🎒 Scrape the courses info from the University of Nottingham's website. (Different campuses and academic years supported.)
This fork is modified to fit the needs of Nott Course:
- EricWay1024/nott-course: React app of an unofficial enhancement of the course catalogue offered by University of Nottingham.
- EricWay1024/nott-course-server-cpp: C++ Web Server for Nott Course, an unofficial enhancement of the course catalogue offered by University of Nottingham.
What have I done?
- Included complete information of the course page;
- Added the scraper for academic plans, with fully parsed plan structures;
- Adapted the project to concurency using pupeteer-cluster;
- Replaced Mongodb support with a converter from JSON to SQLite (for performance reasons).
- Nodejs
- Python
Note that for performance reasons, no file will be written until all courses/plans are obtained.
git clone https://github.com/EricWay1024/uCourse-crawler
cd uCourse-crawler
mkdir dist
npm i
pip3 install pandas numpySet your university user name and password:
echo USER_ID="your_user_id"\nUSER_PASSWORD="your_password" > .envNote that although all information on the resource website can be accessed without logging in, it now occasionally requires authentification. Please ensure the safety of your password.
Launch the course scraper:
node course.js(This will save result to ./dist/courseData.json.)
Launch the plan scraper:
node plan.js(This will save result to ./dist/planData.json. Also, a file ./dist/plans.json containing all possible plan UCAS codes will be created in the process.)
Convert to SQLite:
python3 find_deg.py
python3 to_sqlite.py(This will infer the degree type of all plans and add to plan objects. Then the data is saved to ./dist/data.db.)
For local JSON file, the output will be in a JSON format stored in /dist/[tablename].json.
The output example:
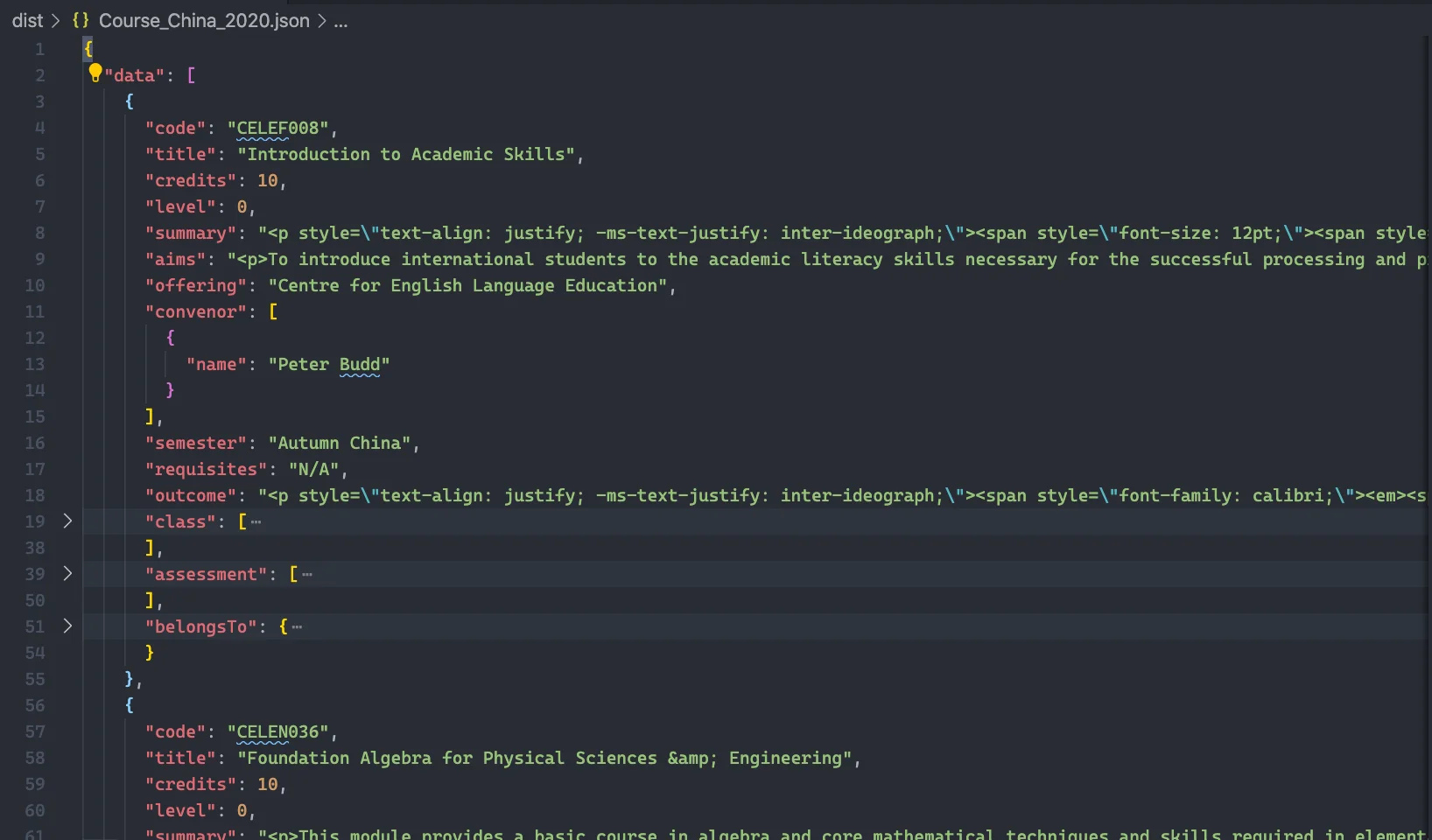
The estimated output size will be 50~60 MB if both courses and plans are crawled for a campus a year.
- Resouce website: https://campus.nottingham.ac.uk/psp/csprd_pub/EMPLOYEE/HRMS/c/UN_PROG_AND_MOD_EXTRACT.UN_PAM_CRSE_EXTRCT.GBL
University of Nottingham has the copyright of all the data on its website. This crawler is intended for general information purposes only.