Feature: Porting unique index for AO table to CBDB#112
Feature: Porting unique index for AO table to CBDB#112my-ship-it merged 19 commits intoapache:mainfrom
Conversation
|
|
There was a problem hiding this comment.
Hiiii, @lss602726449 welcome!🎊 Thanks for taking the effort to make our project better! 🙌 Keep making such awesome contributions!
4f877af to
3c06259
Compare
|
support |
Sure, almost use unique index same as heap, execpt different implementation. |

add some test like |
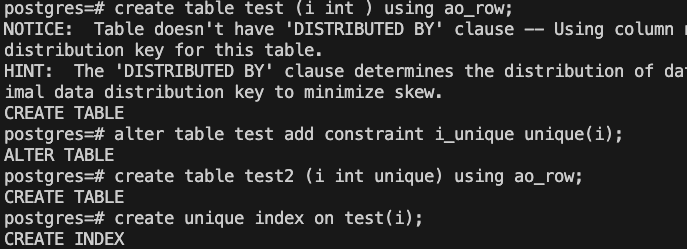
|

This commit introduces the gp_toolkit.__gp_aoblkdir UDF to print all of
the block directory entries for an AO/AOCO relation. It essentially
flattens the minipage binary column in pg_aoblkdir_* relations, printing
a minipage entry in every output row.
This function is in the same spirit as __gp_aovisimap() and can be run
in utility mode or with gp_dist_random() to obtain meaningful results.
Example:
postgres=# create table baz(i int, j int) with (appendonly=true);
postgres=# create index on baz(i);
postgres=# insert into baz select i, i FROM generate_series(1, 10) i;
postgres=# insert into baz select i, i FROM generate_series(1, 10) i;
postgres=# SELECT gp_segment_id, (gp_toolkit.__gp_aoblkdir('baz')).* FROM gp_dist_random('gp_id')
order by 1, 2, 3, 4, 5, 6, 7, 8;
gp_segment_id | tupleid | segno | columngroup_no | entry_no | first_row_no | file_offset | row_count
---------------+---------+-------+----------------+----------+--------------+-------------+-----------
0 | (0,2) | 1 | 0 | 0 | 1 | 0 | 100
0 | (0,2) | 1 | 0 | 1 | 101 | 128 | 5
1 | (0,2) | 1 | 0 | 0 | 1 | 0 | 100
1 | (0,2) | 1 | 0 | 1 | 101 | 40 | 1
2 | (0,2) | 1 | 0 | 0 | 1 | 0 | 100
2 | (0,2) | 1 | 0 | 1 | 101 | 104 | 4
(6 rows)
PGOPTIONS='-c gp_role=utility' psql postgres -p 7002
psql (12beta2)
Type "help" for help.
postgres=# select * from gp_toolkit.__gp_aoblkdir('baz');
tupleid | segno | columngroup_no | entry_no | first_row_no | file_offset | row_count
---------+-------+----------------+----------+--------------+-------------+-----------
(0,2) | 1 | 0 | 0 | 1 | 0 | 100
(0,2) | 1 | 0 | 1 | 101 | 128 | 5
(2 rows)
This UDF also respects gp_select_invisible to report block directory
entries that are invisible. To determine invisible entries we can use
the tupleid projected here and tie it to the corresponding pg_aoblkdir
tuple's xmax.
Background:
(1) Block directory rowcount hole filling: The firstRowNum is allocated on
the basis of gp_fast_sequence and is not always contiguous with the last
minipage entry's (firstRowNum + rowCount) value. Before we insert the
next minipage entry, we "fill" the rowCount of the previous one so that the
range appears contiguous between successive minipage entries.
(2) Hole filling in action:
insert into foo values(1);
-> inserts entry A with (firstRowNum, rowCount) = (1, 1)
insert into foo values(1);
-> updates previous entry A to (firstRowNum, rowCount) = (1, 100)
since firstRowNum = 101 for the next insert, we fill the previous entry
to ensure that there are no holes in the rowCount range.
Motivation:
There is no apparent reason why this mechanism is necessary and it becomes
a hindrance for future work to support unique indexes. That work depends
on the continuity of a block directory entry's range to determine unique
index lookups.
Changes:
(1) Removing this mechanism establishes the invariant: fetching physical
rows in the continuous range of a block directory entry's first and last
rownumbers will always be successful.
(2) We enforce this invariant with suitable ERRORs inside the fetch
machinery. However, since hole filling will still exist in older
versions, we do a AORelationVersion bump and ERROR out only for the
current version and onwards.
Note: We use the formatversion attribute of ao(cs)seg rels instead of
the unused Minipage->version member. This is because even though it
makes more semantic sense and constitutes an equivalent condition for
the ERROR, it means more work for banning code in unique index creation:
If we were to use Minipage->version, we would have to check every
minipage in the block directory, which might be more expensive than the
limited number of ao(cs)seg tuples we would have to check on the other
hand.
Co-authored-by: Ashwin Agrawal <aashwin@vmware.com>
We discovered code in extract_minipage() which "resets" supposedly spurious block directory entries from crashed/cancelled inserts. This code is vestigial as the entries we are trying to fix can never be seen with an MVCC/dirty snapshot, as their block directory row(s) would be invisible (due to tx abort processing). Also, the assertions here such as Assert(fsinfo != NULL) get in the way of implementing unique index lookups for AO/CO, where we need to look up block directory entries which don't back actual on-disk tuples (where the fsinfo is not set etc), in a later commit. Co-authored-by: Ashwin Agrawal <aashwin@vmware.com>
This commit introduces support for INSERT/COPY on AO and AOCO tables with unique indexes. Mechanism: (*) To answer uniqueness checks for AO/AOCO tables, we have a complication. Unlike heap, in AO/CO we don't store the xmin/xmax fields in the tuples. So, we have to rely on block directory rows that "cover" the data rows to satisfy index lookups. The xmin/xmax of the block directory row(s) help determine tuple visibility for uniqueness checks. (*) Since block directory rows are written usually much after the data row has been inserted, there are windows in which there is no block directory row on disk for a given data row - a problem for concurrent unique index checks. So during INSERT/COPY, at the beginning of the insertion operation, we insert a placeholder block directory row to cover ALL future tuples going to the current segment file for this command. (*) To answer unique index lookups, we don't have to physically fetch the tuple from the table. This is key to answering unique index lookups against placeholder rows which predate their corresponding data rows. We simply perform a sysscan of the block directory, and if we have a visible entry that encompasses the rowNum being looked up, we report success. (*) Tableam changes: Since there is a lot of overhead (leads to ~20x performance degradation in the worst case) in setting up and tearing down scan descriptors for AO/CO tables, we avoid the scanbegin..fetch..scanend construct in table_index_fetch_tuple_check(). So, we introduce a new tableam API index_fetch_tuple_exists(), which is implemented only for AO/CO tables. Here, we fetch a UniqueCheckDesc, which stores all the in-memory state to help us perform a unique index check. This descriptor is attached to the DMLState structs. Currently, the descriptor holds only a block directory struct. It will be modified later on to hold a visimap reference to help implement DELETEs/UPDATEs. Furthermore, we initialize this struct on the first unique index check performed, akin to how we initialize descriptors for insert and delete. (*) There is NO change to non-unique index related code paths. Notes: * This only gets INSERT/COPY to work. Other operations may yield unpredictable behavior. So we mark the feature as experimental, and can only be turned on by setting the gp_appendonly_enable_unique_index GUC * We also ban unique index creation if the AO table has a relation version <= AORelationVersion_PG83 and if it already has a block directory. This is because unique index checks need continuity inside a directory entry's range for correct behavior - something that legacy hole filling violates (PS: legacy hole filling was removed in 258ec966b26). Co-authored-by: Ashwin Agrawal <aashwin@vmware.com>
This commit brings DELETE functionality to AO/CO tables with unique indexes. To support DELETE, we simply have to check the visibility map in case a conflict should arise while performing uniqueness checks, to see if the tuple has been deleted. Further, we should only perform such a check if the conflicting tuple was already committed (and not inserted by a concurrent transaction). Since, by design AO/CO tables doesn't support concurrent DELETEs and UPDATEs, we don't have to worry about those during insert existence checks or in DELETE code paths. We simply add to the UniqueCheckDescs a visimap struct, which we initialize, as we would do for a regular index fetch operation. We use this struct to perform the aforementioned lookups.
This commit formally adds support for UPDATEs on AO/CO tables with unique indexes. Technically, UPDATEs were supported by the prior commits for DELETE and INSERT. This commit includes tests to formally support UPDATE and addresses the unsupported edge case: UPDATE foo SET i = 1 WHERE i = 1; Here, within the UPDATE command itself, there is a need to see what tuples are deleted in the delete half of the command, in uniqueness checks done by the insert half of the command. This is crucial to avoid spurious conflicts in similar situations as above, where the source and target keys are equal in the UPDATE invocation. To that end, we reuse the visimap used in the delete half of the command in the uniqueness check performed during the insert half.
Unique index checks use SNAPSHOT_DIRTY, which is stack allocated and a new snapshot object is passed always to table_index_fetch_tuple_check(). While this is fine for heap, for AO/CO tables, we persist this stack allocated object in the unique check descriptor's block directory and visimap data structures, which are palloced. This leads to nasty memory trespassing, resulting in segfaults. Remedy this by deferring the metadata snapshot assignment to index_fetch_tuple_exists(), just before the block directory and visimap are scanned.
This commit refactors block directory and visimap initialization, lookup and teardown code to make the special non-MVCC snapshot manipulation more apparent. Assumptions are also asserted copiously.
By the time we reach AppendOnlyBlockDirectory_End_forUniqueChecks(), there is a guarantee that AppendOnlyBlockDirectory->blkdirIdx is open. Thus there is no need to conditionally close the index.
7cd415d to
54d32b6
Compare
This attribute is used to align with "formatversion" of pg_aoseg catalog for identifying the append-optimized relation version during planning stage. This will simplify validation for version dependent features such like index only scan, unique index creation and so on.
03669e4 to
e9f5e71
Compare
Though no special code was written for unique indexes in the context of subtransactions, add smoke tests all the same: * For added coverage * For illustrative purposes
Now that we have support for unique indexes on AO/CO tables, drop the dev GUC hiding the feature. Update tests accordingly.
AO lazy VACUUM is different from heap vacuum in the sense that ctids of data tuples change (and the index tuples need to be updated as a consequence). It leverages the scan and insert code to scan live tuples from each segfile and to move (insert) them in a target segfile. The previous commit that added support for INSERT on AO tables with unique indexes, is sufficient to entertain uniqueness checks running concurrently with vacuum. That commit did not introduce the placeholder row mechanism to the vacuum code however, as it is not necessary for correctness. This is because the old index entries will still point to the segment being compacted. This will be the case up until the index entries are bulk deleted, but by then the new index entries along with new block directory rows would already have been written and would be able to answer uniqueness checks. This commit has 2 main contributions: 1. Concurrency coverage for uniqueness checks running parallel with VACUUM, to enforce that the mechanism added in the prior INSERT commit is sufficient. 2. Running uniqueness checks in the backend running AO VACUUM results in spurious uniqueness conflicts. Live tuples being moved (inserted into a new segfile) report a unique constraint violation against themselves. Example: test=# SET debug_appendonly_print_blockdirectory TO ON; SET test=# create table bar(i int unique) using ao_row; CREATE TABLE test=# insert into bar select generate_series(1, 10); INSERT 0 10 test=# delete from bar where i = 1; DELETE 1 test=# vacuum full verbose bar; INFO: vacuuming "public.bar" INFO: compacting "public.bar" LOG: For segno = 0, rownum = 2, tid returned: (0,2) tuple (xmin, xmax) = (940, 0), snaptype = 4 ERROR: duplicate key value violates unique constraint "bar_i_key" DETAIL: Key (i)=(2) already exists. The above reports a conflict while trying to move tuple with i = 2. Remedy this by adding the capability to bypass uniqueness checks when inserting index tuples in ExecInsertIndexTuples(). This is done by a new EState member: gp_bypass_unique_check, which AO lazy VACUUM can set. Co-authored-by: Ashwin Agrawal <aashwin@vmware.com>
The test was flaky w/ a diff like this: --- /tmp/build/e18b2f02/gpdb_src/src/test/isolation2/expected/fsync_ao.out 2023-04-10 11:51:22.694100534 +0000 +++ /tmp/build/e18b2f02/gpdb_src/src/test/isolation2/results/fsync_ao.out 2023-04-10 11:51:22.706101385 +0000 @@ -107,7 +107,7 @@ gp_inject_fault ------------ - Success: fault name:'ao_fsync_counter' fault type:'skip' ddl statement:'' database name:'' table name:'' start occurrence:'1' end occurrence:'-1' extra arg:'0' fault injection state:'triggered' num times hit:'3' + Success: fault name:'ao_fsync_counter' fault type:'skip' ddl statement:'' database name:'' table name:'' start occurrence:'1' end occurrence:'-1' extra arg:'0' fault injection state:'triggered' num times hit:'2' (1 row) The reason seems to be that there's one additional checkpoint being replayed by mirror. The exact reason for the additional checkpoint is unknown, but if I were to guess, most probably the mirror was slow in relaying records and it replayed a checkpoint generated from a previous test after the fault 'restartpoint_guts' was inserted. This would be hard to prevent. However, we should be able to fix the flakiness by waiting until the faults 'ao_fsync_counter' is being hit the exact same times as we expect.
In the past, we rely on the visibility map to check if an index entry can be removed. Scanning VM is not such effective. With this new strategy, we do index vacuum iff after we recycle a PendingDrop segment, and think the index entry is removable only check if it points to a dropable segment, so the checking would be effective, and dropable segments also guarantee the index entry is invisible to anyone already. To make the new VACUUM strategy work properly, it is necessary to do following refactor for recycling dead segments logic: - Combine recycling dead segments and index vacuum together for data consistency and crash safety. - Relax the requirement for AccessExclusiveLock in VACUUM drop phase: acquire AccessShareLock for scaning segfiles; acquire ExclusiveLock for truncating dead segfiles. Co-authored-by: Haolin Wang <whaolin@vmware.com>
…ario. We used to call AppendOptimizedRecycleDeadSegments() (current name is ao_vacuum_rel_recycle_dead_segments) to recycle those segfiles to save spaces in AT ADD COLUMN scenario. But it didn't do corresponding index tuples cleanup for unknown reason. With new VACUUM AO strategy, we did refactor for AppendOptimizedRecycleDeadSegments() a little bit and combine dead segfiles cleanup with corresponding indexes cleanup together. While it seems to be impossible to pass index vacuuming parameter in this scenario, so we removed AppendOptimizedRecycleDeadSegments() from this scenario and dedicated it to be called only in VACUUM scenario.
807c034 to
f4b7246
Compare
Firstly, we remove the fill hole mechanism in the BlockDirectory to support the unique index for AO table. In order to distinguish it from the previous BlockDirectory design that did not support unique index, we add the "version" field to the pg_appendonly table. Implement the insert, delete and update of AO table for the unique index. Since the Memtuple in the AO table does not have the xmin and xmax field, we implement unique check by using its auxiliary index structure BlockDirectory (Heaptuple). Specifically, for the scenario with a unique index, when inserting into the AO table, we insert a placeholder in BlockDirectory to block the insertion of the same key. In order to adapt to the insertMultiFiles mechanism, we add a field to each segment file to identify whether the placeholder has alreadly been inserted in the BlockDirectory. Change the vacuum implementation of the AO table and index. When the number of dead tuples in the segment reaches the threshold, we drop the segment and recycle the segment and the corresponding index. Adjust a few function signatures and tests, and add tests and comments.
f4b7246 to
fe505a3
Compare
…full (#112) * Fix bug The relation_cache_entry of temporary table, created during vacuum full, is not be removed after vacuum full. This table will be treated as an uncommitted table, although it has been dropped after vacuum full. And its table size still remains in diskquota.table_size, which causes quota size to be larger than real status. Use RelidByRelfilenode() to check whether the table is committed, and remove its relation_cache_entry. Co-authored-by: hzhang2 <hzhang2@vmware.com> Co-authored-by: Xing Guo <higuoxing+github@gmail.com> Co-authored-by: Xuebin Su (苏学斌) <sxuebin@vmware.com>
* Fix incorrect JOIN condition in test_blackmap.sql (#101)
This PR fixes incorrect JOIN condition in test_blackmap.sql. The
relfilenodes are not always different across segments. Hence, we should
add an additional JOIN condition to the test case or it will produce
unstable results.
* calculate table size for hard limit (#100)
Add calculate_table_size() to calculate any table's size, including uncommitted table.
1. Monitor active table in master.
2. Replace relation_open() with SearchSysCache(), pg_appendonly and pg_index to fetch Form_pg_class of table and index, to avoid DEADLOCK.
3. Use DiskQuotaRelationCacheEntry to calculate table size, instead of pg_table_size(), to avoid DEADLOCK.
Co-authored-by: hzhang2 <hzhang2@vmware.com>
Co-authored-by: Xuebin Su (苏学斌) <sxuebin@vmware.com>
Co-authored-by: Xing Guo <higuoxing+github@gmail.com>
* Add support for adding uncommitted relations to blackmap. (#102)
This patch adds support for adding uncommitted relations to blackmap on
segment servers. Most of the codes share similar logic with adding
committed relations to blackmap. Test will be added in the next
following commits.
* Fix bug: calculate AO table size in CTAS (#105)
The extension file with (segno=0, column=1) is not traversed by
ao_foreach_extent_file(), we need to handle the size of it additionally.
Co-authored-by: hzhang2 <hzhang2@vmware.com>
Co-authored-by: Xing Guo <higuoxing+github@gmail.com>
* Add support for dispatching blackmap to segments. (#104)
This patch adds support for dispatching blackmap to segments. This patch also
introduces two UDFs:
diskquota.enable_hardlimit()
diskquota.disable_hardlimit()
User is able to enable and disable the hardlimit feature by using those UDFs.
