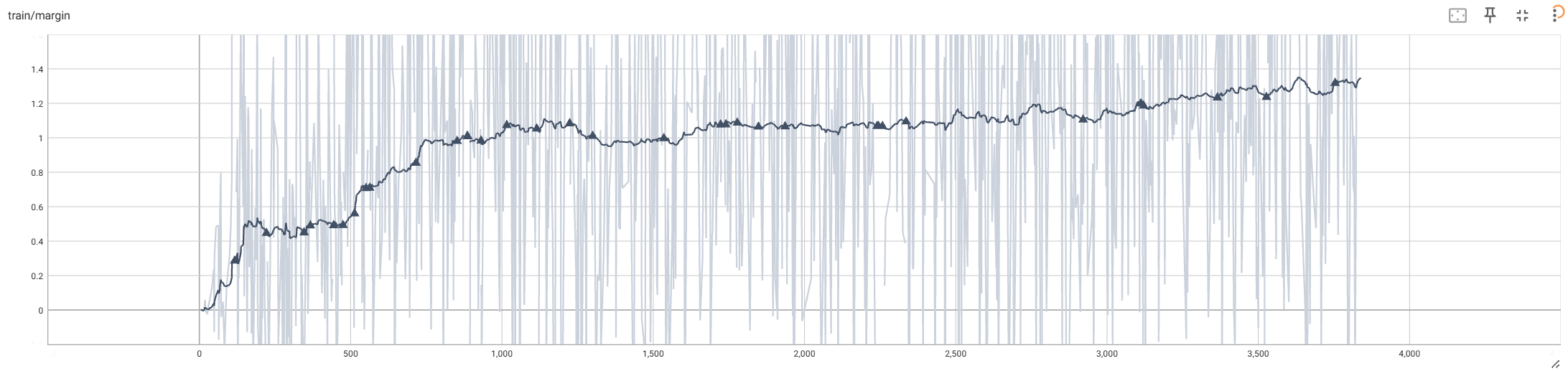
@@ -744,13 +772,50 @@ with a Reference-Free Reward](https://arxiv.org/pdf/2405.14734) (SimPO). Which i ### Alternative Option For RLHF: Odds Ratio Preference Optimization -We support the method introduced in the paper [ORPO: Monolithic Preference Optimization without Reference Model](https://arxiv.org/abs/2403.07691) (ORPO). Which is a reference model free aligment method that mixes the SFT loss with a reinforcement learning loss that uses odds ratio as the implicit reward to enhance training stability and efficiency. Simply set the flag to disable the use of the reference model, set the reward target margin and enable length normalization in the DPO training script. To use ORPO in alignment, use the [train_orpo.sh](./examples/training_scripts/train_orpo.sh) script, You can set the value for `lambda` (which determine how strongly the reinforcement learning loss affect the training) but it is optional. +We support the method introduced in the paper [ORPO: Monolithic Preference Optimization without Reference Model](https://arxiv.org/abs/2403.07691) (ORPO). Which is a reference model free aligment method that mixes the SFT loss with a reinforcement learning loss that uses odds ratio as the implicit reward to enhance training stability and efficiency. To use ORPO in alignment, use the [train_orpo.sh](./training_scripts/train_orpo.sh) script, You can set the value for `lambda` (which determine how strongly the reinforcement learning loss affect the training) but it is optional. #### ORPO Result
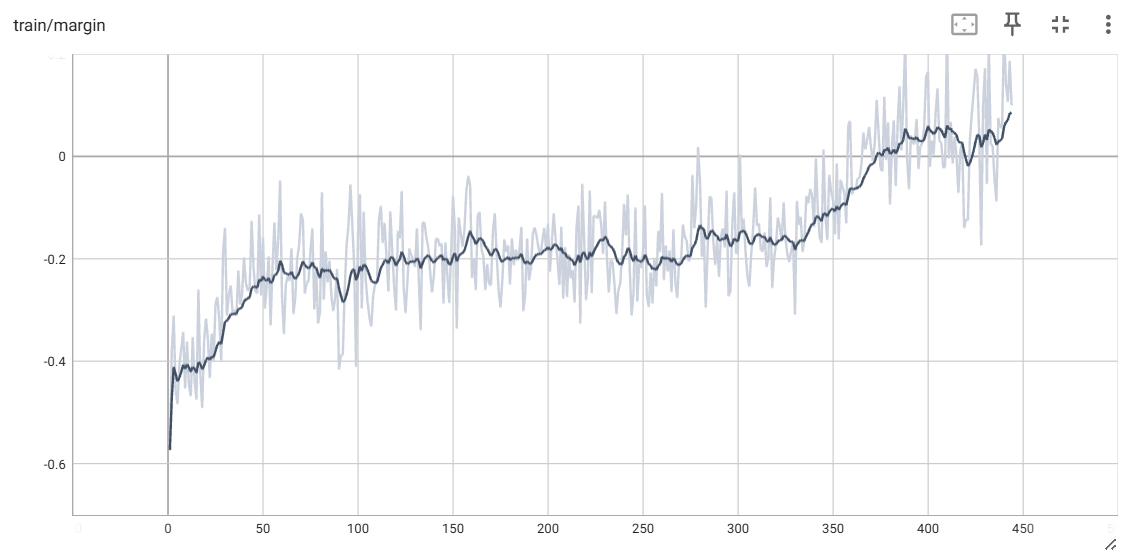
+ +
+
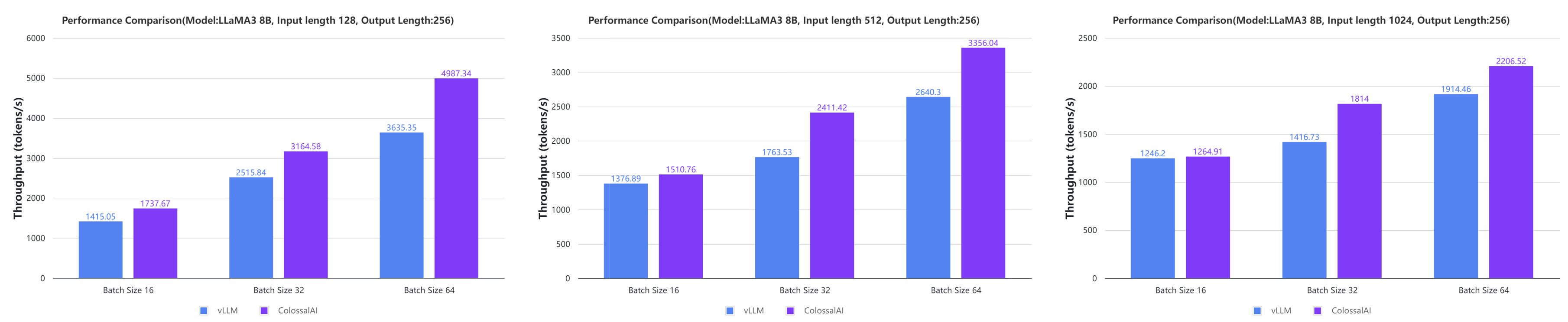 @@ -310,4 +310,14 @@ If you wish to cite relevant research papars, you can find the reference below.
journal={arXiv},
year={2023}
}
+
+# Distrifusion
+@InProceedings{Li_2024_CVPR,
+ author={Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Li, Kai and Han, Song},
+ title={DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month={June},
+ year={2024},
+ pages={7183-7193}
+}
```
diff --git a/colossalai/inference/config.py b/colossalai/inference/config.py
index 1beb86874826..072ddbcfd298 100644
--- a/colossalai/inference/config.py
+++ b/colossalai/inference/config.py
@@ -186,6 +186,7 @@ class InferenceConfig(RPC_PARAM):
enable_streamingllm(bool): Whether to use StreamingLLM, the relevant algorithms refer to the paper at https://arxiv.org/pdf/2309.17453 for implementation.
start_token_size(int): The size of the start tokens, when using StreamingLLM.
generated_token_size(int): The size of the generated tokens, When using StreamingLLM.
+ patched_parallelism_size(int): Patched Parallelism Size, When using Distrifusion
"""
# NOTE: arrange configs according to their importance and frequency of usage
@@ -245,6 +246,11 @@ class InferenceConfig(RPC_PARAM):
start_token_size: int = 4
generated_token_size: int = 512
+ # Acceleration for Diffusion Model(PipeFusion or Distrifusion)
+ patched_parallelism_size: int = 1 # for distrifusion
+ # pipeFusion_m_size: int = 1 # for pipefusion
+ # pipeFusion_n_size: int = 1 # for pipefusion
+
def __post_init__(self):
self.max_context_len_to_capture = self.max_input_len + self.max_output_len
self._verify_config()
@@ -288,6 +294,14 @@ def _verify_config(self) -> None:
# Thereafter, we swap out tokens in units of blocks, and always swapping out the second block when the generated tokens exceeded the limit.
self.start_token_size = self.block_size
+ # check Distrifusion
+ # TODO(@lry89757) need more detailed check
+ if self.patched_parallelism_size > 1:
+ # self.use_patched_parallelism = True
+ self.tp_size = (
+ self.patched_parallelism_size
+ ) # this is not a real tp, because some annoying check, so we have to set this to patched_parallelism_size
+
# check prompt template
if self.prompt_template is None:
return
@@ -324,6 +338,7 @@ def to_model_shard_inference_config(self) -> "ModelShardInferenceConfig":
use_cuda_kernel=self.use_cuda_kernel,
use_spec_dec=self.use_spec_dec,
use_flash_attn=use_flash_attn,
+ patched_parallelism_size=self.patched_parallelism_size,
)
return model_inference_config
@@ -396,6 +411,7 @@ class ModelShardInferenceConfig:
use_cuda_kernel: bool = False
use_spec_dec: bool = False
use_flash_attn: bool = False
+ patched_parallelism_size: int = 1 # for diffusion model, Distrifusion Technique
@dataclass
diff --git a/colossalai/inference/core/diffusion_engine.py b/colossalai/inference/core/diffusion_engine.py
index 75b9889bf28d..8bed508cba55 100644
--- a/colossalai/inference/core/diffusion_engine.py
+++ b/colossalai/inference/core/diffusion_engine.py
@@ -11,7 +11,7 @@
from colossalai.accelerator import get_accelerator
from colossalai.cluster import ProcessGroupMesh
from colossalai.inference.config import DiffusionGenerationConfig, InferenceConfig, ModelShardInferenceConfig
-from colossalai.inference.modeling.models.diffusion import DiffusionPipe
+from colossalai.inference.modeling.layers.diffusion import DiffusionPipe
from colossalai.inference.modeling.policy import model_policy_map
from colossalai.inference.struct import DiffusionSequence
from colossalai.inference.utils import get_model_size, get_model_type
diff --git a/colossalai/inference/modeling/models/diffusion.py b/colossalai/inference/modeling/layers/diffusion.py
similarity index 100%
rename from colossalai/inference/modeling/models/diffusion.py
rename to colossalai/inference/modeling/layers/diffusion.py
diff --git a/colossalai/inference/modeling/layers/distrifusion.py b/colossalai/inference/modeling/layers/distrifusion.py
new file mode 100644
index 000000000000..ea97cceefac9
--- /dev/null
+++ b/colossalai/inference/modeling/layers/distrifusion.py
@@ -0,0 +1,626 @@
+# Code refer and adapted from:
+# https://github.com/huggingface/diffusers/blob/v0.29.0-release/src/diffusers
+# https://github.com/PipeFusion/PipeFusion
+
+import inspect
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.distributed as dist
+import torch.nn.functional as F
+from diffusers.models import attention_processor
+from diffusers.models.attention import Attention
+from diffusers.models.embeddings import PatchEmbed, get_2d_sincos_pos_embed
+from diffusers.models.transformers.pixart_transformer_2d import PixArtTransformer2DModel
+from diffusers.models.transformers.transformer_sd3 import SD3Transformer2DModel
+from torch import nn
+from torch.distributed import ProcessGroup
+
+from colossalai.inference.config import ModelShardInferenceConfig
+from colossalai.logging import get_dist_logger
+from colossalai.shardformer.layer.parallel_module import ParallelModule
+from colossalai.utils import get_current_device
+
+try:
+ from flash_attn import flash_attn_func
+
+ HAS_FLASH_ATTN = True
+except ImportError:
+ HAS_FLASH_ATTN = False
+
+
+logger = get_dist_logger(__name__)
+
+
+# adapted from https://github.com/huggingface/diffusers/blob/v0.29.0-release/src/diffusers/models/transformers/transformer_2d.py
+def PixArtAlphaTransformer2DModel_forward(
+ self: PixArtTransformer2DModel,
+ hidden_states: torch.Tensor,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ timestep: Optional[torch.LongTensor] = None,
+ added_cond_kwargs: Dict[str, torch.Tensor] = None,
+ class_labels: Optional[torch.LongTensor] = None,
+ cross_attention_kwargs: Dict[str, Any] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+):
+ assert hasattr(
+ self, "patched_parallel_size"
+ ), "please check your policy, `Transformer2DModel` Must have attribute `patched_parallel_size`"
+
+ if cross_attention_kwargs is not None:
+ if cross_attention_kwargs.get("scale", None) is not None:
+ logger.warning("Passing `scale` to `cross_attention_kwargs` is deprecated. `scale` will be ignored.")
+ # ensure attention_mask is a bias, and give it a singleton query_tokens dimension.
+ # we may have done this conversion already, e.g. if we came here via UNet2DConditionModel#forward.
+ # we can tell by counting dims; if ndim == 2: it's a mask rather than a bias.
+ # expects mask of shape:
+ # [batch, key_tokens]
+ # adds singleton query_tokens dimension:
+ # [batch, 1, key_tokens]
+ # this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
+ # [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
+ # [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
+ if attention_mask is not None and attention_mask.ndim == 2:
+ # assume that mask is expressed as:
+ # (1 = keep, 0 = discard)
+ # convert mask into a bias that can be added to attention scores:
+ # (keep = +0, discard = -10000.0)
+ attention_mask = (1 - attention_mask.to(hidden_states.dtype)) * -10000.0
+ attention_mask = attention_mask.unsqueeze(1)
+
+ # convert encoder_attention_mask to a bias the same way we do for attention_mask
+ if encoder_attention_mask is not None and encoder_attention_mask.ndim == 2:
+ encoder_attention_mask = (1 - encoder_attention_mask.to(hidden_states.dtype)) * -10000.0
+ encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
+
+ # 1. Input
+ batch_size = hidden_states.shape[0]
+ height, width = (
+ hidden_states.shape[-2] // self.config.patch_size,
+ hidden_states.shape[-1] // self.config.patch_size,
+ )
+ hidden_states = self.pos_embed(hidden_states)
+
+ timestep, embedded_timestep = self.adaln_single(
+ timestep, added_cond_kwargs, batch_size=batch_size, hidden_dtype=hidden_states.dtype
+ )
+
+ if self.caption_projection is not None:
+ encoder_hidden_states = self.caption_projection(encoder_hidden_states)
+ encoder_hidden_states = encoder_hidden_states.view(batch_size, -1, hidden_states.shape[-1])
+
+ # 2. Blocks
+ for block in self.transformer_blocks:
+ hidden_states = block(
+ hidden_states,
+ attention_mask=attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ timestep=timestep,
+ cross_attention_kwargs=cross_attention_kwargs,
+ class_labels=class_labels,
+ )
+
+ # 3. Output
+ shift, scale = (self.scale_shift_table[None] + embedded_timestep[:, None].to(self.scale_shift_table.device)).chunk(
+ 2, dim=1
+ )
+ hidden_states = self.norm_out(hidden_states)
+ # Modulation
+ hidden_states = hidden_states * (1 + scale.to(hidden_states.device)) + shift.to(hidden_states.device)
+ hidden_states = self.proj_out(hidden_states)
+ hidden_states = hidden_states.squeeze(1)
+
+ # unpatchify
+ hidden_states = hidden_states.reshape(
+ shape=(
+ -1,
+ height // self.patched_parallel_size,
+ width,
+ self.config.patch_size,
+ self.config.patch_size,
+ self.out_channels,
+ )
+ )
+ hidden_states = torch.einsum("nhwpqc->nchpwq", hidden_states)
+ output = hidden_states.reshape(
+ shape=(
+ -1,
+ self.out_channels,
+ height // self.patched_parallel_size * self.config.patch_size,
+ width * self.config.patch_size,
+ )
+ )
+
+ # enable Distrifusion Optimization
+ if hasattr(self, "patched_parallel_size"):
+ from torch import distributed as dist
+
+ if (getattr(self, "output_buffer", None) is None) or (self.output_buffer.shape != output.shape):
+ self.output_buffer = torch.empty_like(output)
+ if (getattr(self, "buffer_list", None) is None) or (self.buffer_list[0].shape != output.shape):
+ self.buffer_list = [torch.empty_like(output) for _ in range(self.patched_parallel_size)]
+ output = output.contiguous()
+ dist.all_gather(self.buffer_list, output, async_op=False)
+ torch.cat(self.buffer_list, dim=2, out=self.output_buffer)
+ output = self.output_buffer
+
+ return (output,)
+
+
+# adapted from https://github.com/huggingface/diffusers/blob/v0.29.0-release/src/diffusers/models/transformers/transformer_sd3.py
+def SD3Transformer2DModel_forward(
+ self: SD3Transformer2DModel,
+ hidden_states: torch.FloatTensor,
+ encoder_hidden_states: torch.FloatTensor = None,
+ pooled_projections: torch.FloatTensor = None,
+ timestep: torch.LongTensor = None,
+ joint_attention_kwargs: Optional[Dict[str, Any]] = None,
+ return_dict: bool = True,
+) -> Union[torch.FloatTensor]:
+
+ assert hasattr(
+ self, "patched_parallel_size"
+ ), "please check your policy, `Transformer2DModel` Must have attribute `patched_parallel_size`"
+
+ height, width = hidden_states.shape[-2:]
+
+ hidden_states = self.pos_embed(hidden_states) # takes care of adding positional embeddings too.
+ temb = self.time_text_embed(timestep, pooled_projections)
+ encoder_hidden_states = self.context_embedder(encoder_hidden_states)
+
+ for block in self.transformer_blocks:
+ encoder_hidden_states, hidden_states = block(
+ hidden_states=hidden_states, encoder_hidden_states=encoder_hidden_states, temb=temb
+ )
+
+ hidden_states = self.norm_out(hidden_states, temb)
+ hidden_states = self.proj_out(hidden_states)
+
+ # unpatchify
+ patch_size = self.config.patch_size
+ height = height // patch_size // self.patched_parallel_size
+ width = width // patch_size
+
+ hidden_states = hidden_states.reshape(
+ shape=(hidden_states.shape[0], height, width, patch_size, patch_size, self.out_channels)
+ )
+ hidden_states = torch.einsum("nhwpqc->nchpwq", hidden_states)
+ output = hidden_states.reshape(
+ shape=(hidden_states.shape[0], self.out_channels, height * patch_size, width * patch_size)
+ )
+
+ # enable Distrifusion Optimization
+ if hasattr(self, "patched_parallel_size"):
+ from torch import distributed as dist
+
+ if (getattr(self, "output_buffer", None) is None) or (self.output_buffer.shape != output.shape):
+ self.output_buffer = torch.empty_like(output)
+ if (getattr(self, "buffer_list", None) is None) or (self.buffer_list[0].shape != output.shape):
+ self.buffer_list = [torch.empty_like(output) for _ in range(self.patched_parallel_size)]
+ output = output.contiguous()
+ dist.all_gather(self.buffer_list, output, async_op=False)
+ torch.cat(self.buffer_list, dim=2, out=self.output_buffer)
+ output = self.output_buffer
+
+ return (output,)
+
+
+# Code adapted from: https://github.com/PipeFusion/PipeFusion/blob/main/pipefuser/modules/dit/patch_parallel/patchembed.py
+class DistrifusionPatchEmbed(ParallelModule):
+ def __init__(
+ self,
+ module: PatchEmbed,
+ process_group: Union[ProcessGroup, List[ProcessGroup]],
+ model_shard_infer_config: ModelShardInferenceConfig = None,
+ ):
+ super().__init__()
+ self.module = module
+ self.rank = dist.get_rank(group=process_group)
+ self.patched_parallelism_size = model_shard_infer_config.patched_parallelism_size
+
+ @staticmethod
+ def from_native_module(module: PatchEmbed, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs):
+ model_shard_infer_config = kwargs.get("model_shard_infer_config", None)
+ distrifusion_embed = DistrifusionPatchEmbed(
+ module, process_group, model_shard_infer_config=model_shard_infer_config
+ )
+ return distrifusion_embed
+
+ def forward(self, latent):
+ module = self.module
+ if module.pos_embed_max_size is not None:
+ height, width = latent.shape[-2:]
+ else:
+ height, width = latent.shape[-2] // module.patch_size, latent.shape[-1] // module.patch_size
+
+ latent = module.proj(latent)
+ if module.flatten:
+ latent = latent.flatten(2).transpose(1, 2) # BCHW -> BNC
+ if module.layer_norm:
+ latent = module.norm(latent)
+ if module.pos_embed is None:
+ return latent.to(latent.dtype)
+ # Interpolate or crop positional embeddings as needed
+ if module.pos_embed_max_size:
+ pos_embed = module.cropped_pos_embed(height, width)
+ else:
+ if module.height != height or module.width != width:
+ pos_embed = get_2d_sincos_pos_embed(
+ embed_dim=module.pos_embed.shape[-1],
+ grid_size=(height, width),
+ base_size=module.base_size,
+ interpolation_scale=module.interpolation_scale,
+ )
+ pos_embed = torch.from_numpy(pos_embed).float().unsqueeze(0).to(latent.device)
+ else:
+ pos_embed = module.pos_embed
+
+ b, c, h = pos_embed.shape
+ pos_embed = pos_embed.view(b, self.patched_parallelism_size, -1, h)[:, self.rank]
+
+ return (latent + pos_embed).to(latent.dtype)
+
+
+# Code adapted from: https://github.com/PipeFusion/PipeFusion/blob/main/pipefuser/modules/dit/patch_parallel/conv2d.py
+class DistrifusionConv2D(ParallelModule):
+
+ def __init__(
+ self,
+ module: nn.Conv2d,
+ process_group: Union[ProcessGroup, List[ProcessGroup]],
+ model_shard_infer_config: ModelShardInferenceConfig = None,
+ ):
+ super().__init__()
+ self.module = module
+ self.rank = dist.get_rank(group=process_group)
+ self.patched_parallelism_size = model_shard_infer_config.patched_parallelism_size
+
+ @staticmethod
+ def from_native_module(module: nn.Conv2d, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs):
+ model_shard_infer_config = kwargs.get("model_shard_infer_config", None)
+ distrifusion_conv = DistrifusionConv2D(module, process_group, model_shard_infer_config=model_shard_infer_config)
+ return distrifusion_conv
+
+ def sliced_forward(self, x: torch.Tensor) -> torch.Tensor:
+
+ b, c, h, w = x.shape
+
+ stride = self.module.stride[0]
+ padding = self.module.padding[0]
+
+ output_h = x.shape[2] // stride // self.patched_parallelism_size
+ idx = dist.get_rank()
+ h_begin = output_h * idx * stride - padding
+ h_end = output_h * (idx + 1) * stride + padding
+ final_padding = [padding, padding, 0, 0]
+ if h_begin < 0:
+ h_begin = 0
+ final_padding[2] = padding
+ if h_end > h:
+ h_end = h
+ final_padding[3] = padding
+ sliced_input = x[:, :, h_begin:h_end, :]
+ padded_input = F.pad(sliced_input, final_padding, mode="constant")
+ return F.conv2d(
+ padded_input,
+ self.module.weight,
+ self.module.bias,
+ stride=stride,
+ padding="valid",
+ )
+
+ def forward(self, input: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
+ output = self.sliced_forward(input)
+ return output
+
+
+# Code adapted from: https://github.com/huggingface/diffusers/blob/v0.29.0-release/src/diffusers/models/attention_processor.py
+class DistrifusionFusedAttention(ParallelModule):
+
+ def __init__(
+ self,
+ module: attention_processor.Attention,
+ process_group: Union[ProcessGroup, List[ProcessGroup]],
+ model_shard_infer_config: ModelShardInferenceConfig = None,
+ ):
+ super().__init__()
+ self.counter = 0
+ self.module = module
+ self.buffer_list = None
+ self.kv_buffer_idx = dist.get_rank(group=process_group)
+ self.patched_parallelism_size = model_shard_infer_config.patched_parallelism_size
+ self.handle = None
+ self.process_group = process_group
+ self.warm_step = 5 # for warmup
+
+ @staticmethod
+ def from_native_module(
+ module: attention_processor.Attention, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ model_shard_infer_config = kwargs.get("model_shard_infer_config", None)
+ return DistrifusionFusedAttention(
+ module=module,
+ process_group=process_group,
+ model_shard_infer_config=model_shard_infer_config,
+ )
+
+ def _forward(
+ self,
+ attn: Attention,
+ hidden_states: torch.FloatTensor,
+ encoder_hidden_states: torch.FloatTensor = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ *args,
+ **kwargs,
+ ) -> torch.FloatTensor:
+ residual = hidden_states
+
+ input_ndim = hidden_states.ndim
+ if input_ndim == 4:
+ batch_size, channel, height, width = hidden_states.shape
+ hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
+ context_input_ndim = encoder_hidden_states.ndim
+ if context_input_ndim == 4:
+ batch_size, channel, height, width = encoder_hidden_states.shape
+ encoder_hidden_states = encoder_hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
+
+ batch_size = encoder_hidden_states.shape[0]
+
+ # `sample` projections.
+ query = attn.to_q(hidden_states)
+ key = attn.to_k(hidden_states)
+ value = attn.to_v(hidden_states)
+
+ kv = torch.cat([key, value], dim=-1) # shape of kv now: (bs, seq_len // parallel_size, dim * 2)
+
+ if self.patched_parallelism_size == 1:
+ full_kv = kv
+ else:
+ if self.buffer_list is None: # buffer not created
+ full_kv = torch.cat([kv for _ in range(self.patched_parallelism_size)], dim=1)
+ elif self.counter <= self.warm_step:
+ # logger.info(f"warmup: {self.counter}")
+ dist.all_gather(
+ self.buffer_list,
+ kv,
+ group=self.process_group,
+ async_op=False,
+ )
+ full_kv = torch.cat(self.buffer_list, dim=1)
+ else:
+ # logger.info(f"use old kv to infer: {self.counter}")
+ self.buffer_list[self.kv_buffer_idx].copy_(kv)
+ full_kv = torch.cat(self.buffer_list, dim=1)
+ assert self.handle is None, "we should maintain the kv of last step"
+ self.handle = dist.all_gather(self.buffer_list, kv, group=self.process_group, async_op=True)
+
+ key, value = torch.split(full_kv, full_kv.shape[-1] // 2, dim=-1)
+
+ # `context` projections.
+ encoder_hidden_states_query_proj = attn.add_q_proj(encoder_hidden_states)
+ encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
+ encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
+
+ # attention
+ query = torch.cat([query, encoder_hidden_states_query_proj], dim=1)
+ key = torch.cat([key, encoder_hidden_states_key_proj], dim=1)
+ value = torch.cat([value, encoder_hidden_states_value_proj], dim=1)
+
+ inner_dim = key.shape[-1]
+ head_dim = inner_dim // attn.heads
+ query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+ key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+ value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+
+ hidden_states = hidden_states = F.scaled_dot_product_attention(
+ query, key, value, dropout_p=0.0, is_causal=False
+ ) # NOTE(@lry89757) for torch >= 2.2, flash attn has been already integrated into scaled_dot_product_attention, https://pytorch.org/blog/pytorch2-2/
+ hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
+ hidden_states = hidden_states.to(query.dtype)
+
+ # Split the attention outputs.
+ hidden_states, encoder_hidden_states = (
+ hidden_states[:, : residual.shape[1]],
+ hidden_states[:, residual.shape[1] :],
+ )
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+ if not attn.context_pre_only:
+ encoder_hidden_states = attn.to_add_out(encoder_hidden_states)
+
+ if input_ndim == 4:
+ hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
+ if context_input_ndim == 4:
+ encoder_hidden_states = encoder_hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
+
+ return hidden_states, encoder_hidden_states
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ **cross_attention_kwargs,
+ ) -> torch.Tensor:
+
+ if self.handle is not None:
+ self.handle.wait()
+ self.handle = None
+
+ b, l, c = hidden_states.shape
+ kv_shape = (b, l, self.module.to_k.out_features * 2)
+ if self.patched_parallelism_size > 1 and (self.buffer_list is None or self.buffer_list[0].shape != kv_shape):
+
+ self.buffer_list = [
+ torch.empty(kv_shape, dtype=hidden_states.dtype, device=get_current_device())
+ for _ in range(self.patched_parallelism_size)
+ ]
+
+ self.counter = 0
+
+ attn_parameters = set(inspect.signature(self.module.processor.__call__).parameters.keys())
+ quiet_attn_parameters = {"ip_adapter_masks"}
+ unused_kwargs = [
+ k for k, _ in cross_attention_kwargs.items() if k not in attn_parameters and k not in quiet_attn_parameters
+ ]
+ if len(unused_kwargs) > 0:
+ logger.warning(
+ f"cross_attention_kwargs {unused_kwargs} are not expected by {self.module.processor.__class__.__name__} and will be ignored."
+ )
+ cross_attention_kwargs = {k: w for k, w in cross_attention_kwargs.items() if k in attn_parameters}
+
+ output = self._forward(
+ self.module,
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ **cross_attention_kwargs,
+ )
+
+ self.counter += 1
+
+ return output
+
+
+# Code adapted from: https://github.com/PipeFusion/PipeFusion/blob/main/pipefuser/modules/dit/patch_parallel/attn.py
+class DistriSelfAttention(ParallelModule):
+ def __init__(
+ self,
+ module: Attention,
+ process_group: Union[ProcessGroup, List[ProcessGroup]],
+ model_shard_infer_config: ModelShardInferenceConfig = None,
+ ):
+ super().__init__()
+ self.counter = 0
+ self.module = module
+ self.buffer_list = None
+ self.kv_buffer_idx = dist.get_rank(group=process_group)
+ self.patched_parallelism_size = model_shard_infer_config.patched_parallelism_size
+ self.handle = None
+ self.process_group = process_group
+ self.warm_step = 3 # for warmup
+
+ @staticmethod
+ def from_native_module(
+ module: Attention, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ model_shard_infer_config = kwargs.get("model_shard_infer_config", None)
+ return DistriSelfAttention(
+ module=module,
+ process_group=process_group,
+ model_shard_infer_config=model_shard_infer_config,
+ )
+
+ def _forward(self, hidden_states: torch.FloatTensor, scale: float = 1.0):
+ attn = self.module
+ assert isinstance(attn, Attention)
+
+ residual = hidden_states
+
+ batch_size, sequence_length, _ = hidden_states.shape
+
+ query = attn.to_q(hidden_states)
+
+ encoder_hidden_states = hidden_states
+ k = self.module.to_k(encoder_hidden_states)
+ v = self.module.to_v(encoder_hidden_states)
+ kv = torch.cat([k, v], dim=-1) # shape of kv now: (bs, seq_len // parallel_size, dim * 2)
+
+ if self.patched_parallelism_size == 1:
+ full_kv = kv
+ else:
+ if self.buffer_list is None: # buffer not created
+ full_kv = torch.cat([kv for _ in range(self.patched_parallelism_size)], dim=1)
+ elif self.counter <= self.warm_step:
+ # logger.info(f"warmup: {self.counter}")
+ dist.all_gather(
+ self.buffer_list,
+ kv,
+ group=self.process_group,
+ async_op=False,
+ )
+ full_kv = torch.cat(self.buffer_list, dim=1)
+ else:
+ # logger.info(f"use old kv to infer: {self.counter}")
+ self.buffer_list[self.kv_buffer_idx].copy_(kv)
+ full_kv = torch.cat(self.buffer_list, dim=1)
+ assert self.handle is None, "we should maintain the kv of last step"
+ self.handle = dist.all_gather(self.buffer_list, kv, group=self.process_group, async_op=True)
+
+ if HAS_FLASH_ATTN:
+ # flash attn
+ key, value = torch.split(full_kv, full_kv.shape[-1] // 2, dim=-1)
+ inner_dim = key.shape[-1]
+ head_dim = inner_dim // attn.heads
+
+ query = query.view(batch_size, -1, attn.heads, head_dim)
+ key = key.view(batch_size, -1, attn.heads, head_dim)
+ value = value.view(batch_size, -1, attn.heads, head_dim)
+
+ hidden_states = flash_attn_func(query, key, value, dropout_p=0.0, causal=False)
+ hidden_states = hidden_states.reshape(batch_size, -1, attn.heads * head_dim).to(query.dtype)
+ else:
+ # naive attn
+ key, value = torch.split(full_kv, full_kv.shape[-1] // 2, dim=-1)
+
+ inner_dim = key.shape[-1]
+ head_dim = inner_dim // attn.heads
+
+ query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+ key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+ value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+
+ # the output of sdp = (batch, num_heads, seq_len, head_dim)
+ # TODO: add support for attn.scale when we move to Torch 2.1
+ hidden_states = F.scaled_dot_product_attention(query, key, value, dropout_p=0.0, is_causal=False)
+
+ hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
+ hidden_states = hidden_states.to(query.dtype)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+
+ if attn.residual_connection:
+ hidden_states = hidden_states + residual
+
+ hidden_states = hidden_states / attn.rescale_output_factor
+
+ return hidden_states
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ scale: float = 1.0,
+ *args,
+ **kwargs,
+ ) -> torch.FloatTensor:
+
+ # async preallocates memo buffer
+ if self.handle is not None:
+ self.handle.wait()
+ self.handle = None
+
+ b, l, c = hidden_states.shape
+ kv_shape = (b, l, self.module.to_k.out_features * 2)
+ if self.patched_parallelism_size > 1 and (self.buffer_list is None or self.buffer_list[0].shape != kv_shape):
+
+ self.buffer_list = [
+ torch.empty(kv_shape, dtype=hidden_states.dtype, device=get_current_device())
+ for _ in range(self.patched_parallelism_size)
+ ]
+
+ self.counter = 0
+
+ output = self._forward(hidden_states, scale=scale)
+
+ self.counter += 1
+ return output
diff --git a/colossalai/inference/modeling/models/pixart_alpha.py b/colossalai/inference/modeling/models/pixart_alpha.py
index d5774946e365..cc2bee5efd4d 100644
--- a/colossalai/inference/modeling/models/pixart_alpha.py
+++ b/colossalai/inference/modeling/models/pixart_alpha.py
@@ -14,7 +14,7 @@
from colossalai.logging import get_dist_logger
-from .diffusion import DiffusionPipe
+from ..layers.diffusion import DiffusionPipe
logger = get_dist_logger(__name__)
diff --git a/colossalai/inference/modeling/models/stablediffusion3.py b/colossalai/inference/modeling/models/stablediffusion3.py
index d1c63a6dc665..b123164039c8 100644
--- a/colossalai/inference/modeling/models/stablediffusion3.py
+++ b/colossalai/inference/modeling/models/stablediffusion3.py
@@ -4,7 +4,7 @@
import torch
from diffusers.pipelines.stable_diffusion_3.pipeline_stable_diffusion_3 import retrieve_timesteps
-from .diffusion import DiffusionPipe
+from ..layers.diffusion import DiffusionPipe
# TODO(@lry89757) temporarily image, please support more return output
diff --git a/colossalai/inference/modeling/policy/pixart_alpha.py b/colossalai/inference/modeling/policy/pixart_alpha.py
index 356056ba73e7..1150b2432cc5 100644
--- a/colossalai/inference/modeling/policy/pixart_alpha.py
+++ b/colossalai/inference/modeling/policy/pixart_alpha.py
@@ -1,9 +1,17 @@
+from diffusers.models.attention import BasicTransformerBlock
+from diffusers.models.transformers.pixart_transformer_2d import PixArtTransformer2DModel
from torch import nn
from colossalai.inference.config import RPC_PARAM
-from colossalai.inference.modeling.models.diffusion import DiffusionPipe
+from colossalai.inference.modeling.layers.diffusion import DiffusionPipe
+from colossalai.inference.modeling.layers.distrifusion import (
+ DistrifusionConv2D,
+ DistrifusionPatchEmbed,
+ DistriSelfAttention,
+ PixArtAlphaTransformer2DModel_forward,
+)
from colossalai.inference.modeling.models.pixart_alpha import pixart_alpha_forward
-from colossalai.shardformer.policies.base_policy import Policy
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
class PixArtAlphaInferPolicy(Policy, RPC_PARAM):
@@ -12,9 +20,46 @@ def __init__(self) -> None:
def module_policy(self):
policy = {}
+
+ if self.shard_config.extra_kwargs["model_shard_infer_config"].patched_parallelism_size > 1:
+
+ policy[PixArtTransformer2DModel] = ModulePolicyDescription(
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="pos_embed.proj",
+ target_module=DistrifusionConv2D,
+ kwargs={"model_shard_infer_config": self.shard_config.extra_kwargs["model_shard_infer_config"]},
+ ),
+ SubModuleReplacementDescription(
+ suffix="pos_embed",
+ target_module=DistrifusionPatchEmbed,
+ kwargs={"model_shard_infer_config": self.shard_config.extra_kwargs["model_shard_infer_config"]},
+ ),
+ ],
+ attribute_replacement={
+ "patched_parallel_size": self.shard_config.extra_kwargs[
+ "model_shard_infer_config"
+ ].patched_parallelism_size
+ },
+ method_replacement={"forward": PixArtAlphaTransformer2DModel_forward},
+ )
+
+ policy[BasicTransformerBlock] = ModulePolicyDescription(
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="attn1",
+ target_module=DistriSelfAttention,
+ kwargs={
+ "model_shard_infer_config": self.shard_config.extra_kwargs["model_shard_infer_config"],
+ },
+ )
+ ]
+ )
+
self.append_or_create_method_replacement(
description={"forward": pixart_alpha_forward}, policy=policy, target_key=DiffusionPipe
)
+
return policy
def preprocess(self) -> nn.Module:
diff --git a/colossalai/inference/modeling/policy/stablediffusion3.py b/colossalai/inference/modeling/policy/stablediffusion3.py
index c9877f7dcae6..39b764b92887 100644
--- a/colossalai/inference/modeling/policy/stablediffusion3.py
+++ b/colossalai/inference/modeling/policy/stablediffusion3.py
@@ -1,9 +1,17 @@
+from diffusers.models.attention import JointTransformerBlock
+from diffusers.models.transformers import SD3Transformer2DModel
from torch import nn
from colossalai.inference.config import RPC_PARAM
-from colossalai.inference.modeling.models.diffusion import DiffusionPipe
+from colossalai.inference.modeling.layers.diffusion import DiffusionPipe
+from colossalai.inference.modeling.layers.distrifusion import (
+ DistrifusionConv2D,
+ DistrifusionFusedAttention,
+ DistrifusionPatchEmbed,
+ SD3Transformer2DModel_forward,
+)
from colossalai.inference.modeling.models.stablediffusion3 import sd3_forward
-from colossalai.shardformer.policies.base_policy import Policy
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
class StableDiffusion3InferPolicy(Policy, RPC_PARAM):
@@ -12,6 +20,42 @@ def __init__(self) -> None:
def module_policy(self):
policy = {}
+
+ if self.shard_config.extra_kwargs["model_shard_infer_config"].patched_parallelism_size > 1:
+
+ policy[SD3Transformer2DModel] = ModulePolicyDescription(
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="pos_embed.proj",
+ target_module=DistrifusionConv2D,
+ kwargs={"model_shard_infer_config": self.shard_config.extra_kwargs["model_shard_infer_config"]},
+ ),
+ SubModuleReplacementDescription(
+ suffix="pos_embed",
+ target_module=DistrifusionPatchEmbed,
+ kwargs={"model_shard_infer_config": self.shard_config.extra_kwargs["model_shard_infer_config"]},
+ ),
+ ],
+ attribute_replacement={
+ "patched_parallel_size": self.shard_config.extra_kwargs[
+ "model_shard_infer_config"
+ ].patched_parallelism_size
+ },
+ method_replacement={"forward": SD3Transformer2DModel_forward},
+ )
+
+ policy[JointTransformerBlock] = ModulePolicyDescription(
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="attn",
+ target_module=DistrifusionFusedAttention,
+ kwargs={
+ "model_shard_infer_config": self.shard_config.extra_kwargs["model_shard_infer_config"],
+ },
+ )
+ ]
+ )
+
self.append_or_create_method_replacement(
description={"forward": sd3_forward}, policy=policy, target_key=DiffusionPipe
)
diff --git a/colossalai/shardformer/layer/moe/__init__.py b/colossalai/legacy/moe/layer/__init__.py
similarity index 100%
rename from colossalai/shardformer/layer/moe/__init__.py
rename to colossalai/legacy/moe/layer/__init__.py
diff --git a/colossalai/shardformer/layer/moe/experts.py b/colossalai/legacy/moe/layer/experts.py
similarity index 95%
rename from colossalai/shardformer/layer/moe/experts.py
rename to colossalai/legacy/moe/layer/experts.py
index 1be7a27547ed..8088cf44e473 100644
--- a/colossalai/shardformer/layer/moe/experts.py
+++ b/colossalai/legacy/moe/layer/experts.py
@@ -5,9 +5,9 @@
import torch.nn as nn
from colossalai.kernel.triton.llama_act_combine_kernel import HAS_TRITON
-from colossalai.moe._operation import MoeInGradScaler, MoeOutGradScaler
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import get_activation
+from colossalai.legacy.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.utils import get_activation
+from colossalai.moe._operation import EPGradScalerIn, EPGradScalerOut
from colossalai.shardformer.layer.utils import Randomizer
from colossalai.tensor.moe_tensor.api import get_ep_rank, get_ep_size
@@ -118,7 +118,7 @@ def forward(
Returns:
torch.Tensor: The output tensor of shape (num_groups, num_experts, capacity, hidden_size)
"""
- x = MoeInGradScaler.apply(x, self.ep_size)
+ x = EPGradScalerIn.apply(x, self.ep_size)
e = x.size(1)
h = x.size(-1)
@@ -157,5 +157,5 @@ def forward(
x = torch.cat([x[i].unsqueeze(0) for i in range(e)], dim=0)
x = x.reshape(inshape)
x = x.transpose(0, 1).contiguous()
- x = MoeOutGradScaler.apply(x, self.ep_size)
+ x = EPGradScalerOut.apply(x, self.ep_size)
return x
diff --git a/colossalai/shardformer/layer/moe/layers.py b/colossalai/legacy/moe/layer/layers.py
similarity index 99%
rename from colossalai/shardformer/layer/moe/layers.py
rename to colossalai/legacy/moe/layer/layers.py
index e5b0ef97fd87..e43966f68a8c 100644
--- a/colossalai/shardformer/layer/moe/layers.py
+++ b/colossalai/legacy/moe/layer/layers.py
@@ -7,9 +7,9 @@
import torch.nn as nn
import torch.nn.functional as F
+from colossalai.legacy.moe.load_balance import LoadBalancer
+from colossalai.legacy.moe.utils import create_ep_hierarchical_group, get_noise_generator
from colossalai.moe._operation import AllGather, AllToAll, HierarchicalAllToAll, MoeCombine, MoeDispatch, ReduceScatter
-from colossalai.moe.load_balance import LoadBalancer
-from colossalai.moe.utils import create_ep_hierarchical_group, get_noise_generator
from colossalai.shardformer.layer.moe import MLPExperts
from colossalai.tensor.moe_tensor.api import get_dp_group, get_ep_group, get_ep_group_ranks, get_ep_size
diff --git a/colossalai/shardformer/layer/moe/routers.py b/colossalai/legacy/moe/layer/routers.py
similarity index 95%
rename from colossalai/shardformer/layer/moe/routers.py
rename to colossalai/legacy/moe/layer/routers.py
index 1be7a27547ed..8088cf44e473 100644
--- a/colossalai/shardformer/layer/moe/routers.py
+++ b/colossalai/legacy/moe/layer/routers.py
@@ -5,9 +5,9 @@
import torch.nn as nn
from colossalai.kernel.triton.llama_act_combine_kernel import HAS_TRITON
-from colossalai.moe._operation import MoeInGradScaler, MoeOutGradScaler
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import get_activation
+from colossalai.legacy.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.utils import get_activation
+from colossalai.moe._operation import EPGradScalerIn, EPGradScalerOut
from colossalai.shardformer.layer.utils import Randomizer
from colossalai.tensor.moe_tensor.api import get_ep_rank, get_ep_size
@@ -118,7 +118,7 @@ def forward(
Returns:
torch.Tensor: The output tensor of shape (num_groups, num_experts, capacity, hidden_size)
"""
- x = MoeInGradScaler.apply(x, self.ep_size)
+ x = EPGradScalerIn.apply(x, self.ep_size)
e = x.size(1)
h = x.size(-1)
@@ -157,5 +157,5 @@ def forward(
x = torch.cat([x[i].unsqueeze(0) for i in range(e)], dim=0)
x = x.reshape(inshape)
x = x.transpose(0, 1).contiguous()
- x = MoeOutGradScaler.apply(x, self.ep_size)
+ x = EPGradScalerOut.apply(x, self.ep_size)
return x
diff --git a/colossalai/moe/load_balance.py b/colossalai/legacy/moe/load_balance.py
similarity index 99%
rename from colossalai/moe/load_balance.py
rename to colossalai/legacy/moe/load_balance.py
index 3dc6c02c7445..7339b1a7b0eb 100644
--- a/colossalai/moe/load_balance.py
+++ b/colossalai/legacy/moe/load_balance.py
@@ -7,7 +7,7 @@
from torch.distributed import ProcessGroup
from colossalai.cluster import ProcessGroupMesh
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
from colossalai.shardformer.layer.moe import MLPExperts
from colossalai.zero.low_level import LowLevelZeroOptimizer
diff --git a/colossalai/moe/manager.py b/colossalai/legacy/moe/manager.py
similarity index 100%
rename from colossalai/moe/manager.py
rename to colossalai/legacy/moe/manager.py
diff --git a/examples/language/openmoe/README.md b/colossalai/legacy/moe/openmoe/README.md
similarity index 100%
rename from examples/language/openmoe/README.md
rename to colossalai/legacy/moe/openmoe/README.md
diff --git a/examples/language/openmoe/benchmark/benchmark_cai.py b/colossalai/legacy/moe/openmoe/benchmark/benchmark_cai.py
similarity index 99%
rename from examples/language/openmoe/benchmark/benchmark_cai.py
rename to colossalai/legacy/moe/openmoe/benchmark/benchmark_cai.py
index b9ef915c32a4..5f9447246ae4 100644
--- a/examples/language/openmoe/benchmark/benchmark_cai.py
+++ b/colossalai/legacy/moe/openmoe/benchmark/benchmark_cai.py
@@ -18,9 +18,9 @@
from colossalai.booster import Booster
from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
from colossalai.cluster import DistCoordinator
+from colossalai.legacy.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.utils import skip_init
from colossalai.moe.layers import apply_load_balance
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import skip_init
from colossalai.nn.optimizer import HybridAdam
diff --git a/examples/language/openmoe/benchmark/benchmark_cai.sh b/colossalai/legacy/moe/openmoe/benchmark/benchmark_cai.sh
similarity index 100%
rename from examples/language/openmoe/benchmark/benchmark_cai.sh
rename to colossalai/legacy/moe/openmoe/benchmark/benchmark_cai.sh
diff --git a/examples/language/openmoe/benchmark/benchmark_cai_dist.sh b/colossalai/legacy/moe/openmoe/benchmark/benchmark_cai_dist.sh
similarity index 100%
rename from examples/language/openmoe/benchmark/benchmark_cai_dist.sh
rename to colossalai/legacy/moe/openmoe/benchmark/benchmark_cai_dist.sh
diff --git a/examples/language/openmoe/benchmark/benchmark_fsdp.py b/colossalai/legacy/moe/openmoe/benchmark/benchmark_fsdp.py
similarity index 98%
rename from examples/language/openmoe/benchmark/benchmark_fsdp.py
rename to colossalai/legacy/moe/openmoe/benchmark/benchmark_fsdp.py
index b00fbd001022..1ae94dd90977 100644
--- a/examples/language/openmoe/benchmark/benchmark_fsdp.py
+++ b/colossalai/legacy/moe/openmoe/benchmark/benchmark_fsdp.py
@@ -14,7 +14,7 @@
from transformers.models.llama import LlamaConfig
from utils import PerformanceEvaluator, get_model_numel
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
class RandomDataset(Dataset):
diff --git a/examples/language/openmoe/benchmark/benchmark_fsdp.sh b/colossalai/legacy/moe/openmoe/benchmark/benchmark_fsdp.sh
similarity index 100%
rename from examples/language/openmoe/benchmark/benchmark_fsdp.sh
rename to colossalai/legacy/moe/openmoe/benchmark/benchmark_fsdp.sh
diff --git a/examples/language/openmoe/benchmark/hostfile.txt b/colossalai/legacy/moe/openmoe/benchmark/hostfile.txt
similarity index 100%
rename from examples/language/openmoe/benchmark/hostfile.txt
rename to colossalai/legacy/moe/openmoe/benchmark/hostfile.txt
diff --git a/examples/language/openmoe/benchmark/utils.py b/colossalai/legacy/moe/openmoe/benchmark/utils.py
similarity index 100%
rename from examples/language/openmoe/benchmark/utils.py
rename to colossalai/legacy/moe/openmoe/benchmark/utils.py
diff --git a/examples/language/openmoe/infer.py b/colossalai/legacy/moe/openmoe/infer.py
similarity index 100%
rename from examples/language/openmoe/infer.py
rename to colossalai/legacy/moe/openmoe/infer.py
diff --git a/examples/language/openmoe/infer.sh b/colossalai/legacy/moe/openmoe/infer.sh
similarity index 100%
rename from examples/language/openmoe/infer.sh
rename to colossalai/legacy/moe/openmoe/infer.sh
diff --git a/examples/language/openmoe/model/__init__.py b/colossalai/legacy/moe/openmoe/model/__init__.py
similarity index 100%
rename from examples/language/openmoe/model/__init__.py
rename to colossalai/legacy/moe/openmoe/model/__init__.py
diff --git a/examples/language/openmoe/model/convert_openmoe_ckpt.py b/colossalai/legacy/moe/openmoe/model/convert_openmoe_ckpt.py
similarity index 100%
rename from examples/language/openmoe/model/convert_openmoe_ckpt.py
rename to colossalai/legacy/moe/openmoe/model/convert_openmoe_ckpt.py
diff --git a/examples/language/openmoe/model/convert_openmoe_ckpt.sh b/colossalai/legacy/moe/openmoe/model/convert_openmoe_ckpt.sh
similarity index 100%
rename from examples/language/openmoe/model/convert_openmoe_ckpt.sh
rename to colossalai/legacy/moe/openmoe/model/convert_openmoe_ckpt.sh
diff --git a/examples/language/openmoe/model/modeling_openmoe.py b/colossalai/legacy/moe/openmoe/model/modeling_openmoe.py
similarity index 99%
rename from examples/language/openmoe/model/modeling_openmoe.py
rename to colossalai/legacy/moe/openmoe/model/modeling_openmoe.py
index 1febacd7d226..5d6e91765883 100644
--- a/examples/language/openmoe/model/modeling_openmoe.py
+++ b/colossalai/legacy/moe/openmoe/model/modeling_openmoe.py
@@ -50,8 +50,8 @@
except:
HAS_FLASH_ATTN = False
from colossalai.kernel.triton.llama_act_combine_kernel import HAS_TRITON
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import get_activation, set_moe_args
+from colossalai.legacy.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.utils import get_activation, set_moe_args
from colossalai.shardformer.layer.moe import SparseMLP
if HAS_TRITON:
diff --git a/examples/language/openmoe/model/openmoe_8b_config.json b/colossalai/legacy/moe/openmoe/model/openmoe_8b_config.json
similarity index 100%
rename from examples/language/openmoe/model/openmoe_8b_config.json
rename to colossalai/legacy/moe/openmoe/model/openmoe_8b_config.json
diff --git a/examples/language/openmoe/model/openmoe_base_config.json b/colossalai/legacy/moe/openmoe/model/openmoe_base_config.json
similarity index 100%
rename from examples/language/openmoe/model/openmoe_base_config.json
rename to colossalai/legacy/moe/openmoe/model/openmoe_base_config.json
diff --git a/examples/language/openmoe/model/openmoe_policy.py b/colossalai/legacy/moe/openmoe/model/openmoe_policy.py
similarity index 99%
rename from examples/language/openmoe/model/openmoe_policy.py
rename to colossalai/legacy/moe/openmoe/model/openmoe_policy.py
index f46062128563..ccd566b08594 100644
--- a/examples/language/openmoe/model/openmoe_policy.py
+++ b/colossalai/legacy/moe/openmoe/model/openmoe_policy.py
@@ -9,7 +9,7 @@
from transformers.modeling_outputs import CausalLMOutputWithPast
from transformers.utils import logging
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
from colossalai.pipeline.stage_manager import PipelineStageManager
from colossalai.shardformer.layer import FusedRMSNorm, Linear1D_Col
from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
diff --git a/examples/language/openmoe/requirements.txt b/colossalai/legacy/moe/openmoe/requirements.txt
similarity index 100%
rename from examples/language/openmoe/requirements.txt
rename to colossalai/legacy/moe/openmoe/requirements.txt
diff --git a/examples/language/openmoe/test_ci.sh b/colossalai/legacy/moe/openmoe/test_ci.sh
similarity index 100%
rename from examples/language/openmoe/test_ci.sh
rename to colossalai/legacy/moe/openmoe/test_ci.sh
diff --git a/examples/language/openmoe/train.py b/colossalai/legacy/moe/openmoe/train.py
similarity index 99%
rename from examples/language/openmoe/train.py
rename to colossalai/legacy/moe/openmoe/train.py
index ff0e4bad6ee3..0173f0964453 100644
--- a/examples/language/openmoe/train.py
+++ b/colossalai/legacy/moe/openmoe/train.py
@@ -19,7 +19,7 @@
from colossalai.booster import Booster
from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
from colossalai.cluster import DistCoordinator
-from colossalai.moe.utils import skip_init
+from colossalai.legacy.moe.utils import skip_init
from colossalai.nn.optimizer import HybridAdam
from colossalai.shardformer.layer.moe import apply_load_balance
diff --git a/examples/language/openmoe/train.sh b/colossalai/legacy/moe/openmoe/train.sh
similarity index 100%
rename from examples/language/openmoe/train.sh
rename to colossalai/legacy/moe/openmoe/train.sh
diff --git a/colossalai/moe/utils.py b/colossalai/legacy/moe/utils.py
similarity index 99%
rename from colossalai/moe/utils.py
rename to colossalai/legacy/moe/utils.py
index 3d08ab7dd9b0..d91c41363316 100644
--- a/colossalai/moe/utils.py
+++ b/colossalai/legacy/moe/utils.py
@@ -9,7 +9,7 @@
from torch.distributed.distributed_c10d import get_process_group_ranks
from colossalai.accelerator import get_accelerator
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
from colossalai.tensor.moe_tensor.api import is_moe_tensor
diff --git a/colossalai/moe/__init__.py b/colossalai/moe/__init__.py
index 0623d19efd5f..e69de29bb2d1 100644
--- a/colossalai/moe/__init__.py
+++ b/colossalai/moe/__init__.py
@@ -1,5 +0,0 @@
-from .manager import MOE_MANAGER
-
-__all__ = [
- "MOE_MANAGER",
-]
diff --git a/colossalai/moe/_operation.py b/colossalai/moe/_operation.py
index 01c837ee36ad..ac422a4da98f 100644
--- a/colossalai/moe/_operation.py
+++ b/colossalai/moe/_operation.py
@@ -290,7 +290,7 @@ def moe_cumsum(inputs: Tensor, use_kernel: bool = False):
return torch.cumsum(inputs, dim=0) - 1
-class MoeInGradScaler(torch.autograd.Function):
+class EPGradScalerIn(torch.autograd.Function):
"""
Scale the gradient back by the number of experts
because the batch size increases in the moe stage
@@ -298,8 +298,7 @@ class MoeInGradScaler(torch.autograd.Function):
@staticmethod
def forward(ctx: Any, inputs: Tensor, ep_size: int) -> Tensor:
- if ctx is not None:
- ctx.ep_size = ep_size
+ ctx.ep_size = ep_size
return inputs
@staticmethod
@@ -311,7 +310,7 @@ def backward(ctx: Any, *grad_outputs: Tensor) -> Tuple[Tensor, None]:
return grad, None
-class MoeOutGradScaler(torch.autograd.Function):
+class EPGradScalerOut(torch.autograd.Function):
"""
Scale the gradient by the number of experts
because the batch size increases in the moe stage
@@ -331,6 +330,50 @@ def backward(ctx: Any, *grad_outputs: Tensor) -> Tuple[Tensor, None]:
return grad, None
+class DPGradScalerIn(torch.autograd.Function):
+ """
+ Scale the gradient back by the number of experts
+ because the batch size increases in the moe stage
+ """
+
+ @staticmethod
+ def forward(ctx: Any, inputs: Tensor, moe_dp_size: int, activated_experts: int) -> Tensor:
+ assert activated_experts != 0, f"shouldn't be called when no expert is activated"
+ ctx.moe_dp_size = moe_dp_size
+ ctx.activated_experts = activated_experts
+ return inputs
+
+ @staticmethod
+ def backward(ctx: Any, *grad_outputs: Tensor) -> Tuple[Tensor, None, None]:
+ assert len(grad_outputs) == 1
+ grad = grad_outputs[0]
+ if ctx.moe_dp_size != ctx.activated_experts:
+ grad.mul_(ctx.activated_experts / ctx.moe_dp_size)
+ return grad, None, None
+
+
+class DPGradScalerOut(torch.autograd.Function):
+ """
+ Scale the gradient by the number of experts
+ because the batch size increases in the moe stage
+ """
+
+ @staticmethod
+ def forward(ctx: Any, inputs: Tensor, moe_dp_size: int, activated_experts: int) -> Tensor:
+ assert activated_experts != 0, f"shouldn't be called when no expert is activated"
+ ctx.moe_dp_size = moe_dp_size
+ ctx.activated_experts = activated_experts
+ return inputs
+
+ @staticmethod
+ def backward(ctx: Any, *grad_outputs: Tensor) -> Tuple[Tensor, None, None]:
+ assert len(grad_outputs) == 1
+ grad = grad_outputs[0]
+ if ctx.moe_dp_size != ctx.activated_experts:
+ grad.mul_(ctx.moe_dp_size / ctx.activated_experts)
+ return grad, None, None
+
+
def _all_to_all(
inputs: torch.Tensor,
input_split_sizes: Optional[List[int]] = None,
@@ -393,4 +436,7 @@ def all_to_all_uneven(
group=None,
overlap: bool = False,
):
+ assert (
+ inputs.requires_grad
+ ), "Input must require grad to assure that backward is executed, otherwise it might hang the program."
