Motivation
General motivation for native batch indexing is described in #5543.
We now have the parallel index task, but it doesn't support perfect rollup yet because of lack of the shuffle system.
Proposed changes
I would propose to add a new mode for parallel index task which supports perfect rollup with two-phase shuffle.
Two phase partitioning with shuffle
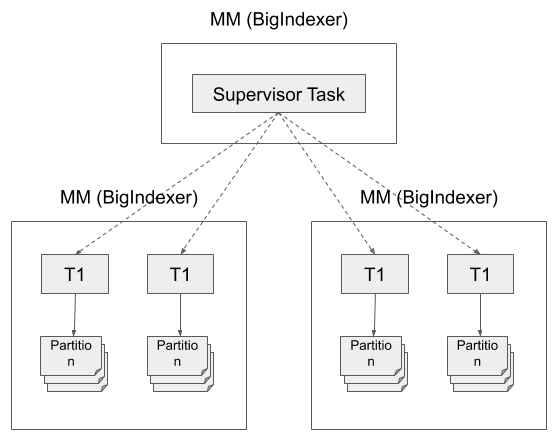
Phase 1: each task partitions data by segmentGranularity and then by hash or range key of some dimensions.
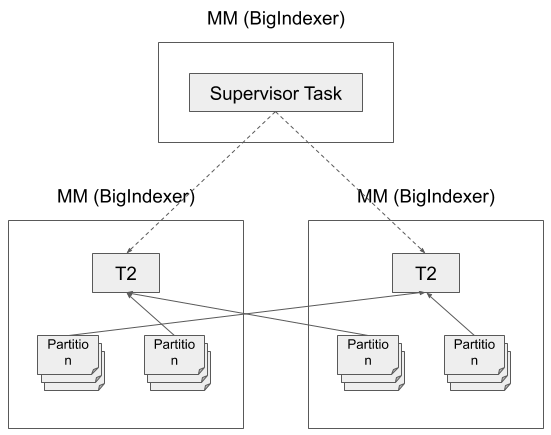
Phase 2: each task reads a set of partitions created by the tasks of Phase 1 and creates a segment per partition.
PartitionsSpec support for IndexTask and ParallelIndexTask
PartitionsSpec is the way to define the secondary partitioning and is currently being used by HadoopIndexTask. This interface should be adjusted to be more general as below.
public interface PartitionsSpec
{
@Nullable
Integer getNumShards();
@Nullable
Integer getMaxRowsPerSegment(); // or getTargetRowsPerSegment()
@Nullable
List<String> getPartitionDimensions();
}Hadoop tasks can use an extended interface which is more specialized for Hadoop.
public interface HadoopPartitionsSpec extends PartitionsSpec
{
Jobby getPartitionJob(HadoopDruidIndexerConfig config);
boolean isAssumeGrouped();
boolean isDeterminingPartitions();
}IndexTask currently provides duplicate configurations for partitioning in its tuningConfig such as maxRowsPerSegment, maxTotalRows, numShards, and partitionDimensions. These configurations will be deprecated and the indexTask will support PartitionsSpec instead.
To support maxRowsPerSegment and maxTotalRows, a new partitionsSpec could be introduced.
/**
* PartitionsSpec for best-effort rollup
*/
public class DynamicPartitionsSpec implements PartitionsSpec
{
private final int maxRowsPerSegment;
private final int maxTotalRows;
}This partitionsSpec will be supported as a new configuration in the tuningConfig of IndexTask and ParallelIndexTask.
New parallel index task runner to support secondary partitioning
ParallelIndexSupervisorTask is the supervisor task which orchestrates the parallel ingestion. It's responsible for spawning and monitoring sub tasks, and publishing created segments at the end of ingestion.
It uses ParallelIndexTaskRunner to run single-phase parallel ingestion without shuffle. To support two-phase ingestion, we can add a new implementation of ParallelIndexTaskRunner, TwoPhaseParallelIndexTaskRunner. ParallelIndexSupervisorTask will choose the new runner if partitionsSpec in tuningConfig is HashedPartitionsSpec or RangePartitionsSpec.
This new taskRunner does the followings:
- Add
TwoPhasesParallelIndexTaskRunner as a new runner for the supervisor task
- Spawns tasks for determining partitions (if
numShards is missing in tuningConfig)
- Spawns tasks for building partial segments (phase 1)
- When all tasks of the phase 1 finish, spawns new tasks for building the complete segments (phase 2)
- Each Phase 2 task is assigned one or multiple partitions
- The assigned partition is represented as an HTTP URL
- Publish the segments reported by phase 2 tasks.
