ARROW-11772: [C++] Provide reentrant IPC file reader #9656
Conversation
This comment has been minimized.
This comment has been minimized.
45ab43f to
e2c3cfa
Compare
|
cc @westonpace |
cpp/src/arrow/ipc/reader.h
Outdated
There was a problem hiding this comment.
Given that we're talking about an asynchronous primitive, forcing the caller to deal with lifetime issues is a bit unfriendly IMHO. It may be simpler to make RecordBatchFileReader inherit from enable_shared_from_this and capture a strong reference inside the generator.
There was a problem hiding this comment.
Thanks - this was actually left over from an earlier approach. I've removed the note and adjusted the test to ensure the reader gets dropped before the generator.
cpp/src/arrow/util/future.h
Outdated
cpp/src/arrow/ipc/reader.cc
Outdated
There was a problem hiding this comment.
This looks a bit tedious. You're essentially copying most of those fields from RandomAccessFile?
There was a problem hiding this comment.
Yes. I'll change it so that it just stores a RecordBatchFileReaderImpl and add a enable_shared_from_this instead to avoid duplicating fields.
There was a problem hiding this comment.
You could also avoid the "state" struct and put the desired fields directly in the generator classes (I'm not sure why you need two of them, by the way, unless you plan to do something else later with the IPC message generator).
There was a problem hiding this comment.
The generators are distinct - one reads from the filesystem and one decompresses/decodes the batch. By separating them, we can also apply readahead independently to each stage.
The state struct was because AsyncGenerators need to be copyable, and since DictionaryMemo is move-only, we had to put it behind an indirection.
cpp/src/arrow/ipc/reader.cc
Outdated
There was a problem hiding this comment.
Can you make those functions static or put them in the anonymous namespace?
cpp/src/arrow/ipc/reader.cc
Outdated
cpp/src/arrow/ipc/reader.cc
Outdated
There was a problem hiding this comment.
I don't think it's desirable to force all processing to go to the global thread pool unconditionally.
(also, are you sure the processing is heavy enough that it benefits from it?)
There was a problem hiding this comment.
Usually not, but it would be in the case of compressed buffers. I could also change it to not offload onto a secondary pool by default (and hence do the work on the same thread used to read data) and/or benchmark if there's any overhead to this.
There was a problem hiding this comment.
The overhead of dispatching tasks to a thread pool is difficult to evaluate rigorously, but you can get an idea by running arrow-thread-pool-benchmark. IMHO the bottom line is that we should aim for tasks in the millisecond range (rather than microsecond or less).
There was a problem hiding this comment.
Looking at the ReadFile benchmark it seems reading a 1 MiB batch takes about 1ms once there are >=1024 columns.
------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
------------------------------------------------------------------------------------------
ReadFile/1/real_time 8130 ns 8130 ns 86111 bytes_per_second=120.115G/s
ReadFile/4/real_time 10734 ns 10734 ns 65153 bytes_per_second=90.9826G/s
ReadFile/16/real_time 21779 ns 21779 ns 32081 bytes_per_second=44.8389G/s
ReadFile/64/real_time 67087 ns 67086 ns 10189 bytes_per_second=14.5567G/s
ReadFile/256/real_time 274905 ns 274901 ns 2543 bytes_per_second=3.55236G/s
ReadFile/1024/real_time 1074018 ns 1074004 ns 650 bytes_per_second=931.083M/s
ReadFile/4096/real_time 4307403 ns 4307316 ns 164 bytes_per_second=232.158M/s
ReadFile/8192/real_time 8266500 ns 8266343 ns 84 bytes_per_second=120.97M/s
So I'll change this to not use a separate thread pool by default. (I'd also like to evaluate this benchmark when compression is involved, though.)
There was a problem hiding this comment.
My learning yesterday (maybe, take this all with a grain of salt, it's always possible I was misreading/misinterpreting) was that even if the processing is light it pays to get off the thread pool quickly. If the I/O is slow you want to trigger the next read as quickly as possible. However, even when the I/O is fast (buffered), the read only ensures the pages accessed are in memory, it does not load it into the CPU caches, that happens when you access the memory.
So if you do some very fast decompression on the I/O thread you will be forcing the actual load into the CPU cache of the I/O thread's CPU. Then later, you will have transferred to the CPU thread for parsing or decoding or filtering or projecting. If you're unlucky the CPU thread you are given is on a different core and you end up having to pay the memory load cost all over again.