Co-authored-by: hzhang2 <hzhang2@vmware.com>
* Ignore distribution notice in regression tests. (#106)
This PR is trying to fix CI building failure by ignoring distribution
notice in CTAS statements.
Co-authored-by: Hao Zhang <hzhang2@vmware.com>
* Trying to make concourse happy. (#108)
* Print the diff files when the tests failed. (#109)
* Fix flaky test cases. NFC. (#110)
* Fix bug: table's relation_cache_entry is not be removed after vacuum full (#112)
* Fix bug
The relation_cache_entry of temporary table, created during vacuum full, is not be removed after vacuum full. This table will be treated as an uncommitted table, although it has been dropped after vacuum full. And its table size still remains in diskquota.table_size, which causes quota size to be larger than real status.
Use RelidByRelfilenode() to check whether the table is committed, and remove its relation_cache_entry.
Co-authored-by: hzhang2 <hzhang2@vmware.com>
Co-authored-by: Xing Guo <higuoxing+github@gmail.com>
Co-authored-by: Xuebin Su (苏学斌) <sxuebin@vmware.com>
* Fix test case bug (#114)
The SQL statement is not equal to the expected output in test_vacuum.sql.
Co-authored-by: hzhang2 <hzhang2@vmware.com>
* Fix bug: can not calculate the size of pg_aoblkdir_xxxx before `create index on ao_table` is committed (#113)
We can not calculate the size of pg_aoblkdir_xxxx before `create index on ao_table` is committed.
1. Lack of the ability to parse the name of pg_aoblkdir_xxxx.
2. pg_aoblkdir_xxxx is created by `create index on ao_table`, which can not be searched by diskquota_get_appendonly_aux_oid_list() before index's creation.
Solution:
1. parse the name begin with `pg_aoblkdir`.
2. When blkdirrelid is missing, we try to fetch it by traversing relation_cache.
Co-authored-by: hzhang2 <hzhang2@vmware.com>
Co-authored-by: Xing Guo <higuoxing+github@gmail.com>
Co-authored-by: Xuebin Su (苏学斌) <sxuebin@vmware.com>
* Add UDF to show worker status (#111)
Co-authored-by: Xuebin Su (苏学斌) <12034000+xuebinsu@users.noreply.github.com>
Co-authored-by: Xing Guo <higuoxing@gmail.com>
Co-authored-by: Hao Zhang <hzhang2@vmware.com>
* Wait until deleted tuples are dead before VACUUM (#118)
Consider a user session that does a DELETE followed by a VACUUM FULL to
reclaim the disk space. If, at the same time, the bgworker loads config
by doing a SELECT, and the SELECT begins before the DELETE ends, while ends
after the VACUUM FULL begins:
bgw: ---------[ SELECT ]----------->
usr: ---[ DELETE ]-[ VACUUM FULL ]-->
then the tuples deleted will be marked as RECENTLY_DEAD instead of DEAD.
As a result, the deleted tuples cannot be removed by VACUUM FULL.
The fix lets the user session wait for the bgworker to finish the current
SELECT before starting VACUUM FULL .
* Make altered relation's oid active when performing 'VACUUM FULL'. (#116)
When doing VACUUM FULL, The table size may not be updated if
the table's oid is pulled before its relfilenode is swapped.
This fix keeps the table's oid in the shared memory if the table
is being altered, i.e., is locked in ACCESS EXCLUSIVE mode.
Co-authored-by: Xuebin Su <sxuebin@vmware.com>
* Refactor pause() to skip refreshing quota (#119)
Currently, diskquota.pause() only takes effect on quota checking.
Bgworkers still go over the loop to refreshing quota even if diskquota
is paused. This wastes computation resources and can cause flaky issues.
This fix makes bgworkers skip refreshing quota when the user pauses
diskquota entirely to avoid those issues. Table sizes can be updated
correctly after resume.
* ci: create rhel8 release build. (#117)
ci: create rhel8 release build.
Signed-off-by: Sasasu <i@sasa.su>
Co-authored-by: Xuebin Su <sxuebin@vmware.com>
* set the scope of pause() to current database
* cleanup header include
* re-dispatch pause status
* allow to re-create extension
* use atomic on flag hardlimit_lock (#124)
* send a error if launcher crashed (#124)
* Pause before DROP EXTENSION (#121)
Currently, deadlock can occur when
1. A user session is doing DROP EXTENSION, and
2. A bgworker is loading quota configs using SPI.
This patch fixes the issue by pausing diskquota before DROP
EXTENSION so that the bgworker will not load config anymore.
Note that this cannot be done using object_access_hook() because
the extension object is dropped AFTER dropping all tables that belong
to the extension.
* add test case for pause hardlimit (#128)
* Attempt to fix flaky test_primary_failure (#132)
Test case test_primary_failure will stop/start segment to produce a
mirror switch. But the segment start could fail while replaying xlog.
The failure was caused by the deleted tablespace directories in previous
test cases.
This commit removes the "rm" statement in those tablespace test cases and
add "-p" to the "mkdir" command line. The corresponding sub-directories
will be deleted by "DROP TABLESPACE" if the case passes.
Relevant logs:
2022-02-08 10:09:30.458183 CST,,,p1182584,th1235613568,,,,0,,,seg1,,,,,"LOG","00000","entering standby mode",,,,,,,0,,"xlog.c",6537,
2022-02-08 10:09:30.458670 CST,,,p1182584,th1235613568,,,,0,,,seg1,,,,,"LOG","00000","redo starts at E/24638A28",,,,,,,0,,"xlog.c",7153,
2022-02-08 10:09:30.468323 CST,"cc","postgres",p1182588,th1235613568,"[local]",,2022-02-08 10:09:30 CST,0,,,seg1,,,,,"FATAL","57P03","the database system is starting up"
,"last replayed record at E/2481EA70",,,,,,0,,"postmaster.c",2552,
2022-02-08 10:09:30.484792 CST,,,p1182584,th1235613568,,,,0,,,seg1,,,,,"FATAL","58P01","directory ""/tmp/test_spc"" does not exist",,"Create this directory for the table
space before restarting the server.",,,"xlog redo create tablespace: 2590660 ""/tmp/test_spc""",,0,,"tablespace.c",749,
* ereportif uses the 1st param as the condition (#131)
Otherwise, compiler reports a warning:
"comparison of constant ‘20’ with boolean expression is always false"
* add diskquota.status() to show if hardlimit or softlimit enabled or not
* ci: fix flaky test
* Add timeout when waiting for workers (#130)
Each time the state of Diskquota is changed, we need to wait for the
change to take effect using diskquota.wait_for_worker_new_epoch().
However, when the bgworker is not alive, such wait can last forever.
This patch fixes the issue by adding a timeout GUC so that wait() will
throw an NOTICE if it times out, making it more user-friendly.
To fix a race condition when CREATE EXTENSION, the user needs to
SELECT wait_for_worker_new_epoch() manually before writing data.
This is to wait until the current database is added to the monitored
db cache so that active tables in the current database can be
recorded.
This patch also fix test script for activating standby and rename
some of the cases to make them more clear.
* Add git commit message template (#141)
The template is copied from
https://gist.github.com/lisawolderiksen/a7b99d94c92c6671181611be1641c733
* Use guc for hardlimit (#142)
- Change to use GUC to set hardlimit instead of UDF. Since the hardlimit
setting needs to be persistent after postmaster restarting.
- Fix relevant test cases.
* be nice with scheduler when naptime = 0 (#120)
* Create worker entry before starting worker (#144)
Currently, the Diskquota launcher first starts a worker, then creates
the worker entry. However, after the worker starts, it cannot find the
entry when trying to check the is_paused status. Also, after a GPDB
restart, when the QD checks whether the worker is running by
checking the epoch, it might also fail to find the entry.
This patch fixes the issue by first create the worker entry then
starting the bgworker process.
* Extend fetch_table_stat() to update db cache (#138)
The db cache stores which databases enables diskquota. Active tables
will be recorded only if they are in those databases. Previously,
we created a new UDF update_diskquota_db_list() to add the current db
to the cache. However, the UDF is install in a wrong database. As a
result, after the user upgrade from a previous version to 1.0.3, the
bgworker does not find the UDF and can do nothing.
This patch fixes the issue by removing update_diskquota_db_list() and
using fetch_table_stat() to update db cache. fetch_table_stat() already
exists since version 1.0.0 so that no new UDF is needed.
This PR is to replace PR #99 , and depends on PR #130 to fix a race
condition that occurs after CREATE EXTENSION.
* Use ytt to create pipelines (#143)
- Rewrite the pipelines by using ytt for code reuse.
- Add `fly.sh` for easier manipulating with pipelines.
- Create configs for pr, commit and dev pipelines.
- Fix the test task for rhel8.
- Use build/test images pair for all distros. And modify the
`build_diskquota.sh` so it won't need `Python.h` during the configure
stage.
- Fix the pipiline bug which a `ubuntu` test may use a `rhel6` diskquota
binary to do the test. That is caused by the same name of the task
output.
* Specify DISTRIBUTED BY when CREATE TABLE (#146)
When the distribution policy is not specified explicitly, ORCA
distributes data randomly when CREATE TABLE. This can make the
size of the tables created different from time to time.
This patch fixes the issue by adding DISTRIBUTED BY for each
CREATE TABLE to avoid random distribution.
* Simplify the build script (#148)
No need to have the switch case.
* Revert greenplum-db/diskquota#138 (#150)
Revert "Extend fetch_table_stat() to update db cache (#138)"
This reverts commit 9457fa52f1df6d1715041c551fb5eab3cb0fb0b3.
* Add clang-format and editorconfig (#136)
- clang-format is from https://groups.google.com/a/greenplum.org/g/gpdb-dev/c/rHb4DjSd1iI/m/FKPbqwYcBAAJ
- See editorconfig at https://editorconfig.org/
* Extend fetch_table_stat() to update db cache v2 (#151)
The db cache stores which databases enables diskquota. Active tables
will be recorded only if they are in those databases. Previously,
we created a new UDF update_diskquota_db_list() to add the current db
to the cache. However, the UDF is install in a wrong database. As a
result, after the user upgrade from a previous version to 1.0.3, the
bgworker does not find the UDF and can do nothing.
This patch fixes the issue by removing update_diskquota_db_list() and
using fetch_table_stat() to update db cache. fetch_table_stat() already
exists since version 1.0.0 so that no new UDF is needed.
This PR is a revision of PR #138 , and depends on #130 to fix a race
condition that occurs after CREATE EXTENSION.
Co-authored-by: Chen Mulong <chenmulong@gmail.com>
* Wait after CREATE EXTENSION (#152)
Each time after CREATE EXTENSION, we need to wait until the db cache
gets updated. Otherwise no active table will be recorded.
* Run tests on all platforms for PR pipeline (#153)
Try to catch more flaky tests from the beginning.
Co-authored-by: Chen Mulong <cmulong@vmware.com>
Co-authored-by: Xuebin Su (苏学斌) <12034000+xuebinsu@users.noreply.github.com>
* Reset naptime when test finish (#147)
Add tear_down to regress and isolation2 tests to reset the naptime. When
naptime is 0, quite a lot of cpu will be used. It will be a problem if
there are failing jobs on CI before getting reaped by the concourse. The
concourse worker CPU will be occupied which may impact following tests.
* Fix flaky test case in isolation2/test_relation_size.sql (#123)
* Set PR pending status when start (#157)
Also fixed a syntax issue in pr.yml
* Update CI README for PR trigger issue (#156)
* Make diskquota work for "pg_default" tablespace (#133)
* Make diskquota work for "pg_default" tablespace (#133)
Tracker story ID: #180688138.
Setting role_tablespace quota in "pg_default" using
`set_role_tablespace_quota` doesn't work. Due to a hack
(src/backend/catalog/heap.c) in GPDB, the `reltablespace` of relations
in "pg_default" is `InvalidOid`. When we refresh blackmap we use
`DEFAULTTABLESPACE_OID` instead for those invalid tablespace, this
results in a mismatch. This patch solves the problem by updating tablespace
oid to the real tablespace oid (`MyDatabaseTableSpace`) when reading
from syscache.
Besides, with the hard limits on, we also need to update the tablespace
oid to the real one.
Co-authored-by: Xuebin Su <sxuebin@vmware.com>
Co-authored-by: Sasasu <i@sasa.su>
* build: use cmake as build system (#161)
* rename library file to diskquota-<major.minor>.so (#162)
rename library file to diskquota-<major.minor>.so, this will break
the old gpconfig -v shared_preload_libraries command, please note.
centos6 and centos7 only have cmake 2.8.12, use cmake 2.8.10 as the
minimum version.
use PG_HOME and remove the workaround.
use cpack to create the installer.
clean up SQL define.
* Keep the 1.0 sql the same with 1.x branch (#163)
The added 'DISTRIBUTED BY' clause should have no impact on 1.x.
* Test when table is created before quota is set (#129)
* Test when table is created before quota is set
This patch adds test cases to ensure that diskquota works when table
is created before quota is set. Specifically,
- When diskquota is preloaded, quota usage is updated automatically
for each active table. Therefore, quotas work once they are set and no
more action is required from the user.
- When diskquota is NOT preloaded, no active tables will be recorded.
As a result, when diskquota is preloaded again, the user need to
SELECT diskquota.init_table_size_table(); and restarts GPDB manually
in order to update the quota usage.
This patch also fixes some minor issues in the existing cases.
* Replace wait() with sleep()
* Install the latest cmake on CI (#165)
We need the archive extract feature from cmake 3.18.
Before the new version landing on the test/build images, install them in
our ci scripts.
A cmake binary has been uploaded to the concourse gcs for faster
downloading.
* dump cmake version to 3.18
* fix case test_ctas_no_preload_lib
* Cache CMAKE_INSTALL_PREFIX (#171)
CMAKE_INSTALL_PREFIX needs to be set as CACHE FORCE. Otherwise, next
time call 'make install' without source greenplum_path.sh, it will be
reset to '/usr/local'
See the example of CMAKE_INSTALL_PREFIX_INITIALIZED_TO_DEFAULT
https://cmake.org/cmake/help/latest/variable/CMAKE_INSTALL_PREFIX_INITIALIZED_TO_DEFAULT.html
* Fix empty quota view when no table (#167)
Currently, quota views are implemented using INNER JOIN. As a result,
when there is no table belong to a role, schema, or tablespace, the
quota view is empty even though there is a quota config defined for
that role, schema, or tablespace.
This patch fixes this by re-implementing quota views using OUTER JOIN.
Plus, the implementation also uses CTEs for modularizing big queries
and aggregation pushdown.
* mc/cmake installcheck (#169)
CMake installcheck:
- Regress.cmake is introduced to add some helper functions which can
easily create regress/isolation2 test targets in the CMakeLists.
- When creating regress targets, cmake will generate a series of
diff_<target>_<test> target to show result diff on a specific target.
- Porting the isolation2_regress build from Makefile to cmake.
- Moved the magic trap regress diff from the concourse script to cmake.
If the test target is called with env `SHOW_REGRESS_DIFF=1`, then the
regress.diff will be printed when the case fails.
- 'sql'/`expected` will be linked to the cmake binary directory and run
test from there. So the `results` won't pollute the source directory.
Concourse scripts restructure:
This commit also try to explore the way how the concourse scripts
are structured. Currently, the container is started with root user, and
this cannot be changed in a short time. But we require gpadmin user
basically for everything.
An `entry.sh` is introduced as a simple skeleton for the scripts. It
make sure a gpadmin user is created and everything needed can be
accessed by the gpadmin with a permanent path. So we don't have too much
ENV magic in the task script any more. Most of the setup work should be
done in the `entry.sh` and the task script should only do a few simple
steps with absolute paths.
By doing this, when we hijack to the concourse container, login with
gpadmin user, the environment should be ready. Simple copy & paste from
the task script will just work.
`upgrade_extension.sh` may not be needed anymore, and it won't work. It
will be cleaned up later when we have the full implementation of
upgrade.
* Dispatch only once for all tables when init() (#107)
Add UDF to accelerate init_table_size_table(). In this UDF:
we traverse pg_class to calculate the relation size of each relation;
parse the auxiliary table's name to get the relevant primary table's oid;
add the size of the auxiliary table to the primary table's size.
It can avoid multiple relation_open() and dispatching pg_table_size().
Co-authored-by: Xuebin Su <sxuebin@vmware.com>
* Pack the last released so in the pipeline (#172)
* Pack the last released so in the pipeline
Due to our upgrade design, the newly released diskquota should contain
all the so file of every latest minor release. The packaging system has
been implemented by cmake DISKQUOTA_PREVIOUS_INSTALLER.
This commit get the latest release through gcs regexp and pass it to the
build script.
The pipeline has been split into different jobs based on the OS type
because of:
- Easier to use the common resource name for build_diskquota.yml
- job_def.lib.yml becomes shorter
- Can span jobs into different concourse workers, which may bring some
better performance.
- Running a flaky test again is easier.
Also, a gate job has been added which is the main entrance for all
pipelines. In the future, we may want to have different gate jobs for
different pipelines, like a clang-format checking gate for the PR
pipeline.
* add upgrade and downgrade test (#166)
* Fix gcc warning (#175)
Reported by gcc 11.2.0:
quotamodel.c:2115:25: warning: ‘strncpy’ output truncated before
terminating nul copying 10 bytes from a string of the same length
[-Wstringop-truncation]
2115 | strncpy(targettype_str, "ROLE_QUOTA", 10);
| ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* Remove Makefiles (#174)
Everything has been moved to cmake.
* cmake: also link RESULTS_DIR to working dir
* show current binary and schema version
* Upload every build to GCS and add build-info (#177)
- Upload every build to GCS
- BuildInfo_create cmake function to print some cmake vars into a
build-info file which can be packaged. We avoid to use `cmake -LAH`
here since that misses some important local cmake vars and most of the
cmake cached var are not cared by us.
- Output some info to diskquota-build-info and it will be packaged by
cpack.
