North Market Blvd., Suite N 112 Sacramento, CA 95834, or by telephone at (800) 952-5210 or (916) 445-1254.
diff --git a/content/terms/archives/subprocessors/2022-12-03.md b/content/terms/archives/subprocessors/2022-12-03.md
new file mode 100644
index 00000000..d1a7c540
--- /dev/null
+++ b/content/terms/archives/subprocessors/2022-12-03.md
@@ -0,0 +1,36 @@
+---
+layout: markdown
+title: Sourcegraph Subprocessors (Archived)
+description: This page lists the subsprocessors that Sourcegraph may use
+---
+
+Last modified: December 3, 2021
+
+Sourcegraph, Inc. (“Sourcegraph”) uses certain third party sub-processors (“Sub-processors”) to assist in providing the Services described in the Sourcegraph Terms of Service available at [https://about.sourcegraph.com/terms/](https://about.sourcegraph.com/terms/) and/or as set forth in an applicable Order Form. Capitalized terms used but not otherwise defined herein shall have the meanings ascribed to them in the applicable Sourcegraph Terms of Service.
+
+Sourcegraph will update this page when engaging a new Sub-processor, and if you [subscribe for updates](#sign-up), Sourcegraph will notify you by email of changes to this page.
+
+Sourcegraph engages Sub-processors to perform the functions described in the table below. For Sourcegraph’s On Prem product, personal data will only be processed by Sub-processors to the extent such data is shared by Customer with Sourcegraph for the purpose of delivering support services.
+
+| Third-party Subprocessor | Location | Service Provided | Applicable product |
+| ------------------------ | -------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------ | -------------------------------------------------- |
+| Amazon Web Services | USA | Provides cloud hosting for Sourcegraph Cloud services | Sourcegraph Cloud Managed Instance |
+| Atlassian | Australia | Processes support tickets and tracks bugs | Sourcegraph Cloud Managed Instance On Prem |
+| Cloudflare | USA | Processes customer request data such as IP addresses to optimize security and performance of Sourcegraph Cloud | Sourcegraph Cloud Managed Instance |
+| GitHub | USA | Tracks customer support issues | Sourcegraph Cloud Managed Instance On Prem |
+| Google | USA | Provides cloud hosting for Sourcegraph managed instances and Sourcegraph Cloud (Google Cloud Platform) Processes customer support communication (G Suite) | Sourcegraph Cloud Managed Instance |
+| Grafana | USA | Processes customer logs | Sourcegraph Cloud Managed Instance |
+| Honeycomb | USA | Processes any information Customer sends for debugging purposes | Sourcegraph Cloud |
+| Incident.io | United Kingdom | Processes incidents | Sourcegraph Cloud Managed Instance On Prem |
+| Salesforce | USA | Processes customer support tickets | Sourcegraph Cloud Managed Instance On Prem |
+| Sentry | USA | Processes error data, which can include email addresses and other personal data, for debugging purposes | Sourcegraph Cloud Managed |
+| Slack Technologies | USA | Processes customer support communication | Sourcegraph Cloud Managed Instance On Prem |
+| Zapier | USA | Processes information needed to enable integrations between Sourcegraph and a third-party product | Sourcegraph Cloud Managed Instance On Prem |
+| Zendesk | USA | Processes customer support communication | Sourcegraph Cloud Managed Instance On Prem |
+
+
Sign Up
+
+Complete this form to be notified of changes to our sub-processors.
+
+
+
diff --git a/content/terms/cloud.md b/content/terms/cloud.md
index 6cb3550e..883c90ea 100644
--- a/content/terms/cloud.md
+++ b/content/terms/cloud.md
@@ -3,13 +3,14 @@ layout: markdown
title: Terms of Service for Sourcegraph Cloud
---
-Last modified: February 9, 2022
+Last modified: February 22, 2022
-See the [changes](https://sourcegraph.com/search?q=context:global+repo:%5Egithub%5C.com/sourcegraph/about%24+file:%5Edocs/terms-dotcom%5C.md+type:diff&patternType=literal) since the [previous version](/terms/archives/cloud/2021-12-09/) or visit our [archives](https://github.com/sourcegraph/about/tree/main/docs/archives).
+See the [changes](https://sourcegraph.com/search?q=context:global+repo:%5Egithub%5C.com/sourcegraph/about%24+file:%5Edocs/terms-dotcom%5C.md+type:diff&patternType=literal) since the [previous version](https://about.sourcegraph.com/archives/terms-cloud/2022-02-09/) or visit our [archives](https://github.com/sourcegraph/about/tree/main/docs/archives).
Thank you for using Sourcegraph! This page lays out the basic terms and conditions that apply to your use of Sourcegraph Cloud.
-
+
+
## Is this the right Terms of Service for me?
@@ -49,7 +50,7 @@ PLEASE READ THESE TERMS CAREFULLY TO ENSURE YOUR UNDERSTANDING OF EACH PROVISION
| 8. [Fees](#8-fees) | Rules for payment for paid features |
| 9. [Third party services and software](#9-third-party-services-and-software) | Our use of third party services and software |
| 10. [Copyright infringement and DMCA policy](#10-copyright-infringement-and-dmca-policy) | How we handle IP infringment |
-| 11. [Warranties; disclaimer](#11-no-warranties-disclaimer) | Our warranties about Sourcegraph |
+| 11. [Warranties; disclaimer](#11-warranties-disclaimer) | Our warranties about Sourcegraph |
| 12. [Limitation of liability](#12-limitation-of-liability) | Our liabilities are limited |
| 13. [Indemnification](#13-indemnification) | The parties’ respective indemnification obligations |
| 14. [Location of the Services; export controls](#14-location-of-the-services-export-controls) | Usage restrictions in embargoed locations |
@@ -91,7 +92,7 @@ As used on this page, the following terms have the following specific meanings:
-
**Short version**: You are responsible for your account and its security, as well as everything posted on it. You must be 18 or over to use our services.
+**Short version**: You are responsible for your account and its security, as well as everything posted on it. You must be 18 or over to use our services.
2.1 **Account Responsibility and Security.**
@@ -115,7 +116,7 @@ As used on this page, the following terms have the following specific meanings:
-
**Short version**: You’re allowed to use the services for any reasonable purpose (e.g. don’t use it to host illegal content). Because the services are made available on a hosted basis, we – like most sites – will collect data about your use of the services (e.g., click rates and other metadata) and can use it to run our business. If you give us a great idea about how to improve our services, we can use it.
+**Short version**: You’re allowed to use the services for any reasonable purpose (e.g. don’t use it to host illegal content). Because the services are made available on a hosted basis, we – like most sites – will collect data about your use of the services (e.g., click rates and other metadata) and can use it to run our business. If you give us a great idea about how to improve our services, we can use it.
3.1 **License from Us to You**.
@@ -156,7 +157,7 @@ As used on this page, the following terms have the following specific meanings:
-
**Short version**: We have the right to collect usage data from Sourcegraph, as described in our [Privacy Policy](/terms/privacy).
+**Short version**: We have the right to collect usage data from Sourcegraph, as described in our [Privacy Policy](/terms/privacy).
In the course of your use of the Services, we may collect certain information about your use, including aggregated data derived from you and other users’ access and use of the Services (**“Usage Data”**). You acknowledge and agree that Usage Data is owned solely and exclusively by us, and that we may use it for any legal purpose, including for purposes of operating, analyzing, improving, or marketing our products and services.
@@ -168,13 +169,13 @@ If we share or publicly disclose any information constituting or derived from Us
-
**Short version**: Our privacy policy tells you what you need to know about how we use any personal information you provide to us. The internet is a dangerous place and, while we’ve instituted safeguards to protect your information, you understand that data breaches happen and we can’t guarantee perfect security.
+**Short version**: Our privacy policy tells you what you need to know about how we use any personal information you provide to us. The internet is a dangerous place and, while we’ve instituted safeguards to protect your information, you understand that data breaches happen and we can’t guarantee perfect security.
User privacy is important to us. Please read our [Privacy Policy](/terms/privacy) carefully for details relating to how we collect, use, and disclose personal information you provide to us.
We have implemented commercially reasonable technical and organizational measures designed to secure information you provide us from accidental loss and from unauthorized access, use, alteration or disclosure. However, we cannot guarantee that unauthorized third parties will never be able to defeat those measures or use your information for improper purposes. You understand that internet technologies have the inherent potential for disclosure. You acknowledge that you provide any sensitive information to us at your own risk.
