👋 들어가며
본 포스팅은 Finda(주)와 We-Meet에서 제공받은 과제로 주어진 무비 데이터 와 스파크를 활용해 추천시스템을 개발하는 과제입니다.
📚 목차
1. 프로젝트 소개 2. 수행기간 3. 프로젝트 흐름도 4. 수행 과정 5. 수행 결과 6. 기대효과 및 활용분야 7. 추가 성능 개선 8. 한계점 및 향후 개선 방향 9. 참고자료 10. 프로젝트 결과
Item based Rating Prediction with Dot Production and PySpark
대용량 데이터 처리에 적합한 분산병렬처리플랫폼 PySpark 를 사용하여 Dot production 연산을 진행하고, 이를 활용하여 특정 사용자의 영화 평점을 예측해 사용자가 선호할 영화를 추천하는 시스템을 개발한다.
-
프로젝트 달성 목표 기존 아이템 기반 협업 필터링에서 dot-production 방식을 접목시켜 보다 정확히 사용자의 영화 선호를 예측하여 추천한다.
-
필요성 및 기대효과 단순 아이템 간의 유사성을 기반으로 사용자에게 아이템을 추천해주는 아이템 기반 협업 필터링 방법은 이미 널리 범용화 되어있습니다. 이에 더 나아가
‘아이템 기반‘ 이더라도 dot-production 방식을 통해 개개인의 사용자 rating 점수를 예측하여 사용자에게 개인화된 아이템을 추천해줄 수 있도록 하기 위해 본 프로젝트를 진행하고자 합니다.
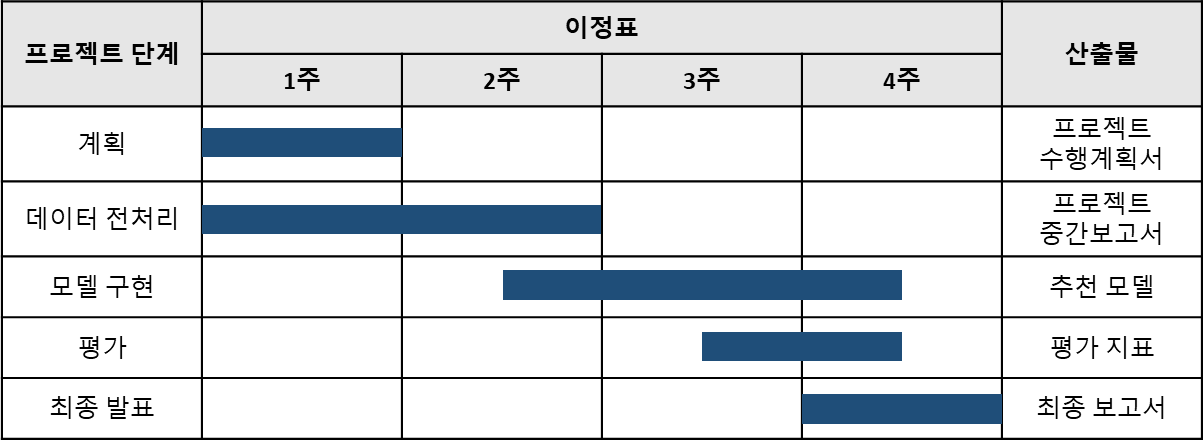
2023/11/06 ~ 2023/12/11
[Github 주소]https://github.com/Jingik/RecommendationSystem

-
Crawling 통해 태그 결측치 Imputation → imputation 실패한 영화 45개 삭제
-
Crawling 통해 장르 결측치 Imputation → 결측치 모두 imputation 성공
-
Crawling 통한 파생변수 생성

