编码的那些事儿 #1
Description
关于编码
那么到底什么是编码呢,官方解释是这样的:编码是信息从一种形式或格式转换为另一种形式的过程也称为计算机编程语言的代码简称编码 ,编码是相对于字符集来说的,每个字符集都有对应的一个或多个编码(如GBK字符集对应的编码是GBK编码,Unicode字符集对应的编码:UTF-8,UTF-16等),而我们往往会把编码和字符集等同看待。从计算机角度来说,编码就是利用计算机位/字节组合出的不同状态,对应现实世界中不同的文字,数字,对象。这样计算机就可以通过编码或者说字节的组合来表示现实世界的一切。
相对于网络传输应用,编码就像一把钥匙,一把钥匙只能开一把锁,如果我们在网络传输中用的是UTF-8编码传输数据,那么数据接收端(客户端或者服务器)端肯定不能用GBK编码这把钥匙打开,这就是乱码产生的原因。不过要想说清楚编码,还的从其发展史谈起。
编码发展史
关于编码的发展史,之前在网上看到过一篇不错的文章,原文地址找不到了,不过网上转载的比较多:http://ydfy6.blog.163.com/blog/static/112305677200942683556906/,根据原文内容,结合不同编码的特点我大致归纳一下:
先从计算机的产生说起,美帝用类似于“灯泡”的晶体管生产出来了第一台计算机,他们用8个“灯泡”(1个字节)组合出不同的状态(256种),然后从00开始,依次给设置一个对应值,直到填满至第127位(0x7f):其中控制码(0-31/0x00-0x19)、空格(32)、标点符号、数字、大小写字母等(具体可参加ASCII码表),这127种状态后来就被称为ASCii码。随后有些西方国家利用127位以后的空位,填充他们需要的新的字符和符号,直至填满,这样这全部的256种状态就构成了新的编码:ISO-8859-1。
当计算机到了中国,为了满足汉字的需要,我们保留前127位ASCii码不变,取2个字节组合的方式(161-255/0xA1-0xFE)来表示汉字(94区94位),这就是GB2312,但是这种组合却仅有7000多个简体汉字,为了支持更多的汉字,于是我们就扩大这两个字节的选取范围,高字节大于128(0x81-0xFE),低字节大于63(0x40-0xFE),这样就增加了20000多字,我们称之为GBK。可是别忘了我们还有少数名族,于是我们在GB2312,GBK这种单(ASCII)双字节(汉字)的基础上添加4个字节表示一个字符,其中一三字节范围_0x81-0xFE_,二四字节范围:0x30-0x39,这就是GB18030。
如此一来各个国家都搞出一套自己的编码,相互重叠,除了ASCII,谁也不支持别人的编码。为了解决这种混乱现象,自然就有组织制定了统一的标准把全球的语言都给便是进去,UCS和unicode应运而生,分别由ISO和unicode.org来设计。为了防止两个组织的带来的混乱,从unicode2.0后,Unicode项目采用了与ISO10646-1相同的字库和字码。
不管是UCS还是unicode,我们更愿意称之为字符集(它的编码方式有:UTF-8,UTF-16等)。在开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题了。其中UCS有两种格式,分别是USC-2(0x0000-0xFFFF),USC-4(0x0000-0x10FFFF)。通过名字可以看出UCS-2就是用两个字节编码,UCS-4就是用4个字节(实际上只用了31位,最高位必须为0)编码,UCS-2有2^16=65536个码位(这大概已经可以覆盖世界上所有文化的符号),UCS-4有2^31=2147483648个码位,UCS-2前面加上2个全是0的字节就变成了UCS-4。由于Unicode则采用两个字节,也就是16位来统一表示所有的字符,因此我们可以暂且将UCS-2与Unicode等同看待。ECMAScript规定里的Code Source字符集即为UCS-2。然而Unicode在制订时没有考虑与任何一种现有的编码方案保持兼容,所以没有一种简单的算术方法可以把文本内容从Unicode编码和另一种编码进行转换,这种转换必须通过查表来进行。
Unicode已经足够用了,但是不管是汉字还是英文字符,在网络中传输时都占用2个字节未免有点浪费资源,于是就有了针对Unicode传输的标准UTF(UCS Transfer Format)编码,我们主要用到的是UTF-8。UTF-8:8位编码, ASCII不作变换, 其他字符做变长编码, 每个字符1-4位。Unicode到UTF并不是直接的对应,可以通过一些算法和规则来转换。下面是Unicode到UTF-8的转换对应关系,我们将Unicode码转换成2进制,然后从右向前依次替代第二列中对应的x,直至填完,空位补0.
