Conversation
|
|
||
| data["source"] = ''.join(cell["source"]) | ||
|
|
||
| data["sockets"] = {} # TODO : add sockets |
There was a problem hiding this comment.
Less TODO comments. That's why there are github comments and issues. One is fine but there are too many.
| data = json.loads(file.read()) | ||
|
|
||
| data["id"] = 0 # TODO : give a proper id | ||
|
|
There was a problem hiding this comment.
Set the height / width of data to match the number of line of the source to avoid scrolling when reading the imported file.
| # Load the default empty block | ||
| # TODO : add something in case the user renames / removes the empty block / changes it too much ? | ||
| data: OrderedDict = {} | ||
| with open("blocks/empty.ocbb", 'r', encoding='utf-8') as file: |
There was a problem hiding this comment.
The empty block might change places in the future. The data fields should be set from scratch.
data = OrderedDict([
("id",0),
# ...
])You can checkout the serialize in block.py as an example
There was a problem hiding this comment.
27022fb
You can do something similar to what you did in this commit.
There was a problem hiding this comment.
In the future, the serialization process will be more robust and we'll be able to not set some fields like splitter and enjoy sane defaults.
opencodeblocks/scene/scene.py
Outdated
| data = json.loads(file.read()) | ||
| return data | ||
|
|
||
| def load_from_ipynb(self, filepath: str) -> OrderedDict: |
There was a problem hiding this comment.
This function is the same as load_from_ipyg. Consider renaming load_from_ipyg to something like load_from_json.
|
Update on the state of the pull request What is there
Here is what it looks like What is missing
|
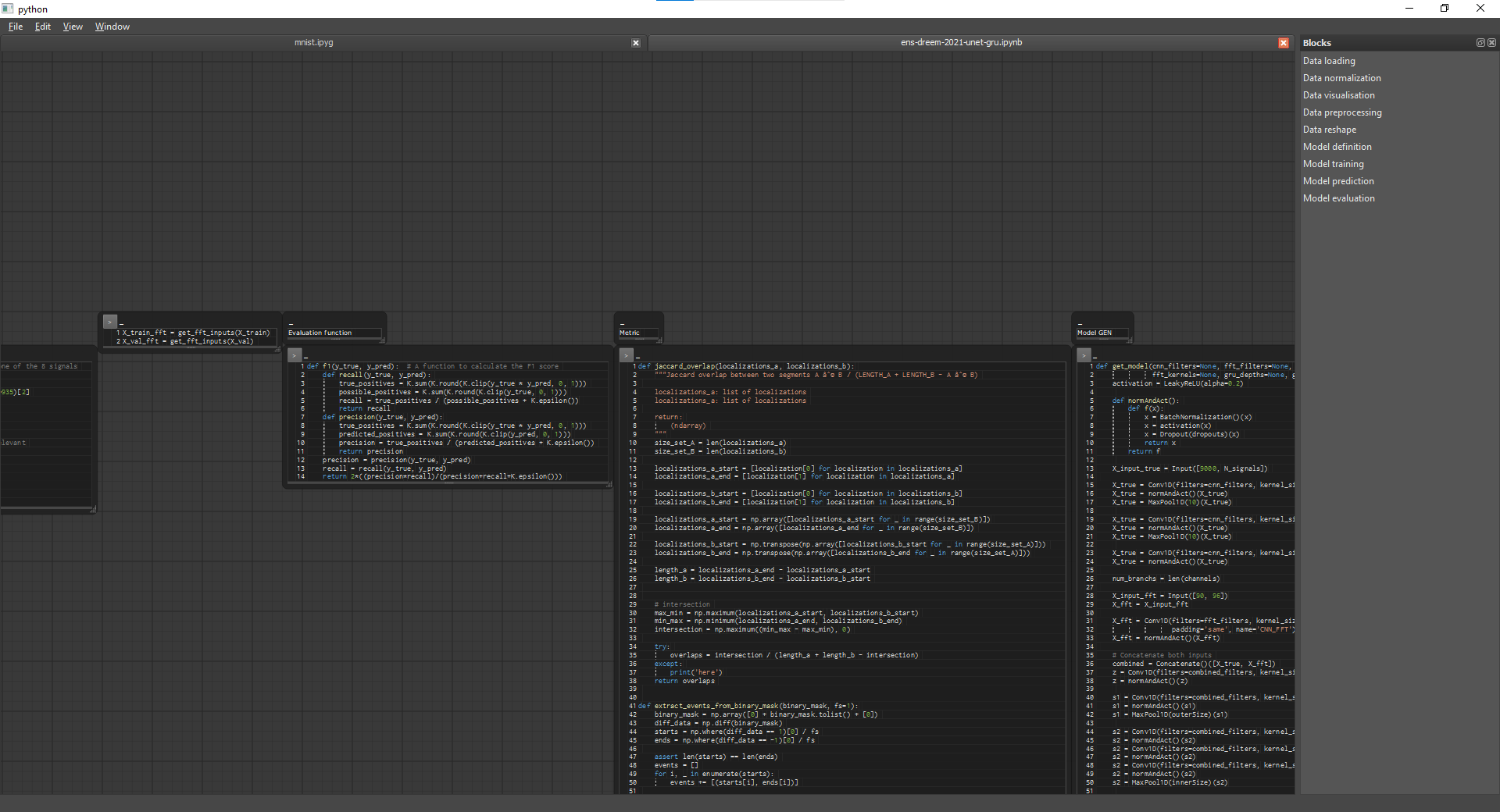
|
You're right about titles. I guess it depends on your use of markdown inside jupyter notebooks. |
|
Sockets are added and I have implemented your suggestion ("One solution would be to merge 2 jupyter notebook cells into one when the markdown cell is short") |
|
What is missing and will be added in future branches :
|
|
I need help with the following:
|
 MathisFederico
left a comment
MathisFederico
left a comment
There was a problem hiding this comment.