- Match the whole GP_VERSION from pg_config.h in Gpdb.cmake
- Modify editorconfig to use 2 spaces for cmake.
- Add Git.cmake to retrieve information from a git repository.
* Use cmake way to add C macro defines (#178)
Otherwise it creates noise with LSP since the '-Dxxxx' is started with a
'\n\t'. And that cannot be parsed by ccls.
* ci: speed up the test
* Small tuning on logs (#154)
- Add logs when launcher/bgworker terminates
- Add missing information to the logs.
* Update gitignore (#180)
- The build objects should always exist in build* directories now.
- Add ignore pattern for idea, LSP and dinosaur developpers.
* Add test cases for postmaster restart (#135)
- When postmaster dies, the launcher and workers should be terminated.
- When postmaster restarts, they should be restarted as well.
- Move common ignored patterns to the top init file.
* Fix memory leak when refresh_blackmap() (#182)
The ever growing part of memory contains the following pattern:
refresh_blackmap.*<segment_name><ip_address>:<port> pid=<pid>
The pattern contains info of segments. This indicates that the results
of dispatching refresh_blackmap() might not be freed properly.
* Format the code and add clang-format to PR pipeline (#183)
- Use clang 13 to format the code
- Rename the job 'gate' to 'entrance', prepare to add 'exit' job
- Add clang-format as an entrance check into the PR pipeline
* remove the in-logic version check.
After https://github.com/greenplum-db/diskquota/pull/166, we do not allow one binary running on two
or more DLL which have different version. By the new method, we will block worker enter normal
status if the DDL version is not match.
NOTE: launcher don't has the version check, if launcher DDL is modified,
will be undefined behavior.
this commit also remove some mem-alloc by using static const char* in
SQL string.
* ci: add upgrade version naming convention check
* Support release build (#186)
- Introduce macro DISKQUOTA_DEBUG through CMAKE_BUILD_TYPE. For the
debug build, check the macro and allow naptime = 0. The min naptime
for release build is 1 to prevent high cpu usage in user's
environment.
- Add EXCLUDE arg to Regree.cmake to skip some tests for the release
build since the release GPDB build doesn't support fault injector.
- Use GPDB release candidate to compile diskquota release. The release
candidate has assertion disabled in the pg_config.h.
- Set naptime=0 in the config.sql won't take effect for diskquota
release since it is less than the min value. So the naptime stays the
same (normally the default value, 2). This fails some of the test,
especially the hardlimit related ones. If the insertion takes less
time than naptime (2 seconds, normally), it fails since the limitation
has not been dispatched before finish. Thus, the naptime is set to 2
seconds instead of 10 in the reset_config.
* feat: github actions for clang-check ci (#185)
* Feat: use GitHub Actions for clang-check `CI`
* Run same regress test multiple times (#188)
- Add RUN_TIMES to RegressTarget_Add to run the same regress test
multiple times.
- Rename script for consistency.
* slack-alert and PR pipeline fix (#187)
- Add a slack alert when commit pipeline fails
- Add exit job to set successful state. That state cannot be set by
individual job since at that point, the whole pipeline is not finished
yet.
* Don't format errno as '%d' in error messages. (#190)
Actually, errno *isn't* strictly an integer. It depends on your
operating system. Instead of formatting it as an integer, we should
transform it to C style string and format it as '%s'.
* fix context corrupted when dirty data exist in pg_extension
* Fix cmake build on Mac (#191)
- Mac needs extra linker options that the symbols in the postgres
executable can be found.
- Mac's grep doesn't have '-P' option.
- To make a extension so file, we use a 'module' target instead of
'shared' on purpose. Since "A SHARED library may be marked with
the FRAMEWORK target property to create an macOS Framework."
Thus, the global link flags should be set through
CMAKE_MODULE_LINKER_FLAGS than CMAK_SHARED_LINKER_FLAGS.
* Bring tests back on CI (#193)
Some tests were accidentally excluded in Debug build.
* Missing EmitErrorReport before FlushErrorState (#155)
FlushErrorState() will clear the error state. To get the error log in
server logs, EmitErrorReport() needs to be called before flushing. All
other places with FlushErrorState() have the Emit before in the
codebase.
For diskquota bgworker, use `SearchSysCache1`. Because the bgworker
should be error-tolerant to keep it running in the background, we
can't throw an error. If we `EmitErrorReport` in bgworker, then the
results returned by `CdbDispatchCommand` would be incorrect. On the
other hand, the diskquota launcher can throw an error if needed.
Co-authored-by: Chen Mulong <chenmulong@gmail.com>
Co-authored-by: Xuebin Su <sxuebin@vmware.com>
* Insert newline before `else` (#194)
Insert newline before `else` to keep aligned with gpdb repository.
* Add the ytt based release pipeline (#198)
The release pipeline will:
- Automatically make a release build for every commit.
- The final release step needs to be started manually.
- Then the build will be pushed to the release bucket.
- And a tag will be pushed to the repository.
* Use on/off in diskquota.status() (#200)
PostgreSQL uses on/off for all bool variables.
soft limits: on (soft will works) / off (soft limit not works)
hard limits: on (hard will works) / off (hard limit not works)
* Update licenses (#195)
Pivotal became a part of VMware in 2020.
* Use released gpdb instead of release candidate (#201)
By the gcs resource regex rule, 6.99.99 will be matched as the most
recent gpdb release candidate, which is not what we want. It is a
testing version from release team. And due to the go regex
implementation, (!?) is not supported to filter out an exact string.
So the release pipeline is changed to use the most recent published gpdb
binary instead.
Compared with the previous gpdb_bin, the published one has
'--enable-debug-extensions' as the configure parameter. That also enables
the isolation2 tests for us. So no need to disable those tests in release build
anymore.
* Fix tablespace per segment ratio (#199)
If one tablespace segratio is configured,
this commit will make sure that ethier
the already existed (schema/role)_tablespace_quota
or new configs after this, will have the
same segratio.
1) Add a new quota type: TABLESPACE_QUOTA
used to store the tablespace segratio value
in quota_config table.
When set_per_segment_quota("xx","1.0) is
called, a new config will be added like:
quota_type = 4 (TABLESPACE_QUOTA)
quota = 0 (invalid quota)
segratio = 1
2) Modify set_quota_config_internal to
support insert/delete/update new type config
3) Add function get_per_segment_ratio
it is called when insert new
(schema/role)_tablespace_quota.
"for share" is used to query segratio,it only
can keep the segratio is consistent in
"read committed" level.
Co-authored-by: Sasasu <i@sasa.su>
* Fix un-expected remove when two tablespace-quota has a same role or schema (#202)
When there are two namespace_tablespace_quota configurations with the
same schema but different tablespaces, removing one quota will remove
another one automatically. The same bug happens for the
role_tabelspace_quota case. The root cause of this bug is that we
can't distinguish these two quotas using only quotaType and targetOid
of diskquota.quota_config.
This PR fixes this by changing the meaning of the targetOid column of
diskquota.quota_config table. When quotaType is
role_quota/schema_quota, targetOid refers to role_oid/schema_oid. When
quotaType is role_tablespace_quota/namespace_tablespace_quota,
targetOid refers to the rowId column of diskquota.target. This will
make it possible to distinguish two namespace_tablespace_quota with
the same schema and different tablespace. Because their rowId will be
different.
Co-authored-by: Xuebin Su <sxuebin@vmware.com>
Co-authored-by: Xiaoran Wang <xiwang@pivotal.io>
* Wait next loop for bgworker to refresh before INSERT in testcase (#205)
`diskquota.naptime` is 2 by default in the release version. So it's better to wait for the bgworker to fresh blackmap after INSERT.
* Add UDF diskquota.show_segment_ratio_quota_view (#204)
* clean blackmap after drop diskquota (#196)
clean blackmap after drop diskquota
Fix hardlimit exceed after drop diskquota.
fix this scenario:
- create hard limit
- blackmap on segment was updated
- drop diskquota
- the blackmap on segment is not cleanup
use ObjectAccess hook on segment. when dropping diskquota. clean up the in
memory blackmap.
* Reset memory account to fix memory leak (#203)
Diskquota workers dispatch queries periodically. For each dispatch,
one or more memory accounts will be created to keep track of the
memory usage. These accounts should be reset after the query
finishes to avoid memory leak.
Part of the stack trace of account creation looks like this:
```
fun:CreateMemoryAccountImpl
fun:MemoryAccounting_CreateAccount
fun:serializeNode
fun:cdbdisp_buildPlanQueryParms
fun:cdbdisp_dispatchX
fun:CdbDispatchPlan
fun:standard_ExecutorStart
fun:_SPI_pquery.constprop.11
fun:_SPI_execute_plan
fun:SPI_execute
fun:do_load_quotas
fun:load_quotas
fun:refresh_disk_quota_model
fun:disk_quota_worker_main
fun:StartBackgroundWorker
fun:do_start_bgworker
fun:maybe_start_bgworker
```
This patch fixes the memory leak issue by calling the reset function
at the end of the worker loop.
* fix test case for test_manytable (#197)
rename manytable test to activetable_limit
activetable_limit is used to test if activetable_limit works.
if number of current activetable > max_active_tables. bgworker will
print some warring message. GPDB should not crash, but diskquota's basic
function does not guarantee.
* some fix for release CI (#206)
clean blackmap after drop diskquota. follow up #196
also fix test case activetable_limit failed when naptime > 0
* Fix mistaken log statement (#207)
And add contraries that the refresh_black_map() should not be executed
on QD.
* Fix flaky ctas_pause on release build (#210)
Caused by the longger naptime for release build.
* Reformat quota exceeded message (#209)
Co-authored-by: Sasasu <i@sasa.su>
* Fix change tablespace test case (#213)
* Fix change tablespace test case
"ALTER TABLE xx SET TABLESPACE" will change the relfilenode of
a table, it will copy files from old relfilenode directory to
the new one and delete all files when commiting the transaction.
As diskquota doesn't acquire a lock on the relation when
fetching table size, so if diskquota is collecting active
tables' size and another session is deleting an active table's
files under an old relfilenode directory in a changing
tablespace transaction, the diskquota can't get all segment's
table size as files on part of segments have been deleted.
To fix it, we try to make a table to be an active table by
inserting data into it and wait for the diskquota to recalculate
the table size after changing tablespace.
* Replace "black" with "reject" for clearity (#214)
* Replace "black" with "reject" for clearity
* Rename in sql files
* Rename test files
* Format .c files
* Re-format using v13
* Update expected test results
* Fix result of upgrade test
* Re-trigger CI
* Add newline at EOF
* Change "list" to "map" for consistency
* Reject set quota for system owner(#215)
* fix set quota with upper case object name
the old code transform all object name to lower case on purpose.
create schema "S1";
select * from diskquota.set_schema_quota("S1", '1MB');
ERROR: schema "s1" does not exist
if the object name wrapped with '"'. eg '"Foo"' will search 'Foo'
if not will always search the lower case 'foo'.
* Hint message when launcher cannot be connected (#216)
* SPI & entry clear in refresh_blackmap (#211)
- refresh_blackmap doesn't need SPI calls.
- Clearing should happen within the same lock of refreshing entries.
Since there will be a short time that other processes see an empty
rejectmap while checking the hard limit.
* Minimize the risk of stale relfilenodes (#217)
Since we do NOT take any lock when accessing info of a relation,
cache invalidation messages may not be delievered in time each time
we SeearchSysCache() for relfilenode. As a result, the relfilenode may
be stale and the table size may be incorrect.
This patch fixes this issue by
- Checking for invalidation messages each time before
SearchSysCache(RELOID).
- Not removing a relation from active table map if the relfilenode
is stale.
Besides, since we do not remove the relfilenode if it maps to no
valid relation oid, we need remove those dangling relfilenodes
when unlink() to avoid memory leak.
* Report error if diskquota is not ready (#218)
Previously, setting quotas when diskquota is not ready is allowed.
But in that case, quotas set will not take effect. This can confuse
the user.
This patch fixes this issue by reporting an error when setting quotas
if diskquota is not ready. This is done by checking diskquota.state.
This patch also fixes possible deadlocks in the existing test cases.
* Allow deleting quota for super user (#219)
* Release pipeline is publishing wrong intermediates (#221)
"get" without "passed" will retrieve the latest content from a resource
which is not expected release. Especially the release and dev pipelines
share the intermediates bucket.
- Move release intermediates to its own bucket
- Add passed the "get" step in the "exit_release" job, to make sure the
resource version generated from previous job will be consumed in this
job.
* Bump version to 2.0.1 (#222)
* Compatible with ancient git (#223)
git 1.7.1 dose not support `git diff /absolute/path/to/current/project`
make our CI happy.
* Fix compiler version on concourse (#225)
cmake will look up c compiler by checking /usr/bin/cc. On CentOS7, that
symbolic linked to the gcc in the same directory. Although a newer gcc
is installed, cmake will not use the newer one.
We always export the CC and CXX, then the gcc/g++ in the $PATH will be
used.
* [CI] Fetch secrets from vault. (#226)
This patch teaches concourse to fetch secrets from vault.
* [cmake] Use C compiler to link the target. (#230)
Since we didn't implement anything in C++, let's invoke C compiler to link the target.
See: https://cmake.org/cmake/help/latest/prop_tgt/LINKER_LANGUAGE.html#prop_tgt:LINKER_LANGUAGE
* Scripts for new pipeline naming rules (#231)
Concourse is deprecating some special characters in the pipeline name.
See details at https://concourse-ci.org/config-basics.html#schema.identifier
The pipelines will be named as:
<rel|pr|merge|dev>[_test].<project_name>[branch_name][.user_defined_postfix]
- Pipeline type 'release' is renamed to 'rel'
- Pipeline type 'commit' is renamed to 'merge'
- '_test' suffix will be added to pipeline type for pipeline debugging
- Instead of setting the whole name of pipeline, user can only set the
postfix.
Patch from https://github.com/pivotal/ip4r/pull/2
Co-authored-by: Chen Mulong <cmulong@vmware.com>
Co-authored-by: Xing Guo <higuoxing+github@gmail.com>
* Log readiness message only once (#229)
Currently a diskquota worker will log an error message when the
database is not ready to be mornitored by Diskquota once for each
iteration. When the naptime is small, the log will be flooded by this
error message.
This patch adds a flag in the worker map in the shared memory so
that the error message will only be logged once per startup.
* Fix flaky test due to slow worker startup (#232)
When creating the extension, a diskquota worker will be started
to mornitor the db. However, it might take longer than expected
until it checks whether it is ready to monitor, which will make
some tests flaky.
This patch increases the time to wait for worker startup to avoid
flaky tests.
* Downgrade severity of the readiness issue (#235)
Downgrade the severity of the readiness check failure from `ERROR` to
`WARNING` so that the error stack will not be logged.
* Fix creating artifact (#234)
The artifact was tared without "c", which is a tar only but not gzipped.
untar it with "xzvf" will report error:
"
tar xzvf diskquota_rhel7_gpdb6.tar.gz
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Error is not recoverable: exiting now
"
* Dynamic bgworker for diskquota extension
As the num of bgworkers is limited in gpdb, if we want to support
unlimited numbers of database to run diskquota extension , we
need to dynamically allocate bgworkers for databases. Each
bgworker only runs "refresh_disk_quota_model" once, then exits.
GUC diskquota.max_workers is added in this pr, to set the max
bgworkers running in parallel.
Const MAX_NUM_MONITORED_DB, the databases' num is still
limited as we store each database's status in shared memory.
When there are fewer databases running diskquota extension than
diskquota.max_workers, will start one bgworker for each database
statically. Otherwise, will start bgworkers dynamically.
Launcher:
* workers: in shared memory
freeWorkers,runningWorkers are 2 double linked list.
Move a worker from freeWorkers to runningWorkers when picking
up a worker to serve for a database.
Move a worker from runningWorkers to freeWorkers when the
process exits. The length of freeWorkers plus runningWorkers is
diskquota.max_workers.
And each worker has a workerId, referenced by DiskquotaDBEntry.
* dbArray: an array in shared memory too, the length of it is
MAX_NUM_MONITORED_DB, storing DiskquotaDBEntry info.
The related things to dbArray:
- curDB: an iterator pointer for DBArray. When curDB is
NULL means that diskquota has finished one loop, and is ready
for the next loop. When curDB is dbArrayTail, it means it finished
on the loop but needs to sleep; otherwise, it points to a DB needed
to run.
- next_db(): function to pick the next database to run.
* DiskquotaDBEntry:
- in_use: it holds a diskquota database info.
- workerId: if the workerId is not Invalid, it means the db is running.
To check if a db is running by this field.
If the naptime is short, and after one loop, the database is still
running, then it will not be picked up to run.
- inited: check If the things for the diskquota extension, especially
the items in shared memory, have been inited.
* Diskquota worker:
Each diskquota extension worker has something in shared memory,
inited by function init_disk_quota_model,.
* Schedule
If it is ok to start workers, then pick one db in dbArray from beginning
to end to run. Otherwise, it means it's not time to start workers or
there are no available free workers. For the first reason, just sleep
until timeout. For the second point, to wait for the SIGUSR1 signal
which means there are diskquota workers exiting and workers freed.
* Fix the test failure on release pipeline
Regress tests failed on the release
pipeline due to the diskquota.naptime
is not 0. As diskquota launcher
firstly sleep, then starts diskquota
workers. When naptime is not 0, workers
are started very late, then some tests
which checking them failed.
In this pr, fix the test by starting
diskquota workers in the launcher before
it sleeps. This makes diskquota workers
will be started immediately when the
launcher starts.
Also, increased the sleep time in
the tests.
Sometimes, after restarting gpdb cluster, the db
has not yet been added to monitored_db_cache,
but worker_get_epoch is called to fetch the db
from the cache, then it will fail. Shouldn't to
report error here, printing a warning is ok.
* Move pr/merge pipeline to dev2 (#238)
And the docker clang-format image exists on the extensions gcp, I am too
lazy to move it here and it will be unnecessary to do that since we have
the check as github actions.
