Add DataflowStartSQLQuery operator #8553
Conversation
|
@jaketf Can I ask for review? I know that you are also interested in integration with Dataflow. |
There was a problem hiding this comment.
Who is going to create this dataset? Can we use a public dataset so that examples works for anyone?
There was a problem hiding this comment.
This bucket is created in system tests. https://github.com/apache/airflow/pull/8553/files#
Unfortunately, Dataflow SQL is not compatible with the public datasets I know.
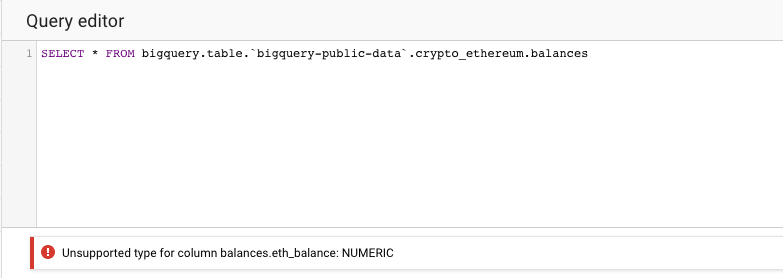
I got the following error when I referred to the public dataset.
Caused by: java.lang.UnsupportedOperationException: Field type 'NUMERIC' is not supported (field 'value')
Its error message from BigQuery console
There was a problem hiding this comment.
@ibzib - is there a public dataset that could be used?
There was a problem hiding this comment.
Unfortunately, Dataflow SQL is not compatible with the public datasets I know.
Yeah, the table will have to have a schema that is compatible with DF SQL. A canonical public BQ dataset seems like something we should definitely have in the docs, but I couldn't find one.
There was a problem hiding this comment.
Yeah Dataflow SQL doesn't support GEOGRAPHY or NUMERIC, but I'm sure there are many public datasets that don't use those types. chicago_taxi_trips.taxi_trips looks like it will work.
There was a problem hiding this comment.
Just a note, I can review Dataflow aspects but not very familiar with Airflow. For example I am not sure what do_xcom_push is. It would be good to get an airflow review as well.
There was a problem hiding this comment.
I still asked @jaketfI to review. Before this change is merged, it will also be reviewed by at least one Apache Airflow commiter. .
There was a problem hiding this comment.
JOB_STATE_STOPPED is not a failed state. (See: https://cloud.google.com/dataflow/docs/reference/rest/v1b3/projects.jobs#jobstate)
There was a problem hiding this comment.
I agree with @aaltay . It looks like proper place for this status is in AWAITING_STATES.
There was a problem hiding this comment.
This is modifying user provided input. Is this your intention?
There was a problem hiding this comment.
might be better to check that labels adhere to these regex (in API docs):
Keys must conform to regexp: [\p{Ll}\p{Lo}][\p{Ll}\p{Lo}\p{N}_-]{0,62}
Values must conform to regexp: [\p{Ll}\p{Lo}\p{N}_-]{0,63}
and raise exception.
There was a problem hiding this comment.
@jaketf do you know maybe are these regexes are used for labels by all google apis?
I see that google provides a comprehensive information when labels do not comply with these regex, with regex included, however we could make validation of labels for whole google provider and throw some warning to the user (before it fails during run).
WDYT @jaketf @mik-laj
There was a problem hiding this comment.
On the other hand, I don't think it is good idea to add unnecessary complexity to the it and limit user. Google logs already provide extensive information about problems with labels when they occur
There was a problem hiding this comment.
This is modifying user provided input. Is this your intention?
@aaltay the reason of this replace was to avoid spaces in json, change of the user input was side effect.
I changed it to variables['labels'] = json.dumps(variables['labels'], separators=(',', ':')) so the json is compact as well and labels provided by the user are not touched.
There was a problem hiding this comment.
Why is this formatter different than the one from L521?
Could we move all label fomating to the place where dataflow job is triggered?
There was a problem hiding this comment.
It depends on the SDK that is used. These two SDK require different argument formats.
We have three related methods.
- start_python_dataflow
- start_java_dataflow
- _start_dataflow
The first two methods are public and dependent on the SDK. This is responsible for actions regarding a specific SDK e.g. environment preparation.
_start_dataflow is an internal method. This starts the system process and supervises execution. I have the impression that this separation is helpful.
There was a problem hiding this comment.
OK. Thank you for the explanation.
There was a problem hiding this comment.
Is the beta still required, do you know?
There was a problem hiding this comment.
Adds escape characters if needed.
Example:
If you want to display the contents of the /tmp/ directory then you can use the command ls /tmp/
If you want to display the contents of the /tmp/i love pizza directory then you can use the command ls '/tmp/ i love pizza'. ls /tmp/i love pizza is incorrect command. The decision about quotation characeters was made by shlex.quote. This also supports other cases required by sh e.g. quote character in an argument
There was a problem hiding this comment.
but this is only for logging? Do users normally copy paste these commands out of the logs?
