8720 allow metadata re export in smaller batches#8721
Conversation
…etadata-reExport-in-smaller-batches # Conflicts: # src/main/java/edu/harvard/iq/dataverse/DatasetServiceBean.java
|
Could not built the 'guides' , got an error where running |
@PaulBoon hi. Yes, because we merged PR #8647 you now have to pip install a package (sphinx-icon). Please see https://groups.google.com/g/dataverse-dev/c/fZpTQYQKR0g/m/DQTARER7AwAJ |
Thanks @pdurbin, I was so naive to think Probably no problem for the PR, this did bring back memories about this 'dot' tool that I used decades ago. |
@PaulBoon yes, it's the same old Here's we explain that you need to install dot/graphviz: https://guides.dataverse.org/en/5.11/developers/documentation.html#installing-graphviz |
|
What is holding you back to push it through? |
|
@PaulBoon hi! Sorry, this is one of currently 33 open pull requests that is sitting in the "On Deck" column on our board. In total, there are 81 open pull requests. Please be patient with us as we work through the queue and thank you once again for another contribution to Dataverse! |
|
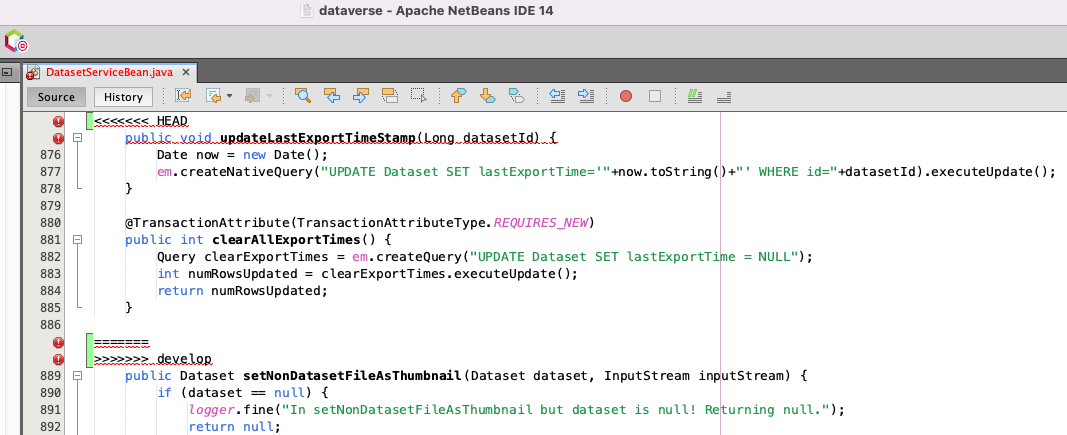
@PaulBoon I noticed there are merge conflicts in this file for you (after merging develop in): src/main/java/edu/harvard/iq/dataverse/DatasetServiceBean.java Here's a screenshot from Netbeans showing the conflict:
It looks like @landreev removed the updateLastExportTimeStamp method in 8135490 as part of PR #8782 so I made sure it's still gone in your PR. I can't push to your branch so I made this PR against your PR: PaulBoon#4 Alternatively, you are welcome to merge "develop" in and resolve the merge conflicts yourself. Thanks! |
 pdurbin
left a comment
pdurbin
left a comment
There was a problem hiding this comment.
Overall, this is looking good! In addition to new APIs we're getting much better docs. 😄
I haven't run the code (and left a comment about the need to resolve merge conflicts) but in this review I'm giving suggestions for the docs and ask a question.
| } | ||
| Dataset dataset = null; | ||
| try { | ||
| dataset = datasetService.findByGlobalId(persistentId); |
There was a problem hiding this comment.
Hmm, shouldn't we support both PID and ID (database ID)? We have patterns for this in Datasets.java.