I will setup some micro-benchmarks later this week to try and suss out how accurate this statement is.
dfdac6e to
f11cf6a
Compare
|
FWIW, here's a benchmark of reading a compressed file, with and without readahead: |
48a67a2 to
67bb3e3
Compare
 westonpace
left a comment
westonpace
left a comment
There was a problem hiding this comment.
This is good, thanks for doing this.
cpp/src/arrow/ipc/reader.cc
Outdated
There was a problem hiding this comment.
Why arrow:All instead of your new fail-fast version? Seems that would work here.
There was a problem hiding this comment.
Here, I actually want the results, not just the status. I've renamed this - this future is to just read the dictionary messages, not to actually parse them.
There was a problem hiding this comment.
Nit: Does this readahead actually help given you have one at the message level? Also, you're consuming them pretty rapidly. My guess is you could probably do away with it.
There was a problem hiding this comment.
I think actually the one at the message level is the redundant one here, since that's trivial (the file's in memory), but the decoding work is nontrivial (compression). Note that the compression isn't done in the IpcMessageGenerator, but is done as part of decoding the record batch.
With both sets of readahead:
ReadaheadCompressedFile/1/real_time 65481827 ns 4493732 ns 8 bytes_per_second=1.90893G/s
ReadaheadCompressedFile/4/real_time 29108664 ns 3322772 ns 24 bytes_per_second=4.29425G/s
ReadaheadCompressedFile/16/real_time 31461325 ns 6222532 ns 22 bytes_per_second=3.97313G/s
ReadaheadCompressedFile/64/real_time 44750635 ns 24064817 ns 16 bytes_per_second=2.79326G/s
ReadaheadCompressedFile/256/real_time 122477440 ns 91270202 ns 6 bytes_per_second=1045.09M/s
ReadaheadCompressedFile/1024/real_time 515403669 ns 381340640 ns 1 bytes_per_second=248.349M/s
With only I/O-level readahead:
ReadaheadCompressedFile/1/real_time 533258427 ns 11385747 ns 1 bytes_per_second=240.034M/s
ReadaheadCompressedFile/4/real_time 71233474 ns 2145576 ns 9 bytes_per_second=1.75479G/s
ReadaheadCompressedFile/16/real_time 45455989 ns 3591831 ns 15 bytes_per_second=2.74991G/s
ReadaheadCompressedFile/64/real_time 64612808 ns 8730379 ns 11 bytes_per_second=1.9346G/s
ReadaheadCompressedFile/256/real_time 188120059 ns 18770867 ns 4 bytes_per_second=680.417M/s
ReadaheadCompressedFile/1024/real_time 699025221 ns 58355812 ns 1 bytes_per_second=183.112M/s
With only batch-level readahead:
ReadaheadCompressedFile/1/real_time 59513029 ns 3280963 ns 11 bytes_per_second=2.10038G/s
ReadaheadCompressedFile/4/real_time 27160986 ns 2378473 ns 25 bytes_per_second=4.60219G/s
ReadaheadCompressedFile/16/real_time 30018574 ns 3746521 ns 23 bytes_per_second=4.16409G/s
ReadaheadCompressedFile/64/real_time 41358054 ns 11515016 ns 17 bytes_per_second=3.02239G/s
ReadaheadCompressedFile/256/real_time 80396235 ns 26029905 ns 9 bytes_per_second=1.5548G/s
ReadaheadCompressedFile/1024/real_time 473883489 ns 96278350 ns 2 bytes_per_second=270.109M/s
With no readahead:
ReadaheadCompressedFile/1/real_time 544947010 ns 8763782 ns 2 bytes_per_second=234.885M/s
ReadaheadCompressedFile/4/real_time 73232625 ns 1522407 ns 8 bytes_per_second=1.70689G/s
ReadaheadCompressedFile/16/real_time 47781962 ns 2977593 ns 15 bytes_per_second=2.61605G/s
ReadaheadCompressedFile/64/real_time 64026555 ns 7882798 ns 11 bytes_per_second=1.95231G/s
ReadaheadCompressedFile/256/real_time 187098473 ns 18156513 ns 4 bytes_per_second=684.132M/s
ReadaheadCompressedFile/1024/real_time 696976648 ns 57355852 ns 1 bytes_per_second=183.65M/s
So I'll change this to only test batch-level readahead. I/O level readahead would help more on something like S3, which we could set up a benchmark for as well.
cpp/src/arrow/ipc/read_write_test.cc
Outdated
There was a problem hiding this comment.
