Improve and fix bugs about fused softmax layer#133
Closed
hyunwoongko wants to merge 5 commits intoNVIDIA:mainfrom
hyunwoongko:main
Closed
Improve and fix bugs about fused softmax layer#133hyunwoongko wants to merge 5 commits intoNVIDIA:mainfrom hyunwoongko:main
hyunwoongko wants to merge 5 commits intoNVIDIA:mainfrom
hyunwoongko:main
Conversation
Contributor
Author
|
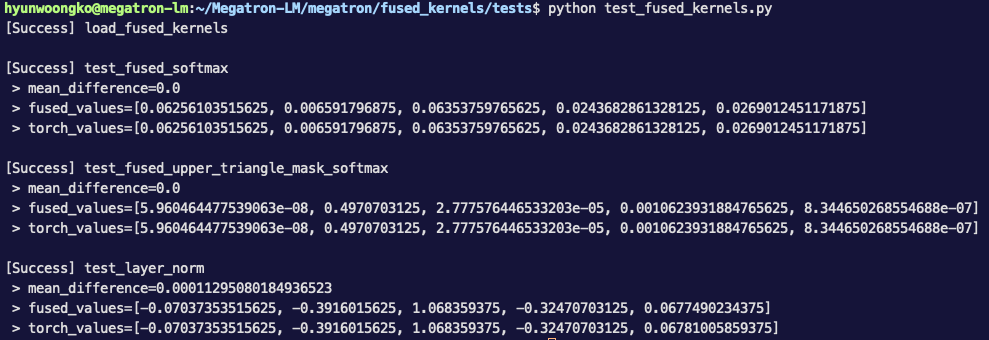
Everything works well. |
kvareddy
reviewed
Aug 16, 2021
| int softmax_elements_stride, | ||
| int attn_batches) | ||
| { | ||
| TORCH_INTERNAL_ASSERT(softmax_elements >= 0 && softmax_elements <= 2048 ); |
Contributor
There was a problem hiding this comment.
I think we should retain these asserts if someone wants to use the cuda code directly.
Contributor
Author
There was a problem hiding this comment.
Ok I see. I agree with you.
kvareddy
reviewed
Aug 17, 2021
| self.scaled_masked_softmax_fusion # user want to fuse | ||
| and self.input_in_float16 # input must be fp16 | ||
| and mask is not None # mask tensor must not be None | ||
| and 16 < sq <= 2048 # sq must be 16 ~ 2048 |
Contributor
There was a problem hiding this comment.
it should be 16 < sk <= 2048 and sq % 4 == 0
Contributor
Author
There was a problem hiding this comment.
custom_kernel_constraint = key_seq_len > 16 and key_seq_len <= 2048 and \
query_seq_len % 4 == 0 and attn_batch_size % 4 == 0
Yes. You are right,. It was my mistake. I will change these things.
Contributor
Author
|
@kvareddy I fixed codes.:) |
kvareddy
approved these changes
Aug 18, 2021
jaredcasper
added a commit
that referenced
this pull request
Sep 1, 2021
Fused softmax checks and additions from Github (#133) See merge request ADLR/megatron-lm!312
Contributor
|
These changes should all be merged in now. Thanks again for the PR! |
itlamp
pushed a commit
to itlamp/Megatron-LM-comms
that referenced
this pull request
Apr 7, 2025
* [SW-212054] W/A for dtype mismatch with CAG * Narrow wa for CAG enabled only * add TODO remove comment * Reduced impact of workround to mixtral failing case only * Revert not needed changes * Remove empty spaces * Remove one more empty space * More generic local usage of get_args inside LinearWithGradAccumulationAndAsyncCommunication's backward * Fix local import of get_args * Remove usage of get_args in megatron/core * Remove not needed empty line * Style fixes * Reorder import in layers.py * Add/modify headers regarding 2025 year * Reorder copyright headers, link todo with jira ticket
andresnowak
pushed a commit
to andresnowak/SwissAi-Megatron-LM
that referenced
this pull request
Oct 28, 2025
* [feat] add yi & llama sparse upcycling model * add run script * tokenizer may be empty for megatron
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
3 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
ELEMENTS_PER_LDG_STG(reported in Error in fused softmax kernel result #132)0 <= length_key <= 2048(originally it was in the header file asTORCH_INTERNAL_ASSERT)batch_per_block(originally it was in the header file asTORCH_INTERNAL_ASSERT)