[New commondata format] FTDY#1679
Conversation
|
FWIW I find ugly. Can we at least make the examples read like ? More generally, I don't know if I have the appetite to reopen this, but I feel the theory metadata has deviated quite a bit from the "we would like experimentalist to be able to write this" goal that we had at some point. In addition the current definition has a bunch of backwards compatible and "transactional" semantics. I do wonder if we are better off having all that in a separate file, that would be less stable for the moment. |
What do you mean? I don't think it has changed since we defined it in Milan one year ago?
like? |
Probably not, but then again one year has passed.
|
|
Ah, but only on the theory part. Not sure how transactional they will be though since we need them for the old theories, unless we completely regenerate the affected grids (specially the ones that skip points in the middle). |
This is not required and should be deleted. |
|
I've updated E605, E866P/R and E906 to follow the new format proposed by @t7phy For the name convention I'm following what has been proposed by @cschwan, i.e., EXPERIMENT_PROCESS_ENERGY_OBSERVABLE_EXTRA stopping at the point in which the information makes the dataset unique. In this case for E605 and E906, the commondata is under the E605/E906 folders. Instead for E866 there were two publications and so the data is under the folders E866_FTDY_800GEV_PXSEC and E866_FTDY_800GEV_PDXSECRATIO. Please @cschwan and @felixhekhorn have a look at the name convention and let me know whether it is correct. I've also added two keys under The first is The second is And one top-level key with I also think the @tgiani one question, you added also a folder Please, let me know whether all this is correct and whether I can move forward with the reader using these files as target. |
|
I'd
|
| version: 1 | ||
| tables: [1,2,3,4,5,6,7] | ||
| npoints: [17,18,18,18,18,18,12] # number of datapoints in each table | ||
| energy: "38.8EV" |
There was a problem hiding this comment.
Should probably be GEV instead of EV.
|
@scarlehoff if you have a look at https://github.com/NNPDF/nnpdf/blob/more_efficient_metadata_for_new_commondata/buildmaster/CMS_ttBar_8TeV_lj_dif/metadata.yaml#L3 and also have a look at line 23, 48, 73, etc. which contain the observable_name, if you were to concat the line 3 setname with observable_name, you can uniquely identify every observable. In the above example, I will have to capitalize them ofc. In your example, the observable_name would just be empty as the implementation is only with a single observable which is uniquely identified by the setname itself. |
Actually for the reader I would very much like to have all fields: experiment, energy, process and observable. And 4 of these 3 are required anyway (the process is needed for MHOU). Energy is new but I'm guessing it will be necessary in all LHC datasets. Of course, we can say that the minimum name for the commondata is EXPERIMENT_ENERGY_PROCESS* and then it is not necessary to have it in the metadata. That will also be fine. Can we have one paper with two different processes/energies? *with extra information being added in a case-by-case basis |
Actually I have implemented both cases. Papers with different processes and papers with different energies. For example H1 datasets containing jets and dijets, or LHC papers containing both 7 and 8 TeV datsets. In these cases we separate the implementations for the processes or energies (suggest by @enocera), so the setname+observable_name can be used for unique identification without any issues. |
|
So I should rename: E605 -> E605_DY_38P8GEV And if one wants to add another process from E605 then that will be a separate folder even if it happens to be the same paper. Did I understand it correctly? |
Si |
|
I would say even the dataset key in every observable is redundant. All you need is the global key: setname, and the observable specific key: observable_name for unique identification |
|
Ok, I've updated now with all the suggested changes. I've left the In general the name of the dataset will be: _ and is EXPERIMENT_PROCESS_ENERGY, so the full name is EXPERIMENT_PROCESS_ENERGY_OBSERVABLE However, in E866 the folder also includes the observable name, therefore the observable would get added twice. Note that this is also a problem currently in #1684 which is called CMS_TTBAR_8TEV_LJ_DIFF where under this convention What is the proposed solution for this? As I've said before I would like to avoid having keys that appear in some metadata files and not in others regarding the names. (I don't have any strong opinion regarding what the correct way should be, I just want to know for sure that I have only one rule to create the name and that I can apply the same rule to all commondata). |
