fwrite() UTF-8 csv file #4785
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -5,18 +5,23 @@ | |
| #define DATETIMEAS_EPOCH 2 | ||
| #define DATETIMEAS_WRITECSV 3 | ||
|
|
||
| static bool utf8=false; | ||
| static bool native=false; | ||
| #define TO_UTF8(s) (utf8 && NEED2UTF8(s)) | ||
|
Member
There was a problem hiding this comment. nit: Nothing comes to mind unfortunately, worth considering some more though. |
||
| #define TO_NATIVE(s) (native && (s)!=NA_STRING && !IS_ASCII(s)) | ||
|
Member
There was a problem hiding this comment. @jangorecki I think you recommended putting |
||
| #define ENCODED_CHAR(s) (TO_UTF8(s) ? translateCharUTF8(s) : (TO_NATIVE(s) ? translateChar(s) : CHAR(s))) | ||
|
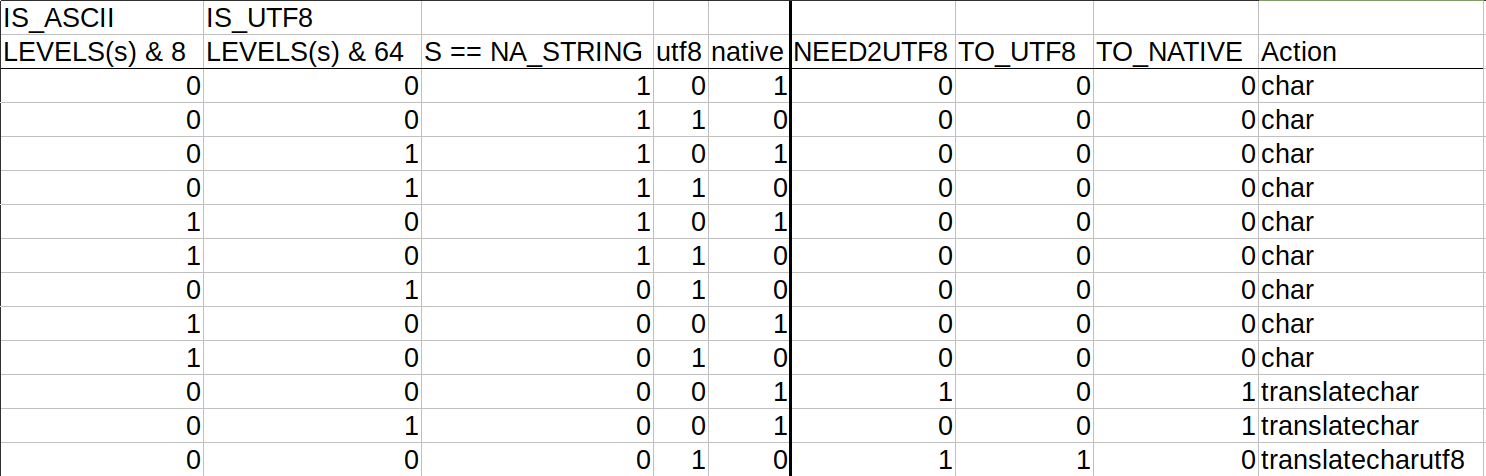
Member
There was a problem hiding this comment. note that how about or based on this truth table (the other 22/32 combinations are impossible because
Member
Author
There was a problem hiding this comment. Yes, you're right but after a 2nd thought, I still prefer the current version. The reasons are:
|
||
|
|
||
| static char sep2; // '\0' if there are no list columns. Otherwise, the within-column separator. | ||
| static bool logical01=true; // should logicals be written as 0|1 or true|false. Needed by list column writer too in case a cell is a logical vector. | ||
| static int dateTimeAs=0; // 0=ISO(yyyy-mm-dd), 1=squash(yyyymmdd), 2=epoch, 3=write.csv | ||
| static const char *sep2start, *sep2end; | ||
| // sep2 is in main fwrite.c so that writeString can quote other fields if sep2 is present in them | ||
| // if there are no list columns, set sep2=='\0' | ||
| // Non-agnostic helpers ... | ||
|
|
||
| const char *getString(SEXP *col, int64_t row) { // TODO: inline for use in fwrite.c | ||
| SEXP x = col[row]; | ||
| return x==NA_STRING ? NULL : ENCODED_CHAR(x); | ||
| } | ||
|
|
||
| int getStringLen(SEXP *col, int64_t row) { | ||
|
|
@@ -45,7 +50,7 @@ int getMaxCategLen(SEXP col) { | |
| const char *getCategString(SEXP col, int64_t row) { | ||
| // the only writer that needs to have the header of the SEXP column, to get to the levels | ||
| int x = INTEGER(col)[row]; | ||
| return x==NA_INTEGER ? NULL : ENCODED_CHAR(STRING_ELT(getAttrib(col, R_LevelsSymbol), x-1)); | ||
| } | ||
|
|
||
| writer_fun_t funs[] = { | ||
|
|
@@ -164,10 +169,12 @@ SEXP fwriteR( | |
| SEXP is_gzip_Arg, | ||
| SEXP bom_Arg, | ||
| SEXP yaml_Arg, | ||
| SEXP verbose_Arg, | ||
| SEXP encoding_Arg | ||
| ) | ||
| { | ||
| if (!isNewList(DF)) error(_("fwrite must be passed an object of type list; e.g. data.frame, data.table")); | ||
|
|
||
| fwriteMainArgs args = {0}; // {0} to quieten valgrind's uninitialized, #4639 | ||
| args.is_gzip = LOGICAL(is_gzip_Arg)[0]; | ||
| args.bom = LOGICAL(bom_Arg)[0]; | ||
|
|
@@ -224,6 +231,8 @@ SEXP fwriteR( | |
| dateTimeAs = INTEGER(dateTimeAs_Arg)[0]; | ||
| logical01 = LOGICAL(logical01_Arg)[0]; | ||
| args.scipen = INTEGER(scipen_Arg)[0]; | ||
| utf8 = !strcmp(CHAR(STRING_ELT(encoding_Arg, 0)), "UTF-8"); | ||
| native = !strcmp(CHAR(STRING_ELT(encoding_Arg, 0)), "native"); | ||
|
|
||
| int firstListColumn = 0; | ||
| for (int j=0; j<args.ncol; j++) { | ||
|
|
||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
nit: could have signature
encoding = c("", "UTF-8", "native")and usematch.argsinstead of the check belowThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
The encoding arg of
fread()doesn't use this signature, either. The reason is the empty string seems not work well withmatch.arg():Created on 2020-10-30 by the reprex package (v0.3.0)
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Filed the bug to https://bugs.r-project.org/bugzilla/show_bug.cgi?id=17959