* Combine two object_access_hook into one (#220)
* Remove free writer gang in launcher (#233)
As launcher and worker both run in bgworker, they are clients when
connecting to segments. They know when should close the connections.
So we directly call `DisconnectAndDestroyAllGangs` to close them and
remove the code that only closes free read gangs based on timeout.
For the launcher, we destroy gangs after init_datbase_list or after each
time processing create/drop diskquota extension.
For workers, we only destroy gangs after the extension is paused.
* Fix bug: diskquota quota usage doesn't include uncommitted table (#228)
* Fix bug: diskquota quota usage doesn't include uncommitted table
Modify the show_fast_schema_quota_view, show_fast_role_quota_view, show_fast_schema_tablespace_quota_view and show_fast_role_tablespace_quota_view. Combine pg_class with relation_cache into all_relation, and join all_relation with diskquota.table_size to calculate quota usage.
Add upgrade and downgrade procedure between diskquota2.0 and diskquota2.1. Add upgrade and downgrade test for diskquota-2.1.
* Fix flaky test (#240)
* Fix flaky test test_ctas_role (#242)
creating table runs too fast to trigger the hard quota limit.
* Support at least 20000 tables for each database (#239)
Currently, diskquota supports max to 8000 tables, including partition tables. It may cause unexpected results if there are too many tables in the customer cluster.
This PR change `init_size` of table_size_map to 20000, instead of MAX_TABLES, so that we can
economize the actual usage of SHM. To handle scenarios with a large number of tables,
we set `max_size` to MAX_TABLES (1000000).
And To avoid memory waste, only the master should be allocated shared memory for diskquota_launcher and diskquota_worker.
* Reduce MAX_TABLES to 200K. (#243)
The scale of 50 databases with 200K tables is large enough, so we
reduce MAX_TABLES to 200K to avoid memory waste.
* Fix test_rejectmap flaky test (#246)
Why the test case can run successfully before, but sometimes fails?
Because it adds the reject entry after starting inserting data into the
table. If the inserting has hang up on `check_rejectmap_by_relfilenode`
and then adding the reject entry, hardlimit will be triggered. Otherwise,
softlimit will be triggered.
* Add SECURITY.md
* Add SECURITY.md (#249)
* Rewrite the diskquota worker scheduler (#245)
Rewrite the diskquota worker scheduler. Each DB entry manages the
running time by itself to make the scheduler more simple.
I have tested the performance, nearly the same as before.
Add a UDF db_status to help debug or monitor the diskquota, related
SQL is in test_util.sql. I didn't put it into diskquota--2.1.sql, because I
don't want users to use it now. I didn't use any shared lock when getting
that status info, so they may be not consistent.
Co-authored-by: Xing Guo <higuoxing+github@gmail.com>
Co-authored-by: Zhang Hao <hzhang2@vmware.com>
* Remove PR pipeline base branch (#252)
So all PRs can trigger build.
* Fix bug: relation_cache cannot isolate table info for each database (#241)
Previously, users will see the information of tables in db2 when accessing db1 and executing select diskquota.show_relation_cache(). Meanwhile, if db1's bgworker can see the table in db2, the performance will be influenced, because the table size in db2 will be calculated although it is not useful for db1 diskquota.
This PR has added a judgment to prevent this situation.
* Fix flaky test (#250)
When diskquota is in dynamic mode, it may take a long time to start a worker for a database (because the worker is busy), so some tests will fail after pg_sleep.
Add the diskquota_test extension to resolve the issue. In it, there is a UDF diskquota_test.wait(SQL test), which we can run by passing any SQL whose select result is true or false to it, it runs the SQL and waits for the selection result to be true at most 10 seconds. diskquota_test.db_status will return all the databases which are monitored by diskquota and their status and epoch. diskquota_test.cur_db_status() and diskquota_test.db_status() are just wrappers of it, which are more useful in the tests.
In the regress tests, replace the sleep with diskquota_test.wait or diskquota.wait_for_worker_new_epoch().
What's more, I have extracted the monitored_dbid_cache related data and functions into the monitored_db.c file.
Disable the regress test test_init_table_size_table, there is a bug making it fail, I will fix it in another pr.
* Filter the useless relation type. (#254)
Co-authored-by: Xiaoran Wang <wxiaoran@vmware.com>
* Fix worker time out and diskquota.max_workers (#255)
* Fix flaky "database not found" (#256)
* Change the max value of diskquota.max_workers to 20 (#257)
* Change the max value of diskquota.max_workers to 20
If we set the diskquota.max_workers max value to be
max_worker_processes, when max_worker_processes is less than 10 and we
set diskquota.max_workers value more than max_worker_processes, the
cluster will crash.
Set the max value to be 20, when the max_worker_processes is less than the
diskquota.max_workers, diskquota can work, only some parts of the
databases can not be monitored as diskquota can not start bgworkers for
them.
* Modify diskquota worker schedule test
Test when diskquota.max_workers more than available bgworker.
Co-authored-by: Zhang Hao <hzhang2@vmware.com>
* Revert change of worker_schedule test becuase flaky test (#260)
* Missing pause causes deadlock flaky (#258)
* Fix memory leak when database is not ready (#262)
Co-authored-by: Zhang Hao <hzhang2@vmware.com>
* Change the default value of GUC to reduce default memory cost. (#266)
Change the default vaule of `diskquota.max_active_tables` from 1M
to 300K, the memory usage relevant it is reduced from 300MB to 90MB.
* Refactor TableSizeEntry to reduce memory usage. (#264)
Refactor the structure of TableSizeEntry to reduce memory usage.
Previously, the size of each table in each segment should be maintained in TableSizeEntry, which wastes lots of memory. In this PR, we refactor the TableSizeEntry to:
struct TableSizeEntry
{
Oid reloid;
int segid;
Oid tablespaceoid;
Oid namespaceoid;
Oid owneroid;
uint32 flag;
int64 totalsize[SEGMENT_SIZE_ARRAY_LENGTH];
};
In this way, we can maintain multiple sizes in one TableSizeEntry and efficiently save memory usage.
For 50 segments: reduced by 65%.
For 100 segments: reduced by 82.5%.
For 101 segments: reduced by 65.3%.
For 1000 segments: reduced by 82.5%.
* Correct table_size_entry key (#268)
There is a bug: removing TableSizeEntry from table_size_map by oid.
Actually, the hash map key is TableKeyEntry. Fix it.
* Add cmake opt DISKQUOTA_DDL_CHANGE_CHECK (#270)
* Fix regression caused by #264 (#272)
The #264 caused some segment ratio tests fail. The entry's relevant
fields need to be set at the end of the iteration. Otherwise, only the
first seg will pass the condition check.
* Add a GUC `diskquota.max_table_segments`. (#271)
Use diskquota.max_table_segments to define the max number of table segments in
the cluster. The value equal (segment_number + 1) * max_table_number.
Since hashmap in the shared memory can take over others' memory space
even when it exceeds the limit, a counter is added to count how many tables
have been added to the table_size_map, to prevent too many entries to be
created.
Co-authored-by: Xiaoran Wang <wxiaoran@vmware.com>
Co-authored-by: Chen Mulong <chenmulong@gmail.com>
* Enable tests (#274)
* Optimize dispatching reject map to segments (#275)
Avoid dispatching reject map to segments when it is not changed
* Fix bug: rejectmap entries should not be removed by other databases. (#279)
This commit fixed two bugs:
- Previously, refresh_rejectmap() cleared all entries in rejectmap, including other databases' entries, which causes hardlimit can not to work correctly.
- soft-limit rejectmap entries should not be added into disk_quota_reject_map on segments, otherwise, these entries may remain in segments and trigger the soft-limit incorrectly.
Co-authored-by: Chen Mulong <chenmulong@gmail.com>
* Fix diskquota worker schedule bug (#280)
When a database's diskquota bgworker is killed and the db is dropped,
diskquota scheduler can not work properly. The cause is: if the scheduler
failed to start a bgworker for a database, it will try it again and
again forever.
A different status code is returned when failing to start bg worker. And if it is
failed due to the dropped database (or another other reasons causes
db name cannot be retrieved from db id), just skip this bgwoker for now
For other failure reasons, limit the times of starting a bgworker for a database
to 3 times. If the limit is reached, skip it and pick the next one.
* Bump version to 2.1.1 (#283)
* Fix flaky test_fast_quota_view (#282)
- Drop the table space before rm directory.
- '-f' to alway force rm.
- '-- start-ignore' doesn't seem to be working with retcode since retcode
will add '-- start/stop-ignore' pair automatically to ignore the
output, and the nested start/stop ignore doesn't seem to be handled
well by the ancient perl script. Refer to
'src/test/isolation2/sql_isolation_testcase.py'.
Seen flaky tests as below:
root@96831b9f-9150-4424-63a7-abe8f18c144e:/tmp# cat /home/gpadmin/diskquota_artifacts/tests/isolation2/regression.diffs
--- \/tmp\/build\/4eceba44\/bin_diskquota\/tests\/isolation2\/expected\/test_fast_quota_view\.out 2022-12-12 13:20:56.729354016 +0000
+++ \/tmp\/build\/4eceba44\/bin_diskquota\/tests\/isolation2\/results\/test_fast_quota_view\.out 2022-12-12 13:20:56.733354401 +0000
@@ -175,9 +175,11 @@
(exited with code 0)
!\retcode rm -r /tmp/spc2;
GP_IGNORE:-- start_ignore
+GP_IGNORE:rm: cannot remove '/tmp/spc2/6/GPDB_6_301908232/16384/16413': No such file or directory
+GP_IGNORE:rm: cannot remove '/tmp/spc2/5/GPDB_6_301908232/16384/16413': No such file or directory
GP_IGNORE:
GP_IGNORE:-- end_ignore
-(exited with code 0)
+(exited with code 1)
-- end_ignore
DROP TABLESPACE IF EXISTS spc1;
DROP
* Fix flaky isolation2 test. (#281)
Currently, isolation2/test_rejectmap.sql is flaky if we run isolation2
test multiple times. That's because we set the GUC
'diskquota.hard_limit' to 'on' in test_postmaster_restart.sql and forget
to set it to 'off'. In the next following runs, the hard limit is
enabled and the QD will continuously dispatch reject map to segment
servers. However, test_rejectmap.sql requires the hard limit being
disabled because we're dispatching rejectmap by UDF manually or the
dispatched rejectmap will be cleared by QD.
This patch adds a new injection point to prevent QD from dispatching
rejectmap to make test_rejectmap.sql stateless. This patch also set
'diskquota.hard_limit' to 'off' when test_postmaster_restart.sql
finishes.
* Fix compilation to support gpdb7 (#285)
* Fix diskquota on gpdb7
- Fix some compile issues, especially relstorage has been removed
on gpdb7. Using relam to get the relation's storage type.
- Modify diskquota hash function flag.
- Fix diskquota_relation_open(). NoLock is disabled on gpdb7.
- Add tests schedule and expected results for gpdb7.
- Update some test expectations on gpdb7 due to AO/CO issue: As
something changes about AO/CO table, the size of them is changed.
- Disable some tests on gpdb7.
- Disable upgrade tests.
- Upgrade to diskquota 2.2. Add attribute relam to type
relation_cache_detail and add a param to function relation_size_local.
- Add setup.sql and setup.out for isolation2 test.
- Fix bug: gpstart timeout for gpdb7. We used to set
`Gp_role = GP_ROLE_DISPATCH` in disk_quota_launcher_main(), even
though postmaster boots in utility mode. This seems to be nothing
in gpdb6, but it will cause a dead loop when booting gpdb7. In fact,
there is nothing to do in utility mode for the diskquota launcher. In
this commit, if `Gp_role != GP_ROLE_DISPATCH`,
disk_quota_launcher_main() will simply exit.
- Add gpdb7 pipeline support. Build gpdb7 by rocky8, and test the
same build with rocky8 and rhel8. 'res_test_images' has been changed
to list to support this.
- Add gpdb version into the task name. 'passwd' is unnecessary and '
doesn't exist in the rocky8 build image.
- Use `cmake -DENABLE_UPGRADE_TEST=OFF` to disable the upgrade test.
- TODO: Add upgrade test to CI pipeline. Fix activate standby error on the
CI pipeline. Fix tests for gpdb7.
Co-authored-by: Xiaoran Wang <wxiaoran@vmware.com>
Co-authored-by: Xing Guo <higuoxing@gmail.com>
* Fix released tarball name. (#286)
Co-authored-by: Hao Zhang <hzhang2@vmware.com>
* Add an option to control whether compile with fault injector. (#287)
Usage:
```
cmake -DDISKQUOTA_FAULT_INJECTOR=ON/OFF [default: OFF]
```
Co-authored-by: Hao Zhang <hzhang2@vmware.com>
* Add judgement for fault injector. (#288)
If fault injector is disabled, isolation2 will be disabled.
* Revert "Add judgement for fault injector. (#288)" (#291)
This reverts commit e3e73d2dd24ef0878a6a41b8734e340f5fb7a96a.
Revert "Add an option to control whether compile with fault injector. (#287)"
This reverts commit ae4ab48c97c5e77ecf25bee3ebf58ccd1244429f.
Co-authored-by: Hao Zhang <hzhang2@vmware.com>
* CI: Fix pipeline (#293)
- Switch GPDB binary to release-candidate for release build.
- Remove test_task from the release pipeline.
Co-authored-by: Xing Guo <higuoxing@gmail.com>
* Format code by clang-format. (#296)
* Add command to compile isolation2. (#297)
Isolation2 compilation command is removed by #285. We add it into
Regress.cmake in this commit.
Co-authored-by: Xing Guo higuoxing@gmail.com
* Fix flaky test (#294)
- Fix flaky test test_ctas_before_set_quota. pg_type will be an active table
after `CREATE TABLE`. It does not affect the function of diskquota but
makes the test results unstable. In fact, we do not care about the table
size of the system catalog table. So we simply skip the active table oid
of these tables.
- Fix test_vacuum/test_truncate. gp_wait_until_triggered_fault
should be called after gp_inject_fault_infinite with suspend flag.
Co-authored-by: Xing Guo <higuoxing@gmail.com>
Co-authored-by: Xiaoran Wang <wxiaoran@vmware.com>
* Fix flaky test test_rejectmap_mul_db (#295)
When creating a new table, pg_type will be in active tables.
Filter the system catalog table. And remove pause in the test.
* Fix bug (#298)
Fix the following bugs:
- Judgement condition for update_relation_cache should be `&&`, instead of `||`
- The lock for relation_open/relation_close should be AccessShareLock for gpdb7.
- For `truncate table`, we cannot get the table's oid by new relfilenode
immediately after `file_create_hook` is finished. So we should keep
the relfilenode in active_table_file_map and wait for the next loop to
calculate the correct size for this table.
* Enable upgrade test for CI (#299)
Revert some modification from #285.
- Add last_released_diskquota_bin back for CI.
- Enable upgradecheck.
- Add -DDISKQUOTA_LAST_RELEASE_PATH for cmake.
* Skip fault injector case for release build (#302)
Due to the release build change for GP7, the fault injector doesn't work
with the release build. So, all the tests were temporally disabled for
release pipelines.
Since we switched to use the `--disable-debug-extensions` gpdb build, the
fault injector is not available for the release pipeline.
- Add 'EXCLUDE_FAULT_INJECT_TEST' to Regress.cmake, so it will be smart
enough to check if there are any fault injector case in the give tests
set. Ignore them if so.
- Skip the fault injector tests for the release pipeline.
- Enable the CI test task for GP7.
* VAR replace for Regress.cmake and fix test_rejectmap (#304)
Since GP7 doesn't support plpythonu, the test_rejectmap was broken for
GP7. This commit:
- Improve the Regress.cmake, so if the input sql file has a "in.sql"
extension, "@VAR@" in it will be replaced by the corresponding cmake
VAR.
- SQL_DIR/EXPECTED_DIR takes list as the argument now. So only the
different cases need to be put into the expected7. Others will be used
from expected directly.
- Due to above change, same tests for gp6 and gp7 are removed from
gp7, only diff is needed.
- Set different @PLPYTHON_LANG_STR@ for GP6 & GP7
- Due to plpython composite type behavior change, the python code in
the test has been modified. The behavior change is probably related
to PG commit 94aceed317.
* Fix update test failures caused by segid diff (#305)
Due the GPDB change b80e969844, upgrade_test failed because the segid
in the view dump is surrounded by quotes.
Expected failure diff:
-WHERE (table_size.segid = (-1)))) AS dbsize;
+WHERE (table_size.segid = '-1'::integer))) AS dbsize;
* Replace relation_open/relation_close with RelationIdGetRelation/RelationClose. (#300)
This PR replaces relation_open()/relation_close() with RelationIdGetRelation()/RelationClose() to avoid deadlock. We can only call relation_open() with AccessSharedLock in object_access_hook(OAT_POST_CREATE) in GPDB7, which may cause deadlock. While RelationIdGetRelation()/RelationClose() just locks pg_class instead of user-defined relation, so we use these functions to get the information of relations.
* Fix flaky test of test_rejectmap_mul_db (#301)
Add back the pause in the test, to avoid the changes of active table.
* Fix test_primary_failure test case (#303)
* subprocess.check_output of python3, needs encoding
* Add @PLPYTHON_LANG_STR@ in the test_primary_failure.in.sql
* Move files to src and control dirs. (#307)
- Move .c and .h files to src dir.
- Move diskquota ddl file to control/ddl dir.
- Move diskquota_test--1.0.sql file to control/test dir.
* Fix gpdb release binary regex (#311)
The release candidate contains the build number now. Change the regex to
match the latest release candidate for release pipeline.
* Enable test_postmaster_restart (#309)
The isolation2 test `test_postmaster_restart` is disabled because the
postmaster start command is different between GPDB6 and GPDB7. We
should enable this test by passing distinct commands for GPDB6 and
GPDB7 to test_postmaster_restart.sql.
Meanwhile, we can merge isolation2_schedule7 and isolation2_schedule
to one.
