[Feature] support dynami schema table #16351
Description
Search before asking
- I had searched in the issues and found no similar issues.
Description
Background
Dynamic schema table is a special type of table, it's schema change with loading procedure.Now we implemented this feature mainly for semi-structure data such as JSON, since JSON is schema self-described we could extract schema info from the original documents and inference the final type infomation.This speical table could reduce manual schema change operation and easily import semi-structure data and extends it's schema automatically.
Design detail
Type inference
A special column is introduced to doris ColumnObjet it's represent a special dynamic column, A column that represents object with dynamic set of subcolumns.Subcolumns are identified by paths in document and are stored in a trie-like structure. Subcolumns stores values in several parts of column and keeps current common type of all parts. We add a new column part with a new type, when we insert a field, which can't be converted to the current common type.After insertion of all values subcolumn should be finalized for writing and other operations.As batch of data imported, we could extract the common type of all types to a detail column type.
For example bellow we have some documents as bellow:

After the type inference, the trie-like structure will be like:
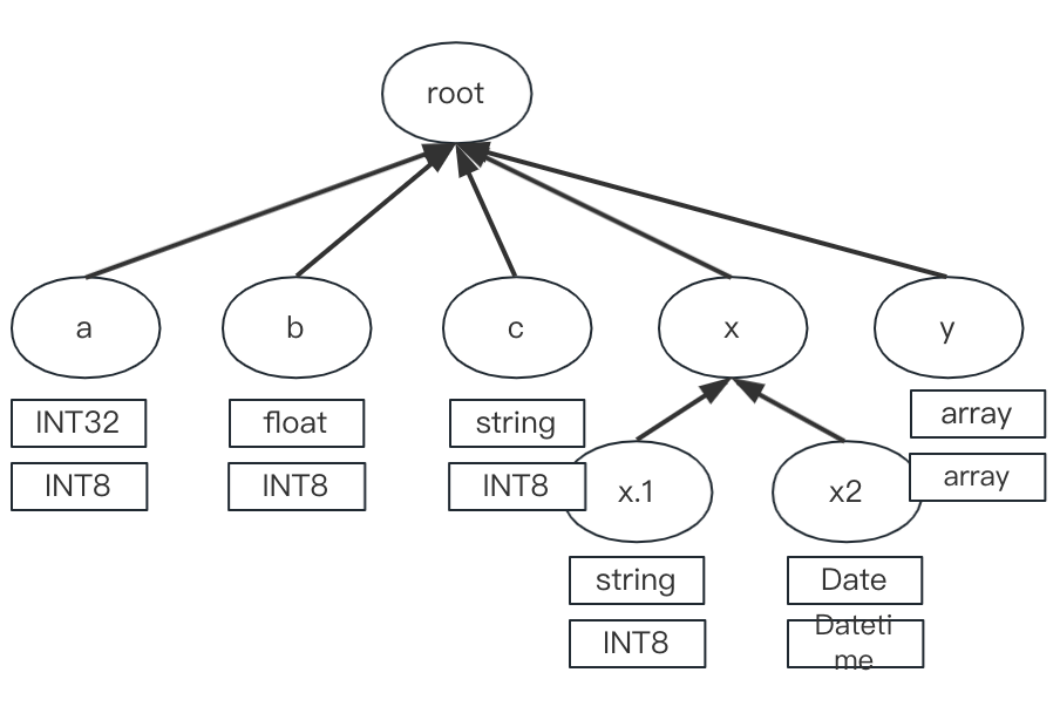
Type conflict handling
The rule is simple, like above metioned, the type evolution will follow the Least Common Ancestors rule.
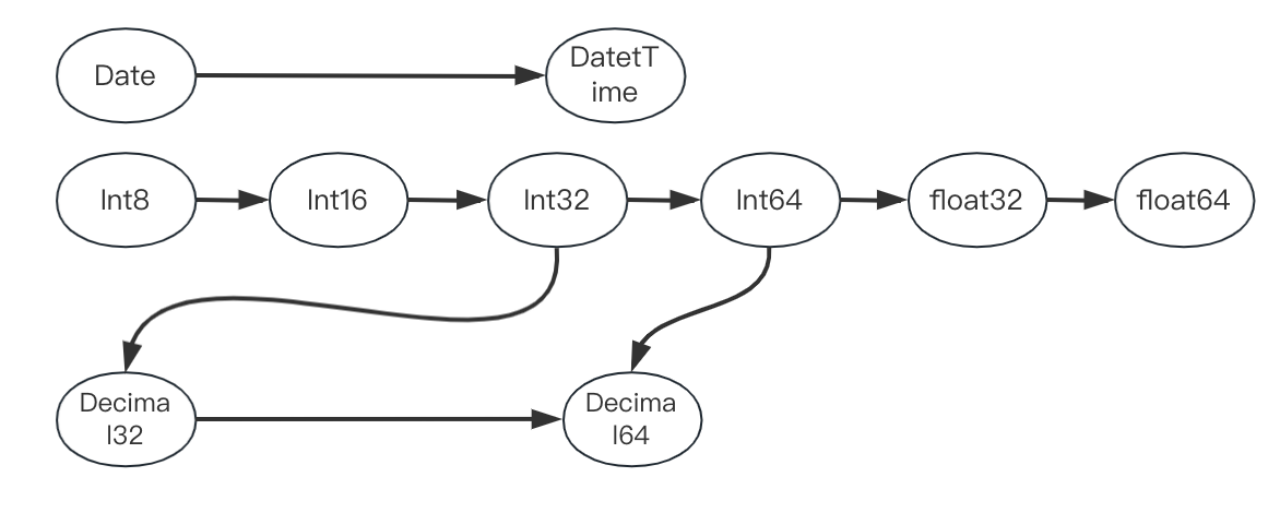
If no Ancestors could be found, then a type conflict is detected we have two method to handling such conflict:
- Abort this load, tell the user we are encountering type conflict bettween some types
- Cast all conflict types to string
Eg. if a path likea.b.cis abigint1234 type in doc1, butarray<bigint>[1234] in doc2, for method 1 we abort this load, for method 2, we convert bothbigintandarray<bigint>to string"1234","[1234]", so the final type ofa.b.cisstring
Schema Change
As type infos infered from previous solution, we could handle schema change procedure.Compare generated column with local schema info, we know that some columns were first met.For those columns, we extract type info from and issue a addColumns RPC to FE master, this is a simple schema change RPC and will go through the light schema change procedure.
Storage Engine Adapt
Some columns were auto generated, but storage engine schema only perceive TabletSchema which was generated by FE meta and not aware of the new generated columns.For persist such columns info in tablet meta and segment footer we need query such infomation from FE master.
Performance
Use case
No response
Related issues
No response
Are you willing to submit PR?
- Yes I am willing to submit a PR!
Code of Conduct
- I agree to follow this project's Code of Conduct