AIRFLOW-5701: Don't clear xcom explicitly before execution #6370
Conversation
Travis is sad. Can you fix it? |
|
Yes. I also still have to do the database migrations. The issue here is that for sqlite the migrations are quite limited, and don't support dropping of columns. The changes to the xcom table are not breaking any queries, since we're not using the |
Codecov Report
@@ Coverage Diff @@
## master #6370 +/- ##
==========================================
- Coverage 80.57% 80.26% -0.31%
==========================================
Files 626 626
Lines 36237 36229 -8
==========================================
- Hits 29198 29081 -117
- Misses 7039 7148 +109
Continue to review full report at Codecov.
|

|
Test failure looks unrelated, pulled in master: |
|
Actually, the current database layout is backward compatible. We don't use the |
|
@Fokko jira still open |
|
Thank you @OmerJog |
| dag_id = Column(String(ID_LEN), primary_key=True, nullable=False) | ||
|
|
||
| __table_args__ = ( | ||
| Index('idx_xcom_dag_task_date', dag_id, task_id, execution_date, unique=False), |
There was a problem hiding this comment.
@Fokko couple things / questions
- it seems we don't need this index anymore, now that there is a primary key with the same columns
- i could be wrong (i am new to alembic and sqlalchemy) but aren't you missing a migration script for users who are upgrading?
- should we add
PrimaryKeyConstraint('dag_id', 'task_id', 'execution_date', 'key')here to clarify order of index columns? Although it seems that table structure is entirely managed by alembic, and these table args have no effect, we should probably be consistent (and if i understand correctly, if not specified, primary key cols are ordered as they appear in table def).
There was a problem hiding this comment.
Yes, you're right. The index has been replaced by the PrimaryKey.
- For sqlite the only way of doing these kinds of changes is dropping and recreating the table. Because sqlite does not have any support for altering columns.
- The table is actually more or less the same, only the ID column is removed (which wasn't being used).
- I looked at other
__table_args__, and I don't see aPrimaryKeyConstraintbeing defined. I think it would make sense to add this.
There was a problem hiding this comment.
I was mainly looking at this PR mainly to learn how to do DB change, in case I ever want to propose something involving DB schema change. But noticed these things and wanted to surface in case something was possibly missed.
Clarification of observations
- I noticed that only migration changes in this PR are in the
current_schemamigration script, and they are only applied if table not exists. So this indicated to me that this change would not be applied on upgrades, whether sqlite or any other database. - I tried doing a new install (on sqlite) and both index and primary key were present.
- I tried doing upgrade (on sqlite) and the
idcolumn was not dropped.
sqlite migration issues
Re sqlite migrations, this stack overflow post that indicates that table alters on sqlite are supported with alembic > 0.7.0 using batch mode, where it will handle creating new tables and copying data. Wondering if that is possibly relevant here.
alembic revision issues
I tried running alembic revision locally and encountered 2 issues. 1 was typing import resolution error due to new airflow/typing.py module being in same directory where we try to run alembic. 2 was FAILED: Multiple heads are present; in alembic. Are migrations are handled by release manager so we don't deal with them in PRs?
This blog post suggests adding unit test for detecting multiple revision heads. Maybe that's a good idea.
upgrades
are we meant to be able to upgrade to 2.0 from 1.10.X? cus i tried installing fresh install of 1.10.6 and then checking out master and running airflow db upgrade and got an error. Is this something that we should be testing for possibly?
Sorry, know, these questions sort of venture off out of scope of this PR...
There was a problem hiding this comment.
The change is fully backward compatible. The only chance is getting rid of the id column because that one wasn't used anywhere in the code. The index on there has been replaced by the primary key. Because this is such a small change, I thought this would be okay to keep this only for new installations.
The merging of the alembic should have been fixed here: #6362 Please check if you're on the latest master. The unit test sounds like an excellent idea.
Regarding the upgrade, that should work. Could you share the error?
I'll work on a migration script: https://jira.apache.org/jira/browse/AIRFLOW-5767
There was a problem hiding this comment.