-If you are an Organization established in the European Economic Area, the United Kingdom or Switzerland, or otherwise obliged to comply with the General Data Protection Regulation, we will process any information relating to identified or identifiable natural persons in accordance with our [Data Processing Addendum](/dpa.pdf), which will be incorporated by reference into the terms of this Agreement.
+If you are an Organization established in the European Economic Area, the United Kingdom or Switzerland, or otherwise obliged to comply with the General Data Protection Regulation, we will process any information relating to identified or identifiable natural persons in accordance with our [Data Processing Addendum](/dpa), which will be incorporated by reference into the terms of this Agreement.
@@ -182,7 +183,7 @@ If you are an Organization established in the European Economic Area, the United
-
**Short version**: We will each protect the other party's confidential information.
+**Short version**: We will each protect the other party's confidential information.
6.1 **Definition**. **"Confidential Information"** means all non-public information disclosed by us to you, or vice-versa, that is designated by the discloser as confidential or that reasonably should be considered confidential given the nature of the information or circumstances of its disclosure.
@@ -193,7 +194,7 @@ If you are an Organization established in the European Economic Area, the United
3. is approved by the disclosing party for disclosure without restriction in a written document or electronic record; or
4. the receiving party independently develops without access to or use of the other party’s Confidential Information.
-6.3 **Restrictions on Use and Disclosure**. Neither party will use the other party’s Confidential Information except as permitted under this Agreement. Each party agrees to maintain in confidence and protect the other party’s Confidential Information using at least the same degree of care as it uses for its own information of a similar nature, but in any event at least a reasonable degree of care. Each party agrees to take all reasonable precautions to prevent any unauthorized disclosure of the other party’s Confidential Information, including, without limitation, disclosing such Confidential Information only to its employees, independent contractors, consultants, and legal and financial advisors (collectively, **“Representatives”**) who (i) have a need to know such information, and (ii) are subject to confidentiality obligations at least as protective of the Confidential Information as the terms of this Agreement. Each party is responsible for all acts and omissions of its Representatives. The foregoing obligations will not restrict either party from disclosing Confidential Information of the other party if required by any governmental body, so long as, to the extent allowed under applicable law, the party required to make the disclosure gives reasonable notice to the other party to enable it to contest the requirement. The restrictions set forth in this Section will survive the termination or expiration of this Agreement.
+6.3 **Restrictions on Use and Disclosure**. Neither party will use the other party’s Confidential Information except as permitted under this Agreement. Each party agrees to maintain in confidence and protect the other party’s Confidential Information using at least the same degree of care as it uses for its own information of a similar nature, but in any event at least a reasonable degree of care. Each party agrees to take all reasonable precautions to prevent any unauthorized disclosure of the other party’s Confidential Information, including, without limitation, disclosing such Confidential Information only to its employees, independent contractors, consultants, and legal and financial advisors (collectively, **“Representatives”**) who (i) have a need to know such information, and (ii) are subject to confidentiality obligations at least as protective of the Confidential Information as the terms of this Agreement. Each party is responsible for all acts and omissions of its Representatives. The foregoing obligations will not restrict either party from disclosing Confidential Information of the other party if required by any governmental body, so long as, to the extent allowed under applicable law, the party required to make the disclosure gives reasonable notice to the other party to enable it to contest the requirement. The restrictions set forth in this Section will survive the termination or expiration of this Agreement. The terms of this Section 6 supersede any non-disclosure or confidentiality agreement entered into by the parties prior to the effective date of this Agreement.
@@ -201,7 +202,7 @@ If you are an Organization established in the European Economic Area, the United
-
**Short version**: You may shut down your Account any time. We may terminate the agreement at any time, at which point your right to use the Services will immediately expire.
+**Short version**: You may shut down your Account any time. We may terminate the agreement at any time, at which point your right to use the Services will immediately expire.
7.1 **Subscription Period**. Unless otherwise stated in an Order Form, this Agreement starts on the earlier of the date on which you: (a) agree to the terms and conditions of this Agreement; or (b) first register for an Account and will continue in effect until either you or we terminate it (the “Subscription Period” or “Term”).
@@ -217,7 +218,7 @@ If you are an Organization established in the European Economic Area, the United
-
**Short version**: You’re responsible for any fees associated with your use of Sourcegraph. Your subscription will automatically renew, unless an Order Form states otherwise.
+**Short version**: You’re responsible for any fees associated with your use of Sourcegraph. Your subscription will automatically renew, unless an Order Form states otherwise.
8.1 **Pricing**. You are responsible for paying any applicable fees as set forth on our [Pricing and Payment Terms](/pricing) or in an Order Form and applicable taxes associated with the Services in a timely manner with a valid payment method. Unless otherwise stated in an Order Form, you will pay all invoices within thirty (30) days of receipt. You agree that we may charge for any such fees owed. You are required to keep your billing information current.
@@ -235,7 +236,7 @@ If you are an Organization established in the European Economic Area, the United
-
**Short version**: Third party services and software may be necessary for Sourcegraph Cloud to work (examples include libraries Sourcegraph uses internally, code hosts, authentication providers, external code analyzers, monitoring and tracing tools, etc.). We’re not responsible for anything provided by a third party, and additional terms and conditions may apply.
+**Short version**: Third party services and software may be necessary for Sourcegraph Cloud to work (examples include libraries Sourcegraph uses internally, code hosts, authentication providers, external code analyzers, monitoring and tracing tools, etc.). We’re not responsible for anything provided by a third party, and additional terms and conditions may apply.
You may enable the Services to call the servers of other websites or services (**“Third Party Services”**) in order to help you analyze Your Code. We do not share Your Code with third-party services, unless you enable the integration or extension. We make no warranties of any kind with regard to anything that is contained on or accessible through them. Access and use of Third Party Services is solely at your own risk.
@@ -249,7 +250,7 @@ If there's ever a conflict between the terms of this Agreement and the terms app
-
**Short version**: If you think we (or a user of the services) is infringing your copyrights, let us know and we’ll handle it in compliance with law.
+**Short version**: If you think we (or a user of the services) is infringing your copyrights, let us know and we’ll handle it in compliance with law.
We respect the intellectual property of others and ask that you do too. We reserve the right to delete or disable content alleged to be infringing and terminate accounts of repeat infringers. If you believe that your copyrighted work has been copied in a way that constitutes copyright infringement and is accessible via the Services, please notify our copyright agent as set forth in the DMCA. For your complaint to be valid under the DMCA, you must provide the following information in writing:
@@ -282,7 +283,7 @@ In accordance with the DMCA and other applicable law, we have adopted a policy o
-
**Short version**: Other than the warranties explicitly described in this Section, the Services and Code Data are provided “as is” with no guarantees of any kind (unless applicable law provides you additional mandatory rights). Please read this section carefully.
+**Short version**: Other than the warranties explicitly described in this Section, the Services and Code Data are provided “as is” with no guarantees of any kind (unless applicable law provides you additional mandatory rights). Please read this section carefully.
We warrant that (1) the Services will perform materially in accordance with the applicable Documentation when accessed and used as recommended in the Documentation and in accordance with the Agreement and (2) to the best of our knowledge, the Services are free from, and we will not knowingly introduce, software viruses, worms, Trojan horses or other code, files, scripts, or agents intended to do harm. Your sole and exclusive remedy for breach of the warranties in this section is set forth in Section 7.2.
@@ -296,7 +297,7 @@ CERTAIN JURISDICTIONS DO NOT ALLOW LIMITATIONS ON IMPLIED WARRANTIES OR THE EXCL
-
**Short version**: Our liability is limited to direct damages wherever possible, and to no more than $100 or the amount you paid us for access to the services. Please read this section carefully.
+**Short version**: Our liability is limited to direct damages wherever possible, and to no more than $100 or the amount you paid us for access to the services. Please read this section carefully.