- Triggers intermediary data cleanup when the supervisor task is finished regardless of its last status.
The supervisor task provides an additional configuration in its tuningConfig, i.e., numSecondPhaseTasks or inputRowsPerSecondPhaseTask, to support control of parallelism of the phase 2. This will be improved to automatically determine the optimal parallelism in the future.
New sub task types
Partition determine task
- Similar to what indexTask or HadoopIndexTask do.
- Scan the whole input data and collect
HyperLogLog per interval to compute approximate cardinality.
- numShards could be computed as below:
numShards = (int) Math.ceil(
(double) numRows / Preconditions.checkNotNull(maxRowsPerSegment, "maxRowsPerSegment")
);Phase 1 task
- Read data via the given firehose
- Partition data by segmentGranularity by hash or range (and aggregates if rollup)
- Should be able to access by (supervisorTaskId, timeChunk, partitionId)
- Write partitioned segments in local disk. Multiple disks can be configured, and each task would write partitions in a round-robin manner to utilize disk bandwidth efficiently
Phase 2 task
- Download all partial segments from middleManagers where phase 1 tasks ran.
- Merge all fetched segments into a single segment per partitionId.
- Push the merged segments and report them to the supervisor task.
MiddleManager as Intermediary data server
MiddleManager (and new Indexer) should be responsible for serving intermediary data during shuffle.
Each phase 1 task partitions input data and generates partitioned segments. These partitioned segments are stored in local disk of middleManager (or indexer proposed in #7900). The partitioned segment location would be /configured/prefix/supervisorTaskId/ directory. The same configurations with StorageLocationConfig would be provided for intermediary segment location.
MiddleManagers and indexers would clean up intermediary segments using the below mechanism.
- MM will keep expiration time in memory. This expiration time is initialized with current time + configured timeout.
- MM periodically checks there are any new partitions created for new supervisorTasks and initializes the expiration time if it finds any.
- When a subtask accesses a partition, the expiration time for the supervisorTask is initialized or updated if it's already there.
- MM periodically checks those expiration times for supervisorTasks. If it finds any expired supervisorTask, then it will ask the overlord if the task is still running. If not, MM will remove all partitions for the supervisorTask.
- The overlord will also send a cleanup request to MM when the supervisorTask is finished. This will clean up the expiration time.
New API lists of MiddleManager
- GET
/druid/worker/v1/shuffle/tasks/{supervisorTaskId}/partition?start={startTimeOfSegment}&end={endTimeOfSegment}&partitionId={partitionId}
Return all partial segments generated by sub tasks of the given supervisor task, falling in the given interval, and having the given partitionId.
- DELETE
/druid/worker/v1/shuffle/tasks/{supervisorTaskId}
Removes all partial segments generated by sub tasks of the given supervisor task.
New metrics & task reports
ingest/task/time: how long each task tookingest/task/bytes/processed: how large data each task processedingest/shuffle/bytes: how large data each middleManager servedingest/shuffle/requests: how many requests each middleManager served
Task failure handling
Task failure handling is same with the current behavior.
- If the supervisorTask process is killed normally, stopGracefully method is called which kills all running subtasks. If it's killed abnormally, then parallel index task doesn't handle this case for now.
- SupervisorTask monitors subtask statuses and counts how many subtasks have failed to process the same input. If it notices more failures than configured maxRetry, it regards that input can't be processed and exists with an error. Otherwise, it respawns a new task which processes the same input.
Rationale
There could be two alternate designs for the shuffle system, especially for intermediary data server.
MiddleManager (or indexer) as intermediary data server is the simplest design. In an alternative design, phase 1 tasks could serve intermediary data for shuffle. In this alternate, phase 1 tasks should be guaranteed to run until the phase 2 is finished, which means task 1 resources should be held until the phase 2 is finished. This is rejected for better resource utilization.
Another alternate is a single set of tasks would process both phase 1 and phase 2. This design is rejected because it's not very flexible to use cluster resource efficiently.
Operational impact
maxRowsPerSegment, numShards, partitionDimensions, and maxTotalRows in tuningConfig will be deprecated for indexTask. partitionsSpec will be provided instead. The deprecated values will be removed in the next major release after the upcoming one.
Test plan
Unit tests and integration tests will be implemented. I will also test this with our internal cluster once it's ready.
Future work
- The optimal parallelism for the phase 2 should be able to be determined automatically by collecting statistics during the phase 1.
- To avoid "too many open files" problem, middleManager should be able to smoosh the intermediary segments into several large files.
- If rollup is set, it could be better to combine intermediate data in middleManager before sending them. It would be similar to Hadoop's combiner.