Documentation textual improvements Co-authored-by: Philip Durbin <philipdurbin@gmail.com>
8720 merge conflicts
|
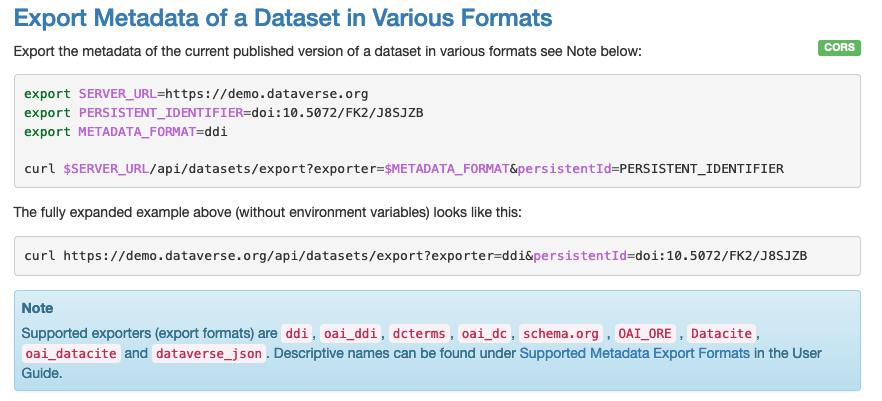
@PaulBoon I just made another PR against this PR: PaulBoon#5 I added a test (heads up to @landreev that I re-enabled a test you had disabled in 3962a19 as part of #5771.) While added the test I discovered an API that seems quite similar: https://guides.dataverse.org/en/5.11.1/api/native-api.html#export-metadata-of-a-dataset-in-various-formats
In that PR I'm also crosslinking the two APIs, existing and new. These are my current questions: 😄
|
|
Hi @pdurbin, I must confess that my thought are elsewhere and this PR was a while ago so I am happy that you put some effort into this. The main thing was the "clearExportTimestamps", so I would definitely want that functionality in there. The naming and API endpoint details could be debatable. From a developers (API user) perspective it is nice to have the 'metadata re-export' API similar to the 'search re-index' API I think. |
8720 reexport
|
@PaulBoon from standup today it sounds like @landreev and I are quite happy with this PR but we (and others) do think it would be nice if the API you added supported both PIDs (as it does now) and IDs. I can make a PR to add this in the coming days or if you want to go ahead, please do. Either way, please merge the latest from develop (I don't have permission to your branch) because we've been on a mini merge fest. 🚀 Thanks! p.s. We know about the failing test but it's just this flaky one: #8973 |
|
@PaulBoon when you get a chance, can you please merge develop into your branch? Thanks! |
PR made: PaulBoon#6 @PaulBoon I think the next steps for you are:
Thanks! |
|
@PaulBoon we discussed this issue at standup this morning and decided to move it to "community dev" until you've had a chance to review and maybe act on the steps above. Thanks! |
support database IDs too (as well as PIDs) IQSS#8720
…etadata-reExport-in-smaller-batches
What this PR does / why we need it:
This PR adds extra API endpoints:
Which issue(s) this PR closes:
Special notes for your reviewer:
Suggestions on how to test this:
The most likely 'use case' is that after a change of the metadata 'schema' a reExport all is needed, but you could the reExport a specific dataset and see if it changed correspondingly.
A simpler scenario for testing would be to note the filesystem timestamp of the cached files, check these, check the database timestamps and also check the export log after re-exporting has been done.
Example call:
curl http://localhost:8080/api/admin/metadata/reExportDataset?persistentId=doi:10.5072/FK2/AAA000Example call for clearing the timestamps:
curl http://localhost:8080/api/admin/metadata/clearExportTimestampsTest the reexport of a single dataset
Select a dataset and lookup the cached export files on the disk;
In my case I have a local filesystem with a dataset doi: 10.5072/FK2/O9LNLQ.
$ ls -al /data/dataverse/files/10.5072/FK2/O9LNLQ/*.cachedGives me the listing of the files with the (filesystem) timestamp.
Next we wil do the reindexing.
$ curl http://localhost:8080/api/admin/metadata/reExportDataset?persistentId=doi:10.5072/FK2/O9LNLQ.returns
{"status":"OK","data":{"message":"export started"}}.Check the timestamps, these should be 'updated' to the current time.
Check the payara log
/var/lib/payara5/glassfish/domains/domain1/logs/server.log. At the end it should have a line stating the export of that dataset succeeded, similar to the following;[#|2022-06-14T11:34:50.181+0200|INFO|Payara 5.2021.6|edu.harvard.iq.dataverse.DatasetServiceBean|_ThreadID=249;_ThreadName=__ejb-thread-pool6;_TimeMillis=1655199290181;_LevelValue=800;| Success exporting dataset: Manual Test doi:10.5072/FK2/O9LNLQ|#]To confirm that this dataset is the only dataset updated you could check the 'cached' files of other datasets.
You can repeat it for this dataset or any other dataset and check the timestamp of the cached files.
Test for correct handling of wrong input:
$ curl http://localhost:8080/api/admin/metadata/reExportDatasetShould return
{"status":"ERROR","message":"No persistent id given."}.And
$ curl http://localhost:8080/api/admin/metadata/reExportDataset?persistentId=doi:10.5072/NONEXISTING/O9LNLQShould return:
{"status":"ERROR","message":"Could not find dataset with persistent id doi:10.5072/NONEXISTING/O9LNLQ"}.Test the clearing of the export timestamps
Note that this is easier to test on a system with only a few datasets, otherwise reexporting can take a long time.
For simplicity select the same dataset as before and have a look at the file timestamps again;
$ ls -al /data/dataverse/files/10.5072/FK2/O9LNLQ/*.cached.Run exportAll:
curl http://localhost:8080/api/admin/metadata/exportAllReturns
{"status":"WORKFLOW_IN_PROGRESS"}The timestamps should not have changed, because it only exports if it is needed like when the export timestamps (in the database) are cleared.
Then clear those export timestamps:
$ curl http://localhost:8080/api/admin/metadata/clearExportTimestampsReturns
{"status":"OK","data":{"message":"cleared: 1"}}in case we only have one dataset in the archive, because the number should be the total amount of datasets.Then run exportAll again, but this time all datasets should be re-exported.
Check the timestamps in the filesystem and the export log file and confirm that this is indeed the case.
The export log can be checked in your log dir; a new file should appear with the timestamp in the filename, for example with Payara in '/var/lib':
/var/lib/payara5/glassfish/domains/domain1/logs/export_2022-06-09T15-20-23.log.Running exportAll yet again should not change the filesystem timestamps of the 'cached' files.