I don't think this is safe the way the macro works. Use ASSERT_FINISHES_OK_AND_ASSIGN. It also adds a 10 second timeout in case something gunks up for whatever reason.
There was a problem hiding this comment.
I had to define an EXPECT_FINISHES_OK_AND_ASSIGN to get it to work here.
cpp/src/arrow/ipc/read_write_test.cc
Outdated
There was a problem hiding this comment.
Same as below, ASSERT_FINISHES_OK_AND_ASSIGN
cpp/src/arrow/ipc/reader.cc
Outdated
There was a problem hiding this comment.
An unavoidable naming nit I think. This is the sync counterpart to RecordBatchFileReader and the two names aren't very parallel. Ideally the other could be named IpcFileRecordBatchReader.
|
Can you rebase this? I'm using it as part of ARROW-12014 |
|
@westonpace done. |
|
I've rebased this to use the background generator, however, it doesn't help much, and it makes us non-reentrant, so we also lose any advantage with compressed data as we can't parallelize the decompression anymore. The async reader gets anywhere from 30-90% of the throughput of the synchronous one. Cases here are numbered by the number of columns in the file. The cases with very few columns are a worst case for async, since decoding is basically 0-cost and async is purely overhead. Conversely the cases with many columns are a best case, since decoding is expensive. However async doesn't help because I/O is relatively cheap in all cases benchmarked here and there is no pipelining to be had. Frankly, the fastest approach I tested was to just wrap the synchronous reader in a Future and block the caller, which isn't encouraging. A flamegraph shows that using the thread pool for decoding work is still rather expensive, and so it might be better if we used something like the background generator for that as well. In that case it would be convenient if we could somehow pull directly from the background generator's queue instead of having to get and block on futures; also this still means we can't get any benefit from parallelizing decompression if needed. For datasets with files >= cores that's probably not a big deal if you only care about throughput (we'll still decode in parallel) but if you need results in order and/or you have few files relative to cores then it won't be optimal. You may question why in-memory (ReadFile) is slower than a temp file (ReadTempFile). In the flamegraphs, the culprit appears to be BufferReader's use of MemoryAdviseWillNeed, which spends a significant amount of time in the kernel. Removing it improves performance drastically. |
|
That said, the case here is not too relevant to Datasets, so the next thing will be to integrate this with the ARROW-7001 WIP and benchmark against local/S3 file systems with varying numbers of files. |
|
I've tested on EC2/S3 now. In terms of Datasets, this doesn't affect scans when files <= cores, but improves performance when files > cores. It also fixes a regression compared to just using ARROW-7001 by itself. (The ARROW-11772 case in the charts is with ARROW-7001 combined with ARROW-11772.)
The dataset tested was a 16-file feather dataset, scanning either 1, 4, or all 16 files. Each file had 32 columns of mixed primitive types with 128 batches of 4096 rows per batch. Files had LZ4 compression. The EC2 instance tested was a t3.xlarge (4 cores). |
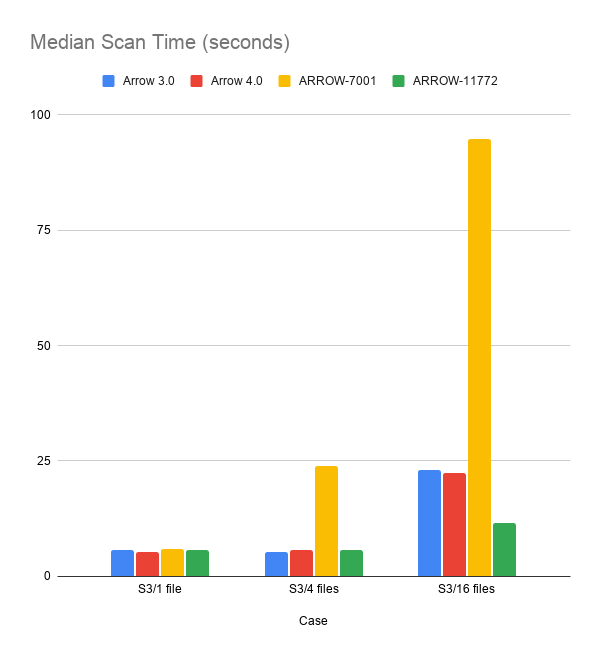
|
And these are all the cases tested: Details |
|
However, it is still a large regression with local files:
|

cpp/src/arrow/ipc/reader.cc
Outdated
There was a problem hiding this comment.