A first review !
Thanks for the contribution !
opencodeblocks/scene/scene.py
Outdated
| def load_from_ipyg(self, filepath: str): | ||
| """ Load an interactive python graph (.ipyg) into the scene. | ||
| def load_from_json(self, filepath: str) -> OrderedDict: | ||
| """Load the ipynb json data into an ordered dict |
There was a problem hiding this comment.
It's not only .ipynb json data, it can be .ipyg json data too (see lines 148-149)
| edges: List[OrderedDict] = add_sockets(blocks) | ||
|
|
||
| return { | ||
| "id": 0, |
There was a problem hiding this comment.
| "id": 0, |
id should not be present to be generated
| """Convert ipynb data (ipynb file, as ordered dict) into ipyg data (ipyg, as ordered dict)""" | ||
|
|
||
| blocks: List[OrderedDict] = get_blocks(data) | ||
| edges: List[OrderedDict] = add_sockets(blocks) |
There was a problem hiding this comment.
| edges: List[OrderedDict] = add_sockets(blocks) | |
| edges_data: List[OrderedDict] = get_edges_data(data, blocks) |
add_sockets should be named get_edges_data to match get_blocks_data
Also original data should be passed to get_edges_data in case edges data is present in .ipynb metadata
| def ipynb_to_ipyg(data: OrderedDict) -> OrderedDict: | ||
| """Convert ipynb data (ipynb file, as ordered dict) into ipyg data (ipyg, as ordered dict)""" | ||
|
|
||
| blocks: List[OrderedDict] = get_blocks(data) |
There was a problem hiding this comment.
| blocks: List[OrderedDict] = get_blocks(data) | |
| blocks_data: List[OrderedDict] = get_blocks_data(data) |
blocks_data should be used instead of blocks. blocks should referer to actual OCBBlock instances
| def get_integers_generator() -> Generator[int, None, None]: | ||
| n = 0 | ||
| while True: | ||
| yield n | ||
| n += 1 |
There was a problem hiding this comment.
Unused function
| def get_integers_generator() -> Generator[int, None, None]: | |
| n = 0 | |
| while True: | |
| yield n | |
| n += 1 |
| def get_default_input_socket(socket_id: int) -> OrderedDict: | ||
| """Returns the default input socket with the corresponding id""" | ||
| return { | ||
| "id": socket_id, | ||
| "type": "input", | ||
| "position": [0.0, SOCKET_HEIGHT], | ||
| "metadata": { | ||
| "color": "#FF55FFF0", | ||
| "linecolor": "#FF000000", | ||
| "linewidth": 1.0, | ||
| "radius": 10.0, | ||
| }, | ||
| } |
There was a problem hiding this comment.
Should not add random metadata, deserialization should handle missing arguments with default ones. If that's not the case, raise an issue and start a bugfix branch from master.
| def get_default_input_socket(socket_id: int) -> OrderedDict: | |
| """Returns the default input socket with the corresponding id""" | |
| return { | |
| "id": socket_id, | |
| "type": "input", | |
| "position": [0.0, SOCKET_HEIGHT], | |
| "metadata": { | |
| "color": "#FF55FFF0", | |
| "linecolor": "#FF000000", | |
| "linewidth": 1.0, | |
| "radius": 10.0, | |
| }, | |
| } | |
| def get_default_input_socket(socket_id: int) -> OrderedDict: | |
| """Returns the default input socket with the corresponding id""" | |
| return {"id": socket_id, "type": "input"} |
| def get_default_output_socket(socket_id: int, block_width: int) -> OrderedDict: | ||
| """ | ||
| Returns the default input socket with the corresponding id | ||
| and at the correct relative position with respect to the block | ||
| """ | ||
| return { | ||
| "id": socket_id, | ||
| "type": "output", | ||
| "position": [block_width, SOCKET_HEIGHT], | ||
| "metadata": { | ||
| "color": "#FF55FFF0", | ||
| "linecolor": "#FF000000", | ||
| "linewidth": 1.0, | ||
| "radius": 10.0, | ||
| }, | ||
| } |
There was a problem hiding this comment.