There was a problem hiding this comment.
This is only for logs. I used it to test this operator. A normal user will not copy it, but it may be helpful to him for debugging only.
There was a problem hiding this comment.
These logs are available in Airflow Web UI, so a normal user can easily access them.
There was a problem hiding this comment.
Is this really required if it is only for logs? subprocess.run does not need to escape them anyway.
There was a problem hiding this comment.
IMHO it is not particularly required but nice to have it :)
There was a problem hiding this comment.
stderr often contains developer information. There are not only errors. I will change it to log.warning
There was a problem hiding this comment.
Airflow saves all credentials(MySQL, GCP, AWS, and other) in one table in the database. It's called connection. This is the entry ID in this table.
There was a problem hiding this comment.
Do you want to call this even if job is cancelled/stopped/finished?
There was a problem hiding this comment.
Good point. I will skip jobs in the terminal state.
|
/cc @kennknowles |
There was a problem hiding this comment.
Are these lists used anywhere else? I think that the success/fail distinction is artificial. You cannot really say if CANCELED is a failure or not. Probably the same with DRAINED and UPDATED. Whatever is looking at the job status probably wants the full details.
There was a problem hiding this comment.
Airflow does not have the ability to display full information about the status of the job in an external system. We only have two states - SUCCESS/FAILED. What are you proposing then? Can the user specify expected end-states?
There was a problem hiding this comment.
I do not know airflow that well. I just tried to see how these variables were used. I missed the place where they actually affect the Airflow result. It is a good idea to let the user say what they expect, and then a failure can be anything else.
Example: we have had real use cases where we deliberately cancel jobs we do not need anymore, and that can be success for streaming jobs.
I think the only certain failed state is JOB_STATE_FAILED.
There was a problem hiding this comment.
I think these are reasonable defaults, but I agree it would be nice to let the users set as parameters.
I could even see DRAINING as a failed state (if airflow never expects a human to make manual intervention)
I could see wanting to fail earlier on CANCELLING (rather than waiting til CANCELLED)
There was a problem hiding this comment.
I agree with you. I created issue for it: #11721 and I will work on in separate PR.
There was a problem hiding this comment.
nit: for var names is JOB_STATE_ prefix really necessary on all these?
IMO slightly more readable to drop it and this causes "stutter" DataflowJobStatus.JOB_STATE_xxx.
A forward looking thought (though not backwards compatible so not immediate suggestion) in python 3.8+ this set could be more concise with walrus operator e.g.
FAILED_END_STATES = {
(FAILED := "JOB_STATE_FAILED"),
(CANCELLED := "JOB_STATE_CANCELLED"),
(STOPPED := "JOB_STATE_STOPPED")
}There was a problem hiding this comment.
I think these are reasonable defaults, but I agree it would be nice to let the users set as parameters.
I could even see DRAINING as a failed state (if airflow never expects a human to make manual intervention)
I could see wanting to fail earlier on CANCELLING (rather than waiting til CANCELLED)
There was a problem hiding this comment.
This makes me think (larger scope than just SQL operator) of should we have Beam Operators that support other runners?
For example some users it does not make sense Dataflow for smaller/shorter batch jobs say (because you have the overhead of waiting for workers to come up) For a job < 30 mins worker spin up time can be 10% performance hit. But they may still want to use Apache Beam (on say spark runner) that submits to non-ephemeral cluster (dataproc, EMR, spark on k8s, on prem infra, etc).
Would this be easy enough to achieve on Dataproc / EMR / Spark Operators ?
There was a problem hiding this comment.
It will be quite huge task to write Apache Beam Hooks and Operators but worth to keep it in mind to do this in future.
There was a problem hiding this comment.
In current Q, we want to start working on operators for Apache Beam.
There was a problem hiding this comment.
might be better to check that labels adhere to these regex (in API docs):
Keys must conform to regexp: [\p{Ll}\p{Lo}][\p{Ll}\p{Lo}\p{N}_-]{0,62}
Values must conform to regexp: [\p{Ll}\p{Lo}\p{N}_-]{0,63}
and raise exception.
There was a problem hiding this comment.
nit: this if and the next elif take the same action and could be combined
| if value is None: | |
| if value is None or (isinstance(value, bool) and value): |
There was a problem hiding this comment.
Unfortunately, Dataflow SQL is not compatible with the public datasets I know.
Yeah, the table will have to have a schema that is compatible with DF SQL. A canonical public BQ dataset seems like something we should definitely have in the docs, but I couldn't find one.
There was a problem hiding this comment.
Unless you have a good reason to rename this location, I would use region because it is more specific and consistent with Beam/Dataflow usage.
There was a problem hiding this comment.
The main reason behind it is to keep consistency across all google provider which uses location parameter.
There was a problem hiding this comment.