Ok, I don't think this is the right approach. Basically you are taking a blocking message reader (ReadMessageFromBlock) and pushing it to a thread pool to hide latencies. But when reading a message from a mmap'ed file, you are adding the thread pool overhead to a very small execution cost.
Instead, there should be a ReadMessageFromBlockAsync that returns a Future<Message>. It's up to the underlying IO object (memory mapped file, S3 object...) to decide whether the async read goes to a thread pool or is synchronous.
|
Transferring off of the I/O pool fixes the performance degradation (at some cost to the 16-file S3 case, but even then, we're still much faster than before). This also gets us in about the same position as we were when testing ARROW-7001.
|
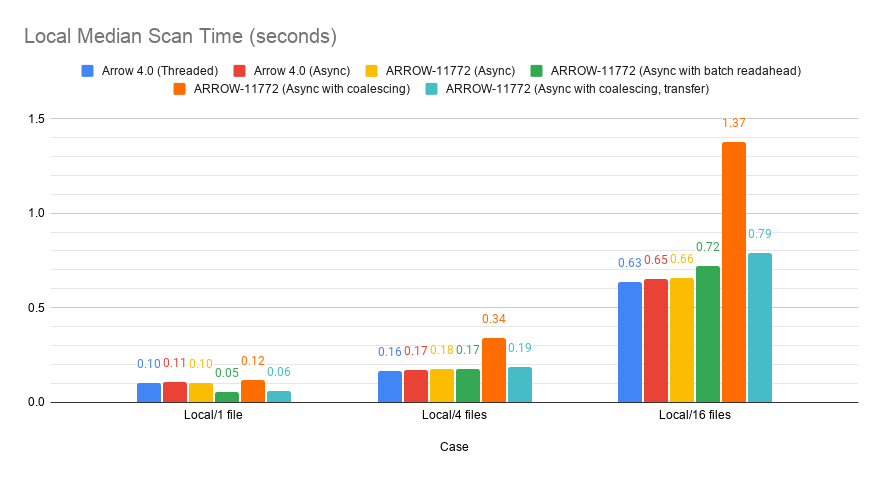
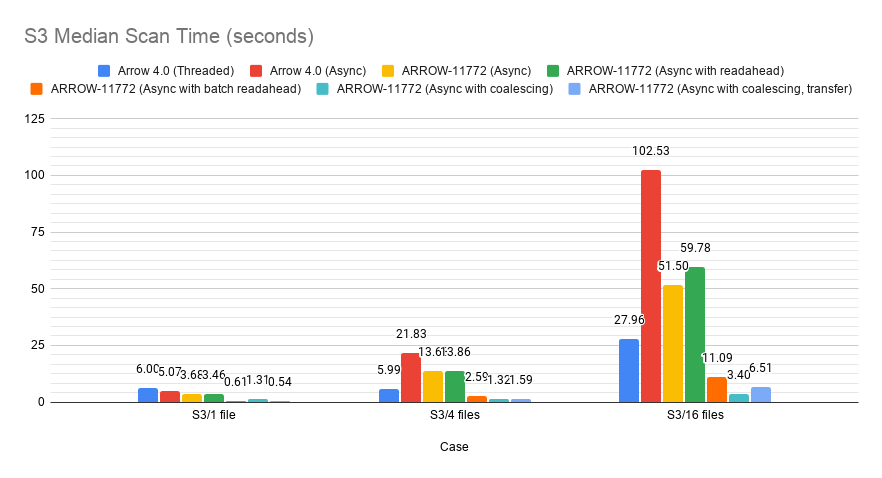
westonpace
left a comment
There was a problem hiding this comment.
Just a few minor cleanup notes.
cpp/src/arrow/dataset/file_ipc.cc
Outdated
There was a problem hiding this comment.
Nit: I'm pretty sure you can do const ScanOptions& scan_options here.
cpp/src/arrow/dataset/file_ipc.cc
Outdated
cpp/src/arrow/dataset/file_ipc.cc
Outdated
There was a problem hiding this comment.
Why force use_threads to false?
cpp/src/arrow/dataset/file_ipc.cc
Outdated
There was a problem hiding this comment.
Nit: Change reader to a const reference. Since there could be multiple callbacks we can never move into a callback so it's always const reference or a copy.
There was a problem hiding this comment.
Maybe kBatchSize? kTotalSize makes me think it is the size of all the batches.
cpp/src/arrow/ipc/reader.h
Outdated
There was a problem hiding this comment.
This overhead seems superfluous to me given there is one that takes io::RandomAccessFile* already.