- This could be implemented to support seamless incremental segment merge in middleManager.
- In Phase 1, tasks might skip index generation for faster shuffle. In this case, Phase 2 tasks should be able to generate the complete indexes.
Motivation
General motivation for native batch indexing is described in #5543.
We now have the parallel index task, but it doesn't support perfect rollup yet because of lack of the shuffle system.
Proposed changes
I would propose to add a new mode for parallel index task which supports perfect rollup with two-phase shuffle.
Two phase partitioning with shuffle
Phase 1: each task partitions data by segmentGranularity and then by hash or range key of some dimensions.
Phase 2: each task reads a set of partitions created by the tasks of Phase 1 and creates a segment per partition.
PartitionsSpecsupport forIndexTaskandParallelIndexTaskPartitionsSpecis the way to define the secondary partitioning and is currently being used byHadoopIndexTask. This interface should be adjusted to be more general as below.Hadoop tasks can use an extended interface which is more specialized for Hadoop.
IndexTaskcurrently provides duplicate configurations for partitioning in its tuningConfig such asmaxRowsPerSegment,maxTotalRows,numShards, andpartitionDimensions. These configurations will be deprecated and the indexTask will supportPartitionsSpecinstead.To support
maxRowsPerSegmentandmaxTotalRows, a new partitionsSpec could be introduced.This partitionsSpec will be supported as a new configuration in the tuningConfig of
IndexTaskandParallelIndexTask.New parallel index task runner to support secondary partitioning
ParallelIndexSupervisorTaskis the supervisor task which orchestrates the parallel ingestion. It's responsible for spawning and monitoring sub tasks, and publishing created segments at the end of ingestion.It uses
ParallelIndexTaskRunnerto run single-phase parallel ingestion without shuffle. To support two-phase ingestion, we can add a new implementation ofParallelIndexTaskRunner,TwoPhaseParallelIndexTaskRunner.ParallelIndexSupervisorTaskwill choose the new runner if partitionsSpec in tuningConfig isHashedPartitionsSpecorRangePartitionsSpec.This new taskRunner does the followings:
TwoPhasesParallelIndexTaskRunneras a new runner for the supervisor tasknumShardsis missing in tuningConfig)The supervisor task provides an additional configuration in its tuningConfig, i.e.,
numSecondPhaseTasksorinputRowsPerSecondPhaseTask, to support control of parallelism of the phase 2. This will be improved to automatically determine the optimal parallelism in the future.New sub task types
Partition determine task
HyperLogLogper interval to compute approximate cardinality.Phase 1 task
Phase 2 task
MiddleManager as Intermediary data server
MiddleManager (and new Indexer) should be responsible for serving intermediary data during shuffle.
Each phase 1 task partitions input data and generates partitioned segments. These partitioned segments are stored in local disk of middleManager (or indexer proposed in #7900). The partitioned segment location would be
/configured/prefix/supervisorTaskId/directory. The same configurations withStorageLocationConfigwould be provided for intermediary segment location.MiddleManagers and indexers would clean up intermediary segments using the below mechanism.
New API lists of MiddleManager
/druid/worker/v1/shuffle/tasks/{supervisorTaskId}/partition?start={startTimeOfSegment}&end={endTimeOfSegment}&partitionId={partitionId}Return all partial segments generated by sub tasks of the given supervisor task, falling in the given interval, and having the given partitionId.
/druid/worker/v1/shuffle/tasks/{supervisorTaskId}Removes all partial segments generated by sub tasks of the given supervisor task.
New metrics & task reports
ingest/task/time: how long each task tookingest/task/bytes/processed: how large data each task processedingest/shuffle/bytes: how large data each middleManager servedingest/shuffle/requests: how many requests each middleManager servedTask failure handling
Task failure handling is same with the current behavior.
Rationale
There could be two alternate designs for the shuffle system, especially for intermediary data server.
MiddleManager (or indexer) as intermediary data server is the simplest design. In an alternative design, phase 1 tasks could serve intermediary data for shuffle. In this alternate, phase 1 tasks should be guaranteed to run until the phase 2 is finished, which means task 1 resources should be held until the phase 2 is finished. This is rejected for better resource utilization.
Another alternate is a single set of tasks would process both phase 1 and phase 2. This design is rejected because it's not very flexible to use cluster resource efficiently.
Operational impact
maxRowsPerSegment,numShards,partitionDimensions, andmaxTotalRowsin tuningConfig will be deprecated for indexTask.partitionsSpecwill be provided instead. The deprecated values will be removed in the next major release after the upcoming one.Test plan
Unit tests and integration tests will be implemented. I will also test this with our internal cluster once it's ready.
Future work