Here is the error message:
~/code/airflow master ⇡
v1-10 ❯ airflow db upgrade
/Users/dstandish/code/airflow/airflow/models/dagbag.py:21: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
DB: sqlite:////Users/dstandish/airflow/airflow.db
[2019-10-26 15:23:49,454] {db.py:318} INFO - Creating tables
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
Traceback (most recent call last):
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/base.py", line 162, in _catch_revision_errors
yield
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/base.py", line 364, in _upgrade_revs
revs = list(revs)
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/revision.py", line 819, in _iterate_revisions
select_for_downgrade and requested_lowers
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/revision.py", line 814, in <genexpr>
rev.revision
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/revision.py", line 746, in _iterate_related_revisions
", ".join(r.revision for r in overlaps),
alembic.script.revision.RevisionError: Requested revision a56c9515abdc overlaps with other requested revisions 004c1210f153, 74effc47d867
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/dstandish/.virtualenvs/v1-10/bin/airflow", line 7, in <module>
exec(compile(f.read(), __file__, 'exec'))
File "/Users/dstandish/code/airflow/airflow/bin/airflow", line 39, in <module>
args.func(args)
File "/Users/dstandish/code/airflow/airflow/utils/cli.py", line 74, in wrapper
return f(*args, **kwargs)
File "/Users/dstandish/code/airflow/airflow/bin/cli.py", line 1236, in upgradedb
db.upgradedb()
File "/Users/dstandish/code/airflow/airflow/utils/db.py", line 326, in upgradedb
command.upgrade(config, 'heads')
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/command.py", line 298, in upgrade
script.run_env()
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/base.py", line 489, in run_env
util.load_python_file(self.dir, "env.py")
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/util/pyfiles.py", line 98, in load_python_file
module = load_module_py(module_id, path)
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/util/compat.py", line 173, in load_module_py
spec.loader.exec_module(module)
File "<frozen importlib._bootstrap_external>", line 728, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/Users/dstandish/code/airflow/airflow/migrations/env.py", line 103, in <module>
run_migrations_online()
File "/Users/dstandish/code/airflow/airflow/migrations/env.py", line 97, in run_migrations_online
context.run_migrations()
File "<string>", line 8, in run_migrations
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/runtime/environment.py", line 846, in run_migrations
self.get_context().run_migrations(**kw)
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/runtime/migration.py", line 507, in run_migrations
for step in self._migrations_fn(heads, self):
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/command.py", line 287, in upgrade
return script._upgrade_revs(revision, rev)
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/base.py", line 369, in _upgrade_revs
for script in reversed(list(revs))
File "/usr/local/Cellar/python/3.7.3/Frameworks/Python.framework/Versions/3.7/lib/python3.7/contextlib.py", line 130, in __exit__
self.gen.throw(type, value, traceback)
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/base.py", line 196, in _catch_revision_errors
compat.raise_from_cause(util.CommandError(err.args[0]))
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/util/compat.py", line 297, in raise_from_cause
reraise(type(exception), exception, tb=exc_tb, cause=exc_value)
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/util/compat.py", line 290, in reraise
raise value.with_traceback(tb)
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/base.py", line 162, in _catch_revision_errors
yield
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/base.py", line 364, in _upgrade_revs
revs = list(revs)
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/revision.py", line 819, in _iterate_revisions
select_for_downgrade and requested_lowers
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/revision.py", line 814, in <genexpr>
rev.revision
File "/Users/dstandish/.virtualenvs/v1-10/lib/python3.7/site-packages/alembic/script/revision.py", line 746, in _iterate_related_revisions
", ".join(r.revision for r in overlaps),
alembic.util.exc.CommandError: Requested revision a56c9515abdc overlaps with other requested revisions 004c1210f153, 74effc47d867
To reproduce here's what I did:
git pull upstream master # ensure we have latest
git checkout v-10-stable # 1.10.6rc2
rm ~/airflow/airflow.db
airflow initdb
git checkout master
airflow db upgrade
There was a problem hiding this comment.
Thanks for pointing this out @dstandish. This is indeed an issue. Could you create a ticket for this? And include the stack trace and how to reproduce this? That would be very helpful. Thanks
There was a problem hiding this comment.
OK created issue here & assigned to you for now
|
@Fokko How do you view this in context of task idempotency? This is a design change and should have been configurable imho, and, at the very least, be part of the upgrade instructions. Basically XCom and tasks are now async. |
|
The idea started with PR #6210 We needed to store state because we're now having a sensor that allows you to give back the slot, and repoke again later on. However, sometimes you need to keep state. For example, when you are poking a Dataproc operator, and waiting for it to get started, you want to keep the ID of the operator. I've suggested this to store this in xcom. Xcom is initially intended to share data between operators/senors, but in this case, I think it would be great to also use it to share state between operator/sensor instances. It is already in there, and you can also look at it through the GUI. If you clear the xcom fields upfront, then the state would have been wiped before the next instance of the operator/sensor would run. I've poked Bas and we've had a discussion about why this was in there, and what the implications are when doing an upsert of the xcom fields, instead of clearing them upfront. We could not come to an obvious reason. To give some history, it was initially added 4 yours ago: f238f1d. And then it was moved to later in the task process: #1951 Personally I don't expect the user to notice a lot since it will only keep the xcom values a little longer.