Should not add random metadata, deserialization should handle missing arguments with default ones. If that's not the case, raise an issue and start a bugfix branch from master.
| def get_default_output_socket(socket_id: int, block_width: int) -> OrderedDict: | |
| """ | |
| Returns the default input socket with the corresponding id | |
| and at the correct relative position with respect to the block | |
| """ | |
| return { | |
| "id": socket_id, | |
| "type": "output", | |
| "position": [block_width, SOCKET_HEIGHT], | |
| "metadata": { | |
| "color": "#FF55FFF0", | |
| "linecolor": "#FF000000", | |
| "linewidth": 1.0, | |
| "radius": 10.0, | |
| }, | |
| } | |
| def get_default_output_socket(socket_id: int, block_width: int) -> OrderedDict: | |
| """Returns the default output socket with the corresponding id""" | |
| return {"id": socket_id, "type": "output"} |
| def get_default_edge( | ||
| edge_id: int, | ||
| edge_start_block_id: int, | ||
| edge_start_socket_id: int, | ||
| edge_end_block_id: int, | ||
| edge_end_socket_id: int, | ||
| ) -> OrderedDict: | ||
| return { | ||
| "id": edge_id, | ||
| "path_type": "bezier", | ||
| "source": {"block": edge_start_block_id, "socket": edge_start_socket_id}, | ||
| "destination": {"block": edge_end_block_id, "socket": edge_end_socket_id}, | ||
| } |
There was a problem hiding this comment.
path_type should be handled by deserialization
| def get_default_edge( | |
| edge_id: int, | |
| edge_start_block_id: int, | |
| edge_start_socket_id: int, | |
| edge_end_block_id: int, | |
| edge_end_socket_id: int, | |
| ) -> OrderedDict: | |
| return { | |
| "id": edge_id, | |
| "path_type": "bezier", | |
| "source": {"block": edge_start_block_id, "socket": edge_start_socket_id}, | |
| "destination": {"block": edge_end_block_id, "socket": edge_end_socket_id}, | |
| } | |
| def get_default_edge( | |
| edge_id: int, | |
| edge_start_block_id: int, | |
| edge_start_socket_id: int, | |
| edge_end_block_id: int, | |
| edge_end_socket_id: int, | |
| ) -> OrderedDict: | |
| return { | |
| "id": edge_id, | |
| "source": {"block": edge_start_block_id, "socket": {"id": socket_id, "type": "output"}, | |
| "destination": {"block": edge_end_block_id, "socket": {"id": socket_id, "type": "output"}}, | |
| } |
You can use a generator or just select a number of unique random high enough integers.
Do you mean how to set the font size ? For source text or/and titles ? If yes you can add it in metadata. |
|
Nice suggestions ! I added them.
Blocks width and heights are chosen such that the code fits. I need the text size (or a better solution) to find how much space the code takes. |
I see ! It's not that important for now, we will improve this in a future branch, just choose a 'good enough value' for now. |
MathisFederico
left a comment
There was a problem hiding this comment.
I would not have thought of it like this, but I like this Serializable refactor !
Let's wait for @vanyle approval before merging anything, but it looks good to me !
| """Convert ipynb data (ipynb file, as ordered dict) into ipyg data (ipyg, as ordered dict)""" | ||
|
|
||
| blocks_data: List[OrderedDict] = get_blocks_data(data) | ||
| edges_data: List[OrderedDict] = get_sockets_data(blocks_data) |
There was a problem hiding this comment.
I still think this should be edges_data though
| edges_data: List[OrderedDict] = get_sockets_data(blocks_data) | |
| edges_data: List[OrderedDict] = get_edges_data(blocks_data) |
|
We cannot hardcode Look into the |
|
Apart from that, I would also like to say that putting all the default values for cells serialization in their own file was a great idea ! |
 vanyle
left a comment
vanyle
left a comment
There was a problem hiding this comment.
Code is very clean !
Just look at the comment for the remaining issue. You can merge it anyway if you want. Because the issue is specific to my machine, it might be better if I focus on fixing it as ratios between real height and height inside a QGraphicsView might be involved.
|
There is still an issue determining block size with the newlines that isn't present in the ipynb files I tested it with. I will try to fix that latter. |
This is a draft, many required features are missing.
What is there
What is missing