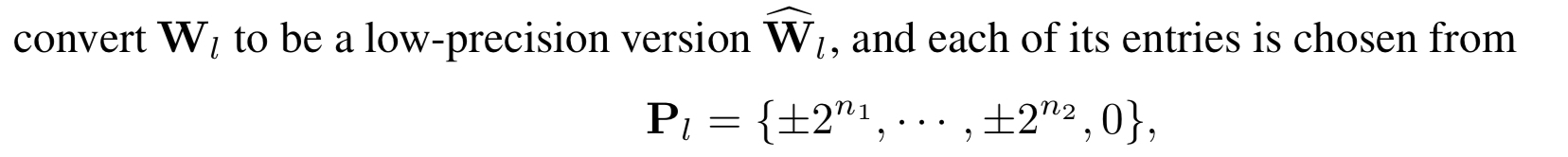
-
提出了渐进式神经网络量化的思想,引入了三种操作:参数分组,量化,重训练 简单的说就是在训练得到一个网络模型后, 首先将这个全精度浮点网络模型中的每一层参数分为两组, 第一组中的参数直接被量化固定, 另一组参数通过重训练来补偿量化给模型造成的精度损失。 然后这三个操作依次迭代应用到刚才的第二组完成重训练之后的全精度浮点参数部分,直到模型全部量化为止。
可以说参数分组分成的这两个部分是互补的作用, 一个建立低精度模型的基础, 另一个通过retrain(重训练,微调)补偿精度损失; 这样迭代最终得到渐进式的量化和精度提升。 通过巧妙耦合参数分组、量化和重训练操作,该技术抑制了模型量化造成的性能损失,从而在实际中适用于任意结构的神经网络模型。 INQ渐进式网络量化策略:

(绿线代表当前已经被量化的网络连接;蓝线代表需要重新训练的网络连接)
该技术还包含另外两个亮点。
其一,在模型量化过程中,所有参数被限制成二进制表示,并包含零值,极限量化结果即为三值网络或者二值网络。
这种量化使得最后的模型非常适合在硬件上部署和加速。
比如在FPGA上,复杂的全精度浮点乘法运算将被直接替换为简单的移位操作。
其二,现有神经网络量化压缩方法在处理二值网络或者三值网络时,为了让模型精度损失不至于太大,
往往将模型第一层和最后一层参数依然保留为全精度浮点型,
而我们的技术在对模型的所有参数进行量化的同时,实现了性能的全面领先 。

INQ渐进式网络量化示例
第一行:依次为参数分组、量化与重训练;
第二行:迭代过程
(绿色区域代表当前已经被量化的网络参数;浅紫区域代表需要重新训练的网络参数)
Caffe Implementation for Incremental network quantization, we modify the original caffe, the Installation is follow caffe. the default source code is 5 bits weights-only quantization, 量化位数精度修改 you can by changing parameter "partition"(/src/caffe/blob.cpp) to control the quantization step.
0. 编译
依赖fft sudo apt-get install libfftw3-dev libfftw3-doc
0.you must be farmilar with caffe training [imagenet tutorial](http://caffe.berkeleyvision.org/gathered/examples/imagenet.html)
1. 默认为5bits的量化精度 Train 5 bits Alexnet with Imagenet:
python run.py
Please download float-point ImageNet-pre-trained AlexNet/VGG models and power-of-two model manually from [BaiduYun](https://pan.baidu.com/s/1qYHkbus), and put it into $/models/bvlc_alexnet/.
2.At continuous partition steps, the output logs are saved as run1_log.out, run2_log.out, run3_log.out,..., respectively
If you find INQ useful in your research, please consider citing: @inproceedings{zhou2017, title={Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights}, author={Aojun Zhou, Anbang Yao, Yiwen Guo, Lin Xu, Yurong Chen}, booktitle={International Conference on Learning Representations,ICLR2017}, year={2017}, }
- Real-time data shuffling is useful
The authors adopted the proposed method to several model, including AlexNet, VGG-16, GoogleNet, ResNet-18 and ResNet-50. More experiments for exploration was conducted on ResNet-18. Experimental results on ImageNet using center crop validation are shown as follows.