I'm not sure which other GCP products you are referring to, but in Dataflow it's usually --region.
https://cloud.google.com/dataflow/docs/concepts/regional-endpoints
There was a problem hiding this comment.
This is an essential feature of Airflow. In Airflow, you can define default arguments that will be all operators, but the parameter name must be consistent across all operators.
default_args = {
'dataflow_default_options': {
'tempLocation': GCS_TMP,
'stagingLocation': GCS_STAGING,
},
'location': 'europe-west3'
}
with models.DAG(
"example_gcp_dataflow_native_java",
schedule_interval=None, # Override to match your needs
start_date=days_ago(1),
tags=['example'],
) as dag_native_java:
start_java_job = DataflowCreateJavaJobOperator(
task_id="start-java-job",
jar=GCS_JAR,
job_name='{{task.task_id}}',
options={
'output': GCS_OUTPUT,
},
poll_sleep=10,
job_class='org.apache.beam.examples.WordCount',
check_if_running=CheckJobRunning.IgnoreJob,
location='europe-west3',
)
# [START howto_operator_bigquery_create_table]
create_table = BigQueryCreateEmptyTableOperator(
task_id="create_table",
dataset_id=DATASET_NAME,
table_id="test_table",
schema_fields=[
{"name": "emp_name", "type": "STRING", "mode": "REQUIRED"},
{"name": "salary", "type": "INTEGER", "mode": "NULLABLE"},
],
)
# [END howto_operator_bigquery_create_table]In the above example, task create_table and start-java-job is executed in one location - europe-west3.
Dataflow also uses the word "location" in its API to denote this field.
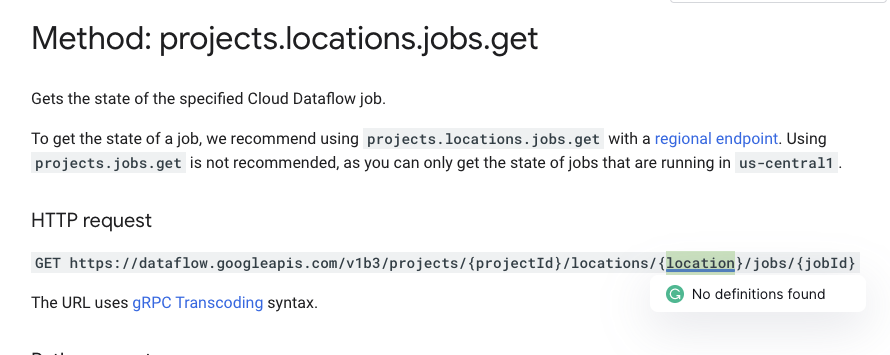
https://cloud.google.com/dataflow/docs/reference/rest/v1b3/projects.locations.jobs/get
There was a problem hiding this comment.
In Airflow, you can define default arguments that will be all operators, but the parameter name must be consistent across all operators.
Makes sense, thanks for the explanation.
There was a problem hiding this comment.
Dataflow has deliberately been trying to move away from using a default location, because many users may not realize that their job is running in us-central1 even if that is not intended.
There was a problem hiding this comment.
@ibzib I think we have to change it to all operators in the future. To keep consistency across all dataflow operators I would like to keep it for now.
There was a problem hiding this comment.
Nit: parameters itself is one of the arguments that can be passed here (see https://cloud.google.com/dataflow/docs/guides/sql/parameterized-queries). Maybe use "arguments" instead.
There was a problem hiding this comment.
This is related to what @mik-laj said here: #8553 (comment)
I added parametrization to example dag so it would be nice hint for the users in case of doubts how to use it.
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
I rebased on the latest master |
|
The Build Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks$,^Build docs$,^Spell check docs$,^Backport packages$,^Checks: Helm tests$,^Test OpenAPI*. |
|
I replied to all comments, made requested changes, rebased on the master, made CI happy. IMHO PR is ready for final review and hopefully to be merged :) |
770b296 to
399a1d2
Compare
|
The PR should be OK to be merged with just subset of tests as it does not modify Core of Airflow. The committers might merge it or can add a label 'full tests needed' and re-run it to run all tests if they see it is needed! |
|
Rebased on the latest master |
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks,^Build docs$,^Spell check docs$,^Backport packages$,^Provider packages,^Checks: Helm tests$,^Test OpenAPI*. |
7f44c15 to
a063523
Compare
|
The Workflow run is cancelling this PR. It has some failed jobs matching ^Pylint$,^Static checks,^Build docs$,^Spell check docs$,^Backport packages$,^Provider packages,^Checks: Helm tests$,^Test OpenAPI*. |
Make sure to mark the boxes below before creating PR: [x]
In case of fundamental code change, Airflow Improvement Proposal (AIP) is needed.
In case of a new dependency, check compliance with the ASF 3rd Party License Policy.
In case of backwards incompatible changes please leave a note in UPDATING.md.
Read the Pull Request Guidelines for more information.