University of Pennsylvania, CIS 565: GPU Programming and Architecture, Project 2
- Wenqing Wang
- Tested on: Windows 11, i7-11370H @ 3.30GHz 16.0 GB, GTX 3050 Ti
-
This project implemented the scan (exclusive prefix sum) and string compact based on the following methods.
- CPU scan/compact (for comparision purpose)
- GPU Naïve parallel scan/compact
- GPU Work-efficient scan/compact
- Thrust scan (for comparision purpose)
-
A sample output of this project would like this:
(Note: Results are tested on with blockSize = 256 and ArraySize = 2^24 )
****************
** SCAN TESTS **
****************
[ 5 27 39 37 38 10 22 28 45 5 12 35 19 ... 10 0 ]
==== cpu scan, power-of-two ====
elapsed time: 28.2238ms (std::chrono Measured)
[ 0 5 32 71 108 146 156 178 206 251 256 268 303 ... 410870447 410870457 ]
==== cpu scan, non-power-of-two ====
elapsed time: 27.9835ms (std::chrono Measured)
[ 0 5 32 71 108 146 156 178 206 251 256 268 303 ... 410870378 410870402 ]
passed
==== naive scan, power-of-two ====
elapsed time: 21.7824ms (CUDA Measured)
passed
==== naive scan, non-power-of-two ====
elapsed time: 21.7999ms (CUDA Measured)
passed
==== work-efficient scan, power-of-two ====
elapsed time: 14.9641ms (CUDA Measured)
passed
==== work-efficient scan, non-power-of-two ====
elapsed time: 15.037ms (CUDA Measured)
passed
==== thrust scan, power-of-two ====
elapsed time: 1.55648ms (CUDA Measured)
passed
==== thrust scan, non-power-of-two ====
elapsed time: 1.56058ms (CUDA Measured)
passed
*****************************
** STREAM COMPACTION TESTS **
*****************************
[ 3 3 3 1 0 2 2 2 3 1 2 3 1 ... 0 0 ]
==== cpu compact without scan, power-of-two ====
elapsed time: 42.3925ms (std::chrono Measured)
