Motivation
In our experience, the number of dimensions of a datasource typically range from a dozen to dozens. However, queries about the datasource always only involve several dimensions. As we know, the fewer dimensions a datasource has, the less time a query cost. Based on the idea of changing time with space, druid can build a derived datasource which only contains several common dimensions of the datasource. When users query the datasource, druid calculates results based on the derived datasource if the derived datasource contains all dimensions the query required.
From another perspective, it is also a compromise between druid and kylin. Druid has minimal degree of pre-calculation, while kylin has maximum degree of pre-calculation. That is, druid only pre-calculation the combined value of all dimensions as shown in Table1(assume there are two dimensions and one metrics). However, kylin pre-calculation all possible combinations of dimensions as shown in Table 1-3. As a result, druid calculates for each query, while kylin stores much useless result data.
Table 1:
| Dimension A |
Dimension B |
Metrics A |
| a1 |
b1 |
1 |
| a2 |
b1 |
3 |
| a1 |
b2 |
5 |
Table 2:
| Dimension A |
Metrics A |
| a1 |
6 |
| a2 |
3 |
Table 3:
| DimensionB |
Metrics A |
| b1 |
4 |
| b2 |
5 |
Virtual datasource is proposed for druid to do more pre-calculation. The datasource which user ingests is called base-datasource, and the datasource which generated based on the base-datasource is called derived-datasource which is very similar to the notion of materialized views in traditional relational databases. Derived-datasource only involves some of dimensions of the base-datasource. It is noteworthy that user only need to know the base-datasource name. When user query the base-datasource, druid can automatically change the datasource of the query to a derived-datasource if the derived-datasource match some conditions, such as including all dimensions the query required.
In this version, we focus on the datasource which is loaded from files.
Implementation
Create and Delete Derived-datasource
Conditions:
- The timeline, metrics and granularities of a derived-datasource and its base-datasources are the same
- Derived-datasource dimensions is a subset of base-datasource dimensions.
Implementation
- Add two http interface in DatasourceResource.java. One is a POST request used to create derived datasource, and the other is a GET request to get information of derived-datasource.
curl -X POST -d @dimensions.json http://localhost:8081/druid/coordinator/v1/datasources/wikiticker/derivatives -H 'Content-Type:application/json'
Dimensions.json stored all dimensions of derived-datasource, such as
["metroCode","namespace","page","regionIsoCode","regionName","user"]
curl -X GET http://localhost:8081/druid/coordinator/v1/datasources/wikiticker/derivatives -H 'Content-Type:application/json'
The return result is all derived-datasources of wikiticker, and related dimensions:
{
"baseDataSource": "wikiticker",
"derivedDataSource": {
"wikiticker-0c224343": [
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user"
]
}
}
-
Add an new class DerivedDatasourceManager, which is responsible for:
- Read and Write information of derived-datasource from database;
- Traverse all derived-datasource. If the timeline of derived-datasource is less than the base datasource, a hadoop-reindex-task will be submit to ingest missing data. On the contrary, if the timeline of derived-datasource is more than the base datasource, druid will set used=false for the excess segments and a kill task will be submit to remove the data.
-
Add a new table "druid_derivatives" to store information of derived-datasource. The table include 3 columns: basedatasource, deriveddatasource,dimensions. The primary key is combination of basedatasource and dimensions
-
For the purpose of submitting hadoop-reindex-tasks when timeline of derived-datasource is less than base-datasource, it is necessary to get metrics and granularities of base-datasource. Therefore, a table "druid_dataschema" is required to add. It includes 5 columns: basedatasource, start, end, ts, datashcema. The primary key is the combination of basedatasource, start, end and ts.
-
In HadoopIndexTask.java, after publishing segments to database, the schema of the task should be inserted into table "druid_dataschema". Besides, if the datasource of the task has derived datasource and the data of the derived-datasource in the interval of the task has already existed, it’s required to delete this data of derived-datasource.
-
When user delete a datasource, derived-datasource of the datasource should be deleted.
