The objective of this project is to convert an English sentence to it's Italian counterpart using a Neural Machine Translation system. The task will be implemented by using attention, specifically Bahdanau attention.
The main reason for not using the encoder-decoder method is because of the infamous bottleneck problem, ie , all the information is encoded in to one fixed-length vector.
The attention model solves this by allowing the network to refer back to the input sequence, instead of forcing it to encode all information into one fixed-length vector.
- Python version : 3.7
- Tensorflow version : 2.2
- Packages Used : numpy,pandas,seaborn,sklearn,tensorflow,nltk.
The model was build using an Attention model(Bahdanau Attention).
The advantage of the attention model is that instead of encoding the input sequence into a single fixed context vector, the attention model develops a context vector that is filtered specifically for each output time step.
In this notebook , I will be using the Additive Attention model by Dzmitry Bahdanau. The model aimed to improve the seq-to-seq model in machine translation, by aligning the decoder with the relevant input sentences and implementing Attention.
To simplify things here is a small image :.
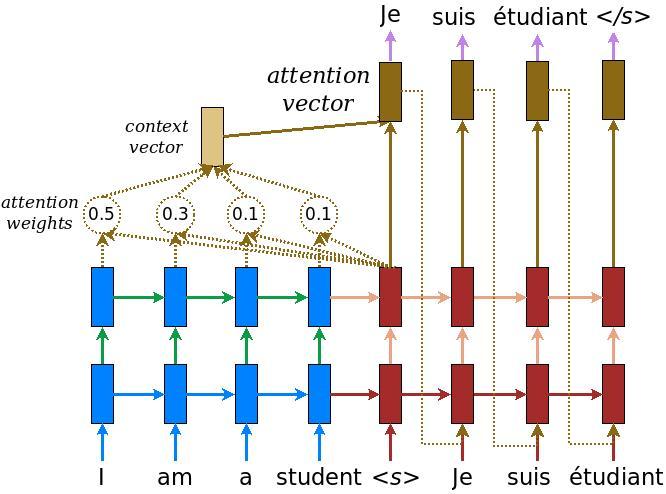
Even though the model was trained with just 70000 samples and only trained for 30 epochs, the model is giving very good results on samples which it has not seen!. This shows the power of Attention!
The Attention mechanism has revolutionised the way we create NLP models and is currently a standard fixture in most state-of-the-art NLP models. This is because it enables the model to “remember” all the words in the input and focus on specific words when formulating a response.
Here are some examples :



Even though the model gave good results on samples which it has never seen before, some were not perfect. The challenge of training an effective model can be attributed largely to the lack of training data and training time. Due to the complex nature of the different languages involved, and a large number of vocabulary and grammatical permutations, an effective model will require tons of data and training time before any perfect results can be seen on the evaluation data.
More examples can be seen in the result folder and also in the last part of the notebook.