Add a discussion of cross-sectional distributions in economics#123
Add a discussion of cross-sectional distributions in economics#123
Conversation
✅ Deploy Preview for taupe-gaufre-c4e660 ready!
To edit notification comments on pull requests, go to your Netlify site settings. |
|
To do:
|
|
Thanks @jstac . I've embedded the code for figures into the lecture. This PR will be ready for review once the databases and imports are getting updated. Looking forward to your comments. |
|
Thanks @shlff , please let me know when it's ready to review. Please add to the |
|
@shlff the execution issue is and there are missing images |
|
@shlff could you please coordinate with @HengchengZhang to get this ready for review. |
287b4a4 to
b8b93f5
Compare
|
Sure thanks @jstac . Hi @HengchengZhang , it would be appreciated if we can get your help to get rid of the building issues here. |
Thanks for your nice work @shlff, I will have a look at this today. |
b8b93f5 to
116fa63
Compare
ac1773b to
b2840dc
Compare
|
Thanks @HengchengZhang . I've fixed the building issue. Hi @jstac please find preview of the lecture here: |
|
Thanks @shlff . Is this ready for review? (the label still says in-work). |
Yep John this lecture is ready for you to review and modify. Looking forward to your comments and suggestions. |
|
Many thanks for your hard work @shlff . It's much appreciated. Once small thing: each solution should follow its exercise. Would you mind to make that change? I'm now wondering if it wouldn't be better to combine this lecture with the more advanced one. Perhaps I'll do that and put the combined one in this series. I might try to do it later this week... |
|
Thanks @jstac . I've made the change and it is ready for review: I think it is good to combine this with the advanced lecture: it will be easier for students to understand if we can explain the heavy tails with theory in a more intuitive way and examples. Very looking forward to it. |
|
@shlff Your data for GDP per capita seems to include regions as well as countries:
|
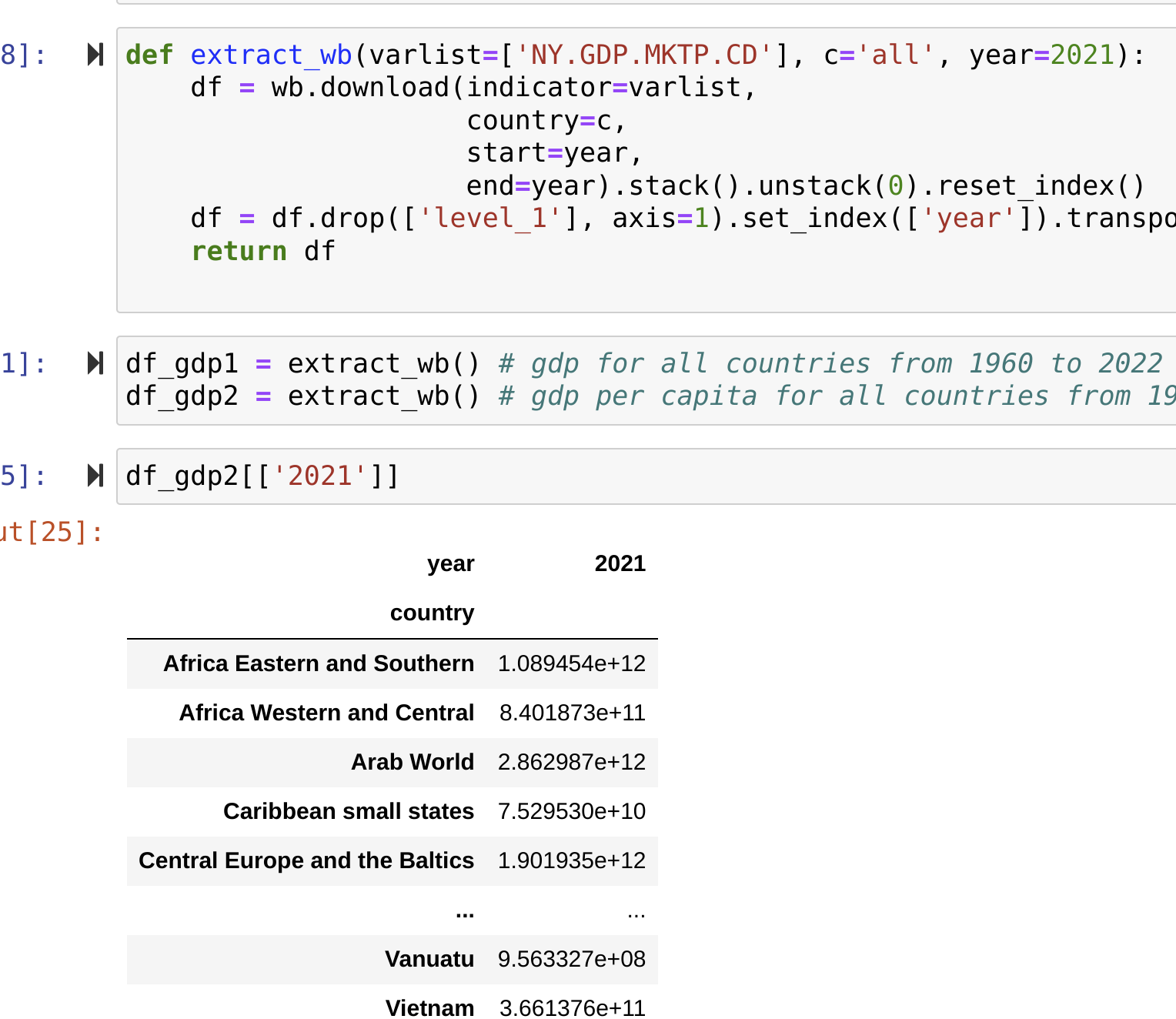
|
We don't need to pip install statsmodels |
| ### GDP | ||
|
|
||
| ```{code-cell} ipython3 | ||