Optimizing Datasource
Conditions:
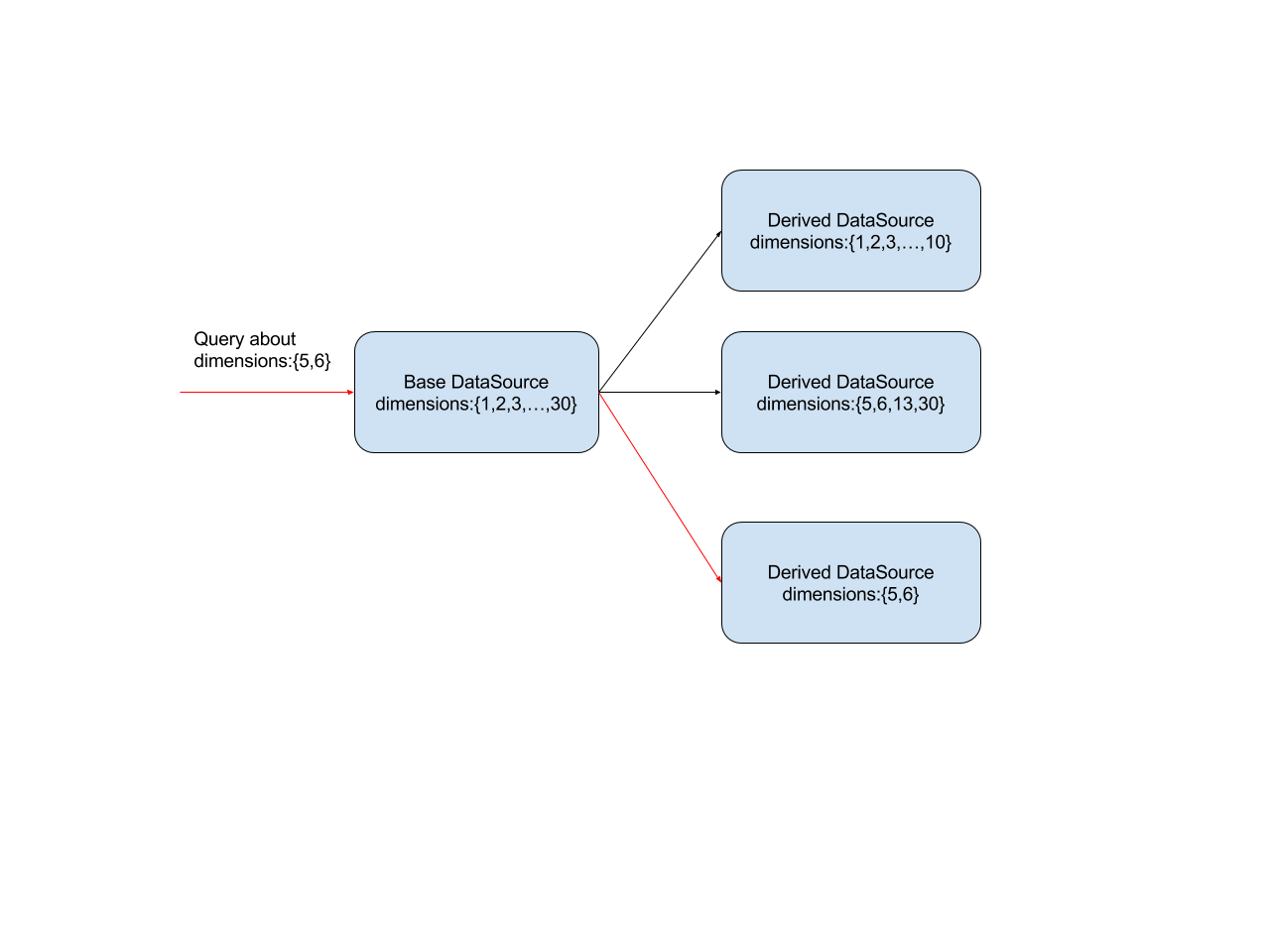
Once druid receives a query, the datasource of the query is replaced by a derived-datasource(Figure 1). The alternatives must meet the following conditions:
- The intersection between base-datasource timeline and query interval is equal to the intersection between derived-datasource timeline and query interval.