- ‘title’ 변수 A, An, The misplace 처리
- Categorical 변수 – One-Hot Encoding
- String 변수 – 불용어 제거, Word2Vec
- Numerical 변수 – Standard Scaling
-
유사도 계산
- Euclidean Similarity : item간 Title/ Genre/ Tag/ Storyline/ All(모든 컬럼 활용) 유사도 계산
- Cosine Similarity : item간 Title/ Genre/ Tag/ Storyline/ All(모든 컬럼 활용) 유사도 계산
- 유사도 계산 후 Min-Max Scaling을 통해 스케일링, 음수값 제거
-
** 추천 모델 구현 **
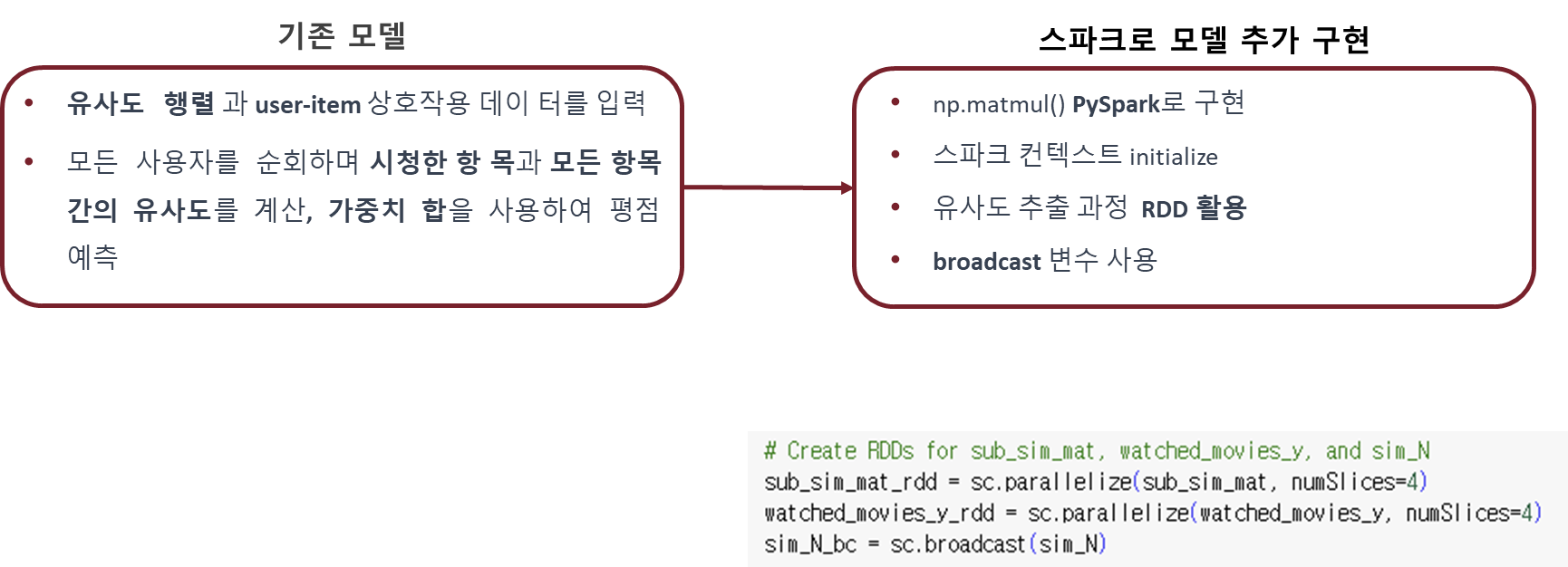
- **사용자 개인별 추천 **
사용자가 보지 않은 영화 중 가장 예측 rating(평점)이 높은 영화 10개 추천
- 사용자가 평가한 rating 정보와 dot-production을 통해 예측한 rating 정보 합침
- 사용자가 아직 보지 않은 영화 선택
- 예측한 rating이 높은 순으로 정렬하고, 상위 10개 추천