return AllToAllUneven.apply(inputs, input_split_sizes, output_split_sizes, group, overlap)
diff --git a/colossalai/shardformer/layer/attn.py b/colossalai/shardformer/layer/attn.py
index 141baf3d3770..5872c64856b9 100644
--- a/colossalai/shardformer/layer/attn.py
+++ b/colossalai/shardformer/layer/attn.py
@@ -139,12 +139,11 @@ def prepare_attn_kwargs(
# no padding
assert is_causal
outputs["attention_mask_type"] = AttnMaskType.CAUSAL
- attention_mask = torch.ones(s_q, s_kv, dtype=dtype, device=device).tril(diagonal=0).expand(b, s_q, s_kv)
+ attention_mask = torch.ones(s_q, s_kv, dtype=dtype, device=device)
+ if s_q != 1:
+ attention_mask = attention_mask.tril(diagonal=0)
+ attention_mask = attention_mask.expand(b, s_q, s_kv)
else:
- assert q_padding_mask.shape == (
- b,
- s_q,
- ), f"q_padding_mask shape {q_padding_mask.shape} should be the same. ({shape_4d})"
max_seqlen_q, cu_seqlens_q, q_indices = get_pad_info(q_padding_mask)
if kv_padding_mask is None:
# self attention
@@ -156,7 +155,7 @@ def prepare_attn_kwargs(
b,
s_kv,
), f"q_padding_mask shape {kv_padding_mask.shape} should be the same. ({shape_4d})"
- attention_mask = q_padding_mask[:, None, :].expand(b, s_kv, s_q).to(dtype=dtype, device=device)
+ attention_mask = kv_padding_mask[:, None, :].expand(b, s_q, s_kv).to(dtype=dtype, device=device)
outputs.update(
{
"cu_seqlens_q": cu_seqlens_q,
@@ -169,7 +168,8 @@ def prepare_attn_kwargs(
)
if is_causal:
outputs["attention_mask_type"] = AttnMaskType.PADDED_CAUSAL
- attention_mask = attention_mask * attention_mask.new_ones(s_q, s_kv).tril(diagonal=0)
+ if s_q != 1:
+ attention_mask = attention_mask * attention_mask.new_ones(s_q, s_kv).tril(diagonal=0)
else:
outputs["attention_mask_type"] = AttnMaskType.PADDED
attention_mask = invert_mask(attention_mask).unsqueeze(1)
diff --git a/colossalai/shardformer/layer/qkv_fused_linear.py b/colossalai/shardformer/layer/qkv_fused_linear.py
index 0f6595a7c4d6..000934ad91a2 100644
--- a/colossalai/shardformer/layer/qkv_fused_linear.py
+++ b/colossalai/shardformer/layer/qkv_fused_linear.py
@@ -695,6 +695,7 @@ def from_native_module(
process_group=process_group,
weight=module.weight,
bias_=module.bias,
+ n_fused=n_fused,
*args,
**kwargs,
)
diff --git a/colossalai/shardformer/modeling/command.py b/colossalai/shardformer/modeling/command.py
index 759c8d7b8d59..5b36fc7db3b9 100644
--- a/colossalai/shardformer/modeling/command.py
+++ b/colossalai/shardformer/modeling/command.py
@@ -116,7 +116,7 @@ def command_model_forward(
# for the other stages, hidden_states is the output of the previous stage
if shard_config.enable_flash_attention:
# in this case, attention_mask is a dict rather than a tensor
- mask_shape = (batch_size, 1, seq_length_with_past, seq_length_with_past)
+ mask_shape = (batch_size, 1, seq_length, seq_length_with_past)
attention_mask = ColoAttention.prepare_attn_kwargs(
mask_shape,
hidden_states.dtype,
diff --git a/colossalai/shardformer/modeling/deepseek.py b/colossalai/shardformer/modeling/deepseek.py
index 6e79ce144cc8..a84a3097231a 100644
--- a/colossalai/shardformer/modeling/deepseek.py
+++ b/colossalai/shardformer/modeling/deepseek.py
@@ -1,21 +1,38 @@
-from typing import List, Optional, Union
+import warnings
+from typing import List, Optional, Tuple, Union
import torch
import torch.distributed as dist
import torch.nn as nn
from torch.distributed import ProcessGroup
-
-# from colossalai.tensor.moe_tensor.moe_info import MoeParallelInfo
from torch.nn import CrossEntropyLoss
-from transformers.modeling_attn_mask_utils import _prepare_4d_causal_attention_mask
-from transformers.modeling_outputs import CausalLMOutputWithPast
+from transformers.cache_utils import Cache, DynamicCache
+from transformers.modeling_attn_mask_utils import (
+ _prepare_4d_causal_attention_mask,
+ _prepare_4d_causal_attention_mask_for_sdpa,
+)
+from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
+from transformers.models.llama.modeling_llama import apply_rotary_pos_emb
from transformers.utils import is_flash_attn_2_available, logging
from colossalai.lazy import LazyInitContext
-from colossalai.moe._operation import MoeInGradScaler, MoeOutGradScaler, all_to_all_uneven
+from colossalai.moe._operation import (
+ DPGradScalerIn,
+ DPGradScalerOut,
+ EPGradScalerIn,
+ EPGradScalerOut,
+ all_to_all_uneven,
+)
from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer.layer._operation import (
+ all_to_all_comm,
+ gather_forward_split_backward,
+ split_forward_gather_backward,
+)
+from colossalai.shardformer.layer.linear import Linear1D_Col, Linear1D_Row
from colossalai.shardformer.shard import ShardConfig
from colossalai.shardformer.shard.utils import set_tensors_to_none
+from colossalai.tensor.moe_tensor.api import set_moe_tensor_ep_group
# copied from modeling_deepseek.py
@@ -42,30 +59,54 @@ def backward(ctx, grad_output):
class EPDeepseekMoE(nn.Module):
def __init__(self):
- super(EPDeepseekMoE, self).__init__()
+ raise RuntimeError(f"Please use `from_native_module` to create an instance of {self.__class__.__name__}")
+
+ def setup_process_groups(self, tp_group: ProcessGroup, moe_dp_group: ProcessGroup, ep_group: ProcessGroup):
+ assert tp_group is not None
+ assert moe_dp_group is not None
+ assert ep_group is not None
- def setup_ep(self, ep_group: ProcessGroup):
- ep_group = ep_group
- self.ep_size = dist.get_world_size(ep_group) if ep_group is not None else 1
- self.ep_rank = dist.get_rank(ep_group) if ep_group is not None else 0
+ self.ep_size = dist.get_world_size(ep_group)
+ self.ep_rank = dist.get_rank(ep_group)
self.num_experts = self.config.n_routed_experts
assert self.num_experts % self.ep_size == 0
+
self.ep_group = ep_group
self.num_experts_per_ep = self.num_experts // self.ep_size
self.expert_start_idx = self.ep_rank * self.num_experts_per_ep
held_experts = self.experts[self.expert_start_idx : self.expert_start_idx + self.num_experts_per_ep]
+
set_tensors_to_none(self.experts, exclude=set(held_experts))
+
+ # setup moe_dp group
+ self.moe_dp_group = moe_dp_group
+ self.moe_dp_size = moe_dp_group.size()
+
+ # setup tp group
+ self.tp_group = tp_group
+ if self.tp_group.size() > 1:
+ for expert in held_experts:
+ expert.gate_proj = Linear1D_Col.from_native_module(expert.gate_proj, self.tp_group)
+ expert.up_proj = Linear1D_Col.from_native_module(expert.up_proj, self.tp_group)
+ expert.down_proj = Linear1D_Row.from_native_module(expert.down_proj, self.tp_group)
+
for p in self.experts.parameters():
- p.ep_group = ep_group
+ set_moe_tensor_ep_group(p, ep_group)
@staticmethod
- def from_native_module(module: Union["DeepseekMoE", "DeepseekMLP"], *args, **kwargs) -> "EPDeepseekMoE":
+ def from_native_module(
+ module,
+ tp_group: ProcessGroup,
+ moe_dp_group: ProcessGroup,
+ ep_group: ProcessGroup,
+ *args,
+ **kwargs,
+ ) -> "EPDeepseekMoE":
LazyInitContext.materialize(module)
if module.__class__.__name__ == "DeepseekMLP":
return module
module.__class__ = EPDeepseekMoE
- assert "ep_group" in kwargs, "You should pass ep_group in SubModuleReplacementDescription via shard_config!!"
- module.setup_ep(kwargs["ep_group"])
+ module.setup_process_groups(tp_group, moe_dp_group, ep_group)
return module
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
@@ -91,15 +132,24 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# [n0, n1, n2, n3] [m0, m1, m2, m3] -> [n0, n1, m0, m1] [n2, n3, m2, m3]
dist.all_to_all_single(output_split_sizes, input_split_sizes, group=self.ep_group)
+ with torch.no_grad():
+ activate_experts = output_split_sizes[: self.num_experts_per_ep].clone()
+ for i in range(1, self.ep_size):
+ activate_experts += output_split_sizes[i * self.num_experts_per_ep : (i + 1) * self.num_experts_per_ep]
+ activate_experts = (activate_experts > 0).float()
+ dist.all_reduce(activate_experts, group=self.moe_dp_group)
+
input_split_list = input_split_sizes.view(self.ep_size, self.num_experts_per_ep).sum(dim=-1).tolist()
output_split_list = output_split_sizes.view(self.ep_size, self.num_experts_per_ep).sum(dim=-1).tolist()
output_states, _ = all_to_all_uneven(dispatch_states, input_split_list, output_split_list, self.ep_group)
- output_states = MoeInGradScaler.apply(output_states, self.ep_size)
+ output_states = EPGradScalerIn.apply(output_states, self.ep_size)
if output_states.size(0) > 0:
if self.num_experts_per_ep == 1:
expert = self.experts[self.expert_start_idx]
+ output_states = DPGradScalerIn.apply(output_states, self.moe_dp_size, activate_experts[0])
output_states = expert(output_states)
+ output_states = DPGradScalerOut.apply(output_states, self.moe_dp_size, activate_experts[0])
else:
output_states_splits = output_states.split(output_split_sizes.tolist())
output_states_list = []
@@ -107,10 +157,16 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
if split_states.size(0) == 0: # no token routed to this experts
continue
expert = self.experts[self.expert_start_idx + i % self.num_experts_per_ep]
+ split_states = DPGradScalerIn.apply(
+ split_states, self.moe_dp_size, activate_experts[i % self.num_experts_per_ep]
+ )
split_states = expert(split_states)
+ split_states = DPGradScalerOut.apply(
+ split_states, self.moe_dp_size, activate_experts[i % self.num_experts_per_ep]
+ )
output_states_list.append(split_states)
output_states = torch.cat(output_states_list)
- output_states = MoeOutGradScaler.apply(output_states, self.ep_size)
+ output_states = EPGradScalerOut.apply(output_states, self.ep_size)
dispatch_states, _ = all_to_all_uneven(output_states, output_split_list, input_split_list, self.ep_group)
recover_token_idx = torch.empty_like(flat_topk_token_idx)
recover_token_idx[flat_topk_token_idx] = torch.arange(
@@ -310,7 +366,14 @@ def custom_forward(*inputs):
next_cache = next_decoder_cache if use_cache else None
if stage_manager.is_last_stage():
- return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
# always return dict for imediate stage
return {
"hidden_states": hidden_states,
@@ -427,3 +490,265 @@ def deepseek_for_causal_lm_forward(
hidden_states = outputs.get("hidden_states")
out["hidden_states"] = hidden_states
return out
+
+
+def get_deepseek_flash_attention_forward(shard_config, sp_mode=None, sp_size=None, sp_group=None):
+ logger = logging.get_logger(__name__)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ if sp_mode is not None:
+ assert sp_mode in ["all_to_all", "split_gather", "ring"], "Invalid sp_mode"
+ assert (sp_size is not None) and (
+ sp_group is not None
+ ), "Must specify sp_size and sp_group for sequence parallel"
+
+ # DeepseekFlashAttention2 attention does not support output_attentions
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
+ )
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop("padding_mask")
+
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ # sp: modify sp_len when sequence parallel mode is ring
+ if sp_mode in ["split_gather", "ring"]:
+ q_len *= sp_size
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ # sp: all-to-all comminucation when introducing sequence parallel
+ if sp_mode == "all_to_all":
+ query_states = all_to_all_comm(query_states, sp_group)
+ key_states = all_to_all_comm(key_states, sp_group)
+ value_states = all_to_all_comm(value_states, sp_group)
+ bsz, q_len, _ = query_states.size()
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids, unsqueeze_dim=0
+ )
+
+ if past_key_value is not None:
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # TODO: These transpose are quite inefficient but Flash Attention requires the layout [batch_size, sequence_length, num_heads, head_dim]. We would need to refactor the KV cache
+ # to be able to avoid many of these transpose/reshape/view.
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in the correct dtype just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not cast the LayerNorms
+ # in fp32. (DeepseekRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ # Handle the case where the model is quantized
+ if hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ elif torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+ attn_output = self._flash_attention_forward(
+ query_states, key_states, value_states, attention_mask, q_len, dropout=dropout_rate
+ )
+ # sp: all-to-all comminucation when introducing sequence parallel
+ if sp_mode == "all_to_all":
+ attn_output = attn_output.reshape(bsz, q_len, self.num_heads * self.head_dim).contiguous() # (1, 8, 128)
+ attn_output = all_to_all_comm(attn_output, sp_group, scatter_dim=1, gather_dim=2) # (1, 4, 256)
+ else:
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ return forward
+
+
+def get_deepseek_flash_attention_model_forward(shard_config, sp_mode=None, sp_size=None, sp_group=None):
+ logger = logging.get_logger(__name__)
+
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape[:2]
+ elif inputs_embeds is not None:
+ batch_size, seq_length = inputs_embeds.shape[:2]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`transformers."
+ )
+ use_cache = False
+
+ past_key_values_length = 0
+ if use_cache:
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+ past_key_values_length = past_key_values.get_usable_length(seq_length)
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.unsqueeze(0)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if self._use_flash_attention_2:
+ # 2d mask is passed through the layers
+ attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
+ elif self._use_sdpa and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ )
+ else:
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
+ )
+
+ if sp_mode in ["ring", "split_gather"]:
+ inputs_embeds = split_forward_gather_backward(inputs_embeds, 1, sp_group)
+ elif sp_mode == "all_to_all":
+ inputs_embeds = split_forward_gather_backward(inputs_embeds, 1, sp_group, 1 / sp_size)
+ # embed positions
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ use_cache,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ if sp_mode == "ring" or sp_mode == "split_gather":
+ hidden_states = gather_forward_split_backward(hidden_states, 1, sp_group)
+ elif sp_mode == "all_to_all":
+ hidden_states = gather_forward_split_backward(hidden_states, 1, sp_group, grad_scale=sp_size)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = None
+ if use_cache:
+ next_cache = next_decoder_cache.to_legacy_cache() if use_legacy_cache else next_decoder_cache
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+ return forward
diff --git a/colossalai/shardformer/modeling/llama.py b/colossalai/shardformer/modeling/llama.py
index 54ff8e321e06..9ffbca517d4c 100644
--- a/colossalai/shardformer/modeling/llama.py
+++ b/colossalai/shardformer/modeling/llama.py
@@ -643,7 +643,7 @@ def forward(
# in this case, attention_mask is a dict rather than a tensor
if shard_config.enable_flash_attention:
- mask_shape = (inputs_embeds.shape[0], 1, past_seen_tokens + seq_len, past_seen_tokens + seq_len)
+ mask_shape = (inputs_embeds.shape[0], 1, seq_len, past_seen_tokens + seq_len)
attention_mask = ColoAttention.prepare_attn_kwargs(
mask_shape,
inputs_embeds.dtype,
diff --git a/colossalai/shardformer/modeling/mistral.py b/colossalai/shardformer/modeling/mistral.py
index 82e8ef5f9af7..ec1a8a00a58a 100644
--- a/colossalai/shardformer/modeling/mistral.py
+++ b/colossalai/shardformer/modeling/mistral.py
@@ -91,7 +91,7 @@ def mistral_model_forward(
if shard_config.enable_flash_attention:
# in this case, attention_mask is a dict rather than a tensor
- mask_shape = (batch_size, 1, seq_length, seq_length)
+ mask_shape = (batch_size, 1, seq_length, seq_length + past_key_values_length)
attention_mask = ColoAttention.prepare_attn_kwargs(
mask_shape,
hidden_states.dtype,
diff --git a/colossalai/shardformer/modeling/mixtral.py b/colossalai/shardformer/modeling/mixtral.py
index 2fbc34302cde..d30ce5ea85cc 100644
--- a/colossalai/shardformer/modeling/mixtral.py
+++ b/colossalai/shardformer/modeling/mixtral.py
@@ -1,52 +1,105 @@
-from typing import List, Optional
+import inspect
+import warnings
+from typing import List, Optional, Tuple, Union
import torch
import torch.distributed as dist
import torch.nn.functional as F
from torch.distributed import ProcessGroup
-
-# from colossalai.tensor.moe_tensor.moe_info import MoeParallelInfo
from torch.nn import CrossEntropyLoss
-from transformers.modeling_attn_mask_utils import _prepare_4d_causal_attention_mask
+from transformers.cache_utils import Cache, DynamicCache
+from transformers.modeling_attn_mask_utils import (
+ _prepare_4d_causal_attention_mask,
+ _prepare_4d_causal_attention_mask_for_sdpa,
+)
from transformers.models.mixtral.modeling_mixtral import (
MixtralSparseMoeBlock,
MoeCausalLMOutputWithPast,
+ MoeModelOutputWithPast,
+ apply_rotary_pos_emb,
load_balancing_loss_func,
+ repeat_kv,
)
from transformers.utils import is_flash_attn_2_available, logging
from colossalai.lazy import LazyInitContext
-from colossalai.moe._operation import MoeInGradScaler, MoeOutGradScaler, all_to_all_uneven
+from colossalai.moe._operation import (
+ DPGradScalerIn,
+ DPGradScalerOut,
+ EPGradScalerIn,
+ EPGradScalerOut,
+ all_to_all_uneven,
+)
from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer.layer._operation import (
+ all_to_all_comm,
+ gather_forward_split_backward,
+ split_forward_gather_backward,
+)
+from colossalai.shardformer.layer.linear import Linear1D_Col, Linear1D_Row
from colossalai.shardformer.shard import ShardConfig
from colossalai.shardformer.shard.utils import set_tensors_to_none
+from colossalai.tensor.moe_tensor.api import set_moe_tensor_ep_group
+
+if is_flash_attn_2_available():
+ from flash_attn import flash_attn_func
+
+ from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
+
+ _flash_supports_window_size = "window_size" in list(inspect.signature(flash_attn_func).parameters)
class EPMixtralSparseMoeBlock(MixtralSparseMoeBlock):
- def __init__(self, config):
- self.moe_info = None
- super().__init__(config)
-
- def setup_ep(self, ep_group: ProcessGroup):
- ep_group = ep_group
- self.ep_size = dist.get_world_size(ep_group) if ep_group is not None else 1
- self.ep_rank = dist.get_rank(ep_group) if ep_group is not None else 0
- assert self.num_experts % self.ep_size == 0
+ def __init__(self, *args, **kwargs):
+ raise RuntimeError(f"Please use `from_native_module` to create an instance of {self.__class__.__name__}")
+
+ def setup_process_groups(self, tp_group: ProcessGroup, moe_dp_group: ProcessGroup, ep_group: ProcessGroup):
+ assert tp_group is not None
+ assert moe_dp_group is not None
+ assert ep_group is not None
+
+ # setup ep group
+ self.ep_size = dist.get_world_size(ep_group)
+ self.ep_rank = dist.get_rank(ep_group)
self.ep_group = ep_group
+
+ if self.num_experts % self.ep_size != 0:
+ raise ValueError("The number of experts must be divisible by the number of expert parallel groups.")
+
self.num_experts_per_ep = self.num_experts // self.ep_size
self.expert_start_idx = self.ep_rank * self.num_experts_per_ep
held_experts = self.experts[self.expert_start_idx : self.expert_start_idx + self.num_experts_per_ep]
+
set_tensors_to_none(self.experts, exclude=set(held_experts))
+
+ # setup moe_dp group
+ self.moe_dp_group = moe_dp_group
+ self.moe_dp_size = moe_dp_group.size()
+
+ # setup global tp group
+ self.tp_group = tp_group
+ if self.tp_group.size() > 1:
+ for expert in held_experts:
+ expert.w1 = Linear1D_Col.from_native_module(expert.w1, self.tp_group)
+ expert.w3 = Linear1D_Col.from_native_module(expert.w3, self.tp_group)
+ expert.w2 = Linear1D_Row.from_native_module(expert.w2, self.tp_group)
+
for p in self.experts.parameters():
- p.ep_group = ep_group
+ set_moe_tensor_ep_group(p, ep_group)
@staticmethod
- def from_native_module(module: MixtralSparseMoeBlock, *args, **kwargs) -> "EPMixtralSparseMoeBlock":
+ def from_native_module(
+ module: MixtralSparseMoeBlock,
+ tp_group: ProcessGroup,
+ moe_dp_group: ProcessGroup,
+ ep_group: ProcessGroup,
+ *args,
+ **kwargs,
+ ) -> "EPMixtralSparseMoeBlock":
+ # TODO: better init
LazyInitContext.materialize(module)
module.__class__ = EPMixtralSparseMoeBlock
- # if "ep_group" in kwargs:
- assert "ep_group" in kwargs, "You should pass ep_group in SubModuleReplacementDescription via shard_config!!"
- module.setup_ep(kwargs["ep_group"])
+ module.setup_process_groups(tp_group, moe_dp_group, ep_group)
return module
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
@@ -65,20 +118,31 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
selected_experts_idx = selected_experts.argsort()
dispatch_states = hidden_states.repeat(self.top_k, 1)[selected_experts_idx]
input_split_sizes = selected_experts.bincount(minlength=self.num_experts)
+
output_split_sizes = torch.zeros_like(input_split_sizes)
dist.all_to_all_single(output_split_sizes, input_split_sizes, group=self.ep_group)
+ with torch.no_grad():
+ activate_experts = output_split_sizes[: self.num_experts_per_ep].clone()
+ for i in range(1, self.ep_size):
+ activate_experts += output_split_sizes[i * self.num_experts_per_ep : (i + 1) * self.num_experts_per_ep]
+ activate_experts = (activate_experts > 0).float()
+ dist.all_reduce(activate_experts, group=self.moe_dp_group)
+
input_split_list = input_split_sizes.view(self.ep_size, self.num_experts_per_ep).sum(dim=-1).tolist()
output_split_list = output_split_sizes.view(self.ep_size, self.num_experts_per_ep).sum(dim=-1).tolist()
+
output_states, _ = all_to_all_uneven(dispatch_states, input_split_list, output_split_list, self.ep_group)
# compute expert output
- output_states = MoeInGradScaler.apply(output_states, self.ep_size)
+ output_states = EPGradScalerIn.apply(output_states, self.ep_size)
if output_states.size(0) > 0:
if self.num_experts_per_ep == 1:
# no need to split
expert = self.experts[self.expert_start_idx]
+ output_states = DPGradScalerIn.apply(output_states, self.moe_dp_size, activate_experts[0])
output_states = expert.act_fn(expert.w1(output_states)) * expert.w3(output_states)
output_states = expert.w2(output_states)
+ output_states = DPGradScalerOut.apply(output_states, self.moe_dp_size, activate_experts[0])
else:
output_states_splits = output_states.split(output_split_sizes.tolist())
output_states_list = []
@@ -86,12 +150,20 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
if split_states.size(0) == 0:
continue
expert = self.experts[self.expert_start_idx + i % self.num_experts_per_ep]
+ split_states = DPGradScalerIn.apply(
+ split_states, self.moe_dp_size, activate_experts[i % self.num_experts_per_ep]
+ )
split_states = expert.act_fn(expert.w1(split_states)) * expert.w3(split_states)
split_states = expert.w2(split_states)
+ split_states = DPGradScalerOut.apply(
+ split_states, self.moe_dp_size, activate_experts[i % self.num_experts_per_ep]
+ )
output_states_list.append(split_states)
output_states = torch.cat(output_states_list)
- output_states = MoeOutGradScaler.apply(output_states, self.ep_size)
+
+ output_states = EPGradScalerOut.apply(output_states, self.ep_size)
dispatch_states, _ = all_to_all_uneven(output_states, output_split_list, input_split_list, self.ep_group)
+
recover_experts_idx = torch.empty_like(selected_experts_idx)
recover_experts_idx[selected_experts_idx] = torch.arange(
selected_experts_idx.size(0), device=selected_experts_idx.device
@@ -107,7 +179,7 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
class MixtralPipelineForwards:
"""
- This class serves as a micro library for forward function substitution of Llama models
+ This class serves as a micro library for forward function substitution of Mixtral models
under pipeline setting.
"""
@@ -300,16 +372,29 @@ def custom_forward(*inputs):
if output_router_logits and past_router_logits is not None:
all_router_logits = past_router_logits + all_router_logits
if stage_manager.is_last_stage():
- return tuple(
- v
- for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_router_logits]
- if v is not None
+ if not return_dict:
+ return tuple(
+ v
+ for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_router_logits]
+ if v is not None
+ )
+ return MoeModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ router_logits=all_router_logits,
)
- # always return dict for imediate stage
- return {
- "hidden_states": hidden_states,
- "past_router_logits": all_router_logits,
- }
+ else:
+ if output_router_logits:
+ return {
+ "hidden_states": hidden_states,
+ "past_router_logits": all_router_logits,
+ }
+ else:
+ return {
+ "hidden_states": hidden_states,
+ }
@staticmethod
def mixtral_for_causal_lm_forward(
@@ -441,3 +526,335 @@ def mixtral_for_causal_lm_forward(
if output_router_logits:
out["past_router_logits"] = outputs["past_router_logits"]
return out
+
+
+def get_mixtral_flash_attention_forward(shard_config, sp_mode=None, sp_size=None, sp_group=None):
+ logger = logging.get_logger(__name__)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Cache]]:
+ if sp_mode is not None:
+ assert sp_mode in ["all_to_all", "split_gather", "ring"], "Invalid sp_mode"
+ assert (sp_size is not None) and (
+ sp_group is not None
+ ), "Must specify sp_size and sp_group for sequence parallel"
+
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
+ )
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop("padding_mask")
+ bsz, q_len, _ = hidden_states.size()
+
+ # sp: modify sp_len when sequence parallel mode is ring
+ if sp_mode in ["split_gather", "ring"]:
+ q_len *= sp_size
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ # sp: all-to-all comminucation when introducing sequence parallel
+ if sp_mode == "all_to_all":
+ query_states = all_to_all_comm(query_states, sp_group)
+ key_states = all_to_all_comm(key_states, sp_group)
+ value_states = all_to_all_comm(value_states, sp_group)
+ bsz, q_len, _ = query_states.size()
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
+ "for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
+ "with a layer index."
+ )
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+
+ # Because the input can be padded, the absolute sequence length depends on the max position id.
+ rotary_seq_len = max(kv_seq_len, position_ids[:, -1].max().item()) + 1
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, "sliding_window", None) is not None
+ and kv_seq_len > self.config.sliding_window
+ )
+ if not _flash_supports_window_size:
+ logger.warning_once(
+ "The current flash attention version does not support sliding window attention, for a more memory efficient implementation"
+ " make sure to upgrade flash-attn library."
+ )
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (
+ getattr(self.config, "sliding_window", None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents
+ ):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ f"past key must have a shape of (`batch_size, num_heads, self.config.sliding_window-1, head_dim`), got"
+ f" {past_key.shape}"
+ )
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat([attention_mask, torch.ones_like(attention_mask[:, -1:])], dim=-1)
+
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ q_len,
+ dropout=dropout_rate,
+ use_sliding_windows=use_sliding_windows,
+ )
+
+ # sp: all-to-all comminucation when introducing sequence parallel
+ if sp_mode == "all_to_all":
+ attn_output = attn_output.reshape(bsz, q_len, self.num_heads * self.head_dim).contiguous() # (1, 8, 128)
+ attn_output = all_to_all_comm(attn_output, sp_group, scatter_dim=1, gather_dim=2) # (1, 4, 256)
+ else:
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+ return attn_output, attn_weights, past_key_value
+
+ return forward
+
+
+def get_mixtral_flash_attention_model_forward(shard_config, sp_mode=None, sp_size=None, sp_group=None):
+ logger = logging.get_logger(__name__)
+
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_router_logits: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, MoeModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_router_logits = (
+ output_router_logits if output_router_logits is not None else self.config.output_router_logits
+ )
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+
+ past_key_values_length = 0
+
+ if (self.gradient_checkpointing or sp_mode in ["ring", "all_to_all"]) and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+ if use_cache:
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+ past_key_values_length = past_key_values.get_usable_length(seq_length)
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if attention_mask is not None and self._attn_implementation == "flash_attention_2" and use_cache:
+ is_padding_right = attention_mask[:, -1].sum().item() != batch_size
+ if is_padding_right:
+ raise ValueError(
+ "You are attempting to perform batched generation with padding_side='right'"
+ " this may lead to unexpected behaviour for Flash Attention version of Mixtral. Make sure to "
+ " call `tokenizer.padding_side = 'left'` before tokenizing the input. "
+ )
+ if self._attn_implementation == "flash_attention_2":
+ # 2d mask is passed through the layers
+ attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
+ elif self._attn_implementation == "sdpa" and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ )
+ else:
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ sliding_window=self.config.sliding_window,
+ )
+
+ if sp_mode in ["ring", "split_gather"]:
+ inputs_embeds = split_forward_gather_backward(inputs_embeds, 1, sp_group)
+ elif sp_mode == "all_to_all":
+ inputs_embeds = split_forward_gather_backward(inputs_embeds, 1, sp_group, 1 / sp_size)
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ all_router_logits = () if output_router_logits else None
+ next_decoder_cache = None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ output_router_logits,
+ use_cache,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ output_router_logits=output_router_logits,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ if output_router_logits:
+ all_router_logits += (layer_outputs[-1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ if sp_mode == "ring" or sp_mode == "split_gather":
+ hidden_states = gather_forward_split_backward(hidden_states, 1, sp_group)
+ elif sp_mode == "all_to_all":
+ hidden_states = gather_forward_split_backward(hidden_states, 1, sp_group, grad_scale=sp_size)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = None
+ if use_cache:
+ next_cache = next_decoder_cache.to_legacy_cache() if use_legacy_cache else next_decoder_cache
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_router_logits]
+ if v is not None
+ )
+ return MoeModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ router_logits=all_router_logits,
+ )
+
+ return forward
diff --git a/colossalai/shardformer/modeling/qwen2.py b/colossalai/shardformer/modeling/qwen2.py
index 55822b1505f1..538e96c32c6d 100644
--- a/colossalai/shardformer/modeling/qwen2.py
+++ b/colossalai/shardformer/modeling/qwen2.py
@@ -136,7 +136,7 @@ def qwen2_model_forward(
# for the other stages, hidden_states is the output of the previous stage
if shard_config.enable_flash_attention:
# in this case, attention_mask is a dict rather than a tensor
- mask_shape = (batch_size, 1, seq_length_with_past, seq_length_with_past)
+ mask_shape = (batch_size, 1, seq_length, seq_length_with_past)
attention_mask = ColoAttention.prepare_attn_kwargs(
mask_shape,
hidden_states.dtype,
@@ -651,6 +651,10 @@ def forward(
seq_length_with_past = seq_length
past_key_values_length = 0
+ if past_key_values is not None:
+ past_key_values_length = past_key_values[0][0].shape[2]
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+
if position_ids is None:
device = input_ids.device if input_ids is not None else inputs_embeds.device
position_ids = torch.arange(
@@ -668,7 +672,7 @@ def forward(
if shard_config.enable_flash_attention:
# in this case, attention_mask is a dict rather than a tensor
- mask_shape = (batch_size, 1, seq_length_with_past, seq_length_with_past)
+ mask_shape = (batch_size, 1, seq_length, seq_length_with_past)
attention_mask = ColoAttention.prepare_attn_kwargs(
mask_shape,
hidden_states.dtype,
diff --git a/colossalai/shardformer/policies/auto_policy.py b/colossalai/shardformer/policies/auto_policy.py
index ae9f3603c96e..7b9c759a66c2 100644
--- a/colossalai/shardformer/policies/auto_policy.py
+++ b/colossalai/shardformer/policies/auto_policy.py
@@ -161,7 +161,7 @@ class PolicyLocation:
file_name="chatglm2", class_name="ChatGLMForConditionalGenerationPolicy"
),
# Deepseek
- "transformers_modules.modeling_deepseek.DeepSeekModel": PolicyLocation(
+ "transformers_modules.modeling_deepseek.DeepseekModel": PolicyLocation(
file_name="deepseek", class_name="DeepseekModelPolicy"
),
"transformers_modules.modeling_deepseek.DeepseekForCausalLM": PolicyLocation(
@@ -200,6 +200,9 @@ class PolicyLocation:
"transformers.models.mixtral.modeling_mixtral.MixtralForCausalLM": PolicyLocation(
file_name="mixtral", class_name="MixtralForCausalLMPolicy"
),
+ "transformers.models.mixtral.modeling_mixtral.MixtralForSequenceClassification": PolicyLocation(
+ file_name="mixtral", class_name="MixtralForSequenceClassificationPolicy"
+ ),
# Qwen2
"transformers.models.qwen2.modeling_qwen2.Qwen2Model": PolicyLocation(
file_name="qwen2", class_name="Qwen2ModelPolicy"
@@ -240,6 +243,9 @@ def _fullname(obj):
# patch custom models which are not in transformers
# it can be like 'transformers_modules.THUDM.chatglm3-6b.103caa40027ebfd8450289ca2f278eac4ff26405.modeling_chatglm' (from huggingface hub)
# or like 'transformers_modules.chatglm.modeling_chatglm' (from local directory)
+ if module.startswith("peft"):
+ klass = obj.base_model.model.__class__
+ module = klass.__module__
if module.startswith("transformers_modules"):
split_module = module.split(".")
if len(split_module) >= 2:
diff --git a/colossalai/shardformer/policies/deepseek.py b/colossalai/shardformer/policies/deepseek.py
index 8ebda357b380..605f69c4a632 100644
--- a/colossalai/shardformer/policies/deepseek.py
+++ b/colossalai/shardformer/policies/deepseek.py
@@ -1,13 +1,20 @@
-import warnings
from functools import partial
from typing import Callable, Dict, List, Union
import torch.nn as nn
from torch import Tensor
from torch.nn import Module
+from transformers.utils import is_flash_attn_greater_or_equal_2_10
from colossalai.shardformer.layer import FusedRMSNorm, Linear1D_Col
-from colossalai.shardformer.modeling.deepseek import DeepseekPipelineForwards, EPDeepseekMoE
+from colossalai.shardformer.layer.embedding import PaddingEmbedding, VocabParallelEmbedding1D
+from colossalai.shardformer.layer.linear import Linear1D_Row
+from colossalai.shardformer.modeling.deepseek import (
+ DeepseekPipelineForwards,
+ EPDeepseekMoE,
+ get_deepseek_flash_attention_forward,
+ get_deepseek_flash_attention_model_forward,
+)
from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ["DeepseekPolicy", "DeepseekForCausalLMPolicy"]
@@ -18,6 +25,13 @@ def config_sanity_check(self):
pass
def preprocess(self):
+ self.tie_weight = self.tie_weight_check()
+ self.origin_attn_implement = self.model.config._attn_implementation
+ """
+ Because transformers library's bug for AutoModel/AutoConfig, who pop “attn_implement” twice from modeling_utils.py and configuration_utils.py.
+ This bug causes attn_cls to be set to sdpa. Here we assign it to "flash_attention_2".
+ """
+ # self.origin_attn_implement = "flash_attention_2"
if self.shard_config.enable_tensor_parallelism:
# Resize embedding
vocab_size = self.model.config.vocab_size
@@ -30,25 +44,118 @@ def preprocess(self):
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
+
+ ATTN_IMPLEMENTATION = {
+ "eager": "DeepseekAttention",
+ "flash_attention_2": "DeepseekFlashAttention2",
+ "sdpa": "DeepseekSdpaAttention",
+ }
policy = {}
+ attn_cls = ATTN_IMPLEMENTATION[self.origin_attn_implement]
+ sp_mode = self.shard_config.sequence_parallelism_mode or None
+ sp_size = self.shard_config.sequence_parallel_size or None
+ sp_group = self.shard_config.sequence_parallel_process_group or None
+ sp_partial_derived = sp_mode in ["split_gather", "ring"]
+ if sp_mode == "all_to_all":
+ decoder_attribute_replacement = {
+ "num_heads": self.model.config.num_attention_heads // sp_size,
+ }
+ if getattr(self.model.config, "num_key_value_heads", False):
+ decoder_attribute_replacement["num_key_value_heads"] = self.model.config.num_key_value_heads // sp_size
+ policy[attn_cls] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ )
if self.shard_config.enable_sequence_parallelism:
- self.shard_config.enable_sequence_parallelism = False
- raise NotImplementedError(
- "Deepseek dosen't support sequence parallelism now, will ignore the sequence parallelism flag."
+ if self.pipeline_stage_manager is not None:
+ # NOTE: we are replacing model forward for both sequence parallelism and pipeline parallelism
+ # if both are enabled, one of them will be ignored
+ raise NotImplementedError("Sequence parallelism is not supported with pipeline parallelism.")
+ self.append_or_create_method_replacement(
+ description={
+ "forward": get_deepseek_flash_attention_forward(self.shard_config, sp_mode, sp_size, sp_group),
+ },
+ policy=policy,
+ target_key=attn_cls,
)
-
+ if self.pipeline_stage_manager is None:
+ self.append_or_create_method_replacement(
+ description={
+ "forward": get_deepseek_flash_attention_model_forward(
+ self.shard_config,
+ sp_mode=sp_mode,
+ sp_size=sp_size,
+ sp_group=sp_group,
+ ),
+ },
+ policy=policy,
+ target_key="DeepseekModel",
+ )
+ embedding_cls = None
+ if self.shard_config.enable_tensor_parallelism:
+ embedding_cls = VocabParallelEmbedding1D
+ else:
+ if self.tie_weight:
+ embedding_cls = PaddingEmbedding
if self.shard_config.enable_tensor_parallelism:
- raise NotImplementedError("Tensor parallelism is not supported for Deepseek model now.")
+ # tensor parallelism for non-moe params
+ assert (
+ self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
+ assert (
+ self.model.config.num_key_value_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of key_value heads must be divisible by tensor parallel size."
+ decoder_attribute_replacement = {
+ "self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "self_attn.num_key_value_heads": self.model.config.num_key_value_heads
+ // self.shard_config.tensor_parallel_size,
+ }
+
+ policy["DeepseekDecoderLayer"] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=Linear1D_Row,
+ ),
+ ],
+ )
+ if embedding_cls is not None:
+ self.append_or_create_submodule_replacement(
+ description=SubModuleReplacementDescription(
+ suffix="embed_tokens",
+ target_module=embedding_cls,
+ kwargs={"make_vocab_size_divisible_by": self.shard_config.make_vocab_size_divisible_by},
+ ),
+ policy=policy,
+ target_key="DeepseekModel",
+ )
- if getattr(self.shard_config, "ep_group", None) is not None:
+ if self.shard_config.ep_group:
# expert parallel
self.append_or_create_submodule_replacement(
description=[
SubModuleReplacementDescription(
suffix="mlp",
target_module=EPDeepseekMoE,
- kwargs={"ep_group": self.shard_config.ep_group},
+ kwargs={
+ "ep_group": self.shard_config.ep_group,
+ "tp_group": self.shard_config.tensor_parallel_process_group,
+ "moe_dp_group": self.shard_config.moe_dp_group,
+ },
)
],
policy=policy,
@@ -62,10 +169,12 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
SubModuleReplacementDescription(
suffix="input_layernorm",
target_module=FusedRMSNorm,
+ kwargs={"sp_partial_derived": sp_partial_derived},
),
SubModuleReplacementDescription(
suffix="post_attention_layernorm",
target_module=FusedRMSNorm,
+ kwargs={"sp_partial_derived": sp_partial_derived},
),
],
policy=policy,
@@ -76,17 +185,39 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
description=SubModuleReplacementDescription(
suffix="norm",
target_module=FusedRMSNorm,
+ kwargs={"sp_partial_derived": sp_partial_derived},
),
policy=policy,
target_key="DeepseekModel",
)
if self.shard_config.enable_flash_attention:
- warnings.warn(
- "Flash attention has already been replaced in deepseek, and now set enable_flash_attention = False."
+ # NOTE: there is a bug for toggling flash attention in AutoModel, which has to be used for deepseek right now
+ from transformers.dynamic_module_utils import get_class_from_dynamic_module
+
+ flash_attn_cls = get_class_from_dynamic_module(
+ "deepseek-ai/deepseek-moe-16b-base--modeling_deepseek.DeepseekFlashAttention2",
+ "deepseek-ai/deepseek-moe-16b-base",
)
- self.shard_config.enable_flash_attention = False
+ class TargetFlashAttn:
+ def __init__(self):
+ raise RuntimeError("This class should not be instantiated")
+
+ @staticmethod
+ def from_native_module(original_attn: nn.Module, *args, **kwargs) -> nn.Module:
+ original_attn.__class__ = flash_attn_cls
+ original_attn._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
+ return original_attn
+
+ self.append_or_create_submodule_replacement(
+ description=SubModuleReplacementDescription(
+ suffix="self_attn",
+ target_module=TargetFlashAttn,
+ ),
+ policy=policy,
+ target_key="DeepseekDecoderLayer",
+ )
return policy
def postprocess(self):
@@ -96,6 +227,10 @@ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, poli
"""If under pipeline parallel setting, replacing the original forward method of huggingface
to customized forward method, and add this changing to policy."""
if self.pipeline_stage_manager:
+ if self.shard_config.enable_sequence_parallelism:
+ # NOTE: we are replacing model forward for both sequence parallelism and pipeline parallelism
+ # if both are enabled, one of them will be ignored
+ raise NotImplementedError("Pipeline parallelism is not supported with sequence parallelism.")
stage_manager = self.pipeline_stage_manager
if self.model.__class__.__name__ == "DeepseekModel":
module = self.model
diff --git a/colossalai/shardformer/policies/mixtral.py b/colossalai/shardformer/policies/mixtral.py
index ad93e94694c8..10df143c99da 100644
--- a/colossalai/shardformer/policies/mixtral.py
+++ b/colossalai/shardformer/policies/mixtral.py
@@ -1,13 +1,21 @@
+import warnings
from functools import partial
from typing import Callable, Dict, List, Union
import torch.nn as nn
from torch import Tensor
from torch.nn import Module
-from transformers.models.mixtral.modeling_mixtral import MixtralDecoderLayer, MixtralForCausalLM, MixtralModel
+from transformers.models.mixtral.modeling_mixtral import MixtralForCausalLM, MixtralModel
from colossalai.shardformer.layer import FusedRMSNorm, Linear1D_Col
-from colossalai.shardformer.modeling.mixtral import EPMixtralSparseMoeBlock, MixtralPipelineForwards
+from colossalai.shardformer.layer.embedding import PaddingEmbedding, VocabParallelEmbedding1D
+from colossalai.shardformer.layer.linear import Linear1D_Row
+from colossalai.shardformer.modeling.mixtral import (
+ EPMixtralSparseMoeBlock,
+ MixtralPipelineForwards,
+ get_mixtral_flash_attention_forward,
+ get_mixtral_flash_attention_model_forward,
+)
from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ["MixtralPolicy", "MixtralForCausalLMPolicy"]
@@ -18,36 +26,136 @@ def config_sanity_check(self):
pass
def preprocess(self):
- if self.shard_config.enable_tensor_parallelism:
- # Resize embedding
- vocab_size = self.model.config.vocab_size
- world_size = self.shard_config.tensor_parallel_size
-
- if vocab_size % world_size != 0:
- new_vocab_size = vocab_size + world_size - vocab_size % world_size
- self.model.resize_token_embeddings(new_vocab_size)
-
+ self.tie_weight = self.tie_weight_check()
+ self.origin_attn_implement = self.model.config._attn_implementation
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
+ from transformers.models.mixtral.modeling_mixtral import (
+ MixtralAttention,
+ MixtralDecoderLayer,
+ MixtralFlashAttention2,
+ MixtralModel,
+ MixtralSdpaAttention,
+ )
+
+ ATTN_IMPLEMENTATION = {
+ "eager": MixtralAttention,
+ "flash_attention_2": MixtralFlashAttention2,
+ "sdpa": MixtralSdpaAttention,
+ }
policy = {}
+ attn_cls = ATTN_IMPLEMENTATION[self.origin_attn_implement]
+
+ sp_mode = self.shard_config.sequence_parallelism_mode or None
+ sp_size = self.shard_config.sequence_parallel_size or None
+ sp_group = self.shard_config.sequence_parallel_process_group or None
+ sp_partial_derived = sp_mode in ["split_gather", "ring"]
+ if sp_mode == "all_to_all":
+ decoder_attribute_replacement = {
+ "num_heads": self.model.config.num_attention_heads // sp_size,
+ }
+ if getattr(self.model.config, "num_key_value_heads", False):
+ decoder_attribute_replacement["num_key_value_heads"] = self.model.config.num_key_value_heads // sp_size
+ policy[attn_cls] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ )
if self.shard_config.enable_sequence_parallelism:
- self.shard_config.enable_sequence_parallelism = False
- raise NotImplementedError(
- "Mixtral dosen't support sequence parallelism now, will ignore the sequence parallelism flag."
+ if self.pipeline_stage_manager is not None:
+ # NOTE: we are replacing model forward for both sequence parallelism and pipeline parallelism
+ # if both are enabled, one of them will be ignored
+ raise NotImplementedError("Sequence parallelism is not supported with pipeline parallelism.")
+ self.append_or_create_method_replacement(
+ description={
+ "forward": get_mixtral_flash_attention_forward(self.shard_config, sp_mode, sp_size, sp_group),
+ },
+ policy=policy,
+ target_key=attn_cls,
+ )
+ self.append_or_create_method_replacement(
+ description={
+ "forward": get_mixtral_flash_attention_model_forward(
+ self.shard_config,
+ sp_mode=sp_mode,
+ sp_size=sp_size,
+ sp_group=sp_group,
+ ),
+ },
+ policy=policy,
+ target_key=MixtralModel,
)
+ embedding_cls = None
if self.shard_config.enable_tensor_parallelism:
- raise NotImplementedError("Tensor parallelism is not supported for Mixtral model now.")
- if getattr(self.shard_config, "ep_group", None) is not None:
+ embedding_cls = VocabParallelEmbedding1D
+ else:
+ if self.tie_weight:
+ embedding_cls = PaddingEmbedding
+
+ if self.shard_config.enable_tensor_parallelism:
+ # tensor parallelism for non-moe params
+ assert (
+ self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
+ assert (
+ self.model.config.num_key_value_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of key_value heads must be divisible by tensor parallel size."
+ decoder_attribute_replacement = {
+ "self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "self_attn.num_key_value_heads": self.model.config.num_key_value_heads
+ // self.shard_config.tensor_parallel_size,
+ }
+
+ policy[MixtralDecoderLayer] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=Linear1D_Row,
+ ),
+ SubModuleReplacementDescription( # or replicate?