| df_gdp1 = extract_wb(varlist=['NY.GDP.MKTP.CD']) # gdp for all countries from 1960 to 2022 |
There was a problem hiding this comment.
Can you please make this for just one year -- the latest available?
I don't think it makes sense to pool this data across years.
|
@shlff Could you please address the points above? Also, could you please try to stay within 80 characters per line, where possible? |
|
@shlff have you had time to address the issues above? |
|
Thanks @shlff . It's helpful if you can let me know when your changes are ready for my review. Here you use # get gdp and gdp per capita for all regions and countries in 2021
df_gdp1 = extract_wb(varlist=['NY.GDP.MKTP.CD'], s="2021", e="2021")[48:]
df_gdp2 = extract_wb(varlist=['NY.GDP.PCAP.CD'], s="2021", e="2021")[48:]
# Keep the data for all countries only
df_gdp1 = df_gdp1[48:]
df_gdp2 = df_gdp2[48:]Is there a more robust way to get just the countries rather than the regions? Is there a way to make it more readable? |
|
Sure @jstac . Really sorry about this. Thanks for spotting the typo. We just want to remove the first A more readable way to get just countries rather than regions could be
I found other users of I will modify it and update you soon. |
| ```{code-cell} ipython3 | ||
| def extract_wb(varlist=['NY.GDP.MKTP.CD'], | ||
| c='all', | ||
| s=1900, | ||
| e=2021, | ||
| varnames=None): | ||
| if c == "all_countries": | ||
| # keep countries only (no aggregated regions) | ||
| countries = wb.get_countries() | ||
| countries_code = countries[countries['region'] != 'Aggregates']['iso3c'].values | ||
|
|
||
| df = wb.download(indicator=varlist, country=countries_code, start=s, end=e).stack().unstack(0).reset_index() | ||
| df = df.drop(['level_1'], axis=1).transpose() # set_index(['year']) | ||
| if varnames != None: | ||
| df.columns = varnames | ||
| df = df[1:] | ||
| return df | ||
| ``` |
There was a problem hiding this comment.
Thanks for your comments @jstac . Please find my solution to get rid of regions for the GDP data and a preview here:
Since we only use this function once? Should we eliminate the function but use the code inside directly?
Looking forward to your comments and review.
|
Thanks @shlff |
Fixes #119
CC @shlff