Summary
When fread is fed with a character string as input the routine spends considerable amount of time detecting that the supplied input is not a filename or an url.
This is due to grepl not scaling well for large input as used in fread.
Example
is_url <- function(x) grepl("^(http|ftp)s?://", x)Although the pattern is anchored at the beginning of the string, running grepl for large inputs will take a lot of time for large inputs (more detailed benchmarks further down).
This will lead then to the full call to fread possibly spending a third of the time for those supposedly simple checks. (example also below)
Possible solutions could be one or more of the following
- changing the call to
grepl to use PERL regexp engine perl=TRUE
Alternatively use another method to determine whether the input starts with url (see benchmarks below)
- adding an explicit optional argument which denotes string input, e.g.
str= to denote that the input is to be considered as the data and skip the tests for url or file. This would be similar in spirit to the file= argument.
As a side-effect this would also allow input to be read which consits only of url's and having no header, e.g.
fread("http://hkhfsk\nhttp://fhdkf\nhttp://kjfhskd\nhttp://hfkjf", header=FALSE)
- consider an input, which exceeds a certain number of characters in length, not being an URL
Profiling example
library(data.table)
# create a random character input in 5 columns with 20000*200 lines
randomString <- function() {
paste(sample(c(LETTERS, letters), sample(1:9,1)), collapse="")
}
input <- paste(rep(paste(replicate(20000,paste(replicate(5, randomString()),
collapse="\t")),
collapse="\n"),200),
collapse="\n")
# profile the call to fread
Rprof()
invisible(fread(input, header=FALSE))
Rprof(NULL)
summaryRprof()$by.self
self.time self.pct total.time total.pct
".Call" 5.34 64.49 5.34 64.49
"grepl" 2.94 35.51 2.94 35.51
Benchmarking grepl and friends
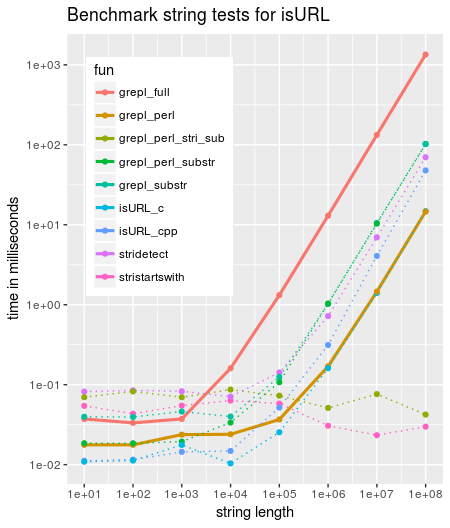
Comparing different functions to verify whether a string starts with any of http(s)/ftp(s) or file shows that grepl scales badly and is by far the slowest of the tested variants.
Adding simply perl=TRUE already improves by around factor 100 for large inputs (code further below)
library(data.table)
library(ggplot2)
library(Rcpp)
# define alternative functions to detect URL's
grepl_full <- function(txt) { grepl("^(http|ftp)s?://", txt) }
grepl_substr <- function(txt) { grepl("^(http|ftp)s?://", substr(txt,1,8)) }
grepl_perl <- function(txt) { grepl("^(http|ftp)s?://", txt, perl=TRUE) }
grepl_perl_substr <- function(txt) { grepl("^(http|ftp)s?://", substr(txt,1,8), perl=TRUE) }
grepl_perl_stri_sub <- function(txt) { grepl("^(http|ftp)s?://", stringi::stri_sub(txt,1,8),
perl=TRUE) }
stridetect <- function(txt) { stringi::stri_detect_regex(txt, "^(http|ftp)s?://") }
stristartswith <- function(txt) {
stringi::stri_startswith_fixed(txt, c("http://", "https://", "ftp://", "ftps://"))
}
cppFunction('bool isURL_cpp(const std::string &x) {
bool ret = FALSE;
if (x.length() >= 8) {
std::string s = x.substr(0,8);
if (s.substr(0,7) == "http://" ||
s == "https://" ||
s.substr(0,6) == "ftp://" ||
s.substr(0,7) == "ftps://") {
ret = TRUE;
}
}
return(ret);
}')
cppFunction('bool isURL_c(const char* x) {
bool ret = FALSE;
if (strlen(x) >= 8) {
if (!strncmp(x, "http://", 7) ||
!strncmp(x, "https://", 8) ||
!strncmp(x, "ftp://", 6) ||
!strncmp(x, "ftps://", 7)) {