UNDER NO CIRCUMSTANCES WILL EITHER PARTY (OR ITS AFFILIATES, EMPLOYEES, AGENTS, LICENSORS, SUCCESSORS, OR ASSIGNS) BE LIABLE FOR ANY SPECIAL, INDIRECT, INCIDENTAL, CONSEQUENTIAL, PUNITIVE, RELIANCE, OR EXEMPLARY DAMAGES (INCLUDING WITHOUT LIMITATION LOSSES OR LIABILITY RESULTING FROM LOSS OF DATA, LOSS OF REVENUE, ANTICIPATED PROFITS, OR LOSS OF BUSINESS OPPORTUNITY) THAT RESULT FROM YOUR USE OR YOUR INABILITY TO USE THE SERVICES, OR ANY OTHER INTERACTIONS WITH US, EVEN IF WE OR A SOURCEGRAPH-AUTHORIZED REPRESENTATIVE HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
@@ -312,7 +313,7 @@ You acknowledge and agree that we have offered our products and services, set ou
-
**Short version**: Each of us agrees to defend the other against third-party lawsuits that result from matters under our respective responsibility.
+**Short version**: Each of us agrees to defend the other against third-party lawsuits that result from matters under our respective responsibility.
13.1 **By You**. You agree to defend us and our affiliates, directors, officers, employees, and contractors from and against any third-party claims, proceedings, demands, and investigations and indemnify us for damages, attorney’s fees, and costs arising from Your Code or Content, your use of the Services in violation of the Agreement including any data or work transmitted or received by you, your violation of the Agreement or applicable laws, your infringement of any third-party intellectual property or other right of any person or entity, or any other party’s access and use of the Services with your unique username, password, or other appropriate security code.
@@ -326,7 +327,7 @@ You acknowledge and agree that we have offered our products and services, set ou
-
**Short version**: The services are located in the US (where we’re located). Don’t use them if you’re located in an embargoed country.
+**Short version**: The services are located in the US (where we’re located). Don’t use them if you’re located in an embargoed country.
14.1 **Location of the Services**. The Services are controlled and operated from our facilities in the United States. We make no representations that the Services is appropriate or available for use in other locations. Those who access or use the Services from other jurisdictions do so at their own volition and are entirely responsible for compliance with local law, including but not limited to export and import regulations. You may not use the Services if you are a resident of a country embargoed by the United States, or are a foreign person or entity blocked or denied by the United States government. Unless otherwise explicitly stated, all materials found on the Services are solely directed to individuals, companies, or other entities located in the U.S. By using the Services, you are consenting to have your personal data transferred to and processed in the United States.
@@ -338,7 +339,7 @@ You acknowledge and agree that we have offered our products and services, set ou
-
**Short version**: We’re based in California, so the agreement is governed by California law, and all disputes must be brought there. If you have a claim against us, you’ll work with us to arbitrate it on an individual basis instead of via class action or jury trial.
+**Short version**: We’re based in California, so the agreement is governed by California law, and all disputes must be brought there. If you have a claim against us, you’ll work with us to arbitrate it on an individual basis instead of via class action or jury trial.
15.1 **Governing Law**. The Agreement shall be governed by the internal substantive laws of the State of California, without respect to its conflict of laws principles. Notwithstanding the preceding sentence with respect to the substantive law, any arbitration conducted pursuant to the terms of these Terms shall be governed by the Federal Arbitration Act (9 U.S.C. §§ 1-16). The application of the United Nations Convention on Contracts for the International Sale of Goods is expressly excluded. You agree to submit to the personal jurisdiction of the federal and state courts located in Santa Clara County, California for any actions for which we retain the right to seek injunctive or other equitable relief in a court of competent jurisdiction to prevent the actual or threatened infringement, misappropriation or violation of a our copyrights, trademarks, trade secrets, patents, or other intellectual property or proprietary rights, as set forth in the Arbitration provision below, including any provisional relief required to prevent irreparable harm. You agree that Santa Clara County, California is the proper forum for any appeals of an arbitration award or for trial court proceedings if the arbitration provision below is found to be unenforceable.
diff --git a/content/terms/privacy.md b/content/terms/privacy.md
index 705d7048..4705f93d 100644
--- a/content/terms/privacy.md
+++ b/content/terms/privacy.md
@@ -3,65 +3,102 @@ layout: markdown
title: Sourcegraph Privacy Policy
---
-Last modified: January 15, 2021
+Last modified: March 28, 2022
-Sourcegraph, Inc. (**"Sourcegraph," "we," "our,"** or **"us"**) understands that privacy is important to our online visitors to our Sourcegraph.com website and users of our online services (collectively, for the purposes of this Privacy Policy, our **"Website"**), as well as users of our private or self-hosted Sourcegraph instances (collectively with our Website, our **"Service"** or **"Services"**). This Privacy Policy explains how we collect, use, share and protect your personal information that we collect through our Service. By using our Service, you agree to the terms of this Privacy Policy and our Terms of Service.
+See the [changes](https://sourcegraph.com/search?q=context:global+repo:%5Egithub%5C.com/sourcegraph/about%24+file:%5Edocs/privacy%5C.md+type:diff&patternType=literal) since the [previous version](https://about.sourcegraph.com/archives/privacy/2021.01.15/) or visit our [archives](https://github.com/sourcegraph/about/tree/main/docs/archives).
+
+At Sourcegraph, Inc. (**"Sourcegraph," "we," "our,"** or **"us"**), we value the privacy of our website visitors and Sourcegraph Cloud users (collectively for the purposes of this Privacy Policy, our **"Website"**) and our self-hosted Sourcegraph instances users (collectively with our Website, our **"Service"** or **"Services"**). This Privacy Policy explains how we collect, use, share and protect your personal information that we collect through our Service. This Privacy Policy applies to our Website, Sourcegraph Cloud, and our self-hosted Sourcegraph instances. By using our Service, you agree to the terms of this Privacy Policy and our Terms of Service.
Capitalized terms that are not defined in this Privacy Policy have the meaning given them in our Terms of Service.
-## Data controller
+## Short version
-The Data Controller for Sourcegraph and our Services is:
+- We do not sell your information. We don’t help companies advertise their products to you. ([read more](#what-is-sourcegraphs-business-model))
+- We use a number of trusted third parties to help provide our products. ([read more](#does-sourcegraph-share-my-information))
+- We use cookies to provide, protect, and promote our own products. ([read more](#cookies))
+- You can exercise your rights under privacy laws. ([read more](#global-privacy-practices))
+
+
-Sourcegraph, Inc. 981 Mission St, San Francisco, CA 94103
+## What is Sourcegraph’s business model?
+
+
+
+We make money through paid subscriptions to use our Services. We do not sell your information.
-## What types of information do we collect, and for what purpose
+## What information do we collect, and for what purpose
-The categories of information we collect can include:
+When you interact with our Services, we collect information that could be used to identify you (**“Personal Information”**). Examples include a username and password, an email address, a name, and an IP address.
-- **Information you provide to us directly:** We may collect personal information such as a username, first and last name, email address, and payment information, when you register for a Sourcegraph account, participate in forums, comment on blog posts, submit a feedback survey, or if you correspond with us.
+Some of the information we collect is stored in a manner that cannot be linked back to you (**“Non-Personal Information”**). Non-Personal Information includes aggregated, non-personally identifying information that does not identify a user or cannot otherwise be reasonably linked or connected with them. We may use such aggregated, non-personally identifying information to improve our Services.
-- **Information we collect from third parties and social media sites:** We may collect information about you from third-party services. For example, we may receive information about you if you interact with our site through various social media, for example, by logging in through or liking us on Facebook or following us on Twitter. The data we receive is dependent upon your privacy settings with the social network. You should always review, and if necessary, adjust your privacy settings on third-party websites and services before linking or connecting them to the Service.
+### Information you provide to us directly
-We use this information to operate, maintain, and provide to you the features of the Services. We may use this information to communicate with you, such as to send you email messages, and to follow up with you to offer news and information about our Services. We may also send you Service-related emails or messages (e.g., account verification, change or updates to features of the Services, technical and security notices). For more information about your communication preferences, see "Your Choices About Your Information" below.
+When you register for a Sourcegraph account, participate in forums, comment on blog posts, submit a feedback survey, or correspond with us, we may collect account information (username, password, email), profile information (display name, avatar URL), Content you post, add, receive, or share on our hosted services, and any payment information. We do not process or store your payment information, but our third-party payment processor does.
-
+### Information we receive from third parties
-## How we use cookies and other tracking technology to collect information
+We may receive information about you from third-party services if you log in or otherwise interact with our Website or Services through a code host or social media, for example, by liking us on Facebook or following us on Twitter. The data we receive depends on your privacy settings with the third party but can include your name, email, third-party user ID, and location. Review, and if necessary, adjust your privacy settings on third-party websites and services before linking or connecting them to the Service.