| Network | Bit-width | Top-1/Top-5 Error | Decrease in Top-1/Top-5 Error | Partition |
|---|---|---|---|---|
| AlexNet ref | 32 | 42.71%/19.77% | ||
| AlexNet | 5 | 42.61%/19.54% | 0.15%/0.23% | {0.3, 0.6, 0.8, 1.0} |
| VGG-16 ref | 32 | 31.46%/11.35% | ||
| VGG-16 | 5 | 29.18%/9.70% | 2.28%/1.65% | {0.5, 0.75, 0.875, 1.0} |
| GoogleNet ref | 32 | 31.11%/10.97% | ||
| GoogleNet | 5 | 30.98%/10.72% | 0.13%/0.25% | {0.2, 0.4, 0.6, 0.8, 1.0} |
| ResNet-18 ref | 32 | 31.73%/11.31 | ||
| ResNet | 5 | 31.02%/10.90% | 0.71%/0.41 | {0.5, 0.75, 0.875, 1.0} |
| ResNet-50 ref | 32 | 26.78%/8.76% | ||
| ResNet-50 | 5 | 25.19%/7.55% | 1.59%/1.21% | {0.5, 0.75, 0.875, 1.0} |
Number of required epochs for training increasing with the expected bit-width going down.
The accumulated portions for weight quantization are set as {0.3, 0.5, 0.8, 0.9, 0.95, 1.0},
{0.2, 0.4, 0.6, 0.7, 0.8, 0.9, 0.95, 1.0}, {0.2, 0.4, 0.6, 0.7, 0.8, 0.85, 0.9, 0.95, 0.975, 1.0}
for 4-bits to 2-bits, respectively. Training epochs required for 2-bits finally
set to 30 which means that 300 training epochs are required for completing a full quantization procedure.
In the other words, the proposed method become time-consuming when the network going deeper.
Although the authors convert weights to the powers of 2 and claim that their
method would be efficient with binary shift operation in hardware,
the computation in there experiments is still using floating operations.
Thus they only show the results of model compression instead of speeding up computation.
#-*- coding: utf-8 -*-
# 分组多次量化
import os
# 对第一组量化=========================
print "First partition and run"
os.system("nohup sh ./examples/INQ/alexnet/train_alexnet.sh >run1_log.out 2>&1")
# 对第二组量化=========================
print "Second partition and run"
# 修改源文件 编译
os.system("sed -i \"s/(count_\*0.7)/(count_\*0.4)/g\" ./src/caffe/blob.cpp")
os.system("make all -j128")
# 进行训练量化
# 前一个阶段的模型文件
os.system("sed -i \"s/bvlc_alexnet.caffemodel/alexnet_part1_iter_63000.caffemodel/g\" ./examples/INQ/alexnet/train_alexnet.sh")
# 保存下一个阶段的模型文件
os.system("sed -i \"s/part1/part2/g\" ./examples/INQ/alexnet/solver.prototxt")
os.system("nohup sh ./examples/INQ/alexnet/train_alexnet.sh >run2_log.out 2>&1")
# 对第三组量化=========================
print "Thrid partition and run"
# 修改源文件 编译
os.system("sed -i \"s/(count_\*0.4)/(count_\*0.2)/g\" ./src/caffe/blob.cpp")
os.system("make all -j128")
# 进行训练量化
os.system("sed -i \"s/alexnet_part1_iter_63000.caffemodel/alexnet_part2_iter_63000.caffemodel/g\" ./examples/INQ/alexnet/train_alexnet.sh")
os.system("sed -i \"s/part2/part3/g\" ./examples/INQ/alexnet/solver.prototxt")