+ suffix="block_sparse_moe.gate", target_module=Linear1D_Col, kwargs={"gather_output": True}
+ ),
+ ],
+ )
+
+ if embedding_cls is not None:
+ self.append_or_create_submodule_replacement(
+ description=SubModuleReplacementDescription(
+ suffix="embed_tokens",
+ target_module=embedding_cls,
+ kwargs={"make_vocab_size_divisible_by": self.shard_config.make_vocab_size_divisible_by},
+ ),
+ policy=policy,
+ target_key=MixtralModel,
+ )
+
+ if self.shard_config.ep_group:
# expert parallel
self.append_or_create_submodule_replacement(
description=[
SubModuleReplacementDescription(
suffix="block_sparse_moe",
target_module=EPMixtralSparseMoeBlock,
- kwargs={"ep_group": self.shard_config.ep_group},
+ kwargs={
+ "ep_group": self.shard_config.ep_group,
+ "tp_group": self.shard_config.tensor_parallel_process_group,
+ "moe_dp_group": self.shard_config.moe_dp_group,
+ },
)
],
policy=policy,
@@ -61,10 +169,12 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
SubModuleReplacementDescription(
suffix="input_layernorm",
target_module=FusedRMSNorm,
+ kwargs={"sp_partial_derived": sp_partial_derived},
),
SubModuleReplacementDescription(
suffix="post_attention_layernorm",
target_module=FusedRMSNorm,
+ kwargs={"sp_partial_derived": sp_partial_derived},
),
],
policy=policy,
@@ -75,13 +185,15 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
description=SubModuleReplacementDescription(
suffix="norm",
target_module=FusedRMSNorm,
+ kwargs={"sp_partial_derived": sp_partial_derived},
),
policy=policy,
target_key=MixtralModel,
)
if self.shard_config.enable_flash_attention:
- raise NotImplementedError("Flash attention has already been replaced in mixtral.")
+ warnings.warn("Flash attention is natively supported in transformers, will ignore the flag.")
+ self.shard_config.enable_flash_attention = False
return policy
@@ -92,6 +204,10 @@ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, poli
"""If under pipeline parallel setting, replacing the original forward method of huggingface
to customized forward method, and add this changing to policy."""
if self.pipeline_stage_manager:
+ if self.shard_config.enable_sequence_parallelism:
+ # NOTE: we are replacing model forward for both sequence parallelism and pipeline parallelism
+ # if both are enabled, one of them will be ignored
+ raise NotImplementedError("Pipeline parallelism is not supported with sequence parallelism.")
stage_manager = self.pipeline_stage_manager
if self.model.__class__.__name__ == "MixtralModel":
module = self.model
@@ -150,7 +266,7 @@ def get_held_layers(self) -> List[Module]:
return held_layers
def get_shared_params(self) -> List[Dict[int, Tensor]]:
- """No shared params in llama model"""
+ """No shared params in mixtral model"""
return []
@@ -206,3 +322,40 @@ def get_shared_params(self) -> List[Dict[int, Tensor]]:
}
]
return []
+
+
+class MixtralForSequenceClassificationPolicy(MixtralPolicy):
+ def module_policy(self):
+ from transformers import MixtralForSequenceClassification
+
+ policy = super().module_policy()
+
+ if self.shard_config.enable_tensor_parallelism:
+ # add a new item for sequence classification
+ new_item = {
+ MixtralForSequenceClassification: ModulePolicyDescription(
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="score", target_module=Linear1D_Col, kwargs=dict(gather_output=True)
+ )
+ ]
+ )
+ }
+ policy.update(new_item)
+
+ if self.pipeline_stage_manager:
+ raise NotImplementedError
+
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ stage_manager = self.pipeline_stage_manager
+ held_layers = super().get_held_layers()
+ if stage_manager.is_last_stage(ignore_chunk=True):
+ held_layers.append(self.model.score)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in mixtral for sequence classification model"""
+ return []
diff --git a/colossalai/shardformer/shard/shard_config.py b/colossalai/shardformer/shard/shard_config.py
index b64300366fc3..163d7a7bbb0c 100644
--- a/colossalai/shardformer/shard/shard_config.py
+++ b/colossalai/shardformer/shard/shard_config.py
@@ -46,7 +46,11 @@ class ShardConfig:
make_vocab_size_divisible_by: int = 64
gradient_checkpoint_config: Optional[GradientCheckpointConfig] = None
extra_kwargs: Dict[str, Any] = field(default_factory=dict)
+
+ # for moe related
+ moe_dp_group: Optional[ProcessGroup] = None
ep_group: Optional[ProcessGroup] = None
+
# pipeline_parallel_size: int
# data_parallel_size: int
# tensor_parallel_mode: Literal['1d', '2d', '2.5d', '3d']
diff --git a/colossalai/zero/low_level/bookkeeping/gradient_store.py b/colossalai/zero/low_level/bookkeeping/gradient_store.py
index e24a67f9de3c..8b6d403f1327 100644
--- a/colossalai/zero/low_level/bookkeeping/gradient_store.py
+++ b/colossalai/zero/low_level/bookkeeping/gradient_store.py
@@ -19,7 +19,6 @@ def __init__(self, *args, partition_grad: bool = False):
"""
self._grads_of_params = dict()
# stage 2
- self._partition_grads = partition_grad
self._working_index = 0 if partition_grad else self._local_rank
# for zero2, it's `param_id: [grad_local_rank]`
self.grad_to_param_mapping = dict()
@@ -91,7 +90,7 @@ def get_working_grads_by_group_id(self, group_id: int) -> List:
return grad_list
- def get_working_grad_by_param_id(self, param_id) -> Tensor:
+ def get_working_grad_by_param_id(self, param_id) -> Optional[Tensor]:
"""
Return the working gradient for the specified parameter.
@@ -112,6 +111,7 @@ def reset_grads_by_group_id(self, group_id: int):
def reset_all_gradients(self):
self._grads_of_params = dict()
+ self.grad_to_param_mapping = dict()
def get_param_id_for_grad(self, grad: Tensor) -> Optional[int]:
"""Return the id of a parameter which the gradient slice belongs to
diff --git a/colossalai/zero/low_level/low_level_optim.py b/colossalai/zero/low_level/low_level_optim.py
index 6ff235b96a5d..51d7d1eaaa33 100644
--- a/colossalai/zero/low_level/low_level_optim.py
+++ b/colossalai/zero/low_level/low_level_optim.py
@@ -20,6 +20,7 @@
)
from colossalai.interface import OptimizerWrapper
from colossalai.logging import get_dist_logger
+from colossalai.tensor.moe_tensor.api import is_moe_tensor
from ._utils import calculate_global_norm_from_list, has_inf_or_nan, release_param_grad, sync_tensor
from .bookkeeping import BucketStore, GradientStore, TensorBucket
@@ -66,7 +67,7 @@ class LowLevelZeroOptimizer(OptimizerWrapper):
def __init__(
self,
optimizer: Optimizer,
- pg_to_param_list: Dict[ProcessGroup, List[nn.Parameter]] = None,
+ pg_to_param_list: Optional[Dict[ProcessGroup, List[nn.Parameter]]] = None,
initial_scale: int = 2**16, # grad scaler config
min_scale: int = 1,
growth_factor: float = 2.0,
@@ -92,7 +93,7 @@ def __init__(
self._logger = get_dist_logger()
self._verbose = verbose
- if dp_process_group is not None and pg_to_param_list is not None:
+ if (dp_process_group is not None) and (pg_to_param_list is not None):
raise ValueError("dp_process_group and pg_to_param_list should not be provided at the same time.")
if pg_to_param_list is None:
@@ -338,14 +339,14 @@ def _run_reduction(self):
self._update_unpartitoned_grad(bucket_store, grad_in_bucket.values(), flat_grads_per_rank, group_id)
else:
flat_grads_list = list(flat_grads.split(len(flat_grads) // bucket_store.world_size))
- recieved_grad = torch.zeros_like(flat_grads_list[0])
- dist.reduce_scatter(recieved_grad, flat_grads_list, group=bucket_store.torch_pg)
+ received_grad = torch.zeros_like(flat_grads_list[0])
+ dist.reduce_scatter(received_grad, flat_grads_list, group=bucket_store.torch_pg)
- if recieved_grad.dtype != grad_dtype:
- recieved_grad = recieved_grad.to(grad_dtype)
+ if received_grad.dtype != grad_dtype:
+ received_grad = received_grad.to(grad_dtype)
grad_in_bucket_current_rank = bucket_store.get_grad()[bucket_store.local_rank]
- self._update_partitoned_grad(bucket_store, grad_in_bucket_current_rank, recieved_grad, group_id, 1)
+ self._update_partitoned_grad(bucket_store, grad_in_bucket_current_rank, received_grad, group_id, 1)
bucket_store.reset()
@@ -649,6 +650,11 @@ def _sync_grad(self):
for group_id in range(self.num_param_groups):
param_group = self._working_param_groups[group_id]
for param in param_group:
+ if is_moe_tensor(param) and param.requires_grad and param.grad is None:
+ # TODO better of of doing this
+ # assign zero grad to unrouted expert to avoid hang during grad reduction
+ param.grad = torch.zeros_like(param)
+
if param.requires_grad and param.grad is not None:
self._add_to_bucket(param, group_id)
@@ -807,8 +813,8 @@ def update_master_params(self, model: nn.Module) -> None:
"""
for p in model.parameters():
p_id = id(p)
- pg = self.param_to_pg[p]
if p_id in self.working_to_master_param:
+ pg = self.param_to_pg[p]
master_param = self.working_to_master_param[p_id]
padding_size = self.get_param_padding_size(p)
working_param = p.data.view(-1)
@@ -869,13 +875,12 @@ def get_padding_map(self) -> Dict[int, Tensor]:
def get_param_grad(self, working_param: nn.Parameter) -> Tensor:
grad_store = self.pid_to_grad_store[id(working_param)]
- partial_grad = grad_store.get_working_grad_by_param_id(id(working_param))
- if partial_grad is None:
+ grad = grad_store.get_working_grad_by_param_id(id(working_param))
+ if grad is None:
return None
- tensor_list = [torch.empty_like(partial_grad) for _ in range(grad_store.world_size)]
- dist.all_gather(tensor_list, partial_grad, group=grad_store.torch_pg)
- grad_flat = torch.cat(tensor_list, dim=0)
- return grad_flat[: working_param.numel()].reshape_as(working_param)
+ grad_flat = torch.empty((grad_store.world_size, *grad.shape), dtype=grad.dtype, device=grad.device)
+ dist.all_gather_into_tensor(grad_flat, grad, group=grad_store.torch_pg)
+ return grad_flat.view(-1)[: working_param.numel()].view_as(working_param)
def get_working_grads_by_group_id(self, group_id: int) -> List[Tensor]:
working_grads = []
diff --git a/docs/source/en/basics/launch_colossalai.md b/docs/source/en/basics/launch_colossalai.md
index 8a6028d6c49a..32748dae1163 100644
--- a/docs/source/en/basics/launch_colossalai.md
+++ b/docs/source/en/basics/launch_colossalai.md
@@ -131,17 +131,18 @@ with one simple command. There are two ways you can launch multi-node jobs.
This is suitable when you only have a few nodes. Let's say I have two nodes, namely `host1` and `host2`, I can start
multi-node training with the following command. Compared to single-node training, you must specify the `master_addr`
-option, which is auto-set to localhost if running on a single node only.
+option, which is auto-set to localhost if running on a single node only. \
+Additionally, you must also ensure that all nodes share the same open ssh port, which can be specified using --ssh-port.
:::caution
-`master_addr` cannot be localhost when running on multiple nodes, it should be the hostname or IP address of a node.
+`master_addr` cannot be localhost when running on multiple nodes, it should be the **hostname or IP address** of a node.
:::
```shell
# run on these two nodes
-colossalai run --nproc_per_node 4 --host host1,host2 --master_addr host1 test.py
+colossalai run --nproc_per_node 4 --host host1,host2 --master_addr host1 test.py --ssh-port 22
```
- Run with `--hostfile`
diff --git a/docs/source/zh-Hans/basics/launch_colossalai.md b/docs/source/zh-Hans/basics/launch_colossalai.md
index a80d16717e40..9e40f64c2124 100644
--- a/docs/source/zh-Hans/basics/launch_colossalai.md
+++ b/docs/source/zh-Hans/basics/launch_colossalai.md
@@ -116,17 +116,17 @@ colossalai run --nproc_per_node 4 --master_port 29505 test.py
- 通过`--hosts`来启动
这个方式适合节点数不多的情况。假设我们有两个节点,分别为`host`和`host2`。我们可以用以下命令进行多节点训练。
-比起单节点训练,多节点训练需要手动设置`--master_addr` (在单节点训练中`master_addr`默认为`127.0.0.1`)。
+比起单节点训练,多节点训练需要手动设置`--master_addr` (在单节点训练中`master_addr`默认为`127.0.0.1`)。同时,你需要确保每个节点都使用同一个ssh port。可以通过--ssh-port设置。
:::caution
-多节点训练时,`master_addr`不能为`localhost`或者`127.0.0.1`,它应该是一个节点的名字或者IP地址。
+多节点训练时,`master_addr`不能为`localhost`或者`127.0.0.1`,它应该是一个节点的**名字或者IP地址**。
:::
```shell
# 在两个节点上训练
-colossalai run --nproc_per_node 4 --host host1,host2 --master_addr host1 test.py
+colossalai run --nproc_per_node 4 --host host1,host2 --master_addr host1 test.py --ssh-port 22
```
diff --git a/examples/inference/stable_diffusion/README.md b/examples/inference/stable_diffusion/README.md
new file mode 100644
index 000000000000..c11b9804392c
--- /dev/null
+++ b/examples/inference/stable_diffusion/README.md
@@ -0,0 +1,22 @@
+## File Structure
+```
+|- sd3_generation.py: an example of how to use Colossalai Inference Engine to generate result by loading Diffusion Model.
+|- compute_metric.py: compare the quality of images w/o some acceleration method like Distrifusion
+|- benchmark_sd3.py: benchmark the performance of our InferenceEngine
+|- run_benchmark.sh: run benchmark command
+```
+Note: compute_metric.py need some dependencies which need `pip install -r requirements.txt`, `requirements.txt` is in `examples/inference/stable_diffusion/`
+
+## Run Inference
+
+The provided example `sd3_generation.py` is an example to configure, initialize the engine, and run inference on provided model. We've added `DiffusionPipeline` as model class, and the script is good to run inference with StableDiffusion 3.
+
+For a basic setting, you could run the example by:
+```bash
+colossalai run --nproc_per_node 1 sd3_generation.py -m PATH_MODEL -p "hello world"
+```
+
+Run multi-GPU inference (Patched Parallelism), as in the following example using 2 GPUs:
+```bash
+colossalai run --nproc_per_node 2 sd3_generation.py -m PATH_MODEL
+```
diff --git a/examples/inference/stable_diffusion/benchmark_sd3.py b/examples/inference/stable_diffusion/benchmark_sd3.py
new file mode 100644
index 000000000000..19db57c33c82
--- /dev/null
+++ b/examples/inference/stable_diffusion/benchmark_sd3.py
@@ -0,0 +1,179 @@
+import argparse
+import json
+import time
+from contextlib import nullcontext
+
+import torch
+import torch.distributed as dist
+from diffusers import DiffusionPipeline
+
+import colossalai
+from colossalai.inference.config import DiffusionGenerationConfig, InferenceConfig
+from colossalai.inference.core.engine import InferenceEngine
+from colossalai.testing import clear_cache_before_run, rerun_if_address_is_in_use, spawn
+
+GIGABYTE = 1024**3
+MEGABYTE = 1024 * 1024
+
+_DTYPE_MAPPING = {
+ "fp16": torch.float16,
+ "bf16": torch.bfloat16,
+ "fp32": torch.float32,
+}
+
+
+def log_generation_time(log_data, log_file):
+ with open(log_file, "a") as f:
+ json.dump(log_data, f, indent=2)
+ f.write("\n")
+
+
+def warmup(engine, args):
+ for _ in range(args.n_warm_up_steps):
+ engine.generate(
+ prompts=["hello world"],
+ generation_config=DiffusionGenerationConfig(
+ num_inference_steps=args.num_inference_steps, height=args.height[0], width=args.width[0]
+ ),
+ )
+
+
+def profile_context(args):
+ return (
+ torch.profiler.profile(
+ record_shapes=True,
+ with_stack=True,
+ with_modules=True,
+ activities=[
+ torch.profiler.ProfilerActivity.CPU,
+ torch.profiler.ProfilerActivity.CUDA,
+ ],
+ )
+ if args.profile
+ else nullcontext()
+ )
+
+
+def log_and_profile(h, w, avg_time, log_msg, args, model_name, mode, prof=None):
+ log_data = {
+ "mode": mode,
+ "model": model_name,
+ "batch_size": args.batch_size,
+ "patched_parallel_size": args.patched_parallel_size,
+ "num_inference_steps": args.num_inference_steps,
+ "height": h,
+ "width": w,
+ "dtype": args.dtype,
+ "profile": args.profile,
+ "n_warm_up_steps": args.n_warm_up_steps,
+ "n_repeat_times": args.n_repeat_times,
+ "avg_generation_time": avg_time,
+ "log_message": log_msg,
+ }
+
+ if args.log:
+ log_file = f"examples/inference/stable_diffusion/benchmark_{model_name}_{mode}.json"
+ log_generation_time(log_data=log_data, log_file=log_file)
+
+ if args.profile:
+ file = f"examples/inference/stable_diffusion/benchmark_{model_name}_{mode}_prof.json"
+ prof.export_chrome_trace(file)
+
+
+def benchmark_colossalai(rank, world_size, port, args):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ from colossalai.cluster.dist_coordinator import DistCoordinator
+
+ coordinator = DistCoordinator()
+
+ inference_config = InferenceConfig(
+ dtype=args.dtype,
+ patched_parallelism_size=args.patched_parallel_size,
+ )
+ engine = InferenceEngine(args.model, inference_config=inference_config, verbose=False)
+
+ warmup(engine, args)
+
+ for h, w in zip(args.height, args.width):
+ with profile_context(args) as prof:
+ start = time.perf_counter()
+ for _ in range(args.n_repeat_times):
+ engine.generate(
+ prompts=["hello world"],
+ generation_config=DiffusionGenerationConfig(
+ num_inference_steps=args.num_inference_steps, height=h, width=w
+ ),
+ )
+ end = time.perf_counter()
+
+ avg_time = (end - start) / args.n_repeat_times
+ log_msg = f"[ColossalAI]avg generation time for h({h})xw({w}) is {avg_time:.2f}s"
+ coordinator.print_on_master(log_msg)
+
+ if dist.get_rank() == 0:
+ log_and_profile(h, w, avg_time, log_msg, args, args.model.split("/")[-1], "colossalai", prof=prof)
+
+
+def benchmark_diffusers(args):
+ model = DiffusionPipeline.from_pretrained(args.model, torch_dtype=_DTYPE_MAPPING[args.dtype]).to("cuda")
+
+ for _ in range(args.n_warm_up_steps):
+ model(
+ prompt="hello world",
+ num_inference_steps=args.num_inference_steps,
+ height=args.height[0],
+ width=args.width[0],
+ )
+
+ for h, w in zip(args.height, args.width):
+ with profile_context(args) as prof:
+ start = time.perf_counter()
+ for _ in range(args.n_repeat_times):
+ model(prompt="hello world", num_inference_steps=args.num_inference_steps, height=h, width=w)
+ end = time.perf_counter()
+
+ avg_time = (end - start) / args.n_repeat_times
+ log_msg = f"[Diffusers]avg generation time for h({h})xw({w}) is {avg_time:.2f}s"
+ print(log_msg)
+
+ log_and_profile(h, w, avg_time, log_msg, args, args.model.split("/")[-1], "diffusers", prof)
+
+
+@rerun_if_address_is_in_use()
+@clear_cache_before_run()
+def benchmark(args):
+ if args.mode == "colossalai":
+ spawn(benchmark_colossalai, nprocs=args.patched_parallel_size, args=args)
+ elif args.mode == "diffusers":
+ benchmark_diffusers(args)
+
+
+"""
+# enable log
+python examples/inference/stable_diffusion/benchmark_sd3.py -m "PixArt-alpha/PixArt-XL-2-1024-MS" -p 2 --mode colossalai --log
+python examples/inference/stable_diffusion/benchmark_sd3.py -m "PixArt-alpha/PixArt-XL-2-1024-MS" --mode diffusers --log
+
+# enable profiler
+python examples/inference/stable_diffusion/benchmark_sd3.py -m "stabilityai/stable-diffusion-3-medium-diffusers" -p 2 --mode colossalai --n_warm_up_steps 3 --n_repeat_times 1 --profile --num_inference_steps 20
+python examples/inference/stable_diffusion/benchmark_sd3.py -m "PixArt-alpha/PixArt-XL-2-1024-MS" -p 2 --mode colossalai --n_warm_up_steps 3 --n_repeat_times 1 --profile --num_inference_steps 20
+python examples/inference/stable_diffusion/benchmark_sd3.py -m "PixArt-alpha/PixArt-XL-2-1024-MS" --mode diffusers --n_warm_up_steps 3 --n_repeat_times 1 --profile --num_inference_steps 20
+"""
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-b", "--batch_size", type=int, default=1, help="Batch size")
+ parser.add_argument("-p", "--patched_parallel_size", type=int, default=1, help="Patched Parallelism size")
+ parser.add_argument("-n", "--num_inference_steps", type=int, default=50, help="Number of inference steps")
+ parser.add_argument("-H", "--height", type=int, nargs="+", default=[1024, 2048], help="Height list")
+ parser.add_argument("-w", "--width", type=int, nargs="+", default=[1024, 2048], help="Width list")
+ parser.add_argument("--dtype", type=str, default="fp16", choices=["fp16", "fp32", "bf16"], help="Data type")
+ parser.add_argument("--n_warm_up_steps", type=int, default=3, help="Number of warm up steps")
+ parser.add_argument("--n_repeat_times", type=int, default=5, help="Number of repeat times")
+ parser.add_argument("--profile", default=False, action="store_true", help="Enable torch profiler")
+ parser.add_argument("--log", default=False, action="store_true", help="Enable logging")
+ parser.add_argument("-m", "--model", default="stabilityai/stable-diffusion-3-medium-diffusers", help="Model path")
+ parser.add_argument(
+ "--mode", default="colossalai", choices=["colossalai", "diffusers"], help="Inference framework mode"
+ )
+ args = parser.parse_args()
+ benchmark(args)
diff --git a/examples/inference/stable_diffusion/compute_metric.py b/examples/inference/stable_diffusion/compute_metric.py
new file mode 100644
index 000000000000..14c92501b66d
--- /dev/null
+++ b/examples/inference/stable_diffusion/compute_metric.py
@@ -0,0 +1,80 @@
+# Code from https://github.com/mit-han-lab/distrifuser/blob/main/scripts/compute_metrics.py
+import argparse
+import os
+
+import numpy as np
+import torch
+from cleanfid import fid
+from PIL import Image
+from torch.utils.data import DataLoader, Dataset
+from torchmetrics.image import LearnedPerceptualImagePatchSimilarity, PeakSignalNoiseRatio
+from torchvision.transforms import Resize
+from tqdm import tqdm
+
+
+def read_image(path: str):
+ """
+ input: path
+ output: tensor (C, H, W)
+ """
+ img = np.asarray(Image.open(path))
+ if len(img.shape) == 2:
+ img = np.repeat(img[:, :, None], 3, axis=2)
+ img = torch.from_numpy(img).permute(2, 0, 1)
+ return img
+
+
+class MultiImageDataset(Dataset):
+ def __init__(self, root0, root1, is_gt=False):
+ super().__init__()
+ self.root0 = root0
+ self.root1 = root1
+ file_names0 = os.listdir(root0)
+ file_names1 = os.listdir(root1)
+
+ self.image_names0 = sorted([name for name in file_names0 if name.endswith(".png") or name.endswith(".jpg")])
+ self.image_names1 = sorted([name for name in file_names1 if name.endswith(".png") or name.endswith(".jpg")])
+ self.is_gt = is_gt
+ assert len(self.image_names0) == len(self.image_names1)
+
+ def __len__(self):
+ return len(self.image_names0)
+
+ def __getitem__(self, idx):
+ img0 = read_image(os.path.join(self.root0, self.image_names0[idx]))
+ if self.is_gt:
+ # resize to 1024 x 1024
+ img0 = Resize((1024, 1024))(img0)
+ img1 = read_image(os.path.join(self.root1, self.image_names1[idx]))
+
+ batch_list = [img0, img1]
+ return batch_list
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--batch_size", type=int, default=64)
+ parser.add_argument("--num_workers", type=int, default=8)
+ parser.add_argument("--is_gt", action="store_true")
+ parser.add_argument("--input_root0", type=str, required=True)
+ parser.add_argument("--input_root1", type=str, required=True)
+ args = parser.parse_args()
+
+ psnr = PeakSignalNoiseRatio(data_range=(0, 1), reduction="elementwise_mean", dim=(1, 2, 3)).to("cuda")
+ lpips = LearnedPerceptualImagePatchSimilarity(normalize=True).to("cuda")
+
+ dataset = MultiImageDataset(args.input_root0, args.input_root1, is_gt=args.is_gt)
+ dataloader = DataLoader(dataset, batch_size=args.batch_size, num_workers=args.num_workers)
+
+ progress_bar = tqdm(dataloader)
+ with torch.inference_mode():
+ for i, batch in enumerate(progress_bar):
+ batch = [img.to("cuda") / 255 for img in batch]
+ batch_size = batch[0].shape[0]
+ psnr.update(batch[0], batch[1])
+ lpips.update(batch[0], batch[1])
+ fid_score = fid.compute_fid(args.input_root0, args.input_root1)
+
+ print("PSNR:", psnr.compute().item())
+ print("LPIPS:", lpips.compute().item())
+ print("FID:", fid_score)
diff --git a/examples/inference/stable_diffusion/requirements.txt b/examples/inference/stable_diffusion/requirements.txt
new file mode 100644
index 000000000000..c4e74162dfb5
--- /dev/null
+++ b/examples/inference/stable_diffusion/requirements.txt
@@ -0,0 +1,3 @@
+torchvision
+torchmetrics
+cleanfid
diff --git a/examples/inference/stable_diffusion/run_benchmark.sh b/examples/inference/stable_diffusion/run_benchmark.sh
new file mode 100644
index 000000000000..f3e45a335219
--- /dev/null
+++ b/examples/inference/stable_diffusion/run_benchmark.sh
@@ -0,0 +1,42 @@
+#!/bin/bash
+
+models=("PixArt-alpha/PixArt-XL-2-1024-MS" "stabilityai/stable-diffusion-3-medium-diffusers")
+parallelism=(1 2 4 8)
+resolutions=(1024 2048 3840)
+modes=("colossalai" "diffusers")
+
+CUDA_VISIBLE_DEVICES_set_n_least_memory_usage() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
+
+for model in "${models[@]}"; do
+ for p in "${parallelism[@]}"; do
+ for resolution in "${resolutions[@]}"; do
+ for mode in "${modes[@]}"; do
+ if [[ "$mode" == "colossalai" && "$p" == 1 ]]; then
+ continue
+ fi
+ if [[ "$mode" == "diffusers" && "$p" != 1 ]]; then
+ continue
+ fi
+ CUDA_VISIBLE_DEVICES_set_n_least_memory_usage $p
+
+ cmd="python examples/inference/stable_diffusion/benchmark_sd3.py -m \"$model\" -p $p --mode $mode --log -H $resolution -w $resolution"
+
+ echo "Executing: $cmd"
+ eval $cmd
+ done
+ done
+ done
+done
diff --git a/examples/inference/stable_diffusion/sd3_generation.py b/examples/inference/stable_diffusion/sd3_generation.py
index fe989eed7c2d..9e146c34b937 100644
--- a/examples/inference/stable_diffusion/sd3_generation.py
+++ b/examples/inference/stable_diffusion/sd3_generation.py
@@ -1,18 +1,17 @@
import argparse
-from diffusers import PixArtAlphaPipeline, StableDiffusion3Pipeline
-from torch import bfloat16, float16, float32
+from diffusers import DiffusionPipeline
+from torch import bfloat16
+from torch import distributed as dist
+from torch import float16, float32
import colossalai
from colossalai.cluster import DistCoordinator
from colossalai.inference.config import DiffusionGenerationConfig, InferenceConfig
from colossalai.inference.core.engine import InferenceEngine
-from colossalai.inference.modeling.policy.pixart_alpha import PixArtAlphaInferPolicy
-from colossalai.inference.modeling.policy.stablediffusion3 import StableDiffusion3InferPolicy
# For Stable Diffusion 3, we'll use the following configuration
-MODEL_CLS = [StableDiffusion3Pipeline, PixArtAlphaPipeline][0]
-POLICY_CLS = [StableDiffusion3InferPolicy, PixArtAlphaInferPolicy][0]
+MODEL_CLS = DiffusionPipeline
TORCH_DTYPE_MAP = {
"fp16": float16,
@@ -43,20 +42,27 @@ def infer(args):
max_batch_size=args.max_batch_size,
tp_size=args.tp_size,
use_cuda_kernel=args.use_cuda_kernel,
+ patched_parallelism_size=dist.get_world_size(),
)
- engine = InferenceEngine(model, inference_config=inference_config, model_policy=POLICY_CLS(), verbose=True)
+ engine = InferenceEngine(model, inference_config=inference_config, verbose=True)
# ==============================
# Generation
# ==============================
coordinator.print_on_master(f"Generating...")
out = engine.generate(prompts=[args.prompt], generation_config=DiffusionGenerationConfig())[0]
- out.save("cat.jpg")
+ if dist.get_rank() == 0:
+ out.save(f"cat_parallel_size{dist.get_world_size()}.jpg")
coordinator.print_on_master(out)
# colossalai run --nproc_per_node 1 examples/inference/stable_diffusion/sd3_generation.py -m MODEL_PATH
+
# colossalai run --nproc_per_node 1 examples/inference/stable_diffusion/sd3_generation.py -m "stabilityai/stable-diffusion-3-medium-diffusers" --tp_size 1
+# colossalai run --nproc_per_node 2 examples/inference/stable_diffusion/sd3_generation.py -m "stabilityai/stable-diffusion-3-medium-diffusers" --tp_size 1
+
+# colossalai run --nproc_per_node 1 examples/inference/stable_diffusion/sd3_generation.py -m "PixArt-alpha/PixArt-XL-2-1024-MS" --tp_size 1
+# colossalai run --nproc_per_node 2 examples/inference/stable_diffusion/sd3_generation.py -m "PixArt-alpha/PixArt-XL-2-1024-MS" --tp_size 1
if __name__ == "__main__":
diff --git a/examples/language/gpt/hybridparallelism/finetune.py b/examples/language/gpt/hybridparallelism/finetune.py
index 777d16cb9ea0..ae6d655f40a6 100644
--- a/examples/language/gpt/hybridparallelism/finetune.py
+++ b/examples/language/gpt/hybridparallelism/finetune.py
@@ -1,4 +1,5 @@
import argparse
+from contextlib import nullcontext
from typing import Callable, List, Union
import evaluate
@@ -17,6 +18,7 @@
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin, TorchDDPPlugin
from colossalai.cluster import DistCoordinator
+from colossalai.lazy import LazyInitContext
from colossalai.nn.optimizer import HybridAdam
# ==============================
@@ -186,7 +188,6 @@ def main():
help="only gpt2 now",
)
parser.add_argument("--target_f1", type=float, default=None, help="target f1 score. Raise exception if not reached")
- parser.add_argument("--use_lazy_init", type=bool, default=False, help="for initiating lazy init context")
args = parser.parse_args()
if args.model_type == "gpt2":
@@ -250,10 +251,16 @@ def main():
pad_token_id=data_builder.tokenizer.pad_token_id,
)
- if model_name == "gpt2":
- model = GPT2ForSequenceClassification.from_pretrained(model_name, config=cfg).cuda()
- else:
- raise RuntimeError
+ init_ctx = (
+ LazyInitContext(default_device=get_accelerator().get_current_device())
+ if isinstance(plugin, (GeminiPlugin))
+ else nullcontext()
+ )
+ with init_ctx:
+ if model_name == "gpt2":
+ model = GPT2ForSequenceClassification.from_pretrained(model_name, config=cfg).cuda()
+ else:
+ raise RuntimeError
# optimizer
no_decay = ["bias", "LayerNorm.weight"]
diff --git a/examples/language/llama/benchmark.py b/examples/language/llama/benchmark.py
index 2b7bd50b8766..e530e2d6a153 100644
--- a/examples/language/llama/benchmark.py
+++ b/examples/language/llama/benchmark.py
@@ -98,6 +98,7 @@ def main():
parser.add_argument("--disable-async-reduce", action="store_true", help="Disable the asynchronous reduce operation")
parser.add_argument("--prefetch_num", type=int, default=0, help="chunk prefetch max number")
parser.add_argument("--no_cache", action="store_true")
+ parser.add_argument("--overlap_allgather", action="store_true")
args = parser.parse_args()
colossalai.launch_from_torch()
@@ -199,9 +200,9 @@ def empty_init():
enable_flash_attention=args.xformers,
microbatch_size=args.mbs,
precision="bf16",
- dp_outside=False,
overlap_p2p=args.overlap,
enable_metadata_cache=not args.no_cache,
+ overlap_allgather=args.overlap_allgather,
**hybrid_kwargs,
)
elif args.plugin == "3d_cpu":
diff --git a/examples/language/opt/opt_benchmark.py b/examples/language/opt/opt_benchmark.py
index c2883d96c16e..ca9b63d1a14a 100755
--- a/examples/language/opt/opt_benchmark.py
+++ b/examples/language/opt/opt_benchmark.py
@@ -1,4 +1,5 @@
import time
+from contextlib import nullcontext
import torch
import tqdm
@@ -8,9 +9,11 @@
from transformers.utils.versions import require_version
import colossalai
+from colossalai.accelerator import get_accelerator
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin, LowLevelZeroPlugin, TorchDDPPlugin
from colossalai.cluster import DistCoordinator
+from colossalai.lazy import LazyInitContext
from colossalai.logging import disable_existing_loggers, get_dist_logger
from colossalai.nn.optimizer import HybridAdam
@@ -62,14 +65,6 @@ def main():
if args.mem_cap > 0:
colo_memory_cap(args.mem_cap)
- # Build OPT model
- config = AutoConfig.from_pretrained(args.model_name_or_path)
- model = OPTForCausalLM(config=config)
- logger.info(f"Finish loading model from {args.model_name_or_path}", ranks=[0])
-
- # Enable gradient checkpointing
- model.gradient_checkpointing_enable()
-
# Set plugin
booster_kwargs = {}
if args.plugin == "torch_ddp_fp16":
@@ -82,6 +77,19 @@ def main():
plugin = LowLevelZeroPlugin(initial_scale=2**5)
logger.info(f"Set plugin as {args.plugin}", ranks=[0])
+ # Build OPT model
+ init_ctx = (
+ LazyInitContext(default_device=get_accelerator().get_current_device())
+ if isinstance(plugin, (GeminiPlugin))
+ else nullcontext()
+ )
+ config = AutoConfig.from_pretrained(args.model_name_or_path)
+ with init_ctx:
+ model = OPTForCausalLM(config=config)
+ logger.info(f"Finish loading model from {args.model_name_or_path}", ranks=[0])
+
+ # Enable gradient checkpointing
+ model.gradient_checkpointing_enable()
# Set optimizer
optimizer = HybridAdam(model.parameters(), lr=args.learning_rate)
diff --git a/examples/language/opt/opt_train_demo.py b/examples/language/opt/opt_train_demo.py
index b5b50305cc34..50dfc7bffd07 100644
--- a/examples/language/opt/opt_train_demo.py
+++ b/examples/language/opt/opt_train_demo.py
@@ -1,3 +1,5 @@
+from contextlib import nullcontext
+
import datasets
import torch
import transformers
@@ -8,9 +10,11 @@
from transformers.utils.versions import require_version
import colossalai
+from colossalai.accelerator import get_accelerator
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin, TorchDDPPlugin
from colossalai.cluster import DistCoordinator
+from colossalai.lazy import LazyInitContext
from colossalai.logging import disable_existing_loggers, get_dist_logger
from colossalai.nn.optimizer import HybridAdam
@@ -78,14 +82,6 @@ def main():
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
- # Build OPT model
- config = AutoConfig.from_pretrained(args.model_name_or_path)
- model = OPTForCausalLM.from_pretrained(args.model_name_or_path, config=config)
- logger.info(f"Finish loading model from {args.model_name_or_path}", ranks=[0])
-
- # Enable gradient checkpointing
- model.gradient_checkpointing_enable()
-
# Set plugin
booster_kwargs = {}
if args.plugin == "torch_ddp_fp16":
@@ -110,6 +106,21 @@ def main():
logger.info(f"Set plugin as {args.plugin}", ranks=[0])
+ # Build OPT model
+ config = AutoConfig.from_pretrained(args.model_name_or_path)
+ # Build OPT model
+ init_ctx = (
+ LazyInitContext(default_device=get_accelerator().get_current_device())
+ if isinstance(plugin, (GeminiPlugin, HybridParallelPlugin))
+ else nullcontext()
+ )
+ with init_ctx:
+ model = OPTForCausalLM.from_pretrained(args.model_name_or_path, config=config)
+ logger.info(f"Finish loading model from {args.model_name_or_path}", ranks=[0])
+
+ # Enable gradient checkpointing
+ model.gradient_checkpointing_enable()
+
# Prepare tokenizer and dataloader
tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path)
dataset = NetflixDataset(tokenizer)
diff --git a/tests/kit/model_zoo/transformers/__init__.py b/tests/kit/model_zoo/transformers/__init__.py
index 05c17f562635..4adc386192d3 100644
--- a/tests/kit/model_zoo/transformers/__init__.py
+++ b/tests/kit/model_zoo/transformers/__init__.py
@@ -3,28 +3,17 @@
from .blip2 import *
from .bloom import *
from .chatglm2 import *
+from .command import *
+from .deepseek import *
from .falcon import *
from .gpt import *
from .gptj import *
from .llama import *
+from .mistral import *
+from .mixtral import *
from .opt import *
+from .qwen2 import *
from .sam import *
from .t5 import *
from .vit import *
from .whisper import *
-
-try:
- from .mistral import *
-except ImportError:
- print("This version of transformers doesn't support mistral.")
-
-try:
- from .qwen2 import *
-except ImportError:
- print("This version of transformers doesn't support qwen2.")
-
-
-try:
- from .command import *
-except ImportError:
- print("This version of transformers doesn't support Command-R.")
diff --git a/tests/kit/model_zoo/transformers/deepseek.py b/tests/kit/model_zoo/transformers/deepseek.py
new file mode 100644
index 000000000000..ad73640a57c5
--- /dev/null
+++ b/tests/kit/model_zoo/transformers/deepseek.py
@@ -0,0 +1,83 @@
+# modified from tests/kit/model_zoo/transformers/mistral.py
+import torch
+import transformers
+from transformers import AutoConfig
+
+from ..registry import ModelAttribute, model_zoo
+
+# ===============================
+# Register single-sentence Mixtral
+# ===============================
+
+
+def data_gen():
+ # Generated from following code snippet
+ #
+ # from transformers import AutoModelForCausalLM, AutoTokenizer
+ # tokenizer = AutoTokenizer.from_pretrained("mixtralai/Mixtral-7B-v0.1")
+ # input = 'My favourite condiment is vinegar' (last two words repeated to satisfy length requirement)
+ # tokenized_input = tokenizer([input], return_tensors="pt")
+ # input_ids = tokenized_input['input_ids']
+ # attention_mask = tokenized_input['attention_mask']
+ input_ids = torch.tensor([[1, 22, 55, 77, 532, 349, 43, 22]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def data_gen_for_lm():
+ # LM data gen
+ # the `labels` of LM is the token of the output, cause no padding, use `input_ids` as `labels`
+ data = data_gen()
+ data["labels"] = data["input_ids"].clone()
+ return data
+
+
+def data_gen_for_sequence_classification():
+ # sequence classification data gen
+ data = data_gen()
+ data["labels"] = torch.tensor([1], dtype=torch.int64)
+ return data
+
+
+# define output transform function
+output_transform_fn = lambda x: x
+
+# define loss function
+loss_fn_for_mixtral_model = lambda x: x[0].mean()
+loss_fn = lambda x: x.loss
+loss_fn_for_seq_classification = lambda output: output.logits.mean()
+
+
+def init_deepseek():
+
+ config = AutoConfig.from_pretrained(
+ "deepseek-ai/deepseek-moe-16b-base",
+ hidden_size=32,
+ intermediate_size=32,
+ moe_intermediate_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=8,
+ num_key_value_heads=8,
+ # vocab_size=2200,
+ first_k_dense_replace=1,
+ attn_implementation="flash_attention_2",
+ torch_dtype="float16",
+ n_routed_experts=8,
+ trust_remote_code=True,
+ )
+
+ if hasattr(config, "pad_token_id"):
+ config.pad_token_id = config.eos_token_id
+ model = transformers.AutoModel.from_config(config, trust_remote_code=True)
+
+ return model
+
+
+model_zoo.register(
+ name="transformers_deepseek",
+ model_fn=init_deepseek,
+ data_gen_fn=data_gen,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn_for_mixtral_model,
+ model_attribute=ModelAttribute(has_control_flow=True),
+)
diff --git a/tests/kit/model_zoo/transformers/mixtral.py b/tests/kit/model_zoo/transformers/mixtral.py
new file mode 100644
index 000000000000..40e5a7b0232d
--- /dev/null
+++ b/tests/kit/model_zoo/transformers/mixtral.py
@@ -0,0 +1,87 @@
+# modified from tests/kit/model_zoo/transformers/mistral.py
+import torch
+import transformers
+from transformers import MixtralConfig
+
+from ..registry import ModelAttribute, model_zoo
+
+# ===============================
+# Register single-sentence Mixtral
+# ===============================
+
+
+def data_gen():
+ # Generated from following code snippet
+ #
+ # from transformers import AutoModelForCausalLM, AutoTokenizer
+ # tokenizer = AutoTokenizer.from_pretrained("mixtralai/Mixtral-7B-v0.1")
+ # input = 'My favourite condiment is vinegar' (last two words repeated to satisfy length requirement)
+ # tokenized_input = tokenizer([input], return_tensors="pt")
+ # input_ids = tokenized_input['input_ids']
+ # attention_mask = tokenized_input['attention_mask']
+ input_ids = torch.tensor([[1, 22, 55, 77, 532, 349, 43, 22]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def data_gen_for_lm():
+ # LM data gen
+ # the `labels` of LM is the token of the output, cause no padding, use `input_ids` as `labels`
+ data = data_gen()
+ data["labels"] = data["input_ids"].clone()
+ return data
+
+
+def data_gen_for_sequence_classification():
+ # sequence classification data gen
+ data = data_gen()
+ data["labels"] = torch.tensor([1], dtype=torch.int64)
+ return data
+
+
+# define output transform function
+output_transform_fn = lambda x: x
+
+# define loss function
+loss_fn_for_mixtral_model = lambda x: x[0].mean()
+loss_fn = lambda x: x.loss
+loss_fn_for_seq_classification = lambda output: output.logits.mean()
+
+config = MixtralConfig(
+ hidden_size=32,
+ intermediate_size=32,
+ num_attention_heads=8,
+ num_hidden_layers=2,
+ vocab_size=1000,
+ attn_implementation="flash_attention_2",
+ torch_dtype="float16",
+ output_router_logits=True,
+)
+
+if hasattr(config, "pad_token_id"):
+ config.pad_token_id = config.eos_token_id
+
+model_zoo.register(
+ name="transformers_mixtral",
+ model_fn=lambda: transformers.MixtralModel(config),
+ data_gen_fn=data_gen,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn_for_mixtral_model,
+ model_attribute=ModelAttribute(has_control_flow=True),
+)
+# model_zoo.register(
+# name="transformers_mixtral_for_casual_lm",
+# model_fn=lambda: transformers.MixtralForCausalLM(config),
+# data_gen_fn=data_gen_for_lm,
+# output_transform_fn=output_transform_fn,
+# loss_fn=loss_fn,
+# model_attribute=ModelAttribute(has_control_flow=True),
+# )
+# model_zoo.register(
+# name="transformers_mixtral_for_sequence_classification",
+# model_fn=lambda: transformers.MixtralForSequenceClassification(config),
+# data_gen_fn=data_gen_for_sequence_classification,
+# output_transform_fn=output_transform_fn,
+# loss_fn=loss_fn_for_seq_classification,
+# model_attribute=ModelAttribute(has_control_flow=True),
+# )
diff --git a/tests/test_legacy/test_moe/moe_utils.py b/tests/test_legacy/test_moe/moe_utils.py
new file mode 100644
index 000000000000..8c133849b000
--- /dev/null
+++ b/tests/test_legacy/test_moe/moe_utils.py
@@ -0,0 +1,136 @@
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from torch.distributed import ProcessGroup
+
+from colossalai.booster.plugin.low_level_zero_plugin import LowLevelZeroModel
+from colossalai.legacy.engine.gradient_handler._base_gradient_handler import BaseGradientHandler
+from colossalai.legacy.engine.gradient_handler.utils import bucket_allreduce
+from colossalai.legacy.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.utils import get_moe_epsize_param_dict
+from colossalai.legacy.registry import GRADIENT_HANDLER
+from colossalai.tensor.moe_tensor.api import get_ep_group, get_ep_size, set_moe_tensor_ep_group
+
+
+def delete_moe_info(model):
+ for _, param in model.named_parameters():
+ if hasattr(param, "ep_group"):
+ delattr(param, "ep_group")
+
+
+class MoeModel(nn.Module):
+ def __init__(self, ep_group: ProcessGroup = None):
+ super().__init__()
+ self.test_embed = nn.Linear(4, 16, bias=False)
+ self.w1 = torch.nn.Parameter(torch.randn(16, 8))
+ if ep_group:
+ set_moe_tensor_ep_group(self.w1, ep_group)
+
+ def forward(self, x):
+ x = self.test_embed(x)
+ x = torch.matmul(x, self.w1)
+
+ return x
+
+
+@GRADIENT_HANDLER.register_module
+class MoeGradientHandler(BaseGradientHandler):
+ """A helper class to handle all-reduce operations in a data parallel group and
+ moe model parallel. A all-reduce collective communication will be operated in
+ :func:`handle_gradient` among a data parallel group.
+ For better performance, it bucketizes the gradients of all parameters that are
+ the same type to improve the efficiency of communication.
+
+ Args:
+ model (Module): Model where the gradients accumulate.
+ optimizer (Optimizer): Optimizer for updating the parameters.
+ """
+
+ def __init__(self, model, optimizer=None):
+ super().__init__(model, optimizer)
+
+ def handle_gradient(self):
+ """A method running an all-reduce operation in a data parallel group.
+ Then running an all-reduce operation for all parameters in experts
+ across moe model parallel group
+ """
+ if dist.get_world_size() > 1:
+ epsize_param_dict = get_moe_epsize_param_dict(self._model)
+
+ # epsize is 1, indicating the params are replicated among processes in data parallelism
+ # use the ParallelMode.DATA to get data parallel group
+ # reduce gradients for all parameters in data parallelism
+ if 1 in epsize_param_dict:
+ bucket_allreduce(param_list=epsize_param_dict[1])
+
+ for ep_size in epsize_param_dict:
+ if ep_size != 1 and ep_size != MOE_MANAGER.world_size:
+ bucket_allreduce(
+ param_list=epsize_param_dict[ep_size], group=MOE_MANAGER.parallel_info_dict[ep_size].dp_group
+ )
+
+
+def assert_not_equal_in_group(tensor, process_group=None):
+ # all gather tensors from different ranks
+ world_size = dist.get_world_size(process_group)
+ tensor_list = [torch.empty_like(tensor) for _ in range(world_size)]
+ dist.all_gather(tensor_list, tensor, group=process_group)
+
+ # check if they are equal one by one
+ for i in range(world_size - 1):
+ a = tensor_list[i]
+ b = tensor_list[i + 1]
+ assert not torch.allclose(a, b), (
+ f"expected tensors on rank {i} and {i + 1} not to be equal " f"but they are, {a} vs {b}"
+ )
+
+
+def run_fwd_bwd(model, data, label, criterion, optimizer, enable_autocast=False):
+ model.train()
+ with torch.cuda.amp.autocast(enabled=enable_autocast):
+ if criterion:
+ y = model(data)
+ loss = criterion(y, label)
+ else:
+ loss = model(data, label)
+ loss = loss.float()
+
+ if isinstance(model, LowLevelZeroModel):
+ optimizer.backward(loss)
+ else:
+ loss.backward()
+ return y
+
+
+def sync_local_from_ep(local_model, ep_model, assert_grad_flag: bool = False) -> None:
+ """Sync the parameters of tp model from ep model
+
+ Args:
+ local_model (MoeModule)
+ ep_model (MoeModule)
+ """
+ for (local_name, local_param), (ep_name, ep_param) in zip(
+ local_model.named_parameters(), ep_model.named_parameters()
+ ):
+ if "experts" not in local_name:
+ if assert_grad_flag:
+ assert torch.allclose(local_param, ep_param), f"local_param: {local_param}, ep_param: {ep_param}"
+ assert torch.allclose(local_param.grad, ep_param.grad)
+ else:
+ local_param.data.copy_(ep_param.data)
+ continue
+
+ # gather param from ep model
+ param_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
+ dist.all_gather(param_list, ep_param, group=get_ep_group(ep_param))
+ all_param = torch.cat(param_list, dim=0)
+ if assert_grad_flag:
+ grad_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
+ dist.all_gather(grad_list, ep_param.grad, group=get_ep_group(ep_param))
+ all_grad = torch.cat(grad_list, dim=0)
+
+ if assert_grad_flag:
+ assert torch.allclose(local_param, all_param)
+ assert torch.allclose(local_param.grad, all_grad)
+ else:
+ local_param.data.copy_(all_param.data)
diff --git a/tests/test_moe/test_grad_handler.py b/tests/test_legacy/test_moe/test_grad_handler.py
similarity index 98%
rename from tests/test_moe/test_grad_handler.py
rename to tests/test_legacy/test_moe/test_grad_handler.py
index 25e61b091729..3a782a6dd445 100644
--- a/tests/test_moe/test_grad_handler.py
+++ b/tests/test_legacy/test_moe/test_grad_handler.py
@@ -5,7 +5,7 @@
import colossalai
from colossalai.accelerator import get_accelerator
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
# from colossalai.shardformer.layer.moe.layers import SparseMLP
from colossalai.testing import assert_equal_in_group, rerun_if_address_is_in_use, spawn
diff --git a/tests/test_moe/test_moe_group.py b/tests/test_legacy/test_moe/test_moe_group.py
similarity index 95%
rename from tests/test_moe/test_moe_group.py
rename to tests/test_legacy/test_moe/test_moe_group.py
index 89baf1d37b1b..68dac4828fa7 100644
--- a/tests/test_moe/test_moe_group.py
+++ b/tests/test_legacy/test_moe/test_moe_group.py
@@ -4,8 +4,8 @@
import colossalai
from colossalai.accelerator import get_accelerator
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import sync_moe_model_param
+from colossalai.legacy.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.utils import sync_moe_model_param
# from colossalai.shardformer.layer.moe import MLPExperts
from colossalai.testing import assert_equal_in_group, rerun_if_address_is_in_use, spawn
diff --git a/tests/test_moe/test_moe_hybrid_zero.py b/tests/test_legacy/test_moe/test_moe_hybrid_zero.py
similarity index 98%
rename from tests/test_moe/test_moe_hybrid_zero.py
rename to tests/test_legacy/test_moe/test_moe_hybrid_zero.py
index 513c4ebda4a5..fdd6d956ef83 100644
--- a/tests/test_moe/test_moe_hybrid_zero.py
+++ b/tests/test_legacy/test_moe/test_moe_hybrid_zero.py
@@ -6,7 +6,7 @@
from colossalai.booster import Booster
from colossalai.booster.plugin import LowLevelZeroPlugin
from colossalai.booster.plugin.low_level_zero_plugin import LowLevelZeroModel
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
from colossalai.tensor.moe_tensor.api import is_moe_tensor
from colossalai.testing import rerun_if_address_is_in_use, spawn
from tests.test_moe.moe_utils import MoeModel
diff --git a/tests/test_moe/test_moe_load_balance.py b/tests/test_legacy/test_moe/test_moe_load_balance.py
similarity index 99%
rename from tests/test_moe/test_moe_load_balance.py
rename to tests/test_legacy/test_moe/test_moe_load_balance.py
index ddd3ea368964..adf2dbc1ccf3 100644
--- a/tests/test_moe/test_moe_load_balance.py
+++ b/tests/test_legacy/test_moe/test_moe_load_balance.py
@@ -6,7 +6,7 @@
from colossalai.booster import Booster
from colossalai.booster.plugin import LowLevelZeroPlugin
from colossalai.booster.plugin.low_level_zero_plugin import LowLevelZeroModel
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
# from colossalai.shardformer.layer.moe import apply_load_balance
from colossalai.tensor.moe_tensor.api import is_moe_tensor
diff --git a/tests/test_lora/test_lora.py b/tests/test_lora/test_lora.py
index b8daf775db0e..1ae17025d31e 100644
--- a/tests/test_lora/test_lora.py
+++ b/tests/test_lora/test_lora.py
@@ -9,7 +9,8 @@
import colossalai
from colossalai.booster import Booster
-from colossalai.booster.plugin import LowLevelZeroPlugin, TorchDDPPlugin
+from colossalai.booster.plugin import HybridParallelPlugin, LowLevelZeroPlugin, TorchDDPPlugin
+from colossalai.booster.plugin.hybrid_parallel_plugin import HybridParallelModule
from colossalai.testing import check_state_dict_equal, clear_cache_before_run, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
from tests.test_checkpoint_io.utils import shared_tempdir
@@ -20,7 +21,7 @@ def check_fwd_bwd(model_fn, data_gen_fn, output_transform_fn, loss_fn, task_type
model = model_fn()
lora_config = LoraConfig(task_type=task_type, r=8, lora_alpha=32, lora_dropout=0.1)
- test_plugins = [TorchDDPPlugin(), LowLevelZeroPlugin()]
+ test_plugins = [TorchDDPPlugin(), LowLevelZeroPlugin(), HybridParallelPlugin(tp_size=1, pp_size=1)]
test_configs = [
{
"lora_config": lora_config,
@@ -59,6 +60,8 @@ def check_fwd_bwd(model_fn, data_gen_fn, output_transform_fn, loss_fn, task_type
# test fwd bwd correctness
test_model = model_load
+ if isinstance(model_load, HybridParallelModule):
+ model_load = model_load.module.module
model_copy = copy.deepcopy(model_load)
data = data_gen_fn()
diff --git a/tests/test_moe/moe_utils.py b/tests/test_moe/moe_utils.py
index 131932dcb3b3..8c411a33fef6 100644
--- a/tests/test_moe/moe_utils.py
+++ b/tests/test_moe/moe_utils.py
@@ -1,142 +1,8 @@
import torch
-import torch.distributed as dist
-import torch.nn as nn
-from torch.distributed import ProcessGroup
-from torch.testing import assert_close
-from colossalai.booster.plugin.low_level_zero_plugin import LowLevelZeroModel
-from colossalai.legacy.engine.gradient_handler._base_gradient_handler import BaseGradientHandler
-from colossalai.legacy.engine.gradient_handler.utils import bucket_allreduce
-from colossalai.legacy.registry import GRADIENT_HANDLER
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import get_moe_epsize_param_dict
-# from colossalai.shardformer.layer.moe import SparseMLP
-from colossalai.tensor.moe_tensor.api import get_ep_group, get_ep_size, set_moe_tensor_ep_group
-
-
-def delete_moe_info(model):
- for _, param in model.named_parameters():
- if hasattr(param, "ep_group"):
- delattr(param, "ep_group")
-
-
-class MoeModel(nn.Module):
- def __init__(self, ep_group: ProcessGroup = None):
- super().__init__()
- self.test_embed = nn.Linear(4, 16, bias=False)
- self.w1 = torch.nn.Parameter(torch.randn(16, 8))
- if ep_group:
- set_moe_tensor_ep_group(self.w1, ep_group)
-
- def forward(self, x):
- x = self.test_embed(x)
- x = torch.matmul(x, self.w1)
-
- return x
-
-
-@GRADIENT_HANDLER.register_module
-class MoeGradientHandler(BaseGradientHandler):
- """A helper class to handle all-reduce operations in a data parallel group and
- moe model parallel. A all-reduce collective communication will be operated in
- :func:`handle_gradient` among a data parallel group.