* Bump cmake min version to 3.20 (#313)
Fix #312
* Resource change for gpdb7 binary (#315)
"""
NOTICE: resource queue required -- using default resource queue "pg_default"
"""
has been removed in gpdb7 82851a0b85 . Ignore it in the tests.
* Fix bug: bgworker enters infinite loop after receiving notices from QE. (#314)
We should not initialize the MyProcPort in bgworker, which will cause the database name to not be automatically added to the log message. In normal, the log printed from the bgworker does not contain the database name but contains the bgworker's pid. In order to facilitate debugging, we should print the database name every BGWORKER_LOG_TIME to ensure that we can find the database name by the bgworker's pid in the log file.
Co-authored-by: Chen Mulong <cmulong@vmware.com>
* Ignore some hint/notice for GPDB7 (#328)
* fix flaky test: test_appendonly (#327)
* Add dbname to DiskQuotaWorkerEntry (#326)
Previously, we passed dbname by bgw_name to bgworker. But refer to https://github.com/greenplum-db/gpdb/blob/f182228992b62e2023e2fac5b4971406abd35c9d/src/backend/postmaster/bgworker.c#L385-L386, bgw_name is copied by ascii_safe_strlcpy(), which replaces non-ASCII bytes with '?'. If the database name is non-ASCII, the bgworker can not connect to the correct database and raises an error. issue: #323 . To solve this problem, we should pass dbname by bgw_main_arg to the main function of the bgworker.
* Replace SPI_execute with SPI_cursor_fetch (#322)
The result buffer of SPI_execute is limited to 1GB. If the number of rows in diskquota.table_size exceeds 3 * 10^7 (500 segments with 60000 tables for example), SPI_execute("select tableid, size, segid from diskquota.table_size") will raise an error for invalid memory alloc request size 1073741824 (context 'SPI TupTable'). We should fetch table-size entries by portions. Replace SPI_execute() with SPI_cursor_fetch() in load_table_size().
* Split update SQL statement for diskquota.table_size (#325)
Fix issue: #318
If the number of entries needed to be updated in diskquota.table_size is too many, the size of StringBuffer will exceed 1GB and raise an error `Cannot enlarge string buffer containing 1073741807 bytes by 20 more bytes.`.
We should limit the number of entries in the update statement to 1000000 every time to ensure the string buffer size does not exceed 1GB.
* Update cmake version in README. (#331)
* Fix flaky test: test_appendonly (#333)
* Skip refresh_disk_quota_model() when receiving a signal (#321)
When with often signals to receive diskquota may call refresh_disk_quota_model
more frequently than diskquota_naptime.
Solution: when receiving a signal, the time waiting for latch sleep_time will be smaller
than diskquota_naptime. We should skip refresh_disk_quota_model() when
sleep_time < diskquota_naptime.
* Allocate more shared memory to quota_info (#334)
Allocate more SHM to quota_info, so that the user can set more quota
configurations.
* Enable stanby test for 6X_STABLE (#335)
* Bump version to 2.2.1 (#336)
* Use install_gpdb_component in CI test (#337)
So the script can be tested as well.
* Fix compiler warnings. (#339)
Note: `TextDatumGetCString()` returns a null-terminated CString.
```
[ 12%] Building C object CMakeFiles/diskquota.dir/src/diskquota.c.o
In file included from /home/v/workspace/diskquota/src/diskquota.h:16,
from /home/v/workspace/diskquota/src/diskquota.c:18:
/home/v/workspace/diskquota/src/diskquota.c: In function ‘diskquota_status_schema_version’:
/home/v/.local/gpdb7/include/postgresql/server/c.h:957:25: warning: ‘strncpy’ specified bound 64 equals destinatio
n size [-Wstringop-truncation]
957 | strncpy(_dst, (src), _len); \
| ^~~~~~~~~~~~~~~~~~~~~~~~~~
/home/v/workspace/diskquota/src/diskquota.c:1548:9: note: in expansion of macro ‘StrNCpy’
1548 | StrNCpy(version, vv, sizeof(version));
| ^~~~~~~
```
Co-authored-by: Hao Zhang <zhrt1446384557@gmail.com>
* Fix bug: diskquota.status() (#344)
Fix bug produced by #339
Co-authored-by: Xing Guo admin@higuoxing.com
* fix pipeline (#345)
fix pipeline resource
* Reduce the number of the log in bgworker. (#346)
* Fix bug: lose monitored_dbid_cache after switching mirror (#342)
# Problem
Recording active tables and permission checking on segments rely on `monitored_dbid_cache`. But after mirror switching, the data in shared memory is lost, and the above behaviors will be blocked.
# Solution
Segments update their `monitored_dbid_cache` after receiving pull_active_tables_oid requests every naptime.
* Enable continuous upgrade. (#340)
To achieve upgrading directly from 2.0 to 2.2, we should do the following things:
- cherry-pick this PR in diskquota-2.0, diskquota-2.1 and diskquota-2.2.
- set the shared_preload_libraries as `diskquota-2.2`: `gpconfig -c shared_preload_libraries -v 'diskquota-2.2'`
- restart cluster: `gpstop -ar`
- execute the following SQLs:
```
ALTER extension diskquota update to '2.2';
```
* Fix pipeline. (#349)
Get the latest package version for release resource.
* Fix upgrade version check (#347)
- Because of 2a73847f1a, the sql file directory has been changed. The
sql version check wouldn't work since it cannot find the sql files
anymore. Change it to the correct ddl directory.
- 'exec_program' is deprecated, use 'execute_process' instead.
- 'git tag | sort' returns the latest version among all branches, but
not the closest tag to the current commit. Use 'git describe --tags'
instead. So the upgrade version check will work for the 2.1.x patch
release.
* Remove gp7 from pipeline (#350)
After creating extension, the `diskquota.state` is always `unready` due to the change https://github.com/greenplum-db/gpdb/pull/15239. It makes the test timeout. We disable the job of gp7 in release/pr/merge pipeline un…
…full (#112) * Fix bug The relation_cache_entry of temporary table, created during vacuum full, is not be removed after vacuum full. This table will be treated as an uncommitted table, although it has been dropped after vacuum full. And its table size still remains in diskquota.table_size, which causes quota size to be larger than real status. Use RelidByRelfilenode() to check whether the table is committed, and remove its relation_cache_entry. Co-authored-by: hzhang2 <hzhang2@vmware.com> Co-authored-by: Xing Guo <higuoxing+github@gmail.com> Co-authored-by: Xuebin Su (苏学斌) <sxuebin@vmware.com>
…full (apache#112) * Fix bug The relation_cache_entry of temporary table, created during vacuum full, is not be removed after vacuum full. This table will be treated as an uncommitted table, although it has been dropped after vacuum full. And its table size still remains in diskquota.table_size, which causes quota size to be larger than real status. Use RelidByRelfilenode() to check whether the table is committed, and remove its relation_cache_entry. Co-authored-by: hzhang2 <hzhang2@vmware.com> Co-authored-by: Xing Guo <higuoxing+github@gmail.com> Co-authored-by: Xuebin Su (苏学斌) <sxuebin@vmware.com>
…full (apache#112) * Fix bug The relation_cache_entry of temporary table, created during vacuum full, is not be removed after vacuum full. This table will be treated as an uncommitted table, although it has been dropped after vacuum full. And its table size still remains in diskquota.table_size, which causes quota size to be larger than real status. Use RelidByRelfilenode() to check whether the table is committed, and remove its relation_cache_entry. Co-authored-by: hzhang2 <hzhang2@vmware.com> Co-authored-by: Xing Guo <higuoxing+github@gmail.com> Co-authored-by: Xuebin Su (苏学斌) <sxuebin@vmware.com>
* Print the diff files when the tests failed. (#109)
* Fix flaky test cases. NFC. (#110)
* Fix bug: table's relation_cache_entry is not be removed after vacuum full (#112)
* Fix bug
The relation_cache_entry of temporary table, created during vacuum full, is not be removed after vacuum full. This table will be treated as an uncommitted table, although it has been dropped after vacuum full. And its table size still remains in diskquota.table_size, which causes quota size to be larger than real status.
Use RelidByRelfilenode() to check whether the table is committed, and remove its relation_cache_entry.
Co-authored-by: hzhang2 <hzhang2@vmware.com>
Co-authored-by: Xing Guo <higuoxing+github@gmail.com>
Co-authored-by: Xuebin Su (苏学斌) <sxuebin@vmware.com>
* Fix test case bug (#114)
The SQL statement is not equal to the expected output in test_vacuum.sql.
Co-authored-by: hzhang2 <hzhang2@vmware.com>
* Fix bug: can not calculate the size of pg_aoblkdir_xxxx before `create index on ao_table` is committed (#113)
We can not calculate the size of pg_aoblkdir_xxxx before `create index on ao_table` is committed.
1. Lack of the ability to parse the name of pg_aoblkdir_xxxx.
2. pg_aoblkdir_xxxx is created by `create index on ao_table`, which can not be searched by diskquota_get_appendonly_aux_oid_list() before index's creation.
Solution:
1. parse the name begin with `pg_aoblkdir`.
2. When blkdirrelid is missing, we try to fetch it by traversing relation_cache.
Co-authored-by: hzhang2 <hzhang2@vmware.com>
Co-authored-by: Xing Guo <higuoxing+github@gmail.com>
Co-authored-by: Xuebin Su (苏学斌) <sxuebin@vmware.com>
* Add UDF to show worker status (#111)
Co-authored-by: Xuebin Su (苏学斌) <12034000+xuebinsu@users.noreply.github.com>
Co-authored-by: Xing Guo <higuoxing@gmail.com>
Co-authored-by: Hao Zhang <hzhang2@vmware.com>
* Wait until deleted tuples are dead before VACUUM (#118)
Consider a user session that does a DELETE followed by a VACUUM FULL to
reclaim the disk space. If, at the same time, the bgworker loads config
by doing a SELECT, and the SELECT begins before the DELETE ends, while ends
after the VACUUM FULL begins:
bgw: ---------[ SELECT ]----------->
usr: ---[ DELETE ]-[ VACUUM FULL ]-->
then the tuples deleted will be marked as RECENTLY_DEAD instead of DEAD.
As a result, the deleted tuples cannot be removed by VACUUM FULL.
The fix lets the user session wait for the bgworker to finish the current
SELECT before starting VACUUM FULL .
* Make altered relation's oid active when performing 'VACUUM FULL'. (#116)
When doing VACUUM FULL, The table size may not be updated if
the table's oid is pulled before its relfilenode is swapped.
This fix keeps the table's oid in the shared memory if the table
is being altered, i.e., is locked in ACCESS EXCLUSIVE mode.
Co-authored-by: Xuebin Su <sxuebin@vmware.com>
* Refactor pause() to skip refreshing quota (#119)
Currently, diskquota.pause() only takes effect on quota checking.
Bgworkers still go over the loop to refreshing quota even if diskquota
is paused. This wastes computation resources and can cause flaky issues.
This fix makes bgworkers skip refreshing quota when the user pauses
diskquota entirely to avoid those issues. Table sizes can be updated
correctly after resume.
* ci: create rhel8 release build. (#117)
ci: create rhel8 release build.
Signed-off-by: Sasasu <i@sasa.su>
Co-authored-by: Xuebin Su <sxuebin@vmware.com>
* set the scope of pause() to current database
* cleanup header include
* re-dispatch pause status
* allow to re-create extension
* use atomic on flag hardlimit_lock (#124)
* send a error if launcher crashed (#124)
* Pause before DROP EXTENSION (#121)
Currently, deadlock can occur when
1. A user session is doing DROP EXTENSION, and
2. A bgworker is loading quota configs using SPI.
This patch fixes the issue by pausing diskquota before DROP
EXTENSION so that the bgworker will not load config anymore.
Note that this cannot be done using object_access_hook() because
the extension object is dropped AFTER dropping all tables that belong
to the extension.
* add test case for pause hardlimit (#128)
* Attempt to fix flaky test_primary_failure (#132)
Test case test_primary_failure will stop/start segment to produce a
mirror switch. But the segment start could fail while replaying xlog.
The failure was caused by the deleted tablespace directories in previous
test cases.
This commit removes the "rm" statement in those tablespace test cases and
add "-p" to the "mkdir" command line. The corresponding sub-directories
will be deleted by "DROP TABLESPACE" if the case passes.
Relevant logs:
2022-02-08 10:09:30.458183 CST,,,p1182584,th1235613568,,,,0,,,seg1,,,,,"LOG","00000","entering standby mode",,,,,,,0,,"xlog.c",6537,
2022-02-08 10:09:30.458670 CST,,,p1182584,th1235613568,,,,0,,,seg1,,,,,"LOG","00000","redo starts at E/24638A28",,,,,,,0,,"xlog.c",7153,
2022-02-08 10:09:30.468323 CST,"cc","postgres",p1182588,th1235613568,"[local]",,2022-02-08 10:09:30 CST,0,,,seg1,,,,,"FATAL","57P03","the database system is starting up"
,"last replayed record at E/2481EA70",,,,,,0,,"postmaster.c",2552,
2022-02-08 10:09:30.484792 CST,,,p1182584,th1235613568,,,,0,,,seg1,,,,,"FATAL","58P01","directory ""/tmp/test_spc"" does not exist",,"Create this directory for the table
space before restarting the server.",,,"xlog redo create tablespace: 2590660 ""/tmp/test_spc""",,0,,"tablespace.c",749,
* ereportif uses the 1st param as the condition (#131)
Otherwise, compiler reports a warning:
"comparison of constant ‘20’ with boolean expression is always false"
* add diskquota.status() to show if hardlimit or softlimit enabled or not
* ci: fix flaky test
* Add timeout when waiting for workers (#130)
Each time the state of Diskquota is changed, we need to wait for the
change to take effect using diskquota.wait_for_worker_new_epoch().
However, when the bgworker is not alive, such wait can last forever.
This patch fixes the issue by adding a timeout GUC so that wait() will
throw an NOTICE if it times out, making it more user-friendly.
To fix a race condition when CREATE EXTENSION, the user needs to
SELECT wait_for_worker_new_epoch() manually before writing data.
This is to wait until the current database is added to the monitored
db cache so that active tables in the current database can be
recorded.
This patch also fix test script for activating standby and rename
some of the cases to make them more clear.
* Add git commit message template (#141)
The template is copied from
https://gist.github.com/lisawolderiksen/a7b99d94c92c6671181611be1641c733
* Use guc for hardlimit (#142)
- Change to use GUC to set hardlimit instead of UDF. Since the hardlimit
setting needs to be persistent after postmaster restarting.
- Fix relevant test cases.
* be nice with scheduler when naptime = 0 (#120)
* Create worker entry before starting worker (#144)
Currently, the Diskquota launcher first starts a worker, then creates
the worker entry. However, after the worker starts, it cannot find the
entry when trying to check the is_paused status. Also, after a GPDB
restart, when the QD checks whether the worker is running by
checking the epoch, it might also fail to find the entry.
This patch fixes the issue by first create the worker entry then
starting the bgworker process.
* Extend fetch_table_stat() to update db cache (#138)
The db cache stores which databases enables diskquota. Active tables
will be recorded only if they are in those databases. Previously,
we created a new UDF update_diskquota_db_list() to add the current db
to the cache. However, the UDF is install in a wrong database. As a
result, after the user upgrade from a previous version to 1.0.3, the
bgworker does not find the UDF and can do nothing.
This patch fixes the issue by removing update_diskquota_db_list() and
using fetch_table_stat() to update db cache. fetch_table_stat() already
exists since version 1.0.0 so that no new UDF is needed.
This PR is to replace PR #99 , and depends on PR #130 to fix a race
condition that occurs after CREATE EXTENSION.
* Use ytt to create pipelines (#143)
- Rewrite the pipelines by using ytt for code reuse.
- Add `fly.sh` for easier manipulating with pipelines.
- Create configs for pr, commit and dev pipelines.
- Fix the test task for rhel8.
- Use build/test images pair for all distros. And modify the
`build_diskquota.sh` so it won't need `Python.h` during the configure
stage.
- Fix the pipiline bug which a `ubuntu` test may use a `rhel6` diskquota
binary to do the test. That is caused by the same name of the task
output.
* Specify DISTRIBUTED BY when CREATE TABLE (#146)
When the distribution policy is not specified explicitly, ORCA
distributes data randomly when CREATE TABLE. This can make the
size of the tables created different from time to time.
This patch fixes the issue by adding DISTRIBUTED BY for each
CREATE TABLE to avoid random distribution.
* Simplify the build script (#148)
No need to have the switch case.
* Revert greenplum-db/diskquota#138 (#150)
Revert "Extend fetch_table_stat() to update db cache (#138)"
This reverts commit 9457fa52f1df6d1715041c551fb5eab3cb0fb0b3.
* Add clang-format and editorconfig (#136)
- clang-format is from https://groups.google.com/a/greenplum.org/g/gpdb-dev/c/rHb4DjSd1iI/m/FKPbqwYcBAAJ
- See editorconfig at https://editorconfig.org/
* Extend fetch_table_stat() to update db cache v2 (#151)
The db cache stores which databases enables diskquota. Active tables
will be recorded only if they are in those databases. Previously,
we created a new UDF update_diskquota_db_list() to add the current db
to the cache. However, the UDF is install in a wrong database. As a
result, after the user upgrade from a previous version to 1.0.3, the
bgworker does not find the UDF and can do nothing.
This patch fixes the issue by removing update_diskquota_db_list() and
using fetch_table_stat() to update db cache. fetch_table_stat() already
exists since version 1.0.0 so that no new UDF is needed.
This PR is a revision of PR #138 , and depends on #130 to fix a race
condition that occurs after CREATE EXTENSION.
Co-authored-by: Chen Mulong <chenmulong@gmail.com>
* Wait after CREATE EXTENSION (#152)
Each time after CREATE EXTENSION, we need to wait until the db cache
gets updated. Otherwise no active table will be recorded.