As I wrote above, for the E866, the simplest solution is to just have an empty value for observable_name as the setname itself uniquely identifies it. As for the convention, it is EXPERIMENT_PROCESS_ENERGY_MISC.INFO_OBSERVABLENAME, this misc info is important as there are datasets in different papers with slight variations (luminosity for instance). The reader could get the exp name by looking at the what comes before 1st _, process before 2nd _ and so on, however the observable name could be obtained by looking at what comes after the last _. I will need to make lots of changes too, because I usually named observables as M_TTBAR or Y_TTBAR which I will modify to MTTBAR and YTTBAR to ensure this convention. Does this seem fine? |
@scarlehoff that was implemented to cross-check some old implementation of the data. I added it for completeness as asked by @enocera, not sure if we want to keep it |
|
Ok, that will basically leave the following convention: where I'm happy with it :D If @cschwan and @felixhekhorn (also @enocera ofc but I'm assuming he's also ok with it) confirm I will update the datasets here and add it to the docs when dealing with #1691. |
@scarlehoff Let me check what that was about before dropping it, please. |
Co-authored-by: Felix Hekhorn <felixhekhorn@users.noreply.github.com>
|
I've updated the names of the two E866 observables. I've also disconnected this branch from the reader (it's easy enough to copy the relevant folders every time I want to test the reader). |
|
@enocera @tgiani I think the However, I don't see the 'add in quadrature' operation in the |
@scarlehoff Let me also check this. However, as I mentioned in #1684 may it be that the difference in the number of sys uncertainties is that we only have absolute uncs (in the new format) instead of absolute and relative (in the old format)? |
|
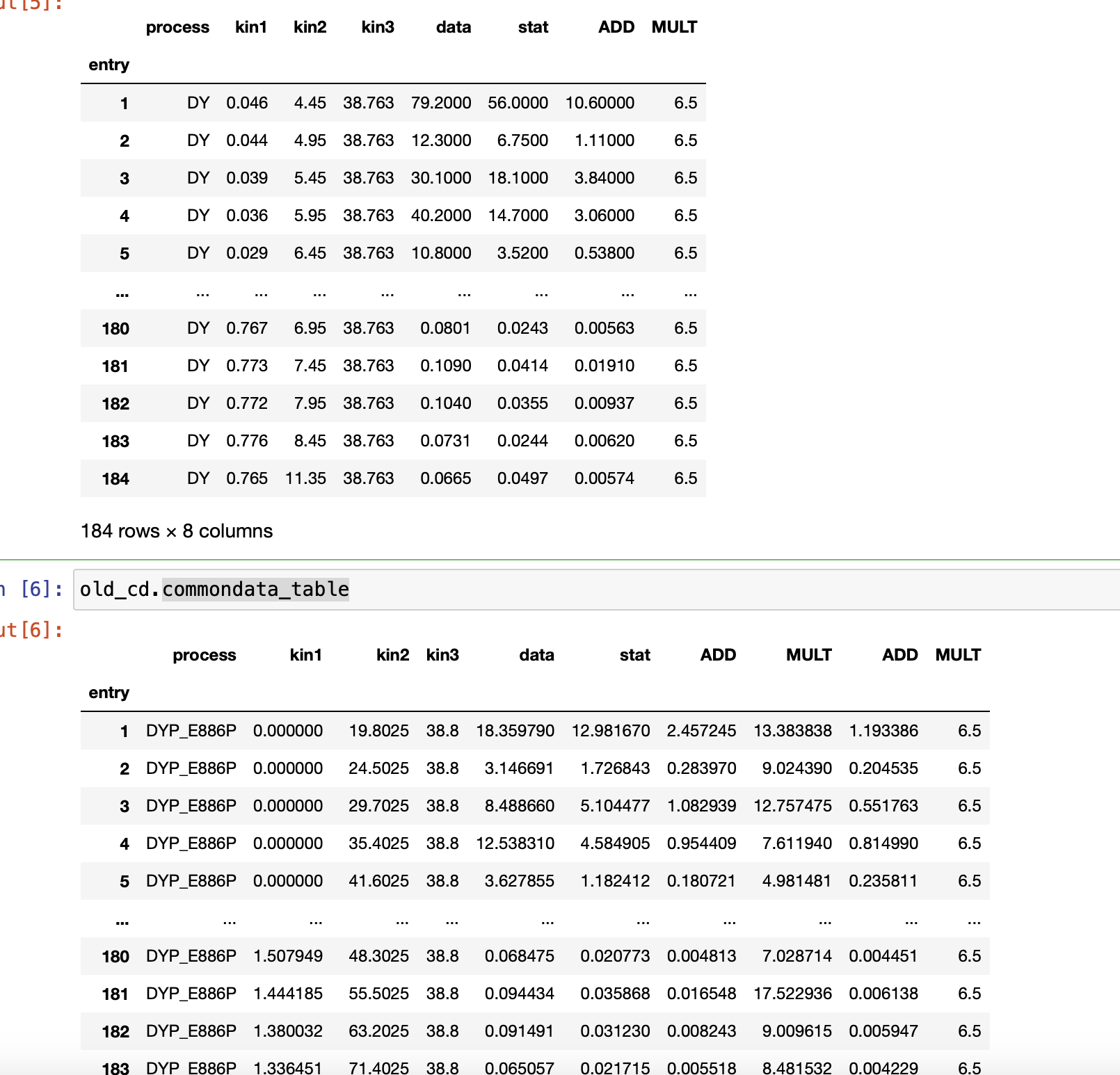
Upon further inspection, they are not swapped as (MULT <-> ADD) but rather as (1st <-> 2nd) (I was comparing old vs new, so they came in a different order). The MULT is ok. But the ADD still looks wrong (scratch the added in quadrature, it's just a factor of two...) For the first 10 points we have: new: old: It's like in the new one we keep 3 digit while the old ones keep only 2? |
@tgiani can correct me if I'm wrong, but I think that this difference is due to the input rawdata which, in the new format, is taken from Hepdata tables, while in the old format comes either from the paper or from some files of unknown origin. |
You can drop it. |
|
Ah, ok! I thought they should match the old ones. Are these kinds of differences always expected? To know what level of accuracy should I expect when testing... I can just do "ok, if it's ok at 5% then I'm ok with it". I would like to automatize this testing as much as possible. |
For old data sets (that is data sets NOT taken from Hepdata) these differences can happen. |
|
@enocera follow up questions
For now the differences for this branch that I don't understand are:
Kinematics are always different. I'll redo the Of course, this is the "raw" datasets... but all the |
Not on top of my head. Let me check.
Let me check all these.
Correct. And that's because I told @tgiani to ignore variants for the time being. Let me implement these variants. |
|
Just to clarify, the factor of 1 is actually of -1 (otherwise it would be silly of me to mention it!) and it happens for |
|
At this point this is very much obsolete. The information is not lost in case it is necessary so I'm just closing the PR. |
I'm reopening #1610 here @tgiani
This is just a rebase of your commits there.
These metadata.yaml files however contains some errors (and some things that we might want to change?)
npointsfield inhepdata. Do we need this field @enocera ? (if so I'll add it to the reader)theoryfield must always come with anoperationeven if it isNULLFK_tablesare actually a list of list.So, the theory right now is:
but it should be
(this is due to some FKTables being a concatenation of grids now)
Point 2 is a bit silly in hindsight but for now it is like that...