- For better performance, it bucketizes the gradients of all parameters that are
- the same type to improve the efficiency of communication.
-
- Args:
- model (Module): Model where the gradients accumulate.
- optimizer (Optimizer): Optimizer for updating the parameters.
- """
-
- def __init__(self, model, optimizer=None):
- super().__init__(model, optimizer)
-
- def handle_gradient(self):
- """A method running an all-reduce operation in a data parallel group.
- Then running an all-reduce operation for all parameters in experts
- across moe model parallel group
- """
- if dist.get_world_size() > 1:
- epsize_param_dict = get_moe_epsize_param_dict(self._model)
-
- # epsize is 1, indicating the params are replicated among processes in data parallelism
- # use the ParallelMode.DATA to get data parallel group
- # reduce gradients for all parameters in data parallelism
- if 1 in epsize_param_dict:
- bucket_allreduce(param_list=epsize_param_dict[1])
-
- for ep_size in epsize_param_dict:
- if ep_size != 1 and ep_size != MOE_MANAGER.world_size:
- bucket_allreduce(
- param_list=epsize_param_dict[ep_size], group=MOE_MANAGER.parallel_info_dict[ep_size].dp_group
- )
-
-
-def assert_not_equal_in_group(tensor, process_group=None):
- # all gather tensors from different ranks
- world_size = dist.get_world_size(process_group)
- tensor_list = [torch.empty_like(tensor) for _ in range(world_size)]
- dist.all_gather(tensor_list, tensor, group=process_group)
-
- # check if they are equal one by one
- for i in range(world_size - 1):
- a = tensor_list[i]
- b = tensor_list[i + 1]
- assert not torch.allclose(a, b), (
- f"expected tensors on rank {i} and {i + 1} not to be equal " f"but they are, {a} vs {b}"
- )
-
-
-def run_fwd_bwd(model, data, label, criterion, optimizer, enable_autocast=False):
- model.train()
- with torch.cuda.amp.autocast(enabled=enable_autocast):
- if criterion:
- y = model(data)
- loss = criterion(y, label)
- else:
- loss = model(data, label)
- loss = loss.float()
-
- if isinstance(model, LowLevelZeroModel):
- optimizer.backward(loss)
- else:
- loss.backward()
- return y
-
-
-def sync_local_from_ep(local_model, ep_model, assert_grad_flag: bool = False) -> None:
- """Sync the parameters of tp model from ep model
-
- Args:
- local_model (MoeModule)
- ep_model (MoeModule)
- """
- for (local_name, local_param), (ep_name, ep_param) in zip(
- local_model.named_parameters(), ep_model.named_parameters()
- ):
- if "experts" not in local_name:
- if assert_grad_flag:
- assert torch.allclose(local_param, ep_param), f"local_param: {local_param}, ep_param: {ep_param}"
- assert torch.allclose(local_param.grad, ep_param.grad)
- else:
- local_param.data.copy_(ep_param.data)
- continue
-
- # gather param from ep model
- param_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
- dist.all_gather(param_list, ep_param, group=get_ep_group(ep_param))
- all_param = torch.cat(param_list, dim=0)
- if assert_grad_flag:
- grad_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
- dist.all_gather(grad_list, ep_param.grad, group=get_ep_group(ep_param))
- all_grad = torch.cat(grad_list, dim=0)
-
- if assert_grad_flag:
- assert torch.allclose(local_param, all_param)
- assert torch.allclose(local_param.grad, all_grad)
- else:
- local_param.data.copy_(all_param.data)
+def assert_loose_close(a, b, dtype: torch.dtype = torch.float32, name=""):
+ assert loose_close(a, b, dtype), f"{name} not close {a.mean()} {b.mean()}"
def loose_close(a, b, dtype: torch.dtype = torch.float32):
@@ -148,8 +14,18 @@ def loose_close(a, b, dtype: torch.dtype = torch.float32):
elif dtype is torch.bfloat16:
rtol = 4e-3
atol = 4e-3
+ else:
+ assert dtype is torch.float32
+ rtol = 1e-05
+ atol = 1e-08
a = a.detach().to(dtype)
b = b.detach().to(dtype).to(a.device)
- assert_close(a, b, rtol=rtol, atol=atol)
+ return torch.allclose(a, b, rtol=rtol, atol=atol)
+
+
+def check_model_equal(model1, model2):
+ assert set(model1.state_dict().keys()) == set(model2.state_dict().keys())
+ for i, ((name, p1), p2) in enumerate(zip(model1.named_parameters(), model2.parameters())):
+ assert_loose_close(p1, p2, p1.dtype)
diff --git a/tests/test_moe/test_deepseek_layer.py b/tests/test_moe/test_deepseek_layer.py
index 85cc986959fd..d18ba2eacd84 100644
--- a/tests/test_moe/test_deepseek_layer.py
+++ b/tests/test_moe/test_deepseek_layer.py
@@ -22,6 +22,7 @@ def check_deepseek_moe_layer():
precision="bf16",
tp_size=1,
pp_size=1,
+ zero_stage=1,
ep_size=dist.get_world_size(),
)
@@ -42,7 +43,12 @@ def check_deepseek_moe_layer():
x = torch.rand(1, tokens, hidden_size, requires_grad=True).cuda()
orig_output = orig_model(x)
model = deepcopy(orig_model)
- model = EPDeepseekMoE.from_native_module(model, ep_group=plugin.ep_group)
+ model = EPDeepseekMoE.from_native_module(
+ model,
+ ep_group=plugin.ep_group,
+ moe_dp_group=plugin.moe_dp_group,
+ tp_group=plugin.tp_group,
+ )
ep_output = model(x)
assert_close(orig_output, ep_output)
orig_loss = orig_output.mean()
@@ -62,7 +68,7 @@ def run_dist(rank: int, world_size: int, port: int):
check_deepseek_moe_layer()
-# @pytest.mark.parametrize("world_size", [2, 4])
+@pytest.mark.skip("tested in corresponding sharderformer")
@pytest.mark.parametrize("world_size", [2])
def test_deepseek_moe_layer(world_size: int):
spawn(run_dist, world_size)
diff --git a/tests/test_moe/test_kernel.py b/tests/test_moe/test_kernel.py
index 28e6db441411..c81023988377 100644
--- a/tests/test_moe/test_kernel.py
+++ b/tests/test_moe/test_kernel.py
@@ -4,8 +4,6 @@
import torch
from colossalai.accelerator import get_accelerator
-
-# from colossalai.moe import SparseMLP
from colossalai.moe._operation import MoeCombine, MoeDispatch, moe_cumsum
NUM_EXPERTS = 4
diff --git a/tests/test_moe/test_mixtral_layer.py b/tests/test_moe/test_mixtral_layer.py
index b7b0322e08b5..bc41ac4f33e9 100644
--- a/tests/test_moe/test_mixtral_layer.py
+++ b/tests/test_moe/test_mixtral_layer.py
@@ -23,6 +23,7 @@ def check_mixtral_moe_layer():
precision="bf16",
tp_size=1,
pp_size=1,
+ zero_stage=1,
ep_size=dist.get_world_size(),
)
config = MixtralConfig(
@@ -36,7 +37,12 @@ def check_mixtral_moe_layer():
x = torch.rand(1, tokens, hidden_size, requires_grad=True).cuda()
orig_output, orig_logits = orig_model(x)
model = deepcopy(orig_model)
- model = EPMixtralSparseMoeBlock.from_native_module(model, ep_group=plugin.ep_group)
+ model = EPMixtralSparseMoeBlock.from_native_module(
+ model,
+ ep_group=plugin.ep_group,
+ tp_group=plugin.tp_group,
+ moe_dp_group=plugin.moe_dp_group,
+ )
ep_output, ep_logits = model(x)
assert_close(orig_logits, ep_logits)
assert_close(orig_output, ep_output)
@@ -57,7 +63,8 @@ def run_dist(rank: int, world_size: int, port: int):
check_mixtral_moe_layer()
-@pytest.mark.parametrize("world_size", [2, 4])
+@pytest.mark.skip("tested in corresponding sharderformer")
+@pytest.mark.parametrize("world_size", [2])
def test_mixtral_moe_layer(world_size: int):
spawn(run_dist, world_size)
diff --git a/tests/test_moe/test_moe_checkpoint.py b/tests/test_moe/test_moe_checkpoint.py
index 164301695865..89f5d1c64d0d 100644
--- a/tests/test_moe/test_moe_checkpoint.py
+++ b/tests/test_moe/test_moe_checkpoint.py
@@ -6,31 +6,23 @@
import pytest
import torch
import torch.distributed as dist
-from torch.optim import Adam
+from torch.optim import SGD, Adam
from transformers.models.mixtral.configuration_mixtral import MixtralConfig
from transformers.models.mixtral.modeling_mixtral import MixtralForCausalLM
import colossalai
from colossalai.booster import Booster
from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
-from colossalai.checkpoint_io import MoECheckpointIO
-from colossalai.tensor.moe_tensor.api import is_moe_tensor
from colossalai.testing import parameterize, spawn
+from colossalai.testing.random import seed_all
from colossalai.testing.utils import spawn
+from tests.test_moe.moe_utils import check_model_equal
tokens, n_experts = 7, 4
hidden_size = 8
top_k = 2
-def check_model_equal(model1, model2):
- assert set(model1.state_dict().keys()) == set(model2.state_dict().keys())
- for i, ((name, p1), p2) in enumerate(zip(model1.named_parameters(), model2.parameters())):
- if not torch.equal(p1.half(), p2.half()):
- print(f"Model parameter {name} is not equal. is_moe_tensor: {is_moe_tensor(p1)}")
- raise AssertionError(f"Model parameter {name} is not equal")
-
-
def get_optimizer_snapshot(optim):
state = {id(k): deepcopy(v) for k, v in optim.state.items()}
param_groups = []
@@ -89,35 +81,33 @@ def check_optimizer_snapshot_equal(snapshot1, snapshot2, param2name, moe_dp_grou
num_experts_per_tok=top_k,
num_attention_heads=2,
num_key_value_heads=2,
+ num_hidden_layers=2,
),
MixtralForCausalLM,
],
],
)
def check_moe_checkpoint(test_config):
+ dtype, precision = torch.float16, "fp16"
+ config, model_cls = test_config
+ torch.cuda.set_device(dist.get_rank())
+
context = tempfile.TemporaryDirectory() if dist.get_rank() == 0 else nullcontext()
with context as f:
- torch.cuda.set_device(dist.get_rank())
if dist.get_rank() == 0:
broadcast_objects = [f] # any picklable object
else:
broadcast_objects = [None]
dist.broadcast_object_list(broadcast_objects, src=0)
- config = test_config[0]
- model_cls = test_config[1]
- torch.manual_seed(0)
input_ids = torch.randint(0, 100, (2, tokens)).cuda()
- orig_model = model_cls(config).cuda()
+ orig_model = model_cls(config).cuda().to(dtype)
+
+ seed_all(10086)
model = deepcopy(orig_model)
- optimizer = Adam(model.parameters(), lr=1e-3)
+ optimizer = SGD(model.parameters(), lr=1e-3)
plugin = MoeHybridParallelPlugin(
- pp_size=2,
- ep_size=2,
- tp_size=1,
- checkpoint_io=MoECheckpointIO,
- microbatch_size=1,
- zero_stage=1,
+ pp_size=2, ep_size=2, tp_size=1, microbatch_size=1, zero_stage=1, precision=precision
)
booster = Booster(plugin=plugin)
model, optimizer, *_ = booster.boost(model=model, optimizer=optimizer)
@@ -139,13 +129,12 @@ def check_moe_checkpoint(test_config):
booster.save_model(model, model_dir, shard=True)
dist.barrier()
if dist.get_rank() == 0:
- saved_model = model_cls.from_pretrained(model_dir).cuda()
+ saved_model = model_cls.from_pretrained(model_dir).cuda().to(dtype)
check_model_equal(orig_model, saved_model)
- # check_model_equal(model, saved_model)
saved_model.save_pretrained(hf_model_dir)
dist.barrier()
# check load model
- new_model = model_cls(config).cuda()
+ new_model = model_cls(config).cuda().to(dtype)
new_optimizer = Adam(new_model.parameters(), lr=1e-3)
new_model, new_optimizer, *_ = booster.boost(model=new_model, optimizer=new_optimizer)
booster.load_model(new_model, hf_model_dir)
diff --git a/tests/test_moe/test_moe_ep_tp.py b/tests/test_moe/test_moe_ep_tp.py
index 9bc11033af6f..e6d2609ee67c 100644
--- a/tests/test_moe/test_moe_ep_tp.py
+++ b/tests/test_moe/test_moe_ep_tp.py
@@ -1,238 +1,132 @@
-import os
-import warnings
-from typing import Dict
+from copy import deepcopy
import pytest
import torch
import torch.distributed as dist
+from transformers.models.mixtral.configuration_mixtral import MixtralConfig
+from transformers.models.mixtral.modeling_mixtral import MixtralModel
import colossalai
-from colossalai.accelerator import get_accelerator
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import sync_moe_model_param
-
-# from colossalai.shardformer.layer import SparseMLP
-from colossalai.tensor.moe_tensor.api import get_ep_group, get_ep_rank, get_ep_size, is_moe_tensor
-from colossalai.testing import assert_equal_in_group, rerun_if_address_is_in_use, spawn
-from tests.test_moe.moe_utils import MoeGradientHandler
-
-
-def sync_tp_from_local(tp_model, local_model, assert_grad_flag: bool = False) -> None:
- """Sync the parameters of tp model from local model
-
- Args:
- tp_model (MoeModule)
- local_model (MoeModule)
- """
- for (tp_name, tp_param), (local_name, local_param) in zip(
- tp_model.named_parameters(), local_model.named_parameters()
- ):
- assert tp_name == local_name
- if not is_moe_tensor(tp_param):
- if assert_grad_flag:
- assert torch.allclose(tp_param, local_param)
- assert torch.allclose(tp_param.grad, local_param.grad)
- else:
- tp_param.data.copy_(local_param.data)
- continue
-
- tp_rank = get_ep_rank(tp_param)
- tp_dim = [i for i, (d1, d2) in enumerate(zip(tp_param.shape, local_param.shape)) if d1 != d2][0]
- tp_slice = [slice(None)] * tp_dim + [
- slice(tp_param.shape[tp_dim] * tp_rank, tp_param.shape[tp_dim] * (tp_rank + 1))
- ]
-
- if assert_grad_flag:
- assert torch.allclose(tp_param, local_param[tuple(tp_slice)])
- assert torch.allclose(tp_param.grad, local_param.grad[tuple(tp_slice)])
- else:
- tp_param.data.copy_(local_param[tuple(tp_slice)].data)
-
-
-def sync_tp_from_ep(tp_model, ep_model, assert_grad_flag: bool = False) -> None:
- """Sync the parameters of tp model from ep model
-
- Args:
- tp_model (MoeModule)
- ep_model (MoeModule)
- """
- for (tp_name, tp_param), (ep_name, ep_param) in zip(tp_model.named_parameters(), ep_model.named_parameters()):
- assert tp_name == ep_name
- if not is_moe_tensor(tp_param):
- if assert_grad_flag:
- assert torch.allclose(tp_param, ep_param)
- assert torch.allclose(tp_param.grad, ep_param.grad)
- else:
- tp_param.data.copy_(ep_param.data)
- continue
-
- # gather param from ep model
- param_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
- dist.all_gather(param_list, ep_param, group=get_ep_group(ep_param))
- all_param = torch.cat(param_list, dim=0)
- if assert_grad_flag:
- grad_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
- dist.all_gather(grad_list, ep_param.grad, group=get_ep_group(ep_param))
- all_grad = torch.cat(grad_list, dim=0)
-
- # get tp param
- tp_dim = [i for i, (d1, d2) in enumerate(zip(tp_param.shape[1:], all_param.shape[1:])) if d1 != d2][0] + 1
- tp_rank = get_ep_rank(tp_param)
- tp_slice = [slice(None)] * tp_dim + [
- slice(tp_param.shape[tp_dim] * tp_rank, tp_param.shape[tp_dim] * (tp_rank + 1))
- ]
- new_tp_param = all_param[tuple(tp_slice)]
- if assert_grad_flag:
- new_grad = all_grad[tuple(tp_slice)]
- if assert_grad_flag:
- assert torch.allclose(tp_param, new_tp_param)
- assert torch.allclose(tp_param.grad, new_grad)
- else:
- tp_param.data.copy_(new_tp_param.data)
-
-
-def sync_local_from_ep(local_model, ep_model, assert_grad_flag: bool = False) -> None:
- """Sync the parameters of tp model from ep model
-
- Args:
- local_model (MoeModule)
- ep_model (MoeModule)
- """
- for (local_name, local_param), (ep_name, ep_param) in zip(
- local_model.named_parameters(), ep_model.named_parameters()
- ):
- assert local_name == ep_name
- if "experts" not in local_name:
- if assert_grad_flag:
- assert torch.allclose(local_param, ep_param)
- assert torch.allclose(local_param.grad, ep_param.grad)
- else:
- local_param.data.copy_(ep_param.data)
- continue
-
- # gather param from ep model
- param_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
- dist.all_gather(param_list, ep_param, group=get_ep_group(ep_param))
- all_param = torch.cat(param_list, dim=0)
- if assert_grad_flag:
- grad_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
- dist.all_gather(grad_list, ep_param.grad, group=get_ep_group(ep_param))
- all_grad = torch.cat(grad_list, dim=0)
-
- if assert_grad_flag:
- assert torch.allclose(local_param, all_param)
- assert torch.allclose(local_param.grad, all_grad)
- else:
- local_param.data.copy_(all_param.data)
-
-
-def run_test(rank: int, world_size: int, port: int, num_experts: int, batch_size: int, dim: int, config: Dict):
- assert batch_size % world_size == 0
-
- colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
-
- MOE_MANAGER.__init__()
- MOE_MANAGER.setup(parallel=None)
- local_model = SparseMLP(num_experts=num_experts, hidden_size=dim, intermediate_size=dim * 2)
- MOE_MANAGER.__init__()
- MOE_MANAGER.setup(parallel="EP")
- enable_hierarchical_comm = config.get("enable_hierarchical_comm", False)
- if enable_hierarchical_comm:
- os.environ["LOCAL_WORLD_SIZE"] = str(world_size)
- ep_model = SparseMLP(
- num_experts=num_experts,
- hidden_size=dim,
- intermediate_size=dim * 2,
- enable_hierarchical_comm=enable_hierarchical_comm,
+from colossalai.booster.booster import Booster
+from colossalai.booster.plugin import HybridParallelPlugin
+from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+from colossalai.testing.random import seed_all
+from tests.test_moe.moe_utils import assert_loose_close
+
+NUM_BATCH = 4
+NUM_TOK_PER_BATCH, NUM_EXPERTS = 7, 4
+HIDDEN_SIZE_PER_HEAD = 4
+NUM_HEADS = 4
+TOP_K = 2
+
+
+@parameterize("stage", [1])
+@parameterize("ep_size", [2])
+def run_zero_with_original_model(stage: int, ep_size: int):
+ tp_size = dist.get_world_size() // ep_size
+ dtype = torch.bfloat16
+
+ rank = torch.distributed.get_rank()
+ torch.cuda.set_device(dist.get_rank())
+
+ seed_all(10086)
+
+ config = MixtralConfig(
+ hidden_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS,
+ intermediate_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS * 2,
+ num_hidden_layers=2,
+ num_attention_heads=NUM_HEADS,
+ num_key_value_heads=NUM_HEADS,
+ num_local_experts=NUM_EXPERTS,
+ num_experts_per_tok=TOP_K,
)
- MOE_MANAGER.__init__()
- MOE_MANAGER.setup(parallel="TP")
- tp_model = SparseMLP(num_experts=num_experts, hidden_size=dim, intermediate_size=dim * 2)
- ep_model = ep_model.to(get_accelerator().get_current_device())
- tp_model = tp_model.to(get_accelerator().get_current_device())
- local_model = local_model.to(get_accelerator().get_current_device())
-
- # sync ep param
- sync_moe_model_param(ep_model)
- dist_dict = MOE_MANAGER.parallel_info_dict
- assert_equal_in_group(ep_model.experts.wi.data, dist_dict[world_size].dp_group)
- assert_equal_in_group(ep_model.experts.wo.data, dist_dict[world_size].dp_group)
- ep_grad_handler = MoeGradientHandler(ep_model)
- # sync local param
- sync_local_from_ep(local_model, ep_model)
- # sync tp param
- sync_tp_from_ep(tp_model, ep_model)
- tp_grad_handler = MoeGradientHandler(tp_model)
-
- rank = dist.get_rank()
- input_data = torch.randn(batch_size, dim, device=get_accelerator().get_current_device())
- micro_batch_size = batch_size // world_size
- index = rank * micro_batch_size
- # NOTE: ep & tp takes in sharded data for each process
- shard_data = input_data.detach()[index : index + micro_batch_size]
-
- out_local = local_model(input_data)
- MOE_MANAGER.reset_loss()
- out_tp = tp_model(shard_data)
- MOE_MANAGER.reset_loss()
- out_ep = ep_model(shard_data)
- MOE_MANAGER.reset_loss()
-
- assert torch.allclose(
- out_tp, out_ep, atol=1e-6
- ), f"Rank {rank} failed, max diff: {torch.max(torch.abs(out_tp - out_ep))}"
- try:
- out_local_slice = out_local[index : index + micro_batch_size]
- assert torch.allclose(
- out_ep, out_local_slice, atol=1e-6
- ), f"Rank {rank} failed, max diff: {torch.max(torch.abs(out_ep - out_local_slice))}"
- except AssertionError:
- """
- e.g., in local model, tokens = 4, capacity = 2, experts = 2, topk = 1
- router yields [01] --> [0], [23] --> [1], this is valid as capacity is 2
- However, in ep mode, there are 2 separate routers dealing with sharded data.
- Assume router 0 handles token [01] and router 1 handles token [23].
- Note that for each router the capacity is only 1 !!!
- Thus, router 0 may yields [0] --> [0] or [1] --> [0], but not both.
- The same thing happens on router 1. And finally some tokens are dropped due to the sharded nature.
- """
- warnings.warn(
- "EP & TP may result in different behavior from local model. " "Please check the comments for details."
+ torch_model = MixtralModel(config).to(dtype).cuda()
+
+ zero_model = deepcopy(torch_model).to(dtype)
+ zero_optimizer = torch.optim.SGD(zero_model.parameters(), lr=1)
+ moe_booster = Booster(
+ plugin=MoeHybridParallelPlugin(
+ tp_size=tp_size,
+ moe_tp_size=tp_size,
+ pp_size=1,
+ ep_size=ep_size,
+ zero_stage=stage,
+ overlap_communication=False,
+ initial_scale=1,
)
-
- out_local.mean().backward()
- out_tp.mean().backward()
- tp_grad_handler.handle_gradient()
- out_ep.mean().backward()
- ep_grad_handler.handle_gradient()
-
- assert_equal_in_group(ep_model.experts.wi.grad, dist_dict[world_size].dp_group)
- assert_equal_in_group(ep_model.experts.wo.grad, dist_dict[world_size].dp_group)
- sync_tp_from_ep(tp_model, ep_model, assert_grad_flag=True)
- try:
- sync_local_from_ep(local_model, ep_model, assert_grad_flag=True)
- except AssertionError:
- warnings.warn(
- "EP & TP may result in different behavior from local model. " "Please check the comments for details."
+ )
+ zero_model, zero_optimizer, _, _, _ = moe_booster.boost(zero_model, zero_optimizer)
+
+ hybird_booster = Booster(
+ plugin=HybridParallelPlugin(
+ tp_size=tp_size,
+ pp_size=1,
+ zero_stage=stage,
+ overlap_communication=False,
+ initial_scale=1,
)
+ )
+ hybrid_model, hybrid_optimizer, _, _, _ = hybird_booster.boost(
+ torch_model, torch.optim.SGD(torch_model.parameters(), lr=1)
+ )
+ # create different input
+ seed_all(1453 + rank)
+
+ hybrid_model.train()
+ zero_model.train()
+ for _ in range(2):
+ # zero-dp forward
+ input_data = torch.rand(
+ NUM_BATCH, NUM_TOK_PER_BATCH, HIDDEN_SIZE_PER_HEAD * NUM_HEADS, requires_grad=True
+ ).cuda()
+ zero_output = zero_model(inputs_embeds=input_data.to(dtype)).last_hidden_state.mean()
+ # zero-dp backward
+ zero_optimizer.backward(zero_output)
+ # torch-ddp forward
+ hybrid_output = hybrid_model(inputs_embeds=input_data.to(dtype)).last_hidden_state.mean()
+ assert_loose_close(zero_output, hybrid_output, dtype=dtype)
+ # torch-ddp backward
+ hybrid_optimizer.backward(hybrid_output)
+
+ # check grad
+ name_to_p = {n: p for n, p in hybrid_model.named_parameters()}
+ for n, p in zero_model.named_parameters():
+ zero_grad = zero_optimizer.get_param_grad(p)
+ if name_to_p[n].grad is None:
+ name_to_p[n].grad = torch.zeros_like(name_to_p[n])
+ continue
+ if zero_grad.shape != name_to_p[n].grad.shape: # TODO check sharded and sliced moe
+ continue
+ assert_loose_close(zero_grad, name_to_p[n].grad, dtype=dtype, name=n)
+
+ # zero-dp step
+ zero_optimizer.step()
+
+ # original model step
+ hybrid_optimizer.step()
+
+ # check updated param
+ for n, p in zero_model.named_parameters():
+ if p.data.shape != name_to_p[n].data.shape: # TODO check sharded and sliced moe
+ continue
+ assert_loose_close(p.data, name_to_p[n].data, dtype=dtype, name=n)
+
+ print(f"{dist.get_rank()} test passed")
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ run_zero_with_original_model()
-@pytest.mark.skip(reason="moe need to be refactored")
+@pytest.mark.skip("tested in corresponding sharderformer")
@pytest.mark.dist
-@pytest.mark.parametrize("num_experts", [4, 64])
-@pytest.mark.parametrize("batch_size", [16])
-@pytest.mark.parametrize("dim", [64])
-@pytest.mark.parametrize(
- "config",
- [
- {"enable_hierarchical_comm": False},
- {"enable_hierarchical_comm": True},
- ],
-)
+@pytest.mark.parametrize("world_size", [4])
@rerun_if_address_is_in_use()
-def test_moe_ep_tp(num_experts: int, batch_size: int, dim: int, config: Dict):
- spawn(run_test, 2, num_experts=num_experts, batch_size=batch_size, dim=dim, config=config)
+def test_moe_ep_tp(world_size):
+ spawn(run_dist, world_size)
if __name__ == "__main__":
- test_moe_ep_tp(num_experts=8, batch_size=32, dim=32)
+ test_moe_ep_tp(world_size=4)
diff --git a/tests/test_moe/test_moe_ep_zero.py b/tests/test_moe/test_moe_ep_zero.py
new file mode 100644
index 000000000000..2d4e638b638a
--- /dev/null
+++ b/tests/test_moe/test_moe_ep_zero.py
@@ -0,0 +1,119 @@
+from copy import deepcopy
+
+import pytest
+import torch
+import torch.distributed as dist
+from torch.nn.parallel import DistributedDataParallel as DDP
+from transformers.models.mixtral.configuration_mixtral import MixtralConfig
+from transformers.models.mixtral.modeling_mixtral import MixtralModel
+
+import colossalai
+from colossalai.booster.booster import Booster
+from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+from colossalai.testing.random import seed_all
+from tests.test_moe.moe_utils import assert_loose_close
+
+NUM_BATCH = 4
+NUM_TOK_PER_BATCH, NUM_EXPERTS = 7, 4
+HIDDEN_SIZE_PER_HEAD = 4
+NUM_HEADS = 2
+TOP_K = 1
+
+
+@parameterize("stage", [1])
+@parameterize("ep_size", [2, 4])
+def run_zero_with_original_model(stage: int, ep_size: int):
+ dtype = torch.bfloat16
+
+ rank = torch.distributed.get_rank()
+ torch.cuda.set_device(dist.get_rank())
+
+ plugin = MoeHybridParallelPlugin(
+ pp_size=1, tp_size=1, ep_size=ep_size, zero_stage=stage, overlap_communication=False, initial_scale=1
+ )
+ booster = Booster(plugin=plugin)
+
+ seed_all(10086)
+
+ config = MixtralConfig(
+ hidden_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS,
+ intermediate_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS * 2,
+ num_hidden_layers=2,
+ num_attention_heads=NUM_HEADS,
+ num_key_value_heads=NUM_HEADS,
+ num_local_experts=NUM_EXPERTS,
+ num_experts_per_tok=TOP_K,
+ )
+
+ torch_model = MixtralModel(config).to(dtype).cuda()
+
+ zero_model = deepcopy(torch_model).to(dtype)
+ zero_optimizer = torch.optim.SGD(zero_model.parameters(), lr=1)
+
+ zero_model, zero_optimizer, _, _, _ = booster.boost(zero_model, zero_optimizer)
+
+ ddp_model = DDP(
+ torch_model.cuda(),
+ process_group=plugin.dp_group,
+ find_unused_parameters=True, # important for torch ddp, not all experts are routed
+ ).cuda()
+ ddp_optimizer = torch.optim.SGD(ddp_model.parameters(), lr=1)
+
+ # create different input
+ seed_all(1453 + rank)
+
+ ddp_model.train()
+ zero_model.train()
+ for _ in range(2):
+ # zero-dp forward
+ input_data = torch.rand(
+ NUM_BATCH, NUM_TOK_PER_BATCH, HIDDEN_SIZE_PER_HEAD * NUM_HEADS, requires_grad=True
+ ).cuda()
+ zero_output = zero_model(inputs_embeds=input_data.to(dtype)).last_hidden_state.mean()
+ # zero-dp backward
+ zero_optimizer.backward(zero_output)
+
+ # torch-ddp forward
+ ddp_output = ddp_model(inputs_embeds=input_data.to(dtype)).last_hidden_state.mean()
+ assert_loose_close(zero_output, ddp_output, dtype=dtype)
+ # torch-ddp backward
+ ddp_output.backward()
+
+ # check grad
+ name_to_p = {n: p for n, p in ddp_model.named_parameters()}
+ for n, p in zero_model.named_parameters():
+ zero_grad = zero_optimizer.get_param_grad(p)
+ if name_to_p[n].grad is None:
+ name_to_p[n].grad = torch.zeros_like(name_to_p[n].data)
+ continue
+ assert_loose_close(zero_grad, name_to_p[n].grad, dtype=dtype, name=n)
+
+ # zero-dp step
+ zero_optimizer.step()
+
+ # original model step
+ ddp_optimizer.step()
+
+ # check updated param
+ for n, p in zero_model.named_parameters():
+ assert_loose_close(p.data, name_to_p[n].data, dtype=dtype, name=n)
+
+ print(f"{dist.get_rank()} test passed")
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ run_zero_with_original_model()
+
+
+@pytest.mark.skip("tested in corresponding sharderformer")
+@pytest.mark.dist
+@pytest.mark.parametrize("world_size", [4])
+@rerun_if_address_is_in_use()
+def test_moe_ep_zero(world_size):
+ spawn(run_dist, world_size)
+
+
+if __name__ == "__main__":
+ test_moe_ep_zero(world_size=4)
diff --git a/tests/test_moe/test_moe_zero_fwd_bwd_optim.py b/tests/test_moe/test_moe_zero_fwd_bwd_optim.py
deleted file mode 100644
index 042b3d8aedc5..000000000000
--- a/tests/test_moe/test_moe_zero_fwd_bwd_optim.py
+++ /dev/null
@@ -1,132 +0,0 @@
-from copy import deepcopy
-
-import pytest
-import torch
-import torch.distributed as dist
-from torch.nn.parallel import DistributedDataParallel as DDP
-from transformers.models.mixtral.configuration_mixtral import MixtralConfig
-from transformers.models.mixtral.modeling_mixtral import MixtralSparseMoeBlock
-
-import colossalai
-from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
-from colossalai.shardformer.modeling.mixtral import EPMixtralSparseMoeBlock
-from colossalai.tensor.moe_tensor.api import is_moe_tensor
-from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
-from colossalai.testing.random import seed_all
-from colossalai.zero import LowLevelZeroOptimizer
-from tests.test_moe.moe_utils import loose_close
-
-tokens, n_experts = 7, 4
-hidden_size = 8
-top_k = 2
-
-
-def split_grad(grad, world_size):
- with torch.no_grad():
- grad = grad.clone().detach().flatten()
- padding_size = (world_size - grad.numel() % world_size) % world_size
- if padding_size > 0:
- grad = torch.nn.functional.pad(grad, [0, padding_size])
- splited_grad = grad.split(grad.numel() // world_size)
- return splited_grad
-
-
-@parameterize("dtype", [torch.float16, torch.bfloat16])
-@parameterize("master_weights", [True, False])
-@parameterize("stage", [1, 2])
-def run_zero_with_original_model(world_size, master_weights: bool, dtype: torch.dtype, stage: int):
- rank = torch.distributed.get_rank()
- torch.cuda.set_device(dist.get_rank())
- plugin = MoeHybridParallelPlugin(
- tp_size=1,
- pp_size=1,
- ep_size=dist.get_world_size() // 2,
- )
-
- seed_all(10086)
- config = MixtralConfig(
- hidden_size=hidden_size,
- intermediate_size=hidden_size * 2,
- num_local_experts=n_experts,
- num_experts_per_tok=top_k,
- )
-
- orig_model = MixtralSparseMoeBlock(config).to(dtype).cuda()
-
- ori_model = DDP(orig_model.cuda(), static_graph=True).cuda()
-
- zero_model = deepcopy(orig_model).to(dtype)
- zero_model = EPMixtralSparseMoeBlock.from_native_module(zero_model, ep_group=plugin.ep_group)
-
- zero_optimizer = torch.optim.SGD(zero_model.parameters(), lr=1)
- pg_param_list = {plugin.global_dp_group: [], plugin.moe_dp_group: []}
- for p in zero_model.parameters():
- if is_moe_tensor(p):
- pg_param_list[plugin.moe_dp_group].append(p)
- else:
- pg_param_list[plugin.global_dp_group].append(p)
-
- zero_optimizer = LowLevelZeroOptimizer(
- zero_optimizer,
- pg_to_param_list=pg_param_list,
- master_weights=master_weights,
- initial_scale=1,
- overlap_communication=False,
- partition_grad=True,
- )
-
- ori_optimizer = torch.optim.SGD(ori_model.parameters(), lr=1)
-
- # create
- seed_all(1453 + rank)
-
- for _ in range(2):
- # zero-dp forward
- input_data = torch.rand(1, tokens, hidden_size).cuda()
- zero_output, zero_logits = zero_model(input_data.to(dtype))
-
- # torch-ddp forward
- ori_output, ori_logits = ori_model(input_data.to(dtype))
- loose_close(zero_output, ori_output, dtype=dtype)
-
- # zero-dp backward
- zero_optimizer.backward(zero_output.mean().float())
-
- # torch-ddp backward
- ori_output.mean().backward()
-
- # check grad
- name_to_p = {n: p for n, p in ori_model.module.named_parameters()}
- for n, p in zero_model.named_parameters():
- zero_grad = zero_optimizer.get_param_grad(p)
- if name_to_p[n].grad is None:
- assert zero_grad is None
- continue
-
- loose_close(zero_grad, name_to_p[n].grad, dtype=dtype)
-
- # zero-dp step
- zero_optimizer.step()
-
- # original model step
- ori_optimizer.step()
-
- # check updated param
- for n, p in zero_model.named_parameters():
- loose_close(p.data, name_to_p[n].data, dtype=dtype)
-
-
-def run_dist(rank, world_size, port):
- colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
- run_zero_with_original_model(world_size=world_size)
-
-
-@pytest.mark.dist
-@pytest.mark.parametrize("world_size", [2, 4])
-@rerun_if_address_is_in_use()
-def test_moe_zero_model(world_size):
- spawn(run_dist, world_size)
-
-
-if __name__ == "__main__":
- test_moe_zero_model(world_size=4)
diff --git a/tests/test_shardformer/test_model/_utils.py b/tests/test_shardformer/test_model/_utils.py
index 1ffcc541a854..190fee12931b 100644
--- a/tests/test_shardformer/test_model/_utils.py
+++ b/tests/test_shardformer/test_model/_utils.py
@@ -1,6 +1,6 @@
import copy
from contextlib import nullcontext
-from typing import Any, Callable, Dict, List, Optional
+from typing import Any, Callable, Dict, List, Optional, Type
import torch
import torch.distributed as dist
@@ -117,7 +117,12 @@ def check_state_dict(org_model: Module, sharded_model: Module, name: str = ""):
def build_model_from_hybrid_plugin(
- model_fn: Callable, loss_fn: Callable, test_config: Dict[str, Any], optim_class=Adam, sharded_optim_class=Adam
+ model_fn: Callable,
+ loss_fn: Callable,
+ test_config: Dict[str, Any],
+ optim_class=Adam,
+ sharded_optim_class=Adam,
+ pluggin_cls: Type[HybridParallelPlugin] = HybridParallelPlugin,
):
use_lazy_init = False
if "use_lazy_init" in test_config:
@@ -149,9 +154,10 @@ def build_model_from_hybrid_plugin(
else:
org_optimizer = optim_class(org_model.parameters(), lr=1e-3)
sharded_optimizer = sharded_optim_class(sharded_model.parameters(), lr=1e-3)
+
criterion = loss_fn
- plugin = HybridParallelPlugin(**test_config)
+ plugin = pluggin_cls(**test_config)
booster = Booster(plugin=plugin)
sharded_model, sharded_optimizer, criterion, _, _ = booster.boost(sharded_model, sharded_optimizer, criterion)
diff --git a/tests/test_shardformer/test_model/test_shard_deepseek.py b/tests/test_shardformer/test_model/test_shard_deepseek.py
new file mode 100644
index 000000000000..46da4522fd9d
--- /dev/null
+++ b/tests/test_shardformer/test_model/test_shard_deepseek.py
@@ -0,0 +1,196 @@
+import os
+import shutil
+from copy import deepcopy
+from typing import Tuple
+
+import pytest
+import torch
+import torch.distributed
+import torch.distributed as dist
+from transformers import AutoConfig, AutoModel
+
+import colossalai
+from colossalai.booster.booster import Booster
+from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+from colossalai.testing.random import seed_all
+from tests.test_moe.moe_utils import assert_loose_close, check_model_equal
+
+NUM_BATCH = 8
+NUM_TOK_PER_BATCH, NUM_EXPERTS = 4, 2
+NUM_LAYERS = 4
+HIDDEN_SIZE_PER_HEAD = 4
+NUM_HEADS = 4
+TOP_K = 2
+
+
+CHECKED_CONFIG = [ # FOR_WORLD=4
+ (1, 4, 1, 1, 1),
+ (1, 1, 4, 1, 1),
+ (1, 1, 1, 4, 1),
+ (1, 1, 1, 1, 4),
+ (0, 1, 4, 1, 1),
+ (0, 1, 1, 4, 1),
+ (0, 1, 1, 1, 4),
+ (1, 2, 1, 1, 1),
+]
+
+
+@parameterize(
+ "config",
+ [
+ (1, 2, 2, 1, 1),
+ (1, 2, 1, 2, 1),
+ (1, 2, 1, 1, 2),
+ ],
+)
+def run_zero_with_original_model(config: Tuple[int, ...]):
+ stage, ep_size, pp_size, tp_size, sp_size = config
+ world_size = dist.get_world_size()
+ rank = dist.get_rank()
+ dtype, precision = torch.float16, "fp16"
+ torch.cuda.set_device(dist.get_rank())
+
+ plugin = MoeHybridParallelPlugin(
+ pp_size=pp_size,
+ num_microbatches=pp_size,
+ tp_size=tp_size,
+ sp_size=sp_size,
+ ep_size=ep_size,
+ zero_stage=stage,
+ enable_sequence_parallelism=sp_size > 1,
+ sequence_parallelism_mode="all_to_all" if sp_size > 1 else None,
+ enable_flash_attention=sp_size > 1,
+ overlap_communication=False,
+ initial_scale=1,
+ precision=precision,
+ find_unused_parameters=True,
+ )
+ dp_size = plugin.dp_size
+
+ booster = Booster(plugin=plugin)
+
+ assert pp_size <= NUM_LAYERS, "pp_size should be less than or equal to NUM_LAYERS"
+ config = AutoConfig.from_pretrained(
+ "deepseek-ai/deepseek-moe-16b-base",
+ hidden_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS,
+ intermediate_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS * 2,
+ moe_intermediate_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS * 2,
+ num_hidden_layers=4,
+ num_attention_heads=NUM_HEADS,
+ num_key_value_heads=NUM_HEADS,
+ first_k_dense_replace=1,
+ attn_implementation="flash_attention_2",
+ torch_dtype="float16",
+ n_routed_experts=NUM_EXPERTS,
+ num_experts_per_tok=TOP_K,
+ trust_remote_code=True,
+ )
+
+ # init model with the same seed
+ seed_all(10086)
+
+ torch_model = AutoModel.from_config(config, trust_remote_code=True).cuda().to(dtype)
+ torch_optimizer = torch.optim.SGD(torch_model.parameters(), lr=1)
+
+ parallel_model = deepcopy(torch_model)
+ parallel_optimizer = torch.optim.SGD(parallel_model.parameters(), lr=1)
+ parallel_model, parallel_optimizer, _, _, _ = booster.boost(parallel_model, parallel_optimizer)
+
+ # create different input along dp axis
+ seed_all(1453 + rank)
+
+ torch_model.train()
+ parallel_model.train()
+ for _ in range(2):
+ # gen random input
+ input_embeddings = torch.rand(
+ NUM_BATCH, NUM_TOK_PER_BATCH, HIDDEN_SIZE_PER_HEAD * NUM_HEADS, requires_grad=True
+ ).cuda()
+ dist.all_reduce(
+ input_embeddings, group=plugin.pp_group
+ ) # pp inputs except the first stage doesn't matter, but need to be replicate for torch model check
+
+ dist.all_reduce(input_embeddings, group=plugin.tp_group) # tp group duplicate input
+ dist.all_reduce(input_embeddings, group=plugin.sp_group) # sp group duplicate input
+
+ # run the model with hybrid parallel
+ if booster.plugin.stage_manager is not None:
+ # for test with pp
+ data_iter = iter([{"inputs_embeds": input_embeddings}])
+ sharded_output = booster.execute_pipeline(
+ data_iter,
+ parallel_model,
+ lambda x, y: x[0].mean(),
+ parallel_optimizer,
+ return_loss=True,
+ return_outputs=True,
+ )
+ if booster.plugin.stage_manager.is_last_stage():
+ parallel_output = sharded_output["loss"]
+ else:
+ parallel_output = torch.tensor(12345.0, device="cuda")
+
+ # broadcast along pp axis
+ dist.broadcast(
+ parallel_output, src=dist.get_process_group_ranks(plugin.pp_group)[-1], group=plugin.pp_group
+ )
+ else:
+ # for test without pp
+ parallel_output = parallel_model(inputs_embeds=input_embeddings.to(dtype)).last_hidden_state.mean()
+ parallel_optimizer.backward(parallel_output)
+ parallel_optimizer.step()
+ parallel_optimizer.zero_grad()
+ dist.all_reduce(parallel_output, group=plugin.dp_group)
+
+ # ===================================================================================
+ # run normal model with all dp(different) inputs
+ all_inputs = [torch.empty_like(input_embeddings) for _ in range(dp_size)]
+ dist.all_gather(all_inputs, input_embeddings, group=plugin.dp_group)
+ torch_output_sum = 0
+ for input_data_ in all_inputs:
+ torch_output = torch_model(inputs_embeds=input_data_.to(dtype)).last_hidden_state.mean()
+ torch_output.backward()
+ torch_output_sum += torch_output.detach()
+ # avg dp grads follows zero optimizer
+ for p in torch_model.parameters():
+ if p.grad is not None:
+ p.grad /= dp_size
+ torch_optimizer.step()
+ torch_optimizer.zero_grad()
+
+ assert_loose_close(parallel_output, torch_output_sum, dtype=dtype)
+
+ # use checkpoint to load sharded zero model
+ model_dir = "./test_deepseek"
+ if rank == world_size - 1:
+ os.makedirs(model_dir, exist_ok=True)
+
+ dist.barrier()
+ booster.save_model(parallel_model, model_dir, shard=True)
+ dist.barrier()
+
+ saved_model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).cuda()
+ check_model_equal(torch_model, saved_model)
+ dist.barrier()
+
+ if rank == world_size - 1:
+ shutil.rmtree(model_dir)
+
+ print(f"rank {dist.get_rank()} test passed")
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ run_zero_with_original_model()
+
+
+@pytest.mark.dist
+@pytest.mark.parametrize("world_size", [4])
+@rerun_if_address_is_in_use()
+def test_deepseek(world_size):
+ spawn(run_dist, world_size)
+
+
+if __name__ == "__main__":
+ test_deepseek(world_size=4)
diff --git a/tests/test_shardformer/test_model/test_shard_mixtral.py b/tests/test_shardformer/test_model/test_shard_mixtral.py
new file mode 100644
index 000000000000..de09eedcbed5
--- /dev/null
+++ b/tests/test_shardformer/test_model/test_shard_mixtral.py
@@ -0,0 +1,190 @@
+import os
+import shutil
+from copy import deepcopy
+from typing import Tuple
+
+import pytest
+import torch
+import torch.distributed
+import torch.distributed as dist
+from transformers.models.mixtral.configuration_mixtral import MixtralConfig
+from transformers.models.mixtral.modeling_mixtral import MixtralModel
+
+import colossalai
+from colossalai.booster.booster import Booster
+from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+from colossalai.testing.random import seed_all
+from tests.test_moe.moe_utils import assert_loose_close, check_model_equal
+
+NUM_BATCH = 8
+NUM_TOK_PER_BATCH, NUM_EXPERTS = 4, 4
+NUM_LAYERS = 4
+HIDDEN_SIZE_PER_HEAD = 4
+NUM_HEADS = 4
+TOP_K = 1
+
+CHECKED_CONFIG = [ # FOR WORLD=4
+ (0, 1, 4, 1, 1),
+ (0, 1, 1, 4, 1),
+ (0, 1, 1, 1, 4),
+ (1, 4, 1, 1, 1),
+ (1, 1, 4, 1, 1),
+ (1, 1, 1, 4, 1),
+ (1, 1, 1, 1, 4),
+ (1, 2, 1, 1, 1),
+]
+
+
+@parameterize(
+ "config",
+ [
+ (1, 2, 2, 1, 1),
+ (1, 2, 1, 2, 1),
+ (1, 2, 1, 1, 2),
+ ],
+)
+def run_zero_with_original_model(config: Tuple[int, ...]):
+ stage, ep_size, pp_size, tp_size, sp_size = config
+ world_size = dist.get_world_size()
+ rank = dist.get_rank()
+ dtype, precision = torch.float16, "fp16"
+ torch.cuda.set_device(dist.get_rank())
+
+ plugin = MoeHybridParallelPlugin(
+ pp_size=pp_size,
+ num_microbatches=pp_size,
+ tp_size=tp_size,
+ sp_size=sp_size,
+ ep_size=ep_size,
+ zero_stage=stage,
+ enable_sequence_parallelism=sp_size > 1,
+ sequence_parallelism_mode="all_to_all" if sp_size > 1 else None,
+ overlap_communication=False,
+ initial_scale=1,
+ precision=precision,
+ find_unused_parameters=True,
+ )
+ dp_size = plugin.dp_size
+
+ booster = Booster(plugin=plugin)
+
+ assert pp_size <= NUM_LAYERS, "pp_size should be less than or equal to NUM_LAYERS"
+ config = MixtralConfig(
+ hidden_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS,
+ intermediate_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS * 2,
+ num_hidden_layers=NUM_LAYERS,
+ num_attention_heads=NUM_HEADS,
+ num_key_value_heads=NUM_HEADS,
+ num_local_experts=NUM_EXPERTS,
+ num_experts_per_tok=TOP_K,
+ attn_implementation="flash_attention_2",
+ )
+
+ # init model with the same seed
+ seed_all(10086)
+
+ torch_model = MixtralModel(config).to(dtype).cuda()
+ torch_optimizer = torch.optim.SGD(torch_model.parameters(), lr=1)
+
+ parallel_model = deepcopy(torch_model)
+ parallel_optimizer = torch.optim.SGD(parallel_model.parameters(), lr=1)
+ parallel_model, parallel_optimizer, _, _, _ = booster.boost(parallel_model, parallel_optimizer)
+
+ # create different input along dp axis
+ seed_all(1453 + rank)
+
+ torch_model.train()
+ parallel_model.train()
+ for _ in range(2):
+ # gen random input
+ input_embeddings = torch.rand(
+ NUM_BATCH, NUM_TOK_PER_BATCH, HIDDEN_SIZE_PER_HEAD * NUM_HEADS, requires_grad=True
+ ).cuda()
+ dist.all_reduce(
+ input_embeddings, group=plugin.pp_group
+ ) # pp inputs except the first stage doesn't matter, but need to be replicate for torch model check
+
+ dist.all_reduce(input_embeddings, group=plugin.tp_group) # tp group duplicate input
+ dist.all_reduce(input_embeddings, group=plugin.sp_group) # sp group duplicate input
+
+ # run the model with hybrid parallel
+ if booster.plugin.stage_manager is not None:
+ # for test with pp
+ data_iter = iter([{"inputs_embeds": input_embeddings}])
+ sharded_output = booster.execute_pipeline(
+ data_iter,
+ parallel_model,
+ lambda x, y: x.last_hidden_state.mean(),
+ parallel_optimizer,
+ return_loss=True,
+ return_outputs=True,
+ )
+ if booster.plugin.stage_manager.is_last_stage():
+ parallel_output = sharded_output["loss"]
+ else:
+ parallel_output = torch.tensor(12345.0, device="cuda")
+
+ # broadcast along pp axis
+ dist.broadcast(
+ parallel_output, src=dist.get_process_group_ranks(plugin.pp_group)[-1], group=plugin.pp_group
+ )
+ else:
+ # for test without pp
+ parallel_output = parallel_model(inputs_embeds=input_embeddings.to(dtype)).last_hidden_state.mean()
+ parallel_optimizer.backward(parallel_output)
+ parallel_optimizer.step()
+ parallel_optimizer.zero_grad()
+ dist.all_reduce(parallel_output, group=plugin.dp_group)
+
+ # ===================================================================================
+ # run normal model with all dp(different) inputs
+ all_inputs = [torch.empty_like(input_embeddings) for _ in range(dp_size)]
+ dist.all_gather(all_inputs, input_embeddings, group=plugin.dp_group)
+ torch_output_sum = 0
+ for input_data_ in all_inputs:
+ torch_output = torch_model(inputs_embeds=input_data_.to(dtype)).last_hidden_state.mean()
+ torch_output.backward()
+ torch_output_sum += torch_output.detach()
+ # avg dp grads follows zero optimizer
+ for p in torch_model.parameters():
+ if p.grad is not None:
+ p.grad /= dp_size
+ torch_optimizer.step()
+ torch_optimizer.zero_grad()
+
+ assert_loose_close(parallel_output, torch_output_sum, dtype=dtype)
+
+ # use checkpoint to load sharded zero model
+ model_dir = "./test_mixtral"
+ if rank == world_size - 1:
+ os.makedirs(model_dir, exist_ok=True)
+
+ dist.barrier()
+ booster.save_model(parallel_model, model_dir, shard=True)
+ dist.barrier()
+
+ saved_model = MixtralModel.from_pretrained(model_dir).cuda().to(dtype)
+ check_model_equal(torch_model, saved_model)
+ dist.barrier()
+
+ if rank == world_size - 1:
+ shutil.rmtree(model_dir)
+
+ print(f"rank {dist.get_rank()} test passed")
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ run_zero_with_original_model()
+
+
+@pytest.mark.dist
+@pytest.mark.parametrize("world_size", [4])
+@rerun_if_address_is_in_use()
+def test_mixtral(world_size):
+ spawn(run_dist, world_size)
+
+
+if __name__ == "__main__":
+ test_mixtral(world_size=4)
diff --git a/version.txt b/version.txt
index 267577d47e49..2b7c5ae01848 100644
--- a/version.txt
+++ b/version.txt
@@ -1 +1 @@
-0.4.1
+0.4.2
@@ -310,4 +310,14 @@ If you wish to cite relevant research papars, you can find the reference below.
journal={arXiv},
year={2023}
}
+
+# Distrifusion
+@InProceedings{Li_2024_CVPR,
+ author={Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Li, Kai and Han, Song},
+ title={DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month={June},
+ year={2024},
+ pages={7183-7193}
+}
```
diff --git a/colossalai/inference/config.py b/colossalai/inference/config.py
index 1beb86874826..072ddbcfd298 100644
--- a/colossalai/inference/config.py
+++ b/colossalai/inference/config.py
@@ -186,6 +186,7 @@ class InferenceConfig(RPC_PARAM):
enable_streamingllm(bool): Whether to use StreamingLLM, the relevant algorithms refer to the paper at https://arxiv.org/pdf/2309.17453 for implementation.
start_token_size(int): The size of the start tokens, when using StreamingLLM.
generated_token_size(int): The size of the generated tokens, When using StreamingLLM.