os.system("nohup sh ./examples/INQ/alexnet/train_alexnet.sh >run3_log.out 2>&1")
# 最后一组量化==========================
print "Last partition and run"
os.system("sed -i \"s/(count_\*0.2)/(count_\*0.)/g\" ./src/caffe/blob.cpp")
os.system("make all -j128")
os.system("sed -i \"s/alexnet_part2_iter_63000.caffemodel/alexnet_part3_iter_63000.caffemodel/g\" ./examples/INQ/alexnet/train_alexnet.sh")
os.system("sed -i \"s/part3/part4/g\" ./examples/INQ/alexnet/solver.prototxt")
os.system("sed -i \"s/snapshot: 3000/snapshot: 1/g\" ./examples/INQ/alexnet/solver.prototxt")
os.system("sed -i \"s/max_iter: 63000/max_iter: 1/g\" ./examples/INQ/alexnet/solver.prototxt")
os.system("nohup sh ./examples/INQ/alexnet/train_alexnet.sh >run4_log.out 2>&1")
# 2乘方权重============================
print "All quantization done and you can enjoy the power-of-two weights using check.py!"// Blob<Dtype>::FromProto() // 510行前后
// net.cpp 中 载入权重函数 CopyTrainedLayersFrom() 会调用 Blob<Dtype>::FromProto()
// 传入标记值(是否量化的标志, is_quantization 可对w、b进行量化,未考虑BN层参数)
// INQ
if(is_quantization)// 根据标志位,对部分进行量化以及不量化
// 如 权重w量化 而 bias不量化
{
Dtype* data_copy=(Dtype*) malloc(count_*sizeof(Dtype));// 新申请blob一样大小的内存
caffe_copy(count_,data_vec,data_copy); // 拷贝数据 x
caffe_abs(count_,data_copy,data_copy); // 绝对值处理 abs(x)
std::sort(data_copy,data_copy+count_); // 排序处理(升序) data_copy order from small to large
// 计算上限 n1
//caculate the n1 上限 : W -> {±2^(n1), ... ,±2^(n2), 0}
Dtype max_data = data_copy[count_-1];// 升序后最后一个数为最大值 为 s = max(abs(x))
int n1=(int)floor(log2(max_data*4.0/3.0));// n1 = floor(log2(4*s/3))
//quantizate the top 30% of each layer, change the "partition" until partition=0
// 量化的分割点
// 第一次 (1-0.7) 第二次(1-0.4) 第三次(1-0.2) 最后一次(1-0)
int partition=int(count_*0.7)-1;// 每次量化的比例 分界点
for (int i = 0; i < (count_); ++i) {
if(std::abs(data_vec[i]) >= data_copy[partition])// 优先量化 绝对值较大的 权重参数==========
{
data_vec[i] = weightCluster_zero(data_vec[i],n1);// 进行量化,在 until/power2.cpp中实现
// data_vec[i] 量化为 +pow(2,ni) / -pow(2,ni) , ni: n1-7:n1, 选择量化误差最小的一个
// 权重值-----> pow(2,i)
mask_vec[i]=0;// 置位 已经量化的标志=======================
}
}
// 代码其实有点小问题,data_copy malloc 使用完之后 没有 free释放
// free data_copy;
}// 量化 权重值-----> pow(2,i)=========
// weight 量化为 +pow(2,ni) / -pow(2,ni) , ni: n1-7:n1, 选择量化误差最小的一个
template <typename Dtype>
double weightCluster_zero( Dtype weight, int M)
{
double min=100;
double ind=0;
double flag=1.0;
// 最小值
if(min > std::abs(weight))
{
min = std::abs(weight);
flag=0.0;// 权重绝对值未超过100
}
// the number 7 (default, n2的值 ) is corresponding to 5 bits in paper,
// you can modify it, 3 for 4 bits, 1 for 3 bits, 0 for 2 bits.
// n2 = n1 + 1 −2^(b−1)/2.