[ 3 3 3 1 2 2 2 3 1 2 3 1 1 ... 1 3 ]
passed
==== cpu compact without scan, non-power-of-two ====
elapsed time: 42.6625ms (std::chrono Measured)
[ 3 3 3 1 2 2 2 3 1 2 3 1 1 ... 3 1 ]
passed
==== cpu compact with scan ====
elapsed time: 96.9729ms (std::chrono Measured)
[ 3 3 3 1 2 2 2 3 1 2 3 1 1 ... 1 3 ]
passed
==== work-efficient compact, power-of-two ====
elapsed time: 18.041ms (CUDA Measured)
passed
==== work-efficient compact, non-power-of-two ====
elapsed time: 18.0232ms (CUDA Measured)
passed
By comparing the time consumed by each method on different array sizes, we can see how much better the GPU performs than the CPU when processing larger data sets.
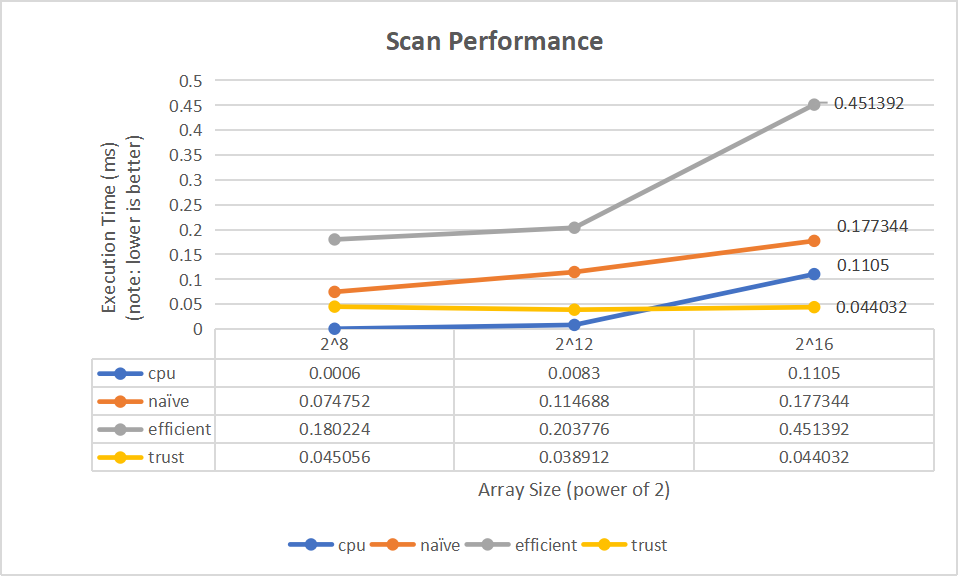
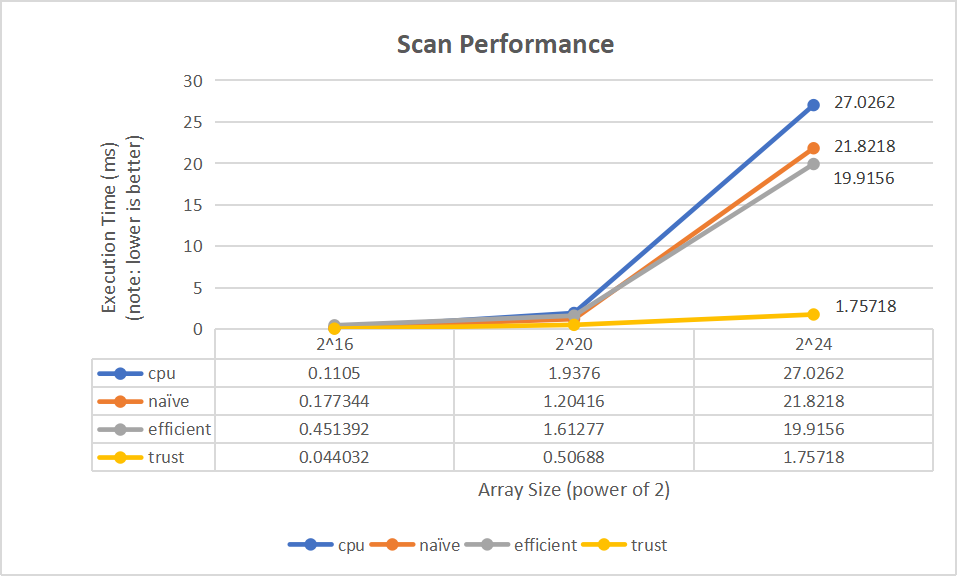
- From the above diagrams, we can see that when the array size is smaller than
2^16, the performance of CPU side scan/compact is actually better than that on GPU. This is probably because the GPU implementation involves a lot of read/write operations to global memory, and the advantages of parallel computing are not obvious when targeting smaller data sets. However, as the array size increases, the GPU starts to outperform the CPU, and the gap of their performance keeps widening. The optimized work-efficient method, which involves fewer scans operations, has a shorter execution time compared to the naive method. The trust method has the best performance on large data sets.
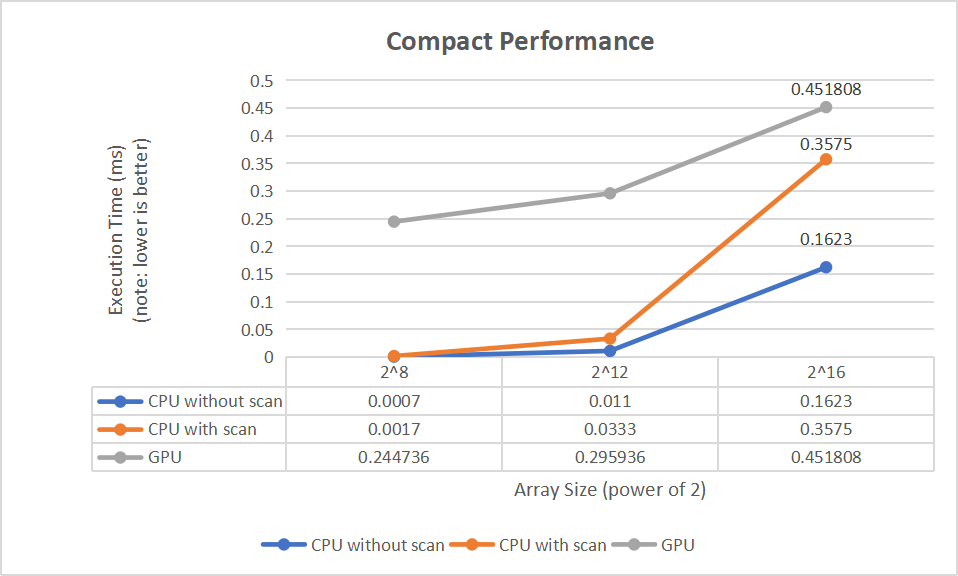
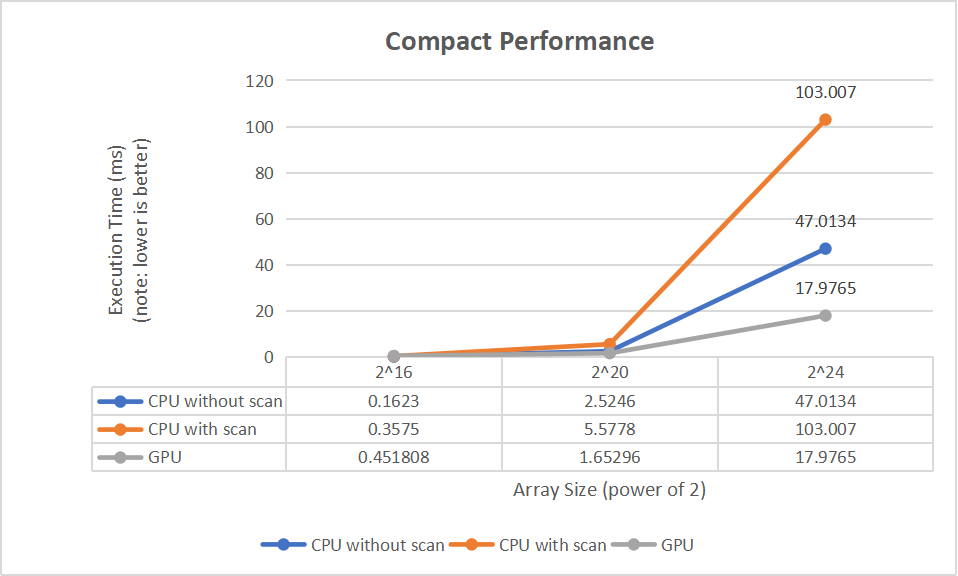
- As can be seen from the above graphs, the performance of the stream compression algorithm trends similarly to the scanning algorithm as the array size increases.