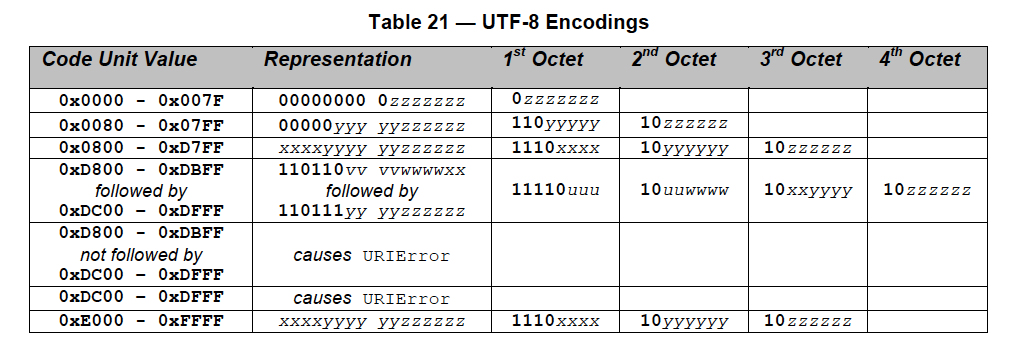
既然UTF-8包含的范围这么广,为什么国内很多互联网大佬还用GBK或者GB2312呢?这里包含着历史的缘故,但是还有个主要原因就是字节,UTF-8中文字符要占2-4个字节,而GB2312/GBK却只需要2个字节。
最后再来说明一下Base64,Base64编码主要用途是为了将二进制数据转换成ASCII字符用于网络传输,如图片数据,XML,电子邮件等,当然也可以理解为简单的加密。具体算法:将3个字节24位数据,以每6位一个ASCII码来表示,一共4个字符
Javascript中的编码转换
ECMA-262 5.1 Edition规定Javascript的source text是Unicode编码,Javascript代码在解释时将被首先会被转换成UTF-16编码。
ECMAScript source text is represented as a sequence of characters in the Unicode character encoding,version 3.0 or later. ... ... ECMAScript source text is assumed to be a sequence of 16-bit code units for the purposes of this specification. Such a source text may include sequences of 16-bit code units that are not valid UTF-16 character encodings. If an actual source text is encoded in a form other than 16-bit code units it must be processed as if it was first converted to UTF-16.
尽管NodeJS给Javascript注入的新的血液,可以做加密运算等很多的编码转换(如 BASE64,哈希),但是对于前端开发人员来说,Javascript仅仅给出了三组编码转换的接口,所以期望Javascript前端工程师在编码上做更多的处理都是想法都是不可取的。这些API都是全局函数,包括:
| Function | Description |
|---|---|
| decodeURI() | Decodes a URI |
| decodeURIComponent() | Decodes a URI component |
| encodeURI() | Encodes a URI |
| encodeURIComponent() | Encodes a URI component |
| escape() | Deprecated in version 1.5. Use encodeURI() or encodeURIComponent() instead |
| unescape() | Deprecated in version 1.5. Use decodeURI() or decodeURIComponent() instead |
escape
For those characters being replaced whose code unit value is 0xFF or less, a two-digit escape sequence of the form %xx is used. For those characters being replaced whose code unit value is greater than 0xFF, a four-digit escape sequence of the form %uxxxx is used.
可以简单的认为escape是以0xFF(255)为界,大于他的将会被转换成unicode编码,而比其小的除了以下这些字符外:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789@*_+-./
会被转换成%xx的形式。
encodeURI 和 encodeURIComponent
The encodeURI or encodeURIComponent function computes a new version of a URI in which each instance of certain characters is replaced by one, two, three, or four escape sequences representing the UTF-8 encoding of the character.