-
+### How does Sourcegraph use my information provided directly by me and third parties?
+
+We use information provided directly by you and third parties to operate, maintain, and provide to you the features of the Services. We may use this information to communicate with you, such as to send you email messages, and to follow up with you to offer news and information about our Services. We may also send you Service-related emails or messages (e.g., account verification, change or updates to features of the Services, technical and security notices). For more information about your communication preferences, see [Will Sourcegraph send me emails](#will-sourcegraph-send-me-emails) below.
+
+### Automatically collected information
+
+#### Usage data
+
+When you use our Services, Sourcegraph collects aggregate and high-level information about usage through a server ping. The server ping sends a payload containing data such as total number of users and whether certain features are enabled or in use.
+
+
-### Usage information from private or self-hosted Sourcegraph instances
+For self-hosted instances, the only personal information collected is the email address of the initial Sourcegraph installer and site admin (or, if that user is deleted or demoted to not be an admin, the first such active site admin). This information allows us to contact the technical administrator of the Sourcegraph instance to deliver information about product updates and policy changes, and for customer development purposes. Other than the initial site admin email address, only aggregates of usage data are sent: no usernames, user emails, user personal information, code, repository names, file names, URLs, or other such private content is sent to Sourcegraph.
-Sourcegraph collects aggregate and high-level information about usage from self-hosted Sourcegraph instances through a server ping. The server ping sends a payload containing data such as total number of users and whether certain features are enabled or in use.
+With regards to connections to the Sourcegraph Cloud extension registry, even from self-hosted Sourcegraph instances, the automatically collected data below will apply.
-
For more information about the specific information we have access to, see our server pings documentation. Customers can contact Sourcegraph at support@sourcegraph.com to opt out of server pings.
+When you visit or use our Website, including when you access the Sourcegraph Cloud extension registry from your self-hosted instance, we may automatically collect the following information.
-The only personal information collected is the email address of the initial Sourcegraph installer and site admin (or, if that user is deleted or demoted to not be an admin, the first such active site admin). This information allows us to contact the technical administrator of the Sourcegraph instance to deliver information about product updates and policy changes, and for customer development purposes. Other than the initial site admin email address, only aggregates of usage data are sent: no usernames, user emails, user personal information, code, repository names, file names, URLs, or other such private content is sent to Sourcegraph.
+#### Cookies
-### Information from Sourcegraph.com visitors
+When you visit or use our Website, we may send one or more cookies — a small text file containing a string of alphanumeric characters — to your computer that uniquely identifies your browser and lets us help you log in faster and enhance your navigation through the Website. A cookie may also convey information to us about how you use the Website(e.g., the pages you view, the links you click, how frequently you access the Website, and other actions you take on the Website), and allow us to track your usage of the Website over time. For more information, see “Third-party tracking and online advertising” below and our [Cookie Policy](/terms/cookie-policy/).
-We and our third-party partners may automatically collect certain types of usage information when you visit or use our Website.
+#### Log data
-- **Cookies**. When visiting our website, we may send one or more cookies — a small text file containing a string of alphanumeric characters — to your computer that uniquely identifies your browser and lets us help you log in faster and enhance your navigation through the site. A cookie may also convey information to us about how you use the Website (e.g., the pages you view, the links you click, how frequently you access the Website, and other actions you take on the Website), and allow us to track your usage of the Website over time.
+As with most websites and technology services delivered over the internet, when you access or use our Website, our servers automatically collect data and record it in log files. This log data may include your web request, IP address, browser type and settings, date and time of use, information about browser configuration, error data, repository name, user ID, and cookie data.
-- **Log file information**. We may collect log file information about your browser or mobile device each time you access the Website. Log file information may include anonymous information such as your web request, Internet Protocol ("IP") address, browser type, information about your mobile device, referring / exit pages and URLs, number of clicks and how you interact with links on the Website, domain names, landing pages, pages viewed, and other such information.
+#### Access, authorization, and activity audit logs
-- **Email beacons**. We may employ clear gifs (also known as web beacons) in HTML-based emails sent to our users to track which emails are opened and which links are clicked by recipients. The information allows for more accurate reporting and improvement of the Website.
+When you visit or use our Website, we may collect information related to accessing systems and data, including IP addresses, usernames, and data accessed. This information is only retained for the purposes of identifying, analyzing, and resolving potential security incidents. Access to this information is limited to those who require access for these purposes and will only be shared with the relevant customers in the event of a security incident.
-- **Web analytics**. We may also collect analytics data, or use third-party analytics tools, to help us measure traffic and usage trends for the Website. These tools collect information sent by your browser or mobile device, including the pages you visit, your use of third-party applications, and other information that assists us in analyzing and improving the Website.
+#### Device data
-Although we do our best to honor the privacy preferences of our Users, we are not able to respond to Do Not Track signals from your browser at this time.
+When you visit or use our Website, we automatically collect information about your device, which may include the type of hardware and software you are using (for example, your operating system and browser type), IP address, and other unique identifiers for devices used to access our Website and Hosted Services.
-We may use the data collected through cookies, log file, device identifiers, location data, and clear gifs information to:
+#### Location data
+
+This is the geographic area where you use your computer or mobile devices (as indicated by an IP address or similar identifier) when interacting with our Website.
+
+#### Email beacons
+
+When we send you emails, we may employ clear gifs (also known as web beacons) in HTML-based emails sent to our users to track which emails are opened and which links are clicked by recipients. The information allows for more accurate reporting and improvement of the Website.
+
+#### Web analytics
+
+We may also collect analytics data, or use third-party analytics tools, to help us measure traffic and usage trends for the Website. These tools collect information sent by your browser or mobile device, including the pages you visit, your use of third-party applications, and other information that assists us in analyzing and improving the Website.
+
+Although we do our best to honor the privacy preferences of our users, we are not able to respond to Do Not Track signals from your browser at this time.
+
+### How does Sourcegraph use my automatically collected data?
+
+We may use the automatically collected data to:
1. remember information so that you will not have to re-enter it during your visit or the next time you visit the site;
1. provide custom, personalized content and information;
@@ -70,53 +107,93 @@ We may use the data collected through cookies, log file, device identifiers, loc
1. diagnose or fix technology problems; and
1. otherwise to plan for and enhance our service
-For more information on what cookies are used, visit our Cookie Policy.
+### What we do not collect
+
+#### Sensitive Personal Information
+
+Sourcegraph does not intentionally collect “Sensitive Personal Information,” such as personal data revealing racial, ethnicity, political and religious beliefs, trade union membership, or genetic, biometric, health, or sexual data. If you choose to store any Sensitive Personal Information on our servers, you are responsible for complying with any regulatory controls regarding that data.
+
+#### Personal Information in Repositories
+
+We do not intentionally collect any Personal Information that is stored in your repositories or other free-form content inputs. Any Personal Information within a user's repository is the responsibility of the repository owner.
-### Third-party services and data processors
+
+
+## Bases for processing your information
-We use third-party automated devices and applications, such as Google Analytics, to evaluate usage of our Website. Google Analytics is a Web-based analysis tool provided by the Google Inc., 1600 Amphitheatre Pkwy, Mountain View, CA 94043-1351, USA. Google provides further information about its own privacy practices and offers a browser add-on to opt out of Google Analytics tracking at https://tools.google.com/dlpage/gaoptout.
+
-We use third-party applications such as Google Apps, HubSpot, GitHub, Slack, DocuSign, and more to track and manage conversations, chats, or email exchanges with our users and customers. These products and companies provide further information about their own privacy practices on their websites.
+Where laws like GDPR govern our processing of your Personal Information, Sourcegraph must tell you about the legal basis under which we process your Personal Information. Sourcegraph processes Personal Information under the following legal bases:
-We use third-party applications such as Google Cloud Platform, Honeycomb, and more to host, serve, store, and analyze our Website's operational infrastructure and operational data collected on our Website. These products and companies provide further information about their own privacy practices on their websites.
+**Performance of a contract:** We use your Personal Information to provide the Services you subscribe to and to fulfill requests you make of us.
-We use third-party applications such as Stripe and Xero to manage corporate billing and invoicing. These companies provide further information about their own privacy practices on their websites.
