ARROW-1784: [Python] Enable zero-copy serialization, deserialization of pandas.DataFrame via components #1390
Conversation
Change-Id: I7c2d71e10e8fb84c0606b62bbc537d5603b04766
Change-Id: I40d43b447d5336a2653c227cdbf6327121538ac0
|
Here's an example of a DataFrame that zero-copies. Serialization time goes from 200ms to 160 microseconds. Deserialization time from 56ms to about the same. This serialization code path is going to Arrow representation as an intermediary -- vanilla pickle is 126ms in, 60ms out.
|
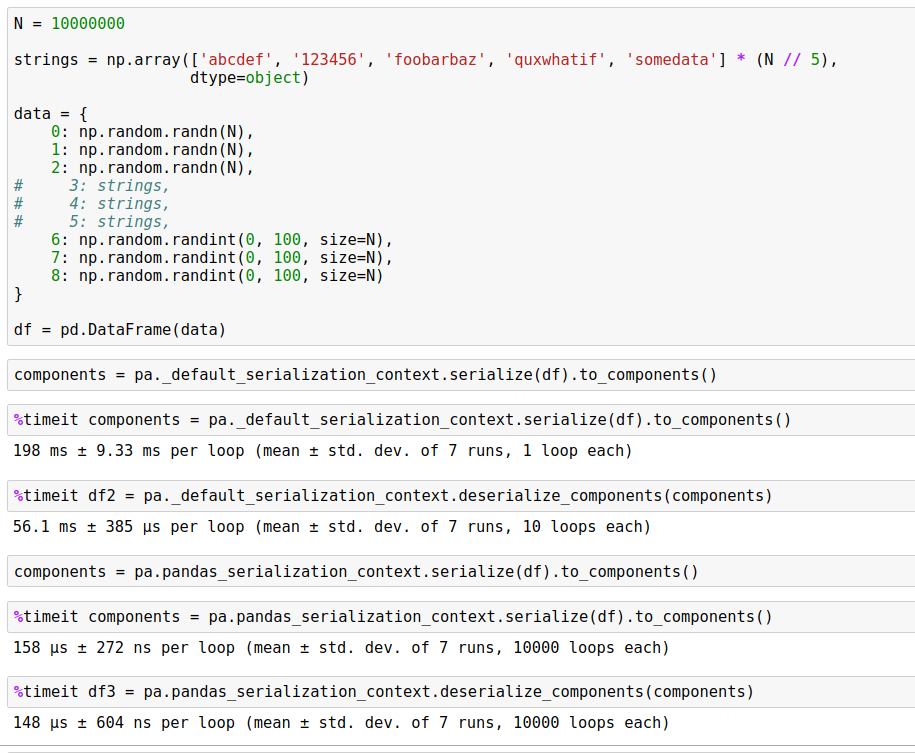
|
Here's the same thing with a bunch of strings.
