[Performance] Use SMID instruction to speed up the page decode of PlainPage and DictPage #6088
Description
Motivation
Now, When we run ssb test for doris. See the CPU Perf find:

There is plenty of CPU compute in page decode of PlainPage and DictPage
try to see the detail, we find there are many of mem allocate in dispose the BitUtil::RoundUpToPowerOf2
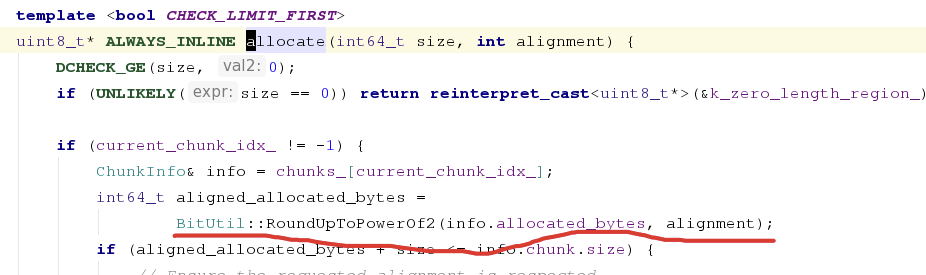
Implementation
Obvious, we can use the SMID to speed up the function BitUtil::RoundUpToPowerOf2
After use SSE to speed up the function, the perf show CPU cost:

| no vectorized | vectorized | |
|---|---|---|
| DictPage | 23.42% | 14.82% |
| PlainPage | 23.38% | 11.93% |
3. More Test In SSB
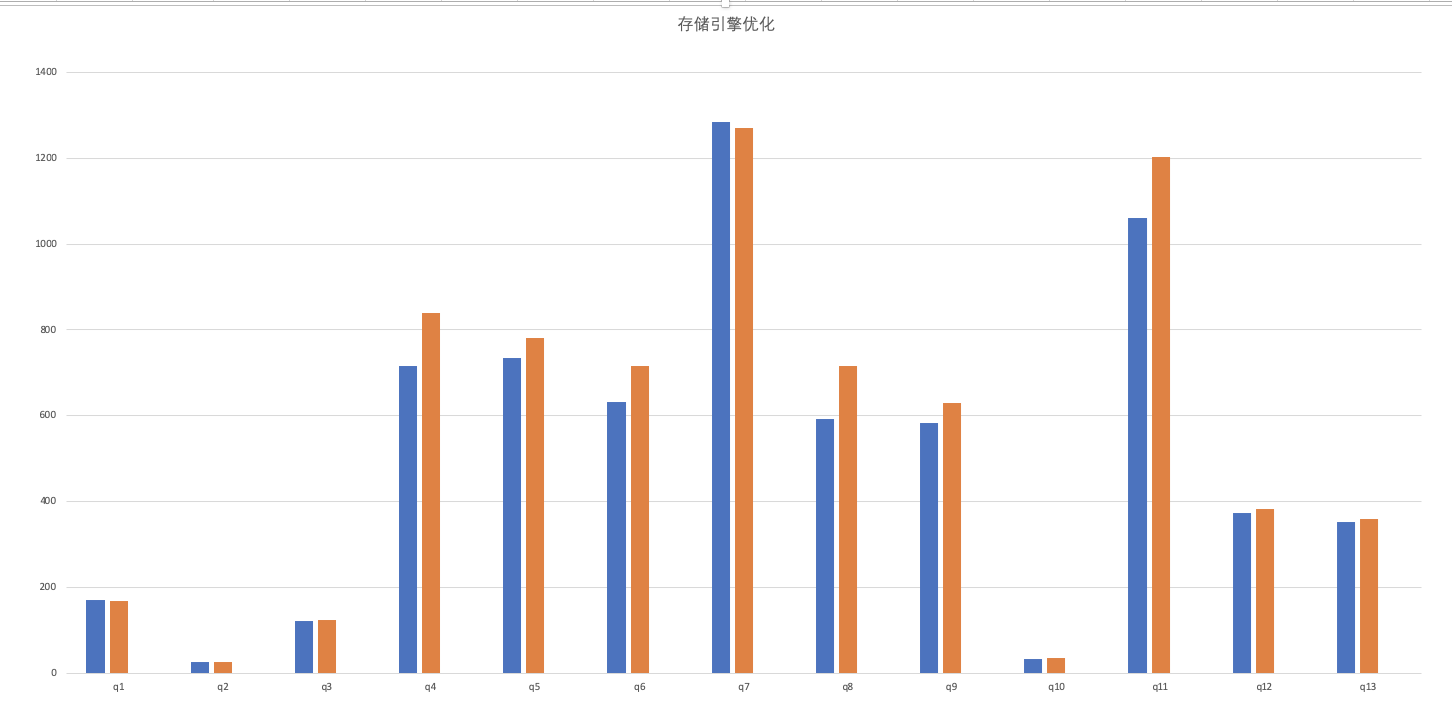
We can find q4,q5,q6,q8,q9,q11 improve about 20%