+**Legitimate interests:** We use your Personal Information for our legitimate interests, such as security and fraud prevention, product improvement, and communications about your use of our Services.
-We and our third-party partners may also use cookies and tracking technologies for the purpose of tracking the effectiveness of our own ads placed on Google, Twitter, etc. on Sourcegraph.com (never on private or self-hosted instances). For more information about tracking technologies, please see [“Third-party tracking and online advertising”](#third-party-tracking-and-online-advertising) below.
+**Consent:** We may rely on your consent to use your personal information for certain direct marketing purposes, such as sending you newsletter updates about Sourcegraph products. You may withdraw your consent at any time through the unsubscribe feature provided with each marketing email or by contacting us at the address given at the end of this Privacy Policy.
-## Bases for processing your information
+## Does Sourcegraph review my repository contents?
-**Performance of a contract:** The use of your information may be necessary to perform the contract that you have with us. For example, if you use our Website to purchase Sourcegraph product subscriptions or services, create a profile, post and comment through our Website, or request information through our Website, we will use your information to carry out our obligation to complete and administer that contract or request.
+### Public repositories
+
+If your repository is public, anyone may view its contents.
+
+### Private repositories
-**Legitimate interests:** We use your information for our legitimate interests, such as to provide you with the best content through our Service and communications with users and the public, to improve and promote our products and services, and for administrative, security, fraud prevention, and legal purposes.
+If you have a private repository on Sourcegraph Cloud or a Sourcegraph managed instance, Sourcegraph personnel do not review your repository contents or any other Content you store or transfer through our Services, except for the following purposes:
-**Consent:** We may rely on your consent to use your personal information for certain direct marketing purposes, such as sending you newsletter updates about Sourcegraph products. You may withdraw your consent at any time through the unsubscribe feature provided with each marketing email or by contacting us at the addresses given at the end of this Privacy Policy.
+- to investigate and respond to a security incident
+- to assist the repository owner with a support matter
+- to comply with our legal obligations such as responding to a court order
+- if we have reason to believe the contents violate the law, or
+- with your consent.
+
+We may scan our servers and content to detect certain tokens or security signatures of known active malware, known vulnerabilities in dependencies, or other content known to violate our Terms of Service, based on algorithmic fingerprinting techniques (collectively, "automated scanning").
-## Sharing your information
+## Does Sourcegraph share my information?
-We may share your personal information in the instances described below. For further information on your choices regarding your information, see the "Your Choices About Your Information" section below.
+We may share your personal information with third parties in the instances described below.
+
+#### Service providers
+
+Our service providers process your Personal Information as needed to provide our Services to you, including hosting and customer support ticketing. They may only process your Personal Information pursuant to our instructions and to perform their duties to us. See our [Subprocessors](/terms/subprocessors) page for a list of our service providers.
+
+#### Security purposes
+
+If you are a member of an Organization, we may share your username, email, IP address, and any collected logs about the user associated with that Organization with an owner or administrator of the Organization to investigate or respond to a security incident that affects or compromises the security of that particular Organization.
+
+#### Legal disclosure
-We may share your personal information with:
+We may share your Personal Information with law enforcement and other third parties if required by law or subpoena or if we reasonably believe that such action is necessary to (a) comply with the law, legal process, and the reasonable requests of law enforcement; (b) to enforce our Terms of Service or to protect the security or integrity of our Service with regard to suspected fraud or other illegal activities; or (c) to exercise or protect the rights, property, or personal safety of Sourcegraph, our users, or others.
-- Other companies owned by or under common ownership with Sourcegraph. These companies will use your personal information in the same way as we can under this Privacy Policy;
+#### Mergers and common ownership
-- Third-party vendors and other service providers that perform services on our behalf, as needed to carry out their work for us, which may include data hosting, billing, payment processing, or providing analytic services;
+We may share your Personal Information with another entity in connection with a company transaction, such as a merger, acquisition, sale of assets or shares, reorganization, or bankruptcy. In these cases we may transfer some or all of your Personal Information to another entity, subject to this Privacy Policy. We may also share your Personal Information with any companies owned by or under common ownership with Sourcegraph, subject to this Privacy Policy.
-- Other parties in connection with a company transaction, such as a merger, sale of company assets or shares, reorganization, financing, change of control, or acquisition of all or a portion of our business by another company or third party or in the event of a bankruptcy or related or similar proceedings; and
+#### With your consent
-- Third parties as required by law or subpoena or to if we reasonably believe that such action is necessary to (a) comply with the law, legal process and the reasonable requests of law enforcement; (b) to enforce our Terms of Service or to protect the security or integrity of our Service; and/or (c) to exercise or protect the rights, property, or personal safety of Sourcegraph, our Users, or others.
+With your consent, we may share your Personal Information with other third parties. If you join an Organization, you agree to provide the administrator of the Organization with the ability to view your activity in the Organization’s access log. Any information or content that you voluntarily disclose by posting to the Website becomes available to the public, as controlled by your privacy settings. If you remove information or content that you posted to the Website, copies may remain viewable in cached and archived pages of the Website, or if other users have copied or saved that information.
-We may also aggregate or otherwise strip data of all personally identifying characteristics and may share that aggregated or pseudonymized data with third parties.
+### Does Sourcegraph share aggregate, Non-Personal Information with third parties?
-Any information or content that you voluntarily disclose for posting to the Website becomes available to the public, as controlled by any applicable privacy settings. If you remove information or content that you posted to the Website, copies may remain viewable in cached and archived pages of the Website, or if other Users have copied or saved that information.
+We share aggregated, Non-Personal Information with others about our product usage like number of users, user growth, and lines of indexed code.
+
+### Does Sourcegraph sell or rent my Personal Information?
+
+No. We do not sell or rent your Personal Information for monetary or other consideration under the CCPA (California Consumer Privacy Act of 2018) or other data privacy laws.
+
+### Will Sourcegraph send me emails
+
+From time to time, we may share information about product announcements, product use, and special offers. You may opt out of our promotional email communications at any time by clicking the “unsubscribe” link provided in such communications.
+
+Sourcegraph users will continue to receive transactional messages related to your use of our Services such as account management, technical, and security notices, even if you unsubscribe from promotional emails.
@@ -124,13 +201,15 @@ Any information or content that you voluntarily disclose for posting to the Webs
-We participate in interest-based advertising and use third-party advertising companies to serve you targeted advertisements based on your online browsing history and your interests. We permit third-party online advertising networks, social media companies, and other third-party services, to collect information about your use of our Service over time so that they may play or display ads for our products on other websites, apps, or services you may use and on other devices you may use. Typically, though not always, the information used for interest-based advertising is collected through cookies or similar tracking technologies. We and our third-party partners use this information to make the advertisements you see online more relevant to your interests, as well as to provide advertising-related services such as reporting, attribution, analytics and market research.
+We participate in interest-based advertising and use third-party advertising companies to serve you targeted advertisements based on your online browsing history and your interests. We permit third-party online advertising networks, social media companies, and other third-party services, to collect information about your use of our Website over time so that they may play or display ads for our products on other websites, apps, or services you may use and on other devices you may use.
+
+We and our third-party partners may use cookies and tracking technologies on our Website for the purpose of tracking the effectiveness of our own ads placed on Google, Twitter, etc. (never on private or self-hosted instances). We and our third-party partners use this information to make the advertisements you see online more relevant to your interests, as well as to provide advertising-related services such as reporting, attribution, analytics and market research.
To learn more about interest-based advertising and how you may be able to opt-out of some of this advertising, you may wish to visit the Network Advertising Initiative’s online resources, at http://www.networkadvertising.org/choices, and/or the DAA’s resources at www.aboutads.info/choices. You may also be able to set your browser to delete or notify you of cookies by actively managing the settings on your browser or mobile device. Please note that some advertising opt-outs may not be effective unless your browser is set to accept cookies. Furthermore, if you use a different device, change browsers or delete the opt-out cookies, you may need to perform the opt-out task again.
You may also be able to limit certain interest-based mobile advertising through the settings on your mobile device by selecting “limit ad tracking” (iOS) or “opt-out of interest based ads” (Android).