+ patched_parallelism_size(int): Patched Parallelism Size, When using Distrifusion
"""
# NOTE: arrange configs according to their importance and frequency of usage
@@ -245,6 +246,11 @@ class InferenceConfig(RPC_PARAM):
start_token_size: int = 4
generated_token_size: int = 512
+ # Acceleration for Diffusion Model(PipeFusion or Distrifusion)
+ patched_parallelism_size: int = 1 # for distrifusion
+ # pipeFusion_m_size: int = 1 # for pipefusion
+ # pipeFusion_n_size: int = 1 # for pipefusion
+
def __post_init__(self):
self.max_context_len_to_capture = self.max_input_len + self.max_output_len
self._verify_config()
@@ -288,6 +294,14 @@ def _verify_config(self) -> None:
# Thereafter, we swap out tokens in units of blocks, and always swapping out the second block when the generated tokens exceeded the limit.
self.start_token_size = self.block_size
+ # check Distrifusion
+ # TODO(@lry89757) need more detailed check
+ if self.patched_parallelism_size > 1:
+ # self.use_patched_parallelism = True
+ self.tp_size = (
+ self.patched_parallelism_size
+ ) # this is not a real tp, because some annoying check, so we have to set this to patched_parallelism_size
+
# check prompt template
if self.prompt_template is None:
return
@@ -324,6 +338,7 @@ def to_model_shard_inference_config(self) -> "ModelShardInferenceConfig":
use_cuda_kernel=self.use_cuda_kernel,
use_spec_dec=self.use_spec_dec,
use_flash_attn=use_flash_attn,
+ patched_parallelism_size=self.patched_parallelism_size,
)
return model_inference_config
@@ -396,6 +411,7 @@ class ModelShardInferenceConfig:
use_cuda_kernel: bool = False
use_spec_dec: bool = False
use_flash_attn: bool = False
+ patched_parallelism_size: int = 1 # for diffusion model, Distrifusion Technique
@dataclass
diff --git a/colossalai/inference/core/diffusion_engine.py b/colossalai/inference/core/diffusion_engine.py
index 75b9889bf28d..8bed508cba55 100644
--- a/colossalai/inference/core/diffusion_engine.py
+++ b/colossalai/inference/core/diffusion_engine.py
@@ -11,7 +11,7 @@
from colossalai.accelerator import get_accelerator
from colossalai.cluster import ProcessGroupMesh
from colossalai.inference.config import DiffusionGenerationConfig, InferenceConfig, ModelShardInferenceConfig
-from colossalai.inference.modeling.models.diffusion import DiffusionPipe
+from colossalai.inference.modeling.layers.diffusion import DiffusionPipe
from colossalai.inference.modeling.policy import model_policy_map
from colossalai.inference.struct import DiffusionSequence
from colossalai.inference.utils import get_model_size, get_model_type
diff --git a/colossalai/inference/modeling/models/diffusion.py b/colossalai/inference/modeling/layers/diffusion.py
similarity index 100%
rename from colossalai/inference/modeling/models/diffusion.py
rename to colossalai/inference/modeling/layers/diffusion.py
diff --git a/colossalai/inference/modeling/layers/distrifusion.py b/colossalai/inference/modeling/layers/distrifusion.py
new file mode 100644
index 000000000000..ea97cceefac9
--- /dev/null
+++ b/colossalai/inference/modeling/layers/distrifusion.py
@@ -0,0 +1,626 @@
+# Code refer and adapted from:
+# https://github.com/huggingface/diffusers/blob/v0.29.0-release/src/diffusers
+# https://github.com/PipeFusion/PipeFusion
+
+import inspect
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.distributed as dist
+import torch.nn.functional as F
+from diffusers.models import attention_processor
+from diffusers.models.attention import Attention
+from diffusers.models.embeddings import PatchEmbed, get_2d_sincos_pos_embed
+from diffusers.models.transformers.pixart_transformer_2d import PixArtTransformer2DModel
+from diffusers.models.transformers.transformer_sd3 import SD3Transformer2DModel
+from torch import nn
+from torch.distributed import ProcessGroup
+
+from colossalai.inference.config import ModelShardInferenceConfig
+from colossalai.logging import get_dist_logger
+from colossalai.shardformer.layer.parallel_module import ParallelModule
+from colossalai.utils import get_current_device
+
+try:
+ from flash_attn import flash_attn_func
+
+ HAS_FLASH_ATTN = True
+except ImportError:
+ HAS_FLASH_ATTN = False
+
+
+logger = get_dist_logger(__name__)
+
+
+# adapted from https://github.com/huggingface/diffusers/blob/v0.29.0-release/src/diffusers/models/transformers/transformer_2d.py
+def PixArtAlphaTransformer2DModel_forward(
+ self: PixArtTransformer2DModel,
+ hidden_states: torch.Tensor,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ timestep: Optional[torch.LongTensor] = None,
+ added_cond_kwargs: Dict[str, torch.Tensor] = None,
+ class_labels: Optional[torch.LongTensor] = None,
+ cross_attention_kwargs: Dict[str, Any] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+):
+ assert hasattr(
+ self, "patched_parallel_size"
+ ), "please check your policy, `Transformer2DModel` Must have attribute `patched_parallel_size`"
+
+ if cross_attention_kwargs is not None:
+ if cross_attention_kwargs.get("scale", None) is not None:
+ logger.warning("Passing `scale` to `cross_attention_kwargs` is deprecated. `scale` will be ignored.")
+ # ensure attention_mask is a bias, and give it a singleton query_tokens dimension.
+ # we may have done this conversion already, e.g. if we came here via UNet2DConditionModel#forward.
+ # we can tell by counting dims; if ndim == 2: it's a mask rather than a bias.
+ # expects mask of shape:
+ # [batch, key_tokens]
+ # adds singleton query_tokens dimension:
+ # [batch, 1, key_tokens]
+ # this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
+ # [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
+ # [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
+ if attention_mask is not None and attention_mask.ndim == 2:
+ # assume that mask is expressed as:
+ # (1 = keep, 0 = discard)
+ # convert mask into a bias that can be added to attention scores:
+ # (keep = +0, discard = -10000.0)
+ attention_mask = (1 - attention_mask.to(hidden_states.dtype)) * -10000.0
+ attention_mask = attention_mask.unsqueeze(1)
+
+ # convert encoder_attention_mask to a bias the same way we do for attention_mask
+ if encoder_attention_mask is not None and encoder_attention_mask.ndim == 2:
+ encoder_attention_mask = (1 - encoder_attention_mask.to(hidden_states.dtype)) * -10000.0
+ encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
+
+ # 1. Input
+ batch_size = hidden_states.shape[0]
+ height, width = (
+ hidden_states.shape[-2] // self.config.patch_size,
+ hidden_states.shape[-1] // self.config.patch_size,
+ )
+ hidden_states = self.pos_embed(hidden_states)
+
+ timestep, embedded_timestep = self.adaln_single(
+ timestep, added_cond_kwargs, batch_size=batch_size, hidden_dtype=hidden_states.dtype
+ )
+
+ if self.caption_projection is not None:
+ encoder_hidden_states = self.caption_projection(encoder_hidden_states)
+ encoder_hidden_states = encoder_hidden_states.view(batch_size, -1, hidden_states.shape[-1])
+
+ # 2. Blocks
+ for block in self.transformer_blocks:
+ hidden_states = block(
+ hidden_states,
+ attention_mask=attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ timestep=timestep,
+ cross_attention_kwargs=cross_attention_kwargs,
+ class_labels=class_labels,
+ )
+
+ # 3. Output
+ shift, scale = (self.scale_shift_table[None] + embedded_timestep[:, None].to(self.scale_shift_table.device)).chunk(
+ 2, dim=1
+ )
+ hidden_states = self.norm_out(hidden_states)
+ # Modulation
+ hidden_states = hidden_states * (1 + scale.to(hidden_states.device)) + shift.to(hidden_states.device)
+ hidden_states = self.proj_out(hidden_states)
+ hidden_states = hidden_states.squeeze(1)
+
+ # unpatchify
+ hidden_states = hidden_states.reshape(
+ shape=(
+ -1,
+ height // self.patched_parallel_size,
+ width,
+ self.config.patch_size,
+ self.config.patch_size,
+ self.out_channels,
+ )
+ )
+ hidden_states = torch.einsum("nhwpqc->nchpwq", hidden_states)
+ output = hidden_states.reshape(
+ shape=(
+ -1,
+ self.out_channels,
+ height // self.patched_parallel_size * self.config.patch_size,
+ width * self.config.patch_size,
+ )
+ )
+
+ # enable Distrifusion Optimization
+ if hasattr(self, "patched_parallel_size"):
+ from torch import distributed as dist
+
+ if (getattr(self, "output_buffer", None) is None) or (self.output_buffer.shape != output.shape):
+ self.output_buffer = torch.empty_like(output)
+ if (getattr(self, "buffer_list", None) is None) or (self.buffer_list[0].shape != output.shape):
+ self.buffer_list = [torch.empty_like(output) for _ in range(self.patched_parallel_size)]
+ output = output.contiguous()
+ dist.all_gather(self.buffer_list, output, async_op=False)
+ torch.cat(self.buffer_list, dim=2, out=self.output_buffer)
+ output = self.output_buffer
+
+ return (output,)
+
+
+# adapted from https://github.com/huggingface/diffusers/blob/v0.29.0-release/src/diffusers/models/transformers/transformer_sd3.py
+def SD3Transformer2DModel_forward(
+ self: SD3Transformer2DModel,
+ hidden_states: torch.FloatTensor,
+ encoder_hidden_states: torch.FloatTensor = None,
+ pooled_projections: torch.FloatTensor = None,
+ timestep: torch.LongTensor = None,
+ joint_attention_kwargs: Optional[Dict[str, Any]] = None,
+ return_dict: bool = True,
+) -> Union[torch.FloatTensor]:
+
+ assert hasattr(
+ self, "patched_parallel_size"
+ ), "please check your policy, `Transformer2DModel` Must have attribute `patched_parallel_size`"
+
+ height, width = hidden_states.shape[-2:]
+
+ hidden_states = self.pos_embed(hidden_states) # takes care of adding positional embeddings too.
+ temb = self.time_text_embed(timestep, pooled_projections)
+ encoder_hidden_states = self.context_embedder(encoder_hidden_states)
+
+ for block in self.transformer_blocks:
+ encoder_hidden_states, hidden_states = block(
+ hidden_states=hidden_states, encoder_hidden_states=encoder_hidden_states, temb=temb
+ )
+
+ hidden_states = self.norm_out(hidden_states, temb)
+ hidden_states = self.proj_out(hidden_states)
+
+ # unpatchify
+ patch_size = self.config.patch_size
+ height = height // patch_size // self.patched_parallel_size
+ width = width // patch_size
+
+ hidden_states = hidden_states.reshape(
+ shape=(hidden_states.shape[0], height, width, patch_size, patch_size, self.out_channels)
+ )
+ hidden_states = torch.einsum("nhwpqc->nchpwq", hidden_states)
+ output = hidden_states.reshape(
+ shape=(hidden_states.shape[0], self.out_channels, height * patch_size, width * patch_size)
+ )
+
+ # enable Distrifusion Optimization
+ if hasattr(self, "patched_parallel_size"):
+ from torch import distributed as dist
+
+ if (getattr(self, "output_buffer", None) is None) or (self.output_buffer.shape != output.shape):
+ self.output_buffer = torch.empty_like(output)
+ if (getattr(self, "buffer_list", None) is None) or (self.buffer_list[0].shape != output.shape):
+ self.buffer_list = [torch.empty_like(output) for _ in range(self.patched_parallel_size)]
+ output = output.contiguous()
+ dist.all_gather(self.buffer_list, output, async_op=False)
+ torch.cat(self.buffer_list, dim=2, out=self.output_buffer)
+ output = self.output_buffer
+
+ return (output,)
+
+
+# Code adapted from: https://github.com/PipeFusion/PipeFusion/blob/main/pipefuser/modules/dit/patch_parallel/patchembed.py
+class DistrifusionPatchEmbed(ParallelModule):
+ def __init__(
+ self,
+ module: PatchEmbed,
+ process_group: Union[ProcessGroup, List[ProcessGroup]],
+ model_shard_infer_config: ModelShardInferenceConfig = None,
+ ):
+ super().__init__()
+ self.module = module
+ self.rank = dist.get_rank(group=process_group)
+ self.patched_parallelism_size = model_shard_infer_config.patched_parallelism_size
+
+ @staticmethod
+ def from_native_module(module: PatchEmbed, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs):
+ model_shard_infer_config = kwargs.get("model_shard_infer_config", None)
+ distrifusion_embed = DistrifusionPatchEmbed(
+ module, process_group, model_shard_infer_config=model_shard_infer_config
+ )
+ return distrifusion_embed
+
+ def forward(self, latent):
+ module = self.module
+ if module.pos_embed_max_size is not None:
+ height, width = latent.shape[-2:]
+ else:
+ height, width = latent.shape[-2] // module.patch_size, latent.shape[-1] // module.patch_size
+
+ latent = module.proj(latent)
+ if module.flatten:
+ latent = latent.flatten(2).transpose(1, 2) # BCHW -> BNC
+ if module.layer_norm:
+ latent = module.norm(latent)
+ if module.pos_embed is None:
+ return latent.to(latent.dtype)
+ # Interpolate or crop positional embeddings as needed
+ if module.pos_embed_max_size:
+ pos_embed = module.cropped_pos_embed(height, width)
+ else:
+ if module.height != height or module.width != width:
+ pos_embed = get_2d_sincos_pos_embed(
+ embed_dim=module.pos_embed.shape[-1],
+ grid_size=(height, width),
+ base_size=module.base_size,
+ interpolation_scale=module.interpolation_scale,
+ )
+ pos_embed = torch.from_numpy(pos_embed).float().unsqueeze(0).to(latent.device)
+ else:
+ pos_embed = module.pos_embed
+
+ b, c, h = pos_embed.shape
+ pos_embed = pos_embed.view(b, self.patched_parallelism_size, -1, h)[:, self.rank]
+
+ return (latent + pos_embed).to(latent.dtype)
+
+
+# Code adapted from: https://github.com/PipeFusion/PipeFusion/blob/main/pipefuser/modules/dit/patch_parallel/conv2d.py
+class DistrifusionConv2D(ParallelModule):
+
+ def __init__(
+ self,
+ module: nn.Conv2d,
+ process_group: Union[ProcessGroup, List[ProcessGroup]],
+ model_shard_infer_config: ModelShardInferenceConfig = None,
+ ):
+ super().__init__()
+ self.module = module
+ self.rank = dist.get_rank(group=process_group)
+ self.patched_parallelism_size = model_shard_infer_config.patched_parallelism_size
+
+ @staticmethod
+ def from_native_module(module: nn.Conv2d, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs):
+ model_shard_infer_config = kwargs.get("model_shard_infer_config", None)
+ distrifusion_conv = DistrifusionConv2D(module, process_group, model_shard_infer_config=model_shard_infer_config)
+ return distrifusion_conv
+
+ def sliced_forward(self, x: torch.Tensor) -> torch.Tensor:
+
+ b, c, h, w = x.shape
+
+ stride = self.module.stride[0]
+ padding = self.module.padding[0]
+
+ output_h = x.shape[2] // stride // self.patched_parallelism_size
+ idx = dist.get_rank()
+ h_begin = output_h * idx * stride - padding
+ h_end = output_h * (idx + 1) * stride + padding
+ final_padding = [padding, padding, 0, 0]
+ if h_begin < 0:
+ h_begin = 0
+ final_padding[2] = padding
+ if h_end > h:
+ h_end = h
+ final_padding[3] = padding
+ sliced_input = x[:, :, h_begin:h_end, :]
+ padded_input = F.pad(sliced_input, final_padding, mode="constant")
+ return F.conv2d(
+ padded_input,
+ self.module.weight,
+ self.module.bias,
+ stride=stride,
+ padding="valid",
+ )
+
+ def forward(self, input: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
+ output = self.sliced_forward(input)
+ return output
+
+
+# Code adapted from: https://github.com/huggingface/diffusers/blob/v0.29.0-release/src/diffusers/models/attention_processor.py
+class DistrifusionFusedAttention(ParallelModule):
+
+ def __init__(
+ self,
+ module: attention_processor.Attention,
+ process_group: Union[ProcessGroup, List[ProcessGroup]],
+ model_shard_infer_config: ModelShardInferenceConfig = None,
+ ):
+ super().__init__()
+ self.counter = 0
+ self.module = module
+ self.buffer_list = None
+ self.kv_buffer_idx = dist.get_rank(group=process_group)
+ self.patched_parallelism_size = model_shard_infer_config.patched_parallelism_size
+ self.handle = None
+ self.process_group = process_group
+ self.warm_step = 5 # for warmup
+
+ @staticmethod
+ def from_native_module(
+ module: attention_processor.Attention, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ model_shard_infer_config = kwargs.get("model_shard_infer_config", None)
+ return DistrifusionFusedAttention(
+ module=module,
+ process_group=process_group,
+ model_shard_infer_config=model_shard_infer_config,
+ )
+
+ def _forward(
+ self,
+ attn: Attention,
+ hidden_states: torch.FloatTensor,
+ encoder_hidden_states: torch.FloatTensor = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ *args,
+ **kwargs,
+ ) -> torch.FloatTensor:
+ residual = hidden_states
+
+ input_ndim = hidden_states.ndim
+ if input_ndim == 4:
+ batch_size, channel, height, width = hidden_states.shape
+ hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
+ context_input_ndim = encoder_hidden_states.ndim
+ if context_input_ndim == 4:
+ batch_size, channel, height, width = encoder_hidden_states.shape
+ encoder_hidden_states = encoder_hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
+
+ batch_size = encoder_hidden_states.shape[0]
+
+ # `sample` projections.
+ query = attn.to_q(hidden_states)
+ key = attn.to_k(hidden_states)
+ value = attn.to_v(hidden_states)
+
+ kv = torch.cat([key, value], dim=-1) # shape of kv now: (bs, seq_len // parallel_size, dim * 2)
+
+ if self.patched_parallelism_size == 1:
+ full_kv = kv
+ else:
+ if self.buffer_list is None: # buffer not created
+ full_kv = torch.cat([kv for _ in range(self.patched_parallelism_size)], dim=1)
+ elif self.counter <= self.warm_step:
+ # logger.info(f"warmup: {self.counter}")
+ dist.all_gather(
+ self.buffer_list,
+ kv,
+ group=self.process_group,
+ async_op=False,
+ )
+ full_kv = torch.cat(self.buffer_list, dim=1)
+ else:
+ # logger.info(f"use old kv to infer: {self.counter}")
+ self.buffer_list[self.kv_buffer_idx].copy_(kv)
+ full_kv = torch.cat(self.buffer_list, dim=1)
+ assert self.handle is None, "we should maintain the kv of last step"
+ self.handle = dist.all_gather(self.buffer_list, kv, group=self.process_group, async_op=True)
+
+ key, value = torch.split(full_kv, full_kv.shape[-1] // 2, dim=-1)
+
+ # `context` projections.
+ encoder_hidden_states_query_proj = attn.add_q_proj(encoder_hidden_states)
+ encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
+ encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
+
+ # attention
+ query = torch.cat([query, encoder_hidden_states_query_proj], dim=1)
+ key = torch.cat([key, encoder_hidden_states_key_proj], dim=1)
+ value = torch.cat([value, encoder_hidden_states_value_proj], dim=1)
+
+ inner_dim = key.shape[-1]
+ head_dim = inner_dim // attn.heads
+ query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+ key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+ value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+
+ hidden_states = hidden_states = F.scaled_dot_product_attention(
+ query, key, value, dropout_p=0.0, is_causal=False
+ ) # NOTE(@lry89757) for torch >= 2.2, flash attn has been already integrated into scaled_dot_product_attention, https://pytorch.org/blog/pytorch2-2/
+ hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
+ hidden_states = hidden_states.to(query.dtype)
+
+ # Split the attention outputs.
+ hidden_states, encoder_hidden_states = (
+ hidden_states[:, : residual.shape[1]],
+ hidden_states[:, residual.shape[1] :],
+ )
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+ if not attn.context_pre_only:
+ encoder_hidden_states = attn.to_add_out(encoder_hidden_states)
+
+ if input_ndim == 4:
+ hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
+ if context_input_ndim == 4:
+ encoder_hidden_states = encoder_hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
+
+ return hidden_states, encoder_hidden_states
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ **cross_attention_kwargs,
+ ) -> torch.Tensor:
+
+ if self.handle is not None:
+ self.handle.wait()
+ self.handle = None
+
+ b, l, c = hidden_states.shape
+ kv_shape = (b, l, self.module.to_k.out_features * 2)
+ if self.patched_parallelism_size > 1 and (self.buffer_list is None or self.buffer_list[0].shape != kv_shape):
+
+ self.buffer_list = [
+ torch.empty(kv_shape, dtype=hidden_states.dtype, device=get_current_device())
+ for _ in range(self.patched_parallelism_size)
+ ]
+
+ self.counter = 0
+
+ attn_parameters = set(inspect.signature(self.module.processor.__call__).parameters.keys())
+ quiet_attn_parameters = {"ip_adapter_masks"}
+ unused_kwargs = [
+ k for k, _ in cross_attention_kwargs.items() if k not in attn_parameters and k not in quiet_attn_parameters
+ ]
+ if len(unused_kwargs) > 0:
+ logger.warning(
+ f"cross_attention_kwargs {unused_kwargs} are not expected by {self.module.processor.__class__.__name__} and will be ignored."
+ )
+ cross_attention_kwargs = {k: w for k, w in cross_attention_kwargs.items() if k in attn_parameters}
+
+ output = self._forward(
+ self.module,
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ **cross_attention_kwargs,
+ )
+
+ self.counter += 1
+
+ return output
+
+
+# Code adapted from: https://github.com/PipeFusion/PipeFusion/blob/main/pipefuser/modules/dit/patch_parallel/attn.py
+class DistriSelfAttention(ParallelModule):
+ def __init__(
+ self,
+ module: Attention,
+ process_group: Union[ProcessGroup, List[ProcessGroup]],
+ model_shard_infer_config: ModelShardInferenceConfig = None,
+ ):
+ super().__init__()
+ self.counter = 0
+ self.module = module
+ self.buffer_list = None
+ self.kv_buffer_idx = dist.get_rank(group=process_group)
+ self.patched_parallelism_size = model_shard_infer_config.patched_parallelism_size
+ self.handle = None
+ self.process_group = process_group
+ self.warm_step = 3 # for warmup
+
+ @staticmethod
+ def from_native_module(
+ module: Attention, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ model_shard_infer_config = kwargs.get("model_shard_infer_config", None)
+ return DistriSelfAttention(
+ module=module,
+ process_group=process_group,
+ model_shard_infer_config=model_shard_infer_config,
+ )
+
+ def _forward(self, hidden_states: torch.FloatTensor, scale: float = 1.0):
+ attn = self.module
+ assert isinstance(attn, Attention)
+
+ residual = hidden_states
+
+ batch_size, sequence_length, _ = hidden_states.shape
+
+ query = attn.to_q(hidden_states)
+
+ encoder_hidden_states = hidden_states
+ k = self.module.to_k(encoder_hidden_states)
+ v = self.module.to_v(encoder_hidden_states)
+ kv = torch.cat([k, v], dim=-1) # shape of kv now: (bs, seq_len // parallel_size, dim * 2)
+
+ if self.patched_parallelism_size == 1:
+ full_kv = kv
+ else:
+ if self.buffer_list is None: # buffer not created
+ full_kv = torch.cat([kv for _ in range(self.patched_parallelism_size)], dim=1)
+ elif self.counter <= self.warm_step:
+ # logger.info(f"warmup: {self.counter}")
+ dist.all_gather(
+ self.buffer_list,
+ kv,
+ group=self.process_group,
+ async_op=False,
+ )
+ full_kv = torch.cat(self.buffer_list, dim=1)
+ else:
+ # logger.info(f"use old kv to infer: {self.counter}")
+ self.buffer_list[self.kv_buffer_idx].copy_(kv)
+ full_kv = torch.cat(self.buffer_list, dim=1)
+ assert self.handle is None, "we should maintain the kv of last step"
+ self.handle = dist.all_gather(self.buffer_list, kv, group=self.process_group, async_op=True)
+
+ if HAS_FLASH_ATTN:
+ # flash attn
+ key, value = torch.split(full_kv, full_kv.shape[-1] // 2, dim=-1)
+ inner_dim = key.shape[-1]
+ head_dim = inner_dim // attn.heads
+
+ query = query.view(batch_size, -1, attn.heads, head_dim)
+ key = key.view(batch_size, -1, attn.heads, head_dim)
+ value = value.view(batch_size, -1, attn.heads, head_dim)
+
+ hidden_states = flash_attn_func(query, key, value, dropout_p=0.0, causal=False)
+ hidden_states = hidden_states.reshape(batch_size, -1, attn.heads * head_dim).to(query.dtype)
+ else:
+ # naive attn
+ key, value = torch.split(full_kv, full_kv.shape[-1] // 2, dim=-1)
+
+ inner_dim = key.shape[-1]
+ head_dim = inner_dim // attn.heads
+
+ query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+ key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+ value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+
+ # the output of sdp = (batch, num_heads, seq_len, head_dim)
+ # TODO: add support for attn.scale when we move to Torch 2.1
+ hidden_states = F.scaled_dot_product_attention(query, key, value, dropout_p=0.0, is_causal=False)
+
+ hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
+ hidden_states = hidden_states.to(query.dtype)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+
+ if attn.residual_connection:
+ hidden_states = hidden_states + residual
+
+ hidden_states = hidden_states / attn.rescale_output_factor
+
+ return hidden_states
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ scale: float = 1.0,
+ *args,
+ **kwargs,
+ ) -> torch.FloatTensor:
+
+ # async preallocates memo buffer
+ if self.handle is not None:
+ self.handle.wait()
+ self.handle = None
+
+ b, l, c = hidden_states.shape
+ kv_shape = (b, l, self.module.to_k.out_features * 2)
+ if self.patched_parallelism_size > 1 and (self.buffer_list is None or self.buffer_list[0].shape != kv_shape):
+
+ self.buffer_list = [
+ torch.empty(kv_shape, dtype=hidden_states.dtype, device=get_current_device())
+ for _ in range(self.patched_parallelism_size)
+ ]
+
+ self.counter = 0
+
+ output = self._forward(hidden_states, scale=scale)
+
+ self.counter += 1
+ return output
diff --git a/colossalai/inference/modeling/models/pixart_alpha.py b/colossalai/inference/modeling/models/pixart_alpha.py
index d5774946e365..cc2bee5efd4d 100644
--- a/colossalai/inference/modeling/models/pixart_alpha.py
+++ b/colossalai/inference/modeling/models/pixart_alpha.py
@@ -14,7 +14,7 @@
from colossalai.logging import get_dist_logger
-from .diffusion import DiffusionPipe
+from ..layers.diffusion import DiffusionPipe
logger = get_dist_logger(__name__)
diff --git a/colossalai/inference/modeling/models/stablediffusion3.py b/colossalai/inference/modeling/models/stablediffusion3.py
index d1c63a6dc665..b123164039c8 100644
--- a/colossalai/inference/modeling/models/stablediffusion3.py
+++ b/colossalai/inference/modeling/models/stablediffusion3.py
@@ -4,7 +4,7 @@
import torch
from diffusers.pipelines.stable_diffusion_3.pipeline_stable_diffusion_3 import retrieve_timesteps
-from .diffusion import DiffusionPipe
+from ..layers.diffusion import DiffusionPipe
# TODO(@lry89757) temporarily image, please support more return output
diff --git a/colossalai/inference/modeling/policy/pixart_alpha.py b/colossalai/inference/modeling/policy/pixart_alpha.py
index 356056ba73e7..1150b2432cc5 100644
--- a/colossalai/inference/modeling/policy/pixart_alpha.py
+++ b/colossalai/inference/modeling/policy/pixart_alpha.py
@@ -1,9 +1,17 @@
+from diffusers.models.attention import BasicTransformerBlock
+from diffusers.models.transformers.pixart_transformer_2d import PixArtTransformer2DModel
from torch import nn
from colossalai.inference.config import RPC_PARAM
-from colossalai.inference.modeling.models.diffusion import DiffusionPipe
+from colossalai.inference.modeling.layers.diffusion import DiffusionPipe
+from colossalai.inference.modeling.layers.distrifusion import (
+ DistrifusionConv2D,
+ DistrifusionPatchEmbed,
+ DistriSelfAttention,
+ PixArtAlphaTransformer2DModel_forward,
+)
from colossalai.inference.modeling.models.pixart_alpha import pixart_alpha_forward
-from colossalai.shardformer.policies.base_policy import Policy
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
class PixArtAlphaInferPolicy(Policy, RPC_PARAM):
@@ -12,9 +20,46 @@ def __init__(self) -> None:
def module_policy(self):
policy = {}
+
+ if self.shard_config.extra_kwargs["model_shard_infer_config"].patched_parallelism_size > 1:
+
+ policy[PixArtTransformer2DModel] = ModulePolicyDescription(
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="pos_embed.proj",
+ target_module=DistrifusionConv2D,
+ kwargs={"model_shard_infer_config": self.shard_config.extra_kwargs["model_shard_infer_config"]},
+ ),
+ SubModuleReplacementDescription(
+ suffix="pos_embed",
+ target_module=DistrifusionPatchEmbed,
+ kwargs={"model_shard_infer_config": self.shard_config.extra_kwargs["model_shard_infer_config"]},
+ ),
+ ],
+ attribute_replacement={
+ "patched_parallel_size": self.shard_config.extra_kwargs[
+ "model_shard_infer_config"
+ ].patched_parallelism_size
+ },
+ method_replacement={"forward": PixArtAlphaTransformer2DModel_forward},
+ )
+
+ policy[BasicTransformerBlock] = ModulePolicyDescription(
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="attn1",
+ target_module=DistriSelfAttention,
+ kwargs={
+ "model_shard_infer_config": self.shard_config.extra_kwargs["model_shard_infer_config"],
+ },
+ )
+ ]
+ )
+
self.append_or_create_method_replacement(
description={"forward": pixart_alpha_forward}, policy=policy, target_key=DiffusionPipe
)
+
return policy
def preprocess(self) -> nn.Module:
diff --git a/colossalai/inference/modeling/policy/stablediffusion3.py b/colossalai/inference/modeling/policy/stablediffusion3.py
index c9877f7dcae6..39b764b92887 100644
--- a/colossalai/inference/modeling/policy/stablediffusion3.py
+++ b/colossalai/inference/modeling/policy/stablediffusion3.py
@@ -1,9 +1,17 @@
+from diffusers.models.attention import JointTransformerBlock
+from diffusers.models.transformers import SD3Transformer2DModel
from torch import nn
from colossalai.inference.config import RPC_PARAM
-from colossalai.inference.modeling.models.diffusion import DiffusionPipe
+from colossalai.inference.modeling.layers.diffusion import DiffusionPipe
+from colossalai.inference.modeling.layers.distrifusion import (
+ DistrifusionConv2D,
+ DistrifusionFusedAttention,
+ DistrifusionPatchEmbed,
+ SD3Transformer2DModel_forward,
+)
from colossalai.inference.modeling.models.stablediffusion3 import sd3_forward
-from colossalai.shardformer.policies.base_policy import Policy
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
class StableDiffusion3InferPolicy(Policy, RPC_PARAM):
@@ -12,6 +20,42 @@ def __init__(self) -> None:
def module_policy(self):
policy = {}
+
+ if self.shard_config.extra_kwargs["model_shard_infer_config"].patched_parallelism_size > 1:
+
+ policy[SD3Transformer2DModel] = ModulePolicyDescription(
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="pos_embed.proj",
+ target_module=DistrifusionConv2D,
+ kwargs={"model_shard_infer_config": self.shard_config.extra_kwargs["model_shard_infer_config"]},
+ ),
+ SubModuleReplacementDescription(
+ suffix="pos_embed",
+ target_module=DistrifusionPatchEmbed,
+ kwargs={"model_shard_infer_config": self.shard_config.extra_kwargs["model_shard_infer_config"]},
+ ),
+ ],
+ attribute_replacement={
+ "patched_parallel_size": self.shard_config.extra_kwargs[
+ "model_shard_infer_config"
+ ].patched_parallelism_size
+ },
+ method_replacement={"forward": SD3Transformer2DModel_forward},
+ )
+
+ policy[JointTransformerBlock] = ModulePolicyDescription(
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="attn",
+ target_module=DistrifusionFusedAttention,
+ kwargs={
+ "model_shard_infer_config": self.shard_config.extra_kwargs["model_shard_infer_config"],
+ },
+ )
+ ]
+ )
+
self.append_or_create_method_replacement(
description={"forward": sd3_forward}, policy=policy, target_key=DiffusionPipe
)
diff --git a/colossalai/shardformer/layer/moe/__init__.py b/colossalai/legacy/moe/layer/__init__.py
similarity index 100%
rename from colossalai/shardformer/layer/moe/__init__.py
rename to colossalai/legacy/moe/layer/__init__.py
diff --git a/colossalai/shardformer/layer/moe/experts.py b/colossalai/legacy/moe/layer/experts.py
similarity index 95%
rename from colossalai/shardformer/layer/moe/experts.py
rename to colossalai/legacy/moe/layer/experts.py
index 1be7a27547ed..8088cf44e473 100644
--- a/colossalai/shardformer/layer/moe/experts.py
+++ b/colossalai/legacy/moe/layer/experts.py
@@ -5,9 +5,9 @@
import torch.nn as nn
from colossalai.kernel.triton.llama_act_combine_kernel import HAS_TRITON
-from colossalai.moe._operation import MoeInGradScaler, MoeOutGradScaler
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import get_activation
+from colossalai.legacy.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.utils import get_activation
+from colossalai.moe._operation import EPGradScalerIn, EPGradScalerOut
from colossalai.shardformer.layer.utils import Randomizer
from colossalai.tensor.moe_tensor.api import get_ep_rank, get_ep_size
@@ -118,7 +118,7 @@ def forward(
Returns:
torch.Tensor: The output tensor of shape (num_groups, num_experts, capacity, hidden_size)
"""
- x = MoeInGradScaler.apply(x, self.ep_size)
+ x = EPGradScalerIn.apply(x, self.ep_size)
e = x.size(1)
h = x.size(-1)
@@ -157,5 +157,5 @@ def forward(
x = torch.cat([x[i].unsqueeze(0) for i in range(e)], dim=0)
x = x.reshape(inshape)
x = x.transpose(0, 1).contiguous()
- x = MoeOutGradScaler.apply(x, self.ep_size)
+ x = EPGradScalerOut.apply(x, self.ep_size)
return x
diff --git a/colossalai/shardformer/layer/moe/layers.py b/colossalai/legacy/moe/layer/layers.py
similarity index 99%
rename from colossalai/shardformer/layer/moe/layers.py
rename to colossalai/legacy/moe/layer/layers.py
index e5b0ef97fd87..e43966f68a8c 100644
--- a/colossalai/shardformer/layer/moe/layers.py
+++ b/colossalai/legacy/moe/layer/layers.py
@@ -7,9 +7,9 @@
import torch.nn as nn
import torch.nn.functional as F
+from colossalai.legacy.moe.load_balance import LoadBalancer
+from colossalai.legacy.moe.utils import create_ep_hierarchical_group, get_noise_generator
from colossalai.moe._operation import AllGather, AllToAll, HierarchicalAllToAll, MoeCombine, MoeDispatch, ReduceScatter
-from colossalai.moe.load_balance import LoadBalancer
-from colossalai.moe.utils import create_ep_hierarchical_group, get_noise_generator
from colossalai.shardformer.layer.moe import MLPExperts
from colossalai.tensor.moe_tensor.api import get_dp_group, get_ep_group, get_ep_group_ranks, get_ep_size
diff --git a/colossalai/shardformer/layer/moe/routers.py b/colossalai/legacy/moe/layer/routers.py
similarity index 95%
rename from colossalai/shardformer/layer/moe/routers.py
rename to colossalai/legacy/moe/layer/routers.py
index 1be7a27547ed..8088cf44e473 100644
--- a/colossalai/shardformer/layer/moe/routers.py
+++ b/colossalai/legacy/moe/layer/routers.py
@@ -5,9 +5,9 @@
import torch.nn as nn
from colossalai.kernel.triton.llama_act_combine_kernel import HAS_TRITON
-from colossalai.moe._operation import MoeInGradScaler, MoeOutGradScaler
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import get_activation
+from colossalai.legacy.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.utils import get_activation
+from colossalai.moe._operation import EPGradScalerIn, EPGradScalerOut
from colossalai.shardformer.layer.utils import Randomizer
from colossalai.tensor.moe_tensor.api import get_ep_rank, get_ep_size
@@ -118,7 +118,7 @@ def forward(
Returns:
torch.Tensor: The output tensor of shape (num_groups, num_experts, capacity, hidden_size)
"""
- x = MoeInGradScaler.apply(x, self.ep_size)
+ x = EPGradScalerIn.apply(x, self.ep_size)
e = x.size(1)
h = x.size(-1)
@@ -157,5 +157,5 @@ def forward(
x = torch.cat([x[i].unsqueeze(0) for i in range(e)], dim=0)
x = x.reshape(inshape)
x = x.transpose(0, 1).contiguous()
- x = MoeOutGradScaler.apply(x, self.ep_size)
+ x = EPGradScalerOut.apply(x, self.ep_size)
return x
diff --git a/colossalai/moe/load_balance.py b/colossalai/legacy/moe/load_balance.py
similarity index 99%
rename from colossalai/moe/load_balance.py
rename to colossalai/legacy/moe/load_balance.py
index 3dc6c02c7445..7339b1a7b0eb 100644
--- a/colossalai/moe/load_balance.py
+++ b/colossalai/legacy/moe/load_balance.py
@@ -7,7 +7,7 @@
from torch.distributed import ProcessGroup
from colossalai.cluster import ProcessGroupMesh
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
from colossalai.shardformer.layer.moe import MLPExperts
from colossalai.zero.low_level import LowLevelZeroOptimizer
diff --git a/colossalai/moe/manager.py b/colossalai/legacy/moe/manager.py
similarity index 100%
rename from colossalai/moe/manager.py
rename to colossalai/legacy/moe/manager.py
diff --git a/examples/language/openmoe/README.md b/colossalai/legacy/moe/openmoe/README.md
similarity index 100%
rename from examples/language/openmoe/README.md
rename to colossalai/legacy/moe/openmoe/README.md
diff --git a/examples/language/openmoe/benchmark/benchmark_cai.py b/colossalai/legacy/moe/openmoe/benchmark/benchmark_cai.py
similarity index 99%
rename from examples/language/openmoe/benchmark/benchmark_cai.py
rename to colossalai/legacy/moe/openmoe/benchmark/benchmark_cai.py
index b9ef915c32a4..5f9447246ae4 100644
--- a/examples/language/openmoe/benchmark/benchmark_cai.py
+++ b/colossalai/legacy/moe/openmoe/benchmark/benchmark_cai.py
@@ -18,9 +18,9 @@
from colossalai.booster import Booster
from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
from colossalai.cluster import DistCoordinator
+from colossalai.legacy.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.utils import skip_init
from colossalai.moe.layers import apply_load_balance
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import skip_init
from colossalai.nn.optimizer import HybridAdam
diff --git a/examples/language/openmoe/benchmark/benchmark_cai.sh b/colossalai/legacy/moe/openmoe/benchmark/benchmark_cai.sh
similarity index 100%
rename from examples/language/openmoe/benchmark/benchmark_cai.sh
rename to colossalai/legacy/moe/openmoe/benchmark/benchmark_cai.sh
diff --git a/examples/language/openmoe/benchmark/benchmark_cai_dist.sh b/colossalai/legacy/moe/openmoe/benchmark/benchmark_cai_dist.sh
similarity index 100%
rename from examples/language/openmoe/benchmark/benchmark_cai_dist.sh
rename to colossalai/legacy/moe/openmoe/benchmark/benchmark_cai_dist.sh
diff --git a/examples/language/openmoe/benchmark/benchmark_fsdp.py b/colossalai/legacy/moe/openmoe/benchmark/benchmark_fsdp.py
similarity index 98%
rename from examples/language/openmoe/benchmark/benchmark_fsdp.py
rename to colossalai/legacy/moe/openmoe/benchmark/benchmark_fsdp.py
index b00fbd001022..1ae94dd90977 100644
--- a/examples/language/openmoe/benchmark/benchmark_fsdp.py
+++ b/colossalai/legacy/moe/openmoe/benchmark/benchmark_fsdp.py
@@ -14,7 +14,7 @@
from transformers.models.llama import LlamaConfig
from utils import PerformanceEvaluator, get_model_numel
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
class RandomDataset(Dataset):
diff --git a/examples/language/openmoe/benchmark/benchmark_fsdp.sh b/colossalai/legacy/moe/openmoe/benchmark/benchmark_fsdp.sh
similarity index 100%
rename from examples/language/openmoe/benchmark/benchmark_fsdp.sh
rename to colossalai/legacy/moe/openmoe/benchmark/benchmark_fsdp.sh
diff --git a/examples/language/openmoe/benchmark/hostfile.txt b/colossalai/legacy/moe/openmoe/benchmark/hostfile.txt
similarity index 100%
rename from examples/language/openmoe/benchmark/hostfile.txt
rename to colossalai/legacy/moe/openmoe/benchmark/hostfile.txt
diff --git a/examples/language/openmoe/benchmark/utils.py b/colossalai/legacy/moe/openmoe/benchmark/utils.py
similarity index 100%
rename from examples/language/openmoe/benchmark/utils.py
rename to colossalai/legacy/moe/openmoe/benchmark/utils.py
diff --git a/examples/language/openmoe/infer.py b/colossalai/legacy/moe/openmoe/infer.py
similarity index 100%
rename from examples/language/openmoe/infer.py
rename to colossalai/legacy/moe/openmoe/infer.py
diff --git a/examples/language/openmoe/infer.sh b/colossalai/legacy/moe/openmoe/infer.sh
similarity index 100%
rename from examples/language/openmoe/infer.sh
rename to colossalai/legacy/moe/openmoe/infer.sh
diff --git a/examples/language/openmoe/model/__init__.py b/colossalai/legacy/moe/openmoe/model/__init__.py
similarity index 100%
rename from examples/language/openmoe/model/__init__.py
rename to colossalai/legacy/moe/openmoe/model/__init__.py
diff --git a/examples/language/openmoe/model/convert_openmoe_ckpt.py b/colossalai/legacy/moe/openmoe/model/convert_openmoe_ckpt.py
similarity index 100%
rename from examples/language/openmoe/model/convert_openmoe_ckpt.py
rename to colossalai/legacy/moe/openmoe/model/convert_openmoe_ckpt.py
diff --git a/examples/language/openmoe/model/convert_openmoe_ckpt.sh b/colossalai/legacy/moe/openmoe/model/convert_openmoe_ckpt.sh
similarity index 100%
rename from examples/language/openmoe/model/convert_openmoe_ckpt.sh
rename to colossalai/legacy/moe/openmoe/model/convert_openmoe_ckpt.sh
diff --git a/examples/language/openmoe/model/modeling_openmoe.py b/colossalai/legacy/moe/openmoe/model/modeling_openmoe.py
similarity index 99%
rename from examples/language/openmoe/model/modeling_openmoe.py
rename to colossalai/legacy/moe/openmoe/model/modeling_openmoe.py
index 1febacd7d226..5d6e91765883 100644
--- a/examples/language/openmoe/model/modeling_openmoe.py
+++ b/colossalai/legacy/moe/openmoe/model/modeling_openmoe.py
@@ -50,8 +50,8 @@
except:
HAS_FLASH_ATTN = False
from colossalai.kernel.triton.llama_act_combine_kernel import HAS_TRITON
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import get_activation, set_moe_args
+from colossalai.legacy.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.utils import get_activation, set_moe_args
from colossalai.shardformer.layer.moe import SparseMLP
if HAS_TRITON:
diff --git a/examples/language/openmoe/model/openmoe_8b_config.json b/colossalai/legacy/moe/openmoe/model/openmoe_8b_config.json
similarity index 100%
rename from examples/language/openmoe/model/openmoe_8b_config.json
rename to colossalai/legacy/moe/openmoe/model/openmoe_8b_config.json
diff --git a/examples/language/openmoe/model/openmoe_base_config.json b/colossalai/legacy/moe/openmoe/model/openmoe_base_config.json
similarity index 100%
rename from examples/language/openmoe/model/openmoe_base_config.json
rename to colossalai/legacy/moe/openmoe/model/openmoe_base_config.json
diff --git a/examples/language/openmoe/model/openmoe_policy.py b/colossalai/legacy/moe/openmoe/model/openmoe_policy.py
similarity index 99%
rename from examples/language/openmoe/model/openmoe_policy.py
rename to colossalai/legacy/moe/openmoe/model/openmoe_policy.py
index f46062128563..ccd566b08594 100644
--- a/examples/language/openmoe/model/openmoe_policy.py
+++ b/colossalai/legacy/moe/openmoe/model/openmoe_policy.py
@@ -9,7 +9,7 @@
from transformers.modeling_outputs import CausalLMOutputWithPast
from transformers.utils import logging
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
from colossalai.pipeline.stage_manager import PipelineStageManager
from colossalai.shardformer.layer import FusedRMSNorm, Linear1D_Col
from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
diff --git a/examples/language/openmoe/requirements.txt b/colossalai/legacy/moe/openmoe/requirements.txt
similarity index 100%
rename from examples/language/openmoe/requirements.txt
rename to colossalai/legacy/moe/openmoe/requirements.txt
diff --git a/examples/language/openmoe/test_ci.sh b/colossalai/legacy/moe/openmoe/test_ci.sh
similarity index 100%
rename from examples/language/openmoe/test_ci.sh
rename to colossalai/legacy/moe/openmoe/test_ci.sh
diff --git a/examples/language/openmoe/train.py b/colossalai/legacy/moe/openmoe/train.py
similarity index 99%
rename from examples/language/openmoe/train.py
rename to colossalai/legacy/moe/openmoe/train.py
index ff0e4bad6ee3..0173f0964453 100644
--- a/examples/language/openmoe/train.py
+++ b/colossalai/legacy/moe/openmoe/train.py
@@ -19,7 +19,7 @@
from colossalai.booster import Booster
from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
from colossalai.cluster import DistCoordinator
-from colossalai.moe.utils import skip_init
+from colossalai.legacy.moe.utils import skip_init
from colossalai.nn.optimizer import HybridAdam
from colossalai.shardformer.layer.moe import apply_load_balance
diff --git a/examples/language/openmoe/train.sh b/colossalai/legacy/moe/openmoe/train.sh
similarity index 100%
rename from examples/language/openmoe/train.sh
rename to colossalai/legacy/moe/openmoe/train.sh
diff --git a/colossalai/moe/utils.py b/colossalai/legacy/moe/utils.py
similarity index 99%
rename from colossalai/moe/utils.py
rename to colossalai/legacy/moe/utils.py
index 3d08ab7dd9b0..d91c41363316 100644
--- a/colossalai/moe/utils.py
+++ b/colossalai/legacy/moe/utils.py
@@ -9,7 +9,7 @@
from torch.distributed.distributed_c10d import get_process_group_ranks
from colossalai.accelerator import get_accelerator
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
from colossalai.tensor.moe_tensor.api import is_moe_tensor
diff --git a/colossalai/moe/__init__.py b/colossalai/moe/__init__.py
index 0623d19efd5f..e69de29bb2d1 100644
--- a/colossalai/moe/__init__.py
+++ b/colossalai/moe/__init__.py
@@ -1,5 +0,0 @@
-from .manager import MOE_MANAGER
-
-__all__ = [
- "MOE_MANAGER",
-]
diff --git a/colossalai/moe/_operation.py b/colossalai/moe/_operation.py
index 01c837ee36ad..ac422a4da98f 100644
--- a/colossalai/moe/_operation.py
+++ b/colossalai/moe/_operation.py
@@ -290,7 +290,7 @@ def moe_cumsum(inputs: Tensor, use_kernel: bool = False):
return torch.cumsum(inputs, dim=0) - 1
-class MoeInGradScaler(torch.autograd.Function):
+class EPGradScalerIn(torch.autograd.Function):
"""
Scale the gradient back by the number of experts
because the batch size increases in the moe stage
@@ -298,8 +298,7 @@ class MoeInGradScaler(torch.autograd.Function):
@staticmethod
def forward(ctx: Any, inputs: Tensor, ep_size: int) -> Tensor:
- if ctx is not None:
- ctx.ep_size = ep_size
+ ctx.ep_size = ep_size
return inputs
@staticmethod
@@ -311,7 +310,7 @@ def backward(ctx: Any, *grad_outputs: Tensor) -> Tuple[Tensor, None]:
return grad, None
-class MoeOutGradScaler(torch.autograd.Function):
+class EPGradScalerOut(torch.autograd.Function):
"""
Scale the gradient by the number of experts
because the batch size increases in the moe stage
@@ -331,6 +330,50 @@ def backward(ctx: Any, *grad_outputs: Tensor) -> Tuple[Tensor, None]:
return grad, None
+class DPGradScalerIn(torch.autograd.Function):
+ """
+ Scale the gradient back by the number of experts
+ because the batch size increases in the moe stage
+ """
+
+ @staticmethod
+ def forward(ctx: Any, inputs: Tensor, moe_dp_size: int, activated_experts: int) -> Tensor:
+ assert activated_experts != 0, f"shouldn't be called when no expert is activated"
+ ctx.moe_dp_size = moe_dp_size
+ ctx.activated_experts = activated_experts
+ return inputs
+
+ @staticmethod
+ def backward(ctx: Any, *grad_outputs: Tensor) -> Tuple[Tensor, None, None]:
+ assert len(grad_outputs) == 1
+ grad = grad_outputs[0]
+ if ctx.moe_dp_size != ctx.activated_experts:
+ grad.mul_(ctx.activated_experts / ctx.moe_dp_size)
+ return grad, None, None
+
+
+class DPGradScalerOut(torch.autograd.Function):
+ """
+ Scale the gradient by the number of experts
+ because the batch size increases in the moe stage
+ """
+
+ @staticmethod
+ def forward(ctx: Any, inputs: Tensor, moe_dp_size: int, activated_experts: int) -> Tensor:
+ assert activated_experts != 0, f"shouldn't be called when no expert is activated"
+ ctx.moe_dp_size = moe_dp_size
+ ctx.activated_experts = activated_experts
+ return inputs
+
+ @staticmethod
+ def backward(ctx: Any, *grad_outputs: Tensor) -> Tuple[Tensor, None, None]:
+ assert len(grad_outputs) == 1
+ grad = grad_outputs[0]
+ if ctx.moe_dp_size != ctx.activated_experts:
+ grad.mul_(ctx.moe_dp_size / ctx.activated_experts)
+ return grad, None, None
+
+
def _all_to_all(
inputs: torch.Tensor,
input_split_sizes: Optional[List[int]] = None,
@@ -393,4 +436,7 @@ def all_to_all_uneven(
group=None,
overlap: bool = False,
):
+ assert (
+ inputs.requires_grad
+ ), "Input must require grad to assure that backward is executed, otherwise it might hang the program."