There was a problem hiding this comment.
This is just mirroring the sync API. If we wanted to cut down on overloads, I'd rather have only this overload as it keeps the file alive (the other one would be prone to dangling pointers/isn't used by datasets).
cpp/src/arrow/ipc/reader.h
Outdated
There was a problem hiding this comment.
Same as above, do we need both versions?
cpp/src/arrow/ipc/reader.cc
Outdated
There was a problem hiding this comment.
Why a macro instead of a small helper function?
There was a problem hiding this comment.
I am not sure why it was originally done that way, I guess to be extra sure it was inlined?
cpp/src/arrow/ipc/reader.cc
Outdated
There was a problem hiding this comment.
I agree with the comment above that this forces read_dictionaries_ to be a rather odd future. Is there any reason you don't want to do:
auto read_messages = read_dictionaries_.Then([] (...) {return read_message;});
I think it cleans up the surrounding code nicely and you can change read_dictionaries_ to Future<>
cpp/src/arrow/ipc/reader.cc
Outdated
There was a problem hiding this comment.
This could trigger a lot of small reads depending on record batch configuration but I think this is tackled with coalescing?
There was a problem hiding this comment.
I intend to rebase on ARROW-12522 and add coalescing.
 lidavidm
left a comment
lidavidm
left a comment
There was a problem hiding this comment.