|
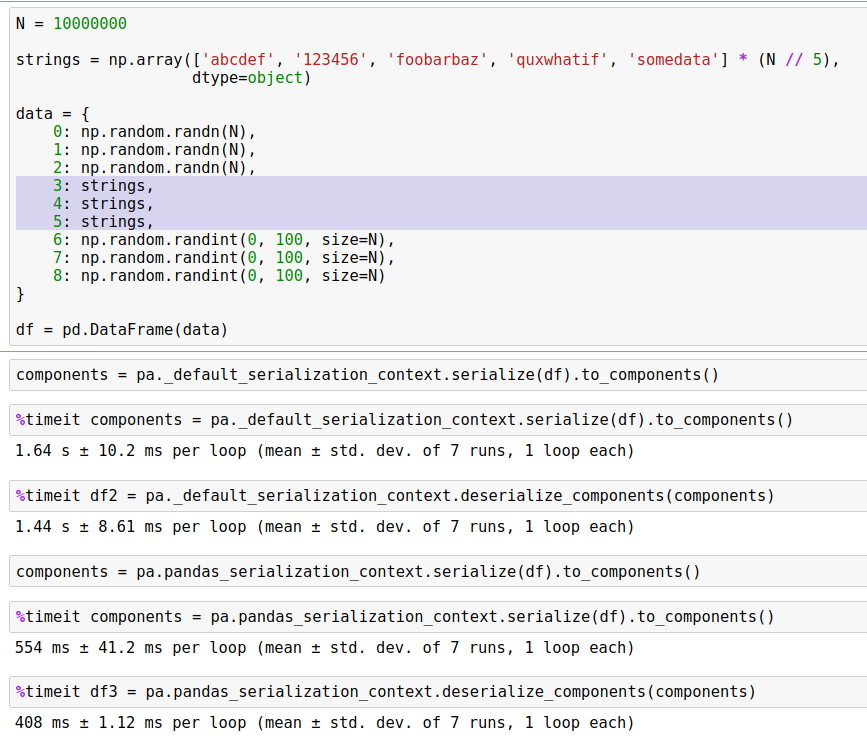
|
Most importantly for consumers like Dask, whenever there is an internal block where a copy can be avoided, it is avoided. This will avoid excess memory use on serialization (no additional copies) and extra memory use on receive (no copies) |
|
Thank you for putting this together. I look forward to trying this out with Dask and seeing if it relieves the memory pressure we're seeing when sending dataframes. What does the current dev-build process look like? I think I read that you all had set up nightly builds on the twosigma channel?
This is to be expected, right?
That's surprisingly nice. Do you have a sense for what is going on here? 100ms in copying memory? |
|
|
||
| def make_datetimetz(tz): | ||
|
|
||
| def dataframe_to_serialized_dict(frame): |
There was a problem hiding this comment.
@jreback let me know if I missed anything on these functions
yes, as soon as this is merged, it should show up in the next nightly https://anaconda.org/twosigma/pyarrow/files. Though we are having a small problem with the version numbers in the nightlies (https://issues.apache.org/jira/browse/ARROW-1881) that needs to get fixed in the next day or two (cc @xhochy)
Yes, it's a nice confirmation that pandas definitely is not making any unexpected memory copies (it can be quite zealous about copying stuff)
Yes, I think this is strictly from copying the internal numeric ndarrays. The memory use vs. pickle will also be less by whatever the total pickled footprint of those numeric arrays that are being copied |
|
Shouldn't |
 jreback
left a comment
jreback
left a comment
There was a problem hiding this comment.
lgtm. might want to test round-trip of Period and Intervals as well; they are serialized as object currently (the Index types are an extension dtype though).
In [62]: pd.DataFrame({'period': pd.period_range('2013', periods=3, freq='M'), 'interval': pd.interval_range(1, 4)})
Out[62]:
interval period
0 (1, 2] 2013-01
1 (2, 3] 2013-02
2 (3, 4] 2013-03
python/pyarrow/pandas_compat.py
Outdated
| block_arr = item['block'] | ||
| placement = item['placement'] | ||
| if 'dictionary' in item: | ||
| cat = pd.Categorical(block_arr, |
There was a problem hiding this comment.
should be .from_codes as going to deprecate fastpath= soon
|
@pitrou the internal conversion functions could / should be exposed in pandas |
…alization Change-Id: Idcc0172f2f0c5189f64ed28fc535e67d3d71009e
|
Done, and added docs. Will merge once the build passes |
Change-Id: I6e173a39d4c508382c383164ecf0cebabfcc6059
|
Seems there is some problem with the manylinux1 build, will dig in |
…pinned at 0.20.1 Change-Id: I55740c93b729b2f800834107cfe7b09c152d23a2
This patch adds a serialization path for pandas.DataFrame (and Series) that decomposes the internal BlockManager into a dictionary structure that can be serialized to the zero-copy component representation from ARROW-1783, and then reconstructed similarly.
The impact of this is that when a DataFrame has no data that requires pickling, the reconstruction is zero-copy. I will post some benchmarks to illustrate the impact of this. The performance improvements are pretty remarkable, nearly 1000x speedup on a large DataFrame.
As some follow-up work, we will need to do more efficient serialization of the different pandas Index types. We should create a new JIRA for this