ret = TRUE;
}
}
return(ret);
}')
# number of string lengths to test with. max len = 1e+nn
nn <- 8
# create random strings of given length
for (i in 1:nn) {
assign(paste0("str_",i), paste(sample(c(LETTERS, letters), 10^i, replace=TRUE),
collapse=""))
}
function_list <- c("grepl_full", "grepl_substr", "grepl_perl", "grepl_perl_substr",
"grepl_perl_stri_sub",
"isURL_cpp", "isURL_c",
"stridetect", "stristartswith")
# cross join of functions and strings
dt <- CJ(fun=function_list, ind=1:nn)
# build code to run microbenchmark
mb_code <- paste("microbenchmark::microbenchmark(",
paste0("'", dt$fun, " ", 10^dt$ind, "'=",
dt$fun, "(str_", dt$ind, ")", collapse=","),",times=10)")
# eval microbenchmark and calculate median
mb <- as.data.table(eval(parse(text=mb_code)))
mb[,c("fun", "nr"):=tstrsplit(as.character(expr), " ", fixed=TRUE)]
mb[,nr:=as.integer(nr)]
mb <- mb[,.(time=median(time)), by=.(fun,nr)]
# plot
ggplot(mapping=aes(nr, time/1e6)) +
geom_line(data=mb[fun %chin% c("grepl_full", "grepl_perl")],
aes(col=fun), size=1.1) +
geom_line(data=mb[!fun %chin% c("grepl_full", "grepl_perl")],
aes(col=fun), size=0.5, linetype="dotted") +
geom_point(data=mb, aes(col=fun)) +
scale_y_log10(breaks=c(0.01,0.1,1,10,100,1000)) +
scale_x_log10(breaks=10^(1:nn)) +
labs(y="time in milliseconds", x="string length",
title="Benchmark string tests for isURL") +
theme(legend.position = c(0.05,0.95), legend.justification = c(0,1))sessionInfo
R version 3.3.1 (2016-06-21)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 16.04.3 LTS
locale:
[1] LC_CTYPE=en_GB.UTF-8 LC_NUMERIC=C LC_TIME=en_IE.UTF-8 LC_COLLATE=en_GB.UTF-8
[5] LC_MONETARY=en_IE.UTF-8 LC_MESSAGES=en_GB.UTF-8 LC_PAPER=en_IE.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C LC_MEASUREMENT=en_IE.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] data.table_1.10.5
loaded via a namespace (and not attached):
[1] tools_3.3.1 yaml_2.1.15
Results are similar with R 3.4.3 / data.table 1.10.4 / Windows 10 64bit
Summary
When
freadis fed with a character string as input the routine spends considerable amount of time detecting that the supplied input is not a filename or an url.This is due to
greplnot scaling well for large input as used in fread.Example
Although the pattern is anchored at the beginning of the string, running
greplfor large inputs will take a lot of time for large inputs (more detailed benchmarks further down).This will lead then to the full call to
freadpossibly spending a third of the time for those supposedly simple checks. (example also below)Possible solutions could be one or more of the following
greplto use PERL regexp engineperl=TRUEAlternatively use another method to determine whether the input starts with url (see benchmarks below)
str=to denote that the input is to be considered as the data and skip the tests for url or file. This would be similar in spirit to thefile=argument.As a side-effect this would also allow input to be read which consits only of url's and having no header, e.g.
Profiling example
Benchmarking
grepland friendsComparing different functions to verify whether a string starts with any of http(s)/ftp(s) or file shows that
greplscales badly and is by far the slowest of the tested variants.Adding simply
perl=TRUEalready improves by around factor 100 for large inputs (code further below)sessionInfo
Results are similar with R 3.4.3 / data.table 1.10.4 / Windows 10 64bit