Thanks for the review. I've addressed the feedback. Now this is rebased on the coalescing PR, so I will re-test this branch and verify that coalescing helps & whether transferring is necessary.
cpp/src/arrow/ipc/reader.h
Outdated
There was a problem hiding this comment.
This is just mirroring the sync API. If we wanted to cut down on overloads, I'd rather have only this overload as it keeps the file alive (the other one would be prone to dangling pointers/isn't used by datasets).
cpp/src/arrow/ipc/message.cc
Outdated
There was a problem hiding this comment.
Unfortunately yes, since MessageDecoder takes shared_ptr/unique_ptr directly.
cpp/src/arrow/ipc/read_write_test.cc
Outdated
There was a problem hiding this comment.
Right, I meant "the generator will keep the reader alive for us".
cpp/src/arrow/ipc/read_write_test.cc
Outdated
There was a problem hiding this comment.
The ASSERT variants don't work in non-void returning contexts so I'll add the EXPECT.
cpp/src/arrow/ipc/read_write_test.cc
Outdated
There was a problem hiding this comment.
They aren't called ever so I assume they are vestigial (I will delete them).
cpp/src/arrow/ipc/reader.cc
Outdated
There was a problem hiding this comment.
I intend to rebase on ARROW-12522 and add coalescing.
cpp/src/arrow/ipc/reader.cc
Outdated
There was a problem hiding this comment.
I am not sure why it was originally done that way, I guess to be extra sure it was inlined?