这两个方法可以将中文字符或者其他一些字符转换成UTF-8编码以16进制表示(%**表示),先来看一下ECMAScript对URI的语法规定(RFC 2396):

从上图可以发现URI的token主要有四部分组成:uriReserved,uriAlpha,uriMark,uriEscaped,而uriEscaped实际上就是对不匹配前三种字符集的那些字符转换成UFT-8的16进制编码。
encodeURI 和 encodeURIComponent的区别在于是否对uriReserved里面的字符进行转换。
编码与安全
我们知道XSS攻击很多时候都是通过分析URI中参数查找漏洞,然后利用页面中给DOM元素的属性赋值或者通过innerHTML添加内容,或者通过CSS Expression等进行攻击的。举个简单的例子:
<div id="xss"></div>
<script type="text/javascript">
//页面的URL是:http://test.com?<script>alert(1)</script>
var data = document.URL.split('?')[1];
document.getElementById('xss').innerHTML = data;
</script>
所以说页面的URL非常重要,有一些特殊字符是利用URI进行攻击的主要原因,如何页面没有对URL中的< >进行编码转换,那就会被利用进行攻击。幸运的是现在浏览器厂商都引用了XSS filter机制,会对一些可能会引起攻击的字符进行编码转换如:< > " ' 等,然而可惜的是IE浏览器并不支持这些字符的编码转换,而Chrome也仅仅对 < > " 这三个字符进行编码,所以当我们需要传递这些参数的时候还是需要通过 encodeURIComponent()`方法对参数进行转换。
还有个问题就是利用浏览器自转码问题。HTML页面可以包含实体编码,如 相当于空格,同时也支持进制编码:&#xH;(十六进制),&#D;(十进制);而Javascript文件除了支持unicode编码外,也支持十六进制的编码\xH。这些特性都可能会成为攻击时被利用的对象,所以一定要在页面的输入和输出点加以判断。
当然前面说的两种情况还是相对比较容易判断,还有一个问题是很难判断,那就是关于宽字节。前面在谈编码历史的时候说到过关于中文是有2个或2个以上的字节组成,有高字节和低字节,这个时候如果页面是GBK编码,用户就可以根据浏览器对特殊字符的处理特性,然后利用一些特殊字符组合在一起伪造成中文字符,从而也可能成为被攻击的漏洞。
关于Web安全这块就不做深入讨论的,至于上面所述的那些问题怎么会成为被攻击的漏洞,推荐研究一下《Web前端黑客技术揭秘》这本书。下面说一下乱码这个比较重要的问题。
乱码问题
关于编码最主要就是乱码问题了,这主要发生在前后端交互中。然而还有个问题需要注意,就是Javascript文件中中文字符的问题。
1.Javascript文件中得中文字符问题
出于性能考虑,我们往往会将JS文件压缩混淆(利用unglifyJS,yuicompressor,closure等),然而假如JS文件采用了GBK编码且里面包含中文字符,这时如果用UTF-8编码进行压缩,那么就会产生乱码。
如何解决这个问题呢?我们知道YUICompressor可以指定压缩编码(--charset gbk),但是并非所有的工具都可以这么做,比如UglifyJS就仅仅支持UTF-8编码,这时我们可以选择那些支持设置编码的压缩工具。当然如果必须使用UglifyJS呢?这时可以将JS文件中的中文字符给转换成unicode字符;或者将JS文件设置成UTF-8编码,然后在加载JS的script标签中设置编码(charset="utf-8")。不要诧异为什么要这么做,因为我们的HTML也页面设置的可能是GBK编码。
2.Ajax请求乱码问题
当我们使用Ajax请求数据时,如果用post方法,不管页面编码是GBK,还是UTF-8,send(data)方法中data数据都将会被转换成encoding:utf-8,所以对于GBK编码的页面,在post数据时,必须对编码进行转换,否则就可能会出现乱码(可以利用Javascript提供的那三种编码转换方法)。下面看一下W3规定xhr send(data)时,如何处理data数据的:
If
datais null, do not include a request entity body and go to the next step.
Otherwise, let encoding be null, mime type be null, and then follow these rules, depending on data:... ...
a string
Let encoding be "UTF-8".
Let mime type be "text/plain;charset=UTF-8".
Let the request entity body be data, utf-8 encoded.
实际上乱码问题是完全可以避免的,前提就是搞清楚一把钥匙只能开一把锁。