So there is no async part in there AFAIK, but the clearing of the xcom is delayed until it is upserted (atomic :-). Does this answer your question Bolke? |
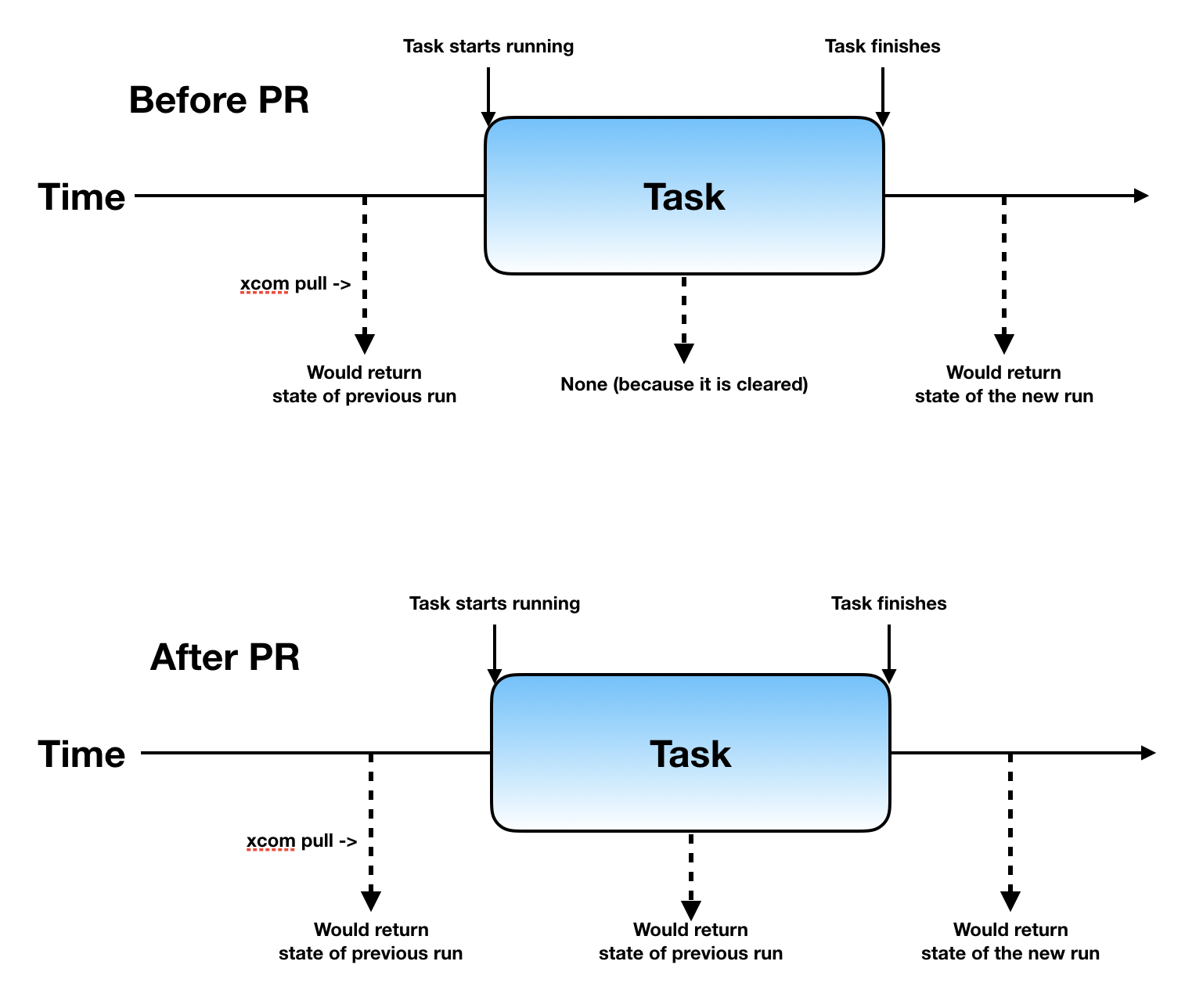
|
So what happens if the task ran successfully first and then was cleared? Does that clear XCOM. It should IMHO. If clearing did not clear the xcom values that was a design mistake. Idempotency should be guaranteed. So the proper change then would have been to fix that. So I understand what you are trying to accomplish but I'm not convinced this is the proper way. Convince me otherwise please :-) |
|
Btw: am I correct that an alembic migration script was edited rather than a new migration was created? That will not work for upgrades. If that's the case I think the change should be reverted and properly implemented. The comment by @dstandish confirms my suspicion: upgrades don't properly work. Also what happened to squashed commits? |
IMHO it should as well, and it does: https://github.com/apache/airflow/blob/master/airflow/models/xcom.py#L103-L107 Idempotency is guaranteed, and it is still as idempotent as before. It is even more atomic than before, as it is now being done in a single transaction. The only chance is that it is done at the end of the run, instead of the beginning.