return AllToAllUneven.apply(inputs, input_split_sizes, output_split_sizes, group, overlap)
diff --git a/colossalai/shardformer/layer/attn.py b/colossalai/shardformer/layer/attn.py
index 141baf3d3770..5872c64856b9 100644
--- a/colossalai/shardformer/layer/attn.py
+++ b/colossalai/shardformer/layer/attn.py
@@ -139,12 +139,11 @@ def prepare_attn_kwargs(
# no padding
assert is_causal
outputs["attention_mask_type"] = AttnMaskType.CAUSAL
- attention_mask = torch.ones(s_q, s_kv, dtype=dtype, device=device).tril(diagonal=0).expand(b, s_q, s_kv)
+ attention_mask = torch.ones(s_q, s_kv, dtype=dtype, device=device)
+ if s_q != 1:
+ attention_mask = attention_mask.tril(diagonal=0)
+ attention_mask = attention_mask.expand(b, s_q, s_kv)
else:
- assert q_padding_mask.shape == (
- b,
- s_q,
- ), f"q_padding_mask shape {q_padding_mask.shape} should be the same. ({shape_4d})"
max_seqlen_q, cu_seqlens_q, q_indices = get_pad_info(q_padding_mask)
if kv_padding_mask is None:
# self attention
@@ -156,7 +155,7 @@ def prepare_attn_kwargs(
b,
s_kv,
), f"q_padding_mask shape {kv_padding_mask.shape} should be the same. ({shape_4d})"
- attention_mask = q_padding_mask[:, None, :].expand(b, s_kv, s_q).to(dtype=dtype, device=device)
+ attention_mask = kv_padding_mask[:, None, :].expand(b, s_q, s_kv).to(dtype=dtype, device=device)
outputs.update(
{
"cu_seqlens_q": cu_seqlens_q,
@@ -169,7 +168,8 @@ def prepare_attn_kwargs(
)
if is_causal:
outputs["attention_mask_type"] = AttnMaskType.PADDED_CAUSAL
- attention_mask = attention_mask * attention_mask.new_ones(s_q, s_kv).tril(diagonal=0)
+ if s_q != 1:
+ attention_mask = attention_mask * attention_mask.new_ones(s_q, s_kv).tril(diagonal=0)
else:
outputs["attention_mask_type"] = AttnMaskType.PADDED
attention_mask = invert_mask(attention_mask).unsqueeze(1)
diff --git a/colossalai/shardformer/layer/qkv_fused_linear.py b/colossalai/shardformer/layer/qkv_fused_linear.py
index 0f6595a7c4d6..000934ad91a2 100644
--- a/colossalai/shardformer/layer/qkv_fused_linear.py
+++ b/colossalai/shardformer/layer/qkv_fused_linear.py
@@ -695,6 +695,7 @@ def from_native_module(
process_group=process_group,
weight=module.weight,
bias_=module.bias,
+ n_fused=n_fused,
*args,
**kwargs,
)
diff --git a/colossalai/shardformer/modeling/command.py b/colossalai/shardformer/modeling/command.py
index 759c8d7b8d59..5b36fc7db3b9 100644
--- a/colossalai/shardformer/modeling/command.py
+++ b/colossalai/shardformer/modeling/command.py
@@ -116,7 +116,7 @@ def command_model_forward(
# for the other stages, hidden_states is the output of the previous stage
if shard_config.enable_flash_attention:
# in this case, attention_mask is a dict rather than a tensor
- mask_shape = (batch_size, 1, seq_length_with_past, seq_length_with_past)
+ mask_shape = (batch_size, 1, seq_length, seq_length_with_past)
attention_mask = ColoAttention.prepare_attn_kwargs(
mask_shape,
hidden_states.dtype,
diff --git a/colossalai/shardformer/modeling/deepseek.py b/colossalai/shardformer/modeling/deepseek.py
index 6e79ce144cc8..a84a3097231a 100644
--- a/colossalai/shardformer/modeling/deepseek.py
+++ b/colossalai/shardformer/modeling/deepseek.py
@@ -1,21 +1,38 @@
-from typing import List, Optional, Union
+import warnings
+from typing import List, Optional, Tuple, Union
import torch
import torch.distributed as dist
import torch.nn as nn
from torch.distributed import ProcessGroup
-
-# from colossalai.tensor.moe_tensor.moe_info import MoeParallelInfo
from torch.nn import CrossEntropyLoss
-from transformers.modeling_attn_mask_utils import _prepare_4d_causal_attention_mask
-from transformers.modeling_outputs import CausalLMOutputWithPast
+from transformers.cache_utils import Cache, DynamicCache
+from transformers.modeling_attn_mask_utils import (
+ _prepare_4d_causal_attention_mask,
+ _prepare_4d_causal_attention_mask_for_sdpa,
+)
+from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
+from transformers.models.llama.modeling_llama import apply_rotary_pos_emb
from transformers.utils import is_flash_attn_2_available, logging
from colossalai.lazy import LazyInitContext
-from colossalai.moe._operation import MoeInGradScaler, MoeOutGradScaler, all_to_all_uneven
+from colossalai.moe._operation import (
+ DPGradScalerIn,
+ DPGradScalerOut,
+ EPGradScalerIn,
+ EPGradScalerOut,
+ all_to_all_uneven,
+)
from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer.layer._operation import (
+ all_to_all_comm,
+ gather_forward_split_backward,
+ split_forward_gather_backward,
+)
+from colossalai.shardformer.layer.linear import Linear1D_Col, Linear1D_Row
from colossalai.shardformer.shard import ShardConfig
from colossalai.shardformer.shard.utils import set_tensors_to_none
+from colossalai.tensor.moe_tensor.api import set_moe_tensor_ep_group
# copied from modeling_deepseek.py
@@ -42,30 +59,54 @@ def backward(ctx, grad_output):
class EPDeepseekMoE(nn.Module):
def __init__(self):
- super(EPDeepseekMoE, self).__init__()
+ raise RuntimeError(f"Please use `from_native_module` to create an instance of {self.__class__.__name__}")
+
+ def setup_process_groups(self, tp_group: ProcessGroup, moe_dp_group: ProcessGroup, ep_group: ProcessGroup):
+ assert tp_group is not None
+ assert moe_dp_group is not None
+ assert ep_group is not None
- def setup_ep(self, ep_group: ProcessGroup):
- ep_group = ep_group
- self.ep_size = dist.get_world_size(ep_group) if ep_group is not None else 1
- self.ep_rank = dist.get_rank(ep_group) if ep_group is not None else 0
+ self.ep_size = dist.get_world_size(ep_group)
+ self.ep_rank = dist.get_rank(ep_group)
self.num_experts = self.config.n_routed_experts
assert self.num_experts % self.ep_size == 0
+
self.ep_group = ep_group
self.num_experts_per_ep = self.num_experts // self.ep_size
self.expert_start_idx = self.ep_rank * self.num_experts_per_ep
held_experts = self.experts[self.expert_start_idx : self.expert_start_idx + self.num_experts_per_ep]
+
set_tensors_to_none(self.experts, exclude=set(held_experts))
+
+ # setup moe_dp group
+ self.moe_dp_group = moe_dp_group
+ self.moe_dp_size = moe_dp_group.size()
+
+ # setup tp group
+ self.tp_group = tp_group
+ if self.tp_group.size() > 1:
+ for expert in held_experts:
+ expert.gate_proj = Linear1D_Col.from_native_module(expert.gate_proj, self.tp_group)
+ expert.up_proj = Linear1D_Col.from_native_module(expert.up_proj, self.tp_group)
+ expert.down_proj = Linear1D_Row.from_native_module(expert.down_proj, self.tp_group)
+
for p in self.experts.parameters():
- p.ep_group = ep_group
+ set_moe_tensor_ep_group(p, ep_group)
@staticmethod
- def from_native_module(module: Union["DeepseekMoE", "DeepseekMLP"], *args, **kwargs) -> "EPDeepseekMoE":
+ def from_native_module(
+ module,
+ tp_group: ProcessGroup,
+ moe_dp_group: ProcessGroup,
+ ep_group: ProcessGroup,
+ *args,
+ **kwargs,
+ ) -> "EPDeepseekMoE":
LazyInitContext.materialize(module)
if module.__class__.__name__ == "DeepseekMLP":
return module
module.__class__ = EPDeepseekMoE
- assert "ep_group" in kwargs, "You should pass ep_group in SubModuleReplacementDescription via shard_config!!"
- module.setup_ep(kwargs["ep_group"])
+ module.setup_process_groups(tp_group, moe_dp_group, ep_group)
return module
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
@@ -91,15 +132,24 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# [n0, n1, n2, n3] [m0, m1, m2, m3] -> [n0, n1, m0, m1] [n2, n3, m2, m3]
dist.all_to_all_single(output_split_sizes, input_split_sizes, group=self.ep_group)
+ with torch.no_grad():
+ activate_experts = output_split_sizes[: self.num_experts_per_ep].clone()
+ for i in range(1, self.ep_size):
+ activate_experts += output_split_sizes[i * self.num_experts_per_ep : (i + 1) * self.num_experts_per_ep]
+ activate_experts = (activate_experts > 0).float()
+ dist.all_reduce(activate_experts, group=self.moe_dp_group)
+
input_split_list = input_split_sizes.view(self.ep_size, self.num_experts_per_ep).sum(dim=-1).tolist()
output_split_list = output_split_sizes.view(self.ep_size, self.num_experts_per_ep).sum(dim=-1).tolist()
output_states, _ = all_to_all_uneven(dispatch_states, input_split_list, output_split_list, self.ep_group)
- output_states = MoeInGradScaler.apply(output_states, self.ep_size)
+ output_states = EPGradScalerIn.apply(output_states, self.ep_size)
if output_states.size(0) > 0:
if self.num_experts_per_ep == 1:
expert = self.experts[self.expert_start_idx]
+ output_states = DPGradScalerIn.apply(output_states, self.moe_dp_size, activate_experts[0])
output_states = expert(output_states)
+ output_states = DPGradScalerOut.apply(output_states, self.moe_dp_size, activate_experts[0])
else:
output_states_splits = output_states.split(output_split_sizes.tolist())
output_states_list = []
@@ -107,10 +157,16 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
if split_states.size(0) == 0: # no token routed to this experts
continue
expert = self.experts[self.expert_start_idx + i % self.num_experts_per_ep]
+ split_states = DPGradScalerIn.apply(
+ split_states, self.moe_dp_size, activate_experts[i % self.num_experts_per_ep]
+ )
split_states = expert(split_states)
+ split_states = DPGradScalerOut.apply(
+ split_states, self.moe_dp_size, activate_experts[i % self.num_experts_per_ep]
+ )
output_states_list.append(split_states)
output_states = torch.cat(output_states_list)
- output_states = MoeOutGradScaler.apply(output_states, self.ep_size)
+ output_states = EPGradScalerOut.apply(output_states, self.ep_size)
dispatch_states, _ = all_to_all_uneven(output_states, output_split_list, input_split_list, self.ep_group)
recover_token_idx = torch.empty_like(flat_topk_token_idx)
recover_token_idx[flat_topk_token_idx] = torch.arange(
@@ -310,7 +366,14 @@ def custom_forward(*inputs):
next_cache = next_decoder_cache if use_cache else None
if stage_manager.is_last_stage():
- return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
# always return dict for imediate stage
return {
"hidden_states": hidden_states,
@@ -427,3 +490,265 @@ def deepseek_for_causal_lm_forward(
hidden_states = outputs.get("hidden_states")
out["hidden_states"] = hidden_states
return out
+
+
+def get_deepseek_flash_attention_forward(shard_config, sp_mode=None, sp_size=None, sp_group=None):
+ logger = logging.get_logger(__name__)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ if sp_mode is not None:
+ assert sp_mode in ["all_to_all", "split_gather", "ring"], "Invalid sp_mode"
+ assert (sp_size is not None) and (
+ sp_group is not None
+ ), "Must specify sp_size and sp_group for sequence parallel"
+
+ # DeepseekFlashAttention2 attention does not support output_attentions
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
+ )
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop("padding_mask")
+
+ output_attentions = False
+
+ bsz, q_len, _ = hidden_states.size()
+
+ # sp: modify sp_len when sequence parallel mode is ring
+ if sp_mode in ["split_gather", "ring"]:
+ q_len *= sp_size
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ # sp: all-to-all comminucation when introducing sequence parallel
+ if sp_mode == "all_to_all":
+ query_states = all_to_all_comm(query_states, sp_group)
+ key_states = all_to_all_comm(key_states, sp_group)
+ value_states = all_to_all_comm(value_states, sp_group)
+ bsz, q_len, _ = query_states.size()
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(
+ query_states, key_states, cos, sin, position_ids, unsqueeze_dim=0
+ )
+
+ if past_key_value is not None:
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # TODO: These transpose are quite inefficient but Flash Attention requires the layout [batch_size, sequence_length, num_heads, head_dim]. We would need to refactor the KV cache
+ # to be able to avoid many of these transpose/reshape/view.
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ dropout_rate = self.attention_dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in the correct dtype just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not cast the LayerNorms
+ # in fp32. (DeepseekRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ # Handle the case where the model is quantized
+ if hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ elif torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+ attn_output = self._flash_attention_forward(
+ query_states, key_states, value_states, attention_mask, q_len, dropout=dropout_rate
+ )
+ # sp: all-to-all comminucation when introducing sequence parallel
+ if sp_mode == "all_to_all":
+ attn_output = attn_output.reshape(bsz, q_len, self.num_heads * self.head_dim).contiguous() # (1, 8, 128)
+ attn_output = all_to_all_comm(attn_output, sp_group, scatter_dim=1, gather_dim=2) # (1, 4, 256)
+ else:
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ return forward
+
+
+def get_deepseek_flash_attention_model_forward(shard_config, sp_mode=None, sp_size=None, sp_group=None):
+ logger = logging.get_logger(__name__)
+
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape[:2]
+ elif inputs_embeds is not None:
+ batch_size, seq_length = inputs_embeds.shape[:2]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`transformers."
+ )
+ use_cache = False
+
+ past_key_values_length = 0
+ if use_cache:
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+ past_key_values_length = past_key_values.get_usable_length(seq_length)
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.unsqueeze(0)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if self._use_flash_attention_2:
+ # 2d mask is passed through the layers
+ attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
+ elif self._use_sdpa and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ )
+ else:
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
+ )
+
+ if sp_mode in ["ring", "split_gather"]:
+ inputs_embeds = split_forward_gather_backward(inputs_embeds, 1, sp_group)
+ elif sp_mode == "all_to_all":
+ inputs_embeds = split_forward_gather_backward(inputs_embeds, 1, sp_group, 1 / sp_size)
+ # embed positions
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ use_cache,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ if sp_mode == "ring" or sp_mode == "split_gather":
+ hidden_states = gather_forward_split_backward(hidden_states, 1, sp_group)
+ elif sp_mode == "all_to_all":
+ hidden_states = gather_forward_split_backward(hidden_states, 1, sp_group, grad_scale=sp_size)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = None
+ if use_cache:
+ next_cache = next_decoder_cache.to_legacy_cache() if use_legacy_cache else next_decoder_cache
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+ return forward
diff --git a/colossalai/shardformer/modeling/llama.py b/colossalai/shardformer/modeling/llama.py
index 54ff8e321e06..9ffbca517d4c 100644
--- a/colossalai/shardformer/modeling/llama.py
+++ b/colossalai/shardformer/modeling/llama.py
@@ -643,7 +643,7 @@ def forward(
# in this case, attention_mask is a dict rather than a tensor
if shard_config.enable_flash_attention:
- mask_shape = (inputs_embeds.shape[0], 1, past_seen_tokens + seq_len, past_seen_tokens + seq_len)
+ mask_shape = (inputs_embeds.shape[0], 1, seq_len, past_seen_tokens + seq_len)
attention_mask = ColoAttention.prepare_attn_kwargs(
mask_shape,
inputs_embeds.dtype,
diff --git a/colossalai/shardformer/modeling/mistral.py b/colossalai/shardformer/modeling/mistral.py
index 82e8ef5f9af7..ec1a8a00a58a 100644
--- a/colossalai/shardformer/modeling/mistral.py
+++ b/colossalai/shardformer/modeling/mistral.py
@@ -91,7 +91,7 @@ def mistral_model_forward(
if shard_config.enable_flash_attention:
# in this case, attention_mask is a dict rather than a tensor
- mask_shape = (batch_size, 1, seq_length, seq_length)
+ mask_shape = (batch_size, 1, seq_length, seq_length + past_key_values_length)
attention_mask = ColoAttention.prepare_attn_kwargs(
mask_shape,
hidden_states.dtype,
diff --git a/colossalai/shardformer/modeling/mixtral.py b/colossalai/shardformer/modeling/mixtral.py
index 2fbc34302cde..d30ce5ea85cc 100644
--- a/colossalai/shardformer/modeling/mixtral.py
+++ b/colossalai/shardformer/modeling/mixtral.py
@@ -1,52 +1,105 @@
-from typing import List, Optional
+import inspect
+import warnings
+from typing import List, Optional, Tuple, Union
import torch
import torch.distributed as dist
import torch.nn.functional as F
from torch.distributed import ProcessGroup
-
-# from colossalai.tensor.moe_tensor.moe_info import MoeParallelInfo
from torch.nn import CrossEntropyLoss
-from transformers.modeling_attn_mask_utils import _prepare_4d_causal_attention_mask
+from transformers.cache_utils import Cache, DynamicCache
+from transformers.modeling_attn_mask_utils import (
+ _prepare_4d_causal_attention_mask,
+ _prepare_4d_causal_attention_mask_for_sdpa,
+)
from transformers.models.mixtral.modeling_mixtral import (
MixtralSparseMoeBlock,
MoeCausalLMOutputWithPast,
+ MoeModelOutputWithPast,
+ apply_rotary_pos_emb,
load_balancing_loss_func,
+ repeat_kv,
)
from transformers.utils import is_flash_attn_2_available, logging
from colossalai.lazy import LazyInitContext
-from colossalai.moe._operation import MoeInGradScaler, MoeOutGradScaler, all_to_all_uneven
+from colossalai.moe._operation import (
+ DPGradScalerIn,
+ DPGradScalerOut,
+ EPGradScalerIn,
+ EPGradScalerOut,
+ all_to_all_uneven,
+)
from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer.layer._operation import (
+ all_to_all_comm,
+ gather_forward_split_backward,
+ split_forward_gather_backward,
+)
+from colossalai.shardformer.layer.linear import Linear1D_Col, Linear1D_Row
from colossalai.shardformer.shard import ShardConfig
from colossalai.shardformer.shard.utils import set_tensors_to_none
+from colossalai.tensor.moe_tensor.api import set_moe_tensor_ep_group
+
+if is_flash_attn_2_available():
+ from flash_attn import flash_attn_func
+
+ from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
+
+ _flash_supports_window_size = "window_size" in list(inspect.signature(flash_attn_func).parameters)
class EPMixtralSparseMoeBlock(MixtralSparseMoeBlock):
- def __init__(self, config):
- self.moe_info = None
- super().__init__(config)
-
- def setup_ep(self, ep_group: ProcessGroup):
- ep_group = ep_group
- self.ep_size = dist.get_world_size(ep_group) if ep_group is not None else 1
- self.ep_rank = dist.get_rank(ep_group) if ep_group is not None else 0
- assert self.num_experts % self.ep_size == 0
+ def __init__(self, *args, **kwargs):
+ raise RuntimeError(f"Please use `from_native_module` to create an instance of {self.__class__.__name__}")
+
+ def setup_process_groups(self, tp_group: ProcessGroup, moe_dp_group: ProcessGroup, ep_group: ProcessGroup):
+ assert tp_group is not None
+ assert moe_dp_group is not None
+ assert ep_group is not None
+
+ # setup ep group
+ self.ep_size = dist.get_world_size(ep_group)
+ self.ep_rank = dist.get_rank(ep_group)
self.ep_group = ep_group
+
+ if self.num_experts % self.ep_size != 0:
+ raise ValueError("The number of experts must be divisible by the number of expert parallel groups.")
+
self.num_experts_per_ep = self.num_experts // self.ep_size
self.expert_start_idx = self.ep_rank * self.num_experts_per_ep
held_experts = self.experts[self.expert_start_idx : self.expert_start_idx + self.num_experts_per_ep]
+
set_tensors_to_none(self.experts, exclude=set(held_experts))
+
+ # setup moe_dp group
+ self.moe_dp_group = moe_dp_group
+ self.moe_dp_size = moe_dp_group.size()
+
+ # setup global tp group
+ self.tp_group = tp_group
+ if self.tp_group.size() > 1:
+ for expert in held_experts:
+ expert.w1 = Linear1D_Col.from_native_module(expert.w1, self.tp_group)
+ expert.w3 = Linear1D_Col.from_native_module(expert.w3, self.tp_group)
+ expert.w2 = Linear1D_Row.from_native_module(expert.w2, self.tp_group)
+
for p in self.experts.parameters():
- p.ep_group = ep_group
+ set_moe_tensor_ep_group(p, ep_group)
@staticmethod
- def from_native_module(module: MixtralSparseMoeBlock, *args, **kwargs) -> "EPMixtralSparseMoeBlock":
+ def from_native_module(
+ module: MixtralSparseMoeBlock,
+ tp_group: ProcessGroup,
+ moe_dp_group: ProcessGroup,
+ ep_group: ProcessGroup,
+ *args,
+ **kwargs,
+ ) -> "EPMixtralSparseMoeBlock":
+ # TODO: better init
LazyInitContext.materialize(module)
module.__class__ = EPMixtralSparseMoeBlock
- # if "ep_group" in kwargs:
- assert "ep_group" in kwargs, "You should pass ep_group in SubModuleReplacementDescription via shard_config!!"
- module.setup_ep(kwargs["ep_group"])
+ module.setup_process_groups(tp_group, moe_dp_group, ep_group)
return module
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
@@ -65,20 +118,31 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
selected_experts_idx = selected_experts.argsort()
dispatch_states = hidden_states.repeat(self.top_k, 1)[selected_experts_idx]
input_split_sizes = selected_experts.bincount(minlength=self.num_experts)
+
output_split_sizes = torch.zeros_like(input_split_sizes)
dist.all_to_all_single(output_split_sizes, input_split_sizes, group=self.ep_group)
+ with torch.no_grad():
+ activate_experts = output_split_sizes[: self.num_experts_per_ep].clone()
+ for i in range(1, self.ep_size):
+ activate_experts += output_split_sizes[i * self.num_experts_per_ep : (i + 1) * self.num_experts_per_ep]
+ activate_experts = (activate_experts > 0).float()
+ dist.all_reduce(activate_experts, group=self.moe_dp_group)
+
input_split_list = input_split_sizes.view(self.ep_size, self.num_experts_per_ep).sum(dim=-1).tolist()
output_split_list = output_split_sizes.view(self.ep_size, self.num_experts_per_ep).sum(dim=-1).tolist()
+
output_states, _ = all_to_all_uneven(dispatch_states, input_split_list, output_split_list, self.ep_group)
# compute expert output
- output_states = MoeInGradScaler.apply(output_states, self.ep_size)
+ output_states = EPGradScalerIn.apply(output_states, self.ep_size)
if output_states.size(0) > 0:
if self.num_experts_per_ep == 1:
# no need to split
expert = self.experts[self.expert_start_idx]
+ output_states = DPGradScalerIn.apply(output_states, self.moe_dp_size, activate_experts[0])
output_states = expert.act_fn(expert.w1(output_states)) * expert.w3(output_states)
output_states = expert.w2(output_states)
+ output_states = DPGradScalerOut.apply(output_states, self.moe_dp_size, activate_experts[0])
else:
output_states_splits = output_states.split(output_split_sizes.tolist())
output_states_list = []
@@ -86,12 +150,20 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
if split_states.size(0) == 0:
continue
expert = self.experts[self.expert_start_idx + i % self.num_experts_per_ep]
+ split_states = DPGradScalerIn.apply(
+ split_states, self.moe_dp_size, activate_experts[i % self.num_experts_per_ep]
+ )
split_states = expert.act_fn(expert.w1(split_states)) * expert.w3(split_states)
split_states = expert.w2(split_states)
+ split_states = DPGradScalerOut.apply(
+ split_states, self.moe_dp_size, activate_experts[i % self.num_experts_per_ep]
+ )
output_states_list.append(split_states)
output_states = torch.cat(output_states_list)
- output_states = MoeOutGradScaler.apply(output_states, self.ep_size)
+
+ output_states = EPGradScalerOut.apply(output_states, self.ep_size)
dispatch_states, _ = all_to_all_uneven(output_states, output_split_list, input_split_list, self.ep_group)
+
recover_experts_idx = torch.empty_like(selected_experts_idx)
recover_experts_idx[selected_experts_idx] = torch.arange(
selected_experts_idx.size(0), device=selected_experts_idx.device
@@ -107,7 +179,7 @@ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
class MixtralPipelineForwards:
"""
- This class serves as a micro library for forward function substitution of Llama models
+ This class serves as a micro library for forward function substitution of Mixtral models
under pipeline setting.
"""
@@ -300,16 +372,29 @@ def custom_forward(*inputs):
if output_router_logits and past_router_logits is not None:
all_router_logits = past_router_logits + all_router_logits
if stage_manager.is_last_stage():
- return tuple(
- v
- for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_router_logits]
- if v is not None
+ if not return_dict:
+ return tuple(
+ v
+ for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_router_logits]
+ if v is not None
+ )
+ return MoeModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ router_logits=all_router_logits,
)
- # always return dict for imediate stage
- return {
- "hidden_states": hidden_states,
- "past_router_logits": all_router_logits,
- }
+ else:
+ if output_router_logits:
+ return {
+ "hidden_states": hidden_states,
+ "past_router_logits": all_router_logits,
+ }
+ else:
+ return {
+ "hidden_states": hidden_states,
+ }
@staticmethod
def mixtral_for_causal_lm_forward(
@@ -441,3 +526,335 @@ def mixtral_for_causal_lm_forward(
if output_router_logits:
out["past_router_logits"] = outputs["past_router_logits"]
return out
+
+
+def get_mixtral_flash_attention_forward(shard_config, sp_mode=None, sp_size=None, sp_group=None):
+ logger = logging.get_logger(__name__)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Cache]]:
+ if sp_mode is not None:
+ assert sp_mode in ["all_to_all", "split_gather", "ring"], "Invalid sp_mode"
+ assert (sp_size is not None) and (
+ sp_group is not None
+ ), "Must specify sp_size and sp_group for sequence parallel"
+
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
+ )
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop("padding_mask")
+ bsz, q_len, _ = hidden_states.size()
+
+ # sp: modify sp_len when sequence parallel mode is ring
+ if sp_mode in ["split_gather", "ring"]:
+ q_len *= sp_size
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ # sp: all-to-all comminucation when introducing sequence parallel
+ if sp_mode == "all_to_all":
+ query_states = all_to_all_comm(query_states, sp_group)
+ key_states = all_to_all_comm(key_states, sp_group)
+ value_states = all_to_all_comm(value_states, sp_group)
+ bsz, q_len, _ = query_states.size()
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
+ "for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
+ "with a layer index."
+ )
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+
+ # Because the input can be padded, the absolute sequence length depends on the max position id.
+ rotary_seq_len = max(kv_seq_len, position_ids[:, -1].max().item()) + 1
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, "sliding_window", None) is not None
+ and kv_seq_len > self.config.sliding_window
+ )
+ if not _flash_supports_window_size:
+ logger.warning_once(
+ "The current flash attention version does not support sliding window attention, for a more memory efficient implementation"
+ " make sure to upgrade flash-attn library."
+ )
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (
+ getattr(self.config, "sliding_window", None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents
+ ):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ f"past key must have a shape of (`batch_size, num_heads, self.config.sliding_window-1, head_dim`), got"
+ f" {past_key.shape}"
+ )
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat([attention_mask, torch.ones_like(attention_mask[:, -1:])], dim=-1)
+
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ q_len,
+ dropout=dropout_rate,
+ use_sliding_windows=use_sliding_windows,
+ )
+
+ # sp: all-to-all comminucation when introducing sequence parallel
+ if sp_mode == "all_to_all":
+ attn_output = attn_output.reshape(bsz, q_len, self.num_heads * self.head_dim).contiguous() # (1, 8, 128)
+ attn_output = all_to_all_comm(attn_output, sp_group, scatter_dim=1, gather_dim=2) # (1, 4, 256)
+ else:
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+ return attn_output, attn_weights, past_key_value
+
+ return forward
+
+
+def get_mixtral_flash_attention_model_forward(shard_config, sp_mode=None, sp_size=None, sp_group=None):
+ logger = logging.get_logger(__name__)
+
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_router_logits: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, MoeModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_router_logits = (
+ output_router_logits if output_router_logits is not None else self.config.output_router_logits
+ )
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+
+ past_key_values_length = 0
+
+ if (self.gradient_checkpointing or sp_mode in ["ring", "all_to_all"]) and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+ if use_cache:
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+ past_key_values_length = past_key_values.get_usable_length(seq_length)
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if attention_mask is not None and self._attn_implementation == "flash_attention_2" and use_cache:
+ is_padding_right = attention_mask[:, -1].sum().item() != batch_size
+ if is_padding_right:
+ raise ValueError(
+ "You are attempting to perform batched generation with padding_side='right'"
+ " this may lead to unexpected behaviour for Flash Attention version of Mixtral. Make sure to "
+ " call `tokenizer.padding_side = 'left'` before tokenizing the input. "
+ )
+ if self._attn_implementation == "flash_attention_2":
+ # 2d mask is passed through the layers
+ attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
+ elif self._attn_implementation == "sdpa" and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ )
+ else:
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ sliding_window=self.config.sliding_window,
+ )
+
+ if sp_mode in ["ring", "split_gather"]:
+ inputs_embeds = split_forward_gather_backward(inputs_embeds, 1, sp_group)
+ elif sp_mode == "all_to_all":
+ inputs_embeds = split_forward_gather_backward(inputs_embeds, 1, sp_group, 1 / sp_size)
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ all_router_logits = () if output_router_logits else None
+ next_decoder_cache = None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ output_router_logits,
+ use_cache,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ output_router_logits=output_router_logits,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ if output_router_logits:
+ all_router_logits += (layer_outputs[-1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ if sp_mode == "ring" or sp_mode == "split_gather":
+ hidden_states = gather_forward_split_backward(hidden_states, 1, sp_group)
+ elif sp_mode == "all_to_all":
+ hidden_states = gather_forward_split_backward(hidden_states, 1, sp_group, grad_scale=sp_size)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = None
+ if use_cache:
+ next_cache = next_decoder_cache.to_legacy_cache() if use_legacy_cache else next_decoder_cache
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_router_logits]
+ if v is not None
+ )
+ return MoeModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ router_logits=all_router_logits,
+ )
+
+ return forward
diff --git a/colossalai/shardformer/modeling/qwen2.py b/colossalai/shardformer/modeling/qwen2.py
index 55822b1505f1..538e96c32c6d 100644
--- a/colossalai/shardformer/modeling/qwen2.py
+++ b/colossalai/shardformer/modeling/qwen2.py
@@ -136,7 +136,7 @@ def qwen2_model_forward(
# for the other stages, hidden_states is the output of the previous stage
if shard_config.enable_flash_attention:
# in this case, attention_mask is a dict rather than a tensor
- mask_shape = (batch_size, 1, seq_length_with_past, seq_length_with_past)
+ mask_shape = (batch_size, 1, seq_length, seq_length_with_past)
attention_mask = ColoAttention.prepare_attn_kwargs(
mask_shape,
hidden_states.dtype,
@@ -651,6 +651,10 @@ def forward(
seq_length_with_past = seq_length
past_key_values_length = 0
+ if past_key_values is not None:
+ past_key_values_length = past_key_values[0][0].shape[2]
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+
if position_ids is None:
device = input_ids.device if input_ids is not None else inputs_embeds.device
position_ids = torch.arange(
@@ -668,7 +672,7 @@ def forward(
if shard_config.enable_flash_attention:
# in this case, attention_mask is a dict rather than a tensor
- mask_shape = (batch_size, 1, seq_length_with_past, seq_length_with_past)
+ mask_shape = (batch_size, 1, seq_length, seq_length_with_past)
attention_mask = ColoAttention.prepare_attn_kwargs(
mask_shape,
hidden_states.dtype,
diff --git a/colossalai/shardformer/policies/auto_policy.py b/colossalai/shardformer/policies/auto_policy.py
index ae9f3603c96e..7b9c759a66c2 100644
--- a/colossalai/shardformer/policies/auto_policy.py
+++ b/colossalai/shardformer/policies/auto_policy.py
@@ -161,7 +161,7 @@ class PolicyLocation:
file_name="chatglm2", class_name="ChatGLMForConditionalGenerationPolicy"
),
# Deepseek
- "transformers_modules.modeling_deepseek.DeepSeekModel": PolicyLocation(
+ "transformers_modules.modeling_deepseek.DeepseekModel": PolicyLocation(
file_name="deepseek", class_name="DeepseekModelPolicy"
),
"transformers_modules.modeling_deepseek.DeepseekForCausalLM": PolicyLocation(
@@ -200,6 +200,9 @@ class PolicyLocation:
"transformers.models.mixtral.modeling_mixtral.MixtralForCausalLM": PolicyLocation(
file_name="mixtral", class_name="MixtralForCausalLMPolicy"
),
+ "transformers.models.mixtral.modeling_mixtral.MixtralForSequenceClassification": PolicyLocation(
+ file_name="mixtral", class_name="MixtralForSequenceClassificationPolicy"
+ ),
# Qwen2
"transformers.models.qwen2.modeling_qwen2.Qwen2Model": PolicyLocation(
file_name="qwen2", class_name="Qwen2ModelPolicy"
@@ -240,6 +243,9 @@ def _fullname(obj):
# patch custom models which are not in transformers
# it can be like 'transformers_modules.THUDM.chatglm3-6b.103caa40027ebfd8450289ca2f278eac4ff26405.modeling_chatglm' (from huggingface hub)
# or like 'transformers_modules.chatglm.modeling_chatglm' (from local directory)
+ if module.startswith("peft"):
+ klass = obj.base_model.model.__class__
+ module = klass.__module__
if module.startswith("transformers_modules"):
split_module = module.split(".")
if len(split_module) >= 2:
diff --git a/colossalai/shardformer/policies/deepseek.py b/colossalai/shardformer/policies/deepseek.py
index 8ebda357b380..605f69c4a632 100644
--- a/colossalai/shardformer/policies/deepseek.py
+++ b/colossalai/shardformer/policies/deepseek.py
@@ -1,13 +1,20 @@
-import warnings
from functools import partial
from typing import Callable, Dict, List, Union
import torch.nn as nn
from torch import Tensor
from torch.nn import Module
+from transformers.utils import is_flash_attn_greater_or_equal_2_10
from colossalai.shardformer.layer import FusedRMSNorm, Linear1D_Col
-from colossalai.shardformer.modeling.deepseek import DeepseekPipelineForwards, EPDeepseekMoE
+from colossalai.shardformer.layer.embedding import PaddingEmbedding, VocabParallelEmbedding1D
+from colossalai.shardformer.layer.linear import Linear1D_Row
+from colossalai.shardformer.modeling.deepseek import (
+ DeepseekPipelineForwards,
+ EPDeepseekMoE,
+ get_deepseek_flash_attention_forward,
+ get_deepseek_flash_attention_model_forward,
+)
from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ["DeepseekPolicy", "DeepseekForCausalLMPolicy"]
@@ -18,6 +25,13 @@ def config_sanity_check(self):
pass
def preprocess(self):
+ self.tie_weight = self.tie_weight_check()
+ self.origin_attn_implement = self.model.config._attn_implementation
+ """
+ Because transformers library's bug for AutoModel/AutoConfig, who pop “attn_implement” twice from modeling_utils.py and configuration_utils.py.
+ This bug causes attn_cls to be set to sdpa. Here we assign it to "flash_attention_2".
+ """
+ # self.origin_attn_implement = "flash_attention_2"
if self.shard_config.enable_tensor_parallelism:
# Resize embedding
vocab_size = self.model.config.vocab_size
@@ -30,25 +44,118 @@ def preprocess(self):
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
+
+ ATTN_IMPLEMENTATION = {
+ "eager": "DeepseekAttention",
+ "flash_attention_2": "DeepseekFlashAttention2",
+ "sdpa": "DeepseekSdpaAttention",
+ }
policy = {}
+ attn_cls = ATTN_IMPLEMENTATION[self.origin_attn_implement]
+ sp_mode = self.shard_config.sequence_parallelism_mode or None
+ sp_size = self.shard_config.sequence_parallel_size or None
+ sp_group = self.shard_config.sequence_parallel_process_group or None
+ sp_partial_derived = sp_mode in ["split_gather", "ring"]
+ if sp_mode == "all_to_all":
+ decoder_attribute_replacement = {
+ "num_heads": self.model.config.num_attention_heads // sp_size,
+ }
+ if getattr(self.model.config, "num_key_value_heads", False):
+ decoder_attribute_replacement["num_key_value_heads"] = self.model.config.num_key_value_heads // sp_size
+ policy[attn_cls] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ )
if self.shard_config.enable_sequence_parallelism:
- self.shard_config.enable_sequence_parallelism = False
- raise NotImplementedError(
- "Deepseek dosen't support sequence parallelism now, will ignore the sequence parallelism flag."
+ if self.pipeline_stage_manager is not None:
+ # NOTE: we are replacing model forward for both sequence parallelism and pipeline parallelism
+ # if both are enabled, one of them will be ignored
+ raise NotImplementedError("Sequence parallelism is not supported with pipeline parallelism.")
+ self.append_or_create_method_replacement(
+ description={
+ "forward": get_deepseek_flash_attention_forward(self.shard_config, sp_mode, sp_size, sp_group),
+ },
+ policy=policy,
+ target_key=attn_cls,
)
-
+ if self.pipeline_stage_manager is None:
+ self.append_or_create_method_replacement(
+ description={
+ "forward": get_deepseek_flash_attention_model_forward(
+ self.shard_config,
+ sp_mode=sp_mode,
+ sp_size=sp_size,
+ sp_group=sp_group,
+ ),
+ },
+ policy=policy,
+ target_key="DeepseekModel",
+ )
+ embedding_cls = None
+ if self.shard_config.enable_tensor_parallelism:
+ embedding_cls = VocabParallelEmbedding1D
+ else:
+ if self.tie_weight:
+ embedding_cls = PaddingEmbedding
if self.shard_config.enable_tensor_parallelism:
- raise NotImplementedError("Tensor parallelism is not supported for Deepseek model now.")
+ # tensor parallelism for non-moe params
+ assert (
+ self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
+ assert (
+ self.model.config.num_key_value_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of key_value heads must be divisible by tensor parallel size."
+ decoder_attribute_replacement = {
+ "self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "self_attn.num_key_value_heads": self.model.config.num_key_value_heads
+ // self.shard_config.tensor_parallel_size,
+ }
+
+ policy["DeepseekDecoderLayer"] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=Linear1D_Row,
+ ),
+ ],
+ )
+ if embedding_cls is not None:
+ self.append_or_create_submodule_replacement(
+ description=SubModuleReplacementDescription(
+ suffix="embed_tokens",
+ target_module=embedding_cls,
+ kwargs={"make_vocab_size_divisible_by": self.shard_config.make_vocab_size_divisible_by},
+ ),
+ policy=policy,
+ target_key="DeepseekModel",
+ )
- if getattr(self.shard_config, "ep_group", None) is not None:
+ if self.shard_config.ep_group:
# expert parallel
self.append_or_create_submodule_replacement(
description=[
SubModuleReplacementDescription(
suffix="mlp",
target_module=EPDeepseekMoE,
- kwargs={"ep_group": self.shard_config.ep_group},
+ kwargs={
+ "ep_group": self.shard_config.ep_group,
+ "tp_group": self.shard_config.tensor_parallel_process_group,
+ "moe_dp_group": self.shard_config.moe_dp_group,
+ },
)
],
policy=policy,
@@ -62,10 +169,12 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
SubModuleReplacementDescription(
suffix="input_layernorm",
target_module=FusedRMSNorm,
+ kwargs={"sp_partial_derived": sp_partial_derived},
),
SubModuleReplacementDescription(
suffix="post_attention_layernorm",
target_module=FusedRMSNorm,
+ kwargs={"sp_partial_derived": sp_partial_derived},
),
],
policy=policy,
@@ -76,17 +185,39 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
description=SubModuleReplacementDescription(
suffix="norm",
target_module=FusedRMSNorm,
+ kwargs={"sp_partial_derived": sp_partial_derived},
),
policy=policy,
target_key="DeepseekModel",
)
if self.shard_config.enable_flash_attention:
- warnings.warn(
- "Flash attention has already been replaced in deepseek, and now set enable_flash_attention = False."
+ # NOTE: there is a bug for toggling flash attention in AutoModel, which has to be used for deepseek right now
+ from transformers.dynamic_module_utils import get_class_from_dynamic_module
+
+ flash_attn_cls = get_class_from_dynamic_module(
+ "deepseek-ai/deepseek-moe-16b-base--modeling_deepseek.DeepseekFlashAttention2",
+ "deepseek-ai/deepseek-moe-16b-base",
)
- self.shard_config.enable_flash_attention = False
+ class TargetFlashAttn:
+ def __init__(self):
+ raise RuntimeError("This class should not be instantiated")
+
+ @staticmethod
+ def from_native_module(original_attn: nn.Module, *args, **kwargs) -> nn.Module:
+ original_attn.__class__ = flash_attn_cls
+ original_attn._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
+ return original_attn
+
+ self.append_or_create_submodule_replacement(
+ description=SubModuleReplacementDescription(
+ suffix="self_attn",
+ target_module=TargetFlashAttn,
+ ),
+ policy=policy,
+ target_key="DeepseekDecoderLayer",
+ )
return policy
def postprocess(self):
@@ -96,6 +227,10 @@ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, poli
"""If under pipeline parallel setting, replacing the original forward method of huggingface
to customized forward method, and add this changing to policy."""
if self.pipeline_stage_manager:
+ if self.shard_config.enable_sequence_parallelism:
+ # NOTE: we are replacing model forward for both sequence parallelism and pipeline parallelism
+ # if both are enabled, one of them will be ignored
+ raise NotImplementedError("Pipeline parallelism is not supported with sequence parallelism.")
stage_manager = self.pipeline_stage_manager
if self.model.__class__.__name__ == "DeepseekModel":
module = self.model
diff --git a/colossalai/shardformer/policies/mixtral.py b/colossalai/shardformer/policies/mixtral.py
index ad93e94694c8..10df143c99da 100644
--- a/colossalai/shardformer/policies/mixtral.py
+++ b/colossalai/shardformer/policies/mixtral.py
@@ -1,13 +1,21 @@
+import warnings
from functools import partial
from typing import Callable, Dict, List, Union
import torch.nn as nn
from torch import Tensor
from torch.nn import Module
-from transformers.models.mixtral.modeling_mixtral import MixtralDecoderLayer, MixtralForCausalLM, MixtralModel
+from transformers.models.mixtral.modeling_mixtral import MixtralForCausalLM, MixtralModel
from colossalai.shardformer.layer import FusedRMSNorm, Linear1D_Col
-from colossalai.shardformer.modeling.mixtral import EPMixtralSparseMoeBlock, MixtralPipelineForwards
+from colossalai.shardformer.layer.embedding import PaddingEmbedding, VocabParallelEmbedding1D
+from colossalai.shardformer.layer.linear import Linear1D_Row
+from colossalai.shardformer.modeling.mixtral import (
+ EPMixtralSparseMoeBlock,
+ MixtralPipelineForwards,
+ get_mixtral_flash_attention_forward,
+ get_mixtral_flash_attention_model_forward,
+)
from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ["MixtralPolicy", "MixtralForCausalLMPolicy"]
@@ -18,36 +26,136 @@ def config_sanity_check(self):
pass
def preprocess(self):
- if self.shard_config.enable_tensor_parallelism:
- # Resize embedding
- vocab_size = self.model.config.vocab_size
- world_size = self.shard_config.tensor_parallel_size
-
- if vocab_size % world_size != 0:
- new_vocab_size = vocab_size + world_size - vocab_size % world_size
- self.model.resize_token_embeddings(new_vocab_size)
-
+ self.tie_weight = self.tie_weight_check()
+ self.origin_attn_implement = self.model.config._attn_implementation
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
+ from transformers.models.mixtral.modeling_mixtral import (
+ MixtralAttention,
+ MixtralDecoderLayer,
+ MixtralFlashAttention2,
+ MixtralModel,
+ MixtralSdpaAttention,
+ )
+
+ ATTN_IMPLEMENTATION = {
+ "eager": MixtralAttention,
+ "flash_attention_2": MixtralFlashAttention2,
+ "sdpa": MixtralSdpaAttention,
+ }
policy = {}
+ attn_cls = ATTN_IMPLEMENTATION[self.origin_attn_implement]
+
+ sp_mode = self.shard_config.sequence_parallelism_mode or None
+ sp_size = self.shard_config.sequence_parallel_size or None
+ sp_group = self.shard_config.sequence_parallel_process_group or None
+ sp_partial_derived = sp_mode in ["split_gather", "ring"]
+ if sp_mode == "all_to_all":
+ decoder_attribute_replacement = {
+ "num_heads": self.model.config.num_attention_heads // sp_size,
+ }
+ if getattr(self.model.config, "num_key_value_heads", False):
+ decoder_attribute_replacement["num_key_value_heads"] = self.model.config.num_key_value_heads // sp_size
+ policy[attn_cls] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ )
if self.shard_config.enable_sequence_parallelism:
- self.shard_config.enable_sequence_parallelism = False
- raise NotImplementedError(
- "Mixtral dosen't support sequence parallelism now, will ignore the sequence parallelism flag."
+ if self.pipeline_stage_manager is not None:
+ # NOTE: we are replacing model forward for both sequence parallelism and pipeline parallelism
+ # if both are enabled, one of them will be ignored
+ raise NotImplementedError("Sequence parallelism is not supported with pipeline parallelism.")
+ self.append_or_create_method_replacement(
+ description={
+ "forward": get_mixtral_flash_attention_forward(self.shard_config, sp_mode, sp_size, sp_group),
+ },
+ policy=policy,
+ target_key=attn_cls,
+ )
+ self.append_or_create_method_replacement(
+ description={
+ "forward": get_mixtral_flash_attention_model_forward(
+ self.shard_config,
+ sp_mode=sp_mode,
+ sp_size=sp_size,
+ sp_group=sp_group,
+ ),
+ },
+ policy=policy,
+ target_key=MixtralModel,
)
+ embedding_cls = None
if self.shard_config.enable_tensor_parallelism:
- raise NotImplementedError("Tensor parallelism is not supported for Mixtral model now.")
- if getattr(self.shard_config, "ep_group", None) is not None:
+ embedding_cls = VocabParallelEmbedding1D
+ else:
+ if self.tie_weight:
+ embedding_cls = PaddingEmbedding
+
+ if self.shard_config.enable_tensor_parallelism:
+ # tensor parallelism for non-moe params
+ assert (
+ self.model.config.num_attention_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of attention heads must be divisible by tensor parallel size."
+ assert (
+ self.model.config.num_key_value_heads % self.shard_config.tensor_parallel_size == 0
+ ), f"The number of key_value heads must be divisible by tensor parallel size."
+ decoder_attribute_replacement = {
+ "self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "self_attn.num_key_value_heads": self.model.config.num_key_value_heads
+ // self.shard_config.tensor_parallel_size,
+ }
+
+ policy[MixtralDecoderLayer] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=Linear1D_Col,
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=Linear1D_Row,
+ ),
+ SubModuleReplacementDescription( # or replicate?
+ suffix="block_sparse_moe.gate", target_module=Linear1D_Col, kwargs={"gather_output": True}
+ ),
+ ],
+ )
+
+ if embedding_cls is not None:
+ self.append_or_create_submodule_replacement(
+ description=SubModuleReplacementDescription(
+ suffix="embed_tokens",
+ target_module=embedding_cls,
+ kwargs={"make_vocab_size_divisible_by": self.shard_config.make_vocab_size_divisible_by},
+ ),
+ policy=policy,
+ target_key=MixtralModel,
+ )
+
+ if self.shard_config.ep_group:
# expert parallel
self.append_or_create_submodule_replacement(
description=[
SubModuleReplacementDescription(
suffix="block_sparse_moe",
target_module=EPMixtralSparseMoeBlock,
- kwargs={"ep_group": self.shard_config.ep_group},
+ kwargs={
+ "ep_group": self.shard_config.ep_group,
+ "tp_group": self.shard_config.tensor_parallel_process_group,
+ "moe_dp_group": self.shard_config.moe_dp_group,
+ },
)
],
policy=policy,
@@ -61,10 +169,12 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
SubModuleReplacementDescription(
suffix="input_layernorm",
target_module=FusedRMSNorm,
+ kwargs={"sp_partial_derived": sp_partial_derived},
),
SubModuleReplacementDescription(
suffix="post_attention_layernorm",
target_module=FusedRMSNorm,
+ kwargs={"sp_partial_derived": sp_partial_derived},
),
],
policy=policy,
@@ -75,13 +185,15 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
description=SubModuleReplacementDescription(
suffix="norm",
target_module=FusedRMSNorm,
+ kwargs={"sp_partial_derived": sp_partial_derived},
),
policy=policy,
target_key=MixtralModel,
)
if self.shard_config.enable_flash_attention:
- raise NotImplementedError("Flash attention has already been replaced in mixtral.")
+ warnings.warn("Flash attention is natively supported in transformers, will ignore the flag.")
+ self.shard_config.enable_flash_attention = False
return policy
@@ -92,6 +204,10 @@ def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, poli
"""If under pipeline parallel setting, replacing the original forward method of huggingface
to customized forward method, and add this changing to policy."""
if self.pipeline_stage_manager:
+ if self.shard_config.enable_sequence_parallelism:
+ # NOTE: we are replacing model forward for both sequence parallelism and pipeline parallelism
+ # if both are enabled, one of them will be ignored
+ raise NotImplementedError("Pipeline parallelism is not supported with sequence parallelism.")
stage_manager = self.pipeline_stage_manager
if self.model.__class__.__name__ == "MixtralModel":
module = self.model
@@ -150,7 +266,7 @@ def get_held_layers(self) -> List[Module]:
return held_layers
def get_shared_params(self) -> List[Dict[int, Tensor]]:
- """No shared params in llama model"""
+ """No shared params in mixtral model"""
return []
@@ -206,3 +322,40 @@ def get_shared_params(self) -> List[Dict[int, Tensor]]:
}
]
return []
+
+
+class MixtralForSequenceClassificationPolicy(MixtralPolicy):
+ def module_policy(self):
+ from transformers import MixtralForSequenceClassification
+
+ policy = super().module_policy()
+
+ if self.shard_config.enable_tensor_parallelism:
+ # add a new item for sequence classification
+ new_item = {
+ MixtralForSequenceClassification: ModulePolicyDescription(
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="score", target_module=Linear1D_Col, kwargs=dict(gather_output=True)
+ )
+ ]
+ )
+ }
+ policy.update(new_item)
+
+ if self.pipeline_stage_manager:
+ raise NotImplementedError
+
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ stage_manager = self.pipeline_stage_manager
+ held_layers = super().get_held_layers()
+ if stage_manager.is_last_stage(ignore_chunk=True):
+ held_layers.append(self.model.score)
+ return held_layers
+
+ def get_shared_params(self) -> List[Dict[int, Tensor]]:
+ """No shared params in mixtral for sequence classification model"""
+ return []
diff --git a/colossalai/shardformer/shard/shard_config.py b/colossalai/shardformer/shard/shard_config.py
index b64300366fc3..163d7a7bbb0c 100644
--- a/colossalai/shardformer/shard/shard_config.py
+++ b/colossalai/shardformer/shard/shard_config.py
@@ -46,7 +46,11 @@ class ShardConfig:
make_vocab_size_divisible_by: int = 64
gradient_checkpoint_config: Optional[GradientCheckpointConfig] = None
extra_kwargs: Dict[str, Any] = field(default_factory=dict)
+
+ # for moe related
+ moe_dp_group: Optional[ProcessGroup] = None
ep_group: Optional[ProcessGroup] = None
+
# pipeline_parallel_size: int
# data_parallel_size: int
# tensor_parallel_mode: Literal['1d', '2d', '2.5d', '3d']
diff --git a/colossalai/zero/low_level/bookkeeping/gradient_store.py b/colossalai/zero/low_level/bookkeeping/gradient_store.py
index e24a67f9de3c..8b6d403f1327 100644
--- a/colossalai/zero/low_level/bookkeeping/gradient_store.py
+++ b/colossalai/zero/low_level/bookkeeping/gradient_store.py
@@ -19,7 +19,6 @@ def __init__(self, *args, partition_grad: bool = False):
"""
self._grads_of_params = dict()
# stage 2
- self._partition_grads = partition_grad
self._working_index = 0 if partition_grad else self._local_rank
# for zero2, it's `param_id: [grad_local_rank]`
self.grad_to_param_mapping = dict()
@@ -91,7 +90,7 @@ def get_working_grads_by_group_id(self, group_id: int) -> List:
return grad_list
- def get_working_grad_by_param_id(self, param_id) -> Tensor:
+ def get_working_grad_by_param_id(self, param_id) -> Optional[Tensor]:
"""
Return the working gradient for the specified parameter.