-**Google Analytics and Advertising**. We may also utilize certain forms of display advertising and other advanced features through Google Analytics, such as Remarketing with Google Analytics, Google Display Network Impression Reporting, the DoubleClick Campaign Manager Integration, and Google Analytics Demographics and Interest Reporting. These features enable us to use first-party cookies (such as the Google Analytics cookie) and third-party cookies (such as the DoubleClick advertising cookie) or other third-party cookies together to inform, optimize, and display ads based on your past visits to the Sites. You may control your advertising preferences or opt-out of certain Google advertising products by visiting the Google Ads Preferences Manager, currently available at https://google.com/ads/preferences, or by vising NAI’s online resources at http://www.networkadvertising.org/choices.
+**Google Analytics and Advertising**. We may also utilize certain forms of display advertising and other advanced features through Google Analytics, such as Remarketing with Google Analytics, Google Display Network Impression Reporting, and Google Analytics Demographics and Interest Reporting. These features enable us to use first-party cookies (such as the Google Analytics cookie) and third-party cookies to inform, optimize, and display ads based on your past visits to the Sites. You may control your advertising preferences or opt-out of certain Google advertising products by visiting the Google Ads Preferences Manager, currently available at https://google.com/ads/preferences, or by vising NAI’s online resources at http://www.networkadvertising.org/choices.Google provides further information about its own privacy practices and offers a browser add-on to opt out of Google Analytics tracking at https://tools.google.com/dlpage/gaoptout.
@@ -138,7 +217,7 @@ You may also be able to limit certain interest-based mobile advertising through
-Information we collect will be stored and processed in the United States in accordance with this Privacy Policy but we understand that users from other countries may have different expectations and rights with regard to their privacy. For all Sourcegraph.com visitors, Website users, and self-hosted Sourcegraph users, no matter their country of location, we will:
+Information we collect will be stored and processed in the United States in accordance with this Privacy Policy but we understand that users from other countries may have different expectations and rights with regard to their privacy. For all Website visitors and users and self-hosted Sourcegraph users, no matter their country of location, we will:
- provide clear methods of unambiguous, informed consent when we do collect your personal information;
- only collect the minimum amount of personal data necessary for the purpose it is collected for, unless you choose to provide us more;
@@ -160,41 +239,37 @@ Additional rights that may apply to you in certain instances:
- Right to object to processing of personal data for direct marketing purposes
- Right of erasure of your personal data from our system (“right to be forgotten”) if certain grounds are met
-To exercise your privacy rights, you can contact us directly at support@sourcegraph.com.
+To exercise your privacy rights, you can contact us directly at support@sourcegraph.com.
-## Your choices about your information
+## Data storage, security, deletion, and retention
-**How to control your communications preferences:** You can stop receiving promotional email communications from us by clicking on the "unsubscribe link" provided in such communications. We make every effort to promptly process all unsubscribe requests. For as long as you are using our Services, you may not opt out of Service-related communications (e.g., account verification, changes/updates to our products or features of the Service, technical, and security notices).
+### Where is my information stored?
-**Modifying or deleting your information:** If you already have an account on the Website, you may access, update, alter, or delete your basic user profile information by logging into your account and updating profile settings.
+We store and process the information that we collect in the United States in accordance with this Privacy Policy, though our employees, contractors, and service providers may store and process data outside the United States.
-Sourcegraph will retain your information for as long as your account is active or as needed to perform our contractual obligations, provide you services, to comply with legal obligations, resolve disputes, preserve legal rights, or enforce our agreements.
+When we transfer the personal data of EEA, Swiss, and UK residents outside of those regions, we do so via appropriate user privacy safeguards, such as using Standard Contractual Clauses or obtaining your consent.
-We will delete inactive accounts and any personal information in them after a period of eighteen (18) months.
+### How secure is my information?
-If you have any questions about reviewing, modifying or deleting your account information, you can contact us directly at support@sourcegraph.com.
+We secure your information by implementing technical and organizational security controls that you can read about in [Security is core to everything we do](/terms/security).
-
-
-## How we store and protect your information
-
-
+When we receive your information, we protect it on our servers using technical, physical, and logical security safeguards. For information stored in any Software installed in your computing system, you are responsible for its security by making use of the security features of your device. We recommend that you take the appropriate steps to secure all computing devices that you use in connection with our Services.
-**Storage and processing:** Your information collected through the Service may be stored and processed in the United States or any other country in which Sourcegraph or its subsidiaries, affiliates or service providers maintain facilities. If you are located in the European Union or other regions with laws governing data collection and use that may differ from U.S. law, please note that we may transfer information, including personal information, to a country and jurisdiction that does not have the same data protection laws as your jurisdiction, and you consent to the transfer of information to the U.S. or any other country in which Sourcegraph or its parent, subsidiaries, affiliates or service providers maintain facilities and the use and disclosure of information about you as described in this Privacy Policy.
+Sourcegraph cares about the security of your information, and uses commercially reasonable physical, administrative, and technological safeguards to preserve the integrity and security of all information collected through the Service. However, no security system is impenetrable and we cannot guarantee the security of our systems 100%. In the event that any information under our control is compromised as a result of a breach of security, Sourcegraph will take reasonable steps to investigate the situation and where appropriate, notify those individuals whose information may have been compromised and take other steps, in accordance with any applicable laws and regulations.
-**Keeping your information safe:** Sourcegraph cares about the security of your information, and uses commercially reasonable physical, administrative, and technological safeguards to preserve the integrity and security of all information collected through the Service. However, no security system is impenetrable and we cannot guarantee the security of our systems 100%. In the event that any information under our control is compromised as a result of a breach of security, Sourcegraph will take reasonable steps to investigate the situation and where appropriate, notify those individuals whose information may have been compromised and take other steps, in accordance with any applicable laws and regulations.
+### How do I update or delete my Personal Information from Sourcegraph?
-
+You can update or remove your Personal Information from Sourcegraph at any time by logging into your account and updating your profile settings, including deleting your account.
-## Usage data
+### How long does Sourcegraph retain my Personal Information?
-
+You can remove your Personal Information from Sourcegraph at any time by deleting your account as described above. Sourcegraph will retain your information for as long as your account is active or as needed to perform our contractual obligations, provide you services, to comply with tax, legal, and audit obligations, resolve disputes, preserve legal rights, or enforce our agreements.
-Sourcegraph's collection, storage, and use of Usage Data, and our responsibilities with respect to such Usage Data, are set forth in our Terms of Service and are not covered by this Privacy Policy.
+For questions about reviewing, modifying, or deleting your account information, contact us at support@sourcegraph.com.
@@ -202,7 +277,7 @@ Sourcegraph's collection, storage, and use of Usage Data, and our responsibiliti
-Sourcegraph does not knowingly collect or solicit any information from anyone under the age of 13 or knowingly allow such persons to register as Users. If you are based in the European Union, we will not knowingly collect your information if you are under the age of 16. In the event that we learn that we have collected personal information from a child under age 13, we will delete that information as quickly as possible. If you believe that we might have any information from a child under 13 or child in the European Union under 16, please contact us at support@sourcegraph.com.
+Sourcegraph does not knowingly collect or solicit any information from anyone under the age of 13 or knowingly allow such persons to register as Users. If you are based in the European Union, we will not knowingly collect your information if you are under the age of 16. Different countries may have different minimum age limits. If you are below the minimum age for providing consent for data collection in your country, you may not have a Sourcegraph account. In the event that we learn that we have collected personal information from a child under age 13 or the applicable minimum age limit, we will delete that information as quickly as possible. If you believe that we might have any information from a child under 13 or otherwise under the applicable minimum age limit, please contact us at support@sourcegraph.com.
@@ -218,7 +293,7 @@ Our Service may integrate with or contain links to other third-party sites and s
-If you have any questions about this Privacy Policy or the Service, please contact us at support@sourcegraph.com.
+If you have any questions about this Privacy Policy or the Service, please contact us at support@sourcegraph.com.
@@ -226,4 +301,4 @@ If you have any questions about this Privacy Policy or the Service, please conta
-Sourcegraph may modify or update this Privacy Policy from time to time to reflect the changes in our business and practices. When we do so, we will revise the "last modified" date at the top of this page.