The change is fully backward compatible. The only chance is getting rid of the
There is a new feature in Github that we use |
|
It should be worth noting where people are trying to get the last execution dates xcom value and are using I don't know how heavily that is relied on, most pushes are probably at the and of the task run. But worth noting maybe. |
|
@Fokko please revert this change. The database schema should not be in a "backwards" compatible mode. Changing alembic scripts is a no go as they represent state. This is particularly true when the script has been in a release.
And probably a somewhat different implementation. Don't get me wrong I like the feature and the improvement on the "atomic" part but it needs a bit more thought. |
|
@notatallshaw Ah I see, this will now also include the task instance itself. Before it would be cleared, and then you would insert the xcom keys again. Again the only thing is that we've changed is instead of clearing them upfront, we'll just overwrite the keys. @bolkedebruin Will do |
|
Just for the record. @bolkedebruin technically you're correct. But I was being pragmatic. We don't use the
|
|
@Fokko gotcha. I'm all for being pragmatic but in certain areas not ;-) |
|
@Fokko here's a proof of concept I am thinking of (requires Python 3.7+ to actually run) that from what I understand would behave differently compared to now vs with this PR: def execute(context):
xcom_pull= context['ti'].xcom_pull
xcom_push = context['ti'].xcom_pull
execution_date = context['execution_date']
old_xcom = xcom_pull(key='test', include_prior_dates=True)
xcom_push(key='test', execution_date.isoformat())
if old_xcom is None or datetime.fromisoformat(old_xcom) < execution_date:
raise ValueErrorCurrently if this was set to retry 3 times it would fail 3 times. But as I understand it after this PR on the 2nd run However a common scenario I have a question about, it was stated that the xcom value is deleted when clearing a task instances, is it also cleared when the user clicks "run" on that task instances? This is the common way to re-run task instances in the Airflow environment I manage. |
|
First of all, you should be able to just serialize the execution_date. Instead of converting it to a string, and parse it again. I don't think your example is complete. What would be the value of the
Bolke triggered me, in combination with your comment about the use of |
Unless I switch a pickle flag it complains that it is not JSON serializable, the comments in the code indicate pickling is going away for for Airflow 2.0. I'm trying to ease my migration ahead of time :).
Correct, as stated it's a proof of concept to show different behavior between the current state and the PR it is not designed to be an actual Operator.
At least for me this would be extremely helpful! I have workflows that would use |
|
Hi @Fokko, Sry I'm late again. Read all the discussion and history but I have to say I'm not really a big fan of this approach. XCOM was designed for inter-task communication and should stay in that way. Reusing it for inside-task communication may just mix up these two purposes and introduce a maintainance headache. And we've already started to see a bit of that through the That's not saying I'm against the idea behind it: having inside-task communication I think is important and can enable a lot more possibility. And I like the atomic change in this PR. But IMO there need to be something else that we use to approach the inside-task communication issue--tho maybe a bit more complicated but purer. |
@notatallshaw I think we should be able to serialize datetimes, could you open a ticket for this? @KevinYang21 No worries, I'd rather have a late reply than no reply. This has been reverted anyway and I love your input on it.
This is obvious since before there wasn't really a need to have inter-task communication. Let me say that I'm not trying to break idempotency, and we should have it by design. However, for efficiency, you might want to cache some state, and this can still be idempotent. My case is that it just feels awkward to create a second table that does exactly the same as xcom. What would your opinion on adding an It is evident that I did not think this through, and did not cover all the edge cases. I'll try to open up some PR's in the upcoming days to at least improve on atomicity and make changes in small steps, I'll include you on the PR's as well. |
|
What motivated this PR was the need to persist state through reschedules, in the service of creating an async operator. I think we can narrow the scope of this change to meet this need without causing these undesired consequences. Namely: only don't clear xcom when the task is resuming after a reschedule. We might have to make changes to state during a poke reschedule because But an async operator, or a sensor in reschedule mode, could take on a "hibernate"-like state when waiting for reschedule time: something not occupying worker slot, but still considered part of the same task instance and same attempt -- so that idempotence is still respected. When merely being reanimated following a hibernate, xcom is not purged; when retrying after a failure, xcom is purged. I personally see value in this being configurable. Suppose you have an incremental load process that utilizes batching and there's a failure. By updating your progress through xcom, you could pick up where you left off; if it's always cleared, you'd have to start over. We can support idempotent processes and stateful processes. |
|
Other ideas:
|
Make sure you have checked all steps below.
idcolumn from the xcom table and make(dag_id, task_id, execution_date, key)the PKJira
Description
Tests
Commits
Documentation