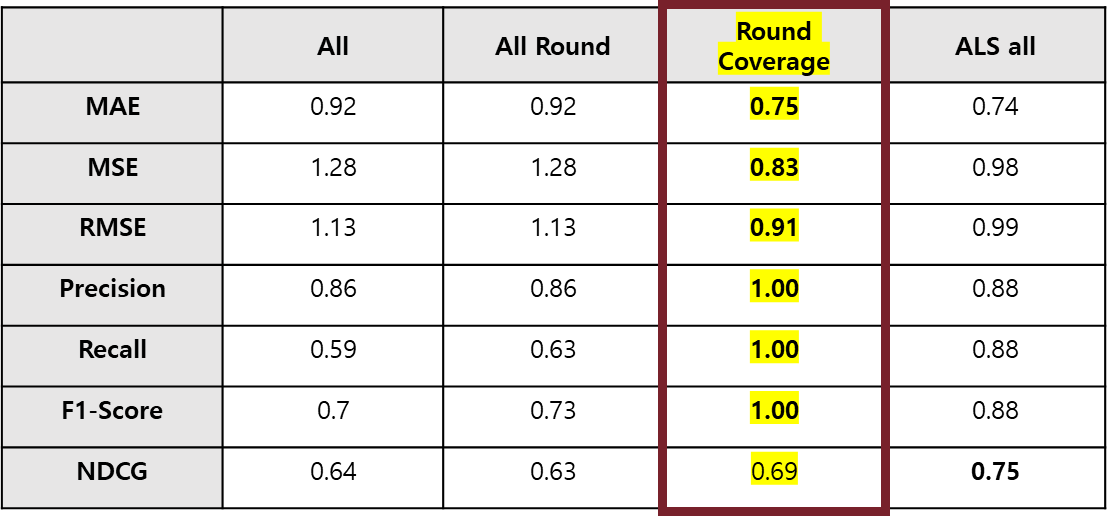
** 평가 지표 : MAE, MSE, RMSE, Precision, Recall, F1-Score, NDCG **
Case 1. Cosine Similarity

Case 2. Euclidean Similarity

-
기대효과 기존 아이템 기반 협업 필터링의 경우, 단순 아이템 간의 유사성을 기반으로 사용자에게 아이템을 추천해줍니다. 이는 개별 사용자의 선호도를 전혀 반영하지 않으며, cold-start 문제 등을 야기합니다. 하지만, 본 프로젝트에서 구현한 추천 시스템의 경우, 기존 아이템 기반 협업 필터링에서 dot-production 방식을 접목시켜 보다 정확히
사용자의 영화 선호도를 파악하여 추천이 가능합니다. -
활용분야 영화나 드라마 같은 미디어 추천 뿐 아니라, 상품 추천, 음식점 추천, 등 아이템(미디어, 상품, 음식점)에 대한 다양한 정보와 사용자가 이전에 경험했던 아이템에 대한 평가만 있다면 어떤 분야든 본 시스템을 통해 각각의 사용자의 아이템 선호도를 예측하여 정확한 추천이 가능합니다.
- Cosine, All-dot production
- Cosine, All-dot production –round
- Round Coverage
- ALS, All-dot
- Random Forest를 활용한 변수 중요도 확인
PySpark에서 지원하는 Random Forest를 활용하여 변수 중요도를 확인하려했지만, PySpark에서는 변수에 대한 중요도가 아닌 결과에 대한 중요도를 도출해주는 기능만 제공함. → 변수중요도를 뽑아 여러 변수의 similarity를 활용하는 multi-dot-production을 수행할 때, 활용하면 보다 사용자의 평점 예측 정확도를 높일 수 있을 것으로 기대됨.
**- 추천 모델 PySpark 미활용 ** 추천 모델 전체 과정을 PySpark를 활용할 때, 시간이 매우 오래 소요되어 중간중간 Python을 활용하여 진행함. → 향후 최적화 과정을 통하여 추천 모델 전체 과정을 PySpark를 활용하여 진행하고자 함.
** - One-Hot Encoding으로 전처리 ** One-Hot Encoding은 각각의 카테고리 간의 거리를 모두 1로 (일정한 간격으로) 둔다는 치명적인 단점이 존재함. (예: 장르 변수에서 Horror와 Thriller 사이의 거리(유사도)가 Horror와 Children 사이의 거리보다 가까워야하는데, One-Hot Encoding은 이러한 점을 반영해주지는 못함.) → 향후 더 다양한 Categorical 변수를 전처리(벡터화)하는 방법을 고안 및 활용하고자 함.
- Sarwar, Badrul & Karypis, George & Konstan, Joseph & Riedl, John. (2001). Item-based Collaborative Filtering Recommendation Algorithms. Proceedings of ACM World Wide Web Conference.
- Shaheen MZ. Memon, Robert Wamala, Ignace H. Kabano, A comparison of imputation methods for categorical data, Informatics in Medicine Unlocked, Volume 42, 2023.
- Galli, S., (2021). Feature-engine: A Python package for feature engineering for machine learning. Journal of Open Source Software.