+Sourcegraph will update this Privacy Policy to keep up with the changes in our business, Services, and applicable laws. When we do so, we will revise the "last modified" date at the top of this page. Every time we update this policy, you will be able to review the changes since the previous version.
diff --git a/content/terms/security.md b/content/terms/security.md
index 240c4246..f77be871 100644
--- a/content/terms/security.md
+++ b/content/terms/security.md
@@ -99,4 +99,5 @@ Sourcegraph is an OSS product licensed under Apache 2.0. We also make great use
## Security Updates
-
+
+
diff --git a/content/terms/self-hosted.md b/content/terms/self-hosted.md
index 34e69b71..ad7152fc 100644
--- a/content/terms/self-hosted.md
+++ b/content/terms/self-hosted.md
@@ -3,13 +3,14 @@ layout: markdown
title: Terms of Service for Self-hosted Sourcegraph Instances
---
-Last modified: February 10, 2022
+Last modified: February 22, 2022
-See the [changes](https://sourcegraph.com/search?q=context:global+repo:%5Egithub%5C.com/sourcegraph/about%24+file:%5Edocs/terms-self-hosted%5C.md+type:diff&patternType=literal) since the [previous version](https://about.sourcegraph.com/archives/terms-self-hosted/2021-10-11/) or visit our [archives](https://github.com/sourcegraph/about/tree/main/docs/archives).
+See the [changes](https://sourcegraph.com/search?q=context:global+repo:%5Egithub%5C.com/sourcegraph/about%24+file:%5Edocs/terms-self-hosted%5C.md+type:diff&patternType=literal) since the [previous version](https://about.sourcegraph.com/archives/terms-self-hosted/2022-02-10/) or visit our [archives](https://github.com/sourcegraph/about/tree/main/docs/archives).
Thank you for using Sourcegraph! This page lays out the basic terms and conditions that apply to your use of self-hosted Sourcegraph instances.
-
+
+
## Is this the right Terms of Service for me?
@@ -20,13 +21,13 @@ Are you interested in terms for...
- **A self-hosted Sourcegraph instance**: You're in the right place! Read on.
-- **[Sourcegraph Cloud](/terms/cloud)**: If you’d like to use Sourcegraph Cloud (the public Sourcegraph instance that can be used to search, navigate, and analyze public code) rather than a self-hosted instance, or if you’d like to use any products (e.g. browser or editor extensions) developed and distributed by us for use with Sourcegraph Cloud, please see our [Sourcegraph Cloud terms and conditions](/terms/cloud).
+- **[Sourcegraph Cloud](/terms/cloud)**: If you’d like to use Sourcegraph Cloud (the public Sourcegraph instance that can be used to search, navigate, and analyze public code) rather than a self-hosted instance, or if you’d like to use any products (e.g. browser or editor extensions) developed and distributed by us for use with Sourcegraph Cloud, please see our Sourcegraph Cloud terms and conditions at https://about.sourcegraph.com/terms-cloud.
- **[Sourcegraph OSS](https://github.com/sourcegraph/sourcegraph/blob/master/LICENSE.apache)**: It is possible to run a version of Sourcegraph without some Enterprise features from our open source code available at https://github.com/sourcegraph/sourcegraph. If you want to follow the instructions there to build and run Sourcegraph OSS from source, please see the open source license (Apache 2.0) at https://github.com/sourcegraph/sourcegraph/blob/master/LICENSE.apache.
- **Sourcegraph extensions**: If you’d like to use any extensions made available via our [Extension Registry](https://sourcegraph.com/extensions), please understand that extensions made available by third-parties are not provided by us and are generally governed by separate terms and conditions. Extensions that are developed and distributed by us are governed by these terms and conditions.
-- **[Government](/terms/gov)**: Certain features of our software may have their own terms and conditions that you must agree to when you sign up for that particular feature. As an example, if you’re using our software as an employee or contractor of the U.S. Government, our [Supplemental Terms for U.S. Government Users](/terms/gov) apply. Those terms and conditions supplement these terms and conditions.
+- **[Government](/terms/gov)**: Certain features of our software may have their own terms and conditions that you must agree to when you sign up for that particular feature. As an example, if you’re using our software as an employee or contractor of the U.S. Government, our Supplemental Terms for U.S. Government Users at https://about.sourcegraph.com/terms-gov apply. Those terms and conditions supplement these terms and conditions.
PLEASE READ THESE TERMS CAREFULLY TO ENSURE YOUR UNDERSTANDING OF EACH PROVISION. THE AGREEMENT CONTAINS A MANDATORY INDIVIDUAL ARBITRATION AND CLASS ACTION/JURY TRIAL WAIVER PROVISION THAT REQUIRES THE USE OF ARBITRATION ON AN INDIVIDUAL BASIS TO RESOLVE DISPUTES, RATHER THAN JURY TRIALS OR CLASS ACTIONS.
@@ -39,21 +40,21 @@ PLEASE READ THESE TERMS CAREFULLY TO ENSURE YOUR UNDERSTANDING OF EACH PROVISION
| Section | Description |
| ------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------- |
-| 1. [Definitions](#1-definitions) | Definitions of specific terms used on this page |
-| 2. [Account terms](#2-account-terms) | Your responsibilities to use Sourcegraph |
-| 3. [Acceptable use](#3-acceptable-use) | Acceptable use of Sourcegraph |
-| 4. [Usage data](#4-usage-data) | Aggregate and high-level data we collect from self-hosted Sourcegraph instances |
-| 5. [Data protection](#5-data-protection) | Our policies for protecting your data |
-| 6. [Confidentiality](#6-confidentiality) | Our mutual responsibilities to protect confidential data |
-| 7. [Term; termination](#7-term-termination) | When and how your account can be terminated |
-| 8. [Fees](#8-fees) | Rules for payment for paid and Enterprise features |
-| 9. [Third party services and software](#9-third-party-services-and-software) | Our use of third party services and software |
-| 10. [Warranties; disclaimer](#10-warranties-disclaimer) | Our warranties about Sourcegraph |
-| 11. [Limitation of liability](#11-limitation-of-liability) | Our liabilities are limited |
-| 12. [Indemnification](#12-indemnification) | The parties’ respective indemnification obligations |
-| 13. [Export controls](#13-export-controls) | Usage restrictions in embargoed locations |
-| 14. [Governing law; arbitration; and class action/jury trial waiver](#14-governing-law-arbitration-and-class-actionjury-trial-waiver) | Where and how disputes would be handled |
-| 15. [Miscellaneous](#15-miscellaneous) | Miscellaneous topics |
+| 1. [Definitions](#1-Definitions) | Definitions of specific terms used on this page |
+| 2. [Account terms](#2-Account-terms) | Your responsibilities to use Sourcegraph |
+| 3. [Acceptable use](#3-Acceptable-use) | Acceptable use of Sourcegraph |
+| 4. [Usage data](#4-Usage-data) | Aggregate and high-level data we collect from self-hosted Sourcegraph instances |
+| 5. [Data protection](#5-Data-protection) | Our policies for protecting your data |
+| 6. [Confidentiality](#6-Confidentiality) | Our mutual responsibilities to protect confidential data |
+| 7. [Term; termination](#7-Term-termination) | When and how your account can be terminated |
+| 8. [Fees](#8-Fees) | Rules for payment for paid and Enterprise features |
+| 9. [Third party services and software](#9-Third-party-services-and-software) | Our use of third party services and software |
+| 10. [Warranties; disclaimer](#10-Warranties-disclaimer) | Our warranties about Sourcegraph |
+| 11. [Limitation of liability](#11-Limitation-of-liability) | Our liabilities are limited |
+| 12. [Indemnification](#12-Indemnification) | The parties’ respective indemnification obligations |
+| 13. [Export controls](#13-Export-controls) | Usage restrictions in embargoed locations |
+| 14. [Governing law; arbitration; and class action/jury trial waiver](#14-Governing-law-arbitration-and-class-actionjury-trial-waiver) | Where and how disputes would be handled |
+| 15. [Miscellaneous](#15-Miscellaneous) | Miscellaneous topics |
@@ -172,7 +173,7 @@ As the Software is provided in the form of a self-hosted Instance, Sourcegraph w
4. the receiving party independently develops without access to or use of the other party's Confidential Information.