@@ -112,6 +111,7 @@ def reset_grads_by_group_id(self, group_id: int):
def reset_all_gradients(self):
self._grads_of_params = dict()
+ self.grad_to_param_mapping = dict()
def get_param_id_for_grad(self, grad: Tensor) -> Optional[int]:
"""Return the id of a parameter which the gradient slice belongs to
diff --git a/colossalai/zero/low_level/low_level_optim.py b/colossalai/zero/low_level/low_level_optim.py
index 6ff235b96a5d..51d7d1eaaa33 100644
--- a/colossalai/zero/low_level/low_level_optim.py
+++ b/colossalai/zero/low_level/low_level_optim.py
@@ -20,6 +20,7 @@
)
from colossalai.interface import OptimizerWrapper
from colossalai.logging import get_dist_logger
+from colossalai.tensor.moe_tensor.api import is_moe_tensor
from ._utils import calculate_global_norm_from_list, has_inf_or_nan, release_param_grad, sync_tensor
from .bookkeeping import BucketStore, GradientStore, TensorBucket
@@ -66,7 +67,7 @@ class LowLevelZeroOptimizer(OptimizerWrapper):
def __init__(
self,
optimizer: Optimizer,
- pg_to_param_list: Dict[ProcessGroup, List[nn.Parameter]] = None,
+ pg_to_param_list: Optional[Dict[ProcessGroup, List[nn.Parameter]]] = None,
initial_scale: int = 2**16, # grad scaler config
min_scale: int = 1,
growth_factor: float = 2.0,
@@ -92,7 +93,7 @@ def __init__(
self._logger = get_dist_logger()
self._verbose = verbose
- if dp_process_group is not None and pg_to_param_list is not None:
+ if (dp_process_group is not None) and (pg_to_param_list is not None):
raise ValueError("dp_process_group and pg_to_param_list should not be provided at the same time.")
if pg_to_param_list is None:
@@ -338,14 +339,14 @@ def _run_reduction(self):
self._update_unpartitoned_grad(bucket_store, grad_in_bucket.values(), flat_grads_per_rank, group_id)
else:
flat_grads_list = list(flat_grads.split(len(flat_grads) // bucket_store.world_size))
- recieved_grad = torch.zeros_like(flat_grads_list[0])
- dist.reduce_scatter(recieved_grad, flat_grads_list, group=bucket_store.torch_pg)
+ received_grad = torch.zeros_like(flat_grads_list[0])
+ dist.reduce_scatter(received_grad, flat_grads_list, group=bucket_store.torch_pg)
- if recieved_grad.dtype != grad_dtype:
- recieved_grad = recieved_grad.to(grad_dtype)
+ if received_grad.dtype != grad_dtype:
+ received_grad = received_grad.to(grad_dtype)
grad_in_bucket_current_rank = bucket_store.get_grad()[bucket_store.local_rank]
- self._update_partitoned_grad(bucket_store, grad_in_bucket_current_rank, recieved_grad, group_id, 1)
+ self._update_partitoned_grad(bucket_store, grad_in_bucket_current_rank, received_grad, group_id, 1)
bucket_store.reset()
@@ -649,6 +650,11 @@ def _sync_grad(self):
for group_id in range(self.num_param_groups):
param_group = self._working_param_groups[group_id]
for param in param_group:
+ if is_moe_tensor(param) and param.requires_grad and param.grad is None:
+ # TODO better of of doing this
+ # assign zero grad to unrouted expert to avoid hang during grad reduction
+ param.grad = torch.zeros_like(param)
+
if param.requires_grad and param.grad is not None:
self._add_to_bucket(param, group_id)
@@ -807,8 +813,8 @@ def update_master_params(self, model: nn.Module) -> None:
"""
for p in model.parameters():
p_id = id(p)
- pg = self.param_to_pg[p]
if p_id in self.working_to_master_param:
+ pg = self.param_to_pg[p]
master_param = self.working_to_master_param[p_id]
padding_size = self.get_param_padding_size(p)
working_param = p.data.view(-1)
@@ -869,13 +875,12 @@ def get_padding_map(self) -> Dict[int, Tensor]:
def get_param_grad(self, working_param: nn.Parameter) -> Tensor:
grad_store = self.pid_to_grad_store[id(working_param)]
- partial_grad = grad_store.get_working_grad_by_param_id(id(working_param))
- if partial_grad is None:
+ grad = grad_store.get_working_grad_by_param_id(id(working_param))
+ if grad is None:
return None
- tensor_list = [torch.empty_like(partial_grad) for _ in range(grad_store.world_size)]
- dist.all_gather(tensor_list, partial_grad, group=grad_store.torch_pg)
- grad_flat = torch.cat(tensor_list, dim=0)
- return grad_flat[: working_param.numel()].reshape_as(working_param)
+ grad_flat = torch.empty((grad_store.world_size, *grad.shape), dtype=grad.dtype, device=grad.device)
+ dist.all_gather_into_tensor(grad_flat, grad, group=grad_store.torch_pg)
+ return grad_flat.view(-1)[: working_param.numel()].view_as(working_param)
def get_working_grads_by_group_id(self, group_id: int) -> List[Tensor]:
working_grads = []
diff --git a/docs/source/en/basics/launch_colossalai.md b/docs/source/en/basics/launch_colossalai.md
index 8a6028d6c49a..32748dae1163 100644
--- a/docs/source/en/basics/launch_colossalai.md
+++ b/docs/source/en/basics/launch_colossalai.md
@@ -131,17 +131,18 @@ with one simple command. There are two ways you can launch multi-node jobs.
This is suitable when you only have a few nodes. Let's say I have two nodes, namely `host1` and `host2`, I can start
multi-node training with the following command. Compared to single-node training, you must specify the `master_addr`
-option, which is auto-set to localhost if running on a single node only.
+option, which is auto-set to localhost if running on a single node only. \
+Additionally, you must also ensure that all nodes share the same open ssh port, which can be specified using --ssh-port.
:::caution
-`master_addr` cannot be localhost when running on multiple nodes, it should be the hostname or IP address of a node.
+`master_addr` cannot be localhost when running on multiple nodes, it should be the **hostname or IP address** of a node.
:::
```shell
# run on these two nodes
-colossalai run --nproc_per_node 4 --host host1,host2 --master_addr host1 test.py
+colossalai run --nproc_per_node 4 --host host1,host2 --master_addr host1 test.py --ssh-port 22
```
- Run with `--hostfile`
diff --git a/docs/source/zh-Hans/basics/launch_colossalai.md b/docs/source/zh-Hans/basics/launch_colossalai.md
index a80d16717e40..9e40f64c2124 100644
--- a/docs/source/zh-Hans/basics/launch_colossalai.md
+++ b/docs/source/zh-Hans/basics/launch_colossalai.md
@@ -116,17 +116,17 @@ colossalai run --nproc_per_node 4 --master_port 29505 test.py
- 通过`--hosts`来启动
这个方式适合节点数不多的情况。假设我们有两个节点,分别为`host`和`host2`。我们可以用以下命令进行多节点训练。
-比起单节点训练,多节点训练需要手动设置`--master_addr` (在单节点训练中`master_addr`默认为`127.0.0.1`)。
+比起单节点训练,多节点训练需要手动设置`--master_addr` (在单节点训练中`master_addr`默认为`127.0.0.1`)。同时,你需要确保每个节点都使用同一个ssh port。可以通过--ssh-port设置。
:::caution
-多节点训练时,`master_addr`不能为`localhost`或者`127.0.0.1`,它应该是一个节点的名字或者IP地址。
+多节点训练时,`master_addr`不能为`localhost`或者`127.0.0.1`,它应该是一个节点的**名字或者IP地址**。
:::
```shell
# 在两个节点上训练
-colossalai run --nproc_per_node 4 --host host1,host2 --master_addr host1 test.py
+colossalai run --nproc_per_node 4 --host host1,host2 --master_addr host1 test.py --ssh-port 22
```
diff --git a/examples/inference/stable_diffusion/README.md b/examples/inference/stable_diffusion/README.md
new file mode 100644
index 000000000000..c11b9804392c
--- /dev/null
+++ b/examples/inference/stable_diffusion/README.md
@@ -0,0 +1,22 @@
+## File Structure
+```
+|- sd3_generation.py: an example of how to use Colossalai Inference Engine to generate result by loading Diffusion Model.
+|- compute_metric.py: compare the quality of images w/o some acceleration method like Distrifusion
+|- benchmark_sd3.py: benchmark the performance of our InferenceEngine
+|- run_benchmark.sh: run benchmark command
+```
+Note: compute_metric.py need some dependencies which need `pip install -r requirements.txt`, `requirements.txt` is in `examples/inference/stable_diffusion/`
+
+## Run Inference
+
+The provided example `sd3_generation.py` is an example to configure, initialize the engine, and run inference on provided model. We've added `DiffusionPipeline` as model class, and the script is good to run inference with StableDiffusion 3.
+
+For a basic setting, you could run the example by:
+```bash
+colossalai run --nproc_per_node 1 sd3_generation.py -m PATH_MODEL -p "hello world"
+```
+
+Run multi-GPU inference (Patched Parallelism), as in the following example using 2 GPUs:
+```bash
+colossalai run --nproc_per_node 2 sd3_generation.py -m PATH_MODEL
+```
diff --git a/examples/inference/stable_diffusion/benchmark_sd3.py b/examples/inference/stable_diffusion/benchmark_sd3.py
new file mode 100644
index 000000000000..19db57c33c82
--- /dev/null
+++ b/examples/inference/stable_diffusion/benchmark_sd3.py
@@ -0,0 +1,179 @@
+import argparse
+import json
+import time
+from contextlib import nullcontext
+
+import torch
+import torch.distributed as dist
+from diffusers import DiffusionPipeline
+
+import colossalai
+from colossalai.inference.config import DiffusionGenerationConfig, InferenceConfig
+from colossalai.inference.core.engine import InferenceEngine
+from colossalai.testing import clear_cache_before_run, rerun_if_address_is_in_use, spawn
+
+GIGABYTE = 1024**3
+MEGABYTE = 1024 * 1024
+
+_DTYPE_MAPPING = {
+ "fp16": torch.float16,
+ "bf16": torch.bfloat16,
+ "fp32": torch.float32,
+}
+
+
+def log_generation_time(log_data, log_file):
+ with open(log_file, "a") as f:
+ json.dump(log_data, f, indent=2)
+ f.write("\n")
+
+
+def warmup(engine, args):
+ for _ in range(args.n_warm_up_steps):
+ engine.generate(
+ prompts=["hello world"],
+ generation_config=DiffusionGenerationConfig(
+ num_inference_steps=args.num_inference_steps, height=args.height[0], width=args.width[0]
+ ),
+ )
+
+
+def profile_context(args):
+ return (
+ torch.profiler.profile(
+ record_shapes=True,
+ with_stack=True,
+ with_modules=True,
+ activities=[
+ torch.profiler.ProfilerActivity.CPU,
+ torch.profiler.ProfilerActivity.CUDA,
+ ],
+ )
+ if args.profile
+ else nullcontext()
+ )
+
+
+def log_and_profile(h, w, avg_time, log_msg, args, model_name, mode, prof=None):
+ log_data = {
+ "mode": mode,
+ "model": model_name,
+ "batch_size": args.batch_size,
+ "patched_parallel_size": args.patched_parallel_size,
+ "num_inference_steps": args.num_inference_steps,
+ "height": h,
+ "width": w,
+ "dtype": args.dtype,
+ "profile": args.profile,
+ "n_warm_up_steps": args.n_warm_up_steps,
+ "n_repeat_times": args.n_repeat_times,
+ "avg_generation_time": avg_time,
+ "log_message": log_msg,
+ }
+
+ if args.log:
+ log_file = f"examples/inference/stable_diffusion/benchmark_{model_name}_{mode}.json"
+ log_generation_time(log_data=log_data, log_file=log_file)
+
+ if args.profile:
+ file = f"examples/inference/stable_diffusion/benchmark_{model_name}_{mode}_prof.json"
+ prof.export_chrome_trace(file)
+
+
+def benchmark_colossalai(rank, world_size, port, args):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ from colossalai.cluster.dist_coordinator import DistCoordinator
+
+ coordinator = DistCoordinator()
+
+ inference_config = InferenceConfig(
+ dtype=args.dtype,
+ patched_parallelism_size=args.patched_parallel_size,
+ )
+ engine = InferenceEngine(args.model, inference_config=inference_config, verbose=False)
+
+ warmup(engine, args)
+
+ for h, w in zip(args.height, args.width):
+ with profile_context(args) as prof:
+ start = time.perf_counter()
+ for _ in range(args.n_repeat_times):
+ engine.generate(
+ prompts=["hello world"],
+ generation_config=DiffusionGenerationConfig(
+ num_inference_steps=args.num_inference_steps, height=h, width=w
+ ),
+ )
+ end = time.perf_counter()
+
+ avg_time = (end - start) / args.n_repeat_times
+ log_msg = f"[ColossalAI]avg generation time for h({h})xw({w}) is {avg_time:.2f}s"
+ coordinator.print_on_master(log_msg)
+
+ if dist.get_rank() == 0:
+ log_and_profile(h, w, avg_time, log_msg, args, args.model.split("/")[-1], "colossalai", prof=prof)
+
+
+def benchmark_diffusers(args):
+ model = DiffusionPipeline.from_pretrained(args.model, torch_dtype=_DTYPE_MAPPING[args.dtype]).to("cuda")
+
+ for _ in range(args.n_warm_up_steps):
+ model(
+ prompt="hello world",
+ num_inference_steps=args.num_inference_steps,
+ height=args.height[0],
+ width=args.width[0],
+ )
+
+ for h, w in zip(args.height, args.width):
+ with profile_context(args) as prof:
+ start = time.perf_counter()
+ for _ in range(args.n_repeat_times):
+ model(prompt="hello world", num_inference_steps=args.num_inference_steps, height=h, width=w)
+ end = time.perf_counter()
+
+ avg_time = (end - start) / args.n_repeat_times
+ log_msg = f"[Diffusers]avg generation time for h({h})xw({w}) is {avg_time:.2f}s"
+ print(log_msg)
+
+ log_and_profile(h, w, avg_time, log_msg, args, args.model.split("/")[-1], "diffusers", prof)
+
+
+@rerun_if_address_is_in_use()
+@clear_cache_before_run()
+def benchmark(args):
+ if args.mode == "colossalai":
+ spawn(benchmark_colossalai, nprocs=args.patched_parallel_size, args=args)
+ elif args.mode == "diffusers":
+ benchmark_diffusers(args)
+
+
+"""
+# enable log
+python examples/inference/stable_diffusion/benchmark_sd3.py -m "PixArt-alpha/PixArt-XL-2-1024-MS" -p 2 --mode colossalai --log
+python examples/inference/stable_diffusion/benchmark_sd3.py -m "PixArt-alpha/PixArt-XL-2-1024-MS" --mode diffusers --log
+
+# enable profiler
+python examples/inference/stable_diffusion/benchmark_sd3.py -m "stabilityai/stable-diffusion-3-medium-diffusers" -p 2 --mode colossalai --n_warm_up_steps 3 --n_repeat_times 1 --profile --num_inference_steps 20
+python examples/inference/stable_diffusion/benchmark_sd3.py -m "PixArt-alpha/PixArt-XL-2-1024-MS" -p 2 --mode colossalai --n_warm_up_steps 3 --n_repeat_times 1 --profile --num_inference_steps 20
+python examples/inference/stable_diffusion/benchmark_sd3.py -m "PixArt-alpha/PixArt-XL-2-1024-MS" --mode diffusers --n_warm_up_steps 3 --n_repeat_times 1 --profile --num_inference_steps 20
+"""
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-b", "--batch_size", type=int, default=1, help="Batch size")
+ parser.add_argument("-p", "--patched_parallel_size", type=int, default=1, help="Patched Parallelism size")
+ parser.add_argument("-n", "--num_inference_steps", type=int, default=50, help="Number of inference steps")
+ parser.add_argument("-H", "--height", type=int, nargs="+", default=[1024, 2048], help="Height list")
+ parser.add_argument("-w", "--width", type=int, nargs="+", default=[1024, 2048], help="Width list")
+ parser.add_argument("--dtype", type=str, default="fp16", choices=["fp16", "fp32", "bf16"], help="Data type")
+ parser.add_argument("--n_warm_up_steps", type=int, default=3, help="Number of warm up steps")
+ parser.add_argument("--n_repeat_times", type=int, default=5, help="Number of repeat times")
+ parser.add_argument("--profile", default=False, action="store_true", help="Enable torch profiler")
+ parser.add_argument("--log", default=False, action="store_true", help="Enable logging")
+ parser.add_argument("-m", "--model", default="stabilityai/stable-diffusion-3-medium-diffusers", help="Model path")
+ parser.add_argument(
+ "--mode", default="colossalai", choices=["colossalai", "diffusers"], help="Inference framework mode"
+ )
+ args = parser.parse_args()
+ benchmark(args)
diff --git a/examples/inference/stable_diffusion/compute_metric.py b/examples/inference/stable_diffusion/compute_metric.py
new file mode 100644
index 000000000000..14c92501b66d
--- /dev/null
+++ b/examples/inference/stable_diffusion/compute_metric.py
@@ -0,0 +1,80 @@
+# Code from https://github.com/mit-han-lab/distrifuser/blob/main/scripts/compute_metrics.py
+import argparse
+import os
+
+import numpy as np
+import torch
+from cleanfid import fid
+from PIL import Image
+from torch.utils.data import DataLoader, Dataset
+from torchmetrics.image import LearnedPerceptualImagePatchSimilarity, PeakSignalNoiseRatio
+from torchvision.transforms import Resize
+from tqdm import tqdm
+
+
+def read_image(path: str):
+ """
+ input: path
+ output: tensor (C, H, W)
+ """
+ img = np.asarray(Image.open(path))
+ if len(img.shape) == 2:
+ img = np.repeat(img[:, :, None], 3, axis=2)
+ img = torch.from_numpy(img).permute(2, 0, 1)
+ return img
+
+
+class MultiImageDataset(Dataset):
+ def __init__(self, root0, root1, is_gt=False):
+ super().__init__()
+ self.root0 = root0
+ self.root1 = root1
+ file_names0 = os.listdir(root0)
+ file_names1 = os.listdir(root1)
+
+ self.image_names0 = sorted([name for name in file_names0 if name.endswith(".png") or name.endswith(".jpg")])
+ self.image_names1 = sorted([name for name in file_names1 if name.endswith(".png") or name.endswith(".jpg")])
+ self.is_gt = is_gt
+ assert len(self.image_names0) == len(self.image_names1)
+
+ def __len__(self):
+ return len(self.image_names0)
+
+ def __getitem__(self, idx):
+ img0 = read_image(os.path.join(self.root0, self.image_names0[idx]))
+ if self.is_gt:
+ # resize to 1024 x 1024
+ img0 = Resize((1024, 1024))(img0)
+ img1 = read_image(os.path.join(self.root1, self.image_names1[idx]))
+
+ batch_list = [img0, img1]
+ return batch_list
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--batch_size", type=int, default=64)
+ parser.add_argument("--num_workers", type=int, default=8)
+ parser.add_argument("--is_gt", action="store_true")
+ parser.add_argument("--input_root0", type=str, required=True)
+ parser.add_argument("--input_root1", type=str, required=True)
+ args = parser.parse_args()
+
+ psnr = PeakSignalNoiseRatio(data_range=(0, 1), reduction="elementwise_mean", dim=(1, 2, 3)).to("cuda")
+ lpips = LearnedPerceptualImagePatchSimilarity(normalize=True).to("cuda")
+
+ dataset = MultiImageDataset(args.input_root0, args.input_root1, is_gt=args.is_gt)
+ dataloader = DataLoader(dataset, batch_size=args.batch_size, num_workers=args.num_workers)
+
+ progress_bar = tqdm(dataloader)
+ with torch.inference_mode():
+ for i, batch in enumerate(progress_bar):
+ batch = [img.to("cuda") / 255 for img in batch]
+ batch_size = batch[0].shape[0]
+ psnr.update(batch[0], batch[1])
+ lpips.update(batch[0], batch[1])
+ fid_score = fid.compute_fid(args.input_root0, args.input_root1)
+
+ print("PSNR:", psnr.compute().item())
+ print("LPIPS:", lpips.compute().item())
+ print("FID:", fid_score)
diff --git a/examples/inference/stable_diffusion/requirements.txt b/examples/inference/stable_diffusion/requirements.txt
new file mode 100644
index 000000000000..c4e74162dfb5
--- /dev/null
+++ b/examples/inference/stable_diffusion/requirements.txt
@@ -0,0 +1,3 @@
+torchvision
+torchmetrics
+cleanfid
diff --git a/examples/inference/stable_diffusion/run_benchmark.sh b/examples/inference/stable_diffusion/run_benchmark.sh
new file mode 100644
index 000000000000..f3e45a335219
--- /dev/null
+++ b/examples/inference/stable_diffusion/run_benchmark.sh
@@ -0,0 +1,42 @@
+#!/bin/bash
+
+models=("PixArt-alpha/PixArt-XL-2-1024-MS" "stabilityai/stable-diffusion-3-medium-diffusers")
+parallelism=(1 2 4 8)
+resolutions=(1024 2048 3840)
+modes=("colossalai" "diffusers")
+
+CUDA_VISIBLE_DEVICES_set_n_least_memory_usage() {
+ local n=${1:-"9999"}
+ echo "GPU Memory Usage:"
+ local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
+ | tail -n +2 \
+ | nl -v 0 \
+ | tee /dev/tty \
+ | sort -g -k 2 \
+ | awk '{print $1}' \
+ | head -n $n)
+ export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
+ echo "Now CUDA_VISIBLE_DEVICES is set to:"
+ echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
+}
+
+for model in "${models[@]}"; do
+ for p in "${parallelism[@]}"; do
+ for resolution in "${resolutions[@]}"; do
+ for mode in "${modes[@]}"; do
+ if [[ "$mode" == "colossalai" && "$p" == 1 ]]; then
+ continue
+ fi
+ if [[ "$mode" == "diffusers" && "$p" != 1 ]]; then
+ continue
+ fi
+ CUDA_VISIBLE_DEVICES_set_n_least_memory_usage $p
+
+ cmd="python examples/inference/stable_diffusion/benchmark_sd3.py -m \"$model\" -p $p --mode $mode --log -H $resolution -w $resolution"
+
+ echo "Executing: $cmd"
+ eval $cmd
+ done
+ done
+ done
+done
diff --git a/examples/inference/stable_diffusion/sd3_generation.py b/examples/inference/stable_diffusion/sd3_generation.py
index fe989eed7c2d..9e146c34b937 100644
--- a/examples/inference/stable_diffusion/sd3_generation.py
+++ b/examples/inference/stable_diffusion/sd3_generation.py
@@ -1,18 +1,17 @@
import argparse
-from diffusers import PixArtAlphaPipeline, StableDiffusion3Pipeline
-from torch import bfloat16, float16, float32
+from diffusers import DiffusionPipeline
+from torch import bfloat16
+from torch import distributed as dist
+from torch import float16, float32
import colossalai
from colossalai.cluster import DistCoordinator
from colossalai.inference.config import DiffusionGenerationConfig, InferenceConfig
from colossalai.inference.core.engine import InferenceEngine
-from colossalai.inference.modeling.policy.pixart_alpha import PixArtAlphaInferPolicy
-from colossalai.inference.modeling.policy.stablediffusion3 import StableDiffusion3InferPolicy
# For Stable Diffusion 3, we'll use the following configuration
-MODEL_CLS = [StableDiffusion3Pipeline, PixArtAlphaPipeline][0]
-POLICY_CLS = [StableDiffusion3InferPolicy, PixArtAlphaInferPolicy][0]
+MODEL_CLS = DiffusionPipeline
TORCH_DTYPE_MAP = {
"fp16": float16,
@@ -43,20 +42,27 @@ def infer(args):
max_batch_size=args.max_batch_size,
tp_size=args.tp_size,
use_cuda_kernel=args.use_cuda_kernel,
+ patched_parallelism_size=dist.get_world_size(),
)
- engine = InferenceEngine(model, inference_config=inference_config, model_policy=POLICY_CLS(), verbose=True)
+ engine = InferenceEngine(model, inference_config=inference_config, verbose=True)
# ==============================
# Generation
# ==============================
coordinator.print_on_master(f"Generating...")
out = engine.generate(prompts=[args.prompt], generation_config=DiffusionGenerationConfig())[0]
- out.save("cat.jpg")
+ if dist.get_rank() == 0:
+ out.save(f"cat_parallel_size{dist.get_world_size()}.jpg")
coordinator.print_on_master(out)
# colossalai run --nproc_per_node 1 examples/inference/stable_diffusion/sd3_generation.py -m MODEL_PATH
+
# colossalai run --nproc_per_node 1 examples/inference/stable_diffusion/sd3_generation.py -m "stabilityai/stable-diffusion-3-medium-diffusers" --tp_size 1
+# colossalai run --nproc_per_node 2 examples/inference/stable_diffusion/sd3_generation.py -m "stabilityai/stable-diffusion-3-medium-diffusers" --tp_size 1
+
+# colossalai run --nproc_per_node 1 examples/inference/stable_diffusion/sd3_generation.py -m "PixArt-alpha/PixArt-XL-2-1024-MS" --tp_size 1
+# colossalai run --nproc_per_node 2 examples/inference/stable_diffusion/sd3_generation.py -m "PixArt-alpha/PixArt-XL-2-1024-MS" --tp_size 1
if __name__ == "__main__":
diff --git a/examples/language/gpt/hybridparallelism/finetune.py b/examples/language/gpt/hybridparallelism/finetune.py
index 777d16cb9ea0..ae6d655f40a6 100644
--- a/examples/language/gpt/hybridparallelism/finetune.py
+++ b/examples/language/gpt/hybridparallelism/finetune.py
@@ -1,4 +1,5 @@
import argparse
+from contextlib import nullcontext
from typing import Callable, List, Union
import evaluate
@@ -17,6 +18,7 @@
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin, TorchDDPPlugin
from colossalai.cluster import DistCoordinator
+from colossalai.lazy import LazyInitContext
from colossalai.nn.optimizer import HybridAdam
# ==============================
@@ -186,7 +188,6 @@ def main():
help="only gpt2 now",
)
parser.add_argument("--target_f1", type=float, default=None, help="target f1 score. Raise exception if not reached")
- parser.add_argument("--use_lazy_init", type=bool, default=False, help="for initiating lazy init context")
args = parser.parse_args()
if args.model_type == "gpt2":
@@ -250,10 +251,16 @@ def main():
pad_token_id=data_builder.tokenizer.pad_token_id,
)
- if model_name == "gpt2":
- model = GPT2ForSequenceClassification.from_pretrained(model_name, config=cfg).cuda()
- else:
- raise RuntimeError
+ init_ctx = (
+ LazyInitContext(default_device=get_accelerator().get_current_device())
+ if isinstance(plugin, (GeminiPlugin))
+ else nullcontext()
+ )
+ with init_ctx:
+ if model_name == "gpt2":
+ model = GPT2ForSequenceClassification.from_pretrained(model_name, config=cfg).cuda()
+ else:
+ raise RuntimeError
# optimizer
no_decay = ["bias", "LayerNorm.weight"]
diff --git a/examples/language/llama/benchmark.py b/examples/language/llama/benchmark.py
index 2b7bd50b8766..e530e2d6a153 100644
--- a/examples/language/llama/benchmark.py
+++ b/examples/language/llama/benchmark.py
@@ -98,6 +98,7 @@ def main():
parser.add_argument("--disable-async-reduce", action="store_true", help="Disable the asynchronous reduce operation")
parser.add_argument("--prefetch_num", type=int, default=0, help="chunk prefetch max number")
parser.add_argument("--no_cache", action="store_true")
+ parser.add_argument("--overlap_allgather", action="store_true")
args = parser.parse_args()
colossalai.launch_from_torch()
@@ -199,9 +200,9 @@ def empty_init():
enable_flash_attention=args.xformers,
microbatch_size=args.mbs,
precision="bf16",
- dp_outside=False,
overlap_p2p=args.overlap,
enable_metadata_cache=not args.no_cache,
+ overlap_allgather=args.overlap_allgather,
**hybrid_kwargs,
)
elif args.plugin == "3d_cpu":
diff --git a/examples/language/opt/opt_benchmark.py b/examples/language/opt/opt_benchmark.py
index c2883d96c16e..ca9b63d1a14a 100755
--- a/examples/language/opt/opt_benchmark.py
+++ b/examples/language/opt/opt_benchmark.py
@@ -1,4 +1,5 @@
import time
+from contextlib import nullcontext
import torch
import tqdm
@@ -8,9 +9,11 @@
from transformers.utils.versions import require_version
import colossalai
+from colossalai.accelerator import get_accelerator
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin, LowLevelZeroPlugin, TorchDDPPlugin
from colossalai.cluster import DistCoordinator
+from colossalai.lazy import LazyInitContext
from colossalai.logging import disable_existing_loggers, get_dist_logger
from colossalai.nn.optimizer import HybridAdam
@@ -62,14 +65,6 @@ def main():
if args.mem_cap > 0:
colo_memory_cap(args.mem_cap)
- # Build OPT model
- config = AutoConfig.from_pretrained(args.model_name_or_path)
- model = OPTForCausalLM(config=config)
- logger.info(f"Finish loading model from {args.model_name_or_path}", ranks=[0])
-
- # Enable gradient checkpointing
- model.gradient_checkpointing_enable()
-
# Set plugin
booster_kwargs = {}
if args.plugin == "torch_ddp_fp16":
@@ -82,6 +77,19 @@ def main():
plugin = LowLevelZeroPlugin(initial_scale=2**5)
logger.info(f"Set plugin as {args.plugin}", ranks=[0])
+ # Build OPT model
+ init_ctx = (
+ LazyInitContext(default_device=get_accelerator().get_current_device())
+ if isinstance(plugin, (GeminiPlugin))
+ else nullcontext()
+ )
+ config = AutoConfig.from_pretrained(args.model_name_or_path)
+ with init_ctx:
+ model = OPTForCausalLM(config=config)
+ logger.info(f"Finish loading model from {args.model_name_or_path}", ranks=[0])
+
+ # Enable gradient checkpointing
+ model.gradient_checkpointing_enable()
# Set optimizer
optimizer = HybridAdam(model.parameters(), lr=args.learning_rate)
diff --git a/examples/language/opt/opt_train_demo.py b/examples/language/opt/opt_train_demo.py
index b5b50305cc34..50dfc7bffd07 100644
--- a/examples/language/opt/opt_train_demo.py
+++ b/examples/language/opt/opt_train_demo.py
@@ -1,3 +1,5 @@
+from contextlib import nullcontext
+
import datasets
import torch
import transformers
@@ -8,9 +10,11 @@
from transformers.utils.versions import require_version
import colossalai
+from colossalai.accelerator import get_accelerator
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin, TorchDDPPlugin
from colossalai.cluster import DistCoordinator
+from colossalai.lazy import LazyInitContext
from colossalai.logging import disable_existing_loggers, get_dist_logger
from colossalai.nn.optimizer import HybridAdam
@@ -78,14 +82,6 @@ def main():
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
- # Build OPT model
- config = AutoConfig.from_pretrained(args.model_name_or_path)
- model = OPTForCausalLM.from_pretrained(args.model_name_or_path, config=config)
- logger.info(f"Finish loading model from {args.model_name_or_path}", ranks=[0])
-
- # Enable gradient checkpointing
- model.gradient_checkpointing_enable()
-
# Set plugin
booster_kwargs = {}
if args.plugin == "torch_ddp_fp16":
@@ -110,6 +106,21 @@ def main():
logger.info(f"Set plugin as {args.plugin}", ranks=[0])
+ # Build OPT model
+ config = AutoConfig.from_pretrained(args.model_name_or_path)
+ # Build OPT model
+ init_ctx = (
+ LazyInitContext(default_device=get_accelerator().get_current_device())
+ if isinstance(plugin, (GeminiPlugin, HybridParallelPlugin))
+ else nullcontext()
+ )
+ with init_ctx:
+ model = OPTForCausalLM.from_pretrained(args.model_name_or_path, config=config)
+ logger.info(f"Finish loading model from {args.model_name_or_path}", ranks=[0])
+
+ # Enable gradient checkpointing
+ model.gradient_checkpointing_enable()
+
# Prepare tokenizer and dataloader
tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path)
dataset = NetflixDataset(tokenizer)
diff --git a/tests/kit/model_zoo/transformers/__init__.py b/tests/kit/model_zoo/transformers/__init__.py
index 05c17f562635..4adc386192d3 100644
--- a/tests/kit/model_zoo/transformers/__init__.py
+++ b/tests/kit/model_zoo/transformers/__init__.py
@@ -3,28 +3,17 @@
from .blip2 import *
from .bloom import *
from .chatglm2 import *
+from .command import *
+from .deepseek import *
from .falcon import *
from .gpt import *
from .gptj import *
from .llama import *
+from .mistral import *
+from .mixtral import *
from .opt import *
+from .qwen2 import *
from .sam import *
from .t5 import *
from .vit import *
from .whisper import *
-
-try:
- from .mistral import *
-except ImportError:
- print("This version of transformers doesn't support mistral.")
-
-try:
- from .qwen2 import *
-except ImportError:
- print("This version of transformers doesn't support qwen2.")
-
-
-try:
- from .command import *
-except ImportError:
- print("This version of transformers doesn't support Command-R.")
diff --git a/tests/kit/model_zoo/transformers/deepseek.py b/tests/kit/model_zoo/transformers/deepseek.py
new file mode 100644
index 000000000000..ad73640a57c5
--- /dev/null
+++ b/tests/kit/model_zoo/transformers/deepseek.py
@@ -0,0 +1,83 @@
+# modified from tests/kit/model_zoo/transformers/mistral.py
+import torch
+import transformers
+from transformers import AutoConfig
+
+from ..registry import ModelAttribute, model_zoo
+
+# ===============================
+# Register single-sentence Mixtral
+# ===============================
+
+
+def data_gen():
+ # Generated from following code snippet
+ #
+ # from transformers import AutoModelForCausalLM, AutoTokenizer
+ # tokenizer = AutoTokenizer.from_pretrained("mixtralai/Mixtral-7B-v0.1")
+ # input = 'My favourite condiment is vinegar' (last two words repeated to satisfy length requirement)
+ # tokenized_input = tokenizer([input], return_tensors="pt")
+ # input_ids = tokenized_input['input_ids']
+ # attention_mask = tokenized_input['attention_mask']
+ input_ids = torch.tensor([[1, 22, 55, 77, 532, 349, 43, 22]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def data_gen_for_lm():
+ # LM data gen
+ # the `labels` of LM is the token of the output, cause no padding, use `input_ids` as `labels`
+ data = data_gen()
+ data["labels"] = data["input_ids"].clone()
+ return data
+
+
+def data_gen_for_sequence_classification():
+ # sequence classification data gen
+ data = data_gen()
+ data["labels"] = torch.tensor([1], dtype=torch.int64)
+ return data
+
+
+# define output transform function
+output_transform_fn = lambda x: x
+
+# define loss function
+loss_fn_for_mixtral_model = lambda x: x[0].mean()
+loss_fn = lambda x: x.loss
+loss_fn_for_seq_classification = lambda output: output.logits.mean()
+
+
+def init_deepseek():
+
+ config = AutoConfig.from_pretrained(
+ "deepseek-ai/deepseek-moe-16b-base",
+ hidden_size=32,
+ intermediate_size=32,
+ moe_intermediate_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=8,
+ num_key_value_heads=8,
+ # vocab_size=2200,
+ first_k_dense_replace=1,
+ attn_implementation="flash_attention_2",
+ torch_dtype="float16",
+ n_routed_experts=8,
+ trust_remote_code=True,
+ )
+
+ if hasattr(config, "pad_token_id"):
+ config.pad_token_id = config.eos_token_id
+ model = transformers.AutoModel.from_config(config, trust_remote_code=True)
+
+ return model
+
+
+model_zoo.register(
+ name="transformers_deepseek",
+ model_fn=init_deepseek,
+ data_gen_fn=data_gen,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn_for_mixtral_model,
+ model_attribute=ModelAttribute(has_control_flow=True),
+)
diff --git a/tests/kit/model_zoo/transformers/mixtral.py b/tests/kit/model_zoo/transformers/mixtral.py
new file mode 100644
index 000000000000..40e5a7b0232d
--- /dev/null
+++ b/tests/kit/model_zoo/transformers/mixtral.py
@@ -0,0 +1,87 @@
+# modified from tests/kit/model_zoo/transformers/mistral.py
+import torch
+import transformers
+from transformers import MixtralConfig
+
+from ..registry import ModelAttribute, model_zoo
+
+# ===============================
+# Register single-sentence Mixtral
+# ===============================
+
+
+def data_gen():
+ # Generated from following code snippet
+ #
+ # from transformers import AutoModelForCausalLM, AutoTokenizer
+ # tokenizer = AutoTokenizer.from_pretrained("mixtralai/Mixtral-7B-v0.1")
+ # input = 'My favourite condiment is vinegar' (last two words repeated to satisfy length requirement)
+ # tokenized_input = tokenizer([input], return_tensors="pt")
+ # input_ids = tokenized_input['input_ids']
+ # attention_mask = tokenized_input['attention_mask']
+ input_ids = torch.tensor([[1, 22, 55, 77, 532, 349, 43, 22]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def data_gen_for_lm():
+ # LM data gen
+ # the `labels` of LM is the token of the output, cause no padding, use `input_ids` as `labels`
+ data = data_gen()
+ data["labels"] = data["input_ids"].clone()
+ return data
+
+
+def data_gen_for_sequence_classification():
+ # sequence classification data gen
+ data = data_gen()
+ data["labels"] = torch.tensor([1], dtype=torch.int64)
+ return data
+
+
+# define output transform function
+output_transform_fn = lambda x: x
+
+# define loss function
+loss_fn_for_mixtral_model = lambda x: x[0].mean()
+loss_fn = lambda x: x.loss
+loss_fn_for_seq_classification = lambda output: output.logits.mean()
+
+config = MixtralConfig(
+ hidden_size=32,
+ intermediate_size=32,
+ num_attention_heads=8,
+ num_hidden_layers=2,
+ vocab_size=1000,
+ attn_implementation="flash_attention_2",
+ torch_dtype="float16",
+ output_router_logits=True,
+)
+
+if hasattr(config, "pad_token_id"):
+ config.pad_token_id = config.eos_token_id
+
+model_zoo.register(
+ name="transformers_mixtral",
+ model_fn=lambda: transformers.MixtralModel(config),
+ data_gen_fn=data_gen,
+ output_transform_fn=output_transform_fn,
+ loss_fn=loss_fn_for_mixtral_model,
+ model_attribute=ModelAttribute(has_control_flow=True),
+)
+# model_zoo.register(
+# name="transformers_mixtral_for_casual_lm",
+# model_fn=lambda: transformers.MixtralForCausalLM(config),
+# data_gen_fn=data_gen_for_lm,
+# output_transform_fn=output_transform_fn,
+# loss_fn=loss_fn,
+# model_attribute=ModelAttribute(has_control_flow=True),
+# )
+# model_zoo.register(
+# name="transformers_mixtral_for_sequence_classification",
+# model_fn=lambda: transformers.MixtralForSequenceClassification(config),
+# data_gen_fn=data_gen_for_sequence_classification,
+# output_transform_fn=output_transform_fn,
+# loss_fn=loss_fn_for_seq_classification,
+# model_attribute=ModelAttribute(has_control_flow=True),
+# )
diff --git a/tests/test_legacy/test_moe/moe_utils.py b/tests/test_legacy/test_moe/moe_utils.py
new file mode 100644
index 000000000000..8c133849b000
--- /dev/null
+++ b/tests/test_legacy/test_moe/moe_utils.py
@@ -0,0 +1,136 @@
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from torch.distributed import ProcessGroup
+
+from colossalai.booster.plugin.low_level_zero_plugin import LowLevelZeroModel
+from colossalai.legacy.engine.gradient_handler._base_gradient_handler import BaseGradientHandler
+from colossalai.legacy.engine.gradient_handler.utils import bucket_allreduce
+from colossalai.legacy.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.utils import get_moe_epsize_param_dict
+from colossalai.legacy.registry import GRADIENT_HANDLER
+from colossalai.tensor.moe_tensor.api import get_ep_group, get_ep_size, set_moe_tensor_ep_group
+
+
+def delete_moe_info(model):
+ for _, param in model.named_parameters():
+ if hasattr(param, "ep_group"):
+ delattr(param, "ep_group")
+
+
+class MoeModel(nn.Module):
+ def __init__(self, ep_group: ProcessGroup = None):
+ super().__init__()
+ self.test_embed = nn.Linear(4, 16, bias=False)
+ self.w1 = torch.nn.Parameter(torch.randn(16, 8))
+ if ep_group:
+ set_moe_tensor_ep_group(self.w1, ep_group)
+
+ def forward(self, x):
+ x = self.test_embed(x)
+ x = torch.matmul(x, self.w1)
+
+ return x
+
+
+@GRADIENT_HANDLER.register_module
+class MoeGradientHandler(BaseGradientHandler):
+ """A helper class to handle all-reduce operations in a data parallel group and
+ moe model parallel. A all-reduce collective communication will be operated in
+ :func:`handle_gradient` among a data parallel group.
+ For better performance, it bucketizes the gradients of all parameters that are
+ the same type to improve the efficiency of communication.
+
+ Args:
+ model (Module): Model where the gradients accumulate.
+ optimizer (Optimizer): Optimizer for updating the parameters.
+ """
+
+ def __init__(self, model, optimizer=None):
+ super().__init__(model, optimizer)
+
+ def handle_gradient(self):
+ """A method running an all-reduce operation in a data parallel group.
+ Then running an all-reduce operation for all parameters in experts
+ across moe model parallel group
+ """
+ if dist.get_world_size() > 1:
+ epsize_param_dict = get_moe_epsize_param_dict(self._model)
+
+ # epsize is 1, indicating the params are replicated among processes in data parallelism
+ # use the ParallelMode.DATA to get data parallel group
+ # reduce gradients for all parameters in data parallelism
+ if 1 in epsize_param_dict:
+ bucket_allreduce(param_list=epsize_param_dict[1])
+
+ for ep_size in epsize_param_dict:
+ if ep_size != 1 and ep_size != MOE_MANAGER.world_size:
+ bucket_allreduce(
+ param_list=epsize_param_dict[ep_size], group=MOE_MANAGER.parallel_info_dict[ep_size].dp_group
+ )
+
+
+def assert_not_equal_in_group(tensor, process_group=None):
+ # all gather tensors from different ranks
+ world_size = dist.get_world_size(process_group)
+ tensor_list = [torch.empty_like(tensor) for _ in range(world_size)]
+ dist.all_gather(tensor_list, tensor, group=process_group)
+
+ # check if they are equal one by one
+ for i in range(world_size - 1):
+ a = tensor_list[i]
+ b = tensor_list[i + 1]
+ assert not torch.allclose(a, b), (
+ f"expected tensors on rank {i} and {i + 1} not to be equal " f"but they are, {a} vs {b}"
+ )
+
+
+def run_fwd_bwd(model, data, label, criterion, optimizer, enable_autocast=False):
+ model.train()
+ with torch.cuda.amp.autocast(enabled=enable_autocast):
+ if criterion:
+ y = model(data)
+ loss = criterion(y, label)
+ else:
+ loss = model(data, label)
+ loss = loss.float()
+
+ if isinstance(model, LowLevelZeroModel):
+ optimizer.backward(loss)
+ else:
+ loss.backward()
+ return y
+
+
+def sync_local_from_ep(local_model, ep_model, assert_grad_flag: bool = False) -> None:
+ """Sync the parameters of tp model from ep model
+
+ Args:
+ local_model (MoeModule)
+ ep_model (MoeModule)
+ """
+ for (local_name, local_param), (ep_name, ep_param) in zip(
+ local_model.named_parameters(), ep_model.named_parameters()
+ ):
+ if "experts" not in local_name:
+ if assert_grad_flag:
+ assert torch.allclose(local_param, ep_param), f"local_param: {local_param}, ep_param: {ep_param}"
+ assert torch.allclose(local_param.grad, ep_param.grad)
+ else:
+ local_param.data.copy_(ep_param.data)
+ continue
+
+ # gather param from ep model
+ param_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
+ dist.all_gather(param_list, ep_param, group=get_ep_group(ep_param))
+ all_param = torch.cat(param_list, dim=0)
+ if assert_grad_flag:
+ grad_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
+ dist.all_gather(grad_list, ep_param.grad, group=get_ep_group(ep_param))
+ all_grad = torch.cat(grad_list, dim=0)
+
+ if assert_grad_flag:
+ assert torch.allclose(local_param, all_param)
+ assert torch.allclose(local_param.grad, all_grad)
+ else:
+ local_param.data.copy_(all_param.data)
diff --git a/tests/test_moe/test_grad_handler.py b/tests/test_legacy/test_moe/test_grad_handler.py
similarity index 98%
rename from tests/test_moe/test_grad_handler.py
rename to tests/test_legacy/test_moe/test_grad_handler.py
index 25e61b091729..3a782a6dd445 100644
--- a/tests/test_moe/test_grad_handler.py
+++ b/tests/test_legacy/test_moe/test_grad_handler.py
@@ -5,7 +5,7 @@
import colossalai
from colossalai.accelerator import get_accelerator
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
# from colossalai.shardformer.layer.moe.layers import SparseMLP
from colossalai.testing import assert_equal_in_group, rerun_if_address_is_in_use, spawn
diff --git a/tests/test_moe/test_moe_group.py b/tests/test_legacy/test_moe/test_moe_group.py
similarity index 95%
rename from tests/test_moe/test_moe_group.py
rename to tests/test_legacy/test_moe/test_moe_group.py
index 89baf1d37b1b..68dac4828fa7 100644
--- a/tests/test_moe/test_moe_group.py
+++ b/tests/test_legacy/test_moe/test_moe_group.py
@@ -4,8 +4,8 @@
import colossalai
from colossalai.accelerator import get_accelerator
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import sync_moe_model_param
+from colossalai.legacy.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.utils import sync_moe_model_param
# from colossalai.shardformer.layer.moe import MLPExperts
from colossalai.testing import assert_equal_in_group, rerun_if_address_is_in_use, spawn
diff --git a/tests/test_moe/test_moe_hybrid_zero.py b/tests/test_legacy/test_moe/test_moe_hybrid_zero.py
similarity index 98%
rename from tests/test_moe/test_moe_hybrid_zero.py
rename to tests/test_legacy/test_moe/test_moe_hybrid_zero.py
index 513c4ebda4a5..fdd6d956ef83 100644
--- a/tests/test_moe/test_moe_hybrid_zero.py
+++ b/tests/test_legacy/test_moe/test_moe_hybrid_zero.py
@@ -6,7 +6,7 @@
from colossalai.booster import Booster
from colossalai.booster.plugin import LowLevelZeroPlugin
from colossalai.booster.plugin.low_level_zero_plugin import LowLevelZeroModel
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
from colossalai.tensor.moe_tensor.api import is_moe_tensor
from colossalai.testing import rerun_if_address_is_in_use, spawn
from tests.test_moe.moe_utils import MoeModel
diff --git a/tests/test_moe/test_moe_load_balance.py b/tests/test_legacy/test_moe/test_moe_load_balance.py
similarity index 99%
rename from tests/test_moe/test_moe_load_balance.py
rename to tests/test_legacy/test_moe/test_moe_load_balance.py
index ddd3ea368964..adf2dbc1ccf3 100644
--- a/tests/test_moe/test_moe_load_balance.py
+++ b/tests/test_legacy/test_moe/test_moe_load_balance.py
@@ -6,7 +6,7 @@
from colossalai.booster import Booster
from colossalai.booster.plugin import LowLevelZeroPlugin
from colossalai.booster.plugin.low_level_zero_plugin import LowLevelZeroModel
-from colossalai.moe.manager import MOE_MANAGER
+from colossalai.legacy.moe.manager import MOE_MANAGER
# from colossalai.shardformer.layer.moe import apply_load_balance
from colossalai.tensor.moe_tensor.api import is_moe_tensor
diff --git a/tests/test_lora/test_lora.py b/tests/test_lora/test_lora.py
index b8daf775db0e..1ae17025d31e 100644
--- a/tests/test_lora/test_lora.py
+++ b/tests/test_lora/test_lora.py
@@ -9,7 +9,8 @@
import colossalai
from colossalai.booster import Booster
-from colossalai.booster.plugin import LowLevelZeroPlugin, TorchDDPPlugin
+from colossalai.booster.plugin import HybridParallelPlugin, LowLevelZeroPlugin, TorchDDPPlugin
+from colossalai.booster.plugin.hybrid_parallel_plugin import HybridParallelModule
from colossalai.testing import check_state_dict_equal, clear_cache_before_run, rerun_if_address_is_in_use, spawn
from tests.kit.model_zoo import model_zoo
from tests.test_checkpoint_io.utils import shared_tempdir
@@ -20,7 +21,7 @@ def check_fwd_bwd(model_fn, data_gen_fn, output_transform_fn, loss_fn, task_type
model = model_fn()
lora_config = LoraConfig(task_type=task_type, r=8, lora_alpha=32, lora_dropout=0.1)
- test_plugins = [TorchDDPPlugin(), LowLevelZeroPlugin()]
+ test_plugins = [TorchDDPPlugin(), LowLevelZeroPlugin(), HybridParallelPlugin(tp_size=1, pp_size=1)]
test_configs = [
{
"lora_config": lora_config,
@@ -59,6 +60,8 @@ def check_fwd_bwd(model_fn, data_gen_fn, output_transform_fn, loss_fn, task_type
# test fwd bwd correctness
test_model = model_load
+ if isinstance(model_load, HybridParallelModule):
+ model_load = model_load.module.module
model_copy = copy.deepcopy(model_load)
data = data_gen_fn()
diff --git a/tests/test_moe/moe_utils.py b/tests/test_moe/moe_utils.py
index 131932dcb3b3..8c411a33fef6 100644
--- a/tests/test_moe/moe_utils.py
+++ b/tests/test_moe/moe_utils.py
@@ -1,142 +1,8 @@
import torch
-import torch.distributed as dist
-import torch.nn as nn
-from torch.distributed import ProcessGroup
-from torch.testing import assert_close
-from colossalai.booster.plugin.low_level_zero_plugin import LowLevelZeroModel
-from colossalai.legacy.engine.gradient_handler._base_gradient_handler import BaseGradientHandler
-from colossalai.legacy.engine.gradient_handler.utils import bucket_allreduce
-from colossalai.legacy.registry import GRADIENT_HANDLER
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import get_moe_epsize_param_dict
-# from colossalai.shardformer.layer.moe import SparseMLP
-from colossalai.tensor.moe_tensor.api import get_ep_group, get_ep_size, set_moe_tensor_ep_group
-
-
-def delete_moe_info(model):
- for _, param in model.named_parameters():
- if hasattr(param, "ep_group"):
- delattr(param, "ep_group")
-
-
-class MoeModel(nn.Module):
- def __init__(self, ep_group: ProcessGroup = None):
- super().__init__()
- self.test_embed = nn.Linear(4, 16, bias=False)
- self.w1 = torch.nn.Parameter(torch.randn(16, 8))
- if ep_group:
- set_moe_tensor_ep_group(self.w1, ep_group)
-
- def forward(self, x):
- x = self.test_embed(x)
- x = torch.matmul(x, self.w1)
-
- return x
-
-
-@GRADIENT_HANDLER.register_module
-class MoeGradientHandler(BaseGradientHandler):
- """A helper class to handle all-reduce operations in a data parallel group and
- moe model parallel. A all-reduce collective communication will be operated in
- :func:`handle_gradient` among a data parallel group.
