DistributedTraining Kubernetes Operator tries to address the following problem: can I come up with a framework to automate and distribute the trainings for ensemble-able models with huge datasets?
Medium post is at here
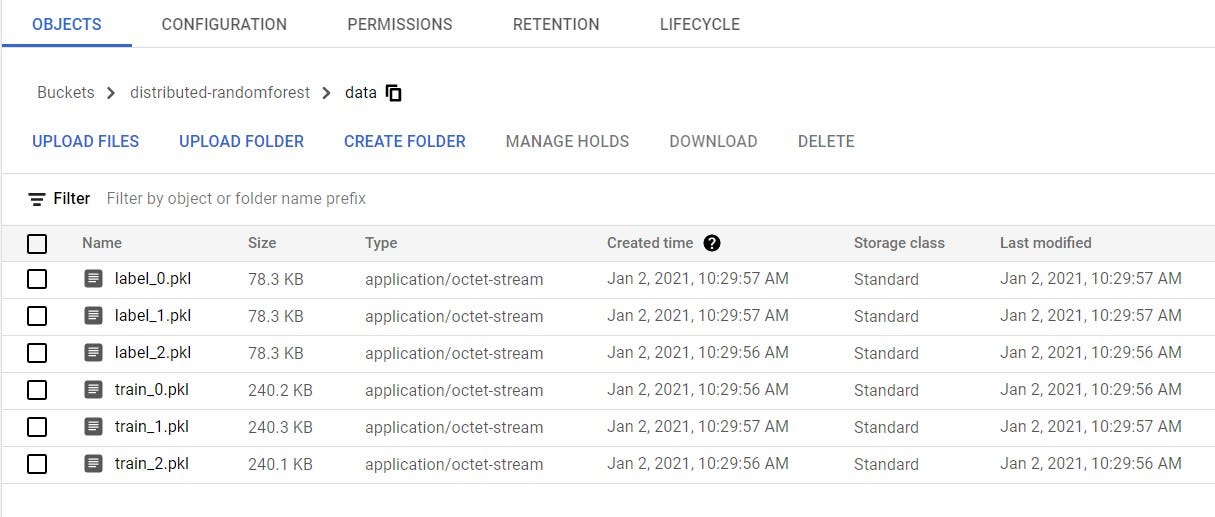
- Prepare your data at the GCS bucket (as specified in baseGcsBucket). Currently there must be a data sub-directory inside the bucket. Inside the data directory, each partition of the training data should be in pickle file format and named as training_x.pkl/label_x.pkl
- Set up ServiceAccount, Role and RoleBinding (only done once)
kubectl create -f deploy/service_account.yaml
kubectl create -f deploy/role.yaml
kubectl create -f deploy/role_binding.yaml- Set up Operator and Custom Resource Definition (only done once)
kubectl create -f deploy/operator.yaml
kubectl apply -f deploy/crds/dt_crd.yaml- Create and Run Your Distributed Training
kubectl apply -f deploy/crds/dt_cr.yaml- Get the combined model from your "GCS_Bucket/combined_model.pkl"