-6.3 **Restrictions on Use and Disclosure**. Neither party will use the other party's Confidential Information except as permitted under this Agreement. Each party agrees to maintain in confidence and protect the other party's Confidential Information using at least the same degree of care as it uses for its own information of a similar nature, but in any event at least a reasonable degree of care. Each party agrees to take all reasonable precautions to prevent any unauthorized disclosure of the other party's Confidential Information, including, without limitation, disclosing such Confidential Information only to its employees, independent contractors, consultants, and legal and financial advisors (collectively, **"Representatives"**) who (i) have a need to know such information, and (ii) are subject to confidentiality obligations at least as protective of the Confidential Information as the terms of this Agreement. Each party is responsible for all acts and omissions of its Representatives. The foregoing obligations will not restrict either party from disclosing Confidential Information of the other party if required by any governmental body, so long as, to the extent allowed under applicable law, the party required to make the disclosure gives reasonable notice to the other party to enable it to contest the requirement. The restrictions set forth in this Section will survive the termination or expiration of this Agreement.
+6.3 **Restrictions on Use and Disclosure**. Neither party will use the other party's Confidential Information except as permitted under this Agreement. Each party agrees to maintain in confidence and protect the other party's Confidential Information using at least the same degree of care as it uses for its own information of a similar nature, but in any event at least a reasonable degree of care. Each party agrees to take all reasonable precautions to prevent any unauthorized disclosure of the other party's Confidential Information, including, without limitation, disclosing such Confidential Information only to its employees, independent contractors, consultants, and legal and financial advisors (collectively, **"Representatives"**) who (i) have a need to know such information, and (ii) are subject to confidentiality obligations at least as protective of the Confidential Information as the terms of this Agreement. Each party is responsible for all acts and omissions of its Representatives. The foregoing obligations will not restrict either party from disclosing Confidential Information of the other party if required by any governmental body, so long as, to the extent allowed under applicable law, the party required to make the disclosure gives reasonable notice to the other party to enable it to contest the requirement. The restrictions set forth in this Section will survive the termination or expiration of this Agreement. The terms of this Section 6 supersede any non-disclosure or confidentiality agreement entered into by the parties prior to the effective date of this Agreement.
diff --git a/content/terms/subprocessors.md b/content/terms/subprocessors.md
index 3214e022..34c2633e 100644
--- a/content/terms/subprocessors.md
+++ b/content/terms/subprocessors.md
@@ -4,9 +4,11 @@ title: Sourcegraph Subprocessors
description: This page lists the subsprocessors that Sourcegraph may use
---
-Last modified: December 3, 2021
+Last modified: March 8, 2022
-Sourcegraph, Inc. (“Sourcegraph”) uses certain third party sub-processors (“Sub-processors”) to assist in providing the Services described in the [Sourcegraph Terms of Service](/terms) available and/or as set forth in an applicable Order Form. Capitalized terms used but not otherwise defined herein shall have the meanings ascribed to them in the applicable Sourcegraph Terms of Service.
+See the [previous version](https://about.sourcegraph.com/archives/subprocessors/2021-12-03/) or visit our [archives](https://github.com/sourcegraph/about/tree/main/docs/archives)
+
+Sourcegraph, Inc. (“Sourcegraph”) uses certain third party sub-processors (“Sub-processors”) to assist in providing the Services described in the Sourcegraph Terms of Service available at [https://about.sourcegraph.com/terms/](https://about.sourcegraph.com/terms/) and/or as set forth in an applicable Order Form. Capitalized terms used but not otherwise defined herein shall have the meanings ascribed to them in the applicable Sourcegraph Terms of Service.
Sourcegraph will update this page when engaging a new Sub-processor, and if you [subscribe for updates](#sign-up), Sourcegraph will notify you by email of changes to this page.
@@ -15,6 +17,7 @@ Sourcegraph engages Sub-processors to perform the functions described in the tab
| Third-party Subprocessor | Location | Service Provided | Applicable product |
| ------------------------ | -------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------ | -------------------------------------------------- |
| Amazon Web Services | USA | Provides cloud hosting for Sourcegraph Cloud services | Sourcegraph Cloud Managed Instance |
+| Amplitude | USA | Processes customer logs | Sourcegraph Cloud |
| Atlassian | Australia | Processes support tickets and tracks bugs | Sourcegraph Cloud Managed Instance On Prem |
| Cloudflare | USA | Processes customer request data such as IP addresses to optimize security and performance of Sourcegraph Cloud | Sourcegraph Cloud Managed Instance |
| GitHub | USA | Tracks customer support issues | Sourcegraph Cloud Managed Instance On Prem |
@@ -23,13 +26,14 @@ Sourcegraph engages Sub-processors to perform the functions described in the tab
| Honeycomb | USA | Processes any information Customer sends for debugging purposes | Sourcegraph Cloud |
| Incident.io | United Kingdom | Processes incidents | Sourcegraph Cloud Managed Instance On Prem |
| Salesforce | USA | Processes customer support tickets | Sourcegraph Cloud Managed Instance On Prem |
-| Sentry | USA | Processes error data, which can include email addresses and other personal data, for debugging purposes | Sourcegraph Cloud Managed |
+| Sentry | USA | Processes error data, which can include email addresses and other personal data, for debugging purposes | Sourcegraph Cloud Managed Instance |
| Slack Technologies | USA | Processes customer support communication | Sourcegraph Cloud Managed Instance On Prem |
| Zapier | USA | Processes information needed to enable integrations between Sourcegraph and a third-party product | Sourcegraph Cloud Managed Instance On Prem |
| Zendesk | USA | Processes customer support communication | Sourcegraph Cloud Managed Instance On Prem |
-
Sign Up
+
Sign Up
-
Complete this form to be notified of changes to our sub-processors.
+Complete this form to be notified of changes to our sub-processors.
-
+
+
diff --git a/src/components/Layout/Footer.tsx b/src/components/Layout/Footer.tsx
index a51e25e7..61ab0f5b 100644
--- a/src/components/Layout/Footer.tsx
+++ b/src/components/Layout/Footer.tsx
@@ -179,14 +179,14 @@ const Footer: FunctionComponent = ({ minimal, className }) => (
 +
+ +
+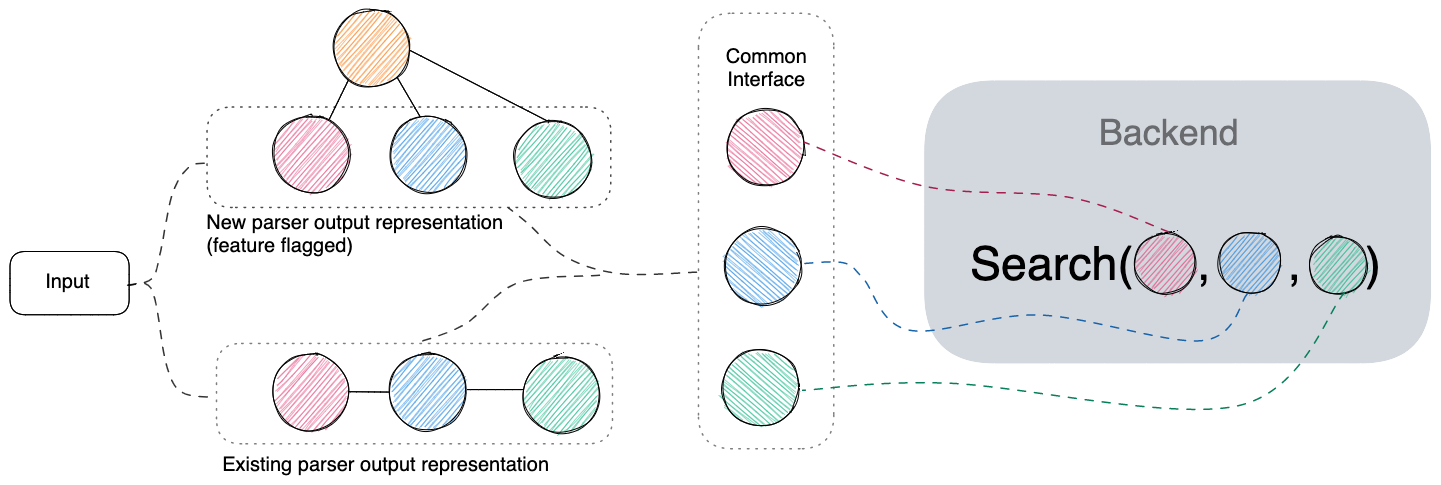 - Integration testing abstracts a common interface for our backend
- to access query values.
- We test that the backend produces the same search results for
- simple queries (ones that don't have, e.g.,
-
- Integration testing abstracts a common interface for our backend
- to access query values.
- We test that the backend produces the same search results for
- simple queries (ones that don't have, e.g.,
-  +
+