support HTTP "Range" header #6937 #8087
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,10 @@ | ||
| ### Support for HTTP "Range" Header for Partial File Downloads | ||
|
|
||
| Dataverse now supports the HTTP "Range" header, which allows users to download parts of a file. Here are some examples: | ||
|
|
||
| - `bytes=0-9` gets the first 10 bytes. | ||
| - `bytes=10-19` gets 10 bytes from the middle. | ||
| - `bytes=-10` gets the last 10 bytes. | ||
| - `bytes=9-` gets all bytes except the first 10. | ||
|
|
||
| Only a single range is supported. For more information, see the [Data Access API](https://guides.dataverse.org/en/5.9/api/dataaccess.html) section of the API Guide. |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -131,6 +131,41 @@ true Generates a thumbnail image by rescaling to the default thumbnai | |
| ``N`` Rescales the image to ``N`` pixels wide. ``imageThumb=true`` and ``imageThumb=64`` are equivalent. | ||
| ============== =========== | ||
|
|
||
| Headers: | ||
| ~~~~~~~~ | ||
|
|
||
| ============== =========== | ||
| Header Description | ||
| ============== =========== | ||
| Range Download a specified byte range. Examples: | ||
|
|
||
| - ``bytes=0-9`` gets the first 10 bytes. | ||
| - ``bytes=10-19`` gets 10 bytes from the middle. | ||
| - ``bytes=-10`` gets the last 10 bytes. | ||
| - ``bytes=9-`` gets all bytes except the first 10. | ||
|
|
||
| Only a single range is supported. The "If-Range" header is not supported. For more on the "Range" header, see https://developer.mozilla.org/en-US/docs/Web/HTTP/Range_requests | ||
| ============== =========== | ||
|
|
||
|
Contributor
There was a problem hiding this comment. I feel like an example of a curl command line would help here (and maybe in the release note too?)
Member
Author
There was a problem hiding this comment. Yes, absolutely. I'll work on adding a curl example. I don't think a curl example is needed in the release notes, though. We typically link to the guides from the release notes.
Member
Author
There was a problem hiding this comment. Ok, example added in eba6563. It looks like this:
As shown, I also added an "Examples" heading with the idea that we can add additional examples for all kinds of basic file access including getting the original, authenticating, etc. The range example is at the top because it's the only one but it can drop down as we add more common examples. |
||
| Examples | ||
| ~~~~~~~~ | ||
|
|
||
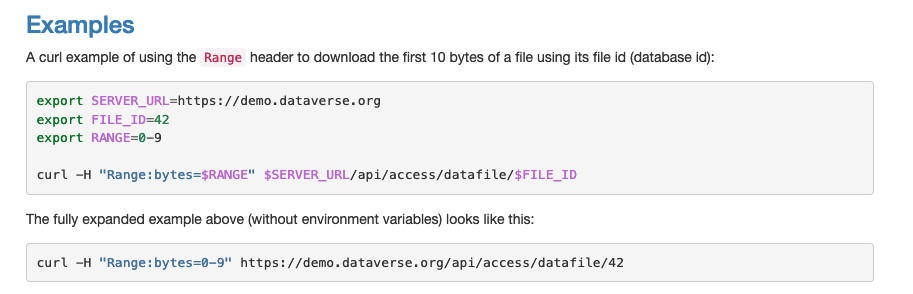
| A curl example of using the ``Range`` header to download the first 10 bytes of a file using its file id (database id): | ||
|
|
||
| .. code-block:: bash | ||
|
|
||
| export SERVER_URL=https://demo.dataverse.org | ||
| export FILE_ID=42 | ||
| export RANGE=0-9 | ||
|
|
||
| curl -H "Range:bytes=$RANGE" $SERVER_URL/api/access/datafile/$FILE_ID | ||
|
|
||
| The fully expanded example above (without environment variables) looks like this: | ||
|
|
||
| .. code-block:: bash | ||
|
|
||
| curl -H "Range:bytes=0-9" https://demo.dataverse.org/api/access/datafile/42 | ||
|
|
||
| Multiple File ("bundle") download | ||
| --------------------------------- | ||
|
|
||
|
|
||
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,28 @@ | ||
| package edu.harvard.iq.dataverse.dataaccess; | ||
|
|
||
| public class Range { | ||
|
|
||
| // Used to set the offset, how far to skip into the file. | ||
| private final long start; | ||
| // Used to calculate the length. | ||
| private final long end; | ||
|
|
||
| public Range(long start, long end) { | ||
| this.start = start; | ||
| this.end = end; | ||
| } | ||
|
|
||
| public long getStart() { | ||
| return start; | ||
| } | ||
|
|
||
| public long getEnd() { | ||
| return end; | ||
| } | ||
|
|
||
| // Used to determine when to stop reading. | ||
| public long getLength() { | ||
| return end - start + 1; | ||
| } | ||
|
|
||
| } |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Uh oh!
There was an error while loading. Please reload this page.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
This could be nitpicking, but maybe "Supported HTTP Headers"? - to indicate that this is not something we made up ourselves, but a standard HTTP feature? (similarly to how the release note describes it)
Uh oh!
There was an error while loading. Please reload this page.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I guess I put "Headers:" (with a colon) to match "Parameters:" which was already on the page. Here's a screenshot:
In the same vein, this could be "Supported HTTP Query Parameters". I don't feel strongly about it. I was just trying to keep it short and consistent with the rest of the page. I'm totally with with "HTTP Headers". I guess I'd leave the colon in there for consistency. Lemme know. I'm happy to do whatever here.
I do think an example will make this more clear. More on that in the next comment.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I was just anticipating a user reading the guide wondering, "why is this implemented as a header, and not as a query parameter like everything else in your api?" - so my idea was to spell it out - the parameters are proprietary to our api; this header is standard http that we support.
I acknowledged I didn't feel strongly about that suggestion. I agree that an example makes it very clear so I'm ok with it as is.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Ok, let's leave it as is for now. At least we link to the MDN docs (screenshot below) so people will probably get the idea that we didn't make it up. 😄
(It's weird to me that the text in these tables is centered but the bullets are not, by the way. I think I'd prefer for it all to be left justified. I googled it but didn't find a fix right away.)
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I just put the same table in another Sphinx project (OpenDP) and it looks much more normal:
I don't think we should fix this now (left justify everything) but it gives me hope that we can fix it someday.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
The table looks completely normal when you view the .rst on github of course...
Yeah, it has to be something in our sphinx customization.