// For instance, if b = 3(量化精度) and n1 = −1, it is easy to get n2 = −2,
// if b=5, n1 = −1, n2= -1 + 1-(2^(5-1))/2 = -8
// 0 for 2 bits
// 1 for 3 bits
// 3 for 4 bits
// 7 for 5 bits
// 15 for 6 bits
// 31 for 7 bits 2^b - 1
// 63 for 8 bits
for(int i=(M-7); i<=M; i++)// 从最高比特位 M=n1 到 n1-7 进行遍历
{
if(min > std::abs(weight - pow(2,i)))// weight 量化为 +pow(2,i) 的 量化差值
{
min = std::abs(weight - pow(2,i));// 最小量化差值
ind=i;
flag=1.0;// weight 量化为 +pow(2,i)
}
if(min > std::abs(weight + pow(2,i)))// weight 量化为 -pow(2,i) 的 量化差值
{
min = std::abs(weight + pow(2,i));// 最小量化差值
ind = i;
flag = -1.0;
}
}
return flag*pow(2,ind);
}/// 从 模型文件中载入 网络权重
// 调用blob.cpp 中 FromProto() 载入每一个卷积核
// 传入标记值(是否量化的标志)
template <typename Dtype>
void Net<Dtype>::CopyTrainedLayersFrom(const NetParameter& param) {
// 总层数量
int num_source_layers = param.layer_size();
for (int i = 0; i < num_source_layers; ++i) // 遍历每一层
{
const LayerParameter& source_layer = param.layer(i);
const string& source_layer_name = source_layer.name();// 层名字 .name()
int target_layer_id = 0;
while (target_layer_id != layer_names_.size() &&
layer_names_[target_layer_id] != source_layer_name)
{
++target_layer_id;
}
if (target_layer_id == layer_names_.size())
{
LOG(INFO) << "Ignoring source layer " << source_layer_name;
continue;
}
DLOG(INFO) << "Copying source layer " << source_layer_name;
vector<shared_ptr<Blob<Dtype> > >& target_blobs =
layers_[target_layer_id]->blobs();
CHECK_EQ(target_blobs.size(), source_layer.blobs_size())
<< "Incompatible number of blobs for layer " << source_layer_name;
for (int j = 0; j < target_blobs.size(); ++j)
{
bool is_quantization=false;
// only quantize the weights and skip the bias
// if your network contains batch normalization, you can skip it by "source_layer_name"
if(j==0)// 权重w 部分==================
is_quantization=true;
else// 偏置bias 部分
is_quantization=false;
// 检查 prototxt文件定义的网络尺寸 和 给定的 预训练 权重weight 的各层参数 维度适量是否一致
if (!target_blobs[j]->ShapeEquals(source_layer.blobs(j)))
{// 不一致,打印 权重weight .caffemodel参数数量
Blob<Dtype> source_blob;
const bool kReshape = true;
// blob.cpp 的读取blob参数 添加了支持 载入并量化的部分 is_quantization
source_blob.FromProto(source_layer.blobs(j), kReshape,is_quantization);
LOG(FATAL) << "Cannot copy param " << j << " weights from layer '"
<< source_layer_name << "'; shape mismatch. Source param shape is "
<< source_blob.shape_string() << "; target param shape is "
<< target_blobs[j]->shape_string() << ". "
<< "To learn this layer's parameters from scratch rather than "
<< "copying from a saved net, rename the layer.";
}
const bool kReshape = false;
target_blobs[j]->FromProto(source_layer.blobs(j), kReshape,is_quantization);
}
}
}template <typename Dtype>
void SGDSolver<Dtype>::ComputeUpdateValue(int param_id, Dtype rate) {
const vector<Blob<Dtype>*>& net_params = this->net_->learnable_params();
const vector<float>& net_params_lr = this->net_->params_lr();
Dtype momentum = this->param_.momentum();
Dtype local_rate = rate * net_params_lr[param_id];
// Compute the update to history, then copy it to the parameter diff.
switch (Caffe::mode()) {
case Caffe::CPU: {
caffe_cpu_axpby(net_params[param_id]->count(), local_rate,
net_params[param_id]->cpu_diff(), momentum,
history_[param_id]->mutable_cpu_data());
caffe_copy(net_params[param_id]->count(),
history_[param_id]->cpu_data(),
net_params[param_id]->mutable_cpu_diff());
break;
}
case Caffe::GPU: {
#ifndef CPU_ONLY
// sgd方法计算各参数 更新权重 diff===================================
sgd_update_gpu(net_params[param_id]->count(),
net_params[param_id]->mutable_gpu_diff(),
history_[param_id]->mutable_gpu_data(),
momentum, local_rate);
// 使用 量化mask 对 diff 进行滤波, 已经量化后的参数不再进行更新========
// diff = mask * diff;
caffe_gpu_mul(net_params[param_id]->count(),net_params[param_id]->gpu_mask(),net_params[param_id]->mutable_gpu_diff(),net_params[param_id]->mutable_gpu_diff());
// 在re-training中,我们只对未量化的那些参数进行更新。
// 待更新的参数,mask中的值都是1,这样和diff相乘仍然不变;
// 不更新的参数,mask中的值都是0,和diff乘起来,相当于强制把梯度变成了0。
#else
NO_GPU;
#endif
break;
}
default:
LOG(FATAL) << "Unknown caffe mode: " << Caffe::mode();
}
}