- derived-datasource includes all dimensions query need
- The chosen derived-datasource has the minimum amount of data among all derived-datasources which meet condition 1 and 2.
- If there is no suitable derived-datasource, base-datasource will not be replaced.
Figure 1:
Implementation
In BrokerResource.java, when receive a query, first optimize datasource: replacing datasource with a suitable derived-datasource. The process of optimization is as follows.
- Check if the datasource is a table datasource. If not, do not optimize. (In this version, we only support table datasource optimization)
- Check if the datasource has derived-datasource. If it has, get the information of these derived-datasources: name, dimensions and timeline.
- Traverse all derived-datasource, and find the derived-datasource which meet condition 1 and 2. If there are some derived-datasources meeting these two conditions, do the 4th step.
- Find the derived-datasource which has the minimum amount of data among all derived-datasources which meet condition 1 and 2.
Motivation
In our experience, the number of dimensions of a datasource typically range from a dozen to dozens. However, queries about the datasource always only involve several dimensions. As we know, the fewer dimensions a datasource has, the less time a query cost. Based on the idea of changing time with space, druid can build a derived datasource which only contains several common dimensions of the datasource. When users query the datasource, druid calculates results based on the derived datasource if the derived datasource contains all dimensions the query required.
From another perspective, it is also a compromise between druid and kylin. Druid has minimal degree of pre-calculation, while kylin has maximum degree of pre-calculation. That is, druid only pre-calculation the combined value of all dimensions as shown in Table1(assume there are two dimensions and one metrics). However, kylin pre-calculation all possible combinations of dimensions as shown in Table 1-3. As a result, druid calculates for each query, while kylin stores much useless result data.
Table 1:
Table 2:
Table 3:
Virtual datasource is proposed for druid to do more pre-calculation. The datasource which user ingests is called base-datasource, and the datasource which generated based on the base-datasource is called derived-datasource which is very similar to the notion of materialized views in traditional relational databases. Derived-datasource only involves some of dimensions of the base-datasource. It is noteworthy that user only need to know the base-datasource name. When user query the base-datasource, druid can automatically change the datasource of the query to a derived-datasource if the derived-datasource match some conditions, such as including all dimensions the query required.
In this version, we focus on the datasource which is loaded from files.
Implementation
Create and Delete Derived-datasource
Conditions:
Implementation
curl -X POST -d @dimensions.json http://localhost:8081/druid/coordinator/v1/datasources/wikiticker/derivatives -H 'Content-Type:application/json'Dimensions.json stored all dimensions of derived-datasource, such as
["metroCode","namespace","page","regionIsoCode","regionName","user"]curl -X GET http://localhost:8081/druid/coordinator/v1/datasources/wikiticker/derivatives -H 'Content-Type:application/json'The return result is all derived-datasources of wikiticker, and related dimensions:
Add an new class DerivedDatasourceManager, which is responsible for:
Add a new table "druid_derivatives" to store information of derived-datasource. The table include 3 columns: basedatasource, deriveddatasource,dimensions. The primary key is combination of basedatasource and dimensions
For the purpose of submitting hadoop-reindex-tasks when timeline of derived-datasource is less than base-datasource, it is necessary to get metrics and granularities of base-datasource. Therefore, a table "druid_dataschema" is required to add. It includes 5 columns: basedatasource, start, end, ts, datashcema. The primary key is the combination of basedatasource, start, end and ts.
In HadoopIndexTask.java, after publishing segments to database, the schema of the task should be inserted into table "druid_dataschema". Besides, if the datasource of the task has derived datasource and the data of the derived-datasource in the interval of the task has already existed, it’s required to delete this data of derived-datasource.
When user delete a datasource, derived-datasource of the datasource should be deleted.
Optimizing Datasource
Conditions:
Once druid receives a query, the datasource of the query is replaced by a derived-datasource(Figure 1). The alternatives must meet the following conditions:
Figure 1:
Implementation
In BrokerResource.java, when receive a query, first optimize datasource: replacing datasource with a suitable derived-datasource. The process of optimization is as follows.