3a4b67c to
a1995f8
Compare
|
I instrumented a bit of the scanner and took a look at pre-buffering's effect on local file performance, to see if I could figure out why it seems detrimental. Without pre-buffering locally, we're utilizing the CPU thread pool (nearly) fully. (I'm not sure why one thread seems to receive little/no work, but I didn't fully instrument the scanner and perhaps it's assembling the table or something like that.) Just enabling pre-buffer causes a slowdown, as it appears nearly all work gets forced onto a single thread! Before I saw that transferring the CPU task helped with this, and indeed, it does, though it doesn't quite get us on par. Also note I had to change the code to force transfer by callling Given this, I'd guess what happens is as follows: with coalescing, since multiple record batches get mapped onto one I/O future, later requests to read a record batch will find an already-completed Future and will synchronously run all the callbacks inline, causing everything to pile onto the main thread. Forcing transfer alleviates this and better utilizes the thread pool, but the CPU-bound tasks are very fast (<< 1ms) and so we face the overhead of creating extra futures/spawning tasks instead. (Note that the non-pre-buffer case probably isn't even touching the CPU thread pool, because we don't transfer in that case - that's why you only see 16 threads (8 I/O + 8 CPU) in the last case.) |
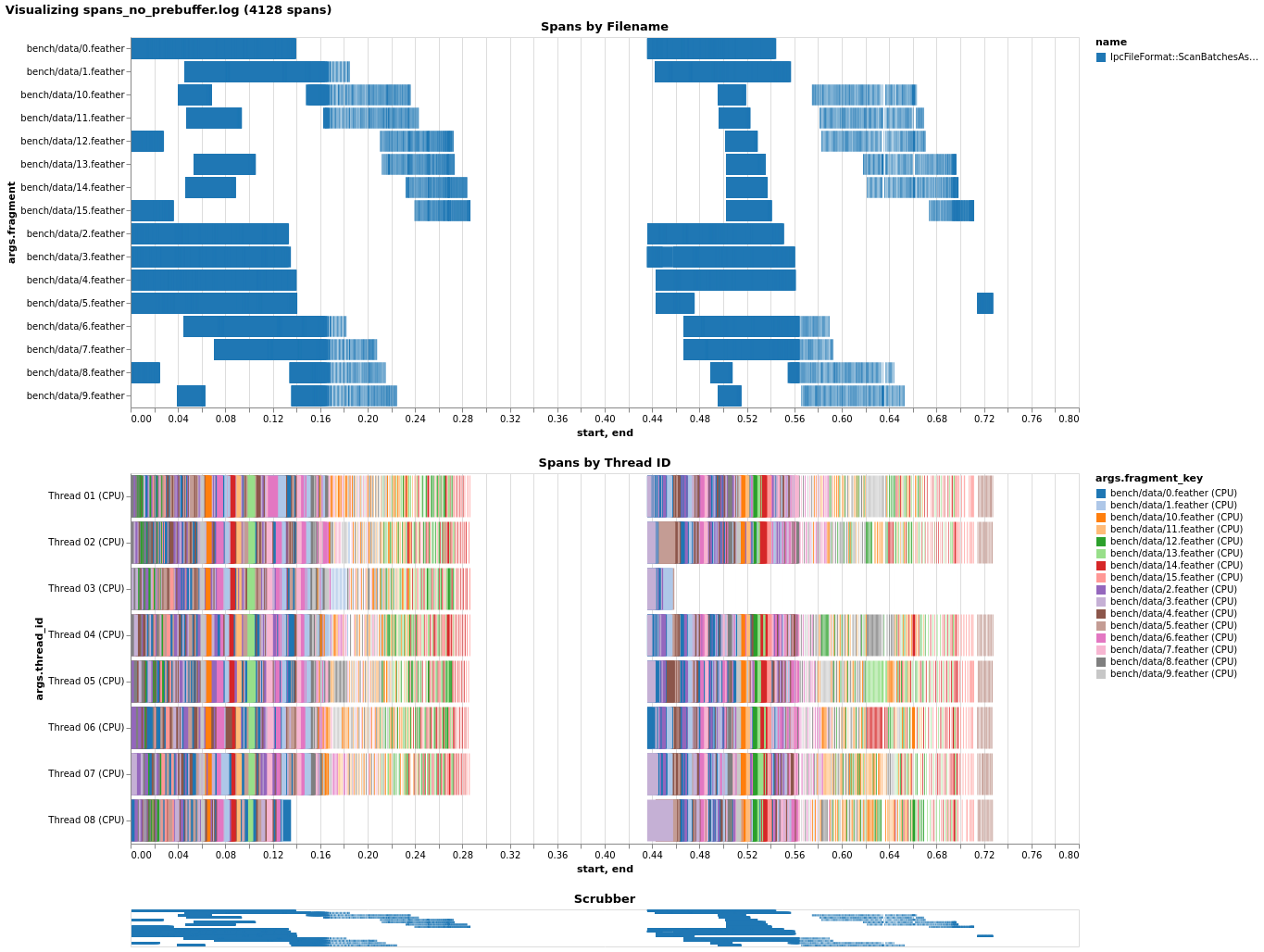
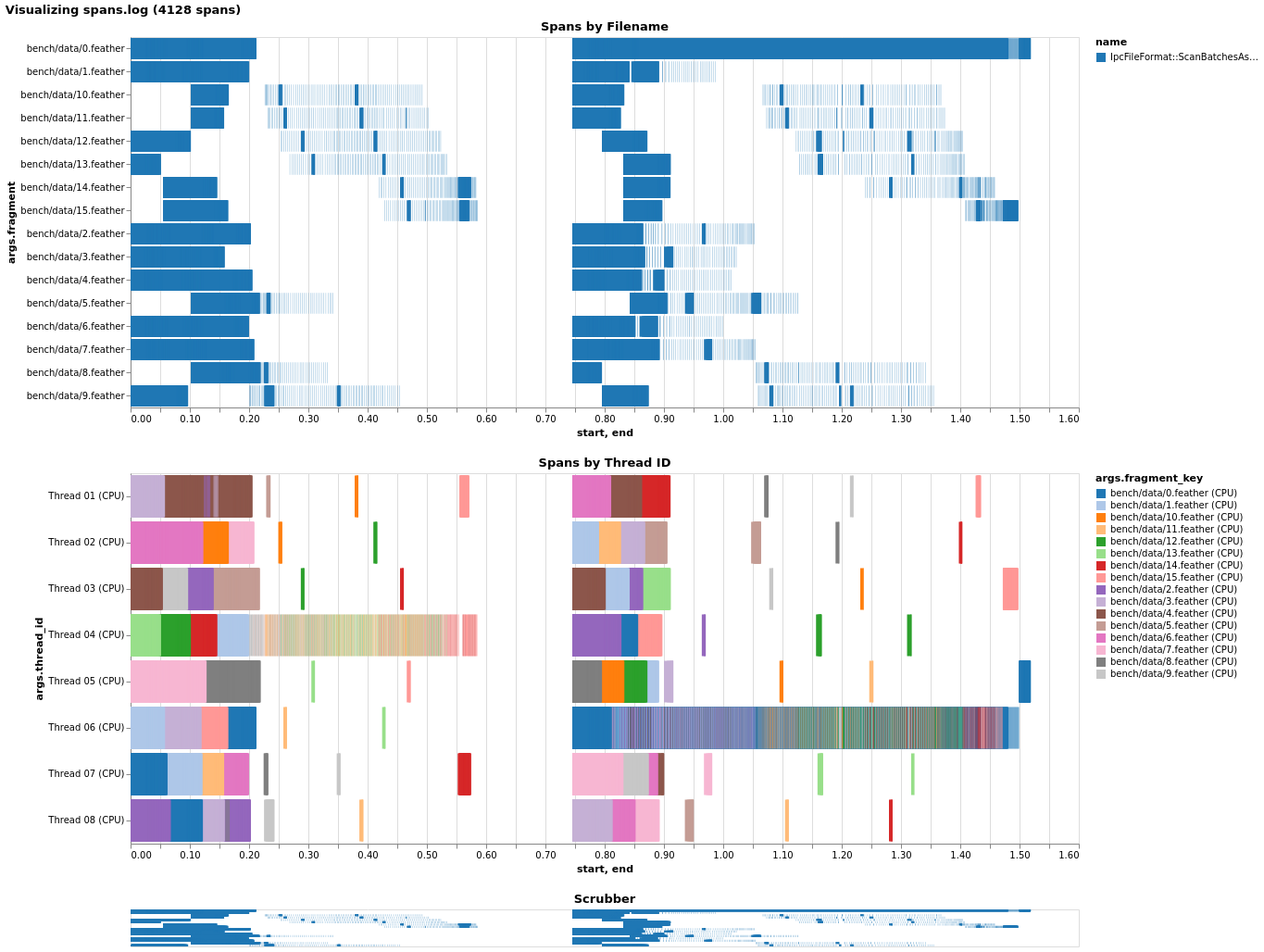
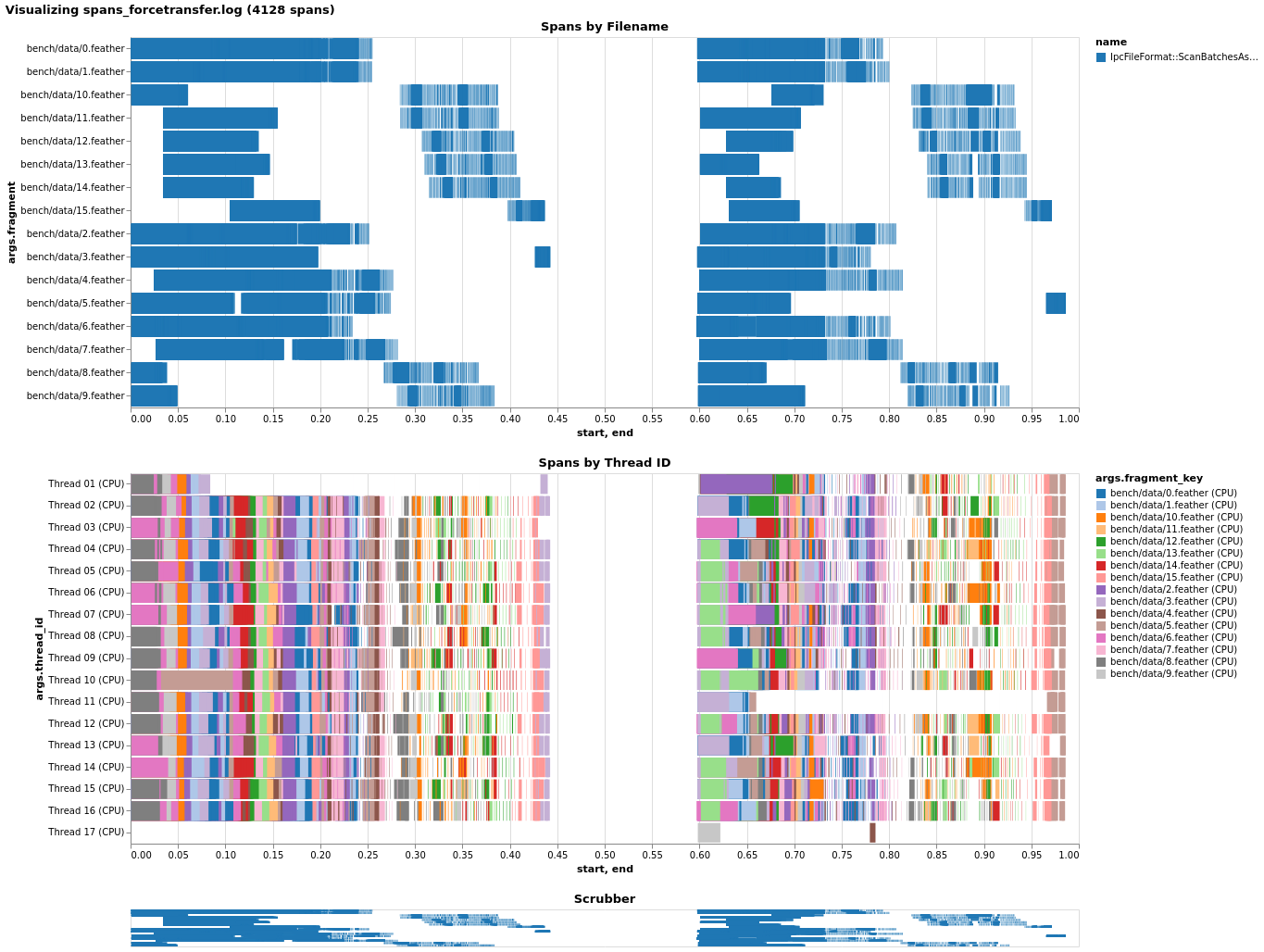
|
Indeed. Check out ARROW-12560 which should achieve the best of both worlds (minimizing spawn while maximizing core utilization). |
|
I verified things on EC2. ARROW-12560 will let us just always 'do the right thing' so to speak, but for now, it looks like always transferring is beneficial in essentially all cases, so I've updated the PR.
|
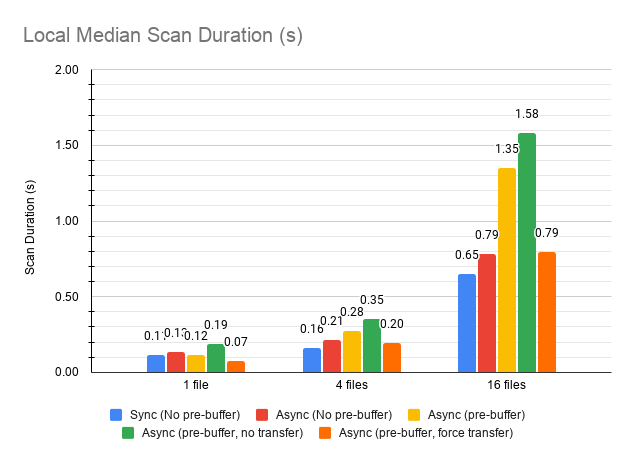

|
Keep in mind too that |
|
Yes, I may have gotten a bit carried away…I'm happy to split this up if that's more manageable. |
|
I don't think that's necessary. I was going more for "this looks really good, let's get it in" and not so much "this is getting too big". |
2e0beca to
85a5d7c
Compare
|
Just to follow up, @pitrou @westonpace did either of you have final comments here? |
|
No final comments from me. I scanned through the last few updates and all seems good. |
10bfcb7 to
f5ab4b5
Compare
|
CI passes, so I'll go ahead and merge this. |
This provides an async-reentrant generator of record batches from an IPC file reader, intended to support Datasets once it becomes async itself.
IPC messages are read on an IO thread pool, then decoded on the CPU thread pool. All dictionaries must be read at the start, then record batches can be read independently.