* Run tests on all platforms for PR pipeline (#153)
Try to catch more flaky tests from the beginning.
Co-authored-by: Chen Mulong <cmulong@vmware.com>
Co-authored-by: Xuebin Su (苏学斌) <12034000+xuebinsu@users.noreply.github.com>
* Reset naptime when test finish (#147)
Add tear_down to regress and isolation2 tests to reset the naptime. When
naptime is 0, quite a lot of cpu will be used. It will be a problem if
there are failing jobs on CI before getting reaped by the concourse. The
concourse worker CPU will be occupied which may impact following tests.
* Fix flaky test case in isolation2/test_relation_size.sql (#123)
* Set PR pending status when start (#157)
Also fixed a syntax issue in pr.yml
* Update CI README for PR trigger issue (#156)
* Make diskquota work for "pg_default" tablespace (#133)
* Make diskquota work for "pg_default" tablespace (#133)
Tracker story ID: #180688138.
Setting role_tablespace quota in "pg_default" using
`set_role_tablespace_quota` doesn't work. Due to a hack
(src/backend/catalog/heap.c) in GPDB, the `reltablespace` of relations
in "pg_default" is `InvalidOid`. When we refresh blackmap we use
`DEFAULTTABLESPACE_OID` instead for those invalid tablespace, this
results in a mismatch. This patch solves the problem by updating tablespace
oid to the real tablespace oid (`MyDatabaseTableSpace`) when reading
from syscache.
Besides, with the hard limits on, we also need to update the tablespace
oid to the real one.
Co-authored-by: Xuebin Su <sxuebin@vmware.com>
Co-authored-by: Sasasu <i@sasa.su>
* build: use cmake as build system (#161)
* rename library file to diskquota-<major.minor>.so (#162)
rename library file to diskquota-<major.minor>.so, this will break
the old gpconfig -v shared_preload_libraries command, please note.
centos6 and centos7 only have cmake 2.8.12, use cmake 2.8.10 as the
minimum version.
use PG_HOME and remove the workaround.
use cpack to create the installer.
clean up SQL define.
* Keep the 1.0 sql the same with 1.x branch (#163)
The added 'DISTRIBUTED BY' clause should have no impact on 1.x.
* Test when table is created before quota is set (#129)
* Test when table is created before quota is set
This patch adds test cases to ensure that diskquota works when table
is created before quota is set. Specifically,
- When diskquota is preloaded, quota usage is updated automatically
for each active table. Therefore, quotas work once they are set and no
more action is required from the user.
- When diskquota is NOT preloaded, no active tables will be recorded.
As a result, when diskquota is preloaded again, the user need to
SELECT diskquota.init_table_size_table(); and restarts GPDB manually
in order to update the quota usage.
This patch also fixes some minor issues in the existing cases.
* Replace wait() with sleep()
* Install the latest cmake on CI (#165)
We need the archive extract feature from cmake 3.18.
Before the new version landing on the test/build images, install them in
our ci scripts.
A cmake binary has been uploaded to the concourse gcs for faster
downloading.
* dump cmake version to 3.18
* fix case test_ctas_no_preload_lib
* Cache CMAKE_INSTALL_PREFIX (#171)
CMAKE_INSTALL_PREFIX needs to be set as CACHE FORCE. Otherwise, next
time call 'make install' without source greenplum_path.sh, it will be
reset to '/usr/local'
See the example of CMAKE_INSTALL_PREFIX_INITIALIZED_TO_DEFAULT
https://cmake.org/cmake/help/latest/variable/CMAKE_INSTALL_PREFIX_INITIALIZED_TO_DEFAULT.html
* Fix empty quota view when no table (#167)
Currently, quota views are implemented using INNER JOIN. As a result,
when there is no table belong to a role, schema, or tablespace, the
quota view is empty even though there is a quota config defined for
that role, schema, or tablespace.
This patch fixes this by re-implementing quota views using OUTER JOIN.
Plus, the implementation also uses CTEs for modularizing big queries
and aggregation pushdown.
* mc/cmake installcheck (#169)
CMake installcheck:
- Regress.cmake is introduced to add some helper functions which can
easily create regress/isolation2 test targets in the CMakeLists.
- When creating regress targets, cmake will generate a series of
diff_<target>_<test> target to show result diff on a specific target.
- Porting the isolation2_regress build from Makefile to cmake.
- Moved the magic trap regress diff from the concourse script to cmake.
If the test target is called with env `SHOW_REGRESS_DIFF=1`, then the
regress.diff will be printed when the case fails.
- 'sql'/`expected` will be linked to the cmake binary directory and run
test from there. So the `results` won't pollute the source directory.
Concourse scripts restructure:
This commit also try to explore the way how the concourse scripts
are structured. Currently, the container is started with root user, and
this cannot be changed in a short time. But we require gpadmin user
basically for everything.
An `entry.sh` is introduced as a simple skeleton for the scripts. It
make sure a gpadmin user is created and everything needed can be
accessed by the gpadmin with a permanent path. So we don't have too much
ENV magic in the task script any more. Most of the setup work should be
done in the `entry.sh` and the task script should only do a few simple
steps with absolute paths.
By doing this, when we hijack to the concourse container, login with
gpadmin user, the environment should be ready. Simple copy & paste from
the task script will just work.
`upgrade_extension.sh` may not be needed anymore, and it won't work. It
will be cleaned up later when we have the full implementation of
upgrade.
* Dispatch only once for all tables when init() (#107)
Add UDF to accelerate init_table_size_table(). In this UDF:
we traverse pg_class to calculate the relation size of each relation;
parse the auxiliary table's name to get the relevant primary table's oid;
add the size of the auxiliary table to the primary table's size.
It can avoid multiple relation_open() and dispatching pg_table_size().
Co-authored-by: Xuebin Su <sxuebin@vmware.com>
* Pack the last released so in the pipeline (#172)
* Pack the last released so in the pipeline
Due to our upgrade design, the newly released diskquota should contain
all the so file of every latest minor release. The packaging system has
been implemented by cmake DISKQUOTA_PREVIOUS_INSTALLER.
This commit get the latest release through gcs regexp and pass it to the
build script.
The pipeline has been split into different jobs based on the OS type
because of:
- Easier to use the common resource name for build_diskquota.yml
- job_def.lib.yml becomes shorter
- Can span jobs into different concourse workers, which may bring some
better performance.
- Running a flaky test again is easier.
Also, a gate job has been added which is the main entrance for all
pipelines. In the future, we may want to have different gate jobs for
different pipelines, like a clang-format checking gate for the PR
pipeline.
* add upgrade and downgrade test (#166)
* Fix gcc warning (#175)
Reported by gcc 11.2.0:
quotamodel.c:2115:25: warning: ‘strncpy’ output truncated before
terminating nul copying 10 bytes from a string of the same length
[-Wstringop-truncation]
2115 | strncpy(targettype_str, "ROLE_QUOTA", 10);
| ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* Remove Makefiles (#174)
Everything has been moved to cmake.
* cmake: also link RESULTS_DIR to working dir
* show current binary and schema version
* Upload every build to GCS and add build-info (#177)
- Upload every build to GCS
- BuildInfo_create cmake function to print some cmake vars into a
build-info file which can be packaged. We avoid to use `cmake -LAH`
here since that misses some important local cmake vars and most of the
cmake cached var are not cared by us.
- Output some info to diskquota-build-info and it will be packaged by
cpack.
- Match the whole GP_VERSION from pg_config.h in Gpdb.cmake
- Modify editorconfig to use 2 spaces for cmake.
- Add Git.cmake to retrieve information from a git repository.
* Use cmake way to add C macro defines (#178)
Otherwise it creates noise with LSP since the '-Dxxxx' is started with a
'\n\t'. And that cannot be parsed by ccls.
* ci: speed up the test
* Small tuning on logs (#154)
- Add logs when launcher/bgworker terminates
- Add missing information to the logs.
* Update gitignore (#180)
- The build objects should always exist in build* directories now.
- Add ignore pattern for idea, LSP and dinosaur developpers.
* Add test cases for postmaster restart (#135)
- When postmaster dies, the launcher and workers should be terminated.
- When postmaster restarts, they should be restarted as well.
- Move common ignored patterns to the top init file.
* Fix memory leak when refresh_blackmap() (#182)
The ever growing part of memory contains the following pattern:
refresh_blackmap.*<segment_name><ip_address>:<port> pid=<pid>
The pattern contains info of segments. This indicates that the results
of dispatching refresh_blackmap() might not be freed properly.
* Format the code and add clang-format to PR pipeline (#183)
- Use clang 13 to format the code
- Rename the job 'gate' to 'entrance', prepare to add 'exit' job
- Add clang-format as an entrance check into the PR pipeline
* remove the in-logic version check.
After https://github.com/greenplum-db/diskquota/pull/166, we do not allow one binary running on two
or more DLL which have different version. By the new method, we will block worker enter normal
status if the DDL version is not match.
NOTE: launcher don't has the version check, if launcher DDL is modified,
will be undefined behavior.
this commit also remove some mem-alloc by using static const char* in
SQL string.
* ci: add upgrade version naming convention check
* Support release build (#186)
- Introduce macro DISKQUOTA_DEBUG through CMAKE_BUILD_TYPE. For the
debug build, check the macro and allow naptime = 0. The min naptime
for release build is 1 to prevent high cpu usage in user's
environment.
- Add EXCLUDE arg to Regree.cmake to skip some tests for the release
build since the release GPDB build doesn't support fault injector.
- Use GPDB release candidate to compile diskquota release. The release
candidate has assertion disabled in the pg_config.h.
- Set naptime=0 in the config.sql won't take effect for diskquota
release since it is less than the min value. So the naptime stays the
same (normally the default value, 2). This fails some of the test,
especially the hardlimit related ones. If the insertion takes less
time than naptime (2 seconds, normally), it fails since the limitation
has not been dispatched before finish. Thus, the naptime is set to 2
seconds instead of 10 in the reset_config.
* feat: github actions for clang-check ci (#185)
* Feat: use GitHub Actions for clang-check `CI`
* Run same regress test multiple times (#188)
- Add RUN_TIMES to RegressTarget_Add to run the same regress test
multiple times.
- Rename script for consistency.
* slack-alert and PR pipeline fix (#187)
- Add a slack alert when commit pipeline fails
- Add exit job to set successful state. That state cannot be set by
individual job since at that point, the whole pipeline is not finished
yet.
* Don't format errno as '%d' in error messages. (#190)
Actually, errno *isn't* strictly an integer. It depends on your
operating system. Instead of formatting it as an integer, we should
transform it to C style string and format it as '%s'.
* fix context corrupted when dirty data exist in pg_extension
* Fix cmake build on Mac (#191)
- Mac needs extra linker options that the symbols in the postgres
executable can be found.
- Mac's grep doesn't have '-P' option.
- To make a extension so file, we use a 'module' target instead of
'shared' on purpose. Since "A SHARED library may be marked with
the FRAMEWORK target property to create an macOS Framework."
Thus, the global link flags should be set through
CMAKE_MODULE_LINKER_FLAGS than CMAK_SHARED_LINKER_FLAGS.
* Bring tests back on CI (#193)
Some tests were accidentally excluded in Debug build.
* Missing EmitErrorReport before FlushErrorState (#155)
FlushErrorState() will clear the error state. To get the error log in
server logs, EmitErrorReport() needs to be called before flushing. All
other places with FlushErrorState() have the Emit before in the
codebase.
For diskquota bgworker, use `SearchSysCache1`. Because the bgworker
should be error-tolerant to keep it running in the background, we
can't throw an error. If we `EmitErrorReport` in bgworker, then the
results returned by `CdbDispatchCommand` would be incorrect. On the
other hand, the diskquota launcher can throw an error if needed.
Co-authored-by: Chen Mulong <chenmulong@gmail.com>
Co-authored-by: Xuebin Su <sxuebin@vmware.com>
* Insert newline before `else` (#194)
Insert newline before `else` to keep aligned with gpdb repository.
* Add the ytt based release pipeline (#198)
The release pipeline will:
- Automatically make a release build for every commit.
- The final release step needs to be started manually.
- Then the build will be pushed to the release bucket.
- And a tag will be pushed to the repository.
* Use on/off in diskquota.status() (#200)
PostgreSQL uses on/off for all bool variables.
soft limits: on (soft will works) / off (soft limit not works)
hard limits: on (hard will works) / off (hard limit not works)
* Update licenses (#195)
Pivotal became a part of VMware in 2020.
* Use released gpdb instead of release candidate (#201)
By the gcs resource regex rule, 6.99.99 will be matched as the most
recent gpdb release candidate, which is not what we want. It is a
testing version from release team. And due to the go regex
implementation, (!?) is not supported to filter out an exact string.
So the release pipeline is changed to use the most recent published gpdb
binary instead.
Compared with the previous gpdb_bin, the published one has
'--enable-debug-extensions' as the configure parameter. That also enables
the isolation2 tests for us. So no need to disable those tests in release build
anymore.
* Fix tablespace per segment ratio (#199)
If one tablespace segratio is configured,
this commit will make sure that ethier
the already existed (schema/role)_tablespace_quota
or new configs after this, will have the
same segratio.
1) Add a new quota type: TABLESPACE_QUOTA
used to store the tablespace segratio value
in quota_config table.
When set_per_segment_quota("xx","1.0) is
called, a new config will be added like:
quota_type = 4 (TABLESPACE_QUOTA)
quota = 0 (invalid quota)
segratio = 1
2) Modify set_quota_config_internal to
support insert/delete/update new type config
3) Add function get_per_segment_ratio
it is called when insert new
(schema/role)_tablespace_quota.
"for share" is used to query segratio,it only
can keep the segratio is consistent in
"read committed" level.
Co-authored-by: Sasasu <i@sasa.su>
* Fix un-expected remove when two tablespace-quota has a same role or schema (#202)
When there are two namespace_tablespace_quota configurations with the
same schema but different tablespaces, removing one quota will remove
another one automatically. The same bug happens for the
role_tabelspace_quota case. The root cause of this bug is that we
can't distinguish these two quotas using only quotaType and targetOid
of diskquota.quota_config.
This PR fixes this by changing the meaning of the targetOid column of
diskquota.quota_config table. When quotaType is
role_quota/schema_quota, targetOid refers to role_oid/schema_oid. When
quotaType is role_tablespace_quota/namespace_tablespace_quota,
targetOid refers to the rowId column of diskquota.target. This will
make it possible to distinguish two namespace_tablespace_quota with
the same schema and different tablespace. Because their rowId will be
different.
Co-authored-by: Xuebin Su <sxuebin@vmware.com>
Co-authored-by: Xiaoran Wang <xiwang@pivotal.io>
* Wait next loop for bgworker to refresh before INSERT in testcase (#205)
`diskquota.naptime` is 2 by default in the release version. So it's better to wait for the bgworker to fresh blackmap after INSERT.
* Add UDF diskquota.show_segment_ratio_quota_view (#204)
* clean blackmap after drop diskquota (#196)
clean blackmap after drop diskquota
Fix hardlimit exceed after drop diskquota.
fix this scenario:
- create hard limit
- blackmap on segment was updated
- drop diskquota
- the blackmap on segment is not cleanup
use ObjectAccess hook on segment. when dropping diskquota. clean up the in
memory blackmap.
* Reset memory account to fix memory leak (#203)
Diskquota workers dispatch queries periodically. For each dispatch,
one or more memory accounts will be created to keep track of the
memory usage. These accounts should be reset after the query
finishes to avoid memory leak.
Part of the stack trace of account creation looks like this:
```
fun:CreateMemoryAccountImpl
fun:MemoryAccounting_CreateAccount
fun:serializeNode
fun:cdbdisp_buildPlanQueryParms
fun:cdbdisp_dispatchX
fun:CdbDispatchPlan
fun:standard_ExecutorStart
fun:_SPI_pquery.constprop.11
fun:_SPI_execute_plan
fun:SPI_execute
fun:do_load_quotas
fun:load_quotas
fun:refresh_disk_quota_model
fun:disk_quota_worker_main
fun:StartBackgroundWorker
fun:do_start_bgworker
fun:maybe_start_bgworker
```
This patch fixes the memory leak issue by calling the reset function
at the end of the worker loop.
* fix test case for test_manytable (#197)
rename manytable test to activetable_limit
activetable_limit is used to test if activetable_limit works.
if number of current activetable > max_active_tables. bgworker will
print some warring message. GPDB should not crash, but diskquota's basic
function does not guarantee.
* some fix for release CI (#206)
clean blackmap after drop diskquota. follow up #196
also fix test case activetable_limit failed when naptime > 0
* Fix mistaken log statement (#207)
And add contraries that the refresh_black_map() should not be executed
on QD.
* Fix flaky ctas_pause on release build (#210)
Caused by the longger naptime for release build.
* Reformat quota exceeded message (#209)
Co-authored-by: Sasasu <i@sasa.su>
* Fix change tablespace test case (#213)
* Fix change tablespace test case
"ALTER TABLE xx SET TABLESPACE" will change the relfilenode of
a table, it will copy files from old relfilenode directory to
the new one and delete all files when commiting the transaction.
As diskquota doesn't acquire a lock on the relation when
fetching table size, so if diskquota is collecting active
tables' size and another session is deleting an active table's
files under an old relfilenode directory in a changing
tablespace transaction, the diskquota can't get all segment's
table size as files on part of segments have been deleted.
To fix it, we try to make a table to be an active table by
inserting data into it and wait for the diskquota to recalculate
the table size after changing tablespace.
* Replace "black" with "reject" for clearity (#214)
* Replace "black" with "reject" for clearity
* Rename in sql files
* Rename test files
* Format .c files
* Re-format using v13
* Update expected test results
* Fix result of upgrade test
* Re-trigger CI
* Add newline at EOF
* Change "list" to "map" for consistency
* Reject set quota for system owner(#215)
* fix set quota with upper case object name
the old code transform all object name to lower case on purpose.
create schema "S1";
select * from diskquota.set_schema_quota("S1", '1MB');
ERROR: schema "s1" does not exist
if the object name wrapped with '"'. eg '"Foo"' will search 'Foo'
if not will always search the lower case 'foo'.