- For better performance, it bucketizes the gradients of all parameters that are
- the same type to improve the efficiency of communication.
-
- Args:
- model (Module): Model where the gradients accumulate.
- optimizer (Optimizer): Optimizer for updating the parameters.
- """
-
- def __init__(self, model, optimizer=None):
- super().__init__(model, optimizer)
-
- def handle_gradient(self):
- """A method running an all-reduce operation in a data parallel group.
- Then running an all-reduce operation for all parameters in experts
- across moe model parallel group
- """
- if dist.get_world_size() > 1:
- epsize_param_dict = get_moe_epsize_param_dict(self._model)
-
- # epsize is 1, indicating the params are replicated among processes in data parallelism
- # use the ParallelMode.DATA to get data parallel group
- # reduce gradients for all parameters in data parallelism
- if 1 in epsize_param_dict:
- bucket_allreduce(param_list=epsize_param_dict[1])
-
- for ep_size in epsize_param_dict:
- if ep_size != 1 and ep_size != MOE_MANAGER.world_size:
- bucket_allreduce(
- param_list=epsize_param_dict[ep_size], group=MOE_MANAGER.parallel_info_dict[ep_size].dp_group
- )
-
-
-def assert_not_equal_in_group(tensor, process_group=None):
- # all gather tensors from different ranks
- world_size = dist.get_world_size(process_group)
- tensor_list = [torch.empty_like(tensor) for _ in range(world_size)]
- dist.all_gather(tensor_list, tensor, group=process_group)
-
- # check if they are equal one by one
- for i in range(world_size - 1):
- a = tensor_list[i]
- b = tensor_list[i + 1]
- assert not torch.allclose(a, b), (
- f"expected tensors on rank {i} and {i + 1} not to be equal " f"but they are, {a} vs {b}"
- )
-
-
-def run_fwd_bwd(model, data, label, criterion, optimizer, enable_autocast=False):
- model.train()
- with torch.cuda.amp.autocast(enabled=enable_autocast):
- if criterion:
- y = model(data)
- loss = criterion(y, label)
- else:
- loss = model(data, label)
- loss = loss.float()
-
- if isinstance(model, LowLevelZeroModel):
- optimizer.backward(loss)
- else:
- loss.backward()
- return y
-
-
-def sync_local_from_ep(local_model, ep_model, assert_grad_flag: bool = False) -> None:
- """Sync the parameters of tp model from ep model
-
- Args:
- local_model (MoeModule)
- ep_model (MoeModule)
- """
- for (local_name, local_param), (ep_name, ep_param) in zip(
- local_model.named_parameters(), ep_model.named_parameters()
- ):
- if "experts" not in local_name:
- if assert_grad_flag:
- assert torch.allclose(local_param, ep_param), f"local_param: {local_param}, ep_param: {ep_param}"
- assert torch.allclose(local_param.grad, ep_param.grad)
- else:
- local_param.data.copy_(ep_param.data)
- continue
-
- # gather param from ep model
- param_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
- dist.all_gather(param_list, ep_param, group=get_ep_group(ep_param))
- all_param = torch.cat(param_list, dim=0)
- if assert_grad_flag:
- grad_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
- dist.all_gather(grad_list, ep_param.grad, group=get_ep_group(ep_param))
- all_grad = torch.cat(grad_list, dim=0)
-
- if assert_grad_flag:
- assert torch.allclose(local_param, all_param)
- assert torch.allclose(local_param.grad, all_grad)
- else:
- local_param.data.copy_(all_param.data)
+def assert_loose_close(a, b, dtype: torch.dtype = torch.float32, name=""):
+ assert loose_close(a, b, dtype), f"{name} not close {a.mean()} {b.mean()}"
def loose_close(a, b, dtype: torch.dtype = torch.float32):
@@ -148,8 +14,18 @@ def loose_close(a, b, dtype: torch.dtype = torch.float32):
elif dtype is torch.bfloat16:
rtol = 4e-3
atol = 4e-3
+ else:
+ assert dtype is torch.float32
+ rtol = 1e-05
+ atol = 1e-08
a = a.detach().to(dtype)
b = b.detach().to(dtype).to(a.device)
- assert_close(a, b, rtol=rtol, atol=atol)
+ return torch.allclose(a, b, rtol=rtol, atol=atol)
+
+
+def check_model_equal(model1, model2):
+ assert set(model1.state_dict().keys()) == set(model2.state_dict().keys())
+ for i, ((name, p1), p2) in enumerate(zip(model1.named_parameters(), model2.parameters())):
+ assert_loose_close(p1, p2, p1.dtype)
diff --git a/tests/test_moe/test_deepseek_layer.py b/tests/test_moe/test_deepseek_layer.py
index 85cc986959fd..d18ba2eacd84 100644
--- a/tests/test_moe/test_deepseek_layer.py
+++ b/tests/test_moe/test_deepseek_layer.py
@@ -22,6 +22,7 @@ def check_deepseek_moe_layer():
precision="bf16",
tp_size=1,
pp_size=1,
+ zero_stage=1,
ep_size=dist.get_world_size(),
)
@@ -42,7 +43,12 @@ def check_deepseek_moe_layer():
x = torch.rand(1, tokens, hidden_size, requires_grad=True).cuda()
orig_output = orig_model(x)
model = deepcopy(orig_model)
- model = EPDeepseekMoE.from_native_module(model, ep_group=plugin.ep_group)
+ model = EPDeepseekMoE.from_native_module(
+ model,
+ ep_group=plugin.ep_group,
+ moe_dp_group=plugin.moe_dp_group,
+ tp_group=plugin.tp_group,
+ )
ep_output = model(x)
assert_close(orig_output, ep_output)
orig_loss = orig_output.mean()
@@ -62,7 +68,7 @@ def run_dist(rank: int, world_size: int, port: int):
check_deepseek_moe_layer()
-# @pytest.mark.parametrize("world_size", [2, 4])
+@pytest.mark.skip("tested in corresponding sharderformer")
@pytest.mark.parametrize("world_size", [2])
def test_deepseek_moe_layer(world_size: int):
spawn(run_dist, world_size)
diff --git a/tests/test_moe/test_kernel.py b/tests/test_moe/test_kernel.py
index 28e6db441411..c81023988377 100644
--- a/tests/test_moe/test_kernel.py
+++ b/tests/test_moe/test_kernel.py
@@ -4,8 +4,6 @@
import torch
from colossalai.accelerator import get_accelerator
-
-# from colossalai.moe import SparseMLP
from colossalai.moe._operation import MoeCombine, MoeDispatch, moe_cumsum
NUM_EXPERTS = 4
diff --git a/tests/test_moe/test_mixtral_layer.py b/tests/test_moe/test_mixtral_layer.py
index b7b0322e08b5..bc41ac4f33e9 100644
--- a/tests/test_moe/test_mixtral_layer.py
+++ b/tests/test_moe/test_mixtral_layer.py
@@ -23,6 +23,7 @@ def check_mixtral_moe_layer():
precision="bf16",
tp_size=1,
pp_size=1,
+ zero_stage=1,
ep_size=dist.get_world_size(),
)
config = MixtralConfig(
@@ -36,7 +37,12 @@ def check_mixtral_moe_layer():
x = torch.rand(1, tokens, hidden_size, requires_grad=True).cuda()
orig_output, orig_logits = orig_model(x)
model = deepcopy(orig_model)
- model = EPMixtralSparseMoeBlock.from_native_module(model, ep_group=plugin.ep_group)
+ model = EPMixtralSparseMoeBlock.from_native_module(
+ model,
+ ep_group=plugin.ep_group,
+ tp_group=plugin.tp_group,
+ moe_dp_group=plugin.moe_dp_group,
+ )
ep_output, ep_logits = model(x)
assert_close(orig_logits, ep_logits)
assert_close(orig_output, ep_output)
@@ -57,7 +63,8 @@ def run_dist(rank: int, world_size: int, port: int):
check_mixtral_moe_layer()
-@pytest.mark.parametrize("world_size", [2, 4])
+@pytest.mark.skip("tested in corresponding sharderformer")
+@pytest.mark.parametrize("world_size", [2])
def test_mixtral_moe_layer(world_size: int):
spawn(run_dist, world_size)
diff --git a/tests/test_moe/test_moe_checkpoint.py b/tests/test_moe/test_moe_checkpoint.py
index 164301695865..89f5d1c64d0d 100644
--- a/tests/test_moe/test_moe_checkpoint.py
+++ b/tests/test_moe/test_moe_checkpoint.py
@@ -6,31 +6,23 @@
import pytest
import torch
import torch.distributed as dist
-from torch.optim import Adam
+from torch.optim import SGD, Adam
from transformers.models.mixtral.configuration_mixtral import MixtralConfig
from transformers.models.mixtral.modeling_mixtral import MixtralForCausalLM
import colossalai
from colossalai.booster import Booster
from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
-from colossalai.checkpoint_io import MoECheckpointIO
-from colossalai.tensor.moe_tensor.api import is_moe_tensor
from colossalai.testing import parameterize, spawn
+from colossalai.testing.random import seed_all
from colossalai.testing.utils import spawn
+from tests.test_moe.moe_utils import check_model_equal
tokens, n_experts = 7, 4
hidden_size = 8
top_k = 2
-def check_model_equal(model1, model2):
- assert set(model1.state_dict().keys()) == set(model2.state_dict().keys())
- for i, ((name, p1), p2) in enumerate(zip(model1.named_parameters(), model2.parameters())):
- if not torch.equal(p1.half(), p2.half()):
- print(f"Model parameter {name} is not equal. is_moe_tensor: {is_moe_tensor(p1)}")
- raise AssertionError(f"Model parameter {name} is not equal")
-
-
def get_optimizer_snapshot(optim):
state = {id(k): deepcopy(v) for k, v in optim.state.items()}
param_groups = []
@@ -89,35 +81,33 @@ def check_optimizer_snapshot_equal(snapshot1, snapshot2, param2name, moe_dp_grou
num_experts_per_tok=top_k,
num_attention_heads=2,
num_key_value_heads=2,
+ num_hidden_layers=2,
),
MixtralForCausalLM,
],
],
)
def check_moe_checkpoint(test_config):
+ dtype, precision = torch.float16, "fp16"
+ config, model_cls = test_config
+ torch.cuda.set_device(dist.get_rank())
+
context = tempfile.TemporaryDirectory() if dist.get_rank() == 0 else nullcontext()
with context as f:
- torch.cuda.set_device(dist.get_rank())
if dist.get_rank() == 0:
broadcast_objects = [f] # any picklable object
else:
broadcast_objects = [None]
dist.broadcast_object_list(broadcast_objects, src=0)
- config = test_config[0]
- model_cls = test_config[1]
- torch.manual_seed(0)
input_ids = torch.randint(0, 100, (2, tokens)).cuda()
- orig_model = model_cls(config).cuda()
+ orig_model = model_cls(config).cuda().to(dtype)
+
+ seed_all(10086)
model = deepcopy(orig_model)
- optimizer = Adam(model.parameters(), lr=1e-3)
+ optimizer = SGD(model.parameters(), lr=1e-3)
plugin = MoeHybridParallelPlugin(
- pp_size=2,
- ep_size=2,
- tp_size=1,
- checkpoint_io=MoECheckpointIO,
- microbatch_size=1,
- zero_stage=1,
+ pp_size=2, ep_size=2, tp_size=1, microbatch_size=1, zero_stage=1, precision=precision
)
booster = Booster(plugin=plugin)
model, optimizer, *_ = booster.boost(model=model, optimizer=optimizer)
@@ -139,13 +129,12 @@ def check_moe_checkpoint(test_config):
booster.save_model(model, model_dir, shard=True)
dist.barrier()
if dist.get_rank() == 0:
- saved_model = model_cls.from_pretrained(model_dir).cuda()
+ saved_model = model_cls.from_pretrained(model_dir).cuda().to(dtype)
check_model_equal(orig_model, saved_model)
- # check_model_equal(model, saved_model)
saved_model.save_pretrained(hf_model_dir)
dist.barrier()
# check load model
- new_model = model_cls(config).cuda()
+ new_model = model_cls(config).cuda().to(dtype)
new_optimizer = Adam(new_model.parameters(), lr=1e-3)
new_model, new_optimizer, *_ = booster.boost(model=new_model, optimizer=new_optimizer)
booster.load_model(new_model, hf_model_dir)
diff --git a/tests/test_moe/test_moe_ep_tp.py b/tests/test_moe/test_moe_ep_tp.py
index 9bc11033af6f..e6d2609ee67c 100644
--- a/tests/test_moe/test_moe_ep_tp.py
+++ b/tests/test_moe/test_moe_ep_tp.py
@@ -1,238 +1,132 @@
-import os
-import warnings
-from typing import Dict
+from copy import deepcopy
import pytest
import torch
import torch.distributed as dist
+from transformers.models.mixtral.configuration_mixtral import MixtralConfig
+from transformers.models.mixtral.modeling_mixtral import MixtralModel
import colossalai
-from colossalai.accelerator import get_accelerator
-from colossalai.moe.manager import MOE_MANAGER
-from colossalai.moe.utils import sync_moe_model_param
-
-# from colossalai.shardformer.layer import SparseMLP
-from colossalai.tensor.moe_tensor.api import get_ep_group, get_ep_rank, get_ep_size, is_moe_tensor
-from colossalai.testing import assert_equal_in_group, rerun_if_address_is_in_use, spawn
-from tests.test_moe.moe_utils import MoeGradientHandler
-
-
-def sync_tp_from_local(tp_model, local_model, assert_grad_flag: bool = False) -> None:
- """Sync the parameters of tp model from local model
-
- Args:
- tp_model (MoeModule)
- local_model (MoeModule)
- """
- for (tp_name, tp_param), (local_name, local_param) in zip(
- tp_model.named_parameters(), local_model.named_parameters()
- ):
- assert tp_name == local_name
- if not is_moe_tensor(tp_param):
- if assert_grad_flag:
- assert torch.allclose(tp_param, local_param)
- assert torch.allclose(tp_param.grad, local_param.grad)
- else:
- tp_param.data.copy_(local_param.data)
- continue
-
- tp_rank = get_ep_rank(tp_param)
- tp_dim = [i for i, (d1, d2) in enumerate(zip(tp_param.shape, local_param.shape)) if d1 != d2][0]
- tp_slice = [slice(None)] * tp_dim + [
- slice(tp_param.shape[tp_dim] * tp_rank, tp_param.shape[tp_dim] * (tp_rank + 1))
- ]
-
- if assert_grad_flag:
- assert torch.allclose(tp_param, local_param[tuple(tp_slice)])
- assert torch.allclose(tp_param.grad, local_param.grad[tuple(tp_slice)])
- else:
- tp_param.data.copy_(local_param[tuple(tp_slice)].data)
-
-
-def sync_tp_from_ep(tp_model, ep_model, assert_grad_flag: bool = False) -> None:
- """Sync the parameters of tp model from ep model
-
- Args:
- tp_model (MoeModule)
- ep_model (MoeModule)
- """
- for (tp_name, tp_param), (ep_name, ep_param) in zip(tp_model.named_parameters(), ep_model.named_parameters()):
- assert tp_name == ep_name
- if not is_moe_tensor(tp_param):
- if assert_grad_flag:
- assert torch.allclose(tp_param, ep_param)
- assert torch.allclose(tp_param.grad, ep_param.grad)
- else:
- tp_param.data.copy_(ep_param.data)
- continue
-
- # gather param from ep model
- param_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
- dist.all_gather(param_list, ep_param, group=get_ep_group(ep_param))
- all_param = torch.cat(param_list, dim=0)
- if assert_grad_flag:
- grad_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
- dist.all_gather(grad_list, ep_param.grad, group=get_ep_group(ep_param))
- all_grad = torch.cat(grad_list, dim=0)
-
- # get tp param
- tp_dim = [i for i, (d1, d2) in enumerate(zip(tp_param.shape[1:], all_param.shape[1:])) if d1 != d2][0] + 1
- tp_rank = get_ep_rank(tp_param)
- tp_slice = [slice(None)] * tp_dim + [
- slice(tp_param.shape[tp_dim] * tp_rank, tp_param.shape[tp_dim] * (tp_rank + 1))
- ]
- new_tp_param = all_param[tuple(tp_slice)]
- if assert_grad_flag:
- new_grad = all_grad[tuple(tp_slice)]
- if assert_grad_flag:
- assert torch.allclose(tp_param, new_tp_param)
- assert torch.allclose(tp_param.grad, new_grad)
- else:
- tp_param.data.copy_(new_tp_param.data)
-
-
-def sync_local_from_ep(local_model, ep_model, assert_grad_flag: bool = False) -> None:
- """Sync the parameters of tp model from ep model
-
- Args:
- local_model (MoeModule)
- ep_model (MoeModule)
- """
- for (local_name, local_param), (ep_name, ep_param) in zip(
- local_model.named_parameters(), ep_model.named_parameters()
- ):
- assert local_name == ep_name
- if "experts" not in local_name:
- if assert_grad_flag:
- assert torch.allclose(local_param, ep_param)
- assert torch.allclose(local_param.grad, ep_param.grad)
- else:
- local_param.data.copy_(ep_param.data)
- continue
-
- # gather param from ep model
- param_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
- dist.all_gather(param_list, ep_param, group=get_ep_group(ep_param))
- all_param = torch.cat(param_list, dim=0)
- if assert_grad_flag:
- grad_list = [torch.zeros_like(ep_param) for _ in range(get_ep_size(ep_param))]
- dist.all_gather(grad_list, ep_param.grad, group=get_ep_group(ep_param))
- all_grad = torch.cat(grad_list, dim=0)
-
- if assert_grad_flag:
- assert torch.allclose(local_param, all_param)
- assert torch.allclose(local_param.grad, all_grad)
- else:
- local_param.data.copy_(all_param.data)
-
-
-def run_test(rank: int, world_size: int, port: int, num_experts: int, batch_size: int, dim: int, config: Dict):
- assert batch_size % world_size == 0
-
- colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
-
- MOE_MANAGER.__init__()
- MOE_MANAGER.setup(parallel=None)
- local_model = SparseMLP(num_experts=num_experts, hidden_size=dim, intermediate_size=dim * 2)
- MOE_MANAGER.__init__()
- MOE_MANAGER.setup(parallel="EP")
- enable_hierarchical_comm = config.get("enable_hierarchical_comm", False)
- if enable_hierarchical_comm:
- os.environ["LOCAL_WORLD_SIZE"] = str(world_size)
- ep_model = SparseMLP(
- num_experts=num_experts,
- hidden_size=dim,
- intermediate_size=dim * 2,
- enable_hierarchical_comm=enable_hierarchical_comm,
+from colossalai.booster.booster import Booster
+from colossalai.booster.plugin import HybridParallelPlugin
+from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+from colossalai.testing.random import seed_all
+from tests.test_moe.moe_utils import assert_loose_close
+
+NUM_BATCH = 4
+NUM_TOK_PER_BATCH, NUM_EXPERTS = 7, 4
+HIDDEN_SIZE_PER_HEAD = 4
+NUM_HEADS = 4
+TOP_K = 2
+
+
+@parameterize("stage", [1])
+@parameterize("ep_size", [2])
+def run_zero_with_original_model(stage: int, ep_size: int):
+ tp_size = dist.get_world_size() // ep_size
+ dtype = torch.bfloat16
+
+ rank = torch.distributed.get_rank()
+ torch.cuda.set_device(dist.get_rank())
+
+ seed_all(10086)
+
+ config = MixtralConfig(
+ hidden_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS,
+ intermediate_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS * 2,
+ num_hidden_layers=2,
+ num_attention_heads=NUM_HEADS,
+ num_key_value_heads=NUM_HEADS,
+ num_local_experts=NUM_EXPERTS,
+ num_experts_per_tok=TOP_K,
)
- MOE_MANAGER.__init__()
- MOE_MANAGER.setup(parallel="TP")
- tp_model = SparseMLP(num_experts=num_experts, hidden_size=dim, intermediate_size=dim * 2)
- ep_model = ep_model.to(get_accelerator().get_current_device())
- tp_model = tp_model.to(get_accelerator().get_current_device())
- local_model = local_model.to(get_accelerator().get_current_device())
-
- # sync ep param
- sync_moe_model_param(ep_model)
- dist_dict = MOE_MANAGER.parallel_info_dict
- assert_equal_in_group(ep_model.experts.wi.data, dist_dict[world_size].dp_group)
- assert_equal_in_group(ep_model.experts.wo.data, dist_dict[world_size].dp_group)
- ep_grad_handler = MoeGradientHandler(ep_model)
- # sync local param
- sync_local_from_ep(local_model, ep_model)
- # sync tp param
- sync_tp_from_ep(tp_model, ep_model)
- tp_grad_handler = MoeGradientHandler(tp_model)
-
- rank = dist.get_rank()
- input_data = torch.randn(batch_size, dim, device=get_accelerator().get_current_device())
- micro_batch_size = batch_size // world_size
- index = rank * micro_batch_size
- # NOTE: ep & tp takes in sharded data for each process
- shard_data = input_data.detach()[index : index + micro_batch_size]
-
- out_local = local_model(input_data)
- MOE_MANAGER.reset_loss()
- out_tp = tp_model(shard_data)
- MOE_MANAGER.reset_loss()
- out_ep = ep_model(shard_data)
- MOE_MANAGER.reset_loss()
-
- assert torch.allclose(
- out_tp, out_ep, atol=1e-6
- ), f"Rank {rank} failed, max diff: {torch.max(torch.abs(out_tp - out_ep))}"
- try:
- out_local_slice = out_local[index : index + micro_batch_size]
- assert torch.allclose(
- out_ep, out_local_slice, atol=1e-6
- ), f"Rank {rank} failed, max diff: {torch.max(torch.abs(out_ep - out_local_slice))}"
- except AssertionError:
- """
- e.g., in local model, tokens = 4, capacity = 2, experts = 2, topk = 1
- router yields [01] --> [0], [23] --> [1], this is valid as capacity is 2
- However, in ep mode, there are 2 separate routers dealing with sharded data.
- Assume router 0 handles token [01] and router 1 handles token [23].
- Note that for each router the capacity is only 1 !!!
- Thus, router 0 may yields [0] --> [0] or [1] --> [0], but not both.
- The same thing happens on router 1. And finally some tokens are dropped due to the sharded nature.
- """
- warnings.warn(
- "EP & TP may result in different behavior from local model. " "Please check the comments for details."
+ torch_model = MixtralModel(config).to(dtype).cuda()
+
+ zero_model = deepcopy(torch_model).to(dtype)
+ zero_optimizer = torch.optim.SGD(zero_model.parameters(), lr=1)
+ moe_booster = Booster(
+ plugin=MoeHybridParallelPlugin(
+ tp_size=tp_size,
+ moe_tp_size=tp_size,
+ pp_size=1,
+ ep_size=ep_size,
+ zero_stage=stage,
+ overlap_communication=False,
+ initial_scale=1,
)
-
- out_local.mean().backward()
- out_tp.mean().backward()
- tp_grad_handler.handle_gradient()
- out_ep.mean().backward()
- ep_grad_handler.handle_gradient()
-
- assert_equal_in_group(ep_model.experts.wi.grad, dist_dict[world_size].dp_group)
- assert_equal_in_group(ep_model.experts.wo.grad, dist_dict[world_size].dp_group)
- sync_tp_from_ep(tp_model, ep_model, assert_grad_flag=True)
- try:
- sync_local_from_ep(local_model, ep_model, assert_grad_flag=True)
- except AssertionError:
- warnings.warn(
- "EP & TP may result in different behavior from local model. " "Please check the comments for details."
+ )
+ zero_model, zero_optimizer, _, _, _ = moe_booster.boost(zero_model, zero_optimizer)
+
+ hybird_booster = Booster(
+ plugin=HybridParallelPlugin(
+ tp_size=tp_size,
+ pp_size=1,
+ zero_stage=stage,
+ overlap_communication=False,
+ initial_scale=1,
)
+ )
+ hybrid_model, hybrid_optimizer, _, _, _ = hybird_booster.boost(
+ torch_model, torch.optim.SGD(torch_model.parameters(), lr=1)
+ )
+ # create different input
+ seed_all(1453 + rank)
+
+ hybrid_model.train()
+ zero_model.train()
+ for _ in range(2):
+ # zero-dp forward
+ input_data = torch.rand(
+ NUM_BATCH, NUM_TOK_PER_BATCH, HIDDEN_SIZE_PER_HEAD * NUM_HEADS, requires_grad=True
+ ).cuda()
+ zero_output = zero_model(inputs_embeds=input_data.to(dtype)).last_hidden_state.mean()
+ # zero-dp backward
+ zero_optimizer.backward(zero_output)
+ # torch-ddp forward
+ hybrid_output = hybrid_model(inputs_embeds=input_data.to(dtype)).last_hidden_state.mean()
+ assert_loose_close(zero_output, hybrid_output, dtype=dtype)
+ # torch-ddp backward
+ hybrid_optimizer.backward(hybrid_output)
+
+ # check grad
+ name_to_p = {n: p for n, p in hybrid_model.named_parameters()}
+ for n, p in zero_model.named_parameters():
+ zero_grad = zero_optimizer.get_param_grad(p)
+ if name_to_p[n].grad is None:
+ name_to_p[n].grad = torch.zeros_like(name_to_p[n])
+ continue
+ if zero_grad.shape != name_to_p[n].grad.shape: # TODO check sharded and sliced moe
+ continue
+ assert_loose_close(zero_grad, name_to_p[n].grad, dtype=dtype, name=n)
+
+ # zero-dp step
+ zero_optimizer.step()
+
+ # original model step
+ hybrid_optimizer.step()
+
+ # check updated param
+ for n, p in zero_model.named_parameters():
+ if p.data.shape != name_to_p[n].data.shape: # TODO check sharded and sliced moe
+ continue
+ assert_loose_close(p.data, name_to_p[n].data, dtype=dtype, name=n)
+
+ print(f"{dist.get_rank()} test passed")
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ run_zero_with_original_model()
-@pytest.mark.skip(reason="moe need to be refactored")
+@pytest.mark.skip("tested in corresponding sharderformer")
@pytest.mark.dist
-@pytest.mark.parametrize("num_experts", [4, 64])
-@pytest.mark.parametrize("batch_size", [16])
-@pytest.mark.parametrize("dim", [64])
-@pytest.mark.parametrize(
- "config",
- [
- {"enable_hierarchical_comm": False},
- {"enable_hierarchical_comm": True},
- ],
-)
+@pytest.mark.parametrize("world_size", [4])
@rerun_if_address_is_in_use()
-def test_moe_ep_tp(num_experts: int, batch_size: int, dim: int, config: Dict):
- spawn(run_test, 2, num_experts=num_experts, batch_size=batch_size, dim=dim, config=config)
+def test_moe_ep_tp(world_size):
+ spawn(run_dist, world_size)
if __name__ == "__main__":
- test_moe_ep_tp(num_experts=8, batch_size=32, dim=32)
+ test_moe_ep_tp(world_size=4)
diff --git a/tests/test_moe/test_moe_ep_zero.py b/tests/test_moe/test_moe_ep_zero.py
new file mode 100644
index 000000000000..2d4e638b638a
--- /dev/null
+++ b/tests/test_moe/test_moe_ep_zero.py
@@ -0,0 +1,119 @@
+from copy import deepcopy
+
+import pytest
+import torch
+import torch.distributed as dist
+from torch.nn.parallel import DistributedDataParallel as DDP
+from transformers.models.mixtral.configuration_mixtral import MixtralConfig
+from transformers.models.mixtral.modeling_mixtral import MixtralModel
+
+import colossalai
+from colossalai.booster.booster import Booster
+from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+from colossalai.testing.random import seed_all
+from tests.test_moe.moe_utils import assert_loose_close
+
+NUM_BATCH = 4
+NUM_TOK_PER_BATCH, NUM_EXPERTS = 7, 4
+HIDDEN_SIZE_PER_HEAD = 4
+NUM_HEADS = 2
+TOP_K = 1
+
+
+@parameterize("stage", [1])
+@parameterize("ep_size", [2, 4])
+def run_zero_with_original_model(stage: int, ep_size: int):
+ dtype = torch.bfloat16
+
+ rank = torch.distributed.get_rank()
+ torch.cuda.set_device(dist.get_rank())
+
+ plugin = MoeHybridParallelPlugin(
+ pp_size=1, tp_size=1, ep_size=ep_size, zero_stage=stage, overlap_communication=False, initial_scale=1
+ )
+ booster = Booster(plugin=plugin)
+
+ seed_all(10086)
+
+ config = MixtralConfig(
+ hidden_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS,
+ intermediate_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS * 2,
+ num_hidden_layers=2,
+ num_attention_heads=NUM_HEADS,
+ num_key_value_heads=NUM_HEADS,
+ num_local_experts=NUM_EXPERTS,
+ num_experts_per_tok=TOP_K,
+ )
+
+ torch_model = MixtralModel(config).to(dtype).cuda()
+
+ zero_model = deepcopy(torch_model).to(dtype)
+ zero_optimizer = torch.optim.SGD(zero_model.parameters(), lr=1)
+
+ zero_model, zero_optimizer, _, _, _ = booster.boost(zero_model, zero_optimizer)
+
+ ddp_model = DDP(
+ torch_model.cuda(),
+ process_group=plugin.dp_group,
+ find_unused_parameters=True, # important for torch ddp, not all experts are routed
+ ).cuda()
+ ddp_optimizer = torch.optim.SGD(ddp_model.parameters(), lr=1)
+
+ # create different input
+ seed_all(1453 + rank)
+
+ ddp_model.train()
+ zero_model.train()
+ for _ in range(2):
+ # zero-dp forward
+ input_data = torch.rand(
+ NUM_BATCH, NUM_TOK_PER_BATCH, HIDDEN_SIZE_PER_HEAD * NUM_HEADS, requires_grad=True
+ ).cuda()
+ zero_output = zero_model(inputs_embeds=input_data.to(dtype)).last_hidden_state.mean()
+ # zero-dp backward
+ zero_optimizer.backward(zero_output)
+
+ # torch-ddp forward
+ ddp_output = ddp_model(inputs_embeds=input_data.to(dtype)).last_hidden_state.mean()
+ assert_loose_close(zero_output, ddp_output, dtype=dtype)
+ # torch-ddp backward
+ ddp_output.backward()
+
+ # check grad
+ name_to_p = {n: p for n, p in ddp_model.named_parameters()}
+ for n, p in zero_model.named_parameters():
+ zero_grad = zero_optimizer.get_param_grad(p)
+ if name_to_p[n].grad is None:
+ name_to_p[n].grad = torch.zeros_like(name_to_p[n].data)
+ continue
+ assert_loose_close(zero_grad, name_to_p[n].grad, dtype=dtype, name=n)
+
+ # zero-dp step
+ zero_optimizer.step()
+
+ # original model step
+ ddp_optimizer.step()
+
+ # check updated param
+ for n, p in zero_model.named_parameters():
+ assert_loose_close(p.data, name_to_p[n].data, dtype=dtype, name=n)
+
+ print(f"{dist.get_rank()} test passed")
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ run_zero_with_original_model()
+
+
+@pytest.mark.skip("tested in corresponding sharderformer")
+@pytest.mark.dist
+@pytest.mark.parametrize("world_size", [4])
+@rerun_if_address_is_in_use()
+def test_moe_ep_zero(world_size):
+ spawn(run_dist, world_size)
+
+
+if __name__ == "__main__":
+ test_moe_ep_zero(world_size=4)
diff --git a/tests/test_moe/test_moe_zero_fwd_bwd_optim.py b/tests/test_moe/test_moe_zero_fwd_bwd_optim.py
deleted file mode 100644
index 042b3d8aedc5..000000000000
--- a/tests/test_moe/test_moe_zero_fwd_bwd_optim.py
+++ /dev/null
@@ -1,132 +0,0 @@
-from copy import deepcopy
-
-import pytest
-import torch
-import torch.distributed as dist
-from torch.nn.parallel import DistributedDataParallel as DDP
-from transformers.models.mixtral.configuration_mixtral import MixtralConfig
-from transformers.models.mixtral.modeling_mixtral import MixtralSparseMoeBlock
-
-import colossalai
-from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
-from colossalai.shardformer.modeling.mixtral import EPMixtralSparseMoeBlock
-from colossalai.tensor.moe_tensor.api import is_moe_tensor
-from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
-from colossalai.testing.random import seed_all
-from colossalai.zero import LowLevelZeroOptimizer
-from tests.test_moe.moe_utils import loose_close
-
-tokens, n_experts = 7, 4
-hidden_size = 8
-top_k = 2
-
-
-def split_grad(grad, world_size):
- with torch.no_grad():
- grad = grad.clone().detach().flatten()
- padding_size = (world_size - grad.numel() % world_size) % world_size
- if padding_size > 0:
- grad = torch.nn.functional.pad(grad, [0, padding_size])
- splited_grad = grad.split(grad.numel() // world_size)
- return splited_grad
-
-
-@parameterize("dtype", [torch.float16, torch.bfloat16])
-@parameterize("master_weights", [True, False])
-@parameterize("stage", [1, 2])
-def run_zero_with_original_model(world_size, master_weights: bool, dtype: torch.dtype, stage: int):
- rank = torch.distributed.get_rank()
- torch.cuda.set_device(dist.get_rank())
- plugin = MoeHybridParallelPlugin(
- tp_size=1,
- pp_size=1,
- ep_size=dist.get_world_size() // 2,
- )
-
- seed_all(10086)
- config = MixtralConfig(
- hidden_size=hidden_size,
- intermediate_size=hidden_size * 2,
- num_local_experts=n_experts,
- num_experts_per_tok=top_k,
- )
-
- orig_model = MixtralSparseMoeBlock(config).to(dtype).cuda()
-
- ori_model = DDP(orig_model.cuda(), static_graph=True).cuda()
-
- zero_model = deepcopy(orig_model).to(dtype)
- zero_model = EPMixtralSparseMoeBlock.from_native_module(zero_model, ep_group=plugin.ep_group)
-
- zero_optimizer = torch.optim.SGD(zero_model.parameters(), lr=1)
- pg_param_list = {plugin.global_dp_group: [], plugin.moe_dp_group: []}
- for p in zero_model.parameters():
- if is_moe_tensor(p):
- pg_param_list[plugin.moe_dp_group].append(p)
- else:
- pg_param_list[plugin.global_dp_group].append(p)
-
- zero_optimizer = LowLevelZeroOptimizer(
- zero_optimizer,
- pg_to_param_list=pg_param_list,
- master_weights=master_weights,
- initial_scale=1,
- overlap_communication=False,
- partition_grad=True,
- )
-
- ori_optimizer = torch.optim.SGD(ori_model.parameters(), lr=1)
-
- # create
- seed_all(1453 + rank)
-
- for _ in range(2):
- # zero-dp forward
- input_data = torch.rand(1, tokens, hidden_size).cuda()
- zero_output, zero_logits = zero_model(input_data.to(dtype))
-
- # torch-ddp forward
- ori_output, ori_logits = ori_model(input_data.to(dtype))
- loose_close(zero_output, ori_output, dtype=dtype)
-
- # zero-dp backward
- zero_optimizer.backward(zero_output.mean().float())
-
- # torch-ddp backward
- ori_output.mean().backward()
-
- # check grad
- name_to_p = {n: p for n, p in ori_model.module.named_parameters()}
- for n, p in zero_model.named_parameters():
- zero_grad = zero_optimizer.get_param_grad(p)
- if name_to_p[n].grad is None:
- assert zero_grad is None
- continue
-
- loose_close(zero_grad, name_to_p[n].grad, dtype=dtype)
-
- # zero-dp step
- zero_optimizer.step()
-
- # original model step
- ori_optimizer.step()
-
- # check updated param
- for n, p in zero_model.named_parameters():
- loose_close(p.data, name_to_p[n].data, dtype=dtype)
-
-
-def run_dist(rank, world_size, port):
- colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
- run_zero_with_original_model(world_size=world_size)
-
-
-@pytest.mark.dist
-@pytest.mark.parametrize("world_size", [2, 4])
-@rerun_if_address_is_in_use()
-def test_moe_zero_model(world_size):
- spawn(run_dist, world_size)
-
-
-if __name__ == "__main__":
- test_moe_zero_model(world_size=4)
diff --git a/tests/test_shardformer/test_model/_utils.py b/tests/test_shardformer/test_model/_utils.py
index 1ffcc541a854..190fee12931b 100644
--- a/tests/test_shardformer/test_model/_utils.py
+++ b/tests/test_shardformer/test_model/_utils.py
@@ -1,6 +1,6 @@
import copy
from contextlib import nullcontext
-from typing import Any, Callable, Dict, List, Optional
+from typing import Any, Callable, Dict, List, Optional, Type
import torch
import torch.distributed as dist
@@ -117,7 +117,12 @@ def check_state_dict(org_model: Module, sharded_model: Module, name: str = ""):
def build_model_from_hybrid_plugin(
- model_fn: Callable, loss_fn: Callable, test_config: Dict[str, Any], optim_class=Adam, sharded_optim_class=Adam
+ model_fn: Callable,
+ loss_fn: Callable,
+ test_config: Dict[str, Any],
+ optim_class=Adam,
+ sharded_optim_class=Adam,
+ pluggin_cls: Type[HybridParallelPlugin] = HybridParallelPlugin,
):
use_lazy_init = False
if "use_lazy_init" in test_config:
@@ -149,9 +154,10 @@ def build_model_from_hybrid_plugin(
else:
org_optimizer = optim_class(org_model.parameters(), lr=1e-3)
sharded_optimizer = sharded_optim_class(sharded_model.parameters(), lr=1e-3)
+
criterion = loss_fn
- plugin = HybridParallelPlugin(**test_config)
+ plugin = pluggin_cls(**test_config)
booster = Booster(plugin=plugin)
sharded_model, sharded_optimizer, criterion, _, _ = booster.boost(sharded_model, sharded_optimizer, criterion)
diff --git a/tests/test_shardformer/test_model/test_shard_deepseek.py b/tests/test_shardformer/test_model/test_shard_deepseek.py
new file mode 100644
index 000000000000..46da4522fd9d
--- /dev/null
+++ b/tests/test_shardformer/test_model/test_shard_deepseek.py
@@ -0,0 +1,196 @@
+import os
+import shutil
+from copy import deepcopy
+from typing import Tuple
+
+import pytest
+import torch
+import torch.distributed
+import torch.distributed as dist
+from transformers import AutoConfig, AutoModel
+
+import colossalai
+from colossalai.booster.booster import Booster
+from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+from colossalai.testing.random import seed_all
+from tests.test_moe.moe_utils import assert_loose_close, check_model_equal
+
+NUM_BATCH = 8
+NUM_TOK_PER_BATCH, NUM_EXPERTS = 4, 2
+NUM_LAYERS = 4
+HIDDEN_SIZE_PER_HEAD = 4
+NUM_HEADS = 4
+TOP_K = 2
+
+
+CHECKED_CONFIG = [ # FOR_WORLD=4
+ (1, 4, 1, 1, 1),
+ (1, 1, 4, 1, 1),
+ (1, 1, 1, 4, 1),
+ (1, 1, 1, 1, 4),
+ (0, 1, 4, 1, 1),
+ (0, 1, 1, 4, 1),
+ (0, 1, 1, 1, 4),
+ (1, 2, 1, 1, 1),
+]
+
+
+@parameterize(
+ "config",
+ [
+ (1, 2, 2, 1, 1),
+ (1, 2, 1, 2, 1),
+ (1, 2, 1, 1, 2),
+ ],
+)
+def run_zero_with_original_model(config: Tuple[int, ...]):
+ stage, ep_size, pp_size, tp_size, sp_size = config
+ world_size = dist.get_world_size()
+ rank = dist.get_rank()
+ dtype, precision = torch.float16, "fp16"
+ torch.cuda.set_device(dist.get_rank())
+
+ plugin = MoeHybridParallelPlugin(
+ pp_size=pp_size,
+ num_microbatches=pp_size,
+ tp_size=tp_size,
+ sp_size=sp_size,
+ ep_size=ep_size,
+ zero_stage=stage,
+ enable_sequence_parallelism=sp_size > 1,
+ sequence_parallelism_mode="all_to_all" if sp_size > 1 else None,
+ enable_flash_attention=sp_size > 1,
+ overlap_communication=False,
+ initial_scale=1,
+ precision=precision,
+ find_unused_parameters=True,
+ )
+ dp_size = plugin.dp_size
+
+ booster = Booster(plugin=plugin)
+
+ assert pp_size <= NUM_LAYERS, "pp_size should be less than or equal to NUM_LAYERS"
+ config = AutoConfig.from_pretrained(
+ "deepseek-ai/deepseek-moe-16b-base",
+ hidden_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS,
+ intermediate_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS * 2,
+ moe_intermediate_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS * 2,
+ num_hidden_layers=4,
+ num_attention_heads=NUM_HEADS,
+ num_key_value_heads=NUM_HEADS,
+ first_k_dense_replace=1,
+ attn_implementation="flash_attention_2",
+ torch_dtype="float16",
+ n_routed_experts=NUM_EXPERTS,
+ num_experts_per_tok=TOP_K,
+ trust_remote_code=True,
+ )
+
+ # init model with the same seed
+ seed_all(10086)
+
+ torch_model = AutoModel.from_config(config, trust_remote_code=True).cuda().to(dtype)
+ torch_optimizer = torch.optim.SGD(torch_model.parameters(), lr=1)
+
+ parallel_model = deepcopy(torch_model)
+ parallel_optimizer = torch.optim.SGD(parallel_model.parameters(), lr=1)
+ parallel_model, parallel_optimizer, _, _, _ = booster.boost(parallel_model, parallel_optimizer)
+
+ # create different input along dp axis
+ seed_all(1453 + rank)
+
+ torch_model.train()
+ parallel_model.train()
+ for _ in range(2):
+ # gen random input
+ input_embeddings = torch.rand(
+ NUM_BATCH, NUM_TOK_PER_BATCH, HIDDEN_SIZE_PER_HEAD * NUM_HEADS, requires_grad=True
+ ).cuda()
+ dist.all_reduce(
+ input_embeddings, group=plugin.pp_group
+ ) # pp inputs except the first stage doesn't matter, but need to be replicate for torch model check
+
+ dist.all_reduce(input_embeddings, group=plugin.tp_group) # tp group duplicate input
+ dist.all_reduce(input_embeddings, group=plugin.sp_group) # sp group duplicate input
+
+ # run the model with hybrid parallel
+ if booster.plugin.stage_manager is not None:
+ # for test with pp
+ data_iter = iter([{"inputs_embeds": input_embeddings}])
+ sharded_output = booster.execute_pipeline(
+ data_iter,
+ parallel_model,
+ lambda x, y: x[0].mean(),
+ parallel_optimizer,
+ return_loss=True,
+ return_outputs=True,
+ )
+ if booster.plugin.stage_manager.is_last_stage():
+ parallel_output = sharded_output["loss"]
+ else:
+ parallel_output = torch.tensor(12345.0, device="cuda")
+
+ # broadcast along pp axis
+ dist.broadcast(
+ parallel_output, src=dist.get_process_group_ranks(plugin.pp_group)[-1], group=plugin.pp_group
+ )
+ else:
+ # for test without pp
+ parallel_output = parallel_model(inputs_embeds=input_embeddings.to(dtype)).last_hidden_state.mean()
+ parallel_optimizer.backward(parallel_output)
+ parallel_optimizer.step()
+ parallel_optimizer.zero_grad()
+ dist.all_reduce(parallel_output, group=plugin.dp_group)
+
+ # ===================================================================================
+ # run normal model with all dp(different) inputs
+ all_inputs = [torch.empty_like(input_embeddings) for _ in range(dp_size)]
+ dist.all_gather(all_inputs, input_embeddings, group=plugin.dp_group)
+ torch_output_sum = 0
+ for input_data_ in all_inputs:
+ torch_output = torch_model(inputs_embeds=input_data_.to(dtype)).last_hidden_state.mean()
+ torch_output.backward()
+ torch_output_sum += torch_output.detach()
+ # avg dp grads follows zero optimizer
+ for p in torch_model.parameters():
+ if p.grad is not None:
+ p.grad /= dp_size
+ torch_optimizer.step()
+ torch_optimizer.zero_grad()
+
+ assert_loose_close(parallel_output, torch_output_sum, dtype=dtype)
+
+ # use checkpoint to load sharded zero model
+ model_dir = "./test_deepseek"
+ if rank == world_size - 1:
+ os.makedirs(model_dir, exist_ok=True)
+
+ dist.barrier()
+ booster.save_model(parallel_model, model_dir, shard=True)
+ dist.barrier()
+
+ saved_model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).cuda()
+ check_model_equal(torch_model, saved_model)
+ dist.barrier()
+
+ if rank == world_size - 1:
+ shutil.rmtree(model_dir)
+
+ print(f"rank {dist.get_rank()} test passed")
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ run_zero_with_original_model()
+
+
+@pytest.mark.dist
+@pytest.mark.parametrize("world_size", [4])
+@rerun_if_address_is_in_use()
+def test_deepseek(world_size):
+ spawn(run_dist, world_size)
+
+
+if __name__ == "__main__":
+ test_deepseek(world_size=4)
diff --git a/tests/test_shardformer/test_model/test_shard_mixtral.py b/tests/test_shardformer/test_model/test_shard_mixtral.py
new file mode 100644
index 000000000000..de09eedcbed5
--- /dev/null
+++ b/tests/test_shardformer/test_model/test_shard_mixtral.py
@@ -0,0 +1,190 @@
+import os
+import shutil
+from copy import deepcopy
+from typing import Tuple
+
+import pytest
+import torch
+import torch.distributed
+import torch.distributed as dist
+from transformers.models.mixtral.configuration_mixtral import MixtralConfig
+from transformers.models.mixtral.modeling_mixtral import MixtralModel
+
+import colossalai
+from colossalai.booster.booster import Booster
+from colossalai.booster.plugin.moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
+from colossalai.testing import parameterize, rerun_if_address_is_in_use, spawn
+from colossalai.testing.random import seed_all
+from tests.test_moe.moe_utils import assert_loose_close, check_model_equal
+
+NUM_BATCH = 8
+NUM_TOK_PER_BATCH, NUM_EXPERTS = 4, 4
+NUM_LAYERS = 4
+HIDDEN_SIZE_PER_HEAD = 4
+NUM_HEADS = 4
+TOP_K = 1
+
+CHECKED_CONFIG = [ # FOR WORLD=4
+ (0, 1, 4, 1, 1),
+ (0, 1, 1, 4, 1),
+ (0, 1, 1, 1, 4),
+ (1, 4, 1, 1, 1),
+ (1, 1, 4, 1, 1),
+ (1, 1, 1, 4, 1),
+ (1, 1, 1, 1, 4),
+ (1, 2, 1, 1, 1),
+]
+
+
+@parameterize(
+ "config",
+ [
+ (1, 2, 2, 1, 1),
+ (1, 2, 1, 2, 1),
+ (1, 2, 1, 1, 2),
+ ],
+)
+def run_zero_with_original_model(config: Tuple[int, ...]):
+ stage, ep_size, pp_size, tp_size, sp_size = config
+ world_size = dist.get_world_size()
+ rank = dist.get_rank()
+ dtype, precision = torch.float16, "fp16"
+ torch.cuda.set_device(dist.get_rank())
+
+ plugin = MoeHybridParallelPlugin(
+ pp_size=pp_size,
+ num_microbatches=pp_size,
+ tp_size=tp_size,
+ sp_size=sp_size,
+ ep_size=ep_size,
+ zero_stage=stage,
+ enable_sequence_parallelism=sp_size > 1,
+ sequence_parallelism_mode="all_to_all" if sp_size > 1 else None,
+ overlap_communication=False,
+ initial_scale=1,
+ precision=precision,
+ find_unused_parameters=True,
+ )
+ dp_size = plugin.dp_size
+
+ booster = Booster(plugin=plugin)
+
+ assert pp_size <= NUM_LAYERS, "pp_size should be less than or equal to NUM_LAYERS"
+ config = MixtralConfig(
+ hidden_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS,
+ intermediate_size=HIDDEN_SIZE_PER_HEAD * NUM_HEADS * 2,
+ num_hidden_layers=NUM_LAYERS,
+ num_attention_heads=NUM_HEADS,
+ num_key_value_heads=NUM_HEADS,
+ num_local_experts=NUM_EXPERTS,
+ num_experts_per_tok=TOP_K,
+ attn_implementation="flash_attention_2",
+ )
+
+ # init model with the same seed
+ seed_all(10086)
+
+ torch_model = MixtralModel(config).to(dtype).cuda()
+ torch_optimizer = torch.optim.SGD(torch_model.parameters(), lr=1)
+
+ parallel_model = deepcopy(torch_model)
+ parallel_optimizer = torch.optim.SGD(parallel_model.parameters(), lr=1)
+ parallel_model, parallel_optimizer, _, _, _ = booster.boost(parallel_model, parallel_optimizer)
+
+ # create different input along dp axis
+ seed_all(1453 + rank)
+
+ torch_model.train()
+ parallel_model.train()
+ for _ in range(2):
+ # gen random input
+ input_embeddings = torch.rand(
+ NUM_BATCH, NUM_TOK_PER_BATCH, HIDDEN_SIZE_PER_HEAD * NUM_HEADS, requires_grad=True
+ ).cuda()
+ dist.all_reduce(
+ input_embeddings, group=plugin.pp_group
+ ) # pp inputs except the first stage doesn't matter, but need to be replicate for torch model check
+
+ dist.all_reduce(input_embeddings, group=plugin.tp_group) # tp group duplicate input
+ dist.all_reduce(input_embeddings, group=plugin.sp_group) # sp group duplicate input
+
+ # run the model with hybrid parallel
+ if booster.plugin.stage_manager is not None:
+ # for test with pp
+ data_iter = iter([{"inputs_embeds": input_embeddings}])
+ sharded_output = booster.execute_pipeline(
+ data_iter,
+ parallel_model,
+ lambda x, y: x.last_hidden_state.mean(),
+ parallel_optimizer,
+ return_loss=True,
+ return_outputs=True,
+ )
+ if booster.plugin.stage_manager.is_last_stage():
+ parallel_output = sharded_output["loss"]
+ else:
+ parallel_output = torch.tensor(12345.0, device="cuda")
+
+ # broadcast along pp axis
+ dist.broadcast(
+ parallel_output, src=dist.get_process_group_ranks(plugin.pp_group)[-1], group=plugin.pp_group
+ )
+ else:
+ # for test without pp
+ parallel_output = parallel_model(inputs_embeds=input_embeddings.to(dtype)).last_hidden_state.mean()
+ parallel_optimizer.backward(parallel_output)
+ parallel_optimizer.step()
+ parallel_optimizer.zero_grad()
+ dist.all_reduce(parallel_output, group=plugin.dp_group)
+
+ # ===================================================================================
+ # run normal model with all dp(different) inputs
+ all_inputs = [torch.empty_like(input_embeddings) for _ in range(dp_size)]
+ dist.all_gather(all_inputs, input_embeddings, group=plugin.dp_group)
+ torch_output_sum = 0
+ for input_data_ in all_inputs:
+ torch_output = torch_model(inputs_embeds=input_data_.to(dtype)).last_hidden_state.mean()
+ torch_output.backward()
+ torch_output_sum += torch_output.detach()
+ # avg dp grads follows zero optimizer
+ for p in torch_model.parameters():
+ if p.grad is not None:
+ p.grad /= dp_size
+ torch_optimizer.step()
+ torch_optimizer.zero_grad()
+
+ assert_loose_close(parallel_output, torch_output_sum, dtype=dtype)
+
+ # use checkpoint to load sharded zero model
+ model_dir = "./test_mixtral"
+ if rank == world_size - 1:
+ os.makedirs(model_dir, exist_ok=True)
+
+ dist.barrier()
+ booster.save_model(parallel_model, model_dir, shard=True)
+ dist.barrier()
+
+ saved_model = MixtralModel.from_pretrained(model_dir).cuda().to(dtype)
+ check_model_equal(torch_model, saved_model)
+ dist.barrier()
+
+ if rank == world_size - 1:
+ shutil.rmtree(model_dir)
+
+ print(f"rank {dist.get_rank()} test passed")
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
+ run_zero_with_original_model()
+
+
+@pytest.mark.dist
+@pytest.mark.parametrize("world_size", [4])
+@rerun_if_address_is_in_use()
+def test_mixtral(world_size):
+ spawn(run_dist, world_size)
+
+
+if __name__ == "__main__":
+ test_mixtral(world_size=4)
diff --git a/version.txt b/version.txt
index 267577d47e49..2b7c5ae01848 100644
--- a/version.txt
+++ b/version.txt
@@ -1 +1 @@
-0.4.1
+0.4.2