* Hint message when launcher cannot be connected (#216)
* SPI & entry clear in refresh_blackmap (#211)
- refresh_blackmap doesn't need SPI calls.
- Clearing should happen within the same lock of refreshing entries.
Since there will be a short time that other processes see an empty
rejectmap while checking the hard limit.
* Minimize the risk of stale relfilenodes (#217)
Since we do NOT take any lock when accessing info of a relation,
cache invalidation messages may not be delievered in time each time
we SeearchSysCache() for relfilenode. As a result, the relfilenode may
be stale and the table size may be incorrect.
This patch fixes this issue by
- Checking for invalidation messages each time before
SearchSysCache(RELOID).
- Not removing a relation from active table map if the relfilenode
is stale.
Besides, since we do not remove the relfilenode if it maps to no
valid relation oid, we need remove those dangling relfilenodes
when unlink() to avoid memory leak.
* Report error if diskquota is not ready (#218)
Previously, setting quotas when diskquota is not ready is allowed.
But in that case, quotas set will not take effect. This can confuse
the user.
This patch fixes this issue by reporting an error when setting quotas
if diskquota is not ready. This is done by checking diskquota.state.
This patch also fixes possible deadlocks in the existing test cases.
* Allow deleting quota for super user (#219)
* Release pipeline is publishing wrong intermediates (#221)
"get" without "passed" will retrieve the latest content from a resource
which is not expected release. Especially the release and dev pipelines
share the intermediates bucket.
- Move release intermediates to its own bucket
- Add passed the "get" step in the "exit_release" job, to make sure the
resource version generated from previous job will be consumed in this
job.
* Bump version to 2.0.1 (#222)
* Compatible with ancient git (#223)
git 1.7.1 dose not support `git diff /absolute/path/to/current/project`
make our CI happy.
* Fix compiler version on concourse (#225)
cmake will look up c compiler by checking /usr/bin/cc. On CentOS7, that
symbolic linked to the gcc in the same directory. Although a newer gcc
is installed, cmake will not use the newer one.
We always export the CC and CXX, then the gcc/g++ in the $PATH will be
used.
* [CI] Fetch secrets from vault. (#226)
This patch teaches concourse to fetch secrets from vault.
* [cmake] Use C compiler to link the target. (#230)
Since we didn't implement anything in C++, let's invoke C compiler to link the target.
See: https://cmake.org/cmake/help/latest/prop_tgt/LINKER_LANGUAGE.html#prop_tgt:LINKER_LANGUAGE
* Scripts for new pipeline naming rules (#231)
Concourse is deprecating some special characters in the pipeline name.
See details at https://concourse-ci.org/config-basics.html#schema.identifier
The pipelines will be named as:
<rel|pr|merge|dev>[_test].<project_name>[branch_name][.user_defined_postfix]
- Pipeline type 'release' is renamed to 'rel'
- Pipeline type 'commit' is renamed to 'merge'
- '_test' suffix will be added to pipeline type for pipeline debugging
- Instead of setting the whole name of pipeline, user can only set the
postfix.
Patch from https://github.com/pivotal/ip4r/pull/2
Co-authored-by: Chen Mulong <cmulong@vmware.com>
Co-authored-by: Xing Guo <higuoxing+github@gmail.com>
* Log readiness message only once (#229)
Currently a diskquota worker will log an error message when the
database is not ready to be mornitored by Diskquota once for each
iteration. When the naptime is small, the log will be flooded by this
error message.
This patch adds a flag in the worker map in the shared memory so
that the error message will only be logged once per startup.
* Fix flaky test due to slow worker startup (#232)
When creating the extension, a diskquota worker will be started
to mornitor the db. However, it might take longer than expected
until it checks whether it is ready to monitor, which will make
some tests flaky.
This patch increases the time to wait for worker startup to avoid
flaky tests.
* Downgrade severity of the readiness issue (#235)
Downgrade the severity of the readiness check failure from `ERROR` to
`WARNING` so that the error stack will not be logged.
* Fix creating artifact (#234)
The artifact was tared without "c", which is a tar only but not gzipped.
untar it with "xzvf" will report error:
"
tar xzvf diskquota_rhel7_gpdb6.tar.gz
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Error is not recoverable: exiting now
"
* Dynamic bgworker for diskquota extension
As the num of bgworkers is limited in gpdb, if we want to support
unlimited numbers of database to run diskquota extension , we
need to dynamically allocate bgworkers for databases. Each
bgworker only runs "refresh_disk_quota_model" once, then exits.
GUC diskquota.max_workers is added in this pr, to set the max
bgworkers running in parallel.
Const MAX_NUM_MONITORED_DB, the databases' num is still
limited as we store each database's status in shared memory.
When there are fewer databases running diskquota extension than
diskquota.max_workers, will start one bgworker for each database
statically. Otherwise, will start bgworkers dynamically.
Launcher:
* workers: in shared memory
freeWorkers,runningWorkers are 2 double linked list.
Move a worker from freeWorkers to runningWorkers when picking
up a worker to serve for a database.
Move a worker from runningWorkers to freeWorkers when the
process exits. The length of freeWorkers plus runningWorkers is
diskquota.max_workers.
And each worker has a workerId, referenced by DiskquotaDBEntry.
* dbArray: an array in shared memory too, the length of it is
MAX_NUM_MONITORED_DB, storing DiskquotaDBEntry info.
The related things to dbArray:
- curDB: an iterator pointer for DBArray. When curDB is
NULL means that diskquota has finished one loop, and is ready
for the next loop. When curDB is dbArrayTail, it means it finished
on the loop but needs to sleep; otherwise, it points to a DB needed
to run.
- next_db(): function to pick the next database to run.
* DiskquotaDBEntry:
- in_use: it holds a diskquota database info.
- workerId: if the workerId is not Invalid, it means the db is running.
To check if a db is running by this field.
If the naptime is short, and after one loop, the database is still
running, then it will not be picked up to run.
- inited: check If the things for the diskquota extension, especially
the items in shared memory, have been inited.
* Diskquota worker:
Each diskquota extension worker has something in shared memory,
inited by function init_disk_quota_model,.
* Schedule
If it is ok to start workers, then pick one db in dbArray from beginning
to end to run. Otherwise, it means it's not time to start workers or
there are no available free workers. For the first reason, just sleep
until timeout. For the second point, to wait for the SIGUSR1 signal
which means there are diskquota workers exiting and workers freed.
* Fix the test failure on release pipeline
Regress tests failed on the release
pipeline due to the diskquota.naptime
is not 0. As diskquota launcher
firstly sleep, then starts diskquota
workers. When naptime is not 0, workers
are started very late, then some tests
which checking them failed.
In this pr, fix the test by starting
diskquota workers in the launcher before
it sleeps. This makes diskquota workers
will be started immediately when the
launcher starts.
Also, increased the sleep time in
the tests.
Sometimes, after restarting gpdb cluster, the db
has not yet been added to monitored_db_cache,
but worker_get_epoch is called to fetch the db
from the cache, then it will fail. Shouldn't to
report error here, printing a warning is ok.
* Move pr/merge pipeline to dev2 (#238)
And the docker clang-format image exists on the extensions gcp, I am too
lazy to move it here and it will be unnecessary to do that since we have
the check as github actions.
* Combine two object_access_hook into one (#220)
* Remove free writer gang in launcher (#233)
As launcher and worker both run in bgworker, they are clients when
connecting to segments. They know when should close the connections.
So we directly call `DisconnectAndDestroyAllGangs` to close them and
remove the code that only closes free read gangs based on timeout.
For the launcher, we destroy gangs after init_datbase_list or after each
time processing create/drop diskquota extension.
For workers, we only destroy gangs after the extension is paused.
* Fix bug: diskquota quota usage doesn't include uncommitted table (#228)
* Fix bug: diskquota quota usage doesn't include uncommitted table
Modify the show_fast_schema_quota_view, show_fast_role_quota_view, show_fast_schema_tablespace_quota_view and show_fast_role_tablespace_quota_view. Combine pg_class with relation_cache into all_relation, and join all_relation with diskquota.table_size to calculate quota usage.
Add upgrade and downgrade procedure between diskquota2.0 and diskquota2.1. Add upgrade and downgrade test for diskquota-2.1.
* Fix flaky test (#240)
* Fix flaky test test_ctas_role (#242)
creating table runs too fast to trigger the hard quota limit.
* Support at least 20000 tables for each database (#239)
Currently, diskquota supports max to 8000 tables, including partition tables. It may cause unexpected results if there are too many tables in the customer cluster.
This PR change `init_size` of table_size_map to 20000, instead of MAX_TABLES, so that we can
economize the actual usage of SHM. To handle scenarios with a large number of tables,
we set `max_size` to MAX_TABLES (1000000).
And To avoid memory waste, only the master should be allocated shared memory for diskquota_launcher and diskquota_worker.
* Reduce MAX_TABLES to 200K. (#243)
The scale of 50 databases with 200K tables is large enough, so we
reduce MAX_TABLES to 200K to avoid memory waste.
* Fix test_rejectmap flaky test (#246)
Why the test case can run successfully before, but sometimes fails?
Because it adds the reject entry after starting inserting data into the
table. If the inserting has hang up on `check_rejectmap_by_relfilenode`
and then adding the reject entry, hardlimit will be triggered. Otherwise,
softlimit will be triggered.
* Add SECURITY.md
* Add SECURITY.md (#249)
* Rewrite the diskquota worker scheduler (#245)
Rewrite the diskquota worker scheduler. Each DB entry manages the
running time by itself to make the scheduler more simple.
I have tested the performance, nearly the same as before.
Add a UDF db_status to help debug or monitor the diskquota, related
SQL is in test_util.sql. I didn't put it into diskquota--2.1.sql, because I
don't want users to use it now. I didn't use any shared lock when getting
that status info, so they may be not consistent.
Co-authored-by: Xing Guo <higuoxing+github@gmail.com>
Co-authored-by: Zhang Hao <hzhang2@vmware.com>
* Remove PR pipeline base branch (#252)
So all PRs can trigger build.
* Fix bug: relation_cache cannot isolate table info for each database (#241)
Previously, users will see the information of tables in db2 when accessing db1 and executing select diskquota.show_relation_cache(). Meanwhile, if db1's bgworker can see the table in db2, the performance will be influenced, because the table size in db2 will be calculated although it is not useful for db1 diskquota.
This PR has added a judgment to prevent this situation.
* Fix flaky test (#250)
When diskquota is in dynamic mode, it may take a long time to start a worker for a database (because the worker is busy), so some tests will fail after pg_sleep.
Add the diskquota_test extension to resolve the issue. In it, there is a UDF diskquota_test.wait(SQL test), which we can run by passing any SQL whose select result is true or false to it, it runs the SQL and waits for the selection result to be true at most 10 seconds. diskquota_test.db_status will return all the databases which are monitored by diskquota and their status and epoch. diskquota_test.cur_db_status() and diskquota_test.db_status() are just wrappers of it, which are more useful in the tests.
In the regress tests, replace the sleep with diskquota_test.wait or diskquota.wait_for_worker_new_epoch().
What's more, I have extracted the monitored_dbid_cache related data and functions into the monitored_db.c file.
Disable the regress test test_init_table_size_table, there is a bug making it fail, I will fix it in another pr.
* Filter the useless relation type. (#254)
Co-authored-by: Xiaoran Wang <wxiaoran@vmware.com>
* Fix worker time out and diskquota.max_workers (#255)
* Fix flaky "database not found" (#256)
* Change the max value of diskquota.max_workers to 20 (#257)
* Change the max value of diskquota.max_workers to 20
If we set the diskquota.max_workers max value to be
max_worker_processes, when max_worker_processes is less than 10 and we
set diskquota.max_workers value more than max_worker_processes, the
cluster will crash.
Set the max value to be 20, when the max_worker_processes is less than the
diskquota.max_workers, diskquota can work, only some parts of the
databases can not be monitored as diskquota can not start bgworkers for
them.
* Modify diskquota worker schedule test
Test when diskquota.max_workers more than available bgworker.
Co-authored-by: Zhang Hao <hzhang2@vmware.com>
* Revert change of worker_schedule test becuase flaky test (#260)
* Missing pause causes deadlock flaky (#258)
* Fix memory leak when database is not ready (#262)
Co-authored-by: Zhang Hao <hzhang2@vmware.com>
* Change the default value of GUC to reduce default memory cost. (#266)
Change the default vaule of `diskquota.max_active_tables` from 1M
to 300K, the memory usage relevant it is reduced from 300MB to 90MB.
* Refactor TableSizeEntry to reduce memory usage. (#264)
Refactor the structure of TableSizeEntry to reduce memory usage.
Previously, the size of each table in each segment should be maintained in TableSizeEntry, which wastes lots of memory. In this PR, we refactor the TableSizeEntry to:
struct TableSizeEntry
{
Oid reloid;
int segid;
Oid tablespaceoid;
Oid namespaceoid;
Oid owneroid;
uint32 flag;
int64 totalsize[SEGMENT_SIZE_ARRAY_LENGTH];
};
In this way, we can maintain multiple sizes in one TableSizeEntry and efficiently save memory usage.
For 50 segments: reduced by 65%.
For 100 segments: reduced by 82.5%.
For 101 segments: reduced by 65.3%.
For 1000 segments: reduced by 82.5%.
* Correct table_size_entry key (#268)
There is a bug: removing TableSizeEntry from table_size_map by oid.
Actually, the hash map key is TableKeyEntry. Fix it.
* Add cmake opt DISKQUOTA_DDL_CHANGE_CHECK (#270)
* Fix regression caused by #264 (#272)
The #264 caused some segment ratio tests fail. The entry's relevant
fields need to be set at the end of the iteration. Otherwise, only the
first seg will pass the condition check.
* Add a GUC `diskquota.max_table_segments`. (#271)
Use diskquota.max_table_segments to define the max number of table segments in
the cluster. The value equal (segment_number + 1) * max_table_number.
Since hashmap in the shared memory can take over others' memory space
even when it exceeds the limit, a counter is added to count how many tables
have been added to the table_size_map, to prevent too many entries to be
created.
Co-authored-by: Xiaoran Wang <wxiaoran@vmware.com>
Co-authored-by: Chen Mulong <chenmulong@gmail.com>
* Enable tests (#274)
* Optimize dispatching reject map to segments (#275)
Avoid dispatching reject map to segments when it is not changed
* Fix bug: rejectmap entries should not be removed by other databases. (#279)
This commit fixed two bugs:
- Previously, refresh_rejectmap() cleared all entries in rejectmap, including other databases' entries, which causes hardlimit can not to work correctly.
- soft-limit rejectmap entries should not be added into disk_quota_reject_map on segments, otherwise, these entries may remain in segments and trigger the soft-limit incorrectly.
Co-authored-by: Chen Mulong <chenmulong@gmail.com>
* Fix diskquota worker schedule bug (#280)
When a database's diskquota bgworker is killed and the db is dropped,
diskquota scheduler can not work properly. The cause is: if the scheduler
failed to start a bgworker for a database, it will try it again and
again forever.
A different status code is returned when failing to start bg worker. And if it is
failed due to the dropped database (or another other reasons causes
db name cannot be retrieved from db id), just skip this bgwoker for now
For other failure reasons, limit the times of starting a bgworker for a database
to 3 times. If the limit is reached, skip it and pick the next one.
* Bump version to 2.1.1 (#283)
* Fix flaky test_fast_quota_view (#282)
- Drop the table space before rm directory.
- '-f' to alway force rm.
- '-- start-ignore' doesn't seem to be working with retcode since retcode
will add '-- start/stop-ignore' pair automatically to ignore the
output, and the nested start/stop ignore doesn't seem to be handled
well by the ancient perl script. Refer to
'src/test/isolation2/sql_isolation_testcase.py'.
Seen flaky tests as below:
root@96831b9f-9150-4424-63a7-abe8f18c144e:/tmp# cat /home/gpadmin/diskquota_artifacts/tests/isolation2/regression.diffs
--- \/tmp\/build\/4eceba44\/bin_diskquota\/tests\/isolation2\/expected\/test_fast_quota_view\.out 2022-12-12 13:20:56.729354016 +0000
+++ \/tmp\/build\/4eceba44\/bin_diskquota\/tests\/isolation2\/results\/test_fast_quota_view\.out 2022-12-12 13:20:56.733354401 +0000
@@ -175,9 +175,11 @@
(exited with code 0)
!\retcode rm -r /tmp/spc2;
GP_IGNORE:-- start_ignore
+GP_IGNORE:rm: cannot remove '/tmp/spc2/6/GPDB_6_301908232/16384/16413': No such file or directory
+GP_IGNORE:rm: cannot remove '/tmp/spc2/5/GPDB_6_301908232/16384/16413': No such file or directory
GP_IGNORE:
GP_IGNORE:-- end_ignore
-(exited with code 0)
+(exited with code 1)
-- end_ignore
DROP TABLESPACE IF EXISTS spc1;
DROP
* Fix flaky isolation2 test. (#281)
Currently, isolation2/test_rejectmap.sql is flaky if we run isolation2
test multiple times. That's because we set the GUC
'diskquota.hard_limit' to 'on' in test_postmaster_restart.sql and forget
to set it to 'off'. In the next following runs, the hard limit is
enabled and the QD will continuously dispatch reject map to segment
servers. However, test_rejectmap.sql requires the hard limit being
disabled because we're dispatching rejectmap by UDF manually or the
dispatched rejectmap will be cleared by QD.
This patch adds a new injection point to prevent QD from dispatching
rejectmap to make test_rejectmap.sql stateless. This patch also set
'diskquota.hard_limit' to 'off' when test_postmaster_restart.sql
finishes.
* Fix compilation to support gpdb7 (#285)
* Fix diskquota on gpdb7
- Fix some compile issues, especially relstorage has been removed
on gpdb7. Using relam to get the relation's storage type.
- Modify diskquota hash function flag.
- Fix diskquota_relation_open(). NoLock is disabled on gpdb7.
- Add tests schedule and expected results for gpdb7.
- Update some test expectations on gpdb7 due to AO/CO issue: As
something changes about AO/CO table, the size of them is changed.
- Disable some tests on gpdb7.
- Disable upgrade tests.
- Upgrade to diskquota 2.2. Add attribute relam to type
relation_cache_detail and add a param to function relation_size_local.
- Add setup.sql and setup.out for isolation2 test.
- Fix bug: gpstart timeout for gpdb7. We used to set
`Gp_role = GP_ROLE_DISPATCH` in disk_quota_launcher_main(), even
though postmaster boots in utility mode. This seems to be nothing
in gpdb6, but it will cause a dead loop when booting gpdb7. In fact,
there is nothing to do in utility mode for the diskquota launcher. In
this commit, if `Gp_role != GP_ROLE_DISPATCH`,
disk_quota_launcher_main() will simply exit.
- Add gpdb7 pipeline support. Build gpdb7 by rocky8, and test the
same build with rocky8 and rhel8. 'res_test_images' has been changed
to list to support this.
- Add gpdb version into the task name. 'passwd' is unnecessary and '
doesn't exist in the rocky8 build image.
- Use `cmake -DENABLE_UPGRADE_TEST=OFF` to disable the upgrade test.
- TODO: Add upgrade test to CI pipeline. Fix activate standby error on the
CI pipeline. Fix tests for gpdb7.
Co-authored-by: Xiaoran Wang <wxiaoran@vmware.com>
Co-authored-by: Xing Guo <higuoxing@gmail.com>
* Fix released tarball name. (#286)
Co-authored-by: Hao Zhang <hzhang2@vmware.com>
* Add an option to control whether compile with fault injector. (#287)
Usage:
```
cmake -DDISKQUOTA_FAULT_INJECTOR=ON/OFF [default: OFF]
```
Co-authored-by: Hao Zhang <hzhang2@vmware.com>
* Add judgement for fault injector. (#288)
If fault injector is disabled, isolation2 will be disabled.
* Revert "Add judgement for fault injector. (#288)" (#291)
This reverts commit e3e73d2dd24ef0878a6a41b8734e340f5fb7a96a.
Revert "Add an option to control whether compile with fault injector. (#287)"
This reverts commit ae4ab48c97c5e77ecf25bee3ebf58ccd1244429f.
Co-authored-by: Hao Zhang <hzhang2@vmware.com>
* CI: Fix pipeline (#293)
- Switch GPDB binary to release-candidate for release build.
- Remove test_task from the release pipeline.
Co-authored-by: Xing Guo <higuoxing@gmail.com>
* Format code by clang-format. (#296)
* Add command to compile isolation2. (#297)
Isolation2 compilation command is removed by #285. We add it into
Regress.cmake in this commit.
Co-authored-by: Xing Guo higuoxing@gmail.com
* Fix flaky test (#294)
- Fix flaky test test_ctas_before_set_quota. pg_type will be an active table
after `CREATE TABLE`. It does not affect the function of diskquota but
makes the test results unstable. In fact, we do not care about the table
size of the system catalog table. So we simply skip the active table oid
of these tables.
- Fix test_vacuum/test_truncate. gp_wait_until_triggered_fault
should be called after gp_inject_fault_infinite with suspend flag.
Co-authored-by: Xing Guo <higuoxing@gmail.com>
Co-authored-by: Xiaoran Wang <wxiaoran@vmware.com>
* Fix flaky test test_rejectmap_mul_db (#295)
When creating a new table, pg_type will be in active tables.
Filter the system catalog table. And remove pause in the test.
* Fix bug (#298)
Fix the following bugs:
- Judgement condition for update_relation_cache should be `&&`, instead of `||`
- The lock for relation_open/relation_close should be AccessShareLock for gpdb7.
- For `truncate table`, we cannot get the table's oid by new relfilenode
immediately after `file_create_hook` is finished. So we should keep
the relfilenode in active_table_file_map and wait for the next loop to
calculate the correct size for this table.
* Enable upgrade test for CI (#299)
Revert some modification from #285.
- Add last_released_diskquota_bin back for CI.
- Enable upgradecheck.
- Add -DDISKQUOTA_LAST_RELEASE_PATH for cmake.
* Skip fault injector case for release build (#302)
Due to the release build change for GP7, the fault injector doesn't work
with the release build. So, all the tests were temporally disabled for
release pipelines.
Since we switched to use the `--disable-debug-extensions` gpdb build, the
fault injector is not available for the release pipeline.
- Add 'EXCLUDE_FAULT_INJECT_TEST' to Regress.cmake, so it will be smart
enough to check if there are any fault injector case in the give tests
set. Ignore them if so.
- Skip the fault injector tests for the release pipeline.
- Enable the CI test task for GP7.
* VAR replace for Regress.cmake and fix test_rejectmap (#304)
Since GP7 doesn't support plpythonu, the test_rejectmap was broken for
GP7. This commit:
- Improve the Regress.cmake, so if the input sql file has a "in.sql"
extension, "@VAR@" in it will be replaced by the corresponding cmake
VAR.
- SQL_DIR/EXPECTED_DIR takes list as the argument now. So only the
different cases need to be put into the expected7. Others will be used
from expected directly.
- Due to above change, same tests for gp6 and gp7 are removed from
gp7, only diff is needed.
- Set different @PLPYTHON_LANG_STR@ for GP6 & GP7
- Due to plpython composite type behavior change, the python code in
the test has been modified. The behavior change is probably related
to PG commit 94aceed317.
* Fix update test failures caused by segid diff (#305)
Due the GPDB change b80e969844, upgrade_test failed because the segid
in the view dump is surrounded by quotes.
Expected failure diff:
-WHERE (table_size.segid = (-1)))) AS dbsize;
+WHERE (table_size.segid = '-1'::integer))) AS dbsize;
* Replace relation_open/relation_close with RelationIdGetRelation/RelationClose. (#300)
This PR replaces relation_open()/relation_close() with RelationIdGetRelation()/RelationClose() to avoid deadlock. We can only call relation_open() with AccessSharedLock in object_access_hook(OAT_POST_CREATE) in GPDB7, which may cause deadlock. While RelationIdGetRelation()/RelationClose() just locks pg_class instead of user-defined relation, so we use these functions to get the information of relations.
* Fix flaky test of test_rejectmap_mul_db (#301)
Add back the pause in the test, to avoid the changes of active table.
* Fix test_primary_failure test case (#303)
* subprocess.check_output of python3, needs encoding
* Add @PLPYTHON_LANG_STR@ in the test_primary_failure.in.sql
* Move files to src and control dirs. (#307)
- Move .c and .h files to src dir.
- Move diskquota ddl file to control/ddl dir.
- Move diskquota_test--1.0.sql file to control/test dir.
* Fix gpdb release binary regex (#311)
The release candidate contains the build number now. Change the regex to
match the latest release candidate for release pipeline.
* Enable test_postmaster_restart (#309)
The isolation2 test `test_postmaster_restart` is disabled because the
postmaster start command is different between GPDB6 and GPDB7. We
should enable this test by passing distinct commands for GPDB6 and
GPDB7 to test_postmaster_restart.sql.
Meanwhile, we can merge isolation2_schedule7 and isolation2_schedule
to one.
* Bump cmake min version to 3.20 (#313)
Fix #312
* Resource change for gpdb7 binary (#315)
"""
NOTICE: resource queue required -- using default resource queue "pg_default"
"""
has been removed in gpdb7 82851a0b85 . Ignore it in the tests.
* Fix bug: bgworker enters infinite loop after receiving notices from QE. (#314)
We should not initialize the MyProcPort in bgworker, which will cause the database name to not be automatically added to the log message. In normal, the log printed from the bgworker does not contain the database name but contains the bgworker's pid. In order to facilitate debugging, we should print the database name every BGWORKER_LOG_TIME to ensure that we can find the database name by the bgworker's pid in the log file.
Co-authored-by: Chen Mulong <cmulong@vmware.com>
* Ignore some hint/notice for GPDB7 (#328)
* fix flaky test: test_appendonly (#327)
* Add dbname to DiskQuotaWorkerEntry (#326)
Previously, we passed dbname by bgw_name to bgworker. But refer to https://github.com/greenplum-db/gpdb/blob/f182228992b62e2023e2fac5b4971406abd35c9d/src/backend/postmaster/bgworker.c#L385-L386, bgw_name is copied by ascii_safe_strlcpy(), which replaces non-ASCII bytes with '?'. If the database name is non-ASCII, the bgworker can not connect to the correct database and raises an error. issue: #323 . To solve this problem, we should pass dbname by bgw_main_arg to the main function of the bgworker.
* Replace SPI_execute with SPI_cursor_fetch (#322)
The result buffer of SPI_execute is limited to 1GB. If the number of rows in diskquota.table_size exceeds 3 * 10^7 (500 segments with 60000 tables for example), SPI_execute("select tableid, size, segid from diskquota.table_size") will raise an error for invalid memory alloc request size 1073741824 (context 'SPI TupTable'). We should fetch table-size entries by portions. Replace SPI_execute() with SPI_cursor_fetch() in load_table_size().
* Split update SQL statement for diskquota.table_size (#325)
Fix issue: #318
If the number of entries needed to be updated in diskquota.table_size is too many, the size of StringBuffer will exceed 1GB and raise an error `Cannot enlarge string buffer containing 1073741807 bytes by 20 more bytes.`.
We should limit the number of entries in the update statement to 1000000 every time to ensure the string buffer size does not exceed 1GB.
* Update cmake version in README. (#331)
* Fix flaky test: test_appendonly (#333)
* Skip refresh_disk_quota_model() when receiving a signal (#321)
When with often signals to receive diskquota may call refresh_disk_quota_model
more frequently than diskquota_naptime.
Solution: when receiving a signal, the time waiting for latch sleep_time will be smaller
than diskquota_naptime. We should skip refresh_disk_quota_model() when
sleep_time < diskquota_naptime.
* Allocate more shared memory to quota_info (#334)
Allocate more SHM to quota_info, so that the user can set more quota
configurations.
* Enable stanby test for 6X_STABLE (#335)
* Bump version to 2.2.1 (#336)
* Use install_gpdb_component in CI test (#337)
So the script can be tested as well.
* Fix compiler warnings. (#339)
Note: `TextDatumGetCString()` returns a null-terminated CString.
```
[ 12%] Building C object CMakeFiles/diskquota.dir/src/diskquota.c.o
In file included from /home/v/workspace/diskquota/src/diskquota.h:16,
from /home/v/workspace/diskquota/src/diskquota.c:18:
/home/v/workspace/diskquota/src/diskquota.c: In function ‘diskquota_status_schema_version’:
/home/v/.local/gpdb7/include/postgresql/server/c.h:957:25: warning: ‘strncpy’ specified bound 64 equals destinatio
n size [-Wstringop-truncation]
957 | strncpy(_dst, (src), _len); \
| ^~~~~~~~~~~~~~~~~~~~~~~~~~
/home/v/workspace/diskquota/src/diskquota.c:1548:9: note: in expansion of macro ‘StrNCpy’
1548 | StrNCpy(version, vv, sizeof(version));
| ^~~~~~~
```
Co-authored-by: Hao Zhang <zhrt1446384557@gmail.com>
* Fix bug: diskquota.status() (#344)
Fix bug produced by #339
Co-authored-by: Xing Guo admin@higuoxing.com
* fix pipeline (#345)
fix pipeline resource
* Reduce the number of the log in bgworker. (#346)
* Fix bug: lose monitored_dbid_cache after switching mirror (#342)
# Problem
Recording active tables and permission checking on segments rely on `monitored_dbid_cache`. But after mirror switching, the data in shared memory is lost, and the above behaviors will be blocked.
# Solution
Segments update their `monitored_dbid_cache` after receiving pull_active_tables_oid requests every naptime.
* Enable continuous upgrade. (#340)
To achieve upgrading directly from 2.0 to 2.2, we should do the following things:
- cherry-pick this PR in diskquota-2.0, diskquota-2.1 and diskquota-2.2.
- set the shared_preload_libraries as `diskquota-2.2`: `gpconfig -c shared_preload_libraries -v 'diskquota-2.2'`
- restart cluster: `gpstop -ar`
- execute the following SQLs:
```
ALTER extension diskquota update to '2.2';
```
* Fix pipeline. (#349)
Get the latest package version for release resource.
* Fix upgrade version check (#347)
- Because of 2a73847f1a, the sql file directory has been changed. The
sql version check wouldn't work since it cannot find the sql files
anymore. Change it to the correct ddl directory.
- 'exec_program' is deprecated, use 'execute_process' instead.
- 'git tag | sort' returns the latest version among all branches, but
not the closest tag to the current commit. Use 'git describe --tags'
instead. So the upgrade version check will work for the 2.1.x patch
release.
* Remove gp7 from pipeline (#350)
After creating extension, the `diskquota.state` is always `unready` due to the change https://github.com/greenplum-db/gpdb/pull/15239. It makes the test timeout. We disable the job of gp7 in release/pr/merge pipeline until the problem is fixed.
* Add alter extension upgrade test (#348)
- By #340, diskquota should be able to upgraded directly from any previous
version. A script is added to test this.
- Modify the cmakefile so before installing/packaing, only previous so
files will copied. This would help us to make patch release for
2.0/2.1.
---------
Co-authored-by: Zhang Hao <hzhang2@vmware.com>
* Add a sleep in alter_test.sh (#351)
Co-authored-by: Chen Mulong chenmulong@gmail.com
* Update to 2.2.2 (#352)
- bump version to 2.2.2
- Modify the check procedure of alter extension.
* Reduce the remain logs in bgworker. (#354)
Fix from #346
* Fix bug: bgworkers only print log once. (#356)
* Disable forks for PR resource (#358)
* Release/gp7 2.2.2 (#361)
Change the CI pipeline to release diskquota for GP7.
TODO:
- enable regress test on CI.
- enable activatestandby test for GP7 on CI.
- fix regress test for GP7. The view in GP7 will be treated as a relation by diskquota. After `CREATE EXTENSION`, the test case should execute `SELECT diskquota.init_table_size_table()` to make the diskquota.state ready on GP7.
* Update to 2.3.0 (#362)
Fix the following issues:
diskquota cannot correctly print a warning when calling
`create extension` in a non-empty database. The diskquota.state shows
whether the current database is empty. Previously, we updated the
status to diskquota.state during `create extension` and queried the
status in UDF `diskquota.diskquota_start_worker`. When querying the
database status, the relations whose `relkind in ('v', 'c', 'f')` are
skipped, while all relations are filtered when updating the database
status. This patch merges the two SQL statements to `INSERT RETURNING`
to solve this problem.
Benefit: we won't need to upgrade the minor version of diskquota when
changing the statement.
Remove useless test `test_update_db_cache`. The behavior of the
bgworker scheduler is changed, so this test is no longer helpful.
Update the upgrade test script `2.2_set_quota`. Since the above issue,
ther…
…full (apache#112) * Fix bug The relation_cache_entry of temporary table, created during vacuum full, is not be removed after vacuum full. This table will be treated as an uncommitted table, although it has been dropped after vacuum full. And its table size still remains in diskquota.table_size, which causes quota size to be larger than real status. Use RelidByRelfilenode() to check whether the table is committed, and remove its relation_cache_entry. Co-authored-by: hzhang2 <hzhang2@vmware.com> Co-authored-by: Xing Guo <higuoxing+github@gmail.com> Co-authored-by: Xuebin Su (苏学斌) <sxuebin@vmware.com>
…full (apache#112) * Fix bug The relation_cache_entry of temporary table, created during vacuum full, is not be removed after vacuum full. This table will be treated as an uncommitted table, although it has been dropped after vacuum full. And its table size still remains in diskquota.table_size, which causes quota size to be larger than real status. Use RelidByRelfilenode() to check whether the table is committed, and remove its relation_cache_entry. Co-authored-by: hzhang2 <hzhang2@vmware.com> Co-authored-by: Xing Guo <higuoxing+github@gmail.com> Co-authored-by: Xuebin Su (苏学斌) <sxuebin@vmware.com>
…full (apache#112) * Fix bug The relation_cache_entry of temporary table, created during vacuum full, is not be removed after vacuum full. This table will be treated as an uncommitted table, although it has been dropped after vacuum full. And its table size still remains in diskquota.table_size, which causes quota size to be larger than real status. Use RelidByRelfilenode() to check whether the table is committed, and remove its relation_cache_entry. Co-authored-by: hzhang2 <hzhang2@vmware.com> Co-authored-by: Xing Guo <higuoxing+github@gmail.com> Co-authored-by: Xuebin Su (苏学斌) <sxuebin@vmware.com>
closes: #68
Change logs
In this PR, we mainly Port unique index for AO/AOCS table to CBDB.
Since the Memtuple in the AO table does not have the xmin and xmax attributes, we realize unique check by using its auxiliary index structure BlockDirectory (Heaptuple). Specifically, for the scenario with a unique index, when inserting into the AO table, we insert a placeholder in BlockDirectory to block the insertion of the same key. Its key design logic, see unique-index README.
Specific changes include:
Why are the changes needed?
Does this PR introduce any user-facing change?
introduce for unique index for AO/AOCS
How was this patch tested?
The main test cases are almost all cherry-picked from GP , mainly including:
isolation2: ao_blkdir, ao_unique_index, aocs_unique_index, ao_unique_index_vacuum
regress: uao_dml_unique_index_update, uao_dml_unique_index_delete, ao_unique_index_build
our changes include: ao_unique_index_vacuum
Change the test of verifying index vacuum to sequential execution. There are inconsistencies under distributed transactions during concurrent execution. For details, see bugs behind and file vaccum_ao.c
Contributor's Checklist
Here are some reminders and checklists before/when submitting your pull request, please check them:
make installcheckmake -C